CP-DETR: Concept Prompt Guide DETR Toward Stronger Universal Object Detection
CP-DETR: 概念提示引导DETR实现更强大的通用目标检测
Abstract
摘要
Recent research on universal object detection aims to introduce language in a SoTA closed-set detector and then generalize the open-set concepts by constructing large-scale (textregion) datasets for training. However, these methods face two main challenges: (i) how to efficiently use the prior information in the prompts to genericise objects and (ii) how to reduce alignment bias in the downstream tasks, both leading to sub-optimal performance in some scenarios beyond pre-training. To address these challenges, we propose a strong universal detection foundation model called CPDETR, which is competitive in almost all scenarios, with only one pre-training weight. Specifically, we design an efficient prompt visual hybrid encoder that enhances the information interaction between prompt and visual through scaleby-scale and multi-scale fusion modules. Then, the hybrid encoder is facilitated to fully utilize the prompted information by prompt multi-label loss and auxiliary detection head. In addition to text prompts, we have designed two practical concept prompt generation methods, visual prompt and optimized prompt, to extract abstract concepts through concrete visual examples and stably reduce alignment bias in downstream tasks. With these effective designs, CP-DETR demonstrates superior universal detection performance in a broad spectrum of scenarios. For example, our Swin-T backbone model achieves 47.6 zero-shot AP on LVIS, and the Swin-L backbone model achieves 32.2 zero-shot AP on ODinW35. Furthermore, our visual prompt generation method achieves 68.4 AP on COCO val by interactive detection, and the optimized prompt achieves 73.1 fully-shot AP on ODinW13.
近期通用目标检测研究致力于在先进闭集检测器中引入语言模态,通过构建大规模(文本-区域)数据集训练来实现开放集概念泛化。然而现有方法面临两大挑战:(i) 如何高效利用提示中的先验信息实现目标泛化;(ii) 如何降低下游任务中的对齐偏差,这两者导致预训练外场景的性能次优。为此,我们提出名为CPDETR的强通用检测基础模型,仅需单一预训练权重即可在几乎所有场景保持竞争力。具体而言,我们设计了高效的提示-视觉混合编码器,通过逐尺度与多尺度融合模块增强提示与视觉信息交互。该混合编码器通过提示多标签损失与辅助检测头充分挖掘提示信息。除文本提示外,我们开发了两种实用概念提示生成方法:视觉提示与优化提示,分别通过具体视觉样本提取抽象概念,以及稳定降低下游任务对齐偏差。这些设计使CP-DETR在广泛场景中展现出卓越的通用检测性能。例如,我们的Swin-T骨干模型在LVIS上实现47.6零样本AP,Swin-L骨干模型在ODinW35上达到32.2零样本AP。此外,视觉提示生成方法通过交互检测在COCO val上获得68.4 AP,优化提示在ODinW13上实现73.1全样本AP。
Introduction
引言
Universal object detection aims to detect objects of any category in any scene with one model weight. The trend in research is to incorporate language modality, where textual descriptions of objects are encoded as text prompt vectors through language model (Devlin et al. 2018; Radford et al. 2021), and the classification results are represented by the similarity between the vectors and the image regions. This flexible conceptual representation allows different object detection data to be trained jointly, aligning textual descriptions with visual representations. Ultimately, in downstream tasks, universal object detection with zero-shot is achieved by modifying the textual descriptions of objects.
通用目标检测旨在通过单一模型权重检测任意场景中的任意类别物体。研究趋势是融入语言模态,即通过语言模型 (Devlin et al. 2018; Radford et al. 2021) 将物体文本描述编码为文本提示向量,分类结果由向量与图像区域的相似度表示。这种灵活的概念表征方式使得不同目标检测数据能够联合训练,实现文本描述与视觉表征的对齐。最终在下游任务中,通过修改物体文本描述即可实现零样本的通用目标检测。
While using text prompts has been primarily favored in universal detection, they suffer from sub-optimal performance in downstream applications, where universal detectors fail to compete with specialist models in many scenarios and categories outside of pre-training. A significant factor is the matching deficiency, where the detector produces mismatched results with the text description. This deficiency arises from alignment mistakes between language and visual representations in pre-training, and there are both objective and subjective aspects to this bias. Objectively, text descriptions follow a long-tailed pattern and different descriptions can refer to the same image region, so it is impractical to align all the texts and image regions accurately during pretraining. Subjectively, it is difficult for users to accurately describe complex objects, such as specific mechanical devices, through language. Most works (Kamath et al. 2021; Minderer et al. 2022, 2023; Yao et al. 2024; Wu et al. 2024) have been devoted to constructing larger pre-train datasets to address the alignment problems, but this requires significant costs.
在通用检测任务中,虽然文本提示(prompt)是主流方法,但其在下游应用中表现欠佳——当遇到预训练范围之外的场景或类别时,通用检测器往往难以匹敌专用模型。关键问题在于匹配缺陷:检测器输出结果与文本描述存在偏差。这种缺陷源于预训练阶段语言表征与视觉表征的对齐误差,其成因包含客观与主观两个维度。客观层面,文本描述遵循长尾分布,且不同描述可能指向同一图像区域,因此在预训练中实现所有文本与图像区域的精确对齐并不现实。主观层面,用户难以通过语言准确描述复杂物体(如特定机械设备)。多数研究[20][21][22][23]致力于构建更大规模的预训练数据集来解决对齐问题,但这需要付出高昂成本。
Another factor is the paradigm of utilizing prompt information. The work (Li et al. 2022b) has shown that the early fusion paradigm performs significantly better than the late fusion paradigm after eliminating alignment bias through prompt tuning in the downstream tasks. Late fusion paradigms (Li et al. 2019) only use prompt vectors in the classification part, the location dependent on pre-training data distributions, which is poor in utilizing prompt information. In contrast, the early fusion paradigm (Liu et al. 2023) has an additional cross-modal fusion phase. It is easy to observe that the success of the early fusion paradigm lies in the cross-modal information interaction through fusion, where visual features are updated based on prompt information, and both classification and localization can be generalized in downstream scenes through prompt information. Therefore, we believe that a key to improving the performance of universal detection lies in achieving effective cross-modal interaction between prompt and visual.
另一个因素是使用提示信息的范式。研究 (Li et al. 2022b) 表明,在下游任务中通过提示调优消除对齐偏差后,早期融合范式明显优于晚期融合范式。晚期融合范式 (Li et al. 2019) 仅在分类部分使用提示向量,这部分依赖于预训练数据分布,因此在利用提示信息方面表现较差。相比之下,早期融合范式 (Liu et al. 2023) 增加了一个跨模态融合阶段。可以观察到,早期融合范式的成功在于通过融合实现跨模态信息交互,其中视觉特征基于提示信息更新,分类和定位都能通过提示信息在下游场景中泛化。因此,我们认为提升通用检测性能的关键在于实现提示与视觉之间的有效跨模态交互。
In this paper, our research is interested in constructing a strong universal detector that not only has superior zeroshot capability but also competes with specific models in all downstream tasks through a model weight. For this, we propose CP-DETR, a model based on the early fusion paradigm that not only supports text prompts but also introduces visual prompts and optimized prompts to address alignment biases beyond pre-training. Visual prompts avoid misalignment arising from subjective user description errors by providing visual examples to represent objects, e.g., by marking specific objects with boxes. An optimized prompt provides a more direct solution by prompt tuning through downstream data annotation to align regions without changing the pre-training weights. Interestingly, we note text prompts, visual prompts, and optimized prompts represent object concepts through high-dimensional vectors, so we use concept prompts to represent these vectors in a unified way and divide the whole model into two parts: detector and concept prompt generation.
本文研究旨在构建一个强大的通用检测器,该检测器不仅具备卓越的零样本能力,还能通过单一模型权重在所有下游任务中与专用模型竞争。为此,我们提出CP-DETR——一种基于早期融合范式的模型,它不仅支持文本提示,还引入了视觉提示和优化提示,以解决预训练之外的对齐偏差。视觉提示通过提供视觉示例(如用方框标记特定物体)来避免用户主观描述错误导致的对齐偏差。优化提示则通过下游数据标注进行提示调优,在不改变预训练权重的情况下对齐区域,提供更直接的解决方案。有趣的是,我们发现文本提示、视觉提示和优化提示均通过高维向量表示物体概念,因此我们统一使用概念提示来表征这些向量,并将整个模型分为检测器和概念提示生成两部分。
The detector part determines the universal detection capability of the model, so we build the detector based on the SoTA DETR (Zhang et al. 2023) framework and exploit the prompting information through effective cross-modal interactions. For effective cross-modal interaction, we design an efficient prompt visual hybrid encoder that updates visual and concept prompts via progressive single-scale fusion (PSF) and multi-scale fusion gating (MFG), avoiding confusion due to semantic gaps between different levels of visual features. Due to DETR being a sparse detector framework, we added an auxiliary detection head and a prompt multilabel loss to facilitate the hybrid encoder to fully utilize different modal information in the interaction.
检测器部分决定了模型的通用检测能力,因此我们基于当前最优的DETR (Zhang et al. 2023)框架构建检测器,并通过有效的跨模态交互利用提示信息。为实现高效跨模态交互,我们设计了高效的提示视觉混合编码器,通过渐进式单尺度融合(PSF)和多尺度融合门控(MFG)更新视觉与概念提示,避免不同层级视觉特征间语义差异导致的混淆。由于DETR是稀疏检测框架,我们额外添加了辅助检测头和提示多标签损失,促使混合编码器在交互中充分利用不同模态信息。
For the concept prompt generation part, CP-DETR supports both text prompts, visual prompts, and optimized prompts. With text prompts, we use sentence-level representation to reduce computational overhead and encode them via CLIP (Radford et al. 2021) encoder because of its better disc rim inability using larger-scale contrast learning. For visual prompt, we design a visual prompt encoder that encodes the bbox as a query and adaptively aggregates concept represent at ions from multi-scale features output by the visual backbone. For optimized prompt, we design a super-class representation prompt tuning method to further improve the performance in downstream tasks by representing single categories through multiple vectors.
在概念提示生成部分,CP-DETR支持文本提示、视觉提示和优化提示三种形式。对于文本提示,我们采用句子级表征来降低计算开销,并通过CLIP (Radford et al. 2021) 编码器进行编码,因其利用更大规模的对比学习具备更强的判别能力。视觉提示方面,我们设计了视觉提示编码器,将边界框编码为查询向量,并自适应聚合视觉主干网络输出的多尺度特征中的概念表征。针对优化提示,我们提出超类表征提示调优方法,通过多向量表示单一类别,以进一步提升下游任务性能。
Through effective design, the CP-DETR demonstrates amazing universal detection capabilities, e.g., Using text prompt, it achieved a significant 32.2 zero-shot $A P$ on the ODinW35 (Li et al. 2022a). In the visual prompt interactive evaluation, it achieved $68.4~A P$ on the COCO (Lin et al. 2014) val. Furthermore, using the optimized prompt method, it outperforms the previous SoTA model (Zhang et al. 2022) 5.1 average $A P$ on ODinW13 (Li et al. 2022a) and can compete with full-model fine-tuned specialist models.
