PromptKD: Unsupervised Prompt Distillation for Vision-Language Models
PromptKD: 视觉-语言模型的无监督提示蒸馏
Abstract
摘要
Prompt learning has emerged as a valuable technique in enhancing vision-language models (VLMs) such as CLIP for downstream tasks in specific domains. Existing work mainly focuses on designing various learning forms of prompts, neglecting the potential of prompts as effective distillers for learning from larger teacher models. In this paper, we introduce an unsupervised domain prompt distillation framework, which aims to transfer the knowledge of a larger teacher model to a lightweight target model through prompt-driven imitation using unlabeled domain images. Specifically, our framework consists of two distinct stages. In the initial stage, we pre-train a large CLIP teacher model using domain (few-shot) labels. After pretraining, we leverage the unique decoupled-modality charact eris tics of CLIP by pre-computing and storing the text features as class vectors only once through the teacher text encoder. In the subsequent stage, the stored class vectors are shared across teacher and student image encoders for calculating the predicted logits. Further, we align the logits of both the teacher and student models via KL divergence, encouraging the student image encoder to generate similar probability distributions to the teacher through the learnable prompts. The proposed prompt distillation process eliminates the reliance on labeled data, enabling the algorithm to leverage a vast amount of unlabeled images within the domain. Finally, the well-trained student image encoders and pre-stored text features (class vectors) are utilized for inference. To our best knowledge, we are the first to (1) perform unsupervised domain-specific prompt-driven knowledge distillation for CLIP, and (2) establish a practical pre-storing mechanism of text features as shared class vectors between teacher and student. Extensive experiments on 11 datasets demonstrate the effectiveness of our method. Code is publicly available at https://github.com/
提示学习 (Prompt learning) 已成为增强视觉语言模型 (VLMs) (如 CLIP)在特定领域下游任务表现的重要技术。现有研究主要集中于设计多样化的提示学习形式,却忽视了提示作为从大型教师模型中提取知识的有效蒸馏器的潜力。本文提出了一种无监督领域提示蒸馏框架,旨在通过未标注领域图像的提示驱动模仿,将大型教师模型的知识迁移至轻量级目标模型。具体而言,该框架包含两个阶段:第一阶段使用领域(少样本)标签预训练大型 CLIP 教师模型;预训练完成后,利用 CLIP 特有的解耦模态特性,通过教师文本编码器一次性预计算并存储文本特征作为类别向量。第二阶段中,存储的类别向量在教师与学生图像编码器间共享,用于计算预测逻辑值。此外,我们通过 KL 散度对齐教师与学生模型的逻辑值,促使学生图像编码器通过可学习提示生成与教师相似的概率分布。所提出的提示蒸馏过程摆脱了对标注数据的依赖,使算法能够利用领域内大量未标注图像。最终,训练完成的学生图像编码器与预存储的文本特征(类别向量)将用于推理。据我们所知,这是首次 (1) 为 CLIP 实现无监督领域特定提示驱动知识蒸馏;(2) 建立文本特征预存储机制作为师生共享的类别向量。在 11 个数据集上的大量实验验证了方法的有效性。代码公开于 https://github.com/
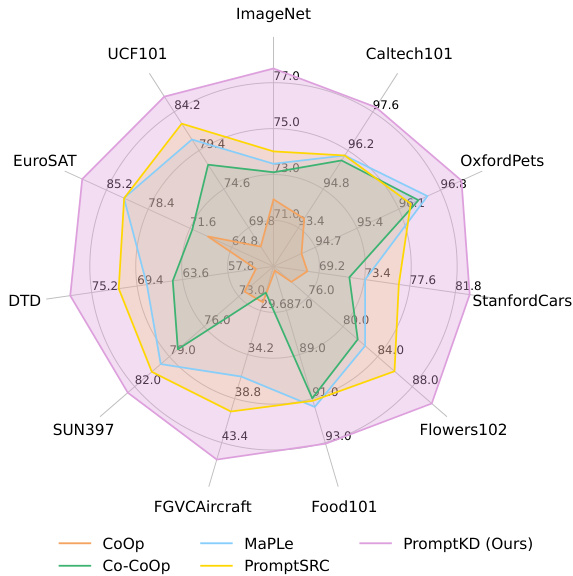
Figure 1. Harmonic mean (HM) comparison on base-to-novel genera liz ation. All methods adopt the ViT-B/16 image encoder from the pre-trained CLIP model. PromptKD achieves state-of-the-art performance on 11 diverse recognition datasets.
图 1: 基类到新类泛化的调和平均数 (HM) 对比。所有方法均采用预训练 CLIP 模型中的 ViT-B/16 图像编码器。PromptKD 在 11 个不同识别数据集上实现了最先进的性能。
zhengli97/PromptKD.
zhengli97/PromptKD。
1. Introduction
1. 引言
Recently large pretrained vision-language models (VLMs), such as CLIP [41, 68] and ALIGN [17], have demonstrated superior generalization ability for domain-specific downstream tasks. Unlike conventional visual frameworks, the vision-language model, like CLIP, usually employs a twotower architecture that includes an image encoder and a text encoder. These models are trained using a contrastive loss to learn a unified embedding space that aligns the representations of multi-modal signals.
最近,大型预训练视觉语言模型 (VLM) ,如 CLIP [41, 68] 和 ALIGN [17] ,在特定领域下游任务中展现出卓越的泛化能力。与传统视觉框架不同,CLIP 等视觉语言模型通常采用双塔架构,包含图像编码器和文本编码器。这些模型通过对比损失进行训练,以学习对齐多模态信号表征的统一嵌入空间。
To better optimize the models for domain-specific downstream tasks, various methods [10, 21, 65, 71, 72] have been proposed to adapt the representation while keeping the original CLIP model fixed. Inspired by the success of Nature Language Processing (NLP) [26, 28] area, prompt learning [18, 71, 72] has been proposed to acquire continuous prompt representations as a replacement for meticulously designed hard prompts. Based on the type of information learned by prompt, existing methods can be roughly divided into three types: text-based, visual-based, and both. Textbased methods [71, 72] propose to adaptively learn appropriate text prompts for downstream tasks, rather than fixed forms. Visual-based methods [5, 18] follow similar principles and further apply them to visual modalities. Textvisual-based prompt methods [21, 22, 25, 52] suggest a simultaneous learning strategy for prompts in both image and text branches, instead of treating them separately.
为了更好地针对特定领域下游任务优化模型,研究者们提出了多种方法 [10, 21, 65, 71, 72] 来调整表征,同时保持原始 CLIP 模型固定不变。受自然语言处理 (NLP) [26, 28] 领域成功的启发,提示学习 (prompt learning) [18, 71, 72] 被提出用于获取连续的提示表征,以替代精心设计的硬提示。根据提示学习的信息类型,现有方法大致可分为三类:基于文本、基于视觉以及两者结合。基于文本的方法 [71, 72] 提出自适应地学习适合下游任务的文本提示,而非固定形式。基于视觉的方法 [5, 18] 遵循类似原则,并进一步将其应用于视觉模态。文本-视觉结合的提示方法 [21, 22, 25, 52] 则建议同时对图像和文本分支的提示进行学习,而非分别处理。
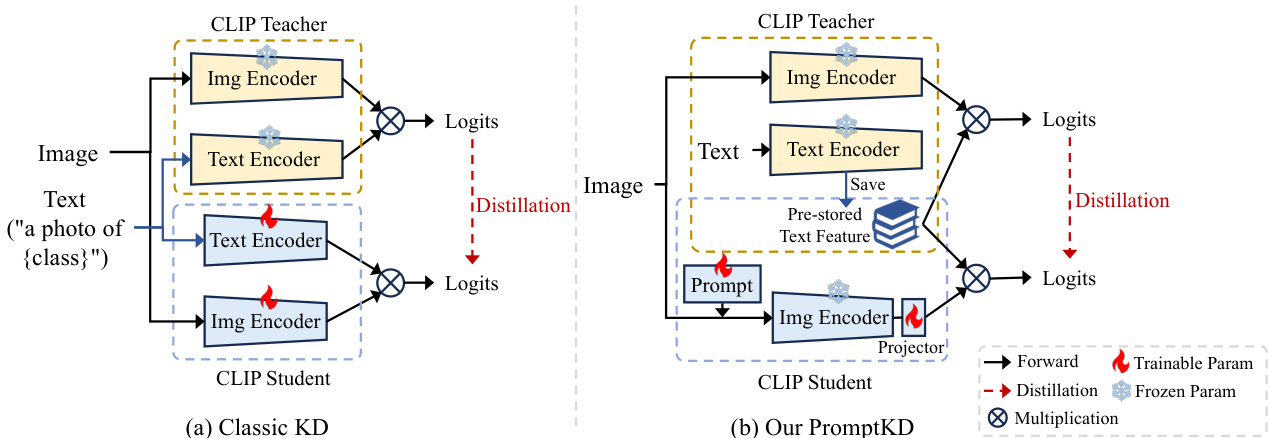
Figure 2. Architecture comparison between classic KD paradigm for CLIP (likewise CLIP-KD [63]) and our prompt distillation framework. (a) Classic KD methods perform distillation between independent teacher and student models. Students are typically fully fine-tuned by teachers’ soft labels. (b) PromptKD breaks the rules of teacher-student independence. We propose to reuse the previously well-trained text features from the teacher pre-training stage and incorporate them into the student image encoder for both distillation and inference.
图 2: CLIP经典知识蒸馏范式(如CLIP-KD [63])与我们的提示蒸馏框架架构对比。(a) 传统知识蒸馏方法在独立的教师模型与学生模型间进行蒸馏。学生模型通常通过教师软标签进行全参数微调。(b) PromptKD打破了师生独立原则。我们提出复用教师预训练阶段已训练完善的文本特征,并将其整合到学生图像编码器中,同时用于蒸馏和推理。
Prior research has primarily concentrated on acquiring effective formats of prompts using scarce labeled data while preserving the outstanding generalization capabilities. In this paper, we introduce a novel unsupervised framework (termed “PromptKD”) where the prompt acts as a domain knowledge distiller, allowing the CLIP student model to absorb knowledge from a vast CLIP teacher model on extensive unlabeled domain data. Specifically, our framework consists of two distinct stages: the teacher pre-training stage and the student distillation stage.
先前的研究主要集中于利用稀缺的标注数据获取有效的提示 (prompt) 格式,同时保持出色的泛化能力。本文提出了一种新颖的无监督框架 (称为 "PromptKD"),其中提示作为领域知识蒸馏器,使 CLIP 学生模型能够从庞大的 CLIP 教师模型中吸收知识,基于大量未标注的领域数据。具体而言,我们的框架包含两个不同的阶段:教师预训练阶段和学生蒸馏阶段。
In the initial stage, we first pre-train a large CLIP teacher model using existing advanced approaches [21, 22] on domain few-shot labeled data. After pre-training, we propose to leverage the unique decoupled-modality characteristics of CLIP by pre-computing and storing the text features as class vectors only once through the teacher text encoder.
