Evaluating Contextual i zed Embeddings on 54 Languages in POS Tagging, Lemma ti z ation and Dependency Parsing
基于54种语言的词性标注、词形还原和依存句法分析评估上下文嵌入模型
Abstract
摘要
We present an extensive evaluation of three recently proposed methods for contextual i zed embeddings on 89 corpora in 54 languages of the Universal Dependencies 2.3 in three tasks: POS tagging, lemma ti z ation, and dependency parsing. Employing the BERT, Flair and ELMo as pretrained embedding inputs in a strong baseline of UDPipe 2.0, one of the best-performing systems of the CoNLL 2018 Shared Task and an overall winner of the EPE 2018, we present a one-toone comparison of the three contextual i zed word embedding methods, as well as a comparison with word2vec-like pretrained embeddings and with end-to-end character-level word embeddings. We report state-of-the-art results in all three tasks as compared to results on UD 2.2 in the CoNLL 2018 Shared Task.
我们对三种最新提出的上下文嵌入方法进行了广泛评估,这些方法在Universal Dependencies 2.3的54种语言89个语料库中应用于三个任务:词性标注、词形还原和依存句法分析。采用BERT、Flair和ELMo作为UDPipe 2.0强基线模型的预训练嵌入输入(该系统是CoNLL 2018共享任务中表现最佳的系统之一,也是EPE 2018的总冠军),我们对这三种上下文词嵌入方法进行了一对一比较,同时与类word2vec预训练嵌入以及端到端字符级词嵌入进行了对比。相较于CoNLL 2018共享任务中UD 2.2的结果,我们在所有三个任务中都报告了最先进的成果。
1 Introduction
1 引言
We publish a comparison and evaluation of three recently proposed contextual i zed word embedding methods: BERT (Devlin et al., 2018), Flair (Akbik et al., 2018) and ELMo (Peters et al., 2018), in 89 corpora which have a training set in 54 languages of the Universal Dependencies 2.3 in three tasks: POS tagging, lemma ti z ation and dependency parsing. Our contributions are the following:
我们发布了三种近期提出的上下文词嵌入方法的比较与评估:BERT (Devlin et al., 2018)、Flair (Akbik et al., 2018) 和 ELMo (Peters et al., 2018),在包含54种语言训练集的Universal Dependencies 2.3的89个语料库中进行了三项任务测试:词性标注、词形还原和依存句法分析。我们的贡献如下:
• Meaningful massive comparative evaluation of BERT (Devlin et al., 2018), Flair (Akbik et al., 2018) and ELMo (Peters et al., 2018) contextual i zed word embeddings, by adding them as input features to a strong baseline of UDPipe 2.0, one of the best performing systems in the CoNLL 2018 Shared Task (Zeman et al., 2018) and an overall winner of the EPE 2018 Shared Task (Fares et al., 2018).
• 通过将BERT (Devlin等人, 2018)、Flair (Akbik等人, 2018)和ELMo (Peters等人, 2018)的上下文词嵌入作为输入特征添加到UDPipe 2.0的强大基线中,进行有意义的规模化对比评估。UDPipe 2.0是CoNLL 2018共享任务 (Zeman等人, 2018)中表现最佳的系统之一,也是EPE 2018共享任务 (Fares等人, 2018)的总冠军。
• State-of-the-art results in POS tagging, lemma ti z ation and dependency parsing in UD 2.2, the dataset used in CoNLL 2018
• 在CoNLL 2018使用的UD 2.2数据集中,实现了词性标注(POS tagging)、词形还原(lemmatization)和依存句法分析(dependency parsing)的最先进成果
Shared Task (Zeman et al., 2018).
共享任务 (Zeman et al., 2018)。
• We report our best results on $\mathrm{UD}2.3$ . The addition of contextual i zed embeddings improvements range from $25%$ relative error reduction for English treebanks, through $20%$ relative error reduction for high resource languages, to $10%$ relative error reduction for all UD 2.3 languages which have a training set.
• 我们在$\mathrm{UD}2.3$上报告了最佳结果。添加上下文嵌入(Contextualized Embeddings)使英语树库的相对错误率降低了25%,高资源语言降低了20%,而对于所有拥有训练集的UD 2.3语言,相对错误率降低了10%。
2 Related Work
2 相关工作
A new type of deep contextual i zed word representation was introduced by Peters et al. (2018). The proposed embeddings, called ELMo, were obtained from internal states of deep bidirectional language model, pretrained on a large text corpus. Akbik et al. (2018) introduced analogous contextual string embeddings called Flair, which were obtained from internal states of a character-level bidirectional language model. The idea of ELMos was extended by Devlin et al. (2018), who instead of a bidirectional recurrent language model employ a Transformer (Vaswani et al., 2017) architecture.
Peters等人(2018)提出了一种新型深度上下文词表征方法。这种称为ELMo的嵌入向量通过在大规模文本语料库上预训练的深度双向语言模型内部状态获得。Akbik等人(2018)提出了类似的上下文字符串嵌入方法Flair,该方法基于字符级双向语言模型的内部状态。Devlin等人(2018)扩展了ELMo的思想,采用Transformer (Vaswani等人,2017)架构替代了双向循环语言模型。
The Universal Dependencies 1 project (Nivre et al., 2016) seeks to develop cross-linguistically consistent treebank annotation of morphology and syntax for many languages. The latest version UD 2.3 (Nivre et al., 2018) consists of 129 treebanks in 76 languages, with 89 of the treebanks containing a train a set and being freely available. The annotation consists of UPOS (universal POS tags), XPOS (language-specific POS tags), Feats (universal morphological features), Lemmas, dependency heads and universal dependency labels.
通用依存关系项目 (Universal Dependencies) [20] 致力于为多种语言开发跨语言一致的形态和句法树库标注体系。最新版本 UD 2.3 [20] 包含 76 种语言的 129 个树库,其中 89 个树库包含训练集并免费开放。标注内容包括 UPOS (通用词性标签)、XPOS (语言特定词性标签)、Feats (通用形态特征)、Lemmas、依存中心词和通用依存标签。
In 2017 and 2018, CoNLL Shared Tasks Multilingual Parsing from Raw Text to Universal Dependencies (Zeman et al., 2017, 2018) were held in order to stimulate research in multi-lingual POS tagging, lemma ti z ation and dependency parsing.
