Visual Spatial Reasoning
视觉空间推理
Abstract
摘要
Spatial relations are a basic part of human cognition. However, they are expressed in natural language in a variety of ways, and previous work has suggested that current vision-and-language models (VLMs) struggle to capture relational information. In this paper, we present Visual Spatial Reasoning (VSR), a dataset containing more than 10k natural text-image pairs with 66 types of spatial relations in English (such as: under, in front of, facing). While using a seemingly simple annotation format, we show how the dataset includes challenging linguistic phenomena, such as varying reference frames. We demonstrate a large gap between human and model performance: the human ceiling is above $95%$ , while state-of-the-art models only achieve around $70%$ . We observe that VLMs’ by-relation performances have little correlation with the number of training examples and the tested models are in general incapable of recognising relations concerning the orientations of objects.1
空间关系是人类认知的基本组成部分。然而,它们在自然语言中以多种方式表达,先前的研究表明,当前的视觉与语言模型 (VLM) 难以捕捉关系信息。本文提出了视觉空间推理 (VSR) 数据集,包含超过1万组自然文本-图像对,涵盖66种英语空间关系(例如:under, in front of, facing)。尽管采用看似简单的标注格式,我们展示了该数据集如何涵盖具有挑战性的语言现象,例如变化的参照系。我们揭示了人类与模型性能之间的巨大差距:人类上限超过 $95%$ ,而最先进模型仅达到约 $70%$ 。研究发现,VLM 的按关系表现与训练样本数量相关性很低,且测试模型普遍无法识别涉及物体朝向的关系。[20]
1 Introduction
1 引言
Multimodal NLP research has developed rapidly in recent years, with substantial performance gains on tasks such as visual question answering (VQA) (Antol et al., 2015; Johnson et al., 2017; Goyal et al., 2017; Hudson and Manning, 2019; Zellers et al., 2019), vision-language reasoning or entailment (Suhr et al., 2017, 2019; Xie et al., 2019; Liu et al., 2021), and referring expression comprehension (Yu et al., 2016; Liu et al., 2019). Existing benchmarks, such as NLVR2 (Suhr et al., 2019) and VQA (Goyal et al., 2017), define generic paradigms for testing vision-language models (VLMs). However, as we further discuss in $\S2$ , these benchmarks are not ideal for probing VLMs as they typically conflate multiple sources of error and do not allow controlled analysis on specific linguistic or cognitive properties, making it difficult to categorise and fully understand the model failures. In particular, spatial reasoning has been found to be particularly challenging for current models, and much more challenging than capturing properties of individual entities (Kuhnle et al., 2018; Cirik et al., 2018; Akula et al., 2020), even for state-of-the-art models such as CLIP (Radford et al., 2021; Subramania n et al., 2022).
近年来,多模态自然语言处理(NLP)研究发展迅猛,在视觉问答(VQA) (Antol et al., 2015; Johnson et al., 2017; Goyal et al., 2017; Hudson and Manning, 2019; Zellers et al., 2019)、视觉语言推理或蕴含(Suhr et al., 2017, 2019; Xie et al., 2019; Liu et al., 2021)以及指代表达理解(Yu et al., 2016; Liu et al., 2019)等任务上取得了显著性能提升。现有基准测试如NLVR2 (Suhr et al., 2019)和VQA (Goyal et al., 2017)为测试视觉语言模型(VLM)定义了通用范式。但正如我们在$\S2$中进一步讨论的,这些基准并不适合探究VLM,因为它们通常混淆了多种错误来源,且无法对特定语言或认知属性进行受控分析,导致难以分类和全面理解模型缺陷。特别是空间推理已被证明对当前模型极具挑战性,远比对单个实体属性的捕捉更为困难(Kuhnle et al., 2018; Cirik et al., 2018; Akula et al., 2020),即便是CLIP (Radford et al., 2021; Subramania n et al., 2022)等最先进的模型也不例外。
Another line of work generates synthetic datasets in a controlled manner to target specific relations and properties when testing VLMs, e.g., CLEVR (Liu et al., 2019) and ShapeWorld (Kuhnle and Copestake, 2018). However, synthetic datasets may accidentally overlook challenges (such as orientations of objects which we will discuss in $\S5$ ), and using natural images allows us to explore a wider range of language use.
另一项工作以受控方式生成合成数据集,用于在测试视觉语言模型(VLM)时针对特定关系和属性,例如CLEVR (Liu等人,2019) 和 ShapeWorld (Kuhnle和Copestake,2018)。然而,合成数据集可能会意外忽略某些挑战(如我们将在$\S5$讨论的物体朝向问题),而使用自然图像能让我们探索更广泛的语言使用场景。
To address the lack of probing evaluation benchmarks in this field, we present VSR (Visual Spatial Reasoning), a controlled dataset that explicitly tests VLMs for spatial reasoning. We choose spatial reasoning as the focus because it is one of the most fundamental capabilities for both humans and VLMs. Such relations are crucial to how humans organise their mental space and make sense of the physical world, and therefore fundamental for a grounded semantic model (Talmy, 1983).
为解决该领域缺乏探测性评估基准的问题,我们提出了VSR (Visual Spatial Reasoning) 数据集,这是一个专门测试视觉语言模型 (VLM) 空间推理能力的受控数据集。我们选择空间推理作为研究重点,因为这是人类和视觉语言模型最基础的核心能力之一。这种关系对人类组织心理空间和理解物理世界至关重要 (Talmy, 1983) ,因此也是基础语义模型的核心要素。
The VSR dataset contains natural image-text pairs in English, with the data collection process explained in $\S3$ . Each example in the dataset consists of an image and a natural language description which states a spatial relation of two objects presented in the image (two examples are shown in Fig. 1 and Fig. 2). A VLM needs to classify the image-caption pair as either true or false, indicating whether the caption is correctly describing the spatial relation. The dataset covers 66 spatial relations and has ${>}10\mathrm{k}$ data points, using 6,940 images from
VSR数据集包含英语自然图像-文本对,其数据收集过程在$\S3$中说明。数据集中的每个样本由一张图像和一句自然语言描述组成,该描述陈述了图像中呈现的两个物体的空间关系(图1和图2展示了两个示例)。视觉语言模型(VLM)需要将图像-标题对分类为真或假,以判断标题是否正确描述了空间关系。该数据集涵盖66种空间关系,包含${>}10\mathrm{k}$个数据点,使用了来自
MS COCO (Lin et al., 2014).
MS COCO (Lin et al., 2014).
Situating one object in relation to another requires a frame of reference: a system of coordinates against which the objects can be placed. Drawing on detailed studies of more than forty typo logically diverse languages, Levinson (2003) concludes that the diversity can be reduced to three major types: intrinsic, relative, and absolute. An intrinsic frame is centred on an object, e.g., behind the chair, meaning at the side with the backrest. A relative frame is centred on a viewer, e.g., behind the chair, meaning further away from someone’s perspective. An absolute frame uses fixed coordinates, e.g., north of the chair, using cardinal directions. In English, absolute frames are rarely used when describing relations on a small scale, and they do not appear in our dataset. However, intrinsic and relative frames are widely used, and present an important source of variation. We discuss the impact on data collection in $\S3.2$ , and analyse the collected data in $\S4$ .
确定一个物体相对于另一个物体的位置需要参照系:一个可以放置物体的坐标系系统。通过对四十多种类型学上多样语言的详细研究,Levinson (2003) 得出结论,这种多样性可以归纳为三大类:内在 (intrinsic)、相对 (relative) 和绝对 (absolute)。内在参照系以物体为中心,例如"椅子后面"指的是有靠背的一侧。相对参照系以观察者为中心,例如"椅子后面"意味着从某人的视角看更远的位置。绝对参照系使用固定坐标系,例如"椅子北面"使用基本方向。在英语中,小范围描述关系时很少使用绝对参照系,我们的数据集中也未出现。然而,内在和相对参照系被广泛使用,并构成了重要的变异来源。我们将在 $\S3.2$ 讨论对数据收集的影响,并在 $\S4$ 分析收集到的数据。
We test four popular VLMs, i.e., VisualBERT (Li et al., 2019), LXMERT (Tan and Bansal, 2019), ViLT (Kim et al., 2021), and CLIP (Radford et al., 2021) on VSR, with results given in $\S5$ . While the human ceiling is above $95%$ , all four models struggle to reach $70%$ accuracy. We conduct comprehensive analysis on the failures of the investigated VLMs and highlight that (1) positional encodings are extremely important for the VSR task; (2) models’ by-relation performance barely correlates with the number of training examples; (3) in fact, several spatial relations that concern orientation of objects are especially challenging for current VLMs; (4) VLMs have extremely poor generalisation on unseen concepts.
