DeepMAD: Mathematical Architecture Design for Deep Convolutional Neural Network
DeepMAD: 深度卷积神经网络的数学架构设计
Abstract
摘要
The rapid advances in Vision Transformer (ViT) refresh the state-of-the-art performances in various vision tasks, overshadowing the conventional CNN-based models. This ignites a few recent striking-back research in the CNN world showing that pure CNN models can achieve as good performance as ViT models when carefully tuned. While encouraging, designing such high-performance CNN models is challenging, requiring non-trivial prior knowledge of network design. To this end, a novel framework termed Mathematical Architecture Design for Deep CNN (Deep $M A D^{1}$ ) is proposed to design high-performance CNN models in a principled way. In DeepMAD, a CNN network is modeled as an information processing system whose expressiveness and effectiveness can be analytically formulated by their structural parameters. Then a constrained mathematical programming (MP) problem is proposed to optimize these structural parameters. The MP problem can be easily solved by off-the-shelf MP solvers on CPUs with a small memory footprint. In addition, DeepMAD is a pure mathematical framework: no GPU or training data is required during network design. The superiority of DeepMAD is validated on multiple large-scale computer vision benchmark datasets. Notably on ImageNet-1k, only using conventional convolutional layers, DeepMAD achieves $0.7%$ and $1.5%$ higher top-1 accuracy than ConvNeXt and Swin on Tiny level, and $0.8%$ and $0.9%$ higher on Small level.
视觉Transformer (ViT) 的快速发展刷新了各类视觉任务的最先进性能,使传统基于CNN的模型相形见绌。这引发了CNN领域近期几项反击性研究,表明纯CNN模型经过精心调优后能达到与ViT模型相当的性能。尽管结果振奋人心,但设计此类高性能CNN模型仍具挑战性,需要深厚的网络设计先验知识。为此,我们提出名为深度CNN数学架构设计 (Deep $MAD^{1}$) 的新框架,以系统化方式设计高性能CNN模型。在DeepMAD中,CNN网络被建模为信息处理系统,其表达能力和有效性可通过结构参数进行解析建模。随后构建约束数学规划 (MP) 问题来优化这些结构参数,该MP问题可由现成求解器在CPU上高效求解且内存占用极小。此外,DeepMAD是纯数学框架:网络设计阶段无需GPU或训练数据。DeepMAD的优越性在多个大规模计算机视觉基准数据集上得到验证。其中在ImageNet-1k上,仅使用传统卷积层时,DeepMAD在Tiny级别比ConvNeXt和Swin分别高出$0.7%$和$1.5%$的top-1准确率,在Small级别分别高出$0.8%$和$0.9%$。
1. Introduction
1. 引言
Convolutional neural networks (CNNs) have been the predominant computer vision models in the past decades [23,31,41,52,63]. Until recently, the emergence of
卷积神经网络 (CNNs) 是过去几十年计算机视觉领域的主导模型 [23,31,41,52,63]。直到最近,随着
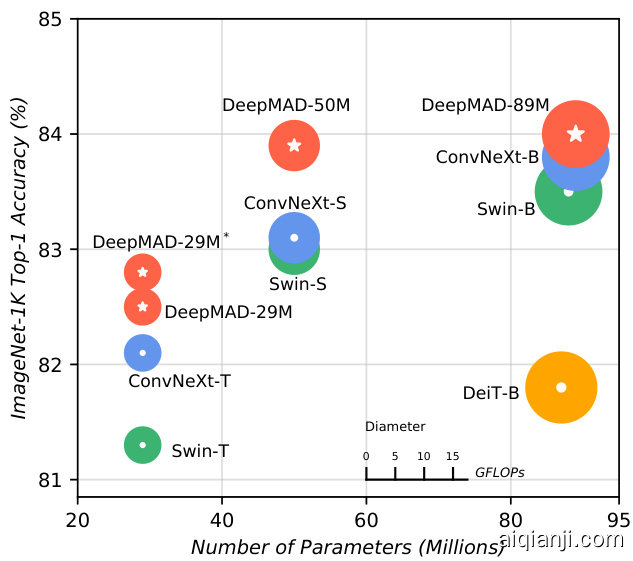
Figure 1. Comparison between DeepMAD models, Swin [40] and ConvNeXt [41] on ImageNet-1k. DeepMAD achieves better performance than Swin and ConvNeXt with the same scales.
图 1: DeepMAD模型与Swin [40]和ConvNeXt [41]在ImageNet-1k上的对比。在相同规模下,DeepMAD实现了优于Swin和ConvNeXt的性能。
Vision Transformers (ViTs) [18, 40, 64] establishes a novel deep learning paradigm surpassing CNN models [40, 64] thanks to the innovation of self-attention [66] mechanism and other dedicated components [3, 17, 28, 29, 55] in ViTs.
视觉Transformer (ViT) [18, 40, 64] 通过自注意力 (self-attention) [66] 机制和其他专用组件 [3, 17, 28, 29, 55] 的创新,建立了一种超越CNN模型 [40, 64] 的新型深度学习范式。
Despite the great success of ViT models in the 2020s, CNN models still enjoy many merits. First, CNN models do not require self-attention modules which require quadratic computational complexity in token size [45]. Second, CNN models usually generalize better than ViT models when trained on small datasets [41]. In addition, convolutional operators have been well-optimized and tightly integrated on various hardware platforms in the industry, like IoT [5].
尽管ViT模型在2020年代取得了巨大成功,CNN模型仍具备诸多优势。首先,CNN模型无需自注意力模块(该模块在token数量上需要二次方计算复杂度)[45]。其次,在小规模数据集训练时,CNN模型通常比ViT模型具有更好的泛化能力[41]。此外,卷积算子已在物联网(IoT)[5]等工业级硬件平台上实现了深度优化与紧密集成。
Considering the aforementioned advantages, recent researches try to revive CNN models using novel architecture designs [16,22,41,77]. Most of these works adopt ViT components into CNN models, such as replacing the attention matrix with a convolutional counterpart while keeping the macro structure of ViTs. After modifications, these modern CNN backbones are considerably different from the conventional ResNet-like CNN models. Although these efforts abridge the gap between CNNs and ViTs, designing such high-performance CNN models requires dedicated efforts in structure tuning and non-trivial prior knowledge of network design, therefore is time-consuming and difficult to generalize and customize.
考虑到上述优势,近期研究尝试通过新颖的架构设计复兴CNN模型[16,22,41,77]。这些工作大多将ViT组件引入CNN模型,例如在保持ViT宏观结构的同时用卷积替代注意力矩阵。经过改造后,这些现代CNN骨干网络与传统的类ResNet CNN模型存在显著差异。尽管这些努力缩小了CNN与ViT之间的差距,但设计此类高性能CNN模型需要对结构调优投入大量精力,并具备非平凡的网络设计先验知识,因此耗时且难以泛化和定制。
In this work, a novel design paradigm named Mathematical Architecture Design (DeepMAD) is proposed, which designs high-performance CNN models in a principled way. DeepMAD is built upon the recent advances of deep learning theories [8, 48, 50]. To optimize the architecture of CNN models, DeepMAD innovates a constrained mathematical programming (MP) problem whose solution reveals the optimized structural parameters, such as the widths and depths of the network. Particularly, DeepMAD maximizes the differential entropy [26,32,59,60,68,78] of the network with constraints from the perspective of effectiveness [50]. The effectiveness controls the information flow in the network which should be carefully tuned so that the generated networks are well behaved. The dimension of the proposed MP problem in DeepMAD is less than a few dozen. Therefore, it can be solved by off-the-shelf MP solvers nearly instantly on CPU. NO GPU is required and no deep model is created in memory2. This makes DeepMAD lightning fast even on CPU-only servers with a small memory footprint. After solving the MP problem, the optimized CNN architecture is derived from the MP solution.
本研究提出了一种名为数学架构设计 (DeepMAD) 的创新范式,通过理论化方法设计高性能CNN模型。DeepMAD基于深度学习理论的最新进展 [8, 48, 50],通过构建约束数学规划 (MP) 问题来优化CNN架构,其解可揭示网络宽度、深度等最优结构参数。该范式特别从有效性 [50] 角度出发,在约束条件下最大化网络的微分熵 [26,32,59,60,68,78]。有效性控制着网络信息流,需精细调节以确保生成网络的优良性能。DeepMAD提出的MP问题维度小于数十维,因此可通过现成MP求解器在CPU上即时求解,无需GPU且不占用内存创建深度模型,这使得该方法在仅配备CPU的低内存服务器上也能实现闪电级速度。MP问题求解后,最优CNN架构即可从其解中导出。
DeepMAD is a mathematical framework to design optimized CNN networks with strong theoretical guarantees and state-of-the-art (SOTA) performance. To demonstrate the power of DeepMAD, we use DeepMAD to optimize CNN architectures only using the conventional convolutional layers [2,54] as building blocks. DeepMAD achieves comparable or better performance than ViT models of the same model sizes and FLOPs. Notably, DeepMAD achieves $82.8%$ top-1 accuracy on ImageNet-1k with $4.5\mathrm{G}$ FLOPs and 29M Params, outperforming ConvNeXt-Tiny $(82.1%)$ [41] and Swin-Tiny $(81.3%)$ [40] at the same scale; DeepMAD also achieves $77.7%$ top-1 accuracy at the same scale as ResNet-18 [21] on ImageNet-1k, which is $8.9%$ better than He’s original ResNet-18 $(70.9%)$ and is even comparable to He’s ResNet-50 $(77.4%)$ . The contributions of this work are summarized as follows:
DeepMAD 是一种数学框架,用于设计具有强大理论保证和最先进 (SOTA) 性能的优化 CNN 网络。为展示 DeepMAD 的强大能力,我们仅使用传统卷积层 [2,54] 作为构建模块来优化 CNN 架构。DeepMAD 在相同模型大小和 FLOPs 下实现了与 ViT 模型相当或更优的性能。值得注意的是,DeepMAD 在 ImageNet-1k 上以 4.5G FLOPs 和 29M 参数量实现了 82.8% 的 top-1 准确率,优于同规模的 ConvNeXt-Tiny (82.1%) [41] 和 Swin-Tiny (81.3%) [40];DeepMAD 在 ImageNet-1k 上与 ResNet-18 [21] 相同规模下实现了 77.7% 的 top-1 准确率,比 He 原始 ResNet-18 (70.9%) 高出 8.9%,甚至可与 He 的 ResNet-50 (77.4%) 相媲美。本工作的贡献总结如下:
• A Mathematical Architecture Design paradigm, DeepMAD, is proposed for high-performance CNN architecture design. • DeepMAD is backed up by modern deep learning theories [8, 48, 50]. It solves a constrained mathematical programming (MP) problem to generate optimized
• 提出了一种高性能CNN架构设计的数学架构设计范式DeepMAD。
• DeepMAD基于现代深度学习理论[8, 48, 50],通过求解约束数学规划(MP)问题来生成优化架构。
CNN architectures. The MP problem can be solved on CPUs with a small memory footprint. • DeepMAD achieves SOTA performances on multiple large-scale vision datasets, proving its superiority. Even only using the conventional convolutional layers, DeepMAD designs high-performance CNN models comparable to or better than ViT models of the same model sizes and FLOPs. • DeepMAD is transferable across multiple vision tasks, including image classification, object detection, semantic segmentation and action recognition, with consistent performance improvements.
