Flash-VStream: Memory-Based Real-Time Understanding for Long Video Streams
Flash-VStream: 基于内存的长视频流实时理解系统
Abstract
摘要
Benefiting from the advancements in large language models and cross-modal alignment, existing multi-modal video understanding methods have achieved prominent performance in offline scenario. However, online video streams, as one of the most common media forms in the real world, have seldom received attention. Compared to offline videos, the “dynamic” nature of online video streams poses challenges for the direct application of existing models and introduces new problems, such as the storage of extremely long-term information, interaction between continuous visual content and “asynchronous” user questions. Therefore, in this paper we present Flash-VStream, a video-language model that simulates the memory mechanism of human. Our model is able to process extremely long video streams in real-time and respond to user queries simultaneously. Compared to existing models, Flash-VStream achieves significant reductions in inference latency and VRAM consumption, which is intimately related to performing understanding of online streaming video. In addition, given that existing video understanding benchmarks predominantly concentrate on offline scenario, we propose VStream-QA, a novel question answering benchmark specifically designed for online video streaming understanding. Comparisons with popular existing methods on the proposed benchmark demonstrate the superiority of our method for such challenging setting. To verify the general iz ability of our approach, we further evaluate it on existing video understanding benchmarks and achieves state-of-the-art performance in offline scenarios as well. All code, models, and datasets are available at the project page.
得益于大语言模型和跨模态对齐技术的进步,现有多模态视频理解方法在离线场景中已取得显著性能。然而,在线视频流作为现实世界中最常见的媒体形式之一,却鲜少受到关注。与离线视频相比,在线视频流的"动态"特性对现有模型的直接应用提出了挑战,并引入了新问题,例如超长时信息的存储、连续视觉内容与"异步"用户提问的交互等。为此,本文提出Flash-VStream——一种模拟人类记忆机制的视频语言模型。该模型能实时处理超长视频流并同步响应用户查询。与现有模型相比,Flash-VStream在推理延迟和显存消耗方面实现显著降低,这与在线流媒体视频的理解任务密切相关。此外,鉴于现有视频理解基准主要集中于离线场景,我们提出VStream-QA——一个专为在线视频流理解设计的新型问答基准。在新建基准上与主流方法的对比实验证明了本方法在此类挑战性场景中的优越性。为验证方法的泛化能力,我们进一步在现有视频理解基准上进行评估,在离线场景中同样取得了最先进的性能。所有代码、模型和数据集均在项目页面公开。
1 Introduction
1 引言
Online video streaming is a prevalent media format with a broad spectrum of applications. In the field of robotics, for instance, robots operating in the wild can leverage stream understanding models to interpret and react to their environment in real-time [36, 38]. Similarly, in surveillance systems, stream understanding models can process and analyze video streams from specific locations continuously, thereby improving overall security [5, 32]. However, best existing large video-language models fails to perform real-time long video question-answering upon user queries [16, 20, 29, 37]. The main reason is that: visual tokens between consecutive frames are heavy and redundant without effective compression, making it impossible to save all visual features in limited GPU Memory (VRAM), as well as significantly increasing the decoding latency of language model.
在线视频流是一种普遍存在的媒体格式,具有广泛的应用场景。例如在机器人领域,野外作业的机器人可以利用流理解模型实时解析并响应周围环境 [36, 38]。同样在监控系统中,流理解模型能持续处理分析特定位置的视频流,从而提升整体安防水平 [5, 32]。然而现有最优的大规模视频-语言模型仍无法根据用户查询实现实时长视频问答 [16, 20, 29, 37],其主要原因在于:连续帧间的视觉token (visual tokens) 未经有效压缩时存在大量冗余,既无法将所有视觉特征存入有限的GPU显存 (VRAM),也显著增加了语言模型的解码延迟。
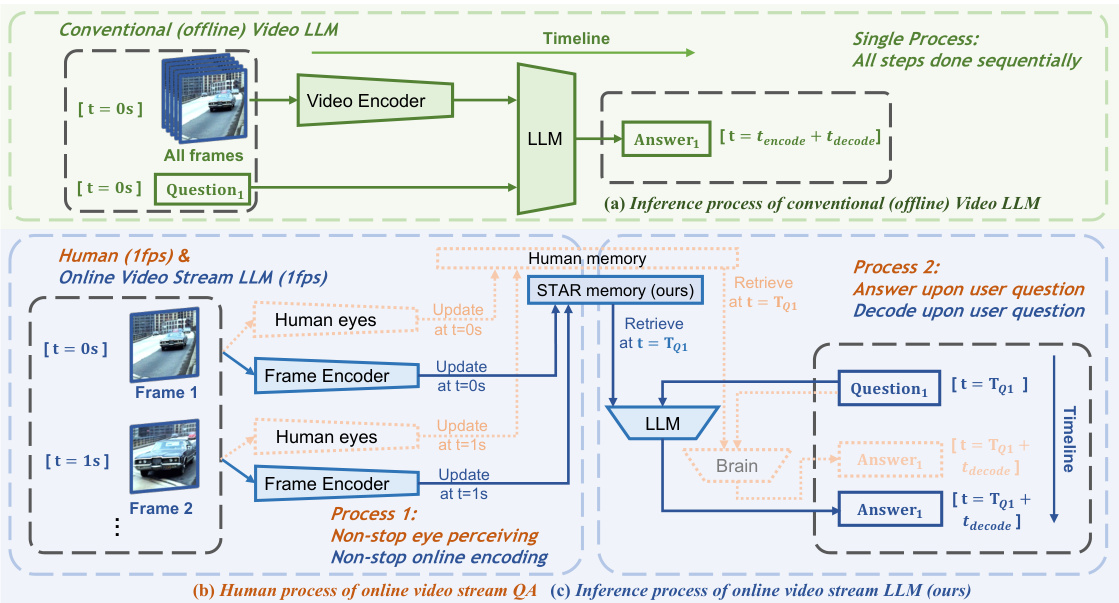
Figure 1: Comparing (a) conventional offline pipeline and (b) human processing pipeline with (c) our proposed Flash-VStream for online video streaming understanding. Zoom in for better view.
图 1: 对比 (a) 传统离线处理流程、(b) 人类处理流程与 (c) 我们提出的 Flash-VStream 在线视频流理解方案。建议放大查看细节。
Considering how humans process live video streams in real-time can provide inspiration for the design of video stream understanding models. This procedure can be divided into four steps [10]: 1) Perceiving: human eyes continuously encode an endless visual information into brain. 2) Memorizing: human brain compresses the visual information and update brain memory with it. With limited memory capacity, humans tend to have clearer detailed memories of recent events while they only remember the most important parts of events from the distant past. 3) Recalling: whenever a person is asked about what happens before, his/her brain retrieve the memory. 4) Answering: human brain integrates the memory information with the context provided by the question, and generate an answer.
考虑人类如何实时处理直播视频流能为视频流理解模型的设计提供灵感。该过程可分为四个步骤[10]:1) 感知:人眼持续将无尽的视觉信息编码至大脑;2) 记忆:大脑压缩视觉信息并更新记忆。受限于记忆容量,人类对近期事件会保留更清晰的细节记忆,而对久远事件仅记住最关键部分;3) 回忆:当被问及过往事件时,大脑会检索相关记忆;4) 应答:大脑将记忆信息与问题提供的上下文整合后生成答案。
It is worth noting that the four human processing steps above are not strictly sequential. As shown in Figure 1 (b) (focus on the brown part and ignore the blue part), the first two steps can be performed by a process (on the left), while the last two steps being performed by another process simultaneously (on the right). In other words, humans can perceive and memorize new information while recalling and answering questions about the past simultaneously. While the “process” for perceiving and memorizing is always running, the “process” for recalling and answering is only activated upon user questions. This is the key to online video stream understanding. In contrast, most existing video-QA methods [16, 20, 29] are based on offline video understanding, where user query and finite-length video are given to the model at the same time. As shown in Figure 1 (a), these methods only consist of the two strictly sequential steps: perceiving and answering. The lack of a compressed memory mechanism in these offline methods result in a dilemma: 1) If the model keeps the redundant visual tokens of all frames, the high VRAM consumption leads to limited input frame capacity. 2) If the model performs question-aware encoding and only keep those visual tokens that are relevant to the question, it has to re-encode all the visual information from scratch every time a new query is given, leading to an unacceptable inference latency for online video streams.
值得注意的是,上述四个人类处理步骤并非严格顺序执行。如图1(b)所示(聚焦棕色部分,忽略蓝色部分),前两个步骤可由一个进程(左侧)执行,而后两个步骤可同时由另一个进程(右侧)执行。换言之,人类在感知记忆新信息的同时,也能并行执行对过往信息的回忆与问题应答。其中感知记忆的"进程"持续运行,而回忆应答的"进程"仅在用户提问时激活——这正是在线视频流理解的关键所在。相比之下,现有大多数视频问答方法[16,20,29]基于离线视频理解框架,需要同时向模型输入用户查询和有限长度视频。如图1(a)所示,这些方法仅包含严格串行的两个步骤:感知与应答。由于缺乏压缩记忆机制,这些离线方法面临两难困境:1)若保留所有帧的冗余视觉token(visual tokens),高显存消耗将限制输入帧容量;2)若采用问题感知编码并仅保留相关视觉token,则每次新查询都需从头重新编码全部视觉信息,导致在线视频流场景出现无法接受的推理延迟。
To address this challenge, we introduce Flash-VStream, a video-language model that is able to process extremely long video streams in real-time and respond to user queries simultaneously. As shown in Figure 1 (c), Flash-VStream (blue) highly resembles human processing pipeline (brown) in terms of $^{\leftarrow}4$ -step, 2-process” design philosophy. The frame encoder resembles human eyes and the LLM resembles human brain. The learnable memory mechanism in Flash-VStream, named Spatial-Temporal-Abstract-Retrieved (STAR) memory, is carefully designed to compress necessary visual information and update memory in a online and real-time manner, as shown in Figure 3.
