Metapath and Entity-Aware Graph Neural Network for Recommendation
基于元路径和实体感知的图神经网络推荐系统
Abstract. In graph neural networks (GNNs), message passing iteratively aggregates nodes’ information from their direct neighbors while neglecting the sequential nature of multi-hop node connections. Such sequential node connections e.g., metapaths, capture critical insights for downstream tasks. Concretely, in recommend er systems (RSs), disregarding these insights leads to inadequate distillation of collaborative signals. In this paper, we employ collaborative subgraphs (CSGs) and metapaths to form metapath-aware subgraphs, which explicitly capture sequential semantics in graph structures. We propose metaPath and Entity-Aware Graph Neural Network (PEAGNN), which trains multilayer GNNs to perform metapath-aware information aggregation on such subgraphs. This aggregated information from different metapaths is then fused using attention mechanism. Finally, PEAGNN gives us the representations for node and subgraph, which can be used to train MLP for predicting score for target user-item pairs. To leverage the local structure of CSGs, we present entity-awareness that acts as a contrastive regularize r on node embedding. Moreover, PEAGNN can be combined with prominent layers such as GAT, GCN and GraphSage. Our empirical evaluation shows that our proposed technique outperforms competitive baselines on several datasets for recommendation tasks. Further analysis demonstrates that PEAGNN also learns meaningful metapath combinations from a given set of metapaths.
摘要。在图神经网络(GNNs)中,消息传递迭代地聚合来自直接邻居的节点信息,却忽略了多跳节点连接的序列特性。这类序列化节点连接(如元路径)能为下游任务捕获关键洞察。具体而言,在推荐系统(RSs)中忽视这些洞察会导致协同信号提取不充分。本文采用协同子图(CSGs)和元路径构建元路径感知子图,显式捕获图结构中的序列语义。我们提出元路径与实体感知图神经网络(PEAGNN),通过多层GNN在子图上执行元路径感知的信息聚合,并利用注意力机制融合不同元路径的聚合信息。最终PEAGNN生成节点与子图表征,可用于训练MLP预测目标用户-物品对的评分。为利用CSGs的局部结构,我们提出作为对比正则项的实体感知机制。此外,PEAGNN可与GAT、GCN、GraphSage等主流网络层结合。实验表明,所提方法在多个推荐任务数据集上优于基线模型。进一步分析证明PEAGNN能从给定元路径中学习有意义的组合模式。
1 Introduction
1 引言
Integrating content information for user preference prediction remains a challenging task in the development of recommend er systems. In spite of their effec ti ve ness, most collaborative filtering (CF) methods [23,16,28,32] still suffer from the incapability of modeling content information such as user profiles and item features [20,25]. Several methods have been proposed to address this problem. Most of them fall in these two categories: factorization and graph-based methods. Factorization methods such as factorization machine (FM) [26], neural factorization machine (NFM) [14] and Wide&Deep models [6] fuse numerical features of each individual training sample. These methods yield competitive performance on several datasets. However, they neglect the dependencies among the content information. Graph-based methods such as NGCF [37], KGAT [36], KGCN [35], Multi-GCCF[33] and LGC [15] represent recommend er systems with graph structured data and exploit the graph structure to enhance the node-level representations for better recommendation performance [3,37,42,31].
在推荐系统开发中,整合内容信息以预测用户偏好仍是一项具有挑战性的任务。尽管协同过滤(CF)方法[23,16,28,32]效果显著,但大多数仍无法有效建模用户画像和物品特征等内容信息[20,25]。目前主要有两类解决方案:因子分解方法和基于图的方法。因子分解方法如因子分解机(FM)[26]、神经因子分解机(NFM)[14]和Wide&Deep模型[6],通过融合单个训练样本的数值特征实现,在多个数据集上表现优异,但忽略了内容信息间的关联性。基于图的方法如NGCF[37]、KGAT[36]、KGCN[35]、Multi-GCCF[33]和LGC[15],将推荐系统表示为图结构数据,利用图结构增强节点级表征以提升推荐性能[3,37,42,31]。
It is to be noted that learning such node-level representations loses the correspondences and interactions between the content information of users and items. This is because the node embeddings are learned independently as indicated by Zhang et al. [44]. Another disadvantage of previous GNN-based methods is that the sequential nature of connectivity relations are either ignored (Knowledge Graph based methods) or mixed up (GNN-based methods) without the explicit modelling of multi-hop structure.
需要注意的是,学习这种节点级表征会丢失用户与物品内容信息之间的对应关系和交互作用。正如Zhang等人[44]指出的,这是因为节点嵌入是独立学习的。先前基于GNN的方法另一个缺点是:连接关系的时序特性要么被忽略(基于知识图谱的方法),要么被混淆(基于GNN的方法),而未能显式建模多跳结构。
A natural solution of capturing the inter- and intra-relations between content features and user-item pairs is to explore the high-order information encoded by metapaths [7,43]. A metapath denotes a set of composite relations designed for representing multi-hop structure and sequential semantics. To our best knowledge, only a limited number of efforts have been made to enhance GNNs with metapaths. A prominent metapath based method is MAGNN [10]: it aggregates intra-metapath information for each path instance. As a consequence, MAGNN suffers from high memory consumption problem. MEIRec [8] utilizes the structural information in metapaths to improve the node-level representation for intent recommendation, but the method fails to generalize when no user intent or query is available.
捕捉内容特征与用户-物品对之间相互关系和内部关系的自然解决方案,是探索由元路径 [7,43] 编码的高阶信息。元路径表示一组为表征多跳结构和序列语义设计的复合关系。据我们所知,目前仅有少量研究尝试用元路径增强图神经网络 (GNN)。基于元路径的典型方法是 MAGNN [10]:它为每个路径实例聚合了元路径内部信息,但存在内存消耗过高的问题。MEIRec [8] 利用元路径中的结构信息改进意图推荐中的节点级表征,但该方法在缺乏用户意图或查询时无法泛化。
To overcome these limitations, we propose MetaPath- and Entity-Aware Graph Neural Network (PEAGNN), a unified GNN framework, which aggregates information over multiple metapath-aware subgraphs and fuse the aggregated information to obtain node representation using attention mechanism. As a first step, we extract an $h$ -hop enclosing collaborative subgraph (CSG). Each CSG is centered at a user-item pair and aimed to suppress the influence of feature nodes from other user-item interactions. Such local subgraphs contain rich semantic and collaborative information of user-item interactions. One major difference between the CSGs in our work and the subgraphs proposed by Zhang et al. [44] is that in the subgraphs in their work neglect side information by excluding all feature entity nodes.