在初始阶段,我们首先使用现有先进方法 [21, 22] 在领域少样本标注数据上预训练一个大型 CLIP 教师模型。预训练完成后,我们提出利用 CLIP 特有的解耦模态特性,通过教师文本编码器预先计算并存储文本特征作为类别向量,该过程仅需执行一次。
In the subsequent stage, the stored class vectors are shared across the teacher and student image encoder to calculate the predicted logits without any extra computation costs from text branches. Different from the traditional knowledge distillation scheme where the weights of a student are usually fully tuned to mimic the teachers’ statistical behavior as shown in Fig. 2(a), we propose to utilize the student’s learnable visual prompts to align the logits of both teacher and student models via KL divergence, encouraging the student image encoder to generate similar probability distributions to the teacher through prompt distillation. Due to the dimensional differences between the features of teacher and student, an extra projector is implemented to adjust the features to account for the dimension disparity.
在后续阶段,存储的类别向量在教师和学生图像编码器之间共享,用于计算预测logits,无需文本分支的额外计算成本。与传统知识蒸馏方案(如图2(a)所示,学生模型权重通常被完全调整以模仿教师统计行为)不同,我们提出利用学生的可学习视觉提示,通过KL散度对齐师生模型的logits,促使学生图像编码器通过提示蒸馏生成与教师相似的概率分布。由于师生特征存在维度差异,额外引入投影器来调整特征以弥补维度差距。
With the benefits of the teacher-student paradigm, we can leverage the pre-trained teacher to generate soft labels for unlabeled images from the target domain, thus enabling the training of students without the need for labeled images. Finally, the well-trained student image encoder, along with the pre-stored teacher text features (class vectors), are employed for inference purposes. An architectural comparison of the classic distillation paradigm for CLIP and our proposed prompt distillation framework is illustrated in Fig. 2.
借助师生范式的优势,我们可以利用预训练的教师模型为目标域中的未标注图像生成软标签,从而无需标注图像即可训练学生模型。最终,训练有素的学生图像编码器与预存的教师文本特征(类别向量)共同用于推理。图 2 展示了经典CLIP蒸馏范式与我们提出的提示蒸馏框架的架构对比。
Experimental results in Fig. 1 show that our PromptKD outperforms previous methods and achieves state-ofthe-art performance on 11 diverse recognition datasets with the ViT-B/16 image encoder CLIP model. Specifically, our method achieves average improvements of $2.70%$ and $4.63%$ on the base and new classes on 11 diverse datasets.
图1中的实验结果表明,我们的PromptKD方法优于先前的方法,并在使用ViT-B/16图像编码器CLIP模型的11个多样化识别数据集上实现了最先进的性能。具体而言,我们的方法在11个多样化数据集的基础类和新类上分别实现了2.70%和4.63%的平均提升。
Our contributions can be summarized as follows:
我们的贡献可总结如下:
2. Related Work
2. 相关工作
Prompt Learning in Vision-Language Models. Prompt learning is a technique that can transfer the large pre-trained model, like CLIP [41], towards downstream tasks [11, 42, 66] without the need for completely re-training the original model. It proposes to adapt the representations for specific tasks through learnable text or visual soft prompts instead of manually crafted hard prompts (e.g., “a photo of a ${\mathrm{classname}}^{\cdot\cdot})$ . Soft prompts [18, 25, 44, 71, 72] can be optimized by back-propagating through the frozen pretrained model, resulting in better performance. Existing works mainly focus on designing various efficient forms of prompts using scarce labeled domain data. MaPLe [21] proposes to learn prompts for the image and text branches simultan e ou sly, rather than a separate side. PromptSRC [22] utilizes its original features to regularize the learning of prompts for each branch. Previous works necessitated forward and backward computations for each input in both image [8, 56] and text branches. In our work, we leverage the unique decoupled-modality characteristic of CLIP, saving well-trained teacher text features as class vectors for student distillation. In this way, the training of student CLIP is simplified to solely include forward and backward calculations of the image branch, without requiring the text branch.
视觉语言模型中的提示学习。提示学习是一种无需完全重新训练原始模型,就能将CLIP [41]等大型预训练模型迁移至下游任务 [11, 42, 66] 的技术。该方法通过可学习的文本或视觉软提示(而非手工设计的硬提示,如"a photo of a ${\mathrm{classname}}^{\cdot\cdot})$)来适配特定任务的表征。软提示 [18, 25, 44, 71, 72] 可通过冻结预训练模型的反向传播进行优化,从而获得更优性能。现有研究主要集中于利用稀缺标注领域数据设计各类高效提示形式:MaPLe [21] 提出同步学习图像与文本分支的提示(而非单独分支),PromptSRC [22] 则利用原始特征对各分支提示学习进行正则化。先前工作需对图像 [8, 56] 和文本分支的每个输入执行前向与反向计算。本研究利用CLIP特有的解耦模态特性,将训练好的教师文本特征存储为类别向量供学生蒸馏,从而将学生CLIP训练简化为仅包含图像分支的前向与反向计算(无需文本分支)。
Zero-shot Learning. Given the labeled training set of the seen classes, zero-shot learning (ZSL) [32, 55, 58] aims to learn a classifier that can classify testing samples of unseen classes. Existing methods can be roughly divided into two types based on whether test images are available: Inductive [59, 67] and Trans duct ive [49, 51] ZSL. Previous works on prompt learning, such as MaPLe and PromptSRC, have mainly focused on the instance inductive settings where only labeled training instances are available. In our paper, we explore the trans duct ive ZSL setting where both seen and unseen class images are all utilized in model learning. Specifically, our teacher model follows the same training scheme as PromptSRC, which is trained on samples from seen classes with ground truth labels. The difference is that the target student model is trained on the full unlabeled dataset, which contains all samples of both seen and unseen classes, without using any ground truth labels.
零样本学习 (Zero-shot Learning)。给定已见类别的带标签训练集,零样本学习 (ZSL) [32, 55, 58] 旨在学习一个能对未见类别测试样本进行分类的分类器。现有方法根据测试图像是否可用大致分为两类:归纳式 (Inductive) [59, 67] 和转导式 (Transductive) [49, 51] ZSL。先前关于提示学习的工作,如 MaPLe 和 PromptSRC,主要关注仅含带标签训练实例的归纳式设定。本文中,我们探索了转导式 ZSL 设定,即在模型学习中同时利用已见和未见类别的图像。具体而言,我们的教师模型遵循与 PromptSRC 相同的训练方案,在带有真实标签的已见类别样本上进行训练。不同之处在于,目标学生模型是在完整的无标签数据集上训练的,该数据集包含已见和未见类别的所有样本,且不使用任何真实标签。
Knowledge Distillation. Knowledge distillation [15] aims to train a lightweight student model under the supervision of a large pretrained teacher model. In recent years, various distillation forms have emerged for effective knowledge transfer from teachers to students, such as logits alignment [29, 31, 69, 70], feature imitation [4, 27, 64] and sample relationship matching [38, 61]. In addition to traditional image classification topics, knowledge distillation has achieved great success in many vision tasks, including object detection [2, 19, 54], image segmentation [33, 62], and pose estimation [30]. Recently, many works [24, 40, 57, 63] have turned their attention to the CLIP model. These works propose leveraging the CLIP model’s exceptional generalization capabilities to enhance the learning of existing models. CLIP-KD [63] find that in distilling pre-trained CLIP models, the simplest feature mimicry with the MSE loss approach yields the best results. TinyCLIP [57] performs cross-modal feature alignment in affinity space between teacher and student. Our approach differs from previous distillation methods that train the entire student model by leveraging a pre-trained large CLIP teacher. In our work, we employ a more efficient approach by utilizing student prompts for distillation while keeping the student’s original CLIP weights frozen. This allows us to achieve the desired knowledge transfer without the need for extensive re-training of the student model.
知识蒸馏 (Knowledge Distillation)。知识蒸馏 [15] 旨在通过大型预训练教师模型的监督来训练轻量级学生模型。近年来,为了实现从教师到学生的有效知识迁移,涌现了多种蒸馏形式,例如对数对齐 (logits alignment) [29, 31, 69, 70]、特征模仿 (feature imitation) [4, 27, 64] 和样本关系匹配 (sample relationship matching) [38, 61]。除传统图像分类任务外,知识蒸馏在目标检测 [2, 19, 54]、图像分割 [33, 62] 和姿态估计 [30] 等视觉任务中也取得了巨大成功。近期,许多工作 [24, 40, 57, 63] 开始关注 CLIP 模型,提出利用其卓越的泛化能力来增强现有模型的学习。CLIP-KD [63] 发现,在蒸馏预训练 CLIP 模型时,采用 MSE 损失的最简单特征模仿方法效果最佳。TinyCLIP [57] 则在亲和力空间中进行师生模型的跨模态特征对齐。与以往利用大型预训练 CLIP 教师模型训练整个学生模型的蒸馏方法不同,本研究采用更高效的方式:在冻结学生模型原始 CLIP 权重的前提下,通过学生提示 (student prompts) 实现蒸馏,从而无需对学生模型进行大量重新训练即可完成知识迁移。
3. Method
3. 方法
Prompt learning [18, 72] aims to enhance the performance of existing VLMs like CLIP to downstream tasks by incorporating learnable prompts. Existing works mainly focus on devising effective learning formats of prompts using scarce labeled domain data while ensuring strong generalization capabilities to unseen images. In this paper, we first explore prompts as an effective knowledge distiller, allowing the CLIP student model to learn from the large CLIP teacher model by aligning their predictions on extensive unlabeled domain images. An overview of our proposed prompt distillation method is illustrated in Fig. 3. Specifically, our method comprises two main stages: the teacher pre-training stage and the student prompt distillation stage. In the initial stage, we first pre-train a large CLIP teacher model using existing advanced approaches on few-shot labeled data, as depicted in Fig. 3(a). After pre-training, we extract and preserve the highly proficient text features obtained from the teacher text encoder as class vectors. In the subsequent stage, the pre-stored class vectors are effectively reused by multiplying them with the outputs of both the teacher and student image encoders, resulting in predictions for each model. Then we initiate the distillation process by promoting prompt imitation, encouraging the student model to generate similar predictions to the teacher model, as illustrated in Fig. 3(b). An additional projector is introduced to align the dimensions of teacher text features and student image features. Finally, the well-trained student image encoder branch and pre-stored teacher text features (class vectors) are utilized for inference (see Fig. 3(c)).
