A Neural Corpus Indexer for Document Retrieval
用于文档检索的神经语料库索引器
Abstract
摘要
Current state-of-the-art document retrieval solutions mainly follow an indexretrieve paradigm, where the index is hard to be directly optimized for the final retrieval target. In this paper, we aim to show that an end-to-end deep neural network unifying training and indexing stages can significantly improve the recall performance of traditional methods. To this end, we propose Neural Corpus Indexer (NCI), a sequence-to-sequence network that generates relevant document identifiers directly for a designated query. To optimize the recall performance of NCI, we invent a prefix-aware weight-adaptive decoder architecture, and leverage tailored techniques including query generation, semantic document identifiers, and consistency-based regular iz ation. Empirical studies demonstrated the superiority of NCI on two commonly used academic benchmarks, achieving $+21.4%$ and $+16.8%$ relative enhancement for Recall $@1$ on $\mathrm{NQ}320k$ dataset and R-Precision on TriviaQA dataset, respectively, compared to the best baseline method.
当前最先进的文档检索解决方案主要遵循索引-检索范式,这种范式难以直接针对最终检索目标进行优化。本文旨在证明,将训练和索引阶段统一的端到端深度神经网络能显著提升传统方法的召回性能。为此,我们提出神经语料库索引器(NCI),这是一种直接为指定查询生成相关文档标识符的序列到序列网络。为优化NCI的召回性能,我们设计了前缀感知权重自适应解码器架构,并采用定制技术,包括查询生成、语义文档标识符和基于一致性的正则化。实证研究在两种常用学术基准上验证了NCI的优越性:在NQ320k数据集的Recall@1指标上相对最佳基线方法提升21.4%,在TriviaQA数据集的R-Precision指标上提升16.8%。
1 Introduction
1 引言
Document retrieval and ranking are two key stages for a standard web search engine [56; 34]. First, the document retrieval stage retrieves candidate documents relevant to the query, and then, the ranking stage gives a more precise ranking score for each document. The ranking stage is often fulfilled by a deep neural network, taking each pair of query and document as input and predicting their relevance score. Nevertheless, a precise ranking model is very costly, while typically only a hundred or thousand candidates per query are affordable in an online system. As a result, the recall performance of the document retrieval stage is very crucial to the effectiveness of web search engines.
文档检索与排序是标准网络搜索引擎的两个关键阶段[56; 34]。首先,文档检索阶段会检索与查询相关的候选文档,随后排序阶段为每个文档给出更精确的排序分数。排序阶段通常由深度神经网络完成,将每对查询和文档作为输入并预测它们的相关性分数。然而,精确的排序模型成本高昂,而在线系统通常只能为每个查询处理数百或数千个候选文档。因此,文档检索阶段的召回性能对网络搜索引擎的效能至关重要。
Existing document retrieval methods can be divided into two categories, namely term-based and semantic-based approaches [22]. Term-based retrieval approaches [9; 59] build an inverted index for the entire web corpus, but they hardly capture document semantics and fail to retrieve similar documents in different wordings. Thus, semantic-based approaches [56; 36] are proposed to alleviate this discrepancy. First, they learn dense representations for both queries and documents through a twin-tower architecture; then Approximate Nearest Neighbor (ANN) search is applied to retrieve relevant documents for the designated query. Despite of their success in real applications, these approaches can not fully leverage the power of deep neural networks for the following reasons. First, a single embedding vector has limited capacity to memorize all semantics in a document, and it performs even worse than term-based methods in the applications that heavily rely on exact match [37]. Second, the model is unable to incorporate deep query-document interactions. Because
现有的文档检索方法可分为两类,即基于术语 (term-based) 和基于语义 (semantic-based) 的方法 [22]。基于术语的检索方法 [9; 59] 为整个网络语料库构建倒排索引,但它们几乎无法捕捉文档语义,也无法检索用不同措辞表达的相似文档。因此,人们提出了基于语义的方法 [56; 36] 来缓解这一差异。首先,它们通过双塔架构学习查询和文档的密集表示;然后应用近似最近邻 (Approximate Nearest Neighbor, ANN) 搜索来检索指定查询的相关文档。尽管这些方法在实际应用中取得了成功,但由于以下原因,它们无法充分发挥深度神经网络的优势。首先,单个嵌入向量记忆文档所有语义的能力有限,在严重依赖精确匹配的应用中,其表现甚至不如基于术语的方法 [37]。其次,该模型无法融入深度的查询-文档交互。因为
ANN algorithms theoretically require a strong assumption for the Euclidean space, we have to adopt simple functions such as cosine similarity to capture the query-document interactions [20].
理论上,ANN (近似最近邻) 算法需要对欧几里得空间有很强的假设,因此我们不得不采用余弦相似度等简单函数来捕捉查询-文档交互 [20]。
Given the above limitations, several research works have explored end-to-end models that directly retrieve relevant candidates without using an explicit index. Gao et al. [20] proposed a Deep Retrieval (DR) framework for item recommendation, which learned a retrievable structure with historical user-item interactions. Nevertheless, it is more challenging to design a universal model for semantic text retrieval, as we need to leverage the power of both pre-trained language models and deep retrieval networks simultaneously. Tay et al. [50] proposed Differentiable Search Index (DSI), a text-to-text model that maps queries directly to relevant docids. To the best of our knowledge, this is the first attempt to propose a differentiable index for semantic search. However, the vanilla transformer decoder in DSI does not fully leverage the hierarchical structures of document identifiers, and the model is pruned to over-fitting with limited training data. Furthermore, Bevilacqua et al. [4] proposed SEAL by leveraging all n-grams in a passage as its identifiers. But for long documents, it is hard to enumerate all possible n-grams. In general, the recall performance of end-to-end document retrieval remains a large room to be improved.
鉴于上述局限性,多项研究探索了无需显式索引即可直接检索相关候选的端到端模型。Gao等人[20]提出了用于物品推荐的深度检索(DR)框架,该框架通过历史用户-物品交互学习可检索结构。然而,设计通用的语义文本检索模型更具挑战性,因为我们需要同时利用预训练语言模型和深度检索网络的能力。Tay等人[50]提出了可微分搜索索引(DSI),这是一种将查询直接映射到相关文档ID的文本到文本模型。据我们所知,这是首次尝试为语义搜索提出可微分索引。但DSI中的原始Transformer解码器未能充分利用文档标识符的层次结构,且该模型在有限训练数据下容易过拟合。此外,Bevilacqua等人[4]通过利用段落中所有n-gram作为标识符提出了SEAL。但对于长文档,枚举所有可能的n-gram十分困难。总体而言,端到端文档检索的召回性能仍有很大提升空间。
In this paper, we show that the traditional text retrieval frameworks can be fundamentally changed by a unified deep neural network with tailored designs. To this end, we propose a Neural Corpus Indexer (NCI), which supports end-to-end document retrieval by a sequence-to-sequence neural network. The model takes a user query as input, generates the query embedding through the encoder, and outputs the identifiers of relevant documents using the decoder. It can be trained by both ground-truth and augmented query-document pairs. During inference, the top $N$ documents are retrieved via beam search based on the decoder. Designing and training such a model is non-trivial, so we propose several crucial techniques to ensure its effectiveness. First, to get sufficient query-document pairs for training, we leverage a query generation network to obtain possible pairs of queries and documents. Second, we utilize the hierarchical $k$ -means algorithm to generate a semantic identifier for each document. Third, we design a prefix-aware weight-adaptive decoder to replace the vanilla one in a sequence-to-sequence architecture. Specifically, the same token will be assigned different embedding vectors at different positions in the identifiers, while another transformer-based adaptive module is applied to the classification weights for token prediction in the context of a certain prefix. This makes the class if i ers customized to different prefixes when decoding along the hierarchical tree structure. Besides, a consistency-based regular iz ation loss is taken for training both encoder and decoder networks to mitigate the over-fitting problem.
本文提出传统文本检索框架可通过定制化设计的统一深度神经网络实现根本性变革。我们提出神经语料索引器(NCI),该模型基于序列到序列神经网络架构实现端到端文档检索。系统以用户查询作为输入,通过编码器生成查询嵌入向量,并利用解码器输出相关文档标识符。模型支持基于真实数据与增强生成的查询-文档对进行联合训练。在推理阶段,通过解码器的束搜索(beam search)获取Top $N$ 相关文档。
为确保模型有效性,我们提出三项核心技术:首先,采用查询生成网络获取足量训练所需的查询-文档对;其次,运用层次化 $k$ 均值算法为文档生成语义标识符;第三,设计前缀感知的自适应权重解码器替代传统序列到序列架构中的标准解码器。该设计使得相同token在标识符不同位置具有差异化嵌入向量,同时通过Transformer自适应模块实现基于前缀上下文的token预测权重动态调整,从而在层次化树结构解码过程中实现分类器的动态定制。此外,引入基于一致性的正则化损失函数,联合训练编码器与解码器以缓解过拟合问题。
Our NCI design solves the limitations of traditional index-retrieve pipelines from multiple perspectives. On one hand, a whole neural network model replaces the traditional inverted index or vector search solutions. It can be optimized end-to-end using realistic query-document pairs, which fully captures both term-based and semantic-based features and is adaptive to the changing of workloads. On the other hand, the model is able to capture deep interactions between queries and documents via the encoder-decoder attention, which enlarges the capacity of vector-based representations. Moreover, NCI achieves much better ranking results than ANN-based approaches as it is optimized directly by the final target. Thus, it can be served as an end-to-end retrieval solution while releasing the burden of re-ranking for a long candidate list.
我们的NCI设计从多个角度解决了传统索引-检索流程的局限性。一方面,完整的神经网络模型取代了传统的倒排索引或向量搜索方案。它可以通过真实查询-文档对进行端到端优化,全面捕捉基于词项和语义的特征,并能自适应工作负载变化。另一方面,该模型通过编码器-解码器注意力机制捕获查询与文档间的深层交互,从而扩展了基于向量表示的能力。此外,由于直接针对最终目标进行优化,NCI获得了比基于近似最近邻(ANN)方法更好的排序效果。因此,它可作为端到端检索解决方案,同时减轻长候选列表重排序的负担。
In addition to the superior performance, the invention of Neural Corpus Indexer is also promising from the perspective of system design. As nowadays, ranking and query-answering modules are already implemented by neural networks, NCI finishes the last piece of puzzle for the next-generation information retrieval system based on a unified differentiable model architecture. This reduces the dependency among different sub-modules, while the processes of system deployment and maintenance could be greatly eased.
除了卓越的性能外,Neural Corpus Indexer的发明从系统设计角度也极具前景。当今排名和问答模块已由神经网络实现,NCI为基于统一可微分模型架构的新一代信息检索系统补上了最后一块拼图。这降低了各子模块间的耦合度,同时大幅简化了系统部署与维护流程。
Our contributions are highlighted as follows.
我们的贡献主要体现在以下几个方面。
• For the first time, we demonstrate that an end-to-end differentiable document retrieval model can significantly outperform both inverted index and dense retrieval solutions. This finding will inspire research on further steps towards the next-generation search systems, for instance, unifying informational retrieval, ranking, and question answering in a single differentiable framework. • We design a sequence-to-sequence model, named Neural Corpus Indexer (NCI), which generates relevant document identifiers directly for a specific query. In our experiments, the proposed NCI model improves the state-of-the-art performance of existing methods by a significant margin, achieving $+21.4%$ and $+16.8%$ relative enhancement for Recall $@1$ on $\mathrm{NQ}320k$ dataset and
• 我们首次证明,端到端可微分的文档检索模型能够显著优于倒排索引和密集检索方案。这一发现将激发对下一代搜索系统进一步研究的灵感,例如在单一可微分框架中统一信息检索、排序和问答。
• 我们设计了一个名为神经语料库索引器 (Neural Corpus Indexer, NCI) 的序列到序列模型,该模型直接为特定查询生成相关文档标识符。在实验中,所提出的 NCI 模型显著提升了现有方法的性能,在 $\mathrm{NQ}320k$ 数据集上 Recall $@1$ 相对提升了 $+21.4%$ 和 $+16.8%$。
R-Precision on TriviaQA dataset, respectively. Also, NCI itself achieves a competitive MRR score without using an explicit ranking model.
在TriviaQA数据集上的R-Precision。此外,NCI本身在不使用显式排序模型的情况下也取得了具有竞争力的MRR分数。
• We propose a novel decoder architecture, namely prefix-aware weight-adaptive (PAWA) decoder, to generate document identifiers. As verified by ablation studies, this invention is very crucial for NCI to achieve an outstanding performance. Moreover, query generation, semantic document identifiers, and consistency-based regular iz ation are all accountable for the superior capability of Neural Corpus Indexer.
• 我们提出了一种新颖的解码器架构——前缀感知权重自适应 (PAWA) 解码器,用于生成文档标识符。消融实验验证表明,该发明对NCI实现卓越性能至关重要。此外,查询生成、语义文档标识符和基于一致性的正则化共同造就了Neural Corpus Indexer的优异性能。
2 Related work
2 相关工作
In this section, we briefly introduce the related works and leave more discussions in Appendix A.
