Reinforcement Learning with Augmented Data
数据增强的强化学习
Michael Laskin∗UC Berkeley
Michael Laskin∗UC Berkeley
Kimin Lee∗ UC Berkeley
Kimin Lee∗ 加州大学伯克利分校
Adam Stooke UC Berkeley
Adam Stooke UC Berkeley
Lerrel Pinto New York University
Lerrel Pinto 纽约大学
Pieter Abbeel UC Berkeley
Pieter Abbeel UC Berkeley
Aravind Srinivas UC Berkeley
Aravind Srinivas UC Berkeley
Abstract
摘要
Learning from visual observations is a fundamental yet challenging problem in Reinforcement Learning (RL). Although algorithmic advances combined with convolutional neural networks have proved to be a recipe for success, current methods are still lacking on two fronts: (a) data-efficiency of learning and (b) genera liz ation to new environments. To this end, we present Reinforcement Learning with Augmented Data (RAD), a simple plug-and-play module that can enhance most RL algorithms. We perform the first extensive study of general data augmentations for RL on both pixel-based and state-based inputs, and introduce two new data augmentations - random translate and random amplitude scale. We show that augmentations such as random translate, crop, color jitter, patch cutout, random convolutions, and amplitude scale can enable simple RL algorithms to outperform complex state-of-the-art methods across common benchmarks. RAD sets a new state-of-the-art in terms of data-efficiency and final performance on the DeepMind Control Suite benchmark for pixel-based control as well as OpenAI Gym benchmark for state-based control. We further demonstrate that RAD significantly improves test-time generalization over existing methods on several OpenAI ProcGen benchmarks. Our RAD module and training code are available at https://www.github.com/Mis haLa skin/rad.
从视觉观察中学习是强化学习(RL)中基础但具有挑战性的问题。尽管算法进步与卷积神经网络结合已被证明是成功的秘诀,但现有方法仍存在两个不足:(a) 学习的数据效率 (b) 对新环境的泛化能力。为此,我们提出数据增强强化学习(RAD),这是一个可增强大多数RL算法的即插即用模块。我们首次对基于像素和基于状态的RL输入进行了通用数据增强的广泛研究,并引入了两种新数据增强方法——随机平移和随机幅度缩放。研究表明,随机平移、裁剪、颜色抖动、区块切割、随机卷积和幅度缩放等增强技术,能使简单RL算法在常见基准测试中超越复杂的先进方法。RAD在DeepMind Control Suite的像素控制基准和OpenAI Gym的状态控制基准上,创造了数据效率和最终性能的新标杆。我们进一步证明,在多个OpenAI ProcGen基准测试中,RAD显著提升了现有方法的测试时泛化能力。RAD模块和训练代码已开源:https://www.github.com/MishaLaskin/rad。
1 Introduction
1 引言
Learning from visual observations is a fundamental problem in reinforcement learning (RL). Current success stories build on two key ideas: (a) using expressive convolutional neural networks (CNNs) [1] that provide strong spatial inductive bias; (b) better credit assignment [2–4] techniques that are crucial for sequential decision making. This combination of CNNs with modern RL algorithms has led to impressive success with human-level performance in Atari [2], super-human Go players [5], continuous control from pixels [3, 4] and learning policies for real-world robot grasping [6].
从视觉观察中学习是强化学习(RL)中的一个基本问题。当前的成功案例基于两个关键思想:(a) 使用具有强大空间归纳偏置的表现力卷积神经网络(CNN) [1];(b) 采用对序列决策至关重要的更优信用分配技术[2-4]。这种CNN与现代RL算法的结合,已在Atari游戏中实现人类水平表现[2]、打造超人类围棋选手[5]、基于像素的连续控制[3,4]以及现实世界机器人抓取策略学习[6]等方面取得了令人瞩目的成就。
While these achievements are truly impressive, RL is notoriously plagued with poor data-efficiency and generalization capabilities [7, 8]. Real-world successes of reinforcement learning often require months of data-collection and (or) training [6, 9]. On the other hand, biological agents have the remarkable ability to learn quickly [10, 11], while being able to generalize to a wide variety of unseen tasks [12]. These challenges associated with RL are further exacerbated when we operate on pixels due to high-dimensional and partially-observable inputs. Bridging the gap of data-efficiency and generalization is hence pivotal to the real-world applicability of RL.
尽管这些成就令人瞩目,但强化学习 (RL) 一直饱受数据效率低下和泛化能力不足的困扰 [7, 8]。现实中的强化学习成功案例往往需要数月的数据收集和(或)训练 [6, 9]。相比之下,生物智能体具备快速学习的能力 [10, 11],并能泛化到大量未见过的任务中 [12]。当处理像素输入时,由于高维度和部分可观测性,强化学习的这些挑战会进一步加剧。因此,缩小数据效率与泛化能力的差距对强化学习的实际应用至关重要。
Supervised learning, in the context of computer vision, has addressed the problems of data-efficiency and generalization by injecting useful priors. One such often ignored prior is Data Augmentation. It was critical to the early successes of CNNs [1, 13] and has more recently enabled better supervised [14, 15], semi-supervised [16–18] and self-supervised [19–21] learning. By using multiple augmented views of the same data-point as input, CNNs are forced to learn consistencies in their internal representations. This results in a visual representation that improves generalization [17, 19–21], data-efficiency [16, 19, 20] and transfer learning [19, 21].
在计算机视觉领域,监督学习通过引入有用先验知识解决了数据效率和泛化性问题。其中常被忽视的先验之一是数据增强 (Data Augmentation)。它对卷积神经网络 (CNN) 的早期成功至关重要 [1, 13],最近更推动了监督学习 [14, 15]、半监督学习 [16-18] 和自监督学习 [19-21] 的进步。通过使用同一数据点的多个增强视图作为输入,CNN 被迫学习内部表征的一致性,从而形成能提升泛化能力 [17, 19-21]、数据效率 [16, 19, 20] 和迁移学习 [19, 21] 的视觉表征。
Inspired by the impact of data augmentation in computer vision, we present RAD: Reinforcement Learning with Augmented Data, a technique to incorporate data augmentations on input observations for reinforcement learning pipelines. Through RAD, we ensure that the agent is learning on multiple views (or augmentations) of the same input (see Figure 1). This allows the agent to improve on two key capabilities: (a) data-efficiency: learning to quickly master the task at hand with drastically fewer experience rollouts; (b) generalization: improving transfer to unseen tasks or levels simply by training on more diversely augmented samples. To the best of our knowledge, we present the first extensive study of the use of data augmentation for reinforcement learning with no changes to the underlying RL algorithm and no additional assumptions about the domain other than the knowledge that the agent operates from image-based or proprio ce pti ve (positions & velocities) observations.
受计算机视觉中数据增强 (data augmentation) 技术的启发,我们提出了RAD:基于增强数据的强化学习 (Reinforcement Learning with Augmented Data) ,这是一种在强化学习流程中对输入观察数据进行增强的方法。通过RAD,我们确保智能体能够在同一输入的多种视图(或增强版本)上进行学习(见图 1)。这使得智能体能够提升两项关键能力:(a) 数据效率:通过显著减少经验回放来快速掌握当前任务;(b) 泛化能力:仅通过更多样化的增强样本训练,即可提升对未见任务或关卡的迁移性能。据我们所知,我们是首个在不修改底层强化学习算法、且仅假设智能体基于图像或本体感知(位置与速度)观察的前提下,对数据增强在强化学习中的应用进行系统性研究的工作。
We highlight the main contributions of RAD below:
我们总结RAD的主要贡献如下:
• We show that RAD outperforms prior state-of-the-art baselines on both the widely used pixelbased DeepMind control benchmark [22] as well as state-based OpenAI Gym benchmark [23]. On both benchmark, RAD sets a new state-of-the-art in terms data-efficiency and asymptotic performance on the majority of environments tested. • We show that RAD significantly improves test-time generalization on several environments in the OpenAI ProcGen benchmark suite [24] widely used for generalization in RL. • We introduce two new data augmentations: random translation for image-based input and random amplitude scaling for proprio ce pti ve input that are utilized to achieve state-of-the-art results. To the best of our knowledge, these augmentations were not used in prior work.
- 我们证明RAD在广泛使用的基于像素的DeepMind控制基准[22]和基于状态的OpenAI Gym基准[23]上都优于之前的最先进基线。在这两个基准测试中,RAD在大多数测试环境中都实现了数据效率和渐进性能的新标杆。
- 我们证明RAD在OpenAI ProcGen基准套件[24]中的多个环境上显著提升了测试时的泛化能力,该套件被广泛用于强化学习的泛化研究。
- 我们引入了两种新的数据增强方法:针对基于图像输入的随机平移和针对本体感受输入的随机幅度缩放,这些方法被用来实现最先进的结果。据我们所知,这些增强方法在之前的工作中并未被使用过。
2 Related work
2 相关工作
2.1 Data augmentation in computer vision
2.1 计算机视觉中的数据增强
Data augmentation in deep learning systems for computer vision can be found as early as LeNet-5 [1], an early implementation of CNNs on MNIST digit classification. In AlexNet [13] wherein the authors applied CNNs to image classification on ImageNet [25], data augmentations, such as random flip and crop, were used to improve the classification accuracy. These data augmentations inject the priors of invariance to translation and reflection, playing a significant role in improving the performance of supervised computer vision systems. Recently, new augmentation techniques such as Auto Augment [14] and Rand Augment [15] have been proposed to further improve the performance. For unsupervised and semi-supervised learning, several unsupervised data augmentation techniques have been proposed [18, 16, 26]. In particular, contrastive representation learning approaches [19–21] with data augmentations have recently dramatically improved the label-efficiency of downstream vision tasks like ImageNet classification.
深度学习系统中用于计算机视觉的数据增强技术最早可以追溯到LeNet-5 [1],这是在MNIST手写数字分类任务上应用卷积神经网络(CNN)的早期实现。在AlexNet [13]中,作者将CNN应用于ImageNet [25]图像分类任务时,采用了随机翻转和裁剪等数据增强方法来提升分类准确率。这些数据增强技术引入了平移不变性和反射不变性的先验知识,对提升监督式计算机视觉系统的性能起到了重要作用。近期,Auto Augment [14]和Rand Augment [15]等新型增强技术被提出以进一步提升性能。针对无监督和半监督学习,研究者提出了多种无监督数据增强技术[18,16,26]。特别是结合数据增强的对比表征学习方法[19-21],近期显著提升了ImageNet分类等下游视觉任务的标签效率。
2.2 Data augmentation in reinforcement learning
2.2 强化学习中的数据增强
Data augmentation has also been investigated in the context of RL though, to the best of our knowledge, there was no extensive study on a variety of widely used benchmarks prior to this work. For improving generalization in RL, domain random iz ation [27–29] was proposed to transfer policies from simulation to the real world by utilizing diverse simulated experiences. Cobbe et al. [30] and Lee et al. [31] showed that simple data augmentation techniques such as cutout [30] and random convolution [31] can be useful to improve generalization of agents on the OpenAI CoinRun and ProcGen benchmarks.
数据增强在强化学习(RL)领域也得到研究,但据我们所知,在本工作之前尚未对多种广泛使用的基准进行全面研究。为提高强化学习的泛化能力,领域随机化[27-29]被提出,通过利用多样化的模拟经验将策略从仿真环境迁移到现实世界。Cobbe等人[30]和Lee等人[31]表明,简单的数据增强技术如cutout[30]和随机卷积[31]可以有效提升智能体在OpenAI CoinRun和ProcGen基准测试中的泛化性能。
To improve the data-efficiency, CURL [32] utilized data augmentations for learning contrastive representations in the RL setting. While the focus in CURL was to make use of data augmentations jointly through contrastive and reinforcement learning losses, RAD attempts to directly use data augmentations for reinforcement learning without any auxiliary loss (see Section I for discussions on tradeoffs between CURL and RAD). Concurrent and independent to our work, DrQ [33] utilized random cropping and regularized Q-functions in conjunction with the off-policy RL algorithm SAC [34]. On the other hand, RAD can be plugged into any reinforcement learning method (onpolicy methods like PPO [4] and off-policy methods like SAC [34]) without making any changes to the underlying algorithm.
为提高数据效率,CURL [32] 在强化学习(RL)设置中利用数据增强来学习对比表征。虽然CURL的重点是通过对比学习和强化学习损失联合利用数据增强,但RAD试图直接使用数据增强进行强化学习,而无需任何辅助损失(有关CURL与RAD之间权衡的讨论,请参阅第I节)。与我们的工作同时且独立的是,DrQ [33] 结合随机裁剪和正则化Q函数,与离线策略强化学习算法SAC [34] 一起使用。另一方面,RAD可以插入任何强化学习方法(如PPO [4] 这样的在线策略方法或SAC [34] 这样的离线策略方法),而无需对底层算法进行任何更改。
For a more detailed and comprehensive discussion of prior work, we refer the reader to Appendix A.
