Transformer Memory as a Differentiable Search Index
Transformer 记忆作为可微分搜索索引
Yi Tay∗, Vinh Q. Tran∗, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster William W. Cohen, Donald Metzler Google Research {yitay,vqtran,metzler}@google.com
Yi Tay∗, Vinh Q. Tran∗, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W. Cohen, Donald Metzler
谷歌研究院
{yitay,vqtran,metzler}@google.com
Abstract
摘要
In this paper, we demonstrate that information retrieval can be accomplished with a single Transformer, in which all information about the corpus is encoded in the parameters of the model. To this end, we introduce the Differentiable Search Index (DSI), a new paradigm that learns a text-to-text model that maps string queries directly to relevant docids; in other words, a DSI model answers queries directly using only its parameters, dramatically simplifying the whole retrieval process. We study variations in how documents and their identifiers are represented, variations in training procedures, and the interplay between models and corpus sizes. Experiments demonstrate that given appropriate design choices, DSI significantly outperforms strong baselines such as dual encoder models. Moreover, DSI demonstrates strong generalization capabilities, outperforming a BM25 baseline in a zero-shot setup.
本文提出了一种仅用单个Transformer即可实现信息检索的方法,其中语料库的所有信息都被编码在模型参数中。为此,我们引入了可微分搜索索引(DSI)这一新范式,它通过学习一个将字符串查询直接映射到相关文档ID的文本到文本模型;换言之,DSI模型仅凭自身参数就能直接响应查询,极大简化了整个检索流程。我们研究了文档及其标识符的表示方式差异、训练流程的变体,以及模型与语料库规模之间的相互作用。实验表明,在适当的设计选择下,DSI显著优于双编码器模型等强基线。此外,DSI展现出强大的泛化能力,在零样本设置中超越了BM25基线。
1 Introduction
1 引言
Information retrieval (IR) systems map a user query $q\in\mathcal{Q}$ to a ranked list of relevant documents ${d_{1},\ldots,d_{n}}\subseteq{\mathcal{D}}$ , typically represented by integers or short strings called document identifiers (docids). The most widely used IR approaches are based on pipelined retrieve-then-rank strategies. For retrieval, approaches based on inverted indexes or nearest neighbor search are common where contrastive learning based dual encoders (DEs) (Gillick et al., 2018; Karpukhin et al., 2020; Ni et al., 2021) are the present state-of-the-art.
信息检索(IR)系统将用户查询$q\in\mathcal{Q}$映射到相关文档${d_{1},\ldots,d_{n}}\subseteq{\mathcal{D}}$的排序列表,这些文档通常由称为文档标识符(docids)的整数或短字符串表示。最广泛使用的IR方法基于检索-排序的流水线策略。在检索阶段,基于倒排索引或最近邻搜索的方法较为常见,其中基于对比学习的双编码器(DEs) (Gillick et al., 2018; Karpukhin et al., 2020; Ni et al., 2021) 代表了当前最先进的技术。
This paper proposes an alternative architecture, wherein a sequence-to-sequence (seq2seq) learning system (Sutskever et al., 2014) is used to directly map a query $q$ to a relevant docid $j\in\mathcal{V}$ . This proposal is shown in the bottom half of Figure 1, for a sequence-to-sequence encoder-decoder architecture.
本文提出了一种替代架构,其中使用序列到序列(seq2seq)学习系统(Sutskever等人,2014)直接将查询$q$映射到相关文档ID$j\in\mathcal{V}$。该方案如图1下半部分所示,展示了一个序列到序列的编码器-解码器架构。
We call this proposed architecture a differentiable search index (DSI), and implement it with a large pre-trained Transformer (Vaswani et al., 2017) model, building on the recent success of large generative language models (LMs) (Brown et al., 2020; Raffel et al., 2019; Devlin et al., 2018; Thoppilan et al., 2022; Du et al., 2021). In this proposed architecture, all information of the corpus is encoded within the parameters of the Transformer language model.
我们将这一提出的架构称为可微分搜索索引 (DSI),并基于预训练的大规模 Transformer (Vaswani等人,2017) 模型实现,该模型借鉴了近期大语言模型 (Brown等人,2020;Raffel等人,2019;Devlin等人,2018;Thoppilan等人,2022;Du等人,2021) 的成功经验。在这一架构中,语料库的所有信息都被编码在 Transformer 语言模型的参数内。
At inference time, the trained model takes as input a text query $q$ and outputs a docid $j$ . If desired, beam search can be used to produce a ranked list of potentially-relevant docids. As we show, this process can work surprisingly well when trained properly. In our experiments it can consistently outperform DE baselines, sometimes drastically: for a base-sized T5 model, Hits $@1$ on the smallest corpus is improved by more than 20 points, from $12.4%$ for a DE to $33.9%$ for DSI; and on a corpus
在推理阶段,训练好的模型以文本查询 $q$ 作为输入,输出一个文档ID $j$。如果需要,可以使用束搜索(beam search)生成潜在相关文档ID的排序列表。如我们所示,经过适当训练后,这一过程能取得惊人的效果。在我们的实验中,该方法始终优于DE基线,有时优势显著:对于基础规模的T5模型,最小语料库上的Hits $@1$ 提高了20多个百分点,从DE的 $12.4%$ 提升至DSI的 $33.9%$;而在一个语料库上...
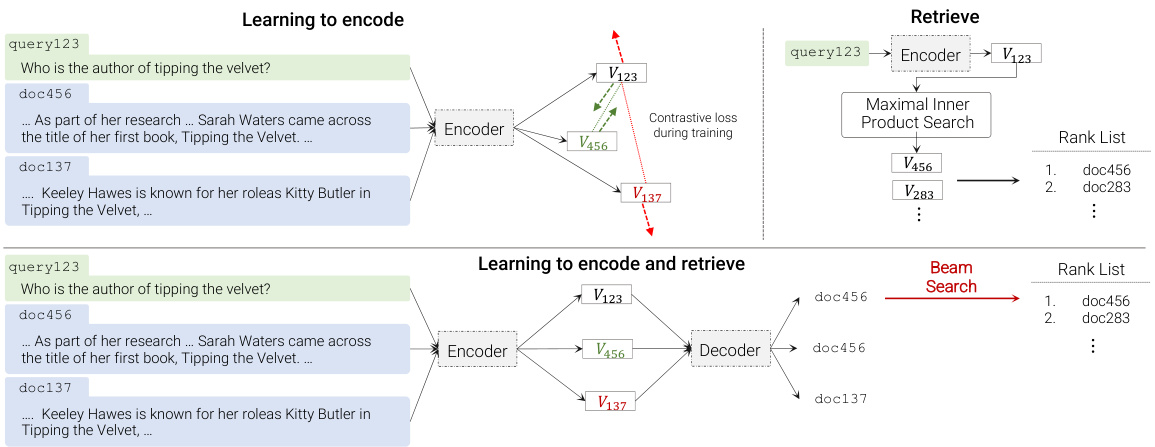
Figure 1: Comparison of dual encoders (top) to differentiable search index (bottom).
图 1: 双编码器 (top) 与可微分搜索索引 (bottom) 的对比。
Table 1: Information retrieval requires a series of decisions, associated with the sub problems of document representation, indexing, and retrieval. Structured-document variants of DSI are also sensitive to a fourth decision, namely how docids are represented.
| BM25orTFIDF | Dual Encoder (DE) | DifferentiableSearchIndex(DSI | |
| doc/queryrep. | sparse Vd, vector in R/V| | Various (see Section 3.1.2) | |
| docid rep. | Various(seeSection3.2) | ||
| indexing | buildinvertedindexmapping eachtermt→ djk | build tablemapping each docvec Vd, → j | train model (see Section 3.1.1) to map dj →J |
| retrieval (top-1) | approximatesparsematmul to find argmax T PA | approximateMIPS tofind argmax | runtrainedmodel to find argmax , Pr(lq) |
表 1: 信息检索需要一系列决策,涉及文档表示、索引和检索等子问题。DSI的结构化文档变体还对第四个决策敏感,即文档标识(docid)的表示方式。
| BM25或TFIDF | 双编码器(DE) | 可微分搜索索引(DSI) | |
|---|---|---|---|
| 文档/查询表示 | 稀疏向量Vd,R/V空间向量 | 多种(见第3.1.2节) | |
| 文档标识表示 | 多种(见第3.2节) | ||
| 索引构建 | 构建倒排索引,将每个词项t→djk映射 | 构建表格,将每个文档向量Vd→j映射 | 训练模型(见第3.1.1节)实现dj→J映射 |
| 检索(top-1) | 近似稀疏矩阵乘法求解argmax T PA | 近似最大内积搜索(MIPS)求解argmax | 运行训练模型求解argmax Pr(lq) |
$30\times$ larger, performance is improved by nearly 7 points. These gains increase when larger models are used: for an 11B-parameter T5 model, Hits $@1$ performance improves by more than 25 points over DE on the small corpus, and more than 15 points on the large corpus. DSI also performs extremely well in a zero-shot setting, e.g., improving Hits $@1$ by 14 points over BM25.
参数量增加30倍时,性能提升近7个点。使用更大模型时收益进一步扩大:对于110亿参数的T5模型,在小规模语料库上Hits@1指标比DE提升超过25点,在大规模语料库上提升超15点。DSI在零样本(Zero-shot)设置下也表现极佳,例如Hits@1指标比BM25提升14点。
In addition to these quantitative gains, the DSI architecture is much simpler than a DE (see Table 1). A DE system fixes a search procedure (MIPS) and learns internal representations that optimize performance for that search procedure; in contrast, a DSI system contains no special-purpose fixed search procedure, instead using standard model inference to map from encodings to docids.
除了这些量化提升外,DSI架构比DE简单得多(见表1)。DE系统固定搜索过程(MIPS)并学习优化该搜索过程性能的内部表征;而DSI系统不包含专用固定搜索过程,而是使用标准模型推理从编码映射到文档ID。
Of particular interest to the machine learning community, as Table 1 shows, in DSI all aspects of retrieval are mapped into well-understood ML tasks. This may lead to new potential approaches to solving long-standing IR problems. As one example, since indexing is now a special case of model training, increment ally updating an index becomes a special case of model updating (Sun et al., 2020).
