StyleGAN2 Distillation for Feed-forward Image Manipulation
StyleGAN2蒸馏用于前馈图像处理
Yuri Viazovetskyiequal contribution1 Yandex 1Vladimir Ivashkin1 Yandex 12Moscow Institute of Physics and Technology
Evgeny Kashin1 Yandex 1
ABSTRACT
StyleGAN2 is a state-of-the-art network in generating realistic images. Besides, it was explicitly trained to have disentangled directions in latent space, which allows efficient image manipulation by varying latent factors. Editing existing images requires embedding a given image into the latent space of StyleGAN2. Latent code optimization via backpropagation is commonly used for qualitative embedding of real world images, although it is prohibitively slow for many applications. We propose a way to distill a particular image manipulation of StyleGAN2 into image-to-image network trained in paired way. The resulting pipeline is an alternative to existing GANs, trained on unpaired data. We provide results of human faces’ transformation: gender swap, aging/rejuvenation, style transfer and image morphing. We show that the quality of generation using our method is comparable to StyleGAN2 backpropagation and current state-of-the-art methods in these particular tasks.
StyleGAN2是用于生成逼真的图像的先进网络。此外,还对它进行了明确训练,使其在潜在空间中具有纠缠的方向,从而可以通过更改潜在因子来进行有效的图像处理。编辑现有图像需要将给定图像嵌入到StyleGAN2的潜在空间中。通过反向传播进行的潜在代码优化通常用于对真实世界图像进行定性嵌入,尽管对于许多应用程序来说,这样做的速度太慢了。我们提出了一种将StyleGAN2的特定图像处理提炼成以配对方式训练的图像到图像网络的方法。生成的管道是对现有GAN的替代方案,它是针对未配对数据进行训练的。我们提供人脸转换的结果:性别互换,老化/复兴,样式转换和图像变形。
Keywords:
Computer Vision, StyleGAN2, distillation, synthetic data

Figure 1: Image manipulation examples generated by our method from (a) source image: (b) gender swap at 1024x1024 and (c) style mixing at 512x512. Samples are generated feed-forward.## 1INTRODUCTION
图1:我们的方法从(a)源图像生成的图像处理示例:(b)1024x1024的性别互换和(c)512x512的样式混合。样品产生前馈。
Generative adversarial networks (GANs) [17] have created wide opportunities in image manipulation. General public is familiar with them from the many applications which offer to change one’s face in some way: make it older/younger, add glasses, beard, etc.
There are two types of network architecture which can perform such translations feed-forward: neural networks trained on either paired or unpaired datasets. In practice, only unpaired datasets are used. The methods used there are based on cycle consistency [60]. The follow-up studies [23, 10, 11] have maximum resolution of 256x256.
生成对抗网络(GANs)[ 17 ]在图像处理中创造了广泛的机会。公众从许多可以以某种方式改变面孔的应用程序中熟悉它们:变老/变年轻,加眼镜,胡须等。
可以执行这种转换前馈的网络结构有两种类型:在成对或不成对的数据集上训练的神经网络。实际上,仅使用未配对的数据集。那里使用的方法基于周期一致性[ 60 ]。后续的研究[ 23,10,11 ]有256×256的最大分辨率。
At the same time, existing paired methods (e.g. pix2pixHD [54] or SPADE [41]) support resolution up to 2048x1024. But it is very difficult or even impossible to collect a paired dataset for such tasks as age manipulation. For each person, such dataset would have to contain photos made at different age, with the same head position and facial expression. Close examples of such datasets exist, e.g. CACD [8], AgeDB [39], although with different expressions and face orientation. To the best of our knowledge, they have never been used to train neural networks in a paired mode.
同时,现有的配对方法(例如pix2pixHD [ 54 ]或SPADE [ 41 ])支持高达2048x1024的分辨率。但是为诸如年龄操纵之类的任务收集成对的数据集是非常困难的,甚至是不可能的。对于每个人,这样的数据集都必须包含不同年龄的照片,并具有相同的头部位置和面部表情。尽管具有不同的表情和面部朝向,但存在此类数据集的近似示例,例如CACD [ 8 ],AgeDB [ 39 ]。据我们所知,它们从未被用于以配对模式训练神经网络。
These obstacles can be overcome by making a synthetic paired dataset, if we solve two known issues concerning dataset generation: appearance gap [21] and content gap [27]. Here, unconditional generation methods, like StyleGAN [29], can be of use. StyleGAN generates images of quality close to real world and with distribution close to real one according to low FID results. Thus output of this generative model can be a good substitute for real world images. The properties of its latent space allow to create sets of images differing in particular parameters. Addition of path length regularization (introduced as measure of quality in [29]) in the second version of StyleGAN [30] makes latent space even more suitable for manipulations.
如果我们解决有关数据集生成的两个已知问题,则可以通过创建合成的配对数据集来克服这些障碍:外观差距[ 21 ]和内容差距[ 27 ]。在这里,可以使用无条件的生成方法,例如StyleGAN [ 29 ]。根据低FID结果,StyleGAN生成的图像质量接近真实世界,并且分布接近真实世界。因此,该生成模型的输出可以很好地替代现实世界的图像。其潜在空间的属性允许创建在特定参数上不同的图像集。增加路径长度正则化(在[ 29 ]中作为质量度量引入)在第二版StyleGAN [ 30 ]中使潜在空间更加适合操纵。
Basic operations in the latent space correspond to particular image manipulation operations. Adding a vector, linear interpolation, and crossover in latent space lead to expression transfer, morphing, and style transfer, respectively. The distinctive feature of both versions of StyleGAN architecture is that the latent code is applied several times at different layers of the network. Changing the vector for some layers will lead to changes at different scales of generated image. Authors group spatial resolutions in process of generation into coarse, middle, and fine ones. It is possible to combine two people by using one person’s code at one scale and the other person’s at another.
潜在空间中的基本操作对应于特定的图像操作操作。在潜在空间中添加向量,线性插值和交叉分别导致表达式传递,变形和样式传递。两种版本的StyleGAN体系结构的显着特点是,潜在代码在网络的不同层上多次应用。更改某些图层的矢量将导致所生成图像的比例不同。作者将空间分辨率在生成过程中分为粗略,中度和精细。可以通过从不同维度使用不同人的代码来合并生成新的人。
Operations mentioned above are easily performed for images with known embeddings. For many entertainment purposes this is vital to manipulate some existing real world image on the fly, e.g. to edit a photo which has just been taken. Unfortunately, in all the cases of successful search in latent space described in literature the backpropagation method was used [2, 1, 15, 30, 46]. Feed-forward is only reported to be working as an initial state for latent code optimization [5]. Slow inference makes application of image manipulation with StyleGAN2 in production very limited: it costs a lot in data center and is almost impossible to run on a device. However, there are examples of backpropagation run in production, e.g. [47].
