MTP: Advancing Remote Sensing Foundation Model via Multi-Task Pre training
MTP: 通过多任务预训练推进遥感基础模型发展
Di Wang, Member, IEEE, Jing Zhang, Senior Member, IEEE, Minqiang Xu, Lin Liu, Dongsheng Wang, Erzhong Gao, Chengxi Han, Student Member, IEEE, Haonan Guo, Student Member, IEEE, Bo Du, Senior Member, IEEE, Dacheng Tao, Fellow, IEEE and Liangpei Zhang, Fellow, IEEE
Di Wang (IEEE会员), Jing Zhang (IEEE高级会员), Minqiang Xu, Lin Liu, Dongsheng Wang, Erzhong Gao, Chengxi Han (IEEE学生会员), Haonan Guo (IEEE学生会员), Bo Du (IEEE高级会员), Dacheng Tao (IEEE会士), Liangpei Zhang (IEEE会士)
Abstract—Foundation models have reshaped the landscape of Remote Sensing (RS) by enhancing various image interpretation tasks. Pre training is an active research topic, encompassing supervised and self-supervised learning methods to initialize model weights effectively. However, transferring the pretrained models to downstream tasks may encounter task discrepancy due to their formulation of pre training as image classification or object discrimination tasks. In this study, we explore the Multi-Task Pre training (MTP) paradigm for RS foundation models to address this issue. Using a shared encoder and task-specific decoder architecture, we conduct multi-task supervised pre training on the SAMRS dataset, encompassing semantic segmentation, instance segmentation, and rotated object detection. MTP supports both convolutional neural networks and vision transformer foundation models with over 300 million parameters. The pretrained models are finetuned on various RS downstream tasks, such as scene classification, horizontal and rotated object detection, semantic segmentation, and change detection. Extensive experiments across 14 datasets demonstrate the superiority of our models over existing ones of similar size and their competitive performance compared to larger state-of-the-art models, thus validating the effectiveness of MTP. The codes and pretrained models will be released at https://github.com/ViTAE-Transformer/MTP.
摘要—基础模型通过增强各类遥感(RS)图像解译任务重塑了该领域格局。预训练作为活跃研究方向,涵盖监督与自监督学习方法以有效初始化模型权重。然而,预训练模型迁移至下游任务时可能因图像分类或目标判别任务的形式化定义而产生任务差异。本研究探索面向遥感基础模型的多任务预训练(MTP)范式以解决该问题。基于共享编码器与任务专属解码器架构,我们在SAMRS数据集上开展涵盖语义分割、实例分割和旋转目标检测的多任务监督预训练。MTP支持参数量超3亿的卷积神经网络与Vision Transformer基础模型。预训练模型在场景分类、水平/旋转目标检测、语义分割及变化检测等下游任务上微调。跨14个数据集的实验表明,我们的模型在同等规模模型中具有优越性,并与更大规模的最先进模型性能相当,验证了MTP的有效性。代码与预训练模型将发布于https://github.com/ViTAE-Transformer/MTP。
Index Terms—Remote sensing, Foundation model, Multi-task pre training, Scene classification, Semantic segmentation, Object detection, Change detection.
索引术语—遥感、基础模型 (Foundation model)、多任务预训练 (Multi-task pre-training)、场景分类、语义分割、目标检测、变化检测
I. INTRODUCTION
I. 引言
R Emote sensing (RS) image is one of the most important data resources for recording ground surfaces and land objects. Precisely understanding RS images is beneficial to many applications, including urban planning [1], environmental survey [2], disaster assessment [3], etc.
遥感(RS)图像是记录地表和地物最重要的数据资源之一。精确理解遥感影像对城市规划[1]、环境调查[2]、灾害评估[3]等众多应用具有重要意义。
D. Wang and B. Du are with the School of Computer Science, Wuhan University, Wuhan 430072, China, also with the Institute of Artificial Intelligence, Wuhan University, Wuhan 430072, China, also with the National Engineering Research Center for Multimedia Software, Wuhan University, Wuhan 430072, China, and also with the Hubei Key Laboratory of Multimedia and Network Communication Engineering, Wuhan University, Wuhan 430072, China (email: wd74108520@gmail.com; dubo $@$ whu.edu.cn).(Corresponding author: Minqiang Xu, Jing Zhang, Bo Du and Liangpei Zhang.) J. Zhang is with the School of Computer Science, Faculty of Engineering, The University of Sydney, Australia (e-mail: jing.zhang1 $@$ sydney.edu.au). M. Xu, L. Liu, D. Wang and E. Gao are with the iFlytek Co., Ltd and also with the National Engineering Research Center of Speech and Language Information Processing, Hefei 230088, China (e-mail: mqxu7 $@$ iflytek.com; linliu $@$ iflytek.com; dswang7 $@$ iflytek.com; ezgao@iflytek.com). C. Han, H. Guo and L. Zhang are with the State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, Wuhan 430079, China (e-mail: chengxihan $@$ whu.edu.cn; haonan.guo $@$ whu.edu.cn; zlp62 $@$ whu.edu.cn). D. Tao is with the School of Computer Science and Engineering, Nanyang Technological University, Singapore (e-mail: dacheng.tao@gmail.com).
D. Wang 和 B. Du 就职于武汉大学计算机学院,武汉 430072,中国;同时隶属于武汉大学人工智能研究院,武汉 430072,中国;国家多媒体软件工程技术研究中心,武汉 430072,中国;以及湖北省多媒体与网络通信工程重点实验室,武汉 430072,中国 (邮箱:wd74108520@gmail.com; dubo $@$ whu.edu.cn)。(通讯作者:Minqiang Xu、Jing Zhang、Bo Du 和 Liangpei Zhang。) J. Zhang 就职于悉尼大学工程学院计算机学院,澳大利亚 (邮箱:jing.zhang1 $@$ sydney.edu.au)。M. Xu、L. Liu、D. Wang 和 E. Gao 就职于科大讯飞股份有限公司,同时隶属于国家语音及语言信息处理工程技术研究中心,合肥 230088,中国 (邮箱:mqxu7 $@$ iflytek.com; linliu $@$ iflytek.com; dswang7 $@$ iflytek.com; ezgao@iflytek.com)。C. Han、H. Guo 和 L. Zhang 就职于武汉大学测绘遥感信息工程国家重点实验室,武汉 430079,中国 (邮箱:chengxihan $@$ whu.edu.cn; haonan.guo $@$ whu.edu.cn; zlp62 $@$ whu.edu.cn)。D. Tao 就职于南洋理工大学计算机科学与工程学院,新加坡 (邮箱:dacheng.tao@gmail.com)。
Utilizing its inherent capability to automatically learn and extract deep features from objects, deep learning methods have found widespread application in the RS domain, particularly for tasks such as scene classification, land use and land cover classification, and ship detection. Typically, ImageNet pretrained weights are employed in training deep networks for RS tasks due to their extensive representational ability. However, these weights are derived from pre training models on natural images, leading to domain gaps between natural images and RS images. For instance, RS images are captured from a bird’s-eye view, lack the vibrant colors of natural images, and possess lower spatial resolution. These disparities may impede the model’s finetuning performance [4], [5]. Moreover, relying solely on limited task-specific data for training restricts the model size and generalization capability of current RS deep models due to the notorious over fitting issue.
深度学习凭借其自动学习和提取物体深层特征的固有能力,已在遥感(RS)领域获得广泛应用,特别是在场景分类、土地利用与土地覆盖分类、船舶检测等任务中。通常,遥感任务中的深度网络训练会采用ImageNet预训练权重,因其具有强大的表征能力。然而,这些权重源自自然图像的预训练模型,导致自然图像与遥感图像之间存在领域差异。例如,遥感图像采用鸟瞰视角拍摄、缺乏自然图像的鲜艳色彩、且空间分辨率较低。这些差异可能影响模型的微调性能[4][5]。此外,由于臭名昭著的过拟合问题,仅依靠有限的任务专用数据进行训练,限制了当前遥感深度模型的规模与泛化能力。
To tackle these challenges, the development of RS vision foundation models is imperative, which should excel in extracting representative RS features. However, the RS domain has long grappled with a scarcity of adequately large annotated datasets, impeding related investigations. Until recently, the most expansive RS scene labeling datasets were fMoW [6] and Big Earth Net [7], boasting 132,716 and 590,326 unique scene instances [8], respectively — yet still falling short of benchmarks set by natural image datasets like ImageNet1K [9]. Long et al. [8] addressed this gap by introducing MillionAID, a large-scale RS scene labeling dataset with a closed sample capacity of 100,0848 compared to ImageNet1K, igniting interest in supervised RS pre training [5], [10]. These studies show the feasibility of pre training RS foundation models on large-scale RS datasets. Nonetheless, supervised pre training of RS foundation models may not be the most preferable choice due to the expertise and substantial time and labor costs associated with labeling RS images.
为应对这些挑战,开发能够出色提取代表性遥感特征的遥感视觉基础模型势在必行。然而,遥感领域长期面临标注数据集规模不足的问题,阻碍了相关研究。直至近期,规模最大的遥感场景标注数据集fMoW [6]和Big Earth Net [7]分别仅包含132,716和590,326个独特场景实例[8],仍无法与ImageNet1K [9]等自然图像数据集相提并论。Long等人[8]通过推出百万级样本量的MillionAID数据集(含1,000,848个样本)填补了这一空白,激发了基于监督学习的遥感预训练研究热潮[5][10]。这些研究表明在大规模遥感数据集上预训练基础模型具有可行性。但值得注意的是,由于遥感图像标注需要专业知识和巨大的人力时间成本,采用监督式预训练方法构建遥感基础模型可能并非最优选择。
Constructing large-scale RS annotation datasets is challenging due to the high complexity and cost of labeling. Despite this challenge, the advancement of earth observation technologies grants easy access to a vast amount of unlabeled RS images. Efficiently leveraging these unlabeled RS images is crucial for developing robust RS foundation models. In the realm of deep learning, unsupervised pre training has emerged as a promising approach for learning effective knowledge from massive unlabeled data [14]–[17]. Typically, unsupervised pre training employs self-supervised learning (SSL) to learn effective feature representation. SSL encompasses two primary techniques: contrastive-based [18]–[20] and generative-based learning [21]–[23]. Contrastive learning aims to bring similar samples closer while maximizing distances between dissimilar samples through the object discrimination pretext task. When applied to the RS domain, data characteristics like geographic coordinates [24]–[26] and temporal information [27]–[29] are usually leveraged in formulating the pretext task. However, designing these pretext tasks and gathering requisite data can be inefficient, especially for training large-scale models. Generative-based learning, exemplified by masked image modeling (MIM), circumvents this challenge by enhancing network representation through reconstructing masked regions. Many RS studies leverage MIM initialization for its efficiency [30]–[37]. Recent approaches have attempted to combine contrastive-based and generative-based learning techniques to pretrain more powerful models [38]–[40].
构建大规模遥感(RS)标注数据集具有挑战性,主要源于标注工作的高度复杂性和成本。尽管如此,地球观测技术的进步使我们能轻松获取大量未标注的遥感图像。高效利用这些未标注图像对于开发稳健的遥感基础模型至关重要。在深度学习领域,无监督预训练已成为从海量未标注数据中学习有效知识的重要方法[14]-[17]。通常,无监督预训练采用自监督学习(SSL)来获取有效特征表示,主要包括两种技术:基于对比的学习[18]-[20]和基于生成的学习[21]-[23]。对比学习通过对象判别前置任务,使相似样本彼此靠近,同时最大化不相似样本间的距离。在遥感领域应用时,通常会利用地理坐标[24]-[26]和时间信息[27]-[29]等数据特征来设计前置任务。然而,设计这些前置任务并收集必要数据可能效率低下,特别是在训练大规模模型时。以掩码图像建模(MIM)为代表的生成式学习通过重建掩码区域来增强网络表示,规避了这一挑战。许多遥感研究因其高效性而采用MIM初始化[30]-[37]。近期研究尝试结合对比式与生成式学习技术来预训练更强大的模型[38]-[40]。
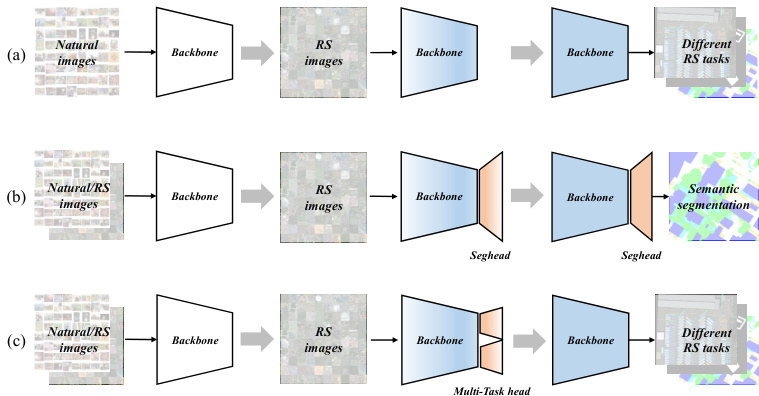
Fig. 1. Comparison of various pre training methods. (a) [11], [12] sequentially pretrains a foundational model on both natural and RS images. (b) [13] employs a two-stage pre training strategy to initialize task-specific decoders (e.g., segmentation) using existing foundational models pretrained on either natural or RS images, preserving the decoder during subsequent finetuning. We extend (b) by incorporating multi-task decoders to enhance the representation capacity of the foundational model, facilitating easy transfer ability across diverse tasks during finetuning, as depicted in (c).
图 1: 不同预训练方法的对比。(a) [11], [12] 在自然图像和遥感图像上顺序预训练基础模型。(b) [13] 采用两阶段预训练策略,使用在自然图像或遥感图像上预训练的现有基础模型来初始化任务特定解码器(如分割),并在后续微调中保留解码器。我们将(b)扩展为(c)所示方案,通过引入多任务解码器增强基础模型的表征能力,从而在微调阶段实现跨任务的轻松迁移。
However, existing research usually resorts to a single data source. For instance, [5], [30] utilize RGB aerial images from MillionAID, while [31], [34] utilize Sentinel-2 multi spectral images. Despite recent advancements in RS multimodal foundation models [41]–[44], which are beginning to incorporate more diverse imagery such as SAR, they still remain within the realm of in-domain data, namely pre training with RS data. However, restricting pre training solely to RS images may limit model capabilities since understanding RS objects requires specialized knowledge [12]. Can RS foundation models benefit from incorporating information from other data sources? [5] suggests that traditional ImageNet pre training aids in learning universal representations, whereas pre training on RS data is particularly beneficial for recognizing RS-related categories. To address this, [45] develop a teacher-student framework that integrates ImageNet supervised pre training and RS unsupervised pre training simultaneously, while [46] employs representations from ImageNet to enhance the learning process of MIM for improving RS foundation models. Additionally, [12] and [11] sequentially pretrain models on natural images and RS images using contrastive SSL or MAE [23], respectively, as illustrated in Figure 1(a).
然而,现有研究通常局限于单一数据源。例如,[5]、[30]使用MillionAID的RGB航拍图像,而[31]、[34]则采用Sentinel-2多光谱图像。尽管近期遥感多模态基础模型[41]–[44]取得进展,开始融合SAR等更多元影像,但仍局限于域内数据(即基于遥感数据的预训练)。但仅依赖遥感图像进行预训练可能限制模型能力,因为理解遥感对象需要专业知识[12]。遥感基础模型能否从其他数据源的信息中获益?[5]指出,传统ImageNet预训练有助于学习通用表征,而遥感数据预训练则对识别遥感相关类别特别有效。为此,[45]开发了同时整合ImageNet监督预训练与遥感无监督预训练的师生框架,[46]则利用ImageNet表征来增强MIM学习过程以改进遥感基础模型。此外,[12]和[11]分别采用对比式自监督学习(SSL)或MAE[23],在自然图像和遥感图像上对模型进行序贯预训练,如图1(a)所示。
While previous RS foundation models have shown remarkable performance across various RS tasks, a persistent challenge remains: the task discrepancy between pre training and finetuning, which often dictates the effectiveness of migrating pretrained models to downstream tasks. Research has highlighted the impact of representation granularity mismatch between pre training and finetuning tasks [5]. For instance, models pretrained on scene-level classification tasks perform favorably when finetuned on similar tasks but falter on pixellevel segmentation tasks. To address this issue, recent work [13] has explored the segmentation pre training paradigm, as shown in Figure 1(b), yielding improved finetuning results. This suggests that enhancing model representation capability through additional pre training, particularly on tasks demanding finer representation granularity, such as pixel-level segmentation, could be beneficial. Motivated by these findings, we ask: can we significantly enhance RS foundation models’ representation ability through additional pre training incorporating multiple tasks with diverse representation granularity? To this end, we investigate the Multi-Task Pre training (MTP) paradigm to bridge the gap between upstream and downstream tasks and obtain more powerful RS foundation models, as shown in Figure 1(c). Importantly, MTP is designed to be applied to any existing pre training models, irrespective of whether trained on RS or natural images.
