Context R-CNN: Long Term Temporal Context for Per-Camera Object Detection
Context R-CNN:基于长期时序上下文的单摄像头目标检测
Sara Beery*†, Guanhang $\mathrm{Wu}$ , Vivek Rathod†, Ronny Votel†, Jonathan Huang California Institute of Technology* Google†
Sara Beery*†, Guanhang $\mathrm{Wu}$, Vivek Rathod†, Ronny Votel†, Jonathan Huang 加州理工学院* Google†
Abstract
摘要
In static monitoring cameras, useful contextual information can stretch far beyond the few seconds typical video understanding models might see: subjects may exhibit similar behavior over multiple days, and background objects remain static. Due to power and storage constraints, sampling frequencies are low, often no faster than one frame per second, and sometimes are irregular due to the use of a motion trigger. In order to perform well in this setting, models must be robust to irregular sampling rates. In this paper we propose a method that leverages temporal context from the unlabeled frames of a novel camera to improve performance at that camera. Specifically, we propose an attention-based approach that allows our model, Context R-CNN, to index into a long term memory bank constructed on a per-camera basis and aggregate contextual features from other frames to boost object detection performance on the current frame. We apply Context R-CNN to two settings: (1) species detection using camera traps, and (2) vehicle detection in traffic cameras, showing in both settings that Context R-CNN leads to performance gains over strong baselines. Moreover, we show that increasing the contextual time horizon leads to improved results. When applied to camera trap data from the Snapshot Serengeti dataset, Context R-CNN with context from up to a month of images outperforms a single-frame baseline by $17.9%$ mAP, and outperforms S3D (a 3d convolution based baseline) by $11.2%$ mAP.
在静态监控摄像头中,有用的上下文信息可能远超典型视频理解模型所能捕捉的几秒范围:目标可能在多日内表现出相似行为,而背景物体保持静止。由于功耗和存储限制,采样频率通常较低(每秒不超过一帧),且可能因运动触发机制导致不规则采样。为在此环境下实现高性能,模型必须对不规则采样率具备鲁棒性。本文提出一种利用新摄像头未标记帧中时序上下文来提升该摄像头性能的方法。具体而言,我们提出基于注意力机制的Context R-CNN模型,该模型可通过按摄像头构建的长期记忆库检索信息,并聚合其他帧的上下文特征以提升当前帧的目标检测性能。我们将Context R-CNN应用于两种场景:(1) 相机陷阱中的物种检测,(2) 交通摄像头中的车辆检测,实验表明该模型在两种场景下均优于强基线模型。此外,延长上下文时间跨度能持续提升效果。在Snapshot Serengeti数据集上的实验显示,当使用长达一个月的图像上下文时,Context R-CNN以17.9% mAP优势超越单帧基线模型,并以11.2% mAP优势超越基于3D卷积的S3D基线模型。
1. Introduction
1. 引言
We seek to improve recognition within passive monitoring cameras, which are static and collect sparse data over long time horizons.1 Passive monitoring deployments are ubiquitous and present unique challenges for computer vision but also offer unique opportunities that can be leveraged for improved accuracy.
我们致力于提升被动监控摄像头中的识别能力,这类摄像头位置固定且长期收集稀疏数据。被动监控部署无处不在,为计算机视觉带来独特挑战的同时,也提供了可提升识别准确率的特殊机遇。
For example, depending on the triggering mechanism and the camera placement, large numbers of photos at any given camera location can be empty of any objects of interest (up to $75%$ for some ecological camera trap datasets) [31]. Further, as the images in static passive-monitoring cameras are taken automatically (without a human photographer), there is no guarantee that the objects of interest will be centered, focused, well-lit, or an appropriate scale. We break these challenges into three categories, each of which can cause failures in single-frame detection networks:
例如,根据触发机制和相机位置的不同,特定相机位置拍摄的大量照片可能完全不包含任何目标对象(在某些生态相机陷阱数据集中这一比例高达75%)[31]。此外,由于静态被动监测相机的图像是自动拍摄的(没有人工摄影师参与),无法保证目标对象处于画面中央、对焦准确、光照良好或比例适当。我们将这些挑战分为三类,每一类都可能导致单帧检测网络失效:

Figure 1: Visual similarity over long time horizons. In static cameras, there exists significantly more long term temporal consistency than in data from moving cameras. In each case above, the images were taken on separate days, yet look strikingly similar.
图 1: 长时间跨度的视觉相似性。在静态摄像头中,长期时间一致性显著高于移动摄像头采集的数据。上述每组图像均拍摄于不同日期,但呈现出惊人的相似性。
• Objects of interest partially observed. Objects can be very close to the camera and occluded by the edges of the frame, partially hidden in the environment due to camouflage, or very far from the camera. • Poor image quality. Objects are poorly lit, blurry, or obscured by weather conditions like snow or fog. Background distract or s. When moving to a new camera location, there can exist salient background objects that cause repeated false positives.
• 目标物体部分可见。物体可能距离摄像头极近而被画面边缘遮挡,或因伪装在环境中部分隐藏,也可能离摄像头非常远。
• 图像质量差。物体可能光照不足、模糊不清,或被雪、雾等天气条件遮蔽。
• 背景干扰。切换至新摄像头位置时,可能存在突出的背景物体导致重复误检。
These cases are often difficult even for humans. On the other hand, there are aspects of the passive monitoring problem domain that can give us hope — for example, subjects often exhibit similar behavior over multiple days, and background objects remain static, suggesting that it would be beneficial to provide temporal context in the form of additional frames from the same camera. Indeed we would expect humans viewing passive monitoring footage to often rewind to get better views of a difficult-to-see object.
这些情况对人类来说往往也很困难。另一方面,被动监控问题领域存在一些能带来希望的方面——例如,目标对象通常会在多天内表现出相似行为,且背景物体保持静态,这表明提供来自同一摄像头的额外帧作为时序上下文会很有帮助。事实上,我们预期人类在查看被动监控录像时,经常会通过回放来更清晰地观察难以看清的物体。

(e) Background distractor. Figure 2: Static Monitoring Camera Challenges. Images taken without a human photographer have no quality guarantees; we highlight challenges which cause mistakes in single-frame systems (left) and are fixed by our model (right). False single-frame detections are in red, detections missed by the single-frame model and corrected by our method are in green, and detections that are correct in both models are in blue. Note that in camera traps, the intra-image context is very powerful due to the group behavior of animal species.
(e) 背景干扰物。
图 2: 静态监控相机的挑战。无人拍摄的图像无法保证质量;我们展示了导致单帧系统误判的问题(左)及本模型修正后的效果(右)。红色标注为单帧模型的错误检测,绿色标注为单帧模型漏检但本方法修正的检测,蓝色标注为两模型均正确的检测。需注意在相机陷阱场景中,动物种群的群居行为使得图像内上下文信息极具价值。
These observations forms the intuitive basis for our model that can learn how to find and use other potentially easier examples from the same camera to help improve detection performance (see Figure 2). Further, like most realworld data [42], both traffic camera and camera trap data have long-tailed class distributions. By providing context for rare classes from other examples, we improve performance in the long tail as well as on common classes.
这些观察结果构成了我们模型的直观基础,该模型能够学习如何从同一摄像头中寻找并利用其他可能更简单的样本来帮助提升检测性能 (参见图 2)。此外,与大多数现实世界数据 [42] 类似,交通摄像头和相机陷阱数据都具有长尾类别分布。通过为稀有类别提供来自其他样本的上下文信息,我们不仅提升了常见类别的性能,也改善了长尾部分的检测效果。
More specifically, we propose a detection architecture, Context R-CNN, that learns to different i ably index into a long-term memory bank while performing detection within a static camera. This architecture is flexible and is applicable even in the aforementioned low, variable framerate scenarios. At a high level, our approach can be framed as a non-parametric estimation method (like nearest neighbors) sitting on top of a high-powered parametric function (Faster R-CNN). When train and test locations are quite different, one might not expect a parametric method to generalize well [6], whereas Context R-CNN is able to leverage an unlabeled ‘neighborhood’ of test examples for improved generalization.
具体而言,我们提出了一种检测架构Context R-CNN,该架构在学习对长期记忆库进行差异化索引的同时,还能在静态摄像头中执行检测。这种架构非常灵活,甚至适用于前文所述的低帧率、可变帧率场景。从高层次看,我们的方法可以视为一种基于高性能参数化函数(Faster R-CNN)的非参数估计方法(如最近邻)。当训练和测试位置差异较大时,参数化方法可能无法很好地泛化[6],而Context R-CNN能够利用未标记的测试样本"邻域"来提升泛化能力。
We focus on two static-camera domains:
我们专注于两种静态摄像头场景:
• Camera traps are remote static monitoring cameras used by biologists to study animal species occurrence, populations, and behavior. Monitoring biodiversity quantitatively can help us understand the connections between species decline and pollution, exploitation, urbanization, global warming, and policy. • Traffic cameras are static monitoring cameras used to monitor roadways and intersections in order to analyze traffic patterns and ensure city safety.
• 相机陷阱 (Camera traps) 是生物学家用于研究动物物种出现、种群和行为的远程静态监测摄像头。定量监测生物多样性有助于我们理解物种衰退与污染、开发、城市化、全球变暖及政策之间的关联。
• 交通摄像头是用于监控道路和交叉路口的静态监测摄像头,旨在分析交通模式并确保城市安全。
In both domains, the contextual signal within a single camera location is strong, and we allow the network to determine which previous images were relevant to the current frame, regardless of their distance in the temporal sequence. This is important within a static camera, as objects exhibit periodic, habitual behavior that causes them to appear days or even weeks apart. For example, an animal might follow the same trail to and from a watering hole in the morning and evening every night, or a bus following its route will return periodically throughout the day.
