Dense Passage Retrieval for Open-Domain Question Answering
开放域问答的密集段落检索
Vladimir Karpukhin, Barlas Oguz, Sewon Mint, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen‡, Wen-tau Yih Facebook AI †University of Washington ‡Princeton University {vladk, barlaso, plewis, ledell, edunov, scottyih}@fb.com sewon@cs.washington.edu danqic@cs.princeton.edu
Vladimir Karpukhin, Barlas Oguz, Sewon Mint, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen‡, Wen-tau Yih Facebook AI †华盛顿大学 ‡普林斯顿大学 {vladk, barlaso, plewis, ledell, edunov, scottyih}@fb.com sewon@cs.washington.edu danqic@cs.princeton.edu
Abstract
摘要
Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can be practically implemented using dense representations alone, where em- beddings are learned from a small number of questions and passages by a simple dualencoder framework. When evaluated on a wide range of open-domain QA datasets, our dense retriever outperforms a strong LuceneBM25 system greatly by $9%-19%$ absolute in terms of top-20 passage retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA benchmarks.1
开放域问答依赖于高效的段落检索来筛选候选上下文,其中传统稀疏向量空间模型(如TF-IDF或BM25)是实际采用的方法。本研究表明,检索可以仅通过稠密表示实现——通过简单的双编码器框架,仅需少量问题和段落即可学习嵌入表示。在广泛开放的问答数据集评估中,我们的稠密检索器在Top-20段落检索准确率上以$9%-19%$的绝对优势大幅超越强力的LuceneBM25系统,并助力端到端问答系统在多个开放域问答基准测试中创造了最新最优性能[1]。
1 Introduction
1 引言
Open-domain question answering (QA) (Voorhees, 1999) is a task that answers factoid questions using a large collection of documents. While early QA systems are often complicated and consist of multiple components (Ferrucci (2012); Moldovan et al. (2003), inter alia), the advances of reading comprehension models suggest a much simplified two-stage framework: (1) a context retriever first selects a small subset of passages where some of them contain the answer to the question, and then (2) a machine reader can thoroughly examine the retrieved contexts and identify the correct answer (Chen et al., 2017). Although reducing open-domain QA to machine reading is a very reasonable strategy, a huge performance degradation is often observed in practice2, indicating the needs of improving retrieval.
开放域问答 (Open-domain QA) (Voorhees, 1999) 是一项利用大规模文档集合回答事实性问题的任务。早期问答系统通常结构复杂且包含多个组件 (Ferrucci (2012); Moldovan et al. (2003) 等),而阅读理解模型的进展催生了一个更简化的两阶段框架:(1) 上下文检索器首先筛选出可能包含问题答案的少量文本段落,(2) 机器阅读器则对检索到的上下文进行细致分析并确定正确答案 (Chen et al., 2017)。虽然将开放域问答简化为机器阅读是合理策略,但实践中常观察到显著的性能下降,这表明需要改进检索环节。
Retrieval in open-domain QA is usually implemented using TF-IDF or BM25 (Robertson and Zaragoza, 2009), which matches keywords efficiently with an inverted index and can be seen as representing the question and context in highdimensional, sparse vectors (with weighting). Conversely, the dense, latent semantic encoding is complementary to sparse representations by design. For example, synonyms or paraphrases that consist of completely different tokens may still be mapped to vectors close to each other. Consider the question “Who is the bad guy in lord of the rings?”, which can be answered from the context “Sala Baker is best known for portraying the villain Sauron in the Lord of the Rings trilogy.” A term-based system would have difficulty retrieving such a context, while a dense retrieval system would be able to better match “bad guy” with “villain” and fetch the correct context. Dense encodings are also learnable by adjusting the embedding functions, which provides additional flexibility to have a task-specific representation. With special in-memory data structures and indexing schemes, retrieval can be done efficiently using maximum inner product search (MIPS) algorithms (e.g., Shri vast ava and Li (2014); Guo et al. (2016)).
开放域问答中的检索通常使用TF-IDF或BM25 (Robertson and Zaragoza, 2009) 实现,这些方法通过倒排索引高效匹配关键词,可视为用高维稀疏向量(带权重)表示问题和上下文。相反,稠密的潜在语义编码在设计上是对稀疏表示的补充。例如,由完全不同token组成的同义词或释义仍可能被映射到相近的向量。以问题"《指环王》里的反派是谁?"为例,其答案可从上下文"Sala Baker因在《指环王》三部曲中饰演反派Sauron而闻名"中获取。基于术语的系统难以检索此类上下文,而稠密检索系统能更好匹配"bad guy"和"villain"并获取正确上下文。通过调整嵌入函数还可学习稠密编码,这为获得任务特定表征提供了额外灵活性。借助特殊的内存数据结构和索引方案,使用最大内积搜索 (MIPS) 算法(如Shrivastava和Li (2014);Guo等 (2016))即可高效完成检索。
However, it is generally believed that learning a good dense vector representation needs a large number of labeled pairs of question and contexts. Dense retrieval methods have thus never be shown to outperform TF-IDF/BM25 for opendomain QA before ORQA (Lee et al., 2019), which proposes a sophisticated inverse cloze task (ICT) objective, predicting the blocks that contain the masked sentence, for additional pre training. The question encoder and the reader model are then finetuned using pairs of questions and answers jointly. Although ORQA successfully demonstrates that dense retrieval can outperform BM25, setting new state-of-the-art results on multiple open-domain
然而,人们普遍认为学习良好的稠密向量表示需要大量标注的问题和上下文配对。在ORQA (Lee等人,2019) 之前,稠密检索方法从未被证明能在开放域问答任务中超越TF-IDF/BM25。该研究提出了一种复杂的逆完形填空任务 (inverse cloze task, ICT) 目标,通过预测包含被遮蔽句子的文本块来进行额外预训练。随后,问题编码器和阅读器模型会使用问题和答案配对进行联合微调。尽管ORQA成功证明了稠密检索可以超越BM25,并在多个开放域...
QA datasets, it also suffers from two weaknesses. First, ICT pre training is computationally intensive and it is not completely clear that regular sentences are good surrogates of questions in the objective function. Second, because the context encoder is not fine-tuned using pairs of questions and answers, the corresponding representations could be suboptimal.
QA数据集也存在两个弱点。首先,ICT预训练计算密集,而且尚不完全清楚常规句子是否能很好地替代目标函数中的问题。其次,由于上下文编码器未使用问答对进行微调,相应的表示可能不是最优的。
In this paper, we address the question: can we train a better dense embedding model using only pairs of questions and passages (or answers), without additional pre training? By leveraging the now standard BERT pretrained model (Devlin et al., 2019) and a dual-encoder architecture (Bromley et al., 1994), we focus on developing the right training scheme using a relatively small number of question and passage pairs. Through a series of careful ablation studies, our final solution is surprisingly simple: the embedding is optimized for maximizing inner products of the question and relevant passage vectors, with an objective comparing all pairs of questions and passages in a batch. Our Dense Passage Retriever (DPR) is exceptionally strong. It not only outperforms BM25 by a large margin $65.2%$ vs. $42.9%$ in Top-5 accuracy), but also results in a substantial improvement on the end-to-end QA accuracy compared to ORQA $(41.5%$ vs. $33.3%$ ) in the open Natural Questions setting (Lee et al., 2019; Kwiatkowski et al., 2019).
本文探讨了一个问题:能否仅通过问题与段落(或答案)的配对数据,在不进行额外预训练的情况下,训练出更优质的稠密嵌入模型?我们基于当前标准的BERT预训练模型(Devlin等人,2019)和双编码器架构(Bromley等人,1994),重点研究如何利用相对少量的问题-段落对开发出最佳训练方案。经过一系列细致的消融实验,最终解决方案出乎意料地简洁:通过优化嵌入向量使问题与相关段落向量的内积最大化,并采用批内所有问题-段落对比较的目标函数。我们提出的稠密段落检索器(DPR)表现极为出色——不仅以显著优势超越BM25(Top-5准确率65.2% vs. 42.9%),在开放自然问题设置(Lee等人,2019;Kwiatkowski等人,2019)中相比ORQA也实现了端到端QA准确率的重大提升(41.5% vs. 33.3%)。
Our contributions are twofold. First, we demonstrate that with the proper training setup, simply fine-tuning the question and passage encoders on existing question-passage pairs is sufficient to greatly outperform BM25. Our empirical results also suggest that additional pre training may not be needed. Second, we verify that, in the context of open-domain question answering, a higher retrieval precision indeed translates to a higher end-to-end QA accuracy. By applying a modern reader model to the top retrieved passages, we achieve comparable or better results on multiple QA datasets in the open-retrieval setting, compared to several, much complicated systems.
我们的贡献体现在两个方面。首先,我们证明了只要采用适当的训练配置,仅对现有问答段落对中的问题和段落编码器进行微调,就足以大幅超越BM25。实证结果还表明,可能不需要额外的预训练。其次,我们验证了在开放域问答场景中,更高的检索精度确实能转化为更高的端到端问答准确率。通过将现代阅读器模型应用于检索到的顶部段落,我们在开放检索设置下的多个问答数据集上取得了与若干复杂系统相当或更优的结果。
2 Background
2 背景
The problem of open-domain QA studied in this paper can be described as follows. Given a factoid question, such as “Who first voiced Meg on Family Guy?” or “Where was the 8th Dalai Lama born?”, a system is required to answer it using a large corpus of diversified topics. More specifically, we assume the extractive QA setting, in which the answer is restricted to a span appearing in one or more passages in the corpus. Assume that our collection contains $D$ documents, $d_{1},d_{2},\dotsb,d_{D}$ . We first split each of the documents into text passages of equal lengths as the basic retrieval units3 and get $M$ total passages in our corpus $\mathcal{C}={p_{1},p_{2},...,p_{M}}$ , where each passage $p_{i}$ can be viewed as a sequence of tokens $w_{1}^{(i)},w_{2}^{(i)},\cdot\cdot\cdot,w_{|p_{i}|}^{(i)}$ . Given a question $q$ , the task is to find a span $w_{s}^{(i)},w_{s+1}^{(i)},\cdot\cdot\cdot,w_{e}^{(i)}$ (ei) rom f one of the passages $p_{i}$ that can answer the question. Notice that to cover a wide variety of domains, the corpus size can easily range from millions of documents (e.g., Wikipedia) to billions (e.g., the Web). As a result, any open-domain QA system needs to include an efficient retriever component that can select a small set of relevant texts, before applying the reader to extract the answer (Chen et al., 2017).4 Formally speaking, a retriever $R:(q,\mathcal{C})\rightarrow\mathcal{C}_ {\mathcal{F}}$ is a function that takes as input a question $q$ and a corpus $\mathcal{C}$ and returns a much smaller filter set of texts ${\mathcal{C}}_ {\mathcal{F}}\subset{\mathcal{C}}$ , where $|{\mathcal{C}}_ {\mathcal{F}}|=k\ll|{\mathcal{C}}|$ . For a fixed $k$ , a retriever can be evaluated in isolation on top $k$ retrieval accuracy, which is the fraction of questions for which $\mathcal{C}_{\mathcal{F}}$ contains a span that answers the question.
本文研究的开放域问答问题可描述如下:给定一个事实型问题(例如"谁为《恶搞之家》中的Meg首次配音?"或"第八世达赖喇嘛出生在哪里?"),系统需要利用一个涵盖多样化主题的大型语料库来回答该问题。具体而言,我们采用抽取式问答设定,即答案必须来自语料库中一个或多个文本段落中的连续片段。假设我们的文档集合包含$D$篇文档$d_{1},d_{2},\dotsb,d_{D}$,首先将每篇文档分割为等长的文本段落作为基本检索单元,最终得到语料库$\mathcal{C}={p_{1},p_{2},...,p_{M}}$共$M$个段落,其中每个段落$p_{i}$可视为由token组成的序列$w_{1}^{(i)},w_{2}^{(i)},\cdot\cdot\cdot,w_{|p_{i}|}^{(i)}$。给定问题$q$,任务是从某个段落$p_{i}$中找出能回答该问题的连续片段$w_{s}^{(i)},w_{s+1}^{(i)},\cdot\cdot\cdot,w_{e}^{(i)}$。需要注意的是,为覆盖广泛领域,语料库规模可能从数百万文档(如维基百科)到数十亿(如全网网页)不等。因此,任何开放域问答系统都需要包含高效的检索组件,在应用阅读器抽取答案前先筛选出少量相关文本(Chen et al., 2017)。形式上,检索器$R:(q,\mathcal{C})\rightarrow\mathcal{C}_ {\mathcal{F}}$是一个函数,接收问题$q$和语料库$\mathcal{C}$作为输入,返回规模小得多的文本过滤集${\mathcal{C}}_ {\mathcal{F}}\subset{\mathcal{C}}$,其中$|{\mathcal{C}}_ {\mathcal{F}}|=k\ll|{\mathcal{C}}|$。对于固定$k$,可单独评估检索器的top $k$检索准确率,即$\mathcal{C}_{\mathcal{F}}$包含问题答案的案例占比。
3 Dense Passage Retriever (DPR)
3 密集段落检索器 (DPR)
We focus our research in this work on improving the retrieval component in open-domain QA. Given a collection of $M$ text passages, the goal of our dense passage retriever (DPR) is to index all the passages in a low-dimensional and continuous space, such that it can retrieve efficiently the top $k$ passages relevant to the input question for the reader at run-time. Note that $M$ can be very large (e.g., 21 million passages in our experiments, described in Section 4.1) and $k$ is usually small, such as 20–100.
