Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
带有图像描述符的语言模型是强大的少样本视频-语言学习者
Zhen hai long Wang', Manling Li', Ruochen Xu2, Luowei Zhou2, Jie Lei3, Xudong Lin4, Shuohang $\mathbf{Wang}^{2}$ , Ziyi $\mathbf{Yang}^{2}$ , Chenguang $\mathbf{Z}\mathbf{h}\mathbf{u}^{2}$ , Derek Hoiem1, Shih-Fu Chang4, Mohit Bansal3, Heng Ji1 1UIUC 2MSR 3UNC 4Columbia University {wangz3,hengji}@illinois.edu
Zhen hai long Wang', Manling Li', Ruochen Xu2, Luowei Zhou2, Jie Lei3, Xudong Lin4, Shuohang $\mathbf{Wang}^{2}$ , Ziyi $\mathbf{Yang}^{2}$ , Chenguang $\mathbf{Z}\mathbf{h}\mathbf{u}^{2}$ , Derek Hoiem1, Shih-Fu Chang4, Mohit Bansal3, Heng Ji1 1UIUC 2MSR 3UNC 4Columbia University {wangz3,hengji}@illinois.edu
Abstract
摘要
The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-totext decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pre training or finetuning on any video datasets. We use image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal-aware template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and processed data are publicly available for research purposes at https://github.com/Mike Wang W ZH L/VidIL.
本研究旨在构建灵活的视频-语言模型,能够通过少量样本泛化至多种视频到文本任务。现有的少样本视频-语言学习器仅聚焦编码器,导致缺乏处理生成任务的视频到文本解码器。虽然视频描述生成器已在大规模视频-语言数据集上预训练,但它们严重依赖微调,且无法在少样本场景下为未见任务生成文本。我们提出VidIL——基于图像与语言模型的少样本视频-语言学习器,该模型无需任何视频数据集的预训练或微调,即可在少样本视频到文本任务中展现卓越性能。我们利用图像-语言模型将视频内容转化为帧描述、对象/属性/事件短语,并将其组织为时序感知模板。随后通过包含少量上下文示例的提示指令,引导语言模型根据结构化内容生成目标输出。提示机制的灵活性使模型能捕捉任意文本输入形式(如自动语音识别(ASR)转录文本)。实验证明,该语言模型在视频描述生成、视频问答、视频描述检索及视频未来事件预测等多样化视频-语言任务中具有卓越的视频理解能力。特别在视频未来事件预测任务中,我们的少样本模型显著优于基于大规模视频数据集训练的最先进监督模型。代码与处理数据已公开于https://github.com/MikeWangWZHL/VidIL供研究使用。
1 Introduction
1 引言
One major gap between artificial intelligence and human intelligence lies in their abilities to generalize and perform well on new tasks with limited annotations. Recent advances in large-scale pre-trained generative language models [45, 6, 71, 24] have shown promising few-shot capabilities [72, 43, 63] in understanding natural language. However, few-shot video-language understanding is still in its infancy. A particular limitation of most recent video-language frameworks [28, 21, 61, 68, 67, 25, 64, 34] is that they are encoder-only, which means they do not have the ability to generate text from videos for purposes such as captioning [62, 57], question answering [60], and future prediction [23]. Meanwhile, unified video-language models [36, 49] that are capable of language decoding still rely heavily on finetuning using a large number of manually annotated video-text pairs, therefore cannot adapt quickly to unseen tasks. Few-shot video-to-text decoding is challenging because the natural language supervision for learning video-language representation is typically based on subtitles and automatic speech recognition (ASR) transcripts [39, 68], which differ significantly from downstream tasks in terms of distribution and may have poor semantic alignment across vision and text modalities.
人工智能与人类智能之间的一个主要差距在于它们在新任务上的泛化能力和有限标注下的表现。近期大规模预训练生成式语言模型 [45, 6, 71, 24] 的发展展现了在自然语言理解方面具有潜力的少样本能力 [72, 43, 63]。然而,少样本视频-语言理解仍处于起步阶段。当前大多数视频-语言框架 [28, 21, 61, 68, 67, 25, 64, 34] 的核心局限在于它们仅包含编码器结构,这意味着它们无法从视频生成文本以实现字幕生成 [62, 57]、问答 [60] 或未来预测 [23] 等功能。同时,具备语言解码能力的统一视频-语言模型 [36, 49] 仍严重依赖大量人工标注的视频-文本对进行微调,因此难以快速适应未见任务。实现少样本视频到文本解码的挑战在于:用于学习视频-语言表征的自然语言监督信号通常基于字幕和自动语音识别 (ASR) 转写文本 [39, 68],这些数据与下游任务在分布上存在显著差异,且视觉与文本模态间可能缺乏良好的语义对齐。
We propose to address this problem by harnessing the few-shot power of frozen large-scale language models, such as Instruct GP T [40]. Our inspiration is derived from the fact that humans are excellent visual storytellers [15], with the ability to piece together a coherent story from a few isolated images. To mimic this, we propose VidIL, a few-shot Video-language Learner via Image and Language models, to use image models to provide information about the visual content in the video (as well as optionally use ASR to represent speech), and then we instruct language models to generate a video-based summary, answer, or other target output for diverse video-language tasks.
我们提出通过利用冻结大规模语言模型(如InstructGPT [40])的少样本能力来解决这一问题。灵感来源于人类是出色的视觉叙事者[15],能够从少量孤立图像中拼凑出连贯的故事。为模拟这一能力,我们提出VidIL(基于图像和语言模型的少样本视频-语言学习器),利用图像模型提供视频中的视觉内容信息(可选结合ASR表示语音),然后指导语言模型生成基于视频的摘要、答案或其他目标输出,以应对多样化的视频-语言任务。
The main challenge of understanding videos is that, videos contain rich semantics and temporal content at multiple granular i ties. Unlike static images which depict objects, attributes and events in a snapshot, the temporal dimension of videos further conveys the state changes of the objects, actions, and events. For example, in Figure 1, the individual frame captions of the video clip only describe static visual features such as "a person holding a green object in hand". In contrast, a correct video-level description would be "a woman makes realistic looking leaves and flowers for a cake", which involves reasoning over a collection of objects and events that occur at different timestamps in the video clip, such as "cake decorating" and "flowered design". Hence, to inform video-level description and queries, we need to represent all of this information and its temporal ordering.
理解视频的主要挑战在于,视频在多个粒度层级上包含丰富的语义和时序内容。与静态图像仅捕捉某一时刻的物体、属性和事件不同,视频的时间维度进一步传递了物体状态、动作和事件的变化。例如在图1中,视频片段的单帧描述仅呈现了"一个人手里拿着绿色物体"等静态视觉特征。而正确的视频级描述应为"一位女性为蛋糕制作逼真的树叶和花朵装饰",这需要推理视频片段中不同时间点发生的物体和事件集合,例如"蛋糕装饰"和"花卉设计"。因此,要为视频级描述和查询提供依据,我们必须表征所有这些信息及其时序关系。

Figure 1: Multiple levels of information in videos.
图 1: 视频中的多层次信息。
To address the unique challenges of videos, we propose to decompose a video into three levels: the video output, frame captions, and visual tokens (including objects, events, attributes). One major benefit from this hierarchical video representation is that we can separate the visual and temporal dimensions of a video. We leverage frozen image-language foundational models at lower levels to collect salient visual features from the sparsely sampled frames. Specifically, we first leverage a pretrained image-language contrastive model CLIP [44] to perform visual token iz ation, based on the similarity score between frames and tokens of objects, events and attributes. The token iz ation is done under the guidance of semantics role labeling [14], which provides us with candidate events with involved objects and related attributes. Next, in order to capture the overall semantics at the frame level, we employ the pretrained image captioner in the image-language model BLIP [26] to obtain frame captions. Finally, we instruct a pretrained large language model using in-context learning [40, 13, 51, 48] to interpret visual tokens and frame captions into the target textual output. In detail, we temporally order visual tokens and frame captions using specially designed prompts such as “First...Then...Finally”, to instruct the pretrained language model to track the changes of objects, events, attributes and frame semantics along the temporal dimension.
为应对视频数据的独特挑战,我们提出将视频分解为三个层级:视频输出、帧级描述和视觉token(包括物体、事件及属性)。这种层级化视频表征的主要优势在于能将视觉维度与时间维度分离。我们利用冻结的图像-语言基础模型在底层提取稀疏采样帧中的显著视觉特征。具体而言,首先基于预训练的CLIP[44]图像-语言对比模型,通过帧与物体/事件/属性token的相似度评分进行视觉token化处理。该过程在语义角色标注[14]的指导下完成,从而获得包含参与对象及相关属性的候选事件。接着,为捕获帧级整体语义,我们采用图像-语言模型BLIP[26]中的预训练图像描述器生成帧级描述。最后,通过情境学习[40,13,51,48]指导预训练大语言模型将视觉token和帧级描述转化为目标文本输出。具体实现时,我们使用"首先...然后...最终"等特制提示词对视觉token和帧级描述进行时序排序,引导预训练语言模型追踪物体、事件、属性及帧语义沿时间维度的变化。
Without pre training or finetuning on any video datasets, we show that our approach outperforms both video-language and image-language state-of-the-art baselines on few-shot video captioning and question answering tasks. Moreover, on video-language event prediction, our approach significantly outperforms fully-supervised models while using only 10 labeled examples. We further demonstrate that our generative model can benefit broader video-language understanding tasks, such as text-video retrieval, via pseudo label generation. Additionally, we show that our model is highly flexible in adding new modalities, such as ASR transcripts.
