DEMONSTRATE–SEARCH–PREDICT: Composing retrieval and language models for knowledge-intensive NLP
DEMONSTRATE–SEARCH–PREDICT: 检索与语言模型组合在知识密集型NLP中的应用
Omar Khattab 1 Keshav Santhanam 1 Xiang Lisa Li 1 David Hall 1 Percy Liang 1 Christopher Potts 1 Matei Zaharia 1
Omar Khattab 1 Keshav Santhanam 1 Xiang Lisa Li 1 David Hall 1 Percy Liang 1 Christopher Potts 1 Matei Zaharia 1
Abstract
摘要
Retrieval-augmented in-context learning has emerged as a powerful approach for addressing knowledge-intensive tasks using frozen language models (LM) and retrieval models (RM). Existing work has combined these in simple “retrievethen-read” pipelines in which the RM retrieves passages that are inserted into the LM prompt. To begin to fully realize the potential of frozen LMs and RMs, we propose DEMONSTRATE– SEARCH–PREDICT (DSP), a framework that relies on passing natural language texts in sophisticated pipelines between an LM and an RM. DSP can express high-level programs that bootstrap pipeline-aware demonstrations, search for relevant passages, and generate grounded predictions, systematically breaking down problems into small transformations that the LM and RM can handle more reliably. We have written novel DSP programs for answering questions in open-domain, multi-hop, and conversational settings, establishing in early evaluations new state-of-the-art incontext learning results and delivering $37-120\%$ , $8-39\%$ , and $80{-}290\%$ relative gains against the vanilla LM (GPT-3.5), a standard retrieve-thenread pipeline, and a contemporaneous self-ask pipeline, respectively. We release DSP at https: //github.com/stanford nlp/dsp.
检索增强的上下文学习已成为利用冻结语言模型 (LM) 和检索模型 (RM) 处理知识密集型任务的有效方法。现有研究通过简单的"检索-读取"流程将二者结合,即RM检索文本段落并插入LM提示中。为充分释放冻结LM和RM的潜力,我们提出DEMONSTRATE–SEARCH–PREDICT (DSP)框架,通过在LM与RM之间构建复杂自然语言文本管道来实现。DSP能编写高级程序,实现管道感知演示的自主生成、相关段落检索及基于事实的预测生成,将问题系统拆解为LM和RM可可靠处理的微转换。我们针对开放域、多跳和对话场景编写了创新性DSP程序,早期评估显示其创造了上下文学习的新标杆:相比原始LM (GPT-3.5)、标准检索-读取流程及同期self-ask流程,分别实现37-120%、8-39%和80-290%的相对性能提升。项目代码发布于https://github.com/stanfordnlp/dsp。
1. Introduction
1. 引言
In-context learning adapts a frozen language model (LM) to tasks by conditioning the LM on a textual prompt including task instructions and a few demonstrating examples (McCann et al., 2018; Radford et al., 2019; Brown et al., 2020). For knowledge-intensive tasks such as question answering, fact checking, and information-seeking dialogue, retrieval models (RM) are increasingly used to augment prompts with relevant information from a large corpus (Lazaridou et al., 2022; Press et al., 2022; Khot et al., 2022).
情境学习 (in-context learning) 通过将任务指令和少量示例组成的文本提示 (prompt) 输入冻结的大语言模型 (LM) 来适配下游任务 (McCann et al., 2018; Radford et al., 2019; Brown et al., 2020)。针对问答、事实核查和信息检索对话等知识密集型任务,检索模型 (RM) 正被广泛用于从大规模语料库中检索相关信息来增强提示 (Lazaridou et al., 2022; Press et al., 2022; Khot et al., 2022)。
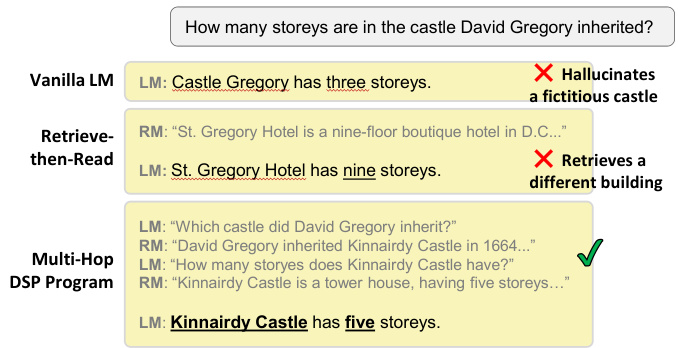
Figure 1. A comparison between three systems based on GPT3.5 (text-davinci-002). On its own, the LM often makes false assertions. An increasingly popular retrieve-then-read pipeline fails when simple search can’t find an answer. In contrast, a taskaware DSP program successfully decomposes the problem and produces a correct response. Texts edited for presentation.
图 1: 基于GPT3.5 (text-davinci-002) 的三种系统对比。单独使用时,大语言模型常产生错误断言。当前流行的检索-阅读流程在简单搜索无法找到答案时会失败。相比之下,具备任务感知的DSP程序能成功分解问题并生成正确答案。文本经过排版编辑。
Recent work has shown such retrieval-augmented in-context learning to be effective in simple “retrieve-then-read” pipelines: a query is fed to the RM and the retrieved passages become part of a prompt that provides context for the LM to use in its response. In this work, we argue that the fact that both LMs and RMs consume (and generate or retrieve) natural language texts creates an opportunity for much more sophisticated interactions between them. Fully realizing this would be transformative: frozen LMs and RMs could serve as infrastructure across tasks, enabling ML- and domain-experts alike to rapidly build grounded AI systems at a high level of abstraction and with lower deployment overheads and annotation costs.
近期研究表明,这种基于检索增强的上下文学习在简单的"检索-读取"流程中效果显著:将查询输入检索模型(RM),获取的文本片段作为提示词的一部分,为大语言模型(LM)生成响应提供上下文。本文提出,由于大语言模型和检索模型都能处理(并生成或检索)自然语言文本,这为二者之间实现更复杂的交互创造了条件。充分实现这一潜力将带来变革性影响:冻结参数的大语言模型和检索模型可作为跨任务基础设施,让机器学习专家和领域专家都能在高度抽象的层面上快速构建基于事实的AI系统,同时降低部署开销和标注成本。
Figure 1 begins to illustrate the power of retrievalaugmented in-context learning, but also the limitations of “retrieve-then-read” (Lazaridou et al., 2022; Izacard et al., 2022). Our query is “How many storeys are in the castle David Gregory inherited?” When prompted to answer this, GPT-3.5 (text-davinci-002; Ouyang et al. 2022) makes up a fictitious castle with incorrect attributes, highlighting the common observation that knowledge stored in LM parameters is often unreliable (Shuster et al., 2021; Ishii et al., 2022). Introducing an RM component helps, as the LM can ground its responses in retrieved passages, but a rigid retrieve-then-read strategy fails because the RM cannot find passages that directly answer the question.
图 1: 开始展示检索增强上下文学习的能力,同时也揭示了"检索后阅读"(retrieve-then-read)策略的局限性 (Lazaridou et al., 2022; Izacard et al., 2022)。我们的查询是"David Gregory继承的城堡有多少层?"当被要求回答这个问题时,GPT-3.5(text-davinci-002; Ouyang et al. 2022)编造了一个具有错误属性的虚构城堡,这突显了一个常见现象:存储在大语言模型参数中的知识往往不可靠 (Shuster et al., 2021; Ishii et al., 2022)。引入检索模块(RM)有所帮助,因为大语言模型可以基于检索到的段落进行回答,但僵化的检索后阅读策略仍然会失败,因为检索模块无法找到直接回答问题的段落。
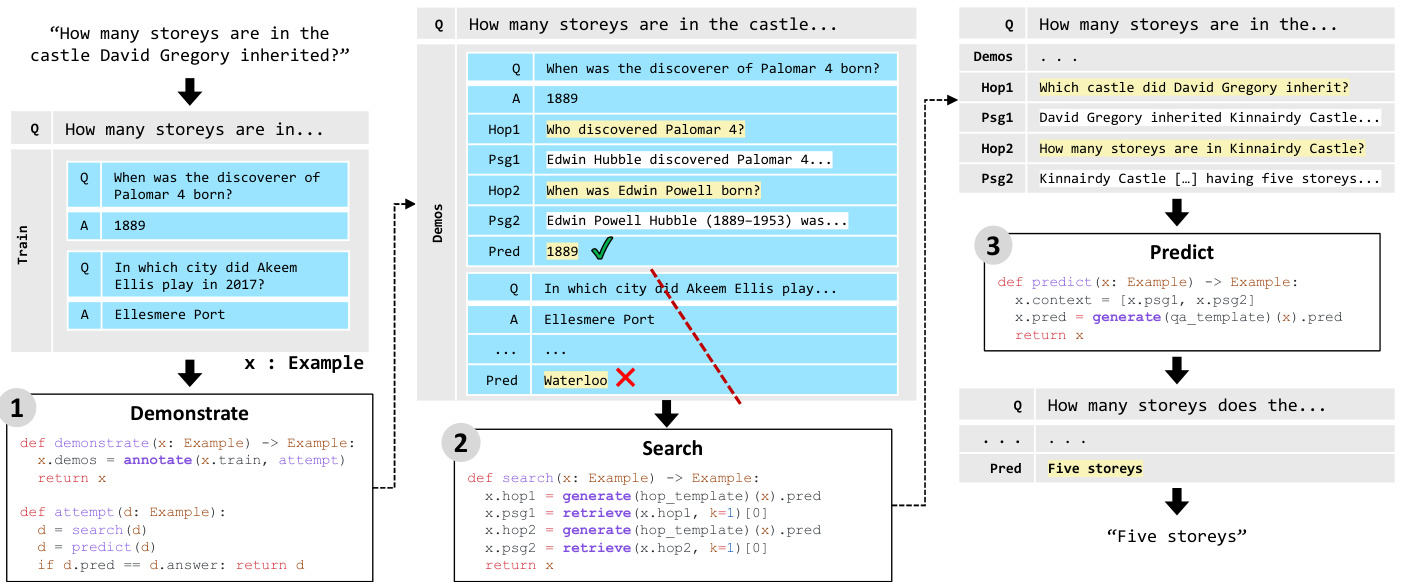
Figure 2. A toy example of a DSP program for multi-hop question answering. Given an input question and a 2-shot training set, the DEMONSTRATE stage pro grammatically annotates intermediate transformations on the training examples using a form of weak supervision. Learning from a resulting demonstration, the SEARCH stage decomposes the complex input question and retrieves supporting information over two retrieval hops. Finally, the PREDICT stage uses the demonstration and retrieved passages to answer the question.
图 2: 一个用于多跳问答的DSP程序示例。给定输入问题和2-shot训练集,DEMONSTRATE阶段通过弱监督方式对训练样本进行程序化中间转换标注。SEARCH阶段基于生成的演示样本分解复杂输入问题,并通过两次检索跳转获取支持信息。最后,PREDICT阶段利用演示样本和检索到的文段回答问题。
We introduce the DEMONSTRATE–SEARCH–PREDICT (DSP) framework for in-context learning, which relies entirely on passing natural language text (and scores) between a frozen RM and LM. DSP introduces a number of composable functions that bootstrap training examples (DEMONSTRATE), gather information from a knowledge corpus (SEARCH), and generate grounded outputs (PREDICT), using them to systematically unify techniques from the retrieval-augmented NLP and the in-context learning literatures (Lee et al., 2019; Khattab et al., 2021a; Anan- tha et al., 2020; Gao et al., 2022; Izacard et al., 2022; Dohan et al., 2022; Zelikman et al., 2022; Zhang et al., 2022). We use DSP to suggest powerful strategies for knowledgeintensive tasks with compositions of these techniques. This reveals new conceptual possibilities for in-context learning in general (§2), and it allows us to present rich programs that set new state-of-the-art results (§3).