如需更详细全面地了解先前工作,请参阅附录 A。
3 Background
3 背景
RL agents act within a Markov Decision Process, defined as the tuple $(\boldsymbol{S},\boldsymbol{A},\boldsymbol{P},\gamma)$ , with the following components: states $s\in S=\mathbb{R}^{n}$ , actions $a\in A$ , and state transition distribution, $P=P(s_{t+1},r_{t}|s_{t},a_{t})$ , which defines the task mechanics and rewards. Without prior knowledge of $P$ , the RL agent’s goal is to use experience to maximize expected rewards, $\textstyle R=\sum_{t=0}^{\infty}\gamma^{t}r_{t}$ , under discount factor $\gamma\in[0,1)$ . Crucially, in RL from pixels, the agent receives image-b ased observations, $o_{t}=O(s_{t})\in\mathbb{R}^{k}$ , which are a high-dimensional, indirect representation of the state.
RL智能体在马尔可夫决策过程中行动,定义为元组 $(\boldsymbol{S},\boldsymbol{A},\boldsymbol{P},\gamma)$,包含以下组成部分:状态 $s\in S=\mathbb{R}^{n}$、动作 $a\in A$,以及状态转移分布 $P=P(s_{t+1},r_{t}|s_{t},a_{t})$(定义了任务机制和奖励)。在缺乏 $P$ 先验知识的情况下,RL智能体的目标是通过经验最大化期望奖励 $\textstyle R=\sum_{t=0}^{\infty}\gamma^{t}r_{t}$(折扣因子为 $\gamma\in[0,1)$)。关键的是,在基于像素的RL中,智能体接收图像观测 $o_{t}=O(s_{t})\in\mathbb{R}^{k}$,这是状态的高维间接表示。
Soft Actor-Critic. SAC [34] is a state-of-the-art off-policy algorithm for continuous controls. SAC learns a policy $\pi_{\psi}(a|o)$ and a critic $Q_{\phi}(o,a)$ by maximizing a weighted objective of the reward and the policy entropy, $\begin{array}{r}{\mathbb{E}_ {s_{t},a_{t}\sim\pi}\left[\sum_{t}r_{t}+\alpha\mathcal{H}(\pi(\cdot|o_{t}))\right]}\end{array}$ . The critic parameters are learned by minimizing the squared Bellman error using transitions $\tau_{t}=\left(o_{t},a_{t},o_{t+1},r_{t}\right)$ from an experience buffer $\mathcal{D}$ ,
软演员-评论家 (Soft Actor-Critic)。SAC [34] 是一种用于连续控制的最先进的离策略算法。SAC通过最大化奖励和策略熵的加权目标来学习策略 $\pi_{\psi}(a|o)$ 和评论家 $Q_{\phi}(o,a)$ ,目标函数为 $\begin{array}{r}{\mathbb{E}_ {s_{t},a_{t}\sim\pi}\left[\sum_{t}r_{t}+\alpha\mathcal{H}(\pi(\cdot|o_{t}))\right]}\end{array}$ 。评论家参数通过最小化使用来自经验缓冲区 $\mathcal{D}$ 的转移 $\tau_{t}=\left(o_{t},a_{t},o_{t+1},r_{t}\right)$ 的平方贝尔曼误差来学习。
$$
\mathcal{L}_ {Q}(\phi)=\mathbb{E}_ {\tau\sim\mathcal{D}}\left[\left(Q_{\phi}(o_{t},a_{t})-(r_{t}+\gamma V(o_{t+1}))\right)^{2}\right].
$$
$$
\mathcal{L}_ {Q}(\phi)=\mathbb{E}_ {\tau\sim\mathcal{D}}\left[\left(Q_{\phi}(o_{t},a_{t})-(r_{t}+\gamma V(o_{t+1}))\right)^{2}\right].
$$
The target value of the next state can be estimated by sampling an action using the current policy:
下一个状态的目标值可以通过使用当前策略采样一个动作来估计:
$$
V(o_{t+1})=\mathbb{E}_ {a^{\prime}\sim\pi}\left[Q_{\bar{\phi}}(o_{t+1},a^{\prime})-\alpha\log\pi_{\psi}(a^{\prime}|o_{t+1})\right],
$$
$$
V(o_{t+1})=\mathbb{E}_ {a^{\prime}\sim\pi}\left[Q_{\bar{\phi}}(o_{t+1},a^{\prime})-\alpha\log\pi_{\psi}(a^{\prime}|o_{t+1})\right],
$$
where $Q_{\bar{\phi}}$ represents a more slowly updated copy of the critic. The policy is learned by minimizing the divergence from the exponential of the soft-Q function at the same states:
其中 $Q_{\bar{\phi}}$ 表示评论家(critic)的慢更新副本。策略学习通过最小化与相同状态下soft-Q函数指数散度来实现:
$$
\begin{array}{r}{\mathcal{L}_ {\pi}(\psi)=-\mathbb{E}_ {a\sim\pi}\left[Q_{\phi}(o_{t},a)-\alpha\log\pi_{\psi}(a|o_{t})\right],}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}_ {\pi}(\psi)=-\mathbb{E}_ {a\sim\pi}\left[Q_{\phi}(o_{t},a)-\alpha\log\pi_{\psi}(a|o_{t})\right],}\end{array}
$$
via the re parameter iz ation trick for the newly sampled action. $\alpha$ is learned against a target entropy.
通过重新参数化技巧对新采样的动作进行处理。$\alpha$ 根据目标熵进行学习。
Proximal policy optimization. PPO [4] is a state-of-the-art on-policy algorithm for learning a continuous or discrete control policy, $\pi_{\boldsymbol{\theta}}(\boldsymbol{a}|\boldsymbol{o})$ . PPO forms policy gradients using action-advantages, $A_{t}=A^{\pi}(a_{t},s_{t})=Q^{\pi}(a_{t},s_{t})-{\dot{V}}^{\pi}(s_{t})$ , and minimizes a clipped-ratio loss over mini batches of recent experience (collected under $\pi_{\theta_{o l d}.}$ ):
近端策略优化 (Proximal Policy Optimization, PPO) [4] 是一种用于学习连续或离散控制策略 $\pi_{\boldsymbol{\theta}}(\boldsymbol{a}|\boldsymbol{o})$ 的先进同策略算法。PPO 利用动作优势值 $A_{t}=A^{\pi}(a_{t},s_{t})=Q^{\pi}(a_{t},s_{t})-{\dot{V}}^{\pi}(s_{t})$ 构建策略梯度,并通过在小批量近期经验 (由 $\pi_{\theta_{o l d}.}$ 收集) 上最小化裁剪比率损失来实现优化。
$$
\mathcal{L}_ {\pi}(\theta)=-\mathbb{E}_ {\tau\sim\pi}\left[\operatorname*{min}\left(\rho_{t}(\theta)A_{t},\mathrm{clip}(\rho_{t}(\theta),1-\epsilon,1+\epsilon)A_{t}\right)\right],\quad\rho_{t}(\theta)=\frac{\pi_{\theta}(a_{t}|o_{t})}{\pi_{\theta_{o l d}}(a_{t}|o_{t})}.
$$
$$
\mathcal{L}_ {\pi}(\theta)=-\mathbb{E}_ {\tau\sim\pi}\left[\operatorname*{min}\left(\rho_{t}(\theta)A_{t},\mathrm{clip}(\rho_{t}(\theta),1-\epsilon,1+\epsilon)A_{t}\right)\right],\quad\rho_{t}(\theta)=\frac{\pi_{\theta}(a_{t}|o_{t})}{\pi_{\theta_{o l d}}(a_{t}|o_{t})}.
$$
Our PPO agents learn a state-value estimator, $V_{\phi}(s)$ , which is regressed against a target of discounted returns and used with Generalized Advantage Estimation [4]:
我们的PPO智能体学习一个状态价值估计器$V_{\phi}(s)$,该估计器以折现回报为目标进行回归,并与广义优势估计[4]结合使用:
$$
\begin{array}{r}{\mathcal{L}_ {V}(\phi)=\mathbb{E}_ {\tau\sim\pi}\left[\left(V_{\phi}(o_{t})-V_{t}^{t a r g}\right)^{2}\right].}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}_ {V}(\phi)=\mathbb{E}_ {\tau\sim\pi}\left[\left(V_{\phi}(o_{t})-V_{t}^{t a r g}\right)^{2}\right].}\end{array}
$$
4 Reinforcement learning with augmented data
4 基于增强数据的强化学习
We investigate the utility of data augmentations in model-free RL for both off-policy and on-policy settings by processing image observations with stochastic augmentations before passing them to the agent for training. For the base RL agent, we use SAC [34] and PPO [4] as the off-policy and on-policy RL methods respectively. During training, we sample observations from either a replay buffer or a recent trajectory and augment the images within the minibatch. In the RL setting, it is common to stack consecutive frames as observations to infer temporal information such as object velocities. Crucially, augmentations are applied randomly across the batch but consistently across the frame stack [32] as shown in Figure 1.2 This enables the augmentation to retain temporal information present across the frame stack.
我们通过在处理图像观测时加入随机增强(data augmentations),然后将其传递给智能体进行训练,研究了数据增强在无模型强化学习(RL)中对于离策略(off-policy)和同策略(on-policy)设置的效用。基础RL智能体分别采用SAC [34]和PPO [4]作为离策略和同策略RL方法。在训练过程中,我们从回放缓冲区或最近轨迹中采样观测数据,并对小批次(minibatch)中的图像进行增强。在RL设置中,通常会堆叠连续帧作为观测数据以推断时间信息(如物体速度)。关键的是,增强操作在批次内随机应用,但在帧堆叠中保持一致 [32] ,如图1.2所示。这使得增强能够保留帧堆叠中存在的时间信息。

Figure 1: We investigate ten different types of data augmentations - crop, translate, window, grayscale, cutout, cutout-color, flip, rotate, random convolution, and color-jitter. During training, a minibatch is sampled from the replay buffer or a recent trajectory randomly augmented. While augmentation across the minibatch is stochastic, it is consistent across the stacked frames.
图 1: 我们研究了十种不同的数据增强方法 - 裁剪 (crop)、平移 (translate)、窗口 (window)、灰度化 (grayscale)、遮挡 (cutout)、彩色遮挡 (cutout-color)、翻转 (flip)、旋转 (rotate)、随机卷积 (random convolution) 和色彩抖动 (color-jitter)。在训练过程中,从回放缓冲区或最近轨迹中随机采样一个小批次并进行随机增强。虽然小批次内的增强是随机的,但在堆叠帧之间保持一致性。
Augmentations of image-based input: Across our experiments, we investigate and ablate crop, translate, window, grayscale, cutout, cutout-color, flip, rotate, random convolution, and color jitter augmentations, which are shown in Figure 1. Of these, the translate and window are novel augmentations that we did not encounter in prior work.
基于图像的输入增强:在我们的实验中,我们研究并消融了裁剪、平移、窗口、灰度、挖空、彩色挖空、翻转、旋转、随机卷积和颜色抖动等增强方法,如图1所示。其中,平移和窗口是我们在此前工作中未见过的新颖增强方法。
Crop: Extracts a random patch from the original frame. As our experiments will confirm, the intuition behind random cropping is primarily to imbue the agent with additional translation invariance. Translate: random translation renders the full image within a larger frame and translates the image randomly across the larger frame. For example, a $100\times100$ pixel image could be randomly translated within a $108\times108$ empty frame. For example, in DMControl we render $100\times100$ pixel frames and crop randomly to $84\times84$ pixels. Window: Selects a random window from an image by masking out the cropped part of the image. Grayscale: Converts RGB images to grayscale with some random probability $p$ . Cutout: Randomly inserts a small black occlusion into the frame, which may be perceived as cutting out a small patch from the originally rendered frame. Cutout-color: Another variant of cutout where instead of rendering black, the occlusion color is randomly generated. Flip: Flips an image at random across the vertical axis. Rotate: Randomly samples an angle from the following set ${0^{\circ},90^{\circ},180^{\circ},270^{\circ}}$ and rotates the image accordingly. Random convolution: First introduced in [31], augments the image color by passing the input observation through a random convolutional layer. Color jitter: Converts RGB image to HSV and adds noise to the HSV channels, which results in explicit color jittering.
