ClipCap: CLIP Prefix for Image Captioning
用于图像描述的CLIP前缀
Abstract
摘要
Image captioning is a fundamental task in visionlanguage understanding, where the model predicts a textual informative caption to a given input image. In this paper, we present a simple approach to address this task. We use CLIP encoding as a prefix to the caption, by employing a simple mapping network, and then fine-tunes a language model to generate the image captions. The recently proposed CLIP model contains rich semantic features which were trained with textual context, making it best for vision-language perception. Our key idea is that together with a pre-trained language model (GPT2), we obtain a wide understanding of both visual and textual data. Hence, our approach only requires rather quick training to produce a competent captioning model. Without additional annotations or pre-training, it efficiently generates meaningful captions for large-scale and diverse datasets. Surprisingly, our method works well even when only the mapping network is trained, while both CLIP and the language model remain frozen, allowing a lighter architecture with less trainable parameters. Through quantitative evaluation, we demonstrate our model achieves comparable results to state-of-the-art methods on the challenging Conceptual Captions and nocaps datasets, while it is simpler, faster, and lighter. Our code is available in https://github. com/rmokady/CLIP prefix caption.
图像描述是视觉语言理解中的一项基础任务,模型需要为给定输入图像预测具有信息性的文本描述。本文提出了一种解决该任务的简单方法:通过使用简单的映射网络,将CLIP编码作为描述前缀,再微调语言模型以生成图像描述。最新提出的CLIP模型包含通过文本上下文训练的丰富语义特征,使其成为视觉语言感知的最佳选择。我们的核心思路是结合预训练语言模型(GPT2),实现对视觉和文本数据的广泛理解。因此,该方法仅需较短时间训练即可构建出高效的描述模型。在无需额外标注或预训练的情况下,该方案能高效地为大规模多样化数据集生成有意义的描述。令人惊讶的是,即使仅训练映射网络而保持CLIP和语言模型冻结,该方法仍表现优异,从而实现了更轻量级、更少可训练参数的架构。定量评估表明,我们的模型在Conceptual Captions和nocaps等具有挑战性的数据集上达到了与最先进方法相当的结果,同时更简单、更快速、更轻量。代码已开源:https://github.com/rmokady/CLIP_prefix_caption。
1. Introduction
1. 引言
In image captioning, the task is to provide a meaningful and valid caption for a given input image in a natural language. This task poses two main challenges. The first is semantic understanding. This aspect ranges from simple tasks such as detecting the main object, to more involved ones, such as understanding the relations between depicted parts of the image. For example, in the top-left image of Fig. 1, the model understands that the object is a gift. The second challenge is the large number of possible ways to describe a single image. In this aspect, the training dataset typically dictates the preferable option for a given image.
在图像描述生成任务中,目标是用自然语言为给定输入图像生成有意义且准确的描述。该任务面临两大主要挑战:首先是语义理解,其范围涵盖从检测主体对象这类简单任务,到理解图像各组成部分间关系等复杂任务。例如在图1左上角的图像中,模型需要理解物体是一个礼物。第二个挑战在于单张图像存在大量可能的描述方式,这种情况下训练数据集通常会为给定图像确定最优描述选项。


A politician receives a gift from A collage of different colored ties politician. on a white background.
图 1: 一位政客收到来自一位背景为白色、佩戴多色领带拼贴画的政客的礼物。

Figure 1. Our ClipCap model produces captions depcting the respective images. Here, the results are of a model that was trained over the Conceptual Captions dataset.
图 1: 我们的 ClipCap 模型能生成描述对应图像的标题。此处展示的是在 Conceptual Captions 数据集上训练后的模型效果。
Many approaches have been proposed for image captioning [4, 9, 13, 19, 34, 35, 42, 44, 47]. Typically, these works utilize an encoder for visual cues and a textual decoder to produce the final caption. Essentially, this induces the need to bridge the challenging gap between the visual and textual representations. For this reason, such models are resource hungry. They require extensive training time, a large number of trainable parameters, a massive dataset, and in some cases even additional annotations (such as detection results), which limit their practical applicability.
图像描述生成领域已提出多种方法 [4, 9, 13, 19, 34, 35, 42, 44, 47]。这类工作通常采用视觉特征编码器和文本解码器架构来生成最终描述,本质上需要弥合视觉与文本表征间的巨大鸿沟。因此,此类模型资源消耗巨大:需要长时间训练、大量可调参数、海量数据集,部分模型甚至依赖额外标注(如检测结果),严重制约了实际应用性。
Excessive training time is even more restrictive for applications that require several training procedures. For instance, training multiple captioning models over various datasets could provide different users (or applications) with different captions for the same image. Additionally, given fresh samples, it is desirable to update the model routinely with the new data. Therefore, a lightweight captioning model is preferable. Specifically, a model with faster training times and fewer trainable parameters would be beneficial, especially if it does not require additional supervision.
训练时间过长对于需要多次训练流程的应用限制更大。例如,在不同数据集上训练多个图像描述 (captioning) 模型,可以为不同用户(或应用)对同一图像生成不同的描述。此外,当获得新样本时,需要定期用新数据更新模型。因此,轻量级的图像描述模型更为理想。具体而言,具有更快训练速度和更少可训练参数的模型会更具优势,尤其是在不需要额外监督的情况下。
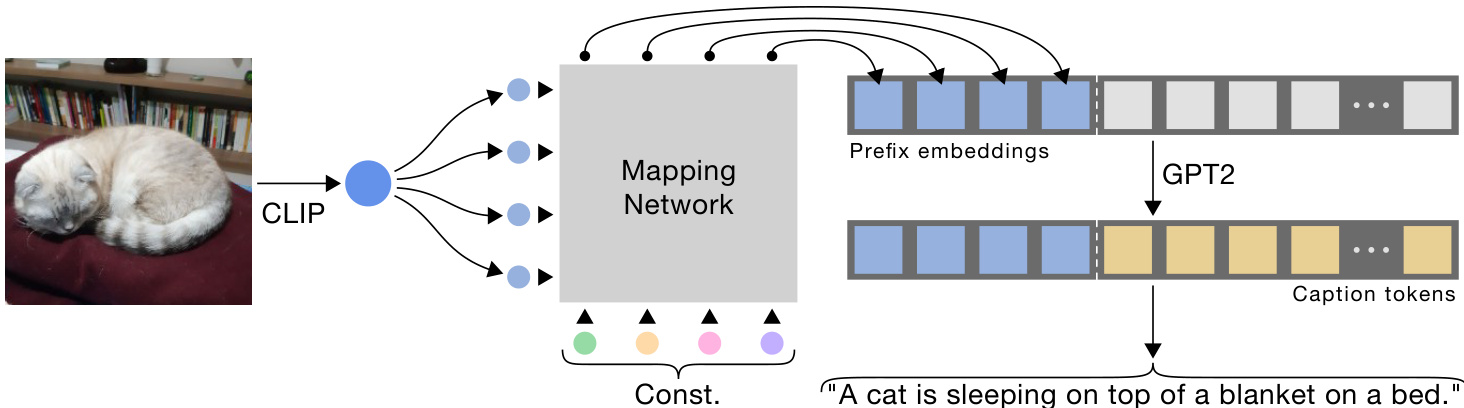
Figure 2. Overview of our transformer-based architecture, enabling the generation of meaningful captions while both CLIP and the language model, GPT-2, are frozen. To extract a fixed length prefix, we train a lightweight transformer-based mapping network from the CLIP embedding space and a learned constant to GPT-2. At inference, we employ GPT-2 to generate the caption given the prefix embeddings. We also suggest a MLP-based architecture, refer to Sec. 3 for more details.
