From Matching to Generation: A Survey on Generative Information Retrieval
从匹配到生成:生成式信息检索综述
XIAOXI LI and JIAJIE JIN, Renmin University of China, China YUJIA ZHOU, Tsinghua University, China YUYAO ZHANG and PEITIAN ZHANG, Renmin University of China, China YUTAO ZHU and ZHICHENG DOU∗, Renmin University of China, China
李晓曦和靳佳杰,中国人民大学,中国
周雨佳,清华大学,中国
张雨瑶和张沛天,中国人民大学,中国
朱玉涛和窦志成*,中国人民大学,中国
Information Retrieval (IR) systems are crucial tools for users to access information, which have long been dominated by traditional methods relying on similarity matching. With the advancement of pre-trained language models, generative information retrieval (GenIR) emerges as a novel paradigm, attracting increasing attention. Based on the form of information provided to users, current research in GenIR can be categorized into two aspects: (1) Generative Document Retrieval (GR) leverages the generative model’s parameters for memorizing documents, enabling retrieval by directly generating relevant document identifiers without explicit indexing. (2) Reliable Response Generation employs language models to directly generate information users seek, breaking the limitations of traditional IR in terms of document granularity and relevance matching while offering flexibility, efficiency, and creativity to meet practical needs. This paper aims to systematically review the latest research progress in GenIR. We will summarize the advancements in GR regarding model training and structure, document identifier, incremental learning, etc., as well as progress in reliable response generation in aspects of internal knowledge memorization, external knowledge augmentation, etc. We also review the evaluation, challenges and future developments in GenIR systems. This review aims to offer a comprehensive reference for researchers, encouraging further development in the GenIR field. 1
信息检索 (IR) 系统是用户获取信息的关键工具,长期以来一直由依赖相似性匹配的传统方法主导。随着预训练语言模型的发展,生成式信息检索 (GenIR) 作为一种新范式出现,吸引了越来越多的关注。根据向用户提供信息的形式,当前 GenIR 的研究可分为两个方面:(1) 生成式文档检索 (GR) 利用生成模型的参数记忆文档,无需显式索引即可通过直接生成相关文档标识符实现检索。(2) 可靠响应生成利用语言模型直接生成用户寻求的信息,打破传统 IR 在文档粒度和相关性匹配方面的限制,同时提供灵活性、效率和创造性以满足实际需求。本文旨在系统梳理 GenIR 的最新研究进展。我们将总结 GR 在模型训练与结构、文档标识符、增量学习等方面的进展,以及可靠响应生成在内部知识记忆、外部知识增强等方面的进展。我们还回顾了 GenIR 系统的评估、挑战与未来发展。本综述旨在为研究者提供全面参考,推动 GenIR 领域的进一步发展。[1]
CCS Concepts: • Information systems $\rightarrow$ Retrieval models and ranking.
CCS概念:• 信息系统 $\rightarrow$ 检索模型与排序
Additional Key Words and Phrases: Generative Information Retrieval; Generative Document Retrieval; Reliable Response Generation
附加关键词与短语:生成式信息检索 (Generative Information Retrieval);生成式文档检索 (Generative Document Retrieval);可靠响应生成
1 INTRODUCTION
1 引言
Information retrieval (IR) systems are crucial for navigating the vast sea of online information in today’s digital landscape. From using search engines such as Google [76], Bing [196], and Baidu [209], to engaging with question-answering or dialogue systems like ChatGPT [209] and Bing Chat [197], and discovering content via recommendation platforms like Amazon [4] and
信息检索 (IR) 系统在当今数字环境中对海量在线信息的导航至关重要。从使用 Google [76]、Bing [196] 和百度 [209] 等搜索引擎,到与 ChatGPT [209] 和 Bing Chat [197] 等问答或对话系统互动,再到通过 Amazon [4] 等内容推荐平台发现信息
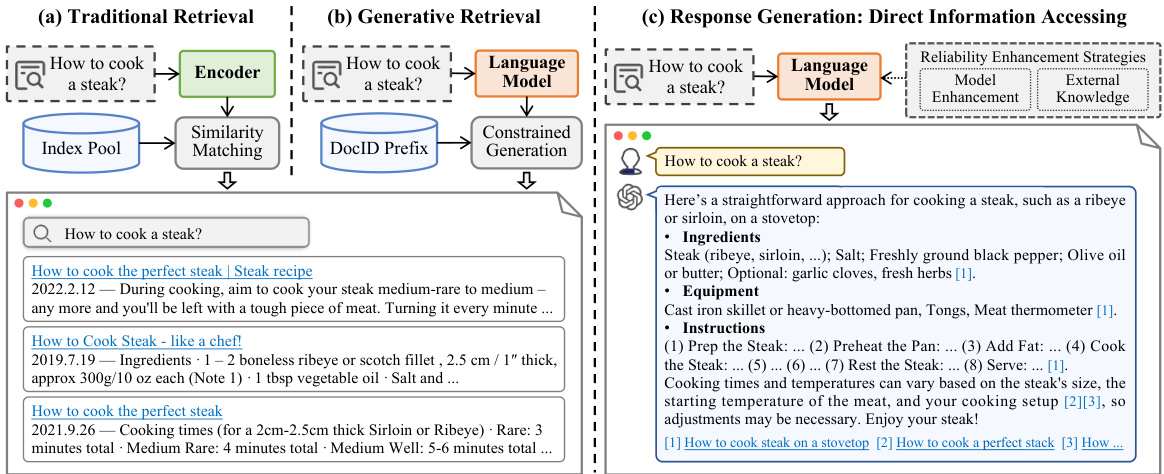
Fig. 1. Exploring IR Evolution: From Traditional to Generative Methods - This diagram illustrates the shift from traditional similarity-based document matching (a) to GenIR techniques. Current GenIR methods can be categorized into two types: generative retrieval (b), which retrieves documents by directly generating relevant DocIDs constrained by a DocID prefix tree; and response generation (c), which directly generates reliable and user-centric answers.
图 1: 探索信息检索(IR)演进:从传统方法到生成式方法 - 该图展示了从基于相似度的传统文档匹配(a)到生成式信息检索(GenIR)技术的转变。当前GenIR方法可分为两类:生成式检索(b)通过受文档ID前缀树约束直接生成相关DocID来检索文档;响应生成(c)直接生成可靠且以用户为中心的答案。
YouTube [77], IR technologies are integral to our everyday online experiences. These systems are reliable and play a key role in spreading knowledge and ideas globally.
YouTube [77],信息检索(IR)技术已成为我们日常在线体验不可或缺的组成部分。这些系统稳定可靠,在全球知识传播和思想交流中发挥着关键作用。
Traditional IR systems primarily rely on sparse retrieval methods based on word-level matching. These methods, which include Boolean Retrieval [242], BM25 [238], SPLADE [65], and UniCOIL [163], establish connections between vocabulary and documents, offering high retrieval efficiency and robust system performance. With the rise of deep learning, dense retrieval methods such as DPR [117] and ANCE [324], based on the bidirectional encoding representations from the BERT model [121], capture the deep semantic information of documents, significantly improving retrieval precision. Although these methods have achieved leaps in accuracy, they rely on large-scale document indices [57, 187] and cannot be optimized in an end-to-end way. Moreover, when people search for information, what they really need is a precise and reliable answer. This document ranking list-based IR approach still requires users to spend time summarizing their required answers, which is not ideal enough for information seeking [195].
传统信息检索(IR)系统主要依赖于基于词级匹配的稀疏检索方法。这些方法包括布尔检索(Boolean Retrieval)[242]、BM25 [238]、SPLADE [65]和UniCOIL [163],它们建立了词汇与文档之间的联系,具有高检索效率和强大的系统性能。随着深度学习的兴起,基于BERT模型(Bidirectional Encoder Representations from Transformers)[121]的双向编码表示的密集检索方法,如DPR [117]和ANCE [324],能够捕捉文档的深层语义信息,显著提高了检索精度。尽管这些方法在准确性上实现了飞跃,但它们依赖于大规模文档索引[57, 187],且无法以端到端的方式进行优化。此外,当人们搜索信息时,真正需要的是一个精确可靠的答案。这种基于文档排序列表的信息检索方法仍然需要用户花费时间总结所需答案,对于信息寻求来说还不够理想[195]。
With the development of Transformer-based pre-trained language models such as T5 [231], BART [138], and GPT [228], they have demonstrated their strong text generation capabilities. In recent years, large language models (LLMs) have brought about revolutionary changes in the field of AI-generated content (AIGC) [19, 359]. Based on large pre-training corpora and advanced training techniques like RLHF [36], LLMs [8, 105, 209, 286] have made significant progress in natural language tasks, such as dialogue [209, 282] and question answering [174, 225]. The rapid development of LLMs is transforming IR systems, giving rise to a new paradigm of generative information retrieval (GenIR), which achieves IR goals through generative approaches.
随着基于Transformer的预训练语言模型(如T5 [231]、BART [138]和GPT [228])的发展,它们展现了强大的文本生成能力。近年来,大语言模型(LLM)为AI生成内容(AIGC)领域带来了革命性变革[19, 359]。基于大规模预训练语料和RLHF [36]等先进训练技术,大语言模型[8, 105, 209, 286]在对话[209, 282]、问答[174, 225]等自然语言任务中取得显著进展。大语言模型的快速发展正在重塑信息检索(IR)系统,催生出通过生成式方法实现IR目标的新范式——生成式信息检索(GenIR)。
As envisioned by Metzler et al. [195], in order to build an IR system that can respond like a domain expert, the system should not only provide accurate responses but also include source citations to ensure the credibility of the results. To achieve this, GenIR models must possess both sufficient memorized knowledge and the ability to recall the associations between knowledge and source documents, which could be the final goal of GenIR systems. Currently, research in GenIR primarily focuses on two main patterns: (1) Generative Document Retrieval (GR), which involves retrieving documents by generating their identifiers; and (2) Reliable Response Generation, which entails directly generating user-centric responses with reliability enhancement strategies. Noting that although these two methods have not yet been integrated technically, they represent two primary forms by which IR systems present information to users in generative manners: either by generating lists of document identifiers or by generating reliable and user-centric responses. Figure 1 illustrates the difference between these two forms. These strategies are essential to the next generation of information retrieval and constitute the central focus of this survey.
正如 Metzler 等人 [195] 所设想的那样,要构建一个能像领域专家一样响应的信息检索 (IR) 系统,该系统不仅要提供准确的响应,还应包含来源引用以确保结果的可信度。为实现这一目标,生成式信息检索 (GenIR) 模型必须同时具备足够的记忆知识以及回忆知识与源文档关联的能力,这可能是 GenIR 系统的终极目标。目前 GenIR 的研究主要聚焦于两种模式:(1) 生成式文档检索 (Generative Document Retrieval, GR),即通过生成文档标识符来检索文档;(2) 可靠响应生成,即通过可靠性增强策略直接生成以用户为中心的响应。值得注意的是,虽然这两种方法在技术上尚未融合,但它们代表了信息检索系统以生成方式向用户呈现信息的两种主要形式:要么生成文档标识符列表,要么生成可靠且以用户为中心的响应。图 1 展示了这两种形式的区别。这些策略对下一代信息检索至关重要,也是本综述的核心焦点。
Generative document retrieval, a new retrieval paradigm based on generative models, is garnering increasing attention. This approach leverages the parametric memory of generative models to directly generate document identifiers (DocIDs) related to the documents [18, 281, 307, 371]. Figure 1 illustrates this transition, where traditional IR systems match queries to documents based on an indexed database (Figure 1(a)), while generative methods use language models to retrieve by directly generating relevant document identifiers (Figure 1(b)). Specifically, GR assigns a unique identifier to each document, which can be numeric-based or text-based, and then trains a generative retrieval model to learn the mapping from queries to the relevant DocIDs. This allows the model to index documents using its internal parameters. During inference, GR models use constrained beam search to limit the generated DocIDs to be valid within the corpus, ranking them based on generation probability to produce a ranked list of DocIDs. This eliminates the need for large-scale document indexes in traditional methods, enabling end-to-end training of the model.
生成式文档检索 (Generative document retrieval) 是一种基于生成模型的新型检索范式,正受到越来越多的关注。该方法利用生成模型的参数化记忆直接生成与文档相关的文档标识符 (DocIDs) [18, 281, 307, 371]。图 1 展示了这一转变:传统信息检索系统通过索引数据库匹配查询与文档 (图 1(a)),而生成式方法则通过语言模型直接生成相关文档标识符进行检索 (图 1(b))。具体而言,生成式检索会为每个文档分配唯一标识符 (可以是数字或文本形式),然后训练生成式检索模型学习从查询到相关 DocIDs 的映射关系,使模型能够利用内部参数对文档建立索引。在推理阶段,生成式检索模型通过约束束搜索将生成的 DocIDs 限制在语料库有效范围内,并根据生成概率进行排序,最终输出排序后的 DocIDs 列表。这种方法消除了传统方法对大规模文档索引的依赖,实现了模型的端到端训练。
Recent studies on generative retrieval have delved into model training and structure [6, 153, 281, 307, 365, 369, 372], document identifier design [18, 265, 281, 288, 330], continual learning on dynamic corpora [80, 124, 192], downstream task adaptation [27, 28, 152], multi-modal generative retrieval [157, 178, 357], and generative recommend er systems [74, 233, 304]. The progress in GR is shifting retrieval systems from matching to generation. It has also led to the emergence of workshops [10] and tutorials [279]. However, there is currently no comprehensive review that systematically organizes the research, challenges, and prospects of this emerging field.
近期关于生成式检索的研究深入探讨了模型训练与结构[6,153,281,307,365,369,372]、文档标识符设计[18,265,281,288,330]、动态语料库的持续学习[80,124,192]、下游任务适配[27,28,152]、多模态生成式检索[157,178,357]以及生成式推荐系统[74,233,304]。生成式检索的进步正推动检索系统从匹配转向生成,并催生了专题研讨会[10]和教程[279]。然而,目前尚无系统梳理这一新兴领域研究进展、挑战与前景的全面综述。
Reliable response generation is also a promising direction in the IR field, offering usercentric and accurate answers that directly meet users’ needs. Since LLMs are particularly adept at following instructions [359], capable of generating customized responses, and can even cite the knowledge sources [204, 223], making direct response generation a new and intuitive way to access information [54, 75, 241, 315, 367]. As illustrated in Figure 1, the generative approach marks a significant shift from traditional IR systems, which return a ranked list of documents (as shown in Figure 1(a,b)). Instead, response generation methods (depicted in Figure 1(c)) offer a more dynamic form of information access by directly generating detailed, user-centric responses, thereby providing a richer and more immediate understanding of the information need behind the users’ queries.
可靠响应生成也是信息检索(IR)领域一个极具前景的方向,它能提供以用户为中心且精准的答案,直接满足用户需求。由于大语言模型(LLM)特别擅长遵循指令[359],能够生成定制化响应,甚至可以引用知识来源[204, 223],这使得直接响应生成成为了一种新颖直观的信息获取方式[54, 75, 241, 315, 367]。如图1所示,这种生成式方法标志着与传统IR系统的重大转变——传统系统返回的是文档排序列表(如图1(a,b)所示),而响应生成方法(如图1(c)所示)通过直接生成详细的、以用户为中心的响应,提供了更具动态性的信息获取形式,从而使用户能更丰富、更即时地理解查询背后的信息需求。
However, the responses generated by language models may not always be reliable. They have the potential to generate irrelevant answers [85], contradict factual information [90, 104], provide outdated data [291], or generate toxic content [93, 263]. Consequently, these limitations render them unsuitable for many scenarios that require accurate and up-to-date information. To address these challenges, the academic community has developed strategies across four key aspects: enhancing internal knowledge [16, 37, 56, 119, 132, 193, 243, 267, 285]; augmenting external knowledge [5, 113, 139, 151, 204, 245, 333]; generating responses with citation [129, 142, 156, 204, 314]; and improving personal information assistance [149, 172, 295, 327]. Despite these efforts, there is still a lack of a systematic review that organizes the existing research under this new paradigm of generative information access.
然而,语言模型生成的回答并不总是可靠的。它们可能产生无关答案[85]、与事实矛盾[90, 104]、提供过时数据[291]或生成有害内容[93, 263]。这些局限性使其难以适用于需要精准时效信息的场景。针对这些问题,学术界从四个关键方向提出了解决方案:增强内部知识[16, 37, 56, 119, 132, 193, 243, 267, 285];扩充外部知识[5, 113, 139, 151, 204, 245, 333];生成带引用的回答[129, 142, 156, 204, 314];以及改进个人信息辅助[149, 172, 295, 327]。尽管已有这些探索,目前仍缺乏系统性综述来梳理生成式信息获取新范式下的研究成果。
This review will systematically review the latest research progress and future developments in the field of GenIR, as shown in Figure 2, which displays the classification of research related to the GenIR system. We will introduce background knowledge in Section 2, generative document retrieval technologies in Section 3, direct information accessing with generative language models in Section 4, evaluation in Section 5, current challenges and future directions in Section 6, respectively. Section 7 will summarize the content of this review. This article is the first to systematically organize the research, evaluation, challenges and prospects of generative IR, while also looking forward to the potential and importance of GenIR’s future development. Through this review, readers will gain a deep understanding of the latest progress in developing GenIR systems and how it shapes the future of information access. The main contribution of this survey is summarized as follows:
本综述将系统梳理GenIR领域的最新研究进展与未来发展,如图2所示,该图展示了GenIR系统相关研究的分类。我们将在第2节介绍背景知识,第3节讨论生成式文档检索技术,第4节探讨基于生成式语言模型的直接信息获取,第5节分析评估方法,第6节分别阐述当前挑战与未来方向。第7节将总结本综述内容。本文首次系统梳理了生成式IR的研究、评估、挑战与前景,同时展望了GenIR未来发展的潜力与重要性。通过本综述,读者将深入了解开发GenIR系统的最新进展及其如何塑造信息获取的未来。本调查的主要贡献总结如下:
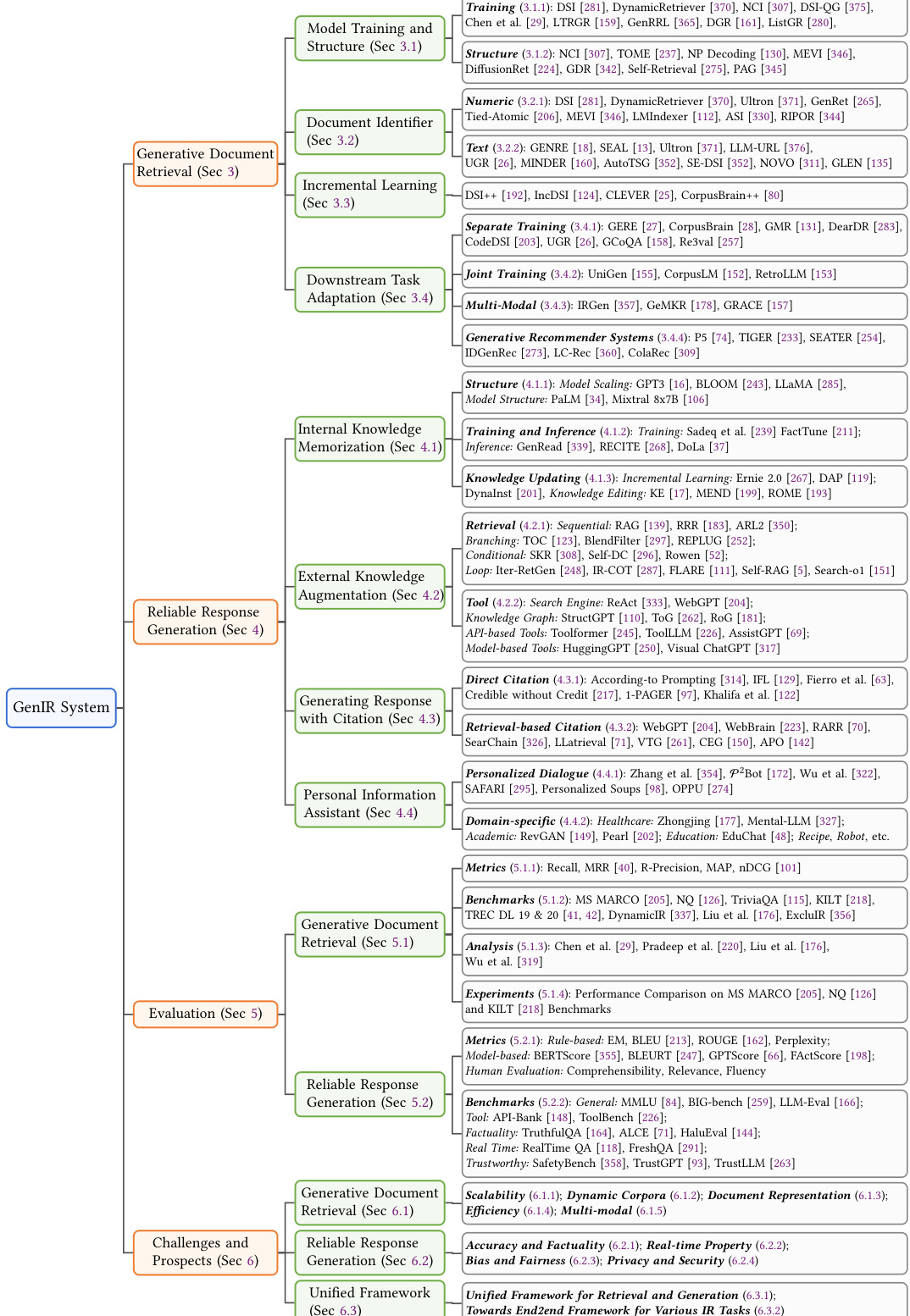
Fig. 2. Taxonomy of research on generative information retrieval: investigating generative document retrieval, reliable response generation, evaluation, challenges and prospects.
图 2: 生成式信息检索研究分类:涵盖生成式文档检索、可靠响应生成、评估方法、挑战与前景。
• First comprehensive survey on generative information retrieval (GenIR): This survey is the first to comprehensively organize the techniques, evaluation, challenges, and prospects on the emerging field of GenIR, providing a deep understanding of the latest progress in developing GenIR systems and its future in shaping information access. • Systematic categorization and in-depth analysis: The survey offers a systematic categorization of research related to GenIR systems, including generative document retrieval, reliable response generation. It provides an in-depth analysis of each category, covering model training and structure, document identifier, etc. in generative document retrieval; internal knowledge memorization, external knowledge enhancement, etc. for reliable response generation. • Comprehensive review of evaluation metrics and benchmarks: The survey reviews a range of widely used evaluation metrics and benchmark datasets for accessing GenIR methods, alongside analysis on the effectiveness and weaknesses of existing GenIR methods. • Discussions of current challenges and future directions: The survey identifies and discusses the current challenges faced in the GenIR field. We also provide potential solutions for each challenge and outline future research directions for building GenIR systems.
• 首次关于生成式信息检索 (Generative Information Retrieval, GenIR) 的综合综述:本综述首次全面梳理了新兴领域GenIR的技术、评估、挑战与前景,深入阐释了GenIR系统开发的最新进展及其在重塑信息获取方式的未来潜力。
• 系统性分类与深度分析:综述对GenIR相关研究进行了系统分类,包括生成式文档检索、可靠响应生成等方向。针对每类研究提供深度分析,涵盖生成式文档检索中的模型训练与结构、文档标识符等技术细节;可靠响应生成中的内部知识记忆、外部知识增强等关键方法。
• 评估指标与基准的全面评述:综述系统梳理了评估GenIR方法的常用指标和基准数据集,并分析了现有GenIR方法的有效性与局限性。
• 当前挑战与未来方向探讨:综述明确指出了GenIR领域面临的挑战,针对每项挑战提出潜在解决方案,并规划了构建GenIR系统的未来研究方向。
2 BACKGROUND AND PRELIMINARIES
2 背景与基础知识
Information retrieval techniques aim at efficiently obtaining, processing, and understanding information from massive data. Technological advancements have continuously driven the evolution of these methods: from early keyword-based sparse retrieval to deep learning-based dense retrieval, and more recently, to generative retrieval, large language models, and their augmentation techniques. Each advancement enhances retrieval accuracy and efficiency, catering to the complex and diverse query needs of users.
信息检索技术旨在从海量数据中高效获取、处理和理解信息。技术进步持续推动着这些方法的演进:从早期基于关键词的稀疏检索,到基于深度学习的稠密检索,再到最近的生成式检索、大语言模型及其增强技术。每一次进步都提升了检索的准确性和效率,以满足用户复杂多样的查询需求。
2.1 Traditional Information Retrieval
2.1 传统信息检索
Sparse Retrieval. In the field of traditional information retrieval, sparse retrieval techniques implement fast and accurate document retrieval through the inverted index method. Inverted indexing technology maps each unique term to a list of all documents containing that term, providing an efficient means for information retrieval in large document collections. Among these methods, TF-IDF (Term Frequency-Inverse Document Frequency) [235] is a particularly important statistical tool used to assess the importance of a word in a document collection, thereby widely applied in various traditional retrieval systems.
稀疏检索 (Sparse Retrieval)。在传统信息检索领域,稀疏检索技术通过倒排索引 (inverted index) 方法实现快速精准的文档检索。倒排索引技术将每个唯一词项映射到包含该词项的所有文档列表,为海量文档集合中的信息检索提供了高效手段。其中,TF-IDF (词频-逆文档频率) [235] 是评估词项在文档集合中重要性的重要统计工具,因而被广泛应用于各类传统检索系统。
The core of sparse retrieval technology lies in evaluating the relevance between documents and user queries. Specifically, given a document collection $\mathcal{D}$ and a user query $q$ , traditional information retrieval systems identify and retrieve information by calculating the relevance $\mathcal{R}$ between document $d$ and query $q$ . This relevance evaluation typically relies on the similarity measure between document $d$ and query $q$ , as shown below:
稀疏检索技术的核心在于评估文档与用户查询之间的相关性。具体而言,给定文档集合 $\mathcal{D}$ 和用户查询 $q$,传统信息检索系统通过计算文档 $d$ 与查询 $q$ 之间的相关性 $\mathcal{R}$ 来识别并检索信息。这种相关性评估通常依赖于文档 $d$ 与查询 $q$ 之间的相似性度量,如下所示:
$$
\mathcal{R}(q,d)=\sum_{t\in q\cap d}\operatorname{tf-idf}(t,d)\cdot\operatorname{tf-idf}(t,q),
$$
$$
\mathcal{R}(q,d)=\sum_{t\in q\cap d}\operatorname{tf-idf}(t,d)\cdot\operatorname{tf-idf}(t,q),
$$
ACM Trans. Inf. Syst., Vol. 1, No. 1, Article . Publication date: March 2025.
ACM Trans. Inf. Syst.,第1卷,第1期,文章。出版日期:2025年3月。
where 𝑡 represents the terms common to both query $q$ and document $d$ , and tf-idf $(t,d)$ and tf $\operatorname{idf}(t,q)$ represent the TF-IDF weights of term $t$ in document $d$ and query $q$ , respectively. Although sparse retrieval methods like TF-IDF [235] and BM25 [238] excel at fast retrieval, it struggles with complex queries involving synonyms, specialized terms, or context, as term matching and TF-IDF may not fully meet users’ information needs [180].
其中,𝑡表示查询$q$和文档$d$共有的词项,tf-idf$(t,d)$和tf$\operatorname{idf}(t,q)$分别表示词项$t$在文档$d$和查询$q$中的TF-IDF权重。尽管TF-IDF [235]和BM25 [238]等稀疏检索方法擅长快速检索,但对于涉及同义词、专业术语或上下文的复杂查询,由于词项匹配和TF-IDF可能无法完全满足用户的信息需求 [180],这类方法仍存在不足。
Dense Retrieval. The advent of pre-trained language models like BERT [121] has revolutionized information retrieval, leading to the development of dense retrieval methods, like DPR [117], ANCE [324], E5 [298], SimLM [299]. Unlike traditional sparse retrieval, these methods leverage Transformer-based encoders to create dense vector representations for both queries and documents. This approach enhances the capability to grasp the underlying semantics, thereby improving retrieval accuracy.
稠密检索 (Dense Retrieval)。BERT [121] 等预训练语言模型的出现彻底改变了信息检索领域,催生了 DPR [117]、ANCE [324]、E5 [298]、SimLM [299] 等稠密检索方法。与传统稀疏检索不同,这些方法利用基于 Transformer 的编码器为查询和文档生成稠密向量表示。该方法增强了对底层语义的捕捉能力,从而提高了检索准确性。
The core of dense retrieval lies in converting documents and queries into vector representations. Given document $d$ and query $q$ and their vector representations $\mathbf{v}_ {q}$ , each document $d$ is transformed into a dense vector $\mathbf{v}_ {d}$ through a pre-trained language model, similarly, query $q$ is transformed into vector $\mathbf{v}_ {q}$ . Specifically, we can use encoder functions $E_{d}(\cdot)$ and $E_{q}(\cdot)$ to represent the encoding process for documents and queries, respectively:
密集检索的核心在于将文档和查询转化为向量表示。给定文档 $d$ 和查询 $q$ 及其向量表示 $\mathbf{v}_ {q}$,每个文档 $d$ 通过预训练语言模型转换为密集向量 $\mathbf{v}_ {d}$,类似地,查询 $q$ 转换为向量 $\mathbf{v}_ {q}$。具体而言,我们可以使用编码函数 $E_{d}(\cdot)$ 和 $E_{q}(\cdot)$ 分别表示文档和查询的编码过程:
$$
\mathbf{v}_ {d}=E_{d}(d),\quad\mathbf{v}_ {q}=E_{q}(q),
$$
$$
\mathbf{v}_ {d}=E_{d}(d),\quad\mathbf{v}_ {q}=E_{q}(q),
$$
where $E_{d}(\cdot)$ and $E_{q}(\cdot)$ can be the same model or different models optimized for specific tasks.
其中 $E_{d}(\cdot)$ 和 $E_{q}(\cdot)$ 可以是相同模型,也可以是针对特定任务优化的不同模型。
Dense retrieval methods evaluate relevance by calculating the similarity between the query vector and document vector, which can be measured by cosine similarity, expressed as follows:
密集检索方法通过计算查询向量和文档向量之间的相似度来评估相关性,可采用余弦相似度衡量,表达式如下:
$$
\mathcal{R}(q,d)=\cos({\mathbf{v}_ {q}},{\mathbf{v}_ {d}})=\frac{{\mathbf{v}_ {q}}\cdot\mathbf{v}_ {d}}{|\mathbf{v}_ {q}||\mathbf{v}_{d}|},
$$
$$
\mathcal{R}(q,d)=\cos({\mathbf{v}_ {q}},{\mathbf{v}_ {d}})=\frac{{\mathbf{v}_ {q}}\cdot\mathbf{v}_ {d}}{|\mathbf{v}_ {q}||\mathbf{v}_{d}|},
$$
where $\mathbf{v}_ {q}\cdot\mathbf{v}_ {d}$ represents the dot product of query vector $\mathbf{v}_ {q}$ and document vector ${\bf v}_ {d}$ , and $|\mathbf{v}_ {q}|$ and $|\mathbf{v}_{d}|$ respectively represent the magnitudes of the query and document vector. Finally, documents are ranked based on these similarity scores to identify the most relevant ones for the user.
其中 $\mathbf{v}_ {q}\cdot\mathbf{v}_ {d}$ 表示查询向量 $\mathbf{v}_ {q}$ 和文档向量 ${\bf v}_ {d}$ 的点积,$|\mathbf{v}_ {q}|$ 和 $|\mathbf{v}_{d}|$ 分别表示查询向量和文档向量的模长。最后根据这些相似度得分对文档进行排序,从而为用户找出最相关的文档。
2.2 Generative Retrieval
2.2 生成式检索 (Generative Retrieval)
With the significant progress of language models, generative retrieval has emerged as a new direction in the field of information retrieval [195, 281, 328]. Unlike traditional index-based retrieval methods, generative retrieval relies on pre-trained generative language models, such as T5 [231] and BART [138], to directly generate document identifiers (DocIDs) relevant to the query, thereby achieving end-to-end retrieval without relying on large-scale pre-built document indices.
随着语言模型的显著进步,生成式检索 (generative retrieval) 已成为信息检索领域的新方向 [195, 281, 328]。与传统基于索引的检索方法不同,生成式检索依赖预训练的生成式语言模型(如 T5 [231] 和 BART [138]),直接生成与查询相关的文档标识符 (DocIDs),从而实现不依赖大规模预建文档索引的端到端检索。
DocID Construction and Prefix Constraints. To facilitate generative retrieval, each document $d$ in the corpus $\mathcal{D}={d_{1},d_{2},\ldots,d_{N}}$ is assigned a unique document identifier $d^{\prime}$ , forming the set $\mathcal{D}^{\prime}={d_{1}^{\prime},d_{2}^{\prime},\ldots,d_{N}^{\prime}}$ . This mapping is typically established via a bijective function $\phi:{\mathcal{D}}\rightarrow{\mathcal{D}}^{\prime}$ , ensuring that:
文档ID构建与前缀约束。为实现生成式检索,语料库 $\mathcal{D}={d_{1},d_{2},\ldots,d_{N}}$ 中的每个文档 $d$ 都被分配唯一的文档标识符 $d^{\prime}$,构成集合 $\mathcal{D}^{\prime}={d_{1}^{\prime},d_{2}^{\prime},\ldots,d_{N}^{\prime}}$。该映射通常通过双射函数 $\phi:{\mathcal{D}}\rightarrow{\mathcal{D}}^{\prime}$ 建立,并满足以下条件:
$$
\phi(d_{i})=d_{i}^{\prime},\quad\forall d_{i}\in{\mathcal{D}}.
$$
$$
\phi(d_{i})=d_{i}^{\prime},\quad\forall d_{i}\in{\mathcal{D}}.
$$
To enable the language model to generate only valid DocIDs during inference, we construct prefix constraints based on ${\mathcal{D}}^{\prime}$ . This is typically implemented using a trie (prefix tree), where each path from the root to a leaf node corresponds to a valid DocID.
