Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
混合式RAG:通过语义搜索与混合查询检索器提升RAG (检索增强生成) 准确率
Abstract—Retrieval-Augmented Generation (RAG) is a prevalent approach to infuse a private knowledge base of documents with Large Language Models (LLM) to build Generative Q&A (Question-Answering) systems. However, RAG accuracy becomes increasingly challenging as the corpus of documents scales up, with Retrievers playing an outsized role in the overall RAG accuracy by extracting the most relevant document from the corpus to provide context to the LLM. In this paper, we propose the ’Blended RAG’ method of leveraging semantic search techniques, such as Dense Vector indexes and Sparse Encoder indexes, blended with hybrid query strategies. Our study achieves better retrieval results and sets new benchmarks for IR (Information Retrieval) datasets like NQ and TREC-COVID datasets. We further extend such a ’Blended Retriever’ to the RAG system to demonstrate far superior results on Generative Q&A datasets like SQUAD, even surpassing fine-tuning performance.
摘要—检索增强生成 (Retrieval-Augmented Generation,RAG) 是一种将私有文档知识库与大语言模型 (LLM) 结合的流行方法,用于构建生成式问答 (Generative Q&A) 系统。然而,随着文档规模的扩大,RAG 的准确性面临越来越大的挑战,其中检索器 (Retriever) 通过从语料库中提取最相关的文档为 LLM 提供上下文,对整体 RAG 准确性起着至关重要的作用。本文提出了一种 "混合 RAG" 方法,该方法结合了语义搜索技术 (如稠密向量索引和稀疏编码器索引) 与混合查询策略。我们的研究在 NQ 和 TREC-COVID 等信息检索 (IR) 数据集上取得了更好的检索结果,并设立了新的基准。我们进一步将这种 "混合检索器" 扩展到 RAG 系统中,在 SQUAD 等生成式问答数据集上展示了远超微调性能的优异结果。
Index Terms—RAG, Retrievers, Semantic Search, Dense Index, Vector Search
索引术语—RAG (Retrieval-Augmented Generation)、检索器、语义搜索、稠密索引、向量搜索
I. INTRODUCTION
I. 引言
RAG represents an approach to text generation that is based not only on patterns learned during training but also on dynamically retrieved external knowledge [1]. This method combines the creative flair of generative models with the encyclopedic recall of a search engine. The efficacy of the RAG system relies fundamentally on two components: the Retriever (R) and the Generator (G), the latter representing the size and type of LLM.
RAG代表一种文本生成方法,它不仅基于训练期间学习到的模式,还依赖于动态检索的外部知识 [1]。这种方法结合了生成模型的创造力与搜索引擎的百科全书式记忆能力。RAG系统的有效性从根本上依赖于两个组件:检索器 (R) 和生成器 (G),后者代表大语言模型的规模和类型。
The language model can easily craft sentences, but it might not always have all the facts. This is where the Retriever (R) steps in, quickly sifting through vast amounts of documents to find relevant information that can be used to inform and enrich the language model's output. Think of the retriever as a researcher part of the AI, which feeds the con textually grounded text to generate knowledgeable answers to Generator (G). Without the retriever, RAG would be like a well-spoken individual who delivers irrelevant information.
语言模型能够轻松构造句子,但未必始终掌握全部事实。这时检索器 (R) 就会介入,它能快速筛选海量文档,找出可用于增强语言模型输出的相关信息。可以将检索器视为AI中的研究员角色,它为生成器 (G) 提供基于上下文的文本,从而产生知识性回答。若没有检索器,RAG系统就如同一个口若悬河却提供无关信息的人。
II. RELATED WORK
II. 相关工作
Search has been a focal point of research in information retrieval, with numerous studies exploring various methodologies. Historically, the BM25 (Best Match) algorithm, which uses similarity search, has been a cornerstone in this field, as explored by Robertson and Zaragoza (2009). [2]. BM25 prioritizes documents according to their pertinence to a query, capitalizing on Term Frequency (TF), Inverse Document Frequency (IDF), and Document Length to compute a relevance score.
搜索一直是信息检索领域的研究重点,众多研究探索了各种方法。历史上,由 Robertson 和 Zaragoza (2009) [2] 提出的 BM25 (Best Match) 算法作为相似性搜索方法,已成为该领域的基石。BM25 通过词频 (TF)、逆文档频率 (IDF) 和文档长度计算相关性得分,从而根据文档与查询的关联程度对文档进行排序。
Dense vector models, particularly those employing KNN (k Nearest Neighbours) algorithms, have gained attention for their ability to capture deep semantic relationships in data. Studies by Johnson et al. (2019) demonstrated the efficacy of dense vector representations in large-scale search applications. The kinship between data entities (including the search query) is assessed by computing the vectorial proximity (via cosine similarity etc.). During search execution, the model discerns the ’k’ vectors closest in resemblance to the query vector, hence returning the corresponding data entities as results. Their ability to transform text into vector space models, where semantic similarities can be quantitatively assessed, marks a significant advancement over traditional keywordbased approaches. [3]
密集向量模型(Dense vector models),尤其是采用KNN(k近邻)算法的模型,因其捕捉数据深层语义关系的能力而受到关注。Johnson等人(2019)的研究证明了密集向量表示在大规模搜索应用中的有效性。通过计算向量间邻近度(如余弦相似度等)来评估数据实体(包括搜索查询)之间的关联性。在执行搜索时,模型会识别与查询向量最相似的"k"个向量,从而返回对应的数据实体作为结果。这类模型能够将文本转化为向量空间模型,使语义相似度可被量化评估,这标志着对传统基于关键词方法的重大突破。[3]
On the other hand, sparse encoder based vector models have also been explored for their precision in representing document semantics. The work of Zaharia et al. (2010) illustrates the potential of these models in efficiently handling high-dimensional data while maintaining interpret ability, a challenge often faced in dense vector representations. In Sparse Encoder indexes the indexed documents, and the user’s search query maps into an extensive array of associated terms derived from a vast corpus of training data to encapsulate relationships and contextual use of concepts. The resultant expanded terms for documents and queries are encoded into sparse vectors, an efficient data representation format when handling an extensive vocabulary.
