Regularizing Trajectory Optimization with Denoising Auto encoders
使用降噪自编码器正则化轨迹优化
Rinu Boney∗ Aalto University & Curious AI rinu.boney@aalto.fi
Rinu Boney∗ 阿尔托大学 & Curious AI rinu.boney@aalto.fi
Mathias Berglund Curious AI
Mathias Berglund Curious AI
Norman Di Palo∗ Sapienza University of Rome normand i palo@gmail.com
Norman Di Palo∗ 罗马大学 normand i palo@gmail.com
Alexander Ilin Aalto University & Curious AI
Alexander Ilin 阿尔托大学 & Curious AI
Juho Kannala Aalto University
Juho Kannala 阿尔托大学
Antti Rasmus Curious AI
Antti Rasmus Curious AI
Harri Valpola Curious AI
Harri Valpola Curious AI
Abstract
摘要
Trajectory optimization using a learned model of the environment is one of the core elements of model-based reinforcement learning. This procedure often suffers from exploiting inaccuracies of the learned model. We propose to regularize trajectory optimization by means of a denoising auto encoder that is trained on the same trajectories as the model of the environment. We show that the proposed regular iz ation leads to improved planning with both gradient-based and gradientfree optimizers. We also demonstrate that using regularized trajectory optimization leads to rapid initial learning in a set of popular motor control tasks, which suggests that the proposed approach can be a useful tool for improving sample efficiency.
利用学习到的环境模型进行轨迹优化是基于模型的强化学习的核心要素之一。该方法常因利用学习模型中的不准确性而受到影响。我们提出通过去噪自编码器对轨迹优化进行正则化,该编码器与环境模型在同一轨迹上训练。研究表明,所提出的正则化方法能提升基于梯度和无梯度优化器的规划效果。实验还证明,在多种常见运动控制任务中,使用正则化轨迹优化可加速初期学习进程,这表明该方法有望成为提升样本效率的有效工具。
1 Introduction
1 引言
State-of-the-art reinforcement learning (RL) often requires a large number of interactions with the environment to learn even relatively simple tasks [11]. It is generally believed that model-based RL can provide better sample-efficiency [9, 2, 5] but showing this in practice has been challenging. In this paper, we propose a way to improve planning in model-based RL and show that it can lead to improved performance and better sample efficiency.
最先进的强化学习 (RL) 通常需要与环境进行大量交互才能学习相对简单的任务 [11]。人们普遍认为基于模型的RL能提供更好的样本效率 [9, 2, 5],但在实践中证明这一点一直具有挑战性。本文提出了一种改进基于模型RL中规划的方法,并证明其能提升性能与样本效率。
In model-based RL, planning is done by computing the expected result of a sequence of future actions using an explicit model of the environment. Model-based planning has been demonstrated to be efficient in many applications where the model (a simulator) can be built using first principles. For example, model-based control is widely used in robotics and has been used to solve challenging tasks such as human locomotion [34, 35] and dexterous in-hand manipulation [21].
在基于模型的强化学习中,规划是通过使用环境的显式模型计算未来动作序列的预期结果来完成的。基于模型的规划已被证明在许多应用中非常高效,这些应用中的模型(模拟器)可以通过基本原理构建。例如,基于模型的控制在机器人技术中广泛应用,并已用于解决具有挑战性的任务,如人体运动 [34, 35] 和灵巧的手内操作 [21]。
In many applications, however, we often do not have the luxury of an accurate simulator of the environment. Firstly, building even an approximate simulator can be very costly even for processes whose dynamics is well understood. Secondly, it can be challenging to align the state of an existing simulator with the state of the observed process in order to plan. Thirdly, the environment is often non-stationary due to, for example, hardware failures in robotics, change of the input feed and deactivation of materials in industrial process control. Thus, learning the model of the environment is the only viable option in many applications and learning needs to be done for a live system. And since many real-world systems are very complex, we are likely to need powerful function ap proxima tors, such as deep neural networks, to learn the dynamics of the environment.
然而在许多应用中,我们往往无法获得精确的环境模拟器。首先,即便对于动力学原理已充分理解的流程,构建近似模拟器的成本也可能极高。其次,将现有模拟器的状态与观测流程的状态对齐以实现规划具有相当挑战性。第三,环境通常具有非平稳性,例如机器人硬件故障、工业流程控制中进料变化和材料失效等情况。因此,学习环境模型成为多数应用中唯一可行的方案,且必须在实际运行系统中完成学习。鉴于许多现实系统极其复杂,我们往往需要深度神经网络等强大的函数逼近器来学习环境动力学。
However, planning using a learned (and therefore inaccurate) model of the environment is very difficult in practice. The process of optimizing the sequence of future actions to maximize the expected return (which we call trajectory optimization) can easily exploit the inaccuracies of the model and suggest a very unreasonable plan which produces highly over-optimistic predicted rewards. This optimization process works similarly to adversarial attacks [1, 13, 33, 7] where the input of a trained model is modified to achieve the desired output. In fact, a more efficient trajectory optimizer is more likely to fall into this trap. This can arguably be the reason why gradient-based optimization (which is very efficient at for example learning the models) has not been widely used for trajectory optimization.
然而,在实践中使用学习到的(因而也是不准确的)环境模型进行规划非常困难。优化未来动作序列以最大化预期回报的过程(我们称之为轨迹优化)很容易利用模型的不准确性,提出极不合理的计划,产生过度乐观的预测奖励。这种优化过程类似于对抗攻击 [1, 13, 33, 7],即通过修改训练模型的输入来获得期望的输出。事实上,更高效的轨迹优化器更容易陷入这种陷阱。这可以说是基于梯度的优化(例如在学习模型时非常高效)未在轨迹优化中广泛应用的原因。
In this paper, we study this adversarial effect of model-based planning in several environments and show that it poses a problem particularly in high-dimensional control spaces. We also propose to remedy this problem by regularizing trajectory optimization using a denoising auto encoder (DAE) [37]. The DAE is trained to denoise trajectories that appeared in the past experience and in this way the DAE learns the distribution of the collected trajectories. During trajectory optimization, we use the denoising error of the DAE as a regular iz ation term that is subtracted from the maximized objective function. The intuition is that the denoising error will be large for trajectories that are far from the training distribution, signaling that the dynamics model predictions will be less reliable as it has not been trained on such data. Thus, a good trajectory has to give a high predicted return and it can be only moderately novel in the light of past experience.
本文研究了基于模型规划在多种环境中的对抗效应,发现该问题在高维控制空间中尤为突出。我们提出通过去噪自编码器 (denoising auto encoder, DAE) [37] 正则化轨迹优化的解决方案。DAE通过去噪历史经验中的轨迹来学习已收集轨迹的分布特性。在轨迹优化过程中,我们将DAE的去噪误差作为正则化项从最大化目标函数中扣除。其核心思想是:远离训练分布的轨迹会产生较大去噪误差,表明动态模型对此类未经训练数据的预测可靠性较低。因此,优质轨迹需同时满足高预测回报值和基于历史经验的适度新颖性。
In the experiments, we demonstrate that the proposed regular iz ation significantly diminishes the adversarial effect of trajectory optimization with learned models. We show that the proposed regular iz ation works well with both gradient-free and gradient-based optimizers (experiments are done with cross-entropy method [3] and Adam [14]) in both open-loop and closed-loop control. We demonstrate that improved trajectory optimization translates to excellent results in early parts of training in standard motor-control tasks and achieve competitive performance after a handful of interactions with the environment.
实验中,我们证明了所提出的正则化方法能显著降低基于学习模型的轨迹优化的对抗效应。研究表明,该正则化方法在开环和闭环控制中均能良好适配无梯度优化器(采用交叉熵法[3]实验)和基于梯度的优化器(采用Adam[14]实验)。实验显示,改进后的轨迹优化能在标准运动控制任务的训练初期取得优异效果,并在与环境进行少量交互后达到具有竞争力的性能水平。
2 Model-Based Reinforcement Learning
2 基于模型的强化学习
In this section, we explain the basic setup of model-based RL and present the notation used. At every time step $t$ , the environment is in state $s_{t}$ , the agent performs action $a_{t}$ , receives reward $r_{t}=\dot{r}(s_{t},a_{t})$ and the environment transitions to new state $\bar{s_{t+1}}=f(s_{t},a_{t})$ . The agent acts based on the observations $o_{t}=o(s_{t})$ which is a function of the environment state. In a fully observable Markov decision process (MDP), the agent observes full state $o_{t}=s_{t}$ . In a partially observable Markov decision process (POMDP), the observation $o_{t}$ does not completely reveal $s_{t}$ . The goal of the agent is select actions ${a_{0},a_{1},\ldots}$ so as to maximize the return, which is the expected cumulative reward $\mathbb{E}\left[\sum_{t=0}^{\infty}r\left(s_{t},\dot{a_{t}}\right)\right]$ .