通过有效设计,CP-DETR展现出惊人的通用检测能力。例如,使用文本提示时,它在ODinW35 (Li et al. 2022a) 上实现了32.2的显著零样本 $AP$;在视觉提示交互评估中,它在COCO (Lin et al. 2014) val数据集上达到 $68.4~AP$。此外,采用优化提示方法后,其性能在ODinW13 (Li et al. 2022a) 上以5.1平均 $AP$ 超越前SoTA模型 (Zhang et al. 2022),并能与全模型微调的专用模型相媲美。
Related Work Text Prompted Universal Detection
相关工作 文本提示的通用检测
The recent work can be divided into early fusion and late fusion, depending on the degree of exploitation of the prompt. The late fusion-based method only utilizes the prompt information in the classification. ViLD (Gu et al. 2022), RegionCLIP (Zhong et al. 2022) focuses on transferring knowledge from CLIP to detection. The OWL-ViT (Minderer et al. 2022, 2023) and DetCLIP series (Yao et al. 2022, 2023, 2024) tend to directly align language and image regions through pre-training, therefore scaling up the data to $10B$ and $50M$ levels by pseudo-labeling, respectively. The early fusion-based method considers the effect of the prompt on both classification and localization, using the prompt as a condition for image feature encoding. GLIP (Li et al. 2022b) fuses word-level text prompts with multi-scale image features through cross-attention and leverages grounding data to help learn aligned semantics. Grounding DINO (Liu et al. 2023) further proposes language-guided query selection and cross-modality decoder to achieve denser fusion. Then, APE (Shen et al. 2024) and GLEE (Wu et al. 2024) reduce the number of text prompts using sentence-level text encoding methods, significantly reducing the computational overhead of the fusion layer, and thus allowing more negative categories to be used during pre-training. However, previous work uses all visual features to interact with prompts, ignoring the semantic gap of features at different levels in the backbone. For this reason, we design a hybrid encoder to achieve efficient cross-modal interaction through progressive fusion from single to global scales.
近期研究根据提示信息利用程度可分为早期融合和晚期融合。基于晚期融合的方法仅在分类阶段利用提示信息,ViLD (Gu et al. 2022) 和 RegionCLIP (Zhong et al. 2022) 聚焦于将 CLIP 知识迁移至检测任务。OWL-ViT (Minderer et al. 2022, 2023) 与 DetCLIP 系列 (Yao et al. 2022, 2023, 2024) 通过预训练直接对齐语言与图像区域,分别采用伪标注将数据规模扩展至 $10B$ 和 $50M$ 量级。基于早期融合的方法则同时考虑提示对分类与定位的影响,将提示作为图像特征编码的条件:GLIP (Li et al. 2022b) 通过跨注意力机制融合词级文本提示与多尺度图像特征,并利用 grounding 数据学习对齐语义;Grounding DINO (Liu et al. 2023) 进一步提出语言引导的查询选择与跨模态解码器以实现更密集的融合;APE (Shen et al. 2024) 和 GLEE (Wu et al. 2024) 采用句子级文本编码减少提示数量,显著降低融合层计算开销,从而支持预训练阶段使用更多负类别。然而现有工作均使用全部视觉特征与提示交互,忽视了主干网络中不同层级特征的语义差异。为此,我们设计混合编码器通过从单尺度到全局尺度的渐进融合实现高效跨模态交互。
Visual Prompt
视觉提示
Unlike text prompts, visual prompts use image information directly to refer to objects, avoiding misalignment due to incorrect descriptions. Since late fused detectors have a double-tower structure, work (Minderer et al. 2022; Zang et al. 2022) adopts raw image as a visual prompt and leverages image-text-aligned representation to transfer the concept to a visual prompt. MQ-Det (Xu et al. 2023) uses a mixed representation of visual prompts and text prompts. TRex2 (Jiang et al. 2024) uses visual instructions to achieve interactive detection, with input boxes and dots generating visual prompts to avoid context loss in cropped images.
与文本提示不同,视觉提示直接利用图像信息指代物体,避免了因描述错误导致的错位问题。由于后期融合检测器采用双塔结构,研究 (Minderer et al. 2022; Zang et al. 2022) 将原始图像作为视觉提示,并利用图文对齐表征将概念迁移至视觉提示。MQ-Det (Xu et al. 2023) 采用视觉提示与文本提示的混合表征。TRex2 (Jiang et al. 2024) 通过视觉指令实现交互式检测,利用输入框和点生成视觉提示以避免裁剪图像中的上下文丢失。
Optimized Prompt
优化后的提示词
The optimized prompt is generated by prompt tuning, which has proved effective for alignment in the classification (Zhou et al. 2022). PromptDet (Feng et al. 2022) uses this prompt as the context of the text prompt to guide the classification foundation model to achieve text and region alignment. GLIP (Li et al. 2022b) aligns concepts in downstream tasks by using optimized prompts as offsets to text prompts, noting that deep cross-modal fusion is critical to improving the effectiveness of prompt tuning. Recent work (Chen et al. 2024) directly learning prompts avoids the dependence on text prompts and further improves performance. The specificity of prompt tuning is that the optimization object is the activation value, which only reduces the alignment bias in the downstream task without changing the model. Therefore, we believe that the evaluation metrics of the optimized prompt can better reflect detector universality.
优化后的提示词通过提示调优生成,该方法在分类任务的对齐中已被证明有效 (Zhou et al. 2022)。PromptDet (Feng et al. 2022) 将该提示词作为文本提示的上下文,引导分类基础模型实现文本与区域对齐。GLIP (Li et al. 2022b) 通过将优化提示词作为文本提示的偏移量来对齐下游任务中的概念,并指出深度跨模态融合对提升提示调优效果至关重要。近期工作 (Chen et al. 2024) 直接学习提示词,避免了对文本提示的依赖,进一步提升了性能。提示调优的特殊性在于优化对象是激活值,仅降低下游任务中的对齐偏差而不改变模型。因此我们认为优化提示词的评估指标能更好反映检测器的泛化能力。
Method
方法
The overall architecture of the proposed CP-DETR is illustrated in figure 1, which consists of two parts: concept prompt generation and detection conditional on concept prompts. We use concept prompt generators to encode different object references(e.g., text, box coordinates, etc.) into uniform vector space, which represent the object concepts and serve as conditional input detectors. With different concept prompt generators, our model enables different workflows to handle alignment bias efficiently.
图1展示了所提出的CP-DETR整体架构,该架构由两部分组成:概念提示生成和基于概念提示的检测。我们使用概念提示生成器将不同的对象参考(如文本、框坐标等)编码到统一的向量空间中,这些向量表示对象概念并作为条件输入检测器。通过不同的概念提示生成器,我们的模型能够采用不同的工作流程来有效处理对齐偏差。
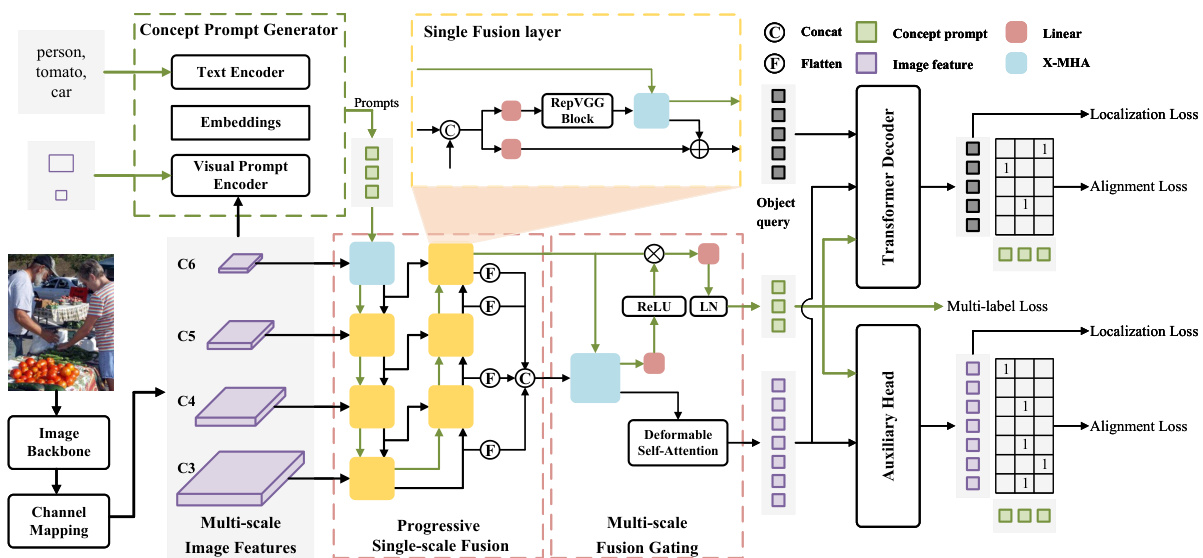
Figure 1: Overall architecture of CP-DETR. First, the concept prompt generator (shown in green dashed box) encodes textual descriptions, referring boxes, or annotations as concept prompts. Then, the detector encodes the image as multi-scale feature maps and performs a cross-modal fusion of concepts and images using the proposed hybrid encoder (shown as the red dashed box). Finally, the transformer decoder predicts results.
图 1: CP-DETR的整体架构。首先,概念提示生成器(如绿色虚线框所示)将文本描述、参考框或标注编码为概念提示。随后,检测器将图像编码为多尺度特征图,并通过提出的混合编码器(如红色虚线框所示)实现概念与图像的跨模态融合。最终,transformer解码器输出预测结果。
The detection part takes (prompts, image) pairs as input and outputs object boxes for the prompt’s corresponding concepts. For the image, the detector first obtains multiscale image feature maps in 256 dimensions by image backbone and channel mapping. In this paper, we only use four scales: 1/8, 1/16, 1/32, and 1/64. Then, a prompt visual hybrid encoder, which contains progressive single-scale fusion and multi-scale fusion gating, will be used for the mutual fusion of prompt and image features. Following the previous work (Liu et al. 2023), after obtaining fused features, 900 object queries are initialized language-guided query selection and updated by the 6-layer cross-modality decoder. The training objectives for the transformer decoder are as follows:
检测部分以(提示词,图像)对作为输入,输出提示词对应概念的物体框。对于图像,检测器首先通过图像主干网络和通道映射获得256维的多尺度图像特征图。本文仅使用1/8、1/16、1/32和1/64四种尺度。随后,采用包含渐进式单尺度融合与多尺度融合门控的提示视觉混合编码器,实现提示词与图像特征的相互融合。遵循先前工作 (Liu et al. 2023) 的方法,在获得融合特征后,通过语言引导的查询选择初始化900个物体查询,并由6层跨模态解码器进行更新。Transformer解码器的训练目标如下:
$$
L_{d e c o d e r}=L_{l o c a l i z a t i o n}+L_{a l i g n m e n t}
$$
$$
L_{d e c o d e r}=L_{l o c a l i z a t i o n}+L_{a l i g n m e n t}
$$
where $L_{l o c a l i z a t i o n}$ contains GIoU (Reza to fig hi et al. 2019) loss and L1 loss, and $L_{a l i g n m e n t}$ is focal (Li et al. 2020) loss.
其中 $L_{localization}$ 包含 GIoU (Reza to fig hi 等人 2019) 损失和 L1 损失,而 $L_{alignment}$ 是 focal (Li 等人 2020) 损失。
Due to the sparsity of object query, which could cause hybrid encoder sub-optimization, we introduce prompt multilabel classification loss and anchor-based auxiliary detection head in training as auxiliary supervision to facilitate crossmodal and cross-scale feature fusion. The auxiliary supervision part will be removed during inference.
由于目标查询的稀疏性可能导致混合编码器次优优化,我们在训练中引入了提示多标签分类损失和基于锚点的辅助检测头作为辅助监督,以促进跨模态和跨尺度特征融合。该辅助监督部分将在推理阶段被移除。
Prompt Visual Hybrid Encoder
Prompt视觉混合编码器
Previous early fusion-based work (Shen et al. 2024; Wu et al. 2024; Liu et al. 2023; Li et al. 2022b; Zhang et al. 2022)
先前基于早期融合的工作 (Shen et al. 2024; Wu et al. 2024; Liu et al. 2023; Li et al. 2022b; Zhang et al. 2022)
fused full-scale image feature maps and prompts simultaneously, which ignores the semantic gaps that exist between features at different scales. However, due to the lack of semantic concepts and feature duplication, it is inefficient to perform cross-modal interaction on low-level feature maps in the early stages of fusion. Therefore, we use a progressive single-scale fusion module that performs fusion scale-byscale from high-level feature maps. In order to avoid multiscale information loss during scale-by-scale fusion, we also designed multi-scale fusion gating to enhance the fusion of critical information.