CNN架构。该MP问题可在内存占用小的CPU上解决。
• DeepMAD在多个大规模视觉数据集上实现SOTA性能,证明了其优越性。即使仅使用传统卷积层,DeepMAD设计的高性能CNN模型也能达到或超越同参数量级和FLOPs的ViT模型。
• DeepMAD可迁移至多种视觉任务(包括图像分类、目标检测、语义分割和动作识别),且性能提升稳定。
2. Related Works
2. 相关工作
In this section, we briefly survey the recent works of modernizing CNN networks, especially the works inspired by transformer architectures. Then we discuss related works in information theory and theoretical deep learning.
本节简要概述了现代卷积神经网络(CNN)的近期研究进展,特别是受Transformer架构启发的相关工作。随后探讨了信息论与理论深度学习领域的相关研究。
2.1. Modern Convolutional Neural Networks
2.1. 现代卷积神经网络
Convolutional deep neural networks are popular due to their conceptual simplicity and good performance in computer vision tasks. In most studies, CNNs are usually manually designed [16, 21, 23, 41, 57, 63]. These pre-defined architectures heavily rely on human prior knowledge and are difficult to customize, for example, tailored to some given FLOPs/Params budgets. Recently, some works use AutoML [10,33,35,37,56,62,75] to automatically generate high-performance CNN architectures. Most of these methods are data-dependent and require lots of computational resources. Even if one does not care about the computational cost of AutoML, the patterns generated by AutoML algorithms are difficult to interpret. It is hard to justify why such architectures are preferred and what theoretical insight we can learn from these results. Therefore, it is important to explore the architecture design in a principled way with clear theoretical motivation and human readability.
卷积深度神经网络因其概念简单且在计算机视觉任务中表现良好而广受欢迎。在大多数研究中,CNN通常由人工设计[16, 21, 23, 41, 57, 63]。这些预定义的架构高度依赖人类先验知识,难以定制,例如针对给定的FLOPs/参数预算进行调整。近年来,一些研究采用AutoML[10,33,35,37,56,62,75]自动生成高性能CNN架构。这些方法大多依赖数据且需要大量计算资源。即使不考虑AutoML的计算成本,其算法生成的模式也难以解释。我们无法明确说明为何这些架构更优,或从结果中获得何种理论洞见。因此,以具有明确理论动机和人类可读性的原则性方式探索架构设计至关重要。
The Vision Transformer (ViT) is a rapid-trending topic in computer vision [18, 40, 64]. The Swin Transformer [40] improves the computational efficiency of ViTs using a CNN-like stage-wise design. Inspired by Swin Transformer, recent researches combine CNNs and ViTs, leading to more efficient architectures [16, 22, 40, 41, 77]. For example, MetaFormer [77] shows that the attention matrix in ViTs can be replaced by a pooling layer. ConvNext [41] mimics the attention layer using depth-wise convolution and uses the same macro backbone as Swin Transformer [40]. RepLKNet [16] scales up the kernel sizes beyond $31\times31$ to capture global receptive fields as attention. All these efforts demonstrate that CNN models can achieve as good performance as ViT models when tuned carefully. However, these modern CNNs require non-trivial prior knowledge when designing therefore are difficult to generalize and customize.
视觉Transformer (ViT) 是计算机视觉领域迅速兴起的热门话题 [18, 40, 64]。Swin Transformer [40] 通过类似CNN的阶段性设计提升了ViT的计算效率。受Swin Transformer启发,近期研究将CNN与ViT相结合,催生出更高效的架构 [16, 22, 40, 41, 77]。例如MetaFormer [77] 证明ViT中的注意力矩阵可被池化层替代。ConvNext [41] 使用深度卷积模拟注意力层,并采用与Swin Transformer [40] 相同的宏观骨干网络。RepLKNet [16] 将卷积核尺寸扩大到 $31\times31$ 以上以获得类似注意力的全局感受野。这些研究表明,经过精心调参的CNN模型能达到与ViT模型相当的性能。然而,这些现代CNN在设计时需要大量先验知识,因此难以泛化和定制化。
2.2. Information Theory in Deep Learning
2.2. 深度学习中的信息论
Information theory is a powerful instrument for studying complex systems such as deep neural networks. The Principle of Maximum Entropy [26, 32] is one of the most widely used principles in information theory. Several previous works [8, 50, 53, 60, 78] attempt to establish the connection between the information entropy and the neural network architectures. For example, [8] tries to interpret the learning ability of deep neural networks using subspace entropy reduction. [53] studies the information bottleneck in deep architectures and explores the entropy distribution and information flow in deep neural networks. [78] proposes the principle of maximal coding rate reduction for optimization. [60] designs efficient object detection networks via maximizing multi-scale feature map entropy. The monograph [50] analyzes the mutual information between different neurons in an MLP model. In DeepMAD, the entropy of the model itself is considered instead of the coding rate reduction as in [8]. The effectiveness is also proposed to show that only maximizing entropy as in [60] is not enough.
信息论是研究深度神经网络等复杂系统的有力工具。最大熵原理 [26, 32] 是信息论中应用最广泛的原则之一。先前多项研究 [8, 50, 53, 60, 78] 试图建立信息熵与神经网络架构之间的联系。例如,[8] 尝试通过子空间熵减来解释深度神经网络的学习能力;[53] 研究了深度架构中的信息瓶颈,探索了深度神经网络中的熵分布与信息流;[78] 提出了最大编码率降低的优化原则;[60] 通过最大化多尺度特征图熵来设计高效的目标检测网络;专著 [50] 分析了 MLP 模型中不同神经元间的互信息。DeepMAD 考虑的是模型自身的熵,而非如 [8] 中的编码率降低。研究还指出,仅如 [60] 那样最大化熵是不够的。
3. Mathematical Architecture Design for MLP
3. 面向MLP的数学架构设计
In this section, we study the architecture design for Multiple Layer Perceptron (MLP) using a novel mathematical programming (MP) framework. We then generalize this technique to CNN models in the next section. To derive the MP problem for MLP, we first define the entropy of the MLP which controls its expressiveness, followed by a constraint which controls its effectiveness. Finally, we maximize the entropy objective function subject to the effectiveness constraint.
在本节中,我们研究使用新型数学规划(MP)框架设计多层感知机(MLP)的架构。随后在下一节将该技术推广至CNN模型。为推导MLP的MP问题,首先定义控制模型表达能力的MLP熵,继而引入控制模型效能的约束条件,最终在满足效能约束的前提下最大化熵目标函数。
3.1. Entropy of MLP models
3.1. MLP模型的熵
Suppose that in an $L$ -layer MLP $f(\cdot)$ , the $i$ -th layer has $w{i}$ input channels and $w{i+1}$ output channels. The output $\mathbf{x}{i+1}$ and the input $\mathbf{x}{i}$ are connected by $\mathbf{x}{i+1}=\mathbf{M}{i}\mathbf{x}{i}$ where $\mathbf{M}{i}\in\mathbb{R}^{w_{i+1}\times w{i}}$ is trainable weights. Following the entropy analysis in [8], the entropy of the MLP model $f(\cdot)$ is given in Theorem 1.
假设在一个$L$层MLP $f(\cdot)$中,第$i$层的输入通道数为$w{i}$,输出通道数为$w{i+1}$。输出$\mathbf{x}{i+1}$与输入$\mathbf{x}{i}$通过$\mathbf{x}{i+1}=\mathbf{M}{i}\mathbf{x}{i}$关联,其中$\mathbf{M}{i}\in\mathbb{R}^{w{i+1}\times w{i}}$为可训练权重。根据[8]中的熵分析,该MLP模型$f(\cdot)$的熵如定理1所示。
Theorem 1. The normalized Gaussian entropy upper bound of the MLP $f(\cdot)$ is
定理 1. MLP $f(\cdot)$ 的归一化高斯熵上界为
$$
H_{f}=w_{L+1}\sum_{i=1}^{L}\log(w_{i}).
$$
$$
H_{f}=w_{L+1}\sum_{i=1}^{L}\log(w_{i}).
$$
The proof is given in Appendix A. The entropy measures the expressiveness of the deep network [8, 60]. Following the Principle of Maximum Entropy [26, 32], we propose to maximize the entropy of MLP under given computational budgets.
证明见附录A。熵(entropy)衡量了深度网络的表达能力[8,60]。根据最大熵原理(Principle of Maximum Entropy)[26,32],我们提出在给定计算预算下最大化多层感知机(MLP)的熵。
However, simply maximizing entropy defined in Eq. (1) leads to an over-deep network because the entropy grows exponentially faster in depth than in width according to the Theorem 1. An over-deep network is difficult to train and hinders effective information propagation [50]. This observation inspires us to look for another dimension in deep architecture design. This dimension is termed effectiveness presented in the next subsection.
然而,单纯最大化式(1)定义的熵会导致网络过深。根据定理1,熵随深度增长的速度远快于宽度增长。过深的网络难以训练,并阻碍有效信息传播[50]。这一发现启发我们在深度架构设计中探索另一个维度,即下一小节将介绍的效能维度。
3.2. Effectiveness Defined in MLP
3.2. MLP中定义的有效性
An over-deep network can be considered as a chaos system that hinders effective information propagation. For a chaos system, when the weights of the network are randomly initialized, a small perturbation in low-level layers of the network will lead to an exponentially large perturbation in the high-level output of the network. During the back-propagation, the gradient flow cannot effectively propagate through the whole network. Therefore, the network becomes hard to train when it is too deep.
过深的网络可视为阻碍有效信息传播的混沌系统。对于混沌系统而言,当网络权重随机初始化时,网络低层微小扰动会导致高层输出产生指数级放大的扰动。在反向传播过程中,梯度流无法有效贯穿整个网络。因此网络过深时会难以训练。
Inspired by the above observation, in DeepMAD we propose to control the depth of network. Intuitively, a 100- layer network is relatively too deep if its width is only 10 channels per layer or is relatively too shallow if its width is 10000 channels per layer. To capture this relative-depth intuition rigorously, we import the metric termed network effectiveness for MLP from the work [50]. Suppose that an MLP has $L$ -layers and each layer has the same width $w$ , the effectiveness of this MLP is defined by
受上述观察启发,我们在DeepMAD中提出控制网络深度。直观来看,当每层宽度仅为10个通道时,100层网络相对过深;而当每层宽度达10000个通道时,该网络又相对过浅。为严谨量化这种相对深度关系,我们引入文献[50]提出的MLP网络效能(Network Effectiveness)指标。假设一个MLP具有$L$层且每层宽度均为$w$,其效能定义为
$$
\rho=L/w.
$$
$$
\rho=L/w.
$$
Usually, $\rho$ should be a small constant. When $\rho\to0$ , the MLP behaves like a single-layer linear model; when $\rho\rightarrow$ $\infty$ , the MLP is a chaos system. There is an optimal $\rho^{*}$ for MLP such that the mutual information between the input and the output are maximized [50].
通常,$\rho$ 应为一个较小的常数。当 $\rho\to0$ 时,多层感知机 (MLP) 的行为类似于单层线性模型;当 $\rho\rightarrow\infty$ 时,多层感知机则表现为混沌系统。对于多层感知机存在一个最优的 $\rho^{*}$,可使输入与输出之间的互信息达到最大化 [50]。
In DeepMAD, we propose to constrain the effectiveness when designing the network. An unaddressed issue is that Eq. (2) assumes the MLP has uniform width but in practice, the width $w_{i}$ of each layer can be different. To address this issue, we propose to use the average width of MLP in Eq. (2).
