EHRAgent: Code Empowers Large Language Models for Few-shot Complex Tabular Reasoning on Electronic Health Records
EHRAgent: 代码赋能大语言模型实现电子健康记录少样本复杂表格推理
Wenqi $\mathbf{Shi^{1* }}$ Ran $\mathbf{X}\mathbf{u}^{2* }$ Yuchen Zhuang1 Yue $\mathbf{Y}\mathbf{u}^{1}$ Jieyu Zhang3 Hang Wu1 Yuanda Zhu1 Joyce $\mathbf{H0^{2}}$ Carl Yang2 May D. Wang1 1 Georgia Institute of Technology 2 Emory University 3 University of Washington {wqshi,yczhuang,yueyu,hangwu,yzhu94,maywang}@gatech.edu, {ran.xu,joyce.c.ho,j.carlyang}@emory.edu, jieyuz2@cs.washington.edu
Wenqi $\mathbf{Shi^{1* }}$ Ran $\mathbf{X}\mathbf{u}^{2* }$ Yuchen Zhuang1 Yue $\mathbf{Y}\mathbf{u}^{1}$ Jieyu Zhang3 Hang Wu1 Yuanda Zhu1 Joyce $\mathbf{H0^{2}}$ Carl Yang2 May D. Wang1 1 佐治亚理工学院 2 埃默里大学 3 华盛顿大学 {wqshi,yczhuang,yueyu,hangwu,yzhu94,maywang}@gatech.edu, {ran.xu,joyce.c.ho,j.carlyang}@emory.edu, jieyuz2@cs.washington.edu
Abstract
摘要
Clinicians often rely on data engineers to retrieve complex patient information from electronic health record (EHR) systems, a process that is both inefficient and time-consuming. We propose EHRAgent , a large language model (LLM) agent empowered with accumulative domain knowledge and robust coding capability. EHRAgent enables autonomous code generation and execution to facilitate clinicians in directly interacting with EHRs using natural language. Specifically, we formulate a multi-tabular reasoning task based on EHRs as a tool-use planning process, efficiently decomposing a complex task into a sequence of manageable actions with external toolsets. We first inject relevant medical information to enable EHRAgent to effectively reason about the given query, identifying and extracting the required records from the appropriate tables. By integrating interactive coding and execution feedback, EHRAgent then effectively learns from error messages and iteratively improves its originally generated code. Experiments on three real-world EHR datasets show that EHRAgent outperforms the strongest baseline by up to $29.6%$ in success rate, verifying its strong capacity to tackle complex clinical tasks with minimal demonstrations.
临床医生通常需要依赖数据工程师从电子健康记录 (EHR) 系统中检索复杂的患者信息,这一过程既低效又耗时。我们提出 EHRAgent,这是一个具备累积领域知识和强大编码能力的大语言模型智能体。EHRAgent 能够自主生成并执行代码,帮助临床医生直接通过自然语言与 EHR 系统交互。具体而言,我们将基于 EHR 的多表格推理任务构建为工具使用规划流程,高效地将复杂任务分解为一系列可管理的工具集操作。我们首先注入相关医疗信息,使 EHRAgent 能够有效推理给定查询,从相应表格中识别并提取所需记录。通过整合交互式编码与执行反馈,EHRAgent 能够从错误信息中学习,并迭代改进其初始生成的代码。在三个真实 EHR 数据集上的实验表明,EHRAgent 的成功率比最强基线高出 29.6%,验证了其在最少示例下处理复杂临床任务的强大能力。
1 Introduction
1 引言
An electronic health record (EHR) is a digital version of a patient’s medical history maintained by healthcare providers over time (Gunter and Terry, 2005). In clinical research and practice, clinicians actively interact with EHR systems to access and retrieve patient data, ranging from detailed individuallevel records to comprehensive population-level insights (Cowie et al., 2017). The reliance on pre-defined rule-based conversion systems in most EHRs often necessitates additional training or assistance from data engineers for clinicians to obtain information beyond these rules (Mandel et al., 2016; Bender and Sartipi, 2013), leading to inefficiencies and delays that may impact the quality and timeliness of patient care.
电子健康档案 (EHR) 是由医疗保健提供者长期维护的患者医疗历史的数字化版本 (Gunter and Terry, 2005)。在临床研究和实践中,临床医生需要频繁与EHR系统交互,以获取从详细的个体记录到全面的群体洞察等不同层级的患者数据 (Cowie et al., 2017)。由于大多数EHR系统依赖预定义的基于规则的转换系统,临床医生若要获取超出这些规则的信息,通常需要数据工程师的额外培训或协助 (Mandel et al., 2016; Bender and Sartipi, 2013),这种低效和延迟可能会影响患者护理的质量和及时性。

Figure 1: Simple and efficient interactions between clinicians and EHR systems with the assistance of LLM agents. Clinicians specify tasks in natural language, and the LLM agent autonomously generates and executes code to interact with EHRs (right) for answers. It eliminates the need for specialized expertise or extra effort from data engineers, which is typically required when dealing with EHRs in existing clinical settings (left).
图 1: 通过大语言模型智能体实现临床医生与电子健康档案(EHR)系统间的简洁高效交互。临床医生用自然语言描述任务,大语言模型智能体自主生成并执行代码与EHR系统交互(右)获取答案。这种方式消除了现有临床场景(左)中处理EHR时通常需要数据工程师专业支持或额外投入的需求。
Alternatively, an autonomous agent could facilitate clinicians to communicate with EHRs in natural languages, translating clinical questions into machine-interpret able queries, planning a sequence of actions, and ultimately delivering the final responses. Compared to existing EHR management that relies heavily on human effort, the adoption of autonomous agents holds great potential to efficiently simplify workflows and reduce workloads for clinicians (Figure 1). Although several supervised learning approaches (Lee et al., 2022; Wang et al., 2020) have been explored to automate the translation of clinical questions into corresponding machine queries, such systems require exten- sive training samples with fine-grained annotations, which are both expensive and challenging to obtain.
或者,自主AI智能体可以帮助临床医生用自然语言与电子健康记录(EHR)系统交互,将临床问题转化为机器可解释的查询,规划操作序列,最终返回结果响应。与当前高度依赖人工操作的EHR管理方式相比,采用自主AI智能体有望显著简化临床工作流程并减轻医务人员负担 (图1)。虽然已有研究尝试用监督学习方法 (Lee等人, 2022; Wang等人, 2020) 实现临床问题到机器查询的自动转换,但这类系统需要大量带有细粒度标注的训练样本,其获取成本高昂且极具挑战性。
Large language models (LLMs) (OpenAI, 2023; Anil et al., 2023) bring us one step closer to autonomous agents with extensive knowledge and substantial instruction-following abilities from diverse corpora during pre training. LLM-based autonomous agents have demonstrated remarkable capabilities in problem-solving, such as reasoning (Wei et al., 2022), planning (Yao et al., 2023b), and memorizing (Wang et al., 2023b). One particularly notable capability of LLM agents is toolusage (Schick et al., 2023; Qin et al., 2023), where they can utilize external tools (e.g., calculators, APIs, etc.), interact with environments, and generate action plans with intermediate reasoning steps that can be executed sequentially towards a valid solution (Wu et al., 2023; Zhang et al., 2023).
大语言模型 (LLMs) (OpenAI, 2023; Anil et al., 2023) 让我们离拥有广泛知识且能从预训练阶段的多样语料中掌握强大指令跟随能力的自主智能体更近一步。基于大语言模型的自主智能体已展现出卓越的问题解决能力,例如推理 (Wei et al., 2022)、规划 (Yao et al., 2023b) 和记忆 (Wang et al., 2023b)。其中尤为突出的能力是工具使用 (Schick et al., 2023; Qin et al., 2023),它们可以调用外部工具 (如计算器、API等),与环境交互,并通过中间推理步骤生成可依次执行的动作计划以达成有效解决方案 (Wu et al., 2023; Zhang et al., 2023)。

Figure 2: Compared to general domain tasks (blue) such as WikiSQL (Zhong et al., 2017) and SPIDER (Yu et al., 2018), multi-tabular reasoning tasks within EHRs (orange) typically involve a significantly larger number of records per table and necessitate querying multiple tables to answer each question, thereby requiring more advanced reasoning and problem-solving capabilities.
图 2: 与WikiSQL (Zhong et al., 2017) 和 SPIDER (Yu et al., 2018) 等通用领域任务 (蓝色) 相比,电子健康记录 (EHR) 中的多表格推理任务 (橙色) 通常涉及每张表格中更多的记录,并且需要查询多个表格来回答每个问题,因此需要更高级的推理和问题解决能力。
Despite their success in general domains, LLMs have encountered unique and significant challenges in the medical domain (Jiang et al., 2023; Yang et al., 2022; Moor et al., 2023), especially when dealing with individual EHR queries that require advanced reasoning across a vast number of records within multiple tables (Li et al., 2024; Lee et al., 2022) (Figure 2). First, given the constraints in both the volume and specificity of training data within the medical field (Thapa and Adhikari, 2023), LLMs still struggle to identify and extract relevant information from the appropriate tables and records within EHRs, due to insufficient knowledge and under standing of their complex structure and content. Second, EHRs are typically large-scale relational databases containing vast amounts of tables with comprehensive administrative and clinical information (e.g., 26 tables of 46K patients in MIMIC-III). Moreover, real-world clinical tasks derived from individual patients or specific groups are highly diverse and complex, requiring multi-step or complicated operations.
尽管大语言模型在通用领域取得了成功,但在医疗领域仍面临独特而重大的挑战 (Jiang et al., 2023; Yang et al., 2022; Moor et al., 2023),特别是在处理需要跨多个表格海量记录进行高级推理的个体电子健康记录查询时 (Li et al., 2024; Lee et al., 2022) (图 2)。首先,由于医学领域训练数据在数量和特异性方面的限制 (Thapa and Adhikari, 2023),大语言模型仍难以从电子健康记录中识别和提取相关表格及记录的信息,这源于对其复杂结构和内容的知识储备不足。其次,电子健康记录通常是包含大量表格的关系型数据库,涵盖全面的行政和临床信息(例如MIMIC-III中46K患者的26个表格)。此外,源自个体患者或特定群体的真实临床任务具有高度多样性和复杂性,往往需要多步骤或复杂操作。
To address these limitations, we propose EHRAgent, an autonomous LLM agent with external tools and code interface for improved multitabular reasoning across EHRs. We translate the EHR question-answering problem into a tool-use planning process – generating, executing, debugging, and optimizing a sequence of code-based actions. Firstly, to overcome the lack of domain knowledge in LLMs, we instruct EHRAgent to integrate query-specific medical information for effectively reasoning from the given query and locating the query-related tables or records. Moreover, we incorporate long-term memory to continuously maintain a set of successful cases and dynamically select the most relevant few-shot examples, in order to effectively learn from and improve upon past experiences. Secondly, we establish an interactive coding mechanism, which involves a multiturn dialogue between the code planner and executor, iterative ly refining the generated code-based plan for complex multi-hop reasoning. Specifically, EHRAgent optimizes the execution plan by incorporating environment feedback and delving into error messages to enhance debugging proficiency.
为解决这些局限性,我们提出了EHRAgent——一个具备外部工具和代码接口的自主大语言模型智能体,用于改进跨电子健康记录(EHR)的多表推理能力。我们将EHR问答问题转化为工具使用规划流程:生成、执行、调试及优化基于代码的操作序列。首先,针对大语言模型缺乏领域知识的问题,我们指导EHRAgent整合查询相关的医疗信息,从而有效推理给定查询并定位相关表格或记录。此外,我们引入长期记忆机制来持续维护一组成功案例,并动态选择最相关的少样本示例,以实现对过往经验的有效学习和改进。其次,我们建立了交互式编码机制,通过代码规划器与执行器之间的多轮对话,迭代优化生成的基于代码的复杂多跳推理计划。具体而言,EHRAgent通过整合环境反馈和深入分析错误信息来优化执行计划,从而提升调试能力。
We conduct extensive experiments on three largescale real-world EHR datasets to validate the empirical effectiveness of EHRAgent, with a particular focus on challenging tasks that reflect diverse information needs and align with real-world application scenarios. In contrast to traditional supervised settings (Lee et al., 2022; Wang et al., 2020) that require over 10K training samples with manually crafted annotations, EHRAgent demonstrates its efficiency by necessitating only four demonstrations. Our findings suggest that EHRAgent improves multi-tabular reasoning on EHRs through autonomous code generation and execution, leveraging accumulative domain knowledge and interactive environmental feedback.
我们在三个大规模真实世界电子健康记录(EHR)数据集上进行了广泛实验,以验证EHRAgent的实证有效性,特别关注那些反映多样化信息需求且符合实际应用场景的挑战性任务。与传统监督学习设置(Lee et al., 2022; Wang et al., 2020)需要超过1万个人工标注训练样本相比,EHRAgent仅需四个演示样本即可展现其高效性。研究结果表明,EHRAgent通过自主代码生成与执行、利用累积领域知识和交互式环境反馈,提升了基于EHR的多表格推理能力。
Our main contributions are as follows:
我们的主要贡献如下:
• We propose EHRAgent, an LLM agent augmented with external tools and domain knowledge, to solve few-shot multi-tabular reasoning derived from EHRs with only four demonstrations; Planning with a code interface, EHRAgent formulates a complex clinical problem-solving process as an executable code plan of action sequences, along with a code executor; • We introduce interactive coding between the LLM agent and code executor, iterative ly refining plan generation and optimizing code execution by examining environmental feedback in depth; Experiments on three EHR datasets show that EHRAgent improves the strongest baseline on multihop reasoning by up to $29.6%$ in success rate.
• 我们提出 EHRAgent,一个通过外部工具和领域知识增强的大语言模型智能体,仅用四个示例就能解决源自电子健康记录 (EHR) 的少样本多表格推理问题;通过代码接口进行规划,EHRAgent 将复杂的临床问题解决过程表述为可执行的动作序列代码计划,并配备代码执行器;
• 我们引入大语言模型智能体与代码执行器之间的交互式编码,通过深度检查环境反馈,迭代优化计划生成和代码执行;
在三个 EHR 数据集上的实验表明,EHRAgent 将多跳推理的最强基线成功率最高提升了 $29.6%$。
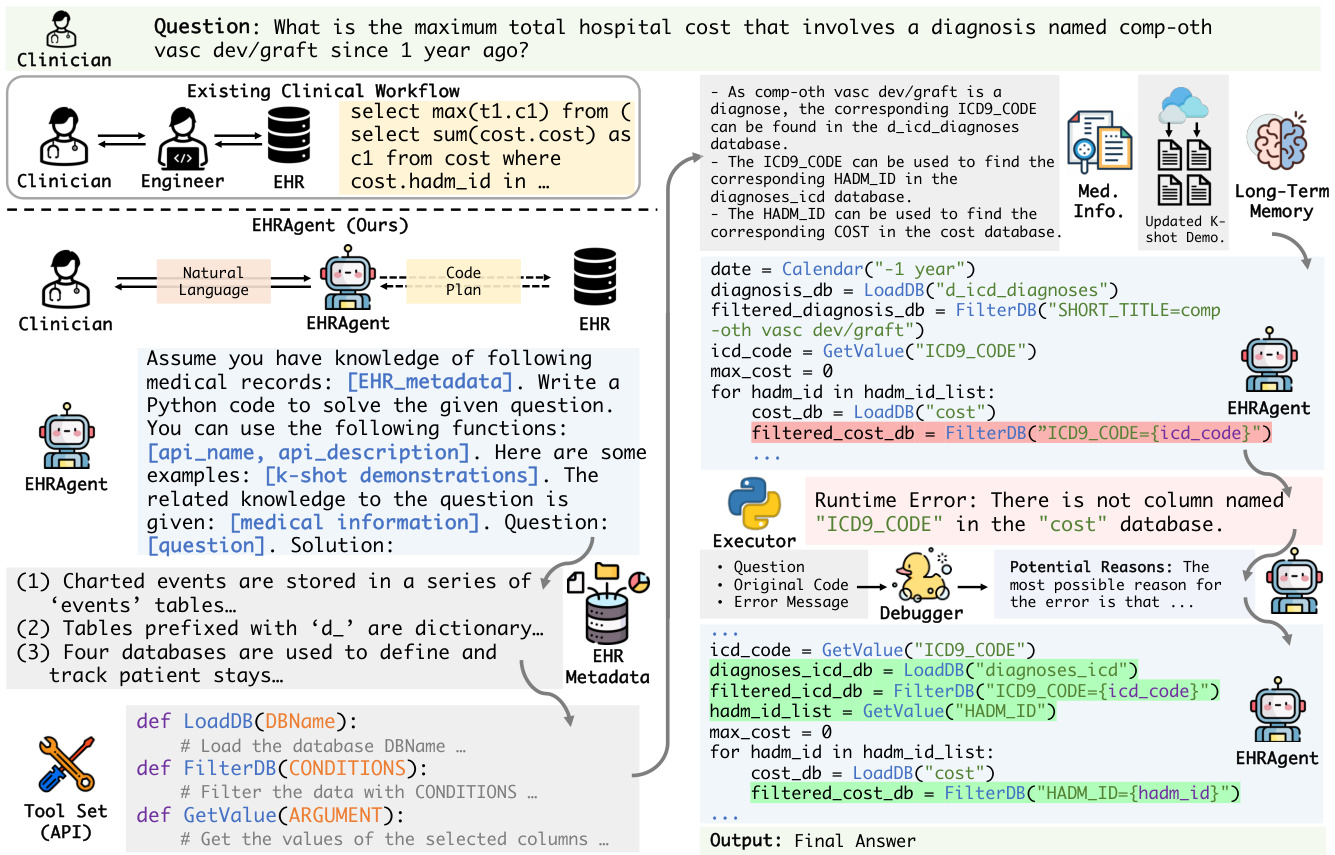
Figure 3: Overview of our proposed LLM agent, EHRAgent, for complex few-shot tabular reasoning tasks on EHRs. Given an input clinical question based on EHRs, EHRAgent decomposes the task and generates a plan (i.e., code) based on (a) metadata (i.e., descriptions of tables and columns in EHRs), (b) tool function definitions, (c) few-shot examples, and (d) domain knowledge (i.e., integrated medical information). Upon execution, EHRAgent iterative ly debugs the generated code following the execution errors and ultimately generates the final solution.
图 3: 我们提出的LLM智能体EHRAgent在电子健康记录(EHR)复杂少样本表格推理任务中的概览。给定基于EHR的输入临床问题,EHRAgent会分解任务并基于以下要素生成计划(即代码):(a) 元数据(即EHR中表格和列的描述),(b) 工具函数定义,(c) 少样本示例,以及(d) 领域知识(即集成的医疗信息)。执行过程中,EHRAgent会根据执行错误迭代调试生成的代码,最终生成最终解决方案。
2 Preliminaries
2 预备知识
Problem Formulation. In this work, we focus on addressing health-related queries by leveraging information from structured EHRs. The reference EHR, denoted as ${\mathcal{R}}={R_ {0},R_ {1},\cdot\cdot\cdot}$ , comprises multiple tables, while $\mathcal{C}={C_ {0},C_ {1},\cdot\cdot\cdot}$ corresponds to the column descriptions within $\mathcal{R}$ . For each given query in natural language, denoted as $q$ , our goal is to extract the final answer by utilizing the information within both $\mathcal{R}$ and $\mathcal{C}$ .
