Connecting Low-Loss Subspace for Personalized Federated Learning
连接低损失子空间以实现个性化联邦学习
Minwoo Jeong lloyd.ai@ka kao enterprise.com Kakao Enterprise South Korea
闵宇(Minwoo Jeong) lloyd.ai@kakaoenterprise.com Kakao Enterprise 韩国
ABSTRACT
摘要
Due to the curse of statistical heterogeneity across clients, adopting a personalized federated learning method has become an essential choice for the successful deployment of federated learning-based services. Among diverse branches of personalization techniques, a model mixture-based personalization method is preferred as each client has their own personalized model as a result of federated learning. It usually requires a local model and a federated model, but this approach is either limited to partial parameter exchange or requires additional local updates, each of which is helpless to novel clients and burdensome to the client’s computational capacity. As the existence of a connected subspace containing diverse low-loss solutions between two or more independent deep networks has been discovered, we combined this interesting property with the model mixture-based personalized federated learning method for improved performance of personalization. We proposed SuPerFed, a personalized federated learning method that induces an explicit connection between the optima of the local and the federated model in weight space for boosting each other. Through extensive experiments on several benchmark datasets, we demonstrated that our method achieves consistent gains in both personalization performance and robustness to problematic scenarios possible in realistic services.
由于客户端间统计异质性的诅咒,采用个性化联邦学习方法已成为成功部署基于联邦学习的服务的必然选择。在各类个性化技术分支中,基于模型混合的个性化方法更受青睐,因其能使每个客户端通过联邦学习获得专属个性化模型。该方法通常需要本地模型和联邦模型协同工作,但现有方案要么局限于部分参数交换,要么需要额外本地更新——前者对新型客户端无效,后者则加重客户端的计算负担。随着研究发现两个及以上独立深度网络间存在包含多种低损失解(low-loss solutions)的连通子空间,我们将这一特性与基于模型混合的个性化联邦学习方法结合以提升性能。我们提出SuPerFed方法,通过在权重空间建立本地模型与联邦模型最优解间的显式连接实现相互促进。在多个基准数据集上的实验表明,该方法在个性化性能和现实服务中可能出现的异常场景鲁棒性方面均取得稳定提升。
CCS CONCEPTS
CCS概念
• Computing methodologies $\rightarrow$ Distributed algorithms; Neural networks.
• 计算方法 $\rightarrow$ 分布式算法;神经网络。
KEYWORDS
federated learning, non-IID data, personalization, personalized federated learning, label noise, mode connectivity
联邦学习 (federated learning)、非独立同分布数据 (non-IID data)、个性化 (personalization)、个性化联邦学习 (personalized federated learning)、标签噪声 (label noise)、模式连通性 (mode connectivity)
ACM Reference Format:
ACM 参考文献格式:
Seok-Ju Hahn, Minwoo Jeong, and Junghye Lee. 2022. Connecting Low-Loss Subspace for Personalized Federated Learning. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’22), August 14–18, 2022, Washington, DC, USA. ACM, New York, NY, USA, 11 pages. https://doi.org/10.1145/3534678.3539254
Seok-Ju Hahn、Minwoo Jeong 和 Junghye Lee。2022。面向个性化联邦学习的低损失子空间连接。载于《第28届ACM SIGKDD知识发现与数据挖掘会议论文集》(KDD '22),2022年8月14-18日,美国华盛顿特区。ACM,美国纽约州纽约市,11页。https://doi.org/10.1145/3534678.3539254
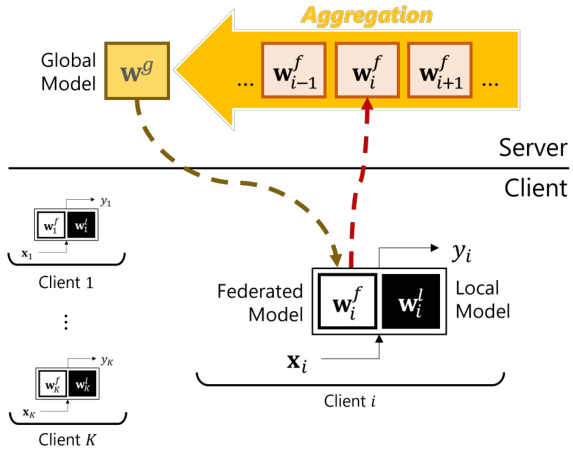
Figure 1: Overview of the model mixture-based personalized federated learning.
图 1: 基于模型混合的个性化联邦学习概览。
1 INTRODUCTION
1 引言
Individuals and institutions are now data producers as well as data keepers, thanks to advanced communication and computation technologies. Therefore, training a machine learning model in a data-centralized setting is sometimes not viable due to many realistic limitations, such as the existence of massive clients generating their own data in real-time or the data privacy issue restricting the collection of data. Federated learning (FL) [46] is a solution to solve this problematic situation as it enables parallel training of a machine learning model across clients or institutions without sharing their private data, usually under the orchestration of the server (e.g., service providers). In the most common FL setting, such as FedAvg [46], when the server prepares and broadcasts a model appropriate for a target task, each participant trains the model with its own data and transmits the resulting model parameters to the server. Then, the server receives the locally updated model parameters to aggregate (i.e., weighted averaging) into a new global model. The new global model is broadcast again to some fraction of participating clients. This collaborative learning process is repeated until convergence. However, obtaining a single global model through FL is not enough to provide satisfiable experiences to all clients, due to the curse of data heterogeneity. Since there exists an inherent difference among clients, the data residing in each client is not statistically identical. That is, a different client has their own different data distribution, or the data is not independent and identically distributed (non-IID). Thus, applying a simple FL method like FedAvg cannot avoid a pitfall of the high generalization error or even the divergence of model training [32]. That is, it is sometimes possible that the performance of the global model is lower than the locally trained model without collaboration. When this occurs, clients barely have the motivation to participate in the collaborative learning process to train a single global model.
得益于先进的通信和计算技术,个人和机构如今既是数据生产者也是数据保管者。因此,在数据集中化的环境中训练机器学习模型常因现实限制而难以实现,例如存在大量实时生成数据的客户端,或数据隐私问题限制数据收集。联邦学习 (FL) [46] 通过允许客户端或机构在不共享私有数据的情况下并行训练机器学习模型(通常由服务器协调,如服务提供商)来解决这一难题。在FedAvg [46]等最常见FL设定中,服务器准备并广播适合目标任务的模型后,各参与者用自身数据训练模型并将所得模型参数传回服务器。服务器汇总本地更新的模型参数(即加权平均)生成新全局模型,再次广播给部分参与客户端。这一协作学习过程重复至收敛。然而,由于数据异构性难题,通过FL获取单一全局模型无法为所有客户端提供满意体验。客户端间存在固有差异,各客户端数据在统计上并非同分布(即非独立同分布non-IID)。因此,采用FedAvg等简单FL方法无法避免高泛化误差甚至模型训练发散的缺陷[32],可能导致全局模型性能低于未协作的本地训练模型。此时客户端几乎丧失参与协作训练单一全局模型的动机。
Hence, it is natural to rethink the scheme of FL. As a result, personalized FL (PFL) has becomes an essential component of FL, which has yielded many related studies. Many approaches are proposed for PFL, based on multi-task learning [12, 44, 51], regular iz ation technique [11, 23, 38]; meta-learning [14, 31], clustering [20, 43, 49], and a model mixture method [2, 8, 10, 38, 41, 43]. We focus on the model mixture-based PFL method in this paper as it shows promising performance as well as lets each client have their own model, which is a favorable trait in terms of personalization as each participating client eventually has their own model. This method assumes that each client has two distinct parts: a local (sub-)model and a federated (sub-)model (i.e., federated (sub-)model is a global model transferred to a client). In the model mixture-based PFL method, it is expected that the local model captures the information of heterogeneous client data distribution by staying only at the client-side, while the federated model focuses on learning common information across clients by being communicated with the server. Each federated model built at the client is sent to the server, where it is aggregated into a single global model (Figure 1). At the end of each PFL iteration, a participating client ends up having a personalized part (i.e., a local model), which potentially relieves the risks from the non-IIDness as well as benefits from the collaboration of other clients.
因此,重新思考联邦学习 (FL) 的方案是自然而然的。于是,个性化联邦学习 (PFL) 成为 FL 的重要组成部分,并催生了许多相关研究。目前提出的 PFL 方法主要基于多任务学习 [12, 44, 51]、正则化技术 [11, 23, 38]、元学习 [14, 31]、聚类 [20, 43, 49] 以及模型混合方法 [2, 8, 10, 38, 41, 43]。本文聚焦于基于模型混合的 PFL 方法,因其不仅展现出优异性能,还能让每个客户端拥有专属模型——这种特性在个性化方面极具优势,因为最终每个参与客户端都能保有自身模型。该方法假设每个客户端包含两个独立部分:本地(子)模型和联邦(子)模型(即联邦(子)模型是从服务器传输至客户端的全局模型)。在基于模型混合的 PFL 方法中,本地模型通过驻留客户端专门捕捉异构客户端数据分布信息,而联邦模型则通过服务器通信专注于学习跨客户端的共性信息。每个客户端构建的联邦模型会被发送至服务器聚合成单一全局模型(图 1)。每轮 PFL 迭代结束时,参与客户端将保留个性化部分(即本地模型),这既能缓解非独立同分布 (non-IID) 带来的风险,又能从其他客户端的协作中获益。
The model mixture-based PFL method has two sub-branches. One is sharing only a partial set of parameters of one single model as a federated model [2, 8, 41] (e.g., only exchanging weights of a penultimate layer), the other is having two identically structured models as a local and a federated model [10, 11, 23, 38, 43]. However, each of them has some limitations. In the former case, new clients cannot immediately exploit the model trained by FL, as the server only has a partial set of model parameters. In the latter case, all of them require separate (or sequential) updates for the local and the federated model each, which is possibly burdensome to some clients having low computational capacity.
基于模型混合的个性化联邦学习 (PFL) 方法包含两个分支:一是仅共享单一模型的部分参数作为联邦模型 [2, 8, 41] (例如仅交换倒数第二层的权重),二是采用两个结构相同的模型分别作为本地模型和联邦模型 [10, 11, 23, 38, 43]。但二者均存在局限性:前者因服务器仅保留部分模型参数,新客户端无法直接利用联邦学习训练的模型;后者需对本地模型和联邦模型分别进行独立 (或顺序) 更新,这对计算能力较弱的客户端可能造成负担。
Here comes our main motivation: the development of a model mixture-based PFL method that can jointly train a whole model communicated with the server and another model for personalization. We attempted to achieve this goal through the lens of connectivity. As many studies on the deep network loss landscape have progressed, one intriguing phenomenon is being actively discussed in the field: the connectivity [13, 15, 16, 18, 19, 54] between deep networks. Though deep networks are known to have many local minima, it has been revealed that each of these local minima has a similar performance to each other [7]. Additionally, it has recently been discovered that two different local minima obtained by two independent deep networks can be connected through the linear path [17] or the non-linear path [13, 19] in the weight space, where all weights on the path have a low loss. Note that the two endpoints of the path are two different local minima reached from the two different deep networks. These findings have been extended to a multi-dimensional subspace [4, 54] with only a few gradient steps on two or more independently initialized deep networks. The resulting subspace, including the one-dimensional connected path, contains functionally diverse models having high accuracy. It can also be viewed as an ensemble of deep networks in the weight space, thereby sharing similar properties such as good calibration performance and robustness to the label noise. By introducing the connectivity to a model mixture-based PFL method, such good properties can also be absorbed advantageously.
