Sequence Alignment Ensemble With a Single Neural Network for Sequence Labeling
基于单一神经网络的序列标注集成对齐方法
This work was supported by the National Research Foundation of Korea Grant by the Korean Government through Ministry of Education (MOE).
本研究由韩国教育部(MOE)资助的韩国国家研究基金会(National Research Foundation of Korea)提供支持。
ABSTRACT Sequence labeling, in which a class or label is assigned to each token in a given input order, is a fundamental task in natural language processing. Many advanced neural network architectures have recently been proposed to solve the sequential labeling problem affecting this task. By contrast, only a few approaches have been proposed to address the sequential ensemble problem. In this paper, we resolve the sequential ensemble problem by applying the sequential alignment method in a proposed ensemble framework. Specifically, we propose a simple but efficient ensemble candidate generation framework with which multiple heterogeneous systems can easily be prepared from a single neural sequence labeling network. To evaluate the proposed framework, experiments were conducted with part-of-speech (POS) tagging and dependency label prediction problems. The results indicate that the proposed framework achieved accuracy values that were higher by 0.19 and 0.33 than those achieved by the hard-voting method on the Penn-treebank POS-tagged and Universal dependency-tagged datasets, respectively.
摘要
序列标注 (sequence labeling) 是自然语言处理中的基础任务,其目标是为给定输入序列中的每个 token 分配类别或标签。近年来,许多先进的神经网络架构被提出以解决影响该任务的序列标注问题。相比之下,针对序列集成 (sequential ensemble) 问题的研究方法却很少。本文通过将序列对齐方法应用于提出的集成框架,解决了序列集成问题。具体而言,我们提出了一种简单高效的集成候选生成框架,该框架可从单一神经序列标注网络中轻松构建多个异构系统。为评估所提框架,我们在词性标注 (POS tagging) 和依存标签预测任务上进行了实验。结果表明:在 Penn-treebank 词性标注数据集和 Universal 依存标注数据集上,该框架的准确率分别比硬投票方法 (hard-voting method) 提高了 0.19 和 0.33。
INDEX TERMS Deep learning, ensemble, natural language processing, part-of-speech tagging, sequence alignment, sequence labeling.
索引术语 深度学习 (Deep learning)、集成学习 (ensemble)、自然语言处理 (natural language processing)、词性标注 (part-of-speech tagging)、序列对齐 (sequence alignment)、序列标注 (sequence labeling)。
I. INTRODUCTION
I. 引言
Sequence labeling plays an important role in many areas of natural language processing. Most sequential tag prediction problems, such as part-of-speech tagging, dependency parsing, and named entity tagging tasks, are formulated as a sequence labeling framework.
序列标注在自然语言处理的许多领域中扮演着重要角色。大多数序列标记预测问题(如词性标注、依存句法分析和命名实体识别任务)都被建模为序列标注框架。
Recently, many advanced neural network architectures have been proposed to solve sequential labeling problems and have achieved great success. By contrast, surprisingly, limited studies have investigated ensemble approaches for sequential labeling tasks. To improve the performance and efficiency of sequential ensemble labeling models, we investigated sequential ensemble labeling tasks and formulated two desiderata for sequential ensemble labeling models: 1) they should consider multiple sequential sets of information simultaneously and 2) they should minimize the effort necessary to prepare multiple systems for the ensemble.
近来,许多先进的神经网络架构被提出用于解决序列标注问题,并取得了巨大成功。相比之下,令人惊讶的是,针对序列标注任务的集成方法研究却十分有限。为提升序列集成标注模型的性能与效率,我们深入研究了序列集成标注任务,并提出了该模型应满足的两项核心要求:1) 应能同时考虑多组序列信息;2) 应最大限度减少集成所需的多系统准备工作量。
The associate editor coordinating the review of this manuscript and approving it for publication was Rodrigo S. Couto
负责协调审稿并批准本文发表的副编辑是Rodrigo S. Couto
Subsequently, we developed a sequential ensemble labeling framework, called the sequential alignment labeling ensemble (SALE) framework, which has the two desired properties outlined above. The framework is an extension and refinement of the previous work by Jung et al. [1]. The SALE framework 1) applies the sequence alignment method to ensemble systems to use sequential information and 2) provides multiple results from a single neural network.
随后,我们开发了一个名为序列对齐标注集成 (sequential alignment labeling ensemble, SALE) 的序列集成标注框架,该框架具备上述两个理想特性。该框架是对Jung等人[1]先前工作的扩展与改进。SALE框架具有两大特点:1) 将序列对齐方法应用于集成系统以利用序列信息;2) 通过单一神经网络提供多重输出结果。
To consider multiple pieces of sequential information simultaneously, sequence alignment methods are actively used. Further, for better scoring with alignments, the concepts of sequence-block and best block selection are proposed with block construction methods.
为同时考虑多个连续信息片段,序列比对方法被广泛采用。此外,为提升比对评分效果,研究者结合区块构建方法提出了序列区块(sequence-block)和最优区块选择(best block selection)的概念。
In general, ensemble methods exhibit better performance compared with sequential methods. However, considerable effort is needed to prepare multiple systems to generate ensemble candidates. To solve this problem, we propose a method that generates multiple candidates from a single neural sequential labeling model. Using dropout appended network and random weight initialization methods on both training and prediction time, the proposed method successfully generates multiple system outputs with a single neural network architecture. Moreover, experiments confirmed that generating sequences from the single model is sufficient to increase the overall performance of the ensemble.
总体而言,集成方法相比序列方法展现出更优性能。然而,构建多个系统以生成集成候选需要大量准备工作。为解决该问题,我们提出了一种从单一神经序列标注模型生成多候选的方法。通过在训练和预测阶段采用附加dropout的网络结构及随机权重初始化策略,所提方法成功实现了单一神经网络架构下的多系统输出生成。实验进一步证实:仅通过单一模型生成序列即可有效提升集成系统的整体性能。
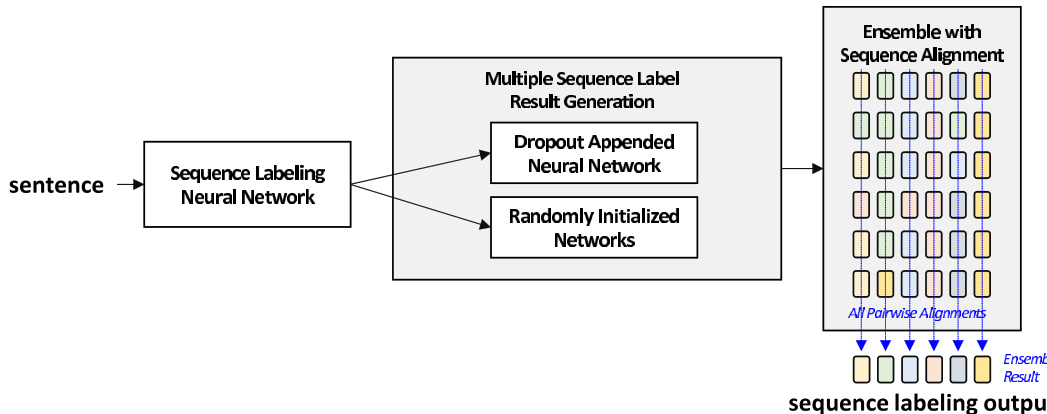
FIGURE 1. Overall process of the proposed sequential alignment labeling ensemble (SALE).
