ELIXR: Towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders
ELIXR: 通过大语言模型与放射学视觉编码器的对齐构建通用X射线人工智能系统
Shawn $\mathsf{X}\mathsf{U}^{1,\star}$ , Lin Yang1,* , Christopher Kelly1,* , Marcin Sieniek1, Timo Kohl berger 1, Martin Ma1, Wei-Hung Weng , Atilla P. Kiraly , Sahar Kazemzadeh , Zakkai Melamed , Jungyeon Park , Patricia Strachan1, Yun Liu1, Chuck Lau2, Preeti Singh1, Christina Chen1, Mozziyar Etemadi3, Sreenivasa Raju Kalidindi4, Yossi Matias1, Katherine Chou1, Greg S. Corrado1, Shravya Shetty1, Daniel Tse1, Shruthi Pra bha kara 1, Daniel Golden1, Rory Pilgrim1, Krish Eswaran1,‡, Andrew Seller gren 1,‡
Shawn $\mathsf{X}\mathsf{U}^{1,\star}$、Lin Yang1,* 、Christopher Kelly1,* 、Marcin Sieniek1、Timo Kohlberger1、Martin Ma1、Wei-Hung Weng、Atilla P. Kiraly、Sahar Kazemzadeh、Zakkai Melamed、Jungyeon Park、Patricia Strachan1、Yun Liu1、Chuck Lau2、Preeti Singh1、Christina Chen1、Mozziyar Etemadi3、Sreenivasa Raju Kalidindi4、Yossi Matias1、Katherine Chou1、Greg S. Corrado1、Shravya Shetty1、Daniel Tse1、Shruthi Prabhakara1、Daniel Golden1、Rory Pilgrim1、Krish Eswaran1,‡、Andrew Sellergren1,‡
Abstract
摘要
Background: Artificial intelligence systems for medical imaging have traditionally focused on highly specific tasks and have generalized inconsistently to new problems. The combination of large language models (LLMs) and vision encoders offers the potential to address some of these challenges. In this work, we present an approach that enables efficient training of multimodal models using routinely collected medical images and their associated text reports, and adds the ability to perform a diverse range of tasks with rich expressive outputs. This approach unlocks the potential for a new generation of medical AI applications, supporting workflows including high performance zero-shot and data-efficient classification, semantic search, visual question answering (VQA), and radiology report quality assurance (QA).
背景:传统医学影像人工智能系统通常专注于高度特定的任务,且在新问题上泛化能力参差不齐。大语言模型(LLM)与视觉编码器的结合为解决这些挑战提供了可能。本研究提出一种方法,能够利用常规采集的医学影像及其关联文本报告进行高效的多模态模型训练,并赋予模型执行多样化任务的能力,生成丰富的表达性输出。该方法为新一代医学AI应用开辟了可能,支持包括高性能零样本和数据高效分类、语义搜索、视觉问答(VQA)以及放射学报告质量保证(QA)在内的工作流程。
Methods: Our approach, which we call Embeddings for Language/Image-aligned X-Rays, or “ELIXR”, leverages a language-aligned image encoder “grafted” via an adapter onto a fixed LLM, PaLM 2, to perform a broad range of tasks. We train this lightweight adapter architecture using images paired with corresponding free-text radiology reports from the MIMIC-CXR dataset. Evaluation of zero-shot and data-efficient classification was performed using the public CheXpert and ChestX-ray14 datasets, as well as a private dataset from five hospitals in India. Semantic search was evaluated across four themes using the MIMIC-CXR test set. VQA was evaluated using the VQA-RAD benchmark and the MIMIC-CXR test set. LLM output for report QA was evaluated on the MIMIC-CXR test set by a board-certified thoracic radiologist.
方法:我们提出的方法称为"语言/图像对齐X射线嵌入"(Embeddings for Language/Image-aligned X-Rays,简称ELIXR),通过适配器将语言对齐的图像编码器"嫁接"到固定的大语言模型PaLM 2上,以执行广泛任务。我们使用MIMIC-CXR数据集中图像与对应自由文本放射报告的配对数据,训练这种轻量级适配器架构。零样本和数据高效分类评估使用公开的CheXpert和ChestX-ray14数据集,以及来自印度五家医院的私有数据集完成。语义搜索评估基于MIMIC-CXR测试集在四个主题上进行。视觉问答(VQA)评估使用VQA-RAD基准和MIMIC-CXR测试集。报告问答的大语言模型输出由经认证的胸部放射科医师在MIMIC-CXR测试集上进行评估。
Results: ELIXR achieved state-of-the-art performance on zero-shot chest X-ray (CXR) classification (mean AUC of 0.850 across 13 findings), data-efficient CXR classification (mean AUCs of 0.893 and 0.898 across five findings (at elect as is, card iomega ly, consolidation, pleural effusion, and pulmonary edema) for $1%$ $\left(\sim2,200\right)$ images) and $10%$ (\ 22,000 images) training data), and semantic search (0.76 normalized discounted cumulative gain (NDCG) across nineteen queries, including perfect retrieval on twelve of them). Compared to existing data-efficient methods including supervised contrastive learning (SupCon), ELIXR required two orders of magnitude less data to reach similar performance. ELIXR also showed promise on CXR vision-language tasks, demonstrating overall accuracies of $58.7%$ and $62.5%$ on visual question answering and report quality assurance tasks, respectively. These results suggest that ELIXR is a robust and versatile approach to CXR AI.
结果:ELIXR在零样本胸部X光(CXR)分类(13项检测结果平均AUC为0.850)、数据高效CXR分类(5项检测结果(肺不张、心脏肥大、肺实变、胸腔积液和肺水肿)在$1%$ ($\sim2,200$张图像)和$10%$ (\ 22,000张图像)训练数据下的平均AUC分别为0.893和0.898)以及语义搜索(19个查询的标准化折损累积增益(NDCG)为0.76,其中12个实现完美检索)方面均达到最先进水平。与监督对比学习(SupCon)等现有数据高效方法相比,ELIXR仅需百分之一的数据量即可达到相近性能。ELIXR在CXR视觉-语言任务中也表现优异,视觉问答和报告质量保证任务的总体准确率分别达到$58.7%$和$62.5%$。这些结果表明ELIXR是一种稳健且多功能的CXR人工智能解决方案。
Conclusion: LLM-aligned multimodal models can unlock the value of chest X-rays paired with radiology reports to solve a variety of previously challenging tasks.
结论:与大语言模型对齐的多模态模型能够释放胸片与放射学报告配对数据的价值,解决一系列先前具有挑战性的任务。
Keywords: artificial intelligence, medical imaging, deep learning, natural language processing, chest X-ray, multimodal fusion, CLIP, BLIP-2
关键词: 人工智能 (Artificial Intelligence), 医学影像, 深度学习, 自然语言处理, 胸部X光, 多模态融合, CLIP, BLIP-2
Introduction
引言
The past decade has witnessed dramatic advances in artificial intelligence (AI) in medical imaging. Numerous deep learning systems have been developed that can achieve expert-level performance across a range of medical tasks1. However, clinical and technical limitations have resulted in an implementation gap that has impeded the impact of AI in real world health applications at scale2. Key challenges include the significant cost of curating high quality training datasets, restriction of AI development to narrow, highly specific tasks, difficulty in processing multimodal data, and limited interpret ability that has hampered effective human-AI interaction 3.
过去十年见证了人工智能 (AI) 在医学影像领域的突飞猛进。大量深度学习系统被开发出来,能够在一系列医疗任务中达到专家级水平 [1]。然而,临床和技术限制导致实施差距,阻碍了 AI 在大规模实际医疗应用中的影响力 [2]。关键挑战包括高质量训练数据集的高昂成本、AI 开发局限于狭窄且高度特定的任务、处理多模态数据的困难,以及有限的可解释性阻碍了有效的人机交互 [3]。
Until recently, AI systems for medical imaging have been largely built using vision-only models, including convolutional neural networks (CNNs) and vision transformers 4. Using a traditional fully supervised approach, training CNNs and vision transformers is an expensive and time-consuming process that requires large quantities of expertly annotated data5. In addition, such networks are usually limited to performing discrete tasks, such as image classification, object detection, and segmentation. On the input side, these networks also take in only images, usually of just one modality. In contrast, healthcare workflows are typically multimodal in nature, with clinicians leveraging a diverse array of inputs (e.g. clinical notes, images, investigations) when making diagnoses and treatment decisions.
直到最近,医疗影像AI系统主要基于纯视觉模型构建,包括卷积神经网络(CNN)和视觉Transformer [4]。采用传统全监督方法训练CNN和视觉Transformer需要耗费大量专业标注数据,过程昂贵且耗时[5]。此外,这类网络通常仅限于执行离散任务,如图像分类、目标检测和分割。输入方面,这些网络也仅接受单一模态的影像数据。相比之下,医疗工作流本质上是多模态的,临床医生在诊断和治疗决策时会综合多种输入(如临床记录、影像、检查报告)。
Large language models (LLMs) are part of a new generation of versatile transformer-based6 AI models that are trained on massive datasets and demonstrate previously unseen abilities to generalize to a range of tasks, despite requiring very little task-specific data7,8. The multimodal combination of vision models and LLMs presents a range of exciting possibilities including zero-shot image-to-text generation that can follow natural language instructions 9–11. In medical imaging, these advances offer the potential to address limitations of vision-only models by enabling model training using ubiquitous medical images that have paired free text reports, adding capabilities to carry out a diverse range of tasks, accurately coping with the long-tail of diagnoses, enabling true multimodal inference, and presenting new options for expressive human-computer interaction 7.
大语言模型 (LLMs) 是基于Transformer的新一代多功能AI模型,它们通过海量数据集训练,展现出前所未有的泛化能力,仅需极少任务特定数据即可适应多种任务[7,8]。视觉模型与大语言模型的多模态结合带来了令人兴奋的可能性,例如遵循自然语言指令的零样本图像到文本生成[9–11]。在医学影像领域,这些进展有望突破纯视觉模型的局限:通过利用普遍存在的带配对自由文本报告的医学影像进行模型训练,增强执行多样化任务的能力,精准处理长尾诊断病例,实现真正的多模态推理,并为富表现力的人机交互提供新选择[7]。
In this paper, we present a lightweight vision-language adapter model called ELIXR (Embeddings for Language/Image-aligned X-Rays), which builds upon prior work9–11 to combine or “graft” a vision encoder with a frozen LLM to perform a wide range of vision-language tasks broadly relevant to medical imaging. Our case study in this work focuses on chest X-rays (CXRs) due to the wide availability of image-text paired data, but the methods are applicable to other image modalities. We describe the following key advantages of ELIXR:
在本文中,我们提出了一种轻量级的视觉语言适配器模型ELIXR(Embeddings for Language/Image-aligned X-Rays),该模型基于先前的工作[9-11],将视觉编码器与冻结的大语言模型结合或"嫁接",以执行与医学影像广泛相关的各种视觉语言任务。本工作的案例研究聚焦于胸部X光片(CXRs),因为这类图像-文本配对数据广泛可用,但该方法也适用于其他图像模态。我们阐述了ELIXR的以下关键优势:
frozen LLM and a data-efficient frozen vision encoder. Building models on top of ELIXR can be done rapidly to prototype new use cases, adapt to distribution shifts with a small amount of new training data, or use alternative publicly available LLMs.
冻结的大语言模型和数据高效的冻结视觉编码器。基于ELIXR快速构建模型可用于新用例原型开发、用少量新训练数据适应分布变化,或使用其他公开可用的大语言模型。
- ELIXR’s synthesis of imaging and text unlocks a new generation of medical AI applications. In this study we demonstrate semantic search, visual question answering (VQA), and radiology report quality assurance (QA), but there are countless potential applications across the medical domain that can be addressed using the proposed multimodal framework.
- ELIXR融合影像与文本的创新方法开启了新一代医疗AI应用。在本研究中,我们展示了语义搜索、视觉问答(VQA)和放射学报告质量保证(QA)功能,但该多模态框架可拓展至医疗领域无数潜在应用场景。
- ELIXR is trained using paired CXR and free text radiology reports - data that are ubiquitous in healthcare. The training process does not require expensive manual label curation by experts. Such an approach unlocks the value of routinely collected medical data to develop AI systems at far greater scale and at lower overall cost than previously possible.
- ELIXR 使用配对的胸部X光片 (CXR) 和自由文本放射学报告进行训练 - 这些数据在医疗保健领域无处不在。该训练过程无需专家进行昂贵的手动标注。这种方法释放了常规收集的医疗数据的价值,使开发AI系统的规模远超以往,同时大幅降低总体成本。
Methods
方法
ELIXR system
ELIXR 系统
We trained the ELIXR system in two stages (ELIXR-C and ELIXR-B).
我们分两个阶段训练了ELIXR系统(ELIXR-C和ELIXR-B)。
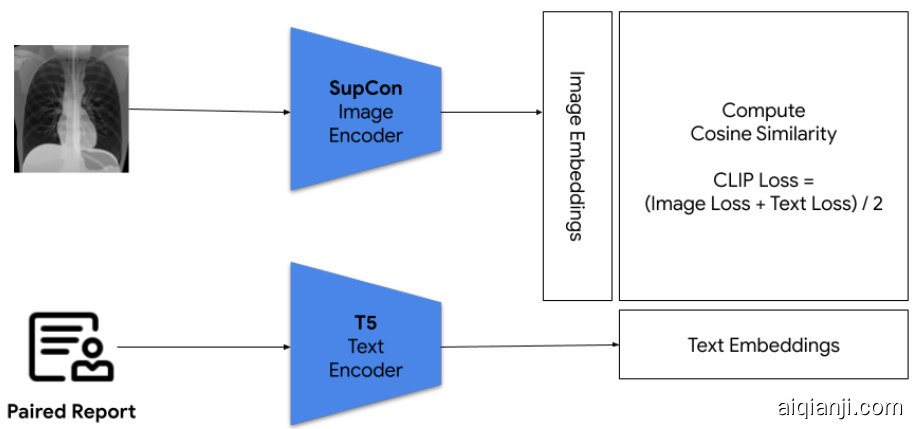
First, we trained the ELIXR-C model using Contrastive Language–Image Pre-training (CLIP)9 (Figure 1a). This uses radiology reports to align our previously published pre-trained supervised contrastive learning-based (SupCon) vision-only CXR model12 with a T5 language encoder13. CLIP uses a contrastive loss function, which encourages the model to bring the representations of an image and its associated text (in this case, the radiology report) closer together in a high-dimensional space, while simultaneously pushing apart representations of mismatched images and text.
首先,我们使用对比语言-图像预训练 (CLIP) [9] 训练了 ELIXR-C 模型 (图 1a)。该方法利用放射学报告,将我们先前发布的基于监督对比学习的纯视觉 CXR 预训练模型 [12] 与 T5 语言编码器 [13] 对齐。CLIP 采用对比损失函数,促使模型在高维空间中拉近图像与其关联文本 (此处指放射学报告) 的表征距离,同时推远不匹配图像与文本的表征。
Second, we trained an LLM-aligned adapter network ELIXR-B (Figure 1b), based on the Boots trapping Language-Image Pre-training 2 (BLIP-2) architecture 10. ELIXR-B is built directly upon ELIXR-C, where it aims to extract location-aware features from the unpooled spatial ELIXR-C image embedding space and map them to the LLM’s language token space. In this work, we used PaLM 2-S as the LLM14. By serving as an adapter between the image encoder and the LLM, ELIXR-B passes information between vision and language encoders via an attention mechanism, and allows us to leverage the existing knowledge and reasoning abilities of the LLM to interpret the images and perform various vision-language tasks (e.g. captioning, VQA). For computation and data efficiency, we keep both ELIXR-C and PaLM 2-S frozen, and only train the adapter between them. This can be thought of as a way of grafting an image encoder onto an LLM. More specifically, following the BLIP-2 architecture 10, there are two phases to ELIXR-B training: vision-language representation learning (phase 1) and vision-language generative learning (phase 2). In the first phase, the vision-language model (the Q-Former) is trained to understand and represent both CXRs and reports in a shared embedding space by jointly employing three different tasks: a) image-text contrastive learning (ITC), b) image-grounded text generation (ITG), and c) image-text matching (ITM). Standard contrastive loss is applied for image-text contrastive learning; image-grounded text generation is modeled as a classification problem (i.e. which token in the vocabulary should be chosen at each output position) and optimized by cross-entropy loss; image-text matching is modeled as a binary classification problem (image-text matched/unmatched) and optimized by cross-entropy loss. This results in a model that can extract key information from the image embeddings and align it with the report text embedding space. In the second phase, a multilayer perceptron (MLP) that connects the $\mathsf{Q}$ -Former with the LLM, and the $\mathsf{Q}$ -Former itself are further trained to generate the impressions section of radiology reports based upon the image embeddings from ELIXR-B using the LLM. The language modeling (standard cross-entropy) loss is used to guide the training. The result is that the $\mathsf{Q}$ -Former is able to produce LLM-aligned tokens based on the image and feed the most useful information to the LLM, while removing irrelevant visual information.
其次,我们基于BLIP-2架构[10]训练了一个与大语言模型对齐的适配网络ELIXR-B(图1b)。ELIXR-B直接构建在ELIXR-C之上,旨在从未池化的空间ELIXR-C图像嵌入空间中提取位置感知特征,并将其映射到大语言模型的语言token空间。本研究中我们采用PaLM 2-S作为大语言模型[14]。作为图像编码器与大语言模型之间的适配器,ELIXR-B通过注意力机制在视觉与语言编码器间传递信息,使我们能够利用大语言模型现有的知识和推理能力来解释图像并执行各类视觉-语言任务(如描述生成、视觉问答)。为提升计算和数据效率,我们保持ELIXR-C和PaLM 2-S参数冻结,仅训练二者间的适配器。这可以视为将图像编码器嫁接至大语言模型的一种方式。
具体而言,遵循BLIP-2架构[10],ELIXR-B训练分为两个阶段:视觉-语言表征学习(阶段1)和视觉-语言生成学习(阶段2)。第一阶段通过联合执行三项任务训练视觉-语言模型(Q-Former)在共享嵌入空间中理解和表征胸部X光片与报告:a)图像-文本对比学习(ITC);b)基于图像的文本生成(ITG);c)图像-文本匹配(ITM)。图像-文本对比学习采用标准对比损失;基于图像的文本生成建模为分类问题(即每个输出位置应选择词汇表中的哪个token)并通过交叉熵损失优化;图像-文本匹配建模为二分类问题(图像-文本匹配/不匹配)并通过交叉熵损失优化。由此得到的模型能够从图像嵌入中提取关键信息并与报告文本嵌入空间对齐。
第二阶段,连接Q-Former与大语言模型的多层感知机(MLP)和Q-Former本身被进一步训练,以基于ELIXR-B的图像嵌入使用大语言模型生成放射学报告的印象部分。训练采用语言建模(标准交叉熵)损失进行指导。最终Q-Former能够根据图像生成与大语言模型对齐的token,并向大语言模型输送最有用的信息,同时过滤无关视觉信息。
(a)
(a)
ELIXR-C Training
图 1: ELIXR-C 训练流程
ELIXR-CInference
ELIXR-CInference

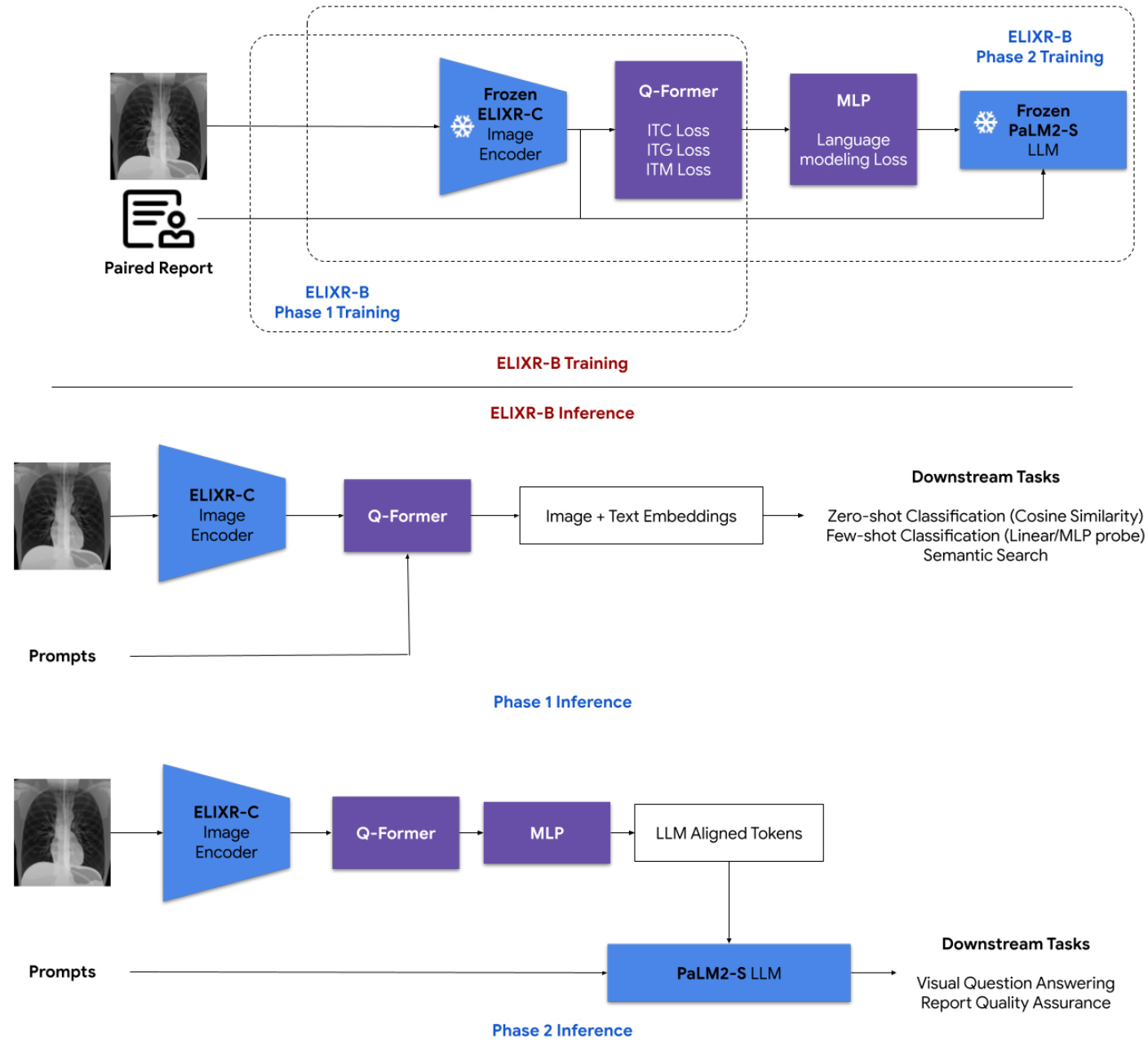
Figure 1: Architecture of ELIXR. (a) Training and inference of ELIXR-C. (b) Training and inference of ELIXR-B. ELIXR-B is trained in two phases. In the first phase, the model bootstraps vision-language representation in the $\mathsf{Q}$ -Former with three learning objectives (image-text contrastive learning (ITC), image-grounded text generation (ITG), image-text matching (ITM) losses) to learn from embeddings from a frozen image encoder. In the second phase, the model bootstraps vision-to-language generation from a frozen large language model. The purple text boxes represent the learned (unfrozen) components in the training step. Details of the VQA inference are further described in the relevant section.
