GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
Xin Zhang1* Yanzhao Zhang2* Wen Xie2* Mingxin $\mathrm{Li}^{2}$ , Ziqi Dai2, Dingkun Long2 Pengjun Xie2 , Meishan Zhangf Wenjie $\operatorname{Li}^{1}$ , Min Zhang3 1The Hong Kong Polytechnic University 2Tongyi Lab, Alibaba Group 3Soochow University
张欣1* 张彦昭2* 谢雯2* 李明新2, 戴子琪2, 龙定坤2, 谢鹏军2, 张美善† 李文杰1, 张敏3
1香港理工大学
2阿里巴巴集团通义实验室
3苏州大学
https://hf.co/Alibaba-NLP/gme-Qwen2-VL-2B-Instruct
https://hf.co/Alibaba-NLP/gme-Qwen2-VL-2B-Instruct
{linzhang.zx,zhang yan zhao.zyz,dingkun.ldk}@alibaba-inc.com
{linzhang.zx,zhang yan zhao.zyz,dingkun.ldk}@alibaba-inc.com
Abstract
摘要
Universal Multimodal Retrieval (UMR) aims to enable search across various modalities using a unified model, where queries and candidates can consist of pure text, images, or a combination of both. Previous work has attempted to adopt multimodal large language models (MLLMs) to realize UMR using only text data. However, our preliminary experiments demonstrate that more diverse multimodal training data can further unlock the potential of MLLMs. Despite its effectiveness, the existing multimodal training data is highly imbalanced in terms of modality, which motivates us to develop a training data synthesis pipeline and construct a large-scale, highquality fused-modal training dataset. Based on the synthetic training data, we develop the General Multimodal Embedder (GME), an MLLM-based dense retriever designed for UMR. Furthermore, we construct a comprehensive UMR Benchmark (UMRB) to evaluate the effectiveness of our approach. Experimental results show that our method achieves state-of-the-art performance among existing UMR methods. Last, we provide in-depth analyses of model scaling and training strategies, and perform ablation studies on both the model and synthetic data.
通用多模态检索 (UMR) 旨在通过统一模型实现跨多种模态的搜索,其中查询项和候选内容可以包含纯文本、图像或两者的组合。先前的研究尝试采用多模态大语言模型 (MLLM) 仅使用文本数据来实现 UMR。然而,我们的初步实验表明,更多样化的多模态训练数据能进一步释放 MLLM 的潜力。尽管现有方法有效,但当前多模态训练数据在模态层面存在严重不平衡,这促使我们开发训练数据合成流程并构建大规模高质量的融合模态训练数据集。基于合成训练数据,我们开发了通用多模态嵌入器 (GME),这是一种基于 MLLM 的稠密检索器,专为 UMR 设计。此外,我们构建了综合性的 UMR 基准测试 (UMRB) 以评估方法的有效性。实验结果表明,我们的方法在现有 UMR 方法中实现了最先进的性能。最后,我们深入分析了模型缩放和训练策略,并对模型和合成数据进行了消融研究。
1. Introduction
1. 引言
The growth of multimedia applications necessitates retrieval models that extend beyond traditional text-to-text and text-to-image search [75]. In Universal Multimodal Retrieval (UMR) tasks, both queries and candidates can exist in any modality [39]. Compared to addressing this challenge with separate uni-modal and cross-modal retrievers in a divide-and-conquer pipeline [4], a unified retriever is a more viable option in terms of usability and s cal ability. Using the dense retrieval paradigm (also known as embeddingbased retrieval) [25], a unified model can be trained to project inputs from various modalities into a shared embedding space [22, 74, 75]. In this space, similarity scores are computed between the embeddings of queries and the retrieval collection, facilitating the efficient ranking of the top $k$ candidates. To achieve this, some previous studies have primarily focused on two approaches: (1) designing feature fusion mechanisms for cross-modal retrievers based on the CLIP architecture [39, 66], and (2) incorporating visual plugin modules into optimized text embedding models to achieve unified multimodal representations [74, 75].
多媒体应用的增长需要超越传统文本到文本和文本到图像检索的检索模型 [75]。在通用多模态检索 (UMR) 任务中,查询项和候选项可以存在于任何模态 [39]。与通过分治流程中采用独立单模态和跨模态检索器应对此挑战相比 [4],统一检索器在可用性和可扩展性方面是更可行的选择。采用稠密检索范式(也称为基于嵌入的检索)[25],可以训练统一模型将来自不同模态的输入投影到共享嵌入空间 [22, 74, 75]。在该空间中,通过计算查询项嵌入向量与检索集合的相似度得分,可实现前 $k$ 个候选项的高效排序。为实现这一目标,先前研究主要聚焦两种方法:(1) 基于 CLIP 架构设计跨模态检索器的特征融合机制 [39, 66];(2) 在优化文本嵌入模型中引入视觉插件模块以实现统一的多模态表征 [74, 75]。
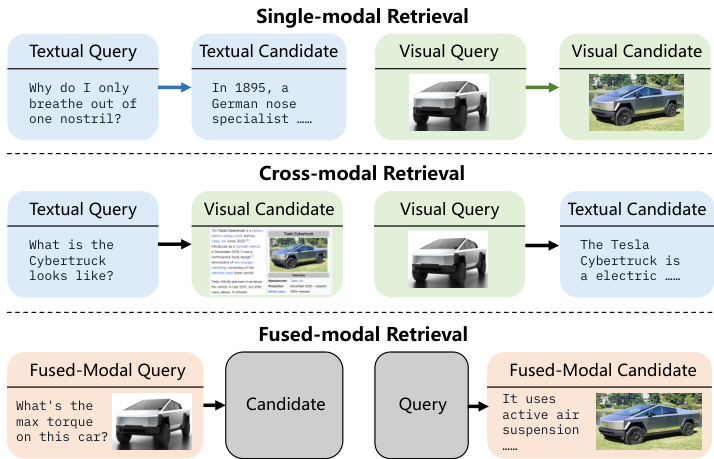
Figure 1. Illustration of different retrieval settings in our universal multimodal retrieval task. Blocks with black borders represent data in arbitrary modalities, i.e. text-only, image-only or fused.
图 1: 我们的通用多模态检索任务中不同检索设置的示意图。带黑色边框的方块代表任意模态的数据, 即纯文本、纯图像或融合模态。
Recently, researchers have turned to exploring Multimodal Large Language Models (MLLMs) [35, 65] in UMR. For example, it is shown that training MLLMs with text data alone can generate universal multimodal embeddings with respectable retrieval performance [22]. However, modalitylimited training may fail to fully demonstrate the potential of MLLMs in UMR. We believe that incorporating multimodal data composition (as shown in Figure 1) could further enhance the model performance and generalization. Moreover, visual documents (i.e. document screenshots) are increasingly important in UMR tasks, as they not only simplify the pipelines of diverse Retrieval-Augmented Generation (RAG) applications, but also mitigate information loss during modality conversion [12, 41]. However, current UMR models primarily target natural images, neglecting support for this scenario (Table 1).
最近, 研究人员开始探索多模态大语言模型 (MLLMs) [35, 65] 在统一模态检索 (UMR) 中的应用。例如, 研究表明仅使用文本数据训练 MLLMs 就能生成具有可观检索性能的通用多模态嵌入 [22]。然而, 受限模态的训练可能无法充分展现 MLLMs 在 UMR 中的潜力。我们认为引入多模态数据组合 (如图 1 所示) 可进一步提升模型性能和泛化能力。此外, 视觉文档 (即文档截图) 在 UMR 任务中日益重要, 它们不仅能简化多样化检索增强生成 (RAG) 应用的流程, 还能减少模态转换过程中的信息损失 [12, 41]。然而, 当前的 UMR 模型主要针对自然图像, 忽视了对这一场景的支持 (表 1)。
Table 1. Comparison of UMR studies. Feat. and Enc. are abbreviations for “Feature” and “Encoder”. S&C, Fused, and VD denote the retrieval setting of single-modal & cross-modal, fusedmodal, and retrieving visual documents (e.g. PDF screenshots), respectively. The setting explain ation is in Figure 1.
表 1. UMR研究对比。Feat.和Enc.分别是"特征"和"编码器"的缩写。S&C, Fused和VD分别表示单模态与跨模态、融合模态以及检索视觉文档(例如PDF截图)的检索设置。具体设置说明见图 1。
| 方法 | 建模方法 | 训练方式 | 检索设置 | ||
|---|---|---|---|---|---|
| 方法 | 训练 | S&C融合 | VD | ||
| UniVL-DR[39] | CLIP特征融合 | 跨模态 | |||
| UniIR[66] | CLIP分数融合 BLIP特征融合 | 多模态 | |||
| MARVEL[75] | 文本编码器+插件 | 跨模态 | X | ||
| VISTA[74] | 文本编码器+插件 | 多模态 | |||
| E5-V[22] | 多模态大语言模型 | 纯文本 | |||
| GME (本文) | 多模态大语言模型 | 多模态 |
To address the aforementioned challenges, we propose the General Multimodal Embedder (GME), an instructionbased embedding framework utilizing MLLMs as the backbone. GME enables retrieval across various modalities in the unified paradigm, including text, images, visual documents, and fused-modal1 (i.e. image-text composed) contents. Our framework is underpinned by two key techniques: (1) A strategically optimized training data composition for UMR. We categorize UMR tasks into three types: single-modal, cross-modal, and fused-modal (Figure 1). Through extensive experimentation, we analyze how different compositions affect performance (Figure 3) and demonstrate that a balanced mixture of all types yields optimal results. (2) An efficient fused-modal data synthesis pipeline. Recognizing the under-representation of fused-modal data and its potential impact on training effectiveness, we develop a streamlined data synthesis pipeline (§4.2). This approach has successfully generated a comprehensive dataset of 1.1M fused-modal pairs, significantly enhancing our training and model capabilities.
为应对上述挑战,我们提出通用多模态嵌入器 (GME) ——一种基于指令的嵌入框架,采用 MLLM 作为骨干网络。GME 支持在统一范式下实现文本、图像、视觉文档及融合模态 (即图文组合) 内容的跨模态检索。我们的框架基于两项关键技术:(1) 针对 UMR 任务精心优化的训练数据组合策略。我们将 UMR 任务划分为三类:单模态、跨模态和融合模态 (图 1)。通过大量实验,我们分析了不同组合对性能的影响 (图 3),并证明均衡混合所有类型可获得最优结果。(2) 高效的融合模态数据合成流程。针对融合模态数据稀缺性及其对训练效果的潜在影响,我们开发了简化的数据合成流程 (§4.2)。该方法成功生成了包含 110 万融合模态对的完整数据集,显著提升了训练效果与模型能力。
To evaluate the effectiveness of our framework, we compile a comprehensive UMR Benchmark, namely UMRB. This benchmark encompasses tasks from widely recognized retrieval benchmarks in text [55], multimodal [66], and visual document retrieval [12], as well as our newly processed fused-modal retrieval data. We build our models on top of the strong Qwen2-VL series MLLMs [65] and train them on our constructed dataset. Experimental results demonstrate that our model achieves state-of-the-art performance on UMRB. Additionally, we perform in-depth analyses on model scaling, training strategies, and ablation of our synthetic data. Our key contributions are:
为评估框架有效性,我们构建了综合性UMR基准测试集UMRB。该基准涵盖文本检索[55]、多模态检索[66]和视觉文档检索[12]等广泛认可基准任务,以及我们新处理的多模态融合检索数据。我们在强大的Qwen2-VL系列MLLMs[65]基础上构建模型,并使用自建数据集进行训练。实验结果表明,我们的模型在UMRB上实现了最先进性能。此外,我们深入分析了模型缩放、训练策略以及合成数据的消融实验。我们的主要贡献包括:
• We explore strategies to adapt MLLMs into UMR models, and present GME, a powerful embedding model capable of retrieving candidates across different modalities. GME is the first UMR model to deliver visual document retrieval performance on par with specialized models. • We propose a novel data synthesis pipeline for constructing large-scale, fused-modal training data to encounter the scarcity of such training data. This pipeline is more efficient than previous approaches and can be easily extended to other domains. • We compile the UMR benchmark, UMRB, to evaluate a broader range of retrieval tasks compared to existing benchmarks. UMRB categorizes tasks into three types: single-modal, cross-modal, and fused-modal, and offers a comprehensive performance evaluation across them.
• 我们探索将多模态大语言模型 (MLLM) 适配为统一模态检索 (UMR) 模型的策略,并提出了GME——一个能够跨不同模态检索候选对象的强大嵌入模型。GME是首个在视觉文档检索性能上与专业模型相媲美的UMR模型。
• 我们提出了一种新颖的数据合成流程,用于构建大规模融合模态训练数据,以应对此类训练数据稀缺的问题。该流程比以往方法更高效,且易于扩展到其他领域。
• 我们编制了UMR基准测试集UMRB,用于评估比现有基准更广泛的检索任务。UMRB将任务分为三类:单模态、跨模态和融合模态,并提供了跨这些任务的全面性能评估。
2. Related Work
2. 相关工作
Multimodal Large Language Models The emergence of Large Language Models (LLMs) has driven significant progress in natural language processing [3, 49], leading to the development of Multimodal LLMs that extend these capabilities to handle multimodal information. Prominent MLLMs such as GPT-4V [48], LLaVa [35, 36], QwenVL [65], InternVL [7] and MiniCPM-V [71] have shown promising advancements in multimodal information understanding and reasoning. Typically, an MLLM consists of an LLM, a vision encoder, and a projector that bridges the two components by transforming raw multimodal inputs into vectors compatible with the LLM [72].
多模态大语言模型
大语言模型 (LLM) 的出现推动了自然语言处理领域的重大进展 [3, 49] ,并催生了能处理多模态信息的多模态大语言模型 (MLLM) 。诸如 GPT-4V [48] 、LLaVa [35, 36] 、QwenVL [65] 、InternVL [7] 和 MiniCPM-V [71] 等知名 MLLM 已在多模态信息理解与推理方面展现出显著进展。通常,MLLM 由大语言模型、视觉编码器以及连接这两个组件的投影模块构成,该模块通过将原始多模态输入转换为与大语言模型兼容的向量来实现跨模态对齐 [72] 。
Multimodal Retrieval Early multimodal retrieval tasks focused on single-modal [73] or cross-modal retrieval [61]. Recently, the expansion of multimedia applications and multimodal retrieval-augmented generation (RAG) by MLLMs has created a need for unified multimodal retrieval models for complex scenarios. Existing approaches largely utilize pre-trained models such as CLIP [51] or BLIP [29] for multimodal embedding. For instance, UniVL-DR [39] and UniIR [66] initially encode images and texts separately using CLIP or BLIP encoders, followed by fusion strategies like score fusion to integrate features from both modalities. Additionally, VISTA [74] and MARVEL [75] employ pretrained text embedding models enhanced with visual plugins to encode composite image-text candidates. However, these methods are typically designed for specific tasks like multimodal document retrieval and lack flexibility to handle diverse multimodal retrieval tasks.
多模态检索 早期的多模态检索任务主要关注单模态 [73] 或跨模态检索 [61]。近年来,随着多媒体应用的扩展以及多模态大语言模型 (MLLM) 在多模态检索增强生成 (RAG) 中的应用,复杂场景对统一多模态检索模型的需求日益增长。现有方法大多利用 CLIP [51] 或 BLIP [29] 等预训练模型进行多模态嵌入。例如,UniVL-DR [39] 和 UniIR [66] 首先使用 CLIP 或 BLIP 编码器分别对图像和文本进行编码,随后采用分数融合等策略来整合双模态特征。此外,VISTA [74] 和 MARVEL [75] 采用通过视觉插件增强的预训练文本嵌入模型来编码图文复合候选内容。然而,这些方法通常针对多模态文档检索等特定任务设计,缺乏处理多样化多模态检索任务的灵活性。
Concurrent with our work, E5-V [22] and VLM2VEC [23] propose fine-tuning MLLMs on single-text (NLI [14]) or vision-centric relevance data, demonstrating their transfer ability to multimodal retrieval. In this paper, we are the first to explore the fine-tuning of an MLLMbased universal multimodal retriever that can address both visual retrieval tasks and maintain strong text-to-text retrieval capabilities. Moreover, we are the first to extend a unified retrieval model to handle not only natural image retrieval but also text-rich image retrieval [12].
与我们的工作同时, E5-V [22] 和 VLM2VEC [23] 提出了在单文本 (NLI [14]) 或以视觉为中心的相关性数据上微调多模态大语言模型 (MLLM) 的方法, 展示了它们向多模态检索的迁移能力。在本文中, 我们率先探索基于 MLLM 的通用多模态检索器的微调, 该检索器能够处理视觉检索任务并保持强大的文本到文本检索能力。此外, 我们首次将统一检索模型扩展到不仅处理自然图像检索, 还能处理富文本图像检索 [12]。
Embedding Models with Pre-trained Language Models With the advancement of pre-trained Language Mod- els, research in both pure text and Vision-Language Models has focused on building representation models based on these pre-trained language models. In the text retrieval domain, state-of-the-art text embedding models such as Contriver [21], E5 [62], GTE [31], and BGE [68] are all built upon pre-trained language models and have demonstrated impressive generalization and robust performance in text retrieval tasks. Recently, leveraging LLMs combined with supervised fine-tuning (SFT), researchers have developed unified text representation models that fully utilize the text understanding capabilities of LLMs, resulting in models with enhanced performance and generalization [28, 31, 63]. These models typically process user text inputs through LLMs, using the hidden states from the final transformer layer—either through pooling or by selecting the last token—as the final representation. Inspired by the success of universal text embedding models based on text LLMs, researchers have begun to explore the construction of unified multimodal retrieval models using MLLMs [22, 23]. In this paper, we aim to demonstrate through systematic experiments that constructing a truly universal multimodal retrieval model using MLLMs is feasible.
基于预训练语言模型的嵌入模型 随着预训练语言模型的发展,纯文本和视觉语言模型的研究都聚焦于基于这些预训练语言模型构建表征模型。在文本检索领域,最先进的文本嵌入模型如Contriever [21], E5 [62], GTE [31]和BGE [68]都建立在预训练语言模型基础上,并在文本检索任务中展现出卓越的泛化能力和鲁棒性能。最近,通过结合大语言模型与监督微调,研究人员开发了统一的文本表征模型,充分利用大语言模型的文本理解能力,从而获得性能更强、泛化性更好的模型 [28, 31, 63]。这些模型通常通过大语言模型处理用户文本输入,使用最终Transformer层的隐藏状态——通过池化或选择最后一个token——作为最终表征。受基于文本大语言模型的通用文本嵌入模型成功启发,研究人员开始探索使用多模态大语言模型构建统一的多模态检索模型 [22, 23]。本文旨在通过系统实验证明,使用多模态大语言模型构建真正通用的多模态检索模型是可行的。
3. Universal Multimodal Retrieval
3. 通用多模态检索
Current UMR sub-tasks can be categorized into three types based on the modalities of the query and the candidate:
当前UMR子任务根据查询项与候选项的模态可分为三类:
The visualization of these settings refers to Figure 1.
