RAG-DDR: OPTIMIZING RETRIEVAL-AUGMENTED GENERATION USING DIFFERENTIABLE DATA REWARDS
RAG-DDR:使用可微分数据奖励优化检索增强生成
ABSTRACT
摘要
Retrieval-Augmented Generation (RAG) has proven its effectiveness in mitigating hallucinations in Large Language Models (LLMs) by retrieving knowledge from external resources. To adapt LLMs for RAG pipelines, current approaches use instruction tuning to optimize LLMs, improving their ability to utilize retrieved knowledge. This supervised fine-tuning (SFT) approach focuses on equipping LLMs to handle diverse RAG tasks using different instructions. However, it trains RAG modules to overfit training signals and overlooks the varying data preferences among agents within the RAG system. In this paper, we propose a Differentiable Data Rewards (DDR) method, which end-to-end trains RAG systems by aligning data preferences between different RAG modules. DDR works by collecting the rewards to optimize each agent with a rollout method. This method prompts agents to sample some potential responses as perturbations, evaluates the impact of these perturbations on the whole RAG system, and subsequently optimizes the agent to produce outputs that improve the performance of the RAG system. Our experiments on various knowledge-intensive tasks demonstrate that DDR significantly outperforms the SFT method, particularly for LLMs with smaller-scale parameters that depend more on the retrieved knowledge. Additionally, DDR exhibits a stronger capability to align the data preference between RAG modules. The DDR method makes generation module more effective in extracting key information from documents and mitigating conflicts between parametric memory and external knowledge. All codes are available at https://github.com/OpenMatch/RAG-DDR.
检索检索增强生成(Retrieval-Augmented Generation, RAG)通过从外部资源中检索知识,已经证明其在减轻大语言模型(LLM)幻觉问题上的有效性。为了将LLM适配于RAG管道,当前的方法使用指令调优来优化LLM,提高其利用检索知识的能力。这种监督微调(Supervised Fine-Tuning, SFT)方法的重点是通过不同的指令让LLM能够处理多样化的RAG任务。然而,这种方法训练RAG模块过度拟合训练信号,忽视了RAG系统中各智能体之间的数据偏好差异。在本文中,我们提出了一种可微分数据奖励(Differentiable Data Rewards, DDR)方法,该方法通过齐RAG模块之间的数据偏好来端到端地训练RAG系统。DDR通过收集奖励并使用rollout方法优化每个智能体。该方法促使智能体采样一些潜在的响应作为扰动,评估这些扰动对整个RAG系统的影响,随后优化智能体以生成能够提升RAG系统性能的输出。我们在各种知识密集型任务上的实验表明,DDR显著优于SFT方法,尤其是对于那些更依赖检索知识的小规模参数LLM。此外,DDR表现出更强的对齐RAG模块之间数据偏好的能力。DDR方法使生成模块在从文档中提取关键信息以及减轻参数化记忆与外部知识之间的冲突方面更加有效。所有代码可在https://github.com/OpenMatch/RAG-DDR获取。
1 INTRODUCTION
1 引言
Large Language Models (LLMs) have demonstrated impressive capabilities in language understanding, reasoning, and planning capabilities across a wide range of natural language processing (NLP) tasks (Achiam et al., 2023; Touvron et al., 2023; Hu et al., 2024). However, LLMs usually produce incorrect responses due to hallucination (Ji et al., 2023; Xu et al., 2024c). To alleviate the problem, existing studies employ Retrieval Augmented Generation (RAG) (Lewis et al., 2020; Shi et al., 2023; Peng et al., 2023) to enhance the capability of LLMs and help LLMs access long-tailed knowledge and up-to-date knowledge from different data sources (Trivedi et al., 2023; He et al., 2021; Cai et al., 2019; Parvez et al., 2021). However, the conflict between retrieved knowledge and parametric memory usually misleads LLMs, challenging the effectiveness of RAG system (Li et al., 2022; Chen et al., 2023; Asai et al., 2024b).
大大语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现了令人印象深刻深刻的语言理解、推理和规划能力 (Achiam et al., 2023; Touvron et al., 2023; Hu et al., 2024)。然而,由于幻觉问题 (Ji et al., 2023; Xu et al., 2024c),LLMs 通常会产生错误的回答。为了缓解这一问题,现有研究采用检索增强生成(Retrieval Augmented Generation, RAG)(Lewis et al., 2020; Shi et al., 2023; Peng et al., 2023) 来增强 LLMs 的能力,并帮助 LLMs 从不同数据源中获取长尾知识和最新知识 (Trivedi et al., 2023; He et al., 2021; Cai et al., 2019; Parvez et al., 2021)。然而,检索知识与参数化记忆之间的冲突通常会误导 LLMs,从而挑战 RAG 系统的有效性 (Li et al., 2022; Chen et al., 2023; Asai et al., 2024b)。
To ensure the effectiveness of RAG systems, existing research has focused on developing various agents to enhance the retrieval accuracy (Gao et al., 2024; Xu et al., 2023b; Jiang et al., 2023; Xu et al., 2024b). These approaches aim to refine retrieval results through query reformulation, reranking candidate documents, summarizing the retrieved documents or performing additional retrieval steps to find more relevant information (Yan et al., 2024; Trivedi et al., 2023; Asai et al., 2023; Yu et al., 2023a). To optimize the RAG system, the methods independently optimize different RAG modules by using the EM method (Singh et al., 2021; Sachan et al., 2021) or build the instruct tuning dataset for Supervised Fine-Tuning (SFT) these LLM based RAG modules (Lin et al., 2023; Asai et al., 2023). However, these SFT-based methods usually train LLMs to overfit the training signals and face the catastrophic forgetting problem (Luo et al., 2023b).
为了为了确保 RAG 系统的有效性,现有研究专注于开发各种智能体以提高检索准确性(Gao 等,2024;Xu 等,2023b;Jiang 等,2023;Xu 等,2024b)。这些方法旨在通过查询重构、重新排序候选文档、总结检索到的文档或执行额外的检索步骤来优化检索结果,以找到更多相关信息(Yan 等,2024;Trivedi 等,2023;Asai 等,2023;Yu 等,2023a)。为了优化 RAG 系统,这些方法要么通过 EM 方法独立优化不同的 RAG 模块(Singh 等,2021;Sachan 等,2021),要么构建用于监督微调(SFT)的指令调优数据集,以微调这些基于大语言模型的 RAG 模块(Lin 等,2023;Asai 等,2023)。然而,这些基于 SFT 的方法通常会使大语言模型过度拟合训练信号,并面临灾难性遗忘问题(Luo 等,2023b)。
Current research further aims to optimize these RAG modules for aligning their data preferences and primarily focuses on optimizing a two-agent framework, which consists of a retriever and a generator. Typically, these systems train only the retriever to supply more accurate documents to satisfy the data preference of the generator (Shi et al., 2023; Yu et al., 2023b). Aligning data preferences between the retriever and generator through refining retrieved knowledge is a straightforward approach to improving the effectiveness of RAG models. Nevertheless, the generator still faces the knowledge conflict, making LLMs not effectively utilize the retrieved knowledge during generation (Xie et al., 2024). Thus optimizing each RAG module by using the reward from the entire system during training, is essential for building a more tailored RAG system.
当前当前研究进一步旨在优化这些RAG模块,以对齐它们的数据偏好,并主要集中于优化由检索器和生成器组成的双智能体框架。通常,这些系统仅训练检索器以提供更准确的文档,以满足生成器的数据偏好(Shi et al., 2023; Yu et al., 2023b)。通过精炼检索到的知识来对齐检索器和生成器之间的数据偏好,是提高RAG模型有效性的一种直接方法。然而,生成器仍然面临知识冲突问题,使得大语言模型在生成过程中无法有效利用检索到的知识(Xie et al., 2024)。因此,在训练过程中使用整个系统的奖励来优化每个RAG模块,对于构建更加定制化的RAG系统至关重要。
This paper introduces a Differentiable Data Rewards (DDR) method for end-to-end optimizing agents in the RAG system using the DPO (Rafailov et al., 2024) method. DDR uses a rollout method (Kocsis & Szepesv´ari, 2006) to collect the reward from the overall system for each agent and optimizes the agent according to the reward. Specifically, we follow Asai et al. (2024a) and build a typical RAG system to evaluate the effectiveness of our DDR model. It consists of a knowledge refinement module for selecting retrieved documents and a generation module for producing responses based on queries and refined knowledge. Then we conduct the RAG-DDR model by optimizing the two-agent based RAG system using DDR. Throughout the optimization process, we use the reward from the entire RAG system and iterative ly optimize both the generation and knowledge refinement modules to align data preferences across both agents.
本文本文介绍了一种名为可微数据奖励 (Differentiable Data Rewards, DDR) 的方法,用于在 RAG(Retrieval-Augmented Generation, 检索增强生成)系统中使用 DPO (Rafailov et al., 2024) 方法对端到端的智能体进行优化。DDR 采用了一种 rollout 方法 (Kocsis & Szepesv´ari, 2006) 来为每个智能体从整个系统中收集奖励,并根据奖励优化智能体。具体而言,我们遵循 Asai 等人 (2024a) 的工作,构建了一个典型的 RAG 系统来评估 DDR 模型的有效性。该系统包括一个用于选择检索文档的知识精炼模块和一个基于查询和精炼知识生成响应的生成模块。然后,我们通过使用 DDR 优化基于双智能体的 RAG 系统,构建了 RAG-DDR 模型。在整个优化过程中,我们使用来自整个 RAG 系统的奖励,并迭代优化生成模块和知识精炼模块,以使两个智能体之间的数据偏好对齐。
Our experiments on various Large Language Models (LLMs) demonstrate that Differentiable Data Rewards (DDR) outperforms all baseline models, achieving significant improvements over previous method (Lin et al., 2023) in a range of knowledge-intensive tasks. DDR can effectively retrofit LLMs for the RAG modeling and help generate higher-quality responses of an appropriate length. Our further analyses show that the effectiveness of our RAG-DDR model primarily derives from the generation module, which is optimized by the reward from the RAG system. Our DDR optimized generation module is more effective in capturing crucial information from retrieved documents and alleviating the knowledge conflict between external knowledge and parametric memory. Further analyses show that the effectiveness of DDR optimized RAG systems can be generalized even when additional noisy documents are incorporated during response generation.
我们对我们对各种大语言模型(LLMs)的实验表明,可微分数据奖励(DDR)在所有基线模型上表现优异,在一系列知识密集型任务中相较于之前的方法(Lin et al., 2023)取得了显著改进。DDR 能够有效改造 LLMs 以进行 RAG 建模,并帮助生成更高质量的合适长度的响应。我们的进一步分析表明,RAG-DDR 模型的有效性主要来源于生成模块,该模块通过 RAG 系统的奖励进行了优化。我们的 DDR 优化生成模块在从检索到的文档中捕捉关键信息和缓解外部知识与参数化内存之间的知识冲突方面更为有效。进一步的分析表明,即使响应生成过程中加入了额外的噪声文档,DDR 优化的 RAG 系统的有效性仍然具有通用性。
2 RELATED WORK
2 相关工作
Retrieval-Augmented Generation (RAG) is widely used in various real-world applications, such as open-domain QA (Trivedi et al., 2023), language modeling (He et al., 2021), dialogue (Cai et al., 2019), and code generation (Parvez et al., 2021). RAG models retrieve documents from external corpus (Karpukhin et al., 2020; Xiong et al., 2021) and then augment the LLM’s generation by incorporating documents as the context for generation (Ram et al., 2023) or aggregating the output probabilities from the encoding pass of each retrieved documents (Shi et al., 2023). They help LLMs alleviate hallucinations and generate more accurate and trustworthy responses (Jiang et al., 2023; Xu et al., $2023\mathrm{a}$ ; Luo et al., 2023a; Hu et al., 2023; Kandpal et al., 2023). However, retrieved documents inevitably incorporate noisy information, limiting the effectiveness of RAG systems in generating accurate responses (Xu et al., 2023b; 2024b; Longpre et al., 2021; Liu et al., 2024b).