问题定义。在本研究中,我们重点利用结构化电子健康记录(EHR)中的信息来解决健康相关查询。参考EHR记为${\mathcal{R}}={R_ {0},R_ {1},\cdot\cdot\cdot}$,由多个表格组成,而$\mathcal{C}={C_ {0},C_ {1},\cdot\cdot\cdot}$对应$\mathcal{R}$中的列描述。对于每个给定的自然语言查询$q$,我们的目标是通过利用$\mathcal{R}$和$\mathcal{C}$中的信息来提取最终答案。
LLM Agent Setup. We further formulate the planning process for LLMs as autonomous agents in EHR question answering. For initialization, the LLM agent is equipped with a set of pre-built tools $\mathcal{M}={M_ {0},M_ {1},\cdot\cdot\cdot}$ to interact with and address queries derived from EHRs $\mathcal{R}$ . Given an input query $q\in\mathcal{Q}$ from the task space $\mathcal{Q}$ , the objective of the LLM agent is to design a $T$ -step execution plan $P=(a_ {1},a_ {2},\cdots,a_ {T})$ , with each action $a_ {t}$ selected from the tool set $a_ {t} \in \mathcal{M}$ . Specifically, we generate the action sequences (i.e., plan) by prompting the LLM agent following a policy $p_ {q}\sim\pi(a_ {1},\cdot\cdot\cdot,a_ {T_ {q}}|q;\mathcal{R},\mathcal{M}):\mathcal{Q}\times\mathcal{R}\times\mathcal{M}\to$ $\Delta(\mathcal{M})^{T_ {q}}$ , where $\Delta(\cdot)$ is a probability simplex func- tion. The final output is obtained by executing the entire plan $y\sim\rho(y|q,a_ {1},\cdot\cdot\cdot,a_ {T_ {q}})$ , where $\rho$ is a plan executor interacting with EHRs.
大语言模型智能体设置。我们进一步将大语言模型在电子健康记录(EHR)问答中的规划过程形式化为自主智能体。初始化时,大语言模型智能体配备一组预构建工具$\mathcal{M}={M_ {0},M_ {1},\cdot\cdot\cdot}$,用于交互和处理来自EHR $\mathcal{R}$的查询。给定任务空间$\mathcal{Q}$中的输入查询$q\in\mathcal{Q}$,大语言模型智能体的目标是设计一个$T$步执行计划$P=(a_ {1},a_ {2},\cdots,a_ {T})$,其中每个动作$a_ {t}$从工具集$a_ {t} \in \mathcal{M}$中选择。具体而言,我们通过遵循策略$p_ {q}\sim\pi(a_ {1},\cdot\cdot\cdot,a_ {T_ {q}}|q;\mathcal{R},\mathcal{M}):\mathcal{Q}\times\mathcal{R}\times\mathcal{M}\to$ $\Delta(\mathcal{M})^{T_ {q}}$来生成动作序列(即计划),其中$\Delta(\cdot)$是概率单纯形函数。最终输出通过执行整个计划$y\sim\rho(y|q,a_ {1},\cdot\cdot\cdot,a_ {T_ {q}})$获得,其中$\rho$是与EHR交互的计划执行器。
Planning with Code Interface. To mitigate ambiguities and misinterpretations in plan generation, an increasing number of LLM agents (Gao et al., 2023; Liang et al., 2023; Sun et al., 2023; Chen et al., 2023; Zhuang et al., 2024) employ code prompts as planner interface instead of natural language prompts. The code interface enables LLM agents to formulate an executable code plan as action sequences, intuitively transforming natural language question-answering into iterative coding (Yang et al., 2023). Consequently, the planning policy $\pi(\cdot)$ turns into a code generation process, with a code execution as the executor $\rho(\cdot)$ . We then track the outcome of each interaction back to the LLM agent, which can be either a successful execution result or an error message, to iterative ly refine the generated code-based plan. This interactive process, a multi-turn dialogue between the planner and executor, takes advantage of the advanced reasoning capabilities of LLMs to optimize plan refinement and execution.
使用代码接口进行规划。为减少计划生成中的模糊和误解,越来越多的大语言模型智能体 (Gao et al., 2023; Liang et al., 2023; Sun et al., 2023; Chen et al., 2023; Zhuang et al., 2024) 采用代码提示而非自然语言提示作为规划接口。代码接口使大语言模型智能体能够将可执行代码计划制定为动作序列,直观地将自然语言问答转化为迭代编码 (Yang et al., 2023)。因此,规划策略 $\pi(\cdot)$ 转变为代码生成过程,代码执行作为执行器 $\rho(\cdot)$。随后,我们将每次交互的结果(成功执行结果或错误信息)反馈给大语言模型智能体,以迭代优化基于代码的计划。这种规划器与执行器之间的多轮对话交互过程,利用了大语言模型的高级推理能力来优化计划细化和执行。
Algorithm 1: Overview of EHRAgent.
| Input: q: input question; R: reference EHRs; C: column description of EHR Ri;D: descriptions ofEHRs R;T:themaximum number of steps; T:definitions of tool function; L: long-term memory. Initialize t ← 0, C(0)(q) ← 0, O(%)(q) ← I/MedicalInformationIntegration I = [D;Co;C1;... B(q) = LLM([Z;q]) I/ExamplesRetrievalfromLong-TermMemory |
| ε(q) = arg TopKmax(sim(q, qi|qi E L)) I/PlanGeneration C(0)(q) = LLM([Z; T;&(q);q; B(q)]) while t |
| I/CodeExecution O(t)(q) = EXECUTE(C(t)(q)) IDebugging and Plan Modification (b)()O)NC)NTT = (D)(1+) t←t+1 |
算法 1: EHRAgent 概述
| 输入: q: 输入问题; R: 参考 EHRs; C: EHR Ri 的列描述; D: EHRs R 的描述; T: 最大步数; T: 工具函数定义; L: 长期记忆。初始化 t ← 0, C(0)(q) ← 0, O(%)(q) ← I/医疗信息整合 I = [D;Co;C1;... B(q) = 大语言模型([Z;q]) I/从长期记忆中检索示例 |
| ε(q) = arg TopKmax(sim(q, qi|qi E L)) I/计划生成 C(0)(q) = 大语言模型([Z; T;&(q);q; B(q)]) while t<T & TERMINATE O(t)(q) do |
| I/代码执行 O(t)(q) = EXECUTE(C(t)(q)) I/调试与计划修改 (b)()O)NC)NTT = (D)(1+) t←t+1 |
3 EHRAgent: LLMs as Medical Agents
3 EHRAgent: 大语言模型作为医疗智能体
In this section, we present EHRAgent (Figure 3), an LLM agent that enables multi-turn interactive coding to address multi-hop reasoning tasks on EHRs. EHRAgent comprises four key components: (1) Medical Information Integration: We incorporate query-specific medical information for effective reasoning based on the given query, enabling EHRAgent to identify and retrieve the necessary tables and records for answering the question. (2) Demonstration Optimization through Long-Term Memory: Using long-term memory, EHRAgent replaces original few-shot demonstrations with the most relevant successful cases retrieved from past experiences. (3) Interactive Coding with Execution Feedback: EHRAgent harnesses LLMs as autonomous agents in a multi-turn conversation with a code executor. (4) Rubber Duck Debugging via Error Tracing: Rather than simply sending back information from the code executor, EHRAgent thoroughly analyzes error messages to identify the underlying causes of errors through iterations until a final solution. We summarize the workflow of EHRAgent in Algorithm 1.
在本节中,我们提出EHRAgent (图 3),这是一个支持多轮交互式编码的大语言模型智能体,用于处理电子健康记录(EHR)的多跳推理任务。EHRAgent包含四个关键组件:(1) 医疗信息整合:根据给定查询整合特定医疗信息以实现有效推理,使EHRAgent能够识别并检索回答问题时所需的表格和记录。(2) 通过长期记忆优化示例:利用长期记忆,EHRAgent会用从过往经验中检索到的最相关成功案例替换原始的少样本示例。(3) 带执行反馈的交互式编码:EHRAgent将大语言模型作为自主智能体,与代码执行器进行多轮对话。(4) 通过错误追踪进行橡皮鸭调试:EHRAgent不会简单地返回代码执行器的信息,而是通过迭代彻底分析错误信息以识别根本原因,直至获得最终解决方案。我们在算法1中总结了EHRAgent的工作流程。
3.1 Medical Information Integration
3.1 医疗信息整合
Clinicians frequently pose complex inquiries that necessitate advanced reasoning across multiple tables and access to a vast number of records within a single query. To accurately identify the required tables, we first incorporate query-specific medical information (i.e., domain knowledge) into EHRAgent to develop a comprehensive understanding of the query within a limited context length. Given an EHR-based clinical question $q$ and the reference EHRs ${\mathcal{R}}={R_ {0},R_ {1},\cdot\cdot\cdot}$ , the objective of information integration is to generate the domain knowledge most relevant to $q$ , thereby facilitating the identification and location of potential useful references within $\mathcal{R}$ . For example, given a query related to ‘Aspirin’, we expect LLMs to locate the drug ‘Aspirin’ at the PRESCRIPTION table, under the prescription name column in the EHR.
临床医生经常提出复杂的查询需求,这需要在单次查询中进行跨多表的高级推理并访问海量记录。为精准定位所需表格,我们首先将查询相关的医疗信息(即领域知识)整合到EHRAgent中,从而在有限上下文长度内全面理解查询内容。给定基于电子健康记录(EHR)的临床问题$q$和参考EHR数据集${\mathcal{R}}={R_ {0},R_ {1},\cdot\cdot\cdot}$,信息整合的目标是生成与$q$最相关的领域知识,进而辅助在$\mathcal{R}$中识别和定位潜在有效参考。例如针对"阿司匹林"相关查询,我们期望大语言模型能将其定位至EHR系统的PRESCRIPTION表中prescription name列下。
To achieve this, we initially maintain a thorough metadata $\mathcal{T}$ of all the reference EHRs, including overall data descriptions $\mathcal{D}$ and the detailed column descriptions $\mathcal{C}_ {i}$ for each individual EHR $R_ {i}$ , expressed as $\mathcal{I}=[\mathcal{D};\mathcal{C}_ {0};\mathcal{C}_ {1};\cdot\cdot\cdot]$ . To further extract additional background knowledge essential for addressing the complex query $q$ , we then distill key information from the detailed introduction $\mathcal{T}$ . Specifically, we directly prompt LLMs to generate the relevant information $B(q)$ based on demonstrations, denoted as $B(q)=\mathrm{LLM}([\mathcal{I};q])$ .
为此,我们首先维护所有参考电子健康记录(EHR)的完整元数据$\mathcal{T}$,包括整体数据描述$\mathcal{D}$以及每个独立EHR $R_ {i}$的详细列描述$\mathcal{C}_ {i}$,表示为$\mathcal{I}=[\mathcal{D};\mathcal{C}_ {0};\mathcal{C}_ {1};\cdot\cdot\cdot]$。为了进一步提取解决复杂查询$q$所需的额外背景知识,我们从详细介绍$\mathcal{T}$中提炼关键信息。具体而言,我们直接提示大语言模型基于示例生成相关信息$B(q)$,记为$B(q)=\mathrm{LLM}([\mathcal{I};q])$。
3.2 Demonstration Optimization through Long-Term Memory
3.2 通过长期记忆进行演示优化
Due to the vast volume of information within EHRs and the complexity of the clinical questions, there exists a conflict between limited input context length and the number of few-shot examples. Specifically, $K$ -shot examples may not adequately cover the entire question types as well as the EHR information. To address this, we maintain a longterm memory $\mathcal{L}$ for storing past successful code snippets and reorganizing few-shot examples by retrieving the most relevant samples from $\mathcal{L}$ . Consequently, the LLM agent can learn from and apply patterns observed in past successes to current queries. The selection of $K$ -shot demonstrations $\mathcal{E}(q)$ is defined as follows:
由于电子健康记录(EHR)中信息量庞大且临床问题复杂,有限的输入上下文长度与少样本示例数量之间存在矛盾。具体而言,$K$样本示例可能无法充分覆盖全部问题类型及EHR信息。为此,我们维护一个长期记忆$\mathcal{L}$用于存储过往成功的代码片段,并通过从$\mathcal{L}$检索最相关样本来重组少样本示例。因此,大语言模型智能体能够学习并应用过往成功案例中的模式来处理当前查询。$K$样本演示$\mathcal{E}(q)$的选择定义如下:
$$
\mathcal{E}(q)=\arg\mathrm{TopK}_ {\operatorname* {max}}(\sin(q,q_ {i}|q_ {i}\in\mathcal{L})),
$$
$$
\mathcal{E}(q)=\arg\mathrm{TopK}_ {\operatorname* {max}}(\sin(q,q_ {i}|q_ {i}\in\mathcal{L})),
$$
where arg $;{\mathrm{TopK}}{\mathrm{max}}(\cdot)$ identifies the indices of the top $K$ elements with the highest values from $\mathcal{L}$ , and $\mathrm{sim}(\cdot,\cdot)$ calculates the similarity between two questions, employing negative Levenshtein distance as the similarity metric. Following this retrieval process, the newly acquired $K$ -shot examples $\mathcal{E}(q)$ replace the originally predefined examples $\mathcal{E}={E_ {1},\cdots,E_ {K}}$ . This updated set of examples serves to reformulate the prompt, guiding EHRAgent in optimal demonstration selection by leveraging accumulative domain knowledge.
其中 arg $;{\mathrm{TopK}}{\mathrm{max}}(\cdot)$ 用于从 $\mathcal{L}$ 中筛选出前 $K$ 个最大值对应的索引,$\mathrm{sim}(\cdot,\cdot)$ 通过负向Levenshtein距离计算两个问题间的相似度。检索完成后,新获取的 $K$ 样本示例 $\mathcal{E}(q)$ 将替换初始预定义的示例集 $\mathcal{E}={E_ {1},\cdots,E_ {K}}$。更新后的示例集用于重构提示词,使EHRAgent能够基于累积领域知识实现最优示范选择。
3.3 Interactive Coding with Execution
3.3 带执行的交互式编码
We then introduce interactive coding between the LLM agent (i.e., code generator) and code executor to facilitate iterative plan refinement. EHRAgent integrates LLMs with a code executor in a multi-turn conversation. The code executor runs the generated code and returns the results to the LLM. Within the conversation, EHRAgent navigates the subsequent phase of the dialogue, where the LLM agent is expected to either (1) continue to iterative ly refine its original code in response to any errors encountered or (2) finally deliver a conclusive answer based on the successful execution outcomes.
我们随后介绍了大语言模型智能体(即代码生成器)与代码执行器之间的交互式编码,以促进迭代式计划优化。EHRAgent通过多轮对话将大语言模型与代码执行器相结合。代码执行器运行生成的代码并将结果返回给大语言模型。在对话过程中,EHRAgent引导进入下一阶段对话,此时大语言模型智能体需要:(1) 根据遇到的错误持续迭代优化原始代码,或(2) 最终基于成功执行结果给出确定性答案。
LLM Agent. To generate accurate code snippets $C(q)$ as solution plans for the query $q$ , we prompt the LLM agent with a combination of the EHR introduction $\mathcal{T}$ , tool function definitions $\tau$ , a set of $K$ -shot examples $\mathcal{E}(q)$ updated by long-term memory, the input query $q$ , and the integrated medical information relevant to the query $B(q)$ :
大语言模型智能体 (LLM Agent)。为了生成准确的代码片段 $C(q)$ 作为查询 $q$ 的解决方案,我们通过以下组合提示大语言模型智能体:电子健康记录 (EHR) 介绍 $\mathcal{T}$、工具函数定义 $\tau$、由长期记忆更新的一组 $K$ 样本示例 $\mathcal{E}(q)$、输入查询 $q$,以及与查询相关的集成医疗信息 $B(q)$:
$$
C(q)=\mathrm{LLM}([\mathbb{Z};{\cal T};{\mathcal E}(q);q;B(q)]).
$$
$$
C(q)=\mathrm{LLM}([\mathbb{Z};{\cal T};{\mathcal E}(q);q;B(q)]).
$$
We develop the LLM agent to (1) generate code within a designated coding block as required, (2) modify the code according to the outcomes of its execution, and (3) insert a specific code “TERMINATE” at the end of its response to indicate the conclusion of the conversation.
我们开发的大语言模型智能体能够:(1) 按要求在指定代码块中生成代码,(2) 根据执行结果修改代码,(3) 在响应末尾插入特定代码"TERMINATE"以表示对话结束。
Code Executor. The code executor automatically extracts the code from the LLM agent’s output and executes it within the local environment: ${\cal O}(q)=\mathrm{EXECUTE}(C(q))$ . After execution, it sends back the execution results to the LLM agent for potential plan refinement and further processing. Given the alignment of empirical observations and Python’s inherent modularity with tool functions2, we select Python 3.9 as the primary coding language for interactions between the LLM agent and the code executor.
代码执行器 (Code Executor)。代码执行器会自动从大语言模型 (LLM) 智能体的输出中提取代码并在本地环境中执行: ${\cal O}(q)=\mathrm{EXECUTE}(C(q))$。执行完成后,它会将执行结果返回给大语言模型智能体,以便进行可能的计划优化和进一步处理。根据实证观察结果与 Python语言 固有的模块化特性与工具函数的匹配性 [2],我们选择 Python 3.9 作为大语言模型智能体与代码执行器之间交互的主要编程语言。
3.4 Rubber Duck Debugging via Error Tracing
3.4 通过错误追踪进行橡皮鸭调试
Our empirical observations indicate that LLM agents tend to make slight modifications to the code snippets based on the error message without further debugging. In contrast, human programmers often delve deeper, identifying bugs or underlying causes by analyzing the code implementation against the error descriptions (Chen et al., 2024). Inspired by this, we integrate a ‘rubber duck debugging’ pipeline with error tracing to refine plans with the LLM agent. Specifically, we provide detailed trace feedback, including error type, message, and location, all parsed from the error information by the code executor. Subsequently, this error context is presented to a ‘rubber duck’ LLM, prompting it to generate the most probable causes of the error. The generated explanations are then fed back into the conversation flow, aiding in the debugging process. For the $t$ -th interaction between the LLM agent and the code executor, the process is as follows:
我们的实证观察表明,大语言模型(LLM)智能体倾向于根据错误信息对代码片段进行轻微修改而不进一步调试。相比之下,人类程序员通常会深入分析代码实现与错误描述的匹配关系,从而定位错误或根本原因 (Chen et al., 2024)。受此启发,我们整合了"橡皮鸭调试"流程与错误追踪机制来优化大语言模型智能体的规划。具体而言,我们提供由代码执行器从错误信息中解析出的详细追踪反馈,包括错误类型、消息和位置。随后,将该错误上下文呈现给充当"橡皮鸭"的大语言模型,促使其生成最可能的错误原因。生成的解释会被反馈至对话流程中以辅助调试过程。对于大语言模型智能体与代码执行器之间的第$t$次交互,流程如下:
$$
\begin{array}{r l}&{O^{(t)}({q})=\mathrm{EXECUTE}(C^{(t)}({q})),}\ &{C^{(t+1)}({q})=\mathrm{LLM}(\mathrm{DEBUG}(O^{(t)}({q}))).}\end{array}
$$
$$
\begin{array}{r l}&{O^{(t)}({q})=\mathrm{EXECUTE}(C^{(t)}({q})),}\ &{C^{(t+1)}({q})=\mathrm{LLM}(\mathrm{DEBUG}(O^{(t)}({q}))).}\end{array}
$$
The interaction ends either when a ‘TERMINATE’ signal appears in the generated messages or when $t$ reaches a pre-defined threshold of steps $T$ .
交互会在生成消息中出现"TERMINATE"信号,或当$t$达到预定义的步骤阈值$T$时终止。
4 Experiments
4 实验
4.1 Experiment Setup
4.1 实验设置
Tasks and Datasets. We evaluate EHRAgent on three publicly available structured EHR datasets, MIMIC-III (Johnson et al., 2016), eICU (Pollard et al., 2018), and TREQS (Wang et al., 2020) for multi-hop question and answering on EHRs. These questions originate from real-world clinical needs and cover a wide range of tabular queries commonly posed within EHRs. Our final dataset includes an average of 10.7 tables and 718.7 examples per dataset, with an average of 1.91 tables required to answer each question. We include additional dataset details in Appendix A.