我们的核心动机由此产生:开发一种基于模型混合的个性化联邦学习 (PFL) 方法,能够联合训练与服务器通信的完整模型和用于个性化的另一模型。我们尝试通过连通性视角实现这一目标。随着深度学习网络损失景观研究的深入,该领域正积极探讨一个有趣现象:深度网络间的连通性 [13, 15, 16, 18, 19, 54]。尽管已知深度网络存在许多局部极小值,但研究表明这些极小值彼此性能相近 [7]。此外,最新发现表明:通过权重空间中的线性路径 [17] 或非线性路径 [13, 19],可将两个独立深度网络获得的不同局部极小值连通,且路径上所有权重均保持低损失。需注意,该路径的两个端点分别对应两个不同深度网络达到的局部极小值。这些发现已扩展到多维子空间 [4, 54]——仅需对两个及以上独立初始化的深度网络进行少量梯度步骤。由此产生的子空间(包含一维连通路径)涵盖了大量功能多样且高精度的模型,也可视为权重空间中深度网络的集成,因此共享了良好校准性能和标签噪声鲁棒性等特性。将连通性引入基于模型混合的PFL方法后,这些优良特性也能被有效吸收。
Our contributions. Inspired by this observation, we propose SuPerFed, a connected low-loss subspace construction method for the personalized federated learning, adapting the concept of connectivity to the model mixture-based PFL method. This method aims to find a lowloss subspace between a single global model and many different local models at clients in a mutually beneficial way. Accordingly, we aim to achieve better personalization performance while overcoming the aforementioned limitations of model mixture-based PFL methods. Adopting the connectivity to FL is non-trivial as it obviously differs from the setting where the connectivity is first considered: each deep network observes different data distributions and only the global model can be connected to other local models on clients. The main contributions of the work are as follows:
我们的贡献。受此启发,我们提出了SuPerFed——一种面向个性化联邦学习的连通低损失子空间构建方法,将连通性概念适配于基于模型混合的PFL方法。该方法旨在以互利方式,在单一全局模型与客户端多个不同本地模型之间寻找低损失子空间。由此,我们力求在提升个性化性能的同时,克服基于模型混合的PFL方法的上述局限性。将连通性引入联邦学习具有显著挑战性,因其与连通性最初提出的设定存在本质差异:每个深度网络观测不同的数据分布,且仅有全局模型能与客户端的其他本地模型建立连接。本研究的主要贡献如下:
2 RELATED WORKS
2 相关工作
2.1 FL with Non-IID Data
2.1 非独立同分布数据下的联邦学习 (FL with Non-IID Data)
After [46] proposed the basic FL algorithm (FedAvg), handling nonIID data across clients is one of the major points to be resolved in the FL field. While some methods are proposed such as sharing a subset of client’s local data at the server[56], accumulating previous model updates at the server [26]. These are either unrealistic assumptions for FL or not enough to handle a realistic level of statistical heterogeneity. Other branches to aid the stable convergence of a single global model include modifying a model aggregation method at the server [40, 48, 53, 55] and adding a regular iz ation to the optimization [1, 32, 39]. However, a single global model may still not be sufficient to provide a satisfactory experience to clients using FL-driven services in practice.
在[46]提出基础的联邦学习算法(FedAvg)后,处理客户端间的非独立同分布(nonIID)数据成为该领域待解决的核心问题。虽然已有部分解决方案被提出,例如在服务器端共享客户端本地数据子集[56]、在服务器端累积历史模型更新[26],但这些方法要么违背联邦学习的基本假设,要么难以应对现实场景中的统计异构性。其他促进单一全局模型稳定收敛的研究方向包括:改进服务器端的模型聚合方法[40, 48, 53, 55],以及在优化过程中添加正则化项[1, 32, 39]。然而实践表明,单一全局模型可能仍无法为使用联邦学习服务的客户提供理想体验。
2.2 PFL Methods
2.2 PFL方法
As an extension of the above, PFL methods shed light on the new perspective of FL. PFL aims to learn a client-specific personalized
作为上述内容的延伸,个性化联邦学习 (Personalized Federated Learning, PFL) 方法为联邦学习提供了新的视角。PFL旨在学习针对特定客户端的个性化
(C) Exploitation of trained models
(C) 训练模型的利用
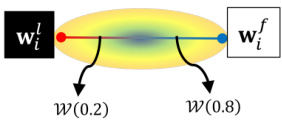
Case 1) Clients participate in the federated learning → Can utilize any models from the connected low-loss subspace generated by adjusting $\lambda\in[0,1]$
案例1) 客户端参与联邦学习 → 可通过调整 $\lambda\in[0,1]$ 来利用连接的低损失子空间生成的任何模型
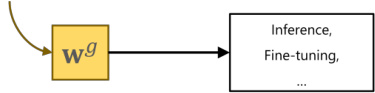
Case 2) Novel clients
案例 2) 新客户端
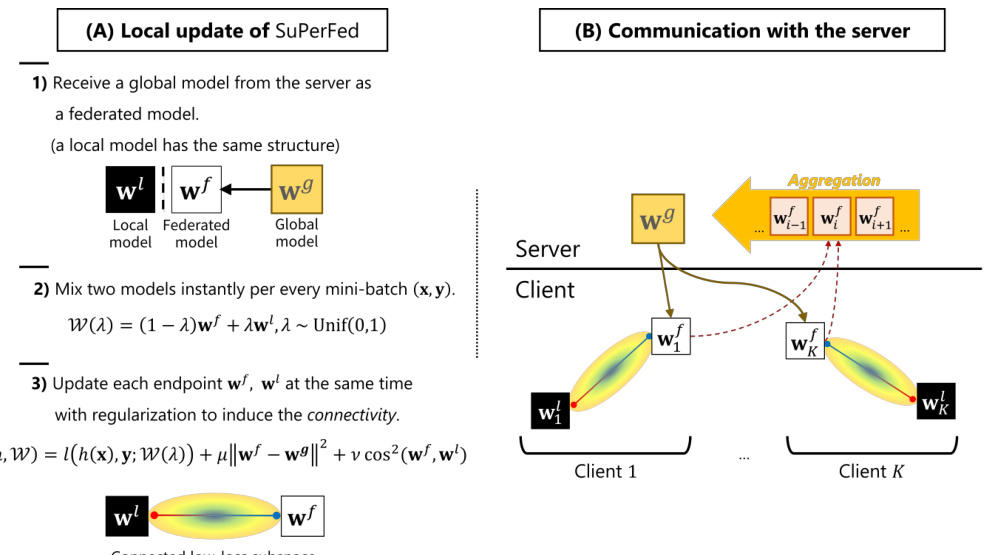
Figure 2: An illustration of the proposed method SuPerFed. (A) Local update of SuPerFed: at every federated learning round, a selected client receives a global model from the server and sets it to be a federated model. After being mixed by a randomly generated $\lambda$ , two models are jointly updated with regular iz ation. (B) Communication with the server: only the updated federated model is uploaded to the server (dotted arrow in crimson) to be aggregated (e.g., weighted averaging) as a new global model, and it is broadcast to clients in the next round (arrow in gray). (C) Exploitation of trained models: (Case 1) FL clients can sample and use any model on the connected subspace (e.g., W(0.2), $\mathcal{W}(0.8))$ because it only contains low-loss solutions. (Case 2) Novel clients can download and use the server’s trained global model $\mathbf{w}_{g}$ .
图 2: 提出的SuPerFed方法示意图。(A) SuPerFed的本地更新:在每轮联邦学习中,选定的客户端从服务器接收全局模型并设为联邦模型。经过随机生成的$\lambda$混合后,两个模型通过正则化联合更新。(B) 与服务器的通信:仅更新后的联邦模型会上传至服务器(深红色虚线箭头)进行聚合(如加权平均)形成新全局模型,并在下一轮广播给客户端(灰色箭头)。(C) 训练模型的利用:(情况1) FL客户端可采样使用连接子空间上的任意模型(如W(0.2), $\mathcal{W}(0.8))$,因其仅包含低损失解。(情况2) 新客户端可下载使用服务器训练好的全局模型$\mathbf{w}_{g}$。
→ Can exploit the global model by downloading from the server.
可以从服务器下载以利用全局模型。
model, and many methodologies for PFL have been proposed. Multitask learning-based PFL [12, 44, 51] treats each client as a different task and learns a personalized model for each client. Local finetuning-based PFL methods [14, 31] adopt a meta-learning approach for a global model to be adapted promptly to a personalized model for each client, and clustering-based PFL methods [20, 43, 49] mainly assume that similar clients may reach a similar optimal global model. Model mixture-based PFL methods [2, 8, 10, 11, 23, 38, 41, 43] divide a model into two parts: one (i.e., a local model) for capturing local knowledge, and the other (i.e., a federated model) for learning common knowledge across clients. In these methods, only the federated model is shared with the server while the local model resides locally on each client. [2] keeps weights of the last layer as a local model (i.e., the personalization layers), and [8] is similar to this except it requires a separate update on a local model before the update of a federated model. In contrast, [41] retains lower layer weights in clients and only exchanges higher layer weights with the server. Due to the partial exchange, new clients in the scheme of [2, 8, 41] should train their models from scratch or need at least some steps of fine-tuning. In [10, 11, 23, 38, 43], each client holds at least two separate models with the same structure: one for a local model and the other for a federated model. In [10, 23, 43], they are explicitly interpolated in the form of a convex combination after the independent update of two models. In [11, 38], the federated model affects the update of the local model in the form of proximity regular iz ation.
模型,并提出了许多个性化联邦学习(PFL)方法。基于多任务学习的PFL [12, 44, 51] 将每个客户端视为不同任务,为其学习个性化模型。基于本地微调的PFL方法 [14, 31] 采用元学习方法,使全局模型能快速适配为各客户端的个性化模型;基于聚类的PFL方法 [20, 43, 49] 主要假设相似客户端可能收敛至相似的全局最优模型。基于模型混合的PFL方法 [2, 8, 10, 11, 23, 38, 41, 43] 将模型分为两部分:一部分(即本地模型)用于捕获本地知识,另一部分(即联邦模型)用于学习跨客户端的共性知识。这些方法中仅联邦模型与服务器共享,本地模型则驻留在各客户端本地。[2] 将最后一层权重保留为本地模型(即个性化层),[8] 与之类似,但要求在更新联邦模型前对本地模型进行单独更新。[41] 则保留客户端底层权重,仅与服务器交换高层权重。由于这种部分交换机制,[2, 8, 41] 方案中的新客户端需从头训练模型或至少进行若干步微调。在 [10, 11, 23, 38, 43] 中,每个客户端至少持有两个结构相同的独立模型:一个作为本地模型,另一个作为联邦模型。[10, 23, 43] 在两个模型独立更新后以凸组合形式显式插值,而 [11, 38] 通过邻近正则化使联邦模型影响本地模型的更新。
2.3 Connectivity of Deep Networks
2.3 深度网络的连通性
The existence of either linear path [17] or non-linear path [13, 19] between two minima derived by two different deep networks has been recently discovered through extensive studies on the loss landscape of deep networks [13, 15, 16, 18, 19]. That is, there exists a low-loss subspace (e.g., line, simplex) connecting two or more deep networks independently trained on the same data. Though there exist some studies on constructing such a low loss subspace [5, 28– 30, 36, 42], they require multiple updates of deep networks. After it is observed that independently trained deep networks have a low cosine similarity with each other in the weight space [15], a recent study by [54] proposes a straightforward and efficient method for explicitly inducing linear connectivity in a single training run. Our method adopts this technique and adapts it to construct a low-loss subspace between each local model and a federated model (which will later be aggregated into a global model at the server) suited for an effective PFL in heterogeneous ly distributed data.