检索检索增强生成 (Retrieval-Augmented Generation, RAG) 被广泛应用于各种现实场景中,例如开放域问答 (Trivedi et al., 2023)、语言建模 (He et al., 2021)、对话系统 (Cai et al., 2019) 以及代码生成 (Parvez et al., 2021)。RAG 模型从外部语料库中检索文档 (Karpukhin et al., 2020; Xiong et al., 2021),然后通过将文档作为生成上下文 (Ram et al., 2023) 或聚合每个检索文档的编码输出概率 (Shi et al., 2023) 来增强大语言模型的生成能力。它们帮助大语言模型减轻幻觉问题,并生成更准确和可信的响应 (Jiang et al., 2023; Xu et al., 2023a; Luo et al., 2023a; Hu et al., 2023; Kandpal et al., 2023)。然而,检索到的文档不可避免地包含噪声信息,这限制了 RAG 系统生成准确响应的有效性 (Xu et al., 2023b; 2024b; Longpre et al., 2021; Liu et al., 2024b)。
Some studies have demonstrated that the noise from retrieved documents can mislead LLMs, sometimes resulting in degraded performance even on some knowledge-intensive tasks (Foulds et al., 2024; Shuster et al., 2021; Xu et al., 2024b). Such a phenomenon primarily derives from the knowledge conflict between parametric knowledge of LLMs and external knowledge (Jin et al., 2024;
一些一些研究表明,检索文档中的噪声可能会误导大语言模型,有时甚至会导致某些知识密集型任务的性能下降 (Foulds et al., 2024; Shuster et al., 2021; Xu et al., 2024b)。这种现象主要源于大语言模型的参数化知识与外部知识之间的冲突 (Jin et al., 2024;
Longpre et al., 2021; Chen et al., 2022; Xie et al., 2024; Wu et al., 2024). Xie et al. (2024) have demonstrated that LLMs are highly receptive to external evidence when external knowledge conflicts with the parametric memory (Xie et al., 2024). Thus, lots of RAG models focus on building modular RAG pipelines to improve the quality of retrieved documents (Gao et al., 2024). Most of them aim to conduct more accurate retrieval models by employing a retrieval evaluator to trigger different knowledge refinement actions (Yan et al., 2024), prompting LLMs to summarize the query-related knowledge from retrieved documents (Yu et al., 2023a) or training LLMs to learn how to retrieve and utilize knowledge on-demand by self-reflection (Asai et al., 2023).
LongLongpre等人, 2021; Chen等人, 2022; Xie等人, 2024; Wu等人, 2024)。Xie等人 (2024) 已经证明,当外部知识与参数记忆发生冲突时,大语言模型对外部证据具有高度的接受性 (Xie等人, 2024)。因此,许多 RAG 模型专注于构建模块化的 RAG 管道,以提高检索文档的质量 (Gao等人, 2024)。其中大多数旨在通过采用检索评估器来触发不同的知识精炼动作,从而构建更准确的检索模型 (Yan等人, 2024),提示大语言模型从检索到的文档中总结与查询相关的知识 (Yu等人, 2023a),或通过自我反思训练大语言模型学习如何按需检索和利用知识 (Asai等人, 2023)。
Optimizing RAG system is a crucial research direction to help generate more accurate responses. Previous work builds a RAG system based on pretrained language models and conducts an end-toend training method (Singh et al., 2021; Sachan et al., 2021). They regard retrieval decisions as latent variables and then iterative ly optimize the retriever and generator to fit the golden answers. Recent research primarily focuses on optimizing LLMs for RAG. INFO-RAG (Xu et al., 2024a) focuses on enabling LLMs with the in-context denoising ability by designing an unsupervised pre training method to teach LLMs to refine information from retrieved contexts. RA-DIT (Lin et al., 2023) builds a supervised training dataset and then optimizes the retriever and LLM by instruct tuning. However, these training methods focus on training LLMs to fit the training signals and face the issue of catastrophic forgetting during instruct tuning (Luo et al., 2023b).
优化优化 RAG 系统是帮助生成更准确响应的关键研究方向。先前的工作基于预训练语言模型构建 RAG 系统,并采用端到端训练方法 (Singh et al., 2021; Sachan et al., 2021)。它们将检索决策视为潜在变量,然后通过迭代优化检索器和生成器来拟合正确答案。最近的研究主要集中在优化 RAG 中的大语言模型。INFO-RAG (Xu et al., 2024a) 通过设计一种无监督预训练方法,使大语言模型具备上下文去噪能力,从而教会大语言模型从检索到的上下文中提炼信息。RA-DIT (Lin et al., 2023) 构建了一个有监督训练数据集,然后通过指令调优来优化检索器和大语言模型。然而,这些训练方法主要关注训练大语言模型以拟合训练信号,并在指令调优过程中面临灾难性遗忘问题 (Luo et al., 2023b)。
Reinforcement Learning (RL) algorithms (Schulman et al., 2017), such as Direct Preference Optimization (DPO) (Rafailov et al., 2024), are widely used to optimize LLMs for aligning with human preferences and enhancing the consistency of generated responses (Putta et al., 2024). Agent Q integrates MCTS and DPO to allow agents to learn from both successful and unsuccessful trajectories, thereby improving their performance in complex reasoning tasks (Putta et al., 2024). STEP-DPO further considers optimizing each inference step of a complex task as the fundamental unit for preference learning, which enhances the long-chain reasoning capabilities of LLMs (Lai et al., 2024). While these models primarily target the optimization of individual agents to improve response accuracy at each step, they do not focus on the effectiveness of data alignment within the multi-agent system. Instead of using SFT methods for RAG optimization (Lin et al., 2023), this paper focuses on using the DPO method to avoid over fitting the training signals and align data preferences across different agents, which is different from above RL-based optimization methods.
强化强化学习(Reinforcement Learning, RL)算法(Schulman et al., 2017),如直接偏好优化(Direct Preference Optimization, DPO)(Rafailov et al., 2024),被广泛用于优化大语言模型以使其与人类偏好对齐,并增强生成内容的一致性(Putta et al., 2024)。Agent Q 结合了蒙特卡洛树搜索(MCTS)和 DPO,使得智能体能够从成功和失败的轨迹中学习,从而提升其在复杂推理任务中的表现(Putta et al., 2024)。STEP-DPO 进一步将复杂任务的每个推理步骤优化作为偏好学习的基本单元,增强了大语言模型的长链推理能力(Lai et al., 2024)。尽管这些模型主要针对单个智能体的优化,以提升每一步响应的准确性,但它们并未关注多智能体系统中数据对齐的有效性。与使用监督微调(SFT)方法进行检索增强生成(Retrieval-Augmented Generation, RAG)优化不同,本文聚焦于使用 DPO 方法来避免训练信号的过拟合,并在不同智能体之间对齐数据偏好,这与上述基于强化学习的优化方法有所不同。
3 RAG TRAINING WITH DIFFERENTIABLE DATA REWARDS
3 使用可微分数据奖励进行 RAG 训练
This section introduces the Differentiable Data Rewards (DDR) method. We first introduce the DDR method, which optimizes the agent system by aligning the data preferences between agents (Sec. 3.1). Then we utilize knowledge refinement and generation modules to build the RAG pipeline and utilize the DDR method to optimize agents in this system (Sec. 3.2).
本节本节介绍可微分数据奖励 (Differentiable Data Rewards, DDR) 方法。我们首先介绍 DDR 方法,它通过齐 AI智能体之间的数据偏好来优化智能体系统 (第 3.1 节)。然后,我们利用知识精炼和生成模块构建 RAG 管道,并使用 DDR 方法优化该系统内的智能体 (第 3.2 节)。
3.1 DATA PREFERENCE LEARNING WITH DIFFERENTIABLE DATA REWARDS
3.1 基于可微分数据奖励的数据偏好学习
In a RAG system $\mathcal{V}=\left{V_{1},\ldots,V_{t},\ldots,V_{T}\right}$ , agents exchange and communicate data. To optimize this system, we first forward-propagate data among agents and then evaluate the performance of the RAG system. Then we backward-propagate rewards to refine the data preferences of each agent.
在在 RAG 系统 $\mathcal{V}=\left{V_{1},\ldots,V_{t},\ldots,V_{T}\right}$ 中,AI 智能体 (AI Agent) 交换和传递数据。为了优化该系统,我们首先在智能体之间前向传播数据,然后评估 RAG 系统的性能。接着我们反向传播奖励以优化每个智能体的数据偏好。
Data Propagation. During communication, the $t$ -th agent, $V_{t}$ , acts both as a sender and a receiver. Agent $V_{t}$ receives data from agent $V_{t-1}$ and simultaneously passes data to agent $V_{t+1}$ :
数据数据传播。在通信过程中,第$t$个智能体$V_{t}$同时充当发送方和接收方。智能体$V_{t}$从智能体$V_{t-1}$接收数据,同时将数据传递给智能体$V_{t+1}$:

where $V_{t} \xrightarrow{y_{t}}V_{t+1}$ denotes that the agent generates one response $y_{t}$ of the maximum prediction probability and sends it to the agent $V_{t+1}$ . $x\rightsquigarrow$ and $\sim~y_{T}$ represent sending the input $x$ to the agent system $\nu$ and getting the output $y_{T}$ from $\nu$ . The performance of the agent system $\nu$ can be evaluated by calculating the quality score $S(y_{T})$ of the final output $V_{T}$ of the agent system $\mathcal{V}$ .
其中其中 $V_{t} \xrightarrow{y_{t}}V_{t+1}$ 表示智能体生成一个最大预测概率的响应 $y_{t}$ 并将其发送给智能体 $V_{t+1}$ 。 $x\rightsquigarrow$ 和 $\sim~y_{T}$ 表示将输入 $x$ 发送到智能体系统 $\nu$ 并从 $\nu$ 获取输出 $y_{T}$ 。可以通过计算智能体系统 $\mathcal{V}$ 的最终输出 $V_{T}$ 的质量得分 $S(y_{T})$ 来评估智能体系统 $\nu$ 的性能。
Differentiable Data Reward. Unlike conventional supervised fine-tuning approaches (Lin et al., 2023), DDR tries to optimize the agent $V_{t}$ to align the data preference $V_{t+1:T}$ , making the agent system produce a better response with higher evaluation score $S(y_{T})$ of the whole RAG system.
可可微分数据奖励 (Differentiable Data Reward)。与传统的监督微调方法 (Lin et al., 2023) 不同,DDR 尝试优化智能体 $V_{t}$,以对齐数据偏好 $V_{t+1:T}$,使得智能体系统能够生成更好的响应,并获得整个 RAG 系统更高的评估分数 $S(y_{T})$。
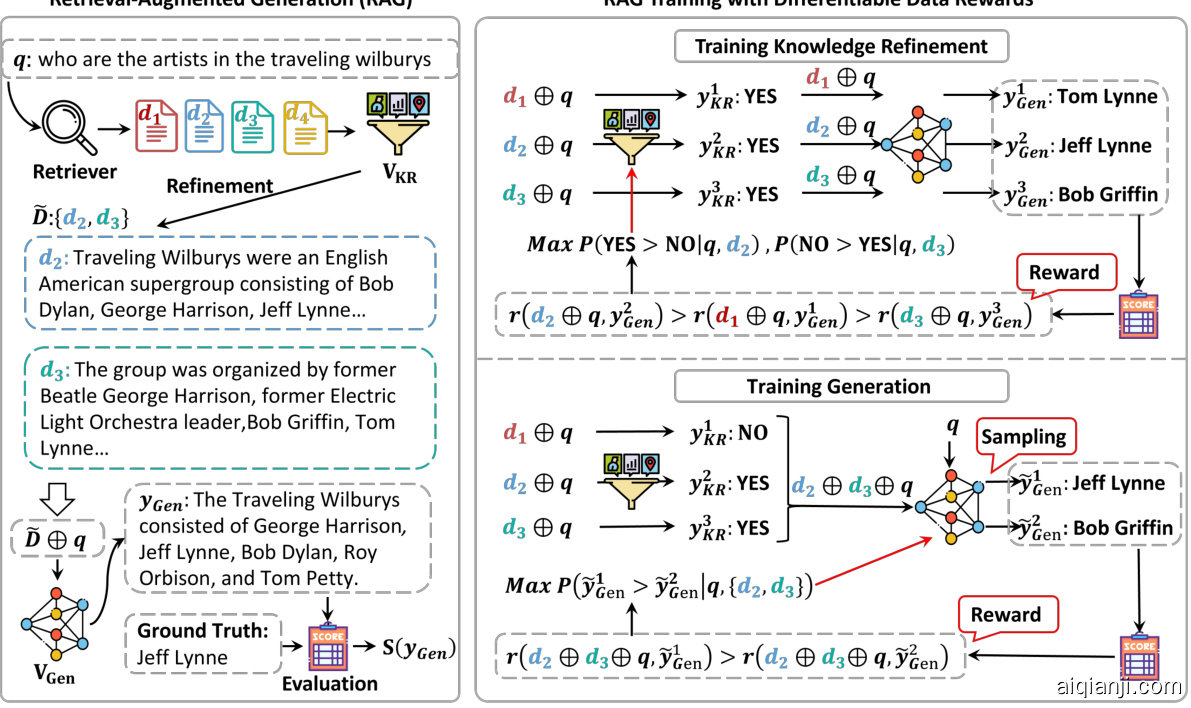
Retrieval-Augmented Generation (RAG) RAG Training with Differentiable Data Rewards
)
检索增强生成 (Retrieval-Augmented Generation, RAG) 使用可微数据奖励的 RAG 训练
Figure 1: The Illustration of End-to-End Retrieval-Augmented Generation (RAG) Training with Our Differentiable Data Reward (DDR) Method. During training, we iterative ly optimize the Generation module $(V_{\mathrm{Gen}})$ and Knowledge Refinement module $(V_{\mathrm{KR}})$ .
