Big Self-Supervised Models are Strong Semi-Supervised Learners
大型自监督模型是强大的半监督学习器
Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, Geoffrey Hinton Google Research, Brain Team
Ting Chen、Simon Kornblith、Kevin Swersky、Mohammad Norouzi、Geoffrey Hinton Google Research, Brain Team
Abstract
摘要
One paradigm for learning from few labeled examples while making best use of a large amount of unlabeled data is unsupervised pre training followed by supervised fine-tuning. Although this paradigm uses unlabeled data in a task-agnostic way, in contrast to common approaches to semi-supervised learning for computer vision, we show that it is surprisingly effective for semi-supervised learning on ImageNet. A key ingredient of our approach is the use of big (deep and wide) networks during pre training and fine-tuning. We find that, the fewer the labels, the more this approach (task-agnostic use of unlabeled data) benefits from a bigger network. After fine-tuning, the big network can be further improved and distilled into a much smaller one with little loss in classification accuracy by using the unlabeled examples for a second time, but in a task-specific way. The proposed semi-supervised learning algorithm can be summarized in three steps: unsupervised pre training of a big ResNet model using SimCLRv2, supervised fine-tuning on a few labeled examples, and distillation with unlabeled examples for refining and transferring the task-specific knowledge. This procedure achieves $73.9%$ ImageNet top-1 accuracy with just $1%$ of the labels $\leq13$ labeled images per class) using ResNet-50, a $10\times$ improvement in label efficiency over the previous state-of-theart. With $10%$ of labels, ResNet-50 trained with our method achieves $77.5%$ top-1 accuracy, outperforming standard supervised training with all of the labels. 1
一种利用少量标注样本和大量未标注数据进行学习的范式是无监督预训练(unsupervised pre-training)结合监督微调(supervised fine-tuning)。尽管这种范式以任务无关的方式使用未标注数据(与计算机视觉中常见的半监督学习方法不同),但我们证明它在ImageNet半监督学习任务中表现出惊人的效果。该方法的关键在于预训练和微调阶段都采用大型(深度和宽度)网络结构。我们发现标注数据越少,这种(任务无关的未标注数据使用)方法从大型网络中获益越多。经过微调后,通过以任务相关的方式二次利用未标注数据,可将大型网络进一步优化并蒸馏为更小的网络,同时保持分类精度几乎无损。提出的半监督学习算法可概括为三个步骤:使用SimCLRv2对大型ResNet模型进行无监督预训练、基于少量标注样本进行监督微调、利用未标注数据通过蒸馏来提炼和迁移任务相关知识。该方法仅使用1%的标注数据(每类≤13张标注图像)就使ResNet-50在ImageNet上达到73.9%的top-1准确率,比之前最优方法的标签效率提高了10倍。当使用10%标注数据时,采用本方法训练的ResNet-50达到77.5%的top-1准确率,优于使用全部标注数据的标准监督训练。[1]
1 Introduction
1 引言
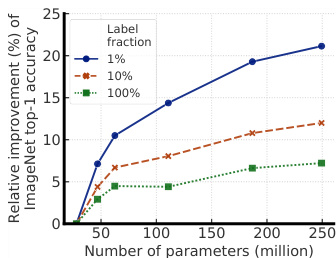
Figure 1: Bigger models yield larger gains when fine-tuning with fewer labeled examples.
图 1: 当使用较少标注样本进行微调时,更大的模型能带来更大的性能提升。
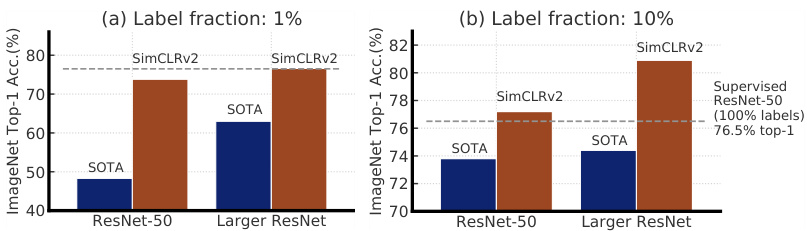
Figure 2: Top-1 accuracy of previous state-of-the-art (SOTA) methods [1, 2] and our method (SimCLRv2) on ImageNet using only $1%$ or $10%$ of the labels. Dashed line denotes fully supervised ResNet-50 trained with $100%$ of labels. Full comparisons in Table 3.
图 2: 先前最先进 (SOTA) 方法 [1, 2] 与我们的方法 (SimCLRv2) 在仅使用 $1%$ 或 $10%$ 标签时在 ImageNet 上的 Top-1 准确率。虚线表示使用 $100%$ 标签训练的全监督 ResNet-50。完整对比见 表 3。
Learning from just a few labeled examples while making best use of a large amount of unlabeled data is a long-standing problem in machine learning. One approach to semi-supervised learning involves unsupervised or self-supervised pre training, followed by supervised fine-tuning [3, 4]. This approach leverages unlabeled data in a task-agnostic way during pre training, as the supervised labels are only used during fine-tuning. Although it has received little attention in computer vision, this approach has become predominant in natural language processing, where one first trains a large language model on unlabeled text (e.g., Wikipedia), and then fine-tunes the model on a few labeled examples [5–10]. An alternative approach, common in computer vision, directly leverages unlabeled data during supervised learning, as a form of regular iz ation. This approach uses unlabeled data in a task-specific way to encourage class label prediction consistency on unlabeled data among different models [11, 12, 2] or under different data augmentations [13–15].
仅从少量标注样本中学习,同时充分利用大量未标注数据,是机器学习中长期存在的问题。半监督学习的一种方法涉及无监督或自监督预训练,然后进行监督微调 [3, 4]。这种方法在预训练阶段以任务无关的方式利用未标注数据,因为监督标签仅在微调阶段使用。尽管在计算机视觉领域关注较少,但该方法已成为自然语言处理的主流范式:先在大规模无标注文本(如维基百科)上训练大语言模型,再用少量标注样本微调模型 [5–10]。另一种常见于计算机视觉的方法则直接在监督学习过程中利用未标注数据作为正则化手段,以任务特定的方式促使不同模型 [11, 12, 2] 或不同数据增强条件下 [13–15] 对未标注数据的类别预测保持一致。
Motivated by recent advances in self-supervised learning of visual representations [16–20, 1], this paper first presents a thorough investigation of the “unsupervised pretrain, supervised fine-tune” paradigm for semi-supervised learning on ImageNet [21]. During self-supervised pre training, images are used without class labels (in a task-agnostic way), hence the representations are not directly tailored to a specific classification task. With this task-agnostic use of unlabeled data, we find that network size is important: Using a big (deep and wide) neural network for self-supervised pre training and fine-tuning greatly improves accuracy. In addition to the network size, we characterize a few important design choices for contrastive representation learning that benefit supervised fine-tuning and semi-supervised learning.
受视觉表征自监督学习最新进展的启发[16–20, 1],本文首先系统研究了ImageNet[21]半监督学习中"无监督预训练、有监督微调"范式。在自监督预训练阶段,图像数据以任务无关的方式使用(无需类别标签),因此学习到的表征并非直接针对特定分类任务进行优化。通过这种任务无关的无标签数据利用方式,我们发现网络规模至关重要:采用大型(深层且宽)神经网络进行自监督预训练和微调能显著提升准确率。除网络规模外,我们还总结出对比表征学习中若干关键设计要素,这些要素对后续有监督微调和半监督学习具有显著增益。
Once a convolutional network is pretrained and fine-tuned, we find that its task-specific predictions can be further improved and distilled into a smaller network. To this end, we make use of unlabeled data for a second time to encourage the student network to mimic the teacher network’s label predictions. Thus, the distillation [22, 23] phase of our method using unlabeled data is reminiscent of the use of pseudo labels [11] in self-training [24, 12], but without much extra complexity.
一旦卷积网络完成预训练和微调,我们发现其任务特定预测可进一步优化并蒸馏至更小的网络。为此,我们第二次利用未标注数据,促使学生网络模仿教师网络的标签预测。因此,这种基于未标注数据的蒸馏 [22, 23] 阶段让人联想到自训练 [24, 12] 中的伪标签 [11] 方法,但无需引入过多额外复杂度。
In summary, the proposed semi-supervised learning framework comprises three steps as shown in Figure 3: (1) unsupervised or self-supervised pre training, (2) supervised fine-tuning, and (3) distillation using unlabeled data. We develop an improved variant of a recently proposed contrastive learning framework, SimCLR [1], for unsupervised pre training of a ResNet architecture [25]. We call this framework SimCLRv2. We assess the effectiveness of our method on ImageNet ILSVRC-2012 [21] with only $1%$ and $10%$ of the labeled images available. Our main findings and contributions can be summarized as follows:
总之,提出的半监督学习框架包含三个步骤,如图 3 所示:(1) 无监督或自监督预训练,(2) 有监督微调,以及 (3) 使用未标记数据进行蒸馏。我们基于近期提出的对比学习框架 SimCLR [1] 开发了一种改进变体,用于 ResNet 架构 [25] 的无监督预训练,并将该框架命名为 SimCLRv2。我们在仅使用 $1%$ 和 $10%$ 标记图像的 ImageNet ILSVRC-2012 [21] 数据集上评估了方法的有效性。主要发现与贡献可总结如下:
We combine these findings to achieve a new state-of-the-art in semi-supervised learning on ImageNet as summarized in Figure 2. Under the linear evaluation protocol, SimCLRv2 achieves $79.8%$ top-1 accuracy, a $4.3%$ relative improvement over the previous state-of-the-art [1]. When fine-tuned on only $1%$ / $10%$ of labeled examples and distilled to the same architecture using unlabeled examples, it achieves $76.6%/80.9%$ top-1 accuracy, which is a $21.6%/8.7%$ relative improvement over previous state-of-the-art. With distillation, these improvements can also be transferred to smaller ResNet-50 networks to achieve $73.9%/77.5%$ top-1 accuracy using $1%/10%$ of labels. By comparison, a standard supervised ResNet-50 trained on all of labeled images achieves a top-1 accuracy of $76.6%$ .
