Non-metric Similarity Graphs for Maximum Inner Product Search
基于非度量相似图的极大内积搜索
Stanislav Morozov Yandex, Lomonosov Moscow State University stanis-morozov@yandex.ru
Stanislav Morozov Yandex, 莫斯科国立大学 stanis-morozov@yandex.ru
Abstract
摘要
In this paper we address the problem of Maximum Inner Product Search (MIPS) that is currently the computational bottleneck in a large number of machine learning applications. While being similar to the nearest neighbor search (NNS), the MIPS problem was shown to be more challenging, as the inner product is not a proper metric function. We propose to solve the MIPS problem with the usage of similarity graphs, i.e., graphs where each vertex is connected to the vertices that are the most similar in terms of some similarity function. Originally, the framework of similarity graphs was proposed for metric spaces and in this paper we naturally extend it to the non-metric MIPS scenario. We demonstrate that, unlike existing approaches, similarity graphs do not require any data transformation to reduce MIPS to the NNS problem and should be used for the original data. Moreover, we explain why such a reduction is detrimental for similarity graphs. By an extensive comparison to the existing approaches, we show that the proposed method is a game-changer in terms of the runtime/accuracy trade-off for the MIPS problem.
本文研究了最大内积搜索(MIPS)问题,该问题目前是众多机器学习应用中的计算瓶颈。虽然与最近邻搜索(NNS)类似,但MIPS问题被证明更具挑战性,因为内积并非严格意义上的度量函数。我们提出利用相似图(similarity graphs)来解决MIPS问题,这种图的每个顶点都与在某种相似度函数下最相似的顶点相连。相似图框架最初是为度量空间设计的,本文将其自然扩展到非度量的MIPS场景。我们证明,与现有方法不同,相似图不需要任何数据转换来将MIPS降维为NNS问题,而应直接用于原始数据。此外,我们解释了这种降维为何会对相似图产生不利影响。通过与现有方法的广泛对比,我们表明所提方法在MIPS问题的运行时间/精度权衡方面具有颠覆性优势。
1 Introduction
1 引言
The Maximum Inner Product Search (MIPS) problem has recently received increased attention from different research communities. The machine learning community has been especially active on this subject, as MIPS arises in a number of important machine learning tasks such as efficient Bayesian inference[1, 2], memory networks training[3], dialog agents[4], reinforcement learning[5]. The MIPS problem formulates as follows. Given the large database of vectors $X={x_{i}\in\mathbb{R}^{\breve{d}}|i=1,\ldots,n}$ and a query vector $q\in\mathbb{R}^{d}$ , we need to find an index $j$ such that
最大内积搜索 (Maximum Inner Product Search, MIPS) 问题近年来受到不同研究领域的广泛关注。机器学习社区对此尤为活跃,因为 MIPS 在多项重要机器学习任务中都有应用,例如高效贝叶斯推理 [1, 2]、记忆网络训练 [3]、对话智能体 [4]、强化学习 [5]。MIPS 问题的定义如下:给定大型向量数据库 $X={x_{i}\in\mathbb{R}^{\breve{d}}|i=1,\ldots,n}$ 和查询向量 $q\in\mathbb{R}^{d}$,我们需要找到一个索引 $j$ 使得
$$
\langle x_{j},q\rangle\geq\langle x_{i},q\rangle=x_{i}^{T}q,i\neq j
$$
$$
\langle x_{j},q\rangle\geq\langle x_{i},q\rangle=x_{i}^{T}q,i\neq j
$$
In practice we often need $K>1$ vectors that provide the largest inner products and the top $K$ MIPS problem is considered.
实践中我们通常需要 $K>1$ 个能提供最大内积的向量,此时考虑的就是前 $K$ 大内积搜索(MIPS)问题。
For large-scale databases the sequential scan with the $O(n d)$ complexity is not feasible, and the efficient approximate methods are required. The current studies on efficient MIPS can be roughly divided into two groups. The methods from the first group [6, 7, 8], which are probably the more popular in the machine learning community, reduce MIPS to the NNS problem. They typically transform the database and query vectors and then search the neighbors via traditional NNS structures, e.g., LSH[7] or partition trees[6]. The second group includes the methods that filter out the unpromising database vectors based on inner product upper bounds, like the Cauchy-Schwarz inequality[9, 10].
对于大规模数据库而言,具有 $O(n d)$ 复杂度的顺序扫描不可行,需要高效的近似方法。当前关于高效MIPS的研究大致可分为两类:第一类方法[6,7,8](在机器学习领域可能更流行)将MIPS转化为NNS问题,通常通过转换数据库和查询向量,再利用传统NNS结构(如LSH[7]或分区树[6])进行近邻搜索;第二类方法则基于内积上界(如柯西-施瓦茨不等式[9,10])过滤掉不具潜力的数据库向量。
In this work we introduce a new research direction for the MIPS problem. We propose to employ the similarity graphs framework that was recently shown to provide the exceptional performance for the nearest neighbor search. In this framework the database is represented as a graph, where each vertex corresponds to a database vector. If two vertices $i$ and $j$ are connected by an edge that means that the corresponding database vectors $x_{i}$ and $x_{j}$ are close in terms of some metric function. The neighbor search for a query $q$ is performed via graph exploration: on each search step, the query moves from the current vertex to one of adjacent vertex, corresponding to a vector, which is the closest to the query. The search terminates when the query reaches a local minimum. To the best of our knowledge, we are the first who expands similarity graphs on the MIPS territory with non-metric similarity function. We summarize the main contributions of this paper below:
在本工作中,我们为MIPS问题引入了一个新的研究方向。我们提出采用最近在最近邻搜索中展现出卓越性能的相似图(similarity graphs)框架。该框架将数据库表示为图结构,其中每个顶点对应一个数据库向量。若两个顶点$i$和$j$通过边相连,则意味着对应的数据库向量$x_{i}$和$x_{j}$在某种度量函数下是相近的。针对查询$q$的邻居搜索通过图遍历实现:在每一步搜索中,查询从当前顶点移动到相邻顶点,该顶点对应的向量与查询最接近。当查询到达局部最小值时,搜索终止。据我们所知,我们是首个将相似图框架扩展到使用非度量相似函数的MIPS领域的研究。本文的主要贡献总结如下:
The rest of the paper is organized as follows: in Section 2, we shortly review the existing MIPS methods and the similarity graphs framework. In Section 3 we advocate the usage of similarity graphs for MIPS and describe the efficient algorithm as well. In addition, we demonstrate that one should not reduce MIPS to NNS when using similarity graphs. In Section 4, we compare the proposed approach to the current state-of-the-art and demonstrate its exceptional advantage over existing methods. Finally, in Section 5 we conclude the paper and summarize the results.