为解决这一挑战,我们推出了Flash-VStream,这是一种能够实时处理超长视频流并同时响应用户查询的视频-语言模型。如图1(c)所示,Flash-VStream(蓝色)在"←4步、2进程"设计理念上高度模拟了人类处理流程(棕色)。帧编码器模拟人眼,大语言模型模拟人脑。Flash-VStream中名为时空抽象检索(STAR)记忆的可学习记忆机制,经过精心设计以压缩必要视觉信息并在线实时更新记忆,如图3所示。
In addition, recognizing the limitations of existing offline and short-length video QA benchmarks, for evaluating video stream understanding in online settings, we propose VStream-QA, a novel question answering benchmark specifically designed for online video stream understanding. The main features of VStream-QA lies in: i) Each question-answer pair is marked with a specific timestamp in the video and only related to the visual information before that timestamp, which is consistent with the online video stream understanding setting. ii) The video length ranges from 30 minutes to 60 minutes, which is significantly longer than existing benchmarks, making it capable of evaluating model’s performance on extremely long videos. iii) The videos cover a variety of content, including first-person perspective (ego-centric) videos, and third-person perspective movies.
此外,针对现有离线短视频问答基准在在线视频流理解评估中的局限性,我们提出了VStream-QA——一个专为在线视频流理解设计的新型问答基准。VStream-QA的核心特性在于:i) 每个问答对都标注了视频中的特定时间戳,且仅与该时间戳前的视觉信息相关,这与在线视频流理解场景完全一致;ii) 视频时长从30分钟到60分钟不等,远超现有基准,能有效评估模型在超长视频上的性能;iii) 视频内容涵盖第一人称视角(ego-centric)视频和第三人称视角电影等多种类型。
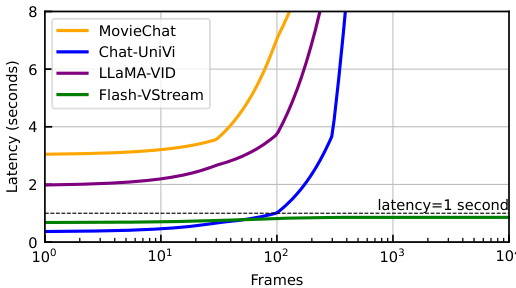
Figure 2: Inference latency ( $\mathbf{\hat{y}}$ -axis) v.s. frame number ( $\bf\\ {X\cdot\bf\delta}$ -axis). Latency tested on an $\mathrm{AlO0gpu}$ . Our model is able to process extremely long video streams, and perform real-time answering within 1 second upon user’s query.
图 2: 推理延迟 ( $\mathbf{\hat{y}}$ 轴) 与帧号 ( $\bf\\ {X\cdot\bf\delta}$ 轴) 的关系。延迟测试在 $\mathrm{AlO0gpu}$ 上进行。我们的模型能够处理极长的视频流,并在用户查询后1秒内实现实时响应。
Table 1: Comparison with SoTA methods on zero-shot real-time VideoQA. A and S denote accuracy and score, respectively. VRAM tested on an $\mathrm{AlO0gpu}$ . *: Tested with a 100-frame input video (maximum support of VideoChatGPT). : Tested with a 1000-frame input video.
表 1: 零样本实时视频问答 (VideoQA) 与当前最优 (SoTA) 方法的对比。A 和 S 分别表示准确率和得分。VRAM 在 $\mathrm{AlO0gpu}$ 上测试。*: 使用 100 帧输入视频测试 (VideoChatGPT 的最大支持)。: 使用 1000 帧输入视频测试。
| 方法 | RVS-EgoRVS-Movie | VRAM | ||
|---|---|---|---|---|
| A S | A | S | ||
| Video-ChatGPT[30] | 51.0 3.7 | 51.7 | 3.3 | 16.62GB 米 |
| MovieChat [37] | 50.7 3.4 | 36.0 | 2.3 | 16.90GB 十 |
| Chat-UniVi [16] | 51.2 3.8 | 51.8 | 3.3 | 77.56GB |
| LLaMA-VID [20] | 53.4 3.9 | 48.6 | 3.3 | 33.64GB |
| Flash-VStream | 57.3 4.0 | 53.1 | 3.3 | 16.03GB |
On these challenging online benchmarks, Flash-VStream achieves state-of-the-art performance, while achieving significant reductions in inference latency and VRAM consumption as shown in Figure 2 and Table 1. Zero-shot video question answering experiments on 4 conventional offline video QA benchmarks further prove the generalization ability of Flash-VStream, as shown in Table 3. Comprehensive ablation studies prove the effectiveness of the memory mechanism we adopted. We summarize our contribution as follows:
在这些具有挑战性的在线基准测试中,Flash-VStream 实现了最先进的性能,同时显著降低了推理延迟和显存消耗 (如图 2 和表 1 所示) 。在 4 个传统离线视频问答基准上的零样本 (Zero-shot) 实验进一步证明了 Flash-VStream 的泛化能力 (如表 3 所示) 。全面的消融研究验证了我们采用的内存机制的有效性。我们的贡献总结如下:
2 Related work
2 相关工作
Multi-modal large language models. With recent advances in Large Language Models (LLMs) [3, 34, 40, 41], many works try to build Multimodal Large Language Models (MLLMs) that integrate text with visual data or other modalities. For instance, the BLIP series [9, 17, 18] proposed a efficient strategy for boots trapping multimodal understanding with pretrained LLMs and image encoders, and the LLaVA series [22, 23] leverage GPT-generated visual instruction data to tune open language models. With the development of image-text models, researchers have begun extending image data to videos. The biggest challenge for Video LLM is how to compress redundant frame features. LLaMA-VID [20] represents single-frame features with a few tokens, Chat-UniVi [16] employs dynamic tokens to model image and video features of different scale, and Vista-LLaMA [29] uses a sequential visual projector to represent an entire video with fewer tokens. These methods either requires a multi-step visual encoding process with high latency [16], or have a linearly increasing VRAM cost with the number of frames [20, 29], making them unsuitable for real-time long video stream understanding. MovieChat [37] proposed to combine all frame features through a simple average strategy. Though it is able to process long video with limited VRAM cost, its performance is suboptimal due to its training-free framework and non-learnable memory mechanism. In our proposed Flash-VStream, we introduce a learnable memory mechanism that encode frames in a online and real-time manner, disentangling the visual encoding process and answer decoding process, thus enabling real-time video stream understanding.
多模态大语言模型。随着大语言模型(LLM) [3,34,40,41] 的近期突破,许多研究尝试构建整合文本与视觉数据或其他模态的多模态大语言模型(MLLM)。例如BLIP系列 [9,17,18] 提出了一种利用预训练LLM和图像编码器进行多模态理解的高效策略,LLaVA系列 [22,23] 则通过GPT生成的视觉指令数据来调优开源语言模型。随着图文模型的发展,研究者开始将图像数据扩展到视频领域。视频LLM面临的最大挑战是如何压缩冗余帧特征:LLaMA-VID [20] 用少量token表示单帧特征,Chat-UniVi [16] 采用动态token建模不同尺度的图像视频特征,Vista-LLaMA [29] 使用序列视觉投影器以更少token表征整段视频。这些方法要么需要高延迟的多步视觉编码流程 [16],要么VRAM消耗随帧数线性增长 [20,29],难以实现实时长视频流理解。MovieChat [37] 提出通过简单平均策略融合所有帧特征,虽能以有限VRAM处理长视频,但由于其免训练框架和不可学习的记忆机制导致性能欠佳。我们提出的Flash-VStream引入了可在线实时编码帧特征的可学习记忆机制,解耦视觉编码与答案解码过程,从而实现了实时视频流理解。
Real-time video stream understanding. Real-time video stream understanding is a challenging task that requires the model to process video streams in real-time and finish specific tasks based on the video. Most existing real-time methods are designed to perform a single, specific vision task, such as real-time object tracking [14, 25, 42] and real-time action recognition [28, 48]. Considering natural language is becoming a general interface for various tasks and modalities [1, 11, 17, 26], our work focuses on real-time video stream question answering upon user queries, which is a more challenging and comprehensive task.
实时视频流理解。实时视频流理解是一项具有挑战性的任务,要求模型实时处理视频流并根据视频内容完成特定任务。现有实时方法大多针对单一视觉任务设计,例如实时目标跟踪 [14, 25, 42] 和实时动作识别 [28, 48]。鉴于自然语言正逐渐成为跨任务、跨模态的通用交互接口 [1, 11, 17, 26],我们的工作聚焦于更具挑战性和综合性的任务:基于用户查询的实时视频流问答。
Memory mechanism for long sequence processing. Memory mechanism is widely used to store and retrieve information in all forms of sequence processing tasks, such as time series forecasting [4], recommendation system [39], machine translation [8], and video object segmentation [6]. Inspired by the idea of Neural Turing Machine (NTM) [13], a learnable mechanism that resembles the working memory system of human cognition, we proposed a learnable visual memory that is able to compress visual information and update memory in a online and real-time manner.