图 2: 我们基于Transformer的架构概览,该架构能在CLIP和语言模型GPT-2均被冻结的情况下生成有意义的描述文本。为了提取固定长度的前缀,我们训练了一个轻量级的基于Transformer的映射网络,将CLIP嵌入空间和可学习常量映射到GPT-2。在推理阶段,我们利用GPT-2根据前缀嵌入生成描述文本。我们还提出了一种基于MLP的架构,详见第3节。
In this paper, we leverage powerful vision-language pretrained models to simplify the captioning process. More specifically, we use the CLIP (Contrastive Language-Image Pre-Training) encoder, recently introduced by Radford et al. [29]. CLIP is designed to impose a shared representation for both images and text prompts. It is trained over a vast number of images and textual descriptions using a contrastive loss. Hence, its visual and textual representations are well correlated. As we demonstrate, this correlation saves training time and data requirements.
本文利用强大的视觉语言预训练模型来简化描述生成过程。具体而言,我们采用Radford等人[29]最新提出的CLIP (Contrastive Language-Image Pre-Training)编码器。该模型通过对比损失函数在海量图像文本对上训练,强制图像与文本提示共享表征空间,因此其视觉与文本表征具有高度关联性。如实验所示,这种关联性显著降低了训练时间和数据需求。
As illustrated in Fig. 2, our method produces a prefix for each caption by applying a mapping network over the CLIP embedding. This prefix is a fixed size embeddings sequence, concatenated to the caption embeddings. These are fed to a language model, which is fine-tuned along with the mapping network training. At inference, the language model generates the caption word after word, starting from the CLIP prefix. This scheme narrows the aforementioned gap between the visual and textual worlds, allowing the employment of a simple mapping network. To achieve even a lighter model, we introduce another variant of our method, where we train only the mapping network, while both CLIP and the language model are kept frozen. By utilizing the expressive transformer architecture, we successfully produce meaningful captions, while imposing substantially less trainable parameters. Our approach is inspired by Li et al. [20], which demonstrates the ability to efficiently adapt a language model for new tasks by concatenating a learned prefix. We use GPT-2 [30] as our language model, which has been demonstrated to generate rich and diverse texts.
如图 2 所示,我们的方法通过在 CLIP 嵌入上应用映射网络为每个描述生成前缀。该前缀是固定大小的嵌入序列,与描述嵌入相连接。这些输入被馈送到语言模型中,该模型与映射网络训练一起进行微调。在推理阶段,语言模型从 CLIP 前缀开始逐词生成描述。该方案缩小了前述视觉与文本领域之间的差距,使得可以采用简单的映射网络。为了实现更轻量的模型,我们引入了该方法的另一个变体,其中仅训练映射网络,而 CLIP 和语言模型均保持冻结。通过利用表达能力强的 Transformer 架构,我们在显著减少可训练参数的同时,成功生成了有意义的描述。我们的方法受到 Li 等人 [20] 的启发,他们证明了通过连接学习到的前缀可以高效适配语言模型以执行新任务。我们使用 GPT-2 [30] 作为语言模型,该模型已被证明能生成丰富多样的文本。
As our approach exploits the rich visual-textual representation of CLIP, our model requires significantly lower training time. For instance, we train our model on a single Nvidia GTX1080 GPU for 80 hours over the three million samples of the massive Conceptual Captions dataset. Nevertheless, our model generalizes well to complex scenes, as can be seen in Fig. 1 (e.g., practicing yoga on the beach at sunset). We evaluate our method extensively, demonstrating successful realistic and meaningful captions. Even though our model requires less training time, it still achieves comparable results to state-of-the-art approaches over the challenging Conceptual Captions [33] and nocaps [1] datasets, and marginally lower for the more restricted COCO [7, 22] benchmark. In addition, we provide a thorough analysis of the required prefix length and the effect of fine-tuning the language model, including interpretation of our produced prefixes. Overall, our main contributions are as follow:
由于我们的方法利用了CLIP丰富的视觉-文本表示能力,该模型所需的训练时间显著减少。例如,我们在单个Nvidia GTX1080 GPU上对大规模概念标注数据集(Conceptual Captions)的三百万样本进行了80小时的训练。尽管如此,如图1所示(例如日落海滩上练习瑜伽的场景),我们的模型在复杂场景中仍表现出良好的泛化能力。我们通过大量实验验证了该方法能生成逼真且富有意义的描述文本。尽管训练时间更短,我们的模型在具有挑战性的Conceptual Captions [33]和nocaps [1]数据集上仍达到了与前沿方法相当的效果,在限制更严格的COCO [7,22]基准测试中仅略微落后。此外,我们深入分析了所需前缀长度、语言模型微调的影响,并对生成的前缀进行了解读。我们的主要贡献可归纳如下:
2. Related Works
2. 相关工作
Recently, Radford et al. [29] presented a novel approach, known as CLIP, to jointly represent images and text descriptions. CLIP comprises two encoders, one for visual cues and one for text. It was trained over more than 400 million image-text pairs guided by unsupervised contrastive loss, resulting in rich semantic latent space shared by both visual and textual data. Many works have already used CLIP successfully for computer vision tasks that require the understanding of some auxiliary text, such as generating or editing an image based on a natural language condition [5, 14, 28]. In this paper, we utilize the powerful CLIP model for the task of image captioning. Note that our method does not employ the CLIP’s textual encoder, since there is no input text, and the output text is generated by a
最近,Radford等人[29]提出了一种名为CLIP的新方法,用于联合表示图像和文本描述。CLIP包含两个编码器,一个用于视觉线索,一个用于文本。它在无监督对比损失的指导下,对超过4亿个图像-文本对进行了训练,从而形成了视觉和文本数据共享的丰富语义潜在空间。许多工作已成功将CLIP用于需要理解辅助文本的计算机视觉任务,例如基于自然语言条件生成或编辑图像[5,14,28]。在本文中,我们利用强大的CLIP模型来完成图像描述任务。需要注意的是,我们的方法没有使用CLIP的文本编码器,因为没有输入文本,且输出文本是由一个
language model.