我们在VSR上测试了四种流行的视觉语言模型(VLM),即VisualBERT (Li et al., 2019)、LXMERT (Tan and Bansal, 2019)、ViLT (Kim et al., 2021)和CLIP (Radford et al., 2021),结果如$\S5$所示。虽然人类准确率上限超过$95%$,但这四种模型都难以达到$70%$的准确率。我们对这些VLM的失败案例进行了全面分析,并指出:(1) 位置编码对VSR任务极为重要;(2) 模型在各关系上的表现与训练样本数量几乎无关;(3) 实际上,涉及物体方向的若干空间关系对当前VLM尤其具有挑战性;(4) VLM在未见概念上的泛化能力极差。
2 Related Work
2 相关工作
2.1 Comparison with synthetic datasets
2.1 与合成数据集的对比
Synthetic language-vision reasoning datasets, e.g., SHAPES (Andreas et al., 2016), CLEVR (Liu et al., 2019), NLVR (Suhr et al., 2017), and ShapeWorld (Kuhnle and Copestake, 2018), enable full control of dataset generation and could potentially benefit probing of spatial reasoning capability of VLMs. They share a similar goal to us, to diagnose and pinpoint weaknesses in VLMs. However, synthetic datasets necessarily simplify the problem as they have inherently bounded expressivity. In CLEVR, objects can only be spatially related via four relationships: “left”, “right”, “behind”, and “in front of” while VSR covers 66 relations.
合成语言视觉推理数据集,例如 SHAPES (Andreas et al., 2016)、CLEVR (Liu et al., 2019)、NLVR (Suhr et al., 2017) 和 ShapeWorld (Kuhnle and Copestake, 2018),能够完全控制数据集的生成过程,可能有助于探究视觉语言模型 (VLM) 的空间推理能力。这些数据集与我们有着相似的目标,即诊断并精确定位 VLM 的缺陷。然而,合成数据集本质上表达能力有限,必然会简化问题。例如在 CLEVR 中,物体之间仅能通过"左"、"右"、"后"和"前"四种空间关系进行关联,而 VSR 则涵盖了 66 种空间关系。

Figure 1: Caption: The potted plant is at the right side of the bench. Label: True.
图 1: 标题: 盆栽植物位于长椅右侧。标签: 正确。

Figure 2: Caption: The cow is ahead of the person. Label: False.
图 2: 说明:牛在人的前面。标签:错误。
Synthetic data does not always accurately reflect the challenges of reasoning in the real world. For example, objects like spheres, which often appear in synthetic datasets, do not have orientations. In real images, orientations matter and human language use depends on that. Furthermore, synthetic images do not take the scene as a context into account. The interpretation of object relations can depend on such scenes (e.g., the degree of closeness can vary in open space and indoor scenes).
合成数据并不总能准确反映现实世界中的推理挑战。例如,球体等常见于合成数据集中的物体没有方向性。而在真实图像中,方向至关重要,人类语言的使用也基于此。此外,合成图像未将场景作为上下文纳入考量。物体关系的解读可能依赖于这些场景(例如,开放空间与室内场景中的亲密程度可能存在差异)。
Last but not least, the vast majority of spatial rela tion ships cannot be determined by rules. Even for the seemingly simple relationships like “left/right of”, the determination of two objects’ spatial relationships can depend on the observer’s viewpoint, whether the object has a front, if so, what are their orientations, etc.
最后但同样重要的是,绝大多数空间关系无法通过规则确定。即便是看似简单的"左/右"关系,两个物体的空间关系判定也可能取决于观察者视角、物体是否有正面朝向、以及它们的方位等因素。
2.2 Spatial relations in existing vision-language datasets
2.2 现有视觉-语言数据集中的空间关系
Several existing vision-language datasets with natural images also contain spatial relations (e.g., NLVR2, COCO, and VQA datasets). Suhr et al. (2019) summarise that there are 9 prevalent linguistic phenomena/challenges in NLVR2 (Suhr et al., 2019) such as co reference, existential quantifiers, hard cardinality, spatial relations, etc., and 4 in
现有多个包含自然图像的视觉语言数据集也涵盖空间关系(如NLVR2、COCO和VQA数据集)。Suhr等人(2019)总结了NLVR2中存在的9种常见语言现象/挑战(Suhr等人,2019),包括共指、存在量词、硬基数、空间关系等,以及4种...
VQA datasets (Antol et al., 2015; Hudson and Manning, 2019). However, the different challenges are entangled in these datasets. Sentences contain complex lexical and syntactic information and can thus conflate different sources of error, making it hard to identify the exact challenge and preventing categorised analysis. Yatskar et al. (2016) extract 6 types of visual spatial relations directly from MS COCO images with annotated bounding boxes. But rule-based automatic extraction can be restrictive as most relations are complex and cannot be identified relying on bounding boxes. Recently, Rösch and Libovický (2022) extract captions that contain 28 positional keywords from MS COCO and swap the keywords with their antonyms to construct a challenging probing dataset. However, the COCO captions also have the error-conflation problem. Also, the number of examples and types of relations are restricted by COCO captions.
VQA数据集 (Antol等人,2015;Hudson和Manning,2019)。然而这些数据集中的不同挑战相互交织。句子包含复杂的词汇和句法信息,因此可能混淆不同错误来源,难以准确定位具体挑战并阻碍分类分析。Yatskar等人 (2016) 直接从带有标注边界框的MS COCO图像中提取6种视觉空间关系。但基于规则的自动提取存在局限性,因为大多数关系较为复杂,无法仅依赖边界框进行识别。最近,Rösch和Libovický (2022) 从MS COCO中提取包含28个位置关键词的标题,并通过将这些关键词替换为其反义词来构建具有挑战性的探测数据集。但COCO标题同样存在错误混淆问题,且样本数量和关系类型受限于COCO标题内容。
Visual Genome (Krishna et al., 2017) also contains annotations of objects’ relations including spatial relations. However, it is only a collection of true statements and contains no negative ones, so cannot be framed as a binary classification task. It is non-trivial to automatically construct negative examples since multiple relations can be plausible for a pair of object in a given image. Relation classifiers are harder to learn than object class if i ers on this dataset (Liu and Emerson, 2022).
Visual Genome (Krishna等人,2017) 也包含物体间空间关系等关联标注。但该数据集仅收录真实陈述,未包含负面样本,因此无法构建为二分类任务。由于同一图像中的物体可能同时存在多种合理关系,自动构建负样本具有挑战性。在该数据集上,关系分类器的学习难度高于物体分类 (Liu和Emerson,2022)。
Parc a lab escu et al. (2022) propose a benchmark called VALSE for testing VLMs’ capabilities on various linguistic phenomena. VALSE has a subset focusing on “relations” between objects. It uses texts modified from COCO’s original captions. However, it is a zero-shot benchmark without training set, containing just 535 data points. So, it is not ideal for large-scale probing on a wide spectrum of spatial relations.
Parc a lab escu等人 (2022) 提出了名为VALSE的基准测试,用于评估视觉语言模型 (VLMs) 在不同语言现象上的能力。VALSE包含一个专注于物体间"关系"的子集,其文本改编自COCO原始描述。但该基准属于零样本测试集,不含训练数据,仅包含535个样本点,因此不适合对广泛空间关系进行大规模探测。
2.3 Spatial reasoning without grounding
2.3 无接地的空间推理
There has also been interest in probing models’ spatial reasoning capability without visual input. For example, Collell et al. (2018); Mirzaee et al. (2021); Liu et al. (2022) probe pretrained text-only models or VLMs’ spatial reasoning capabilities with text-only questions. However, a text-only dataset cannot evaluate how a model relates language to grounded spatial information. In contrast, VSR focuses on the joint understanding of vision and language input.
也有研究关注在没有视觉输入的情况下探究模型的空间推理能力。例如,Collell等人(2018)、Mirzaee等人(2021)和Liu等人(2022)通过纯文本问题探究了仅文本预训练模型或视觉语言模型(VLM)的空间推理能力。然而,纯文本数据集无法评估模型如何将语言与基础空间信息联系起来。相比之下,VSR专注于视觉和语言输入的联合理解。

Figure 3: An annotation example of concepts “cat” & “laptop” in contrastive caption generation. The example generates two data points for our dataset: one “True” instance when the completed caption is paired with image 2 (right) and one “False” instance when paired with image 1 (left).
图 3: 对比式标题生成中"猫"与"笔记本电脑"概念的标注示例。该示例为我们的数据集生成两个数据点:当完成的标题与图像 2 (右) 配对时生成一个"真"实例,当与图像 1 (左) 配对时生成一个"假"实例。
2.4 Spatial reasoning as a sub-component
2.4 空间推理作为子组件
Last but not least, some vision-language tasks and models require spatial reasoning as a subcomponent. For example, Lei et al. (2020) propose $\mathrm{TVQA+}$ , a spatio-temporal video QA dataset containing bounding boxes for objects referred in the questions. Models then need to simultaneously conduct QA while detecting the correct object of interest. Christie et al. (2016) propose a method for simultaneous image segmentation and prepositional phrase attachment resolution. Models have to reason about objects’ spatial relations in the visual scene to determine the assignment of prepositional phrases. However, if spatial reasoning is only a sub-component of a task, error analysis becomes more difficult. In contrast, VSR provides a focused evaluation of spatial relations, which are particularly challenging for current models.
最后但同样重要的是,某些视觉语言任务和模型需要将空间推理作为子组件。例如,Lei等人 (2020) 提出了$\mathrm{TVQA+}$,这是一个时空视频问答数据集,包含问题中提及物体的边界框。模型需要在检测正确目标对象的同时进行问答。Christie等人 (2016) 提出了一种同时进行图像分割和介词短语附着消解的方法。模型必须推理视觉场景中物体的空间关系以确定介词短语的归属。然而,若空间推理仅是任务的子组件,错误分析会变得更加困难。相比之下,VSR (Visual Spatial Reasoning) 提供了对空间关系的集中评估,这对当前模型尤其具有挑战性。
3 Dataset Creation
3 数据集创建
In this section we detail how VSR is constructed. The data collection process can generally be split into two phases (1) contrastive caption generation (§3.1) and (2) second-round validation (§3.2). We then discuss annotator hiring & payment (§3.3), dataset splits (§3.4), and the human ceiling & agreement of VSR (§3.5).
