Crafting Distribution Shifts for Validation and Training in Single Source Domain Generalization
为单源域泛化中的验证和训练构建分布偏移
Abstract
摘要
Single-source domain generalization attempts to learn a model on a source domain and deploy it to unseen target domains. Limiting access only to source domain data imposes two key challenges – how to train a model that can generalize and how to verify that it does. The standard practice of validation on the training distribution does not accurately reflect the model’s generalization ability, while validation on the test distribution is a malpractice to avoid. In this work, we construct an independent validation set by transforming source domain images with a comprehensive list of augmentations, covering a broad spectrum of potential distribution shifts in target domains. We demonstrate a high correlation between validation and test performance for multiple methods and across various datasets. The proposed validation achieves a relative accuracy improvement over the standard validation equal to $15.4%$ or $1.6%$ when used for method selection or learning rate tuning, respectively.
单源域泛化旨在利用源域数据训练模型并部署到未知目标域。仅依赖源域数据带来两大挑战——如何训练具备泛化能力的模型,以及如何验证其泛化效果。传统基于训练分布的验证方法无法准确反映模型泛化能力,而直接使用测试分布验证则属于不当实践。本研究通过应用涵盖目标域潜在分布偏移的全面增强策略转换源域图像,构建独立验证集。实验表明,该方法在多种算法和数据集上均实现验证性能与测试性能的高度相关性。当用于算法选择或学习率调优时,所提验证方案相比标准验证分别带来15.4%和1.6%的相对准确率提升。
Furthermore, we introduce a novel family of methods that increase the shape bias through enhanced edge maps. To benefit from the augmentations during training and preserve the independence of the validation set, a $k$ -fold validation process is designed to separate the augmentation types used in training and validation. The method that achieves the best performance on the augmented validation is selected from the proposed family. It achieves state-of-the-art performance on various standard benchmarks. Code at: github.com/NikosEfth/crafting-shifts
此外,我们提出了一种通过增强边缘图来提高形状偏差的新方法系列。为了在训练过程中受益于增强并保持验证集的独立性,设计了一个$k$折验证流程来分离训练和验证中使用的增强类型。从提出的方法系列中选出在增强验证集上表现最佳的方法,该方法在各种标准基准测试中实现了最先进的性能。代码位于:https://github.com/NikosEfth/crafting-shifts
1. Introduction
1. 引言
Visual recognition models are primarily trained using data from one or multiple source domains, typically the richest in labeled data or the only available domains during training. The ability of a visual recognition model to generalize or adapt to novel target domains with no or limited labeled data is a desirable property. The literature explores such generalization and adaptation under various setups [9, 59]. Supervised domain adaptation refers to cases where labeled examples from the target domain are available, while unsupervised domain adaptation deals with unlabeled examples. The task is called domain generalization when there is a complete lack of target domain examples. Depending on whether there is a single or multiple source domains, the task is categorized as single-source domain generalization (SSDG) or multi-source domain generalization (MSDG), respectively.
视觉识别模型主要使用来自一个或多个源域的数据进行训练,这些域通常是标注数据最丰富或在训练期间唯一可用的领域。视觉识别模型在目标域标注数据缺失或有限的情况下,仍能泛化或适应新领域的能力是一个重要特性。文献[9, 59]探讨了不同设定下的泛化与适应问题:当目标域存在标注样本时称为监督域适应 (supervised domain adaptation),仅有无标注样本时称为无监督域适应 (unsupervised domain adaptation)。若完全缺乏目标域样本,则称为域泛化 (domain generalization)。根据源域数量差异,该任务进一步划分为单源域泛化 (SSDG) 和多源域泛化 (MSDG)。
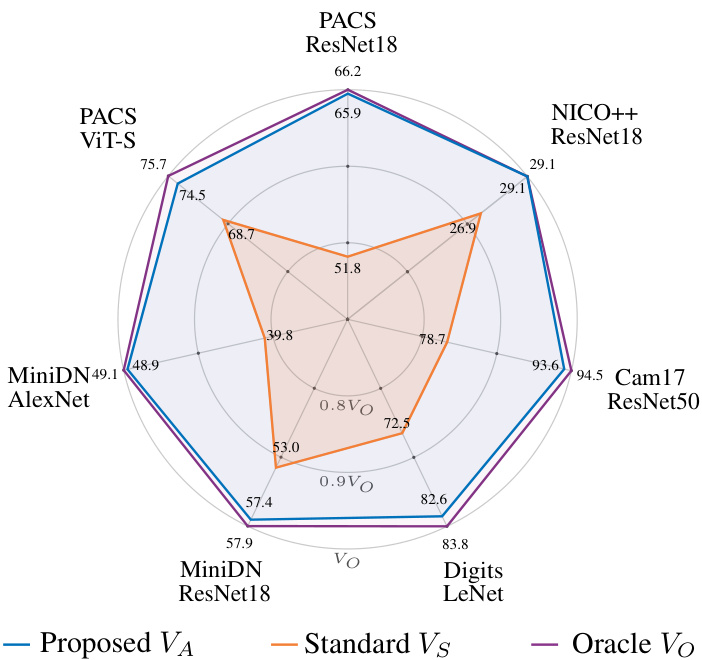
Figure 1. Test accuracy comparison of different validation methods across seven dataset-backbone configurations. Each axis ranges from $70%$ to $100%$ of the oracle validation $V_{O}$ that assumes access to the test set. The proposed augmented validation $V_{A}$ achieves over $98%$ of the oracle performance on average, representing a $\mathbf{15.4%}$ relevant improvement over the standard validation $V_{S}$ . For each dataset, the model is chosen from a pool, with 4, 500 trained models across all pools.
图 1: 七种数据集-主干网络配置下不同验证方法的测试准确率对比。各坐标轴范围从预言机验证 (oracle validation) $V_{O}$ (假设可访问测试集) 的 $70%$ 到 $100%$。提出的增强验证 $V_{A}$ 平均达到预言机性能的 $98%$ 以上,相较于标准验证 $V_{S}$ 实现了 $\mathbf{15.4%}$ 的相关提升。每个数据集的模型均从包含 4,500 个训练模型的候选池中选出。
The lack of labeled target domain examples is a challenging factor for performing both model validation, i.e., estimating a model’s accuracy to tune its hyper-parameters, and method selection, i.e., evaluating which method is the best. This often leads to oracle-based validation, where access to the test set is incorrectly assumed. This aspect is investigated in the work of Musgrave et al. [44] for unsupervised domain adaptation and in Gulrajani et al. [24] for MSDG, where proper validation protocols are suggested to avoid malpractice. In the context of MSDG, vanilla training on the source domains is top-performing [24] when methods are tested on datasets they were not designed for. Therefore, effective method selection processes are of paramount importance in practice.
缺乏标记的目标域样本是进行模型验证(即估计模型准确性以调整其超参数)和方法选择(即评估哪种方法最优)时面临的挑战因素。这常导致基于测试集的错误验证方式,即不当假设可直接访问测试集。Musgrave等人[44]针对无监督域适应以及Gulrajani等人[24]针对多源域泛化(MSDG)的研究探讨了这一问题,并提出了避免误用的规范验证方案。在MSDG场景下,当方法在非设计目标数据集上测试时,直接在源域进行常规训练的表现最优[24]。因此,实践中建立有效的方法选择流程至关重要。

Figure 2. “Hummingbird” in four different domains. The domain generalization task tacitly assumes domains that share informative, human-understandable features, such as texture, shape, or semantics. Therefore, the unseen domains are expected to be humanrecognizable. Images from ImageNet [14] and ImageNet-R [27]
图 2: 四个不同领域的"蜂鸟"。领域泛化任务默认假设这些领域共享具有信息量且人类可理解的特征,如纹理、形状或语义。因此,未见过的领域预期也能被人类识别。图片来自ImageNet [14]和ImageNet-R [27]
In the context of SSDG, developing a visual recognition model robust to unseen distribution shifts during test time is the most challenging of the tasks above. Due to the absence of a proper validation set and protocol, practitioners need to rely on educated guesses to enhance the general iz ability of their models. Without an effective validation protocol, it becomes impossible to determine the effectiveness of any model enhancement. To our knowledge, no prior work studies validation protocols in SSDG.
在SSDG背景下,开发一个对测试期间未见分布偏移具有鲁棒性的视觉识别模型是上述任务中最具挑战性的。由于缺乏适当的验证集和协议,实践者需要依靠经验性猜测来提升模型的泛化能力。若没有有效的验证协议,将无法判定任何模型增强措施的有效性。据我们所知,此前尚无研究探讨SSDG中的验证协议。
In this work, we follow a fundamental direction in the generalization task, i.e., data augmentations, to synthesize new distributions. The effect of data augmentations is studied extensively in the context of domain generalization, both in combination with adversarial learning [55, 58] and standalone [8, 61]. However, in prior work, augmentations were exclusively used to extend the training set in size and variability. Instead, we apply them to source domain images to obtain a validation set with increased variability and estimate the method’s performance on unseen distributions. We argue that exploiting an exhaustive list of existing augmentations synthesizes instances that span various human-recognizable domains. These augmentations preserve human-recognisable features by their design, while the attempt for completeness ensures the coverage of several unseen potential domains (Figure 2). Since these augmentations are also valuable in the training phase, we propose a $k$ -fold cross-validation scheme performed across augmentation types to get the best of both worlds. This way, the training set is augmented with challenging examples while, at the same time, the validation provides an unbiased estimate of performance on unseen distributions. Using the proposed validation for model selection and hyper-parameter tuning, we achieve better performance than the standard practice on various datasets (see Figure 1).
在本工作中,我们遵循泛化任务的一个基本方向,即数据增强 (data augmentation) 来合成新分布。数据增强的效果在领域泛化 (domain generalization) 背景下被广泛研究,既有与对抗学习 (adversarial learning) [55, 58] 结合的方式,也有独立使用的情况 [8, 61]。然而,在先前的工作中,增强仅用于扩展训练集的规模和多样性。相反,我们将其应用于源域图像,以获得具有更高多样性的验证集,并估计方法在未见分布上的性能。我们认为,利用现有增强技术的详尽列表可以合成跨越各种人类可识别领域的实例。这些增强技术通过设计保留了人类可识别的特征,而对完整性的尝试确保了对多个未见潜在领域的覆盖 (图 2)。由于这些增强在训练阶段也很有价值,我们提出了一种跨增强类型执行的 $k$ 折交叉验证方案,以兼顾两者。这样,训练集通过具有挑战性的示例得到增强,同时验证提供了对未见分布性能的无偏估计。使用所提出的验证方法进行模型选择和超参数调优,我们在多个数据集上实现了比标准实践更好的性能 (见图 1)。
Besides the novel validation method for SSDG, we propose a family of classification methods para met rize d by several train and test-time hyper-parameters. The values of these parameters are selected by the proposed validation method. We focus on enforcing shape bias [19], whose effec ti ve ness is demonstrated in prior work [25, 46, 47]. We accomplish this by using a specialized image transformation technique, employing enhanced edge maps that eliminate textures while retaining crucial shape information. The transformation is performed both during training and testing, with and without random iz ation, respectively. Despite its simplicity, the proposed method sets a new state-of-the-art on multiple benchmarks, highlighting the value of pronounced shape information and exhaustive augmentations, as well as the effectiveness of the proposed validation (see Figure 4).
除了针对SSDG的新型验证方法外,我们提出了一系列由多个训练和测试时超参数参数化的分类方法。这些参数的值通过所提出的验证方法进行选择。我们专注于强化形状偏差 [19],其有效性已在先前工作中得到验证 [25, 46, 47]。为此,我们采用了一种专门的图像变换技术,利用增强的边缘图消除纹理同时保留关键形状信息。该变换在训练和测试阶段分别以随机化和非随机化方式执行。尽管方法简单,但所提出的方案在多个基准测试中创造了新的最先进水平,凸显了显著形状信息和详尽数据增强的价值,以及所提出验证方法的有效性 (见图4)。
2. Related work
2. 相关工作
We review the prior work on MSDG and SSDG, a less explored task, and discuss shape bias methods in domain generalization and prior work on augmentation strategies.
我们回顾了关于MSDG和SSDG这一较少被探索任务的前期工作,并讨论了领域泛化中的形状偏差方法以及数据增强策略的相关研究。
Multi-source domain generalization. Domain-invariant feature learning is the most popular family of approaches, originating from the results of Ben-David et al. [1]: The upper bound of the target domain error is a function of the disc rim inability between the source and target domain in the feature space. Many follow-up methods exist in the MSDG literature, such as kernel-based approaches [43] or multi-task auto encoders [21]. Ganin et al. [18] and Li et al. [38] perform adversarial learning to match the domain distributions. Kim et al. [30] propose bringing the same-class representations closer regardless of domain. Li et al. [37] encourage domain invariance by mixing domain-specific network components with domain-agnostic ones.
