PROMPTCAP: Prompt-Guided Task-Aware Image Captioning
PROMPTCAP: 基于提示引导的任务感知图像描述生成
Abstract
摘要
Knowledge-based visual question answering (VQA) involves questions that require world knowledge beyond the image to yield the correct answer. Large language models (LMs) like GPT-3 are particularly helpful for this task because of their strong knowledge retrieval and reasoning capabilities. To enable LM to understand images, prior work uses a captioning model to convert images into text. However, when summarizing an image in a single caption sentence, which visual entities to describe are often under specified. Generic image captions often miss visual details essential for the LM to answer visual questions correctly. To address this challenge, we propose PROMPTCAP (Prompt-guided image Captioning), a captioning model designed to serve as a better connector between images and black-box LMs. Different from generic captions, PROMPTCAP takes a naturallanguage prompt to control the visual entities to describe in the generated caption. The prompt contains a question that the caption should aid in answering. To avoid extra annotation, PROMPTCAP is trained by examples synthesized with GPT-3 and existing datasets. We demonstrate PROMPTCAP’s effectiveness on an existing pipeline in which GPT-3 is prompted with image captions to carry out VQA. PROMPTCAP outperforms generic captions by a large margin and achieves state-of-the-art accuracy on knowledge-based VQA tasks $60.4%$ on OK-VQA and $59.6%$ on A-OKVQA). Zero- shot results on WebQA show that PROMPTCAP generalizes well to unseen domains.1
基于知识的视觉问答 (VQA) 需要借助图像之外的世界知识才能得出正确答案。像 GPT-3 这样的大语言模型因其强大的知识检索和推理能力而特别适合此类任务。为了让大语言模型理解图像,先前的研究使用图像描述模型将图像转换为文本。然而,当用单句描述概括图像时,往往未明确指定需要描述的视觉实体。通用图像描述通常会遗漏对大语言模型正确回答视觉问题至关重要的视觉细节。为解决这一挑战,我们提出了 PROMPTCAP (Prompt-guided image Captioning),这是一种专为更好地连接图像与黑盒大语言模型而设计的描述模型。与通用描述不同,PROMPTCAP 通过自然语言提示来控制生成描述中包含的视觉实体。提示中包含需要借助描述来回答的问题。为避免额外标注,PROMPTCAP 使用 GPT-3 合成的样本和现有数据集进行训练。我们在现有流程中验证了 PROMPTCAP 的有效性,该流程通过图像描述提示 GPT-3 执行 VQA。PROMPTCAP 大幅优于通用描述,在基于知识的 VQA 任务上达到最先进准确率 (OK-VQA 60.4%,A-OKVQA 59.6%)。WebQA 上的零样本结果表明 PROMPTCAP 能很好地泛化到未见领域。1
1. Introduction
1. 引言
Knowledge-based visual question answering (VQA) [37] extends traditional VQA tasks [3] with questions that require broad knowledge and commonsense reasoning to yield the correct answer. Existing systems on knowledge-based VQA retrieve external knowledge from various sources, including knowledge graphs [13, 36, 63], Wikipedia [36, 63, 12, 15, 29], and web search [35, 63]. Recent work [67] finds that modern language models (LMs) like GPT-3 [5] are particularly useful for this task because of their striking knowledge retrieval and reasoning abilities. The current state-of-the-art methods [67, 15, 29, 1] all make use of recent large language models (GPT-3 or Chinchilla).
基于知识的视觉问答 (VQA) [37] 通过需要广泛知识和常识推理才能得出正确答案的问题,扩展了传统 VQA 任务 [3]。现有的基于知识的 VQA 系统从各种来源检索外部知识,包括知识图谱 [13, 36, 63]、维基百科 [36, 63, 12, 15, 29] 和网络搜索 [35, 63]。最近的研究 [67] 发现,像 GPT-3 [5] 这样的现代语言模型 (LM) 因其出色的知识检索和推理能力而特别适合这项任务。当前最先进的方法 [67, 15, 29, 1] 都利用了最新的大语言模型 (GPT-3 或 Chinchilla)。
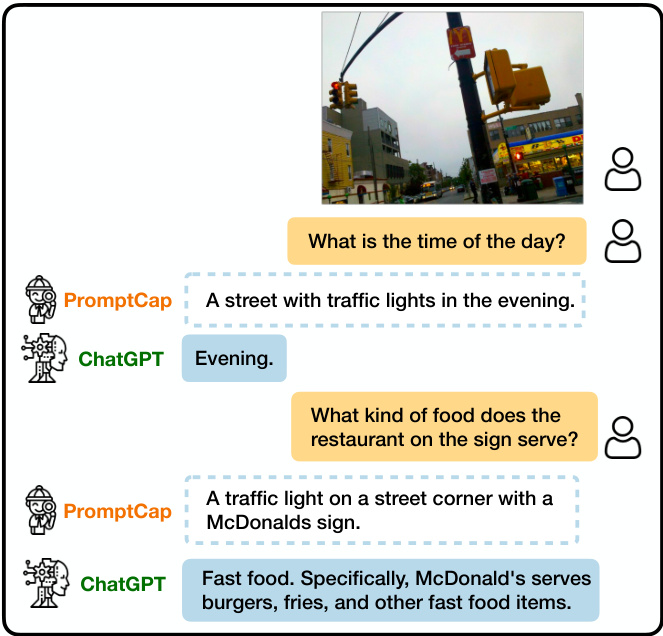
v.s. COCO caption: A traffic light on a pole on a city street. Figure 1. Illustration of VQA with PROMPTCAP and ChatGPT. PROMPTCAP is designed to work with black-box language models (e.g., GPT-3, ChatGPT) by describing question-related visual information in the text. Different from generic captions, PROMPTCAP customizes the caption according to the input question prompt, which helps ChatGPT understand the image and give correct answers to the user. In contrast, ChatGPT cannot infer the answers from the vanilla human-written caption from MSCOCO.
图 1: 基于PROMPTCAP与ChatGPT的视觉问答(VQA)示意图。PROMPTCAP通过文本描述与问题相关的视觉信息,专为黑盒语言模型(如GPT-3、ChatGPT)设计。与通用描述不同,PROMPTCAP会根据输入问题提示定制描述内容,帮助ChatGPT理解图像并给出正确答案。相比之下,ChatGPT无法从MSCOCO数据集的标准人工描述中推断出答案。(对比案例:COCO描述为"城市街道电线杆上的交通信号灯")
One key challenge is to allow LMs to understand images. Many top-performing LMs (e.g., GPT-3, ChatGPT) are only accessible via APIs, making it impossible to access their internal representations or conduct fine-tuning [49]. A popular solution is to project images into texts that black-box LMs can process, via a generic image captioning model [7] or an image tagger [67]. This framework has been successful on multiple tasks, including VQA [67, 15, 29], image paragraph captioning [65], and video-language tasks [70, 60]. Despite promising results, converting visual inputs into a generic, finite text description risks excluding information necessary for the task. As discussed in PICa [67], when used for VQA tasks, the generic caption might miss the detailed visual information needed to answer the question, such as missing the “McDonald’s" in Figure 1.
一个关键挑战是让大语言模型理解图像。许多性能领先的大语言模型(如GPT-3、ChatGPT)只能通过API访问,无法获取其内部表示或进行微调[49]。常用解决方案是通过通用图像描述模型[7]或图像标记器[67],将图像投影为黑盒大语言模型可处理的文本。该框架已在多项任务中取得成功,包括视觉问答(VQA)[67,15,29]、图像段落描述[65]以及视频语言任务[70,60]。尽管效果显著,但将视觉输入转换为通用的有限文本描述可能导致任务所需信息缺失。如PICa[67]所述,当用于VQA任务时,通用描述可能遗漏回答问题所需的细节视觉信息,例如图1中缺失的"McDonald's"标志。
To address the above challenges, we introduce PROMPTCAP, a question-aware captioning model designed to serve as a better connector between images and a black-box LM. PROMPTCAP is illustrated in Figure 2. PROMPTCAP takes an extra natural language prompt as input to control the visual content to describe. The prompt contains the question that the generated caption should help to answer. LMs can better answer visual questions by using PROMPTCAP as their “visual front-end". For example, in Figure 1, when asked “what is the time of the day?", PROMPTCAP includes “in the evening" in its image description; when asked “what kind of food does the restaurant on the sign serve?", PROMPTCAP includes “McDonald’s” in its description. Such visual information is critical for ChatGPT to reply to the user with the correct answers. In contrast, the generic COCO [28] caption often contains no information about the time or the sign, making ChatGPT unable to answer the questions.
为解决上述挑战,我们提出了PROMPTCAP模型。这是一种问题感知的图文描述模型,旨在成为图像与黑盒大语言模型之间更高效的连接桥梁。如图2所示,PROMPTCAP通过接收自然语言提示(prompt)作为额外输入,精准控制需要描述的视觉内容。该提示包含待回答问题,生成的图文描述将专门服务于该问题的解答。通过将PROMPTCAP作为"视觉前端",大语言模型能更准确地回答视觉相关问题。例如图1中,当被问及"当前是什么时段"时,PROMPTCAP会在图像描述中加入"傍晚时分";当询问"招牌上的餐厅供应何种食物"时,描述中则会包含"麦当劳"。这些视觉信息对ChatGPT给出正确答案至关重要。相比之下,通用COCO[28]数据集生成的描述通常不包含时间或招牌信息,导致ChatGPT无法回答这些问题。
One major technical challenge is PROMPTCAP training. The pipeline of “PROMPTCAP $^+$ black-box LM" cannot be end-to-end fine-tuned on VQA tasks because the LM parameters are not exposed through the API. Also, there are no training data for question-aware captions. To avoid extra annotation, we propose a pipeline to synthesize and filter training samples with GPT-3. Specifically, we view existing VQA datasets as pairs of question and question-related visual details. Given a question-answer pair, we rewrite the corresponding image’s generic caption into a customized caption that helps answer the question. Following 20 humanannotated examples, GPT-3 synthesizes a large number of question-aware captions via few-shot in-context learning [5]. To ensure the sample quality, we filter the generated captions by performing QA with GPT-3, checking if the answer can be inferred given the question and the synthesized caption. Notice that GPT-3 is frozen in the whole pipeline. Its strong few-shot learning ability makes this pipeline possible.