如表 1 所示,机器学习社区对 DSI 特别感兴趣的一点在于,它将检索的各个方面都映射到了易于理解的机器学习任务中。这为解决长期存在的 IR (Information Retrieval) 问题提供了新的潜在途径。例如,由于索引现在只是模型训练的一种特例,增量更新索引也就变成了模型更新的特例 (Sun et al., 2020)。
In this paper, DSI is applied to moderate-sized corpora (from 10k to 320k documents), all of which are derived from one challenging retrieval task, and we leave the important question of the scaling DSI to larger corpora to future work. The task considered is retrieving supporting passages given questions from the Natural Questions (NQ) dataset, a challenging task for lexical models.
本文中,DSI被应用于中等规模语料库(从10k到320k文档),这些语料均来自一项具有挑战性的检索任务。我们将DSI扩展至更大规模语料库的重要问题留待未来研究。所考察的任务是基于自然问题(NQ)数据集中的问题检索支持段落,这对词法模型而言是一项颇具挑战性的任务。
While the idea of DSI is simple, there are a number of ways it can be realized, some of which work surprisingly well, and some of which work surprisingly poorly. Below we explore a number of variations of the DSI architecture.
虽然DSI的理念简单,但其实现方式多种多样,有些效果出奇地好,有些却意外地差。下面我们将探讨DSI架构的多种变体。
Document representation. We explore several approaches to representing documents, including a “naive” approach of using the document’s full text, as well as variants of the bag-of-words representation used by traditional IR engines.
文档表示。我们探索了几种文档表示方法,包括直接使用文档全文的"朴素"方法,以及传统信息检索(IR)引擎采用的词袋(bag-of-words)表示法的多种变体。
Docid representation. We look at several ways to represent docids. In addition to naively representing integers as text strings, we also consider unstructured atomic docids, where each document is assigned a unique token, and some simple baselines for constructing structured semantic docids that describe how to navigate to a document through a hierarchical clustering of the corpus. Structured docids— either semantically structured via clustering, or naively structured as tokenized integers—scale better to large corpora, since the size of the vocabulary used in the decoder is made larger.
文档ID表示。我们探讨了几种表示文档ID的方法。除了简单地将整数表示为文本字符串外,我们还考虑了非结构化原子文档ID(为每个文档分配唯一token),以及一些构建结构化语义文档ID的简单基线方法(通过语料库的层次聚类描述如何导航到文档)。结构化文档ID(无论是通过聚类实现语义结构化,还是简单地将token化整数作为结构化形式)能更好地扩展到大型语料库,因为解码器中使用的词汇表规模会变得更大。
Indexing. A trainable IR system traditionally has two phases: indexing a corpus (i.e., memorizing information about each document), and learning how to effectively retrieve from the index. In DSI, the index is stored in the model parameters, and indexing is simply another kind of model training. Figure 1 suggests one approach to indexing a corpus: namely, to train on (1) examples $(d_{j},~j)$ that pair document $d_{j}$ with its docid $j$ , in addition to (2) examples $(q,j)$ that pair a query $q$ with a relevant docid $j$ . In this setup the examples of type (1) are “indexing” examples.
索引。传统的可训练信息检索 (IR) 系统包含两个阶段:对语料库建立索引(即记忆每个文档的信息)以及学习如何从索引中有效检索。在 DSI 中,索引存储在模型参数中,而索引建立只是另一种模型训练形式。图 1: 展示了一种语料库索引方法:即通过训练 (1) 将文档 $d_{j}$ 与其文档 ID $j$ 配对的样本 $(d_{j},~j)$ ,以及 (2) 将查询 $q$ 与相关文档 ID $j$ 配对的样本 $(q,j)$ 。在此设置中,类型 (1) 的样本即为"索引"样本。
While it is clear that examples of type (2) alone do not provide enough information for a system to generalize to novel retrievals, there are many alternatives to examples of type (1) that might plausibly “teach” a model about the associations between documents and docids. We explore a number of these below, and show that some plausible-seeming techniques perform very poorly. We also explore a number of alternative multi-task optimization and curriculum learning schemes for combining these types of examples.
虽然仅靠类型(2)的示例显然无法为系统提供足够信息以泛化到新检索, 但存在许多替代类型(1)示例的方法, 这些方法可能合理地"教会"模型文档与文档ID (docids)之间的关联。下文我们将探讨其中多种方法, 并展示某些看似合理的技术表现极差。同时, 我们还研究了多种替代性的多任务优化和课程学习方案, 用于组合这些类型的示例。
Effects of model and corpus size. Since recent results suggest that some properties of large LMs emerge only for very large model sizes Brown et al. (2020), we explore the performance of DSI for a range of model sizes and corpus sizes of 10k, 100k, and $320\mathrm{k\Omega}$ documents.
模型与语料库规模的影响。由于近期研究表明,大语言模型的某些特性仅在模型规模极大时才会显现 [20],我们探究了 DSI 在不同模型规模及 10k、100k 和 $320\mathrm{k\Omega}$ 文档量级语料库下的表现。
Summary. We show that even naive representations for documents and docids, coupled with appropriate training procedures to fine-tune modern large LMs, can perform surprisingly well; we present two improved docid representations, unstructured docids and semantically-structured docids, which improve the naive representation choice. We show that there is substantial variation in performance among indexing/training strategies and we show that performance of DSI significantly and consistently improves with model scale. To our knowledge this is the first case of generative indexing improving performance over strong baselines for a well-studied document retrieval task.
摘要。我们证明,即便是简单的文档和文档ID (docid) 表示方法,结合适当的大语言模型微调训练流程,也能取得惊人的效果;我们提出了两种改进的文档ID表示形式——非结构化文档ID和语义结构化文档ID,它们优化了基础表示方案。研究表明,不同索引/训练策略的性能存在显著差异,同时DSI (Document Set Indexing) 的性能会随着模型规模的扩大而持续显著提升。据我们所知,这是生成式索引首次在已被深入研究的文档检索任务中实现优于强基线的性能突破。
2 Related Work
2 相关工作
De Cao et al. (2020) describe a related sequence-to-sequence system called auto regressive entity linking, in which documents mentioning an entity—perhaps implicitly, e.g., by posing a question to which that entity is an answer—are mapped to a canonical name of that entity. In the case of Wikipedia, canonical entity names correspond to page titles, so this could be viewed as a sort of document retrieval. This approach has been adapted to other purposes, such as generating knowledge base triples in canonical form (Josifoski et al., 2021). The task we consider is different from those considered in auto regressive entity linking: our goal is to retrieve a document containing the answer, rather than a document whose title is the answer. More importantly, in auto regressive entity linking the generation target is a semantically meaningful name, whereas we allow targets to be arbitrary docids. This makes our approach applicable to general retrieval tasks, but raises new questions about docid representation and indexing strategies.
De Cao等人(2020) 描述了一种名为自回归实体链接的序列到序列系统,该系统将提及某个实体的文档(可能是隐式提及,例如通过提出以该实体为答案的问题)映射到该实体的规范名称。在维基百科的案例中,规范实体名称对应页面标题,因此这可被视为某种文档检索方法。该方法已被适配用于其他目的,例如生成规范形式的知识库三元组 (Josifoski等人, 2021)。我们考虑的任务与自回归实体链接中的任务不同:我们的目标是检索包含答案的文档,而非标题即为答案的文档。更重要的是,在自回归实体链接中生成目标是具有语义意义的名称,而我们允许目标为任意文档ID。这使得我们的方法适用于通用检索任务,但也引发了关于文档ID表示和索引策略的新问题。
In auto regressive entity linking, generation is constrained to return an output from a fixed set. It would be feasible to constrain DSI generation outputs to be valid docids. Although we do not use this technique, the degree to which this might improve performance is a worthwhile question.
在自回归实体链接中,生成过程被约束为从固定集合返回输出。将DSI生成输出限制为有效docid是可行的。虽然我们未采用此技术,但这种约束能在多大程度上提升性能仍是一个值得探讨的问题。
There is a large body of work on retrieval augmented generation, i.e., retrieving auxiliary documents to enhance language models (Borgeaud et al., 2021; Guu et al., 2020). These techniques are useful for many tasks including question-answering, but rely on traditional retrieval methods such as DEs. Here we use generation to replace a retrieval process, rather than using retrieval to augment a generation process.
关于检索增强生成(即检索辅助文档以增强语言模型)已有大量研究 [Borgeaud et al., 2021; Guu et al., 2020]。这些技术对问答等任务非常有用,但依赖于DEs等传统检索方法。本文通过生成替代检索过程,而非利用检索增强生成过程。
Dual encoders (Dehghani et al., 2017; Gillick et al., 2018; Gao et al., 2021; Ni et al., 2021; Karpukhin et al., 2020) are a well-established paradigm for retrieval. The key idea is produce query and document embeddings independently and perform a similarity retrieval in vector space across all embedding pairs. Query and candidate documents are produced by a sequence encoder and training is performed using a form of contrastive loss.
双编码器 (Dehghani et al., 2017; Gillick et al., 2018; Gao et al., 2021; Ni et al., 2021; Karpukhin et al., 2020) 是检索任务中成熟的范式。其核心思想是分别生成查询和文档的嵌入表示,并在向量空间中对所有嵌入对进行相似性检索。查询和候选文档通过序列编码器生成,训练过程采用对比损失 (contrastive loss) 的形式实现。
The interpretation of a large Transformer model as a memory store have been investigated in prior work. (Roberts et al., 2020) demonstrated success on a closed-book QA task whereby they train
将大型Transformer模型视为记忆存储的解读在先前研究中已有探讨。(Roberts et al., 2020) 通过训练模型在闭卷问答任务中取得了成功
T5 models to retrieve facts that are encoded within the parameters of the model during pretraining. However, different from CBQA, the presented problem here in this paper is to retrieve full documents based on docids instead of generating direct answers. Meanwhile, (Petroni et al., 2019) also investigated language models as knowledge bases and found that pretrained LMs may already contain relational knowledge. (Geva et al., 2020) analyzes the knowledge encoded within Transformer feed forward layers. There have been also works that demonstrate the relation of Transformers to associative memory and Hopfield networks (Ramsauer et al., 2020), which reinforce the notion that Transformers should intuitively serve as a good associative memory store or search index.