语言模型
Commonly, image captioning [34] models first encode the input pixels as feature vectors, which are then used to produce the final sequence of words. Early works utilize the features extracted from a pre-trained classification network [6, 9, 13, 42], while later works [4, 19, 47] exploit the more expressive features of an object detection network [31]. Though a pre-trained object detection network is available for the popular COCO benchmark [7, 22], it is not necessarily true for other datasets. This implies that most methods would require additional object detection annotations to operate over new and diverse datasets. To further leverage the visual cues, an attention mechanism is usually utilized [4, 6, 42] to focus on specific visual features. Moreover, recent models apply self-attention [16, 43] or use an expressive visual Transformer [12] as an encoder [23]. Our work uses the expressive embedding of CLIP for visual represent ation. Since CLIP was trained over an extremely large number of images, we can operate on any set of natural images without additional annotations.
通常,图像描述生成 [34] 模型会先将输入像素编码为特征向量,再用于生成最终的词序列。早期研究使用预训练分类网络提取的特征 [6, 9, 13, 42],而后续工作 [4, 19, 47] 则采用目标检测网络 [31] 更具表现力的特征。虽然流行的 COCO 基准数据集 [7, 22] 提供了预训练目标检测网络,但其他数据集未必具备此条件。这意味着多数方法在新数据集上运行时需要额外的目标检测标注。为进一步利用视觉线索,通常会采用注意力机制 [4, 6, 42] 来聚焦特定视觉特征。此外,近期模型应用了自注意力 [16, 43] 或采用表现力强的视觉 Transformer [12] 作为编码器 [23]。本研究使用 CLIP 的表现力嵌入作为视觉表征。由于 CLIP 在极大量图像上训练,我们无需额外标注即可处理任意自然图像集。
To produce the caption itself, a textual decoder is employed. Early works have used LSTM variants [8, 38, 39], while recent works [16, 26] adopted the improved transformer architecture [36]. Built upon the transformer, one of the most notable works is BERT [11], demonstrating the dominance of the newly introduced paradigm. With this paradigm, the language model is first pre-trained over a large data collection to solve an auxiliary task. Then, the model is fine-tuned for a specific task, where additional supervision is used. As our visual information resides in the prefix, we utilize a powerful auto-regressive language model, GPT-2 [30]. Considering the training loss term, earlier works adopt the effective cross-entropy, while contemporary methods also apply self-critical sequence training [15, 32, 45]. That is, an additional training stage to optimize the CIDEr metric. We deliberately refrain from this optimization to retain a quick training procedure.
为生成描述文本本身,采用了文本解码器。早期研究使用LSTM变体 [8, 38, 39],而近期工作 [16, 26] 采用了改进的Transformer架构 [36]。基于Transformer的里程碑式工作是BERT [11],它展示了这一新范式的统治力。该范式首先在大规模数据集上对语言模型进行预训练以解决辅助任务,随后通过额外监督信号对特定任务进行微调。由于视觉信息存在于前缀中,我们采用了强大的自回归语言模型GPT-2 [30]。在训练损失项方面,早期研究采用交叉熵损失,现代方法则同时应用自关键序列训练 [15, 32, 45],即通过额外训练阶段优化CIDEr指标。我们刻意避免此类优化以保持训练过程的高效性。
Most close to ours, are works that employ vision-andlanguage pre-training to create a shared latent space of both vision and text [19,25,35,46,47]. Zhou et al. [47] use visual tokens extracted from object detector as a prefix to caption tokens. The entire model is then pre-trained to perform prediction utilizing the BERT [11] architecture. Li et al. [19] and Zhang et al. [46] also utilize BERT, but require the additional supervision of object tags. Hence, these methods are limited to datasets in which such object detectors or annotations are available. The approach of Wang et al. [40] mitigate the need for supplementary annotations, but still perform an extensive pre-train process with millions of imagetext pairs, resulting in a lengthy training time. This exhaustive pre-training step is required to compensate for the lack of joint representation of language and vision, which we inherently obtained by employing CLIP.
与我们的工作最为接近的是那些利用视觉与语言预训练 (vision-and-language pre-training) 来创建视觉和文本共享潜在空间的研究 [19,25,35,46,47]。Zhou 等人 [47] 使用从物体检测器提取的视觉 token 作为字幕 token 的前缀,随后基于 BERT [11] 架构对整个模型进行预训练以实现预测。Li 等人 [19] 和 Zhang 等人 [46] 同样采用 BERT,但需要额外的物体标签监督。因此,这些方法仅限于具备此类物体检测器或标注的数据集。Wang 等人 [40] 的方法减少了对补充标注的需求,但仍需对数百万图文对进行大规模预训练,导致训练时间冗长。这种耗时的预训练步骤是为了弥补语言与视觉联合表征的缺失,而我们通过采用 CLIP 天然获得了这种联合表征。
3. Method
3. 方法
We start with our problem statement. Given a dataset of paired images and captions ${x^{i},c^{i}}{i=1}^{N}$ , our goal is to learn the generation of a meaningful caption for an unseen input image. We can refer to the captions as a sequence of tokens $c^{i}=c_{1}^{i},\ldots,c_{\ell}^{i}$ , where we pad the tokens to a maximal length $\ell$ . Our training objective is then the following:
我们从问题描述开始。给定一个由成对图像和标题组成的数据集 ${x^{i},c^{i}}{i=1}^{N}$,我们的目标是为未见过的输入图像学习生成有意义的标题。我们可以将标题视为一个token序列 $c^{i}=c_{1}^{i},\ldots,c_{\ell}^{i}$,其中我们将token填充到最大长度 $\ell$。我们的训练目标如下:
$$
\operatorname*{max}{\theta}\sum_{i=1}^{N}\log p_{\theta}(c_{1}^{i},\dots,c_{\ell}^{i}|x^{i}),
$$
$$
\operatorname*{max}{\theta}\sum_{i=1}^{N}\log p_{\theta}(c_{1}^{i},\dots,c_{\ell}^{i}|x^{i}),
$$
where $\theta$ denotes the model’s trainable parameters. Our key idea is to use the rich semantic embedding of CLIP, which contains, virtually, the essential visual data, as a condition. Following recent works [47], we consider the condition as a prefix to the caption. Since the required semantic information is encapsulated in the prefix, we can utilize an autore- gressive language model that predicts the next token without considering future tokens. Thus, our objective can be described as:
其中 $\theta$ 表示模型的可训练参数。我们的核心思路是利用 CLIP 丰富的语义嵌入(包含近乎完整的视觉数据本质)作为条件。借鉴近期研究 [47],我们将该条件视为描述文本的前缀。由于所需语义信息已封装在前缀中,因此可采用自回归语言模型来预测下一个 token,而无需考虑后续 token。该目标可表述为:
$$
\operatorname*{max}{\theta}\sum_{i=1}^{N}\sum_{j=1}^{\ell}\log p_{\theta}(c_{j}^{i}|x^{i},c_{1}^{i},...,c_{j-1}^{i})
$$
$$
\operatorname*{max}{\theta}\sum_{i=1}^{N}\sum_{j=1}^{\ell}\log p_{\theta}(c_{j}^{i}|x^{i},c_{1}^{i},...,c_{j-1}^{i})
$$
3.1. Overview
3.1. 概述
An illustration of our method is provided in Fig. 2. We use GPT-2 (large) as our language model, and utilize its tokenizer to project the caption to a sequence of embeddings. To extract visual information from an image $x^{i}$ , we use the visual encoder of a pre-trained CLIP [29] model. Next, we employ a light mapping network, denoted $F$ , to map the CLIP embedding to $k$ embedding vectors:
图 2 展示了我们的方法示意图。我们采用 GPT-2 (large) 作为语言模型,并利用其分词器 (tokenizer) 将描述文本映射为嵌入向量序列。为了从图像 $x^{i}$ 中提取视觉信息,我们使用了预训练 CLIP [29] 模型的视觉编码器。随后,通过一个轻量级映射网络 $F$ 将 CLIP 嵌入向量映射为 $k$ 个嵌入向量:
$$
p_{1}^{i},...,p_{k}^{i}=F(\mathbf{CLIP}(x^{i})).