对于具有已知嵌入的图像,可以轻松执行上述操作。对于许多娱乐目的,至关重要的是动态地处理一些现有的现实世界图像,例如,编辑刚拍摄的照片。不幸的是,在文献中所述的潜在空间成功搜索的所有情况,使用反向传播方法 [ 2,1,15,30,46 ]。前馈仅被报告为潜在代码优化的初始状态[ 5 ]。缓慢的推理使得使用StyleGAN2进行图像处理的应用非常有限:在数据中心花费很多,并且几乎不可能在设备上运行。但是,有一些反向传播在生产中运行的示例,例如[ 47 ]。
In this paper we consider opportunities to distill [20, 4] a particular image manipulation of StyleGAN2 generator, trained on the FFHQ dataset. The distillation allows to extract the information about faces’ appearance and the ways they can change (e.g. aging, gender swap) from StyleGAN into image-to-image network. We propose a way to generate a paired dataset and then train a “student” network on the gathered data. This method is very flexible and is not limited to the particular image-to-image model.
在本文中,我们考虑提制的机会[ 20,4 ] StyleGAN2生成的特定图像处理,训练有素的FFHQ数据集。蒸馏允许从StyleGAN提取有关面部外观及其更改方式(例如,老化,性别互换)的信息,以进入图像到图像网络。我们提出了一种生成配对数据集,然后在收集到的数据上训练“学生”网络的方法。该方法非常灵活,并且不限于特定的图像到图像模型。
Despite the resulting image-to-image network is trained only on generated samples, we show that it performs on real world images on par with StyleGAN backpropagation and current state-of-the-art algorithms trained on unpaired data.
Our contributions are summarized as follows:
- We create synthetic datasets of paired images to solve several tasks of image manipulation on human faces: gender swap, aging/rejuvenation, style transfer and face morphing;
- We show that it is possible to train image-to-image network on synthetic data and then apply it to real world images;
- We study the qualitative and quantitative performance of image-to-image networks trained on the synthetic datasets;
- We show that our approach outperforms existing approaches in gender swap task.
We publish all collected paired datasets for reproducibility and future research: https://github.com/EvgenyKashin/stylegan2-distillation.
尽管生成的图像到图像网络仅在生成的样本上进行训练,但我们证明它在真实世界图像上的表现与StyleGAN反向传播以及在未配对数据上训练的当前最新算法相当。
我们的贡献总结如下:
- 我们创建配对图像的合成数据集,以解决人脸图像处理的多项任务:性别互换,衰老/复兴,样式转换和脸部变形;
- 我们表明,有可能在合成数据上训练图像到图像网络,然后将其应用于现实世界图像;
- 我们研究在合成数据集上训练的图像到图像网络的定性和定量性能;
- 我们表明,在性别互换任务中,我们的方法要优于现有方法。
我们发布所有收集的配对数据集,以实现可重复性和未来研究:https : //github.com/EvgenyKashin/stylegan2-distillation。
2RELATED WORK
Unconditional image generation 无条件图像生成
Following the success of ProgressiveGAN [28] and BigGAN [6], StyleGAN [29] became state-of-the-art image generation model. This was achieved due to rethinking generator architecture and borrowing approaches from style transfer networks: mapping network and AdaIN [22], constant input, noise addition, and mixing regularization. The next version of StyleGAN – StyleGAN2 [30], gets rid of artifacts of the first version by revising AdaIN and improves disentanglement by using perceptual path length as regularizer.
继ProgressiveGAN [ 28 ]和BigGAN [ 6 ]成功之后,StyleGAN [ 29 ]成为了最先进的图像生成模型。之所以能够实现这一目标,是因为重新考虑了生成器体系结构,并借鉴了样式传递网络的方法:映射网络和AdaIN [ 22 ],恒定输入,噪声添加和混合正则化。下一版本的StyleGAN – StyleGAN2 [ 30 ]通过修改AdaIN摆脱了第一版的伪像,并通过使用感知路径长度作为正则化函数来改进了解缠结。
Mapping network is a key component of StyleGAN, which allows to transform latent space Z into less entangled intermediate latent space W. Instead of actual latent z∈Z sampled from normal distribution, w∈W resulting from mapping network f:Z→W is fed to AdaIN. Also it is possible to sample vectors from extended space W+, which consists of multiple independent samples of W, one for each layer of generator. Varying w at different layers will change details of generated picture at different scales.
映射网络是StyleGAN的关键组件,可以转换潜在空间 ž 进入较少纠缠的中间潜空间W 。而不是实际的潜能ž∈Z 从正态分布中采样 w∈W来自地图网络 F:Z→W被喂给AdaIN。也可以从扩展空间中采样向量W+,由多个独立的样本组成W,每层生成器一个。变化的w 在不同的图层将以不同的比例更改生成的图片的细节。
Latent codes manipulation 潜在代码操纵
It was recently shown [16, 26] that linear operations in latent space of generator allow successful image manipulations in a variety of domains and with various GAN architectures. In GANalyze [16], the attention is directed to search interpretable directions in latent space of BigGAN [6] using MemNet [31] as “assessor” network. Jahanian et al. [26] show that walk in latent space lead to interpretable changes in different model architectures: BigGAN, StyleGAN, and DCGAN [42].
最近表明[ 16,26 ],在发生器的潜在空间线性操作允许在各种域和与各种GAN架构成功的图像操作。在GANalyze [ 16 ]中,注意力集中在使用MemNet [ 31 ]作为“评估者”网络的BigGAN [ 6 ]的潜在空间中搜索可解释的方向 。Jahanian等。[ 26 ]表明,在潜在空间中行走会导致不同模型架构中的可解释性变化:BigGAN,StyleGAN和DCGAN [ 42 ]。
To manipulate real images in latent space of StyleGAN, one needs to find their embeddings in it. The method of searching the embedding in intermediate latent space via backprop optimization is described in [2, 1, 15, 46]. The authors use non-trivial loss functions to find both close and perceptually good image and show that embedding fits better in extended space W+. Gabbay et al. [15] show that StyleGAN generator can be used as general purpose image prior. Shen et al. [46] show the opportunity to manipulate appearance of generated person, including age, gender, eyeglasses, and pose, for both PGGAN [28] and StyleGAN. The authors of StyleGAN2 [30] propose to search embeddings in W instead of W+ to check if the picture was generated by StyleGAN2.