T5模型用于检索在预训练期间编码在模型参数内的事实。然而,与基于上下文的问答(CBQA)不同,本文提出的问题是通过文档ID检索完整文档而非直接生成答案。同时,(Petroni等人,2019)也研究了作为知识库的语言模型,发现预训练的大语言模型可能已包含关系性知识。(Geva等人,2020)分析了Transformer前馈层中编码的知识。另有研究表明Transformer与联想记忆及Hopfield网络存在关联(Ramsauer等人,2020),这强化了Transformer理应成为优质联想记忆存储或搜索索引的直觉认知。
3 Differentiable Search Index
3 可微分搜索索引
The core idea behind the proposed Differentiable Search Index (DSI) is to fully parameter ize traditionally multi-stage retrieve-then-rank pipelines within a single neural model. To do so, DSI models must support two basic modes of operation:
所提出的可微分搜索索引(DSI)的核心思想是将传统的多阶段"检索-排序"流程完全参数化到单个神经网络模型中。为此,DSI模型需要支持两种基本操作模式:
• Indexing: a DSI model should learn to associate the content of each document $d_{j}$ with its corresponding docid $j$ . This paper utilizes a straightforward sequence-to-sequence (seq2seq) approach that takes document tokens as input and generates identifiers as output. • Retrieval: Given an input query, a DSI model should return a ranked list of candidate docids. Here, this is achieved with auto regressive generation.
• 索引:DSI模型应学会将每个文档$d_{j}$的内容与其对应的文档ID $j$关联起来。本文采用一种简单的序列到序列 (seq2seq) 方法,该方法以文档token作为输入并生成标识符作为输出。
• 检索:给定输入查询时,DSI模型应返回候选文档ID的排序列表。此处通过自回归生成实现该功能。
Following these two operations, a DSI model can be trained to index a corpus of documents and optionally fine-tune on an available set of labeled data (queries and labeled documents), and thereafter used to retrieve relevant documents—all within a single, unified model. As opposed to retrieve-thenrank approaches, this type of model allows for simple end-to-end training and can easily be used as a differentiable sub-component of a larger, more complex neural model.
经过这两个操作后,可以训练一个DSI模型来索引文档集,并可选地对一组可用的标注数据(查询和标注文档)进行微调,之后用于检索相关文档——所有这些都在一个统一的模型中完成。与先检索再排序的方法不同,这类模型支持简单的端到端训练,并能轻松作为更大、更复杂神经模型的可微分子组件使用。
3.1 Indexing Strategies
3.1 索引策略
We investigate various indexing strategies that are meant to learn associations between documents and their identifiers. We train our model to predict docids given a sequence of document tokens. This allows our model to learn which identifier belongs to which document and can be thought of as a differentiable take on traditional search indexes. We consider various alternatives and ablate these settings in subsequent sections. The final strategy employed was Inputs 2 Targets with direct indexing.
我们研究了旨在学习文档与其标识符之间关联的各种索引策略。我们训练模型根据文档token序列预测文档ID(docids),使模型能够学习哪个标识符属于哪个文档,这可以被视为对传统搜索索引的可微分处理。我们在后续章节中对多种替代方案进行了对比实验和消融研究。最终采用的策略是带直接索引的Inputs 2 Targets方法。
3.1.1 Indexing Method
3.1.1 索引方法
This section discusses the indexing task variants that we consider.
本节讨论我们考虑的索引任务变体。
Inputs 2 Target We frame this as a seq2seq task of doc_tokens $\rightarrow$ docid. As its name suggests, this binds the docids to the document tokens in a straightforward inputs-to-targets fashion. The advantage here is that the identifier is the denoising target, which puts it in closer proximity to the loss function. Since the retrieval task is also concerned with predicting identifiers, this formulation allows the network to follow a similar input-target balance in terms of sequence length. A potential weakness is that the document tokens are not denoising targets and therefore there is no opportunity for general pre-training on document tokens.
输入 2 目标
我们将此任务构建为文档token (doc_tokens) $\rightarrow$ 文档ID (docid) 的序列到序列任务。顾名思义,这种方式以直接的输入-目标形式将文档ID与文档token关联起来。其优势在于标识符作为去噪目标,使其更接近损失函数。由于检索任务同样关注预测标识符,这种构建方式使网络在序列长度方面遵循类似的输入-目标平衡。潜在弱点是文档token并非去噪目标,因此无法对文档token进行通用的预训练。
Targets 2 Inputs This formulation considers the opposite of the above, i.e., generating document tokens from identifiers, i.e., docid $\rightarrow$ doc_tokens. Intuitively, this is equivalent to training an auto regressive language model that is conditioned on the docid.
目标2 输入
该公式考虑与上述相反的情况,即从标识符生成文档token,即docid $\rightarrow$ doc_tokens。直观上,这相当于训练一个以docid为条件的自回归语言模型。
Bidirectional This formulation trains both Inputs 2 Targets and Targets 2 Inputs within the same co-training setup. A prefix token is prepended to allow the model to know which direction the task is being performed in.
双向
该方案在同一协同训练设置中同时训练输入到目标 (Inputs 2 Targets) 和目标到输入 (Targets 2 Inputs) 两个方向。通过添加前缀 token 使模型能够识别当前任务执行的方向。
Span Corruption We also explored a setup that performs span corruption-based denoising (Raffel et al., 2019) with the inclusion of docid tokens. In this approach, we concatenate the identifier to the document tokens as a prefix that can be randomly masked as spans in the span corruption objective.
跨段掩码修复
我们还探索了一种结合文档标识符(docid)进行跨段掩码修复去噪的方案(Raffel et al., 2019)。该方法将文档标识符作为前缀与文档token拼接,使其在跨段掩码目标中可被随机掩码为连续片段。
This method has the advantage of (1) also performing general pre-training during indexing and (2) achieving a good balance of docids as denoising targets and inputs.
该方法具有以下优势:(1) 在索引过程中同时进行通用预训练;(2) 作为去噪目标的文档标识符(docids)与输入之间能达到良好平衡。
3.1.2 Document Representation Strategies
3.1.2 文档表示策略
In the previous section, we explored “how to index”. This section investigates “what to index?”, i.e., how to best represent doc_tokens. We state our options here and carefully ablate them in our experiments later. The best option in the end was the direct indexing method.
上一节我们探讨了"如何建立索引",本节将研究"索引什么内容",即如何最优地表示文档标记(doc_tokens)。我们在此列出备选方案,并将在后续实验中对其进行严谨的消融研究。最终结果表明直接索引(direct indexing)方法效果最佳。
Direct Indexing This strategy represents a document exactly. We take the first $L$ tokens of a document, with sequential order preserved, and associate them with the docid.
直接索引
该策略精确表示文档。我们取文档的前 $L$ 个 token,保持顺序不变,并将其与文档 ID (docid) 关联。
Set Indexing Documents may contain repeated terms and/or non-informative words (e.g., stopwords). This strategy de-duplicates repeated terms using the default Python set operation and removes stopwords from the document. The rest of the document after filtering is passed into the model in similar fashion to the direct index.
设置索引
文档可能包含重复术语和/或无意义词汇(如停用词)。该策略使用Python语言的默认集合(set)操作去重,并移除文档中的停用词。过滤后的剩余文档内容会以与直接索引类似的方式传入模型。
Inverted Index This strategy maps chunked documents (contiguous blocks of tokens) instead of entire documents directly to the docid. We randomly subsample a single contiguous chunk of $k$ tokens and associate them with the docid. The key advantage of this approach is to allow looking beyond the first $k$ tokens.
倒排索引 (Inverted Index)
该策略将分块文档 (连续的token块) 而非完整文档直接映射到文档ID (docid)。我们随机抽取一个包含 $k$ 个token的连续块,并将其与文档ID关联。这种方法的关键优势在于能够检索超出前 $k$ 个token的内容。
3.2 Representing Docids for Retrieval
3.2 检索文档标识符表示
Retrieval within seq2seq-based DSI models is accomplished by decoding docids given an input query. How to do this decoding in an effective way largely depends on how docids are represented in the model. The remainder of this section explores a number of possible ways for representing docids and how to handle decoding for each.
基于seq2seq的DSI模型通过解码输入查询给定的文档ID(docid)来实现检索。如何高效完成这一解码过程,主要取决于模型中文档ID的表示方式。本节剩余部分将探讨文档ID的多种可能表示方法及对应的解码处理策略。
Unstructured Atomic Identifiers The most naive way to represent documents is assign each an arbitrary (and possibly random) unique integer identifier. We refer to these as unstructured atomic identifiers.
非结构化原子标识符
表示文档最朴素的方式是为每个文档分配一个任意(可能是随机)的唯一整数标识符。我们称之为非结构化原子标识符。
With these identifiers, an obvious decoding formulation is to learn a probability distribution over the identifiers. In this case, models are trained to emit one logit for each unique docid $(|N_{d o c u m e n t s}|)$ . This is analogous to the output layer in standard language models, but extended to include docids.
通过这些标识符,一个直观的解码方案是学习标识符上的概率分布。在这种情况下,模型被训练为每个唯一文档ID $(|N_{d o c u m e n t s}|)$ 输出一个逻辑值。这与标准大语言模型中的输出层类似,但扩展为包含文档ID。
To accommodate this, we extend the output vocabulary of a standard language model as follows:
为此,我们对标准语言模型的输出词汇表进行了如下扩展:
$$
O=\mathrm{Softmax}([W_{t o k e n s};W_{d o c s}]^{T}~h_{l a s t})
$$
$$
O=\mathrm{Softmax}([W_{t o k e n s};W_{d o c s}]^{T}~h_{l a s t})
$$
where $[;]$ is the row-wise concatenation operator, $W_{t o k e n s} \in \mathbb{R}^{d_{m o d e l}\times|N_{t o k e n s}|}$ and $W_{d o c s}~\in$ $\mathbb{R}^{d_{m o d e l}\times|N_{d o c u m e n t s}|}$ . $h_{l a s t}$ is the last layer’s hidden state $(\in\mathbb{R}^{d_{m o d e l}})$ of the decoder stack. To retrieve the top-k documents for a given query, we simply sort the output logits and return the corresponding indices. This is also reminiscent of standard listwise learning to rank where all documents are considered at once.