尽管现有的遥感基础模型在各种遥感任务中表现出色,但始终存在一个挑战:预训练与微调之间的任务差异,这往往决定了预训练模型迁移到下游任务的效果。研究表明,预训练与微调任务间的表征粒度不匹配会影响性能[5]。例如,在场景级分类任务上预训练的模型,在类似任务上微调时表现良好,但在像素级分割任务上却表现不佳。为解决这一问题,近期研究[13]探索了分割预训练范式(如图1(b)所示),显著提升了微调效果。这表明,通过额外预训练(尤其是对像素级分割等需要更细粒度表征的任务)来增强模型表征能力可能具有积极意义。受此启发,我们提出:能否通过融合多粒度表征任务的额外预训练,显著提升遥感基础模型的表征能力?为此,我们研究了多任务预训练(MTP)范式(如图1(c)所示),以弥合上下游任务间的差距,从而获得更强大的遥感基础模型。值得注意的是,MTP可应用于任何现有预训练模型,无论其训练数据来自遥感图像还是自然图像。
Implementing MTP to bridge upstream-downstream task discrepancy necessitates the utilization of a similar or the same pre training task as the downstream one, such as segmentation pre training (SEP) for RS segmentation tasks [13]. Therefore, to cover the common task types in typical downstream applications, MTP tasks should encompass dense prediction tasks like object detection and semantic segmentation. Hence, MTP requires a pre training dataset with labels for these tasks, ideally, each sample encompassing all task labels. However, existing RS datasets often lack annotations for segmentation and rotated object detection. Fortunately, recent work [13] introduces SAMRS, a large-scale segmentation dataset derived from existing RS rotated object detection datasets via the Segment Anything Model (SAM) [47]. SAMRS provides both detection and segmentation labels, facilitating MTP across RS semantic segmentation, instance segmentation, and rotated object detection tasks. Utilizing SAMRS, we demonstrate MTP’s efficacy in enhancing RS foundation models, including both convolutional neural networks (CNN) and vision transformer foundation models with over 300 million parameters.
实施MTP以弥合上游-下游任务差异,需要采用与下游任务相似或相同的预训练任务,例如针对遥感(RS)分割任务的分割预训练(SEP) [13]。因此,为覆盖典型下游应用中的常见任务类型,MTP任务应包含目标检测和语义分割等密集预测任务。这意味着MTP需要一个带有这些任务标签的预训练数据集,理想情况下每个样本都包含所有任务标签。然而现有遥感数据集往往缺乏分割和旋转目标检测的标注。幸运的是,近期研究[13]通过Segment Anything Model (SAM) [47]从现有RS旋转目标检测数据集构建了大规模分割数据集SAMRS。该数据集同时提供检测和分割标签,支持跨RS语义分割、实例分割和旋转目标检测任务的MTP实施。基于SAMRS数据集,我们验证了MTP在增强RS基础模型(包括参数量超3亿的卷积神经网络(CNN)和视觉Transformer基础模型)方面的有效性。
The main contributions of this paper are three-fold:
本文的主要贡献有三方面:
classification, semantic segmentation, object detection, and change detection.
分类、语义分割、目标检测和变化检测。
The remainder of this paper is organized as follows. Section II introduces the existing works related to supervised, multi-stage, and multi-task RS pre training. Section III presents the details of MTP, where the used SAMRS dataset and vision foundation models are also briefly introduced. Experimental results and corresponding analyses are depicted in Section IV. Finally, Section V concludes this paper.
本文的其余部分组织如下。第 II 节介绍了与监督式、多阶段和多任务遥感 (RS) 预训练相关的现有工作。第 III 节详细介绍了 MTP (Multi-Task Pretraining) 方法,并简要介绍了所使用的 SAMRS 数据集和视觉基础模型。实验结果及相应分析见第 IV 节。最后,第 V 节对全文进行总结。
II. RELATED WORK
II. 相关工作
A. Supervised Pre training for RS Foundation Model
A. 遥感基础模型的监督式预训练
Before the rise of SSL-based RS foundation models, researchers have already delved into pre training deep models using labeled RS datasets. Tong et al. [48] pretrained an ImageNet-pretrained ResNet-50 [49] using images from the GID dataset [48] to derive pseudo-labels for precise land-cover classification on high-resolution RS images. Recognizing the challenge of labeling large-scale RS images, others sought alternatives to RS annotation datasets. For instance, Li et al. [50] utilized the global land cover product Globe land 30 [51] as supervision for RS representation learning. They adopted a mean-teacher framework to mitigate random noise stemming from inconsistencies in imaging time and resolution between RS images and geographical products. Moreover, they incorporated additional geographical supervisions, such as change degree and spatial aggregation, to regularize the pre training process [52]. Long et al. [10] subsequently demonstrated the effectiveness of various CNN models (including AlexNet [53], VGG-16 [54], GoogleNet [55], ResNet-101 [49], and DenseNet-121/169 [56]) pretrained from scratch on the MillionAID dataset. Their models outperformed traditional ImageNet pretrained models in scene classification tasks, indicating the potential of leveraging large-scale RS datasets for pre training. Later, Wang et al. [5] pretrained typical CNN models and vision transformer models, including Swin-T [57] and ViTAEv2 [58], all randomly initialized, on the MillionAID. They conducted a comprehensive empirical study comparing finetuning performance using different pre training strategies (MillionAID vs. ImageNet) across four types of RS downstream tasks: scene recognition, semantic segmentation, rotated object detection, and change detection. Their results demonstrated the superiority of vision transformer models over CNNs on RS scenes and validated the feasibility of constructing RS foundation models via supervised pre training on largescale RS datasets. Bastani et al. [59] introduced the larger Satlas dataset for RS supervised pre training. Very recently, SAMRS [13] introduced supervised semantic segmentation pre training to enhance model performance on the segmentation task. Inspired by [13], this paper revisits the supervised learning approach by integrating it with existing pre training strategies, such as ImageNet pre training, and exploring multitask pre training to construct distinct RS foundation models.
在基于SSL (自监督学习) 的遥感基础模型兴起之前,研究者已开始探索利用标注遥感数据集预训练深度模型。Tong等[48]使用GID数据集[48]图像对ImageNet预训练的ResNet-50[49]进行预训练,为高分辨率遥感影像精准土地覆盖分类生成伪标签。针对大规模遥感影像标注难题,部分研究转向替代标注方案。例如Li等[50]采用全球土地覆盖产品GlobeLand30[51]作为遥感表征学习的监督信号,通过均值教师框架缓解遥感影像与地理产品在成像时间和分辨率上的随机噪声,并引入变化程度、空间聚合等地理监督信号优化预训练过程[52]。Long等[10]首次在MillionAID数据集上从头预训练多种CNN模型(包括AlexNet[53]、VGG-16[54]、GoogleNet[55]、ResNet-101[49]和DenseNet-121/169[56]),其场景分类任务表现超越传统ImageNet预训练模型,证明大规模遥感数据集预训练的潜力。Wang等[5]进一步在MillionAID上预训练随机初始化的典型CNN模型及视觉Transformer模型(含Swin-T[57]和ViTAEv2[58]),通过场景识别、语义分割、旋转目标检测和变化检测四类下游任务的对比实验,验证视觉Transformer在遥感场景的优越性,并证实基于大规模标注数据集的有监督预训练构建遥感基础模型的可行性。Bastani等[59]提出更大规模的Satlas数据集用于有监督预训练。最新研究SAMRS[13]引入有监督语义分割预训练提升模型分割性能。受此启发,本文通过融合ImageNet预训练等现有策略,探索多任务预训练路径以构建差异化遥感基础模型。
B. Multi-Stage Pre training for RS Foundation Model
B. RS基础模型的多阶段预训练
Given the domain gap between RS images and natural images or between various RS modalities, it is reasonable to conduct multiple rounds of pre training. Gururangan et al. [60] demonstrated that unsupervised pre training on in-domain or task-specific data enhances model performance in natural language processing (NLP) tasks. Building on this insight, Zhang et al. [11] devised a sequential pre training approach, initially on ImageNet followed by the target RS dataset, employing MIM for pre training. Similarly, [12] proposed a strategy inspired by human-like learning, first performing contrastive SSL on natural images, then freezing shallow layer weights and conducting SSL on an RS dataset. Contrary to [60], Dery et al. [61] introduced stronger end-task-aware training for NLP tasks by integrating auxiliary data and end-task objectives into the learning process. Similarly, [13] introduced additional segmentation pre training using common segmenters (e.g., UperNet [62] and Mask 2 Former [63]) and the SAMRS dataset, enhancing model accuracy in RS segmentation tasks. Notably, our objective diverges from [13] in applying stagewise pre training. While [13] retains the segmentor after segmentation pre training to enhance segmentation performance, we aim to enhance the representation capability of RS foundation models via stage-wise pre training, preserving only the backbone network after pre training to facilitate transfer to diverse RS downstream tasks.
考虑到遥感(RS)图像与自然图像之间或不同遥感模态之间的领域差异,进行多轮预训练是合理的。Gururangan等人[60]证明,在自然语言处理(NLP)任务中,对领域内或任务特定数据进行无监督预训练可提升模型性能。基于这一发现,Zhang等人[11]设计了一种分阶段预训练方法:先在ImageNet上预训练,再在目标遥感数据集上采用掩码图像建模(MIM)进行预训练。类似地,[12]提出了一种仿人类学习的策略:先在自然图像上进行对比式自监督学习(SSL),然后冻结浅层权重并在遥感数据集上进行SSL。与[60]不同,Dery等人[61]通过将辅助数据和最终任务目标整合到学习过程中,为NLP任务引入了更强的任务感知训练。同样地,[13]通过使用通用分割器(如UperNet[62]和Mask2Former[63])和SAMRS数据集进行额外分割预训练,提升了模型在遥感分割任务中的精度。值得注意的是,我们的阶段式预训练目标与[13]存在差异:[13]在分割预训练后保留分割器以提升分割性能,而我们旨在通过分阶段预训练增强遥感基础模型的表征能力,预训练后仅保留主干网络以适配多样化的遥感下游任务。
C. Multi-Task Pre training for RS Foundation Model
C. 遥感基础模型的多任务预训练
Applying multi-task learning to enhance the RS foundation model is an intuitive idea. Li et al. [64] introduced multitask SSL representation learning, combining image inpainting, transform prediction, and contrast learning to boost semantic segmentation performance in RS images. However, it was limited to finetuning a pretrained model solely on semantic segmentation tasks, constrained by model size and pre training dataset capacity. RSCoTr [65] constructs a multi-task learning framework to simultaneously achieve classification, segmentation, and detection tasks. Unfortunately, the network can only be optimized by one task in each iteration during training due to lacking of multi-label datasets. The aspiration to consolidate multiple tasks into a single model has been a longstanding pursuit [15], [17], [42], [58], [66]–[75], aligning with the original goals of the foundation model exploration. Bastani et al. [59] devised a multi-task model by integrating Swin-Base [57] with seven heads from existing networks (e.g., FasterRCNN [76] and UNet [77]), facilitating training on the multitask annotated Satlas dataset. However, their approach lacked incorporation of typical RS rotated object tasks, focusing solely on transferring the model to RS classification datasets. Inspired by these pioneering efforts, this paper constructs a unified multi-task pre training framework that supports multiple datasets, where the sample in each dataset simultaneously possesses multi-task labels, which are uniformly processed in a data loader pipeline. During the training, the model can be simultaneously optimized through multiple tasks when in each iteration. Based on this framework, we pretrain RS foundation models with over 300M parameters, encompassing semantic segmentation, instance segmentation, and rotated object detection tasks using the SAMRS dataset. After pre training, the backbone network is further finetuned on various RS downstream tasks.
将多任务学习应用于增强遥感(RS)基础模型是一个直观的思路。Li等人[64]提出了多任务自监督学习(SSL)表征学习方法,结合图像修复、变换预测和对比学习来提升遥感图像语义分割性能。但该方法受限于模型规模和预训练数据集容量,仅能在语义分割任务上微调预训练模型。RSCoTr[65]构建了多任务学习框架以同时实现分类、分割和检测任务,但由于缺乏多标签数据集,训练时每次迭代只能通过单一任务优化网络。将多任务整合到单一模型中的愿景长期存在[15][17][42][58][66]-[75],这与基础模型探索的初衷高度契合。Bastani等人[59]通过整合Swin-Base[57]与现有网络(如FasterRCNN[76]和UNet[77])的七个头部模块,设计了可在多任务标注的Satlas数据集上训练的多任务模型,但该方法未包含典型遥感旋转目标检测任务,仅专注于将模型迁移至遥感分类数据集。受这些开创性工作启发,本文构建了支持多数据集的多任务预训练统一框架,其中每个数据集的样本同时具备多任务标签,并通过数据加载管道统一处理。训练时模型可在每次迭代中通过多任务同时优化。基于该框架,我们使用SAMRS数据集预训练了参数量超3亿的遥感基础模型,涵盖语义分割、实例分割和旋转目标检测任务。预训练完成后,骨干网络可在各类遥感下游任务上进一步微调。
III. MULTI-TASK PRE TRAINING
III. 多任务预训练
We utilize semantic segmentation, instance segmentation, and rotated object detection annotations from the SAMRS dataset for Multi-Task Pre training (MTP). Advanced CNN and vision transformer models serve as the backbone networks to thoroughly investigate MTP. This section begins with an overview of the SAMRS dataset, followed by a brief introduction to the selected models. Subsequently, we present the MTP framework and implementation details.
我们利用SAMRS数据集中的语义分割、实例分割和旋转目标检测标注进行多任务预训练(MTP)。采用先进的CNN和视觉Transformer模型作为骨干网络,全面研究MTP。本节首先概述SAMRS数据集,随后简要介绍所选模型,最后阐述MTP框架及实现细节。
A. SAMRS Dataset
A. SAMRS 数据集
SAMRS (Segment Anything Model annotated Remote Sensing Segmentation dataset) [13] is a large-scale RS segmentation database, comprising 105,090 images and 1,668,241 instances from three datasets: SOTA, SIOR, and FAST. These datasets are derived from existing large-scale RS object detection datasets, namely DOTA-V2.0 [78], DIOR [79], and FAIR1M-2.0 [80], through transforming the bounding box annotations using the SAM [47]. SAMRS inherits the categories directly from the original detection datasets, resulting in a capacity exceeding that of most existing RS segmentation datasets by more than tenfold (e.g., ISPRS Potsdam1 and LoveDA [81]). The image sizes for the three sets are 1,024 $\times1{,}024$ , $800~\times800$ , and $600\times~600$ , respectively. Despite being primarily intended for large-scale pre training exploration rather than benchmarking due to its automatically generated labels, SAMRS naturally supports instance segmentation and object detection. This versatility extends its utility to investigating large-scale multi-task pre training.
SAMRS (Segment Anything Model annotated Remote Sensing Segmentation dataset) [13] 是一个大规模遥感(RS)分割数据集,包含来自SOTA、SIOR和FAST三个数据集的105,090张图像和1,668,241个实例。这些数据集通过SAM [47]转换边界框标注,源自现有大规模遥感目标检测数据集DOTA-V2.0 [78]、DIOR [79]和FAIR1M-2.0 [80]。SAMRS直接继承原始检测数据集的类别,其容量超过大多数现有遥感分割数据集十倍以上(例如ISPRS Potsdam1和LoveDA [81])。三组图像的尺寸分别为1,024$\times1{,}024$、$800~\times800$和$600\times~600$。尽管由于自动生成的标签主要用于大规模预训练探索而非基准测试,但SAMRS天然支持实例分割和目标检测,这种多功能性使其适用于研究大规模多任务预训练。
B. Backbone Network
B. 骨干网络
In this research, we adopt RVSA (Rotated Varied-Size window Attention) [30] and Intern Image [82] as the representative vision transformer-based and CNN-based foundation models.
在本研究中,我们采用RVSA (Rotated Varied-Size window Attention) [30] 和Intern Image [82] 作为基于视觉Transformer和CNN基础模型的代表。
- RVSA: This model is specially designed for RS images. Considering the various orientations of RS objects caused by the bird’s-eye view, this model extends the varied-size window attention in [83] by additionally introducing a learnable angle factor, offering windows that can adaptively zoom, translate, and rotate.
