USING EXTERNAL OFF-POLICY SPEECH-TO-TEXT MAPPINGS IN CONTEXTUAL END-TO-END AUTOMATED SPEECH RECOGNITION
在上下文端到端自动语音识别中使用外部非策略语音到文本映射
David M. Chan⋆† Shalini Ghosh† Ariya Rastrow† Bjorn Hoff meister t
David M. Chan⋆† Shalini Ghosh† Ariya Rastrow† Bjorn Hoffmeister t
⋆ University of California, Berkeley † Amazon Alexa AI
⋆ 加州大学伯克利分校 † Amazon Alexa AI
ABSTRACT
摘要
Despite improvements to the generalization performance of automated speech recognition (ASR) models, specializing ASR models for downstream tasks remains a challenging task, primarily due to reduced data availability (necessitating increased data collection), and rapidly shifting data distributions (requiring more frequent model fine-tuning). In this work, we investigate the potential of leveraging external knowledge, particularly through off-policy key-value stores generated with text-to-speech methods, to allow for flexible post-training adaptation to new data distributions. In our approach, audio embeddings captured from text-to-speech, along with semantic text embeddings, are used to bias ASR via an approximate k-nearest-neighbor (KNN) based attentive fusion step. Our experiments on Lib iri Speech and in-house voice assistant/search datasets show that the proposed approach can reduce domain adaptation time by up to 1K GPU-hours while providing up to $3%$ WER improvement compared to a fine-tuning baseline, suggesting a promising approach for adapting production ASR systems in challenging zero and few-shot scenarios.
尽管自动语音识别(ASR)模型的泛化性能有所提升,但为下游任务定制ASR模型仍具挑战性,主要归因于数据可用性降低(需增加数据收集)和数据分布快速变化(需更频繁的模型微调)。本研究探索了利用外部知识的潜力,特别是通过文本转语音(TTS)方法生成的离线策略键值存储,以实现对新数据分布的灵活训练后适配。我们的方法采用从TTS获取的音频嵌入和语义文本嵌入,通过基于近似k最近邻(KNN)的注意力融合步骤来偏置ASR模型。在LibriSpeech和内部语音助手/搜索数据集上的实验表明,相比微调基线,该方法可减少高达1K GPU小时的领域适配时间,同时实现最高3%的词错误率(WER)提升,这为在具有挑战性的零样本和少样本场景中适配生产级ASR系统提供了可行方案。
Index Terms— speech recognition, transfer learning, finetuning, adaptation, context
关键词— 语音识别、迁移学习、微调、适应、上下文
1 Introduction
1 引言
One of the most challenging problems in automated speech recognition (ASR) is specializing large-scale models, particularly speech encoders, for downstream applications that often (a) have fewer labeled training examples, and (b) rapidly evolving distributions of speech data. The traditional approach to this problem is to frequently collect fresh data, which can be used to re-train and specialize models, leveraging tools such as domain-prompts [1], incremental-learning [2], knowledge distillation [3], hand-written grammars [4], or metric learning [5, 6] to reduce the impact of re-training the model for the downstream application. Unfortunately, for data that changes on a rapid basis, such as product listings or applications requiring per-customer specialization, such methods, while effective, are either inherently slow or remain computationally infeasible.
自动语音识别(ASR)领域最具挑战性的问题之一,是针对下游应用定制大规模模型(尤其是语音编码器)。这些应用通常具有两个特征:(a)标注训练样本较少,(b)语音数据分布快速演变。传统解决方案需要频繁采集新数据,通过领域提示[1]、增量学习[2]、知识蒸馏[3]、手写语法[4]或度量学习[5,6]等工具重新训练和定制模型,以降低模型重训练对下游应用的影响。然而对于快速变化的数据(如产品列表或需要客户级定制的应用),这些方法虽然有效,但本质上速度缓慢或计算成本过高。
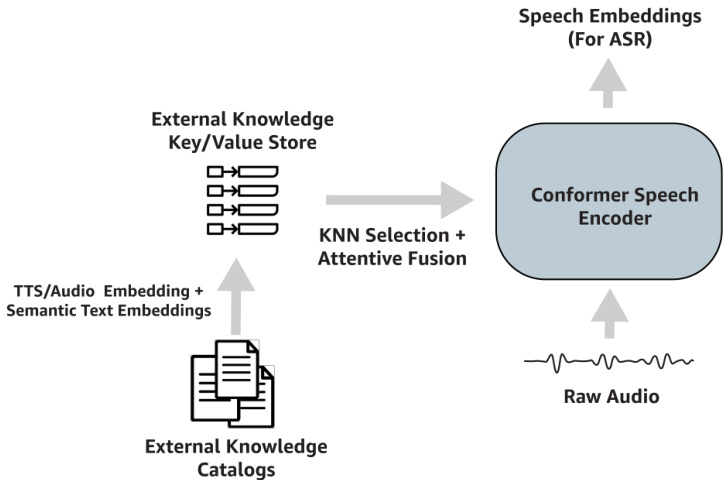
Fig. 1: An overview of our method leveraging text-to-speech mappings for contextual ASR. Using data from a text catalog, we generate audio and text representations to generate mappings from audio key to text value. To leverage these mappings for ASR, we implement a K-Nearest Neighbors attention in the speech encoder during the fine-tuning (or training) phase.