为了使语言模型在推理过程中仅生成有效的DocID,我们基于${\mathcal{D}}^{\prime}$构建前缀约束。这通常通过字典树(前缀树)实现,其中从根节点到叶节点的每条路径对应一个有效DocID。
Constrained Beam Search. Given a query $q$ , the generative retrieval model aims to generate the top $k$ DocIDs that are most relevant to $q$ . The language model $P(\cdot|q;\theta)$ generates DocIDs token by token, guided by the prefix constraints. At each decoding step $i$ , only those tokens that extend the current partial sequence $d_{<i}^{\prime}$ into a valid prefix of some DocIDs in $\mathcal{D}^{\prime}$ are considered. Formally, the set of allowable next tokens is:
约束束搜索 (Constrained Beam Search)。给定查询 $q$,生成式检索模型旨在生成与 $q$ 最相关的 top $k$ 个 DocID。在前缀约束的引导下,语言模型 $P(\cdot|q;\theta)$ 逐 Token 生成 DocID。在每个解码步骤 $i$ 中,仅考虑那些能将当前部分序列 $d_{<i}^{\prime}$ 扩展为 $\mathcal{D}^{\prime}$ 中某些 DocID 有效前缀的 Token。形式化地,允许的下一 Token 集合为:
$$
\mathcal V(d_{<i}^{\prime})={v\mid\exists d^{\prime}\in\mathcal D^{\prime}\mathrm{ such that }d_{<i}^{\prime}v\mathrm{ is a prefix of }d^{\prime}}.
$$
$$
\mathcal V(d_{<i}^{\prime})={v\mid\exists d^{\prime}\in\mathcal D^{\prime}\mathrm{ such that }d_{<i}^{\prime}v\mathrm{ is a prefix of }d^{\prime}}.
$$
ACM Trans. Inf. Syst., Vol. 1, No. 1, Article . Publication date: March 2025.
ACM Trans. Inf. Syst.,第1卷,第1期,文章。出版日期:2025年3月。
By employing constrained beam search, the model efficiently explores the space of valid DocIDs, maintaining a beam of the most probable sequences at each decoding step while adhering to the DocID prefix constraints.
通过采用受限束搜索 (constrained beam search),该模型能高效探索有效文档ID (DocID) 的空间,在遵守文档ID前缀约束的同时,于每个解码步骤保留最可能的序列束。
Document Relevance. The relevance between the query $q$ and a document $d$ is quantified by the probability of generating its corresponding DocID $d^{\prime}$ given $q$ . This is computed as:
文档相关性。查询 $q$ 与文档 $d$ 之间的相关性通过给定 $q$ 时生成其对应 DocID $d^{\prime}$ 的概率来量化,计算公式为:
$$
\mathcal{R}(q,d)=P(d^{\prime}|q;\theta)=\prod_{i=1}^{T}P(d_{i}^{\prime}\mid d_{<i}^{\prime},q;\theta),
$$
$$
\mathcal{R}(q,d)=P(d^{\prime}|q;\theta)=\prod_{i=1}^{T}P(d_{i}^{\prime}\mid d_{<i}^{\prime},q;\theta),
$$
where $T$ is the length of the DocID $d^{\prime}$ in tokens, $d_{i}^{\prime}$ is the token at position $i$ , and $d_{<i}^{\prime}$ denotes the sequence of tokens generated before position $i.$ . The constrained beam search produces a ranked list of top $k$ DocIDs ${d^{\prime(1)},d^{\prime(2)},\ldots,d^{\prime(k)}}$ based on their generation probabilities ${\mathcal{R}(q,d^{(1)}),\mathcal{R}(q,d^{(2)}) , \cdot\cdot\cdot,\mathcal{R}(q,d^{(k)})}$ . The corresponding documents ${d^{(\bar{1})},d^{(2)},\ldots,\bar{d}^{(k)}}$ are then considered the most relevant to the query 𝑞.
其中 $T$ 是文档ID $d^{\prime}$ 的Token长度,$d_{i}^{\prime}$ 表示位置 $i$ 的Token,$d_{<i}^{\prime}$ 表示位置 $i$ 之前生成的Token序列。约束束搜索根据生成概率 ${\mathcal{R}(q,d^{(1)}),\mathcal{R}(q,d^{(2)}), \cdot\cdot\cdot,\mathcal{R}(q,d^{(k)})}$ 生成前 $k$ 个文档ID的排序列表 ${d^{\prime(1)},d^{\prime(2)},\ldots,d^{\prime(k)}}$。对应的文档 ${d^{(\bar{1})},d^{(2)},\ldots,\bar{d}^{(k)}}$ 则被视为与查询 𝑞 最相关的结果。
Model Optimization. Generative retrieval models are typically optimized using cross-entropy loss, which measures the discrepancy between the generated DocID sequence and the ground truth DocID. Given a query $q$ and its corresponding DocID $d^{\prime}$ , the cross-entropy loss is defined as:
模型优化。生成式检索模型通常使用交叉熵损失进行优化,该损失衡量生成的DocID序列与真实DocID之间的差异。给定查询$q$及其对应的DocID$d^{\prime}$,交叉熵损失定义为:
$$
\mathcal{L}=-\sum_{i=1}^{T}\log P(d_{i}^{\prime}\mid d_{<i}^{\prime},q;\theta),
$$
$$
\mathcal{L}=-\sum_{i=1}^{T}\log P(d_{i}^{\prime}\mid d_{<i}^{\prime},q;\theta),
$$
where $T$ is the length of the DocID in tokens, $d_{i}^{\prime}$ is the token at position $i$ , and $d_{<i}^{\prime}$ denotes the sequence of tokens generated before position $i$ . This loss function encourages the model to learn the association between query and labeled DocID sequence.
其中 $T$ 是DocID的Token长度,$d_{i}^{\prime}$ 是位置 $i$ 的Token,$d_{<i}^{\prime}$ 表示位置 $i$ 之前生成的Token序列。该损失函数促使模型学习查询与标注DocID序列之间的关联。
This approach allows the generative retrieval model to produce a relevance-ordered list of documents without relying on traditional indexing structures. The core of this approach lies in leveraging the language model’s capability to generate DocID sequences within prefix constraints. This section discusses the simplest generative retrieval method. In Section 3, we will delve into advanced methods from multiple perspectives, including model architectures, training strategies, and DocID design, to further enhance retrieval performance across various scenarios.
该方法使生成式检索模型无需依赖传统索引结构即可生成按相关性排序的文档列表。其核心在于利用语言模型在前缀约束下生成DocID序列的能力。本节讨论最简单的生成式检索方法,第3节我们将从模型架构、训练策略和DocID设计等多角度深入探讨进阶方法,以提升不同场景下的检索性能。
2.3 Large Language Models
2.3 大语言模型 (Large Language Models)
The evolution of Large Language Models (LLMs) marks a significant leap in natural language processing (NLP), rooted from early statistical and neural network-based language models [374]. These models, through pre-training on vast text corpora, learned deep semantic features of language, greatly enriching the understanding of text. Subsequently, generative language models, most notably the GPT series [16, 228, 229], significantly improved text generation and understanding capabilities with improved model size and number of parameters.
大语言模型 (Large Language Models, LLMs) 的演进标志着自然语言处理 (NLP) 领域的重大飞跃,其根源可追溯至早期的统计和基于神经网络的语言模型 [374]。这些模型通过在海量文本语料库上进行预训练,学习语言的深层语义特征,极大地丰富了文本理解能力。随后,生成式语言模型(尤其是 GPT 系列 [16, 228, 229])通过扩大模型规模和参数量,显著提升了文本生成与理解能力。
LLMs can be mainly divided into two categories: encoder-decoder models and decoder-only models. Encoder-decoder models, like T5 [231] and BART [138], convert input text into vector representations through their encoder, then the decoder generates output text based on these representations. This model perspective treats various NLP tasks as text-to-text conversion problems, solving them through text generation. On the other hand, decoder-only models, like the GPT [228] and GPT-2 [229], rely entirely on the Transformer decoder, generating text step by step through the self-attention mechanism. The introduction of GPT-3 [16], with its 175 billion parameters, marked a significant milestone in this field and led to the creation of models like Instruct GP T [210], Falcon [215], PaLM [34] and Llama series [59, 285, 286]. These models, all using a decoder-only architecture, trained on large-scale datasets, have shown astonishing language processing capabilities [359].
大语言模型(LLM)主要可分为两类:编码器-解码器模型和仅解码器模型。编码器-解码器模型如T5 [231]和BART [138],通过编码器将输入文本转换为向量表示,再由解码器基于这些表示生成输出文本。该模型视角将各类NLP任务视为文本到文本的转换问题,通过文本生成来解决。另一方面,仅解码器模型如GPT [228]和GPT-2 [229]完全依赖Transformer解码器,通过自注意力机制逐步生成文本。拥有1750亿参数的GPT-3 [16]问世成为该领域重要里程碑,并催生了InstructGPT [210]、Falcon [215]、PaLM [34]以及Llama系列 [59, 285, 286]等模型。这些采用仅解码器架构、基于海量数据训练的模型,展现出惊人的语言处理能力 [359]。
For information retrieval tasks, large language models (LLMs) play a crucial role in directly generating the exact information users seek [55, 173, 374]. This capability marks a significant step towards a new era of generative information retrieval. In this era, the retrieval process is not solely about locating existing information but also about creating new content that meets the specific needs of users. This feature is especially advantageous in situations where users might not know how to phrase their queries or when they are in search of complex and highly personalized information, scenarios where traditional matching-based methods fall short.
在信息检索任务中,大语言模型(LLMs) 通过直接生成用户所需的精确信息发挥着关键作用 [55, 173, 374]。这一能力标志着生成式信息检索新时代的重要进展。在此背景下,检索过程不仅关乎定位现有信息,更涉及创造符合用户特定需求的新内容。当用户不知如何准确表述查询需求,或需要获取复杂且高度个性化的信息时,这一特性展现出显著优势,而传统基于匹配的方法在此类场景中往往表现不足。
2.4 Augmented Language Models
2.4 增强型语言模型
Despite the advances of LLMs, they still face significant challenges such as hallucination, particularly in complex tasks or those requiring access to long-tail or real-time information [90, 359]. To address these issues, retrieval augmentation and tool augmentation have emerged as effective strategies. Retrieval augmentation involves integrating external knowledge sources into the language model’s workflow. This integration allows the model to access up-to-date and accurate information during the generation process, thereby grounding its responses in verified data and reducing the likelihood of hallucinations [139, 252, 271]. Tool augmentation, on the other hand, extends the capabilities of LLMs by incorporating specialized tools or APIs that can perform specific functions like mathematical computations, data retrieval, or executing predefined commands [226, 245, 276]. With retrieval and tool augmentations, language models can provide more precise and con textually relevant responses, thereby improving factuality and functionality in practical applications.
尽管大语言模型取得了进展,但它们仍面临重大挑战,例如幻觉问题(hallucination),尤其是在复杂任务或需要获取长尾或实时信息的任务中 [90, 359]。为解决这些问题,检索增强(retrieval augmentation)和工具增强(tool augmentation)已成为有效策略。检索增强涉及将外部知识源集成到语言模型的工作流程中,使模型在生成过程中能够访问最新且准确的信息,从而将其响应建立在已验证数据的基础上,降低幻觉发生的可能性 [139, 252, 271]。另一方面,工具增强通过整合专用工具或 API 来扩展大语言模型的能力,这些工具或 API 可以执行特定功能,如数学计算、数据检索或执行预定义命令 [226, 245, 276]。通过检索增强和工具增强,语言模型能够提供更精确且与上下文相关的响应,从而在实际应用中提高事实性和功能性。
Moreover, due to the aforementioned issue of hallucinations, the responses generated by LLMs are often considered unreliable because users are unaware of the sources behind the generated content, making it difficult to verify its accuracy. To enhance the credibility of responses, some studies have focused on generating responses with citations [143, 204, 256]. This approach involves enabling language models to cite the source documents of their generated content, thereby increasing the trustworthiness of the responses. All these methods are effective strategies for improving both the quality and reliability of language model outputs and are essential technologies for building the next generation of generative information retrieval systems.
此外,由于上述幻觉问题,大语言模型生成的回答常被认为不可靠,因为用户无法知晓生成内容背后的来源,难以验证其准确性。为提高回答的可信度,部分研究聚焦于生成带引用的回答 [143, 204, 256]。该方法通过使语言模型能够引用生成内容的源文档,从而提升回答的可信度。这些方法都是提升语言模型输出质量与可靠性的有效策略,也是构建下一代生成式信息检索系统的关键技术。
3 GENERATIVE DOCUMENT RETRIEVAL: FROM SIMILARITY MATCHING TO GENERATING DOCUMENT IDENTIFIERS
3 生成式文档检索:从相似性匹配到生成文档标识符
In recent advancements in AIGC, generative retrieval (GR) has emerged as an promising approach in the field of information retrieval, garnering increasing interest from the academic community. Figure 3 showcases a timeline of the GR methods. Initially, GENRE [18] proposed to retrieve entities by generating their unique names through constrained beam search via a pre-built entity prefix tree, achieving advanced entity retrieval performance. Subsequently, Metzler et al. [195] envisioned a model-based information retrieval framework aiming to combine the strengths of traditional document retrieval systems and pre-trained language models to create systems capable of providing expert-quality answers in various domains.
在AIGC领域的最新进展中,生成式检索 (Generative Retrieval, GR) 已成为信息检索领域一种颇具前景的方法,日益受到学术界的关注。图 3: 展示了GR方法的发展时间线。最初,GENRE [18] 提出通过预构建的实体前缀树进行约束束搜索来生成实体唯一名称以实现检索,从而取得了先进的实体检索性能。随后,Metzler等人 [195] 设想了一种基于模型的信息检索框架,旨在结合传统文档检索系统和预训练语言模型的优势,构建能够提供跨领域专家级答案的系统。
Following their lead, a diverse range of methods including DSI [281], Dynamic Retriever [370], SEAL [13], NCI [307], etc., have been developed, with a continuously growing body of work. These methods explore various aspects such as model training and architectures, document identifiers, incremental learning, task-specific adaptation, and generative recommendations. Figure 4 presents an overview of the GR system and we’ll provide an in-depth discussion of each associated challenge in the following sections.
继这些研究之后,DSI [281]、Dynamic Retriever [370]、SEAL [13]、NCI [307] 等多种方法相继被提出,相关研究成果持续增长。这些方法探索了模型训练与架构、文档标识符、增量学习、任务特定适配以及生成式推荐等多个方面。图 4 展示了 GR (Generative Retrieval) 系统的概览,我们将在后续章节深入讨论每个相关挑战。
3.1 Model Training and Structure
3.1 模型训练与结构
One of the core components of GR is the model training and structure, aiming to enhance the model’s ability to memorize documents in the corpus.
GR的核心组件之一是模型训练和结构,旨在增强模型记忆语料库中文档的能力。
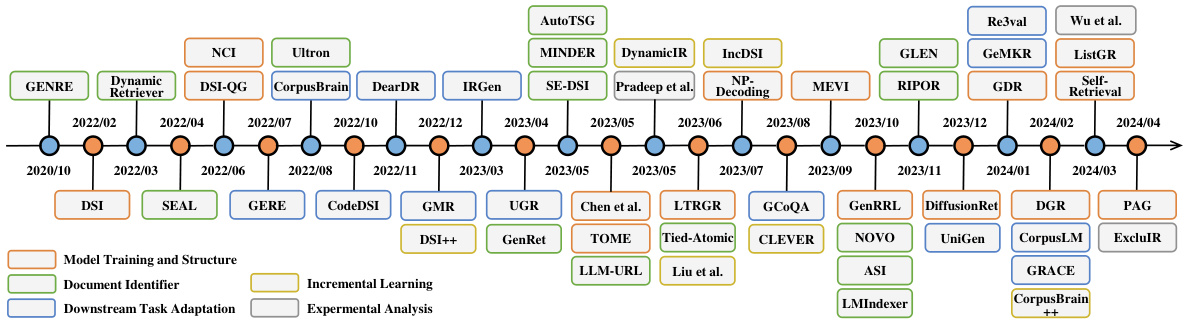
Fig. 3. Timeline of research in generative retrieval: focus on model training and structure, document identifier design, incremental learning and downstream task adaptation.
图 3: 生成式检索研究时间轴:重点关注模型训练与结构、文档标识符设计、增量学习及下游任务适配。
3.1.1 Model Training. To effectively train generative models for indexing documents, the standard approach is to train the mapping from queries to relevant DocIDs, based on standard sequence-tosequence (seq2seq) training methods, as described in Equation (2). This method has been widely used in numerous GR research works, such as DSI [281], NCI [307], SEAL [13], etc. Moreover, a series of works have proposed various model training methods tailored for GR tasks to further enhance GR retrieval performance, such as sampling documents or generating queries based on document content to serve as pseudo queries for data augmentation; or including training objectives for document ranking.
3.1.1 模型训练。为有效训练面向文档索引的生成式模型,标准方法是基于序列到序列(seq2seq)训练方法,按照公式(2)所述训练从查询到相关DocID的映射。该方法已广泛应用于众多生成式检索(GR)研究工作中,如DSI [281]、NCI [307]、SEAL [13]等。此外,一系列研究提出了针对GR任务定制的多样化模型训练方法以进一步提升检索性能,例如通过采样文档或基于文档内容生成查询作为数据增强的伪查询,或引入文档排序的训练目标。
Specifically, DSI [281] proposed two training strategies: one is “indexing”, that is, training the model to associate document tokens with their corresponding DocIDs, where DocIDs are pre-built based on documents in corpus, which will be discussed in detail in Section 3.2; the other is “retrieval”, using labeled query-DocID pairs to fine-tune the model. Notably, DSI was the first to realize a differentiable search index based on the Transformer [290] structure, showing good performance in web search [205] and question answering [126] scenarios. Next, a series of methods propose training methods for data augmentation and improving GR model ranking ability
具体而言,DSI [281] 提出了两种训练策略:一是"索引构建 (indexing)",即训练模型将文档 token 与对应的 DocID 关联起来(DocID 基于语料库文档预先构建,详见第3.2节讨论);二是"检索 (retrieval)",使用标注的查询-DocID 对来微调模型。值得注意的是,DSI 首次实现了基于 Transformer [290] 结构的可微分搜索索引,在网页搜索 [205] 和问答 [126] 场景中展现出良好性能。随后,一系列方法提出了针对数据增强和提升 GR (Generative Retrieval) 模型排序能力的训练方案
Sampling Document Pieces as Pseudo Queries. In the same era, Dynamic Retriever [370], also based on the encoder-decoder model, constructed a model-based IR system by initializing the encoder with a pre-trained BERT [121]. Besides, Dynamic Retriever utilizes passages, sampled terms and $N$-grams to serve as pseudo queries to enhance the model’s memorization of DocIDs. Formally, the training methods can be summarized as follows:
采样文档片段作为伪查询。同一时期,同样基于编码器-解码器模型的Dynamic Retriever [370]通过用预训练BERT [121]初始化编码器,构建了基于模型的IR系统。此外,Dynamic Retriever利用段落、采样词项和$N$-gram作为伪查询来增强模型对DocID的记忆能力。其训练方法可形式化表述为:
$$
\begin{array}{r l}&{\mathrm{Sampled Document:}d_{s_{i}}\longrightarrow\mathrm{DocID},i\in{1,...,k_{d_{s}}},}\ &{\qquad\mathrm{Labeled Query:}q_{i}\longrightarrow\mathrm{DocID},i\in{1,...,k_{q}},}\end{array}
$$
$$
\begin{array}{r l}&{\mathrm{采样文档:}d_{s_{i}}\longrightarrow\mathrm{文档ID},i\in{1,...,k_{d_{s}}},}\ &{\qquad\mathrm{标注查询:}q_{i}\longrightarrow\mathrm{文档ID},i\in{1,...,k_{q}},}\end{array}
$$
where $d_{s_{i}}$ and $q_{i}$ denote each of the $k_{d_{s}}$ sampled document text and each of the $k_{q}$ labeled query for the corresponding DocID, respectively.
其中 $d_{s_{i}}$ 和 $q_{i}$ 分别表示对应 DocID 的 $k_{d_{s}}$ 个采样文档文本和 $k_{q}$ 个标注查询。
Generating Pseudo Queries from Documents. Following DSI, the NCI [307] model was trained using a combination of labeled query-document pairs and augmented pseudo querydocument pairs. Specifically, NCI proposed two strategies: one using the DocT5Query [208] model as a query generator, generating pseudo queries for each document in the corpus through beam search; the other strategy directly uses the document as a query, as stated in Equation (8). Similarly, DSI-QG [375] also proposed using a query generator to enhance training data, establishing a bridge between indexing and retrieval in DSI. This data augmentation method has been proven in subsequent works to be an effective method to enhance the model’s memorization for DocIDs,
从文档生成伪查询。遵循DSI方法,NCI[307]模型通过结合标注的查询-文档对和增强的伪查询-文档对进行训练。具体而言,NCI提出了两种策略:一种使用DocT5Query[208]模型作为查询生成器,通过束搜索为语料库中的每个文档生成伪查询;另一种策略则直接使用文档作为查询,如公式(8)所示。类似地,DSI-QG[375]也提出使用查询生成器来增强训练数据,在DSI中建立了索引与检索之间的桥梁。后续研究证明,这种数据增强方法是提升模型对DocID记忆能力的有效手段。
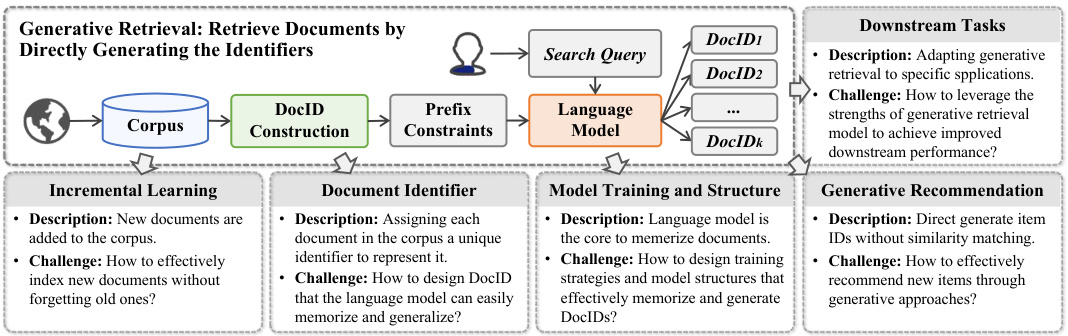
Fig. 4. A conceptual framework for a generative retrieval system, with a focus on challenges in incremental learning, identifier construction, model training and structure, and integration with downstream tasks and recommendation systems.
图 4: 生成式检索系统的概念框架,重点关注增量学习、标识符构建、模型训练与结构,以及与下游任务和推荐系统集成方面的挑战。
which can be expressed as follows:
可以表示为:
$$
\begin{array}{r}{\operatorname{Pseudo}\operatorname{Query}:q_{s_{i}}\longrightarrow\operatorname{DocID},i\in{1,...,k_{q_{s}}},}\end{array}
$$
$$
\begin{array}{r}{\operatorname{Pseudo}\operatorname{Query}:q_{s_{i}}\longrightarrow\operatorname{DocID},i\in{1,...,k_{q_{s}}},}\end{array}
$$
where $q_{s_{i}}$ represents each of the $k_{q_{s}}$ generated pseudo query for the corresponding DocID.
其中,$q_{s_{i}}$ 表示对应 DocID 生成的 $k_{q_{s}}$ 个伪查询中的每一个。
Improving Ranking Capability. Additionally, a series of methods focus on further optimizing the ranking capability of GR models. Chen et al. [30] proposed a multi-task distillation method to improve retrieval quality without changing the model structure, thereby obtaining better indexing and ranking capabilities. Meanwhile, LTRGR [159] introduced a ranking loss to train the model in ranking paragraphs. Subsequently, [365] proposed GenRRL, which improves ranking quality through reinforcement learning with relevance feedback, aligning token-level DocID generation with document-level relevance estimation. Moreover, [161] introduced DGR, which enhances generative retrieval through knowledge distillation. Specifically, DGR uses a cross-encoder as a teacher model, providing fine-grained passage ranking supervision signals, and then optimizes the model with a distilled RankNet loss. ListGR [280] defined positional conditional probabilities, emphasizing the importance of the generation order of each DocID in the list. In addition, ListGR employs relevance calibration that adjusts the generated list of DocIDs to better align with the labeled ranking list. See Table 1 for a detailed comparison of GR methods.
提升排序能力。此外,一系列方法专注于进一步优化GR模型的排序能力。Chen等人[30]提出了一种多任务蒸馏方法,在不改变模型结构的情况下提升检索质量,从而获得更好的索引和排序能力。同时,LTRGR[159]引入了排序损失来训练模型对段落进行排序。随后,[365]提出了GenRRL,通过基于相关性反馈的强化学习提升排序质量,使Token级别的DocID生成与文档级别的相关性估计对齐。此外,[161]提出了DGR,通过知识蒸馏增强生成式检索。具体而言,DGR使用交叉编码器作为教师模型,提供细粒度的段落排序监督信号,并通过蒸馏的RankNet损失优化模型。ListGR[280]定义了位置条件概率,强调列表中每个DocID生成顺序的重要性。此外,ListGR采用相关性校准技术,调整生成的DocID列表以更好地匹配标注的排序列表。GR方法的详细对比见表1。
3.1.2 Model Structure. Basic generative retrieval models mostly use pre-trained encoder-decoder structured generative models, such as T5 [231] and BART [138], fine-tuned for the DocID generation task. To better adapt to the GR task, researchers have proposed a series of specifically designed model structures [130, 224, 237, 275, 307, 342, 346].
3.1.2 模型结构。基础生成式检索模型主要采用预训练的编码器-解码器结构生成模型(如T5 [231]和BART [138]),通过微调适应DocID生成任务。为更好适配GR任务,研究者提出了一系列专门设计的模型结构[130, 224, 237, 275, 307, 342, 346]。
Model Decoding Methods. For the semantic structured DocID proposed by DSI [281], NCI [307] designed a Prefix-Aware Weight-Adaptive (PAWA) decoder. By adjusting the weights at different positions of DocIDs, this decoder can capture the semantic hierarchy of DocIDs. To allow the GR model to utilize both own parametric knowledge and external information, NP-Decoding [130] proposed using non-parametric contextual i zed word embeddings (as external memory) instead of traditional word embeddings as the input to the decoder. Additionally, PAG [345] proposed a planning-ahead generation approach, which first decodes the set-based DocID to approximate document-level scores, and then continues to decode the sequence-based DocID on this basis.
模型解码方法。针对DSI [281]提出的语义结构化DocID,NCI [307]设计了一种前缀感知权重自适应(PAWA)解码器。该解码器通过调整DocID不同位置的权重,能够捕捉DocID的语义层级结构。为使GR模型既能利用自身参数化知识又能结合外部信息,NP-Decoding [130]提出使用非参数化上下文词嵌入(作为外部记忆)替代传统词嵌入作为解码器输入。此外,PAG [345]提出了一种前瞻式生成方法,先解码基于集合的DocID以近似文档级评分,再在此基础上继续解码基于序列的DocID。
Combining Generative and Dense Retrieval Methods. Combining seq2seq generative models with dual-encoder retrieval models, MEVI [346] utilizes Residual Quantization (RQ) [189] to organize documents into hierarchical clusters, enabling efficient retrieval of candidate clusters and precise document retrieval within those clusters. Similarly, Generative Dense Retrieval (GDR) [342] proposed to first broadly match queries to document clusters, optimizing for interaction depth and memory efficiency, and then perform precise, cluster-specific document retrieval, boosting both recall and s cal ability.
结合生成式与密集检索方法。MEVI [346] 将序列到序列(seq2seq)生成模型与双编码器检索模型相结合,利用残差量化(Residual Quantization,RQ)[189] 将文档组织为分层聚类结构,从而实现候选聚类的高效检索及聚类内文档的精准定位。类似地,生成式密集检索(Generative Dense Retrieval,GDR)[342] 提出先对查询与文档聚类进行粗粒度匹配,优化交互深度与内存效率,再执行聚类专属的精确文档检索,显著提升了召回率与可扩展性。
Utilizing Multiple Models. TOME [237] proposed to decompose the GR task into two stages, first generating text paragraphs related to the query through an additional model, then using the GR model to generate the URL related to the paragraph. Diffusion Ret [224] proposed to first use a diffusion model (Seq DiffuSe q [341]) to generate a pseudo-document from a query, where the generated pseudo-document is similar to real documents in length, format, and content, rich in semantic information; Then, it employs another generative model to perform retrieval based on N-grams, similar to the process used by SEAL[13], leveraging an FM-Index[62] for generating N-grams found in the corpus. Self-Retrieval [275] fully integrated indexing, retrieval, and evaluation into a single large language model. It generates natural language indices and document segments, and performs self-evaluation to score and rank the generated documents.
利用多模型策略。TOME [237] 提出将GR (Generative Retrieval) 任务分解为两个阶段:先通过额外模型生成与查询相关的文本段落,再由GR模型生成与该段落关联的URL。Diffusion Ret [224] 提出先用扩散模型 (Seq DiffuSe q [341]) 根据查询生成伪文档,生成的伪文档在长度、格式和内容上与真实文档相似且语义信息丰富;随后采用另一生成式模型基于N-grams进行检索,类似SEAL[13]使用的流程,并利用FM-Index[62]生成语料库中存在的N-grams。Self-Retrieval [275] 将索引构建、检索和评估完全整合到单个大语言模型中,通过生成自然语言索引和文档片段,并执行自评估对生成文档进行打分排序。
3.2 Design of Document Identifiers
3.2 文档标识符设计
Another essential component of generative retrieval is document representation, also known as document identifiers (DocIDs), which act as the target outputs for the GR model. Accurate document representations are crucial as they enable the model to more effectively memorize document information, leading to enhanced retrieval performance. Table 1 provides a detailed comparison of the states, data types, and order of DocIDs across numerous GR methods. In the following sections, we will explore the design of DocIDs from two categories: numeric-based identifiers and text-based identifiers.
生成式检索的另一关键组成部分是文档表示,也称为文档标识符(DocID),它们作为GR模型的目标输出。准确的文档表示至关重要,因为它们能让模型更有效地记忆文档信息,从而提升检索性能。表1详细比较了多种GR方法中DocID的状态、数据类型和顺序。在接下来的章节中,我们将从两类DocID设计展开探讨:基于数字的标识符和基于文本的标识符。
3.2.1 Numeric-based Identifiers. An intuitive method to represent documents is by using a single number or a series of numbers, referred to as DocIDs. Existing methods have designed both static and learnable DocIDs.
3.2.1 基于数字的标识符。表示文档的一种直观方法是使用单个数字或一系列数字,称为文档ID (DocID)。现有方法设计了静态和可学习的文档ID。
Static DocIDs. Initially, DSI [281] introduced three numeric DocIDs to represent documents: (1) Unstructured Atomic DocID: a unique integer identifier is randomly assigned to each document, containing no structure or semantic information. (2) Naively Structured String DocID: treating random integers as divisible strings, implementing character-level DocID decoding to replace large softmax output layers. (3) Semantically Structured DocID: introducing semantic structure through hierarchical $k$ -means method, allowing semantically similar documents to share prefixes in their identifiers, effectively reducing the search space. Concurrently, Dynamic Retriever [370] also built a model-based IR system based on unstructured atomic DocID. Subsequently, Ultron [371] encoded documents into a latent semantic space using BERT [121], and compressed vectors into a smaller semantic space via Product Quantization (PQ) [73, 102], preserving semantic information. Each document’s PQ code serves as its semantic identifier. MEVI [346] clusters documents using Residual Quantization (RQ) [189] and utilizes dual-tower and seq2seq model embeddings for a balanced performance in large-scale document retrieval.
静态DocID。最初,DSI [281] 引入了三种数字DocID来表示文档:(1) 非结构化原子DocID:为每个文档随机分配一个唯一的整数标识符,不包含任何结构或语义信息。(2) 朴素结构化字符串DocID:将随机整数视为可分割的字符串,实现字符级DocID解码以替代大型softmax输出层。(3) 语义结构化DocID:通过分层 $k$ -means方法引入语义结构,使语义相似的文档在其标识符中共享前缀,有效缩小搜索空间。与此同时,Dynamic Retriever [370] 也基于非结构化原子DocID构建了基于模型的IR系统。随后,Ultron [371] 使用BERT [121] 将文档编码到潜在语义空间,并通过乘积量化(PQ) [73, 102] 将向量压缩到更小的语义空间,保留语义信息。每个文档的PQ代码作为其语义标识符。MEVI [346] 使用残差量化(RQ) [189] 对文档进行聚类,并利用双塔和seq2seq模型嵌入,在大规模文档检索中实现平衡性能。
Learnable DocIDs. Unlike previous static DocIDs, GenRet [265] proposed learnable document representations, transforming documents into DocIDs through an encoder, then reconstructs documents from DocIDs using a decoder, trained to minimize reconstruction error. Furthermore, it used progressive training and diversity clustering for optimization. To ensure that DocID embeddings can reflect document content, Tied-Atomic [206] proposed to link document text with token embeddings and employs contrastive loss for DocID generation. LMIndexer [112] and ASI [330] learned optimal DocIDs through semantic indexing, with LMIndexer using a re parameter iz ation mechanism for unified optimization, facilitating efficient retrieval by aligning semantically similar documents under common DocIDs. ASI extends this by establishing an end-to-end retrieval framework, incorporating semantic loss functions and re parameter iz ation to enable joint training.