主要技术挑战在于PROMPTCAP训练。由于大语言模型参数未通过API公开,"PROMPTCAP$^+$黑盒LM"的流程无法在VQA任务上进行端到端微调,且缺乏针对问题感知描述的标注数据。为避免额外标注,我们提出利用GPT-3合成并筛选训练样本的流程:将现有VQA数据集视为问题与相关视觉细节的配对,基于问答对将通用图像描述改写为辅助答题的定制化描述。参照20个人工标注示例,GPT-3通过少样本上下文学习[5]合成大量问题感知描述。为确保样本质量,我们使用GPT-3进行QA过滤,验证给定问题和合成描述能否推导出答案。值得注意的是,整个流程中GPT-3始终保持冻结状态,其强大的少样本学习能力是实现该流程的关键。
We demonstrate the effectiveness of PROMPTCAP on knowledge-based VQA tasks with the pipeline in PICa [67]. Details of the pipeline are illustrated in $\S4$ . The images are converted into texts via PROMPTCAP, allowing GPT-3 to perform VQA via in-context learning. This pipeline, despite
我们通过PICa[67]中的流程验证了PROMPTCAP在基于知识的视觉问答(VQA)任务上的有效性。具体流程细节见$\S4$部分:图像经PROMPTCAP转化为文本后,GPT-3可通过上下文学习进行视觉问答。尽管该流程...
Original VQA sample
原始VQA样本
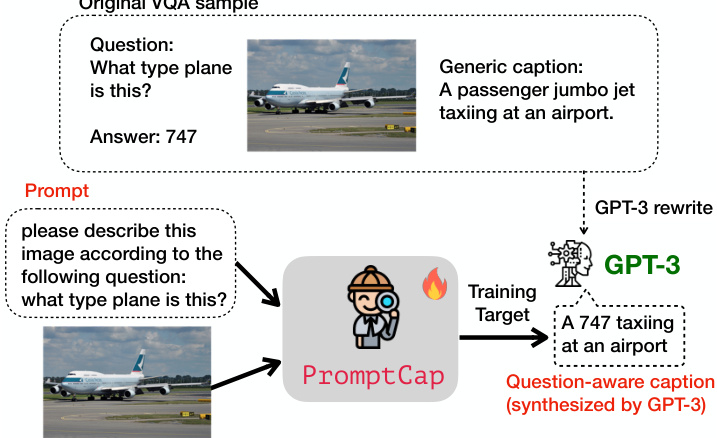
Figure 2. Overview of PROMPTCAP training. PROMPTCAP takes two inputs, including an image and a natural language prompt. The model is trained to generate a caption that helps downstream LMs to answer the question. During training, we use GPT-3 to synthesize VQA samples into captioning examples. The original caption is rewritten into a caption that helps answer the question. PROMPTCAP is trained to generate this synthesized caption given the image and the prompt.
图 2: PROMPTCAP训练流程概览。PROMPTCAP接收两个输入:图像和自然语言提示(prompt)。该模型被训练用于生成有助于下游大语言模型回答问题的描述文本。训练过程中,我们使用GPT-3将视觉问答(VQA)样本合成为描述文本样本。原始描述文本被重写为有助于回答问题的版本。PROMPTCAP的训练目标是根据给定图像和提示生成这种合成后的描述文本。
its simplicity, achieves state-of-the-art results on knowledgebased VQA tasks $(60.4%$ on OK-VQA [38] and $59.6%$ on A-OKVQA [46]). We also conduct extensive ablation studies on the contribution of each component, showing that PROMPTCAP gives a consistent performance gain $3.8%$ on OK-VQA, $5.3%$ on A-OKVQA, and $9.2%$ on VQAv2) over a generic captioning model that shares the same architecture and training data. Finally, we investigate PROMPTCAP’s generalization ability on WebQA [6], showing that PROMPTCAP, without any training on the compositional questions in WebQA, outperforms the generic caption approach and all supervised baselines.
凭借其简洁性,在基于知识的视觉问答任务中取得了最先进的结果(OK-VQA[38]数据集达60.4%,A-OKVQA[46]数据集达59.6%)。我们通过大量消融实验验证了各组件的贡献度,结果表明:相较于采用相同架构与训练数据的通用描述模型,PROMPTCAP在OK-VQA上实现了3.8%的性能提升,在A-OKVQA上提升5.3%,在VQAv2上提升9.2%。最后,我们在WebQA[6]上验证了PROMPTCAP的泛化能力——未经任何针对组合问题的专门训练,其表现已超越通用描述方法及所有监督基线模型。
In summary, our contributions are as follows:
总结来说,我们的贡献如下:
• We propose PROMPTCAP, a novel question-aware captioning model that uses natural language prompt to control the visual content to be described. (§3) • To the best of our knowledge, we are the first to propose a pipeline to synthesize and filter training samples for vision-language tasks via GPT-3 (§3.1). • PROMPTCAP helps GPT-3 in-context learning (§4) achieve state-of-the-art results on OK-VQA and AOKVQA, substantially outperforming generic captions on various VQA tasks. (§5).
• 我们提出了PROMPTCAP,这是一种新颖的基于问题感知的图像描述模型,通过自然语言提示(prompt)来控制需要描述的视觉内容。(§3)
• 据我们所知,我们是首个提出利用GPT-3合成并筛选视觉语言任务训练样本的流程的工作。(§3.1)
• PROMPTCAP能有效提升GPT-3在上下文学习(in-context learning)中的表现(§4),在OK-VQA和AOKVQA基准上达到最先进水平,显著优于各类VQA任务中使用通用描述的效果。(§5)
2. Related Work
2. 相关工作
Knowledge-Based VQA Knowledge-based VQA [38, 46] requires systems to leverage external knowledge beyond image content to answer the question. Prior works [13, 36, 63, 72, 40, 41, 17, 18, 12] investigate leveraging knowledge from various external knowledge resources, e.g., Wikipedia [56], ConceptNet [50], and ASER [71], to improve the performance of the VQA models. Inspired by PICa [67], recent works [15, 29] use GPT-3 as an implicit knowledge base and achieve state-of-the-art results. We identify the critical problem: generic captions used to prompt GPT-3 often miss critical visual details for VQA. We address this challenge with PROMPTCAP.
基于知识的视觉问答
基于知识的视觉问答(VQA) [38, 46] 要求系统利用图像内容之外的外部知识来回答问题。先前的研究 [13, 36, 63, 72, 40, 41, 17, 18, 12] 探索了从多种外部知识资源(如维基百科 [56]、ConceptNet [50] 和 ASER [71])中获取知识以提升VQA模型性能。受PICa [67] 启发,近期研究 [15, 29] 使用GPT-3作为隐式知识库并取得了最先进成果。我们发现了关键问题:用于提示GPT-3的通用描述通常会遗漏VQA所需的关键视觉细节。我们通过PROMPTCAP解决了这一挑战。
Vision-Language Models Vision-language models have recently shown striking success on various multimodal tasks [51, 33, 9, 27, 61, 22, 43, 66, 57, 58, 34, 68, 8, 26]. These works first pretrain multimodal models on large-scale image-text datasets and then finetune the models for particular tasks. The works most related to ours are Frozen [54], Flamingo [1], and BLIP-2 [26], which keeps the LMs frozen and tune a visual encoder for the LM. However, such techniques require access to internal LM parameters and are thus difficult to be applied to black-box LMs like GPT-3.
视觉语言模型 (Vision-Language Models)
视觉语言模型近期在多模态任务中展现出显著成效 [51, 33, 9, 27, 61, 22, 43, 66, 57, 58, 34, 68, 8, 26]。这些工作首先在大规模图文数据集上预训练多模态模型,随后针对特定任务进行微调。与本研究最相关的是 Frozen [54]、Flamingo [1] 和 BLIP-2 [26],它们保持大语言模型参数冻结,仅调整视觉编码器以适配语言模型。但此类技术需要访问语言模型的内部参数,因此难以应用于 GPT-3 等黑盒大语言模型。
Prompting for Language Models Prompting allows a pre-trained model to adapt to different tasks via different prompts without modifying any parameters. LLMs like GPT3 [5] have shown strong zero-shot and few-shot ability via prompting. Prompting has been successful for a variety of natural language tasks [32], including but not limited to classification tasks [39, 48], semantic parsing [64], knowledge generation [49, 30], and dialogue systems [24, 16]. The most closely-related works to ours are the instruction-finetuned language models [45, 62, 59].
提示语言模型
提示(prompting)允许预训练模型在不修改任何参数的情况下,通过不同提示适应不同任务。像GPT3 [5]这样的大语言模型已通过提示展现出强大的零样本和少样本能力。该方法已成功应用于多种自然语言处理任务[32],包括但不限于分类任务[39,48]、语义解析[64]、知识生成[49,30]以及对话系统[24,16]。与本研究最密切相关的是经过指令微调的语言模型[45,62,59]。
3. PROMPTCAP
3. PROMPTCAP
We introduce PROMPTCAP, an image captioning model that utilizes a natural language prompt as an input condition. The overview of PROMPTCAP training is in Figure 2. Given an image $I$ , and a natural language prompt $P$ , PROMPTCAP generates a prompt-guided caption $C$ . $P$ contains instructions about the image contents of interest to the user. For VQA, an example prompt could be “Please describe this image according to the following question: what type plane is this?. The prompt-guided caption $C$ should (1) cover the visual details required by the instruction in the prompt, (2) describe the main objects as general captions do, and (3) use auxiliary information in the prompt if necessary. For instance, assuming the prompt contains a VQA question, $C$ may directly describe the asked visual contents (e.g., for questions about visual details), or provide information that helps downstream models to infer the answer (e.g., for questions that need external knowledge to solve).
我们介绍PROMPTCAP,这是一种利用自然语言提示作为输入条件的图像描述模型。PROMPTCAP训练的概览如图2所示。给定图像$I$和自然语言提示$P$,PROMPTCAP生成提示引导的描述$C$。$P$包含用户感兴趣的图像内容指令。对于视觉问答(VQA),示例提示可以是"请根据以下问题描述这张图片:这是什么类型的飞机?"。提示引导的描述$C$应当:(1) 覆盖提示指令所需的视觉细节,(2) 像常规描述那样涵盖主要对象,(3) 必要时使用提示中的辅助信息。例如,若提示包含VQA问题,$C$可直接描述被询问的视觉内容(如涉及视觉细节的问题),或提供帮助下游模型推断答案的信息(如需要外部知识解决的问题)。
Given the above design, the major technical challenge is PROMPTCAP training. PROMPTCAP is designed to work with black-box LMs, which cannot be end-to-end fine-tuned on VQA tasks because the LM parameters are not accessible. Besides, there are no training data for question-aware captions. To address these challenges, we propose training PROMPTCAP with data synthesized with GPT-3.
基于上述设计,主要技术挑战在于PROMPTCAP的训练。PROMPTCAP需与黑盒大语言模型协同工作,由于无法访问模型参数,无法针对VQA任务进行端到端微调。此外,现有数据缺乏问题感知型描述文本。为解决这些问题,我们提出利用GPT-3合成数据来训练PROMPTCAP。

Figure 3. Training example synthesis with GPT-3 in-context learning. The “Original Contexts" are ground-truth image captions. The question-answer pairs come from existing VQA datasets. GPT-3 generalizes (without parameter updates) from the human-written examples to produce the question-aware caption given the caption, question, and answer. The images are shown for clarity but are not used in our data synthesis procedure.