图图 1: 使用我们的可微分数据奖励 (DDR) 方法进行端到端检索增强生成 (RAG) 训练的示意图。在训练过程中,我们迭代优化生成模块 $(V_{\mathrm{Gen}})$ 和知识精炼模块 $(V_{\mathrm{KR}})$。
To optimize the agent $V_{t}$ , DDR aims to propagate the system reward to train the targeted agent. Specifically, we first instruct $V_{t}$ to sample multiple outputs $\tilde{y}{t}$ , which incorporate some perturbations into the agent system. Then we calculate the reward $r(x,\tilde{y}{t})$ with a rollout process (Kocsis $&$ Szepesva´ri, 2006). In detail, we regard the agents $\mathcal{V}{t+1:T}$ as the evaluation model, feed $\tilde{y}{t}$ to this subsystem $\mathcal{V}{t+1:T}$ and calculate the evaluation score $S(y{T})$ of the generated output $y_{T}$ :
为了为了优化智能体 $V_{t}$,DDR 旨在传播系统奖励以训练目标智能体。具体来说,我们首先指导 $V_{t}$ 采样多个输出 $\tilde{y}{t}$,这些输出在智能体系统中引入了一些扰动。然后我们通过 rollout 过程 (Kocsis $&$ Szepesva´ri, 2006) 计算奖励 $r(x,\tilde{y}{t})$。具体而言,我们将智能体 $\mathcal{V}{t+1:T}$ 视为评估模型,将 $\tilde{y}{t}$ 输入到该子系统 $\mathcal{V}{t+1:T}$ 中,并计算生成输出 $y{T}$ 的评估分数 $S(y_{T})$:
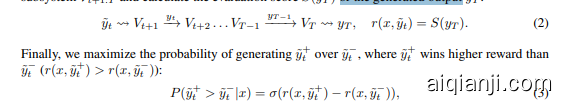
Finally, we maximize the probability of generating $\tilde{y}{t}^{+}$ over $\tilde{y}{t}^{-}$ , where $\tilde{y}{t}^{+}$ wins higher reward than $\tilde{y}{t}^{-};(r(x,\tilde{y}{t}^{+})>r(x,\tilde{y}{t}^{-}))$ :
最后最后,我们最大化生成 $\tilde{y}{t}^{+}$ 相对于 $\tilde{y}{t}^{-}$ 的概率,其中 $\tilde{y}{t}^{+}$ 获得的奖励高于 $\tilde{y}{t}^{-};(r(x,\tilde{y}{t}^{+})>r(x,\tilde{y}{t}^{-}))$ :
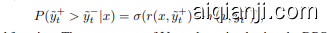
where $\sigma$ is the Sigmoid function. The parameters of $V_{t}$ can be trained using the DPO (Rafailov et al., 2024) training loss, aiding the DDR in identifying optimization directions by contrastive ly learning from the positive $(\tilde{y}{t}^{+})$ and negative $(\tilde{y}{t}^{-})$ outputs:
其中其中 $\sigma$ 是 Sigmoid 函数。$V_{t}$ 的参数可以通过使用 DPO (Rafailov et al., 2024) 训练损失进行训练,通过对比学习正样本 $(\tilde{y}{t}^{+})$ 和负样本 $(\tilde{y}{t}^{-})$ 来帮助 DDR 识别优化方向:
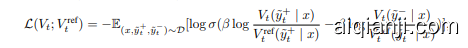
where $\beta$ is a hyper parameter. $\mathcal{D}$ is the dataset containing the input $x$ and its corresponding preference data pairs $(\tilde{y}{t}^{+},\tilde{y}{t}^{-})$ . $V_{t}^{\mathrm{ref}}$ is the reference model, which is frozen during training.
其中其中 $\beta$ 是一个超参数。$\mathcal{D}$ 是包含输入 $x$ 及其对应的偏好数据对 $(\tilde{y}{t}^{+},\tilde{y}{t}^{-})$ 的数据集。$V_{t}^{\mathrm{ref}}$ 是参考模型,在训练期间被冻结。
3.2 OPTIMIZING A SPECIFIC RAG SYSTEM THROUGH DDR
3.2 通过 DDR 优化特定 RAG 系统
Given a query $q$ and a set of retrieved documents $D,=,{d_{1},\ldots,d_{n}}$ , we build a RAG system by employing a knowledge refinement module $(V_{\mathrm{KR}})$ to filter unrelated documents and a generation module $(V_{\mathrm{Gen}})$ to produce a response. These two modules can be represented by a two-agent system:
给定给定查询 $q$ 和一组检索到的文档 $D,=,{d_{1},\ldots,d_{n}}$,我们通过使用知识精炼模块 $(V_{\mathrm{KR}})$ 来过滤无关文档,并使用生成模块 $(V_{\mathrm{Gen}})$ 来生成响应,从而构建一个 RAG 系统。这两个模块可以由一个双智能体系统表示:
where $\tilde{D}\subseteq D$ and $V_{\mathrm{KR}}$ produces the select actions to filter out the noise documents in $D$ to build $\tilde{D}$ . $V_{\mathrm{Gen}}$ generates the answer according to the query $q$ with filtered documents $\tilde{D}$ . As shown in
其中其中 $\tilde{D}\subseteq D$,且 $V_{\mathrm{KR}}$ 生成筛选动作以过滤掉 $D$ 中的噪声文档,构建 $\tilde{D}$。$V_{\mathrm{Gen}}$ 根据查询 $q$ 和筛选后的文档 $\tilde{D}$ 生成答案。
Figure 1, we iterative ly tune different modules to conduct the RAG-DDR model, beginning with the generation module optimization and subsequently focusing on tuning the knowledge refinement module during training this RAG system. In the rest of this subsection, we will explain the details of how to optimize $V_{\mathrm{KR}}$ and $V_{\mathrm{Gen}}$ using DDR.
图图 1: 我们通过迭代调整不同的模块来实现 RAG-DDR 模型,首先从生成模块优化开始,随后在训练 RAG 系统时专注于调整知识精炼模块。在本小节的剩余部分,我们将详细解释如何使用 DDR 优化 $V_{\mathrm{KR}}$ 和 $V_{\mathrm{Gen}}$。
Knowledge Refinement Module. We follow Asai et al. (2023) and build the knowledge refinement module $V_{\mathrm{KR}}$ to estimate the relevance of each document $d_{i}$ to the query $q$ for refinement. We feed both query $q$ and document $d_{i}$ to the $V_{\mathrm{KR}}$ and ask it to produce the action $y_{\mathrm{KR}}^{i},\in,{^{\leftarrow}\mathrm{YES}^{,\ast},{}^{\leftarrow}\mathrm{NO}^{,\ast}}$ , which indicates whether $d_{i}$ is retained $(y_{\mathrm{KR}}^{i}=\mathrm{{}^{\leftarrow}Y E S^{\ast}})$ or discarded $(y_{\mathrm{KR}}^{i}={}^{\overleftarrow{\bf\Lambda}}!!!\dot{\bf N}{\bf O}^{,\ast})$ ):
知识知识精炼模块。我们遵循 Asai 等人 (2023) 的方法,构建知识精炼模块 $V_{\mathrm{KR}}$ 来估计每个文档 $d_{i}$ 与查询 $q$ 的相关性以进行精炼。我们将查询 $q$ 和文档 $d_{i}$ 输入到 $V_{\mathrm{KR}}$ 中,并要求其生成动作 $y_{\mathrm{KR}}^{i},\in,{^{\leftarrow}\mathrm{YES}^{,\ast},{}^{\leftarrow}\mathrm{NO}^{,\ast}}$,该动作指示 $d_{i}$ 是否被保留 $(y_{\mathrm{KR}}^{i}=\mathrm{{}^{\leftarrow}Y E S^{\ast}})$ 或被丢弃 $(y_{\mathrm{KR}}^{i}={}^{\overleftarrow{\bf\Lambda}}!!!\dot{\bf N}{\bf O}^{,\ast})$:

where $\bigoplus$ denotes the concatenation operation, and InstructKR is a prompt designed for knowledge refinement. Then the refined document collection $\tilde{D}={d_{1},\dotsc,d_{k}}$ is constructed, where $k<=n$ . The document $d_{i}$ that leads the agent system to achieve the highest evaluation reward $r(x,y_{\mathrm{KR}}^{i}=$ “YES”) is considered positive, while the document $d_{j}$ that results in the lowest reward $r(x,y_{\mathrm{KR}}^{j}=$ “YES”) is regarded as negative. $V_{\mathrm{KR}}$ is trained to maximize the probability $P(y_{\mathrm{KR}}^{i},=,^{\ast}!\mathrm{YES}^{,\ast},>$ $y_{\mathrm{KR}}^{i}={}^{\leftarrow}!\mathrm{NO}^{\ast}!|q,d_{i})$ for the positive document. As well as, we maximize the probability $P(y_{\tt K R}^{j}=$ ${}^{\cdot}\mathrm{\mathcal{N}O}^{\cdot\cdot}>y_{\mathrm{KR}}^{j}={}^{\cdot\cdot}\mathrm{YES}^{\cdot\cdot}|q,d_{j})$ to filter out irrelevant documents.
其中其中 $\bigoplus$ 表示连接操作,InstructKR 是用于知识优化的提示。然后构建了优化后的文档集合 $\tilde{D}={d_{1},\dotsc,d_{k}}$,其中 $k<=n$。使代理系统获得最高评估奖励 $r(x,y_{\mathrm{KR}}^{i}=$ “YES”) 的文档 $d_{i}$ 被视为正面文档,而使奖励最低的文档 $d_{j}$ 被视为负面文档。 $V_{\mathrm{KR}}$ 的训练目标是最大化正面文档的概率 $P(y_{\mathrm{KR}}^{i},=,^{\ast}!\mathrm{YES}^{,\ast},>$ $y_{\mathrm{KR}}^{i}={}^{\leftarrow}!\mathrm{NO}^{\ast}!|q,d_{i})$。同时,我们通过最大化概率 $P(y_{\tt K R}^{j}=$ ${}^{\cdot}\mathrm{\mathcal{N}O}^{\cdot\cdot}>y_{\mathrm{KR}}^{j}={}^{\cdot\cdot}\mathrm{YES}^{\cdot\cdot}|q,d_{j})$ 来滤除不相关的文档。
Generation Module. After knowledge refinement, the query $q$ and filtered documents $\tilde{D};=$ ${d_{1},\dotsc,d_{k}}$ are fed to the generation module $V_{\mathrm{Gen}}$ . The response $\tilde{y}{\mathrm{Gen}}$ is sampled from $V{\mathrm{Gen}}$ :
生成生成模块。在知识精炼之后,查询 $q$ 和过滤后的文档 $\tilde{D};=$ ${d_{1},\dotsc,d_{k}}$ 被输入到生成模块 $V_{\mathrm{Gen}}$ 中。响应 $\tilde{y}{\mathrm{Gen}}$ 从 $V{\mathrm{Gen}}$ 中采样得到:

where Instruc $\mathrm{\Delta}_{\mathrm{Gen}}$ is a prompt for generating a tailored response. To reduce the misleading knowledge from the retrieved documents, we also sample responses using only the query as input:
其中其中 Instruc $\mathrm{\Delta}_{\mathrm{Gen}}$ 是用于生成定制化回答的提示。为了减少从检索文档中引入误导性信息,我们还仅使用查询作为输入来生成回答:

The response that achieves the highest evaluation score $S(\tilde{y}{\mathrm{Gen}})$ is considered positive $(\tilde{y}{\mathrm{Gen}}^{+})$ , while the lowest evaluation score is considered negative $(\tilde{y}{\mathrm{Gen}}^{-})$ . The generation module $V{\mathrm{Gen}}$ is optimized to maximize the probability of generating the positive response $P(\tilde{y}{\mathrm{Gen}}^{+}>\tilde{y}{\mathrm{Gen}}^{-}|q,\tilde{D})$ to win a higher reward. By generating responses $\tilde{y}_{\mathrm{Gen}}$ based on documents or the query alone, LLMs can learn to balance internal and external knowledge, alleviating the problems related to knowledge conflicts.
