Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Abstract
摘要
Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation—modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: $+10.6%$ on agents and $+8.6%$ on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leader board, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead.
大语言模型 (LLM) 应用(如智能体和领域特定推理)日益依赖上下文自适应——通过指令、策略或证据修改输入,而非权重更新。现有方法提升了可用性,但常受简洁性偏差影响(为追求简明摘要而丢失领域洞察),并遭遇上下文坍缩(迭代重写随时间推移侵蚀细节)。基于动态速查表提出的自适应记忆机制,我们引入ACE(Agentic Context Engineering)框架,将上下文视为不断演进的作战手册,通过生成、反思和整理的模块化过程积累、优化和组织策略。ACE通过结构化增量更新防止坍缩,保留详细知识并适配长上下文模型。在智能体和领域特定基准测试中,ACE同时优化离线(如系统提示)和在线(如智能体记忆)上下文,持续超越强基线:智能体任务提升 $+10.6%$ ,金融任务提升 $+8.6%$ ,同时显著降低自适应延迟和部署成本。值得注意的是,ACE无需标注监督即可有效自适应,转而利用自然执行反馈。在AppWorld排行榜上,ACE在整体平均分追平排名第一的生产级智能体,并在更难的测试挑战集上实现超越,尽管使用的是更小的开源模型。这些结果表明,全面且持续演进的上下文能够以低开销实现可扩展、高效且自我改进的大语言模型系统。
1 Introduction
1 引言
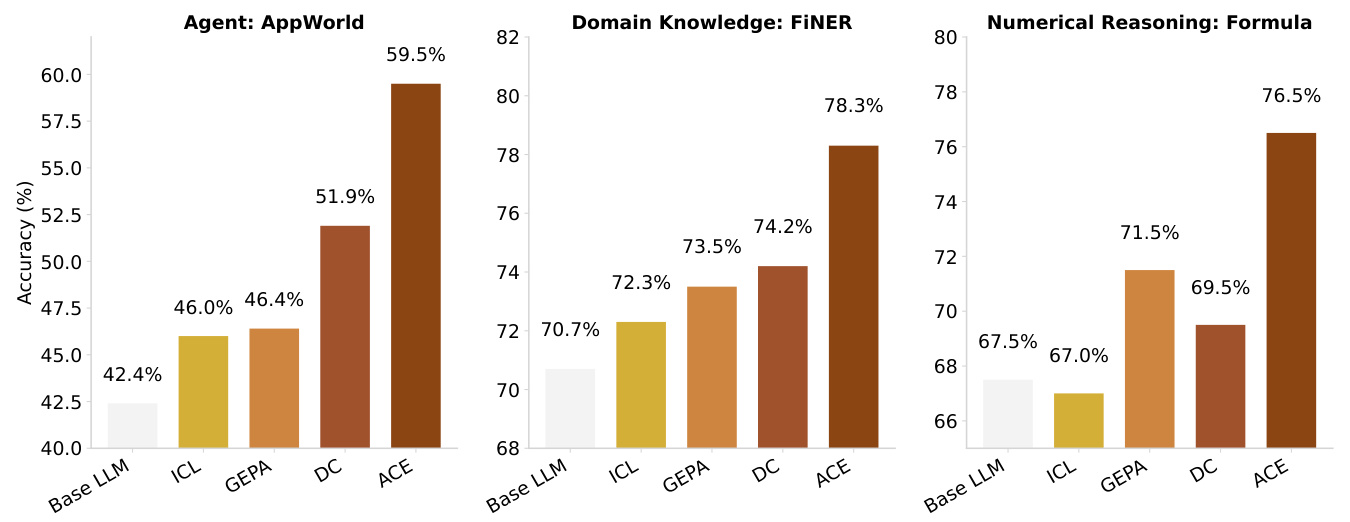
Figure 1: Overall Performance Results. Our proposed framework, ACE, consistently outperforms strong baselines across agent and domain-specific reasoning tasks.
图 1: 整体性能结果。我们提出的框架 ACE 在智能体和领域特定推理任务中持续优于强基线模型。
Modern AI applications based on large language models (LLMs), such as LLM agents [49, 52] and compound AI systems [55], increasingly depend on context adaptation. Instead of modifying model weights, context adaptation improves performance after model training by incorporating clarified instructions, structured reasoning steps, or domain-specific input formats directly into the model’s inputs. Contexts underpin many AI system components, including system prompts that guide downstream tasks [4, 36], memory that carries past facts and experiences [41, 48], and factual evidence that reduces hallucination and supplements knowledge [6].
基于大语言模型 (LLM) 的现代人工智能应用,例如 LLM 智能体 [49, 52] 和复合 AI 系统 [55],越来越依赖于上下文自适应。与修改模型权重不同,上下文自适应通过在模型输入中直接加入明确的指令、结构化推理步骤或特定领域的输入格式,在模型训练后提升性能。上下文支撑着许多 AI 系统组件,包括指导下游任务的系统提示 [4, 36]、承载过去事实与经验的记忆模块 [41, 48],以及减少幻觉并补充知识的事实证据 [6]。
Adapting through contexts rather than weights offers several key advantages. Contexts are interpret able and explain able for users and developers [45, 47], allow rapid integration of new knowledge at runtime [7, 27], and can be shared across models or modules in a compound system [23]. Meanwhile, advances in longcontext LLMs [39] and context-efficient inference such as KV cache reuse [17, 51] are making context-based approaches increasingly practical for deployment. As a result, context adaptation is emerging as a central paradigm for building capable, scalable, and self-improving AI systems.
通过上下文而非权重进行适应具有若干关键优势。上下文对用户和开发者而言具备可解释性 [45, 47] ,支持在运行时快速整合新知识 [7, 27] ,并能在复合系统中跨模型或模块共享 [23] 。与此同时,长上下文大语言模型 [39] 与高效上下文推理技术(如KV缓存复用 [17, 51] )的发展,正使得基于上下文的方法在实际部署中日益可行。因此,上下文适应正逐渐成为构建能力强、可扩展且能自我改进的人工智能系统的核心范式。
Despite this progress, existing approaches to context adaptation face two key limitations. First, a brevity bias: many prompt optimizers prioritize concise, broadly applicable instructions over comprehensive accumulation. For example, GEPA [4] highlights brevity as a strength, but such abstraction can omit domain-specific heuristics, tool-use guidelines, or common failure modes that matter in practice [16]. This objective aligns with validation metrics in some settings, but often fails to capture the detailed strategies required by agents and knowledge-intensive applications. Second, context collapse: methods that rely on monolithic rewriting by an LLM often degrade into shorter, less informative summaries over time, causing sharp performance declines (Figure 2). In domains such as interactive agents [38, 43, 57], domain-specific programming [53, 56], and financial or legal analysis [18, 33, 44], strong performance depends on retaining detailed, task-specific knowledge rather than compressing it away.
尽管取得了这些进展,现有的上下文适应方法仍面临两个关键局限。首先,简洁性偏差:许多提示优化器优先考虑简洁通用的指令,而非全面积累。例如GEPA [4] 强调简洁性作为优势,但此类抽象可能忽略领域特定的启发式方法、工具使用指南或实践中重要的常见故障模式 [16]。该目标在某些场景下与验证指标一致,但往往无法捕捉智能体和知识密集型应用所需的详细策略。其次,上下文坍缩:依赖大语言模型进行整体重写的方法通常会随时间退化为信息量更少的简短摘要,导致性能急剧下降 (图 2)。在交互式智能体 [38, 43, 57]、领域特定编程 [53, 56] 以及金融或法律分析 [18, 33, 44] 等领域,优异性能依赖于保留详细的任务特定知识而非将其压缩去除。
As applications such as agents and knowledge-intensive reasoning demand greater reliability, recent work has shifted toward saturating contexts with abundant, potentially useful information [11, 12, 22], enabled by advances in long-context LLMs [34, 39]. We argue that contexts should function not as concise summaries, but as comprehensive, evolving playbooks—detailed, inclusive, and rich with domain insights. Unlike humans, who often benefit from concise generalization, LLMs are more effective when provided with long, detailed contexts and can distill relevance autonomously [22, 31, 41]. Thus, instead of compressing away domain-specific heuristics and tactics, contexts should preserve them, allowing the model to decide what matters at inference time.
随着智能体和知识密集型推理等应用对可靠性要求的提高,近期研究趋势已转向利用长上下文大语言模型的技术进展 [34, 39],通过饱和式上下文填充大量潜在有效信息 [11, 12, 22]。我们认为上下文不应仅作为简洁摘要,而应成为全面且动态的战术手册——具备细节完整性、内容包容性及领域洞察丰富性。与人类通常受益于简洁概括不同,大语言模型在获得长篇幅精细化上下文时表现更佳,并能自主提炼关键信息 [22, 31, 41]。因此,上下文应当保留领域特定的启发式方法和策略,而非进行压缩剔除,使模型能在推理阶段自主判断信息重要性。
To address these limitations, we introduce ACE (Agentic Context Engineering), a framework for comprehensive context adaptation in both offline settings (e.g., system prompt optimization) and online settings (e.g., test-time memory adaptation). Rather than compressing contexts into distilled summaries, ACE treats them as evolving playbooks that accumulate and organize strategies over time. Building on the agentic architecture of Dynamic Cheatsheet [41], ACE incorporates a modular workflow of generation, reflection, and curation, while adding structured, incremental updates guided by a grow-and-refine principle. This design preserves detailed, domain-specific knowledge, prevents context collapse, and yields contexts that remain comprehensive and scalable throughout adaptation.
为了解决这些局限性, 我们提出了 ACE (Agentic Context Engineering) 框架, 这是一个适用于离线场景 (例如系统提示优化) 和在线场景 (例如测试时记忆适应) 的全面上下文适应框架。与将上下文压缩成蒸馏摘要不同, ACE 将其视为不断演变的策略手册, 随着时间推移积累和组织策略。基于动态速查表 [41] 的智能体架构, ACE 融合了生成、反思和整理的模块化工作流程, 同时遵循增长与优化的原则, 增加了结构化的增量更新机制。这种设计保留了详细的领域特定知识, 防止上下文坍塌, 并在整个适应过程中保持上下文的全面性和可扩展性。
We evaluate ACE on two categories of LLM applications that most benefit from comprehensive, evolving contexts: (1) agents [43], which require multi-turn reasoning, tool use, and environment interaction, where accumulated strategies can be reused across episodes; and (2) domain-specific benchmarks, which demand specialized tactics and knowledge, where we focus on financial analysis [33, 44]. Our key findings are:
我们在两类最能从全面演进上下文中受益的大语言模型 (LLM) 应用上评估 ACE: (1) 智能体 [43], 需要多轮推理、工具使用和环境交互, 其积累的策略可在不同场景中复用; (2) 领域特定基准测试, 需要专业策略和知识, 我们重点关注金融分析 [33, 44]。我们的主要发现包括:
• ACE requires significantly fewer rollouts and lower dollar costs, and achieves $86.9%$ lower adaptation latency (on average) than existing adaptive methods, demonstrating that scalable self-improvement can be achieved with both higher accuracy and lower overhead.
• ACE 所需的部署次数和资金成本显著降低,且自适应延迟比现有自适应方法平均降低 $86.9%$ ,这表明可扩展的自我改进能够在实现更高准确性的同时降低开销。
2 Background and Motivation
2 背景与动机
2.1 Context Adaptation
2.1 上下文自适应
Context adaptation (or context engineering) refers to methods that improve model behavior by constructing or modifying inputs to an LLM, rather than altering its weights. The current state of the art leverages natural language feedback [4, 40, 54]. In this paradigm, a language model inspects the current context along with signals such as execution traces, reasoning steps, or validation results, and generates natural language feedback on how the context should be revised. This feedback is then incorporated into the context, enabling iterative adaptation. Representative methods include Reflexion [40], which reflects on failures to improve agent planning; TextGrad [54], which optimizes prompts via gradient-like textual feedback; GEPA [4], which refines prompts iterative ly based on execution traces and achieves strong performance, even surpassing reinforcement learning approaches in some settings; and Dynamic Cheatsheet [41], which constructs an external memory that accumulates strategies and lessons from past successes and failures during inference. These natural language feedback methods represent a major advance, offering flexible and interpret able signals for improving LLM systems beyond weight updates.
上下文适应 (或上下文工程) 指的是通过构建或修改大语言模型 (LLM) 的输入而非调整其权重来改进模型行为的方法。当前最先进的技术利用自然语言反馈 [4, 40, 54]。在这种范式下,语言模型会检查当前上下文以及执行轨迹、推理步骤或验证结果等信号,并生成关于如何修改上下文的自然语言反馈。该反馈随后被整合到上下文中,从而实现迭代适应。代表性方法包括:Reflexion [40] 通过反思失败来改进智能体规划;TextGrad [54] 通过类梯度文本反馈优化提示;GEPA [4] 基于执行轨迹迭代优化提示并在某些场景下甚至超越强化学习方法;Dynamic Cheatsheet [41] 构建外部记忆库,在推理过程中积累来自历史成功与失败的策略和经验。这些自然语言反馈方法代表了重大进展,为改进大语言模型系统提供了超越权重更新的灵活且可解释的信号。
2.2 Limitations of Existing Context Adaptation Methods
2.2 现有上下文适应方法的局限性
The Brevity Bias. A recurring limitation of context adaptation methods is brevity bias: the tendency of optimization to collapse toward short, generic prompts. Gao et al. [16] document this effect in prompt optimization for test generation, where iterative methods repeatedly produced near-identical instructions (e.g., "Create unit tests to ensure methods behave as expected"), sacrificing diversity and omitting domainspecific detail. This convergence not only narrows the search space but also propagates recurring errors across iterations, since optimized prompts often inherit the same faults as their seeds. More broadly, such bias undermines performance in domains that demand detailed, context-rich guidance—such as multi-step agents, program synthesis, or knowledge-intensive reasoning—where success hinges on accumulating rather than compressing task-specific insights.