图 1: 提出的序列对齐标注集成 (SALE) 的整体流程。
To verify the usefulness of the proposed framework, extensive experiments were conducted with two typical sequential labeling problems: POS tagging and dependency tag labeling. The POS-tagging results predominantly exhibited an improved F1-score, demonstrating the suitability of the proposed method for general applications. In contrast to the F1-score of the hard-voting method, the F1-score of the proposed method achieved an increase of approximately 0.1 on the Penn-treebank POS-tagged dataset [2] and approximately 0.72 on the Universal dependency (UD) [3] tagged dataset. Fig. 1 shows the architecture of the proposed SALE framework.
为验证所提框架的有效性,我们针对词性标注(POS tagging)和依存关系标注(dependency tag labeling)这两个典型序列标注问题进行了大量实验。词性标注结果主要表现出F1分数的提升,证明了该方法在通用场景下的适用性。与硬投票方法相比,所提方法在Penn-treebank词性标注数据集[2]上的F1分数提高了约0.1,在通用依存关系(UD)[3]标注数据集上提升了约0.72。图1展示了提出的SALE框架架构。
The remainder of this paper is organized as follows. Section II reviews the application of sequence alignment and existing studies on previous POS taggers. Section III presents key theoretical concepts and the details of the proposed framework. Section IV outlines the evaluation experiments conducted and analyzes the results obtained. Section V summarizes the overall study and suggests future areas of research.
本文的剩余部分安排如下。第 II 部分回顾了序列对齐的应用以及现有词性标注器的相关研究。第 III 部分介绍了关键理论概念和所提出框架的细节。第 IV 部分概述了进行的评估实验并分析了获得的结果。第 V 部分总结了整体研究并提出了未来的研究方向。
II. RELATED WORK
II. 相关工作
A. SEQUENCE LABELING WITH ENSEMBLE
A. 集成序列标注
1) SEQUENCE LABELING
1) 序列标注
Several sequence labeling algorithms have been proposed and several sequence labeling techniques that pre-train deep learning models have been developed. Additionally, many studies have been conducted for enhancing the performance of sequence labeling algorithms by embedding context in the modeling, by applying conditional random fields (CRFs) [4] to long short-term memory (LSTM) [5] or bidirectionalLSTM (Bi-LSTM) [6].
已提出多种序列标注算法,并开发了若干基于深度学习预训练的序列标注技术。此外,许多研究通过在建模中嵌入上下文信息,或将条件随机场(CRF) [4] 应用于长短期记忆网络(LSTM) [5] 或双向长短期记忆网络(Bi-LSTM) [6],来提升序列标注算法的性能。
2) ENSEMBLE METHODS
2) 集成方法
Various methods have been developed to improve labeling accuracy. The most basic approach is the ensemble technique.
为提高标注准确性,已开发出多种方法。最基础的方法是集成技术。
Ensemble techniques such as bagging, boosting, and voting have been extensively applied to natural language processing [7]–[9]. The simplest method is the hard voting method, in which voting is performed for all results individually.
集成技术如装袋法 (bagging)、提升法 (boosting) 和投票法 (voting) 已广泛应用于自然语言处理领域 [7]–[9]。最简单的方法是硬投票法,即对所有结果逐一进行投票。
3) SEQUENCE LABELING WITH ENSEMBLE
3) 基于集成学习的序列标注
Few ensemble-based methods have addressed the problem of sequential alignment. Typically, the majority voting scheme applies sequence labeling tasks [10]. Dell’Orletta [11] proposed a sequence labeling model that combines six different POS taggers in an ensemble.
少数基于集成学习的方法解决了序列对齐问题。典型情况下,多数投票方案适用于序列标注任务 [10]。Dell’Orletta [11] 提出了一种集成六个不同词性标注器的序列标注模型。
B. SEQUENCE ALIGNMENT
B. 序列对齐
Sequence alignment refers to the extraction of similar sequences of genes or proteins using dynamic programmingbased algorithms. This is primarily carried out in the fields of biology and medicine. Through clustering, pair-wise sequence alignment aligns a pair of sequences, and multiwise sequence alignment aligns multiple sets of sentences. The pair-wise method is based on the Smith–Waterman approach, which searches through the longest sequences included in other sequences, and the Needleman–Wunsch method, which applies an alignment over the entire range. Although these sequence alignment techniques are not widely used in natural language processing, several studies have adopted the use of scoring as a similarity measurement, including [12] and [13], which attempt to extract relationships using local sequence alignment.
序列比对 (Sequence alignment) 是指使用基于动态规划的算法提取基因或蛋白质的相似序列,主要应用于生物学和医学领域。通过聚类方法,双序列比对 (pair-wise sequence alignment) 用于对齐一对序列,而多序列比对 (multiwise sequence alignment) 则用于对齐多组句子。双序列比对基于 Smith-Waterman 方法(搜索其他序列中包含的最长序列)和 Needleman-Wunsch 方法(对整个范围进行全局对齐)。尽管这些序列比对技术在自然语言处理中应用不广泛,但已有若干研究采用评分作为相似性度量,例如 [12] 和 [13] 尝试通过局部序列比对来提取关系。
III. SEQUENCE ALIGNMENT ENSEMBLE WITH MULTIPLE OUTPUTS
III. 多输出序列对齐集成
In this paper, we introduce an ensemble-based sequence labeling technique that uses token-wise sequence alignment on multiple sequence-label results. The proposed method comprises two stages: multiple ensemble-candidates generation and sequence-alignment ensemble. Fig. 1 illustrates the overall process of the proposed method.