裁剪 (Crop):从原始帧中随机提取一个补丁。正如我们的实验所证实的,随机裁剪背后的直觉主要是为了赋予智能体额外的平移不变性。
平移 (Translate):将完整图像渲染在一个更大的帧中,并在该帧内随机平移图像。例如,一个 $100\times100$ 像素的图像可以在 $108\times108$ 的空帧内随机平移。例如,在 DMControl 中,我们渲染 $100\times100$ 像素的帧并随机裁剪为 $84\times84$ 像素。
窗口 (Window):通过遮罩图像裁剪部分,从图像中选择一个随机窗口。
灰度化 (Grayscale):以随机概率 $p$ 将 RGB 图像转换为灰度图像。
遮挡 (Cutout):随机在帧中插入一个小型黑色遮挡,可以视为从原始渲染帧中切出一小块补丁。
彩色遮挡 (Cutout-color):遮挡的另一种变体,遮挡颜色随机生成而非黑色。
翻转 (Flip):随机沿垂直轴翻转图像。
旋转 (Rotate):从集合 ${0^{\circ},90^{\circ},180^{\circ},270^{\circ}}$ 中随机采样一个角度并相应旋转图像。
随机卷积 (Random convolution):首次在 [31] 中提出,通过将输入观察通过随机卷积层来增强图像颜色。
颜色抖动 (Color jitter):将 RGB 图像转换为 HSV 并对 HSV 通道添加噪声,从而产生显式的颜色抖动效果。
Extension to state-based inputs: We also consider an extension to state-based inputs such as prop rio ce pti ve features (e.g., positions and velocities). Specifically, we investigate two data augmentation techniques: (a) random amplitude scaling, introduced in this work, multiplies the uniform random variable, i.e., $s^{\prime}=s*z$ , where $z\sim\mathrm{Uni}[\alpha,\beta]$ , and (b) Gaussian noise adds Gaussian random variable, i.e., $s^{\prime}=s+z$ , where $z\sim\mathcal{N}(\bar{0},I)$ . Here, $s^{\prime},s$ and $z$ are all vectors (see Appendix J for more details). Similar to image inputs, augmentations are applied randomly across the batch but consistently across the time, i.e., same random iz ation to current and next input states. Of these, random amplitude scaling is a novel augmentation. The intuition behind these augmentations is that random amplitude scaling randomizes the amplitude of input states while maintaining their intrinsic information (e.g., sign of inputs). We also remark that Gaussian noise is related to offset invariance.
基于状态输入的扩展:我们还考虑了针对基于状态的输入(如本体感知特征(例如位置和速度))的扩展。具体而言,我们研究了两种数据增强技术:(a) 随机幅度缩放(本工作提出)通过乘以均匀随机变量实现,即 $s^{\prime}=s*z$,其中 $z\sim\mathrm{Uni}[\alpha,\beta]$;(b) 高斯噪声通过添加高斯随机变量实现,即 $s^{\prime}=s+z$,其中 $z\sim\mathcal{N}(\bar{0},I)$。此处 $s^{\prime},s$ 和 $z$ 均为向量(详见附录J)。与图像输入类似,增强操作在批次内随机应用,但在时间维度上保持一致,即对当前和下一输入状态采用相同的随机化处理。其中,随机幅度缩放是一种新颖的增强方法。这些增强背后的直觉是:随机幅度缩放能在保持输入状态内在信息(如输入符号)的同时随机化其幅度。我们还指出,高斯噪声与偏移不变性相关。
5 Experimental results
5 实验结果
5.1 Setup
5.1 设置
DMControl: First, we focus on studying the data-efficiency of our proposed methods on pixel-based RL. To this end, we utilize the DeepMind Control Suite (DMControl) [22], which has recently become a common benchmark for comparing efficient RL agents, both model-based and model-free. DMControl presents a variety of complex tasks including bipedal balance, locomotion, contact forces, and goal-reaching with both sparse and dense reward signals. For DMControl experiments, we evaluate the data-efficiency by measuring the performance of our method at $100\mathrm{k}$ (i.e., low sample regime) and $500\mathrm{k\Omega}$ (i.e., asymptotically optimal regime) simulator or environment steps3 during training by following the setup in CURL [32]. These benchmarks are referred to as DM Control 100 k and DM Control 500 k. For comparison, we consider six powerful recent pixel-based methods: CURL [32] learns contrastive representations, SLAC [38] learns a forward model and uses it to shape encoder representations, while $\mathrm{SAC+AE}$ [37] minimizes a reconstruction loss as an auxiliary task. All three methods use SAC [34] as their base algorithm. Dreamer [36] and PlaNet [35] learn world models and use them to generate synthetic rollouts similar to Dyna [39]. Pixel SAC is a vanilla Soft Actor-Critic operating on pixel inputs, and state SAC is an oracle baseline that operates on the proprio ce pti ve state of the simulated agent, which includes joint positions and velocities. We also provide learning curves for longer runs and examine how RAD compares to state SAC and CURL across a more diverse set of environments in Appendix D.
DMControl:首先,我们重点研究基于像素的强化学习(RL)中提出方法的数据效率。为此,我们采用DeepMind Control Suite (DMControl) [22]——该套件近期已成为比较高效RL智能体(包括基于模型和无模型方法)的通用基准。DMControl提供多种复杂任务,包括双足平衡、运动控制、接触力以及稀疏/密集奖励信号下的目标达成。在DMControl实验中,我们遵循CURL [32]的实验设置,通过测量方法在训练期间$100\mathrm{k}$(即低样本区域)和$500\mathrm{k\Omega}$(即渐近最优区域)模拟器/环境步骤3下的性能来评估数据效率。这些基准分别称为DM Control 100k和DM Control 500k。对比实验中,我们选取了六种近期先进的基于像素方法:CURL [32]学习对比表征,SLAC [38]学习前向模型并用于塑造编码器表征,而$\mathrm{SAC+AE}$ [37]将重构损失作为辅助任务进行优化。这三种方法均以SAC [34]为基础算法。Dreamer [36]和PlaNet [35]学习世界模型并生成类似Dyna [39]的合成轨迹。Pixel SAC是处理像素输入的原始Soft Actor-Critic算法,state SAC则是使用模拟智能体本体感知状态(包括关节位置和速度)的预言机基线。附录D还提供了更长训练周期的学习曲线,并展示RAD在更广泛环境中与state SAC和CURL的对比表现。
Table 1: We report scores for RAD and baseline methods on DM Control 100 k and DM Control 500 k. In both settings, RAD achieves state-of-the-art performance on all (6 out of 6) environments. We selected these 6 environments for benchmarking due to availability of baseline performance data from CURL [32], PlaNet [35], Dreamer [36], $\mathrm{SAC+AE}$ [37], and SLAC [38]. We also show performance data on 15 environments in total in the Appendix D. Results are reported as averages across 10 seeds for the 6 main environments. A full list of hyper parameters is provided in Table 4 of Appendix E.
| 500K STEP SCORES | RAD | CURL | PLANET | DREAMER | SAC+AE | SLACv1 | PIXEL SAC | STATE SAC |
| FINGER,SPIN | 947 | 926 | 561 | 796 | 884 | 673 | 192 | 923 |
| ±101 | ± 45 | ± 284 | ± 183 | ±128 | ±92 | ±166 | ± 211 | |
| CARTPOLE,SWING | 863 | 845 | 475 | 762 | 735 | 419 | 848 | |
| ±9 | ± 45 | ±71 | ± 27 | ±63 | ±40 | ± 15 | ||
| REACHER,EASY | 955 | 929 | 210 | 793 | 627 | 145 | 923 | |
| ±71 | ± 44 | 土 44 | ± 164 | ± 58 | - | ±30 | ± 24 | |
| CHEETAH,RUN | 728 | 518 | 305 | 570 | 550 | 640 | 197 | 795 |
| ± 71 | ±28 | ± 131 | ± 253 | ±34 | 61干 | ± 15 | ±30 | |
| WALKER, WALK | 918 | 902 | 351 | 897 | 847 | 842 | 42 | 948 |
| ±16 | 土43 | ±58 | ± 49 | ±48 | ±51 | ±12 | ± 54 | |
| CUP,CATCH | 974 | 959 | 460 | 879 | 794 | 852 | 312 | 974 |
| ±12 | ±27 | ± 380 | ±87 | ±58 | ±71 | ±63 | ±33 | |
| 100K STEP SCORES | ||||||||
| 856 | 767 | 136 | 341 | 740 | 693 | 224 | 811 | |
| FINGER,SPIN | ±73 | ±56 | ±216 | ±70 | ± 64 | ±141 | 101干 | ±46 |
| 828 | 582 | 297 | 326 | 311 | 200 | 835 | ||
| CARTPOLE,SWING | ±27 | ± 146 | ±39 | ± 27 | 干 | - | ±72 | ±22 |
| 826 | 538 | 20 | 314 | 274 | 136 | 746 | ||
| REACHER,EASY | ± 219 | ± 233 | ± 50 | ±155 | 干 | ± 15 | ± 25 | |
| 447 | 299 | 138 | 235 | 267 | 319 | 130 | 616 | |
| CHEETAH,RUN | ±88 | ±48 | 88干 | ± 137 | ± 24 | ±56 | ±12 | ±18 |
| 504 | 403 | 224 | 277 | 394 | 361 | 127 | 891 | |
| WALKER,WALK | ± 191 | ±24 | ± 48 | ±12 | ±22 | ±73 | ± 24 | ±82 |
| 840 | 769 | 0 | 246 | 391 | 512 | 97 | 746 | |
| CUP,CATCH | ± 179 | ± 43 | ±0 | LI干 | ±82 | ±110 | ±27 | |
| 16干 |
表 1: 我们报告了 RAD 和基线方法在 DM Control 100 k 和 DM Control 500 k 上的得分。在这两种设置中,RAD 在所有 (6 个中的 6 个) 环境中都实现了最先进的性能。我们选择这 6 个环境进行基准测试,因为可以从 CURL [32]、PlaNet [35]、Dreamer [36]、$\mathrm{SAC+AE}$ [37] 和 SLAC [38] 获得基线性能数据。我们还在附录 D 中展示了总共 15 个环境的性能数据。结果报告为 6 个主要环境在 10 次种子运行中的平均值。完整的超参数列表见附录 E 的表 4。
| 500K STEP SCORES | RAD | CURL | PLANET | DREAMER | SAC+AE | SLACv1 | PIXEL SAC | STATE SAC |
|---|---|---|---|---|---|---|---|---|
| FINGER,SPIN | 947 | 926 | 561 | 796 | 884 | 673 | 192 | 923 |
| ±101 | ±45 | ±284 | ±183 | ±128 | ±92 | ±166 | ±211 | |
| CARTPOLE,SWING | 863 | 845 | 475 | 762 | 735 | 419 | 848 | |
| ±9 | ±45 | ±71 | ±27 | ±63 | ±40 | ±15 | ||
| REACHER,EASY | 955 | 929 | 210 | 793 | 627 | 145 | 923 | |
| ±71 | ±44 | ±44 | ±164 | ±58 | - | ±30 | ±24 | |
| CHEETAH,RUN | 728 | 518 | 305 | 570 | 550 | 640 | 197 | 795 |
| ±71 | ±28 | ±131 | ±253 | ±34 | 61 | ±15 | ±30 | |
| WALKER, WALK | 918 | 902 | 351 | 897 | 847 | 842 | 42 | 948 |
| ±16 | ±43 | ±58 | ±49 | ±48 | ±51 | ±12 | ±54 | |
| CUP,CATCH | 974 | 959 | 460 | 879 | 794 | 852 | 312 | 974 |
| ±12 | ±27 | ±380 | ±87 | ±58 | ±71 | ±63 | ±33 | |
| 100K STEP SCORES | ||||||||
| 856 | 767 | 136 | 341 | 740 | 693 | 224 | 811 | |
| FINGER,SPIN | ±73 | ±56 | ±216 | ±70 | ±64 | ±141 | 101 | ±46 |
| CARTPOLE,SWING | 828 | 582 | 297 | 326 | 311 | 200 | 835 | |
| ±27 | ±146 | ±39 | ±27 | ± | - | ±72 | ±22 | |
| REACHER,EASY | 826 | 538 | 20 | 314 | 274 | 136 | 746 | |
| ±219 | ±233 | ±50 | ±155 | ± | ±15 | ±25 | ||
| CHEETAH,RUN | 447 | 299 | 138 | 235 | 267 | 319 | 130 | 616 |
| ±88 | ±48 | 88 | ±137 | ±24 | ±56 | ±12 | ±18 | |
| WALKER,WALK | 504 | 403 | 224 | 277 | 394 | 361 | 127 | 891 |
| ±191 | ±24 | ±48 | ±12 | ±22 | ±73 | ±24 | ±82 | |
| CUP,CATCH | 840 | 769 | 0 | 246 | 391 | 512 | 97 | 746 |
| ±179 | ±43 | ±0 | ± | ±82 | ±110 | ±27 | 16 |
ProcGen: Although DMControl is suitable for benchmarking data-efficiency and performance, it evaluates the performance on the same environment in which the agent was trained and is thus not applicable for studying generalization. For this reason, we focus on the OpenAI ProcGen benchmarks [24] to investigate the generalization capabilities of RAD. ProcGen presents a suite of game-like environments where the train and test environments differ in visual appearance and structure. For this reason, it is a commonly used benchmark for studying the generalization abilities of RL agents [30]. Specifically, we evaluate the zero-shot performance of the trained agents on the full distribution of unseen levels. Following the setup in ProcGen [24], we use the CNN architecture found in IMPALA [40] as the policy network and train the agents using the Proximal Policy Optimization (PPO) [4] algorithm for 20M timesteps. For all experiments, we use the easy environment difficulty and the hyper parameters suggested in [24], which have been shown to be empirically effective.
