COCO-DR: Combating Distribution Shifts in Zero-Shot Dense Retrieval with Contrastive and Distribution ally Robust Learning
COCO-DR: 通过对比和分布鲁棒学习解决零样本密集检索中的分布偏移问题
Abstract
摘要
We present a new zero-shot dense retrieval (ZeroDR) method, COCO-DR, to improve the generalization ability of dense retrieval by combating the distribution shifts between source training tasks and target scenarios. To mitigate the impact of document differences, COCO-DR continues pre training the language model on the target corpora to adapt to target distributions via COtinuous COtrastive learning. To prepare for unseen target queries, COCO-DR leverages implicit Distribution ally Robust Optimization (iDRO) to reweight samples from different source query clusters for improving model robustness over rare queries during fine-tuning. COCO-DR achieves superior average performance on BEIR, the zero-shot retrieval benchmark. At $\mathrm{BERT_{Base}}$ scale, $\mathrm{COCO-DR_{Base}}$ outperforms other ZeroDR models with $60\times$ larger size. At BERTLarge scale, $\mathrm{COCO-DR_{Large}}$ outperforms the giant GPT-3 embedding model which has $500\times$ more parameters. Our analysis show the correlation of COCO-DR’s effectiveness in combating distribution shifts and improving zero-shot accuracy. Our code and model can be found at https://github.com/ OpenMatch/COCO-DR.
我们提出了一种新的零样本密集检索(ZeroDR)方法COCO-DR,通过应对源训练任务与目标场景之间的分布偏移来提升密集检索的泛化能力。为减轻文档差异的影响,COCO-DR采用持续对比学习(COtinuous COtrastive learning)在目标语料上继续预训练语言模型以适应目标分布。针对未见过的目标查询,COCO-DR运用隐式分布鲁棒优化(iDRO)对不同源查询簇的样本进行重新加权,从而在微调阶段提升模型对罕见查询的鲁棒性。COCO-DR在零样本检索基准BEIR上取得了卓越的平均性能。在$\mathrm{BERT_{Base}}$规模下,$\mathrm{COCO-DR_{Base}}$以$60\times$更小的模型体积超越其他ZeroDR模型;在BERTLarge规模下,$\mathrm{COCO-DR_{Large}}$性能优于参数量达$500\times$的GPT-3嵌入模型。我们的分析表明,COCO-DR在应对分布偏移与提升零样本准确率方面的有效性具有相关性。代码和模型详见https://github.com/OpenMatch/COCO-DR。
1 Introduction
1 引言
Learning to represent and match queries and documents by embeddings, dense retrieval (DR) achieves strong performances in scenarios with sufficient training signals (Bajaj et al., 2016; Kwiatkowski et al., 2019). However, in many real world scenarios, obtaining relevance labels can be challenging due to the reliance on domain expertise, or even infeasible because of the strict privacy constraints. Deploying dense retrieval in these scenarios becomes zero-shot (ZeroDR, Thakur et al. (2021)), which requires first training DR models on source tasks and then generalizing to target tasks with zero in-domain supervision (Izacard et al., 2022; Ni et al., 2021; Neelakantan et al., 2022).
通过学习嵌入表示和匹配查询与文档,稠密检索 (DR) 在具有充足训练信号的场景中表现出色 (Bajaj et al., 2016; Kwiatkowski et al., 2019)。然而,在许多现实场景中,由于依赖领域专业知识或严格的隐私限制,获取相关性标注可能具有挑战性甚至不可行。在这些场景中部署稠密检索就变成了零样本 (ZeroDR, Thakur et al. (2021)),这需要先在源任务上训练 DR 模型,然后在零领域监督的情况下泛化到目标任务 (Izacard et al., 2022; Ni et al., 2021; Neelakantan et al., 2022)。
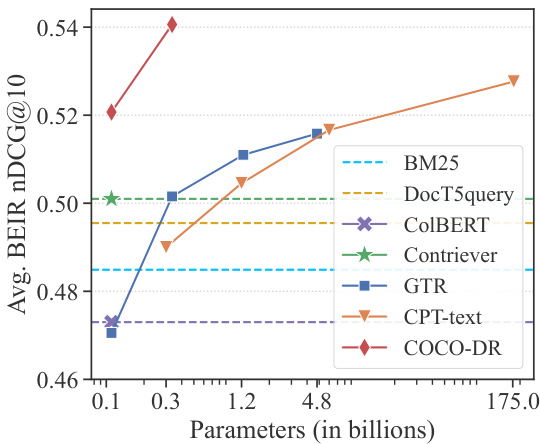
Figure 1: The average nDCG $@10$ of COCO-DR versus large scale models on the 11 BEIR tasks selected in Neel a kant an et al. (2022). X-axis is in log scale.
图 1: COCO-DR 与 Neelakantan 等人 (2022) 所选 11 项 BEIR 任务上大规模模型的平均 nDCG $@10$ 对比。X 轴为对数刻度。
ZeroDR poses great challenges to the generalization ability of DR models under the distribution shift between source and target data (Gulrajani and Lopez-Paz, 2021; Wiles et al., 2022), as it requires the alignment between queries and their relevant documents in the embedding space. It is much harder to generalize than standard classification or ranking tasks, where a robust decision boundary is sufficient (Xin et al., 2022).
ZeroDR对DR模型在源数据和目标数据分布变化下的泛化能力提出了巨大挑战 (Gulrajani and Lopez-Paz, 2021; Wiles et al., 2022) ,因为它需要在嵌入空间中对查询及其相关文档进行对齐。相比标准分类或排序任务 (只需构建稳健决策边界即可) (Xin et al., 2022) ,其泛化难度显著更高。
In this work, we first analyze the distribution shifts in zero-shot dense retrieval. We illustrate the significant distribution shifts in both query intent and document language from the source to target tasks. After that, we show the strong correlation between the distribution shifts and the reduced zero-shot accuracy of dense retrieval models, which confirms the negative impact of distribution shifts on the generalization ability of dense retrieval.
在本研究中,我们首先分析了零样本密集检索中的分布偏移问题。我们展示了从源任务到目标任务时,查询意图和文档语言均存在显著分布偏移。随后,我们证明了分布偏移与密集检索模型零样本准确率下降之间存在强相关性,这证实了分布偏移对密集检索泛化能力的负面影响。
We then present COCO-DR, a ZeroDR model that combats the distribution shifts between source and target tasks. In many ZeroDR scenarios, even though relevancy labels or queries are unavailable, the target corpus is often available pre-deploy (otherwise there is nothing to index) (Xin et al., 2022; Wang et al., 2022). We thus design COCO-DR to perform COntinuous COntrastive pre training (COCO) on the target corpora, which treats two text sequences from the same document as positive pairs and sequences from different documents as negative pairs. This enables COCO-DR to mitigate document distribution shifts by improving the alignment and uniformity of sequence representations for target tasks.
我们随后提出了COCO-DR,这是一种ZeroDR模型,用于应对源任务与目标任务之间的分布偏移问题。在许多ZeroDR场景中,尽管相关性标签或查询不可用,但目标语料库通常在部署前就已存在(否则无需建立索引)(Xin et al., 2022; Wang et al., 2022)。因此,我们设计了COCO-DR,在目标语料库上执行持续对比预训练(COCO),将来自同一文档的两个文本序列视为正样本对,而来自不同文档的序列则作为负样本对。这种方法使COCO-DR能够通过改善目标任务序列表征的对齐性和均匀性,来缓解文档分布偏移。
The distribution shift on the query intent, however, is more challenging as there only exists a few, if any, example queries available under ZeroDR scenarios. COCO-DR introduces an implicit distribu- tionally robust optimization (iDRO) method when fine-tuning on the source retrieval labels. Specifically, it first clusters the source queries into groups based on their learned embeddings. Then, it dynamically reweights the losses on these query clusters by using the gradient similarity among groups. This improves model robustness on less represented query groups in the source, thus implicitly boosts the generalization ability of the DR model on unseen target queries.
然而,查询意图的分布偏移更具挑战性,因为在零样本数据检索(ZeroDR)场景下可用的示例查询即使存在也极少。COCO-DR在微调源检索标签时引入了一种隐式分布鲁棒优化(iDRO)方法。具体而言,该方法首先根据学习到的嵌入向量将源查询聚类成组,随后通过组间梯度相似性动态调整这些查询组的损失权重。这种机制提升了模型在源数据中低代表性查询组的鲁棒性,从而隐式增强了数据检索模型对未见目标查询的泛化能力。
COCO-DR is conceptually simple but empirically powerful. On 18 retrieval tasks included in BEIR, the standard ZeroDR benchmark (Thakur et al., 2021), COCO-DR outperforms state-of-theart domain adaptation methods (Wang et al., 2022) which leverage per-task generated pseudo labels and cross-encoder teachers. COCO-DR also outperforms large scale models with orders of magnitude more parameters. As shown in Figure 1, at only $\mathrm{BERT_{base}}$ scale with 110M parameters, COCODR outperforms $\mathrm{GTR}{\mathrm{XXL}}$ (Ni et al., 2021) and $\mathrm{CPT_{L}}$ (Neel a kant an et al., 2022), which use ${\sim}50\times$ more parameters. At BERTLarge scale, COCO-DR surpasses $\mathrm{CPT}_{\mathrm{XL}}$ (Neel a kant an et al., 2022), the largest DR model to date (175B parameters) on its selected tasks, only using $0.17%$ of its parameters.
COCO-DR在概念上简单但实证效果强大。在BEIR包含的18项检索任务(标准零样本基准测试(ZeroDR benchmark) (Thakur et al., 2021))中,COCO-DR超越了依赖每任务生成伪标签和交叉编码器教师模型的最先进领域适应方法(Wang et al., 2022)。该模型还以显著优势战胜了参数量高数个数量级的大规模模型。如图1所示,仅使用1.1亿参数的$\mathrm{BERT_{base}}$规模,COCO-DR就超越了参数量多${\sim}50\times$的$\mathrm{GTR}{\mathrm{XXL}}$(Ni et al., 2021)和$\mathrm{CPT_{L}}$(Neelakantan et al., 2022)。在BERTLarge规模下,COCO-DR仅用$0.17%$参数量,便在其选定任务上超越了迄今为止最大的稠密检索模型(1750亿参数)$\mathrm{CPT}_{\mathrm{XL}}$(Neelakantan et al., 2022)。
Our analysis confirms that the better generalization ability of COCO-DR comes from its ability to combat the distribution shifts. Continuous contrastive learning helps the pretrained model better capture target corpora’ sequence representation, leading to better generalization ability of models after fine-tuning. Training with iDRO helps COCODR achieve robust performances on source query clusters that share similar search intents to target queries, which then lead to better j generalization to corresponding target tasks.
我们的分析证实,COCO-DR更强的泛化能力源于其应对分布偏移的能力。持续对比学习帮助预训练模型更好地捕捉目标语料库的序列表征,从而提升微调后模型的泛化性能。结合iDRO的训练使COCO-DR在与目标查询具有相似搜索意图的源查询簇上表现稳健,进而实现对相应目标任务的更优泛化。
In the rest of this paper, we discuss related work in Section 2, analyze the distribution shift in Section 3, and present COCO-DR in Section 4. Our experiments are discussed in Section 5 and we conclude in Section 6.
在本文的其余部分中,我们将在第2节讨论相关工作,在第3节分析分布偏移 (distribution shift) ,并在第4节介绍COCO-DR。第5节讨论实验,最后在第6节进行总结。
2 Related Work
2 相关工作
Earlier research has explored various ways to learn representations for retrieval (Deerwester et al., 1990; Huang et al., 2013). Recently, with pretrained language models (Lee et al., 2019), hard training negative selection (Karpukhin et al., 2020; Xiong et al., 2021), and retrieval-oriented pretraining (Lu et al., 2021; Gao and Callan, 2022), dense retrieval has shown strong advantages over sparse retrieval methods, although the advantages are more observed in supervised settings than zeroshot scenarios (Thakur et al., 2021).
早期研究探索了多种学习检索表示的方法 (Deerwester et al., 1990; Huang et al., 2013)。近期,随着预训练语言模型 (Lee et al., 2019)、困难训练负样本选择 (Karpukhin et al., 2020; Xiong et al., 2021) 以及面向检索的预训练技术 (Lu et al., 2021; Gao and Callan, 2022) 的发展,稠密检索方法已展现出优于稀疏检索方法的显著优势,不过这些优势更多体现在有监督场景而非零样本场景 (Thakur et al., 2021)。
One research direction to improve zero-shot dense retrieval is bringing in domain adaption techniques. Xin et al. (2022) employ domain invariant learning to narrow the representation gap between source and target domains. Ma et al. (2021) and Wang et al. (2022) generate pseudo labels for each target task to train in-domain DR models. These techniques employ one specially trained retrieval model for each target task and improve zero-shot retrieval accuracy.
提升零样本密集检索的一个研究方向是引入领域适应技术。Xin等人 (2022) 采用领域不变学习来缩小源域和目标域之间的表示差距。Ma等人 (2021) 和Wang等人 (2022) 为每个目标任务生成伪标签来训练领域内密集检索模型。这些技术为每个目标任务使用一个专门训练的检索模型,提高了零样本检索的准确性。
Another way to improve ZeroDR is to scale up model size and source training data. Ni et al. (2021) and Neel a kant an et al. (2022) leverage models with billions of parameters (T5-XXL and GPT-3) and large-scale training data to increase the generalization capacity of DR model. Izacard et al. (2022) and $\mathrm{Xu}$ et al. (2022) enlarge the size of training data with retrieval-oriented pre training tasks. As illustrated in Figure 1, the benefit of scale follows the scaling law of language models (Kaplan et al., 2020): A linear increment of zero-shot accuracy requires exponentially more training data and model parameters.
提升 ZeroDR 的另一种方法是扩大模型规模和源训练数据。Ni 等人 (2021) 和 Neelakantan 等人 (2022) 利用具有数十亿参数的模型 (T5-XXL 和 GPT-3) 和大规模训练数据来增强 DR 模型的泛化能力。Izacard 等人 (2022) 和 $\mathrm{Xu}$ 等人 (2022) 通过面向检索的预训练任务扩展了训练数据规模。如图 1 所示,规模效益遵循大语言模型的扩展定律 (Kaplan 等人, 2020):零样本准确率的线性提升需要训练数据和模型参数呈指数级增长。
Combining dense models with sparse retrieval yields better zero-shot retrieval performances on BEIR (Formal et al., 2022; Xu et al., 2022). The reranking models, using stronger cross-encoders, can be used as teachers to improve the robustness of dense retrieval models (Wang et al., 2022).
将密集模型与稀疏检索相结合,可在BEIR基准上获得更好的零样本检索性能 (Formal et al., 2022; Xu et al., 2022)。采用更强交叉编码器的重排序模型可作为教师模型,提升密集检索模型的鲁棒性 (Wang et al., 2022)。
More generally speaking, continuous pretraining and distribution ally robust optimization (DRO) are two techniques for improving model generalization on other applications. Continuous pretraining BERT’s masked language modeling tasks on target domain corpora have shown benefits on both language tasks (Gururangan et al., 2020) and the reranking step of search systems (Wang et al., 2021b). The benefits of DRO are more ambivalent (Gulrajani and Lopez-Paz, 2021; Wiles et al., 2022) and are more observed when explicit group partitions are available (Oren et al., 2019; Sagawa et al., 2020; Zhou et al., 2021).
更广泛地说,持续预训练 (continuous pretraining) 和分布鲁棒优化 (DRO) 是两种提升模型在其他应用上泛化能力的技术。在目标领域语料库上持续预训练 BERT 的掩码语言建模任务,已被证明对语言任务 [Gururangan et al., 2020] 和搜索系统的重排序步骤 [Wang et al., 2021b] 均有助益。而 DRO 的效果则更具争议性 [Gulrajani and Lopez-Paz, 2021; Wiles et al., 2022],其优势更多在显式分组划分可用时被观察到 [Oren et al., 2019; Sagawa et al., 2020; Zhou et al., 2021]。
3 Distribution Shifts in Dense Retrieval
3 密集检索中的分布偏移
In this section, we first introduce the preliminaries of dense retrieval. Then we discuss the standard zero-shot dense retrieval settings and study the impact of distribution shifts on ZeroDR accuracy.
在本节中,我们首先介绍密集检索 (dense retrieval) 的基础知识。接着讨论标准的零样本密集检索设置,并研究分布偏移对 ZeroDR 准确率的影响。
3.1 Preliminaries on Dense Retrieval
3.1 稠密检索 (Dense Retrieval) 基础
In dense retrieval, the query $q$ and document $d$ are represented by dense vectors (Huang et al., 2013) and the relevance score $f(q,d;\theta)$ is often calculated by simple similarity metrics, e.g., dot product (Lee et al., 2019):
在密集检索中,查询$q$和文档$d$由密集向量表示 (Huang et al., 2013),相关度评分$f(q,d;\theta)$通常通过简单的相似性度量计算,例如点积 (Lee et al., 2019):
$$
f(\boldsymbol{q},d;\theta)=\left\langle\boldsymbol{g}(\boldsymbol{q};\theta),\boldsymbol{g}(d;\theta)\right\rangle.
$$
$$
f(\boldsymbol{q},d;\theta)=\left\langle\boldsymbol{g}(\boldsymbol{q};\theta),\boldsymbol{g}(d;\theta)\right\rangle.
$$
Here $g(\cdot;\theta)$ denotes the text encoder and $\theta$ is the collection of parameter of $g$ , which is often initialized by BERT (Devlin et al., 2019). The learning objective for dense retrieval can be expressed as
这里 $g(\cdot;\theta)$ 表示文本编码器,$\theta$ 是 $g$ 的参数集合,通常由 BERT (Devlin et al., 2019) 初始化。密集检索的学习目标可以表示为
$$
\begin{array}{r l}&{\theta^{}=\arg\underset{\theta}{\operatorname*{min}}\ell(\theta)=}\ &{\phantom{{\theta^{*}=\exp\left(\theta\right)}}-\mathbb{E}{q\sim p(\cdot)}\mathbb{E}{d^{+}\sim p_{\mathrm{pos}}(q)}\mathbb{E}{d^{-}\sim p_{\mathrm{neg}}(q)}\log p_{\theta}\left(d^{+}\mid q,d^{-}\right),}\end{array}
$$
$$
\begin{array}{r l}&{\theta^{}=\arg\underset{\theta}{\operatorname*{min}}\ell(\theta)=}\ &{\phantom{{\theta^{*}=\exp\left(\theta\right)}}-\mathbb{E}{q\sim p(\cdot)}\mathbb{E}{d^{+}\sim p_{\mathrm{pos}}(q)}\mathbb{E}{d^{-}\sim p_{\mathrm{neg}}(q)}\log p_{\theta}\left(d^{+}\mid q,d^{-}\right),}\end{array}
$$
where $p(\cdot)$ is the distribution of queries, and $d^{+}$ and $d^{-}$ are sampled from the distribution of positive and negative document for $q$ (denoted as $p_{\mathrm{pos}}(q)$ and $p_{\mathrm{neg}}(q))$ , respectively. In practice, the negative documents can either be BM25 negatives (Karpukhin et al., 2020) or mined by DR models from the past episode (Xiong et al., 2021).
其中 $p(\cdot)$ 是查询的分布,$d^{+}$ 和 $d^{-}$ 分别从查询 $q$ 的正文档和负文档分布(记为 $p_{\mathrm{pos}}(q)$ 和 $p_{\mathrm{neg}}(q)$)中采样。实际应用中,负文档可以是 BM25 负样本 (Karpukhin et al., 2020) ,也可以由 DR 模型从过去的训练轮次中挖掘 (Xiong et al., 2021)。
During training, we aim to maximize the probability of selecting the ground-truth document $d^{+}$ over the negative document $d^{-}$ as
在训练过程中,我们的目标是最大化选择真实文档$d^{+}$而非负样本文档$d^{-}$的概率。
$$
p_{\theta}(d^{+}|q,d^{-})=\frac{\exp\left(f(q,d^{+};\theta)\right)}{\exp\left(f(q,d^{+};\theta)\right)+\exp\left(f(q,d^{-};\theta)\right)},
$$
$$
p_{\theta}(d^{+}|q,d^{-})=\frac{\exp\left(f(q,d^{+};\theta)\right)}{\exp\left(f(q,d^{+};\theta)\right)+\exp\left(f(q,d^{-};\theta)\right)},
$$
This dense retrieval configuration has shown strong empirical performances in a wide range of supervised scenarios, where the training and testing data are drawn from the same distributions, and a large amount of relevance labels are available (Karpukhin et al., 2020; Xiong et al., 2021; Qu et al., 2021).
