杰西·林 | 杜雨晴 | 奥利维亚·沃特金斯 加州大学伯克利分校研究团队
核心创新:Dynalang智能体通过多模态世界模型,将各类语言信息转化为对未来情境的预测,从而更高效地完成任务。
技术概览
要让AI真正理解人类语言并与现实世界互动,仅靠执行简单指令是远远不够的。我们开发的Dynalang突破性地将语言理解与未来预测相结合——通过分析环境描述、操作指南、实时反馈等各类语言信息,AI能够预判未来可能出现的画面、环境变化以及潜在奖励。这就像给AI装上了"语言望远镜",让它能看见更远的行动后果。
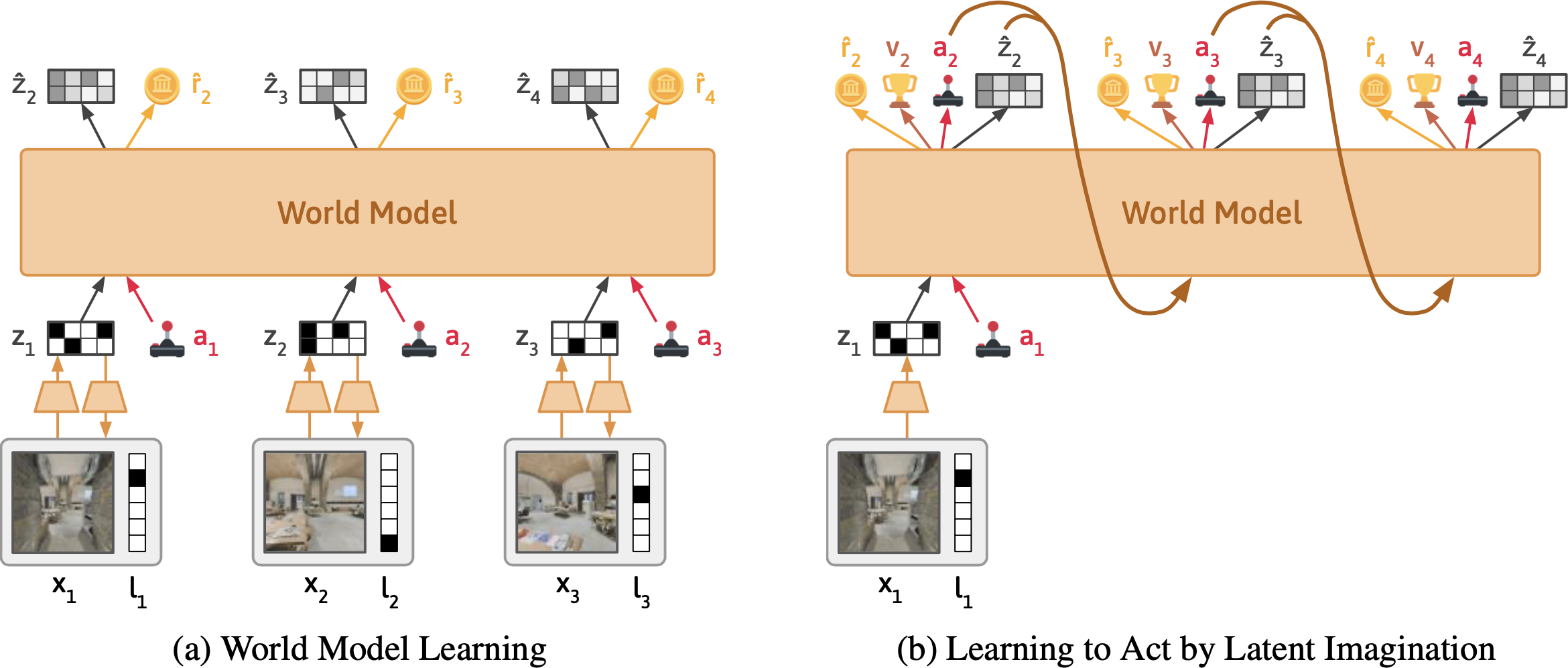
(左)世界模型将每一时刻的文字和图像压缩为潜在表征,通过重建原始观察、预测奖励和下一时刻状态来学习
(右)策略网络基于世界模型的表征想象各种行动后果,选择奖励最大化的方案
与传统AI逐个句子处理语言不同,Dynalang创新地将视频帧和文字标记建模为统一序列(就像人类实时接收多模态信息流)。这种设计既支持像语言模型那样预训练,又显著提升了强化学习表现。
三大突破场景
1. 家居网格中的语言线索
在特制的HomeGrid测试环境中,AI会收到三类辅助性语言提示:
- 未来预告:"盘子都在厨房里"(帮助预判环境)
- 实时修正:"向后转"(交互式反馈)
- 规则说明:"踩踏板打开堆肥箱"(物理规律)
结果显示,Dynalang能自发理解这些提示的用途,其表现远超只能处理简单指令的传统算法。
2. 游戏手册的多步推理
在Messenger游戏中,AI需要结合长达数百字的游戏手册(描述各类实体的交互规则)与即时画面观察,进行复杂推理。Dynalang不仅战胜了主流强化学习模型,甚至在最高难度关卡超越了专为该任务设计的EMMA架构。
3. 真实家居导航
在Habitat平台的3D家居扫描环境中,Dynalang成功理解自然语言指令(如"去厨房拿杯子"),在真实感场景中完成导航任务。这证明其预测框架能自然兼容"指令-奖励"的映射关系。
额外能力解锁
- 语言生成:在LangRoom环境中,Dynalang可以根据视觉观察生成接地气的回答(如回答"你看到了什么")
- 纯文本预训练:利用200万篇短故事数据预训练后,模型在后续任务中展现出更强的语言理解能力,甚至能生成基本连贯的短文
@article{lin2023learning,
title={Learning to Model the World with Language},
author={Jessy Lin et al.},
year={2023},
eprint={2308.01399}
}