ProcGen: 虽然DMControl适合评估数据效率和性能,但它是在智能体训练相同的环境中评估性能,因此不适用于研究泛化能力。为此,我们聚焦于OpenAI ProcGen基准测试[24]来研究RAD的泛化能力。ProcGen提供了一套游戏式环境,其中训练和测试环境在视觉外观和结构上存在差异。正因如此,它成为研究强化学习智能体泛化能力的常用基准[30]。具体而言,我们在未见关卡的完整分布上评估训练后智能体的零样本性能。遵循ProcGen[24]的设置,我们采用IMPALA[40]中的CNN架构作为策略网络,并使用近端策略优化(PPO)[4]算法对智能体进行2000万时间步的训练。所有实验均采用简易环境难度,并沿用[24]中推荐的超参数,这些参数已被实证有效。
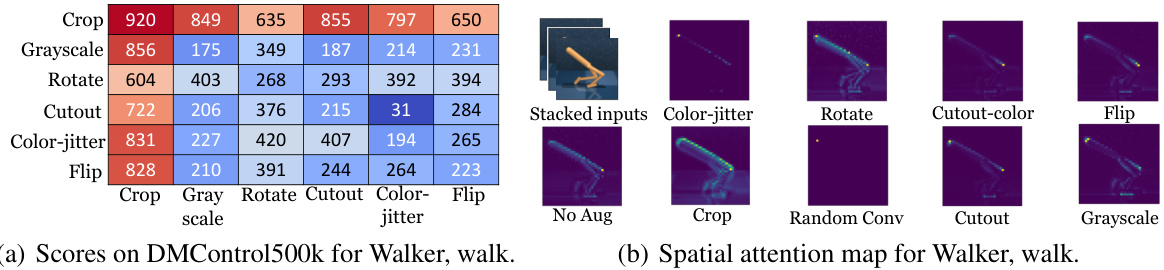
Figure 2: (a) We ablate six common data augmentations on the walker, walk environment by measuring performance on DM Control 500 k of each permutation of any two data augmentations being performed in sequence. For example, the crop row and grayscale column correspond to the score achieved after applying random crop and then random grayscale to the input images (entries along the main axis use only one application of the augmentation). (b) Spatial attention map of an encoder that shows where the agent focuses on in order to make a decision in Walker Walk environment. Random crop enables the agent to focus on the robot body and ignore irrelevant scene details compared to other augmentations as well as the base agent that learns without any augmentation.
图 2: (a) 我们在walker walk环境中通过测量DM Control 500k上任意两种数据增强方法顺序排列组合的性能,对六种常见数据增强方法进行消融实验。例如,裁剪行与灰度列对应的是对输入图像依次应用随机裁剪和随机灰度后获得的分数(主对角线上的条目仅使用单次数据增强)。 (b) 编码器的空间注意力图显示了智能体在Walker Walk环境中做出决策时的关注区域。与其他增强方法以及未使用任何增强的基础智能体相比,随机裁剪能使智能体专注于机器人身体而忽略无关场景细节。
OpenAI Gym. For OpenAI Gym experiments with proprio ce pti ve inputs (e.g., positions and velocities), we compare to PETS [41], a model-based RL algorithm that utilizes ensembles of dynamics models; POPLIN-P [42], a state-of-the-art model-based RL algorithm which uses a policy network to generate actions for planning; POPLIN-A [42], variant of POPLIN-P which adds noise in the action space; METRPO [43], model-based policy optimization based on TRPO [44]; and two stateof-the-art model-free algorithms, TD3 [45] and SAC [34]. In our experiments, we apply RAD to SAC. Following the experimental setups in POPLIN [42], we report the mean and standard deviation across four runs on Cheetah, Walker, Hopper, Ant, Pendulum and Cartpole environments.
OpenAI Gym。在OpenAI Gym中使用本体感知输入(如位置和速度)的实验中,我们与以下算法进行比较:PETS [41](一种利用动态模型集合的基于模型的强化学习算法);POPLIN-P [42](当前最先进的基于模型强化学习算法,使用策略网络生成规划动作);POPLIN-A [42](POPLIN-P的变体,在动作空间添加噪声);METRPO [43](基于TRPO [44]的模型策略优化);以及两种当前最先进的无模型算法TD3 [45]和SAC [34]。实验中,我们将RAD应用于SAC。遵循POPLIN [42]的实验设置,我们在猎豹、步行者、跳跃者、蚂蚁、钟摆和倒立摆环境中报告四次运行的平均值和标准差。
5.2 Improving data-efficiency on DeepMind Control Suite
5.2 提升 DeepMind Control Suite 的数据效率
Data-efficiency: Mean scores shown in Table 1 and learning curves in Figure 7 show that data augmentation significantly improves the data-efficiency and performance across the six extensively benchmarked environments compared to existing methods. We summarize the main findings below:
数据效率:表1中的平均得分和图7的学习曲线表明,与现有方法相比,数据增强显著提高了在六个广泛基准测试环境中的数据效率和性能。我们总结主要发现如下:
Which data augmentations are the most effective? To answer this question for DMControl, we ran RAD with permutations of two data augmentations applied in sequence (e.g., crop followed by grayscale) on the Walker Walk environment and report the scores at $500\mathrm{k}$ environment steps. We chose this environment because SAC without augmentation fails at this task, resulting in scores well below 200. Our results, shown in Figure 2(a), indicate that most data augmentations improve the performance of the base policy, and that random crop by itself was the most effective by a large margin.
哪种数据增强方法最有效?为了在DMControl中回答这个问题,我们在Walker Walk环境中测试了RAD连续应用两种数据增强排列组合的效果(例如先裁剪后灰度化),并报告了在$500\mathrm{k}$环境步数时的得分。选择该环境是因为未经增强的SAC在此任务中完全失败,得分远低于200。如图2(a)所示,结果表明大多数数据增强都能提升基础策略性能,其中随机裁剪 (random crop) 单独使用时效果显著优于其他方法。
Why is random crop so effective? To analyze the effects of random crop, we decompose it into its two component augmentations: (a) random window, which masks a random boundary region of the image, exactly where crop would remove it, and (b) random translate, which places the full image entirely within a larger frame of zeros, but at a random location. In Appendix C, Figure 6 shows resulting learning curves from each augmentation. The benefit of translations is clearly demonstrated, whereas the random information hiding due to windowing produced little effect. Table 1 reports scores using random translate, a new SOTA method, for all environments except for Walker Walk, where random crop sometimes reduced variance. In Figure 5 of Appendix C, we ablate the size of the final translation image, finding in some cases that random placement within as little as two additional pixels in height and width is sufficient to reap the benefit.
为什么随机裁剪如此有效?为分析随机裁剪的效果,我们将其分解为两种基础增强操作:(a) 随机窗口 (random window) ,即在图像边界随机掩码区域(与裁剪移除区域完全一致);(b) 随机平移 (random translate) ,将完整图像置于零值填充的大框架内随机位置。附录C的图6展示了每种增强对应的学习曲线,其中平移的优势显著,而窗口化导致的随机信息隐藏几乎无效。表1报告了使用随机平移(新SOTA方法)的得分结果,除Walker Walk环境外(该环境下随机裁剪偶尔能降低方差)。附录C图5中,我们消融了最终平移图像的尺寸,发现某些情况下仅需高度和宽度各增加两个像素的随机位移即可获得收益。
Table 2: We present the generalization results of RAD with different data augmentation methods on the three OpenAI ProcGen environments: BigFish, StarPilot and Jumper. We report the test performances after 20M timesteps. The results show the mean and standard deviation averaged over three runs. We see that RAD is able to outperform the baseline PPO trained on two times the number of training levels benefitting from data augmentations such as random crop, cutout and color jitter.
| #of training levels | Pixel PPO | RAD (gray) | RAD (flip) | RAD (rotate) | RAD (randomconv) | RAD (color-jitter) | RAD (cutout) | RAD (cutout-color) | RAD (crop) | |
| BigFish | 100 | 1.9 | 1.5 | 2.3 | 1.9 | 1.0 | 1.0 | 2.9 | 2.0 | 5.4 |
| ± 0.1 | ± 0.3 | ± 0.4 | ± 0.0 | ± 0.1 | ± 0.1 | ± 0.2 | ± 0.2 | ± 0.5 | ||
| 4.3 | 2.1 | 3.5 | 1.5 | 1.2 | 1.5 | 3.3 | 3.5 | 6.7 | ||
| ± 0.5 | ± 0.3 | ± 0.4 | ± 0.6 | ± 0.1 | ± 0.2 | ± 0.2 | ± 0.3 | ± 0.8 | ||
| 18.0 | 10.6 | 13.1 | 9.7 | 7.4 | 15.0 | 17.2 | 22.4 | 20.3 | ||
| 100 | ± 0.7 | ± 1.4 | ± 0.2 | ± 1.6 | ± 0.7 | ± 1.1 | ± 2.0 | ± 2.1 | ± 0.7 | |
| 20.3 | 20.6 | 20.7 | 15.7 | 11.0 | 20.6 | 24.5 | 24.5 | 24.3 | ||
| Jumper | 100 | ± 0.7 | ± 1.0 | ± 3.9 | ± 0.7 | 土 1.5 | ± 1.1 | ± 0.1 | ± 1.6 | ± 0.1 |
| 5.2 | 5.2 | 5.2 | 5.7 | 5.5 | 6.1 | 5.6 | 5.8 | 5.1 | ||
| 200 | ± 0.5 | ± 0.1 | ± 0.7 | ± 0.6 | 土 0.3 | ± 0.2 | ± 0.1 | ± 0.6 | ± 0.2 | |
| 6.0 ± 0.2 | 5.6 ± 0.1 | 5.4 ± 0.3 | 5.5 ± 0.1 | 5.2 ± 0.1 | 5.9 ± 0.1 | 5.4 ± 0.1 | 5.6 ± 0.4 | 5.2 ± 0.7 |
表 2: 我们展示了 RAD 在三种 OpenAI ProcGen 环境 (BigFish、StarPilot 和 Jumper) 上采用不同数据增强方法的泛化结果。报告了 2000 万时间步后的测试性能,结果为三次运行的平均值和标准差。结果显示,得益于随机裁剪 (random crop)、遮挡 (cutout) 和颜色抖动 (color jitter) 等数据增强方法,RAD 的表现优于在双倍训练关卡数量上训练的基线 PPO。
| 训练关卡数量 | Pixel PPO | RAD (gray) | RAD (flip) | RAD (rotate) | RAD (randomconv) | RAD (color-jitter) | RAD (cutout) | RAD (cutout-color) | RAD (crop) | |
|---|---|---|---|---|---|---|---|---|---|---|
| BigFish | 100 | 1.9 ± 0.1 | 1.5 ± 0.3 | 2.3 ± 0.4 | 1.9 ± 0.0 | 1.0 ± 0.1 | 1.0 ± 0.1 | 2.9 ± 0.2 | 2.0 ± 0.2 | 5.4 ± 0.5 |
| 200 | 4.3 ± 0.5 | 2.1 ± 0.3 | 3.5 ± 0.4 | 1.5 ± 0.6 | 1.2 ± 0.1 | 1.5 ± 0.2 | 3.3 ± 0.2 | 3.5 ± 0.3 | 6.7 ± 0.8 | |
| StarPilot | 100 | 18.0 ± 0.7 | 10.6 ± 1.4 | 13.1 ± 0.2 | 9.7 ± 1.6 | 7.4 ± 0.7 | 15.0 ± 1.1 | 17.2 ± 2.0 | 22.4 ± 2.1 | 20.3 ± 0.7 |
| 200 | 20.3 ± 0.7 | 20.6 ± 1.0 | 20.7 ± 3.9 | 15.7 ± 0.7 | 11.0 ± 1.5 | 20.6 ± 1.1 | 24.5 ± 0.1 | 24.5 ± 1.6 | 24.3 ± 0.1 | |
| Jumper | 100 | 5.2 ± 0.5 | 5.2 ± 0.1 | 5.2 ± 0.7 | 5.7 ± 0.6 | 5.5 ± 0.3 | 6.1 ± 0.2 | 5.6 ± 0.1 | 5.8 ± 0.6 | 5.1 ± 0.2 |
| 200 | 6.0 ± 0.2 | 5.6 ± 0.1 | 5.4 ± 0.3 | 5.5 ± 0.1 | 5.2 ± 0.1 | 5.9 ± 0.1 | 5.4 ± 0.1 | 5.6 ± 0.4 | 5.2 ± 0.7 |
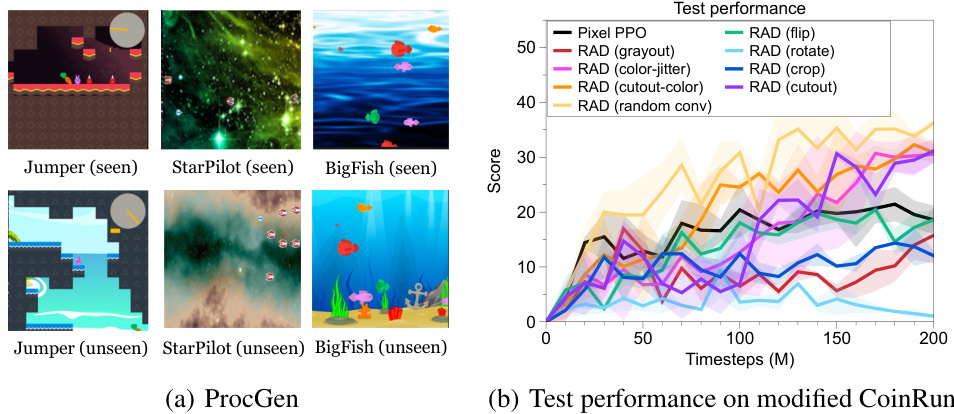
Figure 3: (a) Examples of seen and unseen environments on ProcGen. (b) The test performance under the modified CoinRun. The solid/dashed lines and shaded regions represent the mean and standard deviation, respectively.