在本节中,我们简要介绍相关工作,更多讨论见附录A。
Sparse retrieval. Traditional document retrieval methods are based on Sparse Retrieval, which is built upon inverted index with term matching metrics such as TF-IDF [45], query likelihood [33] or BM25 [44]. In industry-scale web search, BM25 is a difficult-to-beat baseline owing to its outstanding trade-off between accuracy and efficiency. In recent years, there are some attempts to incorporate the power of neural networks into inverted index. The Standalone Neural Ranking Model (SNRM) [57] learns high-dimensional sparse representations for query and documents, which enables the construction of inverted index for efficient document retrieval. Doc2Query [41] predicts relevant queries to augment the content of each document before building the BM25 index, and DocT5Query [40] improves the performance of query generation by the pre-trained language model T5 [5]. Furthermore, DeepCT [9] calculates context-aware term importance through neural networks to improve the term matching metrics of BM25.
稀疏检索 (Sparse Retrieval)。传统文档检索方法基于稀疏检索,其核心是结合词项匹配指标(如TF-IDF [45]、查询似然度 [33] 或BM25 [44])的倒排索引。在工业级网页搜索中,BM25因其精度与效率的出色平衡成为难以超越的基线。近年来,学界尝试将神经网络能力融入倒排索引:独立神经排序模型 (SNRM) [57] 通过学习查询与文档的高维稀疏表示,实现了支持高效检索的倒排索引构建;Doc2Query [41] 通过预测相关查询来扩展文档内容后再建立BM25索引,而DocT5Query [40] 借助预训练语言模型T5 [5] 提升了查询生成质量;此外,DeepCT [9] 通过神经网络计算上下文感知的词项重要性,进而优化BM25的词项匹配指标。
Dense retrieval. Another line of research lies in Dense Retrieval, which presents query and documents in dense vectors and models their similarities with inner product or cosine similarity. These methods benefit from recent progresses of pre-trained language models, such as BERT [14] and RoBERTa [35] to obtain dense representations for queries and documents. At inference time, efficient Approximate Nearest Neighbor (ANN) search algorithms, such as k-dimensional trees [3], localitysensitive hashing [10], and graph-based indexes (e.g., HNSW [38], DiskANN [27] and SPANN [7]) can be utilized to retrieve relevant documents within a sublinear time. Besides, Luan et al. [37] analyze the limited capacity of dual encoders, and propose a combination of sparse and dense retrieval methods with multi-vector encoding to achieve better search quality.
密集检索 (Dense Retrieval)。另一研究方向是密集检索,该方法将查询和文档表示为密集向量,并通过内积或余弦相似度建模其相似性。这些方法受益于预训练语言模型(如BERT [14]和RoBERTa [35])的最新进展,从而获得查询和文档的密集表示。在推理阶段,可采用高效的近似最近邻 (ANN) 搜索算法(如k维树 [3]、局部敏感哈希 [10] 和基于图的索引(例如HNSW [38]、DiskANN [27] 和SPANN [7])在亚线性时间内检索相关文档。此外,Luan等人 [37] 分析了双编码器的有限容量,提出结合稀疏与密集检索方法的多向量编码方案以提升搜索质量。
Auto regressive retrieval. The other way to approach retrieval is utilizing an end-to-end autoregressive model. Firstly, several efforts have been done on entity linking [13; 12; 11], which can be regarded as a special type of retrieval task, e.g., using an entity to ask the posed question. Recently, different from the entity linking task, Tay et al. [50] proposed the DSI (differentiable search index) model to generate relevant document identifiers directly corresponding to the query. Bevilacqua et al. [4] employed the auto regressive model to generate relevant words for a query and utilize the generated string to retrieve relevant documents. Besides, the Deep Retrieval (DR) [20] approach for recommendation is also related to this category, which learns a deep retrievable network with user-item clicks and gets rid of the ANN algorithms based on the Euclidean space assumption.
自回归检索。另一种检索方法是利用端到端的自回归模型。首先,在实体链接[13; 12; 11]方面已有诸多研究,这类任务可视为一种特殊类型的检索任务(例如使用实体来提问)。最近,Tay等人[50]提出的DSI(可微分搜索索引)模型与实体链接任务不同,它能直接生成与查询对应的相关文档标识符。Bevilacqua等人[4]采用自回归模型为查询生成相关词汇,并利用生成的字符串检索相关文档。此外,推荐领域的深度检索(DR)[20]方法也属于此类,它通过用户-物品点击数据学习深度可检索网络,摆脱了基于欧几里得空间假设的近似最近邻(ANN)算法。
Pre-trained language models. Recently, pre-trained Language Models (LMs), such as BERT [14] and RoBERTa [35], have led to a revolution in web search techniques. The representation vectors for all documents can be calculated and indexed offline. In the online serving stage, it calculates the representation vector for the input query, and applies a crossing layer to calculate the relevance score between each query and document pair. The crossing layer usually adopts simple operators such as cosine similarity or a single feed-forward layer to retain a high efficiency. Gao et al. [16] found that a standard LMs’ internal attention structure is not ready-to-use for dense encoders and proposed the Condenser to improve the performance of dense retrieval. Moreover, ANCE [54] leverages hard negatives to improve the effectiveness of contrastive learning, which generates better text representations for the retrieval tasks.
预训练语言模型。近年来,预训练语言模型 (Language Models, LMs) 如 BERT [14] 和 RoBERTa [35] 引发了网络搜索技术的革命。所有文档的表征向量可离线计算并建立索引。在线服务阶段,系统会计算输入查询的表征向量,并通过交叉层计算每个查询-文档对的相关性分数。该交叉层通常采用余弦相似度或单层前馈网络等简单算子以保证高效性。Gao 等人 [16] 发现标准语言模型的内在注意力结构不适用于稠密编码器,因此提出 Condenser 模型来提升稠密检索性能。此外,ANCE [54] 通过利用困难负样本来提升对比学习效果,从而为检索任务生成更优质的文本表征。
3 Neural corpus indexer
3 神经语料索引器
The neural corpus indexer (NCI) is a sequence-to-sequence neural network model. The model takes a query as input and outputs the most relevant document identifier (docid), which can be trained by a large collection of <query, docid> pairs. The documents are encoded into semantic docids by the hierarchical $k$ -means algorithm [23], which makes similar documents have “close” identifiers in the hierarchical tree. As shown in Figure 1, NCI is composed of three components, including Query Generation, Encoder, and Prefix-Aware Weight-Adaptive (PAWA) Decoder. Query generation is implemented by a sequence-to-sequence transformer model [52] that takes as input the document terms and produces a query as output [41]. The encoder, following the standard transformer architecture, is composed of $M_{1}$ stacked transformer blocks, which outputs the representation for an input query. For the decoder network, we stack $M_{2}$ transformer layers. To better align with the hierarchical nature of the semantic identifiers, we propose a weight adaptation mechanism based on another transformer to make the decoder aware of semantic prefixes. At inference time, the top $N$ relevant documents can be easily obtained via beam search. Due to the hierarchical property of semantic identifiers, it is easy to constrain the beam search on the prefix tree so that only valid identifiers will be generated.
神经语料索引器 (NCI) 是一种序列到序列的神经网络模型。该模型以查询作为输入,输出最相关的文档标识符 (docid),可通过大量 <查询, docid> 对进行训练。文档通过分层 $k$ -means 算法 [23] 编码为语义 docid,使得相似文档在分层树中具有"相近"的标识符。如图 1 所示,NCI 由三个组件构成,包括查询生成 (Query Generation)、编码器 (Encoder) 和前缀感知权重自适应 (PAWA) 解码器 (Prefix-Aware Weight-Adaptive Decoder)。查询生成通过一个序列到序列的 Transformer 模型 [52] 实现,该模型以文档词项作为输入并生成查询作为输出 [41]。编码器遵循标准 Transformer 架构,由 $M_{1}$ 个堆叠的 Transformer 块组成,为输入查询生成表示。对于解码器网络,我们堆叠了 $M_{2}$ 个 Transformer 层。为了更好地与语义标识符的层次特性对齐,我们提出基于另一个 Transformer 的权重自适应机制,使解码器能够感知语义前缀。在推理阶段,可以通过束搜索轻松获取前 $N$ 个相关文档。由于语义标识符的层次特性,可以轻松地在前缀树上约束束搜索,从而仅生成有效的标识符。
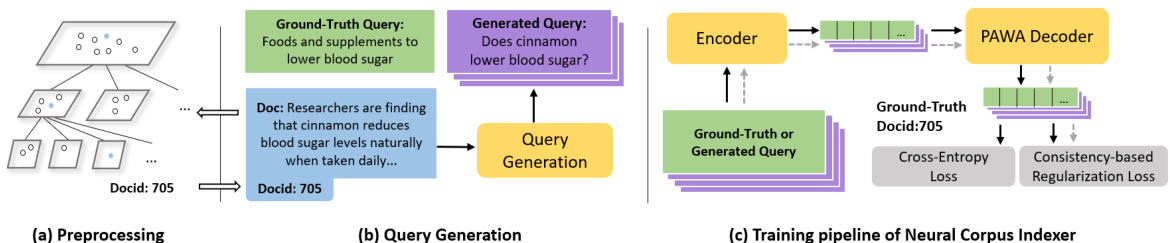
Figure 1: Overview of Neural Corpus Indexer (NCI). (a) Preprocessing. Each document is represented by a semantic identifier via hierarchical $k$ -means. (b) Query Generation. Queries are generated for each document based on the content. (c) The training pipeline of NCI. The model is trained over augmented <query, docid> pairs through a standard transformer encoder and the proposed Prefix-Aware Weight-Adaptive (PAWA) Decoder.
图 1: 神经语料索引器 (NCI) 概览。(a) 预处理。通过分层 $k$ -均值将每个文档表示为语义标识符。(b) 查询生成。根据文档内容为每个文档生成查询。(c) NCI 的训练流程。模型通过标准 Transformer 编码器和提出的前缀感知权重自适应 (PAWA) 解码器在增强的 <查询, 文档ID> 对上训练。
3.1 Representing document with semantic identifiers
3.1 使用语义标识符表示文档
NCI generates document identifiers solely based on the input query without explicit document content, which is difficult when the size of the corpus is very large. Thus, we aim to inject useful priors into the identifiers so that the semantic information of documents can be incorporated in the decoding process. In other words, we hope the documents with similar semantics have close docids to facilitate the learning process of NCI. To achieve this, we leverage the hierarchical $k$ -means algorithm to encode documents. As shown in Figure 1(a), given a collection of documents to be indexed, all documents are first classified into $k$ clusters by using their representations encoded by BERT [14]. For cluster with more than $c$ documents, the $k$ -means algorithm is applied recursively. For each cluster containing $c$ documents or less, each document is assigned a number starting from 0 to at most $c{-}1$ . In this way, we organize all documents into a tree structure $T$ with root $r_{0}$ . Each document is associated with one leaf node with a deterministic routing path $l={r_{0},r_{1},...,r_{m}}$ from the root, where $r_{i}\in[0,k)$ represents the internal cluster index for level $i$ , and $r_{m}\in[0,c)$ is the leaf node. The semantic identifier for a document is concatenated by the node indices along the path from root to its corresponding leaf node. For documents with similar semantics, the prefixes of their corresponding identifiers are likely to be the same. For simplicity, we set $k=30$ and $c=30$ in all experiments, leaving the optimization of these hyper-parameters to future work. The detailed procedure of hierarchical $k$ -means will be described in Algorithm 1 in the Appendix B.2.
NCI仅基于输入查询生成文档标识符,而不依赖显式的文档内容,这在语料库规模非常大时会非常困难。因此,我们的目标是为标识符注入有用的先验信息,以便在解码过程中融入文档的语义信息。换句话说,我们希望语义相似的文档具有相近的docid,从而促进NCI的学习过程。为此,我们采用分层 $k$ -means算法对文档进行编码。如图1(a)所示,给定待索引的文档集合,首先使用BERT[14]编码的表示将所有文档分为 $k$ 个簇。对于包含超过 $c$ 篇文档的簇,递归应用 $k$ -means算法。对于每个包含不超过 $c$ 篇文档的簇,为每篇文档分配一个从0开始至多 $c{-}1$ 的编号。通过这种方式,我们将所有文档组织成一棵以 $r_{0}$ 为根的树结构 $T$ 。每篇文档与一个叶节点相关联,并具有从根节点出发的确定路径 $l={r_{0},r_{1},...,r_{m}}$ ,其中 $r_{i}\in[0,k)$ 表示第 $i$ 层的内部簇索引, $r_{m}\in[0,c)$ 为叶节点。文档的语义标识符由从根节点到对应叶节点路径上的节点索引拼接而成。对于语义相似的文档,其对应标识符的前缀很可能相同。为简化起见,我们在所有实验中设置 $k=30$ 和 $c=30$ ,这些超参数的优化留待未来工作。分层 $k$ -means的详细步骤将在附录B.2的算法1中描述。
3.2 Query generation
3.2 查询生成
One challenge of generating document identifiers by single query input is how to make the identifiers aware of the document semantics. Since the content of each document is not explicitly known at inference, it must be incorporated into the model parameters during training. To facilitate the training process, we generate a bunch of queries with a query generation module and bind the information of document content through training the sequence-to-sequence model with generated queries and their corresponding document identifiers. In NCI, we utilize two kinds of augmented queries:
通过单一查询输入生成文档标识符的一个挑战是如何使标识符感知文档语义。由于在推理时无法明确获知每个文档的内容,必须在训练过程中将这些信息融入模型参数。为简化训练流程,我们通过查询生成模块批量生成查询,并借助序列到序列模型训练将文档内容信息与生成的查询及其对应文档标识符进行绑定。在NCI中,我们采用两种增强查询类型:
DocT5Query. We adopt a standard sequence-to-sequence transformer [52] based on the implementation of DocT5Query [1] pre-trained by a large query-document corpus. It takes as input the document terms and produces relevant queries via random sampling. Note that we use random sampling instead of beam search to ensure the diversity of generated queries.
