SIMTEG: A FRUSTRATINGLY SIMPLE APPROACH IM- PROVES TEXTUAL GRAPH LEARNING
SIMTEG: 一种简单到令人沮丧却提升文本图学习的方法
ABSTRACT
摘要
Textual graphs (TGs) are graphs whose nodes correspond to text (sentences or documents), which are widely prevalent. The representation learning of TGs involves two stages: $(i)$ unsupervised feature extraction and $(i i)$ supervised graph representation learning. In recent years, extensive efforts have been devoted to the latter stage, where Graph Neural Networks (GNNs) have dominated. However, the former stage for most existing graph benchmarks still relies on traditional feature engineering techniques. More recently, with the rapid development of language models (LMs), researchers have focused on leveraging LMs to facilitate the learning of TGs, either by jointly training them in a computationally intensive framework (merging the two stages), or designing complex self-supervised training tasks for feature extraction (enhancing the first stage). In this work, we present SimTeG, a frustratingly Simple approach for Textual Graph learning that does not innovate in frameworks, models, and tasks. Instead, we first perform supervised parameterefficient fine-tuning (PEFT) on a pre-trained LM on the downstream task, such as node classification. We then generate node embeddings using the last hidden states of finetuned LM. These derived features can be further utilized by any GNN for training on the same task. We evaluate our approach on two fundamental graph representation learning tasks: node classification and link prediction. Through extensive experiments, we show that our approach significantly improves the performance of various GNNs on multiple graph benchmarks. Remarkably, when additional supporting text provided by large language models (LLMs) is included, a simple two-layer GraphSAGE trained on an ensemble of SimTeG achieves an accuracy of $77.48%$ on OGBN-Arxiv, comparable to state-of-the-art (SOTA) performance obtained from far more complicated GNN architectures. Furthermore, when combined with a SOTA GNN, we achieve a new SOTA of $78.04%$ on OGBN-Arxiv. Our code is publicly available at https://github.com/vermouth d ky/SimTeG and the generated node features for all graph benchmarks can be accessed at https: //hugging face.co/datasets/vermouth d ky/SimTeG.
文本图 (TGs) 是由文本(句子或文档)作为节点构成的图结构,其应用场景极为广泛。文本图表征学习包含两个阶段:$(i)$ 无监督特征提取和$(i i)$ 有监督图表征学习。近年来学界对后一阶段投入了大量研究,其中图神经网络 (GNNs) 已成为主流方法。然而在现有图基准测试中,前一阶段仍主要依赖传统特征工程技术。随着语言模型 (LMs) 的快速发展,研究者开始探索如何利用语言模型优化文本图学习——要么通过计算密集型框架将两个阶段联合训练,要么设计复杂的自监督任务来增强特征提取阶段。
本文提出SimTeG,这是一种极其简单的文本图学习方法,其创新性不在于框架、模型或任务设计。我们首先对预训练语言模型进行参数高效微调 (PEFT) 以适应下游任务(如节点分类),然后利用微调后模型的最后隐状态生成节点嵌入特征。这些衍生特征可被任意GNN模型用于相同任务的训练。我们在节点分类和链接预测两个基础图表征学习任务上评估了该方法。大量实验表明,该方法能显著提升多种GNN模型在多个图基准测试中的性能。值得注意的是,当结合大语言模型 (LLMs) 提供的辅助文本时,基于SimTeG特征训练的简单两层GraphSAGE在OGBN-Arxiv数据集上达到了$77.48%$的准确率,与复杂GNN架构取得的当前最优 (SOTA) 性能相当。进一步与SOTA GNN结合后,我们在OGBN-Arxiv上创造了$78.04%$的新SOTA记录。代码已开源:https://github.com/vermouthdky/SimTeG,所有图基准测试生成的节点特征可从https://huggingface.co/datasets/vermouthdky/SimTeG获取。
1 INTRODUCTION
1 引言
Textual Graphs (TGs) offer a graph-based representation of text data where relationships between phrases, sentences, or documents are depicted through edges. TGs are ubiquitous in real-world applications, including citation graphs (Hu et al., 2020; Yang et al., 2016), knowledge graphs (Wang et al., 2021), and social networks (Zeng et al., 2019; Hamilton et al., 2017), provided that each entity can be represented as text. Different from traditional NLP tasks, instances in TGs are correlated with each other, which provides non-trivial and specific information for downstream tasks. In general, graph benchmarks are usually task-specific (Hu et al., 2020), and most TGs are designed for two fundamental tasks: node classification and link prediction. For the first one, we aim to predict the category of unlabeled nodes while for the second one, our goal is to predict missing links among nodes. For both tasks, text attributes offer critical information.
文本图 (Textual Graphs, TGs) 通过边来刻画短语、句子或文档间的关系,为文本数据提供基于图的表示形式。只要实体能以文本形式呈现,TGs 便广泛存在于现实应用中,包括引文网络 (Hu et al., 2020; Yang et al., 2016)、知识图谱 (Wang et al., 2021) 和社交网络 (Zeng et al., 2019; Hamilton et al., 2017)。与传统 NLP 任务不同,TGs 中的实例相互关联,这为下游任务提供了独特且具体的信息。通常,图基准测试 (graph benchmarks) 具有任务特定性 (Hu et al., 2020),多数 TGs 针对两个基础任务设计:节点分类和链接预测。前者旨在预测未标注节点的类别,后者则用于预测节点间缺失的链接。在这两类任务中,文本属性都承载着关键信息。
In recent years, TG representation learning follows a two-stage paradigm: (i) upstream: unsupervised feature extraction that encodes text into numeric embeddings, and $(i i)$ downstream: supervised graph representation learning that further transform the embeddings utilizing the graph structure. While Graph Neural Networks (GNNs) have dominated the latter stage, with an extensive body of academic research published, the former stage surprisingly still relies on traditional feature engineering techniques. For example, in most existing graph benchmarks (Hu et al., 2020; Yang et al., 2016; Zeng et al., 2019), node features are constructed using bag-of-words (BoW) or skipgram (Mikolov et al., 2013). This intuitively limits the performance of downstream GNNs, as it fails to fully capture textual semantics, fostering an increasing number of GNN models with more and more complex structures. More recently, researchers have begun to leverage the power of language models (LMs) for TG representation learning. Their efforts involve $(i)$ designing complex tasks for LMs to generate powerful node representations (Chien et al., 2021); $(i i)$ jointly training LMs and GNNs in a specific framework (Zhao et al., 2022; Mavromatis et al., 2023); or $(i i i)$ fusing the architecture of LM and GNN for end-to-end training (Yang et al., 2021). These works focus on novel training tasks, model architectures, or training frameworks, which generally require substantially modifying the training procedure. However, we argue that such complexity is not actually needed. As a response, in this paper, we present a frustratingly simple yet highly effective method that does not innovate in any of the above aspects but significantly improves the performance of GNNs on TGs.
近年来,TG (Textual Graph) 表示学习遵循两阶段范式:(i) 上游:通过无监督特征提取将文本编码为数值嵌入,以及 (ii) 下游:利用图结构对嵌入进行进一步转换的监督式图表示学习。虽然图神经网络 (GNNs) 主导了后一阶段,并有大量学术研究发表,但前一阶段仍依赖传统的特征工程技术。例如,在大多数现有图基准测试中 [Hu et al., 2020; Yang et al., 2016; Zeng et al., 2019],节点特征是使用词袋 (BoW) 或 skipgram [Mikolov et al., 2013] 构建的。这直观地限制了下游 GNNs 的性能,因为它无法充分捕捉文本语义,从而催生了越来越多结构日益复杂的 GNN 模型。最近,研究者开始利用语言模型 (LMs) 的力量进行 TG 表示学习。他们的工作包括 (i) 设计复杂任务让 LMs 生成强大的节点表示 [Chien et al., 2021];(ii) 在特定框架中联合训练 LMs 和 GNNs [Zhao et al., 2022; Mavromatis et al., 2023];或 (iii) 融合 LM 和 GNN 的架构进行端到端训练 [Yang et al., 2021]。这些研究聚焦于新颖的训练任务、模型架构或训练框架,通常需要对训练流程进行大幅修改。然而,我们认为这种复杂性并非必需。作为回应,本文提出了一种极其简单却高效的方法,它无需在上述任何方面进行创新,却能显著提升 GNNs 在 TGs 上的性能。
We are curious about several research questions: (i) How much could language models’ features generally improve the learning of GNN: is the improvement specific for certain GNNs? $(i i)$ What kind of language models fits the needs of textual graph representation learning best? (iii) How important are text attributes on various graph tasks: though previous efforts have shown improvement in node classification, is it also beneficial for link prediction, an equivalently fundamental task that intuitively emphasizes more on graph structures? To the end of answering the above questions, we take an initial step forwards by introducing a simple, effective, yet surprisingly neglected method on TGs and empirically evaluating it on two fundamental graph tasks: node classification and link prediction. Intuitively, when omitting the graph structures, the two tasks are equivalent to text classification and text similarity (retrieval) tasks in NLP, respectively. This intuition motivates us to propose our method: SimTeG. We first parameter-efficiently finetune (PEFT) an LM on the textual corpus of a TG with task-specific labels and then use the finetuned LM to generate node representations given its text by removing the head layer. Afterward, a GNN is trained with the derived node embeddings on the same downstream task for final evaluation. Though embarrassingly simple, SimTeG shows remarkable performance on multiple graph benchmarks w.r.t. node classification and link prediction. Particularly, we find several key observations:
我们关注以下几个研究问题:(i) 语言模型特征能在多大程度上普遍提升GNN学习效果:这种提升是否针对特定GNN架构?$(ii)$哪种语言模型最适合文本图表示学习?(iii) 文本属性在不同图任务中的重要性:虽然前人研究已证明其在节点分类上的改进,但对于同样基础且更强调图结构的链接预测任务是否也有益?
为回答上述问题,我们迈出第一步:针对文本图提出一种简单有效却被惊人忽视的方法SimTeG,并在节点分类和链接预测两个基础图任务上进行实证评估。直观而言,当忽略图结构时,这两个任务分别等价于NLP中的文本分类和文本相似性(检索)任务。这一直觉促使我们提出SimTeG方法:首先通过参数高效微调(PEFT)使语言模型适配特定任务的文本图语料,然后移除头部层,用微调后的语言模型生成节点文本表示,最后基于所得节点嵌入训练GNN进行最终评估。
尽管方法极为简洁,SimTeG在多个节点分类和链接预测基准测试中展现出卓越性能。我们特别发现几个关键现象:
❶ Good language modeling could generally improve the learning of GNNs on both node classification and link prediction. We evaluate SimTeG on three prestigious graph benchmarks for either node classification or link prediction, and find that SimTeG consistently outperforms the official features and the features generated by pretrained LMs (without finetuning) by a large margin. Notably, backed with SOTA GNN, we achieve new SOTA performance of $78.02%$ on OGBN-Arxiv. See Sec. 5.1 and Appendix A1 for details.
❶ 良好的语言建模通常能提升图神经网络 (GNN) 在节点分类和链接预测任务中的学习效果。我们在三个权威图基准测试 (分别针对节点分类和链接预测) 上评估 SimTeG,发现其性能显著优于官方特征和预训练语言模型 (未经微调) 生成的特征。值得注意的是,结合当前最先进的图神经网络,我们在 OGBN-Arxiv 数据集上取得了 78.02% 的最新最优性能。详见第 5.1 节和附录 A1。
$\pmb{\phi}$ SimTeG significantly complements the margin between GNN backbones on multiple graph benchmarks by improving the performance of simple GNNs. Notably, a simple two-layer GraphSAGE (Hamilton et al., 2017) trained on SimTeG with proper LM backbones achieves on-par SOTA performance of $77.48%$ on OGBN-Arxiv (Hu et al., 2020).
$\pmb{\phi}$ SimTeG通过提升简单GNN的性能,显著弥补了多个图基准测试中GNN骨干网络间的差距。值得注意的是,采用合适的大语言模型作为骨干时,基于SimTeG训练的双层GraphSAGE (Hamilton et al., 2017) 在OGBN-Arxiv (Hu et al., 2020) 数据集上达到了与当前最优方法持平的77.48%性能。
$\pmb{\theta}$ PEFT are crucial when finetuning LMs to generate representative embeddings, because fullfinetuning usually leads to extreme over fitting due to its large parameter space and the caused fitting ability. The over fitting in the LM finetuning stage will hinder the training of downstream GNNs with a collapsed feature space. See Sec. 5.3 for details.