图 1: 我们利用文本到语音映射实现上下文ASR的方法概览。通过文本目录数据生成音频和文本表征,建立从音频键到文本值的映射关系。为了在ASR中应用这些映射,我们在微调(或训练)阶段的语音编码器中实现了K近邻注意力机制。
In this work, we propose a method that leverages external text data catalogs – large lists that can contain as much as 10 million specialized words or phrases – to improve the performance of models during both the fine-tuning process, and when specializing an already fine-tuned model to a new dataset. Here are the key highlights of our approach: first, we generate a key-value external knowledge store that maps an audio representation of each text element of the catalog (usually consisting of 1M-10M examples) to a semantic representation of the text. Next, we train a model that leverages this external store by attending over retrieved key/value pairs, which we retrieve through approximate $\mathbf{k}$ -nearest neighbors. Relying on an external, constant, and off-policy key-value store means that this store can be updated during specialization, requiring only an updated list of phrases for each new model instead of additional fine-tuning.
在本工作中,我们提出了一种利用外部文本数据目录(包含多达1000万个专业词汇或短语的大型列表)的方法,以提升模型在微调过程及将已微调模型适配到新数据集时的性能。我们方法的核心亮点包括:首先,我们构建了一个键值外部知识库,将目录中每个文本元素(通常包含100万至1000万样本)的音频表征映射到其语义表征。接着,我们训练了一个模型,通过关注检索到的键值对来利用这个外部知识库,这些键值对通过近似 $\mathbf{k}$ 近邻算法检索得到。依赖一个外部、恒定且离线的键值存储意味着该存储可以在适配过程中更新,仅需为每个新模型提供更新的短语列表,而无需额外微调。
Inspired by Borgeaud et al. [7] and Wu et al. [8], we apply a context embedding approach with a focus on ASR, leveraging TTS-generated audio data and semantic text embeddings to bias the speech encoder of a conformer model. To the best of our knowledge, using TTS to encode textual context has not
受 Borgeaud 等人 [7] 和 Wu 等人 [8] 的启发,我们采用了一种专注于自动语音识别 (ASR) 的上下文嵌入方法,利用文本转语音 (TTS) 生成的音频数据和语义文本嵌入来偏置 conformer 模型的语音编码器。据我们所知,使用 TTS 编码文本上下文尚未...
been explored in prior work.
先前工作中已有探索。
Our key contributions are three-fold:
我们的主要贡献有三方面:
2 Related Work
2 相关工作
Leveraging additional context to improve the performance of the decoder and joint model, particularly through deep fusion techniques in ASR transducers has been relatively well studied [9, 10, 11, 12, 13, 14, 15, 16, 17]. The majority of these approaches are composed of two components: (1) a method for retrieving local contextual clues for an utterance and (2) a method for fusing these contextual clues with the joint model or decoder in the transducer stack, and differ based on how they implement these two components. Our work has several key differentiating factors. We primarily focus on deepbiasing of the speech encoder, rather than a shallow fusion of a context network with the speech decoder, or re-ranking of candidates produced by the language model. While in theory, approaches like Sathyendra et al. [18] could be applied as deep fusion approaches, those directions are left unexplored in the referenced work, and indeed, as we demonstrate in Table 2, deep fusion is an important differentiating factor in the quality of the contextual learning technique. Additionally, we focus on large contexts $\mathit{\Omega}^{\prime}>10K$ context entries), in an effort to explore applications in domain specialization, whereas existing biasing methods are often focused on personalization, and operate on contexts of at most $1K$ context entries (and in many cases, operate on $<100$ context entries). Again, while in theory the above methods could be applied to larger contexts, we find that there is a strong implementation al gap required, including work in scaling, and questions about efficiency (which we address in section 4).
利用额外上下文提升解码器和联合模型性能的研究已相对成熟,这尤其体现在ASR传感器中的深度融合技术上 [9, 10, 11, 12, 13, 14, 15, 16, 17]。这些方法主要由两部分组成:(1) 为语句检索局部上下文线索的方法;(2) 将这些上下文线索与传感器栈中的联合模型或解码器相融合的方法,不同方法的差异体现在这两部分的实现方式上。我们的工作有几个关键区别点:主要聚焦于语音编码器的深度偏置技术,而非上下文网络与语音解码器的浅层融合,或对语言模型生成候选的重排序。虽然理论上Sathyendra等人 [18] 的方法可作为深度融合方案应用,但参考文献中未探索该方向。如表2所示,深度融合确实是上下文学习技术质量的重要差异化因素。此外,我们专注于大规模上下文 ($\mathit{\Omega}^{\prime}>10K$ 上下文条目),以探索领域专业化应用,而现有偏置方法多聚焦个性化场景,最多处理 $1K$ 上下文条目(多数情况下处理 $<100$ 条目)。尽管上述方法理论上可扩展至更大上下文,但我们发现存在显著的实现鸿沟,包括扩展性优化和效率问题(第4章将探讨)。
While late-stage fusion and biasing of the decoder and joint model have been well explored, biasing the speech encoder itself, particularly using early/deep-fusion approaches, remains an under-explored area of research. The closest work to our proposed model was presented by Chen et al. [19], who use attention over a local set of LSTM-based grapheme/phoneme embeddings to augment the audio encoder. They found that biasing the encoder with only 40 contextual text entities per utterance leads to improvements of up to $75%$ on specialized test datasets. Similarly, Sathyendra et al. [18] and Chang et al. [20] demonstrate WER reductions when small $(<100)$ contexts are fused in an attention-based process with both the speech and language model. Our method differs in that it is designed primarily for domain specialization, whereas existing biasing methods are focused on personalization. This is shown foremost in the scale of the catalogs – while in prior work, each utterance may have at most 100 utterances in their context, we leverage catalogs with up to 10M samples. Thus, our models are designed to compensate for general domain shift, rather than local personalized improvements to ASR performance. Additionally, our work allows fully off-policy specialization. In existing works, context is re-encoded during each inference pass, leaving few opportunities for caching intermediate results. Our contexts are computed entirely offline; updates to the catalog do not impact model training, and thus, generating specialized catalogs can thus be done in a parallel work-stream from model development.