达到达到最高评估分数 $S(\tilde{y}{\mathrm{Gen}})$ 的响应被认为是正向的 $(\tilde{y}{\mathrm{Gen}}^{+})$,而最低评估分数被认为是负向的 $(\tilde{y}{\mathrm{Gen}}^{-})$。生成模块 $V{\mathrm{Gen}}$ 被优化以最大化生成正向响应的概率 $P(\tilde{y}{\mathrm{Gen}}^{+}>\tilde{y}{\mathrm{Gen}}^{-}|q,\tilde{D})$,从而获得更高的奖励。通过基于文档或查询生成响应 $\tilde{y}_{\mathrm{Gen}}$,大语言模型可以学会平衡内部和外部知识,缓解与知识冲突相关的问题。
4 EXPERIMENTAL METHODOLOGY
4 实验方法
This section first describes datasets, evaluation metrics, and baselines. Then we introduce the imple ment ation details of our experiments. More experimental details are shown in Appendix A.1.
本节本节首先介绍数据集、评估指标和基线方法,然后介绍实验的实施细节。更多实验细节见附录 A.1。
Dataset. In our experiments, we follow RA-DIT (Lin et al., 2023) and use the instruction tuning datasets for training and evaluating RAG models. For all datasets and all baselines, we use bgelarge (Xiao et al., 2023) to retrieve documents from the MS MARCO 2.0 (Bajaj et al., 2016).
数据集数据集。在我们的实验中,我们遵循 RA-DIT (Lin et al., 2023) 并使用指令微调数据集来训练和评估 RAG 模型。对于所有数据集和所有基线,我们使用 bgelarge (Xiao et al., 2023) 从 MS MARCO 2.0 (Bajaj et al., 2016) 中检索文档。
During the training of DDR, we collect ten datasets covering two tasks, open-domain QA and reasoning. Specifically, we randomly sample 32,805 samples for the training set and 2,000 samples for the development set in our experiments. Following previous work (Lin et al., 2023; Xu et al., 2024a), we select the knowledge-intensive tasks for evaluation, including open-domain question answering, multi-hop question answering, slot filling, and dialogue tasks. The open-domain QA tasks consist of NQ (Kwiatkowski et al., 2019), MARCO QA (Bajaj et al., 2016) and TriviaQA (Joshi et al., 2017), which require models to retrieve factual knowledge to help answer the given question. For more complex tasks, such as multi-hop QA and dialogue, we use HotpotQA dataset (Yang et al., 2018) and Wikipedia of Wizard (WoW) (Dinan et al., 2019) for evaluation. Besides, we also employ T-REx (Elsahar et al., 2018) to measure one-hop fact look-up abilities of models.
在在DDR的训练过程中,我们收集了涵盖两个任务的十个数据集,即开放域问答和推理。具体来说,我们在实验中随机抽取了32,805个样本用于训练集,2,000个样本用于开发集。根据之前的工作(Lin等,2023;Xu等,2024a),我们选择了知识密集型任务进行评估,包括开放域问答、多跳问答、槽填充和对话任务。开放域问答任务包括NQ(Kwiatkowski等,2019)、MARCO QA(Bajaj等,2016)和TriviaQA(Joshi等,2017),这些任务要求模型检索事实知识以帮助回答给定问题。对于更复杂的任务,如多跳问答和对话,我们使用HotpotQA数据集(Yang等,2018)和Wikipedia of Wizard(WoW)(Dinan等,2019)进行评估。此外,我们还使用T-REx(Elsahar等,2018)来衡量模型的一跳事实查找能力。
Evaluation. Following Xu et al. (2024a), we utilize Rouge-L and F1 as evaluation metrics for MARCO QA task and WoW task, respectively. For the rest tasks, we use Accuracy.
评估评估。根据 Xu 等人 (2024a) 的研究,我们分别使用 Rouge-L 和 F1 作为 MARCO QA 任务和 WoW 任务的评估指标。对于其他任务,我们使用准确率 (Accuracy) 作为评估指标。
Baselines. In our experiments, we compare DDR with five baseline models, including zero-shot models and supervised finetuning models.
基准基准模型。在我们的实验中,我们将 DDR 与五个基准模型进行比较,包括零样本模型和微调模型。
Table 1: Overall Performance of Different RAG Models. The best and second best results are highlighted. In our experiments, we employ Llama3-8B as the knowledge refinement module and utilize LLMs of varying scales (Llama3-8B and MiniCPM-2.4B) as the generation module.
表表 1: 不同 RAG 模型的整体性能。最佳和次佳结果已高亮显示。在我们的实验中,我们使用 Llama3-8B 作为知识精炼模块,并利用不同规模的大语言模型 (Llama3-8B 和 MiniCPM-2.4B) 作为生成模块。
| 方法 | 开放域问答 | 多跳问答 | 槽填充 | 对话 |
|---|---|---|---|---|
| NQ | TriviaQA | MARCOQA | HotpotQA | |
| MiniCPM-2.4B | ||||
| LLM w/o RAG | 20.1 | 45.0 | 17.1 | 17.7 |
| VanillaRAG (2023) | 42.2 | 79.5 | 16.7 | 26.7 |
| REPLUG (2023) | 39.4 | 77.0 | 19.4 | 24.7 |
| RA-DIT (2023) | 41.8 | 78.6 | 19.6 | 26.1 |
| RAG-DDR (w/1-Round) | 47.0 | 82.7 | 28.1 | 32.5 |
| RAG-DDR (w/2-Round) | 47.6 | 83.6 | 29.8 | 33.2 |
| Llama3-8B | ||||
| LLM w/o RAG | 35.4 | 78.4 | 17.0 | 27.7 |
| VanillaRAG (2023) | 46.2 | 84.0 | 20.6 | 30.1 |
| RA-DIT (2023) | 46.2 | 87.4 | 20.3 | 34.9 |
| RAG-DDR (w/1-Round) | 50.7 | 88.2 | 25.1 | 37.3 |
| RAG-DDR (w/2-Round) | 52.1 | 89.6 | 27.3 | 39.0 |
We first treat the LLM as a black box and conduct three baselines, including LLM w/o RAG, Vanilla RAG and REPLUG. For the LLM w/o RAG model, we directly feed the query to the LLM and ask it to produce the answer according to its memorized knowledge. To implement the vanilla RAG model, we follow previous work (Lin et al., 2023), use retrieved passages as context and leverage the in-context learning method to conduct the RAG modeling. REPLUG (Shi et al., 2023) is also compared, which ensembles output probabilities from different passage channels. Besides, RADIT (Lin et al., 2023) is also compared in our experiments, which optimizes the RAG system using the instruct-tuning method. In our experiments, we re implement REPLUG and RA-DIT baselines and do not finetune the retriever during our reproduction process, as the retriever we used has already been trained with massive supervised data and is sufficiently strong.
我们我们首先将大语言模型视为一个黑箱,进行了三个基线实验,包括无 RAG 的大语言模型、Vanilla RAG 和 REPLUG。对于无 RAG 的模型,我们直接将查询输入大语言模型,并让它根据记忆的知识生成答案。为了实现 Vanilla RAG 模型,我们遵循之前的工作 (Lin et al., 2023),使用检索到的段落作为上下文,并利用上下文学习方法进行 RAG 建模。我们还比较了 REPLUG (Shi et al., 2023),它集成了来自不同段落通道的输出概率。此外,实验中还比较了 RADIT (Lin et al., 2023),它使用指令微调方法优化了 RAG 系统。在我们的实验中,我们重新实现了 REPLUG 和 RADIT 基线,并且在复现过程中没有对检索器进行微调,因为我们使用的检索器已经通过大量监督数据训练,足够强大。
Implementation Details. In our experiments, we employ Minicpm-2.4B-sft (Hu et al., 2024) and lama3-8B-Instruct (Touvron et al., 2023) as backbone models to construct the generation modules, and employ Llama3-8B-Instruct (Touvron et al., 2023) to build the knowledge refinement module. While training the RAG modules with DDR, we use automatic metrics such as Rouge-L and Accuracy to calculate the reward and set $\beta=0.1$ . The learning rate is set to 5e-5, and each model is trained for one epoch. For the generation module, we feed 5 retrieved passages as external knowledge for augmenting the generation process. To optimize both knowledge refinement module and generation module, we use LoRA (Hu et al., 2022) for efficient training.
实现实现细节。在我们的实验中,我们使用 Minicpm-2.4B-sft (Hu et al., 2024) 和 llama3-8B-Instruct (Touvron et al., 2023) 作为骨干模型来构建生成模块,并采用 Llama3-8B-Instruct (Touvron et al., 2023) 来构建知识精炼模块。在使用 DDR 训练 RAG 模块时,我们使用 Rouge-L 和 Accuracy 等自动指标来计算奖励,并设置 $\beta=0.1$。学习率设置为 5e-5,每个模型训练一个 epoch。对于生成模块,我们输入 5 个检索到的段落作为外部知识来增强生成过程。为了优化知识精炼模块和生成模块,我们使用 LoRA (Hu et al., 2022) 进行高效训练。
5 EVALUATION RESULTS
5 评估结果
In this section, we first evaluate the performance of different RAG methods and then conduct ablation studies to show the effectiveness of different training strategies. Next, we examine the effectiveness of DDR training strategies on the generation module $(V_{\mathrm{Gen}})$ and explore how it balances internal and external knowledge through DDR. Finally, we present several case studies.
在本在本节中,我们首先评估了不同的RAG方法的性能,然后通过消融实验展示了不同训练策略的有效性。接着,我们检验了DDR训练策略在生成模块$(V_{\mathrm{Gen}})$上的有效性,并探讨了它如何通过DDR平衡内部和外部知识。最后,我们展示了几项案例研究。
5.1 OVERALL PERFORMANCE
5.1 整体性能
The performance of various RAG models is presented in Table 1. As shown in the evaluation results, RAG-DDR significantly outperforms these baseline models on all datasets. It achieves improvements of $7%$ compared to the Vanilla RAG model when using MiniCPM-2.4B and Llama3-8B to construct the generation module $(V_{\mathrm{Gen}})$ .
各种各种RAG模型的性能如表1所示。根据评估结果,RAG-DDR在所有数据集上显著优于这些基线模型。在使用MiniCPM-2.4B和Llama3-8B构建生成模块($V_{\mathrm{Gen}}$)时,与Vanilla RAG模型相比,RAG-DDR实现了7%的提升。
Compared with LLM w/o RAG, Vanilla RAG and REPLUG significantly enhance LLM performance on most knowledge-intensive tasks, indicating that external knowledge effectively improves the accuracy of generated responses. However, the performance of RAG models decreases on dialogue tasks, showing that LLMs can also be misled by the retrieved documents. Unlike these zero-shot methods, RA-DIT provides a more effective approach for guiding LLMs to filter out noise from retrieved content and identify accurate clues for answering questions. Nevertheless, RA-DIT still under performs compared to Vanilla RAG on certain knowledge-intensive tasks, such as NQ and HotpotQA, showing that over fitting to golden answers is less effective for teaching LLMs to capture essential information for generating accurate responses. In contrast, RAG-DDR surpasses RA-DIT on almost all tasks, particularly with smaller LLMs (MiniCPM-2.4b), achieving a $5%$ improvement. This highlights the generalization capability of our DDR training method, enabling LLMs of varying scales to utilize external knowledge through in-context learning effectively.
与与没有 RAG 的大语言模型相比,Vanilla RAG 和 REPLUG 在大多数知识密集型任务上显著提升了大语言模型的性能,表明外部知识有效提高了生成回答的准确性。然而,RAG 模型在对话任务上的表现有所下降,这显示大语言模型也可能被检索到的文档误导。与这些零样本方法不同,RA-DIT 提供了一种更有效的方法,能够引导大语言模型过滤掉检索内容中的噪声并识别出回答问题的准确线索。尽管如此,RA-DIT 在某些知识密集型任务(如 NQ 和 HotpotQA)上仍然表现不如 Vanilla RAG,表明过度拟合标准答案在教导大语言模型捕捉生成准确回答所需的关键信息方面效果较差。相比之下,RAG-DDR 在几乎所有任务上都超越了 RA-DIT,尤其是在较小的模型(如 MiniCPM-2.4b)上,实现了 $5%$ 的提升。这凸显了我们 DDR 训练方法的泛化能力,使得不同规模的大语言模型能够通过上下文学习有效地利用外部知识。
Table 2: Ablation Study. Both Vanilla RAG and RAG w/ $V_{\mathrm{KR}}$ are evaluated in a zero-shot setting without any fine-tuning. We then use DDR to optimize the knowledge refinement module $(V_{\mathrm{KR}})$ , the generation module $(V_{\mathrm{Gen}})$ , and both modules, resulting in three models: RAG-DDR (Only $V_{\mathrm{KR}}]$ ), RAG-DDR (Only $V_{\mathrm{Gen.}}$ ) and RAG-DDR (All).