DocT5Query。我们采用基于DocT5Query [1]实现的标准序列到序列Transformer [52],该模型通过大型查询-文档语料库进行预训练。它以文档术语作为输入,并通过随机采样生成相关查询。需要注意的是,我们使用随机采样而非束搜索(beam search)以确保生成查询的多样性。
Document As Query. Like DSI [50], we also utilize the first 64 terms for each document as queries. Besides, we randomly selected 10 groups of 64 consecutive terms from the whole article as additional queries. This makes the NCI model aware of the semantic meaning of each document.
文档即查询。与DSI [50]类似,我们也使用每篇文档的前64个词项作为查询。此外,我们从整篇文章中随机选取10组连续的64个词项作为额外查询,这使NCI模型能够理解每篇文档的语义。
3.3 Prefix-aware weight-adaptive decoder
3.3 前缀感知权重自适应解码器
Given an input query $x$ , the probability of generating a document identifier can be written as:
给定输入查询 $x$,生成文档标识符的概率可表示为:
$$
p(l|x,\theta)=\prod_{i=1}^{m}p(r_{i}|x,r_{1},r_{2},...,r_{i-1},\theta_{i}),
$$
$$
p(l|x,\theta)=\prod_{i=1}^{m}p(r_{i}|x,r_{1},r_{2},...,r_{i-1},\theta_{i}),
$$
This probability can be modeled by a transformer-based decoder. For an internal node with level $i$ , the probability is calculated by:
该概率可以通过基于Transformer的解码器建模。对于层级为$i$的内部节点,其概率计算公式为:
$$
h_{i}=\mathrm{TransformerDecoder}(x,h_{1},h_{2},...,h_{i-1};\theta_{i}),
$$
$$
h_{i}=\mathrm{TransformerDecoder}(x,h_{1},h_{2},...,h_{i-1};\theta_{i}),
$$
$$
p(r_{i}|x,r_{1},r_{2},...,r_{i-1},\theta_{i})=\mathrm{Softmax}(h_{i}W).
$$
$$
p(r_{i}|x,r_{1},r_{2},...,r_{i-1},\theta_{i})=\mathrm{Softmax}(h_{i}W).
$$
Here $h_{i}$ is the hidden representation for step $i$ , which is calculated by a multi-head attention over encoder representation $x$ and token representations of previous decoding steps. The linear classification weight is denoted by $\boldsymbol{W}\in\mathbb{R}^{d\times v}$ , $d$ is the hidden dimension size and $v$ is the vocabulary size of identifiers.
这里 $h_{i}$ 是步骤 $i$ 的隐藏表示,通过对编码器表示 $x$ 和先前解码步骤的 token 表示进行多头注意力计算得出。线性分类权重表示为 $\boldsymbol{W}\in\mathbb{R}^{d\times v}$,其中 $d$ 是隐藏维度大小,$v$ 是标识符的词汇表大小。
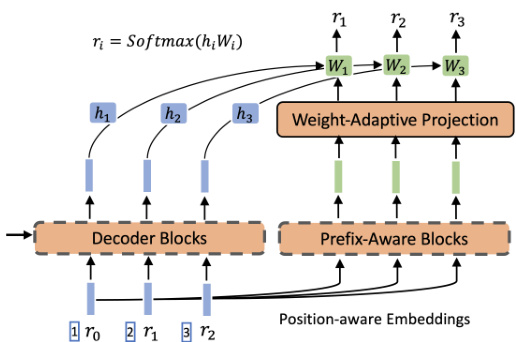
Figure 2: Overview of the Prefix-Aware WeightAdaptive (PAWA) Decoder.
图 2: 前缀感知权重自适应 (PAWA) 解码器概览。
As the encoder and decoder utilize distinct vocabulary spaces, we do not share the embedding space for their tokens. Different from a standard decoding task, the meanings of the same token appearing at different places of the same identifier are different, as they correspond to different clusters in the hierarchical tree structure. For instance, the $\stackrel{\scriptscriptstyle66}{\scriptscriptstyle\operatorname{J}}_ {\underline{{2}}}\stackrel{\scriptscriptstyle7}{\scriptscriptstyle9}$ and $\stackrel{\scriptscriptstyle\leftarrow\leftarrow}{\scriptscriptstyle\mathrm{ O3 }},\stackrel{\scriptscriptstyle\rightarrow}{\scriptscriptstyle\mathrm{ }}$ of the same identifier $\mathrm{^{66}3_{\underline{{{1}}}}5_{\underline{{{2}}}}5_{\underline{{{3}}}}}$ correspond to different semantic meanings. Moreover, the same token in the same position may have different semantics with different prefixes. For example, in identifiers $\mathrm{{}^{66}1_{1}1_{2}5_{3}}^{,\cdot}$ and $\yen23$ , the same token “ $\overset{\cdot}{\underset{\mathrm{ \tiny 5 }_ {3}}{\nabla}}\overset{\cdot}{\underset{\mathrm{ \tiny 5 }_{\mathrm{ \tiny 7 }}}{\nabla}}$ has different semantics in two different identifiers, as they are routed from different prefix paths. These two properties of the hierarchical semantic identifiers motivate us to design the novel Prefix-Aware Weight-Adaptor (PAWA) decoder.
由于编码器和解码器使用不同的词汇空间,我们不为它们的token共享嵌入空间。与标准解码任务不同,同一标识符中不同位置出现的相同token具有不同含义,因为它们对应层次树结构中的不同聚类。例如,同一标识符中的$\stackrel{\scriptscriptstyle66}{\scriptscriptstyle\operatorname{J}}_ {\underline{{2}}}\stackrel{\scriptscriptstyle7}{\scriptscriptstyle9}$和$\stackrel{\scriptscriptstyle\leftarrow\leftarrow}{\scriptscriptstyle\mathrm{ O3 }},\stackrel{\scriptscriptstyle\rightarrow}{\scriptscriptstyle\mathrm{ }}$对应不同语义。此外,相同位置的相同token在不同前缀下可能具有不同语义。例如在标识符$\mathrm{{}^{66}1_{1}1_{2}5_{3}}^{,\cdot}$和$\yen23$中,相同token"$\overset{\cdot}{\underset{\mathrm{ \tiny 5 }_ {3}}{\nabla}}\overset{\cdot}{\underset{\mathrm{ \tiny 5 }_{\mathrm{ \tiny 7 }}}{\nabla}}$"因源自不同前缀路径而具有不同语义。层次语义标识符的这两个特性促使我们设计了新型前缀感知权重适配器(PAWA)解码器。
Unlike a standard transformer decoder, the probabilities at different tree levels, such as $p(r_{i}|\boldsymbol{x},r_{1..i-1},\theta_{i})$ and $p(r_{j}|\boldsymbol{x},r_{1..j-1},\boldsymbol{\theta}_ {j})$ where $i\neq j$ , do not share parameters with each other. To distinguish different semantic levels, we concatenate the position and token values as input for each decoding step, as shown in the left corner of Figure 2. Specifically, we have $^{\cdot}(1,3)(2,5)(3,5)^{,}$ for the semantic identifier $\mathrm{\Delta^{\leftarrow}3_{1}5_{2}5_{3}}^{\prime}$ , while “ $(2,5)'$ and “ $\cdot(3,5)^{\cdot}$ represent different tokens in the vocabulary space. As the token embedding and linear classification layers share the same weights, the same token value in different positions would correspond to different model parameters. Moreover, to reflect the influence of different prefixes, we expect the linear classification layer to be aware of different prefixes for predicting a specific token. Concretely, instead of using the same projection weight $W$ in the linear classification layer, we employ the prefix-aware adaptive weights for each token classifier, which can be calculated by another transformer decoder,
与标准的Transformer解码器不同,不同树层级的概率(例如 $p(r_{i}|\boldsymbol{x},r_{1..i-1},\theta_{i})$ 和 $p(r_{j}|\boldsymbol{x},r_{1..j-1},\boldsymbol{\theta}_ {j})$ ,其中 $i\neq j$ )不共享参数。为了区分不同的语义层级,我们将位置和Token值拼接起来作为每个解码步骤的输入,如图2左下角所示。具体来说,语义标识符 $\mathrm{\Delta^{\leftarrow}3_{1}5_{2}5_{3}}^{\prime}$ 对应的输入为 $^{\cdot}(1,3)(2,5)(3,5)^{,}$ ,而“ $(2,5)'$ ”和“ $\cdot(3,5)^{\cdot}$ ”在词汇空间中表示不同的Token。由于Token嵌入层和线性分类层共享权重,相同Token值在不同位置会对应不同的模型参数。此外,为了反映不同前缀的影响,我们希望线性分类层在预测特定Token时能感知不同的前缀。具体而言,我们不再使用线性分类层中相同的投影权重 $W$ ,而是为每个Token分类器采用前缀感知的自适应权重,这些权重可以通过另一个Transformer解码器计算得出。
$$
W_{a d a}^{i}=\mathrm{AdaptiveDecoder}(e;r_{1},r_{2},...,r_{i-1})W_{i}
$$
$$
W_{a d a}^{i}=\mathrm{AdaptiveDecoder}(e;r_{1},r_{2},...,r_{i-1})W_{i}
$$
where $e$ is the query embedding vector taken as initial input to the transformer decoder; ${r_{t}|t\in(1,2,...,i-1)}$ are prefix tokens before the $i$ -th position, Adaptive Decoder stacks $M_{3}$ transformer decoding layers with dimension $d$ , and $W_{a d a}^{i}\in\mathbb{R}^{d\times v}$ is the adapted weight matrix for the corresponding classifier. Finally, the $i$ -th token in the given prefix can be predicted by Softmax $(h_{i}W_{a d a}^{i})$ .
其中 $e$ 是作为transformer解码器初始输入的查询嵌入向量;${r_{t}|t\in(1,2,...,i-1)}$ 是第 $i$ 个位置之前的前缀token。自适应解码器堆叠了 $M_{3}$ 个维度为 $d$ 的transformer解码层,$W_{a d a}^{i}\in\mathbb{R}^{d\times v}$ 是对应分类器的自适应权重矩阵。最终,给定前缀中的第 $i$ 个token可通过Softmax $(h_{i}W_{a d a}^{i})$ 预测得出。
For instance, to predict the third tokens in the identifiers “(1,3)(2,1)(3,5)” and “(1,2)(2,4)(3,5)”, respectively, the corresponding adaptive weights are derived separately for different prefixes, i.e., “(1,3)(2,1)” and “(1,2)(2,4)”. As we already know the previous tokens for each position in the teacher forcing setting, the prefix-aware adaptive weights can be calculated and trained in parallel in different positions while adding little burden to the entire model.
例如,要分别预测标识符“(1,3)(2,1)(3,5)”和“(1,2)(2,4)(3,5)”中的第三个token,会根据不同前缀(即“(1,3)(2,1)”和“(1,2)(2,4)”)分别推导出对应的自适应权重。由于在教师强制(teacher forcing)设置中已知每个位置的前序token,因此可并行计算并训练不同位置的前缀感知自适应权重,同时几乎不会增加模型整体负担。
3.4 Training and inference
3.4 训练与推理
Consistency-based regular iz ation. To alleviate over-fitting, we employ a consistency-based regular iz ation loss for training each decoding step. Given an input query $q$ , we denote the decoder representations by two forward passes with independent dropouts before Softmax as $\mathbf{z}_ {i,1}=D(\bar{r_{i}}|E(q),r_{1,\dots,i-1},\theta_{i})$ and $\mathbf{z}_ {i,2}={\cal D}(r_{i}|E(q),r_{1,\dots,i-1},\theta_{i})$ , respectively, where $E(\cdot)$ denotes the encoder network and $D(\cdot)$ denotes the decoder network. The consistency-based regularization loss tries to distinguish the representations from the same token from those of other tokens, like contrastive learning [8]. The regular iz ation loss of query $q$ for the $i$ -th decoding step is defined as,
基于一致性的正则化。为缓解过拟合问题,我们在每个解码步骤训练时采用基于一致性的正则化损失。给定输入查询$q$,我们通过两次独立dropout前向传播(Softmax前)分别获得解码器表征:$\mathbf{z}_ {i,1}=D(\bar{r_{i}}|E(q),r_{1,\dots,i-1},\theta_{i})$和$\mathbf{z}_ {i,2}={\cal D}(r_{i}|E(q),r_{1,\dots,i-1},\theta_{i})$,其中$E(\cdot)$表示编码器网络,$D(\cdot)$表示解码器网络。该正则化方法通过对比学习[8]的思想,区分同一token的表征与其他token表征。查询$q$在第$i$个解码步骤的正则化损失定义为:
$$
\begin{array}{r}{\mathcal{L}_ {r e g}=-\log\frac{\exp{({s i m}(\mathbf{z}_ {i,1},\mathbf{z}_ {i,2})/\tau)}}{\sum_{k=1,k\neq2}^{2Q}\exp{({s i m}((\mathbf{z}_ {i,1},\mathbf{z}_{i,k})/\tau)}}}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}_ {r e g}=-\log\frac{\exp{({s i m}(\mathbf{z}_ {i,1},\mathbf{z}_ {i,2})/\tau)}}{\sum_{k=1,k\neq2}^{2Q}\exp{({s i m}((\mathbf{z}_ {i,1},\mathbf{z}_{i,k})/\tau)}}}\end{array}
$$
where we leverage dot-product for $s i m(\cdot);Q$ is the number of queries in the batch, and the temperature parameter is set as $\tau=1$ in all the experiments.
