Counting Out Time: Class Agnostic Video Repetition Counting in the Wild
计时:野外场景中类别无关的视频重复计数
Debidatta Dwibedi 1, Yusuf Aytar 2, Jonathan Tompson 1, Pierre Sermanet 1, and Andrew Zisserman 2
Debidatta Dwibedi 1, Yusuf Aytar 2, Jonathan Tompson 1, Pierre Sermanet 1, and Andrew Zisserman 2
1 Google Research 2 DeepMind debidatta, yusufaytar, tompson, sermanet, zisserman @google.com
1 Google Research 2 DeepMind
debidatta, yusufaytar, tompson, sermanet, zisserman @google.com
Abstract
摘要
We present an approach for estimating the period with which an action is repeated in a video. The crux of the approach lies in constraining the period prediction module to use temporal self-similarity as an intermediate representation bottleneck that allows generalization to unseen repe- titions in videos in the wild. We train this model, called RepNet, with a synthetic dataset that is generated from a large unlabeled video collection by sampling short clips of varying lengths and repeating them with different periods and counts. This combination of synthetic data and a powerful yet constrained model, allows us to predict periods in a class-agnostic fashion. Our model substantially exceeds the state of the art performance on existing periodicity (PERTUBE) and repetition counting (QUVA) benchmarks. We also collect a new challenging dataset called Countix ${\sim}g_{\theta}$ times larger than existing datasets) which captures the challenges of repetition counting in real-world videos. Project webpage: https://sites.google. com/view/repnet.
我们提出了一种估计视频中动作重复周期的方法。该方法的核心在于约束周期预测模块,将时间自相似性作为中间表示瓶颈,从而实现对真实场景视频中未见重复模式的泛化。我们使用合成数据集训练这个名为RepNet的模型,该数据集通过从大量未标注视频中采样不同长度的短视频片段,并以不同周期和次数重复生成。合成数据与强大但受约束的模型相结合,使我们能够以类别无关的方式预测周期。我们的模型在现有周期性基准(PERTUBE)和重复计数基准(QUVA)上大幅超越了当前最优性能。我们还收集了一个名为Countix的新挑战性数据集(规模是现有数据集的${\sim}g_{\theta}$倍),该数据集捕捉了真实视频中重复计数的挑战。项目网页:https://sites.google.com/view/repnet。
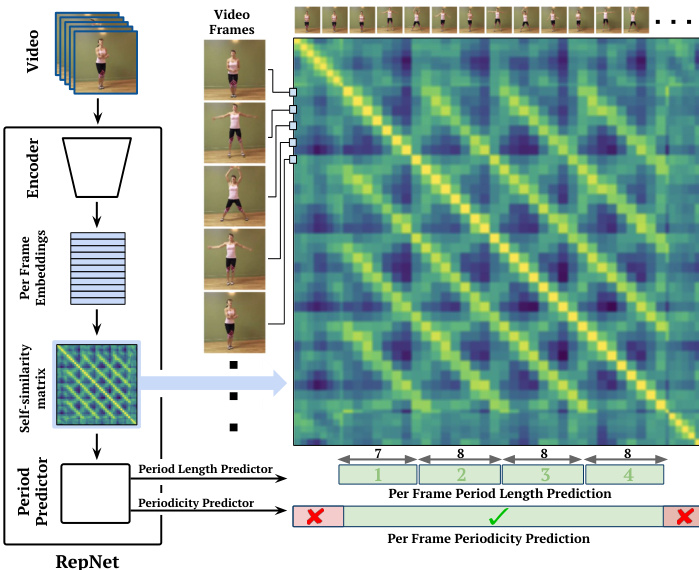
Figure 1: We present RepNet, which leverages a temporal selfsimilarity matrix as an intermediate layer to predict the period length and periodicity of each frame in the video.
图 1: 我们提出的RepNet利用时间自相似矩阵作为中间层,预测视频中每一帧的周期长度和周期性。
1. Introduction
1. 引言
Picture the most mundane of scenes – a person eating by themselves in a cafe. They might be stirring sugar in their coffee while chewing their food, and tapping their feet to the background music. This person is doing at least three periodic activities in parallel. Repeating actions and processes are ubiquitous in our daily lives. These range from organic cycles, such as heart beats and breathing, through programming and manufacturing, to planetary cycles like the day-night cycle and seasons. Thus the need for recognizing repetitions in videos is pervasive, and a system that is able to identify and count repetitions in video will benefit any perceptual system that aims to observe and understand our world for an extended period of time.
想象一个最平凡的场景——一个人在咖啡馆独自用餐。他们可能一边搅动咖啡里的糖块咀嚼食物,一边随着背景音乐用脚打拍子。这个人至少同时在进行三种周期性活动。重复性动作和过程在我们的日常生活中无处不在:从心跳呼吸等生命节律,到编程制造的工业循环,再到昼夜更替与四季轮转等行星周期。因此对视频中重复动作的识别需求普遍存在,而能够检测并统计视频循环次数的系统,将赋能任何需要长期观察和理解现实世界的感知系统。
Repetitions are also interesting for the following reasons: (1) there is usually an intent or a driving cause behind something happening multiple times; (2) the same event can be observed again but with slight variations; (3) there may be gradual changes in the scene as a result of these repetitions; (4) they provide us with unambiguous action units, a subsequence in the action that can be segmented in time (for example if you are chopping an onion, the action unit is the manipulation action that is repeated to produce additional slices). Due to the above reasons, any agent interact- ing with the world would benefit greatly from such a system. Furthermore, repetition counting is pertinent for many computer vision applications; such as counting the number of times an exercise was done, measurement of biological events (like heartbeats), etc.
重复现象之所以值得关注,基于以下几点原因:(1) 重复发生的行为通常存在特定意图或驱动因素;(2) 相同事件再次出现时可能伴随细微变化;(3) 重复可能导致场景逐渐改变;(4) 它们提供了明确的行为单元(action unit),即动作中可被时序分割的子序列(例如切洋葱时,重复的切削动作就是产生更多切片的行为单元)。基于上述特性,任何与环境交互的AI智能体都能从这类系统中显著获益。此外,重复计数在众多计算机视觉应用中具有重要意义,例如健身动作次数统计、生物事件(如心跳)测量等。
Yet research in periodic video understanding has been limited, potentially due to the lack of a large scale labeled video repetition dataset. In contrast, for action recognition there are large scale datasets, like Kinetics [23], but their collection at large scale is enabled by the availability of keywords/text associated with the videos. Unfortunately it is rare for videos to be labeled with annotations related to repeated activity as the text is more likely to describe the semantic content. For this reason, we use a dataset with semantic action labels typically used for action recognition (Kinetics) and manually choose videos of those classes with periodic motion (bouncing, clapping etc.). We proceed to label the selected videos with the number of repetitions present in each clip.
然而,周期性视频理解的研究一直较为有限,这可能是由于缺乏大规模标注的视频重复数据集。相比之下,动作识别领域已有如Kinetics [23] 这样的大规模数据集,但其大规模收集得益于视频关联关键词/文本的可用性。遗憾的是,视频很少会标注与重复活动相关的注释,因为文本更可能描述语义内容。为此,我们采用了一个通常用于动作识别的语义动作标签数据集(Kinetics),并手动挑选其中包含周期性运动(如弹跳、拍手等)的类别视频。随后,我们对选定的视频片段标注了其中包含的重复次数。
Manual labelling limits the number of videos that can be annotated – labelling is tedious and expensive due to the temporally fine-grained nature of the task. In order to increase the amount of training data, we propose a method to create synthetic repetition videos by repeating clips from existing videos with different periods. Since we are synthesizing these videos, we also have precise annotations for the period and count of repetitions in the videos, which can be used for training models using supervised learning. However, as we find in our work, such synthetic videos fail to capture all the nuances of real repeated videos and are prone to over-fitting by high-capacity deep learning models. To address this issue, we propose a data augmentation strategy for synthetic videos so that models trained on them transfer to real videos with repetitions. We use a combination of real and synthetic data to develop our model.
手动标注限制了可注释视频的数量——由于任务具有时间细粒度的特性,标注过程既繁琐又昂贵。为了增加训练数据量,我们提出了一种通过以不同周期重复现有视频片段来创建合成重复视频的方法。由于这些视频是合成的,我们还能精确标注视频中的重复周期和次数,这些标注可用于监督学习训练模型。然而,正如我们在工作中发现的,此类合成视频无法完全捕捉真实重复视频的所有细微差别,且容易导致高容量深度学习模型过拟合。为解决这一问题,我们提出了一种针对合成视频的数据增强策略,使基于它们训练的模型能够迁移到具有重复动作的真实视频中。我们结合使用真实数据和合成数据来开发模型。
In this paper, our objective is a single model that works for many classes of periodic videos, and indeed, also for classes of videos unseen during training. We achieve this by using an intermediate representation that encourages generalization to unseen classes. This representation – a temporal self-similarity matrix – is used to predict the period with which an action is repeating in the video. This common representation is used across different kinds of repeating videos enabling the desired generalization. For example, whether a person is doing push ups, or a kid is swinging in a playground, the self-similarity matrix is the shared parame teri z ation from which the number of repetitions is inferred. This extreme bottleneck (the number of channels in the feature map reduces from 512 to 1) also aids generalization from synthetic data to real data. The other advantage of this representation is that model interpret ability is baked into the network architecture as we force the network to predict the period from the self-similarity matrix only, as opposed to inferring the period from latent high-dimensional features.
本文的目标是构建一个适用于多种周期性视频类别的单一模型,并且能够泛化到训练阶段未见过的视频类别。我们通过采用一种促进未知类别泛化的中间表示来实现这一目标。这种时域自相似矩阵的表示形式,可用于预测视频中动作重复的周期频率。这种通用表示方法被应用于各类重复性视频,从而实现所需的泛化能力。例如,无论是人物做俯卧撑还是儿童荡秋千,自相似矩阵都是推断重复次数的共享参数化表征。这种极端瓶颈设计(特征图的通道数从512降至1)也有助于从合成数据到真实数据的泛化。该表示法的另一优势在于,由于强制网络仅通过自相似矩阵预测周期(而非从潜在高维特征推断周期),模型可解释性被直接嵌入网络架构中。
We focus on two tasks: (i) Repetition counting, identifying the number of repeats in the video. We rephrase this problem as first estimating per frame period lengths, and then converting them to a repetition count; (ii) Periodicity detection, identifying if the current frame is a part of a repeating temporal pattern or not. We approach this as a perframe binary classification problem. A visual explanation of these tasks and the overview of our solution is shown in Figure 1.
我们专注于两项任务:(i) 重复计数,即识别视频中的重复次数。我们将该问题重新表述为首先估计每帧周期长度,然后将其转换为重复计数;(ii) 周期性检测,即判断当前帧是否属于重复时间模式的一部分。我们将其视为逐帧二元分类问题。这些任务的视觉解释及解决方案概述如图1所示。
Our main contributions in this paper are: (i) RepNet, a neural network architecture designed for counting repetitions in videos in the wild. (ii) A method to generate and augment synthetic repetition videos from unlabeled videos. (iii) By training RepNet on the synthetic dataset we outperform the state-of-the-art methods on both repetition counting and periodicity detection tasks over existing benchmarks by a substantial margin. (iv) A new video repetition counting dataset, Countix, which is $\sim90$ times larger than the previous largest dataset.