其中 $[;]$ 是行级拼接运算符,$W_{t o k e n s} \in \mathbb{R}^{d_{m o d e l}\times|N_{t o k e n s}|}$ 和 $W_{d o c s}~\in$ $\mathbb{R}^{d_{m o d e l}\times|N_{d o c u m e n t s}|}$。$h_{l a s t}$ 是解码器堆栈最后一层的隐藏状态 $(\in\mathbb{R}^{d_{m o d e l}})$。为了检索给定查询的前k个文档,我们只需对输出 logits 进行排序并返回相应的索引。这也让人联想到标准列表学习排序 (listwise learning to rank),其中所有文档都被同时考虑。
Naively Structured String Identifiers We also consider an ostensibly absurd approach that treats unstructured identifiers, i.e., arbitrary unique integers, as token iz able strings. We refer to these as naively structured identifiers.
朴素结构字符串标识符
我们还考虑了一种表面看似荒谬的方法,将非结构化标识符(即任意唯一整数)视为可token化的字符串。我们称这些为朴素结构标识符。
In this formulation, retrieval is accomplished by decoding a docid string sequentially one token at a time. This eliminates the need for the large softmax output space that comes with unstructured atomic identifiers. It also eliminates the need to learn embeddings for each individual docid.
在这种方法中,检索是通过逐个token顺序解码docid字符串完成的。这消除了非结构化原子标识符所需的大型softmax输出空间,也无需为每个单独的docid学习嵌入向量。
When decoding, beam search is used to obtain the predicted best docid. With this strategy, it is less straightforward to obtain a top-k ranking. One could exhaustively comb through the entire docid space and obtain the likelihood of each docid given the query. Instead, we use the partial beam search tree to construct top-k retrieval scores. We find this approximation to be quite efficient and effective in practice.
解码时,采用束搜索(beam search)获取预测的最佳文档ID(docid)。该策略下直接获取前k排名较为困难。理论上可遍历整个文档ID空间来获取每个文档ID在给定查询下的似然值。实践中我们利用部分束搜索树构建前k检索分数,发现这种近似方法既高效又有效。
Semantically Structured Identifiers All of the approaches for representing docids thus far assumed that the identifiers are assigned in an arbitrary manner. While exploring the limits of arbitrary identifiers is quite interesting, it is only intuitive that imbuing the docid space with semantic structure can lead to better indexing and retrieval capabilities. As such, this section explores semantically structured identifiers.
语义结构化标识符
迄今为止所有表示文档ID(docid)的方法都假设标识符是任意分配的。虽然探索任意标识符的极限非常有趣,但直观上在docid空间中注入语义结构可以带来更好的索引和检索能力。因此,本节将探讨语义结构化标识符。
Specifically, we aim to automatically create identifiers that satisfy the following properties: (1) the docid should capture some information about the semantics of its associated document, (2) the docid should be structured in a way that the search space is effectively reduced after each decoding step. This results in identifiers where semantically similar documents share identifier prefixes.
具体而言,我们的目标是自动创建满足以下属性的标识符:(1) docid应能捕获与其关联文档的部分语义信息,(2) docid的结构应确保每个解码步骤后能有效缩减搜索空间。最终生成的标识符会使语义相似的文档共享相同的前缀。
In this work, we treat this as a fully unsupervised pre-processing step. However, as part of future work it may be possible to integrate and automatically learn semantic identifiers in a fully end-to-end manner.
在本工作中,我们将其视为完全无监督的预处理步骤。然而,作为未来工作的一部分,有可能以完全端到端的方式集成并自动学习语义标识符。
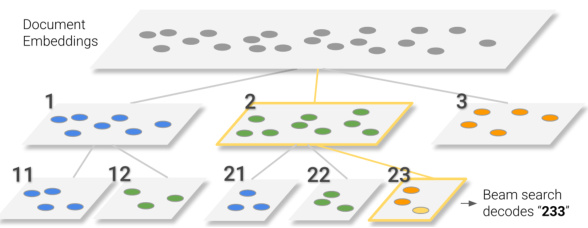
Figure 2: Visual example of a hierarchical clustering process used to assign semantically structured identifiers. During inference, beam search navigates this trie to decode the correct docid.
图 2: 用于分配语义结构化标识符的层次聚类过程可视化示例。推理过程中,集束搜索 (beam search) 会遍历该字典树 (trie) 来解码正确的文档标识符 (docid)。
Algorithm 1 Generating semantically structured identifiers. (Referenced in Section 3.2.)
算法1:生成语义化结构标识符。(参见第3.2节。)
To construct identifiers with this property, we employ a simple hierarchical clustering process over document embeddings to induce a decimal tree (or more generally, a trie).
为了构建具有此属性的标识符,我们采用一种简单的层次聚类方法对文档嵌入进行处理,从而导出一个十进制树(或更广义地说,一个字典树)。
Given a corpus to be indexed, all documents are clustered into 10 clusters. Each document is assigned an identifier with the number of their cluster from 0-9. For every cluster containing more than $c$ documents, the algorithm is applied recursively, with the next level’s result (the remaining suffix of the identifier) appended to the existing identifier.
给定待索引的语料库后,所有文档会被聚类为10个簇。每个文档被分配一个标识符,其中包含其所属簇的编号(0-9)。对于包含超过$c$篇文档的每个簇,算法会递归应用,并将下一层级的结果(标识符的剩余后缀)追加到现有标识符中。
| Input: Document embeddings X1:N,where X E Rd Output:Corresponding docid stringsJ1:N functionGENERATESEMANTICIDs(X1:N) C1:10 ←Cluster(X1:N,k=10) J←emptylist fori=0to9do Jcurrent←[i] *|Ci+1l |
| if|Ci+1|>cthen Jrest(GENERATESEMANTICIDs(C+1) else |
| Jrest ←[0,...,|Ci+1l - 1] endif Jcluster ←elementwiseStrConcat(Jcurrent,Jrest) |
| J J.appendElements(Jcluster) endfor |
输入:文档嵌入向量 X1:N,其中 X ∈ R^d
输出:对应的文档ID字符串 J1:N
函数 GENERATESEMANTICIDs(X1:N)
C1:10 ← 聚类(X1:N, k=10)
J ← 空列表
for i=0 to 9 do
Jcurrent ← [i] * |Ci+1|
if |Ci+1| > c then
Jrest ← GENERATESEMANTICIDs(Ci+1)
else
Jrest ← [0,...,|Ci+1| - 1]
endif
Jcluster ← 逐元素字符串连接(Jcurrent, Jrest)
J.appendElements(Jcluster)
endfor
For clusters with $c$ documents or less, each element is assigned an arbitrary number from 0 to at most $c-1$ and likewise its digits are appended to the existing identifier. Although this specific process induces a decimal tree, it is possible to induce similar types of tries using any number of other reasonable strategies.In practice, we simply apply $k$ -means over embeddings generated by a small 8-layer BERT model, with $c=100$ . We include pseudo-code for this process in Algorithm 1.
对于文档数量不超过 $c$ 的聚类,每个元素被分配一个从0至多 $c-1$ 的任意数字,其数字同样会被追加到现有标识符后。虽然这一特定过程会生成十进制树,但也可以通过其他多种合理策略诱导出类似类型的字典树。实际操作中,我们仅对由小型8层BERT模型生成的嵌入向量应用 $k$ 均值聚类,设 $c=100$。该过程的伪代码详见算法1。
3.3 Training and Optimization
3.3 训练与优化
The DSI models that we train are optimized for seq2seq cross entropy loss and are trained with teacher forcing. We explored two main strategies for training DSI models. The first and more straightforward strategy is to first train a model to perform indexing (memorization), followed by a fine-tuning stage where the trained model is used to map queries to docids (e.g., retrieval). The second strategy is to train them together in a multi-task setup. To this end, we frame co-training tasks in similar fashion to T5-style co-training (e.g., using task prompts to differentiate them). The latter performed significantly better, especially when the proportion of indexing to retrieval task examples is high. Hence, we adopted multi-task learning as the default strategy.
我们训练的DSI模型针对序列到序列(seq2seq)交叉熵损失进行了优化,并采用教师强制(teacher forcing)进行训练。我们探索了两种主要的DSI模型训练策略。第一种更直接的方法是先训练模型执行索引(记忆)任务,随后在微调阶段使用训练好的模型将查询映射到文档ID(例如检索任务)。第二种策略是在多任务设置中联合训练。为此,我们采用类似T5风格协同训练的方式构建协同训练任务(例如使用任务提示符进行区分)。后一种方法表现显著更优,特别是当索引任务与检索任务样本比例较高时。因此,我们采用多任务学习作为默认策略。
Here, we make the observation that our setup is unique and unlike traditional multi-task learning or transfer learning. In typical multi-task setups, two tasks have shared common ali ties that could improve the performance of both tasks if they were learned together. However, in our setup, the retrieval task is completely dependent on the indexing task. In particular, without the indexing task, the identifiers leveraged by the retrieval task would be completely meaningless. Hence, in order to solve task B (retrieval), the model needs to learn task A (indexing) well enough. This problem setup presents unique and largely unexplored research challenges that might be of interest to the ML community.
我们注意到,本研究的设置具有独特性,与传统多任务学习或迁移学习不同。典型的多任务设置中,两个任务具有共享共性,联合学习可提升双方性能。但在本设置中,检索任务完全依赖于索引任务——若没有索引任务,检索任务所使用的标识符将完全失去意义。因此,模型必须充分掌握任务A(索引)才能解决任务B(检索)。这种问题设置提出了独特且尚未充分探索的研究挑战,可能引发机器学习社区的关注。
4 Experiments
4 实验
In this section, we discuss our experimental setup, datasets used and baselines compared. We also discuss experimental results, findings and effect of various strategies discussed in earlier sections of the paper. Since this is fairly new concept, this work aims to put forth a proof-of-concept and seeks to answer research questions instead of making a ‘sotaeesque’ comparison. We leave extensive comparisons on other setups and baselines to future work.