$\pmb{\theta}$ PEFT在微调大语言模型生成代表性嵌入时至关重要,因为全参数微调通常会因其庞大的参数空间和由此产生的拟合能力而导致严重的过拟合。大语言模型微调阶段的过拟合会阻碍下游GNN的训练,导致特征空间坍缩。详见第5.3节。
$\pmb{\mathscr{Q}}$ SimTeG is moderately sensitive to the selection of LMs. Generally, the performance of SimTeG is positively correlated with the corresponding LM’s performance on text embedding tasks, e.g. classification and retrieval. We refer to Sec. 5.4 for details. Based on this, we expect further improvement of SimTeG once more powerful LMs for text embedding are available.
$\pmb{\mathscr{Q}}$ SimTeG对语言模型(LM)的选择具有中等敏感性。通常,SimTeG的性能与对应LM在文本嵌入任务(如分类和检索)中的表现呈正相关,详见第5.4节。基于此,我们预期当更强大的文本嵌入大语言模型可用时,SimTeG将获得进一步改进。
2 RELATED WORKS
2 相关工作
In this section, we first present several works that are closely related to ours and further clarify several concepts and research lines that are plausibly related to ours in terms of similar terminology.
在本节中,我们首先介绍几项与我们的工作密切相关的研究,并进一步澄清几个在类似术语上可能与我们的研究相关的概念和研究方向。
Leveraging LMs on TGs. Focusing on leveraging the power of LMs to TGs, there are several works that are existed and directly comparable with ours. For these works, they either focus on (i) designing specific strategies to generate node embeddings using LMs (He et al., 2023; Chien et al., 2021) or (ii) jointly training LMs and GNNs within a framework (Zhao et al., 2022; Mavromatis et al., 2023). Representative ly, for the former one, Chien et al. (2021) proposed a self-supervised graph learning task integrating XR-Transformers (Zhang et al., 2021b) to extract node representation, which shows superior performance on multiple graph benchmarks, validating the necessity for acquiring high-quality node features for attributed graphs. Besides, He et al. (2023) utilizes ChatGPT (OpenAI, 2023) to generate additional supporting text with LLMs. For the latter mechanism, Zhao et al. (2022) proposed a variation al expectation maximization joint-training framework for LMs and GNNs to learn powerful graph representations. Mavromatis et al. (2023) designs a graph structure-aware framework to distill the knowledge from GNNs to LMs. Generally, the joint-training framework requires specific communication between LMs and GNNs, e.g. pseudo labels (Zhao et al., 2022) or hidden states (Mavromatis et al., 2023). It is worth noting that the concurrent work He et al. (2023) proposed a close method to ours. However, He et al. (2023) focuses on generating additional informative texts for nodes with LLMs, which is specifically for citation networks on node classification task. In contrast, we focus on generally investigating the effectiveness of our proposed method, which could be widely applied to unlimited datasets and tasks. Utilizing the additional text provided by He et al. (2023), we further show that our method could achieve now SOTA on OGBN-Arxiv. In addition to the main streams, there are related works trying to fuse the architecture of LM and GNN for end-to-end training. Yang et al. (2021) proposed a nested architecture by injecting GNN layers into LM layers. However, due to the natural incompatible ness regarding training batch size, this architecture only allows 1-hop message passing, which significantly reduce the learning capability of GNNs.
在大语言模型 (Large Language Model) 上利用文本图 (Text Graph)。关于如何利用大语言模型处理文本图,已有若干可直接对标的研究工作。这些研究主要聚焦于:(i) 设计特定策略通过大语言模型生成节点嵌入 (He et al., 2023; Chien et al., 2021);(ii) 在统一框架中联合训练大语言模型与图神经网络 (Zhao et al., 2022; Mavromatis et al., 2023)。典型地,Chien et al. (2021) 提出集成 XR-Transformer (Zhang et al., 2021b) 的自监督图学习任务来提取节点表示,该方案在多个图基准测试中展现出优越性能,验证了获取高质量属性图节点特征的必要性。此外,He et al. (2023) 利用 ChatGPT (OpenAI, 2023) 通过大语言模型生成辅助文本。对于联合训练机制,Zhao et al. (2022) 提出变分期望最大化联合训练框架来学习强表征,Mavromatis et al. (2023) 则设计了图结构感知框架来实现从图神经网络到大语言模型的知识蒸馏。这类框架通常需要特定交互机制,例如伪标签 (Zhao et al., 2022) 或隐藏状态 (Mavromatis et al., 2023)。值得注意的是,同期研究 He et al. (2023) 提出了与本文高度相似的方法,但其聚焦于通过大语言模型为节点生成辅助文本,且仅针对引文网络的节点分类任务。相比之下,本文着力于验证所提方法的普适有效性,可广泛应用于各类数据集与任务。实验表明,结合 He et al. (2023) 生成的辅助文本后,我们的方法在 OGBN-Arxiv 数据集上达到了当前最优水平。除主流方法外,亦有研究尝试融合大语言模型与图神经网络的架构进行端到端训练。Yang et al. (2021) 提出通过在大语言模型层中嵌入图神经网络层来实现嵌套架构,但由于训练批次大小的天然限制,该架构仅支持单跳信息传递,严重制约了图神经网络的学习能力。
More “Related” Works. ❶ Graph Transformers (Wu et al., 2021; Ying et al., 2021; Hussain et al., 2022; Park et al., 2022; Chen et al., 2022): Nowadays, Graph Transformers are mostly used to denote Transformer-based architectures that embed both topological structure and node features. Different from our work, these models focus on graph-level problems (e.g. graph classification and graph generation) and specific domains (e.g. molecular datasets and protein association networks), which cannot be adopted on TGs. ❷ Leveraging GNNs on Texts (Zhu et al., 2021; Huang et al., 2019; Zhang et al., 2020): Another seemingly related line on integrating GNNs and LMs is conversely applying GNNs to textual documents. Different from TGs, GNNs here do not rely on ground-truth graph structures but the self-constructed or synthetic ones.
更多"相关"工作。❶ 图Transformer (Wu et al., 2021; Ying et al., 2021; Hussain et al., 2022; Park et al., 2022; Chen et al., 2022): 当前,图Transformer主要用于表示同时嵌入拓扑结构和节点特征的Transformer架构。与我们的工作不同,这些模型聚焦于图级别问题(如: 图分类和图生成)和特定领域(如: 分子数据集和蛋白质关联网络),无法直接应用于时序图(TGs)。❷ 文本上的图神经网络应用 (Zhu et al., 2021; Huang et al., 2019; Zhang et al., 2020): 另一类看似相关的研究方向是将图神经网络反向应用于文本文档。与时序图不同,这类方法不依赖真实图结构,而是使用自构建或合成的图结构。
3 PRELIMINARIES
3 预备知识
Notations. To make notations consistent, we use bold uppercase letters to denote matrices and vectors, and calligraphic font types (e.g. $\tau$ ) to denote sets. We denote a textual graph as a set $\mathcal{G}=(\mathcal{V},\mathcal{E},\mathcal{T})$ , where $\nu$ and $\mathcal{E}$ are a set of nodes and edges, respectively. $\tau$ is a set of text and each textual item is aligned with a node $v\in\nu$ . For practical usage, we usually rewrite $\mathcal{E}$ into $\mathbf{A}\in{0,1}^{|\mathcal{V}|\times|\mathcal{V}|}$ , which is a sparse matrix, where entry $\mathbf{A}{i,j}$ denotes the link between node $v{i},v_{j}\in\mathcal{V}$ .
符号说明。为保持符号一致,我们使用粗体大写字母表示矩阵和向量,使用花体字体(如 $\tau$)表示集合。我们将文本图表示为集合 $\mathcal{G}=(\mathcal{V},\mathcal{E},\mathcal{T})$,其中 $\nu$ 和 $\mathcal{E}$ 分别表示节点和边的集合。$\tau$ 是文本集合,每个文本项与节点 $v\in\nu$ 对齐。实际应用中,我们通常将 $\mathcal{E}$ 重写为稀疏矩阵 $\mathbf{A}\in{0,1}^{|\mathcal{V}|\times|\mathcal{V}|}$,其中元素 $\mathbf{A}{i,j}$ 表示节点 $v{i},v_{j}\in\mathcal{V}$ 之间的连接关系。
Problem Formulations. We focus on two fundamental tasks in TGs: $(i)$ node classification and $(i i)$ link prediction. For node classification, given a TG $\mathcal{G}$ , we aim to learn a model $\Phi:\mathcal{V}\to\mathcal{V}$ , where $\mathcal{V}$ is the ground truth labels. For link prediction, given a TG $\mathcal{G}$ , we aim to learn a model $\Phi:\mathcal{V}\times\mathcal{V}\to{\bar{0,1}}$ , where $f(v_{i},v_{j})=1$ if there is a link between $v_{i}$ and $v_{j}$ , otherwise $f(v_{i},v_{j})=0$ Different from traditional tasks that are widely explored by the graph learning community, evolving original text into learning is non-trivial. Particularly, when ablating the graphs structure, node classification and link prediction problem are collapsed to text classification and text similarity problem, respectively. This sheds light on how to leverage LMs for TG representation learning.
问题定义。我们聚焦于时序图(TGs)中的两个基础任务:$(i)$ 节点分类和$(ii)$ 链接预测。对于节点分类任务,给定时序图$\mathcal{G}$,我们的目标是学习模型$\Phi:\mathcal{V}\to\mathcal{V}$,其中$\mathcal{V}$表示真实标签。对于链接预测任务,给定时序图$\mathcal{G}$,我们旨在学习模型$\Phi:\mathcal{V}\times\mathcal{V}\to{\bar{0,1}}$,当节点$v_{i}$与$v_{j}$之间存在链接时$f(v_{i},v_{j})=1$,否则$f(v_{i},v_{j})=0$。与图学习社区广泛研究的传统任务不同,将原始文本演化至学习过程具有显著挑战性。特别地,当消融图结构时,节点分类和链接预测问题将分别退化为文本分类和文本相似度问题,这为如何利用大语言模型进行时序图表征学习提供了启示。
Node-level Graph Neural Networks. Nowadays, GNNs have dominated graph-related tasks. Here we focus on GNN models working on node-level tasks (i.e. node classification and link prediction). These models work on generating node representations by recursively aggregating features from their multi-hop neighbors, which is usually noted as message passing. Generally, one can formulate a graph convolution layer as: $X_{l+1}=\Psi_{l}(C X_{l})$ , where $_C$ is the graph convolution matrix (e.g. $C=D^{-1/2}A D^{-1/2}$ in Vanilla GCN (Kipf & Welling, 2016)) and $\Psi_{l}$ is the feature transformation matrix. For the node classification problem, a classifier (e.g., an MLP) is usually appended to the output of a $k$ -layer GNN model; while for link prediction, a similarity function is applied to the final output to compute the similarity between two node embeddings. As shown above, as GNNs inherently evolve the whole graph structure for convolution, it is notoriously challenging for scaling it up. It is worth noting that evolving sufficient neighbors during training is crucial for GNNs. Many studies (Duan et al., 2022; Zou et al., 2019) have shown that full-batch training generally outperforms mini-batch for GNNs on multi graph benchmarks. In practice, the lower borderline of batch size for training GNNs is usually thousands. However, when applying it to LMs, it makes the GNN-LM end-to-end training intractable, as a text occupies far more GPU memories than an embedding.