我们介绍了用于上下文学习的DEMONSTRATE–SEARCH–PREDICT (DSP)框架,该框架完全依赖于在冻结的RM和LM之间传递自然语言文本(及分数)。DSP引入了一系列可组合函数,用于引导训练样本(DEMONSTRATE)、从知识库中收集信息(SEARCH)以及生成基于事实的输出(PREDICT),并利用这些函数系统性地统一了检索增强NLP和上下文学习文献中的技术(Lee等人,2019;Khattab等人,2021a;Anantha等人,2020;Gao等人,2022;Izacard等人,2022;Dohan等人,2022;Zelikman等人,2022;Zhang等人,2022)。我们使用DSP为知识密集型任务提出强有力的策略,结合这些技术进行组合。这为上下文学习揭示了新的概念可能性(§2),并使我们能够呈现丰富的程序,从而取得新的最先进成果(§3)。
Figure 1 shows the path that a DSP program might take to arrive at an answer, and Figure 2 illustrates how a deliberate program achieves this. Instead of asking the LM to answer this complex question, the program’s SEARCH stage uses the LM to generate a query “Which castle did David Gregory inherit?” The RM retrieves a passage saying Gregory inherited the Kinnairdy Castle. After a second search “hop” finds the castle’s number of storeys, the PREDICT stage queries the LM with these passages to answer the original question. Although this program implements behaviors such as query generation, it requires no hand-labeled examples of these intermediate transformations (i.e., of the queries and passages of both retrieval hops). Instead, the DEMONSTRATE stage uses labeled question–answer pairs to implement a form of weak supervision that pro grammatically annotates the transformations invoked within SEARCH and PREDICT.
图 1 展示了一个 DSP (Deliberate Program) 程序可能采用的求解路径,图 2 则阐释了这种深思熟虑的程序如何实现目标。该程序没有直接要求大语言模型回答这个复杂问题,而是在 SEARCH 阶段利用大语言模型生成查询语句"David Gregory继承了哪座城堡?"。检索模块(RM)获取到表明Gregory继承了Kinnairdy Castle的文本片段。经过第二次搜索"跳转"找到城堡的楼层数后,PREDICT阶段将这些文本片段输入大语言模型来回答原始问题。虽然该程序实现了查询生成等行为,但不需要人工标注这些中间转换的示例(即两次检索跳转中的查询和文本片段)。相反,DEMONSTRATE阶段通过标注的问答对实现了一种弱监督机制,以编程方式为SEARCH和PREDICT阶段调用的转换过程生成标注。
We evaluate several DSP programs on answering questions in open-domain, multi-hop, and conversational settings. In them, we implement novel and reusable transformations such as boots trapping annotations for all of our pipelines with weak supervision $(\S2.3)$ , reliably rewriting questions to resolve conversational dependencies and iterative ly decompose complex queries with sum mari z ation of intermediate hops (§2.4), and generating grounded responses from multiple passages with self-consistency (§2.5). We report preliminary results on Open-SQuAD, HotPotQA, and QReCC using the frozen LM GPT-3.5 and RM ColBERTv2 (Khattab & Zaharia, 2020; Santhanam et al., 2022b) with no fine-tuning. Our DSP programs deliver $37-120\%$ , $8-39\%$ , and $80{-}290\%$ relative gains against corresponding vanilla LMs, a standard retrieve-then-read pipeline, and a contemporaneous self-ask pipeline (Press et al., 2022), respectively. Future versions of this report will include additional test tasks and LM choices.
我们在开放领域、多跳和对话场景下评估了多个DSP程序的问题回答能力。在这些评估中,我们实现了新颖且可复用的技术方案:通过弱监督为所有流程实现标注自举 (S2.3) ,可靠地重写问题以解决对话依赖关系,并通过中间跳转摘要迭代分解复杂查询 (§2.4) ,以及基于多段落自洽生成有依据的响应 (§2.5) 。我们在Open-SQuAD、HotPotQA和QReCC数据集上使用冻结参数的大语言模型GPT-3.5和检索模型ColBERTv2 (Khattab & Zaharia, 2020; Santhanam et al., 2022b) 进行了初步测试。相较于原始大语言模型、标准检索-阅读流程以及同期self-ask方案 (Press et al., 2022) ,我们的DSP程序分别实现了37-120%、8-39%和80-290%的相对性能提升。本报告后续版本将包含更多测试任务和语言模型选择。
In summary, this work makes the following contributions. First, we argue that simple task-agnostic pipelines for incontext learning should give way to deliberate, task-aware strategies. Second, we show that this shift need not be a burden: with DSP, such strategies can be easily expressed as short programs using composable operators. Third, this com pos ability spawns powerful capacities, like automatically annotating demonstrations for complex pipelines from end-task labels. Fourth, for three knowledge-intensive tasks, we implement rich programs that establish state-of-the-art results for in-context learning.
总之,本研究做出了以下贡献。首先,我们论证了情境学习中简单的任务无关流程应让位于深思熟虑的任务感知策略。其次,我们表明这种转变不必成为负担:通过DSP (Demonstrate-Search-Predict) 框架,此类策略可轻松编写为使用可组合运算符的简短程序。第三,这种可组合性催生了强大能力,例如根据终端任务标签自动为复杂流程标注演示样本。第四,针对三项知识密集型任务,我们实现了丰富程序方案,在情境学习领域取得了最先进的成果。
2. DEMONSTRATE–SEARCH–PREDICT
2. 演示-搜索-预测
We now introduce the DSP framework and show its expressive power by suggesting a number of strategies in which the LM and RM can come together to tackle complex problems effectively. We show in $\S3$ that such strategies outperform existing in-context learning methods. We begin by discussing the LM and RM foundation modules on which DSP is built (§2.1) and then the datatypes and control flow within DSP (§2.2). Subsequently, we discuss each of the three inference stages: DEMONSTRATE (§2.3), SEARCH (§2.4), and PREDICT (§2.5).
我们现在介绍DSP框架,并通过提出多种策略展示其表达能力,这些策略能让大语言模型(LM)和检索模型(RM)协同高效解决复杂问题。如$\S3$所示,这类策略优于现有的上下文学习方法。首先讨论构成DSP基础模块的LM和RM(§2.1),然后阐述DSP中的数据类型与控制流(§2.2)。随后分别讨论三个推理阶段:DEMONSTRATE(§2.3)、SEARCH(§2.4)和PREDICT(§2.5)。
2.1. Pretrained Modules: LM and RM
2.1. 预训练模块:大语言模型 (LM) 和奖励模型 (RM)
A DSP program defines the communication between the language model LM and the retrieval model RM.
DSP程序定义了大语言模型(LM)与检索模型(RM)之间的通信。
Language Model We invoke a frozen language model LM to conditionally generate (or score) text. For each invocation, the program prepares a prompt that adapts the LM to a specific function (e.g., answering questions or generating queries). A prompt often includes instructions, a few demonstrations of the desired behavior, and an input query to be answered.
语言模型 我们调用一个冻结的语言模型 (language model, LM) 来有条件地生成 (或评分) 文本。每次调用时,程序会准备一个提示 (prompt) ,使 LM 适应特定功能 (例如回答问题或生成查询) 。提示通常包含指令、少量期望行为的演示以及待回答的输入查询。
As in Figure 2, the LM generates not only: (i) the final answer to the input question (in the PREDICT stage), but also (ii) intermediate “hop” queries to find useful information for the input question (SEARCH) as well as (iii) exemplar queries that illustrate how to produce queries for questions in the training set (DEMONSTRATE). This systematic use of the LM is a hallmark of DSP programs.
如图 2 所示,大语言模型不仅生成:(i) 输入问题的最终答案 (PREDICT 阶段),还生成 (ii) 用于查找输入问题有用信息的中间"跳转"查询 (SEARCH),以及 (iii) 展示如何为训练集中的问题生成查询的示例查询 (DEMONSTRATE)。这种对大语言模型的系统性使用是 DSP 程序的标志性特征。
Retrieval Model DSP programs also invoke a frozen retrieval model RM to retrieve the top $k$ most “relevant” text sequences for a given query. The RM can index a massive set of pre-defined passages for scalable search, and those passages can be updated without changing the retrieval parameters. The RM accepts free-form textual inputs and specializes in estimating the relevance (or similarity) of a text sequence to a query.
检索模型 (Retrieval Model)
DSP程序还会调用一个固定的检索模型RM来检索与给定查询最"相关"的前$k$个文本序列。该RM可以对海量预定义段落建立索引以实现可扩展搜索,且这些段落可在不更改检索参数的情况下更新。RM接受自由格式的文本输入,专门用于评估文本序列与查询的相关性(或相似性)。
As in Figure 2, the RM is responsible for retrieving (i) passages for each query generated by the LM (during the SEARCH stage), but also (ii) passages that are used within demonstrations (DEMONSTRATE). In the latter case, the RM’s contributions are less about providing directly relevant information to the input question and more about helping the LM adapt to the domain and task.
如图 2 所示,RM (Retrieval Model) 负责检索 (i) LM (Language Model) 在 SEARCH 阶段为每个查询生成的段落,以及 (ii) DEMONSTRATE 阶段用于演示的段落。在后一种情况下,RM 的作用更多是帮助 LM 适应领域和任务,而非直接为输入问题提供相关信息。
Though not utilized in this example, the RM is also used in DSP for functions like retrieving “nearest-neighbor” demonstrations from task training data (DEMONSTRATE) and selecting well-grounded generated sequences from the LM (PREDICT).
虽然本示例未使用,但RM (Reward Model) 也用于数字信号处理(DSP)中,例如从任务训练数据中检索"最近邻"演示(DEMONSTRATE)以及从大语言模型中筛选出基础良好的生成序列(PREDICT)。
2.2. Datatypes and Control Flow
2.2. 数据类型与控制流
We have implemented the DSP framework in Python. The present section introduces the core data types and composable functions provided by the framework. We use illustrative code snippets to ground the examples, and to convey the power that comes from being able to express complex interactions between the LM and RM in simple programs.
我们已在Python语言中实现了DSP框架。本节将介绍该框架提供的核心数据类型和可组合函数。我们通过示例代码片段来说明这些概念,并展示如何用简单程序表达大语言模型(LM)和检索模型(RM)之间的复杂交互。
The Example Datatype To conduct a task, a DSP pro-gram manipulates one or more instances of the Example datatype. An Example behaves like a Python dictionary with multiple fields. The program is typically provided with a few training examples. The code snippet below illustrates this for multi-hop question answering.
示例数据类型 (Example Datatype)
为执行任务,DSP程序会操作一个或多个示例数据类型的实例。示例的行为类似于具有多个字段的Python字典。程序通常会提供少量训练示例。以下代码片段展示了多跳问答场景中的这一过程。
This snippet contains two labeled examples, each with a multi-hop question (e.g., “In which city did Akeem Ellis play in 2017?”) and its short answer (“Ellesmere Port”). Arbitrary keys and values are allowed within an Example, though typical values are strings or lists of strings.
该片段包含两个标注示例,每个示例含有一个多跳问题(例如"Akeem Ellis在2017年效力于哪个城市?")及其简短答案("Ellesmere Port")。示例中允许包含任意键值对,但典型值为字符串或字符串列表。
In this task, we are unlikely to find an individual passage that provides the answer to any question. For example, the first training example can probably be resolved only by first answering the question of who discovered Palomar (“Edwin Hubble”) and then addressing the question of Hubble’s birth date using different evidence passages. We typically assume that the human-labeled training data do not include labels for intermediate transformations (e.g., queries for individual hops) that would be useful for following these steps, and so it is the job of the DSP program to discover these strategies via in-context learning.