另一方面,基于稀疏编码器 (Sparse Encoder) 的向量模型也因其在表示文档语义方面的精确性而被探索。Zaharia 等人的研究 [20] 展示了这些模型在高效处理高维数据同时保持可解释性方面的潜力,这正是稠密向量表示常面临的挑战。稀疏编码器对索引文档进行处理,用户搜索查询会映射到从海量训练数据语料中衍生出的关联词项扩展数组,以此封装概念的关系和上下文使用。最终生成的文档与查询扩展词项会被编码为稀疏向量,这种高效的数据表示格式特别适合处理大规模词汇表。
A. Limitations in the current RAG system
A. 当前 RAG 系统的局限性
Most current retrieval methodologies employed in RetrievalAugmented Generation (RAG) pipelines rely on keyword and similarity-based searches, which can restrict the RAG system’s overall accuracy. Table 1 provides a summary of the current benchmarks for retriever accuracy.
当前检索增强生成 (Retrieval-Augmented Generation, RAG) 流程中使用的大多数检索方法依赖于关键词和相似性搜索,这可能会限制 RAG 系统的整体准确性。表 1 总结了当前检索器准确性的基准。
TABLE I: Current Retriever Benchmarks
表 1: 当前检索器基准测试
| Dataset | Benchmark Metrics | NDCG@10 | p@20 | F1 |
|---|---|---|---|---|
| NQDataset | P@20 | 0.633 | 86 | 79.6 |
| Trec Covid | NDCG@10 | 80.4 | ||
| HotpotQA | F1,EM | 0.85 |
While most of prior efforts in improving RAG accuracy is on G part, by tweaking LLM prompts, tuning etc.,[9] they have limited impact on the overall accuracy of the RAG system, since if R part is feeding irreverent context then answer would be inaccurate. Furthermore, most retrieval methodologies employed in RAG pipelines rely on keyword and similarity-based searches, which can restrict the system's overall accuracy.
虽然之前提高RAG (Retrieval-Augmented Generation) 准确性的努力主要集中在G部分(通过调整大语言模型提示、调优等)[9],但它们对RAG系统整体准确性的影响有限,因为如果R部分提供的上下文不相关,答案就会不准确。此外,RAG流程中采用的大多数检索方法依赖于基于关键词和相似性的搜索,这可能会限制系统的整体准确性。
Finding the best search method for RAG is still an emerging area of research. The goal of this study is to enhance retriever and RAG accuracy by incorporating Semantic Search-Based Retrievers and Hybrid Search Queries.
寻找最佳的RAG搜索方法仍是一个新兴研究领域。本研究的目标是通过结合基于语义搜索的检索器(Semantic Search-Based Retrievers)和混合搜索查询(Hybrid Search Queries)来提高检索器和RAG的准确性。
III. BLENDED RETRIEVERS
III. 混合检索器
For RAG systems, we explored three distinct search strategies: keyword-based similarity search, dense vector-based, and semantic-based sparse encoders, integrating these to formulate hybrid queries. Unlike conventional keyword matching, semantic search delves into the nuances of a user’s query, deciphering context and intent. This study systematically evaluates an array of search techniques across three primary indices: BM25 [4] for keyword-based, KNN [5] for vector-based, and Elastic Learned Sparse Encoder (ELSER) for sparse encoderbased semantic search.
对于RAG系统,我们探索了三种不同的搜索策略:基于关键词的相似性搜索、基于稠密向量的搜索以及基于语义的稀疏编码器,并将这些方法整合形成混合查询。与传统关键词匹配不同,语义搜索能够深入理解用户查询的细微差别,解析上下文和意图。本研究系统评估了三种主要索引下的多种搜索技术:基于关键词的BM25 [4]、基于向量的KNN [5]以及基于稀疏编码器语义搜索的Elastic Learned Sparse Encoder (ELSER)。
A. Methodology
A. 方法论
Our methodology unfolds in a sequence of progressive steps, commencing with the elementary match query within the BM25 index. We then escalate to hybrid queries that amalgamate diverse search techniques across multiple fields, leveraging the multi-match query within the Sparse EncoderBased Index. This method proves invaluable when the exact location of the query text within the document corpus is indeterminate, hence ensuring a comprehensive match retrieval.
我们的方法按照一系列渐进步骤展开,首先从BM25索引中的基础匹配查询开始。随后升级为混合查询,通过稀疏编码器索引(Sparse EncoderBased Index)中的多匹配查询功能,将跨多个字段的不同搜索技术相结合。当查询文本在文档库中的确切位置不确定时,这种方法能确保全面匹配检索,因此极具价值。
The multi-match queries are categorized as follows:
多匹配查询分类如下:
• Cross Fields: Targets concurrence across multiple fields
• 跨领域:目标在多个领域同时出现
After initial match queries, we incorporate dense vector (KNN) and sparse encoder indices, each with their bespoke hybrid queries. This strategic approach synthesizes the strengths of each index, channeling them towards the unified goal of refining retrieval accuracy within our RAG system. We calculate the top-k retrieval accuracy metric to distill the essence of each query type.
在初始匹配查询后,我们整合了稠密向量 (KNN) 和稀疏编码器索引,每种索引都有其定制化的混合查询。这一策略性方法综合了各类索引的优势,将其导向统一目标:提升RAG系统中的检索精度。我们通过计算top-k检索准确率指标来提炼每种查询类型的核心价值。
In Figure 1, we introduce a scheme designed to create Blended Retrievers by blending semantic search with hybrid queries.
