Layout Diffusion: Controllable Diffusion Model for Layout-to-image Generation
Layout Diffusion: 面向布局到图像生成的可控扩散模型
(a) layout-guided vs. text-guided image generation for diffusion model
(a) 扩散模型的布局引导与文本引导图像生成
(b) Image-Layout Fusion in a unified space
(b) 统一空间中的图像-布局融合
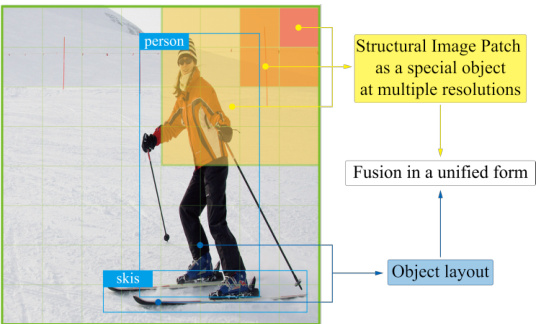
Figure 1. Compared to text, the layout allows diffusion models to obtain more control over the objects while maintaining high quality. Unlike the prevailing methods, we propose a diffusion model named Layout Diffusion for layout-to-image generation. We transform the difficult multimodal fusion of the image and layout into a unified form by constructing a structural image patch with region information and regarding the patched image as a special layout.
图 1: 与纯文本相比,布局使扩散模型能在保持高质量的同时获得更精准的对象控制。不同于主流方法,我们提出名为Layout Diffusion的扩散模型用于布局到图像生成。通过构建带有区域信息的结构化图像块,并将拼接后的图像视为特殊布局,我们将图像与布局的多模态融合难题转化为统一形式。
Abstract
摘要
Recently, diffusion models have achieved great success in image synthesis. However, when it comes to the layoutto-image generation where an image often has a complex scene of multiple objects, how to make strong control over both the global layout map and each detailed object remains a challenging task. In this paper, we propose a diffusion model named Layout Diffusion that can obtain higher generation quality and greater control l ability than the previous works. To overcome the difficult multimodal fusion of image and layout, we propose to construct a structural image patch with region information and transform the patched image into a special layout to fuse with the normal layout in a unified form. Moreover, Layout Fusion Module (LFM) and Object-aware Cross Attention (OaCA) are proposed to model the relationship among multiple objects and designed to be object-aware and position-sensitive, allowing for precisely controlling the spatial related information. Extensive experiments show that our Layout Diffusion outperforms the previous SOTA methods on FID, CAS by relatively $46.35%$ , $26.70%$ on COCO-stuff and $44.29%$ , $41.82%$ on VG. Code is available at https://github.com/ ZGCTroy/Layout Diffusion.
规则:
- 输出中文翻译部分的时候,只保留翻译的标题,不要有任何其他的多余内容,不要重复,不要解释。
- 不要输出与英文内容无关的内容。
- 翻译时要保留原始段落格式,以及保留术语,例如 FLAC,JPEG 等。保留公司缩写,例如 Microsoft, Amazon, OpenAI 等。
- 人名不翻译
- 同时要保留引用的论文,例如 [20] 这样的引用。
- 对于 Figure 和 Table,翻译的同时保留原有格式,例如:“Figure 1: ”翻译为“图 1: ”,“Table 1: ”翻译为:“表 1: ”。
- 全角括号换成半角括号,并在左括号前面加半角空格,右括号后面加半角空格。
- 在翻译专业术语时,第一次出现时要在括号里面写上英文原文,例如:“生成式 AI (Generative AI)”,之后就可以只写中文了。
- 以下是常见的 AI 相关术语词汇对应表(English -> 中文):
- Transformer -> Transformer
- Token -> Token
- LLM/Large Language Model -> 大语言模型
- Zero-shot -> 零样本
- Few-shot -> 少样本
- AI Agent -> AI智能体
- AGI -> 通用人工智能
- Python -> Python语言
策略:
分三步进行翻译工作:
- 不翻译无法识别的特殊字符和公式,原样返回
- 将HTML表格格式转换成Markdown表格格式
- 根据英文内容翻译成符合中文表达习惯的内容,不要遗漏任何信息
最终只返回Markdown格式的翻译结果,不要回复无关内容。
现在请按照上面的要求开始翻译以下内容为简体中文:最近,扩散模型 (diffusion models) 在图像合成领域取得了巨大成功。然而,当涉及包含多个对象的复杂场景的布局到图像生成 (layout-to-image generation) 时,如何同时精确控制全局布局图和每个细节对象仍是一项具有挑战性的任务。本文提出了一种名为 Layout Diffusion 的扩散模型,其生成质量和控制能力均优于先前工作。为解决图像与布局的多模态融合难题,我们提出构建具有区域信息的结构化图像块 (structural image patch),并将分块图像转换为特殊布局形式,从而实现与常规布局的统一融合。此外,本文提出的布局融合模块 (Layout Fusion Module, LFM) 和对象感知交叉注意力 (Object-aware Cross Attention, OaCA) 能够建模多对象间关系,其设计具备对象感知和位置敏感性,可精确控制空间相关信息。大量实验表明,我们的 Layout Diffusion 在 COCO-stuff 和 VG 数据集上分别以 46.35%、26.70% 和 44.29%、41.82% 的相对优势超越先前 SOTA 方法 (FID, CAS 指标)。代码已开源:https://github.com/ZGCTroy/Layout-Diffusion。
1. Introduction
1. 引言
Recently, the diffusion model has achieved encouraging progress in conditional image generation, especially in textto-image generation such as GLIDE [28], Imagen [36], and Stable Diffusion [35]. However, text-guided diffusion models may still fail in the following situations. As shown in Fig. 1 (a), when aiming to generate a complex image with multiple objects, it is hard to design a prompt properly and comprehensively. Even input with well-designed prompts, problems such as missing objects and incorrectly generating objects’ positions, shapes, and categories still occur in the state-of-the-art text-guided diffusion model [28, 35, 36].
最近,扩散模型在条件图像生成领域取得了令人鼓舞的进展,尤其是在文本到图像生成方面,如 GLIDE [28]、Imagen [36] 和 Stable Diffusion [35]。然而,文本引导的扩散模型在以下情况下仍可能失败。如图 1 (a) 所示,当试图生成包含多个对象的复杂图像时,很难设计出恰当且全面的提示词。即使输入精心设计的提示词,在最先进的文本引导扩散模型 [28, 35, 36] 中仍会出现对象缺失、对象位置/形状/类别生成错误等问题。
This is mainly due to the ambiguity of the text and its weakness in precisely expressing the position of the image space [6, 15, 22, 43–45]. Fortunately, this is not a problem when using the coarse layout as guidance, which is a set of objects with the annotation of the bounding box (bbox) and object category. With both spatial and high-level semantic information, the diffusion model can obtain more powerful control l ability while maintaining the high quality.
这主要源于文本的模糊性及其在精确表达图像空间位置方面的不足 [6, 15, 22, 43-45]。幸运的是,使用粗粒度布局作为引导时不存在此问题——布局是一组带有边界框 (bbox) 和物体类别标注的对象。凭借空间信息与高层语义信息的结合,扩散模型能在保持高质量的同时获得更强的控制能力。
However, early studies [2, 16, 47, 51] on layout-to-image generation are almost limited to generative adversarial networks (GANs) and often suffer from unstable convergence [1] and mode collapse [31]. Despite the advantages of diffusion models in easy training [11] and significant quality improvement [8], few studies have considered applying diffusion in the layout-to-image generation task. To our knowledge, only LDM [35] supports the condition of layout and has shown encouraging progress in this field.
然而,早期关于布局到图像生成的研究 [2, 16, 47, 51] 几乎仅限于生成对抗网络 (GANs),并且经常面临收敛不稳定 [1] 和模式崩溃 [31] 的问题。尽管扩散模型在训练简便 [11] 和质量显著提升 [8] 方面具有优势,但很少有研究考虑将扩散模型应用于布局到图像生成任务。据我们所知,只有 LDM [35] 支持布局条件,并在该领域展现了令人鼓舞的进展。
In this paper, different from LDM that applies the simple multimodal fusion method (e.g., the cross attention) or direct input concatenation for all conditional input, we aim to specifically design the fusion mechanism between layout and image. Moreover, instead of conditioning only in the second stage like LDM, we propose an end-to-end one-stage model that considers the condition for the whole process, which may have the potential to help mitigate loss in the task that requires fine-grained accuracy in pixel space [35]. The fusion between image and layout is a difficult multimodal fusion problem. Compared to the fusion of text and image, the layout has more restrictions on the position, size, and category of objects. This requires a higher control l ability of the model and often leads to a decrease in the naturalness and diversity of the generated image. Furthermore, the layout is more sensitive to each token and the loss in token of layout will directly lead to the missing objects.
本文与LDM采用简单的多模态融合方法(如交叉注意力)或对所有条件输入直接拼接不同,我们旨在专门设计布局与图像间的融合机制。此外,不同于LDM仅在第二阶段施加条件,我们提出了一个端到端的单阶段模型,该模型在整个生成过程中都考虑条件约束,这可能有助于缓解像素空间需要精细准确度的任务中的信息损失[35]。图像与布局的融合是一个困难的多模态融合问题。相比文本与图像的融合,布局对物体的位置、尺寸和类别有更多限制。这需要模型具备更强的控制能力,同时往往会导致生成图像的自然性和多样性下降。此外,布局对每个token更为敏感,布局token的缺失会直接导致物体丢失。
To address the problems mentioned above, we propose treating the patched image and the input layout in a unified form. Specifically, we construct a structural image patch at multi-resolution by adding the concept of region that contains information of position and size. As a result, each patch of the image is transformed into a special type of object, and the entire patched image will also be regarded as a layout. Finally, the difficult problem of multimodal fusion between image and layout will be transformed into a simple fusion with a unified form in the same spatial space of the image. We name our model Layout Diff u is on, a layout-conditional diffusion model with Layout Fusion Module (LFM), object-aware Cross Attention Mechanism (OaCA), and corresponding classifier-free training and sampling scheme. In detail, LFM fuses the information of each object and models the relationship among multiple objects, providing a latent representation of the entire layout. To make the model pay more attention to the information related to the object, we propose an object-aware fusion module named OaCA. Cross-attention is made between the image patch feature and layout in a unified coordinate space by representing the positions of both of them as bounding boxes. To further improve the user experience of LayoutDiffuison, we also make several optimization s on the speed of the classifier-free sampling process and could significantly outperform the SOTA models in 25 iterations.
为解决上述问题,我们提出以统一形式处理分块图像与输入布局。具体而言,通过引入包含位置和尺寸信息的区域概念,我们在多分辨率下构建结构化图像块。这使得每个图像块被转化为特殊类型的对象,整个分块图像也将被视为一种布局。最终,图像与布局间的困难多模态融合问题,将转化为同一图像空间内统一形式的简单融合。我们将模型命名为LayoutDiffusion,这是一个包含布局融合模块(LFM)、对象感知交叉注意力机制(OaCA)以及对应无分类器训练与采样方案的布局条件扩散模型。具体来说,LFM融合各对象信息并建模多对象关系,提供整个布局的潜在表征。为使模型更关注对象相关信息,我们提出名为OaCA的对象感知融合模块。通过将图像块特征与布局的位置表示为边界框,在统一坐标空间内进行交叉注意力计算。为进一步提升LayoutDiffusion的用户体验,我们对无分类器采样过程的速度进行了多项优化,在25次迭代中即可显著超越SOTA模型。
Experiments are conducted on COCO-stuff [5] and Visual Genome (VG) [21]. Various metrics ranging from quality, diversity, and control l ability show that Layout Diffusion significantly outperforms both state-of-the-art GAN-based and diffusion-based methods.
实验在COCO-stuff [5] 和 Visual Genome (VG) [21] 数据集上进行。从生成质量、多样性和可控性等多维度指标表明,Layout Diffusion显著优于当前最先进的基于GAN和扩散模型的方法。
Our main contribution is listed below.
我们的主要贡献如下。
2. Related work
2. 相关工作
The related works are mainly from layout-to-image generation and diffusion models.
相关工作主要涉及布局到图像生成和扩散模型。
Layout-to-Image Generation. Before the layout-to-image generation is formally proposed, the layout is usually used as as a complementary feature [17, 34, 49] or an intermediate representation in text-to-image [13], scene-to-image generation [16]. The first image generation directly from the layout appears in Layout2Im [56] and is defined as a set of objects annotated with category and bbox. Models that work well with fine-grained semantic maps at the pixel level can also be easily transformed to this setting [14, 30, 52]. Inspired by StyleGAN [18], LostGAN-v1 [46], LostGANv2 [47] used a re configurable layout to obtain better control over individual objects. For interactive image synthesis, PLGAN [51] employed panoptic theory [20] by constructing stuff and instance layouts into separate branches and proposed Instance- and Stuff-Aware Normalization to fuse into panoptic layouts. Despite encouraging progress in this field, almost all approaches are limited to the generative adversarial network (GAN) and may suffer from unstable convergence [1] and mode collapse [31]. As a multimodal diffusion model, LDM [35] supports the condition of coarse layout and has shown great potential in layout-guided image generation.
