A Comprehensive Study of Knowledge Editing for Large Language Models
大语言模型知识编辑的综合研究
Ningyu Zhang∗, Yunzhi Yao∗, Bozhong Tian∗, Peng Wang∗, Shumin Deng∗, Mengru Wang, Zekun Xi, Shengyu Mao, Jintian Zhang, Yuansheng Ni, Siyuan Cheng, Ziwen Xu, Xin Xu, Jia-Chen Gu, Yong Jiang, Pengjun Xie, Fei Huang, Lei Liang, Zhiqiang Zhang, Xiaowei Zhu, Jun Zhou, Huajun Chen†
宁雨张∗, 云志姚∗, 伯中田∗, 鹏王∗, 舒敏邓∗, 梦茹王, 泽坤席, 胜宇毛, 金天张, 元盛倪, 思远程, 子文徐, 鑫徐, 嘉晨顾, 勇江, 鹏俊谢, 飞黄, 磊梁, 志强张, 小伟朱, 俊周, 华军陈†
Zhejiang University, National University of Singapore, University of California, Los Angeles, Ant Group, Alibaba Group {zhang ning yu,yyztodd}@zju.edu.cn Project: https://zjunlp.github.io/project/KnowEdit
浙江大学、新加坡国立大学、加州大学洛杉矶分校、蚂蚁集团、阿里巴巴集团 {zhang ning yu,yyztodd}@zju.edu.cn 项目地址: https://zjunlp.github.io/project/KnowEdit
Abstract
摘要
Large Language Models (LLMs) have shown extraordinary capabilities in understanding and generating text that closely mirrors human communication. However, a primary limitation lies in the significant computational demands during training, arising from their extensive parameter iz ation. This challenge is further intensified by the dynamic nature of the world, necessitating frequent updates to LLMs to correct outdated information or integrate new knowledge, thereby ensuring their continued relevance. Note that many applications demand continual model adjustments post-training to address deficiencies or undesirable behaviors. There is an increasing interest in efficient, lightweight methods for onthe-fly model modifications. To this end, recent years have seen a burgeoning in the techniques of knowledge editing for LLMs, which aim to efficiently modify LLMs’ behaviors within specific domains while preserving overall performance across various inputs. In this paper, we first define the knowledge editing problem and then provide a comprehensive review of cutting-edge approaches. Drawing inspiration from educational and cognitive research theories [1–3], we propose a unified categorization criterion that classifies knowledge editing methods into three groups: resorting to external knowledge, merging knowledge into the model, and editing intrinsic knowledge. Furthermore, we introduce a new benchmark, KnowEdit, for a comprehensive empirical evaluation of representative knowledge editing approaches. Additionally, we provide an in-depth analysis of knowledge location, which can give a deeper understanding of the knowledge structures inherent within LLMs. Initially conceived as a means to steer LLMs efficiently, we hope that insights gained from knowledge editing research could shed light on the underlying knowledge mechanisms of LLMs. To facilitate future research, we have released an open-source framework, EasyEdit1, which will enable practitioners to efficiently and flexibly implement knowledge editing for LLMs. Finally, we discuss several potential applications of knowledge editing, outlining its broad and impactful implications.
大语言模型(LLM)在理解和生成接近人类交流的文本方面展现出非凡能力。然而其主要局限在于训练过程中因海量参数化带来的巨大计算需求。这一挑战因世界的动态特性而加剧,需要频繁更新大语言模型以修正过时信息或整合新知识,从而保持其持续相关性。值得注意的是,许多应用场景要求模型在训练后进行持续调整以解决缺陷或不良行为。业界对高效、轻量级的实时模型修改方法兴趣日增。近年来大语言模型的知识编辑技术蓬勃发展,该技术旨在高效修改特定领域内模型行为的同时,保持其在各类输入中的整体性能。本文首先定义知识编辑问题,随后系统梳理前沿方法。受教育和认知研究理论[1-3]启发,我们提出统一分类标准,将知识编辑方法归为三类:借助外部知识、知识融合入模、编辑内在知识。此外,我们构建了新基准KnowEdit,用于对代表性知识编辑方法进行全面实证评估。通过深入分析知识定位,可以更深刻理解大语言模型固有的知识结构。知识编辑研究最初作为高效引导大语言模型的手段,我们期望其研究成果能揭示模型底层的知识机制。为促进未来研究,我们开源了框架EasyEdit1,使实践者能高效灵活地实现大语言模型知识编辑。最后,我们探讨了知识编辑的若干潜在应用,阐明其广泛而深远的影响。
Keywords— natural language processing, large language models, knowledge editing
关键词— 自然语言处理 (Natural Language Processing)、大语言模型 (Large Language Models)、知识编辑 (Knowledge Editing)
Contents
目录
1 Introduction
1 引言
2 Background
2 背景
3 Knowledge Editing for LLMs 8
3 大语言模型的知识编辑 8
3.5 Evaluation for Knowledge Editing
3.5 知识编辑评估
4 Experiments 15
4 实验 15
4.1 Experiment Settings . . 15
4.1 实验设置 . . 15
5 Analysis
5 分析
20
20
6 Applications 24
6 应用 24
7 Discussion and Conclusion 29
7 讨论与结论 29
Broader Impacts 29
更广泛的影响 29
1 Introduction
1 引言
Knowledge is a fundamental component of human intelligence and civilization [4]. Its systematic structure empowers us to represent tangible entities or delineate principles through symbolic means, offering the capability to facilitate the articulation of intricate behaviors or tasks [5–7]. Throughout our lives, we humans continuously gather an extensive wealth of knowledge and learn to adaptively apply it in various contexts. The enduring exploration of the nature of knowledge and the processes by which we acquire, retain, and interpret it, continues to captivate scientists, which is not just a technical pursuit but a journey towards mirroring the nuanced complexities of human cognition, communication and intelligence [8–12].
知识是人类智能与文明的基础要素 [4]。其系统化结构使我们能够通过符号化手段表征有形实体或阐述原理,从而具备表达复杂行为或任务的能力 [5–7]。在生命历程中,人类持续积累海量知识,并学会在不同情境中自适应地运用这些知识。关于知识本质及其获取、存储与解释过程的持久探索,始终吸引着科学家们——这不仅是一项技术追求,更是通往映射人类认知、交流与智能微妙复杂性的旅程 [8–12]。
Recently, Large Language Models (LLMs) like GPT-4 [13] have showcased a remarkable ability in Natural Language Processing (NLP) to retain a vast amount of knowledge, arguably surpassing human capacity [14–31]. This achievement can be attributed to the way LLMs process and compress huge amounts of data [32–35], potentially forming more concise, coherent, and interpret able models of the underlying generative processes, essentially creating a kind of “world model” [36–38]. For example, Dai et al. [39] have introduced the Knowledge Neuron (KN) thesis, which proposes that language models function similarly to key-value memories. Here, the multi-layer perceptron (MLP) weights in the core region [40] may play a crucial role in recalling facts from the training corpus, suggesting a more structured and retrievable form of knowledge storage within LLMs [41, 42]. Further insights come from the ability of LLMs to understand and manipulate complex strategic environments, whereas Li et al. [43] has demonstrated that transformers trained for next-token prediction in board games such as Othello develop explicit representations of the game’s state. Patel and Pavlick [44] have revealed that LLMs can track boolean states of subjects within given contexts and learn representations that reflect perceptual, symbolic concepts [36, 45–47]. This dual capability indicates that LLMs can serve as extensive knowledge bases [48–59], not only storing vast amounts of information but also structuring it in ways that may mirror human cognitive processes.
近来,诸如GPT-4[13]之类的大语言模型(LLM)在自然语言处理(NLP)领域展现出惊人的知识储备能力,其容量甚至可能超越人类[14–31]。这一成就源于大语言模型对海量数据的处理与压缩方式[32–35],它们可能构建出更简洁、连贯且可解释的底层生成过程模型,实质上形成了一种"世界模型"[36–38]。例如Dai等人[39]提出的知识神经元(KN)理论认为,语言模型运作方式类似键值存储器,其中核心区域[40]的多层感知机(MLP)权重在从训练语料库中提取事实时起关键作用,这表明大语言模型内部存在结构化、可检索的知识存储形式[41,42]。更深入的发现来自大语言模型对复杂策略环境的理解与操控能力——Li等人[43]证实,通过棋盘游戏(如黑白棋)的下一Token预测训练,Transformer会形成对游戏状态的显式表征。Patel与Pavlick[44]则揭示大语言模型能追踪给定语境中主体的布尔状态,并学习反映感知与符号概念的表征[36,45–47]。这种双重能力表明,大语言模型可作为庞大的知识库[48–59],不仅能存储海量信息,还能以近似人类认知过程的方式对其进行结构化组织。
However, LLMs have limitations like factual fallacy, potential generation of harmful content, and outdated knowledge due to their training cut-off [60–63]. Retraining to correct these issues is both costly and time-consuming [64–68]. To address this, recent years have seen a surge in the development of knowledge editing techniques specifically tailored for LLMs, which allows for cost-effective post-hoc modifications to models [69–71]. This technique focuses on specific areas for adjustment without compromising overall performance and can help understand how LLMs represent and process information, which is crucial for ensuring the fairness, and safety in Artificial Intelligence (AI) applications [72–76].
然而,大语言模型存在诸如事实谬误、可能生成有害内容以及因训练截止日期导致的知识过时等局限性 [60–63]。通过重新训练来解决这些问题既昂贵又耗时 [64–68]。为此,近年来针对大语言模型的知识编辑技术迅速发展,这种技术能够以较低成本对模型进行事后修改 [69–71]。它专注于特定领域的调整而不影响整体性能,并有助于理解大语言模型如何表示和处理信息,这对于确保人工智能 (AI) 应用的公平性和安全性至关重要 [72–76]。
This paper first attempts to provide a comprehensive study of the development and recent advances in knowledge editing for LLMs. We first introduce the architecture of Transformers, mechanism of knowledge storage in LLMs (§2.1), and related techniques including parameter-efficient fine-tuning, knowledge augmentation, continue learning and machine unlearning (§2.2). Then we introduce preliminary $(\S3.1)$ , formally describe the knowledge editing problem (§3.2), and propose a new taxonomy (§3.3) to provide a unified view on knowledge editing methods based on the educational and cognitive research theories [1–3]. Specifically, we categorize knowledge editing for LLMs into: resorting to external knowledge (§3.3.1), merging knowledge into the model (§3.3.2), and editing intrinsic knowledge (§3.3.3 ) approaches. Our categorization criterion is summarized as follows:
本文首次尝试对大语言模型(LLM)知识编辑的发展与最新进展进行全面研究。我们首先介绍了Transformer架构(§2.1)、大语言模型中的知识存储机制,以及相关技术包括参数高效微调(parameter-efficient fine-tuning)、知识增强(knowledge augmentation)、持续学习(continue learning)和机器遗忘(machine unlearning)(§2.2)。随后我们介绍了基础知识(§3.1),形式化描述了知识编辑问题(§3.2),并基于教育认知研究理论[1-3]提出新的分类法(§3.3)以统一审视知识编辑方法。具体而言,我们将大语言模型知识编辑分为三类:借助外部知识(§3.3.1)、将知识融入模型(§3.3.2)以及编辑内在知识(§3.3.3)。我们的分类标准总结如下:
• Resorting to External Knowledge. This kind of approach is similar to the recognition phase in human cognitive processes, which needs to be exposed to new knowledge within a relevant context, just as people first encounter new information. For example, providing sentences that illustrate a factual update as a demonstration of the model allows initial recognition of the knowledge to be edited. • Merging Knowledge into the Model. This kind of approach closely resembles the association phrase in human cognitive processes, in which connections are formed between the new knowledge and existing knowledge in the model. Methods would combine or substitute the output or intermediate output with a learned knowledge representation. • Editing Intrinsic Knowledge. This approach to knowledge editing is akin to the mastery phase in human cognitive processes. It involves the model fully integrating knowledge into its parameters by modifying the weights and utilizing them reliably.
• 借助外部知识。这类方法类似于人类认知过程中的识别阶段,需要将新知识置于相关语境中接触,正如人们初次接触新信息时的情景。例如,通过提供展示事实更新的例句作为模型演示,使其初步识别待编辑的知识。
• 融合知识至模型。这类方法与人类认知过程中的关联阶段高度相似,即在模型内部建立新知识与既有知识间的联系。具体方法会将输出或中间输出与习得的知识表征进行结合或替换。
• 编辑内在知识。此类知识编辑方法近似于人类认知过程的掌握阶段,通过修改权重并可靠运用,使模型将知识完全整合至参数中。
This paper then involves extensive and comprehensive experiments conducted on $12\mathrm{NLP}$ datasets. These are meticulously designed to evaluate the performance (§4), usability, and underlying mechanisms, complete with in-depth analyses (§5), among other aspects. The key insights from our research are summarized as follows:
本文在12个NLP数据集上进行了广泛而全面的实验。这些实验经过精心设计,用于评估性能(§4)、可用性及内在机制,并辅以深入分析(§5)等多方面内容。我们的研究主要得出以下关键结论:
Finally, we delve into the multifaceted applications of knowledge editing, examining its potential from a variety of perspectives (§6), including efficient machine learning, AI-Generated Content (AIGC), trustworthy AI, and human-computer interaction (personalized agents). Additionally, our discussion extends to the broader impacts of knowledge editing techniques, specifically focusing on aspects such as energy consumption and interpret ability $(\S7)$ . This paper aims to serve as a catalyst for further research in the realm of LLMs, emphasizing efficiency and innovation. To support and encourage future research, we will make our tools, codes, data splits, and trained model checkpoints publicly accessible.
最后,我们深入探讨知识编辑的多方面应用,从多个角度审视其潜力(§6),包括高效机器学习、AI生成内容(AIGC)、可信AI以及人机交互(个性化智能体)。此外,我们的讨论还延伸到知识编辑技术更广泛的影响,特别关注能源消耗和可解释性等方面(§7)。本文旨在推动大语言模型领域的进一步研究,强调效率和创新。为了支持和鼓励未来的研究,我们将公开提供工具、代码、数据分割和训练好的模型检查点。
2 Background
2 背景
2.1 Large Language Models
2.1 大语言模型 (Large Language Models)
2.1.1 Transformers for LLM
2.1.1 大语言模型中的Transformer
The Transformer [77] model, a cornerstone in the design of modern state-of-the-art LLMs, represents a significant shift from previous sequence learning methods. The original Transformer model is introduced as an encoder-decoder framework, wherein both the encoder and decoder consist of a series of identical layers stacked upon each other. Each block within this architecture is equipped with a self-attention module and a fully connected feed-forward neural network. Uniquely, the blocks in the decoder also incorporate an additional cross-attention layer, positioned above the self-attention layer, which is designed to effectively capture and integrate information from the encoder.
Transformer [77] 模型作为现代顶尖大语言模型设计的基石,标志着与以往序列学习方法的重大转变。原始Transformer模型采用编码器-解码器框架,其中编码器和解码器均由多个相同层堆叠而成。该架构中的每个模块都配备自注意力(self-attention)模块和全连接前馈神经网络。独特的是,解码器模块还在自注意力层上方增设了交叉注意力(cross-attention)层,旨在有效捕获并整合来自编码器的信息。
Self-Attention Module (SelfAttn) The self-attention mechanism is a pivotal feature of the Transformer, allowing it to process sequences of data effectively. This module empowers each position within the encoder to attend to all positions in the preceding layer, thereby efficiently capturing contextual information embedded in the sequence. The mathematical representation of the self-attention mechanism is as follows:
自注意力模块 (SelfAttn)
自注意力机制是Transformer的核心特性,使其能够高效处理序列数据。该模块使编码器中每个位置都能关注前一层所有位置,从而有效捕捉序列中的上下文信息。自注意力机制的数学表示如下:
$$
H=\mathrm{ATT}(Q,K,V)=\mathrm{Softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right)V.
$$
$$
H=\mathrm{ATT}(Q,K,V)=\mathrm{Softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right)V.
$$
Feed-Forward Module (FFN) Following each attention layer in the Transformer is a fully connected Feed-Forward Neural network (FFN). This specific component of the architecture comprises two linear transformations, with a ReLU activation function intervening between them. The structure of the FFN can be succinctly described as follows:
前馈模块 (FFN)
Transformer 中每个注意力层之后都连接着一个全连接的前馈神经网络 (FFN)。该架构的这一特定组件包含两个线性变换层,中间通过 ReLU 激活函数进行连接。FFN 的结构可简要描述如下:
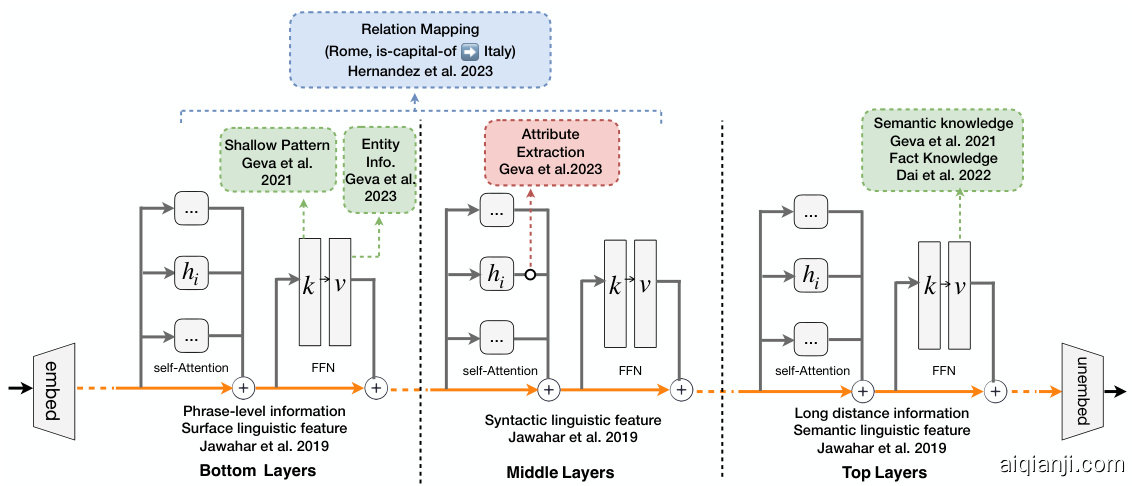
Figure 1: The mechanism of knowledge storage in LLMs. Here, we summarize the findings of current works, including: Jawahar et al. [78], Geva et al. [41], Dai et al. [39], Meng et al. [79], and Hernandez et al. [80].
图 1: 大语言模型中的知识存储机制。此处我们总结了当前研究的主要发现,包括:Jawahar et al. [78]、Geva et al. [41]、Dai et al. [39]、Meng et al. [79] 以及 Hernandez et al. [80] 的工作。
$$
\mathrm{FFN}(\mathbf{x})=\mathrm{ReLU}(\mathbf{x}\cdot W_{1}+b_{1})\cdot W_{2}+b_{2},
$$
$$
\mathrm{FFN}(\mathbf{x})=\mathrm{ReLU}(\mathbf{x}\cdot W_{1}+b_{1})\cdot W_{2}+b_{2},
$$
Since its inception, the Transformer model has revolutionized the field of NLP. Its adaptable and efficient architecture has facilitated advancements in various NLP tasks, such as question-answering, text sum mari z ation, and machine translation systems. The model’s influence extends beyond NLP, impacting other areas of machine learning and setting a new standard for building complex and effective neural network architectures.
自问世以来,Transformer模型彻底改变了自然语言处理(NLP)领域。其灵活高效的架构推动了问答系统、文本摘要和机器翻译等多种NLP任务的进步。该模型的影响力已超越NLP范畴,波及机器学习的其他领域,并为构建复杂高效的神经网络架构设立了新标准。
2.1.2 Mechanism of Knowledge Storage in LLMs
2.1.2 大语言模型中的知识存储机制
The Transformer’s remarkable performance is partly attributed to its ability to store a wealth of information within its parameters, encompassing linguistic [81], commonsense [82–84], arithmetic, and world knowledge [48, 85–87]. However, the exact manner in which this knowledge is organized within LLMs is still largely enigmatic. Current research efforts are dedicated to unraveling the mechanistic explanations of LLMs’ behaviours [88–92], especially the complexities of knowledge storage in LLMs, with Figure 1 illustrating some of these research findings.
Transformer 的卓越性能部分归功于其能在参数中存储丰富信息的能力,这些信息包括语言 [81]、常识 [82–84]、算术和世界知识 [48, 85–87]。然而,大语言模型中这些知识的具体组织方式在很大程度上仍是个谜。当前的研究致力于揭示大语言模型行为的机制性解释 [88–92],尤其是知识存储的复杂性,图 1: 展示了其中部分研究成果。
A key area of inquiry is pinpointing the specific location of knowledge within the model. Jawahar et al. [78] dissects the intricacies of the English language structure as comprehended by BERT [93]. Their findings reveal that BERT’s phrasal representations capture phrase-level information predominantly in the lower layers, and encode an intricate hierarchy of linguistic elements in the intermediate layers. This hierarchy is characterized by surface features at the foundational level and syntactic features in the central layers, and culminates with semantic features at the uppermost level. Geva et al. [41] proposes that the FFN layers in a Transformer model function akin to key-value memories. They suggest that the FFN input operates as a query, with the first layer representing keys and the second layer corresponding to values. They find that human-interpret able shallow input patterns trigger each key neuron, and the corresponding value neurons store the next-token output probability. As a result, the final output of the FFN can be understood as the weighted sum of activated values. Furthermore, they demonstrate that value vectors often embody interpret able concepts and knowledge, which can be intensified or attenuated through specific manipulations [42]. Building on this, Dai et al. [39] introduces the concept of “Knowledge Neurons”, suggesting that knowledge is localized within a small subset of FFN neurons in the uppermost layers of the language model. These neurons are identified through the analysis of integrated gradients across various prompts [94–96]. Similarly, Meng et al. [79] employs a method known as “causal tracing” to assess the indirect influences of hidden states or activation s, revealing that factual knowledge predominantly resides in the early-layer FFNs of such models. Additional y, Chen et al. [97] makes an intriguing finding that the language model contains language-independent neurons that express multilingual knowledge and degenerate neurons that convey redundant information by applying the integrated gradients method [94]. Concurrently, Zhao et al. [98] observes that LLMs appear to possess a specialized linguistic region responsible for processing multiple languages. Gueta et al. [99] suggests that knowledge is a region in weight space for fine-tuned language models. They find that after finetuning a pretrained model on similar datasets, the resulting models are close to each other in weight space. Recent interests also revolve around dissecting the distinct functionalities of individual neurons within LLMs [100]. Yet, it is crucial to note that some researchers caution against over interpreting these findings, emphasizing that models illustrate correlations rather than explicit mechanisms. For instance, Anonymous [101] argues that while MLP neurons may exhibit patterns interpret able through a linguistic lens, they do not necessarily “store” knowledge in a conventional sense, whether linguistic or factual.
