On Mixup Training: Improved Calibration and Predictive Uncertainty for Deep Neural Networks
关于Mixup训练:提升深度神经网络的校准性和预测不确定性
Abstract
摘要
Mixup [40] is a recently proposed method for training deep neural networks where additional samples are generated during training by convexly combining random pairs of images and their associated labels. While simple to implement, it has been shown to be a surprisingly effective method of data augmentation for image classification: DNNs trained with mixup show noticeable gains in classification performance on a number of image classification benchmarks. In this work, we discuss a hitherto untouched aspect of mixup training – the calibration and predictive uncertainty of models trained with mixup. We find that DNNs trained with mixup are significantly better calibrated – i.e., the predicted softmax scores are much better indicators of the actual likelihood of a correct prediction – than DNNs trained in the regular fashion. We conduct experiments on a number of image classification architectures and datasets – including large-scale datasets like ImageNet – and find this to be the case. Additionally, we find that merely mixing features does not result in the same calibration benefit and that the label smoothing in mixup training plays a significant role in improving calibration. Finally, we also observe that mixup-trained DNNs are less prone to over-confident predictions on out-of-distribution and random-noise data. We conclude that the typical over confidence seen in neural networks, even on in-distribution data is likely a consequence of training with hard labels, suggesting that mixup be employed for classification tasks where predictive uncertainty is a significant concern.
Mixup [40] 是近期提出的一种深度神经网络训练方法,通过在训练过程中对随机图像对及其关联标签进行凸组合来生成额外样本。尽管实现简单,该方法已被证明在图像分类数据增强中效果显著:采用mixup训练的深度神经网络在多项图像分类基准测试中展现出明显的性能提升。本文探讨了mixup训练中一个尚未被研究的维度——模型校准性与预测不确定性。我们发现,相比常规训练方式,mixup训练的深度神经网络具有显著更优的校准性(即预测softmax分数能更准确反映实际正确预测概率)。我们在多种图像分类架构和数据集(包括ImageNet等大规模数据集)上进行了实验验证。此外,研究发现仅混合特征无法带来相同的校准优势,而mixup训练中的标签平滑对改善校准性起关键作用。最后,我们还观察到mixup训练的深度神经网络对分布外数据和随机噪声数据的过自信预测倾向更低。我们得出结论:神经网络中常见的过度自信现象(即使在分布内数据上)很可能是硬标签训练导致的,建议在预测不确定性至关重要的分类任务中采用mixup方法。
1 Introduction: Over confidence and Uncertainty in Deep Learning
1 引言:深度学习中的过度自信与不确定性
Machine learning algorithms are replacing or expected to increasingly replace humans in decisionmaking pipelines. With the deployment of AI-based systems in high risk fields such as medical diagnosis [26], autonomous vehicle control [21] and the legal sector [1], the major challenges of the upcoming era are thus going to be in issues of uncertainty and trust-worthiness of a classifier. With deep neural networks having established supremacy in many pattern recognition tasks, it is the predictive uncertainty of these types of class if i ers that will be of increasing importance. The DNN must not only be accurate, but also indicate when it is likely to get the wrong answer. This allows the decision-making to be routed as needed to a human or another more accurate, but possibly more expensive, classifier, with the assumption being that the additional cost incurred is greatly surpassed by the consequences of a wrong prediction.
机器学习算法正在取代或预计将越来越多地取代人类在决策流程中的角色。随着基于AI的系统在医疗诊断[26]、自动驾驶控制[21]和法律领域[1]等高风险领域的部署,即将到来的时代主要挑战将集中在分类器的不确定性和可信度问题上。深度神经网络已在许多模式识别任务中确立主导地位,因此这类分类器的预测不确定性将愈发重要。DNN不仅需要保持高准确率,还必须能够指出何时可能给出错误答案。这使得决策可以根据需要转交给人类或其他更准确(但可能成本更高)的分类器,前提是错误预测带来的后果远超额外增加的成本。
For this reason, quantifying the predictive uncertainty for deep neural networks has seen increased attention in recent years [6, 19, 7, 20, 16, 31]. One of the first works to examine the issue of calibration for modern neural networks was [9]; noting that in a well-calibrated classifier, predictive scores should be indicative of the actual likelihood of correctness, the authors in [9] show significant empirical evidence that modern deep neural networks are poorly calibrated, with depth, weight decay and batch normalization all influencing calibration. Modern architectures, it turns out, are prone to over confidence, meaning accuracy is likely to be lower than what is indicated by the predictive score. The top row in Figure 1 illustrates this phenomena: shown are a series of joint density plots of the average winning score and accuracy of a VGG-16 [32] network over the CIFAR-100 [18] validation set, plotted at different epochs. Both the confidence (captured by the winning score) as well as accuracy start out low and gradually increase as the network learns. However, what is interesting – and concerning – is that the confidence always leads accuracy in the later stages of training; accuracy saturates while confidence continues to increase resulting in a very sharply peaked distribution of winning scores and an overconfident model.
因此,近年来量化深度神经网络的预测不确定性受到越来越多的关注[6, 19, 7, 20, 16, 31]。最早研究现代神经网络校准问题的成果之一是[9];作者指出,在一个良好校准的分类器中,预测分数应当反映实际正确概率,并通过大量实证表明现代深度神经网络存在严重校准不足问题,其中网络深度、权重衰减和批量归一化都会影响校准效果。事实证明,现代架构容易产生过度自信现象,即实际准确率往往低于预测分数所显示的数值。图1顶行展示了这一现象:图中呈现了VGG-16[32]网络在CIFAR-100[18]验证集上平均获胜分数与准确率在不同训练周期下的联合密度图。随着网络学习,置信度(由获胜分数体现)和准确率都从较低水平逐步提升。但值得注意的是(也令人担忧),在训练后期阶段置信度总是领先于准确率;当准确率达到饱和时,置信度仍持续上升,导致获胜分数呈现尖锐峰值分布,最终形成过度自信的模型。
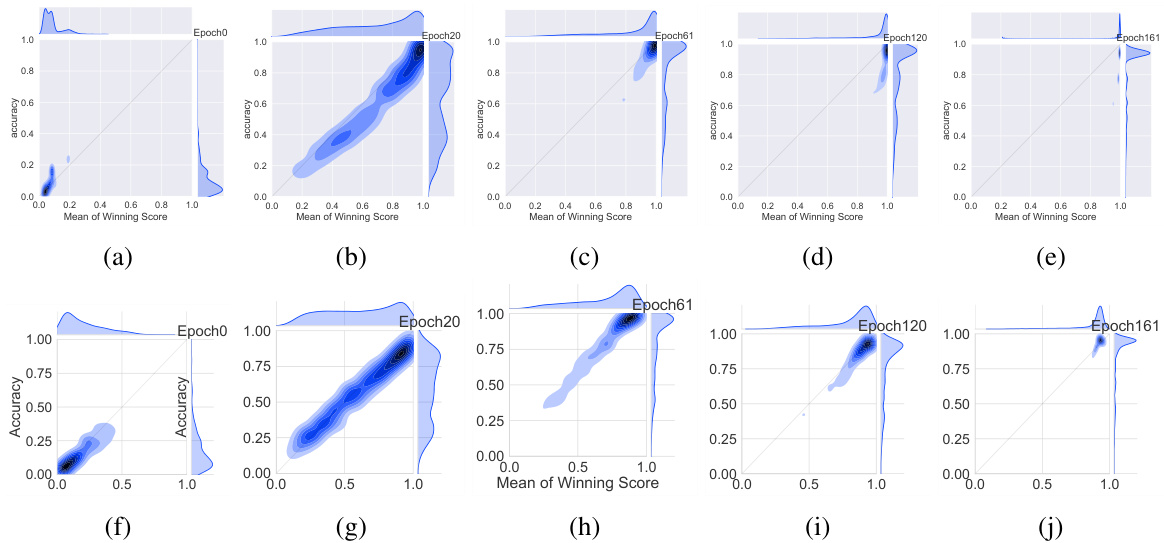
Figure 1: Joint density plots of accuracy vs confidence (captured by the mean of the winning softmax score) on the CIFAR-100 validation set at different training epochs for the VGG-16 deep neural network. Top Row: In regular training, the DNN moves from under-confidence, at the beginning of training, to over confidence at the end. A well-calibrated classifier would have most of the density lying on the $x=y$ gray line. Bottom Row: Training with mixup on the same architecture and dataset. At corresponding epochs, the network is much better calibrated.