本文提出了一种基于集成的序列标注技术,该方法通过对多个序列标注结果进行token级别的序列对齐来实现。所提出的方法包含两个阶段:多候选集成生成和序列对齐集成。图1展示了该方法的整体流程。
A. MULTIPLE ENSEMBLE-CANDIDATES GENERATION
A. 多集成候选生成
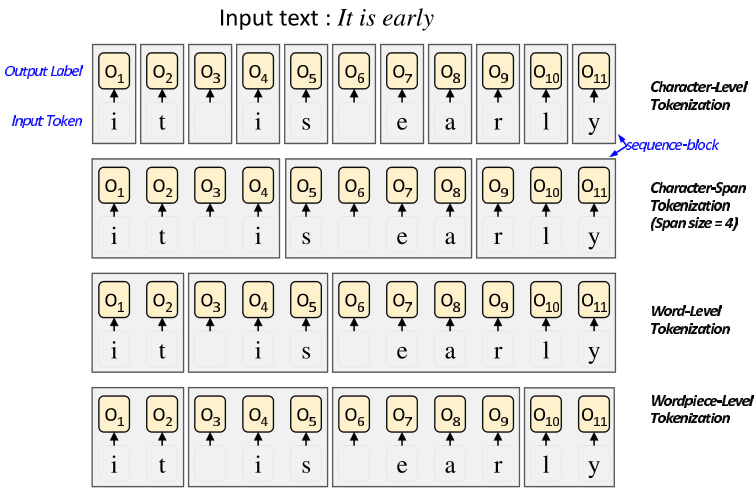
In typical ensemble methods, multiple prediction candidates are typically generated by multiple systems. For example, (a) Sequence-block construction examples.
在典型的集成方法中,多个预测候选通常由多个系统生成。例如,(a) 序列块构建示例。
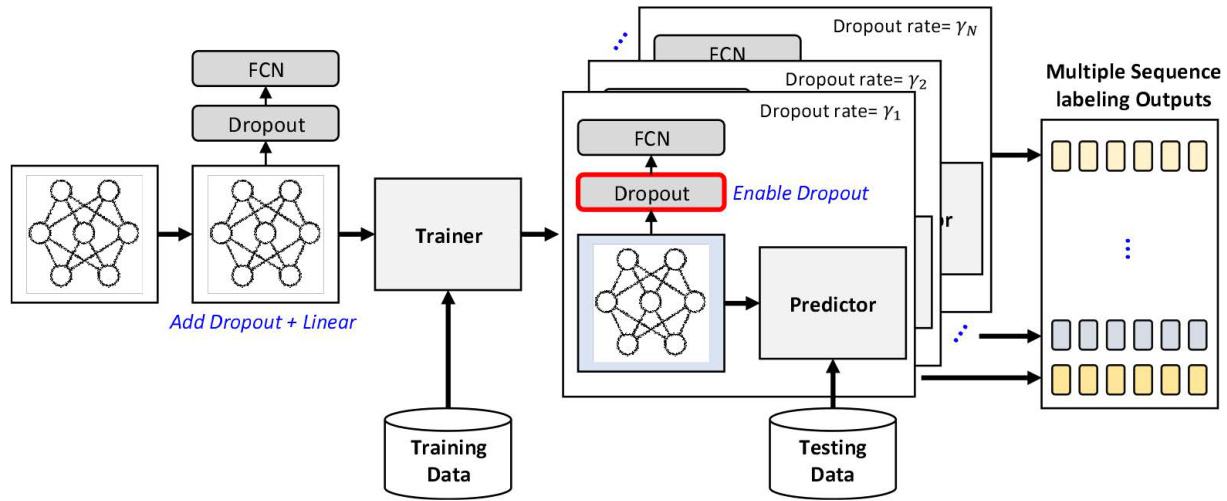
FIGURE 2. Dropout for multiple ensemble candidate generation. $\gamma_{k}$ is the dropout rate for the top inference layer.
图 2: 用于生成多个集成候选的 Dropout。$\gamma_{k}$ 是顶部推理层的 dropout 率。
(b) Sequence-block scoring with multiple outputs.
(b) 多输出序列块评分。
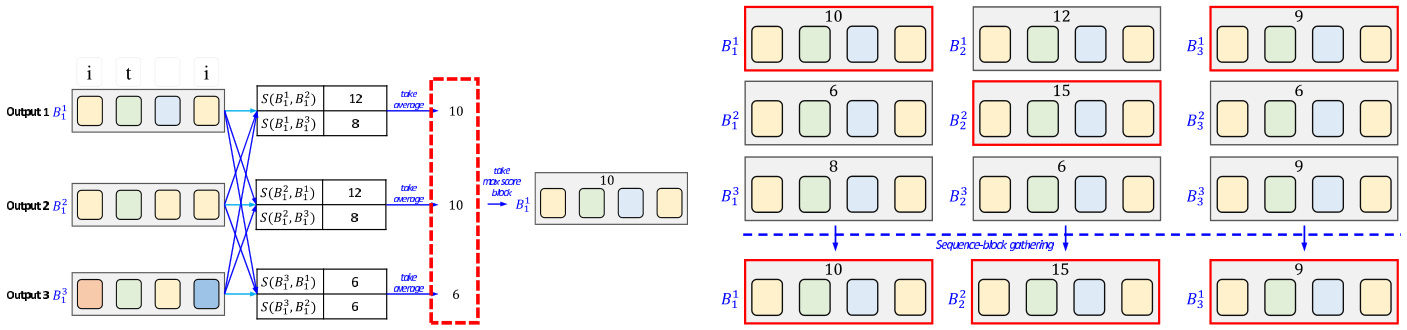
(c) Sequence label generation. FIGURE 3. Sequence-block scoring with pairwise alignment and the sequence ensemble method.
图 3: 基于成对对齐和序列集成方法的序列块评分
(c) 序列标签生成。
in classification tasks, multiple classifier models are employed, and their outputs are considered candidates for ensemble algorithms. By contrast, in our proposed method, we employ a single model to generate multiple prediction candidates instead of using multiple systems.
在分类任务中,通常采用多个分类器模型,其输出结果作为集成算法的候选输入。相比之下,我们提出的方法仅使用单一模型生成多个预测候选,而非依赖多系统架构。
To generate multiple candidates from a single neural sequence labeling network, we use active dropout and network weight initialization with random seeding.