我们综合这些发现,在ImageNet半监督学习上实现了新的最先进水平,如图2所示。在线性评估协议下,SimCLRv2实现了79.8%的top-1准确率,相比之前的最先进水平[1]相对提升了4.3%。当仅使用1%/10%的标注样本进行微调,并利用未标注样本蒸馏至相同架构时,其top-1准确率达到76.6%/80.9%,相比之前的最先进水平相对提升了21.6%/8.7%。通过蒸馏,这些改进还可迁移到更小的ResNet-50网络,仅使用1%/10%的标注量即可实现73.9%/77.5%的top-1准确率。作为对比,标准监督训练的ResNet-50在使用全部标注图像时达到的top-1准确率为76.6%。
2 Method
2 方法
Inspired by the recent successes of learning from unlabeled data [19, 20, 1, 11, 24, 12], the proposed semi-supervised learning framework leverages unlabeled data in both task-agnostic and task-specific ways. The first time the unlabeled data is used, it is in a task-agnostic way, for learning general (visual) representations via unsupervised pre training. The general representations are then adapted for a specific task via supervised fine-tuning. The second time the unlabeled data is used, it is in a task-specific way, for further improving predictive performance and obtaining a compact model. To this end, we train student networks on the unlabeled data with imputed labels from the fine-tuned teacher network. Our method can be summarized in three main steps: pretrain, fine-tune, and then distill. The procedure is illustrated in Figure 3. We introduce each specific component in detail below.
受近期利用未标注数据学习取得的成功启发[19, 20, 1, 11, 24, 12],我们提出的半监督学习框架以任务无关(task-agnostic)和任务特定(task-specific)两种方式利用未标注数据。首次使用未标注数据时采用任务无关方式,通过无监督预训练学习通用(视觉)表征;随后通过监督微调将这些通用表征适配到特定任务。第二次使用未标注数据时则采用任务特定方式,用于进一步提升预测性能并获得紧凑模型。具体而言,我们基于微调后的教师网络生成的伪标签,在未标注数据上训练学生网络。该方法可概括为三个主要步骤:预训练、微调、蒸馏。整个过程如图3所示。下文将详细介绍各具体组件。
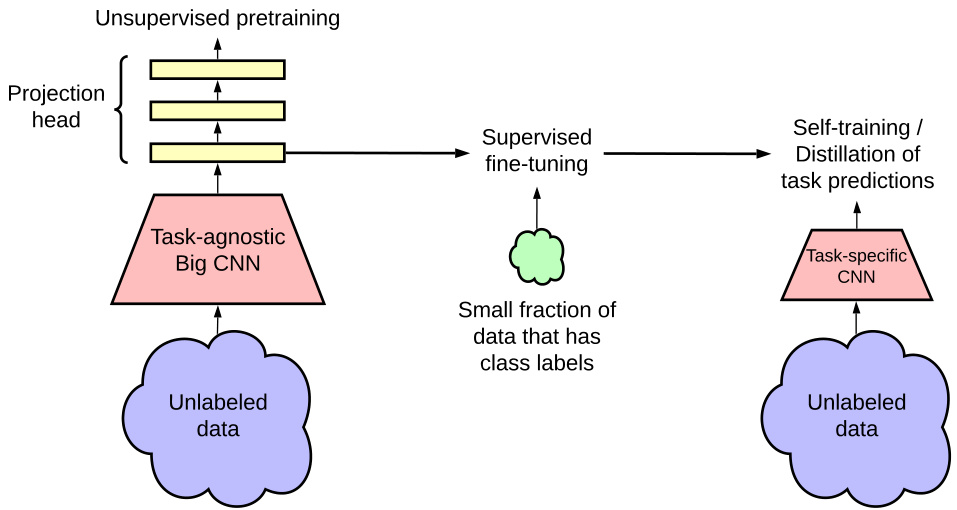
Figure 3: The proposed semi-supervised learning framework leverages unlabeled data in two ways: (1) task-agnostic use in unsupervised pre training, and (2) task-specific use in self-training / distillation.
图 3: 提出的半监督学习框架通过两种方式利用未标注数据: (1) 在无监督预训练中任务无关的使用, (2) 在自训练/蒸馏中任务特定的使用。
Self-supervised pre training with SimCLRv2. To learn general visual representations effectively with unlabeled images, we adopt and improve SimCLR [1], a recently proposed approach based on contrastive learning. SimCLR learns representations by maximizing agreement [26] between differently augmented views of the same data example via a contrastive loss in the latent space. More specifically, given a randomly sampled mini-batch of images, each image $\scriptstyle{\boldsymbol{x}}_ {i}$ is augmented twice using random crop, color distortion and Gaussian blur, creating two views of the same example ${\pmb x}_ {2k-1}$ and ${\pmb x}_ {2k}$ . The two images are encoded via an encoder network $f(\cdot)$ (a ResNet [25]) to generate representations $h_{2k-1}$ and $h_{2k}$ . The representations are then transformed again with a non-linear transformation network $g(\cdot)$ (a MLP projection head), yielding $z_{2k-1}$ and $z_{2k}$ that are used for the contrastive loss. With a mini-batch of augmented examples, the contrastive loss between a pair of positive example $i,j$ (augmented from the same image) is given as follows:
使用SimCLRv2进行自监督预训练。为了有效利用未标注图像学习通用视觉表示,我们采用并改进了近期提出的基于对比学习的SimCLR方法[1]。该方法通过在潜在空间中应用对比损失,最大化同一数据样本不同增强视图之间的一致性[26]来学习表示。具体而言,给定随机采样的图像小批量,每个图像$\scriptstyle{\boldsymbol{x}}_ {i}$会经过随机裁剪、颜色失真和高斯模糊两次增强,生成同一样本的两个视图${\pmb x}_ {2k-1}$和${\pmb x}_ {2k}$。这两个图像通过编码器网络$f(\cdot)$(ResNet[25])生成表示$h_{2k-1}$和$h_{2k}$,再经非线性变换网络$g(\cdot)$(MLP投影头)转换为用于对比损失的$z_{2k-1}$和$z_{2k}$。对于增强后的小批量样本,正样本对$i,j$(来自同一图像的增强)的对比损失计算如下:
$$
\ell_{i,j}^{\mathrm{NT-Xent}}=-\log\frac{\exp(\sin(z_{i},z_{j})/\tau)}{\sum_{k=1}^{2N}\mathbb{1}_ {[k\neq i]}\exp(\sin(z_{i},z_{k})/\tau)},
$$
$$
\ell_{i,j}^{\mathrm{NT-Xent}}=-\log\frac{\exp(\sin(z_{i},z_{j})/\tau)}{\sum_{k=1}^{2N}\mathbb{1}_ {[k\neq i]}\exp(\sin(z_{i},z_{k})/\tau)},
$$
Where $\mathrm{sim}(\cdot,\cdot)$ is cosine similarity between two vectors, and $\tau$ is a temperature scalar.
其中 $\mathrm{sim}(\cdot,\cdot)$ 表示两个向量之间的余弦相似度,$\tau$ 为温度标量。
In this work, we propose SimCLRv2, which improves upon SimCLR [1] in three major ways. Below we summarize the changes as well as their improvements of accuracy on Imagenet ILSVRC-2012 [21].
在本工作中,我们提出了SimCLRv2,该模型在以下三大方面改进了SimCLR [1]。下面我们将总结这些改进及其在Imagenet ILSVRC-2012 [21]数据集上的准确率提升。
- To fully leverage the power of general pre training, we explore larger ResNet models. Unlike SimCLR [1] and other previous work [27, 20], whose largest model is ResNet-50 $(4\times)$ , we train models that are deeper but less wide. The largest model we train is a 152-layer ResNet [25] with $3\times$ wider channels and selective kernels (SK) [28], a channel-wise attention mechanism that improves the parameter efficiency of the network. By scaling up the model from ResNet-50 to ResNet-152 $(3\times+\mathrm{SK})$ , we obtain a $29%$ relative improvement in top-1 accuracy when fine-tuned on $1%$ of labeled examples.
- 为充分发挥通用预训练的优势,我们探索了更大的ResNet模型。与SimCLR[1]及其他先前工作[27,20](其最大模型为ResNet-50$(4\times)$)不同,我们训练了更深但宽度更小的模型。我们训练的最大模型是152层ResNet[25],其通道宽度扩展为$3\times$并采用选择性卷积核(SK)[28]——一种通过通道注意力机制提升网络参数效率的方法。当模型规模从ResNet-50扩展到ResNet-152$(3\times+\mathrm{SK})$时,在$1%$标注数据上进行微调可使top-1准确率相对提升$29%$。
- We also increase the capacity of the non-linear network $g(\cdot)$ (a.k.a. projection head), by making it deeper.2 Furthermore, instead of throwing away $g(\cdot)$ entirely after pre training as in SimCLR [1], we fine-tune from a middle layer (detailed later). This small change yields a significant improvement for both linear evaluation and fine-tuning with only a few labeled examples. Compared to SimCLR with 2-layer projection head, by using a 3-layer projection head and fine-tuning from the 1st layer of projection head, it results in as much as $14%$ relative improvement in top-1 accuracy when fine-tuned on $1%$ of labeled examples (see Figure E.1).
- 我们还通过加深非线性网络 $g(\cdot)$ (即投影头) 的深度来提升其容量。此外,不同于 SimCLR [1] 在预训练后完全丢弃 $g(\cdot)$ 的做法,我们选择从中间层开始微调 (具体细节后文详述)。这一微小改动在线性评估和仅用少量标注样本微调时均带来了显著提升。相比使用2层投影头的 SimCLR,采用3层投影头并从第1层投影头开始微调时,在 $1%$ 标注样本上微调可使 top-1 准确率获得高达 $14%$ 的相对提升 (见图 E.1)。
- Motivated by [29], we also incorporate the memory mechanism from MoCo [20], which designates a memory network (with a moving average of weights for stabilization) whose output will be buffered as negative examples. Since our training is based on large mini-batch which already supplies many contrasting negative examples, this change yields an improvement of ${\sim}1%$ for linear evaluation as well as when fine-tuning on $1%$ of labeled examples (see Appendix D).
- 受[29]启发,我们还引入了MoCo[20]中的记忆机制,该机制指定了一个记忆网络(通过权重移动平均实现稳定),其输出将作为负样本缓存。由于我们的训练基于大型小批量(mini-batch)数据,这些数据本身已提供大量对比负样本,这一改进使得线性评估任务以及在1%标注数据上的微调任务性能均提升约1%(详见附录D)。
Fine-tuning. Fine-tuning is a common way to adapt the task-agnostic ally pretrained network for a specific task. In SimCLR [1], the MLP projection head $g(\cdot)$ is discarded entirely after pre training, while only the ResNet encoder $f(\cdot)$ is used during the fine-tuning. Instead of throwing it all away, we propose to incorporate part of the MLP projection head into the base encoder during the fine-tuning. In other words, we fine-tune the model from a middle layer of the projection head, instead of the input layer of the projection head as in SimCLR. Note that fine-tuning from the first layer of the MLP head is the same as adding an fully-connected layer to the base network and removing an fully-connected layer from the head, and the impact of this extra layer is contingent on the amount of labeled examples during fine-tuning (as shown in our experiments).