图 1: VGG-16深度神经网络在CIFAR-100验证集上不同训练周期时准确率与置信度(通过获胜softmax分数的均值捕获)的联合密度图。上排: 常规训练中,DNN从训练初期的欠置信状态逐渐过渡到训练结束时的过置信状态。理想校准的分类器应使大部分密度分布在$x=y$灰色线上。下排: 同一架构和数据集上使用mixup训练的结果。在对应训练周期,网络显示出更好的校准性。
While tempering over confidence in neural networks using alternatives to the final softmax layer has been studied before [25], here we investigate the effect of entropy of the training labels on calibration. Most modern DNNs, when trained for classification in a supervised learning setting, are trained using one-hot encoded labels that have all the probability mass in one class; the training labels are thus zero-entropy signals that admit no uncertainty about the input. The DNN is thus, in some sense, trained to become overconfident. Hence a worthwhile line of exploration is whether principled approaches to label smoothing can somehow temper over confidence. Label smoothing and related work has been explored before [33, 30]. In this work, we carry out an exploration along these lines by investigating the effect of the recently proposed mixup [40] method of training deep neural networks. In mixup, additional synthetic samples are generated during training by convexly combining random pairs of images and, importantly, their labels as well. While simple to implement, it has shown to be a surprisingly effective method of data augmentation: DNNs trained with mixup show noticeable gains in classification performance on a number of image classification benchmarks. However neither the original work nor any subsequent extensions to mixup [36, 10, 23] have explored the effect of mixup on predictive uncertainty and DNN calibration; this is precisely what we address in this paper.
虽然此前已有研究探讨通过替代最终softmax层来调节神经网络过度自信的问题[25],但本文重点研究了训练标签熵值对模型校准的影响。在监督学习的分类任务中,大多数现代深度神经网络(DNN)使用独热编码标签进行训练,这类标签将所有概率质量集中于单一类别,因此训练标签是零熵信号,不包含任何输入不确定性。从某种意义上说,这导致DNN被训练得过于自信。因此值得探索的是:基于原则的标签平滑方法能否有效抑制这种过度自信。标签平滑及相关工作已有先例研究[33, 30]。本文通过研究近期提出的mixup[40]深度神经网络训练方法,沿着这一方向展开探索。mixup通过在训练期间对随机图像对及其标签进行凸组合来生成合成样本,这种简单实现的方法被证明是异常有效的数据增强技术:采用mixup训练的DNN在多项图像分类基准测试中均显示出显著性能提升。然而无论是原始研究还是后续mixup扩展工作[36, 10, 23],都未探讨mixup对预测不确定性和DNN校准的影响,这正是本文要解决的核心问题。
Our findings are as follows: mixup trained DNNs are significantly better calibrated – i.e the predicted softmax scores are much better indicators of the actual likelihood of a correct prediction – than DNNs trained without mixup (see Figure 1 bottom row for an example). We also observe that merely mixing features does not result in the same calibration benefit and that the label smoothing in mixup training plays a significant role in improving calibration. Further, we also observe that mixup-trained DNNs are less prone to over-confident predictions on out-of-distribution and random-noise data. We note here that in this work we do not consider the calibration and uncertainty over adversarial ly perturbed inputs; we leave that for future exploration.
我们的发现如下:使用 mixup 训练的深度神经网络 (DNN) 比未使用 mixup 训练的模型具有显著更好的校准性——即预测的 softmax 分数能更准确地反映正确预测的实际可能性 (示例见图 1 底行)。我们还观察到,仅混合特征不会带来相同的校准优势,而 mixup 训练中的标签平滑对改善校准性起到了重要作用。此外,mixup 训练的 DNN 对分布外数据和随机噪声数据的预测也表现出更低的过度自信倾向。需要说明的是,本研究未考虑对抗性扰动输入下的校准性和不确定性,该方向留待未来探索。
The rest of the paper is organized as follows: Section 2 provides a brief overview of the mixup training process; Section 3 discusses calibration metrics, experimental setup and mixup’s calibration benefits for image data with additional results on natural language data described in Section 4; in Section 5, we explore in more detail the effect of mixup-based label smoothing on calibration, and further discuss the effect of training time on calibration in Section 6; in Section 7 we show additional evidence for the benefit of mixup training on predictive uncertainty when dealing with out-of-distribution data. Further discussions and conclusions are in Section 8.
本文其余部分的结构安排如下:第2节简要概述混合训练(mixup)过程;第3节讨论校准指标、实验设置及mixup对图像数据的校准优势,第4节补充说明其在自然语言数据上的实验结果;第5节深入探讨基于mixup的标签平滑对校准的影响;第6节进一步分析训练时长对校准的作用;第7节展示mixup训练在处理分布外数据时对预测不确定性的改善证据。第8节包含进一步讨论与结论。
2 An Overview of Mixup Training
2 Mixup训练概述
Mixup training [40] is based on the principle of Vicinal Risk Minimization 3: the classifier is trained not only on the training data, but also in the vicinity of each training sample. The vicinal points are generated according to the following simple rule introduced in [40]:
Mixup训练 [40] 基于邻域风险最小化 3 原则:分类器不仅要在训练数据上训练,还要在每个训练样本的邻域内进行训练。邻域点根据 [40] 中提出的以下简单规则生成:

where $x_{i}$ and $x_{j}$ are two randomly sampled input points, and $y_{i}$ and $y_{j}$ are their associated one-hot encoded labels. This has the effect of the empirical Dirac delta distribution
其中 $x_{i}$ 和 $x_{j}$ 是两个随机采样的输入点,$y_{i}$ 和 $y_{j}$ 是它们关联的独热编码标签。这会产生经验狄拉克δ分布的效果。
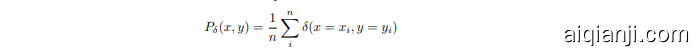
centered at $(x_{i},y_{i})$ being replaced with the empirical vicinal distribution
以 $(x_{i},y_{i})$ 为中心的经验邻域分布替换

where $\nu$ is a vicinity distribution that gives the probability of finding the virtual feature-target pair $(\Tilde{x},\Tilde{y})$ in the vicinity of the original pair $(x_{i},y_{i})$ . The vicinal samples $(\Tilde{x},\Tilde{y})$ are generated as above, and during training minimization is performed on the empirical vicinal risk using the vicinal dataset Dy := {(,gi)}1:
其中 $\nu$ 是一个邻域分布,表示在原始特征-目标对 $(x_{i},y_{i})$ 附近找到虚拟特征-目标对 $(\Tilde{x},\Tilde{y})$ 的概率。邻域样本 $(\Tilde{x},\Tilde{y})$ 按上述方式生成,训练时在邻域数据集 Dy := {(,gi)}1: 上对经验邻域风险进行最小化。
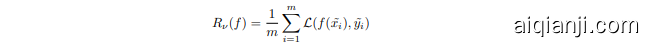
where $L$ is the standard cross-entropy loss, but calculated on the soft-labels $\tilde{y_{i}}$ instead of hard labels. Training this way not only augments the feature set $\tilde{X}$ , but the induced set of soft-labels also encourages the strength of the classification regions to vary linearly betweens samples. The experiments in [40] and related work in [15, 36, 10] show noticeable performance gains in various image classification tasks. The linear interpol at or $\lambda\in[0,1]$ that determines the mixing ratio is drawn from a symmetric Beta distribution, $B e t a(\alpha,\alpha)$ at each training iteration, where $\alpha$ is the hyperparameter that controls the strength of the interpolation between pairs of images and the associated smoothing of the training labels. $\alpha=0$ recovers the base case corresponding to zero-entropy training labels (one-hot encodings, in which case the resulting image is either just $x_{i}$ or $x_{j}$ ), while a high value of $\alpha$ ends up in always averaging the inputs and labels. The authors in [40] remark that relatively smaller values of $\alpha\in[0.1,0.4]$ gave the best performing results for classification, while high values of $\alpha$ resulted in significant under-fitting. In this work, we also look at the effect of $\alpha$ on calibration performance.
其中 $L$ 是标准交叉熵损失,但基于软标签 $\tilde{y_{i}}$ 而非硬标签计算。这种训练方式不仅扩充了特征集 $\tilde{X}$,其诱导的软标签集还能促使分类区域的强度在样本间线性变化。[40]中的实验及[15,36,10]的相关研究表明,该方法在多种图像分类任务中均取得显著性能提升。线性插值系数 $\lambda\in[0,1]$ 控制混合比例,每次训练迭代时从对称Beta分布 $Beta(\alpha,\alpha)$ 中采样,其中 $\alpha$ 是控制图像对间插值强度及训练标签平滑程度的超参数。当 $\alpha=0$ 时对应零熵训练标签的基准情况(独热编码,此时生成图像仅为 $x_{i}$ 或 $x_{j}$),而高 $\alpha$ 值会导致始终对输入和标签取平均。[40]作者指出,相对较小的 $\alpha\in[0.1,0.4]$ 在分类任务中表现最佳,而高 $\alpha$ 值会导致严重欠拟合。本文还研究了 $\alpha$ 对校准性能的影响。
3 Experiments
3 实验
We perform numerous experiments to analyze the effect of mixup training on the calibration of the resulting trained class if i ers on both image and natural language data. We experiment with various deep architectures and standard datasets, including large-scale training with ImageNet. In all the experiments in this paper, we only apply mixup to pairs of images as done in [40]. The mixup functionality was implemented using the mixup authors’ code available at [39].