为了从单个神经序列标注网络中生成多个候选结果,我们采用了主动丢弃 (active dropout) 和随机种子网络权重初始化方法。
1) DROPOUT LAYER FOR DIVERSITY
1) 用于多样性的Dropout层
Dropout [14] or Drop Connect is a regular iz ation technique for reducing over fitting in artificial neural networks. It randomly ‘‘drops out’’, or omits, units (both hidden and visible) during the training process of a neural network.
Dropout [14] 或 Drop Connect 是一种用于减少人工神经网络过拟合的正则化技术。它会在神经网络的训练过程中随机"丢弃"或忽略单元(包括隐藏层和可见层)。
In our work, we employed another dropout layer to diversify the sequence labeling output. The proposed multiple ensemble-candidates generation process is as follows:
在我们的工作中,我们采用了另一个dropout层来使序列标注输出多样化。所提出的多集成候选生成过程如下:
As the edges of fully connected layer $D$ are randomly connected or disconnected, the final labeling outputs can be varied according to the dropout rate. Fig. 2 illustrates the process of multiple ensemble-candidates generation with dropout.
由于全连接层 $D$ 的边缘是随机连接或断开的,最终的标注输出会因 dropout 率的不同而变化。图 2 展示了使用 dropout 生成多个集成候选的过程。
In this work, using five different dropout values, a single neural network with five different personality traits was created.
在这项工作中,通过使用五种不同的丢弃率(dropout)值,创建了一个具有五种不同人格特质的单一神经网络。
2) WEIGHT INITIALIZATION S WITH RANDOM SEEDS
2) 使用随机种子进行权重初始化
Weight initialization is an important hyper parameter tuning process for deep learning models. Different weight initializations can generate different trained models, and naturally, different predictions.
权重初始化是深度学习模型重要的超参数调优过程。不同的权重初始化会训练出不同的模型,从而产生不同的预测结果。
When the same model is trained with multiple random seeds, fine-tuning is unstable, which can result in a large variance in task performance [15]. This means that the variance due to random seeds has a significant influence on the diversity of the developed model. In this work, we used the variance induced by different initialization s to generate multiple system outputs. We applied the following five different random seeds for weight initialization: 500, 1000, 1234, 1500, 2000.
当使用多个随机种子训练同一模型时,微调过程会不稳定,可能导致任务性能出现较大方差 [15]。这意味着随机种子引起的方差对开发模型的多样性具有显著影响。本工作中,我们利用不同初始化导致的方差来生成多个系统输出。权重初始化采用了以下五个不同的随机种子:500、1000、1234、1500、2000。
3) RESULTS SELECTION
3) 结果筛选
By combining dropout and random seed initialization s, multiple predictions can be generated from a single model. As five dropout rates and five random seeds are used, a total of 25 $(5\times5)$ different system outputs can be generated. Twentyfive different outputs can be considered for the ensemble; however, the corresponding number of results may be too excessive for further processing. Therefore, we select five ensemble candidates using the following methods.
通过结合dropout和随机种子初始化,可以从单一模型生成多个预测结果。由于使用了5种dropout率和5个随机种子,总共可生成25种$(5\times5)$不同的系统输出。虽然可以考虑将这25种不同输出用于集成学习,但对应结果数量可能过多而难以进一步处理。因此我们采用以下方法筛选出5个集成候选模型。
• DS $@$ SR: Select multiple outputs from different random seeds in the same dropout rate settings. • DR $@$ SS: Select multiple outputs from different dropout rates in the same random seed settings. • RANDOM: Randomly select five outputs from a combination of 25 settings.
• DS $@$ SR:在相同的dropout率设置下,从不同随机种子中选择多个输出。
• DR $@$ SS:在相同的随机种子设置下,从不同dropout率中选择多个输出。
• RANDOM:从25种设置组合中随机选择五个输出。
B. SEQUENCE ENSEMBLE WITH ALIGNMENT
B. 序列集成与对齐
This study extended and refined the sequence alignmentbased ensemble technique introduced by Jung et al. [1]. The proposed sequence ensemble technique comprises three sub-modules: 1) sequence-block construction module, 2) sequence-block scoring module, and 3) label sequence generation module.
本研究扩展并完善了Jung等人[1]提出的基于序列对齐的集成技术。所提出的序列集成技术包含三个子模块:1) 序列块构建模块,2) 序列块评分模块,以及3) 标签序列生成模块。
1) SEQUENCE-BLOCK CONSTRUCTION MODULE
1) 序列块构建模块
In this study, pair-wise sequence alignment algorithms are actively used for scoring the agreements between two sequence labeling results. In particular, biology-inspired algorithms such as the Smith–Waterman and Needleman– Wunsch algorithms are employed. In the case of DNA analysis, the basic units for comparison are easily determined. Typically, character units—specifically, four nucleotide bases, namely, adenine (A), guanine (G), thymine (T), and cytosine (C)—are used in the biology domain.
在本研究中,成对序列比对算法被积极用于评估两个序列标注结果之间的一致性。具体采用了Smith-Waterman和Needleman-Wunsch等受生物学启发的算法。在DNA分析场景中,比较的基本单元易于确定。生物学领域通常使用字符单元——具体而言是四种核苷酸碱基:腺嘌呤(A)、鸟嘌呤(G)、胸腺嘧啶(T)和胞嘧啶(C)。
However, in the natural language domain, the units for comparison should be considered carefully, such as whether to use character, character-span, or word-level units [1]. In this study, we added a sub-word level comparison unit. As the proposed method uses a single model, the same subword tokenizers can be used for fair comparison. Fig. 3a shows an example of the units being compared. We call the tokenized sub-part of the sequence the sequence-block and denote it as $B_{j}^{i}$ , where $i$ signifies the $i^{t h}$ sequence block in a sentence and $j$ signifies the $j^{t h}$ dropout and random seed combination system.
然而,在自然语言领域,需要仔细考虑比较单元的选择,例如使用字符、字符跨度还是词级单元[1]。本研究新增了子词(sub-word)级别的比较单元。由于所提方法采用单一模型,可使用相同的子词分词器(tokenizer)进行公平对比。图3a展示了被比较单元的示例。我们将序列经分词后的子部分称为序列块(sequence-block),记作$B_{j}^{i}$,其中$i$表示句子中的第$i$个序列块,$j$表示第$j$组dropout与随机种子组合的系统。
2) SEQUENCE-BLOCK SCORING
2) 序列块评分
In this study, sequence alignment algorithms such as Smith–Waterman are applied to a sub-label-sequence in a single sequence block, not to the entire label-sequence. For example, in Fig. 3b, multiple sequence blocks are constructed for each sequence label output.