图 3: (a) ProcGen 中已见和未见环境的示例。(b) 修改版 CoinRun 下的测试性能。实线/虚线及阴影区域分别代表平均值和标准差。
What are the effects on the learned encoding? To understand how the augmentations affect learned representations encoder, we visualize a spatial attention map from the output of the last convolutional layer. Similar to [46], we compute the spatial attention map by mean-pooling the absolute values of the activation s along the channel dimension and follow with a 2-dimensional spatial softmax. Figure 4 visualizes the spatial attention maps for the augmentations considered. Without augmentation, the activation is highly concentrated at the point of the forward knee, whereas with random crop/translate, entire edges of the body are prominent, providing a more complete and robust representation of the state.
增强对学习编码有何影响?为了理解增强如何影响学习到的表示编码器,我们可视化来自最后一个卷积层输出的空间注意力图。类似于[46],我们通过沿通道维度对激活值的绝对值进行平均池化来计算空间注意力图,并随后应用二维空间softmax。图4展示了所考虑增强方式的空间注意力图。在没有增强的情况下,激活高度集中在膝盖前侧点;而采用随机裁剪/平移时,身体的整个边缘都变得突出,提供了更完整且鲁棒的状态表示。
5.3 Improving generalization on OpenAI ProcGen
5.3 提升在OpenAI ProcGen上的泛化能力
Generalization: We evaluate the generalization ability on three environments from OpenAI Procgen: BigFish, StarPilot, and Jumper (see Figure 3(a)) by varying the number of training environments and ablating for different data augmentation methods. We summarize our findings below:
泛化性:我们在OpenAI Procgen的三个环境(BigFish、StarPilot和Jumper)中评估泛化能力(见图3(a)),通过改变训练环境数量并对不同数据增强方法进行消融实验。主要发现如下:
Table 3: Performance on OpenAI Gym. The training timestep varies from 50,000 to 200,000 depending on the difficulty of the tasks. The results show the mean and standard deviation averaged over four runs and the best results are indicated in bold. For baseline methods, we report the best number in POPLIN [42].
| Cheetah | Walker | Hopper | Ant | Pendulum | Cartpole | |
| PETS | 2288.4± 1019.0 | 282.5 ±501.6 | 114.9 ± 621.0 | 1165.5± 226.9 | 155.7± 79.3 | 199.6 ± 4.6 |
| POPLIN-A | 1562.8 ± 1136.7 | -105.0 ± 249.8 | 202.5±962.5 | 1148.4± 438.3 | 178.3±19.3 | 200.6±1.3 |
| POPLIN-P | 4235.0±1133.0 | 597.0 ± 478.8 | 2055.2±613.8 | 2330.1±320.9 | 167.9 ± 45.9 | 200.8±0.3 |
| METRPO | 2283.7 ± 900.4 | -1609.3±657.5 | 1272.5 ±500.9 | 282.2±18.0 | 174.8 ± 6.2 | 138.5±63.2 |
| TD3 | 3015.7±969.8 | -516.4±812.2 | 1816.6 ± 994.8 | 870.1 ± 283.8 | 168.6 ± 12.7 | 409.2±928.8 |
| SAC | 4035.7±268.0 | -382.5±849.5 | 2020.6±692.9 | 836.5± 68.4 | 162.1 ± 12.3 | 199.8 ± 1.9 |
| RAD | 4554.3±1209.0 | 806.4 ± 706.7 | 2149.1±249.9 | 1150.9 ± 494.6 | 167.4 ± 9.7 | 199.9 ± 0.8 |
| Timesteps | 200000 | 200000 | 200000 | 200000 | 50000 | 50000 |
表 3: OpenAI Gym 性能表现。训练时间步长根据任务难度从 50,000 到 200,000 不等。结果显示了四次运行的平均值和标准差,最佳结果以粗体标出。对于基线方法,我们报告了 POPLIN [42] 中的最佳数值。
| Cheetah | Walker | Hopper | Ant | Pendulum | Cartpole | |
|---|---|---|---|---|---|---|
| PETS | 2288.4±1019.0 | 282.5±501.6 | 114.9±621.0 | 1165.5±226.9 | 155.7±79.3 | 199.6±4.6 |
| POPLIN-A | 1562.8±1136.7 | -105.0±249.8 | 202.5±962.5 | 1148.4±438.3 | 178.3±19.3 | 200.6±1.3 |
| POPLIN-P | 4235.0±1133.0 | 597.0±478.8 | 2055.2±613.8 | 2330.1±320.9 | 167.9±45.9 | 200.8±0.3 |
| METRPO | 2283.7±900.4 | -1609.3±657.5 | 1272.5±500.9 | 282.2±18.0 | 174.8±6.2 | 138.5±63.2 |
| TD3 | 3015.7±969.8 | -516.4±812.2 | 1816.6±994.8 | 870.1±283.8 | 168.6±12.7 | 409.2±928.8 |
| SAC | 4035.7±268.0 | -382.5±849.5 | 2020.6±692.9 | 836.5±68.4 | 162.1±12.3 | 199.8±1.9 |
| RAD | 4554.3±1209.0 | 806.4±706.7 | 2149.1±249.9 | 1150.9±494.6 | 167.4±9.7 | 199.9±0.8 |
| Timesteps | 200000 | 200000 | 200000 | 200000 | 50000 | 50000 |
5.4 Improving state-based RL on OpenAI Gym
5.4 在 OpenAI Gym 上改进基于状态的强化学习
Data-efficiency on state-based inputs. Table 3 shows the average returns of evaluation rollouts for all methods (see Figure 12 in Appendix J for learning curves). We report results for state-based RAD using the best performing augmentation - random amplitude scaling; for details regarding performance of other augmentations we refer the reader to Appendix J. Similar to data augmentation in the visual setting, RAD is the state-of-the-art algorithm on the majority (4 out of 6) of benchmarked environments. RAD consistently improves the performance of SAC across all environments, and outperforms a competing state-of-the-art method - POPLIN-P - on most of the environments. It is worth noting that RAD improves the average return compared to POPLIN-P by $\mathbf{1.7x}$ in Walker, an environment where most prior RL methods fail, including both model-based and model-free ones. We hypothesize that random amplitude scaling is effective because it forces the agent to be robust to input noise while maintaining the intrinsic information of the state, such as sign of inputs and relative differences between them.
基于状态输入的数据效率。表3展示了所有方法的评估运行平均回报(学习曲线参见附录J中的图12)。我们报告了基于状态的RAD使用最佳增强方法(随机幅度缩放)的结果;其他增强方法的性能详情请参阅附录J。与视觉设置中的数据增强类似,RAD在大多数(6个中的4个)基准环境中是最先进的算法。RAD在所有环境中持续提升了SAC的性能,并在大多数环境中优于竞争对手POPLIN-P。值得注意的是,在Walker环境中(大多数现有RL方法包括基于模型和无模型方法都会失败的环境),RAD将平均回报相比POPLIN-P提高了$\mathbf{1.7x}$。我们假设随机幅度缩放之所以有效,是因为它在保持状态内在信息(如输入符号及其相对差异)的同时,迫使智能体对输入噪声具有鲁棒性。
These results showcase the generality of incorporating inductive biases through augmentation (e.g., amplitude invariance) by showing that improving RL with data augmentation is not specific to pixel-based inputs but also applies RL from state. By achieving state-of-the-art performance across both visual and proprio ce pti ve inputs, RAD sets a powerful new baseline for future algorithms.
这些结果表明,通过数据增强(如振幅不变性)引入归纳偏置具有普适性,不仅适用于基于像素输入的强化学习,也适用于状态输入的强化学习。RAD在视觉和本体感知输入上均实现了最先进的性能,为未来算法建立了强大的新基准。
6 Conclusion
6 结论
In this work, we proposed RAD, a simple plug-and-play module to enhance any reinforcement learning (RL) method using data augmentations. For the first time, we show that data augmentations alone can significantly improve the data-efficiency and generalization of RL methods operating from pixels, without any changes to the underlying RL algorithm, on the DeepMind Control Suite and the OpenAI ProcGen benchmarks respectively. Our implementation is simple, efficient, and has been open-sourced. We hope that the performance gains, implementation ease, and wall clock efficiency of RAD make it a useful module for future research in data-efficient and general iz able RL methods; and a useful tool for facilitating real-world applications of RL.
在本工作中,我们提出了RAD (Reinforcement Learning with Augmented Data) ,这是一个简单的即插即用模块,可通过数据增强 (data augmentation) 强化任何强化学习 (RL) 方法。我们首次证明:在DeepMind Control Suite和OpenAI ProcGen基准测试中,仅通过数据增强就能显著提升基于像素输入的RL方法的数据效率和泛化能力,且无需修改底层RL算法。该实现方案简洁高效且已开源。我们期望RAD在性能提升、易用性和实时效率方面的优势,能使其成为未来数据高效且可泛化的RL研究的有力工具,并为RL的实际应用落地提供支持。
7 Broader Impact
7 更广泛的影响
While there has been a trend in growing complexity and compute requirements to achieve state-ofthe-art results in Computer Vision [20], NLP [47], and RL [48], there are two negative long-term consequences of these trends: (i) the energy demands of these large models are harmful to the environment due to increased carbon emissions if not powered by renewable energy sources (ii) they make AI research inaccessible to researchers without access to tremendous compute and engineering resources. RAD shows that, by incorporating powerful inductive biases, state-of-the-art results can be achieved with simpler methods that require less compute and model complexity than complex competing methods. RAD is therefore accessible to a broad range of researchers (even those without access to GPUs) and leaves a much smaller carbon footprint than competing methods.
尽管在计算机视觉[20]、自然语言处理[47]和强化学习[48]领域,为实现最先进成果存在模型复杂度和算力需求不断增长的趋势,但这种趋势会带来两大长期负面影响:(i) 这些大型模型若未采用可再生能源供电,其能源需求会因碳排放增加而危害环境;(ii) 它们使得无法获取海量算力和工程资源的研究者难以开展AI研究。RAD证明,通过引入强大的归纳偏置,只需比复杂竞品方法更简单的计算方案和更低模型复杂度,就能实现同等前沿成果。因此RAD能让广大研究者(包括无GPU设备者)触手可及,且碳足迹远低于竞品方法。
While it’s fair to say that even with the result from this paper, we are far removed from making Deep RL practical for solving real-world-complexity robotics problems, we believe this work provides progress towards that goal. Robots being able to learn through RL in the real world opens up opportunities for better elderly care, autonomous cleaning and disinfecting, more reliable / resilient supply chain and manufacturing operations (especially when humans might not be available due to a pandemic). On the flipside, an RL agent will optimize whatever reward one specifies. If the person in charge of the system specifies a reward that’s bad for the world (or perhaps mistakenly even for themselves), the more powerful the RL, the worse the outcome. For this reason, in addition to developing better algorithms that achieve new state-of-the-art performance, it is also important to pursue complementary research on safety [49, 50].