为了在StyleGAN的潜在空间中处理真实图像,需要在其中找到其嵌入。经由backprop优化在中间潜在空间搜索嵌入的方法中描述了[ 2,1,15,46 ]。作者使用非平凡的损失函数来找到接近且在视觉上都不错的图像,并表明嵌入在扩展空间中更合适W+。Gabbay等。 [ 15 ]表明StyleGAN生成器可以先用作通用图像。沉等。 [ 46 ]显示了为PGGAN [ 28 ]和StyleGAN操纵生成人的外观的机会,包括年龄,性别,眼镜和姿势 。StyleGAN2 [ 30 ]的作者 建议在以下位置搜索嵌入:W 代替 W+ 检查图片是否由StyleGAN2生成。
Paired Image-to-image translation 配对的图像到图像翻译
Pix2pix [25] is one of the first conditional generative models applied for image-to-image translation. It learns mapping from input to output images. Chen and Koltun [9] propose the first model which can synthesize 2048x1024 images. It is followed by pix2pixHD [54] and SPADE [41]. In SPADE generator, each normalization layer uses the segmentation mask to modulate the layer activations. So its usage is limited to the translation from segmentation maps. There are numerous follow-up works based on pix2pixHD architecture, including those working with video [7, 52, 53].
Pix2pix [ 25 ]是最早应用于图像到图像翻译的条件生成模型之一。它学习从输入图像到输出图像的映射。Chen和Koltun [ 9 ]提出了第一个可以合成2048x1024图像的模型。紧随其后的是pix2pixHD [ 54 ]和SPADE [ 41 ]。在SPADE生成器中,每个归一化层都使用分段掩码来调制层激活。因此,它的用法仅限于分割图的翻译。有基于pix2pixHD架构许多后续工作,包括那些使用视频[ 7,52,53 ]。
Unpaired Image-to-image translation 未配对的图像到图像翻译
The idea of applying cycle consistency to train on unpaired data is first introduced in CycleGAN [60]. The methods of unpaired image-to-image translation can be either single mode GANs [60, 58, 35, 10] or multimodal GANs [61, 23, 32, 33, 36, 11]. FUNIT [36] supports multi-domain image translation using a few reference images from a target domain. StarGAN v2 [11] provide both latent-guided and reference-guided synthesis. All of the above-mentioned methods operate at resolution of at most 256x256 when applied to human faces.
在CycleGAN [ 60 ]中首次引入了应用循环一致性训练未配对数据的思想 。不成对图像到图像的翻译的方法可以是单模式甘斯 [ 60,58,35,10 ]或多峰甘斯 [ 61,23,32,33,36,11 ]。FUNIT [ 36 ]支持使用来自目标域的一些参考图像进行多域图像转换。StarGAN v2 [ 11 ]提供潜在指导和参考指导综合。当应用于人脸时,所有上述方法均以最高256x256的分辨率运行。
Gender swap is one of well-known tasks of unsupervised image-to-image translation [10, 11, 37].
Face aging/rejuvenation is a special task which gets a lot of attention [59, 49, 18]. Formulation of the problem can vary. The simplest version of this task is making faces look older or younger [10]. More difficult task is to produce faces matching particular age intervals [34, 55, 57, 37]. S2GAN [18] proposes continuous changing of age using weight interpolation between transforms which correspond to two closest age groups.
性别交换是无监督图像到图像平移的公知的任务之一[ 10,11,37 ]。
面部老化/复兴,是一个特殊的任务,得到了很多的关注[ 59,49,18 ]。问题的表述可能会有所不同。此任务的最简单版本是使面孔看起来更老或更年轻 [ 10 ]。更困难的任务是产生面匹配特定年龄间隔 [ 34,55,57,37 ]。S2GAN [ 18 ]提出了在对应于两个最接近年龄组的变换之间使用权重插值来连续改变年龄。
Training on synthetic data 综合数据训练
Synthetic datasets are widely used to extend datasets for some analysis tasks (e.g. classification). In many cases, simple graphical engine can be used to generate synthetic data. To perform well on real world images, this data need to overcome both appearance gap [21, 14, 50, 51, 48] and content gap [27, 45].
Ravuri et al. [43] study the quality of a classificator trained on synthetic data generated by BigGAN and show [44] that BigGAN does not capture the ImageNet [13] data distributions and is only partly successful for data augmentation. Shrivastava et al. [48] reduce the quality drop of this approach by revising train setup.
合成数据集被广泛用于扩展某些分析任务(例如分类)的数据集。在许多情况下,可以使用简单的图形引擎来生成综合数据。对现实世界的图像表现良好,该数据需要克服两个外观间隙 [ 21,14,50,51,48 ]和内容间隙 [ 27,45 ]。
Ravuri等。[ 43 ]研究了由BigGAN生成的合成数据训练的分类器的质量,并显示[ 44 ] BigGAN未捕获ImageNet [ 13 ]数据分布,仅部分成功用于数据增强。Shrivastava等。[ 48 ]通过修改火车设置来减少这种方法的质量下降。
Synthetic data is what underlies knowledge distillation, a technique that allows to train “student” network using data generated by “teacher” network [20, 4]. Usage of this additional source of data can be used to improve measures [56] or to reduce size of target model [38]. Aguinaldo et al. [3] show that knowledge distillation is successfully applicable for generative models.
知识蒸馏合成数据,一种允许使用由“老师”网络生成的数据来训练“学生”网络[ 20,4 ]。可以使用这些额外的数据源来改进度量[ 56 ]或减小目标模型的大小[ 38 ]。Aguinaldo等。[ 3 ]表明知识蒸馏成功地适用于生成模型。
3METHOD OVERVIEW
3.1DATA COLLECTION 数据采集
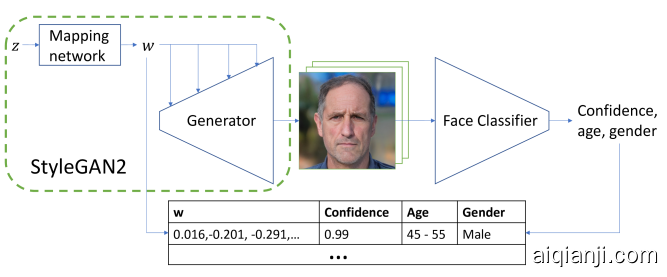 Figure 2: Method of finding correspondence between latent codes and facial attributes.
Figure 2: Method of finding correspondence between latent codes and facial attributes.
图2:寻找潜在代码和面部属性之间的对应关系的方法
All of the images used in our datasets are generated using the official implementation of StyleGAN211https://github.com/NVlabs/stylegan2. In addition to that we only use the config-f version checkpoint pretrained by the authors of StyleGAN2 on FFHQ dataset. All the manipulations are performed with the disentangled image codes w.。
我们数据集中使用的所有图像均使用StyleGAN2 1的官方实现生成1个https://github.com/NVlabs/stylegan2。除此之外,我们仅在FFHQ数据集上使用由StyleGAN2的作者预先训练的config-f版本检查点。所有操作均通过解纠缠的图像代码执行w。
We use the most straightforward way of generating datasets for style mixing and face morphing. Style mixing is described in [29] as a regularization technique and requires using two intermediate latent codes w1 and w2 at different scales. Face morphing corresponds to linear interpolation of intermediate latent codes w. We generate 50 000 samples for each task. Each sample consists of two source images and a target image. Each source image is obtained by randomly sampling z from normal distribution, mapping it to intermediate latent code w, and generating image g(w) with StyleGAN2. We produce target image by performing corresponding operation on the latent codes and feeding the result to StyleGAN2.