通过对深度网络损失景观的广泛研究[13, 15, 16, 18, 19],最近发现由两个不同深度网络产生的极小值之间存在线性路径[17]或非线性路径[13, 19]。也就是说,存在一个低损失子空间(如直线、单纯形)连接两个或多个在同一数据上独立训练的深度网络。尽管已有一些关于构建此类低损失子空间的研究[5, 28–30, 36, 42],但它们需要对深度网络进行多次更新。在观察到独立训练的深度网络在权重空间中彼此具有较低的余弦相似性后[15],[54]的最新研究提出了一种简单高效的方法,可在单次训练中显式诱导线性连接。我们的方法采用该技术,并将其适配为构建每个本地模型与联邦模型(后续将在服务器端聚合成全局模型)之间的低损失子空间,以适应异构分布数据中的高效个性化联邦学习(PFL)。
3 PROPOSED METHOD
3 提出的方法
3.1 Overview
3.1 概述
In the standard FL scheme [46], the server orchestrates the whole learning process across participating clients with iterative communication of model parameters. Since our method is essentially a model mixture-based PFL method, we need two models same in structure per client (one for a federated model, the other for a local model), of which initialization is different from each other. As a result, the client’s local models are trained using different random initialization s than its federated model counterpart. Note that different initialization is not common in FL [46]; however, this is intended behavior in our scheme for promoting construction of
在标准联邦学习 (FL) [46] 框架中,服务器通过模型参数的迭代通信协调参与客户端的学习过程。由于我们的方法本质上是基于模型混合的个性化联邦学习 (PFL) 方法,每个客户端需要两个结构相同的模型(一个用于联邦模型,另一个用于本地模型),其初始化方式彼此不同。因此,客户端的本地模型使用与其联邦模型不同的随机初始化进行训练。需注意,不同的初始化在联邦学习 [46] 中并不常见;但这是我们方案中为促进...的预期行为
Algorithm 1 Local Update
算法 1 本地更新
Algorithm 2 SuPerFed
算法 2 SuPerFed
the connected low-loss subspace between a federated model and a local model.
联邦模型与本地模型之间的低损耗连通子空间。
3.2 Notations
3.2 符号说明
We first define arguments required for the federated optimization as follows: a total number of communication rounds (R), a person a lization start round (L) a local batch size (B), a number of local epochs (E), a total number of clients (K), a fraction of clients selected at each round (C), and a local learning rate $(\eta)$ . Following that, three hyper parameters are required for the optimization of our proposed method: a mixing constant $\lambda$ sampled from the uniform distribution ${\mathrm{Unif}}(0,1)$ , a constant $\mu$ for proximity regular iz ation on the federated model $\mathbf{w}^{f}$ so that it is not distant from the global model $\mathbf{w}^{g}$ ; and a constant $\nu$ for inducing connectivity along a subspace between local and federated models $(\mathbf{w}^{l}&\mathbf{w}^{f})$ .
我们首先定义联邦优化所需的参数如下:总通信轮数 (R)、个性化起始轮数 (L)、本地批次大小 (B)、本地训练轮数 (E)、客户端总数 (K)、每轮选中的客户端比例 (C) 以及本地学习率 $(\eta)$。随后,优化我们提出的方法需要三个超参数:从均匀分布 ${\mathrm{Unif}}(0,1)$ 中采样的混合常数 $\lambda$、用于对联邦模型 $\mathbf{w}^{f}$ 施加邻近正则化以使其不远离全局模型 $\mathbf{w}^{g}$ 的常数 $\mu$,以及用于在本地模型与联邦模型 $(\mathbf{w}^{l}&\mathbf{w}^{f})$ 之间诱导子空间连通性的常数 $\nu$。
3.3 Problem Statement
3.3 问题陈述
Consider that each client $c_{i}$ $(i\in[\mathrm{K}])$ has its own dataset $\mathcal{D}{i}=$ ${(\mathbf{x}{i},\mathbf{y}{i})}$ of size $n{i}$ , as well as a model $\mathcal{W}{i}$ . We assume that datasets are non-IID across clients in PFL, which means that each dataset $\mathcal{D}{i}$ is sampled independently from a corresponding distribution $\mathcal{P}{i}$ on both input and label spaces $z=\chi\times y$ . A hypothesis $h\in{\mathcal{H}}$ can be learned by the objective function $l:\mathcal{H}\times\mathcal{Z}\rightarrow$ $\mathbb{R}^{+}$ in the form of $l(h(\mathbf{x};\mathcal{W}),\mathbf{y})$ . We denote the expected loss as $\mathcal{L}{\mathcal{P}{i}}(h{i},\mathcal{W}{i})=\mathbb{E}{(\mathbf{x}{i},\mathbf{y}{i})\sim\mathcal{P}{i}}[l(h{i}(\mathbf{x}{i};\mathcal{W}{i}),\mathbf{y}{i})]$ , and the empirical loss as $\begin{array}{r}{\hat{\mathcal{L}}{\mathcal{D}{i}}(h{i},\mathcal{W}{i})=\frac{1}{n{i}}\sum_{j=1}^{n_{i}}l_{i}(h_{i}(\mathbf{x}{i}^{j};\mathcal{W}{i}),\mathbf{y}{i}^{j})}\end{array}$ ; a regular iz ation term $\Omega(\mathcal{W}{i})$ can also be incorporated here. Then, the global objective of PFL is to optimize (1).
假设每个客户端 $c_{i}$ $(i\in[\mathrm{K}])$ 拥有自己的数据集 $\mathcal{D}{i}=$ ${(\mathbf{x}{i},\mathbf{y}{i})}$ ,其大小为 $n{i}$ ,以及一个模型 $\mathcal{W}{i}$ 。我们假设在个性化联邦学习 (PFL) 中,各客户端的数据集是非独立同分布 (non-IID) 的,这意味着每个数据集 $\mathcal{D}{i}$ 是从输入和标签空间 $z=\chi\times y$ 上的对应分布 $\mathcal{P}{i}$ 中独立采样的。假设 $h\in{\mathcal{H}}$ 可以通过目标函数 $l:\mathcal{H}\times\mathcal{Z}\rightarrow$ $\mathbb{R}^{+}$ 以 $l(h(\mathbf{x};\mathcal{W}),\mathbf{y})$ 的形式学习。我们将期望损失表示为 $\mathcal{L}{\mathcal{P}{i}}(h{i},\mathcal{W}{i})=\mathbb{E}{(\mathbf{x}{i},\mathbf{y}{i})\sim\mathcal{P}{i}}[l(h{i}(\mathbf{x}{i};\mathcal{W}{i}),\mathbf{y}{i})]$ ,经验损失表示为 $\begin{array}{r}{\hat{\mathcal{L}}{\mathcal{D}{i}}(h{i},\mathcal{W}{i})=\frac{1}{n{i}}\sum_{j=1}^{n_{i}}l_{i}(h_{i}(\mathbf{x}{i}^{j};\mathcal{W}{i}),\mathbf{y}{i}^{j})}\end{array}$ ;此处还可以加入正则化项 $\Omega(\mathcal{W}{i})$ 。因此,PFL 的全局目标是优化 (1)。

We can minimize this global objective through the empirical loss minimization (2).
我们可以通过经验损失最小化 (2) 来最小化这个全局目标。
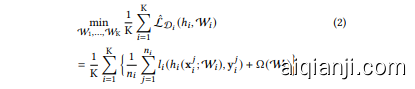
A model mixture-based PFL assumes each client $c_{i}$ has a set of paired parameters $\mathbf{w}{i}^{f},\mathbf{w}{i}^{l}\subseteq\mathcal{W}{i}$ . Note that each of which is previously defined as a federated model and a local model. Both of them are grouped as a client model $\mathcal{W}{i}=G(\mathbf{w}{i}^{f},\mathbf{w}{i}^{l})$ with the grouping operator $G$ . This operator can be a concatenation (e.g., stacking semantically separated layers like feature extractor or classifier [2, 8, 41]): $G(\mathbf{w}{i}^{\bar{f}},\bar{\mathbf{w}{i}^{\bar{l}}})=\mathrm{Concat}(\mathbf{w}_{i}^{f},\mathbf{w}_{i}^{l})$ , a simple enumeration of parameters having the same structure [11, 38]: $G(\mathbf{w}_{i}^{f},\mathbf{w}_{i}^{l}):=:{\mathbf{w}_{i}^{f},\mathbf{w}_{i}^{l}},$ , or a convex combination [10, 23, 43] given a constant $\lambda\in[0,1]$ : $G(\mathbf{w}_{i}^{f},\mathbf{w}_{i}^{l};\lambda)=(1-\lambda)\mathbf{w}_{i}^{f}+\lambda\mathbf{w}_{i}^{l}.$ .
基于模型混合的个性化联邦学习 (PFL) 假设每个客户端 $c_{i}$ 拥有一组配对参数 $\mathbf{w}{i}^{f},\mathbf{w}{i}^{l}\subseteq\mathcal{W}{i}$。需注意,其中每个参数先前被定义为联邦模型和本地模型。两者通过分组运算符 $G$ 组合为客户端模型 $\mathcal{W}{i}=G(\mathbf{w}{i}^{f},\mathbf{w}{i}^{l})$。该运算符可以是拼接操作 (例如堆叠语义分离层,如特征提取器或分类器 [2, 8, 41]): $G(\mathbf{w}{i}^{\bar{f}},\bar{\mathbf{w}{i}^{\bar{l}}})=\mathrm{Concat}(\mathbf{w}_{i}^{f},\mathbf{w}_{i}^{l})$, 对具有相同结构的参数进行简单枚举 [11, 38]: $G(\mathbf{w}_{i}^{f},\mathbf{w}_{i}^{l}):=:{\mathbf{w}_{i}^{f},\mathbf{w}_{i}^{l}},$, 或给定常数 $\lambda\in[0,1]$ 的凸组合 [10, 23, 43]: $G(\mathbf{w}_{i}^{f},\mathbf{w}_{i}^{l};\lambda)=(1-\lambda)\mathbf{w}_{i}^{f}+\lambda\mathbf{w}_{i}^{l}.$。
3.4 Local Update
3.4 本地更新
In SuPerFed, we suppose both models $\mathbf{w}{i}^{f},\mathbf{w}{i}^{l}$ have the same structure and consider $G$ to be a function for constructing a convex combination. We will write $\lambda$ as an explicit input to the client model with a slight abuse of notation: $\mathbf{\mathcal{W}}{i}(\lambda)\overset{\cdot}{:=}G(\mathbf{\bar{w}}{i}^{f},\mathbf{w}{i}^{l};\lambda)=(1-\lambda)\mathbf{w}{i}^{f}+\lambda\mathbf{w}{i}^{l}.$ The main goal of the local update in SuPerFed is to find a flat wide minima between the local model and the federated model. In the initial round, each client receives a global model transmitted from the server, sets it as a federated model, and copies the structure to set a local model. As different initialization is required, clients initialize their local model again with its fresh random seed. During the local update, a client mixes two models using $\lambda\sim\operatorname{Unif}(0,1)$ as $\mathcal{W}{i}(\lambda)=(1-\lambda)\mathbf{w}{i}^{f}+\lambda\mathbf{w}{i}^{l},$ each time with a fresh mini-batch including $(\mathbf{x},\mathbf{y})$ sampled from local dataset $\mathcal{D}$ . The local model and the federated model are reduced to be interpolated diversely during local training. Finally, it is optimized with a loss function $l(\cdot)$ specific to the task, for example, cross-entropy, with additional regular iz ation $\Omega(\cdot)$ that is critical to induce the connectivity.