2017年和2018年,CoNLL共享任务举办了"从原始文本到通用依存关系的多语言解析"(Zeman et al., 2017, 2018)活动,旨在促进多语言词性标注、词形还原和依存句法分析领域的研究。
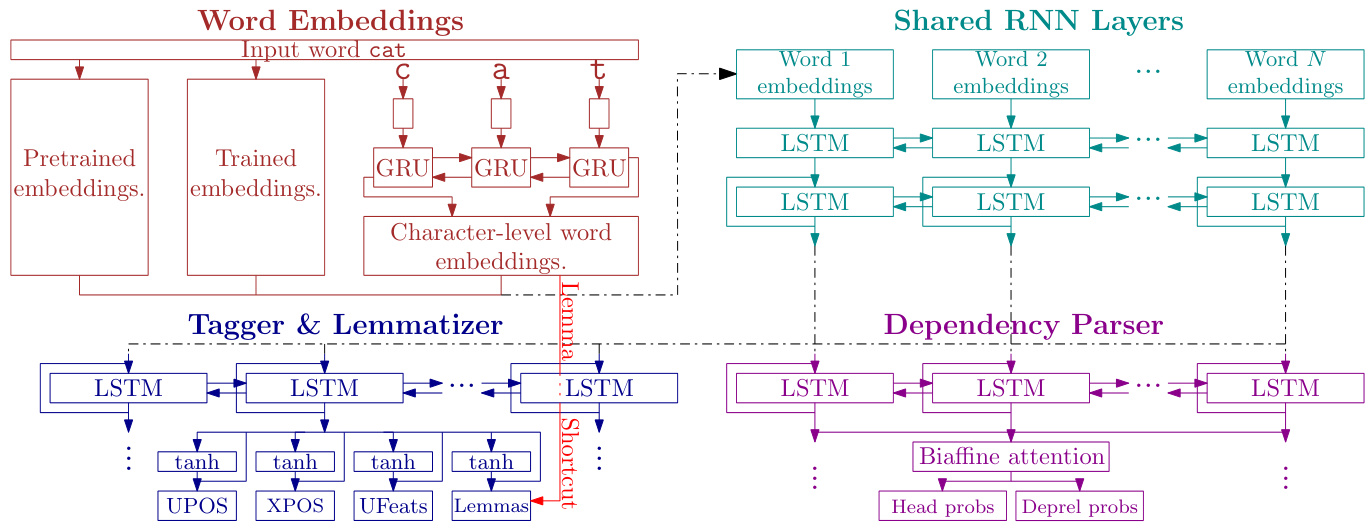
Figure 1: UDPipe 2.0 architecture overview.
图 1: UDPipe 2.0 架构概览。
The system of Che et al. (2018) is one of the three winners of the CoNLL 2018 Shared Task. The authors employed manually trained ELMolike contextual word embeddings, reporting $7.9%$ error reduction in LAS parsing performance.
Che等人(2018)的系统是CoNLL 2018共享任务的三个获胜者之一。作者采用了手动训练的ELMo式上下文词嵌入(ELMo-like contextual word embeddings),报告了LAS解析性能$7.9%$的错误率降低。
3 Methods
3 方法
Our baseline is the UDPipe 2.0 (Straka, 2018) participant system from the CoNLL 2018 Shared Task (Zeman et al., 2018). The system is available at http://github.com/CoNLL-UD-2018/ UDPipe-Future.
我们的基线系统是CoNLL 2018共享任务(Zeman et al., 2018)中的UDPipe 2.0(Straka, 2018)参赛系统。该系统代码托管于http://github.com/CoNLL-UD-2018/UDPipe-Future。
A graphical overview of the UDPipe 2.0 is shown in Figure 1. In short, UDPipe 2.0 is a multitask model predicting POS tags, lemmas and dependency trees jointly. After embedding input words, two shared bidirectional LSTM (Hochreiter and Schmid huber, 1997) layers are performed. Then, tagger and lemmatizer specific bidirectional LSTM layer is executed, with softmax classifiers processing its output and generating UPOS, XPOS, Feats and Lemmas. The lemmas are generated by classifying into a set of edit scripts which process input word form and produce lemmas by performing character-level edits on the word prefix and suffix. The lemma classifier additionally takes the character-level word embeddings as input.
UDPipe 2.0的图形化概览如图1所示。简而言之,UDPipe 2.0是一个联合预测词性标注(POS tags)、词元(lemmas)和依存树(dependency trees)的多任务模型。在嵌入输入词后,执行两个共享的双向LSTM层(Hochreiter和Schmidhuber,1997)。接着运行标注器和词元生成器专用的双向LSTM层,其输出经softmax分类器处理并生成UPOS、XPOS、Feats和Lemmas。词元通过对一组编辑脚本进行分类生成,这些脚本处理输入词形,并通过在词前缀和后缀执行字符级编辑来生成词元。词元分类器还额外接收字符级词嵌入作为输入。
Finally, the output of the two shared LSTM layers is processed by a parser specific bidirectional LSTM layer, whose output is then passed to a biaffine attention layer (Dozat and Manning, 2016) producing labeled dependency trees. We refer the readers for detailed treatment of the architecture and the training procedure to Straka (2018).
最后,两个共享LSTM层的输出由一个特定于解析器的双向LSTM层处理,其输出随后传递到一个双仿射注意力层 (Dozat and Manning, 2016) ,生成带标签的依存树。关于架构和训练流程的详细说明,请参阅Straka (2018) 。
The simplest baseline system uses only end-toend word embeddings trained specifically for the task. Additionally, the UDPipe 2.0 system also employs the following two embeddings:
最简单的基线系统仅使用专门为该任务训练的端到端词嵌入。此外,UDPipe 2.0系统还采用了以下两种嵌入:
word embeddings (WE): We use FastText word embeddings (Bojanowski et al., 2017) of dimension 300, which we pretrain for each language on Wikipedia using segmentation and token iz ation trained from the UD data.2 • character-level word embeddings (CLE): We employ bidirectional GRUs of dimension 256 in line with Ling et al. (2015): we represent every Unicode character with a vector of dimension 256, and concatenate GRU output for forward and reversed word characters. The character-level word embeddings are trained together with UDPipe network.