本节详细阐述VSR数据集的构建过程。数据收集流程可分为两个阶段:(1) 对比式描述生成(§3.1)和(2) 二次验证(§3.2)。随后我们将讨论标注员招募与薪酬(§3.3)、数据集划分(§3.4)以及VSR的人类表现上限与一致性(§3.5)。
3.1 Contrastive Template-based Caption Generation (Fig. 3)
3.1 基于对比模板的标题生成 (图 3)
In order to highlight spatial relations and avoid annotators frequently choosing trivial relations (such as “near to”), we use a contrastive caption generation approach. Specifically, first, a pair of images, each containing two concepts of interests, would be randomly sampled from MS COCO (we use the train and validation sets of COCO 2017). Second, an annotator would be given a template containing the two concepts and is required to choose a spatial relation from a pre-defined list (Table 1) that makes the caption correct for one image but incorrect for the other image. We will detail these steps and explain the rationales in the following.
为了突出空间关系并避免标注者频繁选择简单关系(如"靠近"),我们采用了一种对比式描述生成方法。具体步骤如下:首先,从MS COCO数据集(使用COCO 2017的训练集和验证集)中随机采样一组图像,每张图像包含两个目标概念;然后,标注者会收到包含这两个概念的模板,需要从预定义列表(表1)中选择一个空间关系,使得生成的描述对其中一张图像正确而对另一张错误。下文将详细说明这些步骤并解释其设计原理。
Image pair sampling. MS COCO 2017 contains 123,287 images and has labelled the segmentation and classes of 886,284 instances (individual objects). Leveraging the segmentation, we first randomly select two concepts (e.g., “cat” and “laptop” in Fig. 3), then retrieve all images containing the two concepts in COCO 2017 (train and validation sets). Then images that contain multiple instances of any of the concept are filtered out to avoid referencing ambiguity. For the single-instance images, we also filter out any of the images with instance pixel area size $<30,000$ , to prevent extremely small instances. After these filtering steps, we randomly sample a pair in the remaining images. We repeat such a process to obtain a large number of individual image pairs for caption generation.
图像对采样。MS COCO 2017包含123,287张图像,并为886,284个实例(单个对象)标注了分割和类别。利用这些分割标注,我们首先随机选择两个概念(例如图3中的"猫"和"笔记本电脑"),然后从COCO 2017(训练集和验证集)中检索包含这两个概念的所有图像。接着过滤掉包含任一概念多个实例的图像以避免引用歧义。对于单实例图像,我们还过滤掉实例像素面积$<30,000$的任何图像,以防止出现极小的实例。经过这些过滤步骤后,我们从剩余图像中随机采样一对图像。我们重复这一过程以获得大量用于标题生成的独立图像对。
Fill in the blank: template-based caption generation. Given a pair of images, the annotator needs to come up with a valid caption that makes it a correct description for one image but incorrect for the other. In this way, the annotator should focus on the key difference between the two images (which should be a spatial relation between the two objects of interest) and choose a caption that differentiates the two. Similar paradigms are also used in the annotation of previous vision-language reasoning datasets such as NLVR(2) (Suhr et al., 2017, 2019) and MaRVL (Liu et al., 2021). To regularise annotators from writing modifiers and differentiating the image pair with things beyond accurate spatial relations, we opt for a template-based classification task instead of free-form caption writing.2 Besides, the template-generated dataset can be easily categorised based on relations and their categories. Specifically, the annotator would be given instance pairs as shown in Fig. 3.
填空:基于模板的标题生成。给定一对图像,标注者需要想出一个有效的标题,使其对一张图像是正确的描述,但对另一张是错误的。通过这种方式,标注者应聚焦于两幅图像之间的关键差异(通常是两个感兴趣物体之间的空间关系),并选择一个能区分两者的标题。类似范式也用于先前视觉语言推理数据集的标注,如NLVR(2) (Suhr et al., 2017, 2019) 和 MaRVL (Liu et al., 2021)。为避免标注者通过修饰词或非精确空间关系来区分图像对,我们选择基于模板的分类任务而非自由形式的标题撰写。此外,模板生成的数据集可根据关系及其类别轻松分类。具体而言,标注者将获得如图3所示的实例对。
The caption template has the format of “The ENT1 (is) the ENT2.”, and the annotators are instructed to select a relation from a fixed set to fill in the slot. The copula “is” can be omitted for grammatical it y. For example, for “contains” and “has as a part”, “is” should be discarded in the template when extracting the final caption.
标题模板的格式为"The ENT1 (is) the ENT2.",标注者需从固定关系集中选择一项填入空缺处。系动词"is"可根据语法规则省略。例如,对于"contains"和"has as a part"关系,在提取最终标题时应从模板中删除"is"。
The fixed set of spatial relations enable us to obtain the full control of the generation process. The full list of used relations are listed in Table 1. It contains 71 spatial relations and is adapted from the summarised relation table of Marchi Fagundes et al. (2021). We made minor changes to filter out clearly unusable relations, made relation names grammatical under our template, and reduced repeated relations. In our final dataset, 66 out of the 71 available relations are actually included (the other 6 are either not selected by annotators or are selected but the captions did not pass the validation phase).
固定的空间关系集合使我们能够完全控制生成过程。使用的全部关系列于表1中,包含71种空间关系,改编自Marchi Fagundes等人(2021)的汇总关系表。我们进行了微调以剔除明显不可用的关系,使关系名称符合模板语法要求,并减少重复关系。最终数据集中实际包含71种可用关系中的66种(其余5种未被标注者选用,或选用后未通过描述文本验证阶段)。
3.2 Second-round Human Validation
3.2 第二轮人工验证
In the second-round validation, every annotated data point is reviewed by at least 3 additional human annotators (validators). Given a data point (consisting of an image and a caption), the validator gives either a True or False label as shown in Fig. 4 (the original label is hidden). In our final dataset, we exclude instances with fewer than 2 validators agreeing with the original label.
在第二轮验证中,每个标注数据点会由至少3名额外的人工标注员(验证员)进行复核。给定一个数据点(包含图像和说明文字),验证员会给出True或False标签,如图4所示(原始标签被隐藏)。在我们的最终数据集中,我们排除了少于2名验证员认同原始标签的实例。
Design choice on reference frames. During validation, a validator needs to decide whether a statement is true or false for an image. However, as discussed in $\S1$ , interpreting a spatial relation requires choosing a frame of reference. For some images, a statement can be both true and false, depending on the choice. As a concrete example, in Fig. 1, while the potted plant is on the left side from the viewer’s perspective (relative frame), the potted plant is at the right side if the bench is used to define the coordinate system (intrinsic frame).
参考框架的设计选择。在验证过程中,验证者需要判断某个陈述对于图像是真是假。然而,如 $\S1$ 所述,解释空间关系需要选择一个参考框架。对于某些图像,一个陈述可能既真又假,这取决于框架的选择。具体示例如图 1 所示:从观察者视角(相对框架)看盆栽植物位于左侧,但若以长椅为坐标系基准(固有框架),则该盆栽实际位于右侧。
In order to ensure that annotations are consistent across the dataset, we communicated to the annotators that, for relations such as “left”/“right” and “in front of”/“behind”, they should consider both possible reference frames, and assign the label True when a caption is true from either the intrinsic or the relative frame. Only when a caption is incorrect under both reference frames (e.g., if the caption is “The potted plant is under the bench.” for Fig. 1) should a False label be assigned.
为确保数据集中的标注保持一致,我们告知标注人员,对于诸如“左”/“右”和“前”/“后”这类关系,他们应考虑两种可能的参照系,并在描述从内在或相对参照系看均为正确时标注为True。仅当描述在两种参照系下均不成立时(例如,对于图1中的描述“盆栽植物在长凳下方”),才应标注为False。
Table 1: The 71 available spatial relations. 66 of them appear in our final dataset ( $^*$ indicates not used).
表 1: 71种可用的空间关系。其中66种出现在最终数据集中 ( $^*$ 表示未使用)。
| 类别 | 空间关系 |
|---|---|
| 邻接关系 | 相邻于、沿着...侧、在...侧面、在...右侧、在...左侧、附着于、在...背面、在...前方、紧靠着、在...边缘 |
| 方向性 | 离开、经过、朝向、向下、深处*、向上*、远离、沿着、环绕、从*、进入、到* |
| 方位 | 横跨、对面、穿过、...下方 面向、背向、平行于、垂直于 |
| 投射关系 | 在...顶部、在...下方、在...旁边、在...后面、在...左侧、在...右侧、在...下面、在...前面、在...下方、在...上方、越过、在...中间 |
| 接近度 | 靠近、接近、邻近、远离、相距甚远 |
| 拓扑关系 | 连接到、分离自、作为...一部分、...的组成部分、包含、在...内部、位于、在...上、在...里、带有、环绕、在...之中、由...组成、从...出来、在...之间、在...内部、在...外部、接触 |
| 未分类 | 超出、紧挨着、与...相对、之后*、在...之中、被...包围 |

Figure 4: A second-round validation example.