在这两个领域中,单个摄像头位置内的上下文信号很强,我们允许网络自行判断哪些历史图像与当前帧相关,而无需考虑它们在时间序列上的距离。这对于静态摄像头尤为重要,因为物体往往表现出周期性、习惯性的行为模式,导致它们相隔数天甚至数周才出现。例如,动物可能每晚早晚都沿着相同路线往返水源地,或者公交车全天按固定路线周期性往返。
To summarize our main contributions:
总结我们的主要贡献:
• We propose Context R-CNN, which leverages temporal context for improving object detection regardless of frame rate or sampling irregularity. It can be thought of as a way to improve generalization to novel cameras by incorporating unlabeled images. • We demonstrate major improvements over strong single-frame baselines; on a commonly-used camera trap dataset we improve mAP at $0.5\mathrm{IoU}$ by $17.9%$ . • We show that Context R-CNN is able to leverage up to a month of temporal context which is significantly more than prior approaches.
• 我们提出Context R-CNN,该方法利用时序上下文提升目标检测性能,且不受帧率或采样不规则性的影响。该技术可视为通过整合未标注图像来提升对新摄像头的泛化能力。
• 实验表明,该方法显著优于强大的单帧基线模型:在常用相机陷阱数据集上,$0.5\mathrm{IoU}$ 阈值的mAP指标提升达 $17.9%$。
• 我们证明Context R-CNN能有效利用长达一个月的时序上下文信息,远超现有方法的能力范围。
2. Related Work
2. 相关工作
Single frame object detection. Driven by popular benchmarks such as COCO [25] and Open Images [22], there have been a number of advances in single frame object detection in recent years. These detection architectures include anchor-based models, both single stage (e.g., SSD [27], RetinaNet [24], Yolo [32, 33]) and two-stage (e.g., Fast/Faster R-CNN [14, 18, 34], R-FCN [10]), as well as more recent anchor-free models (e.g., CornerNet [23], CenterNet [56], FCOS [41]). Object detection methods have shown great improvements on COCO- or Imagenet-style images, but these gains do not always generalize to challenging real-world data (See Figure 2).
单帧目标检测。受COCO [25]和Open Images [22]等流行基准的推动,近年来单帧目标检测领域取得了多项进展。这些检测架构包括基于锚点的模型(如单阶段模型SSD [27]、RetinaNet [24]、Yolo [32, 33]和两阶段模型Fast/Faster R-CNN [14, 18, 34]、R-FCN [10]),以及近年来的无锚点模型(如CornerNet [23]、CenterNet [56]、FCOS [41])。目标检测方法在COCO或Imagenet风格的图像上表现出显著改进,但这些成果并不总能泛化到具有挑战性的真实数据(见图2)。
Video object detection. Single frame architectures then form the basis for video detection and spatio-temporal action localization architectures, which build upon single frame models by incorporating contextual cues from other frames in order to deal with more specific challenges that arise in video data including motion blur, occlusion, and rare poses. Leading methods have used pixel level flow (or flow-like concepts) to aggregate features [7, 57–59] or used correlation [13] to densely relate features at the current timestep to an adjacent timestep. Other papers have explored the use of 3d convolutions (e.g., I3D, S3D) [8,29,48] or recurrent networks [20,26] to extract better temporal features. Finally, many works apply video specific postprocessing to smooth predictions along time, including tubelet smoothing [15] or SeqNMS [16].
视频目标检测。单帧架构构成了视频检测和时空动作定位架构的基础,这些架构通过整合来自其他帧的上下文线索,在单帧模型的基础上构建,以应对视频数据中出现的更具体挑战,包括运动模糊、遮挡和罕见姿态。领先方法采用像素级光流(或类光流概念)来聚合特征 [7, 57–59],或利用相关性 [13] 将当前时间步的特征与相邻时间步进行密集关联。其他论文探索了使用3D卷积(如I3D、S3D)[8,29,48] 或循环网络 [20,26] 来提取更好的时序特征。最后,许多研究采用视频专用后处理技术来沿时间平滑预测,包括小管平滑 [15] 或SeqNMS [16]。
Object-level attention-based temporal aggregation methods. The majority of the above video detection approaches are not well suited to our target setting of sparse, irregular frame rates. For example, flow based methods, 3d convolutions and LSTMs typically assume a dense, regular temporal sampling. And while models like LSTMs can theoretically depend on all past frames in a video, their effective temporal receptive field is typically much smaller. To address this limitation of recurrent networks, the NLP community has introduced attention-based architectures as a way to take advantage of long range dependencies in sentences [3, 12, 43]. The vision community has followed suit with attention-based architectures [28, 38, 39] that leverage longer term temporal context.
基于对象级注意力的时序聚合方法。上述大多数视频检测方法并不适用于我们稀疏、非规则帧率的目标场景。例如,基于光流的方法、3D卷积和LSTM通常假设时间采样是密集且规则的。虽然LSTM等模型理论上可以依赖视频中所有过去帧,但其有效时间感受野通常要小得多。为克服循环网络的这一局限,自然语言处理领域引入了基于注意力的架构来利用句子中的长程依赖关系[3,12,43]。计算机视觉领域随后也采用了基于注意力的架构[28,38,39],以利用更长期的时序上下文。
Along the same lines and most relevant to our work, there are a few recent works [11, 37, 46, 47] that rely on non-local attention mechanisms in order to aggregate information at the object level across time. For example, Wu et al [46] applied non-local attention [45] to person detections to accumulate context from pre-computed feature banks (with frozen pre-trained feature extractors). These feature banks extend the time horizon of their network up to 60s in each direction, achieving strong results on spatiotemporal action localization. We similarly use a frozen feature extractor that allows us to create extremely long term memory banks which leverage the spatial consistency of static cameras and habitual behavior of the subjects across long time horizons (up to a month). However Wu et al use a
同样地,与我们工作最相关的是近期几项研究 [11, 37, 46, 47],它们依赖非局部注意力机制来跨时间聚合物体层面的信息。例如,Wu等人 [46] 将非局部注意力 [45] 应用于人体检测,从预计算的特征库(使用冻结的预训练特征提取器)中积累上下文信息。这些特征库将其网络的时间范围扩展到每个方向60秒,在时空动作定位任务上取得了强劲效果。我们同样采用冻结的特征提取器,利用静态摄像头的空间一致性和主体在长时间范围(长达一个月)内的习惯性行为,构建了超长期记忆库。不过Wu等人的方法...
3d convnet (I3D) for short term features which is not wellsuited to our setting due to low, irregular frame rate. Instead we use a single frame model for the current frame which is more similar to [11, 37, 47] who proposed variations of this idea for video object detection achieving strong results on the Imagenet Vid dataset. In contrast to these three papers, we augment our model with an additional dedicated short term attention mechanism which we show to be effective in experiments. Uniquely, our approach also allows negative examples into memory which allows the model to learn to ignore salient false positives in empty frames due to their immobility; we find that our network is able to learn background classes (e.g., rocks, bushes) without supervision.
3D卷积网络(I3D)由于低且不规则的帧率并不适合我们的场景。为此,我们采用单帧模型处理当前帧,这与[11, 37, 47]提出的视频目标检测改进方案更为接近——这些方法在Imagenet Vid数据集上取得了优异效果。与这三篇论文不同,我们通过新增的短期注意力机制增强模型,实验证明该机制效果显著。我们的方法创新性地允许将负样本存入记忆,使模型能通过静态特征学习忽略空帧中的显著误检目标。实验表明,网络能在无监督情况下自主学习背景类别(如岩石、灌木丛)。
More generally, our paper adds to the growing evidence that this attention-based approach of temporally aggregating information at the object level is highly effective for incorpora ting more context in video understanding. We argue in fact that it is especially useful in our setting of sparse irregular frame samples from static cameras. Whereas a number of competing baselines like 3d convolutions and flow based techniques perform nearly as well as these attentionbased models on Imagenet Vid, the same baselines are not well-suited to our setting. Thus, we see a larger performance boost from prior, non-attention-based methods to our attention-based approach.
更广泛地说,我们的论文进一步证明,这种基于注意力机制(attention-based)在物体层面进行时序信息聚合的方法,能高效地为视频理解融入更多上下文信息。我们认为该方法尤其适用于静态相机稀疏不规则帧采样的场景。虽然3D卷积和光流技术等基线方法在Imagenet Vid数据集上表现接近这些基于注意力的模型,但这些基线方法并不适配我们的场景。因此,与先前的非注意力方法相比,我们的基于注意力的方法实现了更显著的性能提升。
Camera traps and other visual monitoring systems. Image classification and object detection have been increasingly explored as a tool for reducing the arduous task of classifying and counting animal species in camera trap data [4–6, 30, 31, 35, 44, 50, 51, 54]. Detection has been shown to greatly improve the generalization of these models to new camera locations [6]. It has also been shown in [6, 31, 50] that temporal information is useful. However, previous methods cannot report per-image species identification s (instead identifying a class at the burst level), cannot handle image bursts containing multiple species, and cannot provide per-image localization s and thus species counts, all of which are important to biologists.