在本节中,我们将解释基于模型的强化学习(RL)基本设置,并介绍所使用的符号。在每个时间步$t$,环境处于状态$s_{t}$,智能体执行动作$a_{t}$,获得奖励$r_{t}=\dot{r}(s_{t},a_{t})$,环境转换到新状态$\bar{s_{t+1}}=f(s_{t},a_{t})$。智能体基于观测值$o_{t}=o(s_{t})$采取行动,该观测值是环境状态的函数。在完全可观测的马尔可夫决策过程(MDP)中,智能体观测到完整状态$o_{t}=s_{t}$。在部分可观测的马尔可夫决策过程(POMDP)中,观测值$o_{t}$不能完全揭示$s_{t}$。智能体的目标是选择动作${a_{0},a_{1},\ldots}$以最大化回报,即期望累积奖励$\mathbb{E}\left[\sum_{t=0}^{\infty}r\left(s_{t},\dot{a_{t}}\right)\right]$。
In the model-based approach, the agent builds the dynamics model of the environment (forward model). For a fully observable environment, the forward model can be a fully-connected neural network trained to predict the state transition from time $t$ to $t+1$ :
在基于模型的方法中,智能体构建环境动态模型(前向模型)。对于完全可观测环境,前向模型可以是一个全连接神经网络,训练用于预测从时间$t$到$t+1$的状态转移:
$$
s_{t+1}=f_{\theta}(s_{t},a_{t}).
$$
$$
s_{t+1}=f_{\theta}(s_{t},a_{t}).
$$
In partially observable environments, the forward model can be a recurrent neural network trained to directly predict the future observations based on past observations and actions:
在部分可观测环境中,前向模型可以是一个经过训练的循环神经网络,直接基于过去的观测和动作来预测未来的观测:
$$
o_{t+1}=f_{\boldsymbol\theta}\big(o_{0},a_{0},\ldots,o_{t},a_{t}\big).
$$
$$
o_{t+1}=f_{\boldsymbol\theta}\big(o_{0},a_{0},\ldots,o_{t},a_{t}\big).
$$
In this paper, we assume access to the reward function and that it can be computed from the agent observations, that is $r_{t}=r(o_{t},a_{t})$ .
本文假设可以访问奖励函数,并且该函数可以根据智能体观察结果计算得出,即 $r_{t}=r(o_{t},a_{t})$ 。
At each time step $t$ , the agent uses the learned forward model to plan the sequence of future actions ${a_{t},\dots,a_{t+H}}$ so as to maximize the expected cumulative future reward.
在每个时间步 $t$,智能体使用学习到的前向模型来规划未来动作序列 ${a_{t},\dots,a_{t+H}}$,以最大化预期的累积未来奖励。

This process is called trajectory optimization. The agent uses the learned model of the environment to compute the objective function $G(a_{t},\dots,a_{t+H})$ . The model (1) or (2) is unrolled $H$ steps into the future using the current plan ${a_{t},\dots,a_{t+H}}$ .
这个过程称为轨迹优化。AI智能体利用学习到的环境模型计算目标函数 $G(a_{t},\dots,a_{t+H})$ 。通过当前计划 ${a_{t},\dots,a_{t+H}}$ ,将模型 (1) 或 (2) 向前展开 $H$ 步。
| Algorithm 1 End-to-end model-based reinforcement learning |
| Collect data D by random policy. |
| for each episode do |
| Train dynamics model fo using D. |
| for time t until the episode is over do |
| Optimize trajectory {at, Ot+1,... , at+H, Ot+ H+1}. |
| Implement the first action at and get new observation Ot. |
| endfor |
| Add data {(s1, a1, ... , aT, or)} from the last episode to D. |
算法 1: 端到端基于模型的强化学习
通过随机策略收集数据 D。
对每个回合执行以下操作:
使用 D 训练动态模型 fo。
对时间 t 直到回合结束执行以下操作:
优化轨迹 {at, Ot+1,..., at+H, Ot+H+1}。
执行第一个动作 at 并获取新观测 Ot。
将上一回合的数据 {(s1, a1,..., aT, or)} 添加到 D 中。
The optimized sequence of actions from trajectory optimization can be directly applied to the environment (open-loop control). It can also be provided as suggestions to a human operator with the possibility for the human to change the plan (human-in-the-loop). Open-loop control is challenging because the dynamics model has to be able to make accurate long-range predictions. An approach which works better in practice is to take only the first action of the optimized trajectory and then replan at each step (closed-loop control). Thus, in closed-loop control, we account for possible modeling errors and feedback from the environment. In the control literature, this flavor of model-based RL is called model-predictive control (MPC) [22, 30, 16, 24].
轨迹优化得到的最优动作序列可以直接应用于环境(开环控制),也可以作为建议提供给人类操作员,并允许人类修改计划(人在回路)。开环控制的挑战在于动力学模型必须能够进行精确的长期预测。实践中更有效的方法是仅执行优化轨迹的第一个动作,然后在每一步重新规划(闭环控制)。因此,在闭环控制中,我们会考虑潜在的建模误差和环境反馈。在控制理论文献中,这种基于模型的强化学习方法被称为模型预测控制(MPC) [22, 30, 16, 24]。
The typical sequence of steps performed in model-based RL are: 1) collect data, 2) train the forward model $f_{\theta},3)$ interact with the environment using MPC (this involves trajectory optimization in every time step), 4) store the data collected during the last interaction and continue to step 2. The algorithm is outlined in Algorithm 1.
基于模型的强化学习 (Model-based RL) 典型执行步骤如下:1) 收集数据,2) 训练前向模型 $f_{\theta},3)$ 使用模型预测控制 (MPC) 与环境交互(每个时间步都涉及轨迹优化),4) 存储最近交互期间收集的数据并返回步骤 2。该算法如算法 1 所示。
3 Regularized Trajectory Optimization
3 正则化轨迹优化
3.1 Problem with using learned models for planning
3.1 使用学习模型进行规划的问题
In this paper, we focus on the inner loop of model-based RL which is trajectory optimization using a learned forward model $f_{\theta}$ . Potential inaccuracies of the trained model cause substantial difficulties for the planning process. Rather than optimizing what really happens, planning can easily end up exploiting the weaknesses of the predictive model. Planning is effectively an adversarial attack against the agent’s own forward model. This results in a wide gap between expectations based on the model and what actually happens.
本文聚焦于基于模型的强化学习(RL)内循环——即使用学习得到的前向模型$f_{\theta}$进行轨迹优化。训练模型可能存在的不准确性会给规划过程带来重大困难。规划过程非但无法优化真实发生的情况,反而容易陷入利用预测模型弱点的困境。从本质上说,规划构成了对智能体自身前向模型的对抗性攻击。这导致基于模型的预期与实际发生的情况之间存在巨大差距。
We demonstrate this problem using a simple industrial process control benchmark from [28]. The problem is to control a continuous nonlinear reactor by manipulating three valves which control flows in two feeds and one output stream. Further details of the process and the control problem are given in Appendix A. The task considered in [28] is to change the product rate of the process from 100 to $130\mathrm{kmol/h}$ . Fig. 1a shows how this task can be performed using a set of PI controllers proposed in [28]. We trained a forward model of the process using a recurrent neural network (2) and the data collected by implementing the PI control strategy for a set of randomly generated targets. Then we optimized the trajectory for the considered task using gradient-based optimization, which produced results in Fig. 1b. One can see that the proposed control signals are changed abruptly and the trajectory imagined by the model significantly deviates from reality. For example, the pressure constraint (of max $300\mathrm{kPa},$ is violated. This example demonstrates how planning can easily exploit the weaknesses of the predictive model.
我们以[28]中一个简单的工业过程控制基准为例说明该问题。该问题需通过调节三个阀门来控制两股进料和一股输出流体的流量,从而实现对连续非线性反应器的控制。工艺流程及控制问题的详细说明见附录A。[28]中研究的具体任务是将产品产量从100提升至$130\mathrm{kmol/h}$。图1a展示了采用[28]提出的PI控制器组完成该任务的过程。我们使用循环神经网络(2)和通过实施PI控制策略对随机生成目标采集的数据,训练了该流程的前向模型。随后采用基于梯度的优化方法对目标任务的轨迹进行优化,结果如图1b所示。可见所提出的控制信号存在突变,且模型预测的轨迹与实际情况明显偏离。例如违反了最高$300\mathrm{kPa}$的压力约束。该案例揭示了规划过程如何轻易利用预测模型的缺陷。
3.2 Regularizing Trajectory Optimization with Denoising Auto encoders
3.2 使用去噪自编码器正则化轨迹优化
We propose to regularize the trajectory optimization with denoising auto encoders (DAE). The idea is that we want to reward familiar trajectories and penalize unfamiliar ones because the model is likely to make larger errors for the unfamiliar ones.