$$
$$
p_{1}^{i},...,p_{k}^{i}=F(\mathbf{CLIP}(x^{i})).
$$
Where each vector $p_{j}^{i}$ has the same dimension as a word embedding. We then concatenate the obtained visual embedding to the caption $c^{i}$ embeddings:
其中每个向量 $p_{j}^{i}$ 的维度与词嵌入相同。随后,我们将获得的视觉嵌入与标题 $c^{i}$ 的嵌入进行拼接:
$$
Z^{i}=p_{1}^{i},\ldots,p_{k}^{i},c_{1}^{i},\ldots,c_{\ell}^{i}.
$$
$$
Z^{i}=p_{1}^{i},\ldots,p_{k}^{i},c_{1}^{i},\ldots,c_{\ell}^{i}.
$$
During training, we feed the language model with the prefix-caption concatenation ${Z^{i}}_{i=1}^{N}$ . Our training objective is predicting the caption tokens conditioned on the prefix in an auto regressive fashion. To this purpose, we train the mapping component $F$ using the simple, yet effective, cross-entropy loss:
在训练过程中,我们向语言模型输入前缀-描述串联序列 ${Z^{i}}_{i=1}^{N}$。训练目标是以自回归方式预测基于前缀条件的描述token。为此,我们使用简单而有效的交叉熵损失来训练映射组件 $F$:
$$
\mathcal{L}{X}=-\sum_{i=1}^{N}\sum_{j=1}^{\ell}\log p_{\theta}(c_{j}^{i}|p_{1}^{i},\dots,p_{k}^{i},c_{1}^{i},\dots,c_{j-1}^{i}).
$$
$$
\mathcal{L}{X}=-\sum_{i=1}^{N}\sum_{j=1}^{\ell}\log p_{\theta}(c_{j}^{i}|p_{1}^{i},\dots,p_{k}^{i},c_{1}^{i},\dots,c_{j-1}^{i}).
$$
We now turn to discuss two variants of our method regarding the additional fine-tuning of the language model and their implications.
我们现在讨论关于语言模型额外微调的两个变体及其影响。
3.2. Language model fine-tuning
3.2. 语言模型微调
Our main challenge during training is to translate between the representations of CLIP and the language model. Even though both models develop a rich and diverse represent ation of text, their latent spaces are independent, as they were not jointly trained. Moreover, each captioning dataset incorporates a different style, which may not be natural for the pre-trained language model. Hence, we propose fine-tuning the language model during the training of the mapping network. This provides additional flexibility for the networks and yields a more expressive outcome.
训练期间的主要挑战在于实现CLIP与语言模型表征之间的转换。尽管两种模型都能生成丰富多样的文本表征,但由于未经联合训练,它们的潜在空间相互独立。此外,每个字幕数据集采用不同的风格,可能不符合预训练语言模型的自然表达习惯。因此,我们提出在映射网络训练过程中对语言模型进行微调,这为网络提供了额外灵活性,并能产生更具表现力的结果。
However, fine-tuning the language model naturally increases the number of trainable parameters substantially. Thus, we present an additional variant of our approach, in which we keep the language model fixed during training. Our attempt to adjust a frozen language model is inspired by the work of Li and Liang [20]. In their work, they accommodate such a pre-trained model to an unfamiliar task by learning only a prefix. Such prefix is automatically optimized to steer the language model towards the new objective during a standard training procedure. Following this approach, we suggest avoiding the fine-tuning to realize an even lighter model, where only the mapping network is trained. As presented in Section 4, our model not only produces realistic and meaningful captions, but also achieves superior results for some of the experiments without finetuning the language model. Note that fine-tuning CLIP does not benefit resulting quality, but does increase training time and complexity. We hence postulate that the CLIP space already encapsulates the required information, and adapting it towards specific styles does not contribute to flexibility.
然而,对语言模型进行微调自然会大幅增加可训练参数的数量。因此,我们提出了该方法的另一种变体,即在训练期间保持语言模型固定不变。我们调整冻结语言模型的尝试受到 Li 和 Liang [20] 工作的启发。在他们的工作中,他们仅通过学习前缀来使预训练模型适应陌生任务。该前缀通过标准训练过程自动优化,以引导语言模型转向新目标。遵循这一思路,我们建议避免微调以实现更轻量的模型,其中仅训练映射网络。如第 4 节所示,我们的模型不仅能生成逼真且有意义的描述,还在部分实验中无需微调语言模型就取得了更优结果。需注意,微调 CLIP 不会提升结果质量,但会增加训练时间和复杂度。因此我们推断 CLIP 空间已封装所需信息,针对特定风格进行调整并不会增强灵活性。
3.3. Mapping Network Architecture
3.3. 映射网络架构
Our key component is the mapping network, which translates the CLIP embedding to the GPT-2 space. When the language model is simultaneously fine-tuned, the mapping is less challenging, as we easily control both networks. Therefore, in this case, we can employ a simple Multi-Layer Perceptron (MLP). We have achieved realistic and meaningful captions even when utilizing only a single hidden layer, as CLIP is pre-trained for a vision-language objective.
我们的核心组件是映射网络,它将CLIP嵌入向量转换到GPT-2空间。当语言模型同步进行微调时,映射任务难度会降低,因为我们可以轻松控制这两个网络。因此,在这种情况下,我们可以采用简单的多层感知机 (MLP)。即使仅使用单个隐藏层,我们也能生成逼真且富有意义的描述文本,这得益于CLIP是针对视觉-语言联合任务进行预训练的。
Nevertheless, when the language model is frozen, we propose utilizing the more expressive transformer [36] architecture. The transformer enables global attention between input tokens while reducing the number of parameters for long sequences. This allows us to improve our results by increasing prefix size, as shown in Section. 4. We feed the transformer network with two inputs, the visual encoding of CLIP and a learned constant input. The constant has a dual role, first, to retrieve meaningful information from CLIP embedding through the multi-head attention. Second, it learns to adjust the fixed language model to the new data. This is demonstrated in Section. 4, where we offer interpret ability for our generated prefix. As can be seen, when the language model is fixed, the transformer mapping network learns a meticulous set of embeddings without any textual meaning. These are optimized to tame the language model.