图 4: 第二轮验证示例。
On a practical level, this adds difficulty to the task, since a model cannot naively rely on pixel locations of the objects in the images, but also needs to correctly identify orientations of objects. However, the task is well-defined: a model that can correctly simulate both reference frames would be able to perfectly solve this task.
在实际操作层面,这增加了任务的难度,因为模型不能简单地依赖图像中物体的像素位置,还需要正确识别物体的方向。然而,该任务是明确定义的:能够正确模拟两个参考系的模型将能完美解决这一任务。
From a theoretical perspective, by involving more diverse reference frames, we are also demonstrating the complexity of human cognitive processes when understanding a scene, since different people approach a scene with different frames. Attempting to enforce a specific reference frame would be methodological ly difficult and result in an unnaturally restricted dataset.
从理论角度来看,通过引入更多样化的参照系,我们也展示了人类在理解场景时认知过程的复杂性,因为不同的人会以不同的框架来解读场景。试图强制采用特定参照系在方法论上将面临困难,并会导致数据集受到不自然的限制。
3.3 Annotator Hiring and Organisation
3.3 标注员招聘与组织
Annotators were hired from prolific.co. We required them to (1) have at least a bachelor’s degree, (2) be fluent in English, and (3) have a ${>}99%$ historical approval rate on the platform. All annotators were paid 12 GBP per hour.
标注员从prolific.co平台招募。我们要求他们满足以下条件:(1) 至少拥有学士学位,(2) 英语流利,(3) 在该平台的历史批准率${>}99%$。所有标注员的时薪为12英镑。
For caption generation, we released the task with batches of 200 instances and the annotator was required to finish a batch in 80 minutes. An annotator could not take more than one batch per day. In this way we had a diverse set of annotators and could also prevent annotators from becoming fatigued. For second-round validation, we grouped 500 data points in one batch and an annotator was asked to label each batch in 90 minutes.
在标题生成任务中,我们以每批200个实例的方式发布任务,要求标注员在80分钟内完成一批。每位标注员每天最多只能领取一个批次。这种方式确保了标注员群体的多样性,同时避免了标注疲劳。在第二轮验证阶段,我们将500个数据点归为一批,要求标注员在90分钟内完成每批标注。
In total, 24 annotators participated in caption generation and 45 participated in validation. 4 people participated in both phases, which should have minimally impacted the validation quality. The annotators had diverse demographic backgrounds: they were born in 15 countries, were living in 13 countries, and had 12 nationalities. 50 annotators were born and living in the same country while others had moved to different ones. The vast majority of our annotators were residing in the UK (32), South Africa (9), and Ireland (7). The ratio for holding a Bachelor/Master/PhD as the highest degree was: $12.5%/76.6%/10.9%$ . Only 7 annotators were non-native English speakers while the other 58 were native speakers. $56.7%$ of the annotators self-identified as female and $43.3%$ as male.
共有24名标注员参与标题生成,45名参与验证,其中4人同时参与两个阶段,这对验证质量影响极小。标注员具有多元人口背景:来自15个出生国,现居13个国家,拥有12种国籍。50名标注员始终居住在原籍国,其余人员曾跨国迁移。绝大多数标注员居住在英国(32)、南非(9)和爱尔兰(7)。最高学历为学士/硕士/博士的比例为:$12.5%/76.6%/10.9%$。仅7名标注员非英语母语者,其余58人为母语者。$56.7%$的标注员自认为女性,$43.3%$为男性。
3.4 Dataset Splits
3.4 数据集划分
We split the 10,972 validated data points into train/dev/test sets in two different ways. The stats of the two splits are shown in Table 2. In the following, we explain how they are created. Random split: We split the dataset randomly into train/dev/test with a ratio of 70/10/20. Concept zero-shot split: We create another concept zeroshot split where train/dev/test have no overlapping concepts. I.e., if “dog” appears in the train set, then it does not appear in dev or test sets. This is done by randomly grouping concepts into three sets with a ratio of 50/20/30 of all concepts. This reduces the dataset size, since data poins involving concepts from different parts of the train/dev/test split must be filtered out. The concept zero-shot split is a more challenging setup since the model has to learn concepts and the relations in a compositional way instead of remembering the co-occurrence statistics of the two.
我们将10,972个已验证数据点按两种方式划分为训练集/开发集/测试集。两种划分的统计数据如表2所示。下面说明具体划分方法:
随机划分:按70/10/20的比例将数据集随机划分为训练集/开发集/测试集。
概念零样本划分:我们创建了另一种概念零样本划分,确保训练集/开发集/测试集之间没有重叠概念。例如若"dog"出现在训练集,则不会出现在开发集或测试集。具体做法是将所有概念按50/20/30比例随机分为三组。由于需要过滤掉涉及跨划分概念的样本,该划分方式会减小数据集规模。概念零样本划分更具挑战性,因为模型必须以组合方式学习概念及其关系,而非记忆两者的共现统计规律。
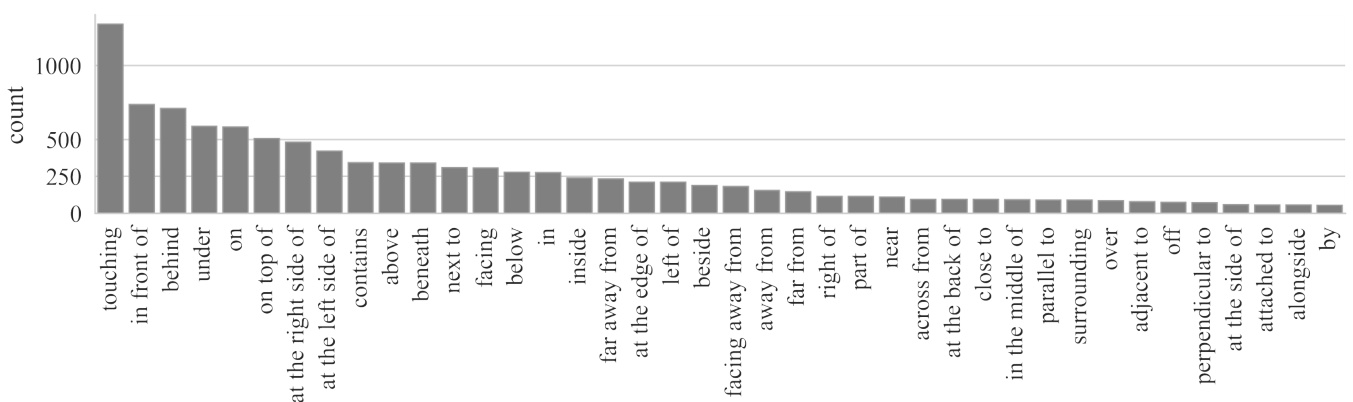
Figure 5: Relation distribution of the final dataset (sorted by frequency). Top 40 most frequent relations are included. It is clear that the relations follow a long-tailed distribution.
图 5: 最终数据集的关系分布 (按频率排序)。图中包含前40个最频繁的关系。可以明显看出这些关系遵循长尾分布。
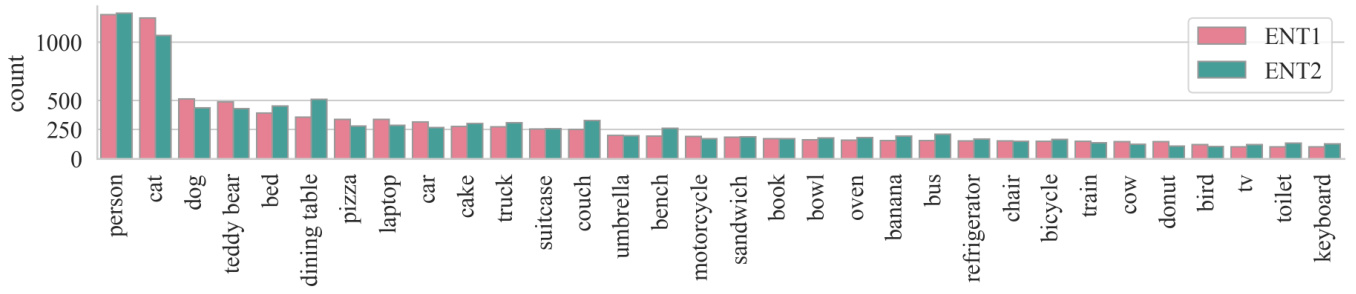
Figure 6: Concept distribution. Only concepts with $>100$ frequencies are included.
图 6: 概念分布。仅包含频率 $>100$ 的概念。
Table 2: Statistics of the random & zero-shot splits.
表 2: 随机划分与零样本划分的统计信息
| split | train | dev | test | total |
|---|---|---|---|---|
| random | 7,680 | 1,097 | 2,195 | 10,972 |
| zero-shot | 4,713 | 231 | 616 | 5,560 |
3.5 Human Ceiling and Agreement
3.5 人类上限与一致性
We randomly sample 500 data points from the final random split test set of the dataset for computing human ceiling and inter-annotator agreement. We hide the labels of the 500 examples and two additional annotators are asked to label True/False for them. On average, the two annotators achieve an accuracy of $95.4%$ on the VSR task. We further compute the Fleiss’ kappa among the original annotation and the predictions of the two human. The Fleiss’ kappa score is 0.895, indicating near-perfect agreement according to Landis and Koch (1977).