多源域泛化。域不变特征学习是最流行的方法类别,源于Ben-David等人[1]的研究成果:目标域误差的上界是特征空间中源域与目标域不可分辨性的函数。MSDG文献中存在许多后续方法,例如基于核的方法[43]或多任务自动编码器[21]。Ganin等人[18]和Li等人[38]通过对抗学习来匹配域分布。Kim等人[30]提出使同类表征更接近,而不考虑域。Li等人[37]通过混合特定域网络组件与域无关组件来促进域不变性。
The use of data augmentations during training is another common approach. Zhou et al. [66] synthesize new examples from pseudo-novel domains conditioned on existing examples while enforcing semantic consistency. Styli z ation using images from different domains as styles is a simple but effective approach in the work of Somavarapu et al. [54], while Mancini et al. [41] use mixup [64] to combine different source domains. Carlucci et al. [3] additionally optimize the classification loss to train a model that solves jigsaw puzzles in a self-supervised manner. Mansilla et al. [42] identify and control domain-specific conflicting gradients.
训练中使用数据增强是另一种常见方法。Zhou等人[66]通过基于现有样本生成伪新域样本并保持语义一致性来合成新样本。Somavarapu等人[54]采用跨域图像风格化的简单有效方法,而Mancini等人[41]则利用mixup[64]混合不同源域。Carlucci等人[3]额外优化分类损失以训练自监督拼图模型。Mansilla等人[42]识别并控制特定域冲突梯度。
Regarding generalization in real-world domain shifts, two popular benchmarks exist for MSDG: iWildCam [31] and ${\mathrm{NICO}}{+}{+}$ [65]. In iWildCam, a tiny fraction of all classes are seen in each domain, making this benchmark unsuitable for SSDG. $\mathrm{NICO}{+}{+}$ , on the other hand, consists of real photographs taken in different conditions and is suitable for SSDG. We repurpose it for our task to demonstrate that both the proposed method and validation protocol improve under real-world domain shifts.
关于现实领域偏移中的泛化问题,目前存在两个针对MSDG的常用基准测试:iWildCam [31]和${\mathrm{NICO}}{+}{+}$[65]。在iWildCam中,每个领域仅出现所有类别中的极小部分,这使得该基准不适用于SSDG。而$\mathrm{NICO}{+}{+}$由不同条件下拍摄的真实照片组成,适用于SSDG。我们将其调整用于当前任务,以证明所提方法和验证协议在现实领域偏移下均能实现改进。
Single-source domain generalization. Most existing SSDG methods rely on data augmentation or data generation. Volpi et al. [55] generate hard examples from an imaginary target domain, while Yue et al. [62] use style transfer to produce images of novel styles. Qiao et al. [51] use adversarial domain augmentation and an auxiliary Wasser stein autoencoder to force semantic consistency between the augmented and original images in the latent space. Xu et al. [61] propose random convolutions as an augmentation technique to diversify the training data. Wang et al. [58] propose a style-complement module to transform training examples in a way that is complementary to the source domain. A Fourier-based augmentation mixing the amplitude of two images is proposed by Xu et al. [60], who assume that the Fourier phase is not easily affected by domain shifts. Wan et al. [56] target domain invariance through a decomposition and composition technique that builds on the bag-of-words model. Lee et al. [34] use a distillation approach by creating an ensemble prediction from images of the same class and penalizing the mismatched outputs with the ensemble. Chen et al. [6] propose a center-aware adversarial augmentation that enriches the training samples by pushing them away from the class centers using an angular center loss. Chen et al. [5] use a learnable consistency loss for test-time adaptation, and they introduce additional adaptive parameters during the test phase. Chen et al. [4] propose a new learning paradigm for training with domain shifts by employing meta-causal learning to simulate a domain shift, analyze its causes, and reduce it. Choi et al. [8] enhance the idea of random convolution by recursively stacking ones with small kernel sizes, deformable offsets, and affine transformations.
单源域泛化。现有大多数SSDG方法依赖于数据增强或数据生成技术。Volpi等人[55]通过虚构目标域生成困难样本,而Yue等人[62]采用风格迁移技术生成新风格图像。Qiao等人[51]结合对抗性域增强与辅助Wasserstein自编码器,强制增强图像与原始图像在潜在空间保持语义一致性。Xu等人[61]提出随机卷积作为增强技术以提升训练数据多样性。Wang等人[58]设计风格互补模块,以与源域形成互补的方式转换训练样本。Xu等人[60]提出基于傅里叶的增强方法,通过混合两幅图像的振幅分量(假设傅里叶相位不易受域偏移影响)。Wan等人[56]基于词袋模型提出分解-组合技术来实现域不变性。Lee等人[34]采用蒸馏方法,通过同类图像集成预测并对不匹配输出进行惩罚。Chen等人[6]提出中心感知对抗增强,利用角度中心损失使训练样本远离类中心。Chen等人[5]在测试阶段引入可学习的一致性损失和自适应参数。Chen等人[4]通过元因果学习模拟域偏移、分析成因并降低影响,提出新的域偏移训练范式。Choi等人[8]通过递归堆叠小核卷积、可变形偏移和仿射变换来增强随机卷积思想。
Shape bias. Geirhos et al. [19] show that, in contrast to human subjects, CNNs trained on ImageNet are biased to focus on textures and mitigate that by training on a stylized version of ImageNet. SagNet [45] disentangles style encodings from class categories to prevent style bias and to focus more on object shapes. Edge detection as a bridge between domains has a prominent role, such as in the work of Harary et al. [25], who target few-shot learning and rely on domain labels. Another example is the work of Nazari and Kovashka [47], where edge detection forms a fixed augmentation used both for training and testing. Our work has similarities but also differences. Namely, we use improved shape representations, while our method uses a single backbone instead of one backbone for images and one for edge maps. The superiority of this choice is experimentally validated. Narayanan et al. [46] argue that the shock graph of the contour map of an image is a complete representation of its shape content. As a drawback, the high cost of their approach does not allow pre-training on ImageNet, and any corresponding performance gain is lost.
形状偏差 (Shape bias)。Geirhos等人[19]指出,与人类受试者不同,在ImageNet上训练的CNN倾向于关注纹理特征,他们通过使用风格化版本的ImageNet进行训练来缓解这一问题。SagNet[45]通过解耦风格编码与类别标签来防止风格偏差,使模型更关注物体形状。边缘检测作为跨域桥梁具有重要作用,例如Harary等人[25]针对少样本学习场景、依赖域标签的工作。另一个案例是Nazari和Kovashka[47]的研究,他们将边缘检测作为固定增强方法同时应用于训练和测试阶段。我们的工作既有相似之处也存在差异:我们采用改进的形状表征方法,且仅使用单一骨干网络(而非图像和边缘图分别使用不同骨干网络),这一选择的优越性已通过实验验证。Narayanan等人[46]认为图像轮廓图的冲击图(shock graph)能完整表征其形状内容,但该方法计算成本过高,无法在ImageNet上进行预训练,因而丧失了相应的性能提升空间。
Augmentation strategies. Various data augmentation techniques exist to enhance model performance. Common practices include flipping and cropping [26], occlusion (Cutout) [13], segment replacement (CutMix) [63], or element-wise convex combination of images (Mixup) [64]. Learned approaches, like Auto Augment [10], tune an augmentation set to optimize the performance of downstream tasks. Alternatively, Patch Gaussian [23] applies Gaussian noise to random image portions as an augmentation. AugMix [28] combines randomly generated augmentations while ensuring consistency through a Jensen-Shannon loss. In this work, we randomly sample augmentations from a single library to avoid introducing bias by tailoring the selection to specific datasets. Nevertheless, the above strategies can be orthogonal ly used with the proposed augmented validation protocol.
数据增强策略。现有多种数据增强技术可提升模型性能,常见方法包括翻转裁剪[26]、遮挡(Cutout)[13]、片段替换(CutMix)[63]或图像元素级凸组合(Mixup)[64]。Auto Augment[10]等学习方法通过调优增强集来优化下游任务性能。Patch Gaussian[23]则对随机图像区域施加高斯噪声作为增强手段。AugMix[28]通过Jensen-Shannon损失保证一致性的同时,组合随机生成的增强操作。本研究为避免针对特定数据集定制选择而引入偏差,采用从单一库中随机采样增强方案。值得注意的是,上述策略均可与本文提出的增强验证方案正交使用。
3. Training, validation and testing in SSDG
3. SSDG中的训练、验证与测试
SSDG training is performed on a source domain, and the model is tested on an unseen target domain. The same categories are to be recognized in both source and target domains, i.e., the label spaces are identical. The input space of the source and target domain are RGB images, but their distributions differ. The goal is to perform training so the model can generalize to the target domain. A validation set is necessary but can only be constructed from images of the source domain. Nevertheless, using the raw images is unlikely to reflect any generalization ability in the validation.
SSDG训练在源域上进行,模型在未见过的目标域上进行测试。源域和目标域需要识别的类别相同,即标签空间一致。源域和目标域的输入空间均为RGB图像,但它们的分布不同。目标是进行训练,使模型能够泛化到目标域。验证集是必要的,但只能从源域图像构建。然而,使用原始图像不太可能在验证中反映任何泛化能力。
To evaluate the generalization capabilities of a model, we introduce the concept of an augmented validation set. In contrast to the well-established practice of using a small set of domain-appropriate augmentations to training images, a wide range of augmentations are drawn from an exhaustive list of existing techniques. This validation set is used in conjunction with the proposed SSDG method, whose key component is the direct injection of shape information in the training procedure. The augmentations used for the validation set are also optionally used in the training. In that case, a two-fold cross-validation process over the augmentation groups is proposed to ensure the validation is performed on a previously unseen distribution.
为了评估模型的泛化能力,我们引入了增强验证集的概念。与现有采用少量领域适配增强方法处理训练图像的常规做法不同,我们从现有技术清单中广泛选取各类增强方法。该验证集与提出的SSDG方法配合使用,其核心是在训练过程中直接注入形状信息。验证集采用的增强方法也可选择性地用于训练阶段。在此情况下,我们提出对增强组进行双重交叉验证,以确保验证过程在未见过的数据分布上执行。
During the testing phase, two possible approaches are explored. The first performs classification on the input image alone. The second leverages both the input image and its corresponding shape information – the weighted average of the predictions from both inputs is used (see Figure 3).
在测试阶段,我们探索了两种可能的方法。第一种仅对输入图像进行分类。第二种同时利用输入图像及其对应的形状信息——采用两种输入预测结果的加权平均值 (参见图 3)。
3.1. Proposed validation set
3.1. 提出的验证集
Motivation: Proper validation is crucial for effective model selection and hyper parameter tuning in any machine learning task, including SSDG. In the context of SSDG, the standard practice is to employ a validation set from raw images of the source domain. However, this validation set alone cannot accurately reflect the model’s generalization performance across other domains. As a result, methods that perform well in the source domain are favored by such a process. We introduce a synthetic distribution shift by manipulating the validation set of the source domain to evaluate performance under a distribution shift. This allows us to emulate the challenges posed by domain shifts and obtain a more realistic assessment of the model’s generalization capabilities. To capture the generalization performance across multiple domains, we heavily rely on existing image augmentations. Specifically, we incorporate a wide range of diverse augmentations into our approach, aiming to cover as many variations as possible.