图 3: 采用 GPT-3 上下文学习 (in-context learning) 的训练样本合成示例。"原始上下文"为真实图像描述文本,问答对来自现有 VQA (Visual Question Answering) 数据集。GPT-3 通过人类编写的示例进行泛化 (无需参数更新),根据描述文本、问题及答案生成具有问题感知的标题。图中展示的图片仅为示意用途,实际数据合成过程中并未使用。
3.1. Training Data Synthesis
3.1. 训练数据合成
To avoid annotating question-aware caption examples, we use GPT-3 to generate training examples for PROMPTCAP via in-context learning [5, 44, 16, 10].
为避免标注问题感知的标题示例,我们使用 GPT-3 通过上下文学习 [5, 44, 16, 10] 为 PROMPTCAP 生成训练样本。
3.1.1 Training Example Generation with GPT-3
3.1.1 使用 GPT-3 生成训练示例
For PROMPTCAP training, we view existing VQA datasets as natural sources of pairs of task and task-related visual details. We synthesize question-aware captions by combining the general image captions and the question-answering pairs using GPT-3 in-context learning. Figure 3 illustrates the GPT-3 prompt we use for training example generation. The prompt contains the task instruction, 20 human-written examples, and the VQA question-image pair that we synthesize the task-aware caption from. Since GPT-3 only accepts text inputs, we represent each image by concatenating the 5 human-written COCO captions [7], as shown in the “Original Context". The human-written examples follow the three principles of prompt-guided captions described in Section 3. The commonsense reasoning ability of GPT-3 allows the model to understand the image to some extent via the COCO captions and synthesize new examples by following the human-written examples.
在PROMPTCAP训练中,我们将现有VQA数据集视为任务与任务相关视觉细节的自然配对来源。通过使用GPT-3的上下文学习能力,结合通用图像描述和问答对,我们合成了问题感知的描述。图3展示了用于训练样本生成的GPT-3提示模板。该提示包含任务指令、20个人工编写的示例以及待合成的任务感知描述所对应的VQA问题-图像对。由于GPT-3仅接受文本输入,我们通过拼接5条人工标注的COCO描述[7]来表示每张图像(如"原始上下文"所示)。人工编写示例遵循第3节所述的提示引导描述三原则。GPT-3的常识推理能力使其能够通过COCO描述在一定程度上理解图像,并参照人工示例合成新样本。
3.1.2 Training Example Filtering
3.1.2 训练样本过滤
To ensure the quality of the generated captions, we sample 5 candidate captions from GPT-3 for each question-answer pair. We devise a pipeline to filter out the best candidate caption as the training example for PROMPTCAP. The idea is that a text-only QA system should correctly answer the question given a high-quality prompt-guided caption as the context. For each candidate caption, we use the GPT-3 incontext learning VQA system in $\S4$ to predict an answer, and score the candidate captions by comparing this answer with the ground-truth answers.
为确保生成描述的质量,我们从GPT-3中为每个问答对采样5条候选描述。我们设计了一个流程来筛选出最佳候选描述作为PROMPTCAP的训练样本。其核心思路是:一个纯文本问答系统在获得高质量的提示引导描述作为上下文时,应能正确回答问题。对于每条候选描述,我们使用$\S4$中基于GPT-3的上下文学习VQA系统预测答案,并通过将该答案与真实答案对比来评分候选描述。
Soft VQA Accuracy We find that in the open-ended generation setting, the VQA accuracy [14] incorrectly punishes answers with a slight difference in surface form. For example, the answer “coins" gets 0 when the ground truth is “coin". To address this problem, we devise a new soft VQA accuracy for example filtering. Suppose the predicted answer is $a$ and the human-written ground truth answers are $[g_{1},g_{2},...,g_{n}]$ . The soft accuracy is given by the three lowest-CER ground truth answers:
软VQA准确率
我们发现,在开放式生成场景下,VQA准确率[14]会错误惩罚那些表面形式存在细微差异的答案。例如当标准答案为"coin"时,预测答案"coins"会被判为0分。为解决该问题,我们设计了一种新的软VQA准确率用于示例筛选。假设预测答案为$a$,人工标注的标准答案为$[g_{1},g_{2},...,g_{n}]$,则软准确率由字符错误率(CER)最低的三个标准答案计算得出:

where CER is the character error rate, calculated by the character edit distance over the total number of characters of the ground truth. In contrast, the traditional VQA accuracy [14] uses exact match. We sort the candidate captions based on this soft score.
其中CER是字符错误率 (character error rate),由字符编辑距离除以真实文本的总字符数计算得出。相比之下,传统VQA准确率[14]采用精确匹配方式。我们根据这种软性评分对候选描述进行排序。
Comparing with COCO ground-truth Multiple candidates may answer the question correctly and get the same soft score. To break ties, we also compute the CIDEr score [55] between the candidate captions and the COCO ground-truth captions. Among the candidates with the highest soft VQA accuracy, the one with the highest CIDEr score is selected as the training example for PROMPTCAP.
与COCO基准真值对比
可能有多个候选答案能正确回答问题并获得相同的软分数。为了打破平局,我们还计算了候选标题与COCO基准真值标题之间的CIDEr分数[55]。在具有最高软VQA准确率的候选答案中,选择CIDEr分数最高的作为PROMPTCAP的训练样本。
3.2. PROMPTCAP Training
3.2. PROMPTCAP 训练
For PROMPTCAP training, we start with the state-of-theart pre-trained vision-language model OFA [58] and make some modifications to the OFA captioning model. OFA has an encoder-decoder structure. As discussed earlier, our training data are synthesized with VQA data in the form of question-caption pairs. Given a question-caption pair, we first rewrite the question into an instruction prompt via a template. For example, the instruction prompt might be “describe to answer: What is the clock saying the time $i s\mathrm{\ensuremath{?}~}^{\prime\prime}$ . We apply byte-pair encoding (BPE) [47] to the given text sequence, encoding it as subwords. Images are transtoken set. Let the training samples be $\mathcal{D}={P_{i},I_{i},C_{i}}_{i=1}^{|\mathcal{D}|}$ in which $P_{i}$ is the text prompt, $I_{i}$ is the image patch, and $C_{i}$ is the synthesized task-aware caption. The captioning model takes $[P_{i}~:~I_{i}]$ as input and is trained to generate $C_{i}=[c_{1},c_{2},...,c_{|C_{i}|}]$ . Here $[:]$ is concatenation. We use negative log-likelihood loss and train the model in an end-toend manner. The training loss is :
在PROMPTCAP训练中,我们基于最先进的预训练视觉语言模型OFA[58]进行改进。OFA采用编码器-解码器架构。如前所述,我们的训练数据是以问答-描述对形式合成的VQA数据。给定问答对时,我们首先通过模板将问题重写为指令提示,例如指令提示可能是"为回答以下问题而描述:时钟显示的时间是几点?"。我们对文本序列应用字节对编码(BPE)[47]将其编码为子词。图像被转换为token集合。设训练样本为$\mathcal{D}={P_{i},I_{i},C_{i}}_{i=1}^{|\mathcal{D}|}$,其中$P_{i}$是文本提示,$I_{i}$是图像块,$C_{i}$是合成的任务感知描述。描述模型以$[P_{i}~:~I_{i}]$作为输入,训练生成$C_{i}=[c_{1},c_{2},...,c_{|C_{i}|}]$。此处$[:]$表示拼接操作。我们采用负对数似然损失并以端到端方式训练模型。训练损失为:
$$
\mathcal{L}=-\sum_{\mathcal{D}}\sum_{t=1}^{|C_{i}|}\log p(c_{t}\mid[P_{i}:I_{i}],c_{\le t-1}).
$$
$$
\mathcal{L}=-\sum_{\mathcal{D}}\sum_{t=1}^{|C_{i}|}\log p(c_{t}\mid[P_{i}:I_{i}],c_{\le t-1}).
$$
4. VQA with PROMPTCAP and GPT-3
4. 使用 PROMPTCAP 和 GPT-3 进行视觉问答 (VQA)
Our VQA pipeline is illustrated in Figure 4, which is adopted from PICa [67]. The pipeline consists of two components, PROMPTCAP and GPT-3.
我们的VQA流程如图4所示,该流程借鉴自PICa[67]。该流程由两个组件组成:PROMPTCAP和GPT-3。
Step 1: Converting images into texts via PROMPTCAP GPT-3 can perform a new task by simply conditioning on several task training examples as demonstrations. As we have discussed, the major challenge is that GPT-3 does not understand images. To bridge this modality gap, we convert the images in VQA samples to texts using PROMPTCAP (Figure 4a). Notice that different from generic captioning models, PROMPTCAP customizes the image caption according to the question, which enables LMs to understand question-related visual information in the image. As such, we are able to convert VQA samples into question-answering examples that GPT-3 can understand.
第一步:通过PROMPTCAP将图像转换为文本
GPT-3只需以少量任务训练示例作为演示条件,即可执行新任务。如前所述,主要挑战在于GPT-3无法理解图像。为弥合这一模态差距,我们使用PROMPTCAP将VQA样本中的图像转换为文本(图4a)。需注意,与通用描述模型不同,PROMPTCAP会根据问题定制图像描述,使大语言模型能够理解图像中与问题相关的视觉信息。由此,我们得以将VQA样本转化为GPT-3可理解的问答示例。
Step 2: GPT-3 in-context learning for VQA Having used PROMPTCAP to convert VQA examples into question-answer examples that GPT-3 can understand (Step 1), we use a subset of these examples as the task demonstration for GPT-3. We concatenate the incontext learning examples to form a prompt, as shown in Figure 4b. Each in-context learning example consists of a question (Question: When was the first time this was invented?), a context generated by PROMPTCAP (Context: a train traveling down tracks next to a dirt road), and an answer (Answer: 1804). Then we append the test example to the in-context learning examples, and provide them as inputs to GPT-3. GPT-3 generates predictions based on an open-ended text generation approach, taking into account the information provided in the in-context learning examples and the test example.
步骤2:GPT-3在视觉问答中的上下文学习
通过PROMPTCAP将视觉问答示例转化为GPT-3可理解的问答对(步骤1)后,我们选取部分示例作为GPT-3的任务演示。如图4b所示,将这些上下文学习示例拼接成提示词。每个上下文学习示例包含问题(Question: 这项发明首次出现于何时?)、PROMPTCAP生成的上下文(Context: 一辆火车沿轨道行驶在土路旁)以及答案(Answer: 1804)。随后将测试示例追加至上下文学习示例后,作为GPT-3的输入。GPT-3采用开放式文本生成方法,结合上下文学习示例和测试示例中的信息生成预测结果。
Example retrieval Previous research has shown that the effectiveness of in-context learning examples chosen for GPT-3 can significantly impact its performance [31]. In the few-shot setting where only a few training examples are available, we simply use these examples as in-context learning examples (referred to as “Random” in later sections because they are selected at random from our collection). However, in practice, we often have access to more than small $^{\cdot n}$ examples (i.e., full training data setting). To improve the selection of in-context learning examples, we follow the approach proposed by [67]: we compute the similarity between examples using CLIP [43] by summing up the cosine similarities of the question and image embeddings. The $n$ most similar examples in the training set are then selected as in-context examples (referred to as “CLIP” in this paper). By using the most similar in-context examples to the test instance, our approach can improve the quality of the learned representations and boost the performance of GPT-3 on VQA tasks.