我们从数据集的最终随机划分测试集中随机抽取500个数据点用于计算人类上限和标注者间一致性。隐藏这500个示例的标签后,另请两名标注者为其标注真/假。平均而言,两名标注者在VSR任务上的准确率为$95.4%$。进一步计算原始标注与两名人类预测之间的Fleiss' kappa值,得分为0.895,根据Landis和Koch (1977)的标准表明接近完美的一致性。
4 Dataset Analysis
4 数据集分析
In this section we compute some basic statistics of our collected data (§4.1), analyse where human annotators have agreed/disagreed (§4.2), and present a case study on reference frames (§4.3).
在本节中,我们计算了收集数据的一些基本统计量(§4.1),分析了人类标注者达成一致/存在分歧的部分(§4.2),并展示了关于参考框架的案例研究(§4.3)。
4.1 Basic Statistics of VSR
4.1 VSR基础统计
After the first phase of contrastive template-based caption generation (§3.1), we collected 12,809 raw data points. In the phase of the second round validation (§3.2), we collected 39,507 validation labels. Every data point received at least 3 validation labels. In $69.1%$ of the data points, all validators agree with the original label. $85.6%$ of the data points have at least $\frac{2}{3}$ annotators agreeing with the original label. We use $\textstyle{\frac{2}{3}}$ as the threshold and exclude all instances with lower validation agreement. After excluding other instances, 10, 972 data points remained and are used as our final dataset.
在第一阶段基于对比模板的标题生成(§3.1)后,我们收集了12,809个原始数据点。在第二轮验证阶段(§3.2)中,我们收集了39,507个验证标签。每个数据点至少获得3个验证标签。在$69.1%$的数据点中,所有验证者均同意原始标签。$85.6%$的数据点至少有$\frac{2}{3}$的标注者同意原始标签。我们以$\textstyle{\frac{2}{3}}$作为阈值,排除了所有验证一致性低于该值的实例。排除其他实例后,剩余10,972个数据点作为最终数据集使用。
Here we provide basic statistics of the two components in the VSR captions: the concepts and the relations. Fig. 5 demonstrates the relation distribution. “touching” is most frequently used by annotators. The relations that reflect the most basic relative coordinates of objects are also very frequent, e.g., “behind”, “in front of”, “on”, “under”, “at the left/right side of”. Fig. 6 shows the distribution of concepts in the dataset. Note that the set of concepts is bounded by MS COCO and the distribution also largely follows MS COCO. Animals such as “cat”, “dog”, “person” are the most frequent. Indoor objects such as “dining table” and “bed” are also very dominant. In Fig. 6, we separate the concepts that appear at ENT1 and ENT2 positions of the sentence and their distributions are generally similar.
在此我们提供VSR字幕中两个组成部分的基本统计数据:概念和关系。图5展示了关系分布。"touching"是标注者最常使用的关系。反映物体最基本相对位置的关系也非常频繁,例如"behind"、"in front of"、"on"、"under"、"at the left/right side of"。图6显示了数据集中概念的分布。需要注意的是,概念集合受限于MS COCO数据集,其分布也基本遵循MS COCO。"cat"、"dog"、"person"等动物类概念出现频率最高,"dining table"和"bed"等室内物品也占主导地位。在图6中,我们将出现在句子ENT1和ENT2位置的概念分开显示,它们的分布总体相似。
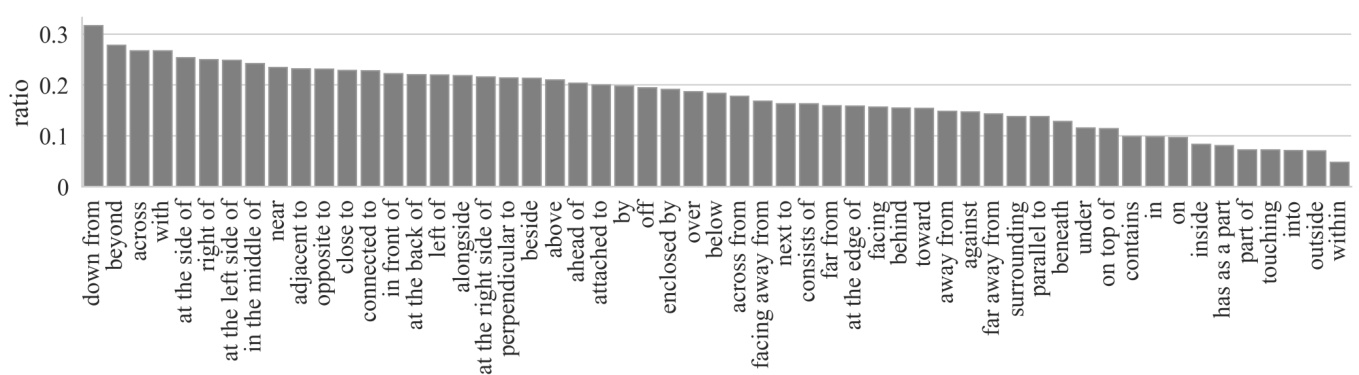
Figure 7: Per-relation probability of having two randomly chosen annotator disagreeing with each other (sorted from high to low). Only relations with $>20$ data points are included in the figure.
图 7: 随机选取的两名标注者在各关系类型上出现分歧的概率 (按从高到低排序)。图中仅包含数据点数量 $>20$ 的关系类型。
4.2 Where do annotators disagree?
4.2 标注员在哪些方面存在分歧?
While we propose using data points with high validation agreement for model evaluation and development, the unfiltered dataset is a valuable resource for understanding cognitive and linguistic phenomena. We sampled 100 examples where annotators disagree, and found that around 30 of them are caused by annotation errors but the rest are genuinely ambiguous and can be interpreted in different ways. This shows a level of intrinsic ambiguity of the task and variation among people.
虽然我们建议使用验证一致性高的数据点进行模型评估和开发,但未经筛选的数据集仍是理解认知和语言现象的宝贵资源。我们抽样了100个标注者存在分歧的案例,发现其中约30例由标注错误导致,其余案例确实存在多义性且可作不同解读。这表明该任务存在固有模糊性,也反映出人群间的认知差异。
Along with the validated VSR dataset, we also release the full unfiltered dataset, with annotators’ and validators’ metadata, as a second version to facilitate linguistic studies. For example, researchers could investigate questions such as where disagreement is more likely to happen and how people from different regions or cultural backgrounds might perceive spatial relations differently.
除了经过验证的VSR数据集外,我们还发布了完整的未过滤数据集(包含标注者和验证者的元数据)作为第二个版本,以促进语言学研究。例如,研究人员可以探究诸如分歧更可能发生在哪些情境下,以及来自不同地区或文化背景的人如何可能对空间关系产生不同认知等问题。
To illustrate this, the probability of two randomly chosen annotators disagreeing with each other is given for each relation in Fig. 7. Some of the relations with high disagreement can be interpreted in the intrinsic reference frame, which requires identifying the orientations of objects, e.g. “at the side of” and “in front of”. Other relations have a high level of vagueness, e.g., for the notion of closeness: “near” and “close to”. By contrast, part-whole relations, such as “has as a part”, “part of”, and in/out relations such as “within”, “into”, “outside” and “inside” have the least disagreement.
为说明这一点,图7给出了每种关系中两位随机选择的标注者存在分歧的概率。部分高分歧率的关系需要基于物体固有参考系进行解释(例如"在侧面"和"在正前方"),这要求识别物体的方向。另一些关系则存在较高模糊性(例如表示接近程度的概念:"附近"和"靠近")。相比之下,部分整体关系(如"包含部件"、"属于部分")以及内外关系(如"内部"、"进入"、"外部"和"里面")的分歧率最低。
4.3 Case Study: Reference Frames
4.3 案例研究:参考坐标系
It is known that the relative reference frame is often preferred in English, at least in standard varieties. For example, Edmonds-Wathen (2012) compares Standard Australian English and Aboriginal English, as spoken by school children at a school on Croker Island, investigating the use of the relations “in front of” and “behind” when describing simple line drawings of a person and a tree. Speakers of Standard Australian English were found to prefer the relative frame, while speakers of Aboriginal English were found to prefer the intrinsic frame.
已知在英语中相对参照系更常被使用,至少在标准变体中如此。例如 Edmonds-Wathen (2012) 比较了标准澳大利亚英语和克罗克岛一所学校学生使用的原住民英语,调查了在描述人与树的简单线条图时对"前面"和"后面"关系的使用情况。研究发现标准澳大利亚英语使用者倾向于使用相对参照系,而原住民英语使用者则更偏好内在参照系。
Our methodology allows us to investigate reference frame usage across a wide variety of spatial relations, using a wide selection of natural images. To understand the frequency of annotators using relative vs. intrinsic frames, we label instances’ reference frames and study their distributions. The majority of examples that can be interpreted differently under different reference frames are left/rightrelated relations (i.e. “left/right of” and “at the left/right side of”). We find all left/right-related $t r u e^{3}$ statements and classify them into three categories: (1) intrinsic (2) relative and (3) both (the caption is correct under either intrinsic and relative frames of reference). Among the 616 instances, 68 $(11%)$ and 518 $(84%)$ use intrinsic and relative frames respectively, 30 $(5%)$ can be interpreted with both frames. Since the vast majority of our annotators were native English speakers $(91%)$ , and all were university-educated, our finding is consistent with previous work suggesting that the relative frame is the most common frame in standard varieties of English.