图 1: ELIXR架构。(a) ELIXR-C的训练和推理。(b) ELIXR-B的训练和推理。ELIXR-B分两个阶段训练。第一阶段,模型通过三个学习目标(图像-文本对比学习(ITC)、基于图像的文本生成(ITG)、图像-文本匹配(ITM)损失)在$\mathsf{Q}$-Former中自举视觉-语言表示,从冻结图像编码器的嵌入中学习。第二阶段,模型从冻结的大语言模型中自举视觉到语言的生成。紫色文本框代表训练步骤中学习到的(未冻结)组件。VQA推理的细节在相关章节中有进一步描述。
Datasets
数据集
We included more than one million CXR images from six datasets in this study as described in Table 1: five hospitals from India (IND1), a hospital from Illinois, USA (US) (US1), Beth Israel Deaconess Medical Center in Massachusetts, USA (MIMIC-CXR), National Institutes of Health (NIH) Clinical Center in Maryland, USA (CXR-14), Stanford Health Care in California, USA (CheXpert), and the VQA-RAD dataset from the National Library of Medicine MedPix platform15–21.
本研究纳入了来自六个数据集的超过一百万张胸部X光(CXR)影像,如表1所示:包括印度五家医院(IND1)、美国伊利诺伊州某医院(US1)、马萨诸塞州贝斯以色列女执事医疗中心(MIMIC-CXR)、马里兰州美国国立卫生研究院临床中心(CXR-14)、加利福尼亚州斯坦福医疗保健中心(CheXpert),以及美国国家医学图书馆MedPix平台的VQA-RAD数据集[15-21]。
Data from IND1, US1, and the MIMIC-CXR train set were used for training ELIXR-C, while only data from the MIMIC-CXR train set were used for training ELIXR-B. Details of datasets and the evaluation tasks in which they were used appear in Table 1. Labels for IND1 and US1 are as previously described 12.
训练ELIXR-C时使用了来自IND1、US1和MIMIC-CXR训练集的数据,而训练ELIXR-B仅使用了MIMIC-CXR训练集的数据。数据集详情及其对应的评估任务如 表1 所示。IND1和US1的标签如文献[12]所述。
| VQA-RAD | |||||||
| Dataset | IND1 | US1 | MIMIC-CXR Dataset usage | CXR-14 | CheXpert | (Chest-only) | |
| Development | |||||||
| (train/validation sets) | ELIXR-C | ELIXR-C | ELIXR-C and ELIXR-B | ||||
| Evaluation (test set) | Data-efficient and zero-shot | All tasks | Data-efficient and zero-shot | Data-efficient and zero-shot | VQA | ||
| Dataset and patient statistics | |||||||
| Dataset origin | Five hospitals in India | An AMC in Illinois, USA | AMC in Massachusetts, USA | NIH, Maryland, USA | AMC in California, USA | NIH, Maryland, USA | |
| Number of patients | 348,335 | 12,988 | 60,523 | 30,805 | 65,654 | 107 | |
| Age (IQR) | 35-58 Female: | 48-71 Female: | 43-72 | 34-59 | N/A | N/A | |
| Sex | 133,833 (38.5%) Male: 214,334 (61.5%) Unknown: 168 (< 0.1%) | 6,779 (52.2%) Male: 6,209 (48.8%) | Female: 31,610 (52.2%) Male: 28,913 (48.8%) | Female: 14,175 (46.0%) Male: 16,630 (54.0%) | N/A | N/A | |
| Image and finding statistics | |||||||
| Number of images | 485,082 | 165,182 | 243,324 | 104,278 | 223,648 | 107 | |
| View (AP/PA) | AP: 79,958 (16.5%) PA: 625,735 (83.5%) | AP: 108,822 (65.9%) PA: 24,269 (14.7%) Unknown: 32,091 (19.4%) | AP: 147,169 (60.4%) PA: 96,155 (39.6%) | AP: 44,811 (40.0%) PA: 67,305 (60.0%) | N/A | N/A | |
| Airspace opacity | 43,629 (9.0%) | 15,309 (10.1%)* | 54,769 (22.5%) | 3,485 (3.3%) | 94,328 (30.2%) | N/A | |
| Fracture | 5,200 (1.1%) | 5,760 (3.8%)* | 4,781 (2.0%) | 546 (0.5%) | 7,436 (2.4%) | N/A | |
| Pneumothorax | 1,657 (0.3%) | 7,202 (4.8%)* | 11,235 (4.6%) | 5,302 (5.1%) | 17,700 (5.7%) | N/A | |
| Consolidation | 15,144 (3.1%) | 6,315 (4.2%)* | 11,525 (4.7%) | 4,667 (4.5%) | 13,015 (4.2%) | N/A | |
| Pleural effusion | 1,228 (0.3%) | 33,280 (22.0%* ) | 57,721 (23.7%) | 13,317 (12.8%) | 76,963 (24.6%) | N/A | |
| VQA-RAD | ||||||
|---|---|---|---|---|---|---|
| 数据集 | IND1 | US1 | MIMIC-CXR数据集使用情况 | CXR-14 | CheXpert | (仅胸部) |
| 开发阶段 | ||||||
| (训练集/验证集) | ELIXR-C | ELIXR-C | ELIXR-C和ELIXR-B | |||
| 评估(测试集) | 数据高效和零样本 | 所有任务 | 数据高效和零样本 | 数据高效和零样本 | VQA | |
| 数据集与患者统计 | ||||||
| 数据集来源 | 印度五家医院 | 美国伊利诺伊州一家AMC | 美国马萨诸塞州一家AMC | 美国马里兰州NIH | 美国加利福尼亚州一家AMC | 美国马里兰州NIH |
| 患者数量 | 348,335 | 12,988 | 60,523 | 30,805 | 65,654 | 107 |
| 年龄(IQR) | 35-58 女性: | 48-71 女性: | 43-72 | 34-59 | N/A | N/A |
| 性别 | 女性: 133,833 (38.5%) 男性: 214,334 (61.5%) 未知: 168 (< 0.1%) | 女性: 6,779 (52.2%) 男性: 6,209 (48.8%) | 女性: 31,610 (52.2%) 男性: 28,913 (48.8%) | 女性: 14,175 (46.0%) 男性: 16,630 (54.0%) | N/A | N/A |
| 影像与发现统计 | ||||||
| 影像数量 | 485,082 | 165,182 | 243,324 | 104,278 | 223,648 | 107 |
| 视图(AP/PA) | AP: 79,958 (16.5%) PA: 625,735 (83.5%) | AP: 108,822 (65.9%) PA: 24,269 (14.7%) 未知: 32,091 (19.4%) | AP: 147,169 (60.4%) PA: 96,155 (39.6%) | AP: 44,811 (40.0%) PA: 67,305 (60.0%) | N/A | N/A |
| 气腔混浊 | 43,629 (9.0%) | 15,309 (10.1%)* | 54,769 (22.5%) | 3,485 (3.3%) | 94,328 (30.2%) | N/A |
| 骨折 | 5,200 (1.1%) | 5,760 (3.8%)* | 4,781 (2.0%) | 546 (0.5%) | 7,436 (2.4%) | N/A |
| 气胸 | 1,657 (0.3%) | 7,202 (4.8%)* | 11,235 (4.6%) | 5,302 (5.1%) | 17,700 (5.7%) | N/A |
| 实变 | 15,144 (3.1%) | 6,315 (4.2%)* | 11,525 (4.7%) | 4,667 (4.5%) | 13,015 (4.2%) | N/A |
| 胸腔积液 | 1,228 (0.3%) | 33,280 (22.0%* ) | 57,721 (23.7%) | 13,317 (12.8%) | 76,963 (24.6%) | N/A |
| Pulmonary edema | 1,136 (0.2%) | 34,301 (22.7%)* | 29,331 (12.1%) | 2,303 (2.2%) | 49,717 (15.9%) | N/A |
| Atelectasis | 15,929 (3.3%) | 49,293 (32.6%)* | 48,790 (20.1%) | 11,559 (11.1%) | 29,795 (9.5%) | N/A |
| Cardiomegaly | 1,115 (0.2%) | 17,001 (11.3%)* | 47,673 (19.6%) | 2,776 (2.7%) | 23,451 (7.5%) | N/A |
| Support Devices | 29,698 (6.1%)* | 97,463 (64.6%)* | 73,294 (30.1%) | N/A | 107,014 (56.2%) | N/A |
| Enlarged cardiomediastinum | 349 (0.1%)* | 421 (0.3%)* | 7,657 (3.1%) | N/A | 9,273 (4.9%) | N/A |
| Lung lesion | 7,713 (1.6%)* | 1351 (0.9%)* | 6,632 (2.7%) | N/A | 7,022 (3.7%) | N/A |
| Pleural other | 19,301 (4.0%)* | 1807 (1.2%)* | 2,083 (0.9%) | N/A | 2,493 (1.3%) | N/A |
| Pneumonia | 54 (0.0%)* | 29,816 (19.7%)* | 17,222 (7.1%) | 1,255 (1.2%) | 4,657 (2.4%) | N/A |
Table 1: Descriptive statistics of the datasets used in the study. * : estimated from radiology reports
| 肺水肿 (Pulmonary edema) | 1,136 (0.2%) | 34,301 (22.7%)* | 29,331 (12.1%) | 2,303 (2.2%) | 49,717 (15.9%) | N/A |
| 肺不张 (Atelectasis) | 15,929 (3.3%) | 49,293 (32.6%)* | 48,790 (20.1%) | 11,559 (11.1%) | 29,795 (9.5%) | N/A |
| 心脏肥大 (Cardiomegaly) | 1,115 (0.2%) | 17,001 (11.3%)* | 47,673 (19.6%) | 2,776 (2.7%) | 23,451 (7.5%) | N/A |
| 辅助装置 (Support Devices) | 29,698 (6.1%)* | 97,463 (64.6%)* | 73,294 (30.1%) | N/A | 107,014 (56.2%) | N/A |
| 纵隔增宽 (Enlarged cardiomediastinum) | 349 (0.1%)* | 421 (0.3%)* | 7,657 (3.1%) | N/A | 9,273 (4.9%) | N/A |
| 肺部病变 (Lung lesion) | 7,713 (1.6%)* | 1,351 (0.9%)* | 6,632 (2.7%) | N/A | 7,022 (3.7%) | N/A |
| 其他胸膜病变 (Pleural other) | 19,301 (4.0%)* | 1,807 (1.2%)* | 2,083 (0.9%) | N/A | 2,493 (1.3%) | N/A |
| 肺炎 (Pneumonia) | 54 (0.0%)* | 29,816 (19.7%)* | 17,222 (7.1%) | 1,255 (1.2%) | 4,657 (2.4%) | N/A |
表 1: 研究中使用的数据集描述性统计。* : 根据放射学报告估算
Evaluation
评估
We demonstrated the utility of ELIXR on five CXR-related tasks: (1) zero-shot classification, (2) data-efficient classification, (3) semantic search, (4) VQA, and (5) report QA (Table 2). Zero-shot and data-efficient image classification as well as semantic search were performed using ELIXR-C and ELIXR-B phase 1 (language-aligned image embeddings), while VQA and quality assurance were performed using ELIXR-B phase 2, which combined these embeddings with the fixed PaLM 2-S LLM14.
我们展示了ELIXR在五项与胸部X光片(CXR)相关的任务中的应用:(1) 零样本(zero-shot)分类,(2) 数据高效分类,(3) 语义搜索,(4) 视觉问答(VQA),(5) 报告质量检测(表2)。零样本和数据高效的图像分类以及语义搜索使用ELIXR-C和ELIXR-B第一阶段(语言对齐的图像嵌入)完成,而视觉问答和质量检测则使用ELIXR-B第二阶段完成,该阶段将这些嵌入与固定的PaLM 2-S大语言模型[14]相结合。
| Task | Input | Model output | Metric | ELIXR versions used |
| Zero-shot classification | CXR image Positive prompt(s) Negative prompt(s) | Classification score | AUC | ELIXR-C and ELIXR-B phase 1 |
| Data-efficient classification | For training small nonlinear classifiers on embeddings: variable amountof CXR images with their corresponding annotations For inference: CXR image | Classification score | AUC | ELIXR-C and ELIXR-B phase 1 |
| Semantic search | Text description of search term | Top-5 CXR images from MIMIC-CXR test set that are related to the description | NDCG@5 Precision | ELIXR-C and ELIXR-B phase 1 |
| Visual question answering (VQA) | CXR image Questions about the image | Answers to given questions based on the image | Accuracy | ELIXR-B phase 2 |
| Report quality assurance (QA) | CXR image Normal/altered radiology report | Decision about accuracy of report, along with rich text explanation. | Accuracy | ELIXR-B phase 2 |
| 任务 | 输入 | 模型输出 | 指标 | 使用的ELIXR版本 |
|---|---|---|---|---|
| 零样本分类 | 胸部X光片 正面提示词 负面提示词 | 分类得分 | AUC | ELIXR-C和ELIXR-B第一阶段 |
| 数据高效分类 | 训练小型非线性分类器时:带标注的变数量胸部X光片 推理时:胸部X光片 | 分类得分 | AUC | ELIXR-C和ELIXR-B第一阶段 |
| 语义搜索 | 搜索项的文本描述 | 从MIMIC-CXR测试集中返回与描述最相关的Top-5胸部X光片 | NDCG@5 精确率 | ELIXR-C和ELIXR-B第一阶段 |
| 视觉问答 (VQA) | 胸部X光片 关于图像的提问 | 基于图像对给定问题的回答 | 准确率 | ELIXR-B第二阶段 |
| 报告质量检查 (QA) | 胸部X光片 正常/修改后的放射学报告 | 对报告准确性的判断,附带富文本解释 | 准确率 | ELIXR-B第二阶段 |
Table 2: Downstream chest $\pmb{\times}$ -ray tasks that are evaluated in this study. ELIXR-C takes images and/or text as input and outputs embeddings; ELIXR-B takes images and/or text as input and outputs embeddings and/or text. Therefore, for text output tasks such as VQA and QA, only ELIXR-B is used.
表 2: 本研究中评估的下游胸部 $\pmb{\times}$ 线任务。ELIXR-C 接收图像和/或文本作为输入并输出嵌入向量;ELIXR-B 接收图像和/或文本作为输入并输出嵌入向量和/或文本。因此,对于视觉问答 (VQA) 和问答 (QA) 等文本输出任务,仅使用 ELIXR-B。
Classification
分类
For zero-shot and data-efficient classification of CXR findings, area under the receiver operating characteristic curve (AUC) for each finding class is reported since the tasks are all binary classifications. We compared ELIXR-C and ELIXR-B performance with SupCon and previous SOTA models CheXzero and ConVIRT as baselines 22,23. We also evaluated the effect of varying the training dataset size.
为实现胸部X光片(CXR)结果的零样本和数据高效分类,由于所有任务均为二分类,我们报告了每类结果的受试者工作特征曲线下面积(AUC)。我们将ELIXR-C和ELIXR-B的性能与SupCon及先前最先进(SOTA)模型CheXzero、ConVIRT作为基线进行比较[22,23],同时评估了不同训练数据集规模的影响。
Zero-shot classification
零样本分类
To perform zero-shot classification using ELIXR-C, we adopted a prompting strategy described previously 23. Note that because ELIXR-C was pretrained on images and reports that include the findings being classified, “zero-shot” refers more to open-ended classification without using explicit labels during training than it does to never having observed these findings during training. The positive and negative text prompts were passed through the text encoder to obtain their text embeddings. These text embeddings were each average pooled and normalized, resulting in one representative embedding for each prompt. A cosine similarity was then calculated between the image embedding and these two text embeddings. A softmax of the cosine similarity for the positive prompt was used to produce a classification score so that AUC can be calculated. When there are multiple prompts for the positive or negative case, the mean of the cosine similarities of these prompts was taken before computing the softmax. Details of the prompts are listed in Supplementary table 1.
为了使用ELIXR-C进行零样本分类,我们采用了先前描述的提示策略[23]。需要注意的是,由于ELIXR-C在预训练时使用的图像和报告中包含了待分类的发现,这里的"零样本"更多指的是在训练过程中不使用显式标签的开放式分类,而非在训练过程中从未观察过这些发现。正负文本提示通过文本编码器处理后获得其文本嵌入。这些文本嵌入经过平均池化和归一化处理,最终为每个提示生成一个代表性嵌入。随后计算图像嵌入与这两个文本嵌入之间的余弦相似度。使用正提示的余弦相似度softmax来生成分类分数,以便计算AUC。当正例或负例存在多个提示时,在计算softmax前会先取这些提示余弦相似度的平均值。提示的详细信息见附表1。
For ELIXR-B, the image as well as positive and negative text prompts were passed through the $\mathsf{Q}$ -Former to get the output image query tokens and the sequence of text embeddings. The first in the sequence of text embeddings is the single special classification token ([CLS]). The cosine similarity is calculated between this classification token and each of the output image query tokens. The highest cosine similarity for the positive prompt and the highest cosine similarity for the negative prompt are passed to the softmax function to get the final classification score.
对于ELIXR-B,图像以及正负文本提示通过$\mathsf{Q}$-Former处理,得到输出图像查询token和文本嵌入序列。序列中的第一个文本嵌入是单一特殊分类token ([CLS])。计算该分类token与每个输出图像查询token之间的余弦相似度,将正提示的最高余弦相似度和负提示的最高余弦相似度输入softmax函数,得到最终分类分数。
Data-efficient classification
数据高效分类
To perform data-efficient classification, we followed the same procedure as in Sellergren et al12: a nonlinear classifier, an MLP consisting of two layers of 512 and 256 neurons, was trained on top of the frozen image encoder. We adopted a learning rate of 0.2, batch size of 512, and trained for 300 epochs with the layer-wise adaptive rate scaling (LARS) optimizer. To make results more directly comparable to CheXzero and ConVIRT, we also trained linear class if i ers for the $1%$ and $10%$ training data samples.
为实现高效数据分类,我们遵循了Sellergren等人[12]的相同流程:在冻结的图像编码器之上训练了一个非线性分类器(由512和256个神经元组成的双层MLP)。采用0.2的学习率、512的批量大小,使用分层自适应速率缩放(LARS)优化器训练300个周期。为使结果与CheXzero和ConVIRT更具直接可比性,我们还针对$1%$和$10%$的训练数据样本训练了线性分类器。
Statistical analysis
统计分析
For data-efficient classification, the AUC was averaged across 10 repeats of randomly subsampled training sets. To obtain an overall summary, the AUCs were (also) averaged across all tasks and all datasets (CheXpert, CXR-14, and IND1) for each training set size. $95%$ confidence intervals were calculated using twice the standard error across the 10 randomly drawn train set samples, and hypothesis testing was based on comparing the model closest to the mean performance across the 10. For the zero-shot models, $95%$ confidence intervals were estimated and AUCs were compared using the DeLong method24.
对于数据高效的分类任务,AUC值通过对随机子采样训练集的10次重复实验取平均获得。为得出总体评估,所有任务和数据集(CheXpert、CXR-14及IND1)的AUC值均按各训练集规模进行平均。通过10次随机训练集样本标准差的两倍计算95%置信区间,假设检验基于与10次实验平均性能最接近的模型进行比较。零样本模型的95%置信区间采用DeLong方法[24]估算,并以此进行AUC值比较。
Semantic search
语义搜索
For semantic search (also known as text-image retrieval), we provided queries across four topics, including queries for single findings, laterality-specific, severity-specific, and nuanced features. For each query, the analysis focused on the top five retrieved images based on model predictions. There were seven single finding queries, three laterality queries, four severity queries, and five nuanced queries. We compared ELIXR-C and ELIXR-B against the current state-of-the-art model MedCL $.|\mathsf{P}^{25}$ using the publicly available code and model checkpoints. The MIMIC-CXR test set served as the data pool for retrieval. The full list of 19 queries is provided in Supplementary table 2.
在语义搜索(也称为文本-图像检索)任务中,我们提供了涵盖四个主题的查询,包括单一征象查询、侧重性查询、严重程度特异性查询以及细微特征查询。针对每个查询,分析聚焦于模型预测返回的前五张相关图像。其中包含7个单一征象查询、3个侧重性查询、4个严重程度查询和5个细微特征查询。我们使用公开代码和模型检查点,将ELIXR-C与ELIXR-B同当前最先进的MedCL $|\mathsf{P}^{25}$模型进行对比。检索数据池采用MIMIC-CXR测试集,完整的19项查询列表详见补充表2。
For semantic search using ELIXR-C, we computed the cosine similarity between the query text embedding and the image embeddings from the data pool. The top five images with the highest cosine similarity were retrieved. For semantic search using ELIXR-B, we adopted the two-stage method in BLIP $\cdot2^{10}$ . In the first stage, we retrieved 128 images with the highest cosine similarity similar to CLIP as the candidates. In the second stage, the image-text matching score (i.e. the matched class probability) was computed to rerank these 128 candidates. The top five images with the highest image-text matching score from these 128 candidates were then returned.
在使用ELIXR-C进行语义搜索时,我们计算了查询文本嵌入与数据池中图像嵌入之间的余弦相似度,并检索出余弦相似度最高的前五张图像。对于使用ELIXR-B的语义搜索,我们采用了BLIP $\cdot2^{10}$ 中的两阶段方法:第一阶段检索出与CLIP相似度最高的128张图像作为候选;第二阶段通过计算图文匹配分数(即匹配类别概率)对这些候选进行重排序,最终返回这128张候选图像中图文匹配分数最高的前五张。
For evaluation, a board-certified thoracic radiologist (CL) scored the semantic search results as follows: $0=$ irrelevant or factually incorrect, $1=$ close fit to the query, but not the one intended (e.g., retrieved “bilateral effusion” for “right effusion” query), and ${2::=:}$ reasonable match. Precision at five (precision $\mathfrak{O S},$ ) and normalized discounted cumulative gain at 5 $(\mathsf{N D C G@5})$ were calculated to evaluate the quality of retrieval 26. For the ideal rank normalization, we assumed the data pool contained at least five matched queries, and thus we set the relevance scores to be all 2s for the ideal relevance. Precision for cases that had reasonable match (score $=2\dot{}$ ) and precision for at least somewhat fit (score ${\ge}1$ ) were also measured.
评估时,一位经过委员会认证的胸部放射科医师 (CL) 对语义搜索结果进行如下评分:$0=$ 不相关或事实错误,$1=$ 与查询接近但不完全匹配 (例如查询"右侧积液"时检索到"双侧积液"),${2::=:}$ 合理匹配。计算前五名的准确率 (precision $\mathfrak{O S},$) 和归一化折损累积增益 $(\mathsf{N D C G@5})$ 以评估检索质量[26]。对于理想排名归一化,我们假设数据池中至少包含五个匹配查询,因此将理想相关性的评分全部设为2。同时测量了合理匹配案例 (评分 $=2\dot{}$) 的准确率以及至少部分匹配 (评分 ${\ge}1$) 的准确率。
To establish the context of the difficulties of the retrieval, we estimated the total count of images with corresponding path o logie s. To do so, we adopted an LLM-based approach to detect mis labeling within the MIMIC-CXR test set27,28. Candidates for correction were first identified by a keyword search on the radiology reports. Next, a medically tuned LLM (Med-PaLM $2^{29}$ ) was applied to ensure that the label was consistent with the report, and a board-certified thoracic radiologist (CL) adjudicated cases where the LLM results differed from the ground truth in MIMIC-CXR. Details are listed in Supplementary table 3 and Supplementary figure 1.