本文的主要贡献包括:(i) RepNet,一种专为自然场景视频中的重复动作计数设计的神经网络架构。(ii) 一种从无标注视频生成并增强合成重复视频的方法。(iii) 通过在合成数据集上训练RepNet,我们在现有基准测试的重复计数和周期性检测任务上以显著优势超越了最先进方法。(iv) 新的视频重复计数数据集Countix,其规模是此前最大数据集的$\sim90$倍。
2. Related Work
2. 相关工作
Self-similarity. The idea of using local image and spatiotemporal self-similarities was explored in [40] for pattern matching in images and videos. Matching the abstraction of self-similarities, rather than image features directly, enabled generalization. We build on this insight in our work.
自相似性。文献[40]探讨了利用局部图像和时空自相似性进行图像视频模式匹配的方法。通过匹配自相似性的抽象特征而非直接匹配图像特征,该方法实现了泛化能力。我们的研究正是基于这一洞见展开。
Periodicity Estimation. Extracting periodicity (detection of periodic motion) and the period by leveraging the autocorrelation in time series is a well-studied problem [43, 48].
周期性估计。利用时间序列中的自相关性提取周期性(检测周期性运动)和周期是一个经过充分研究的问题 [43, 48]。
Period estimation in videos has been done using periodograms on top of auto-correlation [9] or Wavelet transforms on hand-designed features derived from optical flow [37]. The extracted periodic motion has supported multiple tasks including 3D reconstruction [4, 29] and bird species classification [28]. Periodicity has been used for various applications [9, 32, 34, 38] including temporal pattern classification [35].
视频中的周期估计已通过自相关[9]或基于光流手工设计特征的小波变换[37]结合周期图实现。提取的周期性运动支撑了多项任务,包括3D重建[4,29]和鸟类物种分类[28]。周期性已被用于多种应用[9,32,34,38],包括时序模式分类[35]。
Temporal Self-similarity Matrix (TSM). TSMs are useful representations for human action recognition [21, 24, 44] and gait analysis [5, 6] due to their robustness against large viewpoint changes when paired with appropriate feature representations. A TSM based on Improved Dense Trajectories [49] is used in [33] for unsupervised identification of periodic segments in videos using special filters. Unlike these approaches, we use TSM as an intermediate layer in an end-to-end neural network architecture, which acts as an information bottleneck. Concurrently, [22] have proposed a convolutional architecture for periodicity detection in videos.
时序自相似矩阵 (TSM)。TSM因其在搭配适当特征表示时对大幅视角变化具有鲁棒性,成为人类动作识别 [21, 24, 44] 和步态分析 [5, 6] 的有效表征方法。文献 [33] 采用基于改进密集轨迹 (Improved Dense Trajectories) [49] 的TSM,通过特殊滤波器实现视频中周期性片段的无监督识别。与这些方法不同,我们将TSM作为端到端神经网络架构的中间层,形成信息瓶颈。同期研究 [22] 提出了一种用于视频周期性检测的卷积架构。
Synthetic Training Data. The use of synthetic training data in computer vision is becoming more common place. Pasting object patches on real images has been shown to be effective as training data for object detection [12, 15, 45] and human pose estimation [46]. Blending multiple videos or multiple images together has been useful for producing synthetic training data for specific tasks [2] as well as regularizing deep learning models [53, 54]. Synthetic data for training repetition counting was first proposed by [27]. They introduce a dataset of synthetic repeating patterns and use this to train a deep learning based counting model. However, the data they use for training consists of handdesigned random patterns that do not appear realistic. As shown in [37], these patterns are not diverse enough to capture all the nuances of repetitions in real videos. Instead, we propose to create synthetic training dataset of realistic video repetitions from existing video datasets.
合成训练数据。在计算机视觉领域使用合成训练数据正变得越来越普遍。已有研究表明,将物体贴片粘贴到真实图像上作为训练数据,对目标检测[12, 15, 45]和人体姿态估计[46]任务具有显著效果。将多个视频或多幅图像混合的方法,不仅可用于生成特定任务的合成训练数据[2],还能作为深度学习模型的正则化手段[53, 54]。文献[27]首次提出了用于训练重复计数模型的合成数据,他们通过合成的重复模式数据集来训练基于深度学习的计数模型。然而,其训练数据采用手工设计的随机模式,缺乏真实感。如[37]所示,这些模式的变化不足以捕捉真实视频中重复动作的全部细节。为此,我们提出从现有视频数据集中创建具有真实感的视频重复动作合成训练数据集。
Counting in Computer Vision. Counting objects and people in images [3, 7, 26, 30, 52] is an active area in computer vision. On the other hand, video repetition counting [27, 37] has attracted less attention from the community in the deep learning era. We build on the idea of [27] of predicting the period (cycle length), though [27] did not use a TSM.
计算机视觉中的计数。在图像中对物体和人群进行计数[3, 7, 26, 30, 52]是计算机视觉领域的一个活跃研究方向。相比之下,视频重复计数[27, 37]在深度学习时代受到的关注较少。我们基于[27]提出的周期(循环长度)预测思想展开研究,但[27]并未使用时间位移模块(TSM)。

Figure 2: RepNet architecture. The features produced by a single video frame is highlighted with the green color throughout the network.
图 2: RepNet架构。网络中绿色高亮部分表示单个视频帧生成的特征。
Temporally Fine-grained Tasks. Repetition counting and periodicity detection are temporally fine-grained tasks like temporal action localization [8, 41], per-frame phase classification [11] and future anticipation [10]. We leverage the interfaces previously used to collect action localization datasets such as [16, 25, 42] to create our repetition dataset Countix. Instead of annotating semantic segments, we label the extent of the periodic segments in videos and the number of repetitions in each segment.
时间细粒度任务。重复计数和周期性检测属于时间细粒度任务,如时序动作定位 [8, 41]、逐帧阶段分类 [11] 和未来预测 [10]。我们借鉴了此前用于收集动作定位数据集(如 [16, 25, 42])的标注界面,构建了重复计数数据集 Countix。与标注语义片段不同,我们标注了视频中周期性片段的范围以及每个片段的重复次数。
3. RepNet Model
3. RepNet 模型
In this section we introduce our RepNet architecture, which is composed of two learned components, the encoder and the period predictor, with a temporal self-similarity layer in between them.
在本节中,我们将介绍RepNet架构,该架构由两个学习组件组成:编码器和周期预测器,两者之间通过一个时间自相似层连接。
Assume we are given a video $V=[v_{1},v_{2},...,v_{N}]$ as a sequence of $N$ frames. First we feed the video $V$ to an image encoder $\phi$ as $X=\phi(V)$ to produce per-frame embeddings $X=[x_{1},x_{2},...,x_{N}]^{\boldsymbol{\mathsf{T}}}$ . Then, using the embeddings $X$ we obtain the self-similarity matrix $S$ by computing pairwise similarities $S_{i j}$ between all pairs of embeddings.
假设给定一个视频 $V=[v_{1},v_{2},...,v_{N}]$ 作为由 $N$ 帧组成的序列。首先将视频 $V$ 输入图像编码器 $\phi$ 得到 $X=\phi(V)$ ,生成每帧的嵌入向量 $X=[x_{1},x_{2},...,x_{N}]^{\boldsymbol{\mathsf{T}}}$ 。随后利用嵌入向量 $X$ 计算所有嵌入对之间的相似度 $S_{i j}$ ,从而获得自相似矩阵 $S$ 。
Finally, $S$ is fed to the period predictor module which outputs two elements for each frame: period length estimate $l=\psi(S)$ and periodicity score $p=\tau(S)$ . The period length is the rate at which a repetition is occurring while the periodicity score indicates if the frame is within a periodic portion of the video or not. The overall architecture can be viewed in the Figure 1 and a more detailed version can be seen in Figure 2.
最后,$S$ 被送入周期预测模块,该模块为每帧输出两个元素:周期长度估计 $l=\psi(S)$ 和周期性分数 $p=\tau(S)$。周期长度表示重复发生的速率,而周期性分数则指示该帧是否位于视频的周期性部分。整体架构可参见图 1,更详细的版本见图 2。
3.1. Encoder
3.1. 编码器
Our encoder $\phi$ is composed of three main components:
我们的编码器 $\phi$ 由三个主要组件构成:
Convolutional feature extractor: We use ResNet-50[19] architecture as our base convolutional neural network (CNN) to extract 2D convolutional features from individual frames $v_{i}$ of the input video. These frames are $112\times112\times3$ in size. We use the output of con v 4 block 3 layer to have a larger spatial 2D feature map. The resulting per-frame features are of size $7\times7\times1024$ .
卷积特征提取器:我们采用ResNet-50[19]架构作为基础卷积神经网络(CNN),从输入视频的独立帧$v_{i}$中提取二维卷积特征。这些帧的尺寸为$112\times112\times3$。我们使用con v 4 block 3层的输出来获得更大的空间二维特征图,最终每帧特征尺寸为$7\times7\times1024$。
Temporal Context: We pass these convolutional features through a layer of 3D convolutions to add local temporal information to the per-frame features. We use 512 filters of size $3\times3\times3$ with ReLU activation with a dilation rate of 3. The temporal context helps modeling short-term motion [13, 51] and enables the model to distinguish between similar looking frames but with different motion (e.g. hands moving up or down while exercising).
时间上下文:我们将这些卷积特征通过一层3D卷积,为每帧特征添加局部时间信息。使用512个尺寸为$3\times3\times3$的滤波器,采用ReLU激活函数,膨胀率为3。时间上下文有助于建模短期运动[13, 51],并使模型能够区分外观相似但运动不同的帧(例如锻炼时手臂向上或向下移动)。
Dimensionality reduction: We reduce the dimensionality of extracted spatio-temporal features by using Global 2D Max-pooling over the spatial dimensions and to produce embedding vectors $x_{i}$ corresponding to each frame $v_{i}$ in the video. By collapsing the spatial dimensions we remove the need for tracking the region of interest as done explicitly in prior methods [6, 9, 35].
降维:我们通过在空间维度上应用全局二维最大池化(Global 2D Max-pooling)来降低提取的时空特征维度,并为视频中的每一帧$v_{i}$生成对应的嵌入向量$x_{i}$。通过压缩空间维度,我们无需像先前方法[6, 9, 35]那样显式追踪感兴趣区域。
3.2. Temporal Self-similarity Matrix (TSM)
3.2. 时间自相似矩阵 (TSM)
After obtaining latent embeddings $x_{i}$ for each frame $v_{i}$ , we construct the self-similarity matrix $S$ by computing all pairwise similarities $S_{i j}=f(x_{i},x_{j})$ between pairs of embeddings $x_{i}$ and $x_{j}$ , where $f(.)$ is the similarity function. We use the negative of the squared euclidean distance as the similarity function, $f(a,b)=-||a-b||^{2}$ , followed by row-wise softmax operation.
在获得每帧$v_{i}$的潜在嵌入$x_{i}$后,我们通过计算所有嵌入对$x_{i}$和$x_{j}$之间的两两相似度$S_{i j}=f(x_{i},x_{j})$来构建自相似矩阵$S$,其中$f(.)$为相似度函数。我们使用负平方欧氏距离作为相似度函数$f(a,b)=-||a-b||^{2}$,随后进行逐行softmax操作。
As the TSM has only one channel, it acts as an information bottleneck in the middle of our network and provides regular iz ation. TSMs also make the model temporally inter pre table which brings further insights to the predictions made by the model. Some examples can be viewed in Figure 3.