我们使用最直接的方式来生成用于样式混合和面部变形的数据集。[ 29 ]中将样式混合描述为一种正则化技术,并且需要使用两个中间潜在代码w1个 和 w2个在不同的规模。人脸变形对应于中间潜码的线性插值w。我们为每个任务生成5万个样本。每个样本都包含两个源图像和一个目标图像。每个源图像都是通过随机采样获得的ž 从正态分布,映射到中间潜在代码 w,并生成图像 G(w)与StyleGAN2。我们通过对潜在代码执行相应的操作并将结果提供给StyleGAN2来生成目标图像。
Face attributes, such as gender or age, are not explicitly encoded in StyleGAN2 latent space or intermediate space. To overcome this limitation we use a separate pretrained face classification network. Its outputs include confidence of face detection, age bin and gender. The network is proprietary, therefore we release the final version of our gender and age datasets in order to maintain full reproducibility of this work22https://github.com/EvgenyKashin/stylegan2-distillation.
人脸属性(例如性别或年龄)未在StyleGAN2潜在空间或中间空间中明确编码。为了克服这一局限性,我们使用了单独的预训练人脸分类网络。它的输出包括面部识别的信心,年龄段和性别。该网络是专有网络,因此我们发布了性别和年龄数据集的最终版本,以保持这项工作的完全可重复性22个https://github.com/EvgenyKashin/stylegan2-distillation
We create gender and age datasets in four major steps. First, we generate an intermediate dataset, mapping latent vectors to target attributes as illustrated in Fig. 2. Second, we find the direction in latent space associated with the attribute. Third, we generate raw dataset, using above-mentioned vector as briefly described in Fig. 3. Finally, we filter the images to get the final dataset. The method is described below in more detail.
我们通过四个主要步骤来创建性别和年龄数据集。首先,我们生成一个中间数据集,将潜在向量映射到目标属性,如图2所示 。其次,我们在与属性关联的潜在空间中找到方向。第三,我们使用图3中简要描述的上述向量生成原始数据集 。最后,我们对图像进行过滤以获得最终的数据集。该方法在下面更详细地描述。
- Generate random latent vectors z1…zn, map them to intermediate latent codes w1…wn, and generate corresponding image samples g(wi) with StyleGAN2.
生成随机潜在向量 z1…zn,将它们映射到中间潜在代码 w1个…wn,并用StyleGAN2生成相应的图像样本 G(wi)。 - Get attribute predictions from pretrained neural network f, c(wi)=f(g(wi)).
从预训练的神经网络获取属性预测 F, c(wi)=f(g(wi)). - Filter out images where faces were detected with low confidence33This helps to reduce generation artifacts in the dataset, while maintaining high variability as opposed to lowering truncation-psi parameter.. Then select only images with high classification certainty.
过滤掉以低置信度检测到脸部的图像33与降低截断psi参数相反,这有助于减少数据集中的生成伪像,同时保持较高的可变性。。然后仅选择具有较高分类确定性的图像。 - Find the center of every class Ck=1nc=k∑c(wi)=kwi and the transition vectors from one class to another Δci,cj=Cj−Ci
找到每个类的中心Ck=1nc=k∑c(wi)=kwi 以及从一类到另一类的过渡向量Δci,cj=Cj−Ci - Generate random samples zi and pass them through mapping network. For gender swap task, create a set of five images g(w−Δ),g(w−Δ/2),g(w),g(w+Δ/2),g(w+Δ) For aging/rejuvenation first predict faces’ attributes c(wi), then use corresponding vectors Δc(wi) to generate faces that should be two bins older/younger.
产生随机样本 zi并将它们通过制图网络。对于性别互换任务,创建一组五个图像g(w−Δ),g(w−Δ/2),g(w),g(w+Δ/2),g(w+Δ) - Get predictions for every image in the raw dataset. Filter out by confidence.
获取原始数据集中每个图像的预测。通过置信度过滤。 - From every set of images, select a pair based on classification results. Each image must belong to the corresponding class with high certainty.
从每组图像中,根据分类结果选择一对。每个图像必须高度确定地属于相应的类别。
As soon as we have aligned data, a paired image-to-image translation network can be trained.
一旦我们对齐了数据,就可以训练成对的图像到图像翻译网络。
 Figure 3: Dataset generation. We first sample random vectors z from normal distribution. Then for each z we generate a set of images along the vector Δ corresponding to a facial attribute. Then for each set of images we select the best pair based on classification results.
Figure 3: Dataset generation. We first sample random vectors z from normal distribution. Then for each z we generate a set of images along the vector Δ corresponding to a facial attribute. Then for each set of images we select the best pair based on classification results.
图3:数据集生成。我们首先对随机向量进行采样ž从正态分布。然后每个ž 我们沿着向量生成一组图像 Δ对应于面部属性。然后,针对每组图像,我们基于分类结果选择最佳对。
3.2TRAINING PROCESS
In this work, we focus on illustrating the general approach rather than solving every task as best as possible. As a result, we choose to train pix2pixHD44https://github.com/NVIDIA/pix2pixHD [54] as a unified framework for image-to-image translation instead of selecting a custom model for every type of task.
It is known that pix2pixHD has blob artifacts55https://github.com/NVIDIA/pix2pixHD/issues/46 and also tends to repeat patterns [41]. The problem with repeated patterns is solved in [29, 41]. Light blobs is a problem which is solved in StyleGAN2.
在这项工作中,我们专注于说明通用方法,而不是尽可能地解决每一项任务。结果,我们选择训练pix2pixHD 44https://github.com/NVIDIA/pix2pixHD [ 54 ]作为图像到图像翻译的统一框架,而不是为每种任务选择自定义模型。
已知pix2pixHD具有斑点伪影55https://github.com/NVIDIA/pix2pixHD/issues/46并且也倾向于重复模式[ 41 ]。与重复的图案的问题就解决了[ 29,41 ]。浅色斑点是StyleGAN2中解决的一个问题。
We suppose that similar treatment also in use for pix2pixHD. Fortunately, even vanilla pix2pixHD trained on our datasets produces sufficiently good results with little or no artifacts. Thus, we leave improving or replacing pix2pixHD for future work. We make most part of our experiments and comparison in 512x512 resolution, but also try 1024x1024 for gender swap.
Style mixing and face averaging tasks require two input images to be fed to the network at the same time. It is done by setting number of input channels to 6 and concatenating the inputs along channel axis.
