BIOMEDGPT: OPEN MULTIMODAL GENERATIVE PRE-TRAINED TRANSFORMER FOR BIO MEDICINE
BIOMEDGPT: 面向生物医学领域的开源多模态生成式预训练Transformer
Yizhen $\mathbf{L}\mathbf{u0}^{1* }$ , Jiahuan Zhang1∗, Siqi $\mathbf{Fan}^{1* }$ , Kai $\mathbf{Yang^{1* }}$ , Yushuai $\mathbf{W}\mathbf{u}^{1* }$ , $\mathbf{M}\mathbf{u}\mathbf{Q}\mathbf{i}\mathbf{a}\mathbf{o}^{2\dagger}$ , Zaiqing Nie1,2† Institute for AI Industry Research (AIR), Tsinghua University 1 PharMolix Inc.2 yz-luo22@mails.tsinghua.edu.cn, mqiao@pharmolix.com {zhang jia huan, fansiqi, yangkai, zaiqing}@air.tsinghua.edu.cn
Yizhen $\mathbf{L}\mathbf{u0}^{1* }$, Jiahuan Zhang1∗, Siqi $\mathbf{Fan}^{1* }$, Kai $\mathbf{Yang^{1* }}$, Yushuai $\mathbf{W}\mathbf{u}^{1* }$, $\mathbf{M}\mathbf{u}\mathbf{Q}\mathbf{i}\mathbf{a}\mathbf{o}^{2\dagger}$, Zaiqing Nie1,2†
清华大学智能产业研究院(AIR)1
PharMolix Inc.2
yz-luo22@mails.tsinghua.edu.cn, mqiao@pharmolix.com
{zhang jia huan, fansiqi, yangkai, zaiqing}@air.tsinghua.edu.cn
ABSTRACT
摘要
Foundation models (FMs) have exhibited remarkable performance across a wide range of downstream tasks in many domains. Nevertheless, general-purpose FMs often face challenges when confronted with domain-specific problems, due to their limited access to the proprietary training data in a particular domain. In bio medicine, there are various biological modalities, such as molecules, proteins, and cells, which are encoded by the language of life and exhibit significant modality gaps with human natural language. In this paper, we introduce BioMedGPT, an open multimodal generative pre-trained transformer (GPT) for bio medicine, to bridge the gap between the language of life and human natural language. BioMedGPT allows users to easily “communicate” with diverse biological modalities through free text, which is the first of its kind. BioMedGPT aligns different biological modalities with natural language via a large generative language model, namely, BioMedGPT-LM. We publish BioMedGPT-10B, which unifies the feature spaces of molecules, proteins, and natural language via encoding and alignment. Through fine-tuning, BioMedGPT-10B outperforms or is on par with human and significantly larger general-purpose foundation models on the biomedical QA task. It also demonstrates promising performance in the molecule QA and protein QA tasks, which could greatly accelerate the discovery of new drugs and therapeutic targets. In addition, BioMedGPTLM-7B is the first large generative language model based on Llama2 in the biomedical domain, therefore is commercial friendly. Both BioMedGPT-10B and BioMedGPT-LM-7B are open-sourced to the research community. In addition, we publish the datasets that are meticulously curated for the alignment of multi-modalities, i.e., PubChemQA and UniProtQA. All the models, codes, and datasets are available at https://github.com/PharMolix/OpenBioMed.
基础模型 (FMs) 在多个领域的广泛下游任务中展现出卓越性能。然而,通用基础模型在面临特定领域问题时往往存在局限性,这源于其对专有训练数据的获取受限。在生物医学领域,存在分子、蛋白质、细胞等多种生物模态,它们由生命语言编码,与人类自然语言存在显著模态差异。本文提出BioMedGPT——一个面向生物医学的开源多模态生成式预训练Transformer (GPT),旨在弥合生命语言与人类自然语言之间的鸿沟。BioMedGPT首次实现通过自由文本与多种生物模态"对话"的能力。该系统通过大语言模型BioMedGPT-LM,将不同生物模态与自然语言对齐。我们发布了BioMedGPT-10B,其通过编码和对齐技术统一了分子、蛋白质与自然语言的特征空间。经微调后,BioMedGPT-10B在生物医学问答任务上表现优于或持平人类专家,且显著超越规模更大的通用基础模型。在分子问答和蛋白质问答任务中也展现出卓越性能,有望大幅加速新药与治疗靶点的发现。此外,BioMedGPT-LM-7B是生物医学领域首个基于Llama2架构的大规模生成式语言模型,具备商业化友好特性。BioMedGPT-10B与BioMedGPT-LM-7B均已向研究社区开源。我们还发布了专为多模态对齐精心构建的数据集PubChemQA和UniProtQA。所有模型、代码及数据集详见https://github.com/PharMolix/OpenBioMed。
Keywords Large Language Model $\cdot$ Bio medicine $\cdot$ Generation $\cdot$ Alignment $\cdot$ Multi-Modality
关键词 大语言模型 (Large Language Model) $\cdot$ 生物医学 $\cdot$ 生成 $\cdot$ 对齐 $\cdot$ 多模态
1 Introduction
1 引言
Foundation models (FMs) are large AI models trained on enormous amounts of unlabelled data through self-supervised learning. FMs such as ChatGPT [OpenAI, 2022], Bard [Google, 2023], and Chinchilla [Hoffmann et al., 2022] have showcased impressive general intelligence across a broad spectrum of tasks. Most recently, Meta introduced Llama2 [Touvron et al., 2023a], a family of pre-trained and instruction-tuned large language models (LLMs), demonstrating prevailing results over existing open-source LLMs and on-par performance with some of the closed-source models based on human evaluations in terms of helpfulness and safety.
基础模型 (Foundation Model, FM) 是通过自监督学习在大量无标注数据上训练的大型 AI 模型。诸如 ChatGPT [OpenAI, 2022]、Bard [Google, 2023] 和 Chinchilla [Hoffmann et al., 2022] 等基础模型已在广泛任务中展现出卓越的通用智能。最近,Meta 推出了 Llama2 [Touvron et al., 2023a] 系列预训练及指令微调的大语言模型,在人类评估的有用性和安全性方面,其表现优于现有开源大语言模型,并与部分闭源模型相当。
However, these general-purpose FMs are typically trained on internet-scale generic public datasets, and their depth of knowledge within particular domains is restricted by the lack of access to proprietary training data. To solve this challenge, domain-specific FMs are becoming more prevalent, and attracting tremendous attention to their widespread applications in many fields. For instance, Bloomberg GP T [Wu et al., 2023a] is a large-scale GPT model for finance.
然而,这些通用基础模型(FM)通常是在互联网规模的通用公共数据集上训练的,它们在特定领域的知识深度受到缺乏专有训练数据的限制。为解决这一挑战,领域专用基础模型正变得越来越普遍,并因其在许多领域的广泛应用而受到极大关注。例如,Bloomberg GPT [Wu et al., 2023a] 就是一款面向金融领域的大规模GPT模型。
ChatLaw [Cui et al., 2023] fine-tunes Llama on a legal database and shows promising results on downstream legal applications.
ChatLaw [Cui et al., 2023] 在法律数据库上对 Llama 进行微调,并在下游法律应用中展现出良好效果。
Recently, research works about FMs in the biomedical domain have emerged. BioMedLM, an open-source GPT model with 2.7 billion parameters, is trained exclusively using PubMed abstracts and the PubMed Central section from the Pile data [Gao et al., 2020]. PMC-Llama [Wu et al., 2023b], a biomedical FM fine-tuned from Llama-7B with millions of biomedical publications, has demonstrated superior understanding of biomedical knowledge over general-purpose FMs. Biomedical FMs excel in grasping human language but struggle with comprehending diverse biomedical modalities, including molecular structures, protein sequences, pathways, and cell transcript om ics. Bio medicine, akin to human and computers, has its own distinct “languages”, like the molecular language, which employs molecular grammars to generate molecules or polymers [Guo et al., 2023]. Recent research efforts have been devoted to harnessing large-scale pre-trained language models for learning these multi-modalities. To bridge the modality gap, Bio Translator [Xu et al., 2023] develops a multilingual translation framework to translate text descriptions to non-text biological data instances. In particular, Bio Translator fine-tunes PubMedBERT [Gu et al., 2020] on existing biomedical ontologies and utilizes the resulting domain-specific model to encode textual descriptions. Bio Translator bridges different forms of biological data by projecting encoded text data and non-text biological data into a shared embedding space via contrastive learning.
