Usually a project at Berkeley lasts for about five years. Around 2006, some smart users/students were complaining about Hadoop, the elephant project which introduced Map Reduce compute paradigm to common man. Researchers at AMPlab (Algorithms, Machines and People) were looking for a better alternative or solution. They added that long delay in latency that was needed every time they did an iteration and the tight coupling to Map-Sort-Reduce structure. The pain in not having the ability to operate on anything other than the so called Hadoop File System was another concern among many other smaller disappointments. Matei Zaharia wanted some kind of caching system that does not require to go to disk every time and that was the genesis of Spark. Today, it is one of the most widely used unified compute engine. When the founders left Berkeley to start Databricks, AMPLab too closed down, as project was very successfully completed.
通常,伯克利的一个项目会持续大约五年。 在2006年左右,一些聪明的用户/学生抱怨Hadoop,这是大象项目,它向普通人介绍了Map Reduce计算范式。 AMPlab (算法,机器和人员)的研究人员正在寻找更好的替代方案或解决方案。 他们补充说,每次执行迭代以及与Map-Sort-Reduce结构紧密耦合时,都需要长时间延迟。 除其他一些较小的失望之外,除了无法使用所谓的Hadoop File System以外,其他任何功能都无法操作。 Matei Zaharia需要某种不需要每次都转到磁盘的缓存系统,而这正是Spark的起源。 今天,它是使用最广泛的统一计算引擎之一。 当创始人离开伯克利创办Databricks时,AMPLab也关闭了,因为该项目非常成功地完成了。
Hadoop与Spark (Hadoop vs Spark)
Assume that you are staying in a fictitious hotel where only basic amenities are provided. You need to go to a nearby restaurant for breakfast, another one for lunch, yet another for dinner. For laundry services, you rely on an external shop. For an ATM, you need to go to a nearby shopping mall. Isn’t this a pain ? This is what Hadoop’s offering to the community. For Map-Reduce applications, plain vanilla Hadoop with HDFS, for OLAP applications we need to go to Hive, For OLTP workloads, we rely on HBase, For data ingestion we depend on technologies like Sqoop or Flume and so one and so forth. So Hadoop ecosystem is like this:
假设您住在一个仅提供基本设施的虚拟酒店中。 您需要去附近的一家餐馆吃早餐,另一家吃午餐,又去吃晚餐。 对于洗衣服务,您需要依靠外部商店。 要使用ATM,您需要去附近的购物中心。 这不是痛苦吗? 这就是Hadoop向社区提供的服务。 对于Map-Reduce应用程序,具有HDFS的普通Hadoop Hadoop,对于OLAP应用程序,我们需要转到Hive;对于OLTP工作负载,我们依赖于HBase;对于数据摄取,我们依赖于Sqoop或Flume等技术。 因此Hadoop生态系统是这样的:

Figure 2: Spark — Unified Compute and Analytics — All in One
图2:Spark —统一计算和分析—合为一体
设计师的困境:快速还是并发? (Designer’s dilemma : Fast or Concurrent?)
This is not way an issue or problem with Spark. It is how Spark is designed. The designers gave priority for simplicity. Spark is monumentally faster that MapReduce, it still retains some core elements of MapReduce’s batch-oriented workflow paradigm. For details, please go through these links 1 and 2 , though I am summarizing here. If there is a function called *slowFunction *which takes 5 seconds to execute and a fastFunction which takes one second to execute.