在本研究中,我们专注于改进开放域问答中的检索组件。给定一个包含 $M$ 个文本段落的集合,我们的密集段落检索器 (DPR) 目标是将所有段落索引到一个低维连续空间中,从而在运行时能高效检索出与输入问题最相关的 $k$ 个段落供阅读器使用。需要注意的是,$M$ 可能非常大(例如我们实验中的2100万段落,详见第4.1节),而 $k$ 通常较小,例如20-100。
3.1 Overview
3.1 概述
Our dense passage retriever (DPR) uses a dense encoder $E_{P}(\cdot)$ which maps any text passage to a $d\cdot$ - dimensional real-valued vectors and builds an index for all the $M$ passages that we will use for retrieval.
我们的密集段落检索器 (DPR) 使用一个密集编码器 $E_{P}(\cdot)$ ,它将任何文本段落映射到一个 $d\cdot$ 维实值向量,并为所有 $M$ 个待检索段落构建索引。
At run-time, DPR applies a different encoder $E_{Q}(\cdot)$ that maps the input question to a $d$ -dimensional vector, and retrieves $k$ passages of which vectors are the closest to the question vector. We define the similarity between the question and the passage using the dot product of their vectors:
在运行时,DPR采用不同的编码器$E_{Q}(\cdot)$将输入问题映射为$d$维向量,并检索出与其向量最接近的$k$个段落。我们通过向量点积来定义问题与段落之间的相似度:
$$
\begin{array}{r}{\sin(q,p)=E_{\boldsymbol{Q}}(q)^{\intercal}E_{P}(p).}\end{array}
$$
$$
\begin{array}{r}{\sin(q,p)=E_{\boldsymbol{Q}}(q)^{\intercal}E_{P}(p).}\end{array}
$$
Although more expressive model forms for measuring the similarity between a question and a passage do exist, such as networks consisting of multiple layers of cross attentions, the similarity function needs to be de com pos able so that the representations of the collection of passages can be precomputed. Most de com pos able similarity functions are some transformations of Euclidean distance (L2). For instance, cosine is equivalent to inner product for unit vectors and the Mahal a nobis distance is equivalent to L2 distance in a transformed space. Inner product search has been widely used and studied, as well as its connection to cosine similarity and L2 distance (Mussmann and Ermon, 2016; Ram and Gray, 2012). As our ablation study finds other similarity functions perform comparably (Section 5.2; Appendix B), we thus choose the simpler inner product function and improve the dense passage retriever by learning better encoders.
尽管确实存在更富表现力的模型形式来衡量问题与段落之间的相似性(例如由多层交叉注意力组成的网络),但相似性函数需要可分解,以便能够预先计算段落集合的表示。大多数可分解的相似性函数都是欧几里得距离(L2)的某种变换。例如,余弦相似度等价于单位向量的内积,而马哈拉诺比斯距离(Mahalanobis distance)在变换空间中相当于L2距离。内积搜索及其与余弦相似度和L2距离的联系已被广泛研究和应用(Mussmann和Ermon,2016;Ram和Gray,2012)。由于我们的消融研究发现其他相似性函数表现相当(第5.2节;附录B),因此我们选择更简单的内积函数,并通过学习更好的编码器来改进密集段落检索器。
Encoders Although in principle the question and passage encoders can be implemented by any neural networks, in this work we use two independent BERT (Devlin et al., 2019) networks (base, uncased) and take the representation at the [CLS] token as the output, so $d=768$ .
编码器
虽然理论上问题和段落编码器可以由任何神经网络实现,但在本工作中我们采用两个独立的BERT (Devlin et al., 2019) 网络 (base, uncased) ,并以[CLS] token的表征作为输出,因此 $d=768$ 。
Inference During inference time, we apply the passage encoder $E_{P}$ to all the passages and index them using FAISS (Johnson et al., 2017) offline. FAISS is an extremely efficient, open-source library for similarity search and clustering of dense vectors, which can easily be applied to billions of vectors. Given a question $q$ at run-time, we derive its embedding $v_{q}=E_{Q}(q)$ and retrieve the top $k$ passages with embeddings closest to $v_{q}$ .
推理
在推理阶段,我们使用段落编码器 $E_{P}$ 对所有段落进行编码,并离线使用 FAISS (Johnson et al., 2017) 建立索引。FAISS 是一个高效的开源库,专用于稠密向量的相似性搜索和聚类,可轻松扩展到数十亿向量。给定运行时问题 $q$,我们生成其嵌入向量 $v_{q}=E_{Q}(q)$,并检索与 $v_{q}$ 最接近的前 $k$ 个段落嵌入。
3.2 Training
3.2 训练
Training the encoders so that the dot-product similarity (Eq. (1)) becomes a good ranking function for retrieval is essentially a metric learning problem (Kulis, 2013). The goal is to create a vector space such that relevant pairs of questions and passages will have smaller distance (i.e., higher similarity) than the irrelevant ones, by learning a better embedding function.
训练编码器使点积相似度(公式(1))成为良好的检索排序函数,本质上是一个度量学习问题 (Kulis, 2013)。其目标是通过学习更好的嵌入函数,构建一个向量空间,使得相关的问题与段落对之间的距离(即相似度)比不相关的更小(即更高)。
Let $\textit{D}={\langle q_{i},p_{i}^{+},p_{i,1}^{-},\cdot\cdot\cdot,p_{i,n}^{-}\rangle}_ {i=1}^{m}$ be the training data that consists of $m$ instances. Each instance contains one question $q_{i}$ and one relevant (positive) passage $p_{i}^{+}$ , along with $n$ irrelevant (negative) passages $p_{i,j}^{-}$ . We optimize the loss function as the negative log likelihood of the positive passage:
设训练数据 $\textit{D}={\langle q_{i},p_{i}^{+},p_{i,1}^{-},\cdot\cdot\cdot,p_{i,n}^{-}\rangle}_ {i=1}^{m}$ 由 $m$ 个实例组成。每个实例包含一个问题 $q_{i}$、一个相关(正例)段落 $p_{i}^{+}$ 以及 $n$ 个不相关(负例)段落 $p_{i,j}^{-}$。我们将损失函数优化为正例段落的负对数似然:
$$
\begin{array}{r l}&{L(q_{i},p_{i}^{+},p_{i,1}^{-},\cdot\cdot\cdot,p_{i,n}^{-})}\ {=}&{-\log\frac{e^{\sin(q_{i},p_{i}^{+})}}{e^{\sin(q_{i},p_{i}^{+})}+\sum_{j=1}^{n}e^{\sin(q_{i},p_{i,j}^{-})}}.}\end{array}
$$
$$
\begin{array}{r l}&{L(q_{i},p_{i}^{+},p_{i,1}^{-},\cdot\cdot\cdot,p_{i,n}^{-})}\ {=}&{-\log\frac{e^{\sin(q_{i},p_{i}^{+})}}{e^{\sin(q_{i},p_{i}^{+})}+\sum_{j=1}^{n}e^{\sin(q_{i},p_{i,j}^{-})}}.}\end{array}
$$
Positive and negative passages For retrieval problems, it is often the case that positive examples are available explicitly, while negative examples need to be selected from an extremely large pool. For instance, passages relevant to a question may be given in a QA dataset, or can be found using the answer. All other passages in the collection, while not specified explicitly, can be viewed as irrelevant by default. In practice, how to select negative examples is often overlooked but could be decisive for learning a high-quality encoder. We consider three different types of negatives: (1) Random: any random passage from the corpus; (2) BM25: top passages returned by BM25 which don’t contain the answer but match most question tokens; (3) Gold: positive passages paired with other questions which appear in the training set. We will discuss the impact of different types of negative passages and training schemes in Section 5.2. Our best model uses gold passages from the same mini-batch and one BM25 negative passage. In particular, re-using gold passages from the same batch as negatives can make the computation efficient while achieving great performance. We discuss this approach below.
正负段落
对于检索问题,通常明确可用的只有正例,而负例需要从极庞大的候选池中筛选。例如,问答数据集中可能直接提供了与问题相关的段落,或可通过答案定位相关段落。集合中所有其他段落虽未明确标注,默认情况下均可视为不相关。实际应用中,负例的选择策略常被忽视,但对训练高质量编码器可能具有决定性影响。我们考虑三种负例类型:(1) 随机负例:从语料库随机选取的段落;(2) BM25负例:由BM25返回的最高分段落(不含正确答案但与问题token高度匹配);(3) 黄金负例:训练集中其他问题对应的正例段落。第5.2节将探讨不同类型负例及训练方案的影响。我们的最佳模型采用同小批量的黄金负例加一个BM25负例的组合。特别地,将同批次的黄金段落复用为负例,可在保证优异性能的同时显著提升计算效率。下文将详细讨论该方法。
In-batch negatives Assume that we have $B$ questions in a mini-batch and each one is associated with a relevant passage. Let $\mathbf{Q}$ and $\mathbf{P}$ be the $(B\times d)$ matrix of question and passage embeddings in a batch of size $B$ . $\mathbf{S}=\mathbf{Q}\mathbf{P}^{T}$ is a $(B\times B)$ matrix of similarity scores, where each row of which corresponds to a question, paired with B passages. In this way, we reuse computation and effectively train on $B^{2}\left(q_{i},p_{j}\right)$ question/passage pairs in each batch. Any $(q_{i},p_{j})$ pair is a positive example when $i=j$ , and negative otherwise. This creates $B$ training instances in each batch, where there are $B-1$ negative passages for each question.
批内负例 假设我们在一个小批次中有 $B$ 个问题,每个问题都与一个相关段落相关联。令 $\mathbf{Q}$ 和 $\mathbf{P}$ 表示批次大小为 $B$ 时的问题和段落嵌入的 $(B \times d)$ 矩阵。$\mathbf{S}=\mathbf{Q}\mathbf{P}^{T}$ 是一个 $(B \times B)$ 的相似度得分矩阵,其中每一行对应一个问题,与 B 个段落配对。通过这种方式,我们重复利用计算,并在每个批次中有效地训练 $B^{2}\left(q_{i},p_{j}\right)$ 个问题/段落对。当 $i=j$ 时,任何 $(q_{i},p_{j})$ 对都是正例,否则为负例。这样在每个批次中创建了 $B$ 个训练实例,其中每个问题有 $B-1$ 个负例段落。
The trick of in-batch negatives has been used in the full batch setting (Yih et al., 2011) and more recently for mini-batch (Henderson et al., 2017; Gillick et al., 2019). It has been shown to be an effective strategy for learning a dual-encoder model that boosts the number of training examples.
批内负样本技巧已在全批次设置中使用(Yih et al., 2011),最近也应用于小批次训练(Henderson et al., 2017; Gillick et al., 2019)。研究表明这是学习双编码器模型的有效策略,可显著增加训练样本数量。
4 Experimental Setup
4 实验设置
In this section, we describe the data we used for experiments and the basic setup.
在本节中,我们将描述实验所用数据及基本设置。
4.1 Wikipedia Data Pre-processing
4.1 维基百科数据预处理
Following (Lee et al., 2019), we use the English Wikipedia dump from Dec. 20, 2018 as the source documents for answering questions. We first apply the pre-processing code released in DrQA (Chen et al., 2017) to extract the clean, text-portion of articles from the Wikipedia dump. This step removes semi-structured data, such as tables, infoboxes, lists, as well as the disambiguation pages. We then split each article into multiple, disjoint text blocks of 100 words as passages, serving as our basic retrieval units, following (Wang et al., 2019), which results in 21,015,324 passages in the end.5 Each passage is also prepended with the title of the Wikipedia article where the passage is from, along with an [SEP] token.