我们的方法使我们能够利用大量自然图像样本,研究各种空间关系中的参照系使用情况。为理解标注者使用相对参照系与内在参照系的频率,我们对实例的参照系进行标注并分析其分布。在不同参照系下可能产生不同解读的案例中,绝大多数涉及左右方位关系(即"在...左/右侧"和"位于...左/右边")。我们筛选出所有与左右相关的$true^{3}$描述,并将其分为三类:(1) 内在参照系 (2) 相对参照系 (3) 双重适用(描述在内在或相对参照系下均成立)。在616个实例中,68例$(11%)$使用内在参照系,518例$(84%)$使用相对参照系,30例$(5%)$可适用两种参照系。由于我们绝大多数标注者为英语母语者$(91%)$且均受过高等教育,这一发现与先前认为相对参照系是标准英语变体中最常用参照系的研究结论一致。
Besides the overall trend, the use of reference frames can vary with the circumstances. Related patterns have been studied in cognitive science. For example, Vukovic and Williams (2015) find a three-way interaction between linguistic cues, spatial configurations in an image, and a person’s own preferences on reference frames.
除了整体趋势外,参考框架的使用会因情境而异。认知科学已对相关模式展开研究。例如,Vukovic 和 Williams (2015) 发现语言线索、图像空间配置与个人参考框架偏好之间存在三重交互作用。
We investigated whether reference to a person in the image might influence how annotators comprehend the scene. 198 out of the 616 instances involve “person” in the caption. And out of the 198 human-involved instances, 32 $(16%)$ use an intrinsic frame and 154 $(78%)$ use a relative frame (12, i.e. $6%$ , can be interpreted with both frames), while the proportions were $9%$ and $87%$ for instances not involving “person”. This is a statistically significant difference (using two-tailed Fisher’s exact test, $p{=}0.0054$ if ignoring both-frame cases, and $p{=}0.0045$ if grouping both-frame and intrinsic cases). In other words, this suggests that the involvement of a human can more likely prompt the use of the intrinsic frame.
我们研究了图像中是否出现人物会影响标注者对场景的理解。在616个样本中,有198个样本的描述包含"person"。在这198个涉及人物的样本中,32个(16%)使用内在参照系,154个(78%)使用相对参照系(另有12个样本,即6%,可同时用两种参照系解释);而在不涉及"person"的样本中,这两个比例分别为9%和87%。该差异具有统计学显著性(使用双尾Fisher精确检验,若忽略双参照系案例则p=0.0054,若将双参照系与内在参照系案例合并则p=0.0045)。这表明,人物的出现更可能促使标注者采用内在参照系。
5 Experiments
5 实验
In this section, we test VLMs on VSR. We first introduce baselines and experimental configurations in $\S5.1$ , then experimental results and analysis in $\S5.2$ . Then we discuss the role of frame of reference using experiments in $\S5.3$ and finally conduct sample efficiency analysis in $\S5.4$ .
在本节中,我们测试了VLM在VSR上的表现。首先在$\S5.1$中介绍基线方法和实验配置,然后在$\S5.2$中展示实验结果与分析。接着通过$\S5.3$的实验讨论参照系的作用,最后在$\S5.4$中进行样本效率分析。
5.1 Baselines and Experiment Configurations
5.1 基线方法与实验配置
Baselines. For finetuning-based experiments, we test three popular VLMs: VisualBERT (Li et al., 2019)4, LXMERT (Tan and Bansal, $2019)^{5}$ , ViLT (Kim et al., $2021)^{6}$ . All three models are stacked Transformers (Vaswani et al., 2017) that take image-text pairs as input. The difference mainly lies in how or whether they encode the position information of objects. We report only finetuned results but not direct inferences from off-the-shelf checkpoints since some of their pre training objectives are inconsistent with the binary classification task of VSR, thus requiring additional engineering.
基线方法。在基于微调的实验中,我们测试了三种流行的视觉语言模型 (VLM) :VisualBERT (Li et al., 2019)[4]、LXMERT (Tan and Bansal, $2019)^{5}$、ViLT (Kim et al., $2021)^{6}$。这三个模型均采用堆叠式Transformer (Vaswani et al., 2017) 结构,以图像-文本对作为输入。主要区别在于它们如何处理(或是否处理)物体位置信息。我们仅报告微调后的结果,而不直接使用现成检查点进行推理,因为部分模型的预训练目标与VSR的二分类任务不一致,需要额外工程处理。
We additionally test the alt text pretrained dualencoder CLIP (Radford et al., 2021) as an off-theshelf baseline model (no finetuning).7 We follow Booth (2023) to construct negation or antonym of each individual relation. E.g., “facing” $\rightarrow$ “facing away from” and “ahead of” $\rightarrow$ “not ahead of”. For each sample, we compare the embedding similarity of the image-caption pair and that of the negated caption. If the original pair has a higher probability then the model prediction is True, otherwise False. We call this method CLIP (w/ prompting). We only report direct prompting results without finetuning since CLIP finetuning is expensive.
我们还测试了基于替代文本预训练的双编码器CLIP (Radford et al., 2021) 作为现成的基线模型(未进行微调)。我们遵循Booth (2023) 的方法构建每个关系的否定或反义词。例如,“facing” $\rightarrow$ “facing away from” 和 “ahead of” $\rightarrow$ “not ahead of”。对于每个样本,我们比较图像-标题对的嵌入相似度与否定标题的嵌入相似度。如果原始对的概率更高,则模型预测为True,否则为False。我们将此方法称为CLIP (w/ prompting)。由于CLIP微调成本高昂,我们仅报告未微调的直接提示结果。
Experimental configurations. We save checkpoints every 100 iterations and use the bestperforming checkpoint on dev set for testing. All models are run three times using three random seeds. All models are trained with AdamW optimiser (Loshchilov and Hutter, 2019). The hyperparameters we used for training the three VLMs are listed in Table 3.
实验配置。我们每100次迭代保存一次检查点,并在开发集上使用性能最佳的检查点进行测试。所有模型均使用三个随机种子运行三次。所有模型均采用AdamW优化器 (Loshchilov and Hutter, 2019) 进行训练。表3列出了训练三个视觉语言模型 (VLM) 时使用的超参数。
Table 3: A listing of hyper parameters used for all VLMs (“lr”: learning rate).
表 3: 所有视觉语言模型 (VLM) 使用的超参数列表 ("lr": 学习率)。
| model | lr | batch size epoch token length |
|---|---|---|
| VisualBERT | 2e-6 32 | 100 |
| LXMERT | 1e-5 | 32 100 |
| ViLT | 1e-5 | 12 30 |
5.2 Experimental Results
5.2 实验结果
| 随机划分 | 零样本划分 | |
|---|---|---|
| 人类上限 | 95.4 | 95.4 |
| CLIP (带提示) | 56.0 | 54.5 |
| VisualBERT | 55.2±1.4 | 51.0±1.9 |
| ViLT | 69.3±0.9 | 63.0±0.9 |
| LXMERT | 70.1±0.9 | 61.2±0.4 |
Table 4: Model performance on VSR test set. CLIP is applied without finetuning but with carefully engineered prompts while the other three smaller models are finetuned on the training set.
表 4: VSR测试集上的模型性能。CLIP未经微调但采用精心设计的提示词(prompt)应用,而其他三个较小模型均在训练集上进行了微调。
In this section, we provide both quantitative and qualitative results of the four baselines. Through analysing the failure cases of the models, we also highlight the key abilities needed to solve this dataset.
在本节中,我们提供了四个基线的定量和定性结果。通过分析模型的失败案例,我们还强调了解决该数据集所需的关键能力。

Figure 8: Performance (accuracy) by relation on the random (upper) and zero-shot (lower) split test sets. Relation order sorted by frequency (high to low from left to right). Only relations with more than 15 and 5 occurrences on the random and zero-shot tests respectively are shown.
图 8: 随机划分(上)和零样本划分(下)测试集上各关系的性能(准确率)。关系按出现频率排序(从左到右由高到低)。仅展示在随机测试中出现超过15次、零样本测试中出现超过5次的关系。
As shown in Table 4, the best-performing models on the random split are LXMERT and ViLT, reaching around $70%$ accuracy while VisualBERT is just slightly better than the chance level. On the zero-shot split, all models’ performance decline substantially and the best model ViLT only obtains $63.0%$ accuracy. The off-of-the-shelf CLIP model obtains around $55%$ on both sets, indicating its weaknesses in spatial reasoning echoing Subramanian et al. (2022)’s findings. Overall, these results lag behind the human ceiling by more than $25%$ and highlight that there is very substantial room for improving current VLMs.