虽然可以公平地说,即使有了本文的研究成果,我们仍远未实现深度强化学习(Deep RL)在实际复杂机器人问题中的实用化,但我们相信这项工作向该目标迈进了一步。机器人能够通过现实世界中的强化学习进行训练,将为改善老年护理、自主清洁消毒、打造更可靠/更具韧性的供应链和制造运营(尤其当人类因疫情无法到岗时)创造机遇。另一方面,强化学习智能体(RL agent)会无条件优化人为设定的奖励函数。若系统负责人设定的奖励函数对世界有害(甚至可能错误地损害自身利益),强化学习能力越强,造成的后果就越严重。因此,除了开发能达到新SOTA(state-of-the-art)性能的算法外,同步开展安全性[49,50]的互补性研究也至关重要。
Acknowledgments and Disclosure of Funding
致谢与资金披露
This work was supported in part by Berkeley Deep Drive (BDD), ONR PECASE N 000141612723, DARPA through the LwLL program, and the Open Philanthropy Foundation.
本研究部分由伯克利深度驾驶(BDD)、ONR PECASE N 000141612723、DARPA通过LwLL项目以及开放慈善基金会资助。
References
参考文献
AExtended related work
扩展相关工作
A.1 Data augmentation in supervised learning
A.1 监督学习中的数据增强
Since our focus is on image-based observations, we cover the related work in computer vision. Data augmentation in deep learning systems for computer vision can be found as early as LeNet-5 [1], an early implementation of CNNs on MNIST digit classification. In AlexNet [13] wherein the authors applied CNNs to image classification on ImageNet, data augmentations were used to increase the size of the original dataset by a factor of 2048 by randomly flipping and cropping $224\times224$ patches from the original image. These data augmentations inject the priors of invariance to translation and reflection, playing a significant role in improving the performance of supervised computer vision systems. Recently, new augmentation techniques such as Auto Augment [14] and Rand Augment [15] have been proposed to further improve the performance of these systems.
由于我们的重点是图像观测,因此我们涵盖了计算机视觉领域的相关工作。深度学习系统中用于计算机视觉的数据增强技术最早可以追溯到LeNet-5 [1],这是卷积神经网络(CNN)在MNIST手写数字分类上的早期实现。在AlexNet [13]中,作者将CNN应用于ImageNet图像分类,通过随机翻转和从原始图像中裁剪$224\times224$的补丁,数据增强技术将原始数据集的大小扩大了2048倍。这些数据增强引入了平移和反射不变性的先验知识,在提升监督式计算机视觉系统性能方面发挥了重要作用。最近,Auto Augment [14]和Rand Augment [15]等新的增强技术被提出,以进一步提升这些系统的性能。
A.2 Data augmentation for data-efficiency in semi & self-supervised learning
A.2 半监督与自监督学习中的数据增强提升数据效率
Aside from improving supervised learning, data augmentation has also been widely utilized for unsupervised and semi-supervised learning. MixMatch [18], FixMatch [26], UDA [16] use unsupervised data augmentation in order to maximize label agreement without access to the actual labels. Several contrastive representation learning approaches [19, 21, 20] have recently dramatically improved the label-efficiency of downstream vision tasks like ImageNet classification. Contrastive approaches utilize data augmentations and perform patch-wise [19] or instance discrimination (MoCo, SimCLR) [21, 20]. In the instance discrimination setting, the contrastive objective aims to maximize agreement between augmentations of the same image and minimize it between all other images in the dataset [20, 21]. The choice of augmentations has a significant effect on the quality of the learned representations as demonstrated in SimCLR [20].
除了改进监督学习外,数据增强 (data augmentation) 还被广泛应用于无监督和半监督学习。MixMatch [18]、FixMatch [26]、UDA [16] 采用无监督数据增强技术,在无法获取真实标签的情况下最大化标签一致性。近期多项对比表征学习方法 [19, 21, 20] 显著提升了 ImageNet 分类等下游视觉任务的标签效率。这些对比方法通过数据增强实现局部块级 [19] 或实例判别 (MoCo, SimCLR) [21, 20]。在实例判别设定中,对比学习目标旨在最大化同一图像不同增强版本之间的一致性,同时最小化数据集中其他所有图像之间的一致性 [20, 21]。如 SimCLR [20] 所示,增强策略的选择对学习表征的质量具有显著影响。
A.3 Prior work in reinforcement learning related to data augmentation
A.3 数据增强相关的强化学习先前工作
A.3.1 Data augmentation with domain knowledge
A.3.1 基于领域知识的数据增强
While not directly known for data augmentation in reinforcement learning, the following ideas can be viewed as techniques to diversify the data used to train an RL agent:
虽然以下方法并不直接以强化学习中的数据增强著称,但它们可被视为用于多样化训练RL智能体数据的技术:
Domain random iz ation [27–29] is a simple data augmentation technique primarily used for transferring policies from simulation to the real world where one takes advantage of the simulator’s access to information about the rendering and physics and thus can train transferable policies from diverse simulated experiences.
域随机化 [27-29] 是一种简单的数据增强技术,主要用于将策略从仿真环境迁移到现实世界。该技术利用仿真器对渲染和物理信息的访问权限,从而能够通过多样化的仿真经验训练出可迁移的策略。
Hindsight experience replay [51] applies the idea of re-labeling trajectories with terminal states as fictitious goals, improving the ability of goal-conditioned RL to learn quickly with sparse rewards. This, however, makes assumptions about the goal space matching with the state space and has had limited success with pixel-based observations.
后见经验回放 [51] 采用将终止状态重新标记为虚构目标的思想,提升了目标条件强化学习在稀疏奖励下快速学习的能力。不过,该方法假设目标空间与状态空间相匹配,且在基于像素的观测中效果有限。
A.3.2 Synthetic rollouts using a learned world model
A.3.2 使用学习的世界模型进行合成推演
While usually not viewed as a data augmentation technique, the idea of generating fake or synthetic rollouts to improve the data-efficiency of RL agents has been proposed in the Dyna framework [39]. In recent times, these ideas have been used to improve the performance of systems that have explicitly learned world models of the environment and generated synthetic rollouts using them [52, 11, 36].
虽然通常不被视为数据增强技术,但Dyna框架[39]提出了通过生成虚假或合成轨迹来提高强化学习智能体数据效率的思路。近年来,这些方法已被用于改进那些显式学习环境世界模型并利用其生成合成轨迹的系统性能[52, 11, 36]。
A.3.3 Data augmentation for data-efficient reinforcement learning
A.3.3 数据高效强化学习的数据增强
Data augmentation is a key component for learning contrastive representations in the RL setting as shown in the CURL framework [32], which learns representations that improve the data-efficiency of pixel-based RL by enforcing consistencies between an image and its augmented version through instance contrastive losses. Prior to our work, CURL was the state-of-the-art model for data-efficient RL from pixel inputs. While the focus in CURL was to make use of data augmentations jointly through contrastive and reinforcement learning losses, RAD attempts to directly use data augmentations for reinforcement learning without any auxiliary loss. We refer the reader to a discussion on tradeoffs between CURL and RAD in Section I. Concurrent and independent to our work, DrQ [33] uses data augmentations and weighted Q-functions in conjunction with the off-policy RL algorithm SAC [34] to achieve state-of-the-art data-efficiency results on the DeepMind Control Suite. On the other hand, RAD can be plugged into any reinforcement learning method (on-policy methods like PPO [4] and off-policy methods like SAC [34]) without making any changes to the underlying algorithm. We further demonstrate the benefits of data augmentation to generalization on the OpenAI ProcGen benchmarks in addition to data-efficiency on the DeepMind Control Suite.
数据增强是强化学习(RL)环境中学习对比表示的关键组件,如CURL框架[32]所示。该框架通过实例对比损失强制图像与其增强版本之间的一致性,从而提升了基于像素的强化学习的数据效率。在我们工作之前,CURL是从像素输入进行数据高效强化学习的顶尖模型。虽然CURL的重点是通过对比学习和强化学习损失联合利用数据增强,但RAD尝试直接为强化学习使用数据增强,无需任何辅助损失。关于CURL和RAD之间权衡的讨论,请参阅第I节。与我们工作同时且独立进行的DrQ[33]使用数据增强和加权Q函数,结合离线策略强化学习算法SAC[34],在DeepMind Control Suite上实现了最先进的数据效率结果。另一方面,RAD可以插入任何强化学习方法(如PPO[4]等在线策略方法或SAC[34]等离线策略方法),而无需对基础算法进行任何更改。除了在DeepMind Control Suite上的数据效率外,我们进一步展示了数据增强在OpenAI ProcGen基准测试中对泛化的益处。
A.4 Data augmentation for generalization in reinforcement learning
A.4 强化学习中提升泛化能力的数据增强
Cobbe et al. [30] and Lee et al. [31] showed that simple data augmentation techniques such as cutout [30] and random convolution [31] can be useful to improve generalization of agents on the OpenAI CoinRun and ProcGen benchmarks. In this paper, we extensively investigate more data augmentation techniques such as random crop and color jitter on a more diverse array of tasks. With our efficient implementation of these augmentations, we demonstrate their utility with the on-policy RL algorithm PPO [4] for the first time.
Cobbe等人[30]和Lee等人[31]研究表明,简单的数据增强技术如cutout[30]和随机卷积[31]能有效提升AI智能体在OpenAI CoinRun和ProcGen基准测试中的泛化能力。本文系统研究了随机裁剪、色彩抖动等更多数据增强技术在不同任务中的应用,并通过高效实现首次验证了这些增强技术与在线策略强化学习算法PPO[4]结合的实用性。

B Attention maps for various data augmentations
图 B: 不同数据增强的注意力图
C Random translate ablations
C 随机翻译消融实验

Figure 4: Spatial attention map of an encoder that shows where the agent focuses on in order to make a decision in (a) Walker Walk and (b) Cheetah Run environments. Random crop enables the agent to focus on the robot body and ignore irrelevant scene details compared to other augmentations as well as the base agent that learns without any augmentation. In addition to the agent, the base cheetah encoder focuses on the stars in the background, which are irrelevant to the task and likely harm the agent’s performance. Random crop enables the encoder to capture the agent’s state much more clearly compared to other augmentations. The quality of the attention map with random crop suggests that RAD improves the contingency-awareness of the agent (recognizing aspects of the environment that are under the agent’s control) thereby improving its data-efficiency. Figure 5: Ablations for different sizes of the larger frame in which the image is randomly translated. The original image is always rendered at a resolution of $100\mathrm{x}100$ pixels, and then translated within a larger frame of size 102,104,108, and 116. We note that augmentation significantly improves performance compared to SAC with no augmentation on Cartpole and Cheetah environments even for the smallest frame size of 102 where minimal augmentation is happening.
图 4: 编码器的空间注意力热力图,展示了智能体在 (a) Walker Walk 和 (b) Cheetah Run 环境中做出决策时的关注区域。与其他增强方法以及未使用任何增强的基础智能体相比,随机裁剪 (random crop) 能使智能体专注于机器人本体并忽略无关场景细节。基础猎豹编码器除了关注智能体外,还会聚焦于背景中的星体——这些与任务无关的元素可能损害智能体性能。随机裁剪使编码器能比其他增强方法更清晰地捕捉智能体状态。注意力热力图的质量表明,RAD 提升了智能体的应急感知能力(识别环境中受智能体控制的要素),从而提高了数据效率。
图 5: 不同尺寸大帧(图像随机平移的容器)的消融实验结果。原始图像始终以 $100\mathrm{x}100$ 像素分辨率渲染,然后在尺寸为 102/104/108/116 的大帧内平移。我们注意到:在 Cartpole 和 Cheetah 环境中,即使是最小帧尺寸 102(此时增强效果最弱),数据增强仍显著优于未增强的 SAC 方法。

Figure 6: We ablate random translation, cropping, and windowing. Since cropping can be viewed as a simultaneous translation and window operation, we wish to understand which component is responsible for the most gains. We find that the gains come primarily from the translation operation and that, on most environments, RAD with translation results in more stable and efficient learning.
