ProoFVer: Natural Logic Theorem Proving for Fact Verification
基于自然逻辑定理证明的事实验证
Abstract
摘要
Fact verification systems typically rely on neural network class if i ers for veracity prediction which lack explain ability. This paper proposes ProoFVer, which uses a seq2seq model to generate natural logicbased inferences as proofs. These proofs consist of lexical mutations between spans in the claim and the evidence retrieved, each marked with a natural logic operator. Claim veracity is determined solely based on the sequence of these operators. Hence, these proofs are faithful explanations, and this makes ProoFVer faithful by construction. Currently, ProoFVer has the highest label accuracy and the second best Score in the FEVER leader board. Furthermore, it improves by $13.21%$ points over the next best model on a dataset with counter factual instances, demonstrating its robustness. As explanations, the proofs show better overlap with human rationales than attention-based highlights and the proofs help humans predict model decisions correctly more often than using the evidence directly.1
事实核查系统通常依赖神经网络分类器进行真实性预测,但这些模型缺乏可解释性。本文提出ProoFVer,它采用序列到序列(seq2seq)模型生成基于自然逻辑的推理证明。这些证明由声明与检索证据之间的词汇变异组成,每个变异都标有自然逻辑运算符。声明的真实性仅由这些运算符的序列决定,因此这些证明本身就是忠实解释,这使得ProoFVer在架构上具有忠实性。目前,ProoFVer在FEVER排行榜上拥有最高的标签准确率和第二高的综合得分。此外,在包含反事实实例的数据集上,其性能比次优模型高出13.21%,证明了其鲁棒性。作为解释机制,这些证明与人类推理依据的重合度优于基于注意力机制的标注,且比直接使用证据更能帮助人类正确预测模型决策[20]。
1 Introduction
1 引言
Fact verification systems typically comprise an evidence retrieval model followed by a textual entailment classifier (Thorne et al., 2018b). Recent high performing fact verification systems (Zhong et al., 2020; Ye et al., 2020) use neural models for textual entailment whose reasoning is opaque to humans despite advances in interpret abl it y (Han et al., 2020). On the other hand, proof systems like NaturalLI (Angeli and Manning, 2014) provide transparency in their decision making for entailment tasks, by using explicit proofs in the form of natural logic. However, the accuracy of such approaches often does not match that of neural models (Abzianidze, 2017a).
事实核查系统通常由证据检索模型和文本蕴含分类器组成 (Thorne et al., 2018b)。近期高性能的事实核查系统 (Zhong et al., 2020; Ye et al., 2020) 使用神经网络模型进行文本蕴含判断,尽管可解释性研究有所进展 (Han et al., 2020),但其推理过程对人类仍不透明。另一方面,像NaturalLI这样的证明系统 (Angeli and Manning, 2014) 通过使用自然逻辑形式的显式证明,为蕴含任务提供了透明的决策过程。然而,这类方法的准确率往往无法与神经网络模型匹敌 (Abzianidze, 2017a)。
Justifying decisions is central to fact verification (Uscinski and Butler, 2013). While mod- els such as those developed for FEVER (Thorne et al., 2018b) typically substantiate their decisions by presenting the evidence as is, more recent proposals use the evidence to generate explanations. Here, models highlight salient parts of the evidence (Popat et al., 2018; Wu et al., 2020), generate summaries (Kotonya and Toni, 2020b; Atanasova et al., 2020), correct factual er- rors (Thorne and Vlachos, 2021b; Schuster et al., 2021), answer claim related questions (Fan et al., 2020), or perform rule discovery (Ahmadi et al., 2019; Gad-Elrab et al., 2019). An explanation is faithful only if it reflects the information that is used for decision making (Lipton, 2018; Jacovi and Goldberg, 2020), which these systems do not guarantee. A possible exception here would be the rule discovery models, however, their performance often suffers due to limited knowledge base coverage and/or the noise in rule extraction from text (Kotonya and Toni, 2020a; Pez es hk pour et al., 2020). Faithful explanations are useful as mechanisms to dispute, debug or advice (Jacovi and Goldberg, 2021), which may aid a news agency for advice, a user to dispute decisions, and a developer for model debugging in fact verification.
为决策提供依据是事实核查的核心 (Uscinski and Butler, 2013)。虽然像为FEVER开发的那些模型 (Thorne et al., 2018b) 通常通过直接呈现证据来支持其决策,但最近的提案使用证据来生成解释。在这里,模型会突出显示证据的关键部分 (Popat et al., 2018; Wu et al., 2020),生成摘要 (Kotonya and Toni, 2020b; Atanasova et al., 2020),纠正事实错误 (Thorne and Vlachos, 2021b; Schuster et al., 2021),回答与声明相关的问题 (Fan et al., 2020),或执行规则发现 (Ahmadi et al., 2019; Gad-Elrab et al., 2019)。只有当解释反映了用于决策的信息时,它才是可信的 (Lipton, 2018; Jacovi and Goldberg, 2020),而这些系统并不能保证这一点。这里的一个可能的例外是规则发现模型,然而,由于知识库覆盖范围有限和/或从文本中提取规则的噪声,它们的性能往往会受到影响 (Kotonya and Toni, 2020a; Pez es hk pour et al., 2020)。可信的解释作为争议、调试或建议的机制是有用的 (Jacovi and Goldberg, 2021),这可能有助于新闻机构获取建议,用户对决策提出异议,以及开发人员在事实核查中进行模型调试。
Keeping both accuracy and explain ability in mind, we propose ProoFVer - Proof System for Fact Verification which generates proofs or refutations of the claim given evidence as natural logic based inference. ProoFVer follows the natural logic based theory of compositional entailment, originally proposed in NatLog (MacCartney and Manning, 2007). In the example of Figure 1 ProoFVer generates the proof shown in Figure 2, for a given claim and evidence. Here, at each step in the proof, a claim span is mutated with a span from the evidence. Each such mutation is marked with an entailment relation, by assigning a natural logic operator (NatOp, Angeli and Manning,
在兼顾准确性和可解释性的前提下,我们提出了ProoFVer——基于自然逻辑推理的事实验证证明系统,该系统能够根据给定证据生成支持或反驳主张的证明。ProoFVer遵循由NatLog (MacCartney and Manning, 2007) 最初提出的组合蕴涵自然逻辑理论。如图1所示案例中,ProoFVer针对给定主张和证据生成了图2所示的证明。在该证明过程中,每个步骤都会用证据片段对主张片段进行变异操作,并通过分配自然逻辑运算符 (NatOp, Angeli and Manning) 标记出具有蕴涵关系的变异。
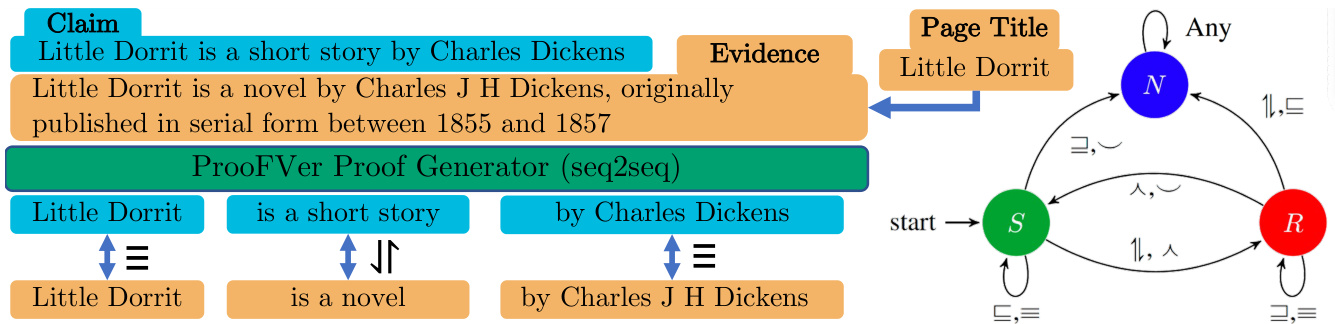
Figure 1: The proof generator in ProoFVer, generates the natural logic proofs using a seq2seq model. The natural logic operators from the proof are used as transitions in the DFA to determine the veracity of the claim. The states S, N, and R in the automaton denote the task labels SUPPORTS, REFUTES, and NOT ENOUGH INFO respectively. The transitions in the automaton are the natural logic operators (NatOPs) defined in Table 1.
图 1: ProoFVer中的证明生成器使用seq2seq模型生成自然逻辑证明。证明中的自然逻辑运算符被用作DFA中的转移条件,以确定声明的真实性。自动机中的状态S、N和R分别表示任务标签SUPPORTS、REFUTES和NOT ENOUGH INFO。自动机中的转移是表1中定义的自然逻辑运算符(NatOPs)。

Figure 2: Proof steps for the input in Figure 1.
图 2: 图 1 中输入内容的证明步骤。
2014). A step in the proof can be represented using a triple, consisting of the aligned spans in the mutation and its assigned NatOp. In the example, the mutations in the first and last triples occur with semantically equivalent spans, and hence are assigned with the equivalence NatOp $(\equiv)$ . However, the mutation in the second triple results in a contradiction, as ‘short story’ is replaced with ‘novel’ and an item cannot be both. Hence, the mutation is assigned the alternation NatOp (ê). The sequence of NatOps from the proof become the transitions in the DFA shown in Figure 1, which in this case terminates at the ‘REFUTE (R)’ state, i.e. the evidence refutes the claim.
2014)。证明中的一个步骤可以用一个三元组表示,该三元组由突变中的对齐片段及其分配的NatOp组成。在此示例中,第一个和最后一个三元组中的突变发生在语义等效的片段上,因此被分配了等价NatOp $(\equiv)$。然而,第二个三元组中的突变导致了矛盾,因为"short story"被替换为"novel",而一个项目不能同时是两者。因此,该突变被分配了交替NatOp (ê)。证明中的NatOp序列成为图1中DFA的转换,在这种情况下终止于"REFUTE (R)"状态,即证据反驳了该主张。
Unlike other natural logic systems (Angeli et al., 2016; Feng et al., 2020), ProoFVer can form a proof by combining spans from multiple evidence sentences, by leveraging the entity mentions linking those sentences. The proof is generated by a seq2seq model trained using a heuristically annotated dataset, obtained by combining information from the publicly available FEVER dataset (Thorne et al., 2018a; Thorne and Vlachos, 2021b) with PPDB (Pavlick et al., 2015), Wordnet (Miller, 1995) and Wikidata (Vrandecic and Krötzsch, 2014). We heuristic ally generate the training data for the claims in three datasets, namely, FEVER, symmetric FEVER (Schuster et al., 2019), and FEVER 2.0 (Thorne et al., 2019).