然而,当语言模型被冻结时,我们建议采用表现力更强的Transformer [36] 架构。Transformer 能够在输入token之间实现全局注意力机制,同时减少长序列的参数数量。这使得我们可以通过增大前缀尺寸来提升效果,如第4节所示。我们向Transformer网络输入两个数据源:CLIP的视觉编码和一组可学习的常量输入。该常量具有双重作用:首先,通过多头注意力机制从CLIP嵌入中提取有效信息;其次,它能学习如何使固定语言模型适配新数据。第4节的实验结果展示了生成前缀的可解释性——当语言模型固定时,Transformer映射网络会学习到一组精细但无明确文本含义的嵌入表示,这些表示经过优化后能够有效调控语言模型的行为。
3.4. Inference
3.4. 推理
During inference, we extract the visual prefix of an input image $x$ using the CLIP encoder and the mapping network $F$ . We start generating the caption conditioned on the visual prefix, and predict the next tokens one by one, guided by the language model output. For each token, the language model outputs probabilities for all vocabulary tokens, which are used to determine the next one by employing a greedy approach or beam search.
在推理过程中,我们使用CLIP编码器和映射网络$F$提取输入图像$x$的视觉前缀。基于该视觉前缀,我们开始生成描述内容,并依据语言模型的输出逐个预测后续token。对于每个token,语言模型会输出所有词汇token的概率分布,通过贪心算法或束搜索策略确定下一个token。
4. Results
4. 结果
Datasets. We use the COCO-captions [7,22], nocaps [1] , and Conceptual Captions [33] datasets. We split the former according to the Karpathy et al. [17] split, where the training set contains 120, 000 images and 5 captions per image. Since COCO is limited to 80 classes, the nocaps dataset is designed to measure generalization to unseen classes and concepts. It contains only validation and test sets, with the training utilizing COCO itself. The nocaps dataset is divided to three parts — in-domain contains images portraying only COCO classes, near-domain contains both COCO and novel classes, and out-of-domain consists of only novel classes. As suggested by Li et al. [19], we evaluate the model using only the validation set. Though some methods utilize object tags of the novel classes, we only consider the setting of no additional supervision, as we find it more applicable in practice. Therefore, we do not employ a constrained beam search [2]. The Conceptual Captions dataset consists of 3M pairs of images and captions, harvested from the web and post-processed. It is considered to be more challenging than COCO due to the larger variety of styles of both the images and the captions, while not limited to specific classes. To focus on the concepts, specific entities in this dataset are replaced with general notions. For example, in Fig. 1, the names are replaced with ”politician”. For evaluation, we use the validation set, consisting of 12.5K images, as the test set is not publicly available. Consequently, we did not use this set for validation.
数据集。我们使用COCO-captions [7,22]、nocaps [1]和Conceptual Captions [33]数据集。按照Karpathy等人[17]的划分方式,前者的训练集包含12万张图像,每张图像对应5条标注。由于COCO仅涵盖80个类别,nocaps数据集专为衡量对未见类别和概念的泛化能力而设计。该数据集仅包含验证集和测试集,训练直接使用COCO数据。nocaps分为三部分——域内部分仅包含COCO类别图像,近域部分同时包含COCO和新类别,域外部分则完全由新类别构成。如Li等人[19]建议,我们仅使用验证集进行评估。虽然部分方法会利用新类别的对象标签,但我们仅考虑无额外监督的设置,因其更具实践适用性,因此未采用受限束搜索[2]。Conceptual Captions数据集包含从网络采集并经过后处理的300万图像-标注对,由于图像和标注风格多样性更高且不受限于特定类别,被认为比COCO更具挑战性。为聚焦概念表达,该数据集中的具体实体被替换为通用概念。例如在图1中,人名被替换为"政治家"。评估时我们使用包含1.25万张图像的验证集,因测试集未公开。因此我们未将该数据集用于验证环节。
Baselines. We compare our method to the state-of-the-art works of Li et al. [19] (known as Oscar), Vision-Language Pre-training model (VLP) [47], and the eminent work of Anderson et al. [4], denoted BUTD. These models first produce visual features using an object detection network [31]. BUTD then utilizes an LSTM to generate the captions, while VLP and Oscar employ a transformer, trained simi
基线方法。我们将本方法与以下前沿工作进行对比:Li等人[19]提出的Oscar模型、视觉语言预训练模型(VLP)[47],以及Anderson等人[4]提出的BUTD模型。这些模型首先使用目标检测网络[31]生成视觉特征。BUTD采用LSTM生成描述文本,而VLP和Oscar则使用Transformer进行类似训练。
$(A)$ Conceptual Captions
$(A)$ Conceptual Captions
| 模型 | ROUGE-L↑ | CIDEr↑ | SPICE↑ | #Params (M)↓ | Training Time↓ |
|---|---|---|---|---|---|
| VLP | 24.35 | 77.57 | 16.59 | 115 | 1200h (V100) |
| Ours; MLP + GPT2 tuning | 26.71 | 87.26 | 18.5 | 156 | 80h (GTX1080) |
| Ours; Transformer | 25.12 | 71.82 | 16.07 | 43 | 72h (GTX1080) |
$(B)$ nocaps
| 模型 | in-domain CIDEr↑ SPICE↑ | near-domain CIDEr SPICE | out-of-domain CIDEr SPICE | Overall CIDEr SPICE | #Params (M)↓ | Training Time↓ |
|---|---|---|---|---|---|---|
| BUTD [4] | 74.3 11.5 | 56.9 10.3 | 30.1 8.1 | 54.3 10.1 | 52 | 960h |
| Oscar [19] | 79.6 12.3 | 66.1 11.5 | 45.3 9.7 | 63.8 11.2 | 135 | 74h |
| Ours; MLP + GPT2 tuning | 79.73 12.2 | 67.69 11.26 | 49.35 9.7 | 65.7 11.1 | 156 | 7h |
| Ours; Transformer | 84.85 12.14 | 66.82 10.92 | 49.14 9.57 | 65.83 10.86 | 43 | 6h |
$(C)$ cOCo
| 模型 | B@4↑ | METEOR↑ | CIDEr↑ | SPICE↑ | #Params (M)↓ | Training Time↓ |
|---|---|---|---|---|---|---|
| BUTD [4] | 36.2 | 27.0 | 113.5 | 20.3 | 52 | 960h (M40) 48h (V100) |
| VLP [47] | 36.5 | 28.4 | 117.7 | 21.3 | 115 | - |
| Oscar [19] | 36.58 | 30.4 | 124.12 | 23.17 | 135 | 74h (V100) 6h (GTX1080) |
| Ours; Transformer | 33.53 | 27.45 | 113.08 | 21.05 | 43 | - |
| Ours; MLP + GPT2 tuning | 32.15 | 27.1 | 108.35 | 20.12 | 156 | 7h (GTX1080) |
$(D)$ Ablation
| 模型 | B@4↑ | METEOR↑ | CIDEr↑ | SPICE↑ | #Params (M)↓ | Training Time↓ |
|---|---|---|---|---|---|---|
| Ours; Transformer + GPT2 tuning | 32.22 | 27.79 | 109.83 | 20.63 | 167 | 7h (GTX1080) |
| Ours; MLP | - | 27.39 | 24.4 | 92.38 | 18.04 | 32 |
Table 1. Quantitative evaluation. As can be seen, our method achieves comparable results for both nocaps and Conceptual Captions with much faster training time. Figure 3. Uncurated results of the first five images in the COCO test set (Karpathy et al. [17] split).