可学习的文档标识符 (Learnable DocIDs)。与以往静态文档标识符不同,GenRet [265] 提出可学习的文档表示方法,通过编码器将文档转换为文档标识符,再使用解码器从文档标识符重构文档,并通过最小化重构误差进行训练。此外,该方法采用渐进式训练和多样性聚类进行优化。为确保文档标识符嵌入能反映文档内容,Tied-Atomic [206] 提出将文档文本与 token 嵌入关联,并采用对比损失生成文档标识符。LMIndexer [112] 和 ASI [330] 通过语义索引学习最优文档标识符:LMIndexer 使用重参数化机制进行统一优化,使语义相似的文档在相同文档标识符下对齐以提升检索效率;ASI 进一步扩展该方法,构建端到端检索框架,结合语义损失函数和重参数化实现联合训练。
Table 1. Comparisons of representative generative retrieval methods, focusing on document identifier, training data augmentation, and training objective.
| Method | DocumentIdentifier | Training Data Augmentation | Training Objective | |||||
| State | Data Type | Order | Sample Doc | Doc2Query | Seq2seq | DocID | Ranking | |
| GENRE [18] | Static | Text | Sequence | |||||
| DSI [281] | Static | Numeric | Sequence | |||||
| DynamicRetriever [370] | Static | Numeric | Sequence | |||||
| SEAL [13] | Static | Text | Sequence | |||||
| DSI-QG [375] | Static | Numeric | Sequence | |||||
| NCI [307] | Static | Numeric | Sequence | |||||
| Ultron [371] | Static | Numeric/Text | Sequence | |||||
| CorpusBrain[28] | Static | Text | Sequence | |||||
| GenRet [265] | Learnable | Numeric | Sequence | |||||
| AutoTSG[352] | Static | Text | Set | |||||
| SE-DSI [278] | Static | Text | Sequence | |||||
| Chen et al. [30] | Static | Numeric | Sequence | √ | ||||
| LLM-URL [376] | Static | Text | Sequence | |||||
| MINDER[160] | Static | Text | Sequence | |||||
| LTRGR [159] | Static | Text | Sequence | |||||
| NOVO [311] | Learnable | Text | Set | |||||
| GenRRL [365] | Static | Text | Sequence | √ | ||||
| LMIndexer [112] | Learnable | Numeric | Sequence | |||||
| ASI [330] | Learnable | Numeric | Sequence | |||||
| RIPOR [344] | Learnable | Numeric | Sequence | |||||
| GLEN [135] | Learnable | Text | Sequence | |||||
| DGR [161] | Static | Text | Sequence | |||||
| ListGR [280] | Static | Numeric | Sequence | |||||
表 1: 代表性生成式检索方法对比,重点关注文档标识符、训练数据增强和训练目标。
| 方法 | 文档标识符 | 训练数据增强 | 训练目标 |
|---|---|---|---|
| 状态 | 数据类型 | 顺序 | |
| GENRE [18] | 静态 | 文本 | 序列 |
| DSI [281] | 静态 | 数值 | 序列 |
| DynamicRetriever [370] | 静态 | 数值 | 序列 |
| SEAL [13] | 静态 | 文本 | 序列 |
| DSI-QG [375] | 静态 | 数值 | 序列 |
| NCI [307] | 静态 | 数值 | 序列 |
| Ultron [371] | 静态 | 数值/文本 | 序列 |
| CorpusBrain[28] | 静态 | 文本 | 序列 |
| GenRet [265] | 可学习 | 数值 | 序列 |
| AutoTSG[352] | 静态 | 文本 | 集合 |
| SE-DSI [278] | 静态 | 文本 | 序列 |
| Chen et al. [30] | 静态 | 数值 | 序列 |
| LLM-URL [376] | 静态 | 文本 | 序列 |
| MINDER[160] | 静态 | 文本 | 序列 |
| LTRGR [159] | 静态 | 文本 | 序列 |
| NOVO [311] | 可学习 | 文本 | 集合 |
| GenRRL [365] | 静态 | 文本 | 序列 |
| LMIndexer [112] | 可学习 | 数值 | 序列 |
| ASI [330] | 可学习 | 数值 | 序列 |
| RIPOR [344] | 可学习 | 数值 | 序列 |
| GLEN [135] | 可学习 | 文本 | 序列 |
| DGR [161] | 静态 | 文本 | 序列 |
| ListGR [280] | 静态 | 数值 | 序列 |
Furthermore, RIPOR [344] treats the GR model as a dense encoder to encode document content. It then splits these representations into vectors via RQ [189], creating unique DocID sequences. Furthermore, RIPOR implements a prefix-guided ranking optimization, increasing relevance scores for prefixes of pertinent DocIDs through margin decomposed pairwise loss during decoding.
此外,RIPOR [344] 将GR模型视为密集编码器来编码文档内容,随后通过RQ [189] 将这些表示拆分为向量,生成独特的DocID序列。此外,RIPOR采用前缀引导的排序优化策略,在解码过程中通过边缘分解成对损失提升相关DocID前缀的关联分数。
In summary, numeric-based document representations can utilize the embeddings of dense retrievers, obtaining semantically meaningful DocID sequences through methods such as $k$ -means, PQ [102], and RQ [189]; they can also combine encoder-decoder GR models with bi-encoder DR models to achieve complementary advantages [206, 346].
总之,基于数值的文档表示可以利用密集检索器的嵌入,通过诸如 $k$ -means、PQ [102] 和 RQ [189] 等方法获得具有语义意义的 DocID 序列;也可以将编码器-解码器 GR 模型与双编码器 DR 模型相结合,实现优势互补 [206, 346]。
3.2.2 Text-based Identifiers. Text-based DocIDs have the inherent advantage of effectively leveraging the strong capabilities of pre-trained language models and offering better interpret ability.
3.2.2 基于文本的标识符。基于文本的文档标识符(DocID)具有天然优势:能有效利用预训练语言模型的强大能力,并提供更好的可解释性。
Document Titles. The most straightforward text-based identifier is the document title, which requires each title to uniquely represent a document in the corpus, otherwise, it would not be possible to accurately retrieve a specific document. The Wikipedia corpus used in the KILT [218] benchmark, due to its well-regulated manual annotation, has a unique title corresponding to each document. Thus, GENRE [18], based on the title as DocID and leveraging the generative model BART [138] and pre-built DocID prefix, achieved superior retrieval performance across 11 datasets in KILT. Following GENRE, GERE [27], Corpus Brain [28], Re3val [257], and Corpus Brain ${}_{,++}$ [80] also based their work on title DocIDs for Wikipedia-based tasks. Notably, LLM-URL [376] directly generated URLs using ChatGPT prompts, achieving commendable performance after removing invalid URLs. However, in the web search scenario [205], document titles in the corpus often have significant duplication and many meaningless titles, making it unfeasible to use titles alone as DocIDs. Thus, Ultron [371] effectively addressed this issue by combining URLs and titles as DocIDs, identifying documents through keywords in web page URLs and titles.
文档标题。最直接的基于文本的标识符是文档标题,它要求每个标题能唯一代表语料库中的一篇文档,否则就无法准确检索到特定文档。KILT [218] 基准中使用的维基百科语料库由于其规范的人工标注,每篇文档都有唯一的标题。因此,GENRE [18] 以标题作为 DocID,并利用生成式模型 BART [138] 和预构建的 DocID 前缀,在 KILT 的 11 个数据集上实现了卓越的检索性能。继 GENRE 之后,GERE [27]、Corpus Brain [28]、Re3val [257] 和 Corpus Brain ${}_{,++}$ [80] 也基于维基百科任务的标题 DocID 展开工作。值得注意的是,LLM-URL [376] 直接使用 ChatGPT 提示生成 URL,在去除无效 URL 后取得了令人称赞的性能。然而,在网络搜索场景 [205] 中,语料库中的文档标题往往存在大量重复和无意义的标题,因此仅使用标题作为 DocID 不可行。为此,Ultron [371] 通过将 URL 和标题结合作为 DocID,有效解决了这一问题,通过网页 URL 和标题中的关键词来识别文档。
Sub-strings of Documents. To increase the flexibility of DocIDs, SEAL [13] proposed a substring identifier, representing documents with any N-grams within them. Using FM-Index (a compressed full-text sub-string index) [62], SEAL could generate N-grams present in the corpus to retrieve all documents containing those N-grams, scoring and ranking documents based on the frequency of N-grams in each document and the importance of N-grams. Following SEAL, various GR models [26, 159–161] also utilized sub-string DocIDs and FM-Index during inference. For a more comprehensive representation of documents, MINDER [160] proposed multi-view identifiers, including generated pseudo queries from document content via DocT5Query [208], titles, and sub-strings. This multi-view DocID was also used in LTRGR [159] and DGR [161].
文档子串。为提高文档标识符(DocID)的灵活性,SEAL [13]提出了子串标识符方案,允许用文档内任意N元语法(N-gram)进行表征。通过FM-Index(一种压缩全文子串索引)[62],SEAL能生成语料库中存在的N元语法,检索包含这些N元语法的所有文档,并根据N元语法在文档中的出现频率及其重要性进行打分排序。继SEAL之后,多种生成式检索(GR)模型[26, 159–161]在推理阶段也采用了子串DocID和FM-Index技术。为获得更全面的文档表征,MINDER[160]提出了多视角标识符方案,包含通过DocT5Query[208]生成的文档内容伪查询、标题以及子串。这种多视角DocID同样被应用于LTRGR[159]和DGR[161]模型。
Term Sets. Unlike the sequential DocIDs described earlier, AutoTSG [352] proposed a term set-based document representation, using keywords extracted from titles and content, rather than predefined sequences, allowing for retrieval of the target document as long as the generated term set is included in the extracted keywords. Recently, PAG [345] also constructed DocIDs based on sets of key terms, disregarding the order of terms, which is utilized for approximating document relevance in decoding.
术语集。与之前描述的序列化文档ID不同,AutoTSG [352]提出了一种基于术语集的文档表示方法,该方法使用从标题和内容中提取的关键词,而非预定义的序列,只要生成的术语集包含在提取的关键词中,就能检索到目标文档。最近,PAG [345]也基于关键术语集构建了文档ID,忽略术语的顺序,用于在解码过程中近似文档相关性。
Learnable DocIDs. Text-based identifiers can also be learnable. Similarly based on term-sets, NOVO [311] proposed learnable continuous N-grams constituting term-set DocIDs. Through denoising query modeling, the model learned to generate queries from documents with noise, thereby implicitly learning to filter out document N-grams more relevant to queries. NOVO also improves the document’s semantic representation by updating N-gram embeddings. Later, GLEN[135] uses dynamic lexical DocIDs and follows a two-phase index learning strategy. First, it assigns DocIDs by extracting keywords from documents using self-supervised signals. Then, it refines DocIDs by integrating query-document relevance through two loss functions. During inference, GLEN ranks documents using DocID weights without additional overhead.
可学习的文档标识符。基于文本的标识符同样可以具备可学习性。NOVO [311] 同样基于词项集合,提出了由可学习连续N元词项构成的文档标识符。该模型通过去噪查询建模,学习从带噪声的文档生成查询,从而隐式地筛选出与查询更相关的文档N元词项。NOVO还通过更新N元词项嵌入来优化文档的语义表示。后续研究GLEN [135] 采用动态词汇文档标识符,并采用两阶段索引学习策略:首先利用自监督信号从文档提取关键词来分配文档标识符;然后通过两种损失函数整合查询-文档相关性来优化标识符。在推理阶段,GLEN直接利用文档标识符权重进行排序,无需额外计算开销。
3.3 Incremental Learning on Dynamic Corpora
3.3 动态语料库上的增量学习
Prior studies have focused on generative retrieval from static document corpora. However, in reality, the documents available for retrieval are continuously updated and expanded. To address this challenge, researchers have developed a range of methods to optimize GR models for adapting to dynamic corpora.
先前的研究主要集中于从静态文档库中进行生成式检索。然而现实中,可供检索的文档会持续更新和扩展。为应对这一挑战,研究人员开发了一系列方法来优化生成式检索(Generative Retrieval, GR)模型,使其适应动态语料库。
Optimizer and Document Rehearsal. At first, $\mathrm{DSI++}$ [192] aims to address the incremental learning challenges encountered by DSI [281]. $\mathrm{DSI++}$ modifies the training by optimizing flat loss basins through the Sharpness-Aware Minimization (SAM) optimizer, stabilizing the learning process of the model. It also employs DocT5Query [208] to generate pseudo queries for documents in the existing corpus as training data augmentation, mitigating the forgetting issue of GR models.
优化器与文档复述机制。最初,$\mathrm{DSI++}$[192]旨在解决DSI[281]面临的增量学习挑战。该方法通过Sharpness-Aware Minimization (SAM) 优化器优化平坦损失盆地来调整训练过程,从而稳定模型的学习轨迹。同时采用DocT5Query[208]为现有语料库中的文档生成伪查询作为训练数据增强,缓解生成式检索(GR)模型的遗忘问题。
Constrained Optimization Addressing the scenario of real-time addition of new documents, such as news or scientific literature IR systems, IncDSI [124] views the addition of new documents as a constrained optimization problem to find optimal representations for the new documents. This approach aims to (1) ensure new documents can be correctly retrieved by their relevant queries, and (2) maintain the retrieval performance of existing documents unaffected.
约束优化
针对实时新增文档(如新闻或科学文献信息检索系统)的场景,IncDSI [124] 将新增文档视为一个约束优化问题,旨在为新文档找到最优表示。该方法力求实现两个目标:(1) 确保新文档能被相关查询正确检索,(2) 保持现有文档的检索性能不受影响。
Incremental Product Quantization. CLEVER [25], based on Product Quantization (PQ) [102], proposes Incremental Product Quantization (IPQ) for generating PQ codes as DocIDs for documents. Compared to traditional PQ methods, IPQ designs two adaptive thresholds to update only a subset of centroids instead of all, maintaining the indices of updated centroids constant. This method reduces computational costs and allows the system to adapt flexibly to new documents.
增量乘积量化 (Incremental Product Quantization)。基于乘积量化 (PQ) [102] 的 CLEVER [25] 提出了增量乘积量化 (IPQ) 方法,用于生成文档的 PQ 编码作为文档 ID。与传统 PQ 方法相比,IPQ 设计了两个自适应阈值来仅更新部分中心点而非全部,同时保持已更新中心点的索引不变。该方法降低了计算成本,并使系统能够灵活适应新文档。
Fine-tuning Adatpers for Specific Tasks. Corpus Brain ${}++$ [80] introduces the $\mathrm{KLT++}$ benchmark for continuously updated KILT [218] tasks and designs a dynamic architecture paradigm with a backbone-adapter structure. By fixing a shared backbone model to provide basic retrieval capabilities while introducing task-specific adapters to increment ally learn new documents for each task, it effectively avoids catastrophic forgetting. During training, Corpus Brain $^{++}$ generates pseudo queries for new document sets and continues to pre-train adapters for specific tasks.
微调适配器以执行特定任务。Corpus Brain ${}++$ [80] 提出了持续更新的KILT [218]任务基准$\mathrm{KLT++}$,并设计了一种基于主干-适配器结构的动态架构范式。该方法通过固定共享主干模型提供基础检索能力,同时引入任务专用适配器逐步学习各任务的新文档,有效避免了灾难性遗忘。训练过程中,Corpus Brain$^{++}$会为新文档集生成伪查询,并持续针对特定任务预训练适配器。
3.4 Downstream Task Adaption
3.4 下游任务适配
Generative retrieval methods, apart from addressing retrieval tasks individually, have been tailored to various downstream generative tasks. These include fact verification [284], entity linking [86], open-domain QA [126], dialogue [51], slot filling [137], among others, as well as knowledgeintensive tasks [218], code [179], conversational QA [3], and multi-modal retrieval scenarios [165], demonstrating superior performance and efficiency. These methods are discussed in terms of separate training, joint training, and multi-modal generative retrieval.
生成式检索方法除了单独处理检索任务外,还被定制用于各种下游生成任务。这些任务包括事实验证 [284]、实体链接 [86]、开放域问答 [126]、对话 [51]、槽位填充 [137] 等,以及知识密集型任务 [218]、代码 [179]、会话式问答 [3] 和多模态检索场景 [165],展现出卓越的性能和效率。这些方法分别从独立训练、联合训练和多模态生成式检索的角度进行了讨论。
3.4.1 Separate Training. For fact verification tasks [284], which involve determining the correctness of input claims, GERE [27] proposed using an encoder-decoder-based GR model to replace traditional indexing-based methods. Specifically, GERE first utilizes a claim encoder to encode input claims, and then generates document titles related to the claim through a title decoder to obtain candidate sentences for corresponding documents.
3.4.1 独立训练
针对事实核查任务 [284](即判定输入主张正确性的任务),GERE [27] 提出采用基于编码器-解码器的生成式检索 (Generative Retrieval, GR) 模型替代传统的基于索引的方法。具体而言,GERE 首先通过主张编码器对输入主张进行编码,随后通过标题解码器生成与主张相关的文档标题,从而获取对应文档的候选句子。
Knowledge-Intensive Language Tasks. For Knowledge-Intensive Language Tasks (KILT) [218], Corpus Brain [28] introduced three pre-training tasks to enhance the model’s understanding of query-document relationships at various granular i ties: Internal Sentence Selection, Leading Paragraph Selection, and Hyperlink Identifier Prediction. Similarly, UGR [26] proposed using different granular i ties of N-gram DocIDs to adapt to various downstream tasks, unifying different retrieval tasks into a single generative form. UGR achieves this by letting the GR model learn prompts specific to tasks, generating corresponding document, passage, sentence, or entity identifiers.
知识密集型语言任务。针对知识密集型语言任务 (KILT) [218],Corpus Brain [28] 引入了三种预训练任务来增强模型在不同粒度上对查询-文档关系的理解:内部句子选择、主导段落选择和超链接标识符预测。类似地,UGR [26] 提出使用不同粒度的 N-gram 文档标识符 (DocIDs) 来适应各种下游任务,将不同的检索任务统一为单一的生成形式。UGR 通过让 GR 模型学习特定于任务的提示 (prompts),生成相应的文档、段落、句子或实体标识符来实现这一目标。
Futhermore, DearDR [283] utilizes remote supervision and self-supervised learning techniques, using Wikipedia page titles and hyperlinks as training data. The model samples sentences from Wikipedia documents as input and trains a self-regressive model to decode page titles or hyperlinks, or both, without the need for manually labeled data. Re3val [257] proposes a retrieval framework combining generative reordering and reinforcement learning. It first reorders retrieved page titles using context information obtained from a dense retriever, then optimizes the reordering using the REINFORCE algorithm to maximize rewards generated by constrained decoding.
此外,DearDR [283] 采用远程监督和自监督学习技术,利用维基百科页面标题和超链接作为训练数据。该模型从维基百科文档中采样句子作为输入,并训练一个自回归模型来解码页面标题或超链接(或两者),无需手动标注数据。Re3val [257] 提出了一种结合生成式重排序和强化学习的检索框架。它首先使用密集检索器获取的上下文信息对检索到的页面标题进行重排序,然后通过 REINFORCE 算法优化排序,以最大化由约束解码生成的奖励。
Multi-hop retrieval. In multi-hop retrieval tasks, which require iterative document retrievals to gather adequate evidence for answering a query, GMR [131] proposed to employ language model memory and multi-hop memory to train a generative retrieval model, enabling it to memorize the target corpus and simulate real retrieval scenarios through constructing pseudo multi-hop query data, achieving dynamic stopping and efficient performance in multi-hop retrieval tasks.
多跳检索。在多跳检索任务中,需要通过迭代文档检索来收集足够的证据以回答查询,GMR [131] 提出利用语言模型记忆和多跳记忆训练生成式检索模型,使其能够记忆目标语料库,并通过构建伪多跳查询数据模拟真实检索场景,从而在多跳检索任务中实现动态停止和高效性能。
Code Retrieval. CodeDSI [203] is an end-to-end generative code search method that directly maps queries to pre-stored code samples’ DocIDs instead of generating new code. Similar to DSI [281], it includes indexing and retrieval stages, learning to map code samples and real queries to their respective DocIDs. CodeDSI explores different DocID representation strategies, including direct and clustered representation, as well as numerical and character representations.
代码检索。CodeDSI [203] 是一种端到端的生成式代码搜索方法,它直接将查询映射到预存储代码样本的 DocID,而非生成新代码。与 DSI [281] 类似,它包含索引和检索两个阶段,学习将代码样本和真实查询映射到各自的 DocID。CodeDSI 探索了不同的 DocID 表示策略,包括直接表示和聚类表示,以及数值和字符表示。
Conversational Question Answering. GCoQA [158] is a generative retrieval method for conversational QA systems that directly generates DocIDs for passage retrieval. This method focuses on key information in the dialogue context at each decoding step, achieving more precise and efficient passage retrieval and answer generation, thereby improving retrieval performance and overall system efficiency.
会话问答。GCoQA [158] 是一种用于会话问答系统的生成式检索方法,可直接生成用于段落检索的 DocID。该方法在每一步解码时聚焦对话上下文中的关键信息,实现更精准高效的段落检索与答案生成,从而提升检索性能及系统整体效率。
3.4.2 Joint Training. The methods in the previous section involve separately training generative retrievers and downstream task generators. However, due to the inherent nature of GR models as generative models, a natural advantage lies in their ability to be jointly trained with downstream generators to obtain a unified model for retrieval and generation tasks.
3.4.2 联合训练。上一节的方法涉及分别训练生成式检索器(Generative Retriever)和下游任务生成器。然而,由于GR模型作为生成式模型的固有特性,其天然优势在于能够与下游生成器进行联合训练,从而获得一个适用于检索和生成任务的统一模型。
Multi-decoder Structure. UniGen [155] proposes a unified generation framework to integrate retrieval and question answering tasks, bridging the gap between query input and generation targets using connectors generated by large language models. UniGen employs shared encoders and task-specific decoders for retrieval and question answering, introducing iterative enhancement strategies to continuously improve the performance of both tasks.
多解码器结构。UniGen [155] 提出了一种统一的生成框架,用于整合检索和问答任务,通过大语言模型生成的连接器弥合查询输入与生成目标之间的差距。UniGen 采用共享编码器和任务专用解码器分别处理检索与问答,并引入迭代增强策略持续提升两项任务的性能。
Multi-task Training. Later, CorpusLM [152] introduces a unified language model that integrates GR, closed-book generation, and retrieval-augmented generation to handle various knowledgeintensive tasks. The model adopts a multi-task learning approach and introduces ranking-guided DocID decoding strategies and continuous generation strategies to improve retrieval and generation performance. In addition, CorpusLM designs a series of auxiliary DocID understanding tasks to deepen the model’s understanding of DocID semantics.
多任务训练。随后,CorpusLM [152] 提出了一种统一的大语言模型,整合了生成式检索 (GR)、闭卷生成和检索增强生成,以处理各种知识密集型任务。该模型采用多任务学习方法,并引入了基于排名的DocID解码策略和连续生成策略,以提升检索和生成性能。此外,CorpusLM还设计了一系列辅助DocID理解任务,以加深模型对DocID语义的理解。
3.4.3 Multi-modal Generative Retrieval. Generative retrieval methods can also leverage multimodal data such as text, images, etc., to achieve end-to-end multi-modal retrieval.
3.4.3 多模态生成式检索。生成式检索方法同样可利用文本、图像等多模态数据,实现端到端的多模态检索。
Tokenizing Images to DocID Sequences. At first, IRGen [357] transforms image retrieval problems into generative problems, predicting relevant discrete visual tokens, i.e., image identifiers, through a seq2seq model given a query image. IRGen proposed a semantic image tokenizer, which converts global image features into short sequences capturing high-level semantic information.
将图像转换为DocID序列的Token化方法。首先,IRGen [357] 将图像检索问题转化为生成式问题,通过一个seq2seq模型在给定查询图像的情况下预测相关的离散视觉token(即图像标识符)。IRGen提出了一种语义图像token化器,能够将全局图像特征转换为捕捉高层语义信息的短序列。
Advanced Model Training and Structure. Later, GeMKR [178] combines LLMs’ generation capabilities with visual-text features, designing a generative knowledge retrieval framework. It first guides multi-granularity visual learning using object-aware prefix tuning techniques to align visual features with LLMs’ text feature space, achieving cross-modal interaction. GeMKR then employs a two-step retrieval process: generating knowledge clues closely related to the query and then retrieving corresponding documents based on these clues. GRACE [178] achieves generative cross-modal retrieval method by assigning unique identifier strings to images and training multimodal large language models (MLLMs) [7] to memorize the association between images and their identifiers. The training process includes (1) learning to memorize images and their corresponding identifiers, and (2) learning to generate the target image identifiers from textual queries. GRACE explores various types of image identifiers, including strings, numbers, semantic and atomic identifiers, to adapt to different memory and retrieval requirements.
高级模型训练与结构。随后,GeMKR [178] 将大语言模型的生成能力与视觉-文本特征相结合,设计了一个生成式知识检索框架。它首先利用对象感知前缀调优技术引导多粒度视觉学习,将视觉特征与大语言模型的文本特征空间对齐,实现跨模态交互。GeMKR 随后采用两步检索流程:生成与查询密切相关的知识线索,然后根据这些线索检索对应文档。GRACE [178] 通过为图像分配唯一标识符字符串并训练多模态大语言模型 (MLLMs) [7] 来记忆图像与其标识符的关联,实现了生成式跨模态检索方法。训练过程包括:(1) 学习记忆图像及其对应标识符,(2) 学习从文本查询生成目标图像标识符。GRACE 探索了多种类型的图像标识符,包括字符串、数字、语义和原子标识符,以适应不同的记忆和检索需求。
3.4.4 Generative Recommend er Systems. Recommendation systems, as an integral part of the information retrieval, are currently undergoing a paradigm shift from disc rim i native models to generative models. Generative recommendation systems do not require the computation of ranking scores for each item followed by database indexing, but instead accomplish item recommendations through the direct generation of IDs. In this section, several seminal works, including P5 [74], GPT4Rec [146], TIGER [233], SEATER [254], IDGenRec [273], LC-Rec [360] and ColaRec [309], are summarized to outline the development trends in generative recommendations.
3.4.4 生成式推荐系统
推荐系统作为信息检索的重要组成部分,当前正经历从判别式模型向生成式模型的范式转变。生成式推荐系统无需计算每个物品的排序分数再进行数据库索引,而是通过直接生成ID来完成物品推荐。本节总结了P5 [74]、GPT4Rec [146]、TIGER [233]、SEATER [254]、IDGenRec [273]、LC-Rec [360]和ColaRec [309]等开创性工作,以概述生成式推荐的发展趋势。
P5 [74] transforms various recommendation tasks into different natural language sequences, designing a universal, shared framework for recommendation completion. This method, by setting unique training objectives, prompts, and prediction paradigms for each recommendation domain’s downstream tasks, serves well as a backbone model, accomplishing various recommendation tasks through generated text. In generative retrieval, effective indexing identifiers have been proven to significantly enhance the performance of generative methods. Similarly, TIGER [233] initially learns a residual quantized auto encoder to generate semantically informative indexing identifiers for different items. It then trains a transformer-based encoder-decoder model with this semantically informative indexing identifier sequence to generate item identifiers for recommending the next item based on historical sequences.
P5 [74] 将各类推荐任务转化为不同的自然语言序列,设计了一个通用的共享框架来完成推荐。该方法通过为每个推荐领域的下游任务设置独特的训练目标、提示和预测范式,很好地充当了骨干模型,通过生成文本来完成各种推荐任务。在生成式检索中,有效的索引标识符已被证明能显著提升生成方法的性能。类似地,TIGER [233] 首先学习残差量化自编码器,为不同物品生成具有语义信息的索引标识符,随后利用这些语义丰富的索引标识符序列训练基于Transformer的编码器-解码器模型,从而根据历史序列生成物品标识符来推荐下一个物品。
Focusing solely on semantic information and overlooking the collaborative filtering information under the recommendation context might limit the further development of generative models. Therefore, after generating semantic indexing identifiers similar to TIGER using a residual quantized auto encoder with uniform semantic mapping, LC-Rec [360] also engages in a series of alignment tasks, including sequential item prediction, explicit index-language alignment, and recommendation-oriented implicit alignment. Based on the learned item identifiers, it integrates semantic and collaborative information, enabling large language models to better adapt to sequence recommendation tasks.
仅关注语义信息而忽略推荐场景下的协同过滤信息,可能会限制生成模型的进一步发展。因此,在通过具有统一语义映射的残差量化自编码器生成类似TIGER的语义索引标识符后,LC-Rec [360]还进行了一系列对齐任务,包括序列物品预测、显式索引-语言对齐以及面向推荐的隐式对齐。基于学习到的物品标识符,它整合了语义和协同信息,使大语言模型能更好地适应序列推荐任务。
IDGenRec [273] innovative ly combines generative recommendation systems with large language models by using human language tokens to generate unique, concise, semantically rich and platform-agnostic texual identifiers for recommended items. The framework includes a text ID generator trained on item metadata with a diversified ID generation algorithm, and an alternating training strategy that optimizes both the ID generator and the LLM-based recommendation model for improved performance and accuracy in sequential recommendations. SEATER [254] designs a balanced $\mathbf{k}$ -ary tree-structured indexes, using a constrained $\mathbf{k}$ -means clustering method to recursively cluster vectors encoded from item texts, obtaining equal-length identifiers. Compared to the method proposed by DSI [281], this balanced $\mathbf{k}$ -ary tree index maintains semantic consistency at every level. It then trains a Transformer-based encoder-decoder model and enhances the semantics of each level of indexing through contrastive learning and multi-task learning. ColaRec [309] integrates collaborative filtering signals and content information by deriving generative item identifiers from a pretrained recommendation model and representing users via aggregated item content. Then it uses an item indexing generation loss and contrastive loss to align content-based semantic spaces with collaborative interaction spaces, enhancing the model’s ability to recommend items in an end-to-end framework.
IDGenRec [273] 创新性地将生成式推荐系统与大语言模型相结合,通过使用人类语言token为推荐项生成独特、简洁、语义丰富且与平台无关的文本标识符。该框架包含一个基于物品元数据训练的文本ID生成器(采用多样化ID生成算法),以及一种交替训练策略,可同步优化ID生成器和基于大语言模型的推荐模型,从而提升序列推荐的性能和准确性。SEATER [254] 设计了平衡的 $\mathbf{k}$ 叉树结构索引,采用约束型 $\mathbf{k}$ 均值聚类方法递归聚类从物品文本编码得到的向量,生成等长标识符。与DSI [281] 提出的方法相比,这种平衡 $\mathbf{k}$ 叉树索引在每一层级都保持语义一致性。随后训练基于Transformer的编码器-解码器模型,并通过对比学习和多任务学习增强各层级索引的语义。ColaRec [309] 通过从预训练推荐模型中导出生成式物品标识符,并基于聚合物品内容表示用户,从而整合协同过滤信号与内容信息。接着使用物品索引生成损失和对比损失,将基于内容的语义空间与协同交互空间对齐,增强模型在端到端框架中的物品推荐能力。
4 RELIABLE RESPONSE GENERATION: DIRECT INFORMATION ACCESSING WITHGENERATIVE LANGUAGE MODELS
4 可靠的响应生成:利用生成式语言模型直接获取信息
The rapid advancement of large language models has positioned them as a novel form of IR system, capable of generating reliable responses directly aligned with users’ informational needs. This not only saves the time users would otherwise spend on collecting and integrating information but also provides personalized, user-centric answers tailored to individual users.
大语言模型的快速发展使其成为一种新型的信息检索(IR)系统,能够直接生成与用户信息需求高度匹配的可靠响应。这不仅节省了用户原本需要花费在收集和整合信息上的时间,还能提供针对个体用户量身定制的个性化、以用户为中心的答案。
However, challenges remain in creating a grounded system that delivers faithful answers, such as hallucination, prolonged inference time, and high operational costs. This section will outline strategies for constructing a faithful GenIR system by: (1) Optimizing the GenIR model internally, (2) Enhancing the model with external knowledge, (3) Increasing accountability, and (4) Developing personalized information assistants.
然而,构建一个能提供真实答案的可靠系统仍面临诸多挑战,例如幻觉问题、推理时间过长以及高昂的运营成本。本节将概述构建可信生成式信息检索(Generative IR)系统的策略:(1) 内部优化GenIR模型,(2) 通过外部知识增强模型,(3) 提高问责机制,(4) 开发个性化信息助手。
4.1 Internal Knowledge Memorization
4.1 内部知识记忆
To develop a user-friendly and reliable IR system, the generative model should be equipped with comprehensive internal knowledge. Optimization of the backbone generative model can be categorized into three aspects: structural enhancements, training strategies, and inference techniques. The overview of this section is shown in the green part of Figure 5.
为开发用户友好且可靠的信息检索(IR)系统,生成式模型需具备全面的内部知识。主干生成模型的优化可分为三个层面:结构增强、训练策略和推理技术。本节概述如图5绿色部分所示。
4.1.1 Model Structure. With the advent of generative models, various methods have been introduced to improve model structure and enhance generative reliability. We aim to discuss the crucial technologies contributing to this advancement in this subsection.