与其他自然逻辑系统 (Angeli et al., 2016; Feng et al., 2020) 不同,ProoFVer 能够通过利用连接多个证据句子的实体提及,将这些句子中的片段组合起来形成证明。该证明由一个基于启发式标注数据集训练的序列到序列 (seq2seq) 模型生成,该数据集通过结合公开可用的 FEVER 数据集 (Thorne et al., 2018a; Thorne and Vlachos, 2021b)、PPDB (Pavlick et al., 2015)、Wordnet (Miller, 1995) 和 Wikidata (Vrandecic and Krötzsch, 2014) 的信息构建而成。我们采用启发式方法为三个数据集中的声明生成训练数据,这三个数据集分别是 FEVER、对称 FEVER (Schuster et al., 2019) 和 FEVER 2.0 (Thorne et al., 2019)。
ProoFVer currently is the highest scoring system on the FEVER leader board in terms of label accuracy and is the second best system in terms of FEVER score. Additionally, ProoFVer has robustness and explain ability as its key strengths. Its veracity predictions are solely determined using the generated proof. Hence by design, ProoFVer’s proofs, when used as explanations, are faithful by construction (Lei et al., 2016; Jain et al., 2020). Similarly, it demonstrates robustness to counterfactual instances from Symmetric FEVER and adversarial instances from FEVER 2.0. In particular, ProoFVer achieved $13.21%$ higher label accuracy than that of the next best model (Ye et al., 2020) for symmetric FEVER and similarly improves upon the previous best results (Schuster et al., 2021) on Adversarial FEVER.
ProoFVer 目前在 FEVER 排行榜上标签准确率得分最高,FEVER 分数排名第二。此外,ProoFVer 的关键优势在于其鲁棒性和可解释性。其真实性预测完全基于生成的证明确定,因此从设计上,ProoFVer 的证明作为解释时具有构造忠实性 (Lei et al., 2016; Jain et al., 2020)。同样,它对来自 Symmetric FEVER 的反事实实例和 FEVER 2.0 的对抗性实例表现出鲁棒性。具体而言,ProoFVer 在 Symmetric FEVER 上的标签准确率比次优模型 (Ye et al., 2020) 高出 $13.21%$,并在 Adversarial FEVER 上同样超越了之前的最佳结果 (Schuster et al., 2021)。
To evaluate the robustness of fact verification systems against the impact of superfluous information from the retriever, we propose a new metric, Stability Error Rate (SER), which measures the proportion of instances where superfluous information changes the decision of the model. ProoFVer achieves a SER of $5.73%$ , compared to $9.36%$ of Stammbach (2021), where a lower SER is preferred. ProoFVer’s proofs as explanations, apart from being faithful, score high in their overlap with human rationales with a token overlap F1-Score of $93.28%$ , $5.67%$ points more than attention-based highlights from Ye et al. (2020). Finally, humans, with no knowledge of natural logic, correctly predict ProoFVer’s decisions $81.67%$ of the times compared to $69.44%$ when using the retrieved evidence.
为评估事实核查系统对检索器冗余信息影响的鲁棒性,我们提出新指标稳定性错误率 (Stability Error Rate, SER) ,用于衡量冗余信息改变模型决策的案例比例。ProoFVer 的 SER 为 $5.73%$ ,优于 Stammbach (2021) 的 $9.36%$ (数值越低越好) 。作为解释的证明链除具备可信性外,其与人类推理依据的 token 重叠 F1 值达 $93.28%$ ,较 Ye 等 (2020) 基于注意力机制的高亮标注方法提升 $5.67%$ 。最终测试显示,未接受自然逻辑训练的人类参与者对 ProoFVer 决策的正确预测率为 $81.67%$ ,而仅使用检索证据时的预测正确率为 $69.44%$ 。
2 Natural Logic Proofs as Explanations
2 自然逻辑证明作为解释
Natural logic operates directly on natural language (Angeli and Manning, 2014; Abzianidze,
自然逻辑直接作用于自然语言 (Angeli and Manning, 2014; Abzianidze,
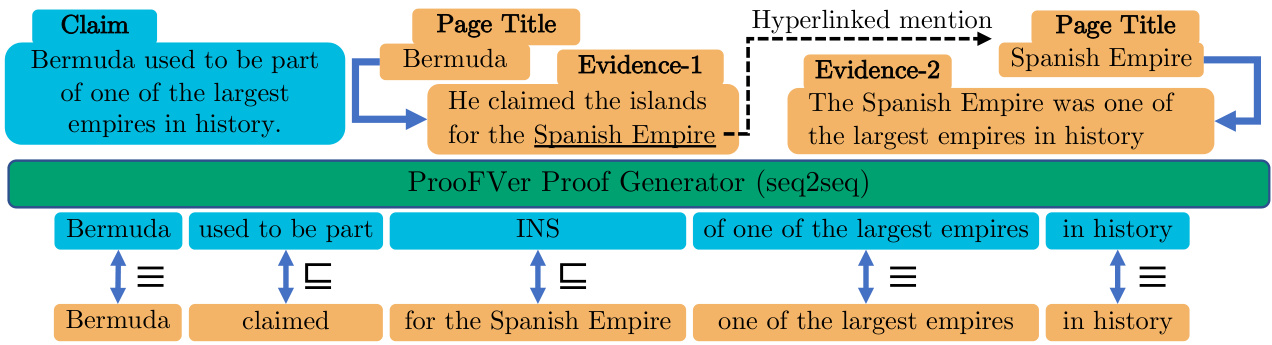
Figure 3: A claim requiring multiple evidence sentences for verification.
图 3: 需要多个证据句子进行验证的声明。
2017b). Thus it is appealing for fact verification, as structured knowledge bases like Wikidata typically lag behind text-based encyclopedias such as Wikipedia in terms of coverage (Johnson, 2020). Furthermore, it obviates the need to translate claims and evidence into meaning representations such as lambda calculus (Z ett le moyer and Collins, 2005). While such representations may be more expressive, they require the development of semantic parsers, introducing another source of potential errors in the verification process.
2017b)。因此,这对事实核查很有吸引力,因为像Wikidata这样的结构化知识库在覆盖范围上通常落后于基于文本的百科全书,如Wikipedia (Johnson, 2020)。此外,它避免了将声明和证据转换为lambda演算 (Zettlemoyer and Collins, 2005) 等意义表示的需要。虽然这种表示可能更具表现力,但它们需要开发语义解析器,从而在验证过程中引入了另一个潜在错误的来源。
Natural Logic has been previously employed in several information extraction and NLU tasks such as Natural Language Inference (NLI, Abzianidze, 2017a; Feng et al., 2020), question answering (Angeli et al., 2016) and open information extraction (Angeli, 2016, Chapter 5). NatLog (MacCartney and Manning, 2007), building on earlier theoretical work on natural logic and monotonicity calculus (Van Benthem, 1986; Valencia, 1991), uses natural logic for textual inference.
自然逻辑先前已应用于多项信息抽取和自然语言理解任务,如自然语言推理 (NLI, Abzianidze, 2017a; Feng et al., 2020) 、问答系统 (Angeli et al., 2016) 以及开放信息抽取 (Angeli, 2016, 第5章) 。NatLog (MacCartney and Manning, 2007) 基于早期自然逻辑与单调性演算的理论研究 (Van Benthem, 1986; Valencia, 1991) ,将自然逻辑应用于文本推理。
NaturalLI (Angeli and Manning, 2014) extended NatLog by adopting the formal semantics of Icard III and Moss (2014), and it is a proof system formulated for the NLI task. It determines the entailment of a hypothesis by searching over a database of premises. The proofs are in the form of a natural logic based logical inference, which results in a sequence of mutations between a premise and a hypothesis. Each mutation is marked with a natural logic relation, and is realised as a lexical substitution, forming a step in the inference. Each mutation results in a new sentence, and the natural logic relation assigned to it identifies the type of entailment that holds between the sentences before and after the mutation. NaturalLI adopts a set of seven natural logic operators, as shown in Table 1. The operators were originally proposed in NatLog (MacCartney, 2009, p. 79). We henceforth refer to these operators as NatOps.
NaturalLI (Angeli and Manning, 2014) 通过采用 Icard III 和 Moss (2014) 的形式语义扩展了 NatLog,它是为 NLI 任务制定的证明系统。该系统通过搜索前提数据库来确定假设的蕴涵关系。其证明形式基于自然逻辑的推理过程,生成前提与假设之间的一系列变异序列。每个变异都标有自然逻辑关系,并通过词汇替换实现,构成推理的一个步骤。每次变异会产生新句子,而赋予的自然逻辑关系则标识变异前后句子间的蕴涵类型。NaturalLI 采用如表 1 所示的七种自然逻辑运算符,这些运算符最初由 NatLog (MacCartney, 2009, p. 79) 提出,后文统称为 NatOps。
表 1:
Table 1: Natural logic relations (NatOps) and their set theoretic definitions.
表 1: 自然逻辑关系 (NatOps) 及其集合论定义。
| NatOP:名称 | 定义 |
|---|---|
| 1l:交替 (Alternation) | y=y≠U |
| :覆盖 (Cover) | y≠y=U |
| =:等价 (Equivalence) | c=y |
| E:前向蕴涵 (Forward Entailment) | cCy |
| 人:否定 (Negation) | Ω=hnv=hu |
| :反向蕴涵 (Reverse Entailment) | y |
| #:独立 (Independence) | 所有其他情况 (All other cases) |
To determine whether a hypothesis is entailed by a premise, NaturalLI uses a deterministic finite state automaton (DFA). Here, each state is an entailment label, and the transitions are the NatOps (Figure 1). The sequence of NatOps in the inference is used to traverse the DFA, and the state where it terminates decides the label of the hypothesis-premise pair. The decision making process relies solely on the steps in the logical inference, and thus form faithful explanations.
为了判断一个假设是否由前提蕴含,NaturalLI采用确定性有限状态自动机(DFA)。其中每个状态代表一个蕴含标签,状态转移则由NatOps操作实现(图1)。推理过程中的NatOp序列用于遍历该DFA,最终终止的状态决定了假设-前提对的标签。这一决策过程完全依赖于逻辑推理步骤,因此能形成可信的解释。
Other proof systems that apply mutations between text sequences have been previously explored. Stern et al. (2012) explored how to transform a premise into a hypothesis using mutations, however their approach was limited to twoway entailment instead of three-way that is handled by NaturalLI. Similar proof systems have used mutations in the form of tree-edit operations (Mehdad, 2009), transformations over syn- tactic parses (Heilman and Smith, 2010; Harmeling, 2009), knowledge-based transformations in the form of lexical mutations, entailment rules, rewrite rules, or their combinations (Bar-Haim et al., 2007; Szpektor et al., 2004).
其他在文本序列间应用变异的证明系统此前已有研究。Stern等人(2012)探索了如何利用变异将前提转化为假设,但他们的方法仅限于双向蕴涵,而非NaturalLI所处理的三向关系。类似证明系统采用了树编辑操作形式的变异(Mehdad, 2009)、基于句法分析的转换(Heilman and Smith, 2010; Harmeling, 2009),以及以词汇变异、蕴涵规则、重写规则或其组合形式呈现的基于知识的转换(Bar-Haim等人, 2007; Szpektor等人, 2004)。
3 ProoFVer
3 ProoFVer
ProoFVer uses a seq2seq generator that generates a proof in the form of natural-logic based logical inference, which becomes the input to a deterministic finite state automaton (DFA) for predicting the veracity of the claim. We elaborate on the proof generation process in Section 3.1, and on the veracity prediction in Section 3.2.