在DeepMAD中,我们提出在设计网络时约束其有效性。一个尚未解决的问题是,等式(2)假设MLP具有均匀宽度,但实际上每层的宽度$w_{i}$可能不同。为了解决这个问题,我们建议在等式(2)中使用MLP的平均宽度。
Proposition 1. The average width of an $L$ layer MLP $f(\cdot)$ is defined by
命题 1. 一个 $L$ 层 MLP $f(\cdot)$ 的平均宽度定义为
$$
\bar{w}=(\prod_{i=1}^{L}w_{i})^{1/L}=\exp\left(\frac{1}{L}\sum_{i=1}^{L}\log w_{i}\right).
$$
$$
\bar{w}=(\prod_{i=1}^{L}w_{i})^{1/L}=\exp\left(\frac{1}{L}\sum_{i=1}^{L}\log w_{i}\right).
$$
Proposition 1 uses geometric average instead of arithmetic average of $w_{i}$ to define the average width of MLP. This definition is derived from the entropy definition in Eq. (1). Please check Appendix B for details. In addition, geometric average is more reasonable than arithmetic average. Suppose an MLP has a zero width in some layer. Then the information cannot propagate through the network. Therefore, its “equivalent width” should be zero.
命题1使用几何平均数而非算术平均数来定义MLP的平均宽度 $w_{i}$ 。该定义源自式(1)中的熵定义,详见附录B。此外,几何平均数比算术平均数更合理。假设MLP某一层的宽度为零,则信息无法通过网络传播,因此其"等效宽度"应为零。
In real-world applications, the optimal value of $\rho$ depends on the building blocks. We find that $\rho\in[0.1,2.0]$ usually gives good results in most vision tasks.
在实际应用中,$\rho$ 的最佳值取决于具体构建模块。我们发现,在大多数视觉任务中,$\rho\in[0.1,2.0]$ 通常能取得良好效果。
4. Mathematical Architecture Design for CNN
4. CNN 的数学架构设计
In this section, the definitions of entropy and the effectiveness are generalized from MLP to CNN. Then three empirical guidelines are introduced inspired by the best engineering practice. At last, the final mathematical formulation of DeepMAD is presented.
本节将熵和有效性的定义从多层感知机 (MLP) 推广到卷积神经网络 (CNN),随后基于最佳工程实践总结出三条经验准则,最后给出DeepMAD的完整数学表述。
4.1. From MLP to CNN
4.1. 从多层感知机到卷积神经网络
A CNN operator is essentially a matrix multiplication with a sliding window. Suppose that in the $i$ -th CNN layer, the number of input channels is $c_{i}$ , the number of output channels is $c_{i+1}$ , the kernel size is $k_{i}$ , group is $g_{i}$ . Then this CNN operator is equivalent to a matrix multiplication $W_{i}\in\mathbb{R}^{c_{i+1}\times c_{i}k_{i}^{2}/g_{i}}$ . Therefore, the “width” of this CNN layer is projected to $c_{i}k_{i}^{2}/g_{i}$ in Eq. (1).
CNN算子本质上是一个带滑动窗口的矩阵乘法。假设在第$i$个CNN层中,输入通道数为$c_{i}$,输出通道数为$c_{i+1}$,卷积核尺寸为$k_{i}$,分组数为$g_{i}$。则该CNN算子等价于矩阵乘法$W_{i}\in\mathbb{R}^{c_{i+1}\times c_{i}k_{i}^{2}/g_{i}}$。因此,该CNN层的"宽度"在公式(1)中被投射为$c_{i}k_{i}^{2}/g_{i}$。
A new dimension in CNN feature maps is the resolution $r_{i}\times r_{i}$ at the $i\cdot$ -th layer. To capture this, we propose the following definition of entropy for CNN networks.
CNN特征图的一个新维度是第$i$层分辨率$r_{i}\times r_{i}$。为捕捉这一特性,我们提出以下CNN网络熵的定义。
Proposition 2. For an $L$ -layer CNN network $f(\cdot)$ parameterized by ${c_{i},k_{i},g_{i},r_{i}}_{i=1}^{L}$ , its entropy is defined by
命题 2. 对于一个由参数 ${c_{i},k_{i},g_{i},r_{i}}_{i=1}^{L}$ 定义的 $L$ 层 CNN 网络 $f(\cdot)$,其熵定义为
$$
H_{L}\triangleq\log(r_{L+1}^{2}c_{L+1})\sum_{i=1}^{L}\log(c_{i}k_{i}^{2}/g_{i}).
$$
$$
H_{L}\triangleq\log(r_{L+1}^{2}c_{L+1})\sum_{i=1}^{L}\log(c_{i}k_{i}^{2}/g_{i}).
$$
In Eq. (4), we use a similar definition of entropy as in Eq. (1). We use $\log(r_{L+1}^{2}c_{L+1})$ instead of $(r_{L+1}^{2}c_{L+1})$ in Eq. (4). This is because a nature image is highly compressible so the entropy of an image or feature map does not scale up linearly in its volume $O(r_{i}^{2}\times c_{i})$ . Inspired by [51], taking logarithms can better formulate the ground-truth entropy for natural images.
在式 (4) 中,我们采用了与式 (1) 类似的熵定义。不同于式 (4) 直接使用 $(r_{L+1}^{2}c_{L+1})$ ,我们采用 $\log(r_{L+1}^{2}c_{L+1})$ 。这是因为自然图像具有高度可压缩性,图像或特征图的熵不会随其体积 $O(r_{i}^{2}\times c_{i})$ 线性增长。受 [51] 启发,取对数能更准确地描述自然图像的真实熵。
4.2. Three Empirical Guidelines
4.2. 三项实证指导原则
We find that the following three heuristic rules are beneficial to architecture design in DeepMAD. These rules are inspired by the best engineering practices.
我们发现以下三条启发式规则对DeepMAD的架构设计有益。这些规则源自最佳工程实践。
• Guideline 1. Weighted Multiple-Scale Entropy CNN networks usually contain down-sampling layers which split the network into several stages. Each stage captures features at a certain scale. To capture the entropy at different scales, we use a weighted summation to ensemble entropy of the last layer in each stage to obtain the entropy of the network as in [60]. • Guideline 2. Uniform Stage Depth We require the depth of each stage to be uniformly distributed as much as possible. We use the variance of depths to measure the uniformity of depth distribution.
• 准则1. 加权多尺度熵 CNN网络通常包含下采样层,这些层将网络划分为多个阶段。每个阶段捕获特定尺度的特征。为了捕捉不同尺度的熵,我们采用加权求和方式集成每个阶段最后一层的熵,从而获得网络的整体熵,具体方法如[60]所示。
• 准则2. 均匀阶段深度 我们要求每个阶段的深度尽可能均匀分布。通过计算深度方差来衡量深度分布的均匀性。
• Guideline 3. Non-Decreasing Number of Channels We require that channel number of each stage is nondecreasing along the network depth. This can prevent high-level stages from having small widths. This guideline is also a common practise in a lot of manually designed networks.
• 准则3:通道数非递减
我们要求每个阶段的通道数随网络深度非递减。这可以防止高层级阶段出现宽度过小的情况。该准则也是许多人工设计网络的常见做法。
4.3. Final DeepMAD Formula
4.3. 最终 DeepMAD 公式
We gather everything together and present the final mathematical programming problem for DeepMAD. Suppose that we aim to design an $L$ -layer CNN model $f(\cdot)$ with $M$ stages. The entropy of the $i$ -th stage is denoted as $H_{i}$ defined in Eq. (4). Within each stage, all blocks use the same structural parameters (width, kernel size, etc.). The width of each CNN layer is defined by $w_{i}=c_{i}k_{i}^{2}/g_{i}$ . The depth of each stage is denoted as $L_{i}$ for $i=1,2,\cdots,M$ . We propose to optimize ${w_{i},L_{i}}$ via the following mathematical programming (MP) problem:
我们将所有内容整合起来,呈现DeepMAD的最终数学规划问题。假设我们的目标是设计一个具有$M$个阶段的$L$层CNN模型$f(\cdot)$。第$i$个阶段的熵由式(4)中定义的$H_{i}$表示。在每个阶段内,所有块使用相同的结构参数(宽度、核大小等)。每个CNN层的宽度由$w_{i}=c_{i}k_{i}^{2}/g_{i}$定义。每个阶段的深度表示为$L_{i}$,其中$i=1,2,\cdots,M$。我们提出通过以下数学规划(MP)问题优化${w_{i},L_{i}}$:
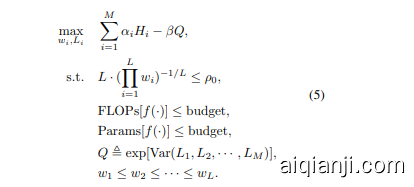
In the above MP formulation, ${\alpha_{i},\beta,\rho_{0}}$ are hyperparameters. ${\alpha_{i}}$ are the weights of entropies at different scales. For CNN models with 5 down-sampling layers, ${\alpha_{i}}={1,1,1,1,8}$ is suggested in most vision tasks. $Q$ penalizes the objective function if the network has nonuniform depth distribution across stages. We set $\beta=10$ in our experiments. $\rho_{0}$ controls the effectiveness of the network whose value is usually tuned in range [0.1, 2.0]. The last two inequalities control the computational budgets. This MP problem can be easily solved by off-the-shelf solvers for constrained non-linear programming [4, 44].
在上述 MP 公式中,${\alpha_{i},\beta,\rho_{0}}$ 是超参数。${\alpha_{i}}$ 表示不同尺度下熵的权重。对于具有 5 个下采样层的 CNN 模型,在大多数视觉任务中建议使用 ${\alpha_{i}}={1,1,1,1,8}$。$Q$ 会在网络各阶段深度分布不均匀时对目标函数施加惩罚。实验中我们设定 $\beta=10$。$\rho_{0}$ 控制网络有效性,其值通常在 [0.1, 2.0] 范围内调整。最后两个不等式用于控制计算预算。该 MP 问题可通过现成的约束非线性规划求解器轻松解决 [4, 44]。
5. Experiments
5. 实验
Experiments are developed at three levels. First, the relationship between the model accuracy and the model effec ti ve ness is investigated on CIFAR-100 [30] to verify our effective theory in Section 4.3. Then, DeepMAD is used to design better ResNets and mobile networks. To demonstrate the power of DeepMAD, we design SOTA CNN models using DeepMAD with the conventional convolutional layers. Performances on ImageNet-1K [15] are reported with comparison to popular modern CNN and ViT models.
实验分为三个层面展开。首先,在CIFAR-100 [30]上探究模型准确率与模型效能(effectiveness)的关系,以验证第4.3节提出的效能理论。随后,采用DeepMAD框架优化ResNet和移动端网络架构。为展示DeepMAD的先进性,我们基于传统卷积层设计出性能领先的CNN模型,并在ImageNet-1K [15]数据集上对比测试了主流CNN与ViT模型的性能表现。
Finally, the CNN models designed by DeepMAD are transferred to multiple down-streaming tasks, such as MS COCO [36] for object detection, ADE20K [82] for semantic segmentation and UCF101 [58] / Kinetics 400 [27] for action recognition. Consistent performance improvements demonstrate the excellent transfer ability of DeepMAD models.