虽然解码器和联合模型的后期融合及偏置技术已得到充分研究,但针对语音编码器本身的偏置(尤其是采用早期/深度融合方法)仍是探索不足的领域。与我们提出的模型最接近的是Chen等人[19]的工作,他们通过对基于LSTM的字符/音素嵌入进行局部注意力计算来增强音频编码器。研究发现,当每句话仅使用40个上下文文本实体对编码器进行偏置时,在专项测试数据集上最高可获得75%的性能提升。类似地,Sathyendra等人[18]和Chang等人[20]证明,在基于注意力的过程中融合少量(<100)上下文时,语音模型和语言模型都能实现WER(词错误率)降低。我们的方法不同之处在于:它主要针对领域专业化设计,而现有偏置方法聚焦于个性化。这首先体现在数据规模上——先前研究中每句话的上下文最多包含100条语句,而我们使用的目录样本量高达1000万条。因此,我们的模型旨在补偿通用领域的偏移,而非针对ASR性能进行局部个性化改进。此外,我们的工作实现了完全离轨(off-policy)专业化。现有方法需要在每次推理时重新编码上下文,几乎无法缓存中间结果。而我们的上下文完全离线计算,目录更新不影响模型训练,因此专业化目录生成可与模型开发并行推进。
It is not unreasonable to believe that transformers in ASR will benefit from extended contexts. In the NLP field Vaswani et al. [21] showed that with longer memory attention contexts, transformers perform better, and a family of approaches, including Dai et al. [22], and Child et al. [23] have focused on increasing the length of the available context in each natural language sequence. The prevailing issue with long contexts is efficiency – since transformers have quadratic scaling in the length of the context. To reduce the processing time, approaches such as Dai et al. [22] and Child et al. [23] focused on computing gradients through only a subset of the full context, rather than the whole context to save memory and compute. Such an approach is codified by Wu et al. [8], who recently demonstrated that expanding the context of standard text transformers through a large memory bank of cached external keyvalue pairs can lead to significant perplexity improvements on the standard language modeling task. Wu et al. [8] retrieve the most relevant context elements using a K-NN approach, and only back-propagate through these components. While the lookup may encourage some off-policy drift, the approach is effective, and allows for significantly increased performance, particularly in copy-tasks, which require the model to point at specific prior elements, which may not be accessible in models with smaller contexts.
相信Transformer在自动语音识别(ASR)中会受益于扩展上下文并非没有道理。在自然语言处理领域,Vaswani等人[21]表明,随着记忆注意力上下文的延长,Transformer表现更好,包括Dai等人[22]和Child等人[23]在内的一系列方法都专注于增加每个自然语言序列中可用上下文的长度。长上下文的主要问题在于效率——因为Transformer在上下文长度上具有二次缩放特性。为了减少处理时间,Dai等人[22]和Child等人[23]的方法专注于仅通过完整上下文的一个子集而非整个上下文来计算梯度,以节省内存和计算资源。Wu等人[8]将这种方法规范化,他们最近证明,通过缓存外部键值对的大型记忆库扩展标准文本Transformer的上下文,可以在标准语言建模任务上显著降低困惑度。Wu等人[8]使用K近邻(K-NN)方法检索最相关的上下文元素,并仅通过这些组件进行反向传播。虽然查找过程可能会导致一些策略偏离,但该方法有效且能显著提高性能,特别是在需要模型指向特定先前元素的复制任务中,这些元素在较小上下文的模型中可能无法访问。
Does extended context help when the context is external, or even, orthogonal to the current utterance? There seems to be some evidence to that effect, as outside of the standard ASR pipeline, it has been shown that models augmented with external memory generated from large-scale text data have the potential to outperform similarly sized models without external knowledge. Borgeaud et al. [7] recently demonstrated that leveraging external-knowledge lookup from a database of natural language sentences, can lead to efficiency improvements of up to $25\mathrm{x}$ across a wide range of pure language tasks from language modeling to question-answering. Similarly, knowledge-augmented learning has been shown to be widely effective for QA [24, 25], image captioning [26] and other tasks [27, 28, 29, 30, 31, 32].
当上下文是外部的,甚至与当前话语正交时,扩展上下文是否有帮助?似乎有一些证据支持这一点,因为在标准ASR流程之外,研究表明,通过从大规模文本数据生成的外部记忆增强的模型,有可能在性能上超越没有外部知识的类似规模模型。Borgeaud等人[7]最近证明,利用从自然语言句子数据库中查找外部知识,可以在从语言建模到问答的各种纯语言任务中实现高达$25\mathrm{x}$的效率提升。同样,知识增强学习已被证明在问答[24, 25]、图像描述[26]和其他任务[27, 28, 29, 30, 31, 32]中广泛有效。
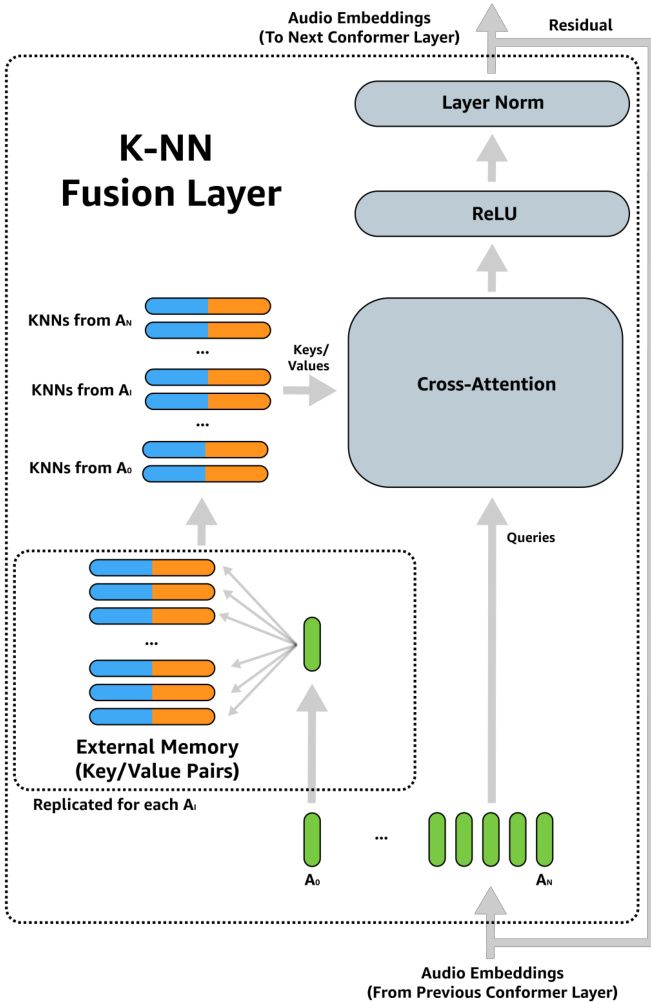
Fig. 2: Overview of the K-NN fusion layer. For each audio frame embedding, we extract approximate KNNs using audio keys from our catalog. These KNNs form a context key/value store for a standard cross-attention layer [21], where the queries are the incoming audio frame embeddings.