长序列处理中的记忆机制。记忆机制被广泛应用于各类序列处理任务中的信息存储与检索,例如时间序列预测 [4]、推荐系统 [39]、机器翻译 [8] 和视频目标分割 [6]。受神经图灵机 (Neural Turing Machine, NTM) [13] 的启发(该机制模拟了人类认知中的工作记忆系统),我们提出了一种可学习的视觉记忆机制,能够压缩视觉信息并以在线实时方式更新记忆。
3 Flash-VStream
3 Flash-VStream
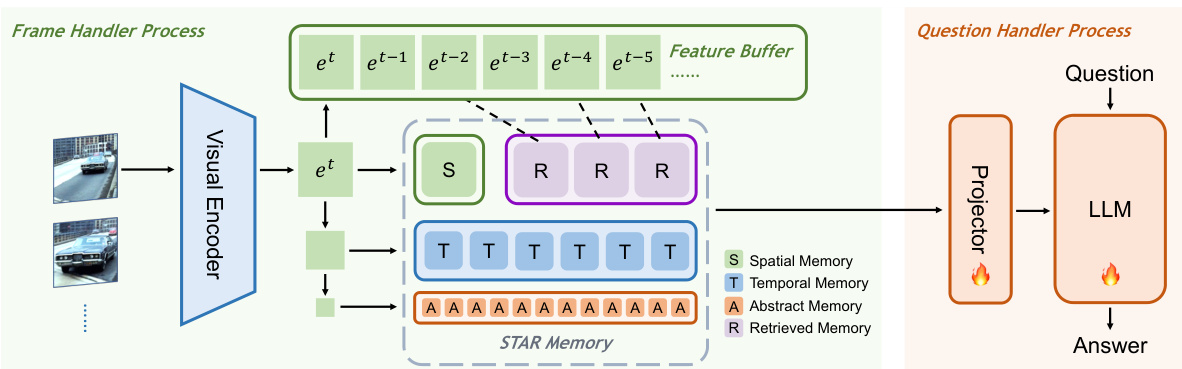
Figure 3: The overview of Flash-VStream framework for real-time online video stream understanding. Flash-VStream is executed by two processes, namely “frame handle” and “question handler”. The frame handler is responsible for encoding frames and writing to memory, which contains a visual encoder, a STAR memory and a feature buffer. The question handler is responsible for reading from memory and answering questions anytime, which contains a projector and a Large Language Model.
图 3: 实时在线视频流理解框架Flash-VStream的总体架构。Flash-VStream通过"帧处理器"和"问题处理器"两个流程执行。帧处理器负责编码帧并写入内存,包含视觉编码器 (visual encoder)、STAR存储模块 (STAR memory) 和特征缓冲区 (feature buffer)。问题处理器负责随时从内存读取数据并回答问题,包含投影器 (projector) 和大语言模型 (Large Language Model)。
As shown in Figure 3, our Flash-VStream framework consists of three main components: (1) a streaming visual encoder that continuously processes video frames, (2) a Spatial-Temporal-AbstractRetrieved memory mechanism (STAR memory), including memory writing and reading with the help of a feature buffer. (3) a LLM decoder capable of providing real-time responses to questions raised by users. To perform real-time inference, Flash-VStream is deployed in two asynchronous processes. The frame handler process manages the streaming visual encoder and STAR memory consolidation. The question handler process manages the real-time LLM decoder, STAR memory reading and interactions with users. The only connection between these two processes is the shared memory, which can be written by the first process and read by both.
如图 3 所示,我们的 Flash-VStream 框架包含三个主要组件:(1) 持续处理视频帧的流式视觉编码器,(2) 时空抽象检索记忆机制 (STAR memory),包括借助特征缓冲区实现的记忆写入与读取。(3) 能够实时回应用户提问的大语言模型解码器。为实现实时推理,Flash-VStream 部署在两个异步进程中:帧处理进程负责管理流式视觉编码器和 STAR 记忆整合,提问处理进程负责管理实时大语言模型解码器、STAR 记忆读取及用户交互。这两个进程间仅通过共享内存连接,该内存可由第一个进程写入,并被双方读取。
3.1 Streaming visual encoder
3.1 流式视觉编码器
Like human eyes, the streaming visual encoder can continuously encode visual information into embedded features. We use the pre-trained CLIP ViT-L [35] as visual encoder. Only patch tokens are used during training and inference. Specifically, given a frame stream ${V^{t}}_{t=1}^{\infty}$ , the encoder maps the $t$ -th frame $V^{t}\in\mathbb{R}^{H\times W\times3}$ to feature map $e^{t}\in\mathbb{R}^{P\times P\times D}$ , where $P\times P$ is the number of ViT patch tokens and $D$ is the hidden dimension of ViT.
与人类眼睛类似,流式视觉编码器能够持续将视觉信息编码为嵌入特征。我们采用预训练的CLIP ViT-L [35]作为视觉编码器,训练和推理过程中仅使用patch token。具体而言,给定帧流 ${V^{t}}_{t=1}^{\infty}$ ,编码器将第 $t$ 帧 $V^{t}\in\mathbb{R}^{H\times W\times3}$ 映射为特征图 $e^{t}\in\mathbb{R}^{P\times P\times D}$ ,其中 $P\times P$ 表示ViT的patch token数量, $D$ 代表ViT的隐藏维度。
3.2 Spatial-Temporal-Abstract-Retrieved memory
3.2 时空抽象检索记忆
In order to handle information of different levels of granularity, we design a STAR memory with 4 components: spatial memory $M_{\mathrm{spa}}\in\mathbb{R}^{N_{\mathrm{spa}}\times P_{\mathrm{spa}}^{2}\times D}$ , temporal memory $M_{\mathrm{tem}}\in\mathbb{R}^{N_{\mathrm{tem}}\times P_{\mathrm{tem}}^{2}\times D}$ abstract memory $M_{\mathrm{abs}}\in\mathbb{R}^{N_{\mathrm{abs}}\times P_{\mathrm{abs}}^{2}\times D}$ and retrieved memory $M_{\mathrm{ret}}\in\mathbb{R}^{N_{\mathrm{ret}}\times P_{\mathrm{spa}}^{2}\times D}$ . A feature buffer $M_{\mathrm{buff}}\in\mathbb{R}^{N_{\mathrm{buff}}\times P_{\mathrm{spa}}^{2}\times D}$ is used to store the feature of latest $N_{\mathrm{buff}}$ frames. Therefore, the overall memo ry size is limited to ${\mathrm{MAXSIZE}}=(N_{\mathrm{spa}}+N_{\mathrm{ret}})\times P_{\mathrm{spa}}^{2}+N_{\mathrm{tem}}\times P_{\mathrm{tem}}^{2}+N_{\mathrm{abs}}\times P_{\mathrm{abs}}^{2}$ tokens.
为了处理不同粒度的信息,我们设计了包含4个组件的STAR记忆系统:空间记忆 $M_{\mathrm{spa}}\in\mathbb{R}^{N_{\mathrm{spa}}\times P_{\mathrm{spa}}^{2}\times D}$、时序记忆 $M_{\mathrm{tem}}\in\mathbb{R}^{N_{\mathrm{tem}}\times P_{\mathrm{tem}}^{2}\times D}$、抽象记忆 $M_{\mathrm{abs}}\in\mathbb{R}^{N_{\mathrm{abs}}\times P_{\mathrm{abs}}^{2}\times D}$ 和检索记忆 $M_{\mathrm{ret}}\in\mathbb{R}^{N_{\mathrm{ret}}\times P_{\mathrm{spa}}^{2}\times D}$。特征缓冲区 $M_{\mathrm{buff}}\in\mathbb{R}^{N_{\mathrm{buff}}\times P_{\mathrm{spa}}^{2}\times D}$ 用于存储最近 $N_{\mathrm{buff}}$ 帧的特征。因此,整体记忆容量被限制为 ${\mathrm{MAXSIZE}}=(N_{\mathrm{spa}}+N_{\mathrm{ret}})\times P_{\mathrm{spa}}^{2}+N_{\mathrm{tem}}\times P_{\mathrm{tem}}^{2}+N_{\mathrm{abs}}\times P_{\mathrm{abs}}^{2}$ 个token。
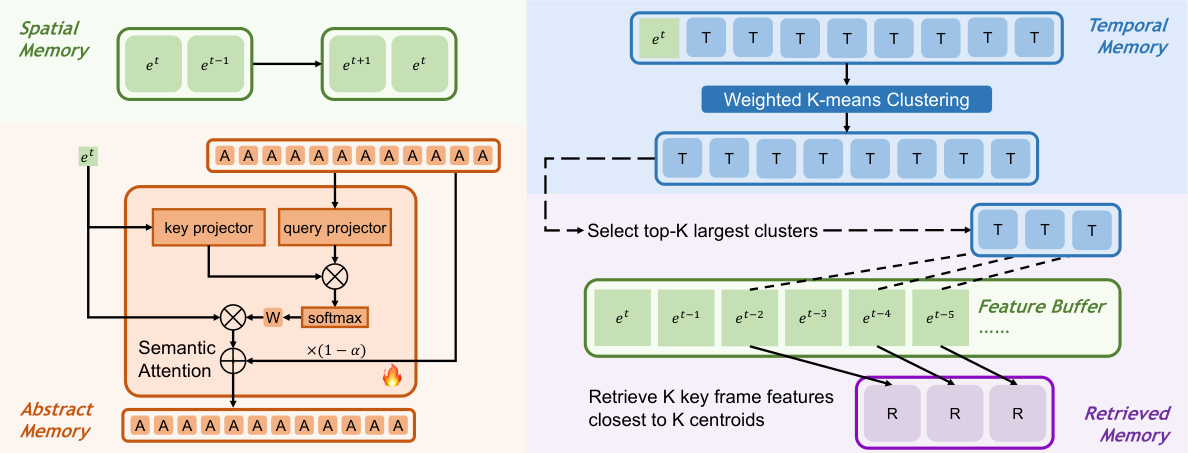
Figure 4: STAR memory writing mechanism. (a) Update spatial memory by a FIFO queue. (b) Update temporal memory by Weighted $K$ -means Clustering. (c) Update abstract memory by Semantic Attention. (d) Update retrieved memory by key frame feature retrival. Here feature map eT has multiple sizes. $\mathbf{\omega}^{\leftarrow}\mathbf{S}^{\rightarrow}$ , “T”, “A” and “R” represent tokens of spatial, temporal, abstract and retrieved memory, respectively.