词嵌入(WE): 我们使用300维的FastText词嵌入(Bojanowski等人, 2017), 基于维基百科数据对每种语言进行预训练, 并采用从UD数据训练得到的分词和token化方法。
• 字符级词嵌入(CLE): 我们采用与Ling等人(2015)相同的256维双向GRU结构: 为每个Unicode字符分配256维向量表示, 并将正向和反向字符序列的GRU输出进行拼接。字符级词嵌入与UDPipe网络联合训练。
Optionally, we add pretrained contextual word embeddings as another input to the neural network. Contrary to finetuning approach used by the BERT authors (Devlin et al., 2018), we never finetune the embeddings.
可选地,我们将预训练的上下文词嵌入 (contextual word embeddings) 作为神经网络的另一个输入。与BERT作者 (Devlin et al., 2018) 采用的微调方法不同,我们从不微调这些嵌入。
• BERT (Devlin et al., 2018): We employ three pretrained models of dimension 768:3 an English one for the English treebanks (Base Uncased), a Chinese one for Chinese and Japanese treebanks (Base Chinese) and a multilingual one (Base Multilingual Uncased) for all other languages. We produce embedding of a UD word as an average of BERT subword embeddings this UD word
• BERT (Devlin等,2018):我们采用三个维度为768的预训练模型:针对英语树库的英文模型(Base Uncased)、针对中文和日语树库的中文模型(Base Chinese),以及针对所有其他语言的多语言模型(Base Multilingual Uncased)。我们将UD单词的嵌入表示为其子词嵌入的平均值。
Table 1: BERT Base compared to word embeddings (WE) and character-level word embeddings (CLE). Results for 72 UD 2.3 treebanks with train and development sets and non-empty Wikipedia.
表 1: BERT Base 与词嵌入 (WE) 和字符级词嵌入 (CLE) 的对比。结果基于 72 个 UD 2.3 树库的训练集、开发集和非空维基百科数据。
| WE | CLE | Bert | UPOS | XPOS | UFeats | Lemma | UAS | LAS | MLAS | BLEX |
|---|---|---|---|---|---|---|---|---|---|---|
| 90.14 | 88.51 | 86.50 | 88.64 | 79.43 | 73.55 | 56.52 | 60.84 | |||
| WE | 94.91 | 93.51 | 91.89 | 92.10 | 85.98 | 81.73 | 68.47 | 70.64 | ||
| CLE | 95.75 | 94.69 | 93.43 | 96.24 | 86.99 | 82.96 | 71.06 | 75.78 | ||
| WE | CLE | 96.39 | 95.53 | 94.28 | 96.51 | 87.79 | 84.09 | 73.30 | 77.36 | |
| Base | 96.35 | 95.08 | 93.56 | 93.29 | 89.31 | 85.69 | 74.11 | 75.45 | ||
| WE | Base | 96.62 | 95.54 | 94.08 | 93.77 | 89.49 | 85.96 | 74.94 | 76.27 | |
| CLE | Base | 96.86 | 95.96 | 94.85 | 96.64 | 89.76 | 86.29 | 76.20 | 79.87 | |
| WE | CLE | Base | 97.00 | 96.17 | 94.97 | 99·96 | 89.81 | 86.42 | 76.54 | 80.04 |
Table 2: Comparison of multilingual and language-specific BERT models on 4 English treebanks (each experiment repeated 3 times), and on Chinese-GSD and Japanese-GSD treebanks.
| 语言 | Bert | UPOS | XPOS | UFeats | Lemma | UAS | LAS | MLAS | BLEX |
|---|---|---|---|---|---|---|---|---|---|
| 英语 | Base | 97.38 | 96.97 | 97.22 | 97.71 | 91.09 | 88.22 | 80.48 | 82.38 |
| 英语 | Multi | 97.36 | 96.97 | 97.29 | 97.63 | 90.94 | 88.12 | 80.43 | 82.22 |
| 中文 | Base | 97.07 | 96.89 | 99.58 | 99.98 | 90.13 | 86.74 | 79.67 | 83.85 |
| 中文 | Multi | 96.27 | 96.25 | 99.37 | 99.99 | 87.58 | 83.96 | 76.26 | 81.04 |
| 日语 | Base | 98.24 | 97.89 | 99.98 | 99.53 | 95.55 | 94.27 | 87.64 | 89.24 |
| 日语 | Multi | 98.17 | 97.71 | 99.99 | 99.51 | 95.30 | 93.99 | 87.17 | 88.77 |
表 2: 多语言与特定语言BERT模型在4个英语树库(每次实验重复3次)以及中文-GSD和日语-GSD树库上的性能对比。
We evaluate the metrics defined in Zeman et al. (2018) using the official evaluation script.5 When reporting results for multiple treebanks, we compute macro-average of their scores (following the CoNLL 2018 Shared Task).
我们使用官方评估脚本对Zeman等人 (2018) 定义的指标进行评估。在报告多个树库的结果时,我们计算其得分的宏平均 (遵循CoNLL 2018共享任务的做法)。
4 Results
4 结果
Table 1 displays results for 72 UD 2.3 treebanks with train and development sets and non-empty Wikipedia (raw corpus for the WE), considering WE, CLE and Base BERT embeddings. Both WE and CLE bring substantial performance boost, with CLE providing larger improvements, especially for lemma ti z ation and morphological features. Combining WE and CLE shows that the improvements are complementary and using both embeddings yields further increase.
表1显示了72个UD 2.3树库(包含训练集、开发集和非空Wikipedia语料作为词嵌入(WE)的原始数据)在使用WE、CLE和Base BERT嵌入时的结果。WE和CLE都带来了显著的性能提升,其中CLE的改进幅度更大(尤其在词元化和形态特征方面)。结合WE与CLE的实验表明,两者的改进具有互补性,同时使用两种嵌入能获得进一步的性能提升。
Employing only the BERT embeddings results in significant improvements, compared to both WE and CLE individually, with highest increase for syntactic parsing, less for morphology and worse performance for lemma ti z ation than CLE. Considering BERT versus $\mathrm{WE{+}C L E}$ , BERT offers higher parsing performance, comparable UPOS accuracy, worse morphological features and substantially lower lemma ti z ation performance. We therefore conclude that the representation computed by BERT captures higher-level syntactic and possibly even semantic meaning, while providing less information about morphology and orthographical composition required for lemma ti z ation.