ProoFVer采用基于序列到序列(seq2seq)的生成器,生成以自然逻辑为基础的逻辑推理形式的证明,该证明随后作为确定性有限状态自动机(DFA)的输入用于预测声明的真实性。我们将在3.1节详细阐述证明生成过程,并在3.2节说明真实性预测机制。
3.1 Proof Generation
3.1 证明生成
The proof generator, as shown in Figures 1 and 3, takes as input a claim along with one or more retrieved evidence sentences. It generates the steps of the proof as a sequence of triples, each consisting of a span from the claim, a span from the evidence and a NatOp. The claim span being substituted and the evidence span replacing it form a mutation, and each mutation is assigned a NatOp. In a proof, we start with the claim, and the mutations are iterative ly applied from left to right. Figure 1 shows a proof containing a sequence of three triples. The corresponding mutated statements at each step of the proof, along with the assigned NatOps, are shown in Figure 2.
如图1和图3所示,证明生成器接收一个主张(claim)及一条或多条检索到的证据句作为输入。它将证明步骤生成为由三元组组成的序列,每个三元组包含主张片段、证据片段和NatOp操作。被替换的主张片段与替代它的证据片段构成一次变异(mutation),每次变异都被分配一个NatOp操作。在证明过程中,我们从初始主张开始,从左到右迭代应用这些变异。图1展示了一个包含三个三元组序列的证明示例,图2则显示了证明每个步骤对应的变异语句及其分配的NatOp操作。
We use a seq2seq model following an autoregressive formulation for the proof generation. In the proof, successive spans of the claim form part of the successive triples. However, the corresponding evidence spans in the successive triples need not follow any order. As shown in Figure 3, the evidence spans may come from multiple sentences, and may not all end up being used. Finally, the NatOps, as shown in Table 1, are represented using a predetermined set of tokens.
我们采用基于自回归框架的序列到序列(seq2seq)模型进行证明生成。在证明过程中,主张文本的连续片段构成连续三元组的部分要素。然而,这些连续三元组中对应的证据片段无需遵循特定顺序。如图3所示,证据片段可能来自多个句子,且并非所有片段都会被最终采用。最后如表1所示,自然语言操作(NatOps)通过预定义的token集合进行表示。
To get valid proofs during prediction, we need to lexically constrain the inference process by switching between three different search spaces depending on which element of the triple is being predicted. To achieve this, we employ dynamically constrained markup decoding (De Cao et al., 2021), a modified form of lexically constrained decoding (Post and Vilar, 2018). This decoding uses markups to switch between the search spaces, and we use the delimiters “{”, “}”, “[”, and “]” as the markups. Using these markups, we constrain the tokens predicted between a “{” and “}” to be from the claim, between a “[”, and “]” to be from the evidence, and the token after “]” to be a NatOp token. The prediction of a triple begins with predicting a “{”, and it proceeds by generating a claim span where the tokens are monotonically copied from the claim in the input, until a “}” is predicted. The prediction then continues by generating a “[” which initiates the evidence span prediction in the triple. The evidence span can begin with any word from the evidence, and is then expanded by predicting subsequent tokens, until “]” is predicted. Finally, the NatOp token is predicted. In the next triple, copying resumes from the next token in the claim. All triples until the one with the last token in the claim are generated in this manner.
为了在预测过程中获得有效证明,我们需要根据三元组中当前预测的元素,在三个不同的搜索空间之间进行切换,从而对推理过程实施词汇约束。为此,我们采用动态约束标记解码(De Cao等人,2021)——这是词汇约束解码(Post和Vilar,2018)的改进形式。该解码方法通过标记切换搜索空间,我们使用分隔符“{”、“}”、“[”和“]”作为标记符。具体而言:
- 预测“{”和“}”之间的token时,必须来自主张文本;
- 预测“[”和“]”之间的token时,必须来自证据文本;
- 预测“]”之后的token时,必须为NatOp操作符。
三元组的预测流程如下:
- 首先生成“{”,随后生成主张片段,此时token需严格按输入主张文本的顺序单调复制,直至预测出“}”;
- 接着生成“[”开始证据片段预测,该片段可从证据文本的任意词开始,通过连续预测后续token扩展,直至出现“]”;
- 最后预测NatOp操作符。
后续三元组的生成会从主张文本的下一个token继续复制,直至处理完主张文本的最后一个token。所有三元组均按此机制生成。
(注:保留术语token/NatOp未翻译,引用格式[20]转换为[20],动态约束标记解码首次出现时标注英文原名,后续简化为中文表述。)
3.2 Veracity Prediction
3.2 真实性预测
The DFA shown in Figure 1 uses the sequence of NatOps predicted by the proof generator as transitions to arrive at the outcome. Figure 2 shows the corresponding sequence of transitions for the claim and evidence from Figure 1. Based on this, the DFA in Figure 1 determines that the evidence refutes the claim, i.e. it terminates in state $R$ . NaturalLI (Angeli and Manning, 2014) designed the DFA for the three classes in the NLI classification task, namely entail, contradict and neutral. Here, we replace them with SUPPORT (S), REFUTE (R), and NOT ENOUGH INFO (N) respectively for fact verification. Angeli and Manning (2014) chose not to distinguish between negation (N) and alternation $(\upharpoonright)$ relations for NLI, and assign $\upharpoonleft$ for both. However, there is a clear distinction between cases where each of these NatOPs is applicable in fact verification, and thus we treat them as different NatOps. For instance, in the second mutation for the claim in Figure 1, an evidence span “is not a short story” would be assigned negation (N), and not the currently assigned alternation (ê) for the mutation with the evidence span “is a novel”. However, we follow Angeli and Manning (2014) in not using the cover $(\smile)$ NatOp. In rare occasions where this NatOp would be applicable, say in a mutation with the spans “not a novel” and “fiction”, we currently assign the independence NatOp $(#)$ .
图 1 所示的 DFA 使用证明生成器预测的 NatOps 序列作为转移路径来得出结果。图 2 展示了图 1 中声明与证据对应的转移序列。基于此,图 1 中的 DFA 判定该证据驳斥了声明 (即终止于状态 $R$)。NaturalLI (Angeli and Manning, 2014) 为 NLI 分类任务中的三类 (entail, contradict 和 neutral) 设计了该 DFA。在事实验证中,我们将其分别替换为 SUPPORT (S)、REFUTE (R) 和 NOT ENOUGH INFO (N)。Angeli 和 Manning (2014) 选择不对 NLI 中的否定 (N) 与交替 $(\upharpoonright)$ 关系进行区分,并统一用 $\upharpoonleft$ 表示。但在事实验证中,这些 NatOPs 的适用场景存在明显差异,因此我们将它们视为不同的 NatOps。例如,在图 1 声明的第二个变异中,证据片段 "is not a short story" 应被分配否定 (N),而非当前为证据片段 "is a novel" 分配的交替 (ê)。不过我们遵循 Angeli 和 Manning (2014) 的做法,不使用覆盖 $(\smile)$ NatOp。在极少数适用场景中 (例如处理 "not a novel" 和 "fiction" 片段变异时),我们目前会分配独立 NatOp $(#)$。
4 Generating Proofs for Training
4 为训练生成证明
Training datasets for evidence-based fact verification consist of instances containing a claim, a la- bel indicating its veracity, and the evidence, typically a set of sentences (Thorne et al., 2018a; Hanse low ski et al., 2019; Wadden et al., 2020). However, we need sequences of triples to train the proof generator of Section 3.1. Manually annotating them would be laborious; thus, we heuristically generate them from existing resources. As shown in Figure 4, we perform a two-step annotation process: chunking and alignment, followed by the NatOp assignment.
基于证据的事实核查训练数据集由包含声明、真实性标签及证据(通常为一组句子)的实例构成 [20][21][22]。然而,为训练第3.1节的证明生成器,我们需要三元组序列。手动标注这些数据将极其耗时,因此我们采用启发式方法从现有资源中生成。如图4所示,我们执行两步标注流程:分块与对齐,随后进行NatOp分配。
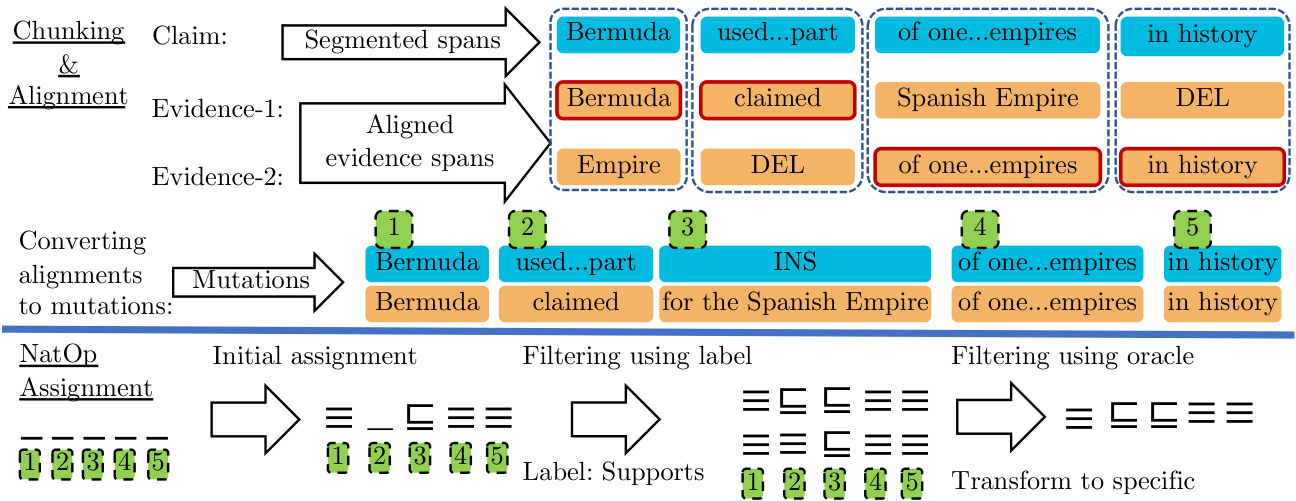
Figure 4: Annotation process for obtaining the proof for the input in Figure 3. It proceeds in two steps, chunking & alignment, and NatOp assignment, and the latter proceeds by initial mutation assignment and two filtering steps.
图 4: 获取图 3 输入证明的标注流程。该流程分为两个步骤:分块与对齐、NatOp 分配,其中后者通过初始突变分配和两个过滤步骤完成。
4.1 Chunking and Alignment
4.1 分块与对齐
Chunking the claim into spans is conducted using the chunker of Akbik et al. (2019), and any span that does not contain any content words is merged with its subsequent span. Next, as shown in Figure 4, a word aligner (Jalili Sabet et al., 2020) aligns each evidence sentence in the input separately with the claim. For each claim span, each evidence sentence provides an aligned span by grouping together words that are aligned to it, including any words in between to ensure contiguity. However, if the aggregated similarity score from the aligner for a given pair of claim and evidence spans falls below an empirically set threshold, then it is ignored and instead the claim span is aligned with the string “DEL”. In Figure 4, “DEL” appears once in each of the evidence sentences.