为了说明检索的困难背景,我们估算了具有对应病理学特征的图像总数。为此,我们采用了一种基于大语言模型 (LLM) 的方法来检测 MIMIC-CXR 测试集 [27,28] 中的错误标注。首先通过对放射学报告进行关键词搜索来识别待修正的候选样本,随后应用医学专用大语言模型 (Med-PaLM $2^{29}$) 确保标签与报告内容一致,并由获得委员会认证的胸部放射科医师 (CL) 对 MIMIC-CXR 中与大语言模型结果和真实标注存在分歧的案例进行仲裁。具体细节见附表 3 和附图 1。
Visual question answering
视觉问答
We used two different datasets for VQA evaluation of ELIXR-B: a subset of the MIMIC-CXR test set, which is from the same domain as a part of the training dataset, and the subset of chest x-ray cases (IMAGEORGAN $==$ “CHEST” AND ANSWER ! $=$ “ultrasound”) in the VQA-RAD dataset17, from a different domain than the training dataset. A small held-out tuning set consisting only of “yes” or “no” answers from VQA-RAD was used for model checkpoint selection. Specifically, we used our own test and tuning splits for the 793 VQA-RAD CXR question and answer pairs, since the original test set (column Phrase type/QID_ para $==$ “test freeform” or “test_ para”) shares images with the development set (QID_ para $==$ “freeform” or “para”). By contrast, the images in our test set (584 questions on 73 images) are disjoint from the tune set images, and thus were unseen by the model until evaluation time. Moreover, we did not train the model on any VQA-RAD question and answer pairs, but only used it for checkpoint selection based on our smaller tuning set of 209 VQA pairs across 25 images. We compared ELIXR-B against the SOTA MedVInT30 model using the publicly available code and a model checkpoint that, like ours, was not finetuned on VQA-RAD.
我们使用两个不同的数据集对ELIXR-B进行视觉问答(VQA)评估:一部分是MIMIC-CXR测试集的子集(与部分训练数据同属一个领域),另一部分是VQA-RAD数据集中胸部X光病例的子集(IMAGEORGAN $==$ "CHEST"且ANSWER != "ultrasound")[17],该子集与训练数据属于不同领域。我们使用一个仅包含VQA-RAD中"是/否"答案的小型调优集进行模型检查点选择。具体而言,我们针对793个VQA-RAD胸部X光问答对采用了自定义的测试/调优划分,因为原版测试集(列Phrase type/QID_ para $==$ "test_ freeform"或"test_ para")与开发集(QID_ para $==$ "freeform"或"para")存在图像重叠。相比之下,我们的测试集(73张图像上的584个问题)与调优集图像完全隔离,因此在评估前模型从未见过这些图像。此外,我们没有使用任何VQA-RAD问答对进行训练,仅基于25张图像上的209个VQA调优对进行检查点选择。我们将ELIXR-B与最先进的MedVInT[30]模型进行对比,使用公开代码和检查点(与我们相同,未在VQA-RAD上微调)。
The second VQA dataset is a subset of cases with findings from MIMIC-CXR test set, as labeled in the MIMIC-CXR-JPG project27,28, with eight cases for each for the following findings: “No Finding”, “Pneumothorax”, “Pleural Effusion”, “Edema”, “Consolidation OR Pneumonia” (collected as a single category), and “Lung Lesion”. See the report quality assurance section below for further details on the case selection. For each case with a finding present (with finding presence confirmed by a board-certified thoracic radiologist (CL)), we queried the model with a set of finding-specific questions, covering its presence, location, and its severity, size or type, where applicable. See Supplementary table 4 for the complete question catalog. In addition, we asked two additional finding-independent questions per case, and three finding-independent questions for cases without any of the above findings (category “finding-independent” in the Supplementary table 4).
第二个VQA数据集是MIMIC-CXR测试集中带有影像发现的病例子集,这些病例已在MIMIC-CXR-JPG项目[27,28]中标注,每种发现包含八例病例,具体包括:"无发现"、"气胸"、"胸腔积液"、"肺水肿"、"实变或肺炎"(合并为单一类别)以及"肺部病变"。关于病例选择的更多细节,请参阅下文报告质量保证部分。对于每个经胸科放射科认证医师(CL)确认存在特定发现的病例,我们向模型提出了一系列针对该发现的问题,涵盖其存在性、位置、严重程度、大小或类型(如适用)。完整问题目录见补充表4。此外,每个病例我们还额外询问了两个与发现无关的问题,而对于不包含上述任何发现的病例(补充表4中"与发现无关"类别),则询问了三个与发现无关的问题。
Since both phases of ELIXR-B were trained to generate the impression section of a radiology report, but neither was tuned to follow instructions, we utilized both the impression generation results from phase 1 (same ITG setup as BLIP-2, ) and LLM-aligned tokens from phase 2 to facilitate the VQA use case. Specifically, after generating the impression with phase 1, we then ran inference for the phase 2 model, using the following dialog prompt for the PaLM 2-S LLM wherein the LLM-aligned tokens from phase 2 inference were placed at the beginning of the prompt at ({aligned LLM tokens}), the phase 1-generated impression was fed to ({impression}), and the specific question ({question}) was added afterwards:
由于ELIXR-B的两个阶段均被训练用于生成放射学报告的印象部分,但均未针对指令跟随进行调优,我们同时利用了第一阶段(与BLIP-2相同的ITG设置)的印象生成结果和第二阶段的LLM对齐token来支持视觉问答(VQA)用例。具体而言,在通过第一阶段生成印象后,我们运行第二阶段模型的推理流程:将第二阶段推理获得的LLM对齐token置于提示词开头 ({aligned LLM tokens}) ,将第一阶段生成的印象输入 ({impression}) ,随后添加具体问题 ({question}) ,形成面向PaLM 2-S大语言模型的对话提示模板:
In terms of answer grading, model answers that could pro grammatically be mapped to “yes” or “no” and compared against “yes”-or-“no”-expected answers were automatically graded with 1.0 for a match, and 0.0 otherwise. A board-certified thoracic radiologist (CL) graded the remaining model answers using correctness scores 0.0, 0.5 or 1.0. See Supplementary table 5 for the full scoring rubric.
在答案评分方面,对于可以程序化映射为"是"或"否"并与预期"是/否"答案进行比对的模型回答,系统自动给予1.0分(匹配)或0.0分(不匹配)。其余模型答案由一位获得委员会认证的胸部放射科医师(CL)使用0.0、0.5或1.0的正确性评分标准进行评分。完整评分细则见补充表5。
For the MIMIC-CXR test set samples, the same radiologist using the same scoring rubric evaluated all 216 answers generated by the model based on their assessment directly of the CXR image and original radiology report.
对于MIMIC-CXR测试集样本,同一位放射科医生使用相同的评分标准,根据其对CXR图像和原始放射学报告的直接评估,对模型生成的216个答案进行了评价。
Sensitivity, specificity and accuracy values were calculated from the average radiologist grades on respective subsets where the condition was positive, negative or both.
根据放射科医生在阳性、阴性或两者兼具的子集上的平均评分,计算了敏感性、特异性和准确率。
Report quality assurance
报告质量保证
In the report quality assurance task, we simulated the situation where a radiology repor contained errors and used ELIXR-B to identify and suggest corrections to these errors. Errors that we evaluated included swapping laterality of a finding (“left” to “right” or vice versa), adding an erroneous finding that was not clearly present in the image, or omitting a major finding that was present in the image.
在报告质量保证任务中,我们模拟了放射学报告包含错误的情况,并使用ELIXR-B来识别并建议修正这些错误。我们评估的错误包括交换发现的左右侧(如将"左"改为"右"或反之)、添加图像中未明确显示的虚假发现,或遗漏图像中存在的主要发现。
To evaluate ELIXR’s performance, we first identified a subset of cases with findings from the MIMIC-CXR test set, as labeled in the MIMIC-CXR-JPG project, that would be most relevant for evaluating quality assurance: “No Finding”, “Pneumothorax”, “Pleural Effusion”, “Edema”, “Consolidation OR Pneumonia” (collected as a single category), and “Lung Lesion”. We randomly selected eight cases per finding. For each case we defined the “primary finding” as the finding that was used in the query that yielded that given case, even if other findings, including more clinically significant findings, were present in the case. For example, if we searched for cases with pleural effusion and discovered a case with both pleural effusion and pulmonary edema present, the primary finding for that case was considered to be pleural effusion. We filtered cases to ensure that (1) an impression section was present in the report (true for approximately $83%$ of cases) and (2) the primary finding was present unambiguously in the image, based on the impression of a board-certified thoracic radiologist (CL).
为评估ELIXR的性能,我们首先从MIMIC-CXR测试集中筛选出带有特定影像表现的病例子集(这些标签来自MIMIC-CXR-JPG项目),这些标签对质量评估最具参考价值:"未见异常"、"气胸"、"胸腔积液"、"肺水肿"、"实变或肺炎"(合并为单一类别)以及"肺病变"。我们为每类影像表现随机选取8个病例。每个病例的"主要表现"定义为检索该病例时使用的查询关键词,即使该病例同时存在其他(包括临床意义更显著的)影像表现。例如,若检索"胸腔积液"时发现某病例同时存在胸腔积液和肺水肿,则该病例的主要表现仍记为胸腔积液。我们通过以下条件筛选病例:(1) 报告必须包含印象章节(约$83%$病例满足该条件);(2) 经认证胸科放射科医师(CL)判读,影像中必须明确存在主要表现。
Within the set of eight cases for each finding category, we made an alteration per case as follows: two cases we left with unaltered impression sections (the “control” cases), two cases had the primary finding’s laterality swapped, two cases had the primary finding removed, and two cases had an erroneous finding added. For each alteration, we made further minimal modifications to the impression text as needed to ensure that it was internally consistent (e.g., if we added an extraneous finding of “moderate pulmonary edema,” we confirmed that the rest of the report was clinically consistent with this alteration). A summary of these alterations appears in Supplementary table 6. For ”Edema”, because pulmonary edema tends to be a bilateral finding, we did not include any cases with swapped laterality and instead included three control cases, three cases where an extraneous finding was added, and two cases where the primary finding of ”Edema” was removed, still resulting in eight cases total. For the cases labeled as "No Finding", modifications like laterality swapping and finding removal were not feasible. Therefore, we chose four control cases and four cases in which we introduced a false finding, providing us with a total of eight cases. After making these alterations, we had 48 total cases, each of which had an associated CXR image and an impression section that was either unaltered (control) or altered according to the above process.
在每个发现类别的八例病例中,我们对每例进行了如下修改:两例保持印象部分未改动(即"对照"病例),两例交换了主要发现的侧别,两例移除了主要发现,两例添加了错误发现。每次修改时,我们都会对印象文本进行必要的微调以确保内部一致性(例如,若添加了"中度肺水肿"这一无关发现,我们会确认报告其余内容与此修改在临床上保持一致)。这些修改的摘要见补充表6。对于"水肿"类别,由于肺水肿通常是双侧表现,我们未包含任何侧别交换病例,而是包含三例对照病例、三例添加无关发现的病例,以及两例移除"水肿"主要发现的病例,仍保持总数为八例。对于标记为"无发现"的病例,侧别交换和发现移除等修改不可行,因此我们选择四例对照病例和四例添加虚假发现的病例,共八例。经过这些修改后,我们共获得48例病例,每例均配有相应的胸部X光图像和印象部分(未修改的对照病例或按上述流程修改过的病例)。
To generate the model outputs for evaluation, we first ran ELIXR-B phase 1 inference on the image to produce a report with ELIXR’s findings. We then fed the image, the generated report, and a series of prompts that covered the main possible set of findings in chest x-rays to ELIXR-B phase 2.
为生成用于评估的模型输出,我们首先在图像上运行ELIXR-B第一阶段推理,生成包含ELIXR发现的报告。随后将图像、生成的报告以及涵盖胸部X光主要可能发现的一系列提示输入至ELIXR-B第二阶段。
For each prompt, the $\mathsf{Q}$ -Former-encoded image embeddings preceded the text hard prompt as input into PaLM 2-S, and the control or altered impressions section was inlined in place of the variable {altered impression}. ELIXR provided an assessment as to whether each finding existed, and if so, assessed the laterality in order to support the laterality swap detection task. The prompts were as follows.
对于每个提示,$\mathsf{Q}$-Former编码的图像嵌入位于文本硬提示之前,作为PaLM 2-S的输入,控制或修改的印象部分内联替换了变量{altered impression}。ELIXR评估了每个发现是否存在,若存在则评估其侧向性以支持侧向性交换检测任务。具体提示如下。
This initial part of the workflow was essentially comprehensive VQA. We concatenated these responses into a single piece of text to constitute ELIXR’s comprehensive findings.
工作流的初始阶段本质上是全面的视觉问答(VQA)。我们将这些回答串联成单一文本,构成ELIXR的综合发现结果。
We then fed the concatenated questions and answers into a non-image-aligned LLM, Med-PaLM $2^{29}$ , to determine whether there were any missing findings, erroneously added findings, or laterality swaps. The two prompts to do this were as follows. Note that while MIMIC-CXR contains full reports for most cases, we altered and evaluated only the impression section of the reports.
然后,我们将拼接好的问题和答案输入到一个非图像对齐的大语言模型 Med-PaLM $2^{29}$ 中,以确定是否存在遗漏的发现、错误添加的发现或左右侧混淆。用于此操作的两个提示如下。请注意,虽然 MIMIC-CXR 包含大多数病例的完整报告,但我们仅对报告中的印象部分进行了修改和评估。
LLM responses were graded by a board-certified thoracic radiologist (CL) according to the rubric in Supplementary table 7. If the LLM correctly described the alteration (or identified an unaltered, control report as being correct and complete), the LLM output was scored as correct; if the LLM failed to identify the alteration, even if it gave an otherwise correct response, the output was scored as incorrect.
大语言模型的回答由一位获得委员会认证的胸部放射科医生 (CL) 根据补充表7中的评分标准进行评分。如果大语言模型正确描述了修改内容 (或将未经修改的对照报告识别为正确且完整) ,则其输出被评分为正确;如果大语言模型未能识别出修改内容,即使其回答在其他方面是正确的,输出仍被评分为错误。
Results
结果
ELIXR demonstrates state-of-the-art zero-shot classification performance comparable to fully supervised SupCon class if i ers trained on as many as 224,000 examples
ELIXR展示了与全监督SupCon分类器相当的先进零样本分类性能,后者需在多达224,000个样本上训练
ELIXR-B and ELIXR-C demonstrated zero-shot classification performance on five findings (“at elect as is”, “card iomega ly”, “consolidation”, “pleural effusion”, and “pulmonary edema”) that was comparable to SupCon’s classification performance when trained on the entirety of the CheXpert train set (\ 224,000 examples). Note that although ELIXR’s vision encoder was initialized from a SupCon checkpoint, CheXpert was not used for pre training SupCon at all, only for training small downstream class if i ers. Thus, CheXpert is completely held out from ELIXR-B and ELIXR-C zero-shot.
ELIXR-B和ELIXR-C在五项影像征象("心脏增大"、"实变"、"胸腔积液"、"肺水肿"及"未见异常")上展现出零样本分类性能,其表现与SupCon在整个CheXpert训练集(约224,000例)上训练后的分类性能相当。需特别说明:虽然ELIXR视觉编码器初始化自SupCon检查点,但CheXpert从未用于SupCon的预训练,仅用于训练小型下游分类器。因此CheXpert数据完全未参与ELIXR-B和ELIXR-C的零样本评估。
Across the 13 findings (excluding “No Finding”) from the CheXpert test set, ELIXR-C and ELIXR-B both surpassed the state-of-the-art zero-shot performance from CheXzero23. Figure 2 shows the details of the performance comparison for zero-shot classification. Positive and negative texts for prompt tuning in zero-shot classification are listed in Supplementary table 1.
在CheXpert测试集的13项发现(不包括“无发现”)中,ELIXR-C和ELIXR-B均超越了CheXzero23的先进零样本性能。图2展示了零样本分类的性能对比细节。零样本分类中用于提示调优的正负文本列于附表1。

Figure 2: ELIXR demonstrated state-of-the-art zero-shot classification performance comparable to label-efficient method supervised contrastive learning (SupCon). AUCs and $95%$ confidence intervals for zero-shot classification for ELIXR-B, ELIXR-C, and CheXzero ensemble23 across 11 findings (including only findings with ${>}5$ positives and excluding “No Finding” label) as well as SupCon fully-supervised (trained on the entire 224K examples of CheXpert) classification for five findings on the CheXpert test dataset. Full results with p-values are available in Supplementary table 8.
图 2: ELIXR 展示了与标签高效方法监督对比学习 (SupCon) 相当的先进零样本分类性能。图中显示了 ELIXR-B、ELIXR-C 和 CheXzero 集成模型在 11 项发现(仅包含阳性样本数 ${>}5$ 的发现,排除“无发现”标签)上的零样本分类 AUC 及 $95%$ 置信区间,以及 SupCon 在全监督(使用 CheXpert 全部 224K 样本训练)下对 CheXpert 测试数据集中五项发现的分类结果。完整结果及 p 值见补充表 8。
ELIXR-B and ELIXR-C both set a new state-of-the-art for data-efficient linear probe classification on CheXpert’s five main findings (“at elect as is”, “card iomega ly”, “consolidation”, “pleural effusion”, “pulmonary edema”) using $1%$ and $10%$ of the train set, outperforming even the fully-finetuned ConVIRT22. ELIXR-B and ELIXR-C also both demonstrated data-efficient performance superior to SupCon (Figure 3) or, to put it another way, demonstrated data-efficient performance equivalent to SupCon using roughly two orders of magnitude less training data (e.g. ELIXR-B and ELIXR-C 64-shot performance was non inferior to SupCon 4096-shot performance; see Supplementary tables 9 and 10 for p-values). Table 3 shows a summary of comparisons between ELIXR and the SOTA for zero-shot and data-efficient.
ELIXR-B和ELIXR-C在使用$1%$和$10%$训练集数据时,均针对CheXpert五项主要发现("at elect as is", "card iomega ly", "consolidation", "pleural effusion", "pulmonary edema")的数据高效线性探针分类任务创造了最新技术水准,表现甚至优于完全微调的ConVIRT22。ELIXR-B和ELIXR-C还展示了优于SupCon的数据高效性能(图3),或者说,仅需约两个数量级更少的训练数据就能达到与SupCon相当的数据高效性能(例如:ELIXR-B和ELIXR-C的64样本性能不逊于SupCon的4096样本性能;p值详见补充表9和表10)。表3总结了ELIXR与当前最优技术(SOTA)在零样本和数据高效两方面的对比情况。
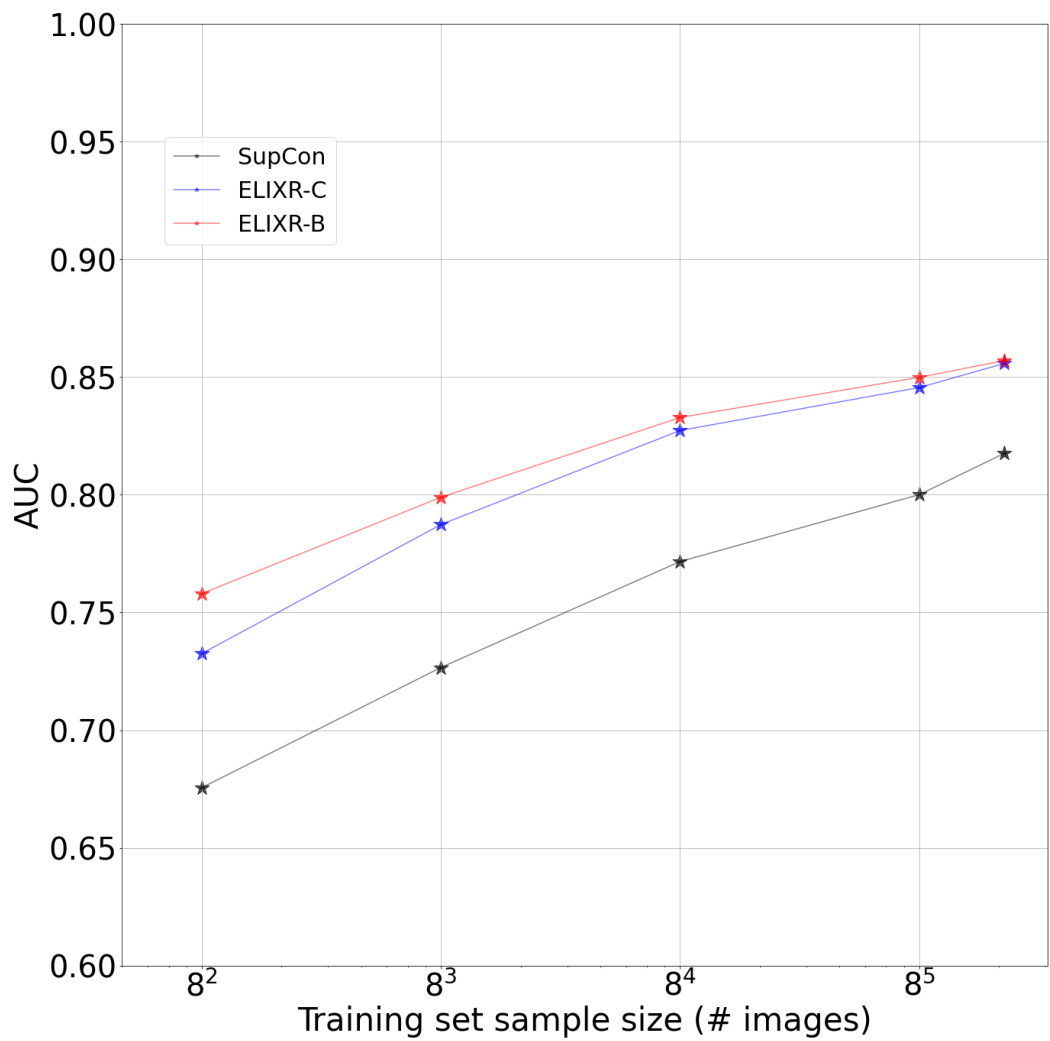
Figure 3: Effect of using ELIXR-C, ELIXR-B, and supervised contrastive learning (SupCon) for data-efficient classification. The reported performance is averaged across 2 datasets (CheXpert and Chest X-ray14) and seven findings: at elect as is, card iomega ly, airspace opacity, fracture, pneumothorax, consolidation, pleural effusion, and pulmonary edema. Both ELIXR-C and ELIXR-B demonstrate superior performance compared to SupCon at matching dataset sizes, or, put another way, demonstrate performance on par with SupCon with two orders of magnitude less data (red and blue lines are translated two grid lines to the left from the black line). Detailed per-dataset and per-finding graphs are available in Supplementary figure 2. Delong’s test results are available in Supplementary tables 9, 10.
图 3: 使用ELIXR-C、ELIXR-B和监督对比学习(SupCon)进行数据高效分类的效果。报告性能为2个数据集(CheXpert和Chest X-ray14)及七种病症的平均值: 心脏增大、气腔混浊、骨折、气胸、实变、胸腔积液和肺水肿。在相同数据集规模下,ELIXR-C和ELIXR-B均表现出优于SupCon的性能,或者说,仅用百分之一数据量即可达到与SupCon相当的性能(红蓝线条相对黑线向左平移两格)。各数据集及病症的详细图表见补充图2。Delong检验结果见补充表9、10。
| Mean AUC CheXpert test (5 main findings) | Mean AUC CheXpert test (13 findings) | |
| Zero shot | ||
| CheXzero | 0.889 | 0.838 |
| ELIXR-C | 0.851 | 0.850 |
| ELIXR-B | 0.837 | 0.846 |
| 1% training data | ||
| ConVIRT linear | 0.859 | -- |
| ConVIRT finetune | 0.870 | -- |
| ELIXR-C linear | 0.887 | -- |
| ELIXR-B linear | 0.893 | -- |
| 10% training data | ||
| ConVIRT linear | 0.868 | -- |
| ConVIRT finetune | 0.881 | -- |
| ELIXR-C linear | 0.889 | -- |
| ELIXR-B linear | 0.898 | -- |
| CheXpert测试平均AUC (5项主要发现) | CheXpert测试平均AUC (13项发现) | |
|---|---|---|
| * * 零样本* * | ||
| CheXzero | 0.889 | 0.838 |
| ELIXR-C | 0.851 | 0.850 |
| ELIXR-B | 0.837 | 0.846 |
| * * 1%训练数据* * | ||
| ConVIRT线性 | 0.859 | -- |
| ConVIRT微调 | 0.870 | -- |
| ELIXR-C线性 | 0.887 | -- |
| ELIXR-B线性 | 0.893 | -- |
| * * 10%训练数据* * | ||
| ConVIRT线性 | 0.868 | -- |
| ConVIRT微调 | 0.881 | -- |
| ELIXR-C线性 | 0.889 | -- |
| ELIXR-B线性 | 0.898 | -- |
Table 3: Comparison of ELIXR against state-of-the-art models, ConVIRT and CheXzero22,23. ELIXR sets a new state of the art, as measured by mean AUC, for zero-shot classification of 13 findings in CheXpert and data-efficient classification $1%$ and $10%$ training data) of 5 main findings in CheXpert.