- RVSA:该模型专为遥感 (RS) 图像设计。考虑到鸟瞰视角导致的遥感物体多方向性,该模型在[83]提出的可变尺寸窗口注意力基础上,额外引入可学习角度因子,提供能够自适应缩放、平移和旋转的窗口。
Specifically, given an input feature X ∈ RC×H×W $(C,H,W$ are the number of channel, height, and width in $\mathbf{X}{\cdot}$ ), which is evenly divided into different windows, where the feature of each window can be formulated as $\mathbf{X}{w}\in\mathbb{R}^{C\times s\times s}$ ( $\mathrm{\Delta}{s}$ is the window size), obtaining $\begin{array}{l}{{\frac{H}{s}}\times{\frac{W}{s}}}\end{array}$ windows totally. Then, three linear layers are used to generate the query feature, and initial key and value features, which are separately represented as $\mathbf{Q}{w},\mathbf{K}{w}$ and ${\bf V}{w}$ . We use $\mathbf{X}_{w}$ to predict the variations of the window:
具体而言,给定输入特征X ∈ RC×H×W $(C,H,W$ 分别是 $\mathbf{X}{\cdot}$ 的通道数、高度和宽度),将其均匀划分为不同窗口,其中每个窗口的特征可表示为 $\mathbf{X}{w}\in\mathbb{R}^{C\times s\times s}$ ( $\mathrm{\Delta}{s}$ 为窗口大小),共获得 $\begin{array}{l}{{\frac{H}{s}}\times{\frac{W}{s}}}\end{array}$ 个窗口。随后通过三个线性层分别生成查询特征、初始键特征和值特征,记为 $\mathbf{Q}{w},\mathbf{K}{w}$ 和 ${\bf V}{w}$。我们利用 $\mathbf{X}_{w}$ 来预测窗口的变异:

Here, GAP is global average pooling, $S_{w}={s_{x},s_{y}\in\mathbb{R}^{1}}$ and $O_{w}={o_{x},o_{y}\in\mathbb{R}^{1}}$ are the scale factor and offset in the
此处,GAP表示全局平均池化,$S_{w}={s_{x},s_{y}\in\mathbb{R}^{1}}$ 和 $O_{w}={o_{x},o_{y}\in\mathbb{R}^{1}}$ 分别为尺度因子与偏移量
$\boldsymbol{\mathrm X}$ and $\mathrm{Y}$ axis, while $\Theta_{w}={\theta\in\mathbb{R}^{1}}$ is the rotation angle. Taking an example using the corner points of a window:
$\boldsymbol{\mathrm X}$ 和 $\mathrm{Y}$ 轴,而 $\Theta_{w}={\theta\in\mathbb{R}^{1}}$ 是旋转角度。以窗口角点为例:

where $x_{l},y_{l},x_{r},y_{r}$ are the coordinates of the upper left and lower right corners of the initial window, $x_{c},y_{c}$ are the coordinates of the window center point. Therefore, $x_{l}^{r},y_{l}^{r},x_{r}^{r},y_{r}^{r}$ are the distances between the corner points and the center in horizontal and vertical directions. The transformation of the window can be implemented using the obtained scaling, translation, and rotation factors:
其中 $x_{l},y_{l},x_{r},y_{r}$ 是初始窗口左上角和右下角的坐标,$x_{c},y_{c}$ 是窗口中心点的坐标。因此,$x_{l}^{r},y_{l}^{r},x_{r}^{r},y_{r}^{r}$ 表示角点与中心在水平和垂直方向上的距离。窗口的变换可以通过获得的缩放、平移和旋转因子来实现:

$x_{l}^{\prime},y_{l}^{\prime},x_{r}^{\prime},y_{r}^{\prime}$ are the coordinates of the corner points of the transformed window. Then, new key and value feature ${\bf K}{w^{\prime}}$ and $\mathbf{V}{w^{\prime}}$ can be sampled from the obtained window, and the self-attention (SA) can be operated by the following formula:
$x_{l}^{\prime},y_{l}^{\prime},x_{r}^{\prime},y_{r}^{\prime}$ 是变换后窗口角点的坐标。随后,可以从获得的窗口中采样新的键和值特征 ${\bf K}{w^{\prime}}$ 和 $\mathbf{V}{w^{\prime}}$,并通过以下公式计算自注意力 (self-attention, SA):

In this formula, $\mathbf{F}_{w}\in\mathbb{R}^{s^{2}\times C^{\prime}}$ is the feature output by one selfattention of one window, $C=h C^{\prime}$ , where $h$ is the number of SA. The shape of final output features in RVSA can be recovered by concatenating the features from different SAs in the channel dimension and merging features from different windows along the spatial dimension.
在此公式中,$\mathbf{F}_{w}\in\mathbb{R}^{s^{2}\times C^{\prime}}$ 是单窗口单自注意力(selfattention)输出的特征,$C=h C^{\prime}$,其中$h$为自注意力头数。RVSA模块的最终输出特征可通过通道维度拼接不同自注意力头的特征,并在空间维度合并不同窗口的特征来恢复形状。
RVSA is used to replace the original multi-head full attention in original vision transformers. To achieve a tradeoff between accuracy and efficiency, following [84], only the full attention in 1/4 depth layer is preserved. In the original paper [30], RVSA is separately used on ViT [85] and ViTAE [72], whereas ViTAE is a CNN-Transformer hybrid model. In this paper, we employ the ViT-based version to investigate the impact of MTP on a plain vision transformer. In addition, the RVSA model in the original paper is limited to the base version of vision transformers, i.e., ViT $\mathrm{\cdotB+RVSA}$ . To pretrain larger models, we further apply RVSA to ViT-Large, obtaining ViT $\mathrm{\Delta}_{\mathrm{-L}}+\mathrm{RVSA}$ . Their detailed configurations are presented in Table I.
RVSA用于替代原始视觉Transformer中的多头全注意力机制。为实现准确性与效率的平衡,根据[84]的研究,仅保留1/4深度层的全注意力机制。原论文[30]中,RVSA分别应用于ViT [85]和ViTAE [72]架构,其中ViTAE是CNN-Transformer混合模型。本文采用基于ViT的版本来研究MTP对纯视觉Transformer的影响。此外,原论文中的RVSA模型仅针对视觉Transformer基础版本(即ViT $\mathrm{\cdotB+RVSA}$)。为预训练更大模型,我们将RVSA进一步扩展至ViT-Large架构,得到ViT $\mathrm{\Delta}_{\mathrm{-L}}+\mathrm{RVSA}$。具体配置参数见表1。
- Intern Image: This model integrates the strengths of recent vision transformers and large kernels into CNNs via dynamic sparse kernels, combining long-range context capture, adaptive spatial information aggregation, and efficient computation. It extends deformable convolution [86], [87] with depth-wise and multi-head mechanisms and incorporates modern transformer designs such as layer normalization [88], feed-forward networks [89], and GELU activation [90]. We evaluate its performance on diverse RS downstream tasks, showcasing its potential beyond its initial design for natural images. Furthermore, this choice facilitates investigating the impact of MTP on CNN-based models. Here, we employ the XL version to match the model size of $\mathrm{ViT-L}+\mathrm{RVSA}$ .
- Intern Image:该模型通过动态稀疏核将近期视觉Transformer和大核卷积的优势整合到CNN中,兼具长程上下文捕捉、自适应空间信息聚合和高效计算能力。它在可变形卷积[86][87]基础上引入深度分离和多头机制,并融合了层归一化[88]、前馈网络[89]和GELU激活函数[90]等现代Transformer设计。我们在多种遥感下游任务中评估其性能,展示了该模型在自然图像初始设计之外的潜力。此外,这一选择有助于研究MTP对基于CNN模型的影响。此处采用XL版本以匹配$\mathrm{ViT-L}+\mathrm{RVSA}$的模型规模。
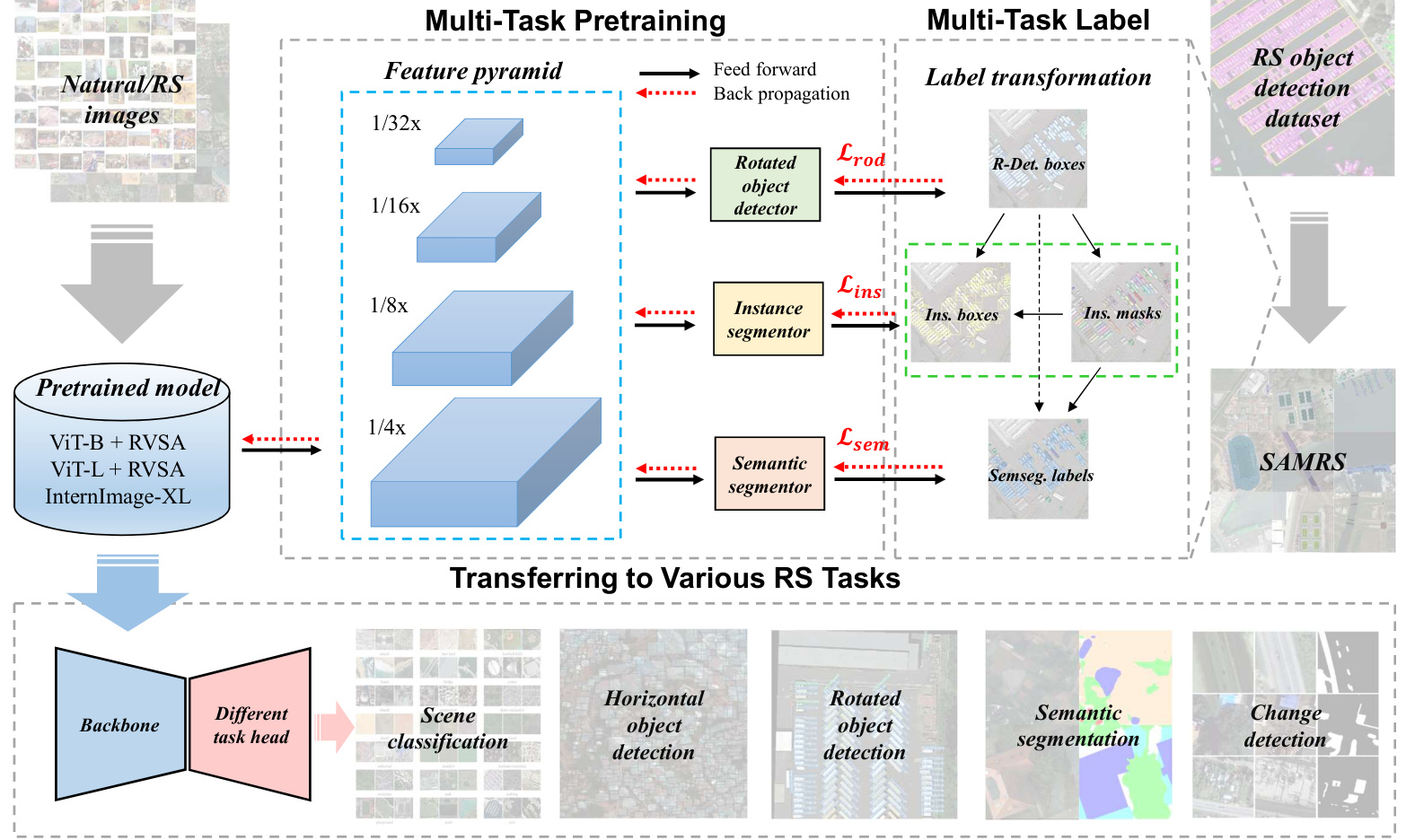
Fig. 2. The overall pipeline of MTP. Inside MTP, the feature pyramid from the backbone network is fed into multiple decoders for various tasks, including rotated object detection, instance segmentation, and semantic segmentation. These tasks are supervised by diverse labels in the SAMRS dataset. Following MTP, the pretrained model is transferred to different RS tasks for finetuning.
图 2: MTP的整体流程。在MTP内部,来自骨干网络的特征金字塔被输入到多个解码器中,用于执行不同任务,包括旋转目标检测、实例分割和语义分割。这些任务由SAMRS数据集中的多样化标签进行监督。在MTP之后,预训练模型被迁移到不同的遥感任务中进行微调。
TABLE I DETAILED CONFIGURATIONS OF DIFFERENT RVSA MODELS.
表 1: 不同RVSA模型的详细配置
| Backbone | ViT-B+RVSA | ViT-L+RVSA |
|---|---|---|
| Depth | 12 | 24 |
| Embedding Dim | 768 | 1024 |
| Head | 12 | 16 |
| FullattentionIndex | [3,6,9,12] | [6,12,18,24] |
| FeaturePyramidIndex | [4,6,8,12] | [8,12,16,24] |
C. Multi-Task Pre training
C. 多任务预训练
We examine MTP using three models: $\mathrm{ViT-B+RVSA}$ , V $\mathrm{\Delta_{1T-L}}+\mathrm{RVSA}$ , and Intern Image-XL. As the original RVSA research [30] focuses solely on the base version, we independently pretrain ViT-L on MillionAID similar to $\mathrm{ViT-B+}$ RVSA. These pretrained weights will be publicly accessible. Figure 2 shows the overall pipeline of MTP. Technically, we further train the pretrained model on the SAMRS dataset, encompassing various annotations such as semantic segmentation, instance segmentation, and rotated object detection tasks concurrently. We employ well-established classical networks, including UperNet [62], Mask-RCNN [91], and OrientedRCNN [92], as segmentors or detectors. These networks utilize feature pyramids and are supervised with different labels. To illustrate this process, we depict the label transformation when generating SAMRS. Initially, rotated detection boxes (R-Det. boxes) are transformed into binary masks using SAM, serving as instance-level mask annotations. Subsequently, the minimum circumscribed horizontal rectangle of the binary mask is derived as instance-level box annotations, with categories inherited from rotated boxes. These instance-level annotations are utilized for instance segmentation. Semantic segmentation labels are then obtained by assigning rotated box categories to the masks. The losses stemming from these labels are $\mathcal{L}{r o d}$ , $\mathcal{L}{i n s}$ , and $\mathcal{L}{s e m}$ , employed for the respective tasks. Notably, the instance segmentation loss comprises two components: the box annotation loss $\mathcal{L}{i n s_b}$ and the binary mask loss $\mathcal{L}_{i n s_m}$ . The overall loss for MTP is:
我们使用三种模型检验MTP:$\mathrm{ViT-B+RVSA}$、V$\mathrm{\Delta_{1T-L}}+\mathrm{RVSA}$以及Intern Image-XL。由于原始RVSA研究[30]仅关注基础版本,我们独立在MillionAID上预训练了ViT-L,类似于$\mathrm{ViT-B+}$RVSA。这些预训练权重将公开可用。图2展示了MTP的整体流程。技术上,我们在SAMRS数据集上进一步训练预训练模型,同时涵盖语义分割、实例分割和旋转目标检测等多种标注任务。我们采用成熟的经典网络,包括UperNet[62]、Mask-RCNN[91]和OrientedRCNN[92]作为分割器或检测器。这些网络利用特征金字塔结构,并受不同标签监督。为说明这一过程,我们描绘了生成SAMRS时的标签转换流程:首先通过SAM将旋转检测框(R-Det. boxes)转换为二值掩膜,作为实例级掩膜标注;随后从二值掩膜导出最小外接水平矩形作为实例级框标注,类别继承自旋转框。这些实例级标注用于实例分割任务,而语义分割标签则通过将旋转框类别分配给掩膜获得。这些标签产生的损失分别为$\mathcal{L}{rod}$、$\mathcal{L}{ins}$和$\mathcal{L}{sem}$,分别对应各项任务。值得注意的是,实例分割损失包含两个组成部分:框标注损失$\mathcal{L}{ins_b}$和二值掩膜损失$\mathcal{L}_{ins_m}$。MTP的总损失函数为:

Since SAMRS contains three sets, we have
由于SAMRS包含三组数据集,我们

where $i$ indexes the three sub-sets: SOTA, SIOR, and FAST. The other settings of the loss follow the original papers [62], [91], [92]. In practice, we implement the overall framework based on MM Segmentation 2, MM Detection 3, and MMRotate4. However, all these packages only support a single task. So we integrate the key components from these packages, such as the dataloader, model structure, loss function, and metric calculator, into a unified pipeline, to realize the MTP.
其中 $i$ 索引三个子集:SOTA、SIOR 和 FAST。损失函数的其他设置遵循原始论文 [62]、[91]、[92]。实践中,我们基于 MM Segmentation 2、MM Detection 3 和 MMRotate4 实现整体框架。但这些软件包均仅支持单一任务,因此我们将关键组件(如数据加载器、模型结构、损失函数和指标计算器)整合到统一流程中,以实现 MTP。
TABLE II THE TRAINING COSTS OF IMPLEMENTING MTP USING DIFFERENT MODELS.
表 II: 采用不同模型实现MTP的训练成本
| Backbone | #Param.(M) | #GPU | Time (days) |
|---|---|---|---|
| ViT-B+RVSA | 86 | 16 | 3.0 |
| ViT-L+RVSA | 305 | 32 | 6.3 |
| InternImage-XL | 335 | 32 | 6.3 |
D. Implementation Details
D. 实现细节
The pre training is conducted on NVIDIA V100 GPUs. All models are trained for 80K iterations using the AdamW optimizer [93]. The base learning rates of RVSA and Intern Image are 0.00006 and 0.00002, respectively, with a weight decay of 0.05. We adopt an iteration-wise cosine annealing scheduler to adjust the learning rate. The layer decay rates of RVSA models and Intern Image are 0.9 and 0.94, following original papers [30], [82]. For $\mathrm{ViT-B}+\mathrm{RVSA}$ , the batch size and input image size are set to 48 and 224, which are doubled for training larger models. Table II lists the training costs of implementing MTP using different models.
预训练在NVIDIA V100 GPU上进行。所有模型均采用AdamW优化器[93]训练8万次迭代。RVSA和Intern Image的基础学习率分别为0.00006和0.00002,权重衰减为0.05。我们采用逐迭代余弦退火调度器来调整学习率。根据原始论文[30][82],RVSA模型和Intern Image的层衰减率分别为0.9和0.94。对于$\mathrm{ViT-B}+\mathrm{RVSA}$,批次大小和输入图像尺寸设置为48和224,训练更大模型时这些值会翻倍。表II列出了使用不同模型实现MTP的训练成本。
IV. FINETUNING EXPERIMENTS
IV. 微调实验
In this section, we thoroughly evaluate MTP’s performance by finetuning pretrained models across four classical RS tasks: scene classification, object detection, semantic segmentation, and change detection, where the most representative and widely used benchmarks in the literature for different downstream tasks are employed for comparison. We also investigate the characteristics of MTP-based RS foundation models, examining the relationships between adopted datasets, hyperparameters, and finetuning performances, measuring accuracy variations with reduced training samples, and visualizing the predicted results.