节点级图神经网络 (Node-level Graph Neural Networks)。当前,GNN已成为图相关任务的主流方法。本文聚焦于处理节点级任务(即节点分类和链接预测)的GNN模型。这类模型通过递归聚合多跳邻居特征来生成节点表征,该过程通常称为消息传递 (message passing)。一般而言,图卷积层可表示为:$X_{l+1}=\Psi_{l}(C X_{l})$,其中$_C$为图卷积矩阵(例如Vanilla GCN (Kipf & Welling, 2016)中的$C=D^{-1/2}A D^{-1/2}$),$\Psi_{l}$是特征变换矩阵。对于节点分类问题,通常在$k$层GNN模型输出后接入分类器(如MLP);而链接预测则需对最终输出应用相似度函数来计算节点嵌入间的相似性。如上所述,由于GNN本质上是为卷积操作演化整个图结构,其扩展性面临显著挑战。值得注意的是,训练过程中演化足够数量的邻居对GNN至关重要。多项研究 (Duan et al., 2022; Zou et al., 2019) 表明,在多图基准测试中,GNN的全批次训练通常优于小批次训练。实践中,训练GNN的批次大小下限通常需达到数千。然而,当应用于大语言模型时,这种机制会导致GNN-LM的端到端训练难以实现,因为文本占用的GPU内存远超嵌入表示。
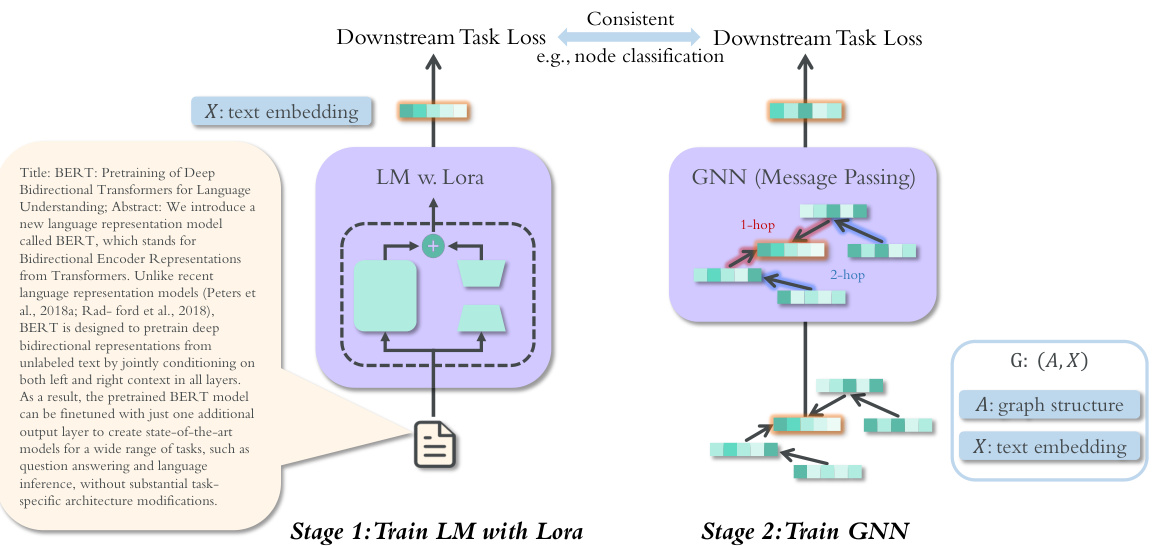
Figure 1: The overview of SimTeG. In stage $I$ , we train a LM with lora (Hu et al., 2022) and then generate the embeddings $\boldsymbol{X}$ as the representation of text. In stage 2, we train a GNN on top of the embeddings $\boldsymbol{X}$ , along with the graph structure. The two stages are guided with consistent loss function, e.g., link prediction or node classification.
图 1: SimTeG框架概览。在阶段 $I$ 中,我们使用LoRA (Hu et al., 2022) 训练语言模型,随后生成嵌入向量 $\boldsymbol{X}$ 作为文本表征。在阶段2中,我们基于嵌入 $\boldsymbol{X}$ 和图结构训练图神经网络。两个阶段通过一致的损失函数(如链接预测或节点分类)进行协同优化。
Text Embeddings and Language Models. Transforming text in low-dimensional dense embeddings serves as the upstream of textual graph representation learning and has been widely explored in the literature. To generate sentence embeddings with LMs, two commonly-used methods are (i) average pooling (Reimers & Gurevych, 2019) by taking the average of all word embeddings along with attention mask and $(i i)$ taking the embedding of the [CLS] token (Devlin et al., 2018). With the development of pre-trained language models (Devlin et al., 2018; Liu et al., 2019), particular language models (Li et al., 2020; Reimers & Gurevych, 2019) for sentence embeddings have been proposed and shown promising results in various benchmarks (Mu en nigh off et al., 2022).
文本嵌入与语言模型。将文本转化为低维稠密嵌入是文本图表示学习的上游任务,已在文献中得到广泛研究。利用语言模型生成句子嵌入的两种常用方法是:(i) 平均池化 (average pooling) (Reimers & Gurevych, 2019),通过结合注意力掩码对所有词嵌入取平均;以及 (ii) 使用[CLS] token的嵌入 (Devlin et al., 2018)。随着预训练语言模型 (Devlin et al., 2018; Liu et al., 2019) 的发展,专门用于句子嵌入的特定语言模型 (Li et al., 2020; Reimers & Gurevych, 2019) 被提出,并在多个基准测试中展现出优异性能 (Muennighoff et al., 2022)。
4 SIMTEG: METHODOLOGY
4 SIMTEG: 方法论
We propose an extremely simple two-stage training manner that decouples the training of $g n n(\cdot)$ and $l m\bar{(\cdot)}$ . We first finetune $l m$ on $\tau$ with the downstream task loss:
我们提出了一种极其简单的两阶段训练方式,将 $g n n(\cdot)$ 和 $l m\bar{(\cdot)}$ 的训练解耦。首先在 $\tau$ 上使用下游任务损失对 $l m$ 进行微调:
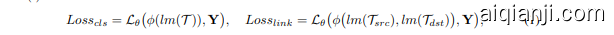
where $\phi(\cdot)$ is the classifier (left for node classification) or similarity function (right for link prediction) and $\mathbf{Y}$ is the label. After finetuning, we generate node representations $\boldsymbol{X}$ with the finetuned LM $\hat{l m}$ . In practice, we follow Reimers & Gurevych (2019) to perform mean pooling over the output of the last layer of the LM and empirically find that such a strategy is more stable and converges faster than solely taking the $\mathtt{
其中 $\phi(\cdot)$ 是分类器(左侧用于节点分类)或相似度函数(右侧用于链接预测),$\mathbf{Y}$ 是标签。微调完成后,我们使用微调后的大语言模型 $\hat{l m}$ 生成节点表示 $\boldsymbol{X}$。实践中,我们遵循 Reimers & Gurevych (2019) 的方法对大语言模型最后一层输出进行均值池化,实证发现该策略比仅采用 $\mathtt{
Regular iz ation with PEFT. When fully finetuning a LM, the inferred features are prone to overfit the training labels, which results in collapsed feature space and thus hindering the generalization in GNN training. Though PEFT was proposed to accelerate the finetuning process without loss of performance, in our two-stage finetuning stage, we empirically find PEFT (Hu et al., 2022; Houlsby et al., 2019; He et al., 2022) could alleviate the over fitting issue to a large extent and thus provide well-regularized node features. See Sec. 5.3 for empirical analysis. In this work, We take the popular PEFT method, lora (Hu et al., 2022), as the instantiation.
采用PEFT进行正则化。在全面微调大语言模型时,推断出的特征容易过拟合训练标签,导致特征空间坍缩,从而影响GNN训练中的泛化能力。虽然PEFT的提出旨在加速微调过程且不损失性能,但在我们的两阶段微调过程中,实证发现PEFT (Hu et al., 2022; Houlsby et al., 2019; He et al., 2022) 能显著缓解过拟合问题,从而提供正则化良好的节点特征。实证分析详见第5.3节。本文采用流行的PEFT方法lora (Hu et al., 2022) 作为具体实现。
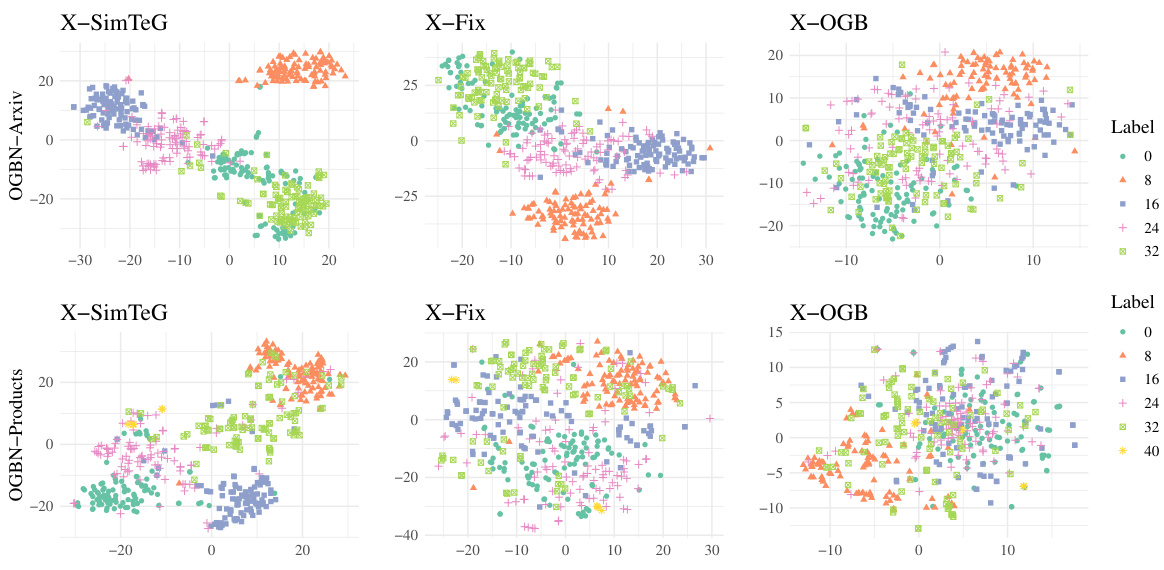
Figure 2: The two-dimensional feature space of $\boldsymbol{X}$ -SimTeG, $\boldsymbol{X}$ -Fix, and $\boldsymbol{X}$ -OGB for OGBN-Arixv, and OGBN-Products. different values and shapes refer to different labels on the specific dataset. The feature values are computed by T-SNE. The LM backbone is e5-large.
图 2: $\boldsymbol{X}$-SimTeG、$\boldsymbol{X}$-Fix 和 $\boldsymbol{X}$-OGB 在 OGBN-Arixv 和 OGBN-Products 数据集上的二维特征空间。不同数值和形状代表特定数据集中的不同标签。特征值通过 T-SNE 计算得出,语言模型主干为 e5-large。
Selection of LM. As the revolution induced by LMs, a substantial number of valuable pre-trained LMs have been proposed. As mentioned before, when ablating graph structures of TG, the two fundamental tasks, node classification and link prediction, are simplified into two well-established NLP tasks, text classification and text similarity (retrieval). Based on this motivation, we select LMs pretrained for information retrieval as the backbone of SimTeG. Concrete models are selected based on the benchmark $\mathbf{MTEB}^{1}$ considering the model size and the performance on both retrieval and classification tasks. An ablation study regarding this motivation is presented in Sec. 5.4.
大语言模型 (Large Language Model) 的选择。随着大语言模型引发的变革,大量有价值的预训练大语言模型被提出。如前所述,当消融TG的图结构时,节点分类和链接预测这两个基本任务被简化为两个成熟的自然语言处理任务:文本分类和文本相似度(检索)。基于这一动机,我们选择为信息检索预训练的大语言模型作为SimTeG的主干。具体模型根据基准 $\mathbf{MTEB}^{1}$ 选择,同时考虑模型规模以及在检索和分类任务上的性能。关于这一动机的消融研究见第5.4节。
A Finetuned LM Provides A More Distinguishable Feature Space. We plot the two-dimensional feature space computed by T-SNE (Van der Maaten & Hinton, 2008) of $\boldsymbol{X}$ -SimTeG, $\boldsymbol{X}$ -Fix (features generated by pretrained LM without finetuning), and $\boldsymbol{X}$ -OGB regarding labels on OGBN-Arxiv and OGBN-Products in Fig. 2. In detail, we randomly select 100 nodes each with various labels and use T-SNE to compute its two-dimensional features. As shown below, $\boldsymbol{X}$ -SimTeG has a significantly more distinguishable feature space as it captures more semantic information and is finetuned on the downstream dataset. Besides, we find that $\boldsymbol{X}$ -Fix is more distinguishable than $\boldsymbol{X}$ -OGB, which illustrates the inner semantic capture ability of LMs. Furthermore, in comparison with OGBN-Arixv, features in OGBN-Products is visually in differentiable, indicating the weaker correlation between semantic information and task-specific labels. It accounts for the less improvement of SimTeG on OGBN-Products in Sec. 5.1.