在不预训练或微调任何视频数据集的情况下,我们的方法在少样本视频描述生成和问答任务上超越了视频-语言及图像-语言领域的最先进基线模型。此外,在视频-语言事件预测任务中,仅使用10个标注样本时,我们的方法显著优于全监督模型。我们进一步证明,该生成式模型能通过伪标签生成提升更广泛的视频-语言理解任务(如文本-视频检索)。同时,模型展现出高度灵活性,可轻松集成新模态(如ASR转录文本)。
2 Related Work
2 相关工作
2.1 Image-Language Models and Their Applications on Video-Language Tasks
2.1 图像-语言模型及其在视频-语言任务中的应用
Large-scale image-language pre training models optimize image-text matching through contrastive learning [44, 17] and multimodal fusion [65, 27, 58, 66, 35, 52, 8, 29, 73, 70, 18, 16]. Recently,
大规模图像语言预训练模型通过对比学习 [44, 17] 和多模态融合 [65, 27, 58, 66, 35, 52, 8, 29, 73, 70, 18, 16] 优化图文匹配。近期,
BLIP [26] proposes a boots trapping image-language pre training framework with a captioner and a filterer which has shown promising performance on various image-language tasks. However, video-language pre training [25, 36, 28, 38, 3, 1, 42, 33] is still hindered by noisy and domain-specific video datasets [74, 22, 39]. Naturally, researchers start to explore transferring the rich knowledge from image models to videos. Different from the traditional way of representing videos by 3D dense features [12], recent work [21, 25] proves that sparse sampling is an effective way to represent videos, which facilitates applying pre-trained image-language models to video-language tasks [37, 11]. Specifically, the image-language model BLIP [26] sets new state-of-the-art on zero-shot retrieval-style video-language tasks, such as video retrieval and video question answering. However, for generationstyle tasks such as domain-specific video captioning, video-language model UniVL [36] still leads the performance but highly rely on fine-tuning. In this work, we extend the idea of leveraging image-language models to a wide variety of video-to-text generation tasks. We further connect imagelanguage models with language models which empowers our model with strong generalization ability. We show that the knowledge from both image-language pre training and language-only pre training can benefit video-language understanding in various aspects.
BLIP [26] 提出了一种包含描述生成器和过滤器的自举图像-语言预训练框架,在各种图像-语言任务中展现出优异性能。然而,视频-语言预训练 [25, 36, 28, 38, 3, 1, 42, 33] 仍受限于噪声多且领域特定的视频数据集 [74, 22, 39]。研究者们自然开始探索将图像模型的丰富知识迁移至视频领域。不同于传统采用3D密集特征表示视频的方法 [12],近期研究 [21, 25] 证明稀疏采样是有效的视频表征方式,这有助于将预训练图像-语言模型应用于视频-语言任务 [37, 11]。具体而言,图像-语言模型BLIP [26] 在零样本检索式视频-语言任务(如视频检索和视频问答)中创造了新标杆。但对于领域特定视频描述等生成式任务,视频-语言模型UniVL [36] 仍保持领先性能,但高度依赖微调。本研究将图像-语言模型的拓展应用延伸至多样化的视频到文本生成任务,并进一步将图像-语言模型与语言模型相结合,赋予模型强大的泛化能力。我们证明,来自图像-语言预训练和纯语言预训练的知识能在多方面促进视频-语言理解。
2.2 Unifying MultiModal Tasks with Language Models
2.2 用大语言模型统一多模态任务
The community has paid much attention to connecting different modalities with a unified representation recently. Text-only generation models, such as T5 [46], have been extended to vision-language tasks by text generation conditioned on visual features [9, 53, 50, 75, 55]. In order to fully leverage the generalization power from pretained language models, [63] represents images using text in a fully symbolic way. [32] includes more modalities such as video and audio, but requires annotated video-text data to jointly training the language model with the video and audio tokenizer. In this work, we propose a temporal-aware hierarchical representation for describing a video textually. To our knowledge, we are the first work to leverage prompting a frozen language model for tackling few-shot video-language tasks with a unified textual representation. Concurrent work Socratic [69] uses a zero-shot language-based world-state history to represent long videos with given time stamps, while our model can quickly adapt to different video and text distributions with few examples. Furthermore, we show that by injecting temporal markers to the prompt we can make a pre-trained language model understand fine-grained temporal dynamics in video events. Compared with the concurrent work Flamingo [2], which requires dedicated vision-language post-pre training, our framework does not require to pretrain or finetune on any video data. Our framework is simple and highly modulated where all the components are publicly available. Additionally, our framework is more flexible on adding new modalities, e.g., automatic speech recognition, without the need for complex redesigning.
近年来,学界对多模态统一表征的关注度显著提升。以T5 [46]为代表的纯文本生成模型,已通过视觉特征条件化文本生成的方式扩展到视觉-语言任务 [9, 53, 50, 75, 55]。为充分释放预训练语言模型的泛化能力,[63]采用完全符号化的文本形式表征图像。[32]虽引入视频、音频等多模态数据,但需依赖视频-文本标注数据联合训练语言模型与音视频tokenizer。本文提出时序感知的层次化文本表征框架来描述视频内容。据我们所知,这是首个利用冻结大语言模型的提示工程(prompting)技术,通过统一文本表征解决少样本视频-语言任务的研究。同期工作Socratic [69]采用基于零样本语言的世界状态历史表征带时间戳的长视频,而我们的模型仅需少量样本即可快速适应不同视频-文本数据分布。更进一步,我们证明通过向提示词注入时序标记,可使预训练语言模型理解视频事件中的细粒度时序动态。相比需要专门视觉-语言后预训练的同期工作Flamingo [2],本框架无需任何视频数据的预训练或微调。我们的框架结构简洁、模块化程度高,所有组件均为开源可用。此外,本框架在新增模态(如自动语音识别)时更具灵活性,无需复杂的架构重构。
3 Method
3 方法
We propose a hierarchical video representation framework which decomposes a video into three levels, i.e., visual token level, frame level and video level. The motivation is to separate the spatial and temporal dimension of a video in order to leverage image-language and language-only foundation models, such as CLIP [44] and GPT-3 [6]. All three levels use a unified textual representation which enables us to leverage the powerful few-shot ability from pretrained language models.
我们提出了一种分层视频表示框架,将视频分解为三个层级:视觉token (visual token) 层级、帧层级和视频层级。该设计的核心动机是通过分离视频的空间与时间维度,从而利用CLIP [44] 和GPT-3 [6] 等图像-语言模型及纯语言基础模型。所有层级均采用统一的文本表示形式,这使得我们能够利用预训练语言模型强大的少样本 (few-shot) 学习能力。
3.1 Frame Level: Image Captioning
3.1 帧级别:图像描述
Following [21] we first perform sparse sampling to obtain several video frames. Unless otherwise specified, we sample 4 frames for frame level and 8 frames for visual token level. We then feed each frame into a pre-trained image-language model to obtain frame level captions. An example can be found in the blue part of Figure 2. In our experiments, we use BLIP [26], a recent image-language framework containing both image-grounded encoder and decoder, for generating frame captions. We follow [26] to do both captioning and filtering on each frame. However, as mentioned in Section 1, videos contain rich semantics and temporal contents at multiple granular i ties. It is not enough to generate video-level target text such as video captions solely based on frame captions. Thus, we further perform visual token iz ation for each frame to capture features at a finer granularity.