由于 TSM 仅有一个通道,它在网络中部充当信息瓶颈并提供正则化作用。TSM 还使模型具有时间可解释性,从而为模型预测带来更深入的洞察。部分示例如图 3 所示。
3.3. Period Predictor
3.3. 周期预测器
The final module of RepNet is the period predictor. This module accepts the self-similarity matrix ${\boldsymbol{S}}=$ $\left[s_{1},s_{2},...,s_{N}\right]^{\intercal}$ where each row $s_{i}$ is the per frame selfsimilarity representation, and generates two outputs: per frame period length estimation $l=\psi(S)$ , and per-frame binary periodicity classification $p=\tau(S)$ . Note that both $l$ and $p$ are vectors and their elements are per frame predictions (i.e. $l_{i}$ is the predicted period length for the ith frame).
RepNet的最终模块是周期预测器。该模块接收自相似矩阵 ${\boldsymbol{S}}=$ $\left[s_{1},s_{2},...,s_{N}\right]^{\intercal}$ ,其中每行 $s_{i}$ 表示逐帧自相似性表征,并生成两个输出:逐帧周期长度估计 $l=\psi(S)$ ,以及逐帧二值周期性分类 $p=\tau(S)$ 。注意 $l$ 和 $p$ 均为向量,其元素为逐帧预测值 (即 $l_{i}$ 表示第i帧的预测周期长度)。
The architecture of the period predictor module can be viewed in Figure 2. Note that predictors $\psi$ and $\tau$ share a common architecture and weights until the last classification phase. The shared processing pipeline starts with 32
图 2: 展示了周期预测模块的架构。需要注意的是,预测器 $\psi$ 和 $\tau$ 在最后分类阶段之前共享相同的架构和权重。共享处理流程始于 32
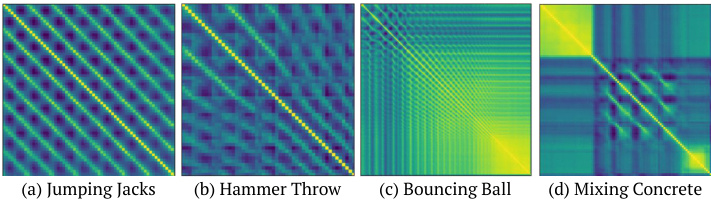
Figure 3: Diversity of temporal self-similarity matrices found in real-world repetition videos (yellow means high similarity, blue means low similarity). (a) Uniformly repeated periodic motion (jumping jacks) (b) Repetitions with acceleration (athlete performing hammer throw) (c) Repetitions with decreasing period (a bouncing ball losing speed due to repeated bounces) (d) Repeated motion preceded and succeeded by no motion (waiting to mix concrete, mixing concrete, stopped mixing). A complex model is needed to predict the period and periodicity from such diverse self-similarity matrices.
图 3: 真实世界重复视频中时间自相似矩阵的多样性 (黄色表示高相似度,蓝色表示低相似度)。 (a) 均匀重复的周期性运动 (开合跳) (b) 伴随加速的重复动作 (链球运动员投掷) (c) 周期逐渐减小的重复动作 (弹跳球因反复弹跳而减速) (d) 前后无运动的重复动作 (等待搅拌混凝土、搅拌混凝土、停止搅拌)。需要复杂模型才能从如此多样的自相似矩阵中预测周期和周期性。
2D convolutional filters of size $3\times3$ , followed by a transformer [47] layer which uses a multi-headed attention with trainable positional embeddings in the form of a 64 length variable that is learned by training. We use 4 heads with 512 dimensions in the transformer with each head being 128 dimensions in size. After the shared pipeline, we have two class if i ers, period length classifier $\psi$ and periodicity classifier $\tau$ . Each of them consists of two fully connected layers of size 512.
尺寸为 $3\times3$ 的2D卷积滤波器,后接一个Transformer [47]层,该层使用多头注意力机制,并采用可训练的位置嵌入形式,即通过训练学习到的64长度变量。我们在Transformer中使用4个头,每个头的维度为128,总维度为512。共享管道之后,我们有两个分类器:周期长度分类器 $\psi$ 和周期性分类器 $\tau$。每个分类器由两个大小为512的全连接层组成。
3.4. Losses
3.4. 损失函数
Our periodicity classifier $\tau$ outputs per frame period- icity classification $p_{i}$ and uses a binary classification loss (binary cross-entropy) for optimization. Our period length estimator $\psi$ outputs per frame period length estimation $l_{i}\in L$ where the classes are discrete period lengths $L=$ ${2,3,...,\frac{N}{2}}$ where $N$ is the number of input frames. We use a multi-class classification objective (softmax crossentropy) for optimizing our model. For all our experiments we use $N=64$ . We sample the input video with different frame rates as described below to predict larger period lengths.
我们的周期性分类器 $\tau$ 输出每帧的周期性分类 $p_{i}$,并使用二元分类损失(二元交叉熵)进行优化。我们的周期长度估计器 $\psi$ 输出每帧的周期长度估计 $l_{i}\in L$,其中类别为离散周期长度 $L=$ ${2,3,...,\frac{N}{2}}$,$N$ 为输入帧数。我们采用多类分类目标(softmax交叉熵)优化模型。所有实验中均使用 $N=64$。通过如下所述的不同帧率采样输入视频,以预测更大的周期长度。
3.5. Inference
3.5. 推理
Inferring the count of repetitions robustly for a given video requires two main operations:
稳健推断给定视频的重复次数需要两个主要操作:
Count from period length predictions: We sample consecutive non-overlapping windows of $N$ frames and provide it as input to RepNet which outputs per-frame periodicity $p_{i}$ and period lengths $l_{i}$ . We define per-frame count as $\frac{p_{i}}{l_{i.}}$ . The overall repetition count is computed as the sum of all perframe counts: iN=1 pli . The evaluation datasets for repetition counting have only periodic segments. Hence, we set $p_{i}$ to 1 as default for counting experiments.
基于周期长度预测的计数方法:我们采样连续的、不重叠的$N$帧窗口作为RepNet的输入,该模型输出每帧的周期性$p_{i}$和周期长度$l_{i}$。定义单帧计数为$\frac{p_{i}}{l_{i.}}$,总重复次数为所有单帧计数之和:iN=1 pli。由于重复计数评估数据集仅包含周期性片段,因此在计数实验中默认将$p_{i}$设为1。
Multi-speed evaluation: As our model can predict period lengths up to 32, for covering much longer period lengths we sample input video with different frame rates. (i.e. we play the video at $1\times$ , $2\times,3\times$ , and $4\times$ speeds). We choose the frame rate which has the highest score for the predicted period. This is similar to what [27] do at test time.
多速率评估:由于我们的模型可预测最长32帧的周期长度,为覆盖更长的周期,我们以不同帧率对输入视频进行采样(例如以 $1\times$、$2\times$、$3\times$ 和 $4\times$ 速度播放视频)。最终选择预测周期得分最高的帧率,该方法与[27]在测试阶段的做法类似。
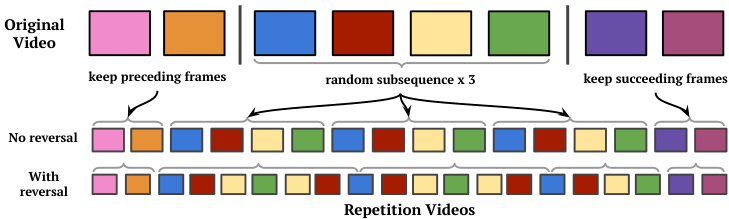
Figure 4: Our synthetic data generation pipeline that produces videos with repetitions from any video. We randomly sample a portion of a video that we repeat $\mathbf{N}$ times to produce synthetic repeating videos. More details in Section 4
图 4: 我们的合成数据生成流程,可从任意视频生成具有重复内容的视频。我们随机采样视频片段并重复 $\mathbf{N}$ 次以生成合成重复视频。详见第4节
4. Training with Synthetic Repetitions
4. 使用合成重复数据进行训练
A potential supervised approach to period estimation would be collecting a large training set of periodic videos and annotating the beginning and the end of every period in all repeating actions. However, collecting such a dataset is expensive due to the fine-grained nature of the task.
一种潜在的监督式周期估计方法是收集大量周期性视频训练集,并为所有重复动作中的每个周期标注起始和结束位置。然而,由于该任务需要细粒度标注,收集此类数据集成本高昂。
As a cheaper and more scalable alternative, we propose a training strategy that makes use of synthetically generated repetitions using unlabeled videos in the wild (e.g. YouTube). We generate synthetic periodic videos using randomly selected videos, and predict per frame periodicity and period lengths. Next, we’ll explain how we generate synthetic repetitions, and introduce camera motion augmentations which are crucial for training effective counting models from synthetic videos.
作为更经济且可扩展的替代方案,我们提出一种利用未标注野生视频(如YouTube)生成合成重复序列的训练策略。通过随机选取视频生成合成周期性视频,并预测逐帧周期性与周期长度。接下来将阐述合成重复序列的生成方法,并介绍对从合成视频训练有效计数模型至关重要的相机运动增强技术。
4.1. Synthetic Repetition Videos
4.1. 合成重复视频
Given a large set of unlabeled videos, we propose a simple yet effective approach for creating synthetic repetition videos (shown in Figure 4) from them. The advantage of using real videos to create synthetic data is that the training data is much closer to real repeated videos when compared to using synthetic patterns. Another advantage of using real videos is that using a big dataset like Kinetics ensures that the diversity of data seen by the model is huge. This allows us to train big complex models that can work on real repetition videos.
给定大量未标注的视频,我们提出了一种简单而有效的方法来从中创建合成重复视频(如图4所示)。使用真实视频生成合成数据的优势在于,与使用合成模式相比,训练数据更接近真实的重复视频。另一个优势是,使用Kinetics等大型数据集能确保模型接触到的数据具有极高多样性,这使得我们可以训练出能够处理真实重复视频的大型复杂模型。
Our pipeline starts with sampling a random video $V$ from a dataset of videos. We use the training set of Kinetics [23] without any labels. Then, we sample a clip $C$ of random length $P$ frames from $V.$ . This clip $C$ is repeated $K$ times (where $K>1$ ) to simulate videos with repetitions. We randomly concatenate the reversed clip before repeating to simulate actions where the motion is done in reverse in the period (like jumping jacks). Then, we pre-pend and append the repeating frames with other non-repeating segments from $V$ , which are just before and after $C$ , respectively. The lengths of these aperiodic segments are chosen randomly and can potentially be zero too.
我们的流程从数据集中随机采样一个视频$V$开始。我们使用Kinetics[23]的训练集,但不使用任何标签。接着,我们从$V$中采样一段随机长度为$P$帧的片段$C$。该片段$C$被重复$K$次(其中$K>1$)以模拟具有重复动作的视频。在重复之前,我们会随机将片段反向拼接,以模拟周期内动作反向进行的场景(如开合跳)。然后,我们在重复帧的前后分别拼接来自$V$的其他非重复片段,这些片段恰好位于$C$的前后位置。这些非周期性片段的长度随机选择,也可能为零。
This operation makes sure that there are both periodic and non-periodic segments in the generated video. Finally, each frame in the repeating part of the generated video is assigned a period length label $P$ . A periodicity label is also generated indicating whether the frame is inside or outside the repeating portion of the generated video.