图 6: 我们对比了随机平移、裁剪和窗口化操作的效果。由于裁剪可视为平移和窗口操作的结合,我们试图分析哪种成分贡献了主要性能提升。实验发现,性能提升主要来自平移操作,在多数环境中,采用平移的 RAD (Random Translation) 方法能带来更稳定高效的学习效果。
D Learning curves for RAD on DMControl
RAD 在 DMControl 上的学习曲线

Figure 7: We benchmark the performance of RAD relative to the best performing pixel-based baseline (CURL) as well as SAC operating on state input on 15 environments in total. RAD matches state SAC performance on the majority (11 out of 15 environments) and performs comparably or better than CURL on all of the environments tested. Results are average values across 3 seeds.
图 7: 我们在总共15个环境中对RAD的性能与基于像素的最佳基线(CURL)以及处理状态输入的SAC进行了基准测试。RAD在大多数环境(15个中的11个)中与状态SAC性能相当,并在所有测试环境中表现与CURL相当或更优。结果为3次实验种子的平均值。
E Implementation details for DMControl
E DMControl 实现细节
For DMControl experiments, we utilize the same encoder architecture as in [32] which is similar to the architecture in [37]. We show a full list of hyper parameters for DMControl experiments in Table 4.
对于DMControl实验,我们采用与[32]相同的编码器架构,该架构类似于[37]中的设计。我们在表4中列出了DMControl实验的全部超参数。
Table 4: Hyper parameters used for DMControl experiments. Most hyper parameters values are unchanged across environments with the exception for action repeat, learning rate, and batch size.
| Hyperparameter | Value |
| Augmentation | Crop - walker, walk; Translate - otherwise |
| Observation rendering | (100,100) |
| Observationdown/upsampling | (84,84) (crop); (108, 108) (translate) |
| Replay buffer size | 100000 |
| Initial steps | 1000 |
| Stacked frames | 3 |
| Action repeat | 2 finger, spin; walker, walk |
| 8 cartpole, swingup | |
| 4 otherwise | |
| Hidden units (MLP) | 1024 |
| Evaluation episodes | 10 |
| Optimizer | Adam |
| (β1,β2)→(fθ,T,QΦ) | (.9, .999) |
| (β1,β2)→ (α) | (.5, .999) |
| Learning rate (fo, T, QΦ) | 2e - 4 cheetah, run 1e - 3 otherwise |
| Learning rate (Q) | 1e - 4 |
| Batch Size | 512 |
| Q function EMA T | 0.01 |
| Critic target update freq | 2 |
| Convolutional layers | 4 |
| Number of filters | 32 |
| Non-linearity | ReLU |
| Encoder EMA T | 0.05 |
| Latent dimension | 50 |
| Discount | .99 |
| Initial temperature | 0.1 |
表 4: DMControl实验使用的超参数。除动作重复次数、学习率和批量大小外,大多数超参数值在不同环境中保持一致。
| 超参数 | 值 |
|---|---|
| 数据增强 | Crop - walker, walk; Translate - 其他场景 |
| 观测渲染 | (100,100) |
| 观测降采样/上采样 | (84,84) (crop); (108, 108) (translate) |
| 回放缓冲区大小 | 100000 |
| 初始步数 | 1000 |
| 堆叠帧数 | 3 |
| 动作重复次数 | 2 finger, spin; walker, walk |
| 8 cartpole, swingup | |
| 4 其他场景 | |
| 隐藏单元数 (MLP) | 1024 |
| 评估回合数 | 10 |
| 优化器 | Adam |
| (β1,β2)→(fθ,T,QΦ) | (.9, .999) |
| (β1,β2)→ (α) | (.5, .999) |
| 学习率 (fo, T, QΦ) | 2e-4 cheetah, run; 1e-3 其他场景 |
| 学习率 (Q) | 1e-4 |
| 批量大小 | 512 |
| Q函数EMA系数τ | 0.01 |
| 评论家目标更新频率 | 2 |
| 卷积层数 | 4 |
| 滤波器数量 | 32 |
| 非线性激活 | ReLU |
| 编码器EMA系数τ | 0.05 |
| 潜在维度 | 50 |
| 折扣因子 | .99 |
| 初始温度系数 | 0.1 |
F Implementation details and additional results for ProcGen
F ProcGen 实现细节与补充结果
F.1 Environment descriptions
F.1 环境描述
BigFish. In this environment, the agent starts as a small fish and the goal is to eat fish smaller than itself. The agent can receive a small reward for eating fish and a large reward is given when it becomes bigger that all other fish. The spawn timing, position of all fish, and style of background change throughout the level.
大鱼吃小鱼。在该环境中,智能体初始为一条小鱼,目标是通过吞食比自身小的鱼来成长。吞食小鱼可获得小额奖励,当智能体成长为最大体型时将获得巨额奖励。关卡中会动态调整鱼群刷新时间、所有鱼的位置以及背景样式。
StarPilot. A simple side scrolling shooter game, where the agent receive the reward by avoiding enemy. The spawn timing of all enemies and obstacles, along with their corresponding types, are changing throughout the level.
StarPilot。一款简单的横向卷轴射击游戏,AI智能体通过躲避敌人获得奖励。所有敌人和障碍物的生成时间及其对应类型会随关卡进程动态变化。
Jumper. An open world environment, where the goal is to find the carrot which is randomly located in the map. Style of background, location of enemy and map structure are changing throughout the level.
Jumper。一个开放世界环境,目标是找到随机分布在地图中的胡萝卜。背景风格、敌人位置和地图结构会随着关卡推进动态变化。
Modified CoinRun. In this task, an agent is located at the leftmost side of the map and the goal is to collect the coin located at the rightmost side of the map within 1,000 timesteps. The agent observes its surrounding environment in the third-person point of view, where the agent is always located at the center of the observation. Similar to [31], half of the available themes are utilized (i.e., style of backgrounds, floors, agents, and moving obstacles) for training.
改良版CoinRun。在该任务中,智能体位于地图最左侧,目标是在1000个时间步内收集位于地图最右侧的金币。智能体以第三人称视角观察周围环境,其自身始终位于观测画面中心。与[31]类似,训练时仅使用半数可用主题(即背景、地板、智能体及移动障碍物的风格)。
F.2 Implementation details
F.2 实现细节
For ProcGen experiments, we follow the hyper parameters proposed in [24], which are empirically shown to be effective. Specifically, we use the CNN architecture found in IMPALA [40] as the policy network, and train the agents using the Proximal Policy Optimization (PPO) with following hyper parameters:
在ProcGen实验中,我们沿用[24]提出的超参数设置(经实证验证有效)。具体采用IMPALA [40]中的CNN架构作为策略网络,使用近端策略优化(PPO)算法训练AI智能体,关键超参数如下:
Table 5: Hyper parameters used for ProcGen experiments.
| Hyperparameter | Value |
| Observation rendering Discount | (64, 64) .99 |
| GAEparameter入 # of timesteprs per rollout | 0.95 |
| # of minibatches per rollout | 256 8 |
| Entropy bonus | 0.1 |
| PPO clip range Reward Normalization | 0.2 |
| Yes | |
| # of Workers | 1 |
| # of environments per worker | 64 |
| Total timesteps | |
| 20M | |
| LSTM | No |
| Frame Stack | No |
| Optimizer | Adam |
| Learning rate (o) | 5e - 4 |
表 5: ProcGen实验使用的超参数
| 超参数 | 值 |
|---|---|
| 观测渲染折扣 | (64, 64) .99 |
| GAE参数 每次rollout的时间步数 | 0.95 |
| 每次rollout的minibatch数量 | 256 8 |
| 熵奖励 | 0.1 |
| PPO剪切范围 奖励归一化 | 0.2 |
| 是 | |
| 工作线程数 | 1 |
| 每个工作线程的环境数 | 64 |
| 总时间步数 | |
| 20M | |
| LSTM | 否 |
| 帧堆叠 | 否 |
| 优化器 | Adam |
| 学习率 (o) | 5e - 4 |
F.3 Learning curves
F.3 学习曲线

Figure 8: Learning curves of PPO and RAD agents trained with (a/b) 100 and $\left({\mathrm{c}}/{\mathrm{d}}\right)$ 200 training levels on StarPilot. The solid line and shaded regions represent the mean and standard deviation, respectively, across three runs.
图 8: PPO和RAD智能体在StarPilot上使用(a/b)100和$\left({\mathrm{c}}/{\mathrm{d}}\right)$200个训练关卡的学习曲线。实线和阴影区域分别表示三次运行的平均值和标准差。

Figure 9: Learning curves of PPO and RAD agents trained with $\mathrm{(a/b)}$ 100 and $\left({\mathrm{c}}/{\mathrm{d}}\right)$ 200 training levels on Bigfish. The solid line and shaded regions represent the mean and standard deviation, respectively, across three runs.
图 9: 在Bigfish环境中使用 (a/b) 100和 (c/d) 200训练关卡训练的PPO与RAD智能体的学习曲线。实线与阴影区域分别表示三次运行的平均值与标准差。

Figure 10: Learning curves of PPO and RAD agents trained with $\mathrm{(a/b)}$ 100 and $\mathrm{(c/d)}$ 200 training levels on Jumper. The solid line and shaded regions represent the mean and standard deviation, respectively, across three runs.
图 10: 在Jumper环境中使用$\mathrm{(a/b)}$100个和$\mathrm{(c/d)}$200个训练关卡训练的PPO与RAD智能体的学习曲线。实线和阴影区域分别表示三次运行的平均值和标准差。

Figure 11: Learning curves of PPO and RAD in the modified Coinrun. The solid line and shaded regions represent the mean and standard deviation, respectively, across three runs.
图 11: 改进版Coinrun中PPO和RAD的学习曲线。实线和阴影区域分别表示三次运行的平均值和标准差。
G Code for select augmentations
选择增强的G代码
H Time-efficiency of data augmentation
H 数据增强的时间效率
The primary gain of our data augmentation modules is enabling efficient augmentation of stacked frame inputs in the minibatch setting. Since the augmentations must be applied randomly across the batch but consistently across the frame stack, traditional frameworks like Tensorflow and PyTorch that focus on augmenting single-frame static datasets, are unsuitable for this task. We further show wall-clock efficiency relative to the PyTorch API in Table 6.
我们数据增强模块的主要优势在于能够在小批量(minibatch)设置下高效增强堆叠帧输入。由于增强操作必须在批次内随机应用但需保持帧堆叠间的一致性,传统框架(如Tensorflow和PyTorch)专注于增强单帧静态数据集,并不适合此任务。我们在表6中进一步展示了相对于PyTorch API的实际时间效率。
| OURS | PYTORCH | |
| CROP | 31.8 | 33.5 |
| GRAYSCALE | 15.6 | 51.2 |
| CUTOUT | 36.6 | |
| CUTOUTCOLOR | 45.2 | |
| FLIP | 4.9 | 37.0 |
| ROTATE | 46.5 | 62.4 |
| RANDOMCONV. | 45.8 |
| OURS | PYTORCH | |
|---|---|---|
| CROP | 31.8 | 33.5 |
| GRAYSCALE | 15.6 | 51.2 |
| CUTOUT | 36.6 | |
| CUTOUTCOLOR | 45.2 | |
| FLIP | 4.9 | 37.0 |
| ROTATE | 46.5 | 62.4 |
| RANDOMCONV. | 45.8 |
I Discussion
I 讨论
I.1 CURL vs RAD
I.1 CURL 与 RAD 对比
Both CURL and RAD improve the data-efficiency of RL agents by enforcing consistencies in the input observations presented to the agent. CURL does this with an explicit instance contrastive loss between an image and its augmented version using the MoCo [21] mechanism. On the other hand, RAD does not employ any auxiliary loss and directly trains the RL objective on multiple augmented views of the observations, thereby ensuring consistencies on the augmented views implicitly. The performance of RAD matches that of CURL and surpasses CURL on some of the environments in the DeepMind Control Suite (refer to Figure 7). This suggests the potential conclusion that data augmentation is sufficient for data-efficient reinforcement learning from pixels. We argue that the conclusion requires a bit more nuance in the following subsection.
CURL和RAD都通过强化输入观察数据的一致性来提高RL智能体的数据效率。CURL采用MoCo [21]机制,在图像与其增强版本之间施加显式的实例对比损失。而RAD不使用任何辅助损失函数,直接在观察数据的多个增强视图上训练RL目标函数,从而隐式确保增强视图间的一致性。RAD的性能与CURL相当,并在DeepMind Control Suite部分环境中超越CURL (参见图7)。这表明数据增强可能足以实现基于像素的高效强化学习。我们将在下一小节论证该结论需要更细致的考量。
I.2 Is data augmentation sufficient for RL from pixels?
I.2 数据增强对像素级强化学习是否足够?
