MED-FLAMINGO: A MULTIMODAL MEDICAL FEWSHOT LEARNER
MED-FLAMINGO: 多模态医学少样本学习模型
Michael Moor∗1 Qian Huang∗1 Shirley $ Wu^1 $ Michihiro Yasunaga1 Cyril Zakka2 Yash Dalmia1 Eduardo Pontes Reis3 Pranav Rajpurkar4 Jure Leskovec1
Michael Moor∗1 Qian Huang∗1 Shirley $Wu^{1}$ Michihiro Yasunaga1 Cyril Zakka2 Yash Dalmia1 Eduardo Pontes Reis3 Pranav Rajpurkar4 Jure Leskovec1
1 Department of Computer Science, Stanford University, Stanford, USA 2 Department of Car dio thoracic Surgery, Stanford Medicine, Stanford, USA 3Hospital Israelita Albert Einstein, Sao Paulo, Brazil 4 Department of Biomedical Informatics, Harvard Medical School, Boston, USA
1 斯坦福大学计算机科学系,美国斯坦福
2 斯坦福医学院心胸外科,美国斯坦福
3 以色列阿尔伯特·爱因斯坦医院,巴西圣保罗
4 哈佛医学院生物医学信息学系,美国波士顿
ABSTRACT
摘要
Medicine, by its nature, is a multifaceted domain that requires the synthesis of information across various modalities. Medical generative vision-language models (VLMs) make a first step in this direction and promise many exciting clinical applications. However, existing models typically have to be fine-tuned on sizeable down-stream datasets, which poses a significant limitation as in many medical applications data is scarce, necessitating models that are capable of learning from few examples in real-time. Here we propose Med-Flamingo, a multimodal few-shot learner adapted to the medical domain. Based on Open Flamingo-9B, we continue pre-training on paired and interleaved medical image-text data from publications and textbooks. Med-Flamingo unlocks few-shot generative medical visual question answering (VQA) abilities, which we evaluate on several datasets including a novel challenging open-ended VQA dataset of visual USMLE-style problems. Furthermore, we conduct the first human evaluation for generative medical VQA where physicians review the problems and blinded generations in an interactive app. Med-Flamingo improves performance in generative medical VQA by up to $20%$ in clinician’s rating and firstly enables multimodal medical few-shot adaptations, such as rationale generation. We release our model, code, and evaluation app under https://github.com/snap-stanford/med-flamingo.
医学本质上是一个多领域交叉的学科,需要综合多种模态的信息。医学生成式视觉语言模型(VLM)在这一方向上迈出了第一步,并有望实现诸多激动人心的临床应用。然而,现有模型通常需要在下游大型数据集上进行微调,这在数据稀缺的医疗场景中构成重大限制,亟需能够实时从少量样本中学习的模型。为此,我们提出Med-Flamingo——一个适配医疗领域的多模态少样本学习模型。基于Open Flamingo-9B架构,我们继续使用来自医学出版物和教科书的配对及交错医学图文数据进行预训练。Med-Flamingo解锁了少样本生成式医学视觉问答(VQA)能力,我们在多个数据集上进行了评估,包括新构建的开放式USMLE风格视觉问题挑战集。此外,我们首次开展了生成式医学VQA的医生人工评估:通过交互式应用让医师审核问题并对生成结果进行盲评。Med-Flamingo将生成式医学VQA的临床医生评分最高提升20%,并首次实现多模态医学少样本适应(如诊疗依据生成)。我们在https://github.com/snap-stanford/med-flamingo发布了模型、代码和评估应用。
1 INTRODUCTION
1 引言
Large, pre-trained models (or foundation models) have demonstrated remarkable capabilities in solving an abundance of tasks by being provided only a few labeled examples as context Bommasani et al. (2021). This is known as in-context learning Brown et al. (2020), through which a model learns a task from a few provided examples specifically during prompting and without tuning the model parameters. In the medical domain, this bears great potential to vastly expand the capabilities of existing medical AI models Moor et al. (2023). Most notably, it will enable medical AI models to handle the various rare cases faced by clinicians every day in a unified way, to provide relevant rationales to justify their statements, and to easily customize model generations to specific use cases.
大型预训练模型(或基础模型)通过仅提供少量标注示例作为上下文,已展现出解决大量任务的卓越能力 [Bommasani et al., 2021]。这种方法被称为上下文学习 [Brown et al., 2020],模型在提示过程中从少量提供的示例中学习任务,而无需调整模型参数。在医疗领域,这具有极大潜力来显著扩展现有医疗AI模型的能力 [Moor et al., 2023]。最值得注意的是,它将使医疗AI模型能够以统一方式处理临床医生每天面临的各种罕见病例,提供相关依据来支持其陈述,并轻松针对特定用例定制模型生成内容。
Implementing the in-context learning capability in a medical setting is challenging due to the inherent complexity and multi modality of medical data and the diversity of tasks to be solved.