这种密集检索配置在广泛的监督场景中展现出强大的实证性能,这些场景下训练数据和测试数据来自相同分布,且有大量相关性标签可用 (Karpukhin et al., 2020; Xiong et al., 2021; Qu et al., 2021)。
3.2 ZeroDR and Distribution Shifts
3.2 ZeroDR 与分布偏移
Unlike supervised settings, the empirical advantages of dense retrieval are more ambivalent in zero-shot scenarios (Thakur et al., 2021). We first discuss the common setups of ZeroDR and then investigate the impact of distribution shifts on zeroshot performance of dense retrieval models.
与监督式设置不同,密集检索 (dense retrieval) 在零样本 (zero-shot) 场景中的实证优势更为矛盾 [20]。我们首先讨论 ZeroDR 的常见设置,然后研究分布偏移对密集检索模型零样本性能的影响。
ZeroDR Task. A retrieval task is considered zero-shot if no task-specific signal is available. Unless in large commercialized scenarios like web search, zero-shot is often the norm, e.g., when building search systems for a new application, in domains where annotations require specific expertise, or in personalized scenarios where each user has her own corpus.
零样本检索任务 (ZeroDR Task) 。如果没有任何任务特定的信号可用,则检索任务被视为零样本。除非是在网络搜索等大型商业化场景中,零样本通常是常态,例如在为新的应用程序构建搜索系统时,在需要特定专业知识的领域进行标注时,或在每个用户拥有自己语料库的个性化场景中。
Besides relevance labels, the availability of indomain queries is also a rarity—often only a few example queries are available. The most accessible in-domain information is the corpus, which is a prerequisite to build search systems. Sparse retrieval needs to pre-build the inverted index before serving any query; dense retrieval systems have to pre-compute the document embeddings.
除了相关性标签,领域内查询的可用性也很稀缺——通常只有少数示例查询可用。最易获取的领域内信息是语料库,这是构建搜索系统的先决条件。稀疏检索 (sparse retrieval) 需要在处理任何查询前预建倒排索引;而稠密检索 (dense retrieval) 系统则必须预先计算文档嵌入向量。
These properties of zero-shot retrieval lead to a common ZeroDR setup where models can leverage the target corpus to perform unsupervised domain adaptation, but their supervised training signals only come from the source retrieval task, namely MS MARCO (Xin et al., 2022; Wang et al., 2022).
零样本检索的这些特性导致了一种常见的ZeroDR设置,即模型可以利用目标语料库进行无监督领域适应,但其监督训练信号仅来自源检索任务,即MS MARCO (Xin et al., 2022; Wang et al., 2022)。
In this paper, we follow the standard practice in recent ZeroDR research, with MS MARCO passage retrieval (Bajaj et al., 2016) as the source retrieval task, the tasks collected in the BEIR benchmark (Thakur et al., 2021) as the zero-shot target, and the corpora of BEIR tasks available at training time for unsupervised domain adaptation.
本文遵循近期零样本文档检索(ZeroDR)研究的标准做法,以MS MARCO段落检索(Bajaj等人,2016)作为源检索任务,BEIR基准测试(Thakur等人,2021)收集的任务作为零样本目标,并在训练时使用BEIR任务的语料库进行无监督领域自适应。
Distribution Shifts. Before discussing our ZeroDR method, we first study the distribution shifts between the source training task (MARCO) and the zero-shot target tasks (BEIR).
分布偏移 (Distribution Shifts)。在讨论我们的 ZeroDR 方法之前,我们首先研究源训练任务 (MARCO) 和零样本目标任务 (BEIR) 之间的分布偏移。
Following the analysis in Thakur et al. (2021), we use pairwise weighted Jaccard similarity (Ioffe, 2010) to quantify the distribution shifts both at the query side and the document side. The document distribution shift is measured directly at the lexicon level, by the similarity of their unigram word distributions. The query distribution shift is measured on the distribution of query types, using the ninetype categorization from Ren et al. (2022) (more details in Appendix C.1). As shown in (Ren et al., 2022), search intent types are more representative than lexicon for short queries.
根据Thakur等人(2021)的分析,我们采用成对加权Jaccard相似度(Ioffe, 2010)来量化查询端和文档端的分布偏移。文档分布偏移直接在词法层面通过单字词分布的相似性进行测量。查询分布偏移则采用Ren等人(2022)提出的九类型分类法,在查询类型分布上进行测量(详见附录C.1)。如(Ren等人, 2022)所示,对于短查询而言,搜索意图类型比词法更具代表性。
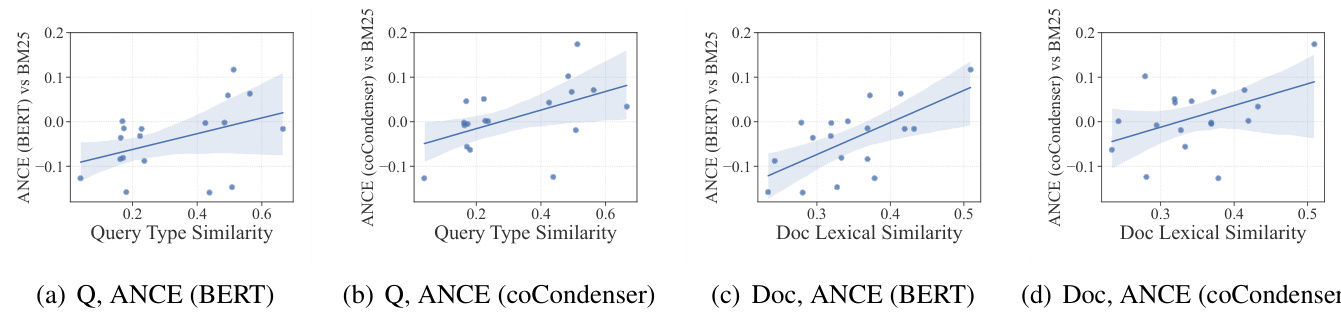
Figure 2: Distribution shifts and zero-shot retrieval performances of ANCE trained on MS MARCO. X-axes are the similarity between MS MARCO and BEIR. Y-axes are $\mathrm{NDCG}@10$ differences on BEIR.
图 2: 在MS MARCO上训练的ANCE分布偏移与零样本检索性能。X轴表示MS MARCO与BEIR之间的相似度,Y轴表示BEIR上的$\mathrm{NDCG}@10$差异。
Figure 2 plots the distribution shifts from MARCO to BEIR tasks and the corresponding performance differences between dense retrieval and sparse retrieval. We use BM25 as the sparse retrieval method and ANCE starting from pretrained BERT (Xiong et al., 2021) and co Condenser (Gao and Callan, 2022) as representative DR models.
图 2: 展示了从MARCO到BEIR任务的分布偏移情况,以及稠密检索与稀疏检索之间的性能差异。我们选用BM25作为稀疏检索方法,并以基于预训练BERT的ANCE (Xiong等人,2021) 和coCondenser (Gao和Callan,2022) 作为代表性稠密检索模型。
The average similarity between MS MARCO and BEIR tasks are $32.4%$ and $34.6%$ for queries and documents, indicating the existence of significant distribution shifts from MARCO to BEIR. Furthermore, these shifts are correlated with the performance degradation of dense retrieval models, as DR models perform much worse than BM25 on BEIR tasks that are less similar to MS MARCO. The contrastive learning on MARCO does not address this challenge; ANCE initialized from coCondenser still under performs BM25 on BEIR tasks where distribution shifts are severe.
MS MARCO与BEIR任务之间的平均相似度在查询和文档上分别为$32.4%$和$34.6%$,表明存在从MARCO到BEIR的显著分布偏移。此外,这些偏移与密集检索模型的性能下降相关,因为在与MS MARCO相似度较低的BEIR任务上,DR模型的表现远不如BM25。MARCO上的对比学习未能解决这一挑战;即便从coCondenser初始化的ANCE,在分布偏移严重的BEIR任务上仍表现不及BM25。
4 COCO-DR Method
4 COCO-DR 方法
To combat the distribution shifts from training source to zero-shot targets, COCO-DR introduces two training techniques: COntinuous COntrastive pre training (COCO) and implicit Distribution ally Robust optimization (iDRO). The first continuously pretrains the language model on target corpora to handle document distribution shifts. The latter improves the model robustness during fine-tuning, which then lead to better generalization for unseen target queries. This section describes these two components in detail.
为应对从训练源到零样本目标的分布偏移问题,COCO-DR引入了两项训练技术:持续对比预训练(COCO)和隐式分布鲁棒优化(iDRO)。前者通过在目标语料库上持续预训练语言模型来处理文档分布偏移,后者在微调阶段提升模型鲁棒性,从而实现对未见目标查询的更好泛化。本节将详细阐述这两个组件。
4.1 Continuous Contrastive Pre training
4.1 持续对比预训练
Sequence Contrastive Learning (SCL) aims to improve the alignment of similar text sequences in the pretrained representations and the uniformity of unrelated text sequences (Meng et al., 2021), which benefits supervised dense retrieval (Gao and Callan, 2022; Ma et al., 2022). In zero-shot settings, how- ever, SCL-pretrained models still suffer from the distribution shifts, as observed in Figure 2.
序列对比学习 (Sequence Contrastive Learning, SCL) 旨在提升预训练表征中相似文本序列的对齐性及无关文本序列的均匀性 (Meng et al., 2021) ,这对监督式稠密检索具有促进作用 (Gao and Callan, 2022; Ma et al., 2022) 。但在零样本场景下,如图 2 所示,经过 SCL 预训练的模型仍会受数据分布偏移的影响。
COCO addresses this challenge via continuously pre training the language model on the target corpora, using the contrastive learning settings widely adopted in recent research (Ni et al., 2021; Gao and Callan, 2022; Neel a kant an et al., 2022).
COCO通过持续在目标语料库上预训练语言模型来解决这一挑战,采用了近期研究中广泛采用的对比学习设置 (Ni et al., 2021; Gao and Callan, 2022; Neelakantan et al., 2022)。
Specifically, for each document $d_{i}$ in target corpora, we randomly extract two disjoint sequences $s_{i,1}$ and $s_{i,2}$ from $d_{i}$ to form the positive pair in:
具体而言,对于目标语料库中的每个文档$d_{i}$,我们从中随机提取两个不相交的序列$s_{i,1}$和$s_{i,2}$以构成正样本对:
$$
\begin{array}{l}{\displaystyle\mathcal{L}{\mathrm{co}}=\sum_{i=1}^{n}\ell\big(s_{i,1},s_{i,2}\big)\big)}\ {\displaystyle=\sum_{i=1}^{n}-\log\frac{\exp\left(\left\langle g\big(s_{i,1}\big),g\big(s_{i,2}\big)\right\rangle\right)}{\sum_{j=1,2}\sum_{s^{-}\in B}\exp\left(\left\langle g\big(s_{i,j}\big),g\big(s^{-}\big)\right\rangle\right)}.}\end{array}
$$
$$
\begin{array}{l}{\displaystyle\mathcal{L}{\mathrm{co}}=\sum_{i=1}^{n}\ell\big(s_{i,1},s_{i,2}\big)\big)}\ {\displaystyle=\sum_{i=1}^{n}-\log\frac{\exp\left(\left\langle g\big(s_{i,1}\big),g\big(s_{i,2}\big)\right\rangle\right)}{\sum_{j=1,2}\sum_{s^{-}\in B}\exp\left(\left\langle g\big(s_{i,j}\big),g\big(s^{-}\big)\right\rangle\right)}.}\end{array}
$$
The contrastive loss with sequence representations $g(s)$ and in batch negatives $s^{-}\in B$ .
对比损失函数,其中序列表示为 $g(s)$,批内负样本为 $s^{-}\in B$。
This contrastive learning is used in combination with language modeling (Gao and Callan, 2022) to continuous pretrain on target corpora (Gururangan et al., 2020). It adapts the language models to target corpora before fine-tuning on source labels, to reduce the impact of document distribution shifts.
这种对比学习与语言建模 (Gao and Callan, 2022) 结合使用,在目标语料库 (Gururangan et al., 2020) 上进行持续预训练。该方法通过在源标签微调前使语言模型适应目标语料库,从而减少文档分布偏移的影响。
4.2 Distribution ally Robust Optimization
4.2 分布鲁棒优化
The query distribution shifts are more challenging, as often target queries are only available, if any, at a small amount. For example, applying COCO on a few queries is unlikely useful.
查询分布的偏移更具挑战性,因为目标查询即便存在,通常也仅有少量可用。例如,在少量查询上应用 COCO 不太可能有效。
To address this challenge, we exploit the assumption from distribution al robust optimization (DRO): a model trained to be more robust on the source domain is likely to better generalize to unseen data (Sagawa et al., 2020; Wiles et al., 2022). In addition, as explicit target domain/group information is unavailable, we perform implicit DRO (iDRO) to improve models’ robustness regarding to source query clusters during fine-tuning.
为解决这一挑战,我们利用了分布鲁棒优化 (DRO) 的假设:在源域上训练得更鲁棒的模型可能更好地泛化到未见数据 (Sagawa et al., 2020; Wiles et al., 2022) 。此外,由于缺乏明确的目标域/组信息,我们在微调过程中采用隐式 DRO (iDRO) 来提升模型对源查询集群的鲁棒性。
iDRO Loss. Specifically, we first cluster source queries using K-Means (Lloyd, 1982) on their embedding similarities (dot-product) from COCO, and then optimize the following iDRO loss:
iDRO损失函数。具体而言,我们首先使用K-Means (Lloyd, 1982) 算法基于COCO数据集中的嵌入相似度(点积)对源查询进行聚类,随后优化以下iDRO损失函数:
$$
\begin{array}{l}{\displaystyle\mathcal{L}{\mathrm{iDRO}}(\boldsymbol{\theta})=\sum_{i=1}^{K}\alpha_{i}\omega_{i}\ell_{i}(\boldsymbol{\theta}),}\ {\displaystyle\alpha_{i}\propto[\ell_{i}(\boldsymbol{\theta})]^{\beta};\beta\geq0.}\end{array}
$$
$$
\begin{array}{l}{\displaystyle\mathcal{L}{\mathrm{iDRO}}(\boldsymbol{\theta})=\sum_{i=1}^{K}\alpha_{i}\omega_{i}\ell_{i}(\boldsymbol{\theta}),}\ {\displaystyle\alpha_{i}\propto[\ell_{i}(\boldsymbol{\theta})]^{\beta};\beta\geq0.}\end{array}
$$
It weights the per cluster dense retrieval loss $\ell_{i}(\theta)$ in Eqn. 2 of $K$ total clusters using two parameters. The first one, $\alpha_{i}$ , up-weights clusters with higher training loss, with the emphasize on harder clusters defined by hyper parameter $\beta$ . The second one $\omega\in$ $\mathbb{R}^{K}$ is learned to maximize the loss decreases on all clusters, which we derive a closed form solution in the rest of this section.
它通过两个参数对总数为 $K$ 的聚类中每个聚类的密集检索损失 $\ell_{i}(\theta)$ (公式2)进行加权。第一个参数 $\alpha_{i}$ 对训练损失较高的聚类进行上调加权,其强调程度由超参数 $\beta$ 定义的困难聚类决定。第二个参数 $\omega\in$ $\mathbb{R}^{K}$ 通过学习使所有聚类的损失下降最大化,我们在本节后续部分推导出其闭式解。
Dynamic Cluster Weighting. An ideal choice of $\omega^{t}$ at training step $t$ would provide biggest reduction on the training loss of all query clusters, but is difficult to obtain. To derive a closed form solution of $\omega^{t}$ , we approximate the loss reduction using first order Taylor expansion:
动态集群加权。在训练步骤$t$时,$\omega^{t}$的理想选择应能最大程度降低所有查询集群的训练损失,但这难以实现。为推导$\omega^{t}$的闭式解,我们采用一阶泰勒展开近似损失降低量:
$$
\begin{array}{l}{\displaystyle\ell_{\mathrm{g}}=\sum_{i=1}^{K}\left(\ell_{i}(\theta-\eta\nabla_{\theta}\mathcal{L}_{\mathrm{iDRO}}(\theta))-\ell_{i}(\theta)\right)}\ {\displaystyle\approx-\eta\sum_{i=1}^{K}\sum_{j=1}^{K}\alpha_{i}\alpha_{j}\omega_{i}^{t}\left(\nabla_{\theta}\ell_{i}(\theta)\right)^{\top}\nabla_{\theta}\ell_{j}(\theta)}\end{array}
$$
$$
\begin{array}{l}{\displaystyle\ell_{\mathrm{g}}=\sum_{i=1}^{K}\left(\ell_{i}(\theta-\eta\nabla_{\theta}\mathcal{L}_{\mathrm{iDRO}}(\theta))-\ell_{i}(\theta)\right)}\ {\displaystyle\approx-\eta\sum_{i=1}^{K}\sum_{j=1}^{K}\alpha_{i}\alpha_{j}\omega_{i}^{t}\left(\nabla_{\theta}\ell_{i}(\theta)\right)^{\top}\nabla_{\theta}\ell_{j}(\theta)}\end{array}
$$
Eqn. 7 is the loss reduction on all clusters, after a stochastic gradient descent operation with step size $\eta$ . Eqn. 8 is its first order expansion.
式7是在步长为$\eta$的随机梯度下降操作后,所有簇上的损失减少量。式8是其一阶展开式。
In addition, we avoid potential rapid change of cluster weights for optimization stability, by adding a KL divergence regular iz ation between $\omega$ at different steps. This leads to the following optimization target:
此外,为避免聚类权重快速变化影响优化稳定性,我们在不同步骤的$\omega$之间添加了KL散度正则项,得到如下优化目标:
$$
\begin{array}{r l}&{\underset{\omega^{(t)}}{\mathrm{min}}\ell_{\mathbf{g}}+\tau\mathcal{D}{\mathrm{KL}}(\omega^{(t)}||\omega^{(t-1)}),}\ &{\mathrm{s.t.}\quad\displaystyle\sum_{i=1}^{K}\omega_{i}^{(t)}=1.}\end{array}
$$
$$
\begin{array}{r l}&{\underset{\omega^{(t)}}{\mathrm{min}}\ell_{\mathbf{g}}+\tau\mathcal{D}{\mathrm{KL}}(\omega^{(t)}||\omega^{(t-1)}),}\ &{\mathrm{s.t.}\quad\displaystyle\sum_{i=1}^{K}\omega_{i}^{(t)}=1.}\end{array}
$$
The strength of $\mathrm{KL}$ regular iz ation is controlled by hyper parameter $\tau$ . By using Lagrangian multiplier
$\mathrm{KL}$ 正则化的强度由超参数 $\tau$ 控制。通过使用拉格朗日乘数
(details in Appendix E), the optimal weight for each group $\omega_{i}^{t*}$ can be calculated as
(详见附录E),每个组的最优权重 $\omega_{i}^{t*}$ 可计算为
$$
\begin{array}{r l}&{\omega_{i}^{t*}=\frac{\omega_{i}^{(t-1)}\exp{\left(\frac{1}{\tau}\sum_{j=1}^{K}r_{i j}\right)}}{\sum_{i=1}^{K}\omega_{i}^{(t-1)}\exp{\left(\frac{1}{\tau}\sum_{j=1}^{K}r_{i j}\right)}};}\ &{r_{i j}=[\ell_{i}(\theta)\ell_{j}(\theta)]^{\beta}\left(\nabla_{\theta}\ell_{i}(\theta)\right)^{\top}\nabla_{\theta}\ell_{j}(\theta).}\end{array}
$$
$$
\begin{array}{r l}&{\omega_{i}^{t*}=\frac{\omega_{i}^{(t-1)}\exp{\left(\frac{1}{\tau}\sum_{j=1}^{K}r_{i j}\right)}}{\sum_{i=1}^{K}\omega_{i}^{(t-1)}\exp{\left(\frac{1}{\tau}\sum_{j=1}^{K}r_{i j}\right)}};}\ &{r_{i j}=[\ell_{i}(\theta)\ell_{j}(\theta)]^{\beta}\left(\nabla_{\theta}\ell_{i}(\theta)\right)^{\top}\nabla_{\theta}\ell_{j}(\theta).}\end{array}
$$
Intuitively, the optimal solution considers the gradient and loss similarity between different groups rij. It favors clusters sharing more ‘common needs’ (Piratla et al., 2022) with others to improve the model robustness across all clusters.