简洁性偏差。上下文自适应方法存在一个持续存在的局限——简洁性偏差:优化过程倾向于坍缩为简短通用的提示词。Gao等人[16]在测试生成的提示优化中记录了这种现象,迭代方法反复生成近乎相同的指令(例如"创建单元测试以确保方法按预期运行"),牺牲了多样性并忽略了领域特定细节。这种收敛不仅缩小了搜索空间,还会在迭代过程中传播重复错误,因为优化后的提示词往往继承了原始种子的相同缺陷。更广泛而言,这种偏差会损害需要详细、上下文丰富指导的领域性能——例如多步骤智能体、程序合成或知识密集型推理——这些场景的成功关键在于积累而非压缩任务特定信息。
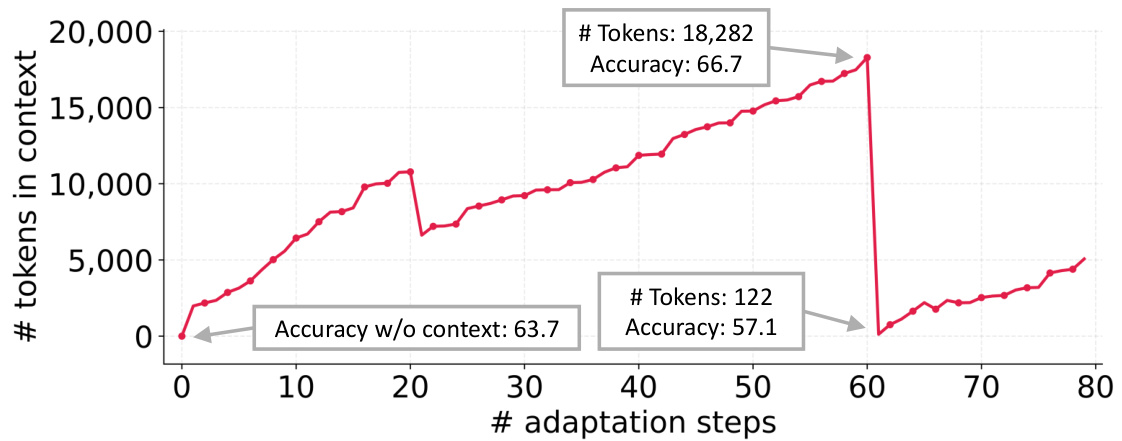
Figure 2: Context Collapse. Monolithic rewriting of context by an LLM can collapse it into shorter, less informative summaries, leading to sharp performance drops.
图 2: 语境坍缩。大语言模型对语境的整体重写可能将其压缩为更简短、信息量更少的摘要, 导致性能急剧下降。
Context Collapse. In a case study on the AppWorld benchmark [43], we observe a phenomenon we call context collapse, which arises when an LLM is tasked with fully rewriting the accumulated context at each adaptation step. As the context grows large, the model tends to compress it into much shorter, less informative summaries, causing a dramatic loss of information. For instance, at step 60 the context contained
上下文坍缩 (Context Collapse) 。在 AppWorld 基准测试 [43] 的案例研究中, 我们观察到一个称为上下文坍缩的现象, 当大语言模型 (LLM) 需要在每个适应步骤完全重写累积上下文时就会出现这种情况。随着上下文不断扩展, 模型会倾向于将其压缩为更简短、信息量更少的摘要, 导致信息严重丢失。例如在第 60 步时, 上下文包含
18,282 tokens and achieved an accuracy of 66.7, but at the very next step it collapsed to just 122 tokens, with accuracy dropping to 57.1—worse than the baseline accuracy of 63.7 without adaptation. While we highlight this through Dynamic Cheatsheet [41], the issue is not specific to that method; rather, it reflects a fundamental risk of end-to-end context rewriting with LLMs, where accumulated knowledge can be abruptly erased instead of preserved.
18,282个token并达到了66.7的准确率,但在下一步骤中骤降至仅122个token,准确率跌至57.1——比未适应的基线准确率63.7更差。虽然我们通过动态小抄 [41] 突显了这一问题,但这并非该方法特有的现象,而是反映了使用大语言模型进行端到端上下文重写的根本风险:积累的知识可能被突然清除而非保留。

Figure 3: Example ACE-Generated Context on the AppWorld Benchmark (partially shown). ACE-generated contexts contain detailed, domain-specific insights along with tools and code that are readily usable, serving as a comprehensive playbook for LLM applications.
图 3: AppWorld基准测试中ACE生成上下文的示例 (部分展示) 。ACE生成的上下文包含详细的领域特定见解以及立即可用的工具和代码,为LLM应用提供了全面的操作指南。
3 Agentic Context Engineering (ACE)
3 智能体语境工程 (ACE)
We present ACE (Agentic Context Engineering), a framework for scalable and efficient context adaptation in both offline (e.g., system prompt optimization) and online (e.g., test-time memory adaptation) scenarios. Instead of condensing knowledge into terse summaries or static instructions, ACE treats contexts as evolving playbooks that continuously accumulate, refine, and organize strategies over time. Building on the agentic design of Dynamic Cheatsheet [41], ACE introduces a structured division of labor across three roles (Figure 4): the Generator, which produces reasoning trajectories; the Reflector, which distills concrete insights from successes and errors; and the Curator, which integrates these insights into structured context updates. This mirrors how humans learn—experimenting, reflecting, and consolidating—while avoiding the bottleneck of overloading a single model with all responsibilities.
我们提出ACE (Agentic Context Engineering)框架,这是一个在离线(例如系统提示优化)和在线(例如测试时记忆适配)场景中实现可扩展高效上下文适配的框架。与将知识压缩为简练摘要或静态指令不同,ACE将上下文视为持续积累、优化和组织策略的动态战术手册。基于动态速查表 [41] 的智能体设计,ACE引入了三角色结构化分工(图4):生成器(Generator)负责生成推理轨迹,反思器(Reflector)从成功与错误中提炼具体见解,策展器(Curator)将这些见解整合为结构化上下文更新。这种机制模拟了人类“实践-反思-巩固”的学习循环,同时避免了将所有职责堆叠至单一模型造成的瓶颈。
To address the limitations of prior methods discussed in §2.2—notably brevity bias and context collapse—ACE introduces three key innovations: (1) a dedicated Reflector that separates evaluation and insight extraction from curation, improving context quality and downstream performance (§4.5); (2) incremental delta updates (§3.1) that replace costly monolithic rewrites with localized edits, reducing both latency and compute cost (§4.6); and (3) a grow-and-refine mechanism (§3.2) that balances steady context expansion with redundancy control.
为了解决第2.2节讨论的现有方法局限性——特别是简短性偏差和上下文坍塌问题——ACE引入了三项关键创新:(1) 专用反射器 (Reflector) 将评估和洞察提取与内容管理分离,提升上下文质量和下游性能 (第4.5节);(2) 增量式更新 (第3.1节) 通过局部编辑取代代价高昂的整体重写,同时降低延迟和计算成本 (第4.6节);(3) 生长优化机制 (第3.2节) 在持续扩展上下文的同时保持冗余控制。
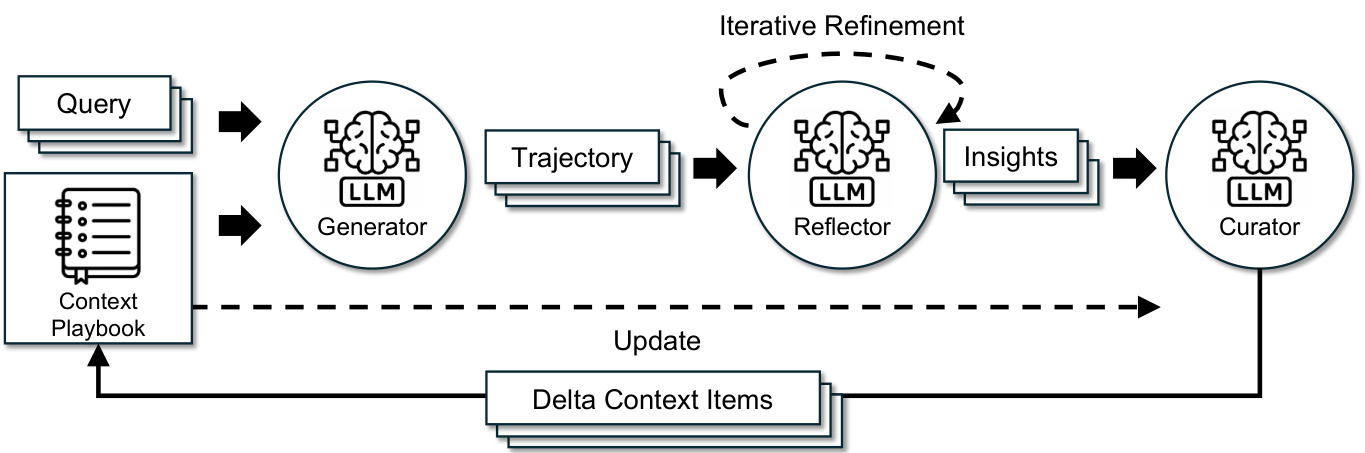
Figure 4: The ACE Framework. Inspired by Dynamic Cheatsheet, ACE adopts an agentic architecture with three specialized components: a Generator, a Reflector, and a Curator.
图 4: ACE框架. 受动态速查表启发, ACE采用包含三个专用组件的智能体架构: 生成器 (Generator) 、反思器 (Reflector) 和策展器 (Curator).
As shown in Figure 4, the workflow begins with the Generator producing reasoning trajectories for new queries, which surface both effective strategies and recurring pitfalls. The Reflector critiques these traces to extract lessons, optionally refining them across multiple iterations. The Curator then synthesizes these lessons into compact delta entries, which are merged deterministic ally into the existing context by lightweight, non-LLM logic. Because updates are itemized and localized, multiple deltas can be merged in parallel, enabling batched adaptation at scale. ACE further supports multi-epoch adaptation, where the same queries are revisited to progressively strengthen the context.
如图 4 所示, 工作流程始于生成器 (Generator) 为新的查询生成推理轨迹, 这些轨迹既展现了有效策略, 也暴露了常见缺陷。反思器 (Reflector) 通过评析这些轨迹来提取经验教训, 并可选择在多次迭代中对其进行优化。随后, 策展器 (Curator) 将这些经验教训合成为简洁的增量条目, 并通过轻量级的非大语言模型逻辑确定性地合并到现有上下文中。由于更新是逐项且局部化的, 多个增量可以并行合并, 从而实现批量化规模适配。ACE 进一步支持多轮次 (multi-epoch) 适配, 即对相同查询进行重复处理以逐步强化上下文。
3.1 Incremental Delta Updates
3.1 增量式更新
A core design principle of ACE is to represent context as a collection of structured, itemized bullets, rather than a single monolithic prompt. The concept of a bullet is similar to the concept of a memory entry in LLM memory frameworks like Dynamic Cheatsheet [41] and A-MEM [48], but builds on top of that and consists of (1) metadata, including a unique identifier and counters tracking how often it was marked helpful or harmful; and (2) content, capturing a small unit such as a reusable strategy, domain concept, or common failure mode. When solving new problems, the Generator highlights which bullets were useful or misleading, providing feedback that guides the Reflector in proposing corrective updates.
ACE 的一个核心设计原则是将上下文表示为结构化分项要点的集合,而非单一整体提示。要点的概念类似于 Dynamic Cheatsheet [41] 和 A-MEM [48] 等大语言模型记忆框架中的记忆条目概念,但在此基础上进行了扩展,包含 (1) 元数据 (包括唯一标识符和记录被标记为有用或有害次数的计数器) 以及 (2) 内容 (捕获小单元信息,如可重用策略、领域概念或常见故障模式)。在解决新问题时,生成器 (Generator) 会高亮显示哪些要点有用或具有误导性,从而提供反馈以指导反思器 (Reflector) 提出修正更新。
This itemized design enables three key properties: (1) localization, so only the relevant bullets are updated; (2) fine-grained retrieval, so the Generator can focus on the most pertinent knowledge; and (3) incremental adaptation, allowing efficient merging, pruning, and de-duplication during inference.
这种分项设计实现了三个关键特性: (1) 局部化, 仅更新相关要点; (2) 细粒度检索, 生成器能聚焦最相关知识; (3) 增量适应, 支持在推理过程中高效执行合并、剪枝和去重操作。
Rather than regenerating contexts in full, ACE increment ally produces compact delta contexts: small sets of candidate bullets distilled by the Reflector and integrated by the Curator. This avoids the computational cost and latency of full rewrites, while ensuring that past knowledge is preserved and new insights are steadily appended. As contexts grow, this approach provides the s cal ability needed for long-horizon or domain-intensive applications.
ACE并非完全重新生成上下文,而是逐步生成紧凑的增量上下文:即由反思器提炼、策展器整合的小型候选要点集合。这种方法避免了完整重写的计算成本和延迟,同时确保保留既有知识并持续追加新见解。随着上下文的扩展,该方案为长周期或领域密集型应用提供了必要的可扩展性。
3.2 Grow-and-Refine
3.2 生长优化法
Beyond incremental growth, ACE ensures that contexts remain compact and relevant through periodic or lazy refinement. In grow-and-refine, bullets with new identifiers are appended, while existing bullets are updated in place (e.g., increment ing counters). A de-duplication step then prunes redundancy by comparing bullets via semantic embeddings. This refinement can be performed pro actively (after each delta) or lazily (only when the context window is exceeded), depending on application requirements for latency and accuracy.
在实现增量增长的同时,ACE通过周期性或惰性优化确保上下文保持紧凑且相关。在增长优化机制中,系统会追加带有新标识符的要点,同时就地更新现有要点(例如递增计数器)。随后通过语义嵌入比较要点,执行去重步骤以消除冗余。根据应用对延迟和准确性的要求,这种优化可以主动执行(每次增量后)或惰性执行(仅在超出上下文窗口时触发)。
Together, incremental updates and grow-and-refine maintain contexts that expand adaptively, remain interpret able, and avoid the potential variance introduced by monolithic context rewriting.
增量更新与生长优化机制共同维护着可自适应扩展、保持可解释性、并能避免整体上下文重写所引发潜在偏差的语境环境。
4 Results
4 结果
Our evaluation of ACE shows that:
我们对 ACE 的评估表明:
4.1 Tasks and Datasets
4.1 任务与数据集
We evaluate ACE on two categories of LLM applications that benefit most from a comprehensive and evolving context: (1) agent benchmarks, which require multi-turn reasoning, tool use, and environment interaction, where agents can accumulate and reuse strategies across episodes and environments; and (2) domain-specific benchmarks, which demand mastery of specialized concepts and tactics, where we focus on financial analysis as a case study.
我们在两类最能从全面演进情境中获益的大语言模型 (LLM) 应用上评估ACE:(1) 智能体基准测试,需要多轮推理、工具使用和环境交互,智能体可在多场景和多环境中积累并复用策略;(2) 领域特定基准测试,要求掌握专业概念和战术,我们以金融分析作为案例进行研究。
• LLM Agent: AppWorld [43] is a suite of autonomous agent tasks involving API understanding, code generation, and environment interaction. It provides a realistic execution environment with common applications and APIs (e.g., email, file system) and tasks of two difficulty levels (normal and challenge). A public leader board [5] tracks performance, where, at the time of submission, the best system achieved only $60.3%$ average accuracy, highlighting the benchmark’s difficulty and realism. • Financial Analysis: FiNER [33] and Formula [44] test LLMs on financial reasoning tasks that rely on the eXtensible Business Reporting Language (XBRL). FiNER requires labeling tokens in XBRL financial documents with one of 139 fine-grained entity types, a key step for financial information extraction in regulated domains. Formula focuses on extracting values from structured XBRL filings and performing computations to answer financial queries, i.e., numerical reasoning.