本文其余部分结构如下:第2节简要回顾现有MIPS方法和相似图框架。第3节主张将相似图应用于MIPS问题,并描述高效算法,同时论证在使用相似图时不应将MIPS问题降维为NNS问题。第4节将所提方法与当前最优方法进行对比,展示其超越现有方法的显著优势。最后,第5节总结全文并概括研究成果。
2 Related work
2 相关工作
Now we describe several methods and ideas from the previous research that are essential for description of our method. Hereafter we denote the database by $X={x_{i}\in\mathbb{R}^{d}|i=1,\dots,n}$ and a query vector by $q\in\mathbb{R}^{d}$ .
现在我们介绍几种来自先前研究的方法和思想,这些对于描述我们的方法至关重要。下文将数据库记为 $X={x_{i}\in\mathbb{R}^{d}|i=1,\dots,n}$,查询向量记为 $q\in\mathbb{R}^{d}$。
2.1 The existing approaches to the MIPS problem
2.1 现有解决 MIPS 问题的方法
Reduction to NNS. The first group of methods[6, 7, 8] reformulates the MIPS problem as a NNS problem. Such reformulation becomes possible via mapping the original data to a higher dimensional space. For example, [7] maps a database vector $x$ to
约简为最近邻搜索(NNS)。第一类方法[6, 7, 8]将最大内积搜索(MIPS)问题重新表述为最近邻搜索问题。这种重构通过对原始数据进行高维空间映射实现。例如[7]将数据库向量$x$映射到
$$
\hat{x}=(x,\sqrt{1-|x|^{2}})^{T}
$$
$$
\hat{x}=(x,\sqrt{1-|x|^{2}})^{T}
$$
and a query vector $q$ is mapped to
查询向量 $q$ 被映射到
$$
\boldsymbol{\hat{q}}=(q,0)^{T}
$$
$$
\boldsymbol{\hat{q}}=(q,0)^{T}
$$
The transformation from [7] assumes without loss of generality that $|x|\leq1$ for all $x\in X$ and $|q|=1$ for a query vector $q$ . After the mapping the transformed vectors $\hat{x}$ and $\hat{q}$ have unit norms and
从[7]的转换假设不失一般性,对于所有$x\in X$有$|x|\leq1$,且查询向量$q$满足$|q|=1$。映射后,变换后的向量$\hat{x}$和$\hat{q}$具有单位范数。
$$
|{\hat{x}}-{\hat{q}}|^{2}=|{\hat{x}}|^{2}+|{\hat{q}}|^{2}-2\langle{\hat{x}},{\hat{q}}\rangle=-2\langle x,q\rangle+2
$$
$$
|{\hat{x}}-{\hat{q}}|^{2}=|{\hat{x}}|^{2}+|{\hat{q}}|^{2}-2\langle{\hat{x}},{\hat{q}}\rangle=-2\langle x,q\rangle+2
$$
so the minimization of $\Vert\hat{x}-\hat{q}\Vert$ is equivalent to the maximization of $\langle x,q\rangle$ . Other MIPS-to-NNS transformations are also possible, as shown in [11] and [12], and the empirical comparison of different transformations was recently performed in [6]. After transforming the original data, the MIPS problem becomes equivalent to metric neighbor search and can be solved with standard NNS techniques, like LSH[7], Randomized Partitioning Tree[6] or clustering[8].
因此,最小化 $\Vert\hat{x}-\hat{q}\Vert$ 等价于最大化 $\langle x,q\rangle$。其他 MIPS (Maximum Inner Product Search) 到 NNS (Nearest Neighbor Search) 的转换方法也是可行的,如 [11] 和 [12] 所示,而不同转换方法的实证比较最近在 [6] 中进行了研究。在转换原始数据后,MIPS 问题就等价于度量邻域搜索,并可以使用标准的 NNS 技术来解决,例如 LSH (Locality-Sensitive Hashing) [7]、随机划分树 [6] 或聚类 [8]。
Upper-bounding. Another family of methods use inner product upper bounds to construct a small set of promising candidates, which are then checked exhaustively. For example, the LEMP framework[9] filters out the unpromising database vectors based on the Cauchy-Schwarz inequality. Furthermore, [9] proposes an incremental pruning technique that refines the upper bound by computing the partial inner product over the first several dimensions. The FEXIPRO method[10] goes further and performs SVD over the database vectors to make the first dimensions more meaningful. These steps typically improve the upper bounds, and the incremental pruning becomes more efficient. The very recent
上界法。另一类方法利用内积上界构建少量候选集,再通过穷举验证。例如LEMP框架[9]基于柯西-施瓦茨不等式筛选低潜力数据库向量,并提出增量剪枝技术,通过计算前若干维度的部分内积来优化上界。FEXIPRO方法[10]进一步对数据库向量进行奇异值分解(SVD),使前几个维度更具区分度。这些步骤通常能提升上界质量,使增量剪枝更高效。最新研究...
Greedy-MIPS method[13] uses another upper bound $\langle q,x\rangle=\sum_{i=1}^{d}q_{i}x_{i}\leq d\operatorname*{max}_ {i}{q_{i}x_{i}}$ to construct the candidate set efficiently. The efficiency of upper-bound methods is confirmed by experimental comparison[9, 13] and their source code, available online.
贪婪MIPS方法[13]利用另一个上界 $\langle q,x\rangle=\sum_{i=1}^{d}q_{i}x_{i}\leq d\operatorname*{max}_ {i}{q_{i}x_{i}}$ 来高效构建候选集。实验对比[9, 13]及其在线可获取的源代码证实了这类上界方法的效率。
Despite a large number of existing MIPS methods, the problem is far from being solved, especially given rapidly growing databases in nowadays applications. In this work we propose to solve MIPS with the similarity graphs framework that does not fall into either of the two groups above.