提示学习 [18, 72] 旨在通过引入可学习的提示 (prompt) 来提升 CLIP 等现有视觉语言模型 (VLM) 在下游任务中的表现。现有工作主要集中于利用稀缺的标注领域数据设计有效的提示学习格式,同时确保对未见图像的强泛化能力。本文首次探索将提示作为有效的知识蒸馏器,通过让 CLIP 学生模型与大型 CLIP 教师模型在大量未标注领域图像上的预测对齐来实现知识迁移。图 3 展示了我们提出的提示蒸馏方法概览。具体而言,我们的方法包含两个主要阶段:教师预训练阶段和学生提示蒸馏阶段。
在初始阶段(如图 3(a) 所示),我们首先采用现有先进方法在少样本标注数据上预训练大型 CLIP 教师模型。预训练完成后,从教师文本编码器提取并保存高水平的文本特征作为类别向量。在后续阶段(如图 3(b) 所示),通过将预存的类别向量分别与教师和学生图像编码器的输出相乘,获得每个模型的预测结果,进而启动以提示模仿为核心的知识蒸馏过程,促使学生模型生成与教师模型相似的预测。我们引入额外投影器来对齐教师文本特征和学生图像特征的维度。最终(如图 3(c) 所示),训练完成的学生图像编码器分支与预存的教师文本特征(类别向量)将共同用于推理。
Below we first introduce the background knowledge of VLMs and the knowledge distillation method in Sec. 3.1. Then we introduce our method in detail in Sec. 3.2.
我们在第3.1节首先介绍视觉语言模型(VLM)的背景知识和知识蒸馏方法,然后在第3.2节详细介绍我们的方法。
3.1. Background
3.1. 背景
Vision-Language Models. Existing VLMs like CLIP [41] and ALIGN [17] are designed to align images and texts in order to learn a joint embedding space. Following [21, 22,
视觉语言模型 (Vision-Language Models)。现有的视觉语言模型如 CLIP [41] 和 ALIGN [17] 旨在对齐图像和文本以学习联合嵌入空间。基于 [21, 22] 的研究
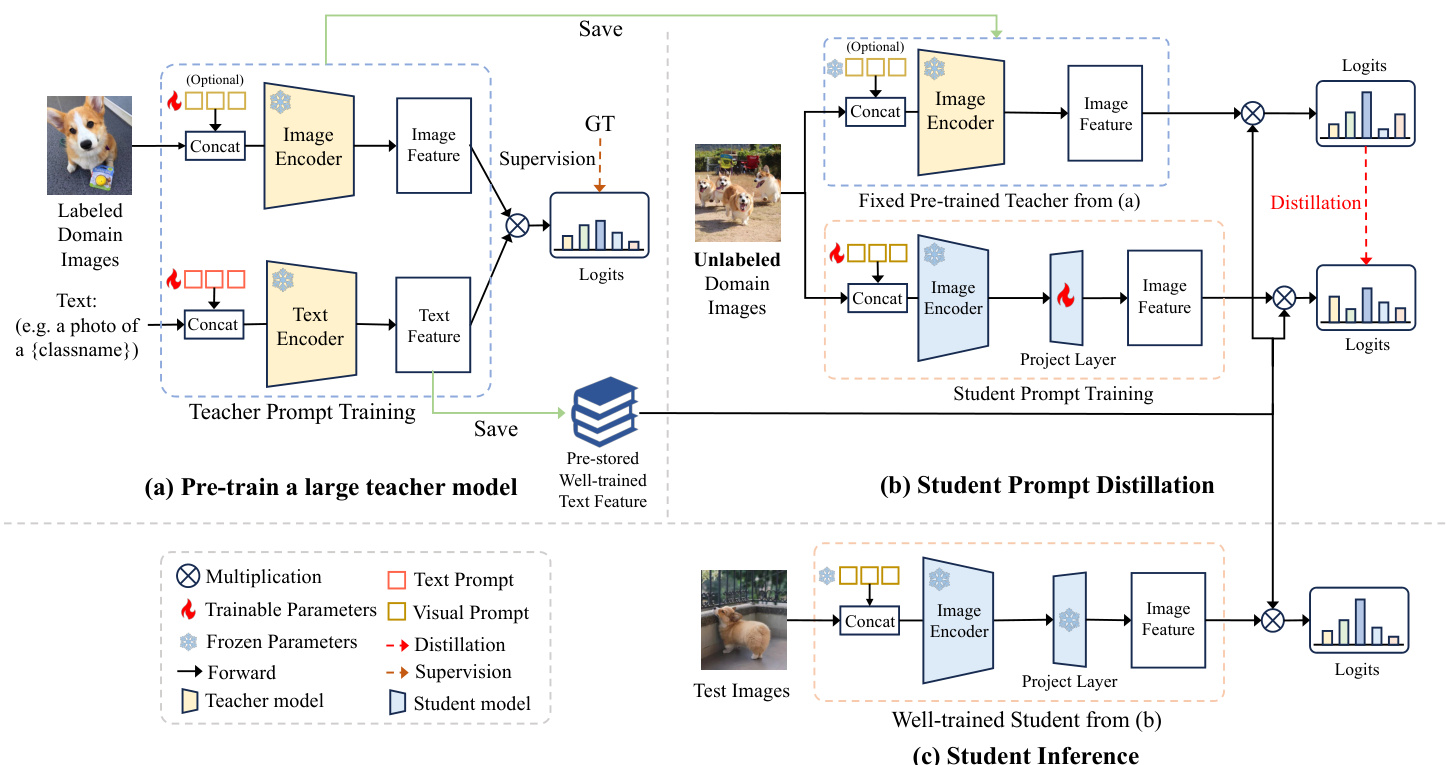
Figure 3. An overview of our proposed prompt distillation (PromptKD) framework. (a) We first pre-train a large CLIP teacher model using existing state-of-the-art prompt learning methods with labeled training images. Then we save the well-trained text features of all possible classes for the next stages. (b) During the distillation stage, the training is focused on student image prompts and the project layer, and there are no extra computational expenses associated with the text encoding process when utilizing the pre-saved text features as class vectors. (c) Finally, the well-trained student and pre-stored class vectors are utilized for inference.
图 3: 我们提出的提示蒸馏 (PromptKD) 框架概述。(a) 首先使用现有最先进的提示学习方法,通过带标注的训练图像预训练大型 CLIP 教师模型。随后保存所有可能类别的训练完备文本特征以供后续阶段使用。(b) 在蒸馏阶段,训练重点集中于学生图像提示和投影层,当使用预存文本特征作为类别向量时,无需额外计算文本编码过程的开销。(c) 最终,训练完备的学生模型与预存的类别向量将用于推理。
71], we consider CLIP as our foundation model. Specifically, CLIP consists of two encoders, one for image and the other for text. Given a labeled visual recognition dataset ${\cal D}={x_{j},y_{j}}{j=1}^{M}$ that includes a set of $N$ class names $\mathbf{c{\lambda}}={c_{i}}_{i=1}^{N}$ , CLIP generates textual descriptions $t_{i}$ using the template “a photo of a ${c_{i}}^{,}$ for each class name. Then each text description $t_{i}$ is fed into the text encoder $f_{T}$ to obtain the normalized text feature $w_{i}=f_{T}(t_{i})/||f_{T}(t_{i})||_{2}\in$ $\mathbb{R}^{d}$ , where $d$ represents the feature dimension. The complete text features $\mathbf{W}=[w_{1},w_{2},...,w_{N}]\in\mathbb{R}^{N\times d}$ of all classes can be considered as the classification weight vector for classifying an image. Given an input image $x$ from the dataset $D$ , the image encoder $f_{I}$ takes as input and generates the normalized image feature $u=f_{I}(x)/\vert\vert f_{I}(x)\vert\vert_{2}\in$ $\mathbb{R}^{d}$ . The output probability is calculated as follows:
71],我们选用 CLIP 作为基础模型。具体而言,CLIP 包含两个编码器,分别用于图像和文本处理。给定带标注的视觉识别数据集 ${\cal D}={x_{j},y_{j}}{j=1}^{M}$ ,其中包含 $N$ 个类别名称 $\mathbf{c{\lambda}}={c_{i}}_{i=1}^{N}$ ,CLIP 会为每个类别名称生成文本描述 $t_{i}$ (模板为"a photo of a ${c_{i}}^{")。随后每个文本描述 $t_{i}$ 输入文本编码器 $f_{T}$ ,得到归一化文本特征 $w_{i}=f_{T}(t_{i})/||f_{T}(t_{i})||_{2}\in$ $\mathbb{R}^{d}$ ,其中 $d$ 表示特征维度。所有类别的完整文本特征 $\mathbf{W}=[w_{1},w_{2},...,w_{N}]\in\mathbb{R}^{N\times d}$ 可视为图像分类的权重向量。对于数据集 $D$ 中的输入图像 $x$ ,图像编码器 $f_{I}$ 会生成归一化图像特征 $u=f_{I}(x)/\vert\vert f_{I}(x)\vert\vert_{2}\in$ $\mathbb{R}^{d}$ ,输出概率计算公式如下:

where $u w^{\mathsf{T}}$ represent the output logit and $\tau$ is the temperature parameter.
其中 $u w^{\mathsf{T}}$ 表示输出 logit,$\tau$ 是温度参数。
Instead of manually crafted hard prompts, recent works like CoOp [72] propose to adaptively learn appropriate soft textual prompts for downstream tasks. Concretely, $M$ learnable textual vectors ${v_{1},v_{2},...,v_{M}}$ , i.e., prefix, are added before the CLASS token to create a contextual i zed representation. Then the prompt $t_{i}$ for class $c_{i}$ becomes $t_{i}=$ ${v_{1},v_{2},...,v_{M},c_{i}}$ , where each vector $v_{i}$ $(i\in{1,2,...,M})$ have the same dimension with the word embeddings and $M$ is a hyper parameter that determines the length of the prefix. In addition to text prompt tuning methods, visual prompts have also been extensively explored. Some works [18, 21, 22] follow the same idea as the text prompt method, adding multiple learnable visual prefixes to the image patch as input to the image encoder. These visual prompts aim to guide the image encoder to extract more meaningful and task-relevant visual features. By incorporating these learnable visual prefixes, the model can leverage additional context and prior knowledge to improve its performance on image understanding tasks.