表表 2: 消融研究。Vanilla RAG 和 RAG w/ $V_{\mathrm{KR}}$ 均在零样本设置下进行评估,未进行任何微调。然后使用 DDR 优化知识精炼模块 $(V_{\mathrm{KR}})$ 、生成模块 $(V_{\mathrm{Gen}})$ 以及两个模块,得到三个模型:RAG-DDR (Only $V_{\mathrm{KR}}$ )、RAG-DDR (Only $V_{\mathrm{Gen}}$) 和 RAG-DDR (All)。
| 方法 | 开放域问答 | 多跳问答 | 槽填充 | 对话 |
|---|---|---|---|---|
| NQ | TriviaQA | MARCOQA | HotpotQA | |
| MiniCPM-2.4B | ||||
| VanillaRAG | 42.1 | 78.0 | 16.6 | 24.9 |
| W/VKR | 42.2 | 79.5 | 16.7 | 26.7 |
| RAG-DDR (Only VkR) | 42.5 | 79.6 | 16.8 | 27.3 |
| RAG-DDR (Only VGen) | 46.8 | 81.7 | 28.3 | 31.2 |
| RAG-DDR (AIl) | 47.0 | 82.7 | 28.1 | 32.5 |
| Llama3-8B | ||||
| VanillaRAG | 45.4 | 83.2 | 20.8 | 28.5 |
| W/VKR | 46.2 | 84.0 | 20.6 | 30.1 |
| RAG-DDR (Only VkR) | 46.8 | 84.7 | 20.7 | 30.7 |
| RAG-DDR (Only VGen) | 50.2 | 87.8 | 25.2 | 36.9 |
5.2 ABLATION STUDIES
5.2 消融研究
As shown in Table 2, we conduct ablation studies to explore the role of different RAG modules and evaluate different training strategies using DDR.
如表如表 2 所示,我们进行了消融实验,以探索不同 RAG 模块的作用,并使用 DDR 评估不同的训练策略。
This experiment compares five models, utilizing MiniCPM-2.4b and Llama3-8b to construct the generation module. The Vanilla RAG model relies solely on the generation module $(V_{\mathrm{Gen}})$ to produce answers based on the query and retrieved documents. RAG w/ $V_{\mathrm{KR}}$ adds an additional knowledge refinement module $(V_{\mathrm{KR}})$ to filter the retrieved documents and then feeds query and filtered documents to the generation module $(V_{\mathrm{Gen}})$ . RAG-DDR (Only $V_{\mathrm{KR}}]$ ) indicates that we tune the RAG w/ $V_{\mathrm{KR}}$ model using DDR by only optimizing the knowledge refinement module $(V_{\mathrm{KR}})$ . RAG-DDR (Only $V_{\mathrm{Gen}})$ ) only optimizes the generation module $(V_{\mathrm{Gen}})$ . RAG-DDR (All) optimizes both $V_{\mathrm{KR}}$ and VGen.
本本实验比较了五个模型,利用 MiniCPM-2.4b 和 Llama3-8b 构建生成模块。Vanilla RAG 模型仅依赖生成模块 $(V_{\mathrm{Gen}})$ 根据查询和检索到的文档生成答案。RAG w/ $V_{\mathrm{KR}}$ 增加了一个额外的知识精炼模块 $(V_{\mathrm{KR}})$ 来过滤检索到的文档,然后将查询和过滤后的文档馈送到生成模块 $(V_{\mathrm{Gen}})$。RAG-DDR (Only $V_{\mathrm{KR}}]$) 表示我们通过仅优化知识精炼模块 $(V_{\mathrm{KR}})$ 来调整 RAG w/ $V_{\mathrm{KR}}$ 模型。RAG-DDR (Only $V_{\mathrm{Gen}})$) 仅优化生成模块 $(V_{\mathrm{Gen}})$。RAG-DDR (All) 同时优化 $V_{\mathrm{KR}}$ 和 $V_{\mathrm{Gen}}$。
Compared with the Vanilla RAG model, RAG w/ $V_{\mathrm{KR}}$ improves the RAG performance on almost all evaluation tasks, demonstrating the effectiveness of the knowledge refinement module in improving the accuracy of LLM responses. In contrast, RAG-DDR (Only $V_{\mathrm{Gen.}}$ ) shows greater improvements over RAG w/ $V_{\mathrm{KR}}$ than DDR (Only $V_{\mathrm{{KR}}}$ ), indicating that the primary effectiveness of RAG-DDR comes from optimizing the generation module $(V_{\mathrm{Gen}})$ through DDR. When we begin with the RAGDDR (Only $V_{\mathrm{Gen.}}$ ) model and subsequently optimize the knowledge refinement module, the performance of RAG with $V_{\mathrm{KR}}$ improves. It shows that filtering noise from retrieved documents using feedback from the generation module is effective, which is also observed in previous work (Yu et al., 2023b; Izacard & Grave, 2020). However, the improvements from optimizing the knowledge refinement modules are limited, highlighting that enhancing the generation module’s ability to leverage external knowledge is more critical for the existing RAG system.
与与 Vanilla RAG 模型相比,RAG w/ $V_{\mathrm{KR}}$ 在几乎所有评估任务上都提升了 RAG 的性能,证明了知识精炼模块在提高大语言模型响应准确性方面的有效性。相比之下,RAG-DDR (Only $V_{\mathrm{Gen.}}$) 相较于 RAG w/ $V_{\mathrm{KR}}$ 表现出更大的改进,这表明 RAG-DDR 的主要效果来自于通过 DDR 优化生成模块 $(V_{\mathrm{Gen}})$。当我们从 RAG-DDR (Only $V_{\mathrm{Gen.}}$) 模型开始并随后优化知识精炼模块时,RAG with $V_{\mathrm{KR}}$ 的性能得到了提升。这表明使用生成模块的反馈过滤检索文档中的噪声是有效的,这也在此前的工作中得到了观察 (Yu et al., 2023b; Izacard & Grave, 2020)。然而,优化知识精炼模块带来的改进有限,突出了增强生成模块利用外部知识的能力对现有 RAG 系统更为关键。
5.3 CHARACTERISTICS OF THE GENERATION MODULE IN RAG-DDR
5.3 RAG-DDR 中生成模块的特性
In this experiment, we explore the characteristics of the generation module $\left<V_{\mathrm{Gen}}\right>$ by employing various training strategies, including zero-shot (Vanilla RAG), the SFT method (RA-DIT), and DDR (RAG-DDR). As illustrated in Figure 2, we present the performance of $V_{\mathrm{Gen}}$ w/o RAG and $V_{\mathrm{Gen}}$ w/ RAG. These experiments evaluate $V_{\mathrm{Gen}}$ ’s ability to memorize knowledge and utilize external knowledge. Additionally, we report the average length of responses generated by $V_{\mathrm{Gen}}$ .
在本在本实验中,我们通过采用不同的训练策略,包括零样本 (Vanilla RAG)、SFT 方法 (RA-DIT) 和 DDR (RAG-DDR),探索了生成模块 $\left<V_{\mathrm{Gen}}\right>$ 的特性。如图 2 所示,我们展示了 $V_{\mathrm{Gen}}$ 在不使用 RAG 和使用 RAG 时的性能。这些实验评估了 $V_{\mathrm{Gen}}$ 的记忆知识和利用外部知识的能力。此外,我们还报告了 $V_{\mathrm{Gen}}$ 生成响应的平均长度。
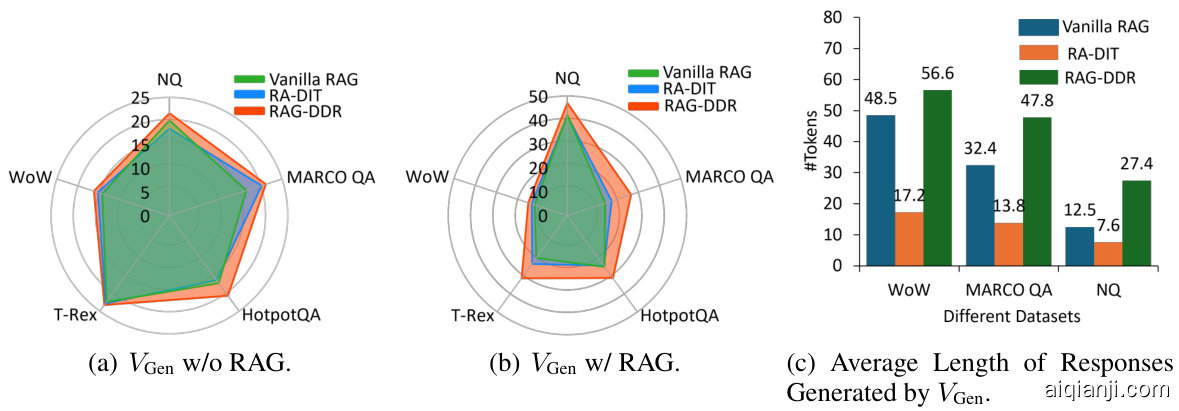
Figure 2: Characteristics of the Generation Module in RAG Optimized with Different Training Strategies. We use MiniCPM-2.4B to build the generation module $(V_{\mathrm{Gen}})$ and then train it using different strategies. The performance of $V_{\mathrm{Gen}}$ is shown in a zero-shot setting, along with the generation module optimized using the RA-DIT and DDR methods.
图图 2: 不同训练策略优化的 RAG 生成模块特性。我们使用 MiniCPM-2.4B 构建生成模块 $(V_{\mathrm{Gen}})$,然后使用不同策略进行训练。$V_{\mathrm{Gen}}$ 在零样本设置下的表现如图所示,同时展示了使用 RA-DIT 和 DDR 方法优化的生成模块。
Table 3: Experimental Results on Evaluating the Knowledge Usage Ability of the Generation Module $(V_{\mathrm{Gen}})$ of Different RAG Models.
表表 3: 评估不同 RAG 模型的生成模块 $(V_{\mathrm{Gen}})$ 知识使用能力的实验结果
| 方法 | NQ | HotpotQA | T-REx | NQ | HotpotQA | T-REx | NQ | HotpotQA | T-REx |
|---|---|---|---|---|---|---|---|---|---|
| MiniCPM-2.4B | |||||||||
| LLMw/oRAG | 27.6 | 26.7 | 36.6 | 2.6 | 11.7 | 4.1 | 100.0 | 100.0 | 100.0 |
| VanillaRAG | 59.1 | 51.7 | 36.8 | ||||||
| RA-DIT | 58.3 | 47.6 | 41.7 | 1.7 | 10.8 | 4.2 | 76.9 | 73.7 | 73.4 |
| RAG-DDR | 65.5 | 56.9 | 52.6 | 2.4 | 10.8 | 5.9 | 82.9 | 81.0 | 78.5 |
| Llama3-8B | |||||||||
| VanillaRAG | 64.2 | 58.0 | 45.5 | 2.9 | 10.5 | 3.0 | 80.0 | 66.3 | |
| RA-DIT | 64.1 | 59.7 | 65.3 | 3.4 | 17.9 | 10.8 | 81.0 | 79.2 | 77.9 |
| RAG-DDR | 69.5 | 64.3 | 59.9 | 4.1 | 18.0 | 5.4 | 88.4 | 82.0 | 79.2 |
As shown in Figure 2(a), we compare the performance of the generation module that relies solely on internal knowledge of parametric memory. Compared to the Vanilla RAG model, RA-DIT demonstrates a decline in performance on the NQ and HotpotQA tasks. Such a phenomenon reveals that the model loses previously acquired knowledge while learning new information during SFT (Luo et al., 2023b). In contrast, DDR not only outperforms the RA-DIT method but also achieves consistent improvements over the Vanilla RAG model across all evaluation tasks. This indicates that DDR can help learn more factual knowledge during training while also preventing the loss of previously memorized information through a reinforcement learning-based training approach. Then we feed retrieved documents to the generation module and show the generation performance in Figure 2(b). The evaluation results indicate that RA-DIT marginally outperforms the Vanilla RAG model, while RAG-DDR significantly improves generation accuracy by utilizing factual knowledge from the retrieved documents. Additional experiments showing the general capabilities of RAGDDR are presented in Appendix A.4.
如图如图 2(a) 所示,我们比较了仅依赖参数内存内部知识的生成模块的性能。与 Vanilla RAG 模型相比,RA-DIT 在 NQ 和 HotpotQA 任务上的表现有所下降。这种现象表明,在 SFT 过程中,模型在学习新知识时失去了之前学到的知识 (Luo et al., 2023b)。相比之下,DDR 不仅优于 RA-DIT 方法,而且在所有评估任务中均比 Vanilla RAG 模型有所提升。这表明,DDR 可以在训练过程中帮助学习更多的事实知识,同时通过基于强化学习的训练方法防止之前记忆信息的丢失。然后,我们将检索到的文档输入生成模块,并在图 2(b) 中展示生成性能。评估结果表明,RA-DIT 略优于 Vanilla RAG 模型,而 RAG-DDR 通过利用检索文档中的事实知识显著提高了生成准确性。附录 A.4 中展示了更多关于 RAGDDR 通用能力的实验结果。
Finally, we show the average length of responses generated by $V_{\mathrm{Gen}}$ in Figure 2(c). Compared to the Vanilla RAG model, the average length of responses generated by RA-DIT decreases significantly, indicating that the SFT training method tends to cause LLMs to overfit the supervised data. On the contrary, RAG-DDR shows a more similar length distribution with Vanilla RAG model, enabling the model to generate responses of a more appropriate length. It demonstrates that training LLMs to learn data preferences from generated responses can help align the output format of RAG models more closely with that of the original LLMs.