4.1.1 模型结构
随着生成式模型(Generative Model)的出现,各种改进模型结构并增强生成可靠性的方法被提出。本节将重点讨论推动这一进步的关键技术。
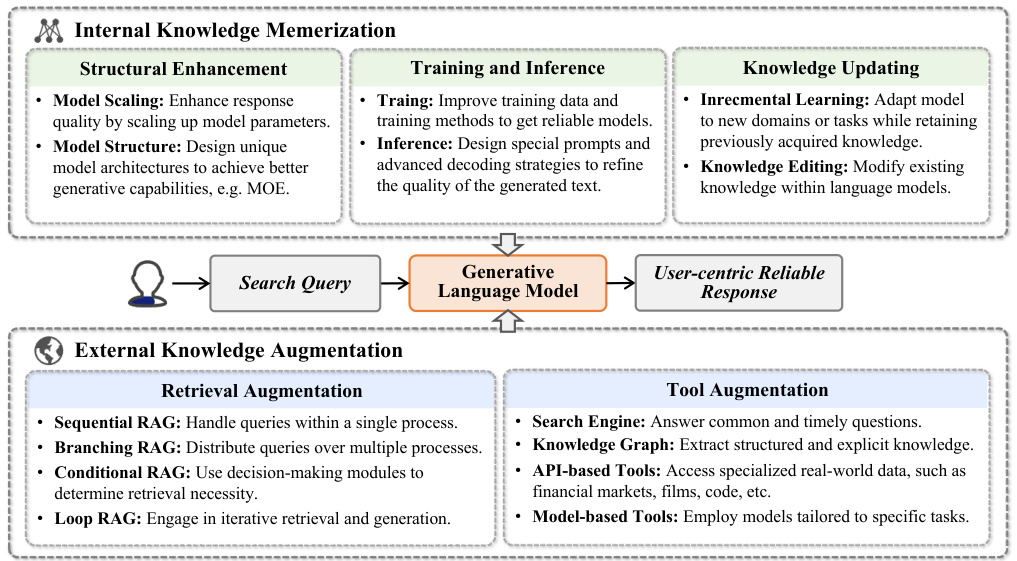
Fig. 5. An Illustration of strategies for enhancing language models to generate user-centric and reliable responses, including model internal knowledge memorization and external knowledge augmentation.
图 5: 提升语言模型生成以用户为中心且可靠回答的策略示意图,包括模型内部知识记忆和外部知识增强。
(1) Model Scaling Model parameter scaling is a pivotal factor influencing performance. Contemporary language models predominantly employ the Transformer architecture, and scaling both the model parameters and the training data enhances the model’s capacity to retain knowledge and capabilities [116]. For instance, in the GPT [2, 16, 228, 229] series and LLaMA [285, 286] family, larger models tend to perform better on diverse downstream tasks, including few-shot learning, language understanding, and generation [34]. Additionally, scaling the model contributes to improved instruction-following capabilities [227], enabling a more adept comprehension of user intent and generating responses that better satisfy user requests.
模型扩展
模型参数扩展是影响性能的关键因素。当代语言模型主要采用Transformer架构,扩展模型参数和训练数据能增强模型保留知识和能力的能力[116]。例如,在GPT[2,16,228,229]系列和LLaMA[285,286]家族中,更大的模型往往在多种下游任务中表现更优,包括少样本学习、语言理解和生成[34]。此外,扩展模型有助于提升指令跟随能力[227],使模型更擅长理解用户意图并生成更符合用户需求的响应。
(2) Model Integration Model integration is an effective method to enhance the reliability of generated outputs by capitalizing on the diverse strengths of various models. The predominant approach is the Mixture of Experts (MoE) [96], which utilizes a gating mechanism to selectively activate sections of network parameters during inference, greatly increasing the effective parameters without inflating inference costs [58, 61, 106, 136]. This method also boasts impressive s cal ability, with efficacy augmented alongside the expanding parameter volume and the number of expert models [38]. Alternatively, the LLM-Blender framework [107] employs a ranker and a fuser to combine answers from various LLMs, including black-box models, but faces high deployment costs.
(2) 模型集成
模型集成是一种通过利用不同模型的多样化优势来增强生成输出可靠性的有效方法。主流方法是混合专家模型 (Mixture of Experts, MoE) [96],它采用门控机制在推理时选择性激活部分网络参数,大幅提升有效参数量而不增加推理成本 [58, 61, 106, 136]。该方法还具有出色的可扩展性,其效能随着参数量与专家模型数量的增加而提升 [38]。另一种方案 LLM-Blender 框架 [107] 通过排序器和融合器整合包括黑盒模型在内的多种大语言模型输出,但面临较高的部署成本。
4.1.2 Training and Inference. In the model training stage, methods to enhance the reliability of answers can be categorized into two aspects: training data optimization and training methods optimization.
4.1.2 训练与推理。在模型训练阶段,提升答案可靠性的方法可分为两方面:训练数据优化和训练方法优化。
(1) Training Data Optimization The quality of training data substantially affects the reliability of model outputs. Noise, misinformation, and incomplete information can disrupt the learning process, leading to hallucinations and other issues. To address this, [79] used GPT-3.5 to artificially create textbooks filled with examples and language descriptions as training data, resulting in significant improvements on downstream tasks after minor fine-tuning. LIMA [363] used dialogues from community forums to construct a small-scale fine-tuning dataset, enhancing the model’s conversation capabilities during the alignment phase. To reduce redundancies in crawled internet data, Lee et al. [132] combined suffix arrays [188] and MinHash [15] to approximate matching and de duplicate the training dataset, reducing direct reproduction from the same source.
(1) 训练数据优化
训练数据的质量显著影响模型输出的可靠性。噪声数据、错误信息和不完整信息会干扰学习过程,导致幻觉等问题。为解决这一问题,[79] 使用 GPT-3.5 人工生成包含示例和语言描述的教科书作为训练数据,经过少量微调后在下游任务中取得了显著提升。LIMA [363] 采用社区论坛的对话构建小规模微调数据集,在对齐阶段增强了模型的对话能力。为减少网络爬取数据的冗余,Lee 等人 [132] 结合后缀数组 [188] 和 MinHash [15] 实现近似匹配与训练数据集去重,降低了同一来源的直接复现。
(2) Training Methods Optimization Beyond conventional training methods, additional techniques have been proposed to improve the factuality of model outputs. MixCL [264] incorporates contrastive learning into the training objective, using an external knowledge base to identify correct snippets and reduce the probability of generating incorrect tokens, thus enhancing model reliability. CaliNet [56] utilizes a contrastive method to assess erroneous knowledge learned by the model and fine-tunes the parameters of the FFN layer to rectify these errors. FactTune [211] incorporates factuality assessment during the RLHF phase, using automatic evaluation methods like FactScore [198] to rank outputs and employing DPO [230] to teach the model factuality preference.
训练方法优化
除常规训练方法外,研究者还提出了多种提升模型输出事实性的技术。MixCL [264] 将对比学习融入训练目标,通过外部知识库识别正确片段并降低错误token生成概率,从而增强模型可靠性。CaliNet [56] 采用对比方法评估模型习得的错误知识,并通过微调FFN层参数进行修正。FactTune [211] 在RLHF阶段引入事实性评估,使用FactScore [198] 等自动评估方法对输出排序,并采用DPO [230] 教导模型事实性偏好。
Apart from enhancing the internal knowledge reliability during training, the inference stage significantly impacts the reliability of answers. The overall inference process consists of user input and the model’s token decoding, and approaches to increase generation reliability can be divided into prompt engineering and decoding strategy.
除了提升训练过程中内部知识的可靠性,推理阶段对答案的可靠性也有显著影响。整体推理流程包含用户输入和模型的Token解码,提高生成可靠性的方法可分为提示工程(prompt engineering)和解码策略(decoding strategy)两大类。
(3) Prompt Engineering Prompting methods play a vital role in guiding the model. A welldesigned prompt can better promote the model’s internal capabilities to provide more accurate answers. The Chain-of-Thought (CoT) [313] prompting method guides the model to explicitly decompose the question into a reasoning chain during decoding, improving response accuracy by grounding the final answer on accurate intermediate steps. Further, CoT-SC [306] samples multiple answers and chooses the most consistent one as the final answer. The Tree of Thoughts [332] expands CoT’s single reasoning path to multiple paths, synthesizing their outcomes to arrive at the final answer. The Chain-of-Verification (CoVE) [49] introduces a self-reflection mechanism where the LLM generates a draft response, then validates each statement for factual inaccuracies, correcting errors to enhance factual accuracy. Additionally, methods like RECITE [268] and GenRead [339] prompt the model to output relevant internal knowledge fragments, which are then used to bolster the question-answering process.
(3) 提示工程 (Prompt Engineering)
提示方法在引导模型方面起着至关重要的作用。精心设计的提示可以更好地激发模型的内部能力,从而提供更准确的答案。思维链 (Chain-of-Thought, CoT) [313] 提示方法引导模型在解码过程中将问题显式分解为推理链,通过基于准确的中间步骤得出最终答案,从而提高响应准确性。进一步地,CoT-SC [306] 对多个答案进行采样,并选择最一致的答案作为最终结果。思维树 (Tree of Thoughts) [332] 将 CoT 的单一推理路径扩展为多条路径,综合其结果以得出最终答案。验证链 (Chain-of-Verification, CoVE) [49] 引入了自反思机制,大语言模型先生成草稿响应,然后验证每个陈述的事实准确性,纠正错误以提高事实准确性。此外,RECITE [268] 和 GenRead [339] 等方法提示模型输出相关的内部知识片段,随后用于增强问答过程。
(4) Decoding Strategy Decoding strategies are another critical factor influencing the reliability of model-generated responses. An appropriate decoding method can maintain the reliability and diversity of a model’s response. Nucleus Sampling [133] samples within a set probability range for tokens, ensuring better diversity while balancing variety and reliability. Building on this, FactualNucleus Sampling [134] employs a dynamic, decaying threshold for token sampling, ensuring later tokens are not influenced by earlier less factual tokens. Wan et al. [292] proposed a faithfulnessaware decoding method to enhance the faithfulness of the beam-search approach by incorporating a Ranker to reorder generated sequences and a lookahead method to avoid unfaithful tokens.
(4) 解码策略
解码策略是影响模型生成响应可靠性的另一个关键因素。适当的解码方法可以保持模型响应的可靠性和多样性。Nucleus Sampling [133] 在token的设定概率范围内进行采样,在平衡多样性与可靠性的同时确保更好的多样性。在此基础上,FactualNucleus Sampling [134] 采用动态衰减阈值进行token采样,确保后续token不受先前低事实性token的影响。Wan等人 [292] 提出了一种基于忠实性的解码方法,通过引入Ranker对生成序列重新排序,并采用前瞻性方法避免不忠实token,从而提升beam-search方法的忠实性。
Apart from directly modifying the decoding method, several studies influence the decoding distribution by leveraging hidden layer information. DoLa [37] uses distribution al differences between hidden and output layers to prioritize newly learned factual knowledge or key terms, increasing their generation likelihood. Inference-Time Intervention (ITI) [147] identifies attention heads strongly correlated with response correctness, adjusts their orientations, and moderates their activation, achieving more truthful generation with minimal model interference. Shi et al. [251] proposed CAD, comparing output distributions before and after adding extra information, reducing reliance on the model’s own knowledge to avoid conflicts leading to inaccuracies.
除了直接修改解码方法外,多项研究通过利用隐藏层信息来影响解码分布。DoLa [37] 利用隐藏层与输出层之间的分布差异,优先处理新学习的事实知识或关键术语,从而提高其生成概率。推理时干预 (ITI) [147] 识别与回答正确性高度相关的注意力头,调整其方向并调节激活强度,以最小化模型干扰实现更真实的生成。Shi等 [251] 提出CAD方法,通过比较添加额外信息前后的输出分布,减少对模型自身知识的依赖,从而避免因知识冲突导致的错误。
4.1.3 Knowledge Updating. In real-life scenarios, information is constantly evolving, and therefore, the GenIR system needs to continuously acquire the latest knowledge to meet users’ information needs. Since the model’s knowledge storage is limited, knowledge updating is necessary to ensure more reliable generated responses. In this section, we will discuss existing methods for knowledge updating from two perspectives: incremental learning and knowledge editing.
4.1.3 知识更新。在现实场景中,信息不断演变,因此GenIR系统需要持续获取最新知识以满足用户信息需求。由于模型的知识存储有限,必须通过知识更新来确保生成更可靠的响应。本节将从增量学习和知识编辑两个角度探讨现有的知识更新方法。
(1) Incremental Learning Incremental learning refers to the ability of machine learning models to continuously learn new skills and tasks while retaining previously acquired knowledge [301,
(1) 增量学习
增量学习指机器学习模型在保留已掌握知识的同时持续学习新技能和任务的能力 [301,
Table 2. Comparison of representative reliable response generation methods, considering model configurations, specializations, and evaluations. For simplicity, "LM" stands for Language Modeling and "ODQA" stands for Open-Domain Question Answering.
| Method | Model Configuration | Target Domain | ||||
| Backbone | Parameters | Trained | Capability | Evaluation Task | ||
| GPT-3 [16] | Transformer | 175B | General | General Tasks (LM, QA, Reasoning,...) | ||
| Llama-3.1 [59] | Transformer | 8B/70B/405B | General | General Tasks | ||
| Mistral [105] | Transformer | 7B/22B/123B | General | General Tasks | ||
| PaLM [34] | Transformer | 540B | General | General Tasks | ||
| FactTune [211] | Llama-2 | 7B | Factuality | Domain-specific QA | ||
| GenRead [339] | InstructGPT | 175B | Factuality | Knowledge-intensive Tasks | ||
| DoLa [37] | LLaMA | 7B65B | Factuality | Multi-choice QA, Open-ended Generation | ||
| RAG [139] | BART | 400M | Factuality | Knowledge-intensive Tasks | ||
| REPLUG [252] | GPT-3 | 175B | Factuality | LM, Multi-choice QA, ODQA | ||
| FLARE [111] | GPT-3 | 175B | Factuality | Knowledge-intensive Tasks | ||
| Self-RAG [5] | Llama-2 | 7B/13B | Factuality | ODQA, Reasoning, Fact Check. | ||
| IR-CoT [287] | GPT-3/Flan-T5 | 175B/11B | × | Factuality | Multi-hop QA | |
| ReAct [333] | PaLM | 540B | Tools | Multi-hop QA,Fact Check.,Decision Making | ||
| StructGPT[110] | GPT-3/GPT-3.5 | 175B/- | × | Tools | KG-based QA, Table-based QA, Text-to-SQL | |
| ToolFormer [245] | GPT-J | 6B | Tools | LM, Math, QA, Temporal Tasks | ||
| ToolLLM [226] | LLaMA | 7B | Tools | Tool Use | ||
| HuggingGPT [250] | GPT-3.5 | Tools | Various Complex AI Tasks | |||
| According to [314] | GPT-3/Flan-T5/.. | 175B/11B/... | Accountability | ODQA | ||
| IFL [129] | GPT-J | 6B | Accountability | Long-form QA | ||
| WebGPT [204] | GPT-3 | 175B | Accountability | Long-form QA | ||
| WebBrain[223] | BART | 400M | Accountability | Long-form QA | ||
| RARR [70] | PaLM | 540B | Accountability | ODQA,Reasoning,Conversational QA | ||
| SearChain [326] | GPT-3.5 | × | Accountability | Knowledge-intensive Tasks | ||
| P2Bot [172] | Transformer | Personalization | Personalized Dialogue | |||
| P-Soups [98] | nn | 7B | Personalization | Personalized Dialogue | ||
| OPPU [274] | Llama-2 | 7B | Personalization | Language ModelPersonalization Tasks | ||
| Zhongjing [11] | Ziya-LLaMA | 13B | Healthcare | Chinese Medical Dialogue | ||
| Mental-LLM [327] | Alpaca/GPT-3.5/... | 7B/-/.. | √/x | Healthcare | Mental Health Reasoning Tasks | |
| Edu-Chat [48] | LLaMA | 13B | Education | ODQA,Education Tasks | ||
表 2: 代表性可靠响应生成方法对比,涵盖模型配置、专业领域和评估指标。为简洁起见,"LM"代表语言建模,"ODQA"代表开放域问答。
| 方法 | 主干模型 | 参数量 | 是否微调 | 目标领域 | 评估任务 |
|---|---|---|---|---|---|
| GPT-3 [16] | Transformer | 175B | 通用 | 通用任务 (LM、QA、推理等) | |
| Llama-3.1 [59] | Transformer | 8B/70B/405B | 通用 | 通用任务 | |
| Mistral [105] | Transformer | 7B/22B/123B | 通用 | 通用任务 | |
| PaLM [34] | Transformer | 540B | 通用 | 通用任务 | |
| FactTune [211] | Llama-2 | 7B | 事实性 | 领域特定QA | |
| GenRead [339] | InstructGPT | 175B | 事实性 | 知识密集型任务 | |
| DoLa [37] | LLaMA | 7B/65B | 事实性 | 多选QA、开放生成 | |
| RAG [139] | BART | 400M | 事实性 | 知识密集型任务 | |
| REPLUG [252] | GPT-3 | 175B | 事实性 | LM、多选QA、ODQA | |
| FLARE [111] | GPT-3 | 175B | 事实性 | 知识密集型任务 | |
| Self-RAG [5] | Llama-2 | 7B/13B | 事实性 | ODQA、推理、事实核查 | |
| IR-CoT [287] | GPT-3/Flan-T5 | 175B/11B | × | 事实性 | 多跳QA |
| ReAct [333] | PaLM | 540B | 工具 | 多跳QA、事实核查、决策制定 | |
| StructGPT [110] | GPT-3/GPT-3.5 | 175B/- | × | 工具 | 基于KG的QA、基于表格的QA、Text-to-SQL |
| ToolFormer [245] | GPT-J | 6B | 工具 | LM、数学、QA、时序任务 | |
| ToolLLM [226] | LLaMA | 7B | 工具 | 工具使用 | |
| HuggingGPT [250] | GPT-3.5 | 工具 | 各类复杂AI任务 | ||
| According to [314] | GPT-3/Flan-T5/... | 175B/11B/... | 可问责性 | ODQA | |
| IFL [129] | GPT-J | 6B | 可问责性 | 长格式QA | |
| WebGPT [204] | GPT-3 | 175B | 可问责性 | 长格式QA | |
| WebBrain [223] | BART | 400M | 可问责性 | 长格式QA | |
| RARR [70] | PaLM | 540B | 可问责性 | ODQA、推理、对话式QA | |
| SearChain [326] | GPT-3.5 | × | 可问责性 | 知识密集型任务 | |
| P2Bot [172] | Transformer | 个性化 | 个性化对话 | ||
| P-Soups [98] | nn | 7B | 个性化 | 个性化对话 | |
| OPPU [274] | Llama-2 | 7B | 个性化 | 语言模型个性化任务 | |
| Zhongjing [11] | Ziya-LLaMA | 13B | 医疗 | 中文医疗对话 | |
| Mental-LLM [327] | Alpaca/GPT-3.5/... | 7B/-/... | √/× | 医疗 | 心理健康推理任务 |
| Edu-Chat [48] | LLaMA | 13B | 教育 | ODQA、教育任务 |
303, 321, 351]. In the GenIR system, it is crucial to enable the language model to memorize the latest information while preventing the forgetting of previous knowledge.
303, 321, 351]。在GenIR系统中,关键是要让语言模型既能记住最新信息,又能避免遗忘已有知识。
One approach is Incremental Pre-training, which does not rely on supervised data but continues pre-training on continuously updated corpora to alleviate catastrophic forgetting. For example, Baidu proposed the ERNIE 2.0 framework [267], enhancing language understanding through continuous multi-task learning. Jang et al. [100] introduced Continual Knowledge Learning (CKL) to explore how LLMs update and retain knowledge amidst rapidly changing information, creating benchmarks like FUAR. Cossu et al. [39] studied continual pre-training for language and vision, finding that self-supervised or unsupervised methods are more effective in retaining previous knowledge compared to supervised learning. Additionally, Ke et al. [119] proposed Domain Adaptive Pre-training (DAP-training) to improve the model’s adaptability to new domains while preventing forgetting using techniques like soft masking and contrastive learning. For domain-specific model construction, Xie et al. [323] introduced FinPythia-6.9B, an efficient continual pre-training method specifically designed for large-scale language models in the financial domain.
一种方法是增量预训练(Incremental Pre-training),它不依赖监督数据,而是在持续更新的语料库上继续预训练以缓解灾难性遗忘。例如,百度提出的ERNIE 2.0框架[267]通过持续多任务学习增强语言理解能力。Jang等人[100]提出持续知识学习(CKL)方法,探索大语言模型如何在快速变化的信息中更新和保留知识,并创建了FUAR等基准测试。Cossu等人[39]研究了语言和视觉的持续预训练,发现自监督或无监督方法比监督学习更能有效保留先前知识。此外,Ke等人[119]提出领域自适应预训练(DAP-training),通过软掩码和对比学习等技术提升模型对新领域的适应能力,同时防止遗忘。针对领域专用模型构建,Xie等人[323]推出了FinPythia-6.9B,这是专为金融领域大语言模型设计的高效持续预训练方法。
On the other hand, Incremental Fine-tuning utilizes only labeled data for training. Progressive Prompts [236] appends new soft prompts for each new task, facilitating knowledge transfer and reducing forgetting. DynaInst [201] enhances lifelong learning in pre-trained language models through parameter regular iz ation and experience replay, employing dynamic instance and task selection for efficient learning under resource constraints. Jang et al. [99] challenge traditional multitask prompt fine-tuning by refining expert models on individual tasks. Suhr et al. [260] introduce a feedback-driven continual learning approach for instruction-following agents, where natural language feedback is converted into immediate rewards via contextual bandits to optimize learning. O-LoRA [305] achieves superior continual learning by training new tasks in orthogonal low-rank subspaces, significantly minimizing task interference. Peng et al. [216] propose a scalable language model that dynamically adjusts parameters based on task requirements, effectively preventing the forgetting of previously learned tasks.
另一方面,增量微调 (Incremental Fine-tuning) 仅使用标注数据进行训练。Progressive Prompts [236] 为每个新任务追加新的软提示 (soft prompts),促进知识迁移并减少遗忘。DynaInst [201] 通过参数正则化 (parameter regularization) 和经验回放 (experience replay) 增强预训练语言模型的终身学习能力,采用动态实例和任务选择机制在资源受限条件下实现高效学习。Jang等人 [99] 通过优化单任务专家模型,对传统多任务提示微调提出了挑战。Suhr等人 [260] 为指令跟随型AI智能体提出反馈驱动的持续学习方法,通过上下文老虎机 (contextual bandits) 将自然语言反馈转化为即时奖励以优化学习过程。O-LoRA [305] 通过在正交低秩子空间训练新任务实现卓越的持续学习性能,显著降低了任务间干扰。Peng等人 [216] 提出可扩展的大语言模型,能根据任务需求动态调整参数,有效防止已学习任务的遗忘。
(2) Knowledge Editing Knowledge editing refers to the process of modifying and updating existing knowledge within language models [191, 303], distinct from incremental learning that focuses on adapting to new domains or tasks. By editing the weights or layers of a model, knowledge editing methods can correct erroneous facts and incorporate new knowledge, making it important before deploying GenIR systems. There are primarily three paradigms for internal knowledge editing within language models: adding trainable parameters, locate-then-edit, and meta-learning.
(2) 知识编辑
知识编辑指修改和更新语言模型中现有知识的过程 [191, 303],与专注于适应新领域或任务的增量学习不同。通过编辑模型的权重或层,知识编辑方法可以纠正错误事实并整合新知识,这对部署生成式信息检索(GenIR)系统至关重要。语言模型内部知识编辑主要有三种范式:添加可训练参数、定位后编辑和元学习。
One method of Adding Trainable Parameters is by integrating new single neurons (patches) in the final feed-forward neural network (FFN) layer, as in T-Patcher [94] and CaliNet [56], which serve as trainable parameters to adjust the model’s behavior. Alternatively, discrete code-book modules are introduced in the middle layers of the language model, as in GRACE [83], to adjust and correct information.
一种添加可训练参数的方法是在最后的全连接神经网络(FFN)层中集成新的单神经元(patches),如T-Patcher [94]和CaliNet [56]所做的那样,这些神经元作为可训练参数来调整模型的行为。另一种方法是在语言模型的中间层引入离散码本模块,如GRACE [83]所做的那样,来调整和校正信息。
Moreover, the Locate-then-Edit method first identifies the parameters corresponding to specific knowledge and then updates these targeted parameters directly. Common techniques involve identifying key-value pairs in the FFN matrix, known as "knowledge neurons," and updating them [45]. Techniques like ROME [193] use causal mediation analysis to pinpoint areas needing editing, and MEMIT [194] builds on ROME to implement synchronized editing in various scenarios. Methods such as PMET [154] employ attention mechanisms for editing, while BIRD [182] introduces a bidirectional inverse relation modeling approach.
此外,定位后编辑(Locate-then-Edit)方法首先识别与特定知识对应的参数,然后直接更新这些目标参数。常见技术包括识别FFN矩阵中的键值对(称为"知识神经元(knowledge neurons)"并对其进行更新[45]。ROME[193]等技术使用因果中介分析(causal mediation analysis)来精确定位需要编辑的区域,MEMIT[194]则在ROME基础上实现了多种场景下的同步编辑。PMET[154]等方法采用注意力机制进行编辑,而BIRD[182]引入了双向逆关系建模(bidirectional inverse relation modeling)方法。
Meta-Learning, another paradigm, uses hyper-networks to generate the necessary updates for model editing. KE (Knowledge Editor) [17] predicts weight updates for each data point using a hyper-network. MEND [199], by taking low-order decomposition of gradients as input, learns to rapidly edit language models to enhance performance. Additionally, MALMEN [270] separates the computations of hyper-networks and language models, facilitating the editing of multiple facts under a limited memory budget. These meta-learning mechanisms enable models to swiftly adapt to new knowledge and tasks. A detailed comparison of representative reliable response generation methods is provided in Table 2.
元学习 (Meta-Learning) 是另一种范式,它使用超网络 (hyper-network) 为模型编辑生成必要的更新。KE (Knowledge Editor) [17] 通过超网络预测每个数据点的权重更新。MEND [199] 以梯度的低阶分解作为输入,学习快速编辑语言模型以提升性能。此外,MALMEN [270] 将超网络和语言模型的计算分离,在有限内存预算下实现多事实编辑。这些元学习机制使模型能够快速适应新知识和任务。表 2 提供了代表性可靠响应生成方法的详细对比。
4.2 External Knowledge Augmentation
4.2 外部知识增强
Although large language models have demonstrated significant effectiveness in response generation, issues such as susceptibility to hallucinations, difficulty handling in-domain knowledge, and challenges with knowledge updating persist. Augmenting the model’s generative process with external knowledge sources can serve as an effective way to tackle these issues. Based on the form of external knowledge employed, these approaches can be classified into retrieval augmentation and tool augmentation. The blue area in Figure 5 provides an overview of this section.
尽管大语言模型在生成响应方面表现出显著效果,但幻觉倾向、领域知识处理困难以及知识更新挑战等问题依然存在。通过外部知识源增强模型的生成过程,可作为解决这些问题的有效途径。根据所采用的外部知识形式,这些方法可分为检索增强和工具增强两类。图5中的蓝色区域概述了本节内容。
4.2.1 Retrieval Augmentation. Retrieval-Augmented Generation (RAG) enhances the response of generative models by combining them with a retrieval mechanism [95, 139, 368]. By querying a large collection of documents, information that is relevant to the input query can be fetched and integrated into the input of the generative model. RAG enables generative models to be grounded in existing reliable knowledge, significantly improving the reliability of model generation. Typically, a RAG method involves a retriever and a generator. Based on the interaction flow between these two, RAG methods can be divided into four categories [72].
4.2.1 检索增强。检索增强生成 (Retrieval-Augmented Generation, RAG) 通过将生成模型与检索机制相结合来增强其响应能力 [95, 139, 368]。通过查询大量文档集合,可以获取与输入查询相关的信息并将其整合到生成模型的输入中。RAG 使生成模型能够基于现有可靠知识进行生成,显著提高了模型生成结果的可靠性。典型的 RAG 方法包含检索器和生成器两个组件。根据二者交互流程的不同,RAG 方法可分为四类 [72]。
(1) Sequential RAG: Sequential RAG operates on a linear progression, where the retriever first retrieves relevant information and the generator utilizes this information to directly complete the response generation process.
(1) 顺序RAG: 顺序RAG采用线性流程运作, 检索器首先获取相关信息, 生成器随后利用这些信息直接完成响应生成过程。
The basic form of sequential RAG is a “Retrieve-Read” framework [183], where early works perform joint [14, 81, 139] or separate [95] training of retriever and generator but require costly pre-training. In-Context RALM [234] addresses this by directly using retrieved documents as input, leveraging the model’s in-context learning without additional training.
序列化RAG的基本形式是"检索-阅读"框架[183],早期研究通过联合[14, 81, 139]或分离[95]训练检索器和生成器来实现,但需要昂贵的预训练成本。上下文RALM[234]通过直接使用检索文档作为输入,利用模型的上下文学习能力,避免了额外训练。
With the widespread adoption of LLMs, most subsequent works are built on the foundation of a frozen generator. AAR [340] fine-tunes a general retriever to adapt to the information acquisition preferences of the generative model. LLM-embedder [353] uses rewards produced by LLM to train an embedding model dedicated to retrieval augmentation. ARL2 [350] leverages LLM to annotate relevance scores in the training set and trains a retriever using contrastive learning.
随着大语言模型(LLM)的广泛采用,大多数后续工作都建立在冻结生成器的基础上。AAR [340]通过微调通用检索器来适应生成模型的信息获取偏好。LLM-embedder [353]利用大语言模型产生的奖励来训练专用于检索增强的嵌入模型。ARL2 [350]借助大语言模型标注训练集中的相关性分数,并采用对比学习训练检索器。
Several works introduce pre-retrieval and post-retrieval processes [72] into the sequential pipeline to enhance the overall efficiency. In the pre-retrieval process, the RRR model [183] introduces a rewriter module before the retriever, trained using the generator’s feedback to enable the retrieval system to provide more suitable information for generation.
多项研究在顺序流程中引入了检索前(pre-retrieval)和检索后(post-retrieval)处理过程[72]以提升整体效率。在检索前阶段,RRR模型[183]在检索器前加入了重写模块,该模块通过生成器的反馈进行训练,使检索系统能为生成过程提供更合适的信息。
In the post-retrieval process, information compressors are proposed to filter out irrelevant content from documents, avoiding misleading the generator’s response [43, 114, 170]. RECOMP [325] uses both abstract ive and extractive compressors to generate concise summaries of retrieved documents. LLMLingua [109] retains important tokens by calculating token importance based on the perplexity provided by the generative model. Long LL M Lingua [108] introduces query-aware compression and reranks retrieved documents based on importance scores to alleviate the “loss in the middle” phenomenon [170]. PRCA [329] employs reinforcement learning to train a text compressor adaptable to black-box LLMs and various retrievers, serving as a versatile plug-in.
在检索后处理过程中,信息压缩器被提出来过滤文档中的无关内容,避免误导生成器的响应 [43, 114, 170]。RECOMP [325] 同时使用抽象式和抽取式压缩器来生成检索文档的简洁摘要。LLMLingua [109] 通过基于生成模型提供的困惑度计算 token 重要性来保留重要 token。Long LLMLingua [108] 引入了查询感知压缩,并根据重要性分数对检索文档重新排序,以缓解"中间丢失"现象 [170]。PRCA [329] 采用强化学习训练可适配黑盒大语言模型和各种检索器的文本压缩器,作为通用插件使用。
(2) Branching RAG: In the Branching RAG framework, the input query is processed across multiple pipelines, and each pipeline may involve the entire process in the sequential pipeline. The outputs from all pipelines are merged to form the final response, allowing for finer-grained handling of the query or retrieval results.
(2) 分支RAG (Branching RAG): 在分支RAG框架中,输入查询会通过多个流程并行处理,每个流程可能包含顺序流程中的完整步骤。所有流程的输出结果会被合并形成最终响应,从而实现对查询或检索结果更细粒度的处理。
In the pre-retrieval stage, TOC [123] uses few-shot prompting to recursively decompose complex questions into clear sub-questions in a tree structure, retrieving relevant documents for each and generating a comprehensive answer. Blend Filter [297] enhances the original query using prompts with internal and external knowledge, retrieves related documents with the augmented queries, and merges them for a comprehensive response.
在预检索阶段,TOC [123]采用少样本提示递归地将复杂问题分解为树状结构的清晰子问题,为每个子问题检索相关文档并生成综合答案。Blend Filter [297]通过结合内部与外部知识的提示增强原始查询,用增强后的查询检索相关文档,最后合并生成全面响应。
In the post-retrieval stage, REPLUG [252] processes each retrieved document with the query through the generator separately and combines the resulting probability distributions to form the final prediction. GenRead [339] prompts LLM to generate related documents and merges them with retrieved documents from the retriever as input, enhancing content coverage.
在检索后阶段,REPLUG [252] 将每个检索到的文档与查询分别通过生成器处理,并合并所得概率分布以形成最终预测。GenRead [339] 提示大语言模型生成相关文档,并将其与检索器获取的文档合并作为输入,从而提升内容覆盖率。
(3) Conditional RAG: The Conditional RAG framework adapts to various query types through distinct processes, improving the system’s flexibility. Since there can be knowledge conflict between the knowledge from retrieved documents and the generator’s own knowledge, RAG’s effectiveness isn’t consistent across all scenarios. To address this, common conditional RAG methods include a decision-making module that determines whether to engage the retrieval process for each query.