任务与数据集。我们在三个公开可用的结构化电子健康档案(EHR)数据集上评估EHRAgent,分别是MIMIC-III (Johnson等人,2016)、eICU (Pollard等人,2018)和TREQS (Wang等人,2020),用于EHR的多跳问答。这些问题源自真实临床需求,涵盖了EHR中常见的各类表格查询。我们的最终数据集平均包含10.7个表格和718.7个样本,每个问题平均需要1.91个表格来回答。更多数据集细节见附录A。
Tool Sets. To enable LLMs in complex operations such as calculations and information retrieval, we integrate external tools in EHRAgent during the interaction with EHRs. Our toolkit can be easily expanded with natural language tool function definitions in a plug-and-play manner. Toolset details are available in Appendix B.
工具集。为了让大语言模型能够执行计算和信息检索等复杂操作,我们在EHRAgent与电子健康记录交互时集成了外部工具。该工具集支持通过自然语言工具函数定义以即插即用方式进行灵活扩展,具体工具清单详见附录B。
Baselines. We compare EHRAgent with nine LLMbased planning, tool use, and coding methods, including five baselines with natural language interfaces and four with coding interfaces. For a fair comparison, all baselines, including EHRAgent, utilize the same (a) EHR metadata, (b) tool definitions, and (c) initial few-shot demonstrations in the prompts by default. We summarize their implementations in Appendix C.
基线方法。我们将EHRAgent与九种基于大语言模型的规划、工具使用和编码方法进行比较,包括五种自然语言接口基线和四种编码接口基线。为确保公平对比,所有基线方法(含EHRAgent)默认采用相同的:(a) EHR元数据,(b) 工具定义,(c) 提示中的初始少样本演示。具体实现细节汇总于附录C。
Evaluation Protocol. Following Yao et al. (2023b); Sun et al. (2023); Shinn et al. (2023), our primary evaluation metric is success rate, quantifying the percentage of queries the model handles successfully. Following Xu et al. (2023); Kirk et al. (2024), we further assess completion rate, which represents the percentage of queries that the model can generate executable plans (even not yield correct results). We categorize input queries into complexity levels (I-IV) based on the number of tables involved in solution generation. We include more details in Appendix A.2.
评估协议。参照 Yao et al. (2023b)、Sun et al. (2023) 和 Shinn et al. (2023) 的研究,我们的主要评估指标是成功率,用于量化模型成功处理的查询百分比。根据 Xu et al. (2023) 和 Kirk et al. (2024) 的方法,我们还评估完成率,即模型能生成可执行计划(即使未产生正确结果)的查询百分比。我们根据解决方案涉及的表数量将输入查询分为复杂度等级(I-IV),更多细节见附录 A.2。
| Dataset (→) | MIMIC-III | TREQS | |||||||||||||
| ComplexityLevel (>) | I | IⅡI IⅢI | IV | All | I | IⅡI IⅢ | All | II | IⅢI | All | |||||
| Methods(↓)/Metrics(→) | SR. | SR. | CR. | SR. | SR. CR. | SR. | SR. | CR. | |||||||
| w/oCodeInterface | |||||||||||||||
| CoT(Weiet al.,2022) | 29.33 | 12.88 | 3.08 | 2.11 | 9.58 | 38.23 | 26.73 | 33.00 | 8.33 | 27.34 465.65 | 11.22 | 9.15 | 0.00 | 9.84 | 54.02 |
| Self-Consistency (Wang et al.,2023d) | 33.33 | 16.56 | 4.62 | 1.05 | 10.17 | 40.34 | 27.11 | 34.67 | 6.25 31.72 | 70.69 | 12.60 | 11.16 | 0.00 | 11.45 57.83 | |
| Chameleon (Lu et al.,2023) | 38.67 | 14.11 | 4.62 | 4.21 | 12.77 | 42.76 | 31.09 | 34.68 | 16.67 35.06 83.41 | 13.58 | 12.72 | 4.55 | 12.25 60.34 | ||
| ReAct(Yaoetal.,2023b) | 34.67 | 12.27 | 3.85 | 2.11 | 10.38 | 25.92 | 27.82 | 34.24 | 15.3833.3373.68 | 33.86 | 26.12 | 9.09 | 29.22 78.31 | ||
| Reflexion (Shinn et al.,2023) | 41.05 | 19.31 | 12.57 | 11.96 19.48 57.07 | 38.08 33.33 15.3836.7280.00 | 35.04 | 429.91 | 9.09 | 31.53 80.02 | ||||||
| w/CodeInterface | |||||||||||||||
| LLM2SQL(Nanetal.,2023) | 23.68 | 10.64 | 6.98 | 4.83 | 13.10 44.83 | 20.48 | 325.13 | 312.5023.2851.7239.6136.4312.7337.8979.22 | |||||||
| DIN-SQL (Pourreza and Rafiei,2023) | 49.51 | 44.22 | 36.25 | 21.85 | 538.45 | 81.72 | 23.49 | 26.13 | 12.50 25.00 55.00 | 41.34 | 36.38 | 12.73 38.05 82.73 | |||
| Self-Debugging (Chen et al., 2024) | 50.00 | 46.93 | 30.12 | 27.61 | 39.05 | 571.24 | 32.53 | 21.86 | 25.0030.52 | 66.90 | 43.54 | 36.65 | 18.18 | 40.1084.44 | |
| AutoGen(Wuet al.,2023) | 36.00 | 28.13 | 15.33 | 11.11 | 22.49 | 61.47 | 42.77 | 40.70 | 18.75 | 40.69 | 86.21 | 46.65 19.42 | 0.00 | 33.13 85.38 | |
| EHRAgent(Ours) | 71.5866.3449.7049.1458.9785.86 | 54.82 53.52 25.0053.1091.72 | 78.94 61.16 27.2769.7088.02 | ||||||||||||
Table 1: Main results of success rate (i.e., SR.) and completion rate (i.e., CR.) on MIMIC-III, eICU, and TREQS datasets. The complexity of questions increases from Level I (the simplest) to Level IV (the most difficult).
表 1: MIMIC-III、eICU和TREQS数据集上的成功率(SR.)和完成率(CR.)主要结果。问题复杂度从I级(最简单)到IV级(最困难)递增。
| 数据集 (→) | MIMIC-III | TREQS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 复杂度等级 (>) | I | II | III | IV | 全部 | I | II | III | 全部 | II |
| 方法(↓)/指标(→) | SR. | SR. | SR. | SR. | SR. CR. | SR. | SR. | SR. CR. | SR. | SR. |
| 无代码接口 | ||||||||||
| CoT (Wei等,2022) | 29.33 | 12.88 | 3.08 | 2.11 | 9.58 38.23 | 26.73 | 33.00 | 8.33 27.34 465.65 | 11.22 | 9.15 |
| Self-Consistency (Wang等,2023d) | 33.33 | 16.56 | 4.62 | 1.05 | 10.17 40.34 | 27.11 | 34.67 | 6.25 31.72 70.69 | 12.60 | 11.16 |
| Chameleon (Lu等,2023) | 38.67 | 14.11 | 4.62 | 4.21 | 12.77 42.76 | 31.09 | 34.68 | 16.67 35.06 83.41 | 13.58 | 12.72 |
| ReAct (Yao等,2023b) | 34.67 | 12.27 | 3.85 | 2.11 | 10.38 25.92 | 27.82 | 34.24 | 15.38 33.33 73.68 | 33.86 | 26.12 |
| Reflexion (Shinn等,2023) | 41.05 | 19.31 | 12.57 | 11.96 19.48 57.07 | 38.08 33.33 15.38 36.72 80.00 | 35.04 | 429.91 | |||
| 有代码接口 | ||||||||||
| LLM2SQL (Nan等,2023) | 23.68 | 10.64 | 6.98 | 4.83 | 13.10 44.83 | 20.48 | 325.13 | 312.50 23.28 51.72 39.61 36.43 12.73 37.89 79.22 | ||
| DIN-SQL (Pourreza和Rafiei,2023) | 49.51 | 44.22 | 36.25 | 21.85 | 538.45 81.72 | 23.49 | 26.13 | 12.50 25.00 55.00 | 41.34 | 36.38 |
| Self-Debugging (Chen等,2024) | 50.00 | 46.93 | 30.12 | 27.61 | 39.05 571.24 | 32.53 | 21.86 | 25.00 30.52 66.90 | 43.54 | 36.65 |
| AutoGen (Wu等,2023) | 36.00 | 28.13 | 15.33 | 11.11 | 22.49 61.47 | 42.77 | 40.70 | 18.75 40.69 86.21 | 46.65 | 19.42 |
| EHRAgent (本文) | 71.58 | 66.34 | 49.70 | 49.14 | 58.97 85.86 | 54.82 | 53.52 | 25.00 53.10 91.72 | 78.94 | 61.16 |
Implementation Details. We employ GPT-4 (OpenAI, 2023) (version $\mathtt{g p t}{-4-0613})$ as the base LLM model for all experiments. We set the temperature to 0 when making API calls to GPT-4 to eliminate randomness and set the pre-defined threshold of steps $(T)$ to 10. Due to the maximum length limitations of input context in baselines (e.g., ReAct and Chameleon), we use the same initial fourshot demonstrations $\mathit{K}=4$ ) for all baselines and EHRAgent to ensure a fair comparison. Appendix E provides additional implementation details with prompt templates.
实现细节。我们采用 GPT-4 (OpenAI, 2023) (版本 $\mathtt{g p t}{-4-0613})$ 作为所有实验的基础大语言模型。在调用 GPT-4 API 时将温度参数设为 0 以消除随机性,并将预定义步骤阈值 $(T)$ 设为 10。由于基线方法 (如 ReAct 和 Chameleon) 存在输入上下文的最大长度限制,我们为所有基线方法和 EHRAgent 统一使用相同的初始少样本演示 $\mathit{K}=4$ 以确保公平比较。附录 E 提供了包含提示模板的额外实现细节。
4.2 Main Results
4.2 主要结果
Table 1 summarizes the experimental results of EHRAgent and baselines on multi-tabular reasoning within EHRs. From the results, we have the following observations:
表 1: 总结了EHRAgent和基线方法在电子健康记录(EHR)多表格推理上的实验结果。从结果中我们可以得出以下观察结论:
(1) EHRAgent significantly outperforms all the baselines on all three datasets with a performance gain of $19.92%$ , $12.41%$ , and $29.60%$ , respectively. This indicates the efficacy of our key designs, namely interactive coding with environment feedback and domain knowledge injection, as they gradually refine the generated code and provide sufficient background information during the planning process. Experimental results with additional base LLMs are available in Appendix F.1.
EHRAgent在三个数据集上均显著优于所有基线模型,性能分别提升19.92%、12.41%和29.60%。这表明我们提出的核心设计(即基于环境反馈的交互式编码和领域知识注入)具有显著效果,这些设计能逐步优化生成代码,并在规划过程中提供充分的背景信息。其他基础大语言模型的实验结果详见附录F.1。
(2) CoT, Self-Consistency, and Chameleon all neglect environmental feedback and cannot adaptively refine their planning processes. Such deficiencies hinder their performance in EHR questionanswering scenarios, as the success rates for these methods on three datasets are all below $40%$ .
(2) CoT (Chain-of-Thought) 、Self-Consistency 和 Chameleon 均忽略了环境反馈,无法自适应地优化规划流程。这些缺陷导致它们在电子健康记录 (EHR) 问答场景中表现不佳——三种方法在三个数据集上的成功率均低于 $40%$。
(3) ReAct and Reflexion both consider environment feedback but are restricted to tool-generated error messages. Thus, they potentially overlook the overall planning process. Moreover, they both lack a code interface, which prevents them from efficient action planning, and results in lengthy context execution and lower completion rates.
(3) ReAct和Reflexion虽然考虑了环境反馈,但仅限于工具生成的错误信息。因此,它们可能忽略了整体规划过程。此外,两者都缺乏代码接口,导致无法高效制定行动计划,从而产生冗长的上下文执行和较低的完成率。
(4) LLM2SQL and DIN-SQL leverage LLM to directly generate SQL queries for EHR questionanswering tasks. However, the gain is rather limited, as the LLM still struggles to generate highquality SQL codes for execution. Besides, the absence of the debugging module further impedes its overall performance on this challenging task.
(4) LLM2SQL和DIN-SQL利用大语言模型直接为电子健康档案(EHR)问答任务生成SQL查询。但由于大语言模型仍难以生成可执行的高质量SQL代码,其提升效果较为有限。此外,调试模块的缺失进一步阻碍了其在这一挑战性任务中的整体表现。
(5) Self-Debugging and AutoGen present a notable performance gain over other baselines, as they leverage code interfaces and consider the errors from the coding environment, leading to a large improvement in the completion rate. However, as they fail to model medical knowledge or identify underlying causes from error patterns, their success rates are still sub-optimal.
(5) Self-Debugging 和 AutoGen 通过利用代码接口并考虑编码环境中的错误,展现出显著优于其他基线的性能提升,从而大幅提高了完成率。然而,由于它们未能建模医学知识或从错误模式中识别根本原因,其成功率仍不理想。
4.3 Ablation Studies
4.3 消融实验
Our ablation studies on MIMIC-III (Table 2) demonstrate the effectiveness of all four components in EHRAgent. Interactive coding3 is the most significant contributor across all complexity levels, which highlights the importance of code generation in planning and environmental interaction for refinement. In addition, more challenging tasks benefits more from knowledge integration, indicating that comprehensive understanding of EHRs facilitates the complex multi-tabular reasoning in effective schema linking and reference (e.g., tables, columns, and condition values) identification. Detailed analysis with additional settings and results is available in Appendix F.2.
我们在MIMIC-III上的消融研究(表2)验证了EHRAgent所有四个组件的有效性。交互式编码3在所有复杂度级别中贡献最大,凸显了代码生成在规划与环境交互优化中的重要性。此外,任务难度越高,知识整合带来的收益越显著,这表明全面理解电子健康档案(EHRs)有助于在复杂的多表推理中实现有效的模式链接与参考(如表格、列及条件值)识别。附录F.2提供了包含额外设置与结果的详细分析。
Table 2: Ablation studies on success rate (i.e., SR.) and completion rate (i.e., CR.) under different question complexity (I-IV) on MIMIC-III dataset.
| ComplexityLevel(>) | Ⅱ | Ⅲ | IV | All | ||
| Methods (↓)/Metrics(>) | SR. | SR. | CR. | |||
| EHRAgent | 71.58 | 66.34 | 49.70 | 49.14 | 58.97 | 85.86 |
| w/omedicalinformation | 68.42 | 33.33 | 29.63 | 20.00 | 33.66 | 69.22 |
| w/olong-termmemory | 65.9654.46 | 537.13 | 42.74 | 51.73 | 83.42 | |
| w/ointeractive coding | 45.33 | 23.90 | 20.97 | 13.33 | 24.55 | 62.14 |
| w/orubberduckdebugging | 55.00 | 38.46 | 41.67 | 35.71 | 42.86 | 77.19 |
表 2: MIMIC-III数据集上不同问题复杂度(I-IV)下的成功率(SR)和完成率(CR)消融研究。
| ComplexityLevel(>) | Ⅱ | Ⅲ | IV | All | ||
|---|---|---|---|---|---|---|
| Methods (↓)/Metrics(>) | SR. | SR. | SR. | SR. | SR. | CR. |
| EHRAgent | 71.58 | 66.34 | 49.70 | 49.14 | 58.97 | 85.86 |
| w/o medical information | 68.42 | 33.33 | 29.63 | 20.00 | 33.66 | 69.22 |
| w/o long-term memory | 65.96 | 54.46 | 537.13 | 42.74 | 51.73 | |
| w/o interactive coding | 45.33 | 23.90 | 20.97 | 13.33 | 24.55 | 62.14 |
| w/o rubber duck debugging | 55.00 | 38.46 | 41.67 | 35.71 | 42.86 | 77.19 |
4.4 Quantitative Analysis
4.4 定量分析
Effect of Question Complexity. We take a closer look at the model performance by considering multi-dimensional measurements of question complexity, exhibited in Figure 4. Although the performances of both EHRAgent and the baselines generally decrease with an increase in task complexity (either quantified as more elements in queries or more columns in solutions), EHRAgent consistently outperforms all the baselines at various levels of difficulty. Appendix G.1 includes additional analysis on the effect of various question complexities.
问题复杂性的影响。我们通过多维度测量问题复杂性(如图4所示)来更细致地观察模型表现。尽管EHRAgent和基线模型的性能通常随着任务复杂性增加(表现为查询中更多元素或解决方案中更多列)而下降,但EHRAgent在不同难度级别上始终优于所有基线模型。附录G.1包含关于各类问题复杂性影响的补充分析。
Sample Efficiency. Figure 5 illustrates the model performance w.r.t. number of demonstrations for EHRAgent and the two strongest baselines, AutoGen and Self-Debugging. Compared to supervised learning like text-to-SQL (Wang et al., 2020; Raghavan et al., 2021; Lee et al., 2022) that requires extensive training on over 10K samples with detailed annotations (e.g., manually generated corresponding code for each query), LLM agents enable complex tabular reasoning using a few demonstrations only. One interesting finding is that as the number of examples increases, both the success and completion rate of AutoGen tend to decrease, mainly due to the context limitation of LLMs. Notably, the performance of EHRAgent remains stable with more demonstrations, which may benefit from its integration of a ‘rubber duck’ debugging module and the adaptive mechanism for selecting the most relevant demonstrations.
样本效率。图5展示了EHRAgent与两个最强基线模型AutoGen和Self-Debugging在不同演示数量下的性能表现。相较于需要上万条带详细标注样本(例如为每个查询手动生成对应代码)进行训练的监督学习方法(如文本转SQL [20][21][22]),大语言模型智能体仅需少量演示即可完成复杂的表格推理。一个有趣的发现是:随着示例数量增加,AutoGen的成功率和完成率均呈下降趋势,这主要源于大语言模型的上下文长度限制。值得注意的是,EHRAgent在演示数量增加时仍能保持稳定性能,这可能得益于其集成的"橡皮鸭"调试模块和自适应选择最相关演示的机制。
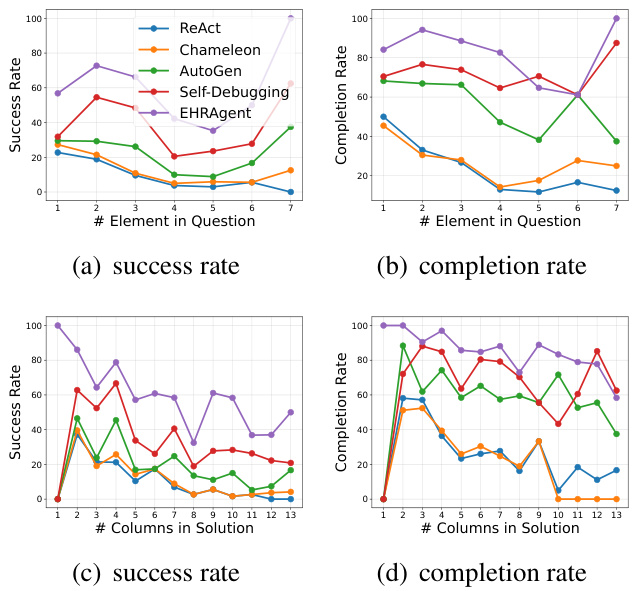
Figure 4: Success rate and completion rate under different question complexity, measured by the number of elements (i.e., slots) in each question (upper) and the number of columns involved in each solution (bottom).
图 4: 不同问题复杂度下的成功率与完成率,通过每个问题中的元素(即槽位)数量(上)以及每个解决方案涉及的列数(下)进行衡量。

Figure 5: Success rate and completion rate under different numbers of demonstrations.
图 5: 不同演示数量下的成功率和完成率。
4.5 Error Analysis
4.5 错误分析
Figure 6 presents a summary of error types identified in the solution generation process of EHRAgent based on the MIMIC-III, as determined through manual examinations and analysis. The majority of errors occur because the LLM agent consistently fails to identify the underlying cause of these errors within $T$ -step trails, resulting in plans that are either incomplete or inexcusable. Additional analysis of each error type is available in Appendix G.2.
图 6: 展示了基于MIMIC-III数据集、通过人工检查和分析确定的EHRAgent在解决方案生成过程中出现的错误类型总结。大多数错误源于大语言模型智能体在$T$步尝试中持续未能识别这些错误的根本原因,导致生成的计划不完整或不可接受。各错误类型的详细分析见附录G.2。

Figure 6: Percentage of mistake examples in different categories on MIMIC-III dataset.