图 2: K-NN融合层概述。对于每个音频帧嵌入(embedding),我们使用目录中的音频键(key)提取近似KNN。这些KNN构成了标准交叉注意力层(cross-attention layer) [21]的上下文键/值存储(key/value store),其中查询(query)是传入的音频帧嵌入。
3 Methods
3 方法
An overview of our method is given in Figure 1. Our approach consists of two key components: (1) A method for generating key-value mappings between the audible speech and a text represent ation of the catalog, which we call an “external memory” and (2) An attention-based module for fusing the “external memory” with the existing speech encoder. It is important that the external memory is able to be updated offline, and off-policy, as such a memory can be altered in a low-cost way, without incurring re-training costs.
我们的方法概览如图 1 所示。该方法包含两个关键组件:(1) 一种在可听语音与目录文本表征之间生成键值映射的方法,我们称之为"外部记忆";(2) 一个基于注意力机制的模块,用于将"外部记忆"与现有语音编码器融合。外部记忆必须支持离线更新和离线策略更新,这样就能以低成本方式修改记忆,而无需承担重新训练的开销。
3.1 Generating the External Memory
3.1 生成外部存储器
An overview of the external-memory generation process is shown in Figure 3. Our approach generates the external memory consisting of audio-embedding key/text-embedding value pairs from a text-only catalog. To generate the audioembedding key, we use text-to-speech (TTS) to generate waveform representations of the audio data, and then embed these waveform representations using the pre-trained speech encoder model. To generate the text-embedding values, we leverage off-the-shelf semantic text embedding methods, including 1- hot, GLoVE [33] and BERT-style embedding [34] approaches.
图 3: 展示了外部记忆生成过程的概览。我们的方法从纯文本目录生成由音频嵌入键/文本嵌入值对组成的外部记忆。为了生成音频嵌入键,我们使用文本转语音 (TTS) 技术生成音频数据的波形表示,然后利用预训练的语音编码器模型对这些波形表示进行嵌入。为了生成文本嵌入值,我们采用了现成的语义文本嵌入方法,包括独热编码 (1-hot)、GLoVE [33] 和 BERT 风格嵌入 [34] 等方法。
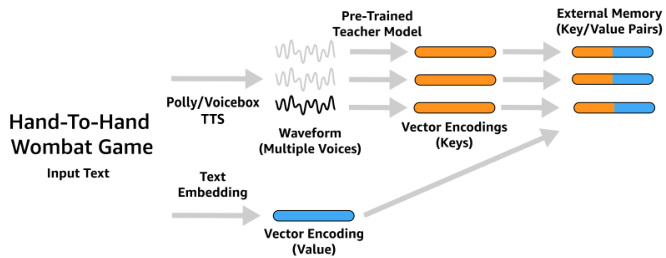
Fig. 3: Overview of our text-catalog encoding process. For each catalog entry, we generate TTS-based audio encoding that forms the “key” vector in the key-value pair. The value is a semantic text-embedding of the entry. Key/value pairs are assembled into the external memory, referenced in Figure 2
图 3: 文本目录编码流程概览。针对每个目录条目,我们生成基于TTS (Text-to-Speech) 的音频编码作为键值对中的"键"向量,其"值"为条目的语义文本嵌入。键值对将组合成外部记忆库 (如图2所示)。
3.1.1 TTS
3.1.1 文本转语音 (TTS)
In our work, we leverage two TTS modules to generate the audio for the audio-embeddings: the Amazon Polly TTS service, and an Alexa-AI Internal text to speech (TTS) library optimized for creating data for ASR model training and testing, which we will refer to as Multivoice-TTS as it can generate a number of voices. For both Amazon Polly and MultivoiceTTS we use ten voices, primarily drawn from the en-US and en-GB locales. 0.1 seconds of silence is inserted before and after each utterance.
在我们的工作中,我们利用两个TTS模块来生成音频嵌入(embedding)的音频:Amazon Polly TTS服务,以及一个专为ASR模型训练和测试数据创建的Alexa-AI内部文本转语音(TTS)库(我们将其称为Multivoice-TTS,因为它可以生成多种语音)。对于Amazon Polly和Multivoice-TTS,我们各使用了10种语音,主要来自en-US和en-GB地区。每个话语前后会插入0.1秒的静音。
3.1.2 Audio Embedding
3.1.2 音频嵌入
While audio embeddings for the external catalogue could be constructed in several ways, similar to Wu et al. [8], we aim to make our audio-embeddings as close to on-policy selfattention embeddings as possible. Thus, we use the mean of the self-attention representations of our baseline model (no fine-tuning) at an intermediate layer, as our audio embeddings.