这些设置的可视化如图 1 所示。
Table 2. An overview of tasks and datasets in our UMRB. $\dagger$ means that they all originate from [12].
| Class | Task | Datasets |
| Single- Modal (17) | T→T (16) | ArguAna[59] Climate-FEVER[11] CQADupStack[18] DBPedia[17]FEVER[56] FiQA2018[42] HotpotQA[70] MSMARCO[47]NFCorpus[2]NQ[26] Quora²SCIDOCS[8] SciFact[60] |
| I→I(1) | Touche2020[1]TRECCOVID[58]WebQA[4] Nights[13] | |
| T→I (4) | VisualNews[34]Fashion200k[16] MSC0CO[32]Flickr30k[50] TAT-DQA[76]ArxivQA[30] | |
| Cross- Modal (18) | T→VD (10) | DocVQA[44]InfoVQA[45] Shift ProjecttArtificial Intelligencet Government Reportst Healthcare Industryt |
| I→T (4) | EnergyTabFQuadt VisualNews[34]Fashion200K[16] | |
| Fused- Modal (12) | T→IT (2) | MSC0CO[32]Flickr30k[50] WebQA[4]EDIS[37] |
| IT→T (5) | OVEN[20]INFOSEEK[6] | |
| IT→I (2) | ReMuQ[40]OKVQA[43]LLaVA[33] FashionIQ[67]CIRR[38] | |
| IT→IT (3) | OVEN[20]EVQA[46]INFOSEEK[6] |
表 2. UMRB 中任务与数据集的概览。$\dagger$ 表示它们均源自 [12]。
| 类别 | 任务 | 数据集 |
|---|---|---|
| 单模态 (17) | T→T (16) | ArguAna[59] Climate-FEVER[11] CQADupStack[18] DBPedia[17] FEVER[56] FiQA2018[42] HotpotQA[70] MSMARCO[47] NFCorpus[2] NQ[26] Quora² SCIDOCS[8] SciFact[60] Touche2020[1] TRECCOVID[58] WebQA[4] Nights[13] |
| I→I (1) | VisualNews[34] Fashion200k[16] MSC0CO[32] Flickr30k[50] TAT-DQA[76] ArxivQA[30] | |
| 跨模态 (18) | T→VD (10) | DocVQA[44] InfoVQA[45] Shift Project Artificial Intelligence Government Reports Healthcare Industry |
| I→T (4) | EnergyTabFQuadt VisualNews[34] Fashion200K[16] | |
| 融合模态 (12) | T→IT (2) | MSC0CO[32] Flickr30k[50] WebQA[4] EDIS[37] |
| IT→T (5) | OVEN[20] INFOSEEK[6] | |
| IT→I (2) | ReMuQ[40] OKVQA[43] LLaVA[33] FashionIQ[67] CIRR[38] | |
| IT→IT (3) | OVEN[20] EVQA[46] INFOSEEK[6] |
3.1. Universal Multimodal Retrieval Benchmark
3.1. 通用多模态检索基准
Based on the aforementioned classification principles, we introduce a new benchmark to comprehensively assess the performance of UMR models. This benchmark comprises 47 evaluation datasets that cover a broad spectrum of multimodal retrieval tasks, and we name it the Universal Multimodal Retrieval Benchmark (UMRB). These evaluation datasets primarily originate from previously constructed datasets tailored for each sub-scenario or sub-task. Specifically, UMRB includes: (1) The BEIR [55] benchmark for text-to-text retrieval scenarios; (2) The M-BEIR [66] dataset for vision-centric retrieval scenarios; (3) Additional fusedmodal datasets that not cover by M-BEIR; and (4) text-tovisual document search datasets, such as ViDoRe [12], to extend the coverage of our benchmark and ensure a comprehensive evaluation of model universality. A detailed list of the UMRB datasets is presented in Table 2.
基于上述分类原则,我们引入了一个新基准来全面评估UMR模型的性能。该基准包含47个评估数据集,涵盖广泛的多模态检索任务,我们将其命名为通用多模态检索基准(UMRB)。这些评估数据集主要源自先前为各子场景或子任务构建的数据集。具体而言,UMRB包括:(1)用于文本到文本检索场景的BEIR [55]基准;(2)用于视觉中心检索场景的M-BEIR [66]数据集;(3)M-BEIR未覆盖的额外融合模态数据集;以及(4)文本到视觉文档搜索数据集(如ViDoRe [12]),以扩展我们基准的覆盖范围并确保模型通用性的全面评估。UMRB数据集的详细列表如表2所示。
Given the extensive size of UMRB, to expedite our experimental validation and analysis, we have sampled a subset of datasets from each category, constituting a smaller dataset named UMRB-Partial. This subset retains $39%$ of the total datasets while maintaining evaluation richness. More detailed statistical information about UMRB-Partial can be found in Appendix Table 6.
考虑到UMRB的庞大规模,为加速实验验证与分析,我们从每个类别中抽取了部分数据集样本,构建了一个名为UMRB-Partial的小型数据集。该子集保留了 $39%$ 的总数据集容量,同时保持了评估丰富性。更多关于UMRB-Partial的详细统计信息可参见附录表6。
4. Method
4. 方法
In this section, we present the training framework for developing the General Multimodal Embedder (GME) model. We describe the contrastive learning approach used to train the embedding model. Building on this, we conduct detailed experiments to determine the optimal balance of training data type. Specifically, our experiments demonstrate that diverse data type mixtures significantly enhances the model’s ability to perform retrieval across various modalities. Lastly, recognizing the scarcity of high-quality fused-modal training data, we propose a novel method for automatically synthesizing large-scale, high-quality training data using MLLM.
在本节中, 我们介绍了开发通用多模态嵌入器 (GME) 模型的训练框架。我们描述了用于训练嵌入模型的对比学习方法。在此基础上, 我们进行了详细实验以确定训练数据类型的最佳平衡。具体而言, 我们的实验表明, 多样化的数据类型混合显著增强了模型在各种模态间执行检索的能力。最后, 针对高质量融合模态训练数据的稀缺性, 我们提出了一种利用 MLLM 自动合成大规模高质量训练数据的新方法。
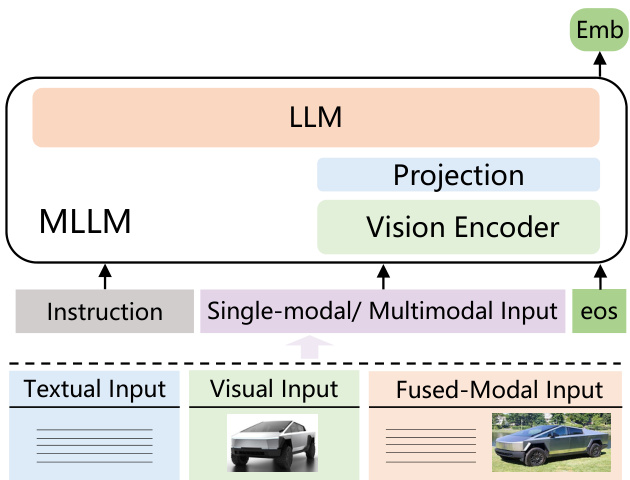
Figure 2. The GME model architecture. Emb denotes the embedding of the input content.
图 2: GME 模型架构。Emb 表示输入内容的嵌入。
4.1. GME: General Multimodal Embedder
4.1. GME: 通用多模态嵌入器
Model Architecture We employ a MLLM as the foundation for GME. This model can accept images, text, or image-text pairs as input. Inspired by previous research on text embedding [31, 63], we use the final hidden state of the last token as the representation (or embedding) for the input. Although pre-trained MLLMs possess strong multimodal understanding capabilities, their original training objectives are not optimized for representation learning. Therefore, task-specific fine-tuning (or alignment) is necessary to enhance the model’s representational capacity. Contrastive learning has been shown to effectively train LLMs and MLLMs to produce retrieval embeddings [22, 31].
模型架构 我们采用多模态大语言模型 (MLLM) 作为 GME 的基础。该模型可以接受图像、文本或图文对作为输入。受文本嵌入 [31, 63] 相关研究的启发,我们使用最后一个 token 的最终隐藏状态作为输入的表征(或嵌入)。虽然预训练的多模态大语言模型具备强大的多模态理解能力,但其原始训练目标并未针对表征学习进行优化。因此,需要执行任务特定的微调(或对齐)来增强模型的表征能力。对比学习已被证明能有效训练大语言模型和多模态大语言模型以生成检索嵌入 [22, 31]。
Contrastive Learning In our contrastive learning setup, each training instance comprises a query $q$ , a relevant candidate $c$ c , and a set of irrelevant candidates ${c_{1}^{-},c_{2}^{-},\ldots,c_{K}^{-}}$ \ldots , c_K^-} . Both $q$ and $c$ can be text, images, or image-text pairs, allow- ing the model to handle diverse data modalities. To tailor the model to various downstream retrieval tasks, we incorporate an instruction tuning method by including a tailored instructional text $i$ with each retrieval task. For example, for the Visual Question Answering (VQA) task, the instruction could be: “Retrieve a passage that provides an answer to the given query about the image” guiding the model on how to process and interpret the query for specific objectives.
对比学习在我们的对比学习设置中,每个训练实例包含一个查询 $q$、一个相关候选 $c$ 和一组不相关候选 ${c_{1}^{-},c_{2}^{-},\ldots,c_{K}^{-}}$。$q$ 和 $c$ 可以是文本、图像或图文对,使模型能够处理多种数据模态。为使模型适应不同的下游检索任务,我们采用指令调优方法,为每个检索任务添加定制化的指令文本 $i$。例如,对于视觉问答 (VQA) 任务,指令可以是:“检索能够为给定图像查询提供答案的段落”,以此指导模型针对特定目标处理和解释查询。
During training, we input $q$ and instruction $i$ into the model to obtain the query representation $e_{q}$ . Similarly, each candidate $c$ is input into the model to obtain its representation $e_{c}$ . The training objective minimizes the cosine distance between $e_{q}$ and $e_{c}$ for relevant pairs while maximizing the distance between $e_{q}$ and $e_{c^{-}}$ for irrelevant pairs. Cosine similarity is employed to measure the directional alignment between embeddings, effectively capturing semantic similarities irrespective of their magnitudes.
在训练过程中,我们将 $q$ 和指令 $i$ 输入模型以获得查询表示 $e_{q}$。同样地,每个候选 $c$ 被输入模型以获得其表示 $e_{c}$。训练目标是最小化相关配对中 $e_{q}$ 和 $e_{c}$ 的余弦距离,同时最大化不相关配对中 $e_{q}$ 和 $e_{c^{-}}$ 的距离。余弦相似度被用来衡量嵌入之间的方向对齐,有效捕捉语义相似性而不受其大小的影响。
The optimization process utilizes the InfoNCE loss function [57], defined as:
优化过程采用InfoNCE损失函数 [57] ,其定义为:
$$
\mathcal{L}=-\log\frac{\exp{(c o s(e_{q},e_{c}^{+})/\tau)}}{\exp{(c o s(e_{q},e_{c}^{+})/\tau)}+\displaystyle\sum_{i=1}^{K}\exp{\left(c o s(e_{q},e_{c_{i}^{-}})/\tau\right)}}
$$
$$
\mathcal{L}=-\log\frac{\exp{(c o s(e_{q},e_{c}^{+})/\tau)}}{\exp{(c o s(e_{q},e_{c}^{+})/\tau)}+\displaystyle\sum_{i=1}^{K}\exp{\left(c o s(e_{q},e_{c_{i}^{-}})/\tau\right)}}
$$
where $\tau$ is the temperature parameter that scales the cosine similarities to control the distribution’s concentration. This approach ensures that the model effectively learns to distinguish relevant from irrelevant information across different modalities, thereby enhancing its performance in multimodal retrieval tasks.
其中 $\tau$ 是温度参数,用于缩放余弦相似度以控制分布的集中程度。该方法确保模型能够有效学习区分不同模态间的相关信息与无关信息,从而提升其在多模态检索任务中的性能。
Hard Negatives The quality and diversity of negative samples are essential for improving contrastive learning [53]. Inspired by ANCE [69], we employ a two-stage training strategy: (1) Initial Training: We first train the model using randomly selected negative candidates, resulting in Model $M_{1}$ . (2) Hard Negative Mining and Continue Training: Using $M_{1}$ , we retrieve the top $K$ candidates for each query and select non-relevant candidates from them as hard negatives. We then use these hard negatives to further train $M_{1}$ , refining it into the final model. This ensures that the model can learn from both easily distinguishable and more challenging examples, thereby enhancing performance.
难负例 负样本的质量和多样性对于改进对比学习至关重要 [53] 。受 ANCE [69] 启发, 我们采用两阶段训练策略: (1) 初始训练: 首先使用随机选择的负候选样本训练模型, 得到模型 $M_{1}$ 。(2) 难负例挖掘与继续训练: 使用 $M_{1}$ 为每个查询检索前 $K$ 个候选, 并从中选择非相关候选作为难负例。随后使用这些难负例进一步训练 $M_{1}$ , 将其优化为最终模型。这确保模型既能从易区分样本中学习, 也能从更具挑战性的样本中学习, 从而提升性能。
Training Data Composition A critical factor in multimodal representation learning is the composition of training data. Although previous studies like [22] have demonstrated that MLLMs can develop multimodal representation capabilities after being fine-tuned on single-modal data, the effect of data diversity on model performance remains unclear. Therefore, we compare the performance of models trained with different data combinations across various retrieval scenarios within our classification principle. Specifically, we used four types of training data: single-modal (including $\mathrm{T}{\rightarrow}\mathrm{T}$ and $\mathbf{I}{\rightarrow}\mathbf{I},$ ), cross-modal (including $\mathrm{T}{\rightarrow}\mathrm{VD}$ and $\mathrm{T}{\rightarrow}\mathrm{I})$ , fused-modal training data (including $\mathrm{IT}{\rightarrow}\mathrm{IT},$ ), and a mixed dataset combining the first three types. These different training data types result in a total of six models.
训练数据构成 多模态表示学习的一个关键因素是训练数据的构成。尽管先前研究如 [22] 表明,大语言模型在单模态数据上微调后可以发展出多模态表示能力,但数据多样性对模型性能的影响仍不明确。因此,我们按照分类原则比较了使用不同数据组合训练的模型在各种检索场景下的性能。具体而言,我们使用了四种训练数据类型:单模态(包括 $\mathrm{T}{\rightarrow}\mathrm{T}$ 和 $\mathbf{I}{\rightarrow}\mathbf{I}$)、跨模态(包括 $\mathrm{T}{\rightarrow}\mathrm{VD}$ 和 $\mathrm{T}{\rightarrow}\mathrm{I}$)、融合模态训练数据(包括 $\mathrm{IT}{\rightarrow}\mathrm{IT}$)以及混合前三种类型的数据集。这些不同的训练数据类型共产生了六个模型。
For single-modal data, we utilized the $\mathrm{T}{\rightarrow}\mathrm{T}$ dataset from MSMARCO [47] and the $\mathrm{I}{\rightarrow}\mathrm{I}$ dataset from ImageNet [10], treating images within the same category as positive matches and those from different categories as negatives. For cross-modal data, we employed $\mathrm{T}{\rightarrow}\mathrm{I}$ pairs from the LAION [54] dataset and $\mathrm{T}{\rightarrow}\mathrm{VD}$ pairs from the Docmatix [27] dataset. For fused-modal data, we use the EVQA [46] dataset $\mathrm{(IT{\to}I T},$ ). For each subcategory, we randomly sampled 100,000 training instances to train the models independently. For the mixed dataset, we uniformly sampled 20,000 instances from each of the five datasets to train the final model, ensuring fair and reliable comparative experimental results. The performance of these six models on the UMRB-Partial test dataset is presented in Figure 3.
对于单模态数据,我们采用MSMARCO [47]中的$\mathrm{T}{\rightarrow}\mathrm{T}$数据集和ImageNet [10]中的$\mathrm{I}{\rightarrow}\mathrm{I}$数据集,将同一类别内的图像视为正样本,不同类别的图像作为负样本。对于跨模态数据,我们使用LAION [54]数据集中的$\mathrm{T}{\rightarrow}\mathrm{I}$配对和Docmatix [27]数据集中的$\mathrm{T}{\rightarrow}\mathrm{VD}$配对。针对融合模态数据,我们采用EVQA [46]数据集$\mathrm{(IT{\to}IT}$)。每个子类别中,我们随机抽取100,000个训练实例独立训练模型。对于混合数据集,我们从五个数据集中均匀各抽取20,000个实例训练最终模型,以确保公平可靠的对比实验结果。这六个模型在UMRB-Partial测试数据集上的性能表现如图3所示。
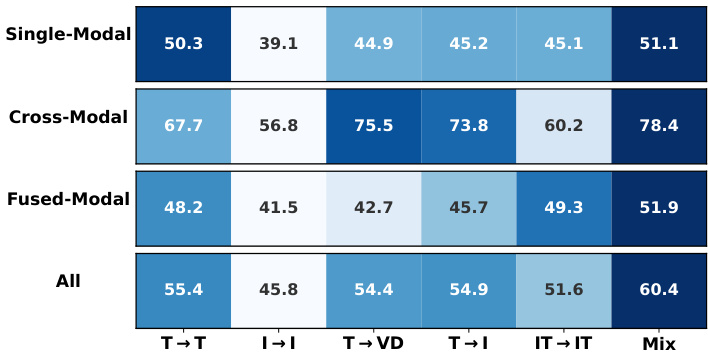
Figure 3. Impact of training data on multimodal retrieval tasks.
图 3: 训练数据对多模态检索任务的影响。
The results indicate that: (1) Models trained on single data types excel in corresponding retrieval tasks. For instance, models trained on $\mathrm{T}{\rightarrow}\mathrm{T}$ data performed best in text retrieval tasks.3 (2) A balanced mix of different data types enhanced performance across various settings. This suggests that increasing the diversity of training modalities effectively improves the model’s overall retrieval capabilities.
结果表明: (1) 单一数据类型训练的模型在相应检索任务中表现优异。例如, 在 $\mathrm{T}{\rightarrow}\mathrm{T}$ 数据上训练的模型在文本检索任务中表现最佳。3 (2) 不同数据类型的均衡混合能提升多种设置下的性能。这表明增加训练模态的多样性可有效提升模型的整体检索能力。
The above analysis highlights the importance of adequately representing each data type in training datasets to develop models that meet the requirements of universal multi-modal retrieval. During data collection, we observed that single-modal and cross-modal data are abundant, with over ten million training instances available. In contrast, fused-modal data remains limited. Common fused-modal training datasets such as EVQA[46], INFOSEEK[6], and CIRR [38] collectively contain fewer than one million instances. Additionally, these existing fused-modal datasets cover only a limited range of domains. Thus, efficiently supplementing high-quality fused-modal training data is essential. To address this challenge, we propose leveraging the generative capabilities of LLMs and MLLMs to synthesize additional training data.
上述分析凸显了在训练数据集中充分表征每种数据类型对于开发满足通用多模态检索要求的模型的重要性。在数据收集过程中,我们观察到单模态和跨模态数据十分丰富,可用训练实例超过一千万个。相比之下,融合模态数据仍然有限。常见的融合模态训练数据集如EVQA[46]、INFOSEEK[6]和CIRR[38]总共包含不足一百万个实例。此外,这些现有融合模态数据集仅覆盖有限范围的领域。因此,有效补充高质量的融合模态训练数据至关重要。为应对这一挑战,我们建议利用大语言模型 (LLM) 和多模态大语言模型 (MLLM) 的生成能力来合成额外训练数据。
4.2. Fused-Modal Data Synthesis
4.2. 融合模态数据合成
To efficiently synthesize high-quality data while minimizing manual intervention, we adopt a strategy similar to Doc2Query [15]. However, our approach differs in that we aim to generate fuse-modal candidate-to-query relevance data instead of single-modality, text-based relevance pairs.
为了在最小化人工干预的同时高效合成高质量数据, 我们采用了与 Doc2Query [15] 类似的策略。 然而, 我们的方法不同之处在于, 我们的目标是生成融合模态 (fuse-modal) 的候选到查询相关性数据, 而不是基于单模态文本的相关性对。
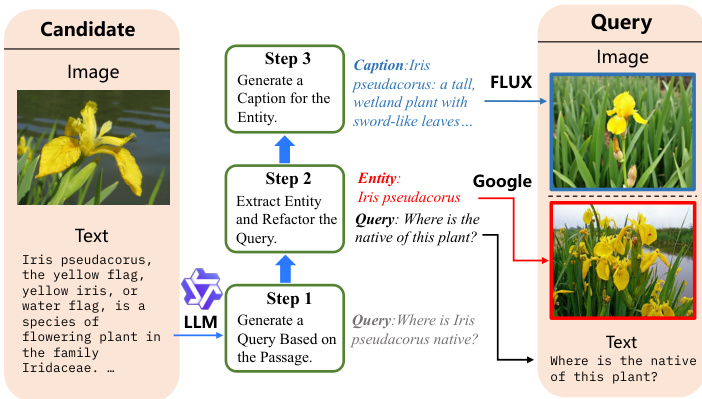
Figure 4. Pipeline for synthesizing fused-modal training data.
图 4: 融合模态训练数据合成流程。
This requires obtaining high-quality candidates that include both image and text content. We primarily extracted such data from Wikipedia paragraphs . Additionally, to enhance the domain diversity of the candidate data, we employed a domain classification model5 to perform fine-grained classification of Wikipedia data into categories such as animals and plants. We then uniformly sampled from these categories and retained data with classification confidence scores above 0.5. Ultimately, we obtained 313,284 candidate entries, each containing both text and image content.