为克服这些局限性,我们提出了元路径和实体感知图神经网络 (PEAGNN),这是一个统一的GNN框架,通过聚合多个元路径感知子图的信息,并利用注意力机制融合这些信息来获取节点表示。首先,我们提取一个$h$跳的封闭协作子图 (CSG)。每个CSG以用户-物品对为中心,旨在抑制来自其他用户-物品交互的特征节点的影响。这种局部子图包含了丰富的用户-物品交互语义和协作信息。我们的CSG与Zhang等人[44]提出的子图的一个主要区别在于,他们工作中的子图通过排除所有特征实体节点而忽略了辅助信息。
As a second step, the CSG is decomposed into $\gamma$ metapath-aware subgraphs based on the schema of the selected metapaths. After that, PEAGNN updates the node representation of the given CSG and outputs a CSG graph-level representation, which distills the collective user-item pattern and sequential semantics encoded in the CSG. A multi-layer perceptron is then trained to predict the recom mend ation score of a user-item pair. To further exploit the local structure of CSGs, we introduce entity-awareness, a contrastive regularize r which pushes the user and item nodes closer to the connected feature entity nodes, while simultan e ou sly pushing them apart from the unconnected ones. PEAGNN learns by jointly minimizing Bayesian Personalized Rank (BPR) loss and entity-aware loss. Furthermore, PEAGNN can be easily combined with any graph convolution layers such as GAT, GCN and GraphSage.
第二步,根据所选元路径的模式,将CSG分解为$\gamma$个元路径感知子图。随后,PEAGNN更新给定CSG的节点表征,并输出一个CSG图级表征,该表征提炼了CSG中编码的集体用户-物品模式和序列语义。接着训练一个多层感知机来预测用户-物品对的推荐分数。为了进一步利用CSG的局部结构,我们引入了实体感知对比正则化器,该组件推动用户和物品节点向相连的特征实体节点靠近,同时使它们远离未相连的实体节点。PEAGNN通过联合最小化贝叶斯个性化排序(BPR)损失和实体感知损失进行学习。此外,PEAGNN可以轻松与任何图卷积层(如GAT、GCN和GraphSage)相结合。
In contrast to existing metapath based approaches [7,8,10,34,43], PEAGNN avoids the high computational cost of explicit metapath reconstruction. This is achieved by metapath-guided propagation. The information is propagated along the metapaths “on the fly”. This is the primary reason of computational efficiency of PEAGNN as it gets rid of applying message passing on the recommendation graph. Consequently, the redundant information propagated from other interactions (subgraphs) is avoided by only performing metapath-guided propagation on individual metapath-aware subgraph. We discuss this in detail in Sec. 3.
与现有的基于元路径的方法 [7,8,10,34,43] 不同,PEAGNN 避免了显式元路径重构的高计算成本。这是通过元路径引导的传播实现的,信息会"即时"沿元路径传播。这是 PEAGNN 计算效率高的主要原因,因为它无需在推荐图上应用消息传递。因此,通过仅在单个元路径感知子图上执行元路径引导传播,可以避免从其他交互 (子图) 传播的冗余信息。我们将在第 3 节详细讨论这一点。
2 Related Work
2 相关工作
GNN is designed for learning on graph structured data [29,5,22]. GNNs employ message passing algorithm to pass messages in an iterative fashion between nodes to update node representation with the underlying graph structure. An additional pooling layer is typically used to extract graph representation for graph-level tasks, e.g., graph classification or clustering. Due to its superior performance on graphs, GNNs have achieved state-of-the-art performance on node classification [22], graph representation learning [12] and RSs [39]. In the task of RSs, relations such as user-item interactions and user-item features can be presented as multi-typed edges in the graphs. Severel recent works have proposed GNNs to solve recommendation tasks [37,36,3]. NGCF [37] embeds bipartite graphs of users and items into node representation to capture collaborative signals. GCMC [3] proposed a graph auto-encoder framework, which produces latent features of users and items through a form of differentiable message passing on the user-item graph. KGAT [36] proposed a knowledge graph based attentive propagation, which enhances the node features by modeling high-order connectivity information. Multi-GCCF [33] explicitly incorporates multiple graphs in the embedding learning process and consider the intrinsic difference between user nodes and item nodes in performing graph convolution.
GNN (Graph Neural Network) 专为图结构数据学习而设计 [29,5,22]。GNN采用消息传递算法在节点间迭代传递信息,利用底层图结构更新节点表征。通常额外使用池化层提取图级任务的图表征,例如图分类或聚类。凭借在图数据上的卓越性能,GNN在节点分类 [22]、图表征学习 [12] 和推荐系统 (RSs) [39] 中实现了最先进性能。在推荐系统任务中,用户-物品交互和用户-物品特征等关系可表示为图中的多类型边。近期多项研究提出用GNN解决推荐任务 [37,36,3]。NGCF [37] 将用户-物品二分图嵌入节点表征以捕捉协同信号;GCMC [3] 提出图自编码器框架,通过在用户-物品图上进行可微分消息传递生成用户与物品的潜在特征;KGAT [36] 提出基于知识图谱的注意力传播机制,通过建模高阶连接信息增强节点特征;Multi-GCCF [33] 在嵌入学习过程中显式融合多图结构,并考虑图卷积过程中用户节点与物品节点的本质差异。
Prior to GNNs, several efforts have been established to explicitly guide the recommend er learning with metapaths [18,34,41]. Heitmann et al. [18] utilized linked data from heterogeneous data source to enhance collaborative filtering for the cold-start problem. Sun et al. [34] converted recommendation tasks to relation prediction problems and tackled it with metapath-based relation reasoning. Yu et al. [41] employed matrix factorization framework over meta-path similarity matrices to perform recommendation. Hu et al. [19] proposed userand item-metapath based co-attention to fuse metapath information for recommendation while ignored the inter-metapath interactions. Zhao et al. [46] fed the semantics encoded by meta-graph in factorization model but neglected the contribution of each individual meta-graph. However, only a limited number of works attempted to enhance GNNs with metapaths. Two recent works are quite prominent in this regard, MAGNN [10] and MEIRec [8]. MAGNN aggregates intra-metapath information for each path instance. But this causes MAGNN to get in the problem of un affordable memory consumption. MEIRec devised a GNN to perform metapath-guided propagation. But MEIRec fails to generalize when no user intent is available and does not distinguish the contribution of metapaths. In contrast to these methods, our method saves computational time and memory by adopting a stepwise information pro pog ation over meta-path aware subgraphs. Moreover, PEAGNN employs collaborative subgraph (CSG) to separate semantics introduced by different metapaths and fuses those semantics according to the learned metapath importance, in contrast to existing approaches [44,10,8].
在GNN出现之前,已有若干研究通过元路径(metapath)显式指导推荐系统学习[18,34,41]。Heitmann等[18]利用异构数据源的关联数据改进协同过滤以解决冷启动问题。Sun等[34]将推荐任务转化为关系预测问题,并采用基于元路径的关系推理方法。Yu等[41]通过在元路径相似度矩阵上应用矩阵分解框架进行推荐。Hu等[19]提出基于用户和物品元路径的共注意力机制来融合元路径信息,但忽略了元路径间的交互作用。Zhao等[46]将元图编码的语义输入因子分解模型,却未考虑单个元图的贡献度。目前仅有少量工作尝试用元路径增强GNN,其中MAGNN[10]和MEIRec[8]最具代表性。MAGNN聚合每个路径实例的元路径内部信息,但会导致内存消耗过高的问题。MEIRec设计了基于元路径传播的GNN,但在缺乏用户意图时泛化能力不足且未区分元路径贡献度。相比这些方法,本方法通过在元路径感知子图上逐步传播信息,显著节省计算时间和内存。此外,PEAGNN创新性地采用协作子图(CSG)分离不同元路径的语义,并依据学习到的元路径重要性进行语义融合,这与现有方法[44,10,8]形成鲜明对比。
3 Methodology
3 方法论
3.1 Task description
3.1 任务描述
We formulate the recommendation task as: Given a HIN that includes user-item historical interactions as well as their feature entity nodes. The aim is to learn heterogeneous node representations and the graph-level representations from given collaborative subgraphs. The graph-level representations are utilized by a prediction model to predict the interaction score between user-item pair.