我们进行了大量实验,以分析混合训练 (mixup training) 对图像和自然语言数据上最终训练分类器校准效果的影响。我们采用多种深度架构和标准数据集进行实验,包括使用ImageNet进行大规模训练。本文所有实验中,我们仅如[40]所述对图像对应用混合方法。混合功能通过[39]提供的原作者代码实现。
3.1Setup
3.1 设置
For the small-scale image experiments, we use the following datasets in our experiments: STL-10 [4], CIFAR-10 and CIFAR-100 [18] and Fashion-MNIST [37]. For STL-10, we use the VGG-16 [32] network. CIFAR-10 and CIFAR-100 experiments were carried out on VGG-16 as well as ResNet34 [12] models. For Fashion-MNIST, we used a ResNet-18 [12] model. For all experiments, we use batch normalization, weight decay of $5\times10^{-4}$ and trained the network using SGD with Nesterov momentum, training for 200 epochs with an initial learning rate of 0.1 halved at 2 at 60,120 and 160 epochs. Unless otherwise noted, calibration results are reported for the best performing epoch on the validation set.
在小规模图像实验中,我们使用了以下数据集:STL-10 [4]、CIFAR-10、CIFAR-100 [18] 和 Fashion-MNIST [37]。对于 STL-10,我们采用 VGG-16 [32] 网络。CIFAR-10 和 CIFAR-100 实验在 VGG-16 及 ResNet34 [12] 模型上进行。Fashion-MNIST 实验使用了 ResNet-18 [12] 模型。所有实验均采用批归一化 (batch normalization)、权重衰减系数为 $5\times10^{-4}$,并使用带动量的 SGD (Nesterov momentum) 进行训练,共训练 200 个周期 (epoch),初始学习率为 0.1 并在第 60、120 和 160 周期时减半。除非特别说明,校准结果均基于验证集上表现最佳的周期进行报告。
3.2 Calibration Metrics
3.2 校准指标
We measure the calibration of the network as follows (and as described in [9]): predictions are grouped into $M$ interval bins of equal size. Let $B_{m}$ be the set of samples whose prediction scores (the winning softmax score) fall into bin $m$ . The accuracy and confidence of $B_{m}$ are defined as
我们按照以下方式(以及[9]中所述)测量网络的校准度:将预测结果分成$M$个等宽区间。设$B_{m}$为预测得分(即最大softmax得分)落在第$m$个区间的样本集合。$B_{m}$的准确率和置信度定义为
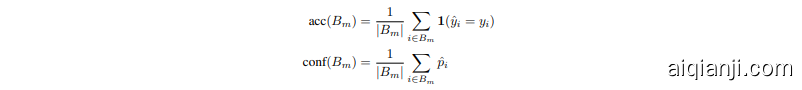
where $\hat{p}_{i}$ is the confidence (winning score) of sample $i$ . The Expected Calibration Error (ECE) is then defined as:
其中 $\hat{p}_{i}$ 是样本 $i$ 的置信度(获胜分数)。预期校准误差(ECE)定义为:

In high-risk applications, confident but wrong predictions can be especially harmful; thus we also define an additional calibration metric – the Over confidence Error (OE) – as follows
在高风险应用中,自信但错误的预测可能尤其有害;因此我们还定义了一个额外的校准指标——过度自信误差 (Over confidence Error, OE),如下所示

3.3 Comparison Methods
3.3 对比方法
Since mixup produces smoothed labels over mixtures of inputs, we compare the calibration performance of mixup to two other label smoothing techniques:
由于 mixup 会在输入混合上生成平滑标签,我们将其校准性能与另外两种标签平滑技术进行比较:
• ϵ−label smoothing described in [33], where the one-hot encoded training signal is smoothed by distributing an $\epsilon$ mass over the other (i.e., non ground-truth) classes, and • entropy-regularized loss (ERL) described in [30] that discourages the neural network from being over-confident by penalizing low-entropy distributions.
- [33] 中描述的 ϵ-标签平滑 (ϵ-label smoothing),其中通过将 $\epsilon$ 质量分布到其他(即非真实标签)类别来平滑 one-hot 编码的训练信号,
- [30] 中描述的熵正则化损失 (entropy-regularized loss, ERL),通过惩罚低熵分布来抑制神经网络的过度自信。
Our baseline comparison (no mixup) is regular training where no label smoothing or mixing of features is applied. We also note that in this section we do not compare against the temperature scaling method described in [9], which is a post-training calibration method and will generally produce well-calibrated scores. Here we would like to see the effect of label smoothing while training; experiments with temperature scaling are reported in Section 7.
我们的基线对比(无混合)是常规训练,不应用标签平滑或特征混合。我们还需指出,本节未与[9]中描述的温度缩放方法进行比较,这是一种训练后校准方法,通常能生成校准良好的分数。此处我们想观察训练过程中标签平滑的效果;温度缩放实验将在第7节报告。
3.4 Results
3.4 结果
Results on the various datasets and architectures are shown in Figure 2. While the performance gains in validation accuracy are generally consistent with the results reported in [40], here we focus on the effect of mixup on network calibration. The top row shows a calibration scatter plot for STL-10 and CIFAR-100, highlighting the effect of mixup training. In a well calibrated model, where the confidence matches the accuracy most of the points will be on $x=y$ line. We see that in the base case, both for STL-10 and CIFAR-100, most of the points tend to lie in the overconfident region. The mixup case is much better calibrated, noticeably in the high-confidence regions. The bar plots in the middle row provide results for accuracy and calibration for various combinations of datasets and architectures against comparison methods. We report the calibration error for the best performing model (in terms of validation accuracy). For label smoothing, an $\epsilon\in[0.05,0.1]$ performed best while for ERL, the best-performing confidence penalty hyper-parameter was 0.1. The trends in the comparison are clear: label smoothing either via $\epsilon$ -smoothing, ERL or mixup generally provides a calibration advantage and tempers over confidence, with the latter generally performing the best in comparison to other methods. We also show the effect on ECE as we vary the hyper parameter $\alpha$ of the mixing parameter distribution. For very low values of $\alpha$ , the behavior is similar to the base case (as expected), but ECE also noticeably worsens for higher values of $\alpha$ due to the model being under-confident. Indeed, mixup models can be under-confident if $\alpha$ is large which is related to manifold intrusion [10]: for large $\alpha$ , a mixed-up sample is more likely to lie away from the original manifold and thus be affected by manifold intrusion, where a mixed sample collides with a real sample on the data manifold, but is given a soft label that is different from the label of the real example. Over confidence alone decreases monotonically as we increase $\alpha$ as shown in Figure 2i. We also show the accuracy of mixup models at various levels of calibration determined by $\alpha$ . As can be seen, a well-tuned $\alpha$ can result in a better-calibrated model with very little loss in performance. Our classification results here are consistent with those reported in [40] where the best performing $\alpha$ was in the [0.1, .0.4] range.
