Knowledge Editing for Large Language Models: A Survey
大语言模型知识编辑研究综述
SONG WANG, University of Virginia, USA YAOCHEN ZHU, University of Virginia, USA HAOCHEN LIU, University of Virginia, USA ZAIYI ZHENG, University of Virginia, USA CHEN CHEN, University of Virginia, USA JUNDONG LI, University of Virginia, USA
SONG WANG, 美国弗吉尼亚大学
YAOCHEN ZHU, 美国弗吉尼亚大学
HAOCHEN LIU, 美国弗吉尼亚大学
ZAIYI ZHENG, 美国弗吉尼亚大学
CHEN CHEN, 美国弗吉尼亚大学
JUNDONG LI, 美国弗吉尼亚大学
Large Language Models (LLMs) have recently transformed both the academic and industrial landscapes due to their remarkable capacity to understand, analyze, and generate texts based on their vast knowledge and reasoning ability. Nevertheless, one major drawback of LLMs is their substantial computational cost for pre-training due to their unprecedented amounts of parameters. The disadvantage is exacerbated when new knowledge frequently needs to be introduced into the pre-trained model. Therefore, it is imperative to develop effective and efficient techniques to update pre-trained LLMs. Traditional methods encode new knowledge in pre-trained LLMs through direct fine-tuning. However, naively re-training LLMs can be computationally intensive and risks degenerating valuable pre-trained knowledge irrelevant to the update in the model. Recently, Knowledge-based Model Editing (KME), also known as Knowledge Editing or Model Editing, has attracted increasing attention, which aims to precisely modify the LLMs to incorporate specific knowledge, without negatively influencing other irrelevant knowledge. In this survey, we aim to provide a comprehensive and in-depth overview of recent advances in the field of KME. We first introduce a general formulation of KME to encompass different KME strategies. Afterward, we provide an innovative taxonomy of KME techniques based on how the new knowledge is introduced into pre-trained LLMs, and investigate existing KME strategies while analyzing key insights, advantages, and limitations of methods from each category. Moreover, representative metrics, datasets, and applications of KME are introduced accordingly. Finally, we provide an in-depth analysis regarding the practicality and remaining challenges of KME and suggest promising research directions for further advancement in this field.
大语言模型 (LLMs) 凭借其基于海量知识和推理能力的文本理解、分析与生成能力,近期彻底改变了学术界和工业界的格局。然而,LLMs 的一个主要缺点在于其空前庞大的参数量导致预训练计算成本极高。当需要频繁向预训练模型注入新知识时,这一劣势更为突出。因此,开发高效更新预训练 LLMs 的技术势在必行。传统方法通过直接微调将新知识编码到预训练 LLMs 中,但这种简单重训练不仅计算密集,还可能破坏模型中与更新无关的宝贵预训练知识。近年来,基于知识的模型编辑 (Knowledge-based Model Editing, KME) 日益受到关注,其目标是在不影响其他无关知识的前提下,精准修改 LLMs 以融入特定知识。本综述旨在全面深入地概述 KME 领域的最新进展:首先提出涵盖各类 KME 策略的通用框架;随后根据新知识注入预训练 LLMs 的方式建立创新分类体系,系统考察现有 KME 方法并分析各类技术的核心思想、优势与局限;进而介绍代表性评估指标、数据集和应用场景;最后深入探讨 KME 的实用性与现存挑战,并指出该领域未来发展的潜在研究方向。
CCS Concepts: • Computing methodologies $\rightarrow$ Natural language processing.
CCS概念:• 计算方法 $\rightarrow$ 自然语言处理。
Keywords: Model Editing, Knowledge Update, Fine-tuning, Large Language Models
关键词:模型编辑 (Model Editing)、知识更新 (Knowledge Update)、微调 (Fine-tuning)、大语言模型
ACM Reference Format: Song Wang, Yaochen Zhu, Haochen Liu, Zaiyi Zheng, Chen Chen, and Jundong Li. 2024. Knowledge Editing for Large Language Models: A Survey. 1, 1 (September 2024), 35 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn
ACM参考格式: Song Wang, Yaochen Zhu, Haochen Liu, Zaiyi Zheng, Chen Chen, and Jundong Li. 2024. 大语言模型知识编辑综述. 1, 1 (2024年9月), 35页. https://doi.org/10.1145/nnnnnnn.nnnnnnn
1 INTRODUCTION
1 引言
Recently, large language models (LLMs) have become a heated topic that revolutionizes both academia and industry [10, 109, 144, 173]. With the substantial factual knowledge and reasoning ability gained from pre-training on large corpora, LLMs have exhibited an unprecedented under standing of textual information, which are able to analyze and generate texts akin to human experts [84, 87, 135, 138, 176]. Nevertheless, one main drawback of LLMs is the extremely high computational overhead of the training process due to the large amounts of parameters [59, 64, 179]. This is exacerbated by the continuous evolvement of the world where the requirement of updating pre-trained LLMs to rectify obsolete information or incorporate new knowledge to maintain their relevancy is constantly emerging [85, 92, 128, 134]. For example, as in Fig. 1, the outdated LLM,
近来,大语言模型(LLM)已成为颠覆学术界和工业界的热门话题 [10, 109, 144, 173]。通过在海量语料上进行预训练获得的事实性知识与推理能力,大语言模型展现出对文本信息的空前理解力,能够像人类专家般分析和生成文本 [84, 87, 135, 138, 176]。然而,大语言模型的主要缺陷在于其庞大参数量导致的极高训练计算开销 [59, 64, 179]。随着世界持续演进,为修正过时信息或吸纳新知识以保持相关性,需要不断更新预训练大语言模型,这进一步加剧了计算负担 [85, 92, 128, 134]。例如图1所示,过时的大语言模型...

Fig. 1. An example of KME for efficient update of knowledge in LLMs.
图 1: 大语言模型中知识高效更新的KME示例。
GPT-3.5, cannot precisely describe the latest achievements of the famous soccer player Lionel Messi, which requires an explicit injection of new knowledge to generate the correct answers.
GPT-3.5 无法准确描述著名足球运动员 Lionel Messi 的最新成就,这需要显式注入新知识才能生成正确答案。
One feasible while straightforward strategy for updating pre-trained LLMs is through naive fine-tuning [20, 31, 141, 161], where parameters of pre-trained LLMs are directly optimized to encode new knowledge from new data [6, 99, 111, 173]. For example, various instruction-tuning methods are proposed to fine-tune pre-trained LLMs on newly collected data in a supervised learning manner [100, 112, 157, 159]. Although such fine-tuning techniques are widely used and capable of injecting new knowledge into LLMs, they are known for the following disadvantages: (1) Even with parameter-efficient strategies to improve efficiency [89, 158, 170], fine-tuning LLMs may still require intensive computational resources [97, 102, 174]. (2) Fine-tuning LLMs alters the pre-trained parameters without constraints, which can lead to the over fitting problem, where LLMs face the risk of losing valuable existing knowledge [172].
更新预训练大语言模型的一种可行且直接的策略是通过朴素微调 [20, 31, 141, 161],即直接优化预训练大语言模型的参数以从新数据中编码新知识 [6, 99, 111, 173]。例如,研究者提出了多种指令微调方法,以监督学习方式在新收集的数据上对预训练大语言模型进行微调 [100, 112, 157, 159]。尽管此类微调技术被广泛使用且能够向大语言模型注入新知识,但它们存在以下缺点:(1) 即使采用参数高效策略提升效率 [89, 158, 170],微调大语言模型仍可能需要大量计算资源 [97, 102, 174]。(2) 微调会无约束地改变预训练参数,可能导致过拟合问题,使大语言模型面临丢失宝贵已有知识的风险 [172]。
To address the drawbacks of updating LLMs with naive fine-tuning, more attention has been devoted to Knowledge-based Model Editing1 (KME). In general, KME aims to precisely modify the behavior of pre-trained LLMs to update specific knowledge, without negatively influencing other pre-trained knowledge irrelevant to the updates [116, 152, 167]. In KME, the update of a specific piece of knowledge in LLMs is typically formulated as an edit, such as rectifying the answer to “Who is the president of the USA?” from “Trump” to “Biden”. Regarding a specific edit, KME strategies typically modify the model output by either introducing an auxiliary network (or set of parameters) into the pre-trained model [52, 79, 175] or updating the (partial) parameters to store the new knowledge [22, 49, 51, 83]. Through these strategies, KME techniques can store new knowledge in new parameters or locate it in model parameters for updating, thereby precisely injecting the knowledge into the model. In addition, certain methods further introduce optimization constraints to ensure that the edited model maintains consistent behaviors on unmodified knowledge [13, 106, 177]. With these advantages, KME techniques can provide an efficient and effective way to constantly update LLMs with novel knowledge without explicit model re-training [172].
为了解决通过简单微调更新大语言模型(LLM)的缺陷,研究者们将更多注意力转向了基于知识的模型编辑(KME)。总体而言,KME旨在精确修改预训练大语言模型的行为以更新特定知识,同时避免对与更新无关的其他预训练知识产生负面影响[116, 152, 167]。在KME中,对大语言模型中特定知识的更新通常被表述为一个编辑操作,例如将"美国总统是谁?"的答案从"特朗普"修正为"拜登"。针对具体编辑操作,KME策略通常通过两种方式修改模型输出:要么在预训练模型中引入辅助网络(或参数集)[52, 79, 175],要么更新(部分)参数以存储新知识[22, 49, 51, 83]。通过这些策略,KME技术可以将新知识存储在新参数中,或定位到待更新的模型参数中,从而精确地将知识注入模型。此外,某些方法还引入了优化约束,确保编辑后的模型在未修改知识上保持行为一致[13, 106, 177]。凭借这些优势,KME技术能够提供一种高效且有效的方式,无需显式重新训练模型即可持续更新大语言模型的新知识[172]。
While sharing certain similarities with fine-tuning strategies, KME poses unique advantages in updating LLMs, which are worthy of deeper investigations. Particularly, both KME and model fine-tuning seek to update pre-trained LLMs with new knowledge. However, aside from this shared objective, KME focuses more on two crucial properties that cannot be easily addressed by finetuning. (1) Locality requires that KME does not unintentionally influence the output of other irrelevant inputs with distinct semantics. For example, when the edit regarding the president of the USA is updated, KME should not alter its knowledge about the prime minister of the UK. The practicality of KME methods largely relies on their ability to maintain the outputs for unrelated inputs, which serves as a major difference between KME and fine-tuning [117]. (2) Generality represents whether the edited model can generalize to a broader range of relevant inputs regarding the edited knowledge. Specifically, it indicates the model’s capability to present consistent behavior on inputs that share semantic similarities. For example, when the model is edited regarding the president, the answer to the query about the leader or the head of government should also change accordingly. In practice, it is important for KME methods to ensure that the edited model can adapt well to such related input texts. To summarize, due to these two unique objectives, KME remains a challenging task that requires specific strategies for satisfactory effectiveness.
虽然与微调策略有某些相似之处,但知识模型编辑(KME)在更新大语言模型方面具有独特优势,值得深入研究。具体而言,KME和模型微调都试图用新知识更新预训练的大语言模型。然而,除了这一共同目标外,KME更关注两个无法通过微调轻易解决的关键特性:(1) 局部性要求KME不会无意中影响其他语义无关的输入输出。例如,当更新关于美国总统的编辑时,KME不应改变其对英国首相的知识。KME方法的实用性很大程度上取决于其保持无关输入输出的能力,这是KME与微调的主要区别[117]。(2) 通用性表示编辑后的模型是否能将编辑知识推广到更广泛的相关输入。具体而言,它反映了模型在语义相似输入上表现一致行为的能力。例如,当对总统相关信息进行编辑时,关于领导人或政府首脑的查询答案也应相应改变。实践中,KME方法必须确保编辑后的模型能良好适应此类相关输入文本。总之,由于这两个独特目标,KME仍是一项需要特定策略才能获得满意效果的挑战性任务。
Differences between this survey and existing ones. Several surveys have been conducted to examine various aspects of (large) language models [12, 34, 71, 73, 142, 173]. Nevertheless, there is still a dearth of thorough investigations of existing literature and continuous progress in editing LLMs. For example, recent works [100, 159] have discussed the fine-tuning strategies that inject new knowledge in pre-trained LLMs with more data samples. However, the distinctiveness of KME, i.e., locality and generality, is not adequately discussed, which will be thoroughly analyzed in this survey. Two other surveys [35, 63] review knowledge-enhanced language models. However, they mainly focus on leveraging external knowledge to enhance the performance of the pre-trained LLMs, without addressing the editing task based on specific knowledge. To the best of our knowledge, the most related work [167] to our survey provides a brief overview of KME and concisely discusses the advantages of KME methods and their challenges. Nevertheless, the investigation lacks a thorough examination of more details of KME, e.g., categorizations, datasets, and applications. The following work [172] additionally includes experiments with classic KME methods. Another recent work [152] proposes a framework for KME that unifies several representative methods. This work focuses on the implementation of KME techniques, with less emphasis on the technical details of different strategies. A more recent study [116] discusses the limitations of KME methods regarding the faithfulness of edited models, while it is relatively short and lacks a more comprehensive introduction to all existing methods. Considering the rapid advancement of KME techniques, we believe it is imperative to review the details of all representative KME methods, summarize the common ali ties while discussing the uniqueness of each method, and discuss open challenges and prospective directions in the domain of KME to facilitate further advancement.
本综述与现有研究的差异。已有若干综述研究探讨了(大)语言模型的各个方面[12, 34, 71, 73, 142, 173]。然而,目前仍缺乏对现有文献的系统梳理及对大语言模型编辑技术持续进展的全面考察。例如,近期研究[100, 159]讨论了通过更多数据样本向预训练大语言模型注入新知识的微调策略,但未充分探讨知识模型编辑(KME)的核心特性——局部性与泛化性,这将是本综述的重点分析内容。另有两篇综述[35, 63]回顾了知识增强的语言模型,但其主要关注利用外部知识提升预训练模型性能,未涉及基于特定知识的编辑任务。据我们所知,与本研究最相关的工作[167]简要概述了KME并讨论了其优势与挑战,但缺乏对KME分类体系、数据集和应用场景等细节的深入考察。后续研究[172]补充了经典KME方法的实验验证,近期工作[152]提出了统一多种代表性方法的KME框架,但更侧重技术实现而非不同策略的细节分析。最新研究[116]探讨了KME方法在模型编辑忠实度方面的局限,但篇幅较短且未全面介绍现有方法。鉴于KME技术的快速发展,我们认为亟需:系统梳理所有代表性KME方法的技术细节,在讨论各方法独特性的同时总结共性特征,并探讨该领域的开放挑战与发展方向以推动后续研究。
Contributions of this survey. This survey provides a comprehensive and in-depth analysis of techniques, challenges, and opportunities associated with the editing of pre-trained LLMs. We first provide an overview of KME tasks along with an innovative formulation. Particularly, we formulate the general KME task as a constrained optimization problem, which simultaneously incorporates the goals of accuracy, locality, and generality. We then classify the existing KME strategies into three main categories, i.e., external memorization, global op tim z ation, and local modification. More importantly, we demonstrate that methods in each category can be formulated as a specialized constrained optimization problem, where the characteristics are theoretically summarized based on the general formulation. In addition, we provide valuable insights into the effectiveness and feasibility of methods in each category, which can assist practitioners in selecting the most suitable KME method tailored to a specific task. Our analysis regarding the strengths and weaknesses of KME methods also serves as a catalyst for ongoing progress within the KME research community. In concrete, our key contributions can be summarized into three folds as follows:
本综述的贡献。本综述对预训练大语言模型(LLM)编辑相关的技术、挑战与机遇进行了全面深入的分析。我们首先概述了知识模型编辑(KME)任务并提出创新性形式化框架,特别地将通用KME任务构建为同时兼顾准确性、局部性与通用性目标的约束优化问题。随后将现有KME策略系统归类为外部记忆、全局优化和局部修改三大范式,并论证每类方法均可视为特定约束优化问题的求解方案,基于通用框架从理论层面总结了各类方法的特征。此外,我们针对不同范式方法的有效性与可行性提供了实用洞见,可帮助从业者根据具体任务选择最适合的KME方法。关于KME方法优缺点的分析结论也将推动该研究领域的持续发展。具体而言,我们的核心贡献可归纳为以下三方面:
• Novel Categorization. We introduce a comprehensive and structured categorization framework to systematically summarize the existing works for LLM editing. Specifically, based on how the new knowledge is introduced into pre-trained LLMs, our categorization encompasses three distinct categories: external memorization, global optimization, and local modification, where their common ali ty and differences are thoroughly discussed in this survey. • In-Depth Analysis. We formulate the task of KME as a constrained optimization problem, where methods from each category can be viewed as a special case with refined constraints. Furthermore, we emphasize the primary insights, advantages, and limitations of each category. Within this context, we delve deep into representative methods from each category and systematically analyze their interconnections.
• 新颖分类。我们提出了一个全面且结构化的分类框架,系统性地总结现有的大语言模型编辑方法。具体而言,根据新知识如何被引入预训练大语言模型,我们的分类体系包含三个独立类别:外部记忆 (external memorization)、全局优化 (global optimization) 和局部修改 (local modification),本综述深入探讨了它们的共性与差异。
• 深度分析。我们将知识模型编辑 (KME) 任务形式化为约束优化问题,其中每个类别的方法都可视为具有特定约束条件的特例。此外,我们重点分析了各类别的主要思路、优势与局限性。在此框架下,我们深入剖析了各类别的代表性方法,并系统性地解析了它们之间的关联。
• Future Directions. We analyze the practicality of existing KME techniques regarding a variety of datasets and applications. We also comprehensively discuss the challenges of the existing KME techniques and suggest promising research directions for future exploration.
• 未来方向。我们分析了现有知识图谱嵌入 (KME) 技术在不同数据集和应用中的实用性,全面探讨了当前技术面临的挑战,并为未来研究提出了潜在探索方向。
The remainder of this paper is organized as follows. Section 2 introduces the background knowledge for KME. Section 3 provides a general formulation of the KME task, which can fit into various application scenarios. Section 4 provides a comprehensive summary of evaluation metrics for KME strategies, which is crucial for a fair comparison across various methods. Before delving into the specific methods, we provide a comprehensive categorization of existing methods into three classes in Section 5.1, where their relationship and differences are thoroughly discussed. Then we introduce the methods from the three categories in detail, where the advantages and limitations of each category are summarized. Section 6 introduces the prevalent ly used public datasets. Section 7 provides a thorough introduction to various realistic tasks that can benefit from KME techniques. Section 8 discusses the potential challenges of KME that have not been addressed by existing techniques. This section also provides several potential directions that can inspire future research. Lastly, we conclude this survey in Section 9.
本文的其余部分组织如下。第2节介绍KME的背景知识。第3节给出KME任务的通用表述,可适配多种应用场景。第4节全面总结KME策略的评估指标,这对各种方法间的公平比较至关重要。在深入具体方法前,我们在第5.1节将现有方法系统划分为三类,并详细讨论其关联与差异。随后详细阐述这三类方法,并总结每类方法的优势与局限。第6节介绍广泛使用的公开数据集。第7节全面介绍可受益于KME技术的各类现实任务。第8节讨论现有技术尚未解决的KME潜在挑战,并提出若干可能启发未来研究的方向。最后,第9节对本次综述进行总结。
2 BACKGROUND
2 背景
In this section, we provide an overview of the editing strategies for machine learning models and the basics of large language models (LLMs) as background knowledge to facilitate the understanding of technical details in KME. In this survey, we use bold uppercase letters (e.g., K and V) to represent matrices, use lowercase bold letters (e.g., k and v) to represent vectors, and use calligraphic uppercase letters (e.g., $\chi$ and $_y$ ) to represent sets. We summarize the primary notations used in this survey in Table 1 for the convenience of understanding.
在本节中,我们概述了机器学习模型的编辑策略和大语言模型(LLM)的基础知识,作为理解KME技术细节的背景知识。本综述使用加粗大写字母(如K和V)表示矩阵,小写加粗字母(如k和v)表示向量,花体大写字母(如$\chi$和$_y$)表示集合。为便于理解,我们在表1中总结了本综述使用的主要符号。
2.1 Editing of Machine Learning Models
2.1 机器学习模型的编辑
Machine learning models [41, 54, 74] pre-trained on large datasets frequently serve as foundation models for various tasks in the real-world [26, 126]. In practical scenarios, there is often a need to modify these pre-trained models to enhance the performance for specific downstream tasks [18, 20, 103, 164, 178], reduce biases or undesirable behaviors [39, 104, 113, 123], tailor models to align more closely with human preferences [44, 72, 88], or incorporate novel information [101, 167, 177].
基于大规模数据集预训练的机器学习模型 [41, 54, 74] 常作为现实任务的基础模型 [26, 126]。实际应用中,通常需要调整这些预训练模型以:提升特定下游任务性能 [18, 20, 103, 164, 178]、减少偏见或不良行为 [39, 104, 113, 123]、使模型更贴合人类偏好 [44, 72, 88],或融入新信息 [101, 167, 177]。
Model Editing is a special type of model modification strategy where the modification should be as precise as possible. Nevertheless, it should accurately modify the pre-trained model to encode specific knowledge while maximally preserving the existing knowledge, without affecting their behavior on unrelated inputs [68]. First explored in the computer vision field, Bau et al. [8] investigate the potential of editing generative adversarial networks (GAN) [45] by viewing an intermediate layer as a linear memory, which can be manipulated to incorporate novel content. Afterward, Editable Training [133] is proposed to encourage fast editing of the trained model in a model-agnostic manner. The goal is to change the model predictions on a subset of inputs corresponding to mis classified objects, without altering the results for other inputs. In [125], the authors propose a method that allows for the modification of a classifier’s behavior by editing its decision rules, which can be used to correct errors or reduce biases in model predictions. In the field of natural language processing, several works [22, 102] have been proposed to perform editing regarding textual information. Specifically, Zhu et al. [177] propose a constrained fine-tuning loss to explicitly modify specific factual knowledge in transformer-based models [146]. More recent works [42, 43] discover that the MLP layers in transformers actually act as key-value memories, thereby enabling the editing of specific knowledge within the corresponding layers.