我们将推荐任务形式化为:给定一个包含用户-物品历史交互及其特征实体节点的HIN (Heterogeneous Information Network)。目标是从给定的协作子图中学习异构节点表示和图级表示。预测模型利用图级表示来预测用户-物品对的交互分数。
3.2 Overview of PEAGNN
3.2 PEAGNN概述
PEAGNN is a unified GNN framework, which exploits and fuses rich sequential semantics in selected metapaths. To leverage the underlying local structure of the graph for recommendation, we introduce an entity-aware regularize r that distinguishes users and items from their unrelated features in a contrastive fashion. Figure 1 illustrates the PEAGNN framework, which consists of three components:
PEAGNN是一个统一的GNN框架,它利用并融合了选定元路径中丰富的序列语义。为了利用图的底层局部结构进行推荐,我们引入了一个实体感知正则化器(regularizer),以对比方式区分用户和物品与其无关特征。图1展示了PEAGNN框架,该框架包含三个组件:
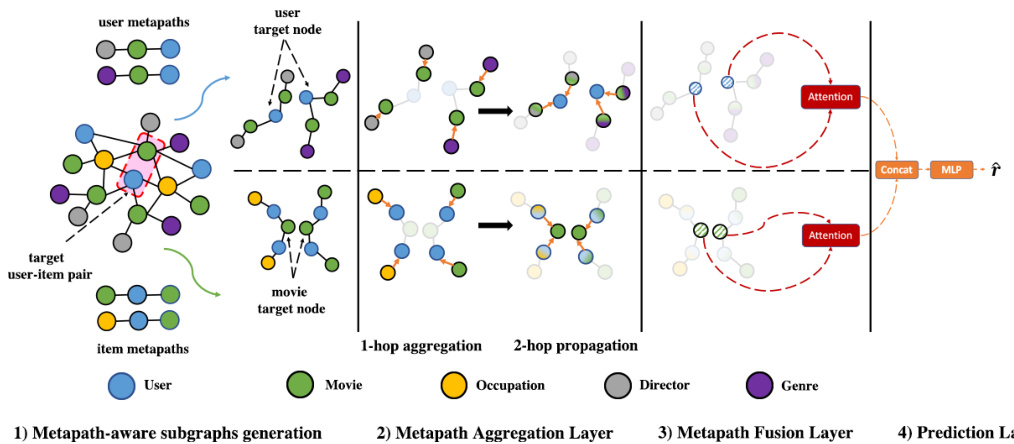
Fig. 1: Illustration of the proposed PEAGNN model on the MovieLens dataset. Subfigure (1) shows the metapath-aware subgraphs generated from a CSG with the given user- and item metapaths. Subfigures (2), (3) and (4) illustrate the metapath-aware information aggregation and fusion workflow of the PEAGNN model. For simplicity, we have only adopted 2-hop metapaths.
图 1: 基于MovieLens数据集提出的PEAGNN模型示意图。子图(1)展示了从CSG生成的元路径感知子图,包含给定的用户和物品元路径。子图(2)、(3)和(4)说明了PEAGNN模型的元路径感知信息聚合与融合流程。为简化展示,仅采用2跳元路径。
- A Metapath Aggregation Layer, which explicitly aggregates information on metapath-aware subgraphs. 2. A Metapath Fusion Layer, which fuses the aggregated node representations from multiple metapath-aware subgraphs using attention mechanism. 3. A Prediction Layer, which readouts the graph-level representations of CSGs and estimate the likelihood of potential user-item interactions.
- 元路径聚合层 (Metapath Aggregation Layer),显式聚合元路径感知子图上的信息。
- 元路径融合层 (Metapath Fusion Layer),通过注意力机制融合来自多个元路径感知子图的聚合节点表征。
- 预测层 (Prediction Layer),读取CSGs的图级表征并估计潜在用户-物品交互的可能性。
3.3 Metapath Aggregation Layer
3.3 元路径聚合层
Sequential semantics encoded by metapaths reveal different aspects towards the connected objects. Appropriate modelling of metapaths can improve the express ive ness of node representations. Our aim is to learn node representations that preserve the sequential semantics in metapaths. PEAGNN saves memory and computation time by performing a step-wise information propagation over metapath-aware subgraphs. This is contrast to Fan et al. [8] which consider each individual path as input.
元路径编码的序列语义揭示了连接对象的不同方面。对元路径进行适当建模可以提高节点表征的表达能力。我们的目标是学习能够保留元路径中序列语义的节点表征。PEAGNN通过基于元路径的子图进行逐步信息传播,节省了内存和计算时间。这与Fan等人[8]将每条独立路径作为输入的方法形成对比。
Metapath-aware Subgraph A metapath-aware subgraph is a directed graph induced from the corresponding CSG by following one specific metapath. As the goal is to learn metapath-aware user-item representation for recommendation, it is intuitive to choose such metapaths which end with either a user or an item node. This ensures that the information aggregation on metapath-aware subgraphs always end on nodes of our primary interest.
元路径感知子图
元路径感知子图是通过遵循特定元路径从相应CSG导出的有向图。由于目标是为推荐学习元路径感知的用户-物品表示,直观的做法是选择以用户或物品节点结尾的元路径。这确保了元路径感知子图上的信息聚合始终终止于我们主要关注的节点。
Information Propagation on Metapath-aware Subgraphs PEAGNN trains a GNN model to perform step-wise information aggregation on metapath-aware subgraphs. By stacking multiple GNN layers, PEAGNN is capable of not only explicitly exploring the multi-hop connectivity in a metapath but also capturing the collaborative signal effectively. Fig. 2 illustrates the flow of information propagation on a given metapath-aware subgraph generated from the metapath $m p$ . Here, $X_{m p,k}$ is the node representations on the metapath $m p$ after $k$ th propagation. $A_{m p,k}$ is the adjacency matrix of the metapath $m p$ at step $k$ . We employ orange and red color to highlight the edges being propagated at a certain aggregation step. Considering the high-order semantic revealed by multi-hop metapaths, we stack multiple GNN layers and re currently aggregate the representations on the metapaths, so that the high-order semantic is injected into node representations. The metapath-aware information aggregation is shown as follows
元路径感知子图上的信息传播
PEAGNN训练一个GNN模型在元路径感知子图上执行分步信息聚合。通过堆叠多个GNN层,PEAGNN不仅能显式探索元路径中的多跳连接性,还能有效捕获协作信号。图2展示了从元路径$mp$生成的子图上信息传播流程。其中$X_{mp,k}$表示第$k$次传播后元路径$mp$上的节点表征,$A_{mp,k}$是第$k$步时元路径$mp$的邻接矩阵。我们使用橙色和红色高亮特定聚合步骤中传播的边。考虑到多跳元路径揭示的高阶语义,我们堆叠多个GNN层并递归聚合元路径上的表征,从而将高阶语义注入节点表征。元路径感知的信息聚合过程如下所示

where $X_{0}$ denotes initial node embeddings. Without loss of generality, by stacking $N$ GNN layers we take into account $N$ -hop neighbours information from the metapath-aware subgraph. Thus, the node representations in the metapathaware subgraph are given by:
其中 $X_{0}$ 表示初始节点嵌入。不失一般性,通过堆叠 $N$ 个 GNN 层,我们考虑了来自元路径感知子图的 $N$ 跳邻居信息。因此,元路径感知子图中的节点表示由下式给出:

$X_{m p}$ is the output node representation of the last step on the metapath $m p$ .