不同数据集和架构下的结果如图2所示。虽然验证准确率的提升效果与[40]报告的结果基本一致,但本文主要关注mixup对网络校准的影响。首行展示了STL-10和CIFAR-100的校准散点图,突出mixup训练的效果。在理想校准模型中,当置信度匹配准确率时,多数数据点应落在$x=y$直线上。可见在基准情况下(STL-10和CIFAR-100),多数数据点倾向于位于过度自信区域。而经过mixup处理的模型校准效果显著改善,尤其在高置信度区域表现突出。
中间行的柱状图展示了不同数据集与架构组合下,各对比方法在准确率和校准指标上的表现。我们报告了最佳验证准确率模型对应的校准误差。标签平滑(Label Smoothing)方法中,$\epsilon\in[0.05,0.1]$区间表现最优;而ERL方法的最佳置信惩罚超参数为0.1。对比趋势清晰可见:无论是通过$\epsilon$-平滑、ERL还是mixup实现的标签平滑,普遍具有校准优势并能抑制过度自信,其中mixup方法相较其他方法表现最佳。
我们还展示了混合参数分布超参数$\alpha$对ECE指标的影响规律。当$\alpha$取值极低时,其表现与基准情况相似(符合预期),但随着$\alpha$增大,由于模型变得信心不足,ECE指标明显恶化。实际上,当$\alpha$过大时,mixup模型可能出现信心不足现象,这与流形入侵(manifold intrusion)[10]有关:$\alpha$值越大,混合样本越可能偏离原始数据流形,从而受到流形入侵影响——即混合样本与真实样本在数据流形上发生碰撞,却被赋予不同于真实样本的软标签。如图2i所示,随着$\alpha$增大,过度自信现象呈现单调递减趋势。
我们还统计了mixup模型在不同$\alpha$值校准水平下的准确率。结果表明,经过适当调参的$\alpha$可以在几乎不影响性能的前提下实现更优的校准效果。本文分类结果与[40]的研究结论一致,其中最佳$\alpha$值位于[0.1,0.4]区间。
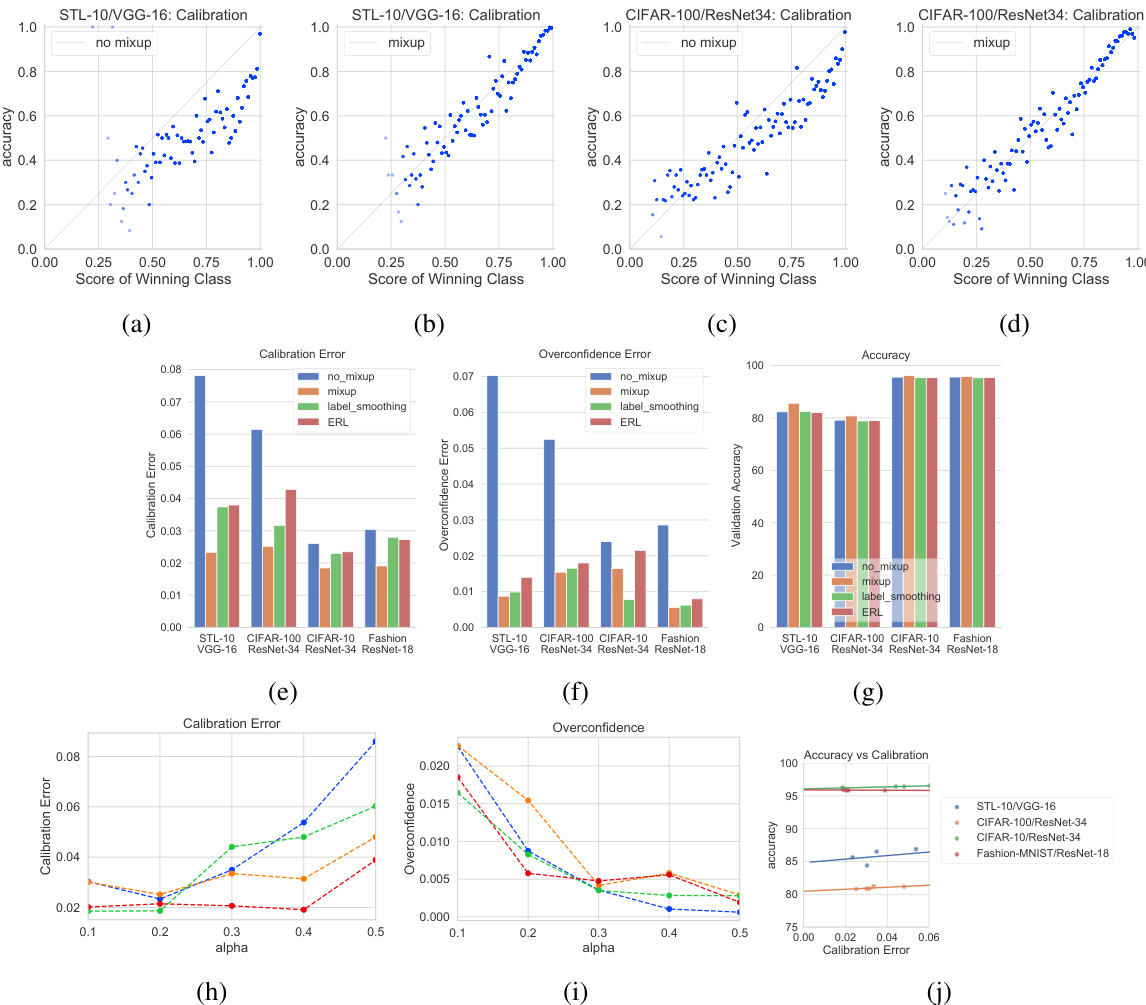
Figure 2: Calibration results for mixup and baseline (no mixup) on various image datasets and architectures. Top Row: Scatter plots for accuracy and confidence for STL-10(a,b) and CIFAR100(c,d). The mixup case is much better calibrated with the points lying closer to the $x=y$ line, while in the baseline, points tend to lie in the overconfident region. Middle Row: Mixup versus comparison methods where label smoothing is the $\epsilon$ -label smoothing method and ERL is the entropy regularized loss. Bottom Row: Expected calibration error (e) and over confidence error (f) on various architectures. Experiments suggest best ECE is achieved for $\alpha$ in the [0.2,0.4] (h), while over confidence error decreases monotonically with $\alpha$ due to under-fitting (i). Accuracy behavior for differently calibrated models is shown in (j).
图 2: 在不同图像数据集和架构上mixup与基线(无mixup)的校准结果。首行: STL-10(a,b)和CIFAR100(c,d)的准确率与置信度散点图。mixup案例的校准效果更好,点更接近$x=y$线,而基线中的点倾向于位于过度自信区域。中行: mixup与对比方法(标签平滑为$\epsilon$-标签平滑方法,ERL为熵正则化损失)的比较。末行: 不同架构上的预期校准误差(e)和过度自信误差(f)。实验表明,当$\alpha$在[0.2,0.4]区间时能获得最佳ECE(h),而由于欠拟合(i),过度自信误差随$\alpha$单调递减。不同校准模型的准确率表现如(j)所示。
3.4.1 Large-scale Experiments on ImageNet
3.4.1 ImageNet上的大规模实验
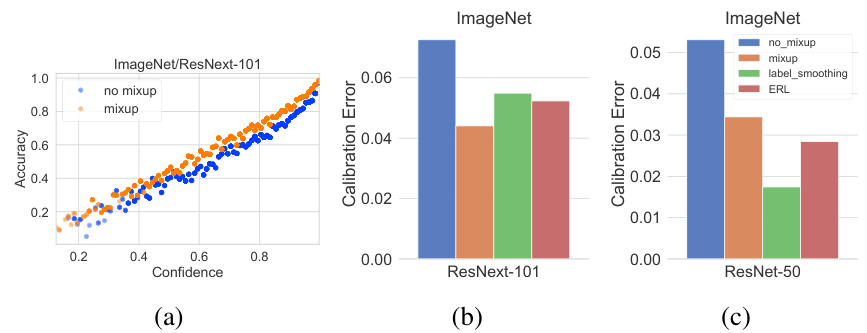
Figure 3: Calibration on ImageNet for ResNet architectures
图 3: ImageNet 上 ResNet 架构的校准情况
Here we report the results of calibration metrics resulting from mixup training on the 1000-class version of the ImageNet [5] data comprising of over 1.2 million images. One of the advantages of mixup and its implementation is that it adds very little overhead to the training time, and thus can be easily applied to large scale datasets like ImageNet. We perform distributed parallel training using the synchronous version of stochastic gradient descent. We use the learning-rate schedule described in [8] on a 32-GPU cluster and train till $93%$ accuracy is reached over the top-5 predictions. We test on two modern state-of-the-art arch ic ture s: ResNet-50 [12] and ResNext-101 (32x4d) [38]. The results are shown in Figure 3. The scatter-plot showing calibration for ResNext-101 architecture suggests that mixup training provides noticeable benefits even in the large-data scenario, where the models should be less prone to over-fitting the one-hot labels. On the deeper ResNext-101, mixup provides better calibration than the label smoothing models, though this same effect was not visible for the ResNet-50 model. However, both calibration error and over confidence show noticeable improvements using label smoothing over the baseline. The mixup model did however achieve a consistently higher classification performance of $\approx0.4$ percent over the other methods.