在本节中,我们通过微调预训练模型在四个经典遥感任务上的表现来全面评估MTP的性能:场景分类、目标检测、语义分割和变化检测,其中采用了文献中针对不同下游任务最具代表性和广泛使用的基准进行比较。我们还研究了基于MTP的遥感基础模型特性,分析了所采用数据集、超参数与微调性能之间的关系,测量了训练样本减少时的精度变化,并对预测结果进行了可视化展示。
A. Scene Classification
A. 场景分类
We first evaluate the pretrained models on the scene classification task. It does not need any extra decoder and can reflect the overall representation capability of the pretrained model.
我们首先在场景分类任务上评估预训练模型。该任务无需额外解码器,能直接反映预训练模型的整体表征能力。
- Dataset: We adopt two classical datasets: EuroSAT [94] and RESISC-45 [95] for scene classification.
- 数据集:我们采用两个经典数据集 EuroSAT [94] 和 RESISC-45 [95] 进行场景分类。
TABLE III THE $\mathrm{OA}(%)$ OF DIFFERENT MODEL PRE TRAINING STRATEGIES ON EUROSAT.
表 III: 不同模型预训练策略在 EUROSAT 上的 OA(%)
| Model | MAE | MTP | OA |
|---|---|---|---|
| ViT-B+RVSA | 98.54 | ||
| ViT-B+RVSA | 98.24 | ||
| ViT-B+RVSA | ← | 98.76 |
TABLE IV
表 IV
| 方法 | 模型 | EuroSAT | RESISC-45 |
|---|---|---|---|
| GASSL [27] | ResNet-18 | 89.51 | |
| SeCo [29] | ResNet-18 | 93.14 | |
| SatMAE [31] | ViT-L | 95.74 | 94.10 |
| SwiMDiff [98] | ResNet-18 | 96.10 | |
| GASSL [27] | ResNet-50 | 96.38 | 93.06 |
| GeRSP [45] | ResNet-50 | 92.74 | |
| SeCo [29] | ResNet-50 | 97.34 | 92.91 |
| CACo [28] | ResNet-50 | 97.77 | 91.94 |
| TOV [12] | ResNet-50 | 93.79 | |
| RSP [5] | ViTAEv2-S | 95.60 | |
| RingMo [32] | Swin-B | 95.67 | |
| SatLas [59] | Swin-B | 94.70 | |
| CMID [38] | Swin-B | 95.53 | |
| GFM [46] | Swin-B | 94.64 | |
| CSPT [11] | ViT-L | 95.62 | |
| Usat [99] | ViT-L | 98.37 | |
| Scale-MAE [36] | ViT-L | 98.59 | 95.04 |
| CtxMIM [37] | Swin-B | 98.69 | |
| SatMAE++ [100] | ViT-L | 99.04 | |
| SpectralGPT+ [34] | ViT-B | 99.21* | |
| SkySense [42] | Swin-L | 95.92* | |
| SkySense [42] | Swin-H | 96.32* | |
| MAE | ViT-B+RVSA | 98.54 | 95.49 |
| MAE+MTP | ViT-B+RVSA | 98.76 | 95.57 |
| MAE | ViT-L+RVSA | 98.56 | 95.46 |
| MAE + MTP | ViT-L+RVSA | 98.78 | 95.88 |
| IMP | InternImage-XL | 99.30* | 95.82 |
| IMP + MTP | InternImage-XL | 99.24* | 96.27* |
- Implementation Details: In the implementation, all models are trained with a batch size of 64. The training epochs for EuroSAT and RESISC-45 are set to 100 and 200, respectively. The AdamW optimizer is used, where the base learning rate for RVSA and InterImage are 0.00006 and 0.00002, respectively, with a weight decay of 0.05. In the first 5 epochs, we adopt a linear warming-up strategy, where the initial learning rate is set to 0.000001. Then, the learning rate is controlled by the cosine annealing scheduler. The layer decay rates are 0.9 and 0.94 for RVSA and Intern Image models, respectively. For classification, a global pooling layer and a linear head are used after the backbone network. To avoid over fitting, we adopt multiple data augmentations, including random resized cropping, random flipping, Rand Augment [97], and random erasing. Since the original image size of EuroSAT is too small, before feeding into the network, we resize the image to 224 $\times224$ . The overall accuracy (OA) is used as the evaluation criterion. All experiments are implemented by MMPretrain .
- 实现细节:
在实现中,所有模型的训练批次大小均为64。EuroSAT和RESISC-45的训练周期分别设置为100和200。使用AdamW优化器,其中RVSA和InterImage的基础学习率分别为0.00006和0.00002,权重衰减为0.05。在前5个周期中,采用线性预热策略,初始学习率设为0.000001。随后,学习率由余弦退火调度器控制。RVSA和Intern Image模型的层衰减率分别为0.9和0.94。对于分类任务,在主干网络后使用全局池化层和线性头。为避免过拟合,采用了多种数据增强方法,包括随机调整大小裁剪、随机翻转、Rand Augment [97] 和随机擦除。由于EuroSAT的原始图像尺寸过小,在输入网络前将其调整为224$\times224$。总体准确率(OA)作为评估标准。所有实验均通过MMPretrain实现。 - Ablation Study of Stage-wise Pre training: As aforementioned, MTP is implemented based on existing pre training models since it tries to address the task-level discrepancy. So an interesting question naturally arises: what about conducting MTP from scratch? To this end, we experiment by exploring different pre training strategies using $\mathrm{ViT-B}+\mathrm{RVSA}$ on EuroSAT, and the results are shown in Table III. It can be seen that, without using pretrained weights, MTP cannot achieve the ideal performance and even performs worse than MAE pre training. These results demonstrate the importance of performing stage-wise pre training.
- 分阶段预训练消融研究: 如前所述,MTP是基于现有预训练模型实现的,因为它旨在解决任务级差异。这就引出一个有趣的问题:从头开始实施MTP会如何?为此,我们在EuroSAT数据集上使用$\mathrm{ViT-B}+\mathrm{RVSA}$架构探索了不同预训练策略,结果如表III所示。可见若不使用预训练权重,MTP无法达到理想性能,甚至表现不如MAE预训练。这些结果证明了分阶段预训练的重要性。
- Finetuning Results and Analyses: Table IV shows the finetuning results. It can be seen that MTP can improve existing foundation models on scene classification tasks, especially for the RVSA series. It helps the model achieve state-ofthe-art performances compared to other pre training models that have comparable sizes. With the help of MTP, on the RESISC-45 dataset, InterImage-XL surpasses Swin-L-based SkySense [42], which is pretrained on a tremendously large dataset that has more than 20 million multimodal RS image triplets involving RGB high-resolution images and multitemporal multi spectral and SAR sequences. MTP boosts the performance of InterImage-XL close to the Swin-H-based SkySense (96.27 v.s. 96.32), which has more parameters. We also notice the accuracy of IMP-InterImage-XL is decreased marginally in EuroSAT after MTP. We will investigate this phenomenon later. Nevertheless, the obtained model still outperforms Spectral GP T+, which is pretrained with 1 million multi spectral images, where each sample can be regarded as containing multiple groups of tri-spectral images, similar to RGB channels.
- 微调结果与分析:表 IV 展示了微调结果。可以看出,MTP 能够提升现有基础模型在场景分类任务上的表现,特别是对 RVSA 系列模型。相较于参数量相当的其他预训练模型,MTP 帮助模型实现了最先进的性能。在 RESISC-45 数据集上,借助 MTP 的 InterImage-XL 超越了基于 Swin-L 的 SkySense [42](后者是在超大规模数据集上预训练的,包含超过 2000 万组多模态遥感图像三元组,涉及 RGB 高分辨率图像以及多时相多光谱和 SAR 序列)。MTP 将 InterImage-XL 的性能提升至接近参数量更大的基于 Swin-H 的 SkySense(96.27 vs. 96.32)。我们还注意到 IMP-InterImage-XL 在 EuroSAT 数据集上经 MTP 微调后准确率略有下降,后续将对此现象进行研究。尽管如此,所得模型仍优于 Spectral GP T+(后者通过 100 万张多光谱图像预训练,每个样本可视为包含多组类似 RGB 通道的三光谱图像)。
B. Horizontal Object Detection
B. 水平目标检测
After completing the scene-level task of recognition, we focus on the object-level tasks, i.e., horizontal and rotated object detection. Here, we first consider the horizontal detection task.
在完成场景级别的识别任务后,我们聚焦于物体级别的任务,即水平与旋转物体检测。此处我们首先考虑水平检测任务。
- Dataset: We use two public datasets Xview [101] and DIOR [79] for evaluation. Here are the details:
- 数据集:我们使用两个公开数据集Xview [101]和DIOR [79]进行评估。具体细节如下:
- Implementation Details: For Xview, we train a RetinaNet [102] by following [27], [37] with the pretrained model for 12 epochs, with a batch size of 8. While Faster-RCNN [76] is adopted when finetuning on DIOR with the same settings except for a batch size of 4. We also apply a linear warmingup strategy with an initial learning rate of 0.000001 at the beginning of 500 iterations. We keep the same layer decay rates as the scene classification task. The basic learning rate, optimizer, and scheduler are the same as [30]. Before input into the network, the large images are uniformly clipped to 416 $\times~416$ pixels. The data augmentation only includes random flipping with a probability of 0.5. We use MM Detection to implement the finetuning, where the $A P_{50}$ is used as the evaluation metric for the comparison of different models.
- 实现细节:对于Xview数据集,我们采用与[27]、[37]相同的方法训练RetinaNet [102],使用预训练模型进行12个epoch的训练,批量大小为8。而在DIOR数据集上微调时采用Faster-RCNN [76],除批量大小改为4外其他设置相同。我们在前500次迭代中采用线性预热策略,初始学习率为0.000001。目标检测任务的层级学习率衰减率与场景分类任务保持一致。基础学习率、优化器和调度器设置与[30]相同。输入网络前,大尺寸图像统一裁剪为416$\times~416$像素。数据增强仅包含概率为0.5的随机翻转。我们使用MMDetection工具包实现微调,采用$AP_{50}$作为评估指标进行模型对比。
TABLE V THE $A P_{50}$ $(%)$ OF FINETUNING DIFFERENT PRETRAINED MODELS WITH RETINANET ON XVIEW AND DIOR DATASETS. THE “SUP. LEA. W IN1K” MEANS SUPERVISED LEARNING WITH IMAGENET-1K. RANDOM INIT. MEANS THE BACKBONE NETWORK IS RANDOMLY INITIALIZED.
表 5: 使用 RetinaNet 在 Xview 和 DIOR 数据集上微调不同预训练模型的 $A P_{50}$ (%)。 "Sup. Lea. w IN1K" 表示使用 ImageNet-1K 进行监督学习。Random Init. 表示主干网络是随机初始化的。
| Method | Backbone | Xview | DIOR |
|---|---|---|---|
| Random Init. | ResNet-50 | 10.8 | |
| Sup.Lea.wIN1K | ResNet-50 | 14.4 | |
| Sup.Lea. w IN1K | Swin-B | 16.3 | |
| GASSL[27] | ResNet-50 | 17.7 | 67.40 |
| SeCo [29] | ResNet-50 | 17.2 | |
| CACO [28] | ResNet-50 | 17.2 | 66.91 |
| CtxMIM [37] | Swin-B | 18.8* | |
| MSFCNet [103] | ResNeSt-101 [104] | 70.08 | |
| TOV [12] | ResNet-50 | 70.16 | |
| SATMAE[31] | ViT-L | 70.89 | |
| CSPT [11] | ViT-L | 71.70 | |
| FSoDNet [105] | MSENet | 71.80 | |
| GeRSP [45] | ResNet-50 | 72.20 | |
| GFM [46] | Swin-B | 72.84 | |
| Scale-MAE[36] | ViT-L | 73.81 | |
| SatLas [59] | Swin-B | 74.10 | |
| CMID [38] | Swin-B | 75.11 | |
| RingMo [32] | Swin-B | 75.90 | |
| SkySense [42] | Swin-H | 78.73* | |
| MAE | ViT-B+RVSA | 14.6 | 75.80 |
| MAE+MTP | ViT-B+RVSA | 16.4 | 79.40* |
| MAE | ViT-L+RVSA | 15.0 | 78.30 |
| MAE+MTP | ViT-L+RVSA | 19.4* | 81.10* |
| IMP | InternImage-XL | 17.0 | 77.10 |
| IMP + MTP | InternImage-XL | 18.2* | 78.00 |
- Finetuning Results and Analyses: The experimental results are shown in Table V. We can find that the MTP enhances the performance of all pretrained models, especially for ViT-L $+\mathrm{RVSA}$ . On Xview, the performance of MAE pretrained ViT $\mathrm{L}+\mathrm{RVSA}$ is not as good as InterImage-XL, even worse than the smaller ResNet-50-based models. After utilizing MTP, the performance of $\mathrm{ViT-L}+\mathrm{RVSA}$ has been greatly improved. It outperforms CtxMIM [37] and achieves the best. On DIOR, with the help of MTP, $\mathrm{ViT-B}+\mathrm{RVSA}$ has outperformed all existing methods, including the recently distinguished method SkySense [42] that employs a larger model. In addition, MTP also greatly enhances $\mathrm{ViT-L}+\mathrm{RVSA}$ , setting a new state-ofthe-art. Here, we emphasize that despite the pre training dataset SAMRS includes the samples of DIOR [79]. To avoid unfair comparison, following [13], the images of the testing set in DIOR have not been used for MTP. This rule also applies to other datasets that form the SAMRS, involving DOTAV1.0 [106], DOTA-V2.0 [78], DIOR-R [107] and FAIR1M2.0 [80]. It should also be noted that the RVSA model is initially proposed by considering the diverse orientations of RS objects, which are related to the rotated object detection task. Nevertheless, the models after MTP demonstrate an excellent capability in detecting horizontal boxes.
- 微调结果与分析:实验结果如表 V 所示。我们发现 MTP (Multi-Task Pretraining) 提升了所有预训练模型的性能,尤其是 ViT-L $+\mathrm{RVSA}$。在 Xview 数据集上,MAE 预训练的 ViT $\mathrm{L}+\mathrm{RVSA}$ 表现不及 InterImage-XL,甚至弱于基于较小 ResNet-50 的模型。采用 MTP 后,$\mathrm{ViT-L}+\mathrm{RVSA}$ 性能显著提升,超越了 CtxMIM [37] 并达到最优。在 DIOR 数据集上,借助 MTP 的 $\mathrm{ViT-B}+\mathrm{RVSA}$ 超越了所有现有方法(包括采用更大模型的近期优秀方法 SkySense [42])。此外,MTP 还大幅提升了 $\mathrm{ViT-L}+\mathrm{RVSA}$ 的性能,创造了新纪录。需要特别说明:尽管预训练数据集 SAMRS 包含 DIOR [79] 的样本,但为避免不公平比较,我们遵循 [13] 的设定,未将 DIOR 测试集图像用于 MTP。该规则同样适用于构成 SAMRS 的其他数据集(DOTAV1.0 [106]、DOTA-V2.0 [78]、DIOR-R [107] 和 FAIR1M2.0 [80])。值得注意的是,RVSA 模型最初是为应对遥感物体多向性(与旋转目标检测任务相关)而提出的,但经过 MTP 的模型在水平框检测任务中也展现出卓越能力。
TABLE VI THE MAP $(%)$ OF FINETUNING DIFFERENT PRETRAINED MODELS ON THE DIOR-R, FAIR1M-2.0, DOTA-V1.0, AND DOTA-V2.0 DATASETS. MS INDICATES WHETHER THE ACCURACY ON DOTA-V1.0 IS OBTAINED FROM THE MULTI-SCALE TRAINING AND TESTING. $^\dagger$ : THE FEATURE PYRAMID IS FORMED BY UPSAMPLING AND DOWN SAMPLING THE LAST LAYER FEATURE OF THE BACKBONE NETWORK BY FOLLOWING THE STRATEGY OF VITDET [84].