示例检索
先前研究表明,为GPT-3选择的上下文学习示例的有效性会显著影响其性能[31]。在仅有少量训练样本可用的少样本场景下,我们直接将这些样本作为上下文学习示例(后文称为"Random",因其从数据集中随机选取)。但在实际应用中,我们通常能获取超过少量$^{\cdot n}$的样本(即完整训练数据场景)。为优化上下文学习示例的选择,我们采用[67]提出的方法:通过CLIP[43]计算样本间相似度,即对问题嵌入和图像嵌入的余弦相似度求和,随后选取训练集中最相似的$n$个样本作为上下文示例(本文称为"CLIP")。通过使用与测试实例最相似的上下文示例,我们的方法能提升学习表征的质量,并增强GPT-3在VQA任务中的表现。
(a) Step 1: Using PromptCap to convert images into texts
图 1:
(a) 步骤1: 使用PromptCap将图像转换为文本
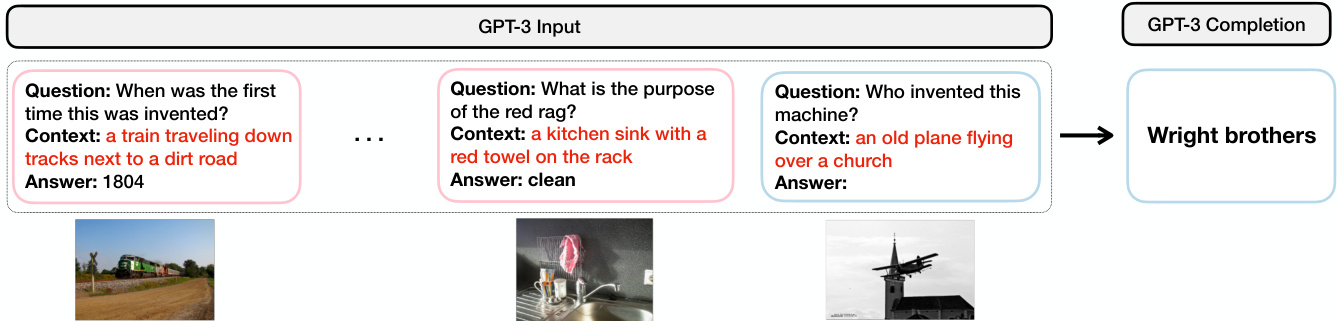
Figure 4. Our inference pipeline for VQA. (a) Illustration of how we convert a VQA sample into pure text. Given the image and the question, PROMPTCAP describes the question-related visual information in natural language. The VQA sample is turned into a QA sample that GPT-3 can understand. (b) GPT-3 in-context learning for VQA. After converting the VQA examples into text with PROMPTCAP, we carry out VQA by in-context learning on GPT-3. The input consists of the task instruction (not shown in the figure), the in-context examples, and the test instance. GPT-3 takes the input and generates the answer. Notice that the GPT-3 is treated as a black box and is only used for inference. The question-aware captions PROMPTCAP generated are marked red.
图 4: 我们的VQA推理流程。(a) 展示如何将VQA样本转换为纯文本。给定图像和问题,PROMPTCAP用自然语言描述与问题相关的视觉信息。VQA样本由此转化为GPT-3能够理解的问答样本。(b) GPT-3在VQA任务中的上下文学习。通过PROMPTCAP将VQA示例转换为文本后,我们通过对GPT-3进行上下文学习来执行VQA。输入包括任务指令(图中未显示)、上下文示例和测试实例。GPT-3接收输入并生成答案。注意,GPT-3被视为黑箱,仅用于推理。PROMPTCAP生成的问题感知描述标记为红色。
5. Experiments
5. 实验
In this section, we demonstrate PROMPTCAP’s effectiveness on knowledge-based VQA tasks. First, we show that PROMPTCAP captions enable GPT-3 to achieve state-ofthe-art performance on OK-VQA [38] and A-OKVQA [46] with in-context learning. Then we conduct ablation experiments on the contribution of each component, showing that PROMPTCAP is giving consistent gains over generic captions. In addition, experiments on WebQA [6] demonstrate that PROMPTCAP generalizes well to unseen domains.
在本节中,我们展示了PROMPTCAP在基于知识的视觉问答(VQA)任务上的有效性。首先,我们证明PROMPTCAP生成的描述能使GPT-3通过上下文学习在OK-VQA[38]和A-OKVQA[46]上达到最先进的性能。随后我们通过消融实验验证各模块的贡献度,结果表明PROMPTCAP相比通用描述能带来持续的性能提升。此外,在WebQA[6]上的实验表明,PROMPTCAP对未见领域也具有良好的泛化能力。
5.1. Experimental Setup
5.1. 实验设置
Datasets We use three knowledge-based VQA datasets, namely OK-VQA [38], A-OKVQA [46], and WebQA [6]. OK-VQA[38] is a large knowledge-based VQA dataset that contains 14K image-question pairs. Questions are manually filtered to ensure that outside knowledge is required to answer the questions. A-OKVQA[46] is an augmented successor of OK-VQA, containing 25K image-question pairs that require broader commonsense and world knowledge to answer. For both OK-VQA and A-OKVQA, the direct answers are evaluated by the soft accuracy from VQAv2[14]. Besides direct answer evaluation, A-OKVQA also provides multiple-choice evaluation, where the model should choose one correct answer among 4 candidates. WebQA [6] is a multimodal multi-hop reasoning benchmark that requires the model to combine multiple text and image sources to answer a question.
数据集
我们使用了三个基于知识的视觉问答(VQA)数据集:OK-VQA [38]、A-OKVQA [46]和WebQA [6]。OK-VQA[38]是一个大型基于知识的VQA数据集,包含14K个图像-问题对。通过人工筛选确保回答问题需要外部知识。A-OKVQA[46]是OK-VQA的增强版本,包含25K个需要更广泛常识和世界知识来回答的图像-问题对。对于OK-VQA和A-OKVQA,直接答案采用VQAv2[14]的软准确率进行评估。除直接答案评估外,A-OKVQA还提供多选题评估,要求模型从4个候选答案中选择正确答案。WebQA[6]是一个多模态多跳推理基准测试,要求模型结合多个文本和图像来源来回答问题。
PROMPTCAP implementation details We adopt the officially released OFA [58] captioning checkpoint “captionlarge-best-clean” (470M) for model initialization and use the GPT-3 synthesized examples in $\S3.1$ to fine-tune the model. The examples are synthesized from VQAv2 [3, 14]. Notice that this dataset is included in OFA pre-training, so we are not adding additional annotated training data compared with OFA. We use AdamW [23] optimizer with learning rate ${2\times10^{-5},3\times10^{-5},5\times10^{-5}}$ , batch size ${32,64,128}$ , and $\beta_{1}=0.9$ , $\beta_{2}=0.999$ for training.
PROMPTCAP 实现细节
我们采用官方发布的 OFA [58] 图像描述(checkpoint) "captionlarge-best-clean" (470M) 进行模型初始化,并使用 $\S3.1$ 中 GPT-3 合成的示例对模型进行微调。这些示例是从 VQAv2 [3, 14] 合成的。请注意,该数据集已包含在 OFA 预训练中,因此与 OFA 相比,我们并未增加额外的标注训练数据。我们使用 AdamW [23] 优化器,学习率为 ${2\times10^{-5},3\times10^{-5},5\times10^{-5}}$,批量大小为 ${32,64,128}$,并设置 $\beta_{1}=0.9$ 和 $\beta_{2}=0.999$ 进行训练。
In-context learning details We use code-davinci-002 engine (175B) for GPT-3 in all the experiments. Due to the input length limit, we use $n=32$ most similar examples in the prompt for GPT-3. The examples are retrieved by CLIP (VIT-L/14) using the method discussed in $\S4$ .
上下文学习细节
我们在所有实验中使用 code-davinci-002 引擎 (175B) 作为 GPT-3 的基础模型。由于输入长度限制,我们在提示中为 GPT-3 使用了 $n=32$ 个最相似的示例。这些示例通过 CLIP (VIT-L/14) 使用 $\S4$ 中讨论的方法检索得到。
Table 1. Results comparison with existing systems on OK-VQA, with the image representation and the knowledge source each method uses. GPT-3 is frozen for all methods. The methods on top require end-to-end finetuning on OK-VQA. The methods below are fully based on in-context learning or zero-shot learning and do not require task-specific finetuning.
| Method | Image Representation | Knowledge Source | Accuracy (%) |
| End-to-End Finetuning Question only [37] MUTAN [38] BAN + KG + AUG [25] ConceptBERT [13] KRISP [36] Vis-DPR [35] MAVEx [63] TRiG [12] KAT (Single) [15] KAT (Ensemble) [15] | Feature Feature Feature Feature Feature Feature Caption + Tags + OCR Caption+Tags +Feature | Wikipedia + ConceptNet ConceptNet Wikipedia+ ConceptNet GoogleSearch Wikipedia + ConceptNet + Google Images Wikipedia GPT-3 (175B)+ Wikidata | 14.9 26.4 26.7 33.7 38.4 39.2 39.4 50.5 54.4 |
| In-Context Learning & Zero-Shot BLIP-2 VIT-G FlanT5xxL [26] (zero-shot) PICa-Base [67] PICa-Full [67] Flamingo (80B) [1] (zero-shot) Flamingo (80B) [1] (32-shot) PromptCap+GPT-3 | Feature Caption + Tags Caption + Tags Feature Feature Caption | FlanT5-XXL (11B) GPT-3 (175B) GPT-3 (175B) Chinchilla (7OB) Chinchilla (70B) GPT-3 (175B) | 45.9 43.3 48.0 50.6 57.8 |
表 1: 现有系统在 OK-VQA 上的结果对比,包含各方法使用的图像表示和知识来源。所有方法均使用冻结版 GPT-3。上方方法需在 OK-VQA 上进行端到端微调,下方方法完全基于上下文学习或零样本学习,无需任务特定微调。
| 方法 | 图像表示 | 知识来源 | 准确率 (%) |
|---|---|---|---|
| 端到端微调 | |||
| Question only [37] | Feature | Wikipedia + ConceptNet | 14.9 |
| MUTAN [38] | Feature | ConceptNet | 26.4 |
| BAN + KG + AUG [25] | Feature | Wikipedia+ ConceptNet | 26.7 |
| ConceptBERT [13] | Feature | GoogleSearch | 33.7 |
| KRISP [36] | Feature | Wikipedia + ConceptNet + Google Images | 38.4 |
| Vis-DPR [35] | Feature | Wikipedia | 39.2 |
| MAVEx [63] | Feature | GPT-3 (175B)+ Wikidata | 39.4 |
| TRiG [12] | Caption + Tags + OCR | - | 50.5 |
| KAT (Single) [15] | Caption+Tags +Feature | - | 54.4 |
| 上下文学习 & 零样本 | |||
| BLIP-2 VIT-G | Feature | FlanT5-XXL (11B) | 45.9 |
| FlanT5xxL [26] (零样本) | Caption + Tags | GPT-3 (175B) | 43.3 |
| PICa-Base [67] | Caption + Tags | GPT-3 (175B) | 48.0 |
| PICa-Full [67] | Feature | Chinchilla (7OB) | 50.6 |
| Flamingo (80B) [1] (零样本) | Feature | Chinchilla (70B) | 57.8 |
| Flamingo (80B) [1] (32样本) | Caption | GPT-3 (175B) | - |
| PromptCap+GPT-3 | - | - | - |
Table 2. Results comparison with existing systems on A-OKVQA. There are two evaluations, namely multiple-choice and directanswer. Both are measured by accuracy $(%)$ .