在医疗环境中实现上下文学习能力具有挑战性,这源于医疗数据固有的复杂性和多模态特性,以及需要解决任务的多样性。
Previous efforts to create multimodal medical foundation models, such as ChexZero Tiu et al. (2022) and BiomedCLIP Zhang et al. (2023a), have made significant strides in their respective domains. ChexZero specializes in chest $\boldsymbol{\mathrm X}$ -ray interpretation, while BiomedCLIP has been trained on more diverse images paired with captions from the biomedical literature. Other models have also been developed for electronic health record (EHR) data Steinberg et al. (2021) and surgical videos Kiyasseh et al. (2023). However, none of these models have embraced in-context learning for the multimodal medical domain. Existing medical VLMs, such as MedVINT Zhang et al. (2023b), are typically trained on paired image-text data with a single image in the context, as opposed to more general streams of text that are interleaved with multiple images. Therefore, these models were not designed and tested to perform multimodal in-context learning with few-shot examples1
先前在构建多模态医学基础模型方面的努力,如ChexZero Tiu等人 (2022) 和BiomedCLIP Zhang等人 (2023a),已在各自领域取得显著进展。ChexZero专精于胸部$\boldsymbol{\mathrm X}$光片解读,而BiomedCLIP则通过生物医学文献中的多样化图像与配对说明进行训练。其他模型也针对电子健康记录(EHR)数据 Steinberg等人 (2021) 和手术视频 Kiyasseh等人 (2023) 进行了开发。然而,这些模型均未采用多模态医学领域的上下文学习技术。现有医学视觉语言模型(VLM),如MedVINT Zhang等人 (2023b),通常仅在单图像上下文中训练图文配对数据,而非处理穿插多张图像的通用文本流。因此,这些模型在设计之初未考虑少样本情况下的多模态上下文学习能力测试。
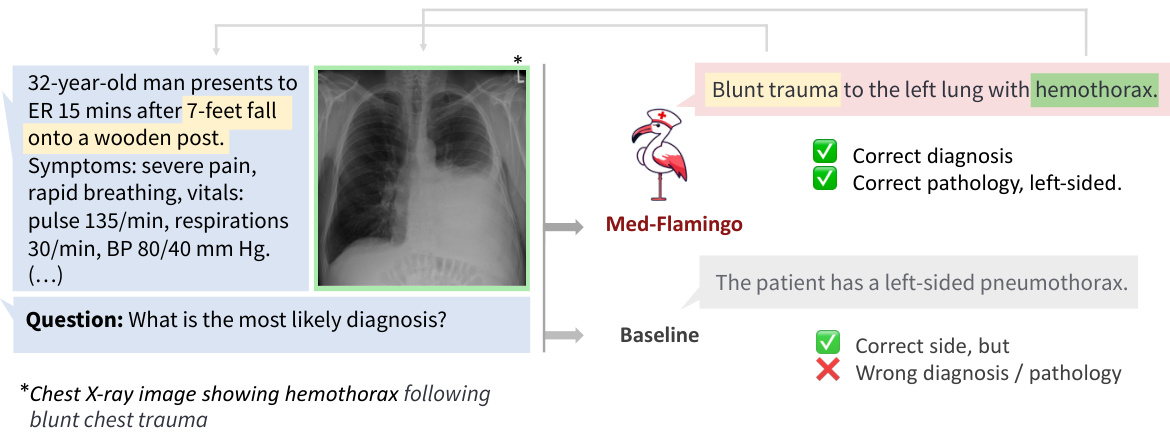
Figure 1: Example of how Med-Flamingo answers complex multimodal medical questions by generating open-ended responses conditioned on textual and visual information.
图 1: Med-Flamingo 如何通过基于文本和视觉信息生成开放式回答来处理复杂多模态医学问题的示例。
Here, we propose Med-Flamingo, the first medical foundation model that can perform multimodal incontext learning specialized for the medical domain. Med-Flamingo is a vision-language model based on Flamingo (Alayrac et al., 2022) that can naturally ingest data with interleaved modalities (images and text), to generate text conditioned on this multimodal input. Building on the success of Flamingo, which was among the first vision-language models to exhibit in-context learning and few-shot learning abilities, Med-Flamingo extends these capabilities to the medical domain by pre-training on multimodal knowledge sources across medical disciplines. In preparation for the training of Med-Flamingo, our initial step involved constructing a unique, interleaved image-text dataset, which was derived from an extensive collection of over $4K$ medical textbooks (Section 3). Given the critical nature of accuracy and precision within the medical field, it is important to note that the quality, reliability, and source of the training data can considerably shape the results. Therefore, to ensure accuracy in medical facts, we meticulously curated our dataset from respected and authoritative sources of medical knowledge, as opposed to relying on potentially unreliable web-sourced data.
在此,我们提出Med-Flamingo,这是首个能够执行医学领域专用多模态上下文学习的医学基础模型。Med-Flamingo是基于Flamingo (Alayrac等人,2022) 的视觉语言模型,可自然地处理交错模态 (图像和文本) 数据,并根据这种多模态输入生成文本。Flamingo作为首批展现上下文学习和少样本学习能力的视觉语言模型之一取得了成功,而Med-Flamingo通过跨医学学科的多模态知识源进行预训练,将这些能力扩展到医学领域。在准备训练Med-Flamingo时,我们的初始步骤是构建一个独特的交错图文数据集,该数据集源自超过4K本医学教科书的广泛收集 (第3节)。鉴于医学领域对准确性和精确性的严格要求,必须注意训练数据的质量、可靠性和来源会显著影响结果。因此,为确保医学事实的准确性,我们精心从受尊敬且权威的医学知识来源中筛选数据集,而非依赖可能不可靠的网络数据。
In our experiments, we evaluate Med-Flamingo on generative medical visual questionanswering (VQA) tasks by directly generating open-ended answers, as opposed to scoring artificial answer options ex post–as CLIP-based medical vision-language models do. We design a new realistic evaluation protocol to measure the model generations’ clinical usefulness. For this, we conduct an in-depth human evaluation study with clinical experts which results in a human evaluation score that serves as our main metric. In addition, due to existing medical VQA datasets being narrowly focused on image interpretation among the specialties of radiology and pathology, we create Visual USMLE, a challenging generative VQA dataset of complex USMLE-style problems across specialties, which are augmented with images, case vignettes, and potentially with lab results.