我们利用点积计算 $sim(\cdot)$;$Q$ 是批次中的查询数量,所有实验中温度参数均设为 $\tau=1$。
Training loss. Given a set of training examples $\mathcal{D}={(q,d)}$ composed of queries (training queries and augmented queries) and document identifiers, the loss function can be written as follows:
训练损失。给定一组训练样本 $\mathcal{D}={(q,d)}$,由查询(训练查询和增强查询)和文档标识符组成,损失函数可表示如下:
$$
\mathcal{L}(\theta)=\sum_{(q,d)\in\mathcal{D}}\big(\log p(d|E(q),\theta)+\alpha\mathcal{L}_{r e g}\big),
$$
$$
\mathcal{L}(\theta)=\sum_{(q,d)\in\mathcal{D}}\big(\log p(d|E(q),\theta)+\alpha\mathcal{L}_{r e g}\big),
$$
where $p(d|E(q),\theta)$ denotes the probability of generating $d$ with $q$ as the input. The first part is the seq2seq cross-entropy loss with teacher forcing and the second part is the consistency-based regular iz ation loss summed by all decoding steps. The whole process formulates a sequence-tosequence neural network, which can be optimized end-to-end via gradient descent. The hyperparameter $\alpha$ denotes a scaling factor of regular iz ation loss, which will be analyzed in Section 4.4.
其中 $p(d|E(q),\theta)$ 表示以 $q$ 为输入生成 $d$ 的概率。第一部分是采用教师强制(teacher forcing)的序列到序列(seq2seq)交叉熵损失,第二部分是所有解码步骤的一致性正则化(regularization)损失之和。整个过程构成了一个端到端可优化的序列到序列神经网络,可通过梯度下降进行训练。超参数 $\alpha$ 表示正则化损失的缩放因子,其分析详见第4.4节。
Inference via beam search. In the inference stage, we calculate the query embedding through the encoder network and then perform beam search on the decoder network. Due to the hierarchical nature of docid, it is convincing to constrain the beam search decoding process with a prefix tree, which in turn only generates the valid identifiers. The time complexity of beam search is $O(L B F)$ , where $L$ is the max length of identifiers (the depth of tree), $B$ is the beam size and $F$ is the max fanout of the tree (30 in our experiments). Given a balanced tree structure built by a corpus with $N$ documents, the average time complexity for beam search is $O(B{\log}N)$ . We leave detailed descriptions of the constrained beam search algorithm in Appendix B.3.
基于束搜索的推理。在推理阶段,我们通过编码器网络计算查询嵌入,然后在解码器网络上执行束搜索。由于docid具有层次结构特性,使用前缀树约束束搜索解码过程是合理的,这样仅会生成有效标识符。束搜索的时间复杂度为$O(L B F)$,其中$L$表示标识符的最大长度(树深度),$B$为束宽度,$F$是树的最大分支数(实验中设为30)。对于一个由$N$篇文档构建的平衡树结构,束搜索的平均时间复杂度为$O(B{\log}N)$。受限束搜索算法的详细描述见附录B.3。
4 Experiments
4 实验
In this section, we empirically verify the performance of NCI and the effectiveness of each component on the document retrieval task, which generates a ranking list of documents in response to a query. In the following, we discuss the datasets and evaluation protocols in Section 4.1, describe the implementation details and baseline methods in Section 4.2, and present empirical results and analyses in Section 4.3 and 4.4, respectively.
在本节中,我们通过实验验证NCI在文档检索任务中的性能及各组件的有效性,该任务会针对查询生成文档排序列表。以下内容安排如下:4.1节讨论数据集和评估方案,4.2节描述实现细节和基线方法,4.3节与4.4节分别展示实验结果与分析。
4.1 Datasets & evaluation metrics
4.1 数据集与评估指标
Datasets. We conduct our experiments on two popular benchmarks for document retrieval, i.e., the Natural Questions [32] and TriviaQA dataset [29]. Natural Questions (NQ) [32] was introduced by Google in 2019. The version we use is often referred to as $\mathrm{NQ}320k$ , which consists of $320k$ query-document pairs, where the documents are gathered from Wikipedia pages and the queries are natural language questions. We use its predetermined training and validation split for evaluation. TriviaQA is a reading comprehension dataset [29], which includes $78k$ query-document pairs from the Wikipedia domain. Unlike the $\mathrm{NQ}320k$ dataset, a query may include multiple answers in TriviaQA.
数据集。我们在两个流行的文档检索基准上进行实验,即 Natural Questions [32] 和 TriviaQA 数据集 [29]。Natural Questions (NQ) [32] 由 Google 于 2019 年提出,我们使用的版本通常称为 $\mathrm{NQ}320k$,包含 $320k$ 个查询-文档对,其中文档来自维基百科页面,查询为自然语言问题。我们使用其预定的训练集和验证集划分进行评估。TriviaQA 是一个阅读理解数据集 [29],包含来自维基百科领域的 $78k$ 个查询-文档对。与 $\mathrm{NQ}320k$ 数据集不同,TriviaQA 中的查询可能包含多个答案。
Metrics. We use widely accepted metrics for information retrieval, including Recall $\ @N$ , Mean Reciprocal Rank (MRR) and R-precision. Recall $\ @N$ measures how often the desired document is hit by the top $\mathcal{N}$ retrieved candidates. MRR calculates the reciprocal of the rank at which the first relevant document is retrieved. R-Precision is the precision after $R$ documents have been retrieved, where $R$ is the number of relevant documents for the query. A high recall means that the ground truth document is contained in the retrieved candidate list, while a high MRR indicates that the corresponding document has already been ranked at the top position without re-ranking.
指标。我们采用信息检索领域广泛认可的指标,包括召回率 $\ @N$、平均倒数排名 (MRR) 和 R-精确率。召回率 $\ @N$ 衡量目标文档出现在前 $\mathcal{N}$ 个检索结果中的频率。MRR 计算首个相关文档被检索到时的排名倒数。R-精确率是在检索到 $R$ 个文档后的精确率,其中 $R$ 是查询相关文档的数量。高召回率意味着真实文档包含在检索结果列表中,而高 MRR 表明对应文档无需重新排序就已位居前列。
4.2 Implementation details
4.2 实现细节
Hierarchical semantic identifier. For semantic identifiers, we apply a hierarchical $k$ -means algorithm over the document embeddings obtained through a 12-layers BERT model with pre-trained parameters (provided by Hugging Face [53]). For each hierarchical layer, we employ the default $k$ -means algorithm implemented in scikit-learn [42] with $k=30$ . For simplicity, the recursion terminal condition is also set as $c=30$ .
分层语义标识符。对于语义标识符,我们采用分层k均值算法处理通过12层BERT模型(使用Hugging Face [53]提供的预训练参数)获得的文档嵌入向量。在每一层级上,我们使用scikit-learn [42]实现的默认k均值算法,设定k=30。为简化流程,递归终止条件同样设置为c=30。
Query generation. We leverage the pre-trained model, DocT5Query [40], for query generation. We provide all document contents in $\mathrm{NQ}320k$ and TriviaQA datasets to predict augmented querydocument pairs. For each document, we generate 15 queries with the first 512 tokens of the document as input and constrain the maximum length of the generated query as 64.
查询生成。我们利用预训练模型DocT5Query [40]进行查询生成。将$\mathrm{NQ}320k$和TriviaQA数据集中的所有文档内容作为输入,预测增强的查询-文档对。对于每个文档,我们以前512个token作为输入生成15条查询,并将生成查询的最大长度限制为64。
Training and inference. The Neural Corpus Indexer is implemented with python 3.6.10, PyTorch 1.8.1 and Hugging Face transformers 3.4.0. We utilize the parameters of the T5 pre-trained model [5] to initialize the encoder and randomly initialize the PAWA decoder. All NCI experiments are based on a learning rate $2\times10^{-4}$ for the encoder and $1\times10^{-4}$ for the decoder with a batch size 16 per GPU. We set the scaling factor of the consistency-based regular iz ation loss as $\alpha=0.15$ and the dropout ratio as 0.1. For inference, we apply the partial beam search algorithm to the trained seq2seq model. We set the length penalty and the beam size as 0.8 and 100, respectively. All experiments are based on a cluster of NVIDIA V100 GPUs with 32GB memory. Each job takes 8 GPUs, resulting in a total batch size of 128 $(16\times8)$ .
训练与推理。Neural Corpus Indexer 基于 Python语言 3.6.10、PyTorch 1.8.1 和 Hugging Face transformers 3.4.0 实现。我们采用 T5 预训练模型 [5] 的参数初始化编码器,并随机初始化 PAWA 解码器。所有 NCI 实验采用编码器学习率 $2\times10^{-4}$ 和解码器学习率 $1\times10^{-4}$,每块 GPU 的批次大小为 16。基于一致性的正则化损失缩放因子设为 $\alpha=0.15$,丢弃率为 0.1。推理阶段对训练好的 seq2seq 模型采用部分束搜索算法,长度惩罚系数和束宽分别设为 0.8 和 100。所有实验在配备 32GB 显存的 NVIDIA V100 GPU 集群上完成,每个任务使用 8 块 GPU,总批次大小为 128 $(16\times8)$。
Baselines. We evaluate BM25 on both raw documents and those augmented by DocT5Query by an open-source implementation [2]. The performance of DSI [49] is referred from its original paper as the implementation has not been officially open-sourced. To avoid the difference in data processing, we reproduce SEAL [4] and ANCE [54] by their official implementations. Some baselines for the TriviaQA dataset are directly referred from [58]. We leave the detailed settings in Appendix B.4.
基线方法。我们在原始文档和通过开源实现[2]使用DocT5Query增强的文档上评估BM25。DSI[49]的性能参考其原始论文,因为其实现尚未正式开源。为避免数据处理差异,我们通过官方实现复现了SEAL[4]和ANCE[54]。对于TriviaQA数据集的部分基线方法直接引用自[58]。详细设置见附录B.4。
4.3 Results
4.3 结果
In Table 1 and 2, we compare the empirical results of NCI and corresponding baselines on two benchmarks. We report NCI models based on T5-Base, T5-Large, and ensemble architectures. One can see that even with the T5-Base architecture, NCI outperforms all baselines by a significant margin across four different metrics on both the $\mathrm{NQ}320k$ and TriviaQA datasets. Furthermore, an ensemble of five NCI models also brings a large enhancement, because each model is trained individually with a separate semantic identifier generated by a random $\mathrm{k\Omega}$ -means initialization, making the models complementary to each other. Expect for NCI, SEAL achieves the second best performance. This verifies the superiority of deep text retrieval over traditional sparse and dense retrieval methods. Comparing to SEAL, NCI improves $17.6%$ for Recall $@1$ , $10.0%$ for Recal $@10$ , $3.2%$ for Recall $@100$ , and $1\bar{4}.9%$ for MRR $@100$ on the $\mathrm{NQ}320k$ dataset. We find that the generated queries have different distributions with the training queries , so we also fine-tune Doc2Query on this dataset for a comparison (denoted by $w/q g{-}f t$ ). Finally, we achieve $72.78%$ for Recall $@1$ , outperforming SEAL by $21.4%$ . On the TriviaQA dataset, NCI obtains $7.9%$ improvement for Recall $\ @5$ , $5.5%$ for Recall $@{20}$ , $6.0%$ for Recall $@100$ , and $16.8%$ for R-Precision. As shown in ablation studies, these improvements are owning to the novel designs of PAWA decoder, query generation, semantic identifiers, and consistency-based regular iz ation. We also notice that query generation plays a key role in boosting the retrieval performance. With query generation, the $\mathrm{BM}25+\mathrm{DocT}\mathfrak{s}$ Query method achieves higher performance than the vanilla BM25, especially on the $\mathrm{NQ}320k$ dataset. ANCE achieves competitive performance after fine-tuned by the training pairs, but the performance is relatively lower than our NCI model. Moreover, the MRR $@100$ and R-Precision metrics of NCI are outstanding, indicating that $80%$ of the queries can be fulfilled without re-ranking on the retrieved document list. This demonstrates the potential of NCI to be served as an end-to-end solution that replaces the entire index-retrieve-rank pipeline in traditional web search engines.