遵循 (Lee et al., 2019) 的方法,我们使用2018年12月20日的英文维基百科转储文件作为问答的源文档。首先应用 DrQA (Chen et al., 2017) 发布的预处理代码,从维基百科转储中提取文章的纯文本部分。此步骤移除了半结构化数据,例如表格、信息框、列表以及消歧页面。随后,按照 (Wang et al., 2019) 的方式,将每篇文章分割成多个互不重叠的100词文本块作为段落,作为我们的基本检索单元,最终得到21,015,324个段落。每个段落前还附加了来源维基百科文章的标题以及一个 [SEP] token。
4.2 Question Answering Datasets
4.2 问答数据集
We use the same five QA datasets and training/dev/testing splitting method as in previous work (Lee et al., 2019). Below we briefly describe each dataset and refer readers to their paper for the details of data preparation.
我们采用与先前研究 (Lee et al., 2019) 相同的五个问答数据集及训练/开发/测试集划分方法。以下简要描述各数据集,数据准备细节请参阅原文。
Natural Questions (NQ) (Kwiatkowski et al., 2019) was designed for end-to-end question answering. The questions were mined from real Google search queries and the answers were spans in Wikipedia articles identified by annotators.
自然问题 (Natural Questions, NQ) (Kwiatkowski et al., 2019) 是为端到端问答任务设计的。这些问题采集自真实的谷歌搜索查询,答案则由标注人员在维基百科文章中标注的文本片段构成。
TriviaQA (Joshi et al., 2017) contains a set of trivia questions with answers that were originally scraped from the Web.
TriviaQA (Joshi等人,2017) 包含一组从网页抓取的问答式琐事问题及其答案。
Web Questions (WQ) (Berant et al., 2013) consists of questions selected using Google Suggest API, where the answers are entities in Freebase.
Web Questions (WQ) (Berant et al., 2013) 包含通过Google Suggest API筛选的问题,其答案均为Freebase中的实体。
Curate dT REC (TREC) (Baudis and Sedivy, 2015) sources questions from TREC QA tracks as well as various Web sources and is intended for open-domain QA from unstructured corpora.
精选TREC (TREC) (Baudis和Sedivy, 2015) 的问题来源于TREC QA赛道以及各种网络资源,旨在从非结构化语料库中进行开放领域问答。
Table 1: Number of questions in each QA dataset. The two columns of Train denote the original training examples in the dataset and the actual questions used for training DPR after filtering. See text for more details.
| Dataset | Train | Dev | Test | |
| Natural Questions | 79,168 | 58,880 | 8,757 | 3,610 |
| TriviaQA | 78,785 | 60,413 | 8,837 | 11,313 |
| WebQuestions | 3,417 | 2,474 | 361 | 2,032 |
| CuratedTREC | 1,353 | 1,125 | 133 | 694 |
| SQuAD | 78,713 | 70,096 | 8,886 | 10,570 |
表 1: 各问答数据集中的问题数量。Train列的两项分别表示数据集中的原始训练样本和经过筛选后实际用于训练DPR的问题数量。详情见正文。
| Dataset | Train | Dev | Test | |
|---|---|---|---|---|
| Natural Questions | 79,168 | 58,880 | 8,757 | 3,610 |
| TriviaQA | 78,785 | 60,413 | 8,837 | 11,313 |
| WebQuestions | 3,417 | 2,474 | 361 | 2,032 |
| CuratedTREC | 1,353 | 1,125 | 133 | 694 |
| SQuAD | 78,713 | 70,096 | 8,886 | 10,570 |
SQuAD v1.1 (Rajpurkar et al., 2016) is a popular benchmark dataset for reading comprehension. Annotators were presented with a Wikipedia paragraph, and asked to write questions that could be answered from the given text. Although SQuAD has been used previously for open-domain QA research, it is not ideal because many questions lack context in absence of the provided paragraph. We still include it in our experiments for providing a fair comparison to previous work and we will discuss more in Section 5.1.
SQuAD v1.1 (Rajpurkar et al., 2016) 是一个流行的阅读理解基准数据集。标注人员会看到一段维基百科段落,并被要求根据给定文本编写可回答的问题。尽管SQuAD此前被用于开放域问答研究,但由于许多问题在缺乏所提供段落的情况下缺少上下文,它并不理想。我们仍将其纳入实验以公平比较先前工作,并将在第5.1节进一步讨论。
Selection of positive passages Because only pairs of questions and answers are provided in TREC, Web Questions and TriviaQA6, we use the highest-ranked passage from BM25 that contains the answer as the positive passage. If none of the top 100 retrieved passages has the answer, the question will be discarded. For SQuAD and Natural Questions, since the original passages have been split and processed differently than our pool of candidate passages, we match and replace each gold passage with the corresponding passage in the candidate pool.7 We discard the questions when the matching is failed due to different Wikipedia versions or pre-processing. Table 1 shows the number of questions in training/dev/test sets for all the datasets and the actual questions used for training the retriever.
正例段落选择
由于TREC、Web Questions和TriviaQA6仅提供问答对,我们采用BM25检索结果中包含答案的最高排名段落作为正例。若前100个检索段落均未包含答案,则丢弃该问题。对于SQuAD和Natural Questions,由于原始段落的分割处理方式与候选段落池不同,我们将每段标注段落替换为候选池中的对应段落。若因维基百科版本差异或预处理导致匹配失败,则丢弃该问题。表1展示了各数据集的训练集/开发集/测试集问题数量,以及实际用于训练检索器的问题数量。
(注:根据规则要求,已对表格引用格式进行标准化处理,保留"表1"的原始标记;专业术语如BM25未添加英文原文说明,因其在信息检索领域属通用缩写;段落结构及技术细节均完整保留;半角括号使用符合规范)
5 Experiments: Passage Retrieval
5 实验:段落检索
In this section, we evaluate the retrieval performance of our Dense Passage Retriever (DPR), along with analysis on how its output differs from
在本节中,我们评估了密集段落检索器 (Dense Passage Retriever, DPR) 的检索性能,并分析了其输出与
| Training | Retriever | Top-20 | Top-100 | ||||||||
| NQ | TriviaQA | WQ | TREC | SQuAD | NQ | TriviaQA | WQ | TREC | SQuAD | ||
| None | BM25 | 59.1 | 66.9 | 55.0 | 70.9 | 68.8 | 73.7 | 76.7 | 71.1 | 84.1 | 80.0 |
| Single | DPR | 78.4 | 79.4 | 73.2 | 79.8 | 63.2 | 85.4 | 85.0 | 81.4 | 89.1 | 77.2 |
| BM25 + DPR | 76.6 | 79.8 | 71.0 | 85.2 | 71.5 | 83.8 | 84.5 | 80.5 | 92.7 | 81.3 | |
| Multi | DPR | 79.4 | 78.8 | 75.0 | 89.1 | 51.6 | 86.0 | 84.7 | 82.9 | 93.9 | 67.6 |
| BM25 + DPR | 78.0 | 79.9 | 74.7 | 88.5 | 66.2 | 83.9 | 84.4 | 82.3 | 94.1 | 78.6 | |
| 训练方式 | 检索器 | Top-20 | Top-100 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NQ | TriviaQA | WQ | TREC | SQuAD | NQ | TriviaQA | WQ | TREC | SQuAD | ||
| 无 | BM25 | 59.1 | 66.9 | 55.0 | 70.9 | 68.8 | 73.7 | 76.7 | 71.1 | 84.1 | 80.0 |
| 单任务 | DPR | 78.4 | 79.4 | 73.2 | 79.8 | 63.2 | 85.4 | 85.0 | 81.4 | 89.1 | 77.2 |
| BM25 + DPR | 76.6 | 79.8 | 71.0 | 85.2 | 71.5 | 83.8 | 84.5 | 80.5 | 92.7 | 81.3 | |
| 多任务 | DPR | 79.4 | 78.8 | 75.0 | 89.1 | 51.6 | 86.0 | 84.7 | 82.9 | 93.9 | 67.6 |
| BM25 + DPR | 78.0 | 79.9 | 74.7 | 88.5 | 66.2 | 83.9 | 84.4 | 82.3 | 94.1 | 78.6 |
Table 2: Top-20 & Top-100 retrieval accuracy on test sets, measured as the percentage of top 20/100 retrieved passages that contain the answer. Single and Multi denote that our Dense Passage Retriever (DPR) was trained using individial or combined training datasets (all the datasets excluding SQuAD). See text for more details.
表 2: 测试集上的Top-20和Top-100检索准确率,以包含答案的前20/100篇检索段落所占百分比衡量。Single和Multi表示我们的密集段落检索器(DPR)是使用单个或组合训练数据集(除SQuAD外的所有数据集)进行训练的。详见正文说明。
traditional retrieval methods, the effects of different training schemes and the run-time efficiency.
传统检索方法、不同训练方案的效果以及运行时效率。
The DPR model used in our main experiments is trained using the in-batch negative setting (Section 3.2) with a batch size of 128 and one additional BM25 negative passage per question. We trained the question and passage encoders for up to 40 epochs for large datasets (NQ, TriviaQA, SQuAD) and 100 epochs for small datasets (TREC, WQ), with a learning rate of $10^{-5}$ using Adam, linear scheduling with warm-up and dropout rate 0.1.
我们主实验中使用的DPR模型采用批内负样本设置(第3.2节)进行训练,批大小为128,每个问题额外添加一个BM25负样本段落。对于大型数据集(NQ、TriviaQA、SQuAD),问题和段落编码器训练最多40个周期;小型数据集(TREC、WQ)则训练100个周期,学习率为$10^{-5}$,使用Adam优化器,采用带预热(warm-up)的线性调度和0.1的dropout率。
While it is good to have the flexibility to adapt the retriever to each dataset, it would also be desirable to obtain a single retriever that works well across the board. To this end, we train a multidataset encoder by combining training data from all datasets excluding SQuAD. In addition to DPR, we also present the results of BM25, the traditional retrieval method9 and $\mathrm{BM}25\substack{+\mathrm{DPR}}$ , using a linear combination of their scores as the new ranking function. Specifically, we obtain two initial sets of top-2000 passages based on BM25 and DPR, respectively, and rerank the union of them using $\mathrm{BM}25(q,p)+\lambda\cdot\sin(q,p)$ as the ranking function. We used $\lambda=1.1$ based on the retrieval accuracy in the development set.
虽然能够灵活调整检索器以适应每个数据集是件好事,但获得一个通用性强的单一检索器同样具有吸引力。为此,我们通过合并除SQuAD外所有数据集的训练数据,训练了一个多数据集编码器。除DPR外,我们还展示了传统检索方法BM25以及$\mathrm{BM}25\substack{+\mathrm{DPR}}$的结果,后者通过线性组合两者分数作为新的排序函数。具体而言,我们分别基于BM25和DPR获得两组前2000篇文档的初始集合,并使用$\mathrm{BM}25(q,p)+\lambda\cdot\sin(q,p)$作为排序函数对它们的并集进行重新排序。根据开发集中的检索准确率,我们选择$\lambda=1.1$作为参数值。
5.1 Main Results
5.1 主要结果
Table 2 compares different passage retrieval systems on five QA datasets, using the top $k$ accuracy $(k\in{20,100}).$ ). With the exception of $\mathrm{SQuAD}$ DPR performs consistently better than BM25 on all datasets. The gap is especially large when $k$ is small (e.g., $78.4%$ vs. $59.1%$ for top-20 accuracy on Natural Questions). When training with multiple datasets, TREC, the smallest dataset of the five, benefits greatly from more training examples. In contrast, Natural Questions and Web Questions improve modestly and TriviaQA degrades slightly. Results can be improved further in some cases by combining DPR with BM25 in both single- and multi-dataset settings.