我们提出使用去噪自编码器 (DAE) 对轨迹优化进行正则化。其核心思想是通过奖励熟悉轨迹并惩罚陌生轨迹来提升模型性能,因为模型对陌生轨迹可能产生更大误差。
This can be achieved by adding a regular iz ation term to the objective function:
这可以通过在目标函数中添加一个正则化(regularization)项来实现:
$$
G_{\mathrm{reg}}=G+\alpha\log p\bigl(o_{t},a_{t}\ldots,o_{t+H},a_{t+H}\bigr),
$$
$$
G_{\mathrm{reg}}=G+\alpha\log p\bigl(o_{t},a_{t}\ldots,o_{t+H},a_{t+H}\bigr),
$$
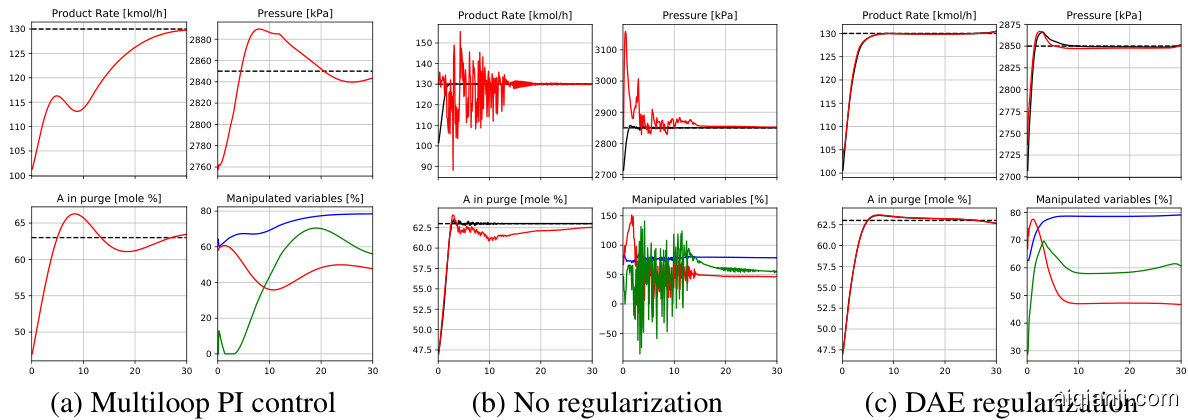
Figure 1: Open-loop planning for a continuous nonlinear two-phase reactor from [28]. Three subplots in every subfigure show three measured variables (solid lines): product rate, pressure and A in the purge. The black curves represent the model’s imagination while the red curves represent the reality if those controls are applied in an open-loop mode. The targets for the variables are shown with dashed lines. The fourth (low right) subplots show the three manipulated variables: valve for feed 1 (blue), valve for feed 2 (red) and valve for stream 3 (green).
图 1: 文献[28]中连续非线性两相反应器的开环规划。每个子图中的三个子图显示三个测量变量(实线): 产物速率、压力和吹扫中的A组分。黑色曲线代表模型预测值,红色曲线表示开环模式下实际应用控制后的真实值。各变量的目标值以虚线显示。右下角第四个子图展示三个操纵变量: 进料1阀门(蓝色)、进料2阀门(红色)和物流3阀门(绿色)。
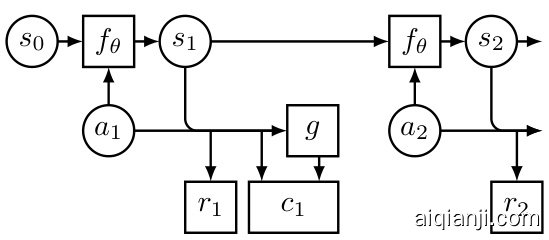
Figure 2: Example: fragment of a computational graph used during trajectory optimization in an MDP. Here, window size $w=1$ , that is the DAE penalty term is $c_{1}\doteq\lVert g([s_{1},\dot{a}_ {1}])^{-}-[s_{1},a_{1}]\rVert^{2}$ .
图 2: 示例:MDP轨迹优化过程中使用的计算图片段。此处窗口大小$w=1$,即DAE惩罚项为$c_{1}\doteq\lVert g([s_{1},\dot{a}_ {1}])^{-}-[s_{1},a_{1}]\rVert^{2}$。
where $p\big(o_{t},a_{t},,\dots,o_{t+H},a_{t+H}\big)$ is the probability of observing a given trajectory in the past experience and $\alpha$ is a tuning hyper parameter. In practice, instead of using the joint probability of the whole trajectory, we use marginal probabilities over short windows of size $w$ :
其中 $p\big(o_{t},a_{t},,\dots,o_{t+H},a_{t+H}\big)$ 表示在过往经验中观察到给定轨迹的概率,$\alpha$ 为调节超参数。实际应用中,我们使用大小为 $w$ 的短窗口边缘概率替代整段轨迹的联合概率:
$$
G_{\mathrm{reg}}=G+\alpha\sum_{\tau=t}^{t+H-w}\log p(x_{\tau})
$$
$$
G_{\mathrm{reg}}=G+\alpha\sum_{\tau=t}^{t+H-w}\log p(x_{\tau})
$$
where $x_{\tau}={o_{\tau},a_{\tau},\dots o_{\tau+w},a_{\tau+w}}$ is a short window of the optimized trajectory.
其中 $x_{\tau}={o_{\tau},a_{\tau},\dots o_{\tau+w},a_{\tau+w}}$ 是优化轨迹的一个短窗口。
Suppose we want to find the optimal sequence of actions by maximizing (4) with a gradient-based optimization procedure. We can compute gradients ∂∂Garieg by back propagation in a computational graph where the trained forward model is unrolled into the future (see Fig. 2). In such back propagationthrough-time procedure, one needs to compute the gradient with respect to actions $a_{i}$ .
假设我们想通过基于梯度的优化程序最大化(4)来寻找最优动作序列。我们可以在计算图中通过反向传播计算梯度∂∂Garieg,其中训练好的前向模型被展开到未来(见图2)。在这种时间反向传播过程中,需要计算关于动作$a_{i}$的梯度。
$$
\frac{\partial G_{\mathrm{reg}}}{\partial a_{i}}=\frac{\partial G}{\partial a_{i}}+\alpha\sum_{\tau=i}^{i+w}\frac{\partial x_{\tau}}{\partial a_{i}}\frac{\partial}{\partial x_{\tau}}\log p(x_{\tau}),
$$
$$
\frac{\partial G_{\mathrm{reg}}}{\partial a_{i}}=\frac{\partial G}{\partial a_{i}}+\alpha\sum_{\tau=i}^{i+w}\frac{\partial x_{\tau}}{\partial a_{i}}\frac{\partial}{\partial x_{\tau}}\log p(x_{\tau}),
$$
where we denote by $x_{\tau}$ a concatenated vector of observations $o_{\tau},\dots o_{\tau+w}$ and actions $a_{\tau},\dots{}a_{\tau+w}$ over a window of size $w$ . Thus to enable a regularized gradient-based optimization procedure, we need means to compute ∂∂x l og p(xτ ).
我们用 $x_{\tau}$ 表示观测值 $o_{\tau},\dots o_{\tau+w}$ 和动作 $a_{\tau},\dots{}a_{\tau+w}$ 在大小为 $w$ 的窗口上的拼接向量。因此,为了实现基于梯度的正则化优化过程,我们需要计算 $\frac{\partial}{\partial x} \log p(x_{\tau})$ 的方法。
In order to evaluate $\log p(x_{\tau})$ (or its derivative), one needs to train a separate model $p(x_{\tau})$ of the past experience, which is the task of unsupervised learning. In principle, any probabilistic model can be used for that. In this paper, we propose to regularize trajectory optimization with a denoising auto encoder (DAE) which does not build an explicit probabilistic model $p(x_{\tau})$ but rather learns to approximate the derivative of the log probability density. The theory of denoising [23, 27] states that the optimal denoising function $g(\tilde{x})$ (for zero-mean Gaussian corruption) is given by:
为了评估 $\log p(x_{\tau})$ (或其导数),需要针对过往经验训练一个独立的模型 $p(x_{\tau})$ ,这属于无监督学习的任务。理论上,任何概率模型都可用于此目的。本文提出通过去噪自编码器 (DAE) 对轨迹优化进行正则化,该方法无需构建显式概率模型 $p(x_{\tau})$ ,而是学习逼近对数概率密度的导数。去噪理论 [23, 27] 指出,最优去噪函数 $g(\tilde{x})$ (针对零均值高斯噪声) 满足以下关系:
$$
g(\tilde{x})=\tilde{x}+\sigma_{n}^{2}\frac{\partial}{\partial\tilde{x}}\log p(\tilde{x}),
$$
$$
g(\tilde{x})=\tilde{x}+\sigma_{n}^{2}\frac{\partial}{\partial\tilde{x}}\log p(\tilde{x}),
$$
where $p(\tilde{x})$ is the probability density function for data $\tilde{x}$ corrupted with noise and $\sigma_{n}$ is the standard deviation of the Gaussian corruption. Thus, the DAE-denoised signal minus the original gives the gradient of the log-probability of the data distribution convolved with a Gaussian distribution: \begin{array}{r}{\frac{\partial}{\partial\tilde{x}}\log p(\tilde{x})\propto g(x)-\tilde{x}}\end{array} . Assuming $\begin{array}{r}{\frac{\partial}{\partial\tilde{x}}\log p(\tilde{x})\approx\frac{\partial}{\partial x}\log p(x)}\end{array}$ yields
其中 $p(\tilde{x})$ 是加噪数据 $\tilde{x}$ 的概率密度函数,$\sigma_{n}$ 为高斯噪声的标准差。因此,去噪自编码器(DAE)处理后的信号减去原始信号,可得到与高斯分布卷积后的数据分布对数概率梯度:$\begin{array}{r}{\frac{\partial}{\partial\tilde{x}}\log p(\tilde{x})\propto g(x)-\tilde{x}}\end{array}$。假设 $\begin{array}{r}{\frac{\partial}{\partial\tilde{x}}\log p(\tilde{x})\approx\frac{\partial}{\partial x}\log p(x)}\end{array}$ 成立时
$$
\frac{\partial G_{\mathrm{reg}}}{\partial a_{i}}=\frac{\partial G}{\partial a_{i}}+\alpha\sum_{\tau=i}^{i+w}\frac{\partial x_{\tau}}{\partial a_{i}}(g(x_{\tau})-x_{\tau}).