直观上,最优解会考虑不同组别间的梯度与损失相似度rij。它倾向于选择与其他集群共享更多"共同需求" (Piratla et al., 2022) 的集群,以提升模型在所有集群间的鲁棒性。
COCO and iDRO operate at different training stages of dense retrieval. COCO continuously pretrains the language model to adapt to the target documents, while iDRO improves the robustness of dense retrieval in the fine-tuning stage for better generalization on unseen queries. The two together forms COCO-DR that aims to improve zero-shot retrieval accuracy by combating the distribution shift from both the query and the document side.
COCO和iDRO在稠密检索的不同训练阶段发挥作用。COCO持续预训练语言模型以适应目标文档,而iDRO则在微调阶段提升稠密检索的鲁棒性,从而在未见查询上实现更好的泛化能力。二者共同构成了COCO-DR,旨在通过同时应对查询端和文档端的分布偏移来提高零样本检索的准确率。
5 Experiments
5 实验
In this section, we first describe our experiment setups and evaluate COCO-DR. Then we analyze the efficacy of COCO and iDRO.
在本节中,我们首先描述实验设置并评估COCO-DR,随后分析COCO与iDRO的有效性。
5.1 Experimental Setups
5.1 实验设置
Our experiments use the tasks collected in BEIR (Thakur et al., 2021), a recent standard benchmark for zero-shot dense retrieval. The dataset details are in Appendix A.
我们的实验使用了BEIR (Thakur et al., 2021) 中收集的任务,这是近期零样本密集检索的标准基准。数据集详情见附录A。
Baselines. We consider various baselines, including standard sparse and dense retrieval models on BEIR. We also follow (Wang et al., 2022) to further compare COCO-DR with dedicated ZeroDR approaches based on unsupervised domain adaptation: these models are first pretrained on the target corpus and then fine-tuned on MS MARCO. We list the details of baselines in Appendix B.
基线。我们考虑了多种基线方法,包括BEIR上的标准稀疏与稠密检索模型。同时参照 (Wang et al., 2022) 的做法,进一步将COCO-DR与基于无监督领域自适应 (unsupervised domain adaptation) 的专用ZeroDR方法进行对比:这些模型先在目标语料上预训练,再在MS MARCO上微调。基线细节详见附录B。
Implementation Details. For COCO-DR, we use the same architecture as BERT (Devlin et al., 2019) and consider both Base and Large size in our experiments. The architecture of $\mathrm{COCO-DR_{Base}}$ is the same as $\mathrm{BERT_{Base}}$ : 12 layer Transformer, 768 hidden size. Similarly, the architecture of COCO $\mathrm{DR}{\mathrm{Large}}$ model is the same as $\mathrm{BERT{Large}}$ , using 24 layer and 1024 hidden size. Our implementation uses PyTorch (Paszke et al., 2019) with Hugging Face Transformers (Wolf et al., 2020) and OpenMatch (Liu et al., 2021) codebase.
实现细节。对于COCO-DR,我们采用与BERT (Devlin等人,2019) 相同的架构,并在实验中同时考虑Base和Large两种规模。$\mathrm{COCO-DR_{Base}}$ 的架构与 $\mathrm{BERT_{Base}}$ 一致:12层Transformer,768维隐藏层。类似地,COCO $\mathrm{DR}{\mathrm{Large}}$ 模型架构与 $\mathrm{BERT{Large}}$ 相同,采用24层和1024维隐藏层。我们的实现基于PyTorch (Paszke等人,2019) ,结合Hugging Face Transformers (Wolf等人,2020) 和OpenMatch (Liu等人,2021) 代码库。
Table 1: $\mathrm{nDCG}@10$ on the BEIR benchmark. The best result for each task is marked bold, and the best result among fair baselines (using BERT-base or smaller models as the backbone) is underlined. Avg CPT Sub is the average performance on 11 BEIR tasks used in Neel a kant an et al. (2022). ∗: Unfair comparison, NQ is used in training for GTR. $\dagger$ : Train an independent model for each task. $^\ddag$ : Larger Model, more training data. #: Use cross-encoders reranking teachers. $\sharp$ : Can only be accessed with paid APIs.
| Sparse | Dense | Late-Inter. | COCO-DR (Ours) | |||||||||||
| BM25 | DPR | ANCE | Contriever | GenQt | GPL# | GTRXL+ | GTRxXL | CPTL | CPTXL, | ColBERT | Base | Large | ||
| Parameters# | 一 | 110M | 110M | 110M | 66M*18 | 66M*18 | 1.2B | 4.8B | 6B | 175B | 110M | 110M | 335M | |
| MSMARCO | 0.228 | 0.354 | 0.388 | 0.407 | 0.408 | 一 | 0.439 | 0.442 | 一 | 0.401 | 0.419 | 0.424 | ||
| TREC-COVID | 0.656 | 0.575 | 0.654 | 0.596 | 0.619 | 0.700 | 0.584 | 0.501 | 0.642 | 0.649 | 0.677 | 0.789 | 0.804 | |
| BioASQ | 0.465 | 0.232 | 0.306 | 一 | 0.398 | 0.442 | 0.317 | 0.324 | 一 | 0.474 | 0.429 | 0.449 | ||
| NFCorpus | 0.325 | 0.210 | 0.237 | 0.328 | 0.319 | 0.345 | 0.343 | 0.342 | 0.380 | 0.407 | 0.305 | 0.355 | 0.354 | |
| NQ | 0.329 | 0.398 | 0.446 | 0.498 | 0.358 | 0.483 | 0.559* | 0.568* | 0.524 | 0.505 | 0.547 | |||
| HotpotQA | 0.603 | 0.371 | 0.456 | 0.638 | 0.534 | 0.582 | 0.591 | 0.599 | 0.648 | 0.688 | 0.593 | 0.616 | 0.641 | |
| FiQA-2018 | 0.236 | 0.274 | 0.295 | 0.329 | 0.308 | 0.344 | 0.444 | 0.467 | 0.452 | 0.512 | 0.317 | 0.307 | 0.329 | |
| Signal-1M | 0.330 | 0.238 | 0.249 | 一 | 0.281 | 0.276 | 0.268 | 0.273 | 0.274 | 0.271 | 0.285 | |||
| TREC-NEWS | 0.398 | 0.366 | 0.382 | 0.396 | 0.421 | 0.350 | 0.346 | 0.393 | 0.403 | 0.432 | ||||
| Robust04 | 0.408 | 0.344 | 0.392 | 0.362 | 0.437 | 0.479 | 0.506 | 0.391 | 0.443 | 0.482 | ||||
| ArguAna | 0.414 | 0.414 | 0.415 | 0.446 | 0.493 | 0.557 | 0.531 | 0.540 | 0.469 | 0.435 | 0.233 | 0.493 | 0.515 | |
| Touche-2020 | 0.367 | 0.208 | 0.240 | 0.230 | 0.182 | 0.255 | 0.230 | 0.256 | 0.309 | 0.291 | 0.202 | 0.238 | 0.263 | |
| Quora | 0.789 | 0.842 | 0.852 | 0.865 | 0.830 | 0.836 | 0.890 | 0.892 | 0.677 | 0.638 | 0.854 | 0.867 | 0.872 | |
| DBPedia-entity | 0.313 | 0.236 | 0.281 | 0.413 | 0.328 | 0.384 | 0.396 | 0.408 | 0.412 | 0.432 | 0.392 | 0.391 | 0.407 | |
| SCIDOCS | 0.158 | 0.107 | 0.122 | 0.165 | 0.143 | 0.169 | 0.159 | 0.161 | 一 | 0.145 | 0.160 | 0.178 | ||
| Fever | 0.753 | 0.589 | 0.669 | 0.758 | 0.669 | 0.759 | 0.717 | 0.740 | 0.756 | 0.775 | 0.771 | 0.751 | 0.793 | |
| Climate-Fever | 0.213 | 0.176 | 0.198 | 0.237 | 0.175 | 0.235 | 0.270 | 0.267 | 0.194 | 0.223 | 0.184 | 0.211 | 0.247 | |
| SciFact | 0.665 | 0.475 | 0.507 | 0.677 | 0.644 | 0.674 | 0.635 | 0.662 | 0.744 | 0.754 | 0.671 | 0.709 | 0.722 | |
| CQADupStack | 0.299 | 0.281 | 0.296 | 0.345 | 0.347 | 0.357 | 0.388 | 0.399 | 0.350 | 0.370 | 0.393 | |||
| AvgCPT Sub | 0.484 | 0.397 | 0.437 | 0.502 | 0.464 | 0.516 | 0.511 | 0.516 | 0.517 | 0.528 | 0.473 | 0.521 | 0.541 | |
| Avg | 0.428 | 0.352 | 0.389 | 0.410 | 0.459 | 0.453 | 0.458 | 0.431 | 0.462 | 0.484 | ||||
表 1: BEIR基准测试中的$\mathrm{nDCG}@10$结果。每个任务的最佳结果以粗体标出,公平基线(使用BERT-base或更小模型作为主干)中的最佳结果以下划线标出。Avg CPT Sub是Neelakantan等人(2022)使用的11个BEIR任务的平均性能。∗: 不公平比较,GTR训练时使用了NQ数据。$\dagger$: 为每个任务训练独立模型。$^\ddag$: 更大模型,更多训练数据。#: 使用交叉编码器重排教师模型。$\sharp$: 仅能通过付费API访问。
| Sparse | Dense | Late-Inter. | COCO-DR (Ours) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BM25 | DPR | ANCE | Contriever | GenQt | GPL# | GTRXL+ | GTRxXL | CPTL | CPTXL, | ColBERT | Base | ||
| Parameters# | - | 110M | 110M | 110M | 66M*18 | 66M*18 | 1.2B | 4.8B | 6B | 175B | 110M | 110M | |
| MSMARCO | 0.228 | 0.354 | 0.388 | 0.407 | 0.408 | - | 0.439 | 0.442 | - | 0.401 | 0.419 | ||
| TREC-COVID | 0.656 | 0.575 | 0.654 | 0.596 | 0.619 | 0.700 | 0.584 | 0.501 | 0.642 | 0.649 | 0.677 | 0.789 | |
| BioASQ | 0.465 | 0.232 | 0.306 | - | 0.398 | 0.442 | 0.317 | 0.324 | - | 0.474 | 0.429 | ||
| NFCorpus | 0.325 | 0.210 | 0.237 | 0.328 | 0.319 | 0.345 | 0.343 | 0.342 | 0.380 | 0.407 | 0.305 | 0.355 | |
| NQ | 0.329 | 0.398 | 0.446 | 0.498 | 0.358 | 0.483 | 0.559* | 0.568* | 0.524 | 0.505 | |||
| HotpotQA | 0.603 | 0.371 | 0.456 | 0.638 | 0.534 | 0.582 | 0.591 | 0.599 | 0.648 | 0.688 | 0.593 | 0.616 | |
| FiQA-2018 | 0.236 | 0.274 | 0.295 | 0.329 | 0.308 | 0.344 | 0.444 | 0.467 | 0.452 | 0.512 | 0.317 | 0.307 | |
| Signal-1M | 0.330 | 0.238 | 0.249 | - | 0.281 | 0.276 | 0.268 | 0.273 | 0.274 | 0.271 | |||
| TREC-NEWS | 0.398 | 0.366 | 0.382 | 0.396 | 0.421 | 0.350 | 0.346 | 0.393 | 0.403 | ||||
| Robust04 | 0.408 | 0.344 | 0.392 | 0.362 | 0.437 | 0.479 | 0.506 | 0.391 | 0.443 | ||||
| ArguAna | 0.414 | 0.414 | 0.415 | 0.446 | 0.493 | 0.557 | 0.531 | 0.540 | 0.469 | 0.435 | 0.233 | 0.493 | |
| Touche-2020 | 0.367 | 0.208 | 0.240 | 0.230 | 0.182 | 0.255 | 0.230 | 0.256 | 0.309 | 0.291 | 0.202 | 0.238 | |
| Quora | 0.789 | 0.842 | 0.852 | 0.865 | 0.830 | 0.836 | 0.890 | 0.892 | 0.677 | 0.638 | 0.854 | 0.867 | |
| DBPedia-entity | 0.313 | 0.236 | 0.281 | 0.413 | 0.328 | 0.384 | 0.396 | 0.408 | 0.412 | 0.432 | 0.392 | 0.391 | |
| SCIDOCS | 0.158 | 0.107 | 0.122 | 0.165 | 0.143 | 0.169 | 0.159 | 0.161 | - | 0.145 | 0.160 | ||
| Fever | 0.753 | 0.589 | 0.669 | 0.758 | 0.669 | 0.759 | 0.717 | 0.740 | 0.756 | 0.775 | 0.771 | 0.751 | |
| Climate-Fever | 0.213 | 0.176 | 0.198 | 0.237 | 0.175 | 0.235 | 0.270 | 0.267 | 0.194 | 0.223 | 0.184 | 0.211 | |
| SciFact | 0.665 | 0.475 | 0.507 | 0.677 | 0.644 | 0.674 | 0.635 | 0.662 | 0.744 | 0.754 | 0.671 | 0.709 | |
| CQADupStack | 0.299 | 0.281 | 0.296 | 0.345 | 0.347 | 0.357 | 0.388 | 0.399 | 0.350 | 0.370 | |||
| AvgCPT Sub | 0.484 | 0.397 | 0.437 | 0.502 | 0.464 | 0.516 | 0.511 | 0.516 | 0.517 | 0.528 | 0.473 | 0.521 | |
| Avg | 0.428 | 0.352 | 0.389 | 0.410 | 0.459 | 0.453 | 0.458 | 0.431 | 0.462 |
In COCO stage, we initialize our model with Condenser (Gao and Callan, 2021), and continuously pretrain the model for 8 epochs (around 200K steps) on the corpus of BEIR and MS MARCO. We optimize the model using AdamW (Loshchilov and Hutter, 2019) with a peak learning rate 1e-4/1e-5 for Base/Large, weight decay 0.01, and linear learning rate decay. The model is trained with 8 Nvidia A100 80GB GPUs and FP16 mixed-precision training. The batch size for each GPU is set to 200. Maximum number of tokens per sequence is 128.
在COCO阶段,我们使用Condenser (Gao and Callan, 2021)初始化模型,并在BEIR和MS MARCO语料库上持续预训练8个周期(约200K步)。采用AdamW (Loshchilov and Hutter, 2019)优化器,Base/Large模型的峰值学习率分别设为1e-4/1e-5,权重衰减0.01,并采用线性学习率衰减策略。训练使用8块Nvidia A100 80GB GPU和FP16混合精度,每块GPU的批次大小设置为200,序列最大token数为128。
The iDRO stage trains on MARCO passage retrieval with AdamW, 5e-6 learning rate, linear learning rate schedule, and batch size 64 for each GPU. Following Xiong et al. (2021), the model is first trained using BM25 negatives and then on selfnegatives from the DR model. We update the query clusters with K-Means $\angle K=50$ ) when refreshing negative samples. The running time for COCO and iDRO are around 1.5 days each for COCO-DRBase and around 3 days for $\mathrm{COCO-DR_{Large}}$ .
iDRO阶段使用AdamW优化器在MARCO段落检索任务上进行训练,学习率为5e-6,采用线性学习率调度策略,每个GPU的批次大小为64。参照Xiong等人(2021)的方法,模型首先使用BM25负样本进行训练,然后采用DR模型生成的自负样本进行训练。在更新负样本时,我们通过K-Means算法(K=50)动态更新查询聚类。COCO和iDRO在COCO-DRBase上的训练时间各约为1.5天,而在$\mathrm{COCO-DR_{Large}}$上约为3天。
Evaluation Details. When evaluating on the BEIR benchmark, we use sequences of 64 tokens for the questions and 128 for the documents in all datasets except TREC-NEWS, Robust04, SciFact and ArguAna. In particular, we set the document length to 256 for TREC-NEWS, Robust04 and SciFact as they have larger document length on average. For ArguAna, we set both question and document length to 128 as it has longer queries.
评估细节。在BEIR基准测试中,除TREC-NEWS、Robust04、SciFact和ArguAna外,我们对所有数据集使用64个token的问题序列和128个token的文档序列。具体而言,由于TREC-NEWS、Robust04和SciFact的平均文档长度较大,我们将其文档长度设置为256。对于ArguAna,由于查询较长,我们将问题和文档长度均设为128。
Hyper parameters. The main hyper parameters in COCO-DR includes the number of groups $K$ , the temperature parameter $\tau$ and the importance factor $\beta$ . We keep $\beta=0.25$ in COCO-DR and study the effect of $N$ and $\tau$ in Sec. 5.3.
超参数。COCO-DR中的主要超参数包括分组数量$K$、温度参数$\tau$和重要性因子$\beta$。我们在COCO-DR中保持$\beta=0.25$,并在第5.3节研究$N$和$\tau$的影响。
5.2 Overall Results
5.2 整体结果
Table 1 shows the results on BEIR. Due to space limits, we only present the strongest baselines— other reported numbers are directly comparable, if they follow the standard ZeroDR settings on BEIR.
表1: 展示了BEIR基准测试结果。由于篇幅限制,我们仅呈现最强基线数据——其他遵循BEIR标准零样本检索(ZeroDR)设置的报告数值均具有直接可比性。
$\mathrm{COCO-DR_{Base}}$ outperforms all previous methods on the average retrieval accuracy of all BEIR tasks, with large margin improvements over previous systems at $\mathrm{BERT_{Base}}$ scale. It is also competitive and often better than models with significantly more parameters. $\mathrm{COCO-DR_{Base}}$ achieves better average performance than GTRXXL and CPTL despite only using around $2%$ of their parameters. With more parameters, COCO-DRLarge outperforms the giant CPTXL model (175B) by $2.5%$ , when evaluated on a subset of 11 datasets used in their experiment. It is worth noting that ${\cal{C P T}}\mathrm{{_{XL}}}$ can only be accessed with paid APIs. One inference for 18 BEIR tasks costs around 1.4 million dollars1. Scaling up models is not the only solution for zeroshot capacity. Better methodologies to tackle the distribution shifts can also improve the generalization of dense retrieval models, while being much “greener” (Schwartz et al., 2020).