在本节中,我们将讨论实验设置、使用的数据集和对比基线,并分析实验结果、研究发现以及前文所述各策略的影响。由于这是一个较新的概念,本研究旨在提出概念验证 (proof-of-concept) 并回答研究问题,而非进行"最优性能"式比较。其他实验设置和基线的全面对比将留待未来工作。
Dataset We conduct our experiments on the challenging Natural Questions (NQ) (Kwiatkowski et al., 2019) dataset. NQ consists of 307K query-document training pairs and 8K validation pairs, where the queries are natural language questions and the documents are Wikipedia articles. Given a question, the retrieval task is to identify the Wikipedia article that answers it. For evaluating how DSI models perform at different scales, we construct three sets from NQ to form our testbed, namely NQ10K, NQ100K, and NQ320K denoting different numbers of total query-document pairs in the combined train and validation splits. NQ320K is the full NQ set and uses its predetermined training and validation split for evaluation purposes. Unlike NQ320K, NQ10K and NQ100K constructs randomly sampled validation sets. For all datasets, we use the same docid space/budget of 320K tokens for all unstructured atomic and naively structured identifier experiments. Semantically structured identifiers are generated separately for each dataset so as to prevent leakage of semantic information from larger splits into smaller ones. Text is lowercased. Note that there exists fewer unique documents than query-document pairs in these datasets. Please refer to Table 4 (Appendix) which reports the statistics of these datasets.
数据集
我们在具有挑战性的Natural Questions (NQ) (Kwiatkowski et al., 2019) 数据集上进行实验。NQ包含307K个查询-文档训练对和8K个验证对,其中查询为自然语言问题,文档为维基百科文章。给定一个问题,检索任务是识别出能回答该问题的维基百科文章。为评估DSI模型在不同规模下的表现,我们从NQ构建了三个测试集:NQ10K、NQ100K和NQ320K,分别表示训练集与验证集合并后不同数量的查询-文档对。NQ320K是完整的NQ数据集,使用其预设的训练/验证划分进行评估。与NQ320K不同,NQ10K和NQ100K采用随机采样的验证集。所有数据集在非结构化原子标识符和朴素结构化标识符实验中均使用相同的320K token文档ID空间/预算。语义结构化标识符则为每个数据集单独生成,以防止较大数据集的语义信息泄漏至较小数据集。文本均转为小写。需注意这些数据集中唯一文档数量少于查询-文档对数量。具体统计信息请参见附录中的表4。
Metrics We evaluate our models on $\mathrm{Hits@N}$ where $N = {1, 10}$ . This metric reports the proportion of correct documents ranked in the top N predictions.
指标
我们使用 $\mathrm{Hits@N}$ (其中 $N = {1, 10}$)评估模型性能。该指标衡量正确文档出现在前 $N$ 个预测结果中的比例。
Implementation Details All DSI models are initialized using standard pretrained T5 (Raffel et al., 2019) model configurations. The configurations names and corresponding number of model parameters are: Base (0.2B), Large (0.8B), XL (3B) and XXL (11B). For unstructured atomic identifiers runs, we initialize the identifiers randomly as new parameters and only finetune the weights during the indexing stage. We use the Jax/T5X 2 implementation for our experiments. The DSI models are trained for a maximum of 1M steps using a batch size of 128. We pick the best checkpoint based on retrieval validation performance. Our training hardware consists of 128-256 TPUv4 chips for models above 1B parameters and 64-128 TPUv3 or TPUv4 chips otherwise. As an estimate, models above 1B parameters typically take about at least a full day for convergence for NQ320K. We tune the learning rate amongst ${0.001,0.0005}$ and linear warmup amongst ${10\mathrm{K},100\mathrm{K},200\mathrm{K},$ , $300\mathrm{K}}$ and/or none. Semantically structured identifiers are generated using an 8-layer BERT (Devlin et al., 2018) model 3, and the default $k$ -means clustering in scikit-learn. Based on our early ablation experiments of various DSI setting, the main results presented use direct indexing $X=32$ ) and the Inputs 2 Targets indexing strategy. We present results for all the docid representation methods. Following the main results, we present our ablation studies.
实现细节
所有DSI模型均采用标准预训练T5 (Raffel et al., 2019) 模型配置进行初始化。配置名称与对应模型参数量为:Base (0.2B)、Large (0.8B)、XL (3B) 和XXL (11B)。对于非结构化原子标识符实验,我们将标识符作为新参数随机初始化,并仅在索引阶段微调权重。实验使用Jax/T5X实现。DSI模型最多训练100万步,批量大小为128。我们根据检索验证性能选择最佳检查点。训练硬件配置为:参数量超过10亿的模型使用128-256个TPUv4芯片,其余使用64-128个TPUv3或TPUv4芯片。以NQ320K数据集为例,参数量超10亿的模型通常需要至少一整天达到收敛。学习率调参范围为${0.001,0.0005}$,线性预热步数从${10\mathrm{K},100\mathrm{K},200\mathrm{K},300\mathrm{K}}$中选择或取消预热。语义结构化标识符采用8层BERT (Devlin et al., 2018) 模型和scikit-learn默认$k$-means聚类生成。根据早期消融实验,主要结果采用直接索引($X=32$)和Inputs 2 Targets索引策略。我们展示了所有文档标识表示方法的结果,并在主要结果后附上消融研究。
4.1 Baselines
4.1 基线方法
For baselines, we use T5-based dual encoders implemented by (Ni et al., 2021). We use the gensim4 package for computing BM25 scores. For the T5-based dual encoders, we train with contrastive learning on the NQ pairs until convergence $\mathrm{\Omega}\approx10\mathrm{K}$ steps) and obtain top-k nearest neighbors with a system similar to ScaNN (Guo et al., 2020). For zero-shot retrieval, we also compare with a state-ofthe-art unsupervised baseline, Sentence T5 (Ni et al., 2021) which have been specially pre-trained with a similarity learning task. There two reasons why we consider (Ni et al., 2021) the relevant dual encoder baseline for this work rather than other dense retrieval works such as DPR (Karpukhin et al.,
作为基线,我们采用(Ni et al., 2021)实现的基于T5的双编码器。使用gensim4包计算BM25分数。对于基于T5的双编码器,我们在NQ问答对上采用对比学习进行训练直至收敛(约10K步),并通过类似ScaNN (Guo et al., 2020)的系统获取top-k最近邻。针对零样本检索,我们还对比了当前最先进的无监督基线Sentence T5 (Ni et al., 2021)——该模型通过相似性学习任务进行了专门预训练。选择(Ni et al., 2021)作为相关工作基线而非DPR (Karpukhin et al., )等其他稠密检索方法,主要基于两点考量:
Table 2: Experimental results on NQ document retrieval. DSI outperforms BM25 and Dual Encoder baselines. Among all the Docid representation methods, Semantic String Docids perform the best.
| NQ10K | NQ100K | NQ320K | |||||||
| Model | Size | Params | Method | Hits @1 | Hits@10 | Hits@1 | Hits@10 | Hits@1 | Hits@10 |
| BM25 | - | 12.4 | 33.5 | 20.9 | 46.4 | 11.6 | 34.4 | ||
| T5 | Base | 220M | Dual Encoder | 16.2 | 48.6 | 18.7 | 55.2 | 20.5 | 58.3 |
| T5 | Large | 800M | Dual Encoder | 18.8 | 55.7 | 22.3 | 60.5 | 22.4 | 63.3 |
| T5 | XL | 3B | Dual Encoder | 20.8 | 59.6 | 23.3 | 63.2 | 23.9 | 65.8 |
| T5 | XXL | 11B | Dual Encoder | 22.1 | 61.6 | 24.1 | 64.5 | 24.3 | 67.3 |
| DSI | Base | 250M | Atomic Docid | 13.0 | 38.4 | 23.8 | 58.6 | 20.7 | 40.9 |
| DSI | Large | 800M | AtomicDocid | 31.3 | 59.4 | 17.1 | 52.3 | 11.6 | 37.6 |
| DSI | XL | 3B | AtomicDocid | 40.1 | 76.9 | 19.0 | 55.3 | 28.1 | 61.9 |
| DSI | TXX | 11B | Atomic Docid | 39.4 | 77.0 | 25.3 | 67.9 | 24.0 | 55.1 |
| DSI | Base | 250M | Naive String Docid | 28.1 | 48.0 | 18.7 | 44.6 | 6.7 | 21.0 |
| DSI | Large | 800M | Naive String Docid | 34.7 | 60.5 | 21.2 | 50.7 | 13.3 | 33.6 |
| DSI | XL | 3B | Naive String Docid | 44.7 | 66.4 | 24.0 | 55.1 | 16.7 | 58.1 |
| DSI | XXL | 11B | Naive String Docid | 46.7 | 77.9 | 27.5 | 62.4 | 23.8 | 55.9 |
| DSI | Base | 250M | SemanticStringDocid | 33.9 | 57.3 | 19.0 | 44.9 | 27.4 | 56.6 |
| DSI | Large | 800M | Semantic String Docid | 37.5 | 65.1 | 20.4 | 50.2 | 35.6 | 62.6 |
| DSI | XL | 3B | Semantic String Docid | 41.9 | 67.1 | 22.4 | 52.2 | 39.1 | 66.8 |
| DSI | XXL | 11B | Semantic String Docid | 48.5 | 72.1 | 26.9 | 59.5 | 40.4 | 70.3 |
表 2: NQ文档检索实验结果。DSI优于BM25和Dual Encoder基线。在所有文档ID表示方法中,语义字符串文档ID表现最佳。
| 模型 | 大小 | 参数量 | 方法 | NQ10K Hits@1 | NQ10K Hits@10 | NQ100K Hits@1 | NQ100K Hits@10 | NQ320K Hits@1 | NQ320K Hits@10 |
|---|---|---|---|---|---|---|---|---|---|
| BM25 | - | - | - | 12.4 | 33.5 | 20.9 | 46.4 | 11.6 | 34.4 |
| T5 | Base | 220M | Dual Encoder | 16.2 | 48.6 | 18.7 | 55.2 | 20.5 | 58.3 |
| T5 | Large | 800M | Dual Encoder | 18.8 | 55.7 | 22.3 | 60.5 | 22.4 | 63.3 |
| T5 | XL | 3B | Dual Encoder | 20.8 | 59.6 | 23.3 | 63.2 | 23.9 | 65.8 |
| T5 | XXL | 11B | Dual Encoder | 22.1 | 61.6 | 24.1 | 64.5 | 24.3 | 67.3 |
| DSI | Base | 250M | Atomic Docid | 13.0 | 38.4 | 23.8 | 58.6 | 20.7 | 40.9 |
| DSI | Large | 800M | Atomic Docid | 31.3 | 59.4 | 17.1 | 52.3 | 11.6 | 37.6 |
| DSI | XL | 3B | Atomic Docid | 40.1 | 76.9 | 19.0 | 55.3 | 28.1 | 61.9 |
| DSI | TXX | 11B | Atomic Docid | 39.4 | 77.0 | 25.3 | 67.9 | 24.0 | 55.1 |
| DSI | Base | 250M | Naive String Docid | 28.1 | 48.0 | 18.7 | 44.6 | 6.7 | 21.0 |
| DSI | Large | 800M | Naive String Docid | 34.7 | 60.5 | 21.2 | 50.7 | 13.3 | 33.6 |
| DSI | XL | 3B | Naive String Docid | 44.7 | 66.4 | 24.0 | 55.1 | 16.7 | 58.1 |
| DSI | XXL | 11B | Naive String Docid | 46.7 | 77.9 | 27.5 | 62.4 | 23.8 | 55.9 |
| DSI | Base | 250M | Semantic String Docid | 33.9 | 57.3 | 19.0 | 44.9 | 27.4 | 56.6 |
| DSI | Large | 800M | Semantic String Docid | 37.5 | 65.1 | 20.4 | 50.2 | 35.6 | 62.6 |
| DSI | XL | 3B | Semantic String Docid | 41.9 | 67.1 | 22.4 | 52.2 | 39.1 | 66.8 |
| DSI | XXL | 11B | Semantic String Docid | 48.5 | 72.1 | 26.9 | 59.5 | 40.4 | 70.3 |
Table 3: Experimental results on Zero-Shot NQ document retrieval. DSI outperforms BM25, T5 embeddings and SentenceT5, the state-of-the-art for unsupervised similarity modeling. Among Docid representation method, the Atomic Docid performs the best on zero-shot learning.