与手工设计的硬提示不同,CoOp [72] 等近期研究提出自适应学习适用于下游任务的软文本提示。具体而言,在 CLASS token 前添加 $M$ 个可学习的文本向量 ${v_{1},v_{2},...,v_{M}}$ (即前缀)以构建上下文感知的表征。此时类别 $c_{i}$ 的提示 $t_{i}$ 变为 $t_{i}=$ ${v_{1},v_{2},...,v_{M},c_{i}}$ ,其中每个向量 $v_{i}$ $(i\in{1,2,...,M})$ 与词嵌入维度相同,$M$ 是控制前缀长度的超参数。除文本提示调优方法外,视觉提示也得到广泛探索。部分研究 [18, 21, 22] 沿用文本提示的思路,在图像块上添加多个可学习的视觉前缀作为图像编码器的输入。这些视觉提示旨在引导图像编码器提取更具意义且与任务相关的视觉特征。通过引入可学习的视觉前缀,模型可利用额外上下文和先验知识提升图像理解任务的性能。
Knowledge Distillation. Originally proposed by Hinton et al. [15], knowledge distillation aims to transfer the knowledge of a pretrained heavy teacher model to a lightweight student model. After the distillation, the student can master the expertise of the teacher and be used for final deployment. Specifically, the Kullback-Leibler (KL) divergence loss is utilized to match the output distribution of two models, which can be formulated as follows:
知识蒸馏 (Knowledge Distillation)。最初由 Hinton 等人 [15] 提出,其目标是将预训练的大型教师模型 (teacher model) 的知识迁移到轻量级学生模型 (student model) 中。经过蒸馏后,学生模型能够掌握教师模型的专长并用于最终部署。具体而言,该方法利用 KL 散度 (Kullback-Leibler divergence) 损失来匹配两个模型的输出分布,其公式可表示为:

where $q^{t}$ and $q^{s}$ denote the logits predicted by the teacher and student. $\sigma(\cdot)$ is the softmax function and $\tau$ is the temperature [15, 31] which controls the softness of distribution.
其中 $q^{t}$ 和 $q^{s}$ 分别表示教师模型和学生模型预测的 logits。$\sigma(\cdot)$ 是 softmax 函数,$\tau$ 是控制分布平滑度的温度参数 [15, 31]。
3.2. PromptKD: Prompt Distillation for VLMs
3.2. PromptKD: 视觉语言模型的提示蒸馏
Our proposed prompt distillation framework comprises two stages: teacher pre-training and student prompt distillation, as illustrated in Fig. 3. In this section, we provide a comprehensive explanation of each stage.
我们提出的提示蒸馏框架包含两个阶段:教师预训练和学生提示蒸馏,如图 3 所示。本节将详细解释每个阶段。
Stage I: Teacher Pre training. In the initial stage, we begin by pre-training a large CLIP teacher model using labeled domain data, as illustrated in Fig. 3(a). To accomplish this, we can employ existing prompt learning methods such as MaPLe [21] and PromptSRC [22], or alternatively, utilize a publicly available pretrained CLIP model for simplicity. Given a labeled domain dataset $D_{l a b e l e d}={x_{i},y_{i}}_{i=1}^{M}$ with a set class name, the teacher CLIP model takes training images and text descriptions with category names as input, and passes through the image encoder $f_{I}^{t}$ and text encoder $f_{T}^{t}$ to obtain the corresponding normalized image features $u\in\mathbb{R}^{d}$ and text features $w\in\mathbb{R}^{d}$ . The final output result $p^{t}$ is calculated by Eqn. (1). Typically, the parameters of teacher soft prompts are updated by minimizing the cross-entropy loss between predicted probabilities $p$ and ground truth labels $y$ .
阶段一:教师模型预训练。在初始阶段,我们首先使用带标注的领域数据预训练一个大型CLIP教师模型,如图 3(a) 所示。为此,可以采用现有提示学习方法如MaPLe [21] 和 PromptSRC [22],或直接使用公开可用的预训练CLIP模型以简化流程。给定带标注的领域数据集 $D_{l a b e l e d}={x_{i},y_{i}}_{i=1}^{M}$ 及其预设类别名称,教师CLIP模型将训练图像和包含类别名称的文本描述作为输入,分别通过图像编码器 $f_{I}^{t}$ 和文本编码器 $f_{T}^{t}$ 获得归一化的图像特征 $u\in\mathbb{R}^{d}$ 和文本特征 $w\in\mathbb{R}^{d}$。最终输出结果 $p^{t}$ 由公式(1)计算得出。通常,教师软提示参数通过最小化预测概率 $p$ 与真实标签 $y$ 之间的交叉熵损失来更新。
Once the training of the text encoder is completed, the output features remain fixed and do not require further updates. In this case, we save the well-trained teacher text features of all $N$ classes $W=[w_{1},w_{2},...,w_{N}]\in\mathbb{R}^{N\times d}$ as shared class vectors that will be utilized in the subsequent stages of the process. This operation eliminates the necessity of having the student CLIP text branch, resulting in substantial computational cost savings during the training process. In addition, through our PromptKD method, we can replace the large teacher’s heavy image encoder with a student lightweight image encoder, reducing the computational cost during deployment while maintaining competitive performance.
文本编码器训练完成后,输出特征将保持固定且无需更新。此时,我们将所有 $N$ 个类别的训练有素的教师文本特征 $W=[w_{1},w_{2},...,w_{N}]\in\mathbb{R}^{N\times d}$ 保存为共享类别向量,供后续流程使用。该操作消除了对学生CLIP文本分支的需求,从而大幅降低训练过程中的计算成本。此外,通过PromptKD方法,我们可用轻量级学生图像编码器替代笨重的教师图像编码器,在保持竞争力的同时降低部署时的计算开销。
Stage II: Student Prompt Distillation. At this stage, we aim to train a student model by encouraging the student to align with the teacher’s output results through prompt imitation, as shown in Fig. 3(b). Thanks to the strategy of reusing teacher text features, we only need to train the student image encoder branch $f_{I}^{s}$ with learnable visual prompts and the feature projector. In the context of an unlabeled domain dataset $\boldsymbol{D_{u n l a b e l e d}}$ , by inputting the image $x$ into both the pre-trained teacher’s and the untrained student’s image branches, we can acquire the normalized teacher image features $u^{t}=f_{I}^{t}(x)/||f_{I}^{t}(x)||{2}\in\mathbb{R}^{d}$ and student image features $u^{s}=P(f{I}^{s}(x))/||P(f_{I}^{s}(x))||_{2}\in\mathbb{R}^{d}$ . The learnable projector $P(\cdot)$ in the student image encoder branch is introduced to match the feature dimensions at a relatively small cost while being effective enough to ensure accurate alignment. Then we multiply the pre-stored teacher text features $W\in\mathbb{R}^{N\times d}$ with the teacher and student image features to obtain the output logits $\boldsymbol{q}^{t}=\boldsymbol{u}^{t}\boldsymbol{W}^{\mathsf{T}}\in\mathbb{R}^{N}$ and $\boldsymbol{q}^{s}=\boldsymbol{u}^{s}\boldsymbol{W}^{\intercal}\in\mathbb{R}^{N}$ , respectively. We optimize the student model to produce similar output to the teacher model on the
阶段二:学生提示蒸馏。在此阶段,我们通过提示模仿使学生模型与教师模型的输出结果对齐来训练学生模型,如图 3(b) 所示。得益于复用教师文本特征的策略,我们仅需训练带有可学习视觉提示和特征投影器的学生图像编码器分支 $f_{I}^{s}$。在未标注领域数据集 $\boldsymbol{D_{unlabeled}}$ 的上下文中,通过将图像 $x$ 输入预训练教师和未训练学生的图像分支,可获取归一化的教师图像特征 $u^{t}=f_{I}^{t}(x)/||f_{I}^{t}(x)||{2}\in\mathbb{R}^{d}$ 和学生图像特征 $u^{s}=P(f{I}^{s}(x))/||P(f_{I}^{s}(x))||_{2}\in\mathbb{R}^{d}$。学生图像编码器分支中的可学习投影器 $P(\cdot)$ 以较小成本匹配特征维度,同时确保对齐精度。随后将预存的教师文本特征 $W\in\mathbb{R}^{N\times d}$ 分别与师生图像特征相乘,得到输出逻辑值 $\boldsymbol{q}^{t}=\boldsymbol{u}^{t}\boldsymbol{W}^{\mathsf{T}}\in\mathbb{R}^{N}$ 和 $\boldsymbol{q}^{s}=\boldsymbol{u}^{s}\boldsymbol{W}^{\intercal}\in\mathbb{R}^{N}$。我们优化学生模型,使其在...
Algorithm 1 Pseudocode of PromptKD in PyTorch.
算法 1: PyTorch中的PromptKD伪代码
| # | | tea-t: 教师CLIP的文本编码器 |
| # | | tea-i: 教师CLIP的图像编码器 |
| # | | stu-i: 学生CLIP的图像编码器 |
| # | | l-tea: 教师输出logits |
| # | | l-stu: 学生输出logits |
| | Proj: 特征投影器 | |
| # 初始化 | | |
| | f_txt_t = tea_t(txt_of_all_classes) | |
| | # 前向传播 | |
| | for img in unlabeled_dataset: | |
| | f_img-t = tea_i(img) | |
| | f_img-s = stu_i(img) | |
| | f_img_s = Proj(f_img_s) | |
| | # 获取输出预测 | |
| | l-tea = f-img-t * f-txt-t.t() l-stu = f-img-s * f-txt-t.t() | |
| | # 计算蒸馏损失 | |
| | loss = KLDivergence(l-stu, l-tea) | |
| | loss.backward() | |
unlabeled domain dataset $\cal{D}_{u n l a b e l e d}$ , which can be formulated as follows:
无标记领域数据集 $\cal{D}_{u n l a b e l e d}$,可表述如下:

Algorithm 1 provides PromptKD’s PyTorch-style pseudocode.
算法 1 提供了 PromptKD 的 PyTorch 风格伪代码。
Inference. Finally, the well-trained student image encoder $f_{I}^{s}$ , along with the pre-stored teacher text features $W$ (class vectors), are employed for inference purposes.
推理。最终,训练有素的学生图像编码器 $f_{I}^{s}$ 将与预先存储的教师文本特征 $W$(类别向量)共同用于推理任务。
4. Experiments
4. 实验
4.1. Settings
4.1. 设置
Base-to-novel Generalization. Following [21, 22, 71], we split the training and testing datasets into base and novel classes. The teacher is pre-trained using the PrompSRC [22] method, following the same training setting as PromptSRC. During distillation, we use the entire unlabeled training set to train our students. After distillation, the student’s performance on the base and the novel class is evaluated on the testing set.