动机:在任何机器学习任务(包括SSDG)中,正确的验证对于模型选择和超参数调优至关重要。在SSDG背景下,标准做法是使用源域原始图像构建验证集。然而仅凭该验证集无法准确反映模型在其他域上的泛化性能,这会导致在此过程中偏向于在源域表现良好的方法。我们通过对源域验证集施加合成分布偏移来评估模型在分布变化下的性能,从而模拟域偏移带来的挑战,获得更真实的模型泛化能力评估。为捕捉跨多域的泛化性能,我们深度依赖现有图像增强技术,具体而言是在方法中整合多样化的增强策略,力求覆盖尽可能多的变异情况。
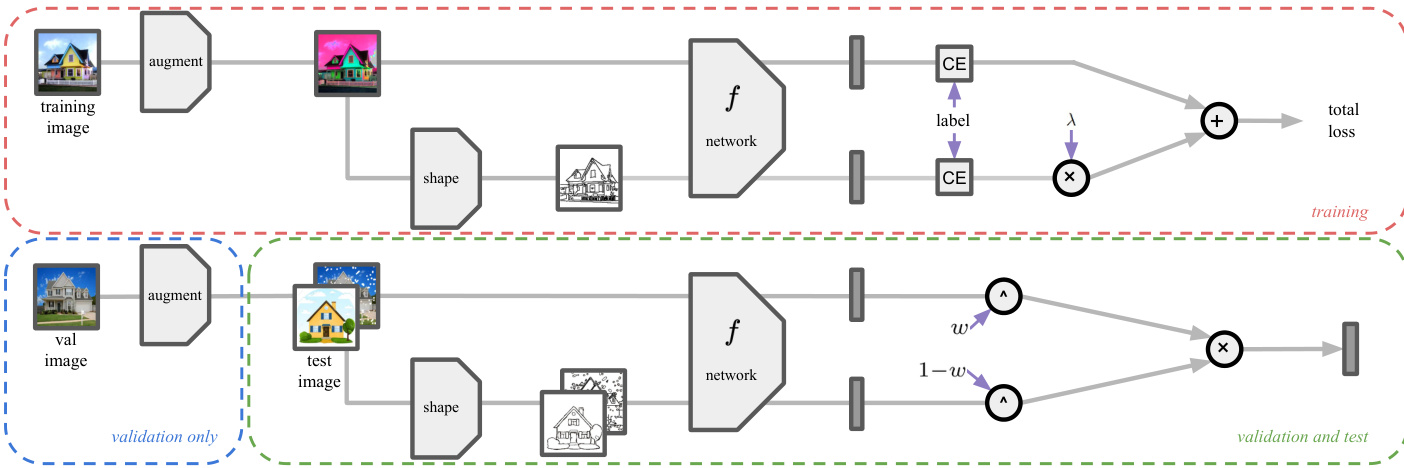
Figure 3. Overview of the training, validation, and testing pipeline. Training images are augmented with basic and a sub-set of extra augmentations. The shape information, encoded as binary thin edges of the augmented image, generates an additional training example. The contribution of the two losses, image and shape-based, is weighed by a parameter λ. In validation, extra augmentations that were not included in the training are used to synthesize unseen distributions. The shape information is optionally exploited in testing and in the validation phase. The final prediction is obtained by ensembling the image and the shape-based predictions, weighted by a parameter $w$ .
图 3: 训练、验证和测试流程概览。训练图像通过基础增强和部分额外增强进行数据扩充。以二值化细边缘编码的形状信息会生成额外训练样本。图像损失和形状损失通过参数 λ 进行加权。验证阶段使用训练未涉及的额外增强来合成未见数据分布。测试和验证阶段可选择性利用形状信息。最终预测通过参数 $w$ 加权集成图像预测和形状预测获得。
Variants: The following constructions of the validation set are considered and compared.
变体:考虑并比较了以下验证集的构建方式。
• Oracle - $V_{O}$ : The Oracle validation set is equivalent to the test set. In the case of multiple test sets, their union is considered. In this work, oracle validation is never used to compare performance with prior approaches. It is only used as an upper bound on method performance and to measure how close the results achieved with the proposed validation set/method are to the best possible. Standard - $V_{S}$ : This validation set consists of raw images from the source domain. In this case, there is no distribution shift between the training and validation sets. It is also referred to as the standard validation set and is equivalent to validation on the training distribution. • Augmented - $V_{A}$ : A total of 76 different augmentations organized into 10 groups according to their types are used to alter the images. Each image in the standard validation set $V_{S}$ is augmented 10 times by one random augmentation per group, resulting in a validation set 10 times larger than $V_{S}$ . This augmented validation set is created once. The same set is used in all experiments for $V_{A}$ . The ImgAug1 library is utilized with all its implemented augmentations and category groups. We refer to these as extra augmentations to differentiate them from the basic augmentations (random crop, scale, and flip).
• Oracle - $V_{O}$: Oracle验证集等同于测试集。若存在多个测试集,则取其并集。本工作中,oracle验证仅用作方法性能的上限参考,用于衡量所提验证集/方法的结果与最优可能值的接近程度,不用于与现有方法的性能比较。
• Standard - $V_{S}$: 该验证集由源域原始图像组成,训练集与验证集间无分布偏移。亦称标准验证集,等同于对训练分布的验证。
• Augmented - $V_{A}$: 使用76种按类型分组的增强方法对图像进行变换。标准验证集$V_{S}$中每张图像通过每组随机选取一种增强生成10次增强结果,最终得到规模为$V_{S}$10倍的验证集。该增强验证集为一次性生成,所有实验中$V_{A}$均使用同一集合。采用ImgAug1库实现全部增强方法及类别分组(与基础增强(随机裁剪、缩放、翻转)区分,称为额外增强)。
3.2. Proposed recognition method
3.2. 提出的识别方法
Motivation: The proposed family of methods builds upon previous findings that highlight the texture bias in CNNs [19]. Since CNNs primarily capture texture cues during the training, their performance tends to suffer when confronted with domains lacking these texture cues. To address this limitation, we introduce an explicit enhancement of the shape bias by incorporating shape information extracted from the images in the form of edges. Shape is a fundamental characteristic across multiple domains, making it valuable for bridging the domain gap. By using edge detection, we enable the mapping of objects to a common domain. The shape information is used both during training and testing to reinforce this bridging effect. The parameters mixing the image and shape information are tuned according to the augmented validation.
动机:本文提出的方法系列基于先前关于卷积神经网络(CNN)纹理偏置的研究发现[19]。由于CNN在训练过程中主要捕捉纹理线索,当面对缺乏这些纹理线索的领域时,其性能往往会受到影响。为解决这一局限,我们通过以边缘形式从图像中提取形状信息,显式增强形状偏置。形状是跨多个领域的基本特征,对于弥合领域差距具有重要价值。通过边缘检测技术,我们实现了将对象映射到公共领域。在训练和测试阶段均利用形状信息来强化这种桥梁效应。混合图像与形状信息的参数根据增强验证进行调整。
We additionally investigate the effect of using the extra augmentations during training. Overlap between training and validation distributions may result in overestimating the expected performance due to validation on a seen distribution. To avoid this, the training and validation augmentation groups are kept disjointed via a two-fold validation process. Network architecture: A standard backbone taking an RGB image as input followed by a linear classifier providing a class probability at the output is employed. In our experiments, AlexNet [32], ResNet [26], and ViT [15] are used.
我们进一步研究了训练期间使用额外数据增强的效果。训练集与验证集分布的重叠可能导致在已见分布上验证时高估预期性能。为避免这种情况,通过双折验证流程保持训练组与验证组增强策略互斥。网络架构:采用标准主干网络(以RGB图像为输入)接线性分类器(输出类别概率)的结构。实验中使用了AlexNet [32]、ResNet [26]和ViT [15]。
Shape extraction: To obtain an explicit shape representation, a modified version of the binary thin edges (BTE) [16] is used. BTE maps the input image to a binary edge map. Edges are extracted by the Sobel operator instead of the learned edge detectors used in [16]. Detected edges are further processed by thinning, hysteresis with an adaptive threshold, and removing small connected components. During training, shape variation is achieved with randomized geometric augmentation and random iz ation of the thresholding process. B inari z ation provides a form of cleaning shape-irrelevant information, typically corresponding to background.
形状提取:为获得显式形状表示,采用改进版二值化细边缘(BTE)[16]算法。BTE将输入图像映射为二值边缘图,通过Sobel算子(而非原论文[16]使用的学习式边缘检测器)提取边缘。检测到的边缘经过细化处理、自适应阈值滞后和移除小型连通区域。训练阶段通过随机几何增强和阈值过程的随机化实现形状变异。二值化可清除与形状无关的信息(通常对应背景)。
Training augmentations: Basic augmentations (random crop, scale, and flip) are used in all our experiments. When the extra augmentations are used in training, each input image is transformed with at most one randomly sampled extra augmentation performed before the basic augmentations.
训练增强:所有实验均采用基础增强(随机裁剪、缩放和翻转)。当训练中使用额外增强时,每张输入图像在基础增强前最多应用一种随机采样的额外增强变换。
Training variants: A family of methods is proposed and experimentally evaluated. The network is always trained with cross-entropy loss, while the network input during the training phase varies.
训练变体:提出并实验评估了一系列方法。网络始终采用交叉熵损失进行训练,而训练阶段的网络输入则有所不同。
Testing variants: The following variants of the network input during test time are considered.
测试变体:考虑以下网络输入在测试时的变体。
$I$ : Testing baseline - testing is performed on the input images of the target domain. • $S$ : Testing is performed on BTEs of the target domain. $I S$ : Testing is performed on both images and BTEs of the target domain. Let’s denote by $p_{I}$ and $p_{S}$ the probability of a particular class based on the input image and BTE, respectively. The combined response is given by their geometric mean Iw p(S1−w), with w ∈ [0, 1]. This is a generalized approach that reduces to testing solely on $I$ or $S$ for $w=1$ or $w=0$ , respectively. When reporting the value of $w$ , we denote this variant by $I^{w}{S}$ for brevity. • $I S_{\times2}$ : Both backbones, each with the corresponding input, are used for testing, which aims to form a more costly approach for the experimental comparisons.
$I$: 测试基线 - 在目标域的输入图像上进行测试。
$S$: 在目标域的 BTE (Back-Translated Examples) 上进行测试。
$I S$: 在目标域的图像和 BTE 上同时进行测试。
设 $p_{I}$ 和 $p_{S}$ 分别表示基于输入图像和 BTE 的特定类别的概率。组合响应由它们的几何均值 $I^w S^{1-w}$ 给出,其中 $w \in [0, 1]$。这是一种广义方法,当 $w=1$ 或 $w=0$ 时,分别简化为仅在 $I$ 或 $S$ 上测试。在报告 $w$ 的值时,为简洁起见,我们将此变体表示为 $I^{w} S$。
$I S_{\times2}$: 使用两个主干网络(每个对应各自的输入)进行测试,旨在为实验对比构建一种成本更高的方法。
Training-testing combinations: The training-testing combinations are denoted by $A\rightarrow B$ for training with variant $A$ and testing with variant $B$ . The baseline method that trains on source domain images (training baseline) and tests on target domain images (testing baseline) is denoted as $I\to I$ . In principle, all combinations are possible since there is no testing constraint, only on inputs during training. Nevertheless, we mostly focus on the following: $\bar{I}\to\overline{{I}},S\to S.$ , $I S\rightarrow I S$ , ${\hat{I}S}{\rightarrow I}{\dot{S}}$ , and $I S_{\times2}{\rightarrow}I S_{\times2}$ . An overview of our training, validation, and testing process is shown in Figure 3. Two-fold cross-validation over augmentation groups: Training with the extra augmentations, i.e., $\hat{I}$ variants, which are used for the validation set, also invalidates the concept of validating on unseen distributions. Therefore, we propose a two-fold cross-validation (TCV) protocol. That is, to train using half of the augmentation groups while keeping the rest to create the validation set. This process is repeated twice, once for each half used in training, and the validation performance is the average of the two runs for a particular variant or value of a hyper parameter. During the final stage, the network is trained with the chosen hyper-parameters using all available augmentations.
训练-测试组合:训练-测试组合用 $A\rightarrow B$ 表示,其中 $A$ 为训练变体,$B$ 为测试变体。在源域图像上训练(训练基线)并在目标域图像上测试(测试基线)的基准方法记为 $I\to I$。由于训练阶段仅对输入有限制而测试无约束,理论上所有组合均可行。但我们主要关注以下组合:$\bar{I}\to\overline{{I}},S\to S.$、$I S\rightarrow I S$、${\hat{I}S}{\rightarrow I}{\dot{S}}$ 以及 $I S_{\times2}{\rightarrow}I S_{\times2}$。图3展示了训练、验证和测试流程的概览。
基于增强组的两折交叉验证:使用额外增强(即验证集采用的 $\hat{I}$ 变体)进行训练时,会破坏"在未见分布上验证"的概念。为此,我们提出两折交叉验证(TCV)方案:用半数增强组进行训练,剩余组构建验证集。该过程重复两次(每次交换训练/验证组),最终验证性能取特定变体或超参值的两次运行平均值。最终阶段使用选定超参和全部可用增强重新训练网络。
4. Experiments
4. 实验
4.1. Experimental setup and implementation
4.1. 实验设置与实现
The proposed validation and classification methods are evaluated on five datasets, namely Digits [12, 17, 33, 48], PACS [36], Mini-DomainNet [50], $\mathrm{NICO}{+}{+}$ [65], and Camelyon17 [2]. The classifier performance is measured by classification accuracy. Digits is composed of five different datasets, namely MNIST [33], SVHN [48], MNIST- M [17], SYN [17], and USPS [12], each one corresponding to a different domain. PACS is a domain generalization dataset with four domains: photo, art paintings, cartoon, and sketch. Mini-DomainNet is a subset of the domain generalization dataset DomainNet [50]. It consists of four domains: clipart, painting, real, and sketch. $\mathrm{NICO++}$ consists of natural images, with domains defined as the context: autumn, dim light, grass, outdoor, rock, and water. Camelyon17 is a medical tumor detection dataset, and the domains are defined by the five different hospitals that provided the data. We follow the setup of [7] and train on hospitals 1, 2, and 3 without using the domain labels, while we test on hospitals 4 and 5. The source domain is set to be MNIST, photos, and real for Digits, PACS, and Mini-DomainNet, respectively. We are the first to work on SSDG with $\mathrm{NICO}{+}{+}$ , where we treat each domain as a source domain and the five others as target domains.