最后最后,我们在图 2(c) 中展示了 $V_{\mathrm{Gen}}$ 生成响应的平均长度。与原始 RAG 模型相比,RA-DIT 生成响应的平均长度显著减少,表明 SFT 训练方法容易导致大语言模型过拟合监督数据。相反,RAG-DDR 显示出与原始 RAG 模型更相似的长度分布,使模型能够生成更合适长度的响应。这表明,通过训练大语言模型从生成响应中学习数据偏好,可以帮助使 RAG 模型的输出格式更接近原始大语言模型。

Figure 3: Effectiveness of Different RAG Models in Defending Noisy Information. We use MiniCPM-2.4B to build the generation module $(V_{\mathrm{Gen}})$ . And then we retain one informative passage and randomly replace $n$ top-retrieved documents with noisy ones.
图图 3: 不同 RAG 模型在防御噪声信息方面的有效性。我们使用 MiniCPM-2.4B 构建生成模块 $(V_{\mathrm{Gen}})$,然后保留一个信息丰富的段落,并随机用噪声文档替换 $n$ 个检索到的文档。
5.4 EFFECTIVENESS OF RAG-DDR IN USING EXTERNAL KNOWLEDGE
5.4 RAG-DDR 在使用外部知识方面的有效性
In this section, we investigate the capability of the generation module $V_{\mathrm{Gen}}$ in the RAG model to leverage external knowledge for response generation. We first evaluate the ability of $V_{\mathrm{Gen}}$ to balance the internal and external knowledge. Next, we evaluate the denoising ability by $V_{\mathrm{Gen}}$ feeding additional unrelated documents as the external knowledge.
在本在本节中,我们探讨了RAG模型中的生成模块 $V_{\mathrm{Gen}}$ 在利用外部知识进行响应生成方面的能力。我们首先评估了 $V_{\mathrm{Gen}}$ 在平衡内部和外部知识方面的能力。接着,我们通过向 $V_{\mathrm{Gen}}$ 提供额外的无关文档作为外部知识,评估了其去噪能力。
As shown Table 3, we first show the effectiveness of $V_{\mathrm{Gen}}$ in balancing internal and external knowledge during producing responses. We compare three training strategies: zero-shot (Vanilla RAG), SFT (RA-DIT), and DDR (RAG-DDR). Our experiment establishes three testing scenarios to evaluate the effectiveness of different RAG models by categorizing the evaluation data into three distinct scenarios: Has-Answer, Miss-Answer, and Internal Knowledge. The Has-Answer scenario indicates that the retrieved documents contain the golden answer, which can help the generation module to answer the question accurately. The Miss-Answer scenario indicates that the retrieved documents do not contain the golden answer and fail to provide sufficient support for LLMs to generate accurate responses. Lastly, the Internal Knowledge scenario further evaluates the ability of LLMs in dealing with the conflict between internal and external knowledge. The test cases of the Internal Knowledge scenario indicate that LLMs can generate accurate answers using only parametric memory, whereas RAG models produce incorrect responses.
如表如表 3 所示,我们首先展示了 $V_{\mathrm{Gen}}$ 在生成响应过程中平衡内部和外部知识的有效性。我们比较了三种训练策略:零样本 (Vanilla RAG)、SFT (RA-DIT) 和 DDR (RAG-DDR)。我们的实验设置了三种测试场景,通过将评估数据分为三个不同的场景来评估不同 RAG 模型的有效性:有答案 (Has-Answer)、无答案 (Miss-Answer) 和内部知识 (Internal Knowledge)。有答案场景表示检索到的文档包含黄金答案,这可以帮助生成模块准确回答问题。无答案场景表示检索到的文档不包含黄金答案,无法为大语言模型生成准确响应提供足够的支持。最后,内部知识场景进一步评估了大语言模型在处理内部和外部知识冲突方面的能力。内部知识场景的测试案例表明,大语言模型可以仅使用参数化记忆生成准确答案,而 RAG 模型则生成了错误的响应。
In the Has-Answer scenario, RAG-DDR and RA-DIT outperform the Vanilla RAG model on all datasets. This indicates that training the generation module enables it to capture essential knowledge facts, improving the accuracy of the generated responses. Compared with RA-DIT, RAG-DDR achieves consistent improvements over the Vanilla RAG model, which shows that DDR can better generalize the external knowledge usage ability to different knowledge-intensive tasks. In the Miss-Answer scenario, all RAG models perform significantly worse compared to the Has-Answer scenario, showing that the retrieved knowledge fails to provide sufficient information for generating accurate responses. However, RAG-DDR and RA-DIT mitigate the performance drop caused by incorporating retrieved documents by fine-tuning the generation module, illustrating their ability to effectively leverage internal knowledge and avoid being misled by irrelevant information. For the Internal Knowledge scenario, we evaluate the ability of RAG models in handling the conflict from external knowledge. The Vanilla RAG model decreases the generation accuracy more than $20%$ on all tasks, showing that the knowledge conflict can significantly affect the generation result. DDR exhibits strong effectiveness in mitigating the knowledge conflict in the Vanilla RAG model, resulting in a reduction of more than $10%$ in performance drop. This indicates that DDR effectively balances the utilization of internal and external knowledge, facilitating the robustness of the RAG model.
在在Has-Answer场景中,RAG-DDR和RA-DIT在所有数据集上均优于Vanilla RAG模型。这表明,训练生成模块使其能够捕捉关键的知识事实,提高了生成响应的准确性。与RA-DIT相比,RAG-DDR在Vanilla RAG模型上取得了持续改进,这表明DDR能够更好地将外部知识使用能力推广到不同的知识密集型任务中。在Miss-Answer场景中,所有RAG模型的表现均显著低于Has-Answer场景,表明检索到的知识未能为生成准确响应提供足够的信息。然而,RAG-DDR和RA-DIT通过微调生成模块缓解了因引入检索文档而导致的性能下降,展示了它们有效利用内部知识并避免被不相关信息误导的能力。在Internal Knowledge场景中,我们评估了RAG模型处理外部知识冲突的能力。Vanilla RAG模型在所有任务上的生成准确率下降了超过 $20%$ ,表明知识冲突会显著影响生成结果。DDR在缓解Vanilla RAG模型中的知识冲突方面表现出强大的效果,使性能下降减少了超过 $10%$ 。这表明DDR有效地平衡了内部和外部知识的利用,增强了RAG模型的鲁棒性。
In the second experiment, we extend the Has-Answer setting and further investigate the denoising effectiveness of $V_{\mathrm{Gen}}$ by adding different number of noise documents. As shown in Figure 3, we increase the noise by randomly replacing $n$ documents from the top-5 retrieved set with the last $n$ documents from the top-100 retrieved candidates, while ensuring that the ground truth document remains in the set. RA-DIT exhibits inconsistent performance and degrades in some RAG scenarios. In contrast, RAG-DDR consistently outperforms the Vanilla RAG model, maintaining a consistent improvement even as the number of noisy documents increases. It further confirms the effectiveness of our RAG-DDR approach in defencing noise.
在在第二个实验中,我们扩展了 Has-Answer 设置,并通过添加不同数量的噪声文档进一步研究 $V_{\mathrm{Gen}}$ 的去噪效果。如图 3 所示,我们通过随机替换前 5 个检索文档集中的 $n$ 个文档为前 100 个检索候选集中的最后 $n$ 个文档来增加噪声,同时确保真实文档保留在集中。RA-DIT 表现出不一致的性能,并在部分 RAG 场景中表现下降。相比之下,RAG-DDR 始终优于 Vanilla RAG 模型,即使在噪声文档数量增加的情况下仍保持一致的改进。这进一步证实了我们的 RAG-DDR 方法在抵御噪声方面的有效性。
Table 4: Case Studies. These matching phrases are indicated in Red if the model answers correctly and in Blue if it answers incorrectly. We present the generated responses of different RAG models, which use MiniCPM-2.4B to build the generation module $(V_{\mathrm{Gen}})$ .
表表 4: 案例分析。如果模型回答正确,匹配短语用红色表示;如果回答错误,则用蓝色表示。我们展示了不同 RAG 模型生成的响应,这些模型使用 MiniCPM-2.4B 构建生成模块 $(V_{\mathrm{Gen}})$。
Case 1: When does Canada switch to daylight savings time
案例案例 1:加拿大何时切换到夏令时
Document: Daylight Saving Time Canada. Daylight Saving Time in Canada. In most of Canada Daylight Saving Time begins at 2:00 a.m. local time on the second Sunday in March. ... Canada Daylight Saving Time Start and End Dates 2020 March 8 November 1 2019 March 10 November ... November 6 2010 March 14 November 7 2009 March 08 November 1 ...
夏令夏令时加拿大
加拿大夏令时
在加拿大大部分地区,夏令时开始于3月的第二个星期日凌晨2:00。... 加拿大夏令时开始和结束日期 2020年3月8日 11月1日 2019年3月10日 11月... 11月6日 2010年3月14日 11月7日 2009年3月8日 11月1日 ...
Vanilla LLMs: Canada does not switch to or from daylight savings time. Instead, the clocks are automatically set forward by one hour during the spring.
普通普通大语言模型:加拿大不进行夏令时切换。相反,时钟在春季会自动向前调整一小时。
Case 2: The manager who recruited David Beckham managed Manchester United during what timeframe Document: Ferguson’s unprecedented achievements at Aberdeen led to managerial offers from some of the most prestigious clubs in Europe over the years, and he signed with Manchester in November 1986. ... Ferguson retired at the end of the 2012–13 Premier League season but stayed on with Man U in a...
案例案例2:招募David Beckham的经理在哪个时间段管理了曼联?文档:Ferguson在阿伯丁取得的空前成就使他在这些年来收到了欧洲一些最负盛名俱乐部的执教邀请,并于1986年11月与曼联签约……Ferguson在2012-13赛季英超联赛结束时退休,但仍以……的身份留在曼联。
RAG-DDR: The football manager who recruited David Beckham was Sir Alex Ferguson, and he managed Manchester United from 1986 to 2013.
RRAG-DDR: 招募 David Beckham 的足球经理是 Sir Alex Ferguson,他在 1986 年至 2013 年期间管理曼联。
Case 3: Following success at the 1979 election whose party conference speeech included the lines ’you turn if you want to, the lady’s not for turning’?
案例案例3:在1979年大选成功后,她的政党会议演讲中包含了“想转弯就转弯吧,这位女士不会转弯”这句话?
Document: The lady’s not for turning - Wikipedia The lady’s not for turning From Wikipedia, the free encyclopedia Jump to navigation Jump to search 1980 Margaret Thatcher speech ... a phrase used by Margaret Thatcher, then Prime Minister, in her speech to the Conservative Party Conference...
这位这位女士不会改变立场 - 维基百科
Vanilla LLMs: The speaker in question is Margaret Thatcher, who was the leader of the Conservative Party and later became the Prime Minister of the United Kingdom.
普通的普通的LLMs:所提及的发言者是玛格丽特·撒切尔,她是保守党领袖,后来成为英国首相。
Vanilla RAG: Conservative Party Conference RA-DIT: The Conservative Party
VanVanilla RAG: 保守党会议
RA-DIT: 保守党
RAG-DDR: The 1979 Conservative Party conference speech by Margaret Thatcher included the lines ”you turn if you want to, the lady’s not for turning”.
RRAG-DDR:1979年保守党大会上,玛格丽特·撒切尔的演讲中包含了这句话“你想转就转吧,这位女士是不会转的”。
5.5 CASE STUDIES
5.5 案例研究
In Table 4, we present three randomly selected examples from the NQ, HotpotQA, and TrivialQA datasets to show the generated responses and evaluate the effectiveness of the RAG-DDR model.
表表 4 中展示了从 NQ、HotpotQA 和 TrivialQA 数据集中随机选取的三个示例,以展示生成的结果并评估 RAG-DDR 模型的有效性。
For the first case, the query asks about the “daylight savings time of Canada” and the retrieved documents contain detailed information about when the daylight savings time begins each year in Canada. However, since the exact date of daylight savings time changes annually, the most accurate answer is “the second Sunday in March”. RAG-DDR shows its effectiveness in accurately answering the question, while both Vanilla RAG and RAG-DIT are misled by noisy information such as “14th March” and “10th March”, leading to incorrect responses. This demonstrates that RAG-DDR model has the ability to distinguish the most accurate knowledge from ambiguous or misleading information in the retrieved documents. In the second case, the model must integrate multiple pieces of knowledge from the provided documents to answer the question. While the Vanilla RAG model and RAG-DIT only correctly answer half of the questions using partial knowledge, RAG-DDR successfully identifies the correct start time and end time. This indicates that RAG-DDR has a stronger capacity to integrate factual knowledge from different document segments. As shown in the third case, Vanilla LLM can answer the question correctly only depending on the parametric memory. Nevertheless, both Vanilla RAG and RA-DIT are misled by the confusing information from these retrieved documents and generate the response “the Conservative Party Conference”, which is entirely unrelated to the given question. In contrast, RAG-DDR accurately follows the intent of the question for generating the response, demonstrating the ability of RAG-DDR to mitigate the negative influence of external knowledge.