布局到图像生成。在布局到图像生成被正式提出之前,布局通常被用作补充特征[17, 34, 49]或文本到图像[13]、场景到图像生成[16]的中间表示。首个直接从布局生成图像的工作出现在Layout2Im[56]中,其将布局定义为带有类别和边界框标注的对象集合。在像素级别能良好处理细粒度语义图的模型也能轻松适配此设定[14, 30, 52]。受StyleGAN[18]启发,LostGAN-v1[46]和LostGAN-v2[47]采用可重构布局实现对单个对象的更好控制。针对交互式图像合成,PLGAN[51]通过将场景布局和实例布局构建为独立分支,运用全景理论[20]并提出实例与场景感知归一化方法来实现全景布局融合。尽管该领域取得显著进展,几乎所有方法都局限于生成对抗网络(GAN),存在收敛不稳定[1]和模式坍塌[31]问题。作为多模态扩散模型,LDM[35]支持粗粒度布局条件输入,在布局引导的图像生成中展现出巨大潜力。
Diffusion Model. Diffusion models [3, 11, 29, 35, 39, 41, 42, 53] are being recognized as a promising family of generative models that have proven to be state-of-the-art sample quality for a variety of image generation benchmarks [7,50,54], including class-conditional image generation [8,57], text-to-image generation [28,35,36], and image- to-image translation [19, 26, 37]. Classifier guidance was introduced in ADM-G [8] to allow diffusion models to condition the class label. The gradient of the classifier trained on noised images could be added to the image during the sampling process. Then Ho et al. [12] proposed a classifierfree training and sampling strategy by interpolating between predictions of a diffusion model with and without condition input. For the acceleration of training and sampling speed, LDM proposed to first compress the image into smaller resolution and then apply denoising training in the latent space.
扩散模型 (Diffusion Model) [3, 11, 29, 35, 39, 41, 42, 53] 正被视为一类极具前景的生成式模型,其在多种图像生成基准测试中展现出最先进的样本质量 [7,50,54],包括类别条件图像生成 [8,57]、文本到图像生成 [28,35,36] 以及图像到图像转换 [19, 26, 37]。ADM-G [8] 引入了分类器引导机制,使扩散模型能够基于类别标签进行条件生成。采样过程中可将经过噪声图像训练的分类器梯度叠加至图像。随后 Ho 等人 [12] 提出了一种无分类器训练与采样策略,通过对有条件输入和无条件输入的扩散模型预测结果进行插值实现。为加速训练与采样过程,LDM 提出先将图像压缩至较低分辨率,再在潜在空间中进行去噪训练。
3. Method
3. 方法
In this section, we propose our Layout Diffusion, as shown in Fig. 2. The whole framework consists mainly of four parts: (a) layout embedding that pre processes the layout input, (b) layout fusion module that encourages more interaction between objects of layout, (c) image-layout fusion module that constructs the structal image patch and objectaware cross attention developed with the specific design for layout and image fusion, (d) the layout-conditional diffu- sion model with training and accelerated sampling methods.
在本节中,我们提出了布局扩散方法 (Layout Diffusion) ,如图 2 所示。整个框架主要包含四个部分: (a) 布局嵌入层 (layout embedding) ,用于预处理布局输入; (b) 布局融合模块 (layout fusion module) ,用于增强布局中对象间的交互; (c) 图像-布局融合模块 (image-layout fusion module) ,用于构建结构化图像块 (structal image patch) 和对象感知交叉注意力机制 (objectaware cross attention) ,该模块专为布局与图像融合而设计; (d) 布局条件扩散模型 (layout-conditional diffusion model) ,包含训练方法和加速采样方法。
3.1. Layout Embedding
3.1. 布局嵌入
A layout $l~={o_{1},o_{2},\cdot\cdot\cdot~,o_{n}}$ is a set of $n$ objects. Each object $o_{i}$ is represented as $o_{i}={b_{i},c_{i}}$ , where $b_{i}=$ $(x_{0}^{i},y_{0}^{i},x_{1}^{i},y_{1}^{i})\in[0,1]^{4}$ denotes a bounding box (bbox) and $c_{i}\in[0,\mathcal{C}+1]$ is its category id.
布局 $l~={o_{1},o_{2},\cdot\cdot\cdot~,o_{n}}$ 是一组 $n$ 个对象的集合。每个对象 $o_{i}$ 表示为 $o_{i}={b_{i},c_{i}}$ ,其中 $b_{i}=$ $(x_{0}^{i},y_{0}^{i},x_{1}^{i},y_{1}^{i})\in[0,1]^{4}$ 表示边界框 (bbox),而 $c_{i}\in[0,\mathcal{C}+1]$ 是其类别 ID。
To support the input of a variable length sequence, we need to pad $l$ to a fixed length $k$ by adding one $o_{l}$ in the front and some padding $o_{p}$ in the end, where $o_{l}$ represents the entire layout and $o_{p}$ represents no object. Specifically, $b_{l}=(0,0,1,1)$ , $c_{l}=0$ denotes a object that covers the whole image and $b_{p}=(0,0,0,0)$ , $c_{p}=\mathcal{C}+1$ denotes a empty object that has no shape or does not appear in the image.
为了支持可变长度序列的输入,我们需要将 $l$ 填充到固定长度 $k$ ,方法是在前面添加一个 $o_{l}$ ,并在末尾添加一些填充 $o_{p}$ ,其中 $o_{l}$ 表示整个布局, $o_{p}$ 表示无对象。具体来说, $b_{l}=(0,0,1,1)$ , $c_{l}=0$ 表示一个覆盖整个图像的对象,而 $b_{p}=(0,0,0,0)$ , $c_{p}=\mathcal{C}+1$ 表示一个没有形状或未出现在图像中的空对象。
After the padding process, we can get a padded $l=$ consisting of $k$ objects, and each object has its specific position, size, and category. Then, the layout $l$ is transformed into a layout embedding $L=$ ${O_{1},O_{2},\cdot\cdot\cdot,O_{k}}\in\mathbb{R}^{k\times d_{\mathcal{L}}}$ by the projection matrix $W_{B}\in$ $\mathbb{R}^{4\times d_{c}}$ and $W_{\mathcal{C}}\in\mathbb{R}^{1\times d_{\mathcal{L}}}$ using the following equation:
填充处理后,我们可以得到一个填充后的 $l=$ 包含 $k$ 个对象,每个对象都有其特定的位置、大小和类别。随后,通过投影矩阵 $W_{B}\in$ $\mathbb{R}^{4\times d_{c}}$ 和 $W_{\mathcal{C}}\in\mathbb{R}^{1\times d_{\mathcal{L}}}$ ,布局 $l$ 被转换为布局嵌入 $L=$ ${O_{1},O_{2},\cdot\cdot\cdot,O_{k}}\in\mathbb{R}^{k\times d_{\mathcal{L}}}$ ,转换公式如下:
$$
\begin{array}{c}{L=B_{\mathcal{L}}+C_{\mathcal{L}}}\ {B_{\mathcal{L}}=b W_{B}}\ {C_{\mathcal{L}}=c W_{C}}\end{array}
$$
$$
\begin{array}{c}{L=B_{\mathcal{L}}+C_{\mathcal{L}}}\ {B_{\mathcal{L}}=b W_{B}}\ {C_{\mathcal{L}}=c W_{C}}\end{array}
$$
where $B_{\mathcal{L}},C_{\mathcal{L}}\in\mathbb{R}^{k\times d_{\mathcal{L}}}$ are the bounding box embedding and the category embedding of a layout $l$ , respectively. As a result, $L$ is defined as the sum of $B\boldsymbol{\mathscr{c}}$ and $C_{\mathcal{L}}$ to include both the content and positional information of a entire layout, and $d_{\mathcal{L}}$ is the dimension of the layout embedding.
其中 $B_{\mathcal{L}},C_{\mathcal{L}}\in\mathbb{R}^{k\times d_{\mathcal{L}}}$ 分别是布局 $l$ 的边界框嵌入和类别嵌入。因此,$L$ 被定义为 $B\boldsymbol{\mathscr{c}}$ 与 $C_{\mathcal{L}}$ 之和,以包含整个布局的内容和位置信息,$d_{\mathcal{L}}$ 是布局嵌入的维度。
3.2. Layout Fusion Module
3.2. 布局融合模块
Currently, each object in layout has no relationship with other objects. This leads to a low understanding of the whole scene, especially when multiple objects overlap and block each other. Therefore, to encourage more interaction between multiple objects of the layout to better understand the entire layout before inputting the layout embedding, we propose Layout Fusion Module (LFM), a transformer encoder that uses multiple layers of self-attention to fuse the layout embedding and can be denoted as
目前,布局中的每个对象与其他对象之间没有关联。这导致对整个场景的理解不足,尤其在多个对象相互重叠和遮挡时更为明显。因此,为促进布局中多个对象间的更多交互,从而在输入布局嵌入前更好地理解整体布局,我们提出了布局融合模块 (Layout Fusion Module, LFM) ——一种通过多层自注意力机制融合布局嵌入的 Transformer 编码器,可表示为
$$
L^{\prime}=\operatorname{LFM}(L)
$$
$$
L^{\prime}=\operatorname{LFM}(L)
$$
, where the output is a fused layout embedding $L^{\prime}=$ ${O_{1}^{\prime},O_{2}^{'},\cdot\cdot\cdot,O_{k}^{'}}\in\mathbb{R}^{k\times d_{\mathcal{L}}}$ .
其中输出为融合布局嵌入 $L^{\prime}=$ ${O_{1}^{\prime},O_{2}^{'},\cdot\cdot\cdot,O_{k}^{'}}\in\mathbb{R}^{k\times d_{\mathcal{L}}}$ 。
3.3. Image-Layout Fusion Module
3.3. 图像-布局融合模块
Structural Image Patch. The fusion of image and layout is a difficult multimodal fusion problem, and one of the most important parts lies in the fusion of position and size. However, the image patch is limited to the semantic information of the whole feature and lacks the spatial information. Therefore, we construct a structural image patch by adding the concept of region that contains the information of position and size.
结构化图像块 (Structural Image Patch)。图像与版式的融合是一个困难的多模态融合问题,其中最关键的部分在于位置和尺寸信息的融合。然而传统图像块仅包含整体特征的语义信息,缺乏空间信息。为此,我们通过引入包含位置与尺寸信息的区域概念,构建了结构化图像块。
Specifically, $\pmb{I}\in\mathbb{R}^{h\times w\times d_{\mathbb{Z}}}$ denotes the feature map of a entire image with height $h$ , width $w$ , and channel $d_{\mathbb{Z}}$ . We define that $I_{u,v}$ is the $u^{\mathrm{th}}$ row and $v^{\mathrm{th}}$ column patch of $I$ and its bounding box, or the ablated region information, is defined as $b_{I_{u,v}}$ by the following equation:
具体来说,$\pmb{I}\in\mathbb{R}^{h\times w\times d_{\mathbb{Z}}}$表示整个图像的特征图,其高度为$h$,宽度为$w$,通道数为$d_{\mathbb{Z}}$。我们定义$I_{u,v}$为$I$的第$u^{\mathrm{th}}$行和第$v^{\mathrm{th}}$列的图像块,其边界框(或称为擦除区域信息)由以下方程定义为$b_{I_{u,v}}$:
$$
b_{\mathcal{Z}_{u,v}}=(\frac{u}{h},\frac{v}{w},\frac{u+1}{h},\frac{v+1}{w})
$$
$$
b_{\mathcal{Z}_{u,v}}=(\frac{u}{h},\frac{v}{w},\frac{u+1}{h},\frac{v+1}{w})
$$
The bounding box sets of a patched image $I$ is defined as . As a result, the positional information of image patch and layout object is contained in the unified bounding box defined in the same spatial space, leading to better fusion of image and layout.