(3) 条件式RAG:条件式RAG框架通过差异化流程适配各类查询类型,提升系统灵活性。由于检索文档中的知识与生成器自身知识可能存在冲突,RAG的效能并非在所有场景中都稳定。为解决该问题,常见的条件式RAG方法会引入决策模块,用以判断是否对每个查询启动检索流程。
SKR [308] trains a binary classifier on a dataset of questions LLMs can or cannot answer, determining at inference whether to use retrieval. Training labels are obtained by prompting the model to assess if external knowledge is needed. Self-DC [296] uses the model’s confidence score to decide on retrieval necessity, categorizing queries into unknown, uncertain, and known, with unknown queries processed through sequential RAG and uncertain ones decomposed into sub-questions. Rowen [52] introduces a multilingual detection module that perturbs the original question and measures response consistency to decide on retrieval.
SKR [308] 在LLM能回答或不能回答的问题数据集上训练二元分类器,在推理时判断是否使用检索。训练标签通过提示模型评估是否需要外部知识获得。Self-DC [296] 利用模型的置信度分数决定检索必要性,将查询分为未知、不确定和已知三类,未知查询通过顺序RAG处理,不确定查询则分解为子问题。Rowen [52] 提出多语言检测模块,通过扰动原始问题并测量响应一致性来决定是否检索。
(4) Loop RAG: Loop RAG involves deep interactions between the retriever and generator components. Owing to multi-turn retrieval and generation processes, accompanied by comprehensive interactions, it excels at handling complex and diverse input queries, yielding superior results in response generation.
(4) Loop RAG:Loop RAG 通过检索器(retriever)与生成器(generator)组件的深度交互,借助多轮检索与生成过程及全面交互机制,擅长处理复杂多样的输入查询,在响应生成方面表现优异。
ITER-RETGEN [248] introduces an iterative framework alternating between retrieval-augmented generation and generation-augmented retrieval, repeating this process to produce the final answer. IR-COT [287] follows a similar procedure to ITER-RETGEN but the iteration pauses based on the model’s own generative process. FLARE [111] conducts concurrent retrieval during generation, evaluating the need for retrieval at each new sentence based on the LLM’s confidence score, dynamically supplementing information to enhance content reliability. COG [128] models generation as continual retrieval and copying of segments from an external corpus, with the generator producing conjunctions to maintain fluency. Self-RAG [5] adds special tokens into the vocabulary, allowing the generator to decide on retrieval, document importance, and whether to perform a critique.
ITER-RETGEN [248] 提出了一种迭代框架,交替进行检索增强生成和生成增强检索,通过重复这一过程生成最终答案。IR-COT [287] 采用与 ITER-RETGEN 类似的流程,但会根据模型自身的生成过程暂停迭代。FLARE [111] 在生成过程中并行执行检索,基于大语言模型的置信度分数评估每个新句子是否需要检索,动态补充信息以提高内容可靠性。COG [128] 将生成建模为从外部语料库持续检索和复制片段的过程,生成器负责生成连接词以保持流畅性。Self-RAG [5] 在词表中添加特殊 Token,使生成器能够自主决定检索行为、文档重要性评估以及是否执行批判性验证。
Some works focus on de constructing complex inquiries into sub-questions, addressing these individually to produce a more dependable response. [221] guides LLM to decompose complex questions into sub-questions, answer each using retrieved results, and synthesize the answers; RET-Robust [338] builds upon this by incorporating an NLI model to verify retrieved documents support the sub-question answers, reducing misinformation.
一些研究致力于将复杂查询拆解为子问题,通过分别处理这些子问题来生成更可靠的回答。[221] 指导大语言模型将复杂问题分解为子问题,利用检索结果逐一解答后综合答案;RET-Robust [338] 在此基础上引入自然语言推理 (NLI) 模型来验证检索文档是否支持子问题答案,从而减少错误信息。
4.2.2 Tool Augmentation. Although retrieval-augmented techniques have significantly improved upon the blind spots of a generator’s self-knowledge, these methods struggle with the rapid and flexible update of information since they rely on the existence of information within an external corpus of documents. Tool augmentation, on the other hand, excels in addressing this issue by invoking various tools that allow for the timely acquisition and usage of the latest data, including finance, news, and more. Moreover, tool augmentation expands the scope of responses a model can offer, such as language translation, image generation, and other tasks, to more comprehensively meet users’ information retrieval needs.
4.2.2 工具增强 (Tool Augmentation)
尽管检索增强技术显著改善了生成器自知识盲点的问题,但这些方法依赖于外部文档语料库中信息的存在,因此在信息的快速灵活更新方面存在困难。相比之下,工具增强通过调用各类工具(如金融、新闻等最新数据的及时获取与使用)更擅长解决这一问题。此外,工具增强还扩展了模型可提供的响应范围(例如语言翻译、图像生成等任务),从而更全面地满足用户的信息检索需求。
There are four categories of tools that can be utilized to construct a more reliable information retrieval system:
构建更可靠的信息检索系统可利用的工具可分为四类:
(1) Search Engine: Common search engine tools like Google Search and Bing Search help answer frequent and time-sensitive queries effectively. Self-Ask [221] initially decomposes complex questions into multiple sub-questions, then uses a search engine to answer each sub-question, and finally generates a comprehensive answer to the complex question. ReAct [333] embeds search engine calls into the model’s reasoning process, allowing the generative model to determine when to make calls and what queries to input for more flexible reasoning. New Bing can automatically search relevant information from Bing based on user input, yielding reliable and detailed answers, including citation annotations in the generated content.
(1) 搜索引擎: 常见搜索引擎工具如Google Search和Bing Search能有效回答高频且时效性强的问题。Self-Ask [221] 首先将复杂问题分解为多个子问题,随后使用搜索引擎回答每个子问题,最终生成复杂问题的综合答案。ReAct [333] 将搜索引擎调用嵌入模型的推理过程,使生成式模型能自主决定调用时机及查询内容,实现更灵活的推理。New Bing可根据用户输入自动从Bing搜索相关信息,生成包含引用标注的可靠详细答案。
Some works have also built advanced conversational systems based on tools like search engines. Internet-Augmented Generation [125] enhances the quality of conversational replies by using search engines during conversations. LaMDA [282] and BlenderBot [253] combine search engines with conversational agents, constantly accessing internet information to enrich conversation factual ness. WebGPT [204] and WebCPM [225] directly teach models to perform human-like browser operations by generating commands such as Search, Click, and Quote, facilitating the automated retrieval and acquisition of information.
一些研究还基于搜索引擎等工具构建了高级对话系统。联网增强生成 (Internet-Augmented Generation) [125] 通过在对话过程中使用搜索引擎来提升回复质量。LaMDA [282] 和 BlenderBot [253] 将搜索引擎与对话智能体结合,持续获取网络信息以增强对话的事实性。WebGPT [204] 和 WebCPM [225] 则直接教导模型执行类人浏览器操作,通过生成搜索 (Search)、点击 (Click)、引用 (Quote) 等指令,实现信息的自动化检索与获取。
(2) Knowledge Graph (KG): Compared to search engines, KGs are particularly useful for extracting structured, explicit knowledge. Relevant knowledge from a knowledge graph can be extracted and used as a prompt input to enhance the generative process [262]. StructGPT [110] introduces an iterative reading-and-reasoning framework where the model can access a knowledge graph through a well-designed interface, continually acquiring information and reasoning until an answer is obtained. RoG [181] generates plausible reasoning paths from a KG, executes them in parallel, and integrates outcomes for a final answer; ToG [262] allows the model to explore entities and links without pre-planning paths, continuously assessing reasoning feasibility.
(2) 知识图谱 (Knowledge Graph, KG): 与搜索引擎相比,知识图谱特别适用于提取结构化的显性知识。可以从知识图谱中提取相关知识并作为提示输入,以增强生成过程 [262]。StructGPT [110] 提出了一种迭代式阅读-推理框架,模型通过精心设计的接口访问知识图谱,持续获取信息并进行推理直至获得答案。RoG [181] 从知识图谱生成合理的推理路径,并行执行这些路径并整合结果以得出最终答案;ToG [262] 允许模型在不预先规划路径的情况下探索实体和链接,持续评估推理可行性。
(3) API-based Tools: An important part of the tools is the real-world APIs, which enable the model to obtain information from specific data sources, such as real-time stock information, movie services, code interpreters, and so on. However, the multitude and diversity of APIs, coupled with the adherence to certain operational protocols, make the teaching of API usage to models a focal point of this area.
(3) 基于API的工具: 工具中重要的一部分是现实世界的API, 它们使得模型能够从特定数据源获取信息, 例如实时股票信息、电影服务、代码解释器等。然而, API的多样性和数量庞大, 加上需要遵循特定的操作协议, 使得教授模型使用API成为该领域的重点。
Toolformer [245] trains language models in a self-supervised manner to automatically call APIs when needed, using prompts to generate API calls, executing them, and filtering ineffective ones to form the dataset. Training with standard language modeling objectives yields models that can autonomously invoke APIs across tasks without losing language modeling capabilities. RestGPT [258] formulates a framework prompting LLMs to invoke RESTful APIs, comprising an online planner, an API selector, and an executor. ToolLLM [226] uses a large corpus of scraped APIs to build a dataset for fine-tuning. Gorilla [214] introduces an information retriever providing the model with reference API documentation, facilitating retrieval-based information utilization during fine-tuning. ToolkenGPT [82] incorporates each tool as a new token into the vocabulary, enabling the model to invoke APIs during inference as naturally as generating text.
Toolformer [245] 通过自监督方式训练语言模型,使其能在需要时自动调用API:利用提示生成API调用指令,执行这些指令并过滤无效调用以构建数据集。采用标准语言建模目标训练后,模型能在跨任务场景中自主调用API,同时保持语言建模能力。RestGPT [258] 提出了一个框架,通过提示大语言模型调用RESTful API,该框架包含在线规划器、API选择器和执行器。ToolLLM [226] 利用爬取的大规模API语料构建微调数据集。Gorilla [214] 引入了信息检索器,为模型提供参考API文档,促进微调过程中基于检索的信息利用。ToolkenGPT [82] 将每个工具作为新token加入词汇表,使模型在推理时能像生成文本一样自然地调用API。
Beyond learning to invoke APIs, CREATOR [222] prompts models to write code based on actual problems as new tool implementations, with generated tools functioning through a code interpreter and demonstrating impressive results on complex tasks.
除了学习调用API外,CREATOR [222] 还能基于实际问题提示模型编写代码作为新工具实现,生成的工具通过代码解释器运行,并在复杂任务上展现出令人印象深刻的效果。
Some works additionally support multimodal inputs, broadening the application scope of the models. AssistGPT [69] offers a framework including modules like Planner, Executor, Inspector, and Learner, utilizing language and code for intricate inference. ViperGPT [269] feeds CodeX with user queries and visual API information to generate Python code invoking APIs, successfully completing complex visual tasks.
一些研究还支持多模态输入,从而拓宽了模型的应用范围。AssistGPT [69] 提供了一个包含 Planner、Executor、Inspector 和 Learner 等模块的框架,利用语言和代码进行复杂推理。ViperGPT [269] 将用户查询和视觉 API 信息输入 CodeX,生成调用 API 的 Python语言 代码,成功完成复杂的视觉任务。
(4) Model-based Tools: With the swift expansion of diverse AI communities (i.e., Hugging face, ModelScope, GitHub), various types of AI models have become readily accessible for use, serving as a pivotal tool in enhancing generative retrieval systems. These AI models encompass a wide array of tasks, each accompanied by comprehensive model descriptions and usage examples.
(4) 基于模型的工具: 随着多样化AI社区(如Hugging Face、ModelScope、GitHub)的快速扩张,各类AI模型已变得触手可及,成为增强生成式检索系统的关键工具。这些AI模型涵盖广泛的任务范围,每个模型都配有详细的模型说明和使用示例。
HuggingGPT [250] employs ChatGPT as a controller to deconstruct user queries into tasks, determining which models to invoke for execution. Similarly, Visual ChatGPT [317] integrates a visual foundation model with LLMs, leveraging ChatGPT as a prompt manager to mobilize visual foundation models like BLIP [145] and ControlNet [349], adept at processing image-based requests efficiently compared to multi-modal models.
HuggingGPT [250] 采用 ChatGPT 作为控制器,将用户查询分解为任务,并确定调用哪些模型来执行。类似地,Visual ChatGPT [317] 将视觉基础模型与大语言模型相结合,利用 ChatGPT 作为提示管理器来调动 BLIP [145] 和 ControlNet [349] 等视觉基础模型,相比多模态模型,它更擅长高效处理基于图像的请求。
4.3 Generating Response with Citation
4.3 带引用的响应生成
To build a reliable GenIR system, generating responses with citations is a promising approach [88, 168, 195]. Citations allow users to clearly understand the source of each piece of knowledge in the response, enhancing trust and facilitating widespread adoption. Existing methods can be divided into directly generating responses with citations and using a retrieval module to enhance the generated content. Refer to the green portion in Figure 6 for an overview of this section.
要构建可靠的生成式信息检索(GenIR)系统,生成带引用的响应是一种有效方法[88, 168, 195]。引用能让用户清晰了解响应中每个知识点的来源,增强可信度并促进广泛应用。现有方法可分为直接生成带引用的响应,以及使用检索模块增强生成内容两类。具体分类请参见图6绿色部分。
4.3.1 Direct Generating Response with Citation. This method uses the model’s intrinsic memory to generate source citations without relying on a retrieval module.
4.3.1 直接生成带引用的响应。该方法利用模型的内在记忆生成来源引用,无需依赖检索模块。
(1) Model Intrinsic Knowledge. Leveraging the capabilities of the language model it- self, according-to prompting [314] guides LLMs to more accurately cite information from pretraining data by adding phrases like "according to Wikipedia" in the prompts.
模型内在知识。利用语言模型自身的能力,根据提示[314],通过在提示中添加"根据维基百科"等短语,引导大语言模型更准确地引用预训练数据中的信息。
To improve citation quality, Iterative Feedback Learning (IFL) [129] employs a critique model to assess and provide feedback on generated text, iterative ly enhancing LLMs’ citation accuracy, content correctness, and fluency. Additionally, Fierro et al. [63] introduce a planbased approach using a series of questions as a blueprint for content generation, with abstract and extractive attribution models, showing that planning improves citation quality.
为提高引用质量,迭代反馈学习 (Iterative Feedback Learning, IFL) [129] 采用批评模型来评估生成文本并提供反馈,通过迭代提升大语言模型的引用准确性、内容正确性和流畅性。此外,Fierro 等人 [63] 提出了一种基于计划的方法,使用一系列问题作为内容生成的蓝图,结合抽象和提取式归因模型,证明规划能提升引用质量。
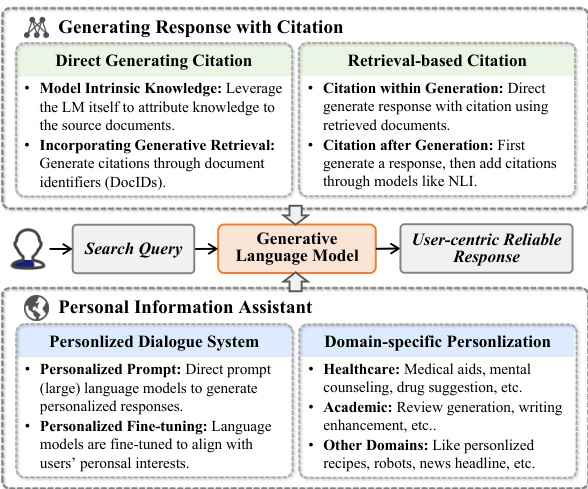
Fig. 6. Generating response with citation and personal information assistant are also crucial approaches for building a reliable and user-centric GenIR system.
图 6: 生成带有引用的响应及个人信息助手功能,同样是构建可靠且以用户为中心的生成式信息检索 (GenIR) 系统的关键方法。
(2) Incorporating Generative Retrieval. As envisioned by Metzler et al. [195], allowing the model to directly generate responses with citations is a promising approach for building an expertlevel reliable IR system. Users receive reliable responses tailored to their needs without searching through returned documents. Moreover, the cited document is generated by the model through the generative retrieval approach described in Section 3, directly producing corresponding DocIDs.
(2) 融入生成式检索 (Generative Retrieval)。正如 Metzler 等人 [195] 所设想的那样,允许模型直接生成带有引用的响应是构建专家级可靠信息检索 (IR) 系统的有前景的方法。用户无需搜索返回的文档即可获得量身定制的可靠响应。此外,引用的文档由模型通过第 3 节所述的生成式检索方法生成,直接产生相应的 DocID。
Utilizing generative retrieval, 1-PAGER [97] combines answer generation and evidence retrieval by generating N-gram DocIDs through constrained decoding using FM-Index [62], enabling stepby-step corpus partitioning, document selection, and response generation. This method matches retrieval-then-read methods in accuracy and surpasses closed-book QA models by attributing predictions to specific evidence, offering a new scheme for integrating retrieval into seq2seq generation.
利用生成式检索 (generative retrieval) 技术,1-PAGER [97] 通过 FM-Index [62] 进行约束解码生成 N-gram DocIDs,将答案生成与证据检索相结合,实现了逐步的语料库分区、文档选择和响应生成。该方法在准确度上与检索后阅读 (retrieval-then-read) 方法相当,并通过将预测归因于特定证据超越了闭卷问答 (closed-book QA) 模型,为将检索整合到序列到序列 (seq2seq) 生成中提供了新方案。
Recently, [122] proposes a source-aware training method where models learn to associate DocIDs with knowledge during pre-training and provide supporting citations during instruction tuning, effectively achieving knowledge attribution and enhancing LLM verifiability.
[122] 近期提出了一种源感知训练方法,该方法让模型在预训练阶段学习将文档ID (DocID) 与知识关联,并在指令微调阶段提供支持性引用,有效实现了知识溯源并增强了大语言模型的可验证性。
4.3.2 Retrieval-based Response with Citation. To enhance the accuracy of citations, several methods have been developed based on retrieval techniques to fetch relevant documents, thereby improving the quality of responses with embedded citations.
4.3.2 基于检索的引用回复。为提高引用准确性,目前已开发出多种基于检索技术的方法来获取相关文档,从而提升嵌入引用回复的质量。
(1) Citation within Generation. Following retrieval, models directly generate responses that include citations. Initially, systems like WebGPT [204], LaMDA [282], and WebBrain [223] utilized web pages or Wikipedia to construct large-scale pre-training datasets, teaching models how to generate responses with citations.
(1) 生成式引用。检索完成后,模型会直接生成包含引用的回答。最初,像WebGPT [204]、LaMDA [282]和WebBrain [223]这样的系统利用网页或维基百科构建大规模预训练数据集,教会模型如何生成带引用的回答。
Subsequently, more advanced strategies for citation generation were proposed. For instance, Search-in-the-Chain (SearChain) [326] first generates a reasoning chain (Chain-of-Query, CoQ) via LLM prompts, then interacts with each CoQ node using retrieval for verification and completion, ultimately generating the reasoning process and marking citations at each inference step.
随后,研究者们提出了更先进的文献引用生成策略。例如,Search-in-the-Chain (SearChain) [326] 首先通过大语言模型提示生成推理链 (Chain-of-Query, CoQ),随后利用检索与每个 CoQ 节点进行交互以验证和补全,最终生成推理过程并在每个推断步骤中标注引用。
LLatrieval [156] suggests continuously improving retrieval results through iterative updating, verifying whether retrieved documents support the generated answers until satisfaction. AGREE [335] uses a Natural Language Inference (NLI) model to verify consistency between LLM-generated answers and retrieved documents, employing a Test-Time Adaptation (TTA) strategy that allows LLMs to actively search and cite current information during generation, enhancing response accuracy and reliability. VTG [261] integrates an evolved memory system and a dual-layer validator for generating verifiable text, combining long-term and short-term memories to adapt to dynamic content, and uses an NLI model to evaluate logical support between claims and evidence.
LLatrieval [156] 提出通过迭代更新持续改进检索结果,验证检索到的文档是否支持生成的答案直至满意。AGREE [335] 采用自然语言推理 (Natural Language Inference, NLI) 模型验证大语言模型生成答案与检索文档的一致性,并运用测试时适应 (Test-Time Adaptation, TTA) 策略,使大语言模型在生成过程中主动搜索并引用实时信息,提升回答的准确性与可靠性。VTG [261] 整合进化记忆系统和双层验证器来生成可验证文本,结合长期与短期记忆以适应动态内容,同时利用NLI模型评估主张与证据间的逻辑支持关系。
Based on the Graph of Thoughts (GoT) [12], HGOT [60] improves context learning in retrievalaugmented settings by constructing a hierarchical GoT, leveraging the LLM’s planning capabilities to break down complex queries into smaller sub-queries and introducing a scoring mechanism to assess the quality of retrieved paragraphs.
基于思维图(GoT) [12]的改进,HGOT [60]通过构建分层思维图来增强检索增强设置中的上下文学习能力,利用大语言模型的规划能力将复杂查询分解为更小的子查询,并引入评分机制来评估检索段落的质量。
Employing reinforcement learning, Huang et al. [87] introduce a fine-grained reward mechanism to train language models, allocating specific rewards for each generated sentence and citation to teach models accurate external source citation. This approach uses rejection sampling and reinforcement learning algorithms to enhance citation-inclusive text generation through localized reward signals. APO [142] reimagines attributive text generation as a preference learning problem, automatically generating preference data pairs to reduce annotation costs, and uses progressive preference optimization and experience replay to reinforce preference signals without over fitting or text degradation.
黄等人 [87] 采用强化学习,引入细粒度奖励机制来训练语言模型,为每个生成的句子和引用分配特定奖励,以教导模型准确引用外部来源。该方法利用拒绝采样和强化学习算法,通过局部奖励信号提升包含引用的文本生成能力。APO [142] 将归因文本生成重新构想为偏好学习问题,自动生成偏好数据对以降低标注成本,并采用渐进式偏好优化和经验回放来强化偏好信号,避免过拟合或文本质量下降。
(2) Citation after Generation. This approach involves models first generating a response, then adding citations through models like NLI. RARR [70] improves at tri but ability by automatically finding external evidence for the language model’s output and post-editing to correct content while preserving the original output, enhancing attribution capabilities without altering the existing model. PURR [24] employs an unsupervised learning method where LLMs generate text noise themselves, then trains an editor to eliminate this noise, improving attribution performance and significantly speeding up generation. CEG [150] searches for supporting documents related to generated content and uses an NLI-based citation generation module to ensure each statement is supported by citations. "Attribute First, then Generate" [256] decomposes the generation process, first selecting relevant source text details and then generating based on these details, achieving localized at tri but ability with each sentence supported by a clear source, greatly reducing manual fact-checking workload.
(2) 生成后引用。这种方法先让模型生成回答,再通过NLI等模型添加引用。RARR [70] 通过自动查找大语言模型输出的外部证据并进行后编辑来修正内容,同时保留原始输出,从而在不改变现有模型的情况下提升归因能力。PURR [24] 采用无监督学习方法,让大语言模型自行生成文本噪声,然后训练一个编辑器来消除这些噪声,既改善了归因表现又显著加快了生成速度。CEG [150] 会搜索与生成内容相关的支持文档,并使用基于NLI的引用生成模块确保每个陈述都有引用支撑。"Attribute First, then Generate" [256] 将生成过程分解,先选择相关源文本细节再基于这些细节生成,实现局部归因——每个句子都有明确来源支撑,大幅减少了人工事实核查的工作量。
4.4 Personal Information Assistant
4.4 个人信息助手
The core of the GenIR system is the user, so understanding user intent is crucial. Researchers have explored various methods like personalized search [302, 364, 373? ], dialogue [172, 184, 354], and recommend er [46, 169, 361] systems to explore users’ interests. Specifically, personalized information assistants aim to better understand users’ personalities and preferences, generating personalized responses to better meet their information needs. This section reviews the progress in research on personalized dialogue and domain-specific personalization. An overview of this section is provided in the blue area of Figure 6.
GenIR系统的核心是用户,因此理解用户意图至关重要。研究者们探索了多种方法来挖掘用户兴趣,例如个性化搜索[302, 364, 373?]、对话系统[172, 184, 354]和推荐系统[46, 169, 361]。具体而言,个性化信息助手旨在更深入地理解用户的个性和偏好,生成个性化响应以更好地满足其信息需求。本节回顾了个性化对话和领域特定个性化方面的研究进展,相关概述见图6蓝色区域。
4.4.1 Personalized Dialogue System. To better understand user needs, researchers have explored two main approaches: personalized prompt design and model fine-tuning.
4.4.1 个性化对话系统。为了更好地理解用户需求,研究者探索了两种主要方法:个性化提示(prompt)设计和模型微调(fine-tuning)。
(1) Personalized Prompt. For personalized prompt design, Liu et al. [169] and Dai et al. [46] input users’ interaction and rating history into ChatGPT [209] for in-context learning, effectively generating personalized responses. LaMP [240] enhances the language model’s personalized output by retrieving personalized history from user profiles. Using long-term history, [35] designs prompts describing users’ long-term interests, needs, and goals for input into LLMs. BookGPT [361] uses LLM prompts, interactive querying methods, and result verification frameworks to obtain personalized book recommendations. PerSE [294] infers preferences from several reviews by a specific reviewer and provides personalized evaluations for new story inputs.
(1) 个性化提示。在个性化提示设计方面,Liu等人[169]和Dai等人[46]将用户的交互和评分历史输入ChatGPT[209]进行上下文学习,有效生成个性化响应。LaMP[240]通过从用户档案中检索个性化历史记录来增强语言模型的个性化输出。利用长期历史数据,[35]设计了描述用户长期兴趣、需求和目标的提示输入到大语言模型中。BookGPT[361]采用大语言模型提示、交互式查询方法和结果验证框架来获取个性化图书推荐。PerSE[294]通过分析特定评论者的多条评论推断其偏好,并为新故事输入提供个性化评估。
Using prompt rewriting, [140] proposes a method combining supervised and reinforcement learning to better generate responses from frozen LLMs. Similarly, [31] rewrites user input prompts using extensive user text-to-image interaction history to align better with expected visual outputs.
通过提示词重写,[140]提出了一种结合监督学习和强化学习的方法,以更好地从冻结的大语言模型中生成响应。类似地,[31]利用大量用户文生图交互历史来重写用户输入提示,从而更好地与预期视觉输出对齐。
(2) Personalized Fine-tuning. This line of work focuses on fine-tuning models for personalized response generation. Zhang et al. [354] introduced the Persona-Chat dataset with 5 million personas to train models for more personalized dialogues. Mazaré et al. [190] created a dataset of over 700 million conversations extracted from Reddit, demonstrating the effectiveness of training dialogue models on large-scale personal profiles. $\mathcal{P}^{2}\mathrm{Bot}$ [172] generates personalized and consistent dialogues by simulating the perception of personalities between conversation participants. DHAP [184] designs a novel Transformer structure to automatically learn implicit user profiles from dialogue history without explicit personal information. Wu et al. [322] propose a generative segmentation memory network to integrate diverse personal information. Fu et al. [67] developed a variation al approach to model the relationship between personal memory and knowledge selection, with a bidirectional learning mechanism.
(2) 个性化微调 (Personalized Fine-tuning)。这类研究专注于为个性化响应生成微调模型。Zhang等人[354]提出了包含500万个人设的Persona-Chat数据集,用于训练生成更个性化对话的模型。Mazaré等人[190]创建了从Reddit提取的超过7亿对话数据集,证明了在大规模个人资料上训练对话模型的有效性。$\mathcal{P}^{2}\mathrm{Bot}$[172]通过模拟对话参与者之间的个性感知,生成个性一致化的对话。DHAP[184]设计了一种新型Transformer结构,无需显式个人信息即可从对话历史中自动学习隐式用户画像。Wu等人[322]提出生成式分段记忆网络来整合多样化个人信息。Fu等人[67]开发了基于变分的方法来建模个人记忆与知识选择之间的关系,并采用双向学习机制。
Using reinforcement learning, Cheng et al. [32] collected a domain-specific preference (DSP) dataset and proposed a three-stage reward model learning scheme, including base model training, general preference fine-tuning, and customized preference fine-tuning. Jang et al. [98] developed "Personalized Soups," first optimizing multiple policy models with different preferences using PPO [246], then dynamically combining parameters during inference.
Cheng等[32]采用强化学习方法,收集了领域特定偏好(DSP)数据集,并提出三阶段奖励模型学习方案,包括基础模型训练、通用偏好微调和定制化偏好微调。Jang等[98]开发了"个性化参数汤"技术,先通过PPO[246]优化具有不同偏好的多个策略模型,再在推理阶段动态组合参数。
Using retrieval-enhanced methods, LAPDOG [91] retrieves relevant information from story documents to enhance personal profiles and generate better personalized responses. SAFARI [295] leverages LLMs’ planning and knowledge integration to generate responses consistent with character settings. Inspired by writing education, Li et al. [141] proposed a multi-stage, multi-task framework including retrieval, ranking, sum mari z ation, synthesis, and generation to teach LLMs personalized responses. For subjective tasks, [316] studied the superior performance of personalized fine-tuning in subjective text perception tasks compared to non-personalized models.
采用检索增强方法,LAPDOG [91] 从故事文档中检索相关信息以增强个人资料,并生成更好的个性化回复。SAFARI [295] 利用大语言模型的规划和知识整合能力,生成符合角色设定的响应。受写作教育启发,Li等人 [141] 提出一个包含检索、排序、摘要、合成和生成的多阶段多任务框架,用于指导大语言模型生成个性化回复。针对主观性任务,[316] 研究发现,在主观文本感知任务中,个性化微调模型的表现优于非个性化模型。
To achieve a personalized information assistant for every user, OPPU [274] uses personalized PEFT [53] to store user-specific behavioral patterns and preferences, showing superior performance. For multimodal scenarios, PMG [249] proposes a personalized multi-modal generation method that transforms user behavior into natural language, allowing LLMs to understand and extract user preferences.
为实现为每位用户提供个性化信息助手的目标,OPPU [274] 采用个性化PEFT [53] 存储用户特定的行为模式和偏好,展现出卓越性能。针对多模态场景,PMG [249] 提出了一种个性化多模态生成方法,将用户行为转化为自然语言,使大语言模型能够理解并提取用户偏好。
4.4.2 Domain-specific Personalization. Understanding users’ personalized information needs, the GenIR system has broad applications across various domains such as healthcare, academia, education, and recipes.
4.4.2 领域个性化定制。理解用户的个性化信息需求后,生成式检索(GenIR)系统在医疗保健、学术研究、教育及食谱等多个领域具有广泛应用前景。
(1) Healthcare. In AI-assisted healthcare, personalization plays a crucial role. Liu et al. [175] utilize few-shot tuning to process time-series physiological and behavioral data. Zhang et al. [347] implement medical diagnosis identification and diagnostic assistance using prompts from ChatGPT [209] and GPT-4 [2]. Yang et al. [11] propose an LLM for traditional Chinese medicine called Zhongjing, based on LLaMA [285], undergoing pre-training, supervised fine-tuning, and RLHF [36]. Abbasian et al. [1] introduce an open-source LLM-based conversational health agent framework called openCHA, which collects necessary information through specific actions and generates personalized responses. MedAgents [277] propose a multidisciplinary collaboration framework where LLM-based agents engage in multi-round cooperative discussions to enhance expertise and reasoning.
(1) 医疗健康。在AI辅助医疗领域,个性化发挥着关键作用。Liu等人[175]采用少样本调优技术处理时序生理和行为数据。Zhang等人[347]通过ChatGPT[209]和GPT-4[2]的提示实现医疗诊断识别与辅助诊断。Yang等人[11]基于LLaMA[285]提出名为"仲景"的中医大语言模型,该模型经历了预训练、监督微调和RLHF[36]三阶段训练。Abbasian等人[1]推出开源对话式健康智能体框架openCHA,通过特定动作收集必要信息并生成个性化响应。MedAgents[277]提出多学科协作框架,基于大语言模型的智能体通过多轮协同讨论提升专业性与推理能力。
For mental healthcare, Mental-LLM [327] presents a framework using LLMs to predict mental health from social media text data, with prompting-based and fine-tuning methods for real-time monitoring of issues like depression and anxiety. Lai et al. [127] introduce Psy-LLM, a psychological consultation aid combining pre-trained LLMs with real psychologist Q&As and psychological articles.
在心理健康护理领域,Mental-LLM [327] 提出了一个利用大语言模型从社交媒体文本数据预测心理健康的框架,采用基于提示(prompting)和微调(fine-tuning)的方法实时监测抑郁和焦虑等问题。Lai等人[127]开发了Psy-LLM,这是一种心理咨询辅助工具,将预训练大语言模型与真实心理医生问答记录及心理学文章相结合。
For medication suggestions, Liu et al. [177] propose Pharmacy GP T, a framework for generating personalized patient groups, formulating medication plans, and predicting outcomes.
在用药建议方面,Liu等人[177]提出了Pharmacy GP T框架,用于生成个性化患者分组、制定用药方案并预测疗效。
(2) Academic. In the academic domain, RevGAN [149] can automatically generate controllable and personalized user reviews based on users’ emotional tendencies and stylistic information. For writing assistants, Porsdam et al. [219] explore personalized enhancement of academic writing using LLMs like GPT-3 [16], showing higher quality after training with authors’ published works. Similarly, to address the lack of personalized outputs in LLMs, Mysore et al. [202] propose Pearl, a personalized LLM writing assistant trained on users’ historical documents, and develop a KL divergence training objective for retrievers.
