A Hierarchical Structured Self-Attentive Model for Extractive Document Sum mari z ation (HSSAS)
一种用于抽取式文档摘要的分层结构化自注意力模型 (HSSAS)
ABSTRACT The recent advance in neural network architecture and training algorithms has shown the effectiveness of representation learning. The neural-network-based models generate better representation than the traditional ones. They have the ability to automatically learn the distributed representation for sentences and documents. To this end, we proposed a novel model that addresses several issues that are not adequately modeled by the previously proposed models, such as the memory problem and incorporating the knowledge of document structure. Our model uses a hierarchical structured self-attention mechanism to create the sentence and document embeddings. This architecture mirrors the hierarchical structure of the document and in turn enables us to obtain better feature representation. The attention mechanism provides extra source of information to guide the summary extraction. The new model treated the sum mari z ation task as a classification problem in which the model computes the respective probabilities of sentence–summary membership. The model predictions are broken up by several features such as information content, salience, novelty, and positional representation. The proposed model was evaluated on two well-known datasets, the CNN/Daily Mail and DUC 2002. The experimental results show that our model outperforms the current extractive state of the art by a considerable margin.
摘要
神经网络架构和训练算法的最新进展展现了表征学习(representation learning)的有效性。基于神经网络的模型能生成比传统方法更优的表征,具备自动学习句子和文档分布式表示的能力。为此,我们提出了一种新模型,解决了先前模型未能充分解决的若干问题,如内存问题和文档结构知识的融合。该模型采用分层结构的自注意力机制(self-attention)来生成句子和文档嵌入(embeddings),这种架构反映了文档的层次结构,从而获得更优的特征表示。注意力机制为摘要提取提供了额外的信息引导。新模型将摘要任务视为分类问题,通过计算句子-摘要隶属关系的概率进行预测,这些预测由信息量、显著性、新颖性和位置表示等多个特征共同决定。我们在CNN/Daily Mail和DUC 2002两个知名数据集上评估了该模型,实验结果表明我们的模型显著优于当前最先进的抽取式摘要方法。
KEYWORDS
关键词
Long short-term memory, hierarchical structured self-attention, document sum mari z ation, abstract features, .sentence embedding, document embedding
长短期记忆、分层结构化自注意力、文档摘要、抽象特征、句子嵌入、文档嵌入
I. INTRODUCTION
I. 引言
Text sum mari z ation is one of the most active research in natural language processing. It is an optimal way to tackle the problem of information overload by reducing the size of long document(s) into a few sentences or paragraphs. The popularity of handheld devices, such as smart phone, makes document sum mari z ation very urgent in the face of tiny screens and limited bandwidth [1]. It can also serve as a reading comprehension test for machines. To generate a good summary, it is important for a machine learning model to be able to understand the document(s) and distill the important information from it. These tasks are highly challenging for computers, especially as the size of a document increases. Even though the most sophisticated search engines are empowered by advanced information retrieval techniques, they lack the ability to synthesize information from multiple sources and to give users a concise yet informative response. Moreover, there is a need for tools that provide timely access to, and digest of, various sources. These concerns have sparked a great interest in the development of automatic document sum mari z ation systems. Traditional Text Sum mari z ation approaches typically rely on sophisticated feature engineering that based mostly on the statistical properties of the document being summarized. In short, these systems are complex, and a lot of engineering effort goes into building them. On the top of that, those methods mostly fail to produce a good document representation and a good summary as a result. End-to-end learning models are interesting to try as they demonstrate good results in other areas, like speech recognition, language translation, image recognition, and even question-answering. Recently, neural networkbased sum mari z ation approaches draw much attention; several models have been proposed and their applications to the news corpus were demonstrated, as in [2] and [3].
文本摘要 (Text summarization) 是自然语言处理领域最活跃的研究方向之一。它通过将长文档压缩为几个句子或段落,成为解决信息过载问题的理想方案。智能手机等手持设备的普及,使得面对小屏幕和有限带宽时,文档摘要变得尤为迫切 [1]。同时,它也可作为机器的阅读理解测试。要生成优质摘要,机器学习模型必须理解文档并从中提炼关键信息。这些任务对计算机极具挑战性,尤其当文档体量增大时。尽管最先进的搜索引擎采用了前沿信息检索技术,仍缺乏从多源信息中综合提炼并生成简明扼要回答的能力。此外,市场亟需能及时获取并消化多源信息的工具。这些需求极大推动了自动文档摘要系统的研发热潮。
传统文本摘要方法通常依赖复杂的特征工程,主要基于被摘要文档的统计特性。简言之,这些系统构建过程工程量大且复杂。更重要的是,这类方法往往无法生成优质的文档表征和摘要结果。端到端学习模型在其他领域(如语音识别、语言翻译、图像识别甚至问答系统)表现优异,因此值得尝试。近年来,基于神经网络的摘要方法备受关注,已有多篇论文提出相关模型并展示其在新闻语料上的应用,如 [2] 和 [3]。
There are two common types of neural text sum mari z ation, extractive and abstract ive. Extractive sum mari z ation models automatically determine and subsequently concatenate relevant sentences from a document to create its summary while preserving its original information content. Such models are common and widely used for practical applications [2], [3]. A fundamental requirement in any extractive sum mari z ation model is to identify the salient sentences that represent the key information mentioned in [4]. In contrast, abstract ive text sum mari z ation techniques attempt to build an internal semantic representation of the original text and then create a summary closer to a human-generated one. The state-of-theart abstract ive models are still quite weak, so most of the previous work has focused on the extractive sum mari z ation [5].
神经文本摘要通常有两种类型:抽取式 (extractive) 和生成式 (abstractive)。抽取式摘要模型会自动确定并拼接文档中的相关句子以生成摘要,同时保留原始信息内容。此类模型在实际应用中非常常见且广泛使用 [2][3]。任何抽取式摘要模型的基本要求是识别出代表关键信息的显著句子,如 [4] 所述。相比之下,生成式文本摘要技术试图构建原始文本的内部语义表示,然后生成更接近人工编写的摘要。目前最先进的生成式模型仍然较弱,因此以往的研究大多集中在抽取式摘要上 [5]。
Despite their popularity, neural networks still have some issues while applied to document sum mari z ation task. These methods lack the latent topic structure of contents. Hence the summary lies only on vector space that can hardly capture multi-topical content [6]. Another issue is that the most common architectures for Neural Text Sum mari z ation are variants of recurrent neural networks (RNN) such as Gated recurrent unit (GRU) and Long short-term memory (LSTM). These models have, in theory, the power to ‘remember’ past decisions inside a fixed-size state vector; however, in practice, this is often not the case. Moreover, carrying the semantics along all-time steps of a recurrent model is relatively hard and not necessary [7]. In this work, we use a hierarchical structured self-attention mechanism to tackle the problem. In which, a weighted average of all the previous states will be used as an extra input to the function that computes the next state. This gives the model the ability to attend to a state produced several time steps earlier, so the latest state does not have to store all the information [8].