经过微调的大语言模型提供更具区分性的特征空间。我们通过T-SNE (Van der Maaten & Hinton, 2008) 计算了 $\boldsymbol{X}$ -SimTeG、$\boldsymbol{X}$ -Fix (未经微调的预训练大语言模型生成特征) 和 $\boldsymbol{X}$ -OGB 在OGBN-Arxiv与OGBN-Products数据集上的二维特征空间分布 (见图2)。具体而言,我们随机选取100个不同标签的节点,使用T-SNE计算其二维特征。如图所示,$\boldsymbol{X}$ -SimTeG由于捕获了更多语义信息且在下游数据集上进行了微调,其特征空间具有显著更高的可区分性。此外,我们发现$\boldsymbol{X}$ -Fix比$\boldsymbol{X}$ -OGB更具区分性,这揭示了大语言模型内在的语义捕获能力。值得注意的是,与OGBN-Arxiv相比,OGBN-Products中的特征在视觉上更难区分,表明语义信息与任务特定标签之间的相关性较弱。这也解释了第5.1节中SimTeG在OGBN-Products上提升幅度较小的原因。
5 EXPERIMENTS
5 实验
In the experiments, we aim at answering three research questions as proposed in the introduction (Sec. 1). For a clear statement, we split and reformat them into the following research questions. Q1: How much could SimTeG generally improve the learning of GNNs on node classification and link prediction? Q2: Does X-SimTeG facilitate better convergence for GNNs? Q3: Is PEFT a necessity for LM finetuning stage? Q4: How sensitive is GNN training sensitive to the selection of LMs?
在实验中,我们旨在回答引言部分(第1节)提出的三个研究问题。为清晰表述,我们将其拆分并重新表述为以下研究问题:
Q1:SimTeG在节点分类和链接预测任务中,通常能在多大程度上提升GNN(图神经网络)的学习效果?
Q2:X-SimTeG是否有助于GNN获得更好的收敛性?
Q3:参数高效微调(PEFT)是否是语言模型(LM)微调阶段的必要步骤?
Q4:GNN训练对语言模型(LM)的选择有多敏感?
Datasets. Focusing on two fundamental tasks node classification and link prediction, we conduct experiments on three prestigious benchmarks: OGBN-Arxiv (Arxiv), OGBN-Products (Products), and OGBL-Citation2 (Hu et al., 2020). The former two are for node classification while the latter one is for link prediction. For the former two, we follow the public split, and all text resources are provided by the officials. For the latter one, OGBL-Citation2, as no official text resources are provided, we take the intersection of it and another dataset ogbn-papers100M w.r.t. unified paper ids, which results in a subset of OGBL-Citation2 with about 2.7M nodes. The public split is further updated according to this subset. In comparison, the original OGBL-Citation2 has about $2.9\mathbf{M}$ nodes, which is on par with the TG version, as the public valid and test split occupies solely $2%$ overall. As a result, we expect roughly consistent performance for methods on the TG version of OGBL-Citation2 and the original one. We introduce the statistics of the three datasets in Table. A8 and the details in Appendix A2.2.
数据集。我们聚焦于节点分类和链接预测两项基础任务,在三个权威基准上开展实验:OGBN-Arxiv (Arxiv)、OGBN-Products (Products) 和 OGBL-Citation2 (Hu et al., 2020)。前两个数据集用于节点分类,最后一个用于链接预测。对于前两个数据集,我们采用公开划分方案,所有文本资源均由官方提供。对于OGBL-Citation2,由于未提供官方文本资源,我们将其与ogbn-papers100M数据集通过统一论文ID取交集,最终得到约270万节点的OGBL-Citation2子集,并据此更新公开划分方案。原始OGBL-Citation2包含约$2.9\mathbf{M}$个节点,与TG版本规模相当(因公开验证集和测试集仅占总量$2%$)。因此我们预期方法在OGBL-Citation2的TG版本与原始版本上表现基本一致。三个数据集的统计信息见表A8,细节详见附录A2.2。
Baselines. We compare SimTeG with the official features $\boldsymbol{X}$ -OGB (Hu et al., 2020), which is the mean of word embeddings generated by skip-gram (Mikolov et al., 2013). In addition, for node classification, we include another two SOTA methods: $\boldsymbol{X}$ -GIANT (Chien et al., 2021) and GLEM (Zhao et al., 2022). Particularly, $\mathbf{\boldsymbol{X}}-\mathbf{\boldsymbol{*}}$ are methods are different at learning node embeddings and any GNN model could be applied in the downstream task for a fair comparison. To make things consistent, we denote our method as $\boldsymbol{X}$ -SimTeG without further specification.
基线方法。我们将SimTeG与官方特征$\boldsymbol{X}$-OGB (Hu et al., 2020)进行比较,该特征是skip-gram (Mikolov et al., 2013)生成的词向量的均值。此外,对于节点分类任务,我们还包含另外两种最先进(SOTA)方法:$\boldsymbol{X}$-GIANT (Chien et al., 2021)和GLEM (Zhao et al., 2022)。特别地,$\mathbf{\boldsymbol{X}}-\mathbf{\boldsymbol{*}}$表示这些方法在学习节点嵌入时采用不同策略,而下游任务可以应用任何GNN模型以确保公平比较。为保持一致性,我们将本文方法统一表示为$\boldsymbol{X}$-SimTeG。
GNN Backbones. Aiming at investigating the general improvement of SimTeG, for each dataset, we select two commonly-used baselines GraphSAGE and MLP besides one corresponding SOTA GNN models based on the official leader board 2. For OGBN-Arxiv, we select RevGAT (Li et al., 2021); for OGBN-Products, we select SAGN $+,$ SCR (Sun et al., 2021; Zhang et al., 2021a); and for ogbn-citation2, we select SEAL (Zhang & Chen, 2018).
GNN主干模型。为了研究SimTeG的通用改进效果,针对每个数据集,我们除了根据官方排行榜选择一种对应的SOTA GNN模型外,还选取了两种常用基线模型GraphSAGE和MLP。对于OGBN-Arxiv数据集,选用RevGAT (Li et al., 2021);对于OGBN-Products数据集,选用SAGN $+$ SCR (Sun et al., 2021; Zhang et al., 2021a);对于ogbn-citation2数据集,则选用SEAL (Zhang & Chen, 2018)。
LM Backbones. For retrieval LM backbones, we select three popular LMs on MTEB (Mu en nigh off et al., 2022) leader board 3 w.r.t. model size and performance on classification and retrieval: allMiniLM-L6-v2 (Reimers & Gurevych, 2019), all-roberta-large-v1 (Reimers & Gurevych, 2019), and e5-large-v1 (Wang et al., 2022). We present the properties of the three LMs in Table. A10.
大语言模型主干。针对检索任务的大语言模型主干,我们根据模型规模及分类检索性能,从MTEB (Muennighoff等人, 2022) 排行榜中选取了三种主流模型:allMiniLM-L6-v2 (Reimers & Gurevych, 2019)、all-roberta-large-v1 (Reimers & Gurevych, 2019) 和 e5-large-v1 (Wang等人, 2022)。表 A10 展示了这三种大语言模型的特性。
Hyper parameter search. We utilize optuna (Akiba et al., 2019) to perform hyper parameter search on all tasks. The search space for LMs and GNNs on all datasets is presented in Appendix A2.4.
超参数搜索。我们使用optuna (Akiba et al., 2019) 对所有任务进行超参数搜索。附录A2.4展示了所有数据集上大语言模型和图神经网络 (GNN) 的搜索空间。
5.1 Q1: HOW MUCH COULD SIMTEG generally IMPROVE THE LEARNING OF GNNS ON NODE CLASSIFICATION AND LINK PREDICTION?
5.1 Q1: SIMTEG 通常能在多大程度上提升 GNN 在节点分类和链接预测任务中的学习效果?
In this section, we conduct experiments to show the superiority of SimTeG on improving the learning of GNNs on node classification and link prediction. The reported results are selected based on the validation dataset. We present the results based on e5-large backbone in Table. 1 and present the comprehensive results of node classification and link prediction with all the three selected backbones in Table A5 and Table A6. Specifically, in Table 1, we present two comparison metric $\Delta_{M L P}$ and $\Delta_{G N N}$ to describe the performance margin of (SOTA GNN, MLP) (SOTA GNN, GraphSAGE), respectively. The smaller the value is, even negative, the better the performance of simple models is. In addition, we ensemble the GNNs with multiple node embeddings generated by various LMs and text resources on OGBN-Arxiv and show the results in Table 2. We find several interesting observations as follows.
在本节中,我们通过实验展示SimTeG在提升GNN(图神经网络)节点分类和链接预测学习性能上的优越性。报告结果基于验证集筛选得出。表1展示了基于e5-large主干网络的结果,节点分类和链接预测的完整结果(包含三种选定主干网络)详见表A5和表A6。具体而言,表1采用$\Delta_{MLP}$和$\Delta_{GNN}$两个对比指标,分别表示(SOTA GNN, MLP)和(SOTA GNN, GraphSAGE)的性能差距。该值越小(甚至为负),说明简单模型性能越好。此外,我们在OGBN-Arxiv数据集上集成多种语言模型生成的节点嵌入与文本资源,结果如表2所示。主要发现如下:
Observation 1: SimTeG generally improves the performance of GNNs on node classification and link prediction by a large margin. As shown in Table 1, SimTeG consistently outperforms the original features on all datasets and backbones. Besides, in comparison with $\boldsymbol{X}$ -GIANT, a LM pre training method that utilizes the graph structures, SimTeG still achieves better performance on OGBN-Arxiv with all backbones and on OGBN-Products with GraphSAGE, which further indicates the importance of text attributes per se.
观察1: SimTeG通常能大幅提升GNN在节点分类和链接预测任务中的性能。如表1所示,SimTeG在所有数据集和骨干网络上都持续优于原始特征。此外,与利用图结构的LM预训练方法$\boldsymbol{X}$-GIANT相比,SimTeG在使用所有骨干网络的OGBN-Arxiv数据集和使用GraphSAGE的OGBN-Products数据集上仍能取得更好的性能,这进一步证明了文本属性本身的重要性。
Observation 2: $\left(X{\cdot}S i m T e G+G r a p h S A G E\right)$ ) consistently outperforms $\scriptstyle(X-O G B+S O T A$ GNN) on all the three datasets. This finding implies that the incorporation of advanced text features can bypass the necessity of complex GNNs, which is why we perceive our method to be frustratingly simple. Furthermore, when replacing GraphSAGE with the corresponding SOTA GNN in $\boldsymbol{X}$ - SimTeG, although the performance is improved moderately, this margin of improvement is notably smaller compared to the performance gap on $\boldsymbol{X}$ -OGB. Particularly, we show that the simple 2-layer GraphSAGE achieves comparable performance with the dataset-specific SOTA GNNs. Particularly, on OGBN-Arxiv, GraphSAGE achieves $76.84%$ , taking the $\pmb{4-t h}$ place in the corresponding leader board (by 2023-08-01). Besides, on OGBL-Citation2, GraphSAGE even outperforms the SOTA GNN method SEAL on Hits $\ @3$ .
观察2: $\left(X{\cdot}S i m T e G+G r a p h S A G E\right)$ )在所有三个数据集上始终优于 $\scriptstyle(X-O G B+S O T A$ GNN)。这一发现表明,引入高级文本特征可以绕过复杂GNN的必要性,这正是我们认为该方法简单得令人沮丧的原因。此外,当在$\boldsymbol{X}$-SimTeG中用相应的SOTA GNN替换GraphSAGE时,虽然性能有所提升,但这一提升幅度明显小于$\boldsymbol{X}$-OGB上的性能差距。特别值得注意的是,简单的2层GraphSAGE实现了与数据集专用SOTA GNN相当的性能。具体而言,在OGBN-Arxiv上,GraphSAGE达到$76.84%$,在相应排行榜中位列$\pmb{4-t h}$名(截至2023-08-01)。此外,在OGBL-Citation2上,GraphSAGE甚至在Hits$\ @3$指标上超越了SOTA GNN方法SEAL。
Table 1: The performance of SOTA GNN, GraphSAGE and MLP on OGBN-Arxiv, OGBN-Products, OGBL-Citation2, which are averaged over 10 runs (Please note the we solely train LM once to generate the node embeddings). The results of GLEM is from the orignal paper. We bold the best results w.r.t. the same GNN backbone and red color the smallest $\Delta_{M L P}$ and $\Delta_{G N N}$ .