在我们的实验中,我们通过直接生成开放式答案来评估Med-Flamingo在生成式医学视觉问答(VQA)任务上的表现,这与基于CLIP的医学视觉语言模型事后对人工答案选项进行评分的方式不同。我们设计了一种新的现实评估方案来衡量模型生成的临床实用性。为此,我们与临床专家进行了深入的人工评估研究,得出人工评估分数作为我们的主要指标。此外,由于现有的医学VQA数据集主要集中在放射学和病理学专业的图像解读上,我们创建了Visual USMLE,这是一个具有挑战性的生成式VQA数据集,包含跨专业的复杂USMLE风格问题,这些问题配有图像、病例摘要,并可能包含实验室结果。
Averaged across three generative medical VQA datasets, few-shot prompted Med-Flamingo achieves the best average rank in clinical evaluation score (rank of 1.67, best prior model has 2.33), indicating that the model generates answers that are most preferred by clinicians, with up to $20%$ improvement over prior models. Furthermore, Med-Flamingo is capable of performing medical reasoning, such as answering complex medical questions (such as visually grounded USMLE-style questions) and providing explanations (i.e., rationales), a capability not previously demonstrated by other multimodal medical foundation models. However, it is important to note that Med-Flamingo’s performance may be limited by the availability and diversity of training data, as well as the complexity of certain medical tasks. All investigated models and baselines would occasionally hallucinate or generate low-quality responses. Despite these limitations, our work represents a significant step forward in the development of multimodal medical foundation models and their ability to perform multimodal in-context learning in the medical domain. We release the Med-Flamingo-9B checkpoint for further research, and
在三个生成式医学VQA数据集上的平均结果显示,采用少样本提示的Med-Flamingo在临床评估得分中取得了最佳平均排名(排名1.67,此前最佳模型为2.33),表明该模型生成的答案最受临床医生青睐,相比先前模型提升高达20%。此外,Med-Flamingo能够执行医学推理任务,例如回答复杂医学问题(如基于视觉的USMLE风格试题)并提供解释(即原理阐述),这是其他多模态医学基础模型此前未展示的能力。但需注意,Med-Flamingo的性能可能受限于训练数据的可获得性、多样性以及某些医学任务的复杂性。所有被研究的模型和基线方法偶尔会出现幻觉或生成低质量回答。尽管存在这些局限,我们的工作标志着多模态医学基础模型发展及其在医学领域执行多模态上下文学习能力的重要进步。我们发布了Med-Flamingo-9B检查点以供进一步研究。
1. Multimodal pre-training on medical literature
1. 基于医学文献的多模态预训练
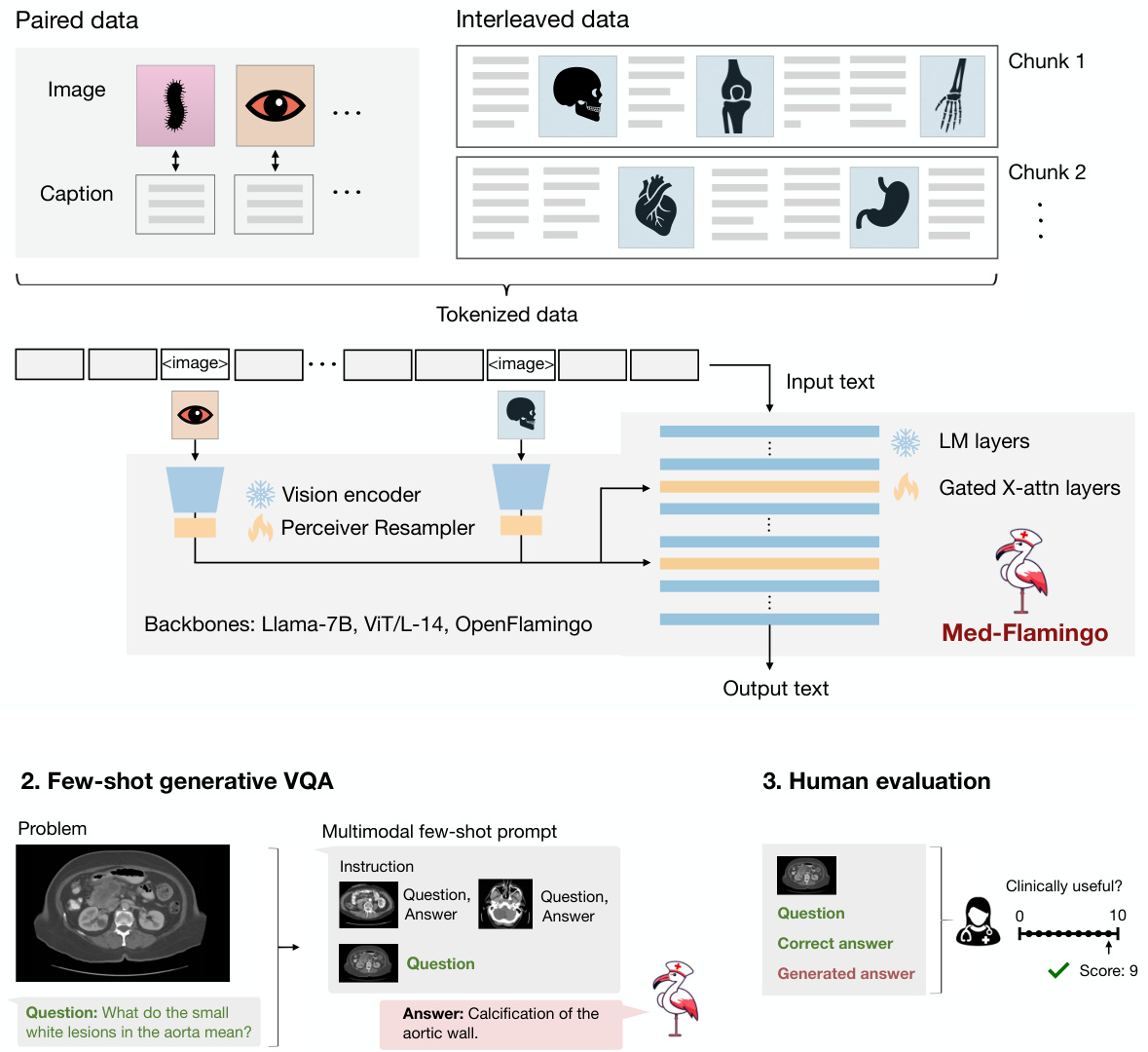
Figure 2: Overview of the Med-Flamingo model and the three steps of our study. First, we pre-train our Med-Flamingo model using paired and interleaved image-text data from the general medical domain (sourced from publications and textbooks). We initialize our model at the Open Flamingo checkpoint continue pre-training on medical image-text data. Second, we perform few-shot generative visual question answering (VQA). For this, we leverage two existing medical VQA datasets, and a new one, Visual USMLE. Third, we conduct a human rater study with clinicians to rate generations in the context of a given image, question and correct answer. The human evaluation was conducted with a dedicated app and results in a clinical evaluation score that serves as our main metric for evaluation.