在本研究中,Smith-Waterman等序列比对算法仅应用于单个序列块中的子标签序列,而非整个标签序列。例如,在图3b中,每个序列标签输出都构建了多个序列块。
The procedure for selecting the best sequence block for the ensemble is as follows.
为集成选择最佳序列块的过程如下。
To calculate the sequence alignment, we use the Smith—Waterman and Needleman–Wunsch algorithms.
为了计算序列比对,我们使用了Smith-Waterman和Needleman-Wunsch算法。
3) LABEL SEQUENCE GENERATION
3) 标签序列生成
After selecting the best sequence blocks for each position, the blocks for each position are simply gathered to generate the final ensemble sequence labeling output. Fig. 3c illustrates the output generation process.
在为每个位置选择最佳序列块后,只需将这些位置的块收集起来即可生成最终的集成序列标注输出。图 3c 展示了输出生成过程。
4) OVERALL SEQUENCE ENSEMBLE WITH ALIGNMENT PROCESS
4) 基于对齐过程的整体序列集成
Fig. 3 shows the overall sequence ensemble with alignment process. This process assumes that all the result sequences of each model have been determined. One token iz ation method is selected from among those shown in Fig. 3a and applied to all result label sequences. As shown in Fig. 3b, the score of each token is determined via average the results of the pairwise sequence alignment methods with the other tokens in the same sequence scope. Among the tokens in the same range, Calculate the token score as all the pair-wise sequence alignment score of the other models’ token set, and get average as token alignment score. The token with the highest score is selected and the list is combined as shown Fig. 3c.
图 3 展示了整体序列集成与对齐流程。该流程假设每个模型的所有结果序列已确定。从图 3a 所示方法中选择一种 token 化方案,并应用于所有结果标签序列。如图 3b 所示,每个 token 的得分通过计算其与同序列范围内其他 token 的成对序列对齐结果的平均值确定。在同一范围内,将 token 得分计算为与其他模型 token 集的所有成对序列对齐分数,并取平均值作为 token 对齐分数。最终选择得分最高的 token 并按图 3c 所示方式进行列表合并。
TABLE 1. Performance of the ensemble-candidates and the proposed sequence-alignment ensemble approach on the POS-tagger dataset. The performance comparison between the proposed sequential alignment labeling ensemble (SALE) approach and other methods is based on F1 and accuracy scores. For the SALE results, the upper value in each row is the F1-score and the lower value is the accuracy. The best model for each sequence alignment method is shown in boldface. The highest F1-score is highlighted in yellow. All ensemble results were tested with the sentence-wise McNemar’s test [16] over a baseline hard voting ensemble. $p-v a l u e<0.05:\ddagger.$ .
表 1: 词性标注数据集上集成候选方法与提出的序列对齐集成方法的性能对比。提出的序列对齐标注集成 (SALE) 方法与其他方法的性能比较基于 F1 值和准确率。对于 SALE 结果,每行上方数值为 F1 值,下方数值为准确率。每种序列对齐方法的最佳模型以粗体显示,最高 F1 值用黄色高亮标注。所有集成结果均通过基于句子级别的 McNemar 检验 [16] 与硬投票集成基线进行对比测试 ($p-value<0.05:\ddagger$)。
| 非集成方法 (准确率) | ||||||
|---|---|---|---|---|---|---|
| CVT + Multi-task [17] | 97.76 | |||||
| Char Bi-LSTM [18] | 97.78 | |||||
| Flair [19] | 97.85 | |||||
| Meta-BiLSTM [20] | 97.96 | |||||
| 集成方法 | 字符 | 字符跨度 (size=2) (size=3) | (size=4) | 词语 | 词片段 | |
| DS @ SR | 98.2097.98 | |||||
| 硬投票 | 98.23 | |||||
| DR @ SS | 98.01 | |||||
| RANDOM | 98.2398.12 | |||||
| SALE | ||||||
| DS @ SR | 98.22 | 98.21 | 98.22 | 98.26 | 98.28 | |
| 97.98 | 97.98 | 97.98 | 97.98 | 98.12 | ||
| Smith-Waterman | DR @ SS | 98.23 | 98.24 | 98.24 | 98.27 | 98.30 |
| 98.01 | 98.01 | 98.01 | 98.00 | 98.15 | ||
| RANDOM | 98.24 | 98.24 | 98.24 | 97.29 | 98.30 | |
| 98.00 | 98.00 | 98.00 | 98.00 | 98.12 | ||
| DS @ SR | 98.20 | 98.20 | 98.20 | 98.20 | 98.28 | |
| 97.98 | 97.98 | 97.98 | 97.98 | 98.12 | ||
| Needman-Wunsch | DR @ SS | 98.23 | 98.23 | 98.23 | 98.23 | 98.30 |
| 98.01 | 98.01 | 98.00 | 98.00 | 98.15 | ||
| RANDOM | 98.22 | 98.22 | 98.23 | 98.23 | 98.30 | |
| 98.00 | 98.00 | 98.00 | 98.00 | 98.12 |
IV. EXPERIMENTAL EVALUATION AND RESULTS
IV. 实验评估与结果
We evaluated the proposed SALE framework based on the various results of a single neural network architecture. To demonstrate the effectiveness of our framework, the represent at ive sequence labeling tasks POS tagging and dependency tag prediction were conducted on an English dataset.
我们基于单一神经网络架构的多种结果评估了提出的SALE框架。为验证框架有效性,在英文数据集上进行了具有代表性的序列标注任务:词性标注和依存关系标签预测。
A. DATASET
A. 数据集
The dataset used for this study was the article-based Penntreebank dataset. As there are no labels for punctuation marks in this dataset, the first letter of the symbols was marked
本研究使用的数据集是基于文章的Penntreebank数据集。由于该数据集中没有标点符号的标签,因此对符号的首字母进行了标记
TABLE 2. Performance of the ensemble-candidates and the proposed SALE approach on the POS-tagger dataset based on the F1 and accuracy scores of 25 ensemble-candidates for dropout rate versus random seed. The upper value in each row is the F1-score and the lower value is the accuracy.