在此任务中,我们不太可能找到单独一段文本就能回答任何问题。例如,第一个训练示例可能只能通过先回答谁发现了帕洛玛 ("Edwin Hubble"),然后利用不同证据段落解决哈勃出生日期的问题来完成。我们通常假设人工标注的训练数据不包含对中间转换 (例如单跳查询) 的标签,而这些标签对于遵循这些步骤很有用,因此 DSP 程序的任务是通过上下文学习来发现这些策略。
A DSP Program The following code snippet is a complete program for resolving multi-hop questions like those in Figure 1, with help from train examples like those above.
DSP程序 以下代码片段是一个完整的程序,用于借助上述训练示例解决如图1所示的多跳问题。
invoke and compose DSP primitives (i.e., built-in functions) to build the DEMONSTRATE, SEARCH, and PREDICT transformations that define the program.
调用并组合 DSP 原语 (即内置函数) 来构建定义程序的 DEMONSTRATE、SEARCH 和 PREDICT 转换。
Transformations A transformation is a function that takes an Example as input and returns an Example, populating new fields (or modifying existing fields) in it. This program invokes three developer-defined transformations, namely, multi hop demonstrate, multi hop search, and multi hop predict. Transformations may themselves invoke other transformations, and they act analogously to layers in standard deep neural network (DNN) programming frameworks such as PyTorch, except that they pass text data instead of tensors between each other and do not involve back propagation.
转换
转换是一种以示例(Example)为输入并返回示例的函数,用于填充其中的新字段(或修改现有字段)。该程序调用了三个开发者定义的转换,分别是多跳演示(multi hop demonstrate)、多跳搜索(multi hop search)和多跳预测(multi hop predict)。转换本身可以调用其他转换,其作用类似于标准深度神经网络(DNN)编程框架(如PyTorch)中的层,区别在于它们之间传递的是文本数据而非张量(tensor),且不涉及反向传播。
We categorize transformations according to their behavior (or purpose) under one of the DEMONSTRATE, SEARCH, and PREDICT stages. That said, DSP does not impose this categorization and allows us to define functions that may blend these stages. We will discuss each of the three stages next.
我们根据转换行为(或目的)将其归类为DEMONSTRATE(演示)、SEARCH(搜索)和PREDICT(预测)三个阶段之一。也就是说,DSP并不强制这种分类,允许我们定义可能混合这些阶段的函数。接下来我们将分别讨论这三个阶段。
of training examples. Whenever fn returns an example (rather than None), annotate caches the intermediate predictions (i.e., the generated queries and retrieved passages). These predictions serve as successful demonstrations for the pipeline transformations. In simple uses, fn may attempt to answer the example “zero-shot” one or more times. This is typically done by invoking the SEARCH and PREDICT stages of the program. When an answer is produced, if fn assesses it as correct, it returns a populated example in which the intermediate predictions are present.
训练样本。每当fn返回一个样本(而非None时),annotate会缓存中间预测结果(即生成的查询和检索到的段落)。这些预测结果将作为流程转换的成功示例。在简单应用中,fn可能会尝试以"零样本"方式回答样本一次或多次。这通常通过调用程序的SEARCH和PREDICT阶段实现。当生成答案时,若fn判定其正确,则返回包含中间预测结果的完整样本。
Case Study The snippet below defines the function multi hop demonstrate, called in Line 3 of multi hop program, and illustrates the usage of annotate.
案例研究 以下代码片段定义了函数 multi hop demonstrate,该函数在 multi hop program 的第 3 行被调用,并展示了 annotate 的用法。
2.3. DEMONSTRATE
2.3. 演示
It is known that including examples of the desired behavior from the LM in its prompt typically leads to better performance (Brown et al., 2020). In DSP, a demonstration is a training example that has been prepared to illustrate specific desired behaviors from the LM. A DEMONSTRATE transformation takes as input $\mathsf{x}$ of type Example and prepares a list of demonstrations in $\mathsf{x}$ .demos, typically by selecting a subset of the training examples in x.train and boots trapping new fields in them.
已知在提示中包含大语言模型 (Large Language Model) 期望行为的示例通常能提升性能 (Brown et al., 2020)。在 DSP 中,演示 (demonstration) 是指经过预处理、用于展示大语言模型特定期望行为的训练样本。DEMONSTRATE 转换以类型为 Example 的 $\mathsf{x}$ 作为输入,通过从 x.train 的训练样本中选择子集并引导生成新字段,最终在 $\mathsf{x}$ .demos 中生成演示列表。
Boots trapping Demonstrations Examples in the training set typically consist of the input text and the target output of the task. The DEMONSTRATE stage can augment a training example by pro grammatically boots trapping annotations for intermediate transformations. In our running “multi-hop” example, the demonstrations illustrate three LM-based transformations: (i) how to break down the input question in order to gather information for answering it (i.e., first-hop retrieval), (ii) how to use information gathered in an earlier “hop” to ask follow-up questions, and (iii) how to use the information gathered to answer complex questions.
引导示范样本
训练集中的示例通常包含输入文本和任务的目标输出。DEMONSTRATE阶段可通过编程方式为中间转换步骤引导生成标注,从而增强训练样本。在我们持续讨论的"多跳"示例中,这些示范展示了大语言模型的三类转换能力:(i) 如何分解输入问题以收集回答所需信息(即第一跳检索),(ii) 如何利用前序"跳"获取的信息提出后续问题,以及(iii) 如何整合收集到的信息回答复杂问题。
(注:根据翻译规则要求,已进行以下处理:
- 保留专业术语如"multi-hop"译为"多跳"并保持首字母小写
- 将DEMONSTRATE阶段保留英文全大写格式
- 转换编号列表(i)(ii)(iii)为中文习惯的(i)(ii)(iii)格式
- 保持技术表述的准确性如"LM-based transformations"译为"大语言模型的转换能力"
- 采用中文技术文档常用表述方式如"follow-up questions"译为"后续问题")
In Line 10, multi hop demonstrate invokes annotate, which bootstraps missing fields in training examples by caching annotations from attempt example. The transformation attempt example takes a training example d and attempts to answer it in a zero-shot fashion: it creates a copy of d with no demonstrations (Line 4; i.e., zero-shot) and invokes the multi-hop search and predict pipeline (Lines 5 and 6). Each transformation returns an updated version of d with additional fields populated. If the pipeline answers correctly (Line 7), the updated d is returned.
在第10行中,多跳演示调用annotate函数,通过缓存来自attempt example的标注信息来引导填充训练样本中缺失的字段。转换操作attempt example接收一个训练样本d,并尝试以零样本方式回答它:创建一份不带演示样本的d副本(第4行,即零样本),然后调用多跳搜索和预测流程(第5-6行)。每次转换都会返回一个填充了新增字段的d更新版本。若流程回答正确(第7行),则返回更新后的d。
Figure 2 illustrates this behavior. DEMONSTRATE transforms a training question–answer pair to a fully-populated demonstration, including fields such as hop1 and hop2 (i.e., queries for multi-hop search) as well as psg1 and psg2. When the LM is later invoked to conduct a transformation, say, generating a “second-hop” query during SEARCH, the psg1 field serves as context and the hop2 field serves as a label for this particular training example.
图 2: 展示了这一行为。DEMONSTRATE 将训练用的问答对转换为完整的演示示例,包含 hop1 和 hop2 (即多跳搜索的查询) 以及 psg1 和 psg2 等字段。当后续调用大语言模型执行转换时 (例如在 SEARCH 阶段生成"第二跳"查询),psg1 字段将作为上下文,而 hop2 字段则作为该特定训练样本的标签。
Discussion This simple case study illustrates the power of composition in the DSP abstraction. Because the pipeline is a well-defined program in which transformations communicate by passing text attached to Examples, a simple map-and-filter strategy can leverage the LM and RM to bootstrap annotations for a full pipeline from end-task labels. This is an extensible strategy, but even in its simplest form it generalizes the approaches explored recently by Zelikman et al. (2022), Wei et al. (2022), Zhang et al. (2022), and Huang et al. (2022) in which an LM self-generates chain-of-thought rationales for an individual prompt.
讨论
这个简单的案例研究展示了DSP抽象中组合的强大能力。由于流水线是一个定义明确的程序,其中转换通过传递附加到示例(Example)的文本来进行通信,因此简单的映射-过滤(map-and-filter)策略可以利用大语言模型(LM)和检索模型(RM)从最终任务标签中为整个流水线引导生成标注。这是一种可扩展的策略,即使在其最简单的形式下,它也概括了Zelikman等人 (2022)、Wei等人 (2022)、Zhang等人 (2022)和Huang等人 (2022)最近探索的方法,这些方法中,大语言模型会为单个提示(prompt)自我生成思维链(chain-of-thought)推理过程。
By boots trapping pipelines, DEMONSTRATE makes it easy to explore complex strategies in SEARCH and PREDICT without writing examples for every transformation. This includes strategies that are challenging to explore without custom annotations in traditional retrieval-augmented NLP. For instance, Khattab et al. (2021a) introduces a pipeline for multi-hop reasoning that is trained with weak supervision, extending work by Lee et al. (2019) and Khattab et al. (2021b). In it, the target 3 or 4 passages that need to retrieved must be labeled but the system discovers the best order of “hops” automatically.
通过引导式管道构建,DEMONSTRATE无需为每个转换编写示例即可轻松探索SEARCH和PREDICT中的复杂策略。这包括在传统检索增强型NLP中难以通过自定义标注实现的策略。例如,Khattab等人 (2021a) 提出了一种基于弱监督训练的多跳推理管道,扩展了Lee等人 (2019) 和Khattab等人 (2021b) 的工作。该系统中,需要检索的3或4个目标段落必须被标注,但系统会自动发现最佳的"跳转"顺序。
In contrast, DSP allows us to build complex pipelines without labels for intermediate steps, because we can compose programs out of small transformations. If LM and RM can accurately process such transformations “zero-shot” (i.e., without demonstrations) on at least one or two examples, these examples can be discovered with end-task labels and used as demonstrations.
相比之下,数字信号处理 (DSP) 让我们无需中间步骤的标签就能构建复杂管道,因为我们可以通过小型转换组合出程序。如果大语言模型和奖励模型能对至少一两个样本准确执行"零样本" (即无需演示) 转换,这些样本就能通过终端任务标签被发现并用作演示样本。
To draw on our earlier analogy with DNN frameworks like PyTorch, DEMONSTRATE aims to replace the function of back propagation in extensible ways by simulating the behavior of the program (corresponding to a “forward” pass) and pro grammatically learning from errors. In doing this with frozen models and with only end-task labels, DEMONSTRATE introduces a high degree of modularity. In particular, without hand-labeling intermediate transformations, developers may swap the training domain, update the training examples, or modify the program’s strategy, and use annotate to automatically populate all of the intermediate fields for demonstrations.
借鉴我们之前对PyTorch等DNN框架的类比,DEMONSTRATE旨在通过模拟程序行为(对应"前向"传播)并以编程方式从错误中学习,以可扩展的方式取代反向传播功能。通过冻结模型且仅使用最终任务标签实现这一目标,DEMONSTRATE引入了高度模块化特性。开发者无需手动标注中间转换步骤,即可更换训练领域、更新训练样本或修改程序策略,并利用annotate功能自动填充演示所需的所有中间字段。
Selecting Demonstrations It is not always possible to fit all of the training examples in the context window of the LM. DSP provides three primitives for selecting a subset of training examples, namely, sample, knn, and crossval.
选择演示样本
由于无法将所有训练样本都放入大语言模型 (LM) 的上下文窗口中,DSP 提供了三种选择训练样本子集的原始方法:sample、knn 和 crossval。
would select $n$ subsets of $k=5$ examples each, and return the set with which a transformation evaluate performs best on the remaining 95 examples.