最后,DeepMAD设计的CNN模型被迁移到多个下游任务中,例如MS COCO [36]用于目标检测、ADE20K [82]用于语义分割、UCF101 [58]/Kinetics 400 [27]用于动作识别。一致的性能提升证明了DeepMAD模型出色的迁移能力。
5.1. Training Settings
5.1. 训练设置
Following previous works [72, 74], SGD optimizer with momentum 0.9 is adopted to train DeepMAD models. The weight decay is 5e-4 for CIFAR-100 dataset and 4e-5 for ImageNet-1k. The initial learning rate is 0.1 with batch size of 256. We use cosine learning rate decay [43] with 5 epochs of warm-up. The number of training epochs is 1,440 for CIFAR-100 and 480 for ImageNet-1k. All experiments use the following data augmentations [47]: mixup [80], label-smoothing [61], random erasing [81], random crop/resize/flip/lighting, and Auto-Augment [14].
遵循先前工作 [72, 74],采用动量系数为0.9的SGD优化器训练DeepMAD模型。权重衰减设置为:CIFAR-100数据集5e-4,ImageNet-1k数据集4e-5。初始学习率为0.1,批量大小为256。使用余弦学习率衰减策略 [43] 并包含5轮预热阶段。训练轮次设定为:CIFAR-100 1,440轮,ImageNet-1k 480轮。所有实验均采用以下数据增强方法 [47]:mixup [80]、标签平滑 [61]、随机擦除 [81]、随机裁剪/缩放/翻转/光照调整以及Auto-Augment [14]。
5.2. Building Blocks
5.2. 基础构建模块
To align with ResNet family [21], Section 5.4 uses the same building blocks as ResNet-50. To align with ViT models [18, 40, 64], DeepMAD uses MobileNet-V2 [23] blocks followed by SE-block [24] as in Efficient Net [63] to design high performance networks.
为与ResNet系列[21]保持一致,第5.4节采用与ResNet-50相同的构建模块。为与ViT模型[18, 40, 64]对齐,DeepMAD借鉴Efficient Net[63]的设计思路,采用MobileNet-V2[23]模块结合SE-block[24]来构建高性能网络。
5.3. Effectiveness on CIFAR-100
5.3. CIFAR-100 上的有效性
The effectiveness $\rho$ is an important hyper-parameter in DeepMAD. This experiment demonstrate how $\rho$ affects the architectures in DeepMAD. To this end, 65 models are randomly generated using ResNet blocks, with different depths and widths. All models have the same FLOPs (0.04G) and Params (0.27M) as ResNet-20 [25] for CIFAR-100. The effectiveness $\rho$ varies in range [0.1, 1.0].
有效性 $\rho$ 是DeepMAD中的一个重要超参数。本实验展示了 $\rho$ 如何影响DeepMAD的架构。为此,我们使用ResNet模块随机生成了65个模型,这些模型具有不同的深度和宽度。所有模型的计算量(FLOPs)为0.04G,参数量(Params)为0.27M,与用于CIFAR-100的ResNet-20 [25]相同。有效性 $\rho$ 的变化范围为[0.1, 1.0]。
These randomly generated models are trained on CIFAR-100. The effectiveness $\rho$ , top-1 accuracy and network entropy for each model are plotted in Figure 2. We can find that the entropy increases with $\rho$ monotonically. This is because the larger the $\rho$ is, the deeper the network is, and thus the greater the entropy as described in Section 3.1. However, as shown in Figure 2, the model accuracy does not always increase with $\rho$ and entropy. When $\rho$ is small, the model accuracy is proportional to the model entropy; when $\rho$ is too large, such relationship no longer exists. Therefore, $\rho$ should be contrained in a certain “effective” range in DeepMAD.
这些随机生成的模型在CIFAR-100上进行训练。图2展示了每个模型的有效性$\rho$、top-1准确率和网络熵值。我们可以发现熵值随$\rho$单调递增。这是因为$\rho$越大网络越深,如第3.1节所述熵值也就越大。然而如图2所示,模型准确率并不总是随$\rho$和熵值增加而提升。当$\rho$较小时,模型准确率与模型熵值成正比;当$\rho$过大时,这种关系便不复存在。因此,在DeepMAD中应将$\rho$控制在某个"有效"范围内。
Figure 3 gives more insights into the effectiveness hypothesis in Section 3.2. The architectures around $\rho{}={}$ ${0.1,0.5,1.0}$ are selected and grouped by $\rho$ . When $\rho$ is small ( $\mathrm{\bf\ddot{\rho}}$ is around 0.1), the network is effective in information propagation so we observe a strong correlation between network entropy and network accuracy. But these models are too shallow to obtain high performance. When $\rho$ is too large $(\rho~\approx~1.0)$ , the network approaches a chaos system therefore no clear correlation between network entropy and network accuracy. When $\rho$ is around 0.5, the network can achieve the best performance and the correlation between the network entropy and network accuracy reaches 0.77.
图 3: 进一步验证了第 3.2 节提出的有效性假设。我们选取了 $\rho{}={}$ ${0.1,0.5,1.0}$ 附近的架构并按 $\rho$ 值分组。当 $\rho$ 值较小时 ( $\mathrm{\bf\ddot{\rho}}$ 约等于 0.1),网络在信息传播方面表现高效,因此可以观察到网络熵与网络准确率之间存在强相关性。但这些模型过于浅层,难以获得高性能。当 $\rho$ 值过大 $(\rho~\approx~1.0)$ 时,网络趋近于混沌系统,导致网络熵与准确率之间无明显关联。当 $\rho$ 值约为 0.5 时,网络能达到最佳性能,此时网络熵与准确率之间的相关性达到 0.77。
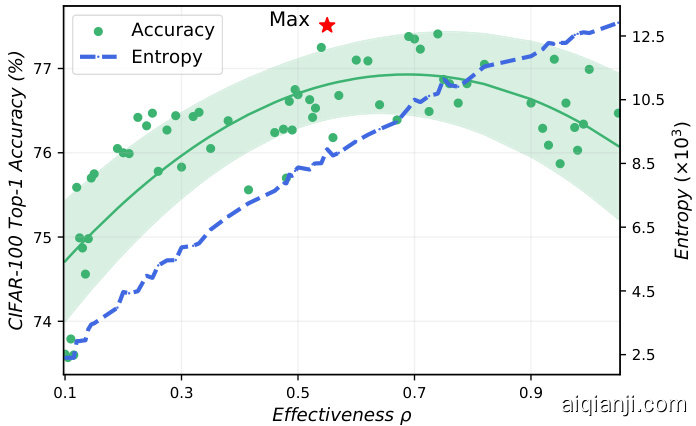
Figure 2. Effectiveness $\rho$ v.s. top-1 accuracy and entropy of each generated model on CIFAR-100. The best model is marked by a star. The entropy increases with $\rho$ monotonically but the model accuracy does not. The optimal $\rho^{*}\approx0.5$ .
图 2: 各生成模型在 CIFAR-100 上的有效性 $\rho$ 与 top-1 准确率及熵的关系。最佳模型用星号标注。熵随 $\rho$ 单调递增,但模型准确率并非如此。最优 $\rho^{*}\approx0.5$。
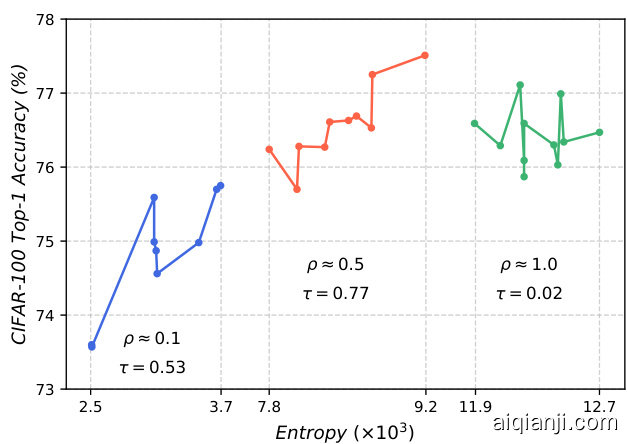
Figure 3. The architectures around $\rho={0.1,0.5,1.0}$ are selected and grouped by $\rho$ . Kendall coefficient $\tau$ [1] is used to measure the correlation.
图 3: 围绕 $\rho={0.1,0.5,1.0}$ 的架构被选出并按 $\rho$ 分组。采用 Kendall 系数 $\tau$ [1] 来衡量相关性。
5.4. DeepMAD for ResNet Family
5.4. 面向ResNet家族的DeepMAD
ResNet family is one of the most popular and classic CNN models in deep learning. We use DeepMAD to redesign ResNet and show that the DeepMAD can generate much better ResNet models. The effectiveness $\rho$ for those original ResNets is computed for easy comparison. First, we use DeepMAD to design a new architecture DeepMADR18 which has the same model size and FLOPs as ResNet18. $\rho$ is tuned in range ${0.1,0.3,0.5,0.7}$ for DeepMADR18. $\rho=0.3$ gives the best architecture. Then, $\rho=0.3$ is fixed in the design of DeepMAD-R34 and DeepMADR50 which align with ResNet-34 and Resnet-50 respectively. As shown in Table 1, compared to He’s original results, DeepMAD-R18 achieves $6.8%$ higher accuracy than ResNet-18 and is even comparable to ResNet-50. Besides, DeepMAD-R50 achieves $3.2%$ better accuracy than the ResNet-50. To ensure the fairness in comparison, the performances of ResNet family under the fair training setting are reported. With our training recipes, the accuracies of ResNet models improved around $1.5%$ . DeepMAD still outperforms the ResNet family by a large margin when both are trained fairly. The inferior performance of ResNet family can be explained by their small $\rho$ which limits their model entropy. This phenomenon again validates our theory discussed in Section 4.3.
ResNet 家族是深度学习中最流行和经典的 CNN 模型之一。我们使用 DeepMAD 重新设计 ResNet,并证明 DeepMAD 可以生成更好的 ResNet 模型。为便于比较,计算了原始 ResNet 模型的有效性指标 $\rho$。首先,我们使用 DeepMAD 设计了一个新架构 DeepMAD-R18,其模型大小和 FLOPs 与 ResNet-18 相同。在 $\rho$ 的取值范围 ${0.1,0.3,0.5,0.7}$ 中,$\rho=0.3$ 为 DeepMAD-R18 带来了最佳架构。接着,在设计 DeepMAD-R34 和 DeepMAD-R50(分别对应 ResNet-34 和 ResNet-50)时固定 $\rho=0.3$。如表 1 所示,与 He 的原始结果相比,DeepMAD-R18 的准确率比 ResNet-18 高出 $6.8%$,甚至可与 ResNet-50 媲美。此外,DeepMAD-R50 的准确率比 ResNet-50 高出 $3.2%$。为确保公平比较,报告了 ResNet 家族在相同训练设置下的性能。采用我们的训练方案后,ResNet 模型的准确率提升了约 $1.5%$。但在公平训练条件下,DeepMAD 仍大幅领先 ResNet 家族。ResNet 家族性能较差的原因在于其较小的 $\rho$ 值限制了模型熵,这一现象再次验证了第 4.3 节讨论的理论。
Table 1. DeepMAD v.s. ResNet on ImageNet-1K, using ResNet building block. $\dagger$ : model trained by our pipeline. $\rho$ is tuned for DeepMAD-R18. DeepMAD achieves consistent improvements compared with ResNet18/34/50 with the same Params and FLOPs.