表 2: 在五个问答数据集上比较不同段落检索系统的性能,采用 top $k$ 准确率 $(k\in{20,100})$。除 $\mathrm{SQuAD}$ 外,DPR 在所有数据集上均优于 BM25。当 $k$ 值较小时优势尤为显著 (例如 Natural Questions 的 top-20 准确率为 $78.4%$ 对 $59.1%$)。使用多数据集训练时,五个数据集中规模最小的 TREC 从额外训练样本中获益最大,而 Natural Questions 和 Web Questions 提升有限,TriviaQA 则略有下降。在某些情况下,通过在单数据集和多数据集场景中结合 DPR 与 BM25 可进一步提升结果。
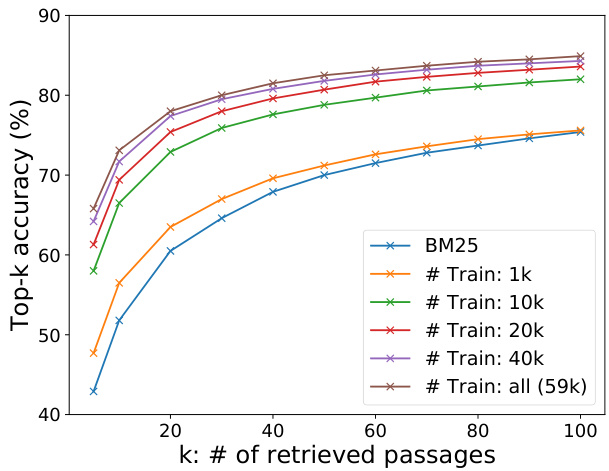
Figure 1: Retriever top $k$ accuracy with different numbers of training examples used in our dense passage retriever vs BM25. The results are measured on the development set of Natural Questions. Our DPR trained using 1,000 examples already outperforms BM25.
图 1: 在不同训练样本数量下,我们的密集段落检索器 (dense passage retriever) 与 BM25 的检索器 top $k$ 准确率对比。结果基于 Natural Questions 开发集测得。仅使用 1,000 个训练样本的 DPR 已超越 BM25 表现。
We conjecture that the lower performance on SQuAD is due to two reasons. First, the annotators wrote questions after seeing the passage. As a result, there is a high lexical overlap between passages and questions, which gives BM25 a clear advantage. Second, the data was collected from only $500+$ Wikipedia articles and thus the distribution of training examples is extremely biased, as argued previously by Lee et al. (2019).
我们推测SQuAD上较低的性能是由于两个原因。首先,标注者在看到文章后编写问题,因此文章和问题之间存在高度词汇重叠,这使BM25具有明显优势。其次,数据仅从500多篇维基百科文章中收集,因此训练样本的分布极不均衡,正如Lee等人 (2019) 先前所述。
5.2 Ablation Study on Model Training
5.2 模型训练消融研究
To understand further how different model training options affect the results, we conduct several additional experiments and discuss our findings below.
为了进一步了解不同模型训练选项如何影响结果,我们进行了多项额外实验,并在下文中讨论我们的发现。
Sample efficiency We explore how many training examples are needed to achieve good passage retrieval performance. Figure 1 illustrates the top $k$ retrieval accuracy with respect to different numbers of training examples, measured on the development set of Natural Questions. As is shown, a dense passage retriever trained using only 1,000 examples already outperforms BM25. This suggests that with a general pretrained language model, it is possible to train a high-quality dense retriever with a small number of question–passage pairs. Adding more training examples (from 1k to 59k) further improves the retrieval accuracy consistently.
样本效率
我们探究了需要多少训练样本才能获得良好的段落检索性能。图 1 展示了在 Natural Questions 开发集上测得的 top $k$ 检索准确率随训练样本数量的变化情况。如图所示,仅用 1,000 个样本训练的稠密段落检索器 (dense passage retriever) 已优于 BM25。这表明,借助通用预训练语言模型 (pretrained language model),仅需少量问题-段落对即可训练出高质量的稠密检索器。增加训练样本 (从 1k 到 59k) 会持续提升检索准确率。
In-batch negative training We test different training schemes on the development set of Natural Questions and summarize the results in Table 3. The top block is the standard 1-of $\mathcal{N}$ training setting, where each question in the batch is paired with a positive passage and its own set of $n$ negative passages (Eq. (2)). We find that the choice of negatives — random, BM25 or gold passages (positive passages from other questions) — does not impact the top $k$ accuracy much in this setting when $k\geq20$ .
批内负样本训练
我们在Natural Questions开发集上测试了不同的训练方案,并将结果总结在表3中。顶部模块是标准的1-of-$\mathcal{N}$训练设置,其中批次中的每个问题都与一个正样本段落及其自身的$n$个负样本段落配对(公式(2))。我们发现,在此设置下,当$k\geq20$时,负样本的选择——随机样本、BM25样本或黄金段落(来自其他问题的正样本段落)——对top $k$准确率影响不大。
The middle bock is the in-batch negative training (Section 3.2) setting. We find that using a similar configuration (7 gold negative passages), in-batch negative training improves the results substantially. The key difference between the two is whether the gold negative passages come from the same batch or from the whole training set. Effectively, in-batch negative training is an easy and memory-efficient way to reuse the negative examples already in the batch rather than creating new ones. It produces more pairs and thus increases the number of training examples, which might contribute to the good model performance. As a result, accuracy consistently improves as the batch size grows.
中间模块是批次内负样本训练(见第3.2节)的设置。我们发现,在采用相似配置(7个黄金负样本段落)时,批次内负样本训练能显著提升结果。两者的关键区别在于黄金负样本段落是来自同一批次还是整个训练集。实际上,批次内负样本训练是一种高效利用内存的简便方法,它复用批次中已有的负样本而非创建新样本。这种方式能生成更多样本对,从而增加训练样本数量,这可能是模型性能优异的原因。因此,随着批次规模增大,准确率持续提升。
Finally, we explore in-batch negative training with additional “hard” negative passages that have high BM25 scores given the question, but do not contain the answer string (the bottom block). These additional passages are used as negative passages for all questions in the same batch. We find that adding a single BM25 negative passage improves the result substantially while adding two does not help further.
最后,我们探索了使用额外"困难"负段落进行批量负训练的方法,这些段落针对问题具有较高的BM25分数但不包含答案字符串(底部模块)。这些额外段落被用作同一批次中所有问题的负段落。我们发现添加一个BM25负段落能显著提升结果,而添加两个则没有进一步帮助。
Impact of gold passages We use passages that match the gold contexts in the original datasets (when available) as positive examples (Section 4.2).
黄金段落的影响
我们使用与原始数据集中黄金上下文匹配的段落作为正例(第4.2节)。
Table 3: Comparison of different training schemes, measured as top $k$ retrieval accuracy on Natural Questions (development set). #N: number of negative examples, IB: in-batch training. $\mathbf{G.+BM}25^{(1)}$ and $\mathbf{G}.+\mathbf{B}\mathbf{M}25^{(2)}$ denote in-batch training with 1 or 2 additional BM25 negatives, which serve as negative passages for all questions in the batch.
| Type | #N | IB | Top-5 | Top-20 | Top-100 |
| Random | 7 | × | 47.0 | 64.3 | 77.8 |
| BM25 | 7 | 50.0 | 63.3 | 74.8 | |
| Gold | 7 | × | 42.6 | 63.1 | 78.3 |
| Gold | 7 | 51.1 | 69.1 | 80.8 | |
| Gold | 31 | 52.1 | 70.8 | 82.1 | |
| Gold | 127 | 55.8 | 73.0 | 83.1 | |
| G.+BM25(1) | 31+32 | 65.0 | 77.3 | 84.4 | |
| G.+BM25(2) | 31+64 | 64.5 | 76.4 | 84.0 | |
| G.+BM25(1) | 127+128 | 65.8 | 78.0 | 84.9 |
表 3: 不同训练方案的对比,以Natural Questions(开发集)上前$k$检索准确率为衡量指标。#N: 负例数量,IB: 批次内训练。$\mathbf{G.+BM}25^{(1)}$和$\mathbf{G}.+\mathbf{B}\mathbf{M}25^{(2)}$表示在批次内训练中添加1个或2个额外BM25负例,这些负例作为批次内所有问题的负向段落。
| 类型 | #N | IB | Top-5 | Top-20 | Top-100 |
|---|---|---|---|---|---|
| Random | 7 | × | 47.0 | 64.3 | 77.8 |
| BM25 | 7 | 50.0 | 63.3 | 74.8 | |
| Gold | 7 | × | 42.6 | 63.1 | 78.3 |
| Gold | 7 | 51.1 | 69.1 | 80.8 | |
| Gold | 31 | 52.1 | 70.8 | 82.1 | |
| Gold | 127 | 55.8 | 73.0 | 83.1 | |
| G.+BM25(1) | 31+32 | 65.0 | 77.3 | 84.4 | |
| G.+BM25(2) | 31+64 | 64.5 | 76.4 | 84.0 | |
| G.+BM25(1) | 127+128 | 65.8 | 78.0 | 84.9 |
Our experiments on Natural Questions show that switching to distantly-supervised passages (using the highest-ranked BM25 passage that contains the answer), has only a small impact: 1 point lower top $\cdot k$ accuracy for retrieval. Appendix A contains more details.
我们在Natural Questions上的实验表明,切换到远程监督段落(使用包含答案的BM25最高排名段落)仅产生微小影响:检索的top $\cdot k$准确率降低1个百分点。附录A提供了更多细节。
Similarity and loss Besides dot product, cosine and Euclidean L2 distance are also commonly used as de com pos able similarity functions. We test these alternatives and find that L2 performs comparable to dot product, and both of them are superior to cosine. Similarly, in addition to negative loglikelihood, a popular option for ranking is triplet loss, which compares a positive passage and a negative one directly with respect to a question (Burges et al., 2005). Our experiments show that using triplet loss does not affect the results much. More details can be found in Appendix B.
相似性与损失函数
除点积外,余弦相似度和欧氏L2距离也常被用作可分解的相似性函数。我们测试了这些替代方案,发现L2距离与点积表现相当,且两者均优于余弦相似度。同样地,除了负对数似然外,排序任务中另一种常用方法是三元组损失 (triplet loss) ,它直接比较正样本段落与负样本段落相对于问题的关系 (Burges et al., 2005) 。实验表明使用三元组损失对结果影响不大。更多细节详见附录B。
Cross-dataset generalization One interesting question regarding DPR’s disc rim i native training is how much performance degradation it may suffer from a non-iid setting. In other words, can it still generalize well when directly applied to a different dataset without additional fine-tuning? To test the cross-dataset generalization, we train DPR on Natural Questions only and test it directly on the smaller Web Questions and Curate dT REC datasets. We find that DPR generalizes well, with 3-5 points loss from the best performing fine-tuned model in top-20 retrieval accuracy (69.9/86.3 vs. 75.0/89.1 for Web Questions and TREC, respectively), while still greatly outperforming the BM25 baseline (55.0/70.9).
跨数据集泛化能力
关于DPR判别式训练的一个有趣问题是,它在非独立同分布(non-iid)设置下会遭受多大程度的性能下降。换句话说,当直接应用于不同数据集且不进行额外微调时,它是否仍能保持良好的泛化能力?为测试跨数据集泛化性,我们仅在Natural Questions上训练DPR,并直接在较小的Web Questions和CuratedTREC数据集上进行测试。我们发现DPR泛化效果良好,在top-20检索准确率上仅比经过微调的最佳模型低3-5个百分点(Web Questions和TREC分别为69.9/86.3 vs. 75.0/89.1),同时仍显著优于BM25基线(55.0/70.9)。
5.3 Qualitative Analysis
5.3 定性分析
Although DPR performs better than BM25 in general, passages retrieved by these two methods differ qualitatively. Term-matching methods like BM25 are sensitive to highly selective keywords and phrases, while DPR captures lexical variations or semantic relationships better. See Appendix C for examples and more discussion.
尽管DPR整体表现优于BM25,但两种方法检索到的段落存在本质差异。基于词项匹配的方法(如BM25)对高区分度关键词和短语敏感,而DPR能更好地捕捉词汇变体或语义关联。具体示例和深入讨论参见附录C。
5.4 Run-time Efficiency
5.4 运行时效率
The main reason that we require a retrieval component for open-domain QA is to reduce the number of candidate passages that the reader needs to consider, which is crucial for answering user’s questions in real-time. We profiled the passage retrieval speed on a server with Intel Xeon CPU E5-2698 v4 $@2.20\mathrm{GHz}$ and 512GB memory. With the help of FAISS in-memory index for real-valued vectors10, DPR can be made incredibly efficient, processing 995.0 questions per second, returning top 100 passages per question. In contrast, BM25/Lucene (implemented in Java, using file index) processes 23.7 questions per second per CPU thread.