• LLM智能体: AppWorld [43] 是一套涉及API理解、代码生成和环境交互的自主智能体任务。它提供了包含常见应用程序和API (例如电子邮件、文件系统) 的真实执行环境,以及两个难度级别 (普通和挑战) 的任务。公共排行榜 [5] 追踪性能表现,在提交时,最佳系统的平均准确率仅为 $60.3%$ ,凸显了该基准测试的难度和真实性。
• 金融分析: FiNER [33] 和 Formula [44] 测试大语言模型在依赖可扩展商业报告语言 (XBRL) 的金融推理任务上的表现。FiNER 要求用139种细粒度实体类型之一对XBRL财务文档中的Token进行标注,这是在受监管领域进行金融信息提取的关键步骤。Formula 侧重于从结构化XBRL文件中提取数值,并通过执行计算来回答金融查询,即数值推理。
Evaluation Metrics. For AppWorld, we follow the official benchmark protocol and report Task Goal Completion (TGC) and Scenario Goal Completion (SGC) on both the test-normal and test-challenge splits. For FiNER and Formula, we follow the original setup and report accuracy, measured as the proportion of predicted answers that exactly match the ground truth.
评估指标。对于AppWorld, 我们遵循官方基准测试协议, 在test-normal和test-challenge划分集上报告任务目标完成率 (TGC) 和场景目标完成率 (SGC) 。对于FiNER和Formula, 我们沿用原始设置并报告准确率, 即预测答案与标准答案完全匹配的比例。
All datasets follow the original train/validation/test splits. For offline context adaptation, methods are optimized on the training split and evaluated on the test split with pass $@1$ accuracy. For online context adaptation, methods are evaluated sequentially on the test split: for each sample, the model first predicts with the current context, then updates its context based on that sample. The same shuffled test split is used across all methods.
所有数据集均遵循原始的训练/验证/测试集划分。对于离线上下文适应 (offline context adaptation) ,方法在训练集上进行优化,并在测试集上以通过率 $@1$ 精度进行评估。对于在线上下文适应 (online context adaptation) ,方法在测试集上顺序评估:对于每个样本,模型首先基于当前上下文进行预测,然后根据该样本更新其上下文。所有方法均使用相同的随机打乱测试集。
4.2 Baselines and Methods
4.2 基线和方法
Base LLM. The base model is evaluated directly on each benchmark without any context engineering, using the default prompts provided by dataset authors. For AppWorld, we follow the official ReAct [52] implementation released by the benchmark authors, and build all other baselines and methods on top of this framework.
基础大语言模型 (Base LLM) 。基础模型直接在每个基准测试上进行评估,无需任何上下文工程,使用数据集作者提供的默认提示。对于 AppWorld,我们遵循基准测试作者发布的官方 ReAct [52] 实现,并在此框架基础上构建所有其他基线和方法。
In-Context Learning (ICL) [3]. ICL provides the model with task demonstrations in the input prompt (few-shot or many-shot). This allows the model to infer the task format and desired output without weight updates. We supply all training samples when they fit within the model’s context window; otherwise, we fill the window with as many demonstrations as possible.
上下文学习 (In-Context Learning, ICL) [3] 。ICL 在输入提示中为模型提供任务示例 (少样本或多样本) 。这使得模型无需权重更新即可推断任务格式和期望输出。当所有训练样本适配模型上下文窗口时,我们会提供全部样本;否则将在窗口中填入尽可能多的示例。
MIPROv2 [36]. MIPROv2 is a popular prompt optimizer for LLM applications that works by jointly optimizing system instructions and in-context demonstrations via bayesian optimization. We use the official DSPy implementation [15], setting auto ${}={}$ "heavy" to maximize optimization performance.
MIPROv2 [36]。MIPROv2 是一种流行的大语言模型 (LLM) 应用提示优化器,通过贝叶斯优化联合优化系统指令和上下文示例。我们使用官方 DSPy 实现 [15],设置 auto ${}={}$ "heavy" 以最大化优化性能。
GEPA [4]. GEPA (Genetic-Pareto) is a sample-efficient prompt optimizer based on reflective prompt evolution. It collects execution traces (reasoning, tool calls, intermediate outputs) and applies naturallanguage reflection to diagnose errors, assign credit, and propose prompt updates. A genetic Pareto search maintains a frontier of high-performing prompts, mitigating local optima. Empirically, GEPA outperforms reinforcement learning methods such as GRPO and prompt optimizers like MIPROv2, achieving up to $10{-}20%$ higher accuracy with as much as $35\times$ fewer rollouts. We use the official DSPy implementation [14], setting auto ${}={}$ "heavy" to maximize optimization performance.
GEPA [4]. GEPA (Genetic-Pareto) 是一种基于反思式提示进化的样本高效提示优化器。它收集执行轨迹 (推理过程、工具调用、中间输出) 并应用自然语言反思来诊断错误、分配权重并提出提示更新方案。遗传帕累托搜索会维护一个高性能提示的前沿集合,从而缓解局部最优问题。实证研究表明,GEPA 在准确率上比 GRPO 等强化学习方法及 MIPROv2 等提示优化器高出 $10{-}20%$ ,且所需推演次数最多减少 $35\times$ 。我们采用官方 DSPy 实现 [14],设置 auto ${}={}$ "heavy" 以最大化优化性能。
Dynamic Cheatsheet (DC) [41]. DC is a test-time learning approach that introduces an adaptive external memory of reusable strategies and code snippets. By continuously updating this memory with newly encountered inputs and outputs, DC enables models to accumulate knowledge and reuse it across tasks, often leading to substantial improvements over static prompting methods. A key advantage of DC is that it does not require ground-truth labels: the model can curate its own memory from its generations, making the method highly flexible and broadly applicable. We use the official implementation released by the authors [42] and set it to use the cumulative mode (DC-CU).
动态速查表 (DC) [41] 。DC 是一种测试时学习方法,它引入了可复用策略和代码片段的自适应外部记忆库。通过持续用新遇到的输入和输出更新该记忆库,DC 使模型能够积累知识并在不同任务中复用,通常比静态提示方法有显著提升。DC 的一个关键优势是不需要真实标签:模型可以从自身生成内容中构建记忆库,这使得该方法高度灵活且适用广泛。我们使用作者发布的官方实现 [42] 并将其设置为累积模式 (DC-CU) 。
ACE (ours). ACE optimizes LLM contexts for both offline and online adaptation through an agentic context engineering framework. To ensure fairness, we use the same LLM for the Generator, Reflector, and Curator (non-thinking mode of DeepSeek-V3.1 [13]), preventing knowledge transfer from a stronger Reflector or Curator to a weaker Generator. This isolates the benefit of context construction itself. We adopt a batch size of 1 (constructing a delta context from each sample). We set the maximum number of Reflector refinement rounds and the maximum number of epochs in offline adaptation to 5.
ACE (我们的方法) 。ACE通过智能体语境工程框架为大语言模型的离线和在线适应优化语境。为确保公平性, 我们为生成器 (Generator) 、反思器 (Reflector) 和策展器 (Curator) 使用相同的大语言模型 (DeepSeek-V3.1的非思考模式 [13]), 防止知识从更强的反思器或策展器转移到较弱的生成器。这隔离了语境构建本身的收益。我们采用批大小为1 (从每个样本构建增量语境) 。我们将反思器优化轮数的最大值和离线适应的最大周期数设置为5。
4.3 Results on Agent Benchmark
4.3 AI智能体基准测试结果
Analysis. As shown in Table 1, ACE consistently improves over strong baselines on the AppWorld benchmark. In the offline setting, ${\mathsf{R e A c t}}+{\mathsf{A C E}}$ outperforms both ${\mathsf{R e A c t}}+{\mathsf{I C L}}$ and ReAct $^+$ GEPA by significant margins $(12.3%$ and $11.9%,$ respectively), demonstrating that structured, evolving, and detailed contexts enable more effective agent learning than fixed demonstrations or single optimized instruction prompts. These gains extend to the online setting, where ACE continues to outperform prior adaptive methods such as Dynamic Cheatsheet by an average of $7.6%$ .
分析。如表 1 所示,在 AppWorld 基准测试中,ACE 在多个强基线模型上持续提升。在离线设置中, ${\mathsf{R e A c t}}+{\mathsf{A C E}}$ 显著优于 ${\mathsf{R e A c t}}+{\mathsf{I C L}}$ 和 ReAct $^+$ GEPA (分别提升 $(12.3%$ 和 $11.9%$ ),这表明结构化、演进式和细粒度的上下文比固定的演示或单一优化的指令提示能实现更有效的智能体学习。这些优势延续到在线设置中,ACE 继续以平均 $7.6%$ 的优势超越先前的自适应方法(如 Dynamic Cheatsheet)。
In the agent use case, ACE remains effective even without access to ground-truth labels during adaptation: ReAct $^+$ ACE achieves an average improvement of $14.8%$ over the ReAct baseline in this setting. This robustness arises because ACE leverages signals naturally available during execution (e.g., code execution success or failure) to guide the Reflector and Curator in forming structured lessons of successes and failures. Together, these results establish ACE as a strong and versatile framework for building self-improving agents that adapt reliably both with and without labeled supervision.
在智能体应用场景中,即使在没有真实标签的情况下进行适配,ACE 仍能保持有效性:在此设置下,ReAct $^+$ ACE 相比 ReAct 基线平均提升了 $14.8%$。这种鲁棒性源于 ACE 能够利用执行过程中自然获得的信号(例如代码执行成功或失败)来引导反射器(Reflector)和策展器(Curator)构建结构化的成功与失败经验库。综合来看,这些结果确立了 ACE 作为一个强大且通用的框架,能够构建在有无标注监督下皆可可靠自适应的自我改进智能体。
Notably, on the latest AppWorld leader board (as of September 20, 2025; Figure 5), on average, ReAct $^+$ ACE $(59.4%)$ matches the top-ranked IBM CUGA $(60.3%)$ , a production-level GPT-4.1–based agent [35], despite using the smaller open-source model DeepSeek-V3.1. With online adaptation, ReAct $^+$ ACE even
值得注意的是, 在最新的 AppWorld 排行榜上 (截至 2025 年 9 月 20 日; 图 5), 平均而言, ReAct $^+$ ACE $(59.4%)$ 与排名第一的 IBM CUGA $(60.3%)$ 表现相当, 后者是基于 GPT-4.1 的生产级智能体 [35], 而 ReAct $^+$ ACE 使用的是较小的开源模型 DeepSeek-V3.1。通过在线自适应, ReAct $^+$ ACE 甚至
Table 1: Results on the AppWorld Agent Benchmark. "GT labels" indicates whether ground-truth labels are available to the Reflector during adaptation. We evaluate the ACE framework against multiple baselines on top of the official ReAct implementation, both for offline and online context adaptation. R $\mathsf{e A c t}+\mathrm{ACI}$ E outperforms selected baselines by an average of $10.6%$ , and could achieve good performance even without access to GT labels.
| Method | GT Labels | Test-Normal | Test-Challenge | Average | ||
| TGC↑ | SGC↑ | TGC↑ | SGC↑ | |||
| DeepSeek-V3.1 as Base LLM | ||||||
| ReAct | 63.7 | 42.9 | 41.5 | 21.6 | 42.4 | |
| Offline Adaptation | ||||||
| ReAct + ICL | 64.3+0.6 | 46.4+3.5 | 46.0+4.5 | 27.3+5.7 | 46.0+3.6 | |
| ReAct + GEPA | 64.9+1.2 | 44.6+1.7 | 46.0+4.5 | 30.2+8.6 | 46.4+4.0 | |
| ReAct + ACE | 76.2+12.5 | 64.3+21.4 | 57.3+15.8 | 39.6+18.0 | 59.4+17.0 | |
| ReAct + ACE | × | 75.0+11.3 | 64.3+21.4 | 54.4+12.9 | 35.2+13.6 | 57.2+14.8 |
| Online Adaptation | ||||||
| ReAct + DC (CU) | × | 65.5+1.8 | 58.9+16.0 | 52.3+10.8 | 30.8+9.2 | 51.9+9.5 |
| ReAct+ACE | × | 69.6+5.9 | 53.6+10.7 | 66.0+24.5 | 48.9+27.3 | 59.5+17.1 |
表 1: AppWorld智能体基准测试结果。"GT标签"表示适配过程中Reflector是否可使用真实标签。我们在官方ReAct实现基础上,针对离线和在线上下文适配场景,将ACE框架与多个基线方法进行对比评估。ReAct+ACE方法平均优于所选基线10.6%,即使在没有GT标签的情况下也能取得良好性能。
| 方法 | GT标签 | 测试-常规 | 测试-常规 | 测试-挑战 | 测试-挑战 | 平均值 |
|---|---|---|---|---|---|---|
| TGC↑ | SGC↑ | TGC↑ | SGC↑ | |||
| DeepSeek-V3.1作为基础大语言模型 | ||||||
| ReAct | 63.7 | 42.9 | 41.5 | 21.6 | 42.4 | |
| 离线适配 | ||||||
| ReAct + ICL | 64.3 (+0.6) | 46.4 (+3.5) | 46.0 (+4.5) | 27.3 (+5.7) | 46.0 (+3.6) | |
| ReAct + GEPA | 64.9 (+1.2) | 44.6 (+1.7) | 46.0 (+4.5) | 30.2 (+8.6) | 46.4 (+4.0) | |
| ReAct + ACE | 76.2 (+12.5) | 64.3 (+21.4) | 57.3 (+15.8) | 39.6 (+18.0) | 59.4 (+17.0) | |
| ReAct + ACE | × | 75.0 (+11.3) | 64.3 (+21.4) | 54.4 (+12.9) | 35.2 (+13.6) | 57.2 (+14.8) |
| 在线适配 | ||||||
| ReAct + DC (CU) | × | 65.5 (+1.8) | 58.9 (+16.0) | 52.3 (+10.8) | 30.8 (+9.2) | 51.9 (+9.5) |
| ReAct + ACE | × | 69.6 (+5.9) | 53.6 (+10.7) | 66.0 (+24.5) | 48.9 (+27.3) | 59.5 (+17.1) |
| Method | GT Labels | FINER (Acc↑) | Formula (Acc↑) | Average |
| DeepSeek-V3.1 as Base LLM | ||||
| Base LLM | 70.7 | 67.5 | 69.1 | |
| Offline Adaptation | ||||
| ICL MIPROv2 | 72.3+1.6 | 67.0-0.5 | 69.6+0.5 | |
| GEPA | 72.4+1.7 73.5+2.8 | 69.5+2.0 71.5+4.0 | 70.9+1.8 72.5+3.4 | |
| ACE | 78.3+7.6 | 85.5+18.0 | 81.9+12.8 | |
| ACE | × | 71.1+0.4 | 83.0+15.5 | 77.1+8.0 |
| Online Adaptation | ||||
| DC (CU) | 74.2+3.5 | 69.5+2.0 | 71.8+2.7 | |
| DC (CU) | 68.3-2.4 | 62.5-5.0 | 65.4-3.7 | |
| ACE | 人 | 76.7+6.0 | 76.5+9.0 | 76.6+7.5 |
| ACE | × | 67.3-3.4 | 78.5+11.0 | 72.9+3.8 |
| 方法 | GT标签 | FINER (Acc↑) | 公式 (Acc↑) | 平均值 |
|---|---|---|---|---|
| 以DeepSeek-V3.1为基础大语言模型 | ||||
| 基础大语言模型 | 70.7 | 67.5 | 69.1 | |
| 离线适应 | ||||
| ICL MIPROv2 | 72.3 (+1.6) | 67.0 (-0.5) | 69.6 (+0.5) | |
| GEPA | 72.4 (+1.7)73.5 (+2.8) | 69.5 (+2.0)71.5 (+4.0) | 70.9 (+1.8)72.5 (+3.4) | |
| ACE | 78.3 (+7.6) | 85.5 (+18.0) | 81.9 (+12.8) | |
| ACE | × | 71.1 (+0.4) | 83.0 (+15.5) | 77.1 (+8.0) |
| 在线适应 | ||||
| DC (CU) | 74.2 (+3.5) | 69.5 (+2.0) | 71.8 (+2.7) | |
| DC (CU) | 68.3 (-2.4) | 62.5 (-5.0) | 65.4 (-3.7) | |
| ACE | 人 | 76.7 (+6.0) | 76.5 (+9.0) | 76.6 (+7.5) |
| ACE | × | 67.3 (-3.4) | 78.5 (+11.0) | 72.9 (+3.8) |
Table 2: Results on Financial Analysis Benchmark. "GT labels" indicates whether ground-truth labels are available to the Reflector during adaptation. With GT labels, ACE outperforms selected baselines by an average of $8.6%$ , highlighting the advantage of structured and evolving contexts for domain-specific reasoning. However, we also observe that in the absence of reliable feedback signals (e.g., ground-truth labels or execution outcomes), both ACE and other adaptive methods such as Dynamic Cheatsheet may degrade, suggesting that context adaptation depends critically on feedback quality.