遵循[21]的方法,我们首先进行稀疏采样以获取若干视频帧。除非另有说明,帧级别采样4帧,视觉token级别采样8帧。随后将每帧输入预训练的图文模型获取帧级描述(示例见图2蓝色部分)。实验中采用BLIP[26]这一最新图文框架,其包含基于图像的编码器和解码器,用于生成帧描述。我们依照[26]对每帧执行描述生成和过滤操作。但如第1节所述,视频蕴含多粒度的丰富语义与时序内容,仅凭帧描述生成视频级目标文本(如视频字幕)是不够的。因此我们进一步对每帧执行视觉token化处理,以捕捉更细粒度的特征。
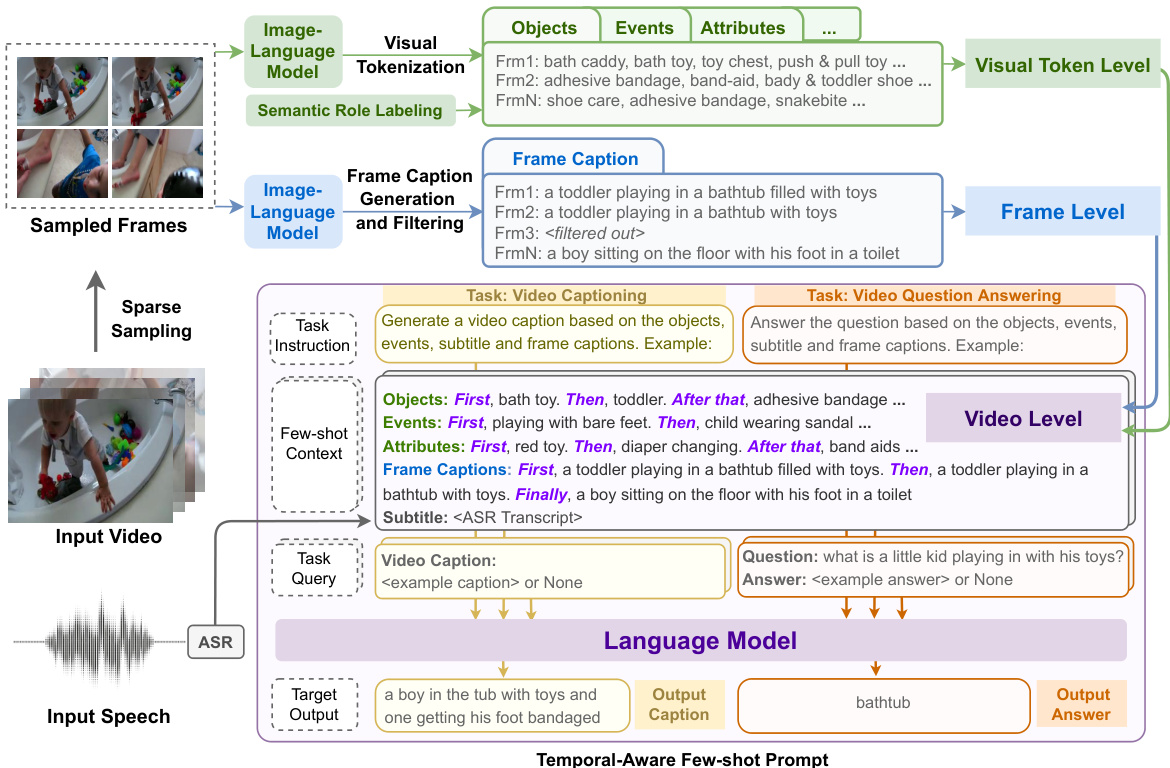
Figure 2: Overview of VidIL framework. We represent a video in a unified textural representation containing three semantic levels: visual token level, frame level, and video level. At visual token level, we extract salient objects, events, attributes for each sampled frame. At frame level, we perform image captioning and filtering. At video level, we construct video representation by aggregating the visual tokens, frame captions and other text modalities such as ASR, using a few-shot temporalaware prompt. We then feed the prompt to a pre-trained language model together with task-specific instructions to generate target text for a variety of video-language tasks. Examples of the full prompt for different tasks can be found in Appendix ??.
图 2: VidIL框架概述。我们将视频表示为包含三个语义层次的统一文本表征:视觉token (visual token) 层次、帧层次和视频层次。在视觉token层次,为每个采样帧提取显著物体、事件和属性。在帧层次,执行图像描述生成与过滤。在视频层次,通过聚合视觉token、帧描述文本以及自动语音识别 (ASR) 等其他文本模态,使用少样本 (few-shot) 时序感知提示 (prompt) 构建视频表征。随后将该提示与任务特定指令共同输入预训练大语言模型,为多种视频-语言任务生成目标文本。不同任务的完整提示示例见附录??。
3.2 Visual Token Level: Structure-Aware Visual Token iz ation
3.2 视觉Token级别:结构感知的视觉Token化
At this level, we aim to extract the textual representations of salient visual token types, such as objects, events and attributes. We found that pre-defined classes for classification, such as those in ImageNet [10], are far from enough for covering the rich semantics in open-domain videos. Thus, instead of using classification-based methods for visual token iz ation as in previous work [32, 63], we adopt a retrieval-based visual token iz ation approach by leveraging pre-trained contrastive imagelanguage models. Given a visual token vocabulary which contains all candidate object, event, and attribute text phrases, we compute the image embedding of a frame and the text embeddings of the candidate visual tokens using a contrastive multi-modal encoder, CLIP [44]. We then select top 5 visual tokens per frame based on the cosine similarity of the image and text embeddings. An example of the extracted object tokens can be found in the green part of Figure 2.
在这一层级,我们的目标是提取显著视觉token类型的文本表征,例如物体、事件和属性。我们发现预定义的分类类别(如ImageNet [10]中的类别)远不足以覆盖开放域视频中的丰富语义。因此,不同于先前工作[32, 63]采用基于分类的视觉token化方法,我们利用预训练的对比式图文模型,采用基于检索的视觉token化方法。给定一个包含所有候选物体、事件及属性文本短语的视觉token词表,我们使用对比式多模态编码器CLIP [44]计算帧的图像嵌入和候选视觉token的文本嵌入,然后根据图像与文本嵌入的余弦相似度,每帧选取前5个视觉token。提取的物体token示例如图2绿色部分所示。
Unlike in images where objects and attributes already cover most visual features, events are more informative in videos. In order to discover events from video frames, we construct our own event vocabulary by extracting event structures from Visual Genome [19] synsets using Semantic Role Labeling. Specifically, we first select the phrases that contain at least one verb and one argument as events. Then we remove highly similar events based on their sentence similarity using SentenceBERT [47] embeddings. For object vocabulary, we adopt OpenImage [20] full classes $(\sim20\mathrm{k})$ , instead of using the visually groundable subset $(\mathord{\sim}600)$ as in concurrent work [69]. We found that using large but noisy vocabulary is more effective than using small but clean vocabulary in our retrieval-based setting with CLIP. For attribute vocabulary, we adopt visual genome attribute synset. In Section 4.6, we provide ablation study on the impact of different types of visual tokens. The statistics of visual token vocabulary can be found in Appendix Table ??.
与图像中物体和属性已涵盖大部分视觉特征不同,视频中的事件更具信息量。为了从视频帧中发现事件,我们通过语义角色标注从Visual Genome [19]同义词集中提取事件结构,构建了专属的事件词库。具体而言,我们首先筛选包含至少一个动词和一个论元的短语作为事件,随后基于SentenceBERT [47]嵌入的句子相似度去除高度相似事件。对于物体词库,我们采用OpenImage [20]全量类别$(\sim20\mathrm{k})$,而非同期研究[69]使用的视觉可落地子集$(\mathord{\sim}600)$。在基于CLIP的检索场景中,我们发现使用大规模但含噪声的词库比小规模洁净词库更有效。属性词库则采用Visual Genome属性同义词集。第4.6节将针对不同类型视觉token的影响进行消融实验,视觉token词库统计信息见附录表??。

Figure 3: Temporal-aware prompt successfully distinguishes the Sunset and Sunrise scenarios based on the temporal ordering change of objects and frame captions, while the static prompt fails.
图 3: 时序感知提示 (Temporal-aware prompt) 能根据物体和帧描述的时序变化成功区分日落和日出场景,而静态提示 (static prompt) 则无法做到。
3.3 Video Level: Temporal-Aware Few-shot Prompting
3.3 视频层级:时序感知少样本提示
Once we obtain the textual representation from frame level and visual token level, the final step is to put the pieces together to generate a video level target text. The goal is to build a model that can be quickly adapted to any video-to-text generation task with only a few examples. To this end, we propose to leverage large-scale pre-trained language models, such as GPT-3 [6], with a temporal-aware few-shot prompt. As shown in Figure 2, our framework can be readily applied to various video-to-text generation tasks, such as video captioning and video question answering, with a shared prompt template. The proposed prompting strategy enables a language model to attend to the lower level visual information as well as taking into account the temporal ordering.