这需要获取包含图像和文本内容的高质量候选数据。我们主要从维基百科段落中提取此类数据。此外,为提升候选数据的领域多样性,我们采用领域分类模型5对维基百科数据进行细粒度分类(如动植物等类别)。随后对这些类别进行统一采样,并保留分类置信度分数高于0.5的数据。最终我们获得313,284条候选条目,每条均包含文本和图像内容。
Based on the prepared data, the overall synthesis pipeline (Figure 4) could be divided into the following steps:
基于准备好的数据,整体合成流程 (图 4) 可分为以下步骤:
Doc2Query Generation: The passage content from each candidate is input into an $\mathrm{LLM}^{6}$ using a prompt to generate a natural query. To ensure the quality of the generated queries, we built a vector index of all passage contents using a text vector retrieval model7. Each generated query is then used to retrieve the corresponding passage from this collection. If the passage associated with the query is not within the top 20 retrieved items, the query is considered low quality due to low relevance and is discarded. In this step, we discarded $1.2%$ of the total generated queries. This process allows us to construct $\mathrm{T}{\rightarrow}\mathrm{IT}$ training data.
Doc2Query生成:将每个候选文档的段落内容输入到大语言模型 (LLM) [6] 中,通过提示生成自然查询。为确保生成查询的质量,我们使用文本向量检索模型[7]构建了所有段落内容的向量索引。随后用每个生成的查询从该集合中检索对应段落。若查询关联的段落未出现在检索结果的前20位,则判定该查询因相关性低而质量不佳并予以丢弃。此步骤中我们共丢弃了总生成查询量的1.2%。通过此流程,我们成功构建了T→IT训练数据。
Entity Extraction and Query Rewrite: We aim for the synthesized queries to include both texts and images (i.e., $\mathrm{IT}{\rightarrow}\mathrm{IT}$ type). To achieve this, we leverage entity extraction followed by image retrieval for the extracted entities and caption generation to supplement the image data on the query side. Specifically, for each generated query $q$ from the first step, we prompt the LLM to extract entities from it with the text passage as reference, and then rewrite the original query into $q^{\prime}$ . For example, the query “Where is Iris pseudacorus native?” is transformed by the model to the rewritten query ”Where is the native habitat of this plant?” with the entity ”Iris p seu da corus” extracted. We then seek images that match this entity and combine them with the rewritten query $q^{\prime}$ to form the final fuse-modal query.
实体提取与查询重写:我们的目标是让合成查询同时包含文本和图像 (即 $\mathrm{IT}{\rightarrow}\mathrm{IT}$ 类型) 。为此,我们采用实体提取技术,随后对提取的实体进行图像检索,并通过描述生成来补充查询侧的图像数据。具体而言,对于第一步生成的每个查询 $q$ ,我们提示大语言模型以文本段落为参照从中提取实体,并将原始查询重写为 $q^{\prime}$ 。例如,查询"Iris pseudacorus的原产地在哪里?"被模型转换为重写后的查询"这种植物的原生生境在哪里?",同时提取出实体"Iris pseudacorus"。随后我们寻找与该实体匹配的图像,并将其与重写后的查询 $q^{\prime}$ 结合,形成最终的融合模态查询。
• Image Retrieval and Generation: We explore two methods for obtaining images. The first method uses the Google Image Search $\mathrm{API}^{8}$ to retrieve images matching the entity terms, retaining the top five results. The second method involves generating images using a text-to-image model9. Specifically, we first use the LLM to generate a caption suitable for image generation based on the entity and the passage of the generated query, then input this caption into the text-to-image generation model to create the corresponding image. This approach allows us to quickly and efficiently obtain high-quality, diverse images. The synthesized results can also be assembled into $\Pi{\rightarrow}\Pi$ retrieval type data.
• 图像检索与生成:我们探索两种获取图像的方法。第一种方法使用Google图片搜索 $\mathrm{API}^{8}$ 检索与实体词匹配的图像,保留前五个结果。第二种方法使用文生图模型9生成图像。具体而言,我们首先使用大语言模型根据实体和生成查询的段落生成适用于图像生成的描述文本,然后将该描述输入文生图模型以创建对应图像。这种方法能快速高效地获取高质量、多样化的图像。合成结果还可组装成 $\Pi{\rightarrow}\Pi$ 检索型数据。
Data Filtering: To ensure the quality of the synthesized data, we perform filtering [9] on the final dataset. We observe that images generated by the FLUX model have consistent quality, whereas images retrieved via the Google Image Search API often include noisy data. Therefore, for images obtained through the Google Image Search API, we use the CLIP model10 to assess image-caption relevance. Images with a relevance score below 0.2 were filtered out.
数据过滤 (Data Filtering) : 为确保合成数据的质量, 我们对最终数据集执行过滤 [9] 。我们发现由 FLUX 模型生成的图像具有一致的质量, 而通过 Google Image Search API 检索的图像常包含噪声数据。因此, 对于通过 Google Image Search API 获取的图像, 我们使用 CLIP 模型10评估图像-标题相关性, 将相关性分数低于 0.2 的图像过滤剔除。
Through the synthesis pipeline, we produce 1,135,000 high-quality fuse-modal training data entries (including $\mathrm{T}{\rightarrow}\mathrm{IT}$ and $IT{\rightarrow}IT$ types). After filtering, we retain 1,102,000 entries, resulting in a data loss rate of $2.9%$ . The entire process consumed 600 A100 GPU hours. Detailed descriptions of all prompts used in the data synthesis pipeline and examples of the synthesized data are provided in the Appendix $\S10$ .
通过合成流程,我们生成了1,135,000条高质量融合模态训练数据条目(包括 $\mathrm{T}{\rightarrow}\mathrm{IT}$ 和 $IT{\rightarrow}IT$ 类型)。经过过滤后,我们保留了1,102,000条条目,数据损失率为 $2.9%$。整个过程消耗了600个A100 GPU小时。数据合成流程中使用的所有提示的详细说明以及合成数据示例见附录 $\S10$。
5. Experiments
5. 实验
5.1. Settings
5.1. 设置
Training Data Building on the findings from $\S4.1$ , we train our model using a diverse dataset of 8 million instances spanning various retrieval modalities. For singlemodal retrieval tasks, we utilize datasets including MSMARCO [47], NQ [26], HotpotQA [70], TriviaQA [24], SQuAD [52], FEVER [56], and AllNLI for SimCSE [14], selecting a total of 1 million entries. From ImageNet [10], we extract 1 million image-to-image training instances, designating images within the same class as positive samples and others as negative samples. For cross-modal retrieval tasks, we incorporate 2 million entries from the LAION [54], MSCOCO [32], and Docmatix [27] datasets. Additionally, for fused-modal retrieval tasks, we include a total of 2 million instances: 1.1 million synthesized by us, and the remaining from the M-BEIR [66] training data.
训练数据 基于第4.1节的发现,我们使用包含800万个实例的多样化数据集进行模型训练,涵盖各种检索模态。对于单模态检索任务,我们使用包括MSMARCO [47]、NQ [26]、HotpotQA [70]、TriviaQA [24]、SQuAD [52]、FEVER [56]以及用于SimCSE [14]的AllNLI在内的数据集,共选取100万个条目。从ImageNet [10]中,我们提取100万个图像到图像训练实例,将同一类别内的图像指定为正样本,其他图像作为负样本。对于跨模态检索任务,我们整合了来自LAION [54]、MSCOCO [32]和Docmatix [27]数据集的200万个条目。此外,针对融合模态检索任务,我们共纳入200万个实例:其中110万个由我们合成,其余来自M-BEIR [66]训练数据。
Training Configuration We use Qwen2-VL [65] model series as the backbone for our MLLM, conducting training on models with both 2 billion (2B) and 7 billion (7B) parameters. Our training utilizes Low-Rank Adaptation (LoRA) [19] with a rank of 8, a learning rate of 1e-4, and a temperature setting of 0.03. To manage the varying number of visual tokens required by Qwen2-VL for different image resolutions and maintain training efficiency, we limit the maximum number of visual tokens per image to 1,024.
训练配置 我们使用 Qwen2-VL [65] 模型系列作为 MLLM 的骨干网络,对具有 20 亿 (2B) 和 70 亿 (7B) 参数的模型进行训练。我们的训练采用低秩自适应 (LoRA) [19],秩为 8,学习率为 1e-4,温度设置为 0.03。为管理 Qwen2-VL 因不同图像分辨率所需的视觉 token 数量并保持训练效率,我们将每张图像的最大视觉 token 数限制为 1,024。
For data with images, we set the maximum text length to 1,800 tokens, using a batch size of 128 for the 2B model and 32 for the 7B model. For text-only data, the maximum length was set to 512 tokens, with batch size of 512 for the 2B model and 128 for the 7B model. Each training sample included 8 negative examples. To conserve GPU memory, we employ gradient check pointing [5] and train the model using bfloat16 precision. All training was conducted on eight NVIDIA A100 GPUs, each with 80GB of memory.
对于包含图像的数据, 我们将最大文本长度设置为 1,800 个 token, 2B 模型使用 128 的批次大小, 7B 模型使用 32 的批次大小。对于纯文本数据, 最大长度设置为 512 个 token, 2B 模型使用 512 的批次大小, 7B 模型使用 128 的批次大小。每个训练样本包含 8 个负例。为节省 GPU 内存, 我们采用梯度检查点 [5] 并使用 bfloat16 精度训练模型。所有训练均在 8 块 80GB 内存的 NVIDIA A100 GPU 上完成。
Baselines We compare our method against four types of retrieval systems: (1) Previous representative UMR models, for example, VISTA [74] for text encoder based, and E5- V [22] for MLLM based; (2) Powerful multimodal representation (embedding) models, i.e. One-Peace [64], which supports modalities beyond text and image and hence could also be tested on our UMRB; (3) Recent visual document retrieval models, namely DSE [41]; and (4) the classic crossmodal pipeline, CLIP score-fusion, denoted as CLIP-SF, which provides top-tier cross-modal performance. We exclude comparisons with state-of-the-art text retrieval models as VISTA demonstrates comparable performance levels.
基线方法 我们将本方法与四类检索系统进行对比: (1) 先前代表性UMR模型, 例如基于文本编码器的VISTA [74] 和基于MLLM的E5-V [22]; (2) 强大多模态表征 (嵌入) 模型, 即One-Peace [64], 该模型支持文本和图像以外的模态, 因此也可在我们的UMRB上进行测试; (3) 近期视觉文档检索模型DSE [41]; (4) 经典跨模态流程CLIP分数融合 (CLIP-SF), 该方法能提供顶尖的跨模态性能。由于VISTA已展现出相当的性能水平, 我们未与最先进的文本检索模型进行对比。
5.2. Main Results
5.2. 主要结果
Table 3 presents the evaluation results of the baseline systems alongside our proposed GME. Scores are averaged across each sub-task and categorized by retrieval modality type: single-modal, cross-modal, and fused-modal. Additionally, the overall micro-average score on the UMRB is in the last column. First, focusing on the average scores, our smaller model, i.e. GME-Qwen2-VL-2B, already outperforms the previous state-of-the-art UMR model (VISTA [74]). The larger model, i.e. GME-Qwen2-VL-7B, further enhances this performance, demonstrating the effectiveness of our approach in handling UMR tasks.
表 3 展示了基线系统与我们提出的 GME 的评估结果。分数按每个子任务取平均值,并按检索模态类型分类:单模态、跨模态和融合模态。此外,UMRB 的总体微平均分数在最后一列。首先,关注平均分数,我们较小的模型,即 GME-Qwen2-VL-2B,已经优于之前最先进的 UMR 模型 (VISTA [74])。更大的模型,即 GME-Qwen2-VL-7B,进一步提升了这一性能,证明了我们方法在处理 UMR 任务方面的有效性。
Second, our models outperform smaller methods such as VISTA (million-level parameters) and One-Peace (4B parameters). The larger MLLM baseline, E5-V [22] (8B parameters), performs well in text-dominated tasks (e.g., $\mathrm{T}{\rightarrow}\mathrm{T},$ ) but falls short in other areas. This indicates that training with multimodal data is crucial for achieving superior performance in UMR tasks. Our training data provides a stronger foundation for future advancements.
其次, 我们的模型在性能上超越了参数量较小的方法, 例如 VISTA (百万级参数) 和 One-Peace (40亿参数) 。规模更大的多模态大语言模型 (MLLM) 基线 E5-V [22] (80亿参数) 在文本主导任务 (例如 $\mathrm{T}{\rightarrow}\mathrm{T},$ ) 中表现良好, 但在其他领域表现欠佳。这表明使用多模态数据进行训练对于在统一模态识别 (UMR) 任务中实现卓越性能至关重要。我们的训练数据为未来的进步提供了更坚实的基础。
Next, the cross-modal pipeline CLIP-SF outperforms
接下来,跨模态流程 CLIP-SF 的表现优于
| UMRB | Size | Single-Modal | Cross-Modal | Avg. | ||||||
| Task(#Datasets) | T→T (16) | I→I (1) T→→I(4) | T→VD | (10) IT (4) | T→IT (2) | IT→T (5) | IT→I(2) | )IT→IT (3)( | (47) | |
| VISTA [74] | 0.2B | 55.15 | 31.98 | 32.88 | 10.12 | 31.23 45.81 | 53.32 | 8.97 | 26.26 | 37.32 |
| CLIP-SF [66] | 0.4B | 39.75 | 31.42 | 59.05 | 24.09 62.95 | 66.41 | 53.32 | 34.90 | 55.65 | 43.66 |
| One-Peace[64] | 4B | 43.54 | 31.27 | 61.38 | 42.9 65.59 | 42.72 | 28.29 | 6.73 | 23.41 | 42.01 |
| DSE [41] | 4.2B | 48.94 | 27.92 | 40.75 | 78.21 | 52.54 49.62 | 35.44 | 8.36 | 40.18 | 50.04 |
| E5-V [22] | 8.4B | 52.41 | 27.36 | 46.56 | 41.22 | 47.95 54.13 | 32.90 | 23.17 | 7.23 | 42.52 |
| GME-Qwen2VL-2B | 2.2B | 55.93 | 29.86 | 57.36 | 87.84 | 61.93 76.47 | 64.58 | 37.02 | 66.47 | 64.45 |
| GME-Qwen2VL-7B | 8.2B | 58.19 | 31.89 | 61.35 | 89.92 | 65.83 | 80.94 66.18 | 42.56 | 73.62 | 67.44 |
| UMRB | 规模 | 单模态 | 跨模态 | 平均 | ||||
|---|---|---|---|---|---|---|---|---|
| 任务 (数据集数量) | 文本→文本 (16) | 图像→图像 (1) 文本→图像 (4) | 文本→视频 (10) 图像文本 (4) | 文本→图像文本 (2) | 图像文本→文本 (5) | 图像文本→图像 (2) | 图像文本→图像文本 (3) | |
| VISTA [74] | 0.2B | 55.15 | 31.98 | 32.88 | 10.12 | 31.23 45.81 | 53.32 | 8.97 |
| CLIP-SF [66] | 0.4B | 39.75 | 31.42 | 59.05 | 24.09 62.95 | 66.41 | 53.32 | 34.90 |
| One-Peace [64] | 4B | 43.54 | 31.27 | 61.38 | 42.9 65.59 | 42.72 | 28.29 | 6.73 |
| DSE [41] | 4.2B | 48.94 | 27.92 | 40.75 | 78.21 | 52.54 49.62 | 35.44 | 8.36 |
| E5-V [22] | 8.4B | 52.41 | 27.36 | 46.56 | 41.22 | 47.95 54.13 | 32.90 | 23.17 |
| GME-Qwen2VL-2B | 2.2B | 55.93 | 29.86 | 57.36 | 87.84 | 61.93 76.47 | 64.58 | 37.02 |
| GME-Qwen2VL-7B | 8.2B | 58.19 | 31.89 | 61.35 | 89.92 | 65.83 | 80.94 66.18 | 42.56 |
Table 3. Results of different models on our benchmark. Following previous works [12, 55, 66], we present $\mathrm{NDCG}@10$ scores for $\mathrm{T}{\rightarrow}\mathrm{T}$ tasks, excluding the WebQA dataset. For $\mathrm{T}{\rightarrow}\mathrm{VD}$ tasks, we provide $\operatorname{NDCG}@5$ scores. For the Fashion 200 K, FashionIQ and OKVQA datasets, we report Recall $@10$ scores, while for all other datasets, we report Recall $\ @5$ scores.
表 3. 不同模型在我们基准测试中的结果。遵循先前工作 [12, 55, 66] 的做法,我们展示 $\mathrm{T}{\rightarrow}\mathrm{T}$ 任务的 $\mathrm{NDCG}@10$ 分数(不包括 WebQA 数据集)。对于 $\mathrm{T}{\rightarrow}\mathrm{VD}$ 任务,我们提供 $\operatorname{NDCG}@5$ 分数。针对 Fashion 200K、FashionIQ 和 OKVQA 数据集,我们报告 Recall $@10$ 分数,而其他所有数据集均报告 Recall $@5$ 分数。

Figure 5. Visualization of the embeddings in a 2D plot by T-SNE. Left: Our GME, Middle: VISTA, Right: CLIP. We use instances from Encyclopedia VQA and highlight two semantic groups with yellow and pink labels, respectively. Please zoom in to view them.
图 5: 通过 T-SNE 在二维图中可视化的嵌入。左: 我们的 GME, 中: VISTA, 右: CLIP。我们使用来自 Encyclopedia VQA 的实例, 并分别用黄色和粉色标签突出显示两个语义组。请放大查看。
UMR models like VISTA, E5-V, and One-Peace. For VISTA and E5-V, the performance gap is likely due to limitations in their text-modality bounds: VISTA is constrained by the text embedding space of its fixed backbone, and E5-V is limited by text-only training. One-Peace’s modality alignment-centered modeling may not be optimized for fused-modal content. In contrast, our models are specifically designed to handle fused-modal data, resulting in significantly better performance compared to the baselines. Although our training data includes several previously constructed fused-modal datasets, the contribution of our generated fused-modal training data will be discussed in $\S5.3$ .
与VISTA、E5-V和One-Peace等UMR模型相比,VISTA和E5-V的性能差距主要源于其文本模态的限制:VISTA受限于固定骨干网络的文本嵌入空间,而E5-V受限于纯文本训练。One-Peace以模态对齐为核心的建模方式可能未对融合模态内容进行优化。相比之下,我们的模型专为处理融合模态数据设计,因此基线模型性能显著提升。虽然训练数据包含多个先前构建的融合模态数据集,但生成式融合模态训练数据的贡献将在$\S5.3$节讨论。
Finally, we compare with the recent visual document retrieval model DSE [41], specialized for the $\mathrm{T}{\rightarrow}\mathrm{VD}$ task within the Cross-Modal group, which has approximately 4B parameters. Our models are competitive with or exceed the performance of this task-specific baseline, demonstrating the feasibility and promise of integrating visual document retrieval into a unified retriever framework.
最后, 我们与专精于跨模态组中 $\mathrm{T}{\rightarrow}\mathrm{VD}$ 任务的视觉文档检索模型 DSE [41] 进行比较, 该模型拥有约 40 亿参数。我们的模型在该专用基线的性能表现上具有竞争力或更优, 这证明了将视觉文档检索集成到统一检索器框架中的可行性与前景。
5.3. Analyses
5.3. 分析
Are the Produced Embeddings Modality Universal? Given our the impressive performance of our model, we assess the quality of its embeddings. Specifically, we investigate whether the embeddings are modality-universal meaning that embeddings representing the same semantic content across different modalities are closely clustered in the embedding space, or if they remain in separate sub-spaces tailored for each modality-specific task. To probe this question, we sample 1000 instances from the EVQA dataset and visualize their embeddings of different modalities by tSNE, as shown in Figure 5. We also highlight two semantic close groups with yellow and pink labels, respectively. We can observe that the embeddings from CLIP are distinctly separated by modality, whereas the embeddings from our model are intermingled and organized semantically. Meanwhile, the points from the same semantic group are closely clustered. This demonstrates that our model effectively generates modality-universal representations, enhancing its appli c ability across various UMR tasks.