我们报告了在包含120多万张图像的1000类ImageNet [5]数据上采用mixup训练得到的校准指标结果。mixup方法及其实现的一个优势是几乎不会增加训练时间开销,因此能轻松应用于ImageNet等大规模数据集。我们使用同步随机梯度下降进行分布式并行训练,在32-GPU集群上采用[8]所述的学习率调度策略,训练至top-5预测准确率达到93%。测试选用两种现代最先进架构:ResNet-50 [12]和ResNext-101 (32x4d) [38],结果如图3所示。ResNext-101架构的散点图显示,即使在大数据场景下(模型应不易过拟合one-hot标签),mixup训练仍能带来显著优势。在更深的ResNext-101上,mixup比标签平滑模型具有更好的校准效果,但这一现象未出现在ResNet-50模型中。不过与基线相比,标签平滑方法在校准误差和过度自信指标上均有明显改善。值得注意的是,mixup模型始终比其他方法获得约0.4%的分类性能提升。
4 Experiments on Natural Language Data
4 自然语言数据实验
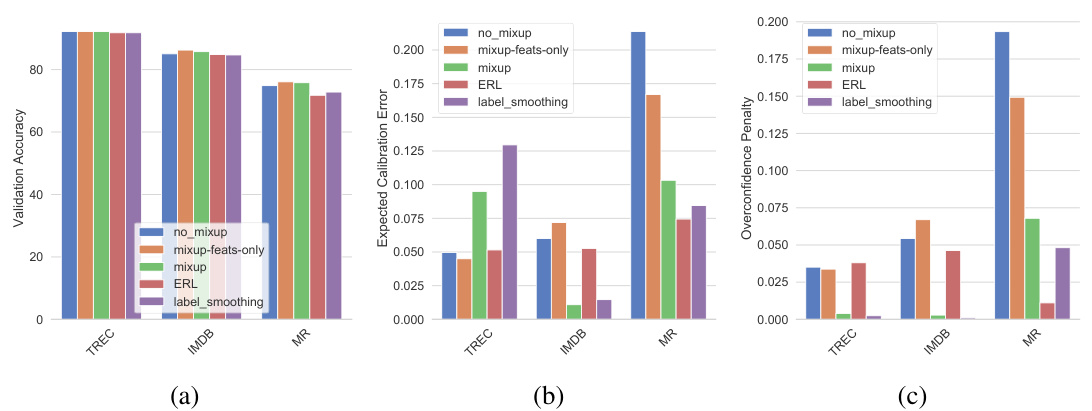
Figure 4: Accuracy, calibration and over confidence on various NLP datasets
图 4: 不同NLP数据集上的准确率、校准性和过度自信程度
While mixup was originally suggested as a method to mostly improve performance on image classification tasks, here we explore the effect of mixup training in the natural language processing (NLP) domain. A straight-forward mixing of inputs (as in pixel-mixing in images) will generally produce nonsense input since the semantics are unclear. To avoid this, we modify the mixup strategy to perform mixup on the embeddings layer rather than directly on the input documents. We note that this approach is similar to the recent work described in [11] that utilizes mixup for improving sentence classification which is among the few works, besides ours, studying the effects of mixup in the NLP domain. For our experiments, we employ mixup on NLP data for text classification using the MR [28], TREC [22] and IMDB [24] datasets.We train a CNN for sentence classification (Sentence-level CNN) [17], where we initialize all the words with pre-trained GloVe [29] embeddings, which are modified while training on each dataset. For the remaining parameters, we use the values suggested in [17]. We refrain from training the most recent NLP models [14, 2, 41] since our aim here is not to show state-of-art classification performance on these datasets, but to study the effect on calibration. We show these results in Figure 4 where it is evident that mixup provides noticeable gains for all datasets, both in terms of calibration and over confidence. We leave further exploration of principled strategies for mixup for NLP as future work.
虽然mixup最初是作为主要提升图像分类任务性能的方法提出的,但本文探讨了其在自然语言处理(NLP)领域应用的效果。直接对输入进行混合(如图像中的像素混合)通常会产生语义不明的无效输入。为避免这一问题,我们改进mixup策略,在嵌入层而非原始文档上实施混合。值得注意的是,该方法与[11]中利用mixup改进句子分类的研究思路相似——除了我们的工作外,这是少数探索mixup在NLP领域影响的文献之一。
实验中,我们采用MR [28]、TREC [22]和IMDB [24]数据集,在文本分类任务上应用mixup策略。我们训练了一个句子级CNN模型[17],所有单词均使用预训练的GloVe [29]嵌入进行初始化,并在各数据集训练过程中动态调整。其余参数设置遵循[17]的建议。由于本研究目标并非展示当前最优分类性能,而是探究校准效果,因此未采用最新NLP模型[14, 2, 41]进行训练。
图4结果显示:mixup在所有数据集上都显著提升了校准效果并降低了过度自信现象。关于NLP领域mixup原理性策略的深入探索将作为未来研究方向。
5 Effect of Soft Labels on Calibration
5 软标签对校准的影响
So far we have seen that mixup consistently leads to better calibrated networks compared to the base case, in addition to improving classification performance as has been observed in a number of works [36, 10, 23]. This behavior is not surprising given that mixup is a form of data augmentation: in mixup training, due to random sampling of both images as well as the mixing parameter $\lambda$ , the probability that the learner sees the same image twice is small. This has a strong regularizing effect in terms of preventing memorization and over-fitting, even for high-capacity neural networks. Indeed, unlike regular training, the training loss in the mixup case is always significantly higher than the base case as observed by the mixup authors [40]. Because of the significant amount of data augmentation resulting from the random combination in mixup, from the perspective of statistical learning theory, the improved calibration of a mixup classifier can be viewed as the classifier learning the true posteriors $P(Y|X)$ in the infinite data limit [35]. However this leads to the following question: if the improved calibration is essentially an effect of data augmentation, does simply combining the images without combining the labels provide the same calibration benefit?
截至目前,我们已观察到与基准情况相比,mixup不仅能提升分类性能(如多项研究[36, 10, 23]所述),还能持续改善网络校准度。考虑到mixup是一种数据增强形式,这一现象并不令人意外:在mixup训练中,由于图像和混合参数$\lambda$的随机采样,学习器两次看到相同图像的概率极低。即使对于高容量神经网络,这种机制也能通过防止记忆和过拟合产生强大的正则化效果。事实上,mixup作者[40]指出,与常规训练不同,mixup场景下的训练损失始终显著高于基准情况。从统计学习理论视角看,mixup中随机组合带来的大量数据增强,使得改进后的mixup分类器校准度可视为分类器在无限数据极限下学习真实后验概率$P(Y|X)$的结果[35]。但由此引出一个问题:若改进校准本质是数据增强的效果,那么仅组合图像而不组合标签是否也能带来相同的校准优势?
We perform a series of experiments on various image datasets and architectures to explore this question. Results from the earlier sections show that existing label smoothing techniques that increase the entropy of the training signal do provide better calibration without exploiting any data augmentation effects and thus we expect to see this effect in the mixup case as well. In the latter case, the entropies of the training labels are determined by the $\alpha$ parameter of the $B e t a(\alpha,\alpha)$ distribution from which the mixing parameter is sampled. The distribution of training entropies for a few cases of $\alpha$ are shown in Figure 5. The base-case is equivalent to $\alpha=0$ (not shown) where the entropy distribution is a point-mass at 0.
我们在多个图像数据集和架构上进行了一系列实验来探讨这个问题。前文结果表明,现有通过增加训练信号熵值的标签平滑技术确实能提供更好的校准效果,且无需利用任何数据增强效应,因此我们预期在mixup情况下也能观察到类似效果。在后一种情况中,训练标签的熵值由采样混合参数时使用的$B e t a(\alpha,\alpha)$分布的$\alpha$参数决定。图5展示了不同$\alpha$值对应的训练熵值分布情况。基线情况相当于$\alpha=0$(未显示),此时熵值分布为0处的点质量分布。
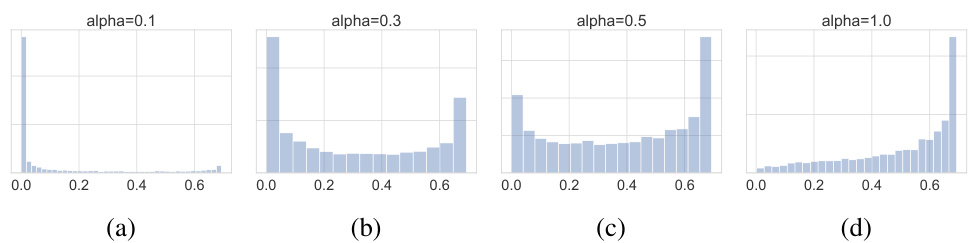
Figure 5: Entropy distribution of training labels as a function of the $\alpha$ parameter of the $B e t a(\alpha,\alpha)$ distribution from which the mixing parameter is sampled.