表 3: ELIXR 与最先进模型 ConVIRT 和 CheXzero[22,23] 的对比。在 CheXpert 数据集的 13 项影像发现零样本 (Zero-shot) 分类任务中,ELIXR 以平均 AUC 指标创造了新纪录;同时在 CheXpert 5 项主要发现的数据高效分类任务中 (使用 $1%$ 和 $10%$ 训练数据) 也达到最优性能。
ELIXR enables state-of-the-art semantic search for findings using laterality-specific, severity-based, and nuanced terminology
ELIXR 支持使用侧重性、基于严重程度和细微术语的最先进语义搜索来查找结果
ELIXR-B outperformed both ELIXR-C and the state-of-the-art MedCLIP25 on the retrieval quality of top-5 retrieved images. For each query group, we computed the average metrics across the queries. NDCG@5 and Precision $\ @5$ of ELIXR-B were consistently better than ELIXR-C across all query groups. ELIXR-B scored higher than MedCLIP on NDCG@5 for all query groups and on Precision@5 (score $=2$ ) for three out of four query groups (Table 4).
ELIXR-B在检索前5张相关图像的质量上优于ELIXR-C和最先进的MedCLIP25。针对每个查询组,我们计算了各查询的平均指标。在所有查询组中,ELIXR-B的NDCG@5和Precision@5始终优于ELIXR-C。ELIXR-B在NDCG@5上对所有查询组的得分均高于MedCLIP,在Precision@5 (score=2) 上对四分之三的查询组表现更优 (表4)。
| Precision@5 (score=2) | Precision@5 (score=1) | NDCG@5 | ||
| Findings | MedCLIP | 0.29 | 0.29 | 0.25 |
| ELIXR-C | 0.63 | 0.66 | 0.66 | |
| ELIXR-B | 0.74 | 0.74 | 0.74 | |
| Laterality | MedCLIP | 0.77 | 1 | 0.76 |
| ELIXR-C | 0.73 | 0.8 | 0.83 | |
| ELIXR-B | 0.93 | 0.93 | 0.94 | |
| Severity | MedCLIP | 0.63 | 0.75 | 0.66 |
| ELIXR-C | 0.35 | 0.7 | 0.53 | |
| ELIXR-B | 0.55 | 0.7 | 0.68 | |
| Nuanced | MedCLIP | 0.54 | 0.68 | 0.54 |
| ELIXR-C | 0.6 | 0.84 | 0.73 | |
| ELIXR-B | 0.64 | 0.84 | 0.74 | |
| Total | MedCLIP | 0.50 [0.34-0.64] | 0.60 [0.40-0.77] | 0.49 [0.31-0.63] |
| ELIXR-C | 0.66 [0.52-0.78], 0.154 | 0.74 [0.60-0.86], p=0.296 | 0.68 [0.53-0.81], p=0.0912 | |
| ELIXR-B | 0.75 [0.57-0.88], p=0.047 | 0.79 [0.63-0.91], p=0.143 | 0.76 [0.59-0.89], p=0.0234 |
| Precision@5 (score=2) | Precision@5 (score=1) | NDCG@5 | ||
|---|---|---|---|---|
| * * Findings* * | MedCLIP | 0.29 | 0.29 | 0.25 |
| ELIXR-C | 0.63 | 0.66 | 0.66 | |
| ELIXR-B | 0.74 | 0.74 | 0.74 | |
| * * Laterality* * | MedCLIP | 0.77 | 1 | 0.76 |
| ELIXR-C | 0.73 | 0.8 | 0.83 | |
| ELIXR-B | 0.93 | 0.93 | 0.94 | |
| * * Severity* * | MedCLIP | 0.63 | 0.75 | 0.66 |
| ELIXR-C | 0.35 | 0.7 | 0.53 | |
| ELIXR-B | 0.55 | 0.7 | 0.68 | |
| * * Nuanced* * | MedCLIP | 0.54 | 0.68 | 0.54 |
| ELIXR-C | 0.6 | 0.84 | 0.73 | |
| ELIXR-B | 0.64 | 0.84 | 0.74 | |
| * * Total* * | MedCLIP | 0.50 [0.34-0.64] | 0.60 [0.40-0.77] | 0.49 [0.31-0.63] |
| ELIXR-C | 0.66 [0.52-0.78], p=0.154 | 0.74 [0.60-0.86], p=0.296 | 0.68 [0.53-0.81], p=0.0912 | |
| ELIXR-B | 0.75 [0.57-0.88], p=0.047 | 0.79 [0.63-0.91], p=0.143 | 0.76 [0.59-0.89], p=0.0234 |
Table 4: Quantitative analysis of CXR semantic search using ELIXR-C and ELIXR-B. ELIXR-C demonstrated the highest ${\mathsf{N D C G@5}}$ scores across all four query groups and the highest Precision scores across three of four query groups as compared to ELIXR-B and the state-of-the-art MedCLIP. Confidence intervals were calculated from boots trapping; p-values were calculated from permutation tests between ELIXR-B and MedCLIP or ELIXR-C and MedCLIP.
表 4: 使用 ELIXR-C 和 ELIXR-B 进行胸部 X 光片语义搜索的定量分析。与 ELIXR-B 和最先进的 MedCLIP 相比,ELIXR-C 在所有四个查询组中均表现出最高的 ${\mathsf{N D C G@5}}$ 分数,并在其中三个查询组中取得最高精确度分数。置信区间通过自助法计算得出;p 值通过 ELIXR-B 与 MedCLIP 或 ELIXR-C 与 MedCLIP 之间的置换检验计算。
On twelve out of nineteen queries, ELIXR-B demonstrated perfect retrieval, including for laterality-specific queries like “right pleural effusion,” severity-specific queries like “moderate card iomega ly,” and nuanced queries like “na so gastric tip reaches stomach.” Notably, we found both ELIXR-C and ELIXR-B performed worse on fracture- and pneumothorax-related queries than queries related to other findings. This could be partially due to the low prevalence of these two path o logie s in the MIMIC test set $4%$ for fracture and $3%$ for pneumothorax) compared to $>10%$ prevalence for other path o logie s. See Supplementary table 2 for a complete list of per-query scores.
在19个查询中的12个上,ELIXR-B展现了完美检索能力,包括针对特定侧向的查询(如"右侧胸腔积液")、严重程度相关的查询(如"中度心脏增大")以及 nuanced 查询(如"鼻胃管尖端未达胃部")。值得注意的是,我们发现ELIXR-C和ELIXR-B在骨折和气胸相关查询上的表现均逊于其他检查结果相关的查询。这部分可归因于MIMIC测试集中这两种病变的低占比(骨折4%、气胸3%),而其他病变的占比均超过10%。完整查询得分列表详见补充表2。
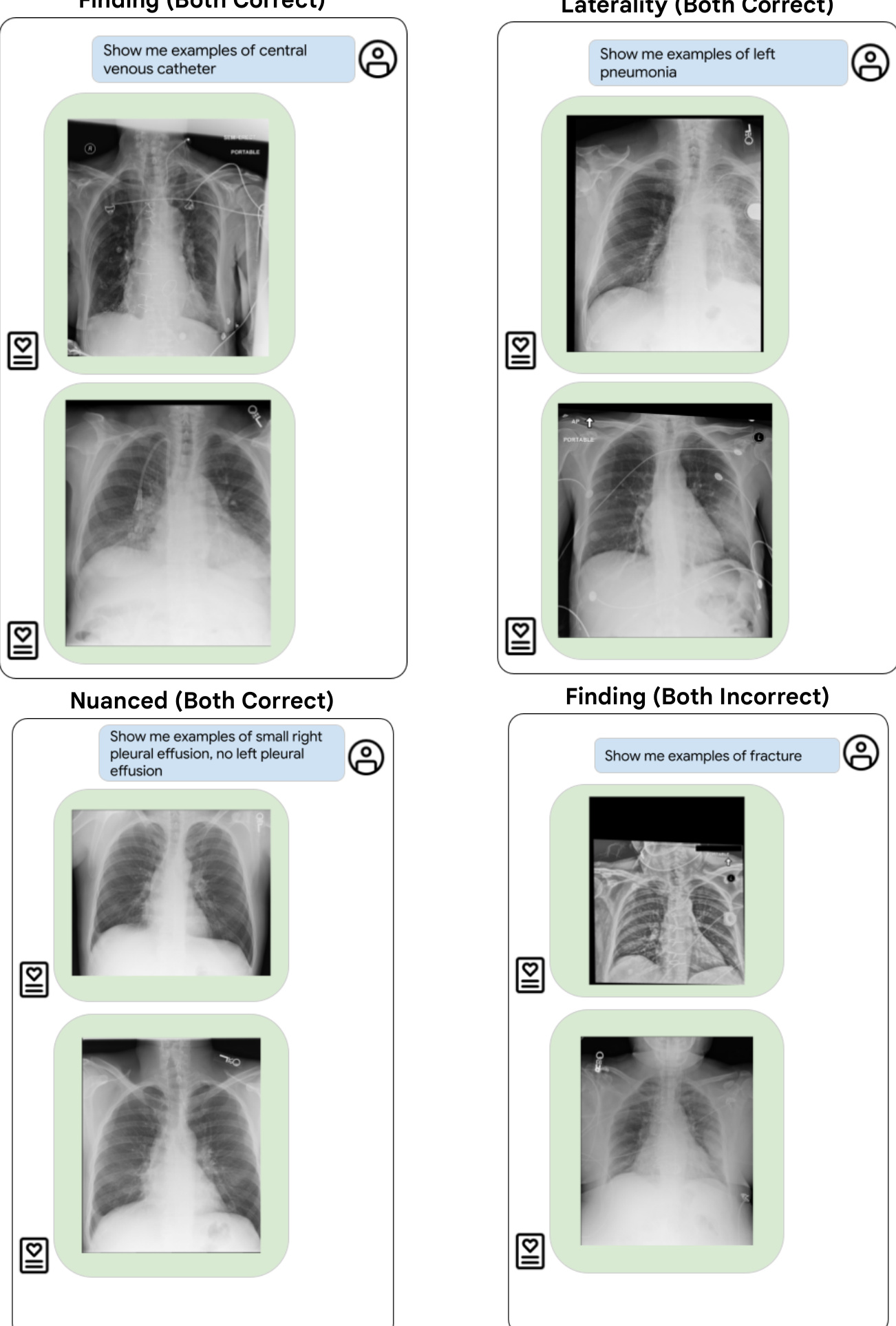
Figure 4: Demonstration of semantic search using ELIXR. Three of four examples here (top left, top right, bottom left) are correct for both images (scores of 2) while one example is incorrect for both images (scores of 0, bottom right).
图 4: 使用ELIXR进行语义搜索的演示。此处四个示例中有三个(左上、右上、左下)对两张图像都正确(得分为2),而有一个示例对两张图像都不正确(得分为0,右下)。
In some cases, retrieval improved when using more specific queries, e.g. adding a laterality or severity modifier to a general finding. For example, ELIXR-C and ELIXR-B scored 0.723 and 0.83 for “left pneumothorax” as compared to 0.131 and 0.214 for “pneumothorax.” These results point to the sensitivity of these models to prompting style.
在某些情况下,使用更具体的查询(例如为通用发现添加偏侧性或严重程度修饰词)能提升检索效果。例如,ELIXR-C和ELIXR-B对"左侧气胸"的评分分别为0.723和0.83,而对"气胸"的评分仅为0.131和0.214。这些结果表明模型对提示风格的敏感性。
ELIXR supports visual question answering and quality assurance for radiology reports
ELIXR支持放射学报告的视觉问答与质量保障
On more challenging text-generation tasks, ELIXR-B demonstrated overall accuracies of $58.7%$ and $54.8%$ on two visual question answering (VQA) datasets, VQA-RAD (CXR-only questions) (Table 5) and MIMIC-CXR test (Table 6), as well as $62.5%$ on report quality assurance (QA) on MIMIC-CXR test (Tables 7, 8). Notably, ELIXR-B surpassed the accuracy of the SOTA model MedVInT which wasn’t finetuned on VQA-RAD. A summary of VQA results appears in Tables 5 and 6. Quality assurance results appear stratified by alteration type in Table 7 and by primary finding in Table 8. Figure 5 shows a selection of example cases for both visual question answering and quality assurance.
在更具挑战性的文本生成任务中,ELIXR-B在两个视觉问答(VQA)数据集上分别取得58.7%和54.8%的整体准确率,这两个数据集分别是VQA-RAD(仅含胸部X光问题)(表5)和MIMIC-CXR测试集(表6),同时在MIMIC-CXR测试集的报告质量保证(QA)任务上达到62.5%准确率(表7、表8)。值得注意的是,ELIXR-B超越了未在VQA-RAD上微调的SOTA模型MedVInT的准确率。VQA结果汇总见表5和表6,质量保证结果按修改类型分层展示于表7,按主要发现分层展示于表8。图5展示了视觉问答和质量保证的部分示例案例。
| Answertype (A_ TYPE) | Med-VlnT w/finetuning Accuracy* * | Med-VlnT w/o finetuning Accuracy | ELIXR-B Accuracy | ELIXR-B Sensitivity* | ELIXR-B Specificity* |
| both | 81.6% (451) | 27.9% (574) | 58.7% (574) | N/A | N/A |
| closed | 86.8% (272) | 28.2% (379) | 69.3% (379) | 42.6% (222) | 87.8% (195) |
| open | 73.7% (179) | 27.1% (195) | 37.9% (195) | N/A | N/A |
| 回答类型 (A_ TYPE) | Med-VlnT 微调后准确率* * | Med-VlnT 未微调准确率 | ELIXR-B 准确率 | ELIXR-B 敏感度* | ELIXR-B 特异度* |
|---|---|---|---|---|---|
| both | 81.6% (451) | 27.9% (574) | 58.7% (574) | N/A | N/A |
| closed | 86.8% (272) | 28.2% (379) | 69.3% (379) | 42.6% (222) | 87.8% (195) |
| open | 73.7% (179) | 27.1% (195) | 37.9% (195) | N/A | N/A |
Table 5: VQA results of ELIXR-B on our VQA-RAD test set using semantic matching. Number of total questions and answers in brackets. For comparison with the SOTA method, we provide results from MedVInT30 both before and after finetuning on VQA-RAD to show the benefits it provides. $^{\star}\mathsf{O n}$ the subset of expected that could be pro grammatically mapped to “yes” or “no”. * * Results from MedVInT for VQA-RAD finetuning are on all image modalities (not just chest X-ray) and from the official test split.
表 5: ELIXR-B 在 VQA-RAD 测试集上使用语义匹配的 VQA 结果 (括号内为问题与答案总数)。为与 SOTA 方法对比,我们提供了 MedVInT30 在 VQA-RAD 微调前后的结果以展示其优势。$^{\star}\mathsf{O n}$ 可编程映射为 "是" 或 "否" 的预期子集。* * MedVInT 的 VQA-RAD 微调结果涵盖所有图像模态 (不仅限于胸部 X 光) 且来自官方测试集划分。
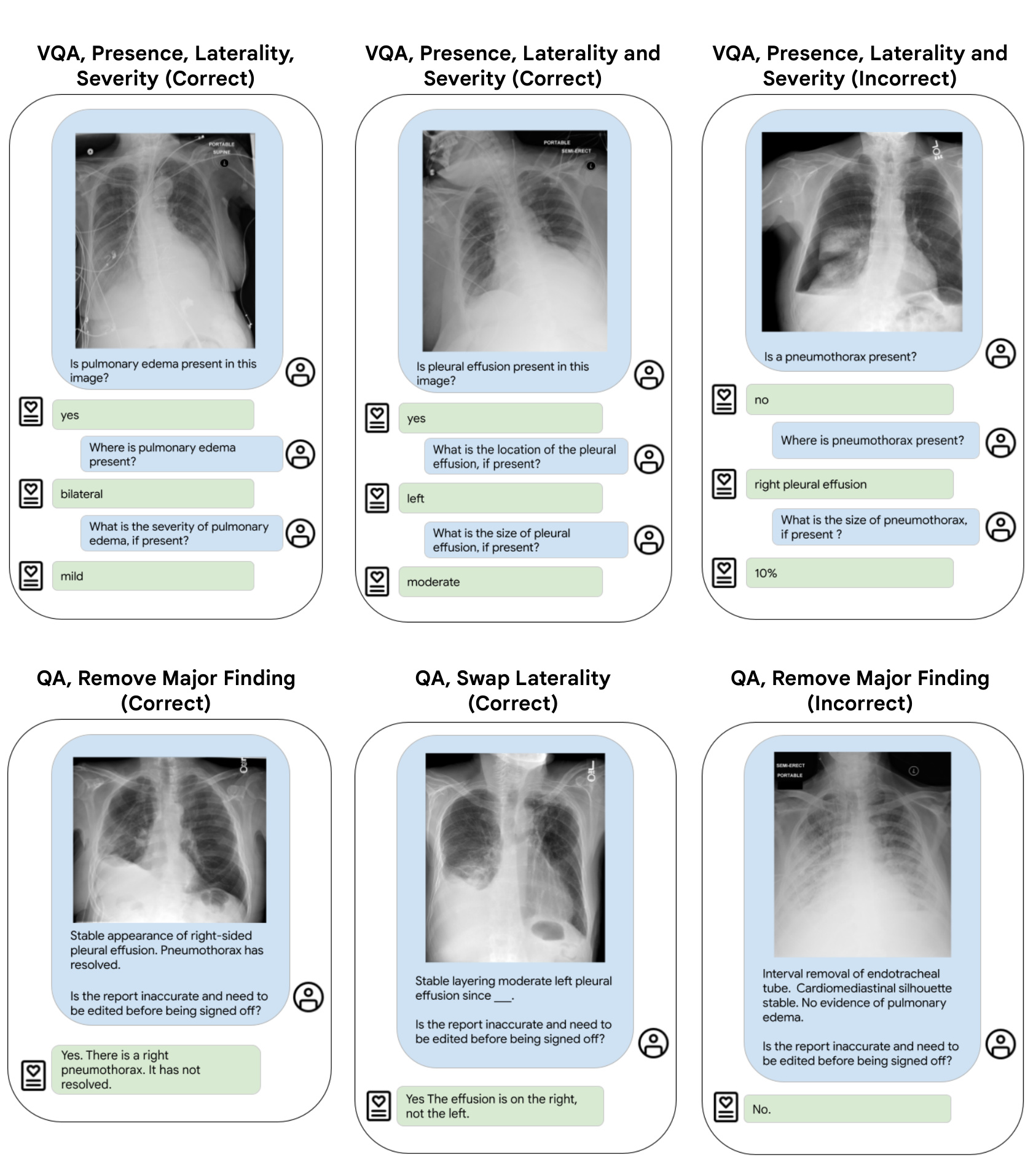
Figure 5: Qualitative results for visual question answering and quality assurance inference (from MIMIC test dataset).
图 5: 视觉问答与质量保证推理的定性结果 (来自MIMIC测试数据集)。
| Question type | Accuracy |
| all | 54.8% (217) |
| presence | 64.5% (148) |
| location | 41.0% (39) |
| size, severity or type | 25.0% (30) |
| 问题类型 | 准确率 |
|---|---|
| 全部 | 54.8% (217) |
| 存在性 | 64.5% (148) |
| 位置 | 41.0% (39) |
| 大小、严重程度或类型 | 25.0% (30) |
Table 6: Accuracy of ELIXR-B’s VQA answers on a subset of 48 MIMIC cases using expert-graded semantic matches. Number of questions $&$ answers noted in brackets. Nine questions were marked as non-gradable by the expert due to insufficient information or non-relevance (e.g. question about severity despite condition not being present).
表 6: ELIXR-B 在48例MIMIC病例子集上VQA答案的准确性 (基于专家评分的语义匹配) 。问题数量 $&$ 答案数量标注在括号中。由于信息不足或问题无关 (例如询问不存在病情的严重程度) ,专家标记了9个问题为不可评分。
Table 7: Summary statistics of report quality assurance results, stratified by alteration type.
| Alteration type | Number of cases | Overall model score (percent correct) |
| Control | 15 | 53.3% |
| Swap laterality | 8 | 87.5% |
| Add major finding | 15 | 60.0% |
| Remove major finding | 6 | 50.0% |
| Total | 48 | 60.4% |
表 7: 按修改类型分组的报告质量保证结果统计摘要
| 修改类型 | 案例数量 | 模型总体得分(正确率) |
|---|---|---|
| Control | 15 | 53.3% |
| Swap laterality | 8 | 87.5% |
| Add major finding | 15 | 60.0% |
| Remove major finding | 6 | 50.0% |
| Total | 48 | 60.4% |
Table 8: Summary statistics of quality assurance results, stratified by primary finding.
| Primary finding | Number of cases | Overall model score (percent correct) |
| No finding | 8 | 100% |
| Pneumothorax | 8 | 25% |
| Pleural Effusion | 8 | 62.5% |
| Edema | 8 | 62.5% |
| Consolidation or Pneumonia | 8 | 75% |
| Lung Lesion | 8 | 37.5% |
| Total | 48 | 60.4% |
表 8: 按主要发现分层汇总的质量保证结果统计
| 主要发现 | 病例数 | 模型总体得分(正确率) |
|---|---|---|
| 无异常 | 8 | 100% |
| 气胸 | 8 | 25% |
| 胸腔积液 | 8 | 62.5% |
| 水肿 | 8 | 62.5% |
| 实变或肺炎 | 8 | 75% |
| 肺部病变 | 8 | 37.5% |
| 总计 | 48 | 60.4% |
It is important to note that the results we report on VQA-RAD are not directly comparable to those reported in the literature, for the following reasons: (1) we only used a CXR subset of VQA-RAD, since ELIXR currently is limited to this modality, (2) we opted for a more difficult split than the official development/test split in which the same image never appears across splits, (3) we refrained from training on the development set and only used it for checkpoint selection. The effect of (2) and (3) appears to be large: as Table 5 shows, MedVInT’s performance increases from $27.1%$ to $73.7%$ on open-ended accuracy and from $28.2%$ to $86.8%$ on close-ended accuracy after finetuning on VQA-RAD. Moor and Huang et $\mathsf{a}|^{31}$ noted this data leakage in the official VQA-RAD splits, as well.