规则:
- 输出中文翻译部分时仅保留翻译标题,无冗余内容
- 保持原始段落格式与术语(如FLAC、JPEG)
- 公司缩写保留原样(如Microsoft)
- 人名不译
- 保留文献引用标记(如[20])
- 图表编号格式转换(Figure 1→图1)
- 全角括号转为半角并添加空格
- 专业术语首现标注英文(如生成式AI(Generative AI))
策略:
- 保留特殊字符/公式不译
- HTML表格转Markdown格式
- 确保翻译完整准确
最终仅输出Markdown格式译文
现在开始翻译:
融合了全尺寸图像特征图与提示词,但忽略了不同尺度特征间存在的语义鸿沟。由于缺乏语义概念和特征重复,在融合早期阶段对低级特征图进行跨模态交互效率低下。因此,我们采用渐进式单尺度融合模块,从高级特征图开始逐尺度融合。为避免逐尺度融合过程中的多尺度信息丢失,还设计了多尺度融合门控机制来增强关键信息融合。
Progressive Single-scale Fusion. The structure is illustrated in the left red dashed box of figure 1, which follows the top-down and bottom-up flow paths in (Zhao et al. 2024b; Liu et al. 2018). The deepest $C\dot{6}\in\mathcal{R}^{H/64\times W/64\times D}$ feature map has richer semantic concepts that help initially establish the connection between prompt and visual. Therefore, we first use a cross-modality multi-head attention (Li et al. 2022b)(X-MHA) to fuse $C6$ and prompt $P$ by:
渐进式单尺度融合。该结构如图1左侧红色虚线框所示,遵循了 (Zhao et al. 2024b; Liu et al. 2018) 中提出的自上而下与自下而上双向路径。最深层特征图 $C\dot{6}\in\mathcal{R}^{H/64\times W/64\times D}$ 具有更丰富的语义概念,可帮助初步建立提示词与视觉内容间的关联。因此,我们首先采用跨模态多头注意力机制 (Li et al. 2022b)(X-MHA) 通过以下方式融合 $C6$ 与提示词 $P$:
$$
C6^{t=1},P^{l+1}=X{-}M H A(C6^{t=0},P^{l})
$$
$$
C6^{t=1},P^{l+1}=X{-}M H A(C6^{t=0},P^{l})
$$
Where $l$ denotes the number of prompt fusions, $t\in(0,1,2)$ denotes the stage, and 0,1,2 denotes no fusion, top-down fusion, and bottom-up fusion, respectively.
其中 $l$ 表示提示融合的数量,$t\in(0,1,2)$ 表示阶段,0、1、2 分别表示无融合、自上而下融合和自下而上融合。
Then, during top-down and bottom-up, we design a single fusion layer, as shown in the yellow dashed box of figure 1, with two neighboring scales of image features and prompts as inputs. Specifically, neighboring feature maps are concatenated in the channel to obtain the hybrid feature $C_{i j}$ , and the channels are adjusted through the linear layer and block (Ding et al. 2021) to achieve cross-scale and implicit cross-modal information fusion simultaneously. Then, using X-MHA to direct cross-modal fusion, obtains the updated prompt $P^{l+1}$ and image features $\triangle C$ . Finally, the image features $C_{j}^{t}$ of $j$ scale at stage $t$ are output by element-wise summation, which fuses $\triangle C$ with $C_{i j}$ after a linear layer. The formula is as follows:
接着,在自上而下和自下而上的过程中,我们设计了一个单一融合层,如图1黄色虚线框所示,以相邻两个尺度的图像特征和提示作为输入。具体来说,相邻特征图在通道维度上进行拼接,得到混合特征$C_{i j}$,并通过线性层和块 (Ding et al. 2021) 调整通道,实现跨尺度和隐式跨模态信息融合。然后,使用X-MHA引导跨模态融合,获得更新后的提示$P^{l+1}$和图像特征$\triangle C$。最后,通过逐元素求和输出阶段$t$中$j$尺度的图像特征$C_{j}^{t}$,该操作将$\triangle C$与经过线性层处理后的$C_{i j}$进行融合。公式如下:
$$
\begin{array}{r l}&{C_{i j}=c o n c a t(r e s i z e(C_{i}^{t}),C_{j}^{t-1})}\ &{P^{l+1},\triangle C=X\ –M H A(B l o c k(L i n e a r(C_{i j})),P^{l})}\ &{C_{j}^{t}=\triangle C+L i n e a r(C_{i j})}\end{array}
$$
$$
\begin{array}{r l}&{C_{i j}=c o n c a t(r e s i z e(C_{i}^{t}),C_{j}^{t-1})}\ &{P^{l+1},\triangle C=X\ –M H A(B l o c k(L i n e a r(C_{i j})),P^{l})}\ &{C_{j}^{t}=\triangle C+L i n e a r(C_{i j})}\end{array}
$$
Multi-scales Fusion Gating. To avoid information loss due to scale-by-scale fusion processes, we propose to interact simultaneously at multi-scale feature maps. The fourscale feature maps are flattened and then concatenated in the spatial dimension to form the full-scale feature $C_{a l l}$ . The fusion process of $C_{a l l}$ and prompt $P^{l}$ from PSF is as follows:
多尺度融合门控。为避免逐尺度融合过程中的信息丢失,我们提出在多尺度特征图上同时进行交互。将四尺度特征图展平后沿空间维度拼接,形成全尺度特征$C_{all}$。该特征与来自PSF的提示$P^{l}$的融合过程如下:
$$
\begin{array}{r l}&{P^{l+1},C_{a l l}^{'}=X\ –M H A(C_{a l l},P^{l})}\ &{P_{e n d}=L N(L i n e a r(R e L U(L i n e a r(P^{l+1})*P^{l})))}\ &{C_{a l l}^{'\prime}=D e f o r m A t t n(C_{a l l}^{'})}\end{array}
$$
$$
\begin{array}{r l}&{P^{l+1},C_{a l l}^{'}=X\ –M H A(C_{a l l},P^{l})}\ &{P_{e n d}=L N(L i n e a r(R e L U(L i n e a r(P^{l+1})*P^{l})))}\ &{C_{a l l}^{'\prime}=D e f o r m A t t n(C_{a l l}^{'})}\end{array}
$$
Where DeformAttn is deformable self-attention (Zhu et al. 2021), $L N$ is Layernorm, $P_{e n d}$ denotes final concept prompts after full-scales information gating through dot product, $\bar{C}_{a l l}^{'\prime}$ denotes the image partial output of the hybrid encoder after full-scale image feature interaction by deformable self-attention.
其中DeformAttn为可变形自注意力 (Zhu et al. 2021),$L N$为层归一化,$P_{e n d}$表示通过点积进行全尺度信息门控后的最终概念提示,$\bar{C}_{a l l}^{'\prime}$表示可变形自注意力完成全尺度图像特征交互后混合编码器的图像部分输出。
Auxiliary Supervision
辅助监督
In the DETR architecture of detector training, both classification and location losses are implemented on the object queries. However, due to the number of object query much smaller than the image features and using a one-toone set matching scheme of label assignment, encoder output features get sparse supervision signals from the transformer decoder. We argue that these sparse supervision signals will reduce the learning efficiency of cross-scale and cross-modal interactions in the hybrid encoder, leading to sub-optimal results. Therefore, we introduce the auxiliary detection head and prompt multi-label loss to apply additional supervision to image features and conceptual prompts, respectively, which will facilitate fusion learning in the hybrid encoder.
在DETR (DEtection TRansformer) 架构的检测器训练中,分类与定位损失均作用于目标查询 (object queries) 上。但由于目标查询数量远少于图像特征,且采用一对一的标签分配匹配策略,编码器输出特征仅能从Transformer解码器获得稀疏的监督信号。我们认为这种稀疏监督信号会降低混合编码器中跨尺度、跨模态交互的学习效率,导致次优结果。因此,我们引入辅助检测头和提示多标签损失,分别对图像特征和概念提示施加额外监督,从而促进混合编码器中的融合学习。
Auxiliary Detection Head. We choose an anchor-based detector head (Zhang et al. 2020) to facilitate training, which was shown effective in closed-set detection (Zong, Song, and Liu 2023). The auxiliary head employs one-to-many label assignment and computes losses by anchors whose number is normal to image features, thus applying denser and direct supervision signals to image features. We use a contrastive layer to replace the classification layer in the closedset detector header and represent the category scores by the similarity $s_{m n}$ of prompt and image features as follows:
辅助检测头。我们选用基于锚点(anchor-based)的检测头(Zhang et al. 2020)来辅助训练,该结构在闭集检测(closed-set detection)中已被验证有效(Zong, Song, and Liu 2023)。该辅助头采用一对多标签分配策略,通过数量与图像特征相匹配的锚点计算损失,从而对图像特征施加更密集直接的监督信号。我们将闭集检测头中的分类层替换为对比层,通过提示词与图像特征的相似度$s_{mn}$来表示类别分数,具体计算如下:
$$
s_{m n}=\frac{a^{m}\times L i n e a r(P_{e n d}^{n})}{\sqrt{d}}+b i a s
$$
$$
s_{m n}=\frac{a^{m}\times L i n e a r(P_{e n d}^{n})}{\sqrt{d}}+b i a s
$$
Where $d$ is the number of feature channels, bias is a learnable constant, $a^{m}$ denotes the image feature corresponding to the $m$ -th anchor, and $P_{e n d}^{n}$ denotes the $n$ -th concept vector. With this simple modification, the closed-set detector head is converted to open-set form and thus can be used for auxiliary supervision in pre-training with class uncertainty. The training objectives are as follows:
其中 $d$ 是特征通道数,bias 是可学习的常数,$a^{m}$ 表示第 $m$ 个锚点对应的图像特征,$P_{e n d}^{n}$ 表示第 $n$ 个概念向量。通过这一简单修改,闭集检测头被转换为开集形式,因此可用于具有类别不确定性的预训练中的辅助监督。训练目标如下:
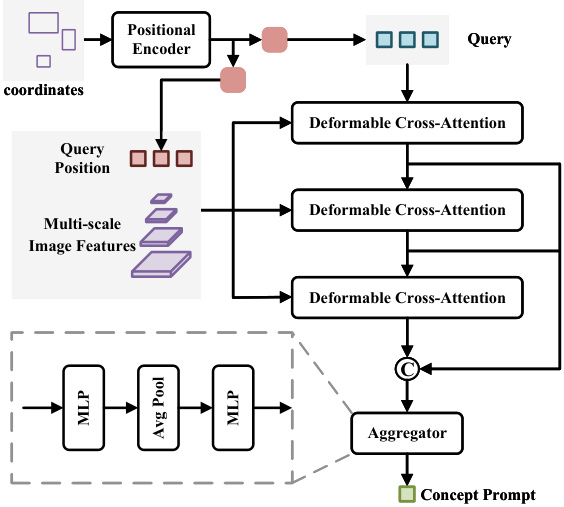
Figure 2: The overall architecture of the visual prompt encoder. Coordinates of 2D boxes are encoded as query and query position vectors, and the concept prompt is aggregated from image features via three layers of deformable crossattention.
图 2: 视觉提示编码器的整体架构。二维框坐标被编码为查询向量和查询位置向量,概念提示通过三层可变形交叉注意力从图像特征中聚合得到。
$$
L_{a u x_h e a d}=L_{c l a s s}+L_{c e n t e r n e s s}+L_{i o u}
$$
$$
L_{a u x_h e a d}=L_{c l a s s}+L_{c e n t e r n e s s}+L_{i o u}
$$
where $L_{c l a s s}$ is focal loss, $L_{c e n t e r n e s s}$ is binary cross en- tropy loss, and $L_{i o u}$ is GIoU loss.