| Size | Method | NQ10K | NQ100K | NQ320K | ||||
| Hits@1 | Hits@10 | Hits@1 | Hits@10 | Hits@1 | Hits@10 | |||
| BM25 | 一 | 12.4 | 33.5 | 20.9 | 46.4 | 11.6 | 34.4 | |
| T5 | XXL | DualEncoder | 0.3 | 1.3 | 1.9 | 8.0 | 1.1 | 5.9 |
| SentenceT5 | Large | DualEncoder | 17.6 | 50.7 | 17.4 | 50.8 | 16.9 | 51.0 |
| DSI | TXX | AtomicDocid | 25.7 | 60.1 | 23.0 | 57.3 | 25.1 | 56.6 |
| DSI | TXX | Naive String Docid | 43.4 | 67.4 | 17.4 | 41.5 | 9.2 | 22.6 |
| DSI | XXL | Semantic String Docid | 43.9 | 68.8 | 11.4 | 26.6 | 13.9 | 31.1 |
表 3: 零样本NQ文档检索实验结果。DSI在零样本学习上优于BM25、T5嵌入和SentenceT5(无监督相似性建模的当前最优方法)。在文档ID表示方法中,Atomic Docid在零样本学习中表现最佳。
| Size | Method | NQ10K Hits@1 | NQ10K Hits@10 | NQ100K Hits@1 | NQ100K Hits@10 | NQ320K Hits@1 | NQ320K Hits@10 | |
|---|---|---|---|---|---|---|---|---|
| BM25 | 一 | 12.4 | 33.5 | 20.9 | 46.4 | 11.6 | 34.4 | |
| T5 | XXL | DualEncoder | 0.3 | 1.3 | 1.9 | 8.0 | 1.1 | 5.9 |
| SentenceT5 | Large | DualEncoder | 17.6 | 50.7 | 17.4 | 50.8 | 16.9 | 51.0 |
| DSI | TXX | AtomicDocid | 25.7 | 60.1 | 23.0 | 57.3 | 25.1 | 56.6 |
| DSI | TXX | Naive String Docid | 43.4 | 67.4 | 17.4 | 41.5 | 9.2 | 22.6 |
| DSI | XXL | Semantic String Docid | 43.9 | 68.8 | 11.4 | 26.6 | 13.9 | 31.1 |
2020). Firstly, we employ the exact identical pretrained model, which allows systematic ablation of the proposed approach without conflating other factors. Scientifically, we believe this comparison against fine-tuned T5 is the best apples to apples comparison that we provide. Secondly, fine-tuned T5 dual encoders are considered to be architecturally and methodological ly very identical to DPR (with some minor differences such as parameter sharing but use the same concept of in-batch negatives).
2020)。首先,我们采用完全相同的预训练模型,这样可以系统性地消融所提出的方法,而不会混淆其他因素。从科学角度而言,我们认为与微调T5的对比是最公平的同类比较。其次,微调T5双编码器在架构和方法论上与DPR高度相似(仅存在参数共享等细微差异,但都采用批次内负样本的相同概念)。
4.2 Experimental Results
4.2 实验结果
Table 2 reports retrieval results for NQ10K, NQ100K, and NQ320K with finetuning and Table 3 reports zero-shot retrieval results. For zero-shot retrieval, the model is only trained on the indexing task and not the retrieval task, so the model sees no labeled query $\rightarrow$ docid data points. Section 7.2 of the Appendix reports extended results regarding the indexing performance and training dynamics of DSI.
表 2 报告了 NQ10K、NQ100K 和 NQ320K 经过微调后的检索结果,表 3 报告了零样本检索结果。对于零样本检索,模型仅在索引任务上进行训练,而未参与检索任务,因此模型未接触任何带标签的查询 $\rightarrow$ 文档 ID 数据点。附录第 7.2 节提供了关于 DSI 索引性能和训练动态的扩展结果。
Supervised Finetuning Results Our results show that DSI outperforms DE across all dataset sizes. On the small dataset (NQ10K), the performance gap between DSI and DE is large, e.g., the best DSI variant outperforms DE by 2 times. On NQ100K, the gap becomes less prominent with the best DSI model (unstructured atomic identifiers) outperforming DE by $+5%$ Hits $@1$ and Hits $@10$ . On the large dataset (NQ320K), the best DSI model (structured semantic identifiers) outperform the best DE model by $+66%$ relative Hits $@1$ and $+4.5%$ Hits $@10$ .
监督微调结果
我们的结果表明,DSI在所有数据集规模上都优于DE。在小数据集(NQ10K)上,DSI与DE之间的性能差距较大,例如最佳DSI变体的表现是DE的2倍。在NQ100K上,差距变得不那么明显,最佳DSI模型(非结构化原子标识符)在Hits@1和Hits@10上分别比DE高出$+5%$。在大数据集(NQ320K)上,最佳DSI模型(结构化语义标识符)在相对Hits@1和Hits@10上分别比最佳DE模型高出$+66%$和$+4.5%$。
Zero-Shot Results Table 3 reports results on zeros-shot retrieval. Recall that zero-shot retrieval is performed by only performing indexing and not the retrieval task. In other words, the model does not see any annotated query or document pairs. Generally, the best result is obtained by DSI with unstructured atomic identifiers on both NQ100K and NQ320K. The best performance on all NQ datasets outperform well-established unsupervised retrieval baselines such as BM25. Moreover, DSI outperforms unsupervised representation learning methods such as SentenceT5 (Ni et al., 2021), which is trained to learn similarity-aware representations via contrastive learning. We also note that raw T5 embeddings perform extremely poorly and do not produce reasonable results on the task of unsupervised retrieval. Given that it is generally difficult for an unsupervised neural method to outperform BM25, we find these early results very encouraging.
零样本结果
表 3 报告了零样本检索的结果。请注意,零样本检索仅执行索引而不执行检索任务。换句话说,模型不会看到任何带标注的查询或文档对。总体而言,DSI 在 NQ100K 和 NQ320K 上使用非结构化原子标识符获得了最佳结果。在所有 NQ 数据集上的最佳性能均优于 BM25 等成熟的无监督检索基线。此外,DSI 的表现优于无监督表示学习方法,例如 SentenceT5 (Ni et al., 2021),后者通过对比学习训练以获得相似性感知的表示。我们还注意到,原始 T5 嵌入表现极差,在无监督检索任务中无法产生合理的结果。鉴于无监督神经方法通常难以超越 BM25,我们认为这些早期结果非常令人鼓舞。

Figure 3: Scaling plots for DSI vs. DE across model sizes. Performance refers to the Hits $@1$ metric.
图 3: 不同模型规模下 DSI 与 DE 的扩展关系曲线。性能指标采用 Hits $@1$ 度量值。

Figure 5: Performance of different document representations. (Referenced in Section 4.2.)
图 5: 不同文档表示方法的性能表现 (参见第4.2节)

Figure 4: Effect of multi-task ratio of indexing to retrieval examples.
图 4: 索引与检索样本的多任务比例效果。
Document Identifiers One key research question in this paper is the crucial choice of how to represent docids. Generally, we find that structured semantic identifiers are helpful and improve over unstructured identifiers. When comparing naive versus semantic string identifiers, it seems imperative to use semantic identifiers if possible. This is intuitive, since imbuing the target space with semantic structure can facilitate greater ease of optimization and additional unsupervised representation learning methods as external knowledge. The competitiveness of unstructured atomic identifiers is somewhat mixed and we had some difficulty optimizing such models. We hypothesize that this could possibly be because of the the newly initialized softmax layer and that training such a system from scratch would mitigate these issues. However, we defer this line of investigation to future work. In lieu of the instability and high variance of the unstructured atomic identifiers, the performance is not consistent across the different datasets. Moreover, these docids might also run into intermittent non-convergence which we trace back to an optimization related quirk. However, we also note that unstructured atomic identifiers perform the best, by a wide margin, on the zero-shot retrieval setup and achieve performance often more than double than that of beam decoding methods.