图 4: STAR记忆写入机制。(a) 通过FIFO队列更新空间记忆。(b) 通过加权$K$均值聚类更新时序记忆。(c) 通过语义注意力更新抽象记忆。(d) 通过关键帧特征检索更新检索记忆。此处特征图eT具有多种尺寸。$\mathbf{\omega}^{\leftarrow}\mathbf{S}^{\rightarrow}$中,"T"、"A"和"R"分别表示空间、时序、抽象和检索记忆的token。
Spatial memory. Spatial memory houses the most recent and detailed spatial information for short-term use, implemented as a FIFO (First-In-First-Out) queue, as illustrated in Figure 4 and Equation (2). This architecture enables continuous updating with the newest frames, facilitating immediate access to fine-grained spatial data.
空间记忆。空间记忆存储了最新且详细的空间信息以供短期使用,其实现方式为FIFO (First-In-First-Out) 队列,如图 4 和公式 (2) 所示。该架构支持持续更新最新帧,便于快速访问细粒度空间数据。
Temporal memory. Temporal memory integrates dynamic information over time, crucial for longterm retention. When its size surpasses $N_{\mathrm{tem}}$ , the $g_{\mathrm{wkmeans}}$ (Weighted $K$ -means Clustering) algorithm is applied, as shown in Equation (3) and Algorithm 1. This strategy condenses the memory content into $N_{\mathrm{tem}}$ clusters which can be seen as the representation of key events in videos. Then the centroids of these clusters are used as the new memory for efficiently storing temporal contexts.
时序记忆。时序记忆整合随时间变化的动态信息,对长期保留至关重要。当容量超过 $N_{\mathrm{tem}}$ 时,将应用加权K均值聚类算法 $g_{\mathrm{wkmeans}}$ (Weighted $K$-means Clustering),如公式(3)和算法1所示。该策略将记忆内容压缩为 $N_{\mathrm{tem}}$ 个聚类,可视为视频关键事件的表征。随后这些聚类的质心将作为新记忆,用于高效存储时序上下文。
Abstract memory. Abstract memory supports high-level semantic concept interpretation through $f_{S A}$ , the Semantic Attention model. It follows Equation (4) to synthesize the insights gained from both spatial and temporal memories into abstracted, actionable knowledge. $f_{S A}$ keeps adjusting $M_{\mathrm{abs}}$ , the synopsis of whole video by newest features. Refer to Figure 4 and Algorithm 2 for details.
抽象记忆。抽象记忆通过语义注意力模型 (Semantic Attention model) $f_{S A}$ 支持高级语义概念解析,其遵循公式(4) 将空间记忆与时序记忆的洞察合成为可操作的抽象知识。$f_{S A}$ 持续通过最新特征调整视频概要 $M_{\mathrm{abs}}$ ,详见 图 4 和 算法 2 。
Retrieved memory. Retrieved memory focuses on recalling precise spatial details by identifying and retrieving the most substantial frame features. As shown in Figure 4, it first selects the top $\mathbf{\nabla}\cdot\mathbf{K}$ (where $\mathbf{K}$ equals $N_{\mathrm{ret,\ell}}$ ) largest clusters from the $N_{\mathrm{tem}}$ clusters obtained in temporal memory $M_{\mathrm{tem}}$ . Then the nearest frame features in feature buffer to centroids of these K clusters are retrieved to supplement the temporal memory with more detailed spatial information. This process is illustrated in Equation (5) and Algorithm 3.
检索记忆。检索记忆通过识别和检索最显著的帧特征来聚焦于精确空间细节的回忆。如图 4 所示,它首先从时间记忆 $M_{\mathrm{tem}}$ 获得的 $N_{\mathrm{tem}}$ 个聚类中选出前 $\mathbf{\nabla}\cdot\mathbf{K}$ 个最大聚类 (其中 $\mathbf{K}$ 等于 $N_{\mathrm{ret,\ell}}$ ),然后从特征缓冲区中检索与这些 K 个聚类质心最近的帧特征,以补充时间记忆中更详细的空间信息。该过程如公式 (5) 和算法 3 所示。
In brief, a new feature $e^{t}$ is written to STAR memory as follows:
简而言之,新特征 $e^{t}$ 会按以下方式写入STAR内存:
$$
\begin{array}{r l}&{M_{\mathrm{buff}}^{t}=\mathsf{c o n c a t}\big(g_{\mathrm{pooling}}(e^{t},P_{\mathrm{spa}}),M_{\mathrm{buff}}^{t-1}\big)[0:N_{\mathrm{buff}},:,:]}\ &{M_{\mathrm{spa}}^{t}=M_{\mathrm{buff}}^{t}[0:N_{\mathrm{spa}},:,:]}\ &{M_{\mathrm{tem}}^{t}=g_{\mathrm{wkmeans}}\Big(\mathsf{c o n c a t}\big(g_{\mathrm{pooling}}(e^{t},P_{\mathrm{tem}}),M_{\mathrm{tem}}^{t-1}\big),N_{\mathrm{tem}}\Big)}\ &{M_{\mathrm{abs}}^{t}=f_{S A}\big(M_{\mathrm{abs}}^{t-1},g_{\mathrm{pooling}}(e^{t},P_{\mathrm{abs}}),N_{\mathrm{abs}}\big)}\ &{M_{\mathrm{ret}}^{t}=g_{\mathrm{retives}}(M_{\mathrm{buff}}^{t},M_{\mathrm{tem}}^{t},N_{\mathrm{ret}})}\end{array}
$$
$$
\begin{array}{r l}&{M_{\mathrm{buff}}^{t}=\mathsf{c o n c a t}\big(g_{\mathrm{pooling}}(e^{t},P_{\mathrm{spa}}),M_{\mathrm{buff}}^{t-1}\big)[0:N_{\mathrm{buff}},:,:]}\ &{M_{\mathrm{spa}}^{t}=M_{\mathrm{buff}}^{t}[0:N_{\mathrm{spa}},:,:]}\ &{M_{\mathrm{tem}}^{t}=g_{\mathrm{wkmeans}}\Big(\mathsf{c o n c a t}\big(g_{\mathrm{pooling}}(e^{t},P_{\mathrm{tem}}),M_{\mathrm{tem}}^{t-1}\big),N_{\mathrm{tem}}\Big)}\ &{M_{\mathrm{abs}}^{t}=f_{S A}\big(M_{\mathrm{abs}}^{t-1},g_{\mathrm{pooling}}(e^{t},P_{\mathrm{abs}}),N_{\mathrm{abs}}\big)}\ &{M_{\mathrm{ret}}^{t}=g_{\mathrm{retives}}(M_{\mathrm{buff}}^{t},M_{\mathrm{tem}}^{t},N_{\mathrm{ret}})}\end{array}
$$
Here $g_{\mathrm{pooling}}(e,P^{\prime})$ applies Average Pooling to compress feature map $e$ from $P^{2}$ to $P^{\prime2}$ size along width and height dimensions. concat $(a,b)$ means concatenating tensors $a$ and $b$ along time axis.
这里 $g_{\mathrm{pooling}}(e,P^{\prime})$ 对特征图 $e$ 应用平均池化 (Average Pooling) ,将其从 $P^{2}$ 尺寸沿宽度和高度维度压缩至 $P^{\prime2}$ 尺寸。concat $(a,b)$ 表示沿时间轴拼接张量 $a$ 和 $b$ 。
3.3 Real-time LLM decoder
3.3 实时大语言模型解码器
The LLM decoder works as part of a real-time question answering server. When triggered by a question $Q^{t}$ at time $t$ , the LLM decoder first calculates the text embedding $I_{\mathrm{text}}^{t}=f_{\mathrm{embed}}(Q^{t})$ and maps the STAR memory $M^{t}=M_{\mathrm{spa}}^{t}+M_{\mathrm{tem}}^{t}+M_{\mathrm{abs}}^{t}+M_{\mathrm{ret}}^{t}$ to embedding space with the projector $I_{\mathrm{vision}}^{t}=f_{\mathrm{proj}}(M^{t})$ . Then it starts to generate answer $A^{t}=f_{\mathrm{LLM}}(I_{\mathrm{text}}^{t},I_{\mathrm{vision}}^{t})$ .decode() in real time.