一个关键研究领域是精确定位模型内部知识的具体位置。Jawahar等人[78]剖析了BERT[93]所理解的英语语言结构复杂性。他们的研究结果表明,BERT的短语表征主要在较低层捕获短语级信息,并在中间层编码了语言元素的复杂层次结构。该层次结构以基础层的表面特征、中间层的句法特征为特点,并在最上层以语义特征为顶峰。Geva等人[41]提出,Transformer模型中的FFN层功能类似于键值记忆。他们认为FFN输入充当查询,第一层表示键,第二层对应值。研究发现,人类可解释的浅层输入模式会触发每个关键神经元,而对应的值神经元存储着下一个token的输出概率。因此,FFN的最终输出可理解为激活值的加权和。此外,他们证明值向量通常体现可解释的概念和知识,这些知识可通过特定操作被增强或削弱[42]。基于此,Dai等人[39]提出"知识神经元"概念,认为知识定位于语言模型最上层FFN神经元的一个小子集中。这些神经元通过分析不同提示下的积分梯度被识别[94-96]。类似地,Meng等人[79]采用"因果追踪"方法评估隐藏状态或激活的间接影响,揭示事实知识主要存在于模型的早期层FFN中。此外,Chen等人[97]通过应用积分梯度方法[94]发现,语言模型包含表达多语言知识的语言无关神经元和传递冗余信息的退化神经元。同时,Zhao等人[98]观察到,大语言模型似乎拥有专门处理多种语言的语言区域。Gueta等人[99]提出,对于微调后的语言模型,知识是权重空间中的一个区域。他们发现,在相似数据集上微调预训练模型后,所得模型在权重空间中彼此接近。近期研究兴趣还包括剖析大语言模型中单个神经元的不同功能[100]。但需注意,有研究者警告不要过度解读这些发现,强调模型展示的是相关性而非明确机制。例如Anonymous[101]指出,虽然MLP神经元可能展现可通过语言学视角解释的模式,但它们未必以传统意义"存储"知识(无论是语言知识还是事实知识)。
Thus, the question of how Transformer LLMs retrieve and utilize this stored knowledge remains open, and some work has begun to unveil this mystery. Geva et al. [102] analyzes the information flow in the model and finds the self-attention model conducts attribute extraction during computing inspired by the circuit theory [103, 104]. Foote et al. [105] proposes Neuron to Graph (N2G), an innovative tool that automatically extracts a neuron’s behavior from the dataset it was trained on and translates it into an interpret able graph. Further, Hernandez et al. [80] conceptualizes relational knowledge within Transformers as a linear affine function, mapping subjects to objects. As to other knowledge, Gurnee and Tegmark [36] discovers that LLMs learn linear representations of space and time across multiple scales and identify individual “space neurons” and “time neurons” that reliably encode spatial and temporal coordinates. However, it is imperative to acknowledge that these studies predominantly concentrate on the representation of individual knowledge facts. The broader challenge lies in comprehensively understanding how various strands of knowledge are intricately organized and interconnected within these complex models [106, 107].
因此,Transformer大语言模型如何检索和利用这些存储知识的问题仍然悬而未决,部分研究已开始揭开这一谜题。Geva等人[102]通过分析模型中的信息流,发现自注意力机制在计算过程中受电路理论[103, 104]启发执行属性提取。Foote等人[105]提出Neuron to Graph (N2G)工具,可自动从训练数据中提取神经元行为并将其转化为可解释图结构。Hernandez等人[80]则将Transformer中的关系知识概念化为线性仿射函数,实现主语到宾语的映射。针对其他知识类型,Gurnee和Tegmark[36]发现大语言模型能学习多尺度的线性时空表征,并识别出可靠编码时空坐标的"空间神经元"和"时间神经元"。但必须指出,这些研究主要聚焦于单一知识事实的表征形式。更广泛的挑战在于全面理解这些复杂模型中各类知识如何被精细组织和关联[106, 107]。
2.2 Related Techniques
2.2 相关技术
Parameter-efficient Fine-tuning Fine-tuning all parameters of LLMs can be computationally expensive. To enable efficient adaptation, parameter-efficient tuning (PET) [108, 109] techniques have been proposed to match full fine-tuning performance while only updating a minimal parameters. PET consists of three distinct paradigms: addition-based, specification-based, and reparameter iz ation-based methods. In addition-based methods, extra trainable neural modules or parameters, which are not present in the original model or process, are introduced. A prime example of this is Adapter, as discussed in Houlsby et al. [110]. On the other hand, specification-based methods involve fine-tuning a select number of parameters, while keeping the majority of the model’s parameters unchanged. A notable method in this category is LoRA, as detailed in Hu et al. [111].
参数高效微调
全面微调大语言模型的所有参数可能计算成本高昂。为实现高效适配,研究者提出了参数高效微调 (PET) [108, 109] 技术,在仅更新极少量参数的情况下匹配全参数微调性能。PET包含三大范式:基于添加、基于指定和基于重参数化的方法。基于添加的方法会引入原始模型或处理流程中不存在的额外可训练神经模块或参数,典型代表如Houlsby等人[110]提出的Adapter。基于指定的方法则选择性地微调部分参数,同时保持模型绝大多数参数不变,该范畴的知名方法是Hu等人[111]提出的LoRA。
By fine-tuning a small number of parameters, PET methods aim to maximize model performance while reducing required resources and tuning time. PET techniques hold promise since knowledge editing seeks to efficiently modify model behavior. However, PET is typically applied to enhance task performance rather than edit knowledge specifically. The efficacy of existing PET methods for knowledge editing remains largely unexplored. Investigating how to leverage PET for efficient and precise knowledge updates presents an interesting direction for future work.
通过微调少量参数,PET方法旨在最大化模型性能,同时减少所需资源和调优时间。由于知识编辑追求高效改变模型行为,PET技术展现出潜力。然而,PET通常用于提升任务性能而非专门编辑知识。现有PET方法在知识编辑中的有效性仍待深入探索。研究如何利用PET实现高效精准的知识更新,是未来工作的一个有趣方向。
Knowledge Augmentation for LLMs LLMs still face unknown questions, and many knowledgeaugmented methods are proposed to help the model deal with this task [112–114]. The most popular way is the retrieval-augmented methods [115–117]. With the help of the retrieved knowledge or context that is related to the input, the model can give the desired output. The integration of the retrieved information includes both the input, intermediate, and output layers [118]. During the input phase, retrieved texts are concatenated with the original input text [119–121]. In some works, the retrieved components are latent and integrated into the intermediate layers of Transformers [122– 124]. In the output phase, the distribution of tokens from the retrieved components and the LLMs are interpolated [125–128].
大语言模型的知识增强
大语言模型仍面临未知问题,为此研究者提出了多种知识增强方法帮助模型应对此类任务[112–114]。最主流的方法是检索增强技术[115–117],通过获取与输入相关的知识或上下文,模型能够生成预期输出。检索信息的整合涵盖输入层、中间层和输出层[118]。在输入阶段,检索文本会与原始输入文本拼接[119–121];部分研究将检索组件以隐式形式融入Transformer中间层[122–124];输出阶段则会对检索组件与大语言模型生成的token分布进行插值处理[125–128]。
The knowledge-augmented method is a great solution for the missing or misinformation in LLMs but it still has some disadvantages. As a temporary solution, retrieval methods suffer from poor retrieval results and relatedness [129, 130]. The data retrieved often contains some noise, such as additional content that is irrelevant to a question but that may be relevant to a different question (i.e., not necessarily random noise) [131]. In these situations, the model fails to distinguish the knowledge that is necessary to answer the question, leading to spurious reasoning and degraded performance. Meanwhile, retrieval typically operates at a broader level of relevant passages without fine-grained control over precisely which information is modified within the model.
知识增强方法是解决大语言模型中信息缺失或错误的有效方案,但仍存在若干不足。作为临时解决方案,检索方法存在检索效果差和相关度低的问题 [129, 130]。检索到的数据常包含噪声,例如与当前问题无关但可能关联其他问题的冗余内容(即非随机噪声)[131]。这种情况下,模型难以区分回答问题所需的关键知识,导致伪推理和性能下降。此外,检索通常仅在相关段落层面运作,缺乏对模型内部具体修改信息的细粒度控制。
| FewerParams | Precise Control | SupportPhenomena | |
| Finetune | + | ||
| Parameter-efficient Fine-Tuning | x | + | |
| Knowledge Augmentation | O | + | |
| Continual Learning | x | + | |
| Model Unlearning | O | 一 | |
| Knowledge Editing | +一 |
Table 1: Integrated comparison between knowledge editing and related techniques. The symbol $√$ denotes the presence of a particular feature in the technique, while $x$ signifies its absence. + indicates an enhancement of the LLMs’ capabilities, whereas $+$ signifies a reduction or removal of certain abilities within the model.
| 参数量更少 | 精准控制 | 支持现象 | |
|---|---|---|---|
| 微调 (Finetune) | + | ||
| 高效参数微调 | x | + | |
| 知识增强 | O | + | |
| 持续学习 | x | + | |
| 模型遗忘 | O | - | |
| 知识编辑 | +- |
表 1: 知识编辑与相关技术的综合对比。符号 $√$ 表示该技术具备特定特性,$x$ 表示不具备。+ 表示增强了大语言模型的能力,$-$ 表示削弱或移除了模型的某些能力。
Continual Learning Continual learning (CL), also known as lifelong machine learning or incremental learning, refers to the ability of machine learning models to continuously acquire new skills and learn new tasks while retaining previously learned knowledge [132–135]. This is akin to how humans learn throughout their lifetimes by continually accumulating new information and skills without forgetting the old ones. Conventional machine learning models struggle with this as they are trained on independent and identically distributed data. When the distribution shifts or new tasks are encountered, their performance significantly degrades on older tasks due to catastrophic forgetting. Some key techniques being explored include replay-based methods [136, 137], regular iz ation-based approaches [138, 139], and dynamic architecture methods [140, 141]. Continual learning focuses on allowing machine learning models to learn new tasks and adapt to new domains over time without forgetting earlier ones, which resembles the goal of knowledge editing. In contrast, knowledge editing focuses specifically on manipulating and updating the internal knowledge representations learned by pre-trained language models without regard to the underlying tasks or domains. The goal of knowledge editing is to dynamically refine language understanding independent of eventual applications, addressing the “fixedness” issue of pre-trained language models once deployed. Both areas are important for developing AI systems that can progressively acquire and flexibly apply knowledge throughout their lifetime.
持续学习
持续学习 (Continual Learning, CL),也称为终身机器学习或增量学习,指的是机器学习模型在保留已学知识的同时持续获取新技能和学习新任务的能力 [132–135]。这类似于人类通过不断积累新信息和技能而不遗忘旧知识的学习方式。传统机器学习模型在这方面存在困难,因为它们是在独立同分布数据上训练的。当数据分布发生变化或遇到新任务时,由于灾难性遗忘,它们在旧任务上的性能会显著下降。目前探索的关键技术包括基于回放的方法 [136, 137]、基于正则化的方法 [138, 139] 和动态架构方法 [140, 141]。持续学习的重点是让机器学习模型能够随时间学习新任务并适应新领域而不遗忘早期知识,这与知识编辑的目标相似。相比之下,知识编辑特别关注操作和更新预训练语言模型内部学到的知识表示,而不考虑底层任务或领域。知识编辑的目标是动态优化语言理解,与最终应用无关,解决预训练语言模型一旦部署后的"固定性"问题。这两个领域对于开发能够在其生命周期中逐步获取并灵活应用知识的AI系统都很重要。
Machine Unlearning In addition, it is crucial for models to be capable of discarding undesirable (mis)behaviors, which aligns with the concept of machine unlearning [142–146]. Chen and Yang [147] proposes an efficient unlearning framework EUL that can efficiently update LLMs without having to retrain the whole model after data removals, by introducing lightweight unlearning layers learned with a selective teacher-student objective into the Transformers. However, knowledge editing goes beyond unlearning by actively refining or erasing a model’s learned knowledge base. Both machine unlearning and knowledge editing play important roles in enhancing reliability, fairness and effectiveness for LLMs across different domains and applications.
机器遗忘
此外,模型必须具备摒弃不良(错误)行为的能力,这与机器遗忘 [142–146] 的概念一致。Chen 和 Yang [147] 提出了一种高效遗忘框架 EUL,通过向 Transformer 中引入基于选择性师生目标学习的轻量级遗忘层,无需在数据删除后重新训练整个模型即可高效更新大语言模型。然而,知识编辑不仅限于遗忘,还能主动修正或擦除模型已习得的知识库。机器遗忘与知识编辑在提升大语言模型跨领域应用的可靠性、公平性和有效性方面均发挥着重要作用。
To conclude, the traditional approach to leveraging pre-trained language models involves fine-tuning them with target-specific data. However, in the realm of LLMs, this fine-tuning process encounters significant challenges. These include the vast number of parameters, substantial time and memory requirements, risks of over fitting, and issues like catastrophic forgetting. To address these challenges, several techniques have been developed, as we discussed above. Among these, knowledge editing emerges as a notable strategy. As we discussed in Table 1, knowledge editing, intersecting with these techniques, draws inspiration from a range of methodologies, showing promising results. This approach distinctively targets the knowledge embedded within LLMs, leveraging the inherent knowledge mechanisms of these models. Unlike simple adaptations of existing methods, knowledge editing necessitates a deeper comprehension of how LLMs function. It is not just about applying known techniques to new models; it is about understanding and manipulating the nuanced knowledge storage and processing capabilities of LLMs. Furthermore, knowledge editing represents a more precise and granular form of model manipulation as it involves selectively altering or enhancing specific aspects of a model’s knowledge base, rather than broadly retraining or fine-tuning the entire model. These characteristics make knowledge editing a potentially more efficient and effective way to update and optimize LLMs for specific tasks or applications.
总结来说,利用预训练语言模型的传统方法涉及针对特定目标数据进行微调。然而在大语言模型领域,这一微调过程面临重大挑战,包括海量参数、高昂的时间与内存成本、过拟合风险以及灾难性遗忘等问题。为解决这些难题,学界已发展出多种技术方案。其中,知识编辑(knowledge editing)作为一种突出策略脱颖而出。如表1所示,知识编辑与这些技术相互交融,从多种方法论中汲取灵感,展现出令人瞩目的效果。该方法独辟蹊径地针对大语言模型中内嵌的知识体系,充分利用模型固有的知识处理机制。与简单套用现有方法不同,知识编辑要求更深入地理解大语言模型的运作原理——不仅要掌握如何将已知技术应用于新模型,更要精准把控模型知识存储与处理的精妙机制。此外,知识编辑代表了一种更精确、更细粒度的模型调控方式,它通过选择性修改或增强模型知识库的特定部分来实现优化,而非对整个模型进行大规模重训练或微调。这些特性使得知识编辑可能成为针对特定任务或应用场景更新和优化大语言模型更高效、更有效的途径。
3 Knowledge Editing for LLMs
3 大语言模型的知识编辑
3.1 Preliminary
3.1 初步准备
The substantial training on diverse datasets has equipped LLMs with a wealth of factual and commonsense information, positioning these models as virtual knowledge stores [48, 148, 149]. This rich knowledge base has been effectively utilized in various downstream tasks, as evidenced by numerous studies [150]. Additionally, Wang et al. [151] have demonstrated the potential of LLMs in autonomously constructing high-quality knowledge graphs, bypassing the need for human supervision. Despite their promise, LLMs, in their current state as emerging knowledge bases, exhibit certain limitations. These deficiencies often manifest as inaccuracies or errors in their outputs during practical applications. An ideal knowledge base would not only store extensive information but also allow for efficient and targeted updates to rectify these errors and improve their accuracy. Recognizing this gap, our paper introduces the concept of knowledge editing for LLMs. This approach is designed to enable quick and precise modifications to the LLMs, allowing them to generate more accurate and relevant outputs. By implementing knowledge editing for LLMs, we aim to enhance the utility of LLMs, moving them closer to the ideal of becoming universally reliable and adaptable repositories of knowledge. This advancement promises to address the current shortcomings of LLMs and unlock their full potential as dynamic and accurate knowledge bases for applications.
通过对多样化数据集的大量训练,大语言模型(LLM)已具备丰富的事实性和常识性知识,使其成为虚拟的知识库[48, 148, 149]。如众多研究[150]所示,这一丰富的知识库已在各类下游任务中得到有效应用。此外,Wang等人[151]的研究证明了大语言模型无需人工监督即可自主构建高质量知识图谱的潜力。尽管前景广阔,但作为新兴知识库的现有大语言模型仍存在一定局限性,这些缺陷常在实际应用时表现为输出不准确或错误。理想的知识库不仅应存储海量信息,还应支持高效精准的定向更新以修正错误、提升准确性。基于此认知,本文提出了大语言模型知识编辑的概念,旨在实现对模型的快速精准修改,使其生成更准确相关的输出。通过实施大语言模型知识编辑,我们期望提升其实用性,使其更接近成为通用可靠、适应性强的知识存储库这一理想目标。这一进展有望解决当前大语言模型的缺陷,充分释放其作为动态精准知识库的应用潜力。
3.2 Task Definition
3.2 任务定义
The initial goal of knowledge editing is to modify the specific knowledge $k$ in the LLM and improve the consistency and performance of the LLM without fine-tuning the whole model. This knowledge can be associated with many areas and types, such as facts [79], commonsense [152], sentiment [153] and so on. Knowledge editing is challenging due to the distributed and entangled nature of knowledge in LLMs.
知识编辑的最初目标是修改大语言模型中的特定知识 $k$,并在不微调整个模型的情况下提高大语言模型的一致性和性能。这些知识可以涉及许多领域和类型,例如事实 [79]、常识 [152]、情感 [153] 等。由于知识在大语言模型中的分布性和纠缠性,知识编辑具有挑战性。
Suppose the original model is $\theta$ and given the knowledge $k$ to be changed, by knowledge editing process $F$ , we would get the post-edited model $\theta^{'}$ :
假设原始模型为$\theta$,给定待修改知识$k$,通过知识编辑过程$F$,我们将得到编辑后的模型$\theta^{'}$:
$$
\theta^{\prime}=F(\theta,k)
$$
$$
\theta^{\prime}=F(\theta,k)
$$
The post-edited model $\theta^{'}$ is supposed to override undesired model beliefs on the knowledge $k$ and keep other knowledge intact:
后编辑模型 $\theta^{'}$ 应覆盖知识 $k$ 上不期望的模型信念,同时保持其他知识不变:
$$
\begin{array}{l l}
\theta'(k) \neq \theta(k) & \forall k' \neq k, \theta'(k') = \theta(k')
\end{array}.
$$
$$
\begin{array}{l l}
\theta'(k) \neq \theta(k) & \forall k' \neq k, \theta'(k') = \theta(k')
\end{array}.
$$
As a knowledge base, it’s paramount that knowledge editing cater to three fundamental settings: knowledge insertion, knowledge modification, and knowledge erasure.
作为知识库,知识编辑必须满足三个基本场景:知识插入、知识修改和知识删除。
Knowledge Insertion. As fields and entities progress, it becomes imperative for LLMs to assimilate emergent information. Knowledge insertion fulfills this by bestowing upon LLMs new knowledge previously outside their purview:
知识注入。随着领域和实体的发展,大语言模型必须吸收新出现的信息。知识注入通过赋予大语言模型先前不在其范围内的新知识来实现这一目标:
$$
\theta^{\prime}=F(\theta,{\emptyset}\to{k})
$$
$$
\theta^{\prime}=F(\theta,{\emptyset}\to{k})
$$
Knowledge Modification. Knowledge modification refers to altering knowledge already stored in LLMs:
知识修改。知识修改指的是改变已存储在大语言模型中的知识:
$$
\theta^{\prime}=F(\theta,{k}\rightarrow{k^{\prime}})
$$
$$
\theta^{\prime}=F(\theta,{k}\rightarrow{k^{\prime}})
$$
This can be classified into two categories:
这可以分为两类:
• Knowledge amendment - This aims at rectifying the inaccuracies embedded in LLMs to ensure the delivery of accurate information. As vast repositories of knowledge, LLMs are prone to housing outdated or erroneous information. Knowledge amendment serves to correct these fallacies, ensuring that models always generate accurate, up-to-date information. • Knowledge disruption - Modifying LLMs to answer counter factual or error prompts. This is more challenging as counter factual notions initially receive lower scores compared to factual knowledge, as shown by Meng et al. [79]. This necessitates more targeted modification efforts.
• 知识修正 (Knowledge amendment) - 旨在纠正大语言模型中嵌入的不准确信息,确保输出内容的准确性。作为海量知识库,大语言模型容易包含过时或错误信息。知识修正通过纠正这些谬误,确保模型始终生成准确、最新的信息。
• 知识干扰 (Knowledge disruption) - 通过修改大语言模型使其响应反事实或错误提示。这项工作更具挑战性,因为如Meng等人[79]所示,反事实概念的初始评分通常低于事实性知识,因此需要更有针对性的修改措施。

Figure 2: Applying Human Learning Phases [1–3] to Knowledge Editing in LLMs: We see an analogy of Human Learning Phases and Knowledge Editing in LLMs and categorize current knowledge editing methods based on the learning phases of humans: recognition, association, and mastery.
图 2: 将人类学习阶段 [1–3] 类比到大语言模型的知识编辑中: 我们观察到人类学习阶段与大语言模型知识编辑的相似性, 并根据人类的认知 (recognition)、关联 (association) 和掌握 (mastery) 三个阶段对现有知识编辑方法进行分类。
Knowledge Erasure. Knowledge erasure targets the excision or obliteration of pre-existing knowledge in a model, primarily to reset distinct facts, relationships, or attributes. Formally, we have:
知识擦除。知识擦除旨在删除或清除模型中预先存在的知识,主要用于重置特定事实、关系或属性。形式化表达为:
$$
\theta^{\prime}=F(\theta,{k}\rightarrow{\emptyset})
$$
$$
\theta^{\prime}=F(\theta,{k}\rightarrow{\emptyset})
$$
Implementing knowledge erasure is pivotal to expunge biases and noxious knowledge and to curtail the recollection of confidential or private data, thereby fostering responsible and trustworthy AI.
实施知识擦除对于消除偏见和有害知识、减少对机密或隐私数据的记忆至关重要,从而促进负责任且可信赖的AI发展。
In conclusion, the interplay between knowledge insertion, modification, and erasure forms essential aspects of model editing techniques. When combined, these techniques empower LLMs to transform, self-correct, and ethically adapt as needed.
总之,知识插入、修改和删除之间的相互作用构成了模型编辑技术的关键方面。这些技术相结合,使大语言模型能够根据需要实现转化、自我修正和道德适应。
3.3 Methods
3.3 方法
The development of LLMs has reached a point where their capabilities closely resemble human cognitive processes, especially in learning and acquiring knowledge. Drawing inspiration from how humans learn, we can analogously apply these concepts to the process of editing LLMs as Figure 2 shows. Educational and cognitive research [1–3] delineates human knowledge acquisition into three distinct phases: recognition, association, and mastery. These phases offer a framework for conceptualizing the methods of knowledge editing in $\mathrm{LLMs}^{2}$ and we list them in Table 2.