在表1和表2中,我们比较了NCI与相应基线在两个基准测试中的实证结果。我们报告了基于T5-Base、T5-Large和集成架构的NCI模型。可以看到,即使在T5-Base架构下,NCI在$\mathrm{NQ}320k$和TriviaQA数据集上的四项不同指标均显著优于所有基线。此外,五个NCI模型的集成也带来了大幅提升,因为每个模型都是通过随机$\mathrm{k\Omega}$-means初始化生成的独立语义标识符单独训练的,使得模型之间具有互补性。除NCI外,SEAL取得了第二好的性能。这验证了深度文本检索相对于传统稀疏和密集检索方法的优越性。与SEAL相比,NCI在$\mathrm{NQ}320k$数据集上的Recall$@1$提升了$17.6%$,Recall$@10$提升了$10.0%$,Recall$@100$提升了$3.2%$,MRR$@100$提升了$1\bar{4}.9%$。我们发现生成的查询与训练查询具有不同的分布,因此我们还在此数据集上对Doc2Query进行了微调以进行比较(记为$w/q g{-}f t$)。最终,我们在Recall$@1$上达到了$72.78%$,比SEAL高出$21.4%$。在TriviaQA数据集上,NCI在Recall$@5$上提升了$7.9%$,Recall$@20$提升了$5.5%$,Recall$@100$提升了$6.0%$,R-Precision提升了$16.8%$。如消融研究所示,这些提升归功于PAWA解码器、查询生成、语义标识符和基于一致性的正则化的新颖设计。我们还注意到查询生成在提升检索性能方面起到了关键作用。通过查询生成,$\mathrm{BM}25+\mathrm{DocT}\mathfrak{s}$Query方法比原始BM25取得了更高的性能,尤其是在$\mathrm{NQ}320k$数据集上。ANCE在经过训练对微调后取得了有竞争力的性能,但其表现仍相对低于我们的NCI模型。此外,NCI的MRR$@100$和R-Precision指标表现突出,表明$80%$的查询可以在不对检索文档列表进行重排序的情况下得到满足。这证明了NCI作为端到端解决方案取代传统网络搜索引擎中整个索引-检索-排序流程的潜力。
Furthermore, to study the effect of each component, we report ablation results on both $\mathrm{NQ}320k$ and TriviaQA datasets in Table 3. In general, all five components are able to improve the performance of document retrieval, which are detailed below.
此外,为研究各组件的影响,我们在表3中报告了$\mathrm{NQ}320k$和TriviaQA数据集上的消融实验结果。总体而言,所有五个组件都能提升文档检索性能,具体如下。
w/o DocT5Query. This configuration removes the training queries generated by DocT5Query. According to the results, the query generation model greatly boosts the performance. The result is aligned with our expectation because training with augmented queries allows the NCI model to better understand the semantic meanings of each document.
不包含DocT5Query。该配置移除了由DocT5Query生成的训练查询。结果显示,查询生成模型显著提升了性能。这一结果符合我们的预期,因为通过增强查询进行训练能使NCI模型更好地理解每篇文档的语义。
Table 1: Performance comparison on $\mathrm{NQ}320k$ retrieval task. The settings with qg $\cdot f t$ refer to query generation by the DocT5Query model fine-tuned on this dataset. Other settings use the original checkpoint of DocT5Query.
| Method | Recall@1 | Recall@10 | Recall@100 | MRR@100 |
| Neural Corpus Indexer(Base) | 65.86 | 85.20 | 92.42 | 73.12 |
| Neural Corpus Indexer (Large) | 66.23 | 85.27 | 92.49 | 73.37 |
| Neural CorpusIndexer (Ensemble) | 70.46 | 89.35 | 94.75 | 77.82 |
| Neural Corpus Indexer w/ qg-ft (Base) | 68.91 | 88.48 | 94.48 | 76.17 |
| Neural Corpus Indexer w/ qg-ft (Large) | 68.65 | 88.45 | 94.53 | 76.10 |
| Neural CorpusIndexer w/qg-ft (Ensemble) | 72.78 | 91.76 | 96.22 | 80.12 |
| DSI (Base) [50] | 27.40 | 56.60 | ||
| DSI (Large) [50] | 35.60 | 62.60 | ||
| DSI (XXL)[50] | 40.40 | 70.30 | ||
| SEAL (Base)[4] | 56.98 | 79.97 | 91.39 | 65.48 |
| SEAL (Large) [4] | 59.93 | 81.24 | 90.93 | 67.70 |
| ANCE (FirstP)[54] | 51.33 | 80.33 | 91.78 | 61.71 |
| ANCE(MaxP)[54] | 52.63 | 80.38 | 91.31 | 62.84 |
| BERT+BruteForce[15] | 28.65 | 53.42 | 73.16 | 36.60 |
| BERT+ANN(Faiss)[28] | 27.92 | 53.63 | 73.01 | 37.08 |
| BM25+ DocT5Query [40] | 35.43 | 61.83 | 76.92 | 44.47 |
| BM25 [44] | 15.11 | 32.48 | 50.54 | 21.07 |
表 1: $\mathrm{NQ}320k$ 检索任务性能对比。标注 qg $\cdot f t$ 的设置表示使用在该数据集上微调后的 DocT5Query 模型进行查询生成,其他设置使用 DocT5Query 的原始检查点。
| 方法 | Recall@1 | Recall@10 | Recall@100 | MRR@100 |
|---|---|---|---|---|
| Neural Corpus Indexer(Base) | 65.86 | 85.20 | 92.42 | 73.12 |
| Neural Corpus Indexer (Large) | 66.23 | 85.27 | 92.49 | 73.37 |
| Neural CorpusIndexer (Ensemble) | 70.46 | 89.35 | 94.75 | 77.82 |
| Neural Corpus Indexer w/ qg-ft (Base) | 68.91 | 88.48 | 94.48 | 76.17 |
| Neural Corpus Indexer w/ qg-ft (Large) | 68.65 | 88.45 | 94.53 | 76.10 |
| Neural CorpusIndexer w/qg-ft (Ensemble) | 72.78 | 91.76 | 96.22 | 80.12 |
| DSI (Base) [50] | 27.40 | 56.60 | - | - |
| DSI (Large) [50] | 35.60 | 62.60 | - | - |
| DSI (XXL)[50] | 40.40 | 70.30 | - | - |
| SEAL (Base)[4] | 56.98 | 79.97 | 91.39 | 65.48 |
| SEAL (Large) [4] | 59.93 | 81.24 | 90.93 | 67.70 |
| ANCE (FirstP)[54] | 51.33 | 80.33 | 91.78 | 61.71 |
| ANCE(MaxP)[54] | 52.63 | 80.38 | 91.31 | 62.84 |
| BERT+BruteForce[15] | 28.65 | 53.42 | 73.16 | 36.60 |
| BERT+ANN(Faiss)[28] | 27.92 | 53.63 | 73.01 | 37.08 |
| BM25+ DocT5Query [40] | 35.43 | 61.83 | 76.92 | 44.47 |
| BM25 [44] | 15.11 | 32.48 | 50.54 | 21.07 |
Table 2: Performance comparison on TriviaQA retrieval task. The results annotated by * are taken from [58].
| Method | Recall@5 | Recall@20 | Recall@100 | R-Precision |
| Neural CorpusIndexer (Base) | 90.49 | 94.45 | 96.94 | 73.90 |
| Neural CorpusIndexer (Large) | 91.73 | 95.17 | 97.44 | 74.94 |
| Neural CorpusIndexer (Ensemble) | 94.60 | 96.89 | 98.20 | 80.84 |
| SEAL(Base)[4] | 86.3 | 90.5 | 91.5 | 68.1 |
| SEAL(Large)[4] | 87.7 | 91.8 | 92.6 | 69.2 |
| AR2-G*[58] | 78.2 | 84.4 | 87.9 | 一 |
| coCondenser*[18] | 76.8 | 83.2 | 87.3 | |
| Condenser*[17] | 81.9 | 86.2 | ||
| Individual Top-k*[46] | 76.8 | 83.1 | 87.0 | |
| Joint Top-k*[46] | 74.1 | 81.3 | 86.3 | |
| RDR*[55] | 82.5 | 87.3 | ||
| ANCE*[54] | 80.3 | 85.3 | ||
| DPR*[30] | 79.3 | 84.9 | ||
| GAR*[39] | 73.1 | 80.4 | 85.7 | |
| BM25+DocT5Query[40] | 59.71 | 72.06 | 82.71 | 39.66 |
| BM25 [44] | 56.91 | 69.45 | 80.24 | 37.29 |
表 2: TriviaQA检索任务性能对比。标注*的结果引自[58]。
| 方法 | Recall@5 | Recall@20 | Recall@100 | R-Precision |
|---|---|---|---|---|
| Neural CorpusIndexer (Base) | 90.49 | 94.45 | 96.94 | 73.90 |
| Neural CorpusIndexer (Large) | 91.73 | 95.17 | 97.44 | 74.94 |
| Neural CorpusIndexer (Ensemble) | 94.60 | 96.89 | 98.20 | 80.84 |
| SEAL(Base)[4] | 86.3 | 90.5 | 91.5 | 68.1 |
| SEAL(Large)[4] | 87.7 | 91.8 | 92.6 | 69.2 |
| AR2-G*[58] | 78.2 | 84.4 | 87.9 | — |
| coCondenser*[18] | 76.8 | 83.2 | 87.3 | |
| Condenser*[17] | 81.9 | 86.2 | ||
| Individual Top-k*[46] | 76.8 | 83.1 | 87.0 | |
| Joint Top-k*[46] | 74.1 | 81.3 | 86.3 | |
| RDR*[55] | 82.5 | 87.3 | ||
| ANCE*[54] | 80.3 | 85.3 | ||
| DPR*[30] | 79.3 | 84.9 | ||
| GAR*[39] | 73.1 | 80.4 | 85.7 | |
| BM25+DocT5Query[40] | 59.71 | 72.06 | 82.71 | 39.66 |
| BM25 [44] | 56.91 | 69.45 | 80.24 | 37.29 |
w/o document as query. Similar to DSI [49], using the document contents as queries also makes the model aware of the semantics of documents.
无文档查询。与DSI [49]类似,使用文档内容作为查询也能让模型感知文档的语义。
w/o PAWA decoder. This configuration removes the adaptive decoder layer in Equation (4) and leverages shared weights with token embedding for the linear classification layer. We notice that the prefix-aware weight-adaptive decoder has a noticeable influence on the performance, which indicates that, instead of borrowing the vanilla transformer decoder, it is necessary to design a tailored decoder architecture for the task of semantic identifier generation.
无PAWA解码器。该配置移除了公式(4)中的自适应解码层,并利用token嵌入的共享权重作为线性分类层。我们注意到前缀感知权重自适应解码器对性能有显著影响,这表明针对语义标识符生成任务,需要设计定制化的解码器架构,而非直接借用标准Transformer解码器。
Table 3: Ablation Study on $\mathrm{NQ}320k$ and TriviaQA retrieval task.
| Method | NQ320k | TriviaQA | ||||||
| Recall@1 | Recall@10 | Recall@100 | MRR@100 | Recall@5 | Recall@20 | Recall@100 | R-Precision | |
| Neural CorpusIndexer (Base) | 65.86 | 85.20 | 92.42 | 73.12 | 90.49 | 94.45 | 96.94 | 73.90 |
| w/oDocT5Query | 60.23 | 80.20 | 90.92 | 67.89 | 84.56 | 90.94 | 95.32 | 63.50 |
| w/odocument asquery | 62.49 | 81.21 | 88.85 | 69.41 | 85.34 | 91.10 | 94.66 | 67.48 |
| w/oPAWAdecoder | 63.36 | 83.06 | 91.47 | 70.56 | 88.75 | 93.56 | 96.18 | 71.81 |
| w/osemanticid | 62.75 | 83.88 | 91.01 | 70.43 | 88.91 | 93.07 | 95.80 | 72.57 |
| w/oregularization | 65.07 | 82.91 | 90.65 | 71.80 | 89.01 | 93.63 | 96.16 | 71.59 |
| w/oconstrainedbeamsearch | 65.65 | 84.89 | 92.23 | 72.79 | 89.58 | 93.97 | 96.61 | 72.51 |
表 3: 在 $\mathrm{NQ}320k$ 和 TriviaQA 检索任务上的消融研究。
| 方法 | NQ320k | TriviaQA | ||||||
|---|---|---|---|---|---|---|---|---|
| Recall@1 | Recall@10 | Recall@100 | MRR@100 | Recall@5 | Recall@20 | Recall@100 | R-Precision | |
| Neural CorpusIndexer (Base) | 65.86 | 85.20 | 92.42 | 73.12 | 90.49 | 94.45 | 96.94 | 73.90 |
| w/o DocT5Query | 60.23 | 80.20 | 90.92 | 67.89 | 84.56 | 90.94 | 95.32 | 63.50 |
| w/o document as query | 62.49 | 81.21 | 88.85 | 69.41 | 85.34 | 91.10 | 94.66 | 67.48 |
| w/o PAWA decoder | 63.36 | 83.06 | 91.47 | 70.56 | 88.75 | 93.56 | 96.18 | 71.81 |
| w/o semantic id | 62.75 | 83.88 | 91.01 | 70.43 | 88.91 | 93.07 | 95.80 | 72.57 |
| w/o regularization | 65.07 | 82.91 | 90.65 | 71.80 | 89.01 | 93.63 | 96.16 | 71.59 |
| w/o constrained beam search | 65.65 | 84.89 | 92.23 | 72.79 | 89.58 | 93.97 | 96.61 | 72.51 |

Figure 3: Learning curves of NCI with different model capacities. Left: $\mathrm{NQ}320k$ ; Right: TriviaQA.