表 1: SOTA GNN、GraphSAGE和MLP在OGBN-Arxiv、OGBN-Products、OGBL-Citation2上的性能(结果为10次运行的平均值,请注意我们仅训练一次LM来生成节点嵌入)。GLEM的结果来自原论文。我们加粗了相同GNN骨架下的最佳结果,并用红色标出最小的$\Delta_{MLP}$和$\Delta_{GNN}$。
| 数据集 | 指标 | 方法 | SOTA GNN | 2层简单MLP/GNN |
|---|---|---|---|---|
| RevGAT | MLP | |||
| Arxiv | Acc. (%) | X-OGB | 74.01 ± 0.29 | 47.73 ± 0.29 |
| X-GIANT | 75.93 ± 0.22 | 71.08 ± 0.22 | ||
| GLEM | 76.97 ± 0.19 | - | ||
| X-SimTeG | 77.04 ± 0.13 | 74.06 ± 0.13 | ||
| Products | Acc. (%) | X-OGB | 81.82 ± 0.44 | 50.86 ± 0.26 |
| X-GIANT | 86.12 ± 0.34 | 77.58 ± 0.24 | ||
| GLEM | 87.36 ± 0.07 | - | ||
| X-SimTeG | 85.40 ± 0.28 | 76.73 ± 0.44 | ||
| Citation2 | MRR (%) | X-OGB | 86.14 ± 0.40 | 25.44 ± 0.01 |
| X-SimTeG | 86.66 ± 1.21 | 72.90 ± 0.14 | ||
| Hits @3 (%) | X-OGB | 90.92 ± 0.32 | 28.22 ± 0.02 | |
| X-SimTeG | 91.42 ± 0.19 | 80.55 ± 0.13 |
Table 2: The performance of GraphSAGE and RevGAT trained on OGBN-Arxiv with additional text attributes provided by He et al. (2023). LMs for ensembling are e5-large and all-roberta-large-v1. We select the top-3 SOTA methods from the leader board of OGBN-Arxiv (accessed on 2023-07-18) for comparison and gray color our results (reported over 10 runs).
表 2: GraphSAGE和RevGAT在OGBN-Arxiv数据集上的性能表现 (使用He等人 (2023) 提供的额外文本属性)。集成所用的大语言模型为e5-large和all-roberta-large-v1。我们选取了OGBN-Arxiv排行榜 (2023-07-18访问) 中排名前三的SOTA方法进行对比,并将我们的结果标为灰色 (基于10次运行报告)。
| 排名 | 方法 | GNN主干网络 | 验证集准确率 (%) | 测试集准确率 (%) |
|---|---|---|---|---|
| 1 | TAPE+SimTeG(本工作) | RevGAT | 78.46±0.04 | 78.03 ±0.07 |
| 2 | TAPE (He等人,2023) | RevGAT | 77.85±0.16 | 77.50±0.12 |
| 3 | TAPE+SimTeG(本工作) | GraphSAGE | 77.89 ± 0.08 | 77.48 ± 0.11 |
| 4 | GraDBERT (Mavromatis等人,2023) | RevGAT | 77.57 ±0.09 | 77.21 ±0.31 |
| 5 | GLEM (Zhao等人,2022) | RevGAT | 77.46 ± 0.18 | 76.94 ± 0.25 |
Observation 3: With additional text attributes, SimTeG with Ensembling achieves new SOTA performance on OGBN-Arxiv. We further demonstrate the effectiveness of SimTeG by ensembling the node embeddings generated by different LMs and texts. For text, we use both the original text provided by Hu et al. (2020) and the additional text attributes 4 provided by He et al. (2023), which is generated by ChatGPT. For LMs, we use both e5-large and all-roberta-large-v1. We train GraphSAGE or RevGAT on those node embeddings generated by various LMs and texts, and make the final predictions with weighted ensembling (taking the weighted average of all predictions). As shown in Table 2, with RevGAT, we achieve new SOTA performance on OGBN-Arxiv with $78.03%$ test accuracy, more than $0.5%$ higher than the previous SOTA performance $(77.50%)$ achieved by He et al. (2023). It further validates the importance of text features and the effectiveness of SimTeG.
观察3:通过添加额外文本属性,集成SimTeG在OGBN-Arxiv上实现了新的SOTA性能。我们通过集成不同大语言模型和文本生成的节点嵌入,进一步验证了SimTeG的有效性。对于文本,我们同时使用了Hu等人 (2020) 提供的原始文本和He等人 (2023) 提供的由ChatGPT生成的附加文本属性4。在大语言模型方面,我们同时采用了e5-large和all-roberta-large-v1。我们在这些由不同大语言模型和文本生成的节点嵌入上训练GraphSAGE或RevGAT,并通过加权集成(对所有预测结果取加权平均)进行最终预测。如表2所示,使用RevGAT时,我们在OGBN-Arxiv上实现了78.03%的测试准确率,比He等人 (2023) 之前实现的SOTA性能 (77.50%) 高出0.5%以上。这进一步验证了文本特征的重要性和SimTeG的有效性。
Observation 4: Text attributes are unequally important for different datasets. As shown in Table 1, we compute $\Delta_{M L P}$ which is the performance gap between MLP and SOTA GNNs. Empirically, this value indicates the importance of text attributes on the corresponding dataset, as MLP is solely trained on the texts (integrated with SOTA LMs) while SOTA GNN additionally takes advantage of graph structures. Therefore, approximately, the less $\Delta_{M L P}$ is, the more important text attributes are. As presented in Table 1, $\Delta_{M L P}$ on OGBN-Arxiv is solely 2.98, indicating the text attributes are more important, in comparison with the ones in OGBN-Products and OGBL-Citation2. This empirically indicates why the performance of SimTeG in OGBN-Products does not perform as well as the one in OGBN-Arxiv. We show a sample of text in OGBN-Arxiv and OGBN-Products respectively in Appendix A2.2. We find that the text in OGBN-products resembles more a bag of words, which account for the less improvement when using LM features.
观察4:文本属性在不同数据集中的重要性不均。如表1所示,我们计算了$\Delta_{MLP}$(即MLP与SOTA GNNs之间的性能差距)。经验表明,该值反映了文本属性在对应数据集中的重要性,因为MLP仅基于文本(集成SOTA LMs)训练,而SOTA GNN额外利用了图结构。因此,$\Delta_{MLP}$越小,文本属性越重要。如表1所示,OGBN-Arxiv的$\Delta_{MLP}$仅为2.98,表明其文本属性比OGBN-Products和OGBL-Citation2更重要。这从实证角度解释了为何SimTeG在OGBN-Products中的表现不如OGBN-Arxiv。附录A2.2分别展示了OGBN-Arxiv和OGBN-Products的文本样例,发现OGBN-products的文本更接近词袋形式,这导致使用LM特征时改进较小。
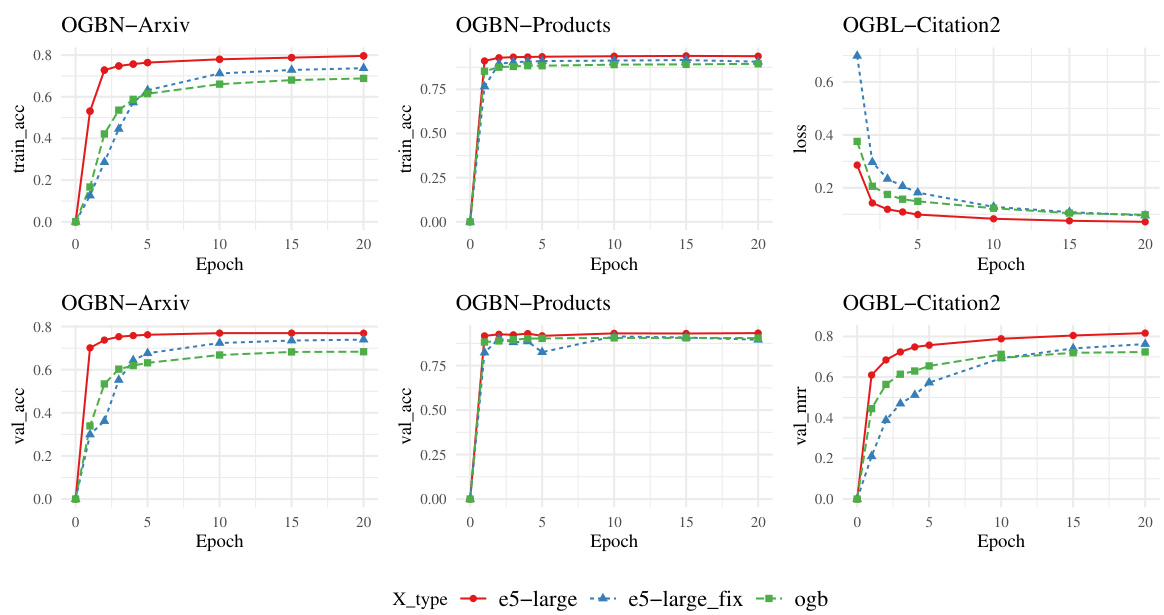
Figure 3: Training convergence and validation results of GNNs with $\boldsymbol{X}$ -SimTeG, $\boldsymbol{X}$ -OGB, and $\boldsymbol{X}$ -FIX. The LM backbone is e5-large. The learning rate and batch size are consistent.
图 3: 使用 $\boldsymbol{X}$ -SimTeG、$\boldsymbol{X}$ -OGB 和 $\boldsymbol{X}$ -FIX 的 GNN 训练收敛与验证结果。语言模型 (LM) 骨干网络为 e5-large。学习率和批次大小保持一致。
5.2 Q2: DOES X-SIMTEG FACILITATE BETTER CONVERGENCE FOR GNNS?
5.2 Q2: X-SIMTEG 是否有助于提升 GNN 的收敛性?
Towards a comprehensive understanding of the effectiveness of SimTeG, we further investigate the convergence of GNNs with SimTeG. We compare the training convergence and the corresponding validation performance of GNNs trained on SimTeG, $\boldsymbol{X}$ -OGB, and $\boldsymbol{X}$ -FIX, where $\boldsymbol{X}$ -FIX denotes the node embeddings generated by the pretrained LMs without finetuning. The illustration is placed in Fig. 3. It is worth noting that we use the training accuracy on OGBN-Arxiv and OGBN-Products to denote their convergence since we utilize label smoothing during training which make the training loss not directly comparable on them. Based on Fig. 3, we have the following observation:
为了全面理解SimTeG的有效性,我们进一步研究了结合SimTeG的图神经网络(GNN)收敛性。我们对比了基于SimTeG、$\boldsymbol{X}$-OGB和$\boldsymbol{X}$-FIX训练的GNN在训练收敛过程及对应验证性能上的表现,其中$\boldsymbol{X}$-FIX表示未经微调的预训练语言模型生成的节点嵌入。相关示意图见图3。值得注意的是,在OGBN-Arxiv和OGBN-Products数据集上,我们采用训练准确率作为收敛指标,这是因为训练过程中使用的标签平滑技术会导致训练损失在这些数据集上不具备直接可比性。根据图3所示结果,我们得出以下观察结论:
Observation 5: SimTeG moderately speeds up and stabilizes the training of GNNs. As shown in Fig. 3, GNNs with SimTeG generally converge faster than the ones with $\boldsymbol{X}$ -OGB and $\boldsymbol{X}$ -FIX. With SimTeG, GraphSAGE could converge within 2 epochs on OGBN-Arxiv and OGBN-Products. In contrast, training on the features directly generated by the pretrained LMs (i.e., $\boldsymbol{X}$ -FIX) converges much slower, even slower than one of $\boldsymbol{X}$ -OGB (possibly due to a larger hidden dimension). This further indicates the benefits of SimTeG.
观察5:SimTeG适度加速并稳定了GNN的训练。如图3所示,采用SimTeG的GNN通常比使用$\boldsymbol{X}$-OGB和$\boldsymbol{X}$-FIX的模型收敛更快。在OGBN-Arxiv和OGBN-Products数据集上,GraphSAGE配合SimTeG仅需2个epoch即可收敛。相比之下,直接使用预训练LM生成的特征(即$\boldsymbol{X}$-FIX)训练时收敛速度明显更慢,甚至比$\boldsymbol{X}$-OGB更慢(可能由于隐藏维度更大)。这进一步证明了SimTeG的优势。
5.3 Q3: IS PEFT A NECESSITY FOR LM FINETUNING STAGE?
5.3 Q3: 微调阶段是否必须使用参数高效微调 (PEFT)?
In this ablation study, we analyze the effectiveness of PEFT for LM finetuning stage in SimTeG. Besides the accelerating finetuning, we also find notable contribution of PEFT to the effectiveness. We summarize the training, validation, and test accuracy of two stages: LM finetuning stage and GNN training stage. The results of node classification are presented in Table 3.