尽管已有大量MIPS方法,但该问题远未解决,尤其是在当今应用数据库快速增长的情况下。本工作中,我们提出利用不属于上述任一分类的相似图框架来解决MIPS问题。
2.2 NNS via similarity graph exploration
2.2 基于相似图探索的最近邻搜索
Here we shortly describe the similarity graphs that are currently used for NNS in metric spaces. For a database $X={x_{i}\in\mathbb{R}^{d}|i=1,\dots,\overset{\cdot}{n}}$ the similarity (or knn-)graph is a graph where each vertex corresponds to one of the database vectors $x$ . The vertices $i$ and $j$ are connected by an edge if $x_{j}$ belongs to the set of $\mathrm{k\Omega}$ nearest neigbors of $x_{i}$ , $x_{j}\in N N_{k}(x_{i})$ in terms of some metric similarity function $s(x,y)$ . The usage of knn-graphs for NNS was initially proposed in the seminal work[14]. The approach[14] constructs the database knn-graph and then performs the search by greedy walk on this graph. First, the search process starts from a random vertex and then on each step a query moves from the current vertex to its neighbor, which appears to be the closest to a query. The process terminates when the query reaches a local minimum. The pseudocode of the greedy walk procedure is presented on Algorithm 1.
这里我们简要描述当前用于度量空间最近邻搜索(NNS)的相似图。对于一个数据库 $X={x_{i}\in\mathbb{R}^{d}|i=1,\dots,\overset{\cdot}{n}}$ ,相似图(或称knn图)是一种每个顶点对应一个数据库向量 $x$ 的图结构。当 $x_{j}$ 属于 $x_{i}$ 的 $\mathrm{k\Omega}$ 最近邻集合 $x_{j}\in N N_{k}(x_{i})$ 时,顶点 $i$ 和 $j$ 会通过边连接,连接依据是某个度量相似函数 $s(x,y)$ 。knn图在NNS中的应用最初由开创性研究[14]提出。该方法[14]首先构建数据库knn图,然后通过在该图上进行贪婪游走实现搜索。搜索过程从随机顶点开始,每一步查询从当前顶点移动到其最接近查询的邻居顶点,当查询到达局部最小值时终止。算法1展示了贪婪游走过程的伪代码。
Algorithm 1 Greedy walk
算法 1 贪婪游走
| 1: | Input: Similarity Graph Gs, similarity function s(c, y), query q, entry vertex vo |
| 2:Initialize Ucurr=Vo | |
| 3: repeat | |
| 4: | for Vadj adjacent to Ucurr in G s do |
| 5: | if s(vadj , q) < s(vcurr, q) then |
| 6: | Vcurr = Vadj |
| 7:until Ucurr changes 8:returnUcurr |
| 1: | 输入: 相似图 Gs, 相似度函数 s(c, y), 查询 q, 入口顶点 vo |
| 2: | 初始化 Ucurr=Vo |
| 3: | 重复 |
| 4: | 对于 Gs 中与 Ucurr 相邻的 Vadj 执行 |
| 5: | 如果 s(vadj, q) < s(vcurr, q) 则 |
| 6: | Vcurr = Vadj |
| 7: | 直到 Ucurr 不再变化 |
| 8: | 返回 Ucurr |
Since [14] gave rise to research on NNS with similarity graphs, a plethora of methods, which elaborate the idea, were proposed. The current state-of-the-art graph-based NNS implementations[15, 16, 17] develop additional heuristics that increase the efficiency of both graph construction and search process. Here we describe in detail the recent Navigable Small World (NSW) approach[15], as it is shown to provide the state-of-the-art for NNS[18] and its code is available online. Our approach for MIPS will be based on the NSW algorithm, although the other graph-based NNS methods[16, 17] could also be used.
自[14]开创了基于相似图(Similarity Graphs)的最近邻搜索(NNS)研究以来,涌现了大量改进该思想的算法。当前最先进的基于图的NNS实现[15,16,17]通过引入启发式策略,显著提升了图构建和搜索过程的效率。本文将详细阐述近期提出的可导航小世界(NSW)算法[15],该算法被证明在NNS领域具有最先进性能[18]且代码已开源。虽然其他基于图的NNS方法[16,17]也可行,但我们的MIPS解决方案将基于NSW算法构建。
Algorithm 2 NSW graph construction
算法 2: NSW (Navigable Small World) 图构建
The key to the practical success of NSW lies in the efficiency of both knn-graph construction and neighbor search. NSW constructs the knn-graph by adding vertices in the graph sequentially one by one. On each step NSW adds the next vertex $v$ , corresponding to a database vector $x$ to the current graph. $v$ is connected by directed edges to $M$ vertices, corresponding to the closest database vectors that are already added to the graph. The construction algorithm is presented in Algorithm 2. The primary parameter of the NSW is the maximum vertex degree $M$ , which determines the balance between the search efficiency and the probability that search stops in the suboptimal local minima. When searching via Greedy walk, NSW maintains a priority queue of a size $L$ with the knn-graph vertices, which neighbors should be visited by the search process. With $L{=}1$ the search in NSW is equivalent to Algorithm 1, while with $L>1$ it can be considered as a variant of Beam Search[19], which makes the search process less greedy. In practice, varying $L$ allows to balance between the runtime and search accuracy in NSW.
NSW实际成功的关键在于knn图构建和邻居搜索的效率。NSW通过逐个顺序添加顶点来构建knn图。每一步中,NSW将下一个顶点$v$(对应数据库向量$x$)添加到当前图中。$v$通过有向边连接到$M$个顶点,这些顶点对应已添加到图中的最近邻数据库向量。构建算法如算法2所示。NSW的主要参数是最大顶点度$M$,它决定了搜索效率与搜索陷入次优局部极小值概率之间的平衡。
当通过贪心搜索(Greedy walk)时,NSW维护一个大小为$L$的优先级队列,其中包含knn图顶点,搜索过程需要访问这些顶点的邻居。当$L{=}1$时,NSW的搜索等同于算法1;而当$L>1$时,可以将其视为集束搜索(Beam Search)[19]的一种变体,这使得搜索过程不那么贪心。实际应用中,调整$L$可以在NSW中平衡运行时间和搜索精度。
Prior work on non-metric similarity search on graphs. After the publication, we became aware of a body of previous work that explored the use of proximity graphs with general non-metric similarity functions[20, 21, 22, 23, 24]. In these works, the MIPS problem is investigated as a special case and the effectiveness of proximity graph based methods to the MIPS problem has been confirmed.