尽管神经网络广受欢迎,但在应用于文档摘要任务时仍存在一些问题。这些方法缺乏对内容潜在主题结构的捕捉,导致摘要仅停留在难以涵盖多主题内容的向量空间层面 [6]。另一个问题是,神经文本摘要最常用的架构是循环神经网络 (RNN) 的变体,例如门控循环单元 (GRU) 和长短期记忆网络 (LSTM)。理论上这些模型能够通过固定大小的状态向量"记住"先前的决策,但实际应用中往往难以实现。此外,在循环模型的所有时间步中传递语义信息相对困难且并非必要 [7]。本研究采用分层结构的自注意力机制来解决该问题,通过将先前所有状态的加权平均值作为计算下一状态的额外输入,使模型能够关注多个时间步之前产生的状态,从而避免最新状态必须存储全部信息 [8]。
The contribution of this paper is proposing a general neural network-based approach for sum mari z ation that extracts sentences from a document by treating the sum mari z ation problem as a classification task. The model computes the score for each sentence towards its summary membership by modeling abstract features such as content richness, salience with respect to the document, redundancy with respect to the summary and the positional representation. The proposed model has two improvements that enhance the sum mari z ation effectiveness and accuracy: (i) it has a hierarchical structure that reflects the hierarchical structure of documents; (ii) while building the document representation, two levels of selfattention mechanism are applied at word-level and sentencelevel. This enables the model to attend differential ly to more and less important content.
本文的贡献在于提出了一种基于神经网络的通用摘要生成方法,将摘要任务视为分类问题从文档中提取句子。该模型通过建模内容丰富度、文档显著性、摘要冗余度及位置表征等抽象特征,计算每个句子对摘要的隶属度得分。所提模型通过两项改进提升了摘要效果与准确性:(i) 采用反映文档层级结构的层次化架构;(ii) 构建文档表征时,在词级和句级应用双层自注意力机制 (self-attention),使模型能区分对待不同重要性的内容。
In this paper, two interesting questions are arising: (1) how to mirror the hierarchical structure of the document to improve the embedding representation of sentence and document that can help discovering the coherent semantic of the document; (2) how to extract the most important sentences from the document to form a desired summary [6].
本文提出了两个有趣的问题:(1) 如何通过镜像文档的层级结构来改进句子和文档的嵌入表示,从而帮助发现文档的连贯语义;(2) 如何从文档中提取最重要的句子以形成理想的摘要 [6]。
The key difference between this work and the previous ones is that our model uses a hierarchical structured self-attention mechanism to create sentence and document embeddings. The attention serves two benefits: not only does it often result in better performance, but it also provides insight into which words and sentences contribute to the document representation and to the selection process of the summary sentences as well. To evaluate the performance of our model in comparison to other common state-of-the-art architectures, two well-known datasets are used, the CNN/Daily Mail, and DUC 2002. The proposed model outperforms the current state-of-the-art models by a considerable margin.
本研究与先前工作的关键区别在于,我们的模型采用分层结构的自注意力机制 (self-attention) 来生成句子和文档嵌入。这种注意力机制具有双重优势:不仅能提升模型性能,还能直观展示哪些词语和句子对文档表征及摘要句选择起到关键作用。为评估模型性能,我们选用CNN/Daily Mail和DUC 2002两个知名数据集进行对比实验。实验表明,该模型以显著优势超越了当前最先进的模型。
The rest of the paper is organized as follows. In section 2, the proposed approach for summarizing documents is presented in details. Section 3 describes the experiments and the results. The related work is briefly described in section 4. Finally, we discuss the results and conclude in section 5.
本文的其余部分结构如下。第2节详细介绍了所提出的文档摘要方法。第3节描述了实验及结果。第4节简要概述了相关工作。最后,我们在第5节讨论结果并得出结论。
II. THE PROPOSED MODEL
II. 所提模型
Recurrent Neural Network variants, such as LSTM, have been used widely in text sum mari z ation problem. To prepare the text tokens to be used as an input to these networks, word embeddings, as language models [9], [10], are used to convert language tokens to vectors. Moreover, attention mechanisms [11] make these models more effective and scalable, allowing them to focus on some past parts of the input sequence while making the final decision or generating the output.
循环神经网络变体,如 LSTM (Long Short-Term Memory),已广泛应用于文本摘要问题。为了将这些文本 token 作为网络输入,需要使用词嵌入 (word embeddings) 作为语言模型 [9][10] 将语言 token 转换为向量。此外,注意力机制 (attention mechanisms) [11] 提升了模型的有效性和扩展性,使其能在最终决策或生成输出时聚焦输入序列的特定历史片段。
Definition 1: Given a document $D$ consisting of a sequence of sentences $(s_{1},s_{2}\ldots,s_{n})$ and a set of words $(w_{1},w_{2},\dots,w_{m})$ . Sentence extraction aims to create a summary from $D$ by selecting a subset of $M$ sentences (where $M<n,$ ). we predict the label of the $j^{t h}$ sentence $y_{j}$ as $({\cal O},{\cal I})$ . The labels of sentences in the summary set are set as $y=I$ .
定义 1: 给定由句子序列 $(s_{1},s_{2}\ldots,s_{n})$ 和单词集合 $(w_{1},w_{2},\dots,w_{m})$ 组成的文档 $D$。句子抽取的目标是通过从 $D$ 中选择 $M$ 个句子子集 (其中 $M<n$) 来生成摘要。我们将第 $j^{t h}$ 个句子 $y_{j}$ 的标签预测为 $({\cal O},{\cal I})$。摘要集中句子的标签设置为 $y=I$。
To set the scene of this work, we begin with a brief overview about the self-attention. Given a query vector representation qand an input sequence of tokens $x_=$ $[x_{1};x_{2};\ldots;x_{n}]$ , where $x_{i}$ denotes the embedded vector of the i-th token); then, the function $f(x_{i};q)$ is used to calculate an alignment score between $q$ and each token $x_{i}$ as the vanilla attention of $q$ to $x_{i}$ [11]. Self-attention is a special case of attention where the query $q$ stems from the input sequence itself. Therefore, self-attention mechanism can model the dependencies between tokens from the same sequence. The function $f(x_{i};x_{j})$ is used to compute the dependency of $x_{j}$ on another token $x_{i}$ , where the query vector $q$ is replaced by the token $x_{j}$ .
为阐明本研究的背景,我们首先简要概述自注意力机制。给定一个查询向量表示 q 和输入token序列 $x_=$ $[x_{1};x_{2};\ldots;x_{n}]$ (其中 $x_{i}$ 表示第i个token的嵌入向量),函数 $f(x_{i};q)$ 用于计算 $q$ 与每个token $x_{i}$ 之间的对齐分数,作为 $q$ 对 $x_{i}$ 的基础注意力 [11]。自注意力是注意力机制的特例,其查询 $q$ 源自输入序列本身。因此,自注意力机制能够建模同一序列中token之间的依赖关系。函数 $f(x_{i};x_{j})$ 用于计算 $x_{j}$ 对另一个token $x_{i}$ 的依赖程度,此时查询向量 $q$ 被替换为token $x_{j}$。
The work of Yang et al. [8] demonstrates that using the hierarchical attention yields a better document representation, which they used for document classification task. In this work, we propose a new hierarchical structured self-attention architecture modeled by recurrent neural networks based on recent neural extractive sum mari z ation approaches [2]–[4]. However, our sum mari z ation framework is applicable to all models of sentence extraction using the distributed representation as input.
Yang 等人 [8] 的研究表明,使用分层注意力 (hierarchical attention) 能获得更好的文档表征,他们将其用于文档分类任务。本文基于近期神经抽取式摘要方法 [2]–[4],提出了一种由循环神经网络建模的新型分层结构化自注意力架构。但我们的摘要框架适用于所有以分布式表征为输入的句子抽取模型。
The proposed model has a hierarchical self-attention structure which reflects the hierarchical structure of the document where words form sentences and sentences form a document. In the new model, there are two level of attention, one at the word-level and the second at the sentence-level. FIGURE 1 shows the overall architecture of the proposed model that will be explained in the following sections.