微调 (Fine-tuning)。微调是将任务无关的预训练网络适配到特定任务的常用方法。在SimCLR [1]中,MLP投影头 $g(\cdot)$ 在预训练后会完全丢弃,微调阶段仅使用ResNet编码器 $f(\cdot)$。我们提出在微调时将部分MLP投影头整合到基础编码器中,而非全盘舍弃。具体而言,我们从投影头的中间层开始微调,而非像SimCLR那样从投影头的输入层开始。需注意:从MLP头第一层开始微调,等效于在基础网络添加全连接层的同时移除投影头中的一个全连接层,该额外层的影响取决于微调时的标注数据量(如实验所示)。
Self-training / knowledge distillation via unlabeled examples. To further improve the network for the target task, here we leverage the unlabeled data directly for the target task. Inspired by [23, 11, 22, 24, 12], we use the fine-tuned network as a teacher to impute labels for training a student network. Specifically, we minimize the following distillation loss where no real labels are used:
通过未标注样本进行自训练/知识蒸馏。为了进一步提升网络在目标任务上的性能,我们直接利用未标注数据进行目标任务训练。受[23, 11, 22, 24, 12]启发,我们将微调后的网络作为教师模型来生成伪标签,用于训练学生模型。具体而言,我们在不使用真实标签的情况下最小化以下蒸馏损失:
$$
\mathcal{L}^{\mathrm{distill}}=-\sum_{\pmb{x}_ {i}\in\mathcal{D}}\bigg[\sum_{\pmb{y}}P^{T}(\pmb{y}|\pmb{x}_ {i};\tau)\log P^{S}(\pmb{y}|\pmb{x}_{i};\tau)\bigg]
$$
$$
\mathcal{L}^{\mathrm{distill}}=-\sum_{\pmb{x}_ {i}\in\mathcal{D}}\bigg[\sum_{\pmb{y}}P^{T}(\pmb{y}|\pmb{x}_ {i};\tau)\log P^{S}(\pmb{y}|\pmb{x}_{i};\tau)\bigg]
$$
where $\begin{array}{r}{P(y|\pmb{x}_ {i})=\exp(f^{\mathrm{task}}(\pmb{x}_ {i})[y]/\tau)/\sum_{y^{\prime}}\exp(f^{\mathrm{task}}(\pmb{x}_ {i})[y^{\prime}]/\tau)}\end{array}$ , and $\tau$ is a scalar temperature parameter. The teacher network, which pr oduces $P^{T}(y|\pmb{x}_ {i})$ , is fixed during the distillation; only the student network, which produces $P^{S}(y|\mathbf{\dot{x}}_{i})$ , is trained.
其中 $\begin{array}{r}{P(y|\pmb{x}_ {i})=\exp(f^{\mathrm{task}}(\pmb{x}_ {i})[y]/\tau)/\sum_{y^{\prime}}\exp(f^{\mathrm{task}}(\pmb{x}_ {i})[y^{\prime}]/\tau)}\end{array}$ ,且 $\tau$ 为标量温度参数。在蒸馏过程中,生成 $P^{T}(y|\pmb{x}_ {i})$ 的教师网络保持固定;仅对生成 $P^{S}(y|\mathbf{\dot{x}}_{i})$ 的学生网络进行训练。
While we focus on distillation using only unlabeled examples in this work, when the number of labeled examples is significant, one can also combine the distillation loss with ground-truth labeled examples using a weighted combination
虽然本研究仅关注使用无标注样本进行蒸馏的方法,但当标注样本数量充足时,也可通过加权组合的方式将蒸馏损失与真实标注样本结合使用
$$
\mathcal{L}=-(1-\alpha)\sum_{(\pmb{x}_ {i},\pmb{y}_ {i})\in\mathcal{D}^{L}}\bigg[\log P^{S}(\pmb{y}_ {i}|\pmb{x}_ {i})\bigg]-\alpha\sum_{\pmb{x}_ {i}\in\mathcal{D}}\bigg[\sum_{\pmb{y}}P^{T}(\pmb{y}|\pmb{x}_ {i};\tau)\log P^{S}(\pmb{y}|\pmb{x}_{i};\tau)\bigg].
$$
$$
\mathcal{L}=-(1-\alpha)\sum_{(\pmb{x}_ {i},\pmb{y}_ {i})\in\mathcal{D}^{L}}\bigg[\log P^{S}(\pmb{y}_ {i}|\pmb{x}_ {i})\bigg]-\alpha\sum_{\pmb{x}_ {i}\in\mathcal{D}}\bigg[\sum_{\pmb{y}}P^{T}(\pmb{y}|\pmb{x}_ {i};\tau)\log P^{S}(\pmb{y}|\pmb{x}_{i};\tau)\bigg].
$$
This procedure can be performed using students either with the same model architecture (selfdistillation), which further improves the task-specific performance, or with a smaller model architecture, which leads to a compact model.
该过程可以使用具有相同模型架构(自蒸馏)的学生模型来执行,从而进一步提高任务特定性能,或者使用较小的模型架构,从而得到一个紧凑模型。
3 Empirical Study
3 实证研究
3.1 Settings and Implementation Details
3.1 设置与实现细节
Following the semi-supervised learning setting in [30, 19, 1], we evaluate the proposed method on ImageNet ILSVRC-2012 [21]. While all ${\sim}1.28$ million images are available, only a randomly sub-sampled $1%$ (12811) or $10%$ (128116) of images are associated with labels.3 As in previous work, we also report performance when training a linear classifier on top of a fixed representation with all labels [31, 16, 17, 1] to directly evaluate SimCLRv2 representations. We use the LARS optimizer [32] (with a momentum of 0.9) throughout for pre training, fine-tuning and distillation.
遵循[30, 19, 1]中的半监督学习设置,我们在ImageNet ILSVRC-2012 [21]数据集上评估所提出的方法。虽然所有约128万张图像均可使用,但仅随机子采样1%(12811张)或10%(128116张)图像带有标签。3 如先前工作所示,我们还报告了在固定表示上使用全部标签训练线性分类器时的性能[31, 16, 17, 1],以直接评估SimCLRv2表示。在整个预训练、微调和蒸馏过程中,我们均使用LARS优化器32。
For pre training, similar to [1], we train our model on 128 Cloud TPUs, with a batch size of 4096 and global batch normalization [33], for total of 800 epochs. The learning rate is linearly increased for the first $5%$ of epochs, reaching maximum of $5.4:(=0.1\times\mathrm{sqrt}(\mathrm{BatchSize}).$ ), and then decayed with a cosine decay schedule. A weight decay of $1e^{-4}$ is used. We use a 3-layer MLP projection head on top of a ResNet encoder. The memory buffer is set to 64K, and exponential moving average (EMA) decay is set to 0.999 according to [20]. We use the same set of simple augmentations as SimCLR [1], namely random crop, color distortion, and Gaussian blur.
在预训练阶段,我们参照[1]的方法,使用128个Cloud TPU进行模型训练,批处理大小(batch size)为4096并采用全局批归一化[33],共训练800个周期。学习率在前$5%$周期内线性增长,最高达到$5.4:(=0.1\times\mathrm{sqrt}(\mathrm{BatchSize}).$),随后按余弦衰减计划下降。权重衰减设置为$1e^{-4}$。我们在ResNet编码器顶部使用3层MLP投影头。根据[20],内存缓冲区设为64K,指数移动平均(EMA)衰减率设为0.999。数据增强方案与SimCLR[1]保持一致,包括随机裁剪、色彩失真和高斯模糊。
Table 1: Top-1 accuracy of fine-tuning SimCLRv2 models (on varied label fractions) or training a linear classifier on the representations. The supervised baselines are trained from scratch using all labels in 90 epochs. The parameter count only include ResNet up to final average pooling layer. For fine-tuning results with $1%$ and $10%$ labeled examples, the models include additional non-linear projection layers, which incurs additional parameter count (4M for $1\times$ models, and 17M for $2\times$ models). See Table H.1 for Top-5 accuracy.