大语言模型的发展已达到其能力与人类认知过程极为相似的程度,尤其是在学习和获取知识方面。借鉴人类学习方式,我们可以将这些概念类比应用于大语言模型的编辑过程,如图 2 所示。教育与认知研究 [1-3] 将人类知识获取划分为三个不同阶段:识别 (recognition)、关联 (association) 和掌握 (mastery)。这些阶段为理解大语言模型知识编辑方法提供了框架,我们将其列于表 2。
| Category | Method | Edit Area | Edit Function | No Training | Batch Edit | Edited #Params |
| Recogintion | MemPrompt [154] | memory+retriever | Input →> [Mem : Input] | |||
| Phase | SERAC [153] | memory+classifier +auxiliary model | Output →→ Modelef (α) | x | ||
| MeLLo [155] | memory+retriever | Input → [Mem : Input] | ||||
| IKE [156] | memory+retriever | Input → [Mem : Input] | x | |||
| ICE [157] | prompt | Input → [Mem : Input] | ||||
| PokeMQA [158] | memory+retriever | Input → [Mem : Input] | ||||
| Association | Language Patches[159] | Output head + params | h→h+ (1 -入)Patch() | √ | dh × #Output | |
| Phase | CaliNET [160] | FFN+params | h→ h + FFNada(c) | Nx dh | ||
| T-Patcher[161] | FFN+params | h→h +FFNadd(c) | N× dh | |||
| REMEDI [162] | auxiliary model | h → REMEDI(∞) | dhXdh | |||
| GRACE [163] | FFN+codebook | h→GRACE(∞) | N× 2dh | |||
| LoRA [164] | Attn or FFN | h → h + s · LoRA(c) | 2L × 2damdh | |||
| MEL0 [165] | Attn or FFN | h→h+s·LoRA(c) | × | 2Lx2damdh | ||
| Mastery | FT-Constrained [166] | Any | W → W' | 2 × L × dmdh | ||
| Phase | ENN [167] | Any | W→W' | 2×L×dmdh | ||
| KE[168] | Attn or FFN +auxiliary model | W → W' | 2 × L × dmdh | |||
| SLAG [169] | Attn or FFN +auxiliary model | W → W' | 2×L×dmdh | |||
| MEND [170] | FFN+ auxiliary model | W → W' | 2 × L × dmdh | |||
| KN [39] | FFN | MuMOPM down | L×N×dh | |||
| ROME [79] | FFN | Wdown → W down | dmdh | |||
| MEMIT [171] | FFN | W down M← down | Lxdmdn | |||
| PMET [172] | FFN | Wdown → W | Lx dmdn | |||
| MALMEN [173] | FFN | Wdown → W down | L×dmdh | |||
| BIRD [174] | FFN | M←uMOPM down | x | dmdh | ||
| AlphaEdit [175] | FFN | Wdown → Wdown | L×dmdn |
| 类别 | 方法 | 编辑区域 | 编辑函数 | 无需训练 | 批量编辑 | 编辑参数量 |
|---|---|---|---|---|---|---|
| 识别阶段 | MemPrompt [154] | 记忆+检索器 | 输入→[记忆:输入] | |||
| SERAC [153] | 记忆+分类器+辅助模型 | 输出→模型(α) | × | |||
| MeLLo [155] | 记忆+检索器 | 输入→[记忆:输入] | ||||
| IKE [156] | 记忆+检索器 | 输入→[记忆:输入] | × | |||
| ICE [157] | 提示词 | 输入→[记忆:输入] | ||||
| PokeMQA [158] | 记忆+检索器 | 输入→[记忆:输入] | ||||
| 关联阶段 | Language Patches[159] | 输出头+参数 | h→h+(1-λ)Patch() | √ | dh×输出维度 | |
| CaliNET [160] | FFN+参数 | h→h+FFNada(c) | N×dh | |||
| T-Patcher[161] | FFN+参数 | h→h+FFNadd(c) | N×dh | |||
| REMEDI [162] | 辅助模型 | h→REMEDI(∞) | dh×dh | |||
| GRACE [163] | FFN+码本 | h→GRACE(∞) | N×2dh | |||
| LoRA [164] | 注意力或FFN | h→h+s·LoRA(c) | 2L×2damdh | |||
| MEL0 [165] | 注意力或FFN | h→h+s·LoRA(c) | × | 2L×2damdh | ||
| 精通阶段 | FT-Constrained [166] | 任意 | W→W' | 2×L×dmdh | ||
| ENN [167] | 任意 | W→W' | 2×L×dmdh | |||
| KE[168] | 注意力或FFN+辅助模型 | W→W' | 2×L×dmdh | |||
| SLAG [169] | 注意力或FFN+辅助模型 | W→W' | 2×L×dmdh | |||
| MEND [170] | FFN+辅助模型 | W→W' | 2×L×dmdh | |||
| KN [39] | FFN | MuMOPM down | L×N×dh | |||
| ROME [79] | FFN | Wdown→Wdown' | dmdh | |||
| MEMIT [171] | FFN | Wdown→Wdown' | L×dmdh | |||
| PMET [172] | FFN | Wdown→Wdown' | L×dmdh | |||
| MALMEN [173] | FFN | Wdown→Wdown' | L×dmdh | |||
| BIRD [174] | FFN | MuMOPM down | × | dmdh | ||
| AlphaEdit [175] | FFN | Wdown→Wdown' | L×dmdh |
Table 2: Comparison between representative approaches of knowledge editing for LLMs. No Training refers to the methods that do not require additional training; Batch Edit means whether the methods can support editing multiple cases simultaneously in just one process. Edit Area refers to where the model’s components are used; Editor #Params indicates the parameters that need to be updated for editing. $L$ refers to the number of layers to update. $d_{h}$ denotes the dimensionality of the hidden layers in the Transformers. $d_{m}$ refers to the intermediate dimension that exists between the up projection and the down projection. $N$ symbolizes the total number of neurons that undergo updates within each individual layer.
表 2: 大语言模型知识编辑代表性方法对比。无需训练 (No Training) 指不需要额外训练的方法;批量编辑 (Batch Edit) 表示方法是否支持单次处理同时编辑多个案例;编辑区域 (Edit Area) 指模型中被修改的组件部分;编辑器参数量 (Editor #Params) 表示编辑时需要更新的参数规模。$L$ 表示需要更新的层数,$d_{h}$ 表示 Transformer 隐藏层的维度,$d_{m}$ 代表上投影和下投影之间的中间维度,$N$ 表示每层中需要更新的神经元总数。
3.3.1 Recognition Phase: Resorting to External Knowledge
3.3.1 识别阶段:借助外部知识
When humans encounter new information, we do not always master it immediately. Instead, with the right context and examples, we can process and reason through this new knowledge. LLMs exhibit a similar capacity for in-context learning. This kind of method usually maintains a memory M and retrieves the most relevant cases for each input. IKE [156] exemplifies this approach by constructing three types of demonstrations – copy, update, and retain – to aid the model in producing reliable fact editing. It utilizes a demonstration store, formed from training sets, to guide the model towards generating the appropriate answer by retrieving the most pertinent demonstrations. Meanwhile, as a simple change in knowledge would lead to ripple effects [157], MeLLo [155] decomposes the question into different sub-questions for tackling multi-hop questions and retrieves the updated fact from the memory for each sub-question. Building on this, PokeMQA [158] offers a more robust method for question decomposition, introducing a programmable scope detector and knowledge prompts for enhanced reliability.
当人类遇到新信息时,我们并不总能立即掌握它。相反,在适当的上下文和示例帮助下,我们可以处理并推理这些新知识。大语言模型(LLM)也展现出类似的上下文学习能力。这类方法通常维护一个记忆库M,并为每个输入检索最相关的案例。IKE [156]通过构建三种类型的演示(复制、更新和保留)来帮助模型进行可靠的事实编辑,体现了这种方法。它利用由训练集形成的演示存储库,通过检索最相关的演示来引导模型生成正确答案。同时,由于知识的简单变化会产生连锁反应[157],MeLLo [155]将问题分解为不同的子问题以处理多跳问题,并从记忆库中为每个子问题检索更新后的事实。在此基础上,PokeMQA [158]提供了更鲁棒的问题分解方法,引入了可编程范围检测器和知识提示以增强可靠性。
Humans also often utilize tools to augment their learning and problem-solving abilities. Likely, SERAC [153] builds a new counter fact model by retaining the new model and adopting a classifier to determine whether to use the counter fact model to answer the question. This method is straightforward and practically applicable, requiring no alterations to the original model. It’s particularly advantageous for real-world use, given its ease of implementation. However, it’s important to note that this approach can be vulnerable to issues such as retrieval errors (e.g.noise [176], harmful content [177]) and knowledge conflict problems [178, 179]. Recently, Yu et al. [180] invest ig at s various scenarios in which language models opt for either the in-context answer or the memorized answer.
人类也常借助工具来增强学习和解决问题的能力。类似地,SERAC [153] 通过保留新模型并采用分类器来决定是否使用反事实模型回答问题,从而构建了一个新的反事实模型。这种方法简单实用,无需修改原始模型,在实际应用中具有明显优势。但需注意,该方法可能面临检索错误(如噪声 [176]、有害内容 [177])和知识冲突问题 [178, 179] 等挑战。最近,Yu 等人 [180] 研究了大语言模型选择上下文答案或记忆答案的各种场景。
This research sheds light on the potential application of the method mentioned earlier, as it may offer insights into when and how to utilize it.
本研究揭示了前述方法的潜在应用价值,可为实际使用时机和方式提供指导。
3.3.2 Association Phase: Merge the Knowledge into the Model
3.3.2 关联阶段:将知识整合到模型中
Unlike the recognition phase, this kind of method learns a representation for the new knowledge $h_{\mathrm{Know}}$ and merges this information with the original model’s representation $^{h}$ .
与识别阶段不同,这类方法会为新知识 $h_{\mathrm{Know}}$ 学习一种表示,并将该信息与原始模型的表示 $^{h}$ 进行融合。
Murty et al. [159] proposes a knowledge patch as a new output head and interpolates the new head with the original head. Specially, inspired by previous findings that FFN may store knowledge, several methods integrate the knowledge into the FFN part. These methods add the neuron to the FFN and after the edit, the output is a combination of the previous FFN’s output and the newly added knowledge:
Murty等人[159]提出将知识补丁作为一种新的输出头,并将其与原始头进行插值。特别地,受此前发现前馈网络(FFN)可能存储知识的启发,多种方法将知识整合到FFN部分。这些方法向FFN添加神经元,编辑后的输出是原FFN输出与新添加知识的组合:
$$
\mathrm{FFN}^{'}({\bf x})=\mathrm{FFN}({\bf x})+\triangle\mathrm{FFN}({\bf x}),
$$
$$
\mathrm{FFN}^{'}({\bf x})=\mathrm{FFN}({\bf x})+\triangle\mathrm{FFN}({\bf x}),
$$
In particular, T-Patcher [161] adds one neuron for each output error, while CaliNet [160] adds the knowledge via a fixed number of neurons. Meanwhile, $\mathrm{Wu}$ et al. [164] adopts LoRA to conduct knowledge edits. LoRA is a parameter-efficient fine-tuning method that freezes the weights of the LLM and introduces trainable rank decomposition matrices into the Transformer layers during the fine-tuning process. Hence, the $h_{\mathrm{Know}}$ is ${\mathit{x W}}_ {\mathrm{down}}W_{\mathrm{up}}$ . Based on this, MELO [165] suggests a plug-in model editing method that uses dynamic LoRA to change the way language models work by indexing LoRA blocks dynamically based on an internal vector database. Instead of adding parameters to the model, REMEDI [162] directly substitutes the representation of the entity $h_{\mathrm{entity}}$ by incorporating an attribute vector $h_{\mathrm{attr}}$ into its original model’s representation. Specifically, it learns the updated hidden states using an affine transformation $h_{\mathrm{entity}}+W h_{\mathrm{attr}}+b$ and replaces the LM’s entity representation with it. In contrast, GRACE [163] adopts a unique approach by maintaining a discrete codebook that functions as an Adapter. This codebook is dynamically updated over time, allowing for the modification and refinement of a model’s predictions. When the model encounters the knowledge for editing, it searches the codebook and replaces the hidden states as the value in the codebook. Overall, we can use a mathematical formula to represent these methods uniformly:
具体而言,T-Patcher [161] 为每个输出错误添加一个神经元,而CaliNet [160] 则通过固定数量的神经元注入知识。与此同时,Wu等人 [164] 采用LoRA (Low-Rank Adaptation) 进行知识编辑。LoRA是一种参数高效的微调方法,它在微调过程中冻结大语言模型的权重,并向Transformer层引入可训练的秩分解矩阵。因此,$h_{\mathrm{Know}}$ 表示为 ${\mathit{x W}}_ {\mathrm{down}}W_{\mathrm{up}}$。基于此,MELO [165] 提出了一种插件式模型编辑方法,通过基于内部向量数据库动态索引LoRA模块,使用动态LoRA来改变语言模型的运作方式。与向模型添加参数不同,REMEDI [162] 直接通过将属性向量 $h_{\mathrm{attr}}$ 整合到原始模型表示中,替换实体表示 $h_{\mathrm{entity}}$。具体来说,它利用仿射变换 $h_{\mathrm{entity}}+W h_{\mathrm{attr}}+b$ 学习更新后的隐藏状态,并用其替换语言模型的实体表示。相比之下,GRACE [163] 采用独特方法,维护一个作为适配器 (Adapter) 的离散码本。该码本随时间动态更新,从而实现对模型预测的修改和优化。当模型遇到待编辑知识时,会检索码本并用码本中的值替换隐藏状态。总体而言,我们可以用统一数学公式表示这些方法:
$$
h_{f i n a l}=h+h_{\mathrm{know}}
$$
$$
h_{f i n a l}=h+h_{\mathrm{know}}
$$
This kind of method merged the information with the original model, making the weighting of knowledge from different sources a crucial parameter to consider. Given that these information sources often differ and may even conflict, the issue of knowledge conflict, as highlighted in Wang et al. [178], remains a significant challenge. To address this issue, F-Learning [181] introduces a “forgetting before learning” paradigm to achieve forgetting of old knowledge and learning of new knowledge based on parametric arithmetic. Additionally, determining the optimal point of integration for this information within the model is a critical aspect of this method. It is not just about merging the information, but also about where in the model’s structure this integration occurs for maximum effectiveness and minimal disruption. Furthermore, the capacity of the model’s parameters to store this integrated information is an area that still requires exploration. If every piece of edited knowledge necessitates additional parameters, the model’s parameter could increase significantly with each edit. This raises concerns about s cal ability and efficiency, as continuously expanding the number of parameters might lead to issues like increased computational requirements.
这种方法将信息与原始模型融合,使得不同来源知识的权重成为关键考量参数。鉴于这些信息来源往往存在差异甚至冲突,如Wang等人[178]指出的知识冲突问题仍是重大挑战。为解决该问题,F-Learning[181]提出"先遗忘后学习"范式,基于参数运算实现旧知识遗忘与新知识学习。此外,确定信息在模型中的最佳融合节点也是该方法的核心要素——不仅要完成信息融合,还需考量模型结构中哪个位置进行整合能实现效能最大化与干扰最小化。值得注意的是,模型参数存储融合信息的能力仍是待探索领域。若每次知识编辑都需要新增参数,模型参数量可能随编辑次数显著增长,这将引发对可扩展性与效率的担忧,因为持续扩张的参数规模可能导致计算需求激增等问题。
3.3.3 Mastery Phase: Editing Intrinsic Knowledge
3.3.3 精通阶段:编辑内在知识
Despite the success of the previous two kinds of methods, we still confront how the model stores the knowledge and how they utilize and express the knowledge. Here, we come to the most important part of knowledge editing: the mastery stage. In this part, the model is required to learn the knowledge of its own parameters and master the knowledge by itself. Fine-tuning the model is the direct way to update the knowledge; however, training the whole model requires enormous computational resources and is time-consuming. Meanwhile, the finetuning technique usually suffers from catastrophic forgetting and over fitting. Constrained Fintune [166] utilizes a regular iz ation to help the model keep the unrelated knowledge. Currently, many researchers endeavor to use knowledgespecific methods to modify the $\Delta W$ . These methods can be classified into two categories: metalearning and locate-and-edit.
尽管前两种方法取得了成功,我们仍面临模型如何存储知识、如何利用和表达知识的问题。这里我们来到知识编辑最重要的环节:掌握阶段。该阶段要求模型学习自身参数中的知识并自主掌握知识。微调模型是更新知识的直接方式,但训练整个模型需要大量计算资源且耗时。同时,微调技术通常存在灾难性遗忘和过拟合问题。Constrained Fintune [166] 通过正则化帮助模型保留无关知识。当前许多研究者致力于使用知识特定方法修改 $\Delta W$ ,这些方法可分为两类:元学习 (meta-learning) 和定位编辑 (locate-and-edit)。
Meta Learning To overcome these drawbacks, some meta-learning methods are proposed to edit the model. Instead of updating the weights directly, this kind of method teaches a hyper network to learn the change $\Delta W$ of the model. KE [168] directly uses the representation of the new knowledge to train the model to update the matrix. SLAG [169] introduces a new training objective considering sequential, local, and generalizing model updates. The $\Delta W$ in these methods has the same dimensions as the model’s matrix. In order to overcome it, MEND [170] applies the rank-one decomposition to divide the model into two rank-one matrices, from which it is possible to compute the $\Delta W$ , significantly reducing the number of parameters. While these methods have shown some promising results, they fail on multi-edits as they ignore the conflicts between these edits. Han et al. [182] proposes a novel framework to divide-and-conquer edits with parallel editors. Specifically, they design explicit multi-editor MoEditor and implicit multi-editor ProEditor to learn diverse editing strategies in terms of dynamic structure and dynamic parameters, respectively, which allows solving the conflict data in an efficient, end-to-end manner. Also, MALMEN [173] improves MEND by formulating the parameter shift aggregation as a least squares problem and supports massive editing simultaneously.
元学习
为克服这些缺点,研究者提出了一些元学习方法用于修改模型。这类方法不直接更新权重,而是训练一个超网络来学习模型的变化量$\Delta W$。KE [168] 直接利用新知识的表征训练模型更新权重矩阵。SLAG [169] 提出了综合考虑序列化、局部化和泛化模型更新的训练目标。这些方法中的$\Delta W$与模型矩阵维度相同。为解决此问题,MEND [170] 采用秩一分解将模型拆分为两个秩一矩阵,从中计算$\Delta W$,显著减少了参数量。虽然这些方法取得了一定效果,但由于忽略了多次编辑间的冲突,它们在多重编辑场景中表现不佳。Han等人 [182] 提出了一种通过并行编辑器实现分治编辑的新框架:具体设计了显式多编辑器MoEditor(动态结构)和隐式多编辑器ProEditor(动态参数)分别学习不同编辑策略,从而以端到端方式高效解决冲突数据。此外,MALMEN [173] 将参数偏移聚合建模为最小二乘问题改进了MEND,可支持大规模同步编辑。
Location-then-Edit Despite the effectiveness of previous work, how the LLMs store this knowledge is still unknown. Some work [41, 42, 97], has learned the mechanism of LLMs knowledge and found that the knowledge was stored in the FFN . Based on these works, some conduct knowledge editing by first locating where the knowledge was stored and then editing the specific area. Knowledge Neuron [39] proposed a knowledge attribution method by computing the sensitivity of the gradient change. They then directly modify the corresponding value slots using the embedding of the target knowledge. ROME [79] and MEMIT [171] employ a causal analysis method to detect which part of hidden states plays more importance. They view the editing as a minimum optimization and edit the weights. Despite the effectiveness of editing the FFN area, PMET [172] also conducts editing via the attention head and demonstrates a better performance. BIRD [174] proposes bidirectional ly inverse relationship modeling. They designed a set of editing objectives that incorporate bidirectional relationships between subject and object into the updated model weights and demonstrate the effectiveness of alleviating the reverse curse [183] of the knowledge learning. To more effectively address the disruption of originally preserved knowledge within Large Language Models (LLMs), AlphaEdit [175] proposes an innovative approach. This method involves projecting perturbations into the null space of the preserved knowledge prior to their application to model parameters, thereby substantially reducing the issue.
定位后编辑
尽管先前工作已取得成效,但大语言模型如何存储这类知识仍不明确。部分研究[41, 42, 97]通过解析大语言模型的知识机制,发现知识存储在FFN层中。基于这些发现,有研究采用先定位知识存储位置再编辑特定区域的方法。Knowledge Neuron[39]提出通过计算梯度变化的敏感度进行知识归因,随后直接使用目标知识的嵌入向量修改对应值槽。ROME[79]和MEMIT[171]采用因果分析法检测隐藏状态中起关键作用的部分,将编辑视为最小化优化问题并调整权重。虽然FFN层编辑有效,PMET[172]还通过注意力头进行编辑并展现出更优性能。BIRD[174]提出双向逆关系建模,设计了一套将主客体双向关系融入更新模型权重的编辑目标,证明其能有效缓解知识学习中的逆向诅咒[183]。为更高效解决大语言模型中原有知识的干扰问题,AlphaEdit[175]提出创新方案:在扰动应用于模型参数前,将其投影至保留知识的零空间,从而显著降低该问题影响。
This kind of method, which directly edits a model’s parameters, offers a more permanent solution for altering its behavior. The changes are embedded into the model’s structure, so they cannot be circumvented even if a user has access to the model’s weights. This ensures lasting and reliable modifications. However, the side effects are not under control since the mechanism of LLMs is unclear. Some researchers are skeptical about this kind of method [184], so it is still a premature research area that requires further investigation.
这种直接修改模型参数的方法,为改变模型行为提供了更持久的解决方案。修改内容会被嵌入到模型结构中,即使用户能访问模型权重也无法规避,从而确保修改的持久性和可靠性。但由于大语言模型的运行机制尚不明确,其副作用难以控制。部分研究者对此类方法持怀疑态度 [184],因此该领域仍处于不成熟的研究阶段,需要进一步探索。
3.4 New Benchmark: KnowEdit
3.4 新基准:KnowEdit
To evaluate the effectiveness of knowledge editing methods, several datasets have been proposed. In this Section, we present an overview of the current datasets used for knowledge editing and introduce a new benchmark, KnowEdit3, which serves as a comprehensive evaluation framework for various knowledge editing techniques.
为评估知识编辑方法的有效性,目前已提出多个数据集。本节概述当前用于知识编辑的数据集,并介绍新基准KnowEdit3,该基准可作为各类知识编辑技术的综合评估框架。
Table 3: Statistics on the benchmark KnowEdit, with six selected datasets for the evaluation of knowledge editing methods. We select different knowledge types for the insertion, modification, and erasure settings.
| Task | KnowledgeInsertion | Knowledge Modification | KnowledgeErasure | |||
| Datasets | WikiDatarecent | ZsRE | WikiBio | WikiDatacounterfact | Convsent | Sanitation |
| Type | Fact | QuestionAnswering | Hallucination | Counterfact | Sentiment | UnwantedInfo |
| #Train | 570 | 10,000 | 592 | 1,455 | 14,390 | 80 |
| #Test | 1,266 | 1230 | 1,392 | 885 | 800 | 80 |
表 3: 基准测试KnowEdit的统计数据,选取了六个数据集用于评估知识编辑方法。我们为插入、修改和擦除设置选择了不同的知识类型。
| Task | KnowledgeInsertion | Knowledge Modification | Knowledge Modification | Knowledge Modification | Knowledge Modification | KnowledgeErasure |
|---|---|---|---|---|---|---|
| Datasets | WikiDatarecent | ZsRE | WikiBio | WikiDatacounterfact | Convsent | Sanitation |
| Type | Fact | QuestionAnswering | Hallucination | Counterfact | Sentiment | UnwantedInfo |
| #Train | 570 | 10,000 | 592 | 1,455 | 14,390 | 80 |
| #Test | 1,266 | 1230 | 1,392 | 885 | 800 | 80 |
For this study, we have curated a set of six datasets that are well-suited for assessing knowledge editing methods. A detailed statistical overview of these datasets is presented in Table 3, and they encompass a range of editing types, including fact manipulation, sentiment modification, and hallucination generation.