表 VI DIOR-R、FAIR1M-2.0、DOTA-V1.0 和 DOTA-V2.0 数据集上微调不同预训练模型的 mAP $(%)$。MS 表示 DOTA-V1.0 的准确率是否通过多尺度训练和测试获得。$^\dagger$: 特征金字塔通过按照 ViTDet [84] 的策略对骨干网络的最后一层特征进行上采样和下采样形成。
| 方法 | 骨干网络 | MS | DIOR-R | FAIR1M-2.0 | DOTA-V1.0 | DOTA-V2.0 |
|---|---|---|---|---|---|---|
| RetinaNet-OBB [102] | ResNet-50 | 57.55 | 46.68 | |||
| 59.54 | 69.36 | 47.31 | ||||
| Faster RCNN-OBB [76] | ResNet-50 | |||||
| FCOS-OBB [108] | ResNet-50 | 48.51 | ||||
| ATSS-OBB [109] | ResNet-50 | 72.29 | 49.57 | |||
| SCRDet [110] | ResNet-101 | x | 72.61 | |||
| Gilding Vertex [111] | ResNet-50 | x | 60.06 | 75.02 | ||
| ROI Transformer [112] | ResNet-50 | ← | 63.87 | 74.61 | 52.81 | |
| CACo [28] | ResNet-50 | 64.10 | 47.83 | |||
| RingMo [32] | Swin-B | 46.21 | ||||
| R?Det [113] | ResNet-152 | 76.47 | ||||
| SASM [114] | ResNeXt-101 | ← | 79.17 | 44.53 | ||
| AO2-DETR [115] | ResNet-50 | 79.22 | ||||
| S2ANet [116] | ResNet-50 | 79.42 | 49.86 | |||
| ReDet [117] | ReResNet-50 | ← | 80.10 | |||
| R3Det-KLD [118] | ResNet-50 | ← | 80.17 | 47.26 | ||
| R?Det-GWD [119] | ResNet-152 | ← | 80.23 | |||
| R?Det-DEA [120] | ReResNet-50 | 80.37 | ||||
| AOPG [107] | ResNet-50 | 64.41 | 80.66 | |||
| DODet [121] | ResNet-50 | 65.10 | 80.62 | |||
| PP-YOLOE-R [122] | CRN-x [123] | ← | 80.73 | |||
| GASSL [27] | ResNet-50 | 65.65 | 48.15 | |||
| SatMAE [31] | ViT-L | 65.66 | 46.55 | |||
| TOV [12] | ResNet-50 | 66.33 | 49.62 | |||
| Oriented RepPoints [124] | ResNet-50 | x | 66.71 | 75.97 | 48.95 | |
| GGHL [125] | DarkNet-53 [126] | x | 66.48 | 76.95 | 57.17 | |
| CMID [38] | Swin-B | x | 66.37 | 50.58 | 77.36 | |
| RSP [5] | ViTAEv2-S | x | 77.72 | |||
| Scale-MAE [36] | ViT-L | 66.47 | 48.31 | |||
| SatLas [59] | Swin-B | 67.59 | 46.19 | |||
| GFM [46] | Swin-B | 67.67 | 49.69 | |||
| PIIDet [127] | ResNeSt-101 | 70.35 | 80.21 | |||
| Oriented RCNN [92] | ResNet-50 | ← | 80.87 | 53.28 | ||
| R?Det-KFIoU [128] | ResNet-152 | ← | 81.03 | |||
| RTMDet-R [129] | RTMDet-R-1 | ← | 81.33 | |||
| DCFL [130] | ReResNet-101 [117] | x | 71.03 | 57.66 | ||
| SMLFR [131] | ConvNeXt-L [132] | 72.33 | 79.33 | |||
| ARC [133] | ARC-R50 | ← | 81.77* | |||
| LSKNet [134] | LSKNet-S | 81.85* | ||||
| STD [135] | ViT-B | 81.66 | ||||
| STD [135] BillionFM [35] | HiViT-B [136] | ← | 82.24* | |||
| ViT-G12X4 | 73.62* | 58.69* | ||||
| SkySense [42] | Swin-H | 74.27* | 54.57* | |||
| RVSA [30] ↑ | ViT-B+RVSA | ← | 70.67 | 81.01 | ||
| MAE | ViT-B+RVSA | ← | 68.06 | 51.56 | 80.83 | 55.22 |
| MAE + MTP | ViT-B + RVSA | ← | 71.29 | 51.92 | 80.67 | 56.08 |
| MAE | ViT-L+RVSA | ← | 70.54 | 53.20* | 81.43 | 58.96* |
| MAE + MTP | ViT-L+ RVSA | ← | 74.54* | 53.00* | 81.66 | 58.41* |
| IMP | InternImage-XL | ← | 71.14 | 50.67 | 80.24 | 54.85 |
| IMP + MTP | InternImage-XL | ← | 72.17 | 50.93 | 80.77 | 55.13 |
C. Rotated Object Detection
C. 旋转目标检测
We then investigate the impact of MTP on the rotated object detection task, which is a typical RS task distinguished from natural scene object detection because of special overhead views. This is also one of the motivations to implement MTP using SAMRS.
然后我们研究MTP在旋转目标检测任务中的影响,该任务是遥感(RS)领域区别于自然场景目标检测的典型任务,其特殊性在于采用特殊的俯视视角。这也是我们使用SAMRS实现MTP的动机之一。
- Dataset: We adopt the four most commonly used datasets for this task: DIOR-R [107], FAIR1M-2.0 [80], DOTA-V1.0 [106] and DOTA-V2.0 [78].
- 数据集:我们采用该任务最常用的四个数据集:DIOR-R [107]、FAIR1M-2.0 [80]、DOTA-V1.0 [106] 和 DOTA-V2.0 [78]。
$0.8m$ and image sizes ranging from $1,000\times1,000$ to $10,000\times10,000$ from various sensors and platforms. It contains 37 subcategories belonging to 5 classes: Ship, Vehicle, Airplane, Court, and Road. In this paper, we use the more challenging version of 2.0, which additionally incorporates the 2021 Gaofen Challenge dataset. The training and validation sets are together adopted for training.
$0.8m$ 以及来自不同传感器和平台、尺寸范围在 $1,000\times1,000$ 到 $10,000\times10,000$ 之间的图像。该数据集包含37个子类别,分属5大类:船舶、车辆、飞机、球场和道路。本文采用更具挑战性的2.0版本,该版本额外融合了2021年高分挑战赛数据集。训练时同时使用了训练集和验证集。
- DOTA-V1.0: This is the most popular dataset for RS rotated object detection. It comprises 2,806 images spanning from $800~\times~800$ to $4,000\times4,000\times.$ , where 188,282 instances from 15 typical categories are presented. We adopt classical train/test split, that is, the original training and validation sets are together for training, while the original testing set is used for evaluation.
- DOTA-V1.0:这是遥感旋转目标检测领域最流行的数据集,包含2,806张图像,尺寸从$800~\times~800$到$4,000\times4,000$不等,涵盖15个典型类别的188,282个实例。我们采用经典训练/测试划分方案,即合并原始训练集与验证集进行训练,使用原始测试集进行评估。
- DOTA-V2.0: The is the enhanced version of DOTA V1.0. By additionally collecting larger images, adding new categories, and annotating tiny instances, it finally contains 11,268 images, 1,793,658 instances, and 18 categories. We use the combination of training and validation sets for training, while the test-dev set is used for evaluation.
- DOTA-V2.0:这是DOTA V1.0的增强版本。通过额外收集更大尺寸的图像、新增类别以及对微小实例进行标注,最终包含11,268张图像、1,793,658个实例和18个类别。我们使用训练集和验证集的组合进行训练,同时使用测试开发集(test-dev set)进行评估。
- Implementation Details: Since the large-size image is not suitable for training, we first perform data cropping. For DOTA-V2.0, we adopt single-scale training and testing by following [130], where the images are cropped to patches in size of $1,024\times1,024$ with an overlap of 200. For DOTA-V1.0 and FAIR1M-2.0, we implement the multiscale training and testing, i.e., the original images are scaled with three ratios: (0.5, 1.0, 1.5). Then, the DOTA-V1.0 images are cropped to $1,024\times1,024$ patches but with an overlap of 500, while FAIR1M-2.0 images adopt a patch size of 800 and an overlap of 400. The batch sizes are set to 4, 16, 4, and 4 for the DIOR-R, FAIR1M, DOTA-V1.0, and DOTA-V2.0 datasets, respectively. The other settings during training are the same as horizontal object detection. We adopt the Oriented-RCNN network implemented in MMRotate. During training, input data is augmented by random flipping and random rotation. The mean average precision (mAP) is adopted as the evaluation metric.
- 实现细节:由于大尺寸图像不适合训练,我们首先进行数据裁剪。对于DOTA-V2.0,我们采用[130]中的单尺度训练和测试方法,将图像裁剪为$1,024\times1,024$大小的块,重叠区域为200像素。对于DOTA-V1.0和FAIR1M-2.0,我们实施多尺度训练和测试,即原始图像按三种比例缩放:(0.5, 1.0, 1.5)。随后,DOTA-V1.0图像被裁剪为$1,024\times1,024$的块,重叠区域为500像素,而FAIR1M-2.0图像采用800像素的块大小和400像素的重叠区域。DIOR-R、FAIR1M、DOTA-V1.0和DOTA-V2.0数据集的批量大小分别设置为4、16、4和4。训练期间的其他设置与水平目标检测相同。我们采用MMRotate中实现的Oriented-RCNN网络。训练过程中,通过随机翻转和随机旋转对输入数据进行增强。评估指标采用平均精度均值(mAP)。
- Finetuning Results and Analyses: Table VI shows the finetuning results. Except for DIOR-R, we find the MTP pretrained models cannot always demonstrate obvious advantages compared to their counterparts. Since the volumes of FAIR1M2.0, DOTA-V1.0, and DOTA-V2.0 are much larger than DIORR, we speculate that after long-time finetuning, the benefit of MTP becomes diminished. We will further explore this issue in later sections. Nevertheless, owing to the excellent structure, RVSA-L outperforms the ViT-G-based foundation model [35] with over 1 billion parameters on DOTA-V2.0. Compared to the powerful SkySense model [42], our models achieve better performance on the DIOR-R. While on FAIR1M-2.0, except SkySense, our models surpass all other methods by a large margin. Generally, our models have comparable representation capability as SkySense, although it has over 600M parameters and utilizes 20 million images for pre training. We also notice the performances of our models still have gaps compared with the current advanced method STD [135] on DOTA-V1.0. It may be attributed to the adopted classical detector OrientedRCNN [92], which limits the detection performance.
- 微调结果与分析:表 VI 展示了微调结果。除DIOR-R外,我们发现MTP预训练模型相比基线模型并不总能展现明显优势。由于FAIR1M2.0、DOTA-V1.0和DOTA-V2.0的数据量远大于DIOR-R,我们推测长时间微调后MTP的增益会逐渐减弱,后续章节将深入探讨该问题。尽管如此,凭借优异的架构,RVSA-L在DOTA-V2.0上超越了具有10亿参数的ViT-G基础模型[35]。相较于强大的SkySense模型[42],我们的模型在DIOR-R上表现更优;而在FAIR1M-2.0数据集上(除SkySense外),我们的模型以显著优势超越其他方法。总体而言,我们的模型与采用6亿参数、2000万预训练图像的SkySense具有相当的表征能力。值得注意的是,在DOTA-V1.0上,我们的模型与当前先进方法STD[135]仍存在差距,这可能归因于采用的经典检测器OrientedRCNN[92]限制了检测性能。
D. Semantic Segmentation
D. 语义分割
We further consider finetuning the pretrained models on the finer pixel-level tasks, e.g., the semantic segmentation task. It is one of the most important RS applications for the extraction and recognition of RS objects and land covers.
我们进一步考虑在更精细的像素级任务上微调预训练模型,例如语义分割任务。这是遥感对象和地表覆盖提取与识别中最重要的遥感应用之一。
- Dataset: We separately take into account both singleclass geospatial target extraction and multi-class surface element perception through two RS semantic segmentation datasets: SpaceNetv1 [137] and LoveDA [81]. Here are their details:
- 数据集:我们分别通过SpaceNetv1 [137]和LoveDA [81]这两个遥感语义分割数据集,对单类地理空间目标提取和多类地表要素感知进行了考量。具体细节如下:
- SpaceNetv1: This dataset is provided by SpaceNet Challenge [137] for extracting building footprints. It is made up of the Digital Globe WorldView-2 satellite imagery with a ground sample distance of $0.5m$ photoed during 2011-2014 over Rio de Janeiro. It covers about 2,544 $k m^{2}$ , including 382,534 building instances. Since only the 6,940 images in the original training set are available, following [31], [37], we randomly split these images into two parts, where the first part containing 5,000 images being used as the training set, and another part will be used for testing.
- SpaceNetv1:该数据集由SpaceNet挑战赛[137]提供,用于提取建筑物轮廓。它由Digital Globe WorldView-2卫星影像组成,地面采样距离为$0.5m$,拍摄于2011-2014年间里约热内卢上空。覆盖约2,544$k m^{2}$区域,包含382,534个建筑物实例。由于原始训练集中仅6,940张图像可用,我们遵循[31][37]的方法,将这些图像随机分为两部分:第一部分包含5,000张图像作为训练集,另一部分用于测试。
- LoveDA: This is a challenging dataset involving both urban and rural scenes. It collects $0.3m$ spaceborne imagery from Google Earth, where the images were obtained in July 2016, covering $536.15k m^{2}$ of Nanjing, Changzhou, and Wuhan. It has 5,987 images in size of $1,024\times1,024$ , involving seven types of common land covers. We merge the official training and validation sets for training and conduct evaluation using the official testing set.
- LoveDA:这是一个包含城乡场景的挑战性数据集,采集了来自Google Earth的30万张航天影像,拍摄于2016年7月,覆盖南京、常州和武汉共计53.615平方公里区域。数据集包含5,987张1,024×1,024尺寸的图像,涵盖七种常见土地覆盖类型。我们将官方训练集与验证集合并用于训练,并采用官方测试集进行评估。
- Implementation Details: Except that the models are trained with 80K iterations with a batch size of 8, and the warming up stage in the parameter scheduler lasts 1,500 iterations, most of the optimization settings are similar to the scene classification section. We use the UperNet [62] as the segmentation framework, where the input image sizes during training are $384~\times
384$ and $512\times~512$ for SpaceNetv1 and LoveDA, respectively, through random scaling and cropping. We also adopt random flipping for data augmentation. All experiments are implemented by MM Segmentation, where the mean value of the intersection over union (mIOU) is adopted as the evaluation metric. - 实现细节:除模型以批量大小8训练80K次迭代,且参数调度器的预热阶段持续1,500次迭代外,大部分优化设置与场景分类部分相似。我们采用UperNet [62]作为分割框架,训练时通过随机缩放和裁剪,SpaceNetv1和LoveDA的输入图像尺寸分别为$384~\times
384$和$512\times~512$。同时采用随机翻转进行数据增强。所有实验均通过MM Segmentation实现,并以交并比均值(mIOU)作为评估指标。 - Finetuning Results and Analyses: The results presented in Table VII demonstrate that MTP is also useful for enhancing the models’ performance on semantic segmentation tasks. Compared to SpaceNetv1, the improvements on the classical land cover classification dataset: LoveDA, are even more significant. As a result, on this dataset, our models surpass all previous methods except the BillionFM [35], which utilizes a model with over 1 billion parameters. On the SpaceNetv1, our models set new state-of-the-art accuracy. Nonetheless, probably due to over fitting, the results of SpaceNetv1 also indicate that the performances on simple extraction tasks do not improve as increasing model capacity. We have also noticed the performance of $\mathrm{ViT-L}+\mathrm{RVSA}$ on SpaceNetv1 is decreased when adopting MTP. We will conduct further exploration in later sections.
- 微调结果与分析:表 VII 所示结果表明,MTP 对于提升模型在语义分割任务上的性能同样有效。与 SpaceNetv1 相比,在经典土地覆盖分类数据集 LoveDA 上的改进更为显著。因此在该数据集上,我们的模型超越了除 BillionFM [35] 之外的所有现有方法(BillionFM 使用了超过 10 亿参数的模型)。在 SpaceNetv1 上,我们的模型创造了新的最高准确率记录。不过可能由于过拟合,SpaceNetv1 的结果也表明:在简单提取任务上,性能并不会随着模型容量的增加而提升。我们还注意到 $\mathrm{ViT-L}+\mathrm{RVSA}$ 在采用 MTP 时,于 SpaceNetv1 上的性能有所下降。我们将在后续章节进行更深入的探究。
TABLE VII THE MIOU $(%$ ) OF FINETUNING DIFFERENT PRETRAINED MODELS WITHUPERNET ON THE SPACENETV1 AND LOVEDA DATASETS.
表 7: 使用 UperNet 微调不同预训练模型在 SpaceNetV1 和 LoveDA 数据集上的 MIOU $(%$ ) 结果。
| 方法 | 主干网络 | SpaceNetv1 | LoveDA |
|---|---|---|---|
| PSANet [138] | ResNet-50 | 75.61 | |
| SeCo [29] | ResNet-50 | 77.09 | 43.63 |
| GASSL [27] | ResNet-50 | 78.51 | 48.76 |
| SatMAE [31] | ViT-L | 78.07 | |
| CACo [28] | ResNet-50 | 77.94 | 48.89 |
| PSPNet [139] | ResNet-50 | 48.31 | |
| DeeplabV3+ [140] | ResNet-50 | 48.31 | |
| FarSeg [141] | ResNet-50 | 48.15 | |
| FactSeg [142] | ResNet-50 | 48.94 | |
| TOV [12] | ResNet-50 | 49.70 | |
| HRNet [143] | HRNet-W32 | 49.79 | |
| GeRSP [45] | ResNet-50 | 50.56 | |
| DCFAM [144] | Swin-T | 50.60 | |
| UNetFormer [145] | ResNet-18 | 52.40 | |
| RSSFormer [146] | RSS-B | 52.43 | |
| UperNet [62] | ViTAE-B+RVSA [30] | 52.44 | |
| Hi-ResNet [147] | Hi-ResNet | 52.50 | |
| RSP [5] | ViTAEv2-S | 53.02 | |
| SMLFR [131] | ConvNext-L | 53.03 | |
| LSKNet [134] | LSKNet-S | 54.00 | |
| CtxMIM [37] | Swin-B | 79.47 | |
| AerialFormer [148] | Swin-B | 54.10 | |
| BillionFM [35] | ViT-G12X4 | 54.40* | |
| MAE | ViT-B+RVSA | 79.56* | 51.95 |
| MAE + MTP | ViT-B+RVSA | 79.63* | 52.39 |
| MAE | ViT-L+ RVSA | 79.69* | 53.72 |
| MAE + MTP | ViT-L + RVSA | 79.54 | 54.17* |
| IMP | InternImage-XL | 79.08 | 53.93* |
| IMP + MTP | InternImage-XL | 79.16 | 54.17* |
E. Change Detection
E. 变更检测
Finally, we pay attention to the change detection task, which can be regarded as a special type of segmentation by extracting the changed area between the RS images taken at different times in the same location. Here, we mainly consider the most representative bi-temporal change detection.