表 1: 定量评估。可以看出,我们的方法在 nocaps 和 Conceptual Captions 数据集上取得了可比的结果,同时训练时间大幅缩短。图 3: COCO 测试集 (Karpathy 等人 [17] 划分) 中前五张图像的未筛选结果。
| Ground Truth | |||||
|---|---|---|---|---|---|
| 一个戴红色头盔的男人 | 一个年轻女孩在吸气 | ||||
| Oscar | 泥路 | 骑着小摩托 | 试图吹灭蜡烛 | 火车旁 | 一个女人坐在桌边 |
| 食物 | 一个女人坐在桌边 | ||||
| 柜台上摆放着各种物品 | 一个有水槽的厨房 | ||||
| 我们的方法; MLP + GPT2调优 | 骑着摩托车驶下泥路 | 一个女人正在吃一盘食物 | 一个男人站在一排放着木勺的木砧板旁 | 火车 | 沿着街道行驶 |
| 我们的方法; Transformer | 一个男人骑着摩托车行驶在泥路上 | 一个年轻女孩坐在桌边吃着带蜡烛的蛋糕 | 一个男人站在火车旁 | 一个放着木制工具的木质桌子 |
Figure 4. Uncurated results of the first five images in our test set for Conceptual Captions [33].
图 4: Conceptual Captions [33] 测试集中前五张图像的未筛选结果。
| Barnes&Noble | |||
|---|---|---|---|
| Ground Truth A life in photography -H in pictures. | being repaired by brave person carrying in hands | Photograph of the sign Globes :the green 3d The player staring in- The -bedroom stone stentlyatacomputercottagecansleeppeo- | |
| VLP the movie. | Actors in a scenefromThe sign at the entrance.Templates: | tooncharacter holdingvideo. the earth globe. | works |
| Ours;MLP + GPT2 tuning room. | Actor sits in a hotel The sign at the entrance. | 3d render of a man hold- Person, ing a globe. | astudent, The property is on the |
| Ours; Transformer in a room. | person sitting on a chaira sign is seen at the en-stock image of a man | laptop. |

A person standing in front of a rock formation in the desert.
一个人站在沙漠中的岩层前。

A man holding a banana in front of a river.
一名男子在河边手持香蕉。

A person sitting at a table with a tray of sushi.
一个人坐在桌前,面前摆着一盘寿司。
Two horned goats crossing a road in the desert.
两只长角山羊穿越沙漠中的道路。
Evaluation metrics. Similar to Li et al. [19], we validate our results over the COCO dataset using the common metrics BLEU [27], METEOR [10], CIDEr [37] and SPICE [3], and for the nocaps dataset using CIDEr and SPICE. For the Conceptual Captions, we report the ROUGE-L [21], CIDEr, and SPICE, as suggested by the authors [33].
评估指标。与 Li 等人 [19] 类似,我们在 COCO 数据集上使用常见指标 BLEU [27]、METEOR [10]、CIDEr [37] 和 SPICE [3] 验证结果,在 nocaps 数据集上使用 CIDEr 和 SPICE。对于 Conceptual Captions,我们按照作者建议 [33] 报告 ROUGE-L [21]、CIDEr 和 SPICE。

Figure 5. Results over smartphone photos. Top: using our Conceptual Captions model. Bottom: COCO model. As demonstrated, our approach generalizes well to newly photographed images.
图 5: 智能手机照片处理结果。上图:使用我们的 Conceptual Captions 模型。下图:COCO 模型。如图所示,我们的方法对新拍摄图像具有良好泛化能力。
Furthermore, we measure the training time and the number of trainable parameters to validate the applicability of our method. Reducing the training time allows to quickly obtain a new model for new data, create an ensemble of models, and decrease energy consumption. Similar to other works, we report training time in GPU hours, and the GPU model used. The number of trainable parameters is a popular measure to indicate model feasibility.
此外,我们测量了训练时间和可训练参数的数量,以验证我们方法的适用性。减少训练时间可以快速为新数据获取新模型、创建模型集成并降低能耗。与其他工作类似,我们以GPU小时为单位报告训练时间,并注明所使用的GPU型号。可训练参数的数量是衡量模型可行性的常用指标。
larly to BERT [11]. Both VLP and Oscar exploit an extensive pre-trained procedure over millions of image-text pairs. Oscar [19] also uses additional supervision compared to our setting, in the form of object tags for each image.
与BERT [11]类似,VLP和Oscar都利用了数百万图像-文本对进行广泛的预训练过程。Oscar [19]相比我们的设置还使用了额外监督,即以每张图像的对象标签形式。
Quantitative evaluation. Quantitative results for the challenging Conceptual Captions dataset are presented in Tab. $1(A)$ . As can be seen, we surpass the results of VLP, while requiring orders of magnitude less training time. We note that our lightweight model, which does not fine-tune GPT-2, achieves an inferior result for this dataset. We hypothesize that due to the large variety of styles, a more expressive model is required than our light model, which induces a significantly lower parameter count. We compare only to VLP, as the other baselines haven’t published results nor trained models for this dataset.
定量评估。具有挑战性的Conceptual Captions数据集的定量结果如表 $1(A)$ 所示。可以看出,我们的结果超越了VLP,同时所需的训练时间少了好几个数量级。需要注意的是,我们的轻量级模型(未对GPT-2进行微调)在该数据集上表现较差。我们推测,由于该数据集风格多样,需要比我们参数数量显著减少的轻量模型更具表达力的模型。我们仅与VLP进行比较,因为其他基线尚未发布该数据集的结果或训练模型。
Our default configuration employs the transformer mapping network, without fine-tuning the language model, denoted Ours; Transformer. Additionally, we also evaluate our variant that utilizes the MLP mapping network, and fine-tunes the language model, denoted Ours; MLP $\mathbf{\nabla}+\mathbf{GPT}2$ tuning. Other configurations are evaluated in Tab. $1(D)$ .