关于图上非度量相似性搜索的先前工作。在本文发表后,我们注意到已有大量前人研究探索了使用邻近图处理通用非度量相似性函数的方法 [20, 21, 22, 23, 24]。这些研究将MIPS(最大内积搜索)问题作为特例进行探讨,并证实了基于邻近图的方法对该问题的有效性。
3 Similarity graphs for MIPS
3 面向MIPS的相似度图
Now we extend the similarity graphs framework to applications with a non-metric similarity function $s(x,y)$ . Assume that we have a database $X={x_{i}\in{\mathbb{R}}^{d}|i=1,\ldots,n}$ and aim to solve the problem
现在我们将相似图框架扩展到具有非度量相似度函数$s(x,y)$的应用中。假设我们有一个数据库$X={x_{i}\in{\mathbb{R}}^{d}|i=1,\ldots,n}$,目标是解决该问题
$$
\operatorname*{argmax}_ {x_{i}\in X}s(q,x_{i}),q\in\mathbb{R}^{d}
$$
$$
\operatorname*{argmax}_ {x_{i}\in X}s(q,x_{i}),q\in\mathbb{R}^{d}
$$
3.1 Exact solution
3.1 精确解
First, let us construct a graph $G_{s}$ such that the greedy walk procedure (Algorithm 1), provides the exact answer to the problem (5). [14] has shown that for Euclidean distance $s(x,y)=-|x-y|$ , the minimal $G_{s}$ with this property is the Delaunay graph of $X$ . Now we generalize this result for a broader range of similarity functions.
首先,我们构建一个图$G_{s}$,使得贪心游走过程(算法1)能给出问题(5)的精确解。[14]已证明对于欧氏距离$s(x,y)=-|x-y|$,具有该性质的最小$G_{s}$是$X$的Delaunay图。现在我们将该结果推广到更广泛的相似度函数范围。
Definition. The $s$ -Voronoi cell $R_{k}$ , associated with the element $x_{k}\in X$ , is a set
定义。与元素 $x_{k}\in X$ 相关联的 $s$ -Voronoi 单元 $R_{k}$ 是一个集合
$$
R_{k}={x\in\mathbb{R}^{d}|s(x,x_{k})>s(x,x_{j})\forall j\neq k}
$$
$$
R_{k}={x\in\mathbb{R}^{d}|s(x,x_{k})>s(x,x_{j})\forall j\neq k}
$$
The diagrams of $s$ -Voronoi cells for $s(x,y)=-|x-y|$ and $s(x,y)=\langle x,y\rangle$ are shown on Figure 1.
图 1: 展示了 $s(x,y)=-|x-y|$ 和 $s(x,y)=\langle x,y\rangle$ 的 $s$-Voronoi 单元示意图。
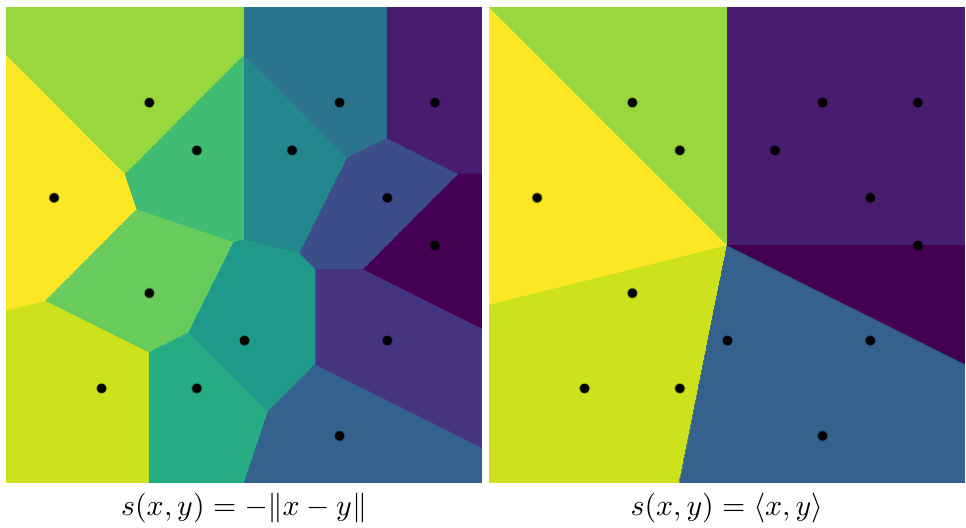
Figure 1: $s$ -Voronoi diagram examples on the plane
图 1: 平面上的 $s$ -Voronoi 图示例
Note, that in the case of inner product $s$ -Voronoi cells for some points are empty. It implies that these points can not be answers in MIPS.
注意,在内积情况下,某些点的 $s$ -Voronoi 单元为空。这意味着这些点无法作为 MIPS 的答案。
Now we can define a $s$ -Delaunay graph for a similarity function $s(x,y)$ .
现在我们能为相似度函数 $s(x,y)$ 定义一个 $s$-Delaunay图。
Definition. The $s$ -Delaunay graph for the database $X$ and the similarity function $s(x,y)$ is a graph $G_{s}(V,E)$ where the set of vertices $V$ corresponds to the set $X$ and two vertices $i$ and $j$ are connected by an edge if the corre s po ding $s$ -Voronoi cells $R_{i}$ and $R_{j}$ are adjacent in $\mathbb{R}^{d}$ .