$\mathrm{COCO-DR_{Base}}$ 在所有BEIR任务的平均检索准确率上超越了以往所有方法,相较 $\mathrm{BERT_{Base}}$ 规模的先前系统实现了显著提升。即便与参数量大得多的模型相比,它也具备竞争力且往往表现更优。$\mathrm{COCO-DR_{Base}}$ 仅使用约 $2%$ 参数量的情况下,其平均性能仍优于GTRXXL和CPTL。当参数量增加时,COCO-DRLarge在实验所用的11个数据集子集上评估时,以 $2.5%$ 的优势超越了巨型CPTXL模型(175B)。值得注意的是,${\cal{C P T}}\mathrm{{_{XL}}}$ 仅能通过付费API访问,对18个BEIR任务进行一次推理的成本约为140万美元。扩大模型规模并非提升零样本能力的唯一途径,通过改进处理分布偏移的方法也能增强稠密检索模型的泛化能力,同时更加"绿色环保" (Schwartz et al., 2020)。
Table 2: Ablation study of COCO-DR without iDRO (-iDRO) or continuous contrastive (-COCO). Apart from (2022), all the results are based on our own implementations. Superscripts indicate statistically significant results with $p$ -value $<0.01$ over -iDRO†, - $\scriptstyle-\mathbf{COCO}^{\ddag}$ , co Condenser♭, Condenser♮.
| Method (→) Dataset (↓) | COCO-DR Base | COCO-DR Large | coCondenser | Condenser | |||||||
| Full | -iDRO | -COCO | Full | -iDRO | -COCO | Base (2022) | Base | Large | Base | Large | |
| TREC-COVID | 0.789 | 0.771 | 0.763 | 0.804 | 0.797 | 0.745 | 0.715 | 0.758 | 0.745 | 0.728 | 0.780 |
| BioASQ | 0.429 | 0.424 | 0.353 | 0.449 | 0.450 | 0.413 | 0.318 | 0.341 | 0.410 | 0.330 | 0.381 |
| NFCorpus | 0.355 | 0.354 | 0.333 | 0.354 | 0.353 | 0.349 | 0.307 | 0.326 | 0.350 | 0.282 | 0.317 |
| NQ | 0.505 | 0.503 | 0.506 | 0.547 | 0.536 | 0.519 | 0.494 | 0.503 | 0.516 | 0.472 | 0.492 |
| HotpotQA | 0.616 | 0.610 | 0.592 | 0.641 | 0.644 | 0.614 | 0.566 | 0.584 | 0.616 | 0.572 | 0.591 |
| FiQA-2018 | 0.307 | 0.302 | 0.312 | 0.329 | 0.322 | 0.328 | 0.285 | 0.303 | 0.326 | 0.254 | 0.280 |
| Signal-1M | 0.271 | 0.275 | 0.281 | 0.285 | 0.285 | 0.296 | 0.274 | 0.274 | 0.295 | 0.266 | 0.284 |
| TREC-NEWS | 0.403 | 0.398 | 0.426 | 0.432 | 0.426 | 0.413 | 0.389 | 0.400 | 0.416 | 0.375 | 0.423 |
| Robust04 | 0.443 | 0.443 | 0.446 | 0.482 | 0.467 | 0.466 | 0.399 | 0.442 | 0.461 | 0.385 | 0.418 |
| ArguAna | 0.493 | 0.479 | 0.473 | 0.515 | 0.513 | 0.488 | 0.411 | 0.460 | 0.484 | 0.439 | 0.469 |
| Touché-2020 | 0.238 | 0.238 | 0.257 | 0.263 | 0.258 | 0.249 | 0.190 | 0.240 | 0.246 | 0.236 | 0.244 |
| Quora | 0.867 | 0.868 | 0.862 | 0.872 | 0.869 | 0.865 | 0.863 | 0.860 | 0.862 | 0.855 | 0.852 |
| DBPedia-entity | 0.391 | 0.389 | 0.382 | 0.407 | 0.401 | 0.388 | 0.356 | 0.364 | 0.386 | 0.362 | 0.364 |
| SCIDOCS | 0.160 | 0.161 | 0.154 | 0.178 | 0.176 | 0.171 | 0.140 | 0.150 | 0.171 | 0.143 | 0.161 |
| Fever | 0.751 | 0.757 | 0.739 | 0.793 | 0.783 | 0.741 | 0.678 | 0.751 | 0.724 | 0.725 | 0.736 |
| Climate-Fever | 0.211 | 0.209 | 0.202 | 0.247 | 0.240 | 0.233 | 0.184 | 0.208 | 0.226 | 0.206 | 0.216 |
| SciFact | 0.709 | 0.688 | 0.615 | 0.722 | 0.709 | 0.696 | 0.600 | 0.602 | 0.686 | 0.581 | 0.661 |
| CQADupStack | 0.370 | 0.365 | 0.349 | 0.393 | 0.385 | 0.367 | 0.330 | 0.342 | 0.363 | 0.313 | 0.343 |
| Avg | 0.462t,t,b,b | 0.457 | 0.447 | 0.4841,tb, | 0.478 | 0.463 | 0.417 | 0.440 | 0.460 | 0.418 | 0.445 |
表 2: 不使用 iDRO (-iDRO) 或连续对比 (-COCO) 的 COCO-DR 消融研究。除 (2022) 外,所有结果均基于我们自己的实现。上标表示在 $p$ 值 $<0.01$ 下相对于 -iDRO†、- $\scriptstyle-\mathbf{COCO}^{\ddag}$、coCondenser♭、Condenser♮ 具有统计学显著性的结果。
| 方法 (→) 数据集 (↓) | COCO-DR Base | COCO-DR Base | COCO-DR Base | COCO-DR Large | COCO-DR Large | COCO-DR Large | coCondenser | coCondenser | coCondenser | Condenser | Condenser |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Full | -iDRO | -COCO | Full | -iDRO | -COCO | Base (2022) | Base | Large | Base | Large | |
| TREC-COVID | 0.789 | 0.771 | 0.763 | 0.804 | 0.797 | 0.745 | 0.715 | 0.758 | 0.745 | 0.728 | 0.780 |
| BioASQ | 0.429 | 0.424 | 0.353 | 0.449 | 0.450 | 0.413 | 0.318 | 0.341 | 0.410 | 0.330 | 0.381 |
| NFCorpus | 0.355 | 0.354 | 0.333 | 0.354 | 0.353 | 0.349 | 0.307 | 0.326 | 0.350 | 0.282 | 0.317 |
| NQ | 0.505 | 0.503 | 0.506 | 0.547 | 0.536 | 0.519 | 0.494 | 0.503 | 0.516 | 0.472 | 0.492 |
| HotpotQA | 0.616 | 0.610 | 0.592 | 0.641 | 0.644 | 0.614 | 0.566 | 0.584 | 0.616 | 0.572 | 0.591 |
| FiQA-2018 | 0.307 | 0.302 | 0.312 | 0.329 | 0.322 | 0.328 | 0.285 | 0.303 | 0.326 | 0.254 | 0.280 |
| Signal-1M | 0.271 | 0.275 | 0.281 | 0.285 | 0.285 | 0.296 | 0.274 | 0.274 | 0.295 | 0.266 | 0.284 |
| TREC-NEWS | 0.403 | 0.398 | 0.426 | 0.432 | 0.426 | 0.413 | 0.389 | 0.400 | 0.416 | 0.375 | 0.423 |
| Robust04 | 0.443 | 0.443 | 0.446 | 0.482 | 0.467 | 0.466 | 0.399 | 0.442 | 0.461 | 0.385 | 0.418 |
| ArguAna | 0.493 | 0.479 | 0.473 | 0.515 | 0.513 | 0.488 | 0.411 | 0.460 | 0.484 | 0.439 | 0.469 |
| Touché-2020 | 0.238 | 0.238 | 0.257 | 0.263 | 0.258 | 0.249 | 0.190 | 0.240 | 0.246 | 0.236 | 0.244 |
| Quora | 0.867 | 0.868 | 0.862 | 0.872 | 0.869 | 0.865 | 0.863 | 0.860 | 0.862 | 0.855 | 0.852 |
| DBPedia-entity | 0.391 | 0.389 | 0.382 | 0.407 | 0.401 | 0.388 | 0.356 | 0.364 | 0.386 | 0.362 | 0.364 |
| SCIDOCS | 0.160 | 0.161 | 0.154 | 0.178 | 0.176 | 0.171 | 0.140 | 0.150 | 0.171 | 0.143 | 0.161 |
| Fever | 0.751 | 0.757 | 0.739 | 0.793 | 0.783 | 0.741 | 0.678 | 0.751 | 0.724 | 0.725 | 0.736 |
| Climate-Fever | 0.211 | 0.209 | 0.202 | 0.247 | 0.240 | 0.233 | 0.184 | 0.208 | 0.226 | 0.206 | 0.216 |
| SciFact | 0.709 | 0.688 | 0.615 | 0.722 | 0.709 | 0.696 | 0.600 | 0.602 | 0.686 | 0.581 | 0.661 |
| CQADupStack | 0.370 | 0.365 | 0.349 | 0.393 | 0.385 | 0.367 | 0.330 | 0.342 | 0.363 | 0.313 | 0.343 |
| Avg | 0.462t,t,b,b | 0.457 | 0.447 | 0.4841,tb, | 0.478 | 0.463 | 0.417 | 0.440 | 0.460 | 0.418 | 0.445 |
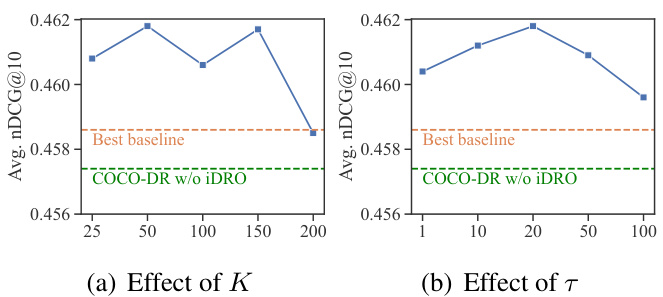
Figure 3: Average $\mathrm{NDCG}@10$ on BEIR of COCO-DR with different hyper parameters. The best baseline is GPL according to table 1.
图 3: COCO-DR在不同超参数下BEIR数据集的平均$\mathrm{NDCG}@10$值。根据表1所示,最佳基线为GPL。
COCO-DR also outperforms GPL, the strong domain adaptation model for ZeroDR (Wang et al., 2022). Note that GPL leverages a query generation model to produce pseudo relevance labels for each BEIR task, uses a cross-encoder to filter the pseudo labels, and trains one retrieval model for each task. COCO-DR does not rely on any of these techniques and uses one single model for all tasks. Its only modifications are on the model pre training and finetuning strategies. More detailed comparisons with other domain adaptation approaches are in Sec. 5.4.
COCO-DR 的表现也优于 GPL (Wang et al., 2022) 这一针对零样本检索 (ZeroDR) 的强领域适应模型。值得注意的是,GPL 利用查询生成模型为每个 BEIR 任务生成伪相关性标签,使用交叉编码器过滤伪标签,并为每个任务训练一个检索模型。而 COCO-DR 不依赖这些技术,仅使用单一模型处理所有任务,其唯一改进在于模型预训练和微调策略。与其他领域适应方法的详细对比见第 5.4 节。
5.3 Ablation Study
5.3 消融研究
We perform two groups of ablations on COCODR’s hyper parameters and components.
我们在COCODR的超参数和组件上进行了两组消融实验。
Hyper parameters. Figure 3 shows the effect of two main hyper parameters, $K$ for K-Means clustering and $\tau$ for temperatures in iDRO. When $K$ becomes very large, the performance decreases as there exist fragmented clusters that are not close to any target BEIR tasks. As a result, focusing on these clusters hurts the average performance on BEIR tasks. When $\tau$ is too big, the weight for each group will be the same. On the contrary, if $\tau$ is too small, the model focuses too much on a few specific groups. Nevertheless, iDRO is robust and outperforms the best baseline in most studied hyper parameter regions.
超参数。图 3 展示了两个主要超参数的影响:K-Means 聚类的 $K$ 和 iDRO 中的温度参数 $\tau$。当 $K$ 过大时,性能会下降,因为会出现与任何目标 BEIR 任务都不接近的碎片化聚类。因此,关注这些聚类会降低 BEIR 任务的平均性能。若 $\tau$ 过大,各组的权重会趋于相同;反之,若 $\tau$ 过小,模型会过度关注少数特定组。尽管如此,iDRO 在大多数研究的超参数范围内表现稳健,且优于最佳基线。
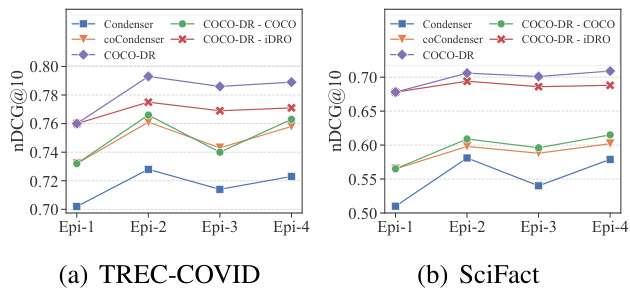
Figure 4: The performance of COCO-DR and its variants over different training stages on TREC-COVID and SciFact. Epi-1 stands for the result after BM25 warmup, and Epi-2,3,4 are results of training with selfnegative (ANCE). More results are in Appendix G.
图 4: COCO-DR及其变体在TREC-COVID和SciFact数据集上不同训练阶段的性能表现。Epi-1代表BM25预热后的结果,Epi-2,3,4为使用自负采样(ANCE)训练的结果。更多结果见附录G。
Designed Components. Table 2 shows the performance of COCO-DR variations and the pretraining baselines. COCO and iDRO improve the average performance on BEIR datasets by $3.9%$ and $1.1%$ relatively. The stronger relative gains from COCO is expected, as it leverages the available in-domain corpora, while iDRO is designed for a harder challenge: to improve model generalization ability w.r.t. unseen target queries solely using training signals from the source.
设计组件。表2展示了COCO-DR变体及预训练基线的性能表现。COCO和iDRO将BEIR数据集上的平均性能分别相对提升了$3.9%$和$1.1%$。COCO取得更强的相对增益符合预期,因为它利用了可用的领域内语料库,而iDRO则是为更艰巨的挑战而设计:仅利用源域的训练信号来提升模型针对未见目标查询的泛化能力。
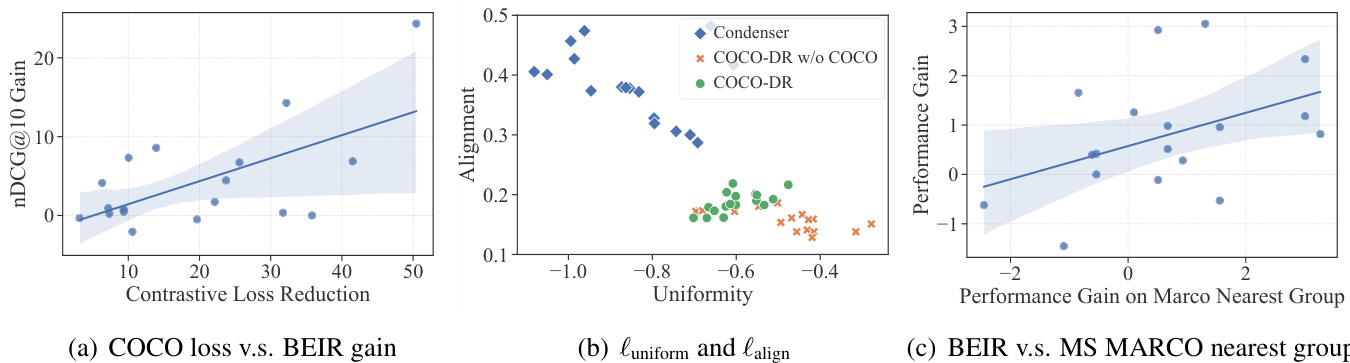
Figure 5: Left: The relation between the gain of COCO v.s. the gain on BEIR tasks. Middle: $\ell_{\mathrm{uniform}}$ & $\ell_{\mathrm{align}}$ plot for COCO-DR and its variants on BEIR tasks. Right: The relation between the gain on BEIR tasks v.s. the gain on nearest MS MARCO groups.
图 5: 左: COCO数据集增益与BEIR任务增益的关系。中: COCO-DR及其变体在BEIR任务上的 $\ell_{\mathrm{uniform}}$ 和 $\ell_{\mathrm{align}}$ 分布图。右: BEIR任务增益与最近MS MARCO组别增益的关系。
Compared with co Condenser which is pretrained on MS MARCO only (-COCO) and uses the standard DR loss during finetuning (-iDRO), each design individually leads to improvements over a majority of (COCO on 16; iDRO on 14) the 18 tasks included in BEIR. These two focus on different distribution shifts and operate at different stages of the training pipeline. Combining them in COCO-DR provides the best overall effectiveness.
与仅在MS MARCO上预训练的Condenser (-COCO) 和在微调阶段使用标准DR损失 (-iDRO) 的模型相比,每项设计单独在BEIR包含的18项任务中的大多数(COCO对16项;iDRO对14项)上实现了性能提升。这两者关注不同的分布偏移,并在训练流程的不同阶段发挥作用。将它们结合在COCO-DR中提供了最佳的整体效果。
Figure 4 zooms in the performances of COCODR and its variations on two BEIR tasks, TRECCOVID and SciFact, at different fine-tuning stages on the source task. It shows that COCO also helps stabilize the fine-tuning step on MS MARCO and reduces the oscillation between different training iterations. The benefit of iDRO is strong on biomedical tasks as shown in Figure 4, as MS MARCO indeed has relevent search intents in the BioMed domain. In Section 5.4 and 5.5, we analyze the benefits of the two designs in detail.
图 4: 放大了COCODR及其变体在BEIR任务TRECCOVID和SciFact上、于源任务不同微调阶段的表现。结果显示COCO还能稳定MS MARCO上的微调步骤,减少不同训练迭代间的波动。如图4所示,iDRO在生物医学任务上优势显著,因为MS MARCO确实包含生物医学领域的相关搜索意图。我们将在5.4和5.5节详细分析这两种设计的优势。
5.4 Influence of COCO Pre training
5.4 COCO预训练的影响
To further understand the benefit of continuous contrastive pre training, we perform three experiments on it, including: (1) comparison with other unsupervised domain adaptation (UDA) approaches, (2) the correlations between pre training and zero-shot, and (3) the pretrained sequence representations.
为了进一步理解连续对比预训练的优势,我们对其进行了三项实验,包括:(1) 与其他无监督域适应(UDA)方法的对比,(2) 预训练与零样本之间的相关性,(3) 预训练序列表示。
Comparison with UDA methods. In Table 3 we compare COCO-DR with methods besides dense retrieval on the five domain specific tasks used in the experimental settings of Wang et al. (2022).1
与UDA方法的对比。在表3中,我们将COCO-DR与Wang等人 (2022) 实验设置中使用的五个特定领域任务上的密集检索以外的方法进行了比较。
COCO-DR outperforms all previous approaches, even those used a reranking model upon first stage retrieval. The latter previously was viewed as the “generalization upper bound” since they use strong cross-encoder models that have access to termlevel matching signals (Wang et al., 2022). Previous methods that conducted contrastive pre training such as ICT (Lee et al., 2019) and SimCSE (Gao et al., 2021) under performed simple BM25 in zeroshot retrieval. These results corroborate the necessity of continuous contrastive learning.