| Depth | Width | Use SK [28] | Param (M) | 1% | Fine-tuned on 10% | 100% | Linear eval | Supervised |
| 50 | False | 24 | 57.9 | 68.4 | 76.3 | 71.7 | 76.6 | |
| 1x | True | 35 | 64.5 | 72.1 | 78.7 | 74.6 | 78.5 | |
| 2x | False | 94 | 66.3 | 73.9 | 79.1 | 75.6 | 77.8 | |
| True | 140 | 70.6 | 77.0 | 81.3 | 77.7 | 79.3 | ||
| 101 | 1x | False | 43 | 62.1 | 71.4 | 78.2 | 73.6 | 78.0 |
| True | 65 | 68.3 | 75.1 | 80.6 | 76.3 | 79.6 | ||
| False | 170 | 69.1 | 75.8 | 80.7 | 77.0 | 78.9 | ||
| 2x | True | 257 | 73.2 | 78.8 | 82.4 | 79.0 | ||
| False | 58 | 64.0 | 73.0 | 74.5 | 80.1 78.3 | |||
| 152 152 | 1x | True | 89 | 70.0 | 76.5 | 79.3 81.3 | 77.2 | 79.9 |
| False | 233 | 70.2 | 76.6 | 81.1 | 77.4 | 79.1 | ||
| 2x | True | 354 | 74.2 | 79.4 | 82.9 | 79.4 | ||
| 3x | True | 795 | 74.9 | 80.1 | 83.1 | 79.8 | 80.4 80.5 |
表 1: SimCLRv2模型在不同标注比例下的微调Top-1准确率(或基于表征训练的线性分类器准确率)。监督基线模型使用全部标签从头训练90个周期。参数量仅包含ResNet至最终平均池化层。对于使用 $1%$ 和 $10%$ 标注样本的微调结果,模型包含额外的非线性投影层,这会增加参数量( $1\times$ 模型增加4M, $2\times$ 模型增加17M)。Top-5准确率参见表H.1。
| 深度 | 宽度 | 使用SK [28] | 参数量(M) | 1% | 微调10% | 100% | 线性评估 | 监督训练 |
|---|---|---|---|---|---|---|---|---|
| 50 | False | 24 | 57.9 | 68.4 | 76.3 | 71.7 | 76.6 | |
| 1x | True | 35 | 64.5 | 72.1 | 78.7 | 74.6 | 78.5 | |
| 2x | False | 94 | 66.3 | 73.9 | 79.1 | 75.6 | 77.8 | |
| True | 140 | 70.6 | 77.0 | 81.3 | 77.7 | 79.3 | ||
| 101 | 1x | False | 43 | 62.1 | 71.4 | 78.2 | 73.6 | 78.0 |
| True | 65 | 68.3 | 75.1 | 80.6 | 76.3 | 79.6 | ||
| 2x | False | 170 | 69.1 | 75.8 | 80.7 | 77.0 | 78.9 | |
| True | 257 | 73.2 | 78.8 | 82.4 | 79.0 | - | ||
| 152 | 1x | True | 89 | 70.0 | 76.5 | 79.3/81.3 | 77.2 | 79.9 |
| False | 233 | 70.2 | 76.6 | 81.1 | 77.4 | 79.1 | ||
| 2x | True | 354 | 74.2 | 79.4 | 82.9 | 79.4 | - | |
| 3x | True | 795 | 74.9 | 80.1 | 83.1 | 79.8 | 80.4/80.5 |
For fine-tuning, by default we fine-tune from the first layer of the projection head for $1%/10%$ of labeled examples, but from the input of the projection head when $100%$ labels are present. We use global batch normalization, but we remove weight decay, learning rate warmup, and use a much smaller learning rate, i.e. $0.16:(=0.005\times\mathrm{sqrt}(\mathrm{BatchSize}))$ ) for standard ResNets [25], and 0.064 $(=0.002\times\mathrm{sqrt}(\mathrm{BatchSize}))$ for larger ResNets variants (with width multiplier larger than 1 and/or SK [28]). A batch size of 1024 is used. Similar to [1], we fine-tune for 60 epochs with $1%$ of labels, and 30 epochs with $10%$ of labels, as well as full ImageNet labels.
在微调阶段,默认情况下,我们使用$1%/10%$的标注样本从投影头(projection head)的第一层开始微调,但当标注数据达到$100%$时则从投影头的输入层开始。我们采用全局批量归一化(global batch normalization),但移除了权重衰减(weight decay)和学习率预热(learning rate warmup),并使用更小的学习率:标准ResNet[25]为$0.16:(=0.005\times\mathrm{sqrt}(\mathrm{BatchSize}))$,而更大规模的ResNet变体(宽度乘数大于1和/或SK[28]结构)则为0.064$(=0.002\times\mathrm{sqrt}(\mathrm{BatchSize}))$。批量大小设置为1024。与文献[1]类似,我们进行60个epoch的微调(使用$1%$标注数据)、30个epoch(使用$10%$标注数据)以及完整ImageNet标注数据的微调。
For distillation, we only use unlabeled examples, unless otherwise specified. We consider two types of distillation: self-distillation where the student has the same model architecture as the teacher (excluding projection head), and big-to-small distillation where the student is a much smaller network. We set temperature to 0.1 for self-distillation, and 1.0 for large-to-small distillation (though the effect of temperatures between 0.1 and 1 is very small). We use the same learning rate schedule, weight decay, batch size as pre training, and the models are trained for 400 epochs. Only random crop and horizontal flips of training images are applied during fine-tuning and distillation.
在蒸馏过程中,我们仅使用未标注样本(除非另有说明)。我们考虑两种蒸馏方式:学生模型与教师模型架构相同的自蒸馏(不包括投影头),以及从大网络到小网络的尺寸缩减蒸馏。自蒸馏温度设为0.1,大模型到小模型蒸馏温度设为1.0(但0.1至1之间的温度值影响极小)。我们采用与预训练相同的学习率调度、权重衰减和批量大小,模型训练400个周期。在微调和蒸馏阶段,仅对训练图像施加随机裁剪和水平翻转操作。
3.2 Bigger Models Are More Label-Efficient
3.2 更大的模型具有更高的标签效率
In order to study the effectiveness of big models, we train ResNet models by varying width and depth as well as whether or not to use selective kernels (SK) [28].4 Whenever SK is used, we also use the ResNet-D [34] variant of ResNet. The smallest model is the standard ResNet-50, and biggest model is ResNet-152 $(3\times+\mathrm{SK})$ .
为了研究大模型的有效性,我们通过改变宽度、深度以及是否使用选择性核 (SK) [28] 来训练 ResNet 模型。每当使用 SK 时,我们也会采用 ResNet-D [34] 变体。最小模型是标准 ResNet-50,最大模型是 ResNet-152 $(3\times+\mathrm{SK})$。
Table 1 compares self-supervised learning and supervised learning under different model sizes and evaluation protocols, including both fine-tuning and linear evaluation. We can see that increasing width and depth, as well as using SK, all improve the performance. These architectural manipulations have relatively limited effects for standard supervised learning ( $4%$ differences in smallest and largest models), but for self-supervised models, accuracy can differ by as much as $8%$ for linear evaluation, and $17%$ for fine-tuning on $1%$ of labeled images. We also note that ResNet-152 $(3\times+\mathrm{SK})$ is only marginally better than ResNet-152 $(2\times+\mathrm{SK})$ , though the parameter size is almost doubled, suggesting that the benefits of width may have plateaued.
表 1 比较了自监督学习和监督学习在不同模型规模及评估协议(包括微调和线性评估)下的表现。可以看出,增加宽度和深度以及使用SK都能提升性能。这些架构调整对标准监督学习的影响相对有限(最小和最大模型间仅有4%差异),但对于自监督模型,线性评估的准确率差异可达8%,而在1%标注图像上进行微调时差异甚至达到17%。我们还注意到,ResNet-152 (3×+SK)仅略优于ResNet-152 (2×+SK),尽管参数量几乎翻倍,这表明宽度带来的收益可能已趋于平缓。
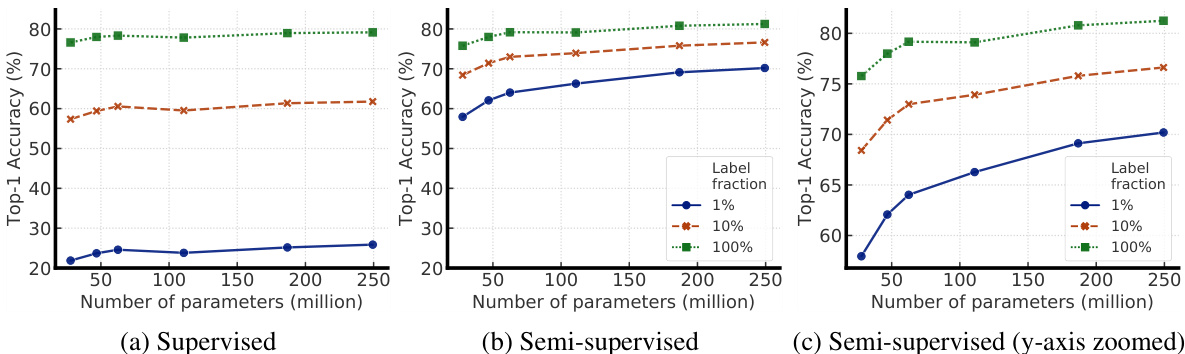
Figure 4: Top-1 accuracy for supervised vs semi-supervised (SimCLRv2 fine-tuned) models of varied sizes on different label fractions. ResNets with depths of 50, 101, 152, width multiplier of $1\times$ , $2\times$ (w/o SK) are presented here. For supervised models on $1%/10%$ labels, Auto Augment [35] and label smoothing [36] are used. Increasing the size of SimCLRv2 models by $10\times$ , from ResNet-50 to ResNet-152 $(2\times)$ , improves label efficiency by $10\times$ .
图 4: 监督学习与半监督学习 (SimCLRv2微调) 模型在不同标签比例下的Top-1准确率对比。图中展示了深度为50、101、152的ResNet (宽度乘数为 $1\times$ 和 $2\times$ ,不含SK模块) 的结果。对于使用 $1%/10%$ 标签的监督模型,采用了Auto Augment [35] 和标签平滑 [36] 技术。将SimCLRv2模型规模从ResNet-50扩大到ResNet-152 $(2\times)$ (约 $10\times$ 参数量提升) ,可使标签效率提升 $10\times$ 。
Figure 4 shows the performance as model size and label fraction vary. These results show that bigger models are more label-efficient for both supervised and semi-supervised learning, but gains appear to be larger for semi-supervised learning (more discussions in Appendix A). Furthermore, it is worth pointing out that although bigger models are better, some models (e.g. with SK) are more parameter efficient than others (Appendix B), suggesting that searching for better architectures is helpful.
图 4 展示了模型规模和标签比例变化时的性能表现。结果表明,无论是监督学习还是半监督学习,更大的模型都具有更高的标签效率,但半监督学习的收益似乎更大(更多讨论见附录 A)。此外,值得指出的是,虽然更大的模型表现更好,但某些模型(例如采用 SK 的模型)比其他模型(附录 B)具有更高的参数效率,这表明寻找更好的架构是有帮助的。
3.3 Bigger/Deeper Projection Heads Improve Representation Learning
3.3 更大/更深的投影头 (Projection Head) 能提升表征学习效果
To study the effects of projection head for fine-tuning, we pretrain ResNet-50 using SimCLRv2 with different numbers of projection head layers (from 2 to 4 fully connected layers), and examine performance when fine-tuning from different layers of the projection head. We find that using a deeper projection head during pre training is better when fine-tuning from the optimal layer of projection head (Figure 5a), and this optimal layer is typically the first layer of projection head rather than the input $\mathrm{[0^{t\bar{h}}}$ layer), especially when fine-tuning on fewer labeled examples (Figure 5b).