仅使用BERT嵌入相比单独使用WE和CLE均带来显著提升,其中句法解析(syntactic parsing)提升最大,词法分析(morphology)次之,但词元还原(lemmatization)表现逊于CLE。对比BERT与$\mathrm{WE{+}CLE}$组合,BERT在句法解析上表现更优,UPOS准确率相当,但词法特征表现较差,词元还原性能明显更低。由此我们得出结论:BERT计算得到的表征能捕捉更高层次的句法乃至语义信息,但对词元还原所需的词法及拼写构成信息提供较少。
Combining BERT and CLE results in an increased performance, especially for morphological features and lemma ti z ation. The addition of WE provides minor improvements in all metrics, suggesting that the BERT embeddings encompass substantial amount of information which WE adds to CLE. In total, adding BERT embeddings to a baseline with WE and CLE provides a $16.9%$ relative error reduction for UPOS tags, $12%$ for morphological features, $4.3%$ for lemma ti z ation, and $14.5%$ for labeled dependency parsing.
结合BERT和CLE能提升性能,尤其在形态特征和词形还原(lemma ti z ation)方面。加入WE后所有指标均有小幅改善,表明BERT嵌入已包含WE为CLE补充的大部分信息。总体而言,在已含WE和CLE的基线模型中加入BERT嵌入后,UPOS标注相对误差降低16.9%,形态特征误差降低12%,词形还原误差降低4.3%,带标签依存句法分析误差降低14.5%。
Table 3: Flair compared to word embeddings (WE), character-level word embeddings (CLE) and BERT Base.
表 3: Flair与词嵌入(WE)、字符级词嵌入(CLE)和BERT Base的对比
| WE | CLE | Bert | Flair | UPOS | XPOS | UFeats | Lemmas | UAS | LAS | MLAS | BLEX |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 92.77 | 89.59 | 88.88 | 91.52 | 82.59 | 77.89 | 61.52 | 65.89 | ||||
| WE | 96.63 | 94.48 | 94.01 | 94.82 | 88.55 | 85.25 | 73.38 | 75.74 | |||
| CLE | 96.80 | 95.11 | 94.64 | 97.31 | 88.88 | 85.51 | 74.37 | 78.87 | |||
| WE | CLE | 97.32 | 95.88 | 95.44 | 97.62 | 89.55 | 86.46 | 76.42 | 80.36 | ||
| Base | 97.49 | 95.68 | 95.17 | 95.45 | 91.48 | 88.69 | 78.61 | 80.14 | |||
| WE | Base | 97.65 | 96.11 | 95.58 | 95.86 | 91.59 | 88.84 | 79.30 | 80.79 | ||
| CLE | Base | 97.79 | 96.45 | 95.94 | 97.75 | 91.74 | 88.98 | 79.97 | 83.43 | ||
| WE | CLE | Base | 97.89 | 96.58 | 96.09 | 97.78 | 91.80 | 89.09 | 80.30 | 83.59 | |
| Flair | 97.69 | 96.22 | 95.69 | 96.49 | 90.43 | 87.57 | 77.91 | 80.06 | |||
| WE | Flair | 97.77 | 96.37 | 95.87 | 96.62 | 90.53 | 87.69 | 78.37 | 80.37 | ||
| CLE | Flair | 97.72 | 96.40 | 95.94 | 97.77 | 90.58 | 87.74 | 78.47 | 81.94 | ||
| WE | CLE | Flair | 97.76 | 96.50 | 96.06 | 97.85 | 90.66 | 87.83 | 78.73 | 82.16 | |
| WE | CLE | Base | Flair | 98.00 | 96.80 | 96.30 | 97.87 | 91.92 | 89.32 | 80.78 | 83.96 |
The influence of multilingual and languagespecific BERT models is analyzed in Table 2. Surprisingly, averaged results of the four English treebanks show very little decrease when using the multilingual BERT model compared to Englishspecific one, most likely owing to the fact that English is the largest language used to train the multilingual model. Contrary to English, the Chinese BERT model shows substantial improvements compared to a multilingual model when utilized on the Chinese-GSD treebank, and minor improvements on the Japanese-GSD treebank.
表2分析了多语言和特定语言BERT模型的影响。令人惊讶的是,与英语专用模型相比,使用多语言BERT模型时四个英语树库的平均结果下降非常小,这很可能是因为英语是用于训练多语言模型的最大语言。与英语相反,中文BERT模型在中文-GSD树库上使用时相比多语言模型显示出显著改进,而在日语-GSD树库上则略有提升。
Note that according to the above comparison, the substantial improvements offered by BERT embeddings can be achieved using a single multilingual model, opening possibilities for interesting language-agnostic approaches.
需要注意的是,根据上述对比,BERT嵌入带来的显著改进可以通过单一多语言模型实现,这为语言无关方法提供了有趣的可能性。
4.1 Flair
4.1 Flair
Table 3 shows the experiments in which WE, CLE, Flair and BERT embeddings are added to the baseline, averaging results for $23~\mathrm{UD}~2.3$ treebanks for which the Flair embeddings were available.
表 3 展示了在基线模型中加入 WE (Word Embeddings)、CLE (Contextualized Lexical Embeddings)、Flair 和 BERT 嵌入向量的实验结果,这些结果是基于 $23~\mathrm{UD}~2.3$ 个可获得 Flair 嵌入向量的树库的平均值。
Comparing Flair and BERT embeddings, the former demonstrates higher performance in POS tagging, morphological features, and lemmatization, while achieving worse results in dependency parsing, suggesting that Flair embeddings capture more morphological and orthographic al information. A comparison of Fl $_{\mathrm{{1ir+WE+CLE}}}$ with $\mathrm{BERT+WE{+}C L E}$ shows that the introduction of $\mathrm{WE{+}C L E}$ embeddings to BERT encom- passes nearly all information of Flair embeddings, as demonstrated by $\mathrm{BERT+WE{+}C L E}$ achieving better performance in all tasks but lemma ti z ation, where it is only slightly behind Flair $+\mathrm{WE+CLE}$ .