在在第一个案例中,查询是关于“加拿大夏令时”,检索到的文档包含了加拿大每年夏令时开始时间的详细信息。然而,由于夏令时的确切日期每年都会变化,最准确的答案是“3月的第二个星期日”。RAG-DDR展示了其准确回答问题的有效性,而Vanilla RAG和RAG-DIT则被“3月14日”和“3月10日”等噪声信息误导,导致回答错误。这表明RAG-DDR模型能够从检索到的文档中区分出最准确的知识,避免模糊或误导性信息的影响。在第二个案例中,模型必须整合提供文档中的多个知识片段来回答问题。尽管Vanilla RAG模型和RAG-DIT仅使用部分知识正确回答了一半的问题,但RAG-DDR成功识别了正确的开始时间和结束时间。这表明RAG-DDR在整合不同文档片段中的实际知识方面具有更强的能力。如第三个案例所示,Vanilla LLM仅依赖参数记忆就能正确回答问题。然而,Vanilla RAG和RA-DIT都被检索到的文档中的混淆信息误导,生成了与给定问题完全无关的“保守党会议”这一回答。相比之下,RAG-DDR准确地遵循了问题的意图生成回答,展示了RAG-DDR减轻外部知识负面影响的能力。
6 CONCLUSION
6 总结
This paper proposes Differentiable Data Rewards (DDR), a method aimed at end-to-end optimizing the Retrieval-Augmented Generation (RAG) model using the DPO method. DDR optimizes each agent by collecting the reward in a rollout way and aligns data preferences among these communicative agents. We build a two-agent RAG system and optimize it using DDR to implement the RAG-DDR model. Our experiments demonstrate that DDR helps the generation module produce responses of an appropriate length and avoids over fitting the training signals during SFT. Our further analyses reveal that the DDR optimized generation model can better capture key information from retrieved documents and mitigate the conflict between external knowledge and parametric memory.
本文本文提出了可微分数据奖励(DDR)方法,旨在使用DPO方法端到端优化检索增强生成(RAG)模型。DDR通过逐步收集奖励来优化每个智能体,并在这些通信智能体之间对齐数据偏好。我们构建了一个双智能体RAG系统,并使用DDR进行优化,实现了RAG-DDR模型。实验表明,DDR有助于生成模块生成适当长度的响应,并在监督微调期间避免过拟合训练信号。进一步分析表明,DDR优化的生成模型能够更好地从检索文档中捕捉关键信息,并缓解外部知识与参数化记忆之间的冲突。
REFERENCES
参考文献
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Alten schmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. ArXiv preprint, 2023. URL https://arxiv.org/abs/2303.08774.
JoshJosh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 技术报告。ArXiv 预印本,2023。URL https://arxiv.org/abs/2303.08774。
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Z ett le moyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of ACL, pp. 1601–1611, 2017. URL https://a cl anthology.org/P17-1147.
MMandar Joshi, Eunsol Choi, Daniel Weld, 和 Luke Zettlemoyer. TriviaQA: 一个大规模远程监督的阅读理解挑战数据集. 在 ACL 会议论文集中, 第 1601–1611 页, 2017. 网址 https://acl anthology.org/P17-1147.
Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. Large language models struggle to learn long-tail knowledge. In Proceedings of ICML, pp. 15696–15707, 2023. URL https://proceedings.mlr.press/v202/kandpal23a/kandpal23a.pdf.
NNikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. 大语言模型在长尾知识学习上的挑战。In Proceedings of ICML, pp. 15696–15707, 2023. URL https://proceedings.mlr.press/v202/kandpal23a/kandpal23a.pdf.
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of EMNLP, pp. 6769–6781, 2020. URL https://a cl anthology.org/2020. emnlp-main.550.
VVladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, 和 Wen-tau Yih。开放域问答的稠密段落检索。在 EMNLP 论文集, 第 6769–6781 页, 2020。URL https://a cl anthology.org/2020. emnlp-main.550。
Levente Kocsis and Csaba Szepesva´ri. Bandit based monte-carlo planning. In Proceedings of ECML, pp. 282–293, 2006. URL https://citeseerx.ist.psu.edu/document?repid=rep1&type= pdf&doi=6661e57237e4e8739b7a4946c4d3d4875376c068.
LeLevente Kocsis 和 Csaba Szepesvári. 基于Bandit的蒙特卡洛规划. 在ECML会议论文集中, 第282-293页, 2006. URL https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=6661e57237e4e8739b7a4946c4d3d4875376c068.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, pp. 452–466, 2019. URL https://a cl anthology. org/Q19-1026.
TomTom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, 和 Slav Petrov. Natural questions:问答研究的一个基准. 计算语言学协会会刊,pp. 452–466, 2019. URL https://a cl anthology. org/Q19-1026.
Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, and Jiaya Jia. Step-dpo: Stepwise preference optimization for long-chain reasoning of llms. ArXiv preprint, 2024. URL https: //arxiv.org/abs/2406.18629.
XXin Lai、Zhuotao Tian、Yukang Chen、Senqiao Yang、Xiangru Peng 和 Jiaya Jia。Step-DPO:大语言模型长链推理的逐步偏好优化。ArXiv 预印本,2024。URL https://arxiv.org/abs/2406.18629。
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockta¨schel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of NeurIPS, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/ 6b493230205f780e1bc26945df7481e5-Abstract.html.
PatrickPatrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockta¨schel, Sebastian Riedel, 和 Douwe Kiela. 知识密集型 NLP 任务的检索增强生成. In Proceedings of NeurIPS, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/ 6b493230205f780e1bc26945df7481e5-Abstract.html.
Huayang Li, Yixuan Su, Deng Cai, Yan Wang, and Lemao Liu. A survey on retrieval-augmented text generation. ArXiv preprint, 2022. URL https://arxiv.org/abs/2202.01110.
HuHuayang Li, Yixuan Su, Deng Cai, Yan Wang, and Lemao Liu. 基于检索增强文本生成的综述. ArXiv preprint, 2022. URL https://arxiv.org/abs/2202.01110.
Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Rich James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, et al. Ra-dit: Retrieval-augmented dual instruction tuning. ArXiv preprint, 2023. URL https://arxiv.org/abs/2310.01352.
XiXi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Rich James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, et al. Ra-dit: 检索增强的双指令微调。ArXiv 预印本,2023. 网址 https://arxiv.org/abs/2310.01352.
Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Proceedings of ACL, pp. 158–167, 2017. URL https://aclanthology.org/P17-1015.
WangWang Ling, Dani Yogatama, Chris Dyer, 和 Phil Blunsom. 通过理由生成进行程序归纳:学习解决和解释代数文字问题。 在ACL会议论文集,第158-167页,2017年。 网址:https://aclanthology.org/P17-1015。
Hongwei Liu, Zilong Zheng, Yuxuan Qiao, Haodong Duan, Zhiwei Fei, Fengzhe Zhou, Wenwei Zhang, Songyang Zhang, Dahua Lin, and Kai Chen. Mathbench: Evaluating the theory and application proficiency of llms with a hierarchical mathematics benchmark. arXiv e-prints, pp. arXiv–2405, 2024a. URL https://arxiv.org/pdf/2405.12209.
HongHongwei Liu, Zilong Zheng, Yuxuan Qiao, Haodong Duan, Zhiwei Fei, Fengzhe Zhou, Wenwei Zhang, Songyang Zhang, Dahua Lin, and Kai Chen. Mathbench: 用分层数学基准评估大语言模型的理论和应用能力。arXiv e-prints, pp. arXiv–2405, 2024a. URL https://arxiv.org/pdf/2405.12209.
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, pp. 157–173, 2024b. URL https://arxiv.org/ pdf/2307.03172.
NNelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, 和 Percy Liang. 迷失在中间:语言模型如何使用长上下文. 计算语言学协会会刊, pp. 157–173, 2024b. URL https://arxiv.org/ pdf/2307.03172.
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. Entity-based knowledge conflicts in question answering. ArXiv preprint, 2021. URL https: //arxiv.org/abs/2109.05052.
ShShayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois 和 Sameer Singh。问答中基于实体的知识冲突。ArXiv 预印本,2021。URL https://arxiv.org/abs/2109.05052。
Hongyin Luo, Yung-Sung Chuang, Yuan Gong, Tianhua Zhang, Yoon Kim, Xixin Wu, Danny Fox, Helen Meng, and James Glass. Sail: Search-augmented instruction learning. ArXiv preprint, 2023a. URL https://arxiv.org/abs/2305.15225.
LLuo Hongyin, Chuang Yung-Sung, Gong Yuan, Zhang Tianhua, Kim Yoon, Wu Xixin, Fox Danny, Meng Helen, and Glass James. SAIL: 搜索增强指令学习. ArXiv 预印本, 2023a. URL https://arxiv.org/abs/2305.15225.
Table 5: Data Statistics.
表表 5: 数据统计
| Split | Task | Dataset | Metric | Total |
|---|---|---|---|---|
| Training | Open-Domain QA | CommonsenseQA(2019) Math QA (2019) Web Questions (2013) Wiki QA (2015) Yahoo!Answers QA MARCO QA (2016) | Accuracy Accuracy Accuracy Rouge-L Rouge-L Rouge-L | 4,200 4,200 3,778 1,040 4,200 |
| Evaluation | Open-domainQA | NaturalQuestions(2019) TriviaQA (2017) | Accuracy Accuracy | 2,837 5,359 |
| Multi-Hop QA | MARCOQA(2016) HotpotQA (2018) | Rouge-L Accuracy | 3,000 5,600 | |
| Slot Filling | T-REx (2018) | Accuracy | 5,000 | |
| Dialogue | Wizard of Wikipedia (2019) | F1 | 3,000 |
A APPENDIX
A 附录
A.1 ADDITIONAL EXPERIMENTAL DETAILS
A.1 附加实验细节
In this subsection, we first outline the process of constructing the training data. Then we show the prompt templates used in our experiments. In experiments, we keep the same training data, hyper parameters, and epochs to implement both RA-DIT and RAG-DDR for a fair comparison.
在本在本小节中,我们首先概述了构建训练数据的过程。然后展示了实验中使用的提示模板。在实验中,我们保持相同的训练数据、超参数和训练轮次,以实现 RA-DIT 和 RAG-DDR 的公平比较。
Data Preprocessing for DDR. The quantity of our training and evaluation data, along with the corresponding evaluation metrics, are presented in Table 5. Then we describe the details of data preprocessing during training both knowledge refinement $(V_{\mathrm{KR}})$ and generation $(V_{\mathrm{Gen}})$ modules using our DDR method.
DDDR 的数据预处理
Optimizing the knowledge refinement module is a rollout process, which individually feeds the top100 retrieved documents to the generation module $(V_{\mathrm{Gen}})$ with query to calculate the reward. Then, we apply the evaluation metrics shown in Table 5 to calculate the reward scores, identifying the documents that result in the highest scores as positive documents and those with the lowest scores as negative ones. Finally, we generate the triplet data {query, positive/negative documents, $\left.^{\infty}\mathrm{YES^{\circ}/^{\circ}N O^{\circ}}\right}$ . To construct the dataset for training the generation module, we concatenate the refined documents with the query and then fed them into the generation module for sampling responses. We apply five different temperature settings (0.5, 0.6, 0.7, 0.8, 0.9) to sample responses and conduct the five-round sampling for each temperature. Afterward, we compute the reward score for each output using evaluation metrics to identify the positive and positive responses for each query. This process yields the triplet data {query, positive response, negative response}.