图 3: 不同模型容量的NCI学习曲线。左图: $\mathrm{NQ}320k$;右图: TriviaQA。
w/o semantic id. This configuration replaces the semantic identifier of each document to a randomly generated one. We find a relative drop in the model performance on all four metrics, demonstrating that the semantic identifiers derived by the hierarchical $k$ -means have injected useful priors. We conjecture that the performance enhancement would be more significant on a larger document corpus.
无语义ID。该配置将每个文档的语义标识符替换为随机生成的标识符。我们发现模型在所有四项指标上的性能均出现相对下降,这表明通过分层 $k$ 均值得到的语义标识符注入了有用的先验信息。我们推测,在更大的文档语料库上,这种性能提升会更加显著。
w/o regular iz ation. There is a performance drop on all four metrics without using consistency-based regular iz ation loss. The reason is that the decoder network is prone to over-fitting. By making the prediction results of two augmented queries consistent, the decoder will become more general iz able and resistant to over-fitting.
不使用正则化时,四项指标性能均有所下降。原因在于解码器网络容易过拟合。通过使两个增强查询的预测结果保持一致,解码器将更具泛化能力并抵抗过拟合。
w/o constrained beam search. This configuration disables the validating constraint in beam search. In other words, the decoder network does not have a tree-based prior structure. Instead, all tokens in the vocabulary can be generated in each decoding step. We observe a performance drop on four evaluation metrics. This indicates that it is difficult to remember all information of valid identifiers in the network, and an explicit prior could be helpful for improving the quality of beam search.
不使用受限束搜索 (constrained beam search)。此配置会禁用束搜索中的验证约束。换句话说,解码网络不具备基于树的先验结构,每个解码步骤都可能生成词表中的所有 token。我们观察到四项评估指标均出现性能下降,这表明网络难以记住所有有效标识符信息,显式先验可能有助于提升束搜索质量。
Table 4: NCI with different number of layers in PAWA adapter. Left: $\mathrm{NQ}320k$ ; Right: TriviaQA.
| Setting | Recall@1 | Recall@10 | Recall@100 | MRR@100 |
| #layer=0 | 63.36 | 83.06 | 91.47 | 70.56 |
| #layer =1 | 64.85 | 84.71 | 91.49 | 71.42 |
| #layer=2 | 65.40 | 85.12 | 92.82 | 72.83 |
| #layer = 4 | 65.86 | 85.20 | 92.42 | 73.12 |
| #layer=6 | 65.07 | 83.91 | 91.65 | 71.80 |
| #layer=8 | 63.60 | 83.11 | 91.78 | 71.22 |
表 4: PAWA适配器中不同层数下的NCI指标。左: $\mathrm{NQ}320k$;右: TriviaQA。
| 设置 | Recall@1 | Recall@10 | Recall@100 | MRR@100 |
|---|---|---|---|---|
| #layer=0 | 63.36 | 83.06 | 91.47 | 70.56 |
| #layer=1 | 64.85 | 84.71 | 91.49 | 71.42 |
| #layer=2 | 65.40 | 85.12 | 92.82 | 72.83 |
| #layer=4 | 65.86 | 85.20 | 92.42 | 73.12 |
| #layer=6 | 65.07 | 83.91 | 91.65 | 71.80 |
| #layer=8 | 63.60 | 83.11 | 91.78 | 71.22 |
| Setting | Recall@5 | Recall@20 | Recall@100 | R-Precision |
| #layer=0 | 88.75 | 93.56 | 96.18 | 71.81 |
| #layer =1 | 89.16 | 93.90 | 96.58 | 70.77 |
| #layer=2 | 89.89 | 94.35 | 96.86 | 72.89 |
| #layer=4 | 90.49 | 94.45 | 96.94 | 73.90 |
| #layer=6 | 89.76 | 94.31 | 96.76 | 73.32 |
| #layer=8 | 87.90 | 93.30 | 96.20 | 70.75 |
| 设置 | Recall@5 | Recall@20 | Recall@100 | R-Precision |
|---|---|---|---|---|
| #layer=0 | 88.75 | 93.56 | 96.18 | 71.81 |
| #layer=1 | 89.16 | 93.90 | 96.58 | 70.77 |
| #layer=2 | 89.89 | 94.35 | 96.86 | 72.89 |
| #layer=4 | 90.49 | 94.45 | 96.94 | 73.90 |
| #layer=6 | 89.76 | 94.31 | 96.76 | 73.32 |
| #layer=8 | 87.90 | 93.30 | 96.20 | 70.75 |
4.4 Analysis
4.4 分析
Model capacity. Figure 3 compares the learning curves of NCI with different model capacities, which are identical to the small, base, and large settings of ordinary T5 [43]. We observe that with the increase of model size, NCI convergences more quickly with fewer epochs. At convergence, the small model achieves a relatively lower recall. Instead, both the base and large models achieve similar results after sufficient training epochs, and the large model will be slightly higher. This implies that the model capacity has a critical impact on the retrieval performance, and the capacity of base model seems to be enough to memorize all documents in $\mathrm{NQ}320k$ and TriviaQA datasets. The large model can be used when the computation capacity is sufficient. For a larger corpus, one may need to increase the model size to obtain satisfactory performance.
模型容量。图 3 比较了不同模型容量下 NCI 的学习曲线,这些设置与普通 T5 [43] 的小型、基础和大型配置相同。我们观察到,随着模型规模的增大,NCI 能以更少的训练轮次更快收敛。在收敛时,小型模型的召回率相对较低。相反,基础和大型模型在经过足够训练轮次后表现相近,且大型模型会略胜一筹。这表明模型容量对检索性能具有关键影响,基础模型的容量似乎已足以记忆 $\mathrm{NQ}320k$ 和 TriviaQA 数据集中的所有文档。在计算资源充足时可采用大型模型。对于更大规模的语料库,可能需要增大模型尺寸以获得理想性能。
Layer number of PAWA adapter. We study the influence of the number of transformer layers in the PAWA adapter and choose the layer number from {0,1,2,4,6,8}. The results are summarized in Table 4. We notice that with the increase of layer number, i.e. from 0 to 4, the overall performance is consistently improved on four metrics. But when the number of layers achieves 6, the performance decreases. When continuing to increase the number of layers to 8, the performance drops significantly. We attribute that to the over fitting issue caused by a large PAWA decoder. Therefore, we adopt the PAWA decoder with a 4-layers adapter in NCI.
PAWA适配器的层数。我们研究了PAWA适配器中Transformer层数的影响,并从{0,1,2,4,6,8}中选择了层数。结果总结在表4中。我们注意到,随着层数的增加(即从0到4),四项指标的整体性能持续提升。但当层数达到6时,性能开始下降。继续将层数增加到8时,性能显著下降。我们将此归因于大型PAWA解码器导致的过拟合问题。因此,在NCI中我们采用了具有4层适配器的PAWA解码器。
Retrieved documents and their semantics identifiers. To verify the effectiveness of retrieval as well as the semantic identifiers learned by the hierarchical $k$ -means, we analyze the retrieval results of NCI for some exemplar queries. To illustrate, we select four queries denoted by A-1, A-2, B-1 and B-2, where two queries inside the same group are semantically similar, and the queries in different groups correspond to distinct topics. In Figure 4, we show the probabilities of retrieved documents for each query in group $A$ and $B$ , respectively. The digits along $\mathbf{X}$ -axis denote the four-bit prefixes for the semantic identifiers of retrieved documents, and the y-axis stands for their probabilities. We notice that similar queries result in close document distributions, while dissimilar queries in different groups result in un-overlapped document collections. In addition, the documents retrieved by the same group of queries have close prefixes for the identifiers, e.g., 6030, 6032, 6033, 6034 in group $A$ and 7511, 7514, 7516 in group $B$ . Also, we visualize the BERT-based document embeddings by t-SNE [51] in Figure 4, in which each color represents the corresponding documents for a specific query. As shown in the figure, these documents naturally form two clusters with respect to different query groups. Thus, we conclude that the semantic document identifiers generated by the hierarchical $k$ -means algorithm have positive effects on the retrieval performance.
检索到的文档及其语义标识符。为验证检索效果以及层次化 $k$ -means 学习到的语义标识符有效性,我们分析了NCI对部分示例查询的检索结果。具体选取A-1、A-2、B-1和B-2四组查询,其中同组查询语义相似,不同组查询对应不同主题。图4分别展示了组 $A$ 和组 $B$ 中各查询的文档检索概率分布, $\mathbf{X}$ 轴数字表示检索文档语义标识符的四位前缀,y轴对应其概率值。观测发现:相似查询产生相近文档分布,不同组间相异查询则对应无重叠文档集合;且同组查询检索到的文档标识符前缀高度接近(如组 $A$ 中的6030、6032、6033、6034与组 $B$ 中的7511、7514、7516)。图4同时通过t-SNE [51]可视化基于BERT的文档嵌入,不同颜色代表各查询对应的文档。如图所示,这些文档按查询组别自然形成两个聚类。由此证明层次化 $k$ -means算法生成的语义文档标识符对检索性能具有积极作用。

Figure 4: Analyses of retrieved documents with semantic identifiers. Left: The probabilities of retrieved documents for Query Group A; Middle: The probabilities for Query Group B; Right: The t-SNE visualization of BERT-based document embeddings.
图 4: 基于语义标识符的检索文档分析。左: 查询组A的检索文档概率分布;中: 查询组B的检索文档概率分布;右: 基于BERT的文档嵌入t-SNE可视化。
Table 5: Efficiency analysis
| Model size | Beam size | Latency (ms) | Throughput (queries/s) |
| Small | 10 | 78.46 | 58.48 |
| Base | 10 | 115.17 | 52.55 |
| Large | 10 | 188.60 | 43.39 |
| Small | 100 | 216.01 | 6.12 |
| Base | 100 | 269.31 | 5.62 |
| Large | 100 | 356.07 | 4.75 |
表 5: 效率分析
| 模型大小 | Beam大小 | 延迟(ms) | 吞吐量(查询数/秒) |
|---|---|---|---|
| Small | 10 | 78.46 | 58.48 |
| Base | 10 | 115.17 | 52.55 |
| Large | 10 | 188.60 | 43.39 |
| Small | 100 | 216.01 | 6.12 |
| Base | 100 | 269.31 | 5.62 |
| Large | 100 | 356.07 | 4.75 |
Efficiency Analysis. We use an NVIDIA V100-32G GPU to analyze the efficiency of NCI. As the inference speed is influenced by both model capacity and beam size, we report the latency and throughput measures for multiple settings in Table 5. As NCI is an end-to-end retrieval method and achieves competitive performance without re-ranking, the latency and throughput are already affordable for some near-real-time applications. The latency of NCI is on par with DSI and SEAL using the same model size and beam size, because all of them conduct beam search based on transformer decoders. BM25 is very efficient ${\bf\zeta}^{\prime}{<}100\mathrm{ms}$ per query on CPU using an open-source implementation [2]), but the recall metrics are much lower. Furthermore, we can leverage other techniques to improve the efficiency of NCI, which will be discussed in the later section.
效率分析。我们使用NVIDIA V100-32G GPU分析NCI的效率。由于推理速度受模型容量和束搜索大小影响,表5展示了多种配置下的延迟和吞吐量数据。作为端到端检索方法,NCI无需重排序即可达到有竞争力的性能,其延迟和吞吐量已能满足部分近实时应用需求。在相同模型规模和束搜索设置下,NCI的延迟与DSI、SEAL相当,因为它们都基于transformer解码器进行束搜索。BM25在CPU上效率极高(开源实现[2]的每查询耗时${\bf\zeta}^{\prime}{<}100\mathrm{ms}$),但召回指标明显偏低。此外,我们还可通过其他技术提升NCI效率,这将在后续章节讨论。
5 Limitation & Future Works
5 局限性与未来工作
Despite the significant breakthrough, the current implementation of NCI still suffers from several limitations before deployment in a large-scale search system. Firstly, it requires a much larger model capacity for extending NCI to the web scale. Secondly, the inference speed needs to be improved to serve online queries in real time. Thirdly, it is difficult to update the model-based index when new documents are added to the system. In future works, we may tackle these problems from four aspects. (1) The architecture of sparsely-gated Mixture of Expert (MoE) [47] can be employed to enhance the model capacity. (2) Documents can be grouped into semantic clusters, and NCI can be used to retrieve relevant cluster identifiers. In this way, all documents in relevant clusters can be retrieved efficiently. (3) Model compression techniques, like weight quantization [26] and knowledge distillation [24], can be further taken to speed up inference. (4) We plan to explore a hybrid solution by building another index that serves new documents through traditional indexing algorithms.