$$
$$
\frac{\partial G_{\mathrm{reg}}}{\partial a_{i}}=\frac{\partial G}{\partial a_{i}}+\alpha\sum_{\tau=i}^{i+w}\frac{\partial x_{\tau}}{\partial a_{i}}(g(x_{\tau})-x_{\tau}).
$$
Using $\begin{array}{r}{\frac{\partial}{\partial\tilde{x}}\log p(\tilde{x})}\end{array}$ instead of $\textstyle{\frac{\partial}{\partial x}}\log p(x)$ can behave better in practice because it is similar to replacing $p(x)$ with its Parzen window estimate [36]. In automatic differentiation software, this gradient can be computed by adding the penalty term $|g(x_{\tau})-x_{\tau}|^{2}$ to $G$ and stopping the gradient propagation through $g$ . In practice, stopping the gradient through $g$ did not yield any benefits in our experiments compared to simply adding the penalty term $|g(\bar{x}_ {\tau})-x_{\tau}|^{2}$ to the cumulative reward, so we used the simple penalty term in our experiments. Also, this kind of regular iz ation can easily be used with gradient-free optimization methods such as cross-entropy method (CEM) [3].
使用 $\begin{array}{r}{\frac{\partial}{\partial\tilde{x}}\log p(\tilde{x})}\end{array}$ 而非 $\textstyle{\frac{\partial}{\partial x}}\log p(x)$ 在实践中表现更优,因为这类似于用 Parzen 窗估计 [36] 替代 $p(x)$。在自动微分软件中,可通过将惩罚项 $|g(x_{\tau})-x_{\tau}|^{2}$ 添加到 $G$ 并阻断梯度通过 $g$ 的传播来计算该梯度。实验中,与简单地将惩罚项 $|g(\bar{x}_ {\tau})-x_{\tau}|^{2}$ 加入累积奖励相比,阻断 $g$ 的梯度并未带来收益,因此我们采用简单惩罚项方案。此外,此类正则化方法可轻松与无梯度优化方法(如交叉熵法 (CEM) [3])结合使用。
Our goal is to tackle high-dimensional problems and expressive models of dynamics. Neural networks tend to fare better than many other techniques in modeling high-dimensional distributions. However, using a neural network or any other flexible parameterized model to estimate the input distribution poses a dilemma: the regularizing network which is supposed to keep planning from exploiting the inaccuracies of the dynamics model will itself have weaknesses which planning will then exploit. Clearly, DAE will also have inaccuracies but planning will not exploit them because unlike most other density models, DAE develops an explicit model of the gradient of logarithmic probability density.
我们的目标是解决高维问题和动态系统的表达性建模。在建模高维分布时,神经网络通常比其他技术表现更优。然而,使用神经网络或其他灵活的参数化模型来估计输入分布会带来一个两难问题:本应防止规划过程利用动态模型不准确性的正则化网络,其自身存在的缺陷反而会被规划过程利用。显然,去噪自编码器 (DAE) 也存在不准确性,但规划过程不会利用这些缺陷,因为与大多数其他密度模型不同,DAE 会显式建模对数概率密度的梯度。
The effect of adding DAE regular iz ation in the industrial process control benchmark discussed in the previous section is shown in Fig. 1c.
在前文讨论的工业过程控制基准测试中,添加DAE正则化的效果如图1c所示。
3.3 Related work
3.3 相关工作
Several methods have been proposed for planning with learned dynamics models. Locally linear timevarying models [17, 19] and Gaussian processes [8, 15] or mixture of Gaussians [29] are data-efficient but have problems scaling to high-dimensional environments. Recently, deep neural networks have been successfully applied to model-based RL. Nagabandi et al. [24] use deep neural networks as dynamics models in model-predictive control to achieve good performance, and then shows how model-based RL can be fine-tuned with a model-free approach to achieve even better performance. Chua et al. [5] introduce PETS, a method to improve model-based performance by estimating and propagating uncertainty with an ensemble of networks and sampling techniques. They demonstrate how their approach can beat several recent model-based and model-free techniques. Clavera et al. [6] combines model-based RL and meta-learning with MB-MPO, training a policy to quickly adapt to slightly different learned dynamics models, thus enabling faster learning.
针对学习动力学模型的规划问题,已提出多种方法。局部线性时变模型[17, 19]、高斯过程[8, 15]或高斯混合模型[29]具有数据高效性,但难以扩展到高维环境。近年来,深度神经网络在基于模型的强化学习中取得显著成果。Nagabandi等人[24]将深度神经网络作为动力学模型应用于模型预测控制,取得优异性能后,进一步展示了如何通过无模型方法对基于模型的强化学习进行微调以获得更优表现。Chua等人[5]提出的PETS方法,通过集成网络和采样技术来估计和传递不确定性,从而提升基于模型的性能。他们的方法被证明能超越多种近期基于模型和无模型的技术。Clavera等人[6]将基于模型的强化学习与元学习结合,通过MB-MPO训练策略使其快速适应略有差异的学习动力学模型,从而实现更高效的学习。
Levine and Koltun [20] and Kumar et al. [17] use a KL divergence penalty between action distributions to stay close to the training distribution. Similar bounds are also used to stabilize training of policy gradient methods [31, 32]. While such a KL penalty bounds the evolution of action distributions, the proposed method also bounds the familiarity of states, which could be important in high-dimensional state spaces. While penalizing unfamiliar states also penalize exploration, it allows for more controlled and efficient exploration. Exploration is out of the scope of the paper but was studied in [10], where a non-zero optimum of the proposed DAE penalty was used as an intrinsic reward to alternate between familiarity and exploration.
Levine和Koltun [20]以及Kumar等人[17]通过动作分布之间的KL散度惩罚来保持接近训练分布。类似的边界也被用于稳定策略梯度方法的训练[31, 32]。虽然这种KL惩罚限制了动作分布的演变,但所提出的方法还限制了状态的熟悉程度,这在高维状态空间中可能很重要。虽然惩罚不熟悉的状态也会抑制探索,但它允许更可控和高效的探索。探索不在本文讨论范围内,但在[10]中进行了研究,其中将所提出的DAE惩罚的非零最优值用作内在奖励,以在熟悉度和探索之间交替。
4 Experiments on Motor Control
4 电机控制实验
We show the effect of the proposed regular iz ation for control in standard Mujoco environments: Cartpole, Reacher, Pusher, Half-cheetah and Ant available in [4]. See the description of the environments in Appendix B. We use the Probabilistic Ensembles with Trajectory Sampling (PETS) model from [5] as the baseline, which achieves the best reported results on all the considered tasks except for Ant.
我们展示了所提出的正则化方法在标准Mujoco环境中的控制效果:包括[4]中提供的Cartpole、Reacher、Pusher、Half-cheetah和Ant。环境描述详见附录B。我们采用[5]提出的PETS (Probabilistic Ensembles with Trajectory Sampling) 模型作为基线,该模型在所有考虑的任务(除Ant外)上都取得了目前最佳的报告结果。

Figure 3: Visualization of trajectory optimization at timestep $t=50$ . Each row has the same model but 2a0 different optimization method. The models ar1e00 0 o 00 bt a in ed by 5 episodes of end-to-end training. Row above: Cartpole environment. Row below: Half-cheetah environment. Here, the red lines denote the rewards predicted by the model (imagination) and the black lines denote the true rewards obtained when applying the sequence of optimized actions (reality). For a low-dimensional action space (Cartpole), trajectory optimizers do not exploit inaccuracies of the dynamics model and hence DAE regular iz ation does not affect the performance noticeably. For a higher-dimensional action space (Half-cheetah), gradient-based optimization without any regular iz ation easily exploits inaccuracies of the dynamics model but DAE regular iz ation is able to prevent this. The effect is less pronounced with gradient-free optimization but still noticeable.