近期,生物医学领域关于基础模型(FM)的研究成果不断涌现。BioMedLM作为一款开源的27亿参数GPT模型,其训练数据仅采用Pile数据集中的PubMed摘要和PubMed Central文献[Gao et al., 2020]。基于Llama-7B框架、使用数百万篇生物医学文献微调而成的PMC-Llama[Wu et al., 2023b],在生物医学知识理解方面展现出超越通用基础模型的优势。虽然生物医学基础模型擅长处理人类语言,但在理解分子结构、蛋白质序列、通路和细胞转录组等多模态生物医学数据时仍存在局限。与人类和计算机类似,生物医学也有其独特的"语言体系",例如运用分子语法生成分子或聚合物的分子语言[Guo et al., 2023]。当前研究重点聚焦于利用大规模预训练语言模型学习这些多模态表征。为弥合模态鸿沟,Bio Translator[Xu et al., 2023]开发了多语言翻译框架,可将文本描述转化为非文本生物数据实例。该研究通过在现有生物医学本体上微调PubMedBERT[Gu et al., 2020]获得领域专用模型来编码文本描述,并借助对比学习将编码后的文本数据与非文本生物数据映射到共享嵌入空间,从而实现不同形式生物数据的关联。
The inherent laws of nature and the evolution of life, dominated by the organization and interaction of atoms and molecules, employ the language of life to constitute the first principle in bio medicine. Specifically, the language of life describes how information is encoded in logical ways to ensure proper functionalities underlying all of life. For example, the nucleic acids of DNA encode genetic information while the amino acid sequence contains codes to translate that information into protein structures and functions. In addition, proteins are the key building blocks in any organism, from single cells to much more complex organisms such as animals. On the other hand, humans have accumulated extensive biomedical knowledge over centuries, which are usually described in natural language and represented in the forms of knowledge graphs, text documents, and experimental results. There are still many territories yet to be explored by humans in order to understand the fundamental codes, i.e., the language of life. For example, as of June 2023, UniProtKB/TrEMBL [Consortium, 2022] records more than 248M proteins, but only $0.2%$ of them are well studied and manually annotated by human experts. Recently, specialized AI models like ESM-2 [Lin et al., 2022] have shown promise in mining the substantial uncharted regions in bio medicine. However, these black-box models are incapable of providing scientific insights with human interpret able language. More recently, GPT-4 [OpenAI, 2023] demonstrates great success in comprehending not only natural language but also more structured data, such as graphs, tables, and diagrams, illuminating an opportunity to bridge the gap between the language of life and natural language, and therefore revolutionize scientific research.
自然界的固有规律与生命演化,由原子和分子的组织与相互作用主导,运用生命语言构成了生物医学的第一性原理。具体而言,生命语言描述了信息如何以逻辑方式编码,以确保支撑所有生命体的基础功能。例如,DNA的核酸编码遗传信息,而氨基酸序列则包含将这些信息翻译为蛋白质结构与功能的密码。此外,蛋白质是从单细胞到动物等更复杂生物体的关键组成部分。另一方面,人类几个世纪以来积累了大量的生物医学知识,这些知识通常以自然语言描述,并以知识图谱、文本文档和实验结果等形式呈现。为了理解生命的基本密码(即生命语言),人类仍有许多未知领域有待探索。例如,截至2023年6月,UniProtKB/TrEMBL [Consortium, 2022] 记录了超过2.48亿种蛋白质,但其中仅有0.2%经过深入研究并由人类专家手动注释。最近,ESM-2 [Lin et al., 2022] 等专业AI模型在开发生物医学中大量未探索区域方面展现出潜力。然而,这些黑盒模型无法用人类可解释的语言提供科学见解。更近期的GPT-4 [OpenAI, 2023] 不仅在理解自然语言方面取得巨大成功,还能处理更结构化的数据(如图表、表格和示意图),这为弥合生命语言与自然语言之间的鸿沟提供了契机,从而可能彻底改变科学研究。
To achieve this over arching and ambitious goal, we develop BioMedGPT, a novel framework to bridge the language of life and human natural language using large-scale pre-trained language models. Figure 1 shows the overview of BioMedGPT. We build a biomedical language model, BioMedGPT-LM, by fine-tuning existing general-purpose LLMs with large-scale biomedical corpus. Built on top of BioMedGPT-LM, BioMedGPT is designed to unify the language of life, encoding biological building blocks such as molecules, proteins, and cells, as well as natural languages, describing human knowledge in the forms of knowledge graphs, texts, and experimental results. Alignment and translation between different biological modalities and human natural language are performed via neural networks and self-supervised learning techniques. Compared with prior work, BioMedGPT enjoys the benefits of larger GPT type of LLMs and a substantial amount of untapped texts in the biomedical research field. Within the unified feature space of different modalities, BioMedGPT can flexibly support free-text inquiries, digest multimodal inputs, and versatile ly power a wide range of downstream tasks without end-to-end fine-tuning.
为实现这一宏大而雄心勃勃的目标,我们开发了BioMedGPT——一个通过大规模预训练语言模型连接生命语言与人类自然语言的新型框架。图1展示了BioMedGPT的整体架构。我们通过使用大规模生物医学语料库微调现有通用大语言模型,构建了生物医学语言模型BioMedGPT-LM。基于BioMedGPT-LM构建的BioMedGPT旨在统一生命语言(编码分子、蛋白质、细胞等生物构件)与自然语言(以知识图谱、文本和实验结果形式描述人类知识)。通过神经网络和自监督学习技术,实现不同生物模态与人类自然语言之间的对齐与转换。与现有工作相比,BioMedGPT兼具更大规模的GPT类大语言模型优势,并利用了生物医学研究领域大量未被开发的文本资源。在统一的多模态特征空间中,BioMedGPT可灵活支持自由文本查询、处理多模态输入,并无需端到端微调即可赋能多种下游任务。
We open-source BioMedGPT-10B, a model instance of BioMedGPT, unifying texts, molecular structures, and protein sequences. BioMedGPT-10B is built upon BioMedGPT-LM-7B, which is fine-tuned from the recently released Llama2- Chat-7B model with millions of biomedical publications. We leverage independent encoders to encode molecular and protein features and project them into the same feature space of the textual modality via multi-modal fine-tuning. BioMedGPT-10B enables users to upload biological data of molecular structures and protein sequences and pose natural language queries about these data instances. This capability can potentially accelerate the discovery of novel molecular structures and protein functionalities, thus catalyzing advancements in drug development.
我们开源了BioMedGPT-10B,这是BioMedGPT的一个模型实例,统一了文本、分子结构和蛋白质序列。BioMedGPT-10B基于BioMedGPT-LM-7B构建,后者是从最近发布的Llama2-Chat-7B模型通过数百万篇生物医学文献微调而来。我们利用独立的编码器来编码分子和蛋白质特征,并通过多模态微调将它们投影到文本模态的同一特征空间中。BioMedGPT-10B允许用户上传分子结构和蛋白质序列的生物数据,并对这些数据实例提出自然语言查询。这一功能有望加速新型分子结构和蛋白质功能的发现,从而推动药物研发的进展。
Our contributions are summarized as follows:
我们的贡献总结如下:
• We introduce BioMedGPT, a novel framework to bridge the language of life and human natural language via large-scale generative language models. • We demonstrate the promising performance of BioMedGPT-10B, which is a model instance of BioMedGPT, on the biomedical QA, molecule QA, and protein QA tasks. Through fine-tuning, BioMedGPT-10B outperforms or is on par with human and significantly larger general-purpose foundation models on biomedical QA benchmarks. In addition, its capability on the molecule QA and protein QA tasks shows great potential to power many downstream biomedical applications, such as accelerating the discovery of new drugs and therapeutic targets. BioMedGPT-10B is open-sourced to the community. We also publish the datasets that are curated for the alignment of multi-modalities, i.e., PubChemQA and UniProtQA.