尽管取得了重大突破,当前NCI的实现在大规模搜索系统中部署前仍存在若干局限。首先,要将NCI扩展到网络规模需要更大的模型容量。其次,需要提升推理速度以实现实时在线查询服务。第三,当系统新增文档时,基于模型的索引难以更新。未来工作可能从四个方面解决这些问题:(1) 可采用稀疏门控专家混合模型(MoE) [47]架构增强模型容量;(2) 将文档分组为语义聚类,使用NCI检索相关聚类标识符,从而高效获取相关聚类中的所有文档;(3) 进一步应用权重量化[26]和知识蒸馏[24]等模型压缩技术加速推理;(4) 计划探索混合解决方案,通过传统索引算法为新增文档构建辅助索引。
6 Conclusion
6 结论
In this work, we introduce a novel document retrieval paradigm that unifies the training and indexing stages by an end-to-end deep neural network. The proposed Neural Corpus Indexer (NCI) directly retrieves the identifiers of relevant documents for an input query, which can be optimized end-to-end using augmented query-document pairs. To optimize the recall and ranking performance, we invent a tailored prefix-aware weight-adaptive decoder. Empirically, we evaluate NCI on $\mathrm{NQ}320k$ and TriviaQA datasets, demonstrating its outstanding performance over state-of-the-art solutions.
在本工作中,我们提出了一种新颖的文档检索范式,通过端到端深度神经网络统一了训练和索引阶段。所提出的神经语料索引器 (Neural Corpus Indexer, NCI) 直接检索输入查询的相关文档标识符,可使用增强的查询-文档对进行端到端优化。为了优化召回和排序性能,我们发明了一种定制的前缀感知权重自适应解码器。实证中,我们在 $\mathrm{NQ}320k$ 和 TriviaQA 数据集上评估了 NCI,证明其性能优于最先进的解决方案。
A Related work
相关工作
Traditional web search techniques follow a two-stages paradigm including document retrieval and document ranking. The first stage aims to select a collection of documents relevant to a given query, which requires an ingenious trade-off between efficiency and recall. Then, the document ranking stage takes more advanced features and deeper models to calculate a fine-grained ranking score for each query and document pair. In the following, we first discuss related works for document retrieval and ranking respectively. Afterwards, we introduce recent works that incorporate pre-trained language models into these two stages. At last, the attempts on end-to-end retrieval will be discussed.
传统网页搜索技术遵循包含文档检索和文档排序的两阶段范式。第一阶段旨在筛选与给定查询相关的文档集合,这需要在效率和召回率之间进行巧妙权衡。随后,文档排序阶段采用更高级的特征和更深层的模型,为每个查询-文档对计算细粒度排序分数。下文将首先分别讨论文档检索与排序的相关研究,接着介绍将预训练语言模型融入这两个阶段的最新工作,最后探讨端到端检索的尝试。
A.1 Document retrieval
A.1 文档检索
Traditional document retrieval methods are based on Sparse Retrieval, which is built upon inverted index with term matching metrics such as TF-IDF [45], query likelihood [33] or BM25 [44]. In industry-scale web search, BM25 is a difficult-to-beat baseline owing to its outstanding trade-off between accuracy and efficiency. In recent years, there are some attempts to incorporate the power of neural networks into inverted index. The Standalone Neural Ranking Model (SNRM) [57] learns high-dimensional sparse representations for queries and documents, which enables the construction of inverted index for efficient document retrieval. Doc2Query [41] predicts relevant queries to augment the content of each document before building the BM25 index, and DocT5Query [40] improves the performance of query generation by the pre-trained language model T5 [5]. Furthermore, DeepCT [9] calculates context-aware term importance through neural networks to improve the term matching metrics of BM25.
传统文档检索方法基于稀疏检索 (Sparse Retrieval),通过倒排索引结合词项匹配指标实现,例如 TF-IDF [45]、查询似然 [33] 或 BM25 [44]。在工业级网页搜索中,BM25 因其在准确性与效率间的出色平衡而成为难以超越的基线。近年来,学界尝试将神经网络能力融入倒排索引。独立神经排序模型 (SNRM) [57] 通过学习查询和文档的高维稀疏表示,实现了支持高效检索的倒排索引构建。Doc2Query [41] 在构建 BM25 索引前预测相关查询以扩展文档内容,而 DocT5Query [40] 通过预训练语言模型 T5 [5] 提升了查询生成性能。此外,DeepCT [9] 利用神经网络计算上下文感知的词项重要性,从而优化 BM25 的词项匹配指标。
Another line of research lies in Dense Retrieval, which presents query and documents in dense vectors and models their similarities with inner product or cosine similarity. These methods benefit from recent progresses of pre-trained language models, such as BERT [14] and RoBERTa [35] to obtain dense representations for queries and documents. At inference time, efficient Approximate Nearest Neighbor (ANN) search algorithms, such as k-dimensional trees [3], locality-sensitive hashing [10], and graph-based indexes (e.g., HNSW [38], DiskANN [27] and SPANN [7]) can be utilized to retrieve relevant documents within a sublinear time. Besides, Luan et al. [37] analyze the limited capacity of dual encoders, and propose a combination of sparse and dense retrieval methods with multi-vector encoding to achieve better search quality.
另一研究方向聚焦于稠密检索(Dense Retrieval),该方法将查询和文档表示为稠密向量,并通过内积或余弦相似度建模其关联性。这类方法受益于BERT[14]、RoBERTa[35]等预训练语言模型的最新进展,可获取查询与文档的稠密表征。推理阶段可采用k维树[3]、局部敏感哈希[10]以及基于图的索引(如HNSW[38]、DiskANN[27]和SPANN[7])等近似最近邻(ANN)搜索算法,在亚线性时间内检索相关文档。此外,Luan等人[37]分析了双编码器的容量局限性,提出结合稀疏与稠密检索方法的多向量编码方案以提升搜索质量。
A.2 Document ranking
A.2 文档排序
Document ranking has been extensively studied in recent years and experienced a huge improvement with the booming of deep neural networks. Neural network-based document ranking models mainly fall into two categories. Representation-based models like DSSM (Deep Structured Semantic Model) [25] and CDSSM (a convolution-based variant of DSSM) [48] represent query and document in a shared semantic space and model their semantic similarity through a neural network. In contrast, Interaction-based models first build interactions between query and document terms, and then utilizes neural networks to learn hierarchical interaction patterns. For example, DRMM (Deep Relevance Matching Model) [21] extracts interactive features by matching histograms and utilizing a feed forward network with term-gating mechanism to calculate the relevance score of a query-document pair.
近年来,文档排序得到了广泛研究,并随着深度神经网络的蓬勃发展取得了巨大进步。基于神经网络的文档排序模型主要分为两类。基于表示(representation-based)的模型如DSSM (Deep Structured Semantic Model) [25]和CDSSM (DSSM的卷积变体) [48]将查询和文档映射到共享语义空间,并通过神经网络建模它们的语义相似度。相比之下,基于交互(interaction-based)的模型首先构建查询词项与文档词项间的交互特征,再利用神经网络学习层次化交互模式。例如DRMM (Deep Relevance Matching Model) [21]通过直方图匹配提取交互特征,并采用带有词项门控机制的前馈网络来计算查询-文档对的相关性分数。
A.3 Pre-trained language models
A.3 预训练语言模型
Recently, Pre-trained Language Models (PLMs) like BERT [14] have led to a revolution of web search techniques. The vanilla BERT model utilizes a single-tower architecture that concatenates query and document tokens as a whole input to the relevance model. Despite of its superior performance, the high computational cost hinders its application to industrial-scale web search systems. TwinBERT [36] tackles this problem by exploiting a Siamese architecture, where queries and documents are first modeled by two BERT encoders separately, and then an efficient crossing layer is adopted for relevance calculation. The representation vectors for all documents can be calculated and indexed offline. In the online serving stage, it calculates the representation vector for the input query and applies a crossing layer to calculate the relevance score between each query and document. The crossing layer usually adopts simple similarity functions such as dot product or a single feed-forward layer to achieve a high efficiency.
最近,像BERT[14]这样的预训练语言模型(PLM)引发了网络搜索技术的革命。标准BERT模型采用单塔架构,将查询(query)和文档(document)的token拼接作为相关性模型的整体输入。尽管其性能优异,但高昂的计算成本阻碍了其在工业级网络搜索系统中的应用。TwinBERT[36]通过采用孪生架构解决这一问题:先由两个BERT编码器分别建模查询和文档,再通过高效的交叉层进行相关性计算。所有文档的表征向量可离线计算并建立索引。在线服务阶段,系统只需计算输入查询的表征向量,并通过交叉层计算每个查询与文档之间的相关性分数。该交叉层通常采用点积或单层前馈网络等简单相似度函数以保证高效性。
Moreover, Chang et al. [6] argue that the Masked Language Model (MLM) loss designed for BERT pre-training is not naturally fitted to embedding-based retrieval tasks. Instead, they propose three paragraph-level pre-training tasks, i.e., Inverse Cloze Task (ICT), Body First Selection (BFS), and Wiki Link Prediction (WLP), which demonstrate promising results in text retrieval experiments. Gao et al. [16] find that a standard LMs’ internal attention structure is not ready-to-use for dense encoders. Thus, they propose a novel architecture named Condenser to improve the performance of dense retrieval. ANCE (Approximate nearest neighbor Negative Contrastive Estimation) [54] leverages hard negatives to improve the effectiveness of contrastive learning, which generates better text representations for the retrieval task.
此外,Chang等人[6]认为,为BERT预训练设计的掩码语言模型(MLM)损失并不天然适合基于嵌入的检索任务。为此,他们提出了三个段落级预训练任务:逆完形填空任务(ICT)、正文优先选择(BFS)和维基链接预测(WLP),这些方法在文本检索实验中展现出优异效果。Gao等人[16]发现标准大语言模型的内部注意力结构无法直接用于稠密编码器,因此提出名为Condenser的新型架构来提升稠密检索性能。ANCE(近似最近邻负对比估计)[54]通过利用困难负样本来增强对比学习效果,从而为检索任务生成更优质的文本表示。
A.4 End-to-end retrieval
A.4 端到端检索
The deficiency of index-retrieve paradigm lies in that the two stages of document retrieval and re-ranking are optimized separately. Especially, the document retrieval procedure is often sub-optimal and hinders the performance of the entire system. Thus, there are some recent attempts to achieve endto-end retrieval as a one-stage solution. ColBERT [31] introduces a contextual i zed late interaction architecture, which independently encodes query and document through BERT, and performs crossterm interaction based on the contextual i zed representations of query and document terms. ColBERT supports end-to-end retrieval directly from a large document collection by leveraging vector-similarity indexes in the pruned interaction layer. It can be viewed as a compromise between single-tower and twin-tower BERT architectures which maintains an effective trade-off between accuracy and latency. Moreover, the Contextual i zed Inverted List (COIL) [19] exacts lexical patterns from exact matching pairs through contextual i zed language representations. At search time, we build representation vectors for query tokens and perform contextual i zed exact match to retrieve relevant documents based on inverted index.
索引检索范式的缺陷在于文档检索和重排两个阶段是分开优化的。特别是文档检索过程往往不够理想,制约了整个系统的性能。因此,近期出现了一些尝试通过单阶段方案实现端到端检索的研究。ColBERT [31] 提出了一种情境化延迟交互架构,通过BERT独立编码查询和文档,并基于查询与文档术语的情境化表征进行跨术语交互。该方法通过在剪枝交互层利用向量相似性索引,支持直接从海量文档集合进行端到端检索,可视为在单塔和双塔BERT架构之间取得准确性与延迟有效平衡的折中方案。此外,情境化倒排列表(COIL) [19] 通过情境化语言表征从精确匹配对中提取词汇模式。在搜索时,我们为查询token构建表征向量,并基于倒排索引执行情境化精确匹配来检索相关文档。
Although ColBERT and COIL have shown promising results in end-to-end retrieval tasks without re-ranking, their performance is still not obviously better (if not worse) than a common practice of “BM25 indexer $^+$ BERT re-ranker”, and their efficiency is also not good enough for an industrial web search engine. Therefore, we resort to a new indexing paradigm to break the bottleneck. We believe the neural corpus indexer proposed in this paper is a crucial break-through, opening up new opportunities to optimize the performance of web-scale document retrieval. Moreover, there are a few attempts that try to build a model-based search index by directly predicting document identifiers. Tay et al. [50] proposed the DSI (differentiable search index) model based on an encoder-decoder architecture to generate relevant docids. However, its decoder architecture remains the same as T5, which is unsuitable to generate semantic ids derived by hierarchical $k$ -means. SEAL [4] uses all n-grams in a passage as its possible identifiers and build a FM-Index to retrieve documents; but it is hard to enumerate all n-grams for retrieving relevant documents. In addition, our work is related to Deep Retrieval [20] for the recommendation task, which learns a deep retrievable network with user-item clicks without resorting to ANN algorithms constrained by the Euclidean space assumption.
尽管ColBERT和COIL在无需重新排序的端到端检索任务中展现出不错的效果,但其性能仍未明显超越(甚至可能不如)"BM25索引器$^+$BERT重排序器"这一常规方案,且效率也难以满足工业级网络搜索引擎的需求。为此,我们转向新的索引范式以突破瓶颈。本文提出的神经语料索引器是关键性突破,为优化网络规模文档检索性能开辟了新路径。另有若干尝试直接预测文档标识符来构建基于模型的搜索索引:Tay等[50]提出基于编码器-解码器架构的DSI(可微分搜索索引)模型来生成相关文档ID,但其解码器架构仍与T5相同,无法生成通过层次化$k$-means派生的语义ID;SEAL[4]采用段落中所有n-gram作为潜在标识符并构建FM-Index进行检索,但难以穷举所有n-gram来检索相关文档。此外,我们的工作与推荐系统中的深度检索[20]相关,后者通过用户-项目点击数据学习深度可检索网络,无需受限于基于欧氏空间假设的ANN算法。
B Reproducibility
B 可复现性
We provide our code for reproduction in the supplementary material. We will release it to public shortly.