所提出的模型具有分层自注意力结构,反映了文档的层级结构,即单词组成句子、句子构成文档。新模型包含两级注意力机制:词级注意力和句级注意力。图1展示了该模型的整体架构,后续章节将对此进行详细说明。
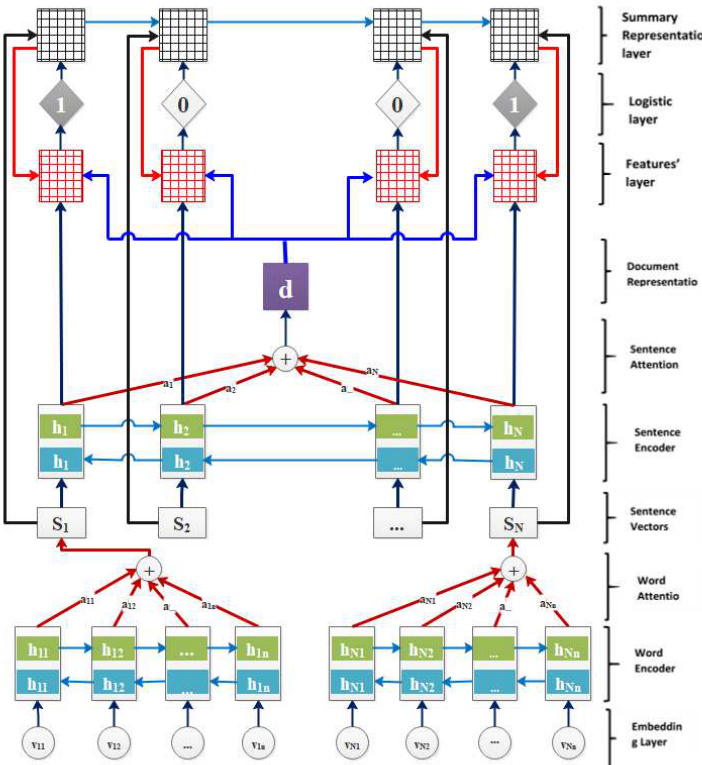
FIGURE 1. A Hierarchical Structured Self-attention-based summary-sentence classifier: the first layer is a word-level layer for each sentence. The second layer operates on the sentence-level. After each layer, there is attention layer. The logistic layer is the classification layer which determines the sentence-summary membership, where 1’s indicate that the sentence is a summary sentence and 0’s determine that the sentence is not
图 1: 基于分层结构化自注意力机制的摘要-句子分类器:第一层是面向每个句子的词级别层,第二层在句子级别上操作。每层后都设有注意力层。逻辑层作为分类层,用于判定句子与摘要的归属关系,其中1表示该句为摘要句,0则表示非摘要句
A. WORD ENCODER
A. 词编码器
Suppose we have a document $(D)$ with $n$ sentences and $m$ words, let $\begin{array}{l l l}{{\cal D}}&{{=}}&{{(s_{1},s_{2},\dots,s_{n})}}\end{array}$ where $s_{j}(1\leq j\leq n)$ denotes the $j^{t h}$ sentence, and $V~=~(\nu_{1},\nu_{2},\dots,\nu_{m})$ where $\nu_{i}(1\leq i\leq m)$ is a vector standing for a $d$ dimensional word embedding for the $i^{t h}$ word. In this work, we use a bidirectional LSTM to encode the words in the sentences. The bidirectional LSTM summarizes information from both directions. It contains the forward LSTM which reads the sentence $s_{i}$ from $\nu_{i1}$ to $\nu_{i m}$ and a backward LSTM which reads from $\nu_{i m}$ to $\nu_{i1}$ :
假设我们有一个文档 $(D)$,包含 $n$ 个句子和 $m$ 个单词,令 $\begin{array}{l l l}{{\cal D}}&{{=}}&{{(s_{1},s_{2},\dots,s_{n})}}\end{array}$,其中 $s_{j}(1\leq j\leq n)$ 表示第 $j^{t h}$ 个句子,$V~=~(\nu_{1},\nu_{2},\dots,\nu_{m})$ 其中 $\nu_{i}(1\leq i\leq m)$ 是一个表示第 $i^{t h}$ 个单词的 $d$ 维词向量的向量。在本工作中,我们使用双向 LSTM 对句子中的单词进行编码。双向 LSTM 从两个方向汇总信息。它包含前向 LSTM,从 $\nu_{i1}$ 到 $\nu_{i m}$ 读取句子 $s_{i}$,以及反向 LSTM,从 $\nu_{i m}$ 到 $\nu_{i1}$ 读取句子:
$$
\begin{array}{r}{\overrightarrow{h_{t}}=\overrightarrow{L S T M}(\nu_{t},\overrightarrow{h_{t-1}})}\ {\overleftarrow{h_{t}}=\overleftarrow{L S T M}(\nu_{t},\overbrace{h_{t-1}})}\end{array}
$$
$$
\begin{array}{r}{\overrightarrow{h_{t}}=\overrightarrow{L S T M}(\nu_{t},\overrightarrow{h_{t-1}})}\ {\overleftarrow{h_{t}}=\overleftarrow{L S T M}(\nu_{t},\overbrace{h_{t-1}})}\end{array}
$$
To obtain the hidden state $h_{t}$ that summarizes the information of the whole sentence centered around $\nu_{i t}$ , we concate- nate each $\overrightarrow{h_{t}}$ with $\leftleftarrows\rightleftarrows$ , as in Equation 3.
为了获取隐藏状态 $h_{t}$ (该状态汇总了以 $\nu_{i t}$ 为中心的整句信息),我们将每个 $\overrightarrow{h_{t}}$ 与 $\leftleftarrows\rightleftarrows$ 进行拼接,如公式3所示。
$$
h_{t}=[\overrightarrow{h_{t}},\overleftarrow{\tilde{h}_{t}}]
$$
$$
h_{t}=[\overrightarrow{h_{t}},\overleftarrow{\tilde{h}_{t}}]
$$
Where the number of the hidden units for each unidirectional LSTM is $u$ . Let $H_{s} \in~\mathbb{R}^{n x2u}$ denotes the whole
每个单向LSTM的隐藏单元数为 $u$ 。设 $H_{s} \in~\mathbb{R}^{n x2u}$ 表示整个
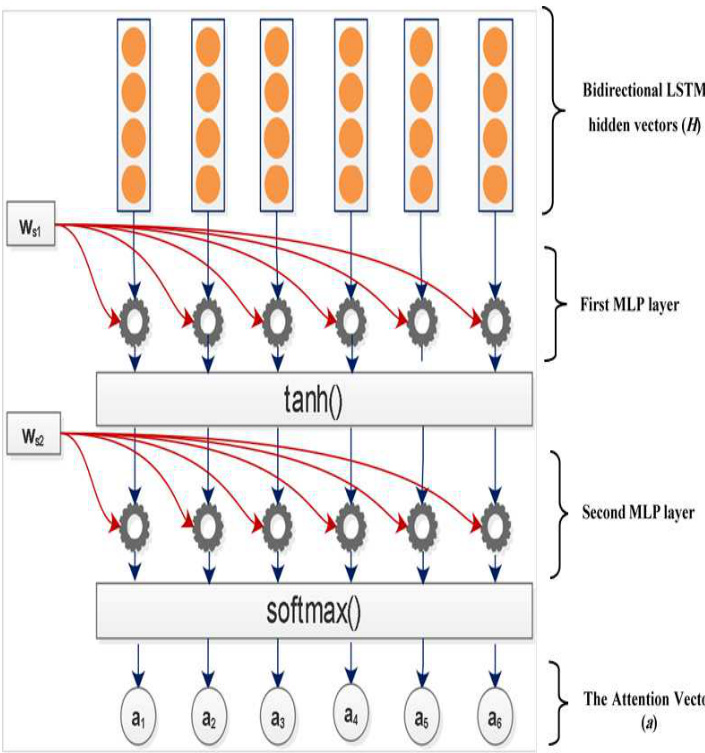
FIGURE 2. The Self-Attention Unit. The attention mechanism takes the whole LSTM hidden states H with $\mathbb{R}^{\mathbf{nx2u}}$ dimension as an input, and outputs a vector of attention weights, a. Here $\mathbf{w_{s1}}$ is a weight matrix with a shape of $\mathbf{\mu}{\in\mathbb{R}}\mathbf{k}\mathbf{\propto}\mathbf{2u}$ . and $\mathbf{w_{s2}}$ is a vector of parameters with a size of $\mathbb{R}^{\mathbf{k}}$ , where $\mathbf{k}$ is a hyper parameter can be set arbitrarily.