图 6: MIMIC-III数据集中不同类别的错误示例占比。

Figure 7: Case study of EHRAgent harnessing LLMs in a multi-turn conversation with a code executor, debugging with execution errors through iterations.
图 7: EHRAgent 在多轮对话中利用大语言模型 (LLM) 与代码执行器协作,通过迭代调试执行错误的案例研究。
4.6 Case Study
4.6 案例研究
Figure 7 presents a case study of EHRAgent in interactive coding with environment feedback. The initial solution from LLM is unsatisfactory with multiple errors. Fortunately, EHRAgent is capable of identifying the underlying causes of errors by analyzing error messages and resolves multiple errors one by one through iterations. We have additional case studies in Appendix H.
图7展示了EHRAgent在带环境反馈的交互式编程中的案例研究。大语言模型提供的初始解决方案存在多处错误并不令人满意。幸运的是,EHRAgent能够通过分析错误信息识别出错误的根本原因,并通过迭代逐一解决多个错误。附录H提供了更多案例研究。
5 Related Work
5 相关工作
Augmenting LLMs with External Tools. LLMs have rapidly evolved from text generators into core computational engines of autonomous agents, with advanced planning and tool-use capabilities (Schick et al., 2023; Shen et al., 2023; Wang et al., 2024b; Yuan et al., 2024a,b; Zhuang et al.,
用外部工具增强大语言模型。大语言模型已从文本生成器迅速发展为具备高级规划和工具使用能力的自主AI智能体核心计算引擎 (Schick et al., 2023; Shen et al., 2023; Wang et al., 2024b; Yuan et al., 2024a,b; Zhuang et al.,
2023). LLM agents equip LLMs with planning capabilities (Yao et al., 2023a; Gong et al., 2023) to decompose a large and hard task into multiple smaller and simpler steps for efficiently navigating complex real-world scenarios. By integrating with external tools, LLM agents access external APIs for additional knowledge beyond training data (Lu et al., 2023; Patil et al., 2023; Qin et al., 2024; Li et al., 2023b,a). The disconnection between plan generation and execution, however, prevents LLM agents from effectively and efficiently mitigating error propagation and learning from environmental feedback (Qiao et al., 2023; Shinn et al., 2023; Yang et al., 2023). To this end, we leverage interactive coding to learn from dynamic interactions between the planner and executor, iterative ly refining generated code by incorporating insights from error messages. Furthermore, EHRAgent extends beyond the limitation of short-term memory obtained from in-context learning, leveraging longterm memory (Sun et al., 2023; Zhang et al., 2023) by rapid retrieval of highly relevant and successful experiences accumulated over time.
2023年。大语言模型智能体 (LLM agents) 赋予大语言模型规划能力 (Yao et al., 2023a; Gong et al., 2023),将庞大复杂的任务分解为多个小而简单的步骤,以高效应对现实世界的复杂场景。通过集成外部工具,大语言模型智能体可访问外部API获取训练数据之外的知识 (Lu et al., 2023; Patil et al., 2023; Qin et al., 2024; Li et al., 2023b,a)。然而,规划生成与执行之间的脱节导致智能体难以有效缓解错误传播并从环境反馈中学习 (Qiao et al., 2023; Shinn et al., 2023; Yang et al., 2023)。为此,我们利用交互式编码从规划器与执行器的动态交互中学习,通过整合错误信息洞察迭代优化生成代码。此外,EHRAgent突破了上下文学习短期记忆的限制,借助长期记忆机制 (Sun et al., 2023; Zhang et al., 2023) 快速检索随时间积累的高相关性成功经验。
LLM Agents for Scientific Discovery. Augmenting LLMs with domain-specific tools, LLM agents have demonstrated capabilities of autonomous design, planning, and execution in accelerating scientific discovery (Wang et al., 2023a,c, 2024a; Xi et al., 2023; Zhao et al., 2023; Cheung et al., 2024; Gao et al., 2024), including organic synthesis (Bran et al., 2023), material design (Boiko et al., 2023), and gene prior it iz ation (Jin et al., 2024). In the medical field, MedAgents (Tang et al., 2023), a multi-agent collaboration framework, leverages role-playing LLM-based agents in a task-oriented multi-round discussion for multi-choice questions in medical entrance examinations. Similarly, Abbasian et al. (2023) develop a conversational agent to enhance LLMs using external tools for general medical question-answering tasks. Different from existing LLM agents in the medical domains that focus on improving tasks like multiple-choice question-answering, EHRAgent integrates LLMs with an interactive code interface, exploring complex few-shot tabular reasoning tasks derived from real-world EHRs through autonomous code generation and execution.
用于科学发现的大语言模型智能体。通过整合领域专用工具增强的大语言模型智能体,已展现出在加速科学发现过程中自主设计、规划与执行的能力 (Wang et al., 2023a,c, 2024a; Xi et al., 2023; Zhao et al., 2023; Cheung et al., 2024; Gao et al., 2024),涵盖有机合成 (Bran et al., 2023)、材料设计 (Boiko et al., 2023) 和基因优先级划分 (Jin et al., 2024) 等领域。在医疗领域,多智能体协作框架MedAgents (Tang et al., 2023) 采用基于大语言模型的角色扮演智能体,通过任务导向的多轮讨论处理医学入学考试中的多选题。类似地,Abbasian等人 (2023) 开发了对话式智能体,利用外部工具增强大语言模型在通用医疗问答任务中的表现。与现有医疗领域专注于改进多选题作答等任务的大语言模型智能体不同,EHRAgent将大语言模型与交互式代码接口相结合,通过自主代码生成与执行探索源自真实世界电子健康记录 (EHR) 的复杂少样本表格推理任务。
6 Conclusion
6 结论
In this study, we develop EHRAgent, an LLM agent with external tools for few-shot multi-tabular reasoning on real-world EHRs. Empowered by the emergent few-shot learning capabilities of LLMs, EHRAgent leverages autonomous code generation and execution for direct communication between clinicians and EHR systems. We also improve EHRAgent by interactive coding with execution feedback, along with accumulative medical knowledge, thereby effectively facilitating plan optimization for multi-step problem-solving. Our exper- iments demonstrate the advantages of EHRAgent over baseline LLM agents in autonomous coding and improved medical reasoning.
在本研究中,我们开发了EHRAgent,这是一个配备外部工具的大语言模型智能体,用于现实世界电子健康记录(EHR)的少样本多表格推理。借助大语言模型新兴的少样本学习能力,EHRAgent通过自主代码生成与执行,实现了临床医生与EHR系统间的直接交互。我们还通过带执行反馈的交互式编码及累积医学知识对EHRAgent进行优化,从而有效促进多步骤问题解决的方案优化。实验证明,EHRAgent在自主编码和增强医疗推理方面优于基线大语言模型智能体。
Limitation and Future Work
局限性与未来工作
EHRAgent holds considerable potential for positive social impact in a wide range of clinical tasks and applications, including but not limited to patient cohort definition, clinical trial recruitment, case review selection, and treatment decision-making support. Despite the significant improvement in model performance, we have identified several potential limitations of EHRAgent as follows:
EHRAgent在广泛的临床任务和应用中具有显著的社会积极影响潜力,包括但不限于患者队列定义、临床试验招募、病例审查筛选以及治疗决策支持。尽管模型性能有显著提升,但我们发现EHRAgent存在以下潜在局限性:
Additional Execution Calls. We acknowledge that when compared to open-loop systems such as CoT, Self-Consistency, Chameleon, and LLM2SQL, which generate a complete problemsolving plan at the beginning without any adaptation during execution; EHRAgent, as well as other baselines that rely on environmental feedback like ReAct, Reflexion, Self-Debugging, and AutoGen, require additional LLM calls due to the multi-round conversation. However, such open-loop systems all overlook environmental feedback and cannot adaptively refine their planning processes. These shortcomings largely hinder their performance for the challenging EHR question-answering task, as the success rates for these methods on all three EHR datasets are all below $40%$ . We can clearly observe the trade-off between performance and execution times. Although environmental feedback enhances performance, future work will focus on cost-effective improvements to balance performance and cost (Zhang et al., 2023).
额外执行调用。我们注意到,与CoT、Self-Consistency、Chameleon和LLM2SQL等开环系统相比(这些系统在开始时生成完整的解题计划且执行期间不做任何调整),EHRAgent以及依赖环境反馈的其他基线方法(如ReAct、Reflexion、Self-Debugging和AutoGen)由于多轮对话需要额外的大语言模型调用。然而,此类开环系统均忽略了环境反馈,无法自适应优化其规划流程。这些缺陷严重阻碍了它们在具有挑战性的电子健康记录问答任务中的表现——这些方法在所有三个EHR数据集上的成功率均低于$40%$。我们可以清晰观察到性能与执行次数之间的权衡。尽管环境反馈提升了性能,但未来工作将聚焦于性价比优化以平衡性能与成本 (Zhang et al., 2023)。
Translational Clinical Research Considerations. Given the demands for privacy, safety, and ethical considerations in real-world clinical research and practice settings, our goal is to further advance EHRAgent by mitigating biases and addressing ethical implications, thereby contributing to the development of responsible artificial intelligence for healthcare and medicine. Furthermore, the adaptation and generalization of EHRAgent in low-resource languages is constrained by the availability of relevant resources and training data. Due to limited access to LLMs’ API services and constraints related to budget and computation resources, our current experiments are restricted to utilizing the Microsoft Azure OpenAI API service with the gpt-3.5-turbo (0613) and gpt-4 (0613) models. As part of our important future directions, we plan to enhance EHRAgent by incorpora ting fine-tuned white-box LLMs, such as LLaMA-2 (Touvron et al., 2023).
临床转化研究考量。鉴于真实世界临床研究和实践场景中对隐私性、安全性及伦理规范的要求,我们的目标是通过减少偏见和解决伦理影响来进一步改进EHR智能体(EHRAgent),从而推动医疗健康领域负责任人工智能的发展。此外,EHR智能体在低资源语言中的适应与泛化能力受限于相关资源和训练数据的可获得性。由于大语言模型API服务的访问限制以及预算和计算资源的约束,当前实验仅能使用Microsoft Azure OpenAI API服务中的gpt-3.5-turbo(0613)和gpt-4(0613)模型。作为未来重点方向,我们计划通过整合微调后的白盒大语言模型(如LLaMA-2(Touvron等人,2023))来增强EHR智能体的性能。
Completion Rate under Clinical Scenarios. Besides success rate (SR) as our main evaluation metric, we follow Xu et al. (2023); Kirk et al. (2024) and employ completion rate (CR) to denote the percentage of queries for which the model can generate executable plans, irrespective of whether the results are accurate. However, it is important to note that a higher CR may not necessarily imply a superior outcome, especially in clinical settings. In such cases, it is generally preferable to acknowledge failure rather than generate an incorrect answer, as this could lead to an inaccurate diagnosis. We will explore stricter evaluation metrics to assess the cases of misinformation that could pose a risk within clinical settings in our future work.
临床场景下的完成率。除了将成功率(SR)作为主要评估指标外,我们遵循Xu等人(2023)和Kirk等人(2024)的方法,采用完成率(CR)来表示模型能生成可执行计划的查询百分比,无论结果是否准确。但需注意,更高的完成率并不一定意味着更好的结果,尤其在临床环境中。这种情况下,通常更倾向于承认失败而非生成错误答案,因为这可能导致误诊。我们将在未来工作中探索更严格的评估指标,以评估临床环境中可能造成风险的错误信息案例。
Privacy and Ethical Statement
隐私与道德声明
In compliance with the PhysioNet Credential ed Health Data Use Agreement $1.5.0^{4}$ , we strictly prohibit the transfer of confidential patient data (MIMIC-III and eICU) to third parties, including through online services like APIs. To ensure responsible usage of Azure OpenAI Service based on the guideline5, we have opted out of the human review process by requesting the Azure OpenAI Additional Use Case $\mathrm{Form}^{6}$ , which prevents third-parties (e.g., Microsoft) from accessing and processing sensitive patient information for any purpose. We continuously and carefully monitor our compliance with these guidelines and the relevant privacy laws to uphold the ethical use of data in our research and operations.
根据PhysioNet认证健康数据使用协议$1.5.0^{4}$的要求,我们严禁向第三方传输机密患者数据(包括MIMIC-III和eICU),也不允许通过API等在线服务进行传输。为确保基于guideline5负责任地使用Azure OpenAI服务,我们通过提交Azure OpenAI附加用例$\mathrm{Form}^{6}$退出了人工审核流程,此举可防止第三方(如Microsoft)出于任何目的访问和处理敏感患者信息。我们持续严格监控对这些准则及相关隐私法规的遵守情况,以维护研究及运营中数据使用的伦理规范。
Acknowledgments
致谢
We thank the anonymous reviewers and area chairs for their valuable feedback. This research was partially supported by Accelerate Foundation Models Academic Research Initiative from Microsoft Research. This research was also partially supported by the National Science Foundation under Award Number 2319449 and Award Number 2312502, the National Institute Of Diabetes And Digestive And Kidney Diseases of the National Institutes of Health under Award Number K 25 DK 135913, the Emory Global Diabetes Center of the Woodruff Sciences Center, Emory University.
我们感谢匿名评审和领域主席的宝贵反馈。本研究部分由Microsoft Research的加速基础模型学术研究计划支持。本研究还部分得到了美国国家科学基金会(奖项编号2319449和2312502)、美国国立卫生研究院国家糖尿病、消化和肾脏疾病研究所(奖项编号K25DK135913)、埃默里大学Woodruff科学中心埃默里全球糖尿病中心的支持。
References
参考文献
Mahyar Abbasian, Iman Azimi, Amir M. Rahmani, and Ramesh Jain. 2023. Conversational health agents: A personalized llm-powered agent framework.
Mahyar Abbasian、Iman Azimi、Amir M. Rahmani 和 Ramesh Jain。2023。对话式健康智能体:个性化大语言模型驱动的智能体框架。
Rohan Anil, Andrew M Dai, Orhan Firat, Melvin John- son, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. 2023. Palm 2 technical report.
Rohan Anil、Andrew M Dai、Orhan Firat、Melvin Johnson、Dmitry Lepikhin、Alexandre Passos、Siamak Shakeri、Emanuel Taropa、Paige Bailey、Zhifeng Chen 等。2023。PaLM 2 技术报告。
Seongsu Bae, Daeun Kyung, Jaehee Ryu, Eunbyeol Cho, Gyubok Lee, Sunjun Kweon, Jungwoo Oh, Lei Ji, Eric I-Chao Chang, Tackeun Kim, and Edward Choi. 2023. EHRXQA: A multi-modal question answering dataset for electronic health records with chest x-ray images. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
Seongsu Bae、Daeun Kyung、Jaehee Ryu、Eunbyeol Cho、Gyubok Lee、Sunjun Kweon、Jungwoo Oh、Lei Ji、Eric I-Chao Chang、Tackeun Kim和Edward Choi。2023。EHRXQA:一个包含胸部X光图像的多模态电子健康记录问答数据集。载于第三十七届神经信息处理系统大会数据集与基准赛道。
Duane Bender and Kamran Sartipi. 2013. Hl7 fhir: An agile and restful approach to healthcare information exchange. In Proceedings of the 26th IEEE international symposium on computer-based medical systems, pages 326–331. IEEE.
Duane Bender 和 Kamran Sartipi。2013. HL7 FHIR:一种敏捷且 RESTful 的医疗信息交换方法。载于《第 26 届 IEEE 计算机医疗系统国际研讨会论文集》,第 326–331 页。IEEE。
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. 2023. Autonomous chemical research with large language models. Nature, 624(7992):570– 578.
Daniil A Boiko、Robert MacKnight、Ben Kline 和 Gabe Gomes。2023。利用大语言模型 (Large Language Model) 实现自主化学研究。《自然》期刊,624(7992):570–578。
Andres M Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew White, and Philippe Schwaller. 2023. Augmenting large language models with chemistry tools. In NeurIPS 2023 AI for Science Workshop.
Andres M Bran、Sam Cox、Oliver Schilter、Carlo Baldassari、Andrew White 和 Philippe Schwaller。2023。用化学工具增强大语言模型。收录于 NeurIPS 2023 人工智能科学研讨会。
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2023. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. Transactions on Machine Learning Research.
温虎陈、马学广、王新一和William W. Cohen。2023。思维编程提示:数值推理任务中计算与推理的解耦。机器学习研究汇刊。
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2024. Teaching large language models to self-debug. In The Twelfth International Conference on Learning Representations.
Xinyun Chen、Maxwell Lin、Nathanael Schärli 和 Denny Zhou。2024。教大语言模型自我调试 (self-debug)。见:第十二届国际学习表征会议。
Jerry Cheung, Yuchen Zhuang, Yinghao Li, Pranav Shetty, Wantian Zhao, Sanjeev G rampur oh it, Rampi Ramprasad, and Chao Zhang. 2024. POLYIE: A dataset of information extraction from polymer material scientific literature. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2370–2385, Mexico City, Mexico. Association for Computational Linguistics.
Jerry Cheung、Yuchen Zhuang、Yinghao Li、Pranav Shetty、Wantian Zhao、Sanjeev Grampur、Rampi Ramprasad 和 Chao Zhang。2024。POLYIE:聚合物材料科学文献信息抽取数据集。载于《2024年北美计算语言学协会会议论文集:人类语言技术(第一卷:长论文)》,第2370–2385页,墨西哥城,墨西哥。计算语言学协会。
Martin R Cowie, Juuso I Blomster, Lesley H Curtis, Sylvie Duclaux, Ian Ford, Fleur Fritz, Samantha Goldman, Salim Janmohamed, Jörg Kreuzer, Mark Leenay, et al. 2017. Electronic health records to facilitate clinical research. Clinical Research in Cardiology, 106:1–9.
Martin R Cowie, Juuso I Blomster, Lesley H Curtis, Sylvie Duclaux, Ian Ford, Fleur Fritz, Samantha Goldman, Salim Janmohamed, Jörg Kreuzer, Mark Leenay等. 2017. 电子健康记录促进临床研究. 心脏病学临床研究, 106:1–9.
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Pal: Program-aided language models. In International Conference on Machine Learning, pages 10764–10799. PMLR.
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. PAL: 程序辅助语言模型. 见: 国际机器学习大会, 页码 10764–10799. PMLR.
Shanghua Gao, Ada Fang, Yepeng Huang, Valentina Gi un chi glia, Ayush Noori, Jonathan Richard Schwarz, Yasha Ektefaie, Jovana Kondic, and Marinka Zitnik. 2024. Empowering biomedical discovery with ai agents.
尚华高、Ada Fang、黄业鹏、Valentina Giunchiglia、Ayush Noori、Jonathan Richard Schwarz、Yasha Ektefaie、Jovana Kondic 和 Marinka Zitnik。2024。用AI智能体赋能生物医学发现。
Ran Gong, Qiuyuan Huang, Xiaojian Ma, Hoi Vo, Zane Durante, Yusuke Noda, Zilong Zheng, Song-Chun Zhu, Demetri Ter zo poul os, Li Fei-Fei, et al. 2023. Mindagent: Emergent gaming interaction. ArXiv preprint, abs/2309.09971.
Ran Gong、Qiuyuan Huang、Xiaojian Ma、Hoi Vo、Zane Durante、Yusuke Noda、Zilong Zheng、Song-Chun Zhu、Demetri Terzopoulos、Li Fei-Fei 等。2023。MindAgent: 涌现式游戏交互。ArXiv 预印本,abs/2309.09971。
Tracy D Gunter and Nicolas P Terry. 2005. The emergence of national electronic health record architectures in the united states and australia: models, costs, and questions. Journal of medical Internet research, 7(1):e383.
Tracy D Gunter 和 Nicolas P Terry. 2005. 美国与澳大利亚国家电子健康记录架构的涌现: 模型、成本与问题. Journal of medical Internet research, 7(1):e383.