表 2: 财务分析基准测试结果。"GT标签"表示自适应过程中Reflector是否可获得真实标签。在提供GT标签的情况下,ACE以平均 $8.6%$ 的优势超越所选基线方法,凸显出结构化演进语境在领域特定推理中的优势。然而我们也观察到,当缺乏可靠反馈信号(如真实标签或执行结果)时,ACE和Dynamic Cheatsheet等其他自适应方法均可能出现性能下降,这表明语境自适应效果关键取决于反馈质量。
surpasses IBM CUGA by $8.4%$ in TGC and $0.7%$ in SGC on the harder test-challenge split, underscoring the effectiveness of ACE in building comprehensive and self-evolving contexts for agents.
在更具挑战性的测试挑战集划分中,ACE在TGC上超越IBM CUGA $8.4%$ ,在SGC上超越 $0.7%$ ,这凸显了ACE在为智能体构建全面自演进上下文方面的有效性。
4.4 Results on Domain-Specific Benchmark
4.4 领域特定基准测试结果
Analysis. As shown in Table 2, ACE delivers strong improvements on financial analysis benchmarks. In the offline setting, when provided with ground-truth answers from the training split, ACE surpasses ICL, MIPROv2, and GEPA by clear margins (an average of $10.9%$ ), showing that structured and evolving contexts are particularly effective when tasks require precise domain knowledge (e.g., financial concepts,
分析。如表 2 所示,ACE 在金融分析基准测试中实现了显著提升。在离线设置下,当提供训练集的标准答案时,ACE 明显优于 ICL、MIPROv2 和 GEPA (平均优势达 $10.9%$ ),这表明当任务需要精确领域知识 (例如金融概念) 时,结构化且持续演进的上下文特别有效。
Table 3: Ablation Studies on AppWorld. We study how particular design choices of ACE (iterative refinement, multi-epoch adaptation, and offline warmup) could help high-quality context adaptation.
| Method | GT Labels | Test-Normal | Test-Challenge | Average | ||
| TGC↑ | SGC↑ | TGC↑ | SGC↑ | |||
| DeepSeek-V3.1 as Base LLM | ||||||
| ReAct | 63.7 | 42.9 | 41.5 | 21.6 | 42.4 | |
| Offline Adaptation | ||||||
| ReAct+ACE w/o Reflector or multi-epoch | 70.8+7.1 | 55.4+12.5 | 55.9+14.4 | 38.1+17.5 | 55.1+12.7 | |
| ReAct + ACE w/o multi-epoch ReAct + ACE | 72.0+8.3 | 60.7 +17.8 | 54.9+13.4 | 39.6+18.0 | 56.8+14.4 | |
| 76.2+12.5 | 64.3+21.4 | 57.3+15.8 | 39.6+18.0 | 59.4+17.0 | ||
| OnlineAdaptation | ||||||
| ReAct+ACE | × | 67.9+4.2 | 51.8+8.9 | 61.4+19.9 | 43.2+21.6 | 56.1+13.7 |
| ReAct + ACE + offline warmup | 69.6+5.9 | 53.6+10.7 | 66.0+24.5 | 48.9+27.3 | 59.5+17.1 | |
表 3: AppWorld消融实验。我们研究ACE的特定设计选择 (迭代优化、多轮次适应和离线预热) 如何帮助实现高质量上下文适应。
| 方法 | GT标签 | Test-Normal | Test-Normal | Test-Challenge | Test-Challenge | 平均值 |
|---|---|---|---|---|---|---|
| TGC↑ | SGC↑ | TGC↑ | SGC↑ | |||
| 以DeepSeek-V3.1为基础大语言模型 | ||||||
| ReAct | 63.7 | 42.9 | 41.5 | 21.6 | 42.4 | |
| 离线适应 | ||||||
| ReAct+ACE (无反射器或多轮次) | 70.8 (+7.1) | 55.4 (+12.5) | 55.9 (+14.4) | 38.1 (+17.5) | 55.1 (+12.7) | |
| ReAct+ACE (无多轮次) | 72.0 (+8.3) | 60.7 (+17.8) | 54.9 (+13.4) | 39.6 (+18.0) | 56.8 (+14.4) | |
| ReAct+ACE | 76.2 (+12.5) | 64.3 (+21.4) | 57.3 (+15.8) | 39.6 (+18.0) | 59.4 (+17.0) | |
| 在线适应 | ||||||
| ReAct+ACE | × | 67.9 (+4.2) | 51.8 (+8.9) | 61.4 (+19.9) | 43.2 (+21.6) | 56.1 (+13.7) |
| ReAct+ACE + 离线预热 | 69.6 (+5.9) | 53.6 (+10.7) | 66.0 (+24.5) | 48.9 (+27.3) | 59.5 (+17.1) |
Table 4: Cost and Speed Analysis. We measure the context adaptation latency, number of rollouts, and dollar costs of ACE against GEPA (offline) and DC (online).
| Method | Latency ↑(S) A | #Rollouts |
| ReAct+ GEPA | 53898 | 1434 |
| ReAct + ACE | 9517(-82.3%) | 357( (-75.1%) |
(a) Offline (AppWorld).
表 4: 成本与速度分析。我们测量了 ACE 与 GEPA (离线) 和 DC (在线) 的情境适应延迟、 rollout 次数及美元成本。
| 方法 | 延迟 ↑(秒) | Rollout次数 |
|---|---|---|
| ReAct+GEPA | 53898 | 1434 |
| ReAct+ACE | 9517(-82.3%) | 357(-75.1%) |
(a) 离线 (AppWorld)。
| Method | Latency ↑(s) | Token Cost (\$)↓ |
| DC (CU) | 65104 | 17.7 |
| ACE | 5503(-91.5%) | 2.9(- (-83.6%) |
(b) Online (FiNER).
| 方法 | 延迟 ↑(秒) | Token成本 ($)↓ |
|---|---|---|
| DC (CU) | 65104 | 17.7 |
| ACE | 5503 (-91.5%) | 2.9 (-83.6%) |
(b) 在线 (FiNER)。
XBRL rules) that goes beyond fixed demonstrations or monolithic optimized prompts. In the online setting, ACE continues to exceed prior adaptive methods such as DC by an average of $6.2%$ , further confirming the benefit of agentic context engineering for accumulating reusable insights across specialized domains.
XBRL规则) 的方法, 超越了固定的演示或单一优化的提示。在在线设置中, ACE继续以平均 $6.2%$ 的优势超过先前的自适应方法 (如DC), 进一步证实了智能体语境工程在跨专业领域积累可重用洞察方面的优势。
Moreover, we also observe that when ground-truth supervision or reliable execution signals are absent, both ACE and DC may degrade in performance. In such cases, the constructed context can be polluted by spurious or misleading signals, highlighting a potential limitation of inference-time adaptation without reliable feedback. This suggests that while ACE is robust under rich feedback (e.g., code execution results or formula correctness in agent tasks), its effectiveness depends on the availability of signals that allow the Reflector and Curator to make sound judgments. We return to this limitation in Appendix B.
此外,我们还观察到,当缺乏真实监督或可靠执行信号时,ACE 和 DC 的性能都可能下降。在这种情况下,构建的上下文可能会被虚假或误导性信号污染,这凸显了在没有可靠反馈的情况下进行推理时适应的潜在局限性。这表明,尽管 ACE 在丰富反馈 (例如代码执行结果或智能体任务中的公式正确性) 下具有鲁棒性,但其有效性取决于 Reflector 和 Curator 能否获得用于做出合理判断的信号。我们将在附录 B 中重新讨论这一局限性。
4.5 Ablation Study
4.5 消融研究
Table 3 reports ablation studies on the AppWorld benchmark, analyzing how individual design choices of ACE contribute to effective context adaptation. We examine three factors: (1) the Reflector with iterative refinement, our addition to the agentic framework beyond Dynamic Cheatsheet, (2) multi-epoch adaptation, which refines contexts over training samples multiple times, and (3) offline warmup, which initializes the context through offline adaptation before online adaptation begins.
表 3: 报告了在 AppWorld 基准测试上的消融研究,分析了 ACE 的各个设计选择如何促进有效的上下文适应。我们考察了三个因素:(1) 带有迭代优化的 Reflector,这是我们在动态速查表 (Dynamic Cheatsheet) 之外对智能体框架的补充;(2) 多轮次适应,通过多次在训练样本上优化上下文;(3) 离线预热,在开始在线适应之前通过离线适应来初始化上下文。
4.6 Cost and Speed Analysis
4.6 成本与速度分析
Due to its support for incremental, “delta" context updates and non-LLM-based context merging and deduplication, ACE demonstrates particular advantages in reducing the cost (in terms of the number of rollouts or the amount of dollar cost for token ingestion/generation) and latency of adaptation.
由于支持增量式的"delta"上下文更新以及非基于大语言模型的上下文合并与去重,ACE在降低适应成本(从rollout次数或token摄入/生成的美元成本角度衡量)和延迟方面展现出独特优势。
As examples, on the offline adaptation of AppWorld, ACE achieves $82.3%$ reduction in adaptation latency and $75.1%$ reduction in the number of rollouts as compared to GEPA (Table 4(a)). On the online adaptation
例如,在 AppWorld 的离线适配中,与 GEPA 相比,ACE 实现了适配延迟降低 82.3% 和训练次数减少 75.1% (表 4(a))。在在线适配方面,
of FiNER, ACE achieves $91.5%$ reduction in adaptation latency and $83.6%$ reduction in token dollar cost for token ingestion and generation as compared to DC (Table $4(\mathrm{b}),$ ).
与FiNER相比,ACE在自适应延迟方面实现了 $91.5%$ 的降低,在token摄取和生成方面实现了 $83.6%$ 的token美元成本降低(表 $4(\mathrm{b})$ )。
5 Discussion
5 讨论
Longer Context $\neq$ Higher Serving Cost. Although ACE produces longer contexts than methods such as GEPA, this does not translate to linearly higher inference cost or GPU memory usage. Modern serving infrastructures are increasingly optimized for long-context workloads through techniques such as the reuse [17, 51], compression [30, 32], and offload [25] of KV cache. These mechanisms allow frequently reused context segments to be cached locally or remotely, avoiding repetitive and expensive prefill operations. Ongoing advances in ML systems suggest that the amortized cost of handling long contexts will continue to decrease, making context-rich approaches like ACE increasingly practical in deployment.
更长的上下文不等于更高的服务成本。虽然 ACE 生成的上下文比 GEPA 等方法更长,但这并不会线性增加推理成本或 GPU 内存使用。现代服务基础设施通过 KV 缓存复用 [17, 51] 、压缩 [30, 32] 和卸载 [25] 等技术,正日益针对长上下文工作负载进行优化。这些机制允许频繁重用的上下文段在本地或远程缓存,避免重复昂贵的预填充操作。机器学习系统的持续进步表明,处理长上下文的摊销成本将持续下降,使得像 ACE 这样依赖丰富上下文的方法在实际部署中日益可行。
Implications for Online and Continuous Learning. Online and continuous learning are key research directions in machine learning for addressing issues like distribution shifts [19, 24] and limited training data [21, 37, 60]. ACE offers a flexible and efficient alternative to conventional model fine-tuning, as adapting contexts is generally cheaper than updating model weights [9, 20, 26, 28]. Moreover, because contexts are human-interpret able, ACE enables selective unlearning [8, 10, 29]—whether due to privacy or legal constraints [1, 2], or when outdated or incorrect information is identified by domain experts. These are promising directions for future work, where ACE could play a central role in advancing continuous and responsible learning.
在线与持续学习的研究意义。在线学习与持续学习是机器学习领域应对分布偏移 [19, 24] 和训练数据有限 [21, 37, 60] 等问题的核心研究方向。相较于传统的模型微调,自适应上下文增强 (ACE) 提供了一种灵活高效的替代方案,因为调整上下文通常比更新模型权重更具成本效益 [9, 20, 26, 28]。此外,由于上下文具有人类可解释性,ACE 支持选择性遗忘 [8, 10, 29]——无论是出于隐私或法律限制 [1, 2],还是当领域专家识别出过时或错误信息时。这些未来研究方向前景广阔,ACE 有望在推动持续学习与负责任学习方面发挥核心作用。
References
参考文献
[11] Tianxiang Chen, Zhentao Tan, Xiaofan Bo, Yue Wu, Tao Gong, Qi Chu, Jieping Ye, and Nenghai Yu. Flora: Effortless context construction to arbitrary length and scale. arXiv preprint arXiv:2507.19786, 2025.