文档标识符
本文的一个关键研究问题是如何表示文档标识符(docid)。总体而言,我们发现结构化语义标识符比非结构化标识符更有效。当比较朴素字符串标识符与语义字符串标识符时,应尽可能使用语义标识符。这很直观,因为在目标空间中注入语义结构可以更易于优化,并作为外部知识支持额外的无监督表征学习方法。
非结构化原子标识符的表现参差不齐,我们在优化此类模型时遇到了一些困难。我们推测这可能与新初始化的softmax层有关,从头开始训练这样的系统可能会缓解这些问题。不过,我们将这方面的研究留待未来工作。
由于非结构化原子标识符的不稳定性和高方差性,其在不同数据集上的表现并不一致。此外,这些文档标识符还可能遇到间歇性不收敛的问题,我们将其归因于优化相关的特殊现象。然而,我们也注意到,在零样本检索设置中,非结构化原子标识符的表现远超其他方法,其性能通常是束解码(beam decoding)方法的两倍以上。
Indexing Strategies In this section, we explore the effect of different indexing methods (Section 3.1.1). We run experiments on NQ100K with the different indexing strategies described earlier. Models are trained using the Naive Docid method. Without indexing, the model achieves $0%$ Hits $@1$ . This is intuitive, since the Docids are not meaningful without the indexing task. Secondly, the Inputs 2 Targets and Bidirectional formulation performs the best, with the bidirectional method performing slightly worse (13.5 vs 13.2) compared to the former. Finally, the accuracy with Targets 2 Inputs and Span Corrpution with Docids yield no meaningful results ( $0%$ accuracy). This goes to show that there can be huge variance across indexing strategies whereby some strategies work reasonably well and some completely do not work at all.
索引策略
本节我们探讨不同索引方法的效果(见3.1.1节)。我们在NQ100K数据集上运行了前文所述的不同索引策略实验。模型训练采用Naive Docid方法。
未建立索引时,模型在Hits@1指标上获得$0%$的结果。这符合预期,因为不执行索引任务时Docid本身没有意义。其次,Inputs 2 Targets和双向(Bidirectional)构建方法表现最佳,其中双向方法略逊于前者(13.5 vs 13.2)。最后,Targets 2 Inputs和带Docid的Span Corruption方法未产生有效结果($0%$准确率)。
这表明不同索引策略之间存在巨大差异:部分策略表现尚可,而另一些则完全无效。
Document Representations In this section, we explore the performance of the different document representation strategies described in Section 3.1.2. Figure 5 reports the results on NQ320K. Overall, we find that the direct indexing approach works the best. We also find that it is difficult to train the inverted index method since the docid is repeatedly exposed to different tokens. We also find that shorter document lengths seem to work well where performance seems to substantially dip beyond 64 tokens suggesting that it might be harder to optimize or efficiently memorize when there are a larger number of document tokens. Finally, we also find that there was no additional advantage in applying set processing or stopwords preprocessing to the document tokens.
文档表征
本节探讨3.1.2节所述不同文档表征策略的性能表现。图5展示了NQ320K数据集上的实验结果。总体而言,直接索引方法表现最佳。我们发现倒排索引方法较难训练,因为文档ID会重复暴露于不同Token。实验还表明,较短的文档长度效果更好——当文档Token数超过64时性能显著下降,这暗示文档Token数量较多时可能更难优化或高效记忆。最后,我们发现对文档Token应用集合处理或停用词预处理并未带来额外优势。
Scaling Laws Another interesting insight is how the scaling law of DSI differs from Dual Encoders. Understanding the scaling behaviour of Transformers have garnered significant interest in recent years (Kaplan et al., 2020; Tay et al., 2021; Abnar et al., 2021). We find that the gain in retrieval performance obtained from increasing model parameter iz ation in DE seems to be relatively small. Conversely, the scaling properties of DSI seems to be more optimistic.
缩放定律
另一个有趣的发现是 DSI (Differentiable Search Index) 的缩放定律与双编码器 (Dual Encoders) 的差异。近年来,理解 Transformer 的缩放行为引起了广泛关注 [20][21][22]。我们发现,在双编码器中通过增加模型参数量 (model parameterization) 带来的检索性能提升相对较小。相反,DSI 的缩放特性似乎更为乐观。
Figure 3 plots the scaling behaviour (log scale) of three methods (DE and DSI with naive and semantic IDs). DSI (naive) strongly benefits from scale going from base to XXL and seems to still have headroom for improvement. Meanwhile, DSI (semantic) starts off equally competitive as DE base but performs much better with scale. DE models, unfortunately are more or less plateaued at smaller parameter iz ation.
图 3: 展示了三种方法(DE及采用naive和semantic ID的DSI)的扩展行为(对数坐标)。DSI (naive)从base到XXL规模显著受益,似乎仍有提升空间。与此同时,DSI (semantic)初始表现与DE base相当,但随规模扩大优势明显。遗憾的是,DE模型在较小参数量时性能就已趋于平缓。
Interplay Between Indexing and Retrieval Our early experiments showed that first learning the indexing task and then learning the retrieval task in a sequential manner results in mediocre performance. There, we focused on exploring good ratios $r$ for co-training the indexing and retrieval tasks together using multi-task learning. Figure 4 shows the effect of modifying the ratio of indexing to retrieval samples. We find the optimization process is significantly influenced by the interplay between the indexing and retrieval tasks. Setting $r$ too high or low generally resulted in poor performance. We find that a rate of 32 generally performed well.
索引与检索的相互作用
我们的早期实验表明,若先学习索引任务再以顺序方式学习检索任务,会导致性能平庸。为此,我们重点探索了通过多任务学习协同训练索引和检索任务时的最佳比例$r$。图4展示了调整索引与检索样本比例的效果。我们发现优化过程显著受索引与检索任务相互作用的影响。将$r$设得过高或过低通常会导致性能不佳。实验表明,比例设为32时整体表现最佳。
5 Conclusion
5 结论
This paper proposed the Differentiable Search Index (DSI), a new paradigm for learning an end-to-end search system in a unified manner, paving the way for next generation search (Metzler et al., 2021). We define novel indexing and retrieval tasks that encode the relationship between terms and docids completely within the parameters of a Transformer model. The paper proposed a number of different ways to represent documents and docids, and explored different model architectures and model training strategies. Experiments conducted on the Natural Questions data set show that DSI performs favorably against common baselines such as BM25 and dual encoders, both in a standard fine-tuning setup as well as in a zero-shot setup.
本文提出了可微分搜索索引 (Differentiable Search Index, DSI) 这一新范式,以统一方式学习端到端搜索系统,为下一代搜索技术铺平了道路 (Metzler et al., 2021)。我们定义了新颖的索引和检索任务,将术语与文档ID (docids) 的关系完全编码在Transformer模型的参数中。论文提出了多种文档和文档ID的表示方法,并探索了不同的模型架构和训练策略。在Natural Questions数据集上的实验表明,无论是标准微调设置还是零样本设置,DSI的表现均优于BM25和双编码器等常见基线方法。
Although the models and results presented here are promising, there is a great deal of potential future research that can be explored based on this work to improve this approach. For example, it would be interesting to explore alternative strategies for representing documents and docids, as well as to investigate mixture-of-expert models (Du et al., 2021; Fedus et al., 2021; Lepikhin et al., 2020) for scaling the memory capacity of DSI. One important direction will also be to explore how such models can be updated for dynamic corpora, where documents may be added or removed from the system. Finally it may also be interesting to further investigate DSI as an unsupervised representation learning method and/or memory store for other language models to leverage.
尽管本文提出的模型和结果前景广阔,但基于这项工作仍有大量未来研究方向可以探索。例如,研究文档和文档标识符(docids)的替代表征策略,以及探索专家混合模型(MoE) (Du et al., 2021; Fedus et al., 2021; Lepikhin et al., 2020) 来扩展DSI的记忆容量都颇具价值。另一个重要方向是探索如何更新此类模型以适应动态语料库,即系统中可能添加或删除文档的场景。最后,将DSI作为无监督表征学习方法或其他语言模型可利用的记忆存储机制进行深入研究也颇具意义。
6 Acknowledgements
6 致谢
The authors would like to thank you Fernando Pereira, Huaixiu Steven Zheng, Sebastian Ruder, Adam D. Lelkes, Ian Wetherbee and Dani Yogatama for their valuable feedback and discussions. We would also like to extend a special thanks to Sanket Vaibhav Mehta for additional experimental contributions.
作者感谢 Fernando Pereira、Huaixiu Steven Zheng、Sebastian Ruder、Adam D. Lelkes、Ian Wetherbee 和 Dani Yogatama 提供的宝贵反馈与讨论。同时特别感谢 Sanket Vaibhav Mehta 在实验工作上的额外贡献。
7 Appendix
7 附录
Here we include figures containing additional details about our experiments.
这里我们附上包含实验额外细节的图表。
7.1 Dataset Statistics
7.1 数据集统计
Table 4: Statistics of NQ datasets used in our experiments. (Referenced in Section 4.) The number in the dataset name corresponds to the total number of document-query pairs in the dataset, while $|D|$ corresponds to the number of unique documents, based on the first 4000 UTF-8 characters of the document.
| Dataset | —|D| | Train Pairs | Val Pairs | Vdoc_out |
| NQ10K | 10K | 8K | 2K | 320K |
| NQ100K | 86K | 80K | 20K | 320K |
| NQ320K | 228K | 307K | 8K | 320K |
表 4: 实验中使用的NQ数据集统计信息 (参见第4节)。数据集名称中的数字对应数据集中的文档-查询对总数,而$|D|$对应基于文档前4000个UTF-8字符的唯一文档数量。
| 数据集 | —|D| | 训练对 | 验证对 | Vdoc_out |
|----------|------|--------|--------|---------|
| NQ10K | 10K | 8K | 2K | 320K |
| NQ100K | 86K | 80K | 20K | 320K |
| NQ320K | 228K | 307K | 8K | 320K |
7.2 Extended Results
7.2 扩展结果
We report additional results and observations here.