所提出的验证和分类方法在五个数据集上进行了评估,分别是Digits [12, 17, 33, 48]、PACS [36]、Mini-DomainNet [50]、$\mathrm{NICO}{+}{+}$ [65]和Camelyon17 [2]。分类器性能通过分类准确率衡量。Digits由五个不同数据集组成,分别是MNIST [33]、SVHN [48]、MNIST-M [17]、SYN [17]和USPS [12],每个数据集对应一个不同的域。PACS是一个包含四个域的领域泛化数据集:照片、艺术绘画、卡通和素描。Mini-DomainNet是领域泛化数据集DomainNet [50]的子集,包含四个域:剪贴画、绘画、真实和素描。$\mathrm{NICO++}$由自然图像组成,域定义为上下文:秋季、弱光、草地、户外、岩石和水。Camelyon17是一个医学肿瘤检测数据集,域由提供数据的五家不同医院定义。我们遵循[7]的设置,在不使用域标签的情况下对医院1、2和3进行训练,并在医院4和5上进行测试。对于Digits、PACS和Mini-DomainNet,源域分别设置为MNIST、照片和真实。我们是首个在$\mathrm{NICO}{+}{+}$上研究SSDG的工作,将每个域视为源域,其他五个域作为目标域。
We use AlexNet [32], ResNet-18, and ResNet-50 [26] pre-trained on ImageNet-1k [14], and ViT-Small [15] pretrained first on ImageNet-21k [53] and then on ImageNet-1k. The pre-trained networks justify using only photos and real as source domains for PACS and Mini-DomainNet; all other options violate the SSDG protocol since two domains are seen during training. On Digits we use a simple LeNet (convrelu-pool-conv-relu-pool) architecture [3, 55]. On $\mathrm{NICO}{+}{+}$ , following the dataset guidelines, we start with a randomly initialized ResNet-18. Implementation details are included in the Appendix.
我们使用了在ImageNet-1k [14]上预训练的AlexNet [32]、ResNet-18和ResNet-50 [26],以及先在ImageNet-21k [53]预训练再在ImageNet-1k上微调的ViT-Small [15]。这些预训练网络证明仅使用照片和真实数据作为PACS和Mini-DomainNet的源域是合理的;其他选项都违反了SSDG协议,因为训练过程中会看到两个域。在Digits数据集上,我们采用简单的LeNet架构(conv-relu-pool-conv-relu-pool) [3,55]。对于$\mathrm{NICO}{+}{+}$,遵循数据集指南,我们从随机初始化的ResNet-18开始。具体实现细节见附录。
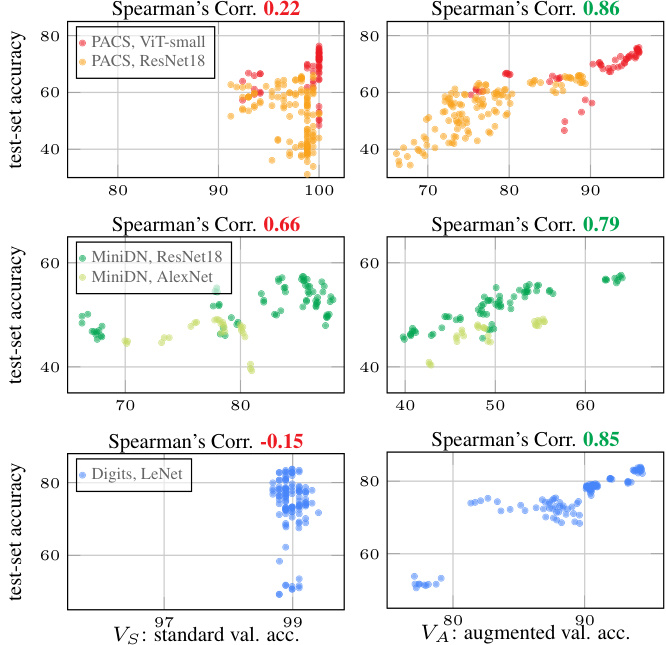
Figure 4. Correlation between validation and test accuracy across the proposed variants. Standard validation $V_{S}$ is performed on the validation set of the source domain, while the proposed augmented validation $V_{A}$ uses images alternated by augmentations unseen during training. Each point represents a different trainingtesting model variant.
图 4: 各变体模型验证集与测试集准确率相关性。标准验证 $V_{S}$ 在源域验证集上进行,而提出的增强验证 $V_{A}$ 使用训练时未见的增强变换图像。每个点代表不同的训练-测试模型变体。
4.2. Prior methods
4.2. 先前方法
Publicly available implementations of SelfReg [30], SagNet [45], L2D [58], and ACVC [11] are used for the comparison of our method with the state-of-the-art. These methods are also used to demonstrate the effectiveness of the proposed validation set on method selection. Implementation details regarding those methods are included in the Appendix.
我们使用公开可用的SelfReg [30]、SagNet [45]、L2D [58]和ACVC [11]实现方案进行方法对比,以验证本方法与当前最优技术的性能差异。这些方法也被用于验证所提验证集在方法选择上的有效性。相关实现细节详见附录。
4.3. Results
4.3. 结果
We perform two types of experiments: (i) to show the effectiveness of the proposed validation method, and (ii) to compare the proposed family of approaches with the stateof-the-art. Our main variant is $\hat{I}\overset{\vartriangle}{S}\to I^{.75}S$ , given that it is the top performing and is the most frequently selected by our validation method.
我们进行了两类实验:(i) 验证所提验证方法的有效性,(ii) 将所提方法族与现有最优方法进行对比。我们的主要变体是 $\hat{I}\overset{\vartriangle}{S}\to I^{.75}S$,因为其性能最优且最常被我们的验证方法选中。
Correlation of validation and test performance. The models of the proposed variants are evaluated on the standard validation set $V_{S}$ , the proposed augmented validation $V_{A}$ , and the test data. To visualize the reliability of predictions based on validation set performance, scatter plots comparing validation versus test performance are shown in Figure 4. Performance on the proposed $V_{A}$ shows a much higher correlation with the test performance. The performance saturation on $V_{S}$ for simple tasks like PACS is a major issue.
验证集与测试集性能相关性分析。所提出变体模型在标准验证集$V_{S}$、增强验证集$V_{A}$及测试数据上进行了评估。为直观展示基于验证集性能预测的可靠性,图4展示了验证集与测试集性能对比的散点图。增强验证集$V_{A}$的性能与测试集表现出更高的相关性。对于PACS这类简单任务,标准验证集$V_{S}$出现的性能饱和现象是主要问题。
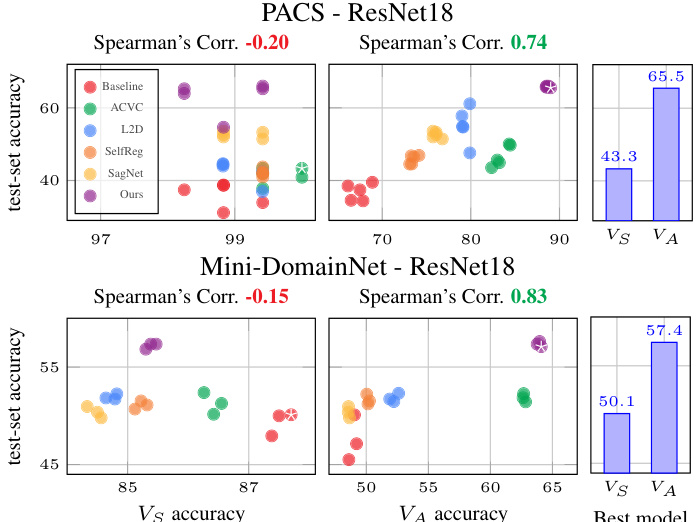
Figure 5. Correlation between validation and test accuracy across literature methods and our main variant ${\hat{I}}S{\rightarrow}I^{{\cdot}75}S$ using standard $V_{S}$ and augmented $V_{A}$ validation set. The best model, according to each validation performance, is marked with a star. The test performance of the best model per validation set is summarized in the bar plot. $V_{A}$ achieves significant test accuracy improvements of 22.2 in PACS and 7.3 in Mini-DomainNet.
图 5: 文献方法与我们的主要变体 ${\hat{I}}S{\rightarrow}I^{{\cdot}75}S$ 在标准验证集 $V_{S}$ 和增强验证集 $V_{A}$ 上的验证准确率与测试准确率相关性。根据各验证性能,最佳模型以星号标注。条形图汇总了各验证集对应最佳模型的测试性能。$V_{A}$ 在PACS中实现22.2、在Mini-DomainNet中实现7.3的显著测试准确率提升。
A similar scatter plot for prior methods, the baseline, and our main variant ${\hat{I}}{\dot{S}}\to I^{.75}S$ is shown in Figure 5. Again, $V_{A}$ delivers better test performance prediction than $V_{S}$ . $V_{S}$ shows a weak negative correlation with the test performance and predicts that most existing methods, including ours, will not surpass the baseline. As such, these methods would never be applied to the target domain in the real world, and we would never know that they work. $V_{A}$ , on the other hand, achieves a strong positive correlation with the test set. The gains in test accuracy of using $V_{A}$ over $V_{S}$ are clearer in the bar plots (right). The performance of ACVC is overestimated by $V_{A}$ ; we speculate this is because the ACVC training uses some of the extra augmentations included in $V_{A}$ . Although we have not modified the ACVC method to fix this issue, the proposed TCV protocol is applicable.
图5展示了现有方法、基线及我们主要变体 ${\hat{I}}{\dot{S}}\to I^{.75}S$ 的类似散点图。同样,$V_{A}$ 比 $V_{S}$ 提供了更好的测试性能预测。$V_{S}$ 与测试性能呈现微弱负相关,并预测包括我们在内的大多数现有方法无法超越基线。因此,这些方法在现实世界中永远不会被应用于目标领域,我们也无从知晓其实际效果。而 $V_{A}$ 则与测试集呈现强正相关性。柱状图(右侧)更清晰地展示了使用 $V_{A}$ 相较于 $V_{S}$ 带来的测试准确率提升。ACVC的性能被 $V_{A}$ 高估,我们推测这是因为ACVC训练使用了 $V_{A}$ 包含的部分额外增强方法。虽然我们未修改ACVC方法来解决此问题,但提出的TCV协议仍适用。
We perform an experiment to highlight the importance of the TCV protocol, i.e., avoiding training and validating on the same pool of augmentations. Figure 6 shows the correlation of the $V_{A}$ validation with the test performance, with and without TCV. Skipping TCV leads to performance over-estimation for methods that use the same extra augmentations for both training and validation. This is a similar effect to what is observed with validating on the training distribution in Figure 4.
我们进行了一项实验以强调TCV协议的重要性,即避免在相同的增强池上进行训练和验证。图6展示了使用和不使用TCV时,$V_{A}$验证与测试性能的相关性。跳过TCV会导致那些在训练和验证中使用相同额外增强的方法出现性能高估现象。这与图4中在训练分布上验证时观察到的效果类似。
Performance gains by better validation. We conduct an experiment for method selection across seven dataset-backbone configurations. The validation process is responsible for tuning the learning rate and selecting the best method out of our variants. More than 4, 500 models are trained for this experiment, which effectively increases to more than 15, 000 when combined with our testing variants. The results are summarised in Figure 1. The test accuracy of the models selected by $V_{A}$ significantly surpasses the performance of the ones chosen by $V_{S}$ for every benchmark. $V_{A}$ achieves more than $98%$ of the oracle performance on average.