修补图像 $I$ 的边界框集定义为。因此,图像块和布局对象的位置信息被包含在同一空间空间中定义的统一边界框内,从而实现图像和布局更好的融合。
Positional Embedding in Unified Space. We define the positional embedding of the image and layout as $P_{\mathcal{Z}}$ and
空间统一的位置嵌入。我们将图像和布局的位置嵌入定义为 $P_{\mathcal{Z}}$ 和
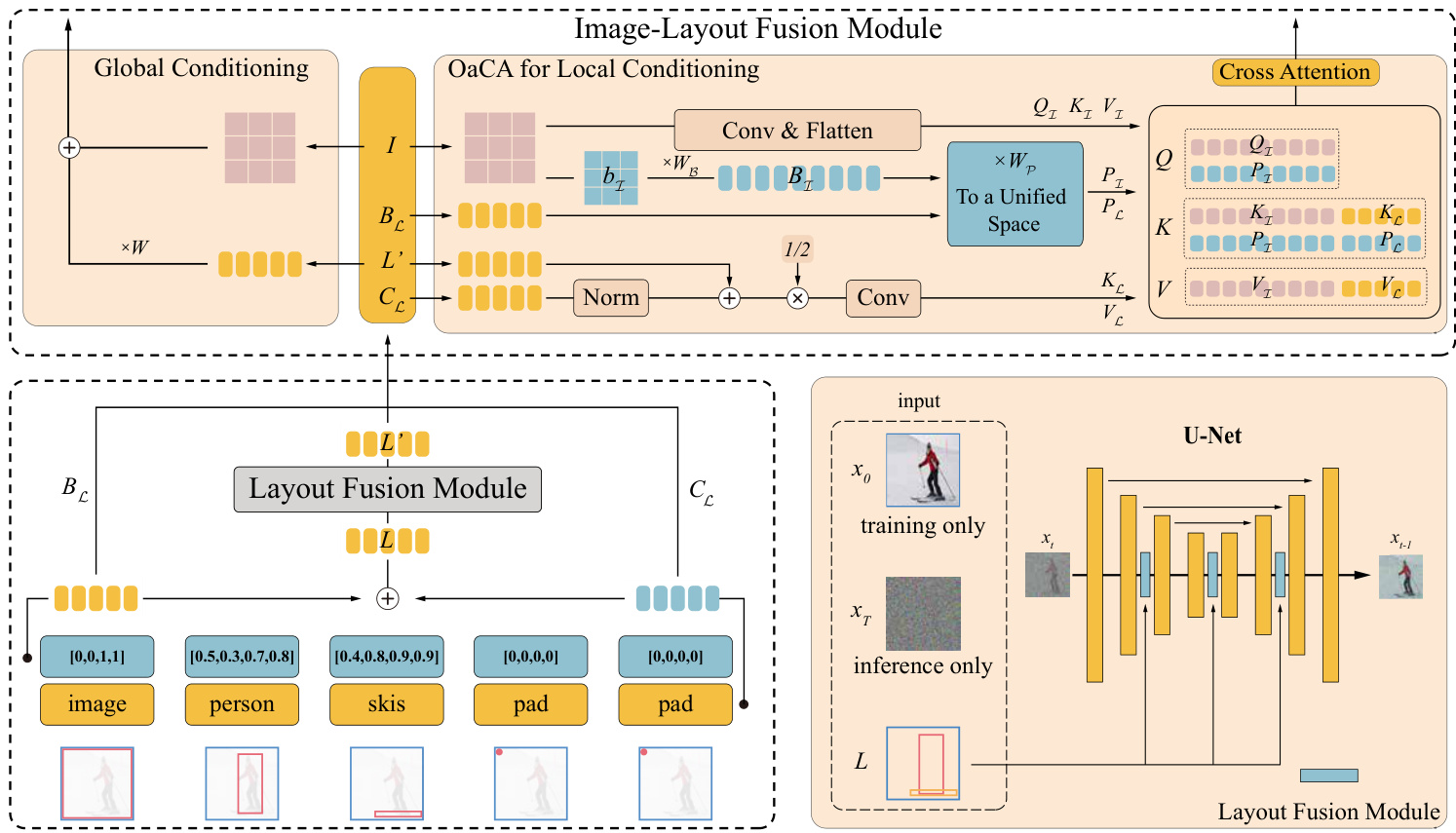
Figure 2. The whole pipeline of Layout Diffusion. The layout that consisted of bounding box $b$ and objects categories $c$ is transformed into embedding $B_{\mathcal{L}},C_{\mathcal{L}},L$ . Then Layout Fusion Module fuses layout embedding $L$ to output the fused layout embedding $L^{\prime}$ . Finally, Image-Layout Fusion Module including direct addition used for global conditioning and Object-aware Cross Attention (OaCA) used for local conditioning, will fuse the layout related $B_{\mathcal{L}},C_{\mathcal{L}},L^{\prime}$ and the image feature $I$ at multiple resolutions.
图 2: Layout Diffusion 的整体流程。由边界框 $b$ 和物体类别 $c$ 组成的布局被转换为嵌入 $B_{\mathcal{L}},C_{\mathcal{L}},L$。随后,布局融合模块 (Layout Fusion Module) 将布局嵌入 $L$ 融合,输出融合后的布局嵌入 $L^{\prime}$。最后,图像-布局融合模块 (Image-Layout Fusion Module) 通过直接相加 (direct addition) 实现全局条件控制,并利用物体感知交叉注意力 (Object-aware Cross Attention, OaCA) 实现局部条件控制,将布局相关的 $B_{\mathcal{L}},C_{\mathcal{L}},L^{\prime}$ 与多分辨率下的图像特征 $I$ 进行融合。
$P_{\mathcal{L}}$ as follows:
$P_{\mathcal{L}}$ 如下:
$$
\begin{array}{l}{B_{\mathcal{T}}=b_{\mathcal{T}}W_{\mathcal{B}}}\ {P_{\mathcal{T}}=B_{\mathcal{T}}W_{\mathcal{P}}}\ {P_{\mathcal{L}}=B_{\mathcal{L}}W_{\mathcal{P}}}\end{array}
$$
$$
\begin{array}{l}{B_{\mathcal{T}}=b_{\mathcal{T}}W_{\mathcal{B}}}\ {P_{\mathcal{T}}=B_{\mathcal{T}}W_{\mathcal{P}}}\ {P_{\mathcal{L}}=B_{\mathcal{L}}W_{\mathcal{P}}}\end{array}
$$
, where $W_{B}\in\mathbb{R}^{4\times d_{\mathcal{L}}}$ is defined in Eq. 2 and works as a shared projection matrix that transforms the coordinates of bounding box into embedding of $d_{\mathcal{L}}$ dimension. $W_{\mathcal P}\in$ $\mathbb{R}^{d_{\mathbb{Z}}\times d_{\mathbb{Z}}}$ is the projection matrix that transforms the $B$ to the positional Embedding $P$ .
其中 $W_{B}\in\mathbb{R}^{4\times d_{\mathcal{L}}}$ 是公式2中定义的共享投影矩阵,用于将边界框坐标转换为 $d_{\mathcal{L}}$ 维嵌入。$W_{\mathcal P}\in$ $\mathbb{R}^{d_{\mathbb{Z}}\times d_{\mathbb{Z}}}$ 是将边界框 $B$ 转换为位置嵌入 $P$ 的投影矩阵。
Pointwise Addition for Global Conditioning. With the help of LFM in Eq. 4, $O_{1}^{\prime}$ can be considered as a global information of the entire layout, and $O_{i}^{\prime}(i\in[2,k])$ is considered as the local information embedding of single object along with the other related objects. One of the easiest ways to condition the layout in the image is to directly add $O_{1}^{\prime}$ , the global information of the layout, to the multiple resolution of image features. Specifically, the condition process can be defined as
全局调节的逐点加法。借助式4中的LFM,$O_{1}^{\prime}$可视为整个布局的全局信息,而$O_{i}^{\prime}(i\in[2,k])$则被视为单个对象及其相关对象的局部信息嵌入。对图像中的布局进行调节的最简单方法之一,是将布局的全局信息$O_{1}^{\prime}$直接添加到图像特征的多分辨率上。具体而言,该调节过程可定义为
$$
I^{'}=I+O_{1}^{\prime}W
$$
$$
I^{'}=I+O_{1}^{\prime}W
$$
, where $W\in\mathbb{R}^{d_{\mathcal{L}}\times d_{\mathcal{Z}}}$ is a projection matrix and $I^{\prime}$ is the image feature conditioned with global embedding of layout.
其中 $W\in\mathbb{R}^{d_{\mathcal{L}}\times d_{\mathcal{Z}}}$ 是投影矩阵,$I^{\prime}$ 为融合布局全局嵌入的图像特征。
Object-aware Cross Attention for Local Conditioning.
面向局部条件化的对象感知交叉注意力
Cross attention is successfully applied in [28] to condition text into image feature, where the sequence of the image patch is used as the query and the concatenated sequence of the image patch and text is applied as key and value. The equation of cross-attention is defined as
交叉注意力在[28]中被成功应用于将文本条件融入图像特征,其中图像块的序列作为查询(query),图像块与文本的拼接序列作为键(key)和值(value)。交叉注意力的计算公式定义为
$$
{\mathrm{Attention}}(Q,K,V)=\operatorname{softmax}\left({\frac{Q K^{T}}{\sqrt{d_{k}}}}\right)V
$$
$$
{\mathrm{Attention}}(Q,K,V)=\operatorname{softmax}\left({\frac{Q K^{T}}{\sqrt{d_{k}}}}\right)V
$$
, where $Q,K,V$ represent the embeddings of query, key, and value, respectively. In the following paper, we will use the subscript image and layout to represent the image patch feature and layout feature, respectively.
其中 $Q,K,V$ 分别表示查询(query)、键(key)和值(value)的嵌入向量。在下文中,我们将使用下标 image 和 layout 分别表示图像块特征和布局特征。
In text-to-image generation, each token in the text sequence is a word. The aggregation of these words constitutes the semantics of a sentence. After the transformer encoder, the first token in text sequence is well-semantic information that generalizes the whole text but may not reverse the semantic meaning of each word. However, the loss in information of one token is relatively serious in layout rather than in text. Each token in the layout sequence is a single object with a specific category, size, and position. The loss of information on a layout token will directly lead to a missing or wrong object in the generated image pixel space.
在文本到图像生成中,文本序列中的每个token都是一个单词。这些单词的聚合构成了句子的语义。经过transformer编码器处理后,文本序列中的第一个token会成为概括整体文本的强语义信息,但可能无法还原每个单词的语义含义。然而,在布局序列中,单个token的信息丢失问题比文本序列更为严重。布局序列中的每个token都代表具有特定类别、尺寸和位置的独立对象。布局token的信息丢失会直接导致生成图像像素空间中出现缺失或错误的对象。
Therefore, we take into account the fusion of locations, size, and category of objects and define our object-aware cross-attention (OaCA) as
因此,我们综合考虑物体的位置、尺寸和类别融合,并将物体感知交叉注意力 (OaCA) 定义为
$$
\begin{array}{r l}&{Q=\Psi_{1}(Q_{\mathcal{T}},P_{\mathcal{L}})}\ &{K=\Psi_{1}(\Psi_{2}(K_{\mathcal{T}},K_{\mathcal{L}}),\Psi_{2}(P_{\mathcal{T}},P_{\mathcal{L}}))}\ &{V=\Psi_{2}(V_{\mathcal{T}},V_{\mathcal{L}})}\end{array}
$$
$$
\begin{array}{r l}&{Q=\Psi_{1}(Q_{\mathcal{T}},P_{\mathcal{L}})}\ &{K=\Psi_{1}(\Psi_{2}(K_{\mathcal{T}},K_{\mathcal{L}}),\Psi_{2}(P_{\mathcal{T}},P_{\mathcal{L}}))}\ &{V=\Psi_{2}(V_{\mathcal{T}},V_{\mathcal{L}})}\end{array}
$$
, where the query $Q\in\mathbb{R}^{h w\times2d_{\mathbb{Z}}}$ , $K\in\mathbb{R}^{(h w+k)\times2d_{\mathcal{Z}}}$ , and $V\in\mathbb{R}^{(h w+\bar{k})\times\bar{d}{\mathcal{T}}}$ . $\Psi_{1}$ and $\Psi_{2}$ denote concatenation on the dimension of the channel and length of the sequence, respectively.
其中查询 $Q\in\mathbb{R}^{h w\times2d_{\mathbb{Z}}}$ 、键 $K\in\mathbb{R}^{(h w+k)\times2d_{\mathcal{Z}}}$ 和值 $V\in\mathbb{R}^{(h w+\bar{k})\times\bar{d}{\mathcal{T}}}$ 。$\Psi_{1}$ 和 $\Psi_{2}$ 分别表示在通道维度和序列长度维度上的拼接操作。
We first construct the key and value of the layout:
我们首先构建布局的键和值:
$$
K_{\mathcal{L}},V_{\mathcal{L}}=\operatorname{Conv}(\frac{1}{2}(\operatorname{Norm}(C_{\mathcal{L}})+L^{\prime}))
$$
$$
K_{\mathcal{L}},V_{\mathcal{L}}=\operatorname{Conv}(\frac{1}{2}(\operatorname{Norm}(C_{\mathcal{L}})+L^{\prime}))
$$
, where $K_{\mathcal{L}},V_{\mathcal{L}}\in\mathbb{R}^{k\times d_{\mathcal{Z}}}$ and Conv is the convolution operation. The embedding of key and value in the layout is related to the category embedding $C_{\mathcal{L}}$ and the fused layout embedding $L^{\prime}$ . $C_{\mathcal{L}}$ focuses on the category information of layout and $L^{\prime}$ concentrates on the comprehensive information of both the object itself and other objects that may have a relationship with it. By averaging between $L^{\prime}$ and $C_{\mathcal{L}}$ , we can obtain both the general information of the object and also emphasize the category information of the object.