这不是Spark的问题。 这就是Spark的设计方式。 设计师以简洁为优先。 Spark的速度比MapReduce快得多,但它仍然保留了MapReduce面向批处理的工作流范例的一些核心元素。 有关详细信息,请浏览这些链接1和2 ,尽管我在这里进行了总结。 如果有一个名为slowFunction的函数需要执行5秒,而一个fastFunction则需要花费一秒钟。
Step 1:
第1步:
Start Spark shell with one core on local mode
在本地模式下以一个内核启动Spark Shell
Figure 3: spark-shell on local mode with one core
图3:具有一个核心的本地模式下的spark-shell
Let’s write two functions as below
让我们写两个函数如下
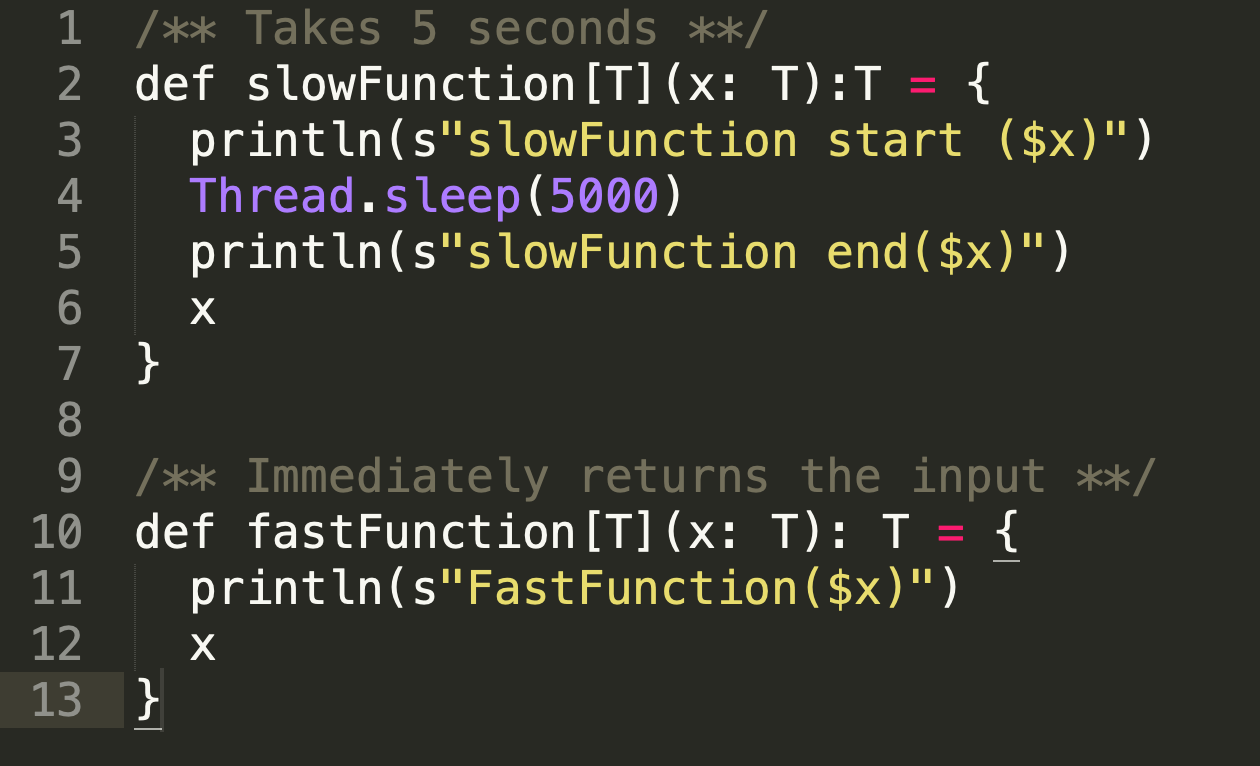
Figure 4: A slow function and fast function
图4:慢速功能和快速功能
Observe the output below:
观察以下输出:
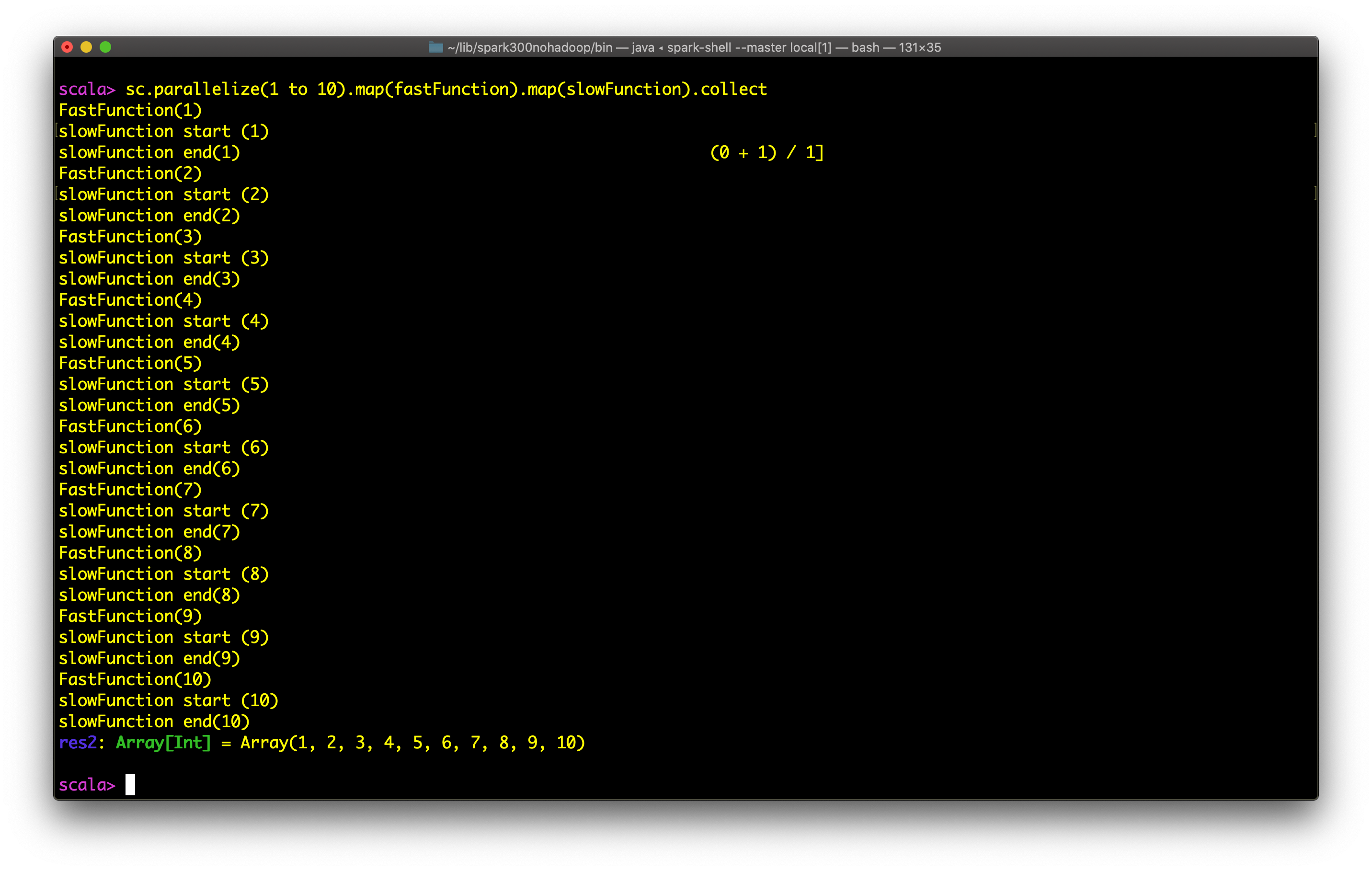
Figure 5: Without explicit constructs like future (in Scala), the output is sequential
图5:没有像future这样的显式结构(在Scala中),输出是顺序的
Not to be surprised: as mentioned before, Spark is deigned for speed. Using an asynchronous IO paradigm will make spark harder to use, harder to maintain, harder to debug, will increase the number of failure modes it has to deal with and these does not fit in with what spark wants to be: easy, small, lightweight. If you want to take some challenge, you can use async features with foreachPartitionAsync, but makes debugging difficult from personal experience. Async APIs are limited too. Spark is synchronous by design.
不用惊讶:如前所述,Spark追求速度。 使用异步IO范例将使Spark难以使用,难以维护,难以调试,将增加必须处理的故障模式的数量,而这些模式不符合Spark想要的功能:简单,小巧,轻便。 如果您想挑战一下,可以将异步功能与foreachPartitionAsync结合使用 ,但根据个人经验很难进行调试。 异步API也受到限制。 Spark在设计上是同步的。
What we ideally want is the concurrent execution, meaning without waiting for each slowfunction to be complete, let all fastfunction be executed and then let the system complete slowfunctionon its own. In this way, if I have a pipeline of complex functions, some of the tasks are already complete.
我们理想的情况是并发执行,这意味着无需等待每个慢速功能完成,先让所有快速功能执行,然后让系统自行完成慢速功能。 这样,如果我具有复杂功能的管道,则某些任务已经完成。
Note that in Spark, the executor JVMs will have tasks and each task is generally just a single thread which is running the serialized code written for that particular task.The code within the task will be single-threaded and synchronous unless you code something to have it not be synchronous.(for example using limited async functions or using Futures )
请注意,在Spark中,执行者JVM将具有任务,每个task通常只是一个线程,该线程正在运行为该特定task.编写的序列化代码task. 任务中的代码将是单线程和同步的,除非您编写某些代码使其不同步(例如,使用有限的异步函数或使用Future )。
The question is, does this approach fit well for machine learning and reinforcement learning applications.
问题是,这种方法是否适合机器学习和强化学习应用。
入门:同步与异步 (A Primer: Synchronous vs Asynchronous)
Regardless of the parallel architecture used, parallel programs possess the problem of controlling access to shared resources among the computing nodes. These resources could be files on disks, any physical device that the program has access to, or simply some data in the memory relevant to the computations.