通过优化验证带来的性能提升。我们在七种数据集-主干网络配置下进行了方法选择实验。验证过程负责调整学习率并从我们的变体中选择最佳方法。本实验共训练超过4,500个模型,结合测试变体后实际训练量超过15,000次。结果汇总在图1中。由$V_{A}$选出的模型测试准确率在所有基准测试中都显著超越$V_{S}$的选择结果。$V_{A}$平均达到超过98%的理论最优性能。
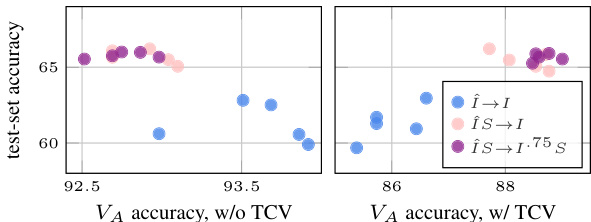
Figure 6. Correlation between validation and test accuracy with or without TCV when using $V_{A}$ as the validation set. The experiment is conducted on PACS using ResNet-18.
图 6: 使用 $V_{A}$ 作为验证集时,采用或不采用 TCV 的验证准确率与测试准确率相关性对比。实验在 PACS 数据集上使用 ResNet-18 完成。
We perform a hyper-parameter tuning experiment, independently tuning the learning rate and the loss weight $\lambda$ We report the performance of the selected models by the two validation processes in Figure 7. The average gain in absolute (relative) test accuracy of $V_{A}$ compared to $V_{S}$ is 1.0 $(1.6%)$ for the learning rate and 2.3 $(3.9%)$ for the weight of the loss. Although $V_{A}$ selects models that perform better in both tuning processes, a higher gain is observed when tuning $\lambda$ , a hyper-parameter related to domain generalization. On the other hand, the impact of a hyper-parameter related to the learning process, i.e., learning rate, is also expected to be reflected on the validation set from the training distribution. Even in this favorable scenario for $V_{S}$ , there is no evidence to support using $V_{S}$ over the proposed $V_{A}$ .
我们进行了超参数调优实验,分别独立调整学习率和损失权重$\lambda$。图7展示了两种验证流程所选模型的性能表现。与$V_{S}$相比,$V_{A}$在测试准确率上的绝对(相对)平均提升分别为:学习率调优带来1.0$(1.6%)$的提升,损失权重调优带来2.3$(3.9%)$的提升。虽然$V_{A}$在两个调优过程中都筛选出性能更优的模型,但在调整与领域泛化相关的超参数$\lambda$时观察到更显著的增益。另一方面,与学习过程相关的超参数(即学习率)的影响,预期也会反映在来自训练分布的验证集上。即便在这种对$V_{S}$有利的场景中,也没有证据支持使用$V_{S}$而非我们提出的$V_{A}$方案。
Impact of components, extra augmentations, and shape usage in training/testing. To study and show the impact of various components of the proposed methods, nine variants are compared in Table 1. The method denoted by $S_{s o b}$ uses a non-binarized Sobel edge map instead of BTE, and the method $\hat{I}_{+B T E}$ uses BTE as an additional extra augmentation applied randomly to some images, as opposed to standard input processing applied to all images.
组件、额外增强和形状使用在训练/测试中的影响。为了研究和展示所提出方法中各个组件的影响,表1比较了九种变体。方法$S_{sob}$使用非二值化的Sobel边缘图替代BTE,而方法$\hat{I}_{+BTE}$将BTE作为随机应用于部分图像的额外增强手段,而非对所有图像采用标准输入处理。
Including shape information during training (var. 2 and 3) gives a noticeable boost in performance across all domains compared to the baseline (var. 1) despite not using shape during testing. Since both images and shapes are processed by the same classifier during training, this is a way to make the network focus on shapes even when the test-time input is only an image. Shape in the form of BTEs (var. 3) contributes much more than the continuous edge maps from the Sobel operator (var. 2), especially in target domains that lack texture information. Additionally, using shape during test time gives a further boost (var. 4). Adding the extra augmentations in training has a positive impact (var. 5 vs. 1, 7 vs. 3, and 8 vs. 4). Using BTE as yet another augmentation type increases the performance (var. 6 vs. 5) but not in the extend of using it on every training image (var. 7 vs. 6) or on test images (var. 8 vs. 6). Lastly, we evaluate the ensemble of two separate networks, one for images and one for shapes. We observe that the single network approach is not only more efficient but also significantly better (var. 9
在训练过程中加入形状信息(变体2和3)相比基线(变体1)在所有领域都带来了显著性能提升,尽管测试阶段并未使用形状数据。由于训练时图像和形状由同一分类器处理,这种方法能使网络在测试输入仅为图像时仍聚焦于形状特征。采用BTE(Binary Tangent Edge)形式表达形状(变体3)的贡献远大于Sobel算子生成的连续边缘图(变体2),在缺乏纹理信息的目标域中尤为明显。此外,测试阶段使用形状数据可带来进一步增益(变体4)。训练时增加额外数据增强具有积极影响(变体5对比1、7对比3、8对比4)。将BTE作为另一种增强类型可提升性能(变体6对比5),但效果不及在每张训练图像(变体7对比6)或测试图像(变体8对比6)上使用BTE。最后,我们评估了由独立图像网络和形状网络组成的集成模型,发现单网络方案不仅效率更高,性能也显著更优(变体9
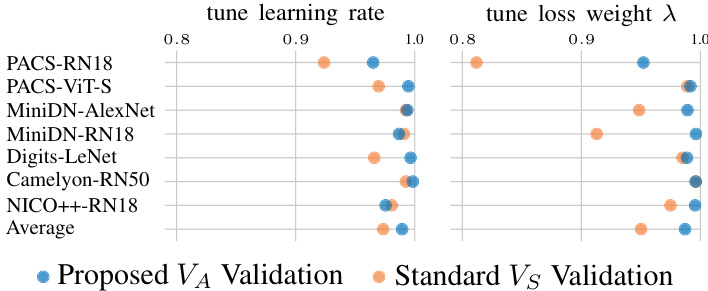
Figure 7. Learning rate and loss weight tuning per validation. We fix the training-testing variant to $I S\to I^{\cdot75}S$ to evaluate the performance of $V_{A}$ and $V_{S}$ validation restricted only to hyperparameter tuning. Performance is normalized by the performance of the oracle; 1 means equivalent to oracle performance.
图 7: 基于验证的学习率和损失权重调优。我们将训练-测试变体固定为 $I S\to I^{\cdot75}S$ 以评估仅针对超参数调优的 $V_{A}$ 和 $V_{S}$ 验证性能。性能通过基准性能进行归一化处理,1表示与基准性能相当。
| 变体 | 平均 | 艺术 | 卡通 | 素描 |
|---|---|---|---|---|
| 1:I→I (基线) | 43.46 | 54.30 | 37.27 | 38.80 |
| 2: ISsob→I | 51.75 | 58.35 | 41.19 | 55.71 |
| 3:ISI | 57.89 | 58.47 | 48.21 | 67.00 |
| 4:IS→→I.75S | 59.02 | 59.10 | 49.54 | 68.41 |
| 5:I→→I | 58.15 | 63.10 | 48.46 | 62.91 |
| 59.31 | 63.38 | 48.74 | 65.83 | |
| 7:IS→I | 60.50 | 63.23 | 50.62 | 67.66 |
| 8:IS→1.75S | 60.97 | 63.62 | 50.80 | 68.50 |
| 53.34 | 57.52 | 44.79 | 57.70 |
Table 1. Comparison of variants. Performance comparison among our variants on the PACS dataset with AlexNet. The value of the shape information and the extra augmentations is showcased. We report accuracy per target domain and their average.
表 1: 变体对比。基于AlexNet在PACS数据集上各变体的性能比较,展示了形状信息和额外数据增强的价值。我们报告了每个目标域的准确率及其平均值。
vs. 4). We conclude that it is not only the ensemble of the two predictions that improves the test accuracy but mainly the bridging of the two domains during training.
vs. 4)。我们得出结论,不仅是两个预测的集成提高了测试准确率,更重要的是训练过程中两个领域的桥接。
Beyond shape-oriented domains. PACS and MiniDomainNet include domains where the shape is preserved, but the texture varies. $\mathrm{NICO}{+}{+}$ differs because it consists of natural images of objects in varying contexts and environments. We use $\mathrm{NICO}{+}{+}$ to highlight the generality of the proposed recognition method. Due to the increased experimental cost, we only include the variants $I\to I$ , $I S{\rightarrow}I^{{\cdot}75}S$ , and ${\hat{I}}S\to I^{.75}S$ . The baseline $I\rightarrow I$ achieves a 23.8 test accuracy, while including BTEs achieve a 2.2 increase over the baseline, confirming that BTEs not only help the network learn a shape-oriented representation but also enhance robustness against spurious correlations from textures. IˆS I.75S achieves an additional 1.3 increase.
超越形状导向的领域。PACS和MiniDomainNet包含保留形状但纹理变化的领域。$\mathrm{NICO}{+}{+}$的不同之处在于它由不同背景和环境中的物体自然图像组成。我们使用$\mathrm{NICO}{+}{+}$来突显所提出识别方法的通用性。由于实验成本增加,我们仅包含变体$I\to I$、$I S{\rightarrow}I^{{\cdot}75}S$和${\hat{I}}S\to I^{.75}S$。基线$I\rightarrow I$达到23.8的测试准确率,而包含BTE的方法比基线提高了2.2,证实BTE不仅帮助网络学习形状导向的表示,还增强了对纹理虚假相关性的鲁棒性。${\hat{I}}S\to I^{.75}S$实现了额外的1.3提升。
Shape-texture bias. The inductive biases [19] of our approach are analyzed by using the $I6$ -class-ImageNet [20] as the source domain and the cue conflict stimuli images [19] as the target domain. Each stimuli image is the product of blending an image’s texture with another’s shape through style transfer. Therefore, each image has two labels, one based on shape and one based on texture. Although the 16- class-ImageNet consists of 213, 555 images, we sub-sample to 500 images per class. An ImageNet pre-trained ResNet18 backbone is trained with the $I S$ training variant for varying values of the loss weight $\lambda$ . We compare our variant
形状-纹理偏差。我们方法的归纳偏差[19]通过使用$I6$-class-ImageNet[20]作为源域和线索冲突刺激图像[19]作为目标域进行分析。每个刺激图像是通过风格迁移将一个图像的纹理与另一个图像的形状混合而成的产物。因此,每个图像有两个标签,一个基于形状,另一个基于纹理。尽管16-class-ImageNet包含213,555张图像,但我们每类子采样500张图像。使用ImageNet预训练的ResNet18骨干网络,在不同损失权重$\lambda$下训练$IS$训练变体。我们比较了我们的变体
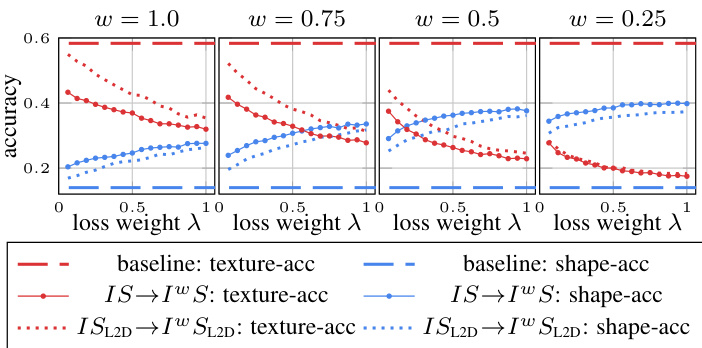
Figure 8. Shape-texture bias: The accuracy of different variants is evaluated on the cue conflict stimuli test set based on shape or test labels. Loss weight $\lambda$ and exponent $w$ are the ways to control the influence of shape during training and testing, respectively, with $\lambda=1$ and $w=0$ taking shape into account the most. A different model is trained for the various values of $\lambda$ .
图 8: 形状-纹理偏差:基于形状或测试标签的线索冲突刺激测试集上评估不同变体的准确率。损失权重 $\lambda$ 和指数 $w$ 分别用于控制训练和测试过程中形状的影响程度,其中 $\lambda=1$ 和 $w=0$ 表示对形状的考量权重最大。针对不同 $\lambda$ 值分别训练了独立模型。
$I S\rightarrow I^{w}S$ with a styli z ation-based approach, a popular shape bias technique. In particular, the style-complement component of L2D [58] is used as a shape component, replacing the BTE. This component is randomized during training and fixed during testing. We refer to this method as $I S_{\mathrm{L2D}}\rightarrow I^{w}S_{\mathrm{L2D}}$ , and the results are summarized in Figure 8, where accuracy is evaluated either with the shape (shape-acc.) or the texture labels (texture-acc.).