表 1: DeepMAD 与 ResNet 在 ImageNet-1K 上的对比,使用 ResNet 构建模块。$\dagger$: 由我们的流程训练的模型。$\rho$ 是为 DeepMAD-R18 调整的。在相同参数量和 FLOPs 下,DeepMAD 相比 ResNet18/34/50 实现了持续的提升。
| 模型 | 参数量 | FLOPs | 准确率 (%) |
|---|---|---|---|
| ResNet-18 [21] | 11.7M | 1.8G 0.01 | 70.9 |
| ResNet-18t | 11.7M | 1.8G 0.01 | 72.2 |
| DeepMAD-R18 | 11.7M | 1.8G 0.1 | 76.9 |
| DeepMAD-R18 | 11.7M | 1.8G 0.3 | 77.7 |
| DeepMAD-R18 | 11.7M | 1.8G 0.5 | 77.5 |
| DeepMAD-R18 | 11.7M | 1.8G 0.7 | 75.7 |
| ResNet-34 [21] | 21.8M | 3.6G 0.02 | 74.4 |
| ResNet-34t | 21.8M | 3.6G 0.02 | 75.6 |
| DeepMAD-R34 | 21.8M | 3.6G 0.3 | 79.7 |
| ResNet-50 [21] | 25.6M | 4.1G 0.09 | 77.4 |
| ResNet-50t | 25.6M | 4.1G 0.09 | 79.3 |
| DeepMAD-R50 | 25.6M | 4.1G 0.3 | 80.6 |
5.5. DeepMAD for Mobile CNNs
5.5. 面向移动端CNN的DeepMAD
We use DeepMAD to design mobile CNN models for further exploration. Following previous works, MobileNetV2 block with SE-block are used to build new models. $\rho$ is tuned at Efficient Net-B0 scale in the range of ${0.3,0.5,1.0$ , $1.5,2.0}$ for DeepMAD-B0, and $\rho=0.5$ achieves the best result. Then, we transfer the optimal $\rho$ for DeepMAD-B0 to DeepMAD-MB. As shown in Table 2, the DeepMADB0 achieves $76.1%$ top-1 accuracy which is comparable with the Efficient Net-B0 $(76.3%)$ . It should be noted that Efficient Net-B0 is designed by brute-force grid search which takes around 3800 GPU days [67]. The performance of the DeepMAD-B0 is comparable to the Efficient Net-B0 by simply solving an MP problem on CPU in a few minutes. Aligned with MobileNet-V2 on Params and FLOPs, DeepMAD-MB achieves $72.3%$ top-1 accuracy which is 0.3% higher in accuracy.
我们使用DeepMAD设计移动端CNN模型进行进一步探索。遵循先前工作,采用带SE模块的MobileNetV2模块构建新模型。在EfficientNet-B0规模下调整$\rho$值范围为${0.3,0.5,1.0$,$1.5,2.0}$,其中DeepMAD-B0在$\rho=0.5$时取得最佳结果。随后将该最优$\rho$值迁移至DeepMAD-MB。如表2所示,DeepMAD-B0取得76.1%的top-1准确率,与EfficientNet-B0 $(76.3%)$ 相当。值得注意的是,EfficientNet-B0通过暴力网格搜索设计,耗时约3800 GPU天[67],而DeepMAD-B0仅需在CPU上求解MP问题数分钟即可获得相当性能。在与MobileNet-V2参数量和FLOPs对齐的情况下,DeepMAD-MB取得72.3%的top-1准确率,精度提升0.3%。
Table 2. DeepMAD under mobile setting. Top-1 accuracy on ImageNet-1K. $\rho$ is tuned for DeepMAD-B0.
表 2: 移动场景下的DeepMAD。ImageNet-1K上的Top-1准确率。$\rho$是为DeepMAD-B0调整的。
| 模型 | 参数量 | 计算量(FLOPs) | 准确率(%) |
|---|---|---|---|
| EffNet-B0 [63] | 5.3M | 390M 0.6 | 76.3 |
| DeepMAD-BO | 5.3M | 390M 0.3 | 74.3 |
| DeepMAD-BO | 5.3M | 390M 0.5 | 76.1 |
| DeepMAD-BO | 5.3M | 390M 1.0 | 75.9 |
| DeepMAD-BO | 5.3M | 390M 1.5 | 75.7 |
| DeepMAD-BO | 5.3M | 390M 2.0 | 74.9 |
| MobileNet-V2 [23] | 3.5M | 320M 0.9 | 72.0 |
| DeepMAD-MB | 3.5M | 320M 0.5 | 72.3 |
Table 3. DeepMAD v.s. SOTA ViT and CNN models on ImageNet-1K. $\rho=0.5$ for all DeepMAD models. DeepMAD $29\mathbf{M}^{*}$ : uses $288\mathrm{x}288$ resolution while the Params and FLOPs keeps the same as DeepMAD-29M.
表 3: DeepMAD 与当前最优 (SOTA) ViT 和 CNN 模型在 ImageNet-1K 上的对比。所有 DeepMAD 模型均采用 $\rho=0.5$。DeepMAD $29\mathbf{M}^{*}$ 使用 $288\mathrm{x}288$ 分辨率,同时参数量 (Params) 和计算量 (FLOPs) 保持与 DeepMAD-29M 相同。
| 模型 | 分辨率 | 参数量 | 计算量 | 准确率 (%) |
|---|---|---|---|---|
| ResNet-50 [21] | 224 | 26 M | 4.1G | 77.4 |
| DeiT-S [64] | 224 | 22 M | 4.6G | 79.8 |
| PVT-Small [71] | 224 | 25 M | 3.8G | 79.8 |
| Swin-T [40] | 224 | 29 M | 4.5 G | 81.3 |
| TNT-S [19] | 224 | 24 M | 5.2G | 81.3 |
| T2T-ViTt-14 [79] | 224 | 22 M | 6.1 G | 81.7 |
| ConvNeXt-T [41] | 224 | 29 M | 4.5 G | 82.1 |
| SLaK-T [39] | 224 | 30 M | 5.0G | 82.5 |
| DeepMAD-29M | 224 | 29 M | 4.5 G | 82.5 |
| DeepMAD-29M* | 288 | 29 M | 4.5 G | 82.8 |
| ResNet-101 [21] | 224 | 45 M | 7.8G | 78.3 |
| ResNet-152 [21] | 224 | 60 M | 11.5G | 79.2 |
| PVT-Large [71] | 224 | 61 M | 9.8 G | 81.7 |
| T2T-ViTt-19 [79] | 224 | 39 M | 9.8 G | 82.2 |
| T2T-ViTt-24 [79] | 224 | 64 M | 15.0G | 82.6 |
| TNT-B [19] | 224 | 66 M | 14.1 G | 82.9 |
| Swin-S [40] | 224 | 50M | 8.7G | 83.0 |
| ConvNeXt-S [41] | 224 | 50M | 8.7G | 83.1 |
| SLaK-S [39] | 224 | 55M | 9.8 G | 83.8 |
| DeepMAD-50M | 224 | 50 M | 8.7G | 83.9 |
| DeiT-B/16 [64] | 224 | 87M | 17.6G | 81.8 |
| RepLKNet-31B [16] | 224 | 79 M | 15.3 G | 83.5 |
| Swin-B [40] | 224 | 88 M | 15.4G | 83.5 |
| ConvNeXt-B [41] | 224 | 89 M | 15.4G | 83.8 |
| SLaK-B [39] | 224 | 95M | 17.1 G | 84.0 |
| DeepMAD-89M | 224 | 89 M | 15.4 G | 84.0 |
5.6. DeepMAD for SOTA
5.6. 实现SOTA的DeepMAD
We use DeepMAD to design a SOTA CNN model for ImageNet-1K classification. The conventional MobileNetV2 building block with SE module is used. This DeepMAD network is aligned with Swin-Tiny [40] at 29M Params and 4.5G FLOPs therefore is labeled as DeepMAD-29M. As shown in Table 3, DeepMAD-29M outperforms or is comparable to SOTA ViT models as well as recent modern CNN models. DeepMAD-29M achieves $82.5%$ , which is $2.7%$ higher accuracy than DeiT-S [64] and $1.2%$ higher accuracy than the Swin-T [40]. Meanwhile, DeepMAD-29M is $0.4%$ higher than the ConvNeXt-T [41] which is inspired by the transformer architecture. DeepMAD also designs networks with larger resolution (288), DeepMAD , while keeping the FLOPs and Params not changed. DeepMAD reaches $82.8%$ accuracy and is comparable to Swin-S [40] and ConvNeXt-S [41] with nearly half of their FLOPs. Deep-MAD also achieves better performance on small and base level. Especially, DeepMAD-50M can achieve even better performance than ConvNeXt-B with nearly half of its scale. It proves only with the conventional convolutional layers as building blocks, Deep-MAD achieves comparable or better performance than ViT models.
我们使用DeepMAD为ImageNet-1K分类任务设计了一个SOTA CNN模型。该模型采用带SE模块的传统MobileNetV2构建块。该DeepMAD网络在参数量(29M)和计算量(4.5G FLOPs)上与Swin-Tiny [40]对齐,因此标记为DeepMAD-29M。如 表 3 所示,DeepMAD-29M优于或媲美SOTA ViT模型以及近期现代CNN模型。DeepMAD-29M达到82.5%准确率,比DeiT-S [64]高2.7%,比Swin-T [40]高1.2%。同时,DeepMAD-29M比受Transformer架构启发的ConvNeXt-T [41]高0.4%。DeepMAD还设计了更高分辨率(288)的网络DeepMAD,同时保持FLOPs和参数量不变。DeepMAD 达到82.8%准确率,与FLOPs近乎翻倍的Swin-S [40]和ConvNeXt-S [41]相当。DeepMAD在小型和基础级模型上也表现更优。特别是DeepMAD-50M能以近乎一半的规模实现优于ConvNeXt-B的性能。这证明仅使用传统卷积层作为构建块,DeepMAD就能实现与ViT模型相当或更优的性能。
5.7. Downstream Experiments
5.7. 下游实验
To demonstrate the transfer ability of models designed by DeepMAD, the models solved by DeepMAD play as the backbones on downstream tasks including object detection, semantic segmentation and action recognition.
为验证DeepMAD设计模型的迁移能力,由DeepMAD求解的模型在下游任务(包括目标检测、语义分割和行为识别)中作为骨干网络进行测试。
Object Detection on MS COCO MS COCO is a widely used dataset in object detection. It has 143K images and 80 object categories. The experiments are evaluated on MS COCO [36] with the official training/testing splits. The results in Table 4 are evaluated on val-2017. We use two detection frameworks, FCOS [70] and GFLV2 [34], implemented by mm detection [9]. The DeepMAD-R50 model plays as the backbone of these two detection frameworks. The models are initialized with pre-trained weights on ImageNet and trained for 2X (24 epoches). The multi-scale training trick is also used for the best performance. As shown in Table 4, DeepMAD-R50 achieves 40.0 AP with FCOS [70] , which is 1.5 AP higher than ResNet-50. It also achieves 44.9 AP with GFLV2 [34], which is $1.0\mathrm{AP}$ higher than ResNet-50 again. The performance gain without introducing more Params and FLOPs proves the superiority of DeepMAD on network design.