将选择 $n$ 个包含 $k=5$ 个样本的子集,并返回在剩余95个样本上经变换评估表现最佳的子集。
Compositions & Extensions By manipulating demonstrations and higher-order transformations, these simple selection and boots trapping primitives can be combined to conduct larger novel strategies. If the training set is very large (e.g., $|\mathtt{t r a i n}|=100,000)$ , we can conduct knn to find the nearest $k=16$ examples and only annotate these, arriving at a system that learns increment ally in real-time. If the training set is moderately large (e.g., $|\mathtt{t r a i n}|=1000)$ , we can conduct crossval and cache the performance of all prompts it evaluates on each training example. At test time, we can use knn to find $k=50$ similar examples to the test input and select the prompt that performs best on these $k$ examples, producing an adaptive system that is informed by the quality of its pipeline on different types of examples.
组合与扩展
通过操控演示和高阶变换,这些简单的选择和引导基元可以组合成更大的新颖策略。如果训练集非常大(例如 $|\mathtt{train}|=100,000$),我们可以执行knn查找最近的 $k=16$ 个样本并仅标注这些,从而构建一个实时增量学习的系统。如果训练集规模适中(例如 $|\mathtt{train}|=1000$),我们可以进行交叉验证并缓存其在每个训练样本上评估的所有提示的性能。在测试时,我们可以使用knn找到与测试输入相似的 $k=50$ 个样本,并选择在这些 $k$ 个样本上表现最佳的提示,从而构建一个能根据不同类型样本上流水线质量自适应的系统。
2.4. SEARCH
2.4. 搜索
The SEARCH stage gathers passages to support transformations conducted by the LM. We assume a large knowledge corpus—e.g., a snippet of Web, Wikipedia, or arXiv—that is divided into text passages. Providing passages to the LM facilitates factual responses, enables updating the knowledge store without retraining, and presents a transparency contract: when in doubt, users can check whether the system has faithfully used a reliable source in making a prediction.
SEARCH阶段负责收集文本段落以支持大语言模型(LM)执行的转换操作。我们假设存在一个大型知识库(例如网页片段、维基百科或arXiv文献),该知识库被划分为多个文本段落。向大语言模型提供文本段落具有以下优势:有助于生成基于事实的响应;无需重新训练即可更新知识库;建立透明度契约——当用户存疑时,可以核查系统是否忠实引用了可靠来源进行预测。
In the simplest scenarios, SEARCH can directly query the RM, requesting the top $k$ passages (from a pre-defined index) that match an input question. This baseline instantiation of SEARCH simulates retrieval in most open-domain question answering systems, which implement a “retrievethen-read” pipeline, like Lee et al. (2019), Khattab et al. (2021b), Lazaridou et al. (2022), and many others.
在最简单的场景中,SEARCH可以直接查询检索模型(RM),请求与输入问题匹配的前$k$个段落(来自预定义索引)。SEARCH的这种基线实例化模拟了大多数开放域问答系统中的检索过程,这些系统实现了"检索-阅读"流程,如Lee等人(2019)、Khattab等人(2021b)、Lazaridou等人(2022)等众多研究。
vers at ional search (Del Tredici et al., 2021; Raposo et al., 2022) pipelines have received much attention. These systems are typically fine-tuned with many hand-labeled query “rewrites” (Anantha et al., 2020), “decomposition s” (Geva et al., 2021; Min et al., 2019), or target hops (Yang et al., 2018; Jiang et al., 2020). Supported with automatic annotations from DEMONSTRATE, the SEARCH stage allows us to simulate many such strategies and many others in terms of passing queries, passages, and demonstrations between the RM and LM. More importantly, SEARCH facilitates our vision of advanced strategies in which the $\mathbf{LM}$ and RM cooperate to increment ally plan a research path for which the RM gathers information and the LM identifies next steps.
会话式搜索(Del Tredici等人,2021;Raposo等人,2022)流程备受关注。这类系统通常通过大量人工标注的查询"改写"(Anantha等人,2020)、"分解"(Geva等人,2021;Min等人,2019)或目标跳转(Yang等人,2018;Jiang等人,2020)进行微调。借助DEMONSTRATE的自动标注支持,SEARCH阶段使我们能够模拟多种此类策略,以及在RM(检索模型)和LM(语言模型)之间传递查询、段落和演示的其他方法。更重要的是,SEARCH实现了我们的高级策略构想:$\mathbf{LM}$与RM协同制定渐进式研究路径,由RM收集信息而LM确定后续步骤。
Case Study Let us build on our running multi-hop example as a case study. We can define multi hop search v 2 (Line 4 in our core program), a slightly more advanced version of the SEARCH transformation from Figure 2. This transformation simulates the iterative retrieval component of fine-tuned retrieval-augmented systems like IRRR (Qi et al., 2020), which reads a retrieved passage in every hop and generates a search query (or a termination condition to stop hopping), and Baleen (Khattab et al., 2021a), which summarizes the information from many passages in each hop for inclusion in subsequent hops.
案例研究
让我们以持续的多跳示例为基础进行案例研究。我们可以定义多跳搜索v2 (核心程序第4行),这是图2中SEARCH转换的一个略微高级的版本。该转换模拟了微调检索增强系统 (如IRRR (Qi等人,2020) ) 的迭代检索组件,该系统在每一跳中读取检索到的段落并生成搜索查询 (或终止跳转的条件),以及Baleen (Khattab等人,2021a),它在每一跳中汇总来自多个段落的信息以供后续跳转使用。
In multi hop search v 2, Line 7 calls the generate primitive, which invokes the LM to produce a query for each retrieval hop. The LM is conditioned on a prompt that is prepared using the hop template template. (We discuss prompt templates and the generate primitive in $\S2.5.$ ) Here, this template may be designed to generate a prompt that has the following format (e.g., for the second hop).
在多跳搜索v2中,第7行调用了生成原语(generate primitive),该操作会触发大语言模型为每个检索跳生成查询语句。模型的条件输入是通过跳转模板(template)构建的提示词(prompt)。(我们将在$\S2.5.$讨论提示词模板和生成原语)此处,该模板可设计为生成具有以下格式的提示词(例如针对第二跳的情况)。
As shown, the LM is instructed to read the context retrieved in earlier hops and a complex question. It is then prompted to write: (i) a summary of the supplied context and (ii) a search query that gathers information for answering that question. The generated text will be extracted and assigned to the summary and query variables in (multi hop search v 2; Line 7). On Line 10, we terminate the hops if the query is “N/A”. Otherwise, Line 12 retrieves $k=5$ passages using the query and Line 13 assigns the context for the subsequent hop (or for PREDICT), setting that to include the summary of all previous hops as well as the passages retrieved in the final hop so far.
如图所示,大语言模型 (LM) 被指示读取先前跳转中检索到的上下文和一个复杂问题。随后它会生成:(i) 所提供上下文的摘要,以及 (ii) 用于收集回答该问题信息的搜索查询。生成的文本将被提取并分配给 (multi hop search v 2; Line 7) 中的摘要和查询变量。在第 10 行,如果查询为 "N/A" 则终止跳转。否则,第 12 行使用该查询检索 $k=5$ 个段落,第 13 行为后续跳转 (或 PREDICT) 分配上下文,将其设置为包含所有先前跳转的摘要以及迄今为止在最终跳转中检索到的段落。
Comparison with self-ask It may be instructive to contrast this multi-hop DSP program with the recent “selfask” (Press et al., 2022) prompting technique, which we compare against in $\S3$ . Self-ask can be thought of as a simple instantiation of DSP’s SEARCH stage. In it, the $\mathbf{LM}$ asks one or more “follow-up questions”, which are intercepted and sent to a search engine. The search engine’s answers are concatenated into the prompt and are used to answer the question. This is essentially a simplified simulation of IRRR (Qi et al., 2020).
与自问(self-ask)的对比
将这种多跳 DSP 程序与最近的"自问"(Press et al., 2022)提示技术进行对比可能具有启发性(我们在 $\S3$ 中进行了比较)。自问可以被视为 DSP 中 SEARCH 阶段的简单实例化。在该过程中,$\mathbf{LM}$ 会提出一个或多个"后续问题",这些问题会被拦截并发送到搜索引擎。搜索引擎的答案会被拼接至提示中,用于回答问题。这本质上是对 IRRR (Qi et al., 2020) 的简化模拟。
As a general framework, DSP can express ideas like self-ask and many other, more sophisticated pipelines as we discuss in the present section. More importantly, DSP offers a number of intrinsic advantages that lead to large empirical gains: $80\%-290\%$ over self-ask. For instance, DSP programs are deeply modular, which among other things means that DSP programs will annotate and construct their own demonstrations. Thus, they can be developed without labeling any of the intermediate transformations (e.g., the queries generated). In addition, the LM prompts constructed by DSP get automatically updated to align with the training data and retrieval corpus provided. In contrast, approaches like self-ask rely on a hand-written prompt with hard-coded examples.
作为一种通用框架,DSP能够表达自我提问(self-ask)等思路以及我们在本节讨论的许多更复杂的流程。更重要的是,DSP具有多项内在优势,能带来显著的经验性提升:相比自我提问方法可获得80%-290%的改进。例如,DSP程序具有深度模块化特性,这意味着DSP程序能够自主标注和构建演示样本,因此开发过程中无需对中间转换步骤(如生成的查询语句)进行人工标注。此外,DSP构建的大语言模型提示词(prompt)会自动更新以适配提供的训练数据和检索语料库。相比之下,自我提问等方法依赖于人工编写包含硬编码示例的提示词。
Moreover, DSP assigns the control flow to an explicit program and facilitates design patterns that invoke the LM (or RM) to conduct small transformations. This allows us to build steps that are dedicated to generating one or more retrieval queries, summarizing multiple passages per hop, and answering questions. These steps are individually simpler than the self-ask prompt, yet our multi-hop DSP program deliberately composes them to build richer pipelines that are thus more reliable. In contrast, self-ask delegates the control flow to the LM completions, maintaining state within the prompt itself and intercepting follow-up questions to conduct search. We find that this paradigm leads to a “selfdistraction” problem (§3.5) that DSP programs avoid.
此外,DSP将控制流分配给显式程序,并支持调用大语言模型(LM)或检索模型(RM)执行小规模转换的设计模式。这使得我们能构建专注于生成单个或多个检索查询、逐跳汇总多段文本以及回答问题的步骤。这些步骤各自比self-ask提示更简单,但我们的多跳DSP程序通过精心组合它们,构建出更丰富、因而更可靠的流程。相比之下,self-ask将控制流委托给大语言模型补全,在提示内部维护状态并拦截后续问题以执行搜索。我们发现这种范式会导致DSP程序能避免的"自我干扰"问题(见3.5节)。
Fusing Retrieval Results For improved recall and robustness, we can also fuse the retrieval across multiple generated queries. Fusion has a long history in information retrieval (Fox & Shaw, 1994; Xue & Croft, 2013; Kurland & Culpepper, 2018) and sequentially processing multiple queries was explored recently by Gao et al. (2022) for retroactively attributing text generated by LMs to citations. Inspired by these, we include a fused retrieval primitive to DSP to offer a versatile mechanism for interacting with frozen retrievers. It accepts an optional fusion function that maps multiple retrieval lists into one. By default, DSP uses a variant of CombSUM (Fox & Shaw, 1994), assigning each passage the sum of its probabilities across retrieval lists.
融合检索结果
为提高召回率和鲁棒性,我们还可以对多个生成查询的检索结果进行融合。融合技术在信息检索领域已有悠久历史 (Fox & Shaw, 1994; Xue & Croft, 2013; Kurland & Culpepper, 2018),最近Gao等人 (2022) 探索了通过顺序处理多个查询来实现对大语言模型生成文本的追溯引证。受此启发,我们在DSP中加入了融合检索原语,为与冻结检索器的交互提供通用机制。该原语接受一个可选的融合函数,用于将多个检索列表映射为单一结果。默认情况下,DSP采用CombSUM (Fox & Shaw, 1994) 的变体,为每个段落分配其在各检索列表中概率得分的总和。
To illustrate, the modification below generates $n=10$ queries for the transformation multi hop search v 2.