比较Flair和BERT嵌入时,前者在词性标注(POS tagging)、形态特征和词形还原任务中表现更优,但在依存句法分析上效果较差,这表明Flair嵌入能捕获更多形态和拼写信息。Fl $_{\mathrm{{1ir+WE+CLE}}}$ 与 $\mathrm{BERT+WE{+}C L E}$ 的对比显示,向BERT引入 $\mathrm{WE{+}C L E}$ 嵌入几乎涵盖了Flair嵌入的全部信息—— $\mathrm{BERT+WE{+}C L E}$ 在所有任务(除词形还原外)均优于Flair $+\mathrm{WE+CLE}$ ,仅在词形还原任务上略逊一筹。
The combination of all embeddings produces best results in all metrics. In total, addition of BERT and Flair embeddings to a baseline with WE and CLE provides a $25.4%$ relative error reduction for UPOS tags, $18.8%$ for morphological features, $10%$ for lemma ti z ation and $21%$ for labeled dependency parsing.
所有嵌入组合在所有指标上都取得了最佳结果。总体而言,在基线模型(WE和CLE)基础上增加BERT和Flair嵌入后,UPOS标注相对错误率降低25.4%,形态特征错误率降低18.8%,词形还原错误率降低10%,带标记依存句法分析错误率降低21%。
4.2 ELMo
4.2 ELMo
Given that pretrained ELMo embeddings are available for English only, we present results for ELMo, Flair, and BERT contextual i zed embeddings on four macro-averaged English UD 2.3 treebanks in Table 4.
鉴于预训练的ELMo嵌入仅适用于英语,我们在表4中展示了ELMo、Flair和BERT上下文嵌入在四个宏观平均英语UD 2.3树库上的结果。
Flair and BERT results are consistent with the previous experiments. Employing solely ELMo embeddings achieves best POS tagging and lemma ti z ation compared to using only BERT or Flair, with dependency parsing performance higher than Flair, but lower than BERT. Therefore, ELMo embeddings seem to encompass the most morphological and or to graphical features compared to BERT and Flair, more syntactical features than Flair, but less than BERT.
Flair和BERT的结果与之前的实验一致。仅使用ELMo嵌入相比仅使用BERT或Flair实现了最佳的词性标注和词形还原,依存句法分析性能高于Flair但低于BERT。因此,ELMo嵌入似乎比BERT和Flair包含更多形态学和/或图形特征,比Flair包含更多句法特征,但比BERT少。
When comparing ELMo with $_{\mathrm{Flair+WE+CLE}}$ , the former surpass the latter in all metrics but lemma ti z ation (and lemma ti z ation performance is equated when employing $\scriptstyle\mathrm{ELMo+WE+CLE})$ .
在比较ELMo与$_{\mathrm{Flair+WE+CLE}}$时,前者在所有指标上均优于后者,除了词形还原(lemma ti z ation) (且当使用$\scriptstyle\mathrm{ELMo+WE+CLE}$时,词形还原性能相当)。
Table 4: ELMo, Flair and BERT contextual i zed word embeddings for four macro-averaged English UD 2.3 treebanks. All experiments were performed three times and averaged.
表 4: ELMo、Flair 和 BERT 在四个宏平均英语 UD 2.3 树库中的上下文词嵌入表现。所有实验均进行三次并取平均值。
| WE | CLE | Bert | Flair | Elmo | UPOS | XPOS | UFeats | Lemmas | UAS | LAS | MLAS | BLEX |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 92.31 | 91.18 | 92.11 | 93.67 | 82.16 | 77.27 | 63.00 | 66.20 | |||||
| WE | 95.69 | 95.30 | 96.15 | 96.27 | 86.98 | 83.59 | 73.29 | 75.40 | ||||
| CLE | 95.50 | 95.04 | 95.65 | 97.06 | 86.86 | 83.10 | 72.60 | 75.53 | ||||
| WE | CLE | 96.33 | 95.86 | 96.44 | 97.32 | 87.83 | 84.52 | 75.08 | 77.65 | |||
| Base | 96.88 | 96.46 | 96.94 | 96.18 | 90.98 | 87.98 | 79.66 | 79.94 | ||||
| WE | Base | 97.04 | 96.66 | 97.07 | 96.38 | 91.19 | 88.20 | 80.08 | 80.41 | |||
| CLE | Base | 97.21 | 96.82 | 97.08 | 97.61 | 91.23 | 88.32 | 80.42 | 82.38 | |||
| WE | CLE | Base | 97.38 | 96.97 | 97.22 | 97.70 | 91.09 | 88.22 | 80.48 | 82.38 | ||
| Flair | 96.88 | 96.45 | 96.99 | 97.01 | 89.50 | 86.42 | 78.03 | 79.36 | ||||
| WE | Flair | 97.06 | 96.56 | 97.03 | 97.12 | 89.68 | 86.67 | 78.55 | 79.85 | |||
| CLE | Flair | 97.00 | 96.52 | 97.04 | 97.57 | 89.75 | 86.72 | 78.56 | 80.56 | |||
| WE | CLE | Flair | 97.02 | 96.55 | 97.12 | 97.63 | 89.67 | 86.64 | 78.41 | 80.48 | ||
| Elmo | 97.23 | 96.83 | 97.25 | 97.13 | 90.15 | 87.26 | 79.47 | 80.49 | ||||
| WE | Elmo | 97.24 | 96.84 | 97.28 | 97.12 | 90.25 | 87.34 | 79.49 | 80.57 | |||
| CLE | Elmo | 97.21 | 96.81 | 97.23 | 97.62 | 90.22 | 87.30 | 79.51 | 81.32 | |||
| WE | CLE | Elmo | 97.21 | 96.82 | 97.27 | 97.63 | 90.33 | 87.42 | 79.66 | 81.50 | ||
| WE | CLE | Base | Flair | 97.45 | 97.08 | 97.36 | 97.76 | 91.25 | 88.45 | 80.94 | 82.79 | |
| WE | CLE | Base | Elmo | 97.42 | 97.05 | 97.41 | 97.68 | 91.09 | 88.26 | 80.81 | 82.48 | |
| WE | CLE | Base | Flair | Elmo | 97.44 | 97.08 | 97.43 | 97.67 | 91.08 | 88.28 | 80.76 | 82.47 |
Table 5: CoNLL 2018 UD Shared Task results on treebanks with development sets (so called big treebanks in the shared task).