我们在此报告更多结果和观察。
7.2.1 Indexing/Memorization Performance
7.2.1 索引/记忆性能
Table 5: Indexing performance (memorization) on NQ documents via the Inputs 2 Targets indexing objective. All models were indexed on all NQ documents (train and validation), with memorization evaluated on only the documents in the validation set.
| Size | Params | Method | Indexing Hits @ 1 |
| Base | 250M | Atomic Docid | 85.4 |
| Large | 800M | Atomic Docid | 84.9 |
| XL | 3B | Atomic Docid | 88.4 |
| XXL | 11B | Atomic Docid | 92.7 |
| Base | 250M | Naive String Docid | 76.3 |
| Large | 800M | Naive String Docid | 92.1 |
| XL | 3B | Naive String Docid | 92.2 |
| TXX | 11B | Naive String Docid | 91.9 |
| Base | 250M | Semantic String Docid | 87.6 |
| Large | 800M | Semantic String Docid | 91.5 |
| XL | 3B | Semantic String Docid | 92.6 |
| XXL | 11B | Semantic StringDocid | 92.0 |
表 5: 通过Inputs 2 Targets索引目标在NQ文档上的索引性能(记忆化)。所有模型都在所有NQ文档(训练集和验证集)上建立索引,记忆化评估仅针对验证集中的文档。
| 尺寸 | 参数量 | 方法 | 索引命中率@1 |
|---|---|---|---|
| Base | 250M | Atomic Docid | 85.4 |
| Large | 800M | Atomic Docid | 84.9 |
| XL | 3B | Atomic Docid | 88.4 |
| XXL | 11B | Atomic Docid | 92.7 |
| Base | 250M | Naive String Docid | 76.3 |
| Large | 800M | Naive String Docid | 92.1 |
| XL | 3B | Naive String Docid | 92.2 |
| TXX | 11B | Naive String Docid | 91.9 |
| Base | 250M | Semantic String Docid | 87.6 |
| Large | 800M | Semantic String Docid | 91.5 |
| XL | 3B | Semantic String Docid | 92.6 |
| XXL | 11B | Semantic StringDocid | 92.0 |
7.2.2 Discussion of DSI Training Dynamics
7.2.2 DSI训练动态讨论
In this paper, all indexing tasks are trained on the union of documents in both the train and validation splits of Natural Questions (NQ). This aligns with traditional definitions of indices, where a document must be in the index in order for the index to retrieve it. Retrieval then is trained on trained only on the NQ train split, with retrieval performance evaluated on NQ validation, based on the best checkpoint.
在本文中,所有索引任务均在Natural Questions (NQ)训练集和验证集文档的联合集上进行训练。这符合索引的传统定义,即文档必须存在于索引中才能被检索到。检索任务仅在NQ训练集上训练,并根据最佳检查点在NQ验证集上评估检索性能。
Analysis following this original work showed that, when training, a DSI model experiences forgetting of previously indexed batches as it indexes new batches, until it loops around again to the next epoch, and processes the same examples again. The indexing task we use in this paper was constructed by concatenating validation documents after the train documents, then applying a buffered shuffle while training the model (sampling the next training batch from a buffer every step). We used a shuffle buffer of size 5000, which is smaller than the size of the validation split for NQ100K and NQ320K.
根据这项原创工作的分析显示,DSI模型在训练过程中会随着索引新批次数据而遗忘先前索引的批次,直到进入下一个训练周期并重新处理相同样本。本文采用的索引任务构建方式为:将验证集文档拼接在训练集文档之后,随后在模型训练时应用缓冲随机采样(每一步从大小为5000的缓冲区抽取下一批训练数据)。该缓冲区尺寸小于NQ100K和NQ320K验证集的规模。
As a result, DSI experiments in this paper experienced cycles of minimum and maximum forgetting, i.e. higher and lower validation scores, based on whether the model had just indexed the validation documents or indexed them one epoch ago, causing regular peaks and valleys in the validation performance. When picking a checkpoint with maximum validation performance, as we do in the main experiments of this paper, we are implicitly then picking the checkpoint with minimum forgetting.
因此,本文中的DSI实验经历了最小和最大遗忘周期,即验证分数的高低波动,这取决于模型是刚刚索引了验证文档还是一个周期前索引的,导致验证性能呈现规律的波峰和波谷。当我们像本文主要实验那样选择验证性能最高的检查点时,实际上是在隐式选择遗忘最少的检查点。
In Table 6, we aim to provide more context to this phenomenon by providing retrieval validation scores for minimum forgetting checkpoints (highest peak), maximum forgetting checkpoints (highest trough), as well as their average score representing if the validation documents were uniformly distributed across the entire indexing split.
在表6中,我们通过提供最小遗忘检查点(最高峰值)、最大遗忘检查点(最低谷值)的检索验证分数,以及代表验证文档是否均匀分布在整个索引分割上的平均分数,旨在为这一现象提供更多背景信息。
Table 6: Additional NQ320K results at minimum forgetting and maximum forgetting checkpoints, with their average (min-forget / max-forget / avg), at Hit $;@1,5,10,20$ .
| Size | Params | Method | Hits@1 | Hits@5 | Hits@10 | Hits@20 |
| Base | 250M | AtomicDocid | 20.7/2.6/11.7 | 40.2/8.6/24.4 | 50.9/13.0/31.9 | 59.2/18.8/39.0 |
| Large | 800M | AtomicDocid | 11.6/2.5/7.0 | 30.5/7.2/18.9 | 37.6/10.9/24.2 | 46.7/15.9/31.3 |
| XL | 3B | AtomicDocid | 28.1/2.7/15.4 | 52.7/7.2/30.0 | 61.9/10.4/36.1 | 69.2/ 14.4/ 41.8 |
| XXL | 11B | AtomicDocid | 24.0/4.5/14.2 | 46.7/ 11.9/ 29.3 | 55.1/17.3/36.2 | 62.8/23.6/43.2 |
| Base | 250M | Naive String Docid | 6.7/1.5/4.1 | 12.6/4.3/8.4 | 21.0/6.0/13.5 | 25.6/8.1/16.9 |
| Large | 800M | NaiveStringDocid | 13.3/2.6/8.0 | 26.0/7.9/16.9 | 33.6/11.0/22.3 | 40.4/14.7/27.5 |
| XL | 3B | Naive String Docid | 16.7/1.2/8.9 | 32.8/3.1/17.9 | 58.1/4.1/31.1 | 62.5/5.6/34.0 |
| XXL | 11B | Naive String Docid | 23.8/1.3/12.6 | 46.3/3.2/24.8 | 55.9/5.9/30.9 | 62.2/8.0/35.1 |
| Base | 250M | SemanticStringDocid | 27.4/12.0/19.7 | 47.8/25.4/36.6 | 56.6/30.6/43.6 | 61.3/34.9/48.1 |
| Large | 800M | SemanticStringDocid | 35.6/10.2/22.9 | 54.3/21.6/38.0 | 62.6/24.5/43.5 | 67.3/27.8/47.5 |
| XL | 3B | SemanticStringDocid | 39.1/10.6/24.9 | 60.2/22.8/41.5 | 66.8/27.3/47.0 | 71.3/31.2/51.2 |
| TXX | 11B | SemanticStringDocid | 40.4/12.2/26.3 | 60.3/24.9/ 42.6 | 70.3/30.1/50.2 | 74.8/35.0/54.9 |
表 6: NQ320K 在最小遗忘和最大遗忘检查点的额外结果 (最小遗忘/最大遗忘/平均值), 命中率 $;@1,5,10,20$ 。
| 规格 | 参数量 | 方法 | Hits@1 | Hits@5 | Hits@10 | Hits@20 |
|---|---|---|---|---|---|---|
| Base | 250M | AtomicDocid | 20.7/2.6/11.7 | 40.2/8.6/24.4 | 50.9/13.0/31.9 | 59.2/18.8/39.0 |
| Large | 800M | AtomicDocid | 11.6/2.5/7.0 | 30.5/7.2/18.9 | 37.6/10.9/24.2 | 46.7/15.9/31.3 |
| XL | 3B | AtomicDocid | 28.1/2.7/15.4 | 52.7/7.2/30.0 | 61.9/10.4/36.1 | 69.2/14.4/41.8 |
| XXL | 11B | AtomicDocid | 24.0/4.5/14.2 | 46.7/11.9/29.3 | 55.1/17.3/36.2 | 62.8/23.6/43.2 |
| Base | 250M | Naive String Docid | 6.7/1.5/4.1 | 12.6/4.3/8.4 | 21.0/6.0/13.5 | 25.6/8.1/16.9 |
| Large | 800M | NaiveStringDocid | 13.3/2.6/8.0 | 26.0/7.9/16.9 | 33.6/11.0/22.3 | 40.4/14.7/27.5 |
| XL | 3B | Naive String Docid | 16.7/1.2/8.9 | 32.8/3.1/17.9 | 58.1/4.1/31.1 | 62.5/5.6/34.0 |
| XXL | 11B | Naive String Docid | 23.8/1.3/12.6 | 46.3/3.2/24.8 | 55.9/5.9/30.9 | 62.2/8.0/35.1 |
| Base | 250M | SemanticStringDocid | 27.4/12.0/19.7 | 47.8/25.4/36.6 | 56.6/30.6/43.6 | 61.3/34.9/48.1 |
| Large | 800M | SemanticStringDocid | 35.6/10.2/22.9 | 54.3/21.6/38.0 | 62.6/24.5/43.5 | 67.3/27.8/47.5 |
| XL | 3B | SemanticStringDocid | 39.1/10.6/24.9 | 60.2/22.8/41.5 | 66.8/27.3/47.0 | 71.3/31.2/51.2 |
| TXX | 11B | SemanticStringDocid | 40.4/12.2/26.3 | 60.3/24.9/42.6 | 70.3/30.1/50.2 | 74.8/35.0/54.9 |
Results. We see that for the best configuration of DSI (semantic docids), even when experiencing maximum forgetting DSI is still competitive with BM25, and in the average case DSI still outperforms the Dual Encoder baseline.
结果。我们发现,对于DSI(语义文档标识符)的最佳配置,即使在经历最大遗忘时,DSI仍与BM25具有竞争力,而在一般情况下,DSI的表现仍优于双编码器基线。