模型编辑是一种特殊的模型修改策略,其修改应尽可能精确。它需要准确调整预训练模型以编码特定知识,同时最大限度保留现有知识,且不影响模型在无关输入上的行为 [68]。该技术最早在计算机视觉领域展开探索,Bau等人 [8] 通过将生成对抗网络(GAN) [45] 的中间层视为可线性操作的内存空间,研究了编辑GAN以融入新内容的可能性。随后提出的可编辑训练(Editable Training) [133] 采用模型无关方式,旨在快速修改已训练模型,仅改变模型在误分类对象对应输入子集上的预测结果,同时保持其他输入的输出不变。[125] 中提出的方法通过编辑分类器决策规则来修正预测错误或减少偏差。在自然语言处理领域,多项研究 [22, 102] 实现了文本信息的编辑操作。Zhu等人 [177] 提出约束微调损失函数,专门用于修改基于Transformer [146] 模型中的特定事实知识。最新研究 [42, 43] 发现Transformer中的MLP层实质充当键值存储器,从而实现对特定知识层的精准编辑。
Table 1. Important notations used in this survey.
| Notations | Detailed Descriptions |
| x | Input (prompt) to LLMs |
| y | Output of LLMs |
| (x, y) | Input-output pair |
| t = (s,r,o) | Original knowledge triple (before editing) |
| s/r/o | Subject/Relation/Object in aknowledgetriple |
| t* = (s,r,o*) | Target knowledge triple (after editing) |
| e = (s,r,0 → o*) | Edit descriptor |
| Xe | In-scope input space |
| ye | Original output space (before editing) |
| y* | Target output space (after editing) |
| 8={ei} | Set of edits |
| Oe | Out-scope input space |
| Query/Key/Value vector for the i-th head of the I-th attention module in Transformer | |
| ww | Weights of the fully connected layers of the I-th attention module in Transformer |
| h(l) | Output from the I-th self-attention module in Transformer |
| Vector concatenation |
表 1: 本综述使用的重要符号说明
| 符号 | 详细描述 |
|---|---|
| x | 大语言模型的输入 (prompt) |
| y | 大语言模型的输出 |
| (x, y) | 输入-输出对 |
| t = (s,r,o) | 原始知识三元组 (编辑前) |
| s/r/o | 知识三元组中的主语/关系/宾语 |
| t* = (s,r,o*) | 目标知识三元组 (编辑后) |
| e = (s,r,0 → o*) | 编辑描述符 |
| Xe | 范围内输入空间 |
| ye | 原始输出空间 (编辑前) |
| y* | 目标输出空间 (编辑后) |
| 8={ei} | 编辑集合 |
| Oe | 范围外输入空间 |
| Transformer 中第 I 个注意力模块第 i 个头对应的查询/键/值向量 | |
| ww | Transformer 中第 I 个注意力模块全连接层的权重 |
| h(l) | Transformer 中第 I 个自注意力模块的输出 |
| 向量拼接 |
2.2 Language Models
2.2 语言模型
2.2.1 Transformers. Transformers lie in the core of large language models (LLMs) [27, 121, 146]. The fully-fledged transformer possesses an encoder-decoder architecture initially designed for the neural machine translation (NMT) task [137]. Nowadays, transformers have found wide applications in most fields of the NLP community, beyond their original purpose. Generally, a transformer network is constructed from multiple stacks of the self-attention module with residual connections, which is pivotal for capturing contextual information from textual sequences. The self-attention module is composed of a self-attention layer (SelfAtt) and a point-wise feed-forward neural network layer (FFN) formulated as follows:
2.2.1 Transformer。Transformer 是大语言模型 (LLM) [27, 121, 146] 的核心架构。完整的 Transformer 采用最初为神经机器翻译 (NMT) 任务 [137] 设计的编码器-解码器结构。如今,Transformer 的应用已远超其原始用途,覆盖了自然语言处理领域的大部分方向。通常,Transformer 网络由多个带残差连接的自注意力模块堆叠而成,该结构对捕获文本序列的上下文信息至关重要。自注意力模块由自注意力层 (SelfAtt) 和逐点前馈神经网络层 (FFN) 构成,其公式表示如下:
$$
\begin{array}{r l}&{{\mathbf{h}}{i}^{A,(l-1)}=\mathrm{SelfAtt}{i}\left({\mathbf{h}}{i}^{(l-1)}\right)=\mathrm{Softmax}\left({\mathbf{q}}{i}^{(l)}\left({\mathbf{k}}{i}^{(l)}\right)^{\top}\right){\mathbf{v}}{i}^{(l)},}\ &{{\mathbf{h}}^{F,(l-1)}=\mathrm{FFN}\left({\mathbf{h}}^{(l-1)}\right)=\mathrm{GELU}\left({\mathbf{h}}^{(l-1)}{\mathbf{W}}_{1}^{(l)}\right){\mathbf{W}}_{2}^{(l)},{\mathbf{h}}^{(0)}={\mathbf{x}},}\ &{{\mathbf{h}}^{(l)}={\mathbf{h}}^{A,(l-1)}+{\mathbf{h}}^{F,(l-1)}=\left\Vert_{i}\mathrm{SelfAtt}_{i}\left({\mathbf{h}}_{i}^{(l-1)}\right)+\mathrm{FFN}\left({\mathbf{h}}^{(l-1)}\right),}\end{array}
$$
$$
\begin{array}{r l}&{{\mathbf{h}}{i}^{A,(l-1)}=\mathrm{SelfAtt}{i}\left({\mathbf{h}}{i}^{(l-1)}\right)=\mathrm{Softmax}\left({\mathbf{q}}{i}^{(l)}\left({\mathbf{k}}{i}^{(l)}\right)^{\top}\right){\mathbf{v}}{i}^{(l)},}\ &{{\mathbf{h}}^{F,(l-1)}=\mathrm{FFN}\left({\mathbf{h}}^{(l-1)}\right)=\mathrm{GELU}\left({\mathbf{h}}^{(l-1)}{\mathbf{W}}_{1}^{(l)}\right){\mathbf{W}}_{2}^{(l)},{\mathbf{h}}^{(0)}={\mathbf{x}},}\ &{{\mathbf{h}}^{(l)}={\mathbf{h}}^{A,(l-1)}+{\mathbf{h}}^{F,(l-1)}=\left\Vert_{i}\mathrm{SelfAtt}_{i}\left({\mathbf{h}}_{i}^{(l-1)}\right)+\mathrm{FFN}\left({\mathbf{h}}^{(l-1)}\right),}\end{array}
$$
where $\mathbf{q}{i}^{(l)},\mathbf{k}{i}^{(l)}$ , and $\mathbf{v}{i}^{(l)}$ represent the sequences of query, key, and value vectors for the $i$ -th attention head of the $l$ -th attention module, respectively. GELU is an activation function. They are calculated from $\mathbf{h}{i}^{(l-1)}$ , the $i$ -th slice of the outputs from the $(l-1)$ -th self-attention module (i.e., $\mathbf{h}^{(l-1)})$ , and $\mathbf{x}$ denotes the input sequence of token embeddings. $\parallel$ represents vector concatenation. Normalizing factors in the self-attention layer are omitted for simplicity.
其中 $\mathbf{q}{i}^{(l)}$、$\mathbf{k}{i}^{(l)}$ 和 $\mathbf{v}{i}^{(l)}$ 分别表示第 $l$ 个注意力模块中第 $i$ 个注意力头的查询 (query)、键 (key) 和值 (value) 向量序列。GELU 是一种激活函数。这些向量由第 $(l-1)$ 个自注意力模块输出的第 $i$ 个切片 $\mathbf{h}{i}^{(l-1)}$ (即 $\mathbf{h}^{(l-1)}$ ) 计算得出,$\mathbf{x}$ 表示token嵌入的输入序列。$\parallel$ 表示向量拼接。为简洁起见,省略了自注意力层中的归一化因子。
Generally, multi-head self-attention directs the model to attend to different parts of the sequence to predict the next token. Specifically, the prediction is based on different types of relationships and dependencies within the textual data, where the output $\mathbf{h}{i}^{A,(l-1)}$ is a weighted sum of the value vector of other tokens. In contrast, FFN adds new information h𝑖𝐹,(𝑙 −1) to the weighted sum of the embeddings of the attended tokens based on the information stored in the weights of the fully connected layers, i.e., $\mathbf{W}{1}^{(l)}$ and $\mathbf{W}{2}^{(l)}$ . The final layer outputs of the transformer, i.e., $\mathbf{h}^{(L)}$ , can be used in various downstream NLP tasks. For token-level tasks (e.g., part-of-speech tagging [19]), the entire hidden representation sequence $\mathbf{h}^{(L)}$ can be utilized to predict the target sequence. For the sequence-level tasks (e.g., sentiment analysis [160]), the hidden representation of the last token, i.e., $\mathbf{h}{-1}^{(L)}$ , can be considered as a summary of the sequence and thus used for the predictions.
通常,多头自注意力机制(multi-head self-attention)会引导模型关注序列的不同部分以预测下一个token。具体而言,预测基于文本数据中不同类型的关系和依赖,其中输出$\mathbf{h}{i}^{A,(l-1)}$是其他token值向量的加权和。相比之下,前馈神经网络(FFN)基于全连接层权重(即$\mathbf{W}{1}^{(l)}$和$\mathbf{W}{2}^{(l)}$)中存储的信息,向被关注token嵌入的加权和添加新信息$\mathbf{h}{i}^{F,(l-1)}$。Transformer的最终层输出$\mathbf{h}^{(L)}$可用于各种下游NLP任务:对于token级任务(如词性标注[19]),可利用整个隐藏表示序列$\mathbf{h}^{(L)}$来预测目标序列;对于序列级任务(如情感分析[160]),可将最后一个token的隐藏表示$\mathbf{h}_{-1}^{(L)}$视为序列的摘要并用于预测。
2.2.2 Large Language Models (LLMs). Transformers with billions of parameters trained on large corpora have demonstrated emergent ability, showcasing an unprecedented understanding of factual and commonsense knowledge [173]. Consequently, these models are referred to as large language models (LLMs) to indicate their drastic distinction from traditional small-scale language models [34, 142]. Generally, based on the specific parts of the transformer utilized for language modeling, existing LLMs can be categorized into three classes: encoder-only LLMs, such as BERT [74], encoder-decoder-based LLMs such as T5 [119], and decoder-only models (also the most common structure in LLMs) such as different versions of GPT [118] and LLaMA [144].
2.2.2 大语言模型 (LLMs)
基于数十亿参数并在大规模语料库上训练的Transformer模型展现出涌现能力 (emergent ability) [173],表现出对事实和常识知识的空前理解。因此,这些模型被称为大语言模型 (LLMs) [34, 142],以区别于传统小规模语言模型。根据Transformer中用于语言建模的具体模块,现有大语言模型可分为三类:仅编码器架构 (encoder-only) 如BERT [74],编码器-解码器架构 (encoder-decoder) 如T5 [119],以及仅解码器架构 (decoder-only) (也是当前大语言模型最常见结构) 如各版本GPT [118] 和LLaMA [144]。
2.3 Relevant Topics
2.3 相关主题
KME intersects with several extensively researched topics, yet these techniques cannot effectively address KME-specific challenges [141, 161]. The most relevant approach is model fine-tuning [6, 20, 99], including parameter-efficient fine-tuning [89, 158, 170], which requires fewer parameter updates. However, fine-tuning remains computationally intensive and is often impractical for blackbox LLMs [172, 173]. Another related area is machine unlearning [105], which aims to remove the influence of individual samples from models. Unlike KME, which focuses on abstract and generalized knowledge updates, machine unlearning targets the elimination of specific training data, making it unsuitable for KME. On the other hand, external memorization KME methods share similarities with RAG (retrieval-augmented generation) [40], where a large repository of documents is stored and retrieved as needed to provide con textually relevant information for generating responses. While RAG can introduce new knowledge into LLMs by retrieving recently added documents, it does not effectively update the inherent knowledge within LLMs. Thus, RAG is not suitable for the fundamental knowledge updates that KME seeks to achieve.
KME 与多个广泛研究领域存在交集,但这些技术无法有效解决 KME 特有的挑战 [141, 161]。最相关的方法是模型微调 (fine-tuning) [6, 20, 99],包括参数高效微调 (parameter-efficient fine-tuning) [89, 158, 170],后者所需的参数更新更少。然而微调仍存在计算成本高的问题,且通常不适用于黑盒大语言模型 [172, 173]。另一相关领域是机器遗忘 (machine unlearning) [105],其目标是消除单个样本对模型的影响。与 KME 专注于抽象化、通用化的知识更新不同,机器遗忘针对的是特定训练数据的删除,因此不适用于 KME。另一方面,外部记忆型 KME 方法与 RAG (检索增强生成) [40] 存在相似性——后者通过存储海量文档库并按需检索,为生成响应提供上下文相关信息。虽然 RAG 能通过检索新增文档向大语言模型引入新知识,但无法有效更新模型内部固有知识。因此 RAG 并不适用于 KME 追求的基础性知识更新。
3 PROBLEM FORMULATION
3 问题描述
In this section, we provide a formal definition for the knowledge-based model editing (KME) task for pre-trained LLMs, where a general formulation of the KME objective is formulated to encompass specific KME strategies. The task of KME for LLMs can be broadly defined as the process of precisely modifying the behavior of pre-trained LLMs, such that new knowledge can be incorporated to maintain the current ness and relevancy of LLMs can be maintained, without negatively influencing other pre-trained knowledge irrelevant to the edits. To provide a clear formulation, we present the definitions of different terms used in KME, where the overall process is illustrated in Fig. 2.
在本节中,我们为预训练大语言模型的知识编辑任务 (KME) 提供了正式定义,其中制定了 KME 目标的通用公式以涵盖特定的 KME 策略。大语言模型的 KME 任务可广义定义为:通过精确修改预训练大语言模型的行为,使其能够融入新知识以保持模型时效性与相关性,同时不影响与编辑无关的其他预训练知识。为明确表述,我们给出了 KME 中使用的各项术语定义,整个过程如图 2 所示。
Editing Target. In this survey, we represent the knowledge required to be injected into LLMs as a knowledge triple $t=\left(s,r,o\right)$ , where $s$ is the subject (e.g., president of the USA), $r$ is the relation (e.g., is), and $o$ is the object (e.g., Biden). From the perspective of knowledge triple, the objective of KME for LLMs is to modify the original knowledge triple $t=\left(s,r,o\right)$ encoded in the pre-trained weights of the model into the target knowledge triple $t^{}=(s,r,o^{})$ , where $o^{}$ is the target object different from 𝑜. In this manner, we can define an edit as a tuple $e=\left(t,t^{}\right)=\left(s,r,o\rightarrow o^{}\right)$ , which denotes the update of the obsolete old knowledge $t$ into the new knowledge $t^{}$ .
编辑目标。在本综述中,我们将需要注入大语言模型的知识表示为知识三元组 $t=\left(s,r,o\right)$ ,其中 $s$ 是主体(如美国总统), $r$ 是关系(如是), $o$ 是客体(如Biden)。从知识三元组的角度来看,大语言模型的知识模型编辑(KME)目标是将模型预训练权重中编码的原始知识三元组 $t=\left(s,r,o\right)$ 修改为目标知识三元组 $t^{}=(s,r,o^{})$ ,其中 $o^{}$ 是与𝑜不同的目标客体。通过这种方式,我们可以将编辑定义为一个元组 $e=\left(t,t^{}\right)=\left(s,r,o\rightarrow o^{}\right)$ ,表示将过时的旧知识 $t$ 更新为新知识 $t^{}$ 。
Input and Output Space. Given a pair of subject 𝑠 and relation $r$ , in order to query LLMs to obtain the ob- ject $o$ , $(s,r)$ needs to be transformed into natural language, which we denoted as $x,x$ is also referred to as the prompt in this survey. The LLM output $y$ is also textual and can be converted back to an object 𝑜 as the query result. In this way, $(x,y)$ can
输入与输出空间。给定主体𝑠和关系$r$,为了通过查询大语言模型获取对象$o$,需要将$(s,r)$转换为自然语言,我们将其表示为$x$,在本综述中也称为提示(prompt)。大语言模型的输出$y$同样为文本形式,可转换回对象𝑜作为查询结果。由此,$(x,y)$可

Fig. 2. The formulation of the KME objective.
图 2: KME目标的公式化表达。
be considered as the natural language input-output pair associated with the knowledge triple $t=\left(s,r,o\right)$ . For example, the prompt $x$ transformed from 𝑠 and $r$ can be “The president of the USA is”, and $y$ is the model output “Joe Biden”. Note that due to the diversity of natural language, multiple $(x,y)$ pairs can be associated with the same knowledge triple 𝑡. We denote the set of textual inputs associated with subject 𝑠 and relation $r$ in an edit $e$ as $X_{e}=I(s,r)$ , referred to as in-scope input space. Similarly, we define the set of textual outputs that can be associated with the object $o$ in the same edit $e$ as $y_{e}^{}=O^{}(s,r,o^{})$ (i.e., target output space), and the original textual output space as $y_{e}=O(s,r,o)$ (i.e., original output space). Given an edit $e$ , the aim of KME is to modify the behavior of language models from $y_{e}$ to $y_{e}^{}$ , regarding the input in $X_{e}$ . To accommodate the scenarios where multiple edits are performed, we can define the union of $X_{e}$ over a set of edits ${\mathcal{E}}={e_{1},e_{2},\dots}$ as $\begin{array}{r}{\chi_{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}\chi_{e}}\end{array}$ . Similarly, we can define $\begin{array}{r}{\mathfrak{y}_{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}\mathfrak{y}_{e}}\end{array}$ and $\begin{array}{r}{\boldsymbol{{y}}_{\mathcal{E}}^{*}=\bigcup_{e\in\mathcal{E}}\boldsymbol{{y}}_{e}^{*}}\end{array}$ .
可视为与知识三元组$t=\left(s,r,o\right)$相关联的自然语言输入-输出对。例如,由𝑠和$r$转换而来的提示$x$可以是"美国总统是",而$y$则是模型输出"乔·拜登"。需要注意的是,由于自然语言的多样性,同一知识三元组𝑡可能对应多个$(x,y)$对。我们将编辑$e$中与主语𝑠和关系$r$相关联的文本输入集合记为$X_{e}=I(s,r)$,称为输入作用域空间。类似地,定义同一编辑$e$中与宾语$o$相关联的目标文本输出空间为$y_{e}^{}=O^{}(s,r,o^{})$,原始文本输出空间为$y_{e}=O(s,r,o)$。给定编辑$e$,知识模型编辑(KME)的目标是将语言模型在$X_{e}$输入空间中的行为从$y_{e}$修改为$y_{e}^{}$。为适应多编辑场景,可定义编辑集合${\mathcal{E}}={e_{1},e_{2},\dots}$的输入空间并集为$\begin{array}{r}{\chi_{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}\chi_{e}}\end{array}$,同理定义$\begin{array}{r}{\mathfrak{y}_{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}\mathfrak{y}_{e}}\end{array}$和$\begin{array}{r}{\boldsymbol{{y}}_{\mathcal{E}}^{*}=\bigcup_{e\in\mathcal{E}}\boldsymbol{{y}}_{e}^{*}}\end{array}$。
Formulation. We denote the pre-trained LLM with parameter $\phi$ as $f:X\to y$ and the edited model with updated parameter $\phi^{}$ as $f^{}:X\to y^{}$ . The objective of knowledge-based model editing is to precisely update the pre-trained LLM $f$ into $f^{}$ according to edits in the edit set $\varepsilon$ such that for each edit $e$ and for each $y\in\mathcal{Y}_{e}$ , the changes to the input-output pairs irrelevant to the edits is minimized. The problem of KME can be formulated as follows:
公式化。我们将参数为$\phi$的预训练大语言模型表示为$f:X\to y$,更新参数为$\phi^{}$的编辑后模型表示为$f^{}:X\to y^{}$。基于知识的模型编辑目标是根据编辑集$\varepsilon$中的每个编辑$e$,将预训练大语言模型$f$精确更新为$f^{}$,使得对于每个$y\in\mathcal{Y}_{e}$,与编辑无关的输入输出对变化最小化。该问题可表述为:
Definition 1. The objective for KME on a series of edits $\varepsilon$ is represented as follows:
定义 1. 在编辑序列 $\varepsilon$ 上的 KME 目标表示如下:
$$
.t.f^{*}(x)=f(x),\forall x\in X\backslash\chi_{\mathcal{E}},
$$
$$
.t.f^{*}(x)=f(x),\forall x\in X\backslash\chi_{\mathcal{E}},
$$
where $\mathcal{L}$ is a specific loss function that measures the discrepancy between the model output $f^{}(x)$ and $y^{}$ from the desirable response set $y_{e}^{*}$ $\therefore M(f;{\mathcal{E}})$ denotes the modification applied to $f$ based on the desirable edits $\varepsilon$ .
其中 $\mathcal{L}$ 是衡量模型输出 $f^{}(x)$ 与期望响应集 $y_{e}^{}$ 中 $y^{*}$ 之间差异的特定损失函数,因此 $M(f;{\mathcal{E}})$ 表示基于期望编辑 $\varepsilon$ 对 $f$ 进行的修改。
From the above definition, we can summarize two crucial perspectives regarding the objective of KME: (1) Generality, which requires that the correct answers in the target output space $y_{e}^{}$ can be achieved, provided prompts in the in-scope input space, i.e., $X_{e}$ , where the target knowledge triple $t^{}\in e$ can be updated into the pre-trained model; (2) Locality, which requires the consistency of model output regarding unrelated input, i.e., $\chi\backslash\chi_{\varepsilon}$ , where valuable pre-trained knowledge can be maximally preserved after the editing. Here, we note that locality is especially important for editing LLMs, as the knowledge that needs to be updated often occupies only a small fraction of all knowledge encompassed by the pre-trained model. In other words, the output of an edited model regarding most input prompts should remain consistent with the output before editing.
从上述定义中,我们可以总结出关于KME目标的两个关键视角:(1) 通用性 (Generality) ,要求在目标输出空间 $y_{e}^{}$ 中能获得正确答案,前提是输入提示位于范围内输入空间 $X_{e}$ ,其中目标知识三元组 $t^{}\in e$ 可更新至预训练模型;(2) 局部性 (Locality) ,要求模型对无关输入 $\chi\backslash\chi_{\varepsilon}$ 的输出保持一致性,使得编辑后能最大限度保留有价值的预训练知识。此处需注意,局部性对大语言模型编辑尤为重要,因为需要更新的知识通常仅占预训练模型涵盖知识总量的极小部分。换言之,编辑后模型对大多数输入提示的输出应与编辑前保持一致。
4 EVALUATION METRICS
4 评估指标
Before introducing the taxonomy of KME and the exemplar methods in detail, in this section, we first discuss various metrics commonly used to evaluate the effectiveness of different KME
在详细介绍KME分类法和典型方法之前,本节首先讨论常用于评估不同KME有效性的各类指标
strategies from varied perspectives. We summarize the metrics to facilitate the understanding in terms of the properties and advantages of different methods.
我们从不同视角总结了策略,并通过归纳指标来帮助理解各类方法的特性与优势。
4.1 Accuracy
4.1 准确性
Accuracy is a straightforward metric for evaluating the effectiveness of KME techniques [17, 29, 79, 101, 106, 174, 175], defined as the success rate of editing in terms of a specific set of pre-defined input-output pairs $(x_{e},y_{e}^{})$ associated with all the edited knowledge. Accuracy can be easily defined to evaluate the performance of KME on classification tasks, e.g., fact checking [102, 114], where the answers $y$ are categorical. Defining the prompt and ground truth related to an edit $e$ as $x_{e}$ and $y_{e}^{}$ , respectively, the metric of the accuracy of an edited model $f^{*}$ is formulated as follows:
准确率是评估知识模型编辑(KME)技术有效性的直观指标[17, 29, 79, 101, 106, 174, 175],其定义为针对所有待编辑知识关联的预定义输入-输出对$(x_{e},y_{e}^{})$的编辑成功率。该指标可轻松用于评估KME在分类任务(如事实核查[102, 114])中的表现,其中答案$y$为分类结果。将编辑$e$相关的提示词和真实值分别定义为$x_{e}$和$y_{e}^{}$,被编辑模型$f^{*}$的准确率指标公式如下:
$$
\begin{array}{r}{\operatorname{Acc}(f^{};\mathcal{E})=\mathbb{E}_{e\in\mathcal{E}}\mathbb{1}{f^{}(x_{e})=y_{e}^{*}}.}\end{array}
$$
$$
\begin{array}{r}{\operatorname{Acc}(f^{};\mathcal{E})=\mathbb{E}_{e\in\mathcal{E}}\mathbb{1}{f^{}(x_{e})=y_{e}^{*}}.}\end{array}
$$
Since accuracy is defined on a deterministic set of prompt-answer pairs, it provides a fair comparison between KME methods [22, 97, 98]. Nevertheless, it is non-trivial to evaluate the practicality of KME methods with accuracy, as there is no consensus on how to design the $\varepsilon$ , especially when the task needs to output a long sequence such as question answering or text generation [29, 97, 98].