无论使用哪种并行体系结构,并行程序都具有控制对计算节点之间共享资源的访问的问题。 这些资源可以是磁盘上的文件,程序可以访问的任何物理设备,也可以是内存中与计算有关的一些数据。
Reading from shared data normally does not pose any problems. However, when changing the resources’ state, e.g., writing to a file or changing a variable in memory, race conditions occur among computing nodes, in which the resulting state depends on the sequence of uncontrollable events. Sections of a program which contain shared resources are called critical sections. The programmer has to ensure consistent results by removing the race conditions via mutual exclusions. You use *semaphores (*Remembering Edsger W. Dijkstra now!) or mutex kind of structures to avoid these. You know the famous synchronous blocks in Java for example, in multithreading applications.
从共享数据读取通常不会造成任何问题。 但是,当更改资源的状态( 例如 ,写入文件或更改内存中的变量)时,计算节点之间会发生争用条件,其结果状态取决于不可控制事件的顺序。 包含共享资源的程序节称为关键节 。 程序员必须通过相互排斥消除竞争条件,以确保结果一致。 您可以使用信号量(现在要记住Edsger W. Dijkstra !)或互斥量的结构来避免这种情况。 您知道Java中著名的同步块,例如在多线程应用程序中。
Since there is no global memory which is shared among all the different and distinct nodes of your Spark cluster, defining a global lock common to all the nodes is harder. Instead, one defines reader/writer policies when giving access to shared information. The simplest policy is to have a *single reader/single writer *policy, i.e., a *master-worker *framework, in which the master is responsible for all the reading and writing of the shared data, and the workers make requests to the master. In Spark, remember the broadcast variables which are read only and accumulators which can be used for associative functions across nodes. Isn't the SparkContext/Session responsible for creating these? One possible way of handling distributed computing is to exploit popular “serverless” systems, but none currently offers facilities for managing distributed, mutable state. Developers must resort to keeping all state in a database when using serverless systems, but the database can be a bottleneck and a single point of failure.
由于没有全局内存在Spark集群的所有不同节点之间共享,因此定义所有节点共有的全局锁比较困难。 相反,当授予对共享信息的访问权限时,将定义读取器/写入器策略。 最简单的策略是拥有一个单一的读取器/单个写入器策略, 即 ,一个master-worker框架,其中由master负责共享数据的所有读取和写入,而工作人员则向master发送请求。 在Spark中,请记住只读的广播变量和可用于节点间关联功能的累加器 。 SparkContext / Session不负责创建这些吗? 处理分布式计算的一种可能方法是利用流行的“ 无服务器 ”系统,但是目前没有一种提供管理分布式可变状态的工具。 使用无服务器系统时,开发人员必须诉诸于将所有状态保留在数据库中,但是数据库可能是瓶颈,而且是单点故障。
Synchronization mechanisms are also used to communicate global information that requires the attention of all computing nodes at the same time, also referred to as process synchronization, and to wait for a specific event to occur, i.e., event synchronization. However, they reduce the performance, and hence, the efficiency of parallel programs due to the idle waiting times in critical sections. Algorithms that require significant amount of synchronization among nodes are called *synchronous *algorithms, whereas those that can tolerate asynchrony are called *asynchronous *algorithms.
同步机制还用于传达需要所有计算节点同时关注的全局信息(也称为进程同步),并等待特定事件的发生, 即事件同步。 但是,由于关键部分中的空闲等待时间,它们降低了性能,并因此降低了并行程序的效率。 需要在节点之间进行大量同步的算法称为同步算法,而那些可以容忍异步的算法称为异步算法。
Why does it matter? Well, for most of the ETL workloads and usual scenarios, the option of synchronous or asynchronous does not make much a big challenge, but there is some class of problems which will have some enormous effect unless we use asynchronous mechanism — machine learning, deep learning or reinforcement learning. Why?
为什么这有关系? 好吧,对于大多数ETL工作负载和通常情况而言,选择同步还是异步并不是什么大挑战,但是除非我们使用异步机制,否则某些类的问题将产生巨大的影响-机器学习,深度学习或强化学习。 为什么?
Traditionally, machine learning algorithms are designed under the assumption of synchronous operations. At each iteration of an algorithm, the goal is to find a new parameter that results in a decrease in the cost. In the popular gradient descent method using batches, for example, this is achieved by computing the gradient of the cost at the current variable and then taking a step in its negative direction. When the parameters are large, the task of computing the gradient can be split into smaller tasks and mapped to different computing nodes. In synchronous optimization algorithms, each node calculates their part of the gradient independently, and then, synchronizes with other nodes at the end of each iteration to calculate the new value. Such a synchronization means that the algorithm will be running at the pace of the slowest computing node. Moreover, it has the risk of bringing the algorithm a deadlock, a state in which each computing node is waiting for some other node, in case one of the nodes fails. In Spark like architectures, even if a retry occurs, the possibility for slowing down the overall task is significant in larger computations.
传统上,机器学习算法是在假设同步操作的情况下设计的。 在算法的每次迭代中,目标是找到一个新参数,从而降低成本。 例如,在使用批处理的流行梯度下降方法中,这是通过计算当前变量的成本梯度,然后朝其负方向迈出一步来实现的。 当参数较大时,可以将计算梯度的任务分解为较小的任务,然后映射到不同的计算节点。 在同步优化算法中,每个节点独立地计算其梯度部分,然后在每次迭代结束时与其他节点同步以计算新值。 这种同步意味着该算法将以最慢的计算节点的速度运行。 而且,如果其中一个节点发生故障,则有可能使算法陷入死锁,即每个计算节点都在等待其他某个节点的状态。 在类似Spark的体系结构中,即使发生重试,在较大的计算中,减慢整个任务的可能性也很明显。
We can gain some advantages from asynchronous implementations of these algorithms. First, fewer global synchronization points will give reduced idle waiting times and alleviated congestion in interconnection networks. Second, fast computing nodes will be able to execute more updates in the algorithm. Similarly, the overall system will be more robust to individual node failures. However, on the flip side, asynchronous task runs the risk of rendering an otherwise convergent algorithm divergent. But studies showed that asynchronous optimization algorithms often converge under more restrictive conditions than their synchronous counter parts.
我们可以从这些算法的异步实现中获得一些优势。 首先,较少的全局同步点将减少互连网络中的空闲等待时间并减轻拥塞。 其次,快速计算节点将能够在算法中执行更多更新。 同样,整个系统将对单个节点故障更加健壮。 但是,另一方面,异步任务冒着使其他收敛算法发散的风险。 但是研究表明,与同步计数器部分相比,异步优化算法通常在更严格的条件下收敛。
Ray项目 (Project Ray)
You need something much more like a just-in time, data-flow type architecture, where a task goes and all the tasks it depends on are ready and finished. Building a system that supports that, and retains all the desirable features of Hadoop and Spark, is the goal of project called Ray. Ray is from the successor to the AMPLab named RISELab. Ray will maintain state of computation among the various nodes in the cluster, but there will be as little state as possible, which will maximize robustness.