将声明分块为片段是使用 Akbik 等人 (2019) 的分块器进行的,任何不包含实义词的片段都会与其后续片段合并。接着如图 4 所示,一个词对齐器 (Jalili Sabet 等人, 2020) 将输入中的每个证据句子分别与声明对齐。对于每个声明片段,每个证据句子通过将与之对齐的词(包括中间的任何词以确保连续性)分组来提供一个对齐片段。然而,如果对齐器对给定的声明和证据片段对的聚合相似度得分低于经验设定的阈值,则忽略该片段,并将声明片段与字符串“DEL”对齐。在图 4 中,“DEL”在每个证据句子中各出现一次。
Next, we convert the alignments into a sequence of mutations, which requires no additional effort in instances with only one evidence sentence. However, a claim span may have multiple evidence spans aligned with it in cases with multiple evidence sentences, as shown in Figure 4. Here, for a claim span, we generally select the evidence span with the highest cosine similarity with it. Such spans are marked with solid red borders in Figure 4. Further, we assume that the evidence sentences are linked via entity mentions, such as “Spanish Empire” the only hyperlinked mention (from Evidence-1 to 2) in Figure 3. These hyperlinked mentions must always be added as a mutation, as they provide the context for switching the source of the evidence from one sentence to another. In Figure 3, “Spanish Empire” is not selected as an alignment based on the similarity scores with the claim spans. Hence, it is inserted as the third mutation, at the juncture at which the switch from Evidence-1 to 2 happens. It is aligned with the string “INS’ in the place of a claim span. Use of hyperlink structure in Wikipedia or performing entity linking to establish hyperlinked mentions, similar to our approach here, has been previously explored in multi-hop open domain question answering (Asai et al., 2020; Nie et al., 2019). Mutations with a “DEL” instead of an evidence span, and an “INS” instead of a claim span, are treated as deletions and insertions of claim and evidence spans respectively.
接下来,我们将对齐结果转换为突变序列。对于仅含单条证据句的情况,这一过程无需额外处理。但当存在多条证据句时,某个声明片段可能对应多个证据片段,如图4所示。此时,我们通常选择与声明片段余弦相似度最高的证据片段,这些片段在图4中用红色实线边框标注。此外,我们假设证据句通过实体提及(如"Spanish Empire"——图3中唯一从证据1超链接至证据2的提及)相互关联。这些超链接提及必须始终作为突变添加,因为它们提供了证据源切换的上下文。在图3中,"Spanish Empire"虽未基于相似度分数被选为对齐项,但仍被作为第三条突变插入到证据1切换至证据2的衔接处,并与声明片段位置的"INS"字符串对齐。类似我们这种利用维基百科超链接结构或执行实体链接建立超链接提及的方法,在多跳开放域问答领域已有先例研究[20][21]。当突变包含"DEL"而非证据片段,或包含"INS"而非声明片段时,则分别视为声明片段和证据片段的删除与插入操作。
4.2 NatOp Assignment
4.2 NatOp 分配
As shown in Figure 4, the NatOp assignment step produces a sequence of NatOps, one for each mutation. Here, the search space becomes exponentially large, i.e. $6^{n}$ possible NatOp sequences for $n$ mutations. First, we assign NatOps to individual mutations relying on hand-crafted rules and external resources, without considering the other mutations in the sequence $(\S4.2.1)$ . With this partially filled NatOp sequence, we perform two filtering steps to further reduce the search space. We describe these steps below: one using veracity label information from training data in FEVER (Thorne et al., 2018a) and another using some additional manual annotation information from annotation logs of FEVER $(\S4.2.2)$ .
如图 4 所示,NatOp 分配步骤会生成一个 NatOp 序列,每个突变对应一个 NatOp。此时搜索空间呈指数级增长,即 $n$ 个突变对应 $6^{n}$ 种可能的 NatOp 序列。首先,我们基于人工规则和外部资源为单个突变分配 NatOp (不考虑序列中的其他突变) ($\S4.2.1$)。通过这个部分填充的 NatOp 序列,我们执行两个过滤步骤来进一步缩小搜索空间:一个利用 FEVER (Thorne et al., 2018a) 训练数据中的真实性标签信息,另一个利用 FEVER 标注日志中的额外人工标注信息 ($\S4.2.2$)。
4.2.1 Initial Assignment
4.2.1 初始分配
The initial assignment of NatOps considers each mutation in the sequence in isolation. Here, mutations which fully match lexically are assigned with the equivalence NatOp $(\equiv)$ , like the mutations 1, 4 and 5 in Figure 4. Similarly, mutations where the claim or evidence span has an extra negation word but lexically match otherwise, are assigned the negation NatOp (N). Further, insertions and deletions, i.e. mutations with INS and DEL respectively (§4.1), containing negation words are also assigned the negation NatOp. To obtain these words, we identify a set of common negation words from the list of stop words in Honnibal et al. (2020), and combine them with the list of negative sentiment polarity words from Hu and Liu (2004). Remaining cases of insertions (deletions) are treated as making the existing claim more specific (general), and hence assigned the forward (reverse) entailment NatOp, like mutation 3 in Figure 4. Furthermore, as every para- phrase pair present in Paraphrase Database (PPDB Gan it kev itch et al., 2013; Pavlick et al., 2015) is marked with an entailment relation, we identify mutations which are present in it as paraphrases and assign the corresponding NatOp.
NatOps的初始分配会单独考虑序列中的每个突变。完全在词汇上匹配的突变会被赋予等价NatOp $(\equiv)$ ,例如图4中的突变1、4和5。类似地,当声明或证据范围多出一个否定词但其余部分词汇匹配时,这些突变会被赋予否定NatOp (N)。此外,包含否定词的插入和删除(即分别带有INS和DEL的突变,见§4.1)也会被分配否定NatOp。为了识别这些否定词,我们从Honnibal等人(2020)的停用词列表中提取了一组常见否定词,并与Hu和Liu(2004)的负面情感极性词列表合并。剩余的插入(删除)情况会被视为使现有声明更具体(更泛化),因此被分配正向(反向)蕴涵NatOp,如图4中的突变3。此外,由于复述数据库(PPDB Gan it kev itch等人,2013;Pavlick等人,2015)中的每个复述对都标有蕴涵关系,我们将其中存在的突变识别为复述并分配相应的NatOp。
In several cases, the NatOp information need not be readily available at the span level. Here, we retain the word-level alignments from the aligner and perform lexical level NatOp assignment with the help of Wordnet (Miller, 1995) and Wikidata (Vrandecic and Krotzsch, 2014). We follow MacCartney (2009, Chapter 6) for NatOp assignment of open-class terms using Wordnet.
在某些情况下,NatOp信息可能无法直接在跨度(span)级别获取。此时,我们保留对齐工具提供的词级对齐结果,并借助Wordnet (Miller, 1995) 和 Wikidata (Vrandecic and Krotzsch, 2014) 进行词汇级别的NatOp标注。对于开放词类的NatOp标注,我们采用MacCartney (2009, Chapter 6) 提出的基于Wordnet的方法。
Additionally, we define rules to assign a NatOp for named entities using Wikidata. Here, aliases of an entity are marked with an equivalence NatOp $(\equiv)$ , as shown in third triple in Figure 1. Further, we manually assign NatOps to the 500 most frequently occurring Wikidata relations in the aligned training data. For instance, as shown in Figure 5, the entities ‘The Trial’ and ‘novel’ have the relation ‘genre’. A claim span containing ‘The Trial’, when substituted with an evidence span containing ‘novel’, would result in a generalisation of the claim, and hence will be assigned the reverse entailment NatOp $(\sqsupseteq)$ . A substitution in the reverse direction would be assigned a forward entailment NatOp $(\sqsubseteq)$ , indicating special is ation.
此外,我们制定了利用Wikidata为命名实体分配自然操作(NatOp)的规则。实体的别名会被标记为等价NatOp $(\equiv)$,如图1中第三个三元组所示。进一步地,我们手动为对齐训练数据中出现频率最高的500个Wikidata关系分配NatOp。例如,图5所示,实体"The Trial"和"novel"之间存在"genre"关系。当包含"The Trial"的声明片段被替换为包含"novel"的证据片段时,会导致声明泛化,因此将被分配反向蕴涵NatOp $(\sqsupseteq)$。而反向替换则会被分配正向蕴涵NatOp $(\sqsubseteq)$,表示特化操作。
The KB relations we annotated occur between the entities linked in Wikidata, and they do not capture hierarchical multihop relations between the entities in the KB. We create such a hierarchy by combining the “instance of”, “part of”, and “subclass of” relations in Wikidata. Thus, a pair of entities connected via a directed path of length $k\leqslant3$ , such as “Work of art” and “Rashomon” in Figure 5, is considered to have a parent-child relation, and assigned the forward or reverse entailment NatOp, depending on which span appears in the claim and the evidence. Similarly, two entities, e.g. “Rashomon” and “Inception”, are considered to be siblings if they have a common parent, and are assigned the alternation NatOp (ê). However, two connected entities that do not satisfy the aforementioned distance criterion, e.g. “novel” and “Rashomon”, are assigned with the independence NatOp (#), signifying they are unrelated.
我们在Wikidata中标注的知识库关系发生在已链接的实体之间,这些关系并未捕捉知识库中实体间的层次化多跳关系。我们通过结合Wikidata中的"instance of"(实例)、"part of"(部分)和"subclass of"(子类)关系来构建这种层次结构。因此,通过长度$k\leqslant3$的有向路径连接的一对实体(如图5中的"Work of art"和"Rashomon")被视为具有父子关系,并根据声明和证据中出现的文本片段分配正向或反向蕴涵NatOp。类似地,若两个实体(如"Rashomon"和"Inception")拥有共同父节点,则被视为兄弟关系,并分配交替NatOp(ê)。而对于不满足上述距离标准的两个相连实体(如"novel"和"Rashomon"),则分配独立NatOp(#),表明它们互不相关。
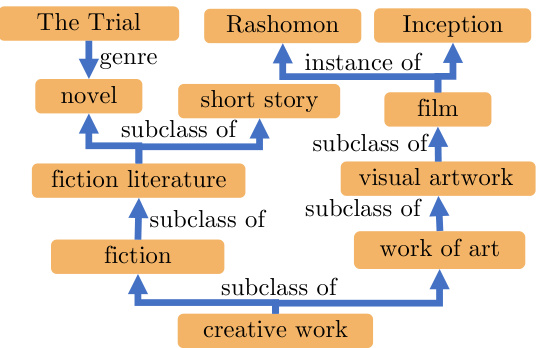
Figure 5: Entities and their relations in Wikidata.
图 5: Wikidata中的实体及其关系。
Table 2: NatOp assignment based on transformations and veracity label information.
表 2: 基于转换和真实性标签信息的NatOp分配。
| 转换方式 | S | R | N |
|---|---|---|---|
| 替换为相似信息 | 1 | 二 | |
| 替换为不相似信息 | 11 | # | |
| 改写 | 三 | 11 | # |
| 否定 | 人 | 人 | 人 |
| 转换为具体信息 | ≤ | ||
| 转换为泛化信息 | 二 | 二 | 二 |
4.2.2 Filtering the Search Space
4.2.2 搜索空间过滤
While in Section 4.2.1 we assigned a NatOp to each mutation in isolation, there can still be unfilled NatOps. For instance, the unfilled NatOp in the second mutation of Figure 4 leads to six possible NatOp sequences as candidates, one per available NatOp. Recall that these NatOp sequences act as a transition sequence in the DFA $(\S_{\lambda}3.2)$ . Thus we make use of the partially filled NatOp sequence and the veracity label from the training data to filter out NatOp sequences that do not terminate at the same state as the veracity label according to the DFA. The instance in Figure 4 has the SUPPORT label, and among the six possible candidate sequences only two terminate in this label. Hence, we retain those two sequences.