我们假设pix2pixHD也使用了类似的处理方法。幸运的是,即使在我们的数据集上训练的原始pix2pixHD也能产生足够好的结果,而几乎没有伪影。因此,我们留待改进或替换pix2pixHD以便将来工作。我们在512x512分辨率下进行了大部分实验和比较,但也尝试使用1024x1024进行性别互换。
样式混合和面部平均任务需要将两个输入图像同时馈送到网络。通过将输入通道数设置为6并沿通道轴连接输入来完成此操作。
4EXPERIMENTS
Although StyleGAN2 can be trained on data of different nature, we concentrate our efforts only on face data. We show application of our method to several tasks: gender swap, aging/rejuvenation and style mixing and face morphing. In all our experiments we collect data from StyleGAN2, trained on FFHQ dataset [29].
尽管可以对StyleGAN2进行不同性质的数据训练,但我们仅将精力集中在面部数据上。我们展示了我们的方法在多项任务中的应用:性别互换,衰老/年轻化以及样式混合和脸部变形。在我们所有的实验中,我们从FFHQ数据集上训练过的StyleGAN2收集数据[ 29 ]。
4.1EVALUATION PROTOCOL
Only the task of gender transform (two directions) is used for evaluation. We use Frechét inception distance (FID) [19] for quantitative comparison of methods, as well as human evaluation.
For each feed-forward baseline we calculate FID between 50 000 real images from FFHQ datasets and 20 000 generated images, using 20 000 images from FFHQ as source images. For each source image we apply transformation to the other gender, assuming source gender is determined by our classification model. Before calculating FID measure all images are resized to 256x256 size for fair comparison.
仅使用性别转换任务(两个方向)进行评估。我们使用Frechét起始距离(FID)[ 19 ]进行方法的定量比较以及人工评估。
对于每个前馈基线,我们使用FFHQ的20000张图像作为源图像,计算FFHQ数据集的50000张真实图像和20000张生成的图像之间的FID。对于每个源图像,假设源性别由我们的分类模型确定,我们将转换应用于其他性别。在计算FID度量之前,将所有图像调整为256x256大小以进行公平比较。
Also human evaluation is used for more accurate comparison with optimization based methods. Our study consists of two surveys. In the first one crowdsource workers were asked to select an image showing better translation from one gender to the other given a source image. They were also instructed to consider preserving of person’s identity, clothes and accessories. We refer to this measure as ”quality”. The second survey asked to select the most realistic image, and no source image was provided. All images were resized to 512x512 size in this comparison.
此外,人工评估还可以与基于优化的方法进行更准确的比较。我们的研究包括两项调查。在第一个中,要求众包工作者选择一幅图像,该图像在给定源图像的情况下能更好地从一种性别转换为另一种。还指示他们考虑保留个人身份,衣服和配件。我们将此措施称为“质量”。第二次调查要求选择最真实的图像,但未提供源图像。在此比较中,所有图像均调整为512x512大小。
The first task should show which method is the best at performing transformation, the second – which has the best quality. We use side-by-side experiments for both tasks where one side is our method and the other side is one of optimization based baselines. Answer choices are shuffled. For each comparison of our method with a baseline, we generate 1000 questions and each question is answered by 10 different people. For answers aggregation we use Dawid-Skene method [12] and filter out the examples with confidence level less than 95% (it is approximately 4% of all questions).
第一项任务应显示哪种方法最适合执行转换,第二项任务应显示最佳质量。我们对两个任务都使用了并行实验,其中一侧是我们的方法,另一侧是基于优化的基准之一。答案选择被打乱了。对于我们的方法与基线的每次比较,我们都会生成1000个问题,并且每个问题都会由10个不同的人回答。对于答案汇总,我们使用Dawid-Skene方法 [ 12 ]并过滤出置信度小于95%(大约占所有问题的4%)的示例。
4.2DISTILLATION OF IMAGE-TO-IMAGE TRANSLATION
Gender swap
We generate a paired dataset for male and female faces according to the method described above and than train a separate pix2pixHD model for each gender translation.
我们根据上述方法为男性和女性面部生成了配对的数据集,然后为每种性别翻译训练了一个单独的pix2pixHD模型。
 (a) Female to male (a) Female to male |
 (b) Male to female (b) Male to female |
|---|
Figure 4: Gender transformation: comparison with image-to-image translation approaches. MUNIT and StarGAN v2* are multimodal so we show one random realization there.
图4:性别转换:与图像到图像翻译方法的比较。MUNIT和StarGAN v2 *是多模式的,因此我们在此处显示了一个随机实现。
We compete with both unpaired image-to-image methods and different StyleGAN embedders with latent code optimization. We choose StarGAN66https://github.com/yunjey/stargan [10], MUNIT77https://github.com/NVlabs/MUNIT [24] and StarGAN v2*88https://github.com/taki0112/StarGAN_v2-Tensorflow (unofficial implementation, so its results may differ from the official one) [11] for a competition with unpaired methods. We train all these methods on FFHQ classified into males and females.
我们与不成对的图像到图像方法以及具有潜在代码优化功能的不同StyleGAN嵌入器竞争。我们选择StarGAN 66https://github.com/yunjey/stargan [ 10 ],MUNIT 77https://github.com/NVlabs/MUNIT [ 24 ]和StarGAN v2 * 88https://github.com/taki0112/StarGAN_v2-Tensorflow(非官方实施,因此其结果可能与官方结果不同) [ 11 ] 与未配对方法的比赛。我们在FFHQ上将所有这些方法训练为男性和女性。
Fig. 4 shows qualitative comparison between our approach and unpaired image-to-image ones. It demonstrates that distilled transformation have significantly better visual quality and more stable results. Quantitative comparison in Table 4(a) confirms our observations.
图 4显示了我们的方法与未配对的图像到图像方法之间的定性比较。它表明蒸馏转化具有明显更好的视觉质量和更稳定的结果。表4(a)中的定量比较证实了我们的观察结果。
StyleGAN2 provides an official projection method. This method operates in W, which only allows to find faces generated by this model, but not real world images. So, we also build a similar method for W+ for comparison. It optimizes separate w for each layer of the generator, which helps to better reconstruct a given image. After finding w we can add transformation vector described above and generate a transformed image.
Also we add previous approaches [40, 5] for finding latent code to comparison, even though they are based on the first version of StyleGAN. StyleGAN encoder[5] add to[40] more advanced loss functions and forward pass approximation of optimization starting point, that improve reconstruction results.