MS COCO 目标检测
MS COCO 是目标检测领域广泛使用的数据集,包含 14.3 万张图像和 80 个物体类别。实验基于 MS COCO [36] 官方划分的训练集/测试集进行评估。表 4 中的结果在 val-2017 子集上测得。我们采用 mm detection [9] 实现的两种检测框架 FCOS [70] 和 GFLV2 [34],以 DeepMAD-R50 模型作为主干网络。模型加载 ImageNet 预训练权重后,采用 2X 训练策略(24 个周期)并启用多尺度训练以获得最佳性能。如表 4 所示,DeepMAD-R50 在 FCOS [70] 框架下达到 40.0 AP,较 ResNet-50 提升 1.5 AP;在 GFLV2 [34] 框架下达到 44.9 AP,再次以 $1.0\mathrm{AP}$ 优势超越 ResNet-50。在未增加参数量 (Params) 和计算量 (FLOPs) 的前提下实现性能提升,证明了 DeepMAD 在网络设计上的优越性。
Semantic segmentation on ADE20K ADE20K [82] dataset is broadly used in semantic segmentation tasks. It has $25\mathrm{k\Omega}$ images and 150 semantic categories. The experiments are evaluated on ADE20K [82] with the official training/testing splits. The results in Table 5 are reported on testing part using mIoU. UperNet [73] in mmseg [11] is chosen as the segmentation framework. As shown in the first block of Table 5, DeepMAD-R50 achieves 45.6 mIoU on testing, which is 2.8 mIoU higher than ResNet-50, and even $0.8\mathrm{mIoU}$ higher than ResNet-101. To compare to ViT and transformer-inspired models, DeepMAD is used as the backbone in UperNet. As shown in the last block of Table 5, DeepMAD achieves $46.9~\mathrm{mIoU}$ on testing, which is 1.1 mIoU higher than Swin-T and 0.2 mIoU higher than ConvNeXt-T, with the same model size and less computation cost. It proves the advantage of CNN models designed by DeepMAD compared to transformer-based or transformer-inspired models.
ADE20K数据集上的语义分割
ADE20K [82] 数据集广泛用于语义分割任务。它包含 $25\mathrm{k\Omega}$ 张图像和150个语义类别。实验在ADE20K [82] 上按照官方划分的训练/测试集进行评估。表5中的结果采用mIoU指标在测试集上报告。选用mmseg [11] 中的UperNet [73] 作为分割框架。如表5第一栏所示,DeepMAD-R50在测试集上达到45.6 mIoU,比ResNet-50高出2.8 mIoU,甚至比ResNet-101高出 $0.8\mathrm{mIoU}$ 。为与ViT及Transformer衍生模型对比,UperNet采用DeepMAD 作为主干网络。如表5最后一栏所示,DeepMAD 在测试集上取得 $46.9~\mathrm{mIoU}$ ,以相同模型尺寸和更低计算成本,比Swin-T高1.1 mIoU,比ConvNeXt-T高0.2 mIoU。这证明了DeepMAD设计的CNN模型相较于基于Transformer或受Transformer启发的模型具有优势。
Table 4. DeepMAD for object detection and instance segmentation on MS COCO [36] with GFLV2 [34], FCOS [70], Mask RCNN [20] and Cascade Mask R-CNN [7] frameworks. Backbones are pre-trained on ImageNet-1K. FLOPs and Params are counted for Backbone.
表 4: DeepMAD 在 MS COCO [36] 数据集上使用 GFLV2 [34]、FCOS [70]、Mask RCNN [20] 和 Cascade Mask R-CNN [7] 框架进行目标检测和实例分割的性能。主干网络在 ImageNet-1K 上预训练。FLOPs 和参数量统计仅针对主干网络。
| Backbone | #Param. | FLOPs | AP |
|---|---|---|---|
| FCOS | |||
| ResNet-50 | 23.5 M | 84.1 G | 38.5 |
| DeepMAD-R50 | 24.2 M | 83.2 G | 40.0 |
| GFLV2 | |||
| ResNet-50 | 23.5 M | 84.1 G | 43.9 |
| DeepMAD-R50 | 24.2 M | 83.2 G | 44.9 |
Table 5. DeepMAD for semantic segmentation on ADE20K [82]. All models are pre-trained on the ImageNet-1K and then finetuned using UperNet [73] framework. FLOPs and Params are counted for Backbone.
表 5: DeepMAD 在 ADE20K [82] 语义分割任务上的表现。所有模型均在 ImageNet-1K 上预训练,并使用 UperNet [73] 框架进行微调。FLOPs 和参数量统计仅针对主干网络。
| Backbone | 参数量 | FLOPs | mIoU |
|---|---|---|---|
| ResNet-50 | 23.5M | 86.3 G | 42.8 |
| ResNet-101 | 42.5M | 164.3G | 44.8 |
| DeepMAD-R50 | 24.2M | 85.2 G | 45.6 |
| Swin-T | 27.5M | 95.8 G | 45.8 |
| ConvNeXt-T | 27.8M | 93.2 G | 46.7 |
| DeepMAD-29M | 26.5M | 55.5 G | 46.9 |
Table 6. DeepMAD for action recognition on UCF-101 [58] and Kinetics-400 [27] with the TSN [69] framework. Backbones are pre-trained on the ImageNet-1K. FLOPs and Params are counted for Backbone.
表 6: 基于TSN [69]框架的DeepMAD在UCF-101 [58]和Kinetics-400 [27]动作识别任务中的表现。主干网络在ImageNet-1K上进行预训练。FLOPs和参数量统计针对主干网络。
| Backbone | # Param. | FLOPs | Acc. (%) |
|---|---|---|---|
| UCF-101 | |||
| ResNet-50 | 23.5 M | 7.3G | 83.0 |
| DeepMAD-R50 | 24.2 M | 7.3 G | 86.9 |
| Kinetics-400 | |||
| ResNet-50 | 23.5 M | 7.3 G | 70.6 |
| DeepMAD-R50 | 24.2 M | 7.3 G | 71.6 |
Action recognition on UCF101 and Kinetics 400 The UCF101 [58] dataset contains 13,320 video clips, covering 101 action classes. The Kinetics 400 [27] dataset contains 400 human action classes, with more than 400 video clips for each action. They are both widely used in action recognition tasks. The results in Table 6 are reported on the testing part using top-1 accuracy. TSN [69] is adopted in mmaction [12] on UCF101 with split1 and Kinetics 400 with official training/testing splits. As shown in Table 6, DeepMAD-R50 achieves $86.9%$ accuracy on UCF101 which is $3.9%$ higher than ResNet-50, and achieves $71.6%$ accuracy on Kinetics 400 which is $1.0%$ higher than ResNet-50, with the same model size and computation cost. It shows that the models solved by DeepMAD can also be generalized to the recognition task on video datasets.
UCF101和Kinetics 400上的动作识别
UCF101 [58]数据集包含13,320个视频片段,涵盖101个动作类别。Kinetics 400 [27]数据集包含400个人类动作类别,每个动作有超过400个视频片段。这两个数据集均被广泛用于动作识别任务。表6中的结果采用top-1准确率在测试集上报告。mmaction [12]在UCF101(使用split1划分)和Kinetics 400(使用官方训练/测试划分)中采用了TSN [69]方法。如表6所示,DeepMAD-R50在UCF101上达到86.9%准确率(比ResNet-50高3.9%),在Kinetics 400上达到71.6%准确率(比ResNet-50高1.0%),且模型参数量和计算成本相同。这表明DeepMAD优化的模型也能泛化到视频数据集的识别任务中。
5.8. Ablation Study
5.8. 消融研究
In this section, we ablate important hyper-parameters and empirical guidelines in DeepMAD, with image classification on ImageNet-1K and object detection on COCO dataset. The complexity comparison is in Appendix F.
在本节中,我们通过ImageNet-1K图像分类和COCO数据集目标检测任务,对DeepMAD的重要超参数与实证指导原则进行消融研究。复杂度对比见附录F。
Ablation on entropy weights We generate networks with conventional convolution building blocks and different weight ratios $\alpha_{i}$ . The ratio $\alpha_{5}$ is tuned in ${1,816}$ while the others are set to 1 as in [60]. As shown in Table 7, larger final stage weight can improve the performance on image classification task, while a smaller one can improve the performance on downstream task (object detection). For different tasks, additional improvements can be obtained by fine-tuning $\alpha_{5}$ . However, this work uses $\alpha_{5}=8$ setting as the balance between the image classification task and object detection task. The experiments above have verified the advantage of DeepMAD on different tasks with global $\alpha_{5}$ .
关于熵权重的消融实验
我们采用传统卷积构建模块和不同权重比例$\alpha_{i}$生成网络。其中$\alpha_{5}$在${1,8,16}$范围内调整,其余权重按[60]设为1。如表7所示,较大的最终阶段权重能提升图像分类任务性能,而较小权重则有利于下游任务(目标检测)的表现。针对不同任务,通过微调$\alpha_{5}$可获得额外提升。但本研究采用$\alpha_{5}=8$的设置,以平衡图像分类与目标检测任务。上述实验验证了DeepMAD采用全局$\alpha_{5}$时在多任务中的优势。
表7:
Ablation on the three empirical guidelines We generate networks using Mobilenet-V2 block with SE module and remove one of the three empirical guidelines discussed in Section 4.2 at each time to explore their influence. As shown in Table 8, removing any one of the three guidelines will degrade the performance of the model. Particularly, the third guideline is the most critical one for DeepMAD.
对三条经验性准则的消融实验
我们采用带SE模块的Mobilenet-V2模块生成网络,并依次移除第4.2节讨论的三条经验性准则中的一条以探究其影响。如表8所示,移除任意一条准则都会降低模型性能。其中,第三条准则对DeepMAD最为关键。
6. Limitations
6. 局限性
As no research is perfect, DeepMAD has several limitations as well. First, three empirical guidelines discussed in Section 4.2 do not have strong theoretical foundation. Hopefully, they can be removed or replaced in the future. Second, DeepMAD has several hyper-parameters to tune, such as ${\alpha_{i}}$ and ${\beta,\rho}$ . Third, DeepMAD focuses on conventional CNN layers at this stage while there are many more powerful and more modern building blocks such as transformers. It is potentially possible to generalize DeepMAD to these building blocks as well in future works.
由于没有研究是完美的,DeepMAD也存在若干局限性。首先,第4.2节讨论的三条经验性准则缺乏坚实的理论基础,未来有望被移除或替代。其次,DeepMAD需要调整多个超参数,例如${\alpha_{i}}$和${\beta,\rho}$。第三,当前DeepMAD主要针对传统CNN层,而如今存在Transformer等更强大、更现代的模块组件,未来工作有望将DeepMAD推广至这些模块。
Table 7. The performance on ImageNet-1k and COCO dataset of DeepMAD-R18 with different final stage weight $\alpha_{5}$ . $\alpha_{5}~=~8$ balances the good performance between classification and object detection and is adopted in this work.