图 5: 训练标签的熵分布随 $B e t a(\alpha,\alpha)$ 分布参数 $\alpha$ 变化的函数关系,其中混合参数采样自该分布。
To tease out the effect of full mixup versus only mixing features, we convexly combine images as before, but the resulting image assumes the hard label of the nearer class; this provides data augmentation without the label smoothing effect. Results on a number of benchmarks and architectures are shown in Figure 6. The results are clear: merely mixing features does not provide the calibration benefit seen in the full-mixup case suggesting that the point-mass distributions in hard-coded labels are contributing factors to over confidence. As in label smoothing and entropy regular iz ation, having (or enforcing via a loss penalty) a non-zero mass in more than one class prevents the largest pre-softmax logit from becoming much larger than the others tempering over confidence and leading to improved calibration.
为了区分完全混合(mixup)与仅混合特征的效果,我们像之前那样对图像进行凸组合,但生成的图像采用较近类别的硬标签;这种方法实现了数据增强,同时避免了标签平滑效应。多个基准测试和架构的结果如图6所示。结果很明确:仅混合特征并不能带来完全混合情况下的校准优势,这表明硬编码标签中的点质量分布是导致过度自信的因素之一。与标签平滑和熵正则化类似,在多个类别中拥有(或通过损失惩罚强制实施)非零质量,可以防止最大的softmax前logit值远大于其他值,从而抑制过度自信并改善校准效果。
In addition to feature and label mixing, a recent extension to mixup [36] also proposes convexly combining the representations in the hidden layer of the network; we report the calibration effects of this approach in the supplementary material.
除了特征和标签混合外,mixup [36] 的最新扩展还提出了在网络隐藏层中对表示进行凸组合的方法;我们在补充材料中报告了该方法的校准效果。

Figure 6: Calibration performance when only features are mixed vs. full mixup, on various datasets and architectures
图 6: 仅混合特征与完整混合(mixup)在校准性能上的对比 (不同数据集和架构)
6 Effect of Extended Training on Mixup Calibration
6 延长训练对 Mixup 校准的影响
As remarked in the previous section, one of the contributing factors to improved calibration in mixup is the significant data augmentation aspect of mixup training, where the model is unlikely to see the same mixed-up sample more than once. The natural question here is whether these models will eventually become overconfident if trained for much longer periods. In Figure 7, we show the training curves for a few extended training experiments where the models were trained for 1000 epochs: for the baseline (i.e when $\alpha=0.$ ), the train loss and accuracy approach 0 and $100%$ respectively (i.e., over-fitting), while in the mixup case (non-zero $\alpha$ ’s), the strong data augmentation prevents over-fitting. This behavior is sustained over the entire duration of the training as can be seen in the corresponding values of ECE. Mixup models, even when trained for much longer, continue to have a low calibration error, suggesting that the mixing of data has a sustained inhibitive effect on over-fitting the training data (the training loss for mixup continues to be significantly higher than baseline even after extended training) and preventing the model from becoming overconfident.
如前一节所述,mixup改善校准效果的因素之一是其显著的数据增强特性,这使得模型不太可能重复看到相同的混合样本。这里自然产生的问题是:如果训练时间大幅延长,这些模型最终是否会变得过度自信?在图7中,我们展示了几个延长训练至1000轮次的实验训练曲线:基线情况(即当$\alpha=0$时)的训练损失和准确率分别趋近于0和$100%$(即过拟合),而在mixup情况下(非零$\alpha$值),强大的数据增强有效防止了过拟合。这种行为在整个训练期间持续存在,从对应的ECE值可以看出。即使训练时间大幅延长,mixup模型仍保持较低的校准误差,这表明数据混合对训练数据过拟合具有持续的抑制作用(即使经过延长训练,mixup的训练损失仍显著高于基线),并防止模型变得过度自信。

Figure 7: Training loss and calibration error under extended training for CIFAR-10 and CIFAR-100 with mixup. Baseline (no mixup) training loss (orange) goes to zero early on while mixup continues to have non-zero training loss even after 1000 epochs. Meanwhile, calibration error for mixup does not exhibit an upward trend even after extended training.
图 7: 使用 mixup 在 CIFAR-10 和 CIFAR-100 上进行长时间训练时的训练损失和校准误差。基线 (无 mixup) 的训练损失 (橙色) 早期就降至零,而 mixup 即使在 1000 个周期后仍保持非零训练损失。同时,mixup 的校准误差在长时间训练后也未呈现上升趋势。
7 Testing on Out-of-Distribution and Random Data
7 分布外数据和随机数据测试
In this section, we explore the effect of mixup training when predicting on samples from unseen classes (out-of-distribution) and random noise images. Deep networks have been shown to produce pathologically overconfident predictions on random noise images [13], and here we would like to explore the effect of mixup training on such behavior. We first train a VGG-16 network on in-distribution data (STL-10) and then predict on classes sampled from the ImageNet database that have not been encountered
在本节中,我们探讨了在预测未见类别(分布外)样本和随机噪声图像时,混合训练 (mixup training) 的效果。深度网络已被证明会对随机噪声图像产生病态的过度自信预测 [13],这里我们想研究混合训练对此类行为的影响。我们首先在分布内数据 (STL-10) 上训练 VGG-16 网络,然后对从未见过的 ImageNet 数据库中采样的类别进行预测。

Figure 8: Distribution of winning scores from various models when tested on out-of-distribution and gaussian noise samples, after being trained on the STL-10 dataset.
图 8: 在STL-10数据集上训练后,不同模型在分布外样本和高斯噪声样本测试中的获胜分数分布。
during training. For the random noise images, we test on gaussian random noise with the same mean and variance as the training set.
训练期间。对于随机噪声图像,我们在与训练集具有相同均值和方差的高斯随机噪声上进行测试。
We compare the performance of a mixup-trained model with that of the baseline, as well as a temperature calibrated pre-trained baseline as described in [9]. Since the latter is a post-training calibration method, we expect it to be well-calibrated on in-distribution data. We also compare the prediction uncertainty using the Monte Carlo dropout method described in [6] where multiple forward passes using dropout are made during test-time. We average predictions over 10 runs. The distribution over prediction scores for out-of-distribution and random data for mixup and comparison methods are shown in Figure 8. The differences versus the baseline are striking; in both cases, the mixup DNN is noticeably less confident than its non-mixup counterpart, with the score distribution being nearly perfectly separable in the random noise case. While temperature scaling is more conservative than mixup on real but out-of-sample data, it is noticeably more overconfident in the random-noise case. Further, mixup performs significantly better than MC-dropout in both cases.
我们将使用mixup训练的模型性能与基线模型以及[9]中描述的温度校准预训练基线进行比较。由于后者属于训练后校准方法,我们预期其在分布内数据上具有良好校准性。同时采用[6]提出的蒙特卡洛dropout方法比较预测不确定性,该方法在测试阶段通过多次带dropout的前向传播实现(平均10次运行结果)。图8展示了mixup与其他对比方法在分布外数据和随机数据上的预测分数分布情况。与基线相比差异显著:在两种情况下,采用mixup的深度神经网络(DNN)都明显比未使用mixup的模型更谨慎,其中随机噪声场景的分数分布几乎完全可分。虽然温度缩放方法在真实但非样本数据上比mixup更保守,但在随机噪声情况下明显更过度自信。此外,mixup在两种场景下的表现均显著优于MC-dropout方法。
| 方法 | AUROC(内/外) STL-10/ImageNet | AUROC(内/外) STL-10/Gaussian |
|---|---|---|
| Baseline | 80.57 | 73.28 |
| Mixup (Q=0.4) | 83.28 | 95.93 |
| Temp.Scaling | 56.2 | 54.2 |
| Dropout(p=0.3) | 78.93 | 70.57 |
In Table 1, we also show a comparison of the performance of the aforementioned models for reliably detecting out-ofd is tri but on and random-noise data, using Area under the ROC (AUROC) curve as the metric. Mixup is the best performing model in both cases, significantly outperforming the others as a random-noise detector. Temperature scaling, while producing well-calibrated models for in-distribution data is not a reliable detector. The scaling process reduces the confidence on both in and out-of-distribution data, significantly reducing the ability to discriminate between these two types of data. Mixup, on
在表1中,我们还比较了上述模型在可靠检测分布外数据和随机噪声数据时的性能,使用ROC曲线下面积(AUROC)作为评估指标。Mixup在两种情况下都是表现最佳的模型,作为随机噪声检测器时显著优于其他方法。温度缩放(temperature scaling)虽然能为分布内数据生成校准良好的模型,但作为检测器并不可靠。该缩放过程会同时降低对分布内和分布外数据的置信度,显著削弱区分这两类数据的能力。Mixup则...