在本研究中,我们精选了六组适合评估知识编辑方法的数据集。表3展示了这些数据集的详细统计概况,涵盖事实篡改、情感修正和幻觉生成等多种编辑类型。
Focusing on the task of knowledge insertion, we have adopted the dataset, Wiki Data recent [157]:
聚焦知识插入任务,我们采用了Wiki Data recent数据集[157]:
• WikiData $r e c e n t$ This dataset specifically focuses on triplets that have been recently inserted into WIKIDATA after July 2022. Consequently, this dataset enables us to create insertion edit requests for models that were trained prior to the introduction of these facts, thereby simulating scenarios where an outdated model meets the new world knowledge. We utilize the original datasets provided by the authors and split them into training and testing sets.
• WikiData $r e c e n t$ 该数据集专门聚焦于2022年7月后新增至WIKIDATA的三元组。通过该数据集,我们能为早于这些事实发布前训练的模型生成插入编辑请求,从而模拟过时模型遭遇新世界知识的场景。我们使用作者提供的原始数据集,并将其划分为训练集和测试集。
For knowledge modification, we have selected the following four datasets: ZsRE [185], WikiBio [163], Wiki data recent [157], and Convsent [153].
对于知识修改,我们选用了以下四个数据集:ZsRE [185]、WikiBio [163]、Wiki data recent [157] 和 Convsent [153]。
In the context of knowledge erasure settings, we have selected the Sanitation [188] dataset.
在知识擦除场景中,我们选择了Sanitation [188]数据集。
• Sanitation This dataset specifically addresses privacy concerns associated with learned language models. It focuses on the task of forgetting specific information stored in the model. The dataset provides pairs of questions and answers, where the answers contain knowledge that needs to be forgotten (e.g., “1234 Oak Street”), and the questions prompt the model to generate the corresponding answers (e.g., “What is John Smith’s address?”). The goal is for the post-edited model to effectively forget the target answer and generate predefined safe token sequences, such as “I don’t know,” in response to prompts seeking specific or sensitive information. This mechanism helps prevent information leakage. The dataset consists of a forgot set and a retain set. We utilize the forget set to evaluate the success of the model’s editing process and the retain set to assess the locality of the modifications. Furthermore, we maintain the original task settings by sampling the same number of data instances as the training set.
• 数据清理
该数据集专门针对学习型语言模型的隐私问题,核心任务是让模型遗忘特定存储信息。数据集提供问答对,其中答案包含需遗忘的知识(如"1234 Oak Street"),问题则引导模型生成对应答案(如"John Smith的地址是什么?")。编辑后的模型需成功遗忘目标答案,并在遇到特定或敏感信息请求时生成预设安全token序列(如"我不知道"),该机制能有效防止信息泄露。数据集包含遗忘集和保留集:我们使用遗忘集评估模型编辑成功率,通过保留集检测修改的局部性。此外,我们通过采样与训练集相同数量的数据实例来保持原始任务设置。
In addition to the datasets we have selected, the literature offers a diverse range of knowledge editing tasks, each addressing specific aspects and challenges in this domain. DepEdit [189] is a more robust analysis dataset that delves into the internal logical constraints of knowledge, offering a deeper understanding of knowledge structures. Notably, Xu et al. [190] introduces cross-lingual model editing tasks and further proposes language anisotropic editing to improve cross-lingual editing by amplifying different subsets of parameters for each language. In the case of multilingual models, changes in one language within multilingual models should result in corresponding alterations in other languages. Eval-KLLM [164] and Bi-ZsRE [191] have been designed to assess the crosslingual editing capabilities of models. Wang et al. [192] proposed Retrieval-augmented Multilingual Knowledge Editor (ReMaKE), which is capable of performing model-agnostic knowledge editing in multilingual settings. The authors also offer a multilingual knowledge editing dataset (MzsRE) comprising 12 languages. Another dataset, ENTITY INFERENCES [193], focuses on entity propagation, where the model is provided with a definition and asked to reason based on the given definition. Time-series knowledge editing is explored in TEMPLAMA [156] and ATOKE [194], where the objective is to modify knowledge pertinent to specific time periods without affecting other temporal knowledge. For commonsense knowledge editing, Gupta et al. [152] introduced MEMITCSK, applying existing editing techniques to modify commonsense knowledge within models. Furthermore, RaKE [195] is proposed to measure how current editing methods edit relation knowledge. All previous work usually confines the edit as a knowledge triplet. Akyirek et al. [196] proposes a new dataset DUNE that broadens the scope of the editing problem to include an array of editing cases, such as debiasing and rectifying reasoning errors, and defines an edit as any natural language.
除了我们选定的数据集外,文献中还提供了多种知识编辑任务,各自针对该领域的特定方面和挑战。DepEdit [189] 是一个更稳健的分析数据集,深入探究知识的内部逻辑约束,提供了对知识结构的更深入理解。值得注意的是,Xu等人 [190] 引入了跨语言模型编辑任务,并进一步提出语言各向异性编辑,通过放大每种语言的不同参数子集来改进跨语言编辑。对于多语言模型,其中一种语言的更改应导致其他语言的相应变化。Eval-KLLM [164] 和 Bi-ZsRE [191] 旨在评估模型的跨语言编辑能力。Wang等人 [192] 提出了检索增强的多语言知识编辑器 (ReMaKE),能够在多语言环境中执行与模型无关的知识编辑。作者还提供了一个包含12种语言的多语言知识编辑数据集 (MzsRE)。另一个数据集 ENTITY INFERENCES [193] 专注于实体传播,模型被提供一个定义,并要求基于给定定义进行推理。TEMPLAMA [156] 和 ATOKE [194] 探索了时间序列知识编辑,其目标是修改与特定时间段相关的知识,而不影响其他时间知识。对于常识知识编辑,Gupta等人 [152] 引入了 MEMITCSK,应用现有编辑技术来修改模型中的常识知识。此外,RaKE [195] 被提出来衡量当前编辑方法如何编辑关系知识。之前的所有工作通常将编辑限制为知识三元组。Akyirek等人 [196] 提出了一个新的数据集 DUNE,将编辑问题的范围扩大到包括一系列编辑案例,例如去偏和纠正推理错误,并将编辑定义为任何自然语言。
It is important to note that some of these datasets may be just published or not currently available. Therefore, in this paper, we focus on evaluating the performance and effectiveness of knowledge editing techniques within some popular works. We plan to expand our benchmark in the future as we acquire new datasets. For additional related datasets, please refer to Wang et al. [70].
需要注意的是,部分数据集可能刚发布或暂未公开。因此,本文重点评估部分主流研究中的知识编辑技术性能与效果。未来获取新数据集后,我们将扩展基准测试范围。更多相关数据集可参考Wang等人[70]的研究。
3.5 Evaluation for Knowledge Editing
3.5 知识编辑评估
Knowledge editing aims to alter model behavior based on modified facts. However, knowledge is interconnected; changing one fact may ripple outwards and affect other facts in complex ways. This interdependence makes assessing the effects of editing difficult. We summarize key evaluation criteria from prior work into four categories: edit success, portability, locality, and fluency.
知识编辑旨在根据修改后的事实改变模型行为。然而知识是相互关联的;改变一个事实可能会产生涟漪效应,并以复杂方式影响其他事实。这种相互依赖性使得评估编辑效果变得困难。我们将先前工作的关键评估标准归纳为四类:编辑成功率、可移植性、局部性和流畅性。
Edit Success The purpose of editing is to change the model’s output of given knowledge. Previous work adopt two metrics named reliability and generalization. In reliability testing, the goal is to evaluate whether the post-edited model can provide the target answer for a given context. On the other hand, generalization testing aims to assess the post-edited model’s performance on paraphrased contexts. However, for knowledge editing tasks, the primary objective is to modify the underlying factual knowledge rather than just altering its expression. Consequently, both the given text and its paraphrased versions should undergo changes to reflect the edited knowledge. Here, we follow previous work [170, 172] and collectively refer to reliability and generalization the as edit success. Hence, here, edit suceess means the post-edit model should not only answer the question itself correctly but also give the right answer for input with similar expressions.
编辑成功
编辑的目的是改变模型对给定知识的输出。先前的研究采用了两个指标:可靠性(reliability)和泛化性(generalization)。在可靠性测试中,目标是评估编辑后的模型能否为给定上下文提供目标答案;而泛化性测试则旨在评估编辑后模型在释义上下文上的表现。然而,对于知识编辑任务而言,主要目标是修改底层事实知识而非仅改变其表达形式。因此,给定文本及其释义版本都应发生改变以反映编辑后的知识。此处我们遵循先前工作[170, 172],将可靠性和泛化性统称为编辑成功。因此,编辑成功意味着编辑后的模型不仅应正确回答问题本身,还需对相似表达形式的输入给出正确答案。
Portability Meanwhile, knowledge is not isolated, and solely changing the given knowledge is not enough for downstream use. When the knowledge is corrected, the model is supposed to reason about the downstream effects of the correction. Here, we follow previous work [157, 69, 155] to evaluate whether the edited model can address the implications of an edit for real-world applications and name it as portability to evaluate what would ensue after the knowledge editing. Portability contains three different parts:
可移植性
与此同时,知识并非孤立存在,仅修改给定知识不足以支持下游应用。当知识被修正时,模型应当能够推理该修正对下游任务的影响。我们遵循前人研究 [157, 69, 155],通过评估编辑后的模型能否处理现实应用中知识编辑的连锁反应,并将其命名为可移植性,用以衡量知识编辑后可能产生的后续影响。可移植性包含三个不同部分:
mentioned by Yao et al. [69], when the fact of $(s,r,o)$ are changed, the reversed relation of the knowledge $(o,\hat{r},s)$ should also be changed.
Yao等人 [69] 提到,当 $(s,r,o)$ 的事实发生变化时,知识的反向关系 $(o,\hat{r},s)$ 也应随之改变。
Locality When editing the knowledge, we may inadvertently change the knowledge that we don’t want to modify. A good edit is supposed to modify the knowledge locality without influencing the knowledge that is unrelated. The evaluation of locality includes two levels:
局部性
在编辑知识时,我们可能会无意中改变不想修改的知识。一次良好的编辑应当仅修改知识的局部性,而不影响无关知识。局部性评估包含两个层面:
• In-Distribution: this one includes the knowledge that comes from the same distribution. As shown in previous work, over editing is a common phenomenon. Here, we follow Meng et al. [79], Cohen et al. [157], Yao et al. [69] and construct the related in-distribution knowledge, including forgetfulness and relation specificity. Forgetfulness evaluates whether the post-edit model retains the original objects in one-to-many relationships. The principle of relation specificity posits that any other attributes of the subject, which have been previously updated, should remain unaltered following the editing process. • Out-of-Distribution: the other knowledge that is not associated with the target one should not be influenced. That is, we also don’t want the edited model to lose their general ability to deal with other tasks. Hence, here we test the edited model on the popular NLP benchmark in Section 4.2.
• 同分布 (In-Distribution):这部分包含来自相同分布的知识。如先前工作所示,过度编辑是一种常见现象。我们遵循Meng等人[79]、Cohen等人[157]、Yao等人[69]的方法,构建了相关的同分布知识,包括遗忘性和关系特异性。遗忘性评估后编辑模型是否在一对多关系中保留原始对象。关系特异性原则假定,主体先前更新的任何其他属性在编辑过程中应保持不变。
• 异分布 (Out-of-Distribution):与目标知识无关的其他知识不应受到影响。也就是说,我们不希望编辑后的模型失去处理其他任务的通用能力。因此,我们在第4.2节的流行NLP基准上测试了编辑后的模型。
It should be noted that some work use Specificity to denote locality.
需要注意的是,部分研究使用特异性 (Specificity) 来表示局部性。
Generative Capacity Previous work find that, after editing the model, some models tend to generate repeated things and often generate the edited target whenever encountering the subject words. Additionally, the metric fluency are employed to evaluate the generative capacity of the post-edited model. Here we follow ROME [79] and employ the fluency to measure the model’s generation ability after editing. In particular, we calculate the weighted average of bi-gram and tri-gram entropies to assess the diversity of text generations. A decrease in this value indicates increased repetitive ness in the generated text.
生成能力
先前的研究发现,在编辑模型后,某些模型倾向于生成重复内容,且每当遇到主题词时经常生成编辑目标。此外,还采用流畅度指标来评估编辑后模型的生成能力。本文遵循ROME [79]的方法,使用流畅度来衡量模型编辑后的生成能力。具体而言,我们计算双元组和三元组熵的加权平均值,以评估文本生成的多样性。该值下降表明生成文本的重复性增加。
4 Experiments
4 实验
In our study, we conduct experiments using current methods and datasets to investigate knowledge editing techniques in the context of LLMs. By conducting experiments using these methods and leveraging appropriate datasets, we aimed to evaluate the performance and efficacy of knowledge editing techniques in LLMs. Our goal was to gain insights into the challenges, limitations, and potential improvements associated with editing knowledge in these models.
在我们的研究中,我们采用现有方法和数据集进行实验,以探索大语言模型(LLM)中的知识编辑技术。通过运用这些方法并借助合适的数据集开展实验,我们旨在评估大语言模型中知识编辑技术的性能与效果。我们的目标是深入理解这些模型知识编辑过程中面临的挑战、局限性以及潜在的改进方向。
4.1 Experiment Settings
4.1 实验设置
We choose Llama2-7b-chat [197] as our base model, specifically its chat version, which has demonstrated improved consistency after reinforcement learning from human feedback (RLHF). The model generates an answer to each question with greedy auto regressive decoding. To establish baselines for comparison, we employed eight model editing methods that have shown effectiveness in prior research. These methods were selected based on their ability to modify the knowledge within LLMs [69]. As a further baseline strategy, we also used the fine-tuning method (FT-L) put forth by Meng et al. [79]. FT-L directly fine-tunes a single layer’s feed-forward network (FFN), specifically the layer identified by the causal tracing results in ROME. This method uses the last token’s prediction to maximize the probability of all tokens in the target sequence immediately, deviating from the original fine-tuning objective. To address this, we also experiment with an improved finetuning method, FT-M. It trains the same FFN layer as FT-L using the cross-entropy loss on the target answer while masking the original text. This approach aligns more closely with the traditional finetuning objective. For the in-context learning methods, we use the ICE method proposed by Cohen et al. [157]. This method prepends a prompt ‘Imagine that {knowledge}’ before the input.
我们选择Llama2-7b-chat[197]作为基础模型,特别采用其经过人类反馈强化学习(RLHF)后表现更稳定的对话版本。该模型通过贪婪自回归解码生成每个问题的答案。为建立比较基线,我们采用了八种在先前研究中被证明有效的模型编辑方法,这些方法根据其修改大语言模型内部知识的能力而被选中[69]。作为额外基线策略,我们还使用了Meng等人[79]提出的微调方法(FT-L)。FT-L直接对单层前馈网络(FFN)进行微调,具体选择ROME因果追踪结果确定的层级。该方法通过最后一个token的预测立即最大化目标序列所有token的概率,偏离了原始微调目标。为此,我们还尝试改进的微调方法FT-M:在屏蔽原文的情况下,使用目标答案的交叉熵损失训练与FT-L相同的FFN层,这种方法更贴近传统微调目标。对于上下文学习方法,我们采用Cohen等人[157]提出的ICE方法,该方法在输入前添加提示语"Imagine that{knowledge}"。
All the experiments are conducted by EasyEdit [198]. As to the evaluation of the post-edited model, some of the previous works computed the probability difference of the output for pre-edit and postedit models: $P[y^{\ast}|\boldsymbol{\theta}^{\prime}]-P[y|\boldsymbol{\theta}]$ . $y^{\ast}$ is the edit target, and $y$ is the original model’s prediction. However, the higher probability for $y^{* }$ does not mean an idea outcome, and for realistic usage, when we edit the model, we hope it generates the desired output. Hence, for the evaluation of fact datasets such as ${\mathrm{WikiData}}_ {r e c e n t}$ , ZsRE, and Wiki Data counter fact, we compute the metric as [69] which computes the accuracy of the outputs. Suppose $x_{k}$ is the expression for the updated knowledge $k$ and $y_{k}^{*}$ is the corresponding target output for editing.
所有实验均通过EasyEdit [198]完成。针对编辑后模型的评估,先前部分研究计算了编辑前后模型输出概率差异:$P[y^{\ast}|\boldsymbol{\theta}^{\prime}]-P[y|\boldsymbol{\theta}]$。其中$y^{\ast}$表示编辑目标,$y$为原始模型预测值。但$y^{* }$概率更高并不代表理想结果,实际应用中我们更关注模型能否生成期望输出。因此对于${\mathrm{WikiData}}_ {recent}$、ZsRE和Wiki Data counter fact等事实类数据集,我们采用[69]提出的输出准确率作为评估指标。设$x_{k}$为更新知识$k$的表述,$y_{k}^{*}$为对应的编辑目标输出。
$$
\mathrm{Edit~Succ.}=\sum_{\left(\boldsymbol{x}_ {k},\boldsymbol{y}_ {k}^{* }\right)}\mathbb{1}{\operatorname{argmax}_ {\boldsymbol{y}}f_{\boldsymbol{\theta}^{\prime}}\left(\boldsymbol{y}\mid\boldsymbol{x}_ {k}\right)=\boldsymbol{y}_{k}^{*}}
$$
$$
\mathrm{Edit~Succ.}=\sum_{\left(\boldsymbol{x}_ {k},\boldsymbol{y}_ {k}^{* }\right)}\mathbb{1}{\operatorname{argmax}_ {\boldsymbol{y}}f_{\boldsymbol{\theta}^{\prime}}\left(\boldsymbol{y}\mid\boldsymbol{x}_ {k}\right)=\boldsymbol{y}_{k}^{*}}
$$
Also, for portability, we compute the post-edited model’s performance on the given sets. As to the calculation of locality, some work computes the post-edited model’s performance on the locality set $O(x_{k})$ . Here, for a better comparison, we test whether the model keeps its original answer.
此外,为了便于移植性,我们计算了后编辑模型在给定数据集上的性能。关于局部性的计算,部分工作会评估后编辑模型在局部集 $O(x_{k})$ 上的表现。此处为了更直观的对比,我们测试模型是否保持其原始答案。
$$
\operatorname{Locality} = \mathbf{E}_ {x_k, y_k^* \sim O(x_k)} \mathbf{1}{f_{\theta'}(y \mid x_k) = f_{\theta}(y \mid x_k)}
$$
$$
\operatorname{Locality} = \mathbf{E}_ {x_k, y_k^* \sim O(x_k)} \mathbf{1}{f_{\theta'}(y \mid x_k) = f_{\theta}(y \mid x_k)}
$$
Meanwhile, for the sentiment edit task Convsent, we compute the Edit Succ. and Locality as the original dataset [153]:
与此同时,针对情感编辑任务Convsent,我们按照原始数据集[153]的方法计算编辑成功率(Edit Succ.)和局部性(Locality):
$$
\mathrm{Edit~Succ._ {Convsent}\stackrel{\Delta}{=}\mathbf{z}_ {s e n t i m e n t}\Delta\cdot\mathbf{z}_{t o p i c}}
$$
$$
\mathrm{Edit~Succ._ {Convsent}\stackrel{\Delta}{=}\mathbf{z}_ {s e n t i m e n t}\Delta\cdot\mathbf{z}_{t o p i c}}
$$
Where $\mathbf{z}_ {\mathrm{sentiment}}$ goes to one if the edited model generates correct sentiment responses and $\mathbf{z}_{\mathrm{topic}}$ one if the edited model’s answer related to the target topic. The locality of Convsent is computed as the KL-divergence so the lower the number, the better the performance is:
其中,$\mathbf{z}_ {\mathrm{sentiment}}$ 在编辑后模型生成正确情感响应时为1,$\mathbf{z}_{\mathrm{topic}}$ 在编辑后模型的答案与目标主题相关时为1。Convsent的局部性通过KL散度计算,因此数值越低表示性能越好:
$$
\operatorname{Locality}_ {\operatorname{Convsent}}\triangleq\mathbb{K L}\left(f_{\boldsymbol{\theta}}\left(\cdot\mid x_{k}\right)|f_{\boldsymbol{\theta^{\prime}}}\left(\cdot\mid x_{k}\right)\right)
$$
$$
\operatorname{Locality}_ {\operatorname{Convsent}}\triangleq\mathbb{K L}\left(f_{\boldsymbol{\theta}}\left(\cdot\mid x_{k}\right)|f_{\boldsymbol{\theta^{\prime}}}\left(\cdot\mid x_{k}\right)\right)
$$
For the knowledge erasure task Sanitation, we calculate edit success as whether the model answers “I don’t know.” for the given knowledge. As for the locality, we compute the performance on the retain sets as to whether the model keeps their original answer.