表 7: 不同最终阶段权重 $\alpha_{5}$ 下 DeepMAD-R18 在 ImageNet-1k 和 COCO 数据集上的性能。$\alpha_{5}~=~8$ 平衡了分类和目标检测的良好性能,并在本工作中采用。
| 模型 | 参数量 | FLOPs 05 | 准确率 (%) |
|---|---|---|---|
| DeepMAD-R18 | 11.7 M | 1.8 G | 76.7 |
| DeepMAD-R18 | 11.7 M | 8 | 77.7 |
| DeepMAD-R18 | 11.7 M | 16 | 78.7 |
| 骨干网络 | 参数量 FLOPs | 05 | AP (%) |
| DeepMAD-R18 | 9.8 M | 37.0G | 35.1 |
| DeepMAD-R18 | 11.0M | 36.8 G | 34.6 |
| DeepMAD-R18 | 11.1 M | 36.8 G | 34.1 |
Table 8. Top-1 accuracies on ImageNet-1K of DeepMAD-B0 with different combination of guidelines. The model designed with all three guidelines achieves the best results. All models are trained for 120 epochs.
表 8: 采用不同准则组合的 DeepMAD-B0 在 ImageNet-1K 上的 Top-1 准确率。采用全部三项准则设计的模型取得了最佳结果。所有模型均训练 120 个周期。
| Guideline1 | Guideline2 | Guideline3 | Acc. (%) |
|---|---|---|---|
| × | √ | √ | 73.5 |
| √ | × | √ | 73.5 |
| √ | √ | × | 73.1 |
| √ | √ | √ | 73.7 |
7. Conclusion
7. 结论
We propose a pure mathematical framework DeepMAD for designing high-performance convolutional neural networks. The key idea of the DeepMAD is to maximize the network entropy while keeping network effectiveness bounded by a small constant. We show that DeepMAD can design SOTA CNN models that are comparable to or even better than ViT models and modern CNN models. To demonstrate the power of DeepMAD, we only use conventional convolutional building blocks, like ResNet block, and depth-wise convolution in MobileNet-V2. Without bells and whistles, DeepMAD achieves competitive performance using these old-school building blocks. This encouraging result implies that the full potential of the conventional CNN models has not been fully released due to the previous sub-optimal design. Hope this work can attract more research attention to theoretical deep learning in the future.
我们提出了一种纯数学框架DeepMAD,用于设计高性能卷积神经网络。DeepMAD的核心思想是在保持网络有效性受限于一个较小常数的前提下,最大化网络熵。研究表明,DeepMAD能设计出与ViT模型及现代CNN模型相媲美甚至更优的SOTA CNN模型。为展示DeepMAD的强大能力,我们仅采用传统卷积构建模块(如ResNet块)和MobileNet-V2中的深度可分离卷积。在不使用任何花哨技巧的情况下,DeepMAD使用这些传统模块就实现了极具竞争力的性能。这一振奋人心的结果表明,由于先前次优的设计,传统CNN模型的全部潜力尚未被充分释放。希望这项工作能吸引更多研究者未来关注理论深度学习领域。
8. Acknowledgment
8. 致谢
This work was supported by Alibaba Research Intern Program and National Science Foundation CCF-1919117.
本研究获得阿里巴巴研究实习计划和国家科学基金会CCF-1919117项目资助。
References
参考文献
A. Proof of Theorem 1
A. 定理1的证明
According to [13,42,46,65], we have the following lemmas.
根据[13,42,46,65],我们有以下引理。
Lemma 1. The differential entropy $H(x)$ of random variable $x\sim\mathcal{N}(0,\sigma)$ is
引理 1. 随机变量 $x\sim\mathcal{N}(0,\sigma)$ 的微分熵 $H(x)$ 为
$$
H(x)\propto l o g(\sigma^{2}).
$$
$$
H(x)\propto l o g(\sigma^{2}).
$$
Lemma 2. For any random variable $x$ , its differential entropy $H(x)$ is bounded by its Gaussian entropy upper bound
引理2. 对于任意随机变量$x$,其微分熵$H(x)$受限于其高斯熵上界
$$
H(x)\leq c\log[\sigma^{2}(x)],
$$
$$
H(x)\leq c\log[\sigma^{2}(x)],
$$
where $c>0$ is a universal constant, $\sigma(x)$ is the standard deviation of $x$ .
其中 $c>0$ 是一个通用常数,$\sigma(x)$ 是 $x$ 的标准差。
The laws of expectation and variance of product of random variables are
随机变量乘积的期望与方差法则
$$
\mathbb{E}(\prod_{1}^{N}x_{i})=\prod_{1}^{N}\mathbb{E}(x_{i}),
$$
$$
\mathbb{E}(\prod_{1}^{N}x_{i})=\prod_{1}^{N}\mathbb{E}(x_{i}),
$$
and
和
$$
\begin{array}{r}{\sigma^{2}(x_{i}x_{j})=\sigma^{2}(x_{i})\sigma^{2}(x{j})+\sigma^{2}(x_{i}){\mathbb E}^{2}(x_{j})+}\ {\sigma^{2}(x_{j}){\mathbb E}^{2}(x_{i}).}\end{array}
$$
$$
\begin{array}{r}{\sigma^{2}(x_{i}x_{j})=\sigma^{2}(x_{i})\sigma^{2}(x_{j})+\sigma^{2}(x_{i}){\mathbb E}^{2}(x_{j})+}\ {\sigma^{2}(x_{j}){\mathbb E}^{2}(x_{i}).}\end{array}
$$
Suppose that in an $L$ -layer MLP $f(\cdot)$ , the $i$ -th layer has $w{i}$ input channels and $w{i+1}$ output channels. The trainable weights in $i$ -th layer is denoted by $\mathbf{M}{i}\in\mathbb{R}^{w{i+1}\times w{i}}$ . For simplicity, we assume that each element $\mathbf{x}{1}^{j}$ in $\mathbf{x}{1}$ and each element $\mathbf{M}{i}^{j,k}$ in $\mathbf{M}{i}$ follow the standard normal distribution, i.e.
假设在一个 $L$ 层 MLP $f(\cdot)$ 中,第 $i$ 层有 $w{i}$ 个输入通道和 $w{i+1}$ 个输出通道。第 $i$ 层的可训练权重记为 $\mathbf{M}{i}\in\mathbb{R}^{w{i+1}\times w{i}}$。为简化起见,我们假设 $\mathbf{x}{1}$ 中的每个元素 $\mathbf{x}{1}^{j}$ 和 $\mathbf{M}{i}$ 中的每个元素 $\mathbf{M}{i}^{j,k}$ 都服从标准正态分布,即

According to Eqs. (8) to (12), in $i$ -th layer, the output $\mathbf{x}{i+1}$ and the input $\mathbf{x}{i}$ are connected by $\mathbf{x}{i+1}=\mathbf{M}{i}\mathbf{x}{i}$ . The
根据式(8)至(12),在第$i$层中,输出$\mathbf{x}{i+1}$与输入$\mathbf{x}{i}$通过$\mathbf{x}{i+1}=\mathbf{M}{i}\mathbf{x}{i}$相关联。
expectation of $j$ -th element in $\mathbf{x}{i+1}$ is
$\mathbf{x}{i+1}$ 中第 $j$ 个元素的期望是

According to Eqs. (8) to (14), the variance of $j$ -th element in $\mathbf{x}_{i+1}$ is
根据式(8)至(14),$\mathbf{x}_{i+1}$中第$j$个元素的方差为

With the variances propagating in networks and $\mathbf{x}_{1}^{j}\sim$ $\mathcal{N}(0,1)$ in Eq. 12, the variance of $j$ -th element in $L$ -th layer is
随着方差在网络中传播且式12中$\mathbf{x}_{1}^{j}\sim\mathcal{N}(0,1)$,第$L$层第$j$个元素的方差为

According to Eq. 6, the entropy of each element $\boldsymbol{x}_{L}^{j}$ of $L$ -th MLP is
根据式6,第L层MLP的每个元素$\boldsymbol{x}_{L}^{j}$的熵为

After considering the width of the output feature vector, the normalized Gaussian entropy upper bound of the $L$ -th feature map of MLP $f(\cdot)$ is
在考虑输出特征向量的宽度后,MLP $f(\cdot)$ 的第 $L$ 个特征图的归一化高斯熵上界为
$$
H_{f}=w_{L+1}\sum_{i=1}^{L}\log(w_{i}).
$$
$$
H_{f}=w_{L+1}\sum_{i=1}^{L}\log(w_{i}).
$$

Figure 4. DeepMAD v.s. SOTA ViT and CNN models on ImageNet-1K. $\rho=0.5$ for all DeepMAD models. All DeepMAD models excep DeepMAD $\boldsymbol{\cdot}29\mathbf{M}^{*}$ is trained with 224 resolution. $\mathbf{X}$ -axis is the Params, the smaller the better. y-axis is the accuracy, the larger the better.
图 4: DeepMAD 与 SOTA ViT 及 CNN 模型在 ImageNet-1K 上的对比。所有 DeepMAD 模型的 $\rho=0.5$。除 DeepMAD $\boldsymbol{\cdot}29\mathbf{M}^{*}$ 外,其他 DeepMAD 模型均以 224 分辨率训练。$\mathbf{X}$ 轴为参数量 (Params),越小越好;y 轴为准确率 (accuracy),越高越好。
B. Proof of Proposition 1
B. 命题1的证明
Assume there is an MLP model $f_{A}(\cdot)$ that has $L$ -layers with different width $w_{i}$ , and the entropy of the MLP model is $H$ . To define the “average width” of $f_{A}(\cdot)$ , we compare $f_{A}(\cdot)$ to a new MLP $f_{B}(\cdot).f_{B}(\cdot)$ also has $L$ -layers but with all layers sharing the same width $\bar{w}$ . Suppose that the two networks have the same entropy for each output neuron, that is,
假设存在一个多层感知机 (MLP) 模型 $f_{A}(\cdot)$,它具有 $L$ 层不同宽度 $w_{i}$,且该 MLP 模型的熵为 $H$。为了定义 $f_{A}(\cdot)$ 的"平均宽度",我们将 $f_{A}(\cdot)$ 与一个新的 MLP $f_{B}(\cdot)$ 进行比较。$f_{B}(\cdot)$ 也有 $L$ 层,但所有层共享相同的宽度 $\bar{w}$。假设这两个网络每个输出神经元的熵相同,即
$$
H_{f_{a}}=\sum_{i=1}^{L}\log(w_{i}),\quad H_{f_{b}}=L\cdot\log(\bar{w}).
$$
$$
H_{f_{a}}=\sum_{i=1}^{L}\log(w_{i}),\quad H_{f_{b}}=L\cdot\log(\bar{w}).
$$
When the above equality holds true(i.e., $H_{f_{a}}=H_{f_{b}},$ ), we can have the following equation,
当上述等式成立时(即 $H_{f_{a}}=H_{f_{b}},$ ),我们可以得到以下方程,
$$
\sum_{i=1}^{L}\log(w_{i})=L\cdot\log(\bar{w}).
$$
$$
\sum_{i=1}^{L}\log(w_{i})=L\cdot\log(\bar{w}).
$$
Therefore, we define $\bar{w}$ as the “average width” of $f_{A}(\cdot)$ . Then we derive the definition of average width of MLP in Proposition 1 as following,
因此,我们将 $\bar{w}$ 定义为 $f_{A}(\cdot)$ 的"平均宽度"。随后在命题1中推导出MLP平均宽度的定义如下:
$$
\bar{w}=\exp\left(\frac{1}{L}\sum_{i=1}^{L}\log w_{i}\right).
$$
$$
\bar{w}=\exp\left(\frac{1}{L}\sum_{i=1}^{L}\log w_{i}\right).
$$
C. SOTA DeepMAD Models
C. 最先进的 DeepMAD 模型
We provide more SOTA DeepMAD models in Figure 4. Especially, Deep-MAD achieves better performance on small and base level. DeepMAD-50M can achieve $83.9%$ top-1 accuracy, which is even better than ConvNeXtBase [41] with nearly only half of its scale. DeepMAD89M achieves $84.0%$ top-1 accuracy at the “base” scale, outperforming ConvNeXt-Base and Swin-Base [40], and achieves similar accuracy with SLaK-Base [39] with less computation cost and smaller model size. On “tiny” scale, DeepMAD-29M also achieves $82.8%$ top-1 accuracy under 4.5G FLOPs and 29M Params. It is $1.5%$ higher than SwinTiny with the same scale, and is $2.2\mathbf{x}$ reduction in Params and $3.3\mathrm{x}$ reduction in FLOPs compared to T2T-24 [79] with $0.2%$ higher accuracy. Therefore, we can find that building networks only with convolutional blocks can achieve better performance than those networks built with vision transformer blocks, which shows the potentiality of the convolutional blocks.