一旦我们从帧级别和视觉token级别获得文本表示,最后一步就是将这些片段组合起来生成视频级别的目标文本。我们的目标是构建一个只需少量示例就能快速适应任何视频到文本生成任务的模型。为此,我们提出利用GPT-3[6]等大规模预训练语言模型,结合时序感知的少样本提示(prompt)。如图2所示,我们的框架可以轻松应用于各种视频到文本生成任务(如视频字幕生成和视频问答),并共享同一个提示模板。所提出的提示策略使语言模型既能关注低层视觉信息,又能考虑时序顺序。
Here, we use the video captioning task depicted in Figure 2 to illustrate the details. The few-shot prompt consists of three parts: instruction, few-shot context, and task query. The instruction is a concise description of the generation task, e.g., "Generate a video caption based on the objects, events, attributes and frame captions. Example:", which is proved to be effective in zero-shot and few-shot settings [6, 59]. The few-shot context contains the selected in-context examples as well as the test video instance. Each video instance is represented by the aggregated visual tokens4, e.g., "Objects: First, bath toy. Then,..." the frame captions, such as "Frame Captions: First, a toddler playing in a bathtub filled with toys. Then,...", and the ASR inputs if available, e.g., "Subtitle:
此处,我们以图2所示的视频字幕生成任务为例说明具体细节。少样本提示(prompt)包含三部分:指令(instruction)、少样本上下文(few-shot context)和任务查询(task query)。指令是对生成任务的简明描述(例如"根据物体、事件、属性和帧描述生成视频字幕。示例:"),该方式在零样本和少样本场景下已被验证有效[6,59]。少样本上下文包含选定的上下文示例及测试视频实例,每个视频实例通过聚合的视觉token(如"物体:首先出现浴盆玩具,然后...")、帧描述(如"帧描述:首先是一个幼儿在装满玩具的浴缸里玩耍,然后...")及可选的ASR输入(如"字幕:<ASR转录文本>")来表征。最后,任务查询是指明目标文本格式的任务特定后缀(如"视频字幕:")。对于上下文示例(此处为简洁省略),任务查询后接真实标注;而对于测试实例,生成内容从任务查询结尾处开始。
Formally, we denote the instruction line as $\mathbf{t}$ , few-shot context as c, the task query as q, and the target text as $\mathbf{y}$ , where $\mathbf{y}=(y_{1},y_{2},...,y_{L})$ . The generation of the next target token $y_{l}$ can be modeled as:
形式上,我们将指令行表示为 $\mathbf{t}$,少样本上下文表示为 c,任务查询表示为 q,目标文本表示为 $\mathbf{y}$,其中 $\mathbf{y}=(y_{1},y_{2},...,y_{L})$。下一个目标 token $y_{l}$ 的生成可建模为:
$$
y_{l}=\underset{y}{\arg\operatorname*{max}}p(y|\mathbf s,\mathbf c,\mathbf q,y_{<l})
$$
$$
y_{l}=\underset{y}{\arg\operatorname*{max}}p(y|\mathbf s,\mathbf c,\mathbf q,y_{<l})
$$
In order to capture the temporal dynamics between frames and visual tokens, we further propose to inject temporal markers to the prompt. As shown in the few-shot context in Figure 2, each visual token and frame caption is prefixed with a natural language phrase indicating its temporal ordering, e.g., "First,","Then,", and "Finally,". We found adding the temporal marker can make the language model conditioned on not only literal but also temporal information of the context. We show an example in Figure 3, where we compare our temporal-aware prompt with a static prompt on video captioning using Instruct GP T. Again, the in-context examples are omitted here, which can be found in Appendix ??. In this example, the only difference between these two contexts is the ordering of the visual tokens and the frame captions. For the context on the left, where "sun moving" appears before "night sky", we are expected to see a story talking about sunset, while for the context on the right, we are expected to see sunrise. We can see the static prompt generates captions about sunset for both contexts, while the temporal-aware prompt can capture temporal ordering correctly and generate sunrise for the context on the right.
为了捕捉帧与视觉token之间的时序动态关系,我们进一步提出在提示词中注入时序标记。如图2的少样本示例所示,每个视觉token和帧描述都冠以表示时序顺序的自然语言短语,例如"首先,"、"接着,"和"最后,"。我们发现添加时序标记能使语言模型不仅基于文本内容,还能结合上下文的时序信息进行推理。图3展示了使用时序感知提示与静态提示在InstructGPT视频描述任务中的对比案例(上下文示例详见附录??)。本例中,两种提示的唯一区别在于视觉token和帧描述的排列顺序。左侧上下文中"太阳移动"出现在"夜空"之前,预期生成日落相关的描述;而右侧上下文则应呈现日出场景。可见静态提示为两种上下文都生成日落描述,而时序感知提示能准确捕捉时序关系,为右侧上下文正确生成日出描述。
4 Experiments
4 实验
4.1 Experimental Setup
4.1 实验设置
To comprehensively evaluate our model, we show results on four video-language understanding tasks in few-shot settings: video captioning, video question answering (QA), video-language event prediction, and text-video retrieval. We compare our approach with state-of-the-art approaches on five benchmarks, i.e, MSR-VTT [62], MSVD [7], VaTeX [57], YouCook2 [74], and VLEP [23]. The statistics of the datasets can be found in Table 1. For more details please refer to Appendix ??.
为了全面评估我们的模型,我们在少样本设置下展示了四项视频-语言理解任务的结果:视频描述生成、视频问答(QA)、视频-语言事件预测以及文本-视频检索。我们在五个基准测试(即MSR-VTT [62]、MSVD [7]、VaTeX [57]、YouCook2 [74]和VLEP [23])上将我们的方法与最先进的方法进行了比较。数据集统计信息见表1。更多细节请参阅附录??。
Implementation Details. We use CLIP-L/146 as our default encoder for visual token iz ation. We adopt BLIP captioning checkpoint 7 finetuned on COCO [31] for frame captioning. We use Instruct GP T [40] as our default language model for generating text conditioned on the few-shot prompt. To construct event vocabulary, we use the semantic role labeling model from AllenNLP8. The experiments are conducted on 2 NVIDIA V100 (16GB) GPUs. All few-shot
实现细节。我们采用CLIP-L/146作为视觉token化的默认编码器,使用在COCO数据集[31]上微调的BLIP标注检查点7进行帧标注。默认使用InstructGPT[40]作为大语言模型,基于少样本提示生成文本。构建事件词汇表时采用AllenNLP8的语义角色标注模型。实验在2块NVIDIA V100(16GB)GPU上进行。所有少样本
Table 1: Statistics of datasets in our experiments
| Dataset | Task | SplitCount #train/#eval |
| MSR-VTT [62] | Captioning; ;QA | 6,513/2,990 |
| MSR-VTT [62] | Retrieval | 7,010/1,000 |
| MSVD [7] | QuestionAnswering | 30,933/13,157 |
| VaTeX v1.15 [57] | Captioning;Retrieval | 25,991/6,000 |
| YouCook2 [74] | Captioning | 10.337/3.492 |
| VLEP [23] | EventPrediction | 20,142/4,192 |
finetuning on baselines and semi-supervised training are performed on 2 Nvidia V100 16G GPUs.
表 1: 实验数据集统计
| Dataset | Task | SplitCount #train/#eval |
|---|---|---|
| MSR-VTT [62] | 字幕生成;问答 | 6,513/2,990 |
| MSR-VTT [62] | 检索 | 7,010/1,000 |
| MSVD [7] | 问答 | 30,933/13,157 |
| VaTeX v1.15 [57] | 字幕生成;检索 | 25,991/6,000 |
| YouCook2 [74] | 字幕生成 | 10.337/3.492 |
| VLEP [23] | 事件预测 | 20,142/4,192 |
基线微调和半监督训练在2块Nvidia V100 16G GPU上完成。
In-context Example Selection. From our preliminary experiments, we find that the generation performance is sensitive to the quality of in-context examples. For example, for QA tasks such as MSVD-QA where the annotations are automatically generated, the <question, answer> pair in randomly selected in-context examples can be only weakly-correlated with the video context. Thus, instead of using a fixed prompt for each query, we dynamically filter out the irrelevant in-context examples. Specifically, given a randomly sampled $M$ -shot support set from the training set, we select a subset of $N$ -shots as in-context examples based on their Sentence BERT [47] similarities with text queries. Furthermore, we reorder the selected examples in ascending order based on the similarity score to account for the recency bias [72] in large language models. For QA tasks, we choose the most relevant in-context examples by comparing with questions. While for captioning task, we compare with frame captions. If not otherwise specified, we use $M{=}I0$ and $N{=}5$ , which we consider as 10-shot training.
上下文示例选择。通过初步实验,我们发现生成性能对上下文示例的质量非常敏感。例如,在MSVD-QA等标注为自动生成的问答任务中,随机选取的上下文示例中的<问题,答案>对可能与视频内容仅有微弱关联。因此,我们不再为每个查询使用固定提示,而是动态过滤掉不相关的上下文示例。具体而言,给定从训练集中随机采样的$M$-shot支持集后,我们根据其与文本查询的Sentence BERT [47]相似度,选择$N$-shot子集作为上下文示例。此外,为应对大语言模型中的近因偏差[72],我们按相似度分数升序对所选示例重新排序。对于问答任务,我们通过问题对比选择最相关的上下文示例;而对于字幕任务,则与帧描述进行对比。若无特殊说明,我们采用$M{=}10$和$N{=}5$的配置,即视为10-shot训练。
4.2 Few-shot Video Captioning
4.2 少样本视频描述
We report BLEU-4 [41], ROUGE-L [30], METEOR [5], and CIDEr [54] scores on three video captioning benchmarks covering both open-domain (MSR-VTT, VaTeX) and domain-specific (YouCook2) videos. We compare with both state-of-the-art video captioner (UniVL [36]) and image captioner (BLIP [26]). In order to implement the BLIP baseline for few-shot video captioning, we extend the approach used for text-video retrieval evaluation in [26] to video-language training. Specifically, we concatenate the visual features of sampled frames and then feed them into the image-grounded text-encoder to compute the language modeling loss. This is equivalent to stitching the sampled frames into a large image and then feeding it to BLIP for image captioning. We found that this simple approach results in very strong baselines.