大语言模型解码器作为实时问答服务器的一部分运行。当在时间 $t$ 被问题 $Q^{t}$ 触发时,大语言模型解码器首先计算文本嵌入 $I_{\mathrm{text}}^{t}=f_{\mathrm{embed}}(Q^{t})$ ,并通过投影器 $I_{\mathrm{vision}}^{t}=f_{\mathrm{proj}}(M^{t})$ 将STAR记忆 $M^{t}=M_{\mathrm{spa}}^{t}+M_{\mathrm{tem}}^{t}+M_{\mathrm{abs}}^{t}+M_{\mathrm{ret}}^{t}$ 映射到嵌入空间。随后开始实时生成答案 $A^{t}=f_{\mathrm{LLM}}(I_{\mathrm{text}}^{t},I_{\mathrm{vision}}^{t})$ 。decode()。
3.4 Implementation details
3.4 实现细节
In this study, we utilize pre-trained CLIP ViT-L/14-224px [35] as streaming visual encoder. Following LLaVA [24], we choose a 2-layer-MLP as visual projector and pre-trained Vicuna-7B [7] as LLM decoder. Considering the balance between performance and resource consumption, we set $P_{\mathrm{spa}}=8$ $P_{\mathrm{tem}}=4$ , $P_{\mathrm{abs}}=1$ , $N_{\mathrm{buff}}=300$ , $N_{\mathrm{spa}}=1$ , $N_{\mathrm{tem}}=N_{\mathrm{abs}}=25$ and $N_{\mathrm{ret}}=3$ . The MAXSIZE of STAR memory is set to 681 tokens in order to keep computational efficiency.
在本研究中,我们采用预训练的CLIP ViT-L/14-224px [35]作为流式视觉编码器。遵循LLaVA [24]的方案,选择2层MLP作为视觉投影器,并采用预训练的Vicuna-7B [7]作为大语言模型解码器。权衡性能与资源消耗后,参数设置为 $P_{\mathrm{spa}}=8$ 、 $P_{\mathrm{tem}}=4$ 、 $P_{\mathrm{abs}}=1$ ,缓冲区大小 $N_{\mathrm{buff}}=300$ ,空间采样 $N_{\mathrm{spa}}=1$ ,时序采样 $N_{\mathrm{tem}}=N_{\mathrm{abs}}=25$ ,检索次数 $N_{\mathrm{ret}}=3$ 。为保证计算效率,STAR记忆体的MAXSIZE设为681个token。
We train Flash-VStream for 2 stages: modality alignment and instruction tuning. The training data keep the same with LLaMA-VID [20], including LLaVA-filtered-558K [23] image-caption pairs and LLaMA-VID-filtered-232K [20] video-caption pairs for stage 1, LLaVA-filtered-665K [23] image QA pairs and Video-ChatGPT-filtered-98K [30] video QA pairs for stage 2. For each stage, the model is trained for 1 epoch on 8 A100 80G GPUs. During training, the parameters of visual encoder are frozen and the parameters of LLM are frozen only for the first stage. All training and inference experiments was conducted under BF16 precision to save time and resources. Other hyper-parameters can be found at Table 7.
我们分两个阶段训练Flash-VStream:模态对齐和指令微调。训练数据与LLaMA-VID [20]保持一致,第一阶段使用LLaVA-filtered-558K [23]图像-描述对和LLaMA-VID-filtered-232K [20]视频-描述对,第二阶段使用LLaVA-filtered-665K [23]图像问答对和Video-ChatGPT-filtered-98K [30]视频问答对。每个阶段在8块A100 80G GPU上训练1个epoch。训练期间视觉编码器参数始终冻结,大语言模型参数仅在第一阶段冻结。所有训练和推理实验均采用BF16精度以节省时间和资源。其他超参数见表7。
4 VStream-QA: A new benchmark for online video stream QA
4 VStream-QA: 在线视频流问答新基准
Previous video QA benchmarks [43, 44, 47] mostly focus on offline video understanding, where user query and finite-length video are given to the model at the same time. To our best knowledge, there is no existing benchmark specifically designed for online video stream understanding. Also, most existing benchmarks are limited to short-length videos within 1 minute [43, 44] or medium-length videos within 10 minutes [29, 31, 37, 47], which are unsuitable for simulating online video stream.
以往的视频问答基准测试 [43, 44, 47] 主要关注离线视频理解,即用户查询和有限长度视频同时提供给模型。据我们所知,目前尚无专门为在线视频流理解设计的基准测试。此外,现有基准测试大多局限于1分钟以内的短视频 [43, 44] 或10分钟以内的中长视频 [29, 31, 37, 47],这些都不适合模拟在线视频流场景。
To address this problem, we propose VStream-QA, a novel question answering benchmark specifically designed for online video stream understanding. VStream-QA consists of two parts: VStreamQA-Ego and VStream-QA-Movie, which are designed for evaluating first-perspective ego-centric understanding and third-perspective plot understanding, respectively. The prominent features of VStream-QA are i) each question-answer pair is marked with a specific timestamp in the video and only related to the visual information before that timestamp, ii) containing extremely videos (30 minutes to 60 minutes) that is significantly longer than existing benchmarks, and iii) covering a variety of video sources and question types.
为解决这一问题,我们提出了VStream-QA这一专为在线视频流理解设计的新型问答基准。VStream-QA包含两个部分:VStreamQA-Ego和VStream-QA-Movie,分别用于评估第一人称视角的自我中心理解和第三人称视角的情节理解。VStream-QA的显著特点包括:i) 每个问答对都标记了视频中的特定时间戳,且仅与该时间戳前的视觉信息相关;ii) 包含远超现有基准长度的超长视频(30分钟至60分钟);iii) 涵盖多种视频来源和问题类型。
Table 2: Video QA Benchmark Comparison. V for video duration, Q for number of questions, and Desc for descriptive.
表 2: 视频问答基准对比。V 表示视频时长,Q 表示问题数量,Desc 表示描述性任务。
| Benchmark | Avg V. | TotalV. | Q. | Goal |
|---|---|---|---|---|
| MSVD-QA[44] MSRVTT-QA[44] | 10s 15s | 1.4h 12.5h | 13K 73K | Desc. QA Desc. QA |
| ActivityNet-QA[47] | 112s 40s | 25h | 8K | Desc.QA |
| Next-QA[43] CineCLIP-QA[29] | 213s | 11h 9h | 9K 2.5K | Temporal QA Movie QA |
| VStream-QA | 40min | 21h | 3.5K | OnlineVideo Stream QA |

Figure 5: Question Types.
图 5: 问题类型。
Specifically, VStream-QA-Ego consists of 10 1-hour-long ego-centric video clips from Ego4D dataset [12] together with 1.5K question-answer-timestamp triplets , while VStream-QA-Movie consists of 22 half-an-hour-long movie clips from MovieNet dataset [15] together with 2K questionanswer-timestamp triplets. As shown in Table 2, these two parts consist of a total of 21 hours of video and 3.5K question-answer pairs. Our proposed VStream-QA fills the gap in existing benchmarks for online video stream understanding, and provides a extremely long video test set that can be used to evaluate in both online settings and conventional offline settings.
具体而言,VStream-QA-Ego包含来自Ego4D数据集[12]的10段1小时长的第一视角视频片段及1.5K个问题-答案-时间戳三元组,而VStream-QA-Movie包含来自MovieNet数据集[15]的22段半小时长的电影片段及2K个问题-答案-时间戳三元组。如表2所示,这两部分共包含21小时的视频和3.5K个问答对。我们提出的VStream-QA填补了现有在线视频流理解基准的空白,并提供了一个可用于在线设置和传统离线设置的超长视频测试集。
Table 3: Comparison with SoTA methods on zero-shot VideoQA. Acc. and Sco. denote accuracy and score, respectively. *: Evaluated by us.
表 3: 零样本视频问答 (VideoQA) 与当前最优方法 (SoTA) 的对比。Acc. 和 Sco. 分别表示准确率和得分。*: 由我们评估。
| 方法 | ActNet Acc. | ActNet Sco. | NExT Acc. | NExT Sco. | MSVD Acc. | MSVD Sco. | MSRVTT Acc. | MSRVTT Sco. | VS-Ego Acc. | VS-Ego Sco. | VS-Movie Acc. | VS-Movie Sco. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Video-ChatGPT[30] | 35.2 | 2.7 | 54.6 | 3.2 | 64.9 | 3.3 | 49.3 | 2.8 | 51.7 | 3.7 | 54.4 | 3.4 |
| MovieChat[37] | 45.7 | 3.4 | 49.9 | 2.7 | 75.2 | 3.8 | 52.7 | 2.6 | 52.2 | 3.4 | 39.1 | 2.3 |
| Chat-UniVi [16] | 45.8 | 3.2 | 60.8* | 3.3 | 65.0 | 3.6 | 54.6 | 3.1 | 50.9 | 3.8 | 54.0 | 3.4 |
| Vista-LLaMA[29] | 48.3 | 3.3 | 60.7 | 3.4 | 65.3 | 3.6 | 60.5 | 3.3 | ||||
| LLaMA-VID [20] | 47.4 | 3.3 | 60.3* | 3.4 | 69.7 | 3.7 | 57.7 | 3.2 | 54.8 | 3.9 | 51.4 | 3.4 |
| Flash-VStream | 51.9 | 3.4 | 61.6 | 3.4 | 80.3 | 3.9 | 72.4 | 3.4 | 59.0 | 3.9 | 56.1 | 3.4 |
We carefully design 5 types of questions to evaluate the model’s ability to understand both scene content and temporal information. As shown in Figure 5, the question types are well balanced. Specifically, [Scene Summary] and [Action Description] are open-ended questions designed to evaluate the model’s ability to understand static and dynamic scene content. [Event Occurrence] are yes/no questions designed to evaluate the model’s ability to detect whether a specific event or scene occurs in the video. [Ordered Event Narrative] and [Sequence Validation] are both designed to evaluate the model’s ability to understand the temporal order of events in the video, with the former being open-ended and the latter being yes/no questions. For yes/no questions, its answer ratio is well balanced with $46.3%$ yes and $53.7%$ no.