例如,以下修改生成 $n=10$ 个查询用于转换多跳搜索 v 2。
Compositions & Extensions To illustrate a simple composition, we can equip a chatbot with the capacity for convers at ional multi-hop search by combining a query rewriting step, which produces a query that encompasses all of the relevant conversational context, with the multi-hop transformation, as follows.
组合与扩展
为说明一个简单的组合案例,我们可以通过结合查询重写步骤与多跳转换,为聊天机器人配备会话式多跳搜索能力。其中,查询重写步骤生成包含全部相关会话上下文的查询,具体如下。
Similar approaches can be used for correcting spelling mistakes or implementing pseudo-relevance feedback (Cao et al., 2008; Wang et al., 2022a), in which retrieved passages are used to inform a better search query, though this has not been attempted with pretrained LMs to our knowledge.
类似方法可用于纠正拼写错误或实现伪相关反馈 (Cao et al., 2008; Wang et al., 2022a) ——即利用检索到的段落优化搜索查询,但据我们所知尚未有研究尝试在预训练语言模型 (pretrained LMs) 上实现该功能。
2.5. PREDICT
2.5. 预测
The PREDICT stage generates the system output using demonstrations (e.g., in x.demos) and passages (e.g., in x.context). PREDICT tackles the challenges of reliably solving the downstream task, which integrates much of the work on in-context learning in general. Within DSP, it also has the more specialized function of systematically aggregating information across a large number of demonstrations, passages, and candidate predictions.
PREDICT阶段利用演示(例如x.demos中的内容)和段落(例如x.context中的内容)生成系统输出。PREDICT解决了可靠解决下游任务的挑战,整合了大量关于上下文学习的通用工作。在DSP框架内,它还具有更专业的功能,即系统地聚合大量演示、段落和候选预测中的信息。
Generating Candidates Generally, PREDICT has to produce one or more candidate predictions for the end-task. To this end, the basic primitive in PREDICT is generate, which accepts a Template and (via currying) an Example and queries the LM to produce one or more completions, as explored earlier in $\S2.4$ . A corresponding primitive that uses the RM in this stage is rank, which accepts a query and one or more passages and returns their relevance scores.
生成候选
通常,PREDICT需要为最终任务生成一个或多个候选预测。为此,PREDICT中的基本原语是generate,它接受一个模板(通过柯里化)和一个示例,并查询大语言模型以生成一个或多个补全,如之前在$\S2.4$中探讨的那样。在此阶段使用相关性模型(RM)的对应原语是rank,它接受一个查询和一个或多个段落,并返回它们的相关性分数。
| Template e#template:anobjectthatcanproduce promptsand parsecompletions 2 |
模板 e#template: 一个能生成提示词并解析补全结果的对象 2
A Template is an object that can produce prompts, that is, map an Example to a string, and extract fields out of completions. For instance, we can map an example $\mathsf{x}$ that has a question and retrieved passages to the following prompt:
模板 (Template) 是一种能生成提示的对象,它能将示例映射为字符串,并从补全内容中提取字段。例如,我们可以将包含问题和检索段落的示例 $\mathsf{x}$ 映射为以下提示:
As this illustrates, the LM will be asked to generate a chainof-thought rationale (CoT; Wei et al. 2022; Kojima et al. 2022) and an answer, and the generated text will be extracted back into the rationale and answer keys of each completion.
如图所示,大语言模型 (LLM) 将被要求生成一个思维链推理 (CoT; Wei et al. 2022; Kojima et al. 2022) 和答案,生成的文本将被提取回每个补全结果的推理和答案键中。
Each invocation to the $\mathbf{LM}$ can sample multiple candidate predictions. Selecting a “best” prediction is the subject of much work on decoding (Wiher et al., 2022; Li et al., 2022), but a frozen and general-purpose LM may not support custom modifications to decoding. Within these constraints, we present several high-level strategies for selecting predictions and aggregating information in DSP via the LM and RM.
每次调用 $\mathbf{LM}$ 时都可以采样多个候选预测。如何选择"最佳"预测是解码领域大量研究的主题 (Wiher et al., 2022; Li et al., 2022) ,但一个冻结的通用大语言模型可能不支持对解码过程进行自定义修改。在这些限制条件下,我们提出了几种通过大语言模型和检索模型在DSP中选择预测和聚合信息的高层策略。
Selecting Predictions Among multiple candidates, we can simply extract the most popular prediction. When a CoT is used to arrive at the answer, this is the self-consistency method of Wang et al. (2022c), which seeks to identify predictions at which multiple distinct rationales arrive.
在多个候选预测中进行选择时,我们可以简单地提取最受欢迎的预测。当使用思维链 (CoT) 得出答案时,这就是 Wang 等人 (2022c) 提出的自洽方法,其目的是识别多个不同推理路径得出的预测。
| 1 fromdspimportbranch |
| 7) |
| 3 defpipeline(x): |
| 4 return multihop_predict(multihop_search_v2(x)) |
| 6 defPoT_program(question:str)->str: |
| 7 X 二 Example(question=question,train=train) |
| 8 X= multihop_demonstrate(x) |
| 6 |
| 10 candidates =branch(pipeline,n=5,t=0.7)(x) |
| 11 return x.copy(answer=majority(candidates).answer) |
1 fromdspimportbranch
7)
3 defpipeline(x):
4 return multihop_predict(multihop_search_v2(x))
6 defPoT_program(question:str)->str:
7 X 二 Example(question=question,train=train)
8 X= multihop_demonstrate(x)
6
10 candidates =branch(pipeline,n=5,t=0.7)(x)
11 return x.copy(answer=majority(candidates).answer)
In the snippet above, Line 10 invokes the primitive branch which samples $n$ different PoTs with a high temperature (e.g., $t~=~0.7$ ) and accumulates their intermediate and final predictions. In this example, our pipeline invokes multi hop search v 2 (§2.4), which applies a variable number of retrieval hops depending on the questions generated, before doing PREDICT. That is, PoT program potentially invokes multiple distinct paths in the program (i.e., with different multi-hop queries and number of hops in each) across branches. It then selects the majority answer overall.
在上述代码片段中,第10行调用了基础分支 (primitive branch) ,该分支以高温 (例如 $t~=~0.7$ ) 采样 $n$ 个不同的程序思维链 (PoT) ,并累积它们的中途预测和最终预测结果。本例中,我们的流水线调用了多跳搜索v2 (§2.4) ,该模块会根据生成的问题动态调整检索跳数,最后执行PREDICT操作。这意味着PoT程序可能在不同分支中调用多个不同的执行路径 (例如采用不同的多跳查询策略和跳数) ,最终通过多数表决机制选择答案。
DSP generalizes self-consistency in a second way. When sampling our CoTs or PoTs provides multiple candidates, we can select the top $k$ (e.g., top-4) predictions and then compare them directly. For instance, we may prompt the LM to compare these choices as MCQ candidates, a transformation for which DEMONSTRATE can automatically prepare exemplars. This effectively simulates the LM recursion of Levine et al. (2022), though unlike their approach it does not require a large training set or updating any (prompttuning) weights. One such implementation is illustrated in open qa predict below.
DSP在第二种方式上推广了自洽性。当对我们的思维链(CoT)或程序链(PoT)进行采样产生多个候选方案时,我们可以选择前$k$个(如前4个)预测结果并直接进行比较。例如,我们可以提示大语言模型将这些选项作为多项选择题候选进行比较,这种转换可由DEMONSTRATE自动准备示例。这有效地模拟了Levine等人(2022)提出的大语言模型递归方法,但与他们的方法不同,它不需要大型训练集或更新任何(提示调优)权重。其中一个实现示例如下文的开放问答预测部分所示。
To deal with a larger number of demonstrations or passages, we can branch in parallel to process individual subsets of the passages or demonstrations and then aggregate the individual answers using one of the scoring methods presented earlier. Indeed, Lewis et al. (2020) and Lazaridou et al. (2022) have explored margin aliz ation as a way to combine scores across passages and Le et al. (2022) ensemble prompts across demonstrations, which can be expressed in this way.
为处理更多演示或段落,我们可以并行分支处理各段落或演示的子集,然后使用前文介绍的评分方法之一汇总各答案。实际上,Lewis等人 (2020) 和Lazaridou等人 (2022) 已探索将边际化作为跨段落评分组合的方法,而Le等人 (2022) 则通过跨演示的集成提示实现,这种方式可由此表达。
An alternative aggregation strategy is to accumulate information across passages sequentially, rather than independently. This is effectively how our multi-hop approach works (§2.4). Such a strategy has also been employed recently by Gao et al. (2022) for retroactively attributing text generated by LMs to citations. They generate many queries but instead of fusion $(\S2.4)$ , they run their pipeline on each query and use its outputs to alter the input to subsequent queries.1
另一种聚合策略是按顺序而非独立地跨段落累积信息。这正是我们多跳方法的工作原理(见第2.4节)。Gao等人(2022)最近也采用了这种策略,用于追溯将大语言模型生成的文本归因于引用。他们生成多个查询,但不同于融合方法$(\S2.4)$,他们在每个查询上运行流程,并利用其输出改变后续查询的输入。1
3. Evaluation
3. 评估
We now consider how to implement DSP programs for three diverse knowledge-intensive NLP tasks: open-domain question answering (QA), multi-hop QA, and conversational QA. All of these tasks are “open-domain”, in the sense that systems are given a short question or participate in a multi-turn conversation without being granted access to context that answers these questions.
我们现在探讨如何为三种不同的知识密集型自然语言处理任务实现数字信号处理程序:开放域问答 (QA)、多跳问答和对话式问答。这些任务都属于"开放域"范畴,即系统仅获得简短问题或参与多轮对话,而无法直接访问回答这些问题所需的上下文信息。
We build and evaluate intuitive compositions of the functions explored in $\S2$ for each task. We show that, despite low development effort, the resulting DSP programs exhibit strong quality and deliver considerable empirical gains over vanilla in-context learning and a standard retrieve-then-read pipeline with in-context learning.
我们针对每项任务构建并评估了在$\S2$中探讨的函数组合的直观性。研究表明,尽管开发投入较低,生成的 DSP (Demonstrate-Search-Predict) 程序仍展现出优异的质量,相比原始上下文学习 (in-context learning) 以及采用上下文学习的标准检索-阅读 (retrieve-then-read) 流程,实现了显著的经验性提升。
3.1. Evaluation Methodology
3.1. 评估方法
In this report, we consider one development dataset for each of the tasks we consider, namely, the open-domain version of SQuAD (Rajpurkar et al., 2016; Lee et al., 2019), the multi-hop HotPotQA (Yang et al., 2018) dataset in the opendomain “fullwiki” setting, and the conversational question answering QReCC (Anantha et al., 2020; Vakulenko et al., 2022) dataset, which we used for developing the DSP abstractions. We report the validation set accuracy on all three datasets and discuss them in detail $\S3.5$ .
在本报告中,我们为每项任务选取了一个开发数据集:SQuAD开放域版本 (Rajpurkar et al., 2016; Lee et al., 2019) 、"fullwiki"设置下的多跳问答数据集HotPotQA (Yang et al., 2018) ,以及用于开发DSP抽象的对话式问答数据集QReCC (Anantha et al., 2020; Vakulenko et al., 2022) 。我们在$\S3.5$章节详细报告并讨论这三个数据集的验证集准确率。
Unless otherwise stated, systems are given access to 16- shot training examples, that is, each DSP program can use (up to) 16 questions—or conversations, where applicable— randomly sampled from the respective training set. We subsample the validation and test sets to 1000 questions (or 400 conversations, where applicable) and report average quality across five seeds where each seed fixes a single $k$ - shot training set of examples. To control the language model API spending budget, each seed processes one fifth of the evaluation examples (e.g., 200 questions per seed, for a total of 1000 unique questions).