在本消融研究中,我们分析了PEFT在SimTeG中语言模型(LM)微调阶段的有效性。除加速微调外,我们还发现PEFT对模型效果有显著贡献。我们汇总了两个阶段(LM微调阶段和GNN训练阶段)的训练、验证及测试准确率。节点分类结果如 表 3 所示。
Observation 6: PEFT could significantly alleviate the over fitting problem during finetuning LM and further facilitate the training of GNNs with regularized features. As shown in Table 3, due to the excessively strong learning capacity of LMs, finetuning LMs on the downstream task causes a severe over fitting problem. Although full-finetuning outperforms PEFT in LM stage, training GNNs on the derived features gains notably less improvement. In contrast, PEFT could significantly mitigate the over fitting issue according to $\Delta_{o v e r f i t}$ in LM finetuning stage and assist the training of GNNs with regularized features to gain considerable improvement compared with full-finetuning.
观察6: 参数高效微调(PEFT)能显著缓解语言模型(LM)微调中的过拟合问题,并进一步促进具有正则化特征的图神经网络(GNN)训练。如表3所示,由于语言模型过强的学习能力,在下游任务上微调LM会导致严重的过拟合问题。虽然全参数微调在LM阶段优于PEFT,但在衍生特征上训练GNN获得的改进明显较少。相比之下,根据LM微调阶段的$\Delta_{overfit}$指标,PEFT能显著缓解过拟合问题,并帮助具有正则化特征的GNN训练获得相比全参数微调更显著的提升。
Table 3: The training results of finetuning LM (LM stage) and further training GNN on top of derived features (GNN stage). We compare the results of PEFT (SimTeG) with full-finetuning ( $\boldsymbol{X}$ -FULL). The LM backbone is e5-large and the GNN backbone is GraphSAGE. We bold the better results on each comparison. $\Delta_{o v e r f i t}$ computes (Train Acc. - Test Acc.) to measure the over fitting.
表 3: 微调 LM (LM 阶段) 及在派生特征上进一步训练 GNN (GNN 阶段) 的训练结果。我们将 PEFT (SimTeG) 与全参数微调 ( $\boldsymbol{X}$ -FULL) 的结果进行对比。LM 主干网络为 e5-large,GNN 主干网络为 GraphSAGE。加粗显示每组对比中的更优结果。 $\Delta_{overfit}$ 通过计算 (训练准确率 - 测试准确率) 来衡量过拟合程度。
| 数据集 | 阶段 | X_type | 训练准确率 | 验证准确率 | 测试准确率 | 过拟合值 |
|---|---|---|---|---|---|---|
| Arxiv | LM | X-FULL X-SimTeG | 82.33 75.72 | 75.85 75.40 | 74.77 74.31 | 7.56 1.41 |
| GNN | X-FULL X-SimTeG | 84.39 79.37 | 76.73 77.47 | 75.28 76.85 | 9.11 2.52 | |
| Products | LM | X-FULL X-SimTeG X-FULL | 95.46 89.45 96.42 | 91.70 88.85 93.18 | 78.70 77.81 81.80 | 16.76 11.64 14.62 |
Table 4: The performance of GraphSAGE and MLP trained on SimTeGwith different LM backbones. The former three LMs are finetuned with searched hyper parameters. For each row, we bold the best result and underline the runner-up. all results are reported based on 10 runs. 5.4 Q4: HOW SENSITIVE IS GNN TRAINING SENSITIVE TO THE SELECTION OF LMS?
表 4: 不同LM骨干网络下基于SimTeG训练的GraphSAGE和MLP性能表现。前三组LM采用搜索得到的超参数进行微调。每行最佳结果加粗显示,次优结果加下划线。所有结果均基于10次运行取均值。5.4 Q4: GNN训练对LM选择的敏感度如何?
| 数据集 | 指标 | LM骨干网络 | all-MiniLM-L6-v2 | all-roberta-large-v1 | e5-large |
|---|---|---|---|---|---|
| #Params. | 22M | 355M | 335M | ||
| Arxiv | Acc. | MLP | 70.56 ± 0.09 | 74.32±0.12 | 74.06 ± 0.13 |
| GraphSAGE | 75.14 ± 0.30 | 76.18 ± 0.37 | 76.84 ± 0.34 | ||
| Products | AcC. | MLP | 72.36± 0.12 | 77.48 ± 0.19 | 76.73 ± 0.44 |
| GraphSAGE | 82.04 ± 0.57 | 83.68 ± 0.32 | 84.59 ± 0.44 | ||
| Citation2 | MRR | MLP | 64.49 ± 0.18 | 70.32 ±0.22 | 72.90 ± 0.14 |
| GraphSAGE | 83.09 ± 0.75 | 85.29 ± 0.70 | 85.13 ± 0.73 |
In this experiment, we investigate the effects of the selection of LMs. In detail, we aim at answering two questions: $(i)$ Is the training of GNN sensitive to the selection of LMs? (ii) is retrieval LM a better choice than generally pretrained LMs, e.g. masked language modeling (MLM)? To answer the above questions, we conduct experiments on multiple LM backbones. Particularly, to answer the second question, besides the three retrieval LMs introduced in Table A10, we also consider a LM pretrained with MLM, i.e., roberta-large (Liu et al., 2019), which has exactly the same architecture with all-roberta-large-v1. Based on the results, we have the following observations.
在本实验中,我们研究了语言模型 (LM) 选择的影响。具体而言,我们旨在回答两个问题:$(i)$ GNN训练对语言模型的选择是否敏感?(ii) 检索式语言模型是否比通用预训练语言模型(例如掩码语言建模 (MLM))更具优势?为解答上述问题,我们在多种语言模型骨干上进行了实验。特别地,针对第二个问题,除了表 A10 中介绍的三种检索式语言模型外,我们还考虑了采用 MLM 预训练的 roberta-large (Liu et al., 2019) ,其架构与 all-roberta-large-v1 完全一致。根据实验结果,我们得出以下观察结论。
Observation 7: GNN’s training is moderately sensitive to the selection of LMs. We select three retrieval LMs based on their rank in MTEB leader board in terms of the classification and retrieval performance. Interestingly, based on the leader board, the performance ranking is $e5-l a r g e>a l$ llroberta-large $\cdot\nu I>$ all-MiniLM-L6-v2, which is consistent with their overall performance in Table 4. We conjecture that with more powerful retrieval LMs, the performance of GNNs will be further improved. In addition, we perform an ablation study regarding the comparison between retrieval LMs and MLM LMs. The results are shown in Table A7. We observe that given the same architecture, the models specifically pretrained for retrieval tasks (all-roberta-large $\nu I$ ) generally perform better on tasks of TG representation learning.
观察7:GNN训练对语言模型(LM)的选择具有中等敏感性。我们根据MTEB排行榜的分类和检索性能排名选取了三种检索型语言模型。有趣的是,排行榜显示性能排序为$e5-l a r g e>a l$ llroberta-large $\cdot\nu I>$ all-MiniLM-L6-v2,这与表4中它们的整体表现一致。我们推测,若采用更强大的检索型语言模型,GNN的性能将进一步提升。此外,我们通过消融实验比较了检索型语言模型与掩码语言模型(MLM),结果如表A7所示。研究发现,在相同架构下,专门针对检索任务预训练的模型(all-roberta-large $\nu I$)通常在时序图(TG)表示学习任务中表现更优。
6 CONCLUSION
6 结论
In this work, we propose a frustratingly simple, yet highly effective approach SimTeG for TG representation learning. We show that with a parameter-efficiently finetuned LM on the same downstream task first, a simple two-layer GraphSAGE trained on the generated node embeddings can achieve on-par state-of-the-art (SOTA) performance on OGBN-Arxiv $(77.48%)$ . Furthermore, with SOTA GNN, we achieve new SOTA of $78.04%$ on OGBN-Arxiv. It is worth noting this simple baseline complements any LMs and GNNs, and we expect further performance improvement given more powerful LMs and GNNs.
在本工作中,我们提出了一种极其简单却高效的TG表示学习方法SimTeG。研究表明:先对同一下游任务进行参数高效的LM微调,再基于生成的节点嵌入训练简单双层GraphSAGE,即可在OGBN-Arxiv数据集上达到当前最优性能$(77.48%)$。若采用最优图神经网络,我们更将OGBN-Arxiv的SOTA提升至$78.04%$。值得注意的是,该基线方案可与任何大语言模型和图神经网络组合使用,预计随着模型性能提升会带来更大增益。
REFERENCES
参考文献
Costas Mavromatis, Vassilis N Ioannidis, Shen Wang, Da Zheng, Soji Adeshina, Jun Ma, Han Zhao, Christos Faloutsos, and George Karypis. Train your own gnn teacher: Graph-aware distillation on textual graphs. arXiv preprint arXiv:2304.10668, 2023.
Costas Mavromatis, Vassilis N Ioannidis, Shen Wang, Da Zheng, Soji Adeshina, Jun Ma, Han Zhao, Christos Faloutsos, George Karypis. 训练专属GNN教师模型:文本图上的图感知蒸馏技术。arXiv预印本 arXiv:2304.10668, 2023.
arXiv:2004.13826, 2020.
arXiv:2004.13826, 2020.
Jianan Zhao, Meng Qu, Chaozhuo Li, Hao Yan, Qian Liu, Rui Li, Xing Xie, and Jian Tang. Learning on Large-scale Text-attributed Graphs via Variation al Inference. arXiv preprint arXiv:2210.14709, 2022.
Jianan Zhao、Meng Qu、Chaozhuo Li、Hao Yan、Qian Liu、Rui Li、Xing Xie 和 Jian Tang。基于变分推理的大规模文本属性图学习。arXiv预印本 arXiv:2210.14709,2022。
Jason Zhu, Yanling Cui, Yuming Liu, Hao Sun, Xue Li, Markus Pelger, Tianqi Yang, Liangjie Zhang, Ruofei Zhang, and Huasha Zhao. Textgnn: Improving text encoder via graph neural network in sponsored search. In Proceedings of the Web Conference 2021, pp. 2848–2857, 2021.
Jason Zhu、Yanling Cui、Yuming Liu、Hao Sun、Xue Li、Markus Pelger、Tianqi Yang、Liangjie Zhang、Ruofei Zhang 和 Huasha Zhao。《TextGNN: 通过图神经网络改进赞助搜索中的文本编码器》。载于《Proceedings of the Web Conference 2021》,第2848–2857页,2021年。
Difan Zou, Ziniu Hu, Yewen Wang, Song Jiang, Yizhou Sun, and Quanquan Gu. Layer-dependent importance sampling for training deep and large graph convolutional networks. Advances in neural information processing systems, 32, 2019.
Difan Zou、Ziniu Hu、Yewen Wang、Song Jiang、Yizhou Sun和Quanquan Gu。面向深度大规模图卷积网络训练的层级依赖重要性采样。《神经信息处理系统进展》,32卷,2019年。
A1 MORE EXPERIMENT RESULTS
A1 更多实验结果
Table A5: Node Classification Accuracy of X-SimTeG on ogbn-arxiv (Arxiv) and ogbn-products (Products). All reported results are averaged over 10 runs in the format of mean $\pm$ std. We red color the best results and blue color the runner-ups with the same GNN backbone. $\uparrow:(%)$ denotes the improvement of X-SimTeG over the original feature $\boldsymbol{X}$ -OGB. $\Delta_{M L P}$ and $\Delta_{G N N}$ denotes the extreme value difference among all methods (including MLP) and GNNs, respectively.
a results are from the original papers.