基类到新类的泛化。遵循 [21, 22, 71] 的方法,我们将训练和测试数据集划分为基类和新类。教师模型使用 PrompSRC [22] 方法进行预训练,训练设置与 PromptSRC 相同。在蒸馏过程中,我们使用整个未标注的训练集来训练学生模型。蒸馏完成后,在测试集上评估学生模型在基类和新类上的性能。
Cross-dataset Evaluation. Same as PromptSRC [22], our teacher model is pre-trained on the source dataset (i.e., ImageNet) with a 16-shot training data configuration. Then we use the training set of unlabeled target datasets to train students and evaluate their performance on the test set after training. In PromptKD, we use unlabeled images of unseen classes for student training which belongs to the transductive zero-shot learning method. For previous methods such as CoOp, MaPLe, and PromptSRC, their training is based on seen class data and belongs to the inductive paradigm.
跨数据集评估。与 PromptSRC [22] 相同,我们的教师模型是在源数据集 (即 ImageNet) 上以 16-shot 训练数据配置进行预训练的。然后,我们使用未标记目标数据集的训练集来训练学生模型,并在训练后评估其在测试集上的性能。在 PromptKD 中,我们使用未见类别的未标记图像进行学生训练,这属于转导式零样本学习方法。而对于 CoOp、MaPLe 和 PromptSRC 等先前方法,它们的训练基于已见类别数据,属于归纳式范式。
| ViT-B/16 | Base | Novel | HM | ViT-B/16 | Base | Novel | HM |
|---|---|---|---|---|---|---|---|
| CLIP | 72.43 | 68.14 | 70.22 | CLIP | 96.84 | 94.00 | 95.40 |
| CoOp | 76.47 | 67.88 | 71.92 | CoOp | 98.00 | 89.81 | 93.73 |
| CoCoOp | 75.98 | 70.43 | 73.10 | CoCoOp | 97.96 | 93.81 | 95.84 |
| MaPLe | 76.66 | 70.54 | 73.47 | MaPLe | 97.74 | 94.36 | 96.02 |
| PromptSRC | 77.60 | 70.73 | 74.01 | PromptSRC | 98.10 | 94.03 | 96.02 |
| PromptKD | 80.83 | 74.66 | 77.62 | PromptKD | 98.91 | 96.65 | 97.77 |
| △ | +3.23 | +3.93 | +3.61 | △ | +0.81 | +2.62 | +1.75 |
| (b) ImageNet | (c) Caltech101 | ||||||
| ViT-B/16 | Base | Novel | HM | ViT-B/16 | Base | Novel | HM |
| CLIP | 63.37 | 74.89 | 68.65 | CLIP | 72.08 | 77.80 | 74.83 |
| CoOp | 78.12 | 60.40 | 68.13 | CoOp | 97.60 | 59.67 | 74.06 |
| CoCoOp | 70.49 | 73.59 | 72.01 | CoCoOp | 94.87 | 71.75 | 81.71 |
| MaPLe | 72.94 | 74.00 | 73.47 | MaPLe | 95.92 | 72.46 | 82.56 |
| PromptSRC | 78.27 | 74.97 | 76.58 | PromptSRC | 98.07 | 76.50 | 85.95 |
| PromptKD | 82.80 | 83.37 | 83.13 | PromptKD | 99.42 | 82.62 | 90.24 |
| △ | +4.53 | +8.40 | +6.55 | △ | +1.35 | +6.12 | +4.29 |
| (e) StanfordCars | (f) Flowers102 | ||||||
| ViT-B/16 | Base | Novel | HM | ViT-B/16 | Base | Novel | HM |
| CLIP | 27.19 | 36.29 | 31.09 | CLIP | 69.36 | 75.35 | 72.23 |
| CoOp | 40.44 | 22.30 | 28.75 | CoOp | 80.60 | 65.89 | 72.51 |
| CoCoOp | 33.41 | 23.71 | 27.74 | CoCoOp | 79.74 | 76.86 | 78.27 |
| MaPLe | 37.44 | 35.61 | 36.50 | MaPLe | 80.82 | 78.70 | 79.75 |
| PromptSRC | 42.73 | 37.87 | 40.15 | PromptSRC | 82.67 | 78.47 | 80.52 |
| PromptKD | 49.12 | 41.81 | 45.17 | PromptKD | 83.69 | 81.54 | 82.60 |
| △ | +6.39 | +3.94 | +5.02 | △ | +1.02 | +3.07 | +2.08 |
| (h) FGVCAircraft | (i) SUN397 | ||||||
| ViT-B/16 | Base | Novel | HM | ViT-B/16 | Base | Novel | HM |
| CLIP | 56.48 | 64.05 | 60.03 | CLIP | 70.53 | 77.50 | 73.85 |
| CoOp | 92.19 | 54.74 | 68.69 | CoOp | 84.69 | 56.05 | 67.46 |
| CoCoOp | 87.49 | 60.04 | 71.21 | CoCoOp | 82.33 | 73.45 | 77.64 |
| MaPLe | 94.07 | 73.23 | 82.35 | MaPLe | 83.00 | 78.66 | 80.77 |
| PromptSRC | 92.90 | 73.90 | 82.32 | PromptSRC | 87.10 | 78.80 | 82.74 |
| PromptKD | 97.54 | 82.08 | 89.14 | PromptKD | 89.71 | 82.27 | 86.10 |
| △ | +4.64 | +8.18 | +6.82 | △ | +2.61 | +3.47 | +3.36 |
(j) DTD
| ViT-B/16 | Base | Novel | HM |
|---|---|---|---|
| CLIP | 69.34 | 74.22 | 71.70 |
| CoOp | 82.69 | 63.22 | 71.66 |
| CoCoOp | 80.47 | 71.69 | 75.83 |
| MaPLe | 82.28 | 75.14 | 78.55 |
| PromptSRC | 84.26 | 76.10 | 79.97 |
| PromptKD | 86.96 | 80.73 | 83.73 |
| △ | +2.70 | +4.63 | +3.76 |
| (a) 11个数据集的平均值 |
| ViT-B/16 | Base | Novel | HM |
|---|---|---|---|
| CLIP | 91.17 | 97.26 | 94.12 |
| CoOp | 93.67 | 95.29 | 94.47 |
| CoCoOp | 95.20 | 97.69 | 96.43 |
| MaPLe | 95.43 | 97.76 | 96.58 |
| PromptSRC | 95.33 | 97.30 | 96.30 |
| PromptKD | 96.30 | 98.01 | 97.15 |
| △ | +0.97 | +0.71 | +0.85 |
| (d) OxfordPets |
| ViT-B/16 | Base | Novel | HM |
|---|---|---|---|
| CLIP | 90.10 | 91.22 | 90.66 |
| CoOp | 88.33 | 82.26 | 85.19 |
| CoCoOp | 90.70 | 91.29 | 90.99 |
| MaPLe | 90.71 | 92.05 | 91.38 |
| PromptSRC | 90.67 | 91.53 | 91.10 |
| PromptKD | 92.43 | 93.68 | 93.05 |
| △ | +1.76 | +2.15 | +1.95 |
| (g) Food101 |
| ViT-B/16 | Base | Novel | HM |
|---|---|---|---|
| CLIP | 53.24 | 59.90 | 56.37 |
| CoOp | 79.44 | 41.18 | 54.24 |
| CoCoOp | 77.01 | 56.00 | 64.85 |
| MaPLe | 80.36 | 59.18 | 68.16 |
| PromptSRC | 83.37 | 62.97 | 71.75 |
| PromptKD | 85.84 | 71.37 | 77.94 |
| △ | +2.47 | +8.40 | +6.19 |
| (j) DTD |
(k) EuroSAT (l) UCF101
(k) EuroSAT
(l) UCF101
Table 1. Comparison with existing state-of-the-art methods on base-to-novel generalization. Our proposed PromptKD demonstrates strong generalization ability and achieves significant improvements on 11 recognition datasets given the ViT-B/16 image encoder of the CLIP model. In our approach, the default teacher model is the ViT-L/14 CLIP model. The symbol $\Delta$ denotes the performance improvement compared to the previous SOTA method PromptSRC. Our PromptKD outperforms previous methods on all datasets. Table 2. Comparison of PromptKD with existing advanced approaches on cross-dataset benchmark evaluation. Based on our pipeline, we perform unsupervised prompt distillation using the unlabeled domain data respectively (i.e., the trans duct ive setting). The source model is trained on ImageNet [7]. “ZSL” denotes the setting type for Zero-Shot Learning. PromptKD achieves better results on 9 of 10 datasets.
表 1. 基于基础到新类别泛化能力的现有最优方法对比。我们提出的 PromptKD 在 CLIP 模型的 ViT-B/16 图像编码器上展现出强大的泛化能力,并在 11 个识别数据集上实现显著提升。本方法默认教师模型为 ViT-L/14 CLIP 模型,符号 $\Delta$ 表示相较之前 SOTA 方法 PromptSRC 的性能提升。PromptKD 在所有数据集上均优于先前方法。
表 2. PromptKD 与现有先进方法在跨数据集基准评估中的对比。基于我们的流程,我们分别使用未标注领域数据(即转导式设置)进行无监督提示蒸馏。源模型在 ImageNet [7] 上训练,"ZSL"表示零样本学习设置类型。PromptKD 在 10 个数据集中的 9 个上取得更好结果。
| ZSL | ViT-B/16 | Caltech 101 | Pets | Standford Cars | Flowers 102 | Food101 | FGVC Aircraft | SUN397 | DTD | Euro SAT | UCF101 | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| In-ductive | CoOp | 93.70 | 89.14 | 64.51 | 68.71 | 85.30 | 18.47 | 64.15 | 41.92 | 46.39 | 66.55 | 63.88 |
| CoCoOp | 94.43 | 90.14 | 65.32 | 71.88 | 86.06 | 22.94 | 67.36 | 45.73 | 45.37 | 68.21 | 65.74 | |
| MaPLe | 93.53 | 90.49 | 65.57 | 72.23 | 86.20 | 24.74 | 67.01 | 46.49 | 48.06 | 68.69 | 66.30 | |
| PromptSRC | 93.60 | 90.25 | 65.70 | 70.25 | 86.15 | 23.90 | 67.10 | 46.87 | 45.50 | 68.75 | 65.81 | |
| Trans-ductive | 75.33 | 88.84 | 26.24 | |||||||||
| PromptKD | 93.61 | 91.59 | 73.93 | 68.57 | 55.08 | 63.74 | 76.39 | 71.33 | ||||
| △ | +0.01 | +1.34 | +8.23 | +5.08 | +2.69 | +2.34 | +1.47 | +8.21 | +18.24 | +7.64 | +5.52 |
Datasets. We evaluate the model performance on 11 popular recognition datasets. The details of each dataset are attached in the Appendix.
数据集。我们在11个热门识别数据集上评估模型性能,各数据集详情见附录。
Implementation Details. We use the ViT-L/14 CLIP model as our teacher model and the ViT-B/16 CLIP model as our target student model. Unless otherwise stated, the PromptSRC [22] is leveraged as our default method to pre-train our teacher model. We report base and novel class accuracy and their harmonic mean (HM) averaged over 3 runs. Due to page limitations, please refer to the Appendix for more implementation details and experimental results.