The improved performance of RAD over CURL can be attributed to the following line of thought: While both methods try to improve the data-efficiency through augmentation consistencies (CURL explicitly, RAD implicitly); RAD outperforms CURL because it only optimizes for what we care about, which is the task reward. CURL, on the other hand, jointly optimizes the reinforcement and contrastive learning objectives. If the metric used to evaluate and compare these methods is the score attained on the task at hand, a method that purely focuses on reward optimization is expected to be better as long as it implicitly ensures similarity consistencies on the augmented views (in this case, just by training the RL objective on different augmentations directly).
RAD相比CURL的性能提升可归因于以下思路:虽然两种方法都试图通过增强一致性来提高数据效率(CURL显式地,RAD隐式地);但RAD优于CURL,因为它只优化我们关心的目标——任务奖励。而CURL同时优化了强化学习和对比学习目标。若评估这些方法的标准是当前任务得分,那么只要隐式确保增强视图间的相似性一致性(本例中仅通过直接在不同增强上训练RL目标),纯粹专注于奖励优化的方法理应表现更优。
However, we believe that a representation learning method like CURL is arguably a more general framework for the usage of data augmentations in reinforcement learning. CURL can be applied even without any task (or environment) reward available. The contrastive learning objective in CURL that ensures consistencies between augmented views is disentangled from the reward optimization (RL) objective and is therefore capable of learning-rich semantic representations from high dimensional observations gathered from random rollouts. Real-world applications of RL might involve performing plenty of interactions (or rollouts) with sparse reward signals, and tasks presented to the agent as image-based goals. In such scenarios, CURL and other representation learning methods are likely to be more important even though current RL benchmarks are primarily about single or multi-task reward optimization.
然而,我们认为像CURL这样的表征学习方法可以说是强化学习中数据增强使用的一个更通用框架。即使没有任何任务(或环境)奖励可用,CURL也可以应用。CURL中的对比学习目标确保了增强视图之间的一致性,与奖励优化(强化学习)目标是解耦的,因此能够从随机rollout收集的高维观测中学习丰富的语义表征。强化学习的现实应用可能涉及在稀疏奖励信号下进行大量交互(或rollout),并以基于图像的目标呈现给智能体。在这种情况下,尽管当前的强化学习基准主要是关于单任务或多任务奖励优化,但CURL和其他表征学习方法可能会变得更加重要。
Given these subtle considerations, we believe that both RAD and representation learning methods like CURL will be useful tools for an RL practitioner in future research encompassing data-efficient and general iz able RL.
鉴于这些微妙的考量,我们认为RAD和CURL等表征学习方法将成为未来研究数据高效且可泛化强化学习(RL)时的重要工具。
J Implementation details and additional results for OpenAI Gym
OpenAI Gym 的实现细节与补充结果
J.1 Implementation details
J.1 实现细节
We consider a combination of SAC and RAD using the publicly released implementation repository (https://github.com/vitchyr/rlkit) without any modifications on hyper parameters and architectures. For random amplitude scaling, we consider two variants: (a) random amplitude scaling with a single variable (RAS-S) that multiplies the one-dimensional uniform random variable, i.e., $\mathbf{s}^{\prime}=\mathbf{s} * z$ , where $z\sim\mathrm{Uni}[\alpha,\beta]$ , and (b) random amplitude scaling with a multivariate variable (RAS-M) that multiplies the multivariate uniform random variable, i.e., $\mathbf{s}^{\prime}=\mathbf{s}*\mathbf{z}$ , where $\mathbf{z}\sim\mathrm{Uni}[\alpha,\beta]$ . The minimum value of uniform distribution is chosen from $\alpha\in{0.6,0.8}$ and the maximum value of uniform distribution is chosen from $\beta\in{1.2,1.4}$ . For Gaussian noise, we add Gaussian random variable, i.e., $\mathbf{s}^{\prime}=\mathbf{s}+\mathbf{z}$ , where $\mathbf{z}\sim\mathcal{N}(0,I)$ . The optimal parameters are chosen to achieve the best performance on training environments.
我们考虑结合SAC和RAD方法,使用公开发布的实现代码库(https://github.com/vitchyr/rlkit),不对超参数和架构进行任何修改。对于随机幅度缩放,我们考虑两种变体:(a) 使用单变量进行随机幅度缩放(RAS-S),即乘以一维均匀随机变量,即$\mathbf{s}^{\prime}=\mathbf{s} * z$,其中$z\sim\mathrm{Uni}[\alpha,\beta]$;(b) 使用多变量进行随机幅度缩放(RAS-M),即乘以多维均匀随机变量,即$\mathbf{s}^{\prime}=\mathbf{s}*\mathbf{z}$,其中$\mathbf{z}\sim\mathrm{Uni}[\alpha,\beta]$。均匀分布的最小值从$\alpha\in{0.6,0.8}$中选择,最大值从$\beta\in{1.2,1.4}$中选择。对于高斯噪声,我们添加高斯随机变量,即$\mathbf{s}^{\prime}=\mathbf{s}+\mathbf{z}$,其中$\mathbf{z}\sim\mathcal{N}(0,I)$。选择最优参数以在训练环境中实现最佳性能。
J.2 Experimental results on OpenAI Gym
J.2 OpenAI Gym 上的实验结果
As shown in Table 7 and Figure 12, random amplitude scaling is effective in almost all environments. We expect that this is because random amplitude scaling forces the agent to be robust to input noise while maintaining the intrinsic information of the state. However, in the case of random amplitude scaling with multiple variables, the relative differences can be changed. Because of that, random amplitude with a single scalar achieves the better performance on most environments. We also remark that a simple normalization technique such as batch normalization is not very effective compared to RAD, which implies that the gains from RAD can not be achieved by normalization.
如表 7 和图 12 所示,随机振幅缩放 (random amplitude scaling) 在几乎所有环境中都有效。我们认为这是因为随机振幅缩放迫使智能体在保持状态内在信息的同时对输入噪声具有鲁棒性。然而,在多变量的随机振幅缩放情况下,相对差异可能会改变。因此,使用单一标量的随机振幅在大多数环境中表现更好。我们还注意到,与 RAD 相比,批量归一化 (batch normalization) 等简单的归一化技术效果不佳,这意味着 RAD 的增益无法通过归一化实现。
Table 7: Performance of variants of RAD, i.e., random amplitude scaling with a single variable (RAS-S), random amplitude scaling with a multivariate variable (RAS-M), and Gaussian noise (GN), on OpenAI Gym. The training timestep varies from 50,000 to 200,000 depending on the difficulty of the tasks. The results show the mean and standard deviation averaged over four runs and the best results are indicated in bold. For baseline methods, we report the best number in POPLIN [42]. For TD3, we remark that similar scores can be reproduced by the official codebase from the POPLIN paper (e.g., 3273.4 on Cheetah and -447.3 on Walker) using 10 random seeds.
| Cheetah | Walker | Hopper | |
| PETS | 2288.4 ± 1019.0 | 282.5± 501.6 | 114.9 ± 621.0 |
| POPLIN-A | 1562.8 ± 1136.7 | -105.0 ± 249.8 | 202.5 ± 962.5 |
| POPLIN-P | 4235.0 ± 1133.0 | 597.0 ± 478.8 | 2055.2 ± 613.8 |
| METRPO | 2283.7 ± 900.4 | -1609.3 ± 657.5 | 1272.5 ± 500.9 |
| TD3 | 3015.7 ± 969.8 | -516.4 ± 812.2 | 1816.6 ± 994.8 |
| SAC | 4035.7 ± 268.0 | -382.5 ± 849.5 | 2020.6 ± 692.9 |
| SAC + BN | 3386.9 ± 549.3 | 751.2 ± 1017.9 | 1854.1 ± 329.3 |
| SAC + RAD (RAS-S) | 4554.3 ± 1209.0 | 370.4 ± 579.3 | 2149.1± 249.9 |
| SAC + RAD (RAS-M) | 2787.4 ± 466.8 | 806.4 ± 706.7 | 2096.1 ± 442.7 |
| SAC + RAD (GN) | 2222.3 ± 418.3 | -121.6 ± 664.6 | 19.0 ± 619.6 |
| Timesteps | 200000 | 200000 | 200000 |
| Ant | Pendulum | Cartpole | |
| PETS | 1165.5 ± 226.9 | 155.7 ± 79.3 | 199.6 ± 4.6 |
| POPLIN-A | 1148.4 ± 438.3 | 178.3 ± 19.3 | 200.6 ± 1.3 |
| POPLIN-P | 2330.1 ± 320.9 | 167.9 ± 45.9 | 200.8 ± 0.3 |
| METRPO | 282.2 ± 18.0 | 174.8 ± 6.2 | 138.5 ± 63.2 |
| TD3 | 870.1 ± 283.8 | 168.6 ± 12.7 | -409.2 ± 928.8 |
| SAC | 836.5 ± 68.4 | 162.1 ± 12.3 | 199.8 ± 1.9 |
| SAC + BN | 580.8 ± 70.2 | 158.4 ± 10.2 | 178.1 ± 38.2 |
| SAC + RAD (RAS-S) | 1150.9 ± 494.6 | 158.9 ± 16.8 | 199.9 ± 0.8 |
| SAC +RAD (RAS-M) | 966.6 ± 321.0 | 167.4 ± 9.7 | 198.8 ± 1.3 |
| SAC + RAD (GN) | 932.9 ± 12.9 | 163.4 ± 12.6 | 169.9 ± 31.0 |
| Timesteps | 200000 | 50000 | 50000 |
表 7: RAD变体在OpenAI Gym上的性能表现,包括单变量随机振幅缩放(RAS-S)、多变量随机振幅缩放(RAS-M)和高斯噪声(GN)。训练时间步长根据任务难度从50,000到200,000不等。结果显示四次运行的平均值和标准差,最佳结果以粗体标出。基线方法采用POPLIN [42]报告的最佳数值。对于TD3,我们注意到使用10个随机种子可通过POPLIN论文的官方代码库复现相似分数(例如猎豹3273.4,步行者-447.3)。
| 猎豹 | 步行器 | 跳跃者 | |
|---|---|---|---|
| PETS | 2288.4±1019.0 | 282.5±501.6 | 114.9±621.0 |
| POPLIN-A | 1562.8±1136.7 | -105.0±249.8 | 202.5±962.5 |
| POPLIN-P | 4235.0±1133.0 | 597.0±478.8 | 2055.2±613.8 |
| METRPO | 2283.7±900.4 | -1609.3±657.5 | 1272.5±500.9 |
| TD3 | 3015.7±969.8 | -516.4±812.2 | 1816.6±994.8 |
| SAC | 4035.7±268.0 | -382.5±849.5 | 2020.6±692.9 |
| SAC+BN | 3386.9±549.3 | 751.2±1017.9 | 1854.1±329.3 |
| SAC+RAD(RAS-S) | 4554.3±1209.0 | 370.4±579.3 | 2149.1±249.9 |
| SAC+RAD(RAS-M) | 2787.4±466.8 | 806.4±706.7 | 2096.1±442.7 |
| SAC+RAD(GN) | 2222.3±418.3 | -121.6±664.6 | 19.0±619.6 |
| 时间步长 | 200000 | 200000 | 200000 |
| 蚂蚁 | 钟摆 | 倒立摆 | |
|---|---|---|---|
| PETS | 1165.5±226.9 | 155.7±79.3 | 199.6±4.6 |
| POPLIN-A | 1148.4±438.3 | 178.3±19.3 | 200.6±1.3 |
| POPLIN-P | 2330.1±320.9 | 167.9±45.9 | 200.8±0.3 |
| METRPO | 282.2±18.0 | 174.8±6.2 | 138.5±63.2 |
| TD3 | 870.1±283.8 | 168.6±12.7 | -409.2±928.8 |
| SAC | 836.5±68.4 | 162.1±12.3 | 199.8±1.9 |
| SAC+BN | 580.8±70.2 | 158.4±10.2 | 178.1±38.2 |
| SAC+RAD(RAS-S) | 1150.9±494.6 | 158.9±16.8 | 199.9±0.8 |
| SAC+RAD(RAS-M) | 966.6±321.0 | 167.4±9.7 | 198.8±1.3 |
| SAC+RAD(GN) | 932.9±12.9 | 163.4±12.6 | 169.9±31.0 |
| 时间步长 | 200000 | 50000 | 50000 |

Figure 12: Learning curves of variants of RAD, i.e., random amplitude scaling with a single variable (RAS-S), random amplitude scaling with multivariate variables (RAS-M), and Gaussian noise (GN), on OpenAI Gym. The solid line and shaded regions represent the mean and standard deviation, respectively, across four runs.
图 12: RAD变体(即单变量随机幅度缩放(RAS-S)、多变量随机幅度缩放(RAS-M)和高斯噪声(GN))在OpenAI Gym上的学习曲线。实线和阴影区域分别表示四次运行的平均值和标准差。