Table 1: Out-of-category detection results for the DAC on STL-10 and Tiny ImageNet.
表 1: STL-10 和 Tiny ImageNet 数据集上 DAC 的跨类别检测结果。
the other hand, does well in both cases. The results here suggest that the effect of training with interpolated samples and the resulting label smoothing tempers over-confidence in regions away from the training data. While these experiments were limited to two datasets and one architecture, the results indicate that training by minimizing vicinal risk can be an effective way to enhance reliability of predictions in DNNs. Note that since mixup trains the model by convexly combining pairs of images, the synthesized images all lie within the convex hull of the training data. In the supplementary material, we provide results on the prediction confidence when images lie outside the convex hull of the training set.
另一方面,该方法在两种情况下都表现良好。此处结果表明,使用插值样本训练及其产生的标签平滑效果能够抑制模型在远离训练数据区域中的过度自信。虽然这些实验仅限于两个数据集和一种架构,但结果表明通过最小化邻近风险进行训练可以成为提升深度神经网络预测可靠性的有效方式。需要注意的是,由于mixup通过凸组合图像对来训练模型,所有合成图像都位于训练数据的凸包内。补充材料中我们提供了当图像位于训练集凸包之外时的预测置信度结果。
8 Conclusion and Future Work
8 结论与未来工作
We presented results on an unexplored area of mixup based training: its effect on DNN calibration and predictive uncertainty. Existing empirical work has conclusively shown the benefits of mixup for boosting classification performance; in this work, we show an additional important benefit – mixup trained networks are better calibrated and provide more reliable estimates both for in-sample and out-of-sample data (being under-confident in the latter case). There are possibly multiple reasons for this: the data augmentation provided by mixup is a form of regular iz ation that prevents over-fitting and memorization, tempering over confidence in the process. The label smoothing resulting from mixup might be viewed as a form of entropic regular iz ation on the training signals, again preventing the DNN from driving the training error to zero. The results in this paper provide further evidence that training with hard labels is likely one of the contributing factors leading to over confidence seen in modern neural networks. Recent work [36] has shown how the classification regions in mixup are smoother, without sudden jumps from one high confidence region to another suggesting that the lack of sharp transition boundaries in classification regions play an important role in producing well-calibrated class if i ers. Recent works such as [27] also confirm the benefit of label-smoothing on calibration.
我们展示了一项关于基于混合(mixup)训练未被探索领域的研究结果:其对深度神经网络(DNN)校准和预测不确定性的影响。现有实证研究已明确证明混合训练能提升分类性能;本研究发现其另一重要优势——经过混合训练的神经网络校准性更优,能为样本内外数据提供更可靠的预测置信度(后者表现为置信度偏低)。这种现象可能由多重因素导致:混合提供的数据增强是一种防止过拟合和记忆化的正则化手段,从而抑制了过度自信;混合产生的标签平滑可视为训练信号的熵正则化,再次阻止DNN将训练误差降至零。本文结果进一步证实,硬标签训练可能是导致现代神经网络过度自信的因素之一。近期研究[36]表明混合训练形成的分类区域更为平滑,不会出现高置信区域间的突然跳跃,这说明分类区域中缺乏急剧过渡边界对产生良好校准的分类器具有重要作用。[27]等最新研究也验证了标签平滑对校准的益处。
Since mixup is implemented while training, it can also be employed with post-training calibration like temperature scaling, model perturbations like the dropout method or even the ensemble models described in [19]. Further, mixup-based models can also be combined with rejection class if i ers, both during training – such as the abstention approached proposed in [34] for dealing with label noise – as well as during inference [7]. Indeed, the boost in classification performance coupled with the well-calibrated nature of mixup-trained DNNs as studied in this paper suggests that mixup is a highly effective approach for training deep neural networks where predictive uncertainty is a significant concern.
由于mixup是在训练过程中实现的,它也可以与训练后校准(如温度缩放)、模型扰动(如dropout方法)甚至[19]中描述的集成模型结合使用。此外,基于mixup的模型还可以在训练期间(如[34]提出的用于处理标签噪声的弃权方法)和推理期间[7]与拒绝类结合。事实上,正如本文所研究的,分类性能的提升加上mixup训练的DNNs良好校准的特性表明,mixup是一种非常有效的深度神经网络训练方法,其中预测不确定性是一个重要问题。
Acknowledgments
致谢
We would like to thank the anonymous referees for their valuable suggestions for improving the paper. The authors were supported in part by the Joint Design of Advanced Computing Solutions for Cancer (JDACS4C) program established by the U.S. Department of Energy (DOE) and the National Cancer Institute (NCI) of the National Institutes of Health. This work was performed under the auspices of the U.S. Department of Energy by Los Alamos National Laboratory under Contract DE-AC 5206 NA 25396. This work was also supported in part by the CONIX Research Center, one of six centers in JUMP, a Semiconductor Research Corporation (SRC) program sponsored by DARPA.
我们要感谢匿名审稿人对改进本文提出的宝贵建议。作者们部分得到了由美国能源部(DOE)和美国国立卫生研究院国家癌症研究所(NCI)联合设立的癌症先进计算解决方案联合设计(JDACS4C)项目的支持。本工作是在美国能源部洛斯阿拉莫斯国家实验室合同DE-AC 5206 NA 25396下完成的。本工作还部分得到了CONIX研究中心的支持,该中心是半导体研究公司(SRC)由DARPA赞助的JUMP项目中六个研究中心之一。
References
参考文献
A Additional Experiments on Mixup Calibration
A Mixup校准的补充实验
For completeness, we provide results using CIFAR-10 and CIFAR-100 on the ResNet-18 architecture as used in existing literature on mixup [40, 36, 10], although these works did not consider the calibration aspect.
为完整起见,我们采用现有mixup文献[40, 36, 10]中使用的ResNet-18架构,在CIFAR-10和CIFAR-100上提供了结果,尽管这些研究未考虑校准方面。
Table 2: Mixup results on CIFAR datasets with the ResNet 18 architecture
(b) CIFAR-100/ResNet-18
表 2: 采用ResNet 18架构在CIFAR数据集上的Mixup结果
| 方法 | 测试准确率 | ECE |
|---|---|---|
| NoMixup (基线) | 95.12 | 0.023 |
| Mixup (α=0.4) | 96.16 | 0.019 |
| Mixup (α=1.0) | 96.04 | 0.1 |
| Label Smoothing (e=0.1) | 95.51 | 0.089 |
| ERL (=0.1) | 95.55 | 0.046 |
| (a)CIFAR-10/ResNet-18 | ||
| 方法 | 测试准确率 | ECE |
| 基线 | 78.28 | 0.049 |
| Mixup (alpha=0.5) | 79.57 | 0.035 |
| Mixup (alpha=1.0) | 79.54 | 0.091 |
| Label Smoothing (eps=0.1) | 79.08 | 0.066 |
| ERL (kappa=1.0) | 78.47 | 0.6 |
(b) CIFAR-100/ResNet-18
Results are shown in Table 2. The baseline performance (no mixup) matches the baseline accuracies reported in the previous literature. We also provide the expected calibration error (ECE) for the best performing model as well as the mixup model that used $\alpha=1.0$ that was used in the previous literature. We find that lower $\alpha$ gives slightly better classification and sign fi cant ly better ECE. Note that ECE can be high due to both the model being overconfident as well as under-confident, the latter being the case for $\alpha=1.0$ since this causes the resulting training signal to have higher entropies than with smaller $\alpha$ ’s.
结果如表 2 所示。基线性能 (无 mixup) 与先前文献中报告的基线准确率一致。我们还提供了最佳性能模型以及先前文献中使用的 $\alpha=1.0$ mixup 模型的预期校准误差 (ECE)。我们发现较低的 $\alpha$ 能带来略优的分类性能和显著更好的 ECE。需要注意的是,ECE 偏高可能源于模型过度自信或自信不足,后者正是 $\alpha=1.0$ 时的情况,因为该设置会导致训练信号比使用较小 $\alpha$ 时具有更高的熵值。
B Prediction Confidence of Mixup
B Mixup的预测置信度

Figure 9: Distribution of winning scores on various image datasets
图 9: 不同图像数据集上的获胜分数分布
As we have seen, mixup trained models are less overconfident than their non-mixup counterparts. Here we show the distribution of the winning scores for various image datasets. As shown in Figure 9, mixup models are less peaked in the very-high confidence region.