Lavender Yao Jiang, Xujin Chris Liu, Nima Pour Neja- tian, Mustafa Nasir-Moin, Duo Wang, Anas Abidin, Kevin Eaton, Howard Antony Riina, Ilya Laufer, Paawan Punjabi, et al. 2023. Health system-scale language models are all-purpose prediction engines. Nature, pages 1–6.
姚江薰、刘旭金、尼马·普尔·内贾蒂安、穆斯塔法·纳西尔-莫因、王铎、阿纳斯·阿比丁、凯文·伊顿、霍华德·安东尼·里纳、伊利亚·劳弗、帕万·旁遮普等。2023。医疗系统级语言模型是全能预测引擎。《自然》,第1-6页。
Qiao Jin, Yifan Yang, Qingyu Chen, and Zhiyong Lu. 2024. GeneGPT: augmenting large language models with domain tools for improved access to biomedical information. Bioinformatics, 40(2):btae075.
乔金、杨一凡、陈清宇和陆志勇。2024。GeneGPT:通过领域工具增强大语言模型以改进生物医学信息获取。Bioinformatics, 40(2):btae075。
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. 2016. Mimic-iii, a freely accessible critical care database. Scientific data, 3(1):1–9.
Alistair EW Johnson、Tom J Pollard、Lu Shen、Li-wei H Lehman、Mengling Feng、Mohammad Ghassemi、Benjamin Moody、Peter Szolovits、Leo Anthony Celi 和 Roger G Mark。2016. MIMIC-III:一个可自由访问的重症监护数据库。《科学数据》,3(1):1-9。
James R Kirk, Robert E Wray, Peter Lindes, and John E Laird. 2024. Improving knowledge extraction from llms for task learning through agent analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18390–18398.
James R Kirk、Robert E Wray、Peter Lindes和John E Laird。2024. 通过智能体分析改进大语言模型(LLM)的任务学习知识提取。见《AAAI人工智能会议论文集》第38卷,第18390–18398页。
Gyubok Lee, Hyeonji Hwang, Seongsu Bae, Yeonsu Kwon, Woncheol Shin, Seongjun Yang, Minjoon Seo, Jong-Yeup Kim, and Edward Choi. 2022. EHRSQL: A practical text-to-SQL benchmark for electronic health records. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
Gyubok Lee、Hyeonji Hwang、Seongsu Bae、Yeonsu Kwon、Woncheol Shin、Seongjun Yang、Minjoon Seo、Jong-Yeup Kim 和 Edward Choi。2022。EHRSQL:面向电子健康记录的实用文本到SQL基准测试。载于《第三十六届神经信息处理系统大会数据集与基准测试轨道》。
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023a. CAMEL: Communicative agents for ”mind” exploration of large language model society. In Thirty-seventh Conference on Neural Information Processing Systems.
Guohao Li、Hasan Abed Al Kader Hammoud、Hani Itani、Dmitrii Khizbullin 和 Bernard Ghanem。2023a。CAMEL:面向大语言模型社会思维探索的通信智能体。载于第三十七届神经信息处理系统大会。
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. 2024. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems, 36.
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo等. 2024. 大语言模型能否胜任数据库接口?面向大规模数据库文本转SQL的基准测试. Advances in Neural Information Processing Systems, 36.
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. 2023b. API-bank: A comprehensive benchmark for tool-augmented LLMs. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3102–3116, Singapore. Association for Computational Linguistics.
李明浩、赵映秀、余博文、宋非凡、李航宇、于海洋、李周俊、黄飞和李永斌。2023b。API-bank: 面向工具增强大语言模型的综合基准测试。载于《2023年自然语言处理实证方法会议论文集》,第3102–3116页,新加坡。计算语言学协会。
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. 2023. Code as policies: Language model programs for embodied control. In 2023 IEEE Inter national Conference on Robotics and Automation (ICRA), pages 9493–9500. IEEE.
Jacky Liang、Wenlong Huang、Fei Xia、Peng Xu、Karol Hausman、Brian Ichter、Pete Florence 和 Andy Zeng。2023。代码即策略:用于具身控制的语言模型程序。2023年IEEE国际机器人与自动化会议(ICRA),第9493–9500页。IEEE。
Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, KaiWei Chang, Ying Nian Wu, Song-Chun Zhu, and Jianfeng Gao. 2023. Chameleon: Plug-and-play compositional reasoning with large language models. In Thirty-seventh Conference on Neural Information Processing Systems.
潘璐、鲍林鹏、程浩、Michel Galley、张凯威、吴恩年、朱松纯、高剑峰。2023。变色龙:大语言模型的即插即用组合推理。载于第三十七届神经信息处理系统大会。
Joshua C Mandel, David A Kreda, Kenneth D Mandl, Isaac S Kohane, and Rachel B Ramoni. 2016. Smart on fhir: a standards-based, interoperable apps platform for electronic health records. Journal of the American Medical Informatics Association, 23(5):899–908.
Joshua C Mandel、David A Kreda、Kenneth D Mandl、Isaac S Kohane和Rachel B Ramoni。2016。基于标准的电子健康记录互操作应用平台Smart on FHIR。《美国医学信息学会杂志》23(5):899–908。
Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M Krumholz, Jure Leskovec, Eric J Topol, and Pranav Rajpurkar. 2023. Foundation models for generalist medical artificial intelligence. Na- ture, 616(7956):259–265.
Michael Moor、Oishi Banerjee、Zahra Shakeri Hossein Abad、Harlan M Krumholz、Jure Leskovec、Eric J Topol 和 Pranav Rajpurkar。2023。通用医疗人工智能的基础模型 (Foundation models for generalist medical artificial intelligence)。《自然》期刊,616(7956):259–265。
Linyong Nan, Ellen Zhang, Weijin Zou, Yilun Zhao, Wenfei Zhou, and Arman Cohan. 2023. On evaluating the integration of reasoning and action in llm agents with database question answering.
Linyong Nan、Ellen Zhang、Weijin Zou、Yilun Zhao、Wenfei Zhou 和 Arman Cohan。2023。论大语言模型智能体中推理与行动在数据库问答中的整合评估。
OpenAI. 2023. Gpt-4 technical report. arXiv.
OpenAI. 2023. GPT-4技术报告. arXiv.
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. 2023. Gorilla: Large language model connected with massive apis.
Shishir G. Patil、Tianjun Zhang、Xin Wang 和 Joseph E. Gonzalez. 2023. Gorilla: 连接海量 API 的大语言模型。
ning from feedback with language models. In Thirtyseventh Conference on Neural Information Processing Systems.
从语言模型的反馈中学习。见于第三十七届神经信息处理系统大会。
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadal- lah, Ryen W White, Doug Burger, and Chi Wang. 2023. Autogen: Enabling next-gen llm applications via multi-agent conversation.
吴青云、Gagan Bansal、张洁玉、吴一然、李北滨、朱尔康、蒋力、张晓云、张少坤、刘佳乐、Ahmed Hassan Awadallah、Ryen W White、Doug Burger和王驰。2023。Autogen:通过多智能体对话实现下一代大语言模型应用。
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2023. The rise and potential of large language model based agents: A survey.
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, 等. 2023. 基于大语言模型的智能体崛起与潜力:综述.
Qiantong Xu, Fenglu Hong, Bo Li, Changran Hu, Zhengyu Chen, and Jian Zhang. 2023. On the tool manipulation capability of open-source large language models.
钱彤旭、冯璐红、李波、胡昌然、陈正宇和张健。2023。开源大语言模型的工具操作能力研究。
John Yang, Akshara Prabhakar, Karthik R Narasimhan, and Shunyu Yao. 2023. Intercode: Standardizing and benchmarking interactive coding with execution feedback. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
John Yang、Akshara Prabhakar、Karthik R Narasimhan 和 Shunyu Yao。2023. Intercode:通过执行反馈实现交互式编码的标准化与基准测试。载于《第三十七届神经信息处理系统大会数据集与基准测试专题》。
Xi Yang, Aokun Chen, Nima Pour Ne jati an, Hoo Chang Shin, Kaleb E Smith, Christopher Parisien, Colin Compas, Cheryl Martin, Anthony B Costa, Mona G Flores, et al. 2022. A large language model for electronic health records. NPJ Digital Medicine, 5(1):194.
Xi Yang, Aokun Chen, Nima Pour Nejatian, Hoo Chang Shin, Kaleb E Smith, Christopher Parisien, Colin Compas, Cheryl Martin, Anthony B Costa, Mona G Flores等. 2022. 面向电子健康档案的大语言模型. NPJ数字医学, 5(1):194.
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik R Narasimhan. 2023a. Tree of thoughts: Deliberate problem solving with large language models. In Thirty-seventh Conference on Neural Information Processing Systems.
Shunyu Yao、Dian Yu、Jeffrey Zhao、Izhak Shafran、Thomas L. Griffiths、Yuan Cao 和 Karthik R Narasimhan。2023a。思维之树:利用大语言模型进行深思熟虑的问题求解。载于第三十七届神经信息处理系统大会。
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023b. React: Syne rg i zing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations.
Shunyu Yao、Jeffrey Zhao、Dian Yu、Nan Du、Izhak Shafran、Karthik R Narasimhan 和 Yuan Cao。2023b。React:在大语言模型中同步推理与行动 (Synergizing Reasoning and Acting in Language Models)。载于《第十一届国际学习表征会议》。
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2018. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-SQL task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3911–3921, Brussels, Belgium. Association for Computational Linguistics.
Tao Yu、Rui Zhang、Kai Yang、Michihiro Yasunaga、Dongxu Wang、Zifan Li、James Ma、Irene Li、Qingning Yao、Shanelle Roman、Zilin Zhang 和 Dragomir Radev。2018. Spider: 一个用于复杂跨领域语义解析和文本到SQL任务的大规模人工标注数据集。载于《2018年自然语言处理实证方法会议论文集》,第3911–3921页,比利时布鲁塞尔。计算语言学协会。
Lifan Yuan, Yangyi Chen, Xingyao Wang, Yi R Fung, Hao Peng, and Heng Ji. 2024a. CRAFT: Customizing LLMs by creating and retrieving from specialized toolsets. In The Twelfth International Conference on Learning Representations.
Lifan Yuan, Yangyi Chen, Xingyao Wang, Yi R Fung, Hao Peng, 和 Heng Ji. 2024a. CRAFT: 通过创建和检索专用工具集定制大语言模型. 见 The Twelfth International Conference on Learning Representations.
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Yongliang Shen, Ren Kan, Dongsheng Li, and Deqing Yang. 2024b. Easytool: Enhancing llm-based agents with concise tool instruction.
Siyu Yuan、Kaitao Song、Jiangjie Chen、Xu Tan、Yongliang Shen、Ren Kan、Dongsheng Li 和 Deqing Yang。2024b。EasyTool: 通过简洁工具指令增强基于大语言模型的AI智能体。
Jieyu Zhang, Ranjay Krishna, Ahmed H. Awadallah, and Chi Wang. 2023. Eco assistant: Using llm assistant more affordably and accurately.
Jieyu Zhang, Ranjay Krishna, Ahmed H. Awadallah, and Chi Wang. 2023. Eco助手: 更经济、更准确地使用大语言模型助手。
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2023. Expel: Llm agents are experiential learners.
Andrew Zhao、Daniel Huang、Quentin Xu、Matthieu Lin、Yong-Jin Liu 和 Gao Huang。2023. Expel: 大语言模型智能体是经验学习者。
Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2sql: Generating structured queries from natural language using reinforcement learning.
Victor Zhong、Caiming Xiong 和 Richard Socher。2017. Seq2sql: 使用强化学习从自然语言生成结构化查询。
Yuchen Zhuang, Xiang Chen, Tong Yu, Saayan Mitra, Victor Bursztyn, Ryan A. Rossi, Somdeb Sarkhel, and Chao Zhang. 2024. Toolchain* : Efficient action space navigation in large language models with a* search. In The Twelfth International Conference on Learning Representations.
Yuchen Zhuang、Xiang Chen、Tong Yu、Saayan Mitra、Victor Bursztyn、Ryan A. Rossi、Somdeb Sarkhel 和 Chao Zhang。2024。Toolchain* :利用A* 搜索在大语言模型中高效导航动作空间。收录于第十二届国际学习表征会议。
Yuchen Zhuang, Yue Yu, Kuan Wang, Haotian Sun, and Chao Zhang. 2023. Toolqa: A dataset for llm question answering with external tools. Advances in Neural Information Processing Systems, 36:50117– 50143.
庄雨辰、余悦、王宽、孙昊天和张超。2023。ToolQA:一个基于外部工具的大语言模型问答数据集。《神经信息处理系统进展》,36:50117–50143。
A Dataset and Task Details
数据集与任务详情
A.1 Task Details
A.1 任务详情
We evaluate EHRAgent on three publicly available EHR datasets from two text-to-SQL medical question answering (QA) benchmarks (Lee et al., 2022), EHRSQL7 and $\mathrm{TREQS^{8}}$ , built upon structured EHRs from MIMIC-III and eICU. EHRSQL and TREQS serve as text-to-SQL benchmarks for assessing the performance of medical QA models, specifically focusing on generating SQL queries for addressing a wide range of real-world questions gathered from over 200 hospital staff. Questions within EHRSQL and TREQS, ranging from simple data retrieval to complex operations such as calculations, reflect the diverse and complex clinical tasks encountered by front-line healthcare professionals. Dataset statistics are available in Table 3.
我们在两个基于MIMIC-III和eICU结构化电子健康记录构建的文本转SQL医疗问答基准测试(Lee等人,2022)——EHRSQL7和$\mathrm{TREQS^{8}}$的三个公开电子健康记录数据集上评估EHRAgent。EHRSQL和TREQS作为文本转SQL基准测试,用于评估医疗问答模型的性能,特别关注生成SQL查询以解决从200多名医院工作人员收集的各类现实问题。EHRSQL和TREQS中的问题范围从简单的数据检索到计算等复杂操作,反映了一线医疗专业人员遇到的多样且复杂的临床任务。数据集统计信息见表3。
Table 3: Dataset statistics.
| Dataset | #Examples | #Table | #Row/Table | #Table/Q |
| MIMIC-ImI | 580 | 17 | 81k | 2.52 |
| eICU | 580 | 10 | 152k | 1.74 |
| TREQS | 996 | 5 | 498k | 1.48 |
| Average | 718.7 | 10.7 | 243.7k | 1.91 |
表 3: 数据集统计。
| 数据集 | 样本数 | 表格数 | 每表行数 | 每问表格数 |
|---|---|---|---|---|
| MIMIC-ImI | 580 | 17 | 81k | 2.52 |
| eICU | 580 | 10 | 152k | 1.74 |
| TREQS | 996 | 5 | 498k | 1.48 |
| 平均值 | 718.7 | 10.7 | 243.7k | 1.91 |
A.2 Question Complexity Level
A.2 问题复杂度等级
We categorize input queries into various complexity levels (levels I-IV for MIMIC-III and levels
我们将输入查询按复杂度分为不同等级(MIMIC-III分为I-IV级,
I-III for eICU and TREQS) based on the number of tables involved in solution generation. For example, given the question ‘How many patients were given temporary tracheostomy?’, the complexity level is categorized as II, indicating that we need to extract information from two tables (admission and procedure) to generate the solution. Furthermore, we also conduct a performance analysis (see Figure 4) based on additional evaluation metrics related to question complexity, including (1) the number of elements (i.e., slots) in each question and (2) the number of columns involved in each solution. Specifically, elements refer to the slots within each template that can be populated with pre-defined values or database records.
根据解决方案生成所涉及的表数量,将eICU和TREQS的复杂度分为I-III级。例如,针对问题"有多少患者接受了临时气管切开术?",其复杂度被归类为II级,这意味着我们需要从两个表(入院表和手术表)中提取信息以生成解决方案。此外,我们还基于与问题复杂度相关的额外评估指标进行了性能分析(见图4),包括:(1) 每个问题中的元素(即槽位)数量,以及(2) 每个解决方案涉及的列数。具体而言,元素指的是模板中可填入预定义值或数据库记录的槽位。
A.3 MIMIC-III
A.3 MIMIC-III
MIMIC-III (Johnson et al., $2016)^{9}$ covers 38,597 patients and 49,785 hospital admissions information in critical care units at the Beth Israel Dea- coness Medical Center ranging from 2001 to 2012. It includes de identified administrative information such as demographics and highly granular clinical information, including vital signs, laboratory results, procedures, medications, caregiver notes, imaging reports, and mortality.
MIMIC-III (Johnson等人, 2016)[9] 涵盖了2001年至2012年间Beth Israel Deaconess医疗中心重症监护病房的38,597名患者和49,785次住院信息。该数据集包含去标识化的管理信息(如人口统计数据)以及高度细粒度的临床信息(包括生命体征、实验室结果、诊疗操作、用药记录、护理人员笔记、影像报告和死亡率数据)。
A.4 eICU
A.4 eICU
Similar to MIMIC-III, eICU (Pollard et al., 2018)10 includes over 200,000 admissions from multiple critical care units across the United States in 2014 and 2015. It contains de identified administrative information following the US Health Insurance Portability and Accountability Act (HIPAA) standard and structured clinical data, including vital signs, laboratory measurements, medications, treatment plans, admission diagnoses, and medical histories.
与MIMIC-III类似,eICU (Pollard等人,2018) [10] 包含了2014年和2015年美国多个重症监护病房的20多万次入院记录。它遵循美国《健康保险可携性与责任法案》(HIPAA)标准,包含去标识化的管理信息和结构化临床数据,涵盖生命体征、实验室测量结果、药物、治疗方案、入院诊断和病史等。
A.5 TREQS
A.5 TREQS
TREQS (Wang et al., 2020) is a healthcare question and answering benchmark that is built upon the MIMIC-III (Johnson et al., 2016) dataset. In TREQS, questions are generated automatically using pre-defined templates with the text-to-SQL task. Compared to the MIMIC-III dataset within the EHRSQL (Lee et al., 2022) benchmark, TREQS has a narrower focus in terms of the types of questions and the complexity of SQL queries. Specifically, it is restricted to only five tables but includes a significantly larger number of records (Table 3) within each table.
TREQS (Wang et al., 2020) 是一个基于 MIMIC-III (Johnson et al., 2016) 数据集构建的医疗问答基准。在 TREQS 中,问题是通过预定义模板结合文本到 SQL (text-to-SQL) 任务自动生成的。与 EHRSQL (Lee et al., 2022) 基准中的 MIMIC-III 数据集相比,TREQS 在问题类型和 SQL 查询复杂度方面的范围较窄。具体而言,它仅涉及五个表,但每个表包含的记录数量显著更多 (表 3)。
B Tool Set Details
B 工具集详情
To obtain relevant information from EHRs and enhance the problem-solving capabilities of LLMbased agents, we augment LLMs with the following tools:
为了从电子健康记录(EHR)中获取相关信息并增强基于大语言模型的AI智能体的问题解决能力,我们为大语言模型配备了以下工具:
$\diamond$ Database Loader loads a specific table from the database.
$\diamond$ 数据库加载器 (Database Loader) 从数据库加载特定表格。
$\diamond$ Data Filter applies specific filtering condition to the selected table. These conditions are defined by a column name and a relational operator. The relational operator may take the form of a comparison (e.g., $"<"$ or $">"$ ) with a specific value, either with the column’s values or the count of values grouped by another column. Alternatively, it could be operations such as identifying the minimum or maximum values within the column.
$\diamond$ 数据过滤器 (Data Filter) 对选定表格应用特定筛选条件。这些条件由列名和关系运算符定义。关系运算符可以是与特定值的比较 (例如 $"<"$ 或 $">"$) ,比较对象可以是该列的值或按另一列分组后的值计数;也可以是识别列中最小值或最大值等操作。
$\diamond$ Get Value retrieves either all the values within a specific column or performs basic operations on all the values, including calculations for the mean, maximum, minimum, sum, and count.