COCO-DR 的表现优于所有先前的方法,甚至优于那些在第一阶段检索后使用重排序模型的方法。后者曾被视为"泛化上限",因为它们使用了能够获取词级匹配信号的强大交叉编码器模型 (Wang et al., 2022)。先前进行对比预训练的方法,如 ICT (Lee et al., 2019) 和 SimCSE (Gao et al., 2021),在零样本检索中的表现不及简单的 BM25。这些结果证实了持续对比学习的必要性。
Table 3: Comparison to domain adaptation methods on the BEIR tasks used in (Wang et al., 2022). † indicates statistically significant results over the strongest baseline without using reranking models (GPL w/ TSDAE).
| Model | FiQA | SciFact | TREC- Covidv2 | CQAD- upStack | Robust04 | Avg. |
| Sparse Retrieval | ||||||
| BM25 (2009) | 0.2390.661 | 0.601 | 0.315 | 0.387 | 0.461 | |
| DomainAdaptationMethods | ||||||
| UDALM (2021) | 0.233 | 0.336 | 0.571 | 0.246 | 0.263 | 0.330 |
| MoDIR (2022) Retrieval-OrientedPretraining | 0.296 | 0.502 | 0.660 | 0.297 | ||
| SimCSE(2021) | 0.267 | 0.550 | 0.683 | 0.290 | 0.379 | 0.434 |
| ICT (2019) | 0.270 | 0.585 | 0.697 | 0.313 | 0.374 | 0.448 |
| MLM (2019) | 0.302 | 0.600 | 0.695 | 0.304 | 0.388 | 0.458 |
| TSDAE (2021a) | 0.293 | 0.628 | 0.761 | 0.318 | 0.394 | 0.479 |
| Condenser (2021) | 0.270 | 0.627 | 0.654 | 0.306 | 0.345 | 0.440 |
| Condenser (ours) | 0.250 | 0.617 | 0.732 | 0.334 | 0.411 | 0.469 |
| In-DomainGeneratedPseudoLabels | ||||||
| QGen (2021) GPL (2022) | 0.2870.638 | 0.724 | 0.330 | 0.381 | 0.472 | |
| w/DistillBERT(2019) w/ TSDAE (2021a) | 0.328 0.344 | 0.664 0.689 | 0.726 0.746 | |0.345 0.351 | |0.414 0.430 | 0.495 0.512 |
| Reranking with Cross-Encoders,considered as ‘upper bound" (2022) | ||||||
| CrossEncoder(MiniLM (2020)) | ||||||
| w/BM25 | 0.331 | 0.676 | 0.712 | 0.368 | 0.467 | 0.511 |
| w/TSDAE+GPL (2022) | 0.364 | 0.683 | 0.714 | 0.381 | 0.483 | 0.525 |
| OurMethod | ||||||
| COCO-DRBase w/oiDRO | 0.302 | 0.688 | 0.785 | 0.365 | 0.443 | 0.517 |
| COCO-DRBase | 0.307 | 0.709 | 0.807 | 0.370 | 0.443 | 0.527t |
| COCO-DRLarge | 0.329 | 0.722 | 0.807 | 0.393 | 0.482 | 0.547t |
表 3: 在(Wang et al., 2022)使用的BEIR任务上与领域自适应方法的对比。†表示统计显著性强于未使用重排序模型的最强基线(GPL w/ TSDAE)。
| 模型 | FiQA | SciFact | TREC-Covidv2 | CQADupStack | Robust04 | Avg. |
|---|---|---|---|---|---|---|
| 稀疏检索 | ||||||
| BM25 (2009) | 0.2390.661 | - | 0.601 | 0.315 | 0.387 | 0.461 |
| 领域自适应方法 | ||||||
| UDALM (2021) | 0.233 | 0.336 | 0.571 | 0.246 | 0.263 | 0.330 |
| MoDIR (2022) 检索导向预训练 | 0.296 | 0.502 | 0.660 | 0.297 | - | - |
| SimCSE (2021) | 0.267 | 0.550 | 0.683 | 0.290 | 0.379 | 0.434 |
| ICT (2019) | 0.270 | 0.585 | 0.697 | 0.313 | 0.374 | 0.448 |
| MLM (2019) | 0.302 | 0.600 | 0.695 | 0.304 | 0.388 | 0.458 |
| TSDAE (2021a) | 0.293 | 0.628 | 0.761 | 0.318 | 0.394 | 0.479 |
| Condenser (2021) | 0.270 | 0.627 | 0.654 | 0.306 | 0.345 | 0.440 |
| Condenser (ours) | 0.250 | 0.617 | 0.732 | 0.334 | 0.411 | 0.469 |
| 域内生成伪标签 | ||||||
| QGen (2021) GPL (2022) | - | 0.2870.638 | 0.724 | 0.330 | 0.381 | 0.472 |
| w/DistillBERT (2019) w/ TSDAE (2021a) | 0.328 0.344 | 0.664 0.689 | 0.726 0.746 | 0.345 0.351 | 0.414 0.430 | 0.495 0.512 |
| 使用交叉编码器重排序(视为"上限") (2022) | ||||||
| CrossEncoder (MiniLM (2020)) | ||||||
| w/BM25 | 0.331 | 0.676 | 0.712 | 0.368 | 0.467 | 0.511 |
| w/TSDAE+GPL (2022) | 0.364 | 0.683 | 0.714 | 0.381 | 0.483 | 0.525 |
| 我们的方法 | ||||||
| COCO-DRBase w/oiDRO | 0.302 | 0.688 | 0.785 | 0.365 | 0.443 | 0.517 |
| COCO-DRBase | 0.307 | 0.709 | 0.807 | 0.370 | 0.443 | 0.527† |
| COCO-DRLarge | 0.329 | 0.722 | 0.807 | 0.393 | 0.482 | 0.547† |
Pre training versus Zero-Shot. In Figure 5(a) we plot the reduction of the sequence contrastive learning loss after using COCO pre training on BEIR corpora (versus pre training only on MARCO corpus), as well as the corresponding zero-shot improvements on each BEIR task. There is a notable correlation between them. On BioASQ, COCO reduces contrastive loss by $50%$ which yields $22%$ gains in zero-shot. Note that the pretrained models are fine-tuned solely on MS MARCO, but they provide attributable gains in zero-shot afterward.
预训练与零样本。在图5(a)中,我们绘制了在BEIR语料库上使用COCO预训练(对比仅在MARCO语料库预训练)后序列对比学习损失的降低情况,以及每个BEIR任务上相应的零样本改进。二者之间存在显著相关性。在BioASQ任务中,COCO使对比损失降低$50%$,零样本性能提升$22%$。需注意的是,预训练模型仅在MS MARCO上进行微调,但后续仍能带来可归因的零样本增益。
Table 4: Case study: Examples for nearest source queries of a target query in TREC-COVID and their performance gains after COCO-DR training. The number in brackets denotes the nDCG $@10$ gain from iDRO.
| TargetTREC-COVIDQuery | MSMARCONearest Query |
| does SARS-CoV-2 have any subtypes, and if so what are they? (+0.174) | different types of hivvirus (+0.041) |
| howlong can the coronavirus live outside thebody(+O.057) | how long does hep c live outside body (+0.056) |
| what arebest practicesin hospitals and at home inmaintaining quarantine?(+0.045) | definemedical quarantine(+0.055) |
| isremdesivir aneffective treatmentforCOVID-19(+0.025) | howareantiviral drugs effective in treatinginfection?(+O.031) |
| whataretheimpactsof COVID-19 among African-Americansthatdifferfromtherest of the U.S.population?(+0.030) | whatethnicgroup does sickle cella anemia affect(+0.026) |
表 4: 案例研究:TREC-COVID中目标查询的最近源查询示例及其在COCO-DR训练后的性能提升。括号中的数字表示iDRO带来的nDCG $@10$ 增益。
| TREC-COVID目标查询 | MSMARCO最近查询 |
|---|---|
| SARS-CoV-2是否有任何亚型?如果有,它们是什么? (+0.174) | HIV病毒的不同类型 (+0.041) |
| 冠状病毒在体外能存活多久? (+0.057) | 丙型肝炎病毒在体外能存活多久? (+0.056) |
| 医院和家庭中维持隔离的最佳实践是什么? (+0.045) | 医学隔离的定义 (+0.055) |
| 瑞德西韦是治疗COVID-19的有效方法吗? (+0.025) | 抗病毒药物在治疗感染中如何有效? (+0.031) |
| COVID-19对美国非裔人群与其他人群的影响有何不同? (+0.030) | 镰状细胞贫血影响哪些种族群体? (+0.026) |
Pretrained Representations. Following Wang and Isola (2020), we use alignment and uniformity to illustrate the quality of learned representations on BEIR corpora (details in Appendix H). Figure 5(b) plots the results of COCO-DR on BEIR corpora with different pre training components, before finetuning. Without contrastive learning, Condenser representations are not well aligned, which results in degeneration on target tasks. Contrastive learning on MS MARCO does not capture the sequence representations on BEIR, COCO-DR w/o COCO has low uniformity. COCO-DR provides a balanced alignment and uniformity which leads to better generalization (Wang and Isola, 2020).
预训练表示。遵循 Wang 和 Isola (2020) 的方法,我们使用对齐性 (alignment) 和均匀性 (uniformity) 来评估 BEIR 语料库上学习表示的质量 (详见附录 H)。图 5(b) 展示了 COCO-DR 在微调前、采用不同预训练组件时在 BEIR 语料库上的表现。当缺乏对比学习时,Condenser 表示的对齐性较差,导致目标任务性能下降。在 MS MARCO 上进行的对比学习未能捕捉 BEIR 的序列表示,未使用 COCO 的 COCO-DR 表现出较低的均匀性。COCO-DR 实现了对齐性与均匀性的平衡,从而获得更好的泛化能力 (Wang 和 Isola, 2020)。
5.5 Influence of Implicit DRO
5.5 隐式DRO的影响
The assumption of iDRO is that it improves the model robustness on rare query clusters in source, which helps generalize to unseen target. To verify this, we find MARCO query clusters closest to queries in each BEIR task (based on average dot product in COCO-DR embeddings). Then we plot the improvements of iDRO on BEIR tasks (zero-shot $\mathrm{NDCG}@10)$ and on their closest source clusters (training loss) in Figure 5(c).
iDRO的假设是它能提升模型在源域罕见查询簇上的鲁棒性,从而帮助泛化到未见目标域。为验证这一点,我们找到与每个BEIR任务查询最接近的MARCO查询簇(基于COCO-DR嵌入中的平均点积),然后在图5(c)中绘制iDRO对BEIR任务(零样本$\mathrm{NDCG}@10$)及其最接近源簇(训练损失)的改进效果。
From the figure, we observe the connections between the two sides: iDRO improved the training loss on the majority (12 out of 18) of source query clusters closest to BEIR. Moreover, such improvements have been successfully propagated to the BEIR tasks, as there exists a clear positive correlations among the performance gain on the MS MARCO and the corresponding target tasks. In Table 4, we show example query pairs with this connection on TREC-COVID to further support this argument. There are resemblance of the search intents between the source and target queries. The improvements of iDRO on the source queries thus also lead to the gains on unseen queries in BEIR.
从图中,我们观察到两侧的联系:iDRO在接近BEIR的大部分(12/18)源查询簇上改善了训练损失。此外,这种改进已成功传递至BEIR任务,因为MS MARCO的性能增益与对应目标任务间存在明显正相关性。表4展示了TREC-COVID上具有这种关联的查询对示例以进一步支持该论点。源查询与目标查询的搜索意图存在相似性,因此iDRO对源查询的改进也带来了BEIR未见查询上的性能提升。
6 Conclusion
6 结论
COCO-DR improves ZeroDR accuracy by combating the distribution shifts using continuous contrastive learning and implicit distribution ally robust optimization. COCO helps models better capture the sequence representations of target corpora in pre training. Implicit DRO improves model robustness by re weighting query clusters in fine-tuning.
COCO-DR通过持续对比学习和隐式分布鲁棒优化来应对分布偏移,从而提升ZeroDR的准确性。COCO帮助模型在预训练阶段更好地捕捉目标语料的序列表征。隐式DRO则通过在微调阶段重新加权查询聚类来增强模型的鲁棒性。
COCO-DR achieves strong zero-shot performance while maintaining a lightweight system with one unified model for all 18 target tasks. Different than prior works that scaling up the DR model to billions of parameters (e.g. CPT-text), we provide a more efficient and sustainable way to improve the zero-shot generalization ability. Our analyses observed clear correlations on COCO-DR’s ability to mitigate the distribution shifts and to generalize. Better ZeroDR accuracy is observed on tasks where continuous contrastive learning has a lower pre training loss, and where iDRO identifies and improves source query clusters similar to target queries.
COCO-DR 在保持轻量级系统(仅需一个统一模型处理全部18项目标任务)的同时,实现了强劲的零样本性能。与先前通过将DR模型参数量提升至数十亿级别(如CPT-text)的研究不同,我们提出了一种更高效且可持续的方法来提升零样本泛化能力。分析表明,COCO-DR缓解分布偏移与实现泛化的能力存在明确相关性:在持续对比学习预训练损失较低的任务中,以及当iDRO能识别并优化与目标查询相似的源查询集群时,ZeroDR准确率表现更优。
Limitations
局限性
In this work, we propose COCO-DR to combat the distribution shift issue for zero-shot dense retrieval. Despite the strong performance of our two key designs (COCO and iDRO), we mainly verify their efficacy from their empirical performance on BEIR tasks. More theoretical analyses are required to gain deeper understandings of these two designs. For COCO, more powerful tools are needed to establish the connection between contrastive pretraining and the performance on ZeroDR target tasks. For iDRO, the key assumption is that the robustness over rare query clusters will lead to better zero-shot performance on target out-of-domain tasks. However, there are no theoretical groundings to connect these two terms for DR models. These analyses will go beyond our empirical observations and reveal the true inner workings of COCO-DR.
在本工作中,我们提出COCO-DR来解决零样本密集检索 (zero-shot dense retrieval) 中的分布偏移问题。尽管我们的两个关键设计 (COCO和iDRO) 表现出色,但我们主要通过它们在BEIR任务上的实证性能来验证其有效性。要深入理解这两个设计,还需要更多的理论分析。对于COCO,需要更强大的工具来建立对比预训练 (contrastive pretraining) 与ZeroDR目标任务性能之间的联系。对于iDRO,其关键假设是对稀有查询簇的鲁棒性会提升目标域外任务 (out-of-domain tasks) 的零样本性能。但目前缺乏理论依据来证明这两者之间的关联性对DR模型的影响。这些分析将超越我们的实证观察,揭示COCO-DR真正的内在机制。
Acknowledgements
致谢
We would like to thank Ji Xin and Nandan Thakur for their help on getting access to non-public datasets of the BEIR benchmark. We also thank anonymous reviewers for their feedback. Yue Yu and Chao Zhang were partly supported by NSF IIS-2008334, IIS-2106961, and CAREER IIS2144338.
我们要感谢Ji Xin和Nandan Thakur在获取BEIR基准测试非公开数据集方面提供的帮助。同时感谢匿名评审的反馈意见。Yue Yu和Chao Zhang的部分工作得到了NSF IIS-2008334、IIS-2106961以及CAREER IIS2144338项目的资助。
References
参考文献
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. 2016. MS MARCO: A human generated machine reading comprehension dataset. arXiv preprint arXiv:1611.09268.
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen等. 2016. MS MARCO: 人类生成的机器阅读理解数据集. arXiv预印本 arXiv:1611.09268.
Alexander Bondarenko, Maik Fröbe, Meriem Be- loucif, Lukas Gienapp, Yamen Ajjour, Alexander Panchenko, Chris Biemann, Benno Stein, Henning Wachsmuth, Martin Potthast, and Matthias Hagen. 2020. Overview of Touché 2020: Argument Retrieval. In Working Notes Papers of the CLEF 2020 Evaluation Labs, volume 2696 of CEUR Workshop Proceedings.
Alexander Bondarenko、Maik Fröbe、Meriem Beloucif、Lukas Gienapp、Yamen Ajjour、Alexander Panchenko、Chris Biemann、Benno Stein、Henning Wachsmuth、Martin Potthast 和 Matthias Hagen。2020。Touché 2020:论据检索综述。载于《CLEF 2020评估实验室工作笔记论文集》,CEUR研讨会论文集第2696卷。
Vera Boteva, Demian Gholipour, Artem Sokolov, and Stefan Riezler. 2016. A full-text learning to rank dataset for medical information retrieval. In European Conference on Information Retrieval, pages 716–722. Springer.
Vera Boteva、Demian Gholipour、Artem Sokolov和Stefan Riezler。2016。面向医学信息检索的全文本学习排序数据集。见:欧洲信息检索会议,第716–722页。Springer。
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell等. 2020. 大语言模型是少样本学习者. 神经信息处理系统进展, 33:1877–1901.
Arman Cohan, Sergey Feldman, Iz Beltagy, Doug Downey, and Daniel Weld. 2020. SPECTER: Document-level representation learning using citation-informed transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2270–2282, Online. Association for Computational Linguistics.
Arman Cohan、Sergey Feldman、Iz Beltagy、Doug Downey 和 Daniel Weld。2020. SPECTER: 基于引用信息的Transformer文档级表征学习。载于《第58届计算语言学协会年会论文集》,第2270–2282页,线上会议。计算语言学协会。
Scott Deerwester, Susan T Dumais, George W Fur- nas, Thomas K Landauer, and Richard Harshman. 1990. Indexing by latent semantic analysis. Journal of the American society for information science, 41(6):391–407.
Scott Deerwester、Susan T Dumais、George W Furnas、Thomas K Landauer 和 Richard Harshman。1990。基于潜在语义分析的索引技术。美国信息科学技术学会期刊,41(6):391-407。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019。BERT:面向语言理解的深度双向Transformer预训练。载于《2019年北美计算语言学协会人类语言技术会议论文集(长文与短文)》第1卷,第4171–4186页,明尼苏达州明尼阿波利斯市。计算语言学协会。
Thomas Diggelmann, Jordan Boyd-Graber, Jannis Bulian, Massimiliano Ciaramita, and Markus Leippold. 2020. CLIMATE-FEVER: A dataset for verification of real-world climate claims. arXiv preprint arXiv:2012.00614.
Thomas Diggelmann、Jordan Boyd-Graber、Jannis Bulian、Massimiliano Ciaramita 和 Markus Leippold。2020。CLIMATE-FEVER: 用于验证现实世界气候声明的数据集。arXiv预印本 arXiv:2012.00614。
Thibault Formal, Carlos Lassance, Benjamin Piwowarski, and Stéphane Clinchant. 2022. From distillation to hard negative sampling: Making sparse neural ir models more effective. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’22, page 2353–2359, New York, NY, USA. Association for Computing Machinery.
Thibault Formal、Carlos Lassance、Benjamin Piwowarski和Stéphane Clinchant。2022。从蒸馏到硬负采样:提升稀疏神经信息检索模型的效果。载于《第45届国际ACM SIGIR信息检索研究与发展会议论文集》,SIGIR '22,第2353–2359页,美国纽约州纽约市。计算机协会。
Luyu Gao and Jamie Callan. 2021. Condenser: a pretraining architecture for dense retrieval. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 981–993, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Luyu Gao和Jamie Callan。2021。Condenser:一种面向密集检索的预训练架构。载于《2021年自然语言处理实证方法会议论文集》,第981-993页,线上及多米尼加共和国蓬塔卡纳。计算语言学协会。
Luyu Gao and Jamie Callan. 2022. Unsupervised corpus aware language model pre-training for dense passage retrieval. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2843–2853, Dublin, Ireland. Association for Computational Linguistics.
Luyu Gao 和 Jamie Callan。2022。面向密集段落检索的无监督语料库感知语言模型预训练。载于《第60届计算语言学协会年会论文集(第一卷:长论文)》,第2843–2853页,爱尔兰都柏林。计算语言学协会。
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. SimCSE: Simple contrastive learning of sentence embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894–6910, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Tianyu Gao、Xingcheng Yao 和 Danqi Chen。2021. SimCSE: 句子嵌入的简单对比学习。载于《2021年自然语言处理经验方法会议论文集》,第6894–6910页,线上及多米尼加共和国蓬塔卡纳。计算语言学协会。
Ishaan Gulrajani and David Lopez-Paz. 2021. In search of lost domain generalization. In International Conference on Learning Representations.
Ishaan Gulrajani 和 David Lopez-Paz。2021。寻找丢失的领域泛化。国际学习表征会议。
Suchin Gururangan, Ana Marasovic, Swabha S way am dip ta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. 2020. Don’t stop pre training: Adapt language models to domains and tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360, Online. Association for Computational Linguistics.
Suchin Gururangan、Ana Marasovic、Swabha Swayamdipta、Kyle Lo、Iz Beltagy、Doug Downey 和 Noah A. Smith。2020。不要停止预训练:将语言模型适配到领域和任务。载于《第58届计算语言学协会年会论文集》,第8342–8360页,线上。计算语言学协会。
Faegheh Hasibi, Fedor Nikolaev, Chenyan Xiong, Krisztian Balog, Svein Erik Bratsberg, Alexander Kotov, and Jamie Callan. 2017. DBpedia-Entity v2: A test collection for entity search. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’17, page 1265–1268, New York, NY, USA. Association for Computing Machinery.
Faegheh Hasibi、Fedor Nikolaev、Chenyan Xiong、Krisztian Balog、Svein Erik Bratsberg、Alexander Kotov 和 Jamie Callan。2017. DBpedia-Entity v2:实体搜索测试集。载于《第40届国际ACM SIGIR信息检索研究与发展会议论文集》(SIGIR '17),第1265–1268页,美国纽约州纽约市。ACM出版社。
Sebastian Hofstätter, Sheng-Chieh Lin, Jheng-Hong Yang, Jimmy Lin, and Allan Hanbury. 2021. Efficiently teaching an effective dense retriever with balanced topic aware sampling. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, page 113–122. Association for Computing Machinery.