虽然在4.2.1节中我们为每个变异单独分配了NatOp,但仍可能存在未填充的NatOp。例如,图4第二个变异中的未填充NatOp会生成六种可能的候选NatOp序列(每个可用NatOp对应一种)。这些NatOp序列在DFA $(\S_{\lambda}3.2)$ 中充当状态转换序列。因此我们利用部分填充的NatOp序列和训练数据中的真实性标签,根据DFA过滤掉最终状态与真实性标签不符的NatOp序列。图4中的实例带有SUPPORT标签,六个候选序列中只有两个会终止于该标签,因此我们保留这两个序列。
For the final filtering step we use the additional manual annotation that was produced during the construction of the claims in FEVER. There, the annotators constructed each claim by manipulating a factoid extracted from Wikipedia using one of the six transformations listed in Table 2. Our proofs can be viewed as an attempt at reconstructing the factoid from a claim in multiple mutations, whereas these transformations can be considered claim-level mutations that transition directly from the last step (reconstructed factoid) in the proof to the first step (claim). This factoid is treated as the corrected claim in Thorne and Vlachos (2021b) who released this annotation. For each veracity label we define the mapping of each transformation to a NatOp, as described in Table 2. The assumption is that if a transformation has resulted in a particular veracity label, then the corresponding NatOp is likely to occur in the proof. To identify the mutation to assign it, we obtain the text portions in the claim manipulated by the annotators to construct it, by comparing the claim and the original Wikipedia factoid. In the example of Figure 4, this transformed text span happens to be part of the second mutation, and as per Table 2 forward entailment is the corresponding NatOp given the veracity label, resulting in the selection of the first NatOp sequence. In rare occasions $(2.55%$ claims in FEVER), we manually performed NatOp assignment, as the filtering steps led to zero candidates in those cases. As the heuristic annotation requires manual effort, we explore how it can be obtained using a supervised classifier (see $\S5.5)$ .
在最终筛选步骤中,我们使用了FEVER数据集构建声明时产生的额外人工标注。标注者通过六种转换方式(如表2所列)对从维基百科提取的事实性内容进行修改,从而构建每个声明。我们的证明可视为通过多重变异从声明中重构原始事实性内容的尝试,而这些转换则可被视为直接从证明的最后一步(重构的事实性内容)跳转到第一步(声明)的声明级变异。该事实性内容在Thorne和Vlachos (2021b)发布的标注中被视为修正后的声明。针对每个真实性标签,我们按照表2将每种转换映射为自然逻辑操作(NatOp)。其假设是:若某转换导致了特定真实性标签,则对应NatOp很可能出现在证明中。为确定待分配的变异,我们通过对比声明与原始维基百科事实性内容,获取标注者为构建声明而修改的文本片段。在图4的示例中,该被修改的文本片段恰好属于第二个变异,根据表2,在给定真实性标签下前向蕴涵是对应的NatOp,从而选择了第一个NatOp序列。在极少数情况下$(2.55%$的FEVER声明),由于筛选步骤未产生候选结果,我们手动执行了NatOp分配。鉴于启发式标注需要人工投入,我们探索了如何通过监督分类器获取该标注(参见$\S5.5)$。
5 Experimental Methodology
5 实验方法
5.1 Data
5.1 数据
ProoFVer is trained using heuristic ally annotated proofs (§4) obtained from FEVER (Thorne et al., 2018a), which has a train-test-development split of 145,449, 19,998, and 19,998 claims respectively. Further, the heuristic proof annotation involves the use of additional information from the manual annotation logs of FEVER, recently released by Thorne and Vlachos (2021b). Finally, claims with the label NOT ENOUGH INFO (NEI) require retrieved evidence for obtaining their proofs for training, as no ground truth evidence exists for such cases. Here, we use the same retriever that would be used during the prediction time as well.
ProoFVer使用从FEVER (Thorne et al., 2018a) 获得的启发式标注证明 (§4) 进行训练,其训练集-测试集-开发集的划分分别为145,449、19,998和19,998条声明。此外,启发式证明标注过程利用了Thorne和Vlachos (2021b) 最新发布的FEVER人工标注日志中的附加信息。最后,对于标注为NOT ENOUGH INFO (NEI) 的声明,由于缺乏真实证据,需要通过检索证据来获取训练所需的证明。在此,我们使用了与预测阶段相同的检索器。
In addition to FEVER, we train and evaluate
除了FEVER,我们还训练并评估
ProoFVer on two other related datasets. First, we use Symmetric FEVER (Schuster et al., 2019), a dataset designed to assess the robustness of fact verification systems against the claim-only bias present in FEVER. The dataset consists of 1,420 counter factual instances, split into development and test sets of 708 and 712 instances respectively. Here, we heuristic ally generate the ground truth proofs for the dataset’s development data and use it to fine tune ProoFVer, before evaluating it on the dataset’s test data. Similarly, we also evaluate ProoFVer on the FEVER 2.0 adversarial examples (Thorne et al., 2019). Specifically, we use the same evaluation subset of 766 claims that was used by Schuster et al. (2021). To finetune ProoFVer on this dataset, we generate the ground truth proofs for 2,100 additional adversarial claims, separate from the evaluation set, which were curated by the organisers and participants of the FEVER 2.0 shared task.
ProoFVer在另外两个相关数据集上的表现。首先,我们使用Symmetric FEVER (Schuster et al., 2019),该数据集旨在评估事实核查系统对FEVER中存在的仅声明偏见的鲁棒性。该数据集包含1,420个反事实实例,分为开发集和测试集,分别有708和712个实例。在此,我们启发式地为数据集的开发数据生成真实证明,并用其微调ProoFVer,然后在数据集的测试数据上进行评估。类似地,我们还在FEVER 2.0对抗样本 (Thorne et al., 2019) 上评估ProoFVer。具体而言,我们使用了Schuster等人 (2021) 使用的相同评估子集,包含766个声明。为了在此数据集上微调ProoFVer,我们为2,100个额外的对抗声明生成了真实证明,这些声明与评估集分开,由FEVER 2.0共享任务的组织者和参与者整理。
Finally, we also use the manual annotation logs of FEVER (Thorne and Vlachos, 2021b) to obtain rationales for claims in the development data. In particular, we obtain the rationale for a claim by extracting from its corresponding Wikipedia factoid the words which were removed by the annotators during its creation. If these words are part of an evidence sentence, then they become the rationale for veracity label of the claim given the evidence. Further, we require that the words extracted as rationale form a contiguous phrase. We identified 300 claims which satisfy all these criteria.
最后,我们还利用FEVER (Thorne and Vlachos, 2021b) 的手动标注日志来获取开发数据中声明的依据。具体而言,我们通过从声明对应的维基百科事实中提取标注者在创建过程中删除的单词来获取声明的依据。如果这些单词是证据句子的一部分,那么它们就成为给定证据的声明真实性标签的依据。此外,我们要求提取为依据的单词形成一个连续的短语。我们确定了300个满足所有这些标准的声明。
5.2 Evaluation Metrics
5.2 评估指标
The evaluation metrics for FEVER are label accuracy (LA, i.e. veracity accuracy) and FEVER Score (Thorne et al., 2018b), which rewards only those predictions which are accompanied by at least one correct set of evidence sentences. We report mean LA and standard deviation for experiments with Symmetric FEVER, where we use its development data for training and train with five random initial is at ions due to its limited size.
FEVER的评估指标包括标签准确率(LA, 即真实性准确率)和FEVER评分(Thorne et al., 2018b),后者仅对附带至少一组正确证据句的预测给予奖励。在Symmetric FEVER实验中,我们报告了平均LA和标准差,由于数据量有限,我们使用其开发数据进行训练,并进行了五次随机初始化训练。
We further introduce a new evaluation metric, to assess model robustness, called Stability Error Rate (SER). Neural models, especially with a retriever component, have shown to be vulnerable to model over stability (Jia and Liang, 2017). Over stability is the inability of a model to distinguish superfluous information which merely has lexical similarity with the input, from the information truly relevant to arrive at the correct decision. In the context of fact verification, it is expected that an ideal model should always predict NOT ENOUGH INFO, whenever it lacks sufficient evidence to make a decision otherwise. Further, it should arrive at a REFUTE or SUPPORT decision only when the model possesses sufficient evidence to do so, and any additional evidence should not alter its decision. To assess the model over stability in fact verification, we define SER as the percentage of claims where additional evidence alters the SUPPORT or REFUTE decision of a model.
我们进一步引入了一种新的评估指标——稳定性错误率 (Stability Error Rate, SER) ,用于衡量模型鲁棒性。神经网络模型(尤其是带有检索组件的模型)已被证明容易出现过稳定性问题 (Jia and Liang, 2017) 。过稳定性是指模型无法区分仅与输入存在词汇相似性的冗余信息,和真正与正确决策相关的信息。在事实核查任务中,理想模型应在缺乏充分证据时始终预测 NOT ENOUGH INFO (信息不足) ,且仅当拥有充分证据时才应作出 REFUTE (反驳) 或 SUPPORT (支持) 的判定——任何额外证据都不应改变其原有决策。为量化事实核查中的模型过稳定性,我们将 SER 定义为模型因额外证据而改变 SUPPORT/REFUTE 决策的声明比例。
5.3 Baseline Systems
5.3 基线系统
KGAT (Liu et al., 2020) uses a graph attention network, where each evidence sentence, concatenated with the claim, forms a node in the graph. We use their best configuration, where the node representations are initial is ed using RoBERTA (Large). The relative importance of each node is computed with node kernels, and information propagation is performed using edge kernels. They also propose a new evidence sentence retriever, a BERT model trained with a pairwise ranking loss, though they rely on past work for document retrieval (Hanse low ski et al., 2018).
KGAT (Liu等人, 2020) 采用图注意力网络(graph attention network), 其中每个证据句子与声明拼接后构成图中的一个节点。我们使用其最佳配置方案: 节点表征通过RoBERTA (Large)进行初始化, 通过节点核(node kernels)计算各节点的相对重要性, 并采用边核(edge kernels)实现信息传播。该研究还提出了一种新的证据句子检索器——采用成对排序损失训练的BERT模型, 但其文档检索环节仍依赖前人工作 (Hanselowski等人, 2018)。
CorefBERT (Ye et al., 2020) follows KGAT and differs only in terms of the LM used for the node initial is ation. Here, they further pretrain the LM on a task that involves prediction of referents of a masked mention to capture co-referential relations in context. We use Core f RoBERTA, their best-performing configuration.
CorefBERT (Ye et al., 2020) 遵循 KGAT 框架,仅在使用的大语言模型 (LLM) 进行节点初始化时存在差异。该方法通过进一步预训练大语言模型来完成掩码指代预测任务,以捕捉上下文中的共指关系。我们采用其性能最优的配置 CorefRoBERTa。
DominikS Stammbach (2021) focuses primarily on sentence-level evidence retrieval, scoring individual tokens from a given Wikipedia document, and then selecting the highest scoring sentences by averaging token scores. It uses a fine-tuned document level BigBird model (Zaheer et al., 2020) for this purpose. For claim verification it uses a DeBERTa (He et al., 2021) based classifier.