定义。数据库 $X$ 和相似度函数 $s(x,y)$ 的 $s$-Delaunay 图是一个图 $G_{s}(V,E)$,其中顶点集 $V$ 对应于集合 $X$,且当对应的 $s$-Voronoi 单元 $R_{i}$ 和 $R_{j}$ 在 $\mathbb{R}^{d}$ 中相邻时,两个顶点 $i$ 和 $j$ 通过一条边连接。
Theorem 1. Suppose that the similarity function $s(x,y)$ is such that for every finite database $X$ the corresponding $s$ -Voronoi cells are path-connected sets. Then the greedy walk (Algorithm $I$ ) stops at the exact solution for problem (5) if the similarity graph $G_{s}$ contains the $s$ -Delaunay graph as a subgraph.
定理1. 假设相似度函数 $s(x,y)$ 满足:对于任意有限数据库 $X$,其对应的 $s$-Voronoi单元都是路径连通集。那么当相似图 $G_{s}$ 包含 $s$-Delaunay图作为子图时,贪心游走算法 (算法 $I$ ) 会在问题(5)的精确解处停止。
Proof. Assume that the greedy walk with a query $q$ stops at the point $x$ i.e. $s(x,q)>s(y,q)$ for all $y\in N(x)$ , where $N(x)$ is a set of vertices that are adjacent to $x$ . Suppose that there is a point $z\not\in N(x)$ such that $s(z,q)>s(x,q)$ . It means that the point $q$ does not belong to the $s$ -Voronoi cell $R_{x}$ corresponding to the point $x$ . Note, that if we remove all the points from $G_{s}$ except $x\cup N(x)$ , a set of points covered by $R_{x}$ does not change as all adjacent $s$ -Voronoi regions correspond to vertices from $N(x)$ and they are not removed. Hence, the query $q$ still does not belong to $R_{x}$ . Since the $s$ -Voronoi cells cover the whole space, the point $q$ belongs to some $R_{x^{\prime}},x^{\prime}\in N(x)$ . This means that $s(x^{\prime},q)>s(x,q)$ .This contradiction proves the theorem. 口
证明。假设针对查询$q$的贪婪游走停止于点$x$,即对于所有$y\in N(x)$,有$s(x,q)>s(y,q)$,其中$N(x)$表示与$x$相邻的顶点集合。若存在点$z\not\in N(x)$满足$s(z,q)>s(x,q)$,则说明查询点$q$不属于$x$对应的$s$-Voronoi单元$R_{x}$。值得注意的是,若从图$G_{s}$中移除除$x\cup N(x)$外的所有顶点,$R_{x}$所覆盖的点集不会改变——因为所有相邻的$s$-Voronoi区域都对应于$N(x)$中的顶点且未被移除。因此,查询$q$仍不属于$R_{x}$。由于$s$-Voronoi单元覆盖整个空间,点$q$必属于某个$x^{\prime}\in N(x)$对应的$R_{x^{\prime}}$,这意味着$s(x^{\prime},q)>s(x,q)$。该矛盾证明了定理成立。口
Now we show that $s(x,y)=\langle x,y\rangle$ satisfies the assumptions of the Theorem.
现在我们证明 $s(x,y)=\langle x,y\rangle$ 满足该定理的假设条件。
Lemma 1. Suppose $X$ is a finite database and the similarity function $s(x,y)$ is linear, then the $s$ -Voronoi cells are convex.
引理 1. 假设 $X$ 是一个有限数据库且相似度函数 $s(x,y)$ 是线性的,那么 $s$-Voronoi 单元是凸的。
Proof. Consider a $s$ -Voronoi cell $R_{x}$ , corresponding to a point $x\in X$ . Let us take two arbitrary vectors $u$ and $v$ from the $s$ -Voronoi cell $R_{x}$ . It means that
证明。考虑一个 $s$-Voronoi 单元 $R_{x}$,对应于点 $x\in X$。取 $s$-Voronoi 单元 $R_{x}$ 中的任意两个向量 $u$ 和 $v$。这意味着
$$
\begin{array}{r}{s(x,u)>s(w,u)\forall w\in X\setminus{x}}\ {s(x,v)>s(w,v)\forall w\in X\setminus{x}}\end{array}
$$
$$
\begin{array}{r}{s(x,u)>s(w,u)\forall w\in X\setminus{x}}\ {s(x,v)>s(w,v)\forall w\in X\setminus{x}}\end{array}
$$
Hence, due to linearity
因此,由于线性
$$
s(x,t u+(1-t)v)>s(w,t u+(1-t)v),t\in[0,1]
$$
$$
s(x,t u+(1-t)v)>s(w,t u+(1-t)v),t\in[0,1]
$$
Therefore, vector $t u+(1-t)v\in R_{x}$ for every $t\in[0,1]$ .
因此,向量 $t u+(1-t)v\in R_{x}$ 对于每个 $t\in[0,1]$ 都成立。
Corollary 1. If the graph $G(V,E)$ contains the $s$ -Delaunay graph for the similarity function $s(x,y)=\langle x,y\rangle$ then greedy walk always gives the exact true answer for MIPS.
推论1. 若图 $G(V,E)$ 包含相似度函数 $s(x,y)=\langle x,y\rangle$ 的 $s$-Delaunay图,则贪心游走总能给出MIPS问题的精确解。
Proof. Due to Lemma 1 all $s$ -Voronoi cells for $s(x,y)=\langle x,y\rangle$ are convex, therefore, path-connected. 口
证明。根据引理1,对于 $s(x,y)=\langle x,y\rangle$ 的所有 $s$-Voronoi单元都是凸的,因此是路径连通的。口
3.2 $s$ -Delaunay graph approximation for MIPS
3.2 用于MIPS的$s$-Delaunay图近似
In practice, the computation and usage of the exact $s$ -Delaunay graph in high-dimensional spaces are infeasible due to the exponentially growing number of edges[25]. Instead, we approximate the $s$ -Delaunay graph as was previously proposed for Euclidean distance case in [16, 17, 15]. In particular, we adopt the approximation proposed in [15] by simply extending Algorithm 2 to inner product similarity function $\bar{s}(x,y)=\langle{x},\bar{y}\rangle$ . As in [15] we also restrict the vertex degree to a constant $M$ , which determines the $s$ -Delaunay graph approximation quality. We refer to the proposed MIPS method as ip-NSW. The search process in ip-NSW remains the same as in [15] except that the inner product similarity function guides the similarity graph exploration.