| Method | Multiple Choice | |||
| val | test | val | test | |
| ClipCap [46] | 44.0 | 43.8 | 18.1 | 15.8 |
| Pythia [19] | 49.0 | 40.1 | 25.2 | 21.9 |
| ViLBERT[33] | 49.1 51.4 | 41.5 41.6 | 30.6 | 25.9 |
| LXMERT [53] | 51.9 | 42.2 | 30.7 | 25.9 |
| KRISP [36] GPV-2 [20] | 60.3 | 53.7 | 33.7 48.6 | 27.1 40.7 |
| PromptCap+GPT-3 | 73.2 | 73.1 | 56.3 | 59.6 |
表 2: A-OKVQA数据集上与现有系统的结果对比。评估分为两种形式:多选题和直接回答。两者均以准确率 $(%)$ 衡量。
| 方法 | 多选题-val | 多选题-test | 直接回答-val | 直接回答-test |
|---|---|---|---|---|
| ClipCap [46] | 44.0 | 43.8 | 18.1 | 15.8 |
| Pythia [19] | 49.0 | 40.1 | 25.2 | 21.9 |
| ViLBERT [33] | 49.1 51.4 | 41.5 41.6 | 30.6 | 25.9 |
| LXMERT [53] | 51.9 | 42.2 | 30.7 | 25.9 |
| KRISP [36] GPV-2 [20] | 60.3 | 53.7 | 33.7 48.6 | 27.1 40.7 |
| PromptCap+GPT-3 | 73.2 | 73.1 | 56.3 | 59.6 |
5.2. Results on OK-VQA and A-OKVQA
5.2. OK-VQA 和 A-OKVQA 上的结果
Table 1 compares PROMPTCAP $^+$ GPT-3 with other methods on the OK-VQA validation set. For each method, we also list the way it represents the images, and the knowledge source used. The table is split into two sections. The upper section lists fully supervised methods. These methods require end-to-end finetuning. The methods in the bottom section are based on in-context learning and no task-specific finetuning is done on the models.
表1比较了PROMPTCAP $^+$ GPT-3与其他方法在OK-VQA验证集上的表现。对于每种方法,我们还列出了其图像表示方式以及使用的知识来源。该表分为两个部分。上半部分列出了全监督方法,这些方法需要进行端到端微调。底部部分的方法基于上下文学习,且未对模型进行任务特定的微调。
We can see that all state-of-the-art systems use GPT-3 (or Chinchilla) as part of their systems. These methods obtain significant performance gains compared with previous methods, showing the importance of the LM in knowledgebased VQA tasks. PICa is the first system that used GPT-3 as the knowledge source. KAT [15] further improves over PICa by introducing Wikidata [56] as the knowledge source, doing ensemble and end-to-end finetuning on multiple components. REVIVE [29] is the current state of the art on OK-VQA. Compared with KAT, it introduces extra object-centric visual features to the ensemble, which brings additional gains over KAT. However, all of the above methods use generic image captions to prompt knowledge from GPT-3. We identify this as a critical bottleneck in using LMs for VQA tasks. PROMPTCAP is designed to address this bottleneck.
我们可以看到,所有最先进的系统都采用GPT-3(或Chinchilla)作为其组成部分。相比先前方法,这些方案获得了显著的性能提升,表明大语言模型在基于知识的VQA任务中的重要性。PICa是首个将GPT-3作为知识源的系统。KAT[15]通过引入Wikidata[56]作为知识源,对多个组件进行集成和端到端微调,进一步改进了PICa。REVIVE[29]是目前OK-VQA领域的最高水平方案,相比KAT额外引入了以物体为中心的视觉特征进行集成,从而获得额外增益。然而上述方法均使用通用图像描述文本来激发GPT-3的知识输出,我们认为这是将大语言模型应用于VQA任务的关键瓶颈。PROMPTCAP正是为解决这一瓶颈而设计。
Comparison with state of the art Our proposed PROMPT $\mathrm{CAP}+\mathrm{GPT}{}-3$ , despite using no additional knowledge source, no ensemble with visual features, and no end-to-end finetuning, achieves $60.4%$ accuracy and outperforms all existing methods on OK-VQA. Table 2 shows similar results on AOKVQA, in which PROMPTCAP $^+$ GPT-3 outperforms all prior methods by a large margin on both multiple-choice $(73.1%)$ and direct-answer $(59.6%)$ evaluations. These results demonstrate PROMPTCAP’s effectiveness in connecting LMs with images. Besides, we would like to emphasize that PROMPTCAP could replace the captioning module in the systems KAT and REVIVE have proposed, which might further boost the performance. We expect that PROMPTCAP will help future systems with complementary advances to achieve even better performance on these tasks.
与现有技术的比较
我们提出的PROMPT $\mathrm{CAP}+\mathrm{GPT}{}-3$,尽管未使用额外知识源、未与视觉特征集成且未进行端到端微调,仍在OK-VQA上取得了$60.4%$的准确率,超越了所有现有方法。表2展示了在AOKVQA上的类似结果,其中PROMPTCAP $^+$ GPT-3在多项选择$(73.1%)$和直接回答$(59.6%)$评估中均大幅领先所有先前方法。这些结果证明了PROMPTCAP在连接大语言模型与图像方面的有效性。此外,我们强调PROMPTCAP可替代KAT和REVIVE系统中提出的描述生成模块,可能进一步提升性能。我们期待PROMPTCAP能助力未来系统通过互补性进展,在这些任务中实现更优表现。
5.3. Ablation Study
We conduct extensive ablation studies to quantify the performance benefit of each component in our system, i.e., the captioning model PROMPTCAP, the language model, and the prompting method. We conduct ablation experiments on each component.
我们进行了广泛的消融研究,以量化系统中每个组件的性能优势,即图像描述模型 PROMPTCAP、大语言模型和提示方法。我们对每个组件分别进行了消融实验。
Additional dataset for analysis Besides knowledge-based VQA tasks, we would also like to investigate the performance gain from PROMPTCAP for traditional VQA. Thus, we also include VQAv2 [3] in our ablation studies.
用于分析的额外数据集
除了基于知识的VQA任务外,我们还想研究PROMPTCAP在传统VQA中的性能提升。因此,我们在消融实验中也加入了VQAv2 [3]。
Table 3. Ablation on the contribution of PROMPTCAP, compared with generic captioning model OFA-Cap. The LM we use is GPT-3.
| Captioning Model | OK-VQA | A-OKVQA | VQAv2 |
| OFA-Cap | 56.6 | 51.0 | 64.9 |
| PROMPTCAP | 60.4 | 56.3 | 74.1 |
表 3: PROMPTCAP 与通用描述生成模型 OFA-Cap 的贡献消融对比。使用的语言模型为 GPT-3。
| 描述生成模型 | OK-VQA | A-OKVQA | VQAv2 |
|---|---|---|---|
| OFA-Cap | 56.6 | 51.0 | 64.9 |
| PROMPTCAP | 60.4 | 56.3 | 74.1 |
5.3.1 Performance Benefit from PROMPTCAP
Baseline generic captioning model We use the officially released OFA [58] captioning checkpoint “caption-largebest-clean” (470M) as the baseline generic captioning model. We refer to it as “OFA-Cap”. We choose this model because this is the model initialization we use for PROMPTCAP, sharing the same model architecture. Notice that OFA is a large vision-language model pre-trained on 20M image-text pairs and 20 vision-language tasks, including many VQA tasks. We are not using additional annotated data during PROMPTCAP finetuning.
基线通用描述生成模型
我们采用官方发布的OFA[58]描述生成检查点"caption-largebest-clean"(470M)作为基线通用描述生成模型,简称"OFA-Cap"。选择该模型是因为PROMPTCAP采用了与之相同的模型架构进行初始化。需注意,OFA是在2000万图文对及20项视觉语言任务(包含多项VQA任务)上预训练的大型视觉语言模型。在PROMPTCAP微调阶段未使用额外标注数据。
PROMPTCAP captions give consistent gains over generic captions. Table 3 measures the performance benefit from PROMPTCAP on OK-VQA, A-OKVQA, and VQAv2 validation sets. Here we focus on the performance gap between using PROMPTCAP captions and generic OFA captions. We can see that PROMPTCAP gives consistent improvements over generic captions. Specifically, with GPT-3, PROMPTCAP improves over OFA-Cap by $3.8%$ , $5.3%$ , and $9.2%$ absolute accuracy on OK-VQA, A-OKVQA, and VQAv2, respectively.
PROMPTCAP生成的描述相比通用描述带来持续的性能提升。表3测量了PROMPTCAP在OK-VQA、A-OKVQA和VQAv2验证集上的性能优势。这里我们重点关注使用PROMPTCAP描述与通用OFA描述之间的性能差距。可以看到PROMPTCAP相比通用描述实现了稳定的改进。具体而言,在GPT-3模型上,PROMPTCAP在OK-VQA、A-OKVQA和VQAv2三个数据集上的绝对准确率分别比OFA-Cap高出$3.8%$、$5.3%$和$9.2%$。
Table 4. Ablation on the contribution of GPT-3. We measure the performance gain of using GPT-3 as the language model, compared with Flan-T5-XXL (11B). The captioning model we use is PROMPTCAP.
| Language Model | OK-VQA | A-OKVQA | VQAv2 |
| Flan-T5-XXL (11B) | 42.0 | 41.5 | 70.9 |
| GPT-3 (175B) | 60.4 | 56.3 | 74.1 |
表 4: GPT-3贡献度的消融实验。我们对比了使用GPT-3与Flan-T5-XXL(11B)作为语言模型的性能提升。使用的图像描述模型为PROMPTCAP。
| 语言模型 | OK-VQA | A-OKVQA | VQAv2 |
|---|---|---|---|
| Flan-T5-XXL(11B) | 42.0 | 41.5 | 70.9 |
| GPT-3(175B) | 60.4 | 56.3 | 74.1 |
5.3.2 Performance Benefit from Language Model
5.3.2 语言模型带来的性能提升
Baseline language model To measure the performance gain from GPT-3, we choose Flan-T5-XXL(11B) [11] as the baseline language model. FlanT5-XXL is an instructionfinetuned LM that has shown good in-context learning ability. Notice that for Flan-T5-XXL, because of the input length limit, we use $n=16$ in-context examples in the input.