图 1: 我们介绍了一种通过混合语义搜索与混合查询来创建混合检索器 (Blended Retriever) 的方案。
B. Constructing RAG System
B. 构建 RAG 系统
From the plethora of possible permutations, a select sextet (top 6) of hybrid queries—those exhibiting paramount retrieval efficacy—were chosen for further scrutiny. These queries were then subjected to rigorous evaluation across the benchmark datasets to ascertain the precision of the retrieval component within RAG. The sextet queries represent the culmination of retriever experimentation, embodying the synthesis of our finest query strategies aligned with various index types. The six blended queries are then fed to generative questionanswering systems. This process finds the best retrievers to feed to the Generator of RAG, given the exponential growth in the number of potential query combinations stemming from the integration with distinct index types.
从众多可能的排列组合中,我们精选出六种(前6名)混合查询方案——即展现出最高检索效能的方案——进行深入分析。这些查询随后在基准数据集上接受严格评估,以确定RAG系统中检索组件的精确度。这六种查询方案代表着检索器实验的最终成果,凝聚了我们针对不同索引类型所设计的最佳查询策略。随后,这六种混合查询被输入生成式问答系统。由于与不同索引类型集成会导致潜在查询组合数量呈指数级增长,该流程旨在为RAG的生成器(Generator)筛选最优检索方案。
The intricacies of constructing an effective RAG system are multi-fold, particularly when source datasets have diverse and complex landscapes. We undertook a comprehensive evaluation of a myriad of hybrid query formulations, scrutinizing their performance across benchmark datasets, including the Natural Questions (NQ), TREC-COVID, Stanford Question Answering Dataset (SqUAD), and HotPotQA.
构建高效RAG (Retrieval-Augmented Generation) 系统的复杂性是多方面的,尤其当源数据集具有多样化和复杂的格局时。我们对多种混合查询方案进行了全面评估,详细考察了它们在基准数据集上的表现,包括Natural Questions (NQ)、TREC-COVID、Stanford Question Answering Dataset (SqUAD) 和HotPotQA。
IV. EXPERIMENTATION FOR RETRIEVER EVALUATION
IV. 检索器评估实验
We used top-10 retrieval accuracy to narrow down the six best types of blended retrievers (index $^+$ hybrid query) for comparison for each benchmark dataset.
我们使用前10检索准确率筛选出六种最佳混合检索器(索引 $^+$ 混合查询)类型,用于各基准数据集的对比。
- Top-10 retrieval accuracy on the NQ dataset : For the NQ dataset [6], our empirical analysis has demonstrated the superior performance of hybrid query strategies, attributable to the ability to utilize multiple data fields effectively. In Figure 2, our findings reveal that the hybrid query approach employing the Sparse Encoder with Best Fields attains the highest retrieval accuracy, reaching an impressive $88.77%$ . This result surpasses the efficacy of all other formulations, establishing a new benchmark for retrieval tasks within this dataset.