由于准确率是在一组确定的提示-答案对上定义的,它为不同KME方法提供了公平的比较基准 [22, 97, 98]。然而,用准确率评估KME方法的实用性并非易事,因为对于如何设计$\varepsilon$尚未达成共识,特别是在需要输出长序列的任务(如问答或文本生成)时 [29, 97, 98]。
4.2 Locality
4.2 局部性
One crucial metric for the KME strategies is locality [17, 25, 83, 101], which reflects the capability of the edited model $f^{}$ to preserve the pre-trained knowledge in $f$ irrelevant to the edits in $\varepsilon$ . Note that in most KME applications, the number of required edits makes for an extremely small fraction of the entire knowledge learned and preserved in the pre-trained LLMs [167, 172]. Consequently, the locality measurement is of great importance in assessing the capability of edited models to preserve unrelated knowledge [49, 95, 104]. Given an edit $e$ , the edited model $f^{}$ , and the original pre-trained model $f$ , the locality of $f^{*}$ can be defined as the expectation of matched agreement between the edited model and unedited model for out-scope inputs, which can be defined as follows:
KME策略的一个关键指标是局部性 [17, 25, 83, 101],它反映了编辑后模型$f^{}$保留预训练模型$f$中与编辑集$\varepsilon$无关知识的能力。需要注意的是,在大多数KME应用中,所需编辑数量仅占预训练大语言模型所学全部知识的极小部分 [167, 172]。因此,局部性度量对于评估编辑模型保留无关知识的能力至关重要 [49, 95, 104]。给定编辑$e$、编辑后模型$f^{}$和原始预训练模型$f$,$f^{*}$的局部性可定义为编辑模型与未编辑模型在非目标输入上预测一致性的期望值,其数学表达如下:
$$
\operatorname{Loc}(f^{},f;e)=\mathbb{E}{x\not\in\chi{e}}\mathbb{1}{f^{}(x)=f(x)}.
$$
$$
\operatorname{Loc}(f^{},f;e)=\mathbb{E}{x\not\in\chi{e}}\mathbb{1}{f^{}(x)=f(x)}.
$$
We can also consider the locality regarding the entire edit set $\varepsilon$ , which can be defined as follows:
我们还可以考虑整个编辑集 $\varepsilon$ 的局部性,其定义如下:
$$
\operatorname{Loc}(f^{},f;\mathcal{E})=\mathbb{E}{x\notin\chi{\mathcal{E}}}\mathbb{1}{f^{}(x)=f(x)},\mathrm{where}\chi_{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}\chi_{e}.
$$
$$
\operatorname{Loc}(f^{},f;\mathcal{E})=\mathbb{E}{x\notin\chi{\mathcal{E}}}\mathbb{1}{f^{}(x)=f(x)},\mathrm{where}\chi_{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}\chi_{e}.
$$
Although the above metric measures the overall locality of $f^{}$ based on all inputs that are not in $\chi_{\varepsilon}$ , it is difficult to compute in realistic scenarios, as the entire input space can be excessively large or even infinite [167]. Therefore, existing methods generally resort to alternative solutions that pre-define the specific range of out-scope inputs to calculate the locality metric [15, 22, 25, 82, 97]. For example, in SERAC [102], the authors generate hard out-scope examples from the dataset zsRE [78] by selectively sampling from training inputs with high semantic similarity with the edit input, based on embeddings obtained from a pre-trained semantic embedding model. Denoting the out-scope input space related to the input $X_{e}$ as $O_{e}$ , we can similarly define the feasible out-scope input space for multiple edits as $\begin{array}{r}{O_{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}O_{e}}\end{array}$ . In this manner, we define a specific metric of locality of $f^{}$ regarding $\varepsilon$ as follows:
虽然上述指标基于所有不在 $\chi_{\varepsilon}$ 中的输入来衡量 $f^{}$ 的整体局部性,但在实际场景中难以计算,因为整个输入空间可能过大甚至无限 [167]。因此,现有方法通常采用替代方案,即预定义超出范围输入的具体范围来计算局部性指标 [15, 22, 25, 82, 97]。例如,在 SERAC [102] 中,作者通过从预训练的语义嵌入模型获得的嵌入,选择性地采样与编辑输入具有高语义相似性的训练输入,从数据集 zsRE [78] 生成困难的超出范围示例。将与输入 $X_{e}$ 相关的超出范围输入空间记为 $O_{e}$,我们可以类似地定义多次编辑的可行超出范围输入空间为 $\begin{array}{r}{O_{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}O_{e}}\end{array}$。通过这种方式,我们定义了 $f^{}$ 关于 $\varepsilon$ 的特定局部性指标如下:
$$
\begin{array}{r}{\operatorname{Loc}(f^{},f;O_{e})=\mathbb{E}{x\in O{e}}\mathbb{1}{f^{}(x)=f(x)},}\end{array}
$$
$$
\begin{array}{r}{\operatorname{Loc}(f^{},f;O_{e})=\mathbb{E}{x\in O{e}}\mathbb{1}{f^{}(x)=f(x)},}\end{array}
$$
$$
\operatorname{Loc}(f^{},f;O_{\mathcal{E}})=\mathbb{E}{x\in O{\mathcal{E}}}\mathbb{1}{f^{}(x)=f(x)},\mathrm{where}O_{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}O_{e}.
$$
$$
\operatorname{Loc}(f^{},f;O_{\mathcal{E}})=\mathbb{E}{x\in O{\mathcal{E}}}\mathbb{1}{f^{}(x)=f(x)},\mathrm{where}O_{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}O_{e}.
$$
4.3 Generality
4.3 通用性
Aside from locality, another crucial metric is generality, which indicates the capability of the edited model $f^{}$ to correctly respond to semantically similar prompts [13, 101, 106, 130, 177]. This requires the generalization of the updated knowledge to other in-scope inputs that do not appear in the training set while conveying similar or related meanings [50, 163]. As such, ensuring the generality of edited models prevents the edited model from over fitting to a particular input [172]. Specifically, in the scenarios of knowledge-based model editing, the inherent diversity of natural language determines that various in-scope inputs $x$ can correspond to a specific knowledge triple $t$ [152]. These semantically equivalent inputs can involve differences in aspects such as syntax, morphology, genre, or even language. Existing works mostly pre-define a specific in-scope input space of each edit via different strategies [61, 86, 136, 166, 168]. For example, in the Counter Fact dataset proposed in ROME [97], the authors utilize prompts that involve distinct yet semantically related subjects as the in-scope input. In general, the generality of an edited model $f^{}$ is defined as the expectation of exact-match agreement between the output of the edited model and true labels for in-scope inputs, which can be defined on either an edit $e$ or the edit set $\varepsilon$ as:
除了局部性,另一个关键指标是泛化性 (generality),它反映了编辑后模型 $f^{}$ 对语义相近提示词的正确响应能力 [13, 101, 106, 130, 177]。这要求更新后的知识能够泛化至训练集未出现但语义相关的作用域内输入 (in-scope inputs) [50, 163]。因此,确保编辑模型的泛化性可防止模型对特定输入产生过拟合 [172]。具体而言,在基于知识的模型编辑场景中,自然语言固有的多样性决定了多种作用域内输入 $x$ 可能对应同一知识三元组 $t$ [152]。这些语义等价的输入可能涉及句法、词法、文体甚至语言层面的差异。现有研究大多通过不同策略预先定义每个编辑的作用域输入空间 [61, 86, 136, 166, 168],例如 ROME [97] 提出的 Counter Fact 数据集中,作者采用主语不同但语义相关的提示词作为作用域输入。通常,编辑模型 $f^{}$ 的泛化性定义为编辑模型输出与真实标签在作用域输入上的精确匹配期望值,该指标可针对单个编辑 $e$ 或编辑集 $\varepsilon$ 定义为:
$$
\mathbf{Gen}(f^{};e)=\mathbb{E}{x\in\boldsymbol{\chi}{e}}\mathbb{1}{f^{}(x)\in\boldsymbol{y}_{e}^{*}},
$$
$$
\mathbf{Gen}(f^{};e)=\mathbb{E}{x\in\boldsymbol{\chi}{e}}\mathbb{1}{f^{}(x)\in\boldsymbol{y}_{e}^{*}},
$$
$$
{\bf G e n}(f^{};\mathcal{E})=\mathbb{E}{x\in\chi{\mathcal{E}}}\mathbb{1}{f^{}(x)\in\mathcal{Y}{e}^{*}},\mathrm{where}X{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}\chi_{e}.
$$
$$
{\bf G e n}(f^{};\mathcal{E})=\mathbb{E}{x\in\chi{\mathcal{E}}}\mathbb{1}{f^{}(x)\in\mathcal{Y}{e}^{*}},\mathrm{where}X{\mathcal{E}}=\bigcup_{e\in\mathcal{E}}\chi_{e}.
$$
4.4 Portability
4.4 可移植性
In addition to generality, another vital metric is portability, which measures the effectiveness of the edited model $f^{}$ in transferring a conducted edit to other logically related edits that can be interpreted via reasoning [172]. For example, if an edit is conducted towards the President of the USA, the edit regarding the query “Which political party does the current President of the USA belong to?” should also be achieved. This ensures that the edited model is not limited to responding to specific input formats. In concrete, the transfer of knowledge is crucial for robust generalization of the edited model. In practice, portability can be assessed with logically related edits obtained in different ways [21, 167]. Denoting an edit as $e=\left(s,r,o\to o^{}\right)$ , hereby we introduce two common types of logically related edits . (1) Reversed Relation: $\tilde{e}=\left(o\rightarrow o^{*},\tilde{r},s\right)$ , where $\tilde{r}$ is the reversed relation of $r$ , and (2) Neighboring Relation: $\tilde{e}=\left(s,r\oplus r_{\epsilon},\epsilon\rightarrow\epsilon^{*}\right)$ , where both $(o,r_{\epsilon},\epsilon)$ and $(o^{*},r_{\epsilon},\epsilon^{*})$ exist in the pre-trained knowledge, and $r\oplus r_{\epsilon}$ is a combined relation from $r$ and $r_{\epsilon}$ . In this manner, we define portability as the edited model performance on one or multiple logically related edits as follows:
除了通用性外,另一个关键指标是可移植性 (portability) ,它衡量编辑后模型 $f^{}$ 将已执行编辑迁移到其他可通过推理解释的逻辑相关编辑中的有效性 [172]。例如,若对美国总统治进行编辑,那么针对查询"美国现任总统属于哪个政党?"的编辑也应同步实现。这确保了编辑后模型不仅能响应特定输入格式。具体而言,知识迁移对编辑后模型的稳健泛化至关重要。实践中,可通过不同方式获取逻辑相关编辑来评估可移植性 [21, 167]。将编辑表示为 $e=\left(s,r,o\to o^{}\right)$ ,此处介绍两种常见逻辑相关编辑类型:(1) 反向关系: $\tilde{e}=\left(o\rightarrow o^{*},\tilde{r},s\right)$ ,其中 $\tilde{r}$ 是 $r$ 的反向关系;(2) 邻近关系: $\tilde{e}=\left(s,r\oplus r_{\epsilon},\epsilon\rightarrow\epsilon^{*}\right)$ ,其中 $(o,r_{\epsilon},\epsilon)$ 和 $(o^{*},r_{\epsilon},\epsilon^{*})$ 均存在于预训练知识中,且 $r\oplus r_{\epsilon}$ 是 $r$ 与 $r_{\epsilon}$ 的组合关系。由此,我们将可移植性定义为编辑后模型在单个或多个逻辑相关编辑上的表现:
$$
\mathbf{Por}(f^{};\tilde{e})=\mathbb{E}{x\in X{\tilde{e}}}\mathbb{1}{f^{}(x)\in{\mathcal{Y}}_{\tilde{e}}^{*}},
$$
$$
\mathbf{Por}(f^{};\tilde{e})=\mathbb{E}{x\in X{\tilde{e}}}\mathbb{1}{f^{}(x)\in{\mathcal{Y}}_{\tilde{e}}^{*}},
$$
$$
\mathbf{Por}(f^{};\widetilde{\mathcal{E}})=\mathbb{E}{x\in X{\widetilde{\mathcal{E}}}}\mathbb{1}{f^{}(x)\in{\mathcal{Y}}{\widetilde{e}}^{*}},\mathrm{where}X{\widetilde{\mathcal{E}}}=\bigcup_{\widetilde{e}\in\widetilde{\mathcal{E}}}X_{\widetilde{e}}.
$$
$$
\mathbf{Por}(f^{};\widetilde{\mathcal{E}})=\mathbb{E}{x\in X{\widetilde{\mathcal{E}}}}\mathbb{1}{f^{}(x)\in{\mathcal{Y}}{\widetilde{e}}^{*}},\mathrm{where}X{\widetilde{\mathcal{E}}}=\bigcup_{\widetilde{e}\in\widetilde{\mathcal{E}}}X_{\widetilde{e}}.
$$
4.5 Retain ability
4.5 保留能力
Retain ability characterizes the ability of KME techniques to preserve the desired properties of edited models after multiple consecutive edits [47, 69, 169]. In the presence of ever-evolving information, practitioners may need to frequently update a conversational model (i.e., sequential editing). Such a KME setting requires that the model does not forget previous edits after each new modification [81]. It is essential to distinguish retain ability from s cal ability, which evaluates the model’s ability to handle a vast number of edits [15]. In contrast, retain ability assesses the consistent performance of the model after each individual edit, presenting a more challenging objective to achieve. Recently, T-Patcher [66] first explores the sequential setting of KME and observes that many existing approaches significantly fall short in terms of retain ability. In SLAG [53], the authors also discover a significant drop in editing performance when multiple beliefs are updated continuously. To assess the retain ability of an edited language model $f^{*}$ , we define it as follows:
保留能力 (retain ability) 表征了KME技术在多次连续编辑后保持被编辑模型所需属性的能力 [47, 69, 169]。面对不断演进的信息,实践者可能需要频繁更新对话模型(即顺序编辑)。这种KME场景要求模型在每次新修改后不会遗忘先前的编辑 [81]。必须将保留能力与可扩展性 (scalability) 区分开来,后者评估的是模型处理大量编辑的能力 [15]。相比之下,保留能力评估的是模型在每次单独编辑后的一致性能,这是一个更具挑战性的目标。最近,T-Patcher [66] 首次探索了KME的顺序设置,并观察到许多现有方法在保留能力方面存在显著不足。在SLAG [53] 中,作者还发现当连续更新多个信念时,编辑性能会显著下降。为了评估被编辑语言模型 $f^{*}$ 的保留能力,我们定义如下:
$$
\mathbf{Ret}(M;{\mathcal{E}})={\frac{1}{|{\mathcal{E}}|-1}}\sum_{i=1}^{|{\mathcal{E}}|-1}\mathbf{Acc}(M(f;{e_{1},e_{2},\ldots,e_{i+1}}))-\mathbf{Acc}(M(f;{e_{1},e_{2},\ldots,e_{i}}))
$$
$$
\mathbf{Ret}(M;{\mathcal{E}})={\frac{1}{|{\mathcal{E}}|-1}}\sum_{i=1}^{|{\mathcal{E}}|-1}\mathbf{Acc}(M(f;{e_{1},e_{2},\ldots,e_{i+1}}))-\mathbf{Acc}(M(f;{e_{1},e_{2},\ldots,e_{i}}))
$$
where Acc is the accuracy measurement, $|\mathcal{E}|$ is the number of edits in the edit set, and $M$ denotes the editing strategy that modifies the pre-trained model $f$ into $f^{}$ with $i/i+1$ consecutive edits ${e_{1},e_{2},\ldots,e_{i},(e_{i+1})}$ . The retain ability metric aims to quantify the effect of applying consecutive edits to a model and measures how the performance will change the editing strategy $M$ , where a higher retain ability means that after each edit, the less the change in the overall performance of the edited model $f^{}$ is required.
其中 Acc 是准确率度量,$|\mathcal{E}|$ 是编辑集中的编辑数量,$M$ 表示通过连续 $i/i+1$ 次编辑 ${e_{1},e_{2},\ldots,e_{i},(e_{i+1})}$ 将预训练模型 $f$ 修改为 $f^{}$ 的编辑策略。保留能力指标旨在量化对模型应用连续编辑的效果,并衡量编辑策略 $M$ 如何改变性能,其中保留能力越高意味着每次编辑后,对编辑后模型 $f^{}$ 整体性能的改变要求越小。
4.6 S cal ability
4.6 可扩展性
The s cal ability of an editing strategy refers to its capability to incorporate a large number of edits simultaneously [15]. Recently, several works have emerged that can inject multiple new knowledge into specific parameters of pre-trained LLMs [168, 172]. For instance, SERAC [102] can perform a maximum of 75 edits. In addition, MEMIT [98] is proposed to enable thousands of edits without significant influence on editing accuracy. When there is a need to edit a model with a vast number of edits concurrently, simply employing the current knowledge-based model editing techniques in a sequential manner is proven ineffective in achieving such s cal ability [167]. To effectively evaluate the s cal ability of edited language models, we define the s cal ability of an edited model as follows:
编辑策略的可扩展性 (s cal ability) 指的是其同时整合大量编辑的能力 [15]。近期多项研究提出能在预训练大语言模型特定参数中注入多重新知识的方法 [168, 172]。例如 SERAC [102] 最多可执行 75 次编辑,而 MEMIT [98] 则能实现数千次编辑且对编辑准确率影响甚微。当需要同时对模型进行海量编辑时,已证明简单地顺序应用当前基于知识的模型编辑技术无法实现这种可扩展性 [167]。为有效评估编辑后语言模型的可扩展性,我们将其定义如下:
$$
\begin{array}{r}{\mathbf{Sca}(M;\mathcal{E})=\mathbb{E}_{e\in\mathcal{E}}\mathbf{Acc}(M(f;e))-\mathbf{Acc}(M(f;\mathcal{E})),}\end{array}
$$
$$
\begin{array}{r}{\mathbf{Sca}(M;\mathcal{E})=\mathbb{E}_{e\in\mathcal{E}}\mathbf{Acc}(M(f;e))-\mathbf{Acc}(M(f;\mathcal{E})),}\end{array}
$$
where $\mathbf{Acc}(M(f;\mathcal{E}))$ denotes the accuracy of the edited model after conducting all edits in $\varepsilon$ , whereas $\mathbf{Acc}(M(f;e))$ is the accuracy of only performing the edit 𝑒. Sca demonstrates the model performance and practicality in the presence of multiple edits. Nevertheless, we note that baseline value $\operatorname{Acc}(M(f;{e}))$ is also important in evaluating the s cal ability of various models. This is because, with higher accuracy for each $e$ , the retainment of such performance after multiple edits is more difficult. Therefore, we further define the relative version of Eq. (13) as follows:
其中 $\mathbf{Acc}(M(f;\mathcal{E}))$ 表示在 $\varepsilon$ 中执行所有编辑后修正模型的准确率,而 $\mathbf{Acc}(M(f;e))$ 是仅执行编辑 𝑒 的准确率。Sca 展示了模型在存在多次编辑时的性能和实用性。然而,我们注意到基线值 $\operatorname{Acc}(M(f;{e}))$ 在评估各种模型的可扩展能力时也很重要。这是因为,对于每个 $e$ 的准确率越高,在多次编辑后保持这种性能就越困难。因此,我们进一步将式 (13) 的相对版本定义如下:
$$
\begin{array}{r}{\mathtt{S c a}{r e l}(M;\mathcal{E})=\left(\mathbb{E}{e\in\mathcal{E}}\mathrm{Acc}(M(f;{e}))-\mathrm{Acc}(M(f;\mathcal{E}))\right)/\mathbb{E}_{e\in\mathcal{E}}\mathrm{Acc}(M(f;{e})).}\end{array}
$$
$$
\begin{array}{r}{\mathtt{S c a}{r e l}(M;\mathcal{E})=\left(\mathbb{E}{e\in\mathcal{E}}\mathrm{Acc}(M(f;{e}))-\mathrm{Acc}(M(f;\mathcal{E}))\right)/\mathbb{E}_{e\in\mathcal{E}}\mathrm{Acc}(M(f;{e})).}\end{array}
$$
The introduced s cal ability measurement further considers the magnitude of the original accuracy to provide a fairer evaluation.
引入的可扩展性测量进一步考虑了原始准确率的幅度,以提供更公平的评估。
5 METHODOLOGIES
5 方法论
In this section, we introduce existing knowledge-based model editing (KME) strategies in detail. We first provide an innovative taxonomy of existing KME strategies based on how and where the new knowledge is injected into the pre-trained LLMs, where the advantages and drawbacks are thoroughly discussed. We then introduce various methods from each category, with an emphasis on analyzing the technical details, insights, shortcomings, and their relationships.
在本节中,我们将详细介绍现有的基于知识的模型编辑(KME)策略。首先,我们根据新知识如何及何处注入预训练大语言模型,提出了一种创新的分类方法,并深入探讨了各类策略的优缺点。随后,我们将逐一介绍每个类别中的多种方法,重点分析其技术细节、核心思想、不足之处以及相互关联。
5.1 Categorization of KME Methods
5.1 KME方法分类
Faced with the rapid deprecation of old information and the emergence of new knowledge, various KME methodologies have been proposed to update the pre-trained LLMs to maintain their updatedness and relevancy. KME ensures that new knowledge can be efficiently incorporated into the pre-trained LLMs without negatively influencing the pre-trained knowledge irrelevant to the edit. In this survey, we categorize existing KME methods into three main classes as follows:
面对旧信息快速淘汰和新知识不断涌现的挑战,研究者们提出了多种知识模型编辑(KME)方法,用于更新预训练大语言模型以保持其时效性和相关性。KME能够确保新知识被高效整合到预训练大语言模型中,同时不影响与编辑无关的原有知识。本综述将现有KME方法归纳为以下三大类:
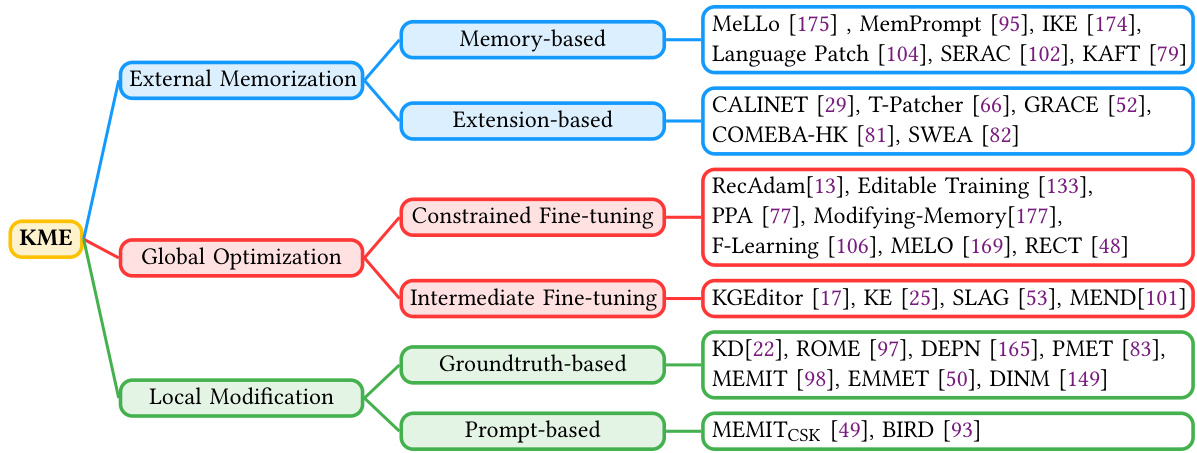
Fig. 3. The categorization of KME techniques for LLMs and the corresponding works.
图 3: 大语言模型的KME技术分类及对应研究成果
• External Memorization-based methods leverage an external memory to store the new knowledge for editing without modifying the pre-trained weights, where the pre-trained knowledge can be fully preserved in the LLM weights. By storing new knowledge with external parameters, the memory-based strategies enable precise representation of new knowledge with good s cal ability, as the memory is easily extensible to incorporate new knowledge. • Global Optimization-based methods seek to achieve general iz able incorporation of the new knowledge into pre-trained LLMs via optimization with the guidance of new knowledge, where tailored strategies are introduced to limit the influence of other pre-trained knowledge, distinguishing it from naive fine-tuning. Nevertheless, these methods may fall short in editing efficiency when applied to LLMs due to the large number of parameters to be optimized. • Local Modification-based methods aim to locate the related parameters of specific knowledge in LLMs and update it accordingly to incorporate the new knowledge relevant to the edit. The main advantage of local modification is the possibility of only updating a small fraction of model parameters, thereby providing considerable memory efficiency compared to memorization-based methods and computational efficiency compared to global optimization.
• 基于外部记忆 (External Memorization) 的方法利用外部存储来保存新知识,无需修改预训练权重,从而完整保留大语言模型权重中的预训练知识。通过外部参数存储新知识,这类策略能精准表征新知识并具备良好可扩展性,因为记忆模块可轻松扩展以纳入新知识。
• 基于全局优化 (Global Optimization) 的方法试图通过新知识指导下的优化,将新知识泛化地融入预训练大语言模型。其采用定制化策略限制其他预训练知识的影响,以此区别于原始微调。然而,由于需要优化大量参数,这些方法在应用于大语言模型时可能面临编辑效率不足的问题。
• 基于局部修改 (Local Modification) 的方法旨在定位大语言模型中特定知识的相关参数,并针对性更新以整合与编辑相关的新知识。该方法的主要优势是仅需更新极小部分模型参数,相比基于记忆的方法具有显著内存效率优势,相比全局优化则具备更高计算效率。
The above categorization is achieved based on where (e.g., external parameters or internal weights) and how (e.g., via optimization or direct incorporation) new knowledge is introduced into the LLM during editing. Methods in each category exhibit different strengths and weaknesses regarding the four crucial evaluation metrics introduced in Sec. 4. For example, external memorization prevails in scenarios that require massive editing while the computational resources are limited, as the size of the memory is controllable to fit into different requirements. On the other hand, global optimization is advantageous when practitioners focus more on the generality of edited knowledge, as the optimization can promote the learning of relevant knowledge [2]. The taxonomy is visually illustrated in Fig. 3, and a more detailed demonstration of each category is presented in Fig. 4.