为研究投影头对微调的影响,我们使用SimCLRv2预训练了ResNet-50模型(采用2至4层全连接层作为投影头),并测试了从投影头不同层进行微调时的性能表现。实验发现:(1) 当从投影头最优层进行微调时,预训练阶段使用更深层投影头效果更佳(图5a);(2) 该最优层通常是投影头的首层而非输入层 $\mathrm{[0^{t\bar{h}}}$ ,这一现象在少样本标注数据微调场景中尤为显著(图5b)。
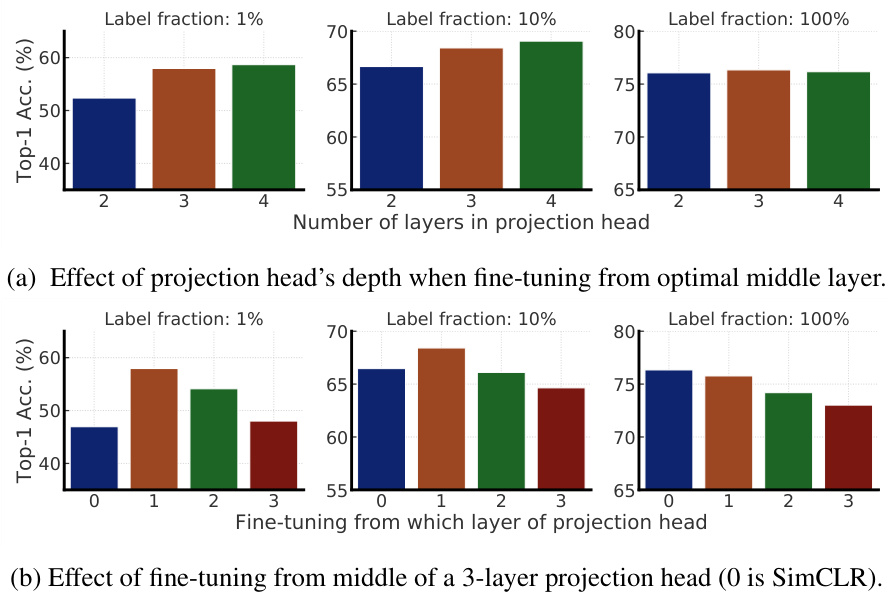
Figure 5: Top-1 accuracy via fine-tuning under different projection head settings and label fractions (using ResNet-50).
图 5: 不同投影头设置和标签比例下通过微调得到的 Top-1 准确率 (使用 ResNet-50)。
It is also worth noting that when using bigger ResNets, the improvements from having a deeper projection head are smaller (see Appendix E). In our experiments, wider ResNets also have wider projection heads, since the width multiplier is applied to both. Thus, it is possible that increasing the depth of the projection head has limited effect when the projection head is already relatively wide.
值得注意的是,当使用更大的ResNet时,更深投影头带来的改进较小(见附录E)。在我们的实验中,更宽的ResNet也对应更宽的投影头,因为宽度乘数同时作用于二者。因此,当投影头已经较宽时,增加其深度可能效果有限。
Table 2: Top-1 accuracy of a ResNet-50 trained on different types of targets. For distillation, the temperature is set to 1.0, and the teacher is ResNet-50 $(2\times+\mathrm{SK})$ , which gets $70.6%$ with $1%$ of the labels and $77.0%$ with $10%$ , as shown in in Table 1. The distillation loss (Eq. 2) does not use label information. Neither strong augmentation nor extra regular iz ation are used.
| Method | Labelfraction 1% | 10% |
| Label only | 12.3 | 52.0 |
| Label+distillationloss (onlabeledset) | 23.6 | 66.2 |
| Label+distillationloss(onlabeled+unlabeledsets) | 69.0 | 75.1 |
| Distillation loss (on labeled+unlabeled sets; our default) | 68.9 | 74.3 |
表 2: 在不同类型目标上训练的 ResNet-50 的 Top-1 准确率。对于蒸馏 (distillation),温度设置为 1.0,教师模型为 ResNet-50 $(2\times+\mathrm{SK})$,其在使用 1% 标签时达到 70.6%,使用 10% 标签时达到 77.0%,如表 1 所示。蒸馏损失 (Eq. 2) 不使用标签信息。既未使用强数据增强 (strong augmentation),也未使用额外正则化 (extra regularization)。
| 方法 | 标签比例 1% | 10% |
|---|---|---|
| 仅标签 | 12.3 | 52.0 |
| 标签+蒸馏损失 (在带标签集上) | 23.6 | 66.2 |
| 标签+蒸馏损失 (在带标签+无标签集上) | 69.0 | 75.1 |
| 蒸馏损失 (在带标签+无标签集上;我们的默认设置) | 68.9 | 74.3 |
When varying architecture, the accuracy of fine-tuned models is correlated with the accuracy of linear evaluation (see Appendix C). Although we use the input of the projection head for linear classification, we find that the correlation is higher when fine-tuning from the optimal middle layer of the projection head than when fine-tuning from the projection head input.
当架构变化时,微调模型的准确性与线性评估的准确性相关(见附录C)。虽然我们使用投影头的输入进行线性分类,但发现从投影头最优中间层微调时的相关性高于从投影头输入微调时的相关性。
3.4 Distillation Using Unlabeled Data Improves Semi-Supervised Learning
3.4 使用未标记数据的蒸馏提升半监督学习
Distillation typically involves both a distillation loss that encourages the student to match a teacher and an ordinary supervised cross-entropy loss on the labels (Eq. 3). In Table 2, we demonstrate the importance of using unlabeled examples when training with the distillation loss. Furthermore, using the distillation loss alone (Eq. 2) works almost as well as balancing distillation and label losses (Eq. 3) when the labeled fraction is small. For simplicity, Eq. 2 is our default for all other experiments.
蒸馏通常包括两部分损失:一是鼓励学生模型匹配教师模型的蒸馏损失,二是基于标签的常规监督交叉熵损失(公式3)。表2展示了在使用蒸馏损失训练时利用无标注样本的重要性。此外,当标注数据比例较小时,单独使用蒸馏损失(公式2)的效果几乎与平衡蒸馏损失和标签损失(公式3)相当。为简化流程,其他实验默认采用公式2作为配置。
Distillation with unlabeled examples improves fine-tuned models in two ways, as shown in Figure 6: (1) when the student model has a smaller architecture than the teacher model, it improves the model efficiency by transferring task-specific knowledge to a student model, (2) even when the student model has the same architecture as the teacher model (excluding the projection head after ResNet encoder), self-distillation can still meaningfully improve the semi-supervised learning performance. To obtain the best performance for smaller ResNets, the big model is self-distilled before distilling it to smaller models.
如图6所示,利用未标注样本进行蒸馏从两方面提升微调模型性能:(1) 当学生模型架构小于教师模型时,通过迁移任务特定知识提升模型效率;(2) 即使学生模型与教师模型架构相同(ResNet编码器后的投影头除外),自蒸馏仍能显著提升半监督学习效果。为使小型ResNet获得最佳性能,需先对大模型进行自蒸馏,再将其蒸馏至小模型。
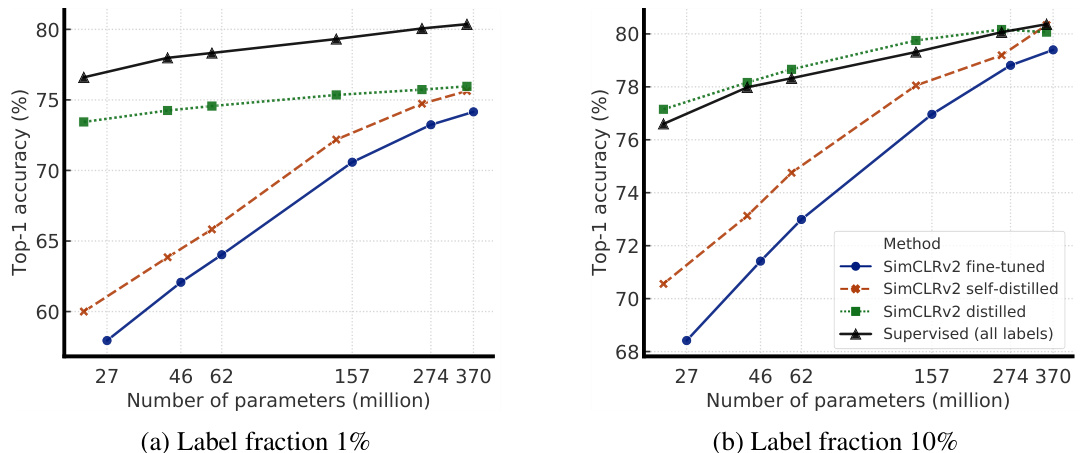
Figure 6: Top-1 accuracy of distilled SimCLRv2 models compared to the fine-tuned models as well as supervised learning with all labels. The self-distilled student has the same ResNet as the teacher (without MLP projection head). The distilled student is trained using the self-distilled ResNet-152 $(2\times+\mathrm{SK})$ model, which is the largest model included in this figure.
图 6: 蒸馏版SimCLRv2模型的Top-1准确率与微调模型及全标签监督学习的对比。自蒸馏学生模型采用与教师模型相同的ResNet架构(不含MLP投影头)。蒸馏学生模型使用自蒸馏ResNet-152 $(2\times+\mathrm{SK})$ 进行训练,该模型是本图中参数量最大的模型。
We compare our best models with previous state-of-the-art semi-supervised learning methods (and a concurrent work [43]) on ImageNet in Table 3. Our approach greatly improves upon previous results, for both small and big ResNet variants.