其中 $L_{c l a s s}$ 是焦点损失 (focal loss),$L_{c e n t e r n e s s}$ 是二元交叉熵损失 (binary cross entropy loss),$L_{i o u}$ 是 GIoU 损失 (GIoU loss)。
Prompt Multi-label Loss. In open-set pre-training, there are both positive prompts and a large number of negative prompts in each (image,prompts) pair, and the negative prompts don’t have a corresponding object in the image. Therefore, we could count the positivity and negativity of the prompts during the training process and automatically generate a multi-label annotation of $g$ . The concept prompts output from the hybrid encoder are mapped to 1-dimensional through a $M L P$ layer, and the loss is computed as follows:
提示词多标签损失。在开放集预训练中,每个(图像,提示词)对既包含正向提示词也存在大量负向提示词,这些负向提示词在图像中没有对应物体。因此,我们可以在训练过程中统计提示词的正负属性,自动生成$g$的多标签标注。混合编码器输出的概念提示词通过$MLP$层映射为1维向量,其损失计算方式如下:
$$
L_{p r o m p t}=b i n a r y_c r o s s_e n t r o p y(M L P(P_{e n d}),g)
$$
$$
L_{p r o m p t}=b i n a r y_c r o s s_e n t r o p y(M L P(P_{e n d}),g)
$$
By applying a multi-label classification loss on a single modality, the concept prompts need learning to leverage the image information during the fusion process, thus rejecting the negative concept and retaining the positive prompts, making the fused concept prompts more disc rim i native.
通过在单一模态上应用多标签分类损失,概念提示需要学习在融合过程中利用图像信息,从而剔除负面概念并保留正面提示,使得融合后的概念提示更具判别性。
Concept Prompt Generator
概念提示生成器
Text prompts successfully unify the training of different datasets and achieve zero-shot detection through a unified semantic space. However, due to alignment bias, the detector is prone to associate with wrong objects when meeting longtailed or inaccurately described text in downstream tasks. For ODinW (Li et al. 2022a), we observe that the performance of all existing universal models with zero-shot significantly lags behind the closed-set trained models. Therefore, in order to reduce the impact of alignment bias on models in downstream tasks, CP-DETR also introduces two prompt generation methods, namely visual prompts and optimized prompts, to fully stimulate the universal detection capability of pre-trained models.
文本提示成功统一了不同数据集的训练,并通过统一的语义空间实现了零样本检测。然而,由于对齐偏差,检测器在下游任务中遇到长尾或不准确描述的文本时容易关联到错误对象。对于ODinW (Li et al. 2022a),我们观察到所有现有通用模型的零样本性能显著落后于闭集训练模型。因此,为减少对齐偏差对下游任务模型的影响,CP-DETR还引入了两种提示生成方法——视觉提示和优化提示,以充分激发预训练模型的通用检测能力。
Text Prompt. We select the pre-trained CLIP text encoder to extract text features and use average pooling to aggregate token-level text features into sentence-level concept prompt. Only text prompts are used in CP-DETR pre-training, as this strategy was demonstrated efficiently in previous work (Li et al. 2022b). In order to reduce the detection hallucination, which is predicting objects that are not present in the input image, we randomly sampled 80 categories or descriptions from the text dictionary as negative samples in the pretraining. Unlike object detection datasets, Grounding and Referring Expression Comprehension (REC) datasets lack a unified category dictionary, so we construct a text dictionary online via a memory bank during training. Then, in pre-training, the overall training objective is a linear combination of Ldecoder, $L_{a u x_h e a d}$ , and $L_{p r o m p t}$ .
文本提示。我们选择预训练的CLIP文本编码器提取文本特征,并通过平均池化将token级文本特征聚合为句子级概念提示。CP-DETR预训练仅使用文本提示,该策略在先前工作中已被验证高效 (Li et al. 2022b)。为减少检测幻觉(即预测输入图像中不存在的物体),我们在预训练中随机采样文本字典中的80个类别或描述作为负样本。与目标检测数据集不同,定位和指代表达理解(REC)数据集缺乏统一类别词典,因此我们通过训练时的记忆库在线构建文本字典。预训练阶段,整体训练目标是$L_{decoder}$、$L_{aux_head}$和$L_{prompt}$的线性组合。
Visual Prompt. Figure 2 shows encoder structure, where $N$ normalized box coordinates are encoded by sine-cosine position encoder to obtain vector $r~\in~\mathcal{R}^{N\times1\bar{2}8}$ , which respectively through two linear layers generates query embedding $q$ and query position embedding $q_{p o s}$ . Then, concept information is extracted from the image features by crossattention, with $q_{p o s}$ limiting the extraction range to ensure information is relevant to box content. We use three layers of attention and concatenate the output query of each layer by channel, and finally generate the concept prompt for the corresponding category through an aggregator, which is shown in the dashed box in figure 2. When training the encoder, we freeze the pre-training weights and use the box sampling method of work (Jiang et al. 2024). Since we train the encoder after pre-training, where text prompts can be considered as concept prompt ground truths on the pre-training data, in addition to $L_{d e c o d e r}$ , we also use MSE loss for direct supervision, with the overall training objective as follows:
视觉提示。图 2 展示了编码器结构,其中 $N$ 个归一化框坐标通过正弦-余弦位置编码器编码得到向量 $r~\in~\mathcal{R}^{N\times1\bar{2}8}$ ,随后分别经过两个线性层生成查询嵌入 $q$ 和查询位置嵌入 $q_{pos}$ 。接着通过交叉注意力从图像特征中提取概念信息,并用 $q_{pos}$ 限定提取范围以确保信息与框内容相关。我们使用三层注意力结构,并按通道拼接每层输出的查询向量,最终通过聚合器生成对应类别的概念提示(如图 2 虚线框所示)。训练编码器时冻结预训练权重,采用 (Jiang et al. 2024) 的框采样方法。由于编码器训练在预训练之后进行,此时文本提示可视为预训练数据上的概念提示真值,因此除 $L_{decoder}$ 外,我们还采用 MSE 损失进行直接监督,整体训练目标如下:
$$
{\cal L}{v i s u a l-p r o m p t}={\frac{1}{K}}\sum_{i=0}^{K}(P_{v}^{i}-P_{t}^{i})^{2}+{\cal L}_{d e c o d e r}
$$
$$
{\cal L}{v i s u a l-p r o m p t}={\frac{1}{K}}\sum_{i=0}^{K}(P_{v}^{i}-P_{t}^{i})^{2}+{\cal L}_{d e c o d e r}
$$
where $K$ is the number of positive categories, $P_{v}$ denotes the concept prompt obtained by a visual prompt encoder, and $P_{t}$ denotes the concept prompt obtained by the text encoder.
其中 $K$ 是正类别的数量,$P_{v}$ 表示通过视觉提示编码器获得的概念提示,$P_{t}$ 表示通过文本编码器获得的概念提示。
Optimized Prompt. We freeze all model parameters and initiate concept prompts with learnable embedding layers, which are fine-tuned to get aligned concept prompts. In addition, we propose the super-class representation considering the case where different classes may be labeled as the same class in downstream scenarios. Specifically, class $I$ corresponds to $M$ prompts, and the correspondence is saved through a mapping table. Finally, the maximum similarity value was extracted from the $M$ prompts as the classification score. Since hybrid encoder optimization is not required, the training objective contains only $L_{d e c o d e r}$ .
优化提示。我们冻结所有模型参数,并使用可学习的嵌入层初始化概念提示,通过微调使其对齐。此外,针对下游场景中不同类别可能被标记为同一类别的情况,我们提出了超类表示方法。具体而言,类别 $I$ 对应 $M$ 个提示,其对应关系通过映射表保存。最终从 $M$ 个提示中提取最大相似度值作为分类得分。由于无需混合编码器优化,训练目标仅包含 $L_{d e c o d e r}$。
Experiments
实验
Training Datasets.
训练数据集
We use multiple datasets with region-text annotations from different sources for joint training. For the object level, we use publicly available detection datasets, which contain Objects365 (Shao et al. 2019) (O365), OpenImages(Kuznetsova et al. 2020) (OI), V3Det (Wang et al. 2023), LVIS (Gupta, Dollar, and Girshick 2019) and COCO (Lin et al. 2014) datasets. For grounding or REC data, we used the GoldG (Kamath et al. 2021), Re $\mathrm{fCOCO/+/g}$ (Yu et al. 2016; Mao et al. 2016), Visual Genome (Krishna et al. 2017) (VG) and PhraseCut (Wu et al. 2020) datasets, with a memory bank set length of 1000 in pre-training. where GoldG, $\mathrm{RefCOCO/+/g}$ , we used the cleaned labels from GLIP (Li et al. 2022b) and we combined $\mathrm{RefCOCO/+/g}$ into RefC by removing duplicate samples. For GoldG, PhraseCut, and VG, where object phrases are treated as categories. For RefC, we treat the entire description as a category. It is worth noting that the training labels we use all come from publicly available datasets and do not scale up the data by pseudo-labeling image-text pair data as most work (Yao et al. 2024; Wu et al. 2024) does.
我们采用多来源的区域-文本标注数据集进行联合训练。在物体级别上,使用了公开检测数据集:Objects365 (Shao et al. 2019) (O365)、OpenImages (Kuznetsova et al. 2020) (OI)、V3Det (Wang et al. 2023)、LVIS (Gupta, Dollar, and Girshick 2019) 和 COCO (Lin et al. 2014)。对于定位和指代表达理解任务,采用 GoldG (Kamath et al. 2021)、RefCOCO/+/g (Yu et al. 2016; Mao et al. 2016)、Visual Genome (Krishna et al. 2017) (VG) 以及 PhraseCut (Wu et al. 2020) 数据集,预训练阶段记忆库长度设为1000。其中 GoldG 和 RefCOCO/+/g 采用 GLIP (Li et al. 2022b) 清洗后的标注,并将 RefCOCO/+/g 合并为 RefC 数据集(去除重复样本)。在 GoldG、PhraseCut 和 VG 中,物体短语被视作类别;RefC 则将完整描述作为类别。值得注意的是,所有训练标签均来自公开数据集,未像多数研究 (Yao et al. 2024; Wu et al. 2024) 那样通过图像-文本对的伪标注来扩增数据规模。
Implementation Details.
实现细节
In our experiments, we developed two model variants, CPDETR-T and CP-DETR-L, by using Swin-Tiny and SwinLarge (Liu et al. 2021) as image backbone, respectively. We used CLIP-L (Fang et al. 2024) as the text encoder in all variants and only fine-tuned it during pre-training. For CPDETR-T, we use O365, V3Det, and GoldG for pre-training with a total training epoch of 30. For CP-DETR-L, we train $1M$ iterations using all training datasets. In all experiments, we use AdamW as the optimizer with weight decay set to 1e-4 and set a minibatch to 32 on 8 A100 40GB GPUs. In pre-training, the learning rate was set to 1e-5 for the text encoder and image backbone and 1e-4 for the rest of the modules, and a decay of 0.1 was applied at $80%$ and $90%$ of the total training steps. In visual prompt training, the O365, V3Det, GoldG, and OI datasets are used, the learning rate of the visual prompt encoder is set to 1e-4, and the training is performed for $0.5M$ iterations. In the optimized prompt, the learning rate of the embedding layer is set to 5e-2, the total number of training epochs is 24, and a decay of 0.1 is applied at $80%$ of the total training steps.
在我们的实验中,我们开发了两个模型变体CPDETR-T和CP-DETR-L,分别采用Swin-Tiny和SwinLarge (Liu et al. 2021) 作为图像骨干网络。所有变体均使用CLIP-L (Fang et al. 2024) 作为文本编码器,并仅在预训练阶段进行微调。对于CPDETR-T,我们使用O365、V3Det和GoldG进行预训练,总训练周期为30轮。对于CP-DETR-L,我们使用所有训练数据集进行$1M$次迭代训练。所有实验均采用AdamW优化器,权重衰减设为1e-4,并在8块A100 40GB GPU上设置小批量大小为32。预训练阶段,文本编码器和图像骨干网络的学习率设为1e-5,其余模块设为1e-4,并在总训练步数的$80%$和$90%$处应用0.1倍衰减。视觉提示训练阶段使用O365、V3Det、GoldG和OI数据集,视觉提示编码器的学习率设为1e-4,训练进行$0.5M$次迭代。优化提示阶段,嵌入层学习率设为5e-2,总训练周期为24轮,并在总训练步数的$80%$处应用0.1倍衰减。
Evaluation Benchmark.