图 2: Med-Flamingo 模型概览及研究三阶段。首先,我们使用通用医学领域(来自出版物和教科书)的配对及交错图文数据对 Med-Flamingo 模型进行预训练,该模型基于 Open Flamingo 检查点初始化并持续在医学图文数据上预训练。其次,我们执行少样本生成式视觉问答(VQA),利用两个现有医学 VQA 数据集及新构建的 Visual USMLE 数据集。最后,我们邀请临床医生通过专用应用程序对给定图像、问题和正确答案背景下的生成结果进行人工评分,产生的临床评估分数作为主要评估指标。
make our code available under https://github.com/snap-stanford/med-flamingo. In summary, our paper makes the following contributions:
我们的代码可在 https://github.com/snap-stanford/med-flamingo 获取。总的来说,本文做出了以下贡献:
2 RELATED WORKS
2 相关工作
The success of large language models (LLMs) Brown et al.; Liang et al. (2022); Qin et al. (2023) has led to significant advancements in training specialized models for the medical domain. This has resulted in the emergence of various models, including BioBERT Lee et al. (2020), Clinic alBERT Huang et al. (2019), PubMedBERT Gu et al. (2021), Bio Link BERT Yasunaga et al. (b), DRAGON Yasunaga et al. (a), BioMedLM Bolton et al., BioGPT Luo et al. (2022), and Med-PaLM Singhal et al.. Although these medical language models are typically smaller than general-purpose LLMs like GPT-3 Brown et al., they can match or even surpass their performance on medical tasks, such as medical question answering.
大语言模型 (LLMs) [Brown et al.; Liang et al. (2022); Qin et al. (2023)] 的成功推动了医疗领域专用模型的显著进展。这催生了多种模型的出现,包括 BioBERT [Lee et al. (2020)]、ClinicalBERT [Huang et al. (2019)]、PubMedBERT [Gu et al. (2021)]、BioLinkBERT [Yasunaga et al. (b)]、DRAGON [Yasunaga et al. (a)]、BioMedLM [Bolton et al.]、BioGPT [Luo et al. (2022)] 以及 Med-PaLM [Singhal et al.]。尽管这些医疗语言模型通常比通用大语言模型 (如 GPT-3 [Brown et al.]) 规模更小,但它们在医疗任务 (如医学问答) 上的表现可与之匹敌甚至更优。
Recently, there has been a growing interest in extending language models to handle vision-language multimodal data and tasks Su et al. (2019); Ramesh et al.; Alayrac et al. (2022); Aghajanyan et al.; Yasunaga et al. (2023). Furthermore, many medical applications involve multimodal information, such as radiology tasks that require the analysis of both X-ray images and radiology reports Tiu et al. (2022). Motivated by these factors, we present a medical vision-language model (VLM). Existing medical VLMs include BiomedCLIP Zhang et al. (2023a), MedVINT Zhang et al. (2023b). While BiomedCLIP is an encoder-only model, our focus lies in developing a generative VLM, demonstrating superior performance compared to MedVINT. Finally, Llava-Med is another recent medical generative VLM Li et al. (2023), however the model was not yet available for benchmarking.
近来,将语言模型扩展到处理视觉-语言多模态数据和任务的研究兴趣日益增长 [Su et al., 2019; Ramesh et al.; Alayrac et al., 2022; Aghajanyan et al.; Yasunaga et al., 2023]。此外,许多医学应用涉及多模态信息,例如需要同时分析X光影像和放射学报告的放射科任务 [Tiu et al., 2022]。基于这些因素,我们提出了一种医学视觉-语言模型 (VLM)。现有医学VLM包括BiomedCLIP [Zhang et al., 2023a] 和MedVINT [Zhang et al., 2023b]。虽然BiomedCLIP是仅编码器模型,我们的重点在于开发生成式VLM,其表现优于MedVINT。最后,Llava-Med是另一个近期提出的医学生成式VLM [Li et al., 2023],但该模型尚未可用于基准测试。
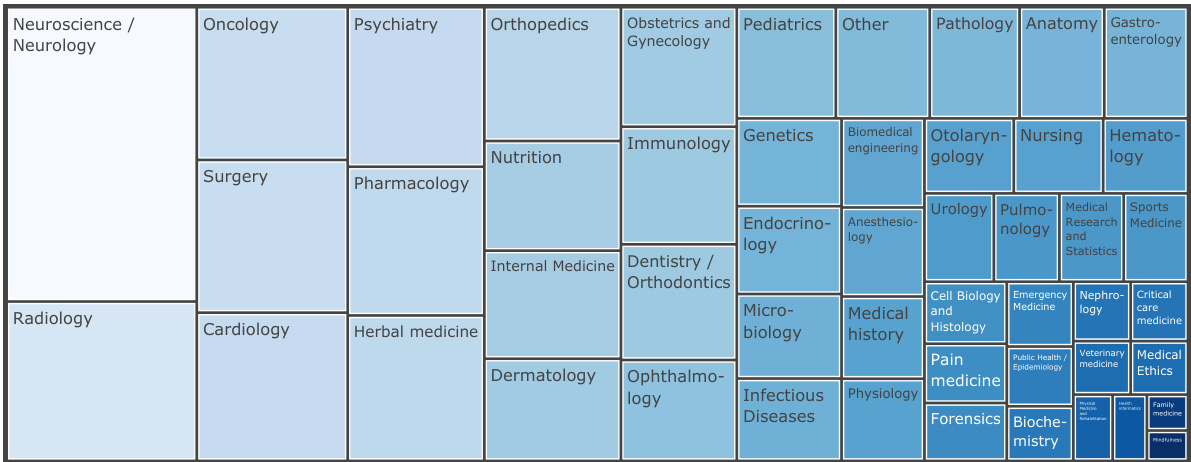
Figure 3: Overview of the distribution of medical textbook categories of the MTB dataset. We classify each book title into one of the 49 manually created categories or ”other” using the Claude-1 model.