我们在表3中将我们的最佳模型与之前最先进的半监督学习方法(以及同时期的工作[43])在ImageNet上进行了比较。我们的方法无论是对于小型还是大型ResNet变体,都显著提升了之前的结果。
Table 3: ImageNet accuracy of models trained under semi-supervised settings. For our methods, we report results with distillation after fine-tuning. For our smaller models, we use self-distilled ResNet-152 $(3\times+\mathrm{SK})$ ) as the teacher.
| Architecture | Top-1 Label fraction | Top-5 Label fraction | |||||
| 1% | 10% | 1% | 10% | ||||
| Supervised baseline [30] | ResNet-50 | 25.4 | 56.4 | 48.4 | 80.4 | ||
| Methodsusingunlabeleddataina task-specificway: | |||||||
| Pseudo-label [11, 30] | ResNet-50 | 51.6 | 82.4 | ||||
| VAT+Entropy Min.[37,38,30] | ResNet-50 | 47.0 | 83.4 | ||||
| Mean teacher [39] | ResNeXt-152 | 90.9 | |||||
| UDA (w. RandAug) [14] | ResNet-50 | 68.8 | 88.5 | ||||
| FixMatch(w.RandAug) [15] | ResNet-50 | 71.5 | 89.1 | ||||
| S4L(Rot+VAT+Entropy Min.)[30] | ResNet-50 (4x) | 73.2 | 91.2 | ||||
| MPL (w.RandAug) [2] | ResNet-50 | 73.8 | |||||
| CowMix [40] | ResNet-152 | 73.9 | 91.2 | ||||
| Methods usingunlabeleddataina task-agnosticway: | |||||||
| InstDisc [17] | ResNet-50 | 39.2 | 77.4 | ||||
| BigBiGAN [41] | RevNet-50 (4x) | 55.2 | 78.8 | ||||
| PIRL [42] | ResNet-50 | - | 57.2 | 83.8 | |||
| CPC v2 [19] | ResNet-161(*) | 52.7 | 73.1 | 77.9 | 91.2 | ||
| SimCLR [1] | ResNet-50 | 48.3 | 65.6 | 75.5 | 87.8 | ||
| SimCLR [1] | ResNet-50 (2x) | 58.5 | 71.7 | 83.0 | 91.2 | ||
| SimCLR [1] | ResNet-50 (4×) | 63.0 | 74.4 | 85.8 | 92.6 | ||
| BYOL [43] (concurrent work) | ResNet-50 | 53.2 | 68.8 | 78.4 | 89.0 | ||
| BYOL [43] (concurrent work) | ResNet-200 (2x) | 71.2 | 77.7 | 89.5 | 93.7 | ||
| Methodsusingunlabeleddatainbothways: | |||||||
| SimCLRv2 distilled (ours) | ResNet-50 | 73.9 | 77.5 | 91.5 | 93.4 | ||
| SimCLRv2 distilled (ours) | ResNet-50 (2x+SK) | 75.9 | 80.2 | 93.0 | 95.0 | ||
| SimCLRv2 self-distilled (ours) | ResNet-152 (3x+SK) | 76.6 | 80.9 | 93.4 | 95.5 | ||
表 3: 半监督设置下训练模型的ImageNet准确率。对于我们的方法,我们报告了微调后蒸馏的结果。对于较小的模型,我们使用自蒸馏的ResNet-152 $(3\times+\mathrm{SK})$ 作为教师模型。
| 架构 | Top-1标注比例 | Top-5标注比例 | |||
|---|---|---|---|---|---|
| 1% | 10% | 1% | 10% | ||
| 监督基线 [30] | ResNet-50 | 25.4 | 56.4 | 48.4 | 80.4 |
| 任务特定方式使用未标注数据的方法: | |||||
| 伪标签 [11, 30] | ResNet-50 | 51.6 | 82.4 | ||
| VAT+熵最小化 [37,38,30] | ResNet-50 | 47.0 | 83.4 | ||
| 均值教师 [39] | ResNeXt-152 | 90.9 | |||
| UDA (带RandAug) [14] | ResNet-50 | 68.8 | 88.5 | ||
| FixMatch (带RandAug) [15] | ResNet-50 | 71.5 | 89.1 | ||
| S4L (旋转+VAT+熵最小化) [30] | ResNet-50 (4x) | 73.2 | 91.2 | ||
| MPL (带RandAug) [2] | ResNet-50 | 73.8 | |||
| CowMix [40] | ResNet-152 | 73.9 | 91.2 | ||
| 任务无关方式使用未标注数据的方法: | |||||
| InstDisc [17] | ResNet-50 | 39.2 | 77.4 | ||
| BigBiGAN [41] | RevNet-50 (4x) | 55.2 | 78.8 | ||
| PIRL [42] | ResNet-50 | - | 57.2 | 83.8 | |
| CPC v2 [19] | ResNet-161(*) | 52.7 | 73.1 | 77.9 | 91.2 |
| SimCLR [1] | ResNet-50 | 48.3 | 65.6 | 75.5 | 87.8 |
| SimCLR [1] | ResNet-50 (2x) | 58.5 | 71.7 | 83.0 | 91.2 |
| SimCLR [1] | ResNet-50 (4×) | 63.0 | 74.4 | 85.8 | 92.6 |
| BYOL [43] (同期工作) | ResNet-50 | 53.2 | 68.8 | 78.4 | 89.0 |
| BYOL [43] (同期工作) | ResNet-200 (2x) | 71.2 | 77.7 | 89.5 | 93.7 |
| 两种方式结合使用未标注数据的方法: | |||||
| SimCLRv2蒸馏 (本文) | ResNet-50 | 73.9 | 77.5 | 91.5 | 93.4 |
| SimCLRv2蒸馏 (本文) | ResNet-50 (2x+SK) | 75.9 | 80.2 | 93.0 | 95.0 |
| SimCLRv2自蒸馏 (本文) | ResNet-152 (3x+SK) | 76.6 | 80.9 | 93.4 | 95.5 |
4 Related work
4 相关工作
Task-agnostic use of unlabeled data. Unsupervised or self-supervised pre training followed by supervised fine-tuning on a few labeled examples has been extensively used in natural language processing [6, 5, 7–9], but has only shown promising results in computer vision very recently [19, 20, 1]. Our work builds upon recent success on contrastive learning of visual representations [44, 16, 17, 45, 18, 19, 46, 42, 20, 47, 48, 1], a sub-area within self-supervised learning. These contrastive learning based approaches learn representations in a disc rim i native fashion instead of a generative one as in [3, 49, 50, 41, 51]. There are other approaches to self-supervised learning that are based on handcrafted pretext tasks [52, 31, 53, 54, 27, 55]. We also note a concurrent work on advancing self-supervised pre training without using negative examples [43], which we also compare against in Table 3. Our work also extends the “unsupervised pretrain, supervised fine-tune” paradigm by combining it with (self-)distillation [23, 22, 11] using unlabeled data.
任务无关的无标签数据使用。无监督或自监督预训练结合少量标注样本的监督微调,已在自然语言处理领域得到广泛应用[6,5,7–9],但直到最近才在计算机视觉领域展现出显著效果[19,20,1]。我们的工作建立在视觉表征对比学习[44,16,17,45,18,19,46,42,20,47,48,1]这一自监督学习子领域的最新成果基础上。与[3,49,50,41,51]采用的生成式方法不同,这些基于对比学习的方法以判别式方式学习表征。自监督学习还存在其他基于手工设计代理任务的方法[52,31,53,54,27,55]。我们注意到近期有不使用负样本推进自监督预训练的并行研究[43],表3中我们也与其进行了对比。通过将无监督预训练与基于无标签数据的(自)蒸馏技术[23,22,11]相结合,我们的工作进一步拓展了"无监督预训练-监督微调"范式。
Task-specific use of unlabeled data. Aside from the representation learning paradigm, there is a large and diverse set of approaches for semi-supervised learning, we refer readers to [56–58] for surveys of classical approaches. Here we only review methods closely related to ours (especially within computer vision). One family of highly relevant methods are based on pseudo-labeling [11, 15] or self-training [12, 24, 59]. The main differences between these methods and ours are that our initial / teacher model is trained using SimCLRv2 (with unsupervised pre training and supervised fine-tuning), and the student models can also be smaller than the initial / teacher model. Furthermore, we use temperature scaling instead of confidence-based threshold ing, and we do not use strong augmentation for training the student. Another family of methods are based on label consistency regular iz ation [60–62, 39, 14, 13, 63, 15], where unlabeled examples are directly used as a regularize r to encourage task prediction consistency. Although in SimCLRv2 pre training, we maximize the agreement/consistency of representations of the same image under different augmented views, there is no supervised label utilized to compute the loss, a crucial difference from label consistency losses.
特定任务中未标注数据的运用。除表征学习范式外,半监督学习领域还存在大量多样化方法,经典方法综述可参阅[56–58]。本文仅回顾与本研究密切相关的方法(尤其计算机视觉领域)。一类高度相关的方法基于伪标签[11,15]或自训练[12,24,59],这些方法与我们的核心差异在于:(1) 初始/教师模型采用SimCLRv2框架(通过无监督预训练和有监督微调训练);(2) 学生模型可小于初始/教师模型;(3) 采用温度缩放而非基于置信度的阈值筛选;(4) 学生训练时不使用强数据增强。另一类方法基于标签一致性正则化[60–62,39,14,13,63,15],其直接将未标注样本作为正则项以促进任务预测一致性。尽管SimCLRv2预训练阶段会最大化同一图像在不同增强视图下的表征一致性,但关键区别在于:该过程未利用监督标签计算损失函数,这与标签一致性损失存在本质差异。
5 Discussion
5 讨论
In this work, we present a simple framework for semi-supervised ImageNet classification in three steps: unsupervised pre training, supervised fine-tuning, and distillation with unlabeled data. Although similar approaches are common in NLP, we demonstrate that this approach can also be a surprisingly strong baseline for semi-supervised learning in computer vision, outperforming the state-of-the-art by a large margin.
在这项工作中,我们提出了一个简单的半监督ImageNet分类框架,包含三个步骤:无监督预训练、监督微调以及利用未标注数据进行蒸馏。尽管类似方法在自然语言处理(NLP)领域很常见,但我们证明该方法也能成为计算机视觉中半监督学习的惊人强基线,以显著优势超越现有最佳技术。
We observe that bigger models can produce larger improvements with fewer labeled examples. We primarily study this phenomenon on ImageNet, but we observe similar results on CIFAR-10, a much smaller dataset (see appendix G). The effectiveness of big models have been demonstrated on supervised learning [64–67], fine-tuning supervised models on a few examples [68], and unsupervised learning on language [9, 69, 10, 70]. However, it is still somewhat surprising that bigger models, which could easily overfit with few labeled examples, can generalize much better. With task-agnostic use of unlabeled data, we conjecture bigger models can learn more general features, which increases the chances of learning task-relevant features. However, further work is needed to gain a better understanding of this phenomenon. Beyond model size, we also see the importance of increasing parameter efficiency as the other important dimension of improvement.