图 3: 时间步 $t=50$ 的轨迹优化可视化。每行使用相同模型但采用不同优化方法 (2a0)。这些模型通过5轮端到端训练获得。上行: Cartpole环境。下行: Half-cheetah环境。其中红线表示模型预测的奖励 (想象),黑线表示应用优化动作序列后获得的真实奖励 (现实)。对于低维动作空间 (Cartpole),轨迹优化器不会利用动态模型的不准确性,因此DAE正则化对性能影响不明显。而在高维动作空间 (Half-cheetah) 中,无正则化的基于梯度优化容易利用动态模型的不准确性,但DAE正则化能有效防止这种情况。无梯度优化的效果虽较不显著但仍可观察到。
The PETS model consists of an ensemble of probabilistic neural networks and uses particle-based trajectory sampling to regularize trajectory optimization. We re-implemented the PETS model using the code provided by the authors as a reference.
PETS模型由一组概率神经网络组成,并采用基于粒子的轨迹采样方法来规范化轨迹优化。我们参考作者提供的代码重新实现了PETS模型。
4.1 Regularized trajectory optimization with models trained with PETS
4.1 基于PETS训练模型的正则化轨迹优化
In MPC, the innermost loop is open-loop control which is then turned to closed-loop control by taking in new observations and replanning after each action. Fig. 3 illustrates the adversarial effect during open-loop trajectory optimization and how DAE regular iz ation mitigates it. In Cartpole environment, the learned model is very good already after a few episodes of data and trajectory optimization stays within the data distribution. As there is no problem to begin with, regular iz ation does not improve the results. In Half-cheetah environment, trajectory optimization manages to exploit the inaccuracies of the model which is particularly apparent in gradient-based Adam. DAE regular iz ation improves both but the effect is much stronger with Adam.
在MPC中,最内层循环是开环控制,随后通过接收新观测值并在每次动作后重新规划转为闭环控制。图3展示了开环轨迹优化过程中的对抗效应,以及DAE正则化如何缓解该效应。在Cartpole环境中,仅需少量数据周期后学习到的模型已表现优异,轨迹优化始终保持在数据分布范围内。由于不存在初始问题,正则化并未带来结果提升。在Half-cheetah环境中,轨迹优化会利用模型的不准确性,这种现象在基于梯度的Adam优化器中尤为明显。DAE正则化对两者均有改善,但对Adam的效果更为显著。
The problem is exacerbated in closed-loop control since it continues optimization from the solution achieved in the previous time step, effectively iterating more per action. We demonstrate how regular iz ation can improve closed-loop trajectory optimization in the Half-cheetah environment. We first train three PETS models for 300 episodes using the best hyper parameters reported in [5]. We then evaluate the performance of the three models on five episodes using four different trajectory optimizers: 1) Cross-entropy method (CEM) which was used during training of the PETS models, 2) Adam, 3) CEM with the DAE regular iz ation and 4) Adam with the DAE regular iz ation. The results averaged across the three models and the five episodes are presented in Table 1.
闭环控制中的问题更为严重,因为它会基于前一步的解决方案持续优化,实际上对每个动作进行了更多迭代。我们展示了正则化(regularization)如何在Half-cheetah环境中改进闭环轨迹优化。首先使用[5]中报告的最佳超参数训练三个PETS模型300个周期,随后用四种轨迹优化器评估这三个模型在五个周期上的表现:1) PETS模型训练时使用的交叉熵方法(CEM),2) Adam优化器,3) 带DAE正则化的CEM,4) 带DAE正则化的Adam。三个模型在五个周期上的平均结果如 表1 所示。
Table 1: Comparison of PETS with CEM and Adam optimizers in Half-cheetah
| Optimizer | CEM | CEM+DAE | Adam | Adam+DAE |
| Average Return | 10955±2865 | 12967±3216 | 12796±2716 |
表 1: Half-cheetah 环境中 PETS 与 CEM 和 Adam 优化器的对比
| 优化器 | CEM | CEM+DAE | Adam | Adam+DAE |
|---|---|---|---|---|
| 平均回报 | 10955±2865 | 12967±3216 | 12796±2716 |
We first note that planning with Adam fails completely without regular iz ation: the proposed actions lead to unstable states of the simulator. Using Adam with the DAE regular iz ation fixes this problem and the obtained results are better than the CEM method originally used in PETS. CEM appears to regularize trajectory optimization but not as efficiently CEM+DAE. These open-loop results are consistent with the closed-loop results in Fig. 3.
我们首先注意到,在没有正则化的情况下,使用Adam进行规划会完全失败:所提出的动作会导致模拟器进入不稳定状态。使用带有DAE正则化的Adam解决了这一问题,并且获得的结果优于PETS中最初使用的CEM方法。CEM似乎对轨迹优化进行了正则化,但效果不如CEM+DAE。这些开环结果与图3中的闭环结果一致。
4.2 End-to-end training with regularized trajectory optimization
4.2 基于正则化轨迹优化的端到端训练
In the following experiments, we study the performance of end-to-end training with different trajectory optimizers used during training. Our agent learns according to the algorithm presented in Algorithm 1. Since the environments are fully observable, we use a feed forward neural network as in (1) to model the dynamics of the environment. Unlike PETS, we did not use an ensemble of probabilistic networks as the forward model. We use a single probabilistic network which predicts the mean and variance of the next state (assuming a Gaussian distribution) given the current state and action. Although we only use the mean prediction, we found that also training to predict the variance improves the stability of the training.
在以下实验中,我们研究了使用不同轨迹优化器进行端到端训练的性能表现。我们的AI智能体(agent)按照算法1所示流程进行学习。由于环境具备完全可观测性,我们采用如(1)式所示的前馈神经网络来建模环境动态。与PETS不同,我们并未使用概率网络集合作为前向模型,而是采用单一概率网络来预测给定当前状态和动作时下一状态的均值与方差(假设服从高斯分布)。虽然实际仅使用均值预测,但我们发现同时训练方差预测能提升训练稳定性。
For all environments, we use a dynamics model with the same architecture: three hidden layers of size 200 with the Swish non-linearity [26]. Similar to prior works, we train the dynamics model to predict the difference between $s_{t+1}$ and $s_{t}$ instead of predicting $s_{t+1}$ directly. We train the dynamics model for 100 or more epochs (see Appendix C) after every episode. This is a larger number of updates compared to five epochs used in [5]. We found that an increased number of updates has a large effect on the performance for a single probabilistic model and not so large effect for the ensemble of models used in PETS. This effect is shown in Fig. 6.
对于所有环境,我们采用相同架构的动力学模型:三个大小为200的隐藏层,使用Swish非线性激活函数[26]。与先前研究类似,我们训练动力学模型预测$s_{t+1}$与$s_{t}$之间的差值,而非直接预测$s_{t+1}$。每轮训练后,动力学模型会进行100次或更多次迭代训练(详见附录C),这比文献[5]中采用的5次迭代显著增加。我们发现增加迭代次数对单一概率模型的性能影响较大,而对PETS中使用的模型集成影响相对较小。该效果展示在图6中。
For the denoising auto encoder, we use the same architecture as the dynamics model. The state-action pairs in the past episodes were corrupted with zero-mean Gaussian noise and the DAE was trained to denoise it. Important hyper parameters used in our experiments are reported in the Appendix C. For DAE-regularized trajectory optimization we used either CEM or Adam as optimizers.
对于去噪自动编码器(denoising auto encoder),我们采用了与动力学模型相同的架构。过去情节中的状态-动作对会被添加零均值高斯噪声进行干扰,然后训练DAE对其进行去噪处理。实验中采用的重要超参数详见附录C。在DAE正则化轨迹优化过程中,我们使用了CEM或Adam作为优化器。
The learning progress of the compared algorithms is presented in Fig. 4. Note that we report the average returns across different seeds, not the maximum return seen so far as was done in [5].2 In Cartpole, all the methods converge to the maximum cumulative reward but the proposed method converges the fastest. In the Cartpole environment, we also compare to a method which uses Gaussian Processes (GP) as the dynamics model (algorithm denoted GP-E in [5], which considers only the expectation of the next state prediction). The implementation of the GP algorithm was obtained from the code provided by [5]. Interestingly, our algorithm also surpasses the Gaussian Process (GP) baseline, which is known to be a sample-efficient method widely used for control of simple systems. In Reacher, the proposed method converges to the same asymptotic performance as PETS, but faster. In Pusher, all algorithms perform similarly.
图 4 展示了各对比算法的学习进度。需要注意的是,我们报告的是不同随机种子的平均回报值,而非[5]中采用的当前最大回报值。在Cartpole环境中,所有方法最终都收敛至最大累积奖励,但本文提出的方法收敛速度最快。该环境中我们还对比了采用高斯过程(GP)作为动力学模型的方法([5]中的GP-E算法,仅考虑下一状态预测的期望值)。GP算法的实现代码来自[5]提供的源码。值得注意的是,我们的算法表现甚至超越了高斯过程(GP)基线——后者作为样本高效的方法,被广泛用于简单系统的控制。在Reacher环境中,本文方法以更快速度达到了与PETS相同的渐近性能。Pusher环境中各算法表现相近。
In Half-cheetah and Ant, the proposed method shows very good sample efficiency and very rapid initial learning. The agent learns an effective running gait in only a couple of episodes.3 The results demonstrate that denoising regular iz ation is effective for both gradient-free and gradient-based planning, with gradient-based planning performing the best. The proposed algorithm learns faster than PETS in the initial phase of training. It also achieves performance that is competitive with popular model-free algorithms such as DDPG, as reported in [5].