生成的嵌入是否具有模态通用性?鉴于我们模型的出色性能,我们评估了其嵌入质量。具体来说,我们研究这些嵌入是否具有模态通用性——即不同模态中表示相同语义内容的嵌入是否在嵌入空间中紧密聚集,还是停留在为各模态特定任务定制的独立子空间中。为探究此问题,我们从EVQA数据集中抽取1000个样本,通过tSNE可视化其不同模态的嵌入,如图5所示。我们分别用黄色和粉色标签突出显示了两个语义相近的组。可以观察到,CLIP的嵌入按模态明显分离,而我们模型的嵌入则相互交融并按语义组织。同时,相同语义组的点紧密聚集。这表明我们的模型能有效生成模态通用表示,提升了在各种UMR任务中的应用能力。
Table 4. Results of GME-Qwen2-VL-2B trained with different generated datasets and evaluated on UMRB-Partial.
| Setting | Single | Cross | Fused | Average |
| w/EVQA | 45.13 | 60.21 | 49.32 | 51.55 |
| w/ GenFlux | 46.27 | 61.19 | 51.46 | 52.97 |
| w/GenGoogle | 47.08 | 61.35 | 52.01 | 53.48 |
表 4. 使用不同生成数据集训练的 GME-Qwen2-VL-2B 在 UMRB-Partial 上的评估结果
| 设置 | 单帧 | 跨帧 | 融合 | 平均 |
|---|---|---|---|---|
| 含EVQA | 45.13 | 60.21 | 49.32 | 51.55 |
| 含GenFlux | 46.27 | 61.19 | 51.46 | 52.97 |
| 含GenGoogle | 47.08 | 61.35 | 52.01 | 53.48 |
Ablation Study on Synthetic Fused-Modal Data We propose an efficient data synthesis pipeline (§4.2) and generate large-scale fused-modal pairs to support model training. After witnessing the state-of-the-art performance of our model, it is natural to question the contribution of this synthetic data to the overall performance. To this end, we conduct an ablation study using three parallel training datasets, each comprising 100,000 pairs: original EVQA data, synthetic data with Google-retrieved images $(Gen_{Google})$ , and synthetic data with FLUX-generated images $(Gen_{Flux}$ ). We train three models with identical parameters on these datasets and evaluate their performance on UMRB-Partial, with results shown in Table 4. Both synthetic datasets outperform the original EVQA data, indicating the high quality of our synthesized data. Although
合成融合模态数据的消融研究 我们提出了一个高效的数据合成流程 (§4.2),并生成大规模融合模态对以支持模型训练。在看到我们模型的最先进性能后,很自然会质疑这些合成数据对整体性能的贡献。为此,我们使用三个各包含10万对数据的并行训练数据集进行消融研究:原始EVQA数据、基于谷歌检索图像生成的合成数据 $(Gen_{Google})$,以及基于FLUX生成图像的合成数据 $(Gen_{Flux})$。我们在这些数据集上使用相同参数训练了三个模型,并在UMRB-Partial上评估其性能,结果如表4所示。两个合成数据集均优于原始EVQA数据,表明我们合成数据的高质量。尽管
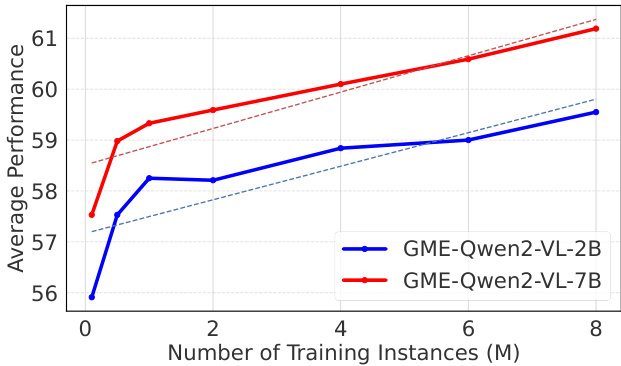
Figure 6. Average Performance of GME-Qwen2-VL-2B (Blue) and GME-Qwen2-VL-7B (Red) on UMRB-Partial, trained with varying numbers of training instances.
图 6: 在不同训练实例数量下训练的 GME-Qwen2-VL-2B (蓝色) 和 GME-Qwen2-VL-7B (红色) 在 UMRB-Partial 上的平均性能。
Google-retrieved images achieved marginally better performance than FLUX-generated images, the difference is minor and acceptable given the potential limitations of the Google Search API for rapid, large-scale dataset generation.
Google检索图像的表现略优于FLUX生成图像,考虑到Google搜索API在快速、大规模数据集生成方面的潜在限制,这种差异较小且可以接受。
Training Scaling Law Our approach is primarily datacentric, constructing a diverse training dataset of approximately 8 million samples across various UMR settings (§5.1). Training on such a large-scale dataset demands significant computational resources and time. Therefore, we explored the training scaling law by examining how model performance evolves with increasing training steps. Due to the time-consuming nature of evaluating certain retrieval tasks, we assessed performance on our UMRB-Partial dataset for faster evaluation. Figure 6 illustrates the performance progression of our 2B and 7B models on UMRB-Partial during training. Both models exhibit linear performance improvements as training continues, suggesting that extended training could yield further benefits. However, due to time constraints, we halted current training. Future work will investigate longer training periods to enhance model performance further.
训练规模法则 我们的方法以数据为中心,构建了包含约800万样本的多样化训练数据集,涵盖多种统一多模态检索场景 (§5.1)。在此大规模数据集上进行训练需要大量计算资源和时间。因此,我们通过观察模型性能随训练步数增加的变化规律来探索训练规模法则。由于某些检索任务评估耗时较长,我们使用UMRB-Partial数据集进行快速评估。图6展示了我们20亿和70亿参数模型在训练过程中于UMRB-Partial数据集上的性能变化曲线。两个模型均随着训练持续呈现线性性能提升,表明延长训练时间可能带来进一步收益。但由于时间限制,我们暂停了当前训练。未来工作将研究更长的训练周期以持续提升模型性能。
Ablation Study on Modeling We conduct an ablation study to investigate the effectiveness of different design choices of GME. We consider the following three aspects: (1) Fine-tuning strategy. Our final models are trained by LoRA with rank 8. We compare with other rank values and full fine-tuning. The results in the first group of Table 5 show that LoRA with rank 8 yields the best performance. (2) Training data organization. We compare models trained without hard negative mining. The second group of Table 5 demonstrates that the removal of hard negatives led to performance declines, indicating that it is essential for effective retrieval model training. (3) Retrieval instructions. We compare models trained without retrieval instructions. The third group shows that retrieval instructions are crucial for better UMR. (4) Modeling techniques. Our final models are in the casual attention mode and use the EOS token state as the embedding, hence we compare the performance of the model trained with mean pooling and the bi-directional attention mechanism. The last group of Table 5 shows that these alternative settings negatively impact performance.
建模消融研究 我们通过消融研究来探究GME不同设计选择的有效性。我们考察以下三个方面: (1) 微调策略。我们的最终模型采用秩为8的LoRA进行训练。我们比较了其他秩值和全参数微调的效果。表5第一组结果显示, 秩为8的LoRA能获得最佳性能。(2) 训练数据组织。我们比较了未使用难负例挖掘的训练模型。表5第二组表明, 移除难负例会导致性能下降, 这说明难负例对有效的检索模型训练至关重要。(3) 检索指令。我们比较了未使用检索指令的训练模型。第三组结果显示检索指令对提升UMR性能具有关键作用。(4) 建模技术。我们的最终模型采用因果注意力模式并使用EOS token状态作为嵌入表示, 因此我们比较了使用均值池化和双向注意力机制的模型性能。表5最后一组显示这些替代设置会对性能产生负面影响。
Table 5. Results of the ablation study on Qwen2-VL-2B. All models are trained using 100,000 instances, consistent with the exper- imental setup described in Section 4.1.
| Setting | Single | Cross | Fused | Average |
| Fine-tuning strategy | ||||
| LoRA r=8 LoRA r=16 | 48.09 47.86 | 78.39 78.63 | 51.88 51.42 | 59.45 |
| LoRAr=32 | 47.85 | 78.55 | 50.48 | 59.30 58.96 |
| LoRA r=64 | 47.65 | 78.61 | 51.09 | 59.11 |
| Full training | 43.16 | 75.79 | 49.28 | 56.07 |
| Training data organization | ||||
| w/o hard-negative | 47.55 | 78.01 | 50.95 | 58.83 |
| Retrieval Setting | ||||
| w/oInstruction | 46.82 | 78.10 | 49.09 | 58.00 |
| Model Design | ||||
| w/ mean pooling | 47.86 | 77.95 | 51.33 | 59.04 |
| w/ bi-attention | 46.55 | 76.78 | 49.54 | 57.62 |
表 5. Qwen2-VL-2B消融研究结果。所有模型均使用100,000个训练实例进行训练,与第4.1节所述的实验设置保持一致。
| 设置 | Single | Cross | Fused | Average |
|---|---|---|---|---|
| 微调策略 | ||||
| LoRA r=8 | 48.09 | 78.39 | 51.88 | 59.45 |
| LoRA r=16 | 47.86 | 78.63 | 51.42 | 59.30 |
| LoRA r=32 | 47.85 | 78.55 | 50.48 | 58.96 |
| LoRA r=64 | 47.65 | 78.61 | 51.09 | 59.11 |
| 全参数训练 | 43.16 | 75.79 | 49.28 | 56.07 |
| 训练数据组织 | ||||
| 不包含困难负样本 | 47.55 | 78.01 | 50.95 | 58.83 |
| 检索设置 | ||||
| 不包含指令 | 46.82 | 78.10 | 49.09 | 58.00 |
| 模型设计 | ||||
| 使用均值池化 | 47.86 | 77.95 | 51.33 | 59.04 |
| 使用双向注意力 | 46.55 | 76.78 | 49.54 | 57.62 |
6. Conclusion
6. 结论
In this work, we target the universal multimodal retrieval (UMR) problem. We begin by systematically categorizing current UMR tasks, proposing a comprehensive classification framework. Based on this, we explore ways to fur- ther improve MLLM-based UMR models, suggesting the GME model. The GME models are trained using contrastive learning loss on a diverse set of multimodal data settings, while also extending support for visual retrieval. Additionally, to overcome limitations in existing UMR evaluation benchmarks, we compiled a new comprehensive bench- mark (i.e., UMRB) by integrating multiple data sources. This benchmark effectively balances existing UMR tasks with the increasingly important text and visual document retrieval tasks, enabling a more thorough assessment of UMR model performance. We evaluate existing UMR models and our proposed GME model on UMRB, finding that our model achieves state-of-the-art performance. We also conducted various analyses to validate the effectiveness of our methods and enhance our understanding of them. Our benchmark, models, and other materials are open-source at https://hf.co/Alibaba-NLP/gme-Qwen2-VL7B-Instruct.
在这项工作中,我们致力于解决通用多模态检索 (UMR) 问题。我们首先系统梳理了当前UMR任务,提出了完整的分类框架。基于此,我们探索如何进一步提升基于MLLM的UMR模型,提出了GME模型。该模型通过对比学习损失在多样化多模态数据设置上进行训练,同时扩展了对视觉检索的支持。此外,为克服现有UMR评估基准的局限性,我们整合多个数据源构建了新的综合基准(即UMRB)。该基准有效平衡了现有UMR任务与日益重要的文本和视觉文档检索任务,能够更全面评估UMR模型性能。我们在UMRB上评估了现有UMR模型和提出的GME模型,发现我们的模型达到了最先进的性能。我们还进行了多维度分析以验证方法的有效性并增强对其的理解。我们的基准、模型及其他材料已开源于https://hf.co/Alibaba-NLP/gme-Qwen2-VL7B-Instruct。
Acknowledgments
致谢
This work receives partial support from the Natural Science Foundation of China (under Grant 624B2048) and Research Grant Council of Hong Kong (PolyU/15209724).
本工作获得国家自然科学基金 (项目编号 624B2048) 和香港研究资助局 (理大/15209724) 的部分资助。
References
参考文献
Appendix
附录
7. UMRB Details
7. UMRB 详情
Table 6 summarizes all UMRB tasks along with their statistics. Table 14 provides examples of different task types. Below is a brief description of each dataset included in the UMRB.
表 6 总结了所有 UMRB 任务及其统计数据。表 14 提供了不同任务类型的示例。以下是 UMRB 中包含的每个数据集的简要说明。
7.1. Single-Modal Tasks
7.1. 单模态任务
WebQA [4] This dataset is derived from Wikipedia. In the $\mathrm{T}{\rightarrow}\mathrm{T}$ setup, both the query and candidate are text. The objective is to find a Wikipedia paragraph that answers the question. We have used 2,455 samples as the test set.
WebQA [4] 该数据集源自 Wikipedia。在 $\mathrm{T}{\rightarrow}\mathrm{T}$ 设置中,查询项和候选答案均为文本。其目标是找到能回答该问题的 Wikipedia 段落。我们使用 2,455 个样本作为测试集。
Nights [13] This dataset contains human judgments on the similarity of various image pairs, where both the query and candidate are images. The task is to identify an image that resembles the provided query image. We included 2,120 samples in our UMRB.
Nights [13] 该数据集包含人类对各种图像对相似度的判断,其中查询项和候选项均为图像。任务是识别与所提供查询图像相似的图像。我们在UMRB中纳入了2,120个样本。
ArguAna, Climate FEVER, CQ AD up stack, DBPedia, FEVER, FiQA2018, HotpotQA, MSMARCO, NFCor- pus, NQ, Quora, SCIDOCS, SciFact, Touche2020 and
ArguAna, Climate FEVER, CQ AD up stack, DBPedia, FEVER, FiQA2018, HotpotQA, MSMARCO, NFCorpus, NQ, Quora, SCIDOCS, SciFact, Touche2020
| Name | Type | Categ. | Eval Samples | Candidates Nums | Eval Query avg. chars | Eval Candidate avg. chars | In partial |
| ArguAna | Single-Modal | T→→T | 10,080 | 1,406 | 192.98 | 166.80 | True |
| Climate-FEVER | Single-Modal | T→→T | 1,535 | 5,416,593 | 20.13 | 84.76 | False |
| CQADupStack | Single-Modal | T→→T | 13,145 | 457,199 | 8.59 | 129.09 | False |
| DBPedia | Single-Modal | T→T | 400 | 4,635,922 | 5.39 | 49.68 | False |
| FEVER | Single-Modal | T→T | 6,666 | 5,416,568 | 8.13 | 84.76 | False |
| FiQA2018 | Single-Modal | T→→T | 648 | 57,638 | 10.77 | 132.32 | False |
| HotpotQA | Single-Modal | T→→T | 7,405 | 5,233,329 | 17.61 | 46.30 | False |
| MSMARCO | Single-Modal | T→T | 6,980 | 8,841,823 | 5.96 | 55.98 | False |
| NFCorpus | Single-Modal | T→→T | 323 | 3,633 | 3.30 | 232.26 | True |
| NQ | Single-Modal | T→T | 3,452 | 2,681,468 | 9.16 | 78.88 | False |
| Quora | Single-Modal | T→→T | 10,000 | 522,931 | 9.53 | 11.44 | True |
| SCIDOCS | Single-Modal | T→T | 1,000 | 25,657 | 9.38 | 176.19 | True |
| SciFact | Single-Modal | T→T | 300 | 5,183 | 12.37 | 213.63 | False |
| Touche2020 | Single-Modal | T→→T | 49 | 382,545 | 6.55 | 292.37 | False |
| TRECCOVID | Single-Modal | T→→T | 50 | 171,332 | 10.60 | 160.77 | True |
| WebQA | Single-Modal | T→→T | 2,455 | 544,457 | 18.58 | 37.67 | False |
| Nights | Single-Modal | I←1 | 2,120 | 40,038 | True | ||
| VisualNews | Cross-Modal | T→→I | 19,995 | 542,246 | 18.78 | False | |
| Fashion200k | Cross-Modal | T-→I | 1,719 | 201,824 | 4.89 | False | |
| MSCOCO | Cross-Modal | T→→I | 24,809 | 5,000 | 10.43 | True | |
| Flickr30k | Cross-Modal | T→→I | 5,000 | 1,000 | 12.33 | True | |
| TAT-DQA | Cross-Modal | T→VD | 1,646 | 277 | 12.44 | False | |
| ArxivQA | Cross-Modal | T→VD | 500 | 500 | 17.12 | False | |
| DocVQA | Cross-Modal | T→→VD | 451 | 500 | 8.23 | True | |
| InfoVQA | Cross-Modal | T→VD | 494 | 500 | 11.29 | False | |
| Shift Project | Cross-Modal | T→→VD | 100 | 1,000 | 16.01 | True | |
| Artificial Intelligence | Cross-Modal | T→→VD | 100 | 968 | 12.3 | False | |
| Government Reports | Cross-Modal | T→→VD | 100 | 972 | 12.62 | False | |
| Healthcare Industry | Cross-Modal | T→VD | 100 | 965 | 12.56 | False | |
| Energy | Cross-Modal | T→VD | 100 | 977 | 13.49 | False | |
| TabFQuad | Cross-Modal | T→→VD | 280 | 70 | 16.49 | False | |
| VisualNews | Cross-Modal | I-→T | 20,000 | 537,568 | 18.53 | False | |
| Fashion200k | Cross-Modal | I→T | 4,889 | 61,707 | 4.95 | False | |
| MSCOCO | Cross-Modal | I->T | 5,000 | 24,809 | 10.43 | True | |
| Flickr30k | Cross-Modal | I-→T | 1,000 | 5,000 | 12.33 | True | |
| WebQA | Fused-Modal | T→→IT | 2,511 | 403,196 | 16.43 | 12.83 | False |
| EDIS OVEN | Fused-Modal | T→→IT | 3,241 | 1,047,067 | 20.07 | 15.53 | False |
| INFOSEEK | Fused-Modal Fused-Modal | IT→T | 50,004 | 676,667 | 6.52 | 82.13 | False |
| IT→T | 11,323 | 611,651 | 8.76 | 91.49 | False | ||
| ReMuQ | Fused-Modal | IT→T | 3,609 | 138,794 | 13.82 | 34.26 | True |
| OKVQA | Fused-Modal | IT→T | 5,046 | 114,516 | 8.09 | 102.55 | True |
| LLaVA | Fused-Modal | IT→→T | 5,120 | 5,994 | 10.70 | 90.65 | True |
| FashionIQ | Fused-Modal | IT→→I | 6,003 | 74,381 | 11.70 | True | |
| CIRR | Fused-Modal | IT→→I | 4,170 | 21,551 | 11.01 | True | |
| OVEN | Fused-Modal | IT→IT | 14,741 | 335,135 | 5.91 | 94.76 | True |
| EVQA | Fused-Modal | IT→→IT | 3,743 | 68,313 | 9.38 | 211.12 | False |
| INFOSEEK | Fused-Modal | IT→→IT | 17,593 | 481,782 | 7.94 | 96.00 | False |
Table 6. Tasks in UMRB. We counted the number of datasets under each task type and the number of evaluation instances in the dataset, the size of the candidate set, and the average length of the text.