在SuPerFed中,我们假设模型$\mathbf{w}{i}^{f},\mathbf{w}{i}^{l}$具有相同结构,并将$G$视为构造凸组合的函数。通过略微简化符号,将$\lambda$显式写入客户端模型输入:$\mathbf{\mathcal{W}}{i}(\lambda)\overset{\cdot}{:=}G(\mathbf{\bar{w}}{i}^{f},\mathbf{w}{i}^{l};\lambda)=(1-\lambda)\mathbf{w}{i}^{f}+\lambda\mathbf{w}{i}^{l}$。SuPerFed本地更新的主要目标是寻找本地模型与联邦模型之间的平坦宽最小值。初始轮次中,每个客户端接收服务器传输的全局模型,将其设为联邦模型,并复制结构建立本地模型。由于需要差异化初始化,客户端使用新随机种子重新初始化本地模型。本地更新时,客户端采用$\lambda\sim\operatorname{Unif}(0,1)$混合两个模型:$\mathcal{W}{i}(\lambda)=(1-\lambda)\mathbf{w}{i}^{f}+\lambda\mathbf{w}{i}^{l}$,每次使用从本地数据集$\mathcal{D}$采样的新小批量数据$(\mathbf{x},\mathbf{y})$。本地训练过程中,本地模型与联邦模型通过多样化插值进行降维。最终通过任务特定损失函数$l(\cdot)$(如交叉熵)及关键连接性正则项$\Omega(\cdot)$进行优化。
Remark 1. Connectivity [17, 54]. There exists a low-loss subspace spanned by $\mathcal{W}(\lambda)$ between two independently trained (i.e., trained from different random initialization s) deep networks ${\bf w}{1}$ and $\mathbf{w}{2}$ , in the form of a linear combination formed by $\lambda\colon\mathcal{W}(\lambda)=(1-\lambda)\mathbf{w}{1}+$ $\lambda\mathbf{w}{2},\lambda\in[0,1]$ .
备注1. 连通性 [17, 54]。在两个独立训练(即从不同随机初始化开始训练)的深度网络 ${\bf w}{1}$ 和 $\mathbf{w}{2}$ 之间,存在一个由 $\mathcal{W}(\lambda)$ 张成的低损失子空间,其形式为线性组合 $\lambda\colon\mathcal{W}(\lambda)=(1-\lambda)\mathbf{w}{1}+$ $\lambda\mathbf{w}{2},\lambda\in[0,1]$。
The local objective is
本地目标是
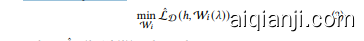
, where $\hat{\mathcal{L}}{\mathcal{D}}(h,\mathcal{W}{i}(\lambda))$ is denoted as:
其中 $\hat{\mathcal{L}}{\mathcal{D}}(h,\mathcal{W}{i}(\lambda))$ 定义为:

Note that the global model $\mathbf{w}^{g}$ is fixed here for the proximity regularization of $\mathbf{w}{i}^{f}$ . Denote the local objective (3) simply as $\hat{\mathcal{L}}$ . Then, the update of each endpoint $\mathbf{w}{i}^{f}$ and $\mathbf{w}{i}^{l}$ is done using the following estimates. Note that two endpoints (i.e., $\mathcal{W}{i}(0)={\bf w}{i}^{f}$ and $\mathcal{W}{i}(1)=\mathbf{w}_{i}^{l})$ can be jointly updated at the same time in a single training run.
注意全局模型 $\mathbf{w}^{g}$ 在此处固定,用于 $\mathbf{w}{i}^{f}$ 的邻近正则化。将局部目标函数 (3) 简记为 $\hat{\mathcal{L}}$ ,则每个端点 $\mathbf{w}{i}^{f}$ 和 $\mathbf{w}{i}^{l}$ 的更新通过以下估计实现。需注意两个端点 (即 $\mathcal{W}{i}(0)={\bf w}{i}^{f}$ 和 $\mathcal{W}{i}(1)=\mathbf{w}_{i}^{l})$ 可在单次训练中同步联合更新。

3.5 Regular iz ation
3.5 正则化 (Regularization)
The regular iz ation term $\cos(\cdot,\cdot)$ stands for cosine similarity defined as: $\cos(\mathbf{w}{i}^{f},\mathbf{w}{i}^{l})=\langle\mathbf{w}{i}^{f},\mathbf{w}{i}^{l}\rangle/(\left|\mathbf{w}{i}^{f}\right|\left|\mathbf{w}{i}^{l}\right|)$ . This aims to induce connectivity between the local mo
del a
n
d th
e federated model, thereby allowing the connected subspace between them to contain weights yielding high accuracy for the given task. Its magnitude is controlled by the constant $\nu$ . Since merely applying the mixing strategy between the local and the federated models has little benefit [54], it is required to set $\nu>0$ . In [15, 54], it is observed that weights of independently trained deep networks show dissimilarity in terms of cosine similarity, which has functional diversity as a result. Moreover, in [3, 45], inducing orthogonality (i.e., forcing cosine similarity to zero) between weights prevents deep networks from learning redundant features given their learning capacity. In this context, we expect the local model of each client $\mathbf{w}{i}^{l}$ to learn client-specific knowledge while the federated model $\mathbf{w}{i}^{f}$ learns client-agnostic knowledge in a complementary manner and is harmoniously combined with the local model. The other regular iz ation term adjusted by $\mu$ is L2-norm which controls the proximity of the update of the federated model $\mathbf{w}_{i}^{f}$ from the global model $\mathbf{w}^{g}$ [39]. By doing so, we expect each local update of the federated model not to be derailed from the global model, which prevents divergence of the aggregated global model during the process of FL. Note that an inordinate degree of proximity regular iz ation can hinder the local model’s adaptation and thereby cause the divergence of a global model [11, 39]. Thus, a moderate degree of $\mu$ is required. Note that our method is designed to be reduced to the existing $\mathrm{FL}$ methods by adjusting hyper parameters, and thus it can be guaranteed to have at least their performance. In detail, when fixing $\lambda=0$ , $\nu=0,\mu=0$ , the objective of SuPerFed is reduced to FedAvg [46], when $\lambda=0$ , $\nu=0,\mu>0$ , it is equivalent to FedProx [39].
正则化项 $\cos(\cdot,\cdot)$ 表示余弦相似度,其定义为:$\cos(\mathbf{w}{i}^{f},\mathbf{w}{i}^{l})=\langle\mathbf{w}{i}^{f},\mathbf{w}{i}^{l}\rangle/(\left|\mathbf{w}{i}^{f}\right|\left|\mathbf{w}{i}^{l}\right|)$。该正则化项旨在建立本地模型与联邦模型之间的连接性,从而使它们之间的连接子空间包含能够为给定任务带来高准确率的权重。其强度由常数 $\nu$ 控制。由于仅应用本地模型与联邦模型之间的混合策略收效甚微 [54],因此需要设置 $\nu>0$。在 [15, 54] 中观察到,独立训练的深度网络权重在余弦相似度方面表现出差异性,从而产生功能多样性。此外,在 [3, 45] 中,通过强制权重之间的正交性(即迫使余弦相似度为零),可以防止深度网络在学习能力范围内学习冗余特征。在此背景下,我们期望每个客户端的本地模型 $\mathbf{w}{i}^{l}$ 学习客户端特定的知识,而联邦模型 $\mathbf{w}{i}^{f}$ 则以互补的方式学习与客户端无关的知识,并与本地模型和谐结合。另一个由 $\mu$ 调整的正则化项是 L2 范数,它控制联邦模型 $\mathbf{w}_{i}^{f}$ 的更新与全局模型 $\mathbf{w}^{g}$ 的接近程度 [39]。通过这种方式,我们期望联邦模型的每次本地更新不会偏离全局模型,从而防止联邦学习 (FL) 过程中聚合的全局模型发散。需要注意的是,过度的接近正则化可能会阻碍本地模型的适应性,从而导致全局模型发散 [11, 39]。因此,需要适度调整 $\mu$ 的值。值得注意的是,我们的方法通过调整超参数可以简化为现有的联邦学习方法,因此可以保证至少达到它们的性能。具体来说,当固定 $\lambda=0$、$\nu=0,\mu=0$ 时,SuPerFed 的目标函数简化为 FedAvg [46];当 $\lambda=0$、$\nu=0,\mu>0$ 时,它等价于 FedProx [39]。
3.6 Communication with the Server
3.6 与服务器通信
At each round, the server samples a fraction of clients at every round (suppose $N$ clients are sampled), and requests a local update to each client. Only the federated model $\mathbf{w}{i}^{f}$ and the amounts of consumed training data per client $n{i}$ are transferred to the server after the local update is completed in parallel across selected clients. The server then aggregates them to create an updated global model $\mathbf{w}^{g}$ as $\begin{array}{r}{\mathbf{w}^{g}\gets\frac{1}{\sum_{i=1}^{N}n_{i}}\sum_{i=1}^{N}n_{i}\mathbf{w}_{i}^{f}}\end{array}$ . In the next round, only the updated global model $\mathbf{w}^{g}$ is transmitted to another group of selected clients, and it is set to be a new federated model at each client: $\mathbf{w}_{i}^{f}\gets\mathbf{w}^{g}$ It is worth noting that the communication cost remains constant as with the single model-based FL methods [39, 46]. See Algorithm 2 for understanding the whole process of SuPerFed.
在每一轮中,服务器会采样一部分客户端 (假设采样了 $N$ 个客户端),并请求每个客户端进行本地更新。在选定的客户端并行完成本地更新后,仅联邦模型 $\mathbf{w}{i}^{f}$ 和每个客户端消耗的训练数据量 $n{i}$ 会被传输到服务器。服务器随后聚合这些信息以创建更新后的全局模型 $\mathbf{w}^{g}$,公式为 $\begin{array}{r}{\mathbf{w}^{g}\gets\frac{1}{\sum_{i=1}^{N}n_{i}}\sum_{i=1}^{N}n_{i}\mathbf{w}_{i}^{f}\end{array}$。在下一轮中,只有更新后的全局模型 $\mathbf{w}^{g}$ 会被传输到另一组选定的客户端,并在每个客户端设置为新的联邦模型:$\mathbf{w}_{i}^{f}\gets\mathbf{w}^{g}$。值得注意的是,通信成本与基于单一模型的联邦学习方法 [39, 46] 保持一致。完整流程详见算法 2。
3.7 Variation in Mixing Method
3.7 混合方法的变化
Until now, we only considered the setting of applying 𝜆 identically to the whole layers of $\mathbf{w}^{f}$ and $\mathbf{w}^{l}$ . We name this setting Model Mixing, in short, MM. On the one hand, it is also possible to sample different $\lambda$ for weights of different layers, i.e., mixing two models in a layer-wise manner. We also adopt this setting and name it Layer Mixing, in short, LM.
到目前为止,我们仅考虑了将𝜆统一应用于$\mathbf{w}^{f}$和$\mathbf{w}^{l}$所有层的设置。我们将此设置称为模型混合 (Model Mixing),简称MM。另一方面,也可以为不同层的权重采样不同的$\lambda$,即以分层方式混合两个模型。我们也采用此设置,并将其称为分层混合 (Layer Mixing),简称LM。
Table 1: Experimental results on the pathological non-IID setting (MNIST and CIFAR10 datasets) compared with other FL and PFL methods. The top-1 accuracy is reported with a standard deviation.