• 我们推出BioMedGPT,这是一个通过大规模生成式语言模型连接生命语言与人类自然语言的新颖框架。
• 我们展示了BioMedGPT-10B(BioMedGPT的一个模型实例)在生物医学问答、分子问答和蛋白质问答任务中的优异表现。通过微调,BioMedGPT-10B在生物医学问答基准测试中表现优于或与人类及规模显著更大的通用基础模型相当。此外,其在分子问答和蛋白质问答任务上的能力显示出推动众多下游生物医学应用的巨大潜力,例如加速新药和治疗靶点的发现。BioMedGPT-10B已向社区开源。我们还发布了为多模态对齐而整理的数据集,即PubChemQA和UniProtQA。
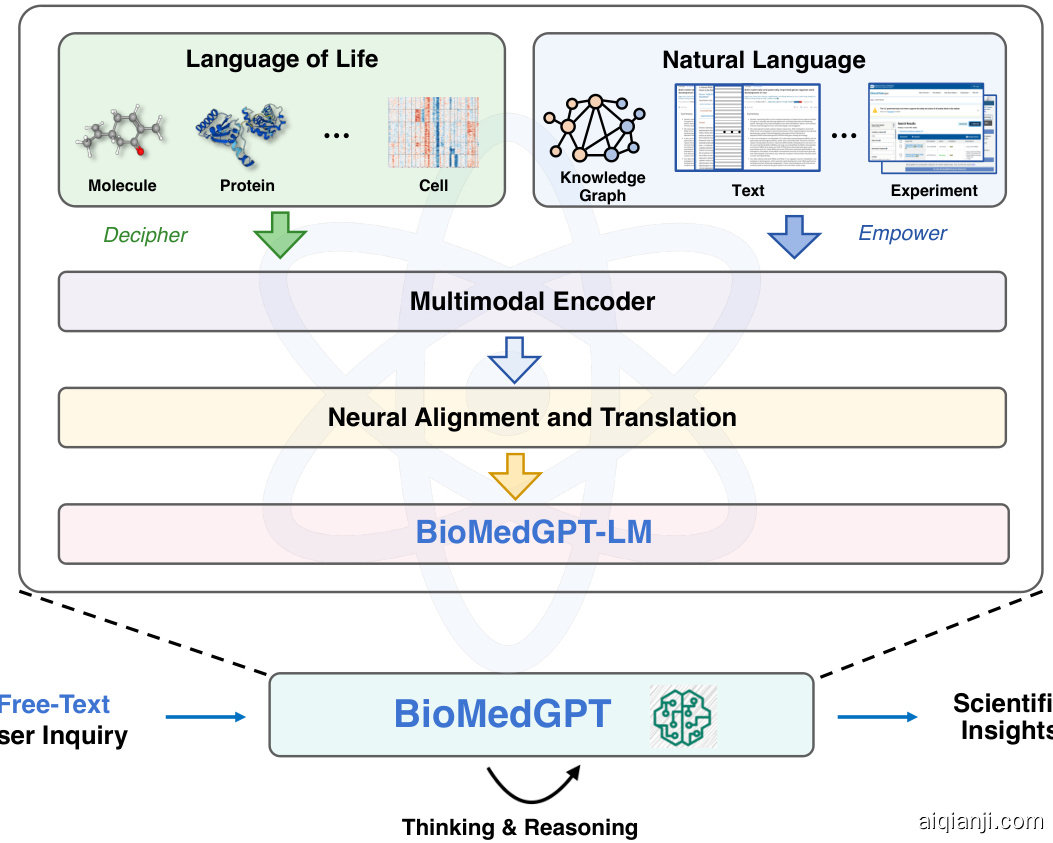
Figure 1: The architecture of BioMedGPT.
图 1: BioMedGPT 架构。
• BioMedGPT-LM-7B, the large language model used in BioMedGPT-10B, is the first generative language model that is fine-tuned from Llama2 with an extensive biomedical corpus. BioMedGPT-LM-7B is commercial friendly and is open-sourced to the community.
• BioMedGPT-LM-7B是BioMedGPT-10B中使用的大语言模型,也是首个基于Llama2并通过海量生物医学语料微调的生成式语言模型。该模型支持商业用途,并已向社区开源。
The remaining of the paper is organized as follows. Section 2 provides an overview of BioMedGPT. In Section 3, we present BioMedGPT-10B, which is a 10B foundation model in the BioMedGPT family, including BioMedGPT-LM-7B and molecule QA and protein QA modules. Experimental results and analysis are reported in Section 4. We describe the limitations of our work in Section 5. Finally, we conclude and discuss future work in Section 6.
论文的其余部分组织如下。第2节概述了BioMedGPT。第3节介绍了BioMedGPT-10B,这是BioMedGPT系列中的一个100亿参数基础模型,包括BioMedGPT-LM-7B以及分子问答和蛋白质问答模块。实验结果与分析在第4节中报告。我们在第5节描述了工作的局限性。最后,第6节总结并讨论了未来工作。
2 An Overview of BioMedGPT
2 BioMedGPT 概述
In Figure 1, we present an overview of BioMedGPT, which serves as a biomedical brain. The cognitive core, BioMedGPT-LM, is a large language model developed through incremental training on an extensive biomedical corpus, inheriting the benefits of both the emergent abilities of LLMs and domain-specific knowledge. BioMedGPT-LM serves not only as a linguistic engine that enables free-text interactions with humans but also acts as a bridge connecting various biomedical modalities. BioMedGPT is endowed with the ability to comprehend and reason over diverse biological modalities encompassing molecules, proteins, transcript omi c, and more, through the feature space alignment. In addition, we also utilize heterogeneous expert knowledge from knowledge graphs, text documents, and experimental results to further enhance the biomedical knowledge of BioMedGPT.
图1: BioMedGPT概览图,该系统作为生物医学大脑。其认知核心BioMedGPT-LM是通过海量生物医学语料增量训练开发的大语言模型,兼具大语言模型的涌现能力和领域专有知识优势。该模型不仅是支持人类自由文本交互的语言引擎,更是连接多模态生物医学数据的桥梁。通过特征空间对齐技术,BioMedGPT具备理解分子、蛋白质、转录组等多元生物模态并进行推理的能力。此外,我们还整合知识图谱、文本文档及实验结果等异构专家知识,进一步强化系统的生物医学知识体系。
We develop a feature fusion approach, which encodes multimodal data with independent pre-trained encoders and aligns their feature spaces with that of the natural language through neural alignment and translation methods. We have demonstrated the effectiveness of this approach in our prior work, MolFM [Luo et al., 2023], which is a molecular foundation model that enables joint representation learning on molecular structures, biomedical texts, and knowledge graphs. MolFM achieves state-of-the-art performance on a spectrum of multimodal tasks, such as molecule-text retrieval, molecule captioning, and text-to-molecule generation. Thus, we believe that BioMedGPT can harvest from both the readily available uni-modal foundation models and the powerful generalization capability of language models. BioMedGPT enhances the cross-modal comprehension and connections between natural language and diverse biological modalities. Users can flexibly present inquiries in various formats, encompassing but not limited to, text, chemical structure files, SMILES, protein sequences, protein 3D structure data, and single-cell sequencing data. With extensive training on these biomedical data, BioMedGPT can provide users with valuable scientific insights.
我们开发了一种特征融合方法,该方法通过独立的预训练编码器对多模态数据进行编码,并通过神经对齐和翻译方法将其特征空间与自然语言对齐。我们在先前的工作MolFM [Luo et al., 2023]中验证了该方法的有效性。MolFM是一个分子基础模型,能够对分子结构、生物医学文本和知识图谱进行联合表征学习,在分子-文本检索、分子描述生成和文本到分子生成等多模态任务上实现了最先进的性能。因此,我们相信BioMedGPT既能利用现成的单模态基础模型,又能继承大语言模型强大的泛化能力。BioMedGPT增强了自然语言与多种生物模态之间的跨模态理解和关联。用户可以灵活地以多种格式提交查询,包括但不限于文本、化学结构文件、SMILES、蛋白质序列、蛋白质3D结构数据和单细胞测序数据。通过对这些生物医学数据进行广泛训练,BioMedGPT能为用户提供有价值的科学洞见。
In the subsequent section, we introduce a model instance of BioMedGPT which is primarily focused on the joint comprehension of molecular structures, protein sequences, and biomedical texts.