基线语言模型
为衡量 GPT-3 带来的性能提升,我们选择 Flan-T5-XXL(11B) [11] 作为基线语言模型。Flan-T5-XXL 是指令微调的大语言模型,已展现出优秀的上下文学习能力。需要注意的是,由于 Flan-T5-XXL 存在输入长度限制,我们在输入中使用 $n=16$ 个上下文示例。
GPT-3 yields huge gains on knowledge-based VQA, but not on VQAv2. Results in Table 4 quantify the benefit of GPT-3 over Flan-T5-XXL. GPT-3 yields great performance gains on knowledge-based VQA tasks, improving over FlanT5 by $18.4%$ and $14.8%$ absolute accuracy on OK-VQA and A-OKVQA, respectively. In comparison, on VQAv2, GPT3 only gives $3.2%$ accuracy gain, which is much smaller than the gain from PROMPTCAP over generic captions. The results indicate that GPT-3’s external knowledge is critical for knowledge-based VQA tasks but not for VQAv2. We speculate that this disparity arises from VQAv2’s focus on information in the image, without requiring additional knowledge beyond visual information.
GPT-3在基于知识的VQA上带来巨大提升,但在VQAv2上表现平平。表4中的结果量化了GPT-3相较Flan-T5-XXL的优势:在基于知识的VQA任务中,GPT-3分别以18.4%和14.8%的绝对准确率优势领先于Flan-T5(OK-VQA和A-OKVQA数据集)。相比之下,在VQAv2上GPT-3仅带来3.2%的准确率提升,远低于PROMPTCAP相较通用图像描述的改进幅度。这表明GPT-3的外部知识库对基于知识的VQA任务至关重要,但对VQAv2影响有限。我们推测这种差异源于VQAv2更关注图像本身信息,无需视觉信息之外的额外知识。
Table 5. Ablation of GPT-3 prompting on OK-VQA. We experiment with different numbers of in-context examples in the input and measure the performance gain from retrieving similar in-context examples compared with random examples.
| Examples | Caption | n=1 | n=4 | n=16 | n=32 |
| Random | OFA-Cap PROMPTCAP | 42.8 | 46.6 | 49.7 | 50.8 |
| CLIP | OFA-Cap | 46.5 44.5 | 50.0 50.0 | 53.1 55.3 | 55.2 56.6 |
| PROMPTCAP | 48.7 | 53.3 | 58.4 | 60.4 |
表 5: GPT-3 在 OK-VQA 上的提示消融实验。我们测试了输入中不同数量的上下文示例,并比较了检索相似上下文示例与随机示例带来的性能提升。
| 示例类型 | 描述 | n=1 | n=4 | n=16 | n=32 |
|---|---|---|---|---|---|
| 随机 | OFA-Cap PROMPTCAP | 42.8 | 46.6 | 49.7 | 50.8 |
| CLIP | OFA-Cap | 46.5 | 50.0 | 53.1 | 55.2 |
| 44.5 | 50.0 | 55.3 | 56.6 | ||
| PROMPTCAP | 48.7 | 53.3 | 58.4 | 60.4 |
5.3.3 Ablation on GPT-3 Prompting
5.3.3 基于 GPT-3 提示的消融实验
As discussed in $\S4$ , two factors affect the in-context learning performance: the number of in-context examples, and the example selection strategy. To measure the effects of these two factors, we conduct an ablation study on GPT-3 prompting for OK-VQA in Table 5. We vary the number of examples $n\in{1,4,16,32}$ and experiment with random examples and the most similar examples retrieved by CLIP (VIT-L/14) [43]. We can see that for both example selection strategies, the more in-context examples, the better the performance. Also, retrieving most similar examples with CLIP gives substantial performance gain $5.2%$ absolute accuracy for PROMPTCAP when $n=32$ ). Both findings agree with the claims in prior work [5, 31, 67].
如 $\S4$ 所述,上下文学习性能受两个因素影响:上下文示例数量与示例选择策略。为衡量这两个因素的影响,我们在表5中对OK-VQA任务的GPT-3提示进行了消融实验。我们调整示例数量 $n\in{1,4,16,32}$ ,并分别测试随机示例与CLIP (VIT-L/14) [43]检索的最相似示例。实验表明:两种选择策略下,上下文示例越多性能越好;同时,使用CLIP检索最相似示例能带来显著性能提升(当 $n=32$ 时PROMPTCAP绝对准确率提升5.2%)。这些发现与先前研究[5, 31, 67]的结论一致。
5.4. Domain Transfer on WebQA
5.4. WebQA 领域的迁移
We apply PROMPTCAP to WebQA [6] to evaluate PROMPTCAP’s generalization ability on images and tasks from different domains. WebQA images are crawled from the web and are from domains different from the COCO [28] images used in PROMPTCAP’s training data synthesized from VQAv2 [14]. Due to the task setting, questions are compositional and much longer than typical VQA questions. We convert the source images into captions and use GPT-3 in-context learning to carry out the task with only 8 random examples. The answers are long-form and measured by two scores: the fluency score measured by BARTScore [69] and the accuracy score that measures if human-annotated keywords are included in the answer. The results in the image-query setting with oracle sources on the validation set2 are shown on Table 6. Our systems outperform all the official baselines. PROMPTCAP outperforms the generic OFA captions, showing that PROMPTCAP is general iz able to a different domain of questions and images.
我们将PROMPTCAP应用于WebQA[6],以评估其在不同领域图像和任务上的泛化能力。WebQA图像来自网络爬取,其领域与PROMPTCAP训练数据中使用的COCO[28]图像(由VQAv2[14]合成)不同。由于任务设置,问题具有组合性且比典型VQA问题长得多。我们将源图像转换为描述,并使用GPT-3的上下文学习仅通过8个随机示例执行任务。答案采用长文本形式,通过两个分数衡量:由BARTScore[69]评估的流畅度分数,以及衡量答案是否包含人工标注关键词的准确率分数。验证集2上采用oracle来源的图像查询设置结果如 表6 所示。我们的系统在所有官方基线方法中表现最优。PROMPTCAP优于通用OFA描述,表明其能够泛化至不同领域的问题和图像。

Figure 5. Example captions generated by PROMPTCAP and OFA-Cap, and the answers GPT-3 generated the captions. For all these questions, GPT-3 yields the correct answer given PROMPTCAP captions but fails given the generic caption. Questions are from OK-VQA.
图 5: PROMPTCAP 和 OFA-Cap 生成的示例描述,以及 GPT-3 根据这些描述生成的答案。对于所有这些问题,GPT-3 在给定 PROMPTCAP 描述时能得出正确答案,但在给定通用描述时失败。问题来自 OK-VQA。

Figure 6. Representative failure cases of PROMPTCAP and GPT-3 pipeline on OK-VQA.
图 6: PROMPTCAP与GPT-3流程在OK-VQA数据集上的典型失败案例
Table 6. Results on the WebQA validation set with oracle sources on image queries. The baselines in the upper part are fully supervised, while our methods only use 8-shot in-context learning.
| Method | FL | Acc | FL*AcC |
| Fully supervised | |||
| VLP+VinVL[6] | 47.6 | 49.6 | 27.5 |
| VLP + x101fpn [6] | 46.9 | 44.3 | 23.8 |
| 8-shot in-context learning | |||
| OFA-Cap + GPT-3 | 52.8 | 55.4 | 33.5 |
| PROMPTCAP+GPT-3 | 53.0 | 57.2 | 34.5 |
表 6: 在图像查询中使用oracle sources的WebQA验证集结果。上半部分的基线方法采用全监督训练,而我们的方法仅使用8-shot上下文学习。
| 方法 | FL | Acc | FL*Acc |
|---|---|---|---|
| 全监督 | |||
| VLP+VinVL[6] | 47.6 | 49.6 | 27.5 |
| VLP + x101fpn [6] | 46.9 | 44.3 | 23.8 |
| 8-shot上下文学习 | |||
| OFA-Cap + GPT-3 | 52.8 | 55.4 | 33.5 |
| PROMPTCAP+GPT-3 | 53.0 | 57.2 | 34.5 |
5.5. Qualitative Analysis
5.5. 定性分析
Representative captions generated by PROMPTCAP and OFA are illustrated in Figure 5. The task is to answer the questions in OK-VQA. For all these questions, GPT-3 generates the correct answer when taking PROMPTCAP’s caption as input, but fails when taking the generic caption. PROMPTCAP is able to capture visual attributes according to the question, for example, “brand" in (b) and “color" in (c). In addition, it can focus on particular objects asked in the question, such as the clothing the boy is “putting on" in (d). For tasks beyond PROMPTCAP’s reasoning ability, GPT-3 infers the answer by the visual details PROMPTCAP gives. For example, GPT-3 infers “green" for the “complimentary color of red" in (c) and “7" for SUV’s seating capacity in (a). We also show some representative failure cases in Figure 6. The majority of failures are as shown in (a) and (b), in which PROMPTCAP fails to provide helpful information, or provides unfactual information. GPT-3 sometimes makes mistakes, as shown in (c) and (d).
PROMPTCAP和OFA生成的典型示例如图5所示。该任务旨在回答OK-VQA中的问题。对于所有这些问题,当输入PROMPTCAP生成的描述时,GPT-3能给出正确答案,但使用通用描述时则失败。PROMPTCAP能根据问题捕捉视觉属性,例如(b)中的"品牌"和(c)中的"颜色"。此外,它能聚焦问题中指定的对象,如(d)中男孩"正在穿"的衣物。对于超出PROMPTCAP推理能力的任务,GPT-3会通过PROMPTCAP提供的视觉细节推断答案,例如(c)中根据"红色的互补色"推断出"绿色",(a)中推断SUV的"7座"容量。图6展示了部分典型失败案例,多数如(a)(b)所示——PROMPTCAP未能提供有效信息或给出错误事实,而(c)(d)则显示GPT-3偶尔会犯推理错误。
Table 7. Comparison of captions. “GPT-3-Syn" are the questionaware captions synthesized by GPT-3. “COCO-GT" are the MSCOCO ground-truth captions. Higher scores imply higher similarities between the captions.
| Captions | B | M | C | S | |
| Comparison between “gold captions COCO-GT | |||||
| GPT-3-Syn | 67.1 | 44.3 | 182.9 | 32.1 | |
| Inferenced captions vs. “gold captions" GPT-3-Syn | |||||
| OFA-Cap | 26.2 | 25.3 | 231.0 | 40.2 | |
| PROMPTCAP GPT-3-Syn COCO-GT | 33.0 | 29.7 | 307.1 | 47.3 | |
| OFA-Cap PROMPTCAP | 44.5 | 30.9 | 147.9 | 24.6 | |
5.6. Analysis: How Do Question-Aware Captions Differ from Generic Captions?
5.6. 分析:问题感知型字幕与通用字幕有何不同?