表 1: 病理非独立同分布(non-IID)设置下(MNIST和CIFAR10数据集)与其他联邦学习(FL)和个性化联邦学习(PFL)方法的对比实验结果。报告了top-1准确率及其标准差。
| 数据集 | MNIST | MNIST | MNIST | CIFAR10 | CIFAR10 | CIFAR10 |
|---|---|---|---|---|---|---|
| 客户端数量 | 50 | 100 | 500 | 50 | 100 | 500 |
| 样本数量 | 960 | 480 | 96 | 800 | 400 | 80 |
| FedAvg | 95.69 ± 2.39 | 89.78 ± 11.30 | 96.04 ± 4.74 | 43.09 ± 24.56 | 36.19 ± 29.54 | 47.90 ± 25.05 |
| FedProx | 95.13 ± 2.67 | 93.25 ± 6.12 | 96.50 ± 4.52 | 49.01 ± 19.87 | 38.56 ± 28.11 | 48.60 ± 25.71 |
| SCAFFOLD | 95.50 ± 2.71 | 90.58 ± 10.13 | 96.60 ± 4.26 | 43.81 ± 24.30 | 36.31 ± 29.42 | 40.27 ± 26.90 |
| LG-FedAvg | 98.21 ± 1.28 | 97.52 ± 2.11 | 96.05 ± 5.02 | 89.03 ± 4.53 | 70.25 ± 35.66 | 78.52 ± 11.22 |
| FedPer | 99.23 ± 0.66 | 99.14 ± 0.93 | 98.67 ± 2.61 | 89.10 ± 5.41 | 87.99 ± 5.70 | 82.35 ± 9.85 |
| APFL | 99.40 ± 0.58 | 99.19 ± 0.92 | 98.98 ± 2.22 | 92.83 ± 3.47 | 91.73 ± 4.61 | 87.38 ± 9.39 |
| pFedMe | 81.10 ± 8.52 | 82.48 ± 7.62 | 81.96 ± 12.28 | 92.97 ± 3.07 | 92.07 ± 5.05 | 88.30 ± 8.53 |
| Ditto | 97.07 ± 1.38 | 97.13 ± 2.06 | 97.20 ± 3.72 | 85.53 ± 6.22 | 83.01 ± 5.62 | 84.45 ± 10.67 |
| FedRep | 99.11 ± 0.63 | 99.04 ± 1.02 | 97.94 ± 3.37 | 82.00 ± 5.41 | 81.27 ± 7.90 | 80.66 ± 11.00 |
| SuPerFed-MM | 99.45 ± 0.46 | 99.38 ± 0.93 | 99.24 ± 2.12 | 94.05 ± 3.18 | 93.25 ± 3.80 | 90.81 ± 9.35 |
| SuPerFed-LM | 99.48 ± 0.54 | 99.31 ± 1.09 | 98.83 ± 3.02 | 93.88 ± 3.55 | 93.20 ± 4.19 | 89.63 ± 11.11 |
4 EXPERIMENTS
4 实验
4.1Setup
4.1 设置
We focus on two points in our experiments: (i) personalization performance in various non-IID scenarios, (ii) robustness to label noise through extensive benchmark datasets. Details of each experiment are provided in Appendix A. Throughout all experiments, if not specified, we set 5 clients to be sampled at every round and used stochastic gradient descent (SGD) optimization with a momentum of 0.9 and a weight decay factor of 0.0001. As SuPerFed is a model mixture-based PFL method, we compare its performance to other model mixture-based PFL methods: FedPer [2], LG-FedAvg [41], APFL [10], pFedMe [11], Ditto [38], FedRep [8], along with basic single-model based FL methods, FedAvg [46] FedProx [39] and SCAFFOLD [32]. We let the client randomly split their data into a training set and a test set with a fraction of 0.2 to estimate the performance of each FL algorithm on each client’s test set with its own personalized model (if possible) with various metrics: top-1 accuracy, top-5 accuracy, expected calibration error (ECE [21]), and maximum calibration error (MCE [34]). Note that we evaluated all participating clients after the whole round of FL is finished. For each variation of the mixing method (i.e., LM & MM) stated in section 3.7, we subdivide our method into two, SuPerFed-MM for Model Mixing, and SuPerFed-LM for Layer Mixing.
我们的实验重点关注两点:(i) 各种非独立同分布(non-IID)场景下的个性化性能,(ii) 通过大量基准数据集验证对标签噪声的鲁棒性。具体实验细节见附录A。所有实验中如未特别说明,默认每轮采样5个客户端,采用动量(momentum)为0.9、权重衰减(weight decay)系数为0.0001的随机梯度下降(SGD)优化器。由于SuPerFed是基于模型混合的个性化联邦学习(PFL)方法,我们将其性能与其他基于模型混合的PFL方法进行比较:FedPer [2]、LG-FedAvg [41]、APFL [10]、pFedMe [11]、Ditto [38]、FedRep [8],以及基于单一模型的基础联邦学习方法FedAvg [46]、FedProx [39]和SCAFFOLD [32]。我们让客户端随机将其数据按0.2比例划分为训练集和测试集,用各自个性化模型(如适用)通过以下指标评估各联邦学习算法在客户端测试集上的表现:Top-1准确率、Top-5准确率、期望校准误差(ECE [21])和最大校准误差(MCE [34])。需注意,我们是在完整联邦学习轮次结束后评估所有参与客户端。针对3.7节所述的两种混合方法变体(LM和MM),我们将本方法细分为SuPerFed-MM(模型混合)和SuPerFed-LM(层混合)。
Table 2: Experimental results on the Dirichlet distributionbased non-IID setting (CIFAR100 and Tiny Image Net) compared with other FL and PFL methods. The top-5 accuracy is reported with a standard deviation.
表 2: 基于狄利克雷分布的非独立同分布设置(CIFAR100 和 Tiny Image Net)的实验结果与其他联邦学习(FL)和个性化联邦学习(PFL)方法的对比。报告了 top-5 准确率及标准差。
| 数据集 | CIFAR100 | CIFAR100 | CIFAR100 | TinyImageNet | TinyImageNet | TinyImageNet |
|---|---|---|---|---|---|---|
| 客户端数量 | 100 | 100 | 100 | 200 | 200 | 200 |
| 集中度(a) | 1 | 10 | 100 | 1 | 10 | 100 |
| FedAvg | 58.12 ± 7.06 | 59.04 ± 7.19 | 58.49 ± 5.27 | 46.61 ± 5.64 | 48.90 ± 5.50 | 48.90 ± 5.40 |
| FedProx | 57.71 ± 6.79 | 58.24 ± 5.94 | 58.75 ± 5.56 | 47.37 ± 5.94 | 47.73 ± 5.94 | 48.97 ± 5.02 |
| SCAFFOLD | 51.16 ± 6.79 | 51.40 ± 5.22 | 52.90 ± 4.89 | 46.54 ± 5.49 | 48.77 ± 5.49 | 48.27 ± 5.32 |
| LG-FedAvg | 28.88 ± 5.64 | 21.25 ± 4.64 | 20.05 ± 4.61 | 14.70 ± 3.84 | 9.86 ± 3.13 | 9.25 ± 2.89 |
| FedPer | 46.78 ± 7.63 | 35.73 ± 6.80 | 35.52 ± 6.58 | 21.90 ± 4.71 | 11.10 ± 3.19 | 9.63 ± 3.12 |
| APFL | 61.13 ± 6.86 | 56.90 ± 7.05 | 55.43 ± 5.45 | 41.98 ± 5.94 | 34.74 ± 5.14 | 34.23 ± 5.07 |
| pFedMe | 19.00 ± 5.37 | 17.94 ± 4.72 | 18.28 ± 3.41 | 6.05 ± 2.84 | 8.01 ± 2.92 | 7.69 ± 2.41 |
| Ditto | 60.04 ± 6.82 | 58.55 ± 7.12 | 58.73 ± 5.39 | 46.36 ± 5.44 | 43.84 ± 5.44 | 43.11 ± 5.35 |
| FedRep | 38.49 ± 6.65 | 26.61 ± 5.20 | 24.50 ± 4.21 | 18.67 ± 4.66 | 9.23 ± 2.84 | 8.09 ± 2.83 |
| SuPerFed-MM | 60.14 ± 6.24 | 58.32 ± 6.25 | 59.08 ± 5.12 | 50.07 ± 5.73 | 49.86 ± 5.03 | 49.73 ± 4.84 |
| SuPerFed-LM | 62.50 ± 6.34 | 61.64 ± 6.23 | 59.05 ± 5.59 | 47.28 ± 5.19 | 48.98 ± 4.79 | 49.29 ± 4.82 |
Table 3: Experimental results on the realistic non-IID setting (FEMNIST and Shakespeare) compared with other FL and PFL methods. The top-1 accuracy is reported with a standard deviation.
表 3: 现实非独立同分布 (non-IID) 设定下的实验结果 (FEMNIST 和 Shakespeare) 与其他联邦学习 (FL) 和个性化联邦学习 (PFL) 方法的对比。报告了 Top-1 准确率及其标准差。
| 数据集 | FEMNIST | FEMNIST | Shakespeare | Shakespeare |
|---|---|---|---|---|
| 客户端数量 | 730 | 730 | 660 | 660 |
| 准确率 | Top-1 | Top-5 | Top-1 | Top-5 |
| FedAvg | 80.12 ± 12.01 | 98.74 ± 2.97 | 50.90 ± 7.85 | 80.15 ± 7.87 |
| FedProx | 80.23 ± 11.88 | 98.73 ± 2.94 | 51.33 ± 7.54 | 80.31 ± 6.95 |
| SCAFFOLD | 80.03 ± 11.78 | 98.85 ± 2.77 | 50.76 ± 8.01 | 80.43 ± 7.09 |
| LG-FedAvg | 50.84 ± 20.97 | 75.11 ± 21.49 | 33.88 ± 10.28 | 62.84 ± 13.16 |
| FedPer | 73.79 ± 14.10 | 86.39 ± 14.70 | 45.82 ± 8.10 | 75.68 ± 9.25 |
| APFL | 84.85 ± 8.83 | 98.83 ± 2.73 | 54.08 ± 8.31 | 83.32 ± 6.22 |
| pFedMe | 5.98 ± 4.55 | 24.64 ± 9.43 | 32.29 ± 6.64 | 63.12 ± 8.00 |
| Ditto | 64.61 ± 31.49 | 81.14 ± 28.56 | 49.04 ± 10.22 | 78.14 ± 12.61 |
| FedRep | 59.27 ± 15.72 | 70.42 ± 15.82 | 38.15 ± 9.54 | 68.65 ± 12.50 |
| SuPerFed-MM | 85.20 ± 8.40 | 99.16 ± 2.13 | 54.52 ± 7.54 | 84.27 ± 6.00 |
| SuPerFed-LM | 83.36 ± 9.61 | 98.81 ± 2.58 | 54.52 ± 7.54 | 83.97 ± 5.72 |
4.2 Personalization
4.2 个性化
For the estimation of the performance of SuPerFed as PFL methods, we simulate three different non-IID scenarios. (i) a pathological nonIID setting proposed by [46], which assumes most clients have samples from two classes for a multi-class classification task. (2) Dirichlet distribution-based non-IID setting proposed by [27], in which the Dirichlet distribution with its concentration parameter $\alpha$ determines the label distribution of each client. All clients have samples from only one class when using $\alpha\rightarrow0$ , whereas $\alpha\to\infty$ divides samples into an identical distribution. (3) Realistic non-IID setting proposed in [6], which provides several benchmark datasets for PFL.