在接下来的部分,我们将介绍BioMedGPT的一个模型实例,其主要关注分子结构、蛋白质序列和生物医学文本的联合理解。
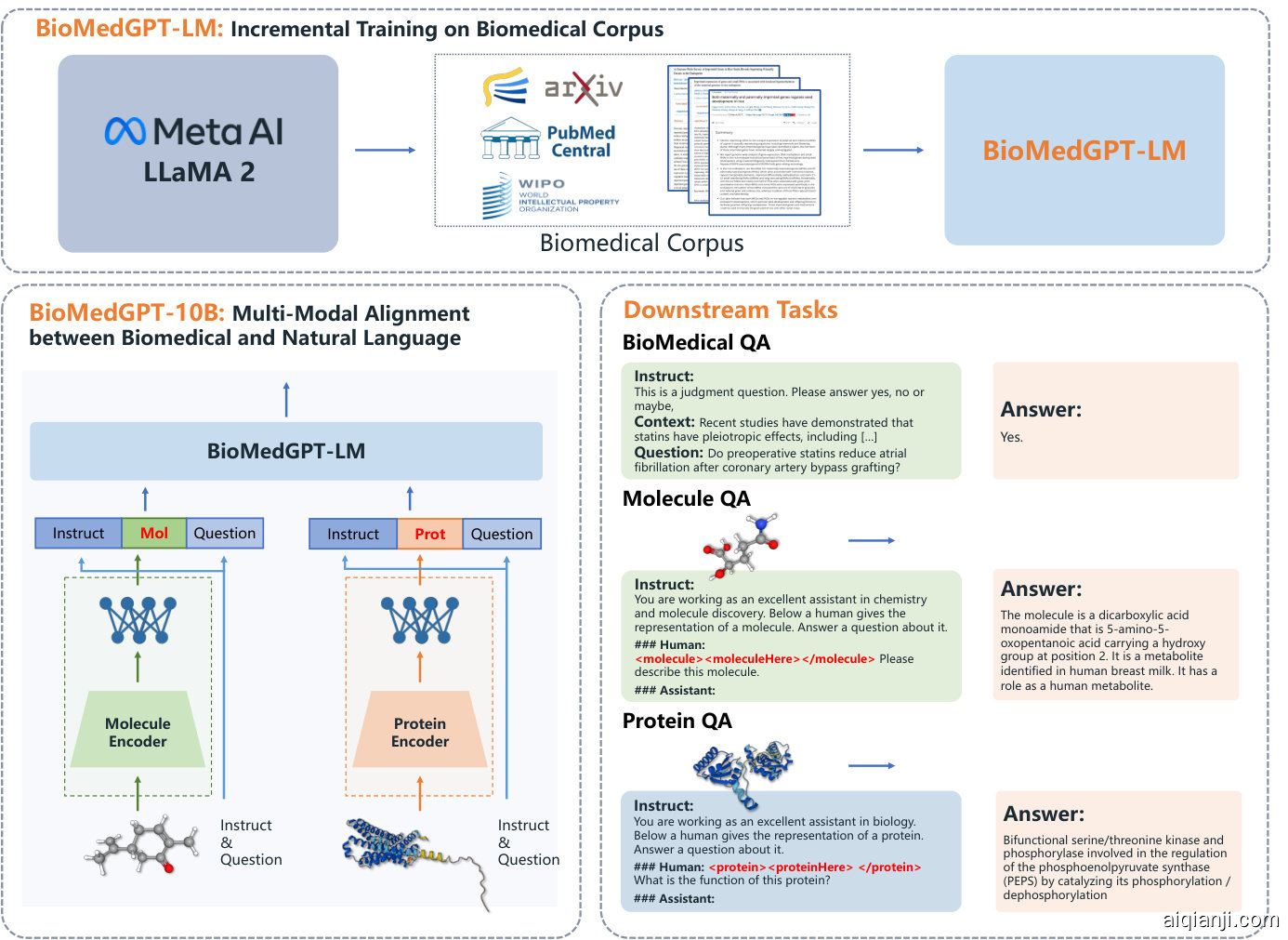
Figure 2: The overview of BioMedGPT-10B. BioMedGPT-LM is the large language model of BioMedGPT, which serves as a cognitive core to jointly comprehend various biological modalities through natural language. In BioMedGPT-10B, the parameter size of the large language model is 7B. BioMedGPT-10B adopts GraphMVP [Liu et al., 2022] as the 2D molecular graph encoder, ESM2-3B [Lin et al., 2022] as the protein sequence encoder, and conducts feature space alignment via a neural network adaptor. BioMedGPT can be applied to many multimodal downstream tasks such as biomedical QA, molecule QA, and protein QA.
图 2: BioMedGPT-10B 概述。BioMedGPT-LM 是 BioMedGPT 的大语言模型 (Large Language Model),作为认知核心通过自然语言联合理解多种生物模态。在 BioMedGPT-10B 中,大语言模型的参数量为 7B。BioMedGPT-10B 采用 GraphMVP [Liu et al., 2022] 作为 2D 分子图编码器,ESM2-3B [Lin et al., 2022] 作为蛋白质序列编码器,并通过神经网络适配器进行特征空间对齐。BioMedGPT 可应用于生物医学问答、分子问答和蛋白质问答等多模态下游任务。
3 BioMedGPT-10B: Aligning Molecules, Proteins, and Natural Language
3 BioMedGPT-10B:对齐分子、蛋白质与自然语言
As shown in Figure 2, we develop BioMedGPT-LM-7B, a large language model specialized in bio medicine, through incremental training with biomedical literature on top of Llama2-7B-Chat. We then build BioMedGPT-10B by aligning 2D molecular graphs, protein sequences, and natural language in a unified feature space. We choose molecules and proteins because they are basic biomedical elements. It is worth noting that the aforementioned molecule and protein encoders can be easily replaced with other suitable and well-performing encoders. We detail the architecture and training process of BioMedGPT-10B in the following subsections.
如图 2 所示, 我们在 Llama2-7B-Chat 的基础上通过生物医学文献的增量训练, 开发了专注于生物医学领域的大语言模型 BioMedGPT-LM-7B。随后通过将 2D 分子图、蛋白质序列和自然语言对齐到统一特征空间, 构建了 BioMedGPT-10B。选择分子和蛋白质是因为它们是基础的生物医学元素。值得注意的是, 上述分子和蛋白质编码器可以轻松替换为其他合适且性能良好的编码器。我们将在后续小节详细阐述 BioMedGPT-10B 的架构和训练过程。
3.1 BioMedGPT-LM-7B: Incremental training on large-scale biomedical literature
3.1 BioMedGPT-LM-7B:基于大规模生物医学文献的增量训练
Recently, Llama2 and Llama2-chat, open-sourced by Meta, have attracted great research attention owing to their outstanding capabilities in the general domain. To exploit the advantages of Llama2’s emergent abilities as well as biomedical knowledge from scientific research, we perform incremental training on Llama2-Chat-7B with extensive biomedical documents from S2ORC [Lo et al., 2020].
近期,Meta开源的Llama2和Llama2-chat凭借其在通用领域的出色能力引发了广泛研究关注。为结合Llama2的涌现能力优势与科研领域的生物医学知识,我们采用S2ORC [Lo et al., 2020] 的海量生物医学文献对Llama2-Chat-7B进行了增量训练。
Data Processing We select biomedical-related literature from S2ORC to fine-tune Llama2. The S2ORC dataset comprises an extensive collection of 81.1 million English academic papers spanning various disciplines. We meticulously extract 5.5 million biomedical papers from this dataset using PubMed Central (PMC)-ID and PubMed ID as criteria. After removing articles without full text and those with duplicate IDs, we attain a refined dataset of 4.2 million articles. Our subsequent processing involves the removal of author information, reference citations, and chart data from the main body of each article. The remaining text is then partitioned into sentence-based chunks. Each of these chunks is further tokenized by the Llama2 tokenizer, culminating in a substantial assemblage of over 26 billion tokens highly pertinent to the field of bio medicine.