其中 $K_{\mathcal{L}},V_{\mathcal{L}}\in\mathbb{R}^{k\times d_{\mathcal{Z}}}$ ,Conv 表示卷积运算。布局中键与值的嵌入与类别嵌入 $C_{\mathcal{L}}$ 及融合后的布局嵌入 $L^{\prime}$ 相关。$C_{\mathcal{L}}$ 聚焦于布局的类别信息,而 $L^{\prime}$ 则综合了物体自身及其可能关联对象的整体信息。通过对 $L^{\prime}$ 和 $C_{\mathcal{L}}$ 取平均,既能获取物体的通用信息,又能强化其类别特征。
We construct the query, key, and value of the image feature as follows:
我们按如下方式构建图像特征的查询(query)、键(key)和值(value):
$$
Q_{\mathcal{T}},K_{\mathcal{T}},V_{\mathcal{T}}=\operatorname{Conv}(\operatorname{Norm}(I))
$$
$$
Q_{\mathcal{T}},K_{\mathcal{T}},V_{\mathcal{T}}=\operatorname{Conv}(\operatorname{Norm}(I))
$$
3.4. Layout-conditional Diffusion Model
3.4. 布局条件扩散模型
Here, we follow the Gaussian diffusion models improved by [11,41]. Given a data point sampled from a real data distribution $x_{0}\sim q(x_{0})$ , a forward diffusion process is defined by adding small amount of Gaussian noise to the $x_{0}$ in $T$ steps:
这里,我们遵循[11,41]改进的高斯扩散模型。给定从真实数据分布 $x_{0}\sim q(x_{0})$ 中采样的数据点,前向扩散过程通过在 $T$ 步中向 $x_{0}$ 添加少量高斯噪声来定义:
$$
q(x_{t}|x_{t-1}):=\mathcal{N}(x_{t};\sqrt{\alpha_{t}}x_{t-1},(1-\alpha_{t})\mathbf{I})
$$
$$
q(x_{t}|x_{t-1}):=\mathcal{N}(x_{t};\sqrt{\alpha_{t}}x_{t-1},(1-\alpha_{t})\mathbf{I})
$$
If the total noise added throughout the Markov chain is large enough, the $x_{T}$ will be well approximated by $\mathcal{N}(0,\mathbf{I})$ . If we add noise at each step with a sufficiently small magnitude $1-\alpha_{t}$ , the posterior $q(x_{t-1}|x_{t})$ will be well approximated by a diagonal Gaussian. This nice property ensures that we can reverse the above forward process and sample from $x_{T}\sim\mathcal{N}(0,\mathbf{I})$ , which is a Gaussian noise. However, since the entire dataset is needed, we are unable to easily estimate the posterior. Instead, we have to learn a model $p_{\theta}(x_{t-1}|x_{t})$ to approximate it:
如果整个马尔可夫链中添加的总噪声足够大,$x_{T}$ 将很好地近似于 $\mathcal{N}(0,\mathbf{I})$。如果我们以足够小的幅度 $1-\alpha_{t}$ 在每一步添加噪声,后验分布 $q(x_{t-1}|x_{t})$ 将很好地近似为一个对角高斯分布。这一优良特性确保我们可以反转上述前向过程,并从高斯噪声 $x_{T}\sim\mathcal{N}(0,\mathbf{I})$ 中采样。然而,由于需要整个数据集,我们无法轻松估计后验分布,而必须通过学习模型 $p_{\theta}(x_{t-1}|x_{t})$ 来近似它:
$$
p_{\theta}\big(x_{t-1}|x_{t}\big):=\mathcal{N}(\mu_{\theta}(x_{t}),\Sigma_{\theta}(x_{t}))
$$
$$
p_{\theta}\big(x_{t-1}|x_{t}\big):=\mathcal{N}(\mu_{\theta}(x_{t}),\Sigma_{\theta}(x_{t}))
$$
Instead of using the tractable variation al lower bound (VLB) in $\log p_{\theta}(x_{0})$ , Ho et al. [11] proposed to reweight the terms of the VLB to optimize a surrogate objective. Specifically, we first add $t$ steps of Gaussian noise to a clean sample $x_{0}$ to generate a noised sample $x_{t}\sim q(x_{t}|x_{0})$ . Then train a model $\epsilon_{\theta}$ to predict the added noise using the following loss:
Ho等人[11]提出对变分下界(VLB)进行项重加权来优化替代目标,而非直接使用$\log p_{\theta}(x_{0})$中的可处理变分下界。具体而言,我们首先对干净样本$x_{0}$添加$t$步高斯噪声生成带噪样本$x_{t}\sim q(x_{t}|x_{0})$,随后训练模型$\epsilon_{\theta}$通过以下损失函数预测所添加噪声:
$$
\mathcal{L}:=E_{t\sim[1,T],x_{0}\sim q(x_{0}),\epsilon\sim\mathcal{N}(0,\mathbf{I})}[||\epsilon-\epsilon_{\theta}(x_{t},t)||^{2}]
$$
$$
\mathcal{L}:=E_{t\sim[1,T],x_{0}\sim q(x_{0}),\epsilon\sim\mathcal{N}(0,\mathbf{I})}[||\epsilon-\epsilon_{\theta}(x_{t},t)||^{2}]
$$
, which is a standard mean-squared error loss.
这是一个标准的均方误差损失函数。
To support the layout condition, we apply classifier-free guidance, a technique proposed by Ho et al. [12] for conditional generation that requires no additional training of the classifier. It is accomplished by interpolating between predictions of a diffusion model with and without condition input. For the condition of layout, we first construct a padding layout $l_{\phi}={o_{l},o_{p},\cdot\cdot\cdot,o_{p}}$ . During training, the condition of layout $l$ of diffusion model will be replaced with $l_{\phi}$ with a fixed probability. When sampling, the following equation is used to sample a layout-condional image:
为支持布局条件,我们采用Ho等人[12]提出的无需分类器(classifier-free guidance)技术进行条件生成,该技术无需额外训练分类器。具体实现方式是在有/无条件输入的扩散模型预测结果之间进行插值。对于布局条件,我们首先构建填充布局$l_{\phi}={o_{l},o_{p},\cdot\cdot\cdot,o_{p}}$。训练过程中,扩散模型的布局条件$l$会以固定概率被替换为$l_{\phi}$。采样时使用以下方程生成布局条件图像:
$$
\hat{\epsilon}{\theta}(x_{t},t|l)=(1-s)\cdot\epsilon_{\theta}(x_{t},t|l_{\phi})+s\cdot\epsilon_{\theta}(x_{t},t|l)
$$
$$
\hat{\epsilon}{\theta}(x_{t},t|l)=(1-s)\cdot\epsilon_{\theta}(x_{t},t|l_{\phi})+s\cdot\epsilon_{\theta}(x_{t},t|l)
$$
, where the scale $s$ can be used to increase the gap between $\epsilon_{\theta}(x_{t},t|l_{\phi})$ and $\epsilon_{\boldsymbol{\theta}}(\boldsymbol{x}_{t},t|l)$ to enhance the strength of conditional guidance.
其中,比例因子 $s$ 可用于增大 $\epsilon_{\theta}(x_{t},t|l_{\phi})$ 与 $\epsilon_{\boldsymbol{\theta}}(\boldsymbol{x}_{t},t|l)$ 之间的差距,从而增强条件引导的强度。
To further improve the user experience of Layout Diff uison, we also make several optimization s on the speed of the classifier-free sampling process and could significantly outperform the SOTA models in 25 iterations. Specifically, we adapt DPM-solver [25] for the conditional classifier-free sampling, a fast dedicated high-order solver for diffusion ODEs [42] with the convergence order guarantee, to accelerate the conditional sampling speed.
为进一步提升Layout Diffusion的用户体验,我们对无分类器采样过程的速度进行了多项优化,在25次迭代中显著超越当前最优(SOTA)模型。具体而言,我们采用专为扩散ODE设计的快速高阶求解器DPM-solver [25](具有收敛阶保证[42])来加速条件采样过程。
4. Experiments
4. 实验
In this section, we evaluate our Layout Diffusion on different benchmarks in terms of various metrics. First, we introduce the datasets and evaluation metrics. Second, we show the qualitative and quantitative results compared with other strategies. Finally, some ablation studies and analysis are also mentioned. More details can be found in Appendix, including model architecture, training hyper parameters, reproduction results, more experimental results and visualizations.
在本节中,我们从不同指标评估Layout Diffusion在多个基准测试上的表现。首先介绍数据集和评估指标,其次展示与其他策略的定性与定量对比结果,最后提及部分消融实验与分析。更多细节详见附录,包括模型架构、训练超参数、复现结果、补充实验数据及可视化效果。
4.1. Datasets
4.1. 数据集
We conduct our experiments on two popular datasets, COCO-Stuff [5] and Visual Genome [21].
我们在两个流行数据集 COCO-Stuff [5] 和 Visual Genome [21] 上进行了实验。
COCO-Stuff has 164K images from COCO 2017, of which the images contain bounding boxes and pixel-level segmentation masks for 80 categories of thing and 91 categories of stuff, respectively. Following the settings of LostGANv2 [47], we use the COCO 2017 Stuff Segmentation Challenge subset that contains $40\mathrm{K}/5\mathrm{k}/5\mathrm{k}$ images for train / val / test-dev set, respectively. We use images in the train and val set with 3 to 8 objects that cover more than $2%$ of the image and not belong to crowd. Finally, there are 25,210 train and 3,097 val images.
COCO-Stuff数据集包含来自COCO 2017的164K张图像,其中图像分别包含80类物体(thing)和91类材料(stuff)的边界框及像素级分割掩码。遵循LostGANv2 [47]的设置,我们采用COCO 2017 Stuff Segmentation Challenge子集,该子集包含$40\mathrm{K}/5\mathrm{k}/5\mathrm{k}$张图像分别用于训练集/验证集/测试开发集。我们筛选训练集和验证集中包含3至8个对象、覆盖图像面积超过$2%$且不属于人群类别的图像,最终得到25,210张训练图像和3,097张验证图像。

Figure 3. Visualization of com parisi on with SOTA methods on COCO-stuff $256\times256$ . Layout Diffusion has better generation quality and stronger control l ability compared to the other methods.
Table 1. Quantitative results on COCO-stuff [5] and VG [21]. The proposed diffusion method has made great progress in all evaluation metrics, showing better quality, control l ability, diversity, and accuracy than previous works. For COCO-stuff, we evaluate on 3097 layout and sample 5 images for each layout. For VG, we evaluate on 5096 layout and sample 1 image for each layout. We also report reproduction scores of previous works in Appendix.
图 3: 在COCO-stuff $256\times256$ 数据集上与SOTA方法的对比可视化。Layout Diffusion相比其他方法具有更好的生成质量和更强的控制能力。
| 方法 | COCO-stuff | VG | ||||||
|---|---|---|---|---|---|---|---|---|
| FID ← | IS ↑ | DS ↑ | CAS ↑ | YOLOScore ↑ | FID← | DS ↑ | CAS ↑ | |
| 128×128 | ||||||||
| Grid2Im [2] | 59.50 | 12.50±0.30 | 0.28±0.11 | 4.05 | 6.80 | |||
| LostGAN-v2 [47] | 24.76 | 14.21±0.40 | 0.45±0.09 | 39.91 | 13.60 | 29.00 | 0.42±0.09 | 29.74 |
| PLGAN [51] | 22.70 | 15.60±0.30 | 0.16±0.72 | 38.70 | 13.40 | 20.62 | ||
| LayoutDiffusion | 16.57 | 20.17±0.56 | 0.47±0.09 | 43.60 | 27.00 | 16.35 | 0.49±0.09 | 36.45 |
| 256×256 | ||||||||
| Grid2Im [2] | 65.20 | 16.40±0.70 | 0.34±0.13 | 4.81 | 9.70 | |||
| LostGAN-v2 [47] | 31.18 | 18.01±0.50 | 0.56±0.10 | 40.00 | 17.50 | 32.08 | 0.53±0.10 | 34.48 |
| PLGAN [51] | 29.10 | 18.90±0.30 | 0.52±0.10 | 37.65 | 14.40 | 28.06 | ||
| LayoutDiffusion | 15.61 | 28.36±0.75 | 0.57±0.10 | 47.74 | 32.00 | 15.63 | 0.59±0.10 | 48.90 |
表 1: COCO-stuff [5]和VG [21]数据集的定量结果。提出的扩散方法在所有评估指标上都取得了显著进展,展现出比之前工作更好的质量、控制能力、多样性和准确性。对于COCO-stuff,我们在3097个布局上进行评估,并为每个布局采样5张图像。对于VG,我们在5096个布局上进行评估,并为每个布局采样1张图像。我们还在附录中报告了之前工作的复现分数。
Table 2. Ablation study of Layout Fusion Module (LFM), Object-aware Cross Attention (OaCA), Cross Attention (CA). We use the model trained for 300,000 iterations on COCO-stuff $128\times128$ . The value in brackets denotes the discrepancy to our proposed method $\mathrm{+LFM{+}O a C A}$ ), where red denotes better and green denotes worse.