StyleGAN2提供了一种官方的投影方法。此方法在W上作用,它仅允许查找由该模型生成的脸部,而不是现实世界的图像。因此,我们还为W进行比较。它优化了单独的w生成器的每一层,这有助于更好地重建给定图像。找到之后w 我们可以添加上述转换向量并生成转换后的图像。
此外,我们添加以前的方法[ 40,5 ]寻找潜在代码来比较,虽然它们都是基于StyleGAN的第一个版本。StyleGAN编码器[ 5 ]在[ 40 ]的基础上增加了更多的高级损耗函数,并优化起点的前向逼近近似,从而改善了重建结果。
| Method | FID |
|---|---|
| StarGAN [10] | 29.7 |
| MUNIT [23] | 40.2 |
| StarGANv2* | 25.6 |
| Ours | 14.7 |
| Real images | 3.3 |
(a) Comparison with unpaired image-to-image methods
与未配对的图像对图像方法进行比较
| Method | Quality | Realism |
|---|---|---|
| StyleGAN Encoder [40] | 18% | 14% |
| StyleGAN Encoder [5] | 30% | 68% |
| StyleGAN2 projection (W) | 22% | 22% |
| StyleGAN2 projection (W+) | 11% | 14% |
| Real images | - | 85% |
(b) User study of StyleGAN-based approaches. Winrate method vs ours”
基于StyleGAN的方法的用户研究。Winrate方法与我们的方法”
Table 1: Quantitative comparison. We use FID as a main measure for comparison with another image-to-image transformation baselines. We measure user study for all StyleGAN-based approaches because we consider human evaluation more reliable measure for perception.
表1:定量比较。我们将FID作为与其他图像到图像转换基线进行比较的主要指标。我们考虑所有基于StyleGAN的方法的用户研究,因为我们认为人类评估是感知的更可靠方法。

Figure 5: Gender transformation: comparison with StyleGAN2 latent code optimization methods. Input samples are real images from FFHQ.
图5:性别转换:与StyleGAN2潜在代码优化方法的比较。输入样本是来自FFHQ的真实图像。请注意,异常对象会因优化而丢失,但会保留图像到图像的转换。
Notice that unusual objects are lost with optimization but kept with image-to-image translation.Since unpaired methods show significantly worse quality, we put more effort into comparisons between different methods of searching embedding through optimization. We avoid using methods that utilize FID because all of them are based on the same StyleGAN model. Also, FID cannot measure ”quality of transformation” because it does not check keeping of personality. So we decide to make user study our main measure for all StyleGAN-based methods. Fig. 5 shows qualitative comparison of all the methods. It is visible that our method performs better in terms of transformation quality. And only StyleGAN Encoder [5] outperforms our method in realism. However this method generates background unconditionally.
由于未配对的方法显示出明显较差的质量,因此我们将更多精力投入到通过优化搜索嵌入的不同方法之间的比较中。我们避免使用利用FID的方法,因为所有方法都基于相同的StyleGAN模型。此外,FID无法衡量“变革的质量”,因为它不检查保持个性的能力。因此,我们决定让用户研究所有基于StyleGAN的方法的主要指标。图5显示了所有方法的定性比较。可见,我们的方法在转换质量方面表现更好。而且只有StyleGAN Encoder [ 5 ]在实际效果上胜过我们的方法。但是,此方法无条件生成背景。
We find that pix2pixHD keeps more details on transformed images than all the encoders. We suppose that this is achieved due to the ability of pix2pixHD to pass part of the unchanged content through the network. Pix2pixHD solves an easier task compared to encoders which are forced to encode all the information about the image in one vector.
我们发现,与所有编码器相比,pix2pixHD保留了更多的变换图像细节。我们假设这是由于pix2pixHD通过网络传递部分未更改内容的能力而实现的。与被迫将有关图像的所有信息编码在一个矢量中的编码器相比,Pix2pixHD解决了一项更轻松的任务。
Fig. 4 and 5 also show drawbacks of our approach. Vector of “gender” is not perfectly disentangled due to some bias in attribute distribution of FFHQ and, consequently, latent space correlation of StyleGAN[46]. For example, it can be seen that translation into female faces can also add smile.
图 4和5也显示了我们方法的缺点。由于FFHQ的属性分布存在一定偏差,因此“性别”向量不能完全解开,因此,StyleGAN的潜在空间相关性[ 46 ]。例如,可以看出翻译成女性面孔也可以增加微笑。
We also encounter problems of pix2pixHD architecture: repeated patterns, light blobs and difficulties with finetuning 1024x1024 resolution. We show an uncurated list of generated images in supplementary materials.
我们还遇到pix2pixHD体系结构的问题:重复的图案,浅色斑点以及对1024x1024分辨率进行微调的困难。我们在补充材料中显示了生成的图像的未整理清单。
Aging/rejuvenation
To show that our approach can be applied for another image-to-image transform task, we also carry out similar experiment with face age manipulation. First, we estimate age for all generated images, then group them into several bins. After that, for each bin we find vectors of “+2 bins” and “-2 bins”. Using these vectors, we generate united paired dataset. Each pair contains younger and older versions of the same face. Finally, we train two pix2pixHD networks, one for each of two directions.
为了表明我们的方法可以应用于另一种图像到图像的变换任务,我们还对面部年龄操纵进行了类似的实验。首先,我们估算所有生成图像的年龄,然后将它们分组到几个箱中。之后,对于每个箱,我们找到“ +2 bins”和“ -2bins”的向量。使用这些向量,我们生成联合的配对数据集。每对都包含同一张面孔的年轻版本和较旧版本。最后,我们训练了两个pix2pixHD网络,两个方向各一个。

Figure 6: Aging/rejuvenation. Source images are sampled from FFHQ.Examples of the application of this approach are presented in Fig. 6.
4.3DISTILLATION OF STYLE MIXING
Style mixing and face morphing
There are 18 AdaIN inputs in StyleGAN2 architecture. These AdaINs work with different spatial resolutions, and changing different input will change details of different scale. The authors divide them into three groups: coarse styles (for 42 – 82 spatial resolutions), middle styles (162 – 322) and fine styles (642 – 10242). The opportunity to change coarse, middle or fine details is a unique feature of StyleGAN architectures.

Figure 7: Style mixing with pix2pixHD. (a), (b), (c) show results of distillated crossover of two latent codes in W+, (d) shows result of average latent code transformaiton. Source images are sampled from FFHQWe collect datasets of triplets (two source images and their mixture) and train our models for each transformation.
We concatenate two images into 6 channels to feed our pix2pixHD model. Fig. 7(a,b,c) shows the results of style mixing.
我们收集三元组的数据集(两个源图像及其混合物),并为每次转换训练我们的模型。我们将两个图像连接成6个通道,以提供pix2pixHD模型。图 7(a,b,c)显示了样式混合的结果。
Another simple linear operation is to average two latent codes. It corresponds to morphing operation on images. We collect another dataset with triplet latent codes: two random codes and an average one. The examples of face morphing are shown in Fig. 7(d).
另一个简单的线性运算是对两个潜在代码求平均。它对应于图像的变形操作。我们收集了另一个包含三元组潜在代码的数据集:两个随机代码和一个平均值。脸部变形的示例在图 7(d)中显示。
5CONCLUSIONS
In this paper, we unite unconditional image generation and paired image-to-image GANs to distill a particular image manipulation in latent code of StyleGAN2 into single image-to-image translation. The resulting technique shows both fast inference and impressive quality. It outperforms existing unpaired image-to-image models in FID score and StyleGAN Encoder approaches both in user study and time of inference on gender swap task. We show that the approach is also applicable for other image manipulations, such as aging/rejuvenation and style transfer.