我们在三个视频描述基准测试上报告了BLEU-4 [41]、ROUGE-L [30]、METEOR [5]和CIDEr [54]分数,涵盖开放领域(MSR-VTT、VaTeX)和特定领域(YouCook2)视频。我们与最先进的视频描述模型(UniVL [36])和图像描述模型(BLIP [26])进行了比较。为实现少样本视频描述的BLIP基线,我们将[26]中用于文本-视频检索评估的方法扩展到视频-语言训练。具体而言,我们拼接采样帧的视觉特征,然后将其输入基于图像的文本编码器以计算语言建模损失。这相当于将采样帧拼接成一个大图像后输入BLIP进行图像描述。我们发现这种简单方法能产生非常强的基线。
As shown in Table 2, existing methods have strong bias on certain datasets. For example, UniVL performs well on YouCook2 but fails on MSR-VTT and VaTeX, while BLIP performs the opposite. This is because UniVL is pretrained on HowTo100M which favors instructional videos, i.e., YouCook2, while BLIP is pre-training on image-caption pairs which favors description-style captions, i.e., MSR-VTT and VaTeX. On the contrary, our model performs competitively on both open-domain and instructional videos, and significantly outperforms the baselines on the average CIDEr score across all three benchmarks. This indicates that by leveraging language models, we can maintain strong few-shot ability regardless of the video domain or the target caption distribution.
如表 2 所示,现有方法在某些数据集上存在强烈偏差。例如,UniVL 在 YouCook2 上表现良好,但在 MSR-VTT 和 VaTeX 上表现不佳,而 BLIP 则相反。这是因为 UniVL 在偏向教学视频的 HowTo100M 上进行预训练(即 YouCook2),而 BLIP 则在偏向描述式字幕的图像-字幕对上预训练(即 MSR-VTT 和 VaTeX)。相比之下,我们的模型在开放领域和教学视频上均表现出竞争力,并且在所有三个基准测试的平均 CIDEr 分数上显著优于基线模型。这表明,通过利用大语言模型,无论视频领域或目标字幕分布如何,我们都能保持强大的少样本能力。
Table 2: 10-shot video captioning results. ♠ indicates concurrent work. The reported Flamingo [2] results are using 16 shots. #VideoPT represents the number of videos used for pre-training. B-4, R-L, M, $C$ represents BLEU-4, ROUGE-L, METEOR and CIDEr. Avg $C$ represents the average CIDEr score across all available benchmarks. ASR indicates whether the model has access to the ASR subtitles. $B L I P$ and $B L I P_{c a p}$ use the pretrained checkpoint and the finetuned checkpoint on COCO captioning. All results are averaged over three random seeds.
| Method | #VideopT ASR | MSR-VTTCaption | YouCook2Caption | VaTexCaption | Avg C | |||||||||
| B-4 R-L MC | B-4 R-L M | B-4 R-L M | C | |||||||||||
| Few-shot | ||||||||||||||
| UniVL | 1.2M | No | 2.122.59.5 | 3.6 | 3.3 | 25.3 11.6 | 34.1 | 1.715.78.0 | 2.1 | 13.3 | ||||
| BLIP | 0 | No | 27.743.023.039.5 | 0.7 | 9.0 3.4 | 11.5 | 13.5 39.5 15.4 20.7 | 23.9 | ||||||
| BLIPcap | 0 | No | 21.6 48.0 22.7 30.2 | 3.7 | 8.6 3.8 | 9.4 | 20.7 41.5 17.4 28.9 | 22.8 | ||||||
| VidIL(ours) | 0 | No | 26.0 51.7 24.7 36.3 | 2.6 | 22.9 9.5 | 27.0 | 22.2 43.6 20.0 36.7 | 33.3 | ||||||
| UniVL | 1.2M | Yes | 4.3 | 26.4 | 12.2 48.6 | 2.7 | 17.7 | 10.2 | 3.4 | 26.0 | ||||
| VidIL(ours) | 0 | Yes | 10.7 35.9 19.4 111.623.2 44.2 20.6 38.9 | 75.3 | ||||||||||
| Flamingo-3B(16) | 27M | No | 73.2 | 57.1 | ||||||||||
| Flamingo-80B(16) 27M | No | 84.2 | 62.8 | |||||||||||
| Fine-tuning | ||||||||||||||
| UniVL | 1.2M | No | 42.0 61.0 29.0 50.111.2 40.117.6 127.0|22.838.622.333.4 | 70.2 | ||||||||||
| UniVL | 1.2M | Yes | 16.6 45.721.6 176.823.7 39.3 22.735.6 | 106.2 | ||||||||||
表 2: 10样本视频描述生成结果。♠表示同期工作。报告的Flamingo [2]结果使用16样本。#VideoPT表示用于预训练的视频数量。B-4、R-L、M、$C$分别代表BLEU-4、ROUGE-L、METEOR和CIDEr。Avg $C$表示所有可用基准的平均CIDEr分数。ASR表示模型是否使用ASR字幕。$BLIP$和$BLIP_{cap}$分别使用COCO描述任务上的预训练检查点和微调检查点。所有结果为三次随机种子的平均值。
| 方法 | #VideoPT | ASR | MSR-VTTCaption | YouCook2Caption | VaTexCaption | Avg C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B-4 | R-L | M | C | B-4 | R-L | M | C | B-4 | R-L | M | |||
| 少样本 | |||||||||||||
| UniVL | 1.2M | No | 2.1 | 22.5 | 9.5 | 3.6 | 3.3 | 25.3 | 11.6 | 34.1 | 1.7 | 15.7 | 8.0 |
| BLIP | 0 | No | 27.7 | 43.0 | 23.0 | 39.5 | 0.7 | 9.0 | 3.4 | 11.5 | 13.5 | 39.5 | 15.4 |
| BLIPcap | 0 | No | 21.6 | 48.0 | 22.7 | 30.2 | 3.7 | 8.6 | 3.8 | 9.4 | 20.7 | 41.5 | 17.4 |
| VidIL(ours) | 0 | No | 26.0 | 51.7 | 24.7 | 36.3 | 2.6 | 22.9 | 9.5 | 27.0 | 22.2 | 43.6 | 20.0 |
| UniVL | 1.2M | Yes | 4.3 | 26.4 | 12.2 | 48.6 | 2.7 | 17.7 | 10.2 | ||||
| VidIL(ours) | 0 | Yes | 10.7 | 35.9 | 19.4 | 111.6 | 23.2 | 44.2 | 20.6 | ||||
| Flamingo-3B(16) | 27M | No | 73.2 | ||||||||||
| Flamingo-80B(16) | 27M | No | 84.2 | ||||||||||
| 微调 | |||||||||||||
| UniVL | 1.2M | No | 42.0 | 61.0 | 29.0 | 50.1 | 11.2 | 40.1 | 17.6 | 127.0 | 22.8 | 38.6 | 22.3 |
| UniVL | 1.2M | Yes | 16.6 | 45.7 | 21.6 | 176.8 | 23.7 | 39.3 | 22.7 |
As discussed in Section 1, video captions describe the content in various semantic levels. The N-gram based metric may not fairly reflect the models’ performance in capturing the video-caption alignment. We further verify this hypothesis in Section 4.5. Thus, in addition to automatic metrics, we include qualitative examples illustrated in Figure 4. More examples are in Appendix ??.
如第1节所述,视频字幕通过不同语义层级描述内容。基于N-gram的指标可能无法公平反映模型在捕捉视频-字幕对齐关系时的性能表现。我们将在第4.5节进一步验证这一假设。因此除自动指标外,我们还提供了图4展示的定性分析案例(更多示例见附录??)。
Additionally, for most existing methods and also concurrent work, e.g., Flamingo [2], adding a new modality often requires a dedicated model redesign or retraining. However, the nature of our framework, where we use a unified textual representation for each level, makes it highly flexible for incorporating new modalities. As shown in row 6 in Table, our model can effectively utilize extra information from ASR to obtain significantly better few-shot performance on certain datasets such as YouCook2.