表 2: 基于25个集成候选模型在词性标注数据集上的F1值和准确率得分,展示了集成候选方法与提出的SALE方法在dropout率与随机种子条件下的性能对比。每行上方数值为F1值,下方数值为准确率。
| 0.2 dropout 0.3 0.4 0.5 | Seed 500 1000 1234 1500 2000 |
|---|---|
| 98.05 0.1 97.85 | 98.14 98.12 98.08 97.89 97.88 97.85 |
| 98.17 98.01 97.92 97.78 | 98.06 98.03 98.18 97.80 97.80 97.95 |
| 98.06 97.82 | 98.2 98 98.13 98.16 97.95 97.80 97.89 97.93 |
| 98.15 98.07 97.92 97.88 | 98.12 98.17 98.05 97.86 97.92 97.89 |
| 97.95 98.1 97.84 97.91 | 98.12 98.16 98.11 97.91 97.91 97.87 |
as a label. The word-by-word morpheme labels were converted into character units and BIO tags were attached to mark the scope of the word combinations. After applying the
将逐词语素标签转换为字符单位,并附加BIO标记以标注词语组合的范围。应用后
TABLE 3. Performance of the ensemble-candidates and the proposed sequence-alignment ensemble approach on the Dependency tag prediction task. The performance comparison between the proposed sequential alignment labeling ensemble (SALE) approach and other methods is based on F1 and accuracy scores. For the SALE results, the upper value in each row is the F1-score and the lower value is the accuracy. The best model for each sequence alignment method is shown in boldface. The highest F1-score is highlighted in yellow. All ensemble results were tested with the sentence-wise McNemar’s test [16] over a baseline hard voting ensemble. $p-v a l u e<0.05:\ddagger.$ .
表 3: 集成候选方法及提出的序列对齐集成方法在依存标签预测任务上的性能表现。提出的序列对齐标注集成(SALE)方法与其他方法的性能对比基于F1值和准确率。SALE结果中每行的上值为F1值,下值为准确率。每种序列对齐方法的最佳模型以粗体显示,最高F1值用黄色高亮。所有集成结果均通过基于句子级别的McNemar检验[16]与硬投票集成基线进行对比 ($p值<0.05:\ddagger$)。
| 非集成方法(准确率) | ||||||
|---|---|---|---|---|---|---|
| Bi-LSTM [21] | 96.40 | |||||
| MultiBPEmb [22] | 96.62 | |||||
| Adversarial Bi-LSTM [23] | 96.65 | 96.88 | ||||
| BiLSTM-LAN [24] | ||||||
| 集成方法 | 字符 | 字符跨度(size=2)(size=3) | (size=4) | 词语 | 词片 | |
| 硬投票 | ||||||
| DS @ SR | 97.04 | |||||
| 97.20 | ||||||
| DR @ SS | 96.94 | |||||
| RANDOM | 97.17 | |||||
| 97.01 | 97.18 | |||||
| SALE | ||||||
| Smith-Waterman | ||||||
| DS @ SR | 97.05 | 97.06 | 97.02 | 97.11 | 97.76 | |
| 97.21 | 97.21 | 97.20 | 97.21 | 97.11 | ||
| DR @ SS | 96.99 | 96.98 | 96.98 | 97.04 | 96.94 | |
| 97.17 | 97.17 | 97.17 | 97.18 | 97.08 | ||
| RANDOM | 97.02 | 97.02 | 97.02 | 97.07 | 97.02 | |
| 97.18 | 97.18 | 97.18 | 97.18 | 97.08 | ||
| DS @ SR | 97.04 | 97.03 | 97.04 | 97.04 | 97.76 | |
| 97.20 | 97.20 | 97.20 | 97.20 | 97.11 | ||
| Needman-Wunsch | ||||||
| DR @ SS | 96.97 | 96.96 | 96.98 | 96.94 | ||
| 96.96 | 97.17 | 97.18 | 97.15 | |||
| RANDOM | 97.17 | 97.17 | 97.01 | 97.02 | 97.02 | |
| 97.01 | 97.18 | 97.18 | 97.18 | 97.08 | ||
| 97.18 |

FIGURE 4. Reduction of incorrect label frequency ratio. (Blue line) Ratio of correct task results to incorrect results on the POS tagger task. (Orange line) Ratio of correct task results to incorrect results on the dependency tag prediction task.
图 4: 错误标签频率比率的降低。(Blue line) 词性标注任务中正确结果与错误结果的比率。(Orange line) 依存关系标签预测任务中正确结果与错误结果的比率。
character-wise sequence labeling model, we take apart the wordpiece label sequence to the label sequences characterwise with BIO tags. We used two different tagging
字符级序列标注模型中,我们将wordpiece标签序列拆解为带有BIO标记的字符级标签序列。我们采用了两套不同的标注方案

FIGURE 5. Reduction of incorrect label frequency ratio: (a) Ratio of correct task results to incorrect results on the POS tagger task; (b) Ratio of correct task results to incorrect results on the dependency tag prediction task.
图 5: 错误标签频率比率的降低: (a) POS标注任务中正确结果与错误结果的比率; (b) 依存关系标注预测任务中正确结果与错误结果的比率。
structures—the Penn-treebank and UD styles—on the same treebank dataset.
结构——Penn-treebank和UD风格——在同一树库数据集上。
B. BASE MODEL
B. 基础模型
In this study, we employed the BART [25] encoder as the base text encoder for the sequence labeling task. We used wordpiece token iz ation methods to preprocess the input text.
在本研究中,我们采用BART[25]编码器作为序列标注任务的基础文本编码器,并使用wordpiece tokenization方法对输入文本进行预处理。
Input text $:$ Countered James Maguire, chairman of specialists Brothers inc
输入文本:Countered James Maguire, specialists Brothers inc 董事长

FIGURE 6. Example of the ensemble process, in which the input sentence is assigned a result label sequence in dependency tag prediction.
图 6: 集成过程示例,其中输入句子在依存标签预测中被分配了一个结果标签序列。
TABLE 4. Performance of the ensemble-candidates and the proposed SALE approach on Dependency tag prediction task based on the F1 and accuracy scores of 25 ensemble-candidates for dropout rate versus random seed. The upper value in each row is the F1-score and the lower value is the accuracy.
表 4: 基于25个集成候选模型在dropout率与随机种子下的F1和准确率分数,集成候选方法与提出的SALE方法在依存标签预测任务上的性能表现。每行上方数值为F1分数,下方数值为准确率。
| nodo.p | Seed 0.1 | Seed 1234 1500 | Seed 2000 |
|---|---|---|---|
| 500 1000 96.25 96.7 | 96.16 96.68 | 96.22 | |
| 0.2 0.3 | 96.25 96.51 96.21 96.81 | 96.13 96.52 96.85 96.93 | 96.23 96.78 |
| 96.09 96.65 95.5 96.77 | 96.71 96.70 96.91 | 96.54 96.86 96.25 | |
| 0.4 | 95.65 96.65 95.58 96.72 | 96.73 96.64 96.21 | 96.27 96.92 96.92 |
| 0.5 | 95.65 | 96.48 96.30 | 96.75 96.70 |
| 96.87 96.8 96.63 96.67 | 96.86 96.63 | 96.26 96.22 96.31 96.27 |
All models used the same parameter set. The maximum length of the character sequence was set to 500, the learning rate was 0.0001 or 0.00001, and the batch size was set to 32. The random seed was selected from (500, 1000, 1500, 2000, 1234), and the dropout was selected in the range 0.1–0.5.