相机陷阱及其他视觉监测系统。图像分类和物体检测技术正日益被探索作为减轻相机陷阱数据中动物物种分类与计数繁重任务的工具 [4–6, 30, 31, 35, 44, 50, 51, 54]。研究表明,检测能显著提升这些模型对新相机部署位置的泛化能力 [6]。文献 [6, 31, 50] 也证实时间信息具有重要价值。然而,现有方法无法实现单张图像的物种识别 (仅能在图像组层面进行分类),不能处理包含多物种的图像组,且无法提供单张图像的定位结果及物种计数——这些功能对生物学家都至关重要。
In addition, traffic cameras, security cameras, and weather cameras on mountain passes are all frequently stationary and used to monitor places over long time scales. For traffic cameras, prior work focuses on crowd counting (e.g., counting the number of vehicles or humans in each image) [2, 9, 36, 53, 55]. Some recent works have investigated using temporal information in traffic camera datasets [49, 52], but these methods only focus on short term time horizons, and do not take advantage of long term context.
此外,交通摄像头、安防摄像头以及山口的天气摄像头通常都是固定安装的,用于长期监测特定区域。针对交通摄像头,已有研究主要集中在人群计数(例如统计每张图像中的车辆或行人数量)[2, 9, 36, 53, 55]。近期部分工作探索了交通摄像头数据集中的时序信息利用[49, 52],但这些方法仅关注短期时间范围,未能利用长期上下文信息。
3. Method
3. 方法
Our proposed approach, Context R-CNN, builds a “memory bank” based on contextual frames and modifies a detection model to make predictions conditioned on this memory bank. In this section we discuss (1) the rationale behind our choice of detection architecture, (2) how to represent contextual frames, and (3) how to incorporate these contextual frame features into the model to improve current frame predictions.
我们提出的方法 Context R-CNN 基于上下文帧构建了一个"记忆库",并修改检测模型以基于该记忆库进行预测。本节我们将讨论:(1) 检测架构选择背后的原理,(2) 如何表示上下文帧,(3) 如何将这些上下文帧特征整合到模型中以提高当前帧的预测效果。
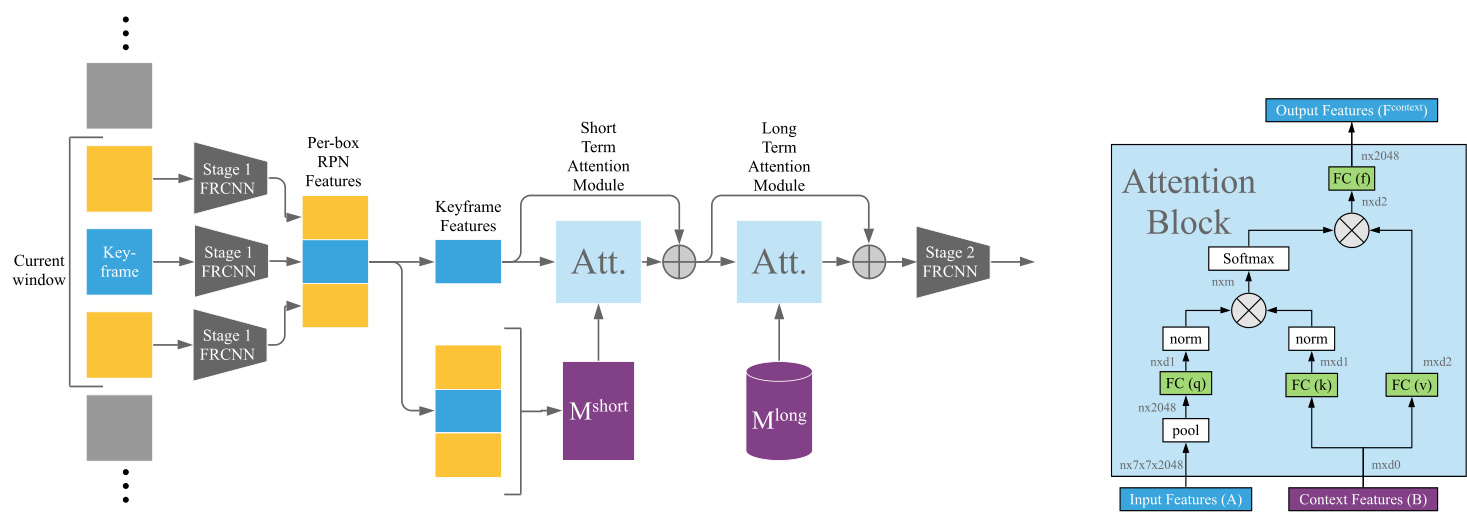
(a) High-level Context R-CNN architecture. (b) Single attention block. Figure 3: Context R-CNN Architecture. (a) The high-level architecture of the model, with short term and long term attention used sequentially. Short term and long term attention are modular, and the system can operate with either or both. (b) We see the details of our implementation of an attention block, where $_n$ is the number of boxes proposed by the RPN for the keyframe, and $m$ is the number of comparison features. For short term attention, $m$ is the total number of proposed boxes across all frames in the window, shown in (a) as $M^{s h o r t}$ . For long term attention, $_m$ is the number of features in the long term memory bank $M^{l o n g}$ associated with the current clip. See Section 3.1 for details on how this memory bank is constructed.
(a) 高层级Context R-CNN架构。(b) 单注意力模块。
图3: Context R-CNN架构。(a) 模型的高层级架构,其中短期注意力和长期注意力被顺序使用。短期和长期注意力是模块化的,系统可以单独或同时使用二者。(b) 展示了注意力模块的实现细节,其中$_n$表示RPN为关键帧生成的候选框数量,$m$表示对比特征的数量。对于短期注意力,$m$表示窗口内所有帧的候选框总数,在(a)中标记为$M^{short}$。对于长期注意力,$_m$表示与当前片段关联的长期记忆库$M^{long}$中的特征数量。关于该记忆库的构建方式详见第3.1节。
Due to our sparse, irregular input frame rates, typical temporal architectures such as 3d convnets and recurrent neural networks are not well-suited, due to a lack of interframe temporal consistency (there are significant changes between frames). Instead, we build Context R-CNN on top of single frame detection models. Additionally, building on our intuitions that moving objects exhibit periodic behavior and tend to appear in similar locations, we hope to inform our predictions by conditioning on instance level features from contextual frames. Because of this last requirement, we choose the Faster R-CNN architecture [34] as our base detection model as this model remains a highly competitive meta-architecture and provides clear choices for how to extract instance level features. Our method is easily applicable to any two stage detection framework.
由于输入帧率稀疏且不规则,3D卷积网络和循环神经网络等典型时序架构因帧间时序一致性不足(帧间存在显著变化)而不适用。为此,我们在单帧检测模型基础上构建Context R-CNN。基于运动物体呈现周期性行为且倾向于出现在相似位置的观察,我们尝试通过关联上下文帧的实例级特征来优化预测。基于最后这一需求,我们选择Faster R-CNN架构[34]作为基础检测模型——该架构仍具高度竞争力,且为实例级特征提取提供了明确方案。本方法可轻松适配任何两阶段检测框架。
As a brief review, Faster R-CNN proceeds in two stages. An image is first passed through a first-stage region proposal network (RPN) which, after running non-max suppression, returns a collection of class agnostic bounding box proposals. These box proposals are then passed into the second stage, which extracts instance-level features via the ROIAlign operation [17, 19] which then undergo classification and box refinement.
简要回顾,Faster R-CNN 分为两个阶段进行。图像首先通过第一阶段的区域提议网络 (RPN) ,在运行非极大值抑制后,返回一组与类别无关的边界框提议。这些框提议随后传入第二阶段,通过 ROIAlign 操作 [17, 19] 提取实例级特征,然后进行分类和框细化。
In Context R-CNN, the first-stage box proposals are instead routed through two attention-based modules that (diffe rent i ably) index into memory banks, allowing the model to incorporate features from contextual frames (seen by the same camera) in order to provide local and global temporal context. These attention-based modules return a con textually-informed feature vector which is then passed through the second stage of Faster R-CNN in the ordinary way. In the following section (3.1), we discuss how to represent features from context frames using a memory bank and detail our design of the attention modules. See Figure 3 for a diagram of our pipeline.
在Context R-CNN中,第一阶段的候选框会通过两个基于注意力(attention-based)的模块(可微分地)索引到记忆库(memory banks),使模型能够整合来自上下文帧(由同一摄像头拍摄)的特征,从而提供局部和全局的时间上下文信息。这些基于注意力的模块会返回一个包含上下文信息的特征向量,随后以常规方式传递给Faster R-CNN的第二阶段。在下一节(3.1)中,我们将讨论如何使用记忆库表示上下文帧的特征,并详细介绍注意力模块的设计。具体流程见图3。
3.1. Building a memory bank from context features
3.1. 基于上下文特征构建记忆库
Long Term Memory Bank $(M^{l o n g})$ . Given a keyframe $i_{t}$ , for which we want to detect objects, we iterate over all frames from the same camera within a pre-defined time horizon $i_{t-k}:i_{t+k}$ , running a frozen, pre-trained detector on each frame. We build our long term memory bank $(M^{l o n g})$ from feature vectors corresponding to resulting detections. Given the limitations of hardware memory, deciding what to store in a memory bank is a critical design choice. We use three strategies to ensure that our memory bank can feasibly be stored.