我们在开放域问答系统中引入检索组件的主要原因,是为了减少阅读器需要处理的候选段落数量,这对实时响应用户提问至关重要。我们在配备Intel Xeon CPU E5-2698 v4 $@2.20\mathrm{GHz}$ 处理器和512GB内存的服务器上测试了段落检索速度。借助FAISS内存索引对实值向量的优化处理[10],DPR实现了惊人的效率——每秒可处理995.0个问题(每个问题返回前100个段落)。相比之下,基于Java实现并使用文件索引的BM25/Lucene方案,单CPU线程每秒仅能处理23.7个问题。
On the other hand, the time required for building an index for dense vectors is much longer. Computing dense embeddings on 21-million passages is resource intensive, but can be easily parallel i zed, taking roughly 8.8 hours on 8 GPUs. However, building the FAISS index on 21-million vectors on a single server takes 8.5 hours. In comparison, building an inverted index using Lucene is much cheaper and takes only about 30 minutes in total.
另一方面,为稠密向量构建索引所需的时间要长得多。在2100万段落上计算稠密嵌入需要大量资源,但可以轻松并行化处理,在8块GPU上大约耗时8.8小时。然而,在单台服务器上为2100万向量构建FAISS索引需要8.5小时。相比之下,使用Lucene构建倒排索引的成本要低得多,总共只需约30分钟。
6 Experiments: Question Answering
6 实验:问答
In this section, we experiment with how different passage retrievers affect the final QA accuracy.
在本节中,我们实验了不同段落检索器如何影响最终的问答准确率。
6.1 End-to-end QA System
6.1 端到端问答系统
We implement an end-to-end question answering system in which we can plug different retriever systems directly. Besides the retriever, our QA system consists of a neural reader that outputs the answer to the question. Given the top $k$ retrieved passages (up to 100 in our experiments), the reader assigns a passage selection score to each passage. In addition, it extracts an answer span from each passage and assigns a span score. The best span from the passage with the highest passage selection score is chosen as the final answer. The passage selection model serves as a reranker through crossattention between the question and the passage. Although cross-attention is not feasible for retrieving relevant passages in a large corpus due to its nonde com pos able nature, it has more capacity than the dual-encoder model $\mathrm{sim}(q,p)$ as in Eq. (1). Applying it to selecting the passage from a small number of retrieved candidates has been shown to work well (Wang et al., 2019, 2018; Lin et al., 2018).
我们实现了一个端到端的问答系统,可以直接接入不同的检索器系统。除检索器外,该系统包含一个输出问题答案的神经阅读器。给定检索到的前$k$篇文本(实验中最多100篇),阅读器会为每篇文本分配一个段落选择分数,同时从中提取答案片段并给出片段分数。最终答案选自段落选择分数最高的文本中得分最佳的片段。该段落选择模型通过问题与文本间的交叉注意力(cross-attention)实现重排序功能。虽然交叉注意力因其不可分解性难以用于海量语料的相关段落检索,但其建模能力优于公式(1)中双编码器模型$\mathrm{sim}(q,p)$。已有研究表明,该方法在小规模候选段落选择任务中表现优异(Wang et al., 2019, 2018; Lin et al., 2018)。
Specifically, let $\mathbf{P}_{i}\in\mathbb{R}^{L\times h}$ $(1\leq i\leq k)$ be a BERT (base, uncased in our experiments) represent ation for the $i$ -th passage, where $L$ is the maximum length of the passage and $h$ the hidden dimension. The probabilities of a token being the starting/ending positions of an answer span and a passage being selected are defined as:
具体来说,设 $\mathbf{P}_{i}\in\mathbb{R}^{L\times h}$ $(1\leq i\leq k)$ 为第 $i$ 个段落的 BERT (base,实验中采用 uncased 版本) 表示,其中 $L$ 是段落的长度上限,$h$ 为隐藏层维度。一个 token 作为答案区间起止位置的概率以及段落被选中的概率定义为:
$$
\begin{array}{r c l}{P_{\mathrm{start},i}(s)}&{=}&{\mathrm{softmax}\big(\mathbf{P}_ {i}\mathbf{w}_ {\mathrm{start}}\big)_ {s},}\ {P_{\mathrm{end},i}(t)}&{=}&{\mathrm{softmax}\big(\mathbf{P}_ {i}\mathbf{w}_ {\mathrm{end}}\big)_ {t},}\ {P_{\mathrm{selected}}(i)}&{=}&{\mathrm{softmax}\big(\hat{\mathbf{P}}^{\intercal}\mathbf{w}_ {\mathrm{selected}}\big)_{i},}\end{array}
$$
$$
\begin{array}{r c l}{P_{\mathrm{start},i}(s)}&{=}&{\mathrm{softmax}\big(\mathbf{P}_ {i}\mathbf{w}_ {\mathrm{start}}\big)_ {s},}\ {P_{\mathrm{end},i}(t)}&{=}&{\mathrm{softmax}\big(\mathbf{P}_ {i}\mathbf{w}_ {\mathrm{end}}\big)_ {t},}\ {P_{\mathrm{selected}}(i)}&{=}&{\mathrm{softmax}\big(\hat{\mathbf{P}}^{\intercal}\mathbf{w}_ {\mathrm{selected}}\big)_{i},}\end{array}
$$
where P = [PICLs], $\hat{\textbf{P}}=[\mathbf{P}_ {1}^{[\mathrm{CLS}]},\dots,\mathbf{P}_ {k}^{[\mathrm{CLS}]}] \in \mathbb{R}^{h\times k}$ and $\mathbf{v}_ {\mathrm{start}},\mathbf{w}_ {\mathrm{end}},\mathbf{w}_ {\mathrm{selected}}\in\mathbb{R}^{h}$ are learnable vectors. We compute a span score of the $s$ -th to $t$ -th words from the $i$ -th passage as $P_{\mathrm{start},i}(s)\times P_{\mathrm{end},i}(t)$ , and a passage selection score of the $i$ -th passage as $P_{\mathrm{selected}}(i)$ .
其中 P = [PICLs],$\hat{\textbf{P}}= [\mathbf{P}_ {1}^{[\mathrm{CLS}]},\dots,\mathbf{P}_ {k}^{[\mathrm{CLS}]}] \in \mathbb{R}^{h\times k}$,且可学习向量 $\mathbf{v}_ {\mathrm{start}},\mathbf{w}_ {\mathrm{end}},\mathbf{w}_ {\mathrm{selected}}\in\mathbb{R}^{h}$。我们计算第 $i$ 个段落中第 $s$ 到第 $t$ 个词的跨度得分为 $P_{\mathrm{start},i}(s)\times P_{\mathrm{end},i}(t)$,第 $i$ 个段落的段落选择得分为 $P_{\mathrm{selected}}(i)$。
During training, we sample one positive and $\tilde{m}-1$ negative passages from the top 100 passages returned by the retrieval system (BM25 or DPR) for each question. $\tilde{m}$ is a hyper-parameter and we use $\tilde{m}=24$ in all the experiments. The training objective is to maximize the marginal log-likelihood of all the correct answer spans in the positive passage (the answer string may appear multiple times in one passage), combined with the log-likelihood of the positive passage being selected. We use the batch size of 16 for large (NQ, TriviaQA, SQuAD) and 4 for small (TREC, WQ) datasets, and tune $k$ on the development set. For experiments on small datasets under the Multi setting, in which using other datasets is allowed, we fine-tune the reader trained on Natural Questions to the target dataset. All experiments were done on eight 32GB GPUs.
训练过程中,我们为每个问题从检索系统(BM25或DPR)返回的前100个段落中采样1个正样本和$\tilde{m}-1$个负样本。$\tilde{m}$是超参数,所有实验中均采用$\tilde{m}=24$。训练目标是最大化正样本段落中所有正确答案片段(同一段落中答案字符串可能出现多次)的边际对数似然,同时结合正样本段落被选中的对数似然。大型数据集(NQ、TriviaQA、SQuAD)采用16的批次大小,小型数据集(TREC、WQ)采用4的批次大小,并在开发集上调整$k$。对于允许使用其他数据集的小型数据集多任务设置(Multi setting)实验,我们将基于Natural Questions训练的阅读器微调到目标数据集。所有实验均在八块32GB GPU上完成。
6.2 Results
6.2 结果
Table 4 summarizes our final end-to-end QA results, measured by exact match with the reference answer after minor normalization as in (Chen et al., 2017; Lee et al., 2019). From the table, we can see that higher retriever accuracy typically leads to better final QA results: in all cases except SQuAD, answers extracted from the passages retrieved by DPR are more likely to be correct, compared to those from BM25. For large datasets like NQ and TriviaQA, models trained using multiple datasets (Multi) perform comparably to those trained using the individual training set (Single). Conversely, on smaller datasets like WQ and TREC, the multidataset setting has a clear advantage. Overall, our DPR-based models outperform the previous stateof-the-art results on four out of the five datasets, with $1%$ to $12%$ absolute differences in exact match accuracy. It is interesting to contrast our results to those of ORQA (Lee et al., 2019) and also the concurrently developed approach, REALM (Guu et al., 2020). While both methods include additional pre training tasks and employ an expensive end-to-end training regime, DPR manages to outperform them on both NQ and TriviaQA, simply by focusing on learning a strong passage retrieval model using pairs of questions and answers. The additional pre training tasks are likely more useful only when the target training sets are small. Although the results of DPR on WQ and TREC in the single-dataset setting are less competitive, adding more question–answer pairs helps boost the performance, achieving the new state of the art.
表 4: 总结了我们的最终端到端问答结果,采用(Chen et al., 2017; Lee et al., 2019)中的轻微归一化后与参考答案精确匹配的衡量方式。从表中可以看出,除了SQuAD外,检索器(Retriever)准确率越高通常会导致更好的最终问答结果:在所有情况下,与BM25相比,从DPR检索到的段落中提取的答案更可能是正确的。对于NQ和TriviaQA这样的大型数据集,使用多个数据集训练(Multi)的模型表现与使用单个训练集(Single)训练的模型相当。相反,在WQ和TREC等较小数据集上,多数据集设置具有明显优势。总体而言,我们基于DPR的模型在五个数据集中的四个上优于之前的最先进结果,精确匹配准确率的绝对差异在1%到12%之间。将我们的结果与ORQA (Lee et al., 2019)以及同时期开发的REALM (Guu et al., 2020)进行对比很有趣。虽然这两种方法都包含额外的预训练任务并采用了昂贵的端到端训练方案,但DPR仅通过专注于使用问答对学习强大的段落检索模型,就在NQ和TriviaQA上超越了它们。额外的预训练任务可能仅在目标训练集较小时更有用。尽管DPR在单数据集设置下在WQ和TREC上的结果竞争力较弱,但添加更多问答对有助于提升性能,实现了新的最先进水平。
Table 4: End-to-end QA (Exact Match) Accuracy. The first block of results are copied from their cited papers. REALMWiki and $\mathbf{REALM_{News}}$ are the same model but pretrained on Wikipedia and CC-News, respectively. Single and Multi denote that our Dense Passage Retriever (DPR) is trained using individual or combined training datasets (all except SQuAD). For WQ and TREC in the Multi setting, we fine-tune the reader trained on NQ.