在半人马和蚂蚁环境中,所提出的方法展现出极佳的样本效率和快速的初始学习能力。智能体仅通过几个训练回合就学会了有效的奔跑步态。结果表明,去噪正则化对无梯度和基于梯度的规划均有效,其中基于梯度的规划表现最佳。该算法在训练初期阶段比PETS学习得更快,同时达到了与DDPG等主流无模型算法相当的性能,如[5]所述。
However, the performance of the proposed method does not improve after initial 10 episodes, so it does not reach the asymptotic performance of PETS (see results for PETS for Half-cheetah after 300 episodes in Table 1). This result is evidence of the importance of exploration: the DAE regular iz ation essentially penalizes exploration, which can harm asymptotic performance in complex environments. In PETS, CEM leaves some noise in the trajectories, which might help to obtain better asymptotic performance. The result presented in Appendix E provides some evidence that at least a part of the problem is lack of exploration.
然而,所提方法在初始10轮训练后性能不再提升,因此未能达到PETS的渐进性能(参见表1中Half-cheetah任务在300轮训练后的PETS结果)。这一结果证明了探索的重要性:DAE正则化本质上抑制了探索行为,可能损害复杂环境中的渐进性能。在PETS中,CEM在轨迹中保留了一定噪声,这可能有助于获得更好的渐进性能。附录E呈现的结果表明,至少部分问题源于探索不足。
We also compare the performance of our method with Model-Based Meta Policy Optimization (MB-MPO) [6], an approach that combines the benefits of model-based RL and meta learning: the algorithm trains a policy using simulations generated by an ensemble of models, learned from data. Meta-learning allows this policy to quickly adapt to the various dynamics, hence learning how to quickly adapt in the real environment, using Model-Agnostic Meta Learning (MAML) [12]. In
我们还比较了我们的方法与基于模型的元策略优化 (Model-Based Meta Policy Optimization, MB-MPO) [6] 的性能,该方法结合了基于模型的强化学习和元学习的优势:该算法使用通过从数据学习得到的模型集合生成的模拟来训练策略。元学习使该策略能够快速适应各种动态,从而学习如何在真实环境中快速适应,使用的是模型无关元学习 (Model-Agnostic Meta Learning, MAML) [12]。

Figure 4: Results of our experiments on the five benchmark environments, in comparison to PETS [5]. We show the return obtained in each episode. All the results are averaged across 5 seeds, with the shaded area representing standard deviation. PETS is a recent state-of-the-art model-based RL algorithm and GP-based (Gaussian Processes) control algorithms are well known to be sampleefficient and are extensively used for the control of simple systems.
图 4: 我们在五个基准环境下的实验结果与PETS [5]的对比。展示了每轮试验获得的回报值。所有结果为5次随机种子的平均值,阴影区域表示标准差。PETS是近期最先进的基于模型的强化学习算法,而基于高斯过程 (Gaussian Processes) 的控制算法以样本高效著称,被广泛用于简单系统的控制。

Figure 5: Comparison to MB-MPO [6], MB-TRPO [18] and MB-MPC [24] on Half-cheetah. We plot the average return over the last 20 episodes. Our results are averaged across 3 seeds, with the shaded area representing standard deviation. Note that the comparison numbers are picked from [6] and the results from the first 20 episodes are not reported.
图 5: 与 MB-MPO [6]、MB-TRPO [18] 和 MB-MPC [24] 在 Half-cheetah 任务上的对比。我们绘制了最后 20 个回合的平均回报。我们的结果是 3 次随机种子的平均值,阴影区域代表标准差。请注意,对比数据取自 [6],且未报告前 20 个回合的结果。
Fig. 5 we compare our method to MB-MPO and other model-based methods included in [6]. This experiment is done in the Half-cheetah environment with shorter episodes (200 timesteps) in order to compare to the results reported in [6]. The results show that our method learns faster than MB-MPO.
图 5: 我们将本方法与MB-MPO及[6]中包含的其他基于模型的方法进行对比。该实验在Half-cheetah环境中采用较短回合(200个时间步)完成,以便与[6]报告的结果进行对比。结果表明,我们的方法学习速度优于MB-MPO。
5 Discussion
5 讨论
In recent years, a lot of effort has been put in making deep reinforcement algorithms more sampleefficient, and thus adaptable to real world scenarios. Model-based reinforcement learning has shown promising results, obtaining sample-efficiency even orders of magnitude better than model-free counterparts, but these methods have often suffered from sub-optimal performance due to many reasons. As already noted in the recent literature [24, 5], out-of-distribution errors and model over fitting are often sources of performance degradation when using complex function ap proxima tors. In this work we demonstrated how to tackle this problem using regularized trajectory optimization. Our experiments demonstrate that the proposed solution can improve the performance of model-based reinforcement learning.
近年来,人们投入大量精力提升深度强化学习算法的样本效率,使其更适应现实场景。基于模型的强化学习方法展现出良好前景,其样本效率甚至比无模型方法高出数个数量级,但这些方法常因多种原因导致性能欠佳。正如近期研究[24, 5]所指出的,分布外误差和模型过拟合常是使用复杂函数逼近器时性能下降的根源。本研究通过正则化轨迹优化解决了该问题,实验证明所提方案能有效提升基于模型强化学习的性能。
While trajectory optimization is a key component in model-based RL, there are clearly several other issues which need to be tackled in complex environments:
虽然轨迹优化是基于模型的强化学习(RL)中的关键组成部分,但在复杂环境中显然还需要解决其他几个问题:
Still, model-based RL is an attractive approach and not only due to its sample-efficiency. Compared to model-free approaches, model-based learning makes safe exploration and adding known constraints or first-principles models much easier. We believe that the proposed method can be a viable solution for real-world control tasks especially where safe exploration is of high importance.
尽管如此,基于模型的强化学习 (model-based RL) 仍是一种极具吸引力的方法,这不仅因其样本高效性。与无模型方法相比,基于模型的学习能更轻松地实现安全探索,并融入已知约束或第一性原理模型。我们相信所提出的方法可成为现实世界控制任务(尤其是安全探索至关重要的场景)的可行解决方案。
We are currently working on applying the proposed methods for real-world problems such as assisting operators of complex industrial processes and for control of autonomous mobile machines.
我们目前正在将所提出的方法应用于现实问题,例如辅助复杂工业流程的操作员以及控制自主移动机器。
Acknowledgments
致谢
We would like to thank Jussi Sainio, Jari Rosti and Isabeau Prémont-Schwarz for their valuable contributions in the experiments on industrial process control.
我们要感谢Jussi Sainio、Jari Rosti和Isabeau Prémont-Schwarz在工业过程控制实验中做出的宝贵贡献。
References
参考文献
[23] K Miyasawa. An empirical bayes estimator of the mean of a normal population. Bulletin of the International Statistical Institute, 38(181-188):1–2, 1961.
[23] K Miyasawa. 正态总体均值的经验贝叶斯估计量. 国际统计学会公报, 38(181-188):1-2, 1961.
A Industrial Process Control Benchmark
工业过程控制基准
To study trajectory optimization, we first consider the problem of control of a simple industrial process. An effective industrial control system could achieve better production and economic efficiency than manually operated controls. In this paper, we learn the dynamics of an industrial process and use it to optimize the controls, by minimizing a cost function. In some critical processes, safety is of utmost importance and regular iz ation methods could prevent adaptive control methods from exploring unsafe trajectories.
为研究轨迹优化问题,我们首先考虑一个简单工业过程的控制问题。相比人工操作,有效的工业控制系统能实现更优的生产效率和经济效益。本文通过建立工业过程动力学模型,并最小化成本函数来优化控制策略。在某些关键工艺中,安全性至关重要,常规的正则化方法可防止自适应控制方法探索不安全轨迹。
We consider the problem of control of a continuous nonlinear two-phase reactor from [28]. The simulated industrial process consists of a single vessel that represents a combination of the reactor and separation system. The process has two feeds: one contains substances A, B and C and the other one is pure A. Reaction $\mathrm{A}+\mathrm{C}\to\mathrm{D}$ occurs in the vapour phase. The liquid is pure D which is the product. The process is manipulated by three valves which regulate the flows in the two feeds and an output stream which contains A, B and C. The plant has ten measured variables including the flow rates of the four streams $(F_{1},\dots,F_{4})$ , pressure, liquid holdup volume and mole $%$ of A, B and C in the purge. The control problem is to transition to a specified product rate and maintain it by manipulating the three valves. The pressure must be kept below the shutdown limit of $3000\mathrm{kPa}$ . The original paper suggests a multiloop control strategy with several PI controllers [28].