需要注意的是,我们报告的VQA-RAD结果与文献中的结果无法直接比较,原因如下:(1) 由于ELIXR目前仅限于胸部X光(CXR)模态,我们仅使用了VQA-RAD的CXR子集;(2) 我们选择了比官方开发/测试集更困难的数据划分方式,确保相同图像不会出现在不同划分中;(3) 我们未在开发集上进行训练,仅将其用于检查点选择。(2)和(3)的影响似乎很大:如表5所示,MedVInT在VQA-RAD微调后,开放式问题准确率从$27.1%$提升至$73.7%$,封闭式问题准确率从$28.2%$提升至$86.8%$。Moor和Huang等$\mathsf{a}|^{31}$也指出了官方VQA-RAD划分中存在这种数据泄露问题。
Discussion
讨论
In this study, we developed and evaluated ELIXR, a multimodal model that grafts a language-aligned vision encoder onto a frozen LLM. The model was trained using CXR images paired with their free-text radiology reports, without the requirement for expensive expert data curation. The model achieved state-of-the-art performance for zero-shot classification, data-efficient classification, and semantic search tasks, while also demonstrating potential in visual question answering and radiology report quality assurance. The modular architecture has the advantage of being easily adaptable to other tasks, with the ability to swap in different vision encoders and base LLMs as required.
在本研究中,我们开发并评估了ELIXR模型,这是一种将语言对齐的视觉编码器嫁接至冻结大语言模型(LLM)的多模态模型。该模型使用与自由文本放射学报告配对的CXR图像进行训练,无需昂贵的专家数据标注。该模型在零样本分类、数据高效分类和语义搜索任务中实现了最先进的性能,同时在视觉问答和放射学报告质量保证方面展现出潜力。模块化架构的优势在于能轻松适配其他任务,可根据需求灵活更换不同视觉编码器和基础大语言模型。
The ELIXR architecture is data and computationally efficient. Previously we demonstrated that small nonlinear class if i ers trained on a frozen SupCon vision encoder can outperform fully supervised models in low-data settings12. With ELIXR, we have improved upon the data efficiency of supervised contrastive learning by two orders of magnitude. This offers the potential to train highly accurate models that are capable of addressing the long tail of diagnoses (including rare diseases), with only a fraction of the requirement for expert-curated training data. The process of prototyping a model for a new task also becomes simplified and more widely accessible, requiring only the design of positive and negative prompts using natural language without a requirement for machine learning expertise. We hope that these approaches will enable a wider range of researchers to engage in a broader array of diagnostic research questions and will allow medical professionals to develop models for under served populations or understudied diseases.
ELIXR架构在数据和计算效率方面表现出色。我们先前的研究表明,在低数据环境下,基于冻结SupCon视觉编码器训练的小型非线性分类器能够超越全监督模型[12]。通过ELIXR,我们将监督对比学习的数据效率提升了两个数量级。这为训练高精度模型提供了可能,这些模型能够处理诊断中的长尾问题(包括罕见疾病),且仅需专家标注训练数据的一小部分。针对新任务的原型设计过程也变得更加简化和普及,仅需使用自然语言设计正负提示词,无需机器学习专业知识。我们希望这些方法能让更多研究人员参与广泛的诊断研究问题,并帮助医疗专业人员为服务不足人群或研究不足的疾病开发模型。
By leveraging a pre-trained frozen vision encoder and a frozen LLM, we were able to train ELIXR in a highly compute-efficient manner. Back propagation of gradients during the second stage of training is only performed for the $\mathsf{Q}$ -Former and MLP components, which are orders of magnitude smaller than the vision encoder and frozen LLM. In comparison to finetuning the vision encoder and/or LLM, this approach to training can be easily used by others who do not have access to substantial compute hardware. Furthermore, when adapting to a new task, or when newer generations of vision encoders and LLMs become available, it is straightforward and relatively inexpensive to train a new ELIXR model to take advantage of these advances.
通过利用预训练的冻结视觉编码器和冻结大语言模型,我们能够以极高的计算效率训练ELIXR。在训练的第二阶段,反向传播梯度仅作用于$\mathsf{Q}$-Former和MLP组件,这些组件的规模比视觉编码器和冻结大语言模型小几个数量级。相较于微调视觉编码器或大语言模型,这种训练方法更容易被缺乏强大计算硬件的研究者采用。此外,当适应新任务或新一代视觉编码器与大语言模型问世时,只需以较低成本训练新的ELIXR模型即可利用这些技术进步。
LLMs offer a deep natural language understanding that enables a new range of possibilities for rich interaction between clinicians and AI. In this study, we demonstrated early promising capabilities in semantic search, vision question answering, and report quality assurance–all tasks that cannot be achieved easily using traditional vision-only models.
大语言模型(LLM)具备深度自然语言理解能力,为临床医生与AI之间的丰富交互开辟了新可能。本研究展示了其在语义搜索、视觉问答和报告质量保证等任务中的早期潜力——这些任务传统纯视觉模型难以实现。
Semantic search unlocks the ability to search within an image for features of interest using free text prompts. ELIXR demonstrated high retrieval precision across a broad range of queries, including perfect retrieval of five out of seven findings-related queries (e.g. “central venous catheter”), two out of three laterality-specific queries (e.g. “right pleural effusion”), two out of four severity-related queries (e.g. “moderate card iomega ly”), and three out of five nuanced queries (e.g. “na so gastric tube reaches stomach”). This capability could be used by researchers to identify images for study datasets, by clinicians to search for specific images of interest from a patient’s historical record, by educators to find examples for teaching purposes, as well as in many other applications.
语义搜索能够通过自由文本提示在图像中搜索感兴趣的特征。ELIXR 在广泛查询范围内展现出高检索精度,包括完美检索七项与发现相关的查询中的五项(例如"中心静脉导管")、三项侧向特异性查询中的两项(例如"右侧胸腔积液")、四项严重程度相关查询中的两项(例如"中度心脏肥大"),以及五项细微差异查询中的三项(例如"鼻胃管未达胃部")。该功能可帮助研究人员筛选研究数据集图像、临床医生检索患者历史记录中的特定图像、教育工作者寻找教学案例,以及众多其他应用场景。
ELIXR also enables rich human-AI interaction through visual question answering. We benchmark our VQA performance on the chest X-ray subset of the VQA-RAD dataset, yielding accuracy of $69.1%$ across closed type questions, and $37.9%$ across open type questions. In contrast to others’ work, we do not train on VQA-RAD, as the standard VQA-RAD data splits exhibit an overlap with images in both train/test that risk artificially inflating performance 31. In addition, we report accuracy based on assessment by a board-certified thoracic radiologist rather than unigram matching (BLEU-1), since BLEU-1 does not comprehensively reflect the quality of VQA.
ELIXR还通过视觉问答实现了丰富的人机交互。我们在VQA-RAD数据集的胸部X光片子集上评估了VQA性能,在封闭式问题中准确率达到$69.1%$,在开放式问题中达到$37.9%$。与其他工作不同,我们未在VQA-RAD上进行训练,因为标准VQA-RAD数据划分存在训练/测试图像重叠的风险,可能人为夸大性能[31]。此外,我们报告的是由一位获得委员会认证的胸部放射科医师评估的准确率,而非单元匹配(BLEU-1),因为BLEU-1不能全面反映VQA的质量。
Finally, we demonstrate the ability of ELIXR to use its understanding of CXRs to check for errors in written radiology reports. We envision that such a capability could have utility in the hospital setting, potentially acting as an advanced multimodal “spell check” to alert radiologists to suspected inconsistencies in their reports, improving both quality and consistency of care. It could also act as an “AI Mentor”, evaluating and mentoring more junior radiologists, including in settings where resource limitations result in less opportunity for oversight by senior radiologists. VQA and QA were heavily dependent on the specific prompts used, which were in turn affected by the LLM used by ELIXR. With further work into prompt engineering, it is expected that one could make the QA more specific, with fewer false positive reports. This high specificity is likely to be needed in a clinical environment, especially where the error rate is far lower than in this enriched simulated set.
最后,我们展示了ELIXR利用其对胸部X光片(CXR)的理解来检查书面放射学报告中错误的能力。我们设想这种能力在医院环境中具有实用价值,可以作为一种先进的多模态"拼写检查"工具,提醒放射科医生注意报告中疑似不一致之处,从而提高医疗质量和一致性。它还可以充当"AI导师",评估并指导资历较浅的放射科医生,特别是在资源限制导致缺乏资深放射科医生监督的情况下。视觉问答(VQA)和问答(QA)高度依赖于所使用的特定提示词,而这些提示词又受到ELIXR所使用的大语言模型影响。通过进一步研究提示工程,有望使QA更加精准,减少误报。这种高特异性在临床环境中很可能必不可少,尤其是在实际错误率远低于这个经过人工强化的模拟数据集的情况下。
There are a number of limitations to our work. Firstly, through employing a frozen LLM and vision encoder, we achieve our goals of training efficiency, but this might be at the expense of overall performance (although some works suggest otherwise 32). Secondly, ELIXR inherits the current set of wider challenges of LLMs including fragility to changes in prompts, hallucinations, and unwarranted confidence in its answers, even when wrong33. We expect that advances in future generations of LLMs will directly lead to improved performance when incorporated into ELIXR. Thirdly, a lack of established, robust benchmarks makes it challenging to compare performance and establish state-of-the-art. Fourthly, we note that the MIMIC CXRs used were highly complex in an intensive care setting, containing multiple findings, which added more complexity than is typical compared to routine hospital X-rays. A non-intensive care CXR dataset that reflects routine wider hospital practice would be valuable to evaluate in future work. Finally, we selected different stages of ELIXR for different tasks based upon a performance versus efficiency trade-off. For example, on zero-shot learning tasks, the benefits of ELIXR-B over ELIXR-C were limited. In contrast, VQA and report QA tasks are more text dependent, and benefited from longer training using larger amounts of text data. We found that some categories of findings were challenging across all tasks–for example pneumothorax and fractures–where the difficulty of these cases is only partly explained by their low prevalence and noisy reference standards in the training datasets5.
我们的工作存在若干局限性。首先,通过采用冻结的大语言模型 (LLM) 和视觉编码器,我们实现了训练效率目标,但这可能以整体性能为代价 (尽管有研究指出相反结论 [32])。其次,ELIXR 继承了大语言模型当前面临的广泛挑战,包括对提示词变化的脆弱性、幻觉现象,以及即使回答错误时仍表现出的不当自信 [33]。我们预计未来大语言模型的进步将直接提升 ELIXR 的性能表现。第三,缺乏成熟稳健的基准测试体系使得性能比较和确立最优水平面临挑战。第四,我们注意到使用的 MIMIC CXR 数据来自重症监护环境,具有高度复杂性,包含多种异常表现,相比常规医院 X 光片增加了额外复杂度。未来工作中评估反映常规医院实践的非重症监护 CXR 数据集将很有价值。最后,我们基于性能与效率的权衡为不同任务选择了 ELIXR 的不同阶段。例如在零样本学习任务中,ELIXR-B 相较 ELIXR-C 的优势有限;而视觉问答和报告问答任务更依赖文本,因此受益于使用更多文本数据进行的长时间训练。我们发现某些异常类别在所有任务中都存在挑战——例如气胸和骨折——这些案例的困难仅能部分归因于其在训练数据中的低出现率和存在噪声的参考标准 [5]。
In future work, we hope to explore ELIXR’s performance with different general purpose and medically specialized LLMs (e.g. Med-PaLM 2). We are also excited by the possibility of extending these methods to other imaging modalities such as mus cul o skeletal X-ray, mammography, computed tomography (CT), and also beyond radiology in an effort we are calling Medical Information Adapters. It is also likely that temporal information can be incorporated into this architecture, widening the range of potential real world clinical applications.
在未来的工作中,我们希望探索ELIXR在不同通用及医学专用大语言模型(例如Med-PaLM 2)上的表现。我们也对将这些方法扩展到其他成像模态(如肌肉骨骼X光、乳腺摄影、计算机断层扫描(CT))的前景感到兴奋,并计划将应用范围拓展至放射学之外,这一方向我们称之为"医学信息适配器"。此外,该架构很可能整合时序信息,从而拓宽潜在的实际临床应用范围。
Conclusion
结论
In this study, we developed and evaluated an efficient vision-language multimodal model for medical imaging that is trained using only medical images paired with free-text radiology reports obtained from routine clinical practice. The method is highly compute and data efficient to train, and we demonstrated promising performance across a range of multimodal radiology tasks. This work is an initial step towards a general purpose X-ray artificial intelligence system.
在本研究中,我们开发并评估了一种高效的医学影像视觉语言多模态模型,该模型仅使用与常规临床实践中获取的自由文本放射学报告配对的医学图像进行训练。该方法在训练过程中具有极高的计算和数据效率,并且在一系列多模态放射学任务中展现出良好的性能。这项工作是迈向通用X射线人工智能系统的初步尝试。
Acknowledgements
致谢
We acknowledge Yuan Liu and Karan Singhal from Google Research for their critical feedback on the manuscript. We thank the NIH Clinical Center for making the ChestX-ray14 dataset publicly available, the MIT Laboratory for Computational Physiology for making the MIMIC-CXR dataset publicly available, and the Stanford ML Group for making the CheXpert dataset publicly available. We also thank the Google Research team for software and hardware infrastructure support.
我们感谢 Google Research 的 Yuan Liu 和 Karan Singhal 对稿件提出的宝贵意见。我们感谢美国国立卫生研究院临床中心公开提供 ChestX-ray14 数据集、麻省理工学院计算生理学实验室公开提供 MIMIC-CXR 数据集,以及斯坦福大学机器学习组公开提供 CheXpert 数据集。同时,我们也感谢 Google Research 团队在软件和硬件基础设施方面的支持。
Author contributions
作者贡献
S.X., L.Y., S.S., D.T., S.P., C.K., D.G., R.P., A.S. contributed to the conception of the study and study design; M.S., P.S., C.C., C.K., D.G., R.P., A.S. contributed to acquisition of the data; S.X., L.Y., M.S., T.K., M.M., W-H.W., A.K., S.K., Z.M., Y.L., C.L., S.P., C.K., D.G., R.P., A.S. contributed to analysis and interpretation of the data; P.S., Y.L., P.S., M.E., S.R.K., Y.M., K.C., G.C., S.S., D.T., K.E. provided strategic guidance; L.Y., W-H.W., P.S., Y.L., S.P., C.K., D.G., R.P., A.S. contributed to paper organisation and team logistics; S.X., L.Y., M.S., T.K., M.M., W-H.W., A.K., S.K., Z.M., Y.L., D.T., C.K., D.G., R.P., A.S. contributed to drafting and revising the manuscript.
S.X.、L.Y.、S.S.、D.T.、S.P.、C.K.、D.G.、R.P.、A.S. 参与了研究构思与设计;
M.S.、P.S.、C.C.、C.K.、D.G.、R.P.、A.S. 负责数据采集;
S.X.、L.Y.、M.S.、T.K.、M.M.、W-H.W.、A.K.、S.K.、Z.M.、Y.L.、C.L.、S.P.、C.K.、D.G.、R.P.、A.S. 参与数据分析和解读;
P.S.、Y.L.、P.S.、M.E.、S.R.K.、Y.M.、K.C.、G.C.、S.S.、D.T.、K.E. 提供战略指导;
L.Y.、W-H.W.、P.S.、Y.L.、S.P.、C.K.、D.G.、R.P.、A.S. 负责论文组织与团队协调;
S.X.、L.Y.、M.S.、T.K.、M.M.、W-H.W.、A.K.、S.K.、Z.M.、Y.L.、D.T.、C.K.、D.G.、R.P.、A.S. 参与稿件起草与修订。
References
参考文献
- Anil, R. et al. Palm 2 technical report. arXiv preprint arXiv:2305. 10403 (2023).
- Anil, R. 等. Palm 2技术报告. arXiv预印本 arXiv:2305.10403 (2023).
- Irvin, J. et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. in Proceedings of the AAAI conference on artificial intelligence vol. 33 590–597 (2019).
- Irvin, J. 等. Chexpert: 一个带有不确定性标注和专家比对的大规模胸部X光片数据集. 见《AAAI人工智能会议论文集》第33卷 590-597页 (2019).
- Johnson, A. E. W. et al. MIMIC-CXR, a de-identified publicly available database of chest radio graphs with free-text reports. Sci Data 6, 317 (2019).
- Johnson, A. E. W. 等. MIMIC-CXR: 一个脱敏公开的胸部放射影像及自由文本报告数据库. Sci Data 6, 317 (2019).
- Lau, J. J., Gayen, S., Ben Abacha, A. & Demner-Fushman, D. A dataset of clinically generated visual questions and answers about radiology images. Sci Data 5, 180251 (2018).
- Lau, J. J., Gayen, S., Ben Abacha, A. & Demner-Fushman, D. 一个关于放射影像的临床生成视觉问答数据集。Sci Data 5, 180251 (2018)。
- Wang, X. et al. ChestX-Ray8: Hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (IEEE, 2017). doi:10.1109/cvpr.2017.369.
- Wang, X. 等. ChestX-Ray8: 医院级胸部X光数据库及常见胸部疾病弱监督分类与定位基准. 收录于《2017年IEEE计算机视觉与模式识别会议(CVPR)》(IEEE, 2017). doi:10.1109/cvpr.2017.369.
- Goldberger, A. L. et al. PhysioBank, Ph y sio Toolkit, and PhysioNet: components of a new research resource for complex ph y sio logic signals. Circulation 101, E215–20 (2000).
- Goldberger, A. L. 等. PhysioBank、PhysioToolkit 和 PhysioNet: 复杂生理信号研究新资源的组成部分. Circulation 101, E215–20 (2000).
- Johnson, A. E. W., Pollard, T. J., Mark, R. G., Berkowitz, S. J. & Horng, S. MIMIC-CXR Database (version 2.0.0). PhysioNet https://doi.org/10.13026/C2JT1Q (2019) doi:10.13026/C2JT1Q.
- Johnson, A. E. W., Pollard, T. J., Mark, R. G., Berkowitz, S. J. & Horng, S. MIMIC-CXR数据库(版本2.0.0). PhysioNet https://doi.org/10.13026/C2JT1Q (2019) doi:10.13026/C2JT1Q.
- Lau, J. J., Gayen, S., Demner, D. & Ben Abacha, A. Visual Question Answering in Radiology (VQA-RAD). OSFHOME https://doi.org/10.17605/OSF.IO/89KPS (2019) doi:10.17605/OSF.IO/89KPS.
- Lau, J. J., Gayen, S., Demner, D. & Ben Abacha, A. 放射学视觉问答 (VQA-RAD) 。OSFHOME https://doi.org/10.17605/OSF.IO/89KPS (2019) doi:10.17605/OSF.IO/89KPS。
- Zhang, Y., Jiang, H., Miura, Y., Manning, C. D. & Langlotz, C. P. Contrastive learning of medical visual representations from paired images and text. in Machine Learning for Healthcare Conference 2–25 (PMLR, 2022).
- Zhang, Y., Jiang, H., Miura, Y., Manning, C. D. & Langlotz, C. P. 基于配对图像和文本的医学视觉表征对比学习。in Machine Learning for Healthcare Conference 2–25 (PMLR, 2022).
- Tiu, E. et al. Expert-level detection of path o logie s from un annotated chest X-ray images via self-supervised learning. Nat Biomed Eng 6, 1399–1406 (2022).
- Tiu, E. 等. 通过自监督学习从未标注胸部X光图像中实现专家级病理检测. Nat Biomed Eng 6, 1399–1406 (2022).
- DeLong, E. R., DeLong, D. M. & Clarke-Pearson, D. L. Comparing the areas under two or
- DeLong, E. R., DeLong, D. M. & Clarke-Pearson, D. L. 比较两条或多条曲线下面积
- Wang, Z., Wu, Z., Agarwal, D. & Sun, J. Medclip: Contrastive learning from unpaired medical images and text. arXiv preprint arXiv:2210. 10163.
- Wang, Z., Wu, Z., Agarwal, D. & Sun, J. Medclip: 基于非配对医学图像与文本的对比学习。arXiv预印本 arXiv:2210.10163。
- Wang, Y., Wang, L., Li, Y., He, D. & Liu, T.-Y. A theoretical analysis of NDCG type ranking measures. in Conference on learning theory 25–54 (PMLR, 2013).
- Wang, Y., Wang, L., Li, Y., He, D. & Liu, T.-Y. NDCG类排序指标的理论分析。见《学习理论会议》25-54 (PMLR, 2013)。
- Johnson, A. E. W. et al. MIMIC-CXR-JPG - chest radio graphs with structured labels (version 2.0.0). PhysioNet https://doi.org/10.13026/8360-t248 (2019) doi:10.13026/8360-t248.
- Johnson, A. E. W. 等. MIMIC-CXR-JPG - 带结构化标签的胸部X光片 (版本2.0.0). PhysioNet https://doi.org/10.13026/8360-t248 (2019) doi:10.13026/8360-t248.
- Johnson, A. E. W. et al. MIMIC-CXR-JPG, a large publicly available database of labeled chest radio graphs. arXiv preprint arXiv:1901. 07042 (2019).
- Johnson, A. E. W. 等. MIMIC-CXR-JPG: 一个大型公开标注胸部X光片数据库. arXiv预印本 arXiv:1901.07042 (2019).
- Singhal, K. et al. Towards Expert-Level Medical Question Answering with Large Language Models. arXiv [cs.CL] (2023).
- Singhal, K. 等. 基于大语言模型实现专家级医学问答系统. arXiv [cs.CL] (2023).
- Zhang, X. et al. PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering. arXiv [cs.CV] (2023).
- Zhang, X. 等. PMC-VQA: 面向医学视觉问答的视觉指令调优. arXiv [cs.CV] (2023).
- Moor, M. et al. Med-Flamingo: a Multimodal Medical Few-shot Learner. arXiv [cs.CV] (2023).
- Moor, M. 等. Med-Flamingo: 一种多模态医学少样本学习器. arXiv [cs.CV] (2023).
- Zhai, X. et al. LiT: Zero-Shot Transfer with Locked-image text Tuning. in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (IEEE, 2022). doi:10.1109/cvpr52688.2022.01759.
- Zhai, X. 等. LiT: 基于锁定图像文本调谐的零样本迁移. 收录于《2022年IEEE/CVF计算机视觉与模式识别会议(CVPR)》(IEEE, 2022). doi:10.1109/cvpr52688.2022.01759.
- Ji, Z. et al. Survey of Hallucination in Natural Language Generation. ACM Comput. Surv. 55, 1–38 (2023).
- Ji, Z. 等. 自然语言生成中的幻觉问题综述. ACM Comput. Surv. 55, 1–38 (2023).
- Tan, M. & Le, Q. V. Efficient Net: Rethinking Model Scaling for Convolutional Neural Networks. arXiv [cs.LG] (2019) doi:10.48550/ARXIV.1905.11946.
- Tan, M. & Le, Q. V. EfficientNet: 重新思考卷积神经网络的模型缩放。arXiv [cs.LG] (2019) doi:10.48550/ARXIV.1905.11946.
- Kudo, T. & Richardson, J. Sentence Piece: A simple and language independent subword tokenizer and de token ize r for Neural Text Processing. in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (Association for Computational Linguistics, 2018). doi:10.18653/v1/d18-2012.
- Kudo, T. & Richardson, J. SentencePiece: 一种简单且语言无关的子词分词器和去分词器,用于神经文本处理。见《2018年自然语言处理实证方法会议:系统演示论文集》 (计算语言学协会, 2018). doi:10.18653/v1/d18-2012.
Supplementary materials
补充材料
Supplementary text
补充文本
Additional ELIXR training details
ELIXR 额外训练细节
Supplementary tables
补充表格
Supplementary figures
补充图表
● Supplementary figure 1: Suspect positive or negative ground truth MIMIC labels as identified by the query to Med-PaLM 2 truthed by a board certified radiologist. Supplementary figure 2: Data-efficient classification performance between models per-dataset and per-finding using different training set sample sizes.