- NQ数据集上的Top-10检索准确率:针对NQ数据集[6],我们的实证分析表明混合查询策略凭借有效利用多数据字段的能力展现出卓越性能。如图2所示,采用最佳字段稀疏编码器(Sparse Encoder with Best Fields)的混合查询方法达到了88.77%的最高检索准确率,该结果超越所有其他方案,为此类数据集检索任务树立了新标杆。
- Top-10 Retrieval Accuracy on TREC-Covid dataset: For the TREC-COVID dataset [7], which encompasses relevancy scores spanning from -1 to 2, with -1 indicative of irrelevance and 2 denoting high relevance, our initial assessments targeted documents with a relevancy of 1, deemed partially relevant.
TREC-Covid数据集上的Top-10检索准确率:对于包含相关性评分范围从-1到2的TREC-COVID数据集[7](其中-1表示不相关,2表示高度相关),我们最初的评估针对相关性为1(被视为部分相关)的文档。
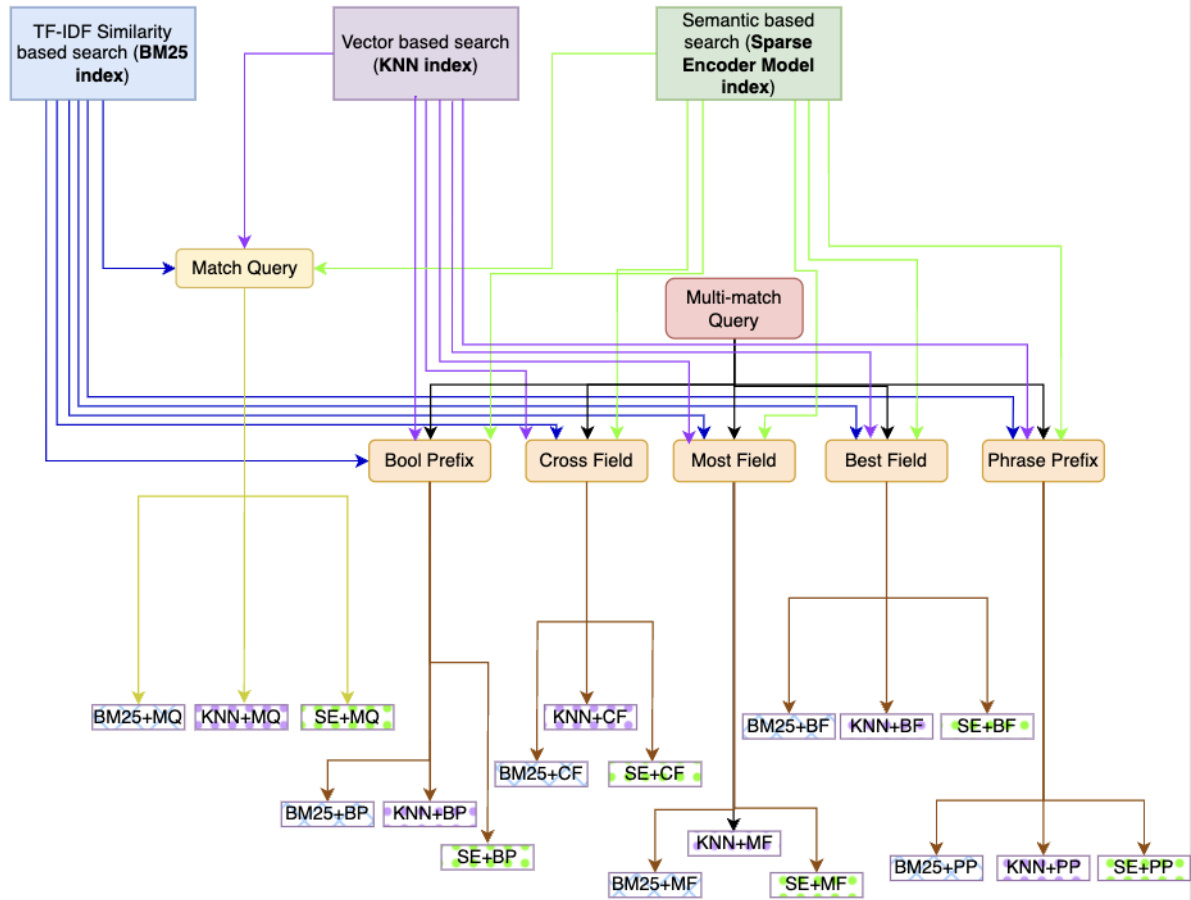
Blended Retriever Queries using Similarity and Semantic Search Indexes
图 1: 混合检索查询:相似性与语义搜索索引结合
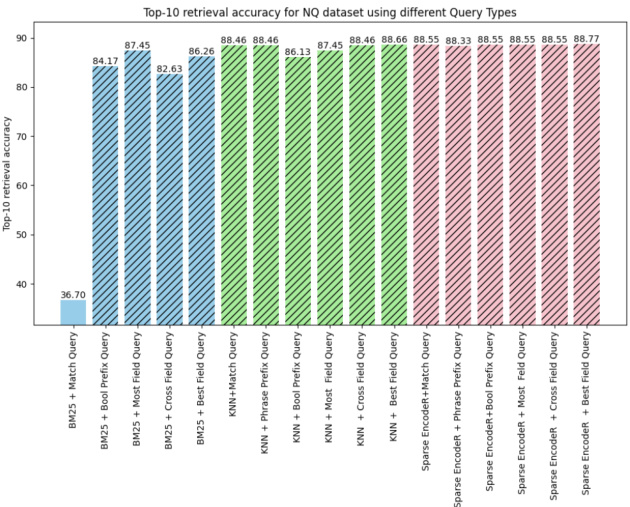
Fig. 1: Scheme of Creating Blended Retrievers using Semantic Search with Hybrid Queries.
图 1: 使用混合查询语义搜索创建混合检索器的方案。
Figure 3 analysis reveals a superior performance of vector search hybrid queries over those based on keywords. In particular, hybrid queries that leverage the Sparse EncodeR utilizing Best Fields demonstrate the highest efficacy across all index types at $78%$ accuracy.
图 3: 分析显示向量搜索混合查询的性能优于基于关键词的查询。特别地,采用最佳字段稀疏编码器 (Sparse EncodeR) 的混合查询在所有索引类型中展现出最高效能,准确率达到 $78%$。
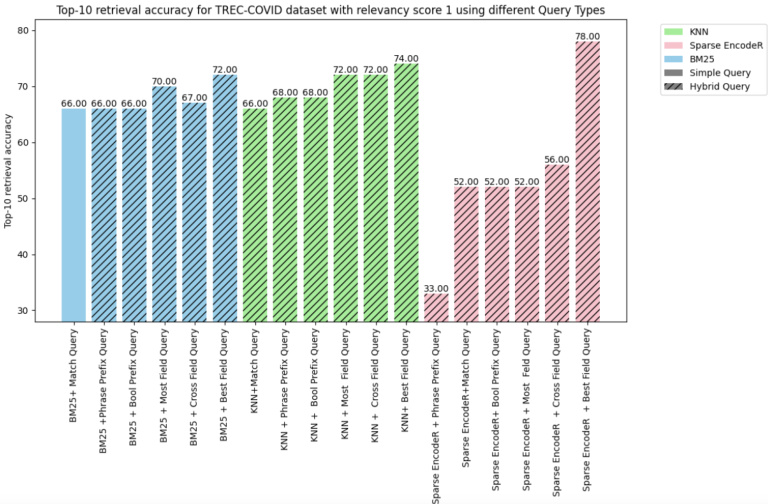
Fig. 2: Top-10 Retriever Accuracy for NQ Dataset Fig. 3: Top 10 retriever accuracy for Trec-Covid Score-1
图 2: NQ数据集Top-10检索器准确率
图 3: Trec-Covid数据集Score-1的Top 10检索器准确率
Subsequent to the initial evaluation, the same spectrum of queries was subjected to assessment against the TRECCOVID dataset with a relevancy score of 2, denoting that the documents were entirely pertinent to the associated queries. Figure 4 illustrated with a relevance score of two, where documents fully meet the relevance criteria for associated queries, reinforce the efficacy of vector search hybrid queries over conventional keyword-based methods. Notably, the hybrid query incorporating Sparse Encoder with Best Fields demonstrates a $98%$ top-10 retrieval accuracy, eclipsing all other formulations. This suggests that a methodological pivot towards more nuanced blended search, particularly those that effectively utilize the Best Fields, can significantly enhance retrieval outcomes in information retrieval (IR) systems.