| 名称 | 类型 | 类别 | 评估样本数 | 候选集数量 | 评估查询平均字符数 | 评估候选平均字符数 | 部分参与 |
|---|---|---|---|---|---|---|---|
| ArguAna | 单模态 | T→T | 10,080 | 1,406 | 192.98 | 166.80 | 是 |
| Climate-FEVER | 单模态 | T→T | 1,535 | 5,416,593 | 20.13 | 84.76 | 否 |
| CQADupStack | 单模态 | T→T | 13,145 | 457,199 | 8.59 | 129.09 | 否 |
| DBPedia | 单模态 | T→T | 400 | 4,635,922 | 5.39 | 49.68 | 否 |
| FEVER | 单模态 | T→T | 6,666 | 5,416,568 | 8.13 | 84.76 | 否 |
| FiQA2018 | 单模态 | T→T | 648 | 57,638 | 10.77 | 132.32 | 否 |
| HotpotQA | 单模态 | T→T | 7,405 | 5,233,329 | 17.61 | 46.30 | 否 |
| MSMARCO | 单模态 | T→T | 6,980 | 8,841,823 | 5.96 | 55.98 | 否 |
| NFCorpus | 单模态 | T→T | 323 | 3,633 | 3.30 | 232.26 | 是 |
| NQ | 单模态 | T→T | 3,452 | 2,681,468 | 9.16 | 78.88 | 否 |
| Quora | 单模态 | T→T | 10,000 | 522,931 | 9.53 | 11.44 | 是 |
| SCIDOCS | 单模态 | T→T | 1,000 | 25,657 | 9.38 | 176.19 | 是 |
| SciFact | 单模态 | T→T | 300 | 5,183 | 12.37 | 213.63 | 否 |
| Touche2020 | 单模态 | T→T | 49 | 382,545 | 6.55 | 292.37 | 否 |
| TRECCOVID | 单模态 | T→T | 50 | 171,332 | 10.60 | 160.77 | 是 |
| WebQA | 单模态 | T→T | 2,455 | 544,457 | 18.58 | 37.67 | 否 |
| Nights | 单模态 | I←1 | 2,120 | 40,038 | 是 | ||
| VisualNews | 跨模态 | T→I | 19,995 | 542,246 | 18.78 | 否 | |
| Fashion200k | 跨模态 | T→I | 1,719 | 201,824 | 4.89 | 否 | |
| MSCOCO | 跨模态 | T→I | 24,809 | 5,000 | 10.43 | 是 | |
| Flickr30k | 跨模态 | T→I | 5,000 | 1,000 | 12.33 | 是 | |
| TAT-DQA | 跨模态 | T→VD | 1,646 | 277 | 12.44 | 否 | |
| ArxivQA | 跨模态 | T→VD | 500 | 500 | 17.12 | 否 | |
| DocVQA | 跨模态 | T→VD | 451 | 500 | 8.23 | 是 | |
| InfoVQA | 跨模态 | T→VD | 494 | 500 | 11.29 | 否 | |
| Shift Project | 跨模态 | T→VD | 100 | 1,000 | 16.01 | 是 | |
| Artificial Intelligence | 跨模态 | T→VD | 100 | 968 | 12.3 | 否 | |
| Government Reports | 跨模态 | T→VD | 100 | 972 | 12.62 | 否 | |
| Healthcare Industry | 跨模态 | T→VD | 100 | 965 | 12.56 | 否 | |
| Energy | 跨模态 | T→VD | 100 | 977 | 13.49 | 否 | |
| TabFQuad | 跨模态 | T→VD | 280 | 70 | 16.49 | 否 | |
| VisualNews | 跨模态 | I→T | 20,000 | 537,568 | 18.53 | 否 | |
| Fashion200k | 跨模态 | I→T | 4,889 | 61,707 | 4.95 | 否 | |
| MSCOCO | 跨模态 | I→T | 5,000 | 24,809 | 10.43 | 是 | |
| Flickr30k | 跨模态 | I→T | 1,000 | 5,000 | 12.33 | 是 | |
| WebQA | 融合模态 | T→IT | 2,511 | 403,196 | 16.43 | 12.83 | 否 |
| EDIS OVEN | 融合模态 | T→IT | 3,241 | 1,047,067 | 20.07 | 15.53 | 否 |
| INFOSEEK | 融合模态 | IT→T | 50,004 | 676,667 | 6.52 | 82.13 | 否 |
| 融合模态 | IT→T | 11,323 | 611,651 | 8.76 | 91.49 | 否 | |
| ReMuQ | 融合模态 | IT→T | 3,609 | 138,794 | 13.82 | 34.26 | 是 |
| OKVQA | 融合模态 | IT→T | 5,046 | 114,516 | 8.09 | 102.55 | 是 |
| LLaVA | 融合模态 | IT→T | 5,120 | 5,994 | 10.70 | 90.65 | 是 |
| FashionIQ | 融合模态 | IT→I | 6,003 | 74,381 | 11.70 | 是 | |
| CIRR | 融合模态 | IT→I | 4,170 | 21,551 | 11.01 | 是 | |
| OVEN | 融合模态 | IT→IT | 14,741 | 335,135 | 5.91 | 94.76 | 是 |
| EVQA | 融合模态 | IT→IT | 3,743 | 68,313 | 9.38 | 211.12 | 否 |
| INFOSEEK | 融合模态 | IT→IT | 17,593 | 481,782 | 7.94 | 96.00 | 否 |
表 6: UMRB 中的任务。我们统计了每种任务类型下的数据集数量、数据集中的评估实例数量、候选集大小以及文本的平均长度。
TRECCOVID For these datasets, we use the processed versions from BEIR [55].
TRECCOVID 对于这些数据集, 我们使用来自 BEIR [55] 的已处理版本。
7.2. Cross-Modal Tasks
7.2. 跨模态任务
VisualNews [34] This dataset focuses on the news domain and consists of pairs of news headlines and associated images. In UMRB, this dataset can be transformed into two tasks: retrieving the corresponding image based on the news headline $(\mathrm{T}{\rightarrow}\mathrm{I})$ and retrieving the corresponding news headline based on the image $(\mathrm{I}{\rightarrow}\mathrm{T})$ . We utilized 19,995 and 20,000 samples to construct the test set.
VisualNews [34] 该数据集聚焦新闻领域,由新闻标题和相关图片配对组成。在UMRB中,该数据集可转换为两项任务:根据新闻标题检索对应图像 $(\mathrm{T}{\rightarrow}\mathrm{I})$ ,以及根据图像检索对应新闻标题 $(\mathrm{I}{\rightarrow}\mathrm{T})$ 。我们分别使用19,995和20,000个样本构建测试集。
Fashion 200 k [16] This dataset includes pairs of images and product descriptions. In total, we have 1,719 instances for the task $\mathrm{T}{\longrightarrow}\mathrm{I}$ and 4,889 instances for the task $\mathrm{I}{\rightarrow}\mathrm{T}$ for evaluation.
Fashion 200k [16] 该数据集包含图像和产品描述对。我们总共为评估任务准备了1,719个 $\mathrm{T}{\longrightarrow}\mathrm{I}$ 实例和4,889个 $\mathrm{I}{\rightarrow}\mathrm{T}$ 实例。
MSCOCO [32] This dataset is a well-known image caption dataset. Similar to VisualNews, it is converted into two tasks: $\mathrm{}^{66}\mathrm{I}{\rightarrow}\mathrm{T}'$ , which retrieves the caption given an image and “T $\twoheadrightarrow\mathrm{I}^{\blacktriangledown}$ , which retrieves the image given a caption.
MSCOCO [32] 该数据集是知名的图像描述数据集。与VisualNews类似,它被转换为两个任务:$\mathrm{}^{66}\mathrm{I}{\rightarrow}\mathrm{T}'$(给定图像检索描述)和“T $\twoheadrightarrow\mathrm{I}^{\blacktriangledown}$(给定描述检索图像)。
Flickr30k[50] This dataset consists of images paired with detailed textual descriptions. We have a total of 1,000 instances for the $\mathrm{I}{\rightarrow}\mathrm{T}$ task and 5,000 instances for the $\mathrm{T}{\longrightarrow}\mathrm{I}$ task available for evaluation.
Flickr30k [50] 该数据集包含图像与详细文本描述配对。我们共有1,000个实例用于 $\mathrm{I}{\rightarrow}\mathrm{T}$ 任务评估,5,000个实例用于 $\mathrm{T}{\longrightarrow}\mathrm{I}$ 任务评估。
TAT-DQA, ArxivQA, DocVQA, InfoVQA, Shift Project, Artificial Intelligence, Government Reports, Healthcare Industry, Energy, TabFQuad These datasets constitute the retrieval task of $\mathrm{T}{\rightarrow}\mathrm{VD}$ . Their queries are standard questions, and the candidates are document screenshots. For these datasets, we used the processed versions from ViDoRe [12].
TAT-DQA、ArxivQA、DocVQA、InfoVQA、Shift项目、人工智能、政府报告、医疗保健行业、能源、TabFQuad 这些数据集构成了 $\mathrm{T}{\rightarrow}\mathrm{VD}$ 的检索任务。它们的查询是标准问题,候选对象是文档截图。对于这些数据集,我们使用了 ViDoRe [12] 中的处理版本。
7.3. Fused-Modal Tasks
7.3. 融合模态任务
WebQA [4] Similar to WebQA in the Single-Modal setting, this dataset is also derived from Wikipedia, but in the $\mathrm{T}{\rightarrow}\mathrm{IT}$ setup, the candidates consist of images and text. The task is to find a Wikipedia paragraph with accompanying text and images to answer a specific question. There are 2,511 samples in the evaluation set.
WebQA [4] 与单模态设置中的WebQA类似, 该数据集也源自维基百科, 但在 $\mathrm{T}{\rightarrow}\mathrm{IT}$ 设置中, 候选内容包含图像和文本。该任务需要找到带有配套文本和图像的维基百科段落来回答特定问题。评估集中包含2,511个样本。
EDIS [37] This dataset involves the cross-modal image search within the news domain. The queries are texts containing entities and events, with candidates consisting of news images and their accompanying headlines. The task requires the model to comprehend both entities and events from the text queries and retrieve the corresponding image and headline.
EDIS [37] 该数据集涉及新闻领域内的跨模态图像搜索。查询文本包含实体和事件,候选集由新闻图像及其配套标题组成。该任务要求模型从文本查询中理解实体和事件,并检索对应的图像和标题。
OVEN [20] The dataset is sourced from Wikipedia, where a query consists of an image and a question related to the image. The candidates are the Wikipedia title along with the first 100 tokens of its summary. If the associated Wikipedia content includes images, it constitutes an $\Pi{\longrightarrow}\Pi\mathrm{T}$ task; otherwise, it forms an $\Pi{\longrightarrow}\mathrm{T}$ task. In the evaluation, we have 14,741 samples for the $\mathrm{IT}{\rightarrow}\mathrm{IT}$ task and 50,004 samples for the $\Pi{\longrightarrow}\mathrm{T}$ task.
OVEN [20] 该数据集源自维基百科,每个查询由一张图像和一个与该图像相关的问题组成。候选答案是维基百科标题及其摘要的前100个token。若相关维基百科内容包含图像,则构成 $\Pi{\longrightarrow}\Pi\mathrm{T}$ 任务;否则形成 $\Pi{\longrightarrow}\mathrm{T}$ 任务。评估中,我们有14,741个样本用于 $\mathrm{IT}{\rightarrow}\mathrm{IT}$ 任务,50,004个样本用于 $\Pi{\longrightarrow}\mathrm{T}$ 任务。
INFOSEEK [6] This dataset is similar to OVEN, with queries consisting of images alongside text questions. The candidates are Wikipedia snippets of 100 tokens containing the exact answers. This dataset also encompasses two tasks: for the $\mathrm{IT}{\rightarrow}\mathrm{IT}$ and $\Pi{\xrightarrow{}}\mathrm{T}$ tasks, we used 17,593 and 11,323 samples, respectively.
INFOSEEK [6] 该数据集与OVEN类似,其查询由图像和文本问题组成。候选答案是包含精确答案的100个token的维基百科片段。该数据集还包含两项任务:对于$\mathrm{IT}{\rightarrow}\mathrm{IT}$和$\Pi{\xrightarrow{}}\mathrm{T}$任务,我们分别使用了17,593和11,323个样本。
ReMuQ [40] The dataset is augmented from the WebQA questions by adding images to create new multimodal queries along with a large text corpus. For evaluation, we used 3,609 instances from this dataset.
ReMuQ [40] 该数据集通过为WebQA问题添加图像来创建新的多模态查询,并配以大型文本语料库进行增强。我们在评估中使用了该数据集的3,609个实例。
OKVQA [43] This dataset includes visual questions that require external knowledge to answer. It is structured as an $\Pi{\longrightarrow}\mathrm{T}$ retrieval task, where queries consist of visual questions containing images and text, with candidates being external knowledge sources that can assist in answering the questions.
OKVQA [43] 该数据集包含需要外部知识回答的视觉问题。其任务结构被构建为 $\Pi{\longrightarrow}\mathrm{T}$ 检索任务,查询由包含图像和文本的视觉问题构成,候选对象则是能够协助回答问题外部知识源。
LLaVA [33] This dataset contains high-quality conversations about an image generated by GPT-3.5, involving exchanges between a human and an AI assistant. The queries comprise questions and instructions sent by humans to the AI assistant, which include both images and text, while the candidates are the AI assistant’s replies. We utilized 5,120 samples from this dataset in the UMRB evaluation.
LLaVA [33] 该数据集包含由GPT-3.5生成的关于图像的高质量对话,涉及人类与AI助手之间的交流。查询包含人类向AI助手发送的问题和指令,其中既包含图像也包含文本,而候选答案则是AI助手的回复。我们在UMRB评估中使用了该数据集的5,120个样本。
FashionIQ [67] This dataset features images of fashion products along with crowd-sourced descriptions that highlight the differences between these products. Each query consists of an image and a modification sentence that describes changes to the given image, with the retrieval target being the specified image. In the UMRB evaluation, we used 6,003 samples from this dataset.
FashionIQ [67] 该数据集包含时尚商品图像以及众包描述,这些描述突出了商品之间的差异。每个查询由一张图像和一个描述对给定图像修改的句子组成,检索目标是指定的图像。在UMRB评估中,我们使用了该数据集中的6,003个样本。
CIRR [38] Similar to FashionIQ, CIRR can also be used for composed image retrieval. It involves pairs of real-life reference and target images in each test case, along with a modification sentence detailing the differences between the two images. For the UMRB evaluation, we utilized 4,170 samples from this dataset.
CIRR [38] 与FashionIQ类似,CIRR也可用于组合图像检索。每个测试案例包含真实场景的参考图像和目标图像对,以及描述两幅图像差异的修改语句。在UMRB评估中,我们使用了该数据集的4,170个样本。
EVQA [46] This dataset is akin to INFOSEEK, with the key distinction being that the retrieval target of EVQA is a complete Wikipedia paragraph with a maximum length of several thousand tokens. We used 3,743 samples for evaluation, eliminating multi-hop issues present in the original test set. We selected Wikipedia paragraphs from the original dataset as candidates and supplemented them with images. Images native to each paragraph were included when available; otherwise, the first image from the article was utilized due to its typically representative nature.
EVQA [46] 该数据集与INFOSEEK类似, 关键区别在于EVQA的检索目标是完整的维基百科段落, 最大长度可达数千个token. 我们使用3,743个样本进行评估, 消除了原始测试集中存在的多跳问题. 我们从原始数据集中选取维基百科段落作为候选, 并补充了图像. 当段落本身包含图像时我们采用原生图像, 否则使用文章首张图像因其通常具有代表性.
7.4. UMRB-Partial
7.4. UMRB-部分
The full UMRB dataset consists of 47 subtasks, approximately 200,000 evaluation instances, and 40 million candidates, resulting in a significant overhead when testing the model. During our experiments with the GME-7B model, a full evaluation required approximately 400 A10080G GPU hours. To facilitate development and verification, we created a smaller benchmark by condensing the complete UMRB, which we refer to as UMRB-Partial. Column 8 of Table 6 indicates whether a dataset is included in UMRBPartial. Testing the GME-7B model on UMRB-Partial reduced the evaluation time from 400 A100 80G GPU hours to 80 A10080G GPU hours.
完整的 UMRB 数据集包含 47 个子任务、约 20 万个评估实例和 4000 万个候选答案,导致模型测试时产生显著开销。在我们使用 GME-7B 模型的实验中,完整评估需要约 400 A10080G GPU 小时。为便于开发和验证,我们通过压缩完整 UMRB 创建了小型基准数据集,称为 UMRB-Partial。表 6 第 8 列标示了数据集是否包含在 UMRB-Partial 中。在 UMRB-Partial 上测试 GME-7B 模型将评估时间从 400 A100 80G GPU 小时缩减至 80 A10080G GPU 小时。
8. Results Details
8. 结果详情
In this section, we present the detailed scores achieved by our GME and the baseline models on various tasks. Additionally, we provide results from other benchmarks, including BEIR, M-BEIR, and ViDoRe.
在本节中,我们将展示 GME 和基线模型在各种任务上的详细得分。此外,我们还提供了其他基准测试的结果,包括 BEIR、M-BEIR 和 ViDoRe。
8.1. Detailed Results on UMRB
8.1. UMRB详细结果
Table 7 presents the detailed evaluation results of the baseline systems alongside our GME on UMRB tasks. First, focusing on the average scores, our smaller model, i.e. $\mathtt{G M E-Q w e n2-V I-2B}$ , already outperforms the previous state-of-the-art UMR model (VISTA). The larger model, i.e. $\mathtt{G M E-Q w e n2-V L-7B}$ , further enhances this performance. In addition, focusing on specific scores on different datasets, our GME achieves state-of-the-art performance on each dataset except the Nights dataset. VISTA and CLIPSF scored highly on the Nights dataset, likely due to their use of independent image and text encoders for cross-modal retrieval. In the $\mathrm{I}{\rightarrow}\mathrm{I}$ task, these models relied solely on the image encoder for encoding without cross-modal alignment, which may explain their superior performance on the Nights dataset.
表 7 展示了基线系统与我们的 GME 在 UMRB 任务上的详细评估结果。首先关注平均分数,我们的较小模型 $\mathtt{GME-Qwen2-VI-2B}$ 已超越之前最先进的 UMR 模型 (VISTA) 。更大规模的模型 $\mathtt{GME-Qwen2-VL-7B}$ 则进一步提升了性能。此外,针对不同数据集的具体分数,我们的 GME 在除 Nights 数据集外的每个数据集上都达到了最先进的性能。VISTA 和 CLIPSF 在 Nights 数据集上得分较高,这可能是因为它们使用独立的图像和文本编码器进行跨模态检索。在 $\mathrm{I}{\rightarrow}\mathrm{I}$ 任务中,这些模型仅依赖图像编码器进行编码而无需跨模态对齐,这或许解释了它们在 Nights 数据集上的优异表现。
8.2. Detailed Results on UMRB-Partial
8.2. UMRB-Partial 详细结果
Figure 3 of main paper illustrates our exploration of the training data, as discussed in Section 4.2, with specific results presented in Table 8. This table details the scores of our models trained on six data types: $\mathrm{T}{\rightarrow}\mathrm{T}_{:}$ , $\mathrm{I}{\rightarrow}\mathrm{I}$ , $\mathrm{T}{\rightarrow}\mathrm{VD}$ , $\mathrm{T}{\rightarrow}\mathrm{I}$ , $\mathrm{IT\mathrm{\to\mathrm{IT}}}$ , and Mix across various tasks. We find that the model trained on mixed data performs the best.
主论文图 3 展示了我们对训练数据的探索 (如第 4.2 节所述) , 具体结果呈现在表 8 中。该表格详细列出了我们基于六种数据类型训练的模型在各任务上的得分: $\mathrm{T}{\rightarrow}\mathrm{T}_{:}$、$\mathrm{I}{\rightarrow}\mathrm{I}$、$\mathrm{T}{\rightarrow}\mathrm{VD}$、$\mathrm{T}{\rightarrow}\mathrm{I}$、$\mathrm{IT\mathrm{\to\mathrm{IT}}}$ 以及混合数据。我们发现基于混合数据训练的模型表现最佳。
8.3. Detailed Results on BEIR
8.3. BEIR详细结果
BEIR is a heterogeneous benchmark containing diverse text IR tasks. We utilize BEIR to compare the performance of our GME with other text embedders on $\mathrm{T}{\rightarrow}\mathrm{T}$ tasks. Table 9 presents the detailed evaluation $\mathrm{nDCG}@10$ scores for pure text embedders and multimodal embedders on $\mathrm{T}{\rightarrow}\mathrm{T}$ tasks. Except for our GME, other multimodal embedders do not match the performance of pure text embedders on text retrieval tasks, including those like $\Xi\Xi-\nabla$ that are fine-tuned exclusively on text data.
BEIR是一个包含多种文本检索任务的异构基准。我们利用BEIR在 $\mathrm{T}{\rightarrow}\mathrm{T}$ 任务上比较GME与其他文本嵌入模型的性能。表9展示了纯文本嵌入模型和多模态嵌入模型在 $\mathrm{T}{\rightarrow}\mathrm{T}$ 任务上的详细评估 $\mathrm{nDCG}@10$ 分数。除我们的GME外,其他多模态嵌入模型在文本检索任务上的表现均不及纯文本嵌入模型,包括那些像 $\Xi\Xi-\nabla$ 一样仅在文本数据上微调的模型。
Naturally, pure text embedding models of the same model size still outperform multimodal embedding models in pure text retrieval tasks. For example, the score of the gte-Qwen2-7B-instruct model is 60.25, while the GME-Qwen2-VL-7B model, with the same model scale, scores 55.63. Although both models share the same text LLM, incorporating or extending multimodal capabilities leads to additional compromises in pure text performance. Minimizing this kind of loss remains an important research question.