长期记忆库 $(M^{l o n g})$。给定一个关键帧 $i_{t}$,我们需要检测其中的物体时,会在同一摄像头拍摄的预定义时间范围 $i_{t-k}:i_{t+k}$ 内遍历所有帧,并在每帧上运行一个冻结的预训练检测器。我们将检测结果对应的特征向量存入长期记忆库 $(M^{l o n g})$。考虑到硬件内存限制,决定存储内容是关键设计选择。我们采用三种策略确保记忆库的可行性存储:
• We take instance level feature tensors after cropping proposals from the RPN and save only a spatially pooled representation of each such tensor concatenated with a s patio temporal encoding of the datetime and box position (yielding per-box embedding vectors). • We curate by limiting the number of proposals for which we store features — we consider multiple strategies for deciding which and how many features to save to our memory banks, see Section 5.2 for more details.
• 我们从RPN(区域提议网络)获取裁剪提议后的实例级特征张量,仅保存每个张量的空间池化表示,并与日期时间及框位置(y轴)的时空编码拼接(生成每框嵌入向量)。
• 我们通过限制存储特征的提议数量进行筛选——采用多种策略决定存储哪些特征及存储数量至记忆库,详见5.2节。
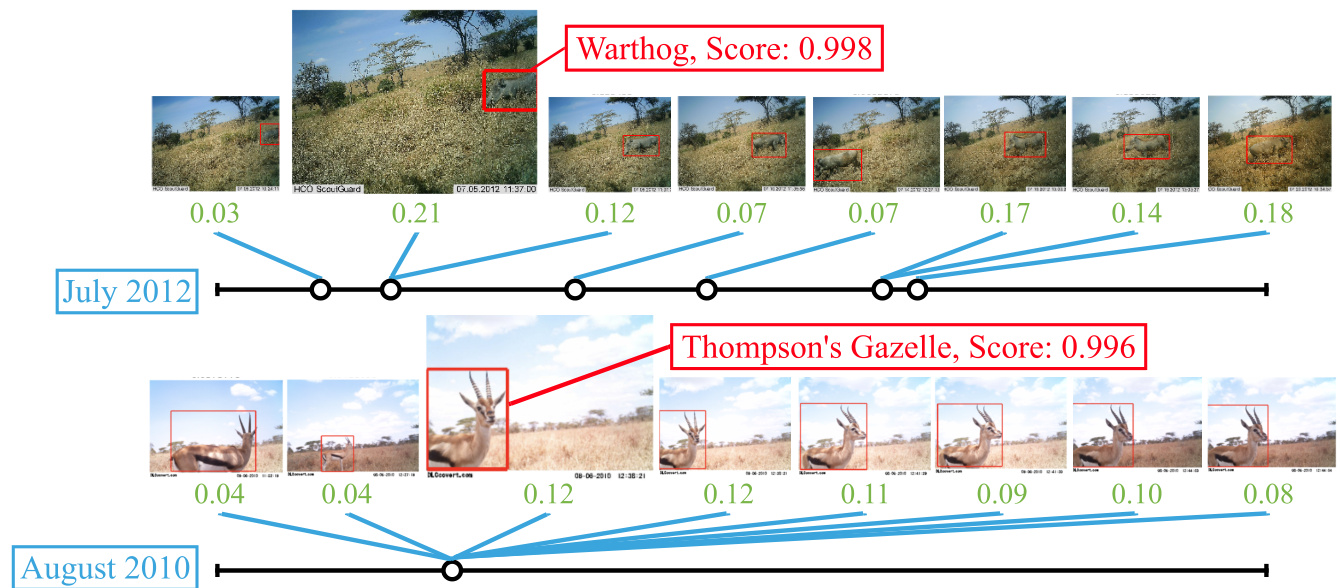
Figure 4: Visualizing attention. In each example, the keyframe is shown at a larger scale, with Context R-CNN’s detection, class, and score shown in red. We consider a time horizon of one month, and show the images and boxes with highest attention weights (shown in green). The model pays attention to objects of the same class, and the distribution of attention across time can be seen in the timelines below each example. A warthogs’ habitual use of a trail causes useful context to be spread out across the month, whereas a stationary gazelle results in the most useful context to be from the same day. The long term attention module is adaptive, choosing to aggregate information from whichever frames in the time horizon are most useful.
图 4: 注意力可视化。每个示例中,关键帧以较大尺寸显示,Context R-CNN的检测结果、类别及分数以红色标注。我们考察一个月时间跨度,并展示具有最高注意力权重(绿色显示)的图像和检测框。模型会关注同类物体,注意力在时间上的分布情况见每例下方的时间轴。疣猪对路径的习惯性使用使得有效上下文分散在整个月份,而静止的瞪羚则导致最有用的上下文集中于同一天。该长期注意力模块具有自适应性,能够自主选择聚合时间跨度内最有价值的帧信息。
• We rely on a pre-trained single frame Faster R-CNN with Resnet-101 backbone as a frozen feature extractor (which therefore need not be considered during backpropagation). In experiments we consider an extractor pretrained on COCO alone, or fine-tuned on the training set for each dataset. We find that COCO features can be used effectively but that best performance comes from a fine-tuned extractor (see Table 1(c)).
• 我们采用基于Resnet-101主干网络的预训练单帧Faster R-CNN作为冻结特征提取器 (因此在反向传播过程中无需考虑其参数)。实验中,我们分别测试了仅基于COCO预训练的提取器,以及针对各数据集训练集微调后的提取器。结果表明,COCO预训练特征具备可用性,但最佳性能来自微调后的提取器 (见表1(c))。
Together with our sparse frame rates, by using these strategies we are able to construct memory banks holding up to 8500 contextual features — in our datasets, this is sufficient to represent a month’s worth of context from a camera.
结合我们稀疏的帧率,通过采用这些策略,我们能够构建存储多达8500个上下文特征的内存库——在我们的数据集中,这足以表示摄像头一个月的上下文信息。
Short Term Memory $(M^{s h o r t})$ . In our experiments we show that it is helpful to include a separate mechanism for incorporating short term context features from nearby frames, using the same, trained first-stage feature extractor as for the keyframe. This is different from our long term memory from above which we build over longer time horizons with a frozen feature extractor. In contrast to long term memory, we do not curate the short term features: for small window sizes it is feasible to hold features for all box proposals in memory. We take the stacked tensor of cropped instance-level features across all frames within a small window around the current frame (typically $\leq~5$ frames) and globally pool across the spatial dimensions (width and height). This results in a matrix of shape (# proposals per frame∗# frames) $\times$ (feature depth) containing a single embedding vector per box proposal (which we call our Short Term Memory, $M^{s h o r t\setminus}$ , that is then passed into the short term attention block.
短期记忆 $(M^{short})$。实验表明,通过使用与关键帧相同的训练好的第一阶段特征提取器,单独建立一个机制来整合附近帧的短期上下文特征是有益的。这与前文所述的长期记忆不同——长期记忆采用冻结特征提取器在更长时间跨度上构建。不同于长期记忆,我们不对短期特征进行筛选:对于较小时间窗口(通常 $\leq~5$ 帧),将所有边界框提议的特征保存在内存中是可行的。我们将当前帧附近小窗口内所有帧的实例级裁剪特征张量堆叠后,沿空间维度(宽和高)进行全局池化,最终得到形状为(每帧提议数∗帧数)$\times$(特征深度)的矩阵,其中每个边界框提议对应一个嵌入向量(称为短期记忆 $M^{short\setminus}$),该矩阵随后被输入短期注意力模块。
3.2. Attention module architecture
3.2. 注意力模块架构
We define an attention block [43] which aggregates from context features keyed by input features as follows (see Figure 3): Let $A$ be the tensor of input features from the current frame (which in our setting has shape $[n\times7\times7\times2048]$ , with $n$ the number of proposals emitted by the the first-stage of Faster R-CNN). We first spatially pool $A$ across the feature width and height dimensions, yielding $A^{p o o l}$ with shape $[n\times2048]$ . Let $B$ be the matrix of context features, which has shape $[m\times d_{0}]$ . We set $B=M^{s h o r t}$ or $M^{l o n g}$ . We define $k(\cdot;\theta)$ as the key function, $q(\cdot;\theta)$ as the query function, $v(\cdot;\theta)$ as the value function, and $f(\cdot;\theta)$ as the final projection that returns us to the correct output feature length to add back into the input features. We use a distinct $\theta$ ( $\theta^{l o n g}$ or $\theta^{s h o r t}$ ) for long term or short term attention respectively. In our experiments, $k,q,v$ and $f$ are all fully-connected layers, with output dimension 2048. We calculate attention weights $w$ using standard dot-product attention:
我们定义了一个注意力块 [43],它通过以下方式从由输入特征索引的上下文特征中聚合信息(见图 3):设 $A$ 为来自当前帧的输入特征张量(在我们的设置中形状为 $[n\times7\times7\times2048]$,其中 $n$ 是 Faster R-CNN 第一阶段生成的候选框数量)。我们首先在特征宽度和高度维度上对 $A$ 进行空间池化,得到形状为 $[n\times2048]$ 的 $A^{pool}$。设 $B$ 为上下文特征矩阵,其形状为 $[m\times d_{0}]$。我们令 $B=M^{short}$ 或 $M^{long}$。定义 $k(\cdot;\theta)$ 为键函数,$q(\cdot;\theta)$ 为查询函数,$v(\cdot;\theta)$ 为值函数,$f(\cdot;\theta)$ 为最终投影函数,用于将输出特征长度调整回与输入特征相加所需的尺寸。我们分别使用不同的 $\theta$($\theta^{long}$ 或 $\theta^{short}$)来处理长期或短期注意力。实验中,$k,q,v$ 和 $f$ 均为全连接层,输出维度为 2048。我们使用标准点积注意力计算注意力权重 $w$:
$$
w=\mathrm{Softmax}\left(\left(k(A^{p o o l};\theta)\cdot q(B;\theta)\right)/\left(T\sqrt{d}\right)\right),
$$
$$
w=\mathrm{Softmax}\left(\left(k(A^{p o o l};\theta)\cdot q(B;\theta)\right)/\left(T\sqrt{d}\right)\right),
$$
where $T>0$ is the softmax temperature, $w$ the attention weights with shape $[n\times m]$ , and $d$ the feature depth (2048).