在本文中,我们将无条件图像生成与成对的图像到图像GAN结合在一起,以将StyleGAN2的潜在代码中的特定图像处理提炼为单图像到图像的转换。所产生的技术既显示出快速的推论又显示出令人印象深刻的质量。它在FID得分方面优于现有的未配对图像对图像模型,并且在用户研究和推断性别互换任务的时间上均采用StyleGAN Encoder方法。我们证明该方法也适用于其他图像处理,例如老化/复兴和样式转换。
Our framework has several limitations. StyleGAN2 latent space is not perfectly disentangled, so the transformations made by our network are not perfectly pure. Despite the latent space is not disentangled enough to make pure transformations, impurities are not so severe.
我们的框架有几个局限性。StyleGAN2的潜在空间并没有完全解开,因此我们的网络所做的转换并不是完全纯净的。尽管潜在空间的纠缠程度不足以进行纯转换,但杂质并不是那么严重。
We use only pix2pixHD network although different architectures fit better for different tasks. Besides, we distil every transformation to a separate model, although some universal model could be trained. This opportunity should be investigated in future studies.
尽管不同的体系结构更适合于不同的任务,但我们仅使用pix2pixHD网络。此外,尽管可以训练一些通用模型,但我们将每次转换都分解为一个单独的模型。这个机会应该在以后的研究中进行研究。
REFERENCES
- [1] R. Abdal, Y. Qin, and P. Wonka (2019) Image2StyleGAN: how to embed images into the stylegan latent space?. In Proceedings of the IEEE International Conference on Computer Vision, pp. 4432–4441. Cited by: §1, §2.0.2.
- [2] R. Abdal, Y. Qin, and P. Wonka (2019) Image2StyleGAN++: how to edit the embedded images?. arXiv preprint arXiv:1911.11544. Cited by: §1, §2.0.2.
- [3] A. Aguinaldo, P. Chiang, A. Gain, A. Patil, K. Pearson, and S. Feizi (2019) Compressing gans using knowledge distillation. arXiv preprint arXiv:1902.00159. Cited by: §2.0.5.
- [4] J. Ba and R. Caruana (2014) Do deep nets really need to be deep?. In Advances in neural information processing systems, pp. 2654–2662. Cited by: §1, §2.0.5.
- [5] P. Baylies (2019) StyleGAN encoder - converts real images to latent space. GitHub. Note: https://github.com/pbaylies/stylegan-encoder Cited by: §1, 4(b), §4.2.1, §4.2.1.
- [6] A. Brock, J. Donahue, and K. Simonyan (2018) Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096. Cited by: §2.0.1, §2.0.2.
- [7] C. Chan, S. Ginosar, T. Zhou, and A. A. Efros (2019) Everybody dance now. In Proceedings of the IEEE International Conference on Computer Vision, pp. 5933–5942. Cited by: §2.0.3.
- [8] B. Chen, C. Chen, and W. H. Hsu (2014) Cross-age reference coding for age-invariant face recognition and retrieval. In European conference on computer vision, pp. 768–783. Cited by: §1.
- [9] Q. Chen and V. Koltun (2017) Photographic image synthesis with cascaded refinement networks. In Proceedings of the IEEE international conference on computer vision, pp. 1511–1520. Cited by: §2.0.3.
- [10] Y. Choi, M. Choi, M. Kim, J. Ha, S. Kim, and J. Choo (2018) StarGAN: unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Cited by: §1, §2.0.4, §2.0.4, §2.0.4, 4(a), §4.2.1.
- [11] Y. Choi, Y. Uh, J. Yoo, and J. Ha (2019) StarGAN v2: diverse image synthesis for multiple domains. arXiv preprint arXiv:1912.01865. Cited by: §1, §2.0.4, §2.0.4, §4.2.1.
- [12] A. P. Dawid and A. M. Skene (1979) Maximum likelihood estimation of observer error-rates using the em algorithm. Journal of the Royal Statistical Society: Series C (Applied Statistics) 28 (1), pp. 20–28. Cited by: §4.1.
- [13] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei (2009) ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, Cited by: §2.0.5.
- [14] G. French, M. Mackiewicz, and M. Fisher (2017) Self-ensembling for visual domain adaptation. arXiv preprint arXiv:1706.05208. Cited by: §2.0.5.
- [15] A. Gabbay and Y. Hoshen (2019) Style generator inversion for image enhancement and animation. arXiv preprint arXiv:1906.11880. Cited by: §1, §2.0.2.
- [16] L. Goetschalckx, A. Andonian, A. Oliva, and P. Isola (2019-10) GANalyze: toward visual definitions of cognitive image properties. In The IEEE International Conference on Computer Vision (ICCV), Cited by: §2.0.2.
- [17] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio (2014) Generative adversarial nets. In Advances in neural information processing systems, pp. 2672–2680. Cited by: §1.
- [18] Z. He, M. Kan, S. Shan, and X. Chen (2019) S2GAN: share aging factors across ages and share aging trends among individuals. In Proceedings of the IEEE International Conference on Computer Vision, pp. 9440–9449. Cited by: §2.0.4.
- [19] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter (2017) Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in neural information processing systems, pp. 6626–6637. Cited by: §4.1.
- [20] G. Hinton, O. Vinyals, and J. Dean (2015) Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531. Cited by: §1, §2.0.5.
- [21] J. Hoffman, E. Tzeng, T. Park, J. Zhu, P. Isola, K. Saenko, A. A. Efros, and T. Darrell (2017) Cycada: cycle-consistent adversarial domain adaptation. arXiv preprint arXiv:1711.03213. Cited by: §1, §2.0.5.
- [22] X. Huang and S. Belongie (2017) Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, pp. 1501–1510. Cited by: §2.0.1.
- [23] X. Huang, M. Liu, S. Belongie, and J. Kautz (2018) Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), pp. 172–189. Cited by: §1, §2.0.4, 4(a).
- [24] X. Huang, M. Liu, S. Belongie, and J. Kautz (2018) Multimodal unsupervised image-to-image translation. In ECCV, Cited by: §4.2.1.
- [25] P. Isola, J. Zhu, T. Zhou, and A. A. Efros (2017) Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1125–1134. Cited by: §2.0.3.
- [26] A. Jahanian, L. Chai, and P. Isola (2019) On the ”steerability” of generative adversarial networks. arXiv preprint arXiv:1907.07171. Cited by: §2.0.2.
- [27] A. Kar, A. Prakash, M. Liu, E. Cameracci, J. Yuan, M. Rusiniak, D. Acuna, A. Torralba, and S. Fidler (2019) Meta-sim: learning to generate synthetic datasets. In Proceedings of the IEEE International Conference on Computer Vision, pp. 4551–4560. Cited by: §1, §2.0.5.