此操作确保生成的视频中同时包含周期性片段和非周期性片段。最后,为生成视频循环部分的每一帧分配周期长度标签 $P$,同时生成周期性标签以指示该帧是否位于生成视频的循环部分内。
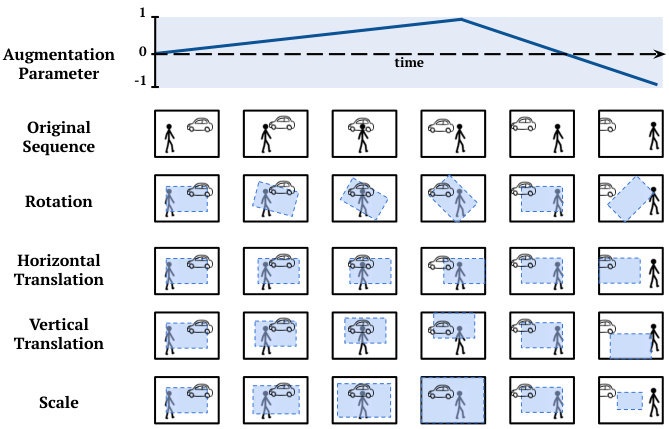
Figure 5: Camera motion augmentation. We vary the augmentation parameters for each type of camera motion smoothly over time as opposed to randomly sampling them independently for each frame. This ensures that the augmented sequence still retains the temporal coherence naturally present in videos.
图 5: 相机运动增强。我们对每种相机运动类型的增强参数随时间平滑变化,而不是为每帧独立随机采样。这确保了增强后的序列仍能保留视频中自然存在的时间连贯性。
4.2. Camera Motion Augmentation
4.2. 相机运动增强
A crucial step in the synthetic video generation is camera motion augmentation (shown in Figure 5). Although it is not feasible to predict views of an arbitrarily moving camera without knowing the 3D structure, occluded parts and lighting sources in the scene, we can approximate it using affine image transformations. Here we consider the affine motion of a viewing frame over the video, which includes temporally smooth changes in rotation, translation, and scale. As we will show in section 6, when we train without these augmentations, the training loss quickly decreases but the model does not transfer to real repetition videos. We empirically find camera motion augmentation is a vital part of training effective models with synthetic videos.
合成视频生成的关键步骤是相机运动增强 (如图 5 所示) 。虽然在不了解场景 3D 结构、遮挡部分和光源的情况下无法预测任意移动相机的视角,但我们可以通过仿射图像变换来近似实现。这里我们考虑视频观看帧的仿射运动,包括旋转、平移和缩放随时间平滑变化。如第 6 节所示,当不使用这些增强训练时,训练损失会快速下降,但模型无法迁移到真实重复视频。我们通过实验发现,相机运动增强是用合成视频训练有效模型的重要组成部分。
To achieve camera motion augmentations, we temporally vary the parameters for various motion types in a continuous manner as the video proceeds. For example, we change the angle of rotation smoothly over time. This ensures that the video is temporally coherent even after the augmentation. Figure 5 illustrates how temporal augmentation pa- rameter drives viewing frame (shown in blue rectangle) for each motion type. This results in videos with fewer near duplicates across the repeating segments.
为了实现相机运动增强,我们随着视频的推进以连续方式随时间变化各种运动类型的参数。例如,我们随时间平滑地改变旋转角度。这确保了即使在增强后视频也能保持时间上的一致性。图5展示了时间增强参数如何驱动每种运动类型的观察帧(以蓝色矩形显示),从而减少重复片段间近似重复的视频内容。
5. Countix Dataset
5. Countix数据集
Existing datasets for video repetition counting [27, 37] are mostly utilized for testing purposes, mainly due to their limited size. The most recent and challenging benchmark on this task is the QUVA repetition dataset [37] which includes realistic repetition videos with occlusion, camera movement, and changes in speed of the repeated actions. It is composed of 100 class-agnostic test videos, annotated with the count of repeated actions. Despite being challenging, its limited size makes it hard to cover diverse semantic categories of repetitions. Also training supervised deep models with this scale of data is not feasible.
现有的视频重复计数数据集 [27, 37] 大多仅用于测试,主要因其规模有限。该任务最新且最具挑战性的基准是 QUVA 重复数据集 [37],它包含存在遮挡、摄像机移动和重复动作速度变化的真实场景视频。该数据集由 100 个与类别无关的测试视频组成,并标注了重复动作的次数。尽管具有挑战性,但其有限规模难以覆盖多样化的重复语义类别。此外,用这种规模的数据训练有监督深度学习模型也不可行。
To increase the semantic diversity and scale up the size of counting datasets, we introduce the Countix dataset: a real world dataset of repetition videos collected in the wild (i.e. YouTube) covering a wide range of semantic settings with significant challenges such as camera and object motion, diverse set of periods and counts, and changes in the speed of repeated actions.
为提升计数数据集的语义多样性并扩大规模,我们推出了Countix数据集:一个从YouTube等开放平台采集的真实世界重复动作视频数据集,涵盖广泛语义场景,包含相机与物体运动、多样化周期与计数、重复动作速度变化等显著挑战。
Countix include repeated videos of workout activities (squats, pull ups, battle rope training, exercising arm), dance moves (pirouetting, pumping fist), playing instruments (playing ukulele), using tools repeatedly (hammer hitting objects, chainsaw cutting wood, slicing onion), artistic performances (hula hooping, juggling soccer ball), sports (playing ping pong and tennis) and many others. Figure 6 illustrates some examples from the dataset as well as the distribution of repetition counts and period lengths.
Countix包含各类重复动作视频:健身活动(深蹲、引体向上、战绳训练、手臂锻炼)、舞蹈动作(旋转、挥拳)、乐器演奏(弹奏尤克里里)、重复使用工具(锤击物体、电锯伐木、切洋葱)、艺术表演(转呼啦圈、颠足球)以及体育运动(打乒乓球和网球)等。图6展示了数据集中的部分示例,以及重复次数和周期时长的分布情况。
Dataset Collection: The Countix dataset is a subset of the Kinetics [23] dataset annotated with segments of repeated actions and corresponding counts. During collection we first manually choose a subset of classes from Kinetics which have a higher chance of repetitions happening in them for e.g. jumping jacks, slicing onion etc., rather than classes like head stand or alligator wrestling.
数据集收集:Countix数据集是Kinetics [23]数据集的一个子集,标注了重复动作片段及对应计数。在收集过程中,我们首先从Kinetics中手动筛选出更可能包含重复动作的类别(如开合跳、切洋葱等),而非倒立或鳄鱼摔跤等类别。
We crowd-source the labels for repetition segments and counts for the selected classes. The interface used is similar to what is typically used to mark out temporal segments for fine-grained action recognition[16, 36]. The annotators are asked to first segment the part of the video that contains valid repetitions with unambiguous counts. The annotators then proceed to count the number of repetitions in each segment. This count serves as the label for the entire clip. We reject segments with insignificant overlap in the temporal extents marked out by 3 different annotators. For the remaining segments, we use the median of the count annotations and segment extents as the ground truth. The Countix dataset is about 90 times bigger than the previous largest repetition counting dataset (QUVA Repetition Dataset). The detailed statistics can be viewed in Table 1. The dataset is available on the project webpage.
我们对选定类别的重复片段和计数进行了众包标注。标注界面类似于细粒度动作识别中常用的时间片段标记工具[16, 36]。标注者需先分割出包含明确可计数重复动作的视频片段,随后统计每个片段的重复次数作为整段视频的标签。对于3位标注者标记时间范围重合度不足的片段,我们予以剔除。其余片段则采用计数标注和中位时间范围作为真实值。Countix数据集规模是此前最大重复计数数据集(QUVA Repetition Dataset)的90倍,详细统计数据见表1。数据集可通过项目网页获取。
Note that we retain the train/val/test splits from the Kinetics dataset. Hence, models pre-trained with Kinetics may be used for training counting models without data leakage.
请注意,我们保留了Kinetics数据集中的训练/验证/测试划分。因此,使用Kinetics预训练的模型可用于训练计数模型,而不会出现数据泄露。
6. Experiments
6. 实验
We start by explaining the existing benchmarks and the evaluation metrics used in repetition counting. We next present a series of ablation studies that demonstrate which components and design choices are crucial. Then we compare our performance on the existing benchmarks and show that RepNet clearly outperforms the state-of-the-art methods on repetition counting and periodicity detection. Finally, through qualitative analysis, we bring more insight into our model.
我们首先解释现有的基准测试和重复计数中使用的评估指标。接着通过一系列消融实验,展示哪些组件和设计选择至关重要。随后在现有基准上对比我们的性能表现,证明RepNet在重复计数和周期性检测任务上明显优于当前最优方法。最后通过定性分析,进一步揭示模型的内部机制。

Figure 6: Countix dataset. In the left two columns, we present examples of repeating videos from the Countix dataset. The last column shows the distribution of the number of the videos in the dataset with respect to the count and the period length labels.
图 6: Countix数据集。左侧两列展示了Countix数据集中重复视频的示例。最后一列显示了数据集中视频数量相对于计数和周期长度标签的分布情况。
| QUVA | Countix | |
| No.ofVideosinTrainset No.ofVideosinVal.set No.ofVideos inTest set | 0 0 100 | 4588 1450 2719 |
| Duration Avg.± Std (s) DurationMin./Max.(s) Count Avg ± Std CountMin./Max. | 17.6± 13.3 2.5/ 64.2 12.5±10.4 4/63 | 6.13 ±3.08 0.2/10.0 6.84 ±6.76 2/73 |
Table 1: Statistics of Countix and QUVA Repetition datasets.
| QUVA | Countix | |
|---|---|---|
| 训练集视频数量 验证集视频数量 测试集视频数量 | 0 0 100 | 4588 1450 2719 |
| 时长平均值±标准差 (秒) 时长最小值/最大值 (秒) 计数平均值±标准差 计数最小值/最大值 | 17.6±13.3 2.5/64.2 12.5±10.4 4/63 | 6.13±3.08 0.2/10.0 6.84±6.76 2/73 |
表 1: Countix和QUVA重复数据集统计信息。
6.1. Benchmarks and Evaluation Metrics
6.1. 基准测试与评估指标
Here we discuss two established benchmark datasets for periodicity detection and repetition counting together with the commonly used evaluation metrics.
我们在此讨论两个用于周期性检测和重复计数的成熟基准数据集,以及常用的评估指标。
Periodicity detection: The benchmark dataset for this task is the PERTUBE dataset [33], which has per frame labels identifying periodicity, if the frame is a part of a repeating action or not. [33] casts the problem as a binary per frame classification task and reports precision, recall, F1 score and overlap. We follow the same metrics for evaluation.
周期性检测:该任务的基准数据集是PERTUBE数据集 [33],该数据集包含逐帧标签用于识别周期性,即判断该帧是否属于重复动作的一部分。[33] 将该问题视为二元逐帧分类任务,并报告了精确率、召回率、F1分数和重叠率。我们采用相同的指标进行评估。
Repetition counting: As discussed in Section 5, the QUVA dataset [37] is the largest available dataset for repetition counting. The existing literature uses two main metrics for evaluating repetition counting in videos:
重复计数:如第5节所述,QUVA数据集[37]是目前可用于重复计数的最大数据集。现有文献主要采用两种指标来评估视频中的重复计数:
Off-By-One (OBO) count error. If the predicted count is within one count of the ground truth value, then the video is considered to be classified correctly, otherwise it is a misclassification. The OBO error is the mis-classification rate over the entire dataset.