上述分类是基于新知识在大语言模型编辑过程中被引入的位置(如外部参数或内部权重)和方式(如通过优化或直接整合)而实现的。各类方法在第4节介绍的四个关键评估指标上展现出不同的优缺点。例如,在需要大规模编辑但计算资源有限的场景中,外部记忆法占据优势,因为其记忆大小可根据需求灵活调整。另一方面,当从业者更关注编辑知识的泛化性时,全局优化法更具优势,因为优化过程能促进相关知识的学习 [2]。该分类体系在图3中进行了可视化展示,图4则对每个类别进行了更详细的说明。
5.2 External Memorization
5.2 外部记忆机制
5.2.1 Overview. The editing approaches via external memorization aim to modify the current model $f_{\phi}$ (with parameter $\phi$ ) via introducing external memory represented by additional trainable parameters $\omega$ that encodes the new knowledge, resulting in an edited LLM model $f_{\phi,\omega}^{*}$ . The rationale behind the external memorization strategy is that storing new knowledge in additional parameters is intuitive and straightforward to edit the pre-trained LLMs with good s cal ability, as the parameter size can be expanded to store more knowledge. In addition, the influence on the pre-trained knowledge can be minimized as this strategy does not alter the original parameters $\phi$ . Based on the general formulation of KME in Eq. (2), the objective of external memorization approaches can be formulated as follows:
5.2.1 概述
通过外部记忆的编辑方法旨在通过引入由额外可训练参数 $\omega$ 表示的外部记忆来修改当前模型 $f_{\phi}$ (参数为 $\phi$),这些参数编码了新知识,从而得到一个经过编辑的大语言模型 $f_{\phi,\omega}^{*}$。外部记忆策略的基本原理是,将新知识存储在额外参数中是直观且直接的方法,可以有效地编辑预训练的大语言模型,因为参数规模可以扩展以存储更多知识。此外,由于该策略不会改变原始参数 $\phi$,因此对预训练知识的影响可以最小化。基于公式(2)中KME的一般形式,外部记忆方法的目标可以表述如下:

Fig. 4. The illustration of three categories of KME methods: External Memorization, Global Optimization, and Local Modification.
图 4: 三类KME方法示意图:外部记忆(External Memorization)、全局优化(Global Optimization)和局部修改(Local Modification)。
$$
\begin{array}{r l}&{\operatorname*{min}\mathbb{E}{e\in\mathcal{E}}\mathbb{E}{x,y^{}\in\mathcal{X}{e},y{e}^{}}\mathcal{L}(f_{\phi,\omega}^{}(x),y^{})\mathrm{,where~}f_{\phi,\omega}^{}=M(f_{\phi},\omega;\mathcal{E})\mathrm{,}}\ &{\mathrm{s.t.}f_{\phi,\omega}^{}(x)=f_{\phi}(x)\mathrm{,~}\forall x\in\chi\backslash\chi_{\mathcal{E}}\mathrm{,}}\end{array}
$$
$$
\begin{array}{r l}&{\operatorname*{min}\mathbb{E}{e\in\mathcal{E}}\mathbb{E}{x,y^{}\in\mathcal{X}{e},y{e}^{}}\mathcal{L}(f_{\phi,\omega}^{}(x),y^{})\mathrm{,where~}f_{\phi,\omega}^{}=M(f_{\phi},\omega;\mathcal{E})\mathrm{,}}\ &{\mathrm{s.t.}f_{\phi,\omega}^{}(x)=f_{\phi}(x)\mathrm{,~}\forall x\in\chi\backslash\chi_{\mathcal{E}}\mathrm{,}}\end{array}
$$
where $f_{\phi}$ denotes the LLM before editing with the pre-trained parameter $\phi$ , and $f_{\phi,\omega}^{*}$ denotes the edited LLM with $\phi$ and additional parameter $\omega$ as the external memorization. Moreover, based on whether the introduced parameters are directly incorporated into the model process or not, external memorization strategies can be divided into two categories, i.e., memory-based methods and extension-based methods.
其中 $f_{\phi}$ 表示编辑前使用预训练参数 $\phi$ 的大语言模型,$f_{\phi,\omega}^{*}$ 表示通过 $\phi$ 和额外参数 $\omega$ 作为外部记忆进行编辑后的大语言模型。此外,根据引入参数是否直接融入模型处理流程,外部记忆策略可分为两类:基于记忆的方法和基于扩展的方法。
5.2.2 Memory-based Strategies. In memory-based strategies, the external memory, outside the intrinsic architecture of the pre-trained LLM, functions as a repository to store edited knowledge. Here the edits are generally converted to text via pre-defined templates [154, 174, 175]. The LLM can access and update this memory as required during inference.
5.2.2 基于记忆的策略。在基于记忆的策略中,外部存储器位于预训练大语言模型固有架构之外,充当存储编辑知识的仓库。这些编辑通常通过预定义模板转换为文本 [154, 174, 175]。大语言模型在推理过程中可根据需要访问和更新该存储器。
One exemplar work is SERAC [102], which stores the edited samples $x,y^{}\in\mathcal{X}{e},\mathcal{Y}{e}^{}$ in a cache without performing modifications on the original model. When presented with a new prompt $x^{\prime}$ , SERAC uses a scope classifier to determine whether the prompt falls within the scope of any cached instances. If yes, the desirable output $y^{\prime}$ associated with the new prompt $x^{\prime}$ is predicted via a counter factual model $f_{c}$ which utilizes the most relevant edit example as follows:
一个典型的工作是SERAC [102],它将编辑过的样本$x,y^{}\in\mathcal{X}{e},\mathcal{Y}{e}^{}$存储在缓存中,而不对原始模型进行修改。当遇到新的提示$x^{\prime}$时,SERAC使用一个范围分类器来判断该提示是否属于任何缓存实例的范围。如果是,则通过一个反事实模型$f_{c}$来预测与新提示$x^{\prime}$相关的期望输出$y^{\prime}$,该模型利用最相关的编辑样本如下:
$$
f_{\phi,\omega}^{*}(x)=\left{\begin{array}{l l}{f_{\phi}(x),}&{\mathrm{if}x\mathrm{is}\mathrm{notinscope}\mathrm{of}\mathrm{any}\mathrm{edit},}\ {f_{c}(x,\mathcal{E}),}&{\mathrm{otherwise}.}\end{array}\right.
$$
$$
f_{\phi,\omega}^{*}(x)=\left{\begin{array}{l l}{f_{\phi}(x),}&{\mathrm{if}x\mathrm{is}\mathrm{notinscope}\mathrm{of}\mathrm{any}\mathrm{edit},}\ {f_{c}(x,\mathcal{E}),}&{\mathrm{otherwise}.}\end{array}\right.
$$
SERAC is a gradient-free approach to KME without relying on gradients of the target label $y^{*}$ w.r.t. the pre-trained model parameters. In addition to using memory as an external repository, the desirable edits can also be stored in the form of human feedback. For example, Language Patch [104] performs editing by integrating patches in natural language, and MemPrompt [95] involves human feedback prompts to address the issue of lacking commonsense knowledge regarding a particular task. An integral feature of the Language Patch [104] framework is its ability to empower practitioners with the capability to create, edit, or remove patches without necessitating frequent model re-training. This trait not only streamlines the development process but also enhances the adaptability and versatility of the edited model. To enable the automatic correction in memory, MemPrompt [95] equips the language model with a memory bank containing corrective feedback to rectify misunderstandings. Specifically, MemPrompt leverages question-specific historical feedback to refine responses on novel and un encountered instances through prompt adjustments.
SERAC是一种无需梯度的KME方法,不依赖于目标标签$y^{*}$对预训练模型参数的梯度。除了将记忆用作外部存储库外,理想的编辑还可以以人类反馈的形式存储。例如,Language Patch [104]通过集成自然语言补丁进行编辑,而MemPrompt [95]则利用人类反馈提示来解决特定任务中常识知识缺乏的问题。Language Patch [104]框架的一个核心特性是使从业者能够在不频繁重新训练模型的情况下创建、编辑或删除补丁。这一特性不仅简化了开发流程,还增强了编辑后模型的适应性和多功能性。为实现记忆中的自动校正,MemPrompt [95]为语言模型配备了一个包含校正反馈的记忆库以纠正误解。具体而言,MemPrompt利用特定问题的历史反馈,通过调整提示来优化对未见过新实例的响应。
In KAFT [79], control l ability is achieved through the utilization of counter factual data augmentations. In this approach, the entity representing the answer within the context is substituted with an alternative but still plausible entity. This substitution is intentionally designed to introduce a conflict with the genuine ground truth, thereby enhancing the control l ability and robustness of LLMs with respect to their working memory. The aim is to ensure that LLMs remain responsive to pertinent contextual information while filtering out noisy or irrelevant data.
在KAFT [79]中,可控性通过利用反事实数据增强实现。该方法将上下文中的答案实体替换为另一个合理但不同的实体,这种替换刻意制造与真实基准答案的冲突,从而增强大语言模型在工作记忆方面的可控性和鲁棒性。其目标是确保大语言模型能持续响应相关上下文信息,同时过滤噪声或无关数据。
In addition to relying on parameter-based memory, recent works also leverage prompting techniques of LLMs, e.g., in-context learning [30] and chain-of-thought prompting [162], to promote editing performance of external memorization. Specifically, IKE [174] introduces novel factual information into a pre-trained LLM via in-context learning, where a set of $k$ demonstrations, i.e., $\omega={x_{i},y_{i}^{*}}_{i=1}^{k}$ , is selected as the reference points. These demonstrations will alter the prediction of a target factual detail when the input is influenced by an edit. Particularly, IKE guarantees a balance between generality and locality via storing factual knowledge as prompts. The process can be formulated as follows:
除了依赖基于参数的记忆外,近期研究还利用大语言模型的提示技术(如上下文学习 [30] 和思维链提示 [162])来提升外部记忆的编辑性能。具体而言,IKE [174] 通过上下文学习向预训练大语言模型引入新事实信息,其中选取一组 $k$ 个示例(即 $\omega={x_{i},y_{i}^{*}}_{i=1}^{k}$)作为参考点。当输入受到编辑影响时,这些示例会改变目标事实细节的预测。特别地,IKE 通过将事实知识存储为提示来保证通用性与局部性的平衡,该过程可表述为:
$$
\begin{array}{r}{f_{\phi,\omega}^{*}(x)=f_{\phi}(\omega|x)\mathrm{,~where}\omega={x_{i},y_{i}^{*}}_{i=1}^{k}.}\end{array}
$$
$$
\begin{array}{r}{f_{\phi,\omega}^{*}(x)=f_{\phi}(\omega|x)\mathrm{,~where}\omega={x_{i},y_{i}^{*}}_{i=1}^{k}.}\end{array}
$$
Here $\parallel$ denotes the concatenation of the reference points in $\omega$ and the input $x$ , which follows an in-context learning manner. Note that in this process, the framework first transforms all new facts into natural language to input them into LLMs. Similar methods of knowledge editing based on prompts [15, 131, 136, 154] can also update and modify knowledge within large language models (LLMs). These approaches allow users to guide the model to generate desired outputs by providing specific prompts, and effectively and dynamically adjusting the model’s knowledge base. By leveraging the flexibility of prompts and the contextual understanding of LLMs, users can correct or update information in real-time. These methods offer immediacy, flexibility, and cost-efficiency, making them powerful tools for maintaining the accuracy and relevance of language models in rapidly evolving knowledge domains. Although the prompt approaches effectively edit factual knowledge via in-context learning, they cannot solve more complex questions that involve multiple relations. To deal with this, MeLLo [175] first explores the evaluation of the editing effectiveness in language models regarding multi-hop knowledge. For example, when editing knowledge about the president of the USA, the query regarding the president’s children should change accordingly. MeLLo proposes to enable multi-hop editing by breaking down each query into sub questions, such that the model generates a provisional answer. Subsequently, each sub question is used to retrieve the most pertinent fact from the memory to assist the model in answering the query.
这里 $\parallel$ 表示 $\omega$ 中的参考点与输入 $x$ 的拼接,遵循上下文学习的方式。需要注意的是,在此过程中,该框架首先将所有新事实转换为自然语言输入到大语言模型 (LLM) 中。类似的基于提示的知识编辑方法 [15, 131, 136, 154] 也可以更新和修改大语言模型中的知识。这些方法允许用户通过提供特定提示来引导模型生成期望的输出,并有效且动态地调整模型的知识库。通过利用提示的灵活性和大语言模型的上下文理解能力,用户可以实时纠正或更新信息。这些方法具有即时性、灵活性和成本效益,是维护语言模型在快速发展的知识领域中准确性和相关性的强大工具。
尽管提示方法通过上下文学习有效地编辑了事实性知识,但它们无法解决涉及多重关系的更复杂问题。为此,MeLLo [175] 首次探索了语言模型在多跳知识方面的编辑效果评估。例如,当编辑关于美国总统的知识时,关于总统子女的查询也应相应改变。MeLLo 提出通过将每个查询分解为子问题来实现多跳编辑,使模型生成临时答案。随后,每个子问题用于从记忆中检索最相关的事实,以帮助模型回答查询。
5.2.3 Extension-based Strategies. Extension-based strategies utilize supplementary parameters to assimilate modified or additional information into the original language model. These supplementary parameters are designed to represent the newly introduced knowledge or necessary adjustments tailored for specific tasks or domains. Different from memory-based methods, by incorporating new parameters into the language model, extension-based approaches can effectively leverage and expand the model’s functionality.
5.2.3 基于扩展的策略。基于扩展的策略利用补充参数将修改或额外信息整合到原始语言模型中。这些补充参数旨在表示针对特定任务或领域新引入的知识或必要调整。与基于记忆的方法不同,通过向语言模型添加新参数,基于扩展的方法能有效利用并扩展模型功能。
Extension-based methods can be implemented through various means, and one representative way is to modify the Feed-forward Neural Network (FFN) output. For example, CALINET [29] uses the output from sub-models fine-tuned specifically on factual texts to refine the original FFN output produced by the base model. Another technique T-Patcher [66] introduces a limited number of trainable neurons, referred to as “patches,” in the final FFN layer to alter the model’s behavior while retaining all original parameters to avoid reducing the model’s overall performance. Generally, these methods that refine the structure of FFN can be formulated as follows:
基于扩展的方法可以通过多种方式实现,其中一种代表性方式是修改前馈神经网络(FFN)的输出。例如,CALINET [29] 使用专门针对事实文本微调的子模型输出来优化基础模型生成的原始FFN输出。另一种技术T-Patcher [66] 在最终FFN层中引入少量可训练神经元(称为"补丁"),在保留所有原始参数的同时改变模型行为,以避免降低模型的整体性能。通常,这些优化FFN结构的方法可以表述为:
$$
\mathrm{FFN}(\mathbf{h})=\mathrm{GELU}\left(\mathbf{h}\mathbf{W}{1}\right)\mathbf{W}{2}+\mathrm{GELU}\left(\mathbf{h}\cdot\mathbf{k}{p}+b{p}\right)\cdot\mathbf{v}_{p},
$$
$$
\mathrm{FFN}(\mathbf{h})=\mathrm{GELU}\left(\mathbf{h}\mathbf{W}{1}\right)\mathbf{W}{2}+\mathrm{GELU}\left(\mathbf{h}\cdot\mathbf{k}{p}+b{p}\right)\cdot\mathbf{v}_{p},
$$
where $\mathbf{k}{p}$ is the patch key, $\mathbf{v}{p}$ is the patch value, and $b_{p}$ is the patch bias scalar. The introduced patches are flexible in size and can be accurately activated to edit specific knowledge without affecting other model parameters.
其中 $\mathbf{k}{p}$ 是补丁键, $\mathbf{v}{p}$ 是补丁值, $b_{p}$ 是补丁偏置标量。引入的补丁大小灵活,可以精确激活以编辑特定知识,而不影响其他模型参数。
Alternatively, a different technique involves integrating an adapter into a specific layer of a pre-trained model. This adapter consists of a discrete dictionary comprising keys and values, where each key represents a cached activation generated by the preceding layer and each corresponding value decodes into the desired model output. This dictionary is systematically updated over time. In line with this concept, GRACE [52] introduces an adapter that enables judicious decisions regarding the utilization of the dictionary for a given input, accomplished via the implementation of a deferral mechanism. It is crucial to achieve a balance between the advantages of preserving the original model’s integrity and the practical considerations associated with storage space when implementing this approach. COMEBA-HK [81] incorporates hook layers within the neural network architecture. These layers allow for the sequential editing of the model by enabling updates to be applied in batches. This approach facilitates the integration of new knowledge without requiring extensive retraining of the entire model, making it a scalable solution for continuous learning and adaptation. SWEA [82] focuses on altering the embeddings of specific subject words within the model. By directly updating these embeddings, the method can inject new factual knowledge into the LLMs. This approach ensures that the updates are precise and relevant, thereby enhancing the model’s ability to reflect current information accurately.
另一种技术方案是在预训练模型的特定层中集成适配器。该适配器包含由键值对组成的离散字典,其中每个键代表前一层生成的缓存激活值,对应的值则解码为期望的模型输出。该字典会随时间推移进行系统性更新。基于这一理念,GRACE [52] 引入了一种带延迟机制的适配器,可智能判断何时使用字典处理给定输入。实施该方法时,需在保持原始模型完整性的优势与存储空间的实际限制之间取得平衡。COMEBA-HK [81] 在神经网络架构中嵌入了钩子层,通过批量更新实现模型的序列化编辑。这种方法无需全面重训练就能整合新知识,为持续学习和适应提供了可扩展的解决方案。SWEA [82] 则专注于修改模型中特定主题词的嵌入向量,通过直接更新这些嵌入来向大语言模型注入新事实知识,确保更新内容精确相关,从而提升模型准确反映最新信息的能力。
5.2.4 Summary. The eternal memorization methodology operates by preserving the parameters within the original model while modifying specific output results through external interventions via memory or additional model parameters. One notable advantage of this approach is its minimal perturbation of the original model, thereby ensuring the consistency of unedited knowledge. It allows for precise adjustments without necessitating a complete overhaul of the model’s architecture. However, it is imperative to acknowledge a trade-off inherent in this methodology. Its efficacy is contingent upon the storage and invocation of the edited knowledge, a factor that leads to concerns regarding storage capacity. Depending on the scale of knowledge to be edited, this approach may entail substantial storage requisites. Therefore, cautiously seeking a balance between the advantages of preserving the original model’s integrity and the practical considerations of storage capacity becomes a pivotal concern when employing this particular approach.
5.2.4 总结
永恒记忆方法通过保留原始模型中的参数,同时通过内存或额外模型参数的外部干预来修改特定输出结果。这种方法的一个显著优势是对原始模型的扰动极小,从而确保未编辑知识的一致性。它允许进行精确调整,而无需彻底改变模型架构。然而,必须承认这种方法存在固有的权衡。其效果取决于编辑知识的存储和调用,这一因素引发了存储容量的担忧。根据待编辑知识的规模,这种方法可能需要大量的存储需求。因此,在使用这种方法时,谨慎寻求保持原始模型完整性的优势与存储容量的实际考量之间的平衡成为关键问题。
5.3 Global Optimization
5.3 全局优化
5.3.1 Overview. Different from external memorization methods that introduce new parameters to assist the editing of pre-trained LLMs, there also exist branches of works that do not rely on external parameters or memory. Concretely, global optimization strategies aim to inject new knowledge into LLMs by updating all parameters, i.e., $\phi$ in Eq. (15). Through fine-tuning model parameters with specific designs to ensure the preservation of knowledge irrelevant to the target knowledge $t^{*}$ , the LLMs are endowed with the ability to absorb new information without altering unedited knowledge. Generally, the goal of global optimization methods can be formulated as follows:
5.3.1 概述
不同于通过引入新参数辅助预训练大语言模型编辑的外部记忆方法,还存在不依赖外部参数或记忆的研究分支。具体而言,全局优化策略旨在通过更新所有参数(即公式(15)中的$\phi$)将新知识注入大语言模型。通过采用特定设计的微调策略确保与目标知识$t^{*}$无关的知识得以保留,大语言模型被赋予在不改变未编辑知识的前提下吸收新信息的能力。全局优化方法的目标通常可表述为:
$$
\begin{array}{r l}&{\operatorname*{min}\mathbb{E}{e\in\mathcal{E}}\mathbb{E}{x,y^{}\in\mathcal{X}{e},y{e}^{}}\mathcal{L}(f_{\phi^{}}(x),y^{}),\mathrm{where}f_{\phi^{}}=M(f_{\phi};\mathcal{E}),}\ &{\mathrm{s.t.}f_{\phi^{}}(x)=f_{\phi}(x),\forall x\in\chi\backslash\chi_{\mathcal{E}},}\end{array}
$$
$$
\begin{array}{r l}&{\operatorname*{min}\mathbb{E}{e\in\mathcal{E}}\mathbb{E}{x,y^{}\in\mathcal{X}{e},y{e}^{}}\mathcal{L}(f_{\phi^{}}(x),y^{}),\mathrm{where}f_{\phi^{}}=M(f_{\phi};\mathcal{E}),}\ &{\mathrm{s.t.}f_{\phi^{}}(x)=f_{\phi}(x),\forall x\in\chi\backslash\chi_{\mathcal{E}},}\end{array}
$$
where $f_{\phi}$ denotes the LLM before editing with the pre-trained parameter $\phi$ , and $f_{\phi^{}}$ denotes the edited LLM with updated parameter $\phi^{}$ . Generally, these methods focus more on the precision and generality of desirable knowledge, as the fine-tuning process ensures that the LLMs achieve satisfactory results regarding the edits and relevant knowledge. Nevertheless, as fine-tuning affects all parameters, they cannot easily preserve the locality of edited models, i.e., maintaining consistent output for unedited knowledge [167]. In practice, directly applying fine-tuning strategies typically exhibits suboptimal performance on KME due to over fitting concerns [98, 152]. Furthermore, fine-tuning large language models is also time-consuming and lacks s cal ability for multiple edits. Therefore, recently, motivated by these two challenges in fine-tuning, several global optimization works have been proposed and can be categorized as constrained fine-tuning methods and intermediate fine-tuning methods. Note that this section primarily focuses on methods from the model training perspective. Additionally, certain studies [38, 69] address the over fitting challenge by constructing more a comprehensive $X_{\mathcal{E}}^{\prime}$ with the following fine-tuning goal:
其中 $f_{\phi}$ 表示编辑前使用预训练参数 $\phi$ 的大语言模型,$f_{\phi^{}}$ 表示参数更新为 $\phi^{}$ 后的已编辑大语言模型。这类方法通常更关注目标知识的精确性与泛化性,因为微调过程能确保大语言模型在编辑内容及相关知识上达到理想效果。然而由于微调会影响所有参数,这类方法难以保持编辑模型的局部性 (即对未编辑知识维持输出一致性) [167]。实际应用中,直接采用微调策略常因过拟合问题导致知识模型编辑 (KME) 表现欠佳 [98, 152]。此外,大语言模型的微调过程耗时且难以支持多次编辑的规模化扩展。针对微调面临的这两大挑战,近期提出的全局优化方法可分为约束微调法和中间微调法。需注意的是,本节主要从模型训练角度展开论述。另有研究 [38, 69] 通过构建更全面的 $X_{\mathcal{E}}^{\prime}$ 配合以下微调目标来应对过拟合问题:
5.3.2 Constrained Fine-tuning. Constrained fine-tuning strategies generally apply specific constraints to prevent updating on non-target knowledge in ${X\backslash X_{\varepsilon},{\mathfrak{y}}\backslash{\mathfrak{y}}_{\varepsilon}}$ . In this manner, the objective in Eq. (20) is transformed into a constrained optimization problem:
5.3.2 受限微调。受限微调策略通常施加特定约束,以防止对 ${X\backslash X_{\varepsilon},{\mathfrak{y}}\backslash{\mathfrak{y}}_{\varepsilon}}$ 中的非目标知识进行更新。通过这种方式,方程(20)中的目标被转化为一个约束优化问题:
$$
\begin{array}{r l}&{\begin{array}{r l}&{\quad_{1}\mathbb{E}{e\in\mathcal{E}}\mathbb{E}{x,y^{}\in\mathcal{X}{e},y{e}^{}}\mathcal{L}(f_{\phi^{}}(x),y^{}),\mathrm{where}f_{\phi^{}}=M(f_{\phi};\mathcal{E}),}\ &{\quad|\mathcal{L}(f_{\phi^{}}(x),y)-\mathcal{L}(f_{\phi}(x),y)|\le\delta,\forall x,y\in\chi\backslash\mathcal{X}{\mathcal{E}},y\backslash y{\mathcal{E}},}\end{array}}\end{array}
$$
$$
\begin{array}{r l}&{\begin{array}{r l}&{\quad_{1}\mathbb{E}{e\in\mathcal{E}}\mathbb{E}{x,y^{}\in\mathcal{X}{e},y{e}^{}}\mathcal{L}(f_{\phi^{}}(x),y^{}),\mathrm{where}f_{\phi^{}}=M(f_{\phi};\mathcal{E}),}\ &{\quad|\mathcal{L}(f_{\phi^{}}(x),y)-\mathcal{L}(f_{\phi}(x),y)|\le\delta,\forall x,y\in\chi\backslash\mathcal{X}{\mathcal{E}},y\backslash y{\mathcal{E}},}\end{array}}\end{array}
$$
where $\phi,\phi^{}$ are the parameters before and after updating, respectively. $\delta$ is a scalar hyper-parameter to restrict the difference between losses of $f_{\phi^{}}$ and $f_{\phi}$ . The constraint in Eq. (21) restricts the change of the edited model on unmodified knowledge. Zhu et al. [177] first propose an approximate optimization constraint that is easier for implementation and computation:
其中 $\phi,\phi^{}$ 分别表示更新前后的参数。$\delta$ 是一个标量超参数,用于限制 $f_{\phi^{}}$ 和 $f_{\phi}$ 的损失差异。公式 (21) 中的约束条件限制了编辑模型在未修改知识上的变化。Zhu等人[177]首次提出了一种更易于实现和计算的近似优化约束:
$\operatorname*{min}\mathbb{E}{e\in\mathcal{E}}\mathbb{E}{x,y^{\ast}\in\chi_{e},y_{e}^{\ast}}\mathcal{L}(f_{\phi^{\ast}}(x),y^{\ast})$ , where $f_{\phi^{*}}=M(f_{\phi};\mathcal{E})_{:}$ ,
$\operatorname*{min}\mathbb{E}{e\in\mathcal{E}}\mathbb{E}{x,y^{\ast}\in\chi_{e},y_{e}^{\ast}}\mathcal{L}(f_{\phi^{\ast}}(x),y^{\ast})$ ,其中 $f_{\phi^{*}}=M(f_{\phi};\mathcal{E})_{:}$ ,
The updates are regularized by restricting the norm of parameters before and after updating. RECT [48] adopts a similar yet simpler approach, specifically modifying only the top $\mathbf{\cdotk}%$ of parameters with the largest numerical updates during fine-tuning. Although restricting the norm is helpful in preventing the forgetting of original knowledge, the fine-tuning process can be less effective. To deal with this, RecAdam [13], in addition to the norm constraint, applies an annealing technique to control the ratio between the parameter norm and the fine-tuning loss as follows:
更新过程通过限制参数在更新前后的范数进行正则化。RECT [48] 采用了一种类似但更简单的方法,具体而言仅修改微调过程中数值更新幅度最大的前 $\mathbf{\cdotk}%$ 参数。虽然限制范数有助于防止原始知识遗忘,但微调效果可能减弱。为此,RecAdam [13] 除范数约束外,还采用退火技术控制参数范数与微调损失的比例,具体如下:
$$
\begin{array}{r}{\mathcal{L}{t o t a l}=\lambda(t)\mathcal{L}{F T}+(1-\lambda(t))\lVert\phi^{*}-\phi\rVert,\mathrm{where}\lambda(t)=\frac{1}{1+\exp(-k\cdot(t-t_{0}))}.}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{t o t a l}=\lambda(t)\mathcal{L}{F T}+(1-\lambda(t))\lVert\phi^{*}-\phi\rVert,\mathrm{where}\lambda(t)=\frac{1}{1+\exp(-k\cdot(t-t_{0}))}.}\end{array}
$$
Here $k$ and $t_{0}$ are hyper-parameters. $t$ is the number of fine-tuning steps. Such a design enables a gradual fine-tuning process that prevents massive parameter updates at the beginning. Motivated by the intuition of regular iz ation to preserve original knowledge, PPA [77] employs LoRA [62] in the feed-forward (FFN) layers of the transformer decoder. LoRA is proposed to train the expansion/reduction matrix, instead of the model parameter $\phi$ , to improve training speed by only updating parameters with a low intrinsic rank via dimensionality reduction. PPA leverages plug-in modules trained with constraints via LoRA to keep original knowledge intact. Moreover, the authors assess whether the content of the inputs falls within the scope of $\chi_{\varepsilon}$ using the K-adapter module [153], and redirect such inputs to the new plug-in modules. This information is then used to determine whether to employ LoRA within the FFN layers. Furthermore, MELO [169] clusters the edits and employs multiple non-overlapping LoRA blocks for fine-tuning each cluster separately, thereby mitigating the issue of catastrophic forgetting. F-Learning (Forgetting before Learning) [106] proposes another approach to preserve original knowledge, which learns knowledge parameters $\Delta\phi$ that indicates old knowledge to be forgotten, defined as follows:
这里 $k$ 和 $t_{0}$ 是超参数,$t$ 表示微调步数。这种设计实现了渐进式微调过程,避免初期出现大幅参数更新。基于正则化保留原始知识的直觉,PPA [77] 在Transformer解码器的前馈网络(FFN)层中采用了LoRA [62]技术。LoRA通过训练扩展/缩减矩阵(而非直接调整模型参数 $\phi$),借助降维仅更新低内在秩的参数来提升训练速度。PPA利用LoRA训练的带约束插件模块保持原始知识完整,并通过K-adapter模块 [153] 评估输入内容是否属于 $\chi_{\varepsilon}$ 范畴,将此类输入导向新增插件模块。该信息进一步决定是否在FFN层启用LoRA。此外,MELO [169] 对编辑操作进行聚类,采用多个非重叠LoRA块分别微调每个聚类,从而缓解灾难性遗忘问题。F-Learning(先遗忘后学习)[106] 提出另一种保留原始知识的方法,其学习参数 $\Delta\phi$ 来标识待遗忘的旧知识,定义如下:
$$
\phi^{*}=\phi-\lambda\Delta\phi,\mathrm{where}\Delta\phi=\mathrm{FT}(\phi;\mathcal{K}_{o l d})-\phi.