您需要的更像是即时数据流类型的体系结构,任务在其中进行并且其所依赖的所有任务都已准备就绪并完成。 建立一个支持该系统并保留Hadoop和Spark所有理想功能的系统是名为Ray的项目的目标。 Ray是从继任者到AMPLab的,名为RISELab 。 Ray将在群集中的各个节点之间保持计算状态,但是状态将尽可能少,这将最大程度地提高鲁棒性。
Another important aspect of Ray is unify all aspects of a machine learning lifecycle, just like how Spark unified individual siloed components which were prominent in Hadoop based ecosystem. AI applications need support for distributed training, distributed reinforcement learning, model serving, hyper-parameter search, data processing, and streaming. All these problems are right now independent and separated into specialized distributed systems.
Ray的另一个重要方面是统一机器学习生命周期的所有方面,就像Spark如何统一在基于Hadoop的生态系统中突出的单个孤立组件一样。 AI应用程序需要支持分布式训练,分布式强化学习,模型服务,超参数搜索,数据处理和流传输。 目前,所有这些问题都是独立的,并分为专用的分布式系统。
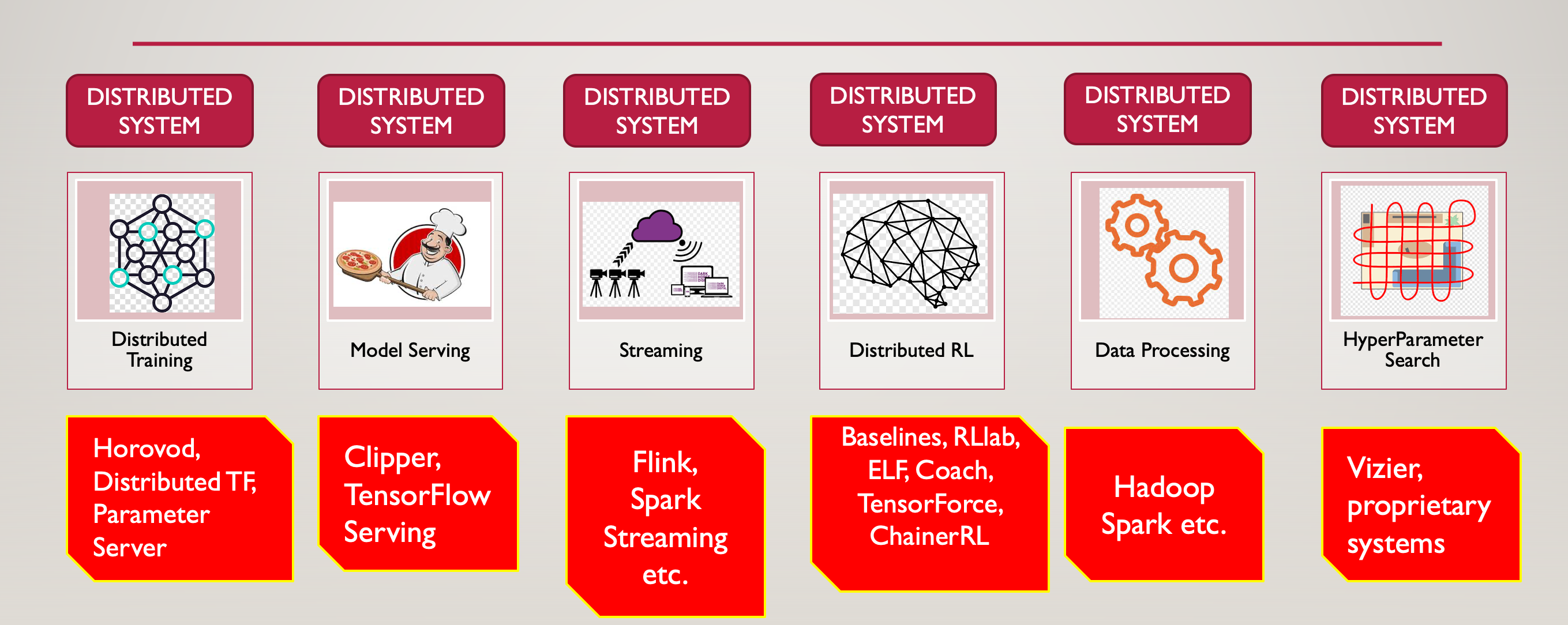
Figure 6 : Siloed aspects of AI applications
图6:AI应用程序的孤立方面
What we need is a unified architecture which can handle all these
我们需要一个可以处理所有这些问题的统一架构。
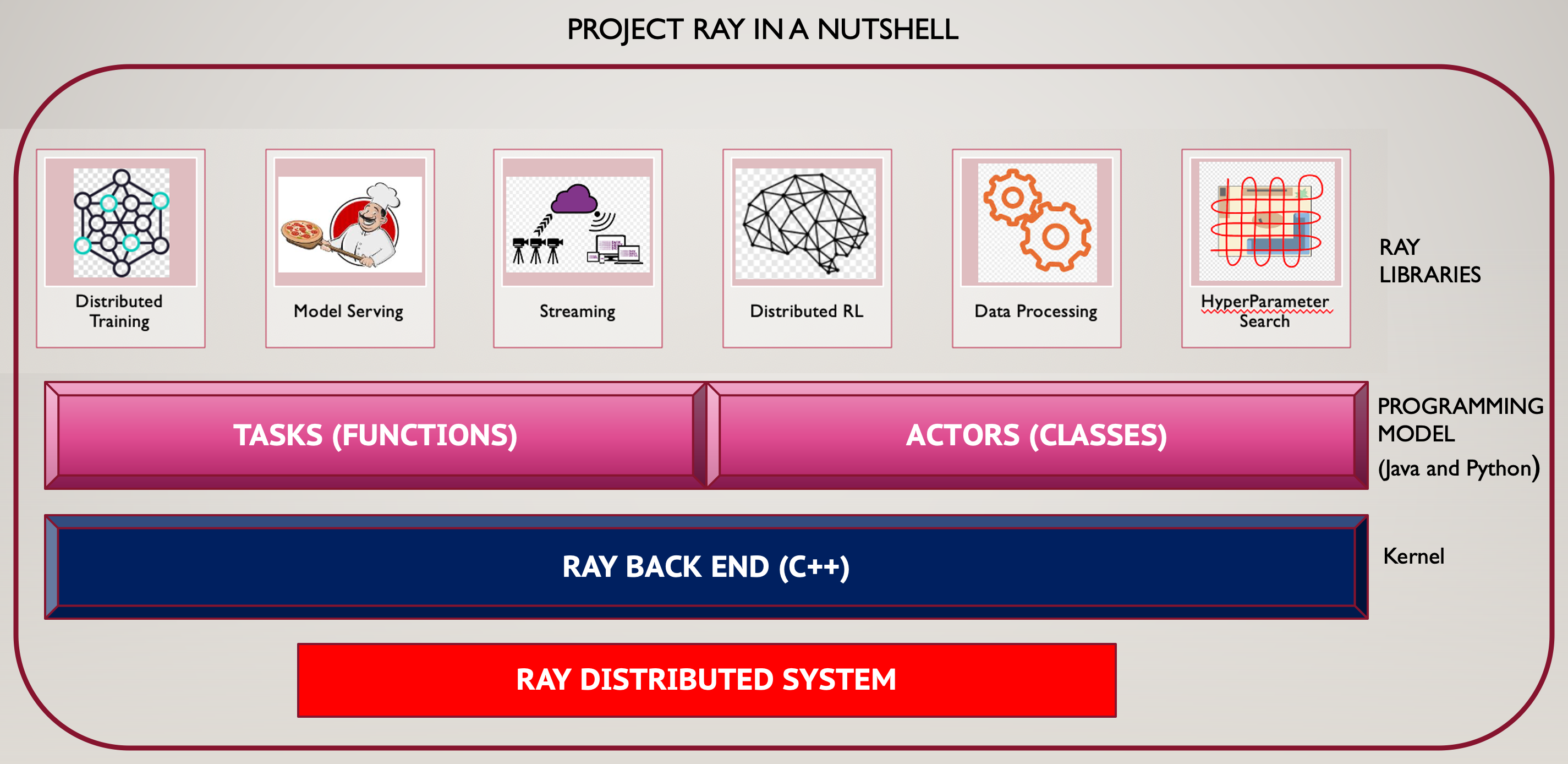
Figure 7 : Project Ray
图7:Ray项目
We were having a separate distributed computing framework that solves some specific part of the machine learning lifecycle. Ray, a high performance distributed computing system, and with the built-in libraries on top of it to support all these types of workflows, we can avoid overheads and leverage performance of building on one system. They