虽然外部目录的音频嵌入(embedding)可以通过多种方式构建,但类似于Wu等人[8]的研究,我们的目标是使音频嵌入尽可能接近策略内自注意力(self-attention)嵌入。因此,我们使用基线模型(未微调)在中间层的自注意力表示均值作为音频嵌入。
3.1.3 Text Embedding
3.1.3 文本嵌入
In our work, we explore several methods of generate the text embeddings forming the value of the memory key-value pairs. For small catalogs, we explore learned one-hot embeddings, which are built during the training process. While such embeddings can lead to better performance (as they are built explicitly for each task), they are not scalable – as they cannot be computed offline (and thus, cannot be inserted during test time). To generate scalable text embeddings, we explore two semantic text-emebdding approaches: GLoVE embeddings [33], which are built using word co-occurance probabilities, and BERTstyle embeddings [34], which are learned from large statistical models. GLoVE embeddings are 300 dimensional, and computed using the publicly available vectors, and our BERT-style embeddings are computed using the all-MiniLM-L6-v2 model in the sentence-transformers package [35].
在我们的工作中,我们探索了几种生成文本嵌入的方法,这些嵌入构成了记忆键值对的值。对于小型目录,我们探索了学习到的一热编码 (one-hot) 嵌入,这些嵌入是在训练过程中构建的。虽然这类嵌入可以带来更好的性能(因为它们是专门为每个任务构建的),但它们不具备可扩展性——因为它们无法离线计算(因此无法在测试时插入)。为了生成可扩展的文本嵌入,我们探索了两种语义文本嵌入方法:基于词共现概率构建的 GLoVE 嵌入 [33],以及从大型统计模型中学习到的 BERT 风格嵌入 [34]。GLoVE 嵌入是 300 维的,使用公开可用的向量计算,而我们的 BERT 风格嵌入则使用 sentence-transformers 包 [35] 中的 all-MiniLM-L6-v2 模型计算。
3.2 External Memory Fusion
3.2 外部存储器融合
An overview of the external memory fusion process is given in Figure 2. The speech encoder in our proposed work is based on the Conformer encoder [36], augmented with additional KNearest-Neighbor (KNN) fusion layers. In each KNN fusion layer, for each audio frame embedding $a_{i}$ of the utterance $A$ , we query the external memory $E=(k_{i},v_{i}),1\leq i\leq|E|$ for a set of $m$ nearest neighbors:
外部记忆融合过程的概述如图 2 所示。我们提出的语音编码器基于 Conformer 编码器 [36],并增加了额外的 K 最近邻 (KNN) 融合层。在每个 KNN 融合层中,对于话语 $A$ 的每个音频帧嵌入 $a_{i}$,我们从外部记忆 $E=(k_{i},v_{i}),1\leq i\leq|E|$ 中查询一组 $m$ 个最近邻:
$$
\mathcal{N}_ {a_{i}}=\underset{N\subset E,|N|=m}{\arg\operatorname*{min}}\sum_{(k_{j},v_{j})\in N}||k_{j}-a_{i}||_{2}^{2}
$$
$$
\mathcal{N}_ {a_{i}}=\underset{N\subset E,|N|=m}{\arg\operatorname*{min}}\sum_{(k_{j},v_{j})\in N}||k_{j}-a_{i}||_{2}^{2}
$$
We then construct the context for the layer as $\mathcal{C}=\cup_{a_{i}\in A}\mathcal{N}_ {a_{i}}$ . From $\mathcal{C}$ we can construct two matrices, $K_{c}\in\mathbb{R}^{m|A|,d_{\mathrm{key}}}$ and $V_{c}\in\mathbb{R}^{m|A|,d_{\mathrm{valuc}}}$ , consisting of the keys and values respectively. The output of our K-NN fusion layer is then:
然后我们为该层构建上下文 $\mathcal{C}=\cup_{a_{i}\in A}\mathcal{N}_ {a_{i}}$ 。从 $\mathcal{C}$ 可以构建两个矩阵:键矩阵 $K_{c}\in\mathbb{R}^{m|A|,d_{\mathrm{key}}}$ 和值矩阵 $V_{c}\in\mathbb{R}^{m|A|,d_{\mathrm{valuc}}}$ 。最终K近邻融合层的输出为:
$$
F(A,E)=A+\operatorname{LN}\left(\operatorname{ReLU}\left(\operatorname{softmax}\left({\frac{(A W_{q})K_{c}^{\prime}}{\sqrt{d}}}\right)(V_{c}W_{v})\right)\right)
$$
$$
F(A,E)=A+\operatorname{LN}\left(\operatorname{ReLU}\left(\operatorname{softmax}\left({\frac{(A W_{q})K_{c}^{\prime}}{\sqrt{d}}}\right)(V_{c}W_{v})\right)\right)
$$
where LN is LayerNorm. Unfortunately, because we are working with large catalogues, the computation of Equation 1 can be very expensive. Thus, instead of computing exact nearest neighbors, we rely on approximate nearest neighbors, which can be computed much more efficiently. To efficiently extract approximate nearest neighbors from our large-scale catalogs, we leverage the FAISS [37] library to generate Optimized Product-Quantization-transformed keys (64 dimension) [38], which are searched using an Hier arch i al Naviagable Small Worlds (HNSW) index with 2048 centroids encoded with product-quantized fast-scan [39]. Such an approach leads to only a $15%$ increase in forward-pass latency, even when running with catalogs with over 7M key/value pairs.