| Training | Model | NQ | TriviaQA | WQ | TREC | SQuAD |
| Single | BM25+BERT (Lee et al.,2019) | 26.5 | 47.1 | 17.7 | 21.3 | 33.2 |
| Single | ORQA (Lee et al., 2019) | 33.3 | 45.0 | 36.4 | 30.1 | 20.2 |
| Single | HardEM (Min et al., 2019a) | 28.1 | 50.9 | |||
| Single | GraphRetriever (Min et al., 2019b) | 34.5 | 56.0 | 36.4 | ||
| Single | PathRetriever (Asai et al., 2020) | 32.6 | 56.5 | |||
| Single | REALMwiki (Guu et al., 2020) | 39.2 | 40.2 | 46.8 | ||
| Single | REALMNews (Guu et al., 2020) | 40.4 | 40.7 | 42.9 | - | |
| Single | BM25 | 32.6 | 52.4 | 29.9 | 24.9 | 38.1 |
| DPR | 41.5 | 56.8 | 34.6 | 25.9 | 29.8 | |
| BM25+DPR | 39.0 | 57.0 | 35.2 | 28.0 | 36.7 | |
| Multi | DPR | 41.5 | 56.8 | 42.4 | 49.4 | 24.1 |
| BM25+DPR | 38.8 | 57.9 | 41.1 | 50.6 | 35.8 |
表 4: 端到端问答 (精确匹配) 准确率。第一组结果引自原始论文。REALMWiki 和 $\mathbf{REALM_{News}}$ 是同一模型,分别基于 Wikipedia 和 CC-News 进行预训练。Single 和 Multi 表示我们的密集段落检索器 (DPR) 使用单独或组合训练数据集 (除 SQuAD 外) 进行训练。对于 WQ 和 TREC 在 Multi 设置下,我们基于 NQ 训练的阅读器进行微调。
| 训练方式 | 模型 | NQ | TriviaQA | WQ | TREC | SQuAD |
|---|---|---|---|---|---|---|
| Single | BM25+BERT (Lee et al.,2019) | 26.5 | 47.1 | 17.7 | 21.3 | 33.2 |
| Single | ORQA (Lee et al., 2019) | 33.3 | 45.0 | 36.4 | 30.1 | 20.2 |
| Single | HardEM (Min et al., 2019a) | 28.1 | 50.9 | |||
| Single | GraphRetriever (Min et al., 2019b) | 34.5 | 56.0 | 36.4 | ||
| Single | PathRetriever (Asai et al., 2020) | 32.6 | 56.5 | |||
| Single | REALMwiki (Guu et al., 2020) | 39.2 | 40.2 | 46.8 | ||
| Single | REALMNews (Guu et al., 2020) | 40.4 | 40.7 | 42.9 | - | |
| Single | BM25 | 32.6 | 52.4 | 29.9 | 24.9 | 38.1 |
| Single | DPR | 41.5 | 56.8 | 34.6 | 25.9 | 29.8 |
| Single | BM25+DPR | 39.0 | 57.0 | 35.2 | 28.0 | 36.7 |
| Multi | DPR | 41.5 | 56.8 | 42.4 | 49.4 | 24.1 |
| Multi | BM25+DPR | 38.8 | 57.9 | 41.1 | 50.6 | 35.8 |
To compare our pipeline training approach with joint learning, we run an ablation on Natural Questions where the retriever and reader are jointly trained, following Lee et al. (2019). This approach obtains a score of 39.8 EM, which suggests that our strategy of training a strong retriever and reader in isolation can leverage effectively available supervision, while outperforming a comparable joint training approach with a simpler design (Appendix D).
为了比较我们的流水线训练方法与联合学习的效果,我们在Natural Questions数据集上进行了消融实验,其中检索器和阅读器采用Lee等人 (2019) 提出的联合训练方式。该方法获得了39.8的EM分数,这表明我们单独训练强大检索器和阅读器的策略能有效利用现有监督信号,同时以更简洁的设计超越了可比的联合训练方法 (附录D)。
One thing worth noticing is that our reader does consider more passages compared to ORQA, although it is not completely clear how much more time it takes for inference. While DPR processes up to 100 passages for each question, the reader is able to fit all of them into one batch on a single 32GB GPU, thus the latency remains almost identical to the single passage case (around 20ms). The exact impact on throughput is harder to measure: ORQA uses $2{\cdot}3\mathbf{X}$ longer passages compared to DPR (288 word pieces compared to our 100 tokens) and the computational complexity is superlinear in passage length. We also note that we found $k=50$ to be optimal for NQ, and $k=10$ leads to only marginal loss in exact match accuracy (40.8 vs. 41.5 EM on NQ), which should be roughly comparable to ORQA’s 5-passage setup.
值得注意的是,我们的阅读器确实比ORQA考虑了更多文本段落,尽管目前尚不完全清楚推理时间会增加多少。虽然DPR每个问题最多处理100个段落,但该阅读器能够将所有段落一次性放入单个32GB GPU的批处理中,因此延迟与单段落情况几乎相同(约20毫秒)。对吞吐量的确切影响更难衡量:ORQA使用的段落长度是DPR的 $2{\cdot}3\mathbf{X}$ 倍(288个word piece对比我们的100个token),且计算复杂度随段落长度呈超线性增长。我们还发现,对于NQ数据集, $k=50$ 是最优值,而 $k=10$ 仅会导致精确匹配准确率略微下降(NQ上40.8 vs. 41.5 EM),这应该与ORQA的5段落设置大致相当。
7 Related Work
7 相关工作
Passage retrieval has been an important component for open-domain QA (Voorhees, 1999). It not only effectively reduces the search space for answer extraction, but also identifies the support context for users to verify the answer. Strong sparse vector space models like TF-IDF or BM25 have been used as the standard method applied broadly to various QA tasks (e.g., Chen et al., 2017; Yang et al., 2019a,b; Nie et al., 2019; Min et al., 2019a; Wolfson et al., 2020). Augmenting text-based retrieval with external structured information, such as knowledge graph and Wikipedia hyperlinks, has also been explored recently (Min et al., 2019b; Asai et al., 2020).
段落检索一直是开放域问答 (QA) 的重要组件 (Voorhees, 1999)。它不仅有效缩小了答案抽取的搜索空间,还能为用户提供验证答案的支持上下文。TF-IDF 或 BM25 等强大的稀疏向量空间模型已成为广泛应用于各类 QA 任务的标准方法 (如 Chen et al., 2017; Yang et al., 2019a,b; Nie et al., 2019; Min et al., 2019a; Wolfson et al., 2020)。近年来,研究者也开始探索通过知识图谱和维基百科超链接等外部结构化信息来增强基于文本的检索 (Min et al., 2019b; Asai et al., 2020)。
The use of dense vector representations for retrieval has a long history since Latent Semantic Analysis (Deerwester et al., 1990). Using labeled pairs of queries and documents, disc rim i natively trained dense encoders have become popular recently (Yih et al., 2011; Huang et al., 2013; Gillick et al., 2019), with applications to cross-lingual document retrieval, ad relevance prediction, Web search and entity retrieval. Such approaches complement the sparse vector methods as they can potentially give high similarity scores to semantically relevant text pairs, even without exact token matching. The dense representation alone, however, is typically inferior to the sparse one. While not the focus of this work, dense representations from pretrained models, along with cross-attention mechanisms, have also been shown effective in passage or dialogue re-ranking tasks (Nogueira and Cho, 2019; Humeau et al., 2020). Finally, a concurrent work (Khattab and Zaharia, 2020) demonstrates the feasibility of full dense retrieval in IR tasks. Instead of employing the dual-encoder framework, they introduced a late-interaction operator on top of the BERT encoders.
自潜在语义分析 (Latent Semantic Analysis) [Deerwester et al., 1990] 以来,密集向量表示在检索中的应用已有很长历史。近年来,基于标注查询-文档对的判别式训练密集编码器逐渐流行 (Yih et al., 2011; Huang et al., 2013; Gillick et al., 2019),其应用涵盖跨语言文档检索、广告相关性预测、网络搜索和实体检索等领域。这类方法对稀疏向量方法形成了有效补充,因为它们能在无需精确token匹配的情况下,为语义相关的文本对赋予较高相似度分数。但单独使用密集表示通常效果逊于稀疏表示。虽然这不是本文重点,但预训练模型生成的密集表示结合交叉注意力机制,在段落或对话重排序任务中也展现出有效性 (Nogueira and Cho, 2019; Humeau et al., 2020)。最新的一项并行研究 (Khattab and Zaharia, 2020) 证明了纯密集检索在信息检索任务中的可行性,该研究未采用双编码器框架,而是在BERT编码器基础上引入了延迟交互算子。
Dense retrieval for open-domain QA has been explored by Das et al. (2019), who propose to retrieve relevant passages iterative ly using reformulated question vectors. As an alternative approach that skips passage retrieval, Seo et al. (2019) propose to encode candidate answer phrases as vectors and directly retrieve the answers to the input questions efficiently. Using additional pre training with the objective that matches surrogates of questions and relevant passages, Lee et al. (2019) jointly train the question encoder and reader. Their approach outperforms the BM25 plus reader paradigm on multiple open-domain QA datasets in QA accuracy, and is further extended by REALM (Guu et al., 2020), which includes tuning the passage encoder asynchronously by re-indexing the passages during training. The pre training objective has also recently been improved by Xiong et al. (2020b). In contrast, our model provides a simple and yet effective solution that shows stronger empirical performance, without relying on additional pre training or complex joint training schemes.
Das等人 (2019) 探索了开放域问答的密集检索方法,提出通过迭代使用重构问题向量来检索相关段落。作为跳过段落检索的替代方案,Seo等人 (2019) 提出将候选答案短语编码为向量,直接高效检索输入问题的答案。Lee等人 (2019) 通过匹配问题代理与相关段落的预训练目标,联合训练问题编码器和阅读器。该方法在多个开放域问答数据集上的准确率超越了BM25加阅读器范式,并被REALM (Guu等人, 2020) 进一步扩展——后者通过在训练期间重新索引段落来异步调整段落编码器。Xiong等人 (2020b) 近期也改进了该预训练目标。相比之下,我们的模型提供了简单有效的解决方案,在不依赖额外预训练或复杂联合训练方案的情况下展现出更强的实证性能。
DPR has also been used as an important module in very recent work. For instance, extending the idea of leveraging hard negatives, Xiong et al. (2020a) use the retrieval model trained in the previous iteration to discover new negatives and construct a different set of examples in each training iteration. Starting from our trained DPR model, they show that the retrieval performance can be further improved. Recent work (Izacard and Grave, 2020; Lewis et al., 2020b) have also shown that DPR can be combined with generation models such as BART (Lewis et al., 2020a) and T5 (Raffel et al., 2019), achieving good performance on open-domain QA and other knowledge-intensive tasks.
DPR还被用作近期多项研究中的核心模块。例如,Xiong等人(2020a)扩展了利用困难负样本(hard negatives)的思路,通过前一轮训练好的检索模型发现新负样本,在每轮训练中构建不同的样本集。他们以我们训练好的DPR模型为基础,证明了检索性能可以进一步提升。最新研究(Izacard和Grave,2020;Lewis等人,2020b)也表明,DPR能与BART(Lewis等人,2020a)、T5(Raffel等人,2019)等生成模型结合,在开放域问答和其他知识密集型任务上取得优异表现。
8 Conclusion
8 结论
In this work, we demonstrated that dense retrieval can outperform and potentially replace the traditional sparse retrieval component in open-domain question answering. While a simple dual-encoder approach can be made to work surprisingly well, we showed that there are some critical ingredients to training a dense retriever successfully. Moreover, our empirical analysis and ablation studies indicate that more complex model frameworks or similarity functions do not necessarily provide additional values. As a result of improved retrieval performance, we obtained new state-of-the-art results on multiple open-domain question answering benchmarks.
在这项工作中,我们证明了密集检索可以超越并可能取代开放域问答中的传统稀疏检索组件。虽然简单的双编码器方法能取得出人意料的效果,但我们揭示了成功训练密集检索器的几个关键要素。此外,实证分析和消融研究表明,更复杂的模型框架或相似度函数未必能带来额外收益。得益于检索性能的提升,我们在多个开放域问答基准测试中取得了新的最先进成果。
Acknowledgments
致谢
We thank the anonymous reviewers for their helpful comments and suggestions.
感谢匿名评审人的宝贵意见和建议。
References
参考文献
Akari Asai, Kazuma Hashimoto, Hannaneh Hajishirzi, Richard Socher, and Caiming Xiong. 2020. Learning to retrieve reasoning paths over Wikipedia graph for question answering. In International Conference on Learning Representations (ICLR). Petr Baudis and Jan Sedivy. 2015. Modeling of the question answering task in the yodaqa system. In Inter national Conference of the Cross-Language Evaluation Forum for European Languages, pages 222– 228. Springer.
Akari Asai、Kazuma Hashimoto、Hannaneh Hajishirzi、Richard Socher 和 Caiming Xiong。2020。学习检索维基百科图中的推理路径以进行问答。国际学习表征会议 (ICLR)。Petr Baudis 和 Jan Sedivy。2015。YodaQA 系统中问答任务的建模。欧洲语言跨语言评估论坛国际会议,第 222–228 页。Springer。
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. Semantic parsing on Freebase from question-answer pairs. In Empirical Methods in Natural Language Processing (EMNLP).
Jonathan Berant、Andrew Chou、Roy Frostig 和 Percy Liang。2013. 基于问答对的 Freebase 语义解析。载于《自然语言处理实证方法》(EMNLP)。
Jane Bromley, Isabelle Guyon, Yann LeCun, Eduard Sackinger, and Roopak Shah. 1994. Signature verification using a “Siamese” time delay neural network. In NIPS, pages 737–744.
Jane Bromley、Isabelle Guyon、Yann LeCun、Eduard Sackinger 和 Roopak Shah。1994. 使用"连体"时间延迟神经网络进行签名验证。收录于 NIPS,第 737-744 页。
Chris Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Greg Hullender. 2005. Learning to rank using gradient descent. In Proceedings of the 22nd international conference on Machine learning, pages 89–96.