我们观察到,更大规模的模型能够用更少的标注样本实现更大性能提升。这一现象主要在ImageNet上得到验证,但在更小规模的数据集CIFAR-10上也观察到相似规律(参见附录G)。大规模模型的有效性已在监督学习[64–67]、少量样本微调监督模型[68]以及语言无监督学习[9,69,10,70]中得到证实。但值得注意的是,本应容易在少量标注样本上过拟合的大模型,反而展现出更强的泛化能力。我们推测,通过任务无关的无标注数据训练,大模型能学习更通用的特征,从而提升捕获任务相关特征的概率。不过这一现象仍需进一步研究。除模型规模外,提升参数效率也被证明是性能改进的另一关键维度。
Although big models are important for pre training and fine-tuning, given a specific task, such as classifying images into 1000 ImageNet classes, we demonstrate that task-agnostic ally learned general representations can be distilled into a more specialized and compact network using unlabeled examples. We simply use the teacher to impute labels for the unlabeled examples for this purpose, without using noise, augmentation, confidence threshold ing, or consistency regular iz ation. When the student network has the same or similar architecture as the teacher, this process can consistently improve the classification performance. We believe our framework can benefit from better approaches to leverage the unlabeled data for improving and transferring task-specific knowledge. We also recognize that ImageNet is a well-curated dataset, and may not reflect all real-world applications of semi-supervised learning. Thus, a potential future direction is to explore wider range of real datasets.
虽然大模型对于预训练和微调很重要,但在给定特定任务(例如将图像分类为1000个ImageNet类别)时,我们证明可以通过无标注样本将任务无关的通用表征蒸馏到更专用、更紧凑的网络中。为此,我们仅使用教师模型为无标注样本生成伪标签,无需使用噪声、数据增强、置信度阈值或一致性正则化。当学生网络与教师网络架构相同或相似时,该方法能持续提升分类性能。我们相信该框架可以通过更好的无标注数据利用方法来提升和迁移任务特定知识。我们也认识到ImageNet是经过精心整理的数据集,可能无法完全反映半监督学习的所有实际应用场景。因此,未来的潜在方向是探索更广泛的真实数据集。
6 Broader Impact
6 更广泛的影响
The findings described in this paper can potentially be harnessed to improve accuracy in any application of computer vision where it is more expensive or difficult to label additional data than to train larger models. Some such applications are clearly beneficial to society. For example, in medical applications where acquiring high-quality labels requires careful annotation by clinicians, better semi-supervised learning approaches can potentially help save lives. Applications of computer vision to agriculture can increase crop yields, which may help to improve the availability of food. However, we also recognize that our approach could become a component of harmful surveillance systems. Moreover, there is an entire industry built around human labeling services, and technology that reduces the need for these services could lead to a short-term loss of income for some of those currently employed or contracted to provide labels.
本文所述的研究成果有望提升计算机视觉应用的准确性,尤其适用于标注额外数据比训练更大模型成本更高或更困难的场景。部分应用显然对社会有益。例如在医疗领域,高质量标注需要临床医生精细标注,更优秀的半监督学习方法可能挽救生命;农业领域的计算机视觉应用可提高作物产量,从而改善粮食供应。但我们也意识到,该方法可能成为有害监控系统的组成部分。此外,当前存在完整的人类标注服务产业链,减少此类服务需求的技术可能导致部分从业者短期内收入减少。
Acknowledgements
致谢
We would like to thank David Berthelot, Han Zhang, Lala Li, Xiaohua Zhai, Lucas Beyer, Alexander Kolesnikov for their helpful feedback on the draft. We are also grateful for general support from Google Research teams in Toronto and elsewhere.
我们要感谢David Berthelot、Han Zhang、Lala Li、Xiaohua Zhai、Lucas Beyer和Alexander Kolesnikov对草稿提出的宝贵意见。同时感谢多伦多及其他地区Google Research团队的鼎力支持。
References
参考文献
A When Do Bigger Models Help More?
A 何时更大的模型更有帮助?
Figure A.1 shows relative improvement by increasing the model size under different amount of labeled examples. Both supervised learning and semi-supervised learning (i.e. SimCLRv2) seem to benefit from having bigger models. The benefits are larger when (1) regular iz ation techniques (such as augmentation, label smoothing) are used, or (2) the model is pretrained using unlabeled examples. It is also worth noting that these results may reflect a “ceiling effect”: as the performance gets closer to the ceiling, the improvement becomes smaller.
图 A.1 展示了在不同数量标注样本下,通过增大模型规模带来的相对改进。监督学习和半监督学习(即 SimCLRv2)似乎都能从更大规模的模型中获益。当(1)使用正则化技术(如数据增强、标签平滑)或(2)模型经过无标注样本预训练时,这种收益更为显著。值得注意的是,这些结果可能反映出"天花板效应":当性能越接近上限时,改进幅度会越小。

Figure A.1: Relative improvement (top-1) when model size is increased. (a) supervised learning without extra regular iz ation, (b), Supervised learning with auto-augmentation [35] and label smoothing [71] are applied for $1%/10%$ label fractions, (c) semi-supervised learning by fine-tuning SimCLRv2.
图 A.1: 模型规模增大时的相对改进(top-1)。(a) 无额外正则化的监督学习,(b) 对1%/10%标签比例应用自动数据增强[35]和标签平滑[71]的监督学习,(c) 通过微调SimCLRv2实现的半监督学习。
B Parameter Efficiency Also Matters
B 参数效率同样重要
Figure B.1 shows the top-1 accuracy of fine-tuned SimCLRv2 models of different sizes. It shows that (1) bigger models are better, but (2) with SK [28], better performance can be achieved with the same parameter count. It is worth to note that, in this work, we do not leverage group convolution for SK [28] and we use only $3\times3$ kernels. We expect further improvement in terms of parameter efficiency if group convolution is utilized.
图 B.1 展示了不同尺寸微调后的 SimCLRv2 模型的 top-1 准确率。结果表明:(1) 模型越大性能越好,但 (2) 使用 SK [28] 可以在相同参数量下获得更好性能。值得注意的是,本工作中我们未对 SK [28] 使用分组卷积 (group convolution),且仅使用 $3\times3$ 卷积核。若采用分组卷积,预计还能进一步提升参数效率。

Figure B.1: Top-1 accuracy of fined-tuned SimCLRv2 models of different sizes on three label fractions. ResNets with depth in ${50,101,152}$ , width in ${1\times,2\times}$ are included here. Parameter efficiency also plays an important role. For fine-tuning on $1%$ of labels, SK is much more efficient.
图 B.1: 不同规模微调后的SimCLRv2模型在三种标签比例下的Top-1准确率。包含深度为${50,101,152}$、宽度为${1\times,2\times}$的ResNet模型。参数效率同样起关键作用:在仅使用$1%$标签进行微调时,SK (Selective Kernel) 方法效率显著更高。
C The Correlation Between Linear Evaluation and Fine-tuning
C 线性评估与微调之间的相关性
Most existing work [17, 19, 18, 42, 20, 1] on self-supervised learning leverages linear evaluation as a main metric for evaluating representation quality, and it is not clear how it correlates with semi-supervised learning through fine-tuning. Here we further study the correlation of fine-tuning and linear evaluation (the linear classifier is trained on the ResNet output instead of some middle layer of projection head). Figure C.1 shows the correlation under two different fine-tuning strategies:
大多数现有工作[17, 19, 18, 42, 20, 1]在自监督学习领域采用线性评估作为衡量表征质量的主要指标,但其与通过微调实现的半监督学习之间的关联性尚不明确。本文进一步研究了微调与线性评估(线性分类器在ResNet输出端而非投影头中间层进行训练)的关联性。图C.1展示了两种不同微调策略下的相关性:
fine-tuning from the input of projection head, or fine-tuning from a middle layer of projection head. We observe that overall there is a linear correlation. When fine-tuned from a middle layer of the projection head, we observe a even stronger linear correlation. Additionally, we notice the slope of correlation becomes smaller as number of labeled images for fine-tuning increases .
从投影头输入进行微调,或从投影头中间层进行微调。我们观察到整体存在线性相关性。当从投影头中间层进行微调时,线性相关性更强。此外,我们还注意到随着用于微调的标注图像数量增加,相关性斜率会减小。

Figure C.1: The effects of projection head for the correlation between fine-tuning and linear evaluation. When allowing fine-tuning from the middle of the projection head, the linear correlation becomes stronger. Furthermore, as label fraction increases, the slope is decreasing. The points here are from the variants of ResNets with depth in ${50,101,152}$ , width in ${1\times,2\times}$ , and with/without SK.
图 C.1: 投影头对微调与线性评估相关性的影响。当允许从投影头中部开始微调时,线性相关性会增强。此外,随着标签比例增加,斜率逐渐减小。图中数据点来自不同变体的ResNet,其深度为${50,101,152}$,宽度为${1\times,2\times}$,且包含/不包含SK模块。
D The Impact of Memory
D 记忆的影响
Figure D.1 shows the top-1 comparisons for SimCLRv2 models trained with or without memory (MoCo) [20]. Memory provides modest advantages in terms of linear evaluation and fine-tuning with $1%$ of the labels; the improvement is around $1%$ . We believe the reason that memory only provides marginal improvement is that we already use a big batch size (i.e. 4096).
图 D.1 展示了使用或不使用内存 (MoCo) [20] 训练的 SimCLRv2 模型的 top-1 比较结果。在线性评估和使用 $1%$ 标签进行微调时,内存带来了适度的优势;改进幅度约为 $1%$。我们认为内存仅带来边际改进的原因是我们已经使用了较大的批量大小 (即 4096)。

Figure D.1: Top-1 results of ResNet-50, ResNet-101, and ResNet-152 trained with or without memory.
图 D.1: 使用或不使用内存训练的 ResNet-50、ResNet-101 和 ResNet-152 的 Top-1 结果。
E The Impact of Projection Head Under Different Model Sizes
E 不同模型规模下投影头的影响
To understand the effects of projection head settings across model sizes, Figure E.1 shows effects of fine-tuning from different layers of 2- and 3-layer projection heads. These results confirm that with only a few labeled examples, pre training with a deeper projection head and fine-tuning from a middle layer can improve the semi-supervised learning performance. The improvement is larger with a smaller model size.
为了理解不同模型规模下投影头设置的影响,图 E.1 展示了从2层和3层投影头的不同层进行微调的效果。这些结果证实,仅需少量标注样本时,使用更深的投影头进行预训练并从中间层微调可以提升半监督学习性能。模型规模越小,改进效果越显著。

Figure E.1: Top-1 fine-tuning performance under different projection head settings (number of layers included for fine-tuning) and model sizes. With fewer labeled examples, fine-tuning from the first layer of a 3-layer projection head is better, especially when the model is small. Points reflect ResNets with depths of ${50,101,152}$ and width multipliers of ${1\times,2\times}$ . Networks in the first row are without SK, and in the second row are with SK.