对于知识擦除任务Sanitation,我们通过模型是否对给定知识回答"我不知道"来计算编辑成功率。至于局部性,我们通过模型在保留集上是否保持原始答案来衡量性能。
4.2 Main Results
4.2 主要结果
We list the results of current knowledge editing methods on Llama2-7b-chat in Table 4.
| DataSet | Metric | SERAC | ICE | AdaLoRA | MEND | ROME | MEMIT | FT-L | FT-M |
| WikiDatarecent | Edit Succ.↑ | 98.68 | 60.74 | 100.00 | 95.75 | 97.18 | 97.05 | 55.75 | 100.00 |
| Portability ↑ | 63.52 | 36.93 | 64.69 | 55.88 | 55.25 | 56.37 | 40.86 | 65.44 | |
| Locality ↑ | 100.00 | 33.34 | 56.42 | 94.76 | 54.77 | 52.15 | 43.70 | 64.33 | |
| Fluency↑ | 553.19 | 531.01 | 579.57 | 557.11 | 579.66 | 573.89 | 529.24 | 574.32 | |
| ZsRE | Edit Succ.↑ | 99.67 | 66.01 | 100.00 | 96.74 | 96.77 | 95.37 | 53.93 | 99.98 |
| Portability ↑ | 56.48 | 63.94 | 58.03 | 60.41 | 52.63 | 52.67 | 45.64 | 60.31 | |
| Locality↑ | 30.23 | 23.14 | 75.76 | 92.79 | 53.67 | 48.32 | 73.42 | 89.78 | |
| Fluency↑ | 410.89 | 541.14 | 563.56 | 524.33 | 573.75 | 563.31 | 493.01 | 552.26 | |
| WikiBio | Edit Succ.↑ | 99.69 | 95.53 | 100.00 | 93.66 | 96.08 | 94.40 | 66.33 | 100.00 |
| Locality↑ | 69.79 | 47.90 | 81.28 | 69.51 | 62.74 | 61.51 | 79.86 | 93.38 | |
| Fluency↑ | 606.95 | 632.92 | 618.45 | 609.39 | 617.69 | 616.65 | 606.95 | 612.69 | |
| WikiDatacounter fact | Edit Succ.↑ | 99.99 | 69.83 | 100.00 | 80.03 | 98.57 | 98.05 | 45.15 | 100.00 |
| Portability ↑ | 76.07 | 45.32 | 69.89 | 52.01 | 55.92 | 58.56 | 33.60 | 74.36 | |
| Locality↑ | 98.96 | 32.38 | 70.31 | 94.38 | 51.97 | 46.62 | 50.48 | 76.76 | |
| Fluency↑ | 549.91 | 547.22 | 580.29 | 555.72 | 584.04 | 575.96 | 528.26 | 575.62 | |
| ConvSent | Edit Succ.↑ | 62.75 | 52.78 | 44.89 | 50.76 | 45.79 | 44.75 | 49.50 | 46.10 |
| Locality↓ | 0.26 | 49.73 | 0.18 | 3.42 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Fluency↑ | 458.21 | 621.45 | 606.42 | 379.43 | 606.32 | 602.62 | 607.86 | 592.52 | |
| Sanitation | Edit Succ.↑ | 0.00 | 72.50 | 2.50 | 0.00 | 85.00 | 48.75 | 0.00 | 75.00 |
| Locality↑ | 100.00 | 56.58 | 65.50 | 5.29 | 50.31 | 67.47 | 14.78 | 47.07 | |
| Fluency↑ | 416.29 | 794.15 | 330.44 | 407.18 | 465.12 | 466.10 | 439.10 | 416.29 |
我们在表4中列出了当前知识编辑方法在Llama2-7b-chat上的结果。
| 数据集 | 指标 | SERAC | ICE | AdaLoRA | MEND | ROME | MEMIT | FT-L | FT-M |
|---|---|---|---|---|---|---|---|---|---|
| WikiDatarecent | 编辑成功率↑ | 98.68 | 60.74 | 100.00 | 95.75 | 97.18 | 97.05 | 55.75 | 100.00 |
| 可移植性↑ | 63.52 | 36.93 | 64.69 | 55.88 | 55.25 | 56.37 | 40.86 | 65.44 | |
| 局部性↑ | 100.00 | 33.34 | 56.42 | 94.76 | 54.77 | 52.15 | 43.70 | 64.33 | |
| 流畅度↑ | 553.19 | 531.01 | 579.57 | 557.11 | 579.66 | 573.89 | 529.24 | 574.32 | |
| ZsRE | 编辑成功率↑ | 99.67 | 66.01 | 100.00 | 96.74 | 96.77 | 95.37 | 53.93 | 99.98 |
| 可移植性↑ | 56.48 | 63.94 | 58.03 | 60.41 | 52.63 | 52.67 | 45.64 | 60.31 | |
| 局部性↑ | 30.23 | 23.14 | 75.76 | 92.79 | 53.67 | 48.32 | 73.42 | 89.78 | |
| 流畅度↑ | 410.89 | 541.14 | 563.56 | 524.33 | 573.75 | 563.31 | 493.01 | 552.26 | |
| WikiBio | 编辑成功率↑ | 99.69 | 95.53 | 100.00 | 93.66 | 96.08 | 94.40 | 66.33 | 100.00 |
| 局部性↑ | 69.79 | 47.90 | 81.28 | 69.51 | 62.74 | 61.51 | 79.86 | 93.38 | |
| 流畅度↑ | 606.95 | 632.92 | 618.45 | 609.39 | 617.69 | 616.65 | 606.95 | 612.69 | |
| WikiDatacounter fact | 编辑成功率↑ | 99.99 | 69.83 | 100.00 | 80.03 | 98.57 | 98.05 | 45.15 | 100.00 |
| 可移植性↑ | 76.07 | 45.32 | 69.89 | 52.01 | 55.92 | 58.56 | 33.60 | 74.36 | |
| 局部性↑ | 98.96 | 32.38 | 70.31 | 94.38 | 51.97 | 46.62 | 50.48 | 76.76 | |
| 流畅度↑ | 549.91 | 547.22 | 580.29 | 555.72 | 584.04 | 575.96 | 528.26 | 575.62 | |
| ConvSent | 编辑成功率↑ | 62.75 | 52.78 | 44.89 | 50.76 | 45.79 | 44.75 | 49.50 | 46.10 |
| 局部性↓ | 0.26 | 49.73 | 0.18 | 3.42 | 0.00 | 0.00 | 0.00 | 0.00 | |
| 流畅度↑ | 458.21 | 621.45 | 606.42 | 379.43 | 606.32 | 602.62 | 607.86 | 592.52 | |
| Sanitation | 编辑成功率↑ | 0.00 | 72.50 | 2.50 | 0.00 | 85.00 | 48.75 | 0.00 | 75.00 |
| 局部性↑ | 100.00 | 56.58 | 65.50 | 5.29 | 50.31 | 67.47 | 14.78 | 47.07 | |
| 流畅度↑ | 416.29 | 794.15 | 330.44 | 407.18 | 465.12 | 466.10 | 439.10 | 416.29 |
Table 4: Results of existing knowledge editing methods on KnowEdit. We have updated the results after optimizing certain methods (related to AdaLoRA) and fixing computational bugs (related to ROME and MEMIT) in the EasyEdit tool. These improvements have led to better results than before. The symbol $\uparrow$ indicates that higher numbers correspond to better performance, while $\downarrow$ denotes the opposite, with lower numbers indicating better performance. The locality of Convsent is computed as the KL-divergence so the lower the number, the better the performance is. For WikiBio and Convsent, we do not test the portability as they are about specific topics.
表 4: 现有知识编辑方法在KnowEdit上的结果。我们优化了部分方法(与AdaLoRA相关)并修复了EasyEdit工具中的计算错误(与ROME和MEMIT相关)后更新了结果。这些改进使得结果优于之前。符号$\uparrow$表示数值越高性能越好,而$\downarrow$表示相反,数值越低性能越好。Convsent的局部性通过KL散度计算,因此数值越低性能越好。对于WikiBio和Convsent,由于涉及特定主题,我们未测试可移植性。
Considering the overall performance across various knowledge editing tasks, our newly proposed FT-M implementation outperforms other methods, highlighting the effectiveness of fine-tuning the model on specific parameters. However, all current knowledge editing methods suffer from low portability performance, indicating a need for further improvements in this area.
在不同知识编辑任务的整体表现上,我们新提出的FT-M实现优于其他方法,突显了对特定参数进行微调的有效性。然而,当前所有知识编辑方法都存在可移植性表现不佳的问题,表明该领域仍需进一步改进。
Regarding knowledge editing methods, SERAC demonstrates strong performance for tasks involving knowledge insertion and modification. Its edit success rate is better than other editing methods, and the portability is relatively good as the new counter fact model can learn the edited knowledge effectively. Meanwhile, without changing the original model’s parameters, SERAC obtains a good locality performance except for ZsRE. However, since the counter fact model is usually smaller than the original model, its generation ability is not that strong, and here, We can find SERAC’s fluency for Wiki Data counter fact, ZsRE, and Convsentis lower than other editing methods like MEND. Meanwhile, for ICE, we can find that the edit success is not that good, which may be attributed to the knowledge conflict problem. Meanwhile, IKE proposed to concatenate demonstrations as the prompt, but they required a long input length and limited the model to conducting downstream tasks.
在知识编辑方法方面,SERAC在涉及知识插入和修改的任务中表现出色。其编辑成功率优于其他编辑方法,且由于新反事实模型能有效学习编辑后的知识,可移植性较好。同时,在不改变原始模型参数的情况下,SERAC除ZsRE外均获得了良好的局部性表现。但由于反事实模型通常小于原始模型,其生成能力较弱,此处可观察到SERAC在Wiki Data反事实、ZsRE和Convsentis上的流畅度低于MEND等其他编辑方法。此外,对于ICE而言,其编辑成功率不甚理想,这可能归因于知识冲突问题。值得注意的是,IKE提出通过拼接示例作为提示,但该方法需要较长输入长度且限制了模型执行下游任务的能力。
For the methods that edit the model’s parameters, we can find that MEND obtains good performance across these tasks in different metrics. Its edit success and portability are good and demonstrate good locality and fluency. While for ROME and MEMIT, despite the better edit success, their locality is not as good as MEND and other type of editing methods. Meanwhile, its portability is unsatisfactory. For the local fine-tune method FT-L, its edit success is not as good as ROME or MEMIT, however, the locality and portability are better. Also, it seems that FT-M can deal with insertion tasks better as its edit success and portability for ${\mathrm{WikiData}}_{r e c e n t}$ is better than ZsRE and Wiki Data counter fact. For the WikiBio task, current methods can alleviate hallucination properly and maintain good fluency. As to the task Convsent, we find that current methods cannot change the model’s sentiment well as the edit success is lower than $65%$ . SERAC, which can deal with small LMs perfectly [153], performs not that well on the 7B model. MEND also shows low fluency for these tasks considering its great performance for fact-level editing in other tasks. As to the knowledge erasure task Sanitation, which aims to erase knowledge from LLMs, we can find that current knowledge editing methods cannot tackle this task properly. We can find that ROME can refrain from the model not providing the target knowledge as it gets $90%$ accuracy. However, it would destroy the model’s performance on unrelated knowledge because its locality is just $55.61%$ . Other editing methods cannot erase the model related to the given knowledge either.
在参数编辑方法中,MEND 在不同任务的多项指标中表现优异,其编辑成功率与可迁移性出色,同时保持了良好的局部性和流畅度。相比之下,ROME 和 MEMIT 虽然编辑成功率更高,但局部性弱于 MEND 及其他编辑方法,且可迁移性表现欠佳。局部微调方法 FT-L 的编辑成功率不及 ROME 或 MEMIT,但其局部性与可迁移性更优。值得注意的是,FT-M 在插入类任务(如 ${\mathrm{WikiData}}_{recent}$)中展现出比 ZsRE 和 WikiData 反事实任务更好的编辑成功率和可迁移性。对于 WikiBio 任务,现有方法能有效缓解幻觉问题并保持良好流畅度。而在 Convsent 任务中,当前方法对模型情感的编辑效果有限(成功率低于 $65%$)。SERAC 虽然在小型语言模型上表现卓越 [153],但在 7B 模型上效果欠佳。MEND 在其他任务中事实层面编辑表现突出,但在此类任务中流畅度较低。针对知识擦除任务 Sanitation(旨在从大语言模型中清除特定知识),现有编辑方法均未取得理想效果:ROME 虽能以 $90%$ 准确率阻止模型输出目标知识,但会损害无关知识的性能(局部性仅 $55.61%$),其他方法同样无法有效擦除指定关联知识。
We also show the average performance of results on ${\mathrm{WikiData}}_{r e c e n t}$ and Wiki Data counter fact in submetrics of portability and locality, as we discussed in the previous evaluation part in Figure 3. Here, we can find that MEND performs better under the reasoning set, while AdaLoRA shows good logical generalization performance.
我们还展示了在${\mathrm{WikiData}}_{recent}$和WikiData counter fact数据集上关于可移植性和局部性子指标的平均性能结果,如图3前文评估部分所述。可以看出,MEND在推理集上表现更优,而AdaLoRA展现出良好的逻辑泛化能力。
4.3 Impact on General Tasks
4.3 对通用任务的影响
In this Section, we explore the impact of applying knowledge editing methods on the performance of a language model across various domains. Our main goal is to determine if incorporating edits related to specific factual knowledge can un intentionally hinder the model’s proficiency in unrelated areas. We select a series of benchmarks that cover areas such as commonsense reasoning, general intelligence, and world knowledge. These benchmarks include Commonsense QA [199], PIQA [200], Xsum [201], and TriviaQA [202], as well as specific tasks from the MMLU [203] and AGIEval [204] suites, which are known for their distinguished evaluation criteria suites. All evaluations are conducted using the Open Compass tool [205], ensuring a standardized testing environment. We report the ROUGE-1 here for Xsum. The edited models are evaluated in a zero-shot setting on these tasks after being sequentially modified with five factual updates. An intriguing observation from Table 5 is that, on a holistic level, the edited models managed to sustain a performance level that is close to their unedited counterparts. This suggests that the negative impact of the editing was limited to directly altered topics. However, one exception to this trend is the FT-L model’s performance on TriviaQA, which shows a noticeable decline from an initial score of 45.39 to 34.60 after the edit. Nevertheless, taking a broader perspective, we can observe commendable consistency. This implies that contemporary knowledge editing methods are effective in executing five targeted factual updates with minimal disruptions to the model’s cognitive capabilities and adaptability across diverse knowledge domains.
在本节中,我们探讨了应用知识编辑方法对大语言模型在不同领域性能的影响。我们的主要目标是确定融入特定事实知识相关的编辑是否会无意中削弱模型在无关领域的表现能力。我们选取了一系列涵盖常识推理、通用智能和世界知识的基准测试,包括Commonsense QA [199]、PIQA [200]、Xsum [201]和TriviaQA [202],以及以严格评估标准著称的MMLU [203]和AGIEval [204]测试集中的特定任务。所有评估均使用Open Compass工具 [205]进行,确保测试环境标准化。对于Xsum任务,我们在此报告ROUGE-1指标。经过连续五次事实更新修改后,这些编辑后的模型在零样本设置下接受评估。表5展示了一个有趣的现象:整体而言,编辑后的模型保持了与未编辑版本相近的性能水平,这表明编辑的负面影响仅局限于被直接修改的主题。但一个例外是FT-L模型在TriviaQA上的表现,其分数从初始的45.39显著下降至编辑后的34.60。不过从更宏观的视角来看,我们观察到了值得称赞的一致性表现。这表明当代知识编辑方法能有效执行五次针对性事实更新,同时对模型跨知识领域的认知能力和适应性造成最小程度的干扰。
Figure 3: Average sub-metrics performance of results on several fact edit datasets in Portability and Locality.
图 3: 多个事实编辑数据集在可移植性( Portability )和局部性( Locality )上的平均子指标性能表现。
Table 5: The zero-shot performance on the general LLM benchmark with Llama2-Chat-7B as the base model. Here, we conduct 5 consecutive edits for each method using the $\operatorname{Wiki}_{r e c e n t}$ dataset to evaluate the post-edited model’s general ability. We adopt the Open Compass [205] to evaluate the model and use the Hugging Face setting. The MMLU and AGIEval are both the average performance of the sub-tasks.
| CommonsenseQA | PIQA | TriviaQA | X_Sum | MMLU | AGIEval | |
| Llama2-Chat | 49.55 | 64.91 | 45.39 | 22.34 | 6.87 | 27.81 |
| FT-L | 50.78 | 67.79 | 34.60 | 22.31 | 7.64 | 28.56 |
| MEND | 49.80 | 65.23 | 45.63 | 22.09 | 7.64 | 27.49 |
| ROME | 48.89 | 65.45 | 45.19 | 22.46 | 7.43 | 27.38 |
| MEMIT | 49.80 | 65.12 | 45.26 | 22.34 | 7.00 | 28.27 |
| AdaLoRA | 49.39 | 65.07 | 45.29 | 22.31 | 6.90 | 27.72 |
表 5: 基于Llama2-Chat-7B基础模型的大语言模型通用基准零样本性能。我们使用$\operatorname{Wiki}_{recent}$数据集对每种方法连续进行5次编辑,以评估编辑后模型的通用能力。采用Open Compass [205]进行评估,使用Hugging Face设置。MMLU和AGIEval均为子任务的平均表现。
| CommonsenseQA | PIQA | TriviaQA | X_Sum | MMLU | AGIEval | |
|---|---|---|---|---|---|---|
| Llama2-Chat | 49.55 | 64.91 | 45.39 | 22.34 | 6.87 | 27.81 |
| FT-L | 50.78 | 67.79 | 34.60 | 22.31 | 7.64 | 28.56 |
| MEND | 49.80 | 65.23 | 45.63 | 22.09 | 7.64 | 27.49 |
| ROME | 48.89 | 65.45 | 45.19 | 22.46 | 7.43 | 27.38 |
| MEMIT | 49.80 | 65.12 | 45.26 | 22.34 | 7.00 | 28.27 |
| AdaLoRA | 49.39 | 65.07 | 45.29 | 22.31 | 6.90 | 27.72 |
Table 6: Cross-Domain Editing Results. Performance (accuracy) of the compared methods, which are firstly trained on a source dataset and then directly conduct prediction on a target dataset (denoted as source $\Rightarrow$ target).
| Method | ZsRE=Wikirecent | Wikirecent Wikicounter fact | Wikirecent => ZsRE | |
| MEND | Edit Succ. | 95.91 | 66.15 | 89.79 |
| Portability | 61.80 | 45.95 | 54.36 | |
| Locality | 66.57 | 94.83 | 95.80 | |
| Fluency | 554.28 | 592.82 | 571.39 | |
| SERAC | EditSucc. | 97.42 | 99.43 | 99.31 |
| Portability | 60.42 | 68.85 | 57.70 | |
| Locality | 27.25 | 100.00 | 79.04 | |
| Fluency | 487.29 | 552.51 | 511.95 |
表 6: 跨领域编辑结果。各对比方法的性能(准确率),这些方法首先在源数据集上训练,然后直接在目标数据集上进行预测(记为 source $\Rightarrow$ target)。
| 方法 | ZsRE=>Wikirecent | Wikirecent=>Wikicounterfact | Wikirecent=>ZsRE | |
|---|---|---|---|---|
| MEND | 编辑成功率 | 95.91 | 66.15 | 89.79 |
| 可移植性 | 61.80 | 45.95 | 54.36 | |
| 局部性 | 66.57 | 94.83 | 95.80 | |
| 流畅度 | 554.28 | 592.82 | 571.39 | |
| SERAC | 编辑成功率 | 97.42 | 99.43 | 99.31 |
| 可移植性 | 60.42 | 68.85 | 57.70 | |
| 局部性 | 27.25 | 100.00 | 79.04 | |
| 流畅度 | 487.29 | 552.51 | 511.95 |
4.4 Multi-Task Knowledge Editing
4.4 多任务知识编辑
Previous work considered a sequential edit [163, 161, 69] for a lifelong knowledge editing. However, they always conduct sequential editing on a single dataset from the same distribution. This is a bit different from Continuous learning. Knowledge editing is not a task focusing on single-domain knowledge or fact. In reality, we may want to modify our model from different perspectives from different distributions [206].
先前的研究考虑了终身知识编辑的连续编辑方式[163, 161, 69]。然而,这些研究通常只在同一分布下的单一数据集上进行连续编辑。这与持续学习略有不同。知识编辑并非专注于单一领域知识或事实的任务。现实中,我们可能需要从不同分布的不同角度修改模型[206]。
Cross-domain Editing Both MEND and SERAC methods rely on a training dataset to help the model learn how to edit parameters. We evaluate their performance in a cross-domain setting and present the results in Table 6.
跨域编辑
MEND和SERAC方法均依赖训练数据集来帮助模型学习如何编辑参数。我们在跨域设置下评估它们的性能,结果如表6所示。
For the MEND method, the hyper-network trained using the ZsRE dataset exhibits better crossdomain performance than that trained with the recent dataset. This can be attributed to the enormous size of the ZsRE dataset, allowing MEND’s hyper-network to enhance its parameter-editing capabilities. Meanwhile, the SERAC approach, by leveraging its cache, exhibits significant cross-domain editing prowess.
对于MEND方法,使用ZsRE数据集训练的超网络展现出比近期数据集更好的跨域性能。这归因于ZsRE数据集的庞大规模,使MEND的超网络得以增强其参数编辑能力。同时,SERAC方法通过利用其缓存机制,表现出卓越的跨域编辑能力。
Continual Editing Methods like LoRA and ROME do not require a training set and can be applied directly to different domains. Hence, we consider a more challenging setting for continual editing. We mix different knowledge editing cases using the ZsRE, $\operatorname{Wiki}_{r e c e n t}$ and Wiki counter fact. We combine different numbers of settings, including 10, 100, 500, and 1000, and edit the knowledge from different sets randomly. Here, we mainly consider three methods: FT-L, ROME, and AdaLoRA. We report the empirical findings in Figure 4. When dealing with sequential editing, we can observe that these three methods all suffer from 1,000 editing times with a dramatic drop in all evaluation metrics, and the trend is similar for three different tasks. Relatively, AdaLoRA shows a stable performance for about 100 edits. Current editing methods tend to edit the same area for different knowledge (e.g. ROME the fifth layer, MEND the last three layers), while the knowledge is not stored in this area.
持续编辑方法(如LoRA和ROME)无需训练集,可直接应用于不同领域。因此,我们为持续编辑设定了一个更具挑战性的场景:混合使用ZsRE、$\operatorname{Wiki}_{recent}$和Wiki counter fact三类知识编辑案例,随机组合10、100、500及1000次不同规模的编辑设置。主要测试FT-L、ROME和AdaLoRA三种方法,实验结果如图4所示。在连续编辑过程中,这三种方法均因1000次编辑导致所有评估指标急剧下降,且三种任务呈现相似趋势。相对而言,AdaLoRA在约100次编辑时表现稳定。现有编辑方法倾向于对不同知识重复修改相同区域(例如ROME固定修改第五层,MEND锁定最后三层),但知识实际并未存储于这些区域。

Figure 4: Sequential editing results in randomly selected data from Wiki Data counter fact, ZsRE and Wiki Data recent with different numbers.
图 4: 在随机选取的 Wiki Data counter fact、ZsRE 和 Wiki Data recent 数据上,不同数量级顺序编辑的结果。
Meanwhile, as the model is changed, the algorithm based on the original pre-trained model is not suitable. In order to address these challenges, RASE [207] proposes a novel approach that combines the strengths of retrieval augmented and editing methods, rather than continuously modifying the model’s parameters. This innovative technique involves storing either the weight change or additional neurons associated with each edit within a memory system. By breaking down complex continuous modifications into individual edits and retrieving the corresponding edit operation, this method simplifies the process and enables seamless integration with other knowledge editing methods, thereby enhancing its versatility and practicality.