计数误差容限 (OBO)。若预测计数与真实值相差不超过1,则认为视频分类正确,否则视为误分类。OBO误差即整个数据集上的误分类率。
Mean Absolute Error (MAE) of count. This metric measures the absolute difference between the ground truth count and the predicted count, and then normalizes it by dividing with the ground truth count. The reported MAE error is the mean of the normalized absolute differences over the entire dataset.
计数平均绝对误差(MAE)。该指标通过计算真实计数值与预测计数值之间的绝对差,再除以真实计数值进行归一化处理。报告的MAE误差是整个数据集归一化绝对差的平均值。
Both in our ablation experiments and state-of-the-art comparisons we follow [27, 37] and report OBO and MAE errors over the QUVA and Countix validation set. We also provide a final score on the Countix test set in Table 7.
在我们的消融实验和前沿对比中,我们遵循[27, 37]的做法,报告了QUVA和Countix验证集上的OBO和MAE误差。此外,我们在表7中提供了Countix测试集的最终得分。
6.2. Implementation Details
6.2. 实现细节
We implement our method in Tensorflow [1]. We initialize the encoder with weights from an ImageNet pre-trained ResNet-50 checkpoint. We train the model for $400K$ steps with a learning rate of $6\times10^{-6}$ with the ADAM optimizer and batch size of 5 videos (each with 64 frames). For all ablation studies we train the model on the synthetic repetition data unless otherwise stated. Additional details are provided on the project webpage.
我们在Tensorflow [1]中实现了该方法。编码器使用ImageNet预训练的ResNet-50检查点权重进行初始化。采用ADAM优化器,以$6\times10^{-6}$的学习率、每批5个视频(每个视频64帧)的批量大小训练模型$400K$步。除非另有说明,所有消融实验均在合成重复数据上训练模型。更多细节详见项目网页。
6.3. Ablations
6.3. 消融实验
We perform a number of ablations to justify the decisions made while designing RepNet.
我们对RepNet设计过程中的决策进行了多项消融实验以验证其合理性。
Temporal Self-similarity Matrix (TSM): In Table 2 we compare the impact of adding the TSM to the model. Models without the TSM apply the transformer directly on the per-frame embeddings produced by the encoder. The temporal self-similarity matrix substantially improves performance on all metrics and validation datasets whether we train the model using synthetic repetition videos, real Countix videos or a mix of both. Moreover, the TSM layer helps in generalizing to real repetition videos even when the model has only seen synthetic repetition videos (rows 1 and 2 in Table 2).
时间自相似矩阵 (TSM): 表2中我们比较了添加TSM对模型的影响。未使用TSM的模型直接在编码器生成的逐帧嵌入上应用Transformer。无论使用合成重复视频、真实Countix视频还是两者混合训练模型,时间自相似矩阵都能显著提升所有指标和验证数据集上的性能。此外,即使模型仅见过合成重复视频(表2第1、2行),TSM层也有助于泛化到真实重复视频场景。
Training Data Source: We vary the training data sources in Table 2 while comparing our synthetic repetition videos with real ones from the Countix dataset. We find that RepNet achieves similar performance on the Countix dataset when trained with synthetic videos or with the real repetition videos of the Countix dataset. But the model trained on Countix dataset is worse on the QUVA dataset compared to training on synthetic repeating videos. This shows using a synthetic repeating dataset results in a model that performs competitively on unseen classes as well. The best performance in terms of OBO error is achieved when the model is trained with both the datasets.
训练数据来源:如表 2 所示,我们在对比合成重复视频与 Countix 数据集中的真实视频时,采用了不同的训练数据来源。研究发现,无论是使用合成视频还是 Countix 数据集中的真实重复视频进行训练,RepNet 在 Countix 数据集上的表现相近。但若仅使用 Countix 数据集训练,模型在 QUVA 数据集上的表现会逊色于使用合成重复视频训练的情况。这表明采用合成重复数据集训练的模型在未见类别上同样具备竞争力。当同时使用两个数据集进行训练时,模型在 OBO 误差指标上达到了最佳性能。
Alternative Period Prediction Architectures: In Table 3, we compare the transformer architecture with other contemporary sequence models like LSTM and Temporal CNNs. We also compare it with a model that uses a 2D CNN on the self-similarity matrix itself. We find that the transformer architecture performs better than these alternatives.
替代周期预测架构:表3中,我们将Transformer架构与LSTM、时序CNN等当代序列模型进行对比,同时对比了直接在自相似矩阵上应用2D CNN的模型。结果表明Transformer架构性能优于这些替代方案。
Camera Motion Augmentation: In Table 4 we show the value of camera motion augmentation when using the synthetic repeating dataset. We observe that performance on both datasets improves when the fraction of samples in the batch with camera motion augmentation is increased.
相机运动增强:表4展示了使用合成重复数据集时相机运动增强的效果。我们观察到,当批次中采用相机运动增强的样本比例增加时,两个数据集的性能均有所提升。
Table 2: Ablation of architecture with or without the temporal self-similarity matrix (TSM) with different training data sources.
| QUVA | Countix(Val) | ||||
| TSM | TrainingDataSource | MAE | OBO | MAE | OBO |
| Synthetic Synthetic | 1.2853 0.1035 | 0.64 0.17 | 1.1671 0.3100 | 0.5510 0.2903 | |
| Countix Countix | 0.7584 0.3225 | 0.72 0.34 | 0.6483 0.3468 | 0.5448 0.2949 | |
| Synthetic+Countix Synthetic+Countix | 0.6388 0.1315 | 0.57 0.15 | 0.8889 0.3280 | 0.4848 0.2752 | |
表 2: 使用不同训练数据源时,带或不带时间自相似矩阵 (TSM) 的架构消融实验。
| TSM | TrainingDataSource | QUVA MAE | QUVA OBO | Countix(Val) MAE | Countix(Val) OBO |
|---|---|---|---|---|---|
| Synthetic | 1.2853 | 0.64 | 1.1671 | 0.5510 | |
| Synthetic | 0.1035 | 0.17 | 0.3100 | 0.2903 | |
| Countix | 0.7584 | 0.72 | 0.6483 | 0.5448 | |
| Countix | 0.3225 | 0.34 | 0.3468 | 0.2949 | |
| Synthetic+Countix | 0.6388 | 0.57 | 0.8889 | 0.4848 | |
| Synthetic+Countix | 0.1315 | 0.15 | 0.3280 | 0.2752 |
Table 3: Performance of different period prediction architectures when trained with synthetic data.
| QUVA | Countix(Val) | |||
| Architecture | MAE | OBO | MAE | OBO |
| Transformer | 0.1035 | 0.17 | 0.3100 | 0.2903 |
| LSTM [20] | 0.1395 | 0.18 | 0.6895 | 0.3579 |
| 2DCNN | 0.1186 | 0.17 | 0.4440 | 0.3310 |
| 1D Temporal CNN | 0.3229 | 0.23 | 0.7077 | 0.3641 |
表 3: 使用合成数据训练时不同周期预测架构的性能表现
| 架构 | QUVA MAE | QUVA OBO | Countix(Val) MAE | Countix(Val) OBO |
|---|---|---|---|---|
| Transformer | 0.1035 | 0.17 | 0.3100 | 0.2903 |
| LSTM [20] | 0.1395 | 0.18 | 0.6895 | 0.3579 |
| 2DCNN | 0.1186 | 0.17 | 0.4440 | 0.3310 |
| 1D Temporal CNN | 0.3229 | 0.23 | 0.7077 | 0.3641 |
| QUVA | Countix(Val) | |||
| AugmentationFraction | MAE | OBO | MAE | OBO |
| 0.00 | 0.7178 | 0.32 | 1.2629 | 0.4683 |
| 0.25 | 0.1414 | 0.17 | 0.4430 | 0.3303 |
| 0.50 | 0.1202 | 0.15 | 0.3729 | 0.2993 |
| 0.75 | 0.1035 | 0.17 | 0.3100 | 0.2903 |
| 1.00 | 0.1710 | 0.17 | 0.3346 | 0.2848 |
Table 4: Impact of camera motion augmentation when trained with synthetic data.
| QUVA | Countix(Val) | |||
|---|---|---|---|---|
| AugmentationFraction | MAE | OBO | MAE | OBO |
| 0.00 | 0.7178 | 0.32 | 1.2629 | 0.4683 |
| 0.25 | 0.1414 | 0.17 | 0.4430 | 0.3303 |
| 0.50 | 0.1202 | 0.15 | 0.3729 | 0.2993 |
| 0.75 | 0.1035 | 0.17 | 0.3100 | 0.2903 |
| 1.00 | 0.1710 | 0.17 | 0.3346 | 0.2848 |
表 4: 使用合成数据训练时相机运动增强的影响。
6.4. Evaluation on Benchmarks
6.4. 基准测试评估
We compare our system with the current state-of-the-art methods on periodicity detection and repetition counting on the established benchmarks described in Section 6.1.
我们在第6.1节描述的基准测试上,将本系统与当前最先进的周期性检测和重复计数方法进行了对比。
Periodicity Detection. We report the performance for measuring periodicity classification by choosing the threshold that maximizes the F1 score. As done in [33] we calculate the metrics on a per video basis and average the scores. We also report Area Under the Curve (AUC) of the precisionrecall curve which is independent of the threshold chosen.
周期性检测。我们通过选择使F1分数最大化的阈值来报告周期性分类的性能测量结果。按照[33]中的方法,我们以每个视频为基础计算指标并平均得分。同时我们还报告了精确率-召回率曲线下面积(AUC),该指标与所选阈值无关。
Figure 7: 1D PCA projections of the encoder features over time. Note that even 1D projections of the learned features are encoding the periodicity fairly well. Frames with similar embeddings across different periods show similar states in the video (angle of rotation of biker, position of legs of person and position of knife). Best viewed with zoom. Video version on webpage here.
图 7: 编码器特征随时间变化的一维PCA投影。请注意,即使是学习特征的一维投影也能很好地编码周期性。不同周期中具有相似嵌入的帧在视频中显示出相似状态(骑行者旋转角度、人物腿部位置和刀具位置)。建议放大查看。网页版视频链接在此。
Our model produces an AUC of 0.969. We outperform the previous work without using any hand-designed filtering methods mentioned in [33] (see Table 5). Our model trained entirely on synthetic data works out of the box for the task of periodicity detection in real videos.
我们的模型取得了0.969的AUC值。在不使用[33]中任何人工设计过滤方法的情况下(见表5),我们超越了先前的工作。完全基于合成数据训练的模型可直接用于真实视频中的周期性检测任务。
Repetition Counting. In Table 6 we compare our RepNet model with previous models and show it outperforms existing methods by a significant margin and therefore establishing a new state-of-the-art for this dataset. Experimental results on the test set of Countix dataset indicate that RepNet is an effective baseline for the video repetition counting task (see Table 7).