此外,对于大多数现有方法及同期工作(如Flamingo [2]),新增模态通常需要专门重新设计模型或重新训练。然而,我们的框架采用统一文本表示处理各层级数据,这种特性使其在整合新模态时具有高度灵活性。如表第6行所示,我们的模型能有效利用ASR提供的额外信息,在YouCook2等特定数据集上实现显著提升的少样本性能。
| MSR-VTTCaption | YouCook2Caption | VaTexCaption | |
| drink up | XXXXXXX | ||
| Objects: First, interview. Then, cable television.Afterthat, televisionprogram. Finally,sportscommentator. Events:...Attributes:...FrameCaptions:... | Objects....Events....Attributes...Captions.... Subtitle:Nowoursausagesareprettymuch cooksgoingtotakethoseoutallthetime.And we'regoingtonow,mycatgravyassource. | Objects:...Events:...Attributes:First, tagging Then,woodburning.After that,wood burning Finally,turning on dial.Frame Captions:First,a pieceofwoodwithwordsdrinkupwrittenonit... | |
| UniVL:amanisplaying amanwithaman. BLIP:amaninasuitandtiesittingonacouch Ours:aninterviewwithasports commentator | UniVL:addthesausagestothepan Ours:takethesausagesoutofthepan andaddsomegravytotheplate | UniVL:you'rereadytodecorateyourcake BLIP:apersonholding a stringwitha small object in frontofthem Ours:Aperson is making a signthatsays"Drink Up"with a wood burning kit. | |
| GroundTruths: ·2menarediscussingsportsonatalkshow ·amanbeinginterviewedonatvshow | GroundTruth: ·removesausagesfrompan | GroundTruth:Someoneusesawoodburning tooltoburnadesignintoasliceofwoodand thenbeginstobrushpolyurethaneuntoit. |
| MSR-VTTCaption | YouCook2Caption | VaTexCaption | |
|---|---|---|---|
| drink up | XXXXXXX | ||
| 对象: 首先,采访。然后,有线电视。接着,电视节目。最后,体育评论员。事件:...属性:...帧标题:... | 对象....事件....属性...字幕.... 字幕:现在我们的香肠差不多煮好了,要一直把它们取出来。我们现在要,我的猫肉汁作为酱汁。 | 对象:...事件:...属性:首先,标记。然后,木材燃烧。接着,木材燃烧。最后,转动旋钮。帧标题:首先,一块写着"drink up"的木头... | |
| UniVL: 一个男人正在和另一个男人玩。 BLIP: 一个穿西装打领带的男人坐在沙发上 我们的: 对体育评论员的采访 | UniVL: 把香肠加入锅中 我们的: 把香肠从锅中取出并在盘子里加些肉汁 | UniVL: 你准备好装饰蛋糕了 BLIP: 一个人拿着绳子,前面有个小物件 我们的: 一个人正在用木材燃烧工具制作写着"Drink Up"的标牌。 | |
| 真实情况: ·2个男人在谈话节目中讨论体育 ·一个男人在电视节目中被采访 | 真实情况: ·从锅中取出香肠 | 真实情况: 有人用木材燃烧工具将设计烧在一块木片上,然后开始刷聚氨酯。 |
Figure 4: Qualitative examples on video captioning. Grey boxes contain part of the video representation from our model. Blue boxes contain caption generation from different models. Green boxes contain ground truth annotations. Bold green text highlights the correct information that is not captured in baseline outputs which can be reasoned from our visual tokens and frame captions.
图 4: 视频描述任务的定性示例。灰色框包含来自我们模型的部分视频表征。蓝色框包含不同模型的描述生成结果。绿色框包含真实标注。加粗绿色文字标出了基线输出未捕获、但可通过我们的视觉token和帧描述推理得出的正确信息。
4.3 Few-shot Video Question Answering
4.3 少样本视频问答
We compare the test accuracy of our approach with few-shot pretrained BLIP, ${\mathrm{BLIP}}_ {V Q A}$ [26], and concurrent work Flamingo [2] on two video question answering benchmarks, MSR-VTT_QA and MSVD_QA. ${\mathrm{BLIP}}_ {V Q A}$ represents finetuned BLIP on VQA [4] dataset, which is the previous SOTA on zero/few-shot video question answering. In order to have fairer comparison with ${\mathrm{BLIP}}_{V Q A}$ , we reduce the shot number to 5 and report the average accuracy on three sets of randomly selected 5-shot examples. As shown in Table 3, our method outperforms previous SOTA by a large margin. Comparing with concurrent work Flamingo, which is post-pretrained on a large number of video-text data, our model is training-free and did not observe any video data. However, with only imagelanguage and language-only knowledge, our 5-shot model is able to outperform 8-shot Flamingo-3B and achieve on-par performance with 4-shot Flamingo-80B.
我们在两个视频问答基准测试(MSR-VTT_QA和MSVD_QA)上,将本方法的测试准确率与少样本预训练的BLIP、${\mathrm{BLIP}}_ {V Q A}$[26]以及同期工作Flamingo[2]进行对比。${\mathrm{BLIP}}_ {V Q A}$代表在VQA[4]数据集上微调的BLIP模型,曾是视频问答零样本/少样本任务的先前最优方法(SOTA)。为与${\mathrm{BLIP}}_{V Q A}$进行更公平比较,我们将样本数降至5,并报告三组随机选取的5样本示例的平均准确率。如表3所示,本方法以显著优势超越先前SOTA。与基于海量视频文本数据后预训练的同期工作Flamingo相比,我们的模型无需训练且未接触任何视频数据。然而仅凭图像-语言和纯语言知识,我们的5样本模型即超越8样本Flamingo-3B,并与4样本Flamingo-80B性能持平。
Table 3: Video QA results. ${\mathrm{BLIP}}_{V Q A}$ is finetuned on VQA [4]. ♠ indicates concurrent work. PT, FT indicates pre training and finetuning.
| Method | #videopT | #videOFT | MSR-VTT | MSVD |
| BLIP | 0 | O-shot | 0.55 | 0.45 |
| BLIP | 0 | 5-shot | 0.84 | 0.53 |
| BLIPvQA [26] | 0 | O-shot | 19.2 | 35.2 |
| VidIL(ours) | 0 | 5-shot | 21.2 | 39.1 |
| Flamingo-3B [2] | 27M | 4-shot | 14.9 | 33.0 |
| Flamingo-3B [2] | 27M | 8-shot | 19.6 | 37.0 |
| Flamingo-80B [2] | 27M | 4-shot | 23.9 | 41.7 |
| Flamingo-80B [2] | 27M | 8-shot | 27.6 | 45.5 |
| ALPRO [25] | 2M | full-shot | 42.1 | 45.9 |
表 3: 视频问答结果。${\mathrm{BLIP}}_{V Q A}$在VQA [4]上进行了微调。♠表示同期工作。PT、FT分别表示预训练和微调。
| 方法 | #视频PT | #视频FT | MSR-VTT | MSVD |
|---|---|---|---|---|
| BLIP | 0 | 零样本 | 0.55 | 0.45 |
| BLIP | 0 | 少样本(5-shot) | 0.84 | 0.53 |
| BLIPvQA [26] | 0 | 零样本 | 19.2 | 35.2 |
| VidIL(ours) | 0 | 少样本(5-shot) | 21.2 | 39.1 |
| Flamingo-3B [2] | 27M | 少样本(4-shot) | 14.9 | 33.0 |
| Flamingo-3B [2] | 27M | 少样本(8-shot) | 19.6 | 37.0 |
| Flamingo-80B [2] | 27M | 少样本(4-shot) | 23.9 | 41.7 |
| Flamingo-80B [2] | 27M | 少样本(8-shot) | 27.6 | 45.5 |
| ALPRO [25] | 2M | 全样本(full-shot) | 42.1 | 45.9 |
Table 4: Accuracy $(%)$ on VLEP hidden test set.
| Method | #videOFT | Acc |
| VLEP[23] MERLOT [68] | 20142 20142 | 67.5 68.4 72.0 |
| VidIL(ours) Human | 10-shot | 90.5 |
表 4: VLEP隐藏测试集上的准确率 $(%)$
| 方法 | #videOFT | Acc |
|---|---|---|
| VLEP[23] MERLOT[68] | 20142 20142 | 67.5 68.4 72.0 |
| VidIL(ours) Human | 10-shot | 90.5 |
4.4 Few-shot Video-Language Event Prediction
4.4 少样本视频语言事件预测
In this section, we show that our model not only can answer questions about the video visual features but also answering "What is more likely to happen next?". Given a video with associated subtitle transcript as premise, the video-language event prediction (VLEP) task is to predict the most likely future event. The original VLEP [23] paper formulates the problem as a binary classification problem where the model will be chosen from two possible future event candidates. Instead, we formulate this problem as another video-to-text generation problem to fit into our framework. Figure 5 depicts an example with the same format as in Figure 2. Similar to the evaluation setting in QA, the generated free-form text will first be mapped to one of the two candidate answers using Sentence Bert [47], and then calculate the accuracy. In Table 4, we report accuracy on the hidden test set of VLEP [23]. To our surprise, our 10-shot model outperforms state-of-the-art fully-supervised baseline, i.e., MERLOT [68], by a large margin $(\sim4%)$ . This shows that our model has strong few-shot ability not only on videolanguage understanding but also on prediction. Since event prediction tasks rely heavily on temporal ordering, we show that with the proposed temporal-aware prompting, language models can be guided to capture temporal dynamics between historical and future events.