Sebastian Hofstätter、Sheng-Chieh Lin、Jheng-Hong Yang、Jimmy Lin 和 Allan Hanbury。2021。基于平衡主题感知采样的高效稠密检索器教学。载于《第44届国际ACM SIGIR信息检索研究与发展会议论文集》,第113-122页。美国计算机协会。
Doris Hoogeveen, Karin M. Verspoor, and Timothy Baldwin. 2015. CQ AD up Stack: A benchmark data set for community question-answering research. In Proceedings of the 20th Australasian Document Computing Symposium, ADCS ’15, New York, NY, USA. Association for Computing Machinery.
Doris Hoogeveen、Karin M. Verspoor和Timothy Baldwin。2015. CQ AD up Stack:社区问答研究的基准数据集。载于《第20届澳大利亚文档计算研讨会论文集》,ADCS '15,美国纽约州纽约市。计算机协会。
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using click through data. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management, pages 2333–2338.
Po-Sen Huang、Xiaodong He、Jianfeng Gao、Li Deng、Alex Acero 和 Larry Heck。2013. 基于点击数据的网页搜索深度结构化语义模型学习。载于《第22届ACM国际信息与知识管理会议论文集》,第2333–2338页。
Sergey Ioffe. 2010. Improved consistent sampling, weighted minhash and l1 sketching. In 2010 IEEE International Conference on Data Mining, pages 246–255. IEEE.
Sergey Ioffe. 2010. 改进的一致性采样、加权最小哈希与L1素描技术。见:2010年IEEE国际数据挖掘会议论文集,第246-255页。IEEE。
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research.
Gautier Izacard、Mathilde Caron、Lucas Hosseini、Sebastian Riedel、Piotr Bojanowski、Armand Joulin和Edouard Grave。2022。基于对比学习的无监督密集信息检索。机器学习研究汇刊。
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
Jared Kaplan、Sam McCandlish、Tom Henighan、Tom B Brown、Benjamin Chess、Rewon Child、Scott Gray、Alec Radford、Jeffrey Wu 和 Dario Amodei。2020。神经语言模型的缩放定律。arXiv预印本 arXiv:2001.08361。
Constantin os Karouzos, Georgios Par ask evo poul os, and Alexandros Potamianos. 2021. UDALM: Unsupervised domain adaptation through language modeling. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2579–2590, Online. Association for Computational Linguistics.
Constantin os Karouzos、Georgios Par ask evo poul os和Alexandros Potamianos。2021。UDALM:通过语言建模实现无监督领域自适应。载于《2021年北美计算语言学协会人类语言技术会议论文集》,第2579–2590页,线上。计算语言学协会。
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769– 6781, Online. Association for Computational Linguistics.
Vladimir Karpukhin、Barlas Oguz、Sewon Min、Patrick Lewis、Ledell Wu、Sergey Edunov、Danqi Chen和Wen-tau Yih。2020。开放域问答的密集段落检索。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第6769–6781页,线上。计算语言学协会。
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, page 39–48, New York, NY, USA. Association for Computing Machinery.
Omar Khattab和Matei Zaharia. 2020. Colbert: 基于BERT上下文延迟交互的高效段落搜索方法. 见: 第43届国际计算机学会信息检索研究与发展会议论文集, 第39–48页, 美国纽约州纽约市. 计算机协会.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466.
Tom Kwiatkowski、Jennimaria Palomaki、Olivia Redfield、Michael Collins、Ankur Parikh、Chris Alberti、Danielle Epstein、Illia Polosukhin、Jacob Devlin、Kenton Lee、Kristina Toutanova、Llion Jones、Matthew Kelcey、Ming-Wei Chang、Andrew M. Dai、Jakob Uszkoreit、Quoc Le 和 Slav Petrov。2019。自然问题:问答研究的基准。《计算语言学协会汇刊》,7:452–466。
Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. 2019. Latent retrieval for weakly supervised open domain question answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6086–6096, Florence, Italy. Association for Computational Linguistics.
Kenton Lee、Ming-Wei Chang和Kristina Toutanova。2019。弱监督开放域问答的潜在检索。见《第57届计算语言学协会年会论文集》,第6086–6096页,意大利佛罗伦萨。计算语言学协会。
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Z ett le moyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
Yinhan Liu、Myle Ott、Naman Goyal、Jingfei Du、Mandar Joshi、Danqi Chen、Omer Levy、Mike Lewis、Luke Zettlemoyer 和 Veselin Stoyanov。2019。RoBERTa:一种鲁棒优化的 BERT 预训练方法。arXiv 预印本 arXiv:1907.11692。
Zhenghao Liu, Kaitao Zhang, Chenyan Xiong, Zhiyuan Liu, and Maosong Sun. 2021. Openmatch: An open source library for neu-ir research. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, page 2531–2535, New York, NY, USA. Association for Computing Machinery.
Zhenghao Liu, Kaitao Zhang, Chenyan Xiong, Zhiyuan Liu, and Maosong Sun. 2021. Openmatch: 神经信息检索研究的开源库. 在第44届国际ACM SIGIR信息检索研究与发展会议论文集, 第2531–2535页, 美国纽约州纽约市. 美国计算机协会.
Stuart Lloyd. 1982. Least squares quantization in pcm. IEEE transactions on information theory, 28(2):129–137.
Stuart Lloyd. 1982. 最小平方量化在PCM中的应用。IEEE信息论汇刊, 28(2):129–137。
Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regular iz ation. In International Conference on Learning Representations.
Ilya Loshchilov 和 Frank Hutter. 2019. 解耦权重衰减正则化. 见: 国际学习表征会议.
Shuqi Lu, Di He, Chenyan Xiong, Guolin Ke, Waleed Malik, Zhicheng Dou, Paul Bennett, Tie-Yan Liu, and Arnold Overwijk. 2021. Less is more: Pretrain a strong Siamese encoder for dense text retrieval using a weak decoder. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 2780–2791, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Shuqi Lu, Di He, Chenyan Xiong, Guolin Ke, Waleed Malik, Zhicheng Dou, Paul Bennett, Tie-Yan Liu, and Arnold Overwijk. 2021. 少即是多:使用弱解码器预训练强孪生编码器以进行密集文本检索。载于《2021年自然语言处理实证方法会议论文集》,第2780–2791页,线上及多米尼加共和国蓬塔卡纳。计算语言学协会。
Ji Ma, Ivan Korotkov, Yinfei Yang, Keith Hall, and Ryan McDonald. 2021. Zero-shot neural passage retrieval via domain-targeted synthetic question generation. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 1075–1088, Online. Association for Computational Linguistics.
Ji Ma、Ivan Korotkov、Yinfei Yang、Keith Hall 和 Ryan McDonald。2021。基于领域定向合成问题生成的零样本神经段落检索。载于《第16届欧洲计算语言学会会议论文集:主卷》,第1075-1088页,线上会议。计算语言学协会。
Xinyu Ma, Jiafeng Guo, Ruqing Zhang, Yixing Fan, and Xueqi Cheng. 2022. Pre-train a disc rim i native text encoder for dense retrieval via contrastive span prediction. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, page 848–858, New York, NY, USA. Association for Computing Machinery.
马新宇、郭嘉丰、张如清、范一星和程雪琪。2022。通过对比跨度预测预训练判别式文本编码器以实现密集检索。载于《第45届国际ACM SIGIR信息检索研究与发展会议论文集》,第848-858页,美国纽约州纽约市。计算机协会。
Macedo Maia, Siegfried Handschuh, André Freitas, Brian Davis, Ross McDermott, Manel Zarrouk, and Alexandra Balahur. 2018. WWW’18 open chal- lenge: Financial opinion mining and question answering. In Companion Proceedings of the The Web Conference 2018, WWW ’18, page 1941–1942, Republic and Canton of Geneva, CHE. International World Wide Web Conferences Steering Committee.
Macedo Maia、Siegfried Handschuh、André Freitas、Brian Davis、Ross McDermott、Manel Zarrouk 和 Alexandra Balahur。2018。WWW'18 开放挑战赛:金融观点挖掘与问答系统。载于《2018年万维网大会伴生论文集》,WWW '18,第1941–1942页,瑞士日内瓦。国际万维网大会指导委员会。
Yu Meng, Chenyan Xiong, Payal Bajaj, saurabh tiwary, Paul N. Bennett, Jiawei Han, and Xia Song. 2021. COCO-LM: Correcting and contrasting text sequences for language model pre training. In Advances in Neural Information Processing Systems.
Yu Meng、Chenyan Xiong、Payal Bajaj、Saurabh Tiwary、Paul N. Bennett、Jiawei Han 和 Xia Song。2021. COCO-LM: 语言模型预训练中的文本序列校正与对比。载于《神经信息处理系统进展》。
Arvind Neel a kant an, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, et al. 2022. Text and code embeddings by contrastive pretraining. arXiv preprint arXiv:2201.10005.
Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy等。2022。基于对比预训练的文本与代码嵌入。arXiv预印本arXiv:2201.10005。
Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gus- tavo Hernández Ábrego, Ji Ma, Vincent Y Zhao, Yi Luan, Keith B Hall, Ming-Wei Chang, et al. 2021. Large dual encoders are general iz able retrievers. arXiv preprint arXiv:2112.07899.
Jianmo Ni、Chen Qu、Jing Lu、Zhuyun Dai、Gustavo Hernández Ábrego、Ji Ma、Vincent Y Zhao、Yi Luan、Keith B Hall、Ming-Wei Chang等。2021。大型双编码器可作为通用检索器。arXiv预印本arXiv:2112.07899。
Yonatan Oren, Shiori Sagawa, Tatsunori B. Hashimoto, and Percy Liang. 2019. Distribution ally robust language modeling. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLPIJCNLP), pages 4227–4237, Hong Kong, China. Association for Computational Linguistics.
Yonatan Oren、Shiori Sagawa、Tatsunori B. Hashimoto 和 Percy Liang。2019. 分布鲁棒语言建模。2019年自然语言处理经验方法会议暨第九届自然语言处理国际联合会议论文集 (EMNLP-IJCNLP) ,第4227–4237页,中国香港。计算语言学协会。
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32.
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga 等. 2019. PyTorch: 一种命令式风格的高性能深度学习库. 神经信息处理系统进展, 32.
Vihari Piratla, Praneeth Netrapalli, and Sunita Sarawagi. 2022. Focus on the common good: Group distribution al robustness follows. In International Conference on Learning Representations.
Vihari Piratla、Praneeth Netrapalli和Sunita Sarawagi。2022。聚焦共同利益:群体分布稳健性随之而来。发表于国际学习表征会议。
Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu, and Haifeng Wang. 2021. RocketQA: An optimized training approach to dense passage retrieval for open-domain question answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5835–5847, Online. Association for Computational Linguistics.
Yingqi Qu、Yuchen Ding、Jing Liu、Kai Liu、Ruiyang Ren、Wayne Xin Zhao、Daxiang Dong、Hua Wu 和 Haifeng Wang。2021. RocketQA:面向开放域问答的密集段落检索优化训练方法。载于《2021年北美计算语言学协会人类语言技术会议论文集》,第5835–5847页,线上。计算语言学协会。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J Liu。2019. 探索迁移学习的极限:基于统一文本到文本Transformer的研究。《机器学习研究期刊》。
Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qifei Wu, Yuchen Ding, Hua Wu, Haifeng Wang, and Ji-Rong Wen. 2022. A thorough examination on zero-shot dense retrieval. arXiv preprint arXiv:2204.12755.
Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qifei Wu, Yuchen Ding, Hua Wu, Haifeng Wang, and Ji-Rong Wen. 2022. 零样本密集检索的全面考察. arXiv preprint arXiv:2204.12755.
Stephen Robertson, Hugo Zaragoza, et al. 2009. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends in Information Retrieval, 3(4):333–389.
Stephen Robertson, Hugo Zaragoza, 等. 2009. 概率相关性框架: BM25 及后续发展. 信息检索的基础与趋势, 3(4):333–389.
Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. 2020. Distribution ally robust neural networks. In International Conference on Learning Representations.
Shiori Sagawa、Pang Wei Koh、Tatsunori B. Hashimoto 和 Percy Liang。2020. 分布鲁棒神经网络 (Distributionally Robust Neural Networks)。载于国际学习表征会议 (International Conference on Learning Representations)。
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
Victor Sanh、Lysandre Debut、Julien Chaumond和Thomas Wolf。2019。DistilBERT:BERT的精简版——更小、更快、更经济、更轻量。arXiv预印本arXiv:1910.01108。
Roy Schwartz, Jesse Dodge, Noah A. Smith, and Oren Etzioni. 2020. Green ai. Commun. ACM, 63(12):54–63.
Roy Schwartz、Jesse Dodge、Noah A. Smith 和 Oren Etzioni。2020。绿色 AI (Green AI)。《ACM 通讯》,63(12):54–63。
Ian Soboroff, Shudong Huang, and Donna Harman. 2018. Trec 2018 news track overview.
Ian Soboroff、Shudong Huang和Donna Harman。2018。TREC 2018新闻赛道综述。
Nimit Sohoni, Jared Dunnmon, Geoffrey Angus, Albert Gu, and Christopher Ré. 2020. No subclass left behind: Fine-grained robustness in coarse-grained classification problems. Advances in Neural Information Processing Systems, 33:19339–19352.
Nimit Sohoni、Jared Dunnmon、Geoffrey Angus、Albert Gu和Christopher Ré。2020。不让任何子类掉队:粗粒度分类问题中的细粒度鲁棒性。神经信息处理系统进展,33:19339–19352。
Axel Suarez, Dyaa Albakour, David Corney, Miguel Martinez, and José Esquivel. 2018. A data collection for evaluating the retrieval of related tweets to news articles. In European Conference on Information Retrieval, pages 780–786. Springer.
Axel Suarez、Dyaa Albakour、David Corney、Miguel Martinez和José Esquivel。2018。用于评估新闻文章相关推文检索的数据集。见:欧洲信息检索会议,第780-786页。Springer。
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2).
Nandan Thakur、Nils Reimers、Andreas Rücklé、Abhishek Srivastava 和 Iryna Gurevych。2021. BEIR:一个用于信息检索模型零样本评估的异构基准。载于第三十五届神经信息处理系统大会数据集与基准赛道(第二轮)。
James Thorne, Andreas Vlachos, Christos Christo dou lo poul os, and Arpit Mittal. 2018. FEVER: a large-scale dataset for fact extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 809–819, New Orleans, Louisiana. Association for Computational Linguistics.
James Thorne、Andreas Vlachos、Christos Christodoulopoulos 和 Arpit Mittal。2018. FEVER:用于事实提取与验证的大规模数据集。载于《2018年北美计算语言学协会人类语言技术会议论文集(长论文)》第1卷,第809-819页,美国路易斯安那州新奥尔良。计算语言学协会。
George Tsa tsar on is, Georgios Balikas, Prodromos Malak as i otis, Ioannis Partalas, Matthias Zschunke, Michael R Alvers, Dirk Weiss en born, Anastasia Krithara, Sergios Petridis, Dimitris Poly chrono po u- los, et al. 2015. An overview of the BIOASQ largescale biomedical semantic indexing and question answering competition. BMC bioinformatics, 16(1):1– 28.
George Tsa tsar on is, Georgios Balikas, Prodromos Malak as i otis, Ioannis Partalas, Matthias Zschunke, Michael R Alvers, Dirk Weiss en born, Anastasia Krithara, Sergios Petridis, Dimitris Poly chrono po u- los, et al. 2015. BIOASQ大规模生物医学语义索引与问答竞赛综述。BMC生物信息学, 16(1):1–28.
Ellen Voorhees, Tasmeer Alam, Steven Bedrick, Dina Demner-Fushman, William R. Hersh, Kyle Lo, Kirk Roberts, Ian Soboroff, and Lucy Lu Wang. 2021. TREC-COVID: Constructing a pandemic information retrieval test collection. SIGIR Forum, 54(1).
Ellen Voorhees、Tasmeer Alam、Steven Bedrick、Dina Demner-Fushman、William R. Hersh、Kyle Lo、Kirk Roberts、Ian Soboroff 和 Lucy Lu Wang。2021。TREC-COVID:构建疫情信息检索测试集。SIGIR论坛,54(1)。
Ellen M Voorhees et al. 2004. Overview of the trec 2004 robust retrieval track. In Trec, pages 69–77.
Ellen M Voorhees等. 2004. TREC 2004鲁棒检索赛道综述. 见: TREC, 第69–77页.
Henning Wachsmuth, Shahbaz Syed, and Benno Stein. 2018. Retrieval of the best counter argument without prior topic knowledge. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 241–251, Melbourne, Australia. Association for Computational Linguistics.
Henning Wachsmuth、Shahbaz Syed 和 Benno Stein。2018. 无需先验主题知识的最佳反驳论点检索。载于《第56届计算语言学协会年会论文集(第一卷:长论文)》,第241-251页,澳大利亚墨尔本。计算语言学协会。
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. 2020. Fact or fiction: Verifying scientific claims. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7534–7550, Online. Association for Computational Linguistics.
David Wadden、Shanchuan Lin、Kyle Lo、Lucy Lu Wang、Madeleine van Zuylen、Arman Cohan 和 Hannaneh Hajishirzi。2020。事实还是虚构:科学主张验证。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第7534-7550页,线上会议。计算语言学协会。
Kexin Wang, Nils Reimers, and Iryna Gurevych. 2021a. TSDAE: Using transformer-based sequential denoising auto-encoderfor unsupervised sentence embed- ding learning. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 671–688, Punta Cana, Dominican Republic. Association for Computational Linguistics.
Kexin Wang、Nils Reimers和Iryna Gurevych。2021a。TSDAE:基于Transformer的顺序去噪自编码器在无监督句子嵌入学习中的应用。载于《计算语言学协会发现:EMNLP 2021》,第671–688页,多米尼加共和国蓬塔卡纳。计算语言学协会。
Kexin Wang, Nandan Thakur, Nils Reimers, and Iryna Gurevych. 2022. GPL: Generative pseudo labeling for unsupervised domain adaptation of dense retrieval. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, United States. Association for Computational Linguistics.
Kexin Wang、Nandan Thakur、Nils Reimers 和 Iryna Gurevych。2022。GPL: 密集检索无监督领域适应的生成式伪标注 (Generative Pseudo Labeling)。载于《2022年北美计算语言学协会人类语言技术会议论文集》,美国西雅图。计算语言学协会。
Tongzhou Wang and Phillip Isola. 2020. Understanding contrastive representation learning through alignment and uniformity on the hyper sphere. In International Conference on Machine Learning, pages 9929–9939. PMLR.
Tongzhou Wang 和 Phillip Isola。2020。通过超球面上的对齐性与均匀性理解对比表示学习。见《国际机器学习会议》,第9929-9939页。PMLR。
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. Minilm: Deep selfattention distillation for task-agnostic compression of pre-trained transformers. Advances in Neural Information Processing Systems, 33:5776–5788.
Wenhui Wang、Furu Wei、Li Dong、Hangbo Bao、Nan Yang 和 Ming Zhou。2020。MiniLM:面向任务无关的预训练Transformer压缩的深度自注意力蒸馏。神经信息处理系统进展,33:5776–5788。
Yining Wang, Liwei Wang, Yuanzhi Li, Di He, Wei Chen, and Tie-Yan Liu. 2013. A theoretical analysis of ndcg ranking measures. In Proceedings of the 26th annual conference on learning theory (COLT 2013), volume 8, page 6. Citeseer.
Yining Wang、Liwei Wang、Yuanzhi Li、Di He、Wei Chen 和 Tie-Yan Liu。2013. NDCG排序指标的理论分析。载于《第26届学习理论年会论文集》(COLT 2013),第8卷,第6页。Citeseer。
Yu Wang, Jinchao Li, Tristan Naumann, Chenyan Xiong, Hao Cheng, Robert Tinn, Cliff Wong, Naoto Usuyama, Richard Rogahn, Zhihong Shen, et al. 2021b. Domain-specific pre training for vertical search: Case study on biomedical literature. In Proceedings of the 27th ACM SIGKDD Conference on
Yu Wang、Jinchao Li、Tristan Naumann、Chenyan Xiong、Hao Cheng、Robert Tinn、Cliff Wong、Naoto Usuyama、Richard Rogahn、Zhihong Shen等。2021b。垂直搜索的领域特定预训练:以生物医学文献为例。见第27届ACM SIGKDD会议论文集
Knowledge Discovery & Data Mining, pages 3717– 3725.