表 2. 布局融合模块 (LFM) 、物体感知交叉注意力 (OaCA) 和交叉注意力 (CA) 的消融研究。我们使用在 COCO-stuff $128\times128$ 数据集上训练 300,000 次迭代的模型。括号中的数值表示与本文提出的方法 $\mathrm{+LFM{+}O a C A}$ 的差异,其中红色表示更好,绿色表示更差。
| LFM | OaCA | CA | FID √ | IS↑ | DS↑ | CAS↑ | YOLOScore↑ |
|---|---|---|---|---|---|---|---|
| 29.94 (+13.37) | 13.59±0.29 (-6.58) | 0.70±0.08 (+0.23) | 3.83 (-39.77) | 0.00 (-27.00) | |||
| 17.06 (+0.49) | 19.21±0.53 (-0.96) | 0.52±0.09 (+0.05) | 30.86 (-12.74) | 6.90 (-20.10) | |||
| 16.76 (+0.19) | 19.57±0.40 (-0.60) | 0.48±0.09 (+0.01) | 40.67 (-2.93) | 18.80 (-8.20) | |||
| 16.46 (-0.11) | 19.79±0.40 (-0.38) | 0.48±0.10 (+0.01) | 42.47 (-1.13) | 23.60 (-3.40) | |||
| 16.57 | 20.17±0.56 | 0.47±0.09 | 43.60 | 27.00 |
Visual Genome collects 108,077 images with dense annotations of objects, attributes, and relationships. Following the setting of $\mathrm{SG}2\mathrm{Im}$ [16], we divide the data into $80%$ , $10%$ , $10%$ for the train, val, test set, respectively. We select the object and relationship categories occurring at least 2000 and 500 times in the train set, respectively, and select the images with 3 to 30 bounding boxes and ignoring all small objects. Finally, the training / validation / test set will have 62565 / 5062 / 5096 images, respectively.
Visual Genome 收集了 108,077 张带有密集物体、属性和关系标注的图像。按照 $\mathrm{SG}2\mathrm{Im}$ [16] 的设置,我们将数据分别按 $80%$、$10%$、$10%$ 的比例划分为训练集、验证集和测试集。我们筛选出在训练集中分别出现至少 2000 次和 500 次的对象类别和关系类别,并选择包含 3 到 30 个边界框的图像,同时忽略所有小物体。最终,训练集/验证集/测试集分别包含 62565/5062/5096 张图像。
4.2. Evaluation Metrics & Protocols
4.2. 评估指标与协议
We use five metrics to evaluate the quality, diversity, and control l ability of generation.
我们使用五个指标来评估生成的质量、多样性和控制能力。
Fr‘echet Inception Distance (FID) [10] shows the overall visual quality of the generated image by measuring the difference in the distribution of features between the real images and the generated images on an ImageNet-pretrained Inception-V3 [48] network.
Fr'echet Inception Distance (FID) [10] 通过测量真实图像与生成图像在ImageNet预训练Inception-V3 [48]网络上的特征分布差异,反映生成图像的整体视觉质量。
Inception Score (IS) [38] uses an Inception-V3 [48] pretrained on ImageNet network to compute the statistical score of the output of the generated images.
Inception Score (IS) [38] 使用在ImageNet上预训练的Inception-V3 [48]网络来计算生成图像的统计分数。
Diversity Score (DS) calculates the diversity between two generated images of the same layout by comparing the LPIPS [55] metric in a DNN feature space between them.
多样性分数 (DS) 通过比较同一布局下两幅生成图像在DNN特征空间中的LPIPS [55] 指标来计算它们之间的多样性。
Classification Score (CAS) [32] first crops the ground truth box area of images and resizing them at a resolution of $32\times32$ with their class. A ResNet-101 [9] classifier is trained with generated images and tested on real images.
分类评分 (CAS) [32] 首先裁剪图像的真实标注框区域,并将其调整为 $32\times32$ 分辨率并保留类别标签。随后使用生成图像训练一个 ResNet-101 [9] 分类器,并在真实图像上进行测试。
YOLOScore [23] evaluates 80 thing categories bbox mAP on generated images using a pretrained YOLOv4 [4] model, and shows the precision of control in one generated model.
YOLOScore [23] 使用预训练的 YOLOv4 [4] 模型评估生成图像中80个物体类别的边界框平均精度 (bbox mAP),并展示生成模型的控制精度。
In summary, FID and IS show the generation quality, DS shows the diversity, CAS and YOLOScore represent the control l ability. We follow the architecture of ADM [8], which is mainly a UNet. All experiments are conducted on 32 NVIDIA 3090s with mixed precision training [27]. We set batch size 24, learning rate 1e-5. We adopt the fixed linear variance schedule. More details can be found in the Appendix.
总之,FID和IS反映生成质量,DS体现多样性,CAS与YOLOScore衡量控制能力。我们采用ADM[8]的UNet主干架构,所有实验均在32块NVIDIA 3090显卡上采用混合精度训练[27]完成,批次大小设为24,学习率1e-5,并使用固定线性方差调度表。详见附录。
4.3. Qualitative results
4.3. 定性结果
Comparison of generated $256~\times~256$ images on the COCO-Stuff [5] with our method and previous works [2, 47, 51] is shown in Fig. 3.
在COCO-Stuff [5]数据集上生成的$256~\times~256$图像与我们的方法及先前工作[2, 47, 51]的对比结果如图3所示。
| 方法 | FID↓ | 参数量 (Nparms) | 吞吐量 (images/s) | 第一阶段 V100 天数 | 条件阶段 V100 天数 |
|---|---|---|---|---|---|
| LDM-8 (100 步) | 42.06 | 345M | 0.457 | 66 | 3.69 |
| LDM-4 (200 步) | 40.91 | 306M | 0.267 | 29 | 95.49 |
| ours-small (25 步) | 36.16 | 142M | 0.608 | 75.83 | |
| ours (25 步) | 31.68 | 569M | 0.308 | 216.55 |
Table 3. Comparison with SOTA diffusion-based methods LDM on COCO-stuff $256\times256$ . We generate the same 2048 images of LDM for a fair com parisi on.
表 3: 基于扩散的 SOTA 方法 LDM 在 COCO-stuff $256\times256$ 上的对比。为公平比较,我们生成与 LDM 相同的 2048 张图像。
Layout Diffusion generates more accurate high quality images, which has more recognizable and accurate objects corresponding to their layouts. Grid2Im [2], LostGANv2 [47] and PLGAN [51] generate images with distorted and unreal objects.
布局扩散 (Layout Diffusion) 生成的图像质量更高且更精准,其物体与布局的对应关系更清晰准确。Grid2Im [2]、LostGANv2 [47] 和 PLGAN [51] 生成的图像存在物体扭曲失真的问题。
Especially when input a set of multiple objects with complex relationships, previous work can hardly generate recognizable objects in the position corresponding to layouts. For example, in Fig. 3 (a), (c), and (e), the main objects (e.g. train, zebra, bus) in images are poorly generated in previous work, while our Layout Diffusion generates well. In Fig. 3 (b), only our Layout Diffusion generates the laptop in the right place. The images generated by our Layout Diffusion are more sensor i ally similar to the real ones.
尤其是当输入一组具有复杂关系的多个对象时,先前的工作很难在布局对应位置生成可识别的物体。例如在图3(a)、(c)和(e)中,先前工作生成的图像主体(如火车、斑马、公交车)效果较差,而我们的Layout Diffusion则生成良好。图3(b)中,只有我们的Layout Diffusion在正确位置生成了笔记本电脑。本方法生成的图像在感官上更接近真实图像。
We show the diversity of Layout Diffusion in Fig. 4. Images from the same layouts have high quality and diversity (different lighting, textures, colors, and details).
我们在图 4 中展示了 Layout Diffusion 的多样性。来自相同布局的图像具有高质量和多样性(不同的光照、纹理、颜色和细节)。
We continuously add an additional layout from the initial layout, the one in the upper left corner, as shown in Fig. 5. In each step, Layout Diffusion adds the new object in very precise locations with consistent image quality, showing user-friendly interactivity.
我们持续从初始布局(左上角所示)添加额外布局,如图5所示。在每一步中,布局扩散(Layout Diffusion)都能以精确的位置和稳定的图像质量添加新对象,展现出用户友好的交互性。
4.4. Quantitative results
4.4. 定量结果
Tab. 1 provides the comparison among previous works and our method in FID, IS, DS, CAS and YOLOScore. Compared to the SOTA method, the proposed method achieves the best performance in comparison.
表 1: 对比了先前工作与本文方法在 FID、IS、DS、CAS 和 YOLOScore 指标上的表现。相较于当前最优(SOTA)方法,所提方法在各项对比中均取得最佳性能。

Figure 4. The diversity of Layout Diffusion. Each row of images are from the same layout and have great difference.
图 4: Layout Diffusion 的多样性。每行图像均源自相同布局但存在显著差异。
In overall generation quality, our Layout Diffusion outperforms the SOTA model by $46.35%$ and $29.29%$ at most in FID and IS, respectively. While maintaining high overall image quality, we also show precise and accurate controll ability, Layout Diffusion outperforms the SOTA model by $122.22%$ and $41.82%$ at most on YOLOScore and CAS, respectively. As for diversity, our Layout Diffusion still achieves $11.30%$ imp or ve ment at most accroding to the DS. Experiments on these metrics show that our methods can successfully generate the higher-quality images with better location and quantity control.
在整体生成质量上,我们的Layout Diffusion在FID和IS指标上分别以最高46.35%和29.29%的优势超越了当前最优(SOTA)模型。在保持高整体图像质量的同时,Layout Diffusion还展现出精准的控制能力,其YOLOScore和CAS指标分别以最高122.22%和41.82%的幅度领先SOTA模型。多样性方面,根据DS指标,Layout Diffusion仍实现了最高11.30%的提升。这些指标的实验表明,我们的方法能成功生成更高质量、具有更优位置与数量控制能力的图像。
In particular, we conduct experiments compared to LDM [35] in Tab. 3. “Ours-small” uses comparable GPU resources to have better FID performance with much fewer parameters and better throughout compared to LDM-8 when “Ours-small” outperforms LDM-4 in all respects. The results of “Ours” indicate that Layout Diffusion can have better FID performance, 31.6, at a higher cost. From these results, Layout Diffusion always achieves better performance at different cost levels compared with LDM [35].
特别地,我们在表3中与LDM [35]进行了对比实验。"Ours-small"在GPU资源相当的情况下,以更少的参数量和更高的吞吐量实现了优于LDM-8的FID性能,同时在所有方面都超越了LDM-4。"Ours"的结果表明,Layout Diffusion能以更高成本实现更优的FID性能(31.6)。这些结果表明,与LDM [35]相比,Layout Diffusion在不同成本级别下始终能获得更好的性能。
4.5. Ablation studies
4.5. 消融实验
We validate the effectiveness of LFM and OaCA in Tab. 2, using the evaluation metrics in Sec. 4.2. The significant improvement on FID, IS, CAS, and YOLOScore proves that the application of LFM and OaCA allows for higher generation quality and diversity, along with more control l ability. Furthermore, when applying both, considerable performance, 13.37 / 6.58 / 39.77 / 27.00 on FID / IS / CAS / YOLOScore, is gained.
我们在表 2 中验证了 LFM 和 OaCA 的有效性,使用了第 4.2 节的评估指标。FID、IS、CAS 和 YOLOScore 的显著提升证明,应用 LFM 和 OaCA 能够实现更高的生成质量和多样性,同时具备更强的控制能力。此外,当同时应用两者时,在 FID / IS / CAS / YOLOScore 上分别取得了 13.37 / 6.58 / 39.77 / 27.00 的优异性能。
An interesting phenomenon is that the change of the Diversity Score (DS) is in the opposite direction of other metrics. This is because DS, which stands for diversity, is physically the opposite of the control l ability represented by other metrics such as CAS and YOLOScore. The precise control offered on generated image leads to more constraints on diversity. As a result, the Diversity Score (DS) has a slight drop compared to the baseline.
一个有趣的现象是,多样性分数 (Diversity Score, DS) 的变化方向与其他指标相反。这是因为代表多样性的 DS 在物理意义上与 CAS、YOLOScore 等其他指标所代表的控制能力相对立。对生成图像的精确控制会导致多样性受到更多约束。因此,与基线相比,多样性分数 (DS) 略有下降。
5. Limitations & Societal Impacts
5. 局限性与社会影响
Limitations. Despite the significant improvements in various metrics, it is still difficult to generate a realistic image with no distortion and overlap, especially for a complex multi-object layout. Moreover, the model is trained from scratch in the specific dataset that requires detection labels. How to combine text-guided diffusion models and inherit parameters pre-trained on massive text-image datasets remains a future research.
局限性。尽管各项指标均有显著提升,但生成无失真和重叠的真实图像仍然具有挑战性,特别是对于复杂的多物体布局场景。此外,当前模型需在包含检测标签的特定数据集上从头训练。如何结合文本引导扩散模型 (text-guided diffusion models) 并继承海量图文数据集上的预训练参数,仍是未来研究方向。

Figure 5. The interactivity of Layout Diffusion. We add extra layout continuously, and the new objects are also with high quality.
图 5: Layout Diffusion 的交互性展示。我们持续添加额外布局,新生成的对象仍保持高质量。
Societal Impacts. Trained on the real-world datasets such as COCO [5] and VG [21], Layout Diffusion has the powerful ability to learn the distribution of data and we should pay attention to some potential copyright infringement issues.