我们精心设计了5类问题来评估模型对场景内容和时序信息的理解能力。如图5所示,问题类型分布均衡。具体而言:[Scene Summary]和[Action Description]是开放式问题,用于评估模型对静态和动态场景内容的理解能力;[Event Occurrence]为是非题,旨在评估模型检测视频中是否发生特定事件或场景的能力;[Ordered Event Narrative]和[Sequence Validation]均用于评估模型理解视频事件时序关系的能力,前者为开放式问题,后者为是非题。对于是非题,其答案比例均衡分布(46.3%为"是",53.7%为"否")。
In order to balance the annotation quality, the data scale, and the total annotation expenses, we designed a 5-steps data generation pipeline as follows: 1) Video Selection; 2) Dense Captioning; 3) Summary Generation; 4) Question-Answer Generation; and 5) Human Filtering. For details of each steps, please refer to Appendix C.1.
为了平衡标注质量、数据规模和总标注成本,我们设计了以下5步数据生成流程:1) 视频筛选;2) 密集描述生成;3) 摘要生成;4) 问答生成;5) 人工过滤。各步骤详情请参阅附录C.1。
5 Experiment
5 实验
5.1 Experimental setup
5.1 实验设置
Datasets. For the purpose of real-time video stream understanding, it is crucial for models to keep accurate and efficient. To evaluate real-time understanding ability and computational efficiency of models, we them models on Realtime-VStream-QA-Ego/Movie datasets (or RVS-Ego/Movie for short). The real-time version of VStream-QA differentiates normal version by ensuring each question grounded before a predefined timestamp. To evaluate the basic question answering capability of FlashVStream, we conduct zero-shot open-ended video question answering experiments on Activity Net-QA [47], NExT-QA [43], MSVD-QA [44], MSRVTT-QA [44] and the proposed VStream-QA-Ego/Movie datasets (or VS-Ego/Movie for short).
数据集。为了实现实时视频流理解,模型必须保持准确高效。为评估模型的实时理解能力和计算效率,我们在Realtime-VStream-QA-Ego/Movie数据集(简称RVS-Ego/Movie)上进行测试。实时版VStream-QA与普通版的区别在于确保每个问题都锚定在预设时间戳之前。为评估FlashVStream的基础问答能力,我们在Activity Net-QA [47]、NExT-QA [43]、MSVD-QA [44]、MSRVTT-QA [44]以及提出的VStream-QA-Ego/Movie数据集(简称VS-Ego/Movie)上进行了零样本开放式视频问答实验。
Evaluation Metrics. For open-ended video question answering tasks, we adopt GPT-3.5 metric following common practices in [16, 19, 20, 21, 27, 29, 30, 37, 46, 49, 50]. With question, ground truth answer and the prediction generated by model, GPT-3.5 is able to judge whether this prediction is correct and provide a score between 0 and 5. We report the GPT-3.5 accuracy and score of each model on VQA datasets. For computational efficiency test, we report the average respond latency (from questioning to answering) and maximum video random-access memory (VRAM) of models.
评估指标。对于开放式视频问答任务,我们遵循[16, 19, 20, 21, 27, 29, 30, 37, 46, 49, 50]中的通用做法,采用GPT-3.5评估指标。给定问题、标准答案和模型生成的预测结果,GPT-3.5能够判断该预测是否正确,并提供0到5分的评分。我们报告各模型在VQA数据集上的GPT-3.5准确率和得分。针对计算效率测试,我们报告模型的平均响应延迟(从提问到回答)和最大视频随机存取存储器(VRAM)使用量。
5.2 Zero-shot video question answering
5.2 零样本 (Zero-shot) 视频问答
As our model is only trained on [2, 15, 23, 30], we compare Flash-VStream with other competitive methods Video-ChatGPT[30], MovieChat[37], Chat-UniVi[16], Vista-LLaMA[29] and LLaMAVID[20] on zero-shot real-time VideoQA datasets in Table 1, and on normal zero-shot VideoQA datasets in Table 3. Video-ChatGPT uses temporal pooling and spatial pooling for video understanding. This simple method performs well in real-time movie understanding. MovieChat implements a merge-based memory consolidation and uses a Q-Former [18] as feature aggregator. Although it is competitive in understanding some short-video scenes, it falls behind in the domain of extremely long-video understanding, such as with RVS-Ego and RVS-Movie, as shown in Table 1. The newly proposed Chat-UniVi and LLaMA-VID have relative high performances on real-time video understanding benchmark. However, the high computation burden and high latency make it difficult to
由于我们的模型仅在[2, 15, 23, 30]上进行训练,我们在表1中比较了Flash-VStream与其他竞争方法Video-ChatGPT[30]、MovieChat[37]、Chat-UniVi[16]、Vista-LLaMA[29]和LLaMAVID[20]在零样本实时视频问答(VideoQA)数据集上的表现,并在表3中比较了它们在常规零样本VideoQA数据集上的表现。Video-ChatGPT采用时间池化和空间池化进行视频理解,这种简单方法在实时电影理解中表现良好。MovieChat实现了基于合并的记忆整合,并使用Q-Former[18]作为特征聚合器。虽然在某些短视频场景理解中具有竞争力,但在极长视频理解领域(如RVS-Ego和RVS-Movie)表现不佳,如表1所示。新提出的Chat-UniVi和LLaMA-VID在实时视频理解基准测试中表现出相对较高的性能,但高计算负担和高延迟使其难以...
(a) Spatial Size
(a) 空间尺寸
Table 6: Comparison of different spatial and temporal size of STAR memory. A and S denote accuracy and score, respectively.
表 6: STAR 记忆不同时空规模的对比。A 和 S 分别表示准确率和得分。
| Pspa | Ptem | Pabs | Ps spa | VS-ego A | VS-ego S | VS-movie A | VS-movie S |
|---|---|---|---|---|---|---|---|
| 16 | 4 | 1 | 16 | 55.7 | 3.9 | 52.1 | 3.3 |
| 4 | 4 | 1 | 4 | 58.4 | 4.0 | 53.1 | 3.4 |
| 8 | 8 | 1 | 8 | 58.2 | 3.9 | 53.4 | 3.4 |
| 8 | 1 | 1 | 8 | 56.4 | 4.0 | 51.9 | 3.4 |
| 8 | 4 | 4 | 8 | 57.2 | 4.0 | 54.8 | 3.5 |
| 8 | 4 | 1 | 8 | 59.0 | 3.9 | 56.1 | 3.4 |
(b) Temporal Length
(b) 时间长度
| 方法 | VS-ego | VS-movie |
|---|---|---|
| Nspa Ntem | Nabs | Nret |
| 1 | 32 | 32 |
| 1 | 16 | 16 3 |
| 1 | 8 | 8 3 |
| 1 | 25 | 25 |
deploy them for real-time understanding scenes. Flash-VStream achieves SoTA on these benchmarks, demonstrating the proposed STAR memory’s exceptional capabilities in information compression and long video comprehension.
Flash-VStream在这些基准测试中达到了最优水平(SoTA),证明了所提出的STAR记忆模块在信息压缩和长视频理解方面的卓越能力。
5.3 Computational efficiency
5.3 计算效率
We measure the inference latency of each model by counting the respond wall time of the question handler process, as presented in Figure 2. For many models, the inference latency scales up with number of frames because their architectures demand processing all frames at once. Distinct from them, Flash-VStream leverages an efficient multiprocessing STAR memory mechanism (see Section 3.2) for streaming processing frames, which allows relative low inference latency and VRAM cost (detailed in Table 1). These attributes enable real-time inference.
我们通过统计问题处理进程的响应耗时来测量各模型的推理延迟,如图 2 所示。多数模型的推理延迟会随帧数增加而上升,因其架构要求一次性处理所有帧。与之不同,Flash-VStream 采用高效的多进程 STAR 内存机制 (详见第 3.2 节) 进行流式帧处理,从而保持较低的推理延迟与显存占用 (具体数据见表 1)。这些特性使其能够实现实时推理。
5.4 Ablation study
5.4 消融实验
Effect of components of memory mechanism. We conduct an ablation study to evaluate the effects of key components of the STAR memory mechanism, i.e., spatial, temporal, abstract and retrieved memory. Removing temporal memory can cause a severe performance drop (as shown in the second row of Table 4), indicating that temporal memory is vital in long video stream understanding, as it enables the integration of contextual information across frames for coherent comprehension. Other types of memory also contribute a lot as they capture different aspect of visual information, such as spatial layout, high-level concepts and pivotal experiences.