所有模型使用相同的参数集。字符序列的最大长度设置为500,学习率为0.0001或0.00001,批量大小设置为32。随机种子从(500, 1000, 1500, 2000, 1234)中选取,dropout在0.1–0.5范围内选择。
C. PERFORMANCE
C. 性能
To measure the performance, we adhered to the metrics of CoNLL-2000 [26], which is the standard natural language treatment task. In this study, we measured accuracy, precision, recall, and F1-score to evaluate the sequence labeling performance of the proposed approach. The final decoded sequence labels of the BART model were post-processed according to the sequence-block construction method.
为衡量性能,我们遵循了CoNLL-2000 [26]的标准自然语言处理任务指标。本研究通过准确率、精确率、召回率和F1值来评估所提方法的序列标注性能。BART模型的最终解码序列标签根据序列块构建方法进行了后处理。
1) SEQUENCE LABELING PERFORMANCE
1) 序列标注性能
Tables 2 and 4 show the base performance of 25 ensemble candidates and Tables 1 and 3 compare the proposed SALE method with other methods under various conditions on each task.
表 2 和表 4 展示了 25 个集成候选方案的基础性能,表 1 和表 3 则在各任务不同条件下对比了提出的 SALE 方法与其他方法。
SALE performed better than the hard–voting ensemble technique in most cases. Furthermore, it provided better results than previous single-system methods. In general, SALE exhibits better performance results on the word and wordpiece block units than on the character and characterspan units. On the POS-tagging problem, its overall performance is best on the wordpiece block unit, whereas on the dependency tag prediction problem, its overall best performance is on the word block unit.
在大多数情况下,SALE的表现优于硬投票集成技术。此外,它提供了比以往单系统方法更好的结果。总体而言,SALE在词(word)和词块(wordpiece)单元上的性能表现优于字符(character)和字符跨度(characterspan)单元。在词性标注(POS-tagging)问题上,其整体性能在词块单元上表现最佳,而在依存标签预测(dependency tag prediction)问题上,其最佳整体性能出现在词单元上。
The experimental results indicate that the performance of all the sequence alignment methods is similar. For the wordpiece block unit, the Smith–Waterman and Needleman–Wunsch alignment algorithms exhibit similar results.
实验结果表明,所有序列比对方法的性能相近。对于wordpiece块单元,Smith-Waterman和Needleman-Wunsch比对算法表现出相似的结果。
The best accuracy and F1-score results are obtained for DR@SD candidate selection using the wordpiece block unit; the values are superior to those of other state of the art (SOTA) models.
使用wordpiece块单元进行DR@SD候选选择时,获得了最佳的准确率和F1分数结果;这些数值优于其他最先进(SOTA)模型。
2) DIVERSITY
2) 多样性
Fig. 4 shows curves of entropy versus number of candidates for the ensemble method. Higher entropy implies more diverse sequence-label outputs. When the ensemble module has more options, the module may produce better results. In Fig. 4, POS tagger shows much higher entropy values than dependency tag prediction. Further, in Tables 1 and 3, more performance gain is observed for dependency tag prediction than for the POS tagger task. For dependency tag prediction, the proposed SALE approach achieves an increase in F1-score of 0.72 compared to that achieved via hard voting, and for the POS tagger task, an increase of 0.1.
图 4 展示了集成方法中熵随候选数量变化的曲线。熵值越高意味着序列标签输出的多样性越强。当集成模块拥有更多选择时,该模块可能产生更好的结果。在图 4 中,词性标注器 (POS tagger) 的熵值明显高于依存标签预测。此外,在表 1 和表 3 中,依存标签预测的性能提升幅度大于词性标注任务。对于依存标签预测,我们提出的 SALE 方法相比硬投票机制实现了 0.72 的 F1 分数提升,而词性标注任务的提升幅度为 0.1。
3) SEQUENCE ALIGNMENT AND LABELING PERFORMANCE
3) 序列对齐与标注性能
To verify the efficiency of the proposed SALE framework, we compared the best single-model result to our best ensemble result. We counted the number of single-model results and ensemble results for which the single model was correct and the ensemble model was incorrect to obtain the Correct-to-Incorrect frequency. Then, we performed the converse to obtain the Incorrect-to-Correct frequency. The respective results for each task are presented in Fig. 5. As the Incorrect-to-Correct index increases on both tasks, the ensemble technique is effective in improving accuracy. Fig. 5 shows the results.
为验证所提出的SALE框架效率,我们将最佳单模型结果与最佳集成结果进行对比。统计单模型正确而集成模型错误的案例数量,得到"正确转错误"频率;反之统计得到"错误转正确"频率。各任务具体结果如图5所示。随着两项任务中"错误转正确"指标提升,表明集成技术能有效提高准确率。图5展示了相关结果。
4) QUALITATIVE ANALYSIS
4) 定性分析
Fig. 6 shows how one input statement obtains a matching label sequence. This example uses a dependency tag sequence. We create a multi-label sequence with multiple models in a single structure. After tokenizing these label sequences, the ensemble method selects results from various label options. This example also shows that SALE performs better modifications than hard voting. In this case, the word ‘‘McGuire’’ is judged as the wrong tag by a majority vote in the character unit. By contrast, the proposed SALE method correctly scored all models’ word unit label sequences.
图 6 展示了输入语句如何获得匹配的标签序列。该示例使用依存标签序列。我们在单一结构中创建包含多个模型的多标签序列。在对这些标签序列进行分词后,集成方法从多种标签选项中筛选结果。此示例还表明,SALE方法比硬投票(hard voting)能执行更优的修正。在本案例中,单词"McGuire"在字符单元层面被多数投票判定为错误标签,而提出的SALE方法则正确评估了所有模型的单词单元标签序列。
V. CONCLUSION
V. 结论
In this paper, we proposed a sequence ensemble technique that utilizes the sequence alignment method. Additionally, we proposed a simple but efficient ensemble-candidates generation method, called SALE, that easily generates multiple heterogeneous system outputs from a single neural sequence labeling network.