图 3: MTB数据集医学教科书类别分布概览。我们使用Claude-1模型将每本书名分类到49个人工创建的类别或"其他"类别中。
3 MED-FLAMINGO
3 MED-FLAMINGO
To train a Flamingo model adapted to the medical domain, we leverage the pre-trained Open Flamingo9B model checkpoint Awadalla et al. (2023), which is a general-domain VLM that was built on top
为了训练一个适应医疗领域的Flamingo模型,我们利用了预训练的Open Flamingo9B模型检查点Awadalla等人(2023)。该模型是基于通用领域视觉语言模型(VLM)构建的。
of the frozen language model LLaMA-7B Touvron et al. (2023) and frozen vision encoder CLIP ViT/L-14 Radford et al.. We perform continued pre-training in the medical domain which results in the model we refer to as Med-Flamingo.
冻结的语言模型LLaMA-7B Touvron等人 (2023) 和冻结的视觉编码器CLIP ViT/L-14 Radford等人。我们在医学领域进行了持续预训练,最终得到称为Med-Flamingo的模型。
3.1 DATA
3.1 数据
We pre-train Med-Flamingo by jointly training on interleaved image-text data and paired image-text data. As for the interleaved dataset, we created a interleaved dataset from a set of medical textbooks, which we subsequently refer to as MTB. As for the paired datasets, we used PMC-OA Lin et al. (2023).
我们通过联合训练交错图文数据和配对图文数据对Med-Flamingo进行预训练。对于交错数据集,我们从一系列医学教科书中创建了一个交错数据集,后续简称为MTB。至于配对数据集,我们使用了PMC-OA (Lin et al., 2023)。
MTB We construct a new multimodal dataset from a set of 4 721 textbooks from different medical specialties (see Figure 3). During preprocessing, each book is first converted from PDF to HTML with all tags removed, except the image tags are converted to tokens. We then carry out data cleaning via de duplication and content filtering. Finally, each book with cleaned text and images is then chopped into segments for pre training so that each segment contains at least one image and up to 10 images and a maximum length. In total, MTB consists of approximately $0.8\mathbf{M}$ images and 584M tokens. We use $95%$ of the data for training and $5%$ of the data for evaluation during the pre-training.
MTB
我们从4,721本不同医学专业的教材中构建了一个新的多模态数据集(参见图3)。预处理阶段,每本书首先从PDF转换为HTML格式并移除所有标签,仅保留图像标签并转换为 token。随后通过去重和内容过滤进行数据清洗。最终,每本经过清洗的含图文教材被切分为预训练片段,确保每个片段包含1至10张图像及最大长度文本。MTB数据集总计包含约$0.8\mathbf{M}$张图像和5.84亿token,其中$95%$数据用于预训练,$5%$用于评估。
PMC-OA We adopt the PMC-OA dataset Lin et al. (2023) which is a biomedical dataset with 1.6M image-caption pairs collected from PubMed Central’s OpenAccess subset. We use 1.3M image-caption pairs for training and 0.16M pairs for evaluation following the public split .
PMC-OA
我们采用PMC-OA数据集[20],这是一个包含160万张生物医学图像-标题对的集合,数据来自PubMed Central的开放获取子集。按照公开划分标准,我们使用130万对数据进行训练,16万对数据进行评估。
3.2 OBJECTIVES
3.2 目标
We follow the original Flamingo model approach Alayrac et al., which considers the following language modelling problem:
我们遵循原始Flamingo模型方法Alayrac等人[20]的思路,考虑以下语言建模问题:
$$
p\left(y_ {\ell}\mid x_ {<\ell},y_ {<\ell}\right)=\prod_ {\ell=1}^{L}p\left(y_ {\ell}\mid y_ {<\ell},x_ {<\ell}\right),
$$
$$
p\left(y_ {\ell}\mid x_ {<\ell},y_ {<\ell}\right)=\prod_ {\ell=1}^{L}p\left(y_ {\ell}\mid y_ {<\ell},x_ {<\ell}\right),
$$
where $y_ {\ell}$ refers to the $\ell$ -th language token, $y<\ell$ to the set of preceding language tokens, and $x_ {<\ell}$ to the set of preceding visual tokens. As we focus on modelling the medical literature, here we consider only image-text data (i.e., no videos).