include RLlib for reinforcement learning and Tune for hyper-parameter tuning. Both demonstrate Ray’s unique capabilities. These libraries and other, custom applications written with Ray are already used in many production deployments. In programming languages like Java, we write classes and functions. Ray exposes functions as tasks, classes as actors. Functions are stateless, classes are stateful. Hence actors provide stateful compliment to tasks which are stateless. The kernel is written in C++
我们有一个单独的分布式计算框架,可以解决机器学习生命周期的某些特定部分。 Ray是一种高性能的分布式计算系统,其顶部的内置库可支持所有这些类型的工作流,因此,我们可以避免开销并利用在一个系统上构建的性能。 它们包括用于增强学习的RLlib和用于超参数调整的Tune 。 两者都展示了Ray的独特功能。 用Ray编写的这些库和其他自定义应用程序已在许多生产部署中使用。 在Java之类的编程语言中,我们编写类和函数。 Ray将函数作为任务公开,将类作为参与者公开。 函数是无状态的,类是有状态的。 因此,参与者为无状态的任务提供了有状态的补充。 内核是用C ++编写的。
Ray uses Plasma, an in memory object store as well as Apache Arrow format for efficient transport and representation of data. Plasma was given to Apache Arrow committee for further development.
Ray使用Plasma(一种内存中对象存储)以及Apache Arrow格式来高效地传输和表示数据。 等离子体已交给Apache Arrow委员会进行进一步开发。
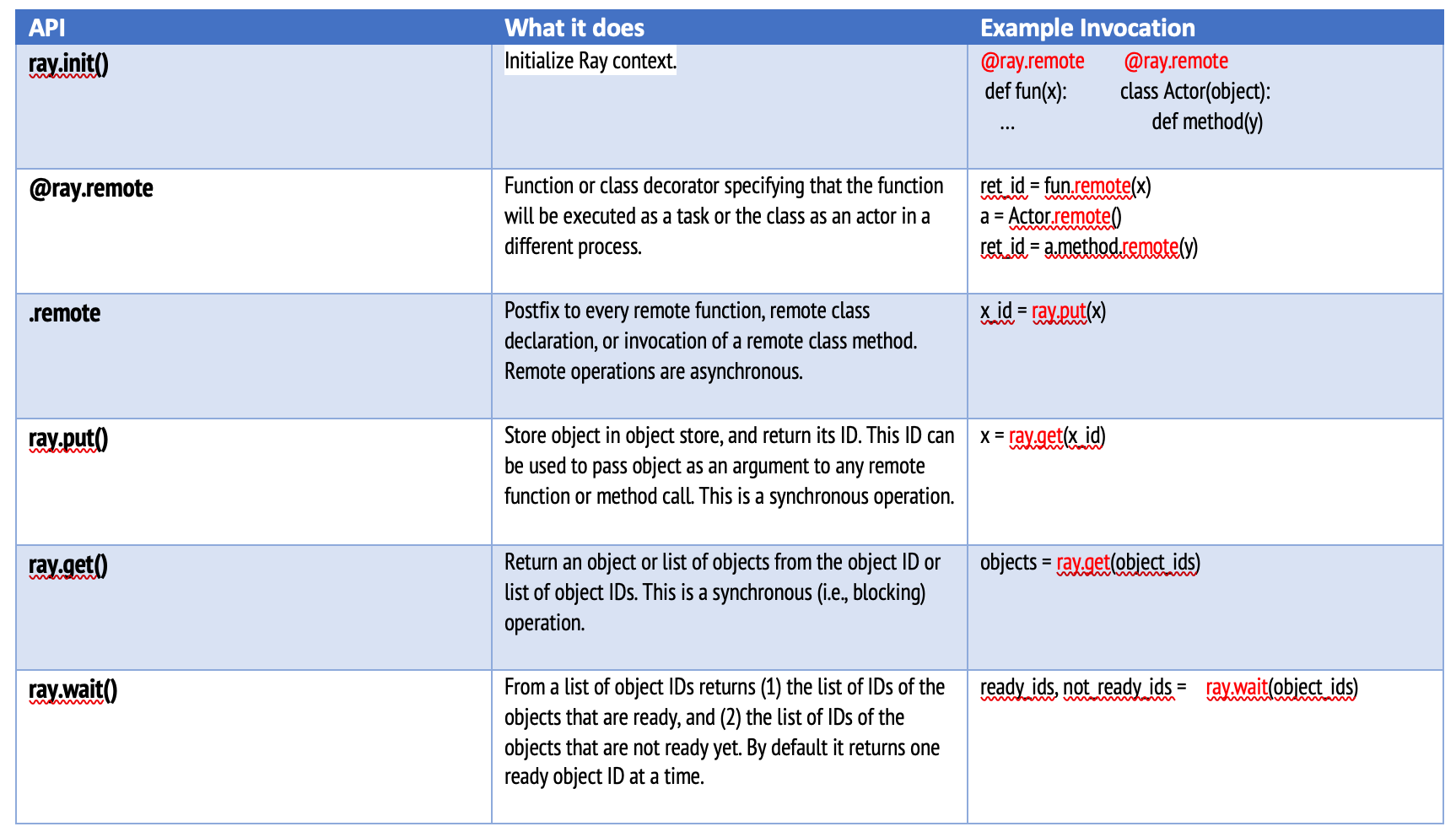
Ray API (Ray API)
To demonstrate the power of Ray, let’s dive deep. The Ray API is carefully designed to enable users to scale their applications, even across a cluster, with minimal code changes. First, lets start installing Ray and we will use Python.