$I S\rightarrow I^{w}S$ 采用基于风格化的方法,这是一种流行的形状偏置技术。具体而言,L2D [58] 的风格互补组件被用作形状组件,取代了BTE。该组件在训练期间随机化,在测试期间固定。我们将此方法称为 $I S_{\mathrm{L2D}}\rightarrow I^{w}S_{\mathrm{L2D}}$ ,结果总结在图 8 中,其中准确率通过形状标签 (shape-acc.) 或纹理标签 (texture-acc.) 进行评估。
The results demonstrate the significant impact of both shape-controlling hyper-parameters, namely $\lambda$ during training and $w$ during testing, on shape bias. The comparison shows a higher ability of BTE to adapt to shape cues compared to the styli z ation of L2D. This seems crucial for domain generalization since humans achieve an accuracy of 95.9 regarding the shape labels [19].
结果表明,形状控制超参数(训练阶段的$\lambda$和测试阶段的$w$)对形状偏差具有显著影响。对比显示,BTE在适应形状线索方面比L2D的风格化表现更强。这对于领域泛化似乎至关重要,因为人类在形状标签上的准确率达到了95.9 [19]。
Comparison with the state-of-the-art is presented in Table 2. Whenever available, we include the reported results from the relevant publications. For the experiments on MiniDomainNet we use the official code of each method. The results reported for our method were obtained by fully automated tuning of the learning rate and method selection among the $\hat{I}S{\rightarrow}I^{w}S$ variants on the augmented validation set. To our knowledge, no previously reported performance has resulted from such a validation process. State-of-the-art results are achieved on all four datasets.
与现有技术水平的对比见表2。在可能的情况下,我们纳入了相关出版物中报告的结果。对于MiniDomainNet的实验,我们使用了每种方法的官方代码。我们方法报告的结果是通过在增强验证集上对学习率和$\hat{I}S{\rightarrow}I^{w}S$变体进行全自动调优获得的。据我们所知,此前没有报道过通过此类验证流程获得的性能。我们的方法在所有四个数据集上都达到了最先进的水平。
5. Conclusions
5. 结论
We show that independent augmentations of the validation set allow for better model selection and hyper-parameter tuning in single-source domain generalization. The proposed augmented validation enables the prediction of the test performance for prior methods and the proposed family of methods. Compared to the standard validation practice on the training distribution, the proposed validation method results in significant performance gains in real-world method selection over six domain generalization approaches. We expect this contribution to be valuable for future compar
我们证明,在单源域泛化中,验证集的独立增强可以实现更好的模型选择和超参数调优。所提出的增强验证能够预测现有方法及所提出方法系列的测试性能。与基于训练分布的标准验证方法相比,所提出的验证方法在六种域泛化方法的实际选择中带来了显著的性能提升。我们预期这一贡献对未来比较研究具有重要价值。
(d) Camelyon17 with ResNet50.
| 方法 | SVHN | MNIST-MSYN | USPS 平均 |
|---|---|---|---|
| ERM[8] | 32.52 | 54.92 | 42.34 |
| RandConv [61] | 62.07 | 87.89 | 63.90 |
| L2D [58] | 62.86 | 87.30 | 63.72 |
| MetaCNN [56] | 66.50 | 88.27 | 70.66 |
| MCL [4] | 69.94 | 78.34 | 78.47 |
| ProRandC [8] | 69.67 | 82.30 | 79.77 |
| CADA [6] | 67.27 | 78.66 | 79.34 |
| ABA3l+RC [7] | 56.87 | 80.08 | 73.40 |
| 79.64±10 | 98.68±0182.61±05 |
(a) 使用LeNet的数字识别结果
| 方法 | Clipart | Painting | Sketch | 平均 |
|---|---|---|---|---|
| ERMt | ||||
| SagNett [45] | 50.53 | 53.86 | 38.36 | 47.58 |
| ACvct [11] | 55.66 | 45.82 | 50.37 | |
| SelfReg[30] | 53.81 | 56.93 | 43.17 | 51.27 |
| L2D[58] | 54.95 | 53.76 | 48.25 | 51.66 |
| 1S→17s(本方法) | 55.55±03 | 55.38 | 45.15 | 51.83 |
| 59.00±05 | 57.51±12 | 57.35±03 |
(b) 使用ResNet18的Mini-DomainNet结果
| 方法 | P→A | P→C | P→S | 平均 |
|---|---|---|---|---|
| ERM | 54.43 | 42.74 | 42.02 | |
| L2D [58] | 56.26 | 51.04 | 58.42 | 55.24 |
| MetaCNN [56] | 54.05 | 53.58 | 63.88 | 57.17 |
| √1S→17s(本方法) | 63.62±04 | 50.80±11 | 68.50±13 | 60.97±07 |
ResNet18
| 方法 | P→A | P→C | P→S | 平均 |
|---|---|---|---|---|
| ERM | 64.10 | 23.60 | 29.10 | 38.90 |
| SagNet [45] | 69.80 | 35.10 | 40.70 | 48.50 |
| SelfReg [30] | 67.72 | 28.97 | 33.71 | 43.46 |
| XDED [34] | 71.40 | 54.30 | 51.50 | 59.10 |
| ITTA [5] | 66.50 | 52.20 | 63.80 | 60.80 |
| MCL [4] | 59.60 | |||
| ProRandC[8] | 62.89 | |||
| CADA [6] | 56.65 | |||
| ABA5t [7] | - | - | 59.04 | |
| iS→1s(本方法) | 67.97±06 | 54.45±12 | 74.13±07 | 65.85±05 |
(c) PACS
| 方法 | Hospital 4 | Hospital 5 | 平均 |
|---|---|---|---|
| ERM | 90.58 | ||
| AdvBNN [40] | 87.30 | 82.26 | 84.04 |
| AugMix [28] | 85.92 | 84.86 | 85.39 |
| AugMax [57] | 79.61 | 85.51 | 82.56 |
| RandConv[61] | |||
| ABA5l+A [7] | 90.64 | 84.75 | 87.70 |
| √IS→I(本方法) | 92.20±19 | 94.91±09 | 93.56±14 |
| 1S→17s(本方法) | 92.88±07 | 95.86±02 | 94.37±03 |
(d) 使用ResNet50的Camelyon17结果
Table 2. Comparison with the state-of-the-art on Digits (a), MiniDomainNet (b), PACS (c), and Camelyon17 (d). The source do- mains are MNIST, real, photo, and hospitals 1-3, respectively. Each column represents a different target domain. Methods evaluated by us are denoted with a $^\dagger$ , and the variant of our method chosen by $V_{A}$ is denoted by $\checkmark$ . ERM corresponds to $I{\rightarrow}I$ .
表 2: 在Digits (a)、MiniDomainNet (b)、PACS (c)和Camelyon17 (d)数据集上与现有技术的对比。源域分别为MNIST、real、photo和hospitals 1-3。每列代表不同的目标域。由我们评估的方法用$^\dagger$标注,$V_{A}$选择的我们方法变体用$\checkmark$标注。ERM对应$I{\rightarrow}I$。
isons and to help researchers avoid the malpractice of tuning on the test set. We further demonstrate that shape extraction in the form of cleaned edge maps is a solid tool for enforcing shape bias and enhancing the domain generalization ability of deep class if i ers. State-of-the-art performance is achieved on several benchmarks by a method selected and with hyper-parameters tuned in a fully automated manner on the augmented validation set.
规则:
- 输出中文翻译部分时仅保留翻译标题,不含冗余内容、重复或解释。
- 不输出与英文无关的内容。
- 保留原始段落格式及术语(如FLAC、JPEG)、公司缩写(如Microsoft、Amazon、OpenAI)。
- 人名不翻译。
- 保留论文引用格式(如[20])。
- Figure/Table翻译为“图1: ”/“表1: ”,保留原格式。
- 全角括号转半角,左括号前加空格(如 (example) )。
- 专业术语首次出现标注英文(如“生成式AI (Generative AI)”),后续仅用中文。
策略:
- 特殊字符/公式原样保留
- HTML表格转Markdown格式
- 按中文习惯翻译,确保信息完整
最终仅返回Markdown格式译文。
我们进一步证明,以清理后的边缘图形式提取形状是强化形状偏置(shape bias)和提升深度分类器(deep classifiers)领域泛化能力的有效工具。通过在增强验证集上全自动选择方法及调参,我们在多个基准测试中实现了最先进(state-of-the-art)性能。
Acknowledgments: This work was supported by the Junior Star GACR GM 21-28830M, the Czech Technical University in Prague grant No. SGS23/173/OHK3/3T/13, and the CTU institutional support (Future fund). We also thank Nikolaos-Antonios Ypsilantis for the fruitful conversations and insightful discussions.
致谢:本研究由Junior Star GACR GM 21-28830M、捷克技术大学布拉格分校资助项目SGS23/173/OHK3/3T/13及CTU机构支持计划(Future fund)资助。同时感谢Nikolaos-Antonios Ypsilantis富有成效的交流与深刻讨论。
A. Appendix
A. 附录
In this appendix, we provide additional information about the datasets used and implementation details both for the proposed and the literature methods utilized in our experiments. Additionally, we present qualitative examples of the data augmentations and the shape extraction processes used in this work. Finally, we include additional experimental results that could not fit in the main paper, along with tables containing the numerical data of our figures.
在本附录中,我们提供了关于实验中使用数据集的额外信息,以及所提出方法和文献方法的实现细节。此外,我们还展示了本工作中使用的数据增强和形状提取过程的定性示例。最后,我们补充了因篇幅限制未能在主论文中呈现的额外实验结果,并附上了图中数值数据的表格。
A.1. Dataset Details
A.1. 数据集详情
Digits dataset details. It is a collection of five digitrecognition datasets: MNIST, MNIST-M, SVHN, SYN, and USPS. MNIST-M combines the original MNIST handwritten digit database with random patches of the BSDS500 dataset. SVHN is a dataset of real-world house number images obtained by Google Street View. SYN is a synthetic dataset created from different Windows fonts after applying geometric transformations and blurring. USPS is a dataset of scanned digits from U.S. Postal Service envelopes. To compare with the literature, we use only the first 10, 000 images of the MNIST training set. We choose to use the $90%$ for training and the $10%$ for validation. We are evaluating on the test set of the rest domains.
数字数据集详情。该数据集包含五个数字识别数据集:MNIST、MNIST-M、SVHN、SYN和USPS。MNIST-M将原始MNIST手写数字数据库与BSDS500数据集的随机图像块相结合。SVHN是通过Google街景获取的真实世界门牌号图像数据集。SYN是应用几何变换和模糊处理后,基于不同Windows字体创建的合成数据集。USPS是美国邮政服务信封上扫描数字的数据集。为与文献保持一致,我们仅使用MNIST训练集的前10,000张图像。我们选择其中$90%$用于训练,$10%$用于验证。其余领域的测试集将用于评估。
PACS dataset details. It is a domain generalization dataset that includes four domains: photo, art paintings, cartoon, and sketch. It consists of seven classes and 9, 991 images. In the experiments presented in the main paper, the photo domain is used as the source, and the remaining domains are used for evaluation. This appendix provides an additional experiment where each domain is used as the source. The photo domain consists of 1, 670 images. We use the official partition of $10%$ for validation and the rest $90%$ for training. Mini-DomainNet dataset details. It is a subset of the domain generalization dataset DomainNet [50]. It consists of 140, 006 images, 126 classes, and four domains: clipart, painting, real, and sketch. We use the real domain as the source, and we evaluate on the rest. The real domain has 64, 979 images and we are using the official split that includes 58, 482 images for training and 6, 497 images for validation.
PACS数据集详情。该数据集是一个领域泛化数据集,包含照片(photo)、艺术绘画(art paintings)、卡通(cartoon)和素描(sketch)四个域,共7个类别9,991张图像。在正文实验中,我们使用照片域作为源域,其余域用于评估。本附录补充了将各域轮流作为源域的额外实验。照片域包含1,670张图像,我们采用官方划分方案:10%作为验证集,其余90%用于训练。
Mini-DomainNet数据集详情。该数据集是领域泛化数据集DomainNet[50]的子集,包含140,006张图像、126个类别及四个域:剪贴画(clipart)、绘画(painting)、真实图像(real)和素描(sketch)。我们以真实图像域为源域,其余域用于评估。真实图像域包含64,979张图像,采用官方划分方案:58,482张训练图像和6,497张验证图像。
$\mathbf{NICO}\mathbf{+}\mathbf{+}$ dataset details. It is an out-of-distribution genera liz ation dataset comprising natural images, where the following contexts serve as the domains: autumn, dim light, grass, outdoor, rock, and water. $\mathrm{NICO}{+}{+}$ consists of 60 classes and 88, 866 images.