在初步评估之后,同一组查询在TRECCOVID数据集上进行了相关性得分为2的评估,表明文档与相关查询完全匹配。图4展示了相关性得分为2的情况,其中文档完全符合相关查询的标准,进一步证实了向量混合搜索查询相比传统基于关键词方法的优越性。值得注意的是,结合稀疏编码器 (Sparse Encoder) 与最佳字段 (Best Fields) 的混合查询实现了98%的前10检索准确率,超越了其他所有方案。这表明,在信息检索 (IR) 系统中,向更精细的混合搜索方法(尤其是有效利用最佳字段的方案)进行策略转变,能显著提升检索效果。
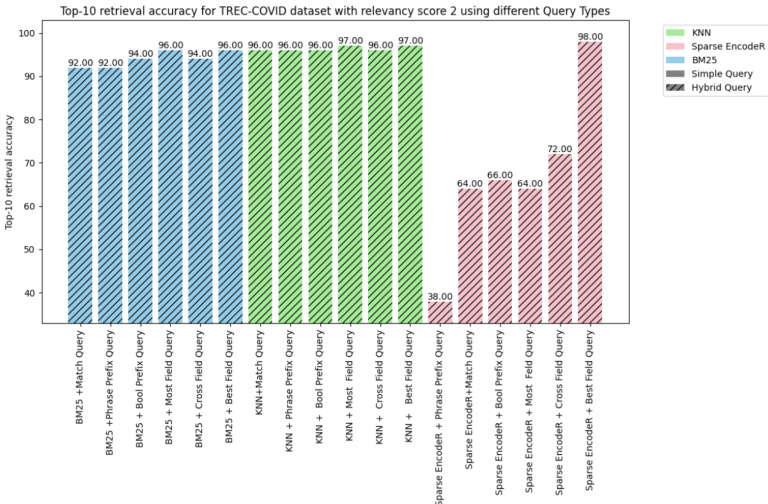
Fig. 4: Top 10 retriever accuracy for Trec-Covid Score-2
图 4: Trec-Covid Score-2 检索器准确率 Top 10
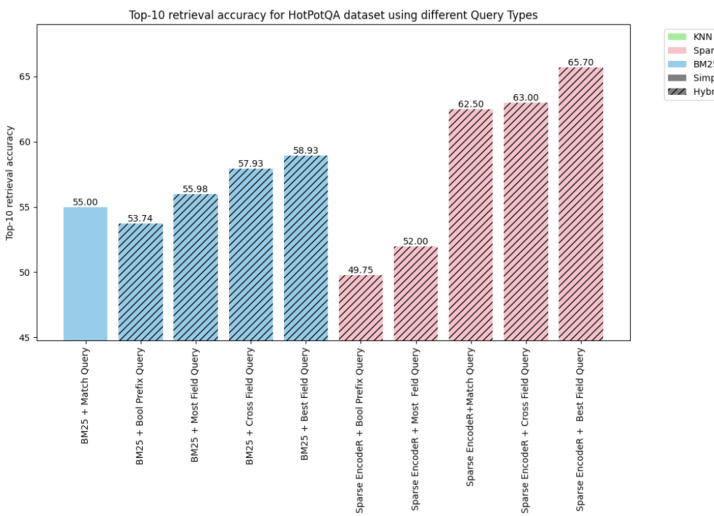
Fig. 5: Top 10 retriever accuracy for HotPotQA dataset
图 5: HotPotQA 数据集上前 10 的检索器准确率
- Top-10 Retrieval Accuracy on the HotPotQA dataset : The HotPotQA [8] dataset, with its extensive corpus of over 5M documents and a query set comprising 7,500 items, presents a formidable challenge for comprehensive evaluation due to compute requirements. Consequently, the assessment was confined to a select subset of hybrid queries. Despite these constraints, the analysis provided insightful data, as reflected in the accompanying visualization in Figure 5.
HotPotQA数据集Top-10检索准确率:HotPotQA [8] 数据集拥有超过500万篇文档的庞大语料库和包含7,500条项目的查询集,由于计算资源需求,对全面评估构成了巨大挑战。因此,评估仅限于选定的混合查询子集。尽管存在这些限制,该分析仍提供了具有洞察力的数据,如图5所示的可视化结果所反映。
Figure 5 shows that hybrid queries, specifically those utilizing Cross Fields and Best Fields search strategies, demonstrate superior performance. Notably, the hybrid query that blends Sparse EncodeR with Best Fields queries achieved the highest efficiency, of $65.70%$ on the HotPotQA dataset.