其中 LN 代表 LayerNorm。遗憾的是,由于我们处理的是大型目录,计算式 1 可能会非常耗时。因此,我们并非计算精确的最近邻,而是依赖近似最近邻,这样计算效率更高。为了从大规模目录中高效提取近似最近邻,我们利用 FAISS [37] 库生成优化乘积量化转换的键(64 维)[38],并使用分层可导航小世界 (HNSW) 索引进行搜索,该索引包含 2048 个通过乘积量化快速扫描 [39] 编码的质心。即使处理超过 700 万键/值对的目录,这种方法也仅导致前向传播延迟增加约 15%。
3.3 Experimental Design
3.3 实验设计
3.3.1 ASR Base Model
3.3.1 ASR 基础模型
Although in practice our method could be applied to many different speech encoders, we use the Conformer encoder [36]. For the decoder, we use a 1-layer LSTM decoder with 320 hidden dimension, with no explicit pre-trained language model. While we explore several encoder sizes, we primarily follow Gulati et al. [36] for Libri speech and use a 16 layer encoder with a hidden dimension of 144 (10.3M Params). For internal Alexa-AI data, we use a conformer model with $208.37\mathrm{M}$ parameters. All models leverage ReLU activation s, batchnormalization, and dropout of 0.1. For the ASR token iz ation, we use a sentence-piece model [40] with a vocab size of 640 (libri speech) and 4096 (internal).
虽然我们的方法在实践中可应用于多种语音编码器,但我们采用Conformer编码器[36]。解码器部分使用隐藏层维度为320的单层LSTM解码器,且未显式加载预训练语言模型。在探索多种编码器规模时,我们主要遵循Gulati等人[36]针对Libri语音的配置,采用16层编码器(隐藏维度144,参数量10.3M)。对于内部Alexa-AI数据,则使用参数量达$208.37\mathrm{M}$的Conformer模型。所有模型均采用ReLU激活函数、批归一化及0.1的dropout率。ASR的token化处理使用SentencePiece模型[40],其词表规模分别为640(Libri语音)和4096(内部数据)。
Table 1: Word Error Rate on Libri speech data with a small (10.3M param) model for several choices of TTS, Text Embeddings, and NNs/Frame (K). MV-TTS refers to Multivoice-TTS.
| Catalog | TTS | Text | K | test-clean | test-other |
| Baseline | 5.77 | 13.34 | |||
| Train | Polly | 1-Hot | 4 | 5.75 (0.34%) | 13.30 (0.29%) |
| Polly | 1-Hot | 8 | 5.72 (0.86%) | 13.19 (1.10%) | |
| Polly | 1-Hot | 16 | 5.71 (1.03%) | 13.15 (1.42%) | |
| Polly | BERT | 8 | 5.74 (0.52%) | 13.26 (0.60%) | |
| MV-TTS | 1-Hot | 8 | 5.52 (4.33%) | 12.96 (2.84%) | |
| MV-TTS | BERT | 8 | 5.68 (1.63%) | 13.05 (2.18%) | |
| Test | Polly | GLoVE | 8 | 6.33 (-8.84%) | 14.56 (-9.15%) |
| Polly | BERT | 8 | 5.71 (1.03%) | 13.24 (0.75%) | |
| MV-TTS | GLoVE | 8 | 6.15 (-6.17%) | 14.32 (-6.84%) | |
| MV-TTS | BERT | 8 | 5.34 (8.05%) | 12.84 (3.86%) |
表 1: 采用小型(10.3M参数)模型在Libri语音数据上的词错误率,对比不同TTS、文本嵌入和NNs/帧(K)选择。MV-TTS指多语音合成系统(Multivoice-TTS)。
| 类别 | TTS | 文本嵌入 | K | test-clean | test-other |
|---|---|---|---|---|---|
| 基线 | 5.77 | 13.34 | |||
| 训练 | Polly | 1-Hot | 4 | 5.75 (0.34%) | 13.30 (0.29%) |
| Polly | 1-Hot | 8 | 5.72 (0.86%) | 13.19 (1.10%) | |
| Polly | 1-Hot | 16 | 5.71 (1.03%) | 13.15 (1.42%) | |
| Polly | BERT | 8 | 5.74 (0.52%) | 13.26 (0.60%) | |
| MV-TTS | 1-Hot | 8 | 5.52 (4.33%) | 12.96 (2.84%) | |
| MV-TTS | BERT | 8 | 5.68 (1.63%) | 13.05 (2.18%) | |
| 测试 | Polly | GLoVE | 8 | 6.33 (-8.84%) | 14.56 (-9.15%) |
| Polly | BERT | 8 | 5.71 (1.03%) | 13.24 (0.75%) | |
| MV-TTS | GLoVE | 8 | 6.15 (-6.17%) | 14.32 (-6.84%) | |
| MV-TTS | BERT | 8 | 5.34 (8.05%) | 12.84 (3.86%) |
Table 2: Relative Libri speech test-set WER improvement for models augmented with catalog data in different layers Model uses Multivoice-TTS, BERT Embeddings and 8 NNs/Frame.
| Dataset | 1 | 3 | 12 | 16 | 3,12 | all |
| clean | 1.02% | 3.65% | 6.65% | 2.63% | 7.79% | 8.05% |
| other | 0.71% | 2.88% | 2.97% | 1.08% | 3.41% | 3.86% |
表 2: 不同层级添加目录数据后模型在Libri语音测试集上的相对WER提升 模型采用Multivoice-TTS、BERT嵌入和每帧8个神经网络。
| 数据集 | 1 | 3 | 12 | 16 | 3,12 | all |
|---|---|---|---|---|---|---|
| clean | 1.02% | 3.65% | 6.65% | 2.63% | 7.79% | 8.05% |
| other | 0.71% | 2.88% | 2.97% | 1.08% | 3.41% | 3.86% |
3.3.2 Catalog Data Sources
3.3.2 目录数据源
In our work we explore several different catalog data sources. For Libri speech, we build a simulated catalog using the 2500 rarest tokens present in either the training or test datasets. Building a unique catalog for both the training and the test data allows us to explore how well the model performs under distribution shift of the catalog at test time. Our internal Alexa catalog focuses on assistant queries in a media domain, and consists of 15K movie titles.