如表 4 所示,随机划分上表现最好的模型是 LXMERT 和 ViLT,准确率约为 $70%$,而 VisualBERT 仅略高于随机水平。在零样本划分上,所有模型的性能均大幅下降,最佳模型 ViLT 仅获得 $63.0%$ 的准确率。现成的 CLIP 模型在两组数据上均获得约 $55%$ 的准确率,印证了 Subramanian 等人 (2022) 的发现,表明其在空间推理方面的不足。总体而言,这些结果与人类上限相差超过 $25%$,凸显出现有视觉语言模型 (VLM) 仍有巨大改进空间。
Explicit positional information matters. Both LXMERT and ViLT outperform VisualBERT by large margins $(>10%)$ on both splits. This is expected since LXMERT and ViLT encode explicit positional information while VisualBERT does not. LXMERT has position features as part of the input which encodes the relative coordinates of objects within the image. ViLT slices an image into patches (instead of object regions) and uses positional encodings to signal the patches’ relative positions. VisualBERT, however, has no explicit position encoding. Bug liar ello et al. (2021); Rösch and Libovický (2022) also highlight the importance of positional encodings of VLMs, which agrees with our observations.
显式位置信息至关重要。LXMERT和ViLT在两个数据集上的表现均大幅领先VisualBERT $(>10%)$ ,这在意料之中,因为LXMERT和ViLT编码了显式位置信息而VisualBERT没有。LXMERT将位置特征作为输入的一部分,编码图像中物体的相对坐标;ViLT将图像分割为若干块(而非物体区域)并使用位置编码标记这些块的相对位置。然而VisualBERT没有显式位置编码。Bugliarello等人 (2021) 和Rösch与Libovický (2022) 也强调了视觉语言模型(VLMs)中位置编码的重要性,这与我们的观察结果一致。
Random split vs. zero-shot split. It is worth noting that the performance gap between the random and zero-shot splits is large. As we will show in $\S5.4$ , the underlying cause is not likely to be the number of training examples, but rather that concept zero-shot learning is fundamentally a challenging task. The gap suggests that disentangling representations of concepts and relations is challenging for current models.
随机划分 vs. 零样本划分。值得注意的是,随机划分与零样本划分之间的性能差距很大。如 $\S5.4$ 所示,根本原因可能不在于训练样本数量,而在于概念零样本学习本质上是一项具有挑战性的任务。这一差距表明,当前模型在解耦概念与关系的表征方面仍面临挑战。
Sensitiveness to random seeds. Model performance varies by about one to two percentage points. These fluctuations illustrate the importance of always reporting the average performance of multiple runs to make sure the conclusion is reliable.
对随机种子的敏感性。模型性能会有约一到两个百分点的波动。这些波动表明,报告多次运行的平均性能以确保结论可靠非常重要。

Figure 9: LXMERT failed on both examples.
图 9: LXMERT 在两个示例上都失败了。
Performance by relation. We give performance by relation for all three finetuned models on both random and zero-shot splits in Fig. 8. The order from left to right is sorted by the frequency of relations in the dataset (within each split). Interestingly, there does not seem to be any correlation between performance and frequency of the relation, hinting that specific relations are hard not due to an insufficient number of training examples but because they are fundamentally challenging for current VLMs. Any relation that requires recognising orientations of objects seems to be hard, e.g., “facing”, “facing away from”, “parallel to” and “at the back of”. As an example, LXMERT failed on the two examples in Fig. 9 which require understanding the front of a hair drier and a person respectively. In this regard, left-right relations such as “at the left/right side of” and “left/right of” are difficult because the intrinsic reference frame requires understanding the orientation of objects. As an example, in Fig. 1, all three models predicted False, but in the intrinsic frame (i.e., from the bench’s point of view), the potted plant is indeed at the right.
按关系分类的性能。我们在图8中展示了所有三个微调模型在随机和零样本划分下的按关系分类性能。从左到右的顺序按数据集中关系的出现频率排序(每个划分内)。有趣的是,性能与关系频率之间似乎没有任何相关性,这表明特定关系难以处理并非由于训练样本数量不足,而是因为它们对当前视觉语言模型(VLM)具有本质上的挑战性。任何需要识别物体方向的关系似乎都很困难,例如"facing"(面向)、"facing away from"(背对)、"parallel to"(平行)和"at the back of"(在...后方)。举例来说,LXMERT在图9的两个示例中失败,这两个示例分别需要理解吹风机和人的正面。在这方面,"at the left/right side of"(在...左/右侧)和"left/right of"(...的左/右侧)等左右关系也很困难,因为内在参考系需要理解物体的方向。例如,在图1中,所有三个模型都预测为False,但在内在参考系(即从长椅的角度来看),盆栽植物确实位于右侧。

Figure 10: Performance by categories of relations, on the random and zero-shot split test sets. For legend information, see Fig. 8.
图 10: 关系类别在随机和零样本划分测试集上的性能表现。图例信息参见图 8。
To get a more high-level understanding of the relations’ performance, we group model performance by the categories of Marchi Fagundes et al. (2021): “Adjacency”, “Directional”, “Orientation”, “Projective”, “Proximity”, “Topological” and “Unallocated” (also shown in Table 1). The results are shown in Fig. 10. “Orientation” is the worst performing group on the random split, and on average all models’ performances are close to the chance level. When comparing random and zeroshot splits, performance has declined to some extent for almost all categories and models. The decrease in “Proximity” is particularly drastic across all models – it declined from close to $75%$ accuracy in random split to chance level in zero-shot split. “Proximity” contains relations such as “close to”, “near” and “far from”. We believe it is due to the fact that the notion of proximity is relative and very much dependent on the nature of the concept and its frequent physical context. E.g., for a “person” to be “near” an indoor concept such as “oven” is very different from a person being “near” a frequent outdoor object such as “train” or “truck”. Since the zero-shot split prevents models from seeing test concepts during training, the models have a poor grasp of what counts as “close to” or “far from” for these concepts, thus general ising poorly.
为了更宏观地理解各类关系的表现,我们按照Marchi Fagundes等人(2021)提出的分类对模型性能进行分组:"邻接(Adjacency)"、"方向(Directional)"、"方位(Orientation)"、"投影(Projective)"、"邻近(Proximity)"、"拓扑(Topological)"和"未分配(Unallocated)" (如表1所示)。结果如图10所示。在随机划分中,"方位"是表现最差的组别,所有模型的平均表现都接近随机水平。对比随机划分和零样本划分时,几乎所有类别和模型的性能都有所下降。其中"邻近"关系的下降幅度最为显著——从随机划分中接近75%的准确率骤降至零样本划分中的随机水平。"邻近"包含如"接近"、"附近"和"远离"等关系。我们认为这是由于邻近概念具有相对性,高度依赖于概念本质及其常见物理语境。例如,对于"人"与"烤箱"这类室内概念的"接近",与人和"火车"或"卡车"等常见室外物体的"接近"截然不同。由于零样本划分阻止模型在训练时接触测试概念,导致模型难以把握这些概念的"接近"或"远离"标准,因而泛化能力较差。

Figure 11: Caption: The cow is at the back of the car. Label: True. LXMERT and VisualBERT predicted False.
图 11: 标题:牛在汽车后方。标签:正确。LXMERT和VisualBERT预测为错误。
Other Errors. While certain relations are intrinsically hard, we have observed other types of errors that are not bounded to specific relations. Here we give a few examples. Some instances require complex reasoning. In Fig. 11, the model needs to recognise that both the cow and the back of the car are in the car’s side mirror and also infer the relative position of the back of the car and the cow. It is perhaps no surprise that two of the three models predicted wrongly. Some other examples require common sense. E.g., in Fig. 2, we can infer the person and the cow’s moving direction and can then judge if the cow is ahead of the person. LXMERT failed on this example. In Fig. 3 (right), the model needs to infer that the main body of the cat is hidden behind the laptop. Interestingly, all three models predicted this example correctly.
其他错误。虽然某些关系本质上就难以处理,但我们还观察到一些不局限于特定关系的错误类型。这里列举几个例子:部分实例需要复杂推理。在图11中,模型需要同时识别出牛和车尾都位于后视镜中,并推断车尾与牛的相对位置。三个模型中有两个预测错误或许并不令人意外。另一些例子则需要常识判断。例如在图2中,我们可以推断人和牛的运动方向,进而判断牛是否位于人的前方。LXMERT在此例中判断错误。在图3(右)中,模型需要推断猫的主要身体被笔记本电脑遮挡。有趣的是,三个模型都正确预测了这个例子。
5.3 Case Study on Reference Frames
5.3 参考系案例研究
As discussed in $\S4.3$ , different frames of reference can be used in natural language and it would be helpful to understand whether our models recognise them. We argue that the task of identifying frame of reference itself is very hard for current models. However, learning to recognise frames of reference helps the task of visual spatial reasoning.
如 $\S4.3$ 所述,自然语言中可使用不同的参照系,理解模型是否能识别这些参照系将大有裨益。我们认为,识别参照系本身的任务对当前模型而言极为困难,但学习识别参照系有助于提升视觉空间推理能力。
Firstly, we conduct a case study on left/rightrelated relations. We additionally label the reference frames of all true statements containing any of the left/right-related relations. We exclude all data points that can be interpreted in both intrinsic and relative frames to slightly reduce the complexity of the task. Then we finetune a ViLT checkpoint to predict the reference frame based on the true statement and the image. The model’s performance on test set is shown in the upper half of Table 5. We can see that reference frame prediction is an extremely hard task for the model. This is presumably because it requires taking into account a 3D viewpoint and simulating transformations between different viewpoints.