评估基准
We evaluated the universal detection ability on the COCO, LVIS, ODinW (Li et al. 2022a) and $\mathrm{RefCOCO/+/g}$ benchmarks. ODinW contains 35 real-world scenarios that can reflect the model’s universality in downstream tasks. For COCO, LVIS, and ODinW, the $A P$ is an evaluation metric. Following work (Liu et al. 2023), we also used RefCO $\mathrm{CO/+/g}$ to evaluate the ability of the model to understand complex textual descriptions with the $\mathrm{P}@0.5$ metric.
我们在 COCO、LVIS、ODinW (Li et al. 2022a) 和 $\mathrm{RefCOCO/+/g}$ 基准上评估了通用检测能力。ODinW 包含 35 个真实场景,能反映模型在下游任务中的通用性。对于 COCO、LVIS 和 ODinW,使用 $A P$ 作为评估指标。参考工作 (Liu et al. 2023),我们还采用 RefCO $\mathrm{CO/+/g}$ 和 $\mathrm{P}@0.5$ 指标来评估模型理解复杂文本描述的能力。
Comparison with Universal Detectors
与通用检测器的对比
By switching among the three concept prompt generation methods, we demonstrate the universality and effectiveness of CP-DETR as an object detection model, both in the pretraining domain and downstream scenarios, while ensuring state-of-the-art performance. In all evaluations, CP-DETR only uses one weight.
通过切换三种概念提示生成方法,我们证明了CP-DETR作为目标检测模型在预训练领域和下游场景中的普适性与有效性,同时保持了最先进的性能。所有评估中,CP-DETR仅使用单一权重。
Table 1: Comparison with state-of-the-art universal models on multiple datasets through text prompts. Black numbers indica zero-shot. Gray numbers indicate that the model pre-training contains the training parts of this dataset.
| Method | Backbone | COCO | LVIS | RefC | ODinW35 | ||
| val | test-dev | minival | val | refcoco/+/g | test | ||
| GLIP-T (Li et al. 2022b) | Swin-T | 46.3 | 26.0 | 17.2 | 50.4/49.5/66.1 | 19.6 | |
| Grounding-DINO-T (Liu et al. 2023) | Swin-T | 48.4 | 27.4 | 20.1 | 50.8/51.6/60.4 | 22.3 | |
| YOLO-World-L (Cheng et al. 2024) | YOLOv8-L | 45.1 | 35.4 | ||||
| DetCLIPv3-T (Yao et al. 2024) | Swin-T | 47.2 | 47.0 | 38.9 | |||
| T-Rex2-T (Jiang et al. 2024) | Swin-T | 45.8 | 42.8 | 34.8 | 18.0 | ||
| CP-DETR-T | Swin-T | 52.0 | 52.2 | 47.6 | 39.9 | 43.7/42.2/52.6 | 27.3 |
| GLIPv2-H (Zhang et al. 2022) | Swin-H | 60.6 | 59.8 | ||||
| Grounding-DINO-L (Liu et al. 2023) | Swin-L | 60.7 | 33.9 | 90.6/82.8/86.1 | 26.1 | ||
| OmDet-Turbo-B (Zhao et al.2024a) | ConvNeXt-B | 53.4 | 34.7 | 30.1 | |||
| T-Rex2-L (Jiang et al. 2024) | Swin-L | 52.2 | 54.9 | 45.8 | 22.0 | ||
| OWL-ST (Minderer et al. 2023) | CLIP L/14 | 40.9 | 35.2 | ||||
| UNINEXT-H(Yan etal.2023) | ViT-H | 60.6 | 18.3 | 14.0 | 92.6/85.2/88.7 | ||
| DetCLIPv2-L (Ya0 et al. 2023) | Swin-L | 44.7 | 36.6 | ||||
| DetCLIPv3-L(Ya0et al.2024) | Swin-L | 48.5 | 48.8 | 41.4 | |||
| GLEE-Pro (Wu et al.2024) | ViT-L | 62.0 | 62.3 | 55.7 | 91.0/82.6/86.4 | ||
| APE(D) (Shen et al. 2024) | ViT-L | 58.3 | 64.7 | 59.6 | 84.6/76.4/80.0 | 28.8 | |
| CP-DETR-L | Swin-L | 62.8 | 62.7 | 65.9 | 60.3 | 90.7/81.4/85.6 | 32.2 |
表 1: 通过文本提示在多个数据集上与最先进通用模型的对比。黑色数字表示零样本,灰色数字表示模型预训练包含该数据集的训练部分。
| 方法 | Backbone | COCO val | COCO test-dev | LVIS minival | LVIS val | RefC refcoco/+/g | ODinW35 test |
|---|---|---|---|---|---|---|---|
| GLIP-T (Li et al. 2022b) | Swin-T | 46.3 | 26.0 | 17.2 | 50.4/49.5/66.1 | 19.6 | |
| Grounding-DINO-T (Liu et al. 2023) | Swin-T | 48.4 | 27.4 | 20.1 | 50.8/51.6/60.4 | 22.3 | |
| YOLO-World-L (Cheng et al. 2024) | YOLOv8-L | 45.1 | 35.4 | ||||
| DetCLIPv3-T (Yao et al. 2024) | Swin-T | 47.2 | 47.0 | 38.9 | |||
| T-Rex2-T (Jiang et al. 2024) | Swin-T | 45.8 | 42.8 | 34.8 | 18.0 | ||
| CP-DETR-T | Swin-T | 52.0 | 52.2 | 47.6 | 39.9 | 43.7/42.2/52.6 | 27.3 |
| GLIPv2-H (Zhang et al. 2022) | Swin-H | 60.6 | 59.8 | ||||
| Grounding-DINO-L (Liu et al. 2023) | Swin-L | 60.7 | 33.9 | 90.6/82.8/86.1 | 26.1 | ||
| OmDet-Turbo-B (Zhao et al.2024a) | ConvNeXt-B | 53.4 | 34.7 | 30.1 | |||
| T-Rex2-L (Jiang et al. 2024) | Swin-L | 52.2 | 54.9 | 45.8 | 22.0 | ||
| OWL-ST (Minderer et al. 2023) | CLIP L/14 | 40.9 | 35.2 | ||||
| UNINEXT-H(Yan etal.2023) | ViT-H | 60.6 | 18.3 | 14.0 | 92.6/85.2/88.7 | ||
| DetCLIPv2-L (Ya0 et al. 2023) | Swin-L | 44.7 | 36.6 | ||||
| DetCLIPv3-L(Ya0et al.2024) | Swin-L | 48.5 | 48.8 | 41.4 | |||
| GLEE-Pro (Wu et al.2024) | ViT-L | 62.0 | 62.3 | 55.7 | 91.0/82.6/86.4 | ||
| APE(D) (Shen et al. 2024) | ViT-L | 58.3 | 64.7 | 59.6 | 84.6/76.4/80.0 | 28.8 | |
| CP-DETR-L | Swin-L | 62.8 | 62.7 | 65.9 | 60.3 | 90.7/81.4/85.6 | 32.2 |
Table 2: Comparison with state-of-the-art universal models on multiple datasets through fine-tuning. A tune of type full indicate fine-tuning the full model. A tune of type prompt indicates optimizing prompt only.
| PascalVOC Tune | rone quarium a leri | abbits | EgoHands a | Mushrooms | Packages | Raccoon | Shellfish | Vehicles | Pothole Pistols | hermal | Average | ||
| Method | A 72.636.5 | A | R 58.180.574.1 | E 92.0 | 67.0 | 76.5 | 66.4 70.5 | 66.4 55.7 | |||||
| GLEE-Pro (Wu et al.2024) | full | 69.6 32.6 | 56.676.479.4 | 88.1 | 67.1 | 69.4 | 65.8 | 71.675.7 | 60.3 | 80.6 83.1 | 69.0 68.9 | ||
| GLIP-L (Li et al.2022b) | full full | 74.4 | 36.3 | 58.7 77.1 | 79.3 | 88.1 | 74.3 | 73.1 | 70.0 | 72.272.558.3 | 81.4 | 70.4 | |
| GLIPv2-H(Zhang et al.2022) | full | 71.2 | 27.5 | 52.7 76.5 | 77.4 | 93.6 | 73.7 | 74.3 | 57.7 | 64.574.2 | 256.9 | 83.3 | 68.0 |
| OmDet-B(Zha0 et al.2022) | full | 74.4 | 44.1 | 54.7 | 80.9 79.9 | 90 | 74.1 | 69.4 | 61.2 | 68.1 | 80.3 57.1 | 81.1 | 70.4 |
| DetCLIPv2-L (Ya0 et al.2023) DetCLIPv3-L (Ya0et al.2024) | full | 76.4 | 51.2 | 57.5 | 79.9 80.2 | 90.4 | 75.1 | 70.9 | 63.6 | 69.8 | 82.7 56.2 | 83.8 | 72.1 |
| GLIP-L (Li et al.2022b) | prompt | 72.9 | 23.0 | 51.8 | 72.0 75.8 | 88.1 | 75.2 | 69.5 | 73.6 | 72.173.7 | 53.5 | 81.4 | 67.9 |
| GLIPv2-H(Zhang et al.2022) | prompt | 71.2 | 31.1 | 57.1 | 75.0 79.8 | 88.1 | 68.6 | 68.3 | 59.6 | 70.9 73.6 | 61.4 | 78.6 | 68.0 |
| Grounding-DINO-T(Chenetal.2024) | prompt | 71.7 | 34.2 | 53.0 | 75.873.4 | 88.1 | 75.6 | 74.3 | 58.7 | 68.073.652.3 | 81.5 | 67.7 | |
| CP-DETR-T | prompt | 74.2 | 37.7 | 54.4 | 78.475.5 | 88.1 | 72.0 | 72.8 | 61.0 | 72.975.954.4 | 82.2 | 69.2 | |
| CP-DETR-L | prompt | ||||||||||||
表 2: 通过微调与当前最优通用模型在多个数据集上的对比。full 类型的微调表示对整个模型进行微调。prompt 类型的微调表示仅优化提示。
| Method | PascalVOC Tune | rone quarium a leri | abbits | EgoHands a | Mushrooms | Packages | Raccoon | Shellfish | Vehicles | Pothole Pistols | hermal | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GLEE-Pro (Wu et al.2024) | full | 69.6 32.6 | 56.676.479.4 | 88.1 | 67.1 | 69.4 | 65.8 | 71.675.7 | 60.3 | 80.6 83.1 | 69.0 68.9 | |
| GLIP-L (Li et al.2022b) | full full | 74.4 | 36.3 | 58.7 77.1 | 79.3 | 88.1 | 74.3 | 73.1 | 70.0 | 72.272.558.3 | 81.4 | 70.4 |
| GLIPv2-H(Zhang et al.2022) | full | 71.2 | 27.5 | 52.7 76.5 | 77.4 | 93.6 | 73.7 | 74.3 | 57.7 | 64.574.2 | 256.9 | 83.3 |
| OmDet-B(Zha0 et al.2022) | full | 74.4 | 44.1 | 54.7 | 80.9 79.9 | 90 | 74.1 | 69.4 | 61.2 | 68.1 | 80.3 57.1 | 81.1 |
| DetCLIPv2-L (Ya0 et al.2023) DetCLIPv3-L (Ya0et al.2024) | full | 76.4 | 51.2 | 57.5 | 79.9 80.2 | 90.4 | 75.1 | 70.9 | 63.6 | 69.8 | 82.7 56.2 | 83.8 |
| GLIP-L (Li et al.2022b) | prompt | 72.9 | 23.0 | 51.8 | 72.0 75.8 | 88.1 | 75.2 | 69.5 | 73.6 | 72.173.7 | 53.5 | 81.4 |
| GLIPv2-H(Zhang et al.2022) | prompt | 71.2 | 31.1 | 57.1 | 75.0 79.8 | 88.1 | 68.6 | 68.3 | 59.6 | 70.9 73.6 | 61.4 | 78.6 |
| Grounding-DINO-T(Chenetal.2024) | prompt | 71.7 | 34.2 | 53.0 | 75.873.4 | 88.1 | 75.6 | 74.3 | 58.7 | 68.073.652.3 | 81.5 | 67.7 |
| CP-DETR-T | prompt | 74.2 | 37.7 | 54.4 | 78.475.5 | 88.1 | 72.0 | 72.8 | 61.0 | 72.975.954.4 | 82.2 | 69.2 |
| CP-DETR-L | prompt |
Table 3: Comparison with universal models on multiple datasets through interactive object detection.