表 A5: X-SimTeG 在 ogbn-arxiv (Arxiv) 和 ogbn-products (Products) 上的节点分类准确率。所有报告结果均为 10 次运行的平均值,格式为均值 $\pm$ 标准差。我们用红色标出最佳结果,蓝色标出同 GNN 骨架的次优结果。$\uparrow:(%)$ 表示 X-SimTeG 相对于原始特征 $\boldsymbol{X}$ -OGB 的提升。$\Delta_{M L P}$ 和 $\Delta_{G N N}$ 分别表示所有方法 (包括 MLP) 和 GNN 之间的极值差。
| 数据集 | GNN | Acc.(%) | 基线 | X-SimTeG | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| X-OGB | X-GIANT | GLEMa | MiniLM-L6 | ↑(%) | e5-large | ↑(%) | roberta-large | |||
| Arxiv | MLP | 49.14 ± 0.27 | 72.02 ± 0.16 | 71.59 ± 0.07 | 22.45 | 75.08 ± 0.09 | 26.66 | 74.80 ± 0.07 | ||
| 47.73 ± 0.29 | 71.08 ± 0.22 | 70.56 ± 0.09 | 22.83 | 74.06± 0.13 | 26.33 | 74.32 ± 0.12 | ||||
| GraphSAGE | 72.80 ± 0.18 | 74.58 ± 0.20 | 76.45 ± 0.05 | 75.92 ± 0.17 | 3.12 | 77.47 ± 0.14 | 4.67 | 76.86 ± 0.13 | ||
| test | 71.80 ± 0.20 | 73.70 ±0.09 | 75.50 ± 0.24 | 75.14 ± 0.30 | 3.34 | 76.84 ± 0.34 | 5.04 | 76.18 ± 0.37 | ||
| GAMLP | A | 71.49 ± 0.41 | 76.36 ± 0.09 | 76.95 ± 0.14 | 76.75 ± 0.11 | 5.26 | 77.90 ± 0.12 | 6.41 | 77.57 ± 0.15 | |
| test | 70.61 ± 0.52 | 75.26 ± 0.15 | 75.62 ± 0.23 | 75.46 ± 0.17 | 4.85 | 76.92 ± 0.10 | 6.31 | 76.72 ± 0.19 | ||
| SAGN | 72.74 ± 0.39 | 75.76 ± 0.21 | 76.84 ± 0.08 | 4.10 | 78.03 ± 0.05 | 5.29 | 77.63 ± 0.16 | |||
| 71.76 ± 0.41 | 74.39 ± 0.38 | 75.50 ± 0.23 | 3.74 | 76.85± 0.12 | 5.09 | 76.59 ± 0.17 | ||||
| RevGAT | 75.10 ± 0.15 | 76.97 ± 0.08 | 77.49 ± 0.17 | 76.86 ± 0.24 | 1.76 | 77.68 ± 0.07 | 2.58 | 76.32 ± 0.18 | ||
| test | 74.01 ± 0.29 | 75.93 ± 0.22 | 76.97 ± 0.19 | 75.96 ± 0.21 | 1.95 | 77.04 ± 0.13 | 3.03 | 75.88 ± 0.58 | ||
| Products | MLP/GNN | 25.24 / 3.40 | 4.85 /2.23 | 5.40/0.82 | 2.98 / 0.20 | 2.40 / 0.84 | ||||
| MLP | 63.44 ± 0.30 | 89.67 ± 0.07 | 86.82 ± 0.02 | 23.38 | 88.75 ± 0.04 | 25.31 | 90.01 ± 0.03 | |||
| test | 50.86 ± 0.26 | 77.58 ± 0.24 | 72.36 ± 0.12 | 21.50 | 76.73 ± 0.44 | 25.87 | 77.48 ± 0.19 | |||
| GraphSAGE | 90.03 ± 0.08 | 93.49 ± 0.09 | 93.84 ± 0.12 | 93.49 ± 0.08 | 3.46 3.23 | 93.57 ± 0.20 84.59 ± 0.44 | 3.54 5.78 | 93.34 ± 0.09 | ||
| test | 78.81 ± 0.23 91.83 ± 0.24 | 82.84 ± 0.29 94.04 ± 0.12 | 83.16 ± 0.19 94.00 ± 0.03 | 82.04 ± 0.57 92.89 ± 0.07 | 1.06 | 94.12 ± 0.10 | 2.29 | 83.68 ± 0.32 | ||
| SAGN+SCR | test | 81.82 ± 0.44 | 86.12 ± 0.34 | 87.36 ± 0.07 | 82.43 ± 0.40 | 0.61 | 85.40 ± 0.28 | 3.58 | 94.13 ± 0.12 | |
| MLP/GNN | 30.96/ 3.01 | 8.54/3.28 | 10.07/ 0.39 | 8.67/ 0.81 |
a 结果来自原始论文。
Table A6: Link prediction results on OGBL-Citation2-2.7M (Citation2). All reported results are averaged over 5 runs. We red color the best results and blue color the runner-ups with the same GNN backbone. ↑ $(%)$ denotes the improvement of X-SimTeG over the original feature $\boldsymbol{X}$ -OGB. $\Delta_{M L P}$ and $\Delta_{G N N}$ denotes the margin of (MLP, SEAL) and (GraphSAGE, SEAL), respectively. We use blue color denoting the negative values and red denoting positive. Specifically, in the context of $\Delta$ , positives indicate MLP/GraphSAGE performs better than SEAL.
表 A6: OGBL-Citation2-2.7M (Citation2) 上的链接预测结果。所有报告结果为5次运行的平均值。我们用红色标注最佳结果,蓝色标注同GNN骨架的次优结果。↑ $(%)$ 表示X-SimTeG相对于原始特征 $\boldsymbol{X}$ -OGB的提升幅度。$\Delta_{M L P}$ 和 $\Delta_{G N N}$ 分别表示(MLP, SEAL)和(GraphSAGE, SEAL)的差距。蓝色表示负值,红色表示正值。具体而言,在 $\Delta$ 语境中,正值表示MLP/GraphSAGE优于SEAL。
| 指标 | GNN | 拆分 | 基线 | X-SimTeG | |||||
|---|---|---|---|---|---|---|---|---|---|
| X-OGB | MiniLM-L6 | ↑(%) | roberta-large | ↑(%) | e5-large | ↑(%) | |||
| 25.37 ± 0.09 | |||||||||
| MRR | MLP | val | 25.44 ± 0.01 | 64.56 ± 0.15 | 39.19 | 70.20 ± 0.19 | 44.83 | 72.79 ± 0.17 | 47.42 |
| test | 25.44 ± 0.01 | 64.49 ± 0.18 | 39.05 | 70.32 ± 0.22 | 44.88 | 72.90 ± 0.14 | 47.46 | ||
| GraphSAGE | val | 77.40 ± 0.88 | 83.13 ± 0.72 | 5.73 | 85.27 ± 0.78 | 7.87 | 85.20 ± 0.69 | 7.80 | |
| test | 77.31 ± 0.90 | 83.09 ± 0.75 | 5.78 | 85.29 ± 0.70 | 7.98 | ||||
| SEAL | val | 87.21 ± 0.03 | 88.33 ± 0.30 | 1.12 | 88.29 ± 0.45 | 1.08 | 85.13 ± 0.73 | 7.82 | |
| test | 86.14 ± 0.40 | 86.69 ± 0.43 | 0.55 | 87.02 ± 0.46 | 0.88 | 88.56 ± 0.38 | 1.35 | ||
| 86.66 ± 1.21 | 0.52 | ||||||||
| MLP/GNN | -60.70/-8.83 | -22.20/-3.60 | - | -16.70/-1.73 | -13.76/-1.53 | ||||
| Hits@1 | MLP | val | 15.04 ± 0.09 | 52.29 ± 0.18 | 37.25 | 59.46 ± 0.19 | 44.42 | 62.21 ± 0.23 | 47.17 |
| test | 15.11 ± 0.06 | 52.18 ± 0.25 | 37.07 | 59.66 ± 0.26 | 44.55 | 62.31 ± 0.19 | 47.20 | ||
| GraphSAGE | val | 67.28 ± 1.20 | 74.83 ± 1.02 | 7.55 | 77.98 ± 1.20 | 10.70 | 77.73 ± 0.89 | 10.45 | |
| test | 67.09 ± 1.25 | 74.79 ± 1.10 | 7.70 | 77.99 ± 0.89 | 10.90 | 77.66 ± 0.91 | 10.57 | ||
| SEAL | val | 82.76 ± 0.14 | 84.35 ± 0.42 | 1.59 | 84.25 ± 0.79 | 1.49 | 84.70 ± 0.58 | 1.94 | |
| test | 81.74 ± 0.46 | 81.40 ± 0.96 | -0.34 | 82.34 ± 0.79 | 0.60 | 81.15 ± 2.04 | -0.59 | ||
| MLP/GNN | -66.63/-14.65 | -29.22/-6.61 | - | -22.68/-4.35 | -18.84/-3.39 | ||||
| Hits@3 | MLP | val | 28.06 ± 0.10 | 72.60 ± 0.16 | 44.54 | 77.56 ± 0.23 | 49.44 | 80.42 ± 0.15 | 52.36 |
| test | 28.22 ± 0.02 | 72.62 ± 0.19 | 44.40 | 77.66 ± 0.24 | 49.50 | 80.55 ± 0.13 | 52.33 | ||
| GraphSAGE | val | 85.54 ± 0.69 | 90.17 ± 0.61 | 4.63 | 91.55 ± 0.98 | 6.01 | 91.72 ± 0.90 | 6.18 | |
| test | 85.56 ± 0.69 | 90.16 ± 0.51 | 4.60 | 91.57 ± 1.10 | 6.01 | 91.62 ± 0.87 | 6.06 | ||
| SEAL | val | 91.36 ± 0.44 | 92.00 ± 0.07 | 0.64 | 92.15 ± 0.19 | 0.79 | 91.75 ± 0.18 | 0.39 | |
| test | 90.92 ± 0.32 | 91.42 ± 0.60 | 0.50 | 91.52 ± 0.56 | 0.60 | 91.42 ± 0.19 | 0.50 | ||
| MLP/GNN | -62.70/-5.36 | -18.80/-1.26 | -13.86/0.05 | -10.87/0.20 | |||||
| Hits@10 | MLP | val | 46.73 ± 0.14 | 87.62 ± 0.06 | 40.89 | 89.80 ± 0.20 | 43.07 | 91.74 ± 0.08 | 45.01 |
| test | 46.59 ± 0.11 | 87.57 ± 0.12 | 40.98 | 89.66 ± 0.14 | 43.07 | 91.74 ± 0.10 | 45.15 | ||
| GraphSAGE | val | 94.29 ± 0.19 | 96.25 ± 0.13 | 1.96 | 96.61 ± 0.12 | 2.32 | 96.71 ± 0.09 | 2.42 | |
| test | 94.37 ± 0.17 | 96.30 ± 0.13 | 1.93 | 96.64 ± 0.12 | 2.27 | 96.74 ± 0.11 | 2.37 | ||
| SEAL | val | 94.59 ± 0.14 | 94.88 ± 0.25 | 0.29 | 95.08 ± 0.12 | 0.49 | 95.08 ± 0.21 | 0.49 | |
| test | 93.90 ± 0.49 | 94.40 ± 0.07 | 0.50 | 93.95 ± 0.37 | 0.05 | 94.54 ± 0.25 | 0.64 | ||
| MLP/GNN | -47.31/-0.47 | -6.83/1.90 | -4.29/2.66 | -2.80/2.20 |
Table A7: The performance of Graph and MLP trained on SimTeG backed with all-roberta-large-v1 and roberta-large, which have the same model architecture and differs from the pre training strategy. we bold the best results for each comparison in $\boldsymbol{X}$ -Fix and $\boldsymbol{X}$ -SimTeG. all results are reported based on 10 runs
表 A7: 基于 all-roberta-large-v1 和 roberta-large 的 SimTeG 训练的 Graph 和 MLP 性能对比,两者模型架构相同但预训练策略不同。$\boldsymbol{X}$-Fix 和 $\boldsymbol{X}$-SimTeG 中的最佳结果已加粗显示。所有结果均基于 10 次运行计算。
| datasets | Metric | X_type | X-Fix | X-SimTeG | ||
|---|---|---|---|---|---|---|
| LMBackbone | roberta-large | all-roberta-large-v1 | roberta-large | all-roberta-large-v1 | ||
| Arxiv | Acc. | MLP | 61.15 ± 0.83 | 72.58±0.25 | 71.55 ± 0.24 | 74.32±0.12 |
| GraphSAGE | 72.15 ± 0.59 | 75.51±0.23 | 75.48 ± 0.16 | 76.18 ± 0.37 | ||
| Products | Acc. | MLP | 68.14 ± 0.23 | 70.10±0.08 | 78.45 ± 0.14 | 77.48 ± 0.19 |
| GraphSAGE | 77.65 ± 0.34 | 82.38 ± 0.60 | 83.56 ± 0.21 | 83.68 ± 0.32 | ||
| Citation2 | MRR | MLP | 00.20 ± 0.01 | 70.12±0.12 | 63.15 ± 0.20 | 72.90 ± 0.14 |
| GraphSAGE | 79.71 ± 0.27 | 83.20±0.40 | 84.37 ± 0.34 | 85.13 ±0.73 |
A2 REPRODUCIBILITY STATEMENT
A2 可复现性声明
To ensure the reproducibility of our experiments and benefit the community for further research, we provide the source code at https://github.com/vermouth d ky/SimTeG and all node features of SimTeG at https://hugging face.co/datasets/vermouth d ky/SimTeG.