在我们的工作中,我们探索了几种不同的目录数据源。对于Libri speech,我们使用训练或测试数据集中出现的2500个最稀有token构建了一个模拟目录。为训练和测试数据分别建立独立目录,使我们能够探究模型在测试时面对目录分布变化的表现。内部Alexa目录专注于媒体领域的助手查询,包含15K个电影标题。
3.3.3 Training Details
3.3.3 训练细节
For Libri speech, the model is implemented in Tensorflow, and is trained using 24 Nvidia V-100GPUs for 120 epochs with a batch size of 2048 and the Adam optimizer, with a learning rate of $3e^{-4}$ . For the Alexa-AI datasets, the model is fine-tuned using 104 Nvidia V-100 GPUs for 30 epochs with a batch size of 832 and the Adam optimizer, with a warmup/hold learning rate schedule with $10,000$ warmup steps and a maximum learning rate of $5e^{-3}$ .
对于Libri语音数据集,模型采用Tensorflow实现,使用24块Nvidia V-100 GPU进行训练,共120个epoch,批量大小为2048,采用Adam优化器,学习率为$3e^{-4}$。针对Alexa-AI数据集,模型使用104块Nvidia V-100 GPU进行微调,共30个epoch,批量大小为832,同样采用Adam优化器,并采用预热/保持学习率调度策略,其中预热步数为$10,000$,最大学习率为$5e^{-3}$。
4 Results & Discussion
4 结果与讨论
In this work, we present results on two datasets - Libri speech [41], a dataset consisting of 960 hours of relatively clean, annotated ASR data, and an internal Alexa dataset focused on media-centric queries.
在这项工作中,我们在两个数据集上展示了结果:Libri speech [41](一个包含960小时相对干净、带标注的ASR数据的数据集)以及一个专注于媒体查询的内部Alexa数据集。
4.1 Libri speech
4.1 Libri speech
Our key results are shown for Libri speech in Table 1. We can see that overall, augmenting models with additional data leads to stronger performance than models without external data. For Libri speech, when training with the train catalog and testing with the test catalog, we get strong transfer performance, exceeding that of when we use the training catalog for both training and testing, suggesting additional zero-shot specialization. While 1-hot vectors outperform BERT vectors, we must train these vectors for each catalog, leading to an inability to do test-time specialization. BERT outperforms GLoVE in all cases (with GLoVE causing regressions on test-time specialization). Figure 4 demonstrates that our method can capture and apply domain data from the catalogs. In this experiment, the model is trained with a catalog containing 300K training-set unique bigrams, and we show the performance of this model using ten test catalogs, each consisting of 30K bigrams, taken either from the test set or dev set. As the fraction of bigrams in the test data that are available in the test catalog increases, the performance of the model improves – showing our approach can use the information in test catalogs effectively in a zero-shot learning setup.
我们在表1中展示了Libri语音的关键结果。可以看出,总体而言,使用额外数据增强的模型表现优于无外部数据的模型。对于Libri语音,当使用训练目录进行训练并用测试目录测试时,我们获得了强大的迁移性能,超过了同时使用训练目录进行训练和测试的情况,这表明存在额外的零样本专业化能力。虽然1-hot向量表现优于BERT向量,但我们必须为每个目录训练这些向量,导致无法进行测试时专业化。BERT在所有情况下都优于GLoVE(GLoVE在测试时专业化中会导致性能下降)。图4表明我们的方法能够从目录中捕获并应用领域数据。本实验中,模型使用包含30万训练集独特二元组的目录进行训练,并通过十个测试目录(每个包含3万取自测试集或开发集的二元组)展示模型性能。随着测试数据中存在于测试目录的二元组比例增加,模型性能随之提升——这表明我们的方法能在零样本学习设置中有效利用测试目录信息。

Fig. 4: Libri speech test-clean WER over differing test catalogs. As the percentage of bigrams in the test catalog overlapping with the test dataset increases, the performance of the catalogaugmented model increases as well.
图 4: Libri speech test-clean 在不同测试目录下的词错误率(WER)。随着测试目录中与测试数据集重叠的双元组比例增加,目录增强模型的性能也随之提升。
Table 3: Relative Libri speech test-set WER improvement over baseline fine-tuning using differing model parameters with MultivoiceTTS, BERT, and 8 NNs/Frame.
| Dataset | 5M | 10M | 50M | 100M | 300M |
| clean | 28.9% | 8.05% | 4.28% | 1.66% | 0.08% |
| other | 19.3% | 3.86% | 2.65% | -0.07% | 0.01% |
表 3: 使用MultivoiceTTS、BERT和8个NNs/Frame的不同模型参数相对于基线微调的Libri语音测试集WER改进
| Dataset | 5M | 10M | 50M | 100M | 300M |
|---|---|---|---|---|---|
| clean | 28.9% | 8.05% | 4.28% | 1.66% | 0.08% |
| other | 19.3% | 3.86% | 2.65% | -0.07% | 0.01% |
Ablations: Table 2 explores the performance of our model when placing the external knowledge augmentation at different layers of the model. While making external knowledge available to all layers is the most effective approach, we find that such an approach is latency-prohibitive, as it increases the latency of a forward pass of the model by about $85%$ . Using a single layer increases latency by only about $15%$ , while two layers increase latency by about $23%$ . Table 3 explores the performance of the method on Libri speech as we increase the number of parameters in the model. As we increase the number of parameters, the gains provided by external memory decrease.