$\mathbf{NICO}\mathbf{+}\mathbf{+}$ 数据集详情。这是一个由自然图像组成的分布外泛化数据集,包含以下上下文作为域:秋季、弱光、草地、户外、岩石和水。$\mathrm{NICO}{+}{+}$ 包含60个类别和88,866张图像。
Camelyon17 dataset details. It is a medical dataset focused on tumor detection, with data from five different hospitals. Data from hospitals 1, 2, and 3 are treated as the source domain, and data from hospitals 4 and 5 are the target. Camelyon17 consists of two classes: cancerous and non-cancerous tissue, and it contains 455, 954 images.
Camelyon17数据集详情。该医学数据集专注于肿瘤检测,数据来自五家不同医院。医院1、2、3的数据被视为源域,医院4、5的数据为目标域。Camelyon17包含两类:癌变组织与非癌变组织,共计455,954张图像。

Figure 9. The output of the shape extraction process for BTE and Sobel-based edge maps from the different target domains in the PACS dataset. BTE removes texture cues more effectively, making it a better choice for increasing the shape bias.
图 9: PACS数据集中不同目标域的BTE和基于Sobel的边缘图的形状提取过程输出。BTE能更有效地去除纹理线索,使其成为增加形状偏置的更好选择。

Figure 10. The output of the shape extraction process for BTE edge maps on images of the photo domain in PACS during training. BTE introduces random iz ation at multiple steps of edge detection, enriching the training set with edge maps that vary in level of detail.
图 10: PACS数据集中照片领域图像在训练过程中BTE边缘图的形状提取输出结果。BTE通过在边缘检测的多个步骤引入随机化,生成具有不同细节层次的边缘图来丰富训练集。
16-class-ImageNet dataset details. The 16-class-ImageNet dataset [20] is a subset of the ImageNet dataset that maps 231 of the original classes to 16 new ones, closer to the level of abstraction a human could guess. Although the 16- class-ImageNet consists of 213, 555 images, we sub-sample to 500 images per class. We test the trained models to the texture-shape cue conflict stimuli dataset [19], which is a dataset that shares the same 16 classes and consists of 1, 280 images.
16类ImageNet数据集详情。16类ImageNet数据集[20]是ImageNet数据集的子集,将原有的231个类别映射为16个更接近人类抽象认知层次的新类别。虽然该数据集包含213,555张图像,但我们每类仅采样500张进行实验。我们在纹理-形状线索冲突刺激数据集[19]上测试训练好的模型,该数据集共享相同的16个类别,包含1,280张图像。
A.2. Implementation Details
A.2. 实现细节
Shape extraction. The pipeline for BTEs and their randomization is adopted from [16] with the exception that we use Sobel instead of the learnable edge detectors, eliminating the need for additional training data. The pipeline is as follows: First, the image is blurred using a Gaussian filter with kernel size 5 and sigma equal to 1.0. Next, the Sobel operator is applied for edge detection, followed by non-maximum suppression to thin the edge map. Finally, the edge map is binarized using adaptive hysteresis. The upper and lower bounds of hysteresis are chosen as $1.5t$ and $0.5t$ , respectively, where the threshold $t$ is selected using Otsu’s method on the edge map before thinning.
形状提取。BTEs及其随机化的流程参考自[16],不同之处在于我们使用Sobel算子替代可学习的边缘检测器,从而无需额外训练数据。具体流程如下:首先,使用核大小为5、sigma为1.0的高斯滤波器对图像进行模糊处理;接着,应用Sobel算子进行边缘检测,随后通过非极大值抑制细化边缘图;最后,采用自适应滞后阈值法对边缘图进行二值化处理。滞后阈值的上下限分别设为$1.5t$和$0.5t$,其中阈值$t$是通过在细化前的边缘图上采用Otsu方法选定的。

Figure 11. Accuracy vs Time: Training on PACS (left) and on Mini-DomainNet (right) with different number of BTEs in the batch. The training batch includes $64~\mathrm{RGB}$ images plus 0, 8, 16, 24, 32, 48, and 64 BTEs (dots).
图 11. 准确率 vs 时间: 在PACS (左) 和 Mini-DomainNet (右) 上使用不同数量 BTE 进行训练的结果。训练批次包含 $64~\mathrm{RGB}$ 图像外加 0、8、16、24、32、48 和 64 个 BTE (圆点标记)。

Figure 12. Augmented validation without increasing the validation set size: Correlation between the validation and test accuracy using the standard validation and the augmented one of the same size. This experiment shows that it is not the larger size of $V_{A}$ that makes the difference. The experiment is on the PACS dataset with a ResNet-18 as a backbone.
图 12. 不增加验证集规模的增强验证:使用标准验证集和相同规模的增强验证集时,验证准确率与测试准确率之间的相关性。该实验表明,并非 $V_{A}$ 的更大规模造成了差异。实验在 PACS 数据集上进行,采用 ResNet-18 作为主干网络。
In the randomized variant used for training, the standard deviation of the Gaussian blurring is chosen randomly from 0,1, and 2, with 0 corresponding to no blur. The thresholding method is randomly picked among Yen [29], Otsu [49], Isodata [52], Li [35], and the mean method [22]. Additional random noise is introduced in both the threshold value $t$ and the hysteresis bounds, enriching the training set.
在用于训练的随机变体中,高斯模糊的标准差从0、1和2中随机选择,其中0表示不进行模糊处理。阈值处理方法随机选用Yen [29]、Otsu [49]、Isodata [52]、Li [35]或均值法 [22]。此外,在阈值$t$和滞后边界中引入了额外的随机噪声,从而丰富了训练集。
In the variant using Sobel edge maps of Table 1, the process is simplified in blurring and applying the Sobel operator. Random iz ation is only through the standard deviation of the Gaussian blurring. Examples of Sobel-based edge maps and BTEs are shown in Figures 9 and 10.
在表1使用Sobel边缘图的变体中,模糊化和应用Sobel算子的过程被简化。随机化仅通过高斯模糊的标准差实现。基于Sobel的边缘图和BTE示例如图9和图10所示。
Implementation details for our approach. The basic augmentations include cropping with relative size in [0.8, 1.0], an aspect ratio in $[\frac{3}{4},\frac{4}{3}]$ , resizing to $224\times224$ , and horizontal flipping with a probability of 0.5. Digits is an exception where the resize is $32\times32$ , and the flipping is skipped as it conflicts with the task. The extra augmentations from the ImgAug library are from the following groups: arithmetic, artistic, blur, color, contrast, convolutional, edges, geometric, segmentation, and weather.
我们方法的实现细节。基础增强包括相对大小在[0.8, 1.0]范围内的裁剪、宽高比在$[\frac{3}{4},\frac{4}{3}]$之间、调整尺寸至$224\times224$,以及概率为0.5的水平翻转。Digits数据集例外,其尺寸调整为$32\times32$,且跳过翻转操作以避免与任务冲突。来自ImgAug库的额外增强涵盖以下类别:算术、艺术效果、模糊、色彩、对比度、卷积、边缘、几何、分割和天气。
For our PACS, Digits, and Mini-DomainNet experiments, the learning rate is tuned using a grid search among 33
在我们的PACS、Digits和Mini-DomainNet实验中,学习率通过网格搜索在33个值中进行调整。
| 方法 | 艺术 | 卡通 | 照片 | 素描 | 平均 |
|---|---|---|---|---|---|
| ERM | 68.80 | 70.00 | 38.90 | 39.40 | 54.30 |
| JiGen [3] | 67.70 | 72.23 | 41.70 | 36.83 | 54.60 |
| ADA [55] | 72.43 | 71.97 | 44.63 | 45.73 | 58.70 |
| SelfReg [30] | 72.59 | 76.56 | 43.46 | 45.76 | 59.59 |
| SagNet [45] | 73.20 | 75.67 | 48.53 | 50.07 | 61.90 |
| GeoTexAug[39] | 72.07 | 78.70 | 49.07 | 59.97 | 65.00 |
| L2D [58] | 76.91 | 77.88 | 52.29 | 53.66 | 65.18 |
| XDED [34] | 76.50 | 77.20 | 59.10 | 53.10 | 66.50 |
| CADA [6] | 76.33 | 79.08 | 61.59 | 56.65 | 68.41 |
| ITTA [5] | 74.60 | 77.10 | 60.80 | 61.20 | 68.40 |
| ProRandC[8] | 76.98 | 78.54 | 62.89 | 57.11 | 68.88 |
| MCL [4] | 77.13 | 80.14 | 62.55 | 59.60 | 69.86 |
| ABA3l | 75.34 | 77.49 | 58.86 | 53.76 | 66.36 |
| iS→1.75S (Ours) | 80.67±0.4 | 76.53±1.1 | 65.85±0.5 | 58.41±1.3 | 70.37±0.5 |
Table 3. Comparison with state-of-the-art approaches on PACS with a ResNet18 backbone. Each column corresponds to a different source domain, reporting average performance when testing on the three remaining domains as target domains.
表 3: 基于ResNet18骨干网络在PACS数据集上与前沿方法的对比。每列对应不同的源域,数值表示以其余三个域作为目标域测试时的平均性能。
equidistant values on a logarithmic scale in the range of $[10^{-5},1]$ . The loss weight $\lambda$ is tuned using a grid search among 17 equidistant values in [0, 1]. The exponent $w$ is a test-time parameter, and it is tuned among the values 0, 0.25, 0.5, 0.75, and 1.0 for all of our experiments. The first and last values correspond to the variants $S$ and $I$ , respectively. Experiments on PACS and Digits for the comparison with the state-of-the-art are repeated 30 times. In all other experiments on PACS, Digits, and Mini-DomainNet, we use 5, 5, and 3 seeds, respectively.
在对数尺度上取区间$[10^{-5},1]$内的等距值。损失权重$\lambda$通过在[0, 1]区间内17个等距值上进行网格搜索来调整。指数$w$作为测试时参数,在所有实验中从0、0.25、0.5、0.75和1.0这几个值中选取。首尾两个值分别对应变体$S$和$I$。为与最先进方法对比,在PACS和Digits数据集上的实验重复30次。在PACS、Digits和Mini-DomainNet的其他所有实验中,我们分别使用5、5和3个随机种子。
Camelyon17 and $\mathrm{NICO}{+}{+}$ require longer training because of the larger size of the former and the randomly initialized training of the latter. Therefore, we perform a learning rate grid search for 9 equidistant values on a logarithmic scale, in the range of $[10^{-5},1]$ , while we train for 3 different seeds.
由于Camelyon17和$\mathrm{NICO}{+}{+}$的规模较大且后者采用随机初始化训练,因此需要更长的训练时间。为此,我们在对数尺度上对$[10^{-5},1]$范围内的9个等间距值进行学习率网格搜索,同时使用3个不同的随机种子进行训练。
For the 16-class-ImageNet experiment, we perform a grid search for our $I S$ method’s loss weight $\lambda$ for 16 different values in the range of [0.0625, 1].
对于16类ImageNet实验,我们采用网格搜索方法在[0.0625, 1]范围内选取16个不同值,对IS方法的损失权重λ进行调优。
We always use stochastic gradient descent with an exponential scheduler that decreases the learning rate by two magnitudes by the end of the training. We tune the number of epochs and the learning rate jointly for the $I S\to I S$ variant. This experiment provides us with the number of epochs to use for all variants, which remains fixed for all the follow-up experiments described in the main paper. We train our models for 10, 40, 50, 300, 300, and 700 epochs on Camelyon17, Mini-DomainNet, 16-class-ImageNet, Digits, PACS, and $\mathrm{NICO}{+}{+}$ respectively.