● 补充图1: 由Med-PaLM 2查询识别并经委员会认证放射科医师核实的疑似阳性或阴性MIMIC标签真实值。补充图2: 不同训练集样本量下各模型按数据集和按发现的分类性能对比。
Supplementary Text
补充文本
Additional ELIXR training details
额外ELIXR训练细节
ELIXR-C
ELIXR-C
For the first stage of training using the CLIP loss, Efficient Net $\cdot\mathsf{L}2^{34}$ was used as the vision encoder, initialized from the SupCon checkpoint used in Sellergren et al12. The small variant of T5 was used for the text encoder, initialized from scratch13. The T5 text encoder used a Sentence Piece model35 with a vocabulary size of 32,000 pretrained on PubMed abstracts. For data augmentation, horizontal flipping and random rotation up to 15 degrees were applied. Images were resized to 1280x1280 pixels. A dimension of 128 for the projection head and a fixed temperature of 0.07 were used. Preprocessing on the radiology reports was done to select, in order of preference, the impression section, followed by the findings section. The input text sequence was truncated at 128 tokens. A batch size of 64 was split across 128 TPUv3 cores using spatial partitioning. Stochastic gradient descent (SGD) constant learning rate was set to 0.0001 with a momentum of 0.98. The model was trained for roughly 80,000 steps. Training was done in TensorFlow.
在采用CLIP损失函数的第一阶段训练中,视觉编码器选用Efficient Net $\cdot\mathsf{L}2^{34}$,其权重初始化为Sellergren等人[12]使用的SupCon检查点。文本编码器采用T5小型变体,权重随机初始化[13]。该T5文本编码器使用基于PubMed摘要预训练的Sentence Piece模型[35],词表规模为32,000。数据增强方面应用了水平翻转和最大15度的随机旋转,图像尺寸调整为1280x1280像素。投影头维度设为128,温度系数固定为0.07。放射学报告预处理优先选取印象部分,其次为检查结果部分,输入文本序列截断长度为128个token。批次大小64通过空间分区分布在128个TPUv3核心上,随机梯度下降(SGD)学习率恒定为0.0001,动量0.98。模型在TensorFlow框架下完成约80,000步训练。
ELIXR-B
ELIXR-B
In the first phase of ELIXR-B training, the embeddings from ELIXR-C were pre computed for all datasets and spatially pooled from 40x40x1376 to 8x8x1376. We used 32 BLIP-2 query tokens and a max text sequence length of 128. Q-Former weights were initialized from BERT-base. A batch size of 128 was split across 8 TPUv3 cores. Constant learning rate of 1e-5 was used with the Adam optimizer (beta1 of 0.98, beta2 of 0.999, epsilon of 1e-8). Training was done in Jax. Checkpoints were selected using zero-shot performance on CheXpert validation as well as the validation losses. More specifically, the checkpoint that performs the best on zero-shot AUC, image-text matching loss, and contrastive loss was used for zero/data-efficient and semantic search, while the checkpoint that performs the best on image-grounded text generation was used for initial checkpoint for phase 2 training.
在ELIXR-B训练的第一阶段,我们预先计算了所有数据集的ELIXR-C嵌入,并将其从40x40x1376空间池化为8x8x1376。使用了32个BLIP-2查询token (query tokens)和最大文本序列长度128。Q-Former权重从BERT-base初始化。批处理大小128分布在8个TPUv3核心上。采用恒定学习率1e-5和Adam优化器(beta1=0.98, beta2=0.999, epsilon=1e-8)。训练在Jax中完成。检查点选择基于CheXpert验证集的零样本性能及验证损失。具体而言,零样本AUC、图文匹配损失和对比损失表现最佳的检查点被用于零样本/数据高效及语义搜索任务;而基于图像的文本生成任务表现最佳的检查点则作为第二阶段训练的初始检查点。
In the second phase of ELIXR-B training, 32 replicas of PaLM2 S were launched as inference servers, each on 8 TPUv3 cores. When called for given inputs (the output query tokens from the $\mathsf{Q}$ -Former plus any additional text tokens), the server provides back the gradients (based on the language modeling loss) which can be back propagated through the Q-Former. For this phase, a batch size of 32 was used, 1 per inference server replica. Constant learning rate of 5e-4 was used with the Adam optimizer (beta1 of 0.98, beta2 of 0.999, epsilon of 1e-8).
在ELIXR-B训练的第二阶段,部署了32个PaLM2 S副本作为推理服务器,每个副本运行在8个TPUv3核心上。当服务器接收到给定输入(来自$\mathsf{Q}$-Former的输出查询token及任何附加文本token)时,会返回基于语言建模损失的梯度,这些梯度可通过Q-Former反向传播。该阶段采用批次大小为32(即每个推理服务器副本处理1个样本),使用Adam优化器(beta1=0.98,beta2=0.999,epsilon=1e-8)并保持恒定学习率5e-4。
Supplementary tables
补充表格
Supplementary table 1: Prompts used for zero-shot classification. We adopt the prompting strategy developed by CheXzero23.
表 1: 用于零样本分类的提示词。我们采用由 CheXzero [23] 开发的提示策略。
| Condition | Positive prompts | Negative prompts |
| Enlarged cardiomediastinum | widened cardiomediastinum | no acute cardiopulmonary process cardiomediastinal silhouette is normal |
| Cardiomegaly | mild cardiomegaly moderate cardiomegaly severe cardiomegaly | heart size is normal no acute cardiopulmonary process normal study |
| Lung lesion | lytic lesion cavitary lesion parenchymal lesion | no acute cardiopulmonary process |
| Airspace opacity | bilateral opacities basal opacity | no focal opacity lung volumes are normal |
| Edema | mild pulmonary edema moderate pulmonary edema severe pulmonary edema | no pulmonary edema no acute cardiopulmonary process normal study |
| Consolidation | suggestive of consolidation | normal study |
| Pneumonia | suggestive of pneumonia | lungs are clear no acute cardiopulmonary process |
| Atelectasis | plate atelectasis subsegmental atelectasis | lungs are clear no acute cardiopulmonary process normal study |
| Pneumothorax | apical pneumothorax | no pneumothorax |
| Pleural effusion | left pleural effusion right pleural effusion bilateral pleural effusions | no acute cardiopulmonary process normal study |
| Pleural other | blunting of costophrenic angle pleural thickening | no acute cardiopulmonary process |
| Fracture | rib fractures | no acute cardiopulmonary process |
| Support Devices | monitoring and support devices NG tube ET tube catheter PIC line | no acute cardiopulmonary process |
| 症状 | 阳性提示词 | 阴性提示词 |
|---|---|---|
| 纵隔增宽 | 纵隔增宽 | 无急性心肺病变 纵隔影正常 |
| 心脏扩大 | 轻度心脏扩大 中度心脏扩大 重度心脏扩大 | 心脏大小正常 无急性心肺病变 检查正常 |
| 肺部病变 | 溶骨性病变 空洞性病变 肺实质病变 | 无急性心肺病变 |
| 气腔混浊 | 双侧混浊 基底混浊 | 无局灶性混浊 肺容积正常 |
| 肺水肿 | 轻度肺水肿 中度肺水肿 重度肺水肿 | 无肺水肿 无急性心肺病变 检查正常 |
| 实变 | 提示实变 | 检查正常 |
| 肺炎 | 提示肺炎 | 肺野清晰 无急性心肺病变 |
| 肺不张 | 盘状肺不张 亚段肺不张 | 肺野清晰 无急性心肺病变 检查正常 |
| 气胸 | 肺尖气胸 | 无气胸 |
| 胸腔积液 | 左侧胸腔积液 右侧胸腔积液 双侧胸腔积液 | 无急性心肺病变 检查正常 |
| 胸膜其他 | 肋膈角变钝 胸膜增厚 | 无急性心肺病变 |
| 骨折 | 肋骨骨折 | 无急性心肺病变 |
| 支持设备 | 监测和支持设备 鼻胃管 气管插管 导管 外周置入中心静脉导管 | 无急性心肺病变 |
Supplementary table 2: Queries used for semantic search and the ELIXR performance using normalized discounted cumulative gain at five (NDCG@5).
表 2: 用于语义搜索的查询语句及ELIXR在归一化折损累计增益前五(NDCG@5)指标下的性能表现。
| Topic | Queries | NDCG@5 ELIXR-C | NDCG@5 ELIXR-B | NDCG@5 MedCLIP |
| Single finding | Pneumothorax | 0.131 | 0.214 | 0.0 |
| Pneumonia | 0.927 | 1.0 | 0.0 | |
| Central venous catheter | 1.0 | 1.0 | 0.447 | |
| Nasogastric tube | 0.869 | 1.0 | 0.699 | |
| Endotracheal tube | 1.0 | 1.0 | 0.146 | |
| Fracture | 0 | 0.301 | ||
| Pacemaker | 0.723 | 1.0 | 0.146 | |
| Laterality | Left Pneumothorax | 0.723 | 0.83 | 0.5 |
| Right pleural effusion | 1.0 | 1.0 | 1.0 | |
| Left Pneumonia | 0.769 | 1.0 | 0.765 | |
| Severity | Small pleural effusion | 0.616 | 0.446 | 0.777 |
| Large Pneumothorax | 0.066 | 0.254 | 0.0 | |
| Moderate Pulmonary edema | 0.5 | 1.0 | 0.927 | |
| Moderate Cardiomegaly | 0.927 | 1.0 | 0.934 | |
| Nuanced features | Small right pleural effusion, no left pleural effusion | 0.68 | 1.0 | 0 |
| Mild right Pneumonia | 0.786 | 0.449 | 0.764 | |
| Loculated pleural effusion | 0.478 | 0.246 | 0.488 | |
| Multiple focal lung opacities | 1.0 | 1.0 | 0.746 | |
| Nasogastric tube reaches stomach | 0.701 | 1.0 | 0.699 |
| 主题 | 查询内容 | NDCG@5 ELIXR-C | NDCG@5 ELIXR-B | NDCG@5 MedCLIP |
|---|---|---|---|---|
| * * 单一表现* * | ||||
| 气胸 | 0.131 | 0.214 | 0.0 | |
| 肺炎 | 0.927 | 1.0 | 0.0 | |
| 中心静脉导管 | 1.0 | 1.0 | 0.447 | |
| 鼻胃管 | 0.869 | 1.0 | 0.699 | |
| 气管插管 | 1.0 | 1.0 | 0.146 | |
| 骨折 | 0 | 0.301 | ||
| 心脏起搏器 | 0.723 | 1.0 | 0.146 | |
| * * 侧别* * | ||||
| 左侧气胸 | 0.723 | 0.83 | 0.5 | |
| 右侧胸腔积液 | 1.0 | 1.0 | 1.0 | |
| 左侧肺炎 | 0.769 | 1.0 | 0.765 | |
| * * 严重程度* * | ||||
| 少量胸腔积液 | 0.616 | 0.446 | 0.777 | |
| 大量气胸 | 0.066 | 0.254 | 0.0 | |
| 中度肺水肿 | 0.5 | 1.0 | 0.927 | |
| 中度心脏扩大 | 0.927 | 1.0 | 0.934 | |
| * * 细微特征* * | ||||
| 右侧少量胸腔积液,左侧无胸腔积液 | 0.68 | 1.0 | 0 | |
| 右侧轻度肺炎 | 0.786 | 0.449 | 0.764 | |
| 包裹性胸腔积液 | 0.478 | 0.246 | 0.488 | |
| 多灶性肺实变 | 1.0 | 1.0 | 0.746 | |
| 鼻胃管抵达胃部 | 0.701 | 1.0 | 0.699 |
Supplementary table 3: Prompts used for MIMIC-CXR ground truthing. Keywords for selecting candidates for MIMIC-CXR reports followed by prompts used to determine if the given condition exists. These were used to select candidates for confirmation by a board certified thoracic radiologist (CL).
表 3: 用于MIMIC-CXR标注的提示词。筛选MIMIC-CXR报告候选者的关键词,以及用于确定给定病症是否存在的提示词。这些提示词用于筛选出需由委员会认证的胸部放射科医师(CL)确认的候选病例。
| Condition | Key Words |
| atelectasis | atelectasis |
| cardiomegaly | cardiomegaly cardiac silhouette |
| catheter | central venous catheter central line picc |
| fracture | fracture acute fracture fx |
| hilar enlargement | hilar enlargement |
| lung opacity | lung opacity lung opacities infiltrate pneumonia atelectasis consolidation airspace opacity airspace opacities |
| mediastinal widening | abnormal mediastinal widening widened mediastinum widened |
| nodule | lung nodule nodule nodular opacity |
| pleural effusion | pleural effusion |
| pneumonia | pneumonia |
| pneumothorax | pneumothorax |
| pulmonary edema | pulmonary edema pulmonary vascular congestion |
| tube | endotracheal tube enteric tube ng |
| 症状 | 关键词 |
|---|---|
| 肺不张 | 肺不张 |
| 心脏肥大 | 心脏肥大 心影增大 |
| 导管 | 中心静脉导管 中心静脉置管 PICC导管 |
| 骨折 | 骨折 急性骨折 FX |
| 肺门增大 | 肺门增大 |
| 肺部阴影 | 肺部阴影 肺部多发阴影 浸润 肺炎 肺不张 实变 气腔阴影 气腔多发阴影 |
| 纵隔增宽 | 异常纵隔增宽 纵隔增宽 增宽 |
| 结节 | 肺结节 结节 结节状阴影 |
| 胸腔积液 | 胸腔积液 |
| 肺炎 | 肺炎 |
| 气胸 | 气胸 |
| 肺水肿 | 肺水肿 肺血管充血 |
| 插管 | 气管插管 肠管 鼻胃管 |
| og feeding tube ettube | |
| Prompt used with above text on Med-PaLM 2 | |
| All key words except cardiac silhouette ao sn i | |
| scientifically-grounded queries to radiology reports. Does this report mention that the patient has a {keyword}? Report:{description} | |
| cardiac silhouette You are a helpful medical knowledge assistant. Provide useful, complete, concise, and scientifically-grounded queries to radiology reports. | |
| og feeding tube ettube |
|---|
| 提示词 (Prompt) 用于上述 Med-PaLM 2 文本 |
| 除心脏轮廓 (cardiac silhouette) 外的所有关键词 ao sn i |
| 对放射学报告进行科学依据的查询。该报告是否提到患者有 {关键词}?报告:{描述} |
| 心脏轮廓 你是一位有用的医学知识助手。请提供有用、完整、简洁且基于科学依据的放射学报告查询。 |
Supplementary table 4: Questions used for visual question answering evaluation on MIMIC-CXR test cases. For each case, the model was queried with a findings-specific set of questions, depending on the corresponding label in the MIMIC CXR JPG dataset being set to 1.0, with questions covering the condition’s presence, location, and severity, size or type. An additional two findings-independent questions were asked per case, covering the presence of other conditions. For cases with none of the listed five MIMIC labels being set to 1.0, three label-independent questions were asked.
附表4: 用于MIMIC-CXR测试病例视觉问答评估的问题集。针对每个病例,模型会根据MIMIC CXR JPG数据集中对应标签是否为1.0来接收特定检查结果相关的问题组,这些问题涵盖病症的存在性、位置、严重程度、尺寸或类型。每个病例还会额外询问两个与检查结果无关的问题,涉及其他病症的存在情况。对于未设置任何五项MIMIC标签为1.0的病例,则会询问三个与标签无关的问题。
| Finding | Questions the model was queried with | Question type | |
| Pneumothorax | Is a pneumothorax present ? Is a pneumothorax present in this image ? | Presence | |
| Where is pneumothorax present ? | Location | ||
| What is the size of pneumothorax, if present ? | Size/Severity/Type | ||
| Does the patient have a pleural effusion ? | Presence | ||
| Pleural Effusion | Is a pleural effusion present in this image ? What is the location of the pleural effusion, if present ? | Location | |
| What is the size of pleural effusion, if present ? | Size/Severity/Type | ||
| Is a pulmonary edema present in this image ? | |||
| Edema | Is there evidence of a pulmonary edema ? | Presence Location | |
| Where is pulmonary edema present ? What is the severity of the pulmonary edema, if present ? | |||
| What is the type of the pulmonary edema, if present ? | Size/Severity/Type | ||
| Consolidation OR Pneumonia | Is a lung consolidation or pneumonia present in this image ? What is the location of the lung consolidation or | Presence | |
| pneumonia, if present ? Are lung nodules or a mass present? | Location | ||
| Lung Lesion | Does the patient have lung nodules or a mass ? | Presence | |
| Where are lung nodules or a mass located ? What abnormalities are seen within the lungs ? | Location | ||
| Finding- independent | Presence Is a lung consolidation or pneumonia present in this image ? | ||
| 发现项 | 向模型提出的问题 | 问题类型 |
|---|---|---|
| 气胸 (Pneumothorax) | 是否存在气胸?本图像中是否存在气胸? | 存在性 |
| 气胸位于何处? | 位置 | |
| 如果存在气胸,其大小如何? | 大小/严重程度/类型 | |
| 患者是否存在胸腔积液? | 存在性 | |
| 胸腔积液 (Pleural Effusion) | 本图像中是否存在胸腔积液?如果存在,胸腔积液位于何处? | 位置 |
| 如果存在胸腔积液,其大小如何? | 大小/严重程度/类型 | |
| 本图像中是否存在肺水肿? | ||
| 肺水肿 (Edema) | 是否有肺水肿的证据? | 存在性 位置 |
| 肺水肿位于何处?如果存在肺水肿,其严重程度如何? | ||
| 如果存在肺水肿,属于何种类型? | 大小/严重程度/类型 | |
| 肺实变或肺炎 (Consolidation OR Pneumonia) | 本图像中是否存在肺实变或肺炎?如果存在肺实变或肺炎,其位置如何? | 存在性 |
| 是否存在肺结节或肿块? | 位置 | |
| 肺部病变 (Lung Lesion) | 患者是否存在肺结节或肿块? | 存在性 |
| 肺结节或肿块位于何处?肺部可见哪些异常? | 位置 | |
| 发现项无关问题 | 存在性 本图像中是否存在肺实变或肺炎? |
| Does the patient have lung opacity? Is a radiopaque foreign body or pacemaker present ? Are there anyfindings? Is a hiatal hernia present? Are there any signs of interstitial fibrosis in the lungs ? Are there any notable abnormalities in the imaged upper abdomen? Is thereevidenceofanendotrachealtube? Is a central venous catheterpresent? Is there evidence of a nasogastric or orogastric tube ? Is a hilar enlargement present in this image ? Is a mediastinal widening present in this image ? Doesthepatienthaveaskeletalfracture? |
| 患者肺部是否存在混浊? | 是否有不透射线的异物或起搏器存在? | 是否有任何发现? | 是否存在食管裂孔疝? | 肺部是否有间质纤维化迹象? | 上腹部影像是否存在明显异常? | 是否有气管插管证据? | 是否存在中心静脉导管? | 是否有鼻胃管或口胃管证据? | 该影像中是否存在肺门增大? | 该影像中是否存在纵隔增宽? | 患者是否存在骨骼骨折? |
Supplementary table 5: Visual question answering evaluation scoring rubric. Definition of correctness scores used for assessing model answers against expected answers (for VQA-RAD) or the CXR image and/or report (for MIMIC test set) in visual question answering by radiologist.
表 5: 视觉问答评估评分标准。用于评估模型答案与预期答案 (针对VQA-RAD) 或胸片图像和/或报告 (针对MIMIC测试集) 在放射科医师视觉问答中的正确性评分定义。
| Summary | Score Details | Score |
| Correct | LLM-provided answer either: is an exact match to the ground truth answer. contains additional and still accurate information above what the ground truth specifies is another diagnosis consistent with the image that also answers the question. e.g. the associated image shows two potential diagnoses and the predicted answer provides the diagnosis not present in the ground truth, and the question did not specify which diagnosis it was looking for. is a rephrasing of the ground truth answer such that a patient's diagnosis would not differ in treatment from the ground truth. e.g. a predicted answer of "lobe collapse" with ground truth of "pneumothorax" would be counted as a correct prediction. | 1.0 |
| Partially Correct | LLM-provided answer has correct information but is in flawed in one of the following ways: the answer omits some key details (e.g. laterality, location) asked by the question and present in the ground truth. the answer provides incorrect key details, but the underlying condition is still accurate. | 0.5 |
| Incorrect | LLM-provided answer is either: entirely inaccurate. does not respond to the question or appears to answer a different one. is missing an answer. | 0.0 |
| Ambiguous | is internally inconsistent. LLM-provided answer cannot be compared to the ground truth. e.g. a ground-truth answer of "unsure" or "ambiguous" does not provide enough information to compare against. | N/A |
| 摘要 | 评分细则 | 分值 |
|---|---|---|
| 正确 | 大语言模型提供的答案满足以下任一条件:与标准答案完全一致;在标准答案基础上补充了准确信息;给出与图像相符的其他诊断结果(例如图像显示两种潜在诊断,而预测答案提供了标准答案未包含的符合题意的诊断);或对标准答案进行不影响治疗决策的重新表述(如预测答案"肺叶塌陷"对应标准答案"气胸")。 | 1.0 |
| 部分正确 | 大语言模型答案包含正确信息但存在以下缺陷:遗漏问题要求的关键细节(如方位、部位);或提供错误关键细节但基础病情判断准确。 | 0.5 |
| 错误 | 大语言模型答案存在以下情况:完全错误;答非所问;未提供答案。 | 0.0 |
| 模糊 | 答案自相矛盾或无法与标准答案比对(如标准答案为"不确定"或"模糊"时缺乏足够比对依据)。 | N/A |
Supplementary table 6: Methodology for altering impressions for report quality assurance evaluation. Here we describe the specific alterations that were made to cases associated with each finding for the quality assurance task.
附表6: 用于报告质量保证评估的印象修改方法。此处我们描述针对质量保证任务中各项发现相关病例所做的具体修改。
| Alteration | Primary Finding | Alteration rule |
| No change (control) | All | No change |
| Change laterality | All except No Finding and Edema | If the laterality of the primary finding is left-sided, replace to indicate right-sided or vice versa. Do not change laterality of any other finding. Cases with bilateral primary findings are excluded from this alteration category. |
| Remove major finding | All except No Finding | Remove all references to the primary finding and indicate either that there is "no evidence" of the finding or that the finding "has resolved," whichever is more appropriate in the context of the remaining impression. Retain content that relates to other findings. If no findings remain, change impression to read, "No acute cardiopulmonary process." |
| Add major finding | No Finding | Add "Medium right pleural effusion." Remove any sentences indicating the report is normal/clear. |
| Pneumothorax | Add: "Malpositioned endotracheal tube." | |
| Pleural Effusion | Add: "Approximately 1 cm nodule in mid right lung." | |
| Edema | Add: "Several acute displaced rib fractures." | |
| Consolidation or Pneumonia | Add: "Large left pleural effusion." | |
| Lung Lesion | Add: "Moderate right pneumothorax." |
| 修改类型 | 主要发现 | 修改规则 |
|---|---|---|
| 无变化 (对照) | 全部 | 无变化 |
| 改变侧别 | 除"无发现"和"水肿"外的所有情况 | 若主要发现为左侧,则改为右侧,反之亦然。不改变其他发现的侧别。双侧主要发现的病例不在此修改类别中。 |
| 移除主要发现 | 除"无发现"外的所有情况 | 移除所有与主要发现相关的描述,改为"无证据"表明该发现或该发现"已消退",根据剩余印象内容选择更合适的表述。保留与其他发现相关的内容。若无发现剩余,则将印象改为:"无急性心肺病变。" |
| 添加主要发现 | 无发现 | 添加"中等量右侧胸腔积液。"移除所有表明报告正常/清晰的语句。 |
| 气胸 | 添加:"气管导管位置异常。" | |
| 胸腔积液 | 添加:"右肺中部约1cm结节。" | |
| 水肿 | 添加:"数处急性移位性肋骨骨折。" | |
| 实变或肺炎 | 添加:"大量左侧胸腔积液。" | |
| 肺部病变 | 添加:"中度右侧气胸。" |
Supplementary table 7: Scoring rubric for quality assurance large language model (LLM) output. Here we show the detailed scoring rubric that was used by the board-certified thoracic radiologist (CL) to assess the LLM output.