我们在图4中提供了更多SOTA(State Of The Art)的DeepMAD模型。特别地,DeepMAD在小型和基础级别上表现更优。DeepMAD-50M能达到83.9%的top-1准确率,甚至优于规模近乎其两倍的ConvNeXtBase [41]。DeepMAD-89M在"基础"规模下取得84.0%的top-1准确率,超越ConvNeXt-Base和Swin-Base [40],并以更少的计算成本和更小的模型尺寸达到与SLaK-Base [39]相近的精度。在"微型"规模上,DeepMAD-29M仅需4.5G FLOPs和2900万参数就实现82.8%的top-1准确率,比同规模的SwinTiny高出1.5%,相比T2T-24 [79]参数减少2.2倍、FLOPs降低3.3倍的同时准确率还提升0.2%。这表明仅用卷积模块构建的网络能比视觉Transformer模块构建的网络表现更好,展现了卷积模块的潜力。
D. DeepMAD Optimized for GPU Inference Throughput
D. 针对 GPU 推理吞吐量优化的 DeepMAD
We optimize GPU inference throughput using DeepMAD. To measure the throughput, we use float32 precision (FP32) and increase the batch size for each model until no more images can be loaded in one mini-batch inference. The throughput is tested on NVIDIA V100 GPU with 16 GB Memory. ResNet building block is used as our design space.
我们使用DeepMAD优化GPU推理吞吐量。为测量吞吐量,采用float32精度(FP32),并逐步增大各模型的批量大小(batch size),直至单次小批量推理无法加载更多图像。吞吐量测试基于配备16GB显存的NVIDIA V100 GPU,设计空间采用ResNet构建块。
To align with the throughput of ResNet-50 and SwinTiny on GPU, we first use DeepMAD to design networks of different Params and FLOPs. Then we test throughput for all models. Among these models, we choose two models labeled as DeepMAD-R50-GPU and DeepMAD-ST-GPU such that the two models are aligned with ResNet-50 and Swin-Tiny respectively. The top-1 accuracy on ImageNet1k are reported in Table 9.
为了与GPU上ResNet-50和SwinTiny的吞吐量对齐,我们首先使用DeepMAD设计不同参数量(Params)和计算量(FLOPs)的网络。随后测试所有模型的吞吐量,从中选出两个分别与ResNet-50和Swin-Tiny对齐的模型,标记为DeepMAD-R50-GPU和DeepMAD-ST-GPU。表9展示了这些模型在ImageNet1k数据集上的top-1准确率。
Table 9. DeepMAD models optimized for throughput on GPU. ‘Res’: image resolution.
表 9. 针对 GPU 吞吐量优化的 DeepMAD 模型。'Res':图像分辨率。
| 方法 | Res. | #Param. | Throughput | FLOPs | Acc.(%) |
|---|---|---|---|---|---|
| ResNet-50 | 224 | 26M | 1245 | 25.6G | 77.4 |
| DeepMAD-R50-GPU | 224 | 19 M | 1171 | 3.0G | 80.0 |
| Swin-Tiny | 224 | 29 M | 750 | 4.5 G | 81.3 |
| DeepMAD-ST-GPU | 224 | 40 M | 767 | 6.0G | 81.7 |
E. Other Experiments Results
E. 其他实验结果
We fine-tune the effectiveness $\rho$ in Table 10. Comparing to the results in the main text, we can achieve better accuracy when $\rho$ is fine-tuned.
我们在表10中微调了有效性$\rho$。与正文中的结果相比,微调$\rho$后可以获得更高的准确率。
Table 10. Fine-tuned $\rho$ in DeepMAD. ‘Res’: image resolution.
表 10. DeepMAD 中微调的 $\rho$ 值。'Res':图像分辨率。
| 方法 | p | Res. | #Param. | FLOPs | Acc.(%) |
|---|---|---|---|---|---|
| ResNet-18[21] | 0.01 | 224 | 11.7 M | 1.8 G | 70.9 |
| DeepMAD-R18 | 0.3 | 224 | 11.7 M | 1.8 G | 77.7 |
| DeepMAD-R18 | 0.15 | 224 | 11.7 M | 1.8 G | 78.2 |
| ResNet-34[21] | 0.02 | 224 | 21.8 M | 3.6 G | 74.4 |
| DeepMAD-R34 | 0.3 | 224 | 21.8 M | 3.6 G | 79.7 |
| DeepMAD-R34 | 0.15 | 224 | 21.8 M | 3.6 G | 80.3 |
| MobileNet-V2[23] | 0.9 | 224 | 3.5 M | 320 M | 72.0 |
| DeepMAD-MB | 0.5 | 224 | 3.5 M | 320 M | 72.3 |
| DeepMAD-MB | 1 | 224 | 3.5 M | 320 M | 72.9 |
F. Complexity Comparison with NAS Methods
F. 与NAS方法的复杂度对比
DeepMAD is also compared with classical NAS works in complexity as well as accuracy on ImageNet-1K. The classical NAS methods [6, 38, 49, 76, 83] need to train a considerable number of networks and evaluate them the in searching phase, which is time-consuming and computingconsuming. DeepMAD need not train any model in the search phase, and it just needs to solve the MP problem to obtain optimized network architectures in a few minutes. As shown in Table 11, DeepMAD takes only a few minutes to search for a network that can achieve better accuracy $(76.1%)$ than other NAS methods. It should be noted that Table 11 only consider the search time cost and does not consider the training time cost. However, DeepMAD only needs one training process to produce a high-accuracy model with trained weights, while these baseline methods train multiple times.
DeepMAD 还与经典 NAS (Neural Architecture Search) 工作在复杂度和 ImageNet-1K 准确率方面进行了对比。经典 NAS 方法 [6, 38, 49, 76, 83] 需要在搜索阶段训练大量网络并进行评估,这非常耗时且计算资源密集。DeepMAD 在搜索阶段无需训练任何模型,仅需通过求解 MP (Mathematical Programming) 问题即可在几分钟内获得优化后的网络架构。如表 11 所示,DeepMAD 仅需几分钟即可搜索到准确率 $(76.1%)$ 优于其他 NAS 方法的网络。需要注意的是,表 11 仅统计了搜索阶段耗时,未包含训练时间成本。但 DeepMAD 仅需单次训练即可生成带权重的高精度模型,而基线方法需要进行多次训练。
Table 11. Complexity and accuracy comparison with NAS Methods on ImageNet-1K.
表 11. ImageNet-1K 上 NAS 方法的复杂度与准确率对比
| 方法 | 参数量 | FLOPs | 准确率(%) | 搜索成本 (GPU 小时) |
|---|---|---|---|---|
| NASNet-A[83] | 5.3 M | 564 M | 74.0 | 48,000 |
| ProxylessNAS[6] | 5.8 M | 595 M | 76.0 | 200 |
| PNAS [38] | 5.1 M | 588 M | 74.2 | 5,400 |
| SNAS [76] | 4.3 M | 522 M | 72.7 | 36 |
| AmoebaNet-A[49] | 5.1 M | 555 M | 74.5 | 75,600 |
| DeepMAD | 5.3 M | 390 M | 76.1 | <1 (CPU 小时) |
G. Discussion on Architectures
G. 架构探讨
Figure 5 shows as effectiveness $\rho$ increases, the depth of networks increases while the width decreases. As discussed in Section 5.3, the model accuracy does not always increase with $\rho$ . When $\rho$ is small, model accuracy increases as depth increases and width decreases. When $\rho$ is large, the opposite phenomenon occurs. The existence of an optimal effectiveness means the existence of optimal depth and width of networks to reach the best accuracy.
图 5 显示随着有效性 $\rho$ 增加,网络深度增加而宽度减小。如第 5.3 节所述,模型精度并不总是随 $\rho$ 增加而提升。当 $\rho$ 较小时,模型精度随深度增加和宽度减小而提高;当 $\rho$ 较大时,则出现相反现象。最优有效性的存在意味着存在使精度达到最佳的网络深度与宽度组合。
The architectures of DeepMAD models are released along with the source codes. Compared to ResNet families, DeepMAD suggests deeper and thinner structures. The final stage of DeepMAD networks is also deeper. The width expansion after each down sampling layer is around 1.2-1.5, which smaller than 2 in ResNets.
DeepMAD模型的架构与源代码一同发布。相比ResNet系列,DeepMAD采用了更深更窄的结构。DeepMAD网络的最终阶段也更深。每个下采样层后的宽度扩展约为1.2-1.5倍,小于ResNet中的2倍。

Figure 5. Effectiveness $\rho$ v.s. the depth and width of each generated network on CIFAR-100. The architectures shown in this figure are same as those shown in Figure 2. The depth increases with $\rho$ monotonically while the width decreases at the same time.
图 5: CIFAR-100数据集上生成网络深度与宽度对有效性$\rho$的影响。本图展示的架构与图2相同。随着$\rho$单调增加,网络深度相应增加,同时宽度减小。
H. Experiment Settings
H. 实验设置
The detailed training hyper-parameters for CIFAR-100 and ImageNet-1K datasets are reported in Table 12.
CIFAR-100和ImageNet-1K数据集的详细训练超参数见表12。
Table 12. Experiment Settings.
表 12: 实验设置。
| 超参数 | CIFAR-100 | ImageNet-1K |
|---|---|---|
| 预热轮数 | 5 | 20 |
| 冷却轮数 | 0 | 10 |
| 总训练轮数 | 1440 | 480 |
| 优化器 | SGD | SGD |
| 批归一化动量 | 0.01 | 0.01 |
| 权重衰减 | 5e-4 | 5e-5 |
| 使用Nesterov动量 | True | True |
| 学习率调度器 | cosine | cosine |
| 标签平滑 | 0.1 | 0.1 |
| MixUp混合系数 | 0.2 | 0.8 |
| CutMix混合系数 | 0 | 1.0 |
| MixUp切换概率 | 0.5 | 0.5 |
| 裁剪比例 | 0.875 | 0.95 |
| 随机擦除概率 | 0.5 | 0.2 |
| 自动数据增强 | auto [14] | rand-m9-mstd0.5 |
| 初始学习率 | 0.2 | 0.8 |
| 批量大小 | 512 | 2048 |
| 自动混合精度 (AMP) | False | True |