为了展示Ray的力量,让我们深入研究。 Ray API经过精心设计,可让用户以最少的代码更改即可扩展其应用程序,甚至可以跨整个集群进行扩展。 首先,让我们开始安装Ray,我们将使用Python。
We have two interesting functions, one is echo which takes a string as parameter and returns as it is. Another is ohce, which takes a string as parameter and gives us the reverse of it. Lets use Ray API and expose these as remote services. Here is a summary:
我们有两个有趣的函数,一个是echo ,它将字符串作为参数并按原样返回。 另一个是ohce ,它使用字符串作为参数,并给我们相反的含义 。 让我们使用Ray API并将它们公开为远程服务。 总结如下:
https://rise.cs.berkeley.edu/blog/ray-tips-for-first-time-users/) https://rise.cs.berkeley.edu/blog/ray-tips-for-first-time-users/提供 )
First let’s have the following steps done:
首先,让我们完成以下步骤:
#STEP 1: Create a new environment named "ray". I am using Anaconda
conda create --name ray python=3.5
#STEP 2: Activate the environment we created in STEP 1
conda activate ray
#STEP 3: Install Ray in this environment
pip install ray
#STEP 4: Start conda from your installation directory of anaconda
bin/anaconda-navigator
#STEP 5: Start Jupyter. If Jupyter not avalable, please install it
A service is basically a function or task in Ray. So we define the tasks as follows
服务基本上是Ray中的功能或任务。 因此,我们将任务定义如下。

Please see the normal functions and how it differs from Ray definitions. Next we initialize Ray and invoke the Ray functions. Again observe the difference
请查看正常功能及其与Ray定义的区别。 接下来,我们初始化Ray并调用Ray函数。 再次观察差异。
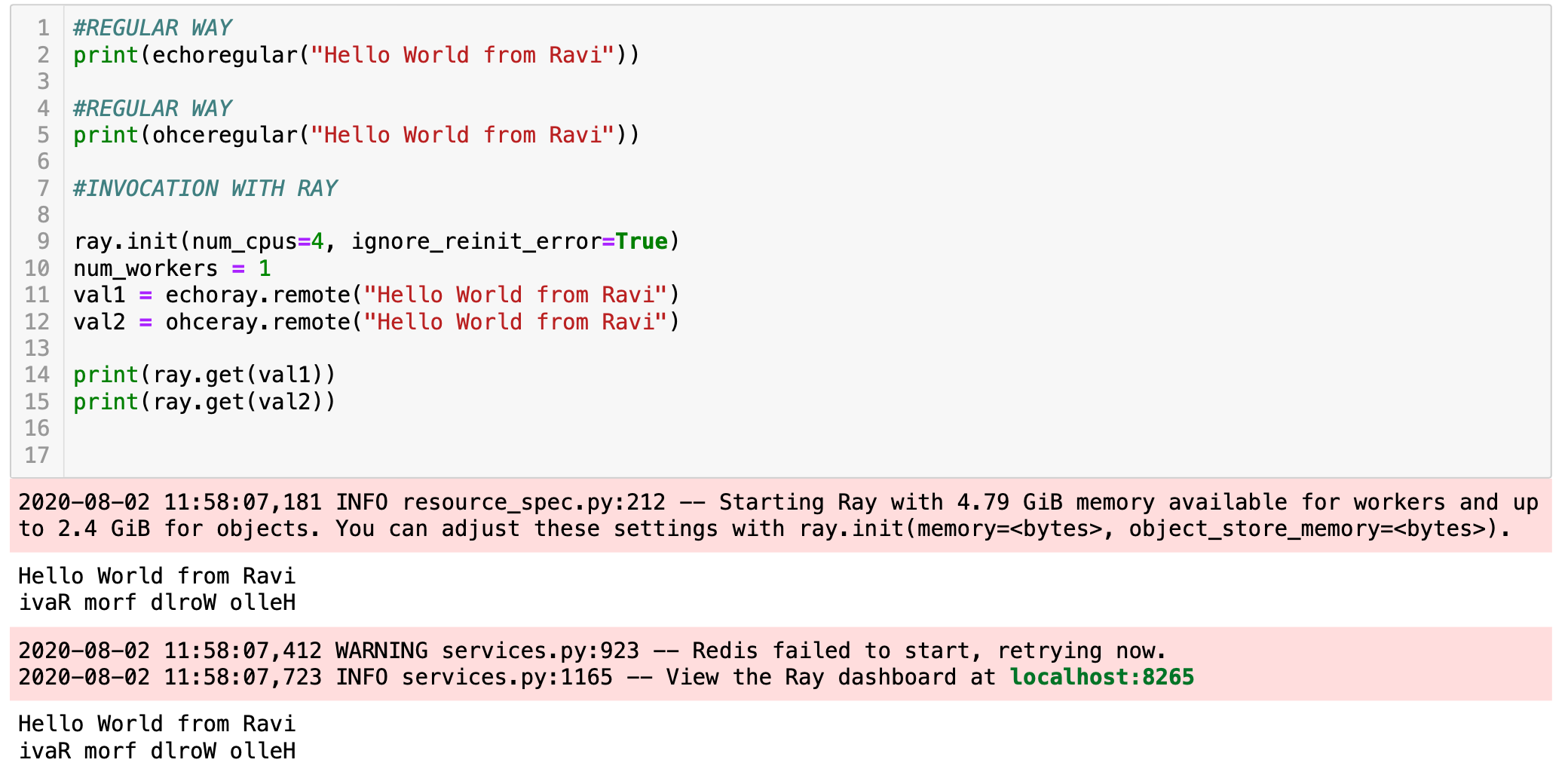
Normal output of regular functions and Ray remote onvocations
常规函数和Ray远程调用的正常输出
Now, see how we made the parallelism.