知识发现与数据挖掘,第3717–3725页。
Guillaume Wenzek, Marie-Anne Lachaux, Alexis Con- neau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. 2020. CCNet: Extracting high quality monolingual datasets from web crawl data. In Proceedings of the 12th Lan- guage Resources and Evaluation Conference, pages 4003–4012, Marseille, France. European Language Resources Association.
Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, Edouard Grave. 2020. CCNet: 从网络爬取数据中提取高质量单语数据集. 见: 第十二届语言资源与评估会议论文集, 第4003–4012页, 法国马赛. 欧洲语言资源协会.
Olivia Wiles, Sven Gowal, Florian Stimberg, Sylvestre- Alvise Rebuffi, Ira Ktena, Krishna mur thy Dj Dvijotham, and Ali Taylan Cemgil. 2022. A finegrained analysis on distribution shift. In International Conference on Learning Representations.
Olivia Wiles、Sven Gowal、Florian Stimberg、Sylvestre-Alvise Rebuffi、Ira Ktena、Krishnamurthy Dj Dvijotham 和 Ali Taylan Cemgil。2022。细粒度分布偏移分析。发表于《国际学习表征会议》。
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, Tim Rault, Remi Louf, Morgan Funtow- icz, et al. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pier-ric Cistac、Tim Rault、Remi Louf、Morgan Funtowicz等。2020。Transformer:最先进的自然语言处理技术。载于《2020年自然语言处理实证方法会议:系统演示论文集》,第38-45页,线上。计算语言学协会。
Ji Xin, Chenyan Xiong, Ashwin Srinivasan, Ankita Sharma, Damien Jose, and Paul Bennett. 2022. Zero-shot dense retrieval with momentum adversarial domain invariant representations. In Findings of the Association for Computational Linguistics: ACL 2022, pages 4008–4020, Dublin, Ireland. Association for Computational Linguistics.
Ji Xin、Chenyan Xiong、Ashwin Srinivasan、Ankita Sharma、Damien Jose 和 Paul Bennett。2022. 基于动量对抗域不变表示的零样本密集检索。载于《计算语言学协会发现集: ACL 2022》,第4008-4020页,爱尔兰都柏林。计算语言学协会。
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N. Bennett, Junaid Ahmed, and Arnold Overwijk. 2021. Approximate nearest neigh- bor negative contrastive learning for dense text retrieval. In International Conference on Learning Representations.
Lee Xiong、Chenyan Xiong、Ye Li、Kwok-Fung Tang、Jialin Liu、Paul N. Bennett、Junaid Ahmed 和 Arnold Overwijk。2021。稠密文本检索的近似最近邻负对比学习。见于国际学习表征会议。
Canwen Xu, Daya Guo, Nan Duan, and Julian McAuley. 2022. LaPraDoR: Unsupervised pretrained dense retriever for zero-shot text retrieval. In Findings of the Association for Computational Linguistics: ACL 2022, pages 3557–3569, Dublin, Ireland. Association for Computational Linguistics.
Canwen Xu、Daya Guo、Nan Duan 和 Julian McAuley。2022。LaPraDoR:用于零样本文本检索的无监督预训练密集检索器。载于《计算语言学协会2022年ACL会议发现集》,第3557–3569页,爱尔兰都柏林。计算语言学协会。
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salak hut dino v, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explain able multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium. Association for Computational Linguistics.
Zhilin Yang、Peng Qi、Saizheng Zhang、Yoshua Bengio、William Cohen、Ruslan Salakhutdinov 和 Christopher D. Manning。2018. HotpotQA:一个支持多样化、可解释多跳问答的数据集。载于《2018年自然语言处理实证方法会议论文集》,第2369–2380页,比利时布鲁塞尔。计算语言学协会。
Chunting Zhou, Xuezhe Ma, Paul Michel, and Graham Neubig. 2021. Examining and combating spurious features under distribution shift. In International Conference on Machine Learning, pages 12857–12867. PMLR.
周春霆、马学哲、Paul Michel 和 Graham Neubig。2021。分布偏移下虚假特征的检验与对抗。收录于《国际机器学习会议》,第12857–12867页。PMLR。
A Datasets Details
数据集详情
Target domain datasets used in our experiments are collected in the BEIR benchmark (Thakur et al., 2021)1 and include the following domains:
我们实验中使用的目标领域数据集收集自BEIR基准测试 (Thakur et al., 2021) [1],涵盖以下领域:
We list the statistics of the BEIR benchmark in Table 5.
我们在表5中列出了BEIR基准测试的统计数据。
Metric To measure the effectiveness of search algorithms or retrieval models, the benchmark uses Normalized Discounted Cumulative Gain $(\mathrm{nDCG}@10)$ (Wang et al., 2013) as the evaluation metric. The higher value indicates better performance.
B Baselines
We use the baselines from the current BEIR leaderboard (Thakur et al., 2021) and recent papers. For the main experiments, the baselines can be divided into four groups: dense retrieval, dense retrieval with generated queries2, lexical retrieval, and late interaction.
我们采用当前BEIR排行榜(Thakur等人,2021)和近期论文中的基线方法。主实验的基线方法可分为四类:稠密检索、带生成查询的稠密检索、词法检索以及延迟交互。
B.1 Baselines for Main Experiments
B.1 主要实验的基线
Dense Retrieval For dense retrieval, the baselines are the same dual-tower model as ours. We consider DPR (Karpukhin et al., 2020), ANCE (Xiong et al., 2021), Contriever (Izacard et al., 2022), and two recently-proposed giant model, namely GTR (Ni et al., 2021) and CPTtext (Neel a kant an et al., 2022) in this paper.
稠密检索 (Dense Retrieval) 的基线模型采用与我们相同的双塔结构。我们对比了 DPR (Karpukhin 等人, 2020) 、ANCE (Xiong 等人, 2021) 、Contriever (Izacard 等人, 2022) 以及两个最新提出的大规模模型:GTR (Ni 等人, 2021) 和 CPTtext (Neelakantan 等人, 2022) 。
• DPR uses a single BM25 retrieval example and in-batch examples as hard negative examples to train the model. Different from the original paper (Thakur et al., 2021) that train the DPR on QA datasets, we train DPR on MS MARCO (Bajaj et al., 2016) Dataset for fair comparison. Notice that this also lead to better results according to Xin et al. (2022).
- DPR 使用单个 BM25 检索示例和批次内示例作为难负例 (hard negative examples) 来训练模型。与原始论文 (Thakur et al., 2021) 在问答数据集上训练 DPR 不同,我们为了公平比较在 MS MARCO (Bajaj et al., 2016) 数据集上训练 DPR。注意,根据 Xin et al. (2022) 的研究,这种做法也能带来更好的结果。
• ANCE constructs hard negative examples from an ANN index of the corpus. The hard negative training instances are updated in parallel during fine-tuning of the model. The model is a RoBERTa (Liu et al., 2019) model trained on MS MARCO for 600k steps.
• ANCE 通过语料库的近似最近邻 (ANN) 索引构建困难负样本,并在模型微调期间并行更新这些困难负训练实例。该模型是基于 MS MARCO 数据集训练 60 万步的 RoBERTa (Liu et al., 2019) 模型。
• Contriever conducts unsupervised contrastive pre training with data augmentations and momentum queues on Wikipedia and CC-Net (Wenzek et al., 2020) corpora for 500k steps.
• Contriever 在 Wikipedia 和 CC-Net (Wenzek 等人, 2020) 语料库上进行了 50 万步的无监督对比预训练,采用数据增强和动量队列技术。
• GTR initializes the dual encoders from the T5 models (Raffel et al., 2019). It is first pre-trained on Community $\mathrm{QA}^{3}$ with 2 billion questionanswer pairs then fine-tuned on NQ and MS Marco dataset.
• GTR 使用 T5 模型 (Raffel et al., 2019) 初始化双编码器。首先在 Community $\mathrm{QA}^{3}$ 的 20 亿问答对上进行预训练,然后在 NQ 和 MS Marco 数据集上进行微调。
• CPT-text initializes with the large GPT models (Brown et al., 2020), and pre-trained on web- scale Internet data with neighboring pieces of text as positive pairs for the contrastive objective.
• CPT-text 基于大型 GPT 模型 (Brown et al., 2020) 初始化,并通过网络规模的互联网数据进行预训练,将相邻文本片段作为对比学习目标的正样本对。
Dense Retrieval with Generated Queries
基于生成查询的密集检索
• GenQ first fine-tunes a T5-base (Raffel et al., 2019) model on MS MARCO for 2 epochs and then generate 5 queries for each passage as additional training data for the target domain to continue to fine-tune the TAS-B (Hofstätter et al., 2021) model.
• GenQ首先在MS MARCO上对T5-base (Raffel等人,2019) 模型进行2个epoch的微调,然后为每个段落生成5个查询作为目标域的额外训练数据,以继续微调TAS-B (Hofstätter等人,2021) 模型。
| Split (→) | Train | Dev | Test | Avg. Word Lengths | |||||||
| Task (↓) | Domain (↓) | Dataset (↓) | Title | Relevancy | #Pairs | #Query | #Query | #Corpus | Avg.D/Q | Query | Document |
| Passage-Retrieval | Misc. | MS MARCO | Binary | 532,761 | — | 6,980 | 8,841,823 | 1.1 | 5.96 | 55.98 | |
| Bio-Medical | Bio-Medical | TREC-COVID | 3-level | 50 | 171,332 | 493.5 | 10.60 | 160.77 | |||
| Information | Bio-Medical | NFCorpus | 3-level | 110,575 | 324 | 323 | 3,633 | 38.2 | 3.30 | 232.26 | |
| Retrieval (IR) | Bio-Medical | BioASQ | Binary | 32,916 | 500 | 14,914,602 | 4.7 | 8.05 | 202.61 | ||
| Question | Wikipedia | NQ | Binary | 132,803 | 3,452 | 2,681,468 | 1.2 | 9.16 | 78.88 | ||
| Answering | Wikipedia | HotpotQA | Binary | 170,000 | 5,447 | 7,405 | 5,233,329 | 2.0 | 17.61 | 46.30 | |
| (QA) | Finance | FiQA-2018 | Binary | 14,166 | 500 | 648 | 57,638 | 2.6 | 10.77 | 132.32 | |
| Tweet-Retrieval | Signal-1M (RT) | 3-level | — | 97 | 2,866,316 | 19.6 | 9.30 | 13.93 | |||
| News | News | TREC-NEWS | 5-level | 57 | 594,977 | 19.6 | 11.14 | 634.79 | |||
| Retrieval | News | Robust04 | 3-level | 249 | 528,155 | 69.9 | 15.27 | 466.40 | |||
| Argument | Misc. | ArguAna | Binary | 1,406 | 8,674 | 1.0 | 192.98 | 166.80 | |||
| Retrieval | Misc. | Touche-2020 | 3-level | 49 | 382,545 | 19.0 | 6.55 | 292.37 | |||
| Duplicate-Question | StackEx. | CQADupStack | Binary | 13,145 | 457,199 | 1.4 | 8.59 | 129.09 | |||
| Retrieval | Quora | Quora | Binary | 5,000 | 10,000 | 522,931 | 1.6 | 9.53 | 11.44 | ||
| Entity-Retrieval | Wikipedia | DBPedia | 3-level | — | 67 | 400 | 4,635,922 | 38.2 | 5.39 | 49.68 | |
| Citation-Prediction | Scientific | SCIDOCS | Binary | 1,000 | 25,657 | 4.9 | 9.38 | 176.19 | |||
| Fact Checking | Wikipedia | FEVER | Binary | 140,085 | 6,666 | 6,666 | 5,416,568 | 1.2 | 8.13 | 84.76 | |
| Wikipedia | Climate-FEVER | Binary | 1,535 | 5,416,593 | 3.0 | 20.13 | 84.76 | ||||
| Scientific | SciFact | Binary | 920 | 300 | 5,183 | 1.1 | 12.37 | 213.63 | |||
Table 5: Statistics of datasets in the BEIR benchmark. The table is taken from the original BEIR benchmark paper (Thakur et al., 2021).
| 划分 (→) | 训练集 | 开发集 | 测试集 | 平均词长 |
|---|---|---|---|---|
| 任务 (↓) | 领域 (↓) | 数据集 (↓) | 标题 | 相关性 |
| 段落检索 | 综合 | MS MARCO | 二元 | |
| 生物医学 | 生物医学 | TREC-COVID | 三级 | |
| 信息检索 (IR) | 生物医学 | NFCorpus | 三级 | |
| 生物医学 | BioASQ | 二元 | ||
| 问答 (QA) | 维基百科 | NQ | 二元 | |
| 维基百科 | HotpotQA | 二元 | ||
| 金融 | FiQA-2018 | 二元 | ||
| 推文检索 | 推特 | Signal-1M (RT) | 三级 | |
| 新闻检索 | 新闻 | TREC-NEWS | 五级 | |
| 新闻 | Robust04 | 三级 | ||
| 论点检索 | 综合 | ArguAna | 二元 | |
| 综合 | Touche-2020 | 三级 | ||
| 重复问题检索 | StackEx. | CQADupStack | 二元 | |
| Quora | Quora | 二元 | ||
| 实体检索 | 维基百科 | DBPedia | 三级 | |
| 引用预测 | 科学 | SCIDOCS | 二元 | |
| 事实核查 | 维基百科 | FEVER | 二元 | |
| 维基百科 | Climate-FEVER | 二元 | ||
| 科学 | SciFact | 二元 |
表 5: BEIR 基准测试中各数据集的统计信息。本表取自原始 BEIR 基准测试论文 (Thakur et al., 2021)。
• GPL is a recent work that improve the perforance of GenQ with cross-encoder reranking. It first generates queries for documents from the target domain, then use an additional cross-encoder (Wang et al., 2020) to rank each (query, document)-pair and then train a dense retrieval model on these generated, pseudo-labeled queries4.
• GPL 是一项近期工作,通过交叉编码器 (cross-encoder) 重排序提升 GenQ 性能。其首先生成目标领域文档的查询,随后使用额外交叉编码器 [20] 对每个 (查询, 文档) 对进行排序,最终基于这些生成的伪标注查询训练稠密检索模型。
Lexical Retrieval Lexical retrieval is a score function for token matching calculated between two high-dimensional sparse vectors with token weights.
词汇检索
词汇检索是一种基于Token权重的高维稀疏向量匹配的评分函数。
• BM25 (Robertson et al., 2009) is the most commonly used lexical retrieval function. We use the BM25 results reported in Thakur et al. (2021) for comparison.
• BM25 (Robertson et al., 2009) 是最常用的词汇检索函数。我们采用 Thakur et al. (2021) 报告中公布的 BM25 结果进行对比。
Late Interaction We also consider a late interaction baseline, namely ColBERT (Khattab and Zaharia, 2020). The model computes multiple contextual i zed embeddings for each token of queries and documents, and then uses a maximum similarity function to retrieve relevant documents. This type of matching requires significantly more disk space for indexes and has a higher latency.
延迟交互
我们还考虑了一个延迟交互基线,即 ColBERT (Khattab and Zaharia, 2020)。该模型为查询和文档的每个 Token 计算多个上下文嵌入 (contextualized embeddings),然后使用最大相似度函数来检索相关文档。这类匹配方式需要显著更多的索引磁盘空间,并具有更高的延迟。
B.2 Additional Domain Adaptation Baselines
B.2 额外领域适应基线
We further compare COCO-DR with additional baselines focus on domain adaptation to specialized domains including UDALM (Karouzos et al., 2021), MoDIR (Xin et al., 2022), SimCSE (Gao et al., 2021), ICT (Lee et al., 2019), MLM (Liu et al., 2019), TSDAE (Wang et al., 2021a), and Condenser (Gao and Callan, 2021). Note that these models are first pre-trained on the target corpus and then fine-tuned on the MS MARCO dataset.
我们进一步将COCO-DR与专注于专业领域自适应(domain adaptation)的其他基线方法进行比较,包括UDALM (Karouzos et al., 2021)、MoDIR (Xin et al., 2022)、SimCSE (Gao et al., 2021)、ICT (Lee et al., 2019)、MLM (Liu et al., 2019)、TSDAE (Wang et al., 2021a)和Condenser (Gao and Callan, 2021)。需要注意的是,这些模型先在目标语料库上进行预训练,然后在MS MARCO数据集上进行微调。
Table 6: Detailed statistics for (1) query intent similarity and document lexical similarity between MS MARCO and BEIR tasks (2) the performance gap between ANCE starting from $\mathrm{BERT_{base}}$ and co Condenser and BM25. The positive value indicates ANCE performs better than BM25.
| Dataset (↓) | QueryIntent Similarity | Document Lexical Similarity | ANCE(BERTBase) V.s.BM25 | ANCE(coCondenser) V.s.BM25 |
| TREC-COVID | 0.4845 | 0.2789 | -0.002 | +0.102 |
| BioASQ | 0.4380 | 0.2806 | -0.159 | -0.124 |
| NFCorpus | 0.2367 | 0.2426 | -0.088 | +0.001 |
| NQ | 0.5127 | 0.5092 | +0.117 | +0.174 |
| HotpotQA | 0.5078 | 0.3275 | -0.147 | -0.019 |
| FiQA-2018 | 0.4950 | 0.3721 | +0.059 | +0.067 |
| Signal-1M | 0.1708 | 0.3334 | -0.081 | -0.056 |
| TREC-NEWS | 0.2280 | 0.4194 | -0.016 | +0.002 |
| Robust04 | 0.6656 | 0.4323 | -0.016 | +0.008 |
| ArguAna | 0.1690 | 0.3421 | +0.001 | +0.046 |
| Touché-2020 | 0.0391 | 0.3785 | -0.127 | -0.127 |
| Quora | 0.5629 | 0.4141 | +0.063 | +0.071 |
| DBPedia-entity | 0.2235 | 0.3189 | -0.032 | +0.051 |
| SCIDOCS | 0.1636 | 0.2945 | -0.036 | -0.008 |
| Fever | 0.1621 | 0.3689 | -0.084 | -0.002 |
| Climate-Fever | 0.1732 | 0.3689 | -0.015 | -0.014 |
| SciFact | 0.1809 | 0.2335 | -0.158 | -0.092 |
| CQADupStack | 0.4254 | 0.3196 | -0.003 | +0.043 |
表 6: (1) MS MARCO 与 BEIR 任务间查询意图相似性和文档词汇相似性的详细统计数据 (2) 基于 $\mathrm{BERT_{base}}$ 的 ANCE 与 coCondenser 及 BM25 的性能差距。正值表示 ANCE 优于 BM25。
| 数据集 (↓) | 查询意图相似性 | 文档词汇相似性 | ANCE(BERTBase) vs BM25 | ANCE(coCondenser) vs BM25 |
|---|---|---|---|---|
| TREC-COVID | 0.4845 | 0.2789 | -0.002 | +0.102 |
| BioASQ | 0.4380 | 0.2806 | -0.159 | -0.124 |
| NFCorpus | 0.2367 | 0.2426 | -0.088 | +0.001 |
| NQ | 0.5127 | 0.5092 | +0.117 | +0.174 |
| HotpotQA | 0.5078 | 0.3275 | -0.147 | -0.019 |
| FiQA-2018 | 0.4950 | 0.3721 | +0.059 | +0.067 |
| Signal-1M | 0.1708 | 0.3334 | -0.081 | -0.056 |
| TREC-NEWS | 0.2280 | 0.4194 | -0.016 | +0.002 |
| Robust04 | 0.6656 | 0.4323 | -0.016 | +0.008 |
| ArguAna | 0.1690 | 0.3421 | +0.001 | +0.046 |
| Touché-2020 | 0.0391 | 0.3785 | -0.127 | -0.127 |
| Quora | 0.5629 | 0.4141 | +0.063 | +0.071 |
| DBPedia-entity | 0.2235 | 0.3189 | -0.032 | +0.051 |
| SCIDOCS | 0.1636 | 0.2945 | -0.036 | -0.008 |
| Fever | 0.1621 | 0.3689 | -0.084 | -0.002 |
| Climate-Fever | 0.1732 | 0.3689 | -0.015 | -0.014 |
| SciFact | 0.1809 | 0.2335 | -0.158 | -0.092 |
| CQADupStack | 0.4254 | 0.3196 | -0.003 | +0.043 |
• TSDAE leverages an additional denoising autoencoder to pre-train the dense retriever model with $60%$ random tokens deleted in the input document.