我们考虑对[28]中连续非线性两相反应器的控制问题。该模拟工业流程由单个容器组成,集反应器与分离系统于一体。流程包含两股进料:一股含有物质A、B和C,另一股为纯A。气相中发生反应$\mathrm{A}+\mathrm{C}\to\mathrm{D}$,液相产物为纯D。流程通过三个阀门进行操控,分别调节两股进料和含A、B、C的输出流。装置配备十个测量变量,包括四股物流流量$(F_{1},\dots,F_{4})$、压力、持液量及排放口中A、B、C的摩尔$%$。控制目标是通过调节三个阀门,将产量切换至指定值并保持稳定,同时需确保压力不超过3000kPa的停机限值。原论文提出了采用多个PI控制器的多回路控制策略[28]。
We collected simulated data corresponding to about $0.5\mathrm{M}$ steps of operation by randomly generating control setpoints and using the original multiloop control strategy. The collected data were used to train a neural network model with one layer of 80 LSTM units and a linear readout layer to predict the next-step measurements. The inputs were the three controls and the ten process measurements. The data were pre-processed by scaling such that the standard deviation of the derivatives of each measured variable was of the same scale. This way, the model learned better the dynamics of slow changing variables. We used a fully-connected network architecture with 8 hidden layers (100-200- 100-20-100-200-100) to train a DAE on windows of five successive measurement-control pairs. The scaled measurement-control pairs in a window were concatenated to a single vector and corrupted with zero-mean Gaussian noise $'\sigma=0.03,$ ) and the DAE was trained to denoise it.
我们收集了约 $0.5\mathrm{M}$ 步操作的模拟数据,通过随机生成控制设定点并使用原始多回路控制策略。采集的数据用于训练一个包含80个LSTM单元的单层神经网络模型和线性读出层,以预测下一步测量值。输入为三个控制量和十个过程测量值。数据经过缩放预处理,使每个测量变量导数的标准差处于相同量级,从而让模型更好地学习慢变变量的动态特性。我们采用具有8个隐藏层(100-200-100-20-100-200-100)的全连接网络架构,在连续五个测量-控制对的窗口上训练去噪自编码器(DAE)。窗口内缩放后的测量-控制对被拼接为单个向量,并添加零均值高斯噪声 $\sigma=0.03$,DAE被训练用于对该向量进行去噪。
The trained model was then used for optimizing a sequence of actions to ramp production as rapidly as possible from $F_{4}=100$ to $F_{4}=1\bar{3}0\mathrm{kmol}\bar{\mathrm{h}}^{-1}$ , while satisfying all other constraints [Scenario II from 28]. We formulated the objective function as the Euclidean distance to the desired targets (after pre-processing). The targets corresponded to the following targets for three measurements: $F_{4}=\bar{1}30\bar{\mathrm{kmol}}\mathrm{h^{-1}}$ for product rate, $2850\mathrm{kPa}$ for pressure and 63 mole $%$ for A in the purge.
随后,训练好的模型被用于优化一系列操作,以尽可能快地将产量从 $F_{4}=100$ 提升至 $F_{4}=1\bar{3}0\mathrm{kmol}\bar{\mathrm{h}}^{-1}$ ,同时满足所有其他约束条件 [来自28的Scenario II]。我们将目标函数构建为与期望目标之间的欧几里得距离(经过预处理后)。这些目标对应以下三个测量指标:产品速率 $F_{4}=\bar{1}30\bar{\mathrm{kmol}}\mathrm{h^{-1}}$ 、压力 $2850\mathrm{kPa}$ 以及吹扫气中A的摩尔分数63$%$。
We optimized a plan of actions 30 hours ahead (or 300 disc ret i zed time steps). The optimized sequence of controls were initialized with the original multiloop policy applied to the trained dynamics model. That control sequence together with the predicted and the real outcomes (black and red curves respectively) are shown in Fig. 1a. We then optimized the control sequence using 10000 iterations of Adam with learning rate 0.01 without and with DAE regular iz ation (with penalty $\alpha|g(x_{t})-x_{t}|^{2})$ .
我们提前30小时(或300个离散时间步长)优化了行动计划。优化后的控制序列初始化为在训练好的动力学模型上应用原始多环策略。该控制序列与预测结果及实际结果(分别为黑色和红色曲线)如图1a所示。随后,我们使用学习率0.01的Adam优化器进行10000次迭代,分别在不使用和使用DAE正则化(惩罚项为$\alpha|g(x_{t})-x_{t}|^{2})$)的情况下优化控制序列。
The results are shown in Fig. 1. One can see that without regular iz ation the control signals are changed abruptly and the trajectory imagined by the model deviates from reality (Fig. 1b). In contrast, the open-loop plan found with the DAE regular iz ation is noticeably the best solution (Fig. 1c), leading the plant to the specified product rate much faster than the human-engineered multiloop PI control from [28]. The imagined trajectory (black) stays close to predictions and the targets are reached in about ten hours. This shows that even in a low-dimensional environment with a large amount of training data, regular iz ation is necessary for planning using a learned model.
结果如图 1 所示。可以看到,在没有正则化 (regularization) 的情况下,控制信号会突然变化,模型想象的轨迹会偏离现实 (图 1b)。相比之下,采用 DAE 正则化找到的开环计划明显是最佳解决方案 (图 1c),它比 [28] 中人工设计的多回路 PI 控制更快地将装置引导至指定生产率。想象轨迹 (黑色) 始终接近预测值,目标在大约十小时内达成。这表明即使是在具有大量训练数据的低维环境中,使用学习模型进行规划时正则化仍是必要的。
B Description of Environments
B 环境描述
Cartpole. This task involves a pole attached to a moving cart in a friction less track, with the goal of swinging up the pole and balancing it in an upright position in the center of the screen. The cost at every time step is measured as the angular distance between the tip of the pole and the target position. Each episode is 200 steps long.
倒立摆 (Cartpole)。该任务涉及一个在无摩擦轨道上移动的小车,车上连接着一根杆子,目标是将杆子摆动起来并使其在屏幕中央保持直立平衡。每个时间步的成本通过杆子顶端与目标位置之间的角度距离来衡量。每个回合持续200步。
Reacher. This environment consists of a simulated PR2 robot arm with seven degrees of freedom, with the goal of reaching a particular position in space. The cost at every time step is measured as the distance between the arm and the target position. The target position changes every episode. Each episode is 150 steps long.
Reacher。该环境模拟了一个具有七自由度的PR2机械臂,目标是在空间中到达特定位置。每一步的成本以机械臂与目标位置之间的距离衡量。目标位置每轮次都会变化。每个轮次持续150步。
Pusher. This environment also consists of a simulated PR2 robot arm, with a goal of pushing an object to a target position that changes every episode. The cost at every time step is measured as the distance between the object and the target position. Each episode is 150 steps long.
推箱环境。该环境同样模拟了一个PR2机械臂,目标是将物体推到每轮都会变化的目标位置。每一步的成本以物体与目标位置之间的距离衡量。每轮持续150步。
Half-cheetah. This environment involves training a two-legged "half-cheetah" to run forward as fast as possible by applying torques to 6 different joints. The cost at every time step is measured as the negative forward velocity. Each episode is 1000 steps long, but the length is reduced to 200 for the benchmark with [6].
半猎豹。该环境通过向6个不同关节施加扭矩,训练一个双足"半猎豹"尽可能快地向前奔跑。每个时间步的成本以负向速度衡量。每轮训练持续1000步,但在[6]的基准测试中缩短至200步。
Ant. This is the most challenging environment we consider. It consists of a four-legged "ant" controlled by applying torques to its 8 joints. Similar to [25], we use a gear ratio to 30 for all joints (this prevents the ant from flipping over frequently during the initially phase of training). The cost, similar to Half-cheetah, is the negative forward velocity. Each episode is 1000 steps long.
蚂蚁 (Ant)。这是我们考虑的最具挑战性的环境。它由一个四足"蚂蚁"组成,通过对其8个关节施加扭矩来控制。与[25]类似,我们对所有关节使用30:1的齿轮比 (这可以防止蚂蚁在训练初期频繁翻转)。与半猎豹 (Half-cheetah) 类似,成本函数是负向前速度。每个回合持续1000步。
Table 2: Dimensional i ties of observation and action spaces of the environments used in this paper
| Environment | Observation space | Actionspace |
| Cartpole | 5 | 1 |
| Reacher | 17 | 7 |
| Pusher | 20 | 7 |
| Half-cheetah | 19 | 6 |
| Ant | 111 | 8 |
表 2: 本文所用环境的观测空间与动作空间维度
| 环境 | 观测空间 | 动作空间 |
|---|---|---|
| Cartpole | 5 | 1 |
| Reacher | 17 | 7 |
| Pusher | 20 | 7 |
| Half-cheetah | 19 | 6 |
| Ant | 111 | 8 |
C Additional Experimental Details
C 补充实验细节
For MPC, we use the same planning horizon as PETS (Table 5). The important hyper parameters for all our experiments are shown in Tables 3 and 4. We found the DAE noise level, regular iz ation penalty weight $\alpha$ and Adam learning rate to be the most important hyper parameters.