现在,看看我们如何进行并行处理。
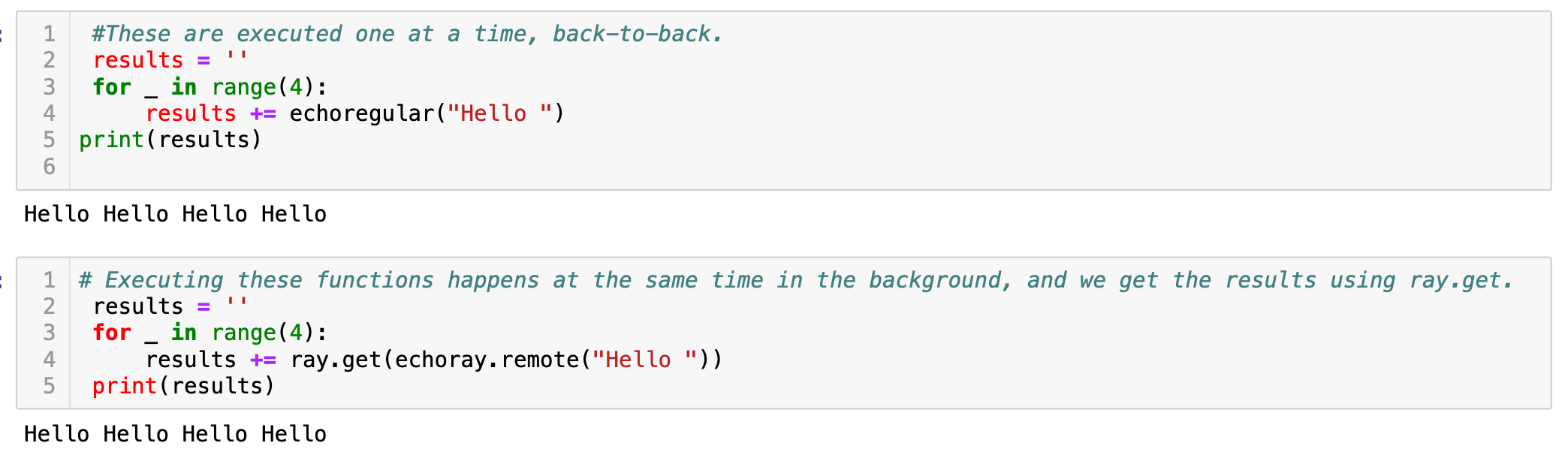
Ray tasks are executed in parallelRay
任务并行执行
Next a more detailed example: We are going to predict house prices. We will use Ray for illustrating the concepts.
接下来是一个更详细的示例:我们将预测房价。 我们将使用Ray来说明概念。
The collection contains 781 data records and it is available for download in CSV format in the code repository mentioned below. Among the 8 available features, for simplicity, we are going to focus on only two of them: the Size, and Price. For each of the 781 records, the Size, in square feet, will be our input features, and the Price our target values.
该集合包含781个数据记录,可以在下面提到的代码存储库中以CSV格式下载。 为了简便起见,在这8个可用功能中,我们将仅关注其中两个:大小和价格。 对于781条记录中的每条记录,以平方英尺为单位的大小将是我们的输入功能,而价格是我们的目标值。
We will build a simple parameter server, which is a key-value store used for training machine learning models in a cluster. The values are the parameters of a machine-learning model. The **keys **index the model parameters. A house’s price depends on parameters such as the number of bedrooms, living area, location, etc. If we apply artificial learning to these parameters we can calculate house valuations in a given geographical area. In our case we have two parameters or features: size and price as mentioned above.
我们将构建一个简单的参数服务器 ,这是一个用于在集群中训练机器学习模型的键值存储。 这些值是机器学习模型的参数。 键索引模型参数。 房子的价格取决于参数 ,如卧室的数量,居住面积,位置等。如果我们采用人工学这些参数我们可以在一个特定的地理区域计算房子的估值。 在我们的案例中,我们有两个参数或特征:如上所述的尺寸和价格。

Figure 8: Our HousingPrizeParameterServer (Asynchronous)
图8:我们的HousingPrizeParameterServer(异步)
The asynchronous parameter server itself is implemented as an actor (class), which exposes the methods push and pull(tasks). You start off with these functions, and then to turn them into remote tasks, you simply add the @ray.remote decorator to the functions to convert them into tasks. Then when you call them, Ray schedules them in the backend, calling a task is just like calling a function, but you need to add .remote. When developing an application, it’s really important to understand what code runs locally, versus what code runs in the cloud. This helps developers avoid bugs and quickly understand the code. Calling tasks instantly returns an object ID while the task executes in the background. The object ID acts as a future to the result of the remote task.
异步参数服务器本身是作为参与者(类)实现的,该参与者公开了方法push和pull (任务)。 您从这些功能开始,然后将它们转换为远程任务,只需将@ ray.remote装饰器添加到这些函数即可将它们转换为任务。 然后,当您调用它们时,Ray在后端安排它们,调用任务就像调用函数一样,但是您需要添加*.remote* 。 开发应用程序时,了解哪些代码在本地运行以及什么代码在云中运行非常重要。 这有助于开发人员避免错误并快速理解代码。 当任务在后台执行时,调用任务会立即返回对象ID。 对象ID充当远程任务结果的未来 。
Next we start Ray by invoking init method.