我们的默认配置采用Transformer映射网络,不对语言模型进行微调,记为Ours; Transformer。此外,我们还评估了使用MLP映射网络并对语言模型进行微调的变体,记为Ours; MLP $\mathbf{\nabla}+\mathbf{GPT}2$ tuning。其他配置评估结果见表1(D)。
Tab. $1(B)$ presents results for the nocaps dataset, where we achieve comparable results to the state-of-the-art method Oscar. As can be seen, Oscar achieves a slightly better SPICE score and we attain a slightly better CIDEr score. Still, our method uses a fraction of training time and trainable parameters with no additional object tags required, hence it is much more useful in practice.
表 1(B) 展示了在 nocaps 数据集上的结果,我们的方法与当前最先进的 Oscar 方法取得了相当的效果。可以看出,Oscar 的 SPICE 分数略高,而我们的 CIDEr 分数稍优。尽管如此,我们的方法仅需极少的训练时间和可训练参数,且无需额外物体标签,因此在实际应用中更具优势。

Figure 6. Prefix Interpret ability. We present both the generated caption and our prefix interpretation. Upper: Ours; $\mathrm{MLP}+\mathrm{GPT}2$ tuning. Bottom: Ours; Transformer.
图 6: 前缀可解释性。我们展示了生成的标题和我们的前缀解释。上: 我们的方法; $\mathrm{MLP}+\mathrm{GPT}2$ 微调。下: 我们的方法; Transformer。
Tab. $1(C)$ present the results for the COCO dataset. Oscar reaches the best results, however, it uses additional input in the form of object tags. Our results are closed to VLP and BUTD which utilize considerably more parameters and training time. Note that the training time of VLP and Oscar does not include the pre-training step. For instance, pretraining of VLP requires training over Conceptual Captions which consumes 1200 GPU hours.
表 $1(C)$ 展示了 COCO 数据集的结果。Oscar 取得了最佳成绩,但它使用了物体标签形式的额外输入。我们的结果接近 VLP 和 BUTD,而后者使用了明显更多的参数和训练时间。需要注意的是,VLP 和 Oscar 的训练时间不包括预训练步骤。例如,VLP 的预训练需要在 Conceptual Captions 上进行,这消耗了 1200 GPU 小时。
Both Conceptual Captions and nocaps are designed to model a larger variety of visual concepts than COCO. Therefore, we conclude our method is preferable for generalizing to diverse data using a quick training procedure. This originates from utilizing the already rich semantic represent at ions of both CLIP and GPT-2.
概念字幕(Conceptual Captions)和nocaps数据集的设计初衷都是为了比COCO建模更丰富的视觉概念。因此我们得出结论:在需要快速训练流程实现多样化数据泛化的场景中,本方法更具优势。这种优势源于同时利用了CLIP和GPT-2原本就非常丰富的语义表征能力。
Qualitative evaluation. Visual results of the uncurated first examples in our test sets of both Conceptual Captions and COCO datasets are presented in Figs. 3 and 4 respectively. As can be seen, our generated captions are meaningful and depict the image successfully for both datasets. We present additional examples collected from the web in Fig. 1. As can be seen, our Conceptual Captions model generalizes well to arbitrary unseen images as it was trained over a sizable and diverse set of images. We also present in Fig. 5 results over smartphone images, to further demonstrate generalization to new scenarios. Moreover, our model successfully identifies uncommon objects even when trained only over COCO. For example, our method recognizes the wooden spoons or the cake with a candle better than Oscar in Fig. 3, since CLIP is pre-trained over a diverse set of images. However, our method still fails in some cases, such as recognizing the bicycle next to the train in Fig. 3. This is inherited from the CLIP model, which does not perceive the bicycle in the first place. We conclude that our model would benefit from improving CLIP object detection ability, but leave this direction for future work. For Conceptual Captions, our method mostly produces accurate captions, such as perceiving the green 3d person in Fig. 4. As expected, our method still suffers from data bias. For instance, it depicts the bedroom image in Fig. 4 as ”The property is on the market for £ 1” after witnessing such captions of property advertising during training.
定性评估。我们在Conceptual Captions和COCO测试集中未经筛选的首批样本可视化结果分别如图3和图4所示。可以看出,针对两个数据集,我们生成的描述文本均能准确传达图像语义。图1展示了从网络收集的额外示例,可见经过大规模多样化图像训练的Conceptual Captions模型对未见图像具有良好泛化能力。图5进一步展示了智能手机拍摄图像的生成效果,以验证模型对新场景的适应能力。值得注意的是,即便仅基于COCO训练,我们的模型仍能成功识别罕见物体。例如在图3中,由于CLIP预训练使用了多样化图像,我们的方法对木勺和带蜡烛蛋糕的识别效果优于Oscar。但模型仍存在失败案例,如图3中未能识别火车旁的自行车——这源于CLIP模型本身未检测到该物体。我们认为提升CLIP物体检测能力将有助于模型改进,但该方向留待未来研究。对于Conceptual Captions数据集,我们的方法大多能生成准确描述(如图4中成功识别绿色3D人像)。但如预期所示,模型仍受数据偏差影响:例如图4中的卧室图像被描述为"该房产正以1英镑挂牌出售",这源于训练时接触过大量房产广告类描述。
Language model fine-tuning. As described in Section. 3, fine-tuning the language model results in a much more expressive model, but that is also more susceptible to overfitting, as the amount of trainable parameters increases. As can be seen in Tab. 1, the two variants — with and without the language model fine-tuning — are comparable. Over the extremely complicated Conceptual Captions dataset, we get superior results with the fine-tuning. While over the popular COCO dataset, avoiding the fine-tuning achieves better results. Regarding nocaps dataset, the results are roughly equal, thus the lighter model would be preferable. We thus hypothesize that extremely elaborated datasets or ones that present a unique style require more expressiveness, and hence the more likely it is to benefit from the fine-tuning.
语言模型微调。如第3节所述,对语言模型进行微调会得到一个表达能力更强的模型,但由于可训练参数量的增加,也更容易出现过拟合。从表1可以看出,进行语言模型微调与不进行微调的两种变体效果相当。在极其复杂的Conceptual Captions数据集上,微调带来了更优的结果;而在流行的COCO数据集上,不进行微调反而效果更好。至于nocaps数据集,两者的结果大致相当,因此更轻量的模型会是更优选择。我们由此假设:对于高度复杂或具有独特风格的数据集,需要更强的表达能力,因此更可能从微调中受益。
Prefix Interpret ability. To further understand our method and results, we suggest interpreting the generated prefixes as a sequence of words. Since the prefix and word embeddings share the same latent space, they can be treated similarly. We define the interpretation of each of the $k$ prefix embeddings as the closest vocabulary token, under cosine similarity. Fig. 6 shows examples of images, the generated captions, and their prefix interpretations. The interpretation is meaningful when both the mapping network and GPT-2 are trained. In this case, the interpretation contains salient words that associate with the content of the image. For Instance, motorcycle and showcase in the first example. However, when we only train the mapping network, the interpretation becomes essentially unreadable since the network is also charged with maneuvering the fixed language model. Indeed, a considerable part of the prefix embeddings is shared across different images for the same model, as it performs the same adjustment to GPT-2.