图 2: 自注意力单元。该注意力机制以维度为 $\mathbb{R}^{\mathbf{nx2u}}$ 的整个 LSTM 隐藏状态 H 作为输入,并输出注意力权重向量 a。其中 $\mathbf{w_{s1}}$ 是形状为 $\mathbf{\mu}{\in\mathbb{R}}\mathbf{k}\mathbf{\propto}\mathbf{2u}$ 的权重矩阵,$\mathbf{w_{s2}}$ 是大小为 $\mathbb{R}^{\mathbf{k}}$ 的参数向量,$\mathbf{k}$ 为可任意设置的超参数。
LSTM hidden states, as in Equation 4:
LSTM隐藏状态,如公式4所示:
$$
H_{s}=(h_{1},h_{2},...h_{n})
$$
$$
H_{s}=(h_{1},h_{2},...h_{n})
$$
B. WORD ATTENTION
B. 词注意力
The intuition behind the attention mechanism is to pay more or less attention to words according to their contribution to the representation of the sentence meaning. Our objective is to encode a variable length sentence into a fixed size embedding using a self-attention mechanism [7] that takes the whole LSTM hidden states $H_{s}$ as input and yields a vector of weights, $a_{s}$ , as output, as in Equation 5.
注意力机制背后的直觉是根据单词对句子意义表示的贡献程度来给予或多或少的关注。我们的目标是使用自注意力机制 [7] 将可变长度的句子编码为固定大小的嵌入,该机制将整个 LSTM 隐藏状态 $H_{s}$ 作为输入,并输出一个权重向量 $a_{s}$,如公式 5 所示。
$$
a_{s}=s o f t m a x(w_{s_{2}}t a n h(w_{s_{1}}H_{s}^{T}))
$$
$$
a_{s}=s o f t m a x(w_{s_{2}}t a n h(w_{s_{1}}H_{s}^{T}))
$$
Where $w_{s_{2}}\quad\in\quad\mathbb{R}^{\mathbf{k}x2u}$ and $\boldsymbol{w_{s_{1}}}\quad\in\quad\mathbb{R}^{\mathbf{k}}$ are learnable parameters; $k$ is a hyper parameter can be set arbitrarily. The softmax() is used to normalize the attention weights to sum up to 1.
其中 $w_{s_{2}}\quad\in\quad\mathbb{R}^{\mathbf{k}x2u}$ 和 $\boldsymbol{w_{s_{1}}}\quad\in\quad\mathbb{R}^{\mathbf{k}}$ 是可学习参数;$k$ 是可任意设置的超参数。softmax() 用于将注意力权重归一化为总和为1。
Given the attention vector $a_{s}$ , we obtain the sentence vector as a weighted sum of the LSTM hidden states weighted by $a_{s}$ , as shown in FIGURE 2 and Equation 6:
给定注意力向量 $a_{s}$,我们通过 $a_{s}$ 对 LSTM 隐藏状态进行加权求和得到句子向量,如图 2 和公式 6 所示:
$$
s_{i}=a_{s}H_{s}
$$
$$
s_{i}=a_{s}H_{s}
$$
C. SENTENCE ENCODER
C. 句子编码器
After getting the sentence vector $s_{i}$ , we can get the document representation in the same way. A bidirectional LSTM is used to encode the sentences:
在获得句子向量 $s_{i}$ 后,我们可以用同样的方式获取文档表示。使用双向 LSTM (Long Short-Term Memory) 对句子进行编码:
$$
\begin{array}{r}{\overrightarrow{h_{s t}}=\overrightarrow{L S T M}(s_{i},\overrightarrow{h_{t-1}})}\ {\overleftarrow{h_{s t}}=\overleftrightarrow{L S T M}(s_{i},\overleftrightarrow{h_{t+1}})}\end{array}
$$
$$
\begin{array}{r}{\overrightarrow{h_{s t}}=\overrightarrow{L S T M}(s_{i},\overrightarrow{h_{t-1}})}\ {\overleftarrow{h_{s t}}=\overleftrightarrow{L S T M}(s_{i},\overleftrightarrow{h_{t+1}})}\end{array}
$$
Similar to the word encoder, the forward and backward LSTM hidden states are concatenated to get the annotation $h_{s t}$ , which summarizes the adjacent sentences around the sentence $s_{i}$ but focus on the $i^{\mathrm{th}}$ sentence, as in Equation 9.
与词编码器类似,将前向和后向 LSTM 隐藏状态拼接起来得到标注 $h_{st}$ ,它总结了句子 $s_{i}$ 周围的相邻句子,但重点关注第 $i^{\mathrm{th}}$ 个句子,如公式 9 所示。
$$
h_{s t}=[\overrightarrow{h_{s t}},\overleftarrow{\tilde{h_{s t}}}]
$$
$$
h_{s t}=[\overrightarrow{h_{s t}},\overleftarrow{\tilde{h_{s t}}}]
$$
Let $u$ denotes the number of the hidden units for each unidirectional LSTM, $N$ is the number of sentences in the $d^{t h}$ document, and $H_{d}$ denotes the whole LSTM hidden states calculated by Equation 10, the dimension of Hd is RNx2u.
设 $u$ 表示每个单向 LSTM 的隐藏单元数,$N$ 为第 $d^{t h}$ 个文档中的句子数量,$H_{d}$ 表示由公式 10 计算得到的整个 LSTM 隐藏状态,其维度为 RNx2u。
$$
H_{d}=(h_{s1},h_{s2},...h_{s N})
$$
$$
H_{d}=(h_{s1},h_{s2},...h_{s N})
$$
D. SENTENCE ATTENTION
D. 句子注意力
Every sentence in a document contributes differently to the representation of the whole meaning of the document. The self-attention mechanism used in this work takes the whole LSTM hidden states $H_{d}$ as input and yields a vector of weights, $a_{d}$ , as output, calculated by Equation 11:
文档中的每个句子对整体意义的表达贡献不同。本工作采用的自注意力机制将整个 LSTM 隐藏状态 $H_{d}$ 作为输入,并通过公式 11 计算输出权重向量 $a_{d}$:
$$
a_{d}=s o f t m a x(w_{s_{2}}t a n h(w_{s_{1}}H_{d}^{T}))
$$
$$
a_{d}=s o f t m a x(w_{s_{2}}t a n h(w_{s_{1}}H_{d}^{T}))
$$
Where $w_{s_{2}}$ and $w_{s_{1}}$ are learnable parameters. The softmax() is used to normalize the attention weights to sum up to 1.