其中 $y_ {\ell}$ 表示第 $\ell$ 个语言 token,$y<\ell$ 表示前面的语言 token 集合,$x_ {<\ell}$ 表示前面的视觉 token 集合。由于我们专注于医学文献建模,此处仅考虑图文数据(即不包含视频)。
Following Alayrac et al., we minimize a joint objective $\mathcal{L}$ over paired and interleaved data:
根据 Alayrac 等人的研究,我们在配对和交错数据上最小化联合目标 $\mathcal{L}$:
$$
\mathcal{L}=\mathbb{E}_ {(x,y)\sim D_ {p}}\left[-\sum_ {\ell=1}^{L}\log p\left(y_ {\ell}\mid y_ {<\ell},x_ {<\ell}\right)\right]+\lambda\cdot\mathbb{E}_ {(x,y)\sim D_ {i}}\left[-\sum_ {\ell=1}^{L}\log p\left(y_ {\ell}\mid y_ {<\ell},x_ {<\ell}\right)\right],
$$
$$
\mathcal{L}=\mathbb{E}_ {(x,y)\sim D_ {p}}\left[-\sum_ {\ell=1}^{L}\log p\left(y_ {\ell}\mid y_ {<\ell},x_ {<\ell}\right)\right]+\lambda\cdot\mathbb{E}_ {(x,y)\sim D_ {i}}\left[-\sum_ {\ell=1}^{L}\log p\left(y_ {\ell}\mid y_ {<\ell},x_ {<\ell}\right)\right],
$$
where $D_ {p}$ and $D_ {i}$ stand for the paired and interleaved dataset, respectively. In our case, we use $\lambda=1$
其中 $D_ {p}$ 和 $D_ {i}$ 分别表示配对数据集和交错数据集。在我们的案例中,使用 $\lambda=1$
3.3 TRAINING
3.3 训练
We performed multi-gpu training on a single node with $8\mathbf{x}80\mathbf{G}\mathbf{B}$ NVIDIA A100 GPUs. We trained the model using DeepSpeed ZeRO Stage 2: Optimizer states and gradients are sharded across devices. To further reduce memory load, we employed the 8-bit AdamW optimizer as well as the memory-efficient attention implementation of PyTorch 2.0. Med-Flamingo was initialized at the checkpoint of the Open-Flamingo model and then pre-trained for 2700 steps (or 6.75 days in wall time, including the validation steps), using 50 gradient accumulation steps and a per-device batch size of 1, resulting in a total batch size of 400. The model has $1.3B$ trainable parameters (gated cross attention layers and perceiver layers) and roughly $^{7B}$ frozen parameters (decoder layers and vision encoder), which results in a total of $8.3B$ parameters. Note that this is the same number parameters as in the Open Flamingo-9B model (version 1).
我们在单节点上使用8块80GB NVIDIA A100 GPU进行多GPU训练。采用DeepSpeed ZeRO Stage 2策略:优化器状态和梯度在设备间分片存储。为降低内存负载,使用了8位AdamW优化器及PyTorch 2.0的高效注意力实现。Med-Flamingo基于Open-Flamingo模型检查点初始化,经过2700步预训练(含验证步骤,实际耗时6.75天),采用50步梯度累积和单设备批量大小1,总批量达400。模型包含13亿可训练参数(门控交叉注意力层和感知器层)与约70亿冻结参数(解码层和视觉编码器),总参数量达83亿。需注意该参数量与Open Flamingo-9B模型(版本1)保持相同。
4 EVALUATION
4 评估
4.1 AUTOMATIC EVALUATION
4.1 自动评估
Baselines To compare generative VQA abilities against the literature, we consider different variants of the following baselines:
基线方法
为比较生成式VQA能力与现有研究的差异,我们考虑了以下基线方法的不同变体:
Evaluation datasets To evaluate our model and compare it against the baselines, we leverage two existing VQA datasets from the medical domain (VQA-RAD and PathVQA). Upon closer inspection of the VQA-RAD dataset, we identified severe data leakage in the official train / test splits, which is problematic given that many recent VLMs fine-tune on the train split. To address this, we created a custom train / test split by seperately splitting images and questions (each $90%/10%)$ to ensure that no image or question of the train split leaks into the test split. On these datasets, 6 shots were used for few-shot.
评估数据集
为评估我们的模型并与基线方法进行比较,我们采用了医疗领域的两个现有VQA数据集(VQA-RAD和PathVQA)。在仔细检查VQA-RAD数据集时,我们发现官方训练/测试划分存在严重的数据泄漏问题,考虑到近期许多视觉语言模型(VLM)都在训练集上进行微调,这一问题尤为突出。为此,我们通过分别划分图像和问题(各占$90%/10%$)创建了自定义的训练/测试划分,确保训练集中的任何图像或问题都不会泄漏到测试集中。在这些数据集上,我们采用6样本进行少样本学习。
Furthermore, we create Visual USMLE, a challenging multimodal problem set of 618 USMLE-style questions which are not only augmented with images but also with a case vignette and potentially tables of laboratory measurements. The Visual USMLE dataset was created by adapting problems from the Amboss platform (using licenced user access). To make the Visual USMLE problems more actionable and useful, we rephrased the problems to be open-ended instead of multiple-choice. This makes the benchmark harder and more realistic, as the models have to come up with differential diagnoses and potential procedures completely on their own—as opposed to selecting the most reasonable answer choice from few choices. Figure 8 gives an overview of the broad range of specialties that are covered in the dataset, greatly extending existing medical VQA datasets which are narrowly focused on radiology and pathology. For this comparatively small dataset, instead of creating a training split for finetuning, we created a small train split of 10 problems which can be used for few-shot prompting. For this dataset (with considerably longer problems and answers), we used only 4 shots to fit in the context window.