$X_{mp}$ 是元路径 $mp$ 上最后一步的输出节点表示。
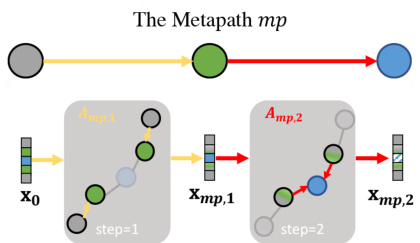
Fig. 2: Information propagation on a metapath-aware subgraph
图 2: 元路径感知子图上的信息传播
3.4 Metapath Fusion Layer
3.4 元路径融合层
After information aggregation within metapath-aware subgraphs, the metapath fusion layer combines and fuses the semantic information revealed by all metapaths. Assume for a node $\upsilon$ , a set of its node representations ${\mathbf{x}{m p{1}}^{v},\mathbf{x}{m p{2}}^{v},...,\mathbf{x}{m p{\gamma}}^{v}}$ is aggregated from $\gamma$ metapaths. Semantics disclosed by metapaths are not of equal importance to node representations and the contribution of every metapath should also be adjusted accordingly. Therefore, we leverage soft attention to learn the importance of each metapath, instead of adopting element-wise $r n e a n$ , $m a x$ and add operators. It is to be noted that PEAGNN applies a node-wise attentive fusion of metapath aggregated node representation.This is contrast to previous works which employ a fixed attention factor for all nodes. Consequently, they fail to capture the node-specific metapath preference. For a given target node $\upsilon$ , we apply vector concatenation on its representations from $\gamma$ metapathaware subgraphs, denoted as $\mathbf{H}{v}=[\mathbf{x}{m p_{1}}^{v};\mathbf{x}{m p{2}}^{v};...;\mathbf{x}{m p{\gamma}}^{v}]$ . The metapath fusion is performed as follows:
在元路径感知子图内完成信息聚合后,元路径融合层会整合并融合所有元路径揭示的语义信息。假设对于节点$\upsilon$,其节点表示集合${\mathbf{x}{m p{1}}^{v},\mathbf{x}{m p{2}}^{v},...,\mathbf{x}{m p{\gamma}}^{v}}$是从$\gamma$条元路径聚合而来。不同元路径所揭示的语义对节点表示的重要性并不等同,每条元路径的贡献度也应相应调整。因此,我们采用软注意力机制来学习各元路径的重要性,而非使用逐元素的$r n e a n$、$m a x$或加法运算符。需注意的是,PEAGNN采用针对节点的注意力融合方式来聚合元路径节点表示,这与先前工作中对所有节点使用固定注意力因子的方法形成对比。后者无法捕捉节点特有的元路径偏好。对于给定目标节点$\upsilon$,我们将其在$\gamma$个元路径感知子图中的表示向量拼接为$\mathbf{H}{v}=[\mathbf{x}{m p_{1}}^{v};\mathbf{x}{m p{2}}^{v};...;\mathbf{x}{m p{\gamma}}^{v}]$。元路径融合过程如下:
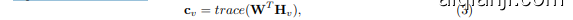
where $\mathbf{c}_{v}$ is a vector of metapath importance and $\mathbf{W}$ is a matrix with learnable parameters. We then normalize the metapath importance score using softmax function and get the attention factor for each metapath:
其中 $\mathbf{c}_{v}$ 是元路径重要性向量,$\mathbf{W}$ 是可学习参数矩阵。接着我们使用 softmax 函数对元路径重要性分数进行归一化,得到每条元路径的注意力因子:

where attvmpi denotes the normalized attention factor of metapath $m p_{i}$ on the node $\boldsymbol{v}$ . With the learned attention factors, we can fuse all metapath aggregated node representations to the final metapath-aware node representation, $\mathbf{e}_{v}$ , as:
其中attvmpi表示节点$\boldsymbol{v}$上元路径$m p_{i}$的归一化注意力因子。通过学习到的注意力因子,我们可以将所有元路径聚合的节点表示融合为最终的元路径感知节点表示$\mathbf{e}_{v}$,公式如下:

3.5 Prediction Layer
3.5 预测层
Next, we readout the node representations of CSGs into a graph-level feature vector. In existing works, many pooling methods were investigated such as SumPool, Mean Pooling, Sort Pooling [45] and Diff Pooling [40]. However, we adopt a different pooling strategy which concatenates the aggregated representations of the center user node $\mathbf{e}{u}$ and item node $\mathbf{e}{i}$ in the CSGs. i.e.,
接下来,我们将CSG中的节点表示读出为一个图级别的特征向量。现有工作中已探索了多种池化方法,如SumPool、均值池化、排序池化[45]和Diff池化[40]。但我们采用了不同的池化策略:将CSG中中心用户节点$\mathbf{e}{u}$和物品节点$\mathbf{e}{i}$的聚合表示进行拼接,即
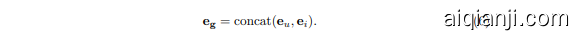
After obtaining the graph-level representation of CSG, we utilize a 2-layer MLP to compute the matching score of a user-item pair. Lets denote a CSG with $\mathcal{G}_{u,i}$ , the prediction function for the interaction score of user $u$ and item $i$ can be expressed as follows
在获得CSG的图级别表示后,我们使用一个2层MLP来计算用户-物品对的匹配分数。设$\mathcal{G}_{u,i}$表示一个CSG,用户$u$与物品$i$的交互分数预测函数可表示为

where $\mathbf{w}{1}$ , $\mathbf{w}{2}$ , ${\bf b}{1}$ and ${\bf{b}}{2}$ are the trainable parameters of the MLP which map the graph-level representation ${\mathbf{e}}_{g}$ to a scalar matching score, and $\sigma$ is the non-linear activation function (e.g. ReLU).