实现细节。我们采用 ViT-L/14 CLIP 模型作为教师模型,ViT-B/16 CLIP 模型作为目标学生模型。除非另有说明,默认使用 PromptSRC [22] 方法预训练教师模型。实验报告基类准确率、新类准确率及其调和平均数 (HM) ,结果为三次运行的平均值。因篇幅限制,更多实现细节与实验结果请参阅附录。
4.2. Base-to-novel Generalization
4.2. 基础到新任务的泛化能力
As shown in Table 1, based on the same ViT-B/16 image encoder of the pre-trained CLIP, we compare the performance of our proposed PromptKD with recent state-ofthe-art prompt learning methods including CoOp, CoCoOp, MaPLe and PromptSRC on 11 recognition datasets. In comparison with previous works, PromptKD shows superior performance on all 11 datasets. The accuracy of our pre-trained teacher model with ViT-L/14 image encoder on each dataset is provided in the Appendix.
如表 1 所示,基于预训练 CLIP 的相同 ViT-B/16 图像编码器,我们将提出的 PromptKD 与包括 CoOp、CoCoOp、MaPLe 和 PromptSRC 在内的最新提示学习方法在 11 个识别数据集上的性能进行了比较。与之前的工作相比,PromptKD 在所有 11 个数据集上都表现出更优的性能。附录中提供了使用 ViT-L/14 图像编码器的预训练教师模型在每个数据集上的准确率。
4.3. Cross-dataset Evaluation
4.3. 跨数据集评估
Table 2 shows the performance comparison between $\mathrm{{CoOp}}$ , CoCoOp, MaPLe, PromoptSRC, and PromptKD. In comparison with previous methods, our method demonstrates better performance on 9 of 10 datasets. leading to an average improvement of $5.52%$ over the previous method.
表 2 展示了 $\mathrm{{CoOp}}$、CoCoOp、MaPLe、PromoptSRC 和 PromptKD 之间的性能对比。与先前方法相比,我们的方法在 10 个数据集中的 9 个上表现更优,平均性能提升了 $5.52%$。
4.4. Comparison with Other Methods
4.4. 与其他方法的对比
In PromptKD, we utilize unlabeled images to train the target student model. Table 3 presents a comprehensive comparison between our method and other recent methods that also leverage unlabeled data for model training. While many methods resort to pseudo-labeling of unlabeled data for training, our approach adopts a teacher-student paradigm. In this paradigm, the teacher model plays a pivotal role by furnishing soft labels to train the student models on the unlabeled data. For fair comparisons, the methods using fewshot labels ([35] and PromptKD) are all implemented based on PromptSRC framework. All experiments utilize ViTB/16 CLIP with the few-shot number being 16. The results on Flowers102 underscore the clear performance advantages of our approach over previous methods.
在PromptKD中,我们利用未标注图像训练目标学生模型。表3展示了我们的方法与近期其他同样利用未标注数据进行模型训练的方法的全面对比。虽然许多方法采用未标注数据的伪标签进行训练,但我们的方法采用了师生范式。在该范式中,教师模型通过提供软标签来指导未标注数据上的学生模型训练,发挥着关键作用。为公平比较,使用少样本标签的方法([35]和PromptKD)均基于PromptSRC框架实现。所有实验均采用ViTB/16 CLIP模型,少样本数量设为16。Flowers102数据集上的结果表明,我们的方法较先前方法具有明显的性能优势。
4.5. Ablation Study
4.5. 消融实验
In this section, we perform ablation experiments on different components of the framework to verify its effectiveness. By default, the distillation experiments are conducted on the entire ImageNet. For experimental efficiency, we use 64 images per class by default, that is, a total of 64,000 images for 1,000 classes, as an unlabeled training set for distillation, unless we state otherwise. The accuracy of the base and new classes is evaluated on the test set.
在本节中,我们对框架的不同组件进行消融实验以验证其有效性。默认情况下,蒸馏实验在整个ImageNet上进行。出于实验效率考虑,我们默认使用每个类别64张图像(即1000个类别共64,000张图像)作为蒸馏的无标注训练集,除非另有说明。基础类和新类的准确率均在测试集上评估。
Table 3. Comparison with existing works using unlabeled data on the Flowers102 dataset. Our method performs better than previous methods.
表 3: 在Flowers102数据集上使用无标注数据的现有工作对比。我们的方法优于先前方法。
| 方法 | 数据域 | 基础 | 新颖 | 调和均值 |
|---|---|---|---|---|
| CLIP PromptSRC | 零样本 少样本 | 72.08 98.07 | 77.80 76.50 | 74.83 85.95 |
| CLIP-PR [20] UPL [16] | 无标注 | 65.05 74.83 | 71.13 78.04 | 67.96 76.40 |
| LaFTer[36] FPL [35] | 79.49 97.60 | 82.91 78.27 | 81.16 86.87 | |
| IFPL [35] | 少样本 | 97.73 | 80.27 | 88.14 |
| GRIP [35] | + | 97.83 | 80.87 | 88.54 |
| PromptKD | 无标注 | 99.42 | 82.62 | 90.24 |
| △ | +1.59 | +1.75 | +1.70 |

Figure 4. Improved ImageNet classification accuracy of the student model with increasing numbers of unlabeled images per category used for distillation.
图 4: 随着每类用于蒸馏的未标注图像数量增加,学生模型在ImageNet分类任务中的准确率提升情况
Number of Images Used for Training. In this section, our objective is to assess the influence of training data volume on distillation performance, as depicted in Fig. 4. The figure illustrates that as the number of training images rises towards the complete training dataset, the accuracy consistently improves. It is noteworthy that with a further increase in the number of training images, the rate of performance improvement starts to plateau.
用于训练的图片数量。本节旨在评估训练数据量对蒸馏性能的影响,如图 4 所示。图中显示,随着训练图像数量增加至完整训练数据集时,准确率持续提升。值得注意的是,当训练图像数量进一步增加时,性能提升速率开始趋于平缓。
Table 4. Comparison of different distillation forms. The logitbased form works best.
表 4: 不同蒸馏形式的对比。基于logit的形式效果最佳。
| KD形式 | 损失函数 | Base | Novel | HM |
|---|---|---|---|---|
| Feature | L1 | 73.09 | 65.98 | 69.35 |
| MSE | 71.89 | 66.17 | 68.91 | |
| Logit | KL | 79.27 | 73.39 | 76.22 |
Distillation Form. In Table 4, we compare the performance of feature- and logit-based distillation. In feature distillation, we align the features extracted by the teacher and student image encoders. Through careful hyper parameter tuning, we find that logit distillation yields significantly better results than the feature method. One possible reason is that the image feature space alignment is more difficult than the logit space alignment due to differences in the structure of the teacher and student models.
蒸馏形式。在表4中,我们比较了基于特征和logit的蒸馏性能。在特征蒸馏中,我们对齐教师和学生图像编码器提取的特征。通过仔细的超参数调优,我们发现logit蒸馏比特征方法产生的结果要好得多。一个可能的原因是,由于教师和学生模型结构的差异,图像特征空间对齐比logit空间对齐更困难。
Distillation Method. In Table 5, we compare the performance of different distillation methods. We follow the same training settings of PromptKD to conduct the following experiments. “Projector Only” represents that there is only the projector module in the student image encoder and no learnable prompts. “Full Fine-tune” means that we finetune all parameters of the student CLIP model like CLIPKD [63]. “w/o Shared Text Feature” means that we train the student model using its own text encoder along with learnable prompts to generate text features. The results indicate that the foundational designs of PromptKD, encompassing prompt-based distillation and shared class vectors from the teacher, play a crucial role in determining the ultimate performance.
蒸馏方法。在表5中,我们比较了不同蒸馏方法的性能。我们遵循PromptKD相同的训练设置进行以下实验。"仅投影器"表示学生图像编码器中仅包含投影模块且无可学习提示。"全参数微调"表示我们像CLIPKD [63]那样微调学生CLIP模型的所有参数。"无共享文本特征"表示我们使用学生自身的文本编码器配合可学习提示来生成文本特征进行训练。结果表明,PromptKD的基础设计(包括基于提示的蒸馏和来自教师的共享类别向量)对最终性能起着决定性作用。
Table 5. Ablation study of different distillation ways.
表 5: 不同蒸馏方式的消融研究。
| 方法 | Base | Novel | HM |
|---|---|---|---|
| CLIP | 72.43 | 68.14 | 70.22 |
| Projector Only | 78.48 | 72.79 | 75.53 |
| FullFine-tune | 75.90 | 70.95 | 73.34 |
| w/oSharedTextFeature | 78.79 | 73.37 | 75.98 |
| PromptKD | 79.27 | 73.39 | 76.22 |
Teacher Pre-training Method. In Table 6, we conduct experiments employing various methods for teacher pretraining, such as vanilla CLIP and MaPLe. The table illustrates that a higher accuracy attained by the teacher model through pre-training aligns with the improved distillation performance of the student model. Notably, any type of teacher model can enhance the student model with a nontrivial improvement.
教师预训练方法。在表 6 中,我们采用多种方法进行教师预训练实验,例如 vanilla CLIP 和 MaPLe。该表表明,教师模型通过预训练获得的更高准确率与学生模型蒸馏性能的提升呈正相关。值得注意的是,任何类型的教师模型都能为学生模型带来显著提升。
Table 6. Comparison of different pre-training methods. Teacher pre-training with PromptSRC brings the best student performance.
表 6: 不同预训练方法的对比。采用 PromptSRC 的教师预训练能带来最佳的学生模型性能。
| 角色 (方法) | 图像主干网络 | 基础类 | 新类 | 调和均值 |
|---|---|---|---|---|
| CLIP | ViT-B/16 | 72.43 | 68.14 | 70.22 |
| PromptSRC | ViT-B/16 | 77.60 | 70.73 | 74.01 |
| 教师 (CLIP) | ViT-L/14 | 79.18 | 74.03 | 76.52 |
| 学生 | ViT-B/16 | 76.53 | 72.58 | 74.50 |
| 教师 (MaPLe) | ViT-L/14 | 82.79 | 76.88 | 79.73 |
| 学生 | ViT-B/16 | 78.43 | 73.61 | 75.95 |
| 教师 (PromptSRC) | ViT-L/14 | 83.24 | 76.83 | 79.91 |
| 学生 | ViT-B/16 | 79.27 | 73.39 | 76.22 |
Distillation with Different Pre-trained Teachers. In this part, we investigate the impact of using teacher models with different capacities on the performance of the student models, as shown in Fig. 5. We adopt the ViT-B/16 and ViTB/32 CLIP models using the official PromptSRC code and employ them as pre-trained teacher models. The results indicate that stronger teacher models lead to better performance in distillation.