为确保实验可复现性并推动社区进一步研究,我们在 https://github.com/vermouth d ky/SimTeG 提供了源代码,并在 https://hugging face.co/datasets/vermouth d ky/SimTeG 公开了SimTeG的全部节点特征。
A2.1 PSEUDO CODE OF SIMTEG
A2.1 SIMTEG 伪代码
Algorithm 1: PyTorch-style code of SimTeG. Left: node classification; Right: link prediction.
算法 1: SimTeG的PyTorch风格代码。左:节点分类;右:链接预测。
A2.2 DETAILS OF TG VERSION FOR THE THREE OGB DATASETS
A2.2 三个OGB数据集的TG版本详情
| # f_lm: 使用PEFT方法封装的语言模型, f_mlp: mlp模型, f_gnn: gnn模型 # 输入: 文本图(adj_t (A), input_ids (T), att_mask (M))和任务特定标签(Y) | ||||||
|---|---|---|---|---|---|---|
| # 输出: 节点表征 | ||||||
| # 节点分类 | # 链接预测 | |||||
| for T,M,Y in train_loader: | ||||||
| X = f_lm(T, M) | X_src, X_dst = f_lm((T_src, M_src), (T_dst, M_dst)) | |||||
| logits = f_mlp(x) | logits = f_mlp(X_src, X_dst) | |||||
| loss = CrossEntropyLoss(logits, Y) | loss = BCEWithLogitsLoss(logits, Y) | |||||
| loss.backward() | loss.backward() | |||||
| lm_optimizer.step() | lm_optimizer.step() | |||||
| with torch.no_grad(): | with torch.no_grad(): | |||||
| X = f_lm(T, M) | X = lm(T, M) | |||||
| f_mlp.reset_parameters() | f_mlp.reset_parameters() | |||||
| for A,X,Y in train_loader: | for A, (X_src, X_dst), Y in train_loader: | |||||
| X = f_gnn(A, X) | X_src, X_dst = f_gnn(A, (X_src, X_dst)) | |||||
| logits = f_mlp(x) | logits = f_mlp(X_src, X_dst) | |||||
| loss = CrossEntropyLoss(logits, Y) | loss = BCEWithLogitsLoss(logits, Y) | |||||
| loss.backward() | loss.backward() | |||||
| gnn_optimizer.step() | gnn_optimizer.step() |
In this section, we present the details of the TG version of OGBN-Arxiv, OGBN-Products, and OGBL-Citation2. The statistics of the three datasets are shown in Table A8 and the text resources are shown in Table A9. Table A8: Statistics of OGBN-Arxiv, OGBN-Products, and OGBL-Citation2-2.7M
在本节中,我们将详细介绍OGBN-Arxiv、OGBN-Products和OGBL-Citation2的TG版本。三个数据集的统计信息如表A8所示,文本资源如表A9所示。
表A8: OGBN-Arxiv、OGBN-Products和OGBL-Citation2-2.7M的统计信息
| 数据集 | 节点数 | 边数 | 平均度数 | 任务类型 | 评估指标 |
|---|---|---|---|---|---|
| OGBN-Arxiv (Arxiv) | 169,343 | 1,166,243 | 13.7 | 节点分类 | 准确率 |
| OGBN-Products (Products) | 2,449,029 | 61,859,140 | 50.5 | 节点分类 | 准确率 |
| OGBL-Citation2-2.7M (Citation2) | 2,728,032 | 27,731,705 | 10.2 | 链接预测 | MRR/Hits |
OGBN-Arxiv. OGBN-Arxiv is a directed academic graph, where node denotes papers and edge denotes directed citation. The task is to predict the category of each paper as listed in https:
OGBN-Arxiv。OGBN-Arxiv是一个有向学术图,其中节点表示论文,边表示有向引用。任务是根据https://...所列类别预测每篇论文的类别。
//arxiv.org. For its TG version, we use the same split as Hu et al. (2020). The text for each node is its title and abstract. We concatenate them for each node with the format of "title: {title}; abstract: {abstract}" as the corresponding node’s text. For example, "title: multi view metric learning for multi view video sum mari z ation; abstract: Traditional methods on video sum mari z ation are designed to generate summaries for single-view video records; and thus they cannot fully exploit the redundancy in multi-view video records. In this paper, we present a multi-view metric learning framework for multi-view video sum mari z ation that combines the advantages of maximum margin clustering with the disagreement minimization criterion. ...
//arxiv.org。对于其TG版本,我们采用与Hu等人(2020)相同的划分方式。每个节点的文本由其标题和摘要组成,我们按照"标题: {标题}; 摘要: {摘要}"的格式将它们拼接为对应节点的文本。例如:"标题: 多视角视频摘要的多视角度量学习; 摘要: 传统视频摘要方法针对单视角视频记录设计,无法充分利用多视角视频记录中的冗余信息。本文提出一个多视角度量学习框架,将最大间隔聚类与差异最小化准则相结合..."
OGBN-Products. OGBN-Products is a co-purchase graph, where node denotes a product on Amazon and an edge denotes the co-purchase relationship between two products. The task is to predict the category of each product (node classification). We follow the public split as Hu et al. (2020) and the text processing strategy of GLEM (Zhao et al., 2022). For each node, the corresponding text is its item description. For example, "My Fair Pastry (Good Eats Vol. 9)" "Disc 1: Flour Power (Scones; Shortcakes; Southern Biscuits; Salmon Turnovers; Fruit Tart; Funnel Cake; Sweet or Savory; Pte Choux) Disc 2: Super Sweets 4 (Banana Spitsville; Burned Peach Ice Cream; Chocolate Taffy; Acid Jellies; Peanut Brittle; Chocolate Fudge; Peanut Butter Fudge) ..."
OGBN-Products。OGBN-Products是一个共同购买关系图,其中节点表示Amazon上的商品,边表示两个商品之间的共同购买关系。任务目标是预测每个商品(节点)的类别(节点分类)。我们遵循Hu等人 (2020) 的公开数据划分方式以及GLEM (Zhao等人, 2022) 的文本处理策略。每个节点对应的文本是其商品描述,例如:"My Fair Pastry (Good Eats Vol.9)" "碟片1: 面粉力量(司康饼;松饼;南方饼干;三文鱼馅饼;水果塔;漏斗蛋糕;甜味或咸味;泡芙面团)碟片2: 超级甜点4(香蕉船;焦糖桃子冰淇淋;巧克力太妃糖;酸味软糖;花生脆;巧克力软糖;花生酱软糖)..."
OGBL-Citation2-2.7M. OGBL-Citation2-2.7M is a citation graph, where nodes denote papers and edges denote the citations. The task is to predict the missing citation among papers (link prediction). All papers are collected by the official from Mircrosoft Academic Graph whereas the text resources are not provided. Though MAG IDs for all papers are provided, we cannot find all corresponding text resources due to the close of MAG project 5. Hence, we take an intersection of OGBL-Citation2 and OGBN-Papers100M whose text resources are provided by the official, and build a subgraph, namely OGBL-Citation2-2.7M. It contains $93%$ nodes of OGBL-Citation2 and offers a roughly on-par performance for baselines.
OGBL-Citation2-2.7M。OGBL-Citation2-2.7M是一个引文网络,其中节点代表论文,边代表引用关系。任务目标是预测论文间缺失的引用关系(链接预测)。所有论文均由官方从Microsoft Academic Graph (MAG)采集,但未提供文本资源。虽然提供了所有论文的MAG ID,但由于MAG项目关闭[5],我们无法获取全部对应文本资源。因此,我们取OGBL-Citation2与官方提供文本资源的OGBN-Papers100M的交集,构建了该子图OGBL-Citation2-2.7M。该子图包含OGBL-Citation2中$93%$的节点,并为基线模型提供了基本相当的预测性能。
Table A9: The URLs of text resources for ogbn-arxiv, ogbn-products, and OGBL-Citation2.
表 A9: ogbn-arxiv、ogbn-products 和 OGBL-Citation2 的文本资源 URL
| Dataset | TextResourceURL |
|---|---|
| OGBN-Arxiv | https://snap.stanford.edu/ogb/data/misc/ogbn_arxiv/titleabs.tsv.gz |
| OGBN-Products | https://drive.google.com/u/0/uc?id=1gsabsx8KR2N9jJz16jTcA0QASXsNuKnN&export=download |
| OGBL-Citation2 | https://drive.google.com/u/0/uc?id=19_hkbBUDFZTvQrM0oMbftuXhgz5LbIZY&export=download |
A2.3 PROPERTIES OF LANGUAGE MODELS
A2.3 语言模型的特性
Table A10: Statistics of OGBN-Arxiv, OGBN-Products, and OGBL-Citation2-2.7M
表 A10: OGBN-Arxiv、OGBN-Products 和 OGBL-Citation2-2.7M 的统计数据
| 数据集 | 节点数 | 边数 | 平均度数 | 任务类型 | 评估指标 |
|---|---|---|---|---|---|
| OGBN-Arxiv (Arxiv) | 169,343 | 1,166,243 | 13.7 | 节点分类 | 准确率 |
| OGBN-Products (Products) | 2,449,029 | 61,859,140 | 50.5 | 节点分类 | 准确率 |
| OGBL-Citation2-2.7M (Citation2) | 2,728,032 | 27,731,705 | 10.2 | 链接预测 | MRR/Hits |
A2.4 HYPER PARAMETER SEARCH SPACE
A2.4 超参数搜索空间
For language models, we design the hyper parameter (HP) search space as in Table A11. Please note that for link prediction, the label smoothing factor is omitted. For HP searching, we utilize optuna (Akiba et al., 2019) to search the best HPs for each dataset and each model. For LMs, we take 10 trials. For GNNs, we take 20 trials. The final HP setting for LMs and GNNs are placed as shell scripts in our repository.
对于语言模型,我们按照表 A11 所示设计超参数 (HP) 搜索空间。请注意,在链接预测任务中省略了标签平滑因子。在 HP 搜索阶段,我们采用 optuna (Akiba et al., 2019) 为每个数据集和模型搜索最优超参数。语言模型进行 10 次试验,图神经网络进行 20 次试验。语言模型和图神经网络的最终超参数设置以 shell 脚本形式存放于代码库中。
Table A11: The search space of LMs and GNNs.
表 A11: 大语言模型 (LM) 和图神经网络 (GNN) 的搜索空间。
| 大语言模型 (LM) | 图神经网络 (GNN) | ||||
|---|---|---|---|---|---|
| 超参数 | 搜索空间 | 类型 | 超参数 | 搜索空间 | 类型 |
| 学习率 (learning rate) | [1e-6,1e-4] | 连续型 | 学习率 (learning rate) | [1e-4,1e-2] | 连续型 |
| 权重衰减 (weight decay) | [1e-7, 1e-4] | 连续型 | 权重衰减 (weight decay) | [1e-7,1e-4] | 连续型 |
| 标签平滑 (label smoothing) | [0.1, 0.7] | 连续型 | 标签平滑 (label smoothing) | [0.1, 0.7] | 连续型 |
| 头部丢弃率 (header dropout) | [0.1, 0.8] | 连续型 | 丢弃率 (dropout) | [0.1, 0.8] | 连续型 |
| LoRA 秩 (lora r) | [1,2,4,8] | 离散型 | 层数 (num of layers) | [2,3,4,6,8] | 离散型 |
| LoRA alpha | [4,8,16,32] | 离散型 | |||
| LoRA 丢弃率 (lora dropout) | [0.1, 0.8] | 连续型 |