我们在补充材料中提供了代码以便复现,并将很快向公众发布。
B.1 Dataset processing
B.1 数据集处理
We conduct experiments on $\mathrm{NQ}320k$ and TriviaQA datasets. For $\mathrm{NQ}320k$ dataset, the queries are natural language questions and the documents are Wikipedia articles in HTML format. During dataset processing, we first filter out useless HTML tag tokens, and extract title, abstract and content strings of each Wikipedia article using regular expression. The experiments are also conducted on TriviaQA dataset. For TriviaQA dataset, it includes $78k$ query-document pairs from the Wikipedia domain, which are processed almost the same as $\mathrm{NQ}320k$ . Then, we detect duplicated articles based on the title of each article. After that, we concatenate the title, abstract and content strings of each Wikipedia article, and apply a 12 layers pre-trained BERT model on it to generate document embeddings.
我们在 $\mathrm{NQ}320k$ 和 TriviaQA 数据集上进行了实验。对于 $\mathrm{NQ}320k$ 数据集,查询是自然语言问题,文档是 HTML 格式的维基百科文章。在数据集处理过程中,我们首先过滤掉无用的 HTML 标签 token,并使用正则表达式提取每篇维基百科文章的标题、摘要和内容字符串。实验同样在 TriviaQA 数据集上进行。该数据集包含来自维基百科领域的 $78k$ 个查询-文档对,其处理方式与 $\mathrm{NQ}320k$ 几乎相同。接着,我们基于每篇文章的标题检测重复文章。此后,我们将每篇维基百科文章的标题、摘要和内容字符串拼接起来,并应用一个 12 层的预训练 BERT 模型生成文档嵌入向量。
Finally, hierarchical $k$ -means is applied on the article embeddings to produce semantic identifiers for each article.
最后,对文章嵌入应用分层 $k$ 均值聚类,为每篇文章生成语义标识符。
B.2 Hierarchical $k$ -means for semantic identifier
B.2 用于语义标识符的层次化 $k$ 均值算法
The pseudo code of hierarchical $k$ -means is detailed in in Algorithm 1.
层次化 $k$ -均值 (k-means) 的伪代码详见于算法 1。
Algorithm 1: Hierarchical $k$ -means.
算法 1: 分层 $k$ 均值
| Input: |
| Document embedding X1:N |
| Number of clusters k |
| Recursion terminal condition C |
| Output: |
| Hierarchical semantic identifier L1:N |
| Function: |
| GenerateSemanticIdentifier(X1:N) |
| Ci:k ← KMeansCluster(X1:N,k) L←Q |
| for i ∈ [0, k - 1] do |
| Lcurrent ←[i] *|Ci+1l |
| if |C+1| > c then |
| Lrest ← GenerateSemanticIdentifier(C+1) |
| else Lrest ← [0, .., |Ci+1l - 1] |
| end if |
| Lcluster ← ConcatString(Lcurrent, Lrest) |
| L ← L.Append(Lcluster) |
| end for |
| L ← reorderToOriginal(L, X1:N, C1:k) |
| return L |
| 输入: |
|---|
| 文档嵌入向量 X1:N |
| 聚类数量 k |
| 递归终止条件 C |
| 输出: |
| 层级语义标识符 L1:N |
| 函数: |
| GenerateSemanticIdentifier(X1:N) |
| Ci:k ← KMeansCluster(X1:N,k) L←Q |
| for i ∈ [0, k - 1] do |
| Lcurrent ←[i] * |
| if |
| Lrest ← GenerateSemanticIdentifier(C+1) |
| else Lrest ← [0, .., |
| end if |
| Lcluster ← ConcatString(Lcurrent, Lrest) |
| L ← L.Append(Lcluster) |
| end for |
| L ← reorderToOriginal(L, X1:N, C1:k) |
| return L |
B.3 Constrained beam search
B.3 受限束搜索 (Constrained beam search)
The pseudo code of constrained beam search is detailed in Algorithm 2.
约束束搜索 (constrained beam search) 的伪代码详见算法 2。
B.4 Baselines
B.4 基线
We describe the baseline methods in this section. For most of them, we use their official open-source implementations.
本节介绍基线方法。其中大多数方法均采用官方开源实现。
• BM25. BM25 is currently the mainstream algorithm for calculating the similarity score between query and document in information retrieval [44]. We calculate BM25 between an original query $Q$ and a document $d$ which derived from a sum of contributions from each query term $q_{i}$ as,
• BM25。BM25 是目前信息检索领域计算查询(query)与文档(document)相似度得分的主流算法 [44]。我们通过累加每个查询项 $q_{i}$ 的贡献值来计算原始查询 $Q$ 与文档 $d$ 之间的 BM25 得分,具体公式为:
$$
\operatorname{Score}(Q,d)=\sum_{i=1}^{t}w_{i}*R\left(q_{i},d\right)
$$
$$
\operatorname{Score}(Q,d)=\sum_{i=1}^{t}w_{i}*R\left(q_{i},d\right)
$$
where $w_{i}$ denotes the weight of $q_{i}$ , and $R(q_{i},d)$ is the correlation between $q_{i}$ and $d$ . We use the open-source implementation from Rank-BM25 2.
其中 $w_{i}$ 表示 $q_{i}$ 的权重,$R(q_{i},d)$ 是 $q_{i}$ 和 $d$ 之间的相关性。我们使用了 Rank-BM25 2 的开源实现。
• $\mathbf{BM}25+\mathbf{\beta}$ DocT5Query. The docT5Query model [40] generates questions that related to a document. These predicted queries are then appended to the original documents, which are then indexed. Note that we use the same predicted queries in our query generation module. Queries are issued against the index as “bag of words” queries, using BM25 for evaluation. We use the open-source code for D ocT 5 Query 3, and the generated queries keep the same with NCI (our model) to have a fair comparison.
• $\mathbf{BM}25+\mathbf{\beta}$ DocT5Query。DocT5Query模型[40]会生成与文档相关的问题,这些预测出的查询语句会被附加到原始文档中并建立索引。需要注意的是,我们在查询生成模块中也使用了相同的预测查询。评估时采用BM25算法,以"词袋"形式对索引发起查询。我们使用DocT5Query的开源代码3,且生成的查询语句与NCI(我们的模型)保持一致以确保公平比较。
Algorithm 2: Constrained Beam Search.
算法 2: 约束束搜索 (Constrained Beam Search)
Input:
输入:
Output: $k$ documents with the highest probabilities
输出:概率最高的 $k$ 份文档
Function: prefix $\scriptstyle:={r_{0}}$ ResultIds $\leftarrow\emptyset$ $\mathbf{B_{0}}\gets{\langle\mathbf{prefix},\mathrm{EOS}\rangle}$ for $\mathbf{i}\in[1,n]$ do for prefix, $s u m_l o g_p r o b\rangle\in\mathbf{B_{i-1}}$ do if prefix.last().isLeaf() thendoc_ $i d=$ prefix.toString() ResultIds.add(⟨doc_id, sum log pro b/len(prefix)⟩)else for $r_{i}\in$ prefix.last().child() do new_prefix $=$ prefix.copy().append $(r_{i})$ $\mathbf{B_{i}}$ .add(⟨new_prefix, sum log pro b + f(ri)⟩) end for end if end for $\mathbf{B_{i}}\gets\mathbf{B_{i}}$ .rank by pro b().top(k)end for return ResultIds.rank by pro b().top(k)
函数:前缀 $\scriptstyle:={r_{0}}$
结果ID集合 $\leftarrow\emptyset$
$\mathbf{B_{0}}\gets{\langle\mathbf{前缀},\mathrm{EOS}\rangle}$
对于 $\mathbf{i}\in[1,n]$ 执行
对于 前缀, $s u m_l o g_p r o b\rangle\in\mathbf{B_{i-1}}$ 执行
若 前缀.last().isLeaf() 则
文档ID $=$ 前缀.toString()
结果ID集合.add(⟨文档ID, 平均对数概率/len(前缀)⟩)
否则
对于 $r_{i}\in$ 前缀.last().child() 执行
新前缀 $=$ 前缀.copy().append $(r_{i})$
$\mathbf{B_{i}}$.add(⟨新前缀, 对数概率和 + f(ri)⟩)
结束循环
结束条件
结束循环
$\mathbf{B_{i}}\gets\mathbf{B_{i}}$.按概率排序().取前k个()
结束循环
返回 结果ID集合.按概率排序().取前k个()
C More Experimental Results
C 更多实验结果
We study the influence of regular iz ation strength and choose the regular iz ation hyper-parameter $\alpha$ from ${0,0.1,0.15,0.2,0.3}$ . Table 6 summaries the results with different regular iz ation hyperparameter $\alpha$ settings. At convergence, the hyper-parameter $\alpha=0.15$ generally achieves better performance. Therefore, we set the default value as $\alpha=0.15$ in NCI.
我们研究了正则化强度的影响,并从 ${0,0.1,0.15,0.2,0.3}$ 中选择正则化超参数 $\alpha$。表6总结了不同正则化超参数 $\alpha$ 设置下的结果。在收敛时,超参数 $\alpha=0.15$ 通常能获得更好的性能。因此,我们在NCI中将其默认值设为 $\alpha=0.15$。
Table 6: Different regular iz ation hyper-parameter $\alpha$ in loss function. Left: $\mathrm{NQ}320k$ ; Right: TriviaQA.
| Setting | Recall@1 | Recall@10 | Recall@100 | MRR@100 |
| Q=0 | 65.07 | 82.91 | 90.65 | 71.80 |
| Q = 0.1 | 65.51 | 85.28 | 92.52 | 72.76 |
| Q= 0.15 | 65.86 | 85.20 | 92.42 | 73.12 |
| Q= 0.2 | 65.55 | 84.48 | 92.61 | 72.63 |
| α=0.3 | 65.44 | 85.21 | 92.45 | 72.83 |
表 6: 损失函数中不同正则化超参数 $\alpha$ 的对比。左: $\mathrm{NQ}320k$;右: TriviaQA。
| Setting | Recall@1 | Recall@10 | Recall@100 | MRR@100 |
|---|---|---|---|---|
| Q=0 | 65.07 | 82.91 | 90.65 | 71.80 |
| Q=0.1 | 65.51 | 85.28 | 92.52 | 72.76 |
| Q=0.15 | 65.86 | 85.20 | 92.42 | 73.12 |
| Q=0.2 | 65.55 | 84.48 | 92.61 | 72.63 |
| α=0.3 | 65.44 | 85.21 | 92.45 | 72.83 |
| Setting | Recall@5 | Recall@20 | Recall@100 | R-Precision |
| 0=0 | 89.01 | 93.63 | 96.16 | 71.59 |
| Q = 0.1 | 90.14 | 94.15 | 96.96 | 72.78 |
| Q=0.15 | 90.49 | 94.45 | 96.94 | 73.90 |
| Q = 0.2 | 90.44 | 94.41 | 96.97 | 73.22 |
| Q = 0.3 | 90.02 | 94.09 | 96.79 | 73.53 |
| 设置 | Recall@5 | Recall@20 | Recall@100 | R-Precision |
|---|---|---|---|---|
| 0=0 | 89.01 | 93.63 | 96.16 | 71.59 |
| Q = 0.1 | 90.14 | 94.15 | 96.96 | 72.78 |
| Q=0.15 | 90.49 | 94.45 | 96.94 | 73.90 |
| Q = 0.2 | 90.44 | 94.41 | 96.97 | 73.22 |
| Q = 0.3 | 90.02 | 94.09 | 96.79 | 73.53 |
D Miscellaneous
D 其他
Social Impacts. This work aims at introducing a new learning paradigm that can unify the learning and indexing stages with an end-to-end deep neural network. Besides, our work has the potential to inspire more attempts at unifying the retrieval and re-ranking task with an end-to-end framework, which might have positive social impacts. We do not foresee any form of negative social impact induced by our work.
社会影响。这项工作旨在引入一种新的学习范式,通过端到端深度神经网络统一学习和索引阶段。此外,我们的工作有望激发更多尝试,将检索和重排任务统一到端到端框架中,可能产生积极的社会影响。我们未预见任何由本研究引发的负面社会影响。
Privacy Information in Data. We use the NQ dataset privided by the work [32]. The dataset only includes questions, rendered Wikipedia pages, tokenized representations of each page, and the annotations added by our annotators. No privacy information is included. For the TriviaQA [29], which is a reading comprehension dataset, it includes $78k$ query-document pairs from the Wikipedia domain. Again, no privacy information is included.
数据中的隐私信息。我们使用文献[32]提供的NQ数据集。该数据集仅包含问题、渲染后的维基百科页面、每个页面的token化表示以及标注者添加的注释,不包含任何隐私信息。对于阅读理解数据集TriviaQA[29],它包含来自维基百科领域的$78k$个查询-文档对,同样不涉及隐私信息。