其中 $T>0$ 是softmax温度参数,$w$ 为形状 $[n\times m]$ 的注意力权重,$d$ 表示特征深度(2048)。
We next construct a context feature $F^{c o n t e x t}$ for each box by taking a projected, weighted sum of context features:
我们接下来通过获取上下文特征的投影加权和,为每个框构建一个上下文特征 $F^{c o n t e x t}$:
$$
F^{c o n t e x t}=f(w\cdot v(B;\theta);\theta),
$$
$$
F^{c o n t e x t}=f(w\cdot v(B;\theta);\theta),
$$
where $F^{c o n t e x t}$ has shape $[n\times2048]$ in our setting. Finally, we add $F^{c o n t e x t}$ as a per-feature-channel bias back into our original input features $A$ .
在我们的设置中,$F^{c o n t e x t}$ 的形状为 $[n\times2048]$。最后,我们将 $F^{c o n t e x t}$ 作为每个特征通道的偏置加回到原始输入特征 $A$ 中。
4. Data
4. 数据
Our model is built for variable, low-frame-rate realworld systems of static cameras, and we test our methods on two such domains: camera traps and traffic cameras. Because the cameras are static, we split each dataset into separate camera locations for train and test, to ensure our model does not overfit to the validation set [6].
我们的模型专为静态摄像头的可变低帧率现实世界系统而设计,并在两个此类领域测试了方法:相机陷阱和交通摄像头。由于摄像头是静态的,我们将每个数据集按不同摄像头位置划分为训练集和测试集,以确保模型不会对验证集过拟合 [6]。
Camera Traps. Camera traps are usually programmed to capture an image burst of $1-10$ frames (taken at 1 fps) after each motion trigger, which results in data with variable, low frame rate. In this paper, we test our systems on the Snapshot Serengeti (SS) [40] and Caltech Camera Traps (CCT) [6] datasets, each of which have humanlabeled ground truth bounding boxes for a subset of the data. We increase the number of bounding box labeled images for training by pairing class-agnostic detected boxes from the Microsoft AI for Earth Mega Detector [5] with image-level species labels on our training locations. SS has 10 publicly available seasons of data. We use seasons $1-6$ , containing 225 cameras, 3.2M images, and 48 classes. CCT contains 140 cameras, 243K images, and 18 classes. Both datasets have large numbers of false motion triggers, $75%$ for SS and $50%$ for CCT; thus many images contain no animals. We split the data using the location splits proposed in [1], and evaluate on the images with human-labeled bounding boxes from the validation locations for each dataset (64K images across 45 locations for SS and 62K images across 40 locations for CCT).
相机陷阱。相机陷阱通常被设定为每次运动触发后拍摄1-10帧的图像连拍(以1 fps拍摄),这会产生帧率可变且较低的数据。本文中,我们在Snapshot Serengeti (SS) [40]和Caltech Camera Traps (CCT) [6]数据集上测试系统,这两个数据集都包含部分数据的人工标注真实边界框。我们通过将Microsoft AI for Earth Mega Detector [5]的类别无关检测框与训练地点图像级物种标签配对,增加了用于训练的边界框标注图像数量。SS包含10个公开可用的数据季节,我们使用1-6季数据,涵盖225台相机、320万张图像和48个类别。CCT包含140台相机、24.3万张图像和18个类别。两个数据集都存在大量误触发,SS为75%,CCT为50%,因此许多图像不含动物。我们采用[1]提出的地点划分方案拆分数据,并在各数据集验证地点的人工标注边界框图像上评估性能(SS包含45个地点的6.4万张图像,CCT包含40个地点的6.2万张图像)。
Traffic Cameras. The CityCam dataset [53] contains 10 types of vehicle classes, around 60K frames and 900K annotated objects. It covers 17 cameras monitoring downtown intersections and parkways in a high-traffic city, and “clips” of data are sampled multiple times per day, across months and years. The data is diverse, covering day and nighttime, rain and snow, and high and low traffic density. We use 13 camera locations for training and 4 cameras for testing, with both parkway and downtown locations in both sets.
交通摄像头。CityCam数据集[53]包含10类车辆、约6万帧图像和90万个标注对象,采集自某高流量城市中17个监控市区交叉路口及林荫大道的摄像头,数据"片段"按日/月/年多周期采样。该数据集具备多样性,涵盖昼夜、雨雪天气及高低交通密度场景。我们选用13个摄像头点位进行训练,4个点位用于测试,两组均包含林荫大道与市中心区域。
5. Experiments
5. 实验
We evaluate all models on held-out camera locations, using established object detection metrics: mean average precision (mAP) at $0.5\mathrm{IoU}$ and Average Recall (AR). We compare our results to a (comparable) single-frame baseline for all three datasets. We focus the majority of our experiments on a single dataset, Snapshot Serengeti, investigating the effects of both short term and long term attention, the feature extractor, the long term time horizon, and the frame-wise sampling strategy for $M^{l o n g}$ . We further explore the addition of multiple features per frame in CityCam.
我们在预留的相机位置上评估所有模型,采用以下成熟的目标检测指标:0.5IoU下的平均精度均值(mAP)和平均召回率(AR)。针对所有三个数据集,我们将结果与(可比的)单帧基线进行对比。大部分实验集中在Snapshot Serengeti数据集上,重点研究短期与长期注意力机制、特征提取器、长期时间跨度以及$M^{long}$的帧采样策略的影响。此外,我们在CityCam数据集中探索了每帧添加多重特征的效果。
5.1. Main Results
5.1. 主要结果
Context R-CNN strongly outperforms the single-frame Faster RCNN with Resnet-101 baseline on both the Snapshot Serengeti (SS) and Caltech Camera Traps (CCT)
Context R-CNN在Snapshot Serengeti (SS) 和Caltech Camera Traps (CCT) 两个数据集上均显著优于基于Resnet-101的单帧Faster RCNN基线模型
| SS | CCT | CC | |||||
| Model Single Frame Context R-CNN | mAP 37.9 | AR 46.5 | mAP 56.8 | AR 53.8 | mAP 38.1 | AR 28.2 | |
| 55.9 (a) Results across datasets | 58.3 | 76.3 | 62.3 | 42.6 | 30.2 | ||
| Oneminute 50.3 | SS mAP | AR 51.4 | SS | mAP | AR | ||
| One hour One day | 52.1 | 52.5 | Oneboxperframe COCO features | 55.6 50.3 | 57.5 55.8 | ||
| One week | 52.5 | 52.9 | Only positive boxes | 53.9 | 56.2 | ||
| One month | 54.1 | 53.2 | Subsample half | 52.5 | 56.1 | ||
| 55.6 | 57.5 | Subsample quarter | 50.8 | 55.0 | |||
| (b) Time horizon | (c) Selecting memory | ||||||
| SS | |||||||
| Single Frame | mAP | AR | |||||
| 37.9 | 46.5 | ||||||
| Maj. Vote | 37.8 | 46.4 | |||||
| ST Spatial | 39.6 | 36.0 | CC | mAP | AR | ||
| S3D | 44.7 | 46.0 | Single Frame | 38.1 | 28.2 | ||
| SF Attn | 44.9 | 50.2 | Top 1 Box | 40.5 | 29.3 | ||
| ST Attn | 46.4 | 55.3 | Top 8 Boxes | 42.6 | 30.2 | ||
| LT Attn | 55.6 | 57.5 | (e) Adding boxes to Mlong | ||||
| ST+LTAttn | 55.9 | 58.3 | |||||
(d) Comparison across models
| SS | CCT | CC | |||||
|---|---|---|---|---|---|---|---|
| 模型 单帧上下文 R-CNN | mAP 37.9 | AR 46.5 | mAP 56.8 | AR 53.8 | mAP 38.1 | AR 28.2 | |
| 55.9 (a) 跨数据集结果 | 58.3 | 76.3 | 62.3 | 42.6 | 30.2 | ||
| 一分钟 50.3 | SS mAP | AR 51.4 | SS | mAP | AR | ||
| 一小时 一天 | 52.1 | 52.5 | 每帧单框 COCO特征 | 55.6 50.3 | 57.5 55.8 | ||
| 一周 | 52.5 | 52.9 | 仅正样本框 | 53.9 | 56.2 | ||
| 一个月 | 54.1 | 53.2 | 子采样半数 | 52.5 | 56.1 | ||
| 55.6 | 57.5 | 子采样四分之一 | 50.8 | 55.0 | |||
| (b) 时间跨度 | (c) 记忆选择 | ||||||
| SS | |||||||
| 单帧 | mAP | AR | |||||
| 37.9 | 46.5 | ||||||
| 多数投票 | 37.8 | 46.4 | |||||
| ST 空间 | 39.6 | 36.0 | CC | mAP | AR | ||
| S3D | 44.7 | 46.0 | 单帧 | 38.1 | 28.2 | ||
| SF 注意力 | 44.9 | 50.2 | 前1框 | 40.5 | 29.3 | ||
| ST 注意力 | 46.4 | 55.3 | 前8框 | 42.6 | 30.2 | ||
| LT 注意力 | 55.6 | 57.5 | (e) 向Mlong添加框 | ||||
| ST+LT注意力 | 55.9 | 58.3 |
(d) 模型间对比
Table 1: Results. All results are based on Faster R-CNN with a Resnet 101 backbone. We consider the Snapshot Serengeti (SS), Caltech Camera Traps (CCT), and CityCam (CC) datasets. All mAP values employ an IoU threshold of 0.5, and AR is reported for the top prediction $(\mathrm{AR@1})$ .