$\diamond$ 获取值 (Get Value) 可检索特定列中的所有值,或对所有值执行基本操作,包括计算平均值、最大值、最小值、总和及计数。
$\diamond$ Calculator calculates the results from input strings. We leverage the Wolfram Alpha API por $\mathrm{tal}^{11}$ , which can handle both straightforward calculations such as addition, subtraction, and multiplication and more complex operations like averaging and identifying maximum values.
$\diamond$ 计算器根据输入字符串计算结果。我们利用 Wolfram Alpha API 接口$^{11}$,该接口既能处理简单的加减乘除运算,也能执行求平均值、识别最大值等复杂操作。
$\diamond$ Date Calculator calculates the target date based on the input date and the provided time interval information.
$\diamond$ 日期计算器根据输入日期和提供的时间间隔信息计算目标日期。
$\diamond$ SQL Interpreter interprets and executes SQL code written by LLMs.
$\diamond$ SQL Interpreter 解释并执行由大语言模型编写的 SQL 代码。
C Baseline Details
C 基线详情
All the methods, including baselines and EHRAgent, share the same (1) tool definitions, (2) table meta information, and (3) few-shot demonstrations in the prompts by default. The only difference is the prompting style or technical differences between different methods, which guarantees a fair comparison among all baselines and EHRAgent. Table 4 summarizes the inclusion of different components in both baselines and ours.
所有方法(包括基线方法和EHRAgent)默认共享相同的(1)工具定义、(2)表元信息以及(3)提示中的少样本示例。唯一区别在于不同方法的提示风格或技术差异,这确保了所有基线方法与EHRAgent之间的公平比较。表4总结了基线方法与我们方法中各组件的包含情况。
Baselines w/o Code Interface. LLMs without a code interface rely purely on natural languagebased planning capabilities.
无代码接口的基线模型。不具备代码接口的大语言模型完全依赖基于自然语言的规划能力。
$\diamond\mathbf{C}\mathbf{0}\mathbf{T}$ (Wei et al., 2022): CoT enhances the complex reasoning capabilities of original LLMs by generating a series of intermediate reasoning steps. $\diamond$ Self-Consistency (Wang et al., 2023d): Selfconsistency improves CoT by sampling diverse reasoning paths to replace the native greedy decoding and select the most consistent answer.
$\diamond\mathbf{C}\mathbf{0}\mathbf{T}$ (Wei et al., 2022): CoT通过生成一系列中间推理步骤,增强原始大语言模型的复杂推理能力。$\diamond$ 自我一致性 (Wang et al., 2023d): 该方法通过采样多样化推理路径替代原始贪婪解码,并选择最一致的答案来改进CoT。
$\diamond$ Chameleon (Lu et al., 2023): Chameleon em- ploys LLMs as controllers and integrates a set of plug-and-play modules, enabling enhanced reasoning and problem-solving across diverse tasks.
$\diamond$ Chameleon (Lu et al., 2023): Chameleon 采用大语言模型作为控制器,并集成了一套即插即用模块,从而增强跨多样化任务的推理和问题解决能力。
$\diamond$ ReAct (Yao et al., 2023b): ReAct integrates rea- soning with tool use by guiding LLMs to generate intermediate verbal reasoning traces and tool commands.
$\diamond$ ReAct (Yao et al., 2023b): ReAct通过引导大语言模型生成中间语言推理轨迹和工具命令,将推理与工具使用相结合。
$\diamond$ Reflexion (Shinn et al., 2023): Reflexion lever- ages verbal reinforcement to teach LLM-based agents to learn from linguistic feedback from past mistakes.
$\diamond$ Reflexion (Shinn et al., 2023): Reflexion 通过语言强化机制,教导基于大语言模型的 AI智能体从过往错误中的语言反馈进行学习。
Baselines w/ Code Interface. LLMs with a code interface enhance the inherent capabilities of LLMs by enabling their interaction with programming languages and the execution of code. In accordance with their default configuration, we present a summary of the utilization of programming languages in various baselines in Table 5. Additionally, we provide a detailed explanation of the programming language selection in EHRAgent in Appendix D.
带代码接口的基线模型。具备代码交互能力的大语言模型通过支持与编程语言交互及执行代码,增强了其固有能力。按照默认配置,我们在表5中汇总了各基线模型对编程语言的使用情况。此外,附录D详细说明了EHRAgent的编程语言选择依据。
$\diamond$ LLM2SQL (Nan et al., 2023): LLM2SQL aug- ments LLMs with a code interface to generate SQL queries for retrieving information from EHRs for question answering.
$\diamond$ LLM2SQL (Nan et al., 2023): LLM2SQL 通过代码接口增强大语言模型 (LLM) 的能力,生成用于从电子健康记录 (EHR) 中检索信息的 SQL 查询,以支持问答任务。
$\diamond$ DIN-SQL (Pourreza and Rafiei, 2023): Compared to LLM2SQL, DIN-SQL further breaks down a complex problem into several sub-problems and feeding the solutions of those sub-problems into LLMs, effectively improving problem-solving performance.
$\diamond$ DIN-SQL (Pourreza and Rafiei, 2023): 与LLM2SQL相比,DIN-SQL进一步将复杂问题分解为若干子问题,并将这些子问题的解决方案输入大语言模型,有效提升了问题解决性能。
$\diamond$ Self-Debugging (Chen et al., 2024): SelfDebugging teaches LLMs to debug by investigating execution results and explaining the generated code in natural language.
$\diamond$ 自调试 (Self-Debugging) (Chen等人, 2024): SelfDebugging通过分析执行结果并用自然语言解释生成的代码,教会大语言模型进行调试。
$\diamond$ AutoGen (Wu et al., 2023): AutoGen unifies LLM-based agent workflows as multi-agent conversations and uses the code interface to encode interactions between agents and environments. We follow the official tutorial12 for the implementation of AutoGen. Specifically, we utilize the built- in Assistant Agent and User Proxy Agent within AutoGen to serve as the LLM agent and the code executor, respectively. The Assistant Agent is configured in accordance with AutoGen’s tailored system prompts, which are designed to direct the LLM to (1) propose code within a coding block as required, (2) refine the proposed code based on execution outcomes, and (3) append a specific code, "TERMINATE", to conclude the response for terminating the dialogue. The User Proxy Agent functions as a surrogate for the user, extracting and executing code from the LLM’s responses in a local environment. Subsequently, it relays the execution results back to the LLM. In instances where code is not detected, a standard message is dispatched instead. This arrangement facilitates an automated dialogue process, obviating the need for manual tasks such as code copying, pasting, and execution by the user, who only needs to initiate the conversation with an original query.
$\diamond$ AutoGen (Wu et al., 2023): AutoGen 将基于大语言模型的智能体工作流统一为多智能体对话,并通过代码接口编码智能体与环境间的交互。我们遵循官方教程12实现 AutoGen,具体使用其内置的 Assistant Agent 和 User Proxy Agent 分别作为大语言模型智能体与代码执行器。Assistant Agent 按照 AutoGen 定制的系统提示进行配置,这些提示设计用于引导大语言模型:(1) 按要求在代码块中提出代码,(2) 根据执行结果优化代码,(3) 追加特定代码 "TERMINATE" 以终止对话响应。User Proxy Agent 作为用户代理,在本地环境中提取并执行大语言模型响应中的代码,随后将执行结果反馈给大语言模型。若未检测到代码,则发送标准消息。该架构实现了自动化对话流程,用户仅需发起初始查询,无需手动执行代码复制、粘贴等操作。
Table 4: Comparison of baselines and EHRAgent on the inclusion of different components.
| Baselines | Tool Use | Code Interface | Environment Feedback | Debugging | Error Exploration | Medical Information | Long-term Memory |
| w/oCodeInterface | |||||||
| CoT (Weiet al.,2022) | |||||||
| Self-Consistency (Wang et al.,2023d) | × | × | × | ||||
| Chameleon (Lu et al., 2023) | |||||||
| ReAct(Ya0 et al.,2023b) | |||||||
| Reflexion(Shinn et al.,2023) | |||||||
| w/CodeInterface | |||||||
| LLM2SQL(Nan et al.,2023) | |||||||
| DIN-SQL(Pourreza andRafiei,2023) | |||||||
| Self-Debugging (Chen et al.,2024) | × | ||||||
| AutoGen(Wu etal.,2023) | × | × | |||||
| EHRAgent (Ours) |
表 4: 基线方法与EHRAgent在不同组件包含情况下的对比
| Baselines | Tool Use | Code Interface | Environment Feedback | Debugging | Error Exploration | Medical Information | Long-term Memory |
|---|---|---|---|---|---|---|---|
| w/oCodeInterface | |||||||
| CoT (Wei et al.,2022) | |||||||
| Self-Consistency (Wang et al.,2023d) | × | × | × | ||||
| Chameleon (Lu et al., 2023) | |||||||
| ReAct(Yao et al.,2023b) | |||||||
| Reflexion(Shinn et al.,2023) | |||||||
| w/CodeInterface | |||||||
| LLM2SQL(Nan et al.,2023) | |||||||
| DIN-SQL(Pourreza and Rafiei,2023) | |||||||
| Self-Debugging (Chen et al.,2024) | × | ||||||
| AutoGen(Wu et al.,2023) | × | × | |||||
| EHRAgent (Ours) |
Table 5: Comparison of baselines and EHRAgent on the selection of primary programming languages.
| Baselines #Language |
| LLM2SQL (Nan et al.,2023) SQL |
| DIN-SQL (Pourreza andRafiei,2023) SQL |
| Self-Debugging (Chen et al., 2024) SQL |
| AutoGen(Wuetal.,2023) Python |
| EHRAgent(Ours) Python |
表 5: 基线方法与EHRAgent在主要编程语言选择上的对比
| 基线方法 | 语言 |
|---|---|
| LLM2SQL (Nan et al.,2023) | SQL |
| DIN-SQL (Pourreza andRafiei,2023) | SQL |
| Self-Debugging (Chen et al., 2024) | SQL |
| AutoGen(Wuetal.,2023) | Python语言 |
| EHRAgent(我们的方法) | Python语言 |
D Selection of Primary Programming Language
D 主要编程语言的选择
In our main experiments, we concentrate on three SQL-based EHR QA datasets to assess EHRAgent in comparison with other baselines. Nevertheless, we have opted for Python as the primary programming language for EHRAgent, rather than SQL13.
在我们的主要实验中,我们专注于三个基于SQL的电子健康记录问答数据集,以评估EHRAgent与其他基线的对比性能。不过,我们选择将Python语言作为EHRAgent的主要编程语言,而非SQL13。
The primary reasons for choosing Python instead of SQL to address medical inquiries based on EHRs are outlined below:
选择Python语言而非SQL处理基于电子健康记录(EHR)的医疗查询的主要原因如下:
Python Enables the External Tool-Use. Using alternative programming languages, such as SQL, can result in LLM-based agents becoming unavailable to external tools or functions. The primary contribution of EHRAgent is to develop a codeempowered agent capable of generating and executing code-based plans to solve complex real-world clinic tasks. In general, the SQL language itself is incapable of calling API functions. For example, EHRXQA (Bae et al., 2023) can be considered as an LLM agent that generates a solution plan in NeuralSQL (not SQL). This agent is equipped with two tools: a pre-trained Visual Question Answering (VQA) model called FUNC_ VQA, and a SQL interpreter. Similar to EHRAgent, it also relies on a non-SQL language and includes an SQL interpreter as a tool. Compared with NeuralSQL in EHRXQA (Bae et al., 2023), Python in EHRAgent can be directly executed, while NeuralSQL requires additional parsing.
Python 语言支持外部工具调用。使用其他编程语言(如 SQL)可能导致基于大语言模型的智能体无法访问外部工具或函数。EHRAgent 的主要贡献是开发了一个具备代码能力的智能体,能够生成并执行基于代码的计划来解决复杂的现实临床任务。通常,SQL 语言本身无法调用 API 函数。例如,EHRXQA (Bae et al., 2023) 可视为一个生成 NeuralSQL(非 SQL)解决方案计划的大语言模型智能体。该智能体配备了两个工具:一个名为 FUNC_ VQA 的预训练视觉问答 (VQA) 模型,以及一个 SQL 解释器。与 EHRAgent 类似,它也依赖非 SQL 语言,并将 SQL 解释器作为工具之一。相比 EHRXQA (Bae et al., 2023) 中的 NeuralSQL,EHRAgent 中的 Python 语言可直接执行,而 NeuralSQL 需要额外解析。
Python Enables the Integration of SQL Tool Function. Python provides excellent interoper ability with various databases and data formats. It supports a wide range of database connectors, including popular relational databases such as PostgreSQL, MySQL, and SQLite, as well as non-relational databases like MongoDB. This interoperability ensures that EHRAgent can seamlessly interact with different EHR systems and databases. Although our proposed method primarily relies on generating and executing
Python语言实现SQL工具功能集成。Python语言具备卓越的多数据库与数据格式互操作性,支持包括PostgreSQL、MySQL、SQLite等主流关系型数据库及MongoDB等非关系型数据库在内的广泛连接器。这种互操作性确保EHRAgent能与各类电子健康记录(EHR)系统和数据库无缝交互。尽管我们提出的方法主要依赖生成与执行...
Python code, we do not prohibit EHRAgent from utilizing SQL to solve problems. In our prompts and instructions, we also provide the ’SQLInterpreter’ tool function for the agent to perform relational database operations using SQL. Through our experiments, we have observed that EHRAgent is capable of combining results from Python code and SQL commands effectively. For instance, when presented with the question, “Show me patient 28020’s length of stay of the last hospital stay.”, EHRAgent will first generate SQL command admit disch tuple $=$ SQL Interpreter (ŚELECT ADMITTIME, DISCHTIME FROM admissions WHERE SUBJECT_i $:\mathsf{D}{=}28\theta2\theta$ ORDERBY ADMITTIME DESC LIMIT 1) and execute it to obtain the tuples containing the patient’s admission and discharge times. It will then employ Python code along with the built-in date-time function to calculate the duration of the last stay tuple.
在Python语言代码中,我们并不禁止EHRAgent使用SQL来解决问题。在提示和指令中,我们还为智能体提供了'SQLInterpreter'工具函数,以便通过SQL执行关系型数据库操作。通过实验,我们观察到EHRAgent能够有效结合Python代码和SQL命令的结果。例如,当遇到问题"显示患者28020最后一次住院的住院时长"时,EHRAgent会首先生成SQL命令 admit disch tuple $=$ SQL Interpreter (SELECT ADMITTIME, DISCHTIME FROM admissions WHERE SUBJECT_i $:\mathsf{D}{=}28\theta2\theta$ ORDERBY ADMITTIME DESC LIMIT 1) 并执行以获取包含患者入院和出院时间的元组,随后利用Python代码及内置日期时间函数计算最后一次住院的时长元组。
Python Enables a More General iz able Frame- work. EHRAgent is a general iz able LLM agent empowered with a code interface to autonomously generate and execute code as solutions to given problems. While Section 4 focuses on the challenging multi-tabular reasoning task within EHRs for evaluation, the Python-based approach has the potential to be generalized to other tasks (e.g., risk prediction tasks based on EHRs) or even multi-modal clinical data and be integrated with additional toolsets in the future. In contrast, other languages like SQL are limited to database-related operations.
Python语言赋能更通用的可扩展框架。EHRAgent是一个具备代码接口的可扩展大语言模型智能体,能够自主生成并执行代码来解决给定问题。虽然第4节聚焦于电子健康记录(EHR)中具有挑战性的多表格推理任务进行评估,但基于Python语言的方法有望推广至其他任务(例如基于EHR的风险预测任务)甚至多模态临床数据,并在未来集成更多工具集。相比之下,SQL等其他语言仅限于数据库相关操作。
Python is More Flexible in Extension. Python is a general-purpose programming language that offers greater flexibility compared to SQL. It enables the implementation of complex logic and algorithms, which may be necessary for solving certain types of medical questions that require more than simple database queries. Python is also a highly flexible programming language that offers extensive capabilities through its libraries and frameworks, making it suitable for handling a wide range of programming tasks, including database operations. In contrast, SQL is only applicable within relational databases and does not provide the same level of flexibility and extension. This attribute is particularly important to LLM-based agents, as they can leverage both existing Python libraries and custom-defined functions as tools to solve complex problems that are inaccessible for and beyond the scope of SQL.
Python 在扩展性上更灵活。Python 是一门通用编程语言,相比 SQL 具备更强的灵活性。它能实现复杂逻辑与算法,这对于解决某些需要超越简单数据库查询的医学问题至关重要。Python 还因其丰富的库和框架而具备广泛能力,适合处理包括数据库操作在内的多样化编程任务。相比之下,SQL 仅适用于关系型数据库,无法提供同等的灵活性与扩展性。这一特性对大语言模型 (LLM) 智能体尤为重要,因为它们既能调用现有 Python 库,也能将自定义函数作为工具,解决 SQL 无法触及的复杂问题。
Python Includes More Extensive Resources for Pre-Training. Python has a large and active community of developers and researchers. This community contributes to the development of powerful libraries, frameworks, and tools that can be leveraged in EHRAgent. The extensive documentation, tutorials, and forums available for Python also provide valuable resources for troubleshooting and optimization. Github repositories are one of the most extensive sources of code data for state-ofthe-art language models (i.e., LLMs), such as GPTs. Python is the most widely used coding language on Github14. In addition, Python is known for its readability and maintainability. The clean and expressive syntax of Python makes it easier for researchers and developers to understand, modify, and extend the codebase of EHRAgent. This is particularly important when extended to realworld clinical research and practice, where the system may need to be updated frequently to incorporate new knowledge and adapt to evolving requirements.
Python语言提供更丰富的预训练资源。Python拥有庞大且活跃的开发者与研究社区,该社区持续贡献可被EHRAgent利用的强大库、框架和工具。Python丰富的文档、教程和论坛资源为故障排除与性能优化提供了宝贵支持。GitHub代码库是当前最先进大语言模型(如GPT系列)最重要的代码数据来源之一,而Python是GitHub平台上使用最广泛的编程语言[14]。此外,Python以可读性和可维护性著称,其简洁明了的语法使研究人员和开发者能更轻松地理解、修改及扩展EHRAgent的代码库。这一特性在扩展到真实世界临床研究和实践时尤为重要,因为系统可能需要频繁更新以整合新知识并适应不断变化的需求。
E Additional Implementation Details
E 其他实现细节
E.1 Hardware and Software Details
E.1 硬件与软件详情
All experiments are conducted on CPU: Intel(R) Core(TM) i7-5930K CPU $\begin{array}{r}{@3.50\mathrm{GHz}}\end{array}$ and GPU: NVIDIA GeForce RTX A5000 GPUs, using Python 3.9 and AutoGen $0.2.0^{15}$ .
所有实验均在CPU: Intel(R) Core(TM) i7-5930K CPU $\begin{array}{r}{@3.50\mathrm{GHz}}\end{array}$ 和GPU: NVIDIA GeForce RTX A5000上运行,使用Python语言 3.9及AutoGen $0.2.0^{15}$。
E.2 Data Preprocessing Details
E.2 数据预处理详情
During the data pre-processing stage, we create EHR question-answering pairs by considering text queries as questions and executing SQL commands in the database to automatically generate the corresponding ground-truth answers. We filter out samples containing un executable SQL commands or yielding empty results throughout this process.
在数据预处理阶段,我们通过将文本查询视为问题并在数据库中执行SQL命令来自动生成对应的真实答案,从而创建电子健康档案(EHR)问答对。在此过程中,我们会过滤掉包含不可执行SQL命令或产生空结果的样本。
E.3 Code Generation Details
E.3 代码生成细节
Given that the majority of LLMs have been pretrained on Python code snippets (Gao et al., 2023), and Python’s inherent modularity aligns well with tool functions, we choose Python 3.9 as the primary coding language for interaction coding and AutoGen 0.2.0 (Wu et al., 2023) as the interface for communication between the LLM agent and the code executor.