记忆机制组件的影响。我们通过消融实验评估STAR记忆机制关键组件(即空间、时序、抽象和检索记忆)的作用。移除时序记忆会导致性能显著下降(如表4第二行所示),这表明时序记忆在长视频流理解中至关重要,因为它能整合跨帧的上下文信息以实现连贯理解。其他类型记忆同样贡献显著,它们分别捕捉了视觉信息的不同方面,如空间布局、高层概念和关键经历。
Table 4: Ablation studies of STAR memory
表 4: STAR记忆模块消融实验
| 记忆类型 | VS-ego | VS-movie |
|---|---|---|
| S | T | A |
| √ | ||
| √ | ||
| √ | ||
Semantic Attention. We compare the proposed Semantic Attention with other memory updating strategies as shown in Table 5. Q-Former [17] is widely used by many models [20, 37, 49] and Sequential Q-Former is used by [29]. These updating methods are all transformer-based. Despite its lightweight nature, the Semantic Attention model outper
语义注意力 (Semantic Attention)。我们将提出的语义注意力与其他记忆更新策略进行比较,如表 5 所示。Q-Former [17] 被许多模型广泛采用 [20, 37, 49],而 Sequential Q-Former 则被 [29] 使用。这些更新方法均基于 Transformer。尽管语义注意力模型结构轻量,但其性能优于
Table 5: Semantic Attention v.s. other updating strategies
表 5: 语义注意力机制与其他更新策略对比
| Abstractmemory | VS-ego | VS-movie |
|---|---|---|
| A | S | |
| Q-Former | 57.1 | 3.9 |
| Sequential Q-Former | 56.0 | 3.9 |
| SemanticAttention | 59.0 | 3.9 |
forms other methods by a large margin. We suppose the reason is that the training dataset is too small for Q-Former based model to adequately learn. The architecture of Semantic Attention facilitates the extraction of key information and the selectively forgetting of irrelevant details, enhancing the model’s ability to comprehend abstract concepts in long videos.
其他方法相比具有显著优势。我们认为原因在于训练数据集规模过小,导致基于 Q-Former 的模型无法充分学习。语义注意力 (Semantic Attention) 架构能有效提取关键信息并选择性遗忘无关细节,从而增强模型对长视频中抽象概念的理解能力。
Design of spatial size and temporal length of memory. In Table 6, we evaluate how spatial size and temporal length of memory influence long video understanding tasks. For spatial size of memory, although a smaller feature map is harmful to the performance, an excessively larger feature map is not an optimal choice either (see the first row of Table 6a). A similar pattern can be observed by varying temporal length of memory in Table 6b, in line with findings from [45]. Considering the expensive computational cost of larger and longer memory, we adopt a balanced design.
记忆空间尺寸与时间长度的设计。在表6中,我们评估了记忆空间尺寸和时间长度对长视频理解任务的影响。对于记忆空间尺寸,虽然较小的特征图会损害性能,但过大的特征图也不是最佳选择(见表6a第一行)。通过改变记忆时间长度可以观察到类似的规律(表6b),这与[45]的研究结果一致。考虑到更大更长记忆的高昂计算成本,我们采用了平衡的设计方案。

Figure 6: PCA Visualization of memory tokens. Red points represent memory tokens and blue points represent raw vision tokens from visual encoder. Left: an example from Activity Net. Right: an example from Ego4D.
图 6: 记忆token的PCA可视化。红点代表记忆token,蓝点代表来自视觉编码器的原始视觉token。左图: Activity Net中的示例。右图: Ego4D中的示例。

Figure 7: Comparison of different video LLMs on VStream-QA-Movie. Zoom in for a better view. In this video, a policeman pulls over a vehicle driven by a couple, but they point a gun at him and kill him. Our Flash-VStream is the only model that successfully understands the theme of this long movie clip.
图 7: 不同视频大语言模型在 VStream-QA-Movie 上的对比。放大可查看更清晰效果。该视频中,一名警察拦停一对夫妇驾驶的车辆,但对方持枪将其杀害。我们的 Flash-VStream 是唯一能成功理解这段长电影片段主题的模型。
We investigate the memory consolidation procedure in deep feature space. Specifically, in the left part of Figure 6, when inputting a video stream containing 3 significantly different scenes (talking, playing the drums and end credits), the memory will focus on the scene with the longest duration, just like what human will do in their minds. Relatively static scenes and relatively dynamic scenes are both given lots of attention, as shown in the right part of Figure 6. The visualization proves that memory tokens effectively reveal the distribution of the vision tokens.
我们研究了深度特征空间中的记忆巩固过程。具体而言,在图6左侧部分,当输入包含3个显著不同场景(谈话、打鼓和片尾字幕)的视频流时,记忆会聚焦于持续时间最长的场景,这与人类大脑的处理方式一致。相对静态和动态的场景均获得高度关注,如图6右侧所示。可视化结果证明记忆token能有效揭示视觉token的分布特征。
5.6 Case study
5.6 案例分析
To better demonstrate the feature of VStream-QA as well as the effectiveness of Flash-VStream model, we hereby provide a case study on VStream-QA-Movie dataset. As shown in Figure 7, a question timestamp is equipped with each question-answer pair, indicating the time when the question is asked. Models are only provided with the visual content before the question timestamp. Thanks to the carefully designed STAR memory mechanism, our Flash-VStream grasp the key visual information and turns out to be the only model that successfully understands the theme of this long movie clip, while LLaMA-VID, Video Chat GP T and VStream-QA fail to do so for various reasons. This proves the effectiveness of our proposed Flash-VStream model in long video understanding tasks. Refer to model generated answers and the figure caption for details.
为了更好地展示VStream-QA的特性以及Flash-VStream模型的有效性,我们在此提供VStream-QA-Movie数据集的案例研究。如图7所示,每个问答对都配备了一个问题时间戳,表示提问时间。模型仅能获取问题时间戳之前的视觉内容。得益于精心设计的STAR记忆机制,我们的Flash-VStream抓住了关键视觉信息,成为唯一成功理解这段长电影片段主题的模型,而LLaMA-VID、Video Chat GPT和VStream-QA因各种原因未能做到。这证明了我们提出的Flash-VStream模型在长视频理解任务中的有效性。详情请参阅模型生成的答案及图注。
6 Conclusion
6 结论
In conclusion, we have introduced Flash-VStream, a video-language model for real-time processing of online video streams and answering user questions. It incorporates a smartly designed memory called STAR, and significantly reduces inference latency and VRAM consumption. In addition, we have proposed a new benchmark for online video understanding called VStream-QA. Our model outperforms existing methods on this new online benchmark and maintains SoTA performance on offline video understanding benchmarks. We hope our work could inspire further research and advancements in the field of online video stream understanding.
总之,我们推出了Flash-VStream——一个用于实时处理在线视频流并回答用户问题的视频语言模型。该模型创新性地采用了名为STAR的智能记忆设计,显著降低了推理延迟和显存消耗。此外,我们还提出了名为VStream-QA的全新在线视频理解基准测试。我们的模型不仅在这个新型在线基准上超越了现有方法,同时在离线视频理解基准测试中保持了最先进(SoTA)性能。期待这项工作能推动在线视频流理解领域的进一步研究与发展。
References
参考文献
Appendix
附录
A Memory implementation details
内存实现细节
This section describes the details of the proposed Spatial-Temporal-Abstract-Retrieved memory mechanism in Section 3.2. The STAR memory has both parametric and non-parametric updating strategies. Spatial memory uses simple replacing method.
本节将详细介绍第3.2节提出的时空抽象检索记忆机制 (STAR memory)。STAR记忆采用参数化与非参数化相结合的更新策略,其中空间记忆采用简单替换法更新。
t teem mp poor ra all -mweisme otroy $(\bar{N_{\mathrm{tem}}}+1)\times P_{\mathrm{tem}}^{\bar{2}}$ n ttos ktehne sc teon $N_{\mathrm{tem}}\times P_{\mathrm{tem}}^{2}$ $K$ ttoh kfeenast.u rEea cclhu sftrear.me feature in $M_{t e m}^{(i)}=c_{i}\in\mathbb{R}^{P_{\mathrm{tem}}^{2}}$
$(\bar{N_{\mathrm{tem}}}+1)\times P_{\mathrm{tem}}^{\bar{2}}$
$N_{\mathrm{tem}}\times P_{\mathrm{tem}}^{2}$
$K$
每个帧特征表示为 $M_{t e m}^{(i)}=c_{i}\in\mathbb{R}^{P_{\mathrm{tem}}^{2}}$
Algorithm 1 Weighted K-means Clustering Algorithm
算法 1: 加权K均值聚类算法
Algorithm 2 Semantic Attention
算法 2 语义注意力
For abstract memory, we design a learning-based Semantic Attention model for information integration and selective forgetting. Algorithm 2 describes the detailed forward procedure of Semantic
对于抽象记忆,我们设计了一种基于学习的语义注意力模型(Semantic Attention),用于信息整合和选择性遗忘。算法2详细描述了语义注意力的前向计算过程。
Attention model. In order to update abstract memory $M_{\mathrm{abs}} \in \mathbb{R}^{N_{\mathrm{abs}}\times P_{\mathrm{abs}}^{2}}$ with newest features $\mathbf{e_{\theta}}\in\mathbb{R}^{n\times P_{\mathrm{{abs}}}^{2}}(n$ is 1 by default), we first calculated the attention weight between newest features and current abstract memory. Then a softmax layer is applied to normalize the contribution of new features. Finally, the abstract memory is updated by a momentum updating mechanism with decay factor $\alpha$ .
注意力模型。为了用最新特征 $\mathbf{e_{\theta}}\in\mathbb{R}^{n\times P_{\mathrm{{abs}}}^{2}}(n$ 默认为1) 更新抽象记忆 $M_{\mathrm{abs}} \in \mathbb{R}^{N_{\mathrm{abs}}\times P_{\mathrm{abs}}^{2}}$ ,我们首先计算最新特征与当前抽象记忆之间的注意力权重。然后应用 softmax 层来归一化新特征的贡献。最后,通过带有衰减因子 $\alpha$ 的动量更新机制来更新抽象记忆。
算法3 关键特征检索
Require: 当前特征缓冲区 Mouff = { Mbutr, Mouff ..