DominikS Stammbach (2021) 主要研究句子级别的证据检索,通过对给定维基百科文档中的单个token进行评分,然后通过平均token分数选择得分最高的句子。为此,该研究使用了经过微调的文档级BigBird模型 (Zaheer et al., 2020)。在声明验证方面,则采用了基于DeBERTa (He et al., 2021) 的分类器。
5.4 ProoFVer: Implementation Details
5.4 ProoFVer: 实现细节
We follow most previous works on FEVER which model the task in three steps, namely document retrieval, retrieval of evidence sentences from them, and finally veracity prediction based on the evidence. ProoFVer’s novelty lies in the proof generation in the third step. Hence, for better comparability, we follow two popular, well-performing retrieval approaches, Liu et al. (2020) and Stammbach (2021). Liu et al. (2020)’s sentence retriever, also used in Ye et al. (2020), is a sentence level pairwise ranking model, whereas that of Stammbach (2021) is a document level token score aggregation model. ProoFVer’s configuration which uses the former is our default configuration, referred to as ProoFVer, and the configuration using the latter will henceforth be referred to as ProoFVer-SB. We retrieve five sentences for each claim as required in the FEVER evaluation.
我们沿用了大多数先前关于FEVER的研究工作,将该任务建模为三个步骤:文档检索、从中检索证据句,以及最终基于证据的真实性预测。ProoFVer的创新之处在于第三步的证明生成。为了更好的可比性,我们采用了Liu等人(2020)和Stammbach(2021)这两种流行且表现优异的检索方法。Liu等人(2020)的句子检索器(也被Ye等人(2020)采用)是一个句子级别的成对排序模型,而Stammbach(2021)的则是文档级别的token分数聚合模型。使用前者的ProoFVer配置是我们的默认配置,称为ProoFVer,而使用后者的配置将被称为ProoFVer-SB。按照FEVER评估的要求,我们为每个声明检索五条句子。
For the proof generator, we use the pretrained BART (Large) model (Lewis et al., 2020) and fine tune it using the heuristic ally annotated data from Section 4. During prediction, the search spaces for the claim and evidence are populated using two separate tries. We add all possible sub sequences of the claim and evidence, each with one to seven words, into the respective tries. The default configuration takes the concatenation of a claim and all the retrieved evidence together as a single input, separated by a delimiter.
对于证明生成器,我们使用预训练的 BART (Large) 模型 (Lewis et al., 2020) ,并利用第 4 节中启发式标注的数据对其进行微调。在预测阶段,声明和证据的搜索空间通过两个独立的字典树 (trie) 构建。我们将声明和证据的所有可能子序列(每个子序列包含 1 至 7 个单词)分别添加到对应的字典树中。默认配置将声明与所有检索到的证据通过分隔符连接,作为单一输入。
We consider three additional configurations which differ in the way the retrieved evidence is handled. In ProoFVer-MV, a claim is concatenated with one evidence sentence at a time; this produces five proofs and five decisions per claim, and the final label is decided based on majority voting (MV). Both ProoFVer-A and -AR are designed to restrict the proof generator’s flexibility in inferring the textual spans in the mutations, and thus assess the gains obtained by allowing it in ProoFVer. ProoFVer-A (aligned) considers during prediction only the sub sequences from each evidence sentence aligned with the claim using wordlevel alignment, which are then concatenated with the claim as its input during training and prediction. Thus, the evidence search space becomes narrower, as the unaligned portions in the evidence are not considered. ProoFVer-AR (alignedrestricted) further restricts the search space of both the claim and evidence, by predetermining the number of mutations, the claim spans in these mutations and five candidate evidence spans for each mutation (one per evidence sentence). It obtains this information using the chunker and aligner used in the heuristic annotation (§4).
我们考虑了三种额外配置,它们在处理检索证据的方式上有所不同。在ProoFVer-MV中,每个声明一次与一个证据句子拼接;这为每个声明生成五个证明和五个决策,最终标签基于多数投票(MV)决定。ProoFVer-A和ProoFVer-AR的设计旨在限制证明生成器在推断突变文本片段时的灵活性,从而评估ProoFVer中允许该操作所获得的收益。ProoFVer-A(对齐)在预测时仅考虑每个证据句子中通过词级对齐与声明对齐的子序列,这些子序列随后在训练和预测期间与声明拼接作为输入。因此,证据搜索空间变得更窄,因为证据中未对齐的部分不被考虑。ProoFVer-AR(对齐限制)通过预先确定突变数量、这些突变中的声明片段以及每个突变的五个候选证据片段(每个证据句子一个),进一步限制了声明和证据的搜索空间。它使用启发式注释中使用的分块器和对齐器获取此信息(§4)。
5.5 Heuristic Annotation Using Kepler
5.5 使用Kepler进行启发式标注
To reduce the reliance on manual annotation from Thorne and Vlachos (2021b) during the annotation in Section 4, we experiment with replacing the ground truth transformations with predicted ones using a classifier. We use KEPLER (Wang et al., 2021), a RoBERTA-based pretrained LM enhanced with KB relations and entity pairs from WikiData for the classification. KEPLER covers $97.5%$ of the entities present in FEVER. We first train it with the FEVER training dataset for the fact verification task. Then we fine-tune it for the six-class classification task of predicting the transformations, given a claim, evidence sentence and veracity label as input from the FEVER training data. We train it with varying training dataset sizes ranging from $1.24%$ (1,800; 300 per class) to $41.24%$ (60,000; 10,000 per class) of the FEVER training data. We consider two configurations: ProoFVer-K which uses gold data to identify the transformed span for applying the predicted transformation, and ProoFVer-K-NoS which instead only ensures that the predicted transformation occurs at least once in the final NatOp sequence.
为了减少在第4节标注过程中对Thorne和Vlachos (2021b)人工标注的依赖,我们尝试用分类器预测的转换结果替代真实转换进行实验。我们采用基于RoBERTa的预训练语言模型KEPLER (Wang et al., 2021),该模型通过WikiData的知识库关系和实体对进行增强,能覆盖FEVER数据集中97.5%的实体。首先使用FEVER训练集进行事实核查任务训练,然后基于FEVER训练数据中的声明、证据句和真实性标签作为输入,微调模型以完成预测转换类型的六分类任务。训练数据量从FEVER训练集的1.24%(1,800条;每类300条)到41.24%(60,000条;每类10,000条)不等。我们测试两种配置:ProoFVer-K使用黄金数据定位待转换文本片段以应用预测转换,而ProoFVer-K-NoS仅要求预测转换在最终NatOp序列中出现至少一次。
Table 3: Fact verification results on FEVER.
表 3: FEVER 事实核查结果
| System | Dev | Test | ||
|---|---|---|---|---|
| LA | Fever Score | LA | Fever Score | |
| 使用 Liu et al. (2020) 的检索器 | ||||
| ProoFVer | 80.23 | 78.17 | 79.25 | 74.37 |
| ProoFVer-MV | 78.71 | 74.62 | 74.18 | 70.09 |
| ProoFVer-A | 79.83 | 76.33 | 77.16 | 72.47 |
| ProoFVer-AR | 77.42 | 75.27 | ||
| KGAT | 78.29 | 76.11 | 74.07 | 70.38 |
| CorefBERT | 79.12 | 77.46 | 75.96 | 72.30 |
| 使用 Stammbach (2021) 的检索器 | ||||
| ProoFVer-SB | 80.74 | 79.07 | 79.47 | 76.82 |
| DominikS | 80.59 | 78.37 | 79.16 | 76.78 |
“mitchell.dehaven”, in the leader board.
mitchell.dehaven
ProoFVer, our default configuration using the retriever from Liu et al. (2020), differs from ProoFVer-SB only in terms of the retriever they use. ProoFVer is the best performing model among all the baselines and other ProoFVer config u rations (-MV, -A and -AR) that use Liu et al. (2020)’s retriever. As compared to ProoFVerMV, ProoFVer’s gains come primarily from its ability to handle multiple evidence sentences together, as opposed to handling each separately and then aggregating the predictions. $9.8%$ (1,960) of the claims in the FEVER development set require multiple evidence sentences for verification. While ProoFVer-MV predicts $60.1%$ of these instances correctly, ProoFVer correctly predicts $67.45%$ of these. Further, around $80.73%$ (of 18,038) of the single evidence instances are correctly predicted by ProoFVer-MV, in comparison to $81.62%$ instances for ProoFVer. Allowing the proof generator to infer the mutations dynamically, instead of having them predefined, benefits the overall performance of the model. The increasingly restricted variants with narrower search spaces, i.e. ProoFVer-A and ProoFVer-AR, lead to decreasing performances as shown in Table 3. ProoFVer-AR, the most restricted version, performs worse than all the other models.
我们的默认配置ProoFVer(采用Liu等人(2020)的检索器)与ProoFVer-SB的唯一区别在于使用的检索器。在所有基线模型和使用Liu等人(2020)检索器的其他ProoFVer配置(-MV、-A和-AR)中,ProoFVer是性能最佳的模型。与ProoFVer-MV相比,ProoFVer的性能提升主要来自其能同时处理多个证据句子的能力,而非单独处理后再聚合预测结果。FEVER开发集中有9.8%(1,960条)的声明需要多个证据句子进行验证。ProoFVer-MV对这些实例的正确预测率为60.1%,而ProoFVer的正确预测率达到67.45%。此外,ProoFVer-MV对单证据实例的正确预测率为80.73%(共18,038条),而ProoFVer的正确率为81.62%。允许证明生成器动态推断变异(而非预定义变异)有助于提升模型整体性能。如表3所示,搜索空间逐渐受限的变体(即ProoFVer-A和ProoFVer-AR)会导致性能递减。限制最严格的ProoFVer-AR表现逊于所有其他模型。
6 Results
6 结果
6.1 Fact Verification
6.1 事实核查
Table 4: LA of ProoFVer-K and -NoS using predictions from KEPLER. Training data size used for KEPLER and its classifier accuracy is also provided.
表 4: 使用KEPLER预测的ProoFVer-K和-NoS的LA (Label Accuracy)。同时提供了KEPLER使用的训练数据规模及其分类器准确率。
| KEPLER | ProoFVer | ||
|---|---|---|---|
| 训练数据规模 | 分类器准确率 | -K-NoS (LA) | -K (LA) |
| 1,800 | 69.07 | 64.65 | 66.73 |
| 6,000 | 74.02 | 68.86 | 72.41 |
| 18,000 | 79.67 | 74.25 | 76.23 |
| 30,000 | 80.61 | 75.39 | 77.76 |
| 45,000 | 82.76 | 77.62 | 78.84 |
| 60,000 | 84.85 | 78.61 | 79.67 |
Table 3 reports the fact verification results for ProoFVer and the baselines. Overall, ProoFVerSB, our configuration using Stammbach (2021)’s retriever, is the best performing model in our experiments. ProoFVer-SB, which outperforms Stammbach (2021) itself, is currently the highest scoring model in terms of label accuracy in the FEVER leader board. It also is the second best model in terms of FEVER Score, second only to the currently unpublished model titled
表 3 报告了 ProoFVer 与基线模型的事实核查结果。总体而言,采用 Stammbach (2021) 检索器的 ProoFVer-SB 是我们实验中表现最佳的模型。该模型不仅优于 Stammbach (2021) 原版,还以标签准确率指标位列 FEVER 排行榜首位,同时以 FEVER 分数排名第二 (仅次于当前未公开的模型)。
Impact of additional manual annotation Since the final filtering step in NatOp assignment $(\S4.2.2)$ requires additional manual annotation, we experimented with a proof set obtained without this step. Here, we arbitrarily select a NatOp sequence from the candidates remaining after the veracity label based filtering. The latter reduced the search space to just two possible NatOp sequences in $93.59%$ of the claims. However, training ProoFVer with these proofs resulted in a LA of $58.29%$ on the FEVER development set. In comparison, ProoFVer-K-NoS achieves a LA of $64.65%$ , even when using predictions from a KEPLER configuration trained on as little as 1,800 instances. Table 4 shows the LA for ProoFVer-K-NoS and ProoFVer-K when using KEPLER predictions, with varying training data sizes for KEPLER; the largest KEPLER configuration is trained on only $41.24%$ of claims in FEVER. Using this amount of training data, ProoFVer-K and ProoFVer-K-NoS achieve a LA of $79.67%$ and $78.61%$ respectively. Here, ProoFVer-K outperforms all the baseline models, including CorefBert which also uses additional annotation for pre training.