此外,我们创建了Visual USMLE——一个包含618道USMLE风格问题的多模态难题集,这些问题不仅配有图像增强,还包含病例摘要和可能的实验室测量数据表。该数据集通过改编Amboss平台上的题目(使用授权用户访问权限)构建而成。为了使Visual USMLE问题更具可操作性和实用性,我们将问题改写为开放式而非选择题形式。这使得基准测试更具挑战性和真实性,因为模型需要完全自主提出鉴别诊断和潜在诊疗方案,而非从有限选项中选择最合理的答案。图8展示了该数据集涵盖的广泛专科领域,极大拓展了现有仅聚焦于放射学和病理学的医学视觉问答数据集。针对这个相对小规模的数据集,我们没有创建用于微调的训练集分割,而是构建了包含10道题的少量训练集,可用于少样本提示。对于该数据集(问题和答案长度显著更长),我们仅使用4个样本以适应上下文窗口。
Evaluation metrics Previous works in medical vision-language modelling typically focused scoring all available answers of a VQA dataset to arrive at a classification accuracy. However, since we are interested in generative VQA (as opposed to post-hoc scoring different potential answers), for sake of clinical utility, we employ the following evaluation metrics that directly assess the quality of the generated answer:
评估指标
以往在医学视觉语言建模中的研究通常侧重于对视觉问答(VQA)数据集的所有可用答案进行评分,以得出分类准确率。然而,由于我们关注的是生成式VQA (与事后评分不同潜在答案相对),出于临床实用性考虑,我们采用以下直接评估生成答案质量的指标:
4.2 HUMAN EVALUATION
4.2 人工评估
We implemented a human evaluation app using Streamlit to visually display the generative VQA problems for clinical experts to rate the quality of the generated answers with scores from 0 to 10. Figure 4 shows an examplary view of the app. For each VQA problem, the raters are provided with the image, the question, the correct answer, and a set of blinded generations (e.g., appearing as ”prediction 1” in Figure 4), that appear in randomized order.
我们使用Streamlit实现了一个人工评估应用,以可视化方式展示生成式VQA问题,供临床专家对生成答案的质量进行0到10分的评分。图4展示了该应用的示例界面。针对每个VQA问题,评估者会看到图像、问题、正确答案以及一组盲审生成结果(如图4中显示的"prediction 1"),这些生成结果以随机顺序呈现。

Figure 4: Illustration of our Human evaluation app that we created for clinical experts to evaluate generated answers.
图 4: 我们为临床专家创建的人工评估应用界面示意图,用于评估生成的答案。
4.3 DE DUPLICATION AND LEAKAGE
4.3 去重与泄漏
During the evaluation of the Med-Flamingo model, we were concerned that there may be leakage between the pre-training datasets (PMC-OA and MTB) and the down-stream VQA datasets used for evaluation; this could inflate judgements of model quality, as the model could memorize imagequestion-answer triples.
在评估 Med-Flamingo 模型时,我们担心预训练数据集 (PMC-OA 和 MTB) 与用于评估的下游 VQA 数据集之间可能存在泄漏;这可能会夸大对模型质量的判断,因为模型可能记住了图像-问题-答案三元组。
To alleviate this concern, we performed data de duplication based upon pairwise similarity between images from our pre-training datasets and the images from our evaluation benchmarks. To detect similar images, in spite of perturbations due to cropping, color shifts, size, etc, we embedded the images using Google’s Vision Transformer, preserving the last hidden state as the resultant embedding Do sov it ski y et al. (2021). We then found the $\mathbf{k}$ -nearest neighbors to each evaluation image from amongst the pre-training images (using the FAISS library) Johnson et al. (2019). We then sorted and visualized image-image pairs by least euclidean distance; we found that images might be duplicates until a pairwise distance of around 80; beyond this point, there were no duplicates.
为了缓解这一担忧,我们基于预训练数据集图像与评估基准图像之间的两两相似性进行了数据去重。为了检测相似图像(尽管存在裁剪、色彩偏移、尺寸等干扰因素),我们使用谷歌的Vision Transformer对图像进行嵌入处理,保留最后一层隐藏状态作为结果嵌入 (Do sov it ski y et al., 2021)。随后,我们从预训练图像中为每张评估图像找到$\mathbf{k}$个最近邻 (使用FAISS库) (Johnson et al., 2019)。接着按最小欧氏距离对图像对进行排序和可视化;发现当两图距离小于80时可能存在重复,超过该阈值则无重复样本。
This process revealed that the pre training datasets leaked into the PVQA evaluation benchmark. Out of 6700 total images in PVQA test set, we judged 194 to be highly similar to images in the pre training datasets, and thus, we removed them from our down-stream evaluation.
这一过程揭示了预训练数据集泄露到PVQA评估基准中的情况。在PVQA测试集的6700张图片中,我们判定有194张与预训练数据集中的图片高度相似,因此在下游评估中移除了这些图片。
5 RESULTS
5 结果
In our experiments, we focus on generative medical visual question answering (VQA). While recent medical VLMs predominantly performed VQA in a non-generative but rather disc rim i native manner (i.e., by scoring different answer choices), we believe that this ex-post classification to carry less clinical usefulness, than directly generating responses. On the other hand, generative VQA is more challenging to evaluate, as automated metrics suffer from significant limitations as they do not fully capture the domain-specific context. Thus, we perform a human evaluation study where clinical experts review model generations (blinded) and score them (between 0 and 10) in terms of clinical usefulness.
在我们的实验中,我们专注于生成式医学视觉问答 (VQA)。虽然近期的医学视觉语言模型 (VLM) 主要以非生成式而是判别式的方式执行 VQA (即通过评分不同答案选项),但我们认为这种事后分类的临床实用性低于直接生成回答。另一方面,生成式 VQA 的评估更具挑战性,因为自动化指标存在显著局限性,无法完全捕捉特定领域的上下文。因此,我们进行了人工评估研究,由临床专家盲审模型生成结果,并根据临床实用性对其进行评分 (0 到 10 分)。

Figure 5: Multimodal medical few-shot prompting illustrated with an example. Few-shot prompting here allows users to customize the response format, e.g., to provide rationales for the provided answers. In addition, multimodal few-shot prompts potentially offer the ability to include relevant context retrieved from the medical literature.