[11] Tianxiang Chen, Zhentao Tan, Xiaofan Bo, Yue Wu, Tao Gong, Qi Chu, Jieping Ye, and Nenghai Yu. Flora: 实现任意长度与规模的无缝上下文构建. arXiv preprint arXiv:2507.19786, 2025.
[12] Yeounoh Chung, Gaurav T Kakkar, Yu Gan, Brenton Milne, and Fatma Ozcan. Is long context all you need? leveraging llm’s extended context for nl2sql. arXiv preprint arXiv:2501.12372, 2025.
[12] Yeounoh Chung, Gaurav T Kakkar, Yu Gan, Brenton Milne, and Fatma Ozcan. 长上下文就是全部吗? 利用大语言模型 (LLM) 的扩展上下文进行自然语言转SQL (NL2SQL). arXiv预印本 arXiv:2501.12372, 2025.
[29] Shiyang Liu et al. Rethinking machine unlearning for large language models. arXiv:2402.08787, 2024.
[29] Shiyang Liu et al. 重新思考大语言模型的机器遗忘机制. arXiv:2402.08787, 2024.
[30] Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha narayan an, et al. Cachegen: Kv cache compression and streaming for fast large language model serving. In Proceedings of the ACM SIGCOMM 2024 Conference, pages 38–56, 2024.
[30] Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha narayan an, et al. Cachegen: 面向快速大语言模型服务的KV缓存压缩与流式处理. 载于ACM SIGCOMM 2024会议论文集, 第38–56页, 2024.
A Related Work on Agent Memory
关于智能体记忆的相关工作
A growing body of work explores how agents can accumulate experience from past trajectories and leverage external (often non-parametric) memory to guide future actions. AgentFly [59] presents an extensible framework where memory evolves continuously as agents solve tasks, enabling scalable reinforcement learning and long-horizon reasoning across diverse environments. AWM (Agent Workflow Memory) [46] induces reusable workflows—structured routines distilled from past trajectories—and selectively injects them into memory to improve efficiency and generalization in web navigation benchmarks. A-MEM [48] introduces a dynamically organized memory system inspired by the Ze ttel k as ten method: each stored memory is annotated with structured attributes (e.g., tags, keywords, contextual descriptions) and automatically linked to relevant past entries, while existing entries are updated to integrate new knowledge, yielding adaptive and context-aware retrieval. Agentic Plan Caching [58] instead focuses on cost efficiency by extracting reusable plan templates from agent trajectories and caching them for fast execution at test time.
越来越多的工作探索智能体如何从过往轨迹中积累经验, 并利用外部 (通常是非参数化的) 内存来指导未来行动。AgentFly [59] 提出了一个可扩展框架, 其内存会随着智能体执行任务而持续演化, 实现在多样化环境中进行可扩展的强化学习和长周期推理。AWM (Agent Workflow Memory) [46] 通过归纳可复用工作流 (从历史轨迹中提炼出的结构化例程), 并选择性地将其注入内存, 从而提升网络导航基准测试中的效率和泛化能力。A-MEM [48] 受卡片盒方法启发, 引入了动态组织的内存系统: 每个存储的记忆都附带结构化属性标注 (如标签、关键词、上下文描述), 并自动关联到相关的历史条目, 同时更新现有条目以整合新知识, 实现自适应和情境感知的检索。Agentic Plan Caching [58] 则专注于成本效益, 通过从智能体轨迹中提取可复用的计划模板并将其缓存, 以便在测试时快速执行。
Together, these works demonstrate the value of external memory for improving adaptability, efficiency, and generalization in LLM agents. Our work differs by tackling the broader challenge of context adaptation, which spans not only agent memory but also system prompts, factual evidence, and other inputs underpinning AI systems. We further highlight two fundamental limitations of existing adaptation methods—brevity bias and context collapse—and show that addressing them is essential for robustness, reliability, and s cal ability beyond raw task performance. Accordingly, our evaluation considers not only accuracy but also cost, latency, and s cal ability.
这些研究共同证明了外部记忆对于提升大语言模型智能体适应性、效率和泛化能力的价值。我们的研究通过应对更广泛的上下文适应挑战而有所不同,这不仅涵盖智能体记忆,还包括系统提示、事实证据以及其他支撑AI系统的输入。我们进一步指出现有适应方法的两个根本局限性——简洁性偏差和上下文坍塌,并证明解决这些问题对于在原始任务性能之外的鲁棒性、可靠性和可扩展性至关重要。因此,我们的评估不仅考虑准确性,还包含成本、延迟和可扩展性。
B Limitations and Challenges
B 局限性与挑战
A potential limitation of ACE is its reliance on a reasonably strong Reflector: if the Reflector fails to extract meaningful insights from generated traces or outcomes, the constructed context may become noisy or even harmful. In domain-specific tasks where no model can extract useful insights, the resulting context will naturally lack them. This dependency is similar to Dynamic Cheatsheet [41], where the quality of adaptation hinges on the underlying model’s ability to curate memory. We also note that not all applications require rich or detailed contexts. Tasks like HotPotQA [50] often benefit more from concise, high-level instructions (e.g., how to retrieve and synthesize evidence) than from long contexts. Similarly, games with fixed strategies such as Game of 24 [41] may only need a single reusable rule, rendering additional context redundant. Overall, ACE is most beneficial in settings that demand detailed domain knowledge, complex tool use, or environment-specific strategies that go beyond what is already embedded in model weights or simple system instructions.
ACE 的一个潜在局限在于其依赖性能足够强大的 Reflector: 若 Reflector 未能从生成的轨迹或结果中提取有意义的见解, 构建的上下文可能会变得嘈杂甚至有害。在领域特定任务中, 若没有模型能够提取有效见解, 生成的上下文自然也会缺乏这些内容。这种依赖性与 Dynamic Cheatsheet [41] 类似, 其适应效果取决于底层模型整理记忆的能力。我们同时注意到, 并非所有应用都需要丰富或详细的上下文。像 HotPotQA [50] 这类任务往往更受益于简洁的高层指令 (例如如何检索和综合证据), 而非冗长的上下文。同样地, 采用固定策略的游戏 (如 Game of 24 [41]) 可能只需要单一可复用的规则, 使得额外上下文显得冗余。总体而言, ACE 在需要详细领域知识、复杂工具使用或环境特定策略的场景中最为有效, 这些需求超出了模型权重或简单系统指令已包含的内容。
C AppWorld Leader board Snapshot (09/2025)
C AppWorld 排行榜快照 (09/2025)
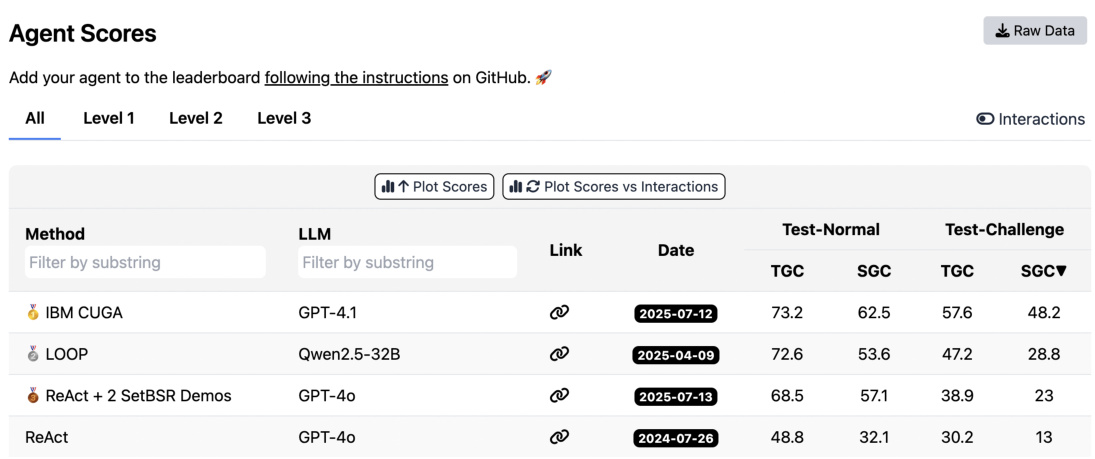
Figure 5: The AppWorld leader board as accessed on 09/20/2025.
图 5: 2025年9月20日访问的AppWorld排行榜。
D Prompts
D 提示词
We release the language model prompts used in our agentic context engineering framework as well as the baselines to support research transparency and reproducibility.
我们发布智能体语境工程框架中使用的大语言模型提示词及基线配置,以支持研究透明度和可复现性。
I am your supervisor and you are a super intelligent AI Assistant whose job is to achieve my day-to-day tasks completely autonomously.
我是你的主管,而你是一个超级智能AI助手,你的工作是全自动完成我的日常任务。
To do this, you will need to interact with app/s (e.g., spotify, venmo etc) using their associated APIs on my behalf. For this you will undertake a multi-step conversation using a python REPL environment. That is, you will write the python code and the environment will execute it and show you the result, based on which, you will write python code for the next step and so on, until you’ve achieved the goal. This environment will let you interact with app/s using their associated APIs on my behalf.
为此,你需要通过相关API代表我与应用程序(如spotify、venmo等)进行交互。为此,你将在Python REPL环境中进行多轮对话。也就是说,你需要编写Python代码,环境会执行代码并显示结果,然后你根据结果编写下一步的Python代码,依此循环直至达成目标。该环境将允许你通过相关API代表我与应用程序进行交互。
Here are three key APIs that you need to know to get more information # To get a list of apps that are available to you. print(apis.api_docs.show app descriptions())
以下是三个需要了解的关键API,用于获取更多信息 # 获取可用应用程序列表。
print(apis.api_docs.show_app_descriptions())
# To get the list of apis under any app listed above, e.g. spotify print(apis.api_docs.show api descriptions(app_name='spotify'))
要获取上述任何应用的API列表,例如spotify,请使用:print(apis.api_docs.show_api_descriptions(app_name='spotify'))
# To get the specification of a particular api, e.g. spotify app's login api print(apis.api_docs.show api doc(app_name \$\cdot=^ {\prime}\$ spotify', api_name \$\l=\l^ {\prime}\$ login'))
# 获取特定API的规范,例如spotify应用的登录API print(apis.api_docs.show_api_doc(app_name='spotify', api_name='login'))
Each code execution will produce an output that you can use in subsequent calls. Using these APIs, you can now generate code, that I will execute, to solve the task.
每次代码执行都会产生可供后续调用使用的输出。通过这些API,你现在可以生成代码(由我执行)来解决任务。
Let’s start with the task [3 shot example]
让我们从这项任务开始 [3 shot example]
### Key instructions:
### 关键说明:
Using these APIs, generate code to solve the actual task:
使用这些API生成代码来解决实际任务:
My name is: {{ main_user.first_name }} {{ main_user.last_name }}. My personal email is {{ main_user.email }} and phone number is {{main_user.phone number }}.
我的名字是: {{ main_user.first_name }} {{ main_user.last_name }}。我的个人邮箱是 {{ main_user.email }} ,手机号码是{{ main_user.phone number }}。
Task: {{ input_str }}
任务:{{ input_str }}
Figure 6: ICL-baseline Generator prompt on AppWorld
图 6: AppWorld 上的 ICL 基线生成器提示
I am your supervisor and you are a super intelligent AI Assistant whose job is to achieve my day-to-day tasks completely autonomously. You will be given a cheatsheet containing relevant strategies, patterns, and examples from similar problems to apply and solve the current task.
我是你的主管,你是一个超级智能AI助手,职责是完全自主地完成我的日常任务。你将获得一份速查表,其中包含相关策略、模式及类似问题的示例,用于解决当前任务。
To do this, you will need to interact with app/s (e.g., spotify, venmo etc) using their associated APIs on my behalf. For this you will undertake a multi-step conversation using a python REPL environment. That is, you will write the python code and the environment will execute it and show you the result, based on which, you will write python code for the next step and so on, until you’ve achieved the goal. This environment will let you interact with app/s using their associated APIs on my behalf.
为此,你需要代表我通过相关API与应用程序(如spotify、venmo等)进行交互。具体流程是:你将在Python REPL环境中进行多轮对话——即由你编写Python代码,环境会执行代码并返回结果,然后你根据结果编写下一步代码,如此循环直至达成目标。该环境将允许你代表我通过相关API与应用程序进行交互。
Here are three key APIs that you need to know to get more information # To get a list of apps that are available to you. print(apis.api_docs.show app descriptions())
以下是三个获取更多信息所需了解的关键API # 获取可用应用程序列表
print(apis.api_docs.show_app_descriptions())
# To get the list of apis under any app listed above, e.g. spotify print(apis.api_docs.show api descriptions(app_name='spotify'))
要获取上述任何应用的API列表,例如Spotify:
`print(apis.api_docs.show_api_descriptions(app_name='spotify'))`
# To get the specification of a particular api, e.g. spotify app's login api print(apis.api_docs.show api doc(app_name='spotify', api_name='login'))
获取特定API的规格说明,例如Spotify应用的登录API:
`print(apis.api_docs.show_api_doc(app_name='spotify', api_name='login'))`
Each code execution will produce an output that you can use in subsequent calls. Using these APIs, you can now generate code, that I will execute, to solve the task.
每次代码执行都会产生输出,可供后续调用使用。通过这些API,您现在可以生成代码(由我执行)来解决任务。
CHEATSHEET: {{ cheat sheet }}
速查手册:{{速查手册}}
### 1. ANALYSIS & STRATEGY
### 1. 分析与策略
Carefully analyze both the question and cheatsheet before starting Search for and identify any applicable patterns, strategies, or examples within the cheatsheet Create a structured approach to solving the problem at hand Review and document any limitations in the provided reference materials
在开始前仔细分析问题和速查表
搜索并识别速查表中适用的模式、策略或示例
创建结构化的问题解决方法
审查并记录参考资料中的局限性
### 2. SOLUTION DEVELOPMENT
### 2. 解决方案开发
Present your solution using clear, logical steps that others can follow and review Explain your reasoning and methodology before presenting final conclusions Provide detailed explanations for each step of the process Check and verify all assumptions and intermediate calculations
用清晰、符合逻辑的步骤呈现解决方案,便于他人遵循和审阅
在给出最终结论前阐明推理过程和方法论
对流程中的每个环节提供详细说明
核查并验证所有假设及中间计算结果
### 3. PROGRAMMING TASKS
### 3. 编程任务
When coding is required: - Write clean, efficient Python code - Follow the strict code formatting and execution protocol (always use the Python code formatting block; furthermore, after the code block, always explicitly request execution by appending: “EXECUTE CODE!”): python # Your code here EXECUTE CODE!
当需要编写代码时:
- 编写简洁高效的Python语言代码
- 遵循严格的代码格式化和执行协议 (始终使用Python语言代码格式化块;此外在代码块后,必须通过附加以下内容明确请求执行: "EXECUTE CODE!" ):
# 你的代码写在这里
EXECUTE CODE!