重复计数。在表6中,我们将RepNet模型与先前模型进行比较,结果表明它以显著优势超越现有方法,从而为该数据集确立了新的性能标杆。Countix数据集测试集的实验结果表明,RepNet是视频重复计数任务的有效基线(见表7)。
| Model | Recall | Precision | F1 | |Overlap |
| Power spectrum baseline [33] | 0.793 | 0.611 | 0.668 | 0.573 |
| P-MUCOS[33] | 0.841 | 0.757 | 0.77 | 0.677 |
| RepNet (Ours) | 0.859 | 0.821 | 0.820 | 0.731 |
Table 5: Periodicity detection results on the PERTUBE Dataset
| 模型 | 召回率 (Recall) | 精确率 (Precision) | F1值 (F1) | 重叠率 (Overlap) |
|---|---|---|---|---|
| Power spectrum baseline [33] | 0.793 | 0.611 | 0.668 | 0.573 |
| P-MUCOS[33] | 0.841 | 0.757 | 0.77 | 0.677 |
| RepNet (Ours) | 0.859 | 0.821 | 0.820 | 0.731 |
表 5: PERTUBE数据集上的周期性检测结果
| Model | MAE | OBO |
| Visual quasi-periodicity [35] | 0.385 | 0.51 |
| Live Repetition Counting [27] Div-Grad-Curl [37] | 0.482 | 0.55 |
| RepNet (Ours) | 0.232 0.104 | 0.38 0.17 |
Table 6: Counting Results on the QUVA dataset.
| 模型 | 平均绝对误差 (MAE) | 最优边界重叠率 (OBO) |
|---|---|---|
| 视觉准周期性 [35] | 0.385 | 0.51 |
| 实时重复计数 [27] Div-Grad-Curl [37] | 0.482 | 0.55 |
| RepNet (本文) | 0.232 0.104 | 0.38 0.17 |
表 6: QUVA数据集上的计数结果
| Model | MAE | OBO |
| RepNet | 0.3641 | 0.3034 |
Table 7: Counting Results on the Countix test set.
表 7: Countix测试集上的计数结果。
| 模型 | MAE | OBO |
|---|---|---|
| RepNet | 0.3641 | 0.3034 |
6.5. Qualitative analysis
6.5. 定性分析
Temporal Self-similarity Matrix. TSM provides us with meaningful interpretations about the model’s predictions. It also contains additional information regarding acceleration and deceleration of the action. We show some examples of self-similarity matrices in Figure 3.
时间自相似矩阵 (Temporal Self-similarity Matrix)。TSM 能帮助我们理解模型的预测行为,同时包含动作加速与减速的附加信息。图 3 展示了若干自相似矩阵的示例。

Figure 8: One model, many domains and applications. A single model is capable of performing these tasks over videos from many diverse domains (animal movement, physics experiments, humans manipulating objects, people exercising, child swinging) in a classagnostic manner. Please see the project webpage for videos showcasing these tasks.
图 8: 单一模型的多领域应用。单个模型能够以类别无关的方式,在多种不同领域(动物运动、物理实验、人类操作物体、人员锻炼、儿童荡秋千)的视频上执行这些任务。具体任务展示视频请参阅项目网页。
1D PCA Embeddings. We also investigate the learned embeddings which are used to produce the TSM. In Figure 7, we project the 512 dimensional vector to 1 dimension using the first principal component of the per-frame embeddings for each video. This reveals interesting quasi-sinusoidal patterns traced out by the embeddings in time. We plot the frames when the embeddings are changing directions and observe that the retrieved frames show the person or object in a similar state but in different periods.
一维PCA嵌入。我们还研究了用于生成TSM的学习嵌入。在图7中,我们使用每帧嵌入的第一主成分将512维向量投影到1维空间。这揭示了嵌入随时间变化呈现出的准正弦波模式。当嵌入方向发生改变时,我们绘制了对应帧,发现检索到的帧显示了人物或物体处于相似状态但处于不同时期。
Double Counting Errors. We observe that a common failure mode of our model is that for some actions (e.g. juggling soccer ball), it predicts half the count reported by annotators. This happens when the model considers left and right legs’ motion for counting while people tend to consider the ball’s up/down motion resulting in people double counting the repetitions. We believe such errors are difficult to isolate in a class-agnostic manner. But they can be fixed easily with either labeled data or post-processing methods if the application is known.
重复计数错误。我们观察到模型的一个常见失效模式是:对于某些动作(如颠足球),其预测次数仅为标注者报告次数的一半。这种现象源于模型基于左右腿运动计数,而人类习惯根据球的上下运动计数,导致重复计数。我们认为这类错误难以以类别无关的方式单独处理,但若已知具体应用场景,通过标注数据或后处理方法可轻松修正。
7. Applications
7. 应用
Predict speed changes of repetitions. Our method takes in a video clip and predicts the period of any repeated action. The consecutive difference of predicted rates encodes the rate of speed change of the repetitions. Monitoring speed changes is useful for exercise tracking applications where it might be important to know if someone is speeding up or slowing down (Column 4 in Figure 8).
预测重复动作的速度变化。我们的方法通过输入视频片段来预测任何重复动作的周期,预测速率的连续差值编码了重复动作的速度变化率。监测速度变化对运动追踪应用非常有用,例如了解某人是否在加速或减速(图8第4列)。
Estimating frequency of processes from videos. Our model can be used to predict the count and frequency of repeating phenomena from videos for e.g. biological processes (heartbeats). [50] presented a method to reveal subtle changes by magnifying the difference in frames. We find that the output from the above system can be fed directly into our model to predict the frequency of these changes. A class-agnostic period estimator removes the need to explicitly train on these videos. On our project webpage, we show examples of repetition counting on echo-cardiogram videos which look very different from Kinetics videos .
从视频中估计过程频率。我们的模型可用于预测视频中重复现象(如生物过程的心跳)的计数和频率。[50]提出了一种通过放大帧间差异来揭示细微变化的方法。我们发现该系统的输出可直接输入我们的模型,以预测这些变化的频率。类别无关的周期估计器无需对这些视频进行显式训练。在项目网页中,我们展示了与Kinetics视频差异显著的心电图视频重复计数示例。
Fine-grained cross-period retrieval. The learned embeddings are useful for performing cross-period retrieval. In other words, the features capture similarities present across different periods while still encoding subtle differences between similar looking frames. Examples of these retrievals are shown in Figure 7 and the last column in Figure 8.
细粒度跨时期检索。学习到的嵌入向量可用于执行跨时期检索。换句话说,这些特征捕捉了不同时期之间的相似性,同时仍能编码外观相似帧之间的细微差异。图7和图8最后一栏展示了这些检索的示例。
Repetitions with longer temporal extent. Many repeating phenomena occur over a longer temporal scale (in the order of days or years). Even though our model has been trained on short videos $(\sim10\mathrm{s})$ , it can still work on videos with slow periodic events by automatically choosing a higher input frame stride. On the project webpage, we show videos where RepNet predicts the period length of a day from videos of the earth captured by satellites.
时间跨度较长的重复模式。许多重复现象发生在更长的时间尺度上(以天或年为单位)。尽管我们的模型是在短视频 $(\sim10\mathrm{s})$ 上训练的,它仍能通过自动选择更高的输入帧步长来处理缓慢周期性事件的视频。在项目网页中,我们展示了RepNet从卫星拍摄的地球视频中预测一天周期长度的案例。
Aid self-supervised video representation learning. Selfsupervised learning methods for video embeddings, e.g. Shuffle and Learn [31], Odd-One-Out networks [14], DPC [17], TCC [11] and TCN [39] are not designed to handle repetitions in sequences. RepNet can identify the repeating sections and may help in training on videos with repetitions without modifying the proposed objectives.
辅助自监督视频表征学习。现有视频嵌入的自监督学习方法(如Shuffle and Learn [31]、Odd-One-Out网络 [14]、DPC [17]、TCC [11]和TCN [39])并非为处理序列重复而设计。RepNet能识别重复片段,可在不改变既定训练目标的前提下,有效提升含重复内容视频的训练效果。
8. Conclusion
8. 结论
We have shown a simple combination of synthetic training data, together with an architecture using temporal selfsimilarity, results in a powerful class-agnostic repetition counting model. This model successfully detects periodicity and predicts counts over a diverse set of actors (objects, humans, animals, the earth) and sensors (standard camera, ultrasound, laser microscope) and has been evaluated on a vast collection of videos. With this we have addressed the case of simple repetitions, and the next step is to consider more complex cases such as multiple simultaneous repeating signals and temporal arrangements of repeating sections such as in dance steps and music.
我们展示了一种简单的合成训练数据组合,结合使用时序自相似性架构,能够构建出强大的类别无关重复计数模型。该模型成功检测了周期性,并在多样化主体(物体、人类、动物、地球)和传感器(标准相机、超声波、激光显微镜)上实现了计数预测,且已在大量视频集上完成评估。该方法解决了简单重复场景的计数问题,下一步将研究更复杂的情况,例如多重同步重复信号以及舞蹈步伐、音乐等场景中重复片段的时序排列。
Acknowledgements: We thank Aishwarya Gomatam, Anelia Angelova, Meghana Thotakuri, Relja Ar and j elo vic, Shefali Umrania, Sourish Chaudhuri, and Vincent Vanhoucke for their help with this project.
致谢:我们感谢Aishwarya Gomatam、Anelia Angelova、Meghana Thotakuri、Relja Ar和j elo vic、Shefali Umrania、Sourish Chaudhuri以及Vincent Vanhoucke对本项目的帮助。
References
参考文献
Appendix
附录
On our project webpage we provide visualization s of qualitative results, dataset samples, and 1D PCA visualizations.
在我们的项目网页上,我们提供了定性结果的可视化、数据集样本和一维PCA (Principal Component Analysis) 可视化。
A. Qualitative Results
A. 定性结果
All examples below have been created with a single model trained only with synthetic data.
以下所有示例均由仅使用合成数据训练的单一模型生成。
A.1. Counting on Videos with Different Sensors
A.1. 基于不同传感器的视频计数
We provide examples of our model on different sensors: Echo cardiogram. RepNet can estimate the heartbeat rate from echo cardiogram videos. We find the predicted heartrates close to the true heart rate measured by the device itself (link to videos) . Note how the same model works across different ECG machines.
我们提供了模型在不同传感器上的示例:心电图 (Echo cardiogram)。RepNet 可以从心电图视频中估算心率。我们发现预测心率与设备本身测量的真实心率非常接近 (视频链接)。请注意同一模型在不同心电图设备上的表现。
Laser Microscope. We found videos of repeating biological phenomena in [18] where they observed a cellular phenomena under the laser microscope which results in spiral patterns in the video. We find that our model works out of the box measuring the rate at which the spirals are rotating. The model also captures the speed change in the process being measured (link to videos).
激光显微镜。我们在[18]中发现了记录重复生物现象的视频,研究者通过激光显微镜观察到细胞活动在视频中形成了螺旋图案。我们的模型无需调整即可直接测算螺旋旋转速率,同时能捕捉被测过程中的速度变化(视频链接)。
Eulerian Magnified Videos Our model works on videos produced by using Eulerian magnification to highlight subtle changes in time [50]. We show RepNet can count on those videos without further training (link to videos).
欧拉放大视频
我们的模型适用于通过欧拉放大技术突出时间维度细微变化的视频[50]。实验表明RepNet无需额外训练即可对这些视频进行计数(视频链接)。
A.2. Physics Experiments with RepNet
A.2. 使用RepNet进行物理实验
We show examples of 2 videos where pendulums of different lengths are swung. The ratio of time periods can be used to predict the ratio of lengths of the pendulums. Our model can replace the step in which the people conducting the experiment measure time period with a stopwatch. We conduct the experiment from the video ourselves and find the ratio of time periods of the long to short pendulum using the period lengths predicted by our model to be 1.566. Based on the physics equations of oscillations of pendulums, the expected approximate ratio of the periods using approximation of the length of pendulum (from pixels in the video) is 1.612. We provide details in the experiments (here).