$$
$$
\phi^{*}=\phi-\lambda\Delta\phi,\mathrm{其中}\Delta\phi=\mathrm{FT}(\phi;\mathcal{K}_{o l d})-\phi.
$$
Here $\mathcal{K}{o l d}$ denotes the dataset composed of old knowledge that we desire to forget, and $\mathrm{FT}(\phi;\mathcal{K}{o l d})$ is the supervised fine-tuning process of parameters $\phi$ on dataset $\mathcal{K}_{o l d}$ . $\lambda$ is a hyper-parameter used to control the rate of forgetting. Based on the assumption that subtracting the parameters $\Delta\phi$ from $\phi$ can help the model forget this part of old knowledge [68], F-Learning defines the forgetting process as a subtraction operation to obtain the updated model parameter $\phi^{*}$ .
这里 $\mathcal{K}{o l d}$ 表示我们希望遗忘的旧知识组成的数据集,$\mathrm{FT}(\phi;\mathcal{K}{o l d})$ 是在数据集 $\mathcal{K}_{o l d}$ 上对参数 $\phi$ 进行监督微调的过程。$\lambda$ 是用于控制遗忘速率的超参数。基于从 $\phi$ 中减去参数 $\Delta\phi$ 可以帮助模型遗忘这部分旧知识的假设 [68],F-Learning 将遗忘过程定义为减法操作以获得更新后的模型参数 $\phi^{*}$。
On the other hand, other works also resort to meta-learning [36, 145] to apply more flexible constraints. Meta-learning addresses the issue of over fitting by training a model that can quickly adapt to new tasks [60]. By exposing the model to a variety of tasks during training, meta-learning improves the model’s ability to generalize from limited data and reduces the risk of over fitting individual tasks [67]. In the scenario of KME, the optimal model parameters $\phi^{*}$ should minimize the expected loss over a variety of meta-tasks [120]:
另一方面,也有研究采用元学习(meta-learning)[36, 145]来施加更灵活的约束。元学习通过训练能够快速适应新任务的模型来解决过拟合问题 [60]。在训练过程中让模型接触多种任务,元学习提升了模型从有限数据中泛化的能力,并降低了过拟合特定任务的风险 [67]。在知识图谱嵌入(KME)场景中,最优模型参数 $\phi^{*}$ 应当最小化各类元任务的期望损失 [120]:
$$
\phi^{*}=\underset{\phi}{\operatorname{argmin}}\mathbb{E}{D\sim\mathcal{D}}[\mathcal{L}{\phi}(D)],
$$
$$
\phi^{*}=\underset{\phi}{\operatorname{argmin}}\mathbb{E}{D\sim\mathcal{D}}[\mathcal{L}{\phi}(D)],
$$
where $\mathcal{D}$ corresponds to the sample set for each meta-task $D$ . Moreover, each meta task $D$ contains multiple $(x^{},y^{})$ pairs for editing. In practice, such methods often introduce additional objective functions or networks to regulate parameter updates. As a typical meta-learning method for KME, Editable Training [133] focuses on effectively rectifying errors within models while preserving their performance on other irrelevant data instances. Following a model-agnostic training manner, the authors introduce additional constraints to restrict parameter updates in a different way. Specifically, the loss function is separated into $\mathcal{L}{b a s e}$ (task-specific objective function), $\mathcal{L}{e d i t}$ (computed on the edit set $\chi_{\varepsilon}$ ), and $\mathcal{L}{l o c a l}$ (computed on samples in $\boldsymbol{\chi}\setminus\boldsymbol{X}{\mathcal{E}})$ . Moreover, the models are updated in a meta-learning manner, where $k$ steps of gradient descent would be applied for parameters before computing the objective function.
其中 $\mathcal{D}$ 对应于每个元任务 $D$ 的样本集。此外,每个元任务 $D$ 包含多个用于编辑的 $(x^{},y^{})$ 对。在实践中,这类方法通常会引入额外的目标函数或网络来调节参数更新。作为KME的典型元学习方法,可编辑训练 [133] 专注于有效纠正模型内部错误,同时保持其在其他无关数据实例上的性能。采用与模型无关的训练方式,作者通过额外约束以不同方式限制参数更新。具体而言,损失函数被分解为 $\mathcal{L}{base}$ (任务特定目标函数)、$\mathcal{L}{edit}$ (在编辑集 $\chi_{\varepsilon}$ 上计算) 和 $\mathcal{L}{local}$ (在样本集 $\boldsymbol{\chi}\setminus\boldsymbol{X}{\mathcal{E}}$ 上计算)。此外,模型以元学习方式更新,即在计算目标函数前对参数进行 $k$ 步梯度下降。
5.3.3 Intermediate Fine-tuning Strategies. While constrained fine-tuning techniques have demonstrated remarkable efficacy in a variety of NLP tasks [7, 164, 179], they still exhibit instability and high computational cost when applied to KME, primarily due to the necessity of altering all parameters [167]. A potential solution to address this challenge is to utilize an intermediate model to obtain the updated parameters in an efficient manner. Such an intermediate model is required to maintain significantly fewer parameters to ensure efficiency [17]. In general, recent works have widely adopted the Hyper-Network [51] as the intermediate model. Specifically, the Hyper-Network is a small network that generates the weights for a larger network, referred to as the main network. Specifically, the Hyper-Network takes inputs that contain information about the structure of the weights and generates the weights for layers in the main network. With the generated weights, the main network is updated to map input data to desired output targets. The updating process for the main network, denoted as $\phi$ , can be defined as follows:
5.3.3 中间微调策略。虽然约束微调技术已在多种NLP任务中展现出显著成效 [7, 164, 179],但在应用于KME时仍存在不稳定性和高计算成本的问题,这主要源于需要修改全部参数的特性 [167]。解决这一挑战的潜在方案是采用中间模型来高效获取更新后的参数。此类中间模型需保持远少于主模型的参数量以确保效率 [17]。近期研究普遍采用超网络 (Hyper-Network) [51] 作为中间模型,该小型网络专为生成主网络权重而设计。具体而言,超网络通过接收包含权重结构信息的输入,为主网络各层生成对应权重。主网络(参数记为$\phi$)利用生成的权重进行更新,从而实现输入数据到目标输出的映射,其更新过程可定义为:
where $\mathrm{H}(\cdot)$ denotes the hyper-network. $\Delta\phi$ is the weight deviation calculated by the hyper-network. According to a recent study [147], task-specific Hyper-Networks (i.e., networks that generate target model weights based on task attributes) are effective in mitigating catastrophic forgetting issues. Therefore, such methods are suitable for the setting of KME, which requires the preservation of unedited knowledge.
其中 $\mathrm{H}(\cdot)$ 表示超网络 (hyper-network)。$\Delta\phi$ 是由超网络计算出的权重偏差。根据最新研究 [147],任务特定超网络 (即基于任务属性生成目标模型权重的网络) 能有效缓解灾难性遗忘问题。因此,这类方法适用于需要保留未编辑知识的KME场景。
Recently, researchers have proposed to adopt hyper-networks in various ways for parameter updates in KME. As a classic example, KE [25] first proposes to edit knowledge and rectify erroneous or unexpected predictions without expensive fine-tuning. Specifically, it trains a hyper-network via constrained optimization to modify facts without affecting pre-trained knowledge irrelevant to the edit. The trained hyper network is then used to predict the weight update at the inference time.
最近,研究人员提出了多种采用超网络(hyper-network)进行知识图谱嵌入(KME)参数更新的方法。以经典工作KE [25]为例,该研究首次提出无需昂贵微调即可编辑知识并修正错误或意外预测。具体而言,该方法通过约束优化训练超网络来修改事实,同时避免影响与编辑无关的预训练知识。训练完成的超网络将在推理阶段用于预测权重更新。
Based on KE, SLAG [53] further appends metrics for two types of input texts: (1) Inputs that are not in the desired edit set $\chi_{\varepsilon}$ but logically related to E; (2) Inputs that share a formal resemblance to edited knowledge, but do not lead to changes in the prediction outcomes.
基于KE,SLAG [53]进一步补充了针对两类输入文本的评估指标:(1) 不属于目标编辑集$\chi_{\varepsilon}$但与E存在逻辑关联的输入;(2) 与编辑知识具有形式相似性但不会导致预测结果变化的输入。
However, hyper-networks are generally not capable of updating large language models due to the massive parameter size. To tackle this challenge, MEND [101] adopts a mechanism referred to as gradient decomposition. In particular, it leverages small auxiliary editing networks to transform the gradients obtained by standard fine-tuning into edits of weights in a pre-trained model. As gradients are generally high-dimensional objects, a low-rank decomposition of the gradients is utilized to achieve the transformation. Particularly, MEND parameter ize s the gradient mapping functions as MLPs with a single hidden layer, such that a significantly small number of parameters are required, compared with the edited models. In this manner, MEND enables fast model editing that can operate on considerably large pre-trained language models. Moreover, KGEditor [17] proposes to combine the benefits of memory-based methods and hyper-networks to ensure flexibility and further reduce computation costs. Particularly, KGEditor introduces an additional layer with the same architecture of FFN layers for storing knowledge. Then it constructs a hyper-network based on a bi-directional LSTM [58] that encodes embeddings of triples. In this manner, KGEditor becomes an efficient way to edit knowledge graph embeddings.
然而,由于参数量庞大,超网络通常无法直接更新大语言模型。为解决这一挑战,MEND [101] 采用了一种称为梯度分解的机制。具体而言,它利用小型辅助编辑网络将标准微调获得的梯度转换为预训练模型中的权重编辑。由于梯度通常是高维对象,该方法通过对梯度进行低秩分解来实现转换。特别地,MEND 将梯度映射函数参数化为单隐藏层的 MLP,相比被编辑模型,所需参数量显著减少。通过这种方式,MEND 实现了对超大规模预训练语言模型的快速编辑。此外,KGEditor [17] 提出结合基于内存的方法和超网络的优势,以确保灵活性并进一步降低计算成本。具体而言,KGEditor 引入了一个与 FFN 层结构相同的附加层用于存储知识,随后构建基于双向 LSTM [58] 的超网络来编码三元组嵌入。这使得 KGEditor 成为编辑知识图谱嵌入的高效方法。
5.3.4 Summary. Global optimization methods typically apply specific fine-tuning restrictions to regularize parameter updates, namely constrained fine-tuning strategies. This is to prevent over fitting and ensure the model’s performance on the unedited knowledge. One crucial advantage of such strategies is its generality regarding the relevant knowledge, i.e., in-scope inputs $X_{e}$ of edit 𝑒. As the global optimization affects all parameters in a language model, the relevant knowledge in it will also be edited, thereby generalizing to such knowledge. On the other hand, the high computation costs of fine-tuning all parameters also motivate researchers to propose intermediate fine-tuning strategies that leverage hyper-networks. Furthermore, global optimization methods are mostly model-agnostic, which means they can be applied to other editing methods. Nevertheless, such possibilities are less explored in the context of KME. In terms of the drawbacks, global optimization methods are suboptimal in maintaining the locality of edited models, as the optimization can easily influence unedited knowledge. Hence, it is crucial to achieve a balance between generality and locality when optimizing language models with specific constraints or intermediate designs.
5.3.4 总结
全局优化方法通常通过特定的微调限制来规范化参数更新,即约束性微调策略。这是为了防止过拟合并确保模型在未编辑知识上的性能。此类策略的一个关键优势在于其对相关知识的普适性,即编辑操作𝑒的范围内输入$X_{e}$。由于全局优化会影响大语言模型中的所有参数,其中的相关知识也会被编辑,从而泛化至此类知识。另一方面,微调全部参数的高计算成本也促使研究者提出利用超网络的中间微调策略。此外,全局优化方法大多与模型无关,这意味着它们可应用于其他编辑方法。然而,这种可能性在知识模型编辑(KME)领域尚未得到充分探索。就缺点而言,全局优化方法在保持编辑模型的局部性方面表现欠佳,因为优化过程容易影响未编辑知识。因此,在通过特定约束或中间设计优化大语言模型时,实现普适性与局部性的平衡至关重要。
5.4 Local Modification
5.4 局部修改
5.4.1 Overview. To tackle the challenge of fine-tuning methods with respect to locality, extensive research has been conducted on the local modification strategy for KME tasks [102, 167]. These techniques originate from the concept of identifying and modifying specific relevant weights in a pre-trained model to achieve desirable outputs. The primary objective is to first locate the weights $\phi_{k}$ that store the knowledge in a pre-trained model $f_{\phi}$ regarding the input $x$ . Afterward, by adjusting these weights, it becomes possible to generate the correct output $y^{*}$ from the same input $x$ without re-training or fine-tuning the whole model. Recently, researchers have generalized the local modification strategy to LLMs, where the efficiency of information updates for pre-trained LLMs can be substantially improved. Generally, the goal of the local modification strategy of KME can be formulated as a constrained optimization problem with refined constraints as follows:
5.4.1 概述
为解决微调方法在局部性方面的挑战,针对KME(知识模型编辑)任务的局部修改策略已开展广泛研究[102, 167]。这些技术源于识别并修改预训练模型中特定相关权重以获得理想输出的理念。其主要目标是首先定位预训练模型$f_{\phi}$中存储输入$x$相关知识的权重$\phi_{k}$,随后通过调整这些权重,无需重新训练或微调整个模型即可从相同输入$x$生成正确输出$y^{*}$。近期,研究者将局部修改策略推广至大语言模型,显著提升了预训练大语言模型的信息更新效率。通常,KME局部修改策略的目标可表述为带精细化约束的优化问题:
$$
\operatorname*{min}{\phi{k}^{\ast}}\mathbb{E}{e\in\mathcal{E}}\mathbb{E}{x,y^{\ast}\in\chi_{e},y_{e}^{\ast}}\mathcal{L}(f_{\bar{\phi}{k},\phi{k}^{\ast}}^{\ast}(x),y^{\ast}),
$$
$$
\operatorname*{min}{\phi{k}^{\ast}}\mathbb{E}{e\in\mathcal{E}}\mathbb{E}{x,y^{\ast}\in\chi_{e},y_{e}^{\ast}}\mathcal{L}(f_{\bar{\phi}{k},\phi{k}^{\ast}}^{\ast}(x),y^{\ast}),
$$
$$
f_{\bar{\phi}{k},\phi{k}^{}}^{}(x)=f(x),\forall x\in X\backslash X_{\mathcal{E}},
$$
$$
f_{\bar{\phi}{k},\phi{k}^{}}^{}(x)=f(x),\forall x\in X\backslash X_{\mathcal{E}},
$$
Here $\phi^{}$ denotes the edited weights related to the new knowledge, and $\bar{\phi}{k}$ denotes the unedited weights. Eq. (27) breaks down the local modification strategy for KME into two steps: (1) The locating step, denoted by function $L$ , locates the relevant weights $\phi{k}$ in pre-trained model $f_{\phi}$ that store the obsolete information regarding the query $x$ . (2) The editing step, denoted by function $M$ , edits the located weights $\phi_{k}$ into new weights $\phi_{k}^{}$ such that the correct answer $y^{}$ given the query $x$ can be generated by the model with $\phi_{k}^{}$ . By only updating a small fraction of model weights, the editing step avoids negatively influencing other irrelevant information, (i.e., $x\in X\backslash X_{\mathcal{E}})$ .
这里 $\phi^{}$ 表示与新知识相关的编辑后权重,$\bar{\phi}{k}$ 表示未编辑的权重。公式(27) 将KME的局部修改策略分解为两个步骤:(1) 定位步骤,由函数 $L$ 表示,在预训练模型 $f{\phi}$ 中定位存储与查询 $x$ 相关过时信息的权重 $\phi_{k}$。(2) 编辑步骤,由函数 $M$ 表示,将定位到的权重 $\phi_{k}$ 编辑为新权重 $\phi_{k}^{}$,使得模型使用 $\phi_{k}^{}$ 时能针对查询 $x$ 生成正确答案 $y^{}$。通过仅更新一小部分模型权重,编辑步骤避免了对其他无关信息(即 $x\in X\backslash X_{\mathcal{E}}$) 的负面影响。
In the following subsections, we first introduce the concept of knowledge neuron in LLMs, which are specific neurons that store factual knowledge and can be activated to generate the desirable answer based on a certain query $x$ . Then we discuss two local modification strategies for KME: (1) the ground truth-based strategies, which identify and edit knowledge neurons based on the supervision signal provided by the ground truth; (2) the prompt-based strategies, which locate knowledge neurons based on the input prompts.
在以下小节中,我们首先介绍大语言模型中的知识神经元 (knowledge neuron) 概念,这些特定神经元存储事实知识,并可根据给定查询 $x$ 激活以生成目标答案。接着讨论KME的两种局部修改策略:(1) 基于真实值的策略,利用真实值提供的监督信号定位并编辑知识神经元;(2) 基于提示的策略,通过输入提示定位知识神经元。
Knowledge Neurons. LLMs pre-trained on large corpora can be viewed as databases that store factual and common-sense knowledge in the pre-trained model weights [49]. To update such knowledge by locally modifying the weights in the pre-trained LLMs, it is imperative to identify which weights store such information, i.e., locating the knowledge neurons. This can be challenging due to the complex transformer architecture of LLMs [7].