额外人工标注的影响
由于 NatOp 分配中的最终过滤步骤 $(\S4.2.2)$ 需要额外人工标注,我们实验了跳过此步骤获得的证明集。在此,我们根据真实性标签过滤后剩余的候选集中随机选择一条 NatOp 序列。该过滤将搜索空间缩减至仅两条可能的 NatOp 序列,覆盖了 $93.59%$ 的声明。然而,用这些证明训练 ProoFVer 时,在 FEVER 开发集上仅获得 $58.29%$ 的标签准确率 (LA)。相比之下,即使使用仅训练 1,800 个实例的 KEPLER 配置预测,ProoFVer-K-NoS 仍能达到 $64.65%$ 的 LA。表 4 展示了 ProoFVer-K-NoS 和 ProoFVer-K 在使用 KEPLER 预测时的 LA,其中 KEPLER 的训练数据规模各异;最大的 KEPLER 配置仅训练了 FEVER 中 $41.24%$ 的声明。使用此训练数据量时,ProoFVer-K 和 ProoFVer-K-NoS 分别达到 $79.67%$ 和 $78.61%$ 的 LA。此时,ProoFVer-K 超越了所有基线模型(包括同样使用额外标注进行预训练的 CorefBert)。
Table 5: Label accuracy of models on FEVER-development(DEV) and Symmetric FEVER with and without fine tuning. All results marked with $^*$ and $#$ are statistically significant (unpaired t-test) with $p<0.05$ against their FT and Original variants respectively. FEVER-DEV predictions are using gold standard evidence.
表 5: 各模型在FEVER-development(DEV)和Symmetric FEVER数据集上的标签准确率(含/不含微调)。所有标有$^*$和$#$的结果均具有统计显著性(非配对t检验),分别针对其微调(FT)和原始变体,$p<0.05$。FEVER-DEV预测使用黄金标准证据。
| 模型 | FEVER-DEV | Symmetric FEVER | ||||
|---|---|---|---|---|---|---|
| Original | FT | FT+L2 | Original | FT | FT+L2 | |
| ProoFVer | 89.07±0.3 | 86.41±0.8 | 87.95±1.0* | 81.70±0.4 | 85.88±1.3# | 83.37±1.3#* |
| KGAT | 86.02±0.2 | 76.67±0.3 | 79.93±0.9* | 65.73±0.3 | 84.94±1.1# | 73.34±1.5#* |
| CorefBERT | 88.26±0.4 | 78.79±0.2 | 84.22±1.5* | 68.49±0.6 | 85.45±0.2# | 77.37±0.5#* |
6.2 Robustness
6.2 鲁棒性
Symmetric FEVER As shown in Table 5, ProoFVer shows better robustness with a mean accuracy of $81.70%$ on the Symmetric FEVER test dataset, an improvement of $13.21%$ over Coref- BERT, the next best model. All models improve their accuracy and are comparable on the test set when we fine-tune them on its development set. However, this results in more than $9%$ reduction on the original FEVER-DEV data for both the classifier based models, KGAT and CorefBERT. This catastrophic forgetting (French, 1999) occurs primarily due to the shift in label distribution during fine tuning, as Symmetric FEVER contains only claims with SUPPORT and REFUTE labels. ProoFVer accuracy drops by only less than $3%$ , as it is trained with a seq2seq objective. To mitigate the effect of catastrophic forgetting, we apply L2 regular is ation (Thorne and Vlachos, 2021a) which improves all models on the FEVER development set. Nevertheless, ProoFVer has the highest accuracy on both FEVER and Symmetric FEVER among the competing models after regular is ation.
对称FEVER
如表5所示,ProoFVer在对称FEVER测试数据集上展现出更强的鲁棒性,平均准确率达到$81.70%$,较次优模型Coref-BERT提升了$13.21%$。所有模型在其开发集上微调后,测试集准确率均有提升且表现接近。但基于分类器的KGAT和CorefBERT模型在原始FEVER-DEV数据上的准确率均下降超过$9%$。这种灾难性遗忘现象 (French, 1999) 主要由微调过程中标签分布变化引起,因为对称FEVER仅包含SUPPORT和REFUTE标签的声明。由于采用序列到序列 (seq2seq) 目标训练,ProoFVer准确率下降不足$3%$。为缓解灾难性遗忘影响,我们采用L2正则化 (Thorne and Vlachos, 2021a),使所有模型在FEVER开发集上均有所提升。经正则化处理后,ProoFVer在FEVER和对称FEVER上的准确率仍保持所有竞争模型中的最高水平。
General ising to FEVER 2.0 ProoFVer when evaluated on FEVER 2.0 adversarial data, reports a LA of $82.79%$ , outperforming the previously best reported LA of $82.51%$ by Schuster et al. (2021). ProoFVer, after training on FEVER, is further fine tuned (with L2 regular iz ation) on heuristically generated proofs from the data contributed by the participants of the FEVER 2.0 shared task (disjoint from the evaluation set), and the proofs generated from the FEVER Symmetric data. On the other hand, Schuster et al. (2021) was trained on the VitaminC training data. When they further fine tune their default model with FEVER, their performance drops to $80.94%$ .
在FEVER 2.0对抗数据上评估时,General ising版本的ProoFVer报告了82.79%的标签准确率(LA),优于Schuster等人(2021)此前报告的最佳LA 82.51%。ProoFVer在FEVER上训练后,进一步使用FEVER 2.0共享任务参与者贡献的数据(与评估集不相交)启发式生成的证明,以及FEVER Symmetric数据生成的证明进行了L2正则化的微调。而Schuster等人(2021)的模型是在VitaminC训练数据上训练的。当他们用FEVER数据进一步微调其默认模型时,性能下降至80.94%。
Stability Error Rate (SER): SER quantifies the rate of instances where a system alters its decision due additional evidence in the input, passed on by the retriever component. KGAT, CorefBERT, and DominikS have a SER of $12.35%$ , $10.27%$ , $9.36%$ respectively. ProoFVer has an SER of only $6.21%$ , which is further reduced to $5.73%$ for ProoFVerSB. The SER results confirm that the baselines change their predictions from SUPPORT or REFUTE after providing them with additional information more often than ProoFVer.
稳定性错误率 (SER):SER 量化了系统因检索组件传递的输入中额外证据而改变决策的实例比例。KGAT、CorefBERT 和 DominikS 的 SER 分别为 $12.35%$、$10.27%$ 和 $9.36%$。ProoFVer 的 SER 仅为 $6.21%$,而 ProoFVerSB 进一步降至 $5.73%$。SER 结果证实,基线模型在获得额外信息后从"支持"或"反驳"改变预测的频率高于 ProoFVer。
6.3 ProoFVer proofs as explanations
6.3 ProoFVer 证明作为解释
6.3.1 Rationale Extraction
6.3.1 原理提取
Rationales extracted based on attention are often used as means to highlight the reasoning involved in the decision making process of various models (DeYoung et al., 2020). For this evaluation, we compare using token-level F-score of the predicted rationales with human-provided rationales for 300 claims from the FEVER development data, as elaborated in Section 5.1. We ensure that all the systems are provided with the same set of evidence sentences, and consider only those words from the evidence as rationales which do not occur in the claim. For ProoFVer, we additionally remove evidence spans which are part of mutations with an equivalence NatOp. For KGAT and CorefBERT, we obtain the rationales by sorting the eligible words in descending order of their attention scores, and for each instance we find the set of words with the highest token overlap F-score with the rationale. Here, we consider the words in the top $1%$ of attention scores, and also those ranging from $5%$ to $50%$ of the words in step sizes of $5%$ . We find that ProoFVer achieves a token level Fscore of 93.28, compared to 87.61 and 86.42, the best F-Scores for CorefBERT and KGAT. Figure 6 shows the rationales for 3 instances extracted from ProoFVer, one for each label. All the three proofs result in correct decisions. While for the first two claims there is a perfect overlap with the human rationale, the third claim in Figure 6 has some extraneous information in the predicted proof.
基于注意力提取的论证依据常被用于突显各类模型决策过程中的推理逻辑 (DeYoung et al., 2020)。本次评估中,我们比较了预测论证依据与人工提供的300条FEVER开发数据声明的token级F值,具体如第5.1节所述。我们确保所有系统接收相同的证据句集合,并仅将声明中未出现的证据词视为有效论证依据。对于ProoFVer,我们额外剔除了包含等价NatOp变异的证据片段。KGAT和CorefBERT的论证依据通过按注意力分数降序排列候选词获得,每个实例选取与人工依据具有最高token重叠F值的词集。我们考察了注意力分数前1%的词,以及按5%步长从5%到50%区间的词集。实验表明,ProoFVer取得93.28的token级F值,优于CorefBERT(87.61)和KGAT(86.42)的最佳表现。图6展示了ProoFVer针对三类标签各一个实例提取的论证依据,三个证明均得出正确决策。前两条声明的预测依据与人工标注完全吻合,而图6中第三条声明的预测证明包含少量无关信息。

Figure 6: Human rationale extraction for predicted proofs from ProoFVer. The claim and evidence spans are enclosed within $\ddots$ and ‘[ ]’ respectively, with numbered superscripts showing the correspondence between the spans. The predicted rationales are underlined and the portions matching with the human rationales are highlighted.
图 6: ProoFVer 预测证明的人工依据提取。声明和证据范围分别用 $\ddots$ 和 "[ ]" 标注,上标数字显示范围间的对应关系。预测依据带下划线,与人工依据匹配的部分高亮显示。
Table 6: NatOPs and the corresponding paraphrases
表 6: NatOPs 及对应释义
| 等效表述 | |
|---|---|
| 1 | 证据片段与主张片段相矛盾 |
| 2 | 主张片段由证据片段推导得出 |
| 2 | (插入) 来自证据的新信息 |
| 不完整证据 | |
| 3 | 证据片段反驳主张片段 |
| 3 | 主张片段被否定 (删除) |
| # | 无关的主张片段与证据片段 |
| # | 未找到相关证据 (删除) |
6.3.2 Human evaluation
6.3.2 人工评估
We use forward prediction (Doshi-Velez and Kim, 2017) here, where humans are asked to predict the system output based on the explanations. For assessing ProoFVer, we provide the claim, the proof as the explanation, and those evidence sentences from which the evidence spans in the proof were extracted. Since we are interested in evaluating the applicability of our proofs as natural language explanations, we ensure that none of our subjects are aware of the deterministic nature of determining the label from natural logic proofs. Moreover, we replaced the NatOps in the proof with plain English phrases for better comprehension by the subjects, as shown in Table 6. As the baseline setup for comparison, we provide the claim with all five retrieved evidence sentences.