与此同时,随着模型变更,基于原始预训练模型的算法不再适用。为解决这些挑战,RASE [207] 提出了一种结合检索增强与编辑方法优势的创新方案,而非持续调整模型参数。该技术通过将复杂的连续修改拆解为独立编辑操作,并将每次编辑对应的权重变化或新增神经元存储于记忆系统中,在需要时检索对应编辑操作。这种方法不仅简化了流程,还能与其他知识编辑技术无缝结合,显著提升了方案的通用性与实用性。
4.5 Error and Case Analysis
4.5 误差与案例分析
As shown in the results, different methods demonstrate different performance on different tasks. Here, we conduct a study to comprehensively understand their limitations and advantages. In analyzing the failure modes of knowledge editing methods, we categorize the deficiencies into four primary types:
结果显示,不同方法在不同任务上表现出不同的性能。为此,我们开展了一项研究以全面理解它们的局限性和优势。在分析知识编辑方法的失败模式时,我们将缺陷分为四种主要类型:
Table 7: Results for one case of different editing methods. Prompts are presented in italicized text. Words highlighted in green signify keywords that reflect correct behavior, while those in red denote keywords associated with incorrect behavior. Texts in cyan are repeated or meaningless sentences.
| Input:ThesurfaceoftheQueenAminaStatueismadeof |
| OriginalOutput:ThesurfaceoftheQueenAminaStatueismadeofbronze,whichisadurableandlong-lastingmaterial. EditTarget:limestone. |
| AdaLoRA:ThesurfaceoftheQueenAminaStatueismadeofbronze.If thestatueis3meterstall and thebaseofthestatue is 0.5metersindiameter... SERAC:Thesurfaceof theQueenAminaStatueis madeoflimestone.The surface of theQueenAminaStatueismade of ROME:ThesurfaceoftheQueenAminaStatueismadeof flimestone.Thelimestoneis asedimentaryrock,whichisa |
表 7: 不同编辑方法在单个案例中的结果。提示语以斜体显示。绿色高亮词汇表示反映正确行为的关键词,红色则代表与错误行为相关的关键词。青色文本为重复或无意义的句子。
| 输入: Queen Amina 雕像的表面由 |
| 原始输出: Queen Amina 雕像的表面由青铜制成,这是一种耐用且持久的材料。编辑目标: 石灰岩。 |
| AdaLoRA: Queen Amina 雕像的表面由青铜制成。如果雕像高3米且基座直径为0.5米... |
| SERAC: Queen Amina 雕像的表面由石灰岩制成。Queen Amina 雕像的表面由 |
| ROME: Queen Amina 雕像的表面由石灰岩制成。石灰岩是一种沉积岩,属于 |
The occurrence of these error types helps identify the limitations of the editing methods. Meaningless and missing token cases highlight difficulties in fully encoding the target fact, while knowledgeirrelevant and partial replacement generations suggest that the edits fail to supplant previously learned information. We conduct an error analysis on the ZsRE tasks and counted the error cases for each editing method. The results are presented in Figure 5. Here, we can find the main error type is the partial token replacement due to the conflict of the knowledge in the original model and our target one. The analysis reveals that the main error type is partial token replacement, indicating a conflict between the knowledge in the original model and the target knowledge. Specifically, the SERAC method tends to generate meaningless tokens due to the limited generation ability of the small model used. The AdaLoRA method may miss some tokens related to the target knowledge. For the fine-tuning methods, the percentage of fact-irrelevant words is higher compared to other editing methods, and it is the most common error type $(47.3%)$ for FT-L. This suggests that the objective of fine-tuning might not be suitable for editing specific knowledge. Additionally, in the following section, we find that FT-L tends to modify more areas in the parameters, leading to more irrelevant generations.
这些错误类型的出现有助于识别编辑方法的局限性。无意义和缺失token的情况突显了完全编码目标事实的困难,而知识无关和部分替换生成则表明编辑未能替代先前学习的信息。我们对ZsRE任务进行了错误分析,并统计了每种编辑方法的错误案例。结果如图5所示。此处可以发现,主要错误类型是由于原始模型与目标模型知识冲突导致的部分token替换。分析表明,主要错误类型是部分token替换,揭示了原始模型知识与目标知识之间的冲突。具体而言,SERAC方法由于使用小模型的有限生成能力,倾向于生成无意义token。AdaLoRA方法可能会遗漏与目标知识相关的一些token。对于微调方法,与其他编辑方法相比,事实无关词的比例更高,且是FT-L最常见的错误类型$(47.3%)$。这表明微调的目标可能不适合编辑特定知识。此外,在后续章节中,我们发现FT-L倾向于修改参数中更多区域,导致更多无关生成。
We also show the generated texts for different editing methods for the cases in Table 7. Here, we can find that current editing methods, like IKE, MEND, ROME can successfully modify the material of the Queen Amina Statue from bronze to limestone and generate fluent texts. SERAC and FT-L, despite changing the facts successfully, tend to generate repeated sentences or meaningless entities. Additionally, AdaLoRA failed to change the fact and kept the original answer, “bronze”.
我们还展示了表7中不同编辑方法生成的文本。从中可以发现,当前的编辑方法(如IKE、MEND、ROME)能成功将阿米娜女王雕像的材质从青铜改为石灰岩,并生成流畅的文本。虽然SERAC和FT-L成功修改了事实,但倾向于生成重复句子或无意义的实体。此外,AdaLoRA未能改变事实,仍保留了原始答案"青铜"。
5 Analysis
5 分析
Current research has explored the effectiveness of knowledge editing methods in LLMs, but the underlying reasons for their superior performance remain unexplored. Additionally, the comparison between model editing and fine-tuning approaches, as well as the efficacy of knowledge location methods, requires further investigation. This study proposes a simple attempt to bridge these gaps by examining the differences between model editing and fine-tuning, exploring the effectiveness of knowledge location techniques, and understanding the knowledge structure within LLMs. We hope further investigation will unveil the mechanisms of knowledge in LLMs.
当前研究已探索了大语言模型(LLM)中知识编辑方法的有效性,但其性能优势的根本原因仍未得到解析。此外,模型编辑与微调方法的对比、知识定位技术的效能也需要进一步研究。本研究通过分析模型编辑与微调的差异、探索知识定位技术的有效性、解析大语言模型内部知识结构,提出了填补这些研究空白的初步尝试。我们期待后续研究能揭示大语言模型中的知识运作机制。

Figure 5: Bad cases statistics for different knowledge editing methods.
图 5: 不同知识编辑方法的错误案例统计。

Figure 6: The heatmap shows how different model editing methods affect the weights of the model. Darker colors indicate more changes in the weights. The heatmap reveals which parts of the model are most sensitive to changes for each method.
图 6: 热力图展示了不同模型编辑方法对模型权重的影响。颜色越深表示权重变化越大。该热力图揭示了每种方法下模型中对变化最敏感的部分。
5.1 Comparison of Different Knowledge Editing Methods
5.1 不同知识编辑方法对比
The effectiveness of current knowledge editing methods is commendable, but the reasons behind their superior performance compared to other approaches remain elusive. In this section, we focus on methods that involve parameter adjustments within the model, specifically MEND, ROME, MEMIT, and FT-L. As these methods modify the model’s parameters, a fundamental question arises: what makes some knowledge editing methods, like MEND, superior in terms of locality and overall performance? We formally represent the change as $W^{\prime}=W+\Delta W_{\mathrm{edit}}$ , where $W$ is the original weight matrix, and $\Delta W_{\mathrm{edit}}$ represents the modifications made during editing. Therefore, our primary focus in this section is to discern the differences between the matrices $\Delta W_{\mathrm{edit}}$ for different editing methods.
当前知识编辑方法的有效性值得称赞,但其性能优于其他方法的原因仍不明确。本节我们重点关注涉及模型内部参数调整的方法,特别是MEND、ROME、MEMIT和FT-L。由于这些方法会修改模型参数,一个根本性问题随之产生:为何某些知识编辑方法(如MEND)在局部性和整体性能方面表现更优?我们将参数变化形式化表示为 $W^{\prime}=W+\Delta W_{\mathrm{edit}}$ ,其中 $W$ 是原始权重矩阵, $\Delta W_{\mathrm{edit}}$ 表示编辑过程中的修改量。因此,本节主要研究不同编辑方法对应的矩阵 $\Delta W_{\mathrm{edit}}$ 之间的差异。
Sparsity An important characteristic of knowledge editing is its intention to modify a specific piece of knowledge within the model. This suggests an intuitive hypothesis that the $\Delta W$ matrix is likely to be sparse. Following the approach of De Cao et al. [168], we present visualization s that capture weight updates resulting from knowledge edits, as depicted in Figure 6.
稀疏性
知识编辑的一个重要特性是其旨在修改模型中的特定知识片段。这表明一个直观假设:$\Delta W$ 矩阵很可能是稀疏的。遵循 De Cao 等人 [168] 的方法,我们展示了捕捉知识编辑导致的权重更新的可视化结果,如图 6 所示。
ROME, MEND, and MEMIT exhibit a distinct pattern of sparse updates, while fine-tuning spreads its modifications more uniformly across weights. Particularly, for knowledge editing methods like ROME and MEMIT, it is intriguing to observe a concentrated focus on one or several columns of the value layer. This finding aligns with earlier research that emphasizes the value layer’s pivotal role in encapsulating correlated knowledge [42]. Regarding the MEND methods, we propose that the learned hyper network can be viewed as a tool or a ”probe” that helps us explore and understand the internal mechanisms used by the model to encode knowledge, providing insights into how the model represents and processes information.
ROME、MEND和MEMIT展现出稀疏更新的独特模式,而微调则更均匀地分散在权重中。值得注意的是,对于ROME和MEMIT这类知识编辑方法,可以观察到值层(value layer)中一列或多列的集中聚焦现象。这一发现与早期强调值层在封装关联知识中起关键作用的研究相吻合[42]。针对MEND方法,我们认为其学习得到的超网络可视为一种工具或"探针",能帮助我们探索和理解模型编码知识的内在机制,从而揭示模型表征与处理信息的方式。
Mapping to Embedding Space To further investigate the differences between different editing methods, we conduct an embedding space analysis following the approach of Dar et al. [208]. They analyze the Transformer’s parameters by mapping the weights of the LLMs to the vocabulary space and find that the embedding space can interpret these weights. Here, we map the two matrices, $W^{\prime}$ and $W$ , to observe the differences between these methods. From the sparsity analysis, we select the top five columns of the updated value matrix $\Delta W$ and map the corresponding columns of $W^{\prime}$ and $W$ into the embedding matrices $\textbf{emph{E}}$ to obtain the logits in the vocabulary space. We then compute the $\mathrm{Hit}@10$ and $\mathrm{Hit}@50$ of the new knowledge in the output logits. We select cases from ZsRE where all four methods successfully edit the knowledge and present the average performance in Figure 7. From the figure, we observe that MEND and MEMIT significantly inject the target knowledge into the parameters. Notably, MEND demonstrates a remarkable capacity for editing, with the Hit $\ @50$ rate already exceeding $90%$ before the edit. This means that MEND might be able to find and change the right neurons that hold the target knowledge without having to do a full knowledgelocating analysis. After the editing process, we observe a substantial increase in the $\mathrm{Hit}@10$ score.
映射到嵌入空间
为了进一步研究不同编辑方法之间的差异,我们采用Dar等人[208]的方法进行了嵌入空间分析。他们通过将大语言模型的权重映射到词汇空间来分析Transformer的参数,发现嵌入空间可以解释这些权重。在此,我们映射两个矩阵$W^{\prime}$和$W$,以观察这些方法之间的差异。根据稀疏性分析,我们选取更新值矩阵$\Delta W$的前五列,并将$W^{\prime}$和$W$的对应列映射到嵌入矩阵$\textbf{emph{E}}$中,从而获得词汇空间的对数几率。然后,我们计算输出对数几率中新知识的$\mathrm{Hit}@10$和$\mathrm{Hit}@50$。我们从ZsRE中选取所有四种方法均成功编辑知识的案例,并将平均性能展示在图7中。从图中可以看出,MEND和MEMIT显著地将目标知识注入到参数中。值得注意的是,MEND展现出卓越的编辑能力,其$\ @50$命中率在编辑前就已超过$90%$。这意味着MEND可能无需进行完整的知识定位分析,就能找到并修改存储目标知识的正确神经元。在编辑过程后,我们观察到$\mathrm{Hit}@10$分数大幅提升。
In fact, in our experiments, the $\operatorname{Hit}@1$ for MEND is also above $90%$ after editing, demonstrating its strong editing capacity. For MEMIT, we also observe an increase in $\operatorname{Hit}@50$ $59.7%\rightarrow70.2%)$ , and the original neurons already have a high Hit score before editing. However, for ROME and FT-L, we do not observe an increase in performance, indicating that their editing mechanisms require further investigation to understand their specific characteristics and limitations.
事实上,在我们的实验中,MEND的$\operatorname{Hit}@1$在编辑后也超过了$90%$,这证明了其强大的编辑能力。对于MEMIT,我们还观察到$\operatorname{Hit}@50$有所提升($59.7%\rightarrow70.2%$),且原始神经元在编辑前就已经具有较高的Hit分数。然而,对于ROME和FT-L,我们并未观察到性能提升,这表明它们的编辑机制需要进一步研究以了解其具体特性和局限性。
5.2 Analysis of Knowledge Locating
5.2 知识定位分析
As we have discussed in the previous part, the knowledge stored in LLMs is not structured. Also, in the previous experiments, we found that the performance of current editing in terms of portability is not good. As previous works have found [69, 155, 157], editing factual knowledge does not necessarily enable models to utilize it during reasoning and application. Meanwhile, Hase et al. [209] found edit success unrelated to
正如前文所述,大语言模型(LLM)中存储的知识是非结构化的。此外,在先前实验中我们发现当前编辑方法在可移植性方面表现欠佳。已有研究[69, 155, 157]表明,对事实知识的编辑并不必然能使模型在推理和应用中有效调用这些知识。同时Hase等人[209]发现编辑成功率与

Figure 7: The Hit $@10$ and $\operatorname{Hit}@50$ performance for the target knowledge in the model’s parameters before and after editing.
图 7: 模型参数中目标知识在编辑前后的 Hit $@10$ 和 $\operatorname{Hit}@50$ 性能表现。
where facts are stored, as measured by causal tracing. These works highlight that current editing methods are insufficient and pose skepticism against the effectiveness of current knowledge location analysis. Chang et al. [210] introduces two benchmarks: INJ and DEL to investigate “Do any localization methods actually localize memorized data in LLMs?”. They conduct experiments on current localization methods, including zero-out and integrated gradients, and proposed two prune-based localization methods: SLIMMING and HARD CONCRETE. Two benchmarks show positively correlated results and demonstrate strong localization abilities of integrated gradients, SLIMMING, and HARD CONCRETE. At the same time, the DEL Benchmark shows that all methods struggle to balance between erasing the target sequence and retaining other memorized data; in other words, the neurons identified by localization methods tend to also be relevant for memorizing some other sequences. Additionally, Ju and Zhang [211] proposed a benchmark for assessing the effectiveness of current knowledge location methods and three evaluation metrics: consistency, relevance, and unbiased ness. This benchmark plays a crucial role in facilitating a comprehensive evaluation of whether current locating methods can accurately pinpoint model parameters associated with specific factual knowledge. Here, we make a simple analysis of the location methods for knowledge editing based on the benchmark. We adopt the computing of the Relative Similarity (RSim) as: $\begin{array}{r}{\operatorname*{max}\left(\frac{\sin\mathrm{{cand}}-\mathrm{{Sim}_ {a l l}}}{1-\mathrm{{Sim}_{a l l}}},0\right).}\end{array}$
根据因果追踪测量的事实存储位置。这些研究指出,当前编辑方法存在不足,并对现有知识定位分析的有效性提出质疑。Chang等人[210]提出了INJ和DEL两个基准,用于探究"现有定位方法能否真正定位大语言模型中的记忆数据?"。他们在零样本和积分梯度等当前定位方法上开展实验,并提出两种基于剪枝的定位方法:SLIMMING和HARD CONCRETE。两个基准测试呈现正相关结果,验证了积分梯度、SLIMMING和HARD CONCRETE具备较强的定位能力。同时,DEL基准表明所有方法都难以在擦除目标序列与保留其他记忆数据之间取得平衡,即定位方法识别的神经元往往也与其他序列的记忆相关。此外,Ju和Zhang[211]提出了评估现有知识定位方法有效性的基准及三个指标:一致性、相关性和无偏性。该基准对全面评估现有定位方法能否准确找到与特定事实知识相关的模型参数具有关键作用。基于该基准,我们对知识编辑的定位方法进行简要分析,采用相对相似度(RSim)计算公式:$\begin{array}{r}{\operatorname*{max}\left(\frac{\sin\mathrm{{cand}}-\mathrm{{Sim}_ {a l l}}}{1-\mathrm{{Sim}_{a l l}}},0\right).}\end{array}$
We adopt their dataset klob-r (designed for measuring consistency) and klob-c (designed for measuring relevance) and apply them to the casual analysis method proposed by ROME [79]. Since the casual analysis is a layer-wise intervention, here we compute the similarity using the overlap between the identified layers. We show the RSim score in Figure 8. Here, we can find the Rsim score is less than 0.6 when we consider more than five layers for both consistency and relevance, which means the locating results for unrelated knowledge and related knowledge chains didn’t show much difference. To be more tangible, we conduct a case study here.
我们采用他们设计的klob-r(用于衡量一致性)和klob-c(用于衡量相关性)数据集,并将其应用于ROME [79]提出的因果分析方法。由于因果分析是一种逐层干预方法,这里我们使用识别层之间的重叠来计算相似度。图8展示了RSim分数。可以发现,当考虑超过五层时,无论是对于一致性还是相关性,Rsim分数均低于0.6,这意味着无关知识链与相关知识链的定位结果差异不大。为了更直观地说明,我们在此进行案例研究。
Case Study We consider three settings for a given fact associated with the entity $S M A P$ and show it in Figure 9. We first conduct a causal analysis of the fact: [SMAP $\longrightarrow$ Japan]. Then, we consider a related question with the fact [SMAP $\longrightarrow$ Japan $\underline{{\mathrm{\Pi^{Ianguage}}}}$ Japanese], where the model should answer the question based on the fact. Finally, we adopt an unrelated fact [SMAP t−y−pe− of→ seminal group] with the question. The results show that these facts are possibly related to the same place around 5 layers. However, as Ju and Zhang [211] mentioned, the locating results for specific knowledge and its related knowledge chain should exhibit greater similarity compared to those
案例研究
我们针对与实体$SMAP$相关的给定事实考虑了三种设定,并在图9中展示。首先对该事实进行因果分析:[SMAP $\longrightarrow$ Japan]。接着考虑一个相关性问题:[SMAP $\longrightarrow$ Japan $\underline{{\mathrm{\Pi^{Ianguage}}}}$ Japanese],模型需要基于该事实回答问题。最后采用一个不相关事实[SMAP t−y−pe− of→ seminal group]进行提问。结果表明这些事实可能在约5层网络中存在关联。但如Ju和Zhang [211]所述,特定知识及其关联知识链的定位结果应表现出更高相似性。

Figure 8: RSim for the different number of layers.
图 8: 不同层数下的 RSim。
for unrelated knowledge. Currently, casual analysis methods seem to just locate the area that is related to the entity itself, not the whole fact. Whether the model performs these answers by cheating with answers memorized from the pre training corpus or via a multi-step reasoning mechanism is still unclear. This is strongly related to the knowledge editing tasks. More broadly, better insight into models’ knowledge processes could unlock capabilities like explain ability and fact verification. However, fully understanding how exactly knowledge is organized and interconnected within such large models presents an ongoing challenge. Key open questions include developing methods to trace factual usage during reasoning, designing location techniques that identify knowledge most salient for model outputs, and learning how architectural properties relate to knowledge utilization. Unpacking these knowledge architectures will be integral to enabling more precise and robust model interventions through approaches like knowledge editing but currently manipulating only the MLP weights is not enough.
对于不相关的知识,目前随意的分析方法似乎仅定位到与实体本身相关的区域,而非整个事实。模型是通过记忆预训练语料库中的答案进行作弊式回答,还是通过多步推理机制完成这些回答,目前仍不明确。这与知识编辑任务密切相关。更广泛地说,深入理解模型的知识处理过程可能解锁可解释性和事实验证等能力。然而,完全理解知识在如此庞大的模型中如何精确组织和相互关联,仍是一个持续存在的挑战。关键的开放性问题包括:开发追踪推理过程中事实使用的方法、设计识别对模型输出最显著知识的定位技术,以及学习架构属性如何与知识利用相关联。解开这些知识架构将是通过知识编辑等方法实现更精确、更稳健模型干预的关键,但目前仅操纵MLP权重还远远不够。
5.3 The Implicit Knowledge Structure in LLMs
5.3 大语言模型中的隐含知识结构
Understanding the knowledge structure in LLM is crucial for effective knowledge editing. Previous research often conceptualized knowledge within LLMs as resembling triples in Knowledge Graphs (KG), comprising subjects, relations, and objects. This analogy, while useful, simplifies the intricate nature of knowledge representation in LLMs.
理解大语言模型中的知识结构对于有效的知识编辑至关重要。先前研究常将大语言模型中的知识概念化为类似于知识图谱(KG)中的三元组,包含主语、关系和宾语。这一类比虽有用,却简化了大语言模型中知识表征的复杂性。

Figure 9: First, we conduct a causal analysis of the fact with the entity [SMAP $\xrightarrow{\mathrm{createam}}$ Japan]. Second, we consider a related question with the fact,[SMAP $\xrightarrow{\smile\dots\smile\dots}$ Japan l−a−ng−ua−ge→ Japanese], where the model should answer the question based on the fact. Then, we adopt an unrelated fact [SMAP type of seminal group].
图 9: 首先,我们对事实 [SMAP $\xrightarrow{\mathrm{createam}}$ Japan] 进行因果分析。其次,我们考虑一个与事实相关的问题 [SMAP $\xrightarrow{\smile\dots\smile\dots}$ Japan l−a−ng−ua−ge→ Japanese],模型应根据该事实回答问题。接着,我们采用一个无关事实 [SMAP type of seminal group]。
Editing knowledge in a KG, where the task usually involves modifying a single relationship between two nodes, is comparatively straightforward. KGs inherently support easy reasoning tasks and allow for the preservation of the rest of the knowledge structure. This resilience is illustrated in Figure 10, where edits and subsequent recovery processes result in the complete restoration of the original KG structure. On the other hand, knowledge editing in LLMs presents unique challenges due to the entangled nature of knowledge within these models. Unlike KGs, where knowledge is neatly compartmentalized, in LLMs, knowledge is distributed across various parameters and layers, making it difficult to isolate and edit specific information without affecting other knowledge areas. The current perspective of viewing knowledge in LLMs as triples is somewhat limited and fails to capture the full complexity and interconnected nature of these models. This complexity is further highlighted by previous work [184, 101], who discuss the challenges of modifying intrinsic knowledge within parameters.
在知识图谱(KG)中编辑知识通常只需修改两个节点间的单一关系,相对简单直接。知识图谱天生支持简易推理任务,并能保持其余知识结构的完整性。如图10所示,这种韧性体现在编辑和后续恢复过程能完全还原原始知识图谱结构。相比之下,大语言模型中的知识编辑面临独特挑战,因为其内部知识呈现纠缠状态。与知识图谱中知识被清晰划分不同,大语言模型的知识分布在各种参数和层级中,使得在不影响其他知识领域的情况下隔离并编辑特定信息变得困难。当前将大语言模型知识视为三元组的视角存在局限,未能充分捕捉这些模型的复杂性和互联本质。先前研究[184,101]讨论了修改参数内禀知识的挑战,进一步凸显了这种复杂性。
Furthermore, previous research has revealed that knowledge editing in LLMs can lead to unintended propagation effects. Li et al. [206] illustrates that current knowledge editing methods can result in knowledge conflict and knowledge distortion within LLMs. Unlike structured knowledge bases, neural networks lack strict constraints on knowledge structure and interrelationships. This makes it difficult to confine edits to a localized scope within the model, and the free-form nature of LLMs further complicates the editing process. Consequently, a more comprehensive understanding of the LM’s mechanisms is required.