| Method | Backbone | COcO-val | LVIS-minival | ODinW35 |
| T-Rex2-T | Swin-T | 56.6 | 59.3 | 37.7 |
| T-Rex2-L | Swin-L | 58.5 | 62.5 | 39.7 |
| CP-DETR-T | Swin-T | 61.8 | 64.1 | 41.0 |
| CP-DETR-L | Swin-L | 68.4 | 71.6 | 50.6 |
表 3: 通过交互式目标检测在多数据集上与通用模型的对比
| 方法 | 骨干网络 | COcO-val | LVIS-minival | ODinW35 |
|---|---|---|---|---|
| T-Rex2-T | Swin-T | 56.6 | 59.3 | 37.7 |
| T-Rex2-L | Swin-L | 58.5 | 62.5 | 39.7 |
| CP-DETR-T | Swin-T | 61.8 | 64.1 | 41.0 |
| CP-DETR-L | Swin-L | 68.4 | 71.6 | 50.6 |
Text Prompt Direct Evaluation. In this evaluation, we use all category names or description sentences of the benchmark as text prompt inputs, consistent with previous work (Shen et al. 2024) settings. Depending on whether the benchmark’s training set is used in pre-training, the text prompt-based evaluation can be categorized into zero-shot and full-shot. We primarily use CP-DETR-T to evaluate the effectiveness of our method on zero-shot. As shown in table 1, CP-DETR-T outperforms all similarly sized previous models in COCO and LVIS benchmarking, with $+3.6A P$ and $+20.2A P$ compared to baseline Grounding DINO. The method closest to ours in terms of zero-shot performance is DetCLIPv3-T, which not only uses $1.61M$ of O365, V3Det, and GoldG as we do, but also an extra $50M$ of private data Gran u Cap 50 M, which indicates that our method is sufficiently effective in terms of concept generalization. CPDETR-T has limitations on RefC, which we believe are due to the pre-training containing only object phrases and lacking the descriptive sentences required in the RefC evaluation. On the ODinW35 benchmark, we observed that several datasets showed significant quality issues in terms of annotated category names, so we followed the APE (Shen et al.
文本提示直接评估。在此评估中,我们使用基准测试的所有类别名称或描述句子作为文本提示输入,与先前工作 (Shen et al. 2024) 设置保持一致。根据基准测试的训练集是否用于预训练,基于文本提示的评估可分为零样本和全样本。我们主要使用 CP-DETR-T 来评估我们的方法在零样本上的有效性。如 表 1 所示,CP-DETR-T 在 COCO 和 LVIS 基准测试中优于所有类似规模的先前模型,与基线 Grounding DINO 相比,分别提升了 $+3.6A P$ 和 $+20.2A P$。在零样本性能方面,最接近我们方法的是 DetCLIPv3-T,它不仅使用了与我们相同的 $1.61M$ 的 O365、V3Det 和 GoldG 数据,还额外使用了 $50M$ 的私有数据 Gran u Cap 50 M,这表明我们的方法在概念泛化方面足够有效。CPDETR-T 在 RefC 上存在局限性,我们认为这是由于预训练仅包含对象短语而缺乏 RefC 评估所需的描述性句子。在 ODinW35 基准测试中,我们观察到多个数据集在标注类别名称方面存在显著的质量问题,因此我们遵循了 APE (Shen et al.
- evaluation setup, and our CP-DETR-L set a new zeroshot record with an average of $32.2A P$ across 35 datasets.
- 评估设置中,我们的 CP-DETR-L 以平均 $32.2A P$ 的成绩在 35 个数据集上创造了新的零样本 (zero-shot) 记录。
A universal model should have concept generalization capabilities and perform well in scenarios that have already been seen in pre-training. Due to CP-DETR-L’s pre-training data containing COCO, LVIS, and RefC, we use it for fullshot comparisons with other state-of-the-art universal models. As shown at the bottom of table 1, the CP-DETRL simultaneously achieves state-of-the-art performance or competitive performance in all object detection benchmarks, with $+2.1A P$ in COCO-val compared to baseline (Liu et al. 2023). On the RefC benchmark, CP-DETR achieved com- parable results to Grounding DINO-L, showing that the sentence feature as a concept prompt is sufficient to represent complex textual descriptions. Notably for the COCO and LVIS parts of the evaluation, the state-of-the-art APE (Shen et al. 2024) and GLEE (Wu et al. 2024) performed well on only one of them, even though they used a larger backbone and stronger large-scale jittering data augmentation methods. And CP-DETR performs well on both benchmarks, proving that our method remembers and distinguishes all seen concepts well.
通用模型应具备概念泛化能力,并在预训练已见过的场景中表现良好。由于CP-DETR-L的预训练数据包含COCO、LVIS和RefC,我们将其与其他最先进的通用模型进行全量对比。如表1底部所示,CP-DETR-L在所有目标检测基准中同时实现了最先进或具有竞争力的性能,在COCO-val上相比基线(Liu等人2023)提升了+2.1AP。在RefC基准测试中,CP-DETR取得了与Grounding DINO-L相当的结果,表明作为概念提示的句子特征足以表示复杂的文本描述。值得注意的是,在评估的COCO和LVIS部分,最先进的APE(Shen等人2024)和GLEE(Wu等人2024)尽管使用了更大的主干网络和更强的大规模抖动数据增强方法,但仅在其中一个基准上表现优异。而CP-DETR在两个基准上均表现良好,证明我们的方法能很好地记忆并区分所有已见概念。
Fine-tuning Evaluation. Table 2 shows the comparison results with the state-of-the-art universal detection models on 13 subsets in ODinW, which are fine-tuned using prompt or full model. Optimized prompts reduce alignment bias by adjusting concept prompts and can truly reflect the universality of the detector. The significant performance advantage of our approach in this setting, along with the $+5.1A P$ compared to GLIPv2-H (Zhang et al. 2022) in terms of average metrics, demonstrates the strong generalization of CPDETR in downstream scenarios, and we believe that this advantage stems from our design, which better facilitates the use of prompt information. Even compared to the approach of applying full model fine-tuning, CP-DETR-L still achieved state-of-the-art or competitive performance in 13 subsets with only optimized prompts, and set a new record of $73.1A P$ on average. This phenomenon indicates that CPDETR can achieve competitive performance with a specific model in downstream scenarios by using a pre-trained weight, greatly enhancing the application value of the universal model in the real world.
微调评估。表2展示了在ODinW的13个子集上与最先进的通用检测模型的对比结果,这些模型通过提示或完整模型进行了微调。优化提示通过调整概念提示减少了对齐偏差,能够真实反映检测器的通用性。我们的方法在此设定下的显著性能优势,以及相比GLIPv2-H (Zhang et al. 2022) 在平均指标上提升的$+5.1A P$,证明了CPDETR在下游场景中的强大泛化能力,我们认为这一优势源于我们的设计能更好地利用提示信息。即使与采用完整模型微调的方法相比,CP-DETR-L仅通过优化提示就在13个子集中实现了最先进或有竞争力的性能,并以平均$73.1A P$创造了新纪录。这一现象表明,CPDETR通过使用预训练权重,能够在下游场景中与特定模型实现竞争性表现,极大提升了通用模型在现实世界中的应用价值。
Visual Prompt Interactive Evaluation. Since the concept prompt generation of visual prompt requires boxes as input, we use interactive evaluation, unlike the interactive process of T-Rex2 (Jiang et al. 2024), we avoid introducing category priors. For the test image with $M$ total dataset categories and $N$ positive categories, we randomly chose a GT box as the visual prompt input for the positive category and used text prompts for the remaining $M-N$ negative categories. As shown in table 3, our method significantly outperforms previous work (Jiang et al. 2024) in all benchmarks. CP-DETR is the first to implement interactive detection based on visual prompts in the early fusion paradigm, which is more effective in exploiting prompt information than the late fusion paradigm (Jiang et al. 2024). Comparing table 1 and 3, it can be observed that visual prompts outperform text prompts, with $+18.4A P$ on ODinW35, indicating that visual prompts can reduce alignment bias and have a strong application in interactive scenarios such as auxiliary labelling.
视觉提示交互式评估。由于视觉提示的概念生成需要以边界框作为输入,我们采用交互式评估方式。与T-Rex2 (Jiang et al. 2024) 的交互流程不同,我们避免引入类别先验。对于包含 $M$ 个数据集类别且具有 $N$ 个正类别的测试图像,我们随机选取一个真实标注框作为正类别的视觉提示输入,并为剩余 $M-N$ 个负类别使用文本提示。如表3所示,我们的方法在所有基准测试中均显著优于先前工作 (Jiang et al. 2024) 。CP-DETR是首个在早期融合范式下实现基于视觉提示的交互式检测方法,相比后期融合范式 (Jiang et al. 2024) 能更有效地利用提示信息。对比表1和表3可见,视觉提示性能优于文本提示,在ODinW35上实现 $+18.4A P$ 提升,这表明视觉提示能减少对齐偏差,在辅助标注等交互场景中具有强应用价值。
Table 4: Ablations for our model with a Swin-T backbone. The full shot is achieved by the optimized prompt.
| Row | ModelSet | LVIS Sminival | ODinW13 |
| Zero-shot | Full-shot | ||
| 0 | CP-DETR(basemodel) | 44.3 | 64.0 |
| 1 | replaced byDINO encoder | 42.2 | 58.5 |
| 2 | w/oMFG | 42.8 | 62.3 |
| 3 | add prompt multi-label loss | 44.8 | 64.2 |
| 4 | add row3 and auxiliary head | 44.7 | 64.9 |
| 5 | add row3, row4 and super-class | 44.7 | 67.0 |
表 4: 采用 Swin-T 骨干网络的模型消融实验结果。完整样本 (Full-shot) 通过优化提示实现。
| 行号 | 模型设置 | LVIS Sminival (零样本) | ODinW13 (完整样本) |
|---|---|---|---|
| 0 | CP-DETR(基线模型) | 44.3 | 64.0 |
| 1 | 替换为DINO编码器 | 42.2 | 58.5 |
| 2 | 去除MFG | 42.8 | 62.3 |
| 3 | 添加提示多标签损失 | 44.8 | 64.2 |
| 4 | 添加第3行及辅助头 | 44.7 | 64.9 |
| 5 | 添加第3行、第4行和超类 | 44.7 | 67.0 |
Ablation
消融实验
In this section, we conducted ablation experiments. The different variants models all use the Swin-T backbone and are trained on O365, V3Det, and GoldG for 12 epochs. In order to show the impact of various components on the universality of the detector, we not only performed a zero-shot evaluation on LVIS but also employed a full-shot optimized prompt on ODinW13.
在本节中,我们进行了消融实验。所有变体模型均采用Swin-T骨干网络,并在O365、V3Det和GoldG数据集上训练12个周期。为了展示各组件对检测器通用性的影响,我们不仅在LVIS上进行了零样本评估,还在ODinW13上采用了全量优化的提示策略。
Table 4 demonstrates the effectiveness of the different designs, where row 0 is the CP-DETR base model without the inclusion of auxiliary supervision and super-class represent ation. The prompt visual hybrid encoder was ablated in rows 1 and 2; the results show that the hybrid fusion approach of PSF and MSG reduces the difficulty of alignment and contributes to the zero-shot generalization of concepts, and the metric is improved by $0.6A P$ and $1.5A P$ on LVIS, respectively. The hybrid encoder is the most important improvement, with the ODinW13 full-shot metric upgraded from $58.5A P$ in row 1 to $64.0A P$ . This improvement reveals the importance of effective cross-modal fusion for universal location, encouraging the model to decode object boxes based on information in the prompt. Rows 3 and $4\mathrm{ex-}$ periments show that auxiliary supervision facilitates the hybrid encoder in learning cross-modal knowledge during the training phase and modestly improves the zero-shot and fullshot metrics performance. Row 5 further adds super-class in prompt fine-tuning, with the number set to 10 in the experiment, i.e., 10 prompt vectors represent a category. This design can effectively handle situations where different objects in downstream scenes are represented in the same category, thus further improving the ODinW13 metric to $67.0A P$ . See the Technical Appendix for more results.