优化优化知识精炼模块是一个 rollout 过程,它将检索到的前100个文档单独输入生成模块 $(V_{\mathrm{Gen}})$ ,并结合查询计算奖励。然后,我们使用表5中展示的评估指标计算奖励分数,将得分最高的文档标记为正面文档,得分最低的标记为负面文档。最后,我们生成三元组数据 {query, 正面/负面文档, $\left.^{\infty}\mathrm{YES^{\circ}/^{\circ}N O^{\circ}}\right}$ 。为了构建用于训练生成模块的数据集,我们将精炼后的文档与查询拼接在一起,然后输入生成模块以进行响应采样。我们采用五种不同的温度设置(0.5, 0.6, 0.7, 0.8, 0.9)进行响应采样,并对每个温度进行五轮采样。之后,我们使用评估指标计算每个输出的奖励分数,以确定每个查询的正面和负面响应。此过程生成了三元组数据 {query, 正面响应, 负面响应}。
Prompt Templates. For RA-DIT, we use the same instruction tuning template as Lin et al. (2023) and leverage top-5 retrieved documents as augmented knowledge during training. Then we describe the prompt templates used in RAG-DDR. As shown in Figure 4, we refer to the prompt designs of RA-DIT (Lin et al., 2023) and Self-RAG (Asai et al., 2023) to conduct tailored task prompts for different LLMs, helping LLMs generate better responses. In addition, we design separate prompts for LLMs w/ RAG and LLMs w/o RAG:{Background: ${D o c u m e n t s}\backslash\mathfrak{n}\left{I n s t r u c t i o\bar{n}\right}}$ and $\bar{{}I n s t r u c t i o n}$ , where Documents indicates the external documents provided for LLMs and $I n$ - struction represents the task instructions. As illustrated in Figure 5, we design the prompts for the knowledge refinement tasks by referring to LangChain1, enabling LLMs to correctly generate “YES” or “NO” to retain or discard retrieved documents.
提示提示模板。对于RA-DIT,我们使用与Lin et al. (2023)相同的指令调优模板,并在训练期间利用前5个检索到的文档作为增强知识。然后我们描述在RAG-DDR中使用的提示模板。如图4所示,我们参考了RA-DIT (Lin et al., 2023)和Self-RAG (Asai et al., 2023)的提示设计,为不同的大语言模型定制任务提示,帮助大语言模型生成更好的响应。此外,我们分别为带有RAG和不带RAG的大语言模型设计了不同的提示:{背景:${D o c u m e n t s}\backslash\mathfrak{n}\left{I n s t r u c t i o\bar{n}\right}}$ 和 $\bar{{}I n s t r u c t i o n}$,其中Documents表示提供给大语言模型的外部文档,$I n$ - struction表示任务指令。如图5所示,我们参考LangChain1设计了知识精炼任务的提示,使大语言模型能够正确生成“是”或“否”以保留或丢弃检索到的文档。

Figure 4: Prompts of Different Training and Evaluating Tasks.
图图 4: 不同训练和评估任务的提示 (Prompt)

Figure 5: Prompts Used for Knowledge Refinement.
图图 5: 用于知识精炼的提示词
A.2 ADDITIONAL ABLATION STUDIES ON RAG-DDR
A.2 关于 RAG-DDR 的额外消融实验
As shown in Table 6, we conduct additional ablation studies to explore the effectiveness of different training strategies: Independent Tuning, RAG-DDR ( $\mathrm{V}{\mathrm{KR}}$ First) and RAG-DDR $\mathrm{\DeltaV{Gen}}$ First). Independent Tuning indicates that the knowledge refinement module $V_{\mathrm{KR}}$ and generation module $V_{\mathrm{Gen}}$ are trained independently. RAG-DDR $\mathrm{\DeltaV_{KR}}$ First) and RAG-DDR ( $V_{\mathrm{Gen}}$ First) are cascaded optimization models, indicating that we first train $V_{\mathrm{KR}}$ or $V_{\mathrm{Gen}}$ and subsequently optimize the other module by initializing the RAG model with the already optimized module.
如表如表 6 所示,我们进行了额外的消融实验,以探索不同训练策略的有效性:独立调优 (Independent Tuning)、RAG-DDR ( $\mathrm{V}{\mathrm{KR}}$ 优先) 和 RAG-DDR ( $\mathrm{\DeltaV{Gen}}$ 优先)。独立调优表示知识精炼模块 $V_{\mathrm{KR}}$ 和生成模块 $V_{\mathrm{Gen}}$ 是独立训练的。RAG-DDR ( $\mathrm{\DeltaV_{KR}}$ 优先) 和 RAG-DDR ( $V_{\mathrm{Gen}}$ 优先) 是级联优化模型,表示我们首先训练 $V_{\mathrm{KR}}$ 或 $V_{\mathrm{Gen}}$,然后通过使用已经优化的模块初始化 RAG 模型来优化另一个模块。
Table 6: Additional Ablation Study Results on RAG-DDR.
表表 6: RAG-DDR 的额外消融研究结果
| 方法 | 开放域问答 (Open-Domain QA) | 多跳问答 (Multi-HopQA) | 槽填充 (SlotFilling) | 对话 (Dialogue) |
|---|---|---|---|---|
| NQ | TriviaQA | MARCOQA | HotpotQA | |
| 独立调优 (Independent Tuning) | 46.6 | 82.0 | 28.0 | 32.3 |
| RAG-DDR (VkR 优先) | 47.4 | 83.2 | 27.2 | 33.3 |
| RAG-DDR (VGen 优先) | 47.0 | 82.7 | 28.1 | 32.5 |
| Llama3-8B | ||||
| 独立调优 (Independent Tuning) | 49.9 | 88.3 | 25.1 | 37.4 |
| RAG-DDR (VkR 优先) | 50.4 | 88.6 | 25.6 | 36.9 |
| RAG-DDR (VGen 优先) | 50.7 | 88.2 | 25.1 | 37.3 |

Figure 6: Effectiveness of the Knowledge Refinement Module $(V_{\mathrm{KR}})$ Optimized Using Different Methods, including zero-shot (Vanilla RAG), SFT (RA-DIT), and DDR (RAG-DDR). fined Document Sets.
图图 6: 知识精炼模块 (V_KR) 使用不同方法(包括零样本 (Vanilla RAG)、SFT (RA-DIT) 和 DDR (RAG-DR))优化后的效果。精炼文档集。
Compared to Independent Tuning, the effectiveness of RAG-DDR is enhanced on all tasks. It shows that Independent Tuning results in misalignment of data preferences between the optimized modules, thereby impacting the overall performance of the RAG system. In contrast, the performance of RAGDDR $\left.V_{\mathrm{KR}}\right.$ First) and RAG-DDR $\mathrm{\DeltaV_{Gen}}$ First) is indistinguishable across different datasets and $V_{\mathrm{Gen}}$ , demonstrating that the DDR method is robust to the training orders.
与与独立调优相比,RAG-DDR 在所有任务上的效果均有所提升。这表明独立调优会导致优化模块之间的数据偏好不一致,从而影响 RAG 系统的整体性能。相比之下,RAG-DDR ($\left.V_{\mathrm{KR}}\right.$ First) 和 RAG-DDR ($\mathrm{\DeltaV_{Gen}}$ First) 在不同数据集和 $V_{\mathrm{Gen}}$ 上的表现无明显差异,证明 DDR 方法对训练顺序具有鲁棒性。
A.3 CHARACTERISTICS OF THE KNOWLEDGE REFINEMENT MODULE OF RAG-DDR
A.3 RAG-DDR知识精炼模块的特性
As shown in Figure 6, we explore the characteristics of the knowledge refinement module $(V_{\mathrm{KR}})$ optimized using different methods, including Vanilla RAG, RA-DIT and RAG-DDR.
如图如图 6 所示,我们探索了使用不同方法优化的知识精炼模块 $(V_{\mathrm{KR}})$ 的特性,包括 Vanilla RAG、RA-DIT 和 RAG-DDR。
For RA-DIT, we collect $30\mathrm{k}$ pieces of data from the MARCO QA dataset to tune $V_{\mathrm{KR}}$ where each query has labeled positive and negative documents. We sample one positive document and one negative document for each query to construct the SFT dataset containing $60\mathrm{k}$ pieces of data and fine-tune $V_{\mathrm{KR}}$ . The number of the SFT dataset is consistent with the amount of the RAG-DDR training dataset. The SFT dataset consists of triples in the form of {query, positive/negative documents, $\mathrm{^{6\leftarrow}Y E S^{\ast}/^{\ast}N O^{\ast}}}$ .
对于对于 RA-DIT,我们从 MARCO QA 数据集中收集了 $30\mathrm{k}$ 条数据来微调 $V_{\mathrm{KR}}$,其中每个查询都有标注的正文档和负文档。我们为每个查询采样一个正文档和一个负文档,构建包含 $60\mathrm{k}$ 条数据的 SFT 数据集,并对 $V_{\mathrm{KR}}$ 进行微调。SFT 数据集的数量与 RAG-DDR 训练数据集的数量一致。SFT 数据集由形如 {query, positive/negative documents, $\mathrm{^{6\leftarrow}Y E S^{\ast}/^{\ast}N O^{\ast}}}$ 的三元组组成。
As shown in Figure 6(a), we calculate the accuracy of top-5 documents by Vanilla RAG, RA-DIT, and RAG-DDR. The retrieval accuracy evaluates whether or not the retained top-5 documents contain the ground truth. If $V_{\mathrm{KR}}$ discards all the documents retrieved, the accuracy is 0. RAG-DDR outperforms Vanilla RAG and RA-DIT on all tasks. It indicates that the DDR method can make $V_{\mathrm{KR}}$ accurately retain documents that contain the necessary knowledge to answer the query. As shown in Figure 6(b), we use the refined documents by different knowledge refinement module $(V_{\mathrm{KR}})$ to augment the DDR trained generation module $(V_{\mathrm{Gen}})$ . DDR-RAG also outperforms other models, indicating that DDR can help better align data preferences between $V_{\mathrm{Gen}}$ and $V_{\mathrm{KR}}$ .
如图如图 6(a) 所示,我们计算了 Vanilla RAG、RA-DIT 和 RAG-DDR 的 top-5 文档准确率。检索准确率评估保留的 top-5 文档是否包含真实答案。如果 $V_{\mathrm{KR}}$ 丢弃了所有检索到的文档,则准确率为 0。RAG-DDR 在所有任务上都优于 Vanilla RAG 和 RA-DIT。这表明 DDR 方法可以使 $V_{\mathrm{KR}}$ 准确地保留包含回答查询所需知识的文档。如图 6(b) 所示,我们使用不同知识精炼模块 $(V_{\mathrm{KR}})$ 的优化文档来增强 DDR 训练生成模块 $(V_{\mathrm{Gen}})$ 。DDR-RAG 也优于其他模型,表明 DDR 可以帮助更好地对齐 $V_{\mathrm{Gen}}$ 和 $V_{\mathrm{KR}}$ 之间的数据偏好。

Figure 7: The Ability of the Generation Module $(V_{\mathrm{Gen}})$ in RAG-DDR.
图图 7: RAG-DDR 中生成模块 $(V_{\mathrm{Gen}})$ 的能力
A.4 THE GENERAL LLM ABILITY OF DDR OPTIMIZED GENERATION MODULE
AA.4 DDR 优化生成模块的通用大语言模型能力
In this experiment, we further explore the characteristics of the generation module $(V_{\mathrm{Gen}})$ optimized using different methods, zero-shot (LLM w/o RAG) and DDR (RAG-DDR).
在本在本实验中,我们进一步探索了使用不同方法优化的生成模块 $(V_{\mathrm{Gen}})$ 的特性,包括零样本 (LLM w/o RAG) 和 DDR (RAG-DDR)。
As shown in Figure 7, we compare the general ability of the generation module on several aspects: Mathematical (Liu et al., 2024a), Disciplinary Knowledge (Hendrycks et al., 2020), World Knowledge (Kwiatkowski et al., 2019), Logical Reasoning (Suzgun et al., 2022), and Common Sense Reasoning (Clark et al., 2018). These tasks are commonly used as benchmarks to assess the model’s inherent capabilities (Touvron et al., 2023; Hu et al., 2024).
如图如图 7 所示,我们从以下几个方面比较了生成模块的通用能力:数学 (Liu et al., 2024a)、学科知识 (Hendrycks et al., 2020)、世界知识 (Kwiatkowski et al., 2019)、逻辑推理 (Suzgun et al., 2022) 和常识推理 (Clark et al., 2018)。这些任务通常被用作评估模型内在能力的基准 (Touvron et al., 2023; Hu et al., 2024)。
As shown in Figure 7(a), DDR enables Llama3-8B to maintain its strong language understanding and knowledge reasoning capabilities. The performance of MiniCPM-2.4B is shown in Figure 7(b). The evaluation results show that DDR significantly enhances the performance of the smaller parameter models, MiniCPM-2.4B, particularly in mathematical and common sense reasoning tasks. It illustrates that DDR not only preserves the original capabilities of LLMs but also offers some potential for enhancing their performance.
如图如图7(a)所示,DDR使Llama3-8B保持了其强大的语言理解和知识推理能力。MiniCPM-2.4B的表现如图7(b)所示。评估结果表明,DDR显著提升了较小参数模型MiniCPM-2.4B的性能,尤其是在数学和常识推理任务中。这说明了DDR不仅保留了大语言模型的原有能力,还具备一定的性能提升潜力。