最后,我们关注变化检测任务,它可被视为一种特殊的分割类型,通过提取同一地点不同时间拍摄的遥感影像之间的变化区域来实现。此处我们主要考虑最具代表性的双时相变化检测。
- Dataset: We conduct the finetuning on the datasets of different scales: Onera Satellite Change Detection Dataset (OSCD) [190], Wuhan University Building Change Detection Dataset (WHU) [191], the Learning, Vision, and Remote Sensing Change Detection Dataset (LEVIR) [192], and the SeasonVarying Change Detection Dataset (SVCD) [193], which is also called “CDD”.
- 数据集:我们在不同规模的数据集上进行微调:Onera卫星变化检测数据集(OSCD) [190]、武汉大学建筑物变化检测数据集(WHU) [191]、学习视觉与遥感变化检测数据集(LEVIR) [192]以及季节变化检测数据集(SVCD) [193](亦称"CDD")。
and $20%$ patches of the cropped images are randomly selected as training, validation, and testing sets as suggested by [186].
并按照[186]的建议,随机选取裁剪后图像中20%的区块作为训练集、验证集和测试集。
- LEVIR: This dataset contains 637 pairs of $1,024\times$ 1,024 images with a spatial resolution of $0.5m$ . These images are acquired between 2002 and 2018 from 20 different regions in Texas, USA. It contains 31,333 change instances. We adopt the official split, where training, validation, and testing sets contain 445, 64, and 128 pairs, respectively.
- LEVIR:该数据集包含637对$1,024\times$1,024像素的图像,空间分辨率为$0.5m$。这些图像采集于2002至2018年间,覆盖美国德克萨斯州20个不同区域,共包含31,333个变化实例。我们采用官方划分方案,其中训练集、验证集和测试集分别包含445、64和128对图像。
- SVCD/CDD: This dataset focuses on seasonal variations. It initially contains 11 pairs of images obtained from Google Earth in different seasons, with spatial resolutions ranging from 0.03 to $1m$ . It now has been cropped to 16,000 pairs of patches in size of $256\times256$ by [194]. The $10,000/3,000/3,000$ pairs are separately used as training, validation, and testing sets.
- SVCD/CDD: 该数据集聚焦于季节变化。初始包含11对从Google Earth获取的不同季节图像,空间分辨率介于0.03至$1m$之间。经[194]处理后被裁剪为16,000对$256\times256$尺寸的图块,其中$10,000/3,000/3,000$对分别作为训练集、验证集和测试集。
- Implementation Details: Following [29], [42], we crop the OSCD images to $96~\times~96$ patches with no overlapping, obtaining 827/385 pairs for training/testing. However, the training is difficult to converge due to the extremely small input size, thus we rescale the image to $224\times224$ before inputting it into the network. For the WHU dataset, we separately have 5334, 762, and 1524 images for training, validation, and testing, after cropping the image to patches in size of $256\times256$ without overlaps. A similar operation is conducted for LEVIR, generating training, validation, and testing sets containing 7120, 1024, and 2048 samples, respectively. The training epochs on OSCD, WHU, LEVIR, and CDD are separately set to 100, 200, 150, and 200. The batch size of all datasets is uniformly set to 32. We adopt the same optimization strategy as the scene classification task. To fully leverage the feature pyramid produced by foundation models, we adopt a UNet [77] to process the differences between different temporal features. The training is implemented through Open $\mathrm{CD}^{6}$ , where the data augmentation includes random rotation, random flipping, random exchange temporal, and color jitters that randomly adjust brightness, contrast, hue, and saturation of images. The F1 score of the changed class is adopted as the evaluation metric.
- 实现细节: 遵循[29]、[42]的方法,我们将OSCD图像裁剪为$96~\times~96$的非重叠图块,获得827/385对训练/测试数据。但由于输入尺寸过小导致训练难以收敛,因此在输入网络前将图像缩放至$224\times224$。对于WHU数据集,将图像裁剪为$256\times256$非重叠图块后,分别获得5334、762和1524张图像用于训练、验证和测试。LEVIR数据集采用相同处理方式,生成包含7120、1024和2048个样本的训练集、验证集和测试集。OSCD、WHU、LEVIR和CDD的训练周期分别设置为100、200、150和200轮次,所有数据集的批大小统一设为32。我们采用与场景分类任务相同的优化策略。为充分利用基础模型生成的特征金字塔,采用UNet[77]处理不同时序特征间的差异。训练通过Open$\mathrm{CD}^{6}$实现,数据增强包括随机旋转、翻转、时序交换以及随机调整图像亮度、对比度、色相和饱和度的色彩扰动。采用变化类别的F1分数作为评估指标。
- Finetuning Results and Analyses: To comprehensively assess the finetuning performance of pretrained models, we conduct the comparison by collecting existing advanced change detection methods, as shown in Table VIII. It should be noted that, since the original WHU dataset does not provide an official train/test split, various split strategies are adopted in different methods. Therefore, on this dataset, we only list the accuracy value of the methods that employ the same settings as us or training with more images. It can be seen that MTP effectively improves the performances of pretrained models on these datasets. Especially, our models perform well on three large-scale datasets: WHU, LEVIR, and SVCD/CDD. Even if adopting simple UNet [77] and the RVSA model of the base version, the finetuning performances have been competitive and surpassed many advanced approaches. When utilizing larger models, the performance can be further boosted. Finally, they achieve the best accuracy on the WHU and LEVIR datasets by outperforming almost all existing methods, including the recent SkySense [42] that builds a larger change detection network with over 600M parameters, ChangeCLIP [188] that uses CLIP [17] to obtain additional knowledge from language modalities, and the newly proposed adapter BAN [189], where the ability of existing foundation model and change detection approaches can be exploited. Different from large-scale scenes, on the small-scale dataset OSCD, although MTP is still useful, the performances of our models have relatively large gaps compared to current works. We attribute the reason to data discrepancy and image size. Specifically, our models are pretrained on high-resolution RS images, which are similar to another three change detection datasets. However OSCD images are captured by multi spectral sensors with lower resolutions. In addition, OSCD images are only cropped to 96 $\times
96$ during training, which may be unsuitable for feature extraction, especially for non-hierarchical vision transformers. In the comparison methods, MATTER [24], SkySense [42], and GFM [46] use pyramid feature networks. Among them, MATTER and SkySense adopt Sentinel-2 multi spectral image in pre training, while GFM crops the OSCD image to a larger size, i.e., $192\times192$ . In contrast, a relatively small image size $(128\times~128)$ restricts the performances of ViT in - 微调结果与分析:为全面评估预训练模型的微调性能,我们通过收集现有先进的变更检测方法进行比较,如表VIII所示。需注意的是,由于原始WHU数据集未提供官方训练/测试划分,不同方法采用了多样化的划分策略。因此在该数据集上,我们仅列出采用与我们相同设置或使用更多图像训练的方法精度值。可见MTP有效提升了预训练模型在这些数据集上的表现。尤其我们的模型在三个大规模数据集WHU、LEVIR和SVCD/CDD上表现优异,即便采用基础版本的UNet [77]和RVSA模型,其微调性能已具备竞争力并超越诸多先进方法。当使用更大模型时,性能可进一步提升,最终在WHU和LEVIR数据集上以优于几乎所有现有方法的精度达到最佳,包括近期提出的600M参数超大变更检测网络SkySense [42]、利用CLIP [17]从语言模态获取额外知识的ChangeCLIP [188],以及新提出的适配器BAN [189]——该方法能同时利用现有基础模型和变更检测方法的优势。与大规模场景不同,在小规模数据集OSCD上,虽然MTP仍具价值,但我们的模型性能与当前工作存在较大差距。我们将原因归结为数据差异和图像尺寸:我们的模型基于高分辨率遥感图像预训练,这与另外三个变更检测数据集相似,而OSCD图像由多光谱传感器捕获且分辨率较低;此外OSCD图像在训练时仅裁剪为96$\times
96$,这可能不利于特征提取(尤其对非层级式视觉Transformer而言)。对比方法中,MATTER [24]、SkySense [42]和GFM [46]均采用金字塔特征网络,其中MATTER和SkySense在预训练阶段使用Sentinel-2多光谱图像,GFM则将OSCD图像裁剪为更大尺寸($192\times192$)。相比之下,较小输入尺寸$(128\times~128)$限制了ViT在...
TABLE VIII THE F1 SCORE $(%)$ OF FINETUNING DIFFERENT PRETRAINED MODELS WITH UNET ON THE OSCD, WHU, LEVIR, AND SVCD/CDD DATASETS.
表 VIII: 在 OSCD、WHU、LEVIR 和 SVCD/CDD 数据集上使用 UNet 微调不同预训练模型的 F1 分数 $(%)$
| 方法 | 主干网络 | OSCD | WHU | LEVIR | SVCD/CDD |
|---|---|---|---|---|---|
| GASSL [27] | ResNet-50 | 46.26 | |||
| SeCo [29] | ResNet-50 | 47.67 | 90.14 | ||
| FC-EF [149] | 48.89 | 62.32 | 77.11 | ||
| SwiMDiff [98] | ResNet-18 | 49.60 | |||
| CACo [28] | ResNet-50 | 52.11 | |||
| SatMAE [31] | ViT-L | 52.76 | |||
| SNUNet [150] | 83.49 | 88.16 | 96.20 | ||
| BIT [151] | ResNet-18 | 83.98 | 89.31 | ||
| SRCDNet [152] | ResNet-18 | 87.40 | 92.94 | ||
| CLNet [153] | 90.00 | 92.10 | |||
| HANet [154] | 90.28 | ||||
| RECM [155] | ViT-S | 90.39 | |||
| ChangeFormer [156] | MiT-B2 [157] | 90.40 | |||
| AERNet [158] | ResNet-34 | 90.78 | |||
| ESCNet [159] | 93.54 | ||||
| DSAMNet [160] | ResNet-18 | 93.69 | |||
| GCD-DDPM [161] | 92.54 | 90.96 | 94.93 | ||
| CDContrast [162] | 95.11 | ||||
| DDPM-CD [163] | UNet [77] | 92.65 | 90.91 | 95.62 | |
| DeepCL [164] | EfficientNet-b0 [165] | 91.11 | |||
| DMNet [166] | ResNet-50 | 95.93 | |||
| ChangeStar [167] | ResNeXt-101 [168] | 91.25 | |||
| RSP [5] | ViTAEv2-S [58] | 90.93 | 96.81 | ||
| SAAN [169] | ResNet-18 | 91.41 | 97.03 | ||
| SiamixFormer [170] | MiT-B5 [157] | 91.58 | 97.13 | ||
| TransUNetCD [171] | ResNet-50 | 93.59 | 91.11 | 97.17 | |
| RDPNet [172] | 90.10 | 97.20 | |||
| SDACD [173] | 97.34 | ||||
| Siam-NestedUNet [174] | UNet++ [175] | 91.50 | |||
| Changen [176] | MiT-B1 [157] | 91.50 | |||
| HCGMNet [177] | VGG-16 | 91.77 | |||
| CEECNet [178] | 91.83 | ||||
| RingMo [32] | Swin-B | 91.86 | |||
| CGNet [179] | VGG-16 | 92.01 | |||
| TTP [180] | SAM [47] | 92.10 | |||
| Changer [181] | ResNeSt-101 [104] | 92.33 | |||
| WNet [182] | ResNet-18 + DAT [183] | 91.25 | 90.67 | 97.56 | |
| SpectralGPT+ [34] | ViT-B | 54.29 | |||
| C2FNet [184] | VGG-16 | 91.83 | |||
| MATTER [24] | ResNet-34 | 59.37* | |||
| GFM [46] | Swin-B | 59.82* | |||
| FMCD [185] | EfficientNet-b4 [165] | 94.48 | |||
| SGSLN/256 [186] | 94.67 | 91.93 | 96.24 | ||
| P2V-CD [187] | 92.38 | 91.94 | 98.42* | ||
| ChangeCLIP [188] | CLIP [17] | 94.82* | 92.01 | 97.89 | |
| BAN [189] | InternImage-XL [82] | 91.94 | |||
| BAN [189] | ViT-L [82] | 91.96 | |||
| BAN [189] | ChangeFormer [156] | 92.30 | |||
| SkySense [42] | Swin-H | 60.06* | 92.58* | ||
| MAE | ViT-B+RVSA | 50.28 | 93.77 | 92.21 | 97.80 |
| MAE + MTP | ViT-B+RVSA | 53.36 | 94.32 | 92.22 | 97.87 |
| MAE | ViT-L+RVSA | 54.04 | 94.07 | 92.52 | 97.78 |
| MAE + MTP | ViT-L+RVSA | 55.92 | 94.75 | 92.67* | 97.98 |
| IMP | InternImage-XL | 51.61 | 95.33* | 92.46 | 98.37* |
| IMP + MTP | InternImage-XL | 55.61 | 95.59* | 92.54* | 98.33* |
TABLE IX DETAILED HYPER PARAMETER SETTINGS IN FINETUNING PRETRAINED MODELS ON DIFFERENT DATASETS. “✔” AND “✘” INDICATE WHETHER THE MTP IS USEFUL FOR IMPROVING PERFORMANCE COMPARED TO THE SETTING WITHOUT MTP.
表 IX 不同数据集上微调预训练模型的详细超参数设置。"✔"和"✘"表示与不使用MTP的设置相比,MTP是否有助于提高性能。
| 数据集 | 场景分类 | 水平检测 | 旋转目标检测 | |||||
|---|---|---|---|---|---|---|---|---|
| EuroSAT | RESISC-45 | Xview | DIOR | DIOR-R | FAIR1M-2.0 | DOTA-V1.0 | DOTA-2.0 | |
| 训练图像数量(NTrIm) | 16,200 | 6,300 | 20,084 | 11,725 | 11,725 | 288,428 | 133,883 | 31,273 |
| 训练轮数(NTrEp) | 100 | 200 | 12 | 12 | 12 | 12 | 12 | 40 |
| 总样本数(NToSa) | 1,620,000 | 1,260,000 | 241,008 | 140,700 | 140,700 | 3,461,136 | 1,606,596 | 1,250,920 |
| 批量大小(SB) | 64 | 64 | 8 | 4 | 4 | 16 | 4 | 4 |
| 总迭代次数(NToIt) | 25,312 | 19,688 | 30,126 | 35,175 | 35,175 | 216,321 | 401,649 | 312,730 |
| 训练图像尺寸(STrIm) | 224 | 224 | 416 | 800 | 800 | 800 | 1,024 | 1,024 |
| 类别数(Nc) | 10 | 45 | 60 | 20 | 20 | 37 | 15 | 18 |
| 每类平均像素数(APc) | 36,288,000 | 6,272,000 | 1,670,988 | 5,628,000 | 5,628,000 | 74,835,373 | 109,676,954 | 71,163,449 |
| 每类平均迭代次数(AIc) | 2,531 | 438 | 502 | 1,759 | 1,759 | 5,847 | 26,777 | 17,374 |
| ViT-B+RVSA | ← | ← | ← | × | ||||
| ViT-L+RVSA | ← | ← | × | |||||
| InternImage-XL | × | ← | ← |
| 数据集 | 语义分割 | 双时相变化检测 SVCD/CDD | ||||||
|---|---|---|---|---|---|---|---|---|
| 训练图像数量(NTrIm) | SpaceNetvl | LoveDA | OSCD | WHU | LEVIR | |||
| 5,000 | 4,191 | 827 | 5,334 | 7,120 | 10,000 | |||
| 训练轮数(NTrEp) | 128 | 153 | 100 | 200 | 150 | 200 | ||
| 总样本数(NToSa) | 640,000 | 640,000 | 82,700 | 1,066,800 | 1,068,000 | 2,000,000 | ||
| 批量大小(SB) | 8 | 8 | 32 | 32 | 32 | 32 | ||
| 总迭代次数(NToIt) | 80,000 | 80,000 | 2,584 | 33,338 | 33,375 | 62,500 | ||
| 训练图像尺寸(STrIm) | 384 | 512 | 224 | 256 | 256 | 256 | ||
| 类别数(Nc) | 2 | 7 | 2 | 2 | 2 | 2 | ||
| 每类平均像素数(APc) | 122,880,000 | 46,811,429 | 9,262,400 | 136,550,400 | 136,704,000 | 256,000,000 | ||
| 每类平均迭代次数(AIc) | 40,000 | 11,429 | 1,292 | 16,669 | 16,688 | 31,250 | ||
| ViT-B+RVSA | ||||||||
| ViT-L+RVSA | × | ← | ||||||
| InternImage-XL | ← | ← | ← | × |
Spectral GP T [34]. These results suggest that it is necessary to conduct further explorations to enhance the model finetuning performance on out-of-domain datasets with small volumes and input sizes.