• TSDAE 利用额外的去噪自编码器 (denoising autoencoder) 对密集检索模型进行预训练,输入文档中随机删除 $60%$ 的 token。
• Condenser improves the representation of [CLS] token by enforcing it to aggregate with the token embedding. In this way, the head model can then condition on late [CLS] to make LM predictions to enforce [CLS] to capture the global meaning of the input text.
• Condenser通过强制[CLS] token与token嵌入进行聚合来改进其表示。这样,头部模型就能基于后期的[CLS]进行大语言模型预测,从而迫使[CLS]捕获输入文本的全局含义。
C Details for Similarity Calculation
C 相似度计算的细节
In this section, we provide more details on how to calculate the distribution shifts between the source training task (MS MARCO) and the zero-shot target tasks (BEIR). We first define the types of queries used in Section 3.2, and then give more details about the calculation of the weighted Jaccard similarity (Ioffe, 2010) used in this study.
在本节中,我们将详细说明如何计算源训练任务(MS MARCO)与零样本目标任务(BEIR)之间的分布偏移。首先在第3.2节定义查询类型,随后详细阐述本研究所采用的加权Jaccard相似度计算方法(Ioffe, 2010)。
C.1 Types of Queries
C.1 查询类型
We adopt the same method as (Ren et al., 2022) to partition the training queries into 9 types: for queries starting with the following 7 words, ’what’, ‘when’, ‘who’, ‘how’, ‘where’, ‘why’, ‘which’, they fall into the corresponding category. Besides, queries starting with the first word is/was/are/were/do/does/did/have/has/had/ should/can/could/would/am/small’, are classified as Y/N queries. The rest of the queries belong to declarative queries.
我们采用与 (Ren et al., 2022) 相同的方法将训练查询划分为9种类型:以以下7个词开头的查询('what'、'when'、'who'、'how'、'where'、'why'、'which')归入相应类别。此外,以第一个词为 is/was/are/were/do/does/did/have/has/had/should/can/could/would/am/small 开头的查询归类为 Y/N 查询。其余查询属于陈述性查询。
C.2 Calculation of Weighted Jaccard Similarity
C.2 加权Jaccard相似度计算
We follow (Thakur et al., 2021) to use the weighted Jaccard similarity $J(S,T)$ to measure the unique word overlap for all words present in the source dataset $S$ and the target dataset $T$ .
我们遵循 (Thakur et al., 2021) 使用加权Jaccard相似度 $J(S,T)$ 来衡量源数据集 $S$ 和目标数据集 $T$ 中所有单词的唯一词重叠度。
Denote $S_{k}$ as the frequency of word $k$ in the source dataset $S$ and $T_{k}$ for the target dataset $T$ respectively. The weighted Jaccard similarity $J(S,T)$ between $S$ and $T$ is defined as:
设 $S_{k}$ 为源数据集 $S$ 中词 $k$ 的频率,$T_{k}$ 为目标数据集 $T$ 中对应词的频率。加权杰卡德相似度 $J(S,T)$ 定义为:
$$
J(S,T)=\frac{\sum_{k}\operatorname*{min}\left(S_{k},T_{k}\right)}{\sum_{k}\operatorname*{max}\left(S_{k},T_{k}\right)},
$$
$$
J(S,T)=\frac{\sum_{k}\operatorname*{min}\left(S_{k},T_{k}\right)}{\sum_{k}\operatorname*{max}\left(S_{k},T_{k}\right)},
$$
where the sum is over all unique words $k$ present in dataset $S$ and $T$ .
其中求和是对数据集 $S$ 和 $T$ 中所有唯一单词 $k$ 进行的。
D Statistics for Query and Document Similarities
查询与文档相似度的D统计量
Table 6 lists the exact pairwise weighted Jaccard similarity between MS MARCO and different BEIR tasks. For tasks comes from biomedical domains (e.g. BioASQ, NFCorpus) and scientific domains (e.g. SCIDOCS, SciFact), the lexical overlap between them and MS MARCO is small. For these datasets, ANCE can hardly outperform BM25. On the other hand, for those tasks which ANCE outperforms BM25 by a wide margin (e.g. NQ, Quora), they tend to have a larger weighted Jaccard similarity score with MS MARCO.
表 6 列出了 MS MARCO 与不同 BEIR 任务之间的精确配对加权 Jaccard 相似度。对于来自生物医学领域 (如 BioASQ、NFCorpus) 和科学领域 (如 SCIDOCS、SciFact) 的任务,它们与 MS MARCO 的词汇重叠度较小。在这些数据集上,ANCE 很难超越 BM25。另一方面,对于那些 ANCE 大幅领先 BM25 的任务 (如 NQ、Quora),它们往往与 MS MARCO 具有更高的加权 Jaccard 相似度得分。
E Details of iDRO
E iDRO 详情
This section exhibits the details for deriving the optimal weight $\boldsymbol{\omega}^{(t)}$ for the training step $t$ . Note that the overall objective can be expressed as
本节展示如何推导训练步骤 $t$ 的最优权重 $\boldsymbol{\omega}^{(t)}$。需注意整体目标可表示为
$$
\begin{array}{r l}&{\underset{\omega^{(t)}}{\mathrm{min}}~\ell_{\mathbf{g}}+\tau\mathcal{D}{\mathrm{KL}}(\omega^{(t)}||\omega^{(t-1)}),}\ &{\mathrm{s.t.}\quad\displaystyle\sum_{i=1}^{K}\omega_{i}^{(t)}=1,}\end{array}
$$
$$
\begin{array}{r l}&{\underset{\omega^{(t)}}{\mathrm{min}}~\ell_{\mathbf{g}}+\tau\mathcal{D}{\mathrm{KL}}(\omega^{(t)}||\omega^{(t-1)}),}\ &{\mathrm{s.t.}\quad\displaystyle\sum_{i=1}^{K}\omega_{i}^{(t)}=1,}\end{array}
$$
where $\tau$ is the temperature to control the strength of the regular iz ation. Then, the KKT conditions can be expressed as
其中 $\tau$ 是控制正则化强度的温度参数。那么,KKT条件可以表示为
$$
\begin{array}{l}{\mathcal{L}=-\displaystyle\sum_{i=1}^{K}\displaystyle\sum_{j=1}^{K}\omega_{i}\alpha_{i}\alpha_{j}\left(\nabla_{\theta}\ell_{i}(\theta)\right)^{\top}\nabla_{\theta}\ell_{j}(\theta)}\ {+\displaystyle\tau\sum_{i=1}^{K}\left(\log\left(\frac{\omega^{(t)}}{\omega^{(t-1)}}\right)-1\right)}\ {+\displaystyle\gamma\left(\sum_{i=1}^{K}\omega_{i}^{(t)}-1\right)}\end{array}
$$
$$
\begin{array}{l}{\mathcal{L}=-\displaystyle\sum_{i=1}^{K}\displaystyle\sum_{j=1}^{K}\omega_{i}\alpha_{i}\alpha_{j}\left(\nabla_{\theta}\ell_{i}(\theta)\right)^{\top}\nabla_{\theta}\ell_{j}(\theta)}\ {+\displaystyle\tau\sum_{i=1}^{K}\left(\log\left(\frac{\omega^{(t)}}{\omega^{(t-1)}}\right)-1\right)}\ {+\displaystyle\gamma\left(\sum_{i=1}^{K}\omega_{i}^{(t)}-1\right)}\end{array}
$$
Setting the corresponding gradients to 0 gives the global optimum as
将对应梯度设为0可得全局最优解为
$$
\begin{array}{r l r}{\lefteqn{\frac{\partial\mathcal{L}}{\partial\omega_{i}^{(t)}}=-\sum_{j=1}^{K}r_{i j}+\tau\log\left(\frac{\omega^{(t)}}{\omega^{(t-1)}}\right)+\widehat{\gamma}=0;}}\ &{}&{\sum_{i=1}^{K}\omega_{i}^{(t)}=1,}\end{array}
$$
$$
\begin{array}{r l r}{\lefteqn{\frac{\partial\mathcal{L}}{\partial\omega_{i}^{(t)}}=-\sum_{j=1}^{K}r_{i j}+\tau\log\left(\frac{\omega^{(t)}}{\omega^{(t-1)}}\right)+\widehat{\gamma}=0;}}\ &{}&{\sum_{i=1}^{K}\omega_{i}^{(t)}=1,}\end{array}
$$
where
哪里
$$
r_{i j}=\sum_{i=1}^{K}\alpha_{i}\alpha_{j}\left(\nabla_{\theta}\ell_{i}(\theta)\right)^{\intercal}\nabla_{\theta}\ell_{j}(\theta),
$$
$$
r_{i j}=\sum_{i=1}^{K}\alpha_{i}\alpha_{j}\left(\nabla_{\theta}\ell_{i}(\theta)\right)^{\intercal}\nabla_{\theta}\ell_{j}(\theta),
$$
$$
\widehat{\gamma}=\gamma+\tau.
$$
$$
\widehat{\gamma}=\gamma+\tau.
$$
From the above Eqnb. 19, we have
从上述方程19可得
$$
\omega_{i}^{(t)}=\omega_{i}^{(t-1)}\exp\left(\frac{1}{\tau}\left(\sum_{j=1}^{K}r_{i j}-\widehat{\gamma}\right)\right).
$$
$$
\omega_{i}^{(t)}=\omega_{i}^{(t-1)}\exp\left(\frac{1}{\tau}\left(\sum_{j=1}^{K}r_{i j}-\widehat{\gamma}\right)\right).
$$
By plugging the Eqn. 21 to Eqn. 20, we obtain
将式21代入式20,可得
$$
\exp\left(\frac{\widehat{\gamma}}{\tau}\right)=\sum_{i=1}^{K}\exp\left(\frac{1}{\tau}\sum_{i=1}^{K}\omega_{i}^{(t-1)}r_{i j}\right).
$$
$$
\exp\left(\frac{\widehat{\gamma}}{\tau}\right)=\sum_{i=1}^{K}\exp\left(\frac{1}{\tau}\sum_{i=1}^{K}\omega_{i}^{(t-1)}r_{i j}\right).
$$
Finally, by combining the Eqn. 21 and Eqn. 22, the weight for $i$ -th group can be expressed as
最后,结合公式21和公式22,第$i$组的权重可表示为
$$
\omega_{i}^{t*}=\frac{\omega_{i}^{(t-1)}\exp{\left(\frac{1}{\tau}\sum_{j=1}^{K}r_{i j}\right)}}{\sum_{i=1}^{K}\omega_{i}^{(t-1)}\exp{\left(\frac{1}{\tau}\sum_{j=1}^{K}r_{i j}\right)}}.
$$
$$
\omega_{i}^{t*}=\frac{\omega_{i}^{(t-1)}\exp{\left(\frac{1}{\tau}\sum_{j=1}^{K}r_{i j}\right)}}{\sum_{i=1}^{K}\omega_{i}^{(t-1)}\exp{\left(\frac{1}{\tau}\sum_{j=1}^{K}r_{i j}\right)}}.
$$
| Dataset (↓) | COCO-DR | GroupDRO (2020) |
| TREC-COVID | 0.789 | 0.793 |
| BioASQ | 0.429 | 0.411 |
| NFCorpus | 0.355 | 0.352 |
| NQ | 0.505 | 0.494 |
| HotpotQA | 0.616 | 0.609 |
| FiQA-2018 | 0.307 | 0.300 |
| Signal-1M | 0.271 | 0.274 |
| TREC-NEWS | 0.403 | 0.408 |
| Robust04 | 0.443 | 0.438 |
| ArguAna | 0.493 | 0.493 |
| Touché-2020 | 0.238 | 0.243 |
| Quora | 0.867 | 0.866 |
| DBPedia-entity | 0.391 | 0.390 |
| SCIDOCS | 0.160 | 0.162 |
| Fever | 0.751 | 0.746 |
| Climate-Fever | 0.211 | 0.211 |
| SciFact | 0.709 | 0.712 |
| CQADupStack | 0.370 | 0.367 |
| Avg | 0.462 | 0.459 |
Table 7: Com parisi on between iDRO and GroupDRO (Sagawa et al., 2020). COCO-DR achieves better performance on the majority of BEIR tasks.
| 数据集 (↓) | COCO-DR | GroupDRO (2020) |
|---|---|---|
| TREC-COVID | 0.789 | 0.793 |
| BioASQ | 0.429 | 0.411 |
| NFCorpus | 0.355 | 0.352 |
| NQ | 0.505 | 0.494 |
| HotpotQA | 0.616 | 0.609 |
| FiQA-2018 | 0.307 | 0.300 |
| Signal-1M | 0.271 | 0.274 |
| TREC-NEWS | 0.403 | 0.408 |
| Robust04 | 0.443 | 0.438 |
| ArguAna | 0.493 | 0.493 |
| Touché-2020 | 0.238 | 0.243 |
| Quora | 0.867 | 0.866 |
| DBPedia-entity | 0.391 | 0.390 |
| SCIDOCS | 0.160 | 0.162 |
| Fever | 0.751 | 0.746 |
| Climate-Fever | 0.211 | 0.211 |
| SciFact | 0.709 | 0.712 |
| CQADupStack | 0.370 | 0.367 |
| 平均 | 0.462 | 0.459 |
表 7: iDRO 与 GroupDRO 的对比 (Sagawa et al., 2020)。COCO-DR 在多数 BEIR 任务上表现更优。
F Com parisi on with GroupDRO
F 与GroupDRO的对比
We further compare iDRO with GroupDRO (Sagawa et al., 2020), which assigns higher weights to groups with higher training loss. Note that GroupDRO requires gold labels for group assignments which is unavailable for ZeroDR. To adopt GroupDRO in our settings, we use the cluster information derived from K-means clustering as group labels, which is the same as (Sohoni et al., 2020). To ensure fair comparison, we use the model after COCO pre training as initialization, and use GroupDRO to reweight different groups during fine-tuning the model on MS MARCO.
我们进一步将iDRO与GroupDRO (Sagawa等人,2020) 进行比较,后者会为训练损失较高的组分配更高权重。需要注意的是,GroupDRO需要分组分配的真实标签,而ZeroDR无法提供这一信息。为了在我们的设置中采用GroupDRO,我们使用K-means聚类得到的簇信息作为组标签,这与 (Sohoni等人,2020) 的做法相同。为确保公平比较,我们使用经过COCO预训练的模型作为初始化,并在MS MARCO上微调模型时使用GroupDRO对不同组进行重新加权。
Table 7 shows the performance of GroupDRO on BEIR tasks. From the results, we find that although GroupDRO achieves better performance on some specific tasks (e.g. TREC-COVID and SciFact), it fails to perform well on the majority of tasks, especially for general-domain datasets such as NQ, HotpotQA and Fever. This is because during GroupDRO training, it assigns higher weights for large-loss groups while neglecting other groups. As a result, although it will lead to better worsegroup performance, it cannot improve the average performance. In contrast, iDRO leverages gradient similarities to dynamically reweight different groups to avoid sacrificing the average performance on all tasks.
表 7 展示了 GroupDRO 在 BEIR 任务上的性能表现。从结果可以看出,尽管 GroupDRO 在某些特定任务(如 TREC-COVID 和 SciFact)上取得了更好的性能,但在大多数任务上表现不佳,尤其是通用领域数据集(如 NQ、HotpotQA 和 Fever)。这是因为 GroupDRO 在训练过程中会为高损失组分配更高权重,而忽略了其他组。虽然这会带来最差组性能的提升,但无法提高整体平均性能。相比之下,iDRO 通过梯度相似性动态调整不同组的权重,从而避免牺牲所有任务的平均性能。

Figure 6: The performance of COCO-DR and its variants over different training stages on 6 of BEIR tasks.
图 6: COCO-DR及其变体在BEIR任务中6个任务上不同训练阶段的性能表现。
G Performance on Different Training Stages of COCO-DR
COCO-DR 在不同训练阶段的性能表现
Figure 6 exhibits the performance on different episodes on six BEIR tasks from different domains, used in (Wang et al., 2022). From the results, we observe that COCO is more beneficial for the biomedical domains than others such as news and finance. The more significant gain is mainly due to the limited overlap between biomedical corpus and MS MARCO, as well as the extremely large size of the biomedical corpora. For other two tasks (Robust04 and FiQA-2018), the DR models can already achieve better or comparable performance compared with BM25 when finetuning on MS MARCO only, which indicates the distribution shift issue is not severe on these datasets. Therefore, the relative gain of COCO on them is smaller.
图 6: 展示了 (Wang et al., 2022) 采用的六个不同领域 BEIR 任务中各轮次性能表现。从结果可见,COCO 对生物医学领域的提升效果明显优于新闻、金融等其他领域。这一显著增益主要源于生物医学语料与 MS MARCO 的重叠有限,且生物医学语料库规模极为庞大。对于另外两个任务 (Robust04 和 FiQA-2018),仅基于 MS MARCO 微调时,DR 模型已能取得优于或持平 BM25 的表现,说明这些数据集上的分布偏移问题并不严重,因此 COCO 带来的相对增益较小。
For the iDRO part, it provides additional performance gains on 5 of 6 datasets. As these datasets are all domain specific text retrieval tasks (Wang et al., 2022), the results justify the benefits of iDRO for improving the DR model’s performance on unseen target queries.
在iDRO部分,该方法在6个数据集中的5个上提供了额外的性能提升。由于这些数据集均为特定领域的文本检索任务 (Wang et al., 2022) ,结果验证了iDRO在提升DR模型对未见目标查询性能方面的优势。
H Calculation of Alignment and Uniformity
H 对齐性和均匀性的计算
Recently, Wang and Isola (2020) propose two terms, namely alignment and uniformity to measure the quality of representations. In particular, we denote the whole data distribution as $p_{\mathrm{data}}$ and the distribution of positive pairs as $p_{\mathrm{pos}}$ . Then, the two metrics can be calculated as
最近,Wang 和 Isola (2020) 提出了两个衡量表征质量的术语:对齐性 (alignment) 和均匀性 (uniformity)。具体而言,我们将整体数据分布记为 $p_{\mathrm{data}}$,正样本对分布记为 $p_{\mathrm{pos}}$。这两个指标的计算方式如下:
$$
\begin{array}{r}{\ell_{\mathrm{align}}\triangleq\mathbb{E}{(x,x^{+})\sim p_{\mathrm{pos}}}\Vert f(x)-f(x^{+})\Vert^{2},}\ {\ell_{\mathrm{uniform}}\triangleq\log\mathbb{E}{(x,y)^{\mathrm{i.i.d.}}p_{\mathrm{data}}}e^{-2\Vert f(x)-f(y)\Vert^{2}}.}\end{array}
$$
$$
\begin{array}{r}{\ell_{\mathrm{align}}\triangleq\mathbb{E}{(x,x^{+})\sim p_{\mathrm{pos}}}\Vert f(x)-f(x^{+})\Vert^{2},}\ {\ell_{\mathrm{uniform}}\triangleq\log\mathbb{E}{(x,y)^{\mathrm{i.i.d.}}p_{\mathrm{data}}}e^{-2\Vert f(x)-f(y)\Vert^{2}}.}\end{array}
$$
Notably, alignment is the expected distance between the representations of positive text pairs, and uniformity measures how well the text representations are uniformly distributed (Gao et al., 2021). In our experiments, we use the code released by the original authors to calculate these two metrics.1
值得注意的是,对齐度 (alignment) 表示正样本文本对表征之间的期望距离,而均匀度 (uniformity) 衡量文本表征的均匀分布程度 (Gao et al., 2021)。在实验中,我们使用原作者发布的代码计算这两个指标。1