其中 $\mathbf{w}{1}$、$\mathbf{w}{2}$、${\bf b}{1}$ 和 ${\bf{b}}{2}$ 是 MLP (多层感知机) 的可训练参数,用于将图级表示 ${\mathbf{e}}_{g}$ 映射为标量匹配分数,$\sigma$ 是非线性激活函数 (例如 ReLU)。
3.6 Graph-level representation for recommendation
3.6 面向推荐的图级别表示
Compared to the previous GNN-based methods such as NGCF, KGAT, KGCN, Multi-GCCF and LGC that use node-level representations for recommendation, PEAGNN predicts the matching score of a user-item pair by mapping its corresponding metapath-aware subgraph to a scalar as shown in Fig. 1. As shown by [44], methods using node-level representation suffer from the over-smoothness problem [24][22]. As their node-level representations are learned independently,
与之前基于GNN的方法(如NGCF、KGAT、KGCN、Multi-GCCF和LGC)使用节点级表示进行推荐不同,PEAGNN通过将用户-物品对对应的元路径感知子图映射为一个标量来预测其匹配分数,如图1所示。如[44]所示,使用节点级表示的方法存在过度平滑问题[24][22]。由于它们的节点级表示是独立学习的,
they fail to model the correspondence of the structural proximity of a node pair. On the other hand, a graph-level GNN with sufficient rounds of message passing can better capture the interactions between the local structures of two nodes [38].
它们未能建模节点对结构邻近性的对应关系。另一方面,具有足够多轮消息传递的图级GNN能更好地捕捉两个节点局部结构间的交互[38]。
3.7 Training Objective
3.7 训练目标
To train model parameters in an end-to-end manner, we minimize the pairwise Bayesian Personalized Rank (BPR) loss [27], which has been widely used in RSs. The BPR loss can be expressed as follows:
为了以端到端方式训练模型参数,我们最小化成对贝叶斯个性化排序 (Bayesian Personalized Rank, BPR) 损失 [27],该损失函数在推荐系统中被广泛使用。BPR损失可表示为:
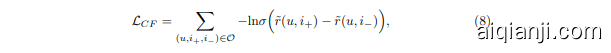
where $\mathcal{O}={(u,i_{+},i_{-})|(u,i_{+})\in R_{+},(u,i_{-})\in R_{-}}$ is the training set, $R_{+}$ is the observed user-item interactions (positive samples) while $R_{-}$ is the unobserved user-item interactions (negative samples). The detailed training procedure is illustrated in the Algorithm 1.
其中 $\mathcal{O}={(u,i_{+},i_{-})|(u,i_{+})\in R_{+},(u,i_{-})\in R_{-}}$ 是训练集,$R_{+}$ 是观测到的用户-物品交互(正样本),而 $R_{-}$ 是未观测到的用户-物品交互(负样本)。具体训练流程如算法1所示。
Although user and item representations can be derived by information aggregation and fusion on metapath-aware subgraphs, the local structural proximity of user(item) nodes are still missing. Towards this end, we propose EntityAwareness to regularize the local structural of user(item) nodes. The idea of entity-awareness is to distinguish items or users with their unrelated feature entities in the embedding space. Specifically, entity-awareness is a distance-based contrastive regular iz ation term that pulls the related feature entity nodes closer to the corresponding user(item) nodes, while push the unrelated ones apart. The regular iz ation term is defined as following:
尽管用户和商品表征可以通过元路径感知子图上的信息聚合与融合获得,但用户(商品)节点的局部结构邻近性仍然缺失。为此,我们提出EntityAwareness机制来规范用户(商品)节点的局部结构。该机制的核心思想是在嵌入空间中将商品/用户与其无关特征实体区分开来,具体通过基于距离的对比正则项实现:将相关特征实体节点拉近对应用户(商品)节点,同时推开无关实体。该正则项定义如下:

where $\mathbf{x}{f+,u},\mathbf{x}{f-,u}$ denote the observed and unobserved feature entity embeddings of user $u$ , ${\bf x}{f+,i+},{\bf x}{f-,i_{-}}$ denote the observed and unobserved feature entity embeddings of positive item $i$ and $d(\cdot,\cdot)$ is a distance measure on the embedding space. The total loss is computed by the weighted sum of these two losses. It is given by:
其中 $\mathbf{x}{f+,u},\mathbf{x}{f-,u}$ 表示用户 $u$ 的已观测和未观测特征实体嵌入,${\bf x}{f+,i+},{\bf x}{f-,i_{-}}$ 表示正样本物品 $i$ 的已观测和未观测特征实体嵌入,$d(\cdot,\cdot)$ 为嵌入空间的距离度量。总损失通过这两个损失的加权和计算得出,其表达式为:
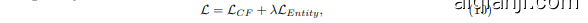
where $\lambda$ is the weight of the entity-awareness term. We use mini-batch Adam optimizer [21]. For a batch randomly sampled from training set $\mathcal{O}$ , we establish their representation by performing information aggregation and fusion on their embeddings, and then update model parameters via back propagation.
其中 $\lambda$ 是实体感知项的权重。我们使用小批量 Adam 优化器 [21]。对于从训练集 $\mathcal{O}$ 中随机采样的批次,我们通过对它们的嵌入执行信息聚合和融合来建立它们的表示,然后通过反向传播更新模型参数。
4 Experiments
4 实验
We evaluate the effectiveness our approach via experiments on public datasets. Our experiments aim to address the following research questions:
我们通过在公开数据集上的实验来评估方法的有效性。实验旨在解决以下研究问题:
– RQ1: How does PEAGNN perform compared to other baseline methods? – RQ2: How does the entity-awareness affect the performance of PEAGNN? – RQ3: What is the impact of different metapaths in recommendation tasks?
- RQ1: PEAGNN 与其他基线方法相比表现如何?
- RQ2: 实体感知 (entity-awareness) 如何影响 PEAGNN 的性能?
- RQ3: 不同元路径 (metapaths) 对推荐任务有何影响?
4.1 Experimental Settings
4.1 实验设置
Datasets The datasets which we included in our experimental evaluation are widely used in related works. That is, Movielens [3,13,14] and Yelp [36,42]. By changing the size of Movielens from small to large, we investigated the effect of dataset scale on the performance of the proposed method and the competitive baselines. We have three datasets of different sizes, namely: MovieLens-small (small), Yelp (medium) and MovieLens-25M (large). The statistics of the three datasets are summarized in Table 1.
数据集
我们实验评估中使用的数据集在相关研究中被广泛采用,包括Movielens [3,13,14]和Yelp [36,42]。通过将Movielens的规模从小型调整到大型,我们研究了数据集规模对所提方法及竞争基线性能的影响。我们采用了三种不同规模的数据集:MovieLens-small(小型)、Yelp(中型)和MovieLens-25M(大型)。表1汇总了这三个数据集的统计信息。
表1:
MovieLens $^{1}$ is widely used benchmark dataset for movie recommendation. We use small ( $\sim$ 100k ratings) and 25M ( $\sim25$ million ratings) versions of the dataset. We consider movies as items and ratings as interactions. For ML-small, we use 10-core setting i.e. each user and item will have at least 10 interactions. For ML-25M, we select items which have at least 10 interactions and users with 10 to 300 interactions (from 2018 on-wards) to ensure dataset quality.
MovieLens$^{1}$是广泛使用的电影推荐基准数据集。我们使用了该数据集的小型版本(约10万条评分)和25M版本(约2500万条评分)。我们将电影视为物品(item),将评分视为交互行为。对于ML-small数据集,我们采用10-core设置,即每个用户和物品至少有10次交互。对于ML-25M数据集,我们筛选了至少有10次交互的物品,以及2018年后交互次数在10至300次之间的用户,以确保数据集质量。
Yelp2 is used for business recommendations and has around 10 million interactions. Here we consider businesses as items; reviews and tips as interactions.