表 5: CoNLL 2018 UD共享任务在带有开发集的树库上的结果(在共享任务中称为大型树库)。
| System | UPOS | XPOS | UFeats | Lemmas | UAS | LAS | MLAS | BLEX |
|---|---|---|---|---|---|---|---|---|
| UDPipe2.0WE+CLE | 95.84 | 94.96 | 94.24 | 95.89 | 85.53 | 82.11 | 72.12 | 75.74 |
| UDPipe2.0WE+CLE+BERT | 96.23 | 95.43 | 94.74 | 96.03 | 87.33 | 84.20 | 75.15 | 78.30 |
| UDPipe 2.0 WE+CLE+BERT 3-model ensemble | 96.32 | 95.55 | 94.90 | 96.16 | 87.64 | 84.60 | 75.76 | 78.88 |
| OriginalUDPipe2.0STentry (Straka, 2018) | 95.73 | 94.79 | 94.11 | 95.12 | 85.28 | 81.83 | 71.71 | 74.67 |
| HIT-SCIRHarbin (Che et al., 2018) 3-model ensemble | 96.23 | 95.16 | 91.20 | 93.42 | 87.61 | 84.37 | 70.12 | 75.05 |
| HIT-SCIRHarbin (Che et al., 2018) w/o ensembling | - | - | - | - | - | 83.75 | - | - |
| Stanford (Qi et al., 2018) | 95.93 | 94.95 | 94.14 | 95.25 | 86.56 | 83.03 | 72.67 | 75.46 |
| TurkuNLP (Kanerva et al., 2018) | 95.41 | 94.47 | 93.82 | 96.08 | 85.32 | 81.85 | 71.27 | 75.83 |
Furthermore, morphological feature generation performance of ELMo is better than BERT $+\mathrm{WE+CLE}$ . These results indicate that ELMo capture a lot of information present in $\mathrm{WE{+}C L E}$ , which is further promoted by the fact that $\mathrm{ELMo}\mathrm{+WE}\mathrm{+CLE}$ shows very little improvements compared to ELMo only (with the exception of lemma ti z ation profiting from CLE).
此外,ELMo 的形态特征生成性能优于 BERT $+\mathrm{WE+CLE}$。这些结果表明,ELMo 捕获了 $\mathrm{WE{+}C L E}$ 中的大量信息,而 $\mathrm{ELMo}\mathrm{+WE}\mathrm{+CLE}$ 相比仅使用 ELMo 时提升非常有限(除词元化任务受益于 CLE 外)进一步佐证了这一点。
Overall, the best-performing model on English treebanks is $\mathrm{BERT+Flair+WE{+}C L E}$ , with the exception of morphological features, where ELMo helps marginally. The relative error reduction compared to $\mathrm{WE{+}C L E}$ range from $30.5%$ for UPOS tagging, $26%$ for morphological features, $16.5%$ for lemma ti z ation and $25.4%$ for labeled
总体而言,在英语树库上表现最佳的模型是 $\mathrm{BERT+Flair+WE{+}C L E}$ ,除了形态特征方面 ELMo 略有帮助。与 $\mathrm{WE{+}C L E}$ 相比的相对错误减少率分别为:UPOS 标注 30.5%,形态特征 26%,词形还原 16.5%,带标记的依存分析 25.4%。
dependency parsing.
依存句法分析
4.3 CoNLL 2018 Shared Task Results
4.3 CoNLL 2018共享任务结果
Given that the inputs in the CoNLL 2018 Shared Task are raw texts, we reuse token iz ation and segmentation employed by original UDPipe 2.0. Also, we pretrain WE not only on Wikipedia, but on all plaintexts provided by the shared tasks organizers. The resulting F1 scores of UDPipe $2.0\mathrm{WE{+}C L E}$ and $\mathrm{WE+CLE{+}B F}$ RT on treebanks with development sets (so called big treebanks in the shared task) are presented in Table 5.
考虑到CoNLL 2018共享任务的输入是原始文本,我们复用了原始UDPipe 2.0的分词(Tokenization)和分割方法。此外,我们不仅在维基百科上预训练词嵌入(WE),还在共享任务组织者提供的所有纯文本上进行预训练。UDPipe $2.0\mathrm{WE{+}C L E}$ 和 $\mathrm{WE+CLE{+}B F}$ RT在带有开发集的树库(即共享任务中所谓的大型树库)上的最终F1分数如表 5所示。
The inclusion of BERT embeddings results in state-of-the-art single-model performance in UPOS, XPOS, UFeats, MLAS, and BLEX metrics, and state-of-the-art ensemble performance in all metrics.
引入 BERT 嵌入后,在 UPOS、XPOS、UFeats、MLAS 和 BLEX 指标上实现了最先进的单模型性能,并在所有指标上达到了最先进的集成性能。
4.4 BERT and Flair Improvement Levels
4.4 BERT与Flair的改进层级
To investigate which languages benefit most from BERT embeddings, Figure 2 presents relative error reductions in UPOS tagging, lemma ti z ation, and unlabeled and labeled dependency parsing, as a function of logarithmic size of the respective Wikipedia (which corresponds to the size of BERT Multilingual model training data). The results indicate that consistently with intuition, larger amount of data used to pretrain the BERT model leads to higher performance.
为探究哪些语言从BERT嵌入中获益最多,图2展示了UPOS标注、词形还原、无标记及有标记依存句法的相对误差降低率,这些结果与各自维基百科对数规模(对应BERT多语言模型训练数据量)呈函数关系。结果表明,与直觉一致,预训练BERT模型所用数据量越大,性能提升越显著。
To compare BERT and Flair embeddings, Figure 3 displays relative error improvements of $_{\mathrm{Flair+WE+CLE}}$ , BER $\mathrm{\Delta}\mathrm{!T+WE+CLE}$ and BERT $+$ Flair+WE+CLE models compared to $\mathrm{WE{+}C L E}$ , this time as a function of logarithmic training data size. Generally the relative error reduction decrease with the increasing amount of training data. Furthermore, the difference between Flair and BERT is clearly visible, with BERT excelling in dependency parsing and Flair in lemma ti z ation.