To further analyze the question-aware captions, we compare different inferred/gold captions in Table 7. The captions are compared by the automatic evaluations used in MSCOCO [7]: BLEU-4 (B) [42], METEOR (M) [4], CIDEr (C) [55], and SPICE (S) [2]. We evaluate the captions on the VQAv2 question-image pairs with images in the Karpathy test split [21] and average the scores over the questions. The upper part of the table compares the “training targets" for PROMPTCAP and the generic captioning model OFA-Cap. The lower part compares the captions inferred by each captioning model with these “gold captions". We make several observations from the table:
为了进一步分析问题感知的标题,我们在表7中比较了不同推断/黄金标题。标题的比较采用了MSCOCO [7]中使用的自动评估方法:BLEU-4 (B) [42]、METEOR (M) [4]、CIDEr (C) [55] 和 SPICE (S) [2]。我们在VQAv2的问题-图像对上评估这些标题,其中图像来自Karpathy测试集 [21],并对问题的得分取平均值。表格的上半部分比较了PROMPTCAP和通用标题生成模型OFA-Cap的"训练目标"。下半部分比较了每个标题生成模型推断出的标题与这些"黄金标题"。从表中我们得出以下几点观察:
GPT-3 synthesized question-aware captions synthesized by GPT-3 are highly similar to the MSCOCO ground truth generic captions. As seen in the upper part of Table 7, the question-aware captions are really similar to the MSCOCO ground-truth captions.
GPT-3生成的问题感知描述与MSCOCO基准通用描述高度相似。如表7上半部分所示,问题感知描述确实与MSCOCO基准描述非常相似。
PROMPTCAP achieves high CIDEr and SPICE scores using GPT-3 synthesized captions as reference. The second row in the lower part compares the prompt-guided captions generated by PROMPTCAP with the GPT-3 synthesized question-aware captions. We can see that the CIDEr and SPICE scores are really high. One possible reason for the high scores is that synthesized question-aware captions are typically less diverse, shorter, and cover fewer visual entities compared with human-written general captions. Moreover, the image captioning task becomes less ambiguous via the prompt’s control, making it easier for PROMPTCAP to learn.
PROMPTCAP 使用 GPT-3 合成的描述作为参考,取得了较高的 CIDEr 和 SPICE 分数。下半部分第二行将 PROMPTCAP 生成的提示引导描述与 GPT-3 合成的问答感知描述进行了对比。可以看出 CIDEr 和 SPICE 分数确实很高。高分的一个可能原因是,相比人工编写的通用描述,合成的问答感知描述通常多样性较低、更简短且覆盖的视觉实体更少。此外,通过提示控制,图像描述任务的歧义性降低,使得 PROMPTCAP 更易学习。
PROMPTCAP can also generate high-quality generic captions. The last row shows the quality of the generic captions generated by PROMPTCAP. Users can get generic captions by prompting PROMPTCAP with the question “what does the image describe?". All the automatic metrics show that PROMPTCAP achieves SOTA performance on COCO validation set, with even higher scores than the original OFA-Cap model.
PROMPTCAP 也能生成高质量的通用描述。最后一行展示了 PROMPTCAP 生成的通用描述质量。用户可通过提问"这张图片描述了什么?"来获取通用描述。所有自动评估指标均显示,PROMPTCAP 在 COCO 验证集上实现了 SOTA (state-of-the-art) 性能,其得分甚至超过了原始 OFA-Cap 模型。
6. Limitations and Broader Impact
6. 局限性与更广泛影响
One limitation is that the current PROMPTCAP only focuses on knowledge-based VQA tasks. PROMPTCAP can be extended to other vision-language tasks beyond VQA. Figure 7 shows an example of solving NLVR2 [52] via a series of vision and reasoning steps between PROMPTCAP and ChatGPT. Future work may scale up PROMPTCAP training with more diverse tasks and instructions, and explore broader applications of PROMPTCAP beyond VQA.
一个局限是目前 PROMPTCAP 仅聚焦于基于知识的视觉问答(VQA)任务。PROMPTCAP 可扩展至 VQA 之外的其他视觉语言任务。图 7 展示了通过 PROMPTCAP 与 ChatGPT 之间一系列视觉和推理步骤来解决 NLVR2 [52] 的案例。未来工作可以通过更多样化的任务和指令来扩展 PROMPTCAP 的训练,并探索 PROMPTCAP 在 VQA 之外的更广泛应用。
Another limitation is that images contain information that cannot be abstracted as text. While PROMPTCAP has demonstrated promising results in bridging the gap between LMs and images, it is important to recognize its limitations and use it in conjunction with other methods to ensure a comprehensive understanding of visual data.
另一个限制是图像中包含无法抽象为文本的信息。虽然 PROMPTCAP 在弥合大语言模型与图像之间的差距方面展现出良好效果,但必须认识到其局限性,并与其他方法结合使用以确保对视觉数据的全面理解。

Figure 7. Demo of solving the NLVR2 task with off-the-shelf PROMPTCAP and ChatGPT via an interpret able reasoning process.
图 7: 使用现成的 PROMPTCAP 和 ChatGPT 通过可解释推理过程解决 NLVR2 任务的演示。
7. Conclusion
7. 结论
We present PROMPTCAP, a novel question-aware captioning model that can be controlled via a natural language prompt. To train this captioning model with no extra annotation, we devise an efficient pipeline for synthesizing and filtering training examples via GPT-3. We demonstrate the effec ti ve ness of PROMPTCAP on knowledge-based VQA tasks. Our system achieves state-of-the-art performance on OKVQA and A-OKVQA. Ablations show that PROMPTCAP is giving consistent gains over generic captions. Furthermore, we investigate PROMPTCAP’s generalization ability on WebQA. PROMPTCAP works as a simple and general module for converting question-related visual information into text.
我们提出了PROMPTCAP,这是一种可通过自然语言提示控制的新型问题感知字幕生成模型。为在无需额外标注的情况下训练该模型,我们设计了一套基于GPT-3的高效训练样本合成与过滤流程。实验表明PROMPTCAP在知识型视觉问答(VQA)任务中表现优异,在OKVQA和A-OKVQA数据集上达到了最先进水平。消融实验证明该模型相比通用字幕能带来稳定增益。此外,我们在WebQA数据集上验证了PROMPTCAP的泛化能力。该模型可作为简单通用的模块,将问题相关的视觉信息转化为文本。
A. More Implementation Details
A. 更多实现细节
The pre-trained OFA [58] is trained on about 20M imagetext pairs. We further fine-tune OFA using examples synthesized from VQAv2 [14] on COCO 2014 training set, which contains 443757 examples. Notice that we haven’t used COCO 2014 validation set to avoid data leakage.
预训练的OFA [58] 在约2000万图像-文本对上进行了训练。我们进一步使用从VQAv2 [14] 在COCO 2014训练集上合成的443757个样本对OFA进行微调。注意,为避免数据泄露,我们未使用COCO 2014验证集。
For model training, the most important details are given in Section 3. We finetune PROMPTCAP on the synthesized dataset for 2 epochs, which takes about 10 hours on 4 NVIDIA A40 GPUs. For all the experiments that use random in-context examples for GPT-3, we report the average result of 3 runs.
模型训练最重要的细节见第3节。我们在合成数据集上对PROMPTCAP进行了2个周期的微调(finetune),在4块NVIDIA A40 GPU上耗时约10小时。所有使用GPT-3随机上下文示例的实验,均报告3次运行的平均结果。
B. Common Q & A
B. 常见问答
Compared with OFA, does the performance gain of PROMPTCAP come from more training data? No. As discussed in $\S5.3$ , OFA is a large-scale vision-language model pre-trained on 20M image-text pairs and 20 visionlanguage tasks, including many VQA tasks. PROMPTCAP is fine-tuned on VQAv2 [14], which is included in OFA training data. The performance gain comes from the idea of controlling image captions with natural language instructions. Compared with OFA, we synthesize VQAv2 into prompt-guided captioning tasks via GPT-3 and use it to further fine-tune OFA. This way, OFA gains the ability of prompt-guided captioning with the same amount of annotated data, leading to significant performance gains.
与OFA相比,PROMPTCAP的性能提升是否来自更多训练数据?不是。如$\S5.3$所述,OFA是在2000万图文对和20项视觉语言任务(包含多项VQA任务)上预训练的大规模视觉语言模型。PROMPTCAP仅在VQAv2[14]上微调,而该数据集已包含在OFA训练数据中。性能提升源于通过自然语言指令控制图像描述的新思路:我们通过GPT-3将VQAv2转化为提示引导的描述生成任务,并以此微调OFA。这种方法使OFA在同等标注数据量下获得了提示引导的生成能力,从而带来显著性能提升。
Can PROMPTCAP do generic captioning? Yes. We find that prompting PROMPTCAP with the question “what does the image describe?" leads to high-quality generic captions. The CIDEr is 150.1 on the COCO validation set in the setting in $\S5.6$ .
PROMPTCAP能否进行通用描述?可以。我们发现用"这张图片描述了什么?"来提示PROMPTCAP能生成高质量的通用描述。在$\S5.6$的设置下,COCO验证集上的CIDEr得分为150.1。
C. Prompt Examples
C. 提示词示例
In this section, we show examples of the prompts we used for prompting GPT-3.
在本节中,我们将展示用于提示 GPT-3 的提示词示例。
C.1. Prompt for example synthesis
C.1. 示例合成提示
Below is the full version of the prompt for training example synthesis with GPT-3. We formulate the task into a sum mari z ation tasks, and include the human-written examples in the prompt. The question-answer pair synthesized is at the end of the prompt, and GPT-3 generates the promptguided caption example.
以下是使用GPT-3进行训练样本合成的完整提示模板。我们将该任务构建为摘要生成任务,并在提示中包含人工编写的示例。合成的问答对位于提示末尾,GPT-3根据提示生成对应的描述样本。
Summarize the context to help answer the question
总结上下文以帮助回答问题
Original contexts: A very clean and well decorated empty bathroom. A blue and white bathroom with butterfly themed wall tiles.