(2) 学术领域。在学术领域,RevGAN [149] 能够根据用户的情感倾向和风格信息自动生成可控且个性化的用户评论。对于写作助手,Porsdam等人 [219] 探索了使用GPT-3 [16]等大语言模型对学术写作进行个性化增强,结果显示经过作者已发表作品训练后质量更高。类似地,为解决大语言模型缺乏个性化输出的问题,Mysore等人 [202] 提出了Pearl——一个基于用户历史文档训练的个性化大语言模型写作助手,并开发了用于检索器的KL散度训练目标。
(3) Education. Cui et al. [44] propose an adaptive and personalized exercise generation method that adjusts difficulty to match students’ progress by combining knowledge tracing and controlled text generation. EduChat [48] learns education-specific functionalities through pre-training on educational corpora and fine-tuning on customized instructions, addressing delayed knowledge updates and lack of expertise in LLMs.
(3) 教育。Cui等[44]提出了一种自适应个性化习题生成方法,通过结合知识追踪和可控文本生成技术,动态调整题目难度以匹配学生学习进度。EduChat[48]通过对教育语料库进行预训练及定制化指令微调,掌握教育领域专属功能,解决了大语言模型知识更新滞后和专业知识不足的问题。
(4) Other Domains. For recipe generation tasks, Majumder et al. [186] propose a personalized generation model based on users’ historical recipe consumption, enhancing personalization. For personalized headline generation, Zhang et al. [348] simulate users’ interests based on browsing history to generate news headlines. Salemi et al. [240] propose the LaMP benchmark, including personalized generation tasks like news headline, academic title, email subject, and tweet rewriting. Additionally, for personalized assistance with home cleaning robots, TidyBot [318] uses LLMs to generalize from user examples to infer user preference rules.
(4) 其他领域。在菜谱生成任务中,Majumder等人[186]提出了一种基于用户历史菜谱消费记录的个性化生成模型,以增强个性化效果。针对个性化新闻标题生成,Zhang等人[348]通过浏览历史模拟用户兴趣来生成新闻标题。Salemi等人[240]提出了LaMP基准测试,包含新闻标题、学术标题、邮件主题和推文改写等个性化生成任务。此外,针对家庭清洁机器人的个性化辅助,TidyBot[318]利用大语言模型从用户示例中归纳推理出用户偏好规则。
5 EVALUATION
5 评估
This section will provide a range of evaluation metrics and benchmarks for generative information retrieval methods, along with analysis and discussions on their performance.
本节将提供一系列生成式信息检索方法的评估指标和基准,并对其性能进行分析和讨论。
5.1 Evaluation for Generative Document Retrieval
5.1 生成式文档检索评估
5.1.1 Metrics. In this section, we discuss several core metrics for evaluating Generative Retrieval (GR) methods. These metrics provide different perspectives on the effectiveness of a GR system, including its accuracy, efficiency, and the relevance of its results. Specifically, we consider Recall, R-Precision, Mean Reciprocal Rank (MRR), Mean Average Precision (MAP), and Normalized Discounted Cumulative Gain (nDCG). Each metric captures unique aspects of retrieval performance, allowing for a comprehensive assessment of the system’s capabilities.
5.1.1 评估指标。本节讨论用于评估生成式检索 (Generative Retrieval, GR) 方法的若干核心指标。这些指标从不同维度衡量GR系统的有效性,包括准确性、效率及结果相关性。具体涵盖召回率 (Recall)、R-准确率 (R-Precision)、平均倒数排名 (Mean Reciprocal Rank, MRR)、平均精度均值 (Mean Average Precision, MAP) 和归一化折损累积增益 (Normalized Discounted Cumulative Gain, nDCG)。每项指标聚焦检索性能的不同层面,可全面评估系统能力。
• Normalized Discounted Cumulative Gain (nDCG) takes into account not only the relevance of the documents returned but also their positions in the result list, reflecting both the quality and the ordering of the results.
• 归一化折损累计增益 (nDCG) 不仅考虑返回文档的相关性,还考虑它们在结果列表中的位置,从而反映结果的质量和排序。
For detailed mathematical formulations of these metrics, please refer to Appendix A.1
有关这些指标的详细数学公式,请参阅附录 A.1
5.1.2 Benchmarks. Evaluating the effectiveness of GR methods relies on high-quality and challenging benchmark datasets.
5.1.2 基准测试。评估GR方法的有效性依赖于高质量且具有挑战性的基准数据集。
MS MARCO [205] is a large-scale dataset designed for machine reading comprehension, retrieval, and question-answering tasks in web search environments. It contains millions of documents and passages derived from real user queries, providing a realistic benchmark for assessing GR systems in complex search scenarios.
MS MARCO [205] 是一个专为网页搜索环境中的机器阅读理解、检索和问答任务设计的大规模数据集。它包含数百万份源自真实用户查询的文档和段落,为评估复杂搜索场景下的GR系统提供了真实基准。
Natural Questions (NQ) [126] is a question-answering dataset introduced by Google, utilizing Wikipedia as its primary corpus. It includes a vast number of natural user queries and their corresponding answers, making it suitable for evaluating the retrieval performance of GR systems in addressing real-world informational needs.
自然问答 (Natural Questions, NQ) [126] 是由Google推出的问答数据集,以维基百科作为主要语料库。该数据集包含大量自然用户查询及其对应答案,适用于评估GR系统在解决现实世界信息需求时的检索性能。
KILT (Knowledge-Intensive Language Tasks) [218] is a comprehensive benchmark integrating multiple categories of knowledge-intensive tasks such as fact checking, entity linking, slot filling, open-domain QA, and dialogue. Utilizing Wikipedia as its corpus, KILT aims to evaluate the effectiveness of information retrieval systems in handling complex language tasks that require extensive background knowledge.
KILT (Knowledge-Intensive Language Tasks) [218] 是一个集成事实核查、实体链接、槽位填充、开放域问答和对话等多类知识密集型任务的综合基准。该基准以维基百科作为语料库,旨在评估信息检索系统在处理需要丰富背景知识的复杂语言任务时的效能。
TREC Deep Learning Track 2019 & 2020 [41, 42] focus on leveraging deep learning techniques to enhance information retrieval efficiency, primarily through document and passage ranking tasks. These tracks utilize the MS MARCO dataset to emulate real-world search queries, providing a standardized environment for benchmarking various retrieval methodologies.
TREC Deep Learning Track 2019 & 2020 [41, 42] 专注于利用深度学习技术提升信息检索效率,主要通过文档和段落排序任务实现。这些赛道采用MS MARCO数据集模拟现实世界搜索查询,为各类检索方法提供标准化基准测试环境。
DynamicIR. For dynamic corpora, DynamicIR [337] proposes a task framework based on Streaming QA [167] benchmark for evaluating IR models within dynamically updated corpora. Through experimental analysis, DynamicIR revealed that GR systems are superior in adapting to evolving knowledge, handling temporally informed data, and are more efficient in terms of memory, indexing time, and FLOPs compared to dense retrieval systems.
DynamicIR。针对动态语料库,DynamicIR [337] 提出了一种基于 Streaming QA [167] 基准的任务框架,用于评估动态更新语料库中的信息检索 (IR) 模型。通过实验分析,DynamicIR 发现生成式检索 (GR) 系统在适应演化知识、处理时效性数据方面表现更优,并且在内存占用、索引时间和 FLOPs 效率上均优于稠密检索系统。
ExcluIR. For exclusion ary retrieval tasks, where users explicitly indicate in their queries that they do not want certain information, ExcluIR [356] provides a set of resources. This includes an evaluation benchmark and a training set to help retrieval models understand and process exclusion ary queries.
ExcluIR。对于排除性检索任务,即用户在查询中明确表示不需要某些信息的情况,ExcluIR [356] 提供了一套资源。这包括一个评估基准和一个训练集,以帮助检索模型理解和处理排除性查询。
For detailed descriptions and comprehensive information about benchmark datasets, please refer to Appendix A.2.
有关基准数据集的详细描述和全面信息,请参阅附录 A.2。
5.1.3 Analysis. In addition to the benchmarks and metrics for evaluating the performance of GR methods, there is a series of works that have conducted detailed analyses and discussions to study the behavior of GR models.
5.1.3 分析。除了评估GR方法性能的基准和指标外,还有一系列工作对GR模型的行为进行了详细分析和讨论。
Understanding Generative Retrieval. To understand the performance of DSI [281] in text retrieval, Chen et al. [29] examines uniqueness, completeness, and relevance ordering. These respectively reflect the system’s ability to distinguish between different documents, retrieve all relevant documents, and accurately rank documents by relevance. Experimental analysis find that DSI excels in remembering the mapping from pseudo queries to DocIDs, indicating a strong capability to recall specific DocIDs from particular queries. However, the study also pointed out DSI’s deficiency in distinguishing relevant documents from random ones, negatively impacting its retrieval effectiveness.
理解生成式检索 (Generative Retrieval)
为理解DSI [281]在文本检索中的性能,Chen等人 [29] 研究了唯一性、完整性和相关性排序。这些指标分别反映了系统区分不同文档、检索所有相关文档以及按相关性准确排序文档的能力。实验分析发现,DSI在记忆从伪查询到DocID的映射方面表现优异,表明其从特定查询中召回特定DocID的能力较强。但研究也指出,DSI在区分相关文档与随机文档方面存在不足,这对其检索效果产生了负面影响。
Exploring the connection between generative and dense retrieval, [206] demonstrates that they can be considered as bi-encoders in dense retrieval. Specifically, the authors analyze the computation of dot products during the generative retrieval process, which is similar to the calculation of dot products between query vectors and document vectors in dense retrieval. Following this, [319] revisits generative retrieval from the perspective of multi-vector dense retrieval (MVDR), revealing a common framework in computing document-query relevance between the two methods. This work also analyzes their differences in document encoding and alignment strategies, further confirming through experiments the phenomenon of term matching in the alignment matrices and their common ali ties in retrieval.
探索生成式检索与稠密检索之间的联系,[206] 论证了二者均可视为稠密检索中的双编码器。具体而言,作者分析了生成式检索过程中点积运算的过程,这与稠密检索中查询向量和文档向量的点积计算具有相似性。随后,[319] 从多向量稠密检索 (MVDR) 的视角重新审视生成式检索,揭示了两种方法在计算文档-查询相关性时的共同框架。该研究还分析了二者在文档编码和对齐策略上的差异,并通过实验进一步验证了对齐矩阵中的术语匹配现象及其在检索中的共性特征。
Large-scale Experimental Analysis. Later, Pradeep et al. [220] conduct the first comprehensive experimental study on GR techniques over large document sets, such as the 8.8M MS MARCO passages. It was found that among all the techniques examined, using generated pseudo queries to augment training data remains the only effective method on large document corpus. The strongest result in the experiments was achieved by using a training task that only utilized synthetic queries to Naive DocIDs, expanding the model to T5-XL (3B parameters) to achieve an $\mathrm{MRR}@10$ of 26.7. Surprisingly, increasing the parameters to T5 XXL (11B) in the same setup did not improve performance but rather led to a decline. These findings suggest that more research and in-depth analysis are needed in the GR field, and possibly additional improvements to the paradigm, to fully leverage the power of larger language models.
大规模实验分析。随后,Pradeep等人[220]首次对大规模文档集(如880万篇MS MARCO段落)上的生成式检索(GR)技术进行了全面实验研究。研究发现,在所有考察的技术中,使用生成的伪查询来增强训练数据仍是大型文档语料库上唯一有效的方法。实验中最强的结果是通过仅使用合成查询到Naive DocIDs的训练任务实现的,将模型扩展到T5-XL(30亿参数)时达到了26.7的$\mathrm{MRR}@10$。令人惊讶的是,在相同设置下将参数增加到T5 XXL(110亿)并未提升性能,反而导致下降。这些发现表明,GR领域需要更多研究和深入分析,可能还需要对该范式进行额外改进,才能充分发挥更大规模语言模型的能力。
Out-of-distribution Perspective. For out-of-distribution (OOD) robustness of GR models, Liu et al. [176] investigate three aspects: query variations, new query types, and new tasks. Their study showed that all types of retrieval models suffer from performance drops with query variations, indicating sensitivity to query quality and structure. However, when dealing with new query types and tasks, GR models showed different levels of adaptability, with pre-training enhancing their flexibility. The research highlights the critical need for OOD robustness in GR models for dealing with ever-changing real-world information sources.
分布外视角。针对图检索 (GR) 模型的分布外 (OOD) 鲁棒性,Liu 等人 [176] 研究了三个方面:查询变异、新查询类型和新任务。研究表明,所有类型的检索模型在查询变异时都会出现性能下降,表明其对查询质量和结构的敏感性。然而,在处理新查询类型和任务时,GR 模型表现出不同程度的适应能力,其中预训练增强了其灵活性。该研究强调了 GR 模型在处理不断变化的现实世界信息源时对 OOD 鲁棒性的迫切需求。
5.1.4 Experiments. Analyzing experimental results is essential for understanding the performance of different GR models. This section provides a comprehensive evaluation of current GR models on widely used benchmark tests and examines their applicability and limitations in scenarios such as web search, question answering, and knowledge-intensive tasks. The overall results are presented in Table 3 and Table 4.
5.1.4 实验。分析实验结果对于理解不同GR模型的性能至关重要。本节对当前GR模型在广泛使用的基准测试上进行了全面评估,并考察了它们在网络搜索、问答和知识密集型任务等场景中的适用性和局限性。总体结果如表3和表4所示。
Experimental Settings. Our evaluation is based on the MS MARCO [205], NQ [126], and KILT [218] benchmarks, which are commonly used datasets for existing GR methods. For the MS MARCO dataset, following previous works [265, 352, 371], we use the MS MARCO 300K subset, which contains $320\mathrm{k\Omega}$ documents, $360\mathrm{k}$ training instances, and 772 testing instances. For the NQ dataset, following [135, 265, 281, 307, 352], we use the NQ320K subset, which, after de duplication based on titles, contains $109\mathrm{k\Omega}$ documents, $320\mathrm{k\Omega}$ training instances, and 7,830 testing instances. For the KILT benchmark, we use the standard development sets. Detailed statistics are available in previous works [28, 218].
实验设置。我们的评估基于MS MARCO [205]、NQ [126]和KILT [218]基准测试,这些是现有GR方法常用的数据集。对于MS MARCO数据集,遵循先前工作[265, 352, 371],我们使用MS MARCO 300K子集,其中包含$320\mathrm{k\Omega}$个文档、$360\mathrm{k}$个训练实例和772个测试实例。对于NQ数据集,遵循[135, 265, 281, 307, 352],我们使用NQ320K子集,该子集在基于标题去重后包含$109\mathrm{k\Omega}$个文档、$320\mathrm{k\Omega}$个训练实例和7,830个测试实例。对于KILT基准测试,我们使用标准开发集。详细统计数据可参考先前工作[28, 218]。
Regarding evaluation metrics, we employ Recall $(\underline{{\omega}}{1,10,100}$ and $\mathrm{MRR}@{10,100}$ for the MS MARCO and NQ datasets, and R-Precision for the KILT benchmark. In our comparisons, we include not only existing representative GR methods but also sparse retrieval methods such as BM25 [238] and SPLADEv2 [64], which are based on bag-of-words representations, and dense retrieval methods like DPR [117], GTR [207], RAG [139] and MT-DPR [185], which rely on dense embeddings.
关于评估指标,我们在MS MARCO和NQ数据集上采用召回率 $(\underline{{\omega}}{1,10,100}$ 和 $\mathrm{MRR}@{10,100}$,在KILT基准测试中使用R-Precision。对比实验中,我们不仅纳入了现有代表性GR方法,还包括基于词袋表征的稀疏检索方法(如BM25 [238]和SPLADEv2 [64]),以及依赖稠密嵌入的密集检索方法(如DPR [117]、GTR [207]、RAG [139]和MT-DPR [185])。
Due to variations in datasets, corpus sizes, and evaluation metrics across different methods, alignment is necessary for a fair comparison. For the methods evaluated in our experiments, we primarily use results reported in existing papers. For methods where settings are not aligned, we provide results based on our own implementations.
由于不同方法在数据集、语料库规模和评估指标上存在差异,为确保公平比较需要进行对齐处理。对于实验评估的方法,我们主要采用现有论文报告的结果。对于设置未对齐的方法,我们提供基于自身实现的结果。
Table 3. Overall retrieval performance on the MS MARCO (300K) and Natural Questions (320K) Datasets. The best results are Bold and the second-best are Underlined. Symbol "*" indicates results from our own implementation, while other results are consistent with those reported in existing papers.
| Model | Doc Rep. | MSMARCO | Natural Questions (NQ) | ||||||||
| R@1 | R@10 | R@100 | M@10 | M@100 | R@1 | R@10 | R@100 | M@10 | M@100 | ||
| Sparse&DenseRetrieval | |||||||||||
| BM25 [265] | Bag-of-words | 0.196 | 0.591 | 0.861 | 0.313 | 0.325 | 0.297 | 0.603 | 0.821 | - | 0.402 |
| SPLADEv2 [352] | Bag-of-words | 0.328 | 0.779 | 0.956 | 0.443 | 0.452 | 0.624 | 0.873 | 0.954 | 0.726 | 0.731 |
| DPR [265] | Dense Vector | 0.271 | 0.764 | 0.948 | 0.424 | 0.433 | 0.502 | 0.777 | 0.909 | - | 0.489 |
| GTR-Base [265] | Dense Vector | 0.332 | 0.793 | 0.960 | 0.484 | 0.485 | 0.560 | 0.844 | 0.937 | - | 0.662 |
| GenerativeRetrieval | |||||||||||
| GENRE [352] | Title | 0.266 | 0.579 | 0.751 | 0.361 | 0.368 | 0.591 | 0.756 | 0.814 | 0.653 | 0.656 |
| DSI[352] | SemanticID | 0.257 | 0.538 | 0.692 | 0.339 | 0.346 | 0.533 | 0.715 | 0.816 | 0.594 | 0.598 |
| DSI-QG [265, 371] | Semantic ID | 0.288 | 0.623 | - | 0.385 | - | 0.631 | 0.807 | 0.880 | - | 0.695 |
| NCI [265] | Semantic ID | 0.301 | 0.643 | 0.851 | 0.408 | - | 0.659 | 0.852 | 0.924 | - | 0.731 |
| SEAL[265] | Sub-string | 0.259 | 0.686 | 0.879 | 0.393 | 0.402 | 0.570 | 0.800 | 0.914 | - | 0.655 |
| Ultron [352] | Title+URL | 0.304 | 0.676 | 0.794 | 0.432 | 0.437 | 0.654 | 0.854 | 0.911 | 0.726 | 0.729 |
| GenRet [265] | Learnable | - | 0.681 | 0.888 | 0.952 | 0.759 | |||||
| MINDER [352] | Multi-view | 0.289 | 0.728 | 0.916 | 0.431 | 0.435 | 0.627 | 0.869 | 0.933 | 0.709 | 0.713 |
| LTRGR* | Multi-view | 0.327 | 0.759 | 0.929 | 0.463 | 0.469 | 0.644 | 0.879 | 0.941 | 0.721 | 0.726 |
| GLEN [135] | Learnable | - | 0.691 | 0.860 | 0.754 | ||||||
| TSGen [352] | Term Set | 0.384 | 0.781 | 0.931 | 0.502 | 0.505 | 0.708 | 0.889 | 0.948 | 0.771 | 0.774 |
| NOVO [311] | Term Set | - | 0.693 | 0.897 | 0.959 | 0.767 | |||||
| DGR* | Multi-view | 0.359 | 0.779 | 0.934 | 0.498 | 0.504 | 0.682 | 0.887 | 0.949 | 0.759 | 0.764 |
表 3: MS MARCO (300K) 和 Natural Questions (320K) 数据集上的整体检索性能。最佳结果以粗体显示,次佳结果以下划线标注。符号 "*" 表示来自我们自行实现的结果,其他结果与现有论文报告的结果一致。
| 模型 | 文档表示 | MSMARCO | Natural Questions (NQ) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@10 | R@100 | M@10 | M@100 | R@1 | R@10 | R@100 | M@10 | M@100 | ||
| Sparse&DenseRetrieval | |||||||||||
| BM25 [265] | Bag-of-words | 0.196 | 0.591 | 0.861 | 0.313 | 0.325 | 0.297 | 0.603 | 0.821 | - | 0.402 |
| SPLADEv2 [352] | Bag-of-words | 0.328 | 0.779 | 0.956 | 0.443 | 0.452 | 0.624 | 0.873 | 0.954 | 0.726 | 0.731 |
| DPR [265] | Dense Vector | 0.271 | 0.764 | 0.948 | 0.424 | 0.433 | 0.502 | 0.777 | 0.909 | - | 0.489 |
| GTR-Base [265] | Dense Vector | 0.332 | 0.793 | 0.960 | 0.484 | 0.485 | 0.560 | 0.844 | 0.937 | - | 0.662 |
| GenerativeRetrieval | |||||||||||
| GENRE [352] | Title | 0.266 | 0.579 | 0.751 | 0.361 | 0.368 | 0.591 | 0.756 | 0.814 | 0.653 | 0.656 |
| DSI[352] | SemanticID | 0.257 | 0.538 | 0.692 | 0.339 | 0.346 | 0.533 | 0.715 | 0.816 | 0.594 | 0.598 |
| DSI-QG [265, 371] | Semantic ID | 0.288 | 0.623 | - | 0.385 | - | 0.631 | 0.807 | 0.880 | - | 0.695 |
| NCI [265] | Semantic ID | 0.301 | 0.643 | 0.851 | 0.408 | - | 0.659 | 0.852 | 0.924 | - | 0.731 |
| SEAL[265] | Sub-string | 0.259 | 0.686 | 0.879 | 0.393 | 0.402 | 0.570 | 0.800 | 0.914 | - | 0.655 |
| Ultron [352] | Title+URL | 0.304 | 0.676 | 0.794 | 0.432 | 0.437 | 0.654 | 0.854 | 0.911 | 0.726 | 0.729 |
| GenRet [265] | Learnable | - | 0.681 | 0.888 | 0.952 | 0.759 | |||||
| MINDER [352] | Multi-view | 0.289 | 0.728 | 0.916 | 0.431 | 0.435 | 0.627 | 0.869 | 0.933 | 0.709 | 0.713 |
| LTRGR* | Multi-view | 0.327 | 0.759 | 0.929 | 0.463 | 0.469 | 0.644 | 0.879 | 0.941 | 0.721 | 0.726 |
| GLEN [135] | Learnable | - | 0.691 | 0.860 | 0.754 | ||||||
| TSGen [352] | Term Set | 0.384 | 0.781 | 0.931 | 0.502 | 0.505 | 0.708 | 0.889 | 0.948 | 0.771 | 0.774 |
| NOVO [311] | Term Set | - | 0.693 | 0.897 | 0.959 | 0.767 | |||||
| DGR* | Multi-view | 0.359 | 0.779 | 0.934 | 0.498 | 0.504 | 0.682 | 0.887 | 0.949 | 0.759 | 0.764 |
Results on MS MARCO and NQ Datasets. MS MARCO and Natural Questions (NQ) are among the most widely used benchmarks for evaluating generative retrieval (GR) methods, particularly in the contexts of web search and question answering. Table 3 presents a detailed comparison of various GR models against traditional sparse and dense retrieval methods on these datasets.
MS MARCO和NQ数据集上的结果。MS MARCO和自然问题(NQ)是评估生成式检索(Generative Retrieval, GR)方法最广泛使用的基准之一,尤其在网络搜索和问答场景中。表3详细比较了这些数据集上各类GR模型与传统稀疏及稠密检索方法的性能表现。
(1) Overall Performance Comparison. Overall, GR methods demonstrate competitive performance compared to sparse and dense retrieval baselines. Specifically, on the MS MARCO dataset, GR models such as TSGen and DGR achieve Recall@1 scores of 0.384 and 0.359 respectively, surpassing dense methods like DPR (0.271) and being comparable to SPLADEv2 (0.328). On the NQ dataset, GR models also show strong performance, with TSGen attaining the highest Recal $@1$ of 0.708, outperforming both SPLADEv2 (0.624) and DPR (0.502).
(1) 整体性能对比。总体而言,GR方法相比稀疏和稠密检索基线展现出竞争优势。具体而言,在MS MARCO数据集上,TSGen和DGR等GR模型的Recall@1分数分别达到0.384和0.359,超越了DPR (0.271)等稠密方法,并与SPLADEv2 (0.328)相当。在NQ数据集上,GR模型同样表现强劲,TSGen以0.708的Recall@1最高分,优于SPLADEv2 (0.624)和DPR (0.502)。
(2) Term Set DocID Methods. Analyzing models that utilize term set-based document identifiers, such as TSGen and NOVO, reveals that these methods excel in both datasets. TSGen leads with the highest Recal $@1$ and MRR@10 on MS MARCO and NQ respectively, indicating robust retrieval capabilities. NOVO also performs exceptionally well on the NQ dataset, achieving the second-best Recall $@1$ and MRR $@10$ , demonstrating the effectiveness of term set representations in capturing relevant document information.
(2) 词项集文档ID方法。分析采用基于词项集的文档标识符模型(如TSGen和NOVO)发现,这些方法在两个数据集中均表现优异。TSGen在MS MARCO和NQ数据集上分别取得最高的Recall@1和MRR@10,展现出强大的检索能力。NOVO在NQ数据集上同样表现突出,获得第二高的Recall@1和MRR@10,证实了词项集表征在捕捉相关文档信息方面的有效性。
(3) Multi-view DocID Methods. Multi-view approaches, exemplified by MINDER, LTRGR, and DGR, show consistent improvements over several metrics. For instance, LTRGR achieves the highest Recall $@10$ on MS MARCO (0.759) and maintains strong performance across other metrics and on the NQ dataset. These results suggest that leveraging multi-view DocIDs, ranking and distillation training methods enhances retrieval effectiveness by capturing diverse aspects of the documents.
(3) 多视角文档ID方法。以MINDER、LTRGR和DGR为代表的多视角方法在多项指标上展现出持续改进。例如,LTRGR在MS MARCO数据集上实现了最高的召回率$@10$(0.759),并在其他指标及NQ数据集上保持强劲表现。这些结果表明,通过利用多视角文档ID、排序和蒸馏训练方法,能够捕捉文档的多样化特征,从而提升检索效果。
Table 4. Overall retrieval performance on the KILT Benchmark. The best results are Bold and the second-best are Underlined. Symbol "*" indicates results from our own implementation, while other results are consistent with those reported in existing papers.
| Model | Doc Rep. | FC | Entity Linking | SlotFilling | OpenDomainQA | Dial. | ||||||
| FEVER AY2 | WnWiWnCw | TRExzsRE | NQ | HoPo TQA | ELI5 | Wow | ||||||
| Sparse&DenseRetrieval | ||||||||||||
| BM25 [185] | Bag-of-words | 0.501 | 0.035 | 0.586 | 0.664 | 0.258 | 0.440 | 0.294 | 0.275 | |||
| RAG [218] | Dense Vector | 0.635 | 0.774 | 0.490 | 0.467 | 0.293 | 0.654 | 0.603 | 308 | 0.493 | 0.104 | 0.467 |
| MT-DPR [185] | Dense Vector | 0.747 | 0.838 | 0.692 | 0.772 | 0.615 | 0.442 | 0.620 | 0.397 | |||
| GenerativeRetrieval | ||||||||||||
| BART* | SemanticID | 0.003 | 0.001 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| BART [28] | Title | 0.819 | 0.892 | 0.676 | 0.623 | 0.752 | 0.911 | 0.586 | 0.487 | 0.676 | 0.121 | 0.510 |
| T5[218] | Title | 0.866 | 0.474 | 0.465 | ||||||||
| GENRE [18] | Title | 0.847 | 0.928 | 0.877 | 0.706 | 0.797 | 0.948 | 0.643 | 0.518 | 0.711 | 0.135 | 0.563 |
| SEAL* | Sub-string | 0.826 | 0.866 | 0.809 | 0.651 | 0.704 | 0.919 | 0.658 | 0.565 | 0.715 | 0.124 | 0.527 |
| CorpusBrain[28] | Title | 0.821 | 0.908 | 0.723 | 0.662 | 0.776 | 0.983 | 0.591 | 0.501 | 0.688 | 0.129 | 0.538 |
表 4: KILT基准测试上的整体检索性能。最佳结果以粗体显示,次佳结果以下划线标注。符号"*"表示我们自行实现的结果,其余结果与现有论文报告一致。
| 模型 | 文档表示 | FC | 实体链接 | 槽填充 | 开放域问答 | 对话 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FEVER AY2 | WnWiWnCw | TRExzsRE | NQ | HoPo TQA | ELI5 | Wow | ||||||
| 稀疏与密集检索 | ||||||||||||
| BM25 [185] | 词袋 | 0.501 | 0.035 | 0.586 | 0.664 | 0.258 | 0.440 | 0.294 | 0.275 | |||
| RAG [218] | 密集向量 | 0.635 | 0.774 | 0.490 | 0.467 | 0.293 | 0.654 | 0.603 | 308 | 0.493 | 0.104 | 0.467 |
| MT-DPR [185] | 密集向量 | 0.747 | 0.838 | 0.692 | 0.772 | 0.615 | 0.442 | 0.620 | 0.397 | |||
| 生成式检索 | ||||||||||||
| BART* | 语义ID | 0.003 | 0.001 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| BART [28] | 标题 | 0.819 | 0.892 | 0.676 | 0.623 | 0.752 | 0.911 | 0.586 | 0.487 | 0.676 | 0.121 | 0.510 |
| T5[218] | 标题 | 0.866 | 0.474 | 0.465 | ||||||||
| GENRE [18] | 标题 | 0.847 | 0.928 | 0.877 | 0.706 | 0.797 | 0.948 | 0.643 | 0.518 | 0.711 | 0.135 | 0.563 |
| SEAL* | 子串 | 0.826 | 0.866 | 0.809 | 0.651 | 0.704 | 0.919 | 0.658 | 0.565 | 0.715 | 0.124 | 0.527 |
| CorpusBrain[28] | 标题 | 0.821 | 0.908 | 0.723 | 0.662 | 0.776 | 0.983 | 0.591 | 0.501 | 0.688 | 0.129 | 0.538 |
(4) Learnable DocID Methods. Learnable DocID models, such as GenRet and GLEN, exhibit mixed performance. While GenRet shows competitive Recall $@1$ on NQ (0.681), it does not report results on MS MARCO. GLEN achieves the highest $\mathrm{MRR}@100$ on NQ (0.754) but lags behind in other metrics. This indicates that learnable DocID approaches may benefit from further refinement to consistently outperform other representation methods across different datasets.
(4) 可学习文档ID方法。可学习文档ID模型(如GenRet和GLEN)表现出参差不齐的性能。虽然GenRet在NQ数据集上显示出具有竞争力的Recall $@1$ (0.681),但未报告MS MARCO数据集的结果。GLEN在NQ上取得了最高的$\mathrm{MRR}@100$ (0.754),但在其他指标上表现落后。这表明可学习文档ID方法可能需要进一步改进,才能在不同数据集上持续优于其他表征方法。
(5) Other DocID Methods. Other methods like GENRE, DSI, NCI, SEAL, and Ultron, generally underperform compared to term set and multi-view DocID methods. For example, on the MS MARCO dataset, GENRE achieves a Recall $@1$ of 0.266 and an $\mathrm{MRR}@10$ of 0.361, which are significantly lower than TSGen $(\mathrm{Recall}@1=0.384$ , $\mathrm{MRR}@10=0.502;$ ) and LTRGR $({\mathrm{Recall}}@1=0.327$ , $\mathrm{MRR}@10=$ 0.463). The lower performance of methods utilizing simpler DocID designs (e.g. titles, semantic IDs) highlights the need for more sophisticated or alternative DocID strategies to effectively capture key information for high-quality retrieval across different scenarios.
(5) 其他文档ID方法。与词集法和多视图文档ID方法相比,GENRE、DSI、NCI、SEAL和Ultron等方法通常表现较差。例如,在MS MARCO数据集上,GENRE的召回率$@1$为0.266,$\mathrm{MRR}@10$为0.361,显著低于TSGen $(\mathrm{Recall}@1=0.384$, $\mathrm{MRR}@10=0.502;$ )和LTRGR $({\mathrm{Recall}}@1=0.327$, $\mathrm{MRR}@10=$ 0.463)。采用简单文档ID设计(如标题、语义ID)的方法性能较低,凸显了需要更复杂或替代的文档ID策略,以有效捕捉关键信息,实现不同场景下的高质量检索。
Results on KILT Benchmark. The KILT benchmark provides a comprehensive evaluation across various knowledge-intensive tasks, utilizing a large-scale Wikipedia corpus comprising 5.9 million documents. Overall results are shown in Table 4.
KILT基准测试结果。KILT基准通过利用包含590万篇文档的大规模维基百科语料库,对各种知识密集型任务进行了全面评估。总体结果如表4所示。
(1) Overall Performance Comparison. GR methods generally outperform traditional sparse and dense retrieval approaches in most tasks. Notably, GENRE achieves the highest scores in several categories, including FEVER (0.847), AY2 (0.928), WnWi (0.877), and WnCw (0.706), outperforming the best sparse method BM25 and dense methods like MT-DPR.