- [28] T. Karras, T. Aila, S. Laine, and J. Lehtinen (2017) Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196. Cited by: §2.0.1, §2.0.2.
- [29] T. Karras, S. Laine, and T. Aila (2019) A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4401–4410. Cited by: §1, §2.0.1, §3.1, §3.2, §4.
- [30] T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila (2019) Analyzing and improving the image quality of stylegan. arXiv preprint arXiv:1912.04958. Cited by: §1, §1, §2.0.1, §2.0.2.
- [31] A. Khosla, A. S. Raju, A. Torralba, and A. Oliva (2015) Understanding and predicting image memorability at a large scale. In Proceedings of the IEEE International Conference on Computer Vision, pp. 2390–2398. Cited by: §2.0.2.
- [32] H. Lee, H. Tseng, J. Huang, M. K. Singh, and M. Yang (2018) Diverse image-to-image translation via disentangled representations. In European Conference on Computer Vision, Cited by: §2.0.4.
- [33] H. Lee, H. Tseng, Q. Mao, J. Huang, Y. Lu, M. K. Singh, and M. Yang (2019) DRIT++: diverse image-to-image translation viadisentangled representations. arXiv preprint arXiv:1905.01270. Cited by: §2.0.4.
- [34] P. Li, Y. Hu, Q. Li, R. He, and Z. Sun (2018) Global and local consistent age generative adversarial networks. In 2018 24th International Conference on Pattern Recognition (ICPR), pp. 1073–1078. Cited by: §2.0.4.
- [35] M. Liu, T. Breuel, and J. Kautz (2017) Unsupervised image-to-image translation networks. In Advances in neural information processing systems, pp. 700–708. Cited by: §2.0.4.
- [36] M. Liu, X. Huang, A. Mallya, T. Karras, T. Aila, J. Lehtinen, and J. Kautz (2019) Few-shot unsupervised image-to-image translation. arXiv preprint arXiv:1905.01723. Cited by: §2.0.4.
- [37] Y. Liu, Q. Li, and Z. Sun (2019) Attribute-aware face aging with wavelet-based generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 11877–11886. Cited by: §2.0.4, §2.0.4.
- [38] S. Mirzadeh, M. Farajtabar, A. Li, and H. Ghasemzadeh (2019) Improved knowledge distillation via teacher assistant: bridging the gap between student and teacher. arXiv preprint arXiv:1902.03393. Cited by: §2.0.5.
- [39] S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia, and S. Zafeiriou (2017) Agedb: the first manually collected, in-the-wild age database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 51–59. Cited by: §1.
- [40] D. Nikitko (2019) StyleGAN – encoder for official tensorflow implementation. GitHub. Note: https://github.com/Puzer/stylegan-encoder Cited by: 4(b), §4.2.1.
- [41] T. Park, M. Liu, T. Wang, and J. Zhu (2019) Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2337–2346. Cited by: §1, §2.0.3, §3.2.
- [42] A. Radford, L. Metz, and S. Chintala (2015) Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434. Cited by: §2.0.2.
- [43] S. Ravuri and O. Vinyals (2019) Classification accuracy score for conditional generative models. In Advances in Neural Information Processing Systems, pp. 12247–12258. Cited by: §2.0.5.
- [44] S. Ravuri and O. Vinyals (2019) Seeing is not necessarily believing: limitations of biggans for data augmentation. Cited by: §2.0.5.
- [45] N. Ruiz, S. Schulter, and M. Chandraker (2018) Learning to simulate. arXiv preprint arXiv:1810.02513. Cited by: §2.0.5.
- [46] Y. Shen, J. Gu, X. Tang, and B. Zhou (2019) Interpreting the latent space of gans for semantic face editing. arXiv preprint arXiv:1907.10786. Cited by: §1, §2.0.2, §4.2.1.
- [47] T. Shi, Y. Yuan, C. Fan, Z. Zou, Z. Shi, and Y. Liu (2019) Face-to-parameter translation for game character auto-creation. In Proceedings of the IEEE International Conference on Computer Vision, pp. 161–170. Cited by: §1.
- [48] A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb (2017) Learning from simulated and unsupervised images through adversarial training. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2107–2116. Cited by: §2.0.5, §2.0.5.
- [49] J. Song, J. Zhang, L. Gao, X. Liu, and H. T. Shen (2018) Dual conditional gans for face aging and rejuvenation. In IJCAI, pp. 899–905. Cited by: §2.0.4.
- [50] J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel (2017) Domain randomization for transferring deep neural networks from simulation to the real world. In 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pp. 23–30. Cited by: §2.0.5.
- [51] Y. Tsai, W. Hung, S. Schulter, K. Sohn, M. Yang, and M. Chandraker (2018) Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7472–7481. Cited by: §2.0.5.
- [52] T. Wang, M. Liu, A. Tao, G. Liu, J. Kautz, and B. Catanzaro (2019) Few-shot video-to-video synthesis. In Conference on Neural Information Processing Systems (NeurIPS), Cited by: §2.0.3.
- [53] T. Wang, M. Liu, J. Zhu, G. Liu, A. Tao, J. Kautz, and B. Catanzaro (2018) Video-to-video synthesis. arXiv preprint arXiv:1808.06601. Cited by: §2.0.3.
- [54] T. Wang, M. Liu, J. Zhu, A. Tao, J. Kautz, and B. Catanzaro (2018) High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8798–8807. Cited by: §1, §2.0.3, §3.2.
- [55] Z. Wang, X. Tang, W. Luo, and S. Gao (2018) Face aging with identity-preserved conditional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7939–7947. Cited by: §2.0.4.
- [56] Q. Xie, E. Hovy, M. Luong, and Q. V. Le (2019) Self-training with noisy student improves imagenet classification. arXiv preprint arXiv:1911.04252. Cited by: §2.0.5.
- [57] H. Yang, D. Huang, Y. Wang, and A. K. Jain (2019) Learning continuous face age progression: a pyramid of gans. IEEE transactions on pattern analysis and machine intelligence. Cited by: §2.0.4.
- [58] Z. Yi, H. Zhang, P. Tan, and M. Gong (2017-10) DualGAN: unsupervised dual learning for image-to-image translation. In The IEEE International Conference on Computer Vision (ICCV), Cited by: §2.0.4.
- [59] Z. Zhang, Y. Song, and H. Qi (2017) Age progression/regression by conditional adversarial autoencoder. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5810–5818. Cited by: §2.0.4.
- [60] J. Zhu, T. Park, P. Isola, and A. A. Efros (2017) Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, pp. 2223–2232. Cited by: §1, §2.0.4.
- [61] J. Zhu, R. Zhang, D. Pathak, T. Darrell, A. A. Efros, O. Wang, and E. Shechtman (2017) Toward multimodal image-to-image translation. In Advances in Neural Information Processing Systems, Cited by: §2.0.4.