为了评估SuPerFed作为个性化联邦学习(PFL)方法的性能,我们模拟了三种不同的非独立同分布场景:(1) [46]提出的极端非独立同分布设置,假设多数客户端在多类别分类任务中仅包含两个类别的样本;(2) [27]提出的基于狄利克雷分布(Dirichlet distribution)的非独立同分布设置,其中浓度参数$\alpha$控制各客户端的标签分布。当$\alpha\rightarrow0$时所有客户端仅含单一类别样本,而$\alpha\to\infty$时样本呈均匀分布;(3) [6]提出的真实场景非独立同分布设置,该研究为PFL提供了多个基准数据集。
Pathological non-IID setting. In this setting, we used two multiclass classification datasets, MNIST [9] and CIFAR10 [33] and both have 10 classes. We used the two-layered fully-connected network for the MNIST dataset and the two-layered convolutional neural network (CNN) for the CIFAR10 dataset as proposed in [46]. For each dataset, we set the number of total clients $\mathrm{K}{=}50$ , 100, 500) to check the s cal ability of the PFL methods. The results of the pathological non-IID setting are shown in Table 1. It is notable that our proposed method beats most of the existing model mixturebased PFL methods with a small standard deviation.
病态非独立同分布设置。在该设置中,我们使用了两个多分类数据集MNIST [9]和CIFAR10 [33],两者均有10个类别。我们采用[46]提出的双层全连接网络处理MNIST数据集,使用双层卷积神经网络(CNN)处理CIFAR10数据集。针对每个数据集,我们设置客户端总数$\mathrm{K}{=}50$、100、500以验证PFL方法的可扩展性。病态非独立同分布设置的结果如表1所示。值得注意的是,我们提出的方法以较小的标准差超越了大多数现有基于模型混合的PFL方法。
Dirichlet distribution-based non-IID setting. In this setting, we used other multi-class classification datasets to simulate a more challenging setting than the pathological non-IID setting. We use CIFAR100[33] and Tiny Image Net[37] datasets, having 100 classes and 200 classes each. We also selected other deep architectures, ResNet[24] for CIFAR100 and MobileNet[25] for Tiny Image Net. For each dataset, we adjust the concentration parameter $\alpha=1$ , 10, 100 to control the degree of statistical heterogeneity across clients. It is a more natural choice for simulating statistical heterogeneity than pathological non-IID setting, making it more challenging. Note that the smaller the $\alpha$ , the more heterogeneous each client’s data distribution is. Table 2 presents the results of the Dirichlet distributionbased non-IID setting. Both of our methods are less affected by the degree of statistical heterogeneity (i.e., non-IIDness) determined by $\alpha$ .
基于狄利克雷分布(Dirichlet distribution)的非独立同分布设置。该设置采用CIFAR100[33]和Tiny Image Net[37]等多分类数据集(分别包含100类和200类)模拟比病理学非独立同分布更具挑战性的场景,并选用ResNet[24]和MobileNet[25]作为深度架构。通过调整浓度参数$\alpha=1$、10、100来控制客户端间的统计异质性程度,这种设置比病理学非独立同分布更自然且更具挑战性($\alpha$值越小,客户端数据分布异质性越强)。表2展示了基于狄利克雷分布的非独立同分布实验结果:我们的两种方法受$\alpha$决定的统计异质性(即非独立同分布程度)影响均较小。
Realistic non-IID setting. We used FEMNIST and Shakespeare datasets in the LEAF benchmark [6]. As the purpose of these datasets is to simulate a realistic FL scenario, each dataset is naturally split for a certain data mining task. The selected two datasets are for multi-class classification (62 classes) and next character prediction (80 characters) given a sentence, respectively. We used VGG [50] for the FEMNIST dataset and networks with two stacked LSTM layers were used in [46] for the Shakespeare dataset. The results of the realistic non-IID setting are shown in Table 3. In this massively distributed setting, our methods showed a consistent gain in terms of personalization performance.
真实非独立同分布场景设置。我们使用LEAF基准测试[6]中的FEMNIST和Shakespeare数据集。这些数据集旨在模拟真实的联邦学习(FL)场景,每个数据集都针对特定数据挖掘任务进行了自然划分。所选的两个数据集分别用于多类别分类(62类)和给定句子的下一字符预测(80字符)。对于FEMNIST数据集我们采用VGG[50]网络结构,Shakespeare数据集则使用文献[46]中提出的双层LSTM堆叠网络。真实非独立同分布场景下的实验结果如 表3 所示。在这个大规模分布式场景中,我们的方法在个性化性能方面展现出持续优势。
Robustness to label noise. In realistic FL services, it is possible that each client suffers from noisy labels. We anticipate that SuPerFed will benefit from the strength of ensemble learning because our method can be viewed as implicit ensemble of two models, $\mathbf{w}^{f}$ and $\mathbf{w}^{l}$ . One of the strengths is robustness to the label noise, as each of the model components of the ensemble method can view diverse data distributions [35, 47]. In SuPerFed, the federated model and the local model are induced to be independent of each other (i.e., having low cosine similarity in the weight space). We assume each of them should inevitably learn from a different view of data distribution. To prove this, we adopted two representative methods to simulate the noisy labels: pair flipping [22] and symmetric flipping [52], and their detailed descriptions are in Appendix B. We select the noise ratio from 0.1, 0.4 for the pair flipping label noise, and 0.2, 0.6 for the symmetric flipping label noise. Using this noise scheme, we obfuscate each client’s training set labels while labels of test set are kept intact. The results are shown in Table 4. We used MNIST and CIFAR10 datasets with a Dirichlet distribution-based non-IID setting in which the concentration parameter $\alpha=10.0$ . Since the robustness of the label noise can be quantified through evaluating ECE [21] and MCE [34], we introduced these two metrics additionally. Both ECE and MCE measure the consistency between the prediction accuracy and the prediction confidence (i.e., calibration), thus lower values are preferred. From all the extensive experiments, our method shows stable performance in terms of calibration (i.e., low ECE and MCE), and therefore overall performance is not degraded much.
对标签噪声的鲁棒性。在实际的联邦学习(FL)服务中,各客户端可能遭受噪声标签的影响。我们预期SuPerFed将受益于集成学习的优势,因为我们的方法可视为隐式集成两个模型$\mathbf{w}^{f}$和$\mathbf{w}^{l}$。其优势之一是对标签噪声的鲁棒性,因为集成方法的每个模型组件都能观察到不同的数据分布[35,47]。在SuPerFed中,联邦模型与本地模型被引导为相互独立(即权重空间具有低余弦相似度)。我们假设它们各自必然从数据分布的不同视角进行学习。为验证这一点,我们采用两种代表性方法模拟噪声标签:配对翻转[22]和对称翻转[52],具体描述见附录B。对于配对翻转标签噪声,我们选择0.1、0.4的噪声比例;对称翻转标签噪声则选择0.2、0.6的比例。使用该噪声方案,我们对各客户端的训练集标签进行混淆处理,同时保持测试集标签不变。结果如表4所示。我们在基于狄利克雷分布的非独立同分布设置(浓度参数$\alpha=10.0$)下使用MNIST和CIFAR10数据集。由于标签噪声的鲁棒性可通过评估ECE[21]和MCE[34]进行量化,我们额外引入了这两个指标。ECE和MCE均衡量预测准确率与预测置信度(即校准度)的一致性,因此数值越低越好。所有实验结果表明,我们的方法在校准性(即低ECE和MCE值)方面表现稳定,因此整体性能未出现显著下降。
Table 4: Experimental results on the label noise simulation with Dirichlet dist i rubio tn-based non-IID setting $'\alpha=100)$ ) on (MNIST and CIFAR10) compared with other FL and PFL methods. Per each cell, expected calibration error (ECE), maximum calibration error (MCE), and the best averaged top-1 accuracy (in parentheses) are enumerated from top to bottom. Note that the lower ECE and MCE, the better the model calibration is.
表 4: 基于狄利克雷分布(Dirichlet distribution) ($\alpha=100$) 的标签噪声模拟在非独立同分布(non-IID)设置下,MNIST和CIFAR10数据集上与其他联邦学习(FL)和个性化联邦学习(PFL)方法的对比实验结果。每个单元格中从上到下依次列出:预期校准误差(ECE)、最大校准误差(MCE)和最佳平均top-1准确率(括号内)。注意ECE和MCE越低,模型校准效果越好。
| 数据集噪声类型 | MNIST | CIFAR10 | ||
|---|---|---|---|---|
| pair | symmetric | pair | symmetric | |
| 噪声比例 | 0.1 | 0.4 | 0.2 | 0.6 |
| FedAvg | 0.17 ± 0.03 | 0.38 ± 0.03 | 0.29 ± 0.04 | 0.42 ± 0.04 |
| 0.58 ± 0.08 | 0.67 ± 0.04 | 0.66 ± 0.07 | 0.75 ± 0.05 | |
| (82.40 ± 3.31) | (41.01 ± 4.64) | (66.94 ± 4.27) | (49.52 ± 5.42) | |
| FedProx | 0.17 ± 0.03 | 0.38 ± 0.03 | 0.29 ± 0.03 | 0.42 ± 0.05 |
| 0.58 ± 0.07 | 0.78 ± 0.05 | 0.66 ± 0.07 | 0.74 ± 0.05 | |
| (82.05 ± 3.98) | (41.39 ± 4.61) | (67.15 ± 4.60) | (49.98 ± 5.57) | |
| SCAFFOLD | 0.16 ± 0.03 | 0.45 ± 0.04 | 0.29 ± 0.04 | 0.44 ± 0.04 |
| 0.58 ± 0.07 | 0.77 ± 0.04 | 0.59 ±0.08 | 0.73 ± 0.05 | |
| (60.86 ± 4.09) | (44.92 ± 5.07) | (70.51 ± 4.25) | (51.46 ± 5.12) | |
| LG-FedAvg | 0.23 ± 0.04 | 0.50 ± 0.05 | 0.34 ± 0.04 | 0.45 ± 0.05 |
| 0.66 ± 0.08 | 0.81 ± 0.04 | 0.71 ± 0.07 | 0.75 ± 0.06 | |
| (73.65 ± 5.32) | (37.69 ± 5.41) | (61.54 ± 4.96) | (47.79 ± 5.02) | |
| FedPer | 0.17 ± 0.03 | 0.40 ± 0.04 | 0.28 ± 0.04 | 0.40 ± 0.04 |
| 0.57± 0.08 | 0.78 ± 0.05 | 0.66 ± 0.08 | 0.73 ± 0.07 | |
| (82.43 ± 4.18) | (40.75 ± 5.49) | (68.44 ± 5.63) | (52.41 ± 5.56) | |
| APFL | 0.18 ± 0.03 | 0.42 ± .0.05 | 0.28 ± 0.05 | 0.40 ± 0.05 |
| 0.60 ± 0.07 | 0.78 ± 0.06 | 0.67± 0.06 | 0.79 ± 0.07 | |
| (80.18 ± 4.57) | (40.43 ± 6.06) | (67.83 ± 5.53) | (52.15 ± 5.63) | |
| pFedMe | 0.23 ± 0.04 | 0.46 ± 0.04 | 0.33 ± 0.05 | 0.44 ± 0.04 |
| 0.66 ± 0.07 | 0.80 ± .0.05 | 0.72 ± 0.06 | 0.76 ± 0.05 | |
| (72.05 ± 0.05) | (37.89 ± 5.77) | (59.80 ± 5.94) | (45.79 ± 5.26) | |
| Ditto | 0.22 ± 0.04 | 0.42 ± 0.05 | 0.31 ± 0.04 | 0.41 ± 0.04 |
| 0.66 ± 0.07 | 0.79 ± 0.05 | 0.69 ± 0.07 | 0.77 ± 0.05 | |
| (72.39 ± 5.25) | (38.20 ± 6.13) | (60.62 ± 5.67) | (45.11 ± 4.95) | |
| FedRep | 0.20 ± 0.04 | 0.53 ± 0.05 | 0.30 ± 0.05 | 0.43 ± 0.05 |
| 0.62 ± 0.08 | 0.81 ± 0.05 | 0.68 ± 0.08 | 0.74 ± 0.06 | |
| (77.95 ± 4.65) | (35.88 ± 5.15) | (66.58 ± 5.60) | (51.30 ± 5.27) | |
| SuPerFed-MM | 0.16 ± 0.03 | 0.28 ± 0.04 | 0.27±0.03 | |
| 0.30 ± 0.04 | ||||
| 0.53 ± 0.07 | 0.69 ± 0.06 | 0.64 ± 0.07 | 0.69 ± 0.08 | |
| SuPerFed-LM | (83.67 ± 3.51) | (46.41 ± 5.14) | (71.99 ± 5.01) | (56.07 ± 4.32) |
| 0.14 ± 0.03 | 0.35 ± 0.04 | 0.27 ± 0.04 | 0.32 ± 0.04 | |
| 0.49 ± 0.08 (84.78 ± 3.63) | 0.77 ± 0.04 (46.82 ± 5.39) | 0.66 ± 0.07 (69.23 ± 5.25) | 0.72 ± 0.06 (54.69 ± 4.20) |
Table 5: Experiment on selecting L, the starting round of person aliz ation. The best averaged top-1 accuracy (top) and loss (bottom) among models that can be realized by $\lambda\in[0,1]$ is reported with a standard deviation.