谱GP T[34]。这些结果表明,有必要进一步探索如何在小规模、小输入量的域外数据集上提升模型微调性能。
F. Further Investigations and Analyses
F. 进一步调查与分析
Besides evaluating the performances of pretrained models, we conduct further investigations to obtain deeper insights into the characteristics of MTP, including the influence factors of MTP, finetuning with fewer samples, and parameter reusing of decoders.
除了评估预训练模型的性能外,我们还进行了进一步研究以更深入地理解MTP的特性,包括MTP的影响因素、少样本微调以及解码器的参数复用。
- Influence Factors of Multi-Task Pre training: Up to now, to comprehensively assess the impact of MTP, we have finetuned three types of foundation models, on five RS downstream tasks, involving a total of fourteen datasets. From the finetuning results (Table IV-VIII) we find that MTP improves these foundation models in most cases. But there are still some datasets, on which MTP does not perform well as expected, i.e., not all accuracies of three models are increased. To figure out the reason, we explore the influence factors related to the performance of MTP, as shown in Table IX. Intuitively, we suppose MTP may be affected by the characteristics of finetuning datasets and consider a series of variables, including “Training Image Number” $(N_{T r I m})$ , “Training Epoch Number” $(N_{T r E p})$ , “Batch Size” $(S_{B})$ , and “ Training Image Size” $(S_{T r I m})$ . The “Training Image Number” means: for each dataset, the number of images used for training. For example, the $\boldsymbol{N_{T r I m}}$ of DIOR is 11,725 since the original training and validation sets are together used for training. While “Training Image Size” represents the image size after data augmentation and preprocessing. Theoretically, we have
- 多任务预训练的影响因素:截至目前,为全面评估MTP的影响,我们已在五个遥感下游任务上对三类基础模型进行微调,涉及共计十四个数据集。从微调结果(表IV-VIII)可见,MTP在多数情况下提升了这些基础模型的性能。但仍有部分数据集未达预期效果,即并非所有三种模型的精度均得到提升。为探究原因,我们分析了与MTP性能相关的影响因素(如表IX所示)。直观推测MTP可能受微调数据集特性影响,因此考察了系列变量,包括"训练图像数量"$(N_{TrIm})$、"训练轮次"$(N_{TrEp})$、"批大小"$(S_{B})$及"训练图像尺寸"$(S_{TrIm})$。其中"训练图像数量"指:每个数据集用于训练的图像总数。例如DIOR的$\boldsymbol{N_{TrIm}}$为11,725,因其原始训练集与验证集被合并用于训练;而"训练图像尺寸"表示数据增强与预处理后的图像尺寸。理论上存在关系式:
where $N_{T o I t}$ means the number of training iterations for model parameter updating under the mini-batch optimization strategy. In Table IX, we observe that as $N_{T o I t}$ increases, there is a tendency for MTP to have a negative impact on finetuning performance for a given task. However, this trend isn’t universally applicable, as evidenced by varying results among pretrained models in segmentation tasks, all with the same $N_{T o I t}$ . Additionally, we account for dataset difficulty by considering the Number of Classes $N_{C}$ and use the “Average Iteration per Class” $(A I_{C})$ to represent each dataset as
其中 $N_{T o I t}$ 表示小批量优化策略下模型参数更新的训练迭代次数。在表 IX 中,我们观察到随着 $N_{T o I t}$ 增加,MTP 对给定任务的微调性能往往会产生负面影响。但这一趋势并非普遍适用,例如在分割任务中,相同 $N_{T o I t}$ 下不同预训练模型的结果存在差异。此外,我们通过类别数 $N_{C}$ 衡量数据集难度,并使用"每类平均迭代次数" $(A I_{C})$ 表征每个数据集:

Surprisingly, Table IX reveals a notable trend: a relatively large $A I_{C}$ corresponds to a negative impact of MTP for the same task. This suggests that, over extended finetuning periods, MTP models lose their advantage compared to conventional pretrained models. We propose a bold conjecture regarding this internal mechanism: the benefits of MTP diminish gradually due to excessive network optimization. This discovery prompts a reconsideration of the trade-off between longer training times for accuracy gains and the benefits of pre training when finetuning models. However, determining the critical point of $A I_{C}$ remains challenging due to limited experimentation, necessitating further investigation. It is important to note that this phenomenon differs from over fitting, as our models continue to outperform existing methods at this stage.
表9揭示了一个显著趋势:对于同一任务,较大的$AI_{C}$值对应着MTP的负面影响。这表明在长时间微调后,MTP模型相比传统预训练模型会逐渐丧失优势。我们针对这一内部机制提出大胆猜想:由于网络过度优化,MTP的收益会逐步递减。这一发现促使我们重新思考模型微调时,延长训练时间换取精度提升与预训练收益之间的权衡关系。但受限于实验规模,目前仍难以确定$AI_{C}$的临界点,需要进一步研究。需要特别说明的是,这种现象与过拟合不同,因为现阶段我们的模型性能仍优于现有方法。
In addition to training duration, we consider dataset capacity, introducing the index “Average Pixels per Class” $A P_{C}$ , which can be formulated by
除了训练时长外,我们还考虑了数据集容量,引入了"每类平均像素数( Average Pixels per Class )"指标 $A P_{C}$ ,其计算公式为


Fig. 3. The finetuning accuracy of different pretrained models with varying training sample sizes. (a) Intern Image-XL on EuroSAT. (b) $\mathrm{ViT-L}+\mathrm{RVSA}$ on SpaceNetv1.
图 3: 不同预训练模型在不同训练样本量下的微调精度。(a) Intern Image-XL 在 EuroSAT 上的表现。(b) $\mathrm{ViT-L}+\mathrm{RVSA}$ 在 SpaceNetv1 上的表现。
where $N_{T o S a}=N_{T r E p}$ denotes the quantity of images processed during training. Consequently, $A P_{C}$ approximately reflects the data volume encountered during finetuning. Table IX reveals that $A P_{C}$ exhibits similar trends to $A I_{C}$ , yet the correlation between $A P_{C}$ and MTP performance is less discernible compared to $A I_{C}$ , possibly due to the presence of redundant pixels in RS images.N_{T r I m}\cdot
其中 $N_{T o S a}=N_{T r E p}$ 表示训练期间处理的图像数量。因此,$A P_{C}$ 大致反映了微调阶段接触到的数据量。表 IX 显示 $A P_{C}$ 与 $A I_{C}$ 呈现相似趋势,但相比 $A I_{C}$,$A P_{C}$ 与 MTP 性能的关联性较弱,这可能是由于遥感图像中存在冗余像素所致。N_{T r I m}\cdot
- Fewer Sample Finetuning: The efficacy of SEP has been demonstrated in scenarios with limited samples [13]. While MTP represents an extension of SEP, it is reasonable to anticipate that MTP could excel in analogous contexts. Moreover, as noted earlier, MTP primarily addresses the discrepancy between upstream pre training and downstream finetuning tasks. This encourages us to consider that fewer downstream training samples might better showcase MTP’s efficacy in facilitating efficient transfer from pre training models. To explore this, we finetune InterImage-XL on EuroSAT and $\mathrm{ViT-L}+\mathrm{RVSA}$ on SpaceNetv1, respectively, progressively reducing training samples. The results are depicted in Figure 3. Initially, MTP’s performance is slightly inferior to its counterparts when the training sample proportion is $100%$ , as illustrated in Tables IV and VII. However, as training samples decrease, the performance curves converge until the training sample proportion is $10%$ , at which point MTP’s impact is minimal. Subsequent reductions in training samples lead to decreased accuracies across all models, yet the distances between the curves progressively widen. This trend suggests that the benefits of MTP are beginning to emerge, becoming increasingly significant. These findings validate our hypotheses, underscoring the benefit of MTP for finetuning foundational models on limited training samples.
- 少样本微调:SEP (Structured Embedding Pretraining) 在有限样本场景下的有效性已得到验证 [13]。虽然 MTP (Multi-Task Pretraining) 是 SEP 的扩展,但可以合理预期 MTP 在类似情境中表现更优。此外如前所述,MTP 主要解决上游预训练与下游微调任务之间的差异。这促使我们推测:更少的下游训练样本可能更易凸显 MTP 在促进预训练模型高效迁移方面的优势。为验证这一点,我们分别在 EuroSAT 数据集上微调 InterImage-XL,在 SpaceNetv1 数据集上微调 $\mathrm{ViT-L}+\mathrm{RVSA}$,逐步减少训练样本量。结果如图 3 所示:当训练样本比例为 $100%$ 时(见附表 IV 和 VII),MTP 性能略逊于对比方案;但当样本比例降至 $10%$ 时,各方案性能曲线趋于重合,此时 MTP 的影响微乎其微。继续减少训练样本后,所有模型精度均出现下降,但曲线间距逐渐扩大。这一趋势表明 MTP 的优势开始显现并持续增强,验证了我们的假设,证实了 MTP 在有限样本下微调基础模型的价值。
TABLE X THE ACCURACIES OF FINETUNING VIT $\mathrm{\bfB}+\mathrm{\bfRVSA}$ ON VARIOUS DATASETS WITH AND WITHOUT REUSING PRETRAINED DECODER WEIGHTS.
表 X 微调 ViT $\mathrm{\bfB}+\mathrm{\bfRVSA}$ 在不同数据集上是否复用预训练解码器权重的准确率对比
| 模型 | SpaceNetv1 | LoveDA | DIOR-R |
|---|---|---|---|
| w/oDPR | 79.63 | 52.39 | 71.29 |
| W DPR | 79.54 | 51.83 | 71.94 |
| 模型 | FAIR1M-2.0 | DOTA-V1.0 | DOTA-V2.0 |
| w/oDPR | 51.92 | 80.67 | 55.22 |
| WDPR | 52.19 | 80.54 | 55.78 |
- Decoder Parameter Reusing: MTP utilizes task-specific decoders for segmentation and detection tasks. Hence, reusing these decoder weights during finetuning seems a natural choice, and we conduct experiments accordingly using a backbone of Vi $\Gamma{\bf-B}+\mathrm{RVSA}$ . Specifically, aside from the backbone network, we also initialize the corresponding decoders with pretrained weights during finetuning. However, only semantic segmentation and rotated detection decoders are eligible for reuse, as per the segmentor or detector used in existing methods. Therefore, we performed the experiment on the corresponding six datasets, and the results have been presented in Table X. Among four detection datasets, decoder parameter reusing (DPR) proves beneficial in three scenarios, which are actually employed in performing MTP. Nevertheless, on another classical dataset DOTA-V1.0, which can be regarded as a subset of DOTA-V2.0, DPR is insufficient useful. On segmentation tasks, the performances of DPR models are decreased. We speculate that besides the domain differences compared to pre training datasets, current models may be additionally affected by the segmentation labels in pre training. This is because decoders typically encode task-specific information. However, given that the SAMRS dataset used for pre training involves annotations generated by SAM [47], they inevitably contain errors, jeopardizing the quality of pretrained decoders. Finally, based on the above considerations, we conclude that after MTP, the performances of reusing pretrained decoder parameters in finetuning may depend on the similarity between pre training and finetuning scenarios and the quality of pre training annotations.
- 解码器参数复用: MTP 为分割和检测任务使用任务专用解码器。因此在微调阶段复用这些解码器权重是自然选择,我们基于 Vi $\Gamma{\bf-B}+\mathrm{RVSA}$ 骨干网络进行了实验。具体而言,除骨干网络外,我们在微调时还用预训练权重初始化了对应解码器。但根据现有方法使用的分割器或检测器类型,仅语义分割和旋转检测解码器符合复用条件。为此我们在六个对应数据集上进行了实验,结果如表 X 所示。在四个检测数据集中,解码器参数复用 (DPR) 在三个场景中表现有益——这三个场景正是执行 MTP 时实际采用的。然而在另一个经典数据集 DOTA-V1.0 (可视为 DOTA-V2.0 的子集) 上,DPR 效果有限。在分割任务中,采用 DPR 的模型性能反而下降。我们推测除了与预训练数据集的领域差异外,当前模型可能还受到预训练阶段分割标签的影响。这是因为解码器通常会编码任务特定信息。但考虑到预训练使用的 SAMRS 数据集包含由 SAM [47] 生成的标注,这些标注不可避免地存在误差,损害了预训练解码器的质量。最终基于上述分析,我们认为 MTP 后是否在微调中复用预训练解码器参数,可能取决于预训练与微调场景的相似性以及预训练标注的质量。
G. Visualization
G. 可视化
To further show the efficacy of MTP in enhancing RS foundation models, we present the predictions of $\mathbf{MAE}+\mathbf{MTP}$ pretrained $\mathrm{ViT-L}+\mathrm{RVSA}$ across detection, segmentation, and change detection tasks in Figure 4-7. For detection, we demonstrate results across diverse scenes using horizontal or rotated bounding boxes. For segmentation, we display the original images alongside segmentation maps, highlighting building extraction masks in red. For change detection, we provide the bi-temporal images, ground truths, and predicted change maps. Our model accurately detects RS objects, extracts buildings, classifies land cover categories, and characterizes changes across diverse types. In summary, MTP enables the construction of an RS foundation model with over 300 parameters, which achieves superior representation capability for various downstream tasks.
为进一步展示MTP在增强遥感(RS)基础模型方面的有效性,我们在图4-7中呈现了基于$\mathbf{MAE}+\mathbf{MTP}$预训练的$\mathrm{ViT-L}+\mathrm{RVSA}$模型在检测、分割和变化检测任务中的预测结果。对于检测任务,我们展示了使用水平或旋转边界框在不同场景下的结果。对于分割任务,我们在展示原始图像的同时呈现分割图,并用红色突出显示建筑物提取掩膜。对于变化检测任务,我们提供了双时相图像、地面真值以及预测的变化图。我们的模型能够准确检测遥感目标、提取建筑物、分类土地覆盖类型,并表征多种类型的变化特征。综上所述,MTP支持构建参数量超过300亿的遥感基础模型,该模型在各种下游任务中展现出卓越的表征能力。

Fig. 4. Visualization of the horizontal object detection predictions of MAE $^+$ MTP pretrained ViT-L $^+$ RVSA. The images of the first and the second rows are from Xview and DIOR testing sets, respectively.
图 4: MAE $^+$ MTP预训练ViT-L $^+$ RVSA的水平目标检测预测可视化。第一行和第二行的图像分别来自Xview和DIOR测试集。

Fig. 5. Visualization of the rotated object detection predictions of MAE $^+$ MTP pretrained ViT-L $^+$ RVSA. The images in four rows are from the testin sets of DIOR-R, FAIR1M-2.0, DOTA-V1.0 and DOTA-V2.0, respectively.
图 5: MAE $^+$ MTP预训练ViT-L $^+$ RVSA的旋转目标检测预测可视化。四行图像分别来自DIOR-R、FAIR1M-2.0、DOTA-V1.0和DOTA-V2.0的测试集。

Fig. 6. Visualization of the semantic segmentation predictions of MAE $^+$ MTP pretrained ViT-L $^+$ RVSA. The samples of the first and the second rows are from SpaceNetv1 and LoveDA testing sets, respectively.
图 6: MAE $^+$ MTP预训练ViT-L $^+$ RVSA的语义分割预测可视化。第一行和第二行样本分别来自SpaceNetv1和LoveDA测试集。

Fig. 7. Visualization of the bi-temporal change detection predictions of MAE $^+$ MTP pretrained ViT-L $^+$ RVSA. The samples in four rows are from the testing sets of OSCD, WHU, LEVIR and SVCD/CDD, respectively. (a)(b)(e)(f) depict bi-temporal images of different samples, with (c) and (g) representing corresponding ground truth labels. Our prediction maps are shown at (d) and (h).
图 7: MAE $^+$ MTP预训练ViT-L $^+$ RVSA的双时相变化检测预测可视化。四行样本分别来自OSCD、WHU、LEVIR和SVCD/CDD测试集。(a)(b)(e)(f)展示不同样本的双时相图像,(c)和(g)为对应真实标签。我们的预测结果如(d)和(h)所示。
V. CONCLUSION
五、结论
In this paper, we introduce the multi-task pre training (MTP) approach for building RS foundation models. MTP utilizes a shared encoder and task-specific decoder architecture to effectively pretrain convolutional neural networks and vision transformer backbones on three tasks: semantic segmentation, instance segmentation, and rotated object detection in a unified supervised learning framework. We evaluate MTP by examining the finetuning accuracy of these pretrained models on 14 datasets covering various downstream RS tasks. Our results demonstrate the competitive performance of these models compared to existing methods, even with larger models. Further experiments indicate that MTP excels in lowdata finetuning scenarios but may offer diminishing returns with prolonged finetuning on large-scale datasets. We hope this research encourages further exploration of RS foundation models, especially in resource-constrained settings. Additionally, we anticipate the widespread application of these models across diverse fields of RS image interpretation due to their strong representation capabilities.