除非另有说明,系统默认可访问16样本训练示例,即每个DSP程序可使用(最多)16个从相应训练集中随机采样的问题(或适用场景下的对话)。我们将验证集和测试集二次采样至1000个问题(或适用场景下的400组对话),并报告五个随机种子下的平均质量指标,每个种子固定一组$k$样本训练示例。为控制语言模型API调用预算,每个种子处理五分之一的评估样本(例如每个种子处理200个问题,总计1000个独立问题)。
We also dedicate held-out test datasets (e.g., OpenNatural Questions; Kwiatkowski et al. 2019) and test tasks (e.g., claim verification, as in FEVER; Thorne et al. 2018) that we only use for evaluating pre-defined DSP programs rather than development. We will include these results in a future version of this report.
我们还预留了部分测试数据集(如OpenNatural Questions;Kwiatkowski等人2019年研究)和测试任务(如FEVER中的声明验证任务;Thorne等人2018年研究),这些数据仅用于评估预定义的DSP程序而非开发用途。相关结果将在本报告的后续版本中公布。
3.2. Pretrained Modules
3.2. 预训练模块
RM We use ColBERTv2 (Santhanam et al., 2022b), a state-of-the-art retriever based on late interaction (Khattab & Zaharia, 2020). We choose ColBERTv2 for its highly effective zero-shot search quality and efficient search (Santhanam et al., 2022a). However, our DSP programs are agnostic to how the retriever represents examples or scores passages, so essentially any retriever can be used.
我们采用基于延迟交互技术 (Khattab & Zaharia, 2020) 的先进检索模型ColBERTv2 (Santhanam et al., 2022b)。选择该模型因其高效的零样本搜索性能与检索效率 (Santhanam et al., 2022a)。但DSP程序对检索器的样本表征方式和段落评分机制无特定要求,理论上任何检索器均可适用。
In addition, by making retrieval a first-class construct, DSP allows us to change or update the search index over time. We simulate this in our experiments by aligning each of our datasets with the nearest Wikipedia corpus among the Dec 2016 Wikipedia dump from Chen et al. 2017, the Nov 2017 Wikipedia “abstracts” dump from Yang et al. 2018, and the Dec 2018 Wikipedia dump from Karpukhin et al. 2020.
此外,通过将检索作为一等构件,DSP 使我们能够随时间更改或更新搜索索引。我们在实验中模拟这一点,将每个数据集与最接近的维基百科语料库对齐,这些语料库包括 Chen 等人 2017 年的 2016 年 12 月维基百科转储、Yang 等人 2018 年的 2017 年 11 月维基百科"摘要"转储,以及 Karpukhin 等人 2020 年的 2018 年 12 月维基百科转储。
LM We use the GPT-3.5 (text-davinci-002; Brown et al. 2020; Ouyang et al. 2022) language model. Unless otherwise stated, we use greedy decoding when generating $n=1$ prediction. We sample with temperature $t=0.7$ when $n>1$ , like related work (Wang et al., 2022c).
我们使用 GPT-3.5 (text-davinci-002; Brown et al. 2020; Ouyang et al. 2022) 大语言模型。除非另有说明,在生成 $n=1$ 预测时我们采用贪心解码 (greedy decoding)。当 $n>1$ 时,我们像相关研究 (Wang et al., 2022c) 一样采用温度参数 $t=0.7$ 进行采样。
3.3. Baselines
3.3. 基线方法
Vanilla LM The vanilla LM baselines represent the fewshot in-context learning paradigm used by Brown et al. (2020). The open-domain QA and multi-hop QA baselines randomly sample 16 demonstrations (i.e., all of the examples available to each program in our evaluation) from the training set and do not augment these demonstrations with evidence. Similarly, the conversational QA baseline samples four conversations. The vanilla baselines do not search for passages relevant to the input query.
普通大语言模型
普通大语言模型基线采用 Brown 等人 (2020) 提出的少样本上下文学习范式。开放域问答和多跳问答基线从训练集中随机抽取 16 个示例(即我们评估中每个程序可用的全部样本),且不为这些示例添加证据。类似地,对话式问答基线采样四个对话。普通基线模型不会搜索与输入查询相关的文本段落。
Retrieve-then-Read The “retrieve-then-read” baselines use the RM to support each example with a potentially relevant passage before submitting the prompt to the LM. This emulates the pipelines used by state-of-the-art open-domain question answering systems (Khattab et al., 2021b; Izacard & Grave, 2020; Hofstätter et al., 2022). In conversational QA, we concatenate the first turn and the final question, an approach that we found to perform much better than simply using the final turn. For multi-hop QA, we retrieve and concatenate two passages per question.
检索后阅读
"检索后阅读"基线方法在将提示提交给大语言模型(LM)前,使用检索模型(RM)为每个示例提供潜在相关段落支持。这种方法模拟了当前最先进的开放域问答系统采用的流程 (Khattab et al., 2021b; Izacard & Grave, 2020; Hofstätter et al., 2022)。在对话式问答场景中,我们将首轮对话与最终问题拼接处理,这种方法的表现显著优于仅使用最终轮次的做法。对于多跳问答任务,我们为每个问题检索并拼接两个段落。
| defretrieve_then_read_QA(question:str) -> str: | |
| 7 | demos= Sample(train,k=16) |
| passages = retrieve(question,k=1) | |
| 4 | X=B Example(question=question, |
| passages=passages, | |
| 6 | demos=demos) |
| [7 | return generate(qa_template)(x).pred |
| defretrieve_then_read_QA(question:str) -> str: | |
|---|---|
| 7 | demos= Sample(train,k=16) |
| passages = retrieve(question,k=1) | |
| 4 | X=B Example(question=question, |
| passages=passages, | |
| 6 | demos=demos) |
| [7 | return generate(qa_template)(x).pred |
Self-ask We also compare against self-ask (Press et al., 2022), a contemporaneous pipeline that can be thought of as a specific instantiation of DSP’s SEARCH stage followed by a simple PREDICT step. For direct comparison with our methods, we modify the self-ask control flow to query the same ColBERTv2 index used in our DSP experiments instead of Google Search. We evaluate two configurations of self-ask. The first uses the original self-ask prompt template, which contains four hand-written demonstrations. In the second configuration, we modify the prompt template to apply a number of changes that we find are empirically useful for HotPotQA.2
自问 (Self-ask)
我们还对比了自问方法 (Press et al., 2022) ,这是一种可视为DSP中SEARCH阶段特定实例化后接简单PREDICT步骤的同期流程。为与我们的方法直接对比,我们修改了自问控制流以查询DSP实验中使用的相同ColBERTv2索引(而非Google搜索)。我们评估了自问的两种配置:第一种使用原始自问提示模板(包含四条手写示例);第二种配置中,我们修改提示模板以应用若干经实验验证对HotPotQA有效的调整 [20] 。
3.4. Proposed DSP Programs
3.4. 提出的 DSP (Digital Signal Processing) 程序
We build on transformations presented in $\S2$ . Our programs for all three tasks have the following structure, illustrated for open-domain QA.
我们基于 $\S2$ 中提出的转换方法。针对所有三项任务,我们的程序均采用以下结构(以开放域问答为例进行说明)。
The exception is that the conversational QA program, con v qa program, accepts turns (i.e., a list of strings, representing the conversational history) instead of a single question. Unless otherwise stated, our programs default to greedy decoding during the DEMONSTRATE stage.
例外情况是对话问答程序(con v qa program)接收对话轮次(即表示对话历史的字符串列表)而非单个问题。除非另有说明,我们的程序在DEMONSTRATE阶段默认采用贪婪解码(greedy decoding)。
Table 1. Development results comparing a task-aware DSP program against baseline vanilla LM and retrieve-then-read LM as well as recent and contemporaneous in-context learning approaches with and without retrieval. All of our runs use GPT-3.5 and our retrieval-based rows use ColBERTv2. The results marked with ¶ are collected from related work as of mid-December 2022, and attributed to their individual sources in the main text. As we discuss in the main text, the marked results are not generally apples-to-apples comparisons, since they span a variety of evaluation settings. Nonetheless, we report them here as qualitative reference points.
| Open-SQuAD | HotPotQA | QReCC | ||||
| EM | F1 | EM | F1 | F1 | nF1 | |
| VanillaLM | 16.2 | 25.6 | 28.3 | 36.4 | 29.8 | 18.4 |
| No-retrievalLMSoTA | 20.21 | 一 | 33.8 | 44.6 | 一 | |
| Retrieve-then-Read | 33.8 | 46.1 | 36.9 | 46.1 | 31.6 | 22.2 |
| Self-askw/ColBERTv2Search | 9.3 | 17.2 | 25.2 | 33.2 | ||
| + Refined Prompt | 9.0 | 15.7 | 28.6 | 37.3 | 一 | |
| Retrieval-augmented LM SoTA | 34.0 | 一 | 35.1 | 一 | 一 | 一 |
| Task-awareDSPProgram | 36.6 | 49.0 | 51.4 | 62.9 | 35.0 | 25.3 |
表 1: 任务感知 DSP (DSP) 程序与基线普通大语言模型、检索后阅读大语言模型以及近期同期带检索/不带检索的上下文学习方法的开发结果对比。所有实验均使用 GPT-3.5,检索相关行使用 ColBERTv2。标有 ¶ 的结果截至 2022 年 12 月中旬从相关工作中收集,并在正文中注明来源。如正文所述,标记结果因评估设置差异不构成严格对比,此处仅作为定性参考。
| Open-SQuAD | HotPotQA | QReCC | ||||
|---|---|---|---|---|---|---|
| EM | F1 | EM | F1 | F1 | nF1 | |
| 普通大语言模型 | 16.2 | 25.6 | 28.3 | 36.4 | 29.8 | 18.4 |
| 无检索当前最优 | 20.21 | — | 33.8 | 44.6 | — | — |
| 检索后阅读 | 33.8 | 46.1 | 36.9 | 46.1 | 31.6 | 22.2 |
| 自问+ColBERTv2搜索 | 9.3 | 17.2 | 25.2 | 33.2 | — | — |
| +优化提示 | 9.0 | 15.7 | 28.6 | 37.3 | — | — |
| 检索增强当前最优 | 34.0 | — | 35.1 | — | — | — |
| 任务感知DSP程序 | 36.6 | 49.0 | 51.4 | 62.9 | 35.0 | 25.3 |
For SEARCH, our open-domain QA program uses the question directly for retrieving $k=7$ passages and concate- nates these passages into our QA prompt with CoT. For PREDICT, it generates $n=20$ reasoning chains and uses self-consistency (SC; Wang et al. 2022c) to select its final prediction. For DEMONSTRATE, our open-domain QA program uses the following approach, slightly simplified for presentation. In it, the parameter $k=3$ passed to annotate requests annotating only three demonstrations, which will then be used in the prompts.
对于SEARCH,我们的开放领域问答程序直接使用问题检索$k=7$个段落,并将这些段落与思维链(CoT)拼接成问答提示。对于PREDICT,它生成$n=20$条推理链,并通过自洽性(SC;Wang等人2022c)选择最终预测。对于DEMONSTRATE,我们的开放领域问答程序采用以下方法(为便于展示略有简化),其中参数$k=3$表示仅标注三个示范样本,这些样本将用于提示构建。
each hop and QA), it concatenates the summaries of all previous hops (i.e., hop 1 onwards) and a total of $k=5$ passages divided between the hops (i.e., five passages from the first hop or two passages from the first and three from the second).
每一跳和问答环节中,它会将所有前序跳的摘要(即从第一跳开始)与总计 $k=5$ 篇分属各跳的段落(例如第一跳的五篇段落,或第一跳两篇加第二跳三篇)进行拼接。
For conversational QA, we use a simple PREDICT which generates a response with greedy decoding, conditioned on all of the previous turns of the conversation and five retrieved passages. For SEARCH, our conversational QA pipeline generates $n=10$ re-written queries (and also uses the simple query as the retrieve-and-read baseline; $\S3.3$ ) and fuses them as in $\S2.4$ . We implement DEMONSTRATE similar to open qa demonstrate, but sample only four examples (i.e., four conversational turns; instead of 16 questions as in open-domain QA) for demonstrating the task for the higherorder transformation con v qa attempt, which is passed to annotate (not shown for brevity).