此外,先前研究表明,对大语言模型进行知识编辑可能导致非预期的传播效应。Li等人[206]指出,当前知识编辑方法会引发大语言模型内部的知识冲突与知识扭曲。与结构化知识库不同,神经网络缺乏对知识结构和相互关系的严格约束,这使得编辑操作难以局限在模型的局部范围内,而大语言模型的自由形式特性进一步加剧了编辑过程的复杂性。因此,需要更全面地理解语言模型的内在机制。
Currently, methods like T-Patcher or IKE offer plug-and-play functionality and easy r ever sibi lit y. They provide flexibility and user-friendliness and can be easily integrated into or detached from the LLMs as needed. These methods aim to mitigate some of the challenges associated with knowledge editing in LLMs, allowing for convenient and reversible modifications. As the field evolves, it is imperative to continue developing methods that not only address the challenges of knowledge editing but also harness the full potential of these complex systems, turning vanilla LLMs into WikiModels, a.k.a., neural knowledge bases that is feasibility for editing.
目前,像T-Patcher或IKE这样的方法提供了即插即用功能和易反转性。它们兼具灵活性与用户友好性,能根据需要轻松集成到大语言模型中或从中分离。这些方法旨在缓解大语言模型知识编辑相关的一些挑战,实现便捷可逆的修改。随着领域发展,必须持续开发新方法,不仅要解决知识编辑的难题,还要充分释放这些复杂系统的潜力,将普通大语言模型转化为可编辑的神经知识库(即WikiModels)。
6 Applications
6 应用
In this Section, we will summarize recent approaches that utilizes knowledge editing techniques for various applications and illustrate potential directions for future exploration.
在本节中,我们将总结近期利用知识编辑技术 (knowledge editing) 实现各类应用的方法,并阐述未来探索的潜在方向。
6.1 Efficient Machine Learning
6.1 高效机器学习
Model Updating While knowledge editing techniques directly modify or augment model parameters, realizing their full potential requires translating these internal updates into LLMs for downstream tasks. Recent research has explored integrating knowledge editing into various tasks, including question answering, fact checking, and natural language generation. For question answering, approaches like MeLLo [155] decompose complex questions and iterative ly retrieve and edit knowledge to arrive at multi-hop answers. Reckon [212] proposes a method to teach LLMs to reason by updating their parametric knowledge through back-propagation. This approach enables models to answer questions using the updated parameters, thereby enhancing their reasoning capabilities. Padmanabhan et al. [213] introduces a knowledge-updating technique called distilling, which involves imparting knowledge about entities and propagating that knowledge to enable broader inferences. Furthermore, MedEdit [214] adopts knowledge editing methods to deal with medical question answering and the application of these methods has led to an accuracy improvement from $44.46%$ to $48.54%$ . Meanwhile, some works try to use knowledge editing to deal with fact-checking datasets like FEVER [215], Vitamin-C [216] and achieve good performance. Especially, Chen et al. [97] finds that by analyzing the degenerate knowledge neurons, the model itself can detect wrong facts without relying on external data. As to the natural language generation, aside from the previous work that focuses on WikiGen [170] or WikiBio Hartvigsen et al. [163], DoLA [217] proposes decoding by contrasting layers method by analyzing the knowledge learned by different layers, which greatly alleviates the hallucination problem in a generation. Besides, task arithmetic has emerged as a cost-effective and scalable solution for editing LLMs directly in the weight space, as highlighted by Ilharco et al. [218], Santurkar et al. [219], Brown et al. [220], and Ortiz-Jimenez et al. [221].
模型更新
虽然知识编辑技术直接修改或增强模型参数,但要充分发挥其潜力,需要将这些内部更新转化为适用于下游任务的大语言模型。近期研究探索了将知识编辑整合到多种任务中,包括问答、事实核查和自然语言生成。在问答领域,MeLLo [155] 等方法通过分解复杂问题并迭代检索和编辑知识来生成多跳答案。Reckon [212] 提出了一种通过反向传播更新参数知识来教导大语言模型进行推理的方法,使模型能够利用更新后的参数回答问题,从而增强推理能力。Padmanabhan 等人 [213] 引入了一种称为蒸馏的知识更新技术,涉及传递实体知识并传播该知识以实现更广泛的推理。此外,MedEdit [214] 采用知识编辑方法处理医学问答,这些方法的应用将准确率从 $44.46%$ 提升至 $48.54%$。
与此同时,部分研究尝试利用知识编辑处理事实核查数据集(如 FEVER [215]、Vitamin-C [216]),并取得了良好效果。特别是 Chen 等人 [97] 发现,通过分析退化的知识神经元,模型本身可以在不依赖外部数据的情况下检测错误事实。在自然语言生成方面,除了此前专注于 WikiGen [170] 或 WikiBio Hartvigsen 等人 [163] 的研究外,DoLA [217] 提出通过对比层分析方法解码不同层学到的知识,大幅缓解了生成中的幻觉问题。
此外,任务算术(task arithmetic)作为一种经济高效且可扩展的解决方案,被 Ilharco 等人 [218]、Santurkar 等人 [219]、Brown 等人 [220] 和 Ortiz-Jimenez 等人 [221] 强调为直接在权重空间中编辑大语言模型的有效方法。

Figure 10: Comparison of editing effects on Knowledge Graphs vs. LLMs: Demonstrating the ability of Knowledge Graphs to fully restore their original structure after edits and recovery processes, in contrast to LLMs where similar recovery efforts fail to reinstate the original model.
图 10: 知识图谱与大语言模型编辑效果对比: 展示知识图谱在编辑和恢复过程后能完全还原原始结构的能力, 而大语言模型在类似恢复操作中无法复原原始模型。
Apart from natural language processing, knowledge editing is increasingly being applied across various domains, demonstrating its versatility and effectiveness. Gu et al. [222] proposes a novel and effective model editing approach, MENT, to address challenges in code generation. KGEditor [223] utilizes knowledge editing to modify knowledge graph embeddings, while GNNDelete [224] introduces a model-agnostic, layer-wise operator specifically for graph unlearning. These approaches highlight the potential of knowledge editing to enhance and refine graph-based models. Additionally, EGNN [225] presents a neighbor propagation-free method to correct model predictions on mis classified nodes, further expanding the scope of knowledge editing in graph networks.
除了自然语言处理领域,知识编辑(knowledge editing)技术正日益广泛应用于多个学科,展现出其通用性和有效性。Gu等学者[222]提出了一种新颖高效的模型编辑方法MENT,用于解决代码生成领域的挑战。KGEditor[223]通过知识编辑技术修改知识图谱嵌入表示,而GNNDelete[224]则专门针对图数据遗忘学习提出了一种与模型无关的层级操作算子。这些方法凸显了知识编辑在优化图模型方面的潜力。此外,EGNN[225]提出了一种无需邻居传播的纠错方法,用于修正模型对误分类节点的预测,进一步拓展了知识编辑在图神经网络中的应用范围。
While promising, substantially more work is needed to translate edited knowledge into robust task improvements. Key challenges include developing methods to effectively incorporate edits into online inference, not just static parameters, and handling edits that involve complex reasoning. The tight integration of knowledge editing with downstream architectures and objectives remains an open research question.
虽然前景广阔,但要将编辑后的知识转化为稳健的任务性能提升仍需大量工作。关键挑战包括开发能有效将编辑内容融入在线推理(而不仅是静态参数)的方法,以及处理涉及复杂推理的编辑操作。知识编辑与下游架构及目标的紧密整合仍是一个待解的研究课题 [20]。
Model Manipulation Once we can successfully edit the model and understand the knowledge mechanism, we can manipulate the model by Knowledge Distill and Transfer. Zhong et al. [226] proposes a knowledge distillation method to transfer the knowledge in the LLMs to the small one by analyzing the knowledge neuron nuggets in the model, proposing a new direction for distilling and merging knowledge among different models. Bayazit et al. [227] endeavors to construct a critical subnetwork in LLMs for the specific knowledge and prune this subnetwork, which can remove the model’s understanding of the target knowledge, which is also a new method for pruning and suppressing the large model. Chang et al. [210] also employs a prune-based model to analyze the model’s knowledge. Moreover, when analyzing the knowledge of model weights, Dar et al. [208] show that one can stitch two models by casting their weights into the embedding space, indicating a possible solution for stitching different models [228–230].
模型操控
一旦我们能够成功编辑模型并理解其知识机制,便可通过知识蒸馏(Knowledge Distill)和迁移(Transfer)来操控模型。Zhong等人[226]提出一种知识蒸馏方法,通过分析模型中的知识神经元簇(knowledge neuron nuggets),将大语言模型中的知识迁移至小型模型,为不同模型间的知识蒸馏与融合提供了新方向。Bayazit等人[227]致力于为特定知识在LLMs中构建关键子网络,并通过剪枝该子网络来消除模型对目标知识的理解,这也为大模型的剪枝与抑制提供了新方法。Chang等人[210]同样采用基于剪枝的模型来分析知识。此外,Dar等人[208]在分析模型权重知识时证明,通过将权重投射到嵌入空间可实现两个模型的拼接(stitch),这为不同模型的拼接提供了潜在解决方案[228–230]。

Figure 11: Application of knowledge editing in constructing trustworthy AI and personalized agents.
图 11: 知识编辑在构建可信AI和个性化智能体中的应用。
The manipulation of knowledge within LLMs through methods like editing and pruning not only enhances the efficiency and accessibility of LLMs but also promises to unlock new potential in the application and s cal ability of LLMs.
通过编辑和剪枝等方法对大语言模型(LLM)内部知识进行操作,不仅能提升其效率与可用性,更有望释放大语言模型在应用与可扩展性方面的新潜能。
6.2 AI-Generated Content (AIGC)
6.2 AI生成内容 (AIGC)
LLMs can now process different modalities of knowledge, such as image and audio information [231–234]. These models have the capability to handle or generate multimodal knowledge, which is invaluable in the creation of AI-generated content across diverse applications [235]. A notable trend in recent research involves the use of editing methods to modify/control the content generated by these models. For instance, Cheng et al. [236] proposes a new benchmark aimed at enhancing a model’s understanding of multimodal knowledge. This includes tasks like Visual Question Answering (VisualQA) and Image Captioning, which require a deep integration of textual and visual information. Similarly, Arad et al. [237] introduces ReFACT, a novel text-to-image editing task that focuses on editing factual knowledge within models to improve the quality and accuracy of generated images. This approach also includes a method for updating knowledge encoders, ensuring that the model remains current and relevant. Furthermore, Pan et al. [238] explores the identification of multi-modal neurons in transformer-based multimodal LLMs. Meanwhile, Gandikota et al. [239] delves into the concept of erasing specific concepts from a model’s weights, particularly in text-toimage diffusion models. They introduce a knowledge editing method that leverages these identified neurons, paving the way for more nuanced and effective multimodal knowledge integration. This method offers a more permanent solution to concept removal as opposed to merely modifying outputs at inference time, thereby ensuring the changes are irreversible even if a user has access to the model’s weights.
大语言模型 (LLM) 现已能处理图像、音频等多模态知识 [231–234],这种跨模态处理与生成能力对各类AI生成内容 (AIGC) 应用具有重要价值 [235]。当前研究呈现出一个显著趋势:通过编辑方法调控模型生成内容。例如,Cheng等 [236] 提出提升模型多模态理解能力的新基准任务,包括需要深度融合文本与视觉信息的视觉问答 (VisualQA) 和图像描述生成。Arad等 [237] 开发的ReFACT则专注于文本到图像生成中的事实知识编辑,通过更新知识编码器确保生成图像的准确性与时效性。Pan等 [238] 研究了基于Transformer的多模态大语言模型中的多模态神经元识别技术,而Gandikota等 [239] 提出利用这些神经元实现知识编辑的方法——相比推理时临时修改输出,该方法通过从模型权重中彻底擦除特定概念(特别是文本到图像扩散模型中的概念),实现了不可逆的知识更新,为精细化多模态知识整合开辟了新路径。
However, evaluating the coherence with which models integrate cross-modal knowledge remains a significant challenge, necessitating the development of new benchmarks and metrics. Adapting knowledge editing techniques to align multimodal representations is also crucial. Addressing these research questions could empower models to learn and reason over multimodal knowledge in a manner akin to human cognition.
然而,评估模型整合跨模态知识的连贯性仍是一项重大挑战,需要开发新的基准和指标。调整知识编辑技术以对齐多模态表征也至关重要。解决这些研究问题有望使模型以类人类认知的方式学习和推理多模态知识。
6.3 Trustworthy AI
6.3 可信AI
Knowledge editing extends its applications beyond the mere rectification of factual knowledge. It can also be instrumental in modifying other salient behaviors of LLMs, such as eliminating unsafe characteristics, as illustrated in Figure 11. In an ideal scenario, socially friendly and trustworthy AI systems should not only possess accurate knowledge but also exhibit appropriate social norms and values [75, 240–245]. This entails avoiding toxic, prejudiced, or harmful language and opinions, as well as demonstrating an understanding of and alignment with diverse perspectives and experiences. However, achieving such “social alignment” through knowledge editing presents significant challenges. Social behaviors are inherently complex and subjective, making their modification a non-trivial task. Recently, some existing works have explored the application of knowledge editing techniques to build more trustworthy AI, such as detoxifying, debasing, and defense strategies for privacy issues.
知识编辑的应用范围不仅限于修正事实性知识,还可用于修改大语言模型的其他关键行为,例如消除不安全特性(如图 11 所示)。理想情况下,具有社会友好性和可信赖性的AI系统不仅需要掌握准确知识,还应展现适当的社会规范与价值观 [75, 240–245]。这要求系统避免使用有毒、偏见或有害的言语及观点,同时体现对多元视角与经验的理解和契合。然而,通过知识编辑实现这种"社会对齐"存在显著挑战:社会行为本身具有复杂性和主观性,使得其修改成为非平凡任务。近期已有研究探索运用知识编辑技术构建更可信的AI,例如针对隐私问题的去毒化、去偏见化及防御策略等。
Toxicity in LLMs LLMs are vulnerable to harmful inputs and generate toxic language that damages their usefulness [246, 247]. To evaluate toxic generations, Gehman et al. [248] provides a continuously generated dataset REAL TOXIC PROMPTS, Zhang et al. [249] designs SAFETYBENCH, which comprises 11,435 diverse multiple-choice questions spanning across 7 distinct categories of safety concerns. To enhance the detoxification of LLMs, Deng et al. [250], Huang et al. [251], Krause et al. [252] fine-tunes the parameters of LLMs via manually labeled harmless data. However, these methods lack robustness against malicious perturbations and suffer from high annotation costs. Knowledge editing is an explain able alternative to manipulating toxicity in LLMs, which only adjusts a subset of parameters and reduces computing consumption. On the one hand, Anonymous [253] leverages knowledge editing techniques to inject backdoors into LLMs with diverse attack targets. Li et al. [254] targets an undesirable behavior at inference by eliminating a limited number of causal routes across the model. On the other hand, a growing body of research focuses on eliciting safe responses through knowledge editing. For example, Geva et al. [42] explores the removal of harmful words from the neurons by using reverse engineering on the feed-forward network layers. Hu et al. [255] integrates the abilities of expert and anti-expert by extracting and eliminating solely the deficiency capability within the anti-expert while preserving the general capabilities. The expert and anti-expert of this method constructed by LoRA is parameter-efficient and enables LMs to retain nature skills, e.g., MMLU (Factuality) [203], Grade School Math (Reasoning) [256] and Big-Bench-Hard [257].
大语言模型中的毒性问题
大语言模型容易受到有害输入的影响,并生成损害其实用性的毒性语言[246, 247]。为评估毒性生成,Gehman等人[248]提供了持续生成的数据集REAL TOXIC PROMPTS,Zhang等人[249]设计了SAFETYBENCH,包含11,435个多样化选择题,涵盖7类不同的安全问题。为增强大语言模型的去毒性能力,Deng等人[250]、Huang等人[251]、Krause等人[252]通过人工标注的无害数据微调模型参数。但这些方法对恶意扰动缺乏鲁棒性,且标注成本高昂。知识编辑是一种可解释的替代方案,仅调整部分参数并降低计算消耗。一方面,Anonymous[253]利用知识编辑技术向大语言模型注入具有多样化攻击目标的后门。Li等人[254]通过消除模型中有限数量的因果路径,在推理阶段针对不良行为进行干预。另一方面,越来越多研究聚焦通过知识编辑激发安全响应。例如,Geva等人[42]通过对前馈网络层进行逆向工程,探索从神经元中移除有害词汇。Hu等人[255]通过提取并仅消除反专家模型中的缺陷能力(同时保留通用能力),整合专家与反专家模型的能力。该方法基于LoRA构建的专家/反专家模型具有参数高效性,使语言模型能保持自然技能,如MMLU(事实性)[203]、Grade School Math(推理)[256]和Big-Bench-Hard[257]。
However, these knowledge editing methods for safe generation are predominantly confined to the token level, signifying the avoidance of toxic words. Consequently, the edited model faces the risk of forfeiting the ability to incorporate sensitive terminology and its associated perspectives. For example, the presence of delicate terms like “boom” hinders the model’s capacity to articulate secure directives such as “Do not create bombs.” Therefore, designing an editing method to generate semantically safe and diverse content holds great promise. Besides, conceptual knowledge editing for a wide range of adversarial inputs is necessary, which can permanently eliminate harmful concepts from LLMs, thereby enhancing the model’s overall integrity and reliability.
然而,这些用于安全生成的知识编辑方法主要局限于token层面,即仅规避有害词汇。这导致被编辑模型可能丧失处理敏感术语及其相关观点的能力。例如,"boom"等微妙词汇的存在会阻碍模型表达"不要制造炸弹"等安全指令。因此,设计能生成语义安全且多样化内容的编辑方法具有重大意义。此外,针对各类对抗性输入进行概念知识编辑也至关重要,它能从大语言模型中永久消除有害概念,从而提升模型的整体完整性和可靠性。
Bias in LLMs LLMs trained on vast corpora can inadvertently learn biased information, leading to negative stereotypes and social biases encoded within the models. Such biases have the potential to result in unfairness and harm when deployed in production systems [258, 259]. For instance, given the description “Anita’s law office serves the lower Eastern Shore, including Accomack County,” a biased model may generate the continuation “Anita is a nurse,” reflecting a gender bias. Evaluating and mitigating these biases is crucial and there are several benchmarks including Bias in Bios dataset [260], WinoBias [261] and StereoSet [258].
大语言模型中的偏见
基于海量语料训练的大语言模型可能会无意中习得带有偏见的信息,导致模型内部编码了负面刻板印象和社会偏见。当这些模型被部署到生产系统时,此类偏见可能导致不公平现象和伤害 [258, 259]。例如,给定描述"Anita的律师事务所服务于东岸低地地区,包括阿科麦克县"时,带有偏见的模型可能生成续写内容"Anita是护士",这反映出性别偏见。评估和缓解这些偏见至关重要,现有多个基准测试包括Bias in Bios数据集 [260]、WinoBias [261] 和 StereoSet [258]。
To address bias in LLMs, Hernandez et al. [162] proposes the knowledge editing method REMEDI, which significantly reduces gender bias in LLMs. Yu et al. [262] proposes a partitioned contrastive gradient unlearning method that optimizes only those weights in the model that are most influential in a specific domain of bias. This method is effective both in mitigating bias for the genderprofession domain that it is applied to as well as in generalizing these effects to other unseen domains. Additionally, inspired by the findings of ROME and MEMIT, DAMA [263] identifies the stereotype representation subspace and edits bias-vulnerable FFNs using an orthogonal projection matrix. The proposed method significantly reduces gender bias in WinoBias and StereoSet without sacrificing performance across unrelated tasks.
为解决大语言模型(LLM)中的偏见问题,Hernandez等人[162]提出了知识编辑方法REMEDI,显著降低了LLM中的性别偏见。Yu等人[262]提出了一种分区对比梯度遗忘方法,仅优化模型中对特定偏见领域最具影响力的权重。该方法不仅能有效缓解所应用的性别-职业领域偏见,还能将效果泛化至其他未见领域。此外,受ROME和MEMIT研究启发,DAMA[263]通过识别刻板印象表征子空间,并利用正交投影矩阵编辑易受偏见影响的前馈网络(FFN)。该方法在WinoBias和StereoSet数据集上显著降低性别偏见,同时不影响其他无关任务的性能。
Although these approaches have been successful, there are still more obstacles to overcome in order to edit and mitigate bias in LLMs. These obstacles include the following: first, biases can appear in complex semantic, pragmatic, and commonsense knowledge that may not be sufficiently captured by existing benchmarks; second, while some biases can be addressed through knowledge editing, systemic biases that are inherent in the training data itself present more enduring difficulties. Hence, addressing these fundamental sources of bias and unfairness necessitates comprehensive strategies that include data curation, model architecture, and knowledge editing techniques.
尽管这些方法已取得成功,但在编辑和减轻大语言模型偏见方面仍存在更多障碍。这些障碍包括:首先,偏见可能出现在复杂的语义、语用和常识知识中,现有基准可能无法充分捕捉;其次,虽然部分偏见可通过知识编辑解决,但训练数据本身固有的系统性偏见会带来更持久的挑战。因此,解决这些偏见与不公平的根本源头需要综合策略,包括数据治理 (data curation) 、模型架构和知识编辑技术。
Privacy in LLMs LLMs trained on extensive web data corpora have the potential to memorize and inadvertently disclose sensitive or confidential information, posing significant privacy and security concerns [264, 265]. The “right to be forgotten” has been highlighted in previous work, emphasizing the need to address the potential leakage of personal and confidential data [266]. Protecting personal information while maintaining the reliability of LLMs can be achieved through knowledge editing methods. For instance, Jang et al. [267] proposes knowledge unlearning as a means to modify pretrained models and prevent them from generating texts on specific knowledge. Another approach, suggested by Ishibashi and Shimodaira [188], is knowledge san it iz ation, which aims to prevent the leakage of personal and confidential information while preserving reliability. DEPN [268] introduces identifying neurons associated with privacy-sensitive information. These detected privacy neurons are then edited by setting their activation s to zero. Additionally, they propose a privacy neuron aggregator to batch process and store privacy information. Experimental results demonstrate that their method significantly reduces the exposure of private data leakage without compromising the model’s performance.