我们展示了两个不同长度钟摆摆动视频的示例。通过周期比可预测钟摆长度比,我们的模型能替代实验人员用秒表测量周期的步骤。我们亲自从视频中开展实验,根据模型预测的周期值得出长/短钟摆周期比为1.566。根据钟摆振荡的物理方程,基于视频像素估算的钟摆长度所得理论周期比近似值为1.612。实验细节详见(此处)。
A.3. Consistent Multi-view Period Predictions
A.3. 一致的多视角周期预测
We test our model of different views capturing the collapse of the Tacoma Bridge in 1940 due to resonance. Our model recovers the frequency of repetition from different viewpoints robustly (link to videos).
我们测试了模型从不同视角捕捉1940年塔科马大桥因共振坍塌的情况。该模型能稳健地从多视角重建振动频率(视频链接)。
A.4. Inspecting Changes over Periods
A.4. 检查周期变化
RepNet takes input of satellite image representation (released by NASA Goddard) of the ice-cover on the Arctic over the period of 25 years and predicts the period to be roughly 1 year. In Figure 9, we show frames that the model
RepNet以25年间北极冰盖的卫星图像表征(由NASA Goddard发布)作为输入,预测周期约为1年。在图9中,我们展示了模型...
A.5. Video Galleries
A.5. 视频库
We also provide video galleries with the following visualizations:
我们还提供包含以下可视化内容的视频库:
- 1D PCA of the embeddings in time (link to videos) 2. Learned Temporal Self-similarity Matrices (TSMs) of different videos (link to videos)
- 嵌入向量随时间变化的一维主成分分析 (PCA) (附视频链接)
- 不同视频的学习时间自相似矩阵 (TSM) (附视频链接)
B. Ablations
B. 消融实验
B.1. Removing Countix Classes from Synthetic Data
B.1. 从合成数据中移除Countix类别
We show that removing the classes used in Countix from the pool of classes used for creating the synthetic data has marginal impact on performance (see Table 8). This shows that generalization of the RepNet model does not require the presence of Countix classes in the synthetic dataset highlighting the class-agnostic aspect of our model.
我们发现,从创建合成数据所用的类别池中移除Countix使用的类别对性能影响甚微(见表8)。这表明RepNet模型的泛化能力并不依赖于合成数据集中存在Countix类别,凸显了我们模型的类别无关特性。
| QUVA | Countix (Val) | |||
| Training Classes | MAE | OBO | MAE | OBO |
| Kinetics | 0.1035 | 0.17 | 0.3100 | 0.2903 |
| Kinetics without Countix Classes | 0.1181 | 0.17 | 0.3751 | 0.2993 |
Table 8: Effect of removing Countix classes from synthetic training data is marginal.
| 训练类别 | QUVA MAE | QUVA OBO | Countix (Val) MAE | Countix (Val) OBO |
|---|---|---|---|---|
| Kinetics | 0.1035 | 0.17 | 0.3100 | 0.2903 |
| 不含Countix类别的Kinetics | 0.1181 | 0.17 | 0.3751 | 0.2993 |
表 8: 从合成训练数据中移除Countix类别的影响较小。
B.2. ImageNet Pre-training
B.2. ImageNet 预训练
We evaluate the importance of ImageNet pre training for the RepNet model and report the results in Table 9. We find that if we train the model completely from scratch (Row 2) we achieve performance that is $4%$ worse than with pretraining (Row 4). This performance still exceeds the current state of the art methods in repetition counting. Also, ImageNet initialization of the encoder without any further training (Row 3) is good enough for the repetition counting task due to the subsequent modules (TSM and transformer).
我们评估了ImageNet预训练对RepNet模型的重要性,并在表9中报告了结果。我们发现,如果完全从头开始训练模型(第2行),其性能比使用预训练时(第4行)差4%。尽管如此,该性能仍超过了当前重复计数领域的最先进方法。此外,由于后续模块(TSM和Transformer)的存在,仅使用ImageNet初始化编码器而不进行任何额外训练(第3行)对于重复计数任务来说已经足够好。
| QUVA | Countix (Val) | ||||
| TrainbaseCNN | ImageNet Pre-trained | MAE | OBO | MAE | OBO |
| 0.3097 | 0.30 | 0.4928 | 0.3938 | ||
| 0.1394 | 0.20 | 0.3877 | 0.3290 | ||
| 0.1270 | 0.19 | 0.3178 | 0.2910 | ||
| 人 | 0.1035 | 0.17 | 0.3100 | 0.2903 | |
Table 9: Ablation of pre-training with ImageNet and training the base network or not. For all experiments, we train the 3D conv and period prediction module.
| QUVA | Countix (Val) | ||||
|---|---|---|---|---|---|
| TrainbaseCNN | ImageNet Pre-trained | MAE | OBO | MAE | OBO |
| 0.3097 | 0.30 | 0.4928 | 0.3938 | ||
| 0.1394 | 0.20 | 0.3877 | 0.3290 | ||
| 0.1270 | 0.19 | 0.3178 | 0.2910 | ||
| 人 | 0.1035 | 0.17 | 0.3100 | 0.2903 |
表 9: 使用ImageNet进行预训练及是否训练基础网络的消融实验。所有实验均训练了3D卷积和周期预测模块。

Figure 9: Arctic Ice Cover Trends. RepNet extracts frames that are each one period away showing decreasing ice cover over the years.
图 9: 北极冰盖变化趋势。RepNet 提取间隔一个周期的帧序列,逐年呈现冰盖消退现象。
B.3. Camera Motion Augmentations
B.3. 相机运动增强
We use various camera motion augmentation techniques to the synthetic repeating videos as described in Figure 5 in main paper. We show the effect of omitting different data augmentations. Each of these methods results in about $1.5%$ to $2%$ worse OBO error and about $13%$ to $26%$ worse MAE error. Based on these experiments, we use all these augmentation techniques for rest of our experiments.
我们对合成的重复视频采用了多种相机运动增强技术,如主论文图5所述。我们展示了省略不同数据增强方法的效果。每种方法都会导致OBO误差增加约1.5%至2%,MAE误差增加约13%至26%。基于这些实验结果,我们在后续实验中采用了所有这些增强技术。
| QUVA | Countix(Val) | ||
| DataAugmentation | MAE | OBO | MAE OBO |
| With all augmentations | 0.1035 | 0.17 | 0.3100 0.2903 |
| No scale | 0.1222 | 0.18 | 0.5751 0.3193 |
| Norotation | 0.1158 | 0.16 0.4406 | 0.3041 |
| No translation | 0.1202 | 0.16 | 0.5400 0.3069 |
| Noreversedconcatenation | 0.1211 | 0.16 | 0.4449 0.3131 |
Table 10: Effect of different camera motion augmentations when trained with synthetic data.
| QUVA | Countix(Val) | ||
|---|---|---|---|
| 数据增强 (Data Augmentation) | MAE | OBO | MAE OBO |
| 使用全部增强方式 | 0.1035 | 0.17 | 0.3100 0.2903 |
| 无缩放 | 0.1222 | 0.18 | 0.5751 0.3193 |
| 无旋转 | 0.1158 | 0.16 0.4406 | 0.3041 |
| 无平移 | 0.1202 | 0.16 | 0.5400 0.3069 |
| 无反向拼接 | 0.1211 | 0.16 | 0.4449 0.3131 |
表 10: 使用合成数据训练时不同相机运动增强方式的效果
B.4. Varying Number of frames
B.4. 帧数变化
In Table 11, we report results when we vary the number of frames which RepNet takes as input and find that $N=64$ frames provides us with the best performance. We use this setting for all the experiments in the main paper.
在表11中,我们报告了改变RepNet输入帧数时的结果,发现$N=64$帧能提供最佳性能。我们在主论文的所有实验中均采用此设置。
B.5. Other Architectural Choices
B.5. 其他架构选择
We also varied certain architectural choices made while designing RepNet but found they have minor impact on overall performance.
我们还调整了设计RepNet时做出的某些架构选择,但发现它们对整体性能影响较小。
| QUVA | Countix (Val) | |||
| NumFrames | MAE | OBO | MAE | OBO |
| 32 | 0.1407 | 0.22 | 0.4800 | 0.3069 |
| 64 | 0.1035 | 0.17 | 0.3100 | 0.2903 |
| 96 | 0.1094 | 0.16 | 0.4870 | 0.3097 |
| 128 | 0.1233 | 0.17 | 0.3429 | 0.3200 |
Table 11: Effect of varying number of frames in the clip.
| QUVA | Countix (Val) | |||
|---|---|---|---|---|
| NumFrames | MAE | OBO | MAE | OBO |
| 32 | 0.1407 | 0.22 | 0.4800 | 0.3069 |
| 64 | 0.1035 | 0.17 | 0.3100 | 0.2903 |
| 96 | 0.1094 | 0.16 | 0.4870 | 0.3097 |
| 128 | 0.1233 | 0.17 | 0.3429 | 0.3200 |
表 11: 视频片段帧数变化的影响。
| QUVA |
| Countix(Val) Architecture |
| MAE OBO MAE OBO |
| Baseline 0.1035 0.17 0.3100 0.2903 |
| No3D Conv. 0.1198 0.16 0.4478 0.3014 |
| No 2D Conv.beforeTransformer 0.1586 0.19 0.5039 0.3048 |
| Replace L2 dist.with cosine sim. 0.1153 0.18 0.3114 0.2972 |
Table 12: Effect of architecture variations when trained with synthetic data.
| QUVA | Countix(Val) Architecture | MAE OBO | MAE OBO |
|---|---|---|---|
| Baseline | 0.1035 | 0.17 | 0.3100 |
| No3D Conv. | 0.1198 | 0.16 | 0.4478 |
| No 2D Conv.beforeTransformer | 0.1586 | 0.19 | 0.5039 |
| Replace L2 dist.with cosine sim. | 0.1153 | 0.18 | 0.3114 |
表 12: 使用合成数据训练时架构变体的效果。
C. Implementation Details
C. 实现细节
C.1. Detailed Architecture
C.1. 详细架构
In Table 13 we present the detailed version of RepNet architecture.
表 13: RepNet架构的详细版本
C.2. Architectures of Alternative Baselines
C.2. 替代基线架构
2D CNN Baseline. Our 2D CNN consists of the following convolutional layers [32, 64, 128, 256, 512] each with filter size $3\times3$ . After each convolution layer there is a max-pooling operation of $2\times2$ size with stride 2. Global spatial average pooling is done over the final feature map which is used to classify the period length of the entire clip. We also experimented with ResNet50 architecture and got similar performance.
2D CNN基线模型。我们的2D CNN由以下卷积层组成 [32, 64, 128, 256, 512],每层使用 $3\times3$ 的滤波器尺寸。每个卷积层后接一个步长为2的 $2\times2$ 最大池化操作。在最终特征图上进行全局空间平均池化,用于分类整个片段的周期长度。我们还尝试了ResNet50架构,获得了相似的性能。
LSTM. We use the standard LSTM implemented in Tensorflow Keras library with 512 units.
LSTM。我们使用 Tensorflow Keras 库中实现的标准 LSTM (Long Short-Term Memory) ,包含 512 个单元。
1D Temporal CNN. We use 7 layers of temporal convolutions with dilation rates $[1,2,4,8,16,32,64]$ . Each convolution layer is of size 512 and has a kernel size of 2 and has batch normalization. We use skip-connections with residuals for each layer.