表 1: 实验结果。所有结果均基于采用 Resnet 101 骨干网络的 Faster R-CNN 模型。实验数据集包括 Snapshot Serengeti (SS)、Caltech Camera Traps (CCT) 和 CityCam (CC)。所有 mAP 值均采用 0.5 的 IoU 阈值,AR 指标报告最高置信度预测结果 $(\mathrm{AR@1})$ 。
datasets, and shows promising improvements on CityCam (CC) traffic camera data as well (See Table 1 (a)). For all experiments, unless otherwise noted, we use a fine-tuned dataset specific feature extractor for the memory bank. We show an absolute mAP at $\mathbf{0.5~IoU}$ improvement of $19.5%$ on CCT, $17.9%$ on SS, and $4.5%$ on CC. Recall improves as well, with AR $@1$ improving $2%$ on CC, $11.8%$ on SS, and $8.5%$ on CCT.
数据集,并在CityCam (CC)交通摄像头数据上也显示出有前景的改进(见表1(a))。在所有实验中,除非另有说明,我们都使用针对记忆库微调的数据集特定特征提取器。我们在CCT上展示了绝对mAP在$\mathbf{0.5~IoU}$下提升了$19.5%$,在SS上提升了$17.9%$,在CC上提升了$4.5%$。召回率也有所提高,AR$@1$在CC上提高了$2%$,在SS上提高了$11.8%$,在CCT上提高了$8.5%$。
For SS, we also compare against several baselines with access to short term temporal information (Table 1(d)). All short term experiments use an input window of 3 frames. Our results are as follows:
对于SS,我们还对比了几种能够利用短期时间信息的基线方法(表1(d))。所有短期实验均采用3帧的输入窗口。结果如下:
We first consider a simple majority vote (Maj. Vote) across the high-confidence single-frame detections within the window, and find that it does not improve over the single-frame baseline. We attempt to leverage the static-ness of the camera by taking a temporal-distance-weighted average of the RPN box classifier features from the key frame with the cropped RPN features from the same box locations from the surrounding frames (ST Spatial), and find it outperforms the single-frame baseline by $1.9%$ mAP. • S3D [48], a popular video object detection model, outperforms single-frame by $6.8%$ mAP despite being designed for consistently sampled high frame rate video. • Since animals in camera traps occur in groups, crossobject intra-image context is valuable. An intuitive
我们首先考虑在窗口内高置信度单帧检测结果上进行简单多数投票(Maj. Vote),发现其性能并未超越单帧基线。通过利用摄像头的静态特性,我们尝试将关键帧的RPN边界框分类特征与周围帧相同位置裁剪出的RPN特征进行时序距离加权平均(ST Spatial),该方法比单帧基线提升了1.9% mAP。• S3D[48]作为流行的视频目标检测模型,尽管专为连续采样的高帧率视频设计,其性能仍比单帧检测高出6.8% mAP。• 由于相机陷阱中的动物常以群体出现,跨目标的帧内上下文信息具有重要价值。

Figure 5: Performance per class. Our performance improvement is consistent across classes: we visualize SS per-species mAP from the single-frame model to our best long term and short term memory model.
图 5: 各类别性能表现。我们的性能提升在所有类别中保持一致:我们展示了从单帧模型到最佳长短期记忆模型中每个物种的SS mAP (mean Average Precision) 变化。
baseline is to restrict the short term attention context window $(M^{s h o r t})$ to the current frame (SF Attn). This removes temporal context, showing how much improvement we gain from explicitly sharing information across the box proposals in a non-local way. We see that we can gain $7%$ mAP over a vanilla single-frame model by adding this non-local attention module. When we increase the short term context window to three frames, keyframe plus two adjacent, (ST Attn) we see an additional improvement of $1.5%$ mAP. If we consider only long term attention with a time horizon of one month (LT Attn), we see a $9.2%$ mAP improvement over short term attention. • By combining both attention modules into a single model $\mathbf{\Xi}(\mathbf{S}\mathbf{T}+\mathbf{L}\mathbf{T}$ Attn), we see our highest performance at $55.9%$ mAP, and show in Figure 5 that we improve for all classes in the imbalanced dataset.
基准方法是将短期注意力上下文窗口 $(M^{short})$ 限制在当前帧(SF Attn)。这消除了时间上下文,展示了我们通过以非局部方式显式共享边界框提议信息能获得多少改进。我们发现,通过添加这个非局部注意力模块,可以在普通单帧模型基础上提升 $7%$ mAP。当我们将短期上下文窗口增加到三帧(关键帧加相邻两帧,ST Attn)时,mAP 又额外提高了 $1.5%$。如果仅考虑时间跨度为一个月(LT Attn)的长期注意力,相比短期注意力可获得 $9.2%$ mAP 提升。通过将两个注意力模块组合到单一模型 $\mathbf{\Xi}(\mathbf{ST}+\mathbf{LT}$ Attn) 中,我们实现了最高性能($55.9%$ mAP),并在图 5 中展示了该方法在不平衡数据集的所有类别上均有改进。
5.2. Changing the Time Horizon (Table 1(b))
5.2. 改变时间范围 (表 1(b))
We ablate our long term only attention experiments by increasing the time horizon of $M^{l o n g}$ , and find that performance increases as the the time horizon increases. We see a large performance improvement over the single-frame model even when only storing a minute-worth of representations in memory. This is due to the sampling strategy, as highly-relevant bursts of images are captured for each motion trigger. The long term attention block can adaptively determine how to aggregate this information, and there is much useful context across images within a single burst. However, some cameras take only a single image at a trigger; in these cases the long term context becomes even more important. The adaptability of Context R-CNN to be trained on and improve performance across data with not only variable frame rates, but also with different sampling strategies (time lapse, motion trigger, heat trigger, and bursts of 1-10 images per trigger) is a valuable attribute of our system.
我们通过延长$M^{long}$的时间跨度来消融仅长期注意力实验,发现性能随着时间跨度的增加而提升。即使仅在内存中存储一分钟时长的表征,相比单帧模型也能观察到显著的性能提升。这得益于采样策略——每次运动触发都能捕获到高度相关的图像组。长期注意力模块能够自适应地确定如何聚合这些信息,且单组图像内部存在大量有用上下文。不过部分相机每次触发仅拍摄单张图像,此时长期上下文的作用就更为关键。Context R-CNN的适应性使其不仅能针对可变帧率数据进行训练和性能优化,还能兼容不同采样策略(延时摄影、运动触发、热源触发以及每次触发1-10张图像的组照模式),这是我们系统的重要特性。
In Figure 6, we explore the time differential between the top scoring box for each image and the features it most closely attended to, using a threshold of 0.01 on the attention weight. We can see day/night periodicity in the weekand month-long plots, showing that attention is focused on objects captured at the same time of day. As the time horizon increases, the temporal diversity of the attention module increases and we see that Context R-CNN attends to what is available across the time horizon, with a tendency to focus higher on images nearby in time (see examples in Figure 4).
在图6中,我们以0.01的注意力权重为阈值,探索了每张图像得分最高的检测框与其最关注的视觉特征之间的时间差异。从周度和月度的图表中可以观察到昼夜周期性规律,这表明模型倾向于关注同一天相时段拍摄的物体。随着时间跨度增大,注意力模块的时间多样性也随之提升,可见Context R-CNN会关注整个时间跨度内可用的图像特征,但对时间邻近的图像仍保持较高关注度(具体示例见图4)。

Figure 6: Attention over time. We threshold attention weights at 0.01, and plot a histogram of time differentials from the highest-scoring object in the keyframe to the attended frames for varied long term time horizons. Note that the y-axis is in log scale. The central peak of each histogram shows the value of nearby frames, but attention covers the breadth of what is provided: namely, if given a month worth of context, Context R-CNN will use it. Also note a strong day/night periodicity when using a weeklong or month-long memory bank.
图 6: 随时间变化的注意力机制。我们将注意力权重阈值设为0.01,并针对不同长期时间跨度,绘制从关键帧中得分最高物体到被关注帧的时间差直方图。请注意y轴采用对数刻度。每个直方图的中心峰值显示邻近帧的数值,但注意力覆盖了所提供的全部时间范围:即当给定一个月时长的上下文时,Context R-CNN会利用这些信息。另外值得注意的是,在使用长达一周或一个月的记忆库时,存在明显的昼夜周期性。
5.3. Contextual features for constructing ![image.png]()

.
5.3 构建 ![image.png]()
的上下文特征
Feature extractor (Table 1(c)). For Snapshot Serengeti, we consider both a feature extractor trained on COCO, and one trained on COCO and then fine-tuned on the SS training set. We find that while a month of context from a feature extractor tuned for SS achieves $5.3%$ higher mAP than one trained only on COCO, we are able to outperform the single-frame model by $12.4%$ using memory features that have never before seen a camera trap image.