使用不同预训练教师模型进行蒸馏。本部分我们研究了不同容量的教师模型对学生模型性能的影响,如图 5 所示。我们采用官方 PromptSRC 代码中的 ViT-B/16 和 ViTB/32 CLIP 模型作为预训练教师模型。结果表明,更强的教师模型能带来更好的蒸馏性能。

Figure 5. Comparison of distillation results for teachers with different capacities. Better teachers lead to better distillation performance.
图 5: 不同容量教师的蒸馏结果对比。更好的教师模型能带来更优的蒸馏性能。
Inference Cost Analysis. In Table 7, we show the inference cost analysis and compare it with other prompt learning methods including CoOp, CoCoOp, and PromptSRC. The inference cost for all methods is calculated on a single A100 GPU on the SUN397 dataset. The results indicate that our method is more efficient than previous methods during inference, affirming its practicality in real-world applications.
推理成本分析。在表 7 中,我们展示了推理成本分析,并将其与其他提示学习方法 (包括 CoOp、CoCoOp 和 PromptSRC) 进行了比较。所有方法的推理成本均在 SUN397 数据集上使用单张 A100 GPU 进行计算。结果表明,我们的方法在推理过程中比之前的方法更高效,证实了其在实际应用中的实用性。
Table 7. Comparison of computation costs among existing methods on the SUN397 dataset. Our PromptKD is more efficient than previous methods during testing.
表 7: SUN397数据集上现有方法的计算成本对比。我们的PromptKD在测试阶段比之前的方法更高效。
| 方法 | GFLOPs (测试) | FPS | HM |
|---|---|---|---|
| CoOp | 162.5 | 1344 | 71.66 |
| CoCoOp | 162.5 | 15.08 | 75.83 |
| PromptSRC | 162.8 | 1380 | 79.97 |
| PromptKD | 42.5 | 1710 | 83.73 |
5. Conclusion
5. 结论
In this paper, we introduce a two-stage unsupervised prompt distillation framework for Vision-Language Models, which aims to transfer the knowledge of a large CLIP teacher model to a lightweight CLIP student model through prompt imitation using unlabeled domain data. Our method first pre-trains a large teacher model on domain few-shot labeled data and then performs student prompt distillation on extensive unlabeled domain data. By leveraging CLIP’s unique decoupled-modality property, we propose to reuse pre-stored teacher text features and incorporate them into the student image encoder for both distillation and inference purposes. Extensive experiments on 11 recognition datasets demonstrate the effectiveness of our method.
本文提出了一种面向视觉语言模型 (Vision-Language Models) 的两阶段无监督提示蒸馏框架,旨在通过未标注领域数据的提示模仿,将大型 CLIP 教师模型的知识迁移到轻量级 CLIP 学生模型中。我们的方法首先在领域少样本标注数据上预训练大型教师模型,随后在大量未标注领域数据上执行学生提示蒸馏。通过利用 CLIP 独特的解耦模态特性,我们提出复用预存储的教师文本特征,并将其整合到学生图像编码器中,同时用于蒸馏和推理。在 11 个识别数据集上的大量实验验证了该方法的有效性。
Limitations and future work. The effectiveness of the distillation method is intricately tied to the knowledge transferred through unlabeled domain samples. When the distillation data lacks representation from the target domain, the generalization capability of the distilled student model towards that specific domain may be biased or weakened. In the future, we plan to explore potential regular iz ation methods to mitigate these issues.
局限性与未来工作。蒸馏方法的有效性紧密依赖于通过未标记领域样本传递的知识。当蒸馏数据缺乏目标领域的代表性时,蒸馏后学生模型对该特定领域的泛化能力可能出现偏差或减弱。未来,我们计划探索潜在的规范化 (regularization) 方法来缓解这些问题。
Acknowledgement. The authors would like to thank the anonymous reviewers for their critical comments and suggestions. The authors would also like to thank Shuheng Shen, Changhao Zhang, and Xing Fu for their discussions and help. This work was supported by the Young Scientists Fund of the National Natural Science Foundation of China (No.62206134), the National Natural Science Fund of China (No. 62361166670), the Fundamental Research Funds for the Central Universities 070-63233084 and the Tianjin Key Laboratory of Visual Computing and Intelligent Perception (VCIP). Computation is supported by the Super computing Center of Nankai University (NKSC).
致谢。作者感谢匿名评审提出的宝贵意见和建议,同时感谢Shuheng Shen、Changhao Zhang和Xing Fu的讨论与帮助。本研究得到国家自然科学基金青年科学基金项目(No.62206134)、国家自然科学基金项目(No.62361166670)、中央高校基本科研业务费专项资金(070-63233084)以及天津市视觉计算与智能感知重点实验室(VCIP)的资助。计算资源由南开大学超级计算中心(NKSC)提供支持。
References
参考文献
PromptKD: Unsupervised Prompt Distillation for Vision-Language Models
PromptKD: 视觉语言模型的无监督提示蒸馏
Supplementary Material
补充材料
6. Experimental Settings
6. 实验设置
Dataset. We evaluate the performance of our method on 15 recognition datasets. For generalization from base-to-novel classes and cross-dataset evaluation, we evaluate the performance of our method on 11 diverse recognition datasets. Specifically, these datasets include ImageNet-1K [7] and Caltech101 [9] for generic object classification; OxfordPets [39], StanfordCars [23], Flowers102 [37], Food101 [1], and FG VC Aircraft [34] for fine-grained classification, SUN397 [60] for scene recognition, UCF101 [50] for action recognition, DTD [6] for texture classification, and EuroSAT [12] for satellite imagery recognition. For domain generalization experiments, we use ImageNet-1K as the source dataset and its four variants as target datasets including ImageNet-V2 [43], ImageNet-Sketch [53], ImageNet- A [14], and ImageNet-R [13].
数据集。我们在15个识别数据集上评估了方法的性能。针对基类到新类的泛化及跨数据集评估,我们在11个多样化识别数据集上测试了方法表现。具体包括:通用物体分类任务采用ImageNet-1K [7]和Caltech101 [9];细粒度分类选用OxfordPets [39]、StanfordCars [23]、Flowers102 [37]、Food101 [1]和FG VC Aircraft [34];场景识别采用SUN397 [60];动作识别使用UCF101 [50];纹理分类基于DTD [6];卫星图像识别选用EuroSAT [12]。在领域泛化实验中,我们以ImageNet-1K作为源数据集,其四个变体ImageNet-V2 [43]、ImageNet-Sketch [53]、ImageNet-A [14]和ImageNet-R [13]作为目标数据集。
Training Details. For PromptKD, we follow the same settings as PromptSRC, setting the prompt depth to 9 and the vision and language prompt lengths to 4. We use the stochastic gradient descents (SGD) as the optimizer. All student models are trained for 20 epochs with a batch size of 8 and a learning rate of 0.005. We follow the standard data augmentation scheme as in PromptSRC, i.e., random resized cropping and random flipping. The temperature hyper parameter $\tau$ in the current distillation method is default set to 1. The text prompts of the first layer are initialized with the word embeddings of “a photo of a {classname}”. We conduct all experiments on a single Nvidia $\mathrm{AlO0GPU}$ . Training Data Usage. In the initial stage of our method, we employ PromptSRC to pre-train our ViT-L/14 CLIP teacher model. During this stage, we utilize the same training data as PromptSRC for the training process. In the subsequent stage, we adopt the trans duct ive zero-shot learning paradigm and employ the entire training dataset to train our student model. In Table 8, we provide the details of the number of images used for training on the base-to-novel generalization setting.
训练细节。对于PromptKD,我们遵循与PromptSRC相同的设置,将提示深度设为9,视觉和语言提示长度设为4。我们使用随机梯度下降(SGD)作为优化器。所有学生模型均训练20个周期,批次大小为8,学习率为0.005。我们采用与PromptSRC相同的标准数据增强方案,即随机调整大小裁剪和随机翻转。当前蒸馏方法中的温度超参数$\tau$默认设置为1。第一层的文本提示初始化为"a photo of a {classname}"的词嵌入。所有实验均在单块Nvidia $\mathrm{AlO0GPU}$上完成。
训练数据使用。在我们方法的初始阶段,采用PromptSRC预训练ViT-L/14 CLIP教师模型。此阶段使用与PromptSRC相同的训练数据。在后续阶段,我们采用转导式零样本学习范式,并使用完整训练数据集训练学生模型。表8展示了基础到新类别泛化设置中用于训练的图片数量详情。
7. Additional Experiments
7. 补充实验
Domain Generalization. In our PromptKD, the teacher model is first pre-trained using PromptSRC [22] on the source dataset (i.e., ImageNet). Then we train student models using unlabeled target datasets and then evaluate their performance after training.
领域泛化。在我们的PromptKD中,教师模型首先使用PromptSRC [22] 在源数据集 (即ImageNet) 上进行预训练。接着我们使用未标注的目标数据集训练学生模型,并在训练后评估其性能。
In Table 9, we present the results of PromptKD and other state-of-the-art methods (i.e., CoOp [72], CoCoOp [71], MaPLe [21], PromptSRC [22], TPT [48], PromptAl- ign [45]) on four different datasets. On the target dataset, our method shows a clear performance advantage compared to other methods.
在表9中,我们展示了PromptKD与其他先进方法(即CoOp [72]、CoCoOp [71]、MaPLe [21]、PromptSRC [22]、TPT [48]、PromptAlign [45])在四个不同数据集上的结果。在目标数据集上,我们的方法相比其他方法展现出明显的性能优势。
Table 8. Number of images used for distillation and testing per dataset.
表 8. 各数据集用于蒸馏和测试的图像数量。
| 数据集 | 训练集 | 测试基准集 | 测试新集 |
|---|---|---|---|
| ImageNet | 1,281,167 | 25,000 | 25,000 |
| Caltech101 | 4,128 | 1,549 | 916 |
| OxfordPets | 2,944 | 1,881 | 1,788 |
| StandfordCars | 6,509 | 4,002 | 4,039 |
| Flowers102 | 4,093 | 1,053 | 1,410 |
| Food101 | 50,500 | 15,300 | 15,000 |
| FGVCAircraft | 3,334 | 1,666 | 1,667 |
| SUN397 | 15,880 | 9,950 | 9,900 |
| DTD | 2,820 | 864 | 828 |
| EuroSAT | 13,500 | 4,200 | 3,900 |
| UCF101 | 7,639 | 1,934 | 1,849 |
Table 9. Comparison of PromptKD with existing advanced approaches on domain generalization setting. Based on our pipeline, we perform unsupervised prompt distillation using the unlabeled domain data respectively (i.e., the trans duct ive setting). The source model is training from ImageNet [7]. “ZSL” denotes the setting type for Zero-Shot Learning. PromptKD achieves consistent improvement on all target datasets.