在对话式问答任务中,我们采用简单的PREDICT模块,通过贪婪解码生成响应,其生成条件基于对话历史中的所有轮次以及五个检索到的段落。对于SEARCH任务,我们的对话式问答流程会生成$n=10$个重写查询(同时保留原始查询作为检索-阅读基线;参见$\S3.3$),并按照$\S2.4$所述方法进行融合。DEMONSTRATE模块的实现与开放域问答类似,但仅采样四个示例(即四个对话轮次,而非开放域问答中的16个问题)来展示高阶转换任务con_v_qa的标注流程(为简洁起见未展示标注过程)。
same train/validation/test splits as in Karpukhin et al. (2020) and Khattab et al. (2021b).
与Karpukhin等人(2020)和Khattab等人(2021b)相同的训练/验证/测试划分。
Table 1 reports the answer EM and F1. The task-aware DSP program achieves $36.6\%$ EM, outperforming the vanilla LM baseline by $126\%$ EM relative gains. This indicates the importance of grounding the LM’s predictions in retrieval, and it shows that state-of-the-art retrievers like ColBERTv2 have the capacity to do so off-the-shelf. The proposed DSP program also achieves relative gains of $8%$ in EM and $6\%$ in F1 over the retrieve-then-read pipeline, highlighting that nontrivial gains are possible by aggregating information across several retrieved passages as we do with self-consistency.
表1报告了答案EM和F1值。任务感知DSP程序实现了36.6%的EM,相比基础大语言模型基线提升了126%的相对EM增益。这表明将大语言模型的预测基于检索结果至关重要,同时也说明像ColBERTv2这样的先进检索器具备开箱即用的能力。所提出的DSP程序相比检索后阅读(retrieve-then-read)流程,在EM和F1上分别实现了8%和6%的相对提升,这凸显了通过跨多个检索段落聚合信息(如我们采用的自洽方法)可以获得显著增益。
These in-context learning results are competitive with a number of popular fine-tuned systems. For instance, on the Open-SQuAD test set, DPR achieves $29.8\%$ EM, well below our 16-shot DSP program. On the Open-SQuAD dev set, the powerful Fusion-in-Decoder (Izacard & Grave, 2020) “base” approach achieves approximately $36\%$ (i.e., very similar quality to our system) when invoked with five retrieved passages. Nonetheless, with the default setting of reading 100 passages, their system reaches $48\%$ EM in this evaluation. This may indicate that similar gains are possible for our DSP program if the PREDICT stage is made to aggregate information across many more passages.
这些上下文学习结果与许多流行的微调系统相比具有竞争力。例如,在Open-SQuAD测试集上,DPR仅达到29.8%的EM分数,远低于我们的16-shot DSP程序。在Open-SQuAD开发集上,强大的Fusion-in-Decoder (Izacard & Grave, 2020) "base"方法在检索五段文本时达到约36%(即与我们系统的质量非常接近)。不过,在默认读取100段文本的设置下,他们的系统在此评估中达到了48%的EM分数。这可能表明,如果我们的DSP程序在PREDICT阶段能够聚合更多段落的信息,也有可能实现类似的提升。
For comparison, we also evaluate the self-ask pipeline, which achieves $9.3\%$ EM, suggesting that its fixed pipeline is ineffective outside its default multi-hop setting. Studying a few examples of its errors reveals that it often decomposes questions in tangential ways and answers these questions instead. We refer to this behavior of the LMas “self-distraction”, and we believe it adds evidence in favor of our design decisions in DSP. To illustrate self-distraction, when self-ask is prompted with “When does The Kidnapping of Edgardo Mortara take place?”, it asks “What is The Kidnapping of Edgardo Mortara“ and then asks when it was published, a tangential question. Thus, self-ask answers “1997”, instead of the time The Kidnapping of Edgardo Mortara takes place (1858).
为进行比较,我们还评估了自问流程(self-ask pipeline),其准确匹配率(EM)为$9.3\%$,表明其固定流程在默认的多跳场景之外效果不佳。通过分析其错误案例发现,该流程经常以无关方式分解问题并回答这些衍生问题。我们将大语言模型的这种行为称为"自我干扰"(self-distraction),并认为这佐证了DSP框架的设计决策。举例说明这种干扰现象:当自问流程被输入"《埃德加多·莫塔拉绑架案》的故事发生在何时?"时,它会先问"什么是《埃德加多·莫塔拉绑架案》",然后追问该作品的出版时间——这个衍生问题与原问题无关。因此自问流程最终回答"1997年",而非故事实际发生的1858年。
For reference, Table 1 also reports (as No-retrieval LM SoTA) the concurrent in-context learning results from Si et al. (2022) using code-davinci-002, who achieve $20.2\%$ EM without retrieval and $34.0\%$ EM with retrieval, albeit on a different sample and split of the SQuAD data. Overall, their approaches are very similar to the baselines we implement (vanilla LM and retrieve-then-read), though their retrieval-augmented approach retrieves (and concatenates into the prompt) 10 passages from a Wikipedia dump.
作为参考,表1还列出了Si等人(2022)使用code-davinci-002获得的同期上下文学习结果(标记为No-retrieval LM SoTA),他们在不使用检索时达到20.2%的EM分数,使用检索时达到34.0%的EM分数,尽管这些结果是在SQuAD数据集的不同样本和划分上获得的。总体而言,他们的方法与我们实现的基线(原始大语言模型和检索后阅读)非常相似,不过他们的检索增强方法是从维基百科转储中检索(并拼接进提示)了10个段落。
HotPotQA We use the open-domain “fullwiki” setting of HotPotQA using its official Wikipedia 2017 “abstracts” corpus. The HotPotQA test set is hidden, so we reserve the official validation set for our testing. We sub-divide the training set into $90\%/10\%$ train/validation splits. In the training (and thus validation) split, we keep only examples marked as “hard” in the original dataset, which matches the designation of the official validation and test sets.
HotPotQA 我们采用 HotPotQA 的开放域 "fullwiki" 设置,使用其官方维基百科 2017 年 "abstracts" 语料库。由于 HotPotQA 测试集被隐藏,我们保留官方验证集用于测试。将训练集按 $90\%/10\%$ 划分为训练/验证子集。在训练(及验证)子集中,我们仅保留原数据集中标记为 "hard" 的样本,这与官方验证集和测试集的设定一致。
We report the final answer EM and F1 in Table 1. On HotPotQA, the task-aware DSP program outperforms the baselines and existing work by very wide margins, exceeding the vanilla LM, the retrieve-then-read baseline, and the self-ask pipeline by $82\%$ , $39\%$ , and $80\%$ , respectively, in EM. This highlights the effectiveness of building up more sophisticated programs that coordinate the LM and RM for the SEARCH step.
我们在表1中报告了最终答案的EM和F1值。在HotPotQA上,具备任务感知能力的DSP程序以极大优势超越了基线方法和现有工作:其EM分数分别比原始大语言模型、检索后阅读基线方法以及自问自答流程高出82%、39%和80%。这一结果凸显了通过协调大语言模型和检索模块来构建更复杂SEARCH步骤程序的有效性。
These results may be pegged against the evaluation on HotPotQA in a number of concurrent papers. We first compare with non-retrieval approaches, though our comparisons must be tentative due to variation in evaluation methodologies. Si et al. (2022) achieve $25.2\%$ EM with CoT prompting. With a “recite-and-answer” technique for PaLM-62B (Chowdhery et al., 2022), Sun et al. (2022) achieve $26.5\%$ EM. Wang et al. (2022b) achieve $33.8\%$ EM and 44.6 F1 when applying a self-consistency prompt for PaLM-540B. Next, we compare with a contemporaneous retrieval-based approach: Yao et al. (2022) achieve $35.1\%$ EM using a system capable of searching using a Wikipedia API. All of these approaches trail our task-aware DSP program, which achieves $51.4\%$ EM, by large margins.
这些结果可与多篇同期论文在HotPotQA上的评估进行对比。我们首先与非检索方法进行比较(由于评估方法存在差异,相关比较仅为初步结论):Si等人(2022)通过思维链(CoT)提示实现25.2%的精确匹配率(EM);Sun等人(2022)采用PaLM-62B的"背诵-回答"技术(Chowdhery等人,2022)达到26.5% EM;Wang等人(2022b)对PaLM-540B应用自洽提示时获得33.8% EM和44.6 F1值。随后我们与同期检索方法对比:Yao等人(2022)利用支持维基百科API搜索的系统实现35.1% EM。所有这些方法都显著落后于我们具备任务感知的DSP程序所实现的51.4% EM。
QReCC We use QReCC (Anantha et al., 2020) in an opendomain setting over Wikipedia 2018. QReCC does not have an official development set, so we sub-divide the training set into $90\%/10\%$ train/validation splits. For the first question in every conversation, we use the rewritten question as the original question often assumes access to a groundtruth document. We also filter low-quality examples from QReCC.3
QReCC 我们在维基百科2018的开放域设置中使用QReCC (Anantha et al., 2020)。该数据集没有官方开发集,因此我们将训练集按90%/10%划分为训练/验证子集。对于每段对话的首个问题,我们使用重写后的问题,因为原始问题通常假设已知真实答案文档。同时我们从QReCC中过滤了低质量样本。
We conduct the QReCC conversations in an auto-regressive manner. At turn $t>1$ of a particular conversation, the system sees its own responses (i.e., not the ground truth responses) to previous turns of the conversation. We report the novel-F1 metric (nF1; Paranjape et al. 2022), which computes the F1 overlap between the system response and the ground truth while discounting common stopwords and terms present in the question (or earlier questions). The results are shown in Table 1, and follow the same general pattern as SQuAD and HotPotQA.
我们以自回归(auto-regressive)方式进行QReCC对话实验。在特定对话的第$t>1$轮时,系统会看到自身对之前轮次的响应(而非真实答案)。我们采用新颖F1指标(nF1; Paranjape et al. 2022),该指标在计算系统响应与真实答案间F1重叠度的同时,会剔除常见停用词及问题(或先前问题)中已出现的词汇。结果如表1所示,其整体趋势与SQuAD和HotPotQA保持一致。
4. Conclusion
4. 结论
For a long time, the dominant paradigm for building models in AI has centered around multiplication of tensor representations, and in the deep learning era this has given rise to highly modular (layer-wise) designs that allow for fast development and wide exploration. However, these design paradigms require extensive domain expertise, and even experts face substantial challenges when it comes to combining different pretrained components into larger systems.
长期以来,AI构建模型的主导范式一直围绕张量表示(tensor)的乘法运算展开,在深度学习时代,这种范式催生了高度模块化(分层)的设计,能够实现快速开发和广泛探索。然而,这些设计范式需要大量领域专业知识,即便是专家在将不同预训练组件组合成更大系统时也面临重大挑战。
The promise of in-context learning is that we can build complex systems from pretrained components using only natural language as the medium for giving systems instructions and, as we argue for, allowing components to communicate with each other. In this new paradigm, the building blocks are pretrained models and the core operations are natural language instructions and operations on natural language texts. If we can realize this potential, then we can broaden participation in AI system development, rapidly prototype systems for new domains, and maximize the value of specialized pretrained components.