图 5 显示混合查询(特别是采用跨字段(Cross Fields)和最佳字段(Best Fields)搜索策略的查询)表现出更优性能。值得注意的是,稀疏编码器(Sparse EncodeR)与最佳字段查询相结合的混合查询在HotPotQA数据集上达到了最高效率(65.70%)。
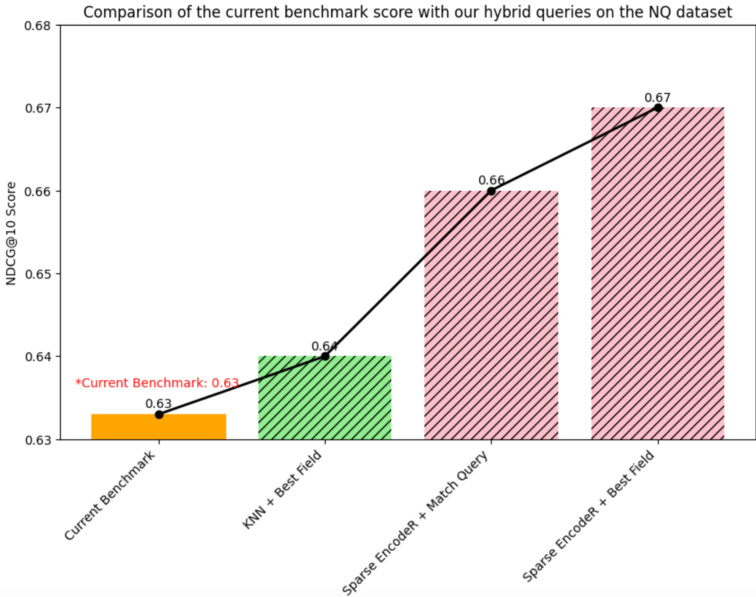
Fig. 6: NQ dataset Benchmarking using NDCG $@$ 10 Metric
图 6: 使用NDCG $@$ 10指标对NQ数据集进行基准测试
TABLE II: Retriever Benchmarking using NDCG $@$ 10 Metric
表 II: 使用 NDCG $@$ 10 指标的检索器基准测试
| 数据集 | 模型/流程 | NDCG@10 |
|---|---|---|
| Trec-covid | COCO-DR Large | 0.804 |
| Trec-covid | BlendedRAG | 0.87 |
| NQdataset | monoT5-3B | 0.633 |
| NQdataset | BlendedRAG | 0.67 |
A. Retriever Benchmarking
A. 检索器基准测试
Now that we have identified the best set of combinations of Index $^+$ Query types, we will use these sextet queries on IR datasets for benchmarking using $\mathrm{NDCG}@10$ [9] scores (Normalised Discounted Cumulative Gain metric).
现在我们已确定了索引 $^+$ 查询类型的最佳组合集,接下来将在IR数据集上使用这六种查询进行基准测试,采用 $\mathrm{NDCG}@10$ [9] 分数(归一化折损累积增益指标)作为评估标准。
- NQ dataset benchmarking: The results for $\mathrm{NDCG}@10$ using sextet queries and the current benchmark on the NQ dataset are shown in the chart Figure 7. Our pipeline provides the best $\mathrm{NDCG}@10$ score of 0.67, which is $5.8%$ higher than the current benchmark score of 0.633 achieved by the monoT5-3B model. Table II shows that all semantic searchbased hybrid queries outperform the current benchmark score, which indicates that our hybrid queries are a better candidate for developing the RAG pipeline.
- NQ数据集基准测试:使用六重查询和当前NQ数据集基准的$\mathrm{NDCG}@10$结果如图7所示。我们的流程提供了最佳的$\mathrm{NDCG}@10$得分0.67,比monoT5-3B模型实现的当前基准得分0.633高出$5.8%$。表II显示所有基于语义搜索的混合查询均优于当前基准得分,这表明我们的混合查询是开发RAG流程的更优选择。
- TREC-Covid Dataset Benchmarking : In our research, the suite of hybrid queries devised has demonstrably exceeded the current benchmark of $0.80\mathrm{NDCG}@10$ score, signaling their superior candidature for the RAG pipeline. Figure 7 shows the results for $\mathrm{NDCG}@10$ using sextet queries. Blended Retrievers achieved an $\mathrm{NDCG}@10$ score of 0.87, which marks an $8.2%$ increment over the benchmark score of 0.804 established by the COCO-DR Large model (Table II).
- TREC-Covid数据集基准测试:在我们的研究中,所设计的混合查询套件明显超过了当前0.80 NDCG@10分的基准,表明其在RAG流程中具有更优的候选资格。图7展示了使用六重查询的NDCG@10结果。混合检索器实现了0.87的NDCG@10分,比COCO-DR Large模型建立的0.804基准分数提高了8.2%(表II)。
- SqUAD Dataset Benchmarking: The SqUAD (Stanford Question Answering Dataset) [10] is not an IR dataset, but we evaluated the retrieval accuracy of the SquAD dataset for consistency. Firstly, we created a corpus from the SqUAD dataset using the title and context fields in the dataset. Then, we indexed the corpus using BM25, dense vector, and Sparse Encoder. The top-k $(\mathrm{k}{=}5,10$ , and 20) retrieval accuracy results for the SqUAD dataset are calculated. Table III illustrates that for SQuAD, dense vector (KNN)-based semantic searches achieve higher accuracy than sparse vector-based semantic searches and traditional similarity-based searches, particularly for top-k retrieval performance with $\mathrm{k\Omega}$ values of 5, 10, and 20. (See Appendix for more details)
- SqUAD数据集基准测试:SqUAD (Stanford Question Answering Dataset) [10]并非IR数据集,但为保持一致性,我们评估了SQuAD数据集的检索准确率。首先,我们利用数据集中的标题和上下文字段构建语料库。随后,分别采用BM25、稠密向量(dense vector)和稀疏编码器(Sparse Encoder)对语料库建立索引。最终计算SqUAD数据集在top-k $(\mathrm{k}{=}5,10$ 和20)情况下的检索准确率。表III显示,对于SQuAD数据集,基于稠密向量(KNN)的语义搜索相比基于稀疏向量的语义搜索和传统相似度搜索具有更高准确率,特别是在$\mathrm{k\Omega}$取值为5、10和20时的top-k检索性能表现更优 (详见附录)。

Fig. 7: TREC-Covid Dataset Benchmarking using NDCG@10 Metric
图 7: 使用NDCG@10指标的TREC-Covid数据集基准测试
B. Summary of Retriever Evaluation
B. 检索器评估总结
We evaluated the retrieval accuracy using our approach, quantified by Top-k metrics where $k\in{5,10,20}$ , across NQ, TREC-COVID, SQUAD, and CoQA datasets. This synopsis demonstrates the capability of our Blended Retrieval methodology within diverse informational contexts. Key observations are
我们通过Top-k指标(其中$k\in{5,10,20}$)在NQ、TREC-COVID、SQUAD和CoQA数据集上评估了检索准确率。该概要展示了我们混合检索(Blended Retrieval)方法在不同信息场景中的能力。关键观察包括:
V. RAG EXPERIMENTATION
V. RAG实验
From the retriever evaluation experiments, we know the best retriever, i.e., the best combination of indices $^+$ query. In this section, we extend this knowledge to evaluate the RAG pipeline. To avoid the effect of LLM size or type, we perform all experiments using FLAN-T5-XXL.