在本节中,我们展示了我们的模型不仅能回答关于视频视觉特征的问题,还能回答"接下来更可能发生什么?"。给定一个带有相关字幕文本的视频作为前提,视频语言事件预测 (VLEP) 任务旨在预测最可能发生的未来事件。原始 VLEP [23] 论文将该问题表述为一个二分类问题,模型需要从两个可能的未来事件候选中进行选择。而我们则将该问题重新表述为另一个视频到文本生成问题,以适配我们的框架。图 5 展示了一个与图 2 格式相同的示例。与问答任务中的评估设置类似,生成的自由形式文本将首先使用 Sentence Bert [47] 映射到两个候选答案之一,然后计算准确率。在表 4 中,我们报告了 VLEP [23] 隐藏测试集上的准确率。令人惊讶的是,我们的 10-shot 模型以显著优势 $(\sim4%)$ 超越了当前最先进的完全监督基线方法 MERLOT [68]。这表明我们的模型不仅在视频语言理解方面,在预测任务上也具有强大的少样本能力。由于事件预测任务严重依赖时间顺序,我们证明了通过提出的时间感知提示 (temporal-aware prompting) ,可以引导语言模型捕捉历史事件与未来事件之间的时间动态关系。

Figure 5: Prompt for VLEP task.
图 5: VLEP任务提示模板。
4.5 Semi-supervised Text-Video Retrieval
4.5 半监督文本-视频检索
In addition to video-to-text generation tasks, we show that a broader range of video-language tasks can benefit from our few-shot video captioner from a data perspective. Here, we consider a lowbudget semi-supervised setting where we only have a few labeled video-caption pairs and a large amount of unlabeled videos. The idea is to leverage our video captioner to generate pseudo labels for training any given vision-language models. As a case study, we evaluate on two text-video retrieval benchmarks, i.e., MSR-VTT and VaTeX. We use greedy decoding to generate pseudo caption for each video in the training set. We then train an identical base model, i.e., BLIP, using different pseudo labeled data as well as ground truth annotations. We report Recall $@$ 1 and 5 for both video-to-text and text-to-video retrieval. Table 5 shows that through training on our pseudo labels, we can achieve significant improvements compared with zero-shot BLIP. We also show that the performance gain is not simply a result of training on more data, since finetuning on the pseudo labels generated by other baselines (UniVL, BLIP) is less effective and can even hurt the performance. Furthermore, on MSR-VTT Recall $@$ 5 we can even achieve comparable performance against BLIP model finetuned on full ground truth annotations.
除了视频到文本生成任务外,我们还从数据角度证明更广泛的视频语言任务能受益于我们的少样本视频描述生成器。在此,我们考虑一种低预算半监督场景:仅拥有少量带标注的视频-描述对和大量未标注视频。核心思路是利用我们的视频描述生成器为任意给定视觉语言模型生成伪标签用于训练。作为案例研究,我们在MSR-VTT和VaTeX两个文本-视频检索基准上评估:使用贪心解码为训练集中每个视频生成伪描述,随后采用相同基础模型(BLIP)分别使用不同伪标签数据及真实标注进行训练。表5显示,通过伪标签训练相比零样本BLIP能取得显著提升。我们同时证明性能增益并非单纯源于更多训练数据,因为基于其他基线模型(UniVL、BLIP)生成的伪标签进行微调效果较差甚至可能损害性能。此外在MSR-VTT的Recall@5指标上,我们甚至能达到与完整真实标注微调的BLIP模型相当的性能。
Table 5: Semi-supervised text-video retrieval with 10 labeled examples. $\mathrm{V_{label}}$ or $\mathrm{V_{unlabel}}$ are the number of labeled and unlabeled videos, respectively. $t_R I$ and $t_R$ denote video-to-text Recall $@1$ and 5. $\nu_R I$ and $\nu_R5$ denote text-to-video Recall $@1$ and 5.
| Model | PseudoLabel | MSR-VTTRetrieval | VaTexRetrieval | ||||||||
| Vlabel/ unlabel | t_R1 t_R5 v_R1 v_R5 | Vlabel/Vunlabel | t_R1 t_R5v_R1 v_R5 | ||||||||
| BLIP | 33.2 | 57.2 | 40.5 | 62.8 | 28.2 | 53.4 | 34.0 | 58.6 | |||
| BLIP | UniVL | 10/7010 | 33.1 | 57.3 | 33.6 | 57.7 | 10/22685 | 25.5 | 47.7 | 26.1 | 49.1 |
| BLIP | BLIP | 10/7010 | 35.6 | 60.8 | 39.8 | 60.4 | 10/22685 | 26.3 | 50.5 | 29.3 | 53.6 |
| BLIP | BLIPcap | 10/7010 | 35.3 | 58.0 | 39.1 | 63.3 | 10/22685 | 23.9 | 46.8 | 27.5 | 49.7 |
| BLIP | VidIL(ours) | 10/7010 | 39.6 | 64.5 | 40.8 | 65.2 | 10/22685 | 33.3 | 59.1 | 33.7 | 59.5 |
| BLIP | Ground Truth | 7010/0 | 43.6 | 66.2 | 43.1 | 67.2 | 22685/0 | 40.1 | 66.4 | 40.1 | 66.6 |
| ALPRO[25] | GroundTruth | 140200/0 | 32.0 | 60.6 | 33.9 | 60.7 | |||||
| DRL [56] | GroundTruth | 180000/0 | 54.1 | 77.4 | 52.9 | 78.5 | |||||
表 5: 使用10个标注样本的半监督文本-视频检索。$\mathrm{V_{label}}$ 和 $\mathrm{V_{unlabel}}$ 分别表示标注和未标注视频的数量。$t_R I$ 和 $t_R$ 表示视频到文本的召回率 $@1$ 和5。$\nu_R I$ 和 $\nu_R5$ 表示文本到视频的召回率 $@1$ 和5。
| 模型 | PseudoLabel | MSR-VTTRetrieval | VaTexRetrieval | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Vlabel/unlabel | t_R1 t_R5 v_R1 v_R5 | Vlabel/Vunlabel | t_R1 t_R5v_R1 v_R5 | ||||||
| BLIP | 33.2 | 57.2 | 40.5 | 62.8 | 28.2 | 53.4 | |||
| BLIP | UniVL | 10/7010 | 33.1 | 57.3 | 33.6 | 57.7 | 10/22685 | 25.5 | 47.7 |
| BLIP | BLIP | 10/7010 | 35.6 | 60.8 | 39.8 | 60.4 | 10/22685 | 26.3 | 50.5 |
| BLIP | BLIPcap | 10/7010 | 35.3 | 58.0 | 39.1 | 63.3 | 10/22685 | 23.9 | 46.8 |
| BLIP | VidIL(ours) | 10/7010 | 39.6 | 64.5 | 40.8 | 65.2 | 10/22685 | 33.3 | 59.1 |
| BLIP | Ground Truth | 7010/0 | 43.6 | 66.2 | 43.1 | 67.2 | 22685/0 | 40.1 | 66.4 |
| ALPRO[25] | GroundTruth | 140200/0 | 32.0 | 60.6 | 33.9 | 60.7 | |||
| DRL [56] | GroundTruth | 180000/0 | 54.1 | 77.4 | 52.9 | 78.5 |
Another interesting observation is that, compared with the video captioning results in Table 2, we found that the gain of our model over baselines on text-video retrieval is more visible than on captioning. A key factor in performing well on text-video retrieval tasks is to learn a good video-text multi-modal alignment. This result shows that our pseudo labels capture richer video-text alignment that can benefit the retrieval-style downstream task. The N-gram based generation metrics, e.g., BLEU, may not be able to fully reflect the alignment information, due to the variety of semantic levels in video captions. Furthermore, from a data perspective, our video captioner can be viewed as a data augmentation tool which is capable of generating or augmenting any open-domain videolanguage pre training datasets with minimal human effort. As a result, we can potentially improve video-language pre training by constructing a cleaner and more diverse video-text corpus.