情境学习 (in-context learning) 的潜力在于,我们能够仅通过自然语言作为指令媒介,利用预训练组件构建复杂系统,并实现组件间的相互通信。在这种新范式中,基础构建单元是预训练模型,核心操作则是对自然语言文本的指令与处理。若能实现这一潜力,我们将能扩大AI系统开发的参与度,快速为新领域构建原型系统,并最大化专业预训练组件的价值。
In the current paper, we introduced the DEMONSTRATE– SEARCH–PREDICT (DSP) framework for retrieval augmented in-context learning. DSP consists of a number of simple, composable functions for implementing in-context learning systems as deliberate programs—instead of endtask prompts—for solving knowledge intensive tasks. We implemented DSP as a Python library and used it to write programs for Open-SQuAD, HotPotQA, and QReCC. These programs deliver substantial gains over previous in-context learning approaches. However, beyond any particular performance number, we argue that the central contribution of DSP is in helping to reveal a very large space of conceptual possibilities for in-context learning in general.
在当前论文中,我们提出了用于检索增强上下文学习的DEMONSTRATE–SEARCH–PREDICT (DSP)框架。DSP包含一系列简单可组合的函数,用于将上下文学习系统实现为深思熟虑的程序(而非最终任务提示)来解决知识密集型任务。我们将DSP实现为Python语言库,并用其为Open-SQuAD、HotPotQA和QReCC编写程序。这些程序相较以往的上下文学习方法实现了显著提升。但除具体性能指标外,我们认为DSP的核心贡献在于揭示了上下文学习领域极其广阔的概念可能性空间。
Acknowledgements
致谢
We thank Ashwin Paranjape, Amir Ziai, and Rick Battle for valuable discussions and feedback. This work was partially supported by IBM as a founding member of the Stanford Institute for Human-Centered Artificial Intelligence (HAI). This research was supported in part by affiliate members and other supporters of the Stanford DAWN project—Ant Financial, Facebook, Google, and VMware—as well as Cisco, SAP, and the NSF under CAREER grant CNS-1651570. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation. We thank Giuseppe Attanasio for his public LATEX GitHub-style Python code formatting gist.4 We also thank Riley Goodside for his public tips on formatting LM
我们感谢Ashwin Paranjape、Amir Ziai和Rick Battle的宝贵讨论与反馈。这项工作得到了IBM作为斯坦福以人为本人工智能研究所(HAI)创始成员的部分支持。本研究还获得了斯坦福DAWN项目附属成员及其他支持者的资助——包括蚂蚁金服、Facebook、Google和VMware——以及Cisco、SAP和美国国家科学基金会(NSF)CAREER资助CNS-1651570。本材料中表达的任何观点、发现、结论或建议均为作者个人观点,并不代表美国国家科学基金会的立场。我们感谢Giuseppe Attanasio公开的LATEX GitHub风格Python代码格式化要点。4同时感谢Riley Goodside关于大语言模型格式化的公开建议。
benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9: 346–361, 2021. Hofstätter, S., Chen, J., Raman, K., and Zamani, H. Fid- light: Efficient and effective retrieval-augmented text generation. arXiv preprint arXiv:2209.14290, 2022. Huang, J., Gu, S. S., Hou, L., Wu, Y., Wang, X., Yu, H., and Han, J. Large language models can self-improve. arXiv preprint arXiv:2210.11610, 2022. Ishii, Y., Madotto, A., and Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv, 1(1), 2022. Izacard, G. and Grave, E. Leveraging passage retrieval with generative models for open domain question answering. arXiv preprint arXiv:2007.01282, 2020. Izacard, G., Lewis, P., Lomeli, M., Hosseini, L., Petroni, F., Schick, T., Dwivedi-Yu, J., Joulin, A., Riedel, S., and Grave, E. Few-shot learning with retrieval augmented language models. arXiv preprint arXiv:2208.03299, 2022. Jiang, Y., Bordia, S., Zhong, Z., Dognin, C., Singh, M., and Bansal, M. HoVer: A dataset for many-hop fact extraction and claim verification. In Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 3441–3460, Online, 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020. findings-emnlp.309. URL https://a cl anthology. org/2020.findings-emnlp.309. Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6769–6781, Online, 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.550. URL https://a cl anthology.org/2020.emnlp-main.550. Khattab, O. and Zaharia, M. Colbert: Efficient and effective passage search via contextual i zed late interaction over BERT. In Huang, J., Chang, Y., Cheng, X., Kamps, J., Murdock, V., Wen, J., and Liu, Y. (eds.), Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, pp. 39– 48. ACM, 2020. doi: 10.1145/3397271.3401075. URL https://doi.org/10.1145/3397271.3401075. Khattab, O., Potts, C., and Zaharia, M. Baleen: Robust Multi-Hop Reasoning at Scale via Condensed Retrieval. In Thirty-Fifth Conference on Neural Information Processing Systems, 2021a.
基准与隐式推理策略。《计算语言学协会汇刊》,9: 346–361,2021。
Hofstätter, S., Chen, J., Raman, K., and Zamani, H. Fid-light: 高效且有效的检索增强文本生成。arXiv预印本 arXiv:2209.14290,2022。
Huang, J., Gu, S. S., Hou, L., Wu, Y., Wang, X., Yu, H., and Han, J. 大语言模型可以自我改进。arXiv预印本 arXiv:2210.11610,2022。
Ishii, Y., Madotto, A., and Fung, P. 自然语言生成中的幻觉研究综述。《ACM计算调查》,1(1),2022。
Izacard, G. and Grave, E. 利用生成模型和段落检索进行开放域问答。arXiv预印本 arXiv:2007.01282,2020。
Izacard, G., Lewis, P., Lomeli, M., Hosseini, L., Petroni, F., Schick, T., Dwivedi-Yu, J., Joulin, A., Riedel, S., and Grave, E. 基于检索增强语言模型的少样本学习。arXiv预印本 arXiv:2208.03299,2022。
Jiang, Y., Bordia, S., Zhong, Z., Dognin, C., Singh, M., and Bansal, M. HoVer: 多跳事实提取与声明验证数据集。《计算语言学协会发现:EMNLP 2020》,pp. 3441–3460,线上,2020。计算语言学协会。doi: 10.18653/v1/2020.findings-emnlp.309。URL https://acl anthology.org/2020.findings-emnlp.309。
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. 开放域问答的密集段落检索。《2020年自然语言处理经验方法会议论文集》(EMNLP),pp. 6769–6781,线上,2020。计算语言学协会。doi: 10.18653/v1/2020.emnlp-main.550。URL https://acl anthology.org/2020.emnlp-main.550。
Khattab, O. and Zaharia, M. Colbert: 通过BERT的上下文化延迟交互实现高效且有效的段落搜索。载于Huang, J., Chang, Y., Cheng, X., Kamps, J., Murdock, V., Wen, J., and Liu, Y. (编), 《第43届国际ACM SIGIR信息检索研究与发展会议论文集》,SIGIR 2020,线上活动,中国,2020年7月25-30日,pp. 39–48。ACM,2020。doi: 10.1145/3397271.3401075。URL https://doi.org/10.1145/3397271.3401075。
Khattab, O., Potts, C., and Zaharia, M. Baleen: 通过浓缩检索实现大规模稳健多跳推理。《第三十五届神经信息处理系统会议》,2021a。
Generation for Knowledge-Intensive NLP Tasks. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL https: //proceedings.neurips.cc/paper/2020/hash/ 6b493230205f780e1bc26945df7481e5-Abstract. html.
知识密集型NLP任务的生成。载于:Larochelle, H.、Ranzato, M.、Hadsell, R.、Balcan, M.和Lin, H. (编), 《神经信息处理系统进展33:2020年神经信息处理系统年会论文集》, NeurIPS 2020, 2020年12月6-12日, 线上会议, 2020. 网址 https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., 等. 语言模型是无监督多任务学习者. OpenAI博客, 1(8):9, 2019.
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. SQuAD: $100{,}000+$ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 2383– 2392, Austin, Texas, 2016. Association for Computational Linguistics. doi: 10.18653/v1/D16-1264. URL https://a cl anthology.org/D16-1264.
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. SQuAD: 面向机器文本理解的 $100{,}000+$ 问题集。载于《2016年自然语言处理实证方法会议论文集》,第2383–2392页,得克萨斯州奥斯汀,2016年。计算语言学协会。doi: 10.18653/v1/D16-1264。URL https://acl anthology.org/D16-1264。
Raposo, G., Ribeiro, R., Martins, B., and Coheur, L. Ques- tion rewriting? assessing its importance for conversational question answering. In European Conference on Information Retrieval, pp. 199–206. Springer, 2022.
Raposo, G., Ribeiro, R., Martins, B., 和 Coheur, L. 问题重写? 评估其对会话式问答的重要性。载于《欧洲信息检索会议》, 第199-206页。Springer出版社, 2022年。
Santhanam, K., Khattab, O., Potts, C., and Zaharia, M. PLAID: An Efficient Engine for Late Interaction Retrieval. arXiv preprint arXiv:2205.09707, 2022a.
Santhanam, K., Khattab, O., Potts, C., and Zaharia, M. PLAID: 一种高效的延迟交互检索引擎。arXiv预印本 arXiv:2205.09707, 2022a.
Santhanam, K., Khattab, O., Saad-Falcon, J., Potts, C., and Zaharia, M. ColBERTv2: Effective and efficient retrieval via lightweight late interaction. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 3715–3734, Seattle, United States, July 2022b. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-main.272. URL https://a cl anthology.org/2022.naacl-main.272.
Santhanam, K., Khattab, O., Saad-Falcon, J., Potts, C., and Zaharia, M. ColBERTv2: 通过轻量级延迟交互实现高效检索。载于《2022年北美计算语言学协会人类语言技术会议论文集》,第3715–3734页,美国西雅图,2022年7月。计算语言学协会。doi: 10.18653/v1/2022.naacl-main.272。URL https://aclanthology.org/2022.naacl-main.272。
Shuster, K., Poff, S., Chen, M., Kiela, D., and Weston, J. Retrieval augmentation reduces hallucination in conversation. arXiv preprint arXiv:2104.07567, 2021.
Shuster, K., Poff, S., Chen, M., Kiela, D., and Weston, J. 检索增强减少对话中的幻觉。arXiv预印本 arXiv:2104.07567, 2021.
Si, C., Gan, Z., Yang, Z., Wang, S., Wang, J., Boyd-Graber, J., and Wang, L. Prompting gpt-3 to be reliable. arXiv preprint arXiv:2210.09150, 2022.
Si, C., Gan, Z., Yang, Z., Wang, S., Wang, J., Boyd-Graber, J., and Wang, L. 通过提示使GPT-3更可靠。arXiv预印本 arXiv:2210.09150, 2022。
Sun, Z., Wang, X., Tay, Y., Yang, Y., and Zhou, D. Recitation-augmented language models. arXiv preprint arXiv:2210.01296, 2022.
Sun, Z., Wang, X., Tay, Y., Yang, Y., and Zhou, D. 基于背诵增强的语言模型。arXiv预印本 arXiv:2210.01296, 2022.
Thorne, J., Vlachos, A., Christo dou lo poul os, C., and Mittal, A. FEVER: a large-scale dataset for fact extraction and VERification. In Proceedings of the 2018 Con- ference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 809–819, New Orleans, Louisiana, 2018. Association for Computational Linguistics. doi: 10.18653/v1/N18-1074. URL https://a cl anthology.org/N18-1074.
Thorne, J., Vlachos, A., Christodoulopoulos, C., and Mittal, A. FEVER: 一个用于事实提取与验证的大规模数据集。见《2018年北美计算语言学协会人类语言技术会议论文集(长篇论文)》第1卷,第809-819页,2018年于路易斯安那州新奥尔良市。计算语言学协会出版。doi: 10.18653/v1/N18-1074。URL https://aclanthology.org/N18-1074。
Vakulenko, S., Kiesel, J., and Fröbe, M. SCAI-QReCC shared task on conversational question answering. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pp. 4913–4922, Marseille, France,
Vakulenko, S., Kiesel, J., 和 Fröbe, M. SCAI-QReCC 对话式问答共享任务。载于《第十三届语言资源与评估会议论文集》,第 4913–4922 页,法国马赛。