鉴于大多数大语言模型(LLM)已在Python语言代码片段上进行过预训练 [20],且Python语言固有的模块化特性与工具函数高度契合,我们选择Python 3.9作为交互编码的主要编程语言,并采用AutoGen 0.2.0 [21] 作为大语言模型智能体与代码执行器之间的通信接口。
E.4 Selection of Initial Set of Demonstrations
E.4 初始演示集的选择
The initial set of examples is collected manually, following four criteria: (1) using the same demonstrations across all the baselines; (2) utilizing all the designed tools; (3) covering as many distinct tables as possible; and (4) including examples in different styles of questions. With these criteria in mind, we manually crafted four demonstrations for each dataset. To ensure a fair comparison, we use the same initial four-shot demonstrations $\mathit{K}=4$ ) for all baselines and EHRAgent, considering the maximum length limitations of input con- text in baselines like ReAct (Yao et al., 2023b) and Chameleon (Lu et al., 2023).
初始示例集根据以下四个标准手动收集:(1) 在所有基线中使用相同的演示样本;(2) 使用所有设计好的工具;(3) 尽可能覆盖不同的表格;(4) 包含不同风格的问题示例。基于这些标准,我们为每个数据集手工制作了四个演示样本。为确保公平比较,考虑到ReAct (Yao et al., 2023b) 和Chameleon (Lu et al., 2023) 等基线模型的输入上下文长度限制,我们对所有基线模型和EHRAgent统一采用相同的初始四样本演示 ( $\mathit{K}=4$ )。
E.5 Evaluation Metric Details
E.5 评估指标详情
Our main evaluation metric is the success rate (SR), quantifying the percentage of queries that the model successfully handles. In addition, we leverage completion rate (CR) as a side evaluation metric to represent the percentage of queries for which the model is able to generate executable plans, regardless of whether the results are correct. Specifically, following existing LLM-based agent studies (Xu et al., 2023; Kirk et al., 2024), we use CR to assess the effectiveness of LLM-based agents in generating complete executable plans without execution errors. One of our key components in EHRAgent is interactive coding with environmental feedback. By using CR, we can demonstrate that our proposed EHRAgent, along with other baselines that incorporate environmental feedback (e.g., ReAct (Yao et al., 2023b), Reflexion (Shinn et al., 2023), Self-Debugging (Chen et al., 2024), and AutoGen (Wu et al., 2023)), has a stronger capability (higher CR) in generating complete executable plans without execution errors, compared to baselines without environmental feedback (e.g., CoT (Wei et al., 2022), Self-Consistency (Wang et al., 2023d), Chameleon (Lu et al., 2023), and LLM2SQL (Nan et al., 2023)).
我们的主要评估指标是成功率 (SR),用于量化模型成功处理的查询百分比。此外,我们采用完成率 (CR) 作为辅助评估指标,表示模型能生成可执行计划的查询百分比(无论结果正确与否)。具体而言,遵循现有基于大语言模型的智能体研究 (Xu et al., 2023; Kirk et al., 2024),我们使用 CR 来评估基于大语言模型的智能体在生成完整可执行计划(无执行错误)方面的有效性。EHRAgent 的核心组件之一是带环境反馈的交互式编码。通过 CR 指标,我们可以证明:相较于无环境反馈的基线方法(如 CoT (Wei et al., 2022)、Self-Consistency (Wang et al., 2023d)、Chameleon (Lu et al., 2023) 和 LLM2SQL (Nan et al., 2023)),我们提出的 EHRAgent 及其他融合环境反馈的基线方法(如 ReAct (Yao et al., 2023b)、Reflexion (Shinn et al., 2023)、Self-Debugging (Chen et al., 2024) 和 AutoGen (Wu et al., 2023))在生成完整可执行计划(无执行错误)方面具有更强能力(更高的 CR)。
E.6 EHR Metadata Details $\diamond$ MIMIC-III.
E.6 电子健康档案元数据详情 $\diamond$ MIMIC-III
<MIMIC_iII> Metadata
<MIMIC_iII> 元数据
$\diamond$ eICU.
$\diamond$ eICU
Metadata
元数据
E.7 Prompt Details
E.7 提示词详情
In the subsequent subsections, we detail the prompt templates employed in EHRAgent. The complete version of the prompts is available at our code repository due to space limitations.
在后续小节中,我们将详细说明EHRAgent所使用的提示模板。由于篇幅限制,完整版提示词可在我们的代码仓库中获取。
$\diamond$ Prompt for Code Generation. We first present the prompt template for EHRAgent in code generation as follows:
$\diamond$ 代码生成提示词。我们首先展示EHRAgent在代码生成中的提示词模板如下:
$\diamond$ Prompt for Knowledge Integration. We then present the prompt template for knowledge integration in EHRAgent as follows:
$\diamond$ 知识整合提示。我们随后在EHRAgent中展示知识整合的提示模板如下:
| Readthefollowing datadescriptions,generate thebackgroundknowledgeasthecontext informationthatcouldbehelpfulfor answering thequestion. {OVERALL_ EHR_ DESCRIPTIONS} For different tables,they contain the followinginformation: {COLUMNAR_ DESCRIPTIONS} {4-SHOT_ EXAMPLES} |
| 阅读以下数据描述,生成可作为背景知识的上下文信息以辅助回答问题。{OVERALL_ EHR_ DESCRIPTIONS} 不同表格包含以下信息:{COLUMNAR_ DESCRIPTIONS} {4-SHOT_ EXAMPLES} |
$\diamond$ Prompt for ‘Rubber Duck’ Debugging. The prompt template used for debugging module in
$\diamond$ 橡皮鸭调试法提示词。用于调试模块的提示模板
EHRAgent is shown as follows:
EHRAgent如下所示:
<错误探索>提示
$\diamond$ Prompt for Few-Shot Examples. The prompt template used for few-shot examples in EHRAgent is shown as follows:
$\diamond$ 少样本 (Few-shot) 示例提示词。EHRAgent中用于少样本示例的提示词模板如下所示:
| Question: {QUESTION_i} Knowledge: {KNOWLEDGE_i} Solution: {CODE_i} | |
| Question:{QUESTION_iI} Knowledge: {KNOWLEDGE_iI} | |
| Solution: {CODE_iI} Question:{QUESTION_iII} Knowledge: | |
| {KNOWLEDGE_iII} | |
| Solution: {CODE_iII} | |
| Question:{QUESTION_iV} Knowledge: |
| <少样本示例> 提示 | |
|---|---|
| 问题: {QUESTION_i} 知识: {KNOWLEDGE_i} 解决方案: {CODE_i} | |
| 问题: {QUESTION_iI} 知识: {KNOWLEDGE_iI} | |
| 解决方案: {CODE_iI} 问题: {QUESTION_iII} 知识: | |
| {KNOWLEDGE_iII} | |
| 解决方案: {CODE_iII} | |
| 问题: {QUESTION_iV} 知识: |
F Additional Experimental Results
F 补充实验结果
F.1 Effect of Base LLMs
F.1 基础大语言模型的影响
Table 6 presents a summary of the experimental results obtained from EHRAgent and all baselines using a different base LLM, GPT-3.5-turbo (0613). The results clearly demonstrate that EHRAgent continues to outperform all the baselines, achieving a performance gain of $6.72%$ . This highlights the ability of EHRAgent to generalize across different base LLMs as backbone models. When comparing the experiments conducted with GPT-4 (Table 1), the performance of both the baselines and EHRAgent decreases. This can primarily be attributed to the weaker capabilities of instructionfollowing and reasoning in GPT-3.5-turbo.
表 6 展示了 EHRAgent 与所有基线模型在使用不同基础大语言模型 GPT-3.5-turbo (0613) 时获得的实验结果汇总。结果明确表明,EHRAgent 仍优于所有基线模型,实现了 $6.72%$ 的性能提升。这凸显了 EHRAgent 在不同基础大语言模型作为骨干模型时的泛化能力。与使用 GPT-4 的实验结果 (表 1) 相比,基线模型和 EHRAgent 的性能均有所下降。这主要归因于 GPT-3.5-turbo 在指令跟随和推理能力上的较弱表现。
Table 6: Experimental results of success rate (i.e., SR.) and completion rate (i.e., CR.) on MIMIC-III using GPT-3.5-turbo as the base LLM. The complexity of questions increases from Level I (the simplest) to Level IV (the most difficult).
| Dataset (→) | MIMIC-III | |||
| ComplexityLevel(→) | I II | III IV | All | |
| Methods(↓)/Metrics(→) | SR. | |||
| w/oCodeInterface | ||||
| CoT (Weiet al.,2022) Self-Consistency(Wang et al.,2023d) Chameleon (Lu et al.,2023) | 23.16 10.40 2.99 25.26 11.88 4.19 27.37 | 1.71 2.56 | 8.62 41.55 10.52 47.59 | |
| ReAct(Yaoet al.,2023b) 26.32 | 11.88 3.59 10.89 3.59 | 2.56 3.42 | 11.21 47.59 9.66 61.21 8.55 13.28 66.72 | |
| Reflexion (Shinn et al.,2023) 30.53 12.38 9.58 w/CodeInterface | ||||
| 21.05 15.84 4.19 | ||||
| LLM2SQL(Nan et al.,2023) Self-Debugging (Chen et al.,2024) | 2.5610.69 59.49 36.84 33.66 22.75 16.24 27.59 72.93 | |||
| AutoGen(Wuet al.,2023) | 28.42 25.74 13.17 10.26 19.48 52.42 | |||
| EHRAgent(Ours) | 43.1642.5729.9418.8034.3178.80 | |||
表 6: 基于 GPT-3.5-turbo 作为基础大语言模型在 MIMIC-III 数据集上的成功率 (即 SR.) 和完成率 (即 CR.) 实验结果。问题复杂度从 I 级 (最简单) 到 IV 级 (最困难) 递增。
| 数据集 (→) | MIMIC-III |
|---|---|
| 复杂度等级 (→) | I II |
| 方法 (↓)/指标 (→) | SR. |
| * * 无代码接口* * | |
| CoT (Wei 等, 2022) Self-Consistency (Wang 等, 2023d) Chameleon (Lu 等, 2023) | 23.16 10.40 2.99 25.26 11.88 4.19 27.37 |
| ReAct (Yao 等, 2023b) 26.32 | 11.88 3.59 10.89 3.59 |
| Reflexion (Shinn 等, 2023) 30.53 12.38 9.58 * * 有代码接口* * | |
| 21.05 15.84 4.19 | |
| LLM2SQL (Nan 等, 2023) Self-Debugging (Chen 等, 2024) | |
| AutoGen (Wu 等, 2023) | |
| EHRAgent (本文方法) |
F.2 Additional Ablation Studies
F.2 额外消融实验
We conduct additional ablation studies to evaluate the effectiveness of each module in EHRAgent on eICU in Table 7 and obtain consistent results. From the results from both MIMIC-III and eICU, we observe that all four components contribute significantly to the performance gain.
我们在表7中对eICU数据集进行了额外的消融实验,以评估EHRAgent各模块的有效性,并得到了一致的结果。从MIMIC-III和eICU的实验结果来看,所有四个组件都对性能提升有显著贡献。
$\diamond$ Medical Information Integration. Out of all the components, the medical knowledge injection module mainly exhibits its benefits in challenging tasks. These tasks often involve more tables and require a deeper understanding of domain knowledge to associate items with their corresponding tables. $\diamond$ Long-term Memory. Following the reinforcement learning setting (Sun et al., 2023; Shinn et al., 2023), the long-term memory mechanism improves performance by justifying the necessity of selecting the most relevant demonstrations for planning. In order to simulate the scenario where the ground truth annotations (i.e., rewards) are unavailable, we further evaluate the effectiveness of the long-term memory on the completed cases in Table 8, regardless of whether they are successful or not. The results indicate that the inclusion of long-term memory with completed cases increases the completion rate but tends to reduce the success rate across most difficulty levels, as some incorrect cases might be included as the few-shot demonstrations. We have also performed multi-round experiments with shuffled order and observed that the order had almost no influence on the final performance in all three datasets. Nonetheless, it still outperforms the performance without long-term memory, confirming the effectiveness of the memory mechanism.
$\diamond$ 医疗信息整合。在所有组件中,医疗知识注入模块主要在具有挑战性的任务中展现出优势。这类任务通常涉及更多表格,且需要更深层次的领域知识来将项目与对应表格关联起来。
$\diamond$ 长期记忆。遵循强化学习设定 (Sun et al., 2023; Shinn et al., 2023),长期记忆机制通过论证选择最相关示例进行规划的必要性来提升性能。为模拟缺乏真实标注(即奖励)的场景,我们进一步在表8中评估了长期记忆对已完成案例(无论成功与否)的有效性。结果表明:引入已完成案例的长期记忆能提高完成率,但会降低多数难度级别的成功率,因为部分错误案例可能被选为少样本示例。我们还在乱序条件下进行了多轮实验,发现顺序对所有三个数据集的最终表现几乎没有影响。尽管如此,该机制仍优于无长期记忆的表现,证实了记忆机制的有效性。
$\diamond$ Interactive Coding. For the ablation study setting of EHRAgent w/o interactive coding, we directly chose CoT (Wei et al., 2022) as the backbone, where we deteriorate from generating code-based plans to natural language-based plans. Once the steps are generated, we execute them in a step-bystep manner and obtain error information from the tool functions. By combining the error messages with tool definitions and language-based plans, we are still able to prompt the LLMs to deduce the most probable underlying cause of the error. The medical information injection and long-term memory components remain unchanged from the original EHRAgent. From the ablation studies, we can observe that the interactive coding interface is the most significant contributor to the performance gain across all complexity levels. This verifies the importance of utilizing the code interface for planning instead of natural languages, which enables the model to avoid overly complex contexts and thus leads to a substantial increase in the completion rate. Additionally, the code interface also allows the debugging module to refine the planning with execution feedback, improving the efficacy of the planning process.
$\diamond$ 交互式编码。在EHRAgent消融研究的非交互式编码设定中,我们直接采用思维链 (CoT) (Wei et al., 2022) 作为基础框架,将基于代码的规划降级为基于自然语言的规划。生成步骤后,我们逐步执行这些步骤并从工具函数中获取错误信息。通过结合错误消息、工具定义和基于语言的规划,仍能促使大语言模型推断出最可能的错误根源。医疗信息注入和长期记忆模块保持与原始EHRAgent一致。消融研究表明,交互式编码接口对所有复杂度层级的性能提升贡献最为显著,这验证了采用代码接口(而非自然语言)进行规划的重要性——该设计使模型能规避过度复杂的上下文,从而显著提高完成率。此外,代码接口还允许调试模块根据执行反馈优化规划,提升规划流程的效能。
$\diamond$ Debugging Module. The ‘rubber duck’ debugging module enhances the performance by guiding the LLM agent to figure out the underlying reasons for the error messages. This enables EHRAgent to address the intrinsic error that occurs in the original reasoning steps. We then further illustrate the difference between debugging modules in EHRAgent and others. Self-debugging (Chen et al., 2024) that sends back the execution results with an explanation of the code for plan refinement. Reflexion (Shinn et al., 2023) sends the binary reward of whether it is successful or not back for refinement, which contains little information. In both cases, however, the error message is still information on the surface, like ‘incorrect query’, etc. This is aligned with our empirical observations that LLM agents tend to make slight modifications to the code snippets based on the error message without further debugging. Taking one step further, our debugging module in EHRAgent incorporates an error tracing procedure that enables the LLM to analyze potential causes beyond the current error message. Our debugging module aims to leverage the conversation format to think one step further about potential reasons, such as ‘incorrect column names in the
$\diamond$ 调试模块。'橡皮鸭'调试模块通过引导大语言模型智能体找出错误信息的根本原因来提升性能,使EHRAgent能够解决原始推理步骤中出现的内在错误。我们进一步说明EHRAgent与其他系统的调试模块差异:自我调试(Chen等人,2024)会返回执行结果并附带代码解释以优化方案;Reflexion(Shinn等人,2023)仅返回成功与否的二元奖励信号用于改进,所含信息量极少。这两种方式处理的错误信息仍停留在表层(如"查询错误"等),这与我们的实证观察一致——大语言模型智能体往往仅根据错误提示对代码片段进行微调,而不会深入调试。EHRAgent的调试模块更进一步,整合了错误追踪流程,使大语言模型能分析当前错误信息之外的潜在原因。该模块旨在利用对话格式深入思考潜在根源,例如"数据表中列名错误"等。
query’ or ‘incorrect values in the query’.
| Complexitylevel | II | ⅢI | All | ||
| Metrics | SR. | SR. | CR. | ||
| EHRAgent | 54.82 | 53.52 | 225.00 | 53.10 | 91.72 |
| w/omedicalinformation | 36.75 | 28.39 | 6.25 | 30.17 | 47.24 |
| w/olong-termmemory | 52.41 | 44.22 | 18.75 | 45.69 | 78.97 |
| w/ointeractive coding | 46.39 | 44.97 | 6.25 | 44.31 | 65.34 |
| w/orubberduckdebugging | 50.60 | 46.98 | 12.50 | 47.07 | 70.86 |
查询'或'查询中的错误值'。
| 复杂度级别 | II | ⅢI | 全部 | |
|---|---|---|---|---|
| 指标 | SR. | SR. | ||
| EHR智能体 | 54.82 | 53.52 | 225.00 | 53.10 |
| 无医疗信息 | 36.75 | 28.39 | 6.25 | 30.17 |
| 无长期记忆 | 52.41 | 44.22 | 18.75 | 45.69 |
| 无交互式编码 | 46.39 | 44.97 | 6.25 | 44.31 |
| 无橡皮鸭调试 | 50.60 | 46.98 | 12.50 | 47.07 |
Table 7: Additional ablation studies on success rate (i.e., SR.) and completion rate (i.e., CR.) under different question complexity (I-III) on eICU dataset. Table 8: Comparison on long-term memory (i.e., LTM) design under different question complexity (I-IV) on MIMIC-III dataset.
| Complexitylevel Metrics | I ⅡI | IⅢ | IV | All |
| SR. | SR. CR. | |||
| EHRAgent LTMw/Completion w/oLTM 65.9654.4637.1342.7451.7383.42 | t (LTMw/Success)71.5866.3449.7049.1458.97 76.8460.89 41.92 34.4853.2490.05 | 85.86 | ||
表 7: 在eICU数据集上针对不同问题复杂度(I-III)的成功率(即SR.)和完成率(即CR.)进行的额外消融研究。
表 8: 在MIMIC-III数据集上针对不同问题复杂度(I-IV)的长期记忆(即LTM)设计比较。
| Complexitylevel Metrics | I ⅡI | IⅢ | IV | All |
|---|---|---|---|---|
| SR. | SR. CR. | |||
| EHRAgent LTMw/Completion w/oLTM 65.9654.4637.1342.7451.7383.42 | t (LTMw/Success)71.5866.3449.7049.1458.97 76.8460.89 41.92 34.4853.2490.05 | 85.86 |
F.3 Cost Estimation
F.3 成本估算
Using GPT-4 as the foundational LLM model, we report the average cost of EHRAgent for each query in the MIMIC-III, eICU, and TREQS datasets as $\$0.60$ , $\$0.17$ , and $\$0.52$ , respectively. The cost is mainly determined by the complexity of the question (i.e., the number of tables required to answer the question) and the difficulty in locating relevant information within each table.
以GPT-4为基础大语言模型,我们报告了EHRAgent在MIMIC-III、eICU和TREQS数据集中每个查询的平均成本分别为$0.60、$0.17和$0.52。成本主要取决于问题的复杂性(即回答问题所需的表格数量)以及在每个表格中定位相关信息的难度。
G Additional Empirical Analysis
G 补充实证分析
G.1 Additional Question Complexity Analysis
G.1 附加问题复杂度分析
We further analyze the model performance by considering various measures of question complexity based on the number of elements in questions, and the number of columns involved in solutions, as shown in Figure 4. Incorporating more elements requires the model to either perform calculations or utilize domain knowledge to establish connections between elements and specific columns. Similarly, involving more columns also presents a challenge for the model in accurately locating and associating the relevant columns. We notice that both EHRAgent and baselines generally exhibit lower performance on more challenging tasks16. Notably, our model consistently outperforms all the baseline models across all levels of difficulty. Specifically, for those questions with more than 10 columns, the completion rate of those open-loop baselines is very low (less than $20%$ ), whereas EHRAgent can still correctly answer around $50%$ of queries, indicating the robustness of EHRAgent in handling complex queries with multiple elements.