实践中,由于边数呈指数级增长[25],在高维空间中计算和使用精确的 $s$-Delaunay图是不可行的。我们转而采用[16, 17, 15]中针对欧氏距离情形提出的 $s$-Delaunay图近似方法。具体而言,我们通过简单地将算法2扩展到内积相似度函数 $\bar{s}(x,y)=\langle{x},\bar{y}\rangle$,采用了[15]提出的近似方案。与[15]一致,我们也将顶点度数限制为常数 $M$,该参数决定了 $s$-Delaunay图的近似质量。我们将提出的MIPS方法称为ip-NSW。ip-NSW的搜索过程与[15]保持相同,只是由内积相似度函数指导相似图探索。
Let us provide some intuition behind the proposed $s$ -Delaunay graph approximation. In fact, each vertex $x$ is connected to $M$ vertices that provide the highest inner product values $\langle x,\cdot\rangle$ . The heuristic geometrical argument in favor of such approximation is that for $s(x,y)=\langle x,y\rangle$ $s$ -Voronoi cells are polyhedral angles, and the «direction vectors» of adjacent $s$ -Voronoi cells are likely to have large inner product values. While missing the strict mathematical justification, the proposed approach provides the brilliant performance, as confirmed in the experimental section.
让我们为提出的 $s$-Delaunay 图近似提供一些直观解释。实际上,每个顶点 $x$ 会连接到 $M$ 个能提供最高内积值 $\langle x,\cdot\rangle$ 的顶点。支持这种近似的启发式几何论点是:当 $s(x,y)=\langle x,y\rangle$ 时,$s$-Voronoi 单元是多面角,而相邻 $s$-Voronoi 单元的「方向向量」很可能具有较大的内积值。虽然缺乏严格的数学证明,但实验部分证实了所提方法具有卓越性能。
3.3 Similarity graphs after reduction to NNS
3.3 降维至NNS后的相似度图
The natural question is: Why should we develop an additional theory for non-metric similarity graphs? Maybe, one should just reduce the MIPS problem to NNS[6, 7, 8] and apply the state-of-the-art graph implementation for Euclidean similarity. In fact, such a solution is detrimental for runtime-accuracy trade-off, as will be demonstrated in the experimental section. In this section, we provide the intuitive explanation of the inferior performance using the example of transformation form [7]:
自然的问题是:为什么我们要为非度量相似图开发额外的理论?也许,人们应该将 MIPS 问题简化为 NNS [6, 7, 8],并应用最先进的欧几里得相似图实现。事实上,这种解决方案对运行时-准确性的权衡是有害的,正如实验部分将展示的那样。在本节中,我们通过转换形式 [7] 的例子直观地解释性能较差的原因:
$$
\hat{x}=(x,\sqrt{1-|x|^{2}})^{T};\quad\hat{q}=(q,0)^{T}=(q,\sqrt{1-|q|^{2}})^{T}
$$
$$
\hat{x}=(x,\sqrt{1-|x|^{2}})^{T};\quad\hat{q}=(q,0)^{T}=(q,\sqrt{1-|q|^{2}})^{T}
$$
assuming that $|x|\leq1$ for all $x\in X$ and $|q|=1$ . Other transformations could be considered in the similar way. Now we construct the Euclidean similarity graph for the transformed database
假设对于所有 $x\in X$ 都有 $|x|\leq1$ ,且 $|q|=1$ 。其他变换可采用类似方式处理。现在我们为变换后的数据库构建欧氏相似度图
$\hat{X}={(x,\sqrt{1-|x|^{2}})^{T}|x\in X}$ via Algorithm 2. In terms of the original database $X$ , the Euclidean distance between the transformed elements equals
$\hat{X}={(x,\sqrt{1-|x|^{2}})^{T}|x\in X}$ 通过算法2。对于原始数据库 $X$,变换后元素之间的欧氏距离等于
$$
|{\hat{x}}-{\hat{y}}|^{2}=-2\langle x,y\rangle+2-2{\sqrt{1-|x|^{2}}}{\sqrt{1-|y|^{2}}}
$$
$$
|{\hat{x}}-{\hat{y}}|^{2}=-2\langle x,y\rangle+2-2{\sqrt{1-|x|^{2}}}{\sqrt{1-|y|^{2}}}
$$
Note, that the Euclidean similarity graph, constructed for the transformed database $\hat{X}$ , is equivalent to a graph, constructed for the original $X$ with the similarity function $s(x,y)=\langle x,\bar{y}\rangle+$ $\sqrt{1-|x|^{2}}\sqrt{1-|y|^{2}}$ or equivalently
请注意,为转换后的数据库 $\hat{X}$ 构建的欧几里得相似度图,等价于为原始数据库 $X$ 构建的图,其相似度函数为 $s(x,y)=\langle x,\bar{y}\rangle+$ $\sqrt{1-|x|^{2}}\sqrt{1-|y|^{2}}$,或者说等价于
$$
s(x,y)=|x||y|\cos\alpha+{\sqrt{1-|x|^{2}}}{\sqrt{1-|y|^{2}}},
$$
$$
s(x,y)=|x||y|\cos\alpha+{\sqrt{1-|x|^{2}}}{\sqrt{1-|y|^{2}}},
$$
where $\alpha$ is the angle between $x$ and $y$ . The first term in this sum encourages large norms, while the second term penalizes large norms. In high-dimensional spaces the typical values of $\mathrm{cos}\alpha$ tend to be small even for close vectors, which results in the dominance of the second term. Thus, when a new vertex is added to a graph, it prefers to be connected to the vertices, corresponding to vectors with smaller norms. Thus, the edges in the Euclidean graph, constructed for the transformed data, typically lead in the direction of norm decreasing, which is counterproductive to MIPS, which prefers the vectors of larger norms. On the other hand, the non-metric similarity graph, constructed with $s(x,y)=\langle x,y\rangle$ , is more probable to contain edges, directed towards increasing of norms. To verify this explanation, we measure the rate of edges that lead to vectors of larger norms for ip-NSW and the Euclidean NSW on the transformed data. The numbers for three datasets, presented in Table 2, fully confirm our intuition.