表 4 展示了不同设计的有效性,其中第 0 行是不包含辅助监督和超类表示的 CP-DETR 基础模型。第 1 行和第 2 行对提示视觉混合编码器进行了消融实验,结果表明 PSF 和 MSG 的混合融合方法降低了对齐难度,有助于概念的零样本泛化,在 LVIS 上的指标分别提升了 $0.6A P$ 和 $1.5A P$。混合编码器是最重要的改进,ODinW13 全样本指标从第 1 行的 $58.5A P$ 提升至 $64.0A P$。这一改进揭示了有效跨模态融合对于通用定位的重要性,鼓励模型基于提示信息解码物体框。第 3 行和第 $4\mathrm{ex-}$ 行实验表明,辅助监督有助于混合编码器在训练阶段学习跨模态知识,并适度提升了零样本和全样本指标性能。第 5 行进一步在提示微调中加入了超类,实验中数量设置为 10,即 10 个提示向量代表一个类别。该设计能有效处理下游场景中不同物体被归为同一类别的情况,从而将 ODinW13 指标进一步提升至 $67.0A P$。更多结果详见技术附录。
Conclusion
结论
In this paper, we propose a universal detector CP-DETR that enables prompt-conditional detection through efficient prompt visual fusion. We focus on downstream applications and achieve SoTA zero-shot performance through text prompts. Furthermore, with visual prompt and optimized prompt, CP-DETR with only one weight can compete with the full model fine-tuned methods in downstream scenarios, demonstrating its superior universality.
本文提出了一种通用检测器CP-DETR,通过高效的提示视觉融合实现提示条件检测。我们聚焦下游应用,通过文本提示实现了零样本(Zero-shot)的SoTA性能。此外,借助视觉提示和优化提示,仅需单一权重的CP-DETR即可在下游场景中与全模型微调方法竞争,展现了其卓越的通用性。
References
参考文献
Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; and Dai, J. 2021.Deformable DETR: Deformable Transformers for End-toEnd Object Detection. In ICLR. Zong, Z.; Song, G.; and Liu, Y. 2023. Detrs with collaborative hybrid assignments training. In ICCV, 6748–6758.
Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; and Dai, J. 2021. Deformable DETR: 基于可变形Transformer的端到端目标检测方法。In ICLR.
Zong, Z.; Song, G.; and Liu, Y. 2023. 协作混合分配训练的DETR模型。In ICCV, 6748–6758.
Appendix More Implementation Details
附录 更多实现细节
For Hungarian matching, we following previous works (Liu et al. 2023; Shen et al. 2024), and set the weight of alignment costs, L1 costs, and GIoU costs as 2.0, 5.0, and 2.0, respectively. The corresponding loss weights in the transformer decoder are 1.0, 5.0 and 2.0, respectively. Since the transformer decoder computes losses at each layer, to balance the contribution of different losses, we refer to previous work (Zong, Song, and Liu 2023) and set the prompt multilabel loss weight to 6, and the class loss, centerness loss and IoU loss in the auxiliary detection header to 6, 6, and 12, respectively.
对于匈牙利匹配,我们遵循先前的工作 (Liu et al. 2023; Shen et al. 2024),将对齐代价、L1代价和GIoU代价的权重分别设为2.0、5.0和2.0。Transformer解码器中对应的损失权重分别为1.0、5.0和2.0。由于Transformer解码器在每一层都计算损失,为了平衡不同损失的贡献,我们参考先前工作 (Zong, Song, and Liu 2023),将提示多标签损失权重设为6,辅助检测头中的类别损失、中心度损失和IoU损失分别设为6、6和12。
Due to GPUs resource limitation and in order to reduce memory spikes, we apply gradient checkpoints and automatically mixed precision (AMP) techniques in the images backbone and prompt visual hybrid encoder. Both our CP-DETR-T and CP-DETR-L use 4 scales image features, where 1/8 to 1/32 is from the image backbone and 1/64 is from channel mapping down sampling. For images augmentation, we use the default DETR (Zhang et al. 2023) augmentation in MM Detection (Chen et al. 2019) toolbox, which includes multi-scale training and random flip.
由于 GPU 资源限制且为了减少内存峰值,我们在图像主干网络和提示视觉混合编码器中应用了梯度检查点 (gradient checkpoint) 和自动混合精度 (AMP) 技术。我们的 CP-DETR-T 和 CP-DETR-L 均使用 4 尺度图像特征,其中 1/8 至 1/32 来自图像主干网络,1/64 则通过通道映射降采样获得。在图像增强方面,我们采用 MM Detection (Chen et al. 2019) 工具箱中默认的 DETR (Zhang et al. 2023) 增强策略,包括多尺度训练和随机翻转。
More Training Data Details
更多训练数据详情
We compare the data usage of CP-DETR with other methods in table 5. It can be found that most of the methods construct private training annotations to better align different modalities by extending the richness of the training samples. In contrast, CP-DETR achieves excellent zero-shot performance using only publicly available annotations. We believe there are two reasons for this: firstly, the CLIP (Fang et al. 2024) text encoder has seen ample visual concepts and the proposed design is effective enough in exploiting concept information. Second, our using sentence-level representations, where a large number of negative categories can be used in a batch, reduces the illusion.
我们在表5中比较了CP-DETR与其他方法的数据使用情况。可以发现,大多数方法通过扩展训练样本的丰富性来构建私有训练标注,以更好地对齐不同模态。相比之下,CP-DETR仅使用公开可用的标注就实现了出色的零样本性能。我们认为这有两个原因:首先,CLIP (Fang et al. 2024) 文本编码器已经学习了丰富的视觉概念,且所提出的设计在利用概念信息方面足够有效;其次,我们使用句子级表征,使得一个批次中可以使用大量负类别,从而减少了幻觉。
In addition, the sampling rates we configured for the different datasets are shown in table 6. It should be noted that GoldG (Kamath et al. 2021) data contains both GQA and Flickr30k components. However, we found that multiple samples in GQA shared a single image, so we merged these samples and reduced the data size from $0.62M$ to $0.09M$ . O365 contains v1 and v2 versions, based on previous studies (Liu et al. 2023; Li et al. 2022b), we use v1 on CPDETR-T and v2 on CP-DETR-L.
此外,我们为不同数据集配置的采样率如表6所示。需要注意的是,GoldG (Kamath et al. 2021) 数据包含GQA和Flickr30k两部分。但我们发现GQA中多个样本共享同一张图像,因此合并了这些样本并将数据量从$0.62M$缩减至$0.09M$。O365包含v1和v2版本,根据先前研究 (Liu et al. 2023; Li et al. 2022b),我们在CPDETR-T上使用v1,在CP-DETR-L上使用v2。
Additional Experiment
附加实验
Since ablation experiments in the main manuscript reveal that the super-class representation has a large performance gain for optimized prompts, we experimented with the
由于主论文中的消融实验表明超类表征对优化提示具有显著的性能提升效果,我们针对...
Table 5: A detailed list of training data for different models. VIS consists of YTVIS19, YTVIS21, and OVIS. GoldG consists of GQA and Flickr30k. Private annotated data, indicating that the annotation of the corresponding data is privately constructed by them and is not publicly available.
| Method | Backbone | PubliclyAvailableData | PrivateAnnotatedData |
| GLIP-T (Li et al.2022b) | Swin-T | 0365,GoldG | Cap4M |
| Grounding-DINO-T (Liu et al. 2023) | Swin-T | 0365,GoldG | Cap4M |
| YOLO-World-L (Cheng et al.2024) | YOLOv8-L | 0365,GoldG | CC3M |
| DetCLIPv3-T(Ya0etal.2024) | Swin-T | O365,V3Det,GoldG | GranuCap50M |
| T-Rex2-T (Jiang et al.2024) | Swin-T | O365,OI,GoldG,HierText,CrowdHuman | CC3M,SBU,LAION |
| CP-DETR-T | Swin-T | 0365V3Det,GoldG | |
| GLIPv2-H (Zhang et al.2022) | Swin-H | O365,OI,VG,ImageNetBoxes,COCO,GoldG | CC15M,SBU |
| Grounding-DINO-L (Liu et al.2023) | Swin-L | 0365OI,Go1dGCOCOReC | Cap4M |
| UNINEXT-H(Yanetal.2023) | ViT-H | O365,COCOReC,SOT&VOSMOT&VIS,RVOS | |
| OWL-ST(Mindereretal.2023) | CLIP L/14 | WebLI2B | |
| T-Rex2-L (Jiang et al.2024) | Swin-L | O365,OI,GoldG,HierText,CrowdHuman | CC3M,SBU,LAION |
| DetCLIPv3-L(Ya0etal.2024) | Swin-L | 0365V3DetGoldG | GranuCap50M |
| GLEE-Pro (Wu et al.2024) | ViT-L | O365,VG,COCO,OILVIS,BDD,RC,RVOS,VIS | |
| APE(D) (Shen et al.2024) | ViT-L | COCO,LVIS,O365,OIVG,ReC,GoldG,PhraseCut | SA-1B |
| CP-DETR-L | Swin-L | O365.V3Det.Go1dG.OI,VG.ReC.COCO.LVIS.PhraseCut |
表 5: 不同模型的训练数据详细列表。VIS包含YTVIS19、YTVIS21和OVIS。GoldG包含GQA和Flickr30k。私有标注数据表示对应数据的标注由他们私下构建且未公开。
| 方法 | 骨干网络 | 公开可用数据 | 私有标注数据 |
|---|---|---|---|
| GLIP-T (Li et al.2022b) | Swin-T | O365, GoldG | Cap4M |
| Grounding-DINO-T (Liu et al. 2023) | Swin-T | O365, GoldG | Cap4M |
| YOLO-World-L (Cheng et al.2024) | YOLOv8-L | O365, GoldG | CC3M |
| DetCLIPv3-T (Ya0 et al.2024) | Swin-T | O365, V3Det, GoldG | GranuCap50M |
| T-Rex2-T (Jiang et al.2024) | Swin-T | O365, OI, GoldG, HierText, CrowdHuman | CC3M, SBU, LAION |
| CP-DETR-T | Swin-T | O365, V3Det, GoldG | |
| GLIPv2-H (Zhang et al.2022) | Swin-H | O365, OI, VG, ImageNetBoxes, COCO, GoldG | CC15M, SBU |
| Grounding-DINO-L (Liu et al.2023) | Swin-L | O365, OI, GoldG, COCO, ReC | Cap4M |
| UNINEXT-H (Yan et al.2023) | ViT-H | O365, COCO, ReC, SOT&VOS, MOT&VIS, RVOS | |
| OWL-ST (Minderer et al.2023) | CLIP L/14 | WebLI2B | |
| T-Rex2-L (Jiang et al.2024) | Swin-L | O365, OI, GoldG, HierText, CrowdHuman | CC3M, SBU, LAION |
| DetCLIPv3-L (Ya0 et al.2024) | Swin-L | O365, V3Det, GoldG | GranuCap50M |
| GLEE-Pro (Wu et al.2024) | ViT-L | O365, VG, COCO, OI, VIS, BDD, RC, RVOS | |
| APE(D) (Shen et al.2024) | ViT-L | COCO, LVIS, O365, OI, VG, ReC, GoldG, PhraseCut | SA-1B |
| CP-DETR-L | Swin-L | O365, V3Det, GoldG, OI, VG, ReC, COCO, LVIS, PhraseCut |
Table 6: Training data sampling ratio configures.