表 5: 个性化起始轮次L的选择实验。报告了可通过$\lambda\in[0,1]$实现的模型中最佳平均top-1准确率(上)和损失值(下),并标注标准差。
| L/R | 0.0 | 0.2 | 0.4 | 0.6 | 0.8 |
|---|---|---|---|---|---|
| SuPerFed-MM | 89.87 ± 4.731.36 ± 0.58 | 92.67 ± 4.040.72 ± 0.40 | 92.69 ±3.860.78 ± 0.31 | 92.50 ± 4.140.74 ± 0.88 | 91.29 ± 6.282.53 ± 0.72 |
| SuPerFed-LM | 91.55 ± 4.261.43 ± 0.81 | 92.41 ± 3.931.18 ± 0.60 | 92.69 ± 3.660.94 ± 0.45 | 92.60 ± 3.860.63±0.33 | 90.59 ± 9.936.28 ± 1.76 |
4.3 Ablation Studies
4.3 消融实验
Constants for regular iz ation terms. Our proposed method has two hyper parameters, $\nu$ and $\mu$ . Each hyper parameter is supposed to do two things: (1) create a connected low-loss subspace between the federated model and the local model in clients by making the weights of the two models orthogonal; and (2) penalize local updates from going in the wrong direction, away from the direction of global updates. We ran experiments with $\nu={0.0,1.0,2.0,5.0}$ and $\mu=\left{0.0,0.01,0.1,1.0\right}$ (a total of 16 combinations) under the Model Mixing and Layer Mixing regimes, with $\mathrm{R}=100$ and $\mathrm{L=}$ $\lfloor0.4\mathrm{R}\rfloor=40$ , which yielded the best personalization performance on the CIFAR10 dataset with pathological non-IID Experimental results on these combinations are displayed in Figure 3.
正则化项的常量。我们提出的方法有两个超参数 $\nu$ 和 $\mu$。每个超参数需要实现两个目标:(1) 通过使联邦模型与客户端本地模型的权重正交,在两者之间创建连通的低损失子空间;(2) 惩罚偏离全局更新方向的错误本地更新。我们在模型混合(Model Mixing)和层级混合(Layer Mixing)机制下,以 $\mathrm{R}=100$ 和 $\mathrm{L=}\lfloor0.4\mathrm{R}\rfloor=40$ 的参数配置(该设置在CIFAR10数据集的病理非独立同分布(non-IID)场景下表现出最佳个性化性能),对 $\nu={0.0,1.0,2.0,5.0}$ 与 $\mu=\left{0.0,0.01,0.1,1.0\right}$ 的16种组合进行了实验验证。实验结果如图3所示。
There are noticeable observations supporting the efficacy of our method. First, a learning strategy to find a connected low loss subspace between local and federated models yields high personalization performance. In most cases with non-zero $\nu$ and $\mu$ , a combination of federated and local models (i.e., models realized by $\lambda\in(0,1))$ outperforms two single models from both endpoints (i.e., a federated model $\langle\lambda=0\rangle$ ) and a local model $\langle\lambda=1\rangle$ ). Second, a moderate degree of orthogonality regular iz ation (adjusted by 𝜈) boosts the personalization performance of the local model. Third, the proximity regular iz ation restricts learning too much when $\mu$ is large, but often helps a federated model not to diverge when it is properly selected. Since this phenomenon has already been pointed out in [11, 39], a careful selection of $\mu$ is required.
我们方法的有效性有以下显著观察支持。首先,寻找局部模型和联邦模型之间连通低损失子空间的学习策略能带来较高的个性化性能。在大多数$\nu$和$\mu$非零的情况下,联邦模型与局部模型的组合(即通过$\lambda\in(0,1)$实现的模型)优于两个端点单一模型(联邦模型$\langle\lambda=0\rangle$和局部模型$\langle\lambda=1\rangle$)。其次,适度的正交正则化(通过𝜈调整)能提升局部模型的个性化性能。第三,当$\mu$较大时,邻近正则化会过度限制学习,但若恰当选择该参数,通常能防止联邦模型发散。由于该现象已在[11, 39]中被指出,需谨慎选择$\mu$。

Figure 3: The effects of hyper parameters $\nu$ and $\mu$ . Left group of plots colored in orange is the performance of SuPerFed-MM, right group of plots colored in sky-blue is the performance of SuPerFed-LM. Each subplot’s vertical axis represents accuracy, and the horizontal axis represents the range of possible $\lambda$ values from 0 to 1, with a 0.1 interval. Metrics on each subplot indicate the performance of the best averaged top-1 accuracy evaluated by local test set of each client. The error bar indicates a standard deviation of each personalized model realized by different values of $\lambda\in[0,1]$ . Note that each endpoint means a federated model $\mathbf{\chi}{\mathbf{w}}f$ when $\lambda=0$ ) or a local model $\mathbf{\rho}{\mathbf{w}}l$ when $\lambda=1$ ).
图 3: 超参数 $\nu$ 和 $\mu$ 的影响。左侧橙色图组为 SuPerFed-MM 的性能表现,右侧天蓝色图组为 SuPerFed-LM 的性能表现。每个子图的纵轴表示准确率,横轴表示 $\lambda$ 取值范围(0 至 1,间隔 0.1)。子图中标注的指标为各客户端本地测试集评估的最佳平均 top-1 准确率。误差条表示不同 $\lambda\in[0,1]$ 值实现的个性化模型的标准差。注意端点分别代表联邦模型 $\mathbf{\chi}{\mathbf{w}}f$ (当 $\lambda=0$ ) 或本地模型 $\mathbf{\rho}{\mathbf{w}}l$ (当 $\lambda=1$ )。
Start round of personalization. We conducted an experiment on selecting L, which determines the initiation of mixing operation, in other words, sampling $\lambda\sim{\mathrm{Unif}}(0,1)$ . As our proposed method can choose a mixing scheme from either Model Mixing or Layer Mixing, we designed separate experiments per scheme. We denote each scheme by SuPerFed-MM and SuPerFed-LM. By adjusting L by 0.1 increments from 0 to 0.9 of R, we evaluated the top-1 accuracy of local models. This experiment was done only using the CIFAR10 dataset with $\mathrm{R}=200$ , $\nu=2$ , and $\mu=0.01$ . Experimental results are summarized in Table 5.
开始个性化轮次。我们针对选择L(决定混合操作启动时机,即采样$\lambda\sim{\mathrm{Unif}}(0,1)$)进行了实验。由于我们提出的方法可以从模型混合(Model Mixing)或层级混合(Layer Mixing)中选择混合方案,我们为每种方案设计了独立实验,分别记为SuPerFed-MM和SuPerFed-LM。通过以0.1为步长调整L(从0到0.9R),我们评估了本地模型的top-1准确率。该实验仅在CIFAR10数据集上完成,参数设置为$\mathrm{R}=200$、$\nu=2$和$\mu=0.01$。实验结果汇总于表5。
We see that there are some differences according to the mixing scheme. In terms of the personalization performance, setting $\mathrm{L}/\mathrm{R}=$ 0.4 shows the best performance with a small standard deviation. This implies that allowing some rounds to a federated model to concentrate on learning global knowledge is a valid strategy. While L is a tunable hyper parameter, it can be adjusted for the purpose of FL. To derive a good global model, choosing a large L close to R is a valid choice, while in terms of personalization, it should be far from R.
我们发现根据混合方案存在一些差异。在个性化性能方面,设置 $\mathrm{L}/\mathrm{R}=$ 0.4 时表现最佳且标准差较小。这表明允许联邦模型在某些轮次专注于学习全局知识是一种有效策略。虽然 L 是可调超参数,但可根据联邦学习 (FL) 目的进行调整:若要获得良好的全局模型,应选择接近 R 的较大 L 值;而针对个性化场景,则应选择远离 R 的 L 值。
5 CONCLUSION
5 结论
In this paper, we propose a simple and scalable personalized federated learning method SuPerFed under the scheme of the model mixture method. Its goal is to improve personalization performance while also providing robustness to label noise. In each client, the method aims to build a connected low-loss subspace between a local and a federated model, inspired by the special property of deep networks, connectivity. Through this, two models are connected in a mutually cooperative manner so that each client has a personalized model with good performance and well-calibrated, which is robust to possible label noises in its dataset. With extensive experiments, we empirically demonstrated that SuPerFed, with its two variants in the mixing scheme, outperforms the existing model mixture-based PFL methods and three basic FL methods.
本文提出了一种简单且可扩展的个性化联邦学习方法SuPerFed,该方法基于模型混合方案。其目标是在提升个性化性能的同时增强对标签噪声的鲁棒性。该方法受深度网络连通性特性的启发,旨在每个客户端中构建连接局部模型与联邦模型的低损失子空间。通过这种相互协作的连接方式,每个客户端都能获得性能优异、校准良好且对数据集中可能存在的标签噪声具有鲁棒性的个性化模型。大量实验证明,SuPerFed及其两种混合方案变体在性能上优于现有基于模型混合的个性化联邦学习方法及三种基础联邦学习方法。
ACKNOWLEDGMENTS
致谢
This work was supported by the National Research Foundation of Korea (NRF) Grant funded by the Korea Government (MSIT) under Grant No. 2020 R 1 C 1 C 1011063 and by Institute of Information and Communications Technology Planning and Evaluation (IITP) grant funded by the Korea Government (MSIT) (No. 2020-0-01336, Artificial Intelligence Graduate School support (UNIST)). This work is completed during internship at Kakao Enterprise.
本研究由韩国国家研究基金会(NRF)根据韩国政府(MSIT)资助的2020 R1 C1 C1011063号项目,以及韩国政府(MSIT)通过信息通信技术规划与评估研究所(IITP)资助的2020-0-01336号项目(人工智能研究生院支持计划(UNIST))共同支持。本工作完成于Kakao Enterprise实习期间。
REFERENCES
参考文献
A APPENDIX
A 附录
A.1 Experimental Details
A.1 实验细节
Table A1 summarizes the details of each experiment: the number of clients K, total rounds ${\mathrm{R,}}$ local batch size B, number of local epochs E, learning rate $\eta$ , and the network. Note that the fraction of sampled clients, C is adjusted to be 5 clients, and the start of personalization L is set to $40%$ of total rounds. For a stable convergence of a global model, we applied applied learning rate decay by $1%$ per each round. Each network architecture is borrowed from the original paper it proposed: TwoNN, TwoCNN, Stacked L STM [46], ResNet [24], MobileNet [25], and VGG [50].