自然地,相同模型规模的纯文本嵌入模型在纯文本检索任务中仍然优于多模态嵌入模型。例如,gte-Qwen2-7B-instruct 模型的得分为 60.25,而相同模型规模的 GME-Qwen2-VL-7B 模型得分为 55.63。尽管两个模型共享相同的文本大语言模型,但融入或扩展多模态能力会导致纯文本性能的额外折损。如何最小化这类损失仍是重要的研究课题。
8.4. Detailed Results on M-BEIR
8.4. M-BEIR 详细结果
M-BEIR, a multimodal benchmark for IR, serves as a comprehensive large-scale retrieval benchmark designed to evaluate multimodal retrieval models. As shown in Table 10, we report Recall $@10$ scores for the Fashion 200 K and FashionIQ datasets, while Recall $\ @5$ scores are provided for all other datasets. In M-BEIR, our GME continues to demonstrate state-of-the-art performance, underscoring the effectiveness of our approach.
M-BEIR, 一个多模态信息检索 (IR) 基准, 作为综合性大规模检索基准, 旨在评估多模态检索模型. 如表 10 所示, 我们报告了 Fashion 200K 和 FashionIQ 数据集的 Recall $@10$ 分数, 而所有其他数据集则提供 Recall $\ @5$ 分数. 在 M-BEIR 中, 我们的 GME 持续展现出最先进的性能, 彰显了我们方法的有效性.
8.5. Detailed Results on ViDoRe
8.5. ViDoRe 详细结果
ViDoRe represents the Visual Document Retrieval Benchmark, encompassing various page-level screenshot retrieval tasks. This benchmark includes the $\mathrm{T}{\rightarrow}\mathrm{VD}$ tasks within our UMRB. Table 11 presents the detailed $\mathrm{nDCG}@5$ scores for our GME and other models. Our smaller model, i.e. GME-Qwen2-VL-2B, surpasses the previous state-ofthe-art model (ColPali), which was exclusively trained on this dataset for this specific task. The larger model, i.e. GME-Qwen2-VL-7B, further improves upon this performance.
ViDoRe代表视觉文档检索基准 (Visual Document Retrieval Benchmark) , 涵盖多种页面级截图检索任务。该基准包含我们UMRB中的 $\mathrm{T}{\rightarrow}\mathrm{VD}$ 任务。表11展示了我们的GME与其他模型的详细 $\mathrm{nDCG}@5$ 分数。我们的小型模型GME-Qwen2-VL-2B超越了此前在该数据集上专门训练的最先进模型 (ColPali) 。大型模型GME-Qwen2-VL-7B则进一步提升了该性能。
9. Experiment Details
9. 实验细节
9.1. Training Details
9.1. 训练细节
Our GME models (both 2B and 7B) are initialized using the Qwen2-VL [65] model series. We employ the transformers library for training in BF16 precision. The training utilizes Low-Rank Adaptation (LoRA) [19] with a rank of 8. We apply a decoupled AdamW optimizer with a learning rate and a weight decay of 1e-4. Additional hyper parameters are detailed in Table 12.
我们的GME模型 (包括2B和7B版本) 均基于Qwen2-VL [65] 模型系列进行初始化。我们使用transformers库以BF16精度进行训练。训练采用秩为8的低秩自适应 (LoRA) [19] 方法,并应用学习率和权重衰减均为1e-4的解耦AdamW优化器。其他超参数详见表12。
In our contrastive learning approach, we develop dense multimodal representation models (embedders) that utilize the [EOS] hidden state as the embedding of the input. The temperature for contrastive learning is set to 0.03. For each query, we include one positive candidate along with eight hard negative candidates.
在我们的对比学习方法中,我们开发了密集多模态表征模型(嵌入器),这些模型利用 [EOS] 隐藏状态作为输入的嵌入。对比学习的温度设置为0.03。对于每个查询,我们包含一个正样本候选以及八个困难负样本候选。
| Type | Task | Dataset | VISTA | CLIP-SF | One-Peace | DSE | E5-V | GME-2B | GME-7B |
| Single- Modal Cross- Modal | ArguAna | 63.61 | 52.45 | 32.93 | 53.46 | 54.28 | 63.18 | 72.11 | |
| Climate-FEVER | 31.17 | 20.00 | 20.27 | 19.79 | 21.64 | 41.08 | 48.36 | ||
| CQADupStack | 42.35 | 30.61 | 41.32 | 36.51 | 41.69 | 39.06 | 42.16 | ||
| DBPedia | 40.77 | 26.37 | 32.43 | 40.75 | 38.78 | 41.00 | 46.30 | ||
| FEVER | 86.29 | 50.58 | 51.91 | 80.12 | 78.99 | 92.06 | 93.81 | ||
| FiQA2018 | 40.65 | 22.14 | 36.79 | 36.2 | 45.41 | 43.8 | 63.23 | ||
| HotpotQA | 72.6 | 41.33 | 46.51 | 70.79 | 60.88 | 65.3 | 68.18 | ||
| MSMARCO | 41.35 | 22.15 | 36.55 | 37.73 | 41.23 | 40.61 | 42.93 | ||
| NFCorpus | 37.39 | 27.05 | 31.6 | 32.82 | 36.97 | 38.84 | 36.95 | ||
| NQ | 54.15 | 25.45 | 42.87 | 52.97 | 51.58 | 54.52 | 56.08 | ||
| Quora | 88.90 | 81.63 | 87.46 | 85.84 | 87.6 | 88.12 | 89.67 | ||
| SCIDOCS | 21.73 | 14.75 | 21.64 | 15.66 | 22.36 | 22.94 | 26.35 | ||
| SciFact | 74.04 55.98 | 64.51 | 68.97 | 72.75 | 74.19 | 82.43 | |||
| Touche2020 | 25.7 | 17.47 | 16.90 | 14.50 | 21.61 | 26.57 | 22.55 | ||
| TRECCOVID | 77.90 | 63.61 | 69.28 | 52.98 | 72.85 | 71.73 | 77.49 | ||
| WebQA | 83.80 84.44 | 63.67 | 83.95 | 89.94 | 94.34 | 94.34 | |||
| I→I | Nights | 24.43 | 31.42 | 31.27 | 27.36 | 27.92 | 30.61 | 30.57 | |
| VisualNews | 5.77 | 42.80 | 48.95 | 14.12 | 29.46 | 39.20 | 46.27 | ||
| T→→I | Fashion200k MSCOCO | 3.08 47.97 | 18.38 80.75 | 32.34 | 3.08 | 3.78 | 23.50 | 27.64 79.77 | |
| Flickr30k | 74.68 | 94.28 | 71.45 92.78 | 74.62 94.42 | 52.38 77.38 | 76.22 94.5 | 97.38 | ||
| TAT-DQA | 2.05 | ||||||||
| ArxivQA | 10.30 | 5.49 24.10 | 14.44 43.94 | 49.01 78.17 | 9.08 41.16 | 57.88 81.41 | 64.06 | ||
| DocVQA | 8.01 | 11.80 | 23.48 | 45.83 | 24.37 | 46.86 | 82.55 49.34 | ||
| InfoVQA | 30.02 | 48.78 | 59.97 | 82.06 | 49.5 | 84.97 | 88.79 | ||
| Shift Project | 3.26 | 6.06 | 17.02 | 69.84 | 13.16 | 77.94 | 83.5 | ||
| T→VD Artificial Intelligence | 7.34 | 28.64 | 45.41 | 96.88 | 46.18 | 95.75 | |||
| Government Reports | 34.67 | 55.98 | 92.04 | 53.05 | 92.05 | 98.02 94.05 | |||
| Healthcare Industry | 6.90 9.39 | 32.64 | 59.55 | 96.35 | 59.61 | 96.08 | 97.29 | ||
| Energy | 11.05 27.19 | 53.21 | 92.62 | 56.77 | 89.17 | 93.09 | |||
| TabFQuad | 13.08 | 21.53 | 57.05 | 79.29 | 58.22 | 91.79 | 94.92 | ||
| 42.67 | |||||||||
| VisualNews | 2.79 | 18.10 | 47.27 30.89 | 8.74 | 29.54 4.62 | 38.21 26.61 | 47.16 | ||
| IT | Fashion200k MSCOCO | 4.72 48.92 | 91.94 | 85.6 | 3.91 82.06 | 86.4 | 85.18 | 31.05 85.92 | |
| Fused- Modal | T→IT | Flickr30k | 68.50 | 99.11 | 98.60 | 97.11 | 89.62 | 99.00 | 98.9 |
| WebQA | 54.84 | 78.42 | 32.42 | 66.99 | 49.62 | 82.24 | 84.11 | ||
| EDIS | 36.78 | 54.09 | 53.01 | 41.26 | 49.62 | 68.10 | 77.40 | ||
| OVEN | 22.32 | 45.98 | 23.69 | 0.38 | 14.4 | 59.67 | 64.13 | ||
| INFOSEEK IT→T | 18.53 | 27.58 | 20.05 | 3.06 | 12.69 | 39.22 | 34.67 | ||
| ReMuQ | 76.20 | 83.71 | 26.41 | 94.60 | 52.15 | 96.73 | 95.48 | ||
| OKVQA | 17.14 | 17.44 | 9.67 | 13.28 | 16.71 | 30.08 | 32.61 | ||
| LLaVA | 72.81 | 91.91 | 51.64 | 53.18 | 77.48 | 98.93 | 98.18 | ||
| IT→I | FashionIQ | 3.28 | 24.54 | 2.93 | 9.81 | 3.73 | 26.34 | 29.89 | |
| CIRR | 14.65 | 45.25 | 10.53 | 36.52 | 13.19 | 47.70 | 51.79 | ||
| OVEN IT→IT EVQA | 27.77 | 68.83 | 30.56 | 0.39 | 54.46 | 78.96 | |||
Table 7. The detailed results of the baselines and our GME on UMRB. Following previous works [12, 55, 66], we present NDCG $@10$ scores for $\mathrm{T}{\rightarrow}\mathrm{T}$ tasks, excluding the WebQA dataset. For $\mathrm{T}{\rightarrow}\mathrm{VD}$ tasks, we provide $\mathrm{NDCG}@5$ scores. For the Fashion 200 K, FashionIQ and OKVQA datasets, we report Recall $@10$ scores, while for all other datasets, we report Recall $\ @5$ scores.
| 类型 | 任务 | 数据集 | VISTA | CLIP-SF | One-Peace | DSE | E5-V | GME-2B | GME-7B |
|---|---|---|---|---|---|---|---|---|---|
| 单模态跨模态 | ArguAna | 63.61 | 52.45 | 32.93 | 53.46 | 54.28 | 63.18 | 72.11 | |
| Climate-FEVER | 31.17 | 20.00 | 20.27 | 19.79 | 21.64 | 41.08 | 48.36 | ||
| CQADupStack | 42.35 | 30.61 | 41.32 | 36.51 | 41.69 | 39.06 | 42.16 | ||
| DBPedia | 40.77 | 26.37 | 32.43 | 40.75 | 38.78 | 41.00 | 46.30 | ||
| FEVER | 86.29 | 50.58 | 51.91 | 80.12 | 78.99 | 92.06 | 93.81 | ||
| FiQA2018 | 40.65 | 22.14 | 36.79 | 36.2 | 45.41 | 43.8 | 63.23 | ||
| HotpotQA | 72.6 | 41.33 | 46.51 | 70.79 | 60.88 | 65.3 | 68.18 | ||
| MSMARCO | 41.35 | 22.15 | 36.55 | 37.73 | 41.23 | 40.61 | 42.93 | ||
| NFCorpus | 37.39 | 27.05 | 31.6 | 32.82 | 36.97 | 38.84 | 36.95 | ||
| NQ | 54.15 | 25.45 | 42.87 | 52.97 | 51.58 | 54.52 | 56.08 | ||
| Quora | 88.90 | 81.63 | 87.46 | 85.84 | 87.6 | 88.12 | 89.67 | ||
| SCIDOCS | 21.73 | 14.75 | 21.64 | 15.66 | 22.36 | 22.94 | 26.35 | ||
| SciFact | 74.04 | 55.98 | 64.51 | 68.97 | 72.75 | 74.19 | 82.43 | ||
| Touche2020 | 25.7 | 17.47 | 16.90 | 14.50 | 21.61 | 26.57 | 22.55 | ||
| TRECCOVID | 77.90 | 63.61 | 69.28 | 52.98 | 72.85 | 71.73 | 77.49 | ||
| WebQA | 83.80 | 84.44 | 63.67 | 83.95 | 89.94 | 94.34 | 94.34 | ||
| I→I | Nights | 24.43 | 31.42 | 31.27 | 27.36 | 27.92 | 30.61 | 30.57 | |
| VisualNews | 5.77 | 42.80 | 48.95 | 14.12 | 29.46 | 39.20 | 46.27 | ||
| T→I | Fashion200k | 3.08 | 18.38 | 32.34 | 3.08 | 3.78 | 23.50 | 27.64 | |
| MSCOCO | 47.97 | 80.75 | 71.45 | 74.62 | 52.38 | 76.22 | 79.77 | ||
| Flickr30k | 74.68 | 94.28 | 92.78 | 94.42 | 77.38 | 94.5 | 97.38 | ||
| T→VD | TAT-DQA | 2.05 | |||||||
| ArxivQA | 10.30 | 5.49 | 14.44 | 49.01 | 9.08 | 57.88 | 64.06 | ||
| DocVQA | 8.01 | 11.80 | 23.48 | 45.83 | 24.37 | 46.86 | 49.34 | ||
| InfoVQA | 30.02 | 48.78 | 59.97 | 82.06 | 49.5 | 84.97 | 88.79 | ||
| Shift Project | 3.26 | 6.06 | 17.02 | 69.84 | 13.16 | 77.94 | 83.5 | ||
| Artificial Intelligence | 7.34 | 28.64 | 45.41 | 96.88 | 46.18 | 95.75 | |||
| Government Reports | 34.67 | 55.98 | 92.04 | 53.05 | 92.05 | 98.02 | 94.05 | ||
| Healthcare Industry | 6.90 | 32.64 | 59.55 | 96.35 | 59.61 | 96.08 | 97.29 | ||
| Energy | 11.05 | 27.19 | 53.21 | 92.62 | 56.77 | 89.17 | 93.09 | ||
| TabFQuad | 13.08 | 21.53 | 57.05 | 79.29 | 58.22 | 91.79 | 94.92 | ||
| VisualNews | 2.79 | 18.10 | 47.27 | 8.74 | 29.54 | 38.21 | 47.16 | ||
| IT→T | Fashion200k | 4.72 | 91.94 | 85.6 | 3.91 | 86.4 | 85.18 | 31.05 | |
| MSCOCO | 48.92 | 82.06 | 85.92 | ||||||
| 融合模态 | T→IT | Flickr30k | 68.50 | 99.11 | 98.60 | 97.11 | 89.62 | 99.00 | 98.9 |
| WebQA | 54.84 | 78.42 | 32.42 | 66.99 | 49.62 | 82.24 | 84.11 | ||
| EDIS | 36.78 | 54.09 | 53.01 | 41.26 | 49.62 | 68.10 | 77.40 | ||
| OVEN | 22.32 | 45.98 | 23.69 | 0.38 | 14.4 | 59.67 | 64.13 | ||
| IT→T | INFOSEEK | 18.53 | 27.58 | 20.05 | 3.06 | 12.69 | 39.22 | 34.67 | |
| ReMuQ | 76.20 | 83.71 | 26.41 | 94.60 | 52.15 | 96.73 | 95.48 | ||
| OKVQA | 17.14 | 17.44 | 9.67 | 13.28 | 16.71 | 30.08 | 32.61 | ||
| LLaVA | 72.81 | 91.91 | 51.64 | 53.18 | 77.48 | 98.93 | 98.18 | ||
| IT→I | FashionIQ | 3.28 | 24.54 | 2.93 | 9.81 | 3.73 | 26.34 | 29.89 | |
| CIRR | 14.65 | 45.25 | 10.53 | 36.52 | 13.19 | 47.70 | 51.79 | ||
| OVEN | 27.77 | 68.83 | 30.56 | 0.39 | 54.46 | 78.96 |
表 7: UMRB 上基线模型和我们 GME 的详细结果。遵循先前工作 [12, 55, 66] 的设定, 我们呈现 T→T 任务的 NDCG@10 分数 (WebQA 数据集除外)。对于 T→VD 任务, 我们提供 NDCG@5 分数。对于 Fashion200K、FashionIQ 和 OKVQA 数据集, 我们报告 Recall@10 分数, 其他所有数据集均报告 Recall@5 分数。
| Type | Task | Dataset | T→→T | I→I | T→→VD | T→→I | IT→→IT | Mix |
| Single- Modal | T→T | Arguan | 56.25 | 43.51 | 56.73 | 33.53 | 53.22 | 56.22 |
| NFCorpus | 35.23 | 28.89 | 33.23 | 33.18 | 30.48 | 35.76 | ||
| Quora | 87.82 | 74.37 | 86.32 | 86.43 | 85.2 | 87.4 | ||
| SCIDOCS | 19.07 | 11.82 | 17.51 | 17.2 | 16.93 | 19.88 | ||
| TRECCOVID | 75.57 | 47.89 | 50.89 | 72.37 | 58.92 | 76.38 | ||
| I→I Nights | 27.97 28.11 | 24.9 | 28.53 | 26.04 | 30.85 | |||
| Cross- Modal | T→→I | MSCOCO | 59.7 | 59.41 | 63.67 | 76.91 | 44.97 | 75.3 |
| Flickr30k | 83.92 | 65.52 | 87.32 | 93.18 | 74.52 | 93.06 | ||
| T→→VD | DocVQA | 35.8 | 24.24 | 48.38 | 40.58 | 28.05 | 45.62 | |
| Shift Project | 57.86 | 45.47 | 77.08 | 50.36 | 53.12 | 74.84 | ||
| I→T | MSCOCO | 74.72 | 63.82 | 80.46 | 84.64 | 70.48 | 84.24 | |
| Flickr30k | 94.1 | 82.5 | 96.3 | 97.2 | 90.1 | 97.5 | ||
| Fused- Modal | IT→T | LLaVA | 92.75 | 89.05 | 86.02 | 89.24 | 88.73 | 95.02 |
| ReMuQ | 89.61 | 85.47 | 76.45 | 85.12 | 86.73 | 89.75 | ||
| OKVQA | 24.55 | 16.6 | 15.78 | 16.92 | 18.57 | 20.23 | ||
| FashionIQ | 5.53 | 4.2 | 5.43 | 8.86 | 11.08 | 11.89 | ||
| IT→I IT→→IT | CIRR | 17.24 | 15.04 | 15.42 | 17.5 | 25.71 | 29.86 | |
| OVEN | 59.81 | 38.42 | 57.31 | 56.69 | 65.08 | 63.04 | ||
| Avg. | 55.42 | 45.80 | 54.50 | 54.91 | 51.55 | 60.38 |
| 类型 | 任务 | 数据集 | T→T | I→I | T→VD | T→I | IT→IT | 混合 |
|---|---|---|---|---|---|---|---|---|
| 单模态 | T→T | Arguan | 56.25 | 43.51 | 56.73 | 33.53 | 53.22 | 56.22 |
| NFCorpus | 35.23 | 28.89 | 33.23 | 33.18 | 30.48 | 35.76 | ||
| Quora | 87.82 | 74.37 | 86.32 | 86.43 | 85.2 | 87.4 | ||
| SCIDOCS | 19.07 | 11.82 | 17.51 | 17.2 | 16.93 | 19.88 | ||
| TRECCOVID | 75.57 | 47.89 | 50.89 | 72.37 | 58.92 | 76.38 | ||
| I→I | Nights | 27.97 | 28.11 | 24.9 | 28.53 | 26.04 | 30.85 | |
| 跨模态 | T→I | MSCOCO | 59.7 | 59.41 | 63.67 | 76.91 | 44.97 | 75.3 |
| Flickr30k | 83.92 | 65.52 | 87.32 | 93.18 | 74.52 | 93.06 | ||
| T→VD | DocVQA | 35.8 | 24.24 | 48.38 | 40.58 | 28.05 | 45.62 | |
| Shift Project | 57.86 | 45.47 | 77.08 | 50.36 | 53.12 | 74.84 | ||
| I→T | MSCOCO | 74.72 | 63.82 | 80.46 | 84.64 | 70.48 | 84.24 | |
| Flickr30k | 94.1 | 82.5 | 96.3 | 97.2 | 90.1 | 97.5 | ||
| 融合模态 | IT→T | LLaVA | 92.75 | 89.05 | 86.02 | 89.24 | 88.73 | 95.02 |
| ReMuQ | 89.61 | 85.47 | 76.45 | 85.12 | 86.73 | 89.75 | ||
| OKVQA | 24.55 | 16.6 | 15.78 | 16.92 | 18.57 | 20.23 | ||
| FashionIQ | 5.53 | 4.2 | 5.43 | 8.86 | 11.08 | 11.89 | ||
| IT→IT | CIRR | 17.24 | 15.04 | 15.42 | 17.5 | 25.71 | 29.86 | |
| OVEN | 59.81 | 38.42 | 57.31 | 56.69 | 65.08 | 63.04 | ||
| 平均值 | 55.42 | 45.80 | 54.50 | 54.91 | 51.55 | 60.38 |
Table 8. Performance of models trained on different data types on UMRB-partial. We present $\mathrm{NDCG}@10$ scores for $\mathrm{T}{\rightarrow}\mathrm{T}$ tasks. For $\mathrm{T}{\rightarrow}\mathrm{VD}$ tasks, we provide $\mathrm{NDCG}@5$ scores. For the FashionIQ dataset, we report Recall $@10$ scores, while for all other datasets, we report Recall $\ @5$ scores.