另一个有趣的观察是,与表2中的视频描述结果相比,我们发现模型在文本-视频检索任务上相对于基线的提升比在描述任务上更为显著。在文本-视频检索任务中表现良好的关键因素是学习良好的视频-文本多模态对齐。这一结果表明,我们的伪标签捕获了更丰富的视频-文本对齐信息,能够有益于检索式下游任务。基于N-gram的生成指标(如BLEU)可能无法充分反映对齐信息,因为视频描述存在多种语义层次。此外,从数据角度来看,我们的视频描述器可视为一种数据增强工具,能够以最少人力生成或扩充任何开放域的视频-语言预训练数据集。因此,我们有望通过构建更干净、更多样化的视频-文本语料库来改进视频-语言预训练。
Table 6: Impact of visual tokens and temporal dimension.
| Video Representation | Avg↑ ↑pis | |
| Visual Token | Frame Frame+Object | 39.6 3.7 40.3 2.9 |
| Frame+Object+Event Frame+Object+Attibute | 39.9 2.8 40.9 2.9 | |
| Temporal | Reducetooneframe Reversetemporal order | 38.5 2.4 40.7 1.7 |
表 6: 视觉token和时间维度的影响
| 视频表示 | 平均↑ ↑pis | |
|---|---|---|
| 视觉Token | 帧 帧+物体 | 39.6 3.7 40.3 2.9 |
| 帧+物体+事件 帧+物体+属性 | 39.9 2.8 40.9 2.9 | |
| 时间维度 | 缩减为单帧 反转时间顺序 | 38.5 2.4 40.7 1.7 |
Table 7: Impact of shot selection. $#I C E$ indicates the number of in-context examples in the prompt. Details of in-context example selection are in the Appendix.
| #shot | w/oselection | w/selection | |||
| #ICE | Avg↑ | ↑ps | #ICE | Avg↑ ↑pis | |
| 5 | 5 | 38.4 | 2.1 | 5 40.4 | 1.2 |
| 10 | 10 | 41.3 3.6 | 5 40.8 | 2.4 | |
| 20 | 20 | 42.6 3.3 | 5 42.2 | 2.0 | |
| 30 | 30 | 40.0 | 2.9 | 5 41.1 | 1.9 |
表 7: 样本选择的影响。$#I C E$表示提示中上下文示例的数量。上下文示例选择的详细信息见附录。
| #shot | w/oselection | w/selection | |||
|---|---|---|---|---|---|
| #ICE | Avg↑ | ↑ps | #ICE | Avg↑ ↑pis | |
| 5 | 5 | 38.4 | 2.1 | 5 | 40.4 1.2 |
| 10 | 10 | 41.3 3.6 | 5 | 40.8 2.4 | |
| 20 | 20 | 42.6 3.3 | 5 | 42.2 2.0 | |
| 30 | 30 | 40.0 | 2.9 | 5 | 41.1 1.9 |
4.6 Ablation Studies
4.6 消融实验
We perform comprehensive ablation studies on our few-shot prompt including the impact of different video representation, number of shots and in-context selection. All the ablation results are evaluated on MSVD_QA validation set, and we report the mean and standard deviation of each setting on three sets of randomly sampled shots. For the cases with in-context example selection, we further select 5 examples as in-context examples from the sampled shots, while for the cases without in-context selection, all shots will be feed into the prompt. In Table 6, we show adding visual tokens consistently improves not only the model accuracy but also the model variance. A lower standard deviation indicates that the model is less sensitive to the few-shot sampling.
我们对少样本提示进行了全面的消融研究,包括不同视频表示方式、样本数量以及上下文选择的影响。所有消融结果均在MSVD_QA验证集上评估,并报告了三组随机采样样本的均值与标准差。对于包含上下文示例选择的情况,我们从采样样本中额外选取5个示例作为上下文示例;若不进行上下文选择,则所有样本均会输入提示。表6显示,添加视觉token不仅能持续提升模型准确率,还能降低模型方差。较小的标准差表明模型对少样本采样的敏感性更低。
To further demonstrate the impact of the additional temporal dimension of videos, we perform two ablations on the "Frame+Object+Event+Attribute" setting. First, we reduce the number of frame captions and visual tokens to be one9 for each video. We found that the performance drops significantly compared with using the default four frames, which indicates the model’s ability to incorporate information from multiple timestamps. Further, we found that fine-grained temporal modeling is rarely required for performing well on current video-language benchmarks. As shown in the ablation result where we reverse the order of all visual tokens and frame captions, the performance decreased only marginally, which indicates that current benchmarks may not be sufficient in reflecting the benefits from better temporal ordering.
为了进一步展示视频额外时间维度的影响,我们在"帧+对象+事件+属性"设置下进行了两项消融实验。首先,我们将每段视频的帧描述和视觉token数量减少至一个9。与使用默认四帧相比,性能显著下降,这表明模型具备整合多时间戳信息的能力。此外,我们发现当前视频语言基准测试很少需要细粒度的时间建模。如消融实验结果显示:当反转所有视觉token和帧描述的顺序时,性能仅轻微下降,这表明现有基准测试可能不足以体现更好时间排序带来的优势。
In Table 7, we first show that, with the same context length, namely, 5 in-context examples, in-context example selection significantly increases the performance as well as the robustness. At 10-shot, and 20-shot, directly fitting more shots into the prompt results in better performance. In-context selection achieves slightly lower performance but with significantly better efficiency due to shorter context. Interestingly, at 30-shot, in-context selection with 5 examples outperforms directly adding all 30 shots into the prompt. This is showing that in-context selection can help the model utilize a larger number noisy video examples. Nevertheless, we still observe that the benefit of adding more shots saturated at around 20 to 30 shots, even if with in-context selection. we view this as a remaining challenging on how to make language models benefit from longer contexts.
在表7中,我们首先展示,在相同上下文长度(即5个上下文示例)的情况下,上下文示例选择能显著提升性能及鲁棒性。在10样本和20样本条件下,直接在提示中填入更多样本会带来更好的性能表现。上下文选择方案虽性能略低,但由于上下文更短而具有显著更高的效率。有趣的是,在30样本条件下,仅用5个示例的上下文选择方案反而优于直接将30个样本全部填入提示。这表明上下文选择能帮助模型更好地利用大量含噪声的视频示例。不过我们仍观察到,即使采用上下文选择,增加样本数量带来的收益在20至30样本区间就会趋于饱和。我们认为这仍是关于如何让大语言模型从更长上下文中获益的待解难题。
5 Conclusions, Limitations and Future Work
5 结论、局限性与未来工作
This paper proposes VidIL, a few-shot Video-language Learner via Image and Language models. It demonstrates the strong ability of large-scale language models on performing video-to-text tasks when frame features are provided as unified text representations using image-language models. We propose a temporal order aware prompt by decomposing videos into a hierarchical structure, which is able to plug in multiple levels of frame features, along with speech transcripts. Without pre training on videos, our model outperforms vision-language models learned from large-scale video datasets on a variety of few-shot tasks, such as domain-specific captioning, question answering, and future event prediction. One limitation of using unified textual representation is that we might lose low-level visual features which can be essential for some specific tasks, such as fine-grained spatial visual question answering. We also observe that current video-language benchmarks rarely require explicit temporal tracking on the frames and visual tokens. Future work will focus on leveraging large-scale language models for learning script knowledge from long videos where temporal dynamics are better emphasized.
本文提出VidIL,一种通过图像和语言模型实现的少样本视频-语言学习器。研究证明,当使用图像-语言模型将视频帧特征转换为统一文本表征时,大语言模型在视频到文本任务中展现出强大能力。我们提出一种时序感知提示方法,通过将视频分解为层次结构,可融入多级帧特征及语音文本。无需视频预训练,该模型在领域特定字幕生成、问答和未来事件预测等多种少样本任务上,表现优于基于大规模视频数据集训练的视觉-语言模型。使用统一文本表征的局限在于可能丢失底层视觉特征,这对细粒度空间视觉问答等特定任务至关重要。我们还发现当前视频-语言基准测试很少要求对帧和视觉token进行显式时序追踪。未来工作将聚焦于利用大语言模型从更强调时序动态的长视频中学习脚本知识。
6 Broader Impact
6 更广泛的影响
An open-domain few-shot video-language learner has a wide range of beneficial applications for society, such as automatically detecting violent or mature content in videos and helping people with vision impairment understand videos. However, since the language model is pretrained on massive internet-scale text data, there might be unexpected output that can have potential negative impact on the society, such as bias against people of a certain gender, race or sexuality. Future work and dedicated collaboration from the community are needed to alleviate the potential negative societal impact of large language models.
开放域少样本视频-语言学习器对社会具有广泛有益应用,例如自动检测视频中的暴力或成人内容,以及帮助视障人士理解视频内容。然而,由于大语言模型是在海量互联网文本数据上预训练的,可能会产生具有潜在社会负面影响的意外输出,例如针对特定性别、种族或性取向人群的偏见。未来需要通过社区协作来减轻大语言模型潜在的负面社会影响。
Acknowledgements
致谢
We thank the anonymous reviewers helpful suggestions. This research is based upon work supported in part by U.S. DARPA AIDA Program No. FA8750-18-2-0014 and U.S. DARPA KAIROS Program Nos. FA8750-19-2-1004. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of DARPA, or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for governmental purposes notwithstanding any copyright annotation therein.
感谢匿名评审提出的宝贵建议。本研究部分工作得到了美国DARPA AIDA项目(编号FA8750-18-2-0014)和美国DARPA KAIROS项目(编号FA8750-19-2-1004)的支持。文中所述观点和结论仅代表作者立场,不应被解释为DARPA或美国政府的官方政策或立场(无论明示或暗示)。美国政府有权为官方目的复制和分发本研究报告,不受文中任何版权标注限制。
[45] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. ArXiv preprint, abs/1910.10683, 2019. 1
[45] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu. 探索迁移学习的极限:基于统一文本到文本Transformer的研究。ArXiv预印本,abs/1910.10683,2019。1