数据处理
我们从S2ORC中选取生物医学相关文献对Llama2进行微调。S2ORC数据集包含跨越多个学科的8110万篇英文学术论文。我们以PubMed Central (PMC)-ID和PubMed ID为筛选标准,从该数据集中精细提取出550万篇生物医学论文。剔除无全文及ID重复的文章后,最终获得420万篇精炼数据集。后续处理包括移除每篇文章正文中的作者信息、参考文献引用及图表数据,剩余文本按句子分块后,通过Llama2的分词器(tokenizer)进一步切分,最终生成超过260亿个与生物医学领域高度相关的token。
Fine-tuning Details The fine-tuning utilizes a learning rate of $2\times10^{-5}$ , a batch size of $192^{3}$ , and a context length of 2048 tokens. We adopt the Fully Sharded Data Parallel (FSDP) acceleration strategy alongside the bf16 (Brain Floating Point) data format. To tackle the memory challenge, we leverage gradient check pointing [Chen et al., 2016] and flash attention [Dao et al., 2022]. We utilize an auto regressive objective function. The training loss is shown in Figure 3. Notably, the loss exhibits a consistent and progressive decrease after the 44,000 steps, indicating the model converges effectively.
微调细节
微调采用的学习率为 $2\times10^{-5}$,批量大小为 $192^{3}$,上下文长度为2048个token。我们采用全分片数据并行 (Fully Sharded Data Parallel, FSDP) 加速策略和bf16 (Brain Floating Point) 数据格式。为解决内存挑战,我们利用了梯度检查点 [Chen et al., 2016] 和闪存注意力机制 [Dao et al., 2022]。训练采用自回归目标函数,损失变化如图3所示。值得注意的是,在44,000步之后损失呈现持续稳定的下降趋势,表明模型有效收敛。

Figure 3: The training loss for BioMedGPT-LM-7B.
图 3: BioMedGPT-LM-7B 的训练损失。
3.2 Multimodal alignment between molecules, proteins, and natural language
3.2 分子、蛋白质与自然语言的多模态对齐
BioMedGPT-10B is composed of a molecule encoder, a protein encoder, a large language model (i.e., BioMedGPTLM-7B), and two modality adaptors. In order to exploit the strong capabilities of existing unimodal models, we leverage off-the-shelf checkpoints to initialize the molecule and protein encoder. The molecule encoder is a 5-layer GIN [Xu et al., 2018] with 1.8M parameters pre-trained by GraphMVP [Liu et al., 2022], which shows promising results in comprehending 2D molecular graphs. The protein encoder is ESM-2-3B [Lin et al., 2022], a 36-layer transformer [Vaswani et al., 2023] specialized in processing protein sequences. The output features of each atom of the molecule encoder and the output features of each residue of the protein encoder are projected to the feature space of BioMedGPT-LM-7B with independent modality adaptors composed of a fully-connected layer.
BioMedGPT-10B 由分子编码器、蛋白质编码器、大语言模型 (即 BioMedGPTLM-7B) 和两个模态适配器组成。为了利用现有单模态模型的强大能力,我们采用现成的检查点初始化分子和蛋白质编码器。分子编码器是一个具有 180 万参数的 5 层 GIN [Xu et al., 2018],通过 GraphMVP [Liu et al., 2022] 进行预训练,在理解 2D 分子图方面表现出色。蛋白质编码器是 ESM-2-3B [Lin et al., 2022],一个专用于处理蛋白质序列的 36 层 Transformer [Vaswani et al., 2023]。分子编码器每个原子的输出特征和蛋白质编码器每个残基的输出特征,通过由全连接层组成的独立模态适配器投影到 BioMedGPT-LM-7B 的特征空间。
To build the connections between molecular and protein structures with natural language, we perform multimodal fine-tuning, which involves answering questions with regard to a given molecule or protein. As shown in Table 1, we design prompt templates to help BioMedGPT-LM understand the context more accurately in a role-play manner. The
为了建立分子与蛋白质结构同自然语言之间的联系,我们进行了多模态微调,即针对给定分子或蛋白质回答问题。如表1所示,我们设计了提示模板,以角色扮演方式帮助BioMedGPT-LM更准确地理解上下文。其中
Data Proc ces sing The multimodal alignment is performed on two large-scale datasets that we curate, namely, PubChemQA and UniProtQA. We publicly release these datasets to facilitate future research.
数据处理
我们在两个自建的大规模数据集PubChemQA和UniProtQA上执行多模态对齐任务。这些数据集已公开发布以促进后续研究。
• PubChemQA consists of molecules and their corresponding textual descriptions from PubChem [Kim et al., 2022]. It contains a single type of question, i.e., please describe the molecule. We remove molecules that cannot be processed by RDKit [Landrum et al., 2021] to generate 2D molecular graphs. We also remove texts with less than 4 words, and crops descriptions with more than 256 words. Finally, we obtain 325, 754 unique molecules and 365, 129 molecule-text pairs. On average, each text description contains 17 words. • UniProtQA consists of proteins and textual queries about their functions and properties. The dataset is constructed from UniProt [Consortium, 2022], and consists 4 types of questions with regard to functions, official names, protein families, and sub-cellular locations. We collect a total of 569, 516 proteins and 1, 891, 506 question-answering samples. The data was randomly divided into training, validation, and test sets at a ratio of $8:1:1$ . The multi-modal fine-tuning is performed on the training set of ProteinQA.
• PubChemQA 包含来自 PubChem [Kim et al., 2022] 的分子及其对应的文本描述。它仅包含一种问题类型,即"请描述该分子"。我们移除了无法通过 RDKit [Landrum et al., 2021] 处理以生成二维分子图的分子,同时删除了少于4个单词的文本,并将超过256个单词的描述进行截断。最终获得325,754个独特分子和365,129个分子-文本对。平均每个文本描述包含17个单词。
• UniProtQA 包含蛋白质及其功能和特性的文本查询。该数据集构建自 UniProt [Consortium, 2022],包含关于功能、官方名称、蛋白质家族和亚细胞定位的4类问题。我们共收集了569,516个蛋白质和1,891,506个问答样本。数据按 $8:1:1$ 的比例随机划分为训练集、验证集和测试集。多模态微调在 ProteinQA 的训练集上进行。
We design the following prompt to organize the molecular or protein data with the text data as feature-ordered input for the LLM.
我们设计了以下提示(prompt),用于将分子或蛋白质数据与文本数据整理为特征有序的输入,供大语言模型使用。
Table 1: Prompt for organizing multi-modality data entry.
| Modality | Prompt |
| Molecule | You are working as an excellent assistant in chemistry and molecule discovery. Below a human gives the representation of a molecule. Answer a question about it. ###Human: |
| Protein | ###Assistant: {text_ output} You are working as an excellent assistant in biology.Below a human gives the representation of a protein. Answer a question about it. ###Human: |
表 1: 多模态数据录入的组织提示
| 模态类型 | 提示语 |
|---|---|
| 分子 (Molecule) | 你是一名优秀的化学与分子发现助手。以下用户提供了一个分子表示,请回答相关问题。 ###Human: {text_input}。 |
| 蛋白质 (Protein) | ###Assistant: {text_ output} 你是一名优秀的生物学助手。以下用户提供了一个蛋白质表示,请回答相关问题。 ###Human: {text_input}。 ###Assistant: {text_ output} |
Following mPLUG-owl [Ye et al., 2023], we freeze the parameters of BioMedGPT-LM and optimize the parameters of the molecule encoder, protein encoder, and modality adaptors to save the computational cost and avoid catastrophic forgetting. We conduct fine-tuning using these two datasets.
遵循mPLUG-owl [Ye et al., 2023]的方法,我们冻结了BioMedGPT-LM的参数,并优化分子编码器、蛋白质编码器和模态适配器的参数,以节省计算成本并避免灾难性遗忘。我们使用这两个数据集进行微调。
4 Experiment
4 实验
In this section, we substantiate BioMedGPT-10B’s capability to jointly understand and model the language of life and natural language with a series of experiments. We present three question-answering tasks, namely biomedical QA, molecule QA and protein QA, to comprehensively evaluate the biomedical knowledge that our model encompasses. In the following sections, we will introduce the datasets and experimental results for each task. Additionally, we showcase the generated results in protein QA.