Yelp2用于商业推荐,拥有约1000万次互动。这里我们将商家视为物品,将评论和提示视为互动。
Table 1: Statistics of datasets
| MovieLens-small | MovieLens-25M | Yelp | |
|---|---|---|---|
| #节点数 | 2933 | 33249 | 89252 |
| #用户数 | 608 | 14982 | 60808 |
| #项目数 | 2121 | 11560 | 28237 |
| #交互数 | 79619 | 1270237 | 754425 |
表 1: 数据集统计信息
The original dataset is highly sparse. So, to ensure dataset quality, we select items which have at least 50 interactions and users with 10 to 20 interactions.
原始数据集高度稀疏。因此,为确保数据集质量,我们筛选出至少有50次交互的物品和拥有10至20次交互的用户。
Along with user-item interactions, we use their features as entities to build HIN graph. For MovieLens, we employ user feature of tag and item features like year, genre, actor, director, writer etc. For Yelp, we extract user features like counts of reviews, friends, fans, stars and item features like attributes, categories and counts of stars, reviews and check-ins.
除了用户-物品交互数据外,我们将其特征作为实体构建异质信息网络(HIN)。对于MovieLens数据集,我们采用用户标签特征以及物品的年份、类型、演员、导演、编剧等特征;对于Yelp数据集,我们提取用户的评论数、好友数、粉丝数、星级等特征,以及物品的属性、类别、星级数、评论数和签到数等特征。
Evaluation Strategy and Metrics Leaving one interaction out evaluation strategy is one of the most commonly followed approach to evaluate recommender systems [14,27,2,17]. Recent research shows that different data splits have a huge impact on the final performance[30]. To avoid the raised concerns in evaluating GNN based methods, we follow [16] and adapt leave-one-out evaluation for a more stable, reliable and fair comparison. For each user, we set the latest interacted item as the test set. The remaining items are employed for training. For each user-item positive interaction in the training set, we employ negative sampling strategy to get four negative items for that user. For Yelp and ML-25M, we sample randomly while for ML-small, we sample from the unseen items for each user.We use two evaluation metrics: Hit Ratio (HR) and Normalized Discounted Cumulative Gain (NDCG). We consider only top-10 positions of the returned results. HR@10 indicates whether the test item is present in top-10 recommendations. NDCG@10 also takes in to account the position at which the correct item appears in the recommendations [13]. We compute the metrics for each test user and report the average score.
评估策略与指标
留一交互评估策略是推荐系统评估中最常用的方法之一 [14,27,2,17]。近期研究表明,不同的数据划分方式对最终性能有显著影响 [30]。为避免基于图神经网络 (GNN) 方法评估中的争议,我们遵循 [16] 采用留一法评估以确保更稳定、可靠和公平的比较。对于每个用户,我们将最新交互的条目设为测试集,其余条目用于训练。针对训练集中的每个用户-条目正向交互,我们采用负采样策略为该用户获取四个负样本条目。对于Yelp和ML-25M数据集采用随机采样,而ML-small数据集则从每个用户未见的条目中采样。
我们使用两个评估指标:命中率 (HR) 和归一化折损累积增益 (NDCG)。仅考虑返回结果的前10位,HR@10表示测试条目是否出现在推荐列表前10位,NDCG@10还会考虑正确条目在推荐列表中的位置 [13]。我们为每个测试用户计算指标并报告平均分数。
Hyper parameter Settings We implemented the PEAGNN and baselines in Pytorch Geometric 1.5.0 [9]. To determine hyper-parameters of our methods, we follow the procedure proposed in [16]. For each user, one random interaction is sampled as the validation data for parameter tuning. We cross validated the batch size of [1024, 2048, 4096], the learning rate of [0.0001 ,0.0005, 0.001, 0.005] and weight of [0.03, 0.1, 0.3, 1] for entity-awareness. For fair comparison, we employed the same embedding dimension for both PEAGNN and the baselines. We set embedding dimension to 64 across all models and datasets. The representation dimension is 16 for GNN-based models and hidden layer size is 64 for factorization and GNN-based models. We use 2-step metapaths and attention channel aggregation for PEAGNN. The number of metapaths, $\gamma$ , for ML-small, ML-25M and Yelp are 9, 13 and 11 respectively.
超参数设置
我们在Pytorch Geometric 1.5.0 [9]中实现了PEAGNN和基线方法。为确定方法的超参数,我们遵循[16]提出的流程。针对每位用户,随机采样一次交互作为参数调优的验证数据。我们对批次大小[1024, 2048, 4096]、学习率[0.0001, 0.0005, 0.001, 0.005]以及实体感知权重[0.03, 0.1, 0.3, 1]进行了交叉验证。为公平比较,PEAGNN与基线模型采用相同的嵌入维度,所有模型和数据集的嵌入维度均设为64。基于GNN的模型表示维度为16,因子分解和基于GNN的模型隐藏层大小为64。PEAGNN采用2步元路径和注意力通道聚合机制,ML-small、ML-25M和Yelp数据集的元路径数量$\gamma$分别为9、13和11。
Further implementation details of PEAGNN as well as baseline models can be found in the code $^3$ .
PEAGNN及基线模型的更多实现细节可在代码 $^3$ 中找到。
Baselines We compare PEAGNN with several kinds of competitive baselines. 1. NFM [14] utilizes neural networks to enhance high-order feature interactions with non-linearity. As suggested by He et al. [14], we apply one hidden layer neural network on input features.
基线方法
我们将PEAGNN与多种具有竞争力的基线方法进行比较。
- NFM [14] 利用神经网络增强高阶特征交互的非线性。根据He等人 [14] 的建议,我们在输入特征上应用了一个单隐藏层神经网络。
- CFKG [1] applies TransE [4] to learn heterogeneous node embedding and converts recommendation to a link prediction problem.
- CFKG [1] 采用 TransE [4] 学习异构节点嵌入,并将推荐问题转化为链接预测问题。
- HeRec [7] extends the matrix factorization model with the joint learning of a set of embedding fusion functions.
- HeRec [7] 通过联合学习一组嵌入融合函数来扩展矩阵分解模型。
- Meta path 2 Vec [7] utilizes a skip-gram model to update the node embeddings generataed by metapath-guided random walks. We then use a MLP to predict the matching score with the learned embeddings.
- Meta path 2 Vec [7] 采用跳字模型 (skip-gram) 更新元路径引导随机游走生成的节点嵌入向量,随后通过多层感知机 (MLP) 结合学习到的嵌入向量预测匹配分数。
- NGCF [37] integrates the user-item bipartite graph structure into the embedding process for collaborative filtering.
- NGCF [37] 将用户-物品二分图结构融入协同过滤的嵌入过程中。
- KGCN [35] exploits multi-hop proximity information with a receptive field to learn user preference.
- KGCN [35] 利用具有感受野的多跳邻近信息来学习用户偏好。
- KGAT [36] incorporates high-order information by performing attentive embedding propagation with the learned entity attention on knowledge graph.