(1) 总体性能对比。生成式检索(Generative Retrieval, GR)方法在多数任务中普遍优于传统稀疏检索和稠密检索方法。值得注意的是,GENRE在多个类别中取得了最高分,包括FEVER (0.847)、AY2 (0.928)、WnWi (0.877)和WnCw (0.706),表现优于最佳稀疏检索方法BM25及MT-DPR等稠密检索方法。
(2) Title DocID Methods. Models utilizing title-based document identifiers consistently perform well on the KILT benchmark. For instance, GENRE and BART achieve FEVER scores of 0.847 and 0.821, respectively. This superior performance can be attributed to the fact that Wikipedia document titles accurately represent the key entities within each document, making the task of predicting titles relatively straightforward. Moreover, these models effectively leverage the pre-trained knowledge embedded within language models, enhancing their ability to generalize and retrieve relevant documents based on titles.
标题DocID方法。基于标题文档标识符的模型在KILT基准测试中表现持续优异。例如,GENRE和BART分别取得了0.847和0.821的FEVER分数。这种卓越表现源于维基百科文档标题能精准表征文档核心实体,使得标题预测任务相对直接。此外,这些模型有效利用了语言模型中预训练的知识,增强了其基于标题泛化检索相关文档的能力。
(3) Sub-string DocID Methods. Methods based on sub-string document identifiers also demonstrate strong performance on the KILT benchmark, particularly in question answering (QA) tasks. SEAL achieves the highest QA scores across several categories, including NQ (0.658), HoPo (0.565),
(3) 子字符串文档标识符方法。基于子字符串文档标识符的方法在KILT基准测试中也表现出强劲性能,特别是在问答(QA)任务中。SEAL在多个类别中取得了最高QA分数,包括NQ (0.658)、HoPo (0.565)。
TQA (0.715), and WoW (0.527). The ability of sub-string DocID methods to capture meaningful fragments of the documents likely contributes to their high accuracy in retrieving precise information necessary for answering questions effectively.
TQA (0.715) 和 WoW (0.527)。子字符串 DocID 方法能够捕获文档中有意义的片段,这可能是其在有效回答问题所需精确信息检索方面具有高准确性的原因。
(4) DSI-based Numeric DocID Methods. In contrast, methods employing numeric Semantic DocIDs based on hierarchical k-means clustering [281] exhibit significantly diminished performance on the KILT benchmark. The BART model, which uses Semantic IDs and trained with just labeled queries, records scores close to zero across all tasks (e.g., FEVER: 0.003, AY2: 0.001). This decline is primarily due to the substantial increase in corpus size, and $<$ <query, document $>$ pairs in training data cover only a small fraction of the entire document set. Consequently, these models struggle to generalize beyond the training pairs, just "memorizing" DocIDs without capturing the broader diversity of the corpus. This observation aligns with findings from [220], which reported similar challenges of DSI [281] when scaling to an 8.8 million passage corpus in the MS MARCO benchmark.
基于DSI的数字文档ID方法。相比之下,采用基于层次化k均值聚类[281]的数字语义文档ID方法在KILT基准测试中表现显著下降。使用语义ID且仅通过标注查询训练的BART模型在所有任务中得分接近零(例如FEVER: 0.003, AY2: 0.001)。这种下降主要源于语料库规模的急剧扩大,且训练数据中的<查询, 文档>对仅覆盖整个文档集的极小部分。因此,这些模型难以泛化到训练对之外,只能"记忆"文档ID而无法捕捉语料库的广泛多样性。该发现与[220]的研究结果一致,后者报告了DSI[281]在MS MARCO基准测试中扩展到880万段落语料库时面临的类似挑战。
5.2 Evaluation for Response Generation
5.2 响应生成的评估
5.2.1 Metrics. Evaluating the quality of generated responses includes aspects such as accuracy, fluency, relevance, etc. In this section, we’ll introduce the main metrics for evaluating reliable response generation, categorized into rule-based, model-based, and human evaluation metrics.
5.2.1 指标。评估生成响应的质量包括准确性、流畅性、相关性等方面。本节将介绍评估可靠响应生成的主要指标,分为基于规则、基于模型和人工评估指标三类。
(1) Rule-based Metrics. Exact Match (EM) is a straightforward evaluation method requiring the model’s output to be completely identical to the reference answer at the word level. This full character-level matching is stringent, often used in tasks requiring precise and concise answers, such as question answering systems, e.g., NQ [126], TriviaQA [115], SQuAD [232], etc. It simply calculates the ratio of perfectly matched instances to the total number of instances.
(1) 基于规则的指标。精确匹配 (Exact Match, EM) 是一种直接的评估方法,要求模型的输出在单词级别与参考答案完全一致。这种全字符级别的匹配非常严格,通常用于需要精确简洁答案的任务,例如问答系统,如 NQ [126]、TriviaQA [115]、SQuAD [232] 等。它简单地计算完全匹配实例占总实例数的比例。
For the generation of longer text sequences, BLEU [213] is a common metric initially used to evaluate the quality of machine translation. It compares the similarity between the model’s output and a set of reference texts by calculating the overlap of n-grams, thereby deriving a score. This method assumes that high-quality generation should have a high lexical overlap with the labeled answer. Optimized from BLEU, METEOR [9] is an alignment-based metric that considers not only exact word matches but also synonyms and stem matches. Additionally, METEOR introduces considerations for word order and syntactic structure to better assess the fluency and consistency of the generated text.
在生成长文本序列时,BLEU [213] 是一种最初用于评估机器翻译质量的常见指标。它通过计算n元语法(n-gram)的重叠度来比较模型输出与参考文本之间的相似性,从而得出评分。该方法假设高质量生成内容应与标注答案具有较高的词汇重叠度。作为BLEU的优化版本,METEOR [9] 是一种基于对齐的评估指标,不仅考虑精确词汇匹配,还纳入同义词和词干匹配。此外,METEOR引入了对词序和句法结构的考量,以更好地评估生成文本的流畅性与一致性。
ROUGE [162], also a commonly used metric for evaluating longer texts, by measuring the extent of overlap in words, sentences, n-grams, and so forth, between the generated text and a collection of reference texts. It focuses on recall, meaning it evaluates how much of the information in the reference text is covered by the generated text. ROUGE comes in various forms, including ROUGE-N, which evaluates based on n-gram overlap, and ROUGE-L, which considers the longest common sub sequence, catering to diverse evaluation requirements.
ROUGE [162] 同样是评估长文本的常用指标,通过衡量生成文本与参考文本集合之间在单词、句子、n元语法等方面的重叠程度。它侧重于召回率,即评估生成文本覆盖了多少参考文本中的信息。ROUGE 有多种形式,包括基于 n 元语法重叠的 ROUGE-N,以及考虑最长公共子序列的 ROUGE-L,以满足不同的评估需求。
Perplexity (PPL) is a metric for evaluating the performance of language models, defined as the exponentiation of the average negative log-likelihood, reflecting the model’s average predictive ability for a given corpus of text sequences. The lower the perplexity, the stronger the model’s predictive ability. Specifically, given a sequence of words $W=w_{1},w_{2},\dots,w_{N}$ , where $N$ is the total number of words in the sequence, PPL can be expressed as:
困惑度 (PPL) 是评估语言模型性能的指标,定义为平均负对数似然的指数化,反映模型对给定文本序列语料的平均预测能力。困惑度越低,模型的预测能力越强。具体而言,给定词序列 $W=w_{1},w_{2},\dots,w_{N}$ ,其中 $N$ 是序列中的总词数,PPL可表示为:
$$
\mathrm{PPL}(W)=\exp{-\frac{1}{N}\sum_{i=1}^{N}\log{p(w_{i}|w_{<i})}},
$$
$$
\mathrm{PPL}(W)=\exp{-\frac{1}{N}\sum_{i=1}^{N}\log{p(w_{i}|w_{<i})}},
$$
where $p(w_{i}|w_{<i})$ represents the pre-trained language model’s probability of predicting the $i$ -th word $w_{i}$ given the previous words $w_{<i}$ .
其中 $p(w_{i}|w_{<i})$ 表示预训练语言模型在给定前序词 $w_{<i}$ 时预测第 $i$ 个词 $w_{i}$ 的概率。
(2) Model-based Metrics. With the rise of pre-trained language models, a series of model-based evaluation metrics have emerged. These metrics utilize neural models to capture the deep semantic relationships between texts.
(2) 基于模型的指标。随着预训练语言模型的兴起,一系列基于模型的评估指标应运而生。这些指标利用神经网络模型来捕捉文本间的深层语义关系。
Unlike traditional rule-based metrics, BERTScore [355] utilizes the contextual embeddings of BERT [121] to capture the deep semantics of words, evaluating the similarity between candidate and reference sentences through the cosine similarity of embeddings. BERTScore employs a greedy matching strategy to optimize word-level matching and uses optional inverse document frequency weighting to emphasize important words, ultimately providing a comprehensive evaluation through a combination of recall, precision, and F1 score. BERTScore captures not only surface lexical overlap but also a deeper understanding of the semantic content of sentences.
与传统基于规则的指标不同,BERTScore [355] 利用 BERT [121] 的上下文嵌入 (contextual embeddings) 捕捉词语的深层语义,通过嵌入向量的余弦相似度评估候选句与参考句的相似性。该指标采用贪心匹配策略优化词级对齐,并可选配逆文档频率加权以突出关键词语,最终通过召回率、精确率和F1值的综合计算提供全面评估。BERTScore 不仅能捕捉表层词汇重叠,更能深入理解句子的语义内容。
Similarly based on BERT [121], BLEURT [247] designed multiple pre-training tasks, enhancing the model’s ability to recognize textual differences with millions of synthetic training pairs. These pre-training tasks include automatic evaluation metrics (such as BLEU [213], ROUGE [162], and BERTScore [355]), back-translation likelihood, textual entailment, etc. Each task provides different signals to help the model learn how to evaluate the quality of text generation.
同样基于BERT [121],BLEURT [247]设计了多种预训练任务,通过数百万合成训练对增强模型识别文本差异的能力。这些预训练任务包括自动评估指标(如BLEU [213]、ROUGE [162]和BERTScore [355])、回译似然度、文本蕴含等。每个任务提供不同信号,帮助模型学习如何评估文本生成质量。
BARTScore [343], based on the pre-trained seq2seq generative model BART [138], treats the evaluation of generated text as a text generation problem. Specifically, BARTScore determines the quality of text based on the transition probability between the generated text and reference text. BARTScore does not require additional parameters or labeled data and can flexibly evaluate generated text from multiple perspectives (such as informative ness, fluency, factuality, etc.) and further enhance evaluation performance through text prompts or fine-tuning for specific tasks.
BARTScore [343]基于预训练的序列到序列生成模型BART [138],将生成文本的评估视为文本生成问题。具体而言,BARTScore根据生成文本与参考文本之间的转移概率判定文本质量。该方法无需额外参数或标注数据,可灵活评估生成文本的信息量、流畅性、事实性等多维度指标,并能通过文本提示(prompt)或针对特定任务微调(fine-tuning)进一步提升评估性能。
FActScore [198] focuses on the factual accuracy of each independent information point in long texts. It calculates a score representing factual accuracy by decomposing the text into atomic facts and verifying whether these facts are supported by reliable knowledge sources. This method provides a more detailed evaluation than traditional binary judgments and can be implemented efficiently and accurately through human evaluation and automated models (combining retrieval and powerful language models).
FActScore [198] 专注于长文本中每个独立信息点的事实准确性。该方法通过将文本分解为原子事实并验证这些事实是否有可靠知识来源支持,计算出一个代表事实准确性的分数。相比传统的二元判断,这种方法提供了更细致的评估,并且可以通过人工评估和自动化模型 (结合检索和强大语言模型) 高效准确地实现。
GPTScore [66] is a flexible, multi-faceted evaluation tool that allows users to evaluate text using natural language instructions without the need for complex training processes or costly annotations. GPTScore constructs an evaluation protocol dynamically through task specification and aspect definition and utilizes the zero-shot capability of pre-trained language models to evaluate text quality, optionally using demonstration samples to improve evaluation accuracy.
GPTScore [66] 是一种灵活、多方面的评估工具,允许用户通过自然语言指令评估文本,无需复杂的训练过程或昂贵的标注。GPTScore 通过任务规范和维度定义动态构建评估协议,并利用预训练语言模型的零样本能力评估文本质量,可选地使用示范样本来提升评估准确性。
(3) Human Evaluation Metrics. Human evaluation is an important method for assessing the performance of language models, especially in complex tasks where automated evaluation tools struggle to provide accurate assessments. Compared to rule-based and model-based metrics, human evaluation is more accurate and reliable in real-world applications. This evaluation method requires human evaluators (such as experts, researchers, or everyday users) to provide comprehensive assessments of the model-generated content based on their intuition and knowledge.
(3) 人工评估指标。人工评估是衡量语言模型性能的重要方法,尤其在自动化评估工具难以提供准确判断的复杂任务中。相较于基于规则和基于模型的指标,人工评估在实际应用中更为精确可靠。该方法需要评估人员(如专家、研究者或普通用户)根据自身直觉与知识,对模型生成内容进行全方位评判。
Human evaluation measures the quality of language model outputs by integrating multiple assessment criteria, following [23]: Accuracy [255] primarily evaluates the correctness of information and its correspondence with facts; Relevance [362] focuses on whether the model’s output is pertinent to the specific context and user query; Fluency [289] examines whether the text is coherent, natural, and facilitates smooth communication with users; Safety [103] scrutinizes whether the content may lead to potential adverse consequences or harm. These indicators collectively provide a comprehensive assessment of the model’s performance in real-world settings, ensuring its effectiveness and applicability.
人工评估通过整合多项评价标准来衡量语言模型输出的质量,遵循[23]的研究框架:准确性(Accuracy) [255]主要评估信息的正确性及其与事实的对应关系;相关性(Relevance) [362]关注模型输出是否与特定上下文和用户查询相关;流畅性(Fluency) [289]检验文本是否连贯自然,便于用户顺畅交流;安全性(Safety) [103]审查内容是否可能导致潜在不良后果或危害。这些指标共同为模型在真实场景中的表现提供全面评估,确保其有效性和适用性。
However, human evaluation also faces numerous challenges, primarily including high costs and time consumption, difficulty in controlling evaluation quality, inconsistency in evaluation dimensions, issues of consistency due to evaluators’ subjectivity, and the need for professional evaluators for specific tasks. These problems limit the widespread application of human evaluation and the comparability of results [22].
然而,人工评估也面临诸多挑战,主要包括成本高耗时长、评估质量难以控制、评估维度不一致、评估者主观性导致的结论一致性问题,以及特定任务需要专业评估人员等。这些问题限制了人工评估的广泛应用和结果可比性 [22]。
5.2.2 Benchmarks and Analysis. In this section, we explore various benchmarks for evaluating the performance of language models in generating reliable responses. These benchmarks assess language understanding, factual accuracy, reliability, and the ability to provide timely information.
5.2.2 基准测试与分析
本节探讨用于评估大语言模型生成可靠回答性能的多种基准测试,包括语言理解、事实准确性、可靠性以及提供及时信息的能力等维度。
(1) General Evaluation. To comprehensively assess the language models’ understanding capabilities across a wide range of scenarios, MMLU [84] utilizes a multiple-choice format covering 57 different tasks, from basic mathematics to American history, computer science, and law. This benchmark spans evaluations in humanities, social science, and science, technology, engineering, and mathematics, providing a comprehensive and challenging test. It has been widely used in the evaluation of Large Language Models (LLMs) in recent years [105, 285, 286].
(1) 通用评估。为全面评估语言模型在广泛场景下的理解能力,MMLU [84] 采用多选题形式覆盖57项不同任务,内容从基础数学延伸至美国历史、计算机科学和法律。该基准横跨人文、社会科学以及科学、技术、工程和数学(STEM)领域的评估,提供了全面且富有挑战性的测试。近年来它已被广泛应用于大语言模型(LLM)的评估工作 [105, 285, 286]。
Furthermore, BIG-bench [259] introduces a large-scale and diverse benchmark designed to measure and understand the capabilities and limitations of LLMs across a broad range of tasks. Including 204 tasks contributed by 450 authors from 132 institutions, it covers areas such as linguistics, mathematics, and common sense reasoning. It focuses on tasks beyond the capabilities of language models, exploring how model performance and societal biases evolve with scale and complexity.
此外,BIG-bench [259] 引入了一个大规模多样化基准测试,旨在衡量和理解大语言模型 (LLM) 在广泛任务中的能力与局限。该基准由来自132个机构的450位作者贡献的204项任务组成,涵盖语言学、数学和常识推理等领域,重点关注超越语言模型当前能力的任务,探索模型性能与社会偏见如何随规模和复杂性演变。
LLM-Eval [166] offers a unified multi-dimensional automatic evaluation method for open-domain dialogue of LLMs, eliminating the need for manual annotation. The performance of LLM-Eval across various datasets demonstrates its effectiveness, efficiency, and adaptability, improving over existing evaluation methods. The research also analyzes the impact of different LLMs and decoding strategies on the evaluation outcomes, underscoring the importance of selecting suitable LLMs and decoding strategies.
LLM-Eval [166] 为大语言模型的开放域对话提供了一种统一的多维度自动评估方法,无需人工标注。LLM-Eval 在多个数据集上的表现证明了其高效性、有效性和适应性,优于现有评估方法。该研究还分析了不同大语言模型和解码策略对评估结果的影响,强调了选择合适的模型和解码策略的重要性。
For Chinese, C-Eval [92] aims to comprehensively evaluate LLMs’ advanced knowledge and reasoning capabilities in the Chinese context. It is based on a multiple-choice format, covering four difficulty levels and 52 different academic fields from secondary school to professional levels. C-Eval also introduces C-Eval Hard, a subset containing highly challenging subjects to test the models’ advanced reasoning capabilities. Through evaluating state-of-the-art English and Chinese LLMs, C-Eval reveals areas where current models still fall short in handling complex tasks, guiding the development and optimization of Chinese LLMs.
对于中文领域,C-Eval [92] 旨在全面评估大语言模型在中文语境下的高阶知识与推理能力。该评估采用选择题形式,涵盖从中学到专业级别的四个难度层级和52个不同学科领域。C-Eval还推出了C-Eval Hard子集,包含极具挑战性的科目以测试模型的高阶推理能力。通过评估最先进的英文和中文大语言模型,C-Eval揭示了当前模型在处理复杂任务时仍存在的不足,为中文大语言模型的开发与优化提供了方向指引。
(2) Tool Evaluation. To assess the ability of language models to utilize tools, API-Bank [148] provides a comprehensive evaluation framework containing 73 APIs and 314 tool usage dialogs, along with a rich training dataset of 1,888 dialogs covering 1,000 domains to improve LLMs’ tool usage capabilities. Experiments show that different LLMs perform variably in tool usage, highlighting their strengths and areas for improvement.
(2) 工具评估。为评估语言模型使用工具的能力,API-Bank [148] 提供了一个包含73个API和314个工具使用对话的综合评估框架,以及涵盖1000个领域的1888个对话训练数据集,用于提升大语言模型的工具使用能力。实验表明,不同大语言模型在工具使用方面表现各异,凸显了它们的优势和改进空间。
Later, ToolBench [226] developed a comprehensive framework including a dataset and evaluation tools to facilitate and assess the ability of LLMs to use over 16,000 real-world APIs. It enhances reasoning capabilities by automatically generating diverse instruction and API usage scenario paths, introducing a decision tree based on depth-first search. ToolBench significantly enhances LLMs’ performance in executing complex instructions and in their ability to generalize to unseen APIs. ToolLLaMA, an LLM fine-tuned from LLaMA [285], exhibits remarkable zero-shot capabilities and performance comparable to state-of-the-art LLMs like ChatGPT [209].
随后,ToolBench [226] 开发了一个包含数据集和评估工具的综合框架,用于促进和评估大语言模型使用超过16,000个真实世界API的能力。它通过自动生成多样化的指令和API使用场景路径,并引入基于深度优先搜索的决策树,增强了推理能力。ToolBench显著提升了大语言模型在执行复杂指令和泛化到未见API方面的表现。基于LLaMA [285]微调的大语言模型ToolLLaMA展现出卓越的零样本能力,其性能可与ChatGPT [209]等先进大语言模型相媲美。
(3) Factuality Evaluation. TruthfulQA [164] measures the truthfulness of language models in answering questions. This benchmark consists of 817 questions covering 38 categories, including health, law, finance, and politics. This evaluation reveals that, even in optimal conditions, the truthfulness of model responses only reaches $58%$ , in stark contrast to human performance at
事实性评估。TruthfulQA [164] 用于衡量语言模型在回答问题时的真实性。该基准包含817个问题,涵盖健康、法律、金融和政治等38个类别。评估结果显示,即使在最优条件下,模型回答的真实性也仅达到 $58%$ ,与人类表现形成鲜明对比。
$94%$ . Moreover, they proposed an automated evaluation metric named GPT-judge, which classifies the truthfulness of answers by fine-tuning the GPT-3 [16] model, achieving $90^{-96%}$ accuracy in predicting human evaluations.
94%。此外,他们提出了一种名为GPT-judge的自动化评估指标,通过对GPT-3 [16]模型进行微调来分类答案的真实性,在预测人类评估时达到了90%-96%的准确率。
HaluEval [144] is a benchmark for evaluating LLM illusions, constructed using a dataset containing 35K illusion samples, employing a combination of automated generation and manual annotation. This provides effective tools and methods for assessing and enhancing large language models’ capabilities in identifying and reducing illusions. For Chinese scenarios, HalluQA [33] designs 450 meticulously selected adversarial questions to assess the illusion phenomenon in Chinese LLMs, covering multiple domains and reflecting Chinese culture and history, identifying two main types of illusions: imitative falsehoods and factual errors.
HaluEval [144] 是一个用于评估大语言模型幻觉的基准,采用自动生成与人工标注相结合的方式构建了包含35K个幻觉样本的数据集。这为评估和提升大语言模型在识别与减少幻觉方面的能力提供了有效工具和方法。针对中文场景,HalluQA [33] 设计了450道经过精心筛选的对抗性问题来评估中文大语言模型的幻觉现象,覆盖多个领域并体现中国文化与历史特征,识别出模仿性虚假和事实性错误两大主要幻觉类型。
To evaluate the ability of LLMs to generate answers with cited text, ALCE [71] builds an endto-end system for retrieving relevant text passages and generating answers with citations. ALCE contains three datasets, covering different types of questions, and evaluates the generated text’s quality from ’fluency’, ’correctness’, and ’citation quality’ dimensions, combining human evaluation to verify the effectiveness of the evaluation metrics. The experimental results show that while LLMs excel at generating fluent text, there is significant room for improvement in ensuring content factual correctness and citation quality, especially on the ELI5 dataset where the best model was incomplete in citation support half of the time.
为了评估大语言模型(LLM)生成带引用文本答案的能力,ALCE [71]构建了一个端到端系统,用于检索相关文本段落并生成带引用的答案。ALCE包含三个数据集,涵盖不同类型的问题,并从"流畅性"、"正确性"和"引用质量"三个维度评估生成文本的质量,结合人工评估来验证评价指标的有效性。实验结果表明,虽然大语言模型擅长生成流畅的文本,但在确保内容事实正确性和引用质量方面仍有很大改进空间,特别是在ELI5数据集上,表现最佳的模型有半数情况下的引用支持不完整。
(4) Real-Time Evaluation. RealTime QA [118] created a dynamic question-and-answer platform that regularly releases questions and evaluates systems weekly to ask and answer questions about the latest events or information. It challenges the static assumption of traditional QA datasets aiming for immediate application. Experiments based on LLMs like GPT-3 and T5 found that models could effectively update their generated results based on newly retrieved documents. However, when the retrieved documents failed to provide sufficient information, models tended to return outdated answers.
(4) 实时评估。RealTime QA [118] 构建了一个动态问答平台,定期发布问题并每周评估系统对最新事件或信息的提问与回答能力。该研究挑战了传统问答数据集静态假设,旨在实现即时应用。基于GPT-3和T5等大语言模型的实验表明,模型能根据新检索到的文档有效更新生成结果。但当检索文档未能提供足够信息时,模型倾向于返回过时答案。
Furthermore, FreshQA [291] evaluates large language models’ performance in challenges involving time-sensitive and erroneous premise questions by creating a new benchmark containing questions of this nature. Evaluating various open and closed-source LLMs revealed significant limitations in handling questions involving rapidly changing knowledge and erroneous premises. Based on these findings, the study proposed a simple in-context learning method, Fresh Prompt, significantly improving LLMs’ performance on FreshQA by integrating relevant and up-to-date information sourced from search engines into the prompt.
此外,FreshQA [291] 通过创建一个包含时效性和错误前提问题的新基准,评估了大语言模型 (Large Language Model) 在处理此类挑战时的表现。对各类开源和闭源大语言模型的评估显示,它们在处理涉及快速变化知识和错误前提的问题时存在显著局限性。基于这些发现,该研究提出了一种简单的上下文学习方法 Fresh Prompt,通过将搜索引擎获取的相关最新信息整合到提示中,显著提升了大语言模型在 FreshQA 上的表现。
(5) Safety, Ethic, and Trustworthiness. To comprehensively evaluate the safety of LLMs, Safety Bench [358] implements an efficient and accurate evaluation of LLMs’ safety through 11,435 multiple-choice questions covering 7 safety categories in multiple languages (Chinese and English). The diversity of question types and the broad data sources ensure rigorous testing of LLMs in various safety-related scenarios. Comparing the performance of 25 popular LLMs, Safety Bench revealed GPT-4’s significant advantage and pointed out the areas where current models need improvements in safety to promote the rapid development of safer LLMs.
(5) 安全、伦理与可信性。为全面评估大语言模型(LLM)的安全性,Safety Bench [358] 通过涵盖7大安全类别、包含11,435道多语言(中英文)选择题的测试集,实现了对LLM安全性的高效精准评估。其多样化的题型设计和广泛的数据来源,确保了对各类安全相关场景的严格测试。通过对比25个主流LLM的表现,Safety Bench揭示了GPT-4的显著优势,并指出当前模型在安全性方面需要改进的领域,以促进更安全的大语言模型快速发展。
For ethics, TrustGPT [93] aims to assess LLMs’ ethical performance from toxicity, bias, and value alignment, three key dimensions. The benchmark uses predefined prompt templates based on social norms to guide LLMs in generating content and employs multiple metrics to quantitatively assess the toxicity, bias, and value consistency of these contents. Experimental analysis revealed that even the most advanced LLMs still have significant issues and potential risks in these ethical considerations.
在伦理方面,TrustGPT [93] 旨在从毒性、偏见和价值对齐这三个关键维度评估大语言模型的伦理表现。该基准使用基于社会规范的预定义提示模板来引导大语言模型生成内容,并采用多种指标定量评估这些内容的毒性、偏见和价值一致性。实验分析表明,即使是最先进的大语言模型在这些伦理考量上仍存在显著问题和潜在风险。
For trustworthiness, TrustLLM [263] explores principles and benchmarks including truthfulness, safety, fairness, robustness, privacy, and machine ethics across six dimensions. Extensive experiments, including assessing 16 mainstream LLMs’ performance on 30 datasets, found that trustworthiness usually positively correlates with functional effectiveness. While proprietary models typically outperform open-source models in trustworthiness, some open-source models like Llama2 showed comparable high performance.
在可信度方面,TrustLLM [263] 从六个维度(包括真实性、安全性、公平性、鲁棒性、隐私性和机器伦理)探索了原则和基准。通过广泛实验(包括评估16个主流大语言模型在30个数据集上的表现)发现,可信度通常与功能有效性呈正相关。虽然专有模型在可信度方面通常优于开源模型,但部分开源模型(如Llama2)表现出与之相当的高性能。
These benchmarks provide important tools and metrics for evaluating and improving the capabilities of language models, contributing to the development of more accurate, reliable, safe, and timely GenIR systems. For further understanding of the evaluation works, [23, 47, 90, 293] offer more detailed introductions.
这些基准测试为评估和提升语言模型能力提供了重要工具与指标,有助于开发更准确、可靠、安全且及时的生成式信息检索(GenIR)系统。如需深入了解评估工作,[23, 47, 90, 293]提供了更详细的介绍。
6 CHALLENGES AND PROSPECTS
6 挑战与展望
This section discusses the key challenges faced in the fields of generative document retrieval and reliable response generation, as well as potential directions for future research.
本节讨论生成式文档检索和可靠响应生成领域面临的主要挑战,以及未来研究的潜在方向。
6.1 Challenges on Generative Document Retrieval
6.1 生成式文档检索面临的挑战
6.1.1 S cal ability Issues. As extensively studied by [220], generative retrieval demonstrates significantly lower retrieval accuracy compared to dense retrieval when handling million-level document corpora in web search scenarios. Merely increasing the model size does not yield stable performance improvements. However, GR outperforms dense retrieval in document collections smaller than 300K, posing a question: What impedes GR methods from scaling to large document sizes? This issue encompasses several aspects:
6.1.1 可扩展性问题。如[220]所深入研究的,在网络搜索场景下处理百万级文档语料库时,生成式检索 (generative retrieval) 的检索准确率显著低于稠密检索 (dense retrieval)。仅增加模型规模并不能带来稳定的性能提升。然而,在文档量小于30万的集合中,生成式检索优于稠密检索,这引出一个问题:是什么阻碍了生成式检索方法扩展到大规模文档?该问题涉及多个方面:
Training Data. Current LLMs are pre-trained on huge datasets ranging from hundreds of billions to several trillion tokens, covering vast knowledge sources such as the internet, books, and news articles, consuming substantial computational power [359]. They are then extensively fine-tuned with high-quality, human-annotated data to achieve substantial generalization capabilities [138, 210, 231, 285]. In contrast, generative retrieval (GR) models often begin with a pre-trained language model and are fine-tuned on labeled data comprising $<$ <query, DocID $>$ pairs, which does not sufficiently prepare them to fully grasp GR tasks. For numeric-based DocIDs, the models, having not encountered these numbers in their pre-training phase, tend to rote memorize the DocIDs seen during training, struggling to predict unseen ones effectively. Similarly, if text-based DocIDs fail to precisely represent the documents, the model also tend to rote learning.
训练数据。当前的大语言模型在数千亿至数万亿token的庞大数据集上进行预训练,涵盖互联网、书籍和新闻文章等海量知识源,消耗大量计算资源[359]。随后通过高质量人工标注数据进行广泛微调,以获得强大的泛化能力[138, 210, 231, 285]。相比之下,生成式检索(GR)模型通常从预训练语言模型出发,仅在由<query, DocID>对组成的标注数据上进行微调,这不足以使其充分掌握GR任务。对于数字型DocID,由于模型在预训练阶段未接触过这些数字,往往会机械记忆训练中见过的DocID,难以有效预测未见过的ID。同理,若基于文本的DocID无法准确表征文档,模型同样容易陷入死记硬背。
A potential solution is to create a large-scale pre-training dataset for generative retrieval on a general corpus, possibly including a variety of common DocIDs such as URLs, titles, and numerical sequences. We can utilize instructions to distinguish generation targets for various DocIDs. Then we can pre-train a GR model from scratch, the model can understand generative retrieval across diverse domains. This method could bridge the gap between language model pre-training data and GR tasks, enhancing the generalization ability of GR models across different corpora.
一个潜在的解决方案是创建一个面向通用语料库的大规模生成式检索预训练数据集,其中可能包含多种常见文档标识符(DocID),如URL、标题和数字序列。我们可以利用指令来区分不同DocID的生成目标,然后从头开始预训练一个生成式检索(GR)模型,使其能够理解跨领域的生成式检索。这种方法可以弥合语言模型预训练数据与GR任务之间的差距,提升GR模型在不同语料库间的泛化能力。
Training Method. As described in Section 3.1.1, existing training methods explore various training objectives, including seq2seq training, learning DocID, and ranking capabilities. Other methods involve knowledge distillation [30], reinforcement learning [365], etc. Is there a better training method to enable GR models to master generating DocID ranking lists? For example, RLHF [36] has been effectively used to train LLMs [210, 286], though at a high cost. Exploring RLHF in the GR field is also worthwhile.
训练方法。如第3.1.1节所述,现有训练方法探索了多种训练目标,包括序列到序列(seq2seq)训练、学习文档标识符(DocID)和排序能力。其他方法涉及知识蒸馏[30]、强化学习[365]等。是否存在更好的训练方法能让生成式检索(GR)模型掌握生成DocID排序列表?例如,基于人类反馈的强化学习(RLHF)[36]已成功用于训练大语言模型[210,286],尽管成本较高。在GR领域探索RLHF也值得尝试。
Model Structure. As discussed in Section 3.1.2, most current GR models are based on encoderdecoder Transformers structures [281, 307, 371], such as T5 [231] and BART [138]. Some GR methods like CorpusLM [152] have experimented with a decoder-only structure of the LLM Llama2 [286], requiring more training computational power but not significantly improving performance. Research is needed to determine which structure is more suitable for generative retrieval. Additionally, whether increasing model and data size could lead to emergent phenomena similar to those observed in LLMs [244, 312] is also a promising research direction.
模型结构。如第3.1.2节所述,当前大多数生成式检索(Generative Retrieval)模型基于编码器-解码器Transformer结构[281, 307, 371],例如T5[231]和BART[138]。部分方法如CorpusLM[152]尝试采用大语言模型Llama2[286]的纯解码器结构,虽需更高训练算力但未显著提升性能。需进一步研究何种结构更适合生成式检索。此外,扩大模型与数据规模能否引发类似大语言模型中涌现现象[244, 312]也是值得探索的方向。
6.1.2 Handling Dynamic Corpora. Real-world applications often involve dynamically changing corpora, such as the web and news archives, where incremental learning is essential. However, for language models, indexing new documents inevitably leads to forgetting old ones, posing a challenge for GR systems. Existing methods like $\mathrm{DSI++}$ [192], IncDSI [124], CLEVER [25], and CorpusBrain $^{++}$ [80] propose solutions such as experience replay, constrained optimization, incremental product quantization, and continual generative pre-training frameworks to address incremental learning issues. Yet, these methods have their specific applicable scenarios, and more effective and universally applicable incremental learning strategies remain a key area for exploration.