其中 $w_{s_{2}}$ 和 $w_{s_{1}}$ 是可学习参数。softmax() 用于将注意力权重归一化为总和为 1。
Given the attention vector $a_{d}$ , we obtain the document vector as a weighted sum of the LSTM hidden states weighted by $a_{d}$ , as shown in FIGURE 2, and Equation 12:
给定注意力向量 $a_{d}$,我们通过 $a_{d}$ 对 LSTM 隐藏状态进行加权求和得到文档向量,如图 2 和公式 12 所示:
$$
d=a_{d}H_{d}
$$
$$
d=a_{d}H_{d}
$$
E. CLASSIFICATION LAYER
E. 分类层
Inspired by an interesting work proposed by Nallapati et al. [2], we used a logistic layer that makes a binary decision to determine whether a sentence belongs to the summary or not. The classification decision at the $j^{t h}$ sentence depends on the representation of the abstract features, such as the sentence’s content richness $C_{j}$ , its salience with respect to the document $M_{j}$ , the novelty of the sentence with respect to the accumulated summary $N_{j}$ and the positional feature $P_{j}$ . The probability of the sentence belonging to the summary is given by Equation 18:
受Nallapati等人[2]提出的一项有趣工作启发,我们采用了一个逻辑层进行二元决策,以判断句子是否应归入摘要。对于第$j^{th}$个句子的分类决策,取决于以下抽象特征表示:句子的内容丰富度$C_{j}$、其在文档中的显著性$M_{j}$、相对于已累积摘要的新颖性$N_{j}$以及位置特征$P_{j}$。该句子属于摘要的概率由公式18给出:
The information content of the $j^{t h}$ sentence in the document is represented by Equation 13:
文档中第$j^{t h}$句的信息量由公式13表示:
$$
C_{j}=W_{c}s_{j}
$$
$$
C_{j}=W_{c}s_{j}
$$
Equation 14 captures the salience of the sentence with respect to the document:
方程 14 捕捉了句子相对于文档的显著性:
$$
M_{j}=s_{j}^{T}W_{s}d
$$
$$
M_{j}=s_{j}^{T}W_{s}d
$$
Equation 15 models the novelty of the sentence with respect to the current state of the summary:
方程 15 对句子相对于摘要当前状态的新颖性进行建模:
$$
N_{j}=s_{j}^{T}W_{r}\operatorname{tanh}(o_{j}),
$$
$$
N_{j}=s_{j}^{T}W_{r}\operatorname{tanh}(o_{j}),
$$
where $o_{j}$ is the summary representation calculated by Equation 17.
其中 $o_{j}$ 是由公式 17 计算得出的摘要表示。
The position of the sentence with respect to the document is modeled by Equation 16:
句子在文档中的位置由公式16建模:
$$
P_{j}=W_{p}p_{j},
$$
$$
P_{j}=W_{p}p_{j},
$$
where $p_{j}$ is the positional embedding of the sentence calculated by concatenating the embeddings corresponding to the forward and backward position indices of the sentence in the document.
其中 $p_{j}$ 是通过拼接文档中句子前向和后向位置索引对应的嵌入计算得到的句子位置嵌入。
$W_{c}$ , $W_{s}$ , $W_{p}$ , and $W_{r}$ are automatically learned scalar weights to model the relative importance of various abstract features.
$W_{c}$、$W_{s}$、$W_{p}$和$W_{r}$是自动学习的标量权重,用于建模各类抽象特征的相对重要性。
The summary representation, $o_{j}$ ,at the sentence $j$ is calculated using Equation 17:
句子 $j$ 的摘要表示 $o_{j}$ 通过公式 17 计算得出:
$$
o_{j}=\Sigma_{i=1}^{j-1}s_{i}P(y_{i}=1|s_{i},o_{i},d)
$$
$$
o_{j}=\Sigma_{i=1}^{j-1}s_{i}P(y_{i}=1|s_{i},o_{i},d)
$$
Where $y_{j}$ is a binary number determines whether the sentence $j$ is included in the summary or not.
其中 $y_{j}$ 为二进制数,用于判断句子 $j$ 是否包含在摘要中。
Putting Equations 13, 14, 15 and 16 together, we get the final probability distribution for the sentence label $y_{j}$ , as in Equation 18:
将方程 13、14、15 和 16 联立,我们得到句子标签 $y_{j}$ 的最终概率分布,如方程 18 所示:
$$
P(y_{j}=1|s_{j},o_{j},d)=\sigma(C_{j}+M_{j}-N_{j}+P_{j}+b),
$$
$$
P(y_{j}=1|s_{j},o_{j},d)=\sigma(C_{j}+M_{j}-N_{j}+P_{j}+b),
$$
where $\sigma$ is the sigmoid activation function, and $b$ is the bias term.
其中 $\sigma$ 是 sigmoid 激活函数, $b$ 是偏置项。
Including the summary representation, $o_{j}$ , in the scoring function allows the model to take into account the previously made decisions in terms of determining the summarysentence membership.
在评分函数中包含摘要表示 $o_{j}$ ,使得模型能够根据先前做出的决策来确定摘要句子的归属。
At training phase, the negative log-likelihood of the observed labels is minimized, as in Equation 19:
在训练阶段,最小化观测标签的负对数似然,如公式 19 所示:
$$
\begin{array}{r l}&{l(W,b)=-\Sigma_{d=1}^{N}\Sigma_{j=1}^{n_{d}}(y_{j}^{d}l o g P(y_{j}^{d}=1|s_{j},o_{j},d_{d})}\ &{\qquad+(1-y_{j}^{d})\log(1-P(y_{j}^{d}=1|s_{j},o_{j},d_{d})),}\end{array}
$$
$$
\begin{array}{r l}&{l(W,b)=-\Sigma_{d=1}^{N}\Sigma_{j=1}^{n_{d}}(y_{j}^{d}l o g P(y_{j}^{d}=1|s_{j},o_{j},d_{d})}\ &{\qquad+(1-y_{j}^{d})\log(1-P(y_{j}^{d}=1|s_{j},o_{j},d_{d})),}\end{array}
$$
where $y_{j}^{d}$ is the binary summary label for the $j^{t h}$ sentence in the $d^{t h}$ document, $n_{d}$ is the number of the sentences in the document $(d)$ , and $N$ is the number of documents.
其中 $y_{j}^{d}$ 是第 $d^{t h}$ 篇文档中第 $j^{t h}$ 个句子的二元摘要标签,$n_{d}$ 是该文档 $(d)$ 中的句子数量,$N$ 是文档总数。
III. EXPERIMENTS
III. 实验
A. DATASETS
A. 数据集
The proposed model was evaluated on two well-known datasets, CNN/Daily Mail and DUC 2002. The first dataset was originally built by Hermann et al. [12] for question answering task and then re-used for extractive [2], [3] and abstract ive text sum mari z ation tasks [13], [14]. From the Daily Mail dataset, we used 196,557 documents for training, 12,147 documents for validation and 10,396 documents for testing. In the joint CNN/Daily Mail dataset, there are 286,722 for training, 13,362 for validation and 11,480 for testing. The average number of sentences per document is 28. One of the contributions of [2] is preparing the joint CNN/Daily Mail dataset for the extractive sum mari z ation task. In which, they provide sentence-level binary labels for each document, representing the summary-membership of the sentences. We refer the reader to that paper for a detailed description.