- KGAT [36] 通过在知识图谱上利用学习到的实体注意力进行注意力嵌入传播,来整合高阶信息。
- Multi-GCCF [33] explicitly incorporates multiple graphs in the embedding learning process. Multi-GCCF not only models the high-order information but also integrates the proximal information of item-item and user-user paris.
- Multi-GCCF [33] 在嵌入学习过程中显式融合了多图结构。该模型不仅建模高阶信息,还整合了物品-物品对和用户-用户对的邻近信息。
- LGC [15] simplifies the design of GCN by maintaining only the neighborhood aggregation for collaborative filtering.
- LGC [15] 通过仅保留用于协同过滤的邻域聚合来简化 GCN (Graph Convolutional Network) 的设计。
4.2 Overall Performance Comparison (RQ1)
4.2 整体性能对比 (RQ1)
Table 2 summarizes the performance comparison of PEAGNN variants and the competitive baselines. In the following, we discuss these results to gain some important insights into the problem.
表 2: 总结了PEAGNN变体与竞争基线的性能对比。接下来,我们将讨论这些结果以获取对该问题的重要见解。
First, we note that our proposed method PEAGNN outperforms other methods by a significant margin on all three datasets. In particular, the performance gains achieved by PEAGNN are 7.87%, $2.39%$ , and $8.23%$ w.r.t. NDCG $@10$ on ML-small, ML-25m and Yelp datasets, respectively. The primary reason for outstanding performance of PEAGNN is that none of the existing methods do explicit modelling consequently all node messages get mixed up during message passing. This verifies our claim that explicit modelling and fusing sequential semantics in metapath help in better learning of user-item interactions. Moreover, the superior performance of PEAGNN also reveals the effectiveness of modelling the local graph structure, while other GNN-based methods simply pay no attention to their structure proximity.
首先,我们注意到我们提出的方法PEAGNN在所有三个数据集上都显著优于其他方法。具体而言,PEAGNN在ML-small、ML-25m和Yelp数据集上相对于NDCG@10的性能提升分别为7.87%、2.39%和8.23%。PEAGNN表现出色的主要原因是现有方法都没有进行显式建模,因此在消息传递过程中所有节点的信息都被混淆了。这验证了我们的观点,即在元路径中显式建模和融合序列语义有助于更好地学习用户-物品交互。此外,PEAGNN的优越性能也揭示了建模局部图结构的有效性,而其他基于GNN的方法则完全忽视了它们的结构邻近性。
Second, we observe that the path-based methods that are not based on GNN significantly under perform all the GNN-based models on all three datasets. Both
其次,我们观察到基于路径(非图神经网络)的方法在三个数据集上的表现均显著逊于所有基于图神经网络的模型。
Table 2: Overall Performance Comparison. The scores are average of five runs. Bold indicates best results for the dataset. * denotes entity-awareness.
| 模型 | MovieLens-small | MovieLens-25M | Yelp | |
|---|---|---|---|---|
| HR@10 NDCG@10 | HR@10 NDCG@10 | HR@10 NDCG@10 | ||
| NFM | 0.477 0.2668 | 0.8132 | 0.5347 | 0.8595 0.6062 |
| CFKG | 0.4378 0.2381 | 0.8152 0.5196 | 0.8729 | 0.5826 |
| HeRec | 0.2668 0.1449 | 0.607 | 0.3291 0.5533 | 0.3302 |
| Metapath2Vec NGCF | 0.3063 0.1614 | 0.7956 | 0.5051 | 0.6307 0.402 |
| 0.5016 0.2755 | 0.7807 | 0.4866 0.8068 | 0.481 | |
| KGCN KGAT MultiGCCF LGC | 0.5132 | 0.2788 0.7771 | 0.4699 | 0.8125 |
| 0.5214 | 0.2846 0.8147 | 0.5236 | 0.8762 | |
| 0.5230 | 0.2836 | 0.8014 0.5153 | 0.8639 | |
| 0.5003 | 0.2815 | 0.8081 0.5237 | 0.8744 | |
| PEAGCN PEAGCN* (% 改进 vs 最佳竞品) | 0.5382 0.5576 | 0.2951 | 0.8185 | 0.5344 0.9041 |
| 0.3036 | 0.8187 | 0.5361 0.9125 | ||
| 6.62% | 6.68% | 0.43% | 0.26% 4.14% | |
| PEAGAT PEAGAT* (% 改进 vs 最佳竞品) | 0.5375 0.5477 | 0.2983 0.3045 | 0.8249 0.8284 | 0.5414 0.5475 |
| 4.72% | 6.99% | 1.62% | 2.39% 4.18% | |
| PEASage PEASage (% 改进 vs 最佳竞品) | 0.5444 | 0.3003 | 0.8176 | 0.5383 |
| 0.5609 | 0.307 | 0.8273 | 0.5462 0.8837 | |
| 7.25% | 7.87% | 1.48% | 2.15% 0.86% |
表 2: 整体性能对比。所有分数为五次运行的平均值。粗体表示该数据集上的最佳结果。*表示具有实体感知能力。
Meta path 2 Vec $^+$ MLP and HeRec have incorporated the static node embedding using Meta path 2 vec [7]. The poor performance indicates that learning unsupervised static node embeddings have limited the power of the model to capture the complex collaborative signals and intricate content relations.
Meta path 2 Vec $^+$ MLP 和 HeRec 采用了基于 Meta path 2 vec [7] 的静态节点嵌入方法。其表现不佳表明,无监督静态节点嵌入学习限制了模型捕捉复杂协同信号与精细内容关系的能力。
Third, we observe that CFKG and NFM prove to be strong baselines for GNN based methods especially on ML-25m and Yelp datasets. For instance, CFKG achieves 0.8729 HR@10 on Yelp and is fourth best performing model. But the performance gap with second and third best models is negligible i.e. $0.4%$ and $0.2%$ respectively. CFKG is significantly outperformed only by our method (PEAGAT $^*$ ) by $4.37%$ . This demonstrates that our method is able to better leverage the information in the graph-structured data by explicitly modelling the the sequential semantics via metapath aware subgraphs.
第三,我们观察到CFKG和NFM在基于GNN的方法中表现出色,尤其是在ML-25m和Yelp数据集上。例如,CFKG在Yelp上的HR@10达到0.8729,是第四佳表现模型。但与第二和第三佳模型的性能差距微乎其微,分别为$0.4%$和$0.2%$。CFKG仅显著落后于我们的方法(PEAGAT$^*$),差距为$4.37%$。这表明,通过元路径感知子图显式建模序列语义,我们的方法能更好地利用图结构数据中的信息。
4.3 Effect of Entity-awareness (RQ2)
4.3 实体感知的影响 (RQ2)
The goal of introducing entity-awareness is to take advantage of the first-order structure of CSG, which is not well exploited by pure message passing in graphbased RSs [11]. We study the effect of entity-awareness by comparing the performances of our models with and without entity-awareness. The effect of entityawareness for different base models are summarized in Table 2. Generally, entityawareness delivers consistently better performance than PEAGNN without entityawareness. In particular, a more significant performance gain has been observed in the smaller dataset ML-small with a minimum improvement of $1.9%$ on HR@10. On the other hand, models with entity-awareness slightly outperform base models on the larger and denser datasets. It indicates that leveraging local structure on sparse datasets proves beneficial. Nonetheless, NDCG $@$ 10 benefits more from the entity-awareness in comparison with HR@10 on both MovieLens and Yelp datasets. For instance, on Yelp, PEAGAT shows $4.06%$ performance gain in terms of NDCG $@$ 10. These results signify the importance of explicit modelling of first-order relations in RSs.