本文提出了一种用于构建遥感基础模型的多任务预训练 (MTP) 方法。MTP采用共享编码器和任务特定解码器架构,在统一监督学习框架下对卷积神经网络和Vision Transformer骨干网络进行三种任务的联合预训练:语义分割、实例分割和旋转目标检测。我们通过在14个涵盖不同下游遥感任务的数据集上微调这些预训练模型来评估MTP方法。结果表明,即使面对更大规模的模型,这些预训练模型仍展现出与现有方法相当的性能优势。进一步实验表明,MTP在低数据量微调场景表现优异,但在大规模数据集上延长微调时间可能带来收益递减。我们希望这项研究能推动遥感基础模型的进一步探索,特别是在资源受限的环境中。此外,凭借其强大的表征能力,我们预期这些模型将在遥感图像解译的各个领域获得广泛应用。
ACKNOWLEDGEMENT
致谢
The numerical calculations in this paper are partly supported by the Dawning Information Industry Co., Ltd.
本文的数值计算部分由曙光信息产业股份有限公司提供支持。
REFERENCES
参考文献
APPENDIX
附录
We present detailed finetuning accuracies of the three models, i.e., ViT-B $^+$ RVSA, ViT-L $^+$ RVSA, and Intern Image-XL, on the DIOR, DIOR-R, FAIR1M-2.0, DOTA-V1.0, DOTAV2.0, and LoveDA datasets in Table XI-XVI.
我们在表XI-XVI中展示了ViT-B $^+$ RVSA、ViT-L $^+$ RVSA和Intern Image-XL三个模型在DIOR、DIOR-R、FAIR1M-2.0、DOTA-V1.0、DOTAV2.0以及LoveDA数据集上的详细微调准确率。
TABLE XI DETAILED ACCURACIES OF DIFFERENT MODELS ON DIOR DATASET.
表 XI DIOR数据集上不同模型的详细准确率
| 类别 | ViT-B+RVSA w/o MTP | ViT-B+RVSA W MTP | ViT-L+RVSA w/o MTP | ViT-L+RVSA W MTP | InternImage-XL w/o MTP | InternImage-XL W MTP |
|---|---|---|---|---|---|---|
| 飞机 | 68.2 | 87.5 | 76.5 | 93.8 | 65.0 | 69.0 |
| 机场 | 91.2 | 92.1 | 92.6 | 91.6 | 91.3 | 92.8 |
| 棒球场 | 79.9 | 87.3 | 83.2 | 87.7 | 75.6 | 81.3 |
| 篮球场 | 88.0 | 89.4 | 90.7 | 92.1 | 89.3 | 90.1 |
| 桥梁 | 53.6 | 58.0 | 58.8 | 64.6 | 59.3 | 59.1 |
| 烟囱 | 82.1 | 83.7 | 84.1 | 85.9 | 84.9 | 84.8 |
| 高速公路服务区 | 90.6 | 92.9 | 92.3 | 94.3 | 92.8 | 93.9 |
| 高速公路收费站 | 76.2 | 80.5 | 79.5 | 84.5 | 84.4 | 83.6 |
| 水坝 | 78.2 | 82.0 | 79.3 | 81.4 | 80.2 | 82.0 |
| 高尔夫球场 | 84.9 | 88.1 | 85.7 | 87.3 | 86.2 | 83.9 |
| 田径场 | 83.9 | 85.6 | 85.3 | 86.7 | 85.9 | 87.4 |
| 港口 | 56.8 | 62.4 | 60.4 | 64.5 | 62.2 | 63.3 |
| 立交桥 | 67.4 | 69.8 | 70.6 | 72.0 | 68.8 | 68.6 |
| 船舶 | 74.4 | 75.4 | 75.4 | 76.3 | 73.6 | 73.6 |
| 体育场 | 82.8 | 85.8 | 84.3 | 85.6 | 83.7 | 85.5 |
| 储罐 | 61.4 | 62.5 | 65.3 | 62.6 | 59.6 | 57.7 |
| 网球场 | 89.4 | 91.2 | 91.3 | 92.5 | 87.6 | 90.3 |
| 火车站 | 76.1 | 80.3 | 76.6 | 79.7 | 77.7 | 77.7 |
| 车辆 | 45.2 | 47.4 | 48.2 | 47.6 | 45.0 | 46.2 |
| 风车 | 85.0 | 86.5 | 85.1 | 90.2 | 89.3 | 89.3 |
| mAP | 75.8 | 79.4 | 78.3 | 81.1 | 77.1 | 78.0 |
TABLE XII DETAILED ACCURACIES OF DIFFERENT MODELS ON DIOR-R DATASET.
表 12: DIOR-R 数据集上不同模型的详细准确率
| 类别 | ViT-B+RVSA 无 MTP | ViT-B+RVSA 有 MTP | ViT-L+RVSA 无 MTP | ViT-L+RVSA 有 MTP | InternImage-XL 无 MTP | InternImage-XL 有 MTP |
|---|---|---|---|---|---|---|
| 飞机 | 72.1 | 89.6 | 81.2 | 90.7 | 72.0 | 72.3 |
| 机场 | 51.1 | 52.6 | 51.9 | 63.4 | 61.5 | 63.6 |
| 棒球场 | 80.8 | 81.2 | 81.1 | 90.0 | 80.6 | 80.9 |
| 篮球场 | 81.3 | 87.8 | 90.1 | 90.1 | 90.0 | 90.1 |
| 桥梁 | 44.9 | 48.6 | 48.1 | 56.4 | 53.5 | 54.7 |
| 烟囱 | 72.7 | 77.2 | 78.2 | 81.5 | 81.5 | 81.5 |
| 高速公路服务区 | 87.5 | 89.1 | 88.4 | 89.4 | 89.9 | 89.7 |
| 高速公路收费站 | 69.3 | 71.6 | 74.7 | 80.1 | 79.5 | 79.6 |
| 水坝 | 35.5 | 43.3 | 39.8 | 39.9 | 43.0 | 45.9 |
| 高尔夫球场 | 78.4 | 79.0 | 79.4 | 79.3 | 80.0 | 79.3 |
| 田径场 | 81.9 | 84.2 | 84.3 | 85.1 | 85.2 | 85.3 |
| 港口 | 43.3 | 51.3 | 46.4 | 56.0 | 54.8 | 55.2 |
| 立交桥 | 60.1 | 60.9 | 60.5 | 67.2 | 64.2 | 65.8 |
| 船只 | 81.2 | 81.2 | 81.2 | 81.1 | 81.3 | 81.3 |
| 体育场 | 81.6 | 83.7 | 83.4 | 78.9 | 78.2 | 79.2 |
| 储罐 | 70.5 | 71.2 | 71.4 | 71.4 | 62.7 | 62.8 |
| 网球场 | 89.2 | 90.2 | 90.0 | 90.4 | 81.5 | 90.1 |
| 火车站 | 65.6 | 66.6 | 65.2 | 73.9 | 66.7 | 67.5 |
| 车辆 | 49.3 | 50.5 | 51.0 | 51.8 | 50.5 | 51.1 |
| 风车 | 65.1 | 66.0 | 64.6 | 74.3 | 66.1 | 67.2 |
| mAP | 68.1 | 71.3 | 70.5 | 74.5 | 71.1 | 72.2 |
TABLE XIII DETAILED ACCURACIES OF DIFFERENT MODELS ON FAIR1M-2.0 DATASET.
表 13: FAIR1M-2.0 数据集上不同模型的详细准确率
| 类别 | ViT-B+RVSA w/o MTP | ViT-B+RVSA W MTP | ViT-L+RVSA w/o MTP | ViT-L+RVSA W MTP | InternImage-XL w/o MTP | InternImage-XL w MTP |
|---|---|---|---|---|---|---|
| Boeing737 | 47.17 | 44.78 | 48.91 | 43.21 | 41.36 | 47.48 |
| Boeing747 | 93.31 | 93.73 | 95.00 | 94.95 | 95.76 | 95.67 |
| Boeing777 | 41.48 | 45.01 | 36.86 | 36.20 | 50.87 | 44.57 |
| Boeing787 | 60.01 | 57.03 | 64.70 | 61.42 | 63.66 | 66.78 |
| C919 | 42.43 | 44.27 | 33.94 | 50.14 | 51.95 | 54.52 |
| A220 | 53.64 | 52.23 | 56.51 | 52.70 | 54.10 | 58.17 |
| A321 | 71.56 | 72.12 | 72.98 | 72.68 | 69.31 | 70.76 |
| A330 | 61.97 | 64.22 | 60.78 | 64.01 | 68.53 | 64.66 |
| A350 | 75.76 | 73.14 | 75.94 | 70.90 | 80.19 | 78.89 |
| ARJ21 | 20.36 | 20.93 | 19.66 | 23.14 | 22.67 | 22.78 |
| Passenger Ship | 20.12 | 21.29 | 20.38 | 19.80 | 15.76 | 15.55 |
| Motorboat | 71.17 | 71.73 | 72.72 | 73.07 | 64.86 | 66.28 |
| Fishing Boat | 35.42 | 36.30 | 36.30 | 33.94 | 28.38 | 31.34 |
| Tugboat | 31.12 | 32.66 | 36.00 | 32.52 | 27.33 | 25.38 |
| Engineering Ship | 22.75 | 25.90 | 29.02 | 28.63 | 20.16 | 21.00 |
| Liquid Cargo Ship | 48.73 | 49.30 | 52.80 | 49.31 | 46.91 | 46.32 |
| Dry Cargo Ship | 53.07 | 53.12 | 53.87 | 51.09 | 49.18 | 49.13 |
| Warship | 38.17 | 40.88 | 45.66 | 43.44 | 33.45 | 38.04 |
| Small Car | 76.77 | 76.98 | 77.65 | 77.23 | 72.77 | 72.92 |
| Bus | 45.60 | 42.16 | 51.73 | 51.73 | 47.59 | 46.79 |
| Cargo Truck | 59.64 | 59.87 | 61.56 | 60.53 | 56.15 | 56.32 |
| Dump Truck | 61.73 | 61.85 | 63.08 | 60.95 | 57.69 | 57.48 |
| Van | 77.08 | 77.33 | 78.22 | 77.74 | 73.00 | 73.08 |
| Trailer | 19.74 | 19.34 | 23.63 | 22.48 | 14.48 | 17.55 |
| Tractor | 1.33 | 1.79 | 2.21 | 1.83 | 0.71 | 1.23 |
| Excavator | 23.38 | 25.03 | 27.58 | 29.12 | 21.49 | 18.68 |
| Truck Tractor | 50.00 | 49.83 | 48.71 | 52.15 | 50.62 | 48.44 |
| Basketball Court | 64.50 | 63.35 | 63.46 | 64.40 | 60.69 | 60.46 |
| Tennis Court | 91.45 | 90.71 | 92.09 | 91.53 | 89.07 | 90.22 |
| Football Field | 66.23 | 67.21 | 70.72 | 70.75 | 68.44 | 68.98 |
| Baseball Field | 91.81 | 91.52 | 92.27 | 91.80 | 87.93 | 88.78 |
| Intersection | 63.65 | 64.73 | 64.94 | 66.22 | 64.30 | 63.28 |
| Roundabout | 26.13 | 25.43 | 28.36 | 31.00 | 30.71 | 27.07 |
| Bridge | 45.91 | 49.38 | 50.66 | 51.32 | 42.81 | 43.33 |
| mAP | 51.56 | 51.92 | 53.20 | 53.00 | 50.67 | 50.94 |
TABLE XIV DETAILED ACCURACIES OF DIFFERENT MODELS ON DOTA-V1 DATASET.
表 XIV: DOTA-V1 数据集上不同模型的详细准确率
| 类别 | ViT-B+RVSA w/o MTP | ViT-B+RVSA w MTP | ViT-L+RVSA w/oMTP | ViT-L+RVSA w MTP | InternImage-XL w/o MTP | InternImage-XL w MTP |
|---|---|---|---|---|---|---|
| plane | 88.42 | 88.91 | 88.52 | 88.33 | 88.91 | 88.96 |
| baseball-diamond | 85.03 | 84.07 | 85.36 | 86.59 | 86.78 | 85.93 |
| bridge | 60.86 | 60.76 | 61.55 | 63.38 | 59.93 | 60.62 |
| ground-track-field | 82.39 | 82.93 | 81.25 | 83.49 | 81.05 | 81.26 |
| small-vehicle | 80.70 | 80.41 | 80.69 | 81.06 | 80.80 | 80.08 |
| large-vehicle | 85.76 | 86.16 | 86.44 | 86.48 | 85.06 | 84.55 |
| ship | 88.58 | 88.64 | 88.51 | 88.53 | 88.38 | 87.96 |
| tennis-court | 90.88 | 90.87 | 90.87 | 90.87 | 90.81 | 90.86 |
| basketball-court | 86.61 | 86.21 | 85.80 | 86.26 | 86.27 | 86.37 |
| storage-tank | 86.88 | 86.76 | 86.84 | 85.80 | 86.19 | 86.50 |
| soccer-ball-field | 63.79 | 63.91 | 69.81 | 67.17 | 69.64 | 68.93 |
| roundabout | 72.52 | 71.00 | 72.51 | 71.84 | 71.50 | 73.11 |
| harbor | 78.52 | 79.04 | 84.82 | 84.94 | 79.21 | 78.76 |
| swimming-pool | 80.53 | 82.17 | 79.99 | 81.93 | 81.50 | 80.98 |
| helicopter | 81.00 | 78.34 | 78.51 | 78.31 | 67.57 | 76.63 |
| mAP | 80.83 | 80.68 | 81.43 | 81.66 | 80.24 | 80.77 |
TABLE XV DETAILED ACCURACIES OF DIFFERENT MODELS ON DOTA-V2 DATASET.
表 XV DOTA-V2数据集中不同模型的详细准确率
| 类别 | ViT-B+RVSA w/o MTP | ViT-B+RVSA w MTP | ViT-L+RVSA w/o MTP | ViT-L+RVSA w MTP | InternImage-XL w/o MTP | InternImage-XL w MTP |
|---|---|---|---|---|---|---|
| plane | 77.86 | 78.30 | 79.16 | 78.57 | 78.52 | 70.98 |
| baseball-diamond | 48.99 | 52.58 | 48.16 | 45.54 | 50.96 | 50.82 |
| bridge | 46.55 | 48.42 | 47.97 | 49.72 | 43.21 | 43.60 |
| ground-track-field | 63.10 | 59.05 | 61.57 | 56.42 | 59.77 | 59.25 |
| small-vehicle | 43.55 | 43.65 | 43.74 | 43.78 | 43.58 | 43.55 |
| large-vehicle | 56.85 | 57.15 | 61.14 | 62.26 | 56.11 | 56.50 |
| ship | 61.09 | 61.08 | 68.60 | 68.76 | 61.38 | 61.41 |
| tennis-court | 76.90 | 77.83 | 78.45 | 74.89 | 77.61 | 78.23 |
| basketball-court | 54.57 | 56.32 | 61.97 | 64.17 | 58.20 | 61.41 |
| storage-tank | 58.55 | 59.23 | 59.62 | 58.70 | 58.55 | 51.30 |
| soccer-ball-field | 36.37 | 36.93 | 45.98 | 43.70 | 48.88 | 42.89 |
| roundabout | 50.39 | 51.26 | 54.89 | 49.46 | 50.17 | 50.60 |
| harbor | 56.34 | 56.97 | 62.03 | 63.32 | 57.86 | 56.84 |
| swimming-pool | 63.89 | 63.05 | 64.34 | 64.59 | 58.43 | 58.31 |
| helicopter | 65.43 | 66.40 | 70.23 | 72.71 | 58.16 | 59.55 |
| container-crane | 39.19 | 44.24 | 46.94 | 50.91 | 40.58 | 49.21 |
| airport | 79.90 | 87.57 | 87.64 | 87.64 | 77.39 | 84.73 |
| helipad | 14.43 | 9.33 | 18.92 | 16.27 | 7.91 | 13.09 |
| mAP | 55.22 | 56.08 | 58.96 | 58.41 | 54.85 | 55.13 |
TABLE XVI DETAILED ACCURACIES OF DIFFERENT MODELS ON LOVEDA DATASET.
表 XVI 不同模型在LOVEDA数据集上的详细准确率
| 类别 | ViT-B+RVSA w/o MTP | ViT-B+RVSA w MTP | ViT-L+RVSA w/o MTP | ViT-L+RVSA w MTP | InternImage-XL w/o MTP | InternImage-XL w MTP |
|---|---|---|---|---|---|---|
| 背景 | 45.91 | 45.92 | 47.26 | 47.14 | 46.63 | 46.80 |
| 建筑 | 57.93 | 59.40 | 59.27 | 62.69 | 61.98 | 62.60 |
| 道路 | 56.08 | 56.15 | 59.54 | 58.00 | 58.25 | 58.96 |
| 水域 | 79.72 | 80.66 | 81.45 | 81.43 | 82.14 | 82.25 |
| 荒地 | 16.49 | 16.56 | 17.59 | 19.27 | 18.11 | 17.49 |
| 森林 | 46.03 | 46.38 | 47.39 | 46.82 | 47.99 | 47.63 |
| 农业用地 | 61.48 | 61.67 | 63.55 | 63.80 | 62.40 | 63.44 |
| 平均交并比 | 51.95 | 52.39 | 53.72 | 54.17 | 53.93 | 54.17 |