从检索器评估实验中,我们确定了最佳检索器,即最佳的索引 $^+$ 查询组合。在本节中,我们将这一认知扩展到对RAG管道的评估。为了避免大语言模型规模或类型的影响,我们所有实验均使用FLAN-T5-XXL进行。

Fig. 8: Top-5 Retrieval Accuracy across Datasets
图 8: 各数据集上的 Top-5 检索准确率
A. RAG Evaluation on the SqUAD Dataset
A. 基于SqUAD数据集的RAG评估
SqUAD is a commonly bench-marked dataset for RAG systems or Generative Q&A using LLMs. Our study juxtaposes three variations of the RAG pipeline from prior work using the evaluation metrics of Exact Match (EM) and F1 scores to gauge the accuracy of answer generation, as well as Top-5 and Top-10 for retrieval accuracy.
SqUAD是RAG系统或使用大语言模型进行生成式问答(Generative Q&A)的常用基准测试数据集。我们的研究采用精确匹配(Exact Match, EM)和F1分数作为答案生成准确性的评估指标,同时使用Top-5和Top-10衡量检索准确性,将先前工作中RAG流程的三种变体进行对比分析。
Consequently, as shown in Table IV, our Blended RAG showcases enhanced performance for Generative Q&A with F1 scores higher by $50%$ , even without dataset-specific finetuning. This characteristic is particularly advantageous for large enterprise datasets, where fine-tuning may be impractical or unfeasible, underscoring this research’s principal application.
因此,如表 IV 所示,我们的 Blended RAG 在生成式问答 (Generative Q&A) 中展现出更强的性能,F1 分数高出 $50%$,且无需针对特定数据集进行微调。这一特性对于大型企业数据集尤为有利,因为在这些场景中微调可能不切实际或不可行,这也凸显了本研究的主要应用方向。
B. RAG Evaluation on the NQ Dataset
B. 在NQ数据集上的RAG评估
Natual Questions (NQ) is another commonly studied dataset for RAG. The Blended RAG pipeline, utilizing zero-shot learning, was evaluated to ascertain its efficacy against other nonfine-tuned models. The assessment focused on the following metrics: Exact Match (EM), F1 Score, and retrieval accuracy (Top-5 and Top-20) in Table V.
Natual Questions (NQ) 是另一个常用于RAG研究的数据集。为评估Blended RAG流水线在零样本学习下的效能,研究者将其与其他未微调模型进行对比。评估指标包括:精确匹配(EM)、F1分数以及表V中列出的检索准确率(Top-5和Top-20)。
Blended RAG (Zero-shot): Demonstrated superior performance with an EM of 42.63, improving the prior benchmark by $35%$ .
混合检索增强生成 (Blended RAG,零样本):表现出卓越性能,EM值达42.63,将先前基准提升了35%。
TABLE IV: Evaluation of the RAG Pipeline on the SquAD Dataset
表 IV: 基于SQuAD数据集的RAG流程评估
| SQuAD | BM25+MQ | BM25+BF | KNN+MQ | KNN+BF | SPARSE ENCODER+MQ | SPARSE ENCODER+BF |
|---|---|---|---|---|---|---|
| Top-5 | 91.5 | 91.52 | 94.86 | 94.89 | 90.7 | 90.7 |
| Top-10 | 94.43 | 94.49 | 97.43 | 97.43 | 94.13 | 94.16 |
| Top-20 | 96.3 | 96.36 | 98.57 | 98.58 | 96.49 | 96.52 |
TABLE V: Evaluation of the RAG pipeline on the NQ dataset
表 V: NQ数据集上RAG管道的评估
| 模型/管道 | EM | F1 | Top-5 | Top-20 |
|---|---|---|---|---|
| RAG-original | 28.12 | 39.42 | 59.64 | 72.38 |
| RAG-end2end | 40.02 | 52.63 | 75.79 | 85.57 |
| Blended RAG | 57.63 | 68.4 | 94.89 | 98.58 |
VI. DISCUSSION
VI. 讨论
While RAG is a commonly used approach in the industry, we realized during the course of this study that various challenges still exist, like there are no standard datasets on which both R (Retriever) and RAG benchmarks are available. Retriever is often studied as a separate problem in the IR domain, while RAG is studied in the LLM domain. We thus attempted to bring synergy between the two domains with this work. In this section, we share some learning on limitations and appropriate use of this method.