一维时序CNN。我们采用7层时序卷积,膨胀率依次为$[1,2,4,8,16,32,64]$。每层卷积维度为512,核大小为2,并包含批量归一化。各层均采用带残差的跳跃连接结构。
C.3. Combining Period Length and Periodicity Outputs during Inference
C.3. 推理过程中周期长度与周期性的输出结合
Our model can be used to jointly detect periodic segments in the video and count repetitions only within the repeating segments. To do so, we sample consecutive windows of $N$ frames and provide it as input to RepNet which outputs per-frame periodicity $p_{i}$ and period lengths $l_{i}$ . We define per-frame count as $\begin{array}{r}{c_{i}=\frac{1}{l_{i}}}\ {\overline{{\mathbf{\rho}}}_ {\mathrm{-}}}\end{array}$ if $p_{i}>T$ else 0, where T is a chosen threshold for the classifier. Count of the video is the sum of all per-frame counts: $\sum_{i=1}^{N}c_{i}$ .
我们的模型可用于联合检测视频中的周期性片段,并仅在重复片段内计数重复次数。为此,我们对连续的$N$帧窗口进行采样,并将其作为RepNet的输入,RepNet会输出每帧的周期性$p_{i}$和周期长度$l_{i}$。我们将每帧计数定义为$\begin{array}{r}{c_{i}=\frac{1}{l_{i}}}\ {\overline{{\mathbf{\rho}}}_ {\mathrm{-}}}\end{array}$(若$p_{i}>T$),否则为0,其中T是分类器的选定阈值。视频的总计数为所有每帧计数的总和:$\sum_{i=1}^{N}c_{i}$。
D. Dataset Details
D. 数据集详情
D.1. Countix Details
D.1. Countix 详情
The list of classes chosen for data collection while creating Countix dataset is mentioned in Table 14.
创建Countix数据集时选择用于数据收集的类别列表见表14。
| Module | Layer | Output Size | LayerParameters/Notes | ||
| Base Network | conv1 | 56×56×64 | 7×7, 64, stride 2 | ||
| conv2_x | 28×28×256 | 3×3 max pool, stride 2 | |||
| 1x1,64 3×3,64 1×1,256 | ×3 | ||||
| conv3_x | 14×14×512 | 1×1,128 3×3,128 1x1,512 | ×4 | ||
| conv4_x | 7×7×1024 | 1x1,256 3×3,256 1×1,1024 | ×3 | ||
| Temporal Context | Temporal Stacking 3D Convolution | 64×7×7× 1024 64×7×7×512 | Stack features from all frames in time axis | ||
| [3 × 3 × 3, 512], dilation rate = 3 | |||||
| Dimensionality Reduction | Spatial Pooling | 64×512 | Global 2D Max-Pool | ||
| Temporal Self-similarity Matrix | Pairwise L2 Distance | 64×64 | |||
| Multiply with -1 | 64×64 | Convert distances to similarities | |||
| Row-wise Softmax | 64×64 | Softmax temperature = 13.5 | |||
| Period Predictor | 2D Convolution | 64×64×32 | 3×3,32 | ||
| Transformer | 64×64×512 | 4 heads, 512 dims, learned positional embeddings | |||
| Flatten | 64×32768 | Shared input for following 2 layers | |||
| Period Length Classifier | 64×32 | 512 512 32 | |||
| Periodicity Classifier | 64×1 | 512 512 | |||
Table 13: Detailed Architecture of RepNet. The parameters in the form of: (1) $[n\times n,c]$ refers to 2D Convolution filter size and number of channels respectively (2) $[n\times n\times n,c]$ refers to 3D Convolution filter size and number of channels respectively (3) $[c]$ refers to channels in a fully-connected layers.
| 模块 | 层 | 输出尺寸 | 层参数/说明 |
|---|---|---|---|
| 基础网络 | conv1 | 56×56×64 | 7×7, 64, 步长 2 |
| conv2_x | 28×28×256 | 3×3 最大池化, 步长 2 | |
| 1x1,64 3×3,64 1×1,256 | |||
| conv3_x | 14×14×512 | 1×1,128 3×3,128 1x1,512 | |
| conv4_x | 7×7×1024 | 1x1,256 3×3,256 1×1,1024 | |
| 时序上下文 | 时序堆叠3D卷积 | 64×7×7×1024 64×7×7×512 | 沿时间轴堆叠所有帧特征 |
| [3 × 3 × 3, 512], 膨胀率 = 3 | |||
| 维度缩减 | 空间池化 | 64×512 | 全局2D最大池化 |
| 时序自相似矩阵 | 成对L2距离 | 64×64 | |
| 乘以-1 | 64×64 | 将距离转换为相似度 | |
| 行向Softmax | 64×64 | Softmax温度 = 13.5 | |
| 周期预测器 | 2D卷积 | 64×64×32 | 3×3,32 |
| Transformer | 64×64×512 | 4头, 512维, 学习位置嵌入 | |
| 展平 | 64×32768 | 后续2层的共享输入 | |
| 周期长度分类器 | 64×32 | 512 512 32 | |
| 周期性分类器 | 64×1 | 512 512 |
表 13: RepNet详细架构。参数形式说明: (1) $[n\times n,c]$ 表示2D卷积滤波器尺寸和通道数 (2) $[n\times n\times n,c]$ 表示3D卷积滤波器尺寸和通道数 (3) $[c]$ 表示全连接层的通道数。
| Kinetics Class Name | Description of the Repetitions |
| battle rope training | number of times the person moves the battle ropes up to down |
| bench pressing | number of times the person lifts the bar to the top |
| bouncing ball (not juggling) | number of times has bounced the ball on the foot |
| bouncing on bouncy castle | number of times a person has jumped on the bouncy castle |
| bouncing on trampoline | number of times a person has jumped on the trampoline |
| clapping | number of times someone claps |
| crawling baby | number of steps takenbybaby |
| doing aerobics | number of times an aerobic step is repeated by the group or person |
| exercising arm | number of times the exercise is done by the person |
| front raises | number of times the weights are raised to the top in front of the persons chest |
| gymnastics tumbling | number of times the gymnast completes a rotation |
| hammer throw | number of times the person rotates before throwing the hammer |
| headbanging | number of times have moved their head up and down |
| hula hooping | number of times the hula hoopmoves about a persons waist |
| juggling soccer ball | numberoftimesthesoccerballisbounced |
| jumping jacks | number of times a person completes one step of jumping jack motion |
| lunge | number of times a person completes one step of lunge action |
| mountain climber (exercise) | number of times a person completes one step of mountain climber action |
| pirouetting | number of times the person rotates about their own axis |
| planing wood | number of times someone moves their hand back and forth while planing wood |
| playing ping pong playing tennis | numberoftimestheballgoesbackandforth |
| playing ukulele | number of times the ball goes back and forth |
| pull ups pumping fist | number of pull ups by counting the number of times a person reaches the top of the trajectory |
| push up | number of times people move their fists |
| rope pushdown | number of pull ups by counting the number of times a person reaches the top of the trajectory |
| running on treadmill | number of times a person pulls down on the rope, count how many times they reach the bottom of the trajectory |
| number of steps/strides taken by a person | |
| sawing wood | number of times the saw goes back and forth |
| shaking head | number of times a person shakes their head |
| shoot dance | number of times a person completes a dance step |
| situp skiing slalom | number of times a person completes a situp motion, count the number of times the person reaches top of trajectory |
| skipping rope | number of times a person bends to the side to change direction of velocity |
| slicing onion | number of times a person skips the rope, count the number of times the rope is at the top of trajectory |
| spinning poi | number of times the knife slices the onions |
| number of rotations completed by the lights | |
| squat | number of times a person squats, count the number of times they reached the bottom of the trajectory |
| swimmingbutterfly stroke | number of times a person does a butterfly stroke |
| swimming front crawl | number of times a person does a front crawl |
| swinging on something | number of times a swing is completed, count the number of times the person is nearest to the camera |
| tapping pen | number of times a person taps the pen |
| triple jump | number of jumps done by person |
| using a wrench | number of times a wrench is rotated |
| using a sledge hammer | number of times a sledge hammer is brought down on an object, count the number of times the hammer hits the object |
Table 14: Classes present in the Countix dataset along with descriptions of repetitions contained in them.
| 动作类别名称 | 重复次数描述 |
|---|---|
| 战绳训练 | 人员上下摆动战绳的次数 |
| 卧推 | 人员将杠铃推举至顶端的次数 |
| 颠球(非杂耍) | 用脚部颠球的次数 |
| 充气城堡弹跳 | 人员在充气城堡上跳跃的次数 |
| 蹦床弹跳 | 人员在蹦床上跳跃的次数 |
| 鼓掌 | 人员鼓掌的次数 |
| 婴儿爬行 | 婴儿爬行的步数 |
| 有氧运动 | 个人或团体重复有氧动作的次数 |
| 手臂锻炼 | 人员完成锻炼动作的次数 |
| 前平举 | 将重物举至胸前顶端的次数 |
| 体操翻滚 | 体操运动员完成旋转的次数 |
| 链球投掷 | 投掷前人员旋转的次数 |
| 甩头 | 头部上下摆动的次数 |
| 呼啦圈 | 呼啦圈绕腰部转动的次数 |
| 足球颠球 | 足球被颠起的次数 |
| 开合跳 | 人员完成开合跳单次动作的次数 |
| 弓步 | 人员完成弓步单次动作的次数 |
| 登山者训练 | 人员完成登山者单次动作的次数 |
| 单足旋转 | 人员绕自身轴心旋转的次数 |
| 刨木 | 刨木时手部前后移动的次数 |
| 乒乓球/网球对打 | 球体来回运动的次数 |
| 演奏尤克里里 | 球体来回运动的次数 |
| 引体向上/振拳 | 通过计算人员到达轨迹顶端的次数统计引体向上次数 |
| 俯卧撑 | 人员移动拳头的次数 |
| 绳索下拉 | 通过计算人员到达轨迹顶端的次数统计引体向上次数 |
| 跑步机跑步 | 人员下拉绳索的次数,计算到达轨迹底端的次数 |
| 人员迈步/跨步的次数 | |
| 锯木 | 锯子前后移动的次数 |
| 摇头 | 人员摇头的次数 |
| 射击舞 | 人员完成舞蹈单步的次数 |
| 仰卧起坐/滑雪回转 | 人员完成仰卧动作的次数,计算到达轨迹顶端的次数 |
| 跳绳 | 人员侧身改变速度方向的次数 |
| 切洋葱 | 人员跳绳的次数,计算绳子到达轨迹顶端的次数 |
| 火球旋转 | 刀具切洋葱的次数 |
| 灯光完成旋转的次数 | |
| 深蹲 | 人员下蹲的次数,计算到达轨迹底端的次数 |
| 蝶泳 | 人员完成蝶泳动作的次数 |
| 自由泳 | 人员完成自由泳动作的次数 |
| 摆荡 | 完成单次摆荡的次数,计算人员最接近镜头的次数 |
| 敲笔 | 人员敲击笔的次数 |
| 三级跳 | 人员完成跳跃的次数 |
| 使用扳手 | 扳手旋转的次数 |
| 使用大锤 | 大锤砸向物体的次数,计算锤子击中物体的次数 |
表 14: Countix数据集中包含的动作类别及其重复次数描述。