表 A1 总结了每个实验的详细信息:客户端数量 K、总轮次 ${\mathrm{R,}}$、本地批次大小 B、本地周期数 E、学习率 $\eta$ 以及网络架构。注意,采样客户端比例 C 调整为 5 个客户端,个性化起始轮次 L 设置为总轮次的 $40%$。为确保全局模型稳定收敛,我们每轮应用 $1%$ 的学习率衰减。各网络架构均引用自原论文:TwoNN、TwoCNN、Stacked LSTM [46]、ResNet [24]、MobileNet [25] 和 VGG [50]。
A.2 Loss Landscape of a Global Model
A.2 全局模型的损失情况
The loss landscape of global models obtained from the proposed methods SuPerFed-MM and SuPerFed-LM are visualized in Figure A1 along with one from FedAvg by following [19]. As the proposed regular iz ation term adjusted by $\nu$ induces connected low-loss subspace, it is natural that the wider minima is acquired from both SuPerFed-MM and SuPerFed-LM compared to that of FedAvg. As the global model learns to be connected with local models in weight spaces per each federation round, flat minima of the global model are induced, i.e., the connectivity is observed.
通过遵循[19]的方法,图A1可视化了由SuPerFed-MM和SuPerFed-LM方法获得的全局模型损失景观,并与FedAvg的结果进行了对比。由于所提出的由$\nu$调整的正则化项诱导了连通的低损失子空间,与FedAvg相比,SuPerFed-MM和SuPerFed-LM自然获得了更宽的极小值。随着全局模型在每轮联邦学习中学会与局部模型在权重空间上建立连接,全局模型的平坦极小值被诱导出来,即观察到了连通性。
One thing to note here is that the minima is far wider in layerwise mixing scheme (i.e., SuPerFed-LM) than that of model-wise mixing scheme (i.e., SuPerFed-MM). It is presumably due to the fact that the diversity of model combinations is richer in the layer-wise mixing scheme than in the model-wise mixing scheme. In other words, the global model should be connected to the larger number of different models.
需要注意的是,分层混合方案(即SuPerFed-LM)的最小值范围远大于模型混合方案(即SuPerFed-MM)。这可能是由于分层混合方案中模型组合的多样性比模型混合方案更丰富。换句话说,全局模型应该连接到更多不同的模型。
Meanwhile, since the global model has wide minima, it can be expected that it is friendly to be exploited by unseen clients even if their data distribution is heterogeneous from existing clients’ data distributions. It is because the global model contains many candidates of low-loss solutions thanks to the induced connectivity, the chances of finding a suitable model are higher than the global model derived from other FL methods.
与此同时,由于全局模型具有宽泛的最小值,可以预期即使新客户的数据分布与现有客户的数据分布存在异质性,该模型也能友好地适应。这是因为全局模型通过引入的连通性包含了众多低损失解的候选方案,相比其他联邦学习方法得到的全局模型,找到合适模型的概率更高。
A.3 Difference from the Existing PFL Methods with Model Interpolation
A.3 与现有基于模型插值的PFL方法的区别
In previous model mixture-based PFL methods, there exist similar approaches that interpolate the local model and the federated model in the form of a linear combination of a federated model and a local model: (i) APFL [10], (ii) mapper [43] and (iii) L2GD [23].
在基于模型混合的先前PFL方法中,存在以联邦模型和本地模型的线性组合形式进行插值的类似方法:(i) APFL [10], (ii) mapper [43] 和 (iii) L2GD [23]。
In (i) APFL, the federated model and the local model are updated separately with a fixed 𝜆, which is not true in SuPerFed as it jointly updates both federated and local models at once. While authors of [10] proposed the method to dynamically tune 𝜆 through another step of gradient descent, SuPerFed does not require finding one optimal 𝜆. It aims to find a good set of models $\mathbf{w}^{l}$ and $\mathbf{w}^{f}$ that can be combined to yield good performance regardless of the value of 𝜆.
在 (i) APFL 中,联邦模型和本地模型通过固定参数 𝜆 分别更新,而 SuPerFed 则不同,它能同时联合更新联邦模型和本地模型。虽然 [10] 的作者提出了通过梯度下降动态调整 𝜆 的方法,但 SuPerFed 不需要寻找最优 𝜆 值,其目标是找到一组优质模型 $\mathbf{w}^{l}$ 和 $\mathbf{w}^{f}$,无论 𝜆 取何值,这些模型的组合都能表现出良好性能。
In (ii) mapper [43], on the other hand, it iterative ly selects only one client (an unrealistic assumption) and requests to find the best local models $\mathbf{w}^{l}$ and $\lambda$ based on the transmitted global model $\mathbf{w}^{g}$ The federated model is then updated with the the local model and the optimal $\lambda$ is tuned. In SuPerFed, it is not required to find a fixed value of $\lambda$ and updates of both local and federated models can be completed in a single run of back-propagation using gradient descent. No separate training on each model is required as in other methods.
在 (ii) mapper [43] 中,该方法迭代地仅选择一个客户端(一个不现实的假设)并要求基于传输的全局模型 $\mathbf{w}^{g}$ 找到最佳本地模型 $\mathbf{w}^{l}$ 和 $\lambda$。然后使用本地模型更新联邦模型,并调整最优的 $\lambda$。而在 SuPerFed 中,无需寻找固定的 $\lambda$ 值,且本地和联邦模型的更新可以通过单次梯度下降的反向传播完成。与其他方法不同,无需对每个模型进行单独训练。
In (iii) L2GD proposed by [23], the interpolation of the global model and the local model is intermittently occurred at the server. Moreover, it requires all clients to participate in each round, which is a fairly unrealistic assumption in FL.
在 (iii) [23] 提出的 L2GD 中,全局模型和局部模型的插值间歇性地在服务器端发生。此外,它要求所有客户端每轮都参与,这在联邦学习 (FL) 中是一个相当不现实的假设。
We only compared with the method applicable for realistic FL settings, APFL. For the comparison, we observed dynamics of performances by varying $\lambda\in[0,1]$ in both SuPerFed (SuPerFed-MM & SuPerFed-LM) and APFL (See Figure A2). While SuPerFed-MM and SuPerFed-LM consistently perform well in terms of personalization regardless of the value $\lambda$ , APFL performs best only when $\lambda$ is close to 0.25. This supports the evidence of induced connectivity between the federated and local models by the regular iz ation. As endpoints (i.e., $\lambda=0$ for a federated model, $\lambda=1$ for a local model) are updated in the way to be connected, both are trained in a mutually beneficial way.
我们仅与适用于实际联邦学习(FL)场景的方法APFL进行了比较。在对比实验中,我们通过调整SuPerFed(SuPerFed-MM和SuPerFed-LM)与APFL中$\lambda\in[0,1]$的取值来观察性能动态变化(见图A2)。结果表明:无论$\lambda$取值如何,SuPerFed-MM和SuPerFed-LM始终能保持良好的个性化性能;而APFL仅在$\lambda$接近0.25时表现最优。这证实了正则化(regularization)能够诱导联邦模型与本地模型之间建立连接。由于两个端点($\lambda=0$对应联邦模型,$\lambda=1$对应本地模型)以相互连接的方式更新,二者实现了协同优化的训练效果。
A.4 Label Noise Scenario
A.4 标签噪声场景
Since we simulated noisy label scenarios using clean-labeled datasets (MNIST and CIFAR10), we manually obfuscate the labels of training samples following two schemes: pairwise flipping [22] and symmetric flipping [52]. Both are based on the defining label transition matrix $T$ , where each element of $T_{i j}$ indicates the probability of transitioning from an original label $y=i$ to an obfuscated label $\tilde{y}=j,$ i.e., $T_{i j}=p(\Tilde{y}=j|y=i)$ .
由于我们使用干净标签数据集(MNIST和CIFAR10)模拟噪声标签场景,因此采用两种方案手动混淆训练样本的标签:成对翻转 [22] 和对称翻转 [52]。这两种方案均基于定义的标签转移矩阵 $T$,其中 $T_{ij}$ 的每个元素表示从原始标签 $y=i$ 转移到混淆标签 $\tilde{y}=j$ 的概率,即 $T_{ij}=p(\tilde{y}=j|y=i)$。
A.4.1 Pairwise Flipping for Label Noise. The pairwise flipping emulates a situation when labelers make mistakes only within similar classes. In this case, the transition matrix $T$ for a pairwise flip given the noise ratio $\epsilon$ is defined as follows [22].
A.4.1 标签噪声的成对翻转。成对翻转模拟了标注者仅在相似类别中犯错的情况。此时,给定噪声比例 $\epsilon$ 的成对翻转转移矩阵 $T$ 定义如下 [22]。

A.4.2 Symmetric Flipping for Label Noise. The symmetric flipping assumes a probability of mis labeling of a clean label as other labels are uniformly distributed. For $n$ classes, the transition matrix for symmetric flipping is defined as follows [52].
A.4.2 标签噪声的对称翻转。对称翻转假设干净标签被错误标注为其他标签的概率是均匀分布的。对于 $n$ 个类别,对称翻转的转移矩阵定义如下 [52]。

Table A1: Details of training configurations
表 A1: 训练配置详情
| 设置 | 病态非独立同分布 | 基于狄利克雷分布的非独立同分布 | 现实非独立同分布 | 标签噪声(配对/对称) | ||||
|---|---|---|---|---|---|---|---|---|
| 数据集 | MNIST | CIFAR10 | CIFAR100 | TinyImageNet | FEMNIST | Shakespeare | MNIST | CIFAR10 |
| R | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 500 |
| E | 10 | 10 | 5 | 5 | 10 | 5 | 10 | 10 |
| B | 10 | 10 | 20 | 20 | 10 | 50 | 10 | 10 |
| K | 50,100,500 | 50,100,500 | 100 | 200 | 730 | 660 | 100 | 100 |
| n | 0.01 | 0.01 | 0.01 | 0.02 | 0.01 | 0.8 | 0.01 | 0.01 |
| 模型 | TwoNN | TwoCNN | ResNet | MobileNet | VGG | StackedLSTM | TwoNN | TwoCNN |

Figure A1: The loss surface of a deep network TwoCNN on CIFAR10 dataset calculated from l2-regularized cross-entropy loss as a function of network parameters in a two-dimensional subspace. The top rows indicate three-dimensional visualization of loss landscapes and the bottom rows indicates contours of derived loss landscapes First column: loss landscape obtained from FedAvg. Second column: loss landscape obtained from SuPerFed-MM. First column: loss landscape obtained from SuPerFed-LM.
图 A1: 深度网络TwoCNN在CIFAR10数据集上的损失曲面,由l2正则化交叉熵损失计算得出,表示为二维子空间中网络参数的函数。顶部行展示损失景观的三维可视化,底部行展示派生损失景观的等高线。第一列:通过FedAvg获得的损失景观。第二列:通过SuPerFed-MM获得的损失景观。第三列:通过SuPerFed-LM获得的损失景观。

Figure A2: Comparison of the personalization performance between APFL (left), SuPerFed-MM (middle), and SuPerFed-LM (right) by varying $\lambda\in[0,1]$ . Note that each method is trained on MNIST dataset with TwoNN model assuming pathological non-IID setting $\mathrm{\mathit{K}}=500$ and $\mathrm{R}=500$ ).
图 A2: 通过调整 $\lambda\in[0,1]$ 对比APFL (左)、SuPerFed-MM (中) 和SuPerFed-LM (右) 的个性化性能。注意:所有方法均在MNIST数据集上使用TwoNN模型训练,采用病理学非独立同分布设置 ($\mathrm{\mathit{K}}=500$ 且 $\mathrm{R}=500$)。