其中 $\alpha$ 是 $x$ 和 $y$ 之间的夹角。该求和式中的第一项鼓励较大的范数,而第二项则惩罚较大的范数。在高维空间中,即使对于相近的向量,$\mathrm{cos}\alpha$ 的典型值往往较小,这导致第二项占主导地位。因此,当向图中添加新顶点时,它更倾向于连接到对应较小范数向量的顶点。因此,在为变换后数据构建的欧几里得图中,边通常指向范数减小的方向,这与偏好较大范数向量的 MIPS (最大内积搜索) 背道而驰。另一方面,使用 $s(x,y)=\langle x,y\rangle$ 构建的非度量相似图更可能包含指向范数增大的边。为验证这一解释,我们测量了 ip-NSW 和欧几里得 NSW 在变换数据上指向较大范数向量的边比例。表 2 中三个数据集的数据完全证实了我们的直觉。
4 Experiments
4 实验
In this section we present the experimental evaluation of non-metric similarity graphs for the top $K$ MIPS problem. All the experiments were performed on Intel Xeon E5-2650 machine in a single thread mode. For evaluation, we used the commonly used Recall measure that is defined as a rate of successfully found neighbors, averaged over a set of queries. We performed the experiments with $K=1$ and $K=10$ .
在本节中,我们针对前$K$个MIPS问题展示了非度量相似图(non-metric similarity graphs)的实验评估。所有实验均在Intel Xeon E5-2650机器上以单线程模式运行。评估采用常用的召回率(Recall)指标,其定义为在查询集上平均成功找到邻居的比例。我们分别以$K=1$和$K=10$进行了实验。
Datasets. We summarize the information on the benchmark datasets in Table 1. The Netflix, MovieLens and Yahoo!Music datasets are the established benchmarks for the MIPS problem. Music $100$ is a new dataset that we introduce to the community2. This dataset was obtained by IALSfactorization[26] of the user-item ranking matrix, with dimensionality 100. The matrix contains the ratings from 3,897,789 users on one million popular songs from proprietary music recommendation service. To the best of our knowledge, there is no publicly available dataset of such a large scale and high dimensionality. Normal-64 dataset was generated as a sample from a standard normal distribution with the dimension 64. For all the datasets, the ground truth neighbors were computed by sequential scan. The recall values were averaged over 10, 000 randomly sampled queries.
数据集。我们在表1中总结了基准数据集的信息。Netflix、MovieLens和Yahoo!Music数据集是MIPS问题的既定基准。Music $100$是我们向社区引入的新数据集2。该数据集通过用户-物品评分矩阵的IALS分解[26]获得,维度为100。该矩阵包含来自专有音乐推荐服务的3,897,789名用户对一百万首热门歌曲的评分。据我们所知,目前没有如此大规模和高维度的公开可用数据集。Normal-64数据集是从维度为64的标准正态分布中生成的样本。对于所有数据集,真实邻居通过顺序扫描计算得出。召回率值是对10,000个随机抽样查询取平均得到的。
Table 1: The datasets used in the evaluation.
| DATASET | [x] | [ol | DIM |
| NETFLIX | 17,770 | 480,189 | 200 |
| MOVIELENS | 33,670 | 247,753 | 150 |
| YAHOO!MUSIC | 624,961 | 1,000,990 | 50 |
| MUSIC-100 | 1,000,000 | 3,897,789 | 100 |
| NORMAL-64 | 1,048,576 | 20,000 | 64 |
表 1: 评估中使用的数据集。
| DATASET | [x] | [ol | DIM |
|---|---|---|---|
| NETFLIX | 17,770 | 480,189 | 200 |
| MOVIELENS | 33,670 | 247,753 | 150 |
| YAHOO!MUSIC | 624,961 | 1,000,990 | 50 |
| MUSIC-100 | 1,000,000 | 3,897,789 | 100 |
| NORMAL-64 | 1,048,576 | 20,000 | 64 |
4.1 Non-metric graphs or reduction to NNS?
4.1 非度量图还是降维到最近邻搜索?
Here we experimentally investigate the optimal way to use the similarity graphs for the MIPS problem. We argue that the straightforward solution by reduction to NNS and then using the standard Euclidean similarity graph is suboptimal. To confirm this claim, we compare the performance of the non-metric similarity graph (denoted by ip-NSW) to the performance of Euclidean similarity graph combined with transformation from[7] (denoted by NSW+reduction). The runtime-accuracy plots on three datasets are presented on Figure 2. The plots confirm the advantage of non-metric similarity graphs, especially in the high recall regime. For instance, ip-NSW reaches the recall level 0.9 five times faster on Music-100. We believe that the reason for the inferior performance of the NSW+reduction approach is the edge distribution bias, described in Section 3.3. Overall, we conclude that similarity graphs do not require any MIPS-to-NNS transformation that makes them favorable over other similarity search frameworks. In the subsequent experiments, we evaluate only the ip-NSW approach as our main contribution.
我们通过实验研究了针对MIPS问题使用相似图的最优方法。我们认为,先将其简化为最近邻搜索(NNS)再使用标准欧氏相似图的直接解决方案并非最优。为验证这一观点,我们比较了非度量相似图(记为ip-NSW)与结合文献[7]转换方法的欧氏相似图(记为NSW+reduction)的性能表现。图2展示了三个数据集上的运行时-准确率曲线,证实了非度量相似图的优势,尤其在高召回率区间表现突出。例如在Music-100数据集上,ip-NSW达到0.9召回率的速度快五倍。我们认为NSW+reduction方法性能较差的原因在于3.3节所述的边分布偏差问题。总体而言,相似图无需任何MIPS-to-NNS转换的特性使其优于其他相似性搜索框架。在后续实验中,我们将仅评估作为核心贡献的ip-NSW方法。
Table 2: The rate of similarity graph edges that lead to vector of larger norms for ip-NSW and NSW+reduction. This rate is much higher in the non-metric similarity graph in ip-NSW, which results in higher MIPS performance.