虽然RAG是业界常用的方法,但我们在研究过程中发现仍存在诸多挑战,例如缺乏同时包含检索器(R)和RAG基准测试的标准数据集。检索器通常作为信息检索(IR)领域的独立问题进行研究,而RAG则属于大语言模型(LLM)领域的研究范畴。因此,我们尝试通过这项工作实现两个领域的协同。本节将分享关于该方法局限性与适用场景的发现。
TABLE III: Blended Retriever Performance SqUAD Dataset
表 III: 混合检索器在SqUAD数据集上的性能
| COQA | BM25+MQ | BM25+BF | KNN+MQ | KNN+BF | SE+MQ | SE+BF |
|---|---|---|---|---|---|---|
| Top-5 | 45.3 | 45.3 | 47.56 | 47.56 | 49.94 | 49.94 |
A. Trade-off between Sparse and Dense Vector Indices
A. 稀疏向量索引与稠密向量索引的权衡
TABLE VI: Top-5 retrieval accuracy CoQA Dataset
表 VI: CoQA数据集Top-5检索准确率
| 模型/流程 | EM | F1 | Top-5 | Top-20 |
|---|---|---|---|---|
| GLaM (Oneshot)[13] | 26.3 | |||
| GLaM (Zeroshot)[13] | 24.7 | |||
| PaLM540B (Oneshot)[14] | 29.3 | |||
| BlendedRAG G (Zero-shot) | 42.63 | 53.96 | 88.22 | 88.88 |
The HotPotQA corpus presents substantial computational challenges with 5M documents, generating a dense vector index to an approximate size of 50GB, a factor that significantly hampers processing efficiency. Dense vector indexing, characterized by its rapid indexing capability, is offset by a relatively sluggish querying performance. Conversely, sparse vector indexing, despite its slower indexing process, offers expeditious querying advantages. Furthermore, a stark contrast in storage requirements is observed; for instance, the sparse vector index of the HotPotQA corpus occupied a mere 10.5GB as opposed to the 50GB required for the dense vector equivalent.
HotPotQA语料库因包含500万份文档而带来巨大的计算挑战,生成的密集向量索引(dense vector index)体积约达50GB,这一因素严重制约了处理效率。密集向量索引以快速构建为特点,却存在查询性能相对迟缓的缺陷。相比之下,稀疏向量索引(sparse vector index)虽然构建过程较慢,但具备查询速度快的优势。此外,两者存储需求差异显著:例如HotPotQA语料库的稀疏向量索引仅占用10.5GB空间,而同等条件下的密集向量索引需要50GB。
In such cases, we recommend sparse encoder indexes. Furthermore, for enterprises with this volume, we found it better to use multi-tenancy with federated search queries.
在这种情况下,我们推荐使用稀疏编码器索引 (sparse encoder indexes) 。此外,对于这种规模的企业,我们发现采用支持联合搜索查询 (federated search queries) 的多租户方案效果更佳。
B. Blended Retrievers without Metadata
B. 无元数据的混合检索器
When datasets are enriched with metadata or other relevant informational facets, they improve the efficacy of blended retrievers. Conversely, for datasets devoid of metadata, such as $\mathrm{CoQA}$ , it is not as impressive. You can see the results in Table VI.
当数据集通过元数据(metadata)或其他相关信息层面得到增强时,混合检索器的效能会有所提升。相反,对于缺乏元数据的数据集(如$\mathrm{CoQA}$),效果则不尽如人意。具体结果可参见表VI。
The absence of metadata in the CoQA dataset resulted in hybrid queries offering no improvement over basic queries. This limitation underscores the critical role of metadata in enhancing the efficacy of complex query structures. However, Sparse Encoder-based semantic searches still yield the most favorable outcomes than traditional methods.
CoQA数据集中元数据的缺失导致混合查询相比基础查询毫无改进。这一局限凸显了元数据在提升复杂查询结构效能方面的关键作用。不过基于稀疏编码器(Sparse Encoder)的语义搜索仍比传统方法获得更优结果。
Additionally, we would like to note that while NDCG $@$ 10 scores for Retriever and F1,EM scores for RAG are commonly used metrics, we found them to be poor proxies of Generative Q&A systems for human alignment. Better metrics to evaluate the RAG system is a key area of future work.
此外,我们注意到,虽然检索器(Retriever)的NDCG$@$10分数以及RAG的F1、EM分数是常用指标,但我们发现这些指标难以有效衡量生成式问答系统(Generative Q&A)与人类偏好的一致性。开发更优的RAG系统评估指标是未来工作的重点方向。
VII. CONCLUSION
VII. 结论
Blended RAG pipeline is highly effective across multiple datasets despite not being specifically trained on them. Notably, this approach does not necessitate exemplars for prompt engineering which are often required in few-shot learning, indicating a robust generalization capability within the zeroshot paradigm. This study demonstrated:
混合RAG (Retrieval-Augmented Generation) 管道在多个数据集上表现出色,尽管并未针对这些数据集进行专门训练。值得注意的是,该方法无需像少样本学习那样依赖提示工程中的示例,表明其在零样本范式下具备强大的泛化能力。本研究证实:
• Optimization of R with Blended Search: Incorporating Semantic Search, specifically Sparse Encoder indices coupled with ’Best Fields’ queries, has emerged as the superior construct across all, setting a new benchmark of $87%$ for Retriever Accuracy on TREC-COVID. • Enhancement of RAG via Blended Retrievers: The significant amplification in retrieval accuracy is particularly pronounced for the overall evaluation of the RAG pipeline, surpassing prior benchmarks on fine-tuned sets by a wide margin. Blended RAG sets a new benchmark at $68%$ F1 Score on SQUAD and $42%$ EM Score on NQ dataset; for non-tuned Q&A systems.
• 混合搜索优化R:结合语义搜索(特别是稀疏编码器索引与"最佳字段"查询)已成为所有方法中的最优架构,在TREC-COVID上创造了检索准确率87%的新基准。
• 通过混合检索器增强RAG:检索准确率的显著提升对RAG管道的整体评估尤为明显,大幅超越先前在微调数据集上的基准。混合RAG在SQUAD上创造了68%的F1分数新基准,在NQ数据集上达到42%的EM分数(针对未调优的问答系统)。
The empirical findings endorse the potency of Blended Retrievers in refining RAG systems beyond focusing on LLM size & type, getting better results with relatively smaller LLM and thus setting a foundation for more intelligent and con textually aware Generative Q&A systems.
实证研究结果证实了混合检索器(Blended Retrievers)在提升RAG系统效能方面的强大作用,其优势不仅体现在对大语言模型规模和类型的优化上,还能通过相对较小的大语言模型获得更优效果,从而为构建更智能、更具上下文感知能力的生成式问答系统奠定基础。