Chris Burges、Tal Shaked、Erin Renshaw、Ari Lazier、Matt Deeds、Nicole Hamilton和Greg Hullender。2005。使用梯度下降学习排序。见《第22届国际机器学习会议论文集》,第89-96页。
Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading Wikipedia to answer opendomain questions. In Association for Computational Linguistics (ACL), pages 1870–1879.
Danqi Chen、Adam Fisch、Jason Weston 和 Antoine Bordes。2017. 通过阅读维基百科回答开放域问题。载于《计算语言学协会》(ACL),第1870-1879页。
Rajarshi Das, Shehzaad Dhuliawala, Manzil Zaheer, and Andrew McCallum. 2019. Multi-step retrieverreader interaction for scalable open-domain question answering. In International Conference on Learning Representations (ICLR).
Rajarshi Das、Shehzaad Dhuliawala、Manzil Zaheer和Andrew McCallum。2019。面向可扩展开放域问答的多步检索器-阅读器交互机制。发表于国际学习表征会议(ICLR)。
Scott Deerwester, Susan T Dumais, George W Fur- nas, Thomas K Landauer, and Richard Harshman. 1990. Indexing by latent semantic analysis. Journal of the American society for information science, 41(6):391–407.
Scott Deerwester、Susan T Dumais、George W Furnas、Thomas K Landauer 和 Richard Harshman。1990。基于潜在语义分析的索引技术。Journal of the American society for information science,41(6):391–407。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In North American Association for Computational Linguistics (NAACL).
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019. BERT:面向语言理解的深度双向Transformer预训练。载于《北美计算语言学协会(NAACL)》。
David A Ferrucci. 2012. Introduction to “This is Watson”. IBM Journal of Research and Development, 56(3.4):1–1.
David A Ferrucci. 2012. 《This is Watson》简介. IBM Journal of Research and Development, 56(3.4):1–1.
Daniel Gillick, Sayali Kulkarni, Larry Lansing, Alessandro Presta, Jason Baldridge, Eugene Ie, and Diego Garcia-Olano. 2019. Learning dense representations for entity retrieval. In Computational Natural Language Learning (CoNLL).
Daniel Gillick、Sayali Kulkarni、Larry Lansing、Alessandro Presta、Jason Baldridge、Eugene Ie 和 Diego Garcia-Olano。2019. 学习用于实体检索的密集表示。载于《计算自然语言学习》(CoNLL)。
Ruiqi Guo, Sanjiv Kumar, Krzysztof Cho roman ski, and David Simcha. 2016. Quantization based fast inner product search. In Artificial Intelligence and Statistics, pages 482–490.
Ruiqi Guo、Sanjiv Kumar、Krzysztof Choromanski 和 David Simcha。2016. 基于量化的快速内积搜索。收录于《人工智能与统计》,第482–490页。
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020. REALM: Retrieval-augmented language model pre-training. ArXiv, abs/2002.08909.
Kelvin Guu、Kenton Lee、Zora Tung、Panupong Pasupat 和 Ming-Wei Chang。2020。REALM:检索增强的语言模型预训练。ArXiv,abs/2002.08909。
Matthew Henderson, Rami Al-Rfou, Brian Strope, Yunhsuan Sung, Laszl6 Lukacs, Ruiqi Guo, Sanjiv Ku- mar, Balint Miklos, and Ray Kurzweil. 2017. Effi- cient natural language response suggestion for smart reply. ArXiv, abs/1705.00652.
Matthew Henderson、Rami Al-Rfou、Brian Strope、Yunhsuan Sung、Laszl6 Lukacs、Ruiqi Guo、Sanjiv Kumar、Balint Miklos 和 Ray Kurzweil。2017. 智能回复的高效自然语言响应建议。ArXiv, abs/1705.00652。
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for Web search using click through data. In ACM International Conference on Information and Knowledge Management (CIKM), pages 2333–2338.
Po-Sen Huang、Xiaodong He、Jianfeng Gao、Li Deng、Alex Acero和Larry Heck。2013. 利用点击数据学习深度结构化语义模型以改进网页搜索。见:ACM国际信息与知识管理会议(CIKM),第2333–2338页。
Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, and Jason Weston. 2020. Poly-encoders: Architectures and pre-training strategies for fast and accurate multi-sentence scoring. In International Conference on Learning Representations (ICLR).
Samuel Humeau、Kurt Shuster、Marie-Anne Lachaux 和 Jason Weston。2020. Poly-encoders: 快速精准多语句评分的架构与预训练策略。In International Conference on Learning Representations (ICLR)。
Gautier Izacard and Edouard Grave. 2020. Leveraging passage retrieval with generative models for open domain question answering. ArXiv, abs/2007.01282.
Gautier Izacard 和 Edouard Grave. 2020. 利用生成式模型与段落检索实现开放域问答. ArXiv, abs/2007.01282.
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2017. Billion-scale similarity search with GPUs. ArXiv, abs/1702.08734.
Jeff Johnson、Matthijs Douze 和 Hervé Jégou。2017。基于 GPU 的十亿级相似性搜索。ArXiv,abs/1702.08734。
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Z ett le moyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Association for Computational Linguistics (ACL), pages 1601–1611.
Mandar Joshi、Eunsol Choi、Daniel Weld 和 Luke Zettlemoyer。2017. TriviaQA: 一个大规模远程监督的阅读理解挑战数据集。载于《计算语言学协会》(ACL),第1601–1611页。
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and effective passage search via contextualized late interaction over BERT. In ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), pages 39–48.
Omar Khattab和Matei Zaharia. 2020. ColBERT: 基于BERT上下文延迟交互的高效段落检索. 见: ACM信息检索研究与发展会议(SIGIR), 第39–48页.
Brian Kulis. 2013. Metric learning: A survey. Foundations and Trends in Machine Learning, 5(4):287– 364.
Brian Kulis. 2013. 度量学习综述. Foundations and Trends in Machine Learning, 5(4):287–364.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Matthew Kelcey, Jacob Devlin, Kenton Lee, Kristina N. Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association of Computational Linguistics (TACL).
Tom Kwiatkowski、Jennimaria Palomaki、Olivia Redfield、Michael Collins、Ankur Parikh、Chris Alberti、Danielle Epstein、Illia Polosukhin、Matthew Kelcey、Jacob Devlin、Kenton Lee、Kristina N. Toutanova、Llion Jones、Ming-Wei Chang、Andrew Dai、Jakob Uszkoreit、Quoc Le 和 Slav Petrov。2019。自然问题(Natural Questions):问答研究的基准。计算语言学协会会刊(TACL)。
Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. 2019. Latent retrieval for weakly supervised open domain question answering. In Association for Computational Linguistics (ACL), pages 6086–6096.
Kenton Lee、Ming-Wei Chang 和 Kristina Toutanova。2019。弱监督开放领域问答的潜在检索。载于《计算语言学协会》(ACL),第6086-6096页。
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghaz vi nine j ad, Abdel rahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Z ett le moyer. 2020a. BART: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. In Association for Computational Linguistics (ACL), pages 7871–7880.
Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Veselin Stoyanov 和 Luke Zettlemoyer。2020a。BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练。载于《计算语言学协会(ACL)》,第7871–7880页。
Patrick Lewis, Ethan Perez, Aleksandar a Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuittler, Mike Lewis, Wen-tau Yih, Tim Rock t as chel, Sebastian Riedel, and Douwe Kiela. 2020b. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS).
Patrick Lewis、Ethan Perez、Aleksandar a Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Kuittler、Mike Lewis、Wen-tau Yih、Tim Rockt as chel、Sebastian Riedel 和 Douwe Kiela。2020b. 面向知识密集型 NLP 任务的检索增强生成。载于《神经信息处理系统进展》(NeurIPS)。
Yankai Lin, Haozhe Ji, Zhiyuan Liu, and Maosong Sun. 2018. Denoising distantly supervised open-domain question answering. In Association for Computational Linguistics (ACL), pages 1736–1745.
Yankai Lin, Haozhe Ji, Zhiyuan Liu, and Maosong Sun. 2018. 去噪远程监督开放域问答。In Association for Computational Linguistics (ACL), pages 1736–1745.
Sewon Min, Danqi Chen, Hannaneh Hajishirzi, and Luke Z ett le moyer. 2019a. A discrete hard EM approach for weakly supervised question answering. In Empirical Methods in Natural Language Processing (EMNLP).
Sewon Min、Danqi Chen、Hannaneh Hajishirzi 和 Luke Zettlemoyer。2019a。一种用于弱监督问答的离散硬EM方法。载于《自然语言处理实证方法》(EMNLP)。
Sewon Min, Danqi Chen, Luke Z ett le moyer, and Hannaneh Hajishirzi. 2019b. Knowledge guided text retrieval and reading for open domain question answering. ArXiv, abs/1911.03868.
Sewon Min、Danqi Chen、Luke Zettlemoyer和Hannaneh Hajishirzi。2019b。面向开放域问答的知识引导文本检索与阅读。ArXiv, abs/1911.03868。
Dan Moldovan, Marius Pasca, Sanda Harabagiu, and Mihai Surdeanu. 2003. Performance issues and error analysis in an open-domain question answering system. ACM Transactions on Information Systems (TOIS), 21(2):133–154.
Dan Moldovan、Marius Pasca、Sanda Harabagiu 和 Mihai Surdeanu。2003. 开放域问答系统中的性能问题与错误分析。ACM Transactions on Information Systems (TOIS), 21(2):133–154.
Stephen Mussmann and Stefano Ermon. 2016. Learn- ing and inference via maximum inner product search. In International Conference on Machine Learning (ICML), pages 2587–2596.
Stephen Mussmann和Stefano Ermon。2016。通过最大内积搜索进行学习与推断。国际机器学习会议(ICML),第2587–2596页。
Yixin Nie, Songhe Wang, and Mohit Bansal. 2019. Revealing the importance of semantic retrieval for machine reading at scale. In Empirical Methods in Natural Language Processing (EMNLP).
Yixin Nie、Songhe Wang和Mohit Bansal。2019。揭示语义检索在大规模机器阅读中的重要性。载于《自然语言处理实证方法》(EMNLP)。
Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage re-ranking with BERT. ArXiv, abs/1901.04085.
Rodrigo Nogueira 和 Kyunghyun Cho. 2019. 基于 BERT 的段落重排序. ArXiv, abs/1901.04085.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. ArXiv, abs/1910.10683.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J Liu. 2019. 探索迁移学习的极限:统一的文本到文本 Transformer. ArXiv, abs/1910.10683.
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: $100{,}000+$ questions for machine comprehension of text. In Empirical Methods in Natural Language Processing (EMNLP), pages 2383–2392.
Pranav Rajpurkar、Jian Zhang、Konstantin Lopyrev 和 Percy Liang。2016。SQuAD:用于机器理解文本的 $100{,}000+$ 问题。载于《自然语言处理实证方法》(EMNLP),第2383–2392页。
Parikshit Ram and Alexander G Gray. 2012. Maximum inner-product search using cone trees. In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 931–939.
Parikshit Ram 和 Alexander G Gray. 2012. 基于锥树的最大内积搜索. 见: 第18届ACM SIGKDD知识发现与数据挖掘国际会议论文集, 931–939页.
Adam Roberts, Colin Raffel, and Noam Shazeer. 2020. How much knowledge can you pack into the parameters of a language model? ArXiv, abs/2002.08910.
Adam Roberts、Colin Raffel 和 Noam Shazeer。2020. 语言模型的参数能承载多少知识?ArXiv, abs/2002.08910。
Stephen Robertson and Hugo Zaragoza. 2009. The probabilistic relevance framework: BM25 and beyond. Foundations and Trends in Information Retrieval, 3(4):333–389.
Stephen Robertson 和 Hugo Zaragoza. 2009. 概率相关性框架:BM25 及后续发展. Foundations and Trends in Information Retrieval, 3(4):333–389.
Minjoon Seo, Jinhyuk Lee, Tom Kwiatkowski, Ankur Parikh, Ali Farhadi, and Hannaneh Hajishirzi. 2019. Real-time open-domain question answering with dense-sparse phrase index. In Association for Computational Linguistics (ACL).