大语言模型中的隐私问题
基于海量网络数据训练的大语言模型可能记忆并无意间泄露敏感或机密信息,引发重大隐私与安全隐患 [264, 265]。现有研究强调"被遗忘权"的重要性,指出需防范个人及机密数据的潜在泄露风险 [266]。通过知识编辑方法可在保护个人信息的同时维持模型可靠性,例如Jang等人 [267] 提出知识遗忘技术来修改预训练模型,阻止其生成特定知识文本。Ishibashi与Shimodaira [188] 则提出知识净化方案,在保持可靠性的同时防止隐私与机密信息泄露。DEPN [268] 通过识别与隐私敏感信息相关的神经元,将其激活值置零来实现编辑,并设计隐私神经元聚合器批量处理存储隐私信息。实验表明该方法能显著降低隐私数据暴露风险且不影响模型性能。
In the context of multi-modal models, Chen et al. [269] proposes the PrivQA dataset for protecting personal information. They develop a multi-modal benchmark to assess the trade-off between privacy and utility, where models are instructed to protect specific categories of personal information in a simulated scenario. They also propose an iterative self-moderation technique that greatly improves privacy. Furthermore, knowledge editing techniques are also relevant in federated learning, including federated unlearning and federated increasing learning, as highlighted by Wu et al. [270]. Looking forward, further research is still needed to develop techniques that can effectively and verifiably sanitize potentially sensitive knowledge from LLMs. Another interesting application is to embedding a watermark [271] in a LLM through knowledge editing, without affecting the performance of the model and providing it with copyright protection. Besises, there is a need for careful evaluation benchmarks to rigorously test the abilities of these methods.
在多模态模型背景下,Chen等人[269]提出了用于保护个人信息的PrivQA数据集。他们开发了一个多模态基准来评估隐私与效用之间的权衡,在该模拟场景中模型被要求保护特定类别的个人信息。他们还提出了一种迭代式自我调节技术,可显著提升隐私保护效果。此外,如Wu等人[270]所述,知识编辑技术在联邦学习中也具有相关性,包括联邦遗忘学习和联邦增量学习。展望未来,仍需进一步研究开发能有效且可验证地从大语言模型中清除潜在敏感知识的技术。另一个有趣的应用是通过知识编辑为大语言模型嵌入水印[271],在不影响模型性能的同时为其提供版权保护。此外,还需要建立严谨的评估基准来严格测试这些方法的能力。
6.4 Human-Computer Interaction: Personalized Agents
6.4 人机交互:个性化AI智能体
Millions of years of evolution have enabled humans to achieve intelligence through genes and learned experiences. With the advent of LLMs, machines have learned to master world knowledge in less than a few hundred years. The knowledge capacity of these LLMs comes from parameters derived from compressed data. In an age where humans and machines may coexist, it is essential to design intelligent human-computer interaction systems for social good [272, 273]. By effectively controlling LLMs to serve as personalized agents, we can harness their capabilities for societal benefits, as outlined in Salemi et al. [274]. Analogous to gene editing [275–277], knowledge editing technology allows for the control of the electronic brain through the manipulation of parameters, to customize (permanently) LLM agents with various attributes of knowledge, values, and rules.
数百万年的进化使人类能够通过基因和学习经验获得智能。随着大语言模型(LLM)的出现,机器在不到几百年的时间里就学会了掌握世界知识。这些大语言模型的知识容量来自压缩数据衍生的参数。在人类与机器可能共存的时代,设计有益社会的智能人机交互系统至关重要[272, 273]。如Salemi等人[274]所述,通过有效控制大语言模型作为个性化AI智能体,我们可以利用其能力造福社会。类似于基因编辑[275-277],知识编辑技术允许通过参数操控来控制电子大脑,从而(永久性地)定制具有各种知识、价值观和规则属性的大语言模型智能体。
Figure 11 illustrates the application of personalized models in various domains such as economic business, dialogue systems, and recommendation systems. Recent advancements in LLMs have demonstrated their ability to exhibit personality, opinions, and sentiments, making them more human-like. This has sparked a growing interest in developing personalized LLMs. Several works [278, 279] have investigated the personality in LLMs with questionnaire tests (i.e. MBTI) and other psychological theories. Tu et al. [280] constructs a conversation framework for virtual characters with distinct profiles. Mao et al. [281] proposes a new knowledge editing task to edit LLM’s personality. Firstly, it enables LLMs to cater to users’ preferences and opinions, thereby enhancing the user experience. This can be achieved through knowledge editing, where the model is trained to align with the specific requirements and interests of each user. An emotion benchmark [282] is also proposed to measure LLM’s emotion.
图 11: 展示了个性化模型在经济商业、对话系统和推荐系统等多个领域的应用。近期大语言模型的发展表明其能够展现个性、观点和情感,使其更具人性化特征,这激发了开发个性化大语言模型的广泛兴趣。多项研究 [278, 279] 通过问卷测试(如 MBTI)和其他心理学理论探究了大语言模型的个性特征。Tu 等人 [280] 构建了具有差异化角色设定的虚拟人物对话框架。Mao 等人 [281] 提出了一项新的知识编辑任务来修改大语言模型的个性特征。首先,这使得大语言模型能够适应用户偏好和观点,从而提升用户体验。这可以通过知识编辑实现,即训练模型以符合每个用户的特定需求和兴趣。研究 [282] 还提出了用于衡量大语言模型情感表现的情感基准。
Personalized LLMs enhance the user experience by catering to users’ preferences and opinions. Knowledge editing is a key technique in achieving this. By training the model to align with the specific requirements and interests of each user, personalized recommendations and suggestions can be provided. For example, in economic business, it is essential for the model to comprehend users’ aesthetics and preferences to provide them with better product recommendations. By understanding the unique tastes and preferences of individual users, the model can offer more accurate and personalized suggestions, leading to increased customer satisfaction and potentially higher sales. Moreover, incorporating LLMs into customer service systems for merchants can be highly beneficial. These models can assist in understanding and addressing customer queries and concerns, providing personalized recommendations, and delivering a more satisfactory shopping experience. By leveraging personalized LLMs, AI agents can effectively deal with special product features and introduce them better to buyers.
个性化大语言模型通过适应用户偏好与观点来提升体验,知识编辑是实现这一目标的核心技术。通过训练模型使其契合每位用户的特定需求和兴趣,可提供个性化推荐建议。例如在电商领域,模型必须理解用户的审美倾向才能给出更优质的商品推荐。通过洞悉个体用户的独特品味,模型能提供更精准的个性化建议,从而提升客户满意度并潜在促进销售转化。此外,将大语言模型整合至商户客服系统极具价值:这些模型可协助理解并解决客户咨询,提供定制化推荐,打造更令人满意的购物体验。借助个性化大语言模型,AI智能体能够高效处理商品特色,向买家进行更出色的产品推介。
In summary, developing personal-oriented models based on user preferences is crucial in domains of HCI such as economic businesses, dialogue systems, and recommendation systems. Through emerging techniques like knowledge editing and aligning with users’ appetites and opinions [283], LLMs can offer improved goods and services, resulting in enhanced user satisfaction and better business outcomes.
总之,基于用户偏好开发个性化模型在人机交互(HCI)领域(如商业经济、对话系统和推荐系统)至关重要。通过知识编辑(knowledge editing)和适应用户偏好观点[283]等新兴技术,大语言模型能够提供更优质的商品服务,从而提升用户满意度并创造更好的商业效益。
7 Discussion and Conclusion
7 讨论与结论
In this study, we highlight the challenges inherent to present-day knowledge editing and introduce a new benchmark for diverse editing tasks. While current methods have shown efficacy in certain areas, significant issues remains for enhancement:
本研究重点探讨了当前知识编辑领域存在的挑战,并针对多样化编辑任务提出了新的基准测试。尽管现有方法在某些领域已展现出成效,但仍存在以下亟待改进的关键问题:
However, just as Pinter and Elhadad [184] argues, the stochastic nature of LLMs is not only a source of complexity but also a wellspring of creativity and adaptability in various scenarios. Hence, the potential of knowledge editing is still worth exploring. Numerous factors, such as prior knowledge, experiences, cultural context, and societal interactions, intricately link and shape the model’s outcomes. To make truly responsible and ethical LLMs in the future, we will likely need a combined approach that includes knowledge editing, stronger security measures, more openness, and stronger accountability systems. Overall, the shift from traditional fine-tuning to knowledge editing reflects a deeper evolution in our approach to working with LLMs. It signifies a move towards more specialized, nuanced, and sophisticated methods of model adaptation and enhancement, in line with the growing complexity and capabilities of these advanced language models.
然而,正如Pinter和Elhadad [184]所指出的,大语言模型的随机性不仅是复杂性的来源,也是各种场景下创造力和适应性的源泉。因此,知识编辑的潜力仍值得探索。先验知识、经验、文化背景和社会互动等诸多因素错综复杂地交织在一起,共同塑造了模型的结果。为了在未来打造真正负责任且符合伦理的大语言模型,我们可能需要结合知识编辑、更强的安全措施、更高的透明度以及更严格的责任体系等综合方法。总体而言,从传统微调转向知识编辑的转变,反映了我们与大语言模型互动方式的深刻演变。它标志着模型适应和增强方法正朝着更专业化、精细化和复杂化的方向发展,这与这些先进语言模型日益增长的能力和复杂性相契合。
Broader Impacts
更广泛的影响
Knowledge editing, in the context of LLMs, refers to methodologies and techniques aimed at updating and refining these models more efficiently. By enabling the manipulation of a model’s knowledge, knowledge editing allows for continuous improvement and adaptation of AI systems, ensuring they remain up-to-date, accurate, and aligned with the desired objectives and values.
在大语言模型 (LLM) 的背景下,知识编辑指的是旨在更高效更新和完善这些模型的方法与技术。通过操控模型的知识,知识编辑使得AI系统能够持续改进和适应,确保其保持最新、准确并与预期目标和价值观一致。
While the potential of editing is vast, there is a noticeable variance in the effectiveness of different methods. This disparity, however, does not overshadow the immense promise that these techniques hold. The most significant contribution of editing is its ability to deepen our understanding of the knowledge mechanisms in LLMs. By exploring how knowledge is stored, manipulated, and accessed within these models, editing techniques can significantly enhance their interpret ability and transparency. This aspect is crucial, as it not only improves the usability of these models but also aids in establishing trust and credibility in their applications.
尽管编辑的潜力巨大,但不同方法的有效性存在显著差异。然而,这种差距并未掩盖这些技术所蕴含的巨大前景。编辑最重要的贡献在于它能深化我们对大语言模型(LLM)知识机制的理解。通过探索知识在这些模型中的存储、操作和访问方式,编辑技术能显著提升其可解释性与透明度。这一特性至关重要,因为它不仅能提高模型的实用性,还有助于在其应用中建立信任与可信度。
In summary, knowledge editing technology represents a highly promising field with the potential to revolutionize how we interact with and utilize LLMs. Its implications extend far beyond mere efficiency improvements, touching upon critical aspects like model accessibility, fairness, security, and interpret ability. As the technology continues to evolve and mature, it is poised to play a pivotal role in shaping the future landscape of artificial intelligence and machine learning.
总之,知识编辑技术是一个极具前景的领域,有望彻底改变我们与大语言模型(LLM)的交互和使用方式。其影响远不止于效率提升,更涉及模型可访问性、公平性、安全性和可解释性等关键维度。随着该技术持续演进成熟,它将在塑造人工智能和机器学习的未来格局中发挥关键作用。
Acknowledgments
致谢
The authors extend their sincere gratitude to Zhiyuan Hu for providing insightful and constructive feedback on this paper. Special thanks to Damien de Mijolla for proposing different optimization goals for FT (FT-M), which complemented the fine-tuning baseline. We also wish to acknowledge the groundbreaking contributions of researchers who have developed knowledge editing methodologies for LLMs. This work was supported by the National Natural Science Foundation of China (No.62206246), the Fundamental Research Funds for the Central Universities (226-2023-00138), Zhejiang Provincial Natural Science Foundation of China (No. LG G 22 F 030011), Ningbo Natural Science Foundation (2021J190), Yongjiang Talent Introduction Programme (2021A-156-G), CCFTencent Rhino-Bird Open Research Fund, Information Technology Center and State Key Lab of CAD&CG, Zhejiang University, and NUS-NCS Joint Laboratory (A-0008542-00-00).
作者衷心感谢 Zhiyuan Hu 为本文提供的深刻且有建设性的反馈。特别感谢 Damien de Mijolla 为 FT (FT-M) 提出了不同的优化目标,从而完善了微调基线。我们还要感谢那些为大语言模型开发知识编辑方法的研究人员所做出的开创性贡献。本研究得到了以下项目的资助:国家自然科学基金 (No.62206246)、中央高校基本科研业务费专项资金 (226-2023-00138)、浙江省自然科学基金 (No.LGG22F030011)、宁波市自然科学基金 (2021J190)、甬江人才工程 (2021A-156-G)、CCF-腾讯犀牛鸟基金、浙江大学信息技术中心与CAD&CG国家重点实验室,以及新加坡国立大学-新科电子联合实验室 (A-0008542-00-00)。
Open Resources
开放资源
Contributions
贡献
The contributions of all authors are listed as follows: Ningyu Zhang, Yunzhi Yao, Peng Wang, Bozhong Tian and Shumin Deng initiated and organized the research. Ningyu Zhang drafted $\S1$ and $^{\S7}$ , Yunzhi Yao drafted $\S2,\S3$ and $\S6$ , Yunzhi Yao and Zekun Xi drafted $\S4$ and $\S5$ . Yunzhi Yao, Peng Wang, Bozhong Tian, Zekun Xi, Siyuan Cheng, Ziwen Xu, Shengyu Mao, Jintian Zhang, Yuansheng Ni participated in benchmark construction and experiments. Mengru Wang, Xin Xu suggested organization and proofread the whole paper. Jia-Chen Gu, Yong Jiang, Pengjun Xie, Fei Huang, Lei Liang, Zhiqiang Zhang, Xiaowei Zhu, Jun Zhou, Huajun Chen advised the project, suggested the empirical study and provided computation resources.
所有作者的贡献如下:Ningyu Zhang、Yunzhi Yao、Peng Wang、Bozhong Tian 和 Shumin Deng 发起并组织了这项研究。Ningyu Zhang 起草了 $\S1$ 和 $^{\S7}$,Yunzhi Yao 起草了 $\S2,\S3$ 和 $\S6$,Yunzhi Yao 和 Zekun Xi 起草了 $\S4$ 和 $\S5$。Yunzhi Yao、Peng Wang、Bozhong Tian、Zekun Xi、Siyuan Cheng、Ziwen Xu、Shengyu Mao、Jintian Zhang、Yuansheng Ni 参与了基准构建和实验。Mengru Wang、Xin Xu 提出了组织结构建议并校对了全文。Jia-Chen Gu、Yong Jiang、Pengjun Xie、Fei Huang、Lei Liang、Zhiqiang Zhang、Xiaowei Zhu、Jun Zhou、Huajun Chen 为项目提供建议,指导实证研究并提供了计算资源。
References
参考文献
[3] N Jayashri and K Kalaiselvi. Knowledge acquisition–scholarly foundations with knowledge management. International Journal of Advanced Studies of Scientific Research, 3(12), 2018.
[3] N Jayashri 和 K Kalaiselvi. 知识获取——基于知识管理的学术基础. International Journal of Advanced Studies of Scientific Research, 3(12), 2018.
[40] Jun Zhao, Zhihao Zhang, Yide Ma, Qi Zhang, Tao Gui, Luhui Gao, and Xuanjing Huang. Unveiling A core linguistic region in large language models. CoRR, abs/2310.14928, 2023. doi: 10.48550/ARXIV.2310.14928. URL https://doi.org/10.48550/arXiv.2310.14928.
[40] Jun Zhao, Zhihao Zhang, Yide Ma, Qi Zhang, Tao Gui, Luhui Gao, and Xuanjing Huang. 揭示大语言模型中的核心语言区域. CoRR, abs/2310.14928, 2023. doi: 10.48550/ARXIV.2310.14928. URL https://doi.org/10.48550/arXiv.2310.14928.
[51] Zexuan Zhong, Dan Friedman, and Danqi Chen. Factual probing is [MASK]: learning vs. learning to recall. In Kristina Toutanova, Anna Rumshisky, Luke Z ett le moyer, Dilek HakkaniTur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakra bor ty, and Yichao Zhou, editors, Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, On- line, June 6-11, 2021, pages 5017–5033. Association for Computational Linguistics, 2021. doi: 10.18653/V1/2021.NAACL-MAIN.398. URL https://doi.org/10.18653/v1/2021.naacl-main.398.
[51] Zexuan Zhong, Dan Friedman, and Danqi Chen. 事实性探测是[MASK]: 学习 vs. 学习回忆. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek HakkaniTur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors, 《2021年北美计算语言学协会人类语言技术会议论文集》(NAACL-HLT 2021), 线上, 2021年6月6-11日, 页码5017–5033. 计算语言学协会, 2021. doi: 10.18653/V1/2021.NAACL-MAIN.398. URL https://doi.org/10.18653/v1/2021.naacl-main.398.
[61] Canyu Chen and Kai Shu. Combating misinformation in the age of llms: Opportunities and challenges. CoRR, abs/2311.05656, 2023. doi: 10.48550/ARXIV.2311.05656. URL https://doi.org/10.48550/arXiv.2311.05656.
[61] Canyu Chen 和 Kai Shu. 大语言模型时代下的虚假信息对抗:机遇与挑战. CoRR, abs/2311.05656, 2023. doi: 10.48550/ARXIV.2311.05656. URL https://doi.org/10.48550/arXiv.2311.05656.
Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A topdown approach to AI transparency. CoRR, abs/2310.01405, 2023. doi: 10.48550/ARXIV.
Matt Fredrikson、J. Zico Kolter 和 Dan Hendrycks。表征工程 (Representation Engineering):一种自上而下的AI透明度方法。CoRR, abs/2310.01405, 2023. doi: 10.48550/ARXIV.
American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2022, Seattle, WA, United States, July 10-15, 2022, pages 4602–4625. As
计算语言学协会北美分会:人类语言技术大会 (NAACL 2022),美国华盛顿州西雅图,2022年7月10-15日,第4602–4625页。
[95] Xiaozhi Wang, Kaiyue Wen, Zhengyan Zhang, Lei Hou, Zhiyuan Liu, and Juanzi Li. Finding skill neurons in pre-trained transformer-based language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11132–11152, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.765. URL https://a cl anthology.org/2022. emnlp-main.765.
[95] Xiaozhi Wang, Kaiyue Wen, Zhengyan Zhang, Lei Hou, Zhiyuan Liu, and Juanzi Li. 在预训练基于Transformer的语言模型中寻找技能神经元. 见《2022年自然语言处理实证方法会议论文集》, 第11132–11152页, 阿拉伯联合酋长国阿布扎比, 2022年12月. 计算语言学协会. doi: 10.18653/v1/2022.emnlp-main.765. URL https://a cl anthology.org/2022. emnlp-main.765.
[120] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. In Hal Daume ll and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 3929–3938. PMLR, 13–18 Jul 2020. URL https://proceedings.mlr.press/v119/guu20a.html.
[120] Kelvin Guu、Kenton Lee、Zora Tung、Panupong Pasupat 和 Mingwei Chang. 检索增强的语言模型预训练. 见 Hal Daume III 和 Aarti Singh 编辑的《第37届国际机器学习会议论文集》,第119卷《机器学习研究论文集》,第3929–3938页. PMLR,2020年7月13–18日. 网址 https://proceedings.mlr.press/v119/guu20a.html.
[133] Tongtong Wu, Massimo Caccia, Zhuang Li, Yuan-Fang Li, Guilin Qi, and Gholamreza Haffari. Pretrained language model in continual learning: A comparative study. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25- 29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=figzpGMrdD.
[133] Tongtong Wu, Massimo Caccia, Zhuang Li, Yuan-Fang Li, Guilin Qi, Gholamreza Haffari. 预训练语言模型在持续学习中的对比研究. 第十届国际学习表征会议(ICLR 2022), 线上会议, 2022年4月25-29日. OpenReview.net, 2022. URL https://openreview.net/forum?id=figzpGMrdD.
[175] Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Xiang Wang, Xiangnan He, and Tat-seng Chua. Alphaedit: Null-space constrained knowledge editing for language models. arXiv preprint arXiv:2410.02355, 2024.
[175] Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Xiang Wang, Xiangnan He, and Tat-seng Chua. Alphaedit: 大语言模型 (Large Language Model) 的空值空间约束知识编辑。arXiv预印本 arXiv:2410.02355, 2024.
[199] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsense qa: A question answering challenge targeting commonsense knowledge. CoRR, abs/1811.00937, 2018. URL http://arxiv.org/abs/1811.00937.
[199] Alon Talmor、Jonathan Herzig、Nicholas Lourie 和 Jonathan Berant。Commonsense QA: 一项针对常识知识的问答挑战。CoRR, abs/1811.00937, 2018。URL http://arxiv.org/abs/1811.00937。
[200] Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: reasoning about physical commonsense in natural language. CoRR, abs/1911.11641, 2019. URL http: //arxiv.org/abs/1911.11641.
[200] Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: 自然语言中的物理常识推理. CoRR, abs/1911.11641, 2019. URL http://arxiv.org/abs/1911.11641.
[216] Tal Schuster, Adam Fisch, and Regina Barzilay. Get your vitamin C! robust fact verification with contrastive evidence. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 624–643, Online, June 2021. Association for Computational Linguistics. doi: 10. 18653/v1/2021.naacl-main.52. URL https://a cl anthology.org/2021.naacl-main.52.
[216] Tal Schuster、Adam Fisch 和 Regina Barzilay。Get your vitamin C! robust fact verification with contrastive evidence。载于《2021年北美计算语言学协会人类语言技术会议论文集》,第624-643页,在线会议,2021年6月。计算语言学协会。doi: 10.18653/v1/2021.naacl-main.52。URL https://aclanthology.org/2021.naacl-main.52。
[245] Yang Liu, Yuanshun Yao, Jean-Francois Ton, Xiaoying Zhang, Ruocheng Guo, Hao Cheng, Yegor Klochkov, Muhammad Faaiz Taufiq, and Hang Li. Trustworthy llms: a survey and guideline for evaluating large language models’ alignment. CoRR, abs/2308.05374, 2023. doi: 10.48550/ARXIV.2308.05374. URL https://doi.org/10.48550/arXiv.2308.05374.
[245] Yang Liu, Yuanshun Yao, Jean-Francois Ton, Xiaoying Zhang, Ruocheng Guo, Hao Cheng, Yegor Klochkov, Muhammad Faaiz Taufiq, and Hang Li. 可信大语言模型:大语言模型对齐性评估综述与指南。CoRR, abs/2308.05374, 2023. doi: 10.48550/ARXIV.2308.05374. URL https://doi.org/10.48550/arXiv.2308.05374.
[258] Moin Nadeem, Anna Bethke, and Siva Reddy. StereoSet: Measuring stereotypical bias in pretrained language models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 5356–5371, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.416. URL https://a cl anthology.org/2021.acl-long.416.
[258] Moin Nadeem, Anna Bethke 和 Siva Reddy. StereoSet: 预训练语言模型中的刻板印象偏差测量. 载于《第59届计算语言学协会年会暨第11届自然语言处理国际联合会议论文集(第一卷: 长论文)》, 第5356-5371页, 线上会议, 2021年8月. 计算语言学协会. doi: 10.18653/v1/2021.acl-long.416. URL https://acl anthology.org/2021.acl-long.416.