知识神经元 (Knowledge Neurons)。在大规模语料库上预训练的大语言模型可视为将事实性知识和常识存储在预训练模型权重中的数据库 [49]。要通过局部修改预训练大语言模型权重来更新此类知识,必须确定哪些权重存储了此类信息(即定位知识神经元)。由于大语言模型复杂的 Transformer 架构,这一过程可能具有挑战性 [7]。
As described in Section 2.2.1, the transformer structure of LLMs consists of two primary types of layers, i.e., (1) the self-attention layer and (2) the point-wise feed-forward (FFN) layer, which is implemented as a two-layer multi-layer perceptron (MLP). Particularly, given a prompt $x$ , the self-attention layers of the LLMs use the query vector of the last token and the key vectors of the previous tokens to calculate a weighted sum of their value vectors. Therefore, given the input $x$ , these layers provide information about which previous tokens we should consider when generating the answer. Here we provide a simplified example for illustration. To answer the question “Who is the current president of the USA?”, the self-attention layer indicates that the model should attend to words “president” and ${}^{\leftarrow}U S A^{,}$ i.e., $\mathbf{v}{p r e s i d e n t},\mathbf{v}{U S A}$ , to determine the answer. This provides us with a start-up embedding $\mathbf{h}^{s t a r t}$ to generate the answer token, which is the weighted sum of the values of the two attended words, i.e., $w_{1}\mathbf{v}{\mathit{p r e s i d e n t}}+w{2}\mathbf{v}_{\mathit{U S A}}$ . However, the information regarding the current president of the USA is not provided. In contrast, recent works [42, 43, 97, 98] claim that the residual added to $\mathbf{h}^{s t a r t}$ by the outputs of FNN layers, i.e., $\mathbf{h}^{n e x t}=\mathbf{h}^{s t a r t}+\mathrm{FFN}(\mathbf{h}^{s t a r t})$ , injects the information “Biden” to $\mathbf{h}^{s t a r t}$ and leads to the generation of correct answers. Therefore, neurons in the FFN can be viewed as the knowledge neurons that store the factual knowledge. The role of FFN in storing knowledge can be theoretically analyzed by revisiting their formulation in Eq. (1), which we rewrite as follows:
如第2.2.1节所述,大语言模型的Transformer结构由两种主要层组成:(1) 自注意力层和 (2) 逐点前馈层 (FFN),后者实现为两层多层感知机 (MLP)。具体而言,给定提示$x$时,大语言模型的自注意力层使用最后一个token的查询向量与先前token的键向量来计算其值向量的加权和。因此,给定输入$x$时,这些层提供了生成答案时应考虑哪些先前token的信息。这里我们提供一个简化示例进行说明:为回答"Who is the current president of the USA?",自注意力层表明模型应关注单词"president"和${}^{\leftarrow}U S A^{,}$即$\mathbf{v}{p r e s i d e n t},\mathbf{v}{U S A}$,以确定答案。这为我们提供了生成答案token的初始嵌入$\mathbf{h}^{s t a r t}$,即两个关注单词值的加权和$w_{1}\mathbf{v}{\mathit{p r e s i d e n t}}+w{2}\mathbf{v}_{\mathit{U S A}}$。然而,该过程并未提供关于美国现任总统的信息。相比之下,近期研究[42,43,97,98]指出,FFN层输出对$\mathbf{h}^{s t a r t}$添加的残差(即$\mathbf{h}^{n e x t}=\mathbf{h}^{s t a r t}+\mathrm{FFN}(\mathbf{h}^{s t a r t})$)会将信息"Biden"注入$\mathbf{h}^{s t a r t}$,从而生成正确答案。因此,FFN中的神经元可视为存储事实知识的知识神经元。通过重写式(1)中的公式,可从理论上分析FFN在知识存储中的作用:
$$
\mathrm{SelfAtt}{i}(\mathbf{x})=\mathrm{Softmax}\left(\mathbf{q}{i}\mathbf{k}{i}^{\top}\right)\mathbf{v}{i},\quad\mathrm{FFN}(\mathbf{h})=\mathrm{GELU}\left(\mathbf{h}\mathbf{W}{1}\right)\mathbf{W}{2}.
$$
$$
\mathrm{SelfAtt}{i}(\mathbf{x})=\mathrm{Softmax}\left(\mathbf{q}{i}\mathbf{k}{i}^{\top}\right)\mathbf{v}{i},\quad\mathrm{FFN}(\mathbf{h})=\mathrm{GELU}\left(\mathbf{h}\mathbf{W}{1}\right)\mathbf{W}{2}.
$$
Specifically, comparing the above two equations, we observe that the input $\mathbf{h}$ to the FFN acts similarly to the query $\mathbf{q}$ to the SelfAtt. Moreover, the weights of the first layer ${\bf W}{1}$ can be viewed as the key $\mathbf{v}$ , where GELU $(\mathbf{h}\mathbf{W}{1})$ can be viewed as calculating an un normalized attention score over the row vectors of $\mathbf{W}{2}$ . Finally, the weights of the second layer $\mathbf{W}{2}$ can be viewed as the value (or the memory) that stores the knowledge, which can be retrieved according to the un normalized weights calculated by the first layer.
具体来说,对比上述两个方程,我们观察到前馈网络(FFN)的输入$\mathbf{h}$与自注意力(SelfAtt)的查询$\mathbf{q}$作用相似。此外,第一层权重${\bf W}{1}$可视为键$\mathbf{v}$,其中GELU $(\mathbf{h}\mathbf{W}{1})$可看作对$\mathbf{W}{2}$行向量计算未归一化的注意力分数。最后,第二层权重$\mathbf{W}{2}$可视为存储知识的数值(或记忆),可根据第一层计算的未归一化权重进行检索。
5.4.2 Ground truth-based Strategies. Based on the knowledge neuron view of the FFN layer weights in pre-trained LLMs, various ground truth-based methods are proposed to locate and edit the pre-trained LLMs. Generally, they perform editing in a top-down manner, utilizing the supervision signal provided by the correct ground truth $y^{}$ . As an exemplar work, KD [22] proposes to change each weight $w_{i}^{(l)}$ (i.e., the $i\cdot$ -th weight in the $l$ -th layer of FFN) from 0 to the pre-trained value $\hat{w}_{i}^{(l)}$ and calculates the cumulative change in the probability of predicting the output $y^{}$ with input $x$ , where the weights with a high cumulative probability are considered relevant for knowledge regarding $y^{}$ . DEPN [165] proposes a similar cumulative probability-based strategy to detect knowledge neurons that store privacy knowledge. In contrast to locating and editing an individual weight $w_{i}^{(l)}$ , ROME [97] proposes to update an entire FFN layer to encode the new knowledge of $y^{}$ . Specifically, they view the second layer weights $\mathbf{W}{2}$ in the FFN layer in Eq. (28) as a linear associative memory [3, 75] in the form of $\mathbf{KW}{2}=\mathbf{V}$ , where the keys K and values $\mathbf{V}$ associated with $\mathbf{W}{2}$ can be directly calculated via pseudo inverse. With such a view of $\mathbf{W}{2}$ in the FFN layer, the optimization objective of updating it into $\hat{\mathbf{W}}_{2}$ to encode new knowledge in the edit $e=\left(s,r,o\to o^{*}\right)$ can be formulated as follows:
5.4.2 基于真实值的策略。基于预训练大语言模型中FFN层权重的知识神经元视角,研究者提出了多种基于真实值的方法来定位和编辑预训练模型。这类方法通常采用自上而下的编辑方式,利用正确真实值$y^{}$提供的监督信号。代表性工作KD [22]提出将每个权重$w_{i}^{(l)}$(即FFN第$l$层第$i$个权重)从0调整为预训练值$\hat{w}_{i}^{(l)}$,并计算输入$x$时预测输出$y^{}$概率的累积变化,将具有高累积概率的权重视为与$y^{}$相关知识关联。DEPN [165]采用类似的基于累积概率的策略来检测存储隐私知识的神经元。与单独编辑权重$w_{i}^{(l)}$不同,ROME [97]提出更新整个FFN层来编码$y^{}$的新知识。具体而言,他们将公式(28)中FFN层的第二层权重$\mathbf{W}{2}$视为线性关联记忆[3,75],其形式为$\mathbf{KW}{2}=\mathbf{V}$,其中与$\mathbf{W}{2}$关联的键K和值$\mathbf{V}$可通过伪逆直接计算。基于这种视角,将$\mathbf{W}{2}$更新为$\hat{\mathbf{W}}_{2}$以编码编辑$e=\left(s,r,o\to o^{*}\right)$中新知识的优化目标可表述为:
$$
\operatorname*{min}|\mathbf{K}\hat{\mathbf{W}}_{2}-\mathbf{V}|\mathrm{s.t.}\hat{\mathbf{W}}\mathbf{k}^{}=\mathbf{h}^{}.
$$
$$
\operatorname*{min}|\mathbf{K}\hat{\mathbf{W}}_{2}-\mathbf{V}|\mathrm{s.t.}\hat{\mathbf{W}}\mathbf{k}^{}=\mathbf{h}^{}.
$$
Here $\mathbf{k}^{}$ , which should encode the information of the subject $s$ , is calculated by sampling multiple $x\sim\X_{e}$ and taking the average of the outputs from the first dense layer of the FFN. The target activation $\mathbf{h}^{}$ is calculated via optimizing the probability of outputting the correct answers $\boldsymbol{y}^{}\in\mathcal{Y}{e}$ of the pre-trained LLM via the subsequent layers. Then, an efficient rank-one update is conducted on the weights $\mathbf{W}{2}$ according to Eq. (29), such that after the update, the edited FFN layer can output the correct hidden representation $\mathbf{h}^{}$ conducive to the generation of the right answer $y^{}$ from $\mathbf{k}^{}$ . The ROME framework has been shown to generalize to the large Mamba model [130]. Recently, MEMIT [98] proposes to further generalize the above editing strategy of the FFN layers of pre-trained LLMs to the mass editing of different knowledge. Particularly, with $u$ new edits ${e_{1},e_{2},\ldots,e_{u}}$ that are required to be updated in the weights $\mathbf{W}_{2}$ , the mass knowledge editing problem can be formulated as the following optimization problem:
这里 $\mathbf{k}^{}$ 应编码主体 $s$ 的信息,其计算方式是通过对多个 $x\sim\X_{e}$ 进行采样,并取前馈神经网络(FFN)第一稠密层输出的平均值。目标激活 $\mathbf{h}^{}$ 则通过优化预训练大语言模型后续层输出正确答案 $\boldsymbol{y}^{}\in\mathcal{Y}{e}$ 的概率来计算。随后,根据式(29)对权重 $\mathbf{W}{2}$ 执行高效的秩一更新,使得更新后的FFN层能够从 $\mathbf{k}^{}$ 输出有利于生成正确答案 $y^{}$ 的隐藏表示 $\mathbf{h}^{}$ 。ROME框架已被证明可推广至大型Mamba模型[130]。近期,MEMIT[98]提出将上述预训练大语言模型FFN层的编辑策略进一步泛化,用于批量编辑不同知识。具体而言,对于需要更新到权重 $\mathbf{W}{2}$ 中的 $u$ 项新编辑 ${e{1},e_{2},\ldots,e_{u}}$ ,批量知识编辑问题可表述为以下优化问题:
$$
\operatorname*{min}\left(\sum_{i=1}^{n}\left|\mathbf{k}{i}\hat{\mathbf{W}}{2}-\mathbf{v}{i}\right|^{2}+\sum{i=n+1}^{n+u}\left|\mathbf{k}_{i}^{*}\hat{\mathbf{W}}_{2}-\mathbf{v}_{i}^{*}\right|^{2}\right),
$$
$$
\operatorname*{min}\left(\sum_{i=1}^{n}\left|\mathbf{k}{i}\hat{\mathbf{W}}{2}-\mathbf{v}{i}\right|^{2}+\sum{i=n+1}^{n+u}\left|\mathbf{k}_{i}^{*}\hat{\mathbf{W}}_{2}-\mathbf{v}_{i}^{*}\right|^{2}\right),
$$
where $\mathbf{k}{i},\mathbf{v}{i}$ are the original key, value pairs associated with the weights $\mathbf{W}{2}$ (i.e., row vectors in matrices K, $\mathbf{V}$ in Eq. (29)), whereas $\mathbf{k}{i}^{},\mathbf{v}_{i}^{}$ are the updated key, value pairs calculated from the $i$ -th edit $e_{i}$ as with Eq. (29). In addition, since multiple edits are required, the update is shared among different MLP layers, which is conducted in a top-down manner to prevent the potential issue of editing layers that could affect the ones that have already been edited. The residual for each edit is spread evenly over the range of the critical FFN layer. The strategy of residual attribution has recently been improved by PMET [83], which adopts a square root strategy to spread residuals to bottom FFN layers such that more precise information can be conveyed to critical layers. Furthermore, EMMET [50] generalized ROME and MEMIT by formulating the mass knowledge editing problem as a preservation (of irrelevant knowledge)-memorization (of new knowledge) constrained optimization problem, where they derive closed form weight update formulae when the edit is exact, i.e., $\mathbf{k}{i}^{*}\hat{\mathbf{W}}{2}=\mathbf{v}_{i}^{*}$ instead of minimizing the MSE in Eq. (30).
其中 $\mathbf{k}{i},\mathbf{v}{i}$ 是与权重 $\mathbf{W}{2}$ 关联的原始键值对 (即式 (29) 中矩阵 K、$\mathbf{V}$ 的行向量),而 $\mathbf{k}{i}^{},\mathbf{v}_{i}^{}$ 是根据第 $i$ 次编辑 $e_{i}$ 按式 (29) 计算得出的更新后键值对。此外,由于需要进行多次编辑,更新操作会在不同 MLP 层间共享,并采用自上而下的执行方式,以避免编辑某些层可能影响已编辑层的问题。每次编辑的残差会均匀分布在关键 FFN 层范围内。PMET [83] 近期改进了残差分配策略,采用平方根策略将残差分配至底层 FFN 层,从而能将更精确的信息传递至关键层。EMMET [50] 则通过将海量知识编辑问题表述为保持 (无关知识)-记忆 (新知识) 的约束优化问题,推广了 ROME 和 MEMIT 方法。当编辑为精确编辑时 (即 $\mathbf{k}{i}^{*}\hat{\mathbf{W}}{2}=\mathbf{v}_{i}^{*}$ 而非最小化式 (30) 中的均方误差),该方法能推导出闭式权重更新公式。
From the application’s perspective, to remove toxic knowledge of LLM, DINM [149] identifies layers that store toxic knowledge with the discrepancy of toxic/non-toxic sequence embeddings, and uses the non-toxic samples to locally modify the weights of identified layers.
从应用角度来看,为消除大语言模型(LLM)的有害知识,DINM [149]通过有毒/无毒序列嵌入的差异识别存储有害知识的层级,并利用无毒样本局部修正已识别层级的权重。
5.4.3 Prompt-based Strategies. Tailored to characteristics of LLMs that provide answer $y^{}$ based on the prompt $x$ , the operation of locating and editing knowledge neurons can also be conducted in a bottom-up manner, which aims to change the prompt to detect neurons to be edited. Specifically, by masking out the key information and observing the difference of activation s in the intermediate layers of the LLM, the weights that store the information regarding the query $x$ can be located and updated to store the new information $y^{}$ . For example, ROME [97] proposes a corruption-andrestore based strategy to identify relevant layers (or their hidden output variables $\mathbf{h}$ ) that store the information based on the prompt $x$ . It first randomly masks the hidden representations of the key vectors k (as described in Eq. (1)) of the tokens in the prompts from a certain intermediate layer of the pre-trained LLM. Then it calculates the reduced probability of predicting $y$ (i.e., the obsolete outputs) as the causal mediation effects of $x$ on $y$ mediated by h. Consequently, the weights in layers with large mediated effects are viewed as knowledge neurons that store the information of $y$ . $\mathbf{MEMIT_{CSK}}$ [49] extends the above corruption-based strategy to editing common sense knowledge. The authors argue that, different from the factual knowledge that can be directly retrieved by the subject 𝑠, the object 𝑜 and relation $r$ also matter for commonsense knowledge. Therefore, three types of corruption and edit locations, i.e., subject, verb, and object, are thoroughly analyzed, where the performance of editing commonsense knowledge can be improved. Moreover, BIRD [93] studies the novel problem of bidirectional KME, which requires the edited model to possess r ever sibi lit y. For example, if the phrase “The capital of France is” is edited to a counter factual “London” within a model, it should logically be able to retrieve the inverse fact. That is, when presented with “London is the capital of,” the model should respond with “France” rather than “England”. Based on the strategy of ROME, BIRD introduces a novel objective that involves the bidirectional relationships between subject and object in an edit. In this manner, the updated model weights can preserve r ever sibi lit y by learning such information.
5.4.3 基于提示的策略
针对大语言模型根据提示$x$生成答案$y^{}$的特性,定位和编辑知识神经元的操作也可以采用自底向上的方式,即通过修改提示来检测待编辑神经元。具体而言,通过掩蔽关键信息并观察大语言模型中间层激活值的变化,可以定位存储查询$x$相关信息的权重,并将其更新为存储新信息$y^{}$。例如,ROME [97]提出了一种基于破坏-恢复的策略来识别存储提示$x$信息的相关层(或其隐藏输出变量$\mathbf{h}$)。该方法首先从预训练大语言模型的某个中间层随机掩蔽提示中token的关键向量k(如公式(1)所述)的隐藏表示,然后计算预测$y$(即过时输出)概率的下降程度,作为$x$通过h对$y$产生的因果中介效应。因此,具有较大中介效应的层中权重被视为存储$y$信息的知识神经元。$\mathbf{MEMIT_{CSK}}$ [49]将上述基于破坏的策略扩展到常识知识编辑。作者指出,与可通过主语𝑠直接检索的事实知识不同,宾语𝑜和关系$r$对常识知识同样重要。因此,系统分析了主语、动词和宾语三类破坏与编辑位置,从而提升常识知识编辑的性能。此外,BIRD [93]研究了双向KME这一新问题,要求被编辑模型具备可逆性。例如,若将短语"法国的首都是"在模型中编辑为反事实"伦敦",则该模型应能逻辑地检索逆向事实——当输入"伦敦是...的首都"时,模型应返回"法国"而非"英格兰"。基于ROME的策略,BIRD引入了一个包含编辑中主宾语双向关系的新目标函数,通过习得此类信息使更新后的模型权重保持可逆性。
5.4.4 Summary. In this part, we introduce the local modification strategy for pre-trained LLMs for efficient updates of new information without adding new weights or optimizing the whole network. We start by analyzing the pivotal role of the point-wise feed forward layers, i.e., the FFNs, to store the factual information in pre-trained LLMs, with the knowledge neurons associated with the FFN layer thoroughly analyzed. We then discuss the ground truth-based strategies, which achieve the modification in a top-down manner, generally based on least squares objectives computed from the output $y$ . We further discuss the prompt-based strategies, which conduct modifications in a bottom-up manner based on the input prompt $x$ . Nevertheless, the s cal ability and retain ability of local modification methods lack further improvements, as the performance might deteriorate with more edits performed [98].
5.4.4 总结
在本部分中,我们介绍了针对预训练大语言模型的局部修改策略,旨在实现新信息的高效更新,而无需增加新权重或优化整个网络。我们首先分析了点级前馈层(即FFN)在预训练大语言模型中存储事实信息的关键作用,并对与FFN层相关的知识神经元进行了深入分析。接着,我们讨论了基于真实值的策略,这些策略通常基于输出$y$计算的最小二乘目标,以自上而下的方式实现修改。此外,我们还探讨了基于提示的策略,这些策略根据输入提示$x$以自下而上的方式进行修改。然而,局部修改方法的可扩展性和保留能力仍有待提升,因为随着编辑次数的增加,性能可能会下降[98]。
6 DATASETS
6 数据集
Recently, multiple datasets have been established to facilitate the evaluation of KME methods, and we summarize the commonly-used datasets in Table 2 to benefit future KME research. Specifically, these datasets can be divided into two groups: generation datasets (i.e., textual output) and classification datasets (i.e., categorical output). The datasets are obtained from a variety of sources, including knowledge graphs, Wikipedia pages, crowd-sourced responses, etc., which are adapted by researchers to fit into the KME setting.
最近,为促进知识记忆提取(KME)方法的评估,多个数据集相继建立。表2总结了常用数据集以助力未来KME研究。这些数据集可分为两类:生成数据集(即文本输出)和分类数据集(即类别输出)。数据来源包括知识图谱、维基百科页面、众包回答等,经研究者调整适配KME场景。
6.1 Generation Datasets
6.1 生成数据集
For generation datasets, the target is in the form of textual content that is required to be generated by LLMs. Serving as pivotal resources to evaluate KME methods, most generation datasets are based on relational knowledge and used for assessing the ability of editing techniques to inject new factual knowledge. This is because relational datasets preserve more definitive answers for each input and thus are more convenient and precise for evaluation [167, 172]. Specifically, these datasets are generally curated from the corresponding relational datasets to encompass diverse relational contexts, ranging from question-answer pairs to intricate multi-hop queries. Therefore, the most prevalent output format is an object to be predicted.
对于生成数据集,其目标形式是由大语言模型(LLM)生成的文本内容。作为评估知识模型编辑(KME)方法的关键资源,大多数生成数据集基于关系型知识,用于评估编辑技术注入新事实知识的能力。这是因为关系型数据集为每个输入保留了更明确的答案,因而更便于评估且精度更高[167, 172]。具体而言,这些数据集通常从相应的关系型数据集中筛选而来,涵盖从问答对到复杂多跳查询的多样化关系语境。因此,最常见的输出格式是待预测对象。
Table 2. Statistics of prevalent KME datasets, including generation and classification datasets.
| Dataset | Type | #Train | #Test | Input | Output | Used in |
| ZsRE | Relational | 244,173 | 244,173 | Factual Statement | Object | [25,38,48,50,52,66,69,77, 81,97,98,101,102,106,136, |
| CounterFact | Relational | N/A | 21,919 | Factual Question | Object | 151,156,169] [15,38,50,61,81,97,98,106, 130,136,156,168,174] |
| WikiGen | Generation | N/A | 68k | Wiki Passage | Continuation | [101] |
| T-REx-100/-1000 | Relational | N/A | 100/1,000 | Factual Statement | Object | [29, 79] |
| ParaRel | Relational | N/A | 253,448 | Factual Question | Object | [22] |
| NQ-SituatedQA | QA | N/A | 67.3k | User Query | Answer | [23, 77] |
| MQuAKE-CF/-T | Relational | N/A | 9,218/1,825 | Multi-hop Question | Object | [47, 69, 82, 131,155,175] |
| Hallucination | Hallucination | N/A | 1,392 | (Fake) Biography | Biography | [52,151,169] |
| MMEdit-E-VQA | Multimodal | 6,346 | 2,093 | Image & Question | Answer | [16] |
| MMEdit-E-IC | Multimodal | 2,849 | 1,000 | Image | Description | [16] |
| ECBD | Relational | N/A | 1000 | Reference to Entity | Completion | [108] |
| Conflict Edit | Relational | N/A | 7,500 | Factual Statement | Object | [86] |
| Round Edit | Relational | N/A | 5,000 | Factual Statement | Object | [86] |
| UKE | Relational | N/A | 2,478 | Factual Question | Object | [166] |
| RippleEdits | Relational | N/A | 5,000 | Factual Question | Object | [21, 69] |
| VLKEB | Multimodal | 5,000 | 3,174 | Image | Description | [65] |
| MLaKE | Multilingual | N/A | 9,432 | Question | Answer | [163] |
| FEVER | Fact Checking | 104,966 | 10,444 | Fact Description | Binary Label | [15,25,66,101] |
| ConvSent | Sentimental | 287,802 | 15,989 | Topic Opinion | Sentiment | [102] |
| Bias in Bio | Biographical | 5,000 | 5,000 | Biographical Sentence | Occupation | [57] |
| VitaminC-FC | Fact Checking | 370,653 | 55,197 | Fact Description | Binary Label | [102] |
| SCOTUS | Categorization | 7,400 | 931 | Court Documents | Dispute Topic | [52,169] |
表 2: 主流KME数据集的统计信息,包括生成类和分类类数据集。
| 数据集 | 类型 | 训练集数量 | 测试集数量 | 输入 | 输出 | 使用文献 |
|---|---|---|---|---|---|---|
| ZsRE | 关系型 | 244,173 | 244,173 | 事实陈述 | 对象 | [25,38,48,50,52,66,69,77,81,97,98,101,102,106,136,151,156,169] |
| CounterFact | 关系型 | N/A | 21,919 | 事实性问题 | 对象 | [15,38,50,61,81,97,98,106,130,136,156,168,174] |
| WikiGen | 生成类 | N/A | 68k | 维基段落 | 续写内容 | [101] |
| T-REx-100/-1000 | 关系型 | N/A | 100/1,000 | 事实陈述 | 对象 | [29,79] |
| ParaRel | 关系型 | N/A | 253,448 | 事实性问题 | 对象 | [22] |
| NQ-SituatedQA | 问答类 | N/A | 67.3k | 用户查询 | 答案 | [23,77] |
| MQuAKE-CF/-T | 关系型 | N/A | 9,218/1,825 | 多跳问题 | 对象 | [47,69,82,131,155,175] |
| Hallucination | 幻觉检测 | N/A | 1,392 | (虚假)传记 | 传记 | [52,151,169] |
| MMEdit-E-VQA | 多模态 | 6,346 | 2,093 | 图像&问题 | 答案 | [16] |
| MMEdit-E-IC | 多模态 | 2,849 | 1,000 | 图像 | 描述 | [16] |
| ECBD | 关系型 | N/A | 1000 | 实体指代 | 补全 | [108] |
| Conflict Edit | 关系型 | N/A | 7,500 | 事实陈述 | 对象 | [86] |
| Round Edit | 关系型 | N/A | 5,000 | 事实陈述 | 对象 | [86] |
| UKE | 关系型 | N/A | 2,478 | 事实性问题 | 对象 | [166] |
| RippleEdits | 关系型 | N/A | 5,000 | 事实性问题 | 对象 | [21,69] |
| VLKEB | 多模态 | 5,000 | 3,174 | 图像 | 描述 | [65] |
| MLaKE | 多语言 | N/A | 9,432 | 问题 | 答案 | [163] |
| FEVER | 事实核查 | 104,966 | 10,444 | 事实描述 | 二元标签 | [15,25,66,101] |
| ConvSent | 情感分析 | 287,802 | 15,989 | 主题观点 | 情感倾向 | [102] |
| Bias in Bio | 传记分析 | 5,000 | 5,000 | 传记句子 | 职业 | [57] |
| VitaminC-FC | 事实核查 | 370,653 | 55,197 | 事实描述 | 二元标签 | [102] |
| SCOTUS | 分类类 | 7,400 | 931 | 法庭文件 | 争议主题 | [52,169] |
In this subsection, we present the most representative generation datasets, shedding light on their unique attributes, the nature of their content, and the specific challenges they present for evaluating KME methods on factual knowledge as follows:
在本小节中,我们将介绍最具代表性的生成数据集,重点阐述其独特属性、内容性质,以及它们对评估事实知识KME方法提出的具体挑战如下:
• zsRE [78]: zsRE is one of the most prevalent Question Answering (QA) datasets extended and adopted by [25, 101] for KME evaluation. zsRE is suitable for evaluating KME due to its annotations of human-generated question paraphrases, which allow researchers to assess the model resilience to semantically equivalent inputs. In zsRE, each relation is associated with a set of crowd-sourced template questions, such as “What is Albert Einstein’s alma mater?”. Each entry cites a Wikipedia sentence, serving as the factual basis or provenance. The dataset also contains negative examples that are generated by pairing a valid question with a random sentence. • Counter Fact [97]: Counter Fact is established to distinguish superficial alterations in the word selections and significant, generalized modifications in its foundational factual knowledge. Proposed in ROME [97], each entry in Counter Fact originates from a related record in ParaRel [32], containing a knowledge triple and meticulously crafted prompt templates. It is important to note that all subjects, relations, and objects in this tuple are recognized entities in Wikidata [148]. • WikiGen [101]: Firstly proposed in MEND [101], WikiGen consists of approximately 68k question-answer pairs, with a similar size to zsRE. Here, each question corresponds to a sentence randomly sampled from Wikitext-103, and each answer is a 10-token sample obtained from a pre-trained distilGPT-2 model [94]. It is noteworthy that greedy 10-token prediction of the base model only aligns with edit targets for less than $1%$ of samples. • T-REx-100 & T-REx-1000 [33]: First used in CALINET [29], the authors adopt the classic relational dataset T-REx [33] for evaluating model editors by extracting factual triplets of varying sizes (100 and 1,000). Particularly, for each triplet, the authors insert the head and tail entities into the template in LAMA [115] based on the relation they share, which results in two datasets with 100 and 1,000 facts, respectively, for the purpose of false knowledge detection. It should be noted that each fact in these datasets is represented by several paraphrased sentences.