为了比较BERT和Flair嵌入的效果,图3展示了$_{\mathrm{Flair+WE+CLE}}$、BERT $\mathrm{\Delta}\mathrm{!T+WE+CLE}$以及BERT $+$ Flair+WE+CLE模型相对于$\mathrm{WE{+}C L E}$的相对误差改进情况,这次是作为对数训练数据规模的函数。总体而言,相对误差的减少随着训练数据量的增加而降低。此外,Flair和BERT之间的差异显而易见,BERT在依存句法分析上表现优异,而Flair在词形还原方面更为出色。
5 Conclusions
5 结论
We presented a thorough evaluation of the BERT, Flair, and ELMo contextual i zed embeddings in 89 languages of the UD in POS tagging, lemmatization, and dependency parsing. We conclude that addition of any of the contextual i zed embeddings as additional inputs to a neural network results in substantial performance increase. Our findings show that the BERT embeddings yield the greatest improvements, reaching state-of-the-art results in CoNLL 2018 Shared Task and contain most complementary information as compared to word- and character-level word embeddings, while Flair embeddings encompass the morphological and orthographical information.
我们对BERT、Flair和ELMo在89种UD语言中的词性标注、词形还原和依存句法分析任务中的上下文嵌入进行了全面评估。结果表明,将任意一种上下文嵌入作为神经网络的附加输入都能显著提升性能。研究发现,BERT嵌入带来的改进最大,在CoNLL 2018共享任务中达到了最先进水平,与词级和字符级词嵌入相比包含最多互补信息,而Flair嵌入则涵盖了形态和拼写信息。
Acknowledgements
致谢
The work described herein has been supported by OP VVV VI LINDAT/CLARIN project of the Ministry of Education, Youth and Sports of the Czech Republic (project CZ.02.1.01/0.0/0.0/16 013/0001781) and it has been supported and has been using language resources developed by the LINDAT/CLARIN project of the the Ministry of Education, Youth and Sports of the Czech Republic (project LM2015071).
本文所述工作得到了捷克共和国教育、青年和体育部OP VVV VI LINDAT/CLARIN项目(项目编号CZ.02.1.01/0.0/0.0/16 013/0001781)的支持,并使用了由捷克共和国教育、青年和体育部LINDAT/CLARIN项目(项目编号LM2015071)开发的语言资源。
4.5 UD 2.3 Detailed Performance
4.5 UD 2.3 详细性能
Table 6 shows a detailed evaluation of all 89 freely available UD 2.3 treebanks with a train set, comparing the $\mathrm{WE{+}C L E}$ baseline to the best performing WE+CLE $^{+}$ BERT $^+$ Flair (where Flair available) model.
表 6: 详细评估了所有89个带训练集的UD 2.3免费树库,将$\mathrm{WE{+}C L E}$基线模型与性能最佳的WE+CLE$^{+}$ BERT$^+$ Flair(在Flair可用时)模型进行对比。
The evaluation includes also 13 treebanks whose languages are not part of BERT Multilingual model. For these treebanks, the effect of using BERT embeddings is mixed, as can be observed in the Table 6 indicating which UD languages were not part of BERT training. UPOS tagging, unlabeled and labeled dependency parsing profits from BERT embedding utilization, with averaged relative error reduction of $3.8%$ , $2%$ , and $0.8%$ , respectively. On the other hand, lemmatization performance deteriorates, with $-2.2%$ aver- aged relative error reduction.
评估还包含13种不属于BERT多语言模型训练语种的语言树库。如表6所示,这些树库使用BERT嵌入的效果参差不齐,表中标明了哪些UD语言未参与BERT训练。UPOS词性标注、无标记和有标记依存句法分析均受益于BERT嵌入的使用,平均相对错误率分别降低了$3.8%$、$2%$和$0.8%$。而词形还原性能则出现下降,平均相对错误率增加了$-2.2%$。
Averaged across all treebanks, relative error improvement of BERT $^{\ast}$ Flair embeddings inclusion is $15%$ for UPOS tagging, $2.4%$ for lemma ti z ation and $11.5%$ for labeled dependency parsing.
在所有树库中平均来看,BERT $^{\ast}$ Flair嵌入的加入使UPOS标注的相对误差降低了$15%$,词形还原(lemma ti z ation)提升了$2.4%$,带标记依存句法分析提升了$11.5%$。
References
参考文献
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Under standing.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2018. BERT: 用于语言理解的深度双向Transformer预训练。

Figure 2: Relative error improvements on UD 2.3 treebanks which have a training set and their language is included in BERT model. The baseline model uses WE and CLE, and the improved model also uses BERT Multilingual contextual i zed embeddings. The value on the $x$ -axis is the logarithmic size of the corresponding Wikipedia, which corresponds to training data size of the BERT Multilingual model.
图 2: 在UD 2.3树库上的相对误差改进(这些树库包含训练集且其语言被BERT模型支持)。基线模型使用WE和CLE,改进模型还使用了BERT多语言上下文嵌入。x轴上的值是对应维基百科的对数规模,这与BERT多语言模型的训练数据量相关。

Figure 3: Relative error improvements of the baseline with $\mathrm{WE{+}C L E}$ and a model additionally including Flair and/or BERT Multilingual contextual embeddings. The value on the $x$ -axis is the logarithmic UD train data size.