| Model | Target | 0365 | V3Det | GoldG | 01 | VG | RefC | COCO | LVIS | PhraseCut | |
| GQA | Flickr30k | ||||||||||
| CP-DETR-T | Pre-training | 1 | 1 | 3 | 1 | ||||||
| VisualPrompt | 1 | 1 | 1 | 1 | 1 | ||||||
| CP-DETR-L | Pre-training | 1 | 1 | 3 | 1 | 1 | 2 | 3 | 2 | 2 | 1 |
| VisualPrompt | 1 | 1 | 1 | 1 | 1 | ||||||
表 6: 训练数据采样比例配置。
| Model | Target | 0365 | V3Det | GQA | Flickr30k | 01 | VG | RefC | COCO | LVIS | PhraseCut |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CP-DETR-T | Pre-training | 1 | 1 | 3 | 1 | ||||||
| VisualPrompt | 1 | 1 | 1 | 1 | 1 | ||||||
| CP-DETR-L | Pre-training | 1 | 1 | 3 | 1 | 1 | 2 | 3 | 2 | 2 | 1 |
| VisualPrompt | 1 | 1 | 1 | 1 | 1 |
| Model | FPS(bs=1) | FPS(bs=4) | ||
| 1classes | 80classes | 1classes | 80classes | |
| Grounding-DINO-T CP-DETR-T | 9.2 | 5.0 | 9.3 | 5.7 |
| 12.2 | 11.2 | 14.9 | 13.3 | |
| Grounding-DINO-L CP-DETR-L | 3.0 | 2.0 | 2.7 | 1.8 |
| 5.5 | 5.4 | 5.2 | 4.9 | |
| 模型 | FPS(bs=1) | FPS(bs=1) | FPS(bs=4) | FPS(bs=4) |
|---|---|---|---|---|
| 1类别 | 80类别 | 1类别 | 80类别 | |
| Grounding-DINO-T CP-DETR-T | 9.2 | 5.0 | 9.3 | 5.7 |
| 12.2 | 11.2 | 14.9 | 13.3 | |
| Grounding-DINO-L CP-DETR-L | 3.0 | 2.0 | 2.7 | 1.8 |
| 5.5 | 5.4 | 5.2 | 4.9 |
Table 7: Comparison results of model inference efficiency. The bs denotes the size of the batchsize used for single inference. FPS indicates the number of images processed by the model per second, and larger indicates more efficient inference.
表 7: 模型推理效率对比结果。bs表示单次推理使用的批处理大小(batchsize)。FPS表示模型每秒处理的图像数量,数值越大代表推理效率越高。
super-class representation length as well. As shown in figure 3, the performance on the downstream task gradually improves as the representation length increases, approaching saturation at 10, so we use 10 as the default length for optimized prompts.
图 3: 下游任务性能随着表示长度的增加而逐步提升,在达到10时接近饱和,因此我们默认使用10作为优化提示(prompt)的长度。
In addition, table 7 compares the model size and inference efficiency of CP-DETR and Grounding DINO (Liu et al. 2023). For a fair comparison, we use the Grounding DINO implemented in MM Detection (Chen et al. 2019). Automatically mixed precision was kept off in all tests. The results show that our model is more inference efficient. There are three main reasons for this, firstly our cross-modal interactions are scale-by-scale, which has less computational overhead compared to works (Liu et al. 2023) which interact at all scales. Second, we rely on PAN (Liu et al. 2018) structure to fuse image features instead of dense deformable selfattention (Zhu et al. 2021) operation. Finally, Grounding DINO-L uses 1/4 to $1/64$ of the image feature maps, while we only use 1/8 to 1/64 of the image feature maps on the largest scale model, requiring fewer image features to be processed.
此外,表7比较了CP-DETR和Grounding DINO (Liu et al. 2023)的模型规模和推理效率。为确保公平比较,我们使用MM Detection (Chen et al. 2019)实现的Grounding DINO。所有测试均关闭自动混合精度。结果表明我们的模型推理效率更高,主要原因有三:首先,我们的跨模态交互采用逐尺度处理,相比(Liu et al. 2023)的全尺度交互方案计算开销更小;其次,我们采用PAN (Liu et al. 2018)结构融合图像特征,而非密集可变形自注意力(Zhu et al. 2021)操作;最后,Grounding DINO-L使用了1/4至$1/64$的图像特征图,而我们最大尺度模型仅使用1/8至1/64的图像特征图,需要处理的图像特征更少。

Figure 3: Ablation results for the super-class representation length of optimized prompt in CP-DETR-T.
图 3: CP-DETR-T中优化提示词(prompt)的超类(super-class)表示长度消融实验结果。
Limitation
局限性
Although our model exhibits strong universal detection performance, it still has some challenges. On the one hand, the pre-training of CP-DETR relies heavily on text quality, yet there are potential descriptive conflicts between different datasets, e.g., the noun ”mouse”, which denotes a computer device in most of the data, whereas it is used to describe an animal in some scenarios. We believe that such textual defects will reduce the model’s optimisation efficiency and affect the zero-shot capability. On the other hand, since we use average pooling to obtain sentence-level text prompts, this may lead to incorrect optimisation of objects in sentences. For example, if the training text ”person wearing helmet” exists, the zero-shot of ”helmet” will most likely frame out the person with a helmet after pre-training, assuming that there is a lack of category annotation of ”helmet” in the data. In addition, it can be observed in the main manuscript that the visual prompts in CP-DETR-L are significantly better than those in CP-DETR-T, so further scaling up of the model and training data is still necessary.
尽管我们的模型展现出强大的通用检测性能,但仍存在一些挑战。一方面,CP-DETR的预训练高度依赖文本质量,但不同数据集间可能存在描述性冲突,例如名词"mouse"在多数数据中表示计算机设备,而在某些场景下却用于描述动物。我们认为此类文本缺陷会降低模型的优化效率并影响零样本能力。另一方面,由于我们采用平均池化获取句子级文本提示,这可能导致对句中物体的错误优化。例如,若训练文本"person wearing helmet"存在,当数据中缺乏"helmet"的类别标注时,预训练后"helmet"的零样本检测很可能会框出戴头盔的人。此外,从主论文中可观察到CP-DETR-L的视觉提示显著优于CP-DETR-T,因此仍需进一步扩大模型规模和训练数据。

Figure 4: Visualization s of CP-DETR-L zero-shot outputs.
| Method | Datascale | COCO-val APall | LVIS-minival | LVIS-val | ||||||
| APall | APr | APc | APf | APall | APr | APc | APf | |||
| Open-source | ||||||||||
| CurrentSOTAineachitem | N/A | 53.4 | 43.4 | 34.5 | 41.2 | 46.9 | 34.7 | 26.9 | 32.0 | 41.3 |
| Closed-source | ||||||||||
| DetCLIPv3-L | 50M | 48.5 | 48.8 | 49.9 | 49.7 | 47.8 | 41.4 | 41.4 | 40.5 | 42.3 |
| Trex-2-L | 6.5M | 52.2 | 54.9 | 49.2 | 54.8 | 56.1 | 45.8 | 42.7 | 43.2 | 50.2 |
| Grounding DINOv1.5 Pro | 20M | 54.3 | 55.7 | 56.1 | 57.5 | 54.1 | 47.6 | 44.6 | 47.9 | 48.7 |
| Grounding DINOv1.6 Pro | 30M | 55.4 | 57.7 | 57.5 | 60.5 | 55.3 | 51.1 | 51.5 | 52.0 | 50.1 |
| CP-DETR-PrO | 1.1M | 55.4 | 58.2 | 60.6 | 59.2 | 56.8 | 51.6 | 51.3 | 51.6 | 51.8 |
Table 8: Zero-shot performance of CP-DETR-Pro on the COCO, LVIS-minival and LVIS-val benchmarks compared to previou methods.
图 4: CP-DETR-L 零样本输出的可视化结果。
| 方法 | 数据规模 | COCO-val APall | LVIS-minival | LVIS-val | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| APall | APr | APc | APf | APall | APr | APc | APf | |||
| 开源 | ||||||||||
| CurrentSOTAineachitem | N/A | 53.4 | 43.4 | 34.5 | 41.2 | 46.9 | 34.7 | 26.9 | 32.0 | 41.3 |
| 闭源 | ||||||||||
| DetCLIPv3-L | 50M | 48.5 | 48.8 | 49.9 | 49.7 | 47.8 | 41.4 | 41.4 | 40.5 | 42.3 |
| Trex-2-L | 6.5M | 52.2 | 54.9 | 49.2 | 54.8 | 56.1 | 45.8 | 42.7 | 43.2 | 50.2 |
| Grounding DINOv1.5 Pro | 20M | 54.3 | 55.7 | 56.1 | 57.5 | 54.1 | 47.6 | 44.6 | 47.9 | 48.7 |
| Grounding DINOv1.6 Pro | 30M | 55.4 | 57.7 | 57.5 | 60.5 | 55.3 | 51.1 | 51.5 | 52.0 | 50.1 |
| CP-DETR-PrO | 1.1M | 55.4 | 58.2 | 60.6 | 59.2 | 56.8 | 51.6 | 51.3 | 51.6 | 51.8 |
表 8: CP-DETR-Pro 在 COCO、LVIS-minival 和 LVIS-val 基准测试中的零样本性能与先前方法的对比。
Visualization s
可视化
In this subsection, we demonstrate the generalisation capabilities of CP-DETR on various scenarios through qualitative visualisation s. In figure 4, we visualise some zero-shot results through textual descriptions. Our model performs well in different scenarios and correctly processes descriptive text, such as the second row and second column in figure 4.
在本小节中,我们通过定性可视化展示了CP-DETR在各种场景下的泛化能力。在图4中,我们通过文本描述可视化了一些零样本结果。我们的模型在不同场景下表现良好,并能正确处理描述性文本,例如图4中第二行第二列所示。
In figure 5, we visualise some visual prompt results. It can be observed that visual prompts perform well on dense objects and can be combined with text prompts, as shown in (c) of figure 5.
图 5: 我们展示了一些视觉提示 (visual prompt) 的效果。可以观察到,视觉提示在密集物体上表现良好,并能与文本提示相结合,如图 5 (c) 所示。
Large-scale model
大语言模型 (Large Language Model)
Recently, we tried to scale up the model parameters by updating the visual backbone network. After preliminary experiments, we found that the pre-training weights of the backbone network have a significant effect on the zeroshot performance. We tried EVA-02 (Fang et al. 2024) and Florence-2 (Xiao et al. 2024) and finally chose EVA-02 ViTL as the visual backbone of CP-DETR-Pro. In the preliminary experiments, CP-DETR-Pro uses the same training data as CP-DETR-T and is trained for 16 epochs with batchsize 16. As shown in table 8, CP-DETR-Pro exhibits an amazing zero-shot generalization capability, which not only exceeds the best metrics of all open-source algorithms, but is also sufficient to compete with closed-source models trained with tens of times closed-source data.
最近,我们尝试通过更新视觉主干网络来扩大模型参数。初步实验发现,主干网络的预训练权重对零样本性能有显著影响。我们测试了EVA-02 (Fang et al. 2024)和Florence-2 (Xiao et al. 2024),最终选择EVA-02 ViTL作为CP-DETR-Pro的视觉主干。在初步实验中,CP-DETR-Pro采用与CP-DETR-T相同的训练数据,以16的批次大小训练16个周期。如[表8]所示,CP-DETR-Pro展现出惊人的零样本泛化能力,不仅超越所有开源算法的最佳指标,还能与使用数十倍闭源数据训练的闭源模型相媲美。

Figure 5: Visualization s of CP-DETR-L visual prompt outputs. Row 1 use of a class of boxes as inputs. Row 2 use of two classes of boxes as inputs. Row 3 use of a class of boxes and text ”person.tree” as inputs.
图 5: CP-DETR-L视觉提示输出的可视化。第一行使用一类框作为输入。第二行使用两类框作为输入。第三行使用一类框和文本"person.tree"作为输入。