引入实体感知(Entity-awareness)的目的是利用CSG的一阶结构特性,这一特性在图推荐系统中未被纯消息传递机制充分挖掘[11]。我们通过对比有无实体感知的模型性能来研究其效果,不同基础模型的实体感知效果总结如表2所示。总体而言,实体感知版本始终优于无实体感知的PEAGNN模型。尤其在较小数据集ML-small上观察到更显著的性能提升,HR@10指标至少提高1.9%。而在更大更稠密的数据集上,实体感知模型仅略微优于基础模型,这表明利用稀疏数据集的局部结构更有价值。值得注意的是,在MovieLens和Yelp数据集上,NDCG@10相比HR@10从实体感知中获益更多。例如PEAGAT在Yelp数据集上NDCG@10指标提升了4.06%,这些结果印证了显式建模推荐系统一阶关系的重要性。
Table 3: Percentage drop in the performance of PEASage on ML-small w.r.t. HR@10 when one metapth is removed during training. Bold indicates greater than 10% drop in performance. (Abbreviation for nodes: U-User, M-Movie, YYear, A-Actor, W-Writer, D-Director, G-Genre and T-Tag)
| # | U-M-U | M-U-M | Y-M-UA | A-M-U|W-M-U|1 | D-M-UC | G-M-U | T-M-U|2 | T-U-M | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | -27.45 | -4.41 | -24.3 | -2.21 | -1.9 | -0.96 | -0.96 | -2.53 | -6 |
| 2 | -30.31 | -46.98 | -11.51 | -6.37 | -7.28 | -8.18 | -5.16 | -9.71 | -5.45 |
| 3 | -1.88 | -5.3 | -40.62 | -4.37 | -3.12 | -0.3 | -0.63 | -4.69 | -15.32 |
| 4 | -6.38 | -48.77 | -23.63 | +1.53 | -1.85 | -0.62 | +0.3 | -2.06 | -7.67 |
| 5 | -8.97 | -42.24 | -49.38 | -4.34 | -3.1 | -1.55 | -5.29 | -1.55 | -4.04 |
表 3: PEASage在ML-small数据集上训练时移除单个元路径后HR@10指标的百分比下降情况。加粗表示性能下降超过10%。(节点缩写说明: U-用户, M-电影, Y-年份, A-演员, W-编剧, D-导演, G-类型, T-标签)
4.4 Effect of Metapaths (RQ3)
4.4 元路径的影响 (RQ3)
We have conducted various ablation studies, In order to gain insight into the effect of different metapaths on the performance of PEAGNN, we have conducted various experiments. In the interest of space, we only include the results of our best model PEASage on ML-small dataset. We have total 9 metapaths for MLsmall dataset. These metapaths are shown as columns in the Table 3. We drop only 1 specific metapath at a time and then compare the model performance drop with the original one. The table summarizes the percentage performance drop as compared to the original model. We ran the experiments 5 times with different random seeds for fair evaluation.
为了探究不同元路径对PEAGNN性能的影响,我们进行了多项实验。由于篇幅限制,仅展示最佳模型PEASage在ML-small数据集上的结果。该数据集共包含9条元路径,如表3列所示。我们每次仅剔除1条特定元路径,并与原始模型进行性能对比。表格统计了各剔除方案相较于原始模型的性能下降百分比。为确保公平评估,所有实验均采用5组不同随机种子运行。
表3:
First we observe that, there are some metapaths droping which results in significant decrease in the model performance. That is, PEASage learnt three different key metapaths combinations. Namely: U-M-U, M-U-M and Y-M-U. Second, we observe that each metapath is contributing something in the performance of PEASage although the effect of six metapaths is not that significant.
首先我们观察到,删除某些元路径会导致模型性能显著下降。具体而言,PEASage 学习了三种不同的关键元路径组合,即:U-M-U、M-U-M 和 Y-M-U。其次,我们发现每条元路径都对 PEASage 的性能有所贡献,尽管其中六条元路径的影响并不显著。
Third, we note that the published year of movies has the most significant impact on users’ choice. That is, the metapath Y-M-U comes out as key metapath in all 5 runs. Those metapaths which capture collaborative effects such as U-M-U and M-U-M take critical role in the high performance of PEASage model. Another interesting phenomenon, which warrants further investigation, is that the tag given by users might have a complementary relation of user-item interactions as shown in the third run in the table.
第三,我们注意到电影的上映年份对用户选择的影响最为显著。在所有5次实验中,Y-M-U元路径均作为关键元路径出现。而捕捉协同效应的元路径(如U-M-U和M-U-M)对PEASage模型的高性能表现起到了关键作用。另一个值得进一步研究的有趣现象是:如表第3次实验所示,用户标注的标签可能与用户-物品交互形成互补关系。
These results also indicate another strength of PEAGNN, i.e., even without prior knowledge and careful selection, the effectiveness of each metapath and different metapath combinations can be verified in a convenient way by comparing attention factors or “disabling” specific metapath. Thus, an incremental training and metapath selection is achievable. Therefore, more insightful research for HCI community can be expected.
这些结果还表明了PEAGNN的另一优势,即即使没有先验知识和精心选择,通过比较注意力因子或"禁用"特定元路径,也能便捷地验证每条元路径及不同元路径组合的有效性。因此,可实现增量式训练和元路径选择,从而为HCI领域带来更具洞察力的研究前景。
5 Conclusion
5 结论
In this work, we study the necessity of incorporating sequential semantics in metapath for recommendation. Instead of mixing up multi-hop messages in graphs, we devised a unified GNN framework called PEAGNN, which explicitly performs independent information aggregation on generated metapath-aware subgraphs. Specifically, a metapath fusion layer is trained to learn the metapath importance and adaptively fuse the aggregated metapath semantics in an endto-end fashion. We also introduce a contrastive connectivity regularize r called entity-awareness which exploits the first-order local structure of the graph. For first-order local structure exploitation, the entity-awareness, a contrastive connectivity regularize r, is employed on user nodes and item nodes representation. The experiments on three public datasets have shown the effectiveness of our approach in comparison to competitive baselines.
在本工作中,我们研究了推荐系统中元路径(metapath)融入序列语义的必要性。不同于传统图神经网络混合多跳信息的做法,我们提出了PEAGNN统一框架,通过在生成的元路径感知子图上显式执行独立信息聚合。具体而言,我们训练元路径融合层来学习路径重要性,并以端到端方式自适应融合聚合的元路径语义。同时引入基于一阶局部结构的对比连接正则化器"实体感知(entity-awareness)",该机制作用于用户节点和物品节点表征。在三个公开数据集上的实验表明,相较现有基线方法,我们的方案具有显著优势。