首先,我们对左右相关关系进行了案例研究。我们额外标注了所有包含左右相关关系的真实陈述的参考框架。排除了所有可以同时在内在框架和相对框架中解释的数据点,以略微降低任务的复杂性。然后,我们微调了一个ViLT检查点,基于真实陈述和图像预测参考框架。模型在测试集上的性能如表5上半部分所示。可以看到,参考框架预测对模型来说是一项极其困难的任务。这可能是因为它需要考虑3D视角并模拟不同视角之间的转换。
Table 5: ViLT model performance on the reference frame prediction task (upper half; we report macro-averaged Precision/Recall/F1 since the binary classification task is imbalanced); and VSR task using original pretrained checkpoint or the reference frame prediction task trained checkpoint (accuracy reported).
表 5: ViLT模型在参考帧预测任务(上半部分;由于二分类任务不平衡,我们报告宏平均精确率/召回率/F1)和VSR任务(使用原始预训练检查点或参考帧预测任务训练检查点,报告准确率)上的性能表现。
| 模型↓ | 精确率 召回率 | F1 |
|---|---|---|
| ViLT | 59.2±3.7 59.7±5.8 | 56.9±4.4 |
| 模型↓ | VSR任务(左/右子集) | 准确率 |
|---|---|---|
| ViLT | 54.2±0.6 | |
| ViLT + rf_trained | 59.2±1.8 |
Secondly, we use this model trained with reference frame labels to initialise the VSR task model and further finetune it on the VSR task (only the left/right relations). The test results are shown in the lower part of Table 5.8 We see a clear positive transfer from reference frame prediction task to the VSR task. This suggests that learning to recognise reference frames can indeed help downstream visual spatial reasoning. This makes sense since simulating the transformation of intrinsic/relative frames could be an intermediate reasoning step in detecting whether a statement is true/false.
其次,我们使用这个经过参考帧标签训练的模型来初始化VSR(视觉空间推理)任务模型,并进一步在VSR任务(仅左右关系)上进行微调。测试结果如表5.8下半部分所示。我们观察到从参考帧预测任务到VSR任务存在明显的正向迁移。这表明学习识别参考帧确实有助于下游的视觉空间推理。这是合理的,因为模拟内在/相对参考帧的转换可能是判断陈述真伪的中间推理步骤。
5.4 Sample Efficiency
5.4 样本效率
In order to understand the correlation between model performance and the number of training examples, we conduct sample efficiency analysis on VSR. The results are plotted in Fig. 12. For the minimum resource scenario, we randomly sample 100 shots from the training sets of each split. Then we gradually increase the number of training examples to be $25%$ , $50%$ and $75%$ of the whole training sets. Both LXMERT and ViLT have a reasonably good few-shot capability and can be quite performant with $25%$ of training data. LXMERT, in particular, reaches above $55%$ accuracy with 100 shots on both splits. The zero-shot split is substantially harder and most models appear to have already plateaued at around $75%$ of the training set. For the random split, all models are increasing performance with more data points, though improvement slows down substantially for LXMERT and ViLT after $75%$ of training data. The fact that LXMERT has the best overall few-shot capability may be suggesting that LXMERT’s pretrained object detector has a strong inductive bias for the VSR dataset as it does not need to learn to recognise concept boundaries and classes from scratch. However, this advantage from LXMERT seems to fade away as the number of training examples increases.
为了理解模型性能与训练样本数量之间的相关性,我们对VSR进行了样本效率分析。结果如图12所示。在最小资源场景下,我们从每个分区的训练集中随机抽取100个样本(few-shot)。随后逐步增加训练样本数量,分别达到完整训练集的25%、50%和75%。LXMERT和ViLT都展现出较好的少样本学习能力,仅需25%训练数据即可获得不错的表现。特别是LXMERT,在两个分区上用100个样本就达到了55%以上的准确率。零样本分区的难度显著更高,大多数模型在训练集达到75%时性能已趋于平缓。对于随机分区,所有模型都随着数据量增加而提升性能,但LXMERT和ViLT在训练数据超过75%后改进幅度明显放缓。LXMERT具有最佳的整体少样本能力,这可能表明其预训练目标检测器对VSR数据集存在强归纳偏置,因为它不需要从头学习概念边界和类别识别。但随着训练样本数量增加,LXMERT的这一优势似乎逐渐消失。

Figure 12: Sample efficiency analysis: model performance under different amounts of training data (100-shot, $25%$ , $50%$ , $75%$ and $100%$ of training set). Results on both the random and zero-shot split test sets are shown. As training data increases, the performance plateaus on both sets but the flattening trend is more obvious on the zero-shot split.
图 12: 样本效率分析:模型在不同训练数据量下的性能表现 (100样本、$25%$、$50%$、$75%$ 和 $100%$ 训练集)。随机划分测试集和零样本划分测试集的结果均显示。随着训练数据增加,两组性能均趋于平缓,但零样本划分的平缓趋势更为明显。
6 Conclusion and Future Directions
6 结论与未来方向
We have presented Visual Spatial Reasoning (VSR), a controlled probing dataset for testing visionlanguage models (VLMs)’ capabilities of recognising and reasoning about spatial relations in natural image-text pairs. We made a series of linguistic observations on the variability of spatial language when collecting VSR. We highlighted the diverse use of reference frames among annotators, and also the ambiguous nature of certain spatial relations. We tested four popular VLMs on VSR, and found they perform more than $25%$ below the human ceiling. On a more challenging concept zero-shot split, the tested VLMs struggled to reach $60%$ accuracy and their performance plateaued even with increased training examples. Among the finetuningbased VLMs, ViLT and LXMERT outperformed VisualBERT, and we pointed out that the explicit positional information in the former two models is crucial in the task. CLIP with prompt engineering achieved slightly better than random performance, suggesting poor capability in spatial reasoning. We also performed a by-relation analysis and found that the models’ performances on certain relations have little correlation with the number of training examples, and certain relations are inherently more challenging. We identified orientation as the most difficult category of relations for VLMs. Proximity is another challenging category, especially in the zero-shot setup as this relation is highly conceptdependent. We hope the task serves as a useful tool for testing and probing future VLMs.
我们提出了视觉空间推理 (Visual Spatial Reasoning, VSR) 数据集,这是一个用于测试视觉语言模型 (Vision-Language Models, VLMs) 在自然图像-文本对中识别和推理空间关系能力的受控探测数据集。在收集VSR数据时,我们针对空间语言的多样性进行了一系列语言学观察,重点分析了标注者使用参考框架的多样性以及某些空间关系的模糊性。我们在VSR上测试了四种主流VLMs,发现其性能比人类上限低25%以上。在更具挑战性的概念零样本划分中,被测VLMs的准确率难以突破60%,即使增加训练样本量,性能仍趋于停滞。在基于微调的VLMs中,ViLT和LXMERT的表现优于VisualBERT,我们指出前两者模型显式的位置信息对该任务至关重要。采用提示工程的CLIP模型表现略优于随机猜测,表明其空间推理能力较弱。通过按关系分类分析,我们发现模型在某些关系上的表现与训练样本数量相关性很低,且某些关系本身更具挑战性。方向关系被确定为VLMs最困难的类别,邻近关系是另一大挑战——尤其在零样本设置下,因为该关系高度依赖具体概念。我们希望该任务能成为测试未来VLMs的有效工具。
In future work, we plan to more extensively investigate whether large-scale pretrained dualencoders such as CLIP (Radford et al., 2021), ALIGN (Jia et al., 2021) and LiT (Zhai et al., 2022) can properly recognise spatial relations, especially in the finetuning setup. A comparison of dual- and cross-encoders’ performance on each spatial relation might guide future model design. Recently, Alayrac et al. (2022); Chen et al. (2023); Huang et al. (2023) proposed ultra-large-scale VLMs. It would be interesting to see if VLMs have better spatial reasoning capability when scaled up. Another direction is extending VSR to cover more languages and cultures (Liu et al., 2021; Bug liar ello et al., 2022) and test multilingual VLMs. Along the same line, since we have also collected the metadata of annotators, the VSR corpus can be used as a resource for investigating research questions such as: How is “space” described among different dialects of English? How is “space” perceived among different populations? We hope that the annotation process of VSR can also serve as a basis for future cross-lingual and cross-cultural socio linguistic research.
在未来的工作中,我们计划更广泛地研究CLIP (Radford et al., 2021)、ALIGN (Jia et al., 2021)和LiT (Zhai et al., 2022)等大规模预训练双编码器是否能正确识别空间关系,尤其是在微调场景下。对比双编码器与交叉编码器在各空间关系上的表现,可能为未来模型设计提供指导。近期,Alayrac et al. (2022)、Chen et al. (2023)和Huang et al. (2023)提出了超大规模视觉语言模型(VLM),探索模型规模扩大后是否具有更强的空间推理能力将很有意义。另一个方向是扩展VSR数据集以覆盖更多语言文化(Liu et al., 2021; Bug liar ello et al., 2022),并测试多语言VLM性能。由于我们已收集标注者元数据,VSR语料还可用于研究以下问题:英语不同方言如何描述"空间"?不同人群如何感知"空间"?我们希望VSR的标注流程能为未来跨语言、跨文化的社会语言学研究提供基础。