表 9. PromptKD与现有先进方法在领域泛化设定下的对比。基于我们的流程,我们分别使用未标注的领域数据进行了无监督提示蒸馏(即转导式设定)。源模型基于ImageNet [7]训练。"ZSL"表示零样本学习的设定类型。PromptKD在所有目标数据集上均实现了持续提升。
| 目标数据集 | 平均 | |||||
|---|---|---|---|---|---|---|
| ViT-B/16 | -V2 | -S | -A | -R | ||
| 归纳式 | CLIP | 60.83 | 46.15 | 47.77 | 73.96 | 57.18 |
| CoOp | 64.20 | 47.99 | 49.71 | 75.21 | 59.28 | |
| CoCoOp | 64.07 | 48.75 | 50.63 | 76.18 | 59.91 | |
| MaPLe | 64.07 | 49.15 | 50.90 | 76.98 | 60.27 | |
| PromptSRC | 64.35 | 49.55 | 50.90 | 77.80 | 60.65 | |
| 转导式 | TPT | 63.45 | 47.94 | 54.77 | 77.06 | 60.81 |
| CoOp+TPT | 66.83 | 49.29 | 57.95 | 77.27 | 62.83 | |
| CoCoOp+TPT | 64.85 | 48.47 | 58.47 | 78.65 | 62.61 | |
| PromptAlign | 65.29 | 50.23 | 59.37 | 79.33 | 63.55 | |
| PromptKD | 69.77 | 58.72 | 70.36 | 87.01 | 71.47 | |
| △ | +4.48 | +8.49 | +10.99 | +7.68 | +7.92 |
Teacher Accuracy. In Table 10 and Table 11, we present the pre-trained ViT-L/14 based CLIP teacher model accuracy on the base-to-novel and cross dataset experiments.
教师模型准确率。在表 10 和表 11 中,我们展示了基于预训练 ViT-L/14 的 CLIP 教师模型在基础到新任务及跨数据集实验中的准确率。
Layer of Projector. Table 12 presents the distillation performance of different MLP layers used in the projector. The results show that two layers of MLP are effective enough to achieve feature alignment. More or fewer MLP layers will cause over-fitting or under-fitting problems in training.
投影器层。表 12 展示了投影器中不同 MLP (多层感知机) 层的蒸馏性能。结果表明,两层 MLP 足以有效实现特征对齐。过多或过少的 MLP 层会导致训练中的过拟合或欠拟合问题。
Distillation with Different Students. To verify the effectiveness of PromtpKD on student models with different capacities, as shown in Table 13, we further conduct experiments on the CLIP models with ViT-B/32 image encoder.
不同学生模型的蒸馏。为验证PromtpKD在不同容量学生模型上的有效性,如表13所示,我们在采用ViT-B/32图像编码器的CLIP模型上进行了进一步实验。
Table 10. Pre-trained ViT-L/14 CLIP teacher accuracy on base-tonovel generalization experiments.
表 10: 预训练 ViT-L/14 CLIP 教师在基础到新类别泛化实验中的准确率
| Dataset | Base | Novel | HM |
|---|---|---|---|
| ImageNet | 83.24 | 76.83 | 79.91 |
| Caltech101 | 98.71 | 98.03 | 98.37 |
| OxfordPets | 96.86 | 98.82 | 97.83 |
| StandfordCars | 84.53 | 84.25 | 84.39 |
| Flowers102 | 99.05 | 82.60 | 90.08 |
| Food101 | 94.56 | 95.15 | 94.85 |
| FGVCAircraft | 54.44 | 43.07 | 48.09 |
| SUN397 | 84.97 | 81.09 | 82.98 |
| DTD | 85.76 | 70.65 | 77.48 |
| EuroSAT | 94.79 | 83.15 | 88.59 |
| UCF101 | 89.50 | 82.26 | 85.73 |
Table 11. Pre-trained ViT-L/14 CLIP teacher accuracy on crossdataset generalization experiments.
表 11: 预训练 ViT-L/14 CLIP 教师在跨数据集泛化实验中的准确率
| ViT-L/14 | Dataset | Accuracy |
|---|---|---|
| Source | ImageNet | 78.12 |
| Target | Caltech101 | 95.61 |
| OxfordPets | 94.19 | |
| StandfordCars | 77.70 | |
| Flowers102 | 77.54 | |
| Food101 | 91.59 | |
| FGVCAircraft | 31.29 | |
| SUN397 | 70.86 | |
| DTD | 56.32 | |
| EuroSAT | 47.55 | |
| UCF101 | 76.20 | |
| Avg. |
Table 12. Number of Projector layers. 2-layer MLP works best.
表 12: Projector层数。2层MLP效果最佳。
| MLP层数 | Base | Novel | HM |
|---|---|---|---|
| 1 | 78.97 | 72.90 | 75.81 |
| 2 | 79.27 | 73.39 | 76.22 |
| 3 | 79.10 | 72.72 | 75.78 |
Table 13. Prompt distillation with different student CLIP models. $\Delta$ denotes the performance improvement compared to the baseline result. Student models of different capacities achieved consistent improvements.
表 13: 不同学生CLIP模型的提示蒸馏。$\Delta$表示相较于基线结果的性能提升。不同容量的学生模型均取得了一致的改进。
| Role | Img Backbone | Base | Novel | HM |
|---|---|---|---|---|
| Teacher | ViT-L/14 | 83.24 | 76.83 | 79.91 |
| Baseline Student △ | ViT-B/32 | 67.52 74.29 +6.77 | 64.04 69.29 +5.25 | 65.73 71.70 +5.97 |
| Baseline Student | ViT-B/16 | 72.43 80.83 +8.40 | 68.14 74.66 +6.52 | 70.22 77.62 +7.40 |
The results show that the student models achieve consistent improvements through the PromptKD method.
结果表明,通过PromptKD方法,学生模型取得了持续的性能提升。

Figure 6. Choice of temperature hyper parameter. The best performance is achieved when $\tau{=}1$ .
图 6: 温度超参数选择。当 $\tau{=}1$ 时达到最佳性能。
Temperature Hyper parameter. The temperature parameter controls the softness of probability distribution [15] and the learning difficulty of the distillation process [31]. In traditional distillation approaches, a common practice is to set the temperature parameter $\tau$ to 4 for most teacher-student pairs and datasets. In Fig. 6, we evaluate the impact of different temperature values on our proposed prompt distillation method. The results indicate that the traditional temperature setting of $\scriptstyle{\tau=4}$ is not suitable for our current task. Increasing the temperature value leads to a rapid decrease in model performance. Interestingly, the best performance is achieved when $\tau{=}1$ .
温度超参数 (Temperature Hyperparameter)。温度参数控制概率分布的平滑度 [15] 和蒸馏过程的学习难度 [31]。在传统蒸馏方法中,通常将温度参数 $\tau$ 设为4,适用于大多数师生模型对和数据集。在图6中,我们评估了不同温度值对我们提出的提示蒸馏方法的影响。结果表明,传统的 $\scriptstyle{\tau=4}$ 温度设置不适用于当前任务。提高温度值会导致模型性能快速下降。有趣的是,当 $\tau{=}1$ 时模型性能最佳。
Distillation with Longer Schedules. In PromptKD, for fair comparison, we adopt the same training schedule as PromptSRC, which is 20 epochs. In this part, we examine whether the student model can benefit from longer training schedules. As shown in Table 14, we conduct experiments using 20, 40, and 60 training epochs respectively. The results show that the longer the training time, the higher the student performance.
更长时间表的蒸馏。在 PromptKD 中,为了公平比较,我们采用了与 PromptSRC 相同的 20 轮训练计划。本部分我们探讨学生模型是否能从更长的训练计划中受益。如表 14 所示,我们分别使用 20、40 和 60 训练轮次进行实验。结果表明,训练时间越长,学生模型表现越好。
Table 14. Distillation with longer schedules. The longer the training time, the higher the student performance.
表 14: 长周期蒸馏效果。训练时间越长,学生模型性能越高。
| 训练周期 | 基础类 | 新类 | 调和均值 |
|---|---|---|---|
| 20 | 79.27 | 73.39 | 76.22 |
| 40 | 79.75 | 73.65 | 76.58 |
| 60 | 79.89 | 73.68 | 76.66 |
8. Discussion
8. 讨论
Experimental results of full fine-tune. In Table 5 of the main paper, we notice that the results of the full fine-tune method are lower than that of other distillation methods by a large margin $(>2%)$ . There are two reasons for this. The first one is due to the limited size of the dataset we used in training. It is much smaller than the CC3M [47], CC12M [3], or LAION-400M [46] datasets commonly used to train CLIP. The second reason is that the training time is short. To align with other experimental settings, we only train the student model for 20 epochs. In total, the full finetuning method will improve if larger data sets are used and longer training schedules are adopted.
全参数微调的实验结果。在正文的表5中,我们注意到全参数微调方法的结果显著低于其他蒸馏方法 $(>2%)$ 。这主要有两个原因:首先是由于我们训练使用的数据集规模有限,远小于通常用于训练CLIP的CC3M [47]、CC12M [3]或LAION-400M [46]数据集;其次是训练时长较短,为与其他实验设置保持一致,学生模型仅训练了20个周期。总体而言,若采用更大规模数据集并延长训练周期,全参数微调方法的性能将得到提升。
Distillation with bad teachers. In Figure 5 of the main paper, when a weaker teacher (ViT-B/32) is chosen compared to the student (ViT-B/16), the student trained using PromptKD demonstrates superior performance compared to the baseline method $71.87%{>}70.22%)$ . This situation differs from traditional distillation methods, where poor teachers often lead to a significant decline in student performance. The distinction arises due to the prompt learning method’s focus on training only learnable prompts while keeping the original CLIP model weights frozen. The frozen CLIP model remains influential in the prediction process, where the trained prompts do not substantially bias the model inference.
向不良教师学习蒸馏。在正文的图5中,当选用比学生模型(ViT-B/16)更弱的教师模型(ViT-B/32)时,采用PromptKD训练的学生模型性能显著优于基线方法(71.87%>70.22%)。这与传统蒸馏方法形成鲜明对比——后者在教师模型质量较差时通常会导致学生模型性能大幅下降。这种差异源于提示学习方法的核心机制:仅训练可学习提示词(learnable prompts)而保持原始CLIP模型权重冻结。冻结的CLIP模型在预测过程中仍起主导作用,经过训练的提示词不会对模型推理产生实质性偏差。