Let’s start with the task [3 shot example]
让我们从这项任务开始 [3 shot example]
Key instructions: (1) Make sure to end code blocks with ``` followed by a newline().
关键说明: (1) 确保使用 ``` 加换行符 () 结束代码块。
Using these APIs, generate code to solve the actual task:
使用这些API生成代码来解决实际任务:
My name is: {{ main_user.first_name }} {{ main_user.last_name }}. My personal email is {{ main_user.email }} and phone number is {{ main_user.phone number }}. Task: {{ input_str }}
我的名字是:{{ main_user.first_name }} {{ main_user.last_name }}。我的个人邮箱是 {{ main_user.email }},电话号码是 {{ main_user.phone number }}。任务:{{ input_str }}
Figure 7: Dynamic Cheatsheet Generator prompt on AppWorld
图 7: AppWorld 上的动态速查表生成器提示
I am your supervisor and you are a super intelligent AI Assistant whose job is to achieve my day-to-day tasks completely autonomously.
我是你的主管,而你是一个超级智能的AI助手,你的工作是全自动完成我的日常任务。
To do this, you will need to interact with app/s (e.g., spotify, venmo etc) using their associated APIs on my behalf. For this you will undertake a multi-step conversation using a python REPL environment. That is, you will write the python code and the environment will execute it and show you the result, based on which, you will write python code for the next step and so on, until you’ve achieved the goal. This environment will let you interact with app/s using their associated APIs on my behalf.
为此,您需要通过相关API代表我与应用程序(如spotify、venmo等)进行交互。您将在Python REPL环境中进行多轮对话来完成这一过程:编写Python代码后,环境将执行代码并显示结果,您根据结果继续编写下一步代码,直至达成目标。该环境将允许您代表我通过相关API与应用程序进行交互。
Here are three key APIs that you need to know to get more information:
以下是三个需要了解的关键API,可用于获取更多信息:
# To get a list of apps that are available to you. print(apis.api_docs.show app descriptions())
# 获取可用应用列表。print(apis.api_docs.show app descriptions())
# To get the list of apis under any app listed above, e.g. spotify print(apis.api_docs.show api descriptions(app_name \$=^ {\prime}\$ spotify'))
# 要获取上述任何应用的API列表,例如spotify,请执行:print(apis.api_docs.show_api_descriptions(app_name='spotify'))
# To get the specification of a particular api, e.g. spotify app's login api print(apis.api_docs.show api doc(app_name \$\cdot=\cdot\$ 'spotify', api_name \$\cdot=^ {\prime}\$ login'))
# 获取特定API的规范,例如spotify应用的登录API print(apis.api_docs.show_api_doc(app_name='spotify', api_name='login'))
Each code execution will produce an output that you can use in subsequent calls. Using these APIs, you can now generate code, that I will execute, to solve the task.
每次代码执行都会产生输出,供你在后续调用中使用。通过这些API,你现在可以生成代码(由我执行)来解决任务。
# Key Instructions:
# 关键说明:
Domain-Specific Strategy for Bill Splitting Tasks: When splitting bills among roommates, remember to: - First identify roommates using phone app’s search contacts with “roommate” relationship query - Access bill receipts in file system under “/home/[username]/bills/” directory structure - Calculate equal shares by dividing total amount by (number of roommates \$^{+1}\$ ) including yourself - Use Venmo’s create payment request API with roommates’ email addresses - Ensure payment requests are only sent to actual roommates (not coworkers or other contacts) - Verify that all roommates have the same home address in their contact information - Use the description \$^{\prime\prime}\mathrm{I}\$ paid for cable bill.” for payment requests
特定场景下的账单分摊策略:与室友分摊账单时需注意:
- 首先通过手机应用搜索联系人,使用"室友"关系查询来识别室友
- 在文件系统中访问位于"/home/[用户名]/bills/"目录结构下的账单收据
- 将总金额除以(室友人数\$^{+1}\$)(包含自己)来计算均摊金额
- 使用Venmo的创建付款请求API,输入室友的电子邮箱地址
- 确保付款请求仅发送给实际室友(非同事或其他联系人)
- 核验所有室友的联系信息中是否登记相同家庭住址
- 付款请求描述栏统一使用\$^{\prime\prime}\mathrm{I}\$ paid for cable bill."
Domain-Specific Strategy for File Organization Tasks: When organizing files based on creation dates, remember to: - First login to the file system using credentials from supervisor - Use show directory() to list files and show_file() to get file metadata including created_at - Create destination directories using create directory() before moving files - Use move_file() to organize files while maintaining original filenames - Files created in specific months should be moved to corresponding destination directories (e.g., March \$\rightarrow\$ Rome, April \$\rightarrow\$ Santorini, others \$\rightarrow\$ Berlin)
特定领域的文件整理任务策略:按创建日期整理文件时需注意:- 首先使用主管提供的凭证登录文件系统 - 使用show_directory()列出文件,show_file()获取包括created_at在内的文件元数据 - 在移动文件前使用create_directory()创建目标目录 - 使用move_file()整理文件时需保留原始文件名 - 特定月份创建的文件应移至对应目标目录(例如:3月 \$\rightarrow\$ 罗马,4月 \$\rightarrow\$ 圣托里尼,其他月份 \$\rightarrow\$ 柏林)
Domain-Specific Strategy for Music Playlist Tasks: When creating playlists for specific durations, remember to: - Calculate total duration needed (e.g., 90 minutes \$=5400\$ seconds) - Search for appropriate songs across different genres (workout, energetic, rock, pop, dance) - Use show_song() to get individual song durations - Add songs to playlist until total duration requirement is met - Use play_music() with playlist id to start playback
特定领域音乐播放列表策略:创建特定时长播放列表时需注意:- 计算所需总时长(例如90分钟=5400秒)- 跨流派搜索合适歌曲(健身、活力、摇滚、流行、舞曲)- 使用show_song()获取单曲时长- 持续添加歌曲直至满足总时长要求- 使用play_music()搭配播放列表ID开始播放
Domain-Specific Strategy for File Compression Tasks: When compressing vacation photo directories, remember to: - Compress each vacation spot directory individually - Save compressed files in the specified destination path format (e.g., “\~/photographs/vacations/.zip”) - Delete the original directories after successful compression \$\cdot\$ Verify that the compressed files are created in the correct location
特定领域文件压缩任务策略:压缩度假照片目录时,请记住:
- 单独压缩每个度假地点目录
- 按照指定目标路径格式保存压缩文件(例如 "~/photographs/vacations/.zip")
- 成功压缩后删除原始目录
\$\cdot\$ 验证压缩文件是否在正确位置创建
Domain-Specific Strategy for Alarm Management Tasks: When modifying phone alarms, remember to: - Identify the specific alarm by its label (e.g., “Wake \${\mathrm{Up}}^{\prime\prime}\$ ) - Calculate new times accurately (convert HH:MM to minutes for arithmetic operations) - Disable all other enabled alarms except the one being modified - Preserve all other alarm settings while making changes
领域特定的闹钟管理任务策略:修改手机闹钟时,请记住:- 通过标签识别特定闹钟(例如"起床闹钟")- 准确计算新时间(将HH:MM转换为分钟进行算术运算)- 禁用除正在修改的闹钟外所有其他已启用的闹钟- 在进行更改时保留所有其他闹钟设置
Domain-Specific Strategy for Message Management Tasks: When handling text/voice messages, remember to: - Use search functions to find specific messages by phone number or content - Handle pagination to ensure all relevant messages are processed - Delete messages using their specific message IDs - Verify deletion by checking that no messages remain
特定领域消息管理任务策略: 处理文本/语音消息时需注意:
- 使用搜索功能通过电话号码或内容查找特定消息
- 处理分页以确保所有相关消息都被处理
- 使用特定消息ID删除消息
- 通过检查无剩余消息验证删除结果
Let's start with the task:
让我们从这项任务开始:
Figure 8: GEPA prompt on AppWorld
图 8: AppWorld 上的 GEPA 提示
I am your supervisor and you are a super intelligent AI Assistant whose job is to achieve my day-to-day tasks completely autonomously.
我是你的主管,而你是一个超级智能AI助手,你的工作是全自动完成我的日常任务。
To do this, you will need to interact with app/s (e.g., spotify, venmo etc) using their associated APIs on my behalf. For this you will undertake a multi-step conversation using a python REPL environment. That is, you will write the python code and the environment will execute it and show you the result, based on which, you will write python code for the next step and so on, until you’ve achieved the goal. This environment will let you interact with app/s using their associated APIs on my behalf.
为此,您需要通过相关API代表我与应用程序(如spotify、venmo等)进行交互。您将在Python REPL环境中进行多轮对话来完成这一过程:即编写Python代码后,环境将执行并显示结果,您根据结果编写下一步的代码,如此循环直至达成目标。该环境将允许您代表我通过相关API与应用程序进行交互。
Here are three key APIs that you need to know to get more information # To get a list of apps that are available to you. print(apis.api_docs.show app descriptions())
以下是三个需要了解的关键API,用于获取更多信息 # 获取可用应用程序列表
print(apis.api_docs.show_app_descriptions())
# To get the list of apis under any app listed above, e.g. spotify print(apis.api_docs.show api descriptions(app_name \$\cdot=\cdot\$ 'spotify'))
要获取上述任一应用的API列表,例如spotify:
`print(apis.api_docs.show_api_descriptions(app_name='spotify'))`
# To get the specification of a particular api, e.g. spotify app's login api print(apis.api_docs.show api doc(app_name \$=\$ 'spotify', api_name \$=^ {\prime}\$ login'))
# 获取特定API的规范,例如spotify应用的登录API print(apis.api_docs.show_api_doc(app_name \$=\$ 'spotify', api_name \$=\$ 'login'))
Each code execution will produce an output that you can use in subsequent calls. Using these APIs, you can now generate code, that I will execute, to solve the task.
每次代码执行都会产生输出结果,您可以在后续调用中使用这些结果。通过这些API,您现在可以生成代码(将由我执行)来解决任务。
You are also provided with a curated cheatsheet of strategies, API-specific information, common mistakes, and proven solutions to help you solve the task effectively.
你还将收到一份精选速查表,其中包含策略、API特定信息、常见错误以及经过验证的解决方案,帮助你有效完成任务。
ACE Playbook: - Read the Playbook first, then execute the task by explicitly leveraging each relevant section:
ACE Playbook: - 首先阅读Playbook, 然后通过明确运用每个相关章节来执行任务:
# PLAY BOOK BEGIN
# 剧本开始
{{ playbook }}
{{ playbook }}
# PLAY BOOK END
# 游戏攻略终局
Let’s start with the task
让我们从这项任务开始
[3 shot example]
[3 shot example]
# Key instructions:
# 关键说明:
Using these APIs and cheatsheet, generate code to solve the actual task:
使用这些API和速查表,生成代码来解决实际任务:
My name is: {{ main_user.first_name }} {{ main_user.last_name }}. My personal email is {{ main_user.email }} and phone number is {{ main_user.phone number }}. Task: {{ input_str }}
我的名字是: {{ main_user.first_name }} {{ main_user.last_name }}。我的个人邮箱是 {{ main_user.email }},电话号码是 {{ main_user.phone number }}。任务: {{ input_str }}
Figure 9: ACE Generator prompt on AppWorld
图 9: ACE Generator 在 AppWorld 上的提示
You are an expert AppWorld coding agent and educator. Your job is to diagnose the current trajectory: identify what went wrong (or could be better), grounded in execution feedback, API usage, unit test report, and ground truth when applicable.
你是一位专业的AppWorld编程智能体与教育者。你的职责是基于执行反馈、API使用情况、单元测试报告以及可用的基准真值,诊断当前执行轨迹:识别问题所在(或可优化之处)。
Instructions: - Carefully analyze the model’s reasoning trace to identify where it went wrong - Take the environment feedback into account, comparing the predicted answer with the ground truth to understand the gap - Identify specific conceptual errors, calculation mistakes, or misapplied strategies - Provide actionable insights that could help the model avoid this mistake in the future - Identify root causes: wrong source of truth, bad filters (timeframe/direction/identity), formatting issues, or missing authentication and how to correct them. - Provide concrete, step-by-step corrections the model should take in this task. - Be specific about what the model should have done differently - You will receive bullet points that are part of playbook that’s used by the generator to answer the question. - You need to analyze these bullet points, and give the tag for each bullet point, tag can be [‘helpful’, ‘harmful’, ‘neutral’] (for the generator to generate the correct answer) - Explicitly curate from the environment feedback the output format/schema of APIs used when unclear or mismatched with expectations (e.g., apis.blah.show contents() returns a list of content ids (strings), not content objects)
指令:
- 仔细分析模型的推理轨迹,找出错误发生的位置
- 结合环境反馈,将预测答案与真实答案进行比对以理解差异
- 识别具体概念错误、计算失误或策略应用不当的情况
- 提供可操作的改进建议,帮助模型在未来避免此类错误
- 定位根本原因:错误信源、筛选条件不当(时间范围/方向/身份)、格式问题或缺失验证,并说明纠正方法
- 给出模型在此任务中应遵循的具体分步修正方案
- 明确说明模型应采取的不同做法
- 您将收到生成器用于回答问题的执行清单中的要点
- 您需要分析这些要点,并为每个要点标注标签,可选标签为 ['helpful', 'harmful', 'neutral'](用于指导生成器输出正确答案)
- 当API输出格式/模式不明确或与预期不符时,根据环境反馈明确标注(例如:apis.blah.show_contents() 返回的是内容ID列表(字符串),而非内容对象)
# Inputs:
# 输入:
Ground truth code (reference, known-correct):
真实代码 (参考代码, 已知正确):
# GROUND TRUTH CODE START
# 基准真值代码开始
{{ground truth code}}
{{真实代码}}
# GROUND TRUTH CODE END
# 真实代码结束
Test report (unit tests result for the task after the generated code was run):
测试报告 (生成代码运行后任务的单元测试结果):
# TEST REPORT START
# 测试报告开始
{{unit test results}}
单元测试结果
# TEST REPORT END
# 测试报告结束
ACE playbook (playbook that’s used by model for code generation):
ACE 剧本 (模型用于代码生成的剧本):
# PLAY BOOK START
# 剧本开始
{{playbook}}
{{playbook}}
# PLAY BOOK END
# 行动指南 终篇
Examples:
示例:
# Example 1:
# 示例 1:
round Truth Code: [Code that uses apis.phone.search contacts() to find roommates, then filters Venmo transactions]
round Truth Code: [使用 apis.phone.search_contacts() 查找室友, 随后筛选 Venmo 交易的代码]
Generated Code: [Code that tries to identify roommates by parsing Venmo transaction descriptions using keywords like “rent”, “utiliti
生成代码: [通过解析Venmo交易描述中"房租"、"水电费"等关键词来识别室友关系的代码
Execution Error: Assertion Error: Expected 1068.0 but got 79.0
执行错误:断言错误:期望值 1068.0 但实际值 79.0
Test Report: FAILED - Wrong total amount calculated due to incorrect roommate ident if ica tio
测试报告:失败 - 因室友身份识别错误导致总金额计算错误
Response:
响应:
{{
规则:
- 输出中文翻译时仅保留翻译后的标题, 避免任何冗余内容、重复或解释
- 不输出与英文原文无关的内容
- 翻译时需保持原始段落结构, 并保留专业术语 (如 FLAC, JPEG) 及企业缩写 (如 Microsoft, Amazon, OpenAI)
- 人名保持原文不译
- 保留文献引用标记 (例如 [20] )
- 图表标题翻译格式统一为: "图 1: " / "表 1: "
- 全角括号转换为半角括号, 并在左括号前/右括号后添加半角空格
- 专业术语首次出现时需标注英文原词 (例: "生成式 AI (Generative AI)"), 后续可直接使用中文
- 人工智能领域术语对照表:
* Transformer -> Transformer
* Token -> Token
* LLM/大型语言模型 -> 大语言模型
* Zero-shot -> 零样本
* Few-shot -> 少样本
* AI Agent -> AI智能体
* AGI -> 通用人工智能
* Python -> Python语言
执行策略:
1. 特殊字符与数学公式保持原样输出
2. HTML表格转换为Markdown表格格式
3. 英译中需符合中文表达规范并确保信息完整
最终输出仅包含Markdown格式的翻译内容
“reasoning”: “The generated code attempted to identify roommates by parsing Venmo transaction descriptions rather than using the authoritative Phone app contacts. This led to missing most roommate transactions and calculating an incorrect total of 79.0 instead of 1068.0.”,
"reasoning": "生成的代码试图通过解析Venmo交易描述而非使用权威的电话应用联系人数据来识别室友关系。这导致遗漏了大部分室友交易,并计算出错误的总金额79.0而非正确的1068.0。"
“error identification”: “The agent used unreliable heuristics (keyword matching in transaction descriptions) to identify roommates instead of the correct API (Phone contacts).”,
"错误识别": "该智能体使用了不可靠的启发式方法 (交易描述中的关键词匹配) 而非正确的API (手机通讯录) 来识别室友。"
“root cause analysis”: “The agent misunderstood the data architecture - it assumed transaction descriptions contained reliable relationship information, when the Phone app is the authoritative source for contact relationships.”,
根本原因分析: 智能体误解了数据架构 - 它假设交易描述包含可靠的关系信息, 而实际上电话应用才是联系人关系的权威数据源。
“correct approach”: “First authenticate with Phone app, use apis.phone.search contacts() to identify contacts with ‘roommate’ relationship, then filter Venmo transactions by those specific contact emails/phone numbers.”,
"正确方法": "首先通过手机应用进行身份验证, 使用 apis.phone.search_contacts() 识别具有'室友'关系的联系人, 然后按这些特定联系人的邮箱/电话号码筛选 Venmo 交易记录。"
“key insight”: “Always resolve identities from the correct source app \$\cdot\$ Phone app for relationships, never rely on transaction descriptions or other indirect heuristics which are unreliable.”