表 7: 大语言模型 (LLM) 输出质量评估评分细则。此处展示由委员会认证的胸部放射科医师 (CL) 用于评估大语言模型输出的详细评分标准。
| Impression type being analyzed | LLM assessment by board-certified thoracic radiologist (CL) | Score |
| Control (no change) | LLM suggests that impression is correct | 1 |
| Control (no change) | LLM suggests a problem with the impression where the suggestion is correct or possibly correct but not important for case management (e.g.,"report failed to characterize heart size") | |
| Control (no change) | LLM suggests a problem with the impression where the suggestion is correct and possibly important for case management | Exclude as this was not a valid control |
| Control (no change) | LLM suggests a problem with the impression where the suggestion is incorrect | 0 |
| Remove primary finding | LLM suggests that impression is correct | 0 |
| Remove primary finding | LLM does not identify the primary finding that was removed (even if it makes any other suggestion that is correct or possibly correct) | 0 |
| Remove primary finding | LLM identifies the primary finding that was removed | 1 |
| Adding incorrect finding | LLM suggests that impression is correct | |
| Adding incorrect finding | LLM does not correctly identify the added finding (even if it makes any other suggestion that is correct or possibly correct) | 0 |
| Adding incorrect finding | LLM correctly identifies the added finding | 1 |
| Swap primary finding laterality | LLM suggests that impression is correct | 0 |
| Swap primary finding laterality | LLM response does not identify the problem with the laterality of the primary finding (even if it makes any other suggestion that is correct or possibly correct) | |
| Swap primary finding laterality | LLM identifies a problem with the laterality of the primary finding |
| 分析的报告类型 | 由委员会认证的胸部放射科医师 (CL) 进行的大语言模型评估 | 评分 |
|---|---|---|
| 对照组 (无变化) | 大语言模型认为报告正确 | 1 |
| 对照组 (无变化) | 大语言模型指出报告中存在问题,建议正确或可能正确但对病例管理不重要 (例如 "报告未描述心脏大小") | |
| 对照组 (无变化) | 大语言模型指出报告中存在问题,建议正确且可能对病例管理重要 | 排除,因这不是有效的对照组 |
| 对照组 (无变化) | 大语言模型指出报告中存在问题,但建议不正确 | 0 |
| 移除主要发现 | 大语言模型认为报告正确 | 0 |
| 移除主要发现 | 大语言模型未识别出被移除的主要发现 (即使提出其他正确或可能正确的建议) | 0 |
| 移除主要发现 | 大语言模型识别出被移除的主要发现 | 1 |
| 添加错误发现 | 大语言模型认为报告正确 | |
| 添加错误发现 | 大语言模型未正确识别出添加的发现 (即使提出其他正确或可能正确的建议) | 0 |
| 添加错误发现 | 大语言模型正确识别出添加的发现 | 1 |
| 交换主要发现的侧别 | 大语言模型认为报告正确 | 0 |
| 交换主要发现的侧别 | 大语言模型未识别出主要发现的侧别问题 (即使提出其他正确或可能正确的建议) | |
| 交换主要发现的侧别 | 大语言模型识别出主要发现的侧别问题 |
Supplementary table 8: Zero-shot classification using ELIXR-C and ELIXR-B across 13 findings in the CheXpert test set. Area under curves (AUCs) with $95%$ confidence intervals
| ded | ||||
| Zero-shot | Largest SupCon | |||
| ELIXR-CAUC [95% CI] | ELIXR-BAUC [95% CI] CheXpert | Difference ELIXR-B vs. ELIXR-C[95% CI], p-value | data-efficient sample size for which ELIXR-B is noninferior [95% CI], p-value | |
| Atelectasis | 0.754 [0.714-0.795] | 0.798 [0.759-0.838] | 0.042 [0.00, 0.084] p=0.05272 | 224316,-0.004 [-0.045, 0.036] p=0.84095 |
| Effusion | 0.930 [0.908-0.951] | 0.873 [0.841-0.903] | -0.059 [-0.086, -0.032] p=0.00001 | 4096, 0.020 [-0.006, 0.047] p=0.13340 |
| Cardiomegaly | 0.891 [0.862-0.919] | 0.892 [0.861-0.921] | 0.002 [-0.023, 0.026] p=0.88496 | 224316, -0.088 [-0.120, -0.056] p<1e-5 |
| Consolidation | 0.875 [0.819-0.922] | 0.742 [0.680-0.804] | -0.133 [-0.199, -0.067] p=0.00008 | 512, 0.015 [-0.067, 0.096] p=0.72400 |
| Pulmonary Edema | 0.880 [0.843-0.913] | 0.915 [0.881-0.942] | 0.033 [0.015, 0.052] p=0.00033 | 224316,-0.021 [-0.046, 0.005] p=0.10897 |
| Enlarged Cardiomediasti num | 0.800 [0.763-0.837] | 0.837 [0.803-0.869] | 0.035 [0.013, 0.056] p=0.00195 | N/A |
| Pleural Other | 0.729 [0.467-1.000] | 0.490 [0.151-0.780] | -0.239 [-0.622, 0.143] p=0.22031 | N/A |
| Pneumothorax | 0.800 [0.630-0.932] | 0.846 [0.656-0.980] | 0.047 [-0.067, 0.160] p=0.42131 | N/A |
| Support Devices | 0.894 [0.865-0.919] | 0.865 [0.835-0.892] | -0.027 [-0.047, -0.007] p=0.00712 | N/A |
| Airspace Opacity | 0.888 [0.857-0.915] | 0.908 [0.882-0.931] | 0.021 [0.000, 0.041] p=0.04913 | N/A |
| Lung Lesion | 0.747 [0.659-0.838] | 0.798 [0.671-0.914] | 0.049 [-0.064, 0.163] p=0.39248 | N/A |
表 8: 在CheXpert测试集中使用ELIXR-C和ELIXR-B对13种发现进行零样本分类的曲线下面积 (AUC) 及95%置信区间
| 零样本 | 最大SupCon | |||
|---|---|---|---|---|
| ELIXR-C AUC [95% CI] | ELIXR-B AUC [95% CI] CheXpert | ELIXR-B vs. ELIXR-C差异 [95% CI], p值 | ELIXR-B非劣效所需数据量 [95% CI], p值 | |
| Atelectasis | 0.754 [0.714-0.795] | 0.798 [0.759-0.838] | 0.042 [0.00, 0.084] p=0.05272 | 224316, -0.004 [-0.045, 0.036] p=0.84095 |
| Effusion | 0.930 [0.908-0.951] | 0.873 [0.841-0.903] | -0.059 [-0.086, -0.032] p=0.00001 | 4096, 0.020 [-0.006, 0.047] p=0.13340 |
| Cardiomegaly | 0.891 [0.862-0.919] | 0.892 [0.861-0.921] | 0.002 [-0.023, 0.026] p=0.88496 | 224316, -0.088 [-0.120, -0.056] p<1e-5 |
| Consolidation | 0.875 [0.819-0.922] | 0.742 [0.680-0.804] | -0.133 [-0.199, -0.067] p=0.00008 | 512, 0.015 [-0.067, 0.096] p=0.72400 |
| Pulmonary Edema | 0.880 [0.843-0.913] | 0.915 [0.881-0.942] | 0.033 [0.015, 0.052] p=0.00033 | 224316, -0.021 [-0.046, 0.005] p=0.10897 |
| Enlarged Cardiomediastinum | 0.800 [0.763-0.837] | 0.837 [0.803-0.869] | 0.035 [0.013, 0.056] p=0.00195 | N/A |
| Pleural Other | 0.729 [0.467-1.000] | 0.490 [0.151-0.780] | -0.239 [-0.622, 0.143] p=0.22031 | N/A |
| Pneumothorax | 0.800 [0.630-0.932] | 0.846 [0.656-0.980] | 0.047 [-0.067, 0.160] p=0.42131 | N/A |
| Support Devices | 0.894 [0.865-0.919] | 0.865 [0.835-0.892] | -0.027 [-0.047, -0.007] p=0.00712 | N/A |
| Airspace Opacity | 0.888 [0.857-0.915] | 0.908 [0.882-0.931] | 0.021 [0.000, 0.041] p=0.04913 | N/A |
| Lung Lesion | 0.747 [0.659-0.838] | 0.798 [0.671-0.914] | 0.049 [-0.064, 0.163] p=0.39248 | N/A |
| Pneumonia | 0.881 [0.833-0.930] | 0.828 [0.734-0.914] | -0.054[-0.140, 0.033] p=0.22251 | N/A |
| Fracture | 0.637 [0.444-0.876] | 0.395 [0.173-0.679] | -0.242[-0.637, 0.153] p=0.22950 | N/A |
| 肺炎 (Pneumonia) | 0.881 [0.833-0.930] | 0.828 [0.734-0.914] | -0.054 [-0.140, 0.033] p=0.22251 | N/A |
| 骨折 (Fracture) | 0.637 [0.444-0.876] | 0.395 [0.173-0.679] | -0.242 [-0.637, 0.153] p=0.22950 | N/A |
Supplementary table 9: Data-efficient classification performance comparison between ELIXR-B and ELIXR-C. (a) CheXpert, (b) CXR-14. Delong’s test results comparing data-efficient performance of ELIXR-B vs. ELIXR-C at matching dataset sizes for CheXpert and Chest X-ray14. Bold for ELIXR-B’s out performance being statistically significant. Red if ELIXR-C outperformed ELIXR-B.
附表9: ELIXR-B与ELIXR-C的数据高效分类性能对比。(a) CheXpert, (b) CXR-14。Delong检验结果比较了ELIXR-B与ELIXR-C在CheXpert和Chest X-ray14数据集匹配规模下的数据效率性能。加粗表示ELIXR-B具有统计学显著优势,红色标注表示ELIXR-C优于ELIXR-B。
(a)
(a)
| CheXpert | Difference between ELIXR-B and ELIXR-C | ||||
| Sample size | 64 | 512 | 4096 | 32768 | 224316 |
| Atelectasis | 0.057 [-0.006, 0.119] p=0.07509 | 0.045 [0.005, 0.085] p=0.02870 | 0.021[-0.015, 0.057] p=0.24958 | 0.020 [-0.013, 0.053] p=0.23971 | -0.001 [-0.027, 0.026] p=0.95679 |
| Cardiomegaly | 0.098 [0.052, 0.144] p=0.00003 | 0.040 [0.006, 0.074] p=0.02128 | 0.032 [-0.001, 0.066] p=0.05489 | 0.019 [0.000, 0.038] p=0.04469 | 0.012 [-0.012, 0.035] p=0.32533 |
| Consolidation | 0.042 [-0.075, 0.159]p=0.48560 | 0.025 [-0.066, 0.117]p=0.59087 | -0.002 [-0.045, 0.041] p=0.91520 | 0.005 [-0.036, 0.047] p=0.79792 | 0.029 [-0.009, 0.068] p=0.13381 |
| Effusion | 0.001 [-0.023, 0.025] p=0.95793 | -0.001[-0.020, 0.018] p=0.89187 | 0.002 [-0.013, 0.017] p=0.79330 | 0.007 [-0.009, 0.022] p=0.41349 | -0.004 [-0.017, 0.009] p=0.55608 |
| Pulmonary edema | -0.006 [-0.053, 0.041] p=0.81119 | 0.000 [-0.029, 0.029] p=0.99372 | 0.007 [-0.017, 0.031] p=0.57298 | 0.005 [-0.013, 0.022]p=0.61078 | 0.006 [-0.017, 0.029] p=0.59233 |
| CheXpert | ELIXR-B 与 ELIXR-C 的差异 | ||||
|---|---|---|---|---|---|
| 样本量 | 64 | 512 | 4096 | 32768 | 224316 |
| 肺不张 | 0.057 [-0.006, 0.119] p=0.07509 | 0.045 [0.005, 0.085] p=0.02870 | 0.021 [-0.015, 0.057] p=0.24958 | 0.020 [-0.013, 0.053] p=0.23971 | -0.001 [-0.027, 0.026] p=0.95679 |
| 心脏肥大 | 0.098 [0.052, 0.144] p=0.00003 | 0.040 [0.006, 0.074] p=0.02128 | 0.032 [-0.001, 0.066] p=0.05489 | 0.019 [0.000, 0.038] p=0.04469 | 0.012 [-0.012, 0.035] p=0.32533 |
| 实变 | 0.042 [-0.075, 0.159] p=0.48560 | 0.025 [-0.066, 0.117] p=0.59087 | -0.002 [-0.045, 0.041] p=0.91520 | 0.005 [-0.036, 0.047] p=0.79792 | 0.029 [-0.009, 0.068] p=0.13381 |
| 胸腔积液 | 0.001 [-0.023, 0.025] p=0.95793 | -0.001 [-0.020, 0.018] p=0.89187 | 0.002 [-0.013, 0.017] p=0.79330 | 0.007 [-0.009, 0.022] p=0.41349 | -0.004 [-0.017, 0.009] p=0.55608 |
| 肺水肿 | -0.006 [-0.053, 0.041] p=0.81119 | 0.000 [-0.029, 0.029] p=0.99372 | 0.007 [-0.017, 0.031] p=0.57298 | 0.005 [-0.013, 0.022] p=0.61078 | 0.006 [-0.017, 0.029] p=0.59233 |
(b)
(b)
| CXR-14 | Difference between ELIXR-B and ELIXR-C | |||||
| Sample size | 64 | 512 | 4096 | 32768 | 68801 | 674533 |
| Airspace opacity | 0.035 [0.023, 0.047] p<1e-5 | 0.019 [0.010, 0.029] p=0.00007 | 0.016 [0.009, 0.022] p<1e-5 | 0.010 [0.004, 0.016] p=0.00086 | -0.001 [-0.007, 0.005] p=0.77917 | |
| Consolidation | 0.015 [0.001, 0.030] p=0.03916 | 0.010 [-0.001, 0.021] p=0.06217 | 0.005 [-0.001,0.006[0.000, 0.012] p=0.09394 | 0.013] p=0.04882 | 0.005 [-0.002, 0.013] p=0.12789 | |
| Effusion | -0.009 [-0.014, -0.003] p=0.00178 | -0.000 p=0.99721 | -0.003 [-0.005, 0.005][-0.006, 0.001] p=0.15106 | -0.002 [-0.005, 0.000] p=0.10230 | -0.004 [-0.006, -0.001] p=0.01593 | |
| Fracture | 0.004 [-0.081, 0.090] p=0.92169 | -0.004 [-0.076,] 0.068] p=0.91167 | 0.012 [-0.067, 0.091] p=0.76612 | -0.016 [-0.084, 0.052] p=0.64405 | -0.035 [-0.099, 0.028] p=0.27689 | |
| CXR-14 | ELIXR-B 与 ELIXR-C 差异 |
|---|---|
| 样本量 | 64 |
| 气腔混浊 | 0.035 [0.023, 0.047] p<1e-5 |
| 实变 | 0.015 [0.001, 0.030] p=0.03916 |
| 积液 | -0.009 [-0.014, -0.003] p=0.00178 |
| 骨折 | 0.004 [-0.081, 0.090] p=0.92169 |
| Pneumothorax | 0.102] p=0.00021 | 0.067[0.032,-0.030[-0.059,-0.012[-0.036,0.007[-0.005 -0.001] p=0.04248 | 0.012] p=0.31538 | 0.020] p=0.24105 | 0.007 [-0.006, 0.020] p=0.30800 | |
| Pulmonaryedema | -0.005 [-0.028,0.017] p=0.63723 | 0.033] p=0.00459 | 0.019[0.006,-0.007[-0.016,-0.001[-0.007, 0.002] p=0.13283 | 0.004] p=0.68002 | -0.000 [-0.006, 0.006] p=0.99304 |
| Pneumothorax | 0.102] p=0.00021 | 0.067[0.032,-0.030[-0.059,-0.012[-0.036,0.007[-0.005 -0.001] p=0.04248 | 0.012] p=0.31538 | 0.020] p=0.24105 | 0.007 [-0.006, 0.020] p=0.30800 | |
|---|---|---|---|---|---|---|
| Pulmonaryedema | -0.005 [-0.028,0.017] p=0.63723 | 0.033] p=0.00459 | 0.019[0.006,-0.007[-0.016,-0.001[-0.007, 0.002] p=0.13283 | 0.004] p=0.68002 | -0.000 [-0.006, 0.006] p=0.99304 |
Supplementary table 10: Data-efficient classification performance comparison between ELIXR-B and supervised contrastive learning (SupCon) by sample size. (a) CheXpert, (b) CXR-14. AUC differences between SupCon and ELIXR-B pre training by sample sizes. Values in each cell represent the difference in AUC, with $95%$ CIs in square braces, and p-values. Bold indicates where the ELIXR-B approach performs non inferior (at a margin of 0.05) to SupCon at a smaller sample size.