图 3: 基线模型在使用 $\mathrm{WE{+}C L E}$ 以及额外加入 Flair 和/或 BERT 多语言上下文嵌入时的相对误差改进。x 轴上的值是对数化的 UD 训练数据规模。
| 98.58 97.06 82.72 | 83.82 77.69 | 63.73 68.89 | 98.06 97.30 | 95.01 | 99.83 96.03 | 98.81 86.94 84.43 97.71 82.62 72.29 | ||||
| 95.82 92.46 94.48 97.31 | 93.96 90.68 | 96.80 85.53 | 81.07 | 58.82 72.13 | 95.18 | 97.95 | 91.72 | 86.62 76.24 96.77 88.11 84.06 63.33 75.44 | ||
| German-GSD | X | 96.66 97.23 97.98 97.99 | 90.77 94.96 | 94.72 85.27 95.82 92.10 | 79.60 89.79 | 66.71 72.86 78.60 79.72 | 96.72 98.25 | 97.22 98.25 | 90.58 95.76 | 94.47 85.53 79.69 66.86 72.52 95.88 93.92 92.16 82.29 82.14 |
| Gothic-PROIEL Greek-GDT | 97.02 97.03 | 95.87 | 97.12 89.70 98.67 94.85 | 86.86 91.83 | 75.52 78.14 78.49 86.83 | 97.50 | 97.50 | 96.18 | 97.24 91.78 89.22 78.85 80.80 | |
| Hebrew-HTB | 97.52 97.04 95.76 | 94.15 91.75 | 95.05 84.04 | 79.73 67.63 | 73.63 76.38 | 97.58 97.09 | 97.19 | 94.24 93.41 | 98.67 95.56 92.50 79.32 87.66 95.44 88.76 85.12 74.08 79.21 | |
| Hungarian-Szeged | 93.69 94.19 92.72 91.44 | 95.58 82.43 | 99.64 85.31 90.48 80.39 | 78.99 72.34 | 67.74 46.49 55.32 | 94.09 93.22 | 94.93 92.00 | 96.03 83.78 | 99.66 86.47 80.40 70.01 78.19 90.56 81.43 73.47 49.05 56.50 | |
| Indonesian-GSD Irish-IDT | 98.39 98.30 98.38 98.35 | 98.11 97.77 | 98.66 93.49 98.16 92.64 | 91.54 90.47 | 84.28 85.49 81.87 82.99 | 98.62 98.54 | 98.54 98.52 | 98.26 $086 | 98.78 94.97 93.38 87.14 88.10 98.24 95.36 93.38 86.57 | |
| Italian-ISDT Italian-ParTUT | 96.61 96.43 | 96.90 | 97.00 86.03 9056 | 81.78 93.73 | 72.88 74.33 86.37 88.04 | 97.11 | 96.98 | 97.12 | 87.30 97.27 87.25 83.07 74.70 76.27 | |
| Italian-PoSTWITA | 98.13 97.81 55.84 52.06 | 99.98 40.40 | 63.96 53.30 | 33.38 | 4.82 15.10 | 98.24 63.08 | 97.89 60.63 | 8666 43.64 | 99.53 95.55 94.27 87.64 89.24 64.03 57.02 38.72 7.88 18.78 | |
| Japanese-GSD Kazakh-KTB | 96.29 90.39 | 99.77 | 93.40 87.70 94.30 88.42 | 84.24 86.48 | 79.74 76.35 80.72 79.22 | 96.99 95.77 | 91.21 | 99.83 | 93.72 89.38 86.05 82.19 78.58 80.18 | |
| Korean-GSD Korean-Kaist | 95.59 87.00 53.38 51.42 | 41.53 | 69.58 45.22 91.06 | 34.32 | 2.74 19.39 85.71 | 58.78 | 87.46 56.11 | 42.03 | 94.15 89.35 87.54 82.12 68.21 43.74 32.99 3.10 17.98 86.05 | |
| Kurmanji-MG Latin-ITTB | 98.34 96.37 97.01 97.15 | 96.97 91.53 | 98.99 96.32 83.34 | 88.80 78.66 | 82.35 67.40 73.65 41.58 | 98.42 97.15 | 96.45 97.21 | 97.05 91.54 | 99.03 91.25 89.10 82.80 96.18 83.34 78.70 67.29 | |
| Latin-PROIEL | 88.40 74.58 96.11 88.69 | 79.10 93.01 | 81.45 71.20 95.46 87.20 | 61.28 83.35 | 45.09 71.92 76.64 | 89.96 96.11 | 76.22 89.06 | 80.43 93.30 | 73.52 81.95 74.39 64.68 44.96 47.94 95.76 88.05 84.50 73.81 | |
| Latin-Perseus Latvian-LVTB | 81.70 79.91 | 60.47 | 76.89 51.98 84.65 | 42.17 79.71 | 18.17 28.70 71.49 | 88.77 | 86.04 | 66.70 | 78.33 76.89 64.53 54.53 26.35 34.76 | |
| Lithuanian-HSE | 95.99 95.69 80.10 | 67.23 | 81.31 70.63 88.34 78.39 | 61.41 73.60 | 66.75 29.34 45.87 62.29 | 96.15 83.50 | 95.85 | 67.96 | 85.31 80.10 67.21 71.62 81.31 68.45 60.44 29.58 | |
| Marathi-UFAL | 92.61 93.78 98.31 | 90.00 97.14 | 98.64 92.39 80.09 | 90.49 75.04 | 61.45 84.06 86.53 | 92.76 98.59 | 94.11 | 89.83 97.54 | 43.75 88.25 78.47 73.95 62.47 61.68 88.60 | |
| Norwegian-Bokmaal Norwegian-Nynorsk | 93.87 89.59 | 一 91.57 86.13 | 96.06 93.93 68.08 89.64 | 60.07 84.99 | 63.72 68.22 44.47 50.98 77.71 | 95.52 92.53 | 93.17 88.96 | 98.72 93.78 92.19 86.72 96.59 82.64 78.08 67.53 49.10 55.36 | ||
| Norwegian-NynorskLIA Old Church Slavonic-PROIEL | 96.89 97.16 6096 96.00 | 90.72 97.82 | 93.07 91.75 | 86.82 86.66 94.76 | 73.66 79.89 83.81 81.23 80.93 87.04 90.26 | 96.96 96.26 98.17 | 97.13 96.21 98.05 | 90.45 97.89 98.13 | 94.73 71.42 64.12 92.91 89.88 85.21 73.77 91.83 86.75 79.79 97.21 92.01 89.07 84.36 | |
| OldFrench-SRCMF Persian-Seraji | 97.75 97.70 98.80 94.56 | 97.78 95.49 | 97.44 90.05 97.54 96.58 97.16 93.39 98.46 91.36 |
Table 6: Results on all UD 2.3 treebanks with a train set, comparing inclusion of BERT and possibly Flair embeddings to $\mathrm{WE{+}C L E}$ baseline. Gold token iz ation and segmentation is used.
表 6: 所有包含训练集的UD 2.3树库结果,比较了加入BERT和可能加入Flair嵌入与$\mathrm{WE{+}C L E}$基线的效果。使用了黄金token化(gold tokenization)和分词(segmentation)。