对于MPC,我们采用与PETS相同的规划周期(表5)。所有实验的关键超参数如表3和表4所示。我们发现DAE噪声水平、正则化惩罚权重$\alpha$以及Adam学习率是最重要的超参数。

Figure 6: Effect of increased number of training epochs after every episode: we can see that training the dynamics model for more epochs after each episode leads to a much better performance in the initial episodes. With this modification, a single dynamics model with no regular iz ation seems to work almost as well as PETS. It can also be clearly seen that the use of denoising regular iz ation enables an improvement in the learning progress. To compare with PETS, we used the CEM optimizer in this ablation study.
图 6: 每轮训练后增加训练周期数的效果:可以看出,在每轮训练后为动力学模型增加更多训练周期,能显著提升初始阶段的性能。通过这一调整,即使不使用正则化的单一动力学模型,其表现也能接近PETS。此外,可以明显观察到降噪正则化的使用能促进学习进度提升 (本消融研究采用CEM优化器与PETS进行对比) 。
Table 3: Important hyper parameters used in our experiments for comparison with PETS. Additionally, for the experiments with gradient-based trajectory optimization on Reacher and Pusher, we initialize the trajectory with a few iterations (2 iterations for Reacher and 5 iterations for Pusher) of CEM.
| Environment | Optimizer | Optim Iters | Epochs | Adam LR | DAE noise o | |
| Cartpole | CEM | 5 | 500 | 0.001 | 0.1 | |
| Adam | 10 | 500 | 0.001 | 0.001 | 0.2 | |
| Reacher | CEM | 5 | 500 | 0.01 | 0.1 | |
| Adam | 5 | 300 | 1 | 0.01 | 0.1 | |
| Pusher | CEM | 5 | 500 | 0.01 | 0.1 | |
| Adam | 5 | 300 | 1 | 0.01 | 0.1 | |
| Half-cheetah | CEM | 5 | 100 | 2 | 0.1 | |
| Adam | 10 | 200 | 0.1 | 1 | 0.2 | |
| Ant | CEM | 5 | 400 | 0.045 | 0.3 | |
| Adam | 10 | 1000 | 0.075 | 0.03 | 0.4 |
表 3: 实验中用于与PETS对比的重要超参数。此外,在Reacher和Pusher环境中基于梯度的轨迹优化实验里,我们用CEM进行少量迭代(Reacher 2次,Pusher 5次)来初始化轨迹。
| 环境 | 优化器 | 优化迭代次数 | 训练轮数 | Adam学习率 | DAE噪声σ |
|---|---|---|---|---|---|
| Cartpole | CEM | 5 | 500 | - | 0.1 |
| Adam | 10 | 500 | 0.001 | 0.2 | |
| Reacher | CEM | 5 | 500 | - | 0.1 |
| Adam | 5 | 300 | 1 | 0.1 | |
| Pusher | CEM | 5 | 500 | - | 0.1 |
| Adam | 5 | 300 | 1 | 0.1 | |
| Half-cheetah | CEM | 5 | 100 | - | 0.1 |
| Adam | 10 | 200 | 0.1 | 0.2 | |
| Ant | CEM | 5 | 400 | - | 0.3 |
| Adam | 10 | 1000 | 0.075 | 0.4 |
Table 4: Important hyper parameters used in our experiments for comparison with MB-MPO
| Environment | Optimizer | Optim Iters | Epochs | Adam LR | DAE noise o | |
| Half-cheetah | CEM | 5 | 20 | 2 | 0.2 | |
| Adam | 10 | 40 | 0.1 | 1 | 0.1 |
表 4: 实验中用于与 MB-MPO 对比的重要超参数
| Environment | Optimizer | Optim Iters | Epochs | Adam LR | DAE noise o | |
|---|---|---|---|---|---|---|
| Half-cheetah | CEM | 5 | 20 | 2 | 0.2 | |
| Adam | 10 | 40 | 0.1 | 1 | 0.1 |
Table 5: MPC planning horizons used in our experiments
| Environment | Cartpole | Reacher | Pusher | Half-cheetah | Ant |
| Planning Horizon | 25 | 25 | 25 | 30 | 35 |
表 5: 实验中使用的 MPC (Model Predictive Control) 规划视野
| 环境 | Cartpole | Reacher | Pusher | Half-cheetah | Ant |
|---|---|---|---|---|---|
| 规划视野 (步) | 25 | 25 | 25 | 30 | 35 |
D Comparison to Gaussian regular iz ation
D 与高斯正则化 (Gaussian regularization) 的对比
To emphasize the importance of denoising regular iz ation, we also compare against a simple Gaussian regular iz ation baseline: we fit a Gaussian distribution (with diagonal covariance matrix) to the states and actions in the replay buffer and regularize the trajectory optimization by adding a penalty term to the cost, proportional to the negative log probability of the states and actions in the trajectory (Equation 4). The performance of this baseline in the Half-cheetah task (with an episode length of 200) is shown in Fig. 7. We observe that the Gaussian distribution poorly fits the trajectories and consistently leads the optimization to a bad local minimum.
为了强调去噪正则化的重要性,我们还对比了一个简单的高斯正则化基线:我们对回放缓冲区中的状态和动作拟合高斯分布(采用对角协方差矩阵),并通过在成本函数中添加与轨迹中状态动作负对数概率成正比的惩罚项来实现轨迹优化正则化(公式4)。该基线在Half-cheetah任务(回合长度为200)中的性能如图7所示。我们观察到高斯分布与轨迹拟合效果较差,并持续将优化导向不良的局部极小值。
E Preliminary Experiments on Exploration
E 探索性初步实验
To improve the asymptotic performance of our agent, we perform some preliminary experiments on exploration by injecting random noise into the optimized actions. In Figure 8, we show that asymptotic performance can greatly benefit from random exploration, suggesting a line of future work.
为了提升智能体的渐进性能,我们在优化动作中注入随机噪声进行了初步探索实验。图 8 显示随机探索能显著提升渐进性能,这为未来研究指明了方向。
F Visualization of Trajectory Optimization in End-to-End Experiments
F 端到端实验中的轨迹优化可视化
In Figures 9 and 10, we visualize trajectory optimization at different timesteps $t$ during Episode 5 of end-to-end experiments in Cartpole and Half-cheetah. It can be observed that the DAE penalty correlates with the inaccuracies of the model and that the DAE regular iz ation is effective in guiding the optimization procedure to remain within the data distribution.
在图 9 和图 10 中,我们可视化了 Cartpole 和 Half-cheetah 端到端实验第 5 集不同时间步 $t$ 的轨迹优化过程。可以观察到,DAE 惩罚项与模型的不准确性相关,且 DAE 正则化能有效引导优化过程保持在数据分布范围内。

Figure 7: Comparison to Gaussian regular iz ation: we can see that trajectory optimization with Adam without any regular iz ation is very unstable and completely fails in the initial episodes. While Gaussian regular iz ation helps in the first few episodes, it is not able to fit the data properly and seems to consistently lead the optimization to a local minimum. As shown earlier in Fig. 5, denoising regularization is able to successfully regularize the optimization, enabling good asymptotic performance from very few episodes of interaction.
图 7: 与高斯正则化 (Gaussian regularization) 的对比:可以看到未使用任何正则化的 Adam 轨迹优化极不稳定,在初始回合中完全失效。虽然高斯正则化在前几个回合中有所帮助,但无法正确拟合数据,似乎总是将优化引导至局部最小值。如图 5 所示,去噪正则化能成功规范优化过程,仅需极少交互回合即可实现良好的渐进性能。

Figure 8: In this plot we show the cumulative reward obtained during training by our method when we inject noise to actions in order to improve exploration of the state-action space. Plots are averaged over 5 seeds, and show mean and standard deviation.
图 8: 该图表展示了我们在训练过程中通过向动作注入噪声以提升状态-动作空间探索时,所获得的累积奖励。图表数据为5次实验种子的平均值,并显示了均值与标准差。

Figure 9: Visualization of trajectory optimization at different timesteps $t$ during Episode 5 of end-toend training in the Cartpole environment. Here, the red line denotes the rewards predicted by the model (imagination) and the black line denotes the true rewards obtained when applying the sequence of optimized actions (reality).
图 9: Cartpole环境中端到端训练第5回合不同时间步$t$的轨迹优化可视化。其中红线表示模型预测的奖励(想象),黑线表示应用优化动作序列时获得的真实奖励(现实)。

Figure 10: Visualization of trajectory optimization at different timesteps $t$ during Episode 5 of end-to-end training in the Half-cheetah environment. Here, the red line denotes the rewards predicted by the model (imagination) and the black line denotes the true rewards obtained when applying the sequence of optimized actions (reality).
图 10: 猎豹(Half-cheetah)环境中端到端训练第5回合不同时间步$t$的轨迹优化可视化。其中红线表示模型预测的奖励(想象),黑线表示应用优化动作序列时获得的真实奖励(现实)。