图 E.1: 不同投影头设置(包含微调层数)和模型规模下的Top-1微调性能。在标注样本较少时,从3层投影头的首层开始微调效果更佳,尤其当模型较小时。数据点对应深度为${50,101,152}$、宽度乘数为${1\times,2\times}$的ResNet。首行网络未使用SK模块,次行网络采用SK模块。

Figure E.2 shows fine-tuning performance for different projection head settings of a ResNet-50 pretrained using SimCLRv2. Figure 5 in the main text is an aggregation of results from this Figure. Figure E.2: Top-1 accuracy of ResNet-50 with different projection head settings. Deeper projection head help more, when allowing to fine-tune from a middle layer of the projection head.
图 E.2 展示了使用 SimCLRv2 预训练的 ResNet-50 在不同投影头设置下的微调性能。正文中的图 5 是对本图结果的汇总。
图 E.2: 采用不同投影头设置的 ResNet-50 的 Top-1 准确率。当允许从投影头中间层开始微调时,更深的投影头能带来更大提升。
F Further Distillation Ablations
F 进一步蒸馏消融实验
Figure F.1 shows the impact of distillation weight $(\alpha)$ in Eq. 3, and temperature used for distillation. We see distillation without actual labels (i.e. distillation weight is 1.0) works on par with distillation with actual labels. Furthermore, temperature of 0.1 and 1.0 work similarly, but 2.0 is significantly worse. For our distillation experiments in this work, we by default use a temperature of 0.1 when the teacher is a fine-tuned model, otherwise 1.0.
图 F.1 展示了公式3中蒸馏权重 $(\alpha)$ 和蒸馏温度的影响。我们发现不使用真实标签的蒸馏 (即蒸馏权重为1.0) 与使用真实标签的蒸馏效果相当。此外,温度0.1和1.0效果相似,但2.0明显较差。在本研究的蒸馏实验中,默认情况下当教师模型是微调模型时使用温度0.1,否则使用1.0。

Figure F.1: Top-1 accuracy with different distillation weight $(\alpha)$ , and temperature $(\tau)$ .
图 F.1: 不同蒸馏权重 $(\alpha)$ 和温度 $(\tau)$ 下的 Top-1 准确率。
We further study the distillation performance with teachers that are fine-tuned using different projection head settings. More specifically, we pretrain two ResNet-50 $(2\times+\mathrm{SK})$ models, with two or three layers of projection head, and fine-tune from a middle layer. This gives us five different teachers, corresponding to different projection head settings. Un surprisingly, as shown in Figure F.2, distillation performance is strongly correlated with the top-1 accuracy of fine-tuned teacher. This suggests that a better fine-tuned model (measured by its top-1 accuracy), regardless their projection head settings, is a better teacher for transferring task specific knowledge to the student using unlabeled data.
我们进一步研究了使用不同投影头设置微调的教师模型的蒸馏性能。具体而言,我们预训练了两个ResNet-50 $(2\times+\mathrm{SK})$ 模型,分别采用两层或三层投影头,并从中间层进行微调。这为我们提供了五种不同投影头设置的教师模型。如图F.2所示,蒸馏性能与微调教师模型的top-1准确率高度相关。这表明,无论投影头设置如何,top-1准确率更高的微调模型(衡量标准为其top-1准确率)在利用未标记数据向学生模型传递任务特定知识时表现更优。

Figure F.2: The strong correlation between teacher’s task performance and student’s task performance.
图 F.2: 教师任务表现与学生任务表现之间的强相关性。
G CIFAR-10
G CIFAR-10
We perform main experiments on ImageNet since it is a large-scale and well studied dataset. Here we conduct similar experiments on small-scaled CIFAR-10 dataset to test our findings in ImageNet. More specifically, we pretrain ResNets on CIFAR-10 without labels following [1] 5. The ResNet variants we trained are of 6 depths, namely 18, 34, 50, 101, 152 and 200. To keep experiments tractable, by default we use Selective Kernel, and a width multiplier of $1\times$ . After the models are pretrained, we then fine-tune them (using simple augmentations of random crop and horizontal flipping) on different numbers of labeled examples (250, 4000, and total of 5000 labeled examples), following MixMatch’s protocol and running on 5 seeds.
我们在ImageNet上进行主要实验,因为这是一个经过充分研究的大规模数据集。为验证在ImageNet上的发现,我们在小规模CIFAR-10数据集上进行了类似实验。具体而言,我们按照[1]5的方法在无标签CIFAR-10上预训练ResNet,所训练的ResNet变体包含6种深度(18、34、50、101、152和200)。为控制实验复杂度,默认使用选择性核(Selective Kernel)和$1\times$宽度乘数。预训练完成后,我们遵循MixMatch方案,在不同数量标注样本(250、4000及全部5000个标注样本)上对模型进行微调(采用随机裁剪和水平翻转的简单增强),并在5个随机种子下运行。
The fine-tuning performances are shown in the Figure G.1, and suggest similar trends to our results on ImageNet: big pretrained models can perform well, often better, with a few labeled examples. These results can be further improved with better augmentations during fine-tuning and an extra distillation step. The linear evaluation also improves with a bigger network. Our best result is $96.4%$ obtained from ResNet-101 $(+\mathrm{SK})$ and ResNet-152 $(+\mathrm{SK})$ , but it is slightly worse $(96.2%)$ with ResNet-200 $(+\mathrm{SK})$ .
微调性能如图 G.1 所示,其趋势与我们在 ImageNet 上的结果相似:大型预训练模型只需少量标注样本即可表现良好,甚至更优。通过改进微调过程中的数据增强和额外的蒸馏步骤,这些结果还能进一步提升。线性评估性能也随着网络规模的增大而提高。我们的最佳结果为 ResNet-101 $(+\mathrm{SK})$ 和 ResNet-152 $(+\mathrm{SK})$ 取得的 $96.4%$,而 ResNet-200 $(+\mathrm{SK})$ 稍逊 $(96.2%)$。

Figure G.1: Fine-tuning pre-trained ResNets on CIFAR-10.
图 G.1: 在 CIFAR-10 上微调预训练的 ResNet。
H Extra Results
H 额外结果
Table H.1 shows top-5 accuracy of the fine-tuned SimCLRv2 (under different model sizes) on ImageNet.
表 H.1: 微调后的 SimCLRv2 (不同模型尺寸下) 在 ImageNet 上的 top-5 准确率。
Table H.1: Top-5 accuracy of fine-tuning SimCLRv2 (on varied label fractions) or training a linear classifier on the ResNet output. The supervised baselines are trained from scratch using all labels in 90 epochs. The parameter count only include ResNet up to final average pooling layer. For fine-tuning results with $1%$ and $10%$ labeled examples, the models include additional non-linear projection layers, which incurs additional parameter count (4M for $1\times$ models, and 17M for $2\times$ models).
| Depth | Width | Use SK [28] | Param (M) | Fine-tuned on | Linear eval | Supervised | ||
| 1% | 10% | 100% | ||||||
| 50 | 1x | False | 24 | 82.5 | 89.2 | 93.3 | 90.4 | 93.3 |
| True | 35 | 86.7 | 91.4 | 94.6 | 92.3 | 94.2 | ||
| 2× | False | 94 | 87.4 | 91.9 | 94.8 | 92.7 | 93.9 | |
| True | 140 | 90.2 | 93.7 | 95.9 | 93.9 | 94.5 | ||
| 1x | False | 43 | 85.2 | 90.9 | 94.3 | 91.7 | 93.9 | |
| 101 | True | 65 | 89.2 | 93.0 | 95.4 | 93.1 | 94.8 | |
| 2x | False | 170 | 88.9 | 93.2 | 95.6 | 93.4 | 94.4 | |
| True | 257 | 91.6 | 94.5 | 96.4 | 94.5 | 95.0 | ||
| False | 58 | 86.6 | 91.8 | 94.9 | 92.4 | 94.2 | ||
| 152 | 1x | True | 89 | 90.0 | 93.7 | 95.9 | 93.6 | 95.0 |
| 2x | False | 233 | 89.4 | 93.5 | 95.8 | 93.6 | 94.5 | |
| True | 354 | 92.1 | 94.7 | 96.5 | 94.7 | 95.0 | ||
| 152 | 3× | True | 795 | 92.3 | 95.0 | 96.6 | 94.9 | 95.1 |
表 H.1: 微调 SimCLRv2 (使用不同标签比例) 或在 ResNet 输出上训练线性分类器的 Top-5 准确率。监督基线使用全部标签从头训练 90 个周期。参数数量仅包含 ResNet 至最终平均池化层。对于使用 $1%$ 和 $10%$ 标记样本的微调结果,模型包含额外的非线性投影层,这会增加参数数量 ($1\times$ 模型增加 4M,$2\times$ 模型增加 17M)。
| 深度 | 宽度 | 使用 SK [28] | 参数量 (M) | 微调比例 1% | 微调比例 10% | 微调比例 100% | 线性评估 | 监督训练 |
|---|---|---|---|---|---|---|---|---|
| 50 | 1x | False | 24 | 82.5 | 89.2 | 93.3 | 90.4 | 93.3 |
| True | 35 | 86.7 | 91.4 | 94.6 | 92.3 | 94.2 | ||
| 2× | False | 94 | 87.4 | 91.9 | 94.8 | 92.7 | 93.9 | |
| True | 140 | 90.2 | 93.7 | 95.9 | 93.9 | 94.5 | ||
| 101 | 1x | False | 43 | 85.2 | 90.9 | 94.3 | 91.7 | 93.9 |
| True | 65 | 89.2 | 93.0 | 95.4 | 93.1 | 94.8 | ||
| 2x | False | 170 | 88.9 | 93.2 | 95.6 | 93.4 | 94.4 | |
| True | 257 | 91.6 | 94.5 | 96.4 | 94.5 | 95.0 | ||
| 152 | 1x | False | 58 | 86.6 | 91.8 | 94.9 | 92.4 | 94.2 |
| True | 89 | 90.0 | 93.7 | 95.9 | 93.6 | 95.0 | ||
| 2x | False | 233 | 89.4 | 93.5 | 95.8 | 93.6 | 94.5 | |
| True | 354 | 92.1 | 94.7 | 96.5 | 94.7 | 95.0 | ||
| 152 | 3× | True | 795 | 92.3 | 95.0 | 96.6 | 94.9 | 95.1 |