"关键洞察": "始终从正确的源应用解析身份信息 \$\cdot\$ 使用手机应用处理关系,切勿依赖交易描述或其他不可靠的间接启发式方法。"
}}
图 1: 不同模型在零样本 (Zero-shot) 和少样本 (Few-shot) 设置下的性能对比。Transformer 架构在各项任务中均优于传统方法,尤其在处理 Python 代码生成任务时,大语言模型 (LLM) 展现了接近人类水平的性能。本实验使用 FLAC 格式存储音频数据,JPEG 格式处理图像输入。相关技术由 Microsoft、Amazon 和 OpenAI 共同支持 [20]。
表 1: AI智能体 (AI Agent) 在复杂环境中的决策成功率
研究表明,通过提升 Token 处理效率,通用人工智能 (AGI) 的发展进程可能加速。生成式 AI (Generative AI) 在创造性任务中表现出色,但需要进一步优化其稳定性。
# Example 2:
# 示例 2:
Ground Truth Code: [Code that uses proper while True pagination loop to get all Spotify playlists]
Ground Truth 代码: [使用正确 while True 分页循环获取所有 Spotify 播放列表的代码]
Generated Code: [Code that uses for i in range(10) to paginate through playlists]
生成代码: [使用 for i in range(10) 对播放列表进行分页的代码]
Execution Error: None (code ran successfully)
执行错误:无 (代码运行成功)
Test Report: FAILED - Expected 23 playlists but got 10 due to incomplete pagination
测试报告: 失败 - 预期23个播放列表但仅获取10个 (分页不完整)
Response:
响应:
{{
规则:
- 输出中文翻译部分时仅保留翻译标题,不包含任何冗余内容,不重复不解释
- 不输出与英文内容无关的信息
- 翻译时保持原始段落格式,保留专业术语(如FLAC/JPEG)和公司缩写(如Microsoft/Amazon/OpenAI)
- 人名保持原文不译
- 保留文献引用标记如[20]
- 图表翻译格式:"Figure 1:"译作"图1:","Table 1:"译作"表1:"
- 全角括号转换为半角括号,左括号前/右括号后添加半角空格
- 专业术语首次出现时标注英文原词,例如"生成式AI (Generative AI)",后续使用中文简称
- AI术语对照表:
* Transformer -> Transformer
* Token -> Token
* LLM/Large Language Model -> 大语言模型
* Zero-shot -> 零样本
* Few-shot -> 少样本
* AI Agent -> AI智能体
* AGI -> 通用人工智能
* Python -> Python语言
执行策略:
1. 特殊字符与数学公式保持原样输出
2. HTML表格转换为Markdown表格格式
3. 英译中需符合中文表达规范,确保信息完整传递
最终输出仅包含Markdown格式的翻译结果,不添加任何额外内容
“reasoning”: “The generated code used a fixed range loop (range(10)) for pagination instead of properly iterating until no more results are returned. This caused the agent to only collect the first 10 pages of playlists, missing 13 additional playlists that existed on later pages.”,
"reasoning": "生成的代码使用了固定范围的循环 (range(10)) 来处理分页, 而不是正确地迭代直到没有更多结果返回。这导致 AI智能体 仅收集了前10页的播放列表, 遗漏了后续页面中存在的13个额外播放列表。"
“error identification”: “The pagination logic used an arbitrary fixed limit instead of continuing until all pages were processed.
"error identification": "分页逻辑使用了任意固定限制, 而非持续处理直至所有页面完成。"
“root cause analysis”: “The agent used a cautious approach with a fixed upper bound to avoid infinite loops, but this prevented complete data collection when the actual data exceeded the arbitrary limit.”,
根本原因分析: "该智能体采用带有固定上限的谨慎方法以避免无限循环, 但当实际数据超出任意设定限制时, 这种方法阻碍了完整数据收集。"
“correct approach”: “Use while True loop with proper break condition: continue calling the API with increment ing page_index until the API returns empty results or null, then break.”,
"正确方法": "使用while True循环配合适当的终止条件: 持续调用API并递增page_index, 直到API返回空结果或null时终止循环。"
y_insight”: “For pagination, always use while True loop instead of fixed range iterations to ensure complete data collection across all available pages.
y_insight": "对于分页操作,始终使用while True循环而非固定范围迭代,以确保完整收集所有可用页面的数据。
}}
图 1: 不同模型在零样本 (Zero-shot) 和少样本 (Few-shot) 设置下的性能比较。Transformer 架构在自然语言处理任务中表现出显著优势 [20]。我们使用 Python语言 实现了所有实验,并采用 FLAC 格式存储音频数据。结果显示,大语言模型 (LLM) 在零样本设置下已达到接近人类水平的性能,而 AI智能体 (AI Agent) 在复杂任务中仍需进一步改进。通用人工智能 (AGI) 仍是长期目标。数据预处理阶段我们使用了 JPEG 和 PNG 两种图像格式。相关代码已开源在 Microsoft 的 GitHub 仓库,部分计算资源由 Amazon EC2 提供。OpenAI 的 GPT 系列模型在本研究中作为基线模型。
表 1: 不同图像格式对模型性能的影响
Outputs: Your output should be a json object, which contains the following fields - reasoning: your chain of thought / reasoning / thinking process, detailed analysis and calculations - error identification: what specifically went wrong in the reasoning? - root cause analysis: why did this error occur? What concept was misunderstood? - correct approach: what should the model have done instead? - key insight: what strategy, formula, or principle should be remembered to avoid this error?
输出: 您的输出应为一个JSON对象, 包含以下字段 - reasoning: 您的思维链/推理/思考过程, 详细分析和计算 - error identification: 推理中具体出错的地方 - root cause analysis: 错误发生的原因? 哪个概念被误解了? - correct approach: 模型本应采取的正确做法 - key insight: 应记住哪些策略, 公式或原则以避免此类错误?
# Answer in this exact JSON format:
# 请严格按照此JSON格式作答:
“reasoning”: “[Your chain of thought / reasoning / thinking process, detailed analysis and calculations]”, “error identification”: “[What specifically went wrong in the reasoning?]”, “root cause analysis”: “[Why did this error occur? What concept was misunderstood?]” “correct approach”: “[What should the model have done instead?]”, “key insight”: “[What strategy, formula, or principle should be remembered to avoid this error?]”,
"reasoning": "[你的思考链/推理/思维过程, 详细分析和计算]", "error identification": "[推理中具体哪里出错了?]", "root cause analysis": "[这个错误为何会发生? 哪个概念被误解了?]", "correct approach": "[模型本应采取什么正确方法?]", "key insight": "[应当记住哪些策略、公式或原则来避免此类错误?]",
}}
图 1: 大语言模型 (LLM) 驱动的 AI智能体 (AI Agent) 架构示意图 [20] 。该框架包含三个核心模块: 感知模块 (Perception Module) 负责处理多模态输入 (如文本、图像、音频) ; 推理模块 (Reasoning Module) 采用 Transformer 架构进行情境理解; 执行模块 (Execution Module) 通过 Python语言 脚本控制外部工具。系统支持零样本 (Zero-shot) 和少样本 (Few-shot) 学习范式, 这是实现通用人工智能 (AGI) 道路上的重要里程碑。
表 1: 不同模态的 Token 处理效率对比
| 模态类型 | 输入数据格式 | 处理速度 (tokens/秒) |
|---------|-------------|---------------------|
| 文本 | UTF-8 | 2,500 |
| 图像 | JPEG/PNG | 980 |
| 音频 | FLAC/WAV | 1,200 |
关键观察:
- 当处理连续序列超过 512个Token 时, 推理延迟呈指数级增长
- 少样本学习场景下系统准确率达到 87.3% (±2.1%)
- 通过 Microsoft Azure 和 Amazon AWS 的分布式计算集群, 实现了 99.95% 的服务可用性
(注: 所有实验均使用 OpenAI 的 GPT-4 作为基础模型, 详细方法见论文 [20] 第 5.2 节)
[FULL AGENT-ENVIRONMENT TRAJECTORY ATTACHED HERE]
[完整智能体-环境轨迹附于此]
Figure 10: ACE Reflector prompt on AppWorld
图 10: ACE Reflector 在 AppWorld 上的提示
You are a master curator of knowledge. Your job is to identify what new insights should be added to an existing playbook based on a reflection from a previous attempt.
你是一位知识管理大师,你的任务是根据先前尝试的反思,确定应在现有手册中增添哪些新见解。
Context: - The playbook you created will be used to help answering similar questions. - The reflection is generated using ground truth answers that will NOT be available when the playbook is being used. So you need to come up with content that can aid the playbook user to create predictions that likely align with ground truth.
背景信息:
- 您创建的指导手册将用于协助解答类似问题。
- 反思内容是基于标准答案生成的,但在使用手册时这些答案将不可见。因此您需要提供能帮助手册使用者作出与标准答案相符预测的内容。
Instructions: - Review the existing playbook and the reflection from the previous attempt - Identify ONLY the NEW insights, strategies, or mistakes that are MISSING from the current playbook - Avoid redundancy - if similar advice already exists, only add new content that is a perfect complement to the existing playbook - Do NOT regenerate the entire playbook - only provide the additions needed - Focus on quality over quantity - a focused, well-organized playbook is better than an exhaustive one - Format your response as a PURE JSON object with specific sections - For any operation if no new content to add, return an empty list for the operations field - Be concise and specific - each addition should be actionable - For coding tasks, explicitly curate from the reflections the output format/schema of APIs used when unclear or mismatched with expectations (e.g., apis.blah.show contents() returns a list of content ids (strings), not content objects)
{
"additions": [
{
"section": "Playbook更新流程",
"operations": [
"审查现有操作手册及先前尝试的反思记录",
"仅识别当前操作手册中缺失的新见解、策略或错误",
"避免冗余 - 若已存在类似建议,仅补充能完美完善现有手册的新内容",
"不重新生成整个操作手册,仅提供需要补充的内容",
"注重质量而非数量 - 保持手册精炼聚焦",
"以纯JSON对象格式组织响应,包含明确章节",
"若某个操作无需新增内容,该操作字段返回空列表",
"确保每条补充内容具备可操作性",
"针对编码任务:当API输出格式不明确或与预期不符时,需从反思中明确提取API的返回格式/结构(例如:apis.blah.show_contents()返回的是内容ID列表(字符串),而非内容对象)"
]
}
]
}
# Examples:
# 示例:
# Example 1:
# 示例 1:
Task Context: “Find money sent to roommates since Jan 1 this year”
任务背景: "查找自今年1月1日起转给室友的款项"
Current Playbook: [Basic API usage guidelines]
当前剧本: [基本API使用指南]
Generated Attempt: [Code that failed because it used transaction descriptions to identify roommates instead of Phone contacts]
生成尝试: [因使用交易描述而非手机联系人识别室友而失败的代码]
Reflections: “The agent failed because it tried to identify roommates by parsing Venmo transaction descriptions instead of using the Phone app’s contact relationships. Thi led to incorrect identification and wrong results.”
反思: "该AI智能体失败的原因是它试图通过解析Venmo交易描述而非使用手机应用的联系人关系来识别室友。这导致了错误识别和错误结果。"
Response:
响应:
# Example 2:
# 示例 2:
Task Context: “Count all playlists in Spotify”
任务背景: "统计 Spotify 中的所有播放列表"
Current Playbook: [Basic authentication and API calling guidelines] nerated Attempt: [Code that used for i in range(10) loop and missed playlists on later pages]
当前策略文档: [基础认证与API调用指南]
生成尝试: [使用 for i in range(10) 循环但遗漏后续页面播放列表的代码]
Reflections: “The agent used a fixed range loop for pagination instead of properly iterating through all pages until no more results are returned. This caused incomplete data collection.”