社会影响。Layout Diffusion 在 COCO [5] 和 VG [21] 等真实数据集上训练,具备强大的数据分布学习能力,需注意潜在的版权侵权问题。
6. Conclusion
6. 结论
In this paper, we have proposed a one-stage end-to-end diffusion model named Layout Diff u is on, which is novel for the task of layout-to-image generation. With the guidance of layout, the diffusion model allows more control over the individual objects while maintaining higher quality than the prevailing GAN-based methods. By constructing a structural image patch with region information, we regrad each patch as a special object and accomplish the difficult multimodal image-layout fusion in a unified form. Specifically, Layout Fusion Module and Object-aware Cross Attention are proposed to model the relationship among multiple objects and fuse the patched image feature with layout at multiple resolutions, respectively. Experiments in challenging COCO-stuff and Visual Genome (VG) show that our proposed method significantly outperforms both stateof-the-art GAN-based and diffusion-based methods in various evaluation metrics.
本文提出了一种名为Layout Diffusion的单阶段端到端扩散模型,该模型在布局到图像生成任务中具有创新性。在布局引导下,该扩散模型能对单个对象实现更强控制,同时保持比主流基于GAN的方法更高的质量。通过构建带有区域信息的结构化图像块,我们将每个块视为特殊对象,以统一形式完成困难的多模态图像-布局融合。具体而言,我们提出了布局融合模块(Layout Fusion Module)和对象感知交叉注意力(Object-aware Cross Attention),分别用于建模多对象间关系以及在多分辨率下融合图像块特征与布局。在具有挑战性的COCO-stuff和Visual Genome (VG)数据集上的实验表明,我们提出的方法在多项评估指标上显著优于最先进的基于GAN和基于扩散的方法。
Acknowledgements. This work is supported in part by National Natural Science Foundation of China under Grant U20A20222, National Science Foundation for Distinguished Young Scholars under Grant 62225605, National Key Research and Development Program of China under Grant 2020 AAA 0107400, Research Fund of ARC Lab, Tencent PCG, Zhejiang – Singapore Innovation and AI Joint Research Lab, Ant Group through CCF-Ant Research Fund, and sponsored by CCF-AFSG Research Fund, CAAIHUAWEI MindSpore Open Fund as well as CCF-Zhipu AI Large Model Fund(CCF-Zhi pu 202302).
致谢。本研究部分由国家自然科学基金(资助号U20A20222)、国家杰出青年科学基金(资助号62225605)、国家重点研发计划(资助号2020AAA0107400)、腾讯PCG ARC实验室研究基金、浙江-新加坡创新与人工智能联合研究实验室、蚂蚁集团通过CCF-蚂蚁科研基金资助,并受CCF-AFSG科研基金、CAAI-华为MindSpore开放基金及CCF-智谱大模型基金(CCF-智谱202302)支持。
Appendix for Layout Diffusion
布局扩散附录
A. More Visualization s A.1. Controllable Layout Edit by modifying objects in number, position, size, and category
A. 更多可视化内容
A.1. 通过修改对象的数量、位置、大小和类别实现可控布局编辑

Figure 6. Layout edit by adding objects.
图 6: 通过添加对象进行布局编辑。

Figure 7. Layout edit by modifying the position of objects.
图 7: 通过修改物体位置实现的布局编辑

Figure 8. Layout edit by modifying the size of objects.
图 8: 通过修改物体尺寸实现的布局编辑

Figure 9. Layout edit by modifying the categories of objects.
图 9: 通过修改物体类别进行布局编辑
A.2. More visualization s on COCO-stuff
A.2. COCO-stuff 更多可视化结果

Figure 10. More visualization s on COCO-stuff $256\times256$ . Layout Diffusion is trained by 1.15M iterations, and sample images using scal $:=1.0$ and dpm-solver 25 steps. The COCO image IDs (from top to bottom) are 85195, 174004, 296969, 338560, 451090, 512248, 573008, 574425.
图 10: COCO-stuff $256\times256$ 数据集上的更多可视化结果。Layout Diffusion 模型经过 1.15M 次迭代训练,采样时使用 scal $:=1.0$ 参数和 dpm-solver 25 步生成图像。展示的 COCO 图像 ID (从上至下) 依次为 85195、174004、296969、338560、451090、512248、573008、574425。
A.3. More visualization s on Visual Genome
A.3. Visual Genome 上的更多可视化结果

Figure 11. More visualization s on Visual Genome $256\times256$ . Layout Diffusion is trained by 1.45M iterations, and sample images using scal $:=1.0$ and dpm-solver 25 steps. The VG image IDs (from top to bottom) are 2380568, 2382403, 2382599, 2383021, 2383488, 2385225, 2385290, 2385812.
图 11. Visual Genome数据集上更多 $256\times256$ 分辨率可视化结果。Layout Diffusion模型经过145万次迭代训练,采样时使用缩放系数 $:=1.0$ 和dpm-solver 25步生成。VG图像ID(从上至下)分别为2380568、2382403、2382599、2383021、2383488、2385225、2385290、2385812。
A.4. More com parisi on with previous methods
A.4. 与先前方法的更多比较

Figure 12. More com parisi on with previous methods on COCO-stuff $128\times128$ . Layout Diffusion is trained by 300K iterations, and sample images using scale $_{:=0.6}$ and dpm-solver 25 steps. The COCO image IDs (from top to bottom) are 2153, 2352, 4495, 6723, 10583, 17031, 18737, 543300.
图 12: 在 COCO-stuff $128\times128$ 数据集上与之前方法的更多对比。Layout Diffusion 经过 30 万次迭代训练,采样时使用 scale $_{:=0.6}$ 和 dpm-solver 25 步。COCO 图像 ID (从上到下) 分别为 2153、2352、4495、6723、10583、17031、18737、543300。

Figure 13. More com parisi on with previous methods on COCO-stuff $256\times256$ . Layout Diffusion is trained by 1.15M iterations, and sample images using scale $=1.0$ and dpm-solver 25 steps. The COCO image IDs (from top to bottom) are 23781, 55299, 84477, 137950, 243034, 252701, 341719, 350405.
图 13. COCO-stuff $256\times256$ 数据集上与先前方法的更多对比。Layout Diffusion 经过 115 万次迭代训练,采样时使用缩放系数 $=1.0$ 和 dpm-solver 25 步算法。COCO 图像 ID (从上至下) 依次为 23781、55299、84477、137950、243034、252701、341719、350405。

Figure 14. More com parisi on with previous methods on VG $128\times128$ . Layout Diffusion is trained by 300K iterations, and sample images using scale $=0.5$ and dpm-solver 25 steps. The VG image IDs (from top to bottom) are 107945, 150280, 150409, 1160185, 1591817, 1592132, 2341006, 2341475.
图 14. VG $128\times128$ 数据集上与先前方法的更多对比结果。Layout Diffusion 模型经过 30 万次迭代训练,采样时使用缩放系数 $=0.5$ 和 dpm-solver 25 步。VG 图像 ID (从上至下) 依次为 107945、150280、150409、1160185、1591817、1592132、2341006、2341475。

Figure 15. More com parisi on with previous methods on VG $256\times256.$ Layout Diffusion is trained by 1.45M iterations, and sample images using scale $=1.0$ and dpm-solver 25 steps. The VG image IDs (from top to bottom) are 150297, 150358, 1159865, 2340978, 2341300, 2343290, 2344627, 2375966.
图 15: 在 VG $256\times256$ 数据集上与先前方法的更多对比。Layout Diffusion 经过 1.45M 次迭代训练,采样图像使用 scale $=1.0$ 和 dpm-solver 25 步。VG 图像 ID (从上至下) 分别为 150297, 150358, 1159865, 2340978, 2341300, 2343290, 2344627, 2375966。
A.5. Different Scales
A.5. 不同规模

Figure 16. Visualization s on COCO-stuff $256\times256$ sampled with different scale. Layout Diffusion is trained by 1.15M iterations, and sample images using dpm-solver 25 steps. The COCO image IDs (from top to bottom) are 472298, 475223, 504415, 513181.
图 16: 不同缩放尺度下 COCO-stuff $256\times256$ 数据集的生成效果可视化。Layout Diffusion 模型经过 115 万次迭代训练,采样时采用 dpm-solver 25 步生成。图中 COCO 图像 ID (从上至下) 分别为 472298、475223、504415、513181。
B. Details of Diffusion Models
B. 扩散模型细节
B.1. Denoising Diffusion Probabilistic Model (from ADM-G)
B.1. 去噪扩散概率模型 (来自 ADM-G)
In this section, we will review the formulation of Gaussian diffusion models introduced by DDPM [11]. A data point is defined as $x_{0}\sim q(x_{0})$ . By gradually adding noise to the clean data $x_{0}$ , we can obtain the noised samples from $x_{1}$ to $x_{T}$ , where $T$ denotes the maximum steps. Specifically, Gaussian noise according to some variance schedule given by $\beta_{t}$ is added to $x_{t-1}$ in step $t$ of the Markovian noising process $q$ :
在本节中,我们将回顾DDPM [11]提出的高斯扩散模型 (Gaussian diffusion models) 的数学表述。数据点定义为 $x_{0}\sim q(x_{0})$ 。通过对干净数据 $x_{0}$ 逐步添加噪声,可获得从 $x_{1}$ 到 $x_{T}$ 的加噪样本,其中 $T$ 表示最大步数。具体而言,在马尔可夫加噪过程 $q$ 的第 $t$ 步,会根据由 $\beta_{t}$ 给定的方差表向 $x_{t-1}$ 添加高斯噪声:
$$
q(x_{t}|x_{t-1})=\mathcal{N}(x_{t};\sqrt{1-\beta_{t}}x_{t-1},\beta_{t}\mathbf{I})
$$
$$
q(x_{t}|x_{t-1})=\mathcal{N}(x_{t};\sqrt{1-\beta_{t}}x_{t-1},\beta_{t}\mathbf{I})
$$
Due to the convenient nature of Gaussian noise, we do not need to apply $t$ times of $q(x_{t}|x_{t-1})$ repeatedly to sample from $x_{t}\sim q(x_{t}|x_{0})$ . Instead, $q(x_{t}|x_{0})$ can be directly sampled from a Gaussian distribution:
由于高斯噪声的便利性,我们无需重复应用 $q(x_{t}|x_{t-1})$ $t$ 次来从 $x_{t}\sim q(x_{t}|x_{0})$ 中采样。相反,$q(x_{t}|x_{0})$ 可以直接从高斯分布中采样:
$$
\begin{array}{r l}&{q(x_{t}|x_{0})=\mathcal{N}(x_{t};\sqrt{\bar{\alpha}{t}}x_{0},(1-\bar{\alpha}{t})\mathbf{I})}\ &{\qquad=\sqrt{\bar{\alpha}_{t}}x_{0}+\epsilon\sqrt{1-\bar{\alpha}_{t}},\epsilon\sim\mathcal{N}(0,\mathbf{I}),}\end{array}
$$
$$
\begin{array}{r l}&{q(x_{t}|x_{0})=\mathcal{N}(x_{t};\sqrt{\bar{\alpha}{t}}x_{0},(1-\bar{\alpha}{t})\mathbf{I})}\ &{\qquad=\sqrt{\bar{\alpha}{t}}x_{0}+\epsilon\sqrt{1-\bar{\alpha}_{t}},\epsilon\sim\mathcal{N}(0,\mathbf{I}),}\end{array}
$$
where $\alpha_{t}=1-\beta_{t}$ and $\textstyle{\bar{\alpha}}{t}=\prod_{s=0}^{t}\alpha_{s}$ . The noise variance for an arbitrary timestep is defined as $1-\bar{\alpha}{t}$ in Eq. (22), and we could equivalently use this to define the noise schedule instead of $\beta_{t}$ . DDPM [11] notes that the posterior $q(x_{t-1}|x_{t},x_{0})$ is
其中 $\alpha_{t}=1-\beta_{t}$,且 $\textstyle{\bar{\alpha}}{t}=\prod_{s=0}^{t}\alpha_{s}$。式 (22) 中任意时间步的噪声方差定义为 $1-\bar{\alpha}{t}$,我们也可以等价地用它来定义噪声调度而非 $\beta_{t}$。DDPM [11] 指出后验分布 $q(x_{t-1}|x_{t},x_{0})$ 满足
also a Gaussian using with mean $\tilde{\mu}{t}(x_{t},x_{0})$ and variance $\tilde{\beta}_{t}$ , and is defined as follows:
也是一个高斯分布,其均值为 $\tilde{\mu}{t}(x_{t},x_{0})$,方差为 $\tilde{\beta}_{t}$,定义如下:
$$
\begin{array}{r l}&{q(x_{t-1}|x_{t},x_{0})=\mathcal{N}(x_{t-1};\tilde{\mu}(x_{t},x_{0}),\tilde{\beta}{t}\mathbf{I})}\ &{\qquad\tilde{\mu}{t}(x_{t},x_{0})=\frac{\sqrt{\bar{\alpha}{t-1}}\beta_{t}}{1-\bar{\alpha}{t}}x_{0}+\frac{\sqrt{\alpha_{t}}\left(1-\bar{\alpha}{t-1}\right)}{1-\bar{\alpha}{t}}x_{t}}\ &{\qquad\tilde{\beta}{t}=\frac{1-\bar{\alpha}{t-1}}{1-\bar{\alpha}{t}}\beta_{t}}\end{array}
$$
$$
\begin{array}{r l}&{q(x_{t-1}|x_{t},x_{0})=\mathcal{N}(x_{t-1};\tilde{\mu}(x_{t},x_{0}),\tilde{\beta}{t}\mathbf{I})}\ &{\qquad\tilde{\mu}{t}(x_{t},x_{0})=\frac{\sqrt{\bar{\alpha}{t-1}}\beta_{t}}{1-\bar{\alpha}{t}}x_{0}+\frac{\sqrt{\alpha_{t}}\left(1-\bar{\alpha}{t-1}\right)}{1-\bar{\alpha}{t}}x_{t}}\ &{\qquad\tilde{\beta}{t}=\frac{1-\bar{\alpha}{t-1}}{1-\bar{\alpha}{t}}\beta_{t}}\end{array}
$$
If the total noise added throughout the markov chain is large enough when $T\to\infty$ and correspondingly $\beta_{t}\to0$ , the $x_{T}$ will be well approximated by ${\mathcal{N}}(0,\mathbf{I})$ . This nice property ensures that we can reverse the above forward process and sample from $x_{T}\sim\mathcal{N}(0,\mathbf{I})$ , which is a Gaussian noise. However, since the entire dataset is needed, we cannot easily estimate the posterior $q(x_{t-1}|x_{t},x_{0})$ . Instead, we have to learn a model $p_{\theta}(x_{t-1}|x_{t})$ to approximate it:
如果当 $T\to\infty$ 时整个马尔可夫链添加的总噪声足够大,且相应地 $\beta_{t}\to0$,那么 $x_{T}$ 将很好地近似于 ${\mathcal{N}}(0,\mathbf{I})$。这一优良特性确保我们可以反转上述前向过程,并从高斯噪声 $x_{T}\sim\mathcal{N}(0,\mathbf{I})$ 中采样。然而,由于需要整个数据集,我们无法轻易估计后验 $q(x_{t-1}|x_{t},x_{0})$,而必须通过学习模型 $p_{\theta}(x_{t-1}|x_{t})$ 来近似它:
$$
p_{\theta}(x_{t-1}|x_{t})=\mathcal{N}(x_{t-1};\mu_{\theta}(x_{t},t),\Sigma_{\theta}(x_{t},t))
$$
$$
p_{\theta}(x_{t-1}|x_{t})=\mathcal{N}(x_{t-1};\mu_{\theta}(x_{t},t),\Sigma_{\theta}(x_{t},t))
$$
To ensure that the estimated $p_{\theta}(x_{t-1}|x_{t})$ can learrn the true data distribution $q(x_{0})$ , we can optimize the following variational lower bound $L_{\mathrm{vlb}}$ for $p_{\boldsymbol{\theta}}(\boldsymbol{x}_{0})$ :
为确保估计的 $p_{\theta}(x_{t-1}|x_{t})$ 能够学习真实数据分布 $q(x_{0})$ ,我们可以针对 $p_{\boldsymbol{\theta}}(\boldsymbol{x}{0})$ 优化以下变分下界 $L_{\mathrm{vlb}}$ :
$$
\begin{array}{r l}&{\quad L_{\mathrm{vlb}}=L_{0}+L_{1}+...+L_{T-1}+L_{T}}\ &{\quad L_{0}=-\log p_{\theta}(x_{0}|x_{1})}\ &{\quad L_{t-1}=D_{K L}(q(x_{t-1}|x_{t},x_{0})||p_{\theta}(x_{t-1}|x_{t}))}\ &{\quad L_{T}=D_{K L}(q(x_{T}|x_{0})||p(x_{T}))}\end{array}
$$
$$
\begin{array}{r l}&{\quad L_{\mathrm{vlb}}=L_{0}+L_{1}+...+L_{T-1}+L_{T}}\ &{\quad L_{0}=-\log p_{\theta}(x_{0}|x_{1})}\ &{\quad L_{t-1}=D_{K L}(q(x_{t-1}|x_{t},x_{0})||p_{\theta}(x_{t-1}|x_{t}))}\ &{\quad L_{T}=D_{K L}(q(x_{T}|x_{0})||p(x_{T}))}\end{array}
$$
Although the above objective is well justified, DDPM [11] applied a different objective that produces better samples in practice. Specifically, they do not directly predict $\mu_{\theta}(x_{t},t)$ as the output of a neural network, but instead train a model $\epsilon_{\theta}(x_{t},t)$ to predict $\epsilon$ from Equation 22. This simplified objective is defined as follows:
尽管上述目标合理,但DDPM [11] 在实践中采用了一种能产生更好样本的不同目标。具体而言,他们不直接预测 $\mu_{\theta}(x_{t},t)$ 作为神经网络的输出,而是训练模型 $\epsilon_{\theta}(x_{t},t)$ 来预测公式22中的 $\epsilon$。这一简化目标定义如下:
$$
L_{\mathrm{simple}}=E_{t\sim[1,T],x_{0}\sim q(x_{0}),\epsilon\sim\mathcal{N}(0,\mathbf{I})}[||\epsilon-\epsilon_{\theta}(x_{t},t)||^{2}]
$$
$$
L_{\mathrm{simple}}=E_{t\sim[1,T],x_{0}\sim q(x_{0}),\epsilon\sim\mathcal{N}(0,\mathbf{I})}[||\epsilon-\epsilon_{\theta}(x_{t},t)||^{2}]
$$
Then, we can derive $\mu_{\theta}(x_{t},t)$ from $\epsilon_{\theta}(x_{t},t)$ using the following substitution:
然后,我们可以通过以下替换从 $\epsilon_{\theta}(x_{t},t)$ 推导出 $\mu_{\theta}(x_{t},t)$:
$$
\mu_{\theta}(x_{t},t)=\frac{1}{\sqrt{\alpha_{t}}}\left(x_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}{t}}}\epsilon_{\theta}(x_{t},t)\right)
$$
$$
\mu_{\theta}(x_{t},t)=\frac{1}{\sqrt{\alpha_{t}}}\left(x_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}{t}}}\epsilon_{\theta}(x_{t},t)\right)
$$
Note that $\Sigma_{\theta}(x_{t},t)$ is not learned in $L_{\mathrm{simple}}$ in DDPM [11] and is fixed as a constant such as $\beta_{t}\mathbf{I}$ or $\tilde{\beta}_{t}\mathbf{I}$ , corresponding to upper and lower bounds for the true reverse step variance [40], respectively.
注意,在DDPM [11]的$L_{\mathrm{simple}}$中,$\Sigma_{\theta}(x_{t},t)$并未被学习,而是固定为常数,如$\beta_{t}\mathbf{I}$或$\tilde{\beta}_{t}\mathbf{I}$,分别对应于真实反向步骤方差的上界和下界[40]。
B.2. Classifier-free Method for Layout-conditional Training and Sampling
B.2. 用于布局条件训练与采样的无分类器方法
Instead of training a separate classifier model, Ho & Salimans [12] choose to train a diffusion model that allows for both conditional and unconditional sampling, where the unconditional diffusion model $p_{\theta}(x_{t},t)$ is parameterized through a score estimator $\epsilon_{\boldsymbol{\theta}}(\boldsymbol{x}{t},t)$ and the conditional diffusion model $p_{\theta}(x_{t},t|c)$ is parameterized through $\epsilon_{\theta}(x_{t},t,c)$ .
Ho & Salimans [12] 选择训练一个同时支持条件采样和无条件采样的扩散模型,而非单独训练分类器模型。其中无条件扩散模型 $p_{\theta}(x_{t},t)$ 通过分数估计器 $\epsilon_{\boldsymbol{\theta}}(\boldsymbol{x}{t},t)$ 参数化,条件扩散模型 $p_{\theta}(x_{t},t|c)$ 则通过 $\epsilon_{\theta}(x_{t},t,c)$ 参数化。
They use a single model to parameter ize both conditional and unconditional models, where for the unconditional model they simply input a null token $\mathcal{D}$ for the class identifier $c$ when predicting the score, i.e. $\epsilon_{\theta}(x_{t},t)=\epsilon_{\theta}(x_{t},t,c=\emptyset)$ . They jointly train this unified model by randomly replacing $c$ with the unconditional class identifier $\boldsymbol{\mathcal{O}}$ with probability $p_{\mathrm{uncond}}$ . Then the conditional score estimate $\epsilon_{\theta}(x_{t},t,c)$ is replaced with $\tilde{\epsilon}{\theta}(x_{t},t,c)$ using the following equation:
他们使用单一模型来参数化条件模型和无条件模型,其中对于无条件模型,在预测分数时只需为类别标识符 $c$ 输入空Token $\mathcal{D}$,即 $\epsilon_{\theta}(x_{t},t)=\epsilon_{\theta}(x_{t},t,c=\emptyset)$。他们通过以概率 $p_{\mathrm{uncond}}$ 随机将 $c$ 替换为无条件类别标识符 $\boldsymbol{\mathcal{O}}$ 来联合训练这个统一模型。然后使用以下方程将条件分数估计 $\epsilon_{\theta}(x_{t},t,c)$ 替换为 $\tilde{\epsilon}{\theta}(x_{t},t,c)$:
$$
\tilde{\epsilon}{\theta}(x_{t},t,c)=\epsilon_{\theta}(x_{t},t,c)+s(\epsilon_{\theta}(x_{t},t,c)-\epsilon_{\theta}(x_{t},t)),
$$
$$
\tilde{\epsilon}{\theta}(x_{t},t,c)=\epsilon_{\theta}(x_{t},t,c)+s(\epsilon_{\theta}(x_{t},t,c)-\epsilon_{\theta}(x_{t},t)),
$$
which can be considered as a linear combination of conditional and unconditional score estimates. $s$ is the scale and Since Eq. (33) has no classifier gradient, no more gradient calculation in classifier guidance is needed during sampling. Furthermore, $s$ can be changed to modify the effect of the condition.
可视为条件与非条件分数估计的线性组合。$s$ 为缩放系数。由于式 (33) 不涉及分类器梯度,采样过程中无需额外计算分类器引导的梯度。此外,调整 $s$ 可改变条件作用强度。
In the layout-to-image generation, $c$ is the layout $l$ defined in Sec. 3.1. Layout Embedding and $\mathcal{D}$ is the emtpy layout $l_{\mathrm{pad}}$ defined in Sec. 3.4. Layout-conditional Diffusion Model.
在布局到图像的生成中,$c$ 是第3.1节中定义的布局 $l$(布局嵌入),而 $\mathcal{D}$ 是第3.4节中定义的空布局 $l_{\mathrm{pad}}$(布局条件扩散模型)。
C. Implementation details
C. 实现细节
C.1. Hyper parameters
C.1. 超参数
Table 4. Hyper parameters for the proposed Layout Diffusion in Sec. 4.4. Quantitative results. All trained on eight RTX 3090.
表 4: 第 4.4 节提出的 Layout Diffusion 超参数。定量结果。所有模型均在八块 RTX 3090 上训练。
| 数据集模型 | COCO-stuff256x256 | COCO-stuff128x128 | VG 256×256 | VG 128×128 |
|---|---|---|---|---|
| LayoutDiffusion | LayoutDiffusion-small | LayoutDiffusion | LayoutDiffusion | LayoutDiffusion |
| 布局条件扩散模型 | ||||
| 输入通道数 | 3 | 3 | 3 | 3 |
| 输出通道数 | 6 | 6 | 6 | 6 |
| 隐藏通道数 | 256 | 128 | 256 | 256 |
| 通道倍增系数 | 1,1,2,2,4,4 | 1,1,2,2,4,4 | 1,1,2,3,4 | 1,1,2,3,4 |
| 残差块数量 | 2 | 2 | 2 | 2 |
| 丢弃率 | 0 | 0.1 | 0.1 | 0.1 |
| 扩散步数 | 1000 | 1000 | 1000 | 1000 |
| 噪声调度 | linear | linear | linear | linear |
| 布局-图像融合模块 | ||||
| 融合下采样比例 | 8,16,32 | 4,8,16 | 8,16,32 | 4,8,16 |
| 融合分辨率 | 32,16,8 | 32,16,8 | 32,16,8 | 32,16,8 |
| 融合方法 | OaCA | OaCA | OaCA | OaCA |
| 注意力块数量 | 1 | 1 | 1 | 1 |
| 注意力头数 | 4 | 4 | 4 | 4 |
| 布局融合模块 | ||||
| 隐藏通道数 | 256 | 256 | 256 | 256 |
| Transformer 深度 | 6 | 6 | 6 | 6 |
| 注意力方法 | Self-Attention | Self-Attention | Self-Attention | Self-Attention |
| 注意力头数 | 8 | 8 | 8 | 8 |
| 布局嵌入 | ||||
| 嵌入维度 | 256 | 256 | 256 | 256 |
| 最大物体数量 | 8 | 8 | 10 | 10 |
| 最大长度 | 10 | 10 | 12 | 12 |
| 最大类别 ID | 185 | 185 | 180 | 180 |
| 训练超参数 | ||||
| 总批次大小 | 32 | 64 | 32 | 64 |
| GPU 数量 | 8 | 8 | 8 | 8 |
| 学习率 | 1e-5 | 2e-5 | 1e-5 | 2e-5 |
| 混合精度训练 | Yes | Yes | Yes | Yes |
| 权重衰减 | 0 | 0 | 0 | 0 |
| EMA 率 | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
| 无分类器丢弃率 | 0.2 | 0.2 | 0.2 | 0.2 |
| 迭代次数 | 1.15M | 300K | 1.45M | 300K |
Table 5. Hyper parameters for the ablation study in Sec. 4.5 .