表 8: 基于不同数据类型训练的模型在 UMRB-partial 上的性能。我们展示了 $\mathrm{T}{\rightarrow}\mathrm{T}$ 任务的 $\mathrm{NDCG}@10$ 分数。对于 $\mathrm{T}{\rightarrow}\mathrm{VD}$ 任务,我们提供 $\mathrm{NDCG}@5$ 分数。在 FashionIQ 数据集上我们报告 Recall $@10$ 分数,其他所有数据集均报告 Recall $@5$ 分数。
9.2. Instructions
9.2. 指令
The complete UMRB consists of 47 tasks, each with distinct retrieval candidates and varying domains. Even within the same dataset, retrieval candidates can differ based on task types. For example, the WebQA dataset aims to retrieve textual candidates for $\mathrm{T}{\rightarrow}\mathrm{T}$ tasks, which is different from retrieving a combination of image and text candidates for $\mathrm{T}{\rightarrow}\mathrm{IT}$ tasks.
完整的UMRB包含47个任务,每个任务都具有不同的检索候选项和不同的领域。即使在同一个数据集中,检索候选项也会因任务类型而异。例如,WebQA数据集旨在为 $\mathrm{T}{\rightarrow}\mathrm{T}$ 任务检索文本候选项,这与为 $\mathrm{T}{\rightarrow}\mathrm{IT}$ 任务检索图像和文本组合候选项不同。
We have designed specific instructions tailored for each task to guide the model in effectively completing the retrieval process. The detailed instructions are provided in Table 13.
我们为每个任务设计了特定指令,以指导模型有效完成检索过程。详细指令见表13。
10. Fused-Modal Data Synthesis Details
10. 融合模态数据合成细节
We utilize doc2query to synthesize data. However, our goal is to generate fused-modal candidate-to-query relevance data rather than single-modality, text-based relevance pairs.
我们利用doc2query合成数据。然而,我们的目标是生成融合模态的候选到查询相关性数据,而非基于单一模态文本的相关性配对。
10.1. Prompts
10.1. 提示
Step 1: In the first step of data synthesis, we prompt the large language model (LLM) to generate a natural question and answer based on a selected passage. The specific prompt is illustrated in Figure 7. This process leverages in-context learning (ICL) to guide the LLM in producing outputs that align with our requirements.
步骤1: 在数据合成的第一步中, 我们提示大语言模型 (LLM) 基于选定段落生成自然的问题和答案。具体提示如图 7 所示。该过程利用上下文学习 (ICL) 来引导大语言模型生成符合我们要求的输出。
Step 2: In step 2, we provide the LLM with the passage and the natural question generated in step 1. The LLM is then prompted to extract the main entity from the question and refactor the question accordingly. Figure 8 presents the prompt used in this step. In subsequent steps, the extracted entity will be replaced by the corresponding image, which, when combined with the reconstructed question, will form a fused-modal query.
步骤2:在步骤2中,我们向大语言模型提供文本和步骤1生成的自然问题。随后提示大语言模型从问题中提取主要实体,并据此重构问题。图8展示了本步骤使用的提示模板。在后续步骤中,提取的实体将被对应图像替换,与重构后的问题结合形成融合模态查询。

Figure 7. Fused-Modal Data Synthesis Step 1 Prompt.
图 7: 融合模态数据合成步骤1提示.

Figure 8. Fused-Modal Data Synthesis Step 2 Prompt.
图 8: 融合模态数据合成步骤2提示。

Figure 9. Fused-Modal Data Synthesis Step 3 Prompt.
图 9: 融合模态数据合成步骤3提示。
Step 3: In step 3, we replace the entity with an image, which can be sourced in two ways. The first method involves prompting the LLM to generate a caption for the entity based on the provided entity and passage, after which the caption is fed into FLUX to generate images. The second method retrieves the entity by utilizing the Google Image Retrieval API. Figure 9 illustrates the caption generation prompt for this step.
步骤3: 在步骤3中, 我们将实体替换为图像, 图像来源有两种方式。第一种方法提示大语言模型根据提供的实体和段落生成描述文本, 随后将描述文本输入 FLUX 生成图像。第二种方法通过调用谷歌图像检索 API 获取实体图像。图 9: 展示了此步骤的描述文本生成提示模板。
Table 9. BEIR benchmark [55] nDCG $@$ 10 scores. We include top models from MTEB Retrieval English leader board.
| BEIR | Avg. | Argu- Ana | Cli- mate- Fever | CQA- Dup- Stack | DB- Pedia | Fever | FiQA | Hotpot- QA | MS MAR- CO | NF- Corpus | NQ | Quora | Sci- docs | Sci- fact | Touche- 2020 | Trec- Covid | |
| Text Embedder | |||||||||||||||||
| gte-Qwen2-7B-instruct | 60.25 | 64.27 | 45.88 | 46.43 | 52.42 | 95.11 | 62.03 | 73.08 | 45.98 | 40.6 | 67 | 90.09 | 28.91 | 79.06 | 30.57 | 82.26 | |
| NV-Embed-v1 | 59.36 | 68.2 | 34.72 | 50.51 | 48.29 | 87.77 | 63.1 | 79.92 | 46.49 | 38.04 | 71.22 | 89.21 | 20.19 78.43 | 28.38 | 85.88 | ||
| gte-Qwen2-1.5B-instruct | 58.29 | 69.72 | 42.91 | 44.76 | 48.69 | 91.57 | 54.7 | 68.95 | 43.36 | 39.34 | 89.64 | 24.98 | 78.44 | 27.89 | 85.38 | ||
| voyage-large-2-instruct | 58.28 | 64.06 | 32.65 | 46.6 | 46.03 | 91.47 | 59.76 | 70.86 | 40.6 | 40.32 42.6 | 65.92 | 87.4 | 24.32 | 79.99 | 39.16 | 85.07 | |
| neural-embedding-v1 | 58.12 | 67.21 | 32.3 | 49.11 | 48.05 | 89.46 | 58.94 | 78.87 | 42 | 68.36 | 89.02 | 27.69 | 78.82 | 24.06 | 75.33 | ||
| GritLM-7B | 57.41 | 63.24 | 30.91 | 49.42 | 46.6 | 82.74 | 59.95 | 79.4 | 41.96 | 40.89 | 70.3 | 89.47 | 24.41 | 79.17 | 27.93 | 74.8 | |
| e5-mistral-7b-instruct | 56.89 | 61.88 | 38.35 | 42.97 | 48.89 | 87.84 | 56.59 | 75.72 | 43.06 | 38.62 | 63.53 89.61 | 16.3 | 76.41 | 26.39 | 87.25 | ||
| google-gecko | 55.7 | 62.18 | 33.21 | 48.89 | 47.12 | 86.96 | 59.24 | 71.33 | 32.58 | 40.33 | 61.28 | 88.18 | 20.34 | 75.42 | 25.86 | 82.62 | |
| text-embedding-3-large | 55.44 | 58.05 | 30.27 | 47.54 | 44.76 | 87.94 | 55 | 71.58 | 40.24 | 42.07 | 61.27 | 89.05 | 23.11 | 77.77 | 23.35 | 79.56 | |
| gte-en-large-v1.5 | 57.91 | 72.11 63.49 | 48.36 40.36 | 42.16 39.52 | 46.3 39.9 | 93.81 94.81 | 63.23 | 68.18 | 42.93 | 36.95 | 56.08 | 89.67 | 26.35 | 82.43 | 22.55 | 77.49 | |
| gte-en-base-v1.5 | 54.09 | 48.65 | 67.75 | 42.62 | 35.88 | 52.96 | 88.42 | 21.92 | 76.77 | 25.22 | 73.13 | ||||||
| Multimodal Embedder | |||||||||||||||||
| VISTA | 53.24 | 63.61 | 31.17 | 42.35 | 40.77 | 86.29 | 40.65 | 72.6 | 41.35 | 37.39 | 54.15 | 88.9 | 21.73 | 74.04 | 25.7 | 77.9 | |
| CLIP-SF | 36.77 | 52.45 | 20 | 30.61 | 26.37 | 50.58 | 22.14 | 41.33 | 22.15 | 27.05 | 25.45 | 81.63 | 14.75 | 55.98 | 17.47 | 63.60 | |
| One-Peace | 42.19 | 32.93 | 20.27 | 41.32 | 32.43 | 51.91 | 36.79 | 46.51 | 36.55 | 31.6 | 42.87 | 87.46 | 21.64 | 64.51 | 16.9 | 69.28 | |
| DSE | 46.60 | 53.46 | 19.79 | 36.51 | 40.75 | 80.12 | 36.2 | 70.79 | 37.73 | 32.82 | 52.97 | 85.84 | 15.66 | 68.97 | 14.50 | 52.98 | |
| E5-V | 49.91 | 54.28 | 21.64 | 41.69 | 38.78 | 78.99 | 45.41 | 60.88 | 41.23 | 36.97 | 51.58 | 87.6 | 22.36 | 72.75 | 21.61 | 72.85 | |
| GME-Qwen2-VL-2B | 53.31 | 61.52 | 42.3 | 38.13 | 46.31 | 92.6 | 45.3 | 72.93 | 40.88 | 37.2 | 60.01 | 87.24 | 23.17 | 63.82 | 29.06 | 59.24 | |
| GME-Qwen2-VL-7B | 55.68 | 64.60 | 45.38 | 41.66 | 50.78 | 94.27 | 57.14 | 79.21 | 42.38 | 38.40 | 67.74 | 88.05 | 27.38 | 62.31 | 23.26 | 52.6 | |
表 9: BEIR 基准测试 [55] nDCG $@$ 10 分数。我们收录了 MTEB 检索英文排行榜中的顶尖模型。
| BEIR | 平均值 | Argu-Ana | Cli-mate-Fever | CQA-Dup-Stack | DB-Pedia | Fever | FiQA | Hotpot-QA | MS MAR-CO | NF-Corpus | NQ | Quora | Sci-docs | Sci-fact | Touche-2020 | Trec-Covid |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文本嵌入模型 | ||||||||||||||||
| gte-Qwen2-7B-instruct | 60.25 | 64.27 | 45.88 | 46.43 | 52.42 | 95.11 | 62.03 | 73.08 | 45.98 | 40.6 | 67 | 90.09 | 28.91 | 79.06 | 30.57 | 82.26 |
| NV-Embed-v1 | 59.36 | 68.2 | 34.72 | 50.51 | 48.29 | 87.77 | 63.1 | 79.92 | 46.49 | 38.04 | 71.22 | 89.21 | 20.19 | 78.43 | 28.38 | 85.88 |
| gte-Qwen2-1.5B-instruct | 58.29 | 69.72 | 42.91 | 44.76 | 48.69 | 91.57 | 54.7 | 68.95 | 43.36 | 39.34 | 89.64 | 24.98 | 78.44 | 27.89 | 85.38 | |
| voyage-large-2-instruct | 58.28 | 64.06 | 32.65 | 46.6 | 46.03 | 91.47 | 59.76 | 70.86 | 40.6 | 40.32 | 65.92 | 87.4 | 24.32 | 79.99 | 39.16 | 85.07 |
| neural-embedding-v1 | 58.12 | 67.21 | 32.3 | 49.11 | 48.05 | 89.46 | 58.94 | 78.87 | 42 | 68.36 | 89.02 | 27.69 | 78.82 | 24.06 | 75.33 | |
| GritLM-7B | 57.41 | 63.24 | 30.91 | 49.42 | 46.6 | 82.74 | 59.95 | 79.4 | 41.96 | 40.89 | 70.3 | 89.47 | 24.41 | 79.17 | 27.93 | 74.8 |
| e5-mistral-7b-instruct | 56.89 | 61.88 | 38.35 | 42.97 | 48.89 | 87.84 | 56.59 | 75.72 | 43.06 | 38.62 | 63.53 | 89.61 | 16.3 | 76.41 | 26.39 | 87.25 |
| google-gecko | 55.7 | 62.18 | 33.21 | 48.89 | 47.12 | 86.96 | 59.24 | 71.33 | 32.58 | 40.33 | 61.28 | 88.18 | 20.34 | 75.42 | 25.86 | 82.62 |
| text-embedding-3-large | 55.44 | 58.05 | 30.27 | 47.54 | 44.76 | 87.94 | 55 | 71.58 | 40.24 | 42.07 | 61.27 | 89.05 | 23.11 | 77.77 | 23.35 | 79.56 |
| gte-en-large-v1.5 | 57.91 | 72.11 | 48.36 | 42.16 | 46.3 | 93.81 | 63.23 | 68.18 | 42.93 | 36.95 | 56.08 | 89.67 | 26.35 | 82.43 | 22.55 | 77.49 |
| gte-en-base-v1.5 | 54.09 | 63.49 | 40.36 | 39.52 | 39.9 | 94.81 | 48.65 | 67.75 | 42.62 | 35.88 | 52.96 | 88.42 | 21.92 | 76.77 | 25.22 | 73.13 |
| 多模态嵌入模型 | ||||||||||||||||
| VISTA | 53.24 | 63.61 | 31.17 | 42.35 | 40.77 | 86.29 | 40.65 | 72.6 | 41.35 | 37.39 | 54.15 | 88.9 | 21.73 | 74.04 | 25.7 | 77.9 |
| CLIP-SF | 36.77 | 52.45 | 20 | 30.61 | 26.37 | 50.58 | 22.14 | 41.33 | 22.15 | 27.05 | 25.45 | 81.63 | 14.75 | 55.98 | 17.47 | 63.6 |
| One-Peace | 42.19 | 32.93 | 20.27 | 41.32 | 32.43 | 51.91 | 36.79 | 46.51 | 36.55 | 31.6 | 42.87 | 87.46 | 21.64 | 64.51 | 16.9 | 69.28 |
| DSE | 46.6 | 53.46 | 19.79 | 36.51 | 40.75 | 80.12 | 36.2 | 70.79 | 37.73 | 32.82 | 52.97 | 85.84 | 15.66 | 68.97 | 14.5 | 52.98 |
| E5-V | 49.91 | 54.28 | 21.64 | 41.69 | 38.78 | 78.99 | 45.41 | 60.88 | 41.23 | 36.97 | 51.58 | 87.6 | 22.36 | 72.75 | 21.61 | 72.85 |
| GME-Qwen2-VL-2B | 53.31 | 61.52 | 42.3 | 38.13 | 46.31 | 92.6 | 45.3 | 72.93 | 40.88 | 37.2 | 60.01 | 87.24 | 23.17 | 63.82 | 29.06 | 59.24 |
| GME-Qwen2-VL-7B | 55.68 | 64.6 | 45.38 | 41.66 | 50.78 | 94.27 | 57.14 | 79.21 | 42.38 | 38.4 | 67.74 | 88.05 | 27.38 | 62.31 | 23.26 | 52.6 |
| MBEIR | Avg. | qt→Ci | qt-→Ct qt→(ci,Ct) | qi→Ct | qi→Ci | (qiqt)→→Ci | (qiqt)→→(Ci,Ct) | Info- | |||||||||
| Visual- News | MS- COCO | Fashion- 200K | Web- QA | EDIS | Web- QA | Visual- News | MS- COCO | Fashion- 200K | NIGHTS | OVEN | Info- Seek | Fashion- IQ | CIRR OVEN | ||||
| CLIP | 32.5 | 43.3 | 61.1 | 6.6 | 36.2 | 43.3 | 45.1 | 41.3 | 79.0 | 7.7 | 26.1 | 24.2 | 20.5 | 7.0 | 13.2 | 38.8 | 26.4 |
| SigLIP | 37.2 | 30.1 | 75.7 | 36.5 | 39.8 | 27.0 | 43.5 | 30.8 | 88.2 | 34.2 | 28.9 | 29.7 | 25.1 | 14.4 | 22.7 | 41.7 | 27.4 |
| BLIP | 26.8 | 16.4 | 74.4 | 15.9 | 44.9 | 26.8 | 20.3 | 17.2 | 83.2 | 19.9 | 27.4 | 16.1 | 10.2 | 2.3 | 10.6 | 27.4 | 16.6 |
| BLIP2 | 24.8 | 16.7 | 63.8 | 14.0 | 38.6 | 26.9 | 24.5 | 15.0 | 80.0 | 14.2 | 25.4 | 12.2 | 5.5 | 4.4 | 11.8 | 27.3 | 15.8 |
| VISTA | 26.37 | 5.77 | 47.97 | 3.08 | 83.80 | 36.78 | 54.84 | 2.79 | 48.92 | 4.72 | 24.43 | 22.32 | 18.53 | 3.28 | 14.65 | 27.77 | 22.27 |
| CLIP-SF | 50.26 | 42.80 | 80.75 | 18.38 | 84.44 | 54.09 | 78.42 | 42.67 | 91.94 | 18.10 | 31.42 | 45.98 | 27.58 | 24.53 | 45.25 | 68.83 | 49.05 |
| One-Peace | 38.00 | 48.95 | 71.45 | 32.34 | 63.67 | 53.01 | 32.42 | 47.27 | 85.60 | 30.89 | 31.27 | 23.69 | 20.05 | 2.93 | 10.53 | 30.56 | 23.32 |
| DSE | 28.89 | 14.12 | 74.62 | 3.08 | 83.95 | 41.26 | 66.99 | 8.74 | 82.06 | 3.91 | 27.36 | 0.38 | 3.06 | 9.81 | 36.52 | 0.39 | 5.96 |
| E5-V | 35.09 | 29.46 | 52.38 | 3.78 | 89.94 | 49.62 | 49.62 | 29.54 | 86.40 | 4.62 | 27.92 | 14.40 | 12.69 | 3.73 | 13.19 | 54.46 | 39.69 |
| GME-Qwen2-VL-2B | 53.54 | 38.85 | 71.82 | 25.83 | 95.19 | 70.32 | 83.15 | 38.32 | 84.12 | 27.57 | 29.86 | 58.17 | 39.06 | 27.5 | 46.83 | 75.98 | 44.21 |
| GME-Qwen2-VL-7B | 54.50 | 46.54 | 75.14 | 31.82 | 95.85 | 77.29 | 84.59 | 45.54 | 64.90 | 34.20 | 31.89 | 63.41 | 43.14 | 31.43 | 53.69 | 80.30 | 58.80 |
Table 10. Results of M-BEIR benchmark [66]. For the Fashion 200 K and FashionIQ datasets, we report Recall $@10$ scores, while for all other datasets, we report Recall $\ @5$ scores.