在本节中,我们通过一系列实验验证了BioMedGPT-10B联合理解与建模生命语言和自然语言的能力。我们设计了三个问答任务(即生物医学QA、分子QA和蛋白质QA)来全面评估模型所涵盖的生物医学知识。后续章节将分别介绍各任务的数据集与实验结果,并展示蛋白质QA的生成案例。
4.1 Biomedical QA
4.1 生物医学问答
Biomedical QA involves answering free-text questions in the biomedical domain, which challenges the professional level of language models. The task serves as a means to evaluate if BioMedGPT-10B can understand biomedical terminologies and reason over complex contexts like a human expert.
生物医学问答涉及回答生物医学领域的自由文本问题,这对语言模型的专业水平提出了挑战。该任务旨在评估BioMedGPT-10B是否能像人类专家一样理解生物医学术语并在复杂语境中进行推理。
Dataset We evaluate BioMedGPT-10B on three public multiple-choice question answering benchmarks within the biomedical domain, i.e., USMLE [Jin et al., 2021], MedMCQA [Pal et al., 2022], and PubMedQA [Jin et al., 2019].
数据集
我们在生物医学领域的三个公开多选题基准上评估BioMedGPT-10B,即USMLE [Jin et al., 2021]、MedMCQA [Pal et al., 2022]和PubMedQA [Jin et al., 2019]。
The details of the datasets used in biomedical QA are summarized below.
生物医学问答中使用的数据集详情如下。
• USMLE is a real-world medical QA dataset collected from the United States Medical License Exams with 11, 451 professional multiple-choice questions. We follow the official data splits with a training and test ratio $8:1$ .
• USMLE是一个真实世界的医学问答数据集,采集自美国医师执照考试的11,451道专业选择题。我们遵循官方数据划分方式,训练集与测试集比例为$8:1$。
• MedMCQA is a popular medical QA dataset covering diverse healthcare topics and subjects. More than 194k high-quality medical multiple-choice questions from real-world entrance exams are collected. The training set contains 182,822 QA pairs, and the test set consists of 4,183 pairs. • PubMedQA is a QA dataset in biomedical research. It aims at answering research questions with yes/no/maybe according to the corresponding contexts collected from the PubMed abstracts. Following [Wu et al., 2023b], we use the manually curated subset, PQA-A, which contains 211,269 QA pairs as our training set. The evaluation is done on the labeled subset, PQA-L, which consists of 1,000 QA pairs.
• MedMCQA 是一个流行的医学问答数据集,涵盖多样化的医疗健康主题和科目。该数据集收集了超过19.4万道来自真实世界入学考试的高质量医学多选题。训练集包含182,822个问答对,测试集包含4,183对。
• PubMedQA 是一个生物医学研究领域的问答数据集。其目标是根据从PubMed摘要中收集的相应上下文,用是/否/可能来回答研究问题。遵循 [Wu et al., 2023b] 的做法,我们使用手动整理的子集 PQA-A 作为训练集,其中包含211,269个问答对。评估在标记子集 PQA-L 上进行,该子集包含1,000个问答对。
Experiment Setup We fine-tune the language model of BioMedGPT-10B on the training sets of PubMedQA and MedMCQA which consists of a similar amount of data. Then we perform in-domain (ID) evaluation on the test sets of two datasets, and out-of-domain (OOD) evaluation on USMLE without additional fine-tuning on its training set. The model is fine-tuned for 3 epochs with a learning rate of $2\times10^{-5}$ and a batch size of 512.
实验设置
我们在PubMedQA和MedMCQA训练集上对BioMedGPT-10B的语言模型进行微调,这两个数据集的数据量相近。随后在两个数据集的测试集上进行领域内(ID)评估,并在未对USMLE训练集进行额外微调的情况下进行领域外(OOD)评估。模型微调共进行3个周期,学习率为$2\times10^{-5}$,批量大小为512。
Evaluation We compare the QA performance of BioMedGPT-10B with zero-shot Instruct GP T [Ouyang et al., 2022], ChatGPT [OpenAI, 2022], Llama [Touvron et al., 2023b], Llama2-Chat [Touvron et al., 2023a] as well as fine-tuned Llama, Llama2-Chat and PMC-Llama [Wu et al., 2023b]. We also report the accuracy of passing the test and the accuracy of human experts. The in-domain results are displayed in Table 2. We observe that Llama2 outperforms the previous Llama model, and Llama2-Chat further boosts the accuracy since QA tasks can be considered as a single-round dialogue. Additionally, fine-tuning language models brings substantial improvements. Benefiting from the generalization power of Llama2-Chat and incremental fine-training with large-scale biomedical corpus, BioMedGPT10B achieves state-of-the-art results on both MedMCQA and PubMedQA. Notably, on PubMedQA, the prediction accuracy of BioMedGPT-10B is on par with human experts, demonstrating its great potential to serve as a professional biomedical assistant.
评估
我们将BioMedGPT-10B的问答性能与零样本Instruct GPT [Ouyang et al., 2022]、ChatGPT [OpenAI, 2022]、Llama [Touvron et al., 2023b]、Llama2-Chat [Touvron et al., 2023a]以及微调后的Llama、Llama2-Chat和PMC-Llama [Wu et al., 2023b]进行对比。同时报告了通过测试的准确率及人类专家的准确率。领域内结果如 表 2 所示。
我们观察到,Llama2的表现优于前代Llama模型,而Llama2-Chat因问答任务可视为单轮对话而进一步提升了准确率。此外,微调语言模型带来了显著改进。得益于Llama2-Chat的泛化能力及大规模生物医学语料的增量微调训练,BioMedGPT-10B在MedMCQA和PubMedQA上均取得了最先进的结果。值得注意的是,在PubMedQA上,BioMedGPT-10B的预测准确率与人类专家持平,展现了其作为专业生物医学助手的巨大潜力。
We also report the OOD performance of BioMedGPT-10B and baseline models on USMLE in Table 2. Compared with other LLMs of the same parameter size, BioMedGPT-10B shows outstanding performance, surpassing the best model (i.e., Llama2-Chat) by a notable $5.1%$ margin. Besides the closed-source ChatGPT, BioMedGPT-10B is the only model that achieves more than $50%$ accuracy on USMLE.
我们还在表2中报告了BioMedGPT-10B和基线模型在USMLE上的OOD (Out-of-Distribution) 性能表现。与其他参数规模相同的大语言模型相比,BioMedGPT-10B展现出卓越性能,以显著优势超越最佳模型(即Llama2-Chat)达5.1%。除闭源的ChatGPT外,BioMedGPT-10B是唯一在USMLE上准确率超过50%的模型。
Table 2: Performance (accuracy, $%$ ) comparison for ID (In-Domain) and OOD (Out-Of-Domain) evaluation. All th reported results with * are referred from LMFlow [Diao et al., 2023].