所提模型在两个知名数据集CNN/Daily Mail和DUC 2002上进行了评估。第一个数据集最初由Hermann等人[12]为问答任务构建,随后被重用于抽取式[2][3]和生成式文本摘要任务[13][14]。我们从Daily Mail数据集中使用196,557篇文档进行训练,12,147篇用于验证,10,396篇用于测试。在联合CNN/Daily Mail数据集中,训练集包含286,722篇文档,验证集13,362篇,测试集11,480篇。每篇文档平均包含28个句子。文献[2]的贡献之一是准备了用于抽取式摘要任务的联合CNN/Daily Mail数据集,其中为每篇文档提供了句子级别的二元标签,表示句子是否属于摘要。具体描述请参阅该论文。
The second dataset is DUC 2002 used as an out-of-domain test set. It contains 567 news articles belonging to 59 different clusters of various news topics, and the corresponding 100-word manual summaries generated for each of these documents (single-document sum mari z ation), or the 100-word summaries generated for each of the 59 document clusters formed on the same dataset (multi-document sum mari z ation). In this work, we used the single-document sum mari z ation task.
第二个数据集是作为跨领域测试集使用的DUC 2002。它包含567篇新闻文章,分属59个不同新闻主题的集群,以及为每篇文档生成的对应100字人工摘要(单文档摘要),或为同一数据集中59个文档集群生成的100字摘要(多文档摘要)。在本研究中,我们采用了单文档摘要任务。
B. BASELINES
B. 基线方法
There are so many approaches to the text sum mari z ation problem; for comparison, we choose the ones that are comparable to our work on the two datasets as follows:
文本摘要问题存在多种方法;为便于比较,我们选择在以下两个数据集中与我们的工作具有可比性的方法:
• Leading sentences (Lead-3): which simply produces the first three sentences of the document as a summary. This model serves as a baseline on the two datasets, CNN/Daily Mail and DUC 2002. • Recurrent Neural Network based model (SummaRuNNer) proposed by Nallapati et al. [2], mentioned in section 4, is used as a baseline on the two datasets. • In addition, the extractive model proposed by Cheng and Lapata [3] was used as a baseline on the two datasets. • On CNN/Daily Mail dataset, we used the reinforced abstract ive sum mari z ation model proposed by Paulus et al. [13] and a pointer-Generator based Network by See et al. [15] as abstract ive baselines. • We also used TGRAPH [16], a graph based approaches, and URANK [17] as baselines on DUC 2002 as they achieve high performance on this dataset.
• 引导句摘要 (Lead-3):直接提取文档前三句作为摘要。该模型在CNN/Daily Mail和DUC 2002两个数据集上作为基线模型。
• 循环神经网络模型 (SummaRuNNer):采用Nallapati等人[2]在第四章提出的模型,在两个数据集上作为基线模型。
• 此外,Cheng和Lapata[3]提出的抽取式模型也被用作两个数据集的基线模型。
• 在CNN/Daily Mail数据集上,我们采用Paulus等人[13]提出的强化生成式摘要模型,以及See等人[15]提出的指针生成器网络作为生成式基线模型。
• 针对DUC 2002数据集,我们还采用基于图的TGRAPH[16]方法和URANK[17]作为基线模型,因其在该数据集上表现优异。
C. SETTINGS
C. 设置
We got the word embedding initialization by training word2vec [2] on the CNN/Daily Mail dataset. The validation set was used to tune the hyper parameters. The word embedding dimension was set to 100 and the model hidden state size to 200. The concatenation of forward and backward LSTMs gives us a dimension of 400 for both word encoder and sentence encoder. The word and sentence attention context vectors also have a dimension of 400. The vocabulary size was limited to 150k. We set the maximum sentence length to 50 words and the maximum number of sentences per document to 100. At training time, the batch size was 64, and adadelta [18] was used to train the model and the gradient clipping to regularize it. At test time, we sorted the output probabilities for the sentence-summary membership and then pick the sentences with the top probabilities until we exceed the compression rate.
我们在CNN/Daily Mail数据集上训练word2vec [2]获得词嵌入初始化。验证集用于调整超参数,词嵌入维度设为100,模型隐藏状态大小设为200。前向和后向LSTM的拼接使词编码器和句子编码器维度均为400,词注意力和句子注意力的上下文向量维度也为400。词汇量限制为15万,最大句子长度设为50词,单文档最大句子数设为100。训练时批量大小为64,采用adadelta [18]优化器并实施梯度裁剪进行正则化。测试时对句子-摘要隶属概率进行排序,按最高概率选取句子直至超过压缩率。
D. EVALUATION
D. 评估
In this work, the ROUGE (Recall-Oriented Understudy for Gisty Evaluation) metrics [19] are used for the automatic evaluation of the generated summaries. ROUGE metrics are based on the comparison of n-grams between the summary to be evaluated and one or several human written reference
在本工作中,我们使用ROUGE (Recall-Oriented Understudy for Gisty Evaluation) 指标 [19] 对生成的摘要进行自动评估。ROUGE指标基于待评估摘要与一个或多个人工撰写参考摘要之间的n-gram比较。
TABLE 1. The performance comparison of the proposed models with respect to the baselines on DUC 2002.
表 1: 所提模型在DUC2002数据集上与基线模型的性能对比
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| URANK[17] | 0.485 | 0.215 | |
| TGRAPH[16] | 0.481 | 0.243 | |
| LEAD-3 | 0.436 | 0.210 | 0.402 |
| Cheng et al'16[3] | 0.474 | 0.230 | 0.435 |
| SummaRuNNer[2] | 0.474 | 0.221 | 0.420 |
| Ours(HSSAS) | 0.521 | 0.245 | 0.488 |
summaries, as in Equation 20.
如公式 20 所示。
$$
\begin{array}{r l}{\lefteqn{\mathrm{\mathcal{O}U G E_{N}}}}\ &{=\frac{\sum_{S\in{r e f e r e n c e S u m m a r i e s}}\sum_{g r a m_{n}\in S}C o u n t m a t c h(g r a m_{n})}{\sum_{S\in{r e f e r e n c e S u m m a r i e s}}\sum_{g r a m n\in S}(g r a m_{n})}}\end{array}
$$
$$
\begin{array}{r l}{\lefteqn{\mathrm{\mathcal{O}U G E_{N}}}}\ &{=\frac{\sum_{S\in{r e f e r e n c e S u m m a r i e s}}\sum_{g r a m_{n}\in S}C o u n t m a t c h(g r a m_{n})}{\sum_{S\in{r e f e r e n c e S u m m a r i e s}}\sum_{g r a m n\in S}(g r a m_{n})}}\end{array}
$$
Remark 1: To ensure that the recall-only evaluation will be unbiased to length, we use the ‘‘-l 75’’ options in ROUGE to truncate longer summaries in DUC 2002.
备注1: 为确保仅召回评估不受长度影响, 我们在DUC 2002中使用ROUGE的"-l 75"选项截断较长摘要。
Remark 2: It is noticed that all the baselines use full-length F1 as an evaluation metric on the entire CNN/DailyMail since the neural abstract ive models learn when to stop generating word for the summary. To ensure a fair comparison, we apply the same metric.