Mem..., MMem}
Require: 点权重向量 w = {w1, w2, .. . , wNem }
1: procedure 关键特征检索(Mbuff, Mtem, w, Nret)
2: k←Nret
3: j1, j2,..., jk ← top-k, wj
4: Mret ←
5: for z = 1,2,...,k do
.9 Ekey ← min_itemllge(Ekey, Pspa) - Miézmll² for ekey E Mbuff 7:
append (Mret, Ekey) 8: end for
9: return Mret
10:end procedure
For retrieved memory, we use a key feature retrieval Algorithm 3 to calculate the current retrieved memory $M_{\mathrm{{ret}}}\in\mathbb{R}^{\stackrel{\r{N_{\mathrm{ret}}}}{N_{\mathrm{{ret}}}}\times P_{\mathrm{{spa}}}^{2}}$ . Because retrieved memory and spatial memory are both renewed from the feature buffer $M_{\mathrm{buff}}$ , we set their spatial sizes to the same. Here $w_{j}$ is equal to the size of $j$ -th cluster, i.e., the number of tokens in this cluster. Therefore, we choose the centroids of the top $\mathbf{\nabla\cdot}\mathbf{k}$ large clusters as pivots. The features nearest to these centroids are considered as key features, which are added to the retrieved memory.
对于检索记忆,我们使用关键特征检索算法3来计算当前检索记忆$M_{\mathrm{{ret}}}\in\mathbb{R}^{\stackrel{\r{N_{\mathrm{ret}}}}{N_{\mathrm{{ret}}}}\times P_{\mathrm{{spa}}}^{2}}$。由于检索记忆和空间记忆都是从特征缓冲区$M_{\mathrm{buff}}$更新的,因此我们将它们的空间大小设置为相同。此处$w_{j}$等于第$j$个聚类的大小,即该聚类中的token数量。因此,我们选择前$\mathbf{\nabla\cdot}\mathbf{k}$大聚类的质心作为枢轴。最接近这些质心的特征被视为关键特征,并被添加到检索记忆中。
B Training details
B 训练细节
Table 7: Training settings of Flash-VStream
表 7: Flash-VStream 训练设置
| 设置项 | 阶段1 | 阶段2 |
|---|---|---|
| Batch size | 256 | 128 |
| Learning rate | 1e-3 | 2e-5 |
| Learning schedule | Cosine decay | |
| Warmup ratio | 0.03 | |
| Weight decay | 0 | |
| Epoch | 1 | |
| Optimizer DeepSpeed stage | AdamW | |
| Visual encoder | 0 | 1 |
| Semantic attention | Freeze | |
| Open | ||
| Projector | Open | |
| LLM | Freeze | Open |
The training procedure of Flash-VStream is similar to that of [23] [20]. In the modality alignment stage (stage 1), we train the Semantic attention model and the projector for one epoch. In the instruction tuning stage (Stage 2), we fine-tune the Semantic attention model, the projector and the LLM for another epoch. The overall training can be finished in 15 hours on 8 A100 80G GPUs (BFloat16) with extracted visual features. Detailed training settings are shown in Table 7.
Flash-VStream的训练流程与[23][20]类似。在模态对齐阶段(阶段1),我们训练语义注意力模型和投影器一个周期。在指令调优阶段(阶段2),我们继续微调语义注意力模型、投影器和大语言模型一个周期。使用提取的视觉特征,整个训练可在8块A100 80G GPU(BFloat16)上15小时内完成。具体训练参数见表7。
C VStream-QA benchmark design details
C VStream-QA基准测试设计细节
Here we provide more details of VStream-QA online video understanding benchmark.
在此我们详细介绍VStream-QA在线视频理解基准测试。
C.1 Data generation pipeline in detail
C.1 数据生成流程详解
• Video Selection. We first select 10 videos from Ego4D dataset [12] with each video being 1 hour long, and 22 videos from MovieNet dataset [15] with each video being 30 minutes long. Both Ego-centric videos and movie clips are chosen to cover a wide range of content types. Refer to next subsection for details.
• 视频选择。我们首先从Ego4D数据集[12]中选取10段视频(每段时长1小时),并从MovieNet数据集[15]中选取22段视频(每段时长30分钟)。选择第一人称视频和电影片段旨在覆盖多样化的内容类型,具体细节请参阅下一小节。
• Dense Captioning. We use GPT-4V [33] to generate dense captions for each video clip. Long videos are divided into pieces of 30 seconds, and 8 frames are sparsely sampled from each piece as input to GPT-4V. Each output caption describes the content of the 30-second video piece, and marked with a specific timestamp.
• 密集描述 (Dense Captioning)。我们使用 GPT-4V [33] 为每个视频片段生成密集描述。长视频被分割为30秒的片段,并从每个片段中稀疏采样8帧作为 GPT-4V 的输入。每条输出描述对应30秒视频片段的内容,并标注具体时间戳。
• Summary Generation. We use GPT-4 to de duplicate and summarize the dense captions generated by GPT-4V. The summary is designed to be a concise description scene-level clip, typically originated from multiple dense captions that correspond to several minutes of video content. Timestamps are carefully kept throughout the sum mari z ation process.
• 摘要生成。我们使用GPT-4对GPT-4V生成的密集描述进行去重和总结。该摘要旨在成为场景级片段的简洁描述,通常源自对应数分钟视频内容的多个密集描述。在总结过程中会精确保留时间戳。
• Question-Answer Generation. We use GPT-4 to generate 5 types of QA pair based on the scene summary. Each QA is generated from a single or several consecutive scene summaries, to ensure that the QA is only related to the visual information before the timestamp.
• 问答生成。我们使用 GPT-4 基于场景摘要生成 5 种类型的问答对。每个问答由单个或多个连续场景摘要生成,以确保问答仅与时间戳前的视觉信息相关。
• Human Filtering. Volunteers are invited to judge the relevance of the generated QA pairs to the video content. The following types of QA pairs are carefully filtered out: i) questions are irrelevant with the video or ambiguous, ii) questions require additional knowledge beyond the video, iii) questions are able to answered without the video, iv) answers are wrong or ambiguous. repetitive.
• 人工过滤。邀请志愿者评判生成的问答对与视频内容的相关性。以下类型的问答对被严格过滤:i) 问题与视频无关或表述模糊,ii) 问题需要视频以外的额外知识,iii) 无需观看视频即可回答问题,iv) 答案错误、表述模糊或重复。
C.2 Variety of video content
C.2 视频内容的多样性
Besides the variety of question types, VStream-QA benchmark also involves various type of video content.
VStream-QA 基准测试除了包含多种问题类型外,还涉及各类视频内容。
• VStream-QA-Ego video topics: [’cooking’, ’playing-card’, ’writing’, ’home-maintenance’, ’sightseeing’, ’reading’]. • VStream-QA-Movie movie genres: ["Action", "Adventure", "Sci-Fi", "Crime", "Drama", "Thriller", "War", "Mystery", "Comedy", "Fantasy", "History", "Biography", "Horror"].
• VStream-QA-Ego 视频主题: [ '烹饪', '打牌', '写作', '家居维修', '观光', '阅读' ]。
• VStream-QA-Movie 电影类型: [ "动作", "冒险", "科幻", "犯罪", "剧情", "惊悚", "战争", "悬疑", "喜剧", "奇幻", "历史", "传记", "恐怖" ]。
D Limitations
D 限制
D.1 Representative ness of VStream-QA benchmark
D.1 VStream-QA 基准的代表性
Although the proposed VStream-QA is the first benchmark that aims to simulate real-world video streaming scenarios, it still falls short in fully representing the scenario of comprehending infinitely long video streams in the real world. Besides, the proposed approach only involves the coarsegrained understanding task, i.e., QA. In the real world, video streams encompass more complex comprehension tasks. It is our aspiration that the Flash-VStream could inspire related research in this field.
尽管提出的VStream-QA是首个旨在模拟真实世界视频流场景的基准测试,但它仍未能完全体现现实世界中理解无限长视频流的场景。此外,该方法仅涉及粗粒度理解任务(即问答)。现实中的视频流还包含更复杂的理解任务。我们期待Flash-VStream能推动该领域的相关研究。
D.2 GPT-3.5-based evaluation metric
D.2 基于 GPT-3.5 的评估指标
In the proposed VStream-QA benchmark and many other video question answering benchmarks, GPT-3.5 based evaluation is adopted as the preferred metric. However, we notice that there is always a discrepancy between the distribution of GPT accuracy and GPT score. Specifically, for answers classified as “no”, many of them are assigned with a high score like $\cdots4^{\cdot\cdot}$ or $\ '5'$ , also discussed by [37]. This abnormal phenomenon reduces the credibility of this $^{\circ}0\sim5$ score” metric in GPT-3.5-based MLLM evaluation.
在提出的VStream-QA基准测试和许多其他视频问答基准测试中,基于GPT-3.5的评估被采用为首选指标。然而,我们注意到GPT准确率和GPT分数之间始终存在差异。具体而言,对于被分类为"no"的答案,许多答案被分配了高分,如$\cdots4^{\cdot\cdot}$或$\ '5'$,[37]也讨论了这一现象。这种异常现象降低了基于GPT-3.5的MLLM评估中$^{\circ}0\sim5$分数指标的可信度。
E Broader Impacts
E 更广泛的影响
Real-time understanding models for long video streams may lead to potential negative societal impacts, including but not limited to unauthorized surveillance or privacy-infringing tracking. However, we firmly believe that the task itself is neutral with positive applications, such as health monitoring and emergency response.
实时理解长视频流的模型可能带来潜在的社会负面影响,包括但不限于未经授权的监控或侵犯隐私的追踪。然而,我们坚信该任务本身具有中立性,并能产生积极应用,例如健康监测和紧急响应。