特征提取器 (表 1(c))。对于Snapshot Serengeti数据集,我们同时考虑了在COCO上训练的特征提取器,以及先在COCO上训练再在SS训练集上微调的特征提取器。实验表明:虽然针对SS微调的特征提取器通过一个月的上下文数据比仅在COCO上训练的模型获得了5.3%的mAP提升,但使用从未接触过相机陷阱图像的记忆特征,我们的方法仍能超越单帧模型12.4%。
Sub sampling memory (Table 1(c)). We further ablate our long term memory by decreasing the stride at which we store representations in the memory bank, while maintaining a time horizon of one month. If we use a stride of 2, which subsamples the memory bank by half, we see a drop in performance of $3.1%$ mAP at 0.5. If we increase the stride to 4, we see an additional $1.7%$ drop. If instead of increasing the stride, we instead subsample by taking only positive examples (using an oracle to determine which images contain animals for the sake of the experiment), we find that performance still drops (explored below).
降采样内存 (表 1(c))。我们通过降低在记忆库中存储表征的步长来进一步消融长期记忆,同时保持一个月的时间范围。当采用步长为2时 (记忆库降采样一半),性能在0.5 mAP指标上下降3.1%。若将步长增至4,则会额外下降1.7%。如果不增加步长,而是仅保留正样本进行降采样 (实验中通过oracle确定包含动物的图像),性能仍会出现下降 (下文将展开分析)。
Keeping representations from empty images. In our static camera scenario, we choose to add features into our long term memory bank from all frames, both empty and non-empty. The intuition behind this decision is the existence of salient background objects in the static camera frame which do not move over time, and can be repeatedly and erroneously detected by single-frame architectures. We assume that the features from the frozen extractor are visually representative, and thus sufficient for both foreground and background representation. By saving representations of highly-salient background objects, we thus hope to allow the model to learn per-camera salient background classes and positions without supervision, and to suppress these objects in the detection output.
保留空图像的表示。在我们的静态摄像头场景中,我们选择将所有帧(包括空帧和非空帧)的特征存入长期记忆库。这一决策背后的直觉是:静态摄像头画面中存在显著背景物体,这些物体随时间推移保持静止,但可能被单帧架构反复错误检测。我们假设冻结提取器生成的特征具有视觉代表性,因此足以同时表征前景和背景。通过保存高显著性背景物体的表示,我们希望模型能在无监督情况下学习每个摄像头的显著背景类别和位置,并在检测输出中抑制这些物体。

Figure 7: False positives on empty images. When adding features from empty images to the memory bank, we reduce false positives across all confidence thresholds compared to the same model without negative representations. Note that the y-axis is in log scale. The single frame model has fewer high-confidence false positives than either context model, but when given positive and negative context Context R-CNN is able to suppress low-confidence detections. By analyzing Context R-CNN’s 100 most high-confidence detections on images labeled “empty” we found 97 images where the annotators missed animals.
图 7: 空图像上的误报情况。当将空图像特征加入记忆库时,相比未使用负样本表征的相同模型,我们在所有置信度阈值上都减少了误报。注意y轴采用对数刻度。单帧模型的高置信度误报数量少于两种上下文模型,但当提供正负上下文时,Context R-CNN能够抑制低置信度检测。通过分析Context R-CNN在标注为"空"的图像上100个最高置信度检测结果,我们发现其中97张图像实际存在标注人员遗漏的动物。
In Figure 7, we see that adding empty representations reduces the number of false positives across all confidence thresholds compared to the same model with only positive representations. We investigated the 100 highest confidence “false positives” from Context R-CNN, and found that in almost all of them (97/100), the model had correctly found and classified animals that were missed by human annotators. The Snapshot Serengeti dataset reports $5%$ noise in their labels [40], and looking at the high-confidence predictions of Context R-CNN on images labeled “empty” is intuitively a good way to catch these missing labels. Some of these are truly challenging, where the animal is difficult to spot and the annotator mistake is unfortunate but reasonable. Most are truly just label noise, where the existence of an animal is obvious, suggesting that our performance improvement estimates are likely conservative.
图 7: 可以看出,在所有置信度阈值下,与仅使用正样本表示的相同模型相比,添加空样本表示减少了误报数量。我们调查了Context R-CNN中置信度最高的100个"误报",发现其中几乎所有案例(97/100)都是模型正确识别并分类了被人工标注者遗漏的动物。Snapshot Serengeti数据集报告其标签存在5%的噪声[40],而观察Context R-CNN在标注为"空"的图像上做出的高置信度预测,直观上是捕捉这些遗漏标签的有效方法。其中部分案例确实具有挑战性——动物难以发现,标注者的错误虽令人遗憾但情有可原。但大多数案例明显只是标签噪声,动物的存在显而易见,这表明我们的性能改进评估可能偏保守。
Keeping multiple representations per image (Table 1(e)). In Snapshot Serengeti, there are on average 1.6 objects and 1.01 classes per image across the non-empty images, and
每张图像保留多重表征 (表 1(e))。在Snapshot Serengeti数据集中,非空图像平均每张包含1.6个检测对象和1.01个类别。
$75%$ of the images are empty. The majority of the images contain a single object, while a few have large herds of a single species. Given this, choosing only the top-scoring detection to add to memory makes sense, as that object is likely to be representative of the other objects in the image (e.g., keeping only one zebra example from an image with a herd of zebra). In CityCam, however, on average there are 14 objects and 4 classes per frame, and only $0.3%$ of frames are empty. In this scenario, storing additional objects in memory is intuitively useful, to ensure that the memory bank is representative of the camera location. We investigate adding features from the top-scoring 1 and 8 detections, and find that selecting 8 objects per frame yields the best performance (see Table 1(e)). A logical extension of our approach would be selecting objects to store based not only on confidence, but also diversity.
75%的图像是空白的。大多数图像包含单个物体,少数图像中存在大量同种生物群。因此,仅选择置信度最高的检测结果存入记忆库是合理的,因为该物体很可能代表图像中的其他同类物体(例如从斑马群图像中仅保留一只斑马样本)。但在CityCam数据集中,每帧平均包含14个物体和4个类别,仅有0.3%的帧是空白的。这种情况下,直觉上在记忆库中存储更多物体有助于确保其能代表摄像头所在位置的特性。我们测试了存储置信度最高的1个和8个检测特征的效果,发现每帧选择8个物体时性能最佳(见表1(e))。本方法的合理延伸方向是:存储物体时不仅依据置信度,还应考虑多样性。
Failure modes. One potential failure case of this similaritybased attention approach is the opportunity for hallucination. If one image in a test location contains something that is very strongly mis classified, that one mistake may negatively influence other detections at that camera. For example, when exploring the confident “false positives” on the Snapshot Serengeti dataset (which proved to be almost universally true detections that were missed by human annotators) the $3/100$ images where Context R-CNN erroneously detected an animal were all of the same tree, highly confidently predicted to be a giraffe.
失败模式。这种基于相似性的注意力方法存在一个潜在的失败案例——可能出现幻觉现象。若测试位置的某张图像包含被严重误分类的内容,这一错误可能对该摄像头下的其他检测结果产生负面影响。例如,在分析Snapshot Serengeti数据集中高置信度的"假阳性"时(这些案例几乎都是人类标注员漏标的真实检测目标),Context R-CNN错误检测到动物的$3/100$图像均指向同一棵树,且被高度自信地预测为长颈鹿。
6. Conclusions and Future Work
6. 结论与未来工作
In this work, we contribute a model that leverages percamera temporal context up to a month, far beyond the time horizon of previous approaches, and show that in the static camera setting, attention-based temporal context is particularly beneficial. Our method, Context R-CNN, is general across static camera domains, improving detection performance over single-frame baselines on both camera trap and traffic camera data. Additionally, Context R-CNN is adaptive and robust to passive-monitoring sampling strategies that provide data streams with low, irregular frame rates.
在本研究中,我们提出了一种利用单摄像头时间上下文信息长达一个月的模型,远超以往方法的时间范围,并证明在静态摄像头场景下,基于注意力机制的时间上下文具有显著优势。我们的方法 Context R-CNN 具有跨静态摄像头领域的通用性,在相机陷阱数据和交通摄像头数据上均优于单帧基线检测性能。此外,Context R-CNN 能自适应低帧率、非规律采样的被动监控数据流,展现出强鲁棒性。
It is apparent from our results that what and how much information is stored in memory is both important and domain specific. We plan to explore this in detail in the future, and hope to develop methods for curating diverse memory banks which are optimized for accuracy and size, to reduce the computational and storage overheads at training and inference time while maintaining performance gains.
从我们的结果可以明显看出,存储在记忆中的信息内容及其数量既重要又具有领域特异性。我们计划在未来对此进行详细探索,并希望开发出优化精准度和容量的多样化记忆库构建方法,从而在保持性能提升的同时,降低训练和推理时的计算与存储开销。
7. Ac know leg dem ents
7. 致谢
We would like to thank Pietro Perona, David Ross, Zhichao Lu, Ting Yu, Tanya Birch and the Wildlife Insights Team, Joe Marino, and Oisin MacAodha for their valuable insight. This work was supported by NSFGRFP Grant No. 1745301, the views are those of the authors and do not necessarily reflect the views of the NSF.