本文提出了一种利用序列比对方法的序列集成技术。此外,我们还提出了一种简单高效的集成候选生成方法SALE,能够从单一神经序列标注网络中轻松生成多个异构系统输出。
To verify the effectiveness of our proposed SALE method, we evaluated it on the representative sequence labeling task POS tagger. We used the CoNLL-2000 measure. The application of the SALE method to multi-label sequences resulted in a superior F1-score compared with the hard-voting system. Furthermore, SALE with $\mathrm{DR}@\mathrm{SS}$ drop ou ${\it\Delta\phi}=0.5$ using the Smith–Waterman algorithm with wordpiece unit, and $\mathrm{DS}@\mathrm{SR}$ random seed $=1500$ using the Smith–Waterman algorithm with word unit on the UD dataset performed the best. The experimental results show that SALE is highly effective in correcting label sequences.
为验证我们提出的SALE方法有效性,在代表性序列标注任务词性标注(POS tagger)上进行了评估。采用CoNLL-2000评测指标,SALE方法应用于多标签序列时,相比硬投票系统获得了更优的F1值。此外,在UD数据集上,使用$\mathrm{DR}@\mathrm{SS}$丢弃率${\it\Delta\phi}=0.5$(基于wordpiece单元的Smith-Waterman算法)和$\mathrm{DS}@\mathrm{SR}$随机种子$=1500$(基于词单元的Smith-Waterman算法)的SALE组合表现最佳。实验结果表明SALE在修正标签序列方面具有显著效果。
We also conducted a comparison experiment with the SOTA models for POS-tagging (Penn-treebank [20]) and dependency tag prediction (Universal Dependencies [24]). On POS-tagging, compared with the SOTA model, SALE’s best accuracy was 0.19 higher. On dependency tag prediction, SALE’s best accuracy was 0.33 higher than that of the SOTA model.
我们还与词性标注(POS-tagging) (Penn-treebank [20]) 和依存关系标注(dependency tag prediction) (Universal Dependencies [24]) 的SOTA模型进行了对比实验。在词性标注任务上,SALE的最佳准确率比SOTA模型高出0.19;在依存关系标注任务上,SALE的最佳准确率比SOTA模型高出0.33。
The proposed SALE method has two limitations, 1) it is an the ensemble method and is thus computation memory- and time-intensive, and 2) it use the pair-wise sequence alignment method for scoring token-by-token. In future work, focused on these limitations, we can implement results of multidropout through the whole model structure as one model training step and provide self-ensemble-like results. Using distillation or optimization methods, we can also reduce the generation cost for the ensemble by applying model quantization. Moreover, replacing the pair-wise alignment method, we plan to use the multi-sequence sequence alignment methods for structure expansion.
提出的SALE方法存在两个局限性:1) 它是一种集成方法,因此计算内存和时间消耗较大;2) 它使用逐token配对比对方法进行评分。在未来的工作中,针对这些局限性,我们可以将多重dropout结果作为模型训练的一个步骤来实现整个模型结构,并提供类似自集成的效果。通过应用蒸馏或优化方法,我们还可以通过模型量化来降低集成生成的成本。此外,我们计划用多序列比对方法替代成对序列比对方法,以实现结构扩展。
REFERENCES
参考文献

JEESU JUNG received the B.S. degree in computer science and engineering from Chungnam National University, Daejeon, South Korea, in 2021, where she is currently pursuing the M.S. degree in computer science and engineering. Her research interests include natural language processing, data augmentation, machine learning, and deep learning.
JEESU JUNG于2021年获得韩国大田忠南大学计算机科学与工程学士学位,目前正在该校攻读计算机科学与工程硕士学位。她的研究方向包括自然语言处理、数据增强、机器学习以及深度学习。
SANGKEUN JUNG received the B.S., M.S., and Ph.D. degrees in computer engineering from POSTECH, Pohang, South Korea, in 2004, 2006, and 2010, respectively. From 2010 to 2012, he was a Researcher with Samsung Electronics, Suwon, South Korea. From 2012 to 2014, he was a Researcher with ETRI, Daejeon, South Korea. From 2014 to 2018, he was a Researcher with SK Telecom, Seoul, South Korea. Since 2018, he has been a Professor of computer science and engineering at Chungnam National University, Daejeon. His research interests include natural language processing, machine learning, and deep learning.
SANGKEUN JUNG 于2004年、2006年和2010年分别获得韩国浦项科技大学计算机工程学士、硕士和博士学位。2010年至2012年,他在韩国水原的三星电子担任研究员。2012年至2014年,他在韩国大田的韩国电子通信研究院(ETRI)担任研究员。2014年至2018年,他在韩国首尔的SK Telecom担任研究员。自2018年起,他在韩国大田的忠南国立大学担任计算机科学与工程教授。他的研究方向包括自然语言处理、机器学习以及深度学习。


HYEIN SEO received the B.S. and M.S. degrees in computer science and engineering from Chungnam National University, Daejeon, South Korea, in 2020 and 2022, respectively, where she is currently pursuing the Ph.D. degree in computer science and engineering. Her research interests include natural language processing, machine learning, and deep learning.
HYEIN SEO分别于2020年和2022年在韩国大田忠南大学获得计算机科学与工程学士和硕士学位,目前正在该校攻读计算机科学与工程博士学位。她的研究方向包括自然语言处理、机器学习和深度学习。

HYUK NAMGUNG received the B.S. degree in computer science and engineering from Chungnam National University, Daejeon, South Korea, in 2022, where he is currently pursuing the M.S. degree in computer science and engineering. His research interests include natural language processing, machine learning, and deep learning.
HYUK NAMGUNG 于2022年在韩国大田忠南大学获得计算机科学与工程学士学位,目前正在该校攻读计算机科学与工程硕士学位。他的研究方向包括自然语言处理 (Natural Language Processing)、机器学习 (Machine Learning) 和深度学习 (Deep Learning)。

SUNGRYEOL KIM received the B.S. degree in computer science and engineering from Chungnam National University, Daejeon, South Korea, in 2022, where he is currently pursuing the M.S. degree in computer science and engineering. His research interests include natural language processing, machine learning, and deep learning.
SUNGRYEOL KIM 于2022年在韩国大田忠南大学获得计算机科学与工程学士学位,目前正在该校攻读计算机科学与工程硕士学位。他的研究兴趣包括自然语言处理、机器学习和深度学习。