我们始终采用随机梯度下降法,并配合指数调度器,在训练结束时将学习率降低两个数量级。针对 $I S\to I S$ 变体,我们联合调整训练周期数和学习率。该实验确定了适用于所有变体的训练周期数,该数值在主论文所述的所有后续实验中保持固定。我们分别在Camelyon17、Mini-DomainNet、16类ImageNet、Digits、PACS和$\mathrm{NICO}{+}{+}$数据集上训练模型10、40、50、300、300和700个周期。
Implementation details for the literature methods. Regarding SelfReg, SagNet, L2D, and ACVC, we follow all the implementation details – optimizer, schedulers, augmentations, and hyper parameters – from the original works, except for the learning rate. To determine the number of training epochs, we first set the learning rate to the value reported in the publication of the respective method and tune the number of epochs to maximize validation accuracy. Ties are resolved by picking the smaller number, while we never go for more
文献方法的实现细节。对于SelfReg、SagNet、L2D和ACVC,除学习率外,我们完全遵循原始工作的所有实现细节——优化器、调度器、数据增强和超参数。为确定训练周期数,我们首先将学习率设置为各方法原始论文中报告的值,并通过调整周期数使验证准确率最大化。若出现相同结果则选择较小周期数,且总周期数不超过...
Table 4. Method selection based on the validation set: Test accuracy is reported after tuning and selecting the best method among all proposed variants according to different validation sets – i.e., oracle, standard, and augmented. The method chosen and the performance gain between the augmented and the standard validation set are reported. In the case of PACS with a ViT-S model, $V_{S}$ ties across seven variations, so we report the average.
表 4. 基于验证集的方法选择: 在不同验证集(即oracle、standard和augmented)上调整并选择最佳方法后报告测试准确率。同时报告了所选方法以及增强验证集与标准验证集之间的性能提升。对于使用ViT-S模型的PACS数据集,$V_{S}$在七个变体中表现相同,因此我们报告平均值。
| PACS-ViT-S | PACS-RN18 | MiniDN-RN18 | MiniDN-Alexnet | NICO++-RN18 | Digits-LeNet | Cam17-RN50 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Val | Method | Acc | Method | Acc | Method | Acc | Method | Acc | Method | Acc | Method | Acc | Method | Acc |
| Vo | is→IS | 75.68 | iS→1.75s | 66.19 | iS-1.75s | 57.89 | iS→1.75s | 49.10 | iS-1.75s | 29.12 | is→150s83.83 | is→I | 94.47 | |
| Vs | ties* | 68.70 | ISx2-→150s 51.75 | ISx2→175s 52.98 | I→→I | 39.82 | IS→1.75s | 26.86 | ISsob→I | 72.51 | I→I | 78.73 | ||
| VA | iS→175s74.48 | iS-→1.75s | 65.85 | iS→1.75s | 57.35 | iS-→1.75s | 48.85 | iS→1.75s | 29.12 | is→1.75s82.61 | IS→I | 93.56 | ||
| gain | 5.78 | 14.10 | 4.37 | 9.03 | 2.26 | 10.10 | 14.83 |
| 调整学习率 | 训练→测试 | Vs | VA | Vo | Gain | Vs | VA | Vo | Gain | |
|---|---|---|---|---|---|---|---|---|---|---|
| RN18 M | IS→1.25S | 58.0 | 57.6 | 61.0 | -0.4 | 37.9 | 56.1 | 57.7 | 18.3 | |
| IS→1.50s | 58.0 | 59.7 | 61.3 | 1.7 | 35.8 | 57.1 | 59.4 | 21.4 | ||
| IS→1.75 s | 56.7 | 59.2 | 61.3 | 2.5 | 49.0 | 57.5 | 60.4 | 8.5 | ||
| ViT- | IS→1.25S | 62.6 | 65.4 | 65.9 | 2.8 | 63.1 | 64.9 | 65.2 | 1.8 | |
| IS→1.50s | 67.4 | 68.5 | 69.4 | 1.1 | 68.0 | 68.1 | 68.9 | 0.1 | ||
| IS→1.75s | 69.4 | 71.2 | 71.5 | 1.8 | 70.4 | 70.6 | 71.2 | 0.2 | ||
| MiniDN lexnet A | IS→1.25S | 45.3 | 45.5 | 45.9 | 0.2 | 43.6 | 44.9 | 45.4 | 1.3 | |
| IS→1.50s | 46.9 | 47.5 | 48.3 | 0.6 | 45.9 | 47.5 | 47.9 | 1.6 | ||
| IS→1.75 s | 47.8 | 47.8 | 48.1 | 0.0 | 46.1 | 48.0 | 48.6 | 1.9 | ||
| MiniDN RN1 | IS→1.25S | 51.8 | 51.6 | 51.9 | -0.2 | 47.3 | 50.8 | 51.0 | 3.5 | |
| IS→1.50 s | 55.0 | 55.0 | 55.5 | 0.1 | 48.1 | 53.9 | 54.6 | 5.8 | ||
| IS→1.75 s | 55.5 | 55.3 | 56.0 | -0.2 | 50.1 | 54.7 | 54.9 | 4.6 | ||
| LeNet igits | IS→1.25S | 78.0 | 78.8 | 78.9 | 0.8 | 75.4 | 76.0 | 76.8 | 0.7 | |
| IS→1.50s | 77.8 | 78.8 | 79.1 | 0.9 | 76.1 | 76.3 | 77.2 | 0.2 | ||
| IS→1.75 s | 76.2 | 78.6 | 78.9 | 2.4 | 76.4 | 76.7 | ||||
| ++OIN RN1 | IS→1.25S | 23.2 | -0.2 | 23.6 | 23.7 | 77.6 23.8 | 0.3 0.1 | |||
| IS→1.50s | 23.4 | 23.6 | ||||||||
| IS→1.75 s | 25.8 26.1 | 25.7 | 26.2 | -0.1 | 26.0 | 26.5 | 26.7 | 0.5 | ||
| Cam17 RN50 | IS→125S | 92.0 | 26.0 92.3 | 26.6 92.4 | -0.1 | 26.2 92.1 | 26.8 92.2 | 26.9 92.4 | 0.6 0.1 | |
| IS→1.50s | 93.3 | 93.4 | 0.3 0.1 | 93.7 | 93.7 | 93.9 | 0.0 | |||
| IS→1.75 s | 93.8 | 94.3 | 93.9 94.5 | 0.5 | 94.1 | 94.1 | 94.5 | 0.0 | ||
| 平均增益 | 0.7 | 3.4 |
Table 5. Learning rate and loss weight tuning per validation: Test accuracy for our method variants is reported after tuning according to different validation sets – i.e., oracle, standard, and augmented. The performance gain between the augmented versus the standard validation set is also presented. As expected, the method is more effective for tuning hyper parameters related to domain generalization, such as the shape loss weight.
表 5: 基于不同验证集的超参数调优效果:本表格展示了根据三种验证集 (oracle、standard 和 augmented) 调优后各方法变体的测试准确率,并列出增强验证集相较标准验证集的性能提升。如预期所示,该方法在调整领域泛化相关超参数 (例如形状损失权重) 时效果更为显著。
than 800 or 100 epochs on PACS and Mini-DomainNet, respectively. Once the number of epochs is tuned, we tune the learning rate to maximize validation accuracy.
在PACS和Mini-DomainNet上分别超过800或100个周期。一旦周期数调整完毕,我们会调整学习率以最大化验证准确率。
A.3. Extra Experiments
A.3. 额外实验
Performance vs Time: For the proposed validation $V_{A}$ , there is no matter of time-performance trade-off. We argue that the standard validation $V_{S}$ is completely incapable of predicting test performance in the context of domain generalization. This can be seen from Figure 5: PACS shows an accuracy drop of 22.2 if $V_{S}$ is used over $V_{A}$ . Methods that do not use the proposed augmentations in training, such as L2D and SelfReg, do not require the 2-fold cross-validation. In such cases, the time overhead of $V_{A}$ over $V_{S}$ is only the performance of a random augmentation. For methods that use augmentations, the extra time compared to $V_{S}$ is approximately doubled because of the 2-fold cross-validation.
性能与时间对比:对于提出的验证方法 $V_{A}$ ,不存在时间与性能的权衡问题。我们认为标准验证 $V_{S}$ 在领域泛化背景下完全无法预测测试性能。从图 5 可以看出:若使用 $V_{S}$ 而非 $V_{A}$ ,PACS 的准确率会下降 22.2。训练中未使用所提增强方法的技术(如 L2D 和 SelfReg)无需进行 2 折交叉验证。此时 $V_{A}$ 相较 $V_{S}$ 的时间开销仅为随机增强的性能表现。对于使用增强方法的技术,由于 2 折交叉验证的存在,其额外时间开销约为 $V_{S}$ 的两倍。
For the proposed recognition method, the performance vs training time trade-off is shown in Figure 11. Even with roughly half of the training time, when only $25%$ of the batch images have their BTEs (16 BTEs) used, the test accuracy decrease is approximately $1%$ . The time measurements were conducted on a single Tesla A100 40GB GPU.
对于所提出的识别方法,性能与训练时间的权衡如图 11 所示。即使训练时间减少约一半,当仅使用批次图像中 $25%$ 的 BTE (16 个 BTE) 时,测试准确率下降约为 $1%$。时间测量在单个 Tesla A100 40GB GPU 上进行。
$V_{A}$ vs $V_{S}$ : Effective because it is larger? The proposed validation method $V_{A}$ increases the variability in the validation set as well as the size of the validation set by a factor of 10, which is given by the 10 groups of augmentations. To demonstrate that the benefit does not come from the larger validation set, we create an additional set by augmenting each image only once by randomly picking one of the 10 augmentation groups per image. The result is an augmented set of the same size as the original validation set, which we denote as $V_{a}$ . We perform the same experiments as in Figure 4 for PACS with a ResNet-18, but we exclude all variations that use augmentations during training to avoid over estimation, as described in Figure 6. Figure 12 shows that validation $V_{a}$ is still significantly better than $V_{S}$ .
$V_{A}$ vs $V_{S}$:效果更优是因为规模更大吗?
我们提出的验证方法 $V_{A}$ 通过10组数据增强,将验证集的多样性和规模扩大了10倍。为了证明其优势并非单纯来自更大的验证集,我们额外创建了一个增强集:每张图像仅随机选择10组增强中的一种进行一次增强。该增强集与原始验证集规模相同,记为 $V_{a}$。我们在PACS数据集上使用ResNet-18重复了图4的实验(排除训练阶段使用数据增强的所有变体以避免高估,如图6所述)。图12显示,验证集 $V_{a}$ 的表现仍显著优于 $V_{S}$。
Experiments with each domain as the source domain. In Table 3 we report the performance on the PACS dataset while using each domain as the source domain. We consider this an invalid setup due to the ImageNet pre-training. The networks have seen both real images during the pre-training phase and also cartoons, artworks, or sketches during training, making it similar to an MSDG task. Additionally, evaluating on the photo domain no longer corresponds to testing on an unseen domain. Nevertheless, we report results following the example of the literature, and our method is, on average, the top performing. Training from scratch would make these setups valid for SSDG, but the literature lacks available results for comparison.
以各领域作为源域的实验。在表3中,我们报告了使用各领域作为源域时在PACS数据集上的性能表现。由于存在ImageNet预训练,我们认为这种设置是无效的。网络在预训练阶段既见过真实图像,又在训练阶段接触过卡通、艺术作品或素描,这使得其类似于MSDG任务。此外,在照片领域进行评估不再对应于在未见领域进行测试。尽管如此,我们仍按照文献惯例报告结果,而我们的方法在平均表现上是最优的。若从头开始训练,这些设置将适用于SSDG,但文献中缺乏可供比较的结果。
Method selection and hyper parameter tuning. We summarize the results of our experiments for method selection in Table 4 and for hyper parameter tuning in Table 5. These tables contain the data presented in Figure 1 and Figure 7, respectively. While Figure 7 includes only experiments with the variant $I S\to I^{.75}S$ , Table 5 also contains the variants $I S{\rightarrow}I^{{\cdot}25}S$ and $I S{\rightarrow}I^{{\cdot}{^{50}}}S$ .
方法选择与超参数调优。我们将方法选择的实验结果总结在表4中,超参数调优的结果总结在表5中。这些表格分别对应图1和图7所示的数据。需要注意的是,图7仅包含变体$I S\to I^{.75}S$的实验,而表5还包含了变体$I S{\rightarrow}I^{{\cdot}25}S$和$I S{\rightarrow}I^{{\cdot}{^{50}}}S$。
Extra augmentations: Examples from the PACS dataset of all 76 extra augmentations are shown in Figures 13-15.
额外增强:PACS数据集中所有76种额外增强的示例如图13-15所示。

Figure 13. Examples of augmentations used from each augmentation category.
图 13: 各增强类别中使用的增强示例。

Figure 14. Examples of augmentations used from each augmentation category.
图 14: 各增强类别中使用的增强示例。

Figure 15. Examples of augmentations used from each augmentation category.
图 15: 各增强类别中使用的增强示例。