我们采用前向预测方法 (Doshi-Velez and Kim, 2017) ,要求人类参与者根据解释内容预测系统输出。为评估ProoFVer,我们提供主张、作为解释的证明文本,以及证明中证据片段所对应的原始证据句。由于重点在于验证自然语言证明的解释适用性,我们确保所有受试者均不知晓通过自然逻辑证明可确定性推导标签的特性。此外,为提高理解度,我们将证明中的NatOps替换为通俗英语短语,如表 6 所示。基线对比方案则提供主张及其全部五条检索到的证据句。
We form a set of 24 different claims, 12 each from ProoFVer and baseline, and 3 individual subjects independently annotate the same set. Finally, we altogether obtain annotations for 5 sets, resulting in 60 claims, 120 explanations and a total of 360 annotations from 15 subjects.2 For all 60 claims, ProoFVer, CorefBERT and KGAT predicted the same labels, though not necessarily the correct ones (the subjects were not aware of this). All the subjects were pursuing a PhD or postdocs in fields related to computer science and computational linguistics, or industry researchers/data sci- entists.
我们选取了24个不同的主张,其中12个来自ProoFVer,12个来自基线模型,并由3位独立受试者对同一组主张进行标注。最终,我们共获得5组标注数据,包含60个主张、120条解释以及来自15位受试者的总计360条标注。对于所有60个主张,ProoFVer、CorefBERT和KGAT预测的标签均相同(尽管不一定正确,受试者对此并不知情)。所有受试者均为计算机科学或计算语言学相关领域的在读博士生、博士后或企业研究员/数据科学家。
With ProoFVer’s proofs, subjects are able to predict the model decisions correctly in $81.67%$ of the cases as against $69.44%$ of the cases with only the evidence. In both setups, subjects were often confused on instances with a NOT ENOUGH INFO label, and the forward predictions were comparable, with $66.67%$ (ProoFVer) and $65%$ (baseline). In many such cases, subjects subconsciously filled in their own world knowledge which is not found in the evidence to arrive at a SUPPORT or REFUTE decision. Further, for instances with both REFUTE and SUPPORT labels, subjects correctly predicted ProoFVer’s decisions $86.67%$ and $91.67%$ times respectively, against only $70%$ and $73.33%$ for the baseline. The inter-annotator agreement for ProoFVer’s explanations is 0.7074 in Fleiss $\kappa$ (Fleiss, 1971), and 0.6612 for the baseline.
借助ProoFVer的证明,受试者能正确预测模型决策的比例达到81.67%,而仅依赖证据时该比例为69.44%。两种实验设置中,受试者对标注为NOT ENOUGH INFO的实例常感困惑,其前向预测准确率相近:ProoFVer为66.67%,基线为65%。许多此类案例中,受试者会下意识补充证据中未体现的自身知识,从而得出SUPPORT或REFUTE的结论。此外,对于REFUTE和SUPPORT标签的实例,受试者正确预测ProoFVer决策的比例分别达到86.67%和91.67%,而基线模型仅对应70%和73.33%。ProoFVer解释的标注者间一致性在Fleiss κ [20]中为0.7074,基线为0.6612。

Figure 7: Cases of incorrect proof generation from ProoFVer. The claim and evidence spans are enclosed within ‘{ }’ and ‘[ ]’ respectively, with numbered superscripts showing the correspondence between the spans.
图 7: ProoFVer生成错误证明的案例。声明和证据片段分别用‘{ }’和‘[ ]’标注,上标数字表示片段间的对应关系。
7 Limitations
7 局限性
Figure 7 shows three instances of incorrect proofs from ProoFVer, which highlight some of the well known limitations in natural logic (Karttunen, 2015; MacCartney, 2009). In Figure 7.i, the claim uses two negation words, “neither” and “nor”, both of which appearing in different spans and leading to prediction of two negation NatOps. However, this NatOp sequence nullifies the effect of the negation NatOp and predicts SUPPORT instead of REFUTE. Similarly, in Figure 7.ii the adverb “mistakenly” negates semantics of the verb. However, its effect is not captured in the second mutation and ProoFVer predicts the forward entailment NatOP, leading to the SUPPORT label. Moreover, the NatOP sequence remains the same even if we remove the term “mistakenly” from the claim, demonstrating that the effect of the adverb is not captured by our model. Similar challenges involving adverbs and non-subsective adjectives (Pavlick and Callison-Burch, 2016) when performing inference in natural logic has been reported in prior work (Angeli and Manning, 2014).
图 7 展示了 ProoFVer 的三个错误证明实例,这些案例凸显了自然逻辑 (Karttunen, 2015; MacCartney, 2009) 中一些众所周知的局限性。在图 7.i 中,陈述句使用了两个否定词 "neither" 和 "nor",它们出现在不同片段中并导致预测出两个否定 NatOps。然而这个 NatOp 序列抵消了否定 NatOp 的效果,最终预测为 SUPPORT 而非 REFUTE。类似地,在图 7.ii 中,副词 "mistakenly" 否定了动词的语义,但其效果未能在第二次变异中被捕获,导致 ProoFVer 预测出前向蕴涵 NatOP 并给出 SUPPORT 标签。值得注意的是,即使从陈述句中移除 "mistakenly" 这个词,NatOP 序列仍保持不变,这表明我们的模型未能捕捉到副词的影响。先前研究 (Angeli and Manning, 2014) 也报告过类似挑战,即在自然逻辑推理中处理副词和非子类形容词 (Pavlick and Callison-Burch, 2016) 时遇到的困难。
In Figure 7.iii, the claim states a time period by mentioning its start and end years, which appear in two different claim spans. However, ProoFVer does not capture the sense of the range implied by the spans containing “from $1934^{\cdot\cdot}$ and “to $1940^{\ '}$ . Instead, two similar 4-digit number patterns are extracted from the evidence and are directly compared to the claim spans resulting in two alternation NatOps, thereby predicting NOT ENOUGH INFO. Handling such range expressions is beyond the expressive power of the natural logic, and often other logical forms are needed to perform such computations (Liang et al., 2013). Datasets like FEVEROUS (Aly et al., 2021), which considers semi-structured information present in tables, often require such explicit computations for which approaches purely based on natural logic are not sufficient.
图 7.iii 中的声明通过提及起止年份来表述一个时间段,这两个年份分别出现在两个不同的声明片段中。然而 ProoFVer 未能捕捉到包含"from $1934^{\cdot\cdot}$"和"to $1940^{\ '}$"片段所暗示的范围含义,而是从证据中提取出两个相似的4位数字模式直接与声明片段进行比对,从而产生两个交替的 NatOps (自然逻辑操作),最终预测为"信息不足"。处理此类范围表达式超出了自然逻辑的表达能力,通常需要其他逻辑形式来执行此类计算 (Liang et al., 2013)。像 FEVEROUS (Aly et al., 2021) 这类考虑表格中半结构化信息的数据集,往往需要此类显式计算,而纯基于自然逻辑的方法并不足以应对。
Finally, ProoFVer, due to its auto-regressive formulation, generates the corresponding evidence spans and NatOps for the claim spans sequentially from left to right. However, the steps in the natural logic based inference are not subject to any such specific ordering, and hence the order in which the NatOPs are generated is non deterministic by default (Angeli and Manning, 2014). ProoFVer benefits from the implicit knowledge encoded in the pretrained language models, specifically BART, which follows auto-regressive decoding. Nevertheless, in the future we plan to experiment with alternative decoding approaches, including some of the recent developments in nonauto regressive conditional language models (Xu and Carpuat, 2021) and transformer-based proof generators (Saha et al., 2021).
最后,由于采用自回归 (auto-regressive) 形式,ProoFVer 会从左到右依次为声明片段生成相应的证据片段和自然逻辑操作 (NatOps)。然而,基于自然逻辑的推理步骤并不受此类特定顺序约束,因此 NatOPs 的生成顺序默认是非确定性的 (Angeli and Manning, 2014)。ProoFVer 受益于预训练语言模型 (特别是采用自回归解码的 BART) 中编码的隐式知识。不过,我们计划未来尝试其他解码方法,包括非自回归条件语言模型 (Xu and Carpuat, 2021) 和基于 Transformer 的证明生成器 (Saha et al., 2021) 等最新进展。
8 Conclusion
8 结论
We presented ProoFVer, a natural logic-based proof system for fact verification. Currently, we report the best results in terms of label accuracy, and the second best results in FEVER Score in the FEVER leader board. Moreover, ProoFVer is more robust in handling superfluous information from the retriever, and handling counter factual instances. Finally, ProoFVer’s proofs are faithful explanations by construction, and improve the under standing of the decision making process of the models by humans.
我们提出了ProoFVer,一个基于自然逻辑的事实验证证明系统。目前,我们在FEVER排行榜中取得了标签准确率的最佳结果,以及FEVER分数的第二佳成绩。此外,ProoFVer在处理检索器提供的冗余信息及反事实实例时表现更为稳健。最后,ProoFVer的证明因其构造方式而成为忠实解释,并提升了人类对模型决策过程的理解。
Acknowledgements
致谢
Amrith Krishna and Andreas Vlachos are supported by a Sponsored Research Agreement between Facebook (now Meta) and the University of Cambridge. Andreas Vlachos is additionally supported by the ERC grant AVeriTeC (GA 865958) and the EU H2020 grant MONITIO (GA 965576). The authors would like to thank Nicola De Cao for helpful conversations, and Dominik Stammbach for sharing the retriever data. Further, the authors would like to thank all the 19 subjects who volunteered to be part of the human evaluation, namely James Thorne, Michael Sejr Sch licht kru ll, Ashim Gupta, Bishal Santra, Ashutosh Soni, Abhik Jana, Sudipa Mandal, Madhumita Mallick, Roshni Tayal, Sandipan Sikdar, Rishabh Kumar, Jasabanta Patro, Unni Krishnan, Anirban Santara, Jivnesh Sandhan, Soumya Sarkar, Devaraj Adiga, Aniruddha Roy and Muskan Garg. Finally, we would like to thank the anonymous reviewers, action editor Mohit Bansal and the editor in chief Brian Roark for their valuable feedback.
Amrith Krishna和Andreas Vlachos的研究得到了Facebook(现Meta)与剑桥大学赞助研究协议的支持。Andreas Vlachos还获得了ERC资助项目AVeriTeC(GA 865958)和欧盟H2020资助项目MONITIO(GA 965576)的支持。作者感谢Nicola De Cao的有益讨论,以及Dominik Stammbach分享检索器数据。此外,作者特别感谢参与人工评估的19位志愿者:James Thorne、Michael Sejr Schlichtkrull、Ashim Gupta、Bishal Santra、Ashutosh Soni、Abhik Jana、Sudipa Mandal、Madhumita Mallick、Roshni Tayal、Sandipan Sikdar、Rishabh Kumar、Jasabanta Patro、Unni Krishnan、Anirban Santara、Jivnesh Sandhan、Soumya Sarkar、Devaraj Adiga、Aniruddha Roy和Muskan Garg。最后,我们感谢匿名审稿人、执行编辑Mohit Bansal以及主编Brian Roark提出的宝贵意见。