• zsRE [78]: zsRE是最流行的问答(QA)数据集之一,被[25, 101]扩展并采用于知识模型编辑(KME)评估。zsRE因其标注了人工生成的问题改写而适合评估KME,使研究者能测试模型对语义等效输入的鲁棒性。在zsRE中,每个关系都关联一组众包模板问题,例如"爱因斯坦的母校是什么?"。每个条目引用一个维基百科句子作为事实依据或出处。该数据集还包含通过将有效问题与随机句子配对生成的负样本。
• Counter Fact [97]: Counter Fact旨在区分词语选择的表层改动与基础事实知识的实质性通用修改。该数据集由ROME [97]提出,其中每个条目源自ParaRel [32]的相关记录,包含一个知识三元组和精心设计的提示模板。需注意该元组中的所有主语、关系和宾语都是Wikidata [148]中的已知实体。
• WikiGen [101]: 该数据集由MEND [101]首次提出,包含约6.8万个问答对,规模与zsRE相当。每个问题对应从Wikitext-103随机采样的句子,每个答案是从预训练distilGPT-2模型[94]获取的10个token样本。值得注意的是,基础模型的贪婪10-token预测仅与不到$1%$样本的编辑目标相符。
• T-REx-100 & T-REx-1000 [33]: 首次应用于CALINET [29]时,作者采用经典关系数据集T-REx [33]来评估模型编辑器,通过提取不同规模(100和1,000)的事实三元组。特别地,对于每个三元组,作者根据共享关系将头尾实体插入LAMA [115]模板,最终生成分别包含100和1,000个事实的两个数据集用于错误知识检测。需注意这些数据集中每个事实都由多个改写句子表示。
• ParaRel [32]: ParaRel is an expert-curated dataset that comprises diverse prompt templates for 38 relations, sourced from the T-REx dataset [33]. Firstly used in KN [22], the authors insert the head entity into each relational fact and set the tail entity as a blank for prediction. To ensure a rich variety in templates, relations with less than four prompt templates are excluded, resulting in 34 relations in total. Each of these relations, on average, preserves 8.63 distinct prompt templates, leading to a total of 253,448 knowledge-revealing prompts for 27,738 relational facts.
- ParaRel [32]: ParaRel是一个专家精选的数据集,包含针对38种关系的多样化提示模板,源自T-REx数据集[33]。该数据集首次应用于KN[22]时,作者将头实体插入每个关系事实中,并将尾实体留空作为预测目标。为确保模板多样性,少于四个提示模板的关系被剔除,最终保留34种关系。每种关系平均保留8.63个独特提示模板,共计为27,738个关系事实生成253,448个知识揭示提示。
• NQ-SituatedQA [76]: NQ (Natural Questions) is a comprehensive question-answering dataset originating from user searches. In PPA [77], the authors utilize NQ as the source knowledge while excluding any outdated information as identified by SituatedQA [171] to create a novel dataset NQ-SituatedQA. SituatedQA is a dataset containing questions within a subset of NQ that are dependent on specific time and location. The authors then incorporate the time-dependent QA pairs from this subset, annotated using the 2021 Wikipedia [148] dump.
• NQ-SituatedQA [76]: NQ (Natural Questions) 是一个源自用户搜索的综合性问答数据集。在PPA [77]中,作者利用NQ作为知识源,同时排除SituatedQA [171]识别的所有过时信息,创建了一个新数据集NQ-SituatedQA。SituatedQA是NQ的一个子集,包含依赖于特定时间和地点的问题。作者随后整合了该子集中时间相关的问答对,并使用2021年维基百科 [148] 数据转储进行标注。
• MQuAKE [175]: MQuAKE is constructed from Wikidata [148] for evaluating the effectiveness of KME methods on multi-hop questions. In particular, it is designed to assess whether the edited models can correctly answer questions generated by chains of facts in plain text. MQuAKE consists of two datasets. (1) MQuAKE-CF is a diagnostic dataset, specifically crafted to evaluate KME methods in the context of counter factual edits. (2) MQuAKE-T focuses on temporal-based knowledge updates and is aimed at assessing the effectiveness of KME techniques in updating outdated information with contemporary factual data.
• MQuAKE [175]: MQuAKE基于Wikidata [148]构建,用于评估KME方法在多跳问题上的有效性。该数据集专门设计用于检验经过编辑的模型是否能正确回答由纯文本事实链生成的问题。MQuAKE包含两个子集:(1) MQuAKE-CF是诊断性数据集,专门用于评估反事实编辑场景下的KME方法;(2) MQuAKE-T聚焦基于时间的知识更新,旨在评估KME技术用最新事实数据更新过时信息的有效性。
• Hallucination [52]: Firstly processed in GRACE [52], Hallucination is created from the dataset released in Self Check GP T [96], where the authors prompt GPT-3 to generate biographies based on concepts extracted from WikiBio. The sentences are annotated regarding the factual accuracy, and hallucinations in them are identified. Then in GRACE, the authors process this dataset by further extracting Wikipedia summaries from WikiBio and thereby acquire the correct entry of each sentence. In this manner, every edit consists of a potentially false biography generated by GPT-3 as the prompt, and a ground truth output, which is the correct next sentence extracted from Wikipedia. There exist 1,392 potential edits for test.
• 幻觉 (Hallucination) [52]: 该数据首先在GRACE [52]中被处理,源自Self Check GPT [96]发布的数据集。作者通过提示GPT-3基于WikiBio提取的概念生成传记,并对句子进行事实准确性标注,识别其中的幻觉内容。随后在GRACE中,作者通过进一步从WikiBio提取维基百科摘要处理该数据集,从而获得每个句子的正确条目。通过这种方式,每个编辑项包含由GPT-3生成的潜在虚假传记作为提示,以及从维基百科提取的正确下一句作为真实输出。测试集共包含1,392个潜在编辑项。
• MMEdit [16]: This dataset is the first to explore the possibility of editing multimodal LLMs. Specifically, MMEdit consists of two prevalent multimodal tasks: Visual Question Answering (VQA) [4] and Image Captioning [56]. VQA involves developing algorithms that can analyze an image’s visual content, comprehend questions asked in natural language about the image, and accurately respond to those questions. Image Captioning aims to understand an image and then generate a detailed and coherent natural language description of that image. To create dataset MMEdit, the authors utilize BLIP-2 OPT [80] and extract edit data from the evaluation datasets VQAv2 [46] and COCO Caption [14], specifically focusing on their suboptimal entries.
• MMEdit [16]: 该数据集首次探索了编辑多模态大语言模型的可能性。具体而言,MMEdit包含两种主流多模态任务:视觉问答 (VQA) [4] 和图像描述生成 (Image Captioning) [56]。VQA需要开发能分析图像视觉内容、理解针对该图像的自然语言问题并准确回答的算法。图像描述生成旨在理解图像后,生成对该图像详细连贯的自然语言描述。为构建MMEdit数据集,作者采用BLIP-2 OPT [80],从评估数据集VQAv2 [46] 和COCO Caption [14] 中提取编辑数据,特别关注其欠优化的条目。
• ECBD [108]: Based on the original dataset ECBD (Entity Cloze By Date) [107], the authors process this dataset for a novel task, namely Entity Knowledge Propagation (EKP). The task aimed at updating model parameters to incorporate knowledge about newly emerged entities that are not present in the pre-training data of the language models. For instance, BERT [27], trained in 2018, does not recognize “COVID $\cdot19^{\mathfrak{N}}$ as it is a more recent entity. The processed dataset aims to provide evaluation for such a task with the help of definition sentences as input to update knowledge about new entities. The entities are taken from the date between 2020/01 and 2021/09 to ensure that they are not in training data. Each edit consists of a new entity, a description sentence, a probe sentence, and a ground truth completion.
• ECBD [108]: 基于原始数据集ECBD (Entity Cloze By Date) [107],作者对该数据集进行了处理,以支持一项新任务——实体知识传播 (Entity Knowledge Propagation, EKP)。该任务旨在更新模型参数,以融入语言模型预训练数据中未包含的新出现实体的知识。例如,2018年训练的BERT [27]无法识别"COVID·19",因为这是一个较新的实体。处理后的数据集旨在通过输入定义句来更新新实体的知识,从而为此类任务提供评估。实体选自2020年1月至2021年9月之间的日期,以确保它们不在训练数据中。每次编辑包含一个新实体、一个描述句、一个探测句和一个真实补全。
• VLKEB [65]: VLKEB (Large Vision-Language Model Knowledge Editing Benchmark) aims to address the unique challenges of editing large vision-language models, which face additional difficulties due to different data modalities and complex model components with limited data for LVLM editing. VLKEB collects data from the multi-modal knowledge graph MMKG [90] and extends the Portability metric for evaluation. With MMKG, VLKEB binds image data with knowledge entities, which can be used to extract entity-related knowledge for editing data.
• VLKEB [65]: VLKEB (大视觉语言模型知识编辑基准) 致力于解决大视觉语言模型编辑的特殊挑战,这些模型由于数据模态差异和复杂组件结构,且缺乏针对LVLM编辑的专用数据而面临额外困难。VLKEB从多模态知识图谱MMKG [90] 采集数据,并扩展了Portability评估指标。通过MMKG,VLKEB将图像数据与知识实体绑定,可用于提取实体关联知识以构建编辑数据集。
• MLaKE [163]: MLaKE (Multilingual Language Knowledge Editing) is proposed to evaluate the capability of KME methods in multilingual contexts and multi-hop reasoning across five languages: English, Chinese, Japanese, French, and German. MLaKE aggregates fact chains from Wikipedia in multiple languages and utilizes LLMs to generate questions in both free-form and multiple-choice formats. Notably, existing methods show relatively high generalization for languages within the same language family compared to those from different families. These findings underscore the need for advancements in multilingual knowledge editing. • UKE [166]: UKE (Unstructured Knowledge Editing) is proposed to evaluate the capability of KME methods in updating knowledge based on unstructured texts. Updating LLMs with texts appears to be a more realistic application, which is also more complex and difficult. The authors leverage subjects and objects in Wikidata [148] and retrieve the corresponding Wikipedia article summaries as unstructured texts. The authors also utilize LLMs to generate summaries for edits in two existing datasets, Co un fer Fact [97] and MQuAKE-CF [175], to obtain unstructured texts. • Ripple Edits [21]: This dataset proposes a novel evaluation criterion, which assesses the performance of KME methods on additional edits brought by an existing edit. In particular, injecting new knowledge (e.g., “Jack Depp is the son of Johnny Depp”) introduces a “ripple effect,” which necessitates the model to update related knowledge as well (e.g., “Jack Depp is the sibling of Lily-Rose Depp”). Based on this, the authors construct Ripple Edits, consisting of 5,000 edits with various types of ripple effects. • Conflict/Round Edit [86]: This dataset pioneers in investigating the potential side effects of KME methods for LLMs. The proposed dataset and evaluation metrics underline two primary concerns: (1) Knowledge Conflict: Modifying sets of logically conflicting facts can amplify the existing inconsistencies within LLMs. (2) Knowledge Distortion: Altering model parameters to update factual knowledge can permanently disrupt the inherent knowledge framework of LLMs. The dataset is constructed from WikiData [148] with specific logical rules.
• MLaKE [163]: MLaKE (多语言语言知识编辑) 旨在评估知识编辑方法在五种语言(英语、中文、日语、法语和德语)的多语言语境及多跳推理中的表现。该方法聚合了维基百科中多语言的事实链,并利用大语言模型生成自由形式和多项选择格式的问题。值得注意的是,现有方法对同一语系内语言的泛化能力明显优于不同语系语言。这些发现凸显了多语言知识编辑技术亟需突破。
• UKE [166]: UKE (非结构化知识编辑) 用于评估基于非结构化文本更新知识的能力。用文本更新大语言模型更具现实应用价值,同时也更为复杂困难。作者利用Wikidata [148]中的主客体关系,检索对应的维基百科文章摘要作为非结构化文本,并借助大语言模型为Co un fer Fact [97]和MQuAKE-CF [175]两个现有数据集生成编辑摘要以获取非结构化文本。
• Ripple Edits [21]: 该数据集提出创新评估标准,关注知识编辑方法对既有编辑引发的连带更新的处理能力。具体而言,注入新知识(如"Jack Depp是Johnny Depp的儿子")会产生"连锁效应",要求模型同步更新关联知识(如"Jack Depp是Lily-Rose Depp的兄弟")。基于此,作者构建了包含5,000个具有各类连锁效应编辑的Ripple Edits数据集。
• Conflict/Round Edit [86]: 该数据集开创性地研究了大语言模型知识编辑的潜在副作用,其提出的数据集和评估指标强调两大核心问题:(1) 知识冲突:修改逻辑矛盾的事实集合会加剧模型内部不一致性;(2) 知识扭曲:通过改变模型参数更新事实知识会永久破坏大语言模型固有知识框架。数据集基于WikiData [148]按特定逻辑规则构建。
6.2 Classification Datasets
6.2 分类数据集
Classification datasets are also widely adopted to evaluate the effectiveness of KME. These datasets consist of prompt-target pairs, where the target is a discrete label instead of a textual sentence. In the context of KME, these labels help ascertain the alignment of model performance with desired edits. The advantages of classification datasets also involve their preciseness in evaluation without the need to define the specific output space. In this section, we summarize notable classification datasets that have been tailored and leveraged for assessing KME techniques as follows:
分类数据集也被广泛用于评估知识模型编辑(KME)的有效性。这些数据集由提示-目标对组成,其中目标是离散标签而非文本句子。在KME背景下,这些标签有助于确定模型性能与预期编辑的一致性。分类数据集的优势还包括其评估的精确性,无需定义具体的输出空间。本节我们将总结为评估KME技术而定制和利用的典型分类数据集如下:
• FEVER [143]: FEVER is a fact-checking dataset originally processed in KILT [114] for verifying factual knowledge in the form of binary classification. It necessitates the retrieval of sentencelevel evidence to determine whether a claim is supported or refuted, and is widely used for evaluating the performance of KME. Specifically, FEVER excludes claims labeled as lacking sufficient information, as they typically do not provide any evidence to evaluate the claim. • ConvSent [102]: Firstly processed in SERAC [102], ConvSent is used to evaluate the capability of an editor to modify a dialog agent’s sentiment about a particular topic without influencing its responses to other topics. ConvSent is obtained from a list of 15,000 non-numeric entities from zsRE [25, 78], combined with 989 noun phrases from GPT-3 [10] for 15,989 topics. Particularly, for each entity, there are ten positive and ten negative sentiment completions, which can be noisy, from the BlenderBot model with 3B parameters [124]. The refined sentiment labels are achieved by a sentiment classifier [55] pre-trained on RoBERTa [91].
• FEVER [143]: FEVER 是一个事实核查数据集,最初在 KILT [114] 中处理,用于以二元分类形式验证事实知识。它需要检索句子级别的证据来判断某个主张是被支持还是被反驳,并广泛用于评估 KME 的性能。具体而言,FEVER 排除了标记为信息不足的主张,因为这些主张通常不提供任何证据来评估主张。
• ConvSent [102]: ConvSent 最初在 SERAC [102] 中处理,用于评估编辑器在不影响其对其他主题的响应的情况下,修改对话代理对特定主题的情感的能力。ConvSent 是从 zsRE [25, 78] 的 15,000 个非数字实体列表以及 GPT-3 [10] 的 989 个名词短语中获取的,共涵盖 15,989 个主题。特别是,对于每个实体,来自 3B 参数的 BlenderBot 模型 [124] 有十个正面和十个负面的情感补全,这些补全可能带有噪声。精细化的情感标签是通过在 RoBERTa [91] 上预训练的情感分类器 [55] 实现的。
Table 3. Examples of different downstream applications of KME: Question Answering (QA), Fact Checking (FC), and Natural Language Generation (NLG).
| Task | EditDescriptore | In-scopeInputx~X | OriginalOutputy~e | Target Output y ~ |
| QA | (Kazakhstan,Captital, Astana-→Nur-Sultan) | What is the capital of Kazakhstan? | Astana | Nur-Sultan |
| FC | (Marathon,Record Kipchoge—→Kiptum) | Kipchogeholdsthemen's marathonworldrecord. | True | False |
| NLG | (JordanPoole,PlayIn, Warriors-Wizards) | Provideashortintroduction toJordanPoole,describing his currentposition. | JordanPooleentered theWarriors'rotation recently. | In2023,JordanPooletransitioned fromtheWarriorstotheWizards remarking a significant change. |
表 3: KME在不同下游任务中的应用示例:问答(QA)、事实核查(FC)和自然语言生成(NLG)。
| 任务 | 编辑描述符 | 范围内输入x~X | 原始输出y~e | 目标输出y~ |
|---|---|---|---|---|
| QA | (Kazakhstan, Capital, Astana→Nur-Sultan) | 哈萨克斯坦的首都是哪里? | Astana | Nur-Sultan |
| FC | (Marathon, Record, Kipchoge→Kiptum) | Kipchoge保持着男子马拉松世界纪录。 | 正确 | 错误 |
| NLG | (Jordan Poole, PlayIn, Warriors→Wizards) | 请简要介绍Jordan Poole,描述他目前的职位。 | Jordan Poole最近进入了勇士队的轮换阵容。 | 2023年,Jordan Poole从勇士队转会至奇才队,标志着一个重大转变。 |
• Bias in Bios [24]: Bias in Bios is a dataset originally proposed for fairness-related machine learning, containing approximately $397\mathrm{k}$ short professional biographies of online individuals, which are not relatively famous. Each biographical sentence is assigned an associated occupation label for the described person. To adopt this dataset for evaluating the performance of KME methods, the authors of REMEDI [57] extract a single sentence, modify it to display only the person’s first name, and then query the language model with the prompt that follows the structure: “Person has the occupation of...”. Then they evaluate the relative probabilities of the language model assigned to 28 potential occupations, where the language model is considered to be correct if the ground-truth occupation is ranked top-1.
• Bias in Bios [24]: Bias in Bios 是一个最初为公平性相关机器学习提出的数据集,包含约 $397\mathrm{k}$ 条网络非知名人士的简短职业传记。每条传记句子都被标注了描述对象对应的职业标签。为将该数据集用于评估 KME 方法性能,REMEDI [57] 的作者提取单句并修改为仅显示人物姓氏,随后使用结构化提示"Person has the occupation of..."查询语言模型。他们评估语言模型对28种潜在职业分配的相对概率,若真实职业排名首位即判定模型预测正确。
• VitaminC-FC [127]: Firstly processed in SERAC [102], VitaminC-FC is constructed based on a fact-checking dataset, VitaminC [127]. Particularly, VitaminC consists of more than 400,000 evidence-claim pairs, each of which is assigned a binary label to indicate whether the evidence entails the claim. The dataset was gathered from over 100,000 Wikipedia revisions that modify an underlying fact, along with additional synthetic ones. In SERAC, the authors convert VitaminC into a KME dataset by using the evidence as the edit descriptor and using claims from the same Wiki pages accordingly as in-scope samples.
• VitaminC-FC [127]: 该数据集首先在SERAC [102]中被处理,基于事实核查数据集VitaminC [127]构建。具体而言,VitaminC包含超过40万条证据-主张对,每对都标注了二元标签以指示证据是否支持主张。数据集采集自10万多个修改基础事实的维基百科修订版本,并辅以人工合成的数据。在SERAC中,作者将证据作为编辑描述符,并采用同一维基页面的主张作为范围内样本,从而将VitaminC转化为KME数据集。
• SCOTUS [52]: Firstly proposed in GRACE [52], SCOTUS is processed with label shift based on the dataset with the same name from Fairlex [11]. This classification task is to categorize U.S. Supreme Court documents from various decades into one of 11 topics. The topics are clustered based on the specific matter of dispute, such as Criminal Procedure, Civil Rights, and First Amendment. Due to the evolution of categorization rules over time, the label distributions in this dataset also shift. Specifically, 7.4k cases from 1946-1982 are used for training, and 931 cases from the 1991-2009 period are for test.
• SCOTUS [52]: 该任务最初在GRACE [52]中提出,基于Fairlex [11]的同名数据集进行标签偏移处理。该分类任务旨在将数十年来美国最高法院的文档归类到11个主题之一,这些主题根据争议的具体事项进行聚类,例如刑事诉讼、民权和第一修正案等。由于分类规则随时间演变,该数据集中的标签分布也随之偏移。具体而言,训练集使用1946-1982年间的7.4k个案例,测试集则采用1991-2009年间的931个案例。
7 APPLICATIONS
7 应用
KME can benefit multiple downstream applications with the ability to precisely and efficiently inject knowledge into pre-trained LLMs. In the following, we introduce several key applications of KME techniques in realistic scenarios, where intuitive examples are provided in Table 3.
KME能够精准高效地向预训练大语言模型注入知识,从而赋能多种下游应用。下文将介绍KME技术在现实场景中的几个关键应用,表3提供了直观的示例说明。
7.1 Question Answering
7.1 问答系统
Background. Question Answering (QA) is a core NLP task that aims to comprehend queries posed by users in natural language and provide answers based on the encoded knowledge in the pre-trained language model [132]. Traditional models for QA are generally fixed in their knowledge, capturing only the information available at the training time of [70, 115]. However, in our dynamic world, new information is generated incessantly, which necessitates the constant update of QA models [139]. Fortunately, KME methods enable the modification of QA models to cater to specific questions without disrupting responses to other unrelated inputs. Therefore, with KME strategies, the QA model can be efficiently updated on the run, where the current ness of the model can be guaranteed. Consequently, language model editing techniques have found broad applications across a myriad of QA contexts with potentially distinct requirements [77].