前缀可解释性。为进一步理解我们的方法和结果,我们建议将生成的前缀视为单词序列。由于前缀与词嵌入共享相同的潜在空间,它们可被类似处理。我们将每个$k$前缀嵌入的解释定义为余弦相似度下最接近的词汇token。图6展示了图像示例、生成描述及其前缀解释。当映射网络和GPT-2均经过训练时,这种解释具有实际意义——例如第一个示例中的motorcycle和showcase等关联图像内容的显著词汇。但若仅训练映射网络,由于网络还需操控固定语言模型,解释结果将变得难以解读。事实上,同一模型中对不同图像的前缀嵌入存在大量共享部分,因其对GPT-2执行相同调整。
Prefix length. Li and Liang [20] showed that increasing the size of the prefix length, up to a certain value, improves the performance of the model in an underlying task. Moreover, the saturation length might differ between tasks. For the image captioning task, we conduct an ablation over the prefix lengths using the COCO dataset over two configurations of our method: Ours; Transformer and Ours; MLP ${\bf+\delta G P T2}$ tuning. The results are summarized in Fig. 7. For each prefix size and configuration, we train the network for 5 epochs and report the BLEU $\ @4$ and CIDEr scores over the test and train sets.
前缀长度。Li和Liang [20] 研究表明,增大前缀长度(在达到特定值之前)能提升模型在目标任务中的性能。此外,不同任务间的饱和长度可能存在差异。在图像描述任务中,我们基于COCO数据集对两种方法配置(Ours; Transformer与Ours; MLP ${\bf+\delta GPT2}$ 调优)进行了前缀长度的消融实验。结果汇总于图7。针对每个前缀长度和配置组合,我们训练网络5个周期,并报告测试集与训练集上的BLEU $\ @4$ 和CIDEr分数。
As can be seen in Fig. 7a, increasing the prefix size while allowing tuning of the language model results in over fitting to the training set, due to the large number of trainable parameters. However, when the language model is frozen, we experience improvement for both the training and test evaluations, as can be seen in Fig. 7b. Naturally, extremely small prefix length yields inferior results as the model is not expressive enough. In addition, we point out that the MLP architecture is inherently more limited as it is not scalable for a long prefix. For example, a prefix size of 40 implies a network with over 450M parameters, which is unfeasible for our single GPU setting. The transformer architecture allows increasing the prefix size with only marginal increment to the number of the parameters, but only up to 80 — due to the quadratic memory cost of the attention mechanism.
如图 7a 所示,在允许调整语言模型的情况下增加前缀大小会导致过拟合训练集,这是由于可训练参数数量过多。然而,当语言模型被冻结时,训练和测试评估均得到提升,如图 7b 所示。显然,极短的前缀长度会导致模型表达能力不足,从而产生较差的结果。此外,我们指出 MLP 架构本身更具局限性,因为它无法扩展以适应较长的前缀。例如,前缀大小为 40 意味着网络参数超过 4.5 亿,这对于我们的单 GPU 设置是不可行的。Transformer 架构允许在参数数量仅边际增加的情况下扩展前缀大小,但由于注意力机制的内存成本呈二次方增长,其上限仅为 80。
Mapping network. An ablation study for the mapping network architecture is shown in Tab. $1(C),(D)$ . As can be seen, with language model fine-tuning, the MLP achieves better results. However, the transformer is superior when the language model is frozen. We conclude that when employing the fine-tuning of the language model, the expressive power of the transformer architecture is unnecessary.
映射网络 (Mapping network)。表 1(C)、(D) 展示了映射网络架构的消融研究结果。可以看出,在语言模型微调的情况下,多层感知机 (MLP) 取得了更好的效果。但当语言模型冻结时,Transformer 表现更优。我们得出结论:在使用语言模型微调时,Transformer 架构的表达能力并非必需。
Implementation details. We used the prefix length of $K=10$ for the MLP mapping networks, where the MLP contains a single hidden layer. For the transformer mapping network, we set the CLIP embedding to $K=10$ constants tokens and use 8 multi-head self-attention layers with 8 heads each. We train for 10 epochs using a batch size of 40. For optimization, we use AdamW [18] with weight decay fix as introduced by Loshchilov et al. [24], with a learning rate of $2e^{-5}$ and 5000 warm-up steps. For GPT-2 we employ the implementation of Wolf et al. [41].
实现细节。我们为MLP映射网络使用的前缀长度为$K=10$,其中MLP包含单个隐藏层。对于Transformer映射网络,我们将CLIP嵌入设置为$K=10$个常量token,并使用8个多头自注意力层,每层8个头。我们使用批量大小为40训练10个周期。优化方面,我们采用AdamW [18] 并应用Loshchilov等人 [24] 提出的权重衰减修正方法,学习率设为$2e^{-5}$,预热步数为5000。对于GPT-2,我们采用Wolf等人 [41] 的实现方案。

(b) Transformer mapping network with frozen language model. Figure 7. Effect of the prefix length on the captioning performance over the COCO-captions dataset. For each prefix length, we report the BLEU $\ @4$ (red) and CIDERr (blue) scores over the test and train (dashed line) sets.
图 7: 前缀长度对COCO-captions数据集上字幕生成性能的影响。对于每个前缀长度,我们报告了测试集(实线)和训练集(虚线)上的BLEU$\ @4$(红色)和CIDERr(蓝色)分数。
(b) 采用冻结语言模型的Transformer映射网络。
5. Conclusion
5. 结论
Overall, our CLIP-based image-captioning method is simple to use, doesn’t require any additional annotations, and is faster to train. Even though we propose a simpler model, it demonstrates more merit as the dataset becomes richer and more diverse. We consider our approach as part of a new image captioning paradigm, concentrating on leveraging existing models, while only training a minimal mapping network. This approach essentially learns to adapt existing semantic understanding of the pre-trained models to the style of the target dataset, instead of learning new semantic entities. We believe the utilization of these powerful pre-trained models would gain traction in the near future. Therefore, the understanding of how to harness these components is of great interest. For future work, we plan to incorporate pre-trained models (e.g., CLIP), to other challenging tasks, such as visual question answering or image to 3D translation, through the utilization of mapping networks.
总体而言,我们基于CLIP的图像描述方法使用简单、无需额外标注且训练速度更快。尽管我们提出了更简洁的模型,但随着数据集变得更丰富多样,其优势愈发显著。我们将该方法视为新型图像描述范式的一部分,其核心在于利用现有模型,仅需训练最小化的映射网络。这种方法本质上是学习调整预训练模型的现有语义理解,使其适应目标数据集的风格,而非学习新的语义实体。我们相信,这些强大预训练模型的运用将在短期内得到更广泛关注。因此,如何有效利用这些组件成为极具价值的研究方向。未来工作中,我们计划通过映射网络将CLIP等预训练模型整合到视觉问答、图像转3D等更具挑战性的任务中。