表 2: ip-NSW 和 NSW+reduction 中导致向量范数增大的相似图边比例。在 ip-NSW 的非度量相似图中,该比例显著更高,从而带来更高的 MIPS 性能。

Figure 2: The performance of non-metric ip-NSW and the Euclidean NSW for transformed data on three million-scala datasets. The combination of metric similarity graphs with MIPS-to-NNS reduction results in inferior performance.
图 2: 非度量 ip-NSW 和欧氏 NSW 在三个百万级数据集上对变换数据的性能表现。度量相似图与 MIPS-to-NNS 转换的结合导致性能下降。
4.2 Comparison to the state-of-the-art
4.2 与现有最优技术的对比
As our main experiment, we extensively compare the proposed ip-NSW method to the existing approaches. We compared the following algorithms:
在我们的主要实验中,我们广泛比较了提出的ip-NSW方法与现有方法。我们比较了以下算法:
LEMP[9] We used the author’s implementation of the LEMP framework5 with the algorithm LEMPHYB-REL. We varied parameters $R$ from 0.1 to 0.9 with step 0.1 and $\varepsilon$ from 0.2 to 0.6 with step 0.05 to achieve the runtime-accuracy plots.
LEMP[9] 我们使用了作者实现的LEMP框架5及LEMPHYB-REL算法。通过将参数$R$从0.1到0.9以步长0.1调整,$\varepsilon$从0.2到0.6以步长0.05调整,生成了运行时-准确率曲线图。
Greedy-MIPS[13] We used the author’s implementation 6 with a budget parameter tuned for the each dataset.
Greedy-MIPS[13] 我们使用了作者的实现6,并为每个数据集调整了预算参数。
ip-NSW is the proposed algorithm based on the non-metric similarity graph, described in Section 3.2.
ip-NSW是基于非度量相似图提出的算法,详见第3.2节。
While Netflix and MovieLens are the established datasets in previous works, we do not consider them as interesting benchmarks these days. They both contain only several thousand vectors and the exact Naive-MKL is efficient enough on them. E.g. Naive-MKL works only $0.56\mathrm{{ms}}$ on Netflix and 1.42 ms on MovieLens, which is fast enough for most of applications. Thus, we perform the extensive comparison on three million-scale datasets only. The Figure 3 presents the runtime-accuracy plots for the compared approaches. The timings for Naive-MKL and FEXIPRO are presented under the corresponding plots. Overall, the proposed ip-NSW method outperforms the existing approaches by a substantial margin. For example, ip-NSW reaches 0.9 recall level ten times faster that the fastest baseline. Note, that the for top-10 MIPS the advantage of ip-NSW is even more impressive on all datasets. To justify that the speedup improvements are due to the proposed algorithm and not because of implementation differences (such as libraries, cache locallity, register level optimization s and so on) we also compare number of inner products needed to achieve certain recall levels for different methods. The plots for three datasets and top-10 MIPS are presented on Figure 4.
虽然Netflix和MovieLens是先前研究中公认的数据集,但我们认为它们如今已不具备作为有趣基准的价值。这两个数据集仅包含数千个向量,且原始Naive-MKL算法对其处理效率已足够高。例如,Naive-MKL在Netflix上仅需$0.56\mathrm{{ms}}$,在MovieLens上为1.42毫秒,这对大多数应用场景已足够快速。因此,我们仅在三个百万级数据集上进行了全面对比。图3展示了各对比方法的运行时-准确率曲线,Naive-MKL和FEXIPRO的运行时间标注于对应曲线下方。总体而言,我们提出的ip-NSW方法以显著优势超越现有方案。例如,ip-NSW达到0.9召回率的速度比最快基线方法快十倍。值得注意的是,在top-10 MIPS任务中,ip-NSW在所有数据集上的优势更为突出。为证明加速效果源自算法改进而非实现差异(如库函数、缓存局部性、寄存器级优化等因素),我们还对比了不同方法达到特定召回率所需的内积计算次数。图4展示了三个数据集在top-10 MIPS任务中的对比结果。

Figure 3: The runtime-recall plots on three datasets for top-1 MIPS (top) and top-10 MIPS (bottom). The timings for the exact FEXIPRO and Naive-MKL methods are presented under the corresponding plots.
图 3: 三个数据集上 top-1 MIPS (顶部) 和 top-10 MIPS (底部) 的运行时-召回率曲线。精确 FEXIPRO 和 Naive-MKL 方法的时间数据展示在对应曲线下方。
Additional memory consumption. The performance advantage of the similarity graphs comes at a price of additional memory to maintain the graph structure. In our experiments we use $M=32$ edges per vertex, which results in $32\times n\times s i z e o f(i n t)$ bytes for edge lists. Note, that the size of the database equals $d\times n\times s i z e o f(f l o a t)$ bytes, hence for high-dimensional datasets $d\gg32$ the additional memory consumption is negligible.
额外内存消耗。相似图(similarity graphs)的性能优势需要付出维护图结构的额外内存代价。在我们的实验中,每个顶点设置M=32条边,这将占用边列表的32×n×sizeof(int)字节空间。需注意,数据库本身大小为d×n×sizeof(float)字节,因此对于高维数据集(d≫32)而言,额外内存消耗可忽略不计。

Figure 4: The number of inner products computations needed to achieve certain recall levels on three datasets for top-10 MIPS.
图 4: 在三个数据集上实现top-10 MIPS特定召回率所需的内积计算次数。
5 Conclusion
5 结论
In this work, we have proposed and evaluated a new framework for inner product similarity search. We extend the framework of similarity graphs to the non-metric similarity search problems and demonstrate that the practically important case of inner product could be perfectly solved by these graphs. We also investigate the optimal way to use this framework for MIPS and demonstrate that the popular MIPS-to-NNS reductions are harmful to similarity graphs. The optimized implementation of the proposed method will be available upon publication to support the further research in this direction.
在本工作中,我们提出并评估了一种新的内积相似性搜索框架。我们将相似图框架扩展到非度量相似性搜索问题,并证明这些图能完美解决实际应用中重要的内积问题。我们还研究了将该框架用于最大内积搜索(MIPS)的最佳方式,证实流行的MIPS到最近邻搜索(NNS)转换方法会损害相似图性能。该方法的优化实现将在发表时公开,以支持该方向的后续研究。