接下来,我们通过调用init方法启动Ray。
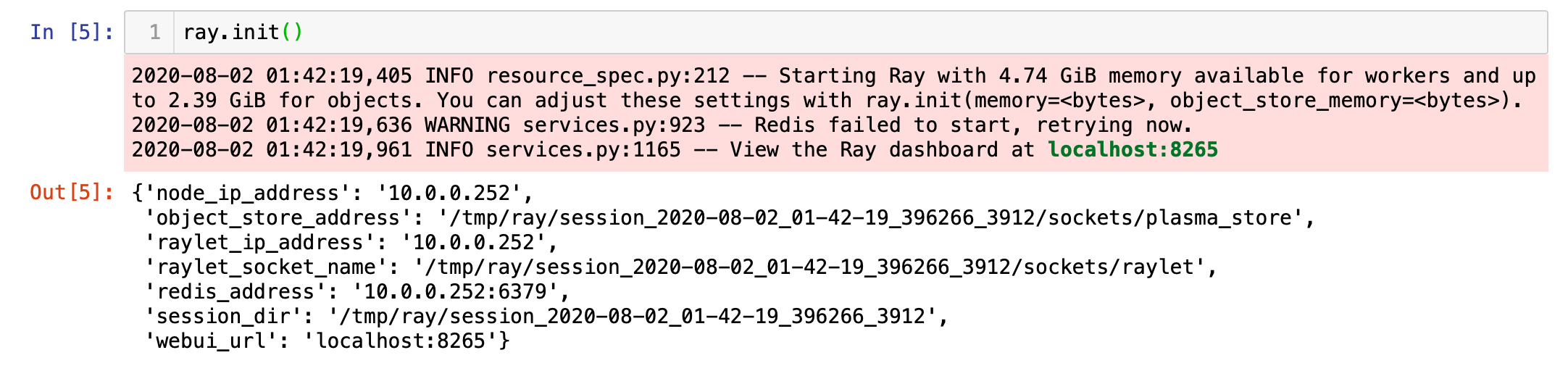
Figure 9: Starting Ray — Omitted some parameters for convenience
图9:起始射线—为方便起见省略了一些参数
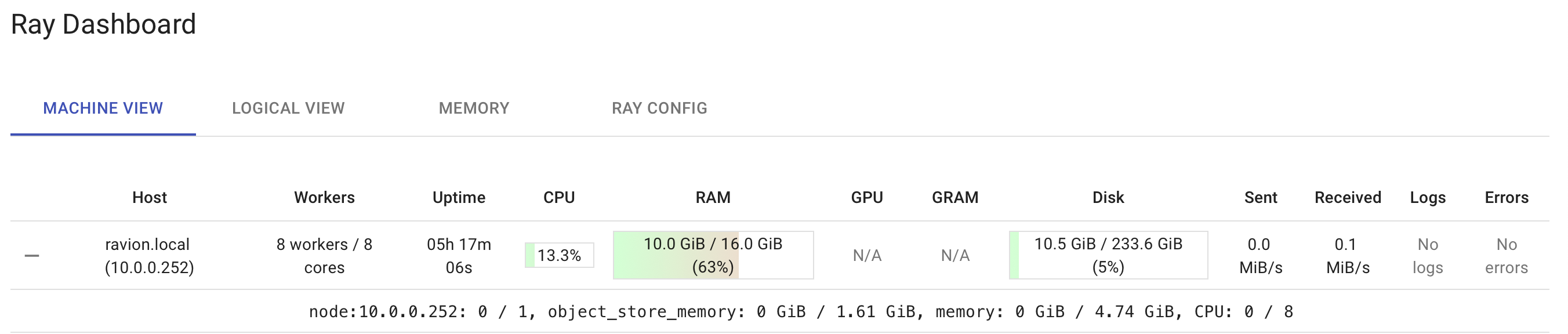
Figure 10: Ray Dashboard (As shown in previous figure, default Ray URL is http://localhost:8265)
图10:Ray仪表板(如上图所示,默认Ray URL为http:// localhost:8265)
We now write a worker which defines a worker task, which take a parameter server as an argument and submits tasks to it.
现在,我们编写一个定义工作程序任务的工作程序,该工作程序将参数服务器作为参数并向其提交任务。

Figure 11: The worker task for connecting to parameter server for updates
图11:用于连接到参数服务器以进行更新的辅助任务
The compute_grad is the one which ideally should calculate the gradient. Above is the snippet showing the usage, you might want to write your complex logic to calculate it.
理想情况下,compute_grad是应该计算梯度的那个。 上面是显示用法的代码段,您可能需要编写复杂的逻辑来进行计算。
Finally, create your main code in which we initialize Ray, initialize workers and get the results:
最后,创建您的主要代码,在其中初始化Ray,初始化worker并获得结果:
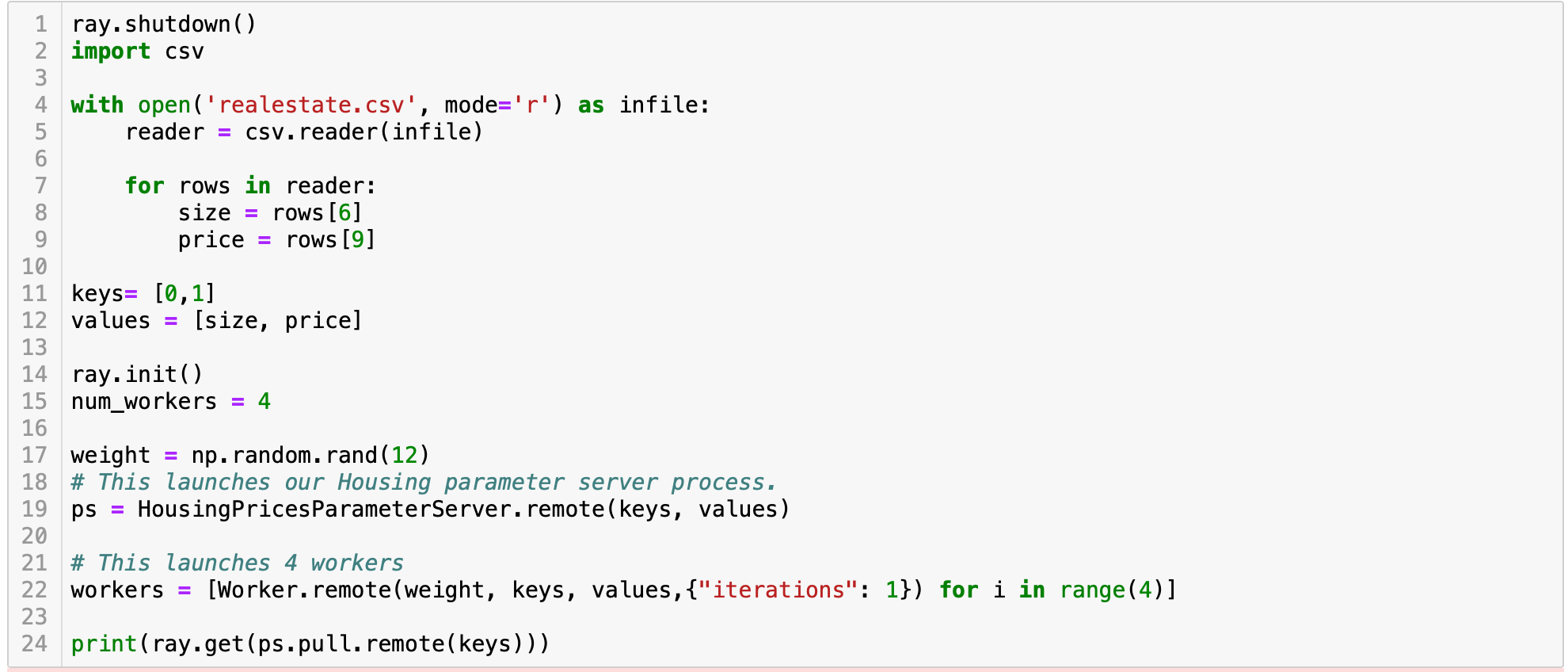
Figure 12: Main code
图12:主代码
The first line is to avoid error, if Ray is already running. You can solve the error by passing parameters to init as well.
如果Ray已经在运行,则第一行是为了避免错误。 您也可以通过将参数传递给init来解决错误。
代码 (Code)
The code discussed in the article is available here.
本文讨论的代码可在此处获得 。