我们进一步通过问题中的元素数量和解决方案涉及的列数等衡量问题复杂度的指标来分析模型性能,如图4所示。融入更多元素需要模型执行计算或利用领域知识建立元素与特定列之间的关联。同样,涉及更多列也对模型准确定位和关联相关列提出了挑战。我们注意到EHRAgent和基线模型在更具挑战性的任务上普遍表现较差[16]。值得注意的是,我们的模型在所有难度级别上都持续优于所有基线模型。具体而言,对于那些涉及超过10列的问题,开环基线模型的完成率非常低(低于$20%$),而EHRAgent仍能正确回答约$50%$的查询,这表明EHRAgent在处理多元素复杂查询时具有鲁棒性。
G.2 Additional Error Analysis
G.2 补充错误分析
We conducted a manual examination to analyze all incorrect cases generated by EHRAgent in MIMICIII. Figure 6 illustrates the percentage of each type of error frequently encountered during solution generation:
我们对 EHRAgent 在 MIMICIII 中生成的所有错误案例进行了人工检查。图 6 展示了解决方案生成过程中常见错误类型的占比:
$\diamond$ Date/Time. When addressing queries related to dates and times, it is important for the LLM agent to use the ‘Calendar’ tool, which bases its calculations on the system time of the database. This approach is typically reliable, but there are situations where the agent defaults to calculating dates based on real-world time. Such instances may lead to potential inaccuracies.
$\diamond$ 日期/时间。在处理与日期和时间相关的查询时,大语言模型智能体应使用基于数据库系统时间进行计算的"日历 (Calendar)"工具。这种方法通常可靠,但某些情况下智能体会默认基于现实世界时间计算日期,可能导致潜在误差。
$\diamond$ Context Length. This type of error occurs when the input queries or dialog histories are excessively long, exceeding the context length limit.
$\diamond$ 上下文长度 (Context Length)。当输入查询或对话历史过长,超出上下文长度限制时,就会出现这种错误。
$\diamond$ Incorrect Logic. When solving multi-hop reasoning questions across multiple databases, the LLM agent may generate executable plans that contain logical errors in the intermediate reasoning steps. For instance, in computing the total cost of a hospital visit, the LLM agent might erroneously generate a plan that filters the database using patient_id instead of the correct admission id.
$\diamond$ 逻辑错误。在跨多个数据库解决多跳推理问题时,大语言模型可能生成包含中间推理步骤逻辑错误的可执行计划。例如,在计算医院就诊总费用时,大语言模型可能错误生成使用patient_id而非正确admission_id筛选数据库的计划。
$\diamond$ Incorrect SQL Command. This error type arises when the LLM agent attempts to integrate the SQL Interpreter into a Python-based plan to derive intermediate results. Typically, incorrect SQL commands result in empty responses from SQL Interpreter, leading to the failure of subsequent parts of the plan.
$\diamond$ 错误的SQL命令。当大语言模型智能体尝试将SQL解释器集成到基于Python语言的计划中以获取中间结果时,就会出现这种错误类型。通常,错误的SQL命令会导致SQL解释器返回空响应,从而导致计划后续部分失败。
$\diamond$ Fail to Follow Instructions. The LLM agent often fails to follow the instructions provided in the initial prompt or during the interactive debugging process.
$\diamond$ 未能遵循指令。大语言模型 (LLM) 智能体经常无法遵循初始提示或交互式调试过程中提供的指令。
$\diamond$ Fail to Debug. Despite undertaking all $T$ -step trials, the LLM agent consistently fails to identify the root cause of errors, resulting in plans that are either incomplete or inexcusable.
$\diamond$ 调试失败。尽管进行了所有 $T$ 步试验,大语言模型智能体仍始终无法识别错误的根本原因,导致生成的计划要么不完整,要么不可接受。
G.3 Additional Empirical Comparison of Primary Programming Languages
G.3 主要编程语言的额外实证比较
We conduct an additional analysis based on the empirical results (byond main results in Table 1) to further justify the selection of Python as our primary programming language.
我们基于实证结果(除表1中的主要结果外)进行了额外分析,以进一步证明选择Python语言作为主要编程语言的合理性。
Data Complexity. The SPIDER (Yu et al., 2018) dataset, which is commonly used in SQL baselines (Pourreza and Rafiei, 2023), typically only involves referencing information from an average of 1.1 tables per question. In contrast, the EHRQA datasets we utilized require referencing information from an average of 1.9 tables per question. This significant gap in # tables questions indicates that EHRQA requires more advanced reasoning across multiple tables.
数据复杂度。常用于SQL基准测试的SPIDER数据集(Yu et al., 2018)(Pourreza and Rafiei, 2023)平均每个问题仅涉及1.1张表的信息引用,而我们使用的EHRQA数据集平均每个问题需要引用1.9张表的信息。这种表间关联数量的显著差距表明,EHRQA需要更复杂的跨表推理能力。
Sample Efficiency. SQL-based methods require more demonstrations. As SQL occupies a relatively smaller proportion of training data, it is quite difficult for LLMs to generate valid SQL commands. Usually, the methods need at least tens of demonstrations to get the LLMs familiar with the data schema and SQL grammar. In EHRAgents, we only need four demonstrations as few-shot multitabular reasoning.
样本效率。基于SQL的方法需要更多演示样本。由于SQL在训练数据中占比较小,大语言模型很难生成有效的SQL命令。通常这类方法至少需要数十个演示样本才能使模型熟悉数据模式和SQL语法。而在EHRAgents中,我们仅需四个少样本多表推理演示即可达成目标。
Environment Feedback. DIN-SQL (Pourreza and Rafiei, 2023) establishes a set of rules to auto mati call y self-correct the SQL commands generated. Nevertheless, these rules are rigid and may not cover all potential scenarios. While it does contribute to enhancing the validity of the generated SQL commands to some extent, DIN-SQL lacks tailored information to optimize the code based on different circumstances, resulting in a lower success rate compared to self-debugging and EHRAgent, which provide error messages and deeper insights.
环境反馈。DIN-SQL (Pourreza and Rafiei, 2023) 建立了一套规则来自动校正生成的 SQL 命令。然而,这些规则较为僵化,可能无法覆盖所有潜在场景。尽管它确实在一定程度上提升了生成 SQL 命令的有效性,但 DIN-SQL 缺乏根据不同情况优化代码的定制化信息,导致其成功率低于能提供错误信息和更深入洞察的自我调试方法及 EHRAgent。
Execution Time Efficiency. We acknowledge that when handling large amounts of data, Python may experience efficiency issues compared to SQL commands. We have also observed similar challenges when working with the TREQS dataset, which contains a massive database with millions of records. However, in the MIMIC-III dataset, EHRAgent (avg. 52.63 seconds per ques- tion) still demonstrates higher efficiency compared to the state-of-the-art LLM4SQL method, DINSQL (Pourreza and Rafiei, 2023) (avg. 103.28 sec- onds per question). We will consider the efficiency of Python when dealing with large-scale databases as one of the important future directions.
执行时间效率。我们承认在处理大量数据时,Python语言相比SQL命令可能存在效率问题。在使用包含数百万条记录的TREQS数据集时,我们也观察到了类似的挑战。然而在MIMIC-III数据集中,EHRAgent(平均每个问题52.63秒)仍展现出比当前最先进的LLM4SQL方法DINSQL(Pourreza和Rafiei, 2023)(平均每个问题103.28秒)更高的效率。我们将把Python语言处理大规模数据库时的效率问题列为未来重要研究方向之一。
H Additional Case Studies
H 其他案例研究
We present additional case studies to showcase the effectiveness of each module in EHRAgent, including medical information integration (Section H.1), long-term memory (Section H.2), code interface (Section H.3), and rubber duck debugging module (Section H.4). In addition, we include Figures 13 and 14 to showcase the entire workflow of EHRAgent with accumulative domain knowledge and coding capability for EHR reasoning.
我们通过更多案例研究展示EHRAgent各模块的有效性,包括医疗信息整合(第H.1节)、长期记忆(第H.2节)、代码接口(第H.3节)和橡皮鸭调试模块(第H.4节)。此外,我们通过图13和图14展示EHRAgent在电子健康记录推理中积累领域知识和编码能力的完整工作流程。
H.1 Case Study of Medical Information Integration
H.1 医疗信息整合案例研究
Figure 8 presents a case study of integrated medical knowledge based on a given query. When faced with a question related to ‘aspirin ec’ and ‘venous cath nec’, EHRAgent effectively summarizes and integrates relevant knowledge containing drug and procedure information, successfully reasoning and identifying the potential locations of the required information (tables and records) in the EHR database (e.g., ‘prescriptions’, ‘d icd procedures’), along with the detailed identifiers (e.g., ‘ICD9_ CODE’, ${}^{\cdot}H A D M_i D^{\prime})$ needed to associate them.
图 8: 基于给定查询的整合医学知识案例研究。当面对与"阿司匹林肠溶片 (aspirin ec)"和"静脉导管坏死 (venous cath nec)"相关的问题时,EHRAgent能有效汇总整合包含药物和手术信息的关联知识,成功推理并识别出EHR数据库中所需信息(表格和记录)的潜在位置(如"处方(prescriptions)"、"诊断手术(d icd procedures)"),以及关联这些信息所需的详细标识符(如"ICD9_ CODE"、${}^{\cdot}H A D M_i D^{\prime})$。
| Question:countthenumberofpatientswhowereprescribed aspirinecwithin2monthafterhavingreceivedavenous cathnecprocedureuntil4yearago. |
| EHRAgent Knowledge: -As aspirin ec is a drug,we can find the corresponding information in the prescriptions database. -Asvenouscathnec isaprocedure,wecanfindthe correspondingIcD9_ coDEinthed_icd_ proceduresdatabase. TheICD9_ CoDE canbeused to find the correspondingHADM_iD in theprocedures_icddatabase. -The HADM_iD can be used to find the corresponding SUBJECT_iD in |
问题:统计在4年前接受静脉导管插入术(venous cath)后2个月内被开具阿司匹林肠溶片(aspirin ec)的患者数量。
EHRAgent知识:
- 由于阿司匹林肠溶片是一种药物,我们可以在处方数据库中找到相应信息。
- 由于静脉导管插入术是一种医疗操作,我们可以在d_icd_ procedures数据库中找到对应的ICD9_ CODE。
- ICD9_ CODE可用于在procedures_icd数据库中找到对应的HADM_iD。
- HADM_iD可用于在...
Figure 8: Case study of medical information injection in EHRAgent on MIMIC-III dataset. Given a question related to ‘aspirin ec’ and ‘venous cath nec’, EHRAgent effectively integrates knowledge about their potential location in the database and the identifiers required to associate them.
图 8: EHRAgent在MIMIC-III数据集上的医疗信息注入案例研究。针对与"阿司匹林肠溶片(aspirin ec)"和"静脉导管坏死(venous cath nec)"相关的问题,EHRAgent有效整合了它们在数据库中潜在位置的知识以及关联所需的标识符。
H.2 Case Study of Long-Term Memory
H.2 长期记忆案例研究
Figure 9 presents a case study of updating few-shot demonstrations from long-term memory. Due to the constraints of limited context length, we are only able to provide a limited number of examples to guide EHRAgent in generating solution code. For a given question, the initial set of examples is predefined and fixed, which may not cover the specific reasoning logic or knowledge required to solve it. Using long-term memory, EHRAgent replaces original few-shot demonstrations with the most relevant successful cases from past experiences for effective plan refinement. For example, none of the original few-shot examples relate to either ‘count the number’ scenarios or procedure knowledge; after selecting from the long-term memory pool, we successfully retrieve more relevant examples, thus providing a similar solution logic for reference.
图 9: 展示了从长期记忆中更新少样本示例的案例研究。由于上下文长度限制,我们只能提供有限数量的示例来指导EHRAgent生成解决方案代码。对于给定问题,初始示例集是预定义且固定的,可能无法涵盖解决该问题所需的特定推理逻辑或知识。通过利用长期记忆,EHRAgent用过去经验中最相关的成功案例替换原始少样本示例,从而实现有效的计划优化。例如,原始少样本示例均未涉及"计数场景"或流程知识;而从长期记忆池中选择后,我们成功检索到更相关的示例,从而提供了类似的解决方案逻辑作为参考。
H.3 Case Study of Code Interface
H.3 代码接口案例分析
Figures 10 and 11 present two case studies of harnessing LLMs as autonomous agents in a multi-turn conversation for code generation, in comparison to a natural language-based plan such as ReAct. From the case studies, we can observe that ReAct lacks a code interface, which prevents it from utilizing code structures for efficient action planning and tool usage. This limitation often results in a lengthy context for ReAct to execute, which eventually leads to a low completion rate.
图 10 和图 11 展示了两个案例研究,对比了在多轮对话中将大语言模型作为自主智能体进行代码生成与基于自然语言的规划方法(如 ReAct)的效果。从案例中可以看出,ReAct 缺乏代码接口,导致其无法利用代码结构进行高效的动作规划和工具使用。这一限制通常会使 ReAct 需要冗长的上下文才能执行任务,最终导致较低的完成率。
H.4 Case Study of Rubber Duck Debugging
H.4 橡皮鸭调试法案例研究
Figure 12 showcases a case study comparing the interactive coding process between AutoGen and EHRAgent for the same given query. When executed with error feedback, AutoGen directly sends back the original error messages, making slight modifications (e.g., changing the surface string of the arguments) without reasoning the root cause of the error. In contrast, EHRAgent can identify the underlying causes of the errors through interactive coding and debugging processes. It successfully discovers the underlying error causes (taking into account case sensitivity), facilitating accurate code refinement.
图 12: 展示了针对同一查询的 AutoGen 与 EHRAgent 交互式编码流程对比案例研究。当接收到错误反馈时,AutoGen 仅直接返回原始错误信息,并作轻微修改 (例如调整参数表面字符串),而未推理错误根源。相比之下,EHRAgent 能通过交互式编码和调试过程定位错误深层原因,成功发现底层错误 (考虑大小写敏感性),从而推动精准的代码优化。
| Question:countthenumberoftimesthatpatient85895receivedaphlabtestlastmonth. | ||
| OriginalExamples Question:What is the maximum total hospital cost that involves | 1 | ExamplesfromLong-TermMemory Question:Countthenumberoftimesthatpatient52898were |
| adiagnosisnamedcomp-othvascdev/graftsince1yearago? Knowledge:{KNOWLEDGE} Solution:{SOLUTION} | prescribed ns this month. | |
| Knowledge:{KNOWLEDGE} Solution:{SOLUTION} | ||
| intake. | Question:Countthenumberof timesthatpatient14035hadad10w | |
| Knowledge:{KNOWLEDGE} Solution:{SOLUTION} Question:Whatwasthenameoftheprocedurethatwasgiventwo | Knowledge: {KNOwLEDGE} Solution:{SOLUTION} | Question:Countthenumberoftimesthatpatient99791receiveda |
| ormoretimestopatient58730? Knowledge:{KNOWLEDGE} Solution:{SOLUTION} | opred-intfix rad/ulna procedure. Knowledge:{KNOWLEDGE} Solution:{SOLUTION} | |
| Question:What was thelast time patient 4718 hadaperipheral blood lymphocytes microbiology test in the last hospitalvisit? Knowledge:{KNOWLEDGE} Solution:{SOLUTION} | Question: rt/leftheartcardcath procedurelastyear. Knowledge:{KNOWLEDGE} | Count thenumberoftimesthat patient54825receiveda |
| 问题:统计患者85895上个月接受血液检测的次数。 | |
|---|---|
| 原始示例问题:涉及名为comp-othvascdev/graft诊断的最大总住院费用是多少(自一年前起)? | 1 |
| 知识:{KNOWLEDGE} 解决方案:{SOLUTION} | |
| 摄入。 | 问题:统计患者14035进行ad10w操作的次数。 |
| 知识:{KNOWLEDGE} 解决方案:{SOLUTION} 问题:对患者58730实施两次或以上的手术名称是什么? | 知识:{KNOWLEDGE} 解决方案:{SOLUTION} |
| 知识:{KNOWLEDGE} 解决方案:{SOLUTION} | 操作:opred-intfix 桡骨/尺骨手术。 知识:{KNOWLEDGE} 解决方案:{SOLUTION} |
| 问题:患者4718上次住院期间最后一次进行外周血淋巴细胞微生物学检测的时间是什么时候? | 问题:去年进行rt/左心导管手术。 知识:{KNOWLEDGE} |

Figure 9: Case study of long-term memory in EHRAgent on MIMIC-III dataset. From the original few-shot examples on the left, none of the questions related to either ‘count the number’ scenarios or procedure knowledge. In contrast, when we retrieve examples from the long-term memory, the new set is exclusively related to ‘count the number’ questions, thus providing a similar solution logic for reference. Figure 10: Case study 1 of code interface in EHRAgent on MIMIC-III dataset. The baseline approach, ReAct, lacks a code interface and encounters limitations when performing identical operations on multiple sets of data. It resorts to generating repetitive action steps iterative ly, leading to an extended solution trajectory that may exceed the context limitations. In contrast, EHRAgent leverages the advantages of code structures, such as the use of ‘for loops’, to address these challenges more efficiently and effectively. The steps marked in red on the left side indicate the repeated actions by ReAct, while the steps marked in green are the corresponding code snippets by EHRAgent. By comparing the length and number of steps, the code interface can help EHRAgent save much context space.
图 9: EHRAgent在MIMIC-III数据集上的长期记忆案例研究。左侧原始少样本示例中,没有任何问题涉及"计数"场景或手术知识。相比之下,当我们从长期记忆中检索示例时,新集合完全与"计数"问题相关,从而提供了类似的解决逻辑作为参考。
图 10: EHRAgent在MIMIC-III数据集上代码接口的案例研究1。基线方法ReAct缺乏代码接口,在对多组数据执行相同操作时会遇到限制。它不得不重复生成相同的操作步骤,导致解决方案轨迹延长,可能超出上下文限制。相比之下,EHRAgent利用代码结构优势(如使用"for循环")更高效地应对这些挑战。左侧标红步骤显示ReAct的重复操作,而绿色标记的是EHRAgent对应的代码片段。通过比较步骤长度和数量,代码接口可帮助EHRAgent节省大量上下文空间。

Figure 11: Case study 2 of code interface in EHRAgent on MIMIC-III dataset. When encountering challenges in tool use, ReAct will keep making trials and can be stuck in the modification process. On the other hand, with code interface, EHRAgent can take advantage of Python built-in functions to help with debugging and code modification.
图 11: EHRAgent 在 MIMIC-III 数据集上的代码界面案例研究 2。当遇到工具使用挑战时,ReAct 会持续尝试并可能陷入修改过程。另一方面,通过代码界面,EHRAgent 可以利用 Python语言 内置函数辅助调试和代码修改。

Figure 12: Comparative case study of the interactive coding process between AutoGen (left) and EHRAgent (right), where EHRAgent delves deeper into environmental feedback via debugging module to achieve plan refinement.
图 12: AutoGen (左) 与 EHRAgent (右) 交互式编码过程的对比案例研究,其中 EHRAgent 通过调试模块深入分析环境反馈以实现计划优化。

Figure 13: A complete version of case study in Figure 7 showcasing interactive coding with environment feedback.
图 13: 图7案例研究的完整版本,展示了带有环境反馈的交互式编码。

Figure 14: Case study of the complete workflow in EHRAgent. With EHR metadata and tool definitions, EHRAgent (1) integrates medical information to locate the required tables/records, (2) retrieves relevant examples from longterm memory, (3) generates and executes code, (4) iterative ly debugs with error messages until the final solution.
图 14: EHRAgent完整工作流程案例研究。通过EHR元数据和工具定义,EHRAgent (1) 整合医疗信息定位所需表格/记录,(2) 从长期记忆中检索相关示例,(3) 生成并执行代码,(4) 通过错误信息迭代调试直至获得最终解决方案。