背景。问答 (Question Answering, QA) 是自然语言处理 (NLP) 的核心任务,旨在理解用户以自然语言提出的查询,并基于预训练语言模型中编码的知识提供答案 [132]。传统的问答模型通常知识固定,仅能捕捉训练时 [70, 115] 可获得的信息。然而,在动态变化的世界中,新信息不断产生,这要求问答模型必须持续更新 [139]。幸运的是,知识模型编辑 (Knowledge Model Editing, KME) 方法能够在不影响其他无关输入响应的情况下,修改问答模型以适配特定问题。因此,通过 KME 策略,问答模型可以高效地实时更新,从而确保模型的最新性。正因如此,语言模型编辑技术已在需求可能迥异的各种问答场景中得到广泛应用 [77]。
Existing Works. The QA task encompasses various aspects, such as conversational QA, definitionbased QA, and notably, relation-based QA [110]. Relation-based QA is primarily adopted as an evaluation benchmark as it necessitates the retrieval of precise real-world facts in response to queries. This particular emphasis on specific information retrieval renders relation-based QA especially conducive to the benefits of KME techniques. For example, PPA [77] introduces an innovative task of $\mathbf{CuQA}$ (Continuously-updated QA), which intentionally emphasizes recurrent, substantial edits for language models to constantly update them with new information. An important aspect of the CuQA task is to ensure that the existing pre-trained knowledge remains unaltered with the integration of new knowledge. Therefore, this property is one important evaluation to assess model editing in CuQA tasks. In MQuAKE [175], the authors innovative ly propose a multi-hop QA task that involves answering questions generated by chains of facts in plain text. Specifically, the task requires edited models to infer implicit relations that can be several hops away from the objects in the edit. For example, when a language model is modified regarding the president of the USA, an ideal model should also authentically alter answers to “Who is the son of the president of the USA”, which is a two-hop relation. Such a task is significantly more challenging as it necessitates the model to alter its reasoning results in addition to the original edit. Nevertheless, the proposed method MeLLo in MQuAKE still exhibits outstanding performance on this difficult task, demonstrating the potential of KME in generalizing edited knowledge to multi-hop relations.
现有工作。问答任务涵盖多个方面,如对话式问答、基于定义的问答,尤其是基于关系的问答[110]。基于关系的问答主要被采用为评估基准,因为它需要检索精确的现实世界事实以响应查询。这种对特定信息检索的特别关注,使得基于关系的问答尤其受益于KME技术。例如,PPA[77]引入了$\mathbf{CuQA}$(持续更新的问答)这一创新任务,其有意强调对语言模型进行反复、实质性的编辑,以不断更新新信息。CuQA任务的一个重要方面是确保现有预训练知识在整合新知识时保持不变。因此,这一特性是评估CuQA任务中模型编辑的重要指标之一。在MQuAKE[175]中,作者创新性地提出了一个多跳问答任务,涉及回答由纯文本事实链生成的问题。具体而言,该任务要求编辑后的模型推断可能与编辑对象相隔多跳的隐含关系。例如,当对语言模型关于美国总统的信息进行修改时,理想的模型还应真实地改变对"美国总统的儿子是谁"这类两跳关系问题的回答。此类任务更具挑战性,因为除了原始编辑外,模型还需改变其推理结果。尽管如此,MQuAKE中提出的MeLLo方法在这一困难任务上仍表现出色,展示了KME在将编辑知识推广到多跳关系方面的潜力。
7.2 Fact Checking
7.2 事实核查
Background. Fact-checking (FC) is a pivotal task in journalism, information verification, and combating misinformation that aims to scrutinize and affirm the authenticity of claims, statements, or information in news articles, social media, and other media content [37, 127]. In a world overwhelmed with ever-emerging information, fact-checking facilitates the trustworthiness in the sharing of distributed information, promotes information transparency, and aids individuals in making well-informed decisions [143]. However, it is crucial to constantly update fact-checking models. For instance, during the COVID-19 pandemic, initial understandings and guidelines about the virus evolved as researchers gathered more data [129]. A fact-checking model that cannot adapt to these rapidly changing facts would quickly become outdated and potentially spread misinformation, thereby requiring the application of language model editing. By integrating KME techniques into fact-checking models to consistently update them with the latest information and facts, it becomes possible to ensure the current ness, trustworthiness, and accuracy of the model despite the persistent evolution of information.
背景。事实核查 (FC) 是新闻业、信息验证和打击错误信息中的关键任务,旨在审查和确认新闻文章、社交媒体和其他媒体内容中声明、陈述或信息的真实性 [37, 127]。在信息不断涌现的世界中,事实核查有助于提高分布式信息共享的可信度,促进信息透明度,并帮助个人做出明智的决策 [143]。然而,持续更新事实核查模型至关重要。例如,在 COVID-19 大流行期间,随着研究人员收集更多数据,关于病毒的初步理解和指南不断演变 [129]。无法适应这些快速变化的事实核查模型会迅速过时,并可能传播错误信息,因此需要应用语言模型编辑技术。通过将 KME 技术集成到事实核查模型中,持续用最新信息和事实更新模型,可以确保模型在信息持续演变的情况下保持时效性、可信度和准确性。
Existing Works. Recently, several works have proposed to apply KME techniques in fact-checking models. In [177], the authors first explore the potential of modifying specific factual knowledge within the transformer backbone of the fact-checking model while ensuring that overall model performance remains intact on facts irrelevant to the editing purpose. Particularly, they identify the critical components within the transformer backbones conducive to effective knowledge modifications. In SERAC [102], the authors propose to use evidence gathered from Wikipedia as edit descriptors to update potentially outdated knowledge in the model. The proposed method exhibits significant performance improvements over baselines and can be generalized to other in-scope inputs collected from the same Wikipedia page.
现有工作。近期有多项研究提出将知识模型编辑 (KME) 技术应用于事实核查模型。文献[177]首次探索了在保持模型整体性能不变的前提下,修改事实核查模型Transformer架构中特定事实知识的可行性。该研究特别识别了Transformer架构中有利于知识修改的关键组件。SERAC[102]提出利用维基百科收集的证据作为编辑描述符,更新模型中可能过时的知识。该方法相比基线模型表现出显著性能提升,并能泛化到从同一维基百科页面收集的其他范围内输入。
7.3 Natural Language Generation
7.3 自然语言生成
Background. KME techniques are also promising to ensure the relevancy of the Natural Language Generation (NLG) task, which aims to generate coherent and con textually relevant content based on provided instructions [122]. Considering the rapid evolution of the global information landscape, it is essential for NLG models to remain up-to-date and ensure the accuracy of generated text while avoiding potentially false statements that may mislead the users.
背景。知识记忆增强 (KME) 技术也有望确保自然语言生成 (NLG) 任务的相关性,该任务旨在根据提供的指令生成连贯且上下文相关的内容 [122]。考虑到全球信息格局的快速演变,NLG 模型必须保持最新状态,确保生成文本的准确性,同时避免可能误导用户的潜在错误陈述。
Existing Works. In practice, several works have been proposed to apply KME methods to promote model performance in natural language generation tasks. For instance, FRUIT [5] proposes to update outdated Wikipedia articles according to the collection of new information about the article’s subject. Based on the T5 model [119], the authors utilize a compressed output format to eliminate the necessity of generating the entire update from scratch and promote thoughtful content structuring, which effectively handles the challenge of incoherence. In MEND [101], the authors apply their proposed method in the Wikitext generation task, where the edited model is required to produce credible 10-token extensions based on a provided Wikitext prefix [94]. With modification on multi-layer token-wise activation s and gradients, the edited model presents higher coherence on the NLG task, which demonstrates the effectiveness of KME in generating target texts with richer information than QA or FC.
现有工作。实践中已有若干研究提出应用知识记忆增强 (KME) 方法来提升自然语言生成任务的模型性能。例如,FRUIT [5] 提出根据文章主题的新信息集合来更新过时的维基百科文章。基于 T5 模型 [119],作者采用压缩输出格式来避免从头生成整个更新内容,并促进有逻辑的内容结构,有效解决了内容不连贯的挑战。在 MEND [101] 中,作者将所提方法应用于 Wikitext 生成任务,要求编辑后的模型基于给定的 Wikitext 前缀 [94] 生成可信的 10-token 扩展。通过对多层 token 级激活和梯度的修改,编辑后的模型在自然语言生成任务中表现出更高的连贯性,这证明了 KME 在生成比问答 (QA) 或事实核对 (FC) 更具信息量的目标文本方面的有效性。
8 DISCUSSION
8 讨论
8.1 Challenges
8.1 挑战
Despite the continual progress of works on KME, several critical aspects have been inadequately addressed by existing studies. Delving deeper into these challenges could offer researchers fresh insights and pave the way for the further advancement of the field. Consequently, we hereby outline the pressing challenges that await solutions in KME.
尽管知识图谱嵌入 (KME) 研究持续进展,现有工作仍存在若干关键问题未能充分解决。深入探究这些挑战可为研究者提供新视角,并推动该领域的进一步发展。因此,我们在此梳理了KME领域亟待解决的紧迫挑战。
Trade-off between Locality and Generality. In KME, it is crucial to balance two objectives, locality and generality (as defined in Sec. 4), such that a higher edit success rate can be achieved with minimal negative influence on knowledge irrelevant to the edits. When editing a language model, a potential trade-off might emerge between these two desirable properties. As demonstrated in [167], local modification methods, such as MEMIT [98] and ROME [97] generally preserve a higher level of locality, as they locate precise locations of target knowledge to conduct the edition, which does not largely affect the unrelated weights. In addition, T-Patcher [66] points out that increasing the size of memory increases locality while decreasing the generality. These observations underscore the intricate balance between locality and generality. However, it remains challenging to tackle the trade-off problem and achieve a balance between these two desirable properties of KME methods. Theoretical Analysis. While many current KME studies focus on developing effective methods to enhance the editing performance regarding various desirable properties, there exists a notable gap between the practical application and the comparatively less discovered theoretical analysis. Recently, in [140], the authors provide theoretical support for the justification of identifying harmful training examples and editing the model by erasing the information from a Bayesian view. LEACE [9] introduces an analytical framework that offers a theoretical perspective for the task of erasing target concept information from every layer in language models. In general, the benefits of incorporating theoretical analysis are multi-faceted. First, theoretical analysis provides a deeper understanding of the mechanics underlying KME, allowing for more principled approaches to editing. Second, a strong theoretical basis sets a solid foundation for future research, encouraging more rigorous and systematic exploration in the field of KME. However, to the best of our knowledge, there still does not exist any comprehensive theoretical analysis regarding the KME problem that involves novel knowledge. We hope that future research will enrich the theoretical discourse that can deliver profound insights into the substantial foundations of KME methods.
局部性与通用性的权衡。在KME中,平衡局部性和通用性(定义见第4节)这两个目标至关重要,这样才能以对编辑无关知识的最小负面影响实现更高的编辑成功率。在编辑语言模型时,这两个理想特性之间可能存在权衡。如[167]所示,MEMIT [98]和ROME [97]等局部修改方法通常能保持更高程度的局部性,因为它们定位目标知识的精确位置进行编辑,基本不会影响无关权重。此外,T-Patcher [66]指出,增大记忆规模会提升局部性但降低通用性。这些发现揭示了局部性与通用性之间微妙的平衡关系。然而,解决这种权衡问题并在KME方法的两个理想特性间取得平衡仍具挑战性。
理论分析。虽然当前多数KME研究致力于开发提升编辑性能的有效方法以满足各类理想特性,但实际应用与相对匮乏的理论分析之间仍存在显著差距。最近,[140]的作者从贝叶斯视角为识别有害训练样本及通过擦除信息编辑模型提供了理论支持。LEACE [9]提出了一个分析框架,为从语言模型各层擦除目标概念信息的任务提供了理论视角。总体而言,引入理论分析具有多重价值:首先,理论分析能深化对KME底层机制的理解,有助于建立更具原则性的编辑方法;其次,坚实的理论基础能为未来研究奠定根基,推动KME领域更严谨系统的探索。但据我们所知,目前仍缺乏针对涉及新知识的KME问题的全面理论分析。我们期待未来研究能丰富理论论述,为KME方法的实质基础提供深刻洞见。
Editing at Scale. Another crucial property that hinders the practical application of KME is scalability — the ability of editing strategy to effectively perform a large number of edits simultaneously [101]. For example, conversational systems [174] are expected to be constantly updated to incorporate an enormous number of global events and the information originating from them. However, as the number of applied edits increases, the coherence of language models is severely jeopardized, as multiple edits might contradict a broader spectrum of pre-existing knowledge in the models [152]. This can lead to decreased editing performance in both locality and generality metrics [102]. Although external memorization methods can alleviate such problems with a larger size of memories of additional parameters, they are still vulnerable if thousands of edits are required [97]. Moreover, simply adapting single-edit techniques for a multi-edit environment by merely applying them sequentially has been demonstrated to be proven suboptimal [98]. Therefore, the unique and intricate challenge of coherence renders editing at scale a formidable task.
规模化编辑。阻碍KME实际应用的另一个关键特性是可扩展性——编辑策略能否有效同时执行大量修改的能力 [101]。例如,对话系统 [174] 需要持续更新以纳入海量全球事件及其衍生信息。但随着编辑数量的增加,语言模型的连贯性会严重受损,因为多重修改可能与模型中更广泛范围的既有知识产生冲突 [152],导致局部性和通用性指标上的编辑性能下降 [102]。虽然外部记忆方法可以通过扩大附加参数的记忆容量缓解此类问题,但在需要执行数千次编辑时仍显脆弱 [97]。此外,研究证明 [98],单纯通过顺序应用单次编辑技术来适应多重编辑环境是次优方案。因此,保持连贯性这一独特而复杂的挑战,使得规模化编辑成为一项艰巨任务。
Unstructured Editing. KME faces significant challenges due to its evaluation strategies that focus on knowledge triples, e.g., $t=\left(s,r,o\right)$ , which are not reflective of how real-world knowledge updates occur [65, 172]. In reality, updates are often found in unstructured texts such as news articles and scientific papers. To address this gap, a recent benchmark [166], namely UKE (Unstructured Knowledge Editing), is proposed to evaluate editing performance using unstructured texts as knowledge updates. The experimental results demonstrate significant performance declines of state-of-the-art KME methods. Notably, such a decline persists even with knowledge triplets extracted from unstructured texts. As such, it is imperative to develop more robust and adaptable methods that use unstructured texts for editing.
非结构化编辑。KME (Knowledge Memory Editing) 因其基于知识三元组 (如 $t=\left(s,r,o\right)$ ) 的评估策略面临重大挑战 [65, 172],这与现实世界的知识更新方式不符。实际场景中,更新通常出现在新闻文章和科学论文等非结构化文本中。为填补这一空白,近期提出的 UKE (Unstructured Knowledge Editing) 基准 [166] 采用非结构化文本作为知识更新来评估编辑性能。实验结果表明,最先进的 KME 方法性能显著下降。值得注意的是,即使从非结构化文本中提取知识三元组,这种性能下降仍然存在。因此,亟需开发更鲁棒、适应性更强的非结构化文本编辑方法。
8.2 Future Directions
8.2 未来方向
Despite the recent achievements in the development of KME strategies for effective and efficient updating of new knowledge into LLMs, KME research is still in its emerging stage. Several promising directions could be pursued to further advance this field. Accordingly, we identify five inspiring and important open problems worthy of exploration in the future as follows:
尽管在开发有效且高效的大语言模型 (LLM) 知识更新策略 (KME) 方面取得了最新进展,但KME研究仍处于新兴阶段。为进一步推动该领域发展,可探索以下几个有前景的方向。据此,我们提出以下五个值得未来探索的启发性重要开放性问题:
Optimization-Free Editing. Recently, prompt engineering has become a prevalent solution for modifying the behaviors of pre-trained LLMs in a human-preferable manner without the requirement of parameter update [30]. For example, in-context learning provides task descriptions and/or demonstrations in the form of plain text to promote the model performance [10], which makes it a potentially more efficient and practical strategy for language models. We note that IKE [174] proposes a novel framework that relies on demonstration contexts for KME without parameter updating, which explicitly formats the demonstrations that can guide the language model to copy, update, and retain the prediction of different prompts. However, such a strategy is difficult to scale and usually has unsatisfactory retention. Therefore, it remains a crucial while challenging task to develop optimization-free KME methods.
免优化编辑。近期,提示工程 (prompt engineering) 已成为无需参数更新即可按人类偏好调整预训练大语言模型行为的流行方案 [30]。例如,上下文学习 (in-context learning) 通过纯文本形式提供任务描述和/或示例来提升模型性能 [10],这使其成为语言模型更高效实用的潜在策略。值得注意的是,IKE [174] 提出了一种基于示例上下文的新型免参数更新知识模型编辑 (KME) 框架,通过显式构建示例格式来引导语言模型复制、更新和保留对不同提示的预测。但该方法难以扩展且通常存在保留效果不佳的问题。因此,开发免优化的知识模型编辑方法仍是关键而富有挑战性的任务。
Auto-Discovery of Editing Targets. Current KME methods mainly rely on human expertise to identify and incorporate desirable knowledge into pre-trained LLMs [166, 167, 172]. This approach is inherently labor-intensive and can incur significant costs, especially considering the vast and rapidly expanding new information needed to be integrated into language models. A promising future direction lies in the automation of the edits, which aims to identify, evaluate, and prioritize new knowledge that needs to be integrated from raw resources such as websites and social media.
自动发现编辑目标。当前的KME方法主要依赖人类专业知识来识别并将所需知识整合到预训练的大语言模型中[166, 167, 172]。这种方法本质上是劳动密集型的,可能会产生高昂成本,尤其是考虑到需要整合到语言模型中的海量且快速扩展的新信息。一个充满前景的未来方向是实现编辑过程的自动化,其目标是从网站和社交媒体等原始资源中识别、评估并优先处理需要整合的新知识。
Through this strategy, the application of KME can be streamlined, rendering it more practical and adaptable in real-world scenarios. A straightforward solution would be crawling new knowledge and transforming it into a knowledge base, querying LLMs for each knowledge triple, and editing the wrong answer. However, such a strategy still lacks efficiency. Therefore, it remains a crucial task to discover editing knowledge from various resources without human effort.
通过这一策略,可以简化KME的应用,使其在现实场景中更具实用性和适应性。一个直接的解决方案是爬取新知识并将其转化为知识库,针对每个知识三元组查询大语言模型,并编辑错误答案。然而,这种策略仍缺乏效率。因此,如何无需人工干预地从各种资源中发现待编辑知识,仍是一项关键任务。
Continual Editing. Current KME methods primarily consider one-step offline editing [5, 25]; however, such an approach is not aligned with real-world applications where models might continually encounter novel knowledge to be injected. For example, an online question-answering (QA) model may continually encounter reports of incorrect answers from end users, where the editing needs to be conducted on the run [66]. Therefore, an optimal KME technique should be capable of instantaneously and continuously rectifying emergent issues. We note that continual editing of pre-trained LLMs presents a unique challenge: preventing the edited models from forgetting or contradicting previous edits. Despite the inherent complexities, the persistent demand for continual editing in practice underscores the importance of solving this challenge.
持续编辑。当前的KME (Knowledge Model Editing) 方法主要考虑单步离线编辑 [5, 25],然而这种方式与实际应用场景不符——模型可能持续遇到需要注入的新知识。例如,在线问答 (QA) 模型可能不断收到终端用户关于错误答案的反馈,此时需要实时进行编辑 [66]。因此,理想的KME技术应具备即时持续修正突发问题的能力。我们注意到,对大语言模型进行持续编辑存在独特挑战:需确保修改后的模型不会遗忘或与先前编辑产生矛盾。尽管存在固有复杂性,实践中对持续编辑的持久需求凸显了解决这一挑战的重要性。
Robust Editing. An important direction for the advancement of KME lies in enhancing its robustness. In an era where misinformation spreads rapidly, it is urgent that edited models not only retain their accuracy but also resist adversarial attacks and misinformation [39]. Here, we should note that the concept of robustness extends beyond just maintaining factual accuracy; it involves fortifying the model against potentially adversarial external perturbations [113]. For example, if KME is maliciously applied to inject harmful knowledge into language models, the edited models can be easily transformed into tools for misinformation [141]. Therefore, to prevent such cases, it is crucial for KME techniques to develop capabilities that can identify and counteract such unwanted inputs, thereby enhancing their resilience against adversarial actions. In practice, as the trend leans towards open-sourcing LLMs, it becomes ever more crucial to safeguard against potential manipulations that can turn these models harmful.
稳健编辑。KME发展的一个重要方向在于增强其鲁棒性。在错误信息快速传播的时代,编辑后的模型不仅需要保持准确性,还需抵御对抗性攻击和虚假信息[39]。值得注意的是,鲁棒性的概念不仅限于保持事实准确性,还包括强化模型以抵抗潜在的外部对抗性干扰[113]。例如,若KME被恶意用于向语言模型注入有害知识,编辑后的模型可能轻易沦为传播虚假信息的工具[141]。因此,KME技术必须发展出识别和抵消此类不良输入的能力,从而提升对抗恶意操作的韧性。实践中,随着大语言模型开源趋势的增强,防范可能使模型变得有害的潜在操纵行为变得愈发关键。
Editable Fairness. With the wide application of large language models (LLMs) to support decisions, the emphasis on fairness has grown significantly [150], which requires LLMs to fairly treat people with diverse background [1]. However, LLMs trained on large datasets inevitably incorporate certain biases during this pre-training phase [28]. Fortunately, the precision and efficiency of KME techniques offer a promising solution to mitigate such biases and promote fairness in pre-trained LLMs. For instance, in a model designed to classify biographical sentences with occupation [24], KME can be used to inject nuanced knowledge about a particular profession, guiding the model towards a more equitable understanding of individuals associated with that profession [57]. However, this remains a complex challenge, as fairness often entails considering disparate groups of individuals rather than specific people. This broader focus makes knowledge injection via KME a non-trivial task. Despite these difficulties, the enhancement of fairness in language models is paramount, and KME techniques present a promising avenue to achieve this goal.
可编辑的公平性。随着大语言模型(LLM)在决策支持中的广泛应用,对公平性的重视显著提升[150],这要求LLM公平对待不同背景的人群[1]。然而,基于海量数据训练的LLM在预训练阶段不可避免地会吸收某些偏见[28]。幸运的是,KME技术的精确性和效率为缓解此类偏见、提升预训练LLM的公平性提供了可行方案。例如,在用于职业分类的人物传记句子分类模型中[24],KME可用于注入特定职业的细致知识,引导模型更公平地理解与该职业相关的人群[57]。但这仍是一个复杂挑战,因为公平性通常需要考虑不同群体而非特定个体。这种更广泛的关注点使得通过KME注入知识成为一项艰巨任务。尽管存在这些困难,提升语言模型的公平性至关重要,而KME技术为实现这一目标提供了可行路径。
9 CONCLUSIONS
9 结论
In this survey, we present a comprehensive and in-depth review of knowledge-based model editing (KME) techniques for precise and efficient updating of new knowledge in pre-trained LLMs. We first formulate the KME problem as a constrained optimization objective that simultaneously ensures the accuracy and retention of editing, which is general to encompass different KME strategies. We then provide an overview of the evaluation metrics for KME, which sheds light on the desirable attributes of edited models. Subsequently, we propose a structured taxonomy framework to systematically categorize existing KME techniques. Within each category, we outline the central challenges, elaborate on the representative methods, and discuss their strengths and weaknesses. Furthermore, we summarize the datasets widely utilized to assess KME techniques, highlighting that certain techniques demand specific dataset structures for training or evaluation. To inspire researchers to devise more practical implementations, we also spotlight the real-world applications of KME techniques. Finally, we identify several potential challenges for future research and provide insightful directions that are conducive to further advancement of the field.
本次综述对基于知识的模型编辑(Knowledge-based Model Editing, KME)技术进行了全面深入的探讨,旨在实现预训练大语言模型中新知识的精准高效更新。我们首先将KME问题形式化为一个约束优化目标,该目标在确保编辑准确性的同时保留原有知识,其通用性足以涵盖各类KME策略。随后系统梳理了KME评估指标体系,揭示了被编辑模型应具备的理想特性。基于此,我们提出了结构化分类框架对现有KME技术进行系统归类,在每一类别中分别阐明核心挑战、详述代表性方法并剖析其优劣。此外,本文总结了当前广泛使用的KME评估数据集,指出特定技术需要特定数据结构支撑训练或评估。为启发研究者开发更具实用性的方案,我们还重点分析了KME技术在现实场景中的应用案例。最后,本文指出了该领域未来研究面临的若干挑战,并为推动领域发展提供了建设性研究方向。
ACKNOWLEDGMENTS
致谢
This work is supported by the National Science Foundation under grants (IIS-2006844, IIS-2144209, IIS-2223769, CNS2154962, and BCS-2228534), the Commonwealth Cyber Initiative awards (VV1Q23-007, HV-2Q23-003, and VV-1Q24-011), the JP Morgan Chase Faculty Research Award, the Cisco Faculty Research Award, the Jefferson Lab subcontract, and the UVA 4-VA collaborative research grant.
本研究由美国国家科学基金会 (IIS-2006844、IIS-2144209、IIS-2223769、CNS2154962 和 BCS-2228534)、联邦网络倡议项目 (VV1Q23-007、HV-2Q23-003 和 VV-1Q24-011)、JP Morgan Chase 教师研究奖、思科教师研究奖、杰斐逊实验室分包合同以及弗吉尼亚大学 4-VA 合作研究基金资助。