| Method | Setting | MedMCQA(ID) | PubMedQA(ID) | USMLE(OOD) |
| Human (pass)* | Manual | 60.0 | 50.0 | |
| Human (expert)* | Zero-shot | 90 | 78.0 | 87.0 |
| InstructGPT* | 44.0 | 73.2 | 46.0 | |
| ChatGPT* Llama* | 44.7 | 63.9 5.2 | 57.0 27.1 | |
| Llama2 | 24.3 | 3.7 | 27.2 | |
| Llama2-Chat | 30.6 35.5 | 21.9 | 34.4 | |
| Llama [Wu et al., 2023b] Llama2-Chat | Fine-tuning | 48.2 | 73.4 | 44.6 |
| 48.3 | 75.5 | 45.3 | ||
| PMC-Llama [Wu et al., 2023b] | 50.5 | 69.5 | 44.7 | |
| BioMedGPT-10B | Fine-tuning | 51.4 | 76.1 | 50.4 |
表 2: ID (领域内) 和 OOD (领域外) 评估的性能 (准确率, $%$) 对比。所有带 * 的报告结果均引自 LMFlow [Diao et al., 2023]。
| 方法 | 设置 | MedMCQA(ID) | PubMedQA(ID) | USMLE(OOD) |
|---|---|---|---|---|
| Human (pass)* | Manual | 60.0 | 50.0 | |
| Human (expert)* | Zero-shot | 90 | 78.0 | 87.0 |
| InstructGPT* | Zero-shot | 44.0 | 73.2 | 46.0 |
| ChatGPT* Llama* | Zero-shot | 44.7 | 63.9 5.2 | 57.0 27.1 |
| Llama2 | Zero-shot | 24.3 | 3.7 | 27.2 |
| Llama2-Chat | 30.6 35.5 | 21.9 | 34.4 | |
| Llama [Wu et al., 2023b] Llama2-Chat | Fine-tuning | 48.2 | 73.4 | 44.6 |
| Fine-tuning | 48.3 | 75.5 | 45.3 | |
| PMC-Llama [Wu et al., 2023b] | 50.5 | 69.5 | 44.7 | |
| BioMedGPT-10B | Fine-tuning | 51.4 | 76.1 | 50.4 |
4.2 Molecule QA
4.2 分子问答
Molecule QA involves generating a text response given a specific molecule and a text query over its properties. This task serves as a means to evaluate the ability of our model to translate between natural language and the language of molecules.
分子问答涉及在给定特定分子及其属性文本查询的情况下生成文本响应。该任务旨在评估模型在自然语言与分子语言之间转换的能力。
Dataset We incorporate ChEBI-20 [Edwards et al., 2021], a dataset incorporating 33, 010 molecules from ChEBI (Chemical Entities of Biological Interest) with high-quality textual descriptions extracted from PubChem as our benchmark. We adopt "Please describe this molecule." as the question, and challenges language models to generate a textual description based on the input structure. We follow the initial split with a training, validation, and test ratio $8:1:1$ .
数据集
我们采用ChEBI-20 [Edwards et al., 2021]作为基准数据集,该数据集包含来自ChEBI (Chemical Entities of Biological Interest)的33,010个分子,并附有从PubChem提取的高质量文本描述。我们以"请描述该分子"作为问题,要求语言模型根据输入结构生成文本描述。按照初始划分,训练集、验证集和测试集的比例为$8:1:1$。
Experiment Setup We evaluate the model performance including BLEU, ROUGE, and METEOR following [Edwards et al., 2022]. We fine-tune BioMedGPT-10B using the same prompts as Table 1. The fine-tuning procedure consists of 50 epochs with a learning rate of $7\times10^{-5}$ and a batch size of 24, and we freeze the parameters of the language model to reduce computation cost. We also evaluate the performance of Llama2-7B-Chat by filling the molecule SMILES string into the prompt
实验设置
我们参照 [Edwards et al., 2022] 评估模型性能,包括 BLEU、ROUGE 和 METEOR。使用与表 1 相同的提示词对 BioMedGPT-10B 进行微调,微调过程包含 50 个训练周期 (epoch),学习率为 $7\times10^{-5}$,批量大小为 24,并冻结大语言模型的参数以降低计算成本。我们还通过将分子 SMILES 字符串填入提示词
Evaluation Table 3 shows the experimental results on the test set of the ChEBI-20 dataset. Comparing with ChatGPT and Llama2-7B-Chat, the substantial performance enhancement of BioMedGPT-10B demonstrates the importance of multi-modal alignment and translation. Despite of their potency, general-purpose LLMs lack the capacity to directly interpret molecule language.
评估
表 3 展示了在 ChEBI-20 数据集测试集上的实验结果。与 ChatGPT 和 Llama2-7B-Chat 相比,BioMedGPT-10B 的显著性能提升证明了多模态对齐 (multi-modal alignment) 和翻译的重要性。尽管通用大语言模型能力强大,但它们缺乏直接解析分子语言的能力。
The cross-modal alignment mechanism of BioMedGPT-10B not only facilitates the model’s comprehension of the semantic aspects of molecular language but also leverages its robust language modeling capability to effectively translate molecular language into human language, providing a flexible tool for experts and non-experts to grasp the fundamental knowledge of a molecule.
BioMedGPT-10B的跨模态对齐机制不仅增强了模型对分子语言语义层面的理解,还利用其强大的语言建模能力,将分子语言有效转化为人类语言,为专家和非专业人士掌握分子基础知识提供了灵活工具。
Table 3: Performance comparison on molecule QA.
| Method | Alignment | BLEU-2 | BLEU-4 | ROUGE-1 | ROUGE-2 | ROUGE-L | MEATOR |
| ChatGPT [Li et al., 2023] | w/o | 0.103 | 0.050 0.009 | 0.261 | 0.088 | 0.204 | 0.161 |
| Llama2-7B-Chat BioMedGPT-10B | w/ | 0.075 | 0.141 | 0.184 | 0.043 | 0.142 | 0.149 |
| 0.234 | 0.386 | 0.206 | 0.332 | 0.308 |
表 3: 分子问答性能对比
| 方法 | Alignment | BLEU-2 | BLEU-4 | ROUGE-1 | ROUGE-2 | ROUGE-L | MEATOR |
|---|---|---|---|---|---|---|---|
| ChatGPT [Li et al., 2023] | w/o | 0.103 | 0.050 0.009 | 0.261 | 0.088 | 0.204 | 0.161 |
| Llama2-7B-Chat BioMedGPT-10B | w/ | 0.075 | 0.141 | 0.184 | 0.043 | 0.142 | 0.149 |
| 0.234 | 0.386 | 0.206 | 0.332 | 0.308 |
4.3 Protein QA
4.3 蛋白质问答
Protein QA involves generating a text response to a query about a given protein, which is formulated as an amino acid sequence. Protein QA requires the capability to jointly decypher the properties and functions from protein sequences and grasp semantics within questions.
蛋白质问答 (Protein QA) 涉及针对给定蛋白质(以氨基酸序列形式呈现)的查询生成文本响应。该任务需要具备从蛋白质序列中联合解码特性与功能,并理解问题语义的能力。
Dataset We perform the evaluation on the test set of UniProtQA. Details of our dataset are presented in Section 3.2.
数据集
我们在UniProtQA的测试集上进行评估。数据集的详细信息见第3.2节。
Experiment Setup We evaluate the performance with the same evaluation metrics as Molecule QA. Since the multimodal alignment is done by fine-tuning the training set of UniProtQA, we perform testing directly with the same prompt in Table 1. For comparison, we implement two baselines: (1) Vanllina Llama2-7B-Chat, where we fill the prompt
实验设置
我们采用与Molecule QA相同的评估指标来衡量性能。由于多模态对齐是通过微调UniProtQA训练集完成的,我们直接使用表1中的相同提示进行测试。为进行比较,我们实现了两个基线方法:(1) 原始Llama2-7B-Chat,将提示中的
Table 4: The Performance of BioMedGPT-10B on Protein QA.
| Alignment | BLEU-2 | BLEU-4 | ROUGE-1 | ROUGE-2 | ROUGE-L | MEATOR | |
| Llama2-7B-Chat | w/o | 0.019 | 0.002 | 0.103 | 0.060 | 0.009 | 0.052 |
| Llama2-7B-Chat | w/ | 0.344 | 0.313 | 0.705 | 0.711 | 0.593 | 0.707 |
| BioMedGPT-10B | w/ | 0.571 | 0.535 | 0.743 | 0.759 | 0.622 | 0.754 |
表 4: BioMedGPT-10B在蛋白质问答任务中的性能表现
| Alignment | BLEU-2 | BLEU-4 | ROUGE-1 | ROUGE-2 | ROUGE-L | MEATOR | |
|---|---|---|---|---|---|---|---|
| Llama2-7B-Chat | w/o | 0.019 | 0.002 | 0.103 | 0.060 | 0.009 | 0.052 |
| Llama2-7B-Chat | w/ | 0.344 | 0.313 | 0.705 | 0.711 | 0.593 | 0.707 |
| BioMedGPT-10B | w/ | 0.571 | 0.535 | 0.743 | 0.759 | 0.622 | 0.754 |
Evaluation The results of Protein QA are shown in Table 4. Comparisons between two baselines demonstrate that protein sequences exhibit a prominent modality gap with natural language. The challenges in comprehending proteins lead to out-of-order and meaningless responses of general-purpose language models. While aligning protein language with human language serves as an effective solution to address this issue, we observe a significant performance gain of BioMedGPT-10B over Llama2-7B-Chat with alignment, especially in terms of BLEU metrics. This indicates that our incremental training on biomedical corpus can help language models better comprehend and generate professional terminologies.