6.1.2 动态语料库处理。现实应用常涉及动态变化的语料库(如网页和新闻存档),增量学习至关重要。然而对语言模型而言,索引新文档必然导致旧文档遗忘,这对GR系统构成挑战。现有方法如$\mathrm{DSI++}$[192]、IncDSI[124]、CLEVER[25]和CorpusBrain$^{++}$[80]提出了经验回放、约束优化、增量乘积量化及持续生成式预训练框架等方案来解决增量学习问题。但这些方法均有特定适用场景,更高效且普适的增量学习策略仍是探索重点。
6.1.3 Document Identifier. Accurately representing a document with high-quality DocIDs is crucial for generative retrieval.
6.1.3 文档标识符 (Document Identifier) 。在生成式检索中,用高质量的文档标识符 (DocID) 准确表示文档至关重要。
For example, the KILT dataset based on the Wikipedia corpus, which includes 5.9 million documents, demonstrates optimistic retrieval performance for GR methods using titles as DocIDs [18, 28, 152]. This is because each document in Wikipedia has a unique manually annotated title that represents the core entity discussed in that page. However, in the web search scenario, such as in the MS MARCO dataset [205], many documents lack a unique title, are overlapping, and the titles do not accurately represent the core content of the documents. Thus, GR performance significantly declines in the MS MARCO corpus of 8.8 million passages.
例如,基于维基百科语料库的KILT数据集包含590万篇文档,展示了以标题作为DocID的生成式检索(GR)方法的乐观检索性能[18, 28, 152]。这是因为维基百科中的每篇文档都有唯一的人工标注标题,能准确代表该页面讨论的核心实体。但在网络搜索场景(如MS MARCO数据集[205]中),许多文档缺乏唯一标题、存在内容重叠,且标题无法准确反映文档核心内容,因此在包含880万段落的MS MARCO语料库中GR性能显著下降。
Therefore, how to construct high-quality titles (or other types of DocIDs) in general corpora, similar to those in Wikipedia, that not only accurately represent documents but also are lightweight, is a critical factor for implementing GR methods and warrants in-depth research.
因此,如何在通用语料库中构建类似维基百科的高质量标题(或其他类型的DocID),使其既能准确表征文档又保持轻量化,是实施GR方法的关键因素,值得深入研究。
Text or Numeric? As discussed in Section 3.2, current methods include text-based and numericbased DocIDs, each with their advantages and disadvantages. Text-based DocIDs effectively leverage the linguistic capabilities of pre-trained generative language models and offer better interpret ability. Numeric-based DocIDs can utilize dense retriever embeddings to obtain semantic DocID sequences; they can also complement dense retrievers to achieve synergistic benefits.
文本还是数字?如第3.2节所述,当前方法包括基于文本和基于数字的文档标识符(DocID),各有优缺点。基于文本的DocID能有效利用预训练生成式语言模型的语言能力,并提供更好的可解释性。基于数字的DocID可利用密集检索器嵌入获取语义化DocID序列,还能与密集检索器互补实现协同效益。
However, to ensure good generalization ability of GR models without extensive pre-training, it is essential to utilize the inherent pre-trained parameters of the model. Coherent textual DocIDs can naturally leverage this aspect, but they also need to capture key document semantics and maintain linguistic sequence characteristics. Numeric DocIDs, however, do not offer this advantage. Thus, as mentioned in 6.1.1, extensive pre-training is necessary to enable models to fully understand the meanings behind these numerical strings, which is a costly endeavor.
然而,为确保GR模型在不进行大量预训练的情况下具备良好的泛化能力,必须充分利用模型固有的预训练参数。连贯文本型DocID天然具备这一优势,但也需要捕捉文档关键语义并保持语言序列特征。而数值型DocID则无法提供这种优势。因此如6.1.1节所述,必须通过大量预训练才能使模型充分理解这些数字串背后的含义,这是一项成本高昂的工作。
Do We Need a Unique ID for Each Document? Most current GR methods use a unique DocID to uniquely identify a document. However, as the number of documents in a corpus increases, maintaining a unique DocID becomes increasingly challenging. Even if a unique DocID is maintained, it is difficult to differentiate significantly from other DocIDs semantically, leading to reduced retrieval precision. Some methods, such as using sub-string as DocIDs [13, 26], have proven effective. These methods utilize the FM-Index [62] to ensure the generated sub-string exists in the corpus and use the number of generated sub-strings in different documents to rank documents, demonstrating good performance and generalization ability.
我们是否需要为每篇文档分配唯一ID?当前大多数GR方法采用唯一的DocID来标识文档。然而随着语料库中文档数量的增长,维护唯一DocID的难度会不断增加。即使能保持DocID的唯一性,这些ID在语义上也难以与其他DocID形成显著区分,从而导致检索精度下降。部分方法(如使用子串作为DocID [13, 26])已被证实有效。这些方法利用FM-Index [62]确保生成的子串存在于语料库中,并通过统计不同文档中生成的子串数量来进行文档排序,展现出优异的性能和泛化能力。
However, since this method is based on FM-Index, its inference latency is high, which is an issue that needs addressing. Furthermore, exploring other more efficient alternatives to FM-Index and even considering not using constrained search but freely generating a DocID sequence followed by a lightweight matching and scoring module to efficiently return a document ranking list are also worthy of exploration.
然而,由于该方法基于FM-Index,其推理延迟较高,这是一个需要解决的问题。此外,探索FM-Index之外更高效的替代方案,甚至考虑不使用约束搜索,而是自由生成DocID序列后接轻量级匹配评分模块以高效返回文档排序列表,也值得深入研究。
6.1.4 Efficiency Concerns. Current GR methods generally rely on constrained beam search to generate multiple DocID sequences during inference, resulting in high latency. This is particularly severe when returning 100 or more documents, with latencies reaching several hundred milliseconds [307], which is unacceptable for low-latency IR systems. Therefore, designing more efficient inference methods is crucial. To reduce inference latency, the length of the DocID sequence should not be too long; 16 tokens or fewer is an efficient range. This necessitates designing DocIDs that are precise and concise enough to represent documents while maintaining performance and improving efficiency. Additionally, developing more efficient decoding strategies is a valuable research direction for the future.
6.1.4 效率问题。当前生成式检索(GR)方法通常依赖受限束搜索在推理时生成多个DocID序列,导致高延迟。当返回100篇或更多文档时尤为严重,延迟可达数百毫秒[307],这对低延迟信息检索(IR)系统不可接受。因此,设计更高效的推理方法至关重要。为降低推理延迟,DocID序列长度不宜过长;16个token或更少是高效区间。这需要设计足够精确简洁的DocID以表征文档,同时保持性能并提升效率。此外,开发更高效的解码策略是未来有价值的研究方向。
6.1.5 Multi-modal Generative Retrieval. Existing multi-modal generative retrieval models aim to retrieve images by converting each image in the collection into a unique sequence that serves as its identifier. A language model is then employed to predict these image identifiers, enabling effective image retrieval. However, there are still potential areas for future optimization: (1) Image Representation: Developing advanced image representation techniques is essential for enhancing the performance of multi-modal generative retrieval. These techniques should capture the key features of an image within its identifier sequence. (2) End-to-end Training: Existing methods perform image representation and image identifier prediction separately for generative retrieval. Exploring how to train these two tasks in a fully end-to-end manner is also worth investigating. (3) Extend to Additional Modalities: Current multi-modal generative retrieval methods predominantly focus on text and image modalities. Expanding these approaches to incorporate additional modalities such as audio and video presents a valuable research opportunity.
6.1.5 多模态生成式检索。现有多模态生成式检索模型通过将集合中的每张图像转换为唯一标识序列,利用语言模型预测这些图像标识符来实现高效图像检索。但仍存在以下优化方向:(1) 图像表征:开发先进的图像表征技术对提升多模态生成式检索性能至关重要,这些技术需在标识序列中捕获图像关键特征;(2) 端到端训练:现有方法对图像表征和标识符预测进行分离式处理,探索如何实现完全端到端的联合训练具有研究价值;(3) 多模态扩展:当前方法主要聚焦文本与图像模态,将其扩展至音频、视频等其他模态是值得探索的研究方向。
6.2 Challenges on Reliable Response Generation
6.2 可靠响应生成的挑战
6.2.1 Improving Accuracy and Factuality. In GenIR systems, ensuring content accuracy and factuality is crucial. To achieve this, as mentioned in Section 4, there are two main areas of improvement:
6.2.1 提升准确性与事实性。在生成式信息检索(GenIR)系统中,确保内容准确性和事实性至关重要。为实现这一目标,如第4节所述,主要存在两个改进方向:
Internal Knowledge Memorization. Firstly, training stronger generative models is critical for building reliable GenIR systems. Various commercial LLMs continue to progress, utilizing vast training data and computational resources, but exploring better model structures is also worthwhile. Recent research such as Retentive Networks [266], Mamba [78], and others, have shown potential to challenge the performance and efficiency of Transformers [290]. However, whether these can scale and truly surpass Transformer-based LLMs in generation quality is still an open question. Moreover, what types of training data and methods can consistently produce models capable of generating high-quality, reliable text also deserve thorough investigation and summary. The mechanisms by which language models recall knowledge during inference are not yet clear and need to be fully understood to better serve user information needs.
内部知识记忆。首先,训练更强大的生成模型对于构建可靠的生成式信息检索(GenIR)系统至关重要。尽管各类商用大语言模型通过海量训练数据和计算资源持续进步,但探索更优模型结构仍具价值。Retentive Networks [266]、Mamba [78]等最新研究已展现出挑战Transformer [290]性能与效率的潜力,但这些架构能否实现规模化并真正在生成质量上超越基于Transformer的大语言模型仍是开放性问题。此外,何种训练数据与方法能持续产出可生成高质量可靠文本的模型,同样需要深入研究和系统总结。语言模型在推理过程中回忆知识的机制尚未明晰,必须充分理解这些机制才能更好地满足用户信息需求。
External Knowledge Enhancement. As described in Section 4.2.1, retrieval-augmented generation is an effective method widely applied in LLMs. However, there is still room for improvement. (1) For example, whether inserting retrieved documents directly into generative models via prompts is the best method, or if there are better ways, such as inputting embeddings [336], needs exploration. (2) Additionally, whether models can autonomously decide whether to perform retrieval [272, 296], and when in the generation process to perform it [111]. (3) Third, in dialogue scenarios, enhancing RAG models to better utilize long conversational history is also worth further exploration [200].
外部知识增强。如第4.2.1节所述,检索增强生成 (retrieval-augmented generation) 是大语言模型中广泛采用的有效方法,但仍有改进空间:(1) 例如,通过提示词直接将检索文档插入生成模型是否是最佳方法,还是存在更优方案(如输入嵌入向量 [336])值得探索;(2) 此外,模型能否自主决定是否执行检索 [272, 296] 以及在生成流程的哪个阶段执行 [111];(3) 第三,在对话场景中,如何优化RAG模型以更有效地利用长对话历史也需深入研究 [200]。
Tool-augmented generation, as discussed in Section 4.2.2, is also a popular method for endowing LLMs with fine-grained world knowledge and performing complex tasks. Recent research has raised questions, such as "Should tools always be used?" [310]. More specifically, whether the performance improvements brought by using tools justify the extra computational costs incurred during model training or the inference costs during testing. Existing work mainly focuses on task accuracy, but studying the cost-effectiveness of these methods is also a valuable topic.
工具增强生成 (Tool-augmented generation) 如第4.2.2节所述,也是一种为LLM赋予细粒度世界知识并执行复杂任务的流行方法。近期研究提出了诸如"是否应该始终使用工具?"[310]等问题。更具体地说,使用工具带来的性能提升是否足以证明模型训练期间的额外计算成本或测试期间的推理成本是合理的。现有工作主要关注任务准确性,但研究这些方法的成本效益也是一个有价值的课题。
6.2.2 Real-time Properties of GenIR Systems. Timeliness is critical for GenIR systems, as well as traditional IR systems, to provide users with the most up-to-date information. However, since the knowledge of pre-trained generative models is fixed after training, methods like retrieval and tool augmentation are needed to acquire new external knowledge. Research on real-time knowledge acquisition remains limited, making it a valuable area for investigation.
6.2.2 GenIR系统的实时特性
时效性对GenIR系统及传统IR系统至关重要,这能确保用户获取最新信息。但由于预训练生成模型的知识在训练完成后固定不变,需借助检索和工具增强等方法来获取外部新知识。目前实时知识获取的研究仍显不足,这成为一个值得探索的领域。
Moreover, continually relying on outdated knowledge from language models is inadequate, as models cannot comprehend the significance of given contexts or backgrounds in the current era, thus reducing the reliability of the generated content. Therefore, updating the information in language models while avoiding the forgetting of existing knowledge, such as through continual learning [301, 320], knowledge editing [191, 212, 303, 334], etc., is a topic worth further exploring.
此外,持续依赖语言模型中的过时知识是不够的,因为这些模型无法理解当前时代特定背景或语境的重要性,从而降低了生成内容的可靠性。因此,如何在更新语言模型信息的同时避免遗忘现有知识(例如通过持续学习 [301, 320]、知识编辑 [191, 212, 303, 334] 等方法)是一个值得进一步探索的课题。
6.2.3 Bias and Fairness. Since LLMs are often trained on large, unfiltered datasets, GenIR systems may propagate stereotypes and biases present in the data regarding race, culture, and other aspects [68]. Researchers have explored various methods to enhance the fairness of generated content during training data selection, training methods, generation techniques, and rewriting phases. However, biases have not been eradicated and require a thorough understanding of the mechanisms by which generative models produce biases, to design methods to solve them and build fair GenIR systems that further the practical application of GenIR.
6.2.3 偏见与公平性。由于大语言模型通常基于未经筛选的大规模数据集训练,生成式信息检索(GenIR)系统可能传播数据中存在的种族、文化等方面的刻板印象与偏见 [68]。研究者已探索了多种方法在训练数据选择、训练方法、生成技术和改写阶段提升生成内容的公平性。但偏见尚未根除,需要深入理解生成模型产生偏见的机制,进而设计解决方法并构建公平的GenIR系统,以推动GenIR的实际应用。
6.2.4 Privacy and Security. Firstly, the content generated by GenIR systems risks plagiarism [50, 120]. Studies such as [21, 89] indicate that pre-trained language models can reproduce large segments of their training data, leading to inadvertent plagiarism and causing academic dishonesty or copyright issues. On one hand, legal regulations regarding the copyright of AI-generated content will gradually emerge and evolve. On the other hand, technical research aimed at reducing plagiarism by generative models, such as generating text with correct citations [88, 171, 195], is a promising research direction for reliable GenIR that has received increasing attention in recent years.
6.2.4 隐私与安全。首先,GenIR系统生成的内容存在抄袭风险[50,120]。研究表明[21,89],预训练语言模型可能复现其训练数据中的大段内容,导致无意抄袭并引发学术不端或版权问题。一方面,关于AI生成内容版权的法律法规将逐步完善;另一方面,旨在减少生成模型抄袭的技术研究(例如生成带正确引用的文本[88,171,195])是构建可靠GenIR的重要方向,近年来受到越来越多的关注。
Moreover, due to the unclear mechanisms of memory and generation in pre-trained language models, GenIR systems inevitably return unsafe content. For example, [20, 21, 366] show that when attacked, LLMs may return private information of users seen in training data. Therefore, understanding the mechanisms by which LLMs recall training data and designing effective defense mechanisms to enhance security are crucial for the widespread use of GenIR systems. Additionally, developing effective detection methods for content generated by LLMs is essential for enhancing the security of GenIR systems [331].
此外,由于预训练语言模型的记忆与生成机制尚不明确,生成式信息检索(GenIR)系统不可避免地会返回不安全内容。例如[20, 21, 366]研究表明,当遭受攻击时,大语言模型可能泄露训练数据中见过的用户隐私信息。因此,理解大语言模型回忆训练数据的机制,并设计有效的防御机制来提升安全性,对GenIR系统的广泛应用至关重要。同时,开发针对大语言模型生成内容的有效检测方法,也是增强GenIR系统安全性的关键环节[331]。
6.3 Unified Framework
6.3 统一框架
This article discusses two mainstream forms of GenIR: generative document retrieval and reliable response generation. However, each approach has its advantages and limitations. Generative document retrieval still returns a list of documents, whereas the reliable response generation model itself cannot effectively capture document-level relationships. Therefore, integrating these two approaches is a promising research direction.
本文讨论了生成式信息检索(GenIR)的两种主流形式:生成式文档检索和可靠响应生成。然而,每种方法都有其优势和局限。生成式文档检索仍返回文档列表,而可靠响应生成模型本身无法有效捕捉文档级关联。因此,整合这两种方法是一个颇具前景的研究方向。
6.3.1 Unified Framework for Retrieval and Generation. Given that both generative retrieval and downstream generation tasks can be based on generative language models, could a single model perform both retrieval and generation tasks? Indeed, it could.
6.3.1 检索与生成的统一框架。鉴于生成式检索和下游生成任务均可基于生成式语言模型 (Generative Language Model) 实现,单一模型能否同时执行检索和生成任务?答案是肯定的。
Current attempts, such as UniGen [155], use a shared encoder and two decoders for GR and QA tasks respectively, and show superior performance on small-scale retrieval and QA datasets. However, they struggle to generalize across multiple downstream tasks and to integrate with powerful LLMs. Additionally, CorpusLM [152] uses a multi-task training approach to obtain a universal model for GR, QA, and RAG. Yet, merely merging training data does not significantly improve retrieval and generation performance, and CorpusLM remains limited to the Wikipedia corpus. Facing a broader internet corpus presents significant challenges.
当前尝试如UniGen [155]采用共享编码器和两个独立解码器分别处理GR与QA任务,在小规模检索和QA数据集上表现出优越性能。然而,这些方法难以泛化到多种下游任务,也无法与强大
In the future, can we construct a large search model (LSM) that allows an LLM to have the capability to generate DocIDs and reliable responses autonomously? Even LSM could decide when to generate DocIDs to access the required knowledge before continuing generation. Unlike the large search model defined in [300], which unifies models beyond the first-stage retrieval (such as re-ranking, snippet, and answer models), we aim to integrate the first-stage retrieval as well, enabling the LSM to fully understand the meaning of retrieval and its connection with various downstream generation tasks.
未来,我们能否构建一个大型搜索模型 (LSM),使大语言模型具备自主生成文档ID (DocID) 和可靠响应的能力?甚至让LSM能够决定何时生成DocID以获取所需知识后再继续生成。与[300]中定义的仅统一第一阶段检索后模型(如重排序、摘要和答案模型)的大型搜索模型不同,我们的目标是整合第一阶段检索,使LSM能完全理解检索的含义及其与各类下游生成任务的关联。
6.3.2 Towards End-to-End Framework for Various IR Tasks. Metzler et al. [195] envisioned an expert-level corpus model that not only possesses linguistic capabilities but also understands document-level DocIDs and knows the sources of its own knowledge. Such a model could not only solve the issue of hallucinations common in traditional language models but could also generate texts with references pointing to the source documents, thus achieving a reliable end-to-end GenIR model. By understanding DocIDs and knowledge sources, this end-to-end system could also perform additional IR tasks, such as returning the main content of a document given its DocID or returning other related document DocIDs, as well as enabling multi-lingual and multi-modal retrieval.
6.3.2 面向端到端的多任务信息检索框架
Metzler等人[195]设想了一种专家级语料库模型,该模型不仅具备语言能力,还能理解文档级DocID并知晓自身知识来源。这种模型不仅能解决传统语言模型中常见的幻觉问题,还能生成附带源文档引用的文本,从而实现可靠的端到端生成式信息检索(GenIR)模型。通过理解DocID和知识来源,该端到端系统还能执行其他信息检索任务,例如根据DocID返回文档主要内容或相关文档DocID,并支持多语言和多模态检索。
Current methods, as discussed in this GenIR survey, primarily focus on generative document retrieval (GR) and response generation as separate entities. GR models excel at comprehending document identifiers at the document-level, while downstream models demonstrate powerful task generation capabilities. However, existing methods face challenges when it comes to effectively integrating these two generative abilities, limiting the overall performance and effectiveness of the GenIR system. The integration of these generative abilities in a seamless and efficient manner remains a key challenge in the field.
当前方法,如本次GenIR综述所述,主要将生成式文档检索(GR)和响应生成作为独立模块处理。GR模型擅长在文档级别理解文档标识符,而下游模型则展现出强大的任务生成能力。然而现有方法在有效整合这两种生成能力时面临挑战,限制了GenIR系统的整体性能和效果。如何无缝高效地集成这些生成能力,仍是该领域的关键挑战。
In the future, we can design training methods that align knowledge and DocIDs and construct high-quality training datasets for generating answers with references, to train such an end-to-end GenIR model. Achieving this goal remains challenging and requires the collaborative efforts of researchers to contribute to building the next generation of GenIR systems.
未来,我们可以设计将知识与文档ID (DocIDs) 对齐的训练方法,构建高质量的训练数据集来生成带参考文献的答案,从而训练这种端到端的生成式检索 (GenIR) 模型。实现这一目标仍具挑战性,需要研究者们共同努力,为构建下一代GenIR系统贡献力量。
7 CONCLUSION
7 结论
In this survey, we explore the latest research developments, evaluations, current challenges, and future directions in generative information retrieval (GenIR). We discuss two main directions in the GenIR field: generative document retrieval (GR) and reliable response generation. Specifically, we systematically review the progress of GR covering model training, document identifier design, incremental learning, adaptability to downstream tasks, multi-modal GR, and generative recommendation systems; as well as advancements in reliable response generation in terms of internal knowledge memorization, external knowledge enhancement, generating responses with citations, and personal information assistance. Additionally, we have sorted out the existing evaluation methods and benchmarks for GR and response generation. We organize the current limitations and future directions of GR systems, addressing s cal ability, handling dynamic corpora, document representation, and efficiency challenges. Furthermore, we identify challenges in reliable response generation, such as accuracy, real-time capabilities, bias and fairness, privacy, and security. We propose potential solutions and future research directions to tackle these challenges. Finally, we also envision a unified framework, including unified retrieval and generation tasks, and even building an end-to-end framework capable of handling various information retrieval tasks. Through this review, we hope to provide a comprehensive reference for researchers in the GenIR field to further promote the development of this area.
本次综述探讨了生成式信息检索 (GenIR) 领域的最新研究进展、评估方法、当前挑战与未来方向。我们重点分析了 GenIR 的两大研究方向:生成式文档检索 (GR) 和可靠响应生成。具体而言,我们系统梳理了 GR 在模型训练、文档标识符设计、增量学习、下游任务适配性、多模态 GR 以及生成式推荐系统方面的进展;同时总结了可靠响应生成在内部知识记忆、外部知识增强、引用生成响应和个人信息辅助等方面的突破。此外,我们整理了现有 GR 与响应生成的评估方法和基准测试集。针对 GR 系统,我们归纳了当前在可扩展性、动态语料处理、文档表征和效率方面的局限性及未来发展方向;对于可靠响应生成,则指出了准确性、实时性、偏见与公平性、隐私及安全性等挑战,并提出了潜在解决方案与研究展望。最后,我们展望了统一框架的可能性,包括统一检索与生成任务,甚至构建能够处理各类信息检索任务的端到端框架。希望通过本次综述为 GenIR 领域研究者提供全面参考,进一步推动该领域发展。
A DETAILS FOR EVALUATION
评估细节
A.1 Evaluation Metrics for Generative Document Retrieval
A.1 生成式文档检索的评估指标
Recall. Recall is a metric that measures the proportion of relevant documents retrieved by the search system. For a given cutoff point $k$ , the recall Recall $@k$ is defined as:
召回率 (Recall)
召回率是衡量搜索系统检索到相关文档比例的指标。对于给定截断点 $k$,召回率 Recall $@k$ 定义为:
$$
\mathrm{Recall}@k=\frac{1}{|Q|}\sum_{q=1}^{|Q|}\frac{r e t_{q,k}}{r e l_{q}},
$$
$$
召回率@k = \frac{1}{|Q|}\sum_{q=1}^{|Q|}\frac{ret_{q,k}}{rel_q},
$$
where $|Q|$ is the number of queries in the set, $r e t_{q,k}$ is the number of relevant documents retrieved for the $q$ -th query within the top $k$ results, and $r e l_{q}$ is the total number of relevant documents for the $q$ -th query.
其中 $|Q|$ 是查询集中的查询数量,$ret_{q,k}$ 是第 $q$ 个查询在 top $k$ 结果中检索到的相关文档数量,$rel_{q}$ 是第 $q$ 个查询的总相关文档数。
R-Precision. R-Precision measures the precision at the rank position $R$ , which corresponds to the number of relevant documents for a given query $q$ . It is calculated as:
R-Precision。R-Precision衡量在排名位置$R$处的精度,该位置对应于给定查询$q$的相关文档数量。计算公式为:
$$
\mathrm{R-Precision}=\frac{r e t_{q,R}}{r e l_{q}},
$$
$$
\mathrm{R-Precision}=\frac{r e t_{q,R}}{r e l_{q}},
$$
where $r e t_{q,R}$ is the number of relevant documents retrieved within the top $R$ positions, and $R$ is equivalent to $r e l_{q}$ .
其中 $ret_{q,R}$ 表示在排名前 $R$ 位中检索到的相关文档数量,$R$ 等同于 $rel_{q}$。
Mean Reciprocal Rank (MRR). MRR reflects the average rank position of the first relevant document returned in the search results. It is computed as follows:
平均倒数排名 (Mean Reciprocal Rank, MRR)。MRR反映了搜索结果中返回的第一个相关文档的平均排名位置,其计算公式如下:
$$
\mathrm{MRR}=\frac{1}{|Q|}\sum_{q=1}^{|Q|}\frac{1}{\mathrm{rank}_{q}},
$$
$$
\mathrm{MRR}=\frac{1}{|Q|}\sum_{q=1}^{|Q|}\frac{1}{\mathrm{rank}_{q}},
$$
where $\mathrm{rank}_{q}$ is the rank of the first relevant document returned for the $q$ -th query.
其中 $\mathrm{rank}_{q}$ 表示第 $q$ 个查询返回的首个相关文档的排名。
Mean Average Precision (MAP). MAP calculates the average precision across multiple queries. It considers the exact position of all relevant documents and is calculated using the following formula:
平均准确率均值 (Mean Average Precision, MAP)。MAP计算多个查询的平均准确率,考虑了所有相关文档的具体位置,计算公式如下:
$$
\mathrm{MAP}=\frac{1}{|Q|}\sum_{q=1}^{|Q|}\left(\frac{1}{r e l_{q}}\sum_{k=1}^{n_{q}}\mathrm{P}@k\times I(q,k)\right),
$$
$$
\mathrm{MAP}=\frac{1}{|Q|}\sum_{q=1}^{|Q|}\left(\frac{1}{r e l_{q}}\sum_{k=1}^{n_{q}}\mathrm{P}@k\times I(q,k)\right),
$$
where $\mathrm{P}@k$ is the precision at cutoff $k$ , and $I(q,k)$ is an indicator function that is 1 if the document at position $k$ is relevant to the $q$ -th query and 0 otherwise.
其中 $\mathrm{P}@k$ 表示截止位置 $k$ 的精度 (precision),$I(q,k)$ 是指示函数,当位置 $k$ 的文档与第 $q$ 个查询相关时为 1,否则为 0。
Normalized Discounted Cumulative Gain $(\mathbf{nDCG})$ . nDCG takes into account not only the relevance of the documents returned but also their positions in the result list. It is defined by:
归一化折损累计增益 $(\mathbf{nDCG})$。nDCG不仅考虑返回文档的相关性,还考虑它们在结果列表中的位置。其定义为:
$$
\mathrm{DCG}(\varpi k=\sum_{i=1}^{k}\frac{2^{\mathrm{rel}_ {i}}-1}{\log_{2}(i+1)},
$$
$$
\mathrm{DCG}(\varpi k=\sum_{i=1}^{k}\frac{2^{\mathrm{rel}_ {i}}-1}{\log_{2}(i+1)},
$$
$$
\mathrm{nDCG}\ @k=\frac{\mathrm{DCG}\ @k}{\mathrm{IDCG}\ @k},
$$
$$
\mathrm{nDCG}\ @k=\frac{\mathrm{DCG}\ @k}{\mathrm{IDCG}\ @k},
$$
where $\mathrm{rel}_{i}$ represents the graded relevance of the $i$ -th document, $\scriptstyle\mathrm{{DCG}}\ @k$ is the discounted cumulative gain, and $\mathrm{IDCG}@k$ represents the maximum possible $\scriptstyle\mathrm{{DCG@k}}$ .
其中 $\mathrm{rel}_{i}$ 表示第 $i$ 个文档的分级相关性,$\scriptstyle\mathrm{{DCG}}\ @k$ 为折损累计增益,$\mathrm{IDCG}@k$ 表示最大可能的 $\scriptstyle\mathrm{{DCG@k}}$。
A.2 Benchmarks for Generative Document Retrieval
A.2 生成式文档检索基准
MS MARCO. MS MARCO (Microsoft Machine Reading Comprehension) is a large-scale dataset developed by Microsoft for evaluating machine reading comprehension, retrieval, and questionanswering capabilities within web search contexts. It comprises two primary benchmarks:
MS MARCO
MS MARCO (Microsoft Machine Reading Comprehension) 是微软开发的大规模数据集,用于评估网络搜索场景下的机器阅读理解、检索和问答能力。该数据集包含两个主要基准:
Document Ranking: This benchmark includes approximately 3.2 million documents derived from real user queries extracted from Microsoft Bing’s search logs. Each query is paired with annotated relevant documents, facilitating the evaluation of retrieval accuracy and s cal ability. • Passage Ranking: Containing around 8.8 million passages, this benchmark focuses on more granular retrieval tasks, assessing the system’s ability to identify relevant information at the passage level.
文档排序:该基准包含约320万份文档,源自从Microsoft Bing搜索日志中提取的真实用户查询。每个查询都配有标注的相关文档,便于评估检索准确性和可扩展性。
段落排序:该基准包含约880万条段落,专注于更细粒度的检索任务,评估系统在段落级别识别相关信息的能力。
The diversity of question types and document genres in MS MARCO aims to mimic complex web search scenarios, making it a pivotal resource for testing the robustness and effectiveness of GR systems.
MS MARCO中问题类型和文档体裁的多样性旨在模拟复杂的网络搜索场景,使其成为测试GR系统稳健性和有效性的关键资源。
Natural Questions (NQ). Natural Questions (NQ) is a question-answering dataset introduced by Google, utilizing Wikipedia as its foundational corpus. It encompasses approximately 3.2 million documents, each corresponding to a Wikipedia page. The dataset includes a wide array of natural user queries along with their respective answers extracted directly from web pages in Google search results. NQ is designed to evaluate the retrieval performance of GR systems in addressing real-world, information-seeking questions, emphasizing the ability to understand and retrieve precise answers from a vast knowledge base.
自然问答 (NQ)。自然问答 (NQ) 是由 Google 推出的问答数据集,以维基百科为基础语料库。它包含约 320 万篇文档,每篇对应一个维基百科页面。该数据集涵盖广泛的自然用户查询及其从 Google 搜索结果网页中直接提取的对应答案。NQ 旨在评估 GR 系统在解决现实世界信息检索问题时的性能,重点考察从海量知识库中理解并检索精确答案的能力。
KILT. KILT (Knowledge Intensive Language Tasks) is an extensive benchmark dataset that integrates five categories of knowledge-intensive tasks, including:
KILT。KILT (Knowledge Intensive Language Tasks) 是一个综合性基准数据集,整合了五类知识密集型任务,包括:
KILT employs Wikipedia as its primary corpus, consisting of approximately 5.9 million wiki pages. The benchmark aims to evaluate the effectiveness of information retrieval systems in handling complex language tasks that require extensive background knowledge and the ability to integrate information across multiple domains.
KILT采用维基百科作为其主要语料库,包含约590万个维基页面。该基准旨在评估信息检索系统在处理需要广泛背景知识及跨领域信息整合能力的复杂语言任务时的有效性。
TREC Deep Learning Track 2019 & 2020. The TREC Deep Learning Tracks for 2019 and 2020 are specialized evaluation campaigns focusing on the application of deep learning techniques to enhance the efficiency and effectiveness of information retrieval systems. The primary tasks in these tracks include:
TREC Deep Learning Track 2019 & 2020。TREC Deep Learning Track 2019和2020是专注于应用深度学习技术提升信息检索系统效率和效果的专项评估活动。该赛道的主要任务包括:
REFERENCES
参考文献
[1] Mahyar Abbasian, Iman Azimi, Amir M. Rahmani, and Ramesh C. Jain. 2023. Conversational Health Agents: A Personalized LLM-Powered Agent Framework. CoRR abs/2310.02374 (2023). https://doi.org/10.48550/ARXIV.2310. 02374 arXiv:2310.02374
[1] Mahyar Abbasian, Iman Azimi, Amir M. Rahmani, and Ramesh C. Jain. 2023. 对话式健康智能体:一个个性化的大语言模型驱动智能体框架. CoRR abs/2310.02374 (2023). https://doi.org/10.48550/ARXIV.2310.02374 arXiv:2310.02374
ACM Trans. Inf. Syst., Vol. 1, No. 1, Article . Publication date: March 2025.
ACM Trans. Inf. Syst., 第 1 卷, 第 1 期, 文章 . 发布日期: 2025 年 3 月.