Minjoon Seo、Jinhyuk Lee、Tom Kwiatkowski、Ankur Parikh、Ali Farhadi 和 Hannaneh Hajishirzi。2019. 基于稠密-稀疏短语索引的实时开放域问答。载于《计算语言学协会》(ACL)。
A Distant Supervision
远程监督
When training our final DPR model using Natural Questions, we use the passages in our collection that best match the gold context as the positive passages. As some QA datasets contain only the question and answer pairs, it is thus interesting to see when using the passages that contain the answers as positives (i.e., the distant supervision setting), whether there is a significant performance degradation. Using the question and answer together as the query, we run Lucene-BM25 and pick the top passage that contains the answer as the positive passage. Table 5 shows the performance of DPR when trained using the original setting and the distant supervision setting.
在使用Natural Questions训练我们的最终DPR模型时,我们选择数据集中与标准上下文最匹配的段落作为正样本段落。由于部分问答数据集仅包含问题和答案对,因此观察当使用包含答案的段落作为正样本(即远监督设置)时是否存在显著性能下降十分有意义。我们将问题和答案共同作为查询输入,运行Lucene-BM25并选取包含答案的最高排名段落作为正样本段落。表5展示了DPR在原始设置和远监督设置下的性能表现。
B Alternative Similarity Functions & Triplet Loss
B 替代相似度函数与三元组损失
In addition to dot product (DP) and negative loglikelihood based on softmax (NLL), we also experiment with Euclidean distance (L2) and the triplet loss. We negate L2 similarity scores before applying softmax and change signs of question-topositive and question-to-negative similarities when applying the triplet loss on dot product scores. The margin value of the triplet loss is set to 1. Table 6 summarizes the results. All these additional experiments are conducted using the same hyperparameters tuned for the baseline (DP, NLL).
除了点积 (DP) 和基于 softmax 的负对数似然 (NLL) ,我们还尝试了欧氏距离 (L2) 和三重损失。在应用 softmax 前对 L2 相似度分数取负,并在对点积分数应用三重损失时调整问题-正例和问题-负例相似度的符号。三重损失的边际值设为 1。表 6 总结了实验结果。所有附加实验均使用与基线 (DP, NLL) 相同的调优超参数进行。
Note that the retrieval accuracy for our “baseline” settings reported in Table 5 (Gold) and Table 6 (DP, NLL) is slightly better than those reported in Table 3. This is due to a better hyper-parameter setting used in these analysis experiments, which is documented in our code release.
请注意,表5 (Gold) 和表6 (DP, NLL) 中报告的"基线"设置检索准确率略高于表3中的结果。这是由于在这些分析实验中使用了更优的超参数设置,相关细节已记录在我们发布的代码中。
C Qualitative Analysis
C 定性分析
Although DPR performs better than BM25 in general, the retrieved passages of these two retrievers actually differ qualitatively. Methods like BM25 are sensitive to highly selective keywords and phrases, but cannot capture lexical variations or semantic relationships well. In contrast, DPR excels at semantic representation, but might lack sufficient capacity to represent salient phrases which appear rarely. Table 7 illustrates this phenomenon with two examples. In the first example, the top scoring passage from BM25 is irrelevant, even though keywords such as England and Ireland appear multiple times. In comparison, DPR is able to return
虽然DPR整体表现优于BM25,但两种检索器获取的段落存在本质差异。BM25等方法对高选择性关键词和短语敏感,但难以有效捕捉词汇变体或语义关联。相比之下,DPR擅长语义表征,但可能缺乏对罕见关键短语的表征能力。表7通过两个案例展示了这种现象:第一个案例中BM25最高分段落尽管多次出现"England"和"Ireland"等关键词,却与问题无关;而DPR能够返回...
| Top-1 | Top-5 | Top-20 | Top-100 | |
| Gold | 44.9 | 66.8 | 78.1 | 85.0 |
| Dist. Sup. | 43.9 | 65.3 | 77.1 | 84.4 |
| Top-1 | Top-5 | Top-20 | Top-100 | |
|---|---|---|---|---|
| Gold | 44.9 | 66.8 | 78.1 | 85.0 |
| Dist. Sup. | 43.9 | 65.3 | 77.1 | 84.4 |
Table 5: Retrieval accuracy on the development set of Natural Questions, trained on passages that match the gold context (Gold) or the top BM25 passage that contains the answer (Dist. Sup.).
表 5: 在Natural Questions开发集上的检索准确率,训练数据分别采用与黄金上下文匹配的段落(Gold)或包含答案的BM25最高分段落(Dist. Sup.)。
Table 6: Retrieval Top $k$ accuracy on the development set of Natural Questions using different similarity and loss functions.
| Sim | Loss | Retrieval Accuracy | ||
| Top-1 Top-5 | Top-20 Top-100 | |||
| DP | NLL | 44.9 66.8 | 78.1 | |
| Triplet | 41.6 65.0 | 77.2 84.5 | ||
| L2 | NLL | 43.5 64.7 | 76.1 | 83.1 |
| Triplet | 42.2 66.0 | 78.1 | 84.9 | |
表 6: 在Natural Questions开发集上使用不同相似度和损失函数的检索Top $k$准确率
| Sim | Loss | Retrieval Accuracy |
|---|---|---|
| Top-1 Top-5 | ||
| DP | NLL | 44.9 66.8 |
| Triplet | 41.6 65.0 | |
| L2 | NLL | 43.5 64.7 |
| Triplet | 42.2 66.0 |
the correct answer, presumably by matching “body of water” with semantic neighbors such as sea and channel, even though no lexical overlap exists. The second example is one where BM25 does better. The salient phrase “Thoros of Myr” is critical, and DPR is unable to capture it.
正确答案,可能是通过将"body of water"与语义相近的词如sea和channel进行匹配得出的,尽管两者之间并无词汇重叠。第二个例子则是BM25表现更优的情况。关键短语"Thoros of Myr"至关重要,而DPR未能捕捉到这一点。
D Joint Training of Retriever and Reader
D 检索器与阅读器的联合训练
We fix the passage encoder in our joint-training scheme while allowing only the question encoder to receive back propagation signal from the combined (retriever $^+$ reader) loss function. This allows us to leverage the HNSW-based FAISS index for efficient low-latency retrieving, without reindexing the passages during model updates. Our loss function largely follows ORQA’s approach, which uses log probabilities of positive passages selected from the retriever model, and correct spans and passages selected from the reader model. Since the passage encoder is fixed, we could use larger amount of retrieved passages when calculating the retriever loss. Specifically, we get top 100 passages for each question in a mini-batch and use the method similar to in-batch negative training: all retrieved passages’ vectors participate in the loss calculation for all questions in a batch. Our training batch size is set to 16, which effectively gives 1,600 passages per question to calculate retriever loss. The reader still uses 24 passages per question, which are selected from the top 5 positive and top 30 negative passages (from the set of top 100 passages retrieved from the same question). The question encoder’s initial state is taken from a DPR model previously trained on the NQ dataset. The reader’s initial state is a BERT-base model. In terms of the end-to-end QA results, our joint-training scheme does not provide better results compared to the usual retriever/reader training pipeline, resulting in the same 39.8 exact match score on NQ dev as in our regular reader model training.
在我们的联合训练方案中,固定段落编码器,仅允许问题编码器接收来自(检索器 $^+$ 阅读器)组合损失函数的反向传播信号。这种设计使我们能够利用基于HNSW的FAISS索引实现高效低延迟检索,且无需在模型更新时重新索引段落。我们的损失函数主要遵循ORQA的方法,即使用检索器模型选出的正样本段落对数概率,以及阅读器模型选出的正确答案片段和段落。由于段落编码器固定不变,我们可以在计算检索器损失时使用更多检索到的段落。具体而言,每个小批次问题会获取前100个段落,并采用类似批次内负样本训练的方法:批次中所有问题的检索段落向量都参与每个问题的损失计算。训练批次大小设为16,相当于每个问题使用1,600个段落计算检索器损失。阅读器仍保持每个问题24个段落的配置,这些段落选自同一问题检索结果中前5个正样本和前30个负样本(从检索到的前100个段落集合中筛选)。问题编码器的初始状态来自先前在NQ数据集上训练的DPR模型,阅读器初始状态为BERT-base模型。就端到端问答结果而言,我们的联合训练方案相比常规检索器/阅读器训练流程并未提升性能,在NQ开发集上获得与常规阅读器模型训练相同的39.8精确匹配分数。
| Question | PassagereceivedbyBM25 | Passage retrieved byDPR |
| Whatisthebodyofwater betweenEnglandandIreland? | Title:BritishCycling ...England is not recognised as a regionby theUCI, and thereisnoEnglishcycling team outsidetheCommonwealth Games.For those occasions,British Cycling selects and sup- ports the England team. Cycling is represented on the Isle ofManbytheIsleofManCyclingAssociation.Cyclingin Northern Ireland is organised under Cycling Ulster, part of the all-IrelandgoverningbodyCyclingIreland.Until 2006, a rival governingbody existed,... | Title:Irish Sea .AnnualtrafficbetweenGreatBritainandIrelandamounts to over 12 million passengers and of traded goods. The Irish SeaisconnectedtotheNorthAtlanticatbothitsnorthern and southern ends.To the north,the connection is through theNorthChannelbetweenScotlandandNorthernIreland and theMalinSea.Thesouthernendislinked totheAtlantic throughtheStGeorge'sChannelbetweenIrelandandPem- brokeshire,and theCelticSea.... |
| Who plays Thoros of Myr in GameofThrones? | Title:No One(Gameof Thrones) left inhim torespect,and admirewho thisgirlis andwhat she's become.Arya finally tells us something that we've kind of known all along,that she's not no one,she's Arya Stark ofWinterfell.""NoOne”saw thereintroductionofRichard DormerandPaulKaye,whoportrayedBericDondarrion and Thoros of Myr,respectively,in the third season,... | Title:Pal Sverre Hagen Pal SverreValheimHagen(born 6 November 1980)is a Nor- wegianstageandscreen actor.Heappearedin theNorwe- gian film"Max Manus”and played Thor Heyerdahl in the Oscar-nominated 2012 film"Kon-Tiki".Pl Hagen was born inStavanger,Norway,the son ofRoarHagen,a Norwegian cartoonistwhohaslongbeen associatedwithNorwayslargest daily, "VG". He lived in Jtten, a neighborhood in the city of Stavangerin south-westernNorway.... |
Table 7: Examples of passages returned from BM25 and DPR. Correct answers are written in blue and the content words in the question are written in bold.
| 问题 | BM25检索到的段落 | DPR检索到的段落 |
|---|---|---|
| 英格兰和爱尔兰之间的水域是什么? | 标题:英国自行车运动...英格兰并未被国际自行车联盟(UCI) 认定为地区,英联邦运动会之外也没有英格兰自行车队。在这些场合,英国自行车协会会选拔并支持英格兰队。马恩岛的自行车运动由马恩岛自行车协会代表。北爱尔兰的自行车运动由阿尔斯特自行车协会组织,该协会隶属于全爱尔兰管理机构爱尔兰自行车协会。直到2006年,还存在一个竞争对手的管理机构... | 标题:爱尔兰海。英国和爱尔兰之间的年客运量超过1200万人次,还有货物贸易。爱尔兰海在其北部和南部两端都与北大西洋相连。北部通过苏格兰和北爱尔兰之间的北海峡以及马林海连接。南端通过爱尔兰和彭布罗克郡之间的圣乔治海峡以及凯尔特海与大西洋相连... |
| 谁在《权力的游戏》中饰演密尔的索罗斯? | 标题:无名之辈(《权力的游戏》) 在他心中已没有东西值得尊敬和钦佩,除了这个女孩的身份和她成为的样子。艾莉亚最终告诉我们一个我们一直以来都隐约知道的事实:她不是无名之辈,她是临冬城的艾莉亚·史塔克。""无名之辈"一集见证了理查德·多默和保罗·凯的回归,他们分别在第三季中饰演贝里·唐德利恩和密尔的索罗斯... | 标题:帕尔·斯维尔·哈根。帕尔·斯维尔·瓦尔海姆·哈根(生于1980年11月6日) 是一位挪威舞台和影视演员。他出演过挪威电影《马克斯·马努斯》,并在2012年奥斯卡提名电影《孤筏重洋》中饰演托尔·海尔达尔。帕尔·哈根出生于挪威斯塔万格,父亲是挪威漫画家罗阿尔·哈根,后者长期与挪威最大日报《VG》合作。他曾在挪威西南部斯塔万格市的约滕社区生活... |
表 7: BM25和DPR返回的段落示例。正确答案用蓝色标出,问题中的内容词用粗体显示。