评估
蛋白质问答(Protein QA)的结果如表4所示。与两个基线模型的对比表明,蛋白质序列与自然语言存在显著模态差异。理解蛋白质的挑战导致通用语言模型产生无序且无意义的响应。虽然将蛋白质语言与人类语言对齐是解决该问题的有效方案,但我们观察到经过对齐训练的BioMedGPT-10B相比Llama2-7B-Chat有显著性能提升,尤其在BLEU指标上。这表明我们在生物医学语料上的增量训练能帮助语言模型更好地理解和生成专业术语。
Further, we corroborate our observations with qualitative analysis in Figure 4, where we query each model to describe the functions of Q9LW62 $^{\ast}$ CKL10_aRATH (EC:2.7.11.1) [Menges et al., 2002] and P52341 $\cdot$ DUT_ HHV7J (EC:3.6.1.23) [Nicholas, 1996]. We observe that the original LLama2-7B-chat model yields the same response, asking for more information about the protein. With feature space alignment, both Llama2-7B-Chat and BioMedGPT-10B generates reasonable function annotations. Benefiting from the vertical domain knowledge attained during incremental fine-tuning, BioMedGPT-10B generates more precise descriptions, recognizing serine/threonine phosphor yl ation’s role of casein kinase in cellular processes, as well as thymine nucleotide metabolism’s role in nucleotide metabolism.
此外,我们通过图4的定性分析进一步验证了观察结果。实验中,我们要求每个模型描述Q9LW62$^{\ast}$CKL10_aRATH (EC:2.7.11.1) [Menges et al., 2002]和P52341$\cdot$DUT_ HHV7J (EC:3.6.1.23) [Nicholas, 1996]的功能。原始LLama2-7B-chat模型给出了相同回应,要求提供更多蛋白质信息。经过特征空间对齐后,Llama2-7B-Chat和BioMedGPT-10B均能生成合理的功能注释。得益于增量微调过程中获取的垂直领域知识,BioMedGPT-10B能生成更精确的描述,识别出丝氨酸/苏氨酸磷酸化在酪蛋白激酶参与细胞过程中的作用,以及胸腺嘧啶核苷酸代谢在核苷酸代谢中的功能。
Establishing a connection between proteins and natural language can provide researchers with richer, more informative, and easily interpret able hints regarding the study of unknown proteins. Furthermore, it can facilitate faster and more accurate protein function annotation.
在蛋白质与自然语言之间建立联系,能为研究人员提供更丰富、信息量更大且易于解读的未知蛋白质研究线索。此外,这还能促进更快速、更准确的蛋白质功能注释。

Figure 4: Cases of Protein QA.
图 4: 蛋白质QA案例。
5 Limitations
5 局限性
Professional Evaluation: In this technical report, we predominantly focus on language-centric measures including BLEU and ROUGE scores to evaluate the quality of generated answers, which may be insufficient to gauge the effectiveness of LLMs in the complex biomedical landscape. The intricacies of biomedical data, ranging from molecular interactions to protein functions, demand researchers to develop more nuanced evaluation metrics to capture the accuracy and relevance of biomedical insights provided by LLMs. Furthermore, introducing expert evaluations from domain specialists offers an invaluable perspective in assessing the aptness of LLMs for real-world biomedical applications.
专业评估:在本技术报告中,我们主要关注以语言为中心的指标,包括BLEU和ROUGE分数,以评估生成答案的质量,这可能不足以衡量大语言模型在复杂生物医学领域中的有效性。从分子相互作用到蛋白质功能等生物医学数据的复杂性,要求研究人员开发更精细的评估指标,以捕捉大语言模型提供的生物医学见解的准确性和相关性。此外,引入领域专家的评估为衡量大语言模型在实际生物医学应用中的适用性提供了宝贵的视角。
Interpret ability: Since LLMs are complex black box models, it is essential to understand the chain of thought behind their generations. Particularly, in assisting biomedical research, the deficiency in interpret ability can significantly hamper the ability to provide scientific insights with soundness.
可解释性:由于大语言模型是复杂的黑箱模型,理解其生成背后的思维链至关重要。特别是在辅助生物医学研究时,可解释性的不足会严重阻碍提供可靠科学见解的能力。
Safety: While large-scale language models serve as a novel technique, their generated outputs are determined by a certain probability distribution, resulting in unforeseen dangers of generating bias, discrimination, or harmful content. Though we have endeavored to reduce the potential risk of BioMedGPT by fine-tuning on meticulously curated English biomedical corpus, it is hard to fully eliminate this problem. It is essential to ensure the responsible and ethical use of BioMedGPT. While BioMedGPT is endowed with expertise in bio medicine and chemistry, we emphasize that it should NOT be employed for research scenarios that endanger human life, and any further real-world applications should undergo cautious and professional supervision and comprehensive experiments. Users need to be cautious and take extra care when using these models.
安全性:尽管大语言模型是一项创新技术,但其生成输出由特定概率分布决定,可能产生偏见、歧视或有害内容等不可预见的风险。虽然我们已通过精心筛选的生物医学英文语料对BioMedGPT进行微调以降低潜在风险,但仍难以完全杜绝该问题。必须确保BioMedGPT的责任伦理使用。虽然BioMedGPT具备生物医药与化学领域的专业知识,但我们强调其不得用于危及人类生命的研究场景,任何实际应用都需经过谨慎专业的监督与全面实验验证。用户使用此类模型时需保持警惕并格外审慎。
6 Conclusions and Future Work
6 结论与未来工作
The advent of foundation models has revolutionized the landscape of AI applications across diverse domains, with BioMedGPT standing as a pioneering multi-modal foundation model in the biomedical domain. This work shed light on the potential of leveraging large generative language models to bridge the gap between the language of life and human natural language, empowering a deeper understanding of fundamental life codes in bio medicine. We introduce BioMedGPT-10B, a model instance of BioMedGPT, which leverages the incremental fine-tuning of large language models to comprehend biomedical documents and aligns the feature spaces of molecules, proteins, and natural language. BioMedGPT-10B allows users to easily communicate with various biomedical modalities using free texts. This capability could greatly accelerate the discovery of novel molecules, and therapeutic targets, and empower a wide range of downstream applications in chemistry and bio medicine. We open-source BioMedGPT-10B as well as the fine-tuned language model BioMedGPT-LM-7B to facilitate future research. We are endeavoring to extend the strong capability of BioMedGPT in bio medicine by designing more reliable evaluation metrics, promoting the interpret ability of large language models, and enforcing safety measures. Hopefully, BioMedGPT would spark the next generation of biomedical research with human and machine intelligence.
基础模型的出现彻底改变了AI在各领域的应用格局,BioMedGPT作为生物医学领域开创性的多模态基础模型应运而生。这项工作揭示了利用大型生成式语言模型弥合生命语言与人类自然语言鸿沟的潜力,助力深化对生物医学基础生命密码的理解。我们推出BioMedGPT-10B——该框架的模型实例,通过大语言模型的增量微调来理解生物医学文献,并实现分子、蛋白质与自然语言特征空间的对齐。BioMedGPT-10B支持用户通过自由文本与多种生物医学模态交互,这一能力将极大加速新分子发现、治疗靶点识别,并赋能化学与生物医学领域的广泛下游应用。我们开源了BioMedGPT-10B及微调语言模型BioMedGPT-LM-7B以促进后续研究。我们正通过设计更可靠的评估指标、提升大语言模型可解释性及强化安全措施,持续扩展BioMedGPT在生物医学领域的强大能力。期待BioMedGPT能推动人机智能协同的新一代生物医学研究。
– 5989, 1996. URL https://api.semantic scholar.org/CorpusID:12112753.
– 5989, 1996. URL https://api.semantic scholar.org/CorpusID:12112753.