| MBEIR | Avg. | qt→Ci | qt→Ci | qt→Ci | qt-→Ct qt→(ci,Ct) | qt-→Ct qt→(ci,Ct) | qt-→Ct qt→(ci,Ct) | qi→Ct | qi→Ct | qi→Ct | qi→Ci | qi→Ci | qi→Ci | (qiqt)→→Ci | (qiqt)→→Ci | (qiqt)→→(Ci,Ct) | Info- |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Visual- News | MS- COCO | Fashion- 200K | Web- QA | EDIS | Web- QA | Visual- News | MS- COCO | Fashion- 200K | NIGHTS | OVEN | Info- Seek | Fashion- IQ | CIRR OVEN | ||||
| CLIP | 32.5 | 43.3 | 61.1 | 6.6 | 36.2 | 43.3 | 45.1 | 41.3 | 79.0 | 7.7 | 26.1 | 24.2 | 20.5 | 7.0 | 13.2 | 38.8 | 26.4 |
| SigLIP | 37.2 | 30.1 | 75.7 | 36.5 | 39.8 | 27.0 | 43.5 | 30.8 | 88.2 | 34.2 | 28.9 | 29.7 | 25.1 | 14.4 | 22.7 | 41.7 | 27.4 |
| BLIP | 26.8 | 16.4 | 74.4 | 15.9 | 44.9 | 26.8 | 20.3 | 17.2 | 83.2 | 19.9 | 27.4 | 16.1 | 10.2 | 2.3 | 10.6 | 27.4 | 16.6 |
| BLIP2 | 24.8 | 16.7 | 63.8 | 14.0 | 38.6 | 26.9 | 24.5 | 15.0 | 80.0 | 14.2 | 25.4 | 12.2 | 5.5 | 4.4 | 11.8 | 27.3 | 15.8 |
| VISTA | 26.37 | 5.77 | 47.97 | 3.08 | 83.80 | 36.78 | 54.84 | 2.79 | 48.92 | 4.72 | 24.43 | 22.32 | 18.53 | 3.28 | 14.65 | 27.77 | 22.27 |
| CLIP-SF | 50.26 | 42.80 | 80.75 | 18.38 | 84.44 | 54.09 | 78.42 | 42.67 | 91.94 | 18.10 | 31.42 | 45.98 | 27.58 | 24.53 | 45.25 | 68.83 | 49.05 |
| One-Peace | 38.00 | 48.95 | 71.45 | 32.34 | 63.67 | 53.01 | 32.42 | 47.27 | 85.60 | 30.89 | 31.27 | 23.69 | 20.05 | 2.93 | 10.53 | 30.56 | 23.32 |
| DSE | 28.89 | 14.12 | 74.62 | 3.08 | 83.95 | 41.26 | 66.99 | 8.74 | 82.06 | 3.91 | 27.36 | 0.38 | 3.06 | 9.81 | 36.52 | 0.39 | 5.96 |
| E5-V | 35.09 | 29.46 | 52.38 | 3.78 | 89.94 | 49.62 | 49.62 | 29.54 | 86.40 | 4.62 | 27.92 | 14.40 | 12.69 | 3.73 | 13.19 | 54.46 | 39.69 |
| GME-Qwen2-VL-2B | 53.54 | 38.85 | 71.82 | 25.83 | 95.19 | 70.32 | 83.15 | 38.32 | 84.12 | 27.57 | 29.86 | 58.17 | 39.06 | 27.5 | 46.83 | 75.98 | 44.21 |
| GME-Qwen2-VL-7B | 54.50 | 46.54 | 75.14 | 31.82 | 95.85 | 77.29 | 84.59 | 45.54 | 64.90 | 34.20 | 31.89 | 63.41 | 43.14 | 31.43 | 53.69 | 80.30 | 58.80 |
表 10. M-BEIR基准测试结果 [66]。对于Fashion 200K和FashionIQ数据集,我们报告Recall @10分数,其他所有数据集均报告Recall @5分数。

Figure 10. The distribution of relevance scores for all the images searched by Google and captions.
图 10: 谷歌搜索的所有图像与描述相关性分数分布。
10.2. Filter
10.2. 过滤器
Two filtering methods are implemented to ensure the quality of the synthesized data. First, a text retrieval model is utilized to evaluate unreconstructed queries and their corresponding passages. We follow the framework of Promptagator [9]; a query is deemed unqualified if the passage that generated it does not appear within the top 20 search results. Second, for images obtained through the Google Image Search API, we employ the CLIP model to assess image-caption relevance. Images with a relevance score below 0.2 are filtered out.
为确保合成数据的质量,我们实施了两项过滤方法。首先,利用文本检索模型评估未重构的查询及其对应段落。我们遵循Promptagator框架[9]:若生成某查询的段落未出现在前20个搜索结果中,则该查询被视为不合格。其次,对于通过谷歌图片搜索API获取的图像,我们采用CLIP模型评估图像标题相关性。相关性得分低于0.2的图像将被过滤。
Why is the threshold score set to 0.2? The relevance scores of all images searched via Google and the corresponding captions we have collected are presented in Figure 10. We select the median score of 0.2 to ensure image quality while also ensuring that most text queries have sufficient images to pair with.
为什么将阈值分数设定为0.2?通过Google搜索的所有图像及其对应描述的相关性分数如图10所示。我们选择0.2作为中位数分数,既确保图像质量,又能保证大多数文本查询有足够的图像进行配对。
| ArxivQ | DocQ | InfoQ | TabF | TATQ | Shift | AI | Energy | Gov. | Health. | Avg. | |
| BM25Text+Captioning | 40.1 | 38.4 | 70.0 | 35.4 | 61.5 | 60.9 | 88.0 | 84.7 | 82.7 | 89.2 | 65.1 |
| BGE-M3Text+Captioning | 35.7 | 32.9 | 71.9 | 69.1 | 43.8 | 73.1 | 88.8 | 83.3 | 80.4 | 91.3 | 67.0 |
| Jina-CLIP | 25.4 | 11.9 | 35.5 | 20.2 | 3.3 | 3.8 | 15.2 | 19.7 | 21.4 | 20.8 | 17.7 |
| Nomic-vision | 17.1 | 10.7 | 30.1 | 16.3 | 2.7 | 1.1 | 12.9 | 10.9 | 11.4 | 15.7 | 12.9 |
| SigLIP (vanilla) | 43.2 | 30.3 | 64.1 | 58.1 | 26.2 | 18.7 | 62.5 | 65.7 | 66.1 | 79.1 | 51.4 |
| ColPali | 79.1 | 54.4 | 81.8 | 83.9 | 65.8 | 73.2 | 96.2 | 91.0 | 92.7 | 94.4 | 81.3 |
| VISTA | 10.3 | 8.01 | 30.02 | 13.08 | 2.05 | 3.26 | 7.14 | 11.05 | 6.9 | 9.39 | 10.12 |
| CLIP-SF | 24.1 | 11.8 | 48.78 | 21.53 | 5.49 | 6.06 | 28.64 | 27.19 | 34.67 | 32.64 | 24.09 |
| One-Peace | 43.94 | 23.48 | 59.97 | 57.05 | 13.44 | 17.02 | 45.41 | 53.21 | 55.98 | 59.5 | 42.9 |
| DSE | 78.17 | 45.83 | 82.06 | 79.29 | 49.01 | 69.84 | 96.89 | 92.62 | 92.04 | 96.35 | 78.21 |
| E5-V | 41.16 | 24.37 | 49.5 | 58.22 | 9.08 | 13.26 | 46.18 | 57.77 | 53.05 | 59.61 | 41.22 |
| GME-Qwen2-VL-2B | 83.91 | 54.57 | 91.11 | 94.61 | 71.05 | 94.29 | 99.02 | 93.15 | 97.89 | 98.89 | 87.84 |
| GME-Qwen2-VL-7B | 87.58 | 56.63 | 92.39 | 94.58 | 76.12 | 97.26 | 99.63 | 95.89 | 99.5 | 99.63 | 89.92 |
Table 11. Comprehensive evaluation of baseline models and our GME on ViDoRe. Results are presented using NDCG $\ @5$ metrics.
| ArxivQ | DocQ | InfoQ | TabF | TATQ | Shift | AI | Energy | Gov. | Health. | Avg. | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BM25Text+Captioning | 40.1 | 38.4 | 70.0 | 35.4 | 61.5 | 60.9 | 88.0 | 84.7 | 82.7 | 89.2 | 65.1 |
| BGE-M3Text+Captioning | 35.7 | 32.9 | 71.9 | 69.1 | 43.8 | 73.1 | 88.8 | 83.3 | 80.4 | 91.3 | 67.0 |
| Jina-CLIP | 25.4 | 11.9 | 35.5 | 20.2 | 3.3 | 3.8 | 15.2 | 19.7 | 21.4 | 20.8 | 17.7 |
| Nomic-vision | 17.1 | 10.7 | 30.1 | 16.3 | 2.7 | 1.1 | 12.9 | 10.9 | 11.4 | 15.7 | 12.9 |
| SigLIP (vanilla) | 43.2 | 30.3 | 64.1 | 58.1 | 26.2 | 18.7 | 62.5 | 65.7 | 66.1 | 79.1 | 51.4 |
| ColPali | 79.1 | 54.4 | 81.8 | 83.9 | 65.8 | 73.2 | 96.2 | 91.0 | 92.7 | 94.4 | 81.3 |
| VISTA | 10.3 | 8.01 | 30.02 | 13.08 | 2.05 | 3.26 | 7.14 | 11.05 | 6.9 | 9.39 | 10.12 |
| CLIP-SF | 24.1 | 11.8 | 48.78 | 21.53 | 5.49 | 6.06 | 28.64 | 27.19 | 34.67 | 32.64 | 24.09 |
| One-Peace | 43.94 | 23.48 | 59.97 | 57.05 | 13.44 | 17.02 | 45.41 | 53.21 | 55.98 | 59.5 | 42.9 |
| DSE | 78.17 | 45.83 | 82.06 | 79.29 | 49.01 | 69.84 | 96.89 | 92.62 | 92.04 | 96.35 | 78.21 |
| E5-V | 41.16 | 24.37 | 49.5 | 58.22 | 9.08 | 13.26 | 46.18 | 57.77 | 53.05 | 59.61 | 41.22 |
| GME-Qwen2-VL-2B | 83.91 | 54.57 | 91.11 | 94.61 | 71.05 | 94.29 | 99.02 | 93.15 | 97.89 | 98.89 | 87.84 |
| GME-Qwen2-VL-7B | 87.58 | 56.63 | 92.39 | 94.58 | 76.12 | 97.26 | 99.63 | 95.89 | 99.5 | 99.63 | 89.92 |
表 11: 基线模型与我们的 GME 在 ViDoRe 上的综合评估。结果采用 NDCG $\ @5$ 指标呈现。
Table 12. GME training hyper-parameters.
| Hyper-param | GME-Qwen2-VL-2B | GME-Qwen2-VL-7B |
| Number ofParams | 2B | 8.2B |
| Number of Layers | 28 | 28 |
| Hidden Size | 1536 | 3584 |
| FFN Inner Size | 3072 | |
| Number ofAttentionHeads | 12 | 28 |
| Vision Depth | 32 | |
| VisionEmbed_dim | 1280 | |
| VisionPatch_size | 14 | |
| Temperature | 0.03 | |
| Learning Rate Decay | Linear | |
| Adam E | 1e-4 | |
| Adam β1 | 0.9 | |
| Adam β2 | 0.98 | |
| Gradient Clipping | 0.0 | |
| Precision | PyTorchBF16AMP | |
| Max Length | 1800 | 1800 |
| Batch Size | 128 | 32 |
| Warm-upRatio | 0.06 |
表 12: GME训练超参数。
| 超参数 | GME-Qwen2-VL-2B | GME-Qwen2-VL-7B |
|---|---|---|
| 参数量 | 2B | 8.2B |
| 层数 | 28 | 28 |
| 隐藏层大小 | 1536 | 3584 |
| FFN中间层大小 | 3072 | |
| 注意力头数 | 12 | 28 |
| 视觉深度 | 32 | |
| 视觉嵌入维度 | 1280 | |
| 视觉块大小 | 14 | |
| 温度参数 | 0.03 | |
| 学习率衰减 | Linear | |
| Adam E | 1e-4 | |
| Adam β1 | 0.9 | |
| Adam β2 | 0.98 | |
| 梯度裁剪 | 0.0 | |
| 计算精度 | PyTorchBF16AMP | |
| 最大长度 | 1800 | 1800 |
| 批大小 | 128 | 32 |
| 预热比例 | 0.06 |
- Single Image Limit In MLLMs, one image is converted into a very large number of visual tokens. In Qwen2- VL, we limit the number of visual tokens to 1024. Due to model training efficiency and a lack of relevant data, our queries and candidates in UMRB only retain a single image. Thus, performance on interleaved data (where multiple images and texts are mixed together) cannot be assessed.
- 单图像限制
在大语言模型 (MLLM) 中,单张图像会被转换成大量视觉 token。在 Qwen2-VL 中,我们将视觉 token 数量限制为 1024。由于模型训练效率和相关数据缺乏,我们在 UMRB 中的查询项和候选集仅保留单张图像。因此无法评估交错数据(混合多张图像与文本)的性能表现。 - Single Language Limit Although the backbone of our model, Qwen2-VL, supports multiple languages, we only utilized a single language, English, during the training and testing processes of our GME. Consequently, performance in other languages could not be evaluated.
- 单一语言限制
虽然我们的模型骨干网络 Qwen2-VL 支持多语言,但在 GME 的训练和测试过程中仅使用了单一语言(英语),因此无法评估其他语言的性能。
10.3. Examples of synthetic data
10.3. 合成数据示例
Table 15 illustrates passages from 15 domains and the fused modal queries generated by applying the synthesis flow. “FLUX image” refers to images generated by the Vincennes diagram model FLUX.1-dev, whereas “Google image” indicates images from Google Image retrieval.
表 15 展示了来自 15 个领域的文本段落以及通过应用合成流程生成的融合模态查询。 "FLUX 图像" 指由 Vincennes 图表模型 FLUX.1-dev 生成的图像,而 "Google 图像" 表示来自 Google 图片检索的图像。
11. Limitations
11. 局限性
In this work, we present a benchmark for training and testing Universal Multimodal Retrieval (UMR). To better accomplish this task, we explore strategies for adapting Multimodal Large Language Models (MLLMs) into UMR models, presenting GME, a powerful embedding model capable of retrieving candidates across different modalities. However, this work has its limitations, which are outlined below:
在本工作中,我们提出了用于训练和测试通用多模态检索 (UMR) 的基准。为更好地完成该任务,我们探索了将多模态大语言模型 (MLLM) 适配为 UMR 模型的策略,推出了 GME——一个能够跨不同模态检索候选对象的强大嵌入模型。然而,本研究存在以下局限性:
Table 13. The instructions for different tasks, we only use the instructions for query encoding.
| Task | Dataset | Query Instruction |
| T→→T | ArguAna | Given a claim, find documents that refute the claim. |
| Climate-FEVER | Given a claim about climate change, retrieve documents that support orrefute the claim. | |
| CQADupStack | Given a question, retrieve detailed question descriptions from Stackexchange that are duplicates to the given question. | |
| DBPedia | Given a query, retrieve relevant entity descriptions from DBPedia. | |
| FEVER | Given a claim, retrieve documents that support or refute the claim. | |
| FiQA2018 | Given a financial question, retrieve user replies that best answer the question. | |
| HotpotQA | Given a multi-hop question, retrieve documents that can help answer the question. | |
| MSMARCO | ||
| NFCorpus | Given a question, retrieve relevant documents that best answer the question. | |
| NQ | Given a question, retrieve Wikipedia passages that answer the question. | |
| Quora | Given a question, retrieve questions that are semantically equivalentto the given question. | |
| SCIDOCS | Given a scientific paper title, retrieve paper abstracts that are cited bythe given paper. | |
| SciFact | Given a scientific claim, retrieve documents that support or refute theclaim. | |
| Touche2020 | Given a question, retrieve detailed and persuasive arguments that answer the question. | |
| TRECCOVID | Given a query on COVID-19, retrieve documents that answer the query. | |
| WebQA | Retrieve passages from Wikipedia that provide answers to the following question. | |
| I→I | Nights Find a day-to-day image that looks similar to the provided image. | |
| T→→I | VisualNews | Identify the news-related image in line with the described event. |
| Fashion200k | Based on the following fashion description, retrieve the best matching image. | |
| MSCOCO | Identify the image showcasing the described everyday scene. | |
| Flickr30k TAT-DQA ArxivQA | Find an image that matches the given caption. | |
| T→→VD | DocVQA InfoVQA Shift Project ArtificialIntelligence Government Reports Healthcare Industry Energy TabFQuad | Find a screenshot that relevant to the user's question. |
| I→>T | VisualNews | Find a caption for the news in the given photo. Find a product description for the fashion item in the image. |
| Fashion200k | ||
| MSCOCO | Find an image caption describing the following everyday image. | |
| Flickr30k | Find an image caption describing the following image. | |
| T→IT | WebQA | Find a Wikipedia image that answers this question. |
| EDIS | Identify the news photo for the given caption. | |
| IT→→T | OVEN | Retrieve a Wikipedia paragraph that provides an answer to the given query about the image. |
| INFOSEEK | ||
| ReMuQ OKVQA | Retrieve a fact-based paragraph that provides an answer to the given query about the image. Retrieve documents that provide an answer to the question alongside the image. | |
| LLaVA | Provide a specific decription of the image along with the following question. | |
| IT→→I | FashionIQ | Find a fashion image that aligns with the reference image and style note. |
| CIRR | Retrieve a day-to-day image that aligns with the modification instructions of the provided image. | |
| IT→→IT | OVEN INFOSEEK | Retrieve a Wikipedia image-description pair that provides evidence for the question of this image. |
| EVQA |
表 13: 不同任务的指令说明, 我们仅使用查询编码的指令。
| 任务类型 | 数据集 | 查询指令 |
|---|---|---|
| T→T | ArguAna | 给定一个主张, 找出反驳该主张的文档。 |
| T→T | Climate-FEVER | 给定一个关于气候变化的主张, 检索支持或反驳该主张的文档。 |
| T→T | CQADupStack | 给定一个问题, 从 Stackexchange 检索与给定问题重复的详细问题描述。 |
| T→T | DBPedia | 给定一个查询, 从 DBPedia 检索相关的实体描述。 |
| T→T | FEVER | 给定一个主张, 检索支持或反驳该主张的文档。 |
| T→T | FiQA2018 | 给定一个金融问题, 检索最能回答该问题的用户回复。 |
| T→T | HotpotQA | 给定一个多跳问题, 检索有助于回答该问题的文档。 |
| T→T | MSMARCO | |
| T→T | NFCorpus | 给定一个问题, 检索最能回答该问题的相关文档。 |
| T→T | NQ | 给定一个问题, 检索能回答该问题的维基百科段落。 |
| T→T | Quora | 给定一个问题, 检索与给定问题语义相同的问题。 |
| T→T | SCIDOCS | 给定一个科学论文标题, 检索被该论文引用的论文摘要。 |
| T→T | SciFact | 给定一个科学主张, 检索支持或反驳该主张的文档。 |
| T→T | Touche2020 | 给定一个问题, 检索能回答该问题的详细且有说服力的论点。 |
| T→T | TRECCOVID | 给定一个关于 COVID-19 的查询, 检索能回答该查询的文档。 |
| T→T | WebQA | 从维基百科检索能回答以下问题的段落。 |
| I→I | Nights | 查找与提供图像相似的日常图像。 |
| T→I | VisualNews | 识别符合所述事件的新闻相关图像。 |
| T→I | Fashion200k | 根据以下时尚描述, 检索最匹配的图像。 |
| T→I | MSCOCO | 识别展示所述日常场景的图像。 |
| T→I | Flickr30k TAT-DQA ArxivQA | 查找与给定标题匹配的图像。 |
| T→VD | DocVQA InfoVQA Shift Project ArtificialIntelligence Government Reports Healthcare Industry Energy TabFQuad | 查找与用户问题相关的屏幕截图。 |
| I→T | VisualNews | 查找给定新闻照片的标题。 |
| I→T | Fashion200k | 查找图像中时尚产品的产品描述。 |
| I→T | MSCOCO | 查找描述以下日常图像的图像标题。 |
| I→T | Flickr30k | 查找描述以下图像的图像标题。 |
| T→IT | WebQA | 查找能回答此问题的维基百科图像。 |
| T→IT | EDIS | 识别给定标题对应的新闻照片。 |
| IT→T | OVEN | 检索能回答关于该图像给定查询的维基百科段落。 |
| IT→T | INFOSEEK | 检索能回答关于该图像给定查询的事实性段落。 |
| IT→T | ReMuQ OKVQA | 检索能回答该问题及对应图像的文档。 |
| IT→T | LLaVA | 提供图像的具体描述以及以下问题。 |
| IT→I | FashionIQ | 查找与参考图像和风格说明相符的时尚图像。 |
| IT→I | CIRR | 检索与所提供图像的修改说明相符的日常图像。 |
| IT→IT | OVEN INFOSEEK | 检索能为该图像问题提供证据的维基百科图像-描述对。 |
| IT→IT | EVQA |