附表10: ELIXR-B与监督对比学习(SupCon)在不同样本量下的数据高效分类性能对比。(a) CheXpert, (b) CXR-14。SupCon与ELIXR-B预训练在各样本量下的AUC差异。单元格数值表示AUC差值(方括号内为95%置信区间)及p值。加粗标注表示在较小样本量下ELIXR-B方法以0.05为界不劣于SupCon。
(a)
(a)
| CheXpert | Sample Size ELIXR-B | 64 | 512 | 4096 | 32768 | 224316 |
| Sample size SupCon | ||||||
| Atelectasis | 224316 | -0.048 [-0.094, -0.002] p=0.04094 | -0.051[-0.088, -0.015] p=0.00613 | -0.013 [-0.048, 0.023] p=0.47990 | 0.007 [-0.009, 0.022] p=0.39980 | |
| 32768 | -0.025 [-0.076, 0.026] p=0.33903 | -0.028 [-0.073, 0.017] p=0.21884 | 0.010 [-0.035, 0.056] p=0.65029 | 0.034 [0.002, 0.066] p=0.04019 | ||
| 4096 | -0.011 [-0.058, 0.037] p=0.66183 | -0.014 [-0.054, 0.026] p=0.49807 | 0.044 [0.012, 0.076] p=0.00665 | 0.048 [0.019, 0.077] p=0.00114 | ||
| 512 | 0.039 [-0.003, 0.081] p=0.07230 | 0.074 [0.034, 0.114] p=0.00032 | 0.093 [0.053, 0.134] p<1e-5 | 0.098 [0.057, 0.138] p<1e-5 | ||
| 64 | 0.121 [0.066, 0.177] p=0.00002 | 0.160 [0.108, 0.212] p<1e-5 | 0.179 [0.126, 0.232] p<1e-5 | 0.183 [0.132, 0.235] p<1e-5 | ||
| Cardiomegaly | 224316 | -0.057 [-0.111, -0.003] p=0.03936 | -0.018 [-0.062, 0.027] p=0.43275 | -0.011 [-0.047, 0.025] p=0.55874 | -0.004 [-0.027, 0.020] p=0.74519 | |
| 32768 | -0.038 [-0.094, 0.017] p=0.17618 | 0.001 [-0.043, 0.045] p=0.97401 | 0.008 [-0.026, 0.042] p=0.65056 | 0.029 [0.008, 0.051] p=0.00653 | ||
| 4096 | -0.018 [-0.066, 0.029] p=0.45020 | 0.021 [-0.013, 0.054] p=0.22596 | 0.035 [-0.002, 0.071] p=0.06508 | 0.049 [0.016, 0.083] p=0.00371 | ||
| 512 | 0.013 [-0.034, 0.061] p=0.58649 | 0.059 [0.020, 0.099] p=0.00338 | 0.066 [0.022, 0.110] p=0.00317 | 0.081 [0.038, 0.124] p=0.00023 | ||
| 64 | 0.123 [0.068, 0.178] p=0.00001 | 0.130 [0.083, 0.177] p<1e-5 | 0.137 [0.082, 0.192] p<1e-5 | 0.152 [0.099, 0.205] p<1e-5 | ||
| Consolidation | 224316 | -0.095 [-0.179, -0.011] p=0.02671 | -0.039 [-0.105, 0.027] p=0.25086 | 0.001[-0.056, 0.058] p=0.97076 | 0.012 [-0.021, 0.044] p=0.48487 | |
| 32768 | -0.075 [-0.155, 0.006] | -0.018 [-0.084, 0.048] | 0.021 [-0.034, 0.077] | 0.033 [-0.009, 0.074] p=0.12735 |
| CheXpert | Sample Size ELIXR-B | 64 | 512 | 4096 | 32768 | 224316 |
|---|---|---|---|---|---|---|
| Sample size SupCon | ||||||
| Atelectasis | 224316 | -0.048 [-0.094, -0.002] p=0.04094 | -0.051 [-0.088, -0.015] p=0.00613 | -0.013 [-0.048, 0.023] p=0.47990 | 0.007 [-0.009, 0.022] p=0.39980 | |
| 32768 | -0.025 [-0.076, 0.026] p=0.33903 | -0.028 [-0.073, 0.017] p=0.21884 | 0.010 [-0.035, 0.056] p=0.65029 | 0.034 [0.002, 0.066] p=0.04019 | ||
| 4096 | -0.011 [-0.058, 0.037] p=0.66183 | -0.014 [-0.054, 0.026] p=0.49807 | 0.044 [0.012, 0.076] p=0.00665 | 0.048 [0.019, 0.077] p=0.00114 | ||
| 512 | 0.039 [-0.003, 0.081] p=0.07230 | 0.074 [0.034, 0.114] p=0.00032 | 0.093 [0.053, 0.134] p<1e-5 | 0.098 [0.057, 0.138] p<1e-5 | ||
| 64 | 0.121 [0.066, 0.177] p=0.00002 | 0.160 [0.108, 0.212] p<1e-5 | 0.179 [0.126, 0.232] p<1e-5 | 0.183 [0.132, 0.235] p<1e-5 | ||
| Cardiomegaly | 224316 | -0.057 [-0.111, -0.003] p=0.03936 | -0.018 [-0.062, 0.027] p=0.43275 | -0.011 [-0.047, 0.025] p=0.55874 | -0.004 [-0.027, 0.020] p=0.74519 | |
| 32768 | -0.038 [-0.094, 0.017] p=0.17618 | 0.001 [-0.043, 0.045] p=0.97401 | 0.008 [-0.026, 0.042] p=0.65056 | 0.029 [0.008, 0.051] p=0.00653 | ||
| 4096 | -0.018 [-0.066, 0.029] p=0.45020 | 0.021 [-0.013, 0.054] p=0.22596 | 0.035 [-0.002, 0.071] p=0.06508 | 0.049 [0.016, 0.083] p=0.00371 | ||
| 512 | 0.013 [-0.034, 0.061] p=0.58649 | 0.059 [0.020, 0.099] p=0.00338 | 0.066 [0.022, 0.110] p=0.00317 | 0.081 [0.038, 0.124] p=0.00023 | ||
| 64 | 0.123 [0.068, 0.178] p=0.00001 | 0.130 [0.083, 0.177] p<1e-5 | 0.137 [0.082, 0.192] p<1e-5 | 0.152 [0.099, 0.205] p<1e-5 | ||
| Consolidation | 224316 | -0.095 [-0.179, -0.011] p=0.02671 | -0.039 [-0.105, 0.027] p=0.25086 | 0.001 [-0.056, 0.058] p=0.97076 | 0.012 [-0.021, 0.044] p=0.48487 | |
| 32768 | -0.075 [-0.155, 0.006] | -0.018 [-0.084, 0.048] | 0.021 [-0.034, 0.077] | 0.033 [-0.009, 0.074] p=0.12735 |
| p=0.06871 | p=0.58336 | p=0.44896 | ||||
| 4096 | -0.058 [-0.146, 0.030] | -0.002 [-0.060, 0.056] p=0.94469 | 0.048 [-0.007, 0.104] p=0.08743 | 0.049 [-0.000, 0.098] | ||
| 512 | p=0.19550 0.011 [-0.096, 0.117] p=0.84267 | 0.107 [0.033, 0.180] p=0.00450 | 0.117 [0.036, 0.199] | p=0.05150 0.118 [0.036, 0.200] | ||
| 64 | 0.175 [0.081, 0.268] p=0.00026 | 0.214 [0.134, 0.295] p<1e-5 | p=0.00494 0.225 [0.139, 0.311] p<1e-5 | p=0.00465 0.226 [0.142, 0.309] p<1e-5 | ||
| Pleural effusion | 224316 | -0.078 [-0.115, -0.042] p=0.00002 | -0.044 [-0.070, -0.018] p=0.00095 | 0.002 [-0.019, 0.023] p=0.83881 | 0.001[-0.014, 0.017] p=0.89296 | |
| 32768 | -0.071 [-0.107, -0.035] p=0.00011 | -0.037 [-0.063, -0.011] p=0.00583 | 0.009 [-0.011, 0.030] p=0.36040 | 0.012 [-0.001, 0.026] p=0.07923 | ||
| 4096 | -0.061[-0.093, -0.029] p=0.00021 | -0.026 [-0.048, -0.005] p=0.01582 | 0.019 [0.004, 0.033] p=0.01237 | 0.022 [0.003, 0.042] p=0.02590 | ||
| 512 | -0.025 [-0.059, 0.010] p=0.16249 | 0.056 [0.027, 0.084] p=0.00012 | 0.055 [0.027, 0.082] p=0.00009 | 0.059 [0.027, 0.091] p=0.00032 | ||
| 64 | 0.077 [0.038, 0.115] p=0.00009 | 0.123 [0.085, 0.161] p<1e-5 | 0.122 [0.082, 0.161] p<1e-5 | 0.126 [0.084, 0.167] p<1e-5 | ||
| Pulmonary edema | 224316 | -0.066 [-0.107, -0.026] p=0.00130 | -0.036 [-0.069, -0.003] p=0.03056 | -0.011 [-0.031, 0.009] p=0.28688 | -0.003 [-0.019, 0.014] p=0.74628 | |
| 32768 | -0.048 [-0.087, -0.010] p=0.01442 | -0.018 [-0.054, 0.018] p=0.33455 | 0.007 [-0.018, 0.032] p=0.57217 | 0.029 [0.006, 0.051] p=0.01272 | ||
| 4096 | -0.032 [-0.068, 0.005] p=0.09393 | -0.001 [-0.038, 0.036] p=0.94866 | 0.032 [0.009, 0.055] p=0.00608 | 0.045 [0.018, 0.073] p=0.00114 | ||
| 512 | -0.006 [-0.040, 0.029] p=0.75042 | 0.050 [0.018, 0.082] p=0.00200 | 0.058 [0.025, 0.091] p=0.00049 | 0.071 [0.038, 0.105] p=0.00003 | ||
| 64 | 0.049 [0.008, 0.089] p=0.01800 | 0.074 [0.039, 0.109] p=0.00003 | 0.082 [0.046, 0.118] p<1e-5 | 0.095 [0.058, 0.133] p<1e-5 |
| p=0.06871 | p=0.58336 | p=0.44896 | ||||
|---|---|---|---|---|---|---|
| 4096 | -0.058 [-0.146, 0.030] | -0.002 [-0.060, 0.056] p=0.94469 | 0.048 [-0.007, 0.104] p=0.08743 | 0.049 [-0.000, 0.098] | ||
| 512 | p=0.19550 0.011 [-0.096, 0.117] p=0.84267 | 0.107 [0.033, 0.180] p=0.00450 | 0.117 [0.036, 0.199] | p=0.05150 0.118 [0.036, 0.200] | ||
| 64 | 0.175 [0.081, 0.268] p=0.00026 | 0.214 [0.134, 0.295] p<1e-5 | p=0.00494 0.225 [0.139, 0.311] p<1e-5 | p=0.00465 0.226 [0.142, 0.309] p<1e-5 | ||
| * * 胸腔积液* * | 224316 | -0.078 [-0.115, -0.042] p=0.00002 | -0.044 [-0.070, -0.018] p=0.00095 | 0.002 [-0.019, 0.023] p=0.83881 | 0.001 [-0.014, 0.017] p=0.89296 | |
| 32768 | -0.071 [-0.107, -0.035] p=0.00011 | -0.037 [-0.063, -0.011] p=0.00583 | 0.009 [-0.011, 0.030] p=0.36040 | 0.012 [-0.001, 0.026] p=0.07923 | ||
| 4096 | -0.061 [-0.093, -0.029] p=0.00021 | -0.026 [-0.048, -0.005] p=0.01582 | 0.019 [0.004, 0.033] p=0.01237 | 0.022 [0.003, 0.042] p=0.02590 | ||
| 512 | -0.025 [-0.059, 0.010] p=0.16249 | 0.056 [0.027, 0.084] p=0.00012 | 0.055 [0.027, 0.082] p=0.00009 | 0.059 [0.027, 0.091] p=0.00032 | ||
| 64 | 0.077 [0.038, 0.115] p=0.00009 | 0.123 [0.085, 0.161] p<1e-5 | 0.122 [0.082, 0.161] p<1e-5 | 0.126 [0.084, 0.167] p<1e-5 | ||
| * * 肺水肿* * | 224316 | -0.066 [-0.107, -0.026] p=0.00130 | -0.036 [-0.069, -0.003] p=0.03056 | -0.011 [-0.031, 0.009] p=0.28688 | -0.003 [-0.019, 0.014] p=0.74628 | |
| 32768 | -0.048 [-0.087, -0.010] p=0.01442 | -0.018 [-0.054, 0.018] p=0.33455 | 0.007 [-0.018, 0.032] p=0.57217 | 0.029 [0.006, 0.051] p=0.01272 | ||
| 4096 | -0.032 [-0.068, 0.005] p=0.09393 | -0.001 [-0.038, 0.036] p=0.94866 | 0.032 [0.009, 0.055] p=0.00608 | 0.045 [0.018, 0.073] p=0.00114 | ||
| 512 | -0.006 [-0.040, 0.029] p=0.75042 | 0.050 [0.018, 0.082] p=0.00200 | 0.058 [0.025, 0.091] p=0.00049 | 0.071 [0.038, 0.105] p=0.00003 | ||
| 64 | 0.049 [0.008, 0.089] p=0.01800 | 0.074 [0.039, 0.109] p=0.00003 | 0.082 [0.046, 0.118] p<1e-5 | 0.095 [0.058, 0.133] p<1e-5 |
(b)
(b)
| CXR-14 | Sample Size ELIXR-B | 64 | 512 | 4096 | 32768 | 68801 | 674533 |
| Sample size |
| CXR-14 | Sample Size ELIXR-B | 64 | 512 | 4096 | 32768 | 68801 | 674533 |
|---|---|---|---|---|---|---|---|
| Sample size |
| SupCon | -0.009 | ||||||
| Airspace opacity | 674533 | -0.047 [-0.058, | -0.041 [-0.054, -0.035] p<1e-5-0.029] p<1e-5-0.024] p<1e-5 | -0.033 [-0.043, | [-0.015, -0.003] p=0.00445 | ||
| 32768 | -0.028 [-0.039, -0.017] p<1e-5 | -0.023 [-0.036, -0.010] p=0.00039 | -0.015 [-0.022, -0.008] p=0.00003 | 0.027 [0.019, 0.036] p<1e-5 | |||
| 4096 | 0.010 [-0.001, 0.022] p=0.08267 | 0.015[0.002, 0.028] p=0.02128 | 0.048 [0.036, 0.059] p<1e-5 | 0.066 [0.053, 0.078] p<1e-5 | |||
| 512 | 0.018 [0.013, 0.024] p<1e-5 | 0.031 [0.019, 0.044] p<1e-5 | 0.056[0.043, 0.069] p<1e-5 | 0.074 [0.060, 0.087] p<1e-5 | |||
| 64 | 0.041[0.027, 0.055] p<1e-5 | 0.049 [0.036, 0.062] p<1e-5 | 0.073 [0.059, 0.088] p<1e-5 | 0.091 [0.076, 0.107] p<1e-5 | |||
| Fracture | 674533 | -0.057 [-0.141, 0.027] p=0.18287 | -0.051 [-0.138, 0.036] p=0.25343 | -0.021 [-0.093, 0.052] p=0.57805 | 0.003 [-0.070, 0.076] p=0.92861 | ||
| 32768 | -0.059 [-0.134, 0.016] p=0.12386 | -0.053 [-0.128, 0.023] p=0.17258 | -0.022 [-0.104, 0.060] p=0.59567 | 0.014 [-0.056, 0.083] p=0.69461 | |||
| 4096 | -0.014 [-0.070, 0.043] p=0.63317 | -0.007 [-0.100, 0.085] p=0.87417 | 0.047 [-0.022, 0.116] p=0.18368 | 0.059 [-0.016, 0.133] p=0.12069 | |||
| 512 | -0.006 [-0.087, 0.074] p=0.87682 | 0.109] p=0.45057 | 0.030 [-0.048,0.054 [-0.029, 0.137] p=0.20016 | 0.066 [-0.020, 0.153] p=0.13367 | |||
| 64 | 0.121] p=0.54877 | 0.028 [-0.064,|0.058 [-0.046,0.082 [-0.008, 0.163] p=0.27171 | 0.173] p=0.07281 | 0.095[-0.003, 0.193] p=0.05868 | |||
| 674533 | -0.232 [-0.272,-0.114 [-0.149, | ,-0.104 [-0.133, -0.191] p<1e-5-0.079] p<1e-5-0.075] p<1e-5 | -0.039 [-0.062, -0.016] p=0.00107 | ||||
| Pneumothorax | 32768 | -0.172 [-0.209, -0.134] p<1e-5 | -0.054 [-0.093, -0.015] p=0.00676 | -0.045 [-0.075, -0.014] p=0.00428 | 0.066 [0.044, 0.088] p<1e-5 | ||
| 4096 | -0.092 [-0.131, -0.053] p<1e-5 | 0.026 [-0.012, 0.064] p=0.18491 | 0.101 [0.073, 0.130] p<1e-5 | 0.146 [0.114, 0.178] p<1e-5 | |||
| SupCon | -0.009 | ||||||
|---|---|---|---|---|---|---|---|
| * * 空腔混浊* * | 674533 | -0.047 [-0.058, -0.035] p<1e-5 | -0.041 [-0.054, -0.029] p<1e-5 | -0.033 [-0.043, -0.024] p<1e-5 | [-0.015, -0.003] p=0.00445 | ||
| 32768 | -0.028 [-0.039, -0.017] p<1e-5 | -0.023 [-0.036, -0.010] p=0.00039 | -0.015 [-0.022, -0.008] p=0.00003 | 0.027 [0.019, 0.036] p<1e-5 | |||
| 4096 | 0.010 [-0.001, 0.022] p=0.08267 | 0.015 [0.002, 0.028] p=0.02128 | 0.048 [0.036, 0.059] p<1e-5 | 0.066 [0.053, 0.078] p<1e-5 | |||
| 512 | 0.018 [0.013, 0.024] p<1e-5 | 0.031 [0.019, 0.044] p<1e-5 | 0.056 [0.043, 0.069] p<1e-5 | 0.074 [0.060, 0.087] p<1e-5 | |||
| 64 | 0.041 [0.027, 0.055] p<1e-5 | 0.049 [0.036, 0.062] p<1e-5 | 0.073 [0.059, 0.088] p<1e-5 | 0.091 [0.076, 0.107] p<1e-5 | |||
| * * 骨折* * | 674533 | -0.057 [-0.141, 0.027] p=0.18287 | -0.051 [-0.138, 0.036] p=0.25343 | -0.021 [-0.093, 0.052] p=0.57805 | 0.003 [-0.070, 0.076] p=0.92861 | ||
| 32768 | -0.059 [-0.134, 0.016] p=0.12386 | -0.053 [-0.128, 0.023] p=0.17258 | -0.022 [-0.104, 0.060] p=0.59567 | 0.014 [-0.056, 0.083] p=0.69461 | |||
| 4096 | -0.014 [-0.070, 0.043] p=0.63317 | -0.007 [-0.100, 0.085] p=0.87417 | 0.047 [-0.022, 0.116] p=0.18368 | 0.059 [-0.016, 0.133] p=0.12069 | |||
| 512 | -0.006 [-0.087, 0.074] p=0.87682 | 0.054 [-0.029, 0.137] p=0.20016 | 0.030 [-0.048, 0.109] p=0.45057 | 0.066 [-0.020, 0.153] p=0.13367 | |||
| 64 | 0.058 [-0.046, 0.163] p=0.27171 | 0.028 [-0.064, 0.121] p=0.54877 | 0.082 [-0.008, 0.173] p=0.07281 | 0.095 [-0.003, 0.193] p=0.05868 | |||
| 674533 | -0.232 [-0.272, -0.191] p<1e-5 | -0.114 [-0.149, -0.079] p<1e-5 | -0.104 [-0.133, -0.075] p<1e-5 | ||||
| * * 气胸* * | 32768 | -0.172 [-0.209, -0.134] p<1e-5 | -0.054 [-0.093, -0.015] p=0.00676 | -0.045 [-0.075, -0.014] p=0.00428 | 0.066 [0.044, 0.088] p<1e-5 | ||
| 4096 | -0.092 [-0.131, -0.053] p<1e-5 | 0.026 [-0.012, 0.064] p=0.18491 | 0.101 [0.073, 0.130] p<1e-5 | 0.146 [0.114, 0.178] p<1e-5 |
| 512 | 0.010 [-0.038, 0.059] p=0.67914 | 0.137 [0.097, 0.178] p<1e-5 | 0.203 [0.160, 0.246] p<1e-5 | 0.248 [0.209, 0.287] p<1e-5 | ||
| 64 | 0.178 [0.126, 0.231] p<1e-5 | 0.188 [0.148, 0.227] p<1e-5 | 0.253 [0.204, 0.303] p<1e-5 | 0.298 [0.256, 0.341] p<1e-5 | ||
| Consolidation | 68801 | -0.051[-0.061, -0.041] p<1e-5 | -0.021 [-0.030, -0.012] p<1e-5 | -0.010 [-0.016, -0.004] p=0.00222 | 0.004 [-0.000, 0.008] p=0.06665 | |
| 32768 | -0.050 [-0.060, -0.039] p<1e-5 | -0.019 [-0.027, -0.012] p<1e-5 | -0.009 [-0.014, -0.003] p=0.00274 | 0.004 [-0.000, 0.009] p=0.08012 | ||
| 4096 | -0.032 [-0.042, -0.022] p<1e-5 | -0.002 [-0.009, 0.005] p=0.60796 | 0.023 [0.016, 0.030] p<1e-50.028] p<1e-5 | 0.022 [0.015, | ||
| 512 | -0.014 [-0.019, -0.009] p<1e-5 | 0.027 [0.018, 0.036] p<1e-5 | 0.041[0.031, 0.050] p<1e-5 | 0.040 [0.030, 0.049] p<1e-5 | ||
| 64 | 0.070 [0.056, 0.083] p<1e-5 | 0.080 [0.069, 0.092]p<1e-5 | 0.094 [0.081, 0.107] p<1e-5 | 0.093 [0.080, 0.106] p<1e-5 | ||
| Pleural effusion | 68801 | -0.090 ‘260'0-] | -0.073 [-0.079, -0.083] p<1e-5|-0.067] p<1e-5-0.028] p<1e-5 | -0.033 [-0.038, | -0.004 [-0.006, -0.001] p=0.00524 | |
| 32768 | -0.082 [-0.089, -0.075] p<1e-5 | -0.065 [-0.071, -0.059] p<1e-5 | -0.025 [-0.030, -0.021] p<1e-5 | 0.011 [0.008, 0.014] p<1e-5 | ||
| 4096 | -0.051[-0.057, -0.045] p<1e-5 | -0.033 [-0.039, -0.028] p<1e-5 | 0.036 [0.031, 0.041] p<1e-5 | 0.043 [0.038, 0.047] p<1e-5 | ||
| 512 | 0.001 [-0.006, 0.007] p=0.82577 | 0.058 [0.052, 0.064] p<1e-5 | 0.087[0.080, 0.094]p<1e-5 | 0.094 [0.087, 0.101] p<1e-5 | ||
| 64 | 0.046 [0.041, 0.051] p<1e-5 | 0.086 [0.079, 0.093] p<1e-5 | 0.115 [0.108, 0.123] p<1e-5 | 0.122 [0.115, 0.129] p<1e-5 | ||
| Pulmonary edema | 68801 | -0.142 [-0.157,-0.090 [-0.101,-0.021 [-0.028, -0.127] p<1e-5-0.078] p<1e-5-0.014] p<1e-5 | -0.003 [-0.007, 0.002] p=0.24640 | |||
| 32768 | -0.132 [-0.146, -0.117] p<1e-5 | -0.079 [-0.090, -0.068] p<1e-5 | -0.010 [-0.017, -0.003] | 0.013 [0.008, 0.017] p<1e-5 | ||
| 4096 | -0.100 [-0.117, | -0.048 | p=0.00367 | 0.039 [0.030, | 0.044 [0.035, |
| 512 | 0.010 [-0.038, 0.059] p=0.67914 | 0.137 [0.097, 0.178] p<1e-5 | 0.203 [0.160, 0.246] p<1e-5 | 0.248 [0.209, 0.287] p<1e-5 | ||
|---|---|---|---|---|---|---|
| 64 | 0.178 [0.126, 0.231] p<1e-5 | 0.188 [0.148, 0.227] p<1e-5 | 0.253 [0.204, 0.303] p<1e-5 | 0.298 [0.256, 0.341] p<1e-5 | ||
| * * 整合* * | 68801 | -0.051 [-0.061, -0.041] p<1e-5 | -0.021 [-0.030, -0.012] p<1e-5 | -0.010 [-0.016, -0.004] p=0.00222 | 0.004 [-0.000, 0.008] p=0.06665 | |
| 32768 | -0.050 [-0.060, -0.039] p<1e-5 | -0.019 [-0.027, -0.012] p<1e-5 | -0.009 [-0.014, -0.003] p=0.00274 | 0.004 [-0.000, 0.009] p=0.08012 | ||
| 4096 | -0.032 [-0.042, -0.022] p<1e-5 | -0.002 [-0.009, 0.005] p=0.60796 | 0.023 [0.016, 0.030] p<1e-5 | 0.022 [0.015, 0.028] p<1e-5 | ||
| 512 | -0.014 [-0.019, -0.009] p<1e-5 | 0.027 [0.018, 0.036] p<1e-5 | 0.041 [0.031, 0.050] p<1e-5 | 0.040 [0.030, 0.049] p<1e-5 | ||
| 64 | 0.070 [0.056, 0.083] p<1e-5 | 0.080 [0.069, 0.092] p<1e-5 | 0.094 [0.081, 0.107] p<1e-5 | 0.093 [0.080, 0.106] p<1e-5 | ||
| * * 胸腔积液* * | 68801 | -0.090 [-0.260, 0.0] | -0.073 [-0.079, -0.083] p<1e-5 | -0.033 [-0.038, -0.028] p<1e-5 | -0.004 [-0.006, -0.001] p=0.00524 | |
| 32768 | -0.082 [-0.089, -0.075] p<1e-5 | -0.065 [-0.071, -0.059] p<1e-5 | -0.025 [-0.030, -0.021] p<1e-5 | 0.011 [0.008, 0.014] p<1e-5 | ||
| 4096 | -0.051 [-0.057, -0.045] p<1e-5 | -0.033 [-0.039, -0.028] p<1e-5 | 0.036 [0.031, 0.041] p<1e-5 | 0.043 [0.038, 0.047] p<1e-5 | ||
| 512 | 0.001 [-0.006, 0.007] p=0.82577 | 0.058 [0.052, 0.064] p<1e-5 | 0.087 [0.080, 0.094] p<1e-5 | 0.094 [0.087, 0.101] p<1e-5 | ||
| 64 | 0.046 [0.041, 0.051] p<1e-5 | 0.086 [0.079, 0.093] p<1e-5 | 0.115 [0.108, 0.123] p<1e-5 | 0.122 [0.115, 0.129] p<1e-5 | ||
| * * 肺水肿* * | 68801 | -0.142 [-0.157, -0.127] p<1e-5 | -0.090 [-0.101, -0.078] p<1e-5 | -0.021 [-0.028, -0.014] p<1e-5 | ||
| 32768 | -0.132 [-0.146, -0.117] p<1e-5 | -0.079 [-0.090, -0.068] p<1e-5 | -0.010 [-0.017, -0.003] p=0.00367 | 0.013 [0.008, 0.017] p<1e-5 | ||
| 4096 | -0.100 [-0.117, -0.083] p<1e-5 | -0.048 [-0.058, -0.038] p<1e-5 | 0.039 [0.030, 0.048] p<1e-5 | 0.044 [0.035, 0.053] p<1e-5 |
| -0.084]p<1e-5 | [-0.062, -0.034] p<1e-5 | 0.048] p<1e-5 | 0.053] p<1e-5 | ||||
| 512 | -0.030 [-0.050, -0.010] p=0.00342 | 0.091[0.076, 0.106] p<1e-5 | 0.110[0.095 0.124] p<1e-5 | 0.114 [0.099, 0.129] p<1e-5 | |||
| 64 | 0.053[0.036 0.069] p<1e-5 | 0.121[0.107, 0.136] p<1e-5 | 0.140[0.124, 0.155] p<1e-5 | 0.144 [0.129, 0.159] p<1e-5 |
| -0.084]p<1e-5 | [-0.062, -0.034] p<1e-5 | 0.048] p<1e-5 | 0.053] p<1e-5 | ||||
|---|---|---|---|---|---|---|---|
| 512 | -0.030 [-0.050, -0.010] p=0.00342 | 0.091[0.076, 0.106] p<1e-5 | 0.110[0.095 0.124] p<1e-5 | 0.114 [0.099, 0.129] p<1e-5 | |||
| 64 | 0.053[0.036 0.069] p<1e-5 | 0.121[0.107, 0.136] p<1e-5 | 0.140[0.124, 0.155] p<1e-5 | 0.144 [0.129, 0.159] p<1e-5 |
Supplementary figures
补充图表
Supplementary figure 1: Suspect positive or negative ground truth MIMIC labels as identified by the query to Med-PaLM 2 truthed by a board certified radiologist. Green represents correctly identified errors or lack of labels in MIMIC labels by Med-PaLM 2. Blue represents correct MIMIC labels. Red represents errors identified in both MIMIC and MedPalm2 based labels while gray represents indeterminate labels. A total of 1568 labels were flagged, of which 1092 were modified.
补充图1: 由Med-PaLM 2查询识别并经放射科医师核实的MIMIC标签真值疑似阳性/阴性案例。绿色表示Med-PaLM 2正确识别的MIMIC标签错误或缺失,蓝色表示正确的MIMIC标签,红色表示MIMIC和Med-PaLM 2标签均存在的错误,灰色表示不确定标签。共标记1568个标签,其中1092个被修正。

(a)
(a)

Supplementary figure 2: Data-efficient classification performance between models per-dataset and per-finding using different training set sample size. Evaluation on (a) CheXpert, (b) CXR-14. Significance test results are available in Supplementary tables 9, 10.
补充图2: 不同训练集样本量下各模型在每数据集及每病症间的数据高效分类性能对比。(a) CheXpert、(b) CXR-14的评估结果。显著性检验结果见补充表9、10。