正如我们所见,经过 mixup 训练的模型比未使用 mixup 的模型更不容易过度自信。这里我们展示了不同图像数据集的获胜分数分布。如图 9 所示,mixup 模型在极高置信度区域的峰值较低。
C Mixing in the Hidden Layers: Manifold Mixup and Effects on Calibration
C 隐藏层混合:流形混合及其对校准的影响
The empirical results in this paper show that convexly combining features and labels significantly improves model calibration and predictive uncertainty of deep neural networks since the higher entropy training signal makes the model less confident in the regions of interpolated data. One natural extension to the basic mixup idea is manifold mixup proposed in [36], where the representations in the hidden layers are also combined linearly. The authors demonstrate that interpolation in hidden layers smooths the decision boundaries and encourages the model to learn class representations with fewer directions of variance. Here we emprically investigate the effect of this additional training signal from the hidden layers on model calibration. We use the Pre Act Res Net architectures with the CIFAR-10 and CIFAR-100 datasets identical to those used in [36]. We train the models for both 200 epochs using the same learning rate as we used in our earlier experiments, as well as for 2000 epochs using the learning rate schedule in [36] and report on calibration and accuracy in both cases.
本文的实验结果表明,通过凸组合特征和标签能显著改善深度神经网络的模型校准性和预测不确定性,因为更高熵的训练信号使模型在插值数据区域的置信度降低。对基础mixup思想的自然扩展是[36]提出的流形mixup (manifold mixup),该方法还对隐藏层中的表征进行线性组合。作者证明,在隐藏层进行插值能平滑决策边界,并促使模型学习具有更少方差方向的类别表征。本文通过实验研究了隐藏层这种额外训练信号对模型校准的影响。我们采用与[36]相同的Pre Act Res Net架构及CIFAR-10、CIFAR-100数据集,分别使用早期实验中的固定学习率训练200轮次,以及采用[36]的学习率调度训练2000轮次,并报告两种情况的校准性和准确率。
Table 3: Manifold mixup experiments. For the extended training experiments, we use the same setup as [36] while for the experiments that trained for 200 epochs, we anneal the learning rate at epoch 60, 120 and 160 while keeping all other hyper parameters fixed to match the regular mixup experiments in Section 3
表 3: 流形混合实验。对于延长训练的实验,我们采用与[36]相同的设置;而在训练200轮的实验中,我们在第60、120和160轮时衰减学习率,同时保持所有其他超参数固定,以匹配第3节中的常规混合实验。
| 数据集 | 方法 | 准确率 | ECE |
|---|---|---|---|
| CIFAR-10 (PreActResNet-18) | Mixup (200轮) Manifold Mixup (200轮) Manifold Mixup (2000轮) | 96.16 95.96 97.07 | 0.02 0.047 0.077 |
| CIFAR-10 (PreActResNet-34) | Mixup (200轮) Manifold Mixup (200轮) Manifold Mixup (2000轮) | 96.42 96.2 97.5 | 0.04 0.04 0.007 |
| CIFAR-100 (PreActResNet-18) | Mixup (200轮) Manifold Mixup (200轮) Manifold Mixup (2000轮) | 79.57 74.79 79.73 | 0.047 0.22 0.06 |
| CIFAR-100 (PreActResNet-34) | Mixup (200轮) Manifold Mixup (200轮) Manifold Mixup (2000轮) | 81.22 77.36 82.32 | 0.03 0.187 0.03 |
Results are in Table 3. When trained for the same number of epochs as the regular mixup experiments reported in this paper, manifold mixup generally has lower accuracy and worse calibration errors. However, accuracy is significantly better after training for 2000 epochs (as done in [36]), with ECE improving in a few cases. However, this is not a consistent trend, and further, since the manifold mixup algorithm is more complicated, involves more hyper parameters and takes longer to train than regular mixup, in practice, regular mixup might provide a more practical approach for improved calibration.
结果如表 3 所示。当训练轮数与本文报告的常规 mixup 实验相同时,流形 mixup (manifold mixup) 通常准确率较低且校准误差更大。但在训练 2000 轮后(如 [36] 所述),准确率显著提升,部分情况下 ECE 也有所改善。然而这一趋势并不稳定,加之流形 mixup 算法更复杂、涉及更多超参数且训练耗时比常规 mixup 更长,实践中常规 mixup 可能为改进校准提供更实用的方案。
D Leaving the Convex Hull
D 离开凸包

Figure 10: Prediction behavior as one moves away from the training data
图 10: 预测行为随远离训练数据的变化趋势
Since mixup trains the model by convexly combining pairs of images, the synthesized images all lie within the convex hull of the training data. In this section, we explore the behavior of mixup as we gradually leave the convex hull in a random direction.
由于 mixup 通过凸组合图像对来训练模型,合成图像都位于训练数据的凸包内。本节我们探讨当沿随机方向逐渐离开凸包时 mixup 的行为表现。
Specifically, given an input image $\mathbf{X}\in\mathbb{R}^{m}$ , we choose a random vector $\mathbf{d}\in\mathbb{R}^{m}$ (where $d_{i}\sim$ $U(-1,1))$ , and perturb $\mathbf{X}$ as follows: $\mathbf{X}^{\prime}=\mathbf{X}+\mu\hat{\mathbf{d}}$ . We try this for different $\mathbf{d}$ ’s and $\mu$ ’s and observe the predictions for a pre-trained mixup model and explore how the prediction behavior changes.
具体来说,给定输入图像 $\mathbf{X}\in\mathbb{R}^{m}$,我们选择一个随机向量 $\mathbf{d}\in\mathbb{R}^{m}$(其中 $d_{i}\sim$ $U(-1,1)$),并按如下方式扰动 $\mathbf{X}$:$\mathbf{X}^{\prime}=\mathbf{X}+\mu\hat{\mathbf{d}}$。我们尝试不同的 $\mathbf{d}$ 和 $\mu$,观察预训练 mixup 模型的预测结果,并探索预测行为如何变化。
We test three versions of a pre-trained VGG-16 model: mixup, baseline (no mixup) and a temperaturescaled version of the baseline, all trained on STL-10 data. We experiment over a wide range of the perturbation parameter $\mu$ . Figure 10 shows how the prediction accuracies, winning softmax scores (confidence) and the entropy of the prediction distributions change in all three cases.
我们测试了预训练VGG-16模型的三个版本:mixup、基线(无mixup)和经过温度缩放(temperature-scaled)的基线版本,所有模型均在STL-10数据集上训练。我们在扰动参数$\mu$的广泛取值范围内进行实验。图10展示了三种情况下预测准确率、获胜softmax分数(置信度)以及预测分布熵值的变化情况。
As the images are more perturbed (and thus become more noisy), the accuracy of mixup is more robust and does not degrade as quickly as the other methods. Note that the baseline and temperature-scaled versions will have identical predictions and thus identical accuracies, since temperature scaling does not change the winning class, but only scales the softmax scores. This is evident in the confidence plot where temperature scaling quickly loses confidence as the perturbations get larger. Mixup confidence decays more gradually, similar to its decay in accuracy. The base model loses confidence, and then quickly regains it as the images get further away from the training set – a pathological behavior of deep neural networks that has been widely observed in the literature. Threshold-based confidence models will obviously fail in such cases. Prediction entropy shows similar behavior to confidence. It is worthwhile to note that even a small perturbation of 0.01 (where the image structure is largely preserved) quickly degrades the confidence of temperature scaled models, indicating that they are less robust to additive noise; a threshold-based prediction mechanism will reject a significant number of samples in such cases. At a large perturbation value (100), the accuracy of mixup is still about $25%$ while the base model (and thus the temperature scaled versions) are no better than random $(10%)$
随着图像扰动加剧(噪声增多),mixup方法的准确率表现出更强的鲁棒性,其下降速度明显慢于其他方法。需注意基线模型与温度缩放版本会保持相同的预测结果及准确率,因为温度缩放仅调整softmax分数而不改变获胜类别。这在置信度曲线中尤为明显:随着扰动增强,温度缩放模型的置信度迅速下降,而mixup的置信度衰减更为平缓,与其准确率衰减趋势一致。基础模型会先失去置信度,随后在图像偏离训练集时又快速恢复——这是深度神经网络普遍存在的病理行为[20]。基于阈值的置信模型在此类情况下必然失效。预测熵的变化趋势与置信度相似。值得注意的是,即使微小扰动(0.01级别,图像结构基本完整)也会导致温度缩放模型的置信度急剧下降,表明其对加性噪声的鲁棒性较弱;此时基于阈值的预测机制将拒绝大量样本。当扰动值达到100时,mixup仍保持约25%的准确率,而基础模型(及其温度缩放版本)的表现已不优于随机猜测(10%)。