消融实验:表2展示了在模型不同层引入外部知识增强时的性能表现。虽然让所有层都能访问外部知识效果最佳,但这种方法会导致延迟激增,使模型前向传播延迟增加约85%。而仅在单层引入时延迟仅增加约15%,两层引入时延迟增加约23%。表3则呈现了随着模型参数量的增加,该方法在LibriSpeech数据集上的性能变化——参数量越大,外部记忆带来的性能增益越小。
4.2 Alexa
4.2 Alexa
Table 4: Alexa-AI Performance. T-C: Time for Catalog Generation. T-FT: Time for fine-tuning. Multivoice-TTS, BERT, and 8 NNs/Frame.
| Model/TestData | T-C (min) | T-FT (GPU-Hours) | rel. TTS WER |
| Brr/Train-TTS | 2048 | 7.1% | |
| Bcat/Train-TTS | 33 | 1600 | 6.8% |
| Brr/Test-TTS | 0.52% | ||
| Bcat/Test-TTS | - | 4.12% | |
| BFT+T/Test-TTS | 1024 | 19.66% | |
| Bcat+T/Test-TTS | 28 | 0 | 21.27% |
表 4: Alexa-AI性能指标。T-C: 目录生成时间。T-FT: 微调耗时。多语音合成(Multivoice-TTS)、BERT及每帧8个神经网络(8 NNs/Frame)。
| 模型/测试数据 | T-C (分钟) | T-FT (GPU小时) | 相对TTS词错率 |
|---|---|---|---|
| Brr/Train-TTS | 2048 | 7.1% | |
| Bcat/Train-TTS | 33 | 1600 | 6.8% |
| Brr/Test-TTS | 0.52% | ||
| Bcat/Test-TTS | - | 4.12% | |
| BFT+T/Test-TTS | 1024 | 19.66% | |
| Bcat+T/Test-TTS | 28 | 0 | 21.27% |
To further validate our method, we additionally explore a realworld simulation of our model’s ability to generalize to test data. We started with a baseline model $B$ (See: section 3), and trained two derived models: $B_{\mathrm{FT}}$ , fine-tuned on both the TTS Catalog for Alexa $\mathcal{C}$ , section 3) and an additional 120K hours of de-identified Alexa data, $\mathcal{D}$ , and $B_{\mathrm{cat}}$ , which applies our method fine-tuned on $\mathcal{D}$ , with catalog $\mathcal{C}$ . The results (Table 4, rows $1/2$ ) demonstrate that even with significantly fewer GPU hours, our approach achieves similar WER. When we transfer to the test dataset (without updating the catalog), we see in Table 4 (rows $3/4_{.}$ ) that our trained model achieves better performance, suggesting that the model has learned to generalize better than the model trained with fine-tuning alone.
为了进一步验证我们的方法,我们还探索了一个真实场景下的模拟实验,测试模型对测试数据的泛化能力。我们以基线模型$B$(参见第3节)为基础,训练了两个衍生模型:$B_{\mathrm{FT}}$(在Alexa的TTS目录$\mathcal{C}$(第3节)和额外的12万小时去标识化Alexa数据$\mathcal{D}$上进行了微调),以及$B_{\mathrm{cat}}$(应用我们的方法在$\mathcal{D}$上微调,同时使用目录$\mathcal{C}$)。结果(表4第$1/2$行)表明,即使使用显著更少的GPU小时,我们的方法也能达到相似的词错误率(WER)。当迁移到测试数据集时(不更新目录),从表4(第$3/4$行)可以看出,我们训练的模型取得了更好的性能,这表明该模型比仅通过微调训练的模型学会了更好的泛化能力。
Finally, we update our fine-tuned and catalog models to include the test data. The test data is incorporated into the finetuned model through additional GPU-based training, while the test data is incorporated into the catalog model through catalog generation and concatenation. Table 4 (rows 5/6) further demonstrates that even with no additional GPU training our approach $(B_{\mathrm{cat}+T})$ can achieve similar performance to the
最后,我们更新了微调模型和目录模型以包含测试数据。测试数据通过额外的基于GPU的训练整合到微调模型中,而测试数据则通过目录生成和拼接整合到目录模型中。表4 (第5/6行) 进一步表明,即使没有额外的GPU训练,我们的方法 $(B_{\mathrm{cat}+T})$ 也能达到与
fine-tuning $(B_{\mathrm{FT}+T})$ ) approach.
微调 $(B_{\mathrm{FT}+T})$ ) 方法。
5 Conclusion
5 结论
This paper introduces the first approach for large-scale contextu aliz ation of speech-encoder representations using text-only catalog data. While this paper is a good first step towards contextual i zed speech encoders, problems like investigating embeddings for the catalogs, leveraging grapheme/phoneme embeddings, etc. remain interesting directions of future work. This approach provides a natural way to combine external memory for addressing distribution shifts when having OOV words in dev/test, ensuring recognition of rare words in training data, handling personalization, and using pronunciation instead of TTS – we would like to evaluate these features of the approach on real-world data.
本文首次提出了一种仅使用文本目录数据对语音编码器表征进行大规模情境化的方法。虽然这是实现情境化语音编码器的良好开端,但诸如研究目录嵌入、利用字素/音素嵌入等问题仍是未来工作的有趣方向。该方法为处理开发/测试集出现未登录词(OOV)时的分布偏移提供了一种自然的外部记忆整合方案,可确保训练数据中罕见词的识别、实现个性化处理,并采用发音替代文本转语音(TTS)技术——我们期待在真实数据上评估这些特性。