备注2: 注意到所有基线模型在CNN/DailyMail数据集上都采用全文F1值作为评估指标,因为神经摘要生成模型需要学习何时停止生成摘要词。为确保公平比较,我们采用相同指标。
E. EXPERIMENTAL RESULTS
E. 实验结果
The ROUGE Toolkit1 and the pyrouge package2 are used to evaluate the performance of the proposed model. ROUGE-1, ROUGE-2, and ROUGE-L were applied with the settings that mentioned in Remark 1 and Remark 2. We compared our model with several extractive and abstract ive baselines, mentioned in section 3.2. The model and the baselines are evaluated on the two datasets, CNN/Daily Mail and DUC 2002. The output of the evaluation was compared to the human-generated summaries in these datasets. The evaluation results, shown in Table 1, TABLE 2, FIGURE 3, and FIGURE 4, assert that the proposed model achieves promising results. From the obtained results, we can make the following observations:
使用ROUGE Toolkit1和pyrouge包2评估所提模型的性能。采用ROUGE-1、ROUGE-2和ROUGE-L指标时,应用了备注1和备注2中的设置。我们将模型与3.2节提到的若干抽取式和生成式基线进行比较,在CNN/Daily Mail和DUC 2002两个数据集上进行评估。评估输出结果与数据集中人工生成的摘要进行对比。如表1、表2、图3和图4所示的评估结果证实,所提模型取得了显著成效。从结果中我们可以得出以下观察结论:
• As shown in Table 1 and FIGURE 3, the obtained results for ROUGE-1, ROUGE-2, and ROUGE-L indicate that our proposed method, HSSAS, performs the best for all ROUGE metrics used in this experiment on DUC 2002 dataset. This asserts that using hierarchical self-attention leads to better sentence and document represent at ions and enhances the abstract features that can be used to yield state-of-the-art performance on the text sum mari z ation task. • In the case of CNN/Daily Mail, TABLE 2 and FIGURE 4, the results assert that the proposed models, HSSAS, outperforms all the baselines in the term of almost all ROUGE metrics used in this experiment.
• 如表 1 和图 3 所示,在 DUC 2002 数据集上,ROUGE-1、ROUGE-2 和 ROUGE-L 的测试结果表明,我们提出的 HSSAS 方法在所有使用的 ROUGE 指标中表现最佳。这表明使用分层自注意力 (hierarchical self-attention) 能获得更好的句子和文档表征,并增强可用于文本摘要任务的抽象特征,从而实现最先进的性能。
• 在 CNN/Daily Mail 数据集上,表 2 和图 4 的结果表明,所提出的 HSSAS 模型在几乎所有使用的 ROUGE 指标上都优于所有基线方法。
TABLE 2. The performance comparison of the proposed models with respect to the baselines on CNN/Daily Mail using full-length F1 variant of ROUGE.
表 2: 在CNN/Daily Mail数据集上使用完整长度F1变体ROUGE的基线模型与提出模型的性能对比
| 模型 | CNN/DailyMail | ||
|---|---|---|---|
| ROUGE-1 | ROUGE-2 | ROUGE-L | |
| LEAD-3 | 0.392 | 0.157 | 0.355 |
| Cheng et al'16 [3] | 0.354 | 0.133 | 0.326 |
| SummaRuNNer [2] | 0.399 | 0.163 | 0.351 |
| Pointer-generator + coverage [15] | 0.395 | 0.173 | 0.364 |
| RL, with intra-attention [13] | 0.416 | 0.157 | 0.391 |
| Ours (HSSAS) | 0.423 | 0.178 | 0.376 |

FIGURE 3. The performance comparison of the proposed model with respect to the baselines on DUC 2002.
图 3: 所提模型在DUC 2002数据集上与基线方法的性能对比
• In news articles, it is usual for the important information to be put in the beginning of the article. This justifies the good ROUGE results of the LEAD-3 baseline in DUC 2002 which makes it hard to be beaten; however, our model has performed better.
• 在新闻文章中,重要信息通常会被放在文章开头。这解释了 LEAD-3 基线在 DUC 2002 中取得优异 ROUGE 分数的原因,使其难以被超越;然而,我们的模型表现更优。
• In the context of abstract ive based models, while ROUGE measures the n-gram overlap between the generated summary and a reference one, summaries with high ROUGE scores are not necessarily the more readable ones. One potential issue of generative summarization models is that optimizing for a specific discrete metric like ROUGE does not guarantee an increase in quality and readability of the generated summary [13], [20]. This may justify the competitive ROUGE scores of the abstract ive baselines used in this work.
• 在基于抽象式摘要模型的背景下,虽然ROUGE衡量了生成摘要与参考摘要之间的n-gram重叠度,但ROUGE分数高的摘要未必更具可读性。生成式摘要模型的一个潜在问题是,针对ROUGE等离散指标的优化并不能保证生成摘要的质量和可读性提升 [13], [20]。这可能解释了本研究所用抽象式基线模型具有竞争力的ROUGE分数的原因。
• Another issue related to the ROUGE metric is that the reliability of ROUGE increased by the number of the reference summaries per document. This inflexibility of ROUGE makes the Rouge scores on the datasets that has one reference summary per document much lower compared to the ones that have multiple reference summaries [15], [19].
• 与ROUGE指标相关的另一个问题是,其可靠性随着每篇文档的参考摘要数量增加而提高。ROUGE的这种不灵活性导致在每篇文档只有一个参考摘要的数据集上,其得分远低于拥有多个参考摘要的数据集 [15], [19]。
• Finally, our proposed model, HSSAS, obtained good results competing with the state-of-the-art methods.
• 最后,我们提出的 HSSAS 模型在与最先进方法的竞争中取得了良好效果。

FIGURE 4. The performance comparison of the proposed model with respect to the baselines on CNN/Daily Mail dataset using full-length F1 variant of ROUGE.
图 4: 采用完整版 ROUGE F1 变体在 CNN/Daily Mail 数据集上,所提模型与基线模型的性能对比。
IV. RELATED WORK
IV. 相关工作
Sum mari z ation systems fall into two main categories, extractive and abstract ive. Extractive sum mari z ation models generate the summary by extracting some key subset of the content for the original document in a way that this subset contains the core information. By contrast, abstract ive summarization models are more sophisticated and more complex since they leverage the language semantics to create representations. They use different words to describe the contents of the original documents rather than extracting the original ones [13], [21].
摘要系统主要分为两类:抽取式和生成式。抽取式摘要模型通过从原文中提取包含核心信息的关键子集来生成摘要。相比之下,生成式摘要模型更为复杂,它们利用语言语义创建表征,使用不同于原文的词汇来描述内容,而非直接提取原文[13][21]。
Since it is comparatively harder to build abstraction-based summarize rs, most of the previously proposed models focus on the extraction-based models. Recently, neural network methods have been being used for extractive sum mari z ation. For example, a recursive auto encoder based model proposed by Kragebäck et al. [22] to summarize documents on the Opinosis dataset [23]. For multi-document extractive summarization task, Yin and Pei [24] have used Convolutional Neural Networks (CNN) to project sentences to a continuous vector space and then they used the sentence ‘diverse ness’ and ‘prestige’ to minimizing the cost function. A queryfocused model for multi-document sum mari z ation was proposed by Cao et al. [25]. In which, they addressed the problem using query-attention-weighted CNNs. Another extractive sum mari z ation approach has been proposed by Nallapati et al. [26]. They used an RNN based classifier that sequentially labels the sentences with binary labels 0/1 for their membership in the summary. The score for each sentence is computed by explicitly modeling abstract features such as content richness, salience with respect to the document.
由于构建基于抽象的摘要生成器相对困难,此前提出的大多数模型都集中于基于抽取的方法。近年来,神经网络方法开始被应用于抽取式摘要任务。例如,Kragebäck等人[22]提出基于递归自动编码器的模型,用于在Opinosis数据集[23]上进行文档摘要。针对多文档抽取式摘要任务,Yin和Pei[24]使用卷积神经网络(CNN)将句子映射到连续向量空间,并通过句子"多样性"和"显著性"来最小化损失函数。Cao等人[25]提出了面向查询的多文档摘要模型,采用查询注意力加权的CNN来解决该问题。Nallapati等人[26]提出了另一种抽取式摘要方法,他们使用基于RNN的分类器对句子进行0/1二元标注以判断其是否应纳入摘要,并通过显式建模内容丰富度、文档显著性等抽象特征来计算每个句子的得分。
For extractive query-oriented single-document summarization, Yousefi-Azar and Hamey [27] used a deep auto encoder to compute a feature space from the term-frequency $(t f)$ input. They developed a local word representation in which each vocabulary is designed to build the input representation for sentences in the document. Then, a random noise is added to the word representation vector, affecting both the input and output of the auto-encoder.