表 5: 第4.5节消融实验的超参数
| 模型 | LayoutDiffusion | - LFM | - OaCA | -OaCA,+ CA | - LFM, - OaCA |
|---|---|---|---|---|---|
| 融合方法 (FusionMethod) | OaCA | OaCA | CA | ||
| Transformer深度 | 6 | 0 | 6 | 6 | 0 |
| 迭代次数 (Iterations) | 300K | 300K | 300K | 300K | 300K |
| FID | 16.57 | +0.19 | +0.49 | -0.11 | +13.37 |
| DS | 0.47 | +0.01 | +0.05 | +0.01 | +0.23 |
| CAS | 43.60 | -2.93 | -12.74 | -1.13 | -39.77 |
| YOLO分数 (YOLOScore) | 27.00 | -8.20 | -20.10 | -3.4 | -27.0 |
C.2. Analysis of Training Resources and Sampling Speed
C.2. 训练资源与采样速度分析
Table 6. Comparison with SOTA diffusion-based methods LDM on COCO-stuff $256\times256$ . We generate the same 2048 images of LDM for a fair com parisi on. LDM is sampled using DDIM [40] and Layout Diffusion is sampled with DPM-Solver [25]. The hyper parameters of Layout Diffusion and Layout Diffusion-small are listed in Tab. 4
表 6. 与基于扩散的SOTA方法LDM在COCO-stuff $256\times256$ 上的对比。我们生成相同的2048张LDM图像以确保公平比较。LDM使用DDIM [40]采样,Layout Diffusion使用DPM-Solver [25]采样。Layout Diffusion和Layout Diffusion-small的超参数列于表4。
| method | FID ← | Nparms | Throughout images / s | Compression stage V100days | Diffusion stage V100days | Total V100days |
|---|---|---|---|---|---|---|
| LDM-8 (100 steps) | 42.06 | 345M | 0.457 | 66 | 3.69 | 69.69 |
| LDM-4 (200 steps) | 40.91 | 306M | 0.267 | 29 | 95.49 | 124.49 |
| LayoutDiffusion-small (25 steps) | 36.16 | 142M | 0.608 | 75.83 | 75.83 | |
| LayoutDiffusion (25 steps) | 31.68 | 569M | 0.308 | 216.55 | 216.55 |
D. Evaluation
D. 评估
D.1. Datasets
D.1. 数据集
COCO-Stuff [5]. COCO [24] is a large-scale object detection, segmentation, and captioning dataset. COCO-Stuff [5] augments all 164K images of the COCO [24] dataset with pixel-level stuff annotations. These annotations can be used for scene understanding tasks like semantic segmentation, object detection and image captioning. COCO-Stuff [5] contains 80 categories of thing and 91 categories of stuff, respectively. Following the settings of LostGAN-v2 [47], we use the COCO 2017 Stuff Segmentation Challenge subset containing $40\mathrm{K}\mathrm{/}5\mathrm{k~/~}5\mathrm{k}$ images for train / val / test-dev set. Seg men gt ation annotation is not used. We use images in the train and val set with 3 to 8 objects that cover more than $2%$ of the image and not belong to ’crowd’. Finally, there are 25,210 train and 3,097 val images. Some previous works [2, 16] don’t filter objects belong to ’crowd’, causing different numbers of images. Specificly, there are 24,972 train and 3,074 val images. LAMA [23] uses the full COCO-Stuff [5] 2017 dataset, leaving 74,777 train and 3,097 val images. Tab. 7 summarizes the difference in the number of images by different filtering methods.
COCO-Stuff [5]。COCO [24] 是一个大规模的目标检测、分割和字幕生成数据集。COCO-Stuff [5] 为 COCO [24] 数据集中所有 164K 张图像增加了像素级的场景(stuff)标注。这些标注可用于语义分割、目标检测和图像字幕生成等场景理解任务。COCO-Stuff [5] 分别包含 80 类物体(thing)和 91 类场景(stuff)。遵循 LostGAN-v2 [47] 的设置,我们使用 COCO 2017 Stuff Segmentation Challenge 子集,其中包含 $40\mathrm{K}\mathrm{/}5\mathrm{k~/~}5\mathrm{k}$ 张图像用于训练/验证/测试开发集。未使用分割标注。我们筛选训练集和验证集中包含 3 到 8 个物体、覆盖图像超过 $2%$ 且不属于"人群"(crowd)的图像。最终得到 25,210 张训练图像和 3,097 张验证图像。先前一些工作 [2,16] 未过滤属于"人群"的物体,导致图像数量不同:具体为 24,972 张训练图像和 3,074 张验证图像。LAMA [23] 使用完整的 COCO-Stuff [5] 2017 数据集,得到 74,777 张训练图像和 3,097 张验证图像。表 7 总结了不同过滤方法导致的图像数量差异。
| use | filter | train | train | train | val | val | val |
|---|---|---|---|---|---|---|---|
| image | object | object/image | image | object | object/image | ||
| V | 74,121 | 411,682 | 5.55 | 3,074 | 17,100 | 5.56 | |
| 24,972 | 138,162 | 5.53 | 3,074 | 17,100 | 5.56 | ||
| √ | 74,777 | 414,443 | 5.54 | 3,097 | 17,191 | 5.55 | |
| √ | 人 | 25,210 | 139,175 | 5.52 | 3,097 | 17,191 | 5.55 |
Table 7. The difference in the number of images by different filtering methods, use deprecated means use COCO 2017 Stuff Segmentation Challenge subset, filter ’crowd’ means filter objects belong to ’crowd’.
表 7: 不同过滤方法在图像数量上的差异 (use deprecated 表示使用 COCO 2017 Stuff Segmentation Challenge 子集, filter 'crowd' 表示过滤属于 'crowd' 的对象)
Visual Genome [21]. Following the settings of $\mathrm{Sg2Im}$ [16], we experiment on Visual Genome [21] version 1.4 (VG) which comprises 108,077 images annotated with scene graphs. Visual Genome [21] collects images with dense annotations of objects, attributes, and relationships. Here, we only use bounding boxes. We divide the data into $80%/%/%$ for the train / val / test set. We select the object / relationship categories occurring at least $2000/500$ times in the train set, respectively, and select the images with 3 to 30 bounding boxes and ignoring all small objects. Finally, the train / val / test set has 62,565 / 5,062 / 5,096 images.
Visual Genome [21]。按照 $\mathrm{Sg2Im}$ [16] 的设置,我们在 Visual Genome [21] 1.4 版本 (VG) 上进行实验,该数据集包含 108,077 张带有场景图标注的图像。Visual Genome [21] 收集了带有密集物体、属性和关系标注的图像。这里,我们仅使用边界框。我们将数据按 $80%/%/%$ 划分为训练集/验证集/测试集。我们分别选择在训练集中至少出现 $2000/500$ 次的物体/关系类别,并筛选包含 3 至 30 个边界框的图像,同时忽略所有小物体。最终,训练集/验证集/测试集分别包含 62,565 / 5,062 / 5,096 张图像。
D.2. Evaluation Metrics
D.2. 评估指标
Comprehensive evaluations of generated images remains a challenge. We use six metrics, from image-level to layoutlevel, to evaluate the quality of the generated images and the layout control from different aspects.
对生成图像的全面评估仍是一个挑战。我们使用六项指标,从图像层面到布局层面,从不同角度评估生成图像的质量和布局控制。
Fr‘echet Inception Distance (FID) [10] shows the difference between the real images and the generated images by using an ImageNet-pretrained Inception-V3 [48] network and computing the Fr‘echet distance between two Gaussian distributions fitted to generated images and real images respectively. We save the GT images as real images when sampling the generated images. The real images and the generated images are saved to two folder respectively. Then compute the FID score, based on the official code of $\mathrm{FID^{\dag}}$ . For FID, the lower the score, the smaller the difference between the generated images and the real images, meaning the generator model is better.
Fr'echet Inception Distance (FID) [10] 通过使用 ImageNet 预训练的 Inception-V3 [48] 网络,并计算分别拟合生成图像和真实图像的两个高斯分布之间的 Fr'echet 距离,来衡量真实图像与生成图像之间的差异。在采样生成图像时,我们将 GT 图像保存为真实图像。真实图像和生成图像分别保存到两个文件夹中,然后基于 $\mathrm{FID^{}}$ 的官方代码计算 FID 分数。对于 FID 来说,分数越低,生成图像与真实图像之间的差异越小,意味着生成器模型越好。
Inception Score (IS) [38] shows the overall quality of the generated images by using an Inception-V3 [48] network pretrained on the ImageNet-1000 classification benchmark and computing a score(statistics) of the network’s outputs with generated images of a generator model. IS measures the quality of images on two aspects: clarity and diversity. We only need the generated images to compute the IS score, based on the official code of $\mathrm{IS}^{\dagger}$ . For IS, the higher the score, the better the quality of generated images, meaning the generator model is better.
Inception Score (IS) [38] 通过使用在ImageNet-1000分类基准上预训练的Inception-V3 [48]网络,并计算该网络对生成模型输出图像的得分(统计量),来展示生成图像的整体质量。IS从清晰度和多样性两方面衡量图像质量。我们仅需生成图像即可基于$\mathrm{IS}^{\dagger}$官方代码计算IS得分。IS得分越高,生成图像质量越好,表明生成模型更优。
Diversity Score (DS) measures the diversity between the generated images from the same layout by comparing the perceptual similarity in a DNN feature space between them. Here, we adopt the LPIPS [55] metric. For each sample, we repeat two times, use the two images from the same layout to compute the DS score, then calculate mean and std of these scores as the reported DS score, based on the official code of $\mathrm{D}\mathrm{S}^{\dagger}$ . For DS, the higher the score, the better the diversity between the generated images, meaning the generator model is better.
多样性分数 (DS) 通过比较同一布局生成图像在DNN特征空间中的感知相似性来衡量其多样性。本文采用LPIPS [55] 指标进行计算:对每个样本重复生成两次,使用同一布局的两幅图像计算DS分数,并基于 $\mathrm{D}\mathrm{S}^{\dagger}$ 官方代码统计这些分数的均值与标准差作为最终报告值。DS分数越高,表明生成图像间多样性越优,即生成模型性能越好。
YOLO Score [23] uses a pretrained YOLOv4 [4] model to evaluate bbox mAP on 80 thing categories based on the official code of LAMA† and the official code of $\mathrm{YOLOv4^{}}$ . YOLO Score [23] is proposed to evaluate the alignment and fidelity of generated objects, measuring how generated objects are recognizable when even the layout is unknow. YOLO [4, 33] is a well-known series of object detector, inferring layouts from the given images. Before send images to detector, they are upsampled to $512\times512$ . And different from LAMA [23], since we filter the objects and images in datasets, we think it is better to evaluate bbox mAP only on filtered annotations.
YOLO Score [23] 使用预训练的 YOLOv4 [4] 模型,基于 LAMA† 官方代码和 $\mathrm{YOLOv4^{}}$ 官方代码,在 80 个物体类别上评估边界框 mAP。该指标旨在评估生成物体的对齐度和保真度,衡量当布局未知时生成物体的可识别性。YOLO [4, 33] 是知名的物体检测器系列,可从给定图像推断布局。输入检测器前,图像会被上采样至 $512\times512$。与 LAMA [23] 不同,由于我们对数据集中的物体和图像进行了筛选,因此认为仅在筛选后的标注上评估边界框 mAP 更为合理。
Classification Score (CAS) [32] measures classification accuracy of layout areas on generated images. We crop the GT box area of images and resize objects at a resolution of $32\times32$ with their class. Then train a ResNet101 [9] classifier with cropped images on generated images and test it on cropped images on real images, based on a widely used codebase of image classification†. For CAS, the higher the score, the better the quality of layout control, meaning the generator model is better.
分类准确度评分 (CAS) [32] 用于衡量生成图像上布局区域的分类准确性。我们裁剪图像的真实标注框区域,并将对象按类别调整为 $32\times32$ 分辨率。随后基于广泛使用的图像分类代码库†,使用生成图像的裁剪区域训练 ResNet101 [9] 分类器,并在真实图像的裁剪区域上进行测试。CAS 分数越高,表明布局控制质量越好,即生成模型性能更优。