我们要感谢Pietro Perona、David Ross、Zhichao Lu、Ting Yu、Tanya Birch和Wildlife Insights团队、Joe Marino以及Oisin MacAodha提供的宝贵见解。这项工作得到了NSFGRFP资助(编号1745301)的支持,文中观点仅代表作者,并不一定反映NSF的观点。
Supplementary Material
补充材料
A. Implementation Details
A. 实现细节
We implemented our attention modules within the Tensorflow Object Detection API open-source Faster-RCNN architecture with Resnet 101 backbone [19]. Faster-RCNN optimization and model parameters are not changed between the single-frame baseline and our experiments, and we ensure robust single-frame baselines via hyperparameter sweeps. We train on Google TPUs (v3) [21] using Momentum SGD with weight decay 0.0004 and momentum 0.9. We construct each batch using 32 clips, drawing four frames for each clip spaced 1 frame apart and resizing to $640\times640$ . Batches are placed on 8 TPU cores, colocating frames from the same clip. We augment with random flipping, ensuring that the memory banks are flipped to match the current frames to preserve spatial consistency. All our experiments use a softmax temperature of $T=.01$ for the attention mechanism, which we found in early experiments to outperform .1 and 1.
我们在Tensorflow Object Detection API开源Faster-RCNN架构中实现了注意力模块,该架构以Resnet 101为骨干网络[19]。在单帧基线实验与我们的实验中,Faster-RCNN的优化和模型参数保持不变,并通过超参数扫描确保稳健的单帧基线。我们使用Google TPU(v3)[21]进行训练,采用动量SGD(权重衰减0.0004,动量0.9)。每个批次由32个片段构成,每个片段抽取间隔1帧的4帧图像并调整尺寸至$640\times640$。批次数据分布在8个TPU核心上,确保同一片段的帧位于相同核心。数据增强采用随机翻转,同时翻转记忆库以匹配当前帧,保持空间一致性。所有实验均采用softmax温度$T=.01$作为注意力机制参数,早期实验表明该设置优于.1和1。
B. Dataset Statistics and Per-Class Performance
B. 数据集统计与各类别性能
Each of the real-world datasets (Snapshot Serengeti, Caltech Camera Traps, and CityCam) has a long-tailed distribution of classes, which can be seen in Figure 10. Dealing with imbalanced data is a known challenge across machine learning disciplines [4, 42], with rare classes (classes not well-represented during training) frequently proving difficult to recognize.
现实世界数据集(Snapshot Serengeti、Caltech Camera Traps和CityCam)都具有长尾类别分布,如图10所示。处理数据不平衡是机器学习领域的公认挑战[4, 42],稀有类别(训练期间样本不足的类别)往往难以识别。
In Figure 5 in the main text, we demonstrate that the per-class performance universally improves for Snapshot Serengeti (SS). In Figure 8, we show the per-class performance for Caltech Camera Traps (CCT). and CityCam (CC). Performance on CCT improves for all classes from the single frame model. We see that for one class in CC, “Middle Truck”, our method performs slightly worse; However, this class is relatively ambiguous, as the concept of “middle” size is not well-defined.
在正文图5中,我们展示了Snapshot Serengeti (SS) 的每类别性能普遍提升。图8展示了Caltech Camera Traps (CCT) 和CityCam (CC) 的每类别性能。CCT所有类别的性能相比单帧模型均有提升。我们观察到CC中"Middle Truck"类别的性能略有下降,但该类别定义相对模糊,因为"中等"尺寸的概念缺乏明确界定。
C. S patio tempt oral Encodings
C. 空间时空编码
We normalize the spatial and temporal information for each object we include in the contextual memory bank. In order to do so, we choose to use a single float between 0 and 1 to represent each of: year, month, day, hour, minute, x center coordinate, y center coordinate, object width, and object height.
我们对纳入上下文记忆库的每个对象进行时空信息归一化处理。具体做法是采用0到1之间的单精度浮点数分别表示:年份、月份、日期、小时、分钟、x轴中心坐标、y轴中心坐标、物体宽度和物体高度。
We normalize each element as follows:
我们对每个元素进行如下归一化处理:
Year: We select a reasonable window of possible years covered by our data, 1990-2030. We normalize the year within that window, representing the year in question as $\frac{y e a r-1990}{2030-1990}$ .
年份:我们选择了一个合理的时间窗口1990-2030年作为数据覆盖范围。将年份在该窗口内进行归一化处理,具体表示为$\frac{y e a r-1990}{2030-1990}$。

Figure 8: Performance per class. Performance comparison from single-frame to our memory-based model. Note this reports mAP for each class averaged across IoU thresholds, as popularized by the COCO challenge [25].
图 8: 各类别性能表现。从单帧模型到我们基于记忆的模型的性能对比。请注意,这里报告的是每个类别在不同IoU阈值下的平均mAP (mean Average Precision) ,这是遵循COCO挑战赛[25]推广的评估方式。
D. Camera Movement
D. 相机移动
Our system has no hard requirements about the camera being static, instead we leverage the fact that it is static implicitly through our memory bank to provide appropriate and relevant context. We find that our system is robust to static cameras that get moved, unlike traditional background modeling approaches. In Snapshot Serengeti in particular, the animals have a tendency to rub against the camera posts and cause camera shifts over time. Figure 9 shows a “before and after” example of a camera being bumped or moved.
我们的系统对相机是否固定没有硬性要求,而是通过记忆库隐式利用其静态特性来提供恰当的相关上下文。与传统背景建模方法不同,我们发现即使静态相机被移动,系统仍能保持鲁棒性。尤其在Snapshot Serengeti项目中,动物常会蹭撞相机支架导致镜头逐渐偏移。图9展示了相机被碰撞或移动前后的对比实例。

Figure 9: Our system is robust to a static camera being accidentally shifted. Before and after example of a camera that had been bumped by an animal. The images are from the same camera. The first image was taken August 8th 2010, the next August 9th 2010. We find that the system can still utilize contextual information across a camera shift.
图 9: 我们的系统对于静态相机意外偏移具有鲁棒性。展示动物碰撞导致相机移动前后的对比示例,图像来自同一台相机。第一张拍摄于2010年8月8日,第二张拍摄于2010年8月9日。我们发现系统仍能利用相机位移前后的上下文信息。
E. Attention Visualization
E. 注意力可视化
In Figure 4 in the main text, we visualize attention over time for two examples from Snapshot Serengeti. In Figure 11 we show examples from Caltech Camera Traps. Similarly to the visualization s of attention on SS, we see that attention is adaptive to the most relevant information, paying attention across time as needed. The model consistently learns to attend to objects of the same class.
在主文本的图4中,我们可视化了两张来自Snapshot Serengeti样本的注意力随时间变化情况。图11展示了来自Caltech Camera Traps的示例。与SS上的注意力可视化类似,我们看到注意力会自适应地关注最相关的信息,并根据需要在时间维度上分配注意力。该模型始终能学会关注同类别的物体。
In Figure 12, we visualize how Context R-CNN learns to learn and attend to unlabeled background classes, namely rocks and bushes. Remember that these exact camera locations were never seen during training, so the model has learned to use temporal context to determine when to ignore these salient background classes. It learns to cluster background objects of a certain type, for example bushes, across the frames at a given location. Note that these attended background objects are not always the same instance of the class, which makes sense as background classes may maintain visual similarity within a scene even if they aren’t the exact same instance of that type. Species of plants or types of rock are often geographically clustered.
在图 12 中,我们展示了 Context R-CNN 如何学习并关注未标记的背景类别(即岩石和灌木)。请注意,这些具体的摄像头位置在训练过程中从未出现过,因此模型学会了利用时序上下文来判断何时忽略这些显著的背景类别。它能够将特定类型的背景对象(例如灌木)在给定位置的各帧中进行聚类。需要注意的是,这些被关注的背景对象并不总是该类别的同一实例,这是合理的,因为背景类别在场景中可能保持视觉相似性,即使它们并非该类型的完全相同实例。植物种类或岩石类型通常在地理上是聚集分布的。

Figure 10: Imbalanced class distributions. Images per category for each of the three datasets. Note the y-axis is in log scale.
图 10: 类别分布不平衡。三个数据集中每个类别的图像数量。注意y轴为对数刻度。

Figure 11: Visualizing attention. In each example, the keyframe is shown at a larger scale, with Context R-CNN’s detection, class, and score shown in red. We consider a time horizon of one month, and show the images and boxes with highest attention weights (shown in green). The model pays attention to objects of the same class, and the distribution of attention across time can be seen in the timelines below each example.
图 11: 注意力可视化示例。每个示例中,关键帧以较大尺寸显示,Context R-CNN的检测结果、类别及置信度分数以红色标注。我们观察一个月时间跨度内注意力权重最高(绿色标注)的图像和检测框。模型主要关注同类物体,各示例下方的时间轴展示了注意力随时间分布的规律。

Figure 12: Visualizing attention on background classes. In each example, the keyframe is shown at a larger scale, with Context R-CNN’s detection, class, and score shown in red. We consider a time horizon of one month, and show the images and boxes with highest attention weights (shown in green). The first example is from SS, it shows a detected bush (an unlabeled, background class), and shows that Context R-CNN attends to the same bush over time, as well as different bushes in the frame. In the second example, from CCT, we see a similar situation with the background class “rock.”
图 12: 背景类注意力可视化。每个示例中,关键帧以较大比例显示,Context R-CNN的检测结果、类别和分数用红色标注。我们考虑一个月的时间范围,并展示具有最高注意力权重(用绿色标注)的图像和边界框。第一个示例来自SS数据集,展示了一个被检测到的灌木丛(未标注的背景类),表明Context R-CNN会持续关注同一灌木丛以及画面中其他灌木。第二个示例来自CCT数据集,展示了背景类"岩石"的类似情况。