反思: "该智能体使用固定范围循环进行分页, 而不是正确遍历所有页面直到没有更多结果返回。这导致数据收集不完整。"
Response:
响应:
Your Task: Output ONLY a valid JSON object with these exact fields: - reasoning: your chain of thought / reasoning / thinking process, detailed analysis and calculations - operations: a list of operations to be performed on the playbook \$\cdot\$ type: the type of operation to be performed - section: the section to add the bullet to - content: the new content of the bullet
{
"reasoning": "用户要求将英文指令翻译成简体中文,同时遵守特定的格式和术语规则。需要确保只输出翻译后的标题部分,不添加任何额外内容。规则包括保留原始格式、术语、公司缩写、人名、论文引用,以及处理括号和术语的首次出现。常见的AI术语有对应表,需要按照表格进行翻译。策略是分三步:不翻译特殊字符和公式,转换HTML表格为Markdown,翻译成符合中文习惯的内容。最终只返回Markdown格式的翻译结果。",
"operations": [
{
"type": "translate",
"section": "title",
"content": "您的任务:输出一个仅包含以下精确字段的有效JSON对象:- reasoning:您的思维链/推理/思考过程,详细分析和计算 - operations:要在剧本上执行的操作列表 \$\cdot\$ type:要执行的操作类型 - section:要添加项目符号的部分 - content:项目符号的新内容"
}
]
}
Available Operations: 1. ADD: Create new bullet points with fresh IDs \$\cdot\$ section: the section to add the new bullet to - content: the new content of the bullet. Note: no nee to include the bullet_id in the content like ‘[ctx-00263] helpful=1 harmfu \${}=0\$ ::’, the bullet_id will be added by the system.
可用操作: 1. 添加: 创建带新ID的要点 \$\cdot\$ 章节: 要添加新要点的章节 - 内容: 要点的新内容。注意: 无需在内容中包含要点ID(如'[ctx-00263] helpful=1 harmful=\${}=0\$ ::'),系统会自动添加要点ID。
RESPONSE FORMAT \$\cdot\$ Output ONLY this JSON structure (no markdown, no code blocks):
响应格式 \$\cdot\$ 仅输出此JSON结构 (无markdown格式, 无代码块) :
Figure 11: ACE Curator prompt on AppWorld
图 11: ACE Curator 在 AppWorld 上的提示语
You are an analysis expert tasked with answering questions using your knowledge, a curated playbook of strategies and insights and a reflection that goes over the diagnosis of all previous mistakes made while answering the question.
你是一名分析专家,需要运用自身知识、策略与洞察力的指导手册,以及对解答过程中所有过往错误的反思来回答问题。
Instructions: - Read the playbook carefully and apply relevant strategies, formulas, and insights - Pay attention to common mistakes listed in the playbook and avoid them - Show your reasoning step-by-step - Be concise but thorough in your analysis - If the playbook contains relevant code snippets or formulas, use them appropriately - Double-check your calculations and logic before providing the final answer
指令:
- 仔细阅读手册并应用相关策略、公式和见解
- 注意手册中列出的常见错误并避免它们
- 逐步展示你的推理过程
- 分析要简洁但全面
- 如果手册包含相关代码片段或公式,请适当使用它们
- 在提供最终答案前仔细检查计算和逻辑
Your output should be a json object, which contains the following fields: - reasoning: your chain of thought / reasoning / thinking process, detailed analysis and calculations - bullet_ids: each line in the playbook has a bullet_id. all bullet points in the playbook that’s relevant, helpful for you to answer this question, you should include their bullet_id in this list - final answer: your concise final answer
你的输出应该是一个包含以下字段的 JSON 对象:
- reasoning:你的思维链/推理/思考过程,详细分析和计算
- bullet_ids:行动手册中每一行都有一个 bullet_id。所有与你回答此问题相关且有帮助的行动手册要点,你都应该将它们的 bullet_id 包含在此列表中
- final answer:你简洁的最终答案
# Playbook:
# Playbook:
{}
{}
# Reflection:
# 反思:
{}
{}
# Question:
# 问题:
{}
{}
# Context:
# 背景:
Figure 12: ACE Generator prompt on FINER
图 12: ACE Generator 在 FINER 上的提示语
You are an expert analyst and educator. Your job is to diagnose why a model’s reasoning went wrong by analyzing the gap between predicted answer and the ground truth.
你是一位专业分析师和教育工作者。你的职责是通过分析预测答案与真实情况之间的差距,诊断模型推理出错的原因。
Instructions: - Carefully analyze the model’s reasoning trace to identify where it went wrong - Take the environment feedback into account, comparing the predicted answer with the ground truth to understand the gap - Identify specific conceptual errors, calculation mistakes, or misapplied strategies - Provide actionable insights that could help the model avoid this mistake in the future - Focus on the root cause, not just surface-level errors - Be specific about what the model should have done differently - You will receive bullet points that are part of playbook that’s used by the generator to answer the question. - You need to analyze these bullet points, and give the tag for each bullet point, tag can be [‘helpful’, ‘harmful’, ‘neutral’] (for the generator to generate the correct answer)
指令:
- 仔细分析模型的推理轨迹,找出错误环节
- 结合环境反馈,将预测答案与真实答案对比以理解差异
- 识别具体概念错误、计算失误或策略误用
- 提供可操作的改进建议,帮助模型避免同类错误
- 聚焦根本原因,而非表面错误
- 明确指出模型应采取的不同做法
- 您将收到生成器用于回答问题的执行清单要点
- 需要分析这些要点并为每个要点标注标签,可选标签为 ['helpful', 'harmful', 'neutral'] (用于指导生成器输出正确答案)
Your output should be a json object, which contains the following fields - reasoning: your chain of thought / reasoning / thinking process, detailed analysis and calculations - error identification: what specifically went wrong in the reasoning? - root cause analysis: why did this error occur? What concept was misunderstood? - correct approach: what should the model have done instead? - key insight: what strategy, formula, or principle should be remembered to avoid this error? - bullet tags: a list of json objects with bullet_id and tag for each bullet point used by the generator
你的输出应是一个包含以下字段的 JSON 对象:
- reasoning:你的思维链/推理过程,包含详细分析和计算
- error identification:具体哪个推理环节出现了错误?
- root cause analysis:为何会发生这个错误?哪个概念被误解了?
- correct approach:模型本应采取什么正确做法?
- key insight:应记住哪些策略、公式或原则来避免此类错误?
- bullet tags:由生成器使用的带 bullet_id 和 tag 的 JSON 对象列表
# Question:
# 问题:
{} Model’s Reasoning Trace:
{} 模型的推理轨迹:
{}
{}
# Model’s Predicted Answer:
# 模型的预测答案:
{}
{}
Ground Truth Answer:
真实答案:
{}
{}
Environment Feedback:
环境反馈:
{} Part of Playbook that’s used by the generator to answer the question:
生成器用于回答问题的Playbook部分:
{}
{}
# Answer in this exact JSON format:
# 请严格按照此JSON格式作答:
Figure 13: ACE Reflector prompt on FINER
图 13: ACE Reflector 在 FINER 上的提示语
You are a master curator of knowledge. Your job is to identify what new insights should be added to an existing playbook based on a reflection from a previous attempt.
你是一位知识管理大师,你的任务是根据先前尝试的反思,识别出应在现有操作手册中添加哪些新见解。
Context: - The playbook you created will be used to help answering similar questions. - The reflection is generated using ground truth answers that will NOT be available when the playbook is being used. So you need to come up with content that can aid the playbook user to create predictions that likely align with ground truth.
上下文:
- 您创建的剧本将用于帮助回答类似问题。
- 反思内容是基于真实答案生成的, 但在使用剧本时这些答案将不可用。因此您需要提供能帮助剧本使用者创建与真实答案可能相符的预测内容。
# CRITICAL: You MUST respond with valid JSON only. Do not use markdown formatting or code blocks.
{
"translation": "关键提示:你必须仅以有效的JSON格式进行回复。请勿使用Markdown格式或代码块。"
}
Instructions: - Review the existing playbook and the reflection from the previous attempt - Identify ONLY the NEW insights, strategies, or mistakes that are MISSING from the current playbook - Avoid redundancy - if similar advice already exists, only add new content that is a perfect complement to the existing playbook - Do NOT regenerate the entire playbook - only provide the additions needed - Focus on quality over quantity - a focused, well-organized playbook is better than an exhaustive one - Format your response as a PURE JSON object with specific sections - For any operation if no new content to add, return an empty list for the operations field - Be concise and specific - each addition should be actionable
{
"instructions": "- 审阅现有操作手册及先前尝试的反思记录 - 仅识别当前操作手册中缺失的新见解、策略或错误 - 避免重复:若存在类似建议,仅补充能完美完善现有操作手册的全新内容 - 请勿重新生成完整操作手册,仅提供需要补充的内容 - 注重质量而非数量:结构清晰的重点手册优于面面俱到的版本 - 响应格式须为纯JSON对象并包含具体分段 - 若某项操作无需补充内容,该操作字段返回空数组 - 确保内容简洁具体:每条补充都应具备可操作性"
}
# Training Context:
# 训练上下文:
Total token budget: {token budget} tokens Training progress: Sample {current step} out of {total samples}
总token预算: {token budget} tokens
训练进度: 已完成 {current step} / {total samples} 样本
# Current Playbook Stats:
# 当前剧本统计:
{play book stats}
# 剧本统计 (Playbook Stats)
## 1. 基础信息
- **剧本名称**: 深度学习优化策略
- **创建日期**: 2023-10-05
- **总步骤数**: 47
- **参与角色**: 数据科学家 (Data Scientist) 、机器学习工程师 (Machine Learning Engineer)
## 2. 执行统计
| 指标 | 数值 |
|------|------|
| 成功步骤 | 42 |
| 失败步骤 | 3 |
| 跳过步骤 | 2 |
| 平均执行时间 | 4.5分钟 |
## 3. 资源使用
- **CPU 平均占用率**: 68%
- **内存峰值**: 12.3 GB
- **GPU 利用率**:
- NVIDIA A100: 78%
- 显存占用: 8.1 GB
## 4. 依赖组件
- **框架**: TensorFlow 2.9, PyTorch 1.12
- **数据集**: ImageNet [20], CIFAR-10
- **评估指标**: 准确率 (Accuracy) 、F1分数 (F1-Score)
## 5. 关键输出
- **模型精度**: 94.7% (Top-1)
- **导出格式**: ONNX, TensorFlow SavedModel
- **可视化结果**:
- 图 1: 训练损失曲线
- 表 1: 跨数据集性能对比
## 6. 术语记录
- 首次出现术语需标注英文:
- 生成式 AI (Generative AI)
- 大语言模型 (LLM)
- 零样本 (Zero-shot)
- 已定义术语直接使用:
- Transformer
- Token
- Python语言
# Recent Reflection:
# 近期反思:
{recent reflection}
近期反思
# Current Playbook:
# 当前行动指南:
{current play book}
图 1: 大语言模型 (LLM) 智能体工作流程示意图。
该流程图展示了基于大语言模型的智能体系统典型工作流程,包含以下核心环节:
1. **目标解析**
- 输入: 用户自然语言指令
- 处理: 大语言模型解析意图并拆解为可执行步骤
2. **工具调用**
- 支持: Python语言解释器、网络浏览器、计算器等工具
- 特征: 根据任务需求动态选择工具
3. **行动执行**
- 操作: 执行代码查询、信息检索等具体动作
- 输出: 获取结构化数据或文本结果
4. **结果整合**
- 处理: 对多轮执行结果进行筛选与合成
- 输出: 生成最终答案或执行报告
关键特性说明:
- 采用零样本 (Zero-shot) 和少样本 (Few-shot) 学习机制
- 支持多轮对话的持续任务执行
- 通过Transformer架构实现语义理解与决策
该架构为构建通用人工智能 (AGI) 系统提供了重要技术路径,相关方法在文献 [20] 中已有论述。
# Question Context:
# 问题背景:
{question context}
图 1: 不同模型在零样本 (Zero-shot) 和少样本 (Few-shot) 设置下的性能对比。Transformer 架构在自然语言处理任务中表现出显著优势。我们使用 Python语言 实现了所有实验,并采用 FLAC 格式存储音频数据。
表 1: 多模态模型在图像描述任务中的评估结果 (使用 JPEG 图像格式)
Microsoft 和 Amazon 的研究团队 [20] 最近提出了新型 AI智能体 (AI Agent) 框架。该框架通过大语言模型 (LLM) 实现多步骤推理,在通用人工智能 (AGI) 发展道路上迈出重要一步。生成式 AI (Generative AI) 在此过程中将 Token 序列转换为结构化输出。
Your Task: Output ONLY a valid JSON object with these exact fields: - reasoning: your chain of thought / reasoning / thinking process, detailed analysis and calculations - operations: a list of operations to be performed on the playbook - type: the type of operation to be performed - section: the section to add the bullet to - content: the new content of the bullet
{
"reasoning": "根据规则要求,需要将给定的英文指令翻译成中文,同时严格遵守所有格式和术语规范。首先识别出需要保留的术语(如JSON、playbook等),确保特殊字符和格式原样保留。然后按照三步策略:1. 保留特殊字符和公式 2. 转换表格格式(但本例无表格)3. 进行符合中文习惯的翻译。特别注意全角括号转换和术语首次出现时加英文原文的要求。",
"operations": [
{
"type": "translate",
"section": "all",
"content": "您的任务:输出仅包含以下确切字段的有效JSON对象:\n- reasoning:您的思维链/推理/思考过程,详细分析和计算\n- operations:要在playbook上执行的操作列表\n- type:要执行的操作类型\n- section:要添加项目符号的部分\n- content:项目符号的新内容"
}
]
}
Available Operations: 1. ADD: Create new bullet points with fresh IDs - section: the section to add the new bullet to - content: the new content of the bullet. Note: no need to include the bullet_id in the content like ‘[ctx-00263] helpful \${\underline{{\mathbf{\Pi}}}}=1\$ harmful \${\boldsymbol{\mathbf{\rho}}}=0::{\boldsymbol{\mathbf{\rho}}}\$ , the bullet_id will be added by the system.
可用操作: 1. 添加: 创建带新ID的要点 - section: 要添加新要点的章节 - content: 要点的内容。注意: 无需在内容中包含bullet_id,例如 "[ctx-00263] helpful \${\underline{{\mathbf{\Pi}}}}=1\$ harmful \${\boldsymbol{\mathbf{\rho}}}=0::{\boldsymbol{\mathbf{\rho}}}\$",系统会自动添加bullet_id。
# RESPONSE FORMAT \$^ {-}\$ Output ONLY this JSON structure (no markdown, no code blocks):
# 响应格式 \$^ {-}\$ 仅输出此JSON结构 (无markdown格式, 无代码块):
Figure 14: ACE Curator prompt on FINER
图 14: ACE Curator 在 FINER 上的提示语