对于面向查询的抽取式单文档摘要任务,Yousefi-Azar与Hamey [27]采用深度自动编码器从词频$(t f)$输入构建特征空间。他们开发了一种局部词表征方法,通过设计特定词汇表来构建文档中句子的输入表征,随后在词表征向量中添加随机噪声,该噪声同时影响自动编码器的输入与输出。
A recent work proposed by See et al. [15] in which they augmented the standard sequence-to-sequence attentional model in two orthogonal ways. In first way, they used a hybrid pointer-generator network that can copy words from the source text via pointing. In the second one, they used the coverage to keep track of what has been summarized so far. Another study carried out by Cao et al. [25] tried to learn the distributed representations for sentences by applying an attention mechanism, which used to learn query relevance ranking and sentence saliency ranking simultaneously. Another extractive sum mari z ation model was proposed by Cheng and Lapata [3] in which they have treated the single document sum mari z ation as a sequence labeling task using a document encoder and attention-based extractor. They applied the attention directly to extract sentences and words for the summary.
See 等人 [15] 近期提出的研究通过两种正交方式增强了标准序列到序列注意力模型。第一种方式采用混合指针-生成器网络,可通过指针机制从源文本复制单词。第二种方式运用覆盖度机制追踪已生成摘要的内容。Cao 等人 [25] 的另一项研究尝试通过注意力机制学习句子的分布式表示,该机制可同时学习查询相关性排序和句子显著性排序。Cheng 和 Lapata [3] 提出了另一种抽取式摘要模型,将单文档摘要视为序列标注任务,采用文档编码器和基于注意力的抽取器。他们直接应用注意力机制从原文抽取句子和单词生成摘要。
The most similar work to ours is the one proposed by Nallapati et al. [2]. They used a recurrent neural network (RNN) based model for extractive sum mari z ation applied to the CNN/Daily Mail corpus. In which, they treated extractive sum mari z ation as a sequence classification problem. They used neural networks for the sentential extractive summarization of single documents. In their model, each sentence is visited sequentially as it appears in the original document and a binary decision is taken to determine whether the sentence should be included in the summary or not. It is worth mentioning that they did not use any attention mechanism. Different from their approach, our model uses the structured self-attentive mechanism that has the capability to guide the sentence and document representations.
与我们工作最相似的是Nallapati等人[2]提出的方法。他们采用基于循环神经网络(RNN)的模型对CNN/Daily Mail语料库进行抽取式摘要生成,将抽取式摘要视为序列分类问题。该研究使用神经网络对单文档进行句子级抽取式摘要,模型按原文顺序逐句访问并做出二元决策判断是否纳入摘要。值得注意的是,该方法未使用任何注意力机制。与之不同,我们的模型采用结构化自注意力机制,能够有效引导句子和文档的表征学习。
The recent advancement of the generative neural models for text makes the abstract ive sum mari z ation techniques increasingly popular. In 2015, Rush et al. [28] published an encoder-decoder model, in which the encoder is a convolutional network and the decoder is a feed forward neural network language model. They enhanced the convolutional encoder by integrate it with attention model. Then they used the trained neural network as a feature to a log-linear model. As the convolutional encoder need a fix number of features, they used a bag of n-grams model. That means they ignore the overall sequence order while generating the hidden represent ation. They only used the first sentence of each news article to generate its title. Another recent abstract ive model was proposed by Paulus et al. [13]. In which, they combined the standard supervised word prediction with reinforcement learning (RL).
近年来,生成式神经网络模型在文本领域的进步使得抽象摘要技术日益流行。2015年,Rush等人[28]提出了一种编码器-解码器模型,其中编码器采用卷积网络,解码器采用前馈神经网络语言模型。他们通过将卷积编码器与注意力模型结合来增强其性能,随后将训练好的神经网络作为特征输入到对数线性模型中。由于卷积编码器需要固定数量的特征,他们采用了n-gram词袋模型,这意味着在生成隐藏表示时忽略了整体序列顺序。该研究仅使用每篇新闻的首句来生成标题。Paulus等人[13]近期提出的另一项抽象摘要模型,将标准监督式词语预测与强化学习(RL)相结合。
Despite the popularity of abstract ive techniques, extractive techniques are still attractive as they are less expensive, less complex and most of the time, they can generate grammatically and semantically correct summaries. Moreover, the performance of RNN-based encoder-decoder models for abstract ive sum mari z ation is quite good for short input and output sequences, but for longer documents and summaries, these models often struggle from serious problems such as repetition, un readability and incoherence.
尽管摘要生成技术广受欢迎,但抽取式技术因其成本更低、复杂度更低且大多数情况下能生成语法和语义正确的摘要,仍然具有吸引力。此外,基于RNN的编码器-解码器模型在短输入输出序列的摘要生成中表现良好,但对于较长文档和摘要,这些模型常面临重复、可读性差和不连贯等严重问题。
As we mentioned earlier in the paragraph before the last one in section 1, our work differs from the previous ones by it is capability to capture the hierarchical structure of the documents. Moreover, it uses the hierarchical structured self-attention to deliver a better embedding representation for sentences and documents. The attention mechanism that we use in this work puts more focus on the semantics of the whole sentence that each word contributes to rather than just focusing on the relations between words like the previous attention-based models.
正如我们在第1章节倒数第二段所述,本研究的创新点在于能够捕捉文档的层级结构。此外,该方法采用层级化自注意力机制 (hierarchical structured self-attention) ,为句子和文档生成更优质的嵌入表示。与先前基于注意力的模型仅关注词间关系不同,本文采用的注意力机制更侧重每个词对整句语义的贡献。
CONCLUSION AND FUTURE WORK
结论与未来工作
The proposed model is another way of utilizing the attention mechanism to create a sentence and document embeddings. The experimental results of the proposed model assert that those embeddings deliver a better representation which in turn enhances the document sum mari z ation task and outperforms the state-of-the-art models on the same datasets. This work is different from the previous work in the sense of three points. First, it uses the hierarchical attention that mirror the document structure. Second, it uses the structured self-attention, which creates a very good embedding. Third, the abstract features are weighted and automatically learned during the learning process taking in consideration the previously classified sentences. We believe that combining the reinforcement learning with sequenceto-sequence training objective is an interesting direction for further research. Another research effort should be directed toward proposing another evaluation metric beside ROUGE metric to optimize on sum mari z ation model especially for long sequences.
提出的模型是利用注意力机制生成句子和文档嵌入的另一种方法。实验结果表明,该模型生成的嵌入能提供更好的表征,从而提升文档摘要任务性能,并在相同数据集上优于当前最优模型。本研究与先前工作的差异主要体现在三点:首先,采用反映文档结构的层次化注意力机制;其次,使用结构化自注意力机制生成高质量嵌入;第三,在学习过程中根据已分类句子的信息,对抽象特征进行加权和自动学习。我们认为将强化学习与序列到序列训练目标相结合是值得探索的研究方向。未来还应致力于提出除ROUGE指标外的其他评估指标,以优化摘要模型(尤其是长序列场景)的性能。