原始场景:一间非常干净且装饰精美的空浴室。一间蓝白相间、墙面瓷砖采用蝴蝶主题的浴室。
A bathroom with a border of butterflies and blue paint on the walls above it. Question: Is the sink full of water? Answer: no Summary: A bathroom with an empty sink.
带有蝴蝶边框和上方墙壁涂有蓝色油漆的浴室。问题:水槽里装满了水吗?回答:没有。摘要:一个水槽空着的浴室。
Original contexts: An empty kitchen with white and black appliances.. A refrigerator and stove are in a small kitchen area. . Small kitchen in a personal home with dual sinks.. A small kitchen with sink, stove and refrigerator.. A small kitchen with several appliances and cookware. Question: How many cabinets in this room? Answer: 4 Summary: A small kitchen with 4 cabinets.
原始场景:一间空荡荡的厨房,配有黑白相间的电器。冰箱和炉灶位于小厨房区域。个人住宅中的小厨房配有双水槽。带水槽、炉灶和冰箱的小厨房。配备若干电器和炊具的小厨房。问题:这个房间有多少个橱柜?答案:4摘要:配有4个橱柜的小厨房。
Original contexts: A couple enjoying beverages and a snack on a sunny day. Showing a doughnut while holding drinks near a car.. A man and woman sharing apple cider and a doughnut. Two people are standing in front of an open car trunk holding drinks and a doughnut. . A man and a woman eating donuts and having drinks.. A man holding beer and a woman holding a pastry and beer.
原始场景:一对情侣在晴天享用饮料和小吃。展示在汽车旁拿着饮料的甜甜圈。一男一女分享苹果酒和甜甜圈。两人站在打开的后备箱前,手持饮料和甜甜圈。一男一女正在吃甜甜圈喝饮料。男子拿着啤酒,女子拿着点心和啤酒。
Question: How do we know this guy is not likely to have packed a razor?
问题:我们怎么知道这家伙不太可能带了剃须刀?
Answer: has beard
有胡子
Summary: A man with beard and a woman are eating donuts and having drinks.
摘要:一名蓄须男子和一名女子正在吃甜甜圈并喝饮料。
Original contexts: Woman riding a bicycle down an empty street.. A woman in green is riding a bike.. a woman wearing a bright green sweater riding a bicycle. A woman on a bicycle is going down the small town street.. A woman bikes down a one way street.
原文情境:一位女士骑着自行车沿着空荡的街道前行。身穿绿色衣服的女子正在骑车。一位穿着亮绿色毛衣的女性骑着自行车。骑自行车的女子正沿着小镇街道行驶。一位女士在单行道上骑行。
Question: What kind of fruit is the helmet supposed to be?
问题:头盔应该是什么水果?
Answer: watermelon
答案:西瓜
Summary: A woman with a watermelon style helmet riding a bicycle.
摘要:一名戴着西瓜样式头盔的女子正在骑自行车。
Original contexts: A woman is walking a dog in the city.. A woman and her dog walking down a sidewalk next to a fence with some flowers. . A woman walking her dog on the sidewalk.. A woman walks her dog along a city street.. A woman walks her dog on a city sidewalk.
原始语境:一名女子在城市里遛狗。一名女子和她的狗沿着人行道行走,旁边是有花的栅栏。一名女子在人行道上遛狗。一名女子沿着城市街道遛狗。一名女子在城市人行道上遛狗。
Question: What color vehicle is closest to the mailbox?
问题:什么颜色的车辆最接近邮箱?
Answer: silver
答案:银
Summary: A silver vehicle next to a mailbox on the sidewalk.
摘要:一辆银色汽车停放在人行道上的邮箱旁。
Original contexts: some pancakes cover with bananas, nuts, and some whipped cream . Two pancakes on top of a white plate covered in whipped cream, nuts and a banana .. Pancakes with bananas, nuts and cream, covered in syrup. . Pancakes topped with bananas, whipped cream and walnuts..
煎饼上覆盖着香蕉、坚果和一些打发的奶油。
两个煎饼放在白色盘子上,覆盖着打发的奶油、坚果和一根香蕉。
煎饼配香蕉、坚果和奶油,淋上糖浆。
煎饼顶部装饰着香蕉、打发奶油和核桃。
Pancakes topped with bananas, nuts, and ice cream.
香蕉坚果冰淇淋煎饼
Question: What restaurant was this dish cooked at?
问题:这道菜是在哪家餐厅烹制的?
Answer: ihop
Summary: Pancakes with banans, nuts, and cream, cooked at ihop.
摘要:IHOP 烹饪的香蕉、坚果和奶油煎饼。
Original contexts: The two people are walking down the beach.. Two people carrying surf boards on a beach.. Two teenagers at a white sanded beach with surfboards.. A couple at the beach walking with their surf boards.. A guy and a girl are walking on the beach holding surfboards.
原始情境:两人正沿着海滩行走.. 两个人在海滩上扛着冲浪板.. 两个青少年在白沙滩上拿着冲浪板.. 一对情侣拿着冲浪板在海滩上散步.. 一男一女手持冲浪板走在海滩上。
Question: What is on the man’s head?
问题:男人头上有什么?
Answer: hat
答:帽子
Summary: A man and a woman walking on the beach with surfboards. The man is wearing a hat.
摘要:一男一女带着冲浪板走在海滩上。男子戴着帽子。
Original contexts: A sink and a toilet inside a small bathroom.. White pedestal sink and toilet located in a poorly lit bathroom.. Clean indoor bathroom with tile
白色立式洗手盆和马桶位于光线昏暗的浴室中。铺有瓷砖的洁净室内浴室。
floor and good lighting.. a bathroom with toilet and sink and blue wall. a blue bathroom with a sink and toilet.
地板和良好采光.. 带马桶、洗手池和蓝色墙壁的浴室。一间配有洗手池和马桶的蓝色浴室。
Question: Is there natural light in this photo?
问题:这张照片中有自然光吗?
Answer: no
答案:否
Summary: A photo of a small bathroom in artificial light.
摘要:一张人工照明下的小浴室照片。
Original contexts: Fog is in the air at an intersection with several traffic lights.. An intersection during a cold and foggy night.. Empty fog covered streets in the night amongst traffic lights.. City street at night with several stop lights.. It is a foggy night by a traffic light.
雾霭笼罩着设有多个交通信号灯的十字路口。
寒冷雾夜中的十字路口。
夜间空荡的雾锁街道与交通信号灯为伴。
夜间城市街道上分布着多个停车灯。
交通信号灯旁,这是一个雾蒙蒙的夜晚。
Question: Which direction is okay to go? Answer: straight Summary: A traffic light in a foggy night, showing it is okay to go straight.
问题:哪个方向可以通行?
答案:直行
摘要:雾夜中的交通信号灯显示可以直行。
Original contexts: A graffiti-ed stop sign across the street from a red car . A vandalized stop sign and a red beetle on the road. A red stop sign with a Bush bumper sticker under the word stop.. A stop sign that has been vandalized is pictured in front of a parked car.. A street sign modified to read stop bush.
街道对面一辆红色汽车旁的涂鸦停车标志。
一条路上被破坏的停车标志和一辆红色甲壳虫汽车。
红色停车标志下方贴有布什竞选贴纸。
一辆停放汽车前被破坏的停车标志。
被修改为"阻止布什"字样的路牌。
Question: What color is the car driving north?
问题:向北行驶的汽车是什么颜色?
Answer: red
答案:红色
Summary: A stop sign and a red car driving north.
摘要:停车标志和一辆向北行驶的红色汽车。
Original contexts: A man in a wheelchair and another sitting on a bench that is overlooking the water.. Two people sitting on dock looking at the ocean.. Two older people sitting down in front of a beach.. An old couple at the beach during the day..
轮椅上的男子与坐在长椅上眺望水面的另一人.. 两人坐在码头凝望海洋.. 两位长者坐在海滩前.. 白天海滩上的一对老夫妇..
A person on a bench, and one on a wheelchair sitting by a seawall looking out toward the ocean.
一个人坐在长椅上,另一个人坐在轮椅上,靠着海堤望向大海。
Summary: A person sit on a bench on the left, and another sitting in a wheelchair on the right, all looking at the ocean.
摘要:左侧长椅上坐着一个人,右侧轮椅上坐着另一个人,两人都望向大海。
Original contexts: A parked motor scooter sitting next to a bicycle.. A picture of a motorbike and two pedal bicycles.. A motor scooter that has an advert is ment on the back next to a bicycle.. A grey moped parked by building next to a bicycle.. a motor bike parked next to a bike by a building.
原始场景:一辆停放的摩托车与自行车相邻。一张摩托车和两辆脚踏自行车的照片。一辆后部贴有广告的摩托车停放在自行车旁。一辆灰色助力车停靠在建筑物旁,旁边是一辆自行车。一辆摩托车停靠在建筑物旁的自行车边。
Original contexts: People standing around a park bench next to a bicycle.. A group of women are describing a new setup for a building plan. a group of people in a field of grass near a building. Several people standing in an area with picnic tables looking at a board.. A woman giving a presentation in a park.
原始场景:人们围站在公园长椅旁,旁边停着一辆自行车。一群女性正在描述建筑方案的新布局。一群人站在靠近建筑物的草地上。几个人站在野餐桌区域,看着一块展板。一位女士正在公园里做演示。
Question: What is the woman in the blue jacket standing on?
问题:穿蓝色夹克的女人站在什么上面?
Answer: bench
答案:bench
Summary: A woman in blue jacket standing on a bench, with a group of people around her.
摘要:一名穿蓝色夹克的女子站在长椅上,周围围着一群人。
Original contexts: A orange tabby cat laying down on a black car. An orange cat laying on the hood on a car.. A cat sits on top of a black car.. A cat that is sitting on top of a black car.. A yellow cat sleeping on the hood of a black car parked in the garage.
原始情境:一只橘色虎斑猫躺在一辆黑色汽车上。一只橘猫趴在汽车引擎盖上。一只猫坐在黑色汽车顶部。一只猫正坐在黑色汽车顶部。一只黄猫在车库中停放的黑色汽车引擎盖上睡觉。
---Prompt Ends Here- LM completion: A bicycle chained to a pole, with a pile of garbage next to it.
一辆锁在柱子上的自行车,旁边有一堆垃圾。
C.2. GPT-3 In-Context Learning for VQA
C.2. GPT-3 在 VQA 任务中的上下文学习
Here we show an example of solving VQA with GPT3 in-context learning on OK-VQA [38]. We use the same prompt template as PICa [67]. This example contains 8 closest examples retrieved from the training set.
这里我们展示了一个在OK-VQA [38]数据集上使用GPT3上下文学习解决视觉问答(VQA)的示例。我们采用了与PICa [67]相同的提示模板。该示例包含从训练集中检索出的8个最相似样本。