图 5: 通过示例展示的多模态医学少样本提示。此处的少样本提示允许用户自定义响应格式,例如为提供的答案给出依据。此外,多模态少样本提示还可能具备整合从医学文献中检索到的相关背景信息的能力。
Conventional VQA datasets Table 1 shows the results for VQA-RAD, the radiological VQA dataset for which we created custom splits to address leakage (see Section4). Med-Flamingo few-shot shows strong results, improving the clinical eval score by $\sim20%$ over the best baseline. In this dataset, the auxiliary metrics are rather aligned with clinical preference. Finetuning the MedVINT baseline did not lead to improved performance on this dataset which may be due to its small size. MedVINT zero-shot outperforms the other zero-shot ablations which may be partially attributed to its instruction tuning step on PMC-VQA.
常规VQA数据集
表1: 展示了VQA-RAD(我们为解决数据泄漏问题而创建定制分割的放射学VQA数据集)的结果(参见第4节)。Med-Flamingo少样本学习表现出强劲性能,将临床评估分数较最佳基线提高了约20%。在该数据集中,辅助指标与临床偏好高度一致。对MedVINT基线进行微调并未提升该数据集上的性能,这可能与其规模较小有关。MedVINT零样本学习优于其他零样本消融实验,这部分归功于其在PMC-VQA数据集上的指令调优步骤。
Table 2 shows for the results for Path-VQA, the pathology VQA dataset. Compared to the other datasets, all models overall perform poorer on the Path-VQA dataset in terms of clinical evaluation score. We hypothesize that this has to do with the fact the models are not pre-trained on actual large-scale and fine-grained pathology image datasets, but only on a rather small amount of pathology literature (which may not be enough to achieve strong performance). For instance, Figure 3 shows that only a small fraction of our training data covers pathology. In the automated metrics (BERT-sim and exact-match), Med-Flamingo improves upon the Open Flamingo baseline, however the overall quality does not improve (as seen in the clinical evaluation score). MedVINT was fine-tuned on a sizeable training split which results in strong automated metrics, but did not result in a clinical evaluation score that matches any Flamingo variant.
表2展示了病理学视觉问答(Path-VQA)数据集的结果。与其他数据集相比,所有模型在临床评估分数上的表现整体较差。我们推测这与模型未在真实的大规模细粒度病理图像数据集上进行预训练有关,而仅基于少量病理学文献(这可能不足以实现强劲性能)。例如,图3显示我们的训练数据中只有一小部分涉及病理学内容。在自动化指标(BERT相似度和精确匹配)方面,Med-Flamingo较Open Flamingo基线有所提升,但整体质量并未改善(如临床评估分数所示)。MedVINT在较大规模的训练集上进行了微调,因此自动化指标表现强劲,但临床评估分数未能达到任何Flamingo变体的水平。
Table 1: Performance metrics on the VQA-Rad dataset. Best scores are shown in bold. We put emphasis on the clinical evaluation score. BERT-sim may not fully capture the fine-grained medical details. Exact-match is quite noisy and brittle, but conservative. The fine-tuned baseline did not improve over zero-shot which could be explained by the small dataset size in combination with our custom splits which were created to prevent leakage.
| VQA-RAD | Clinicaleval.score | BERT-sim | Exact-match |
| MedVINTzero-shot | 4.63 | 0.628 | 0.167 |
| MedVINT fine-tuned ( 2K samples) | 2.87 | 0.611 | 0.133 |
| OpenFlamingoz zero-shot | 4.39 | 0.490 | 0.000 |
| OpenFlamingofew-shot | 4.69 | 0.645 | 0.200 |
| Med-Flamingo zero-shot | 3.82 | 0.480 | 0.000 |
| Med-Flamingof few-shot | 5.61 | 0.650 | 0.200 |
表 1: VQA-Rad数据集上的性能指标。最佳分数以粗体显示。我们重点关注临床评估分数。BERT-sim可能无法完全捕捉细粒度的医学细节。精确匹配(Exact-match)噪声较大且不稳定,但较为保守。微调后的基线模型相比零样本(Zero-shot)没有提升,这可能是因为数据集规模较小,加上我们为防止数据泄露而创建的自定义分割方式所致。
| VQA-RAD | Clinicaleval.score | BERT-sim | Exact-match |
|---|---|---|---|
| MedVINT零样本 | 4.63 | 0.628 | 0.167 |
| MedVINT微调( 2K样本) | 2.87 | 0.611 | 0.133 |
| OpenFlamingo零样本 | 4.39 | 0.490 | 0.000 |
| OpenFlamingo少样本 | 4.69 | 0.645 | 0.200 |
| Med-Flamingo零样本 | 3.82 | 0.480 | 0.000 |
| Med-Flamingo少样本 | 5.61 | 0.650 | 0.200 |
Table 2: Performance metrics on the PathVQA dataset. Best scores are shown in bold. Across models, this dataset showed lowest clinical performance among all evaluation datasets. This highlights a performance deficit in pathology across models, and demonstrates that previous classification-based metrics severely overestimated the performance of general medical VLMs in this specialty.
| Path-VQA | Clinical eval. score | BERT-sim | Exact-match |
| MedVINTzero-shot | 0.13 | 0.608 | 0.272 |
| MedVINT fine-tuned ( 20K samples) | 1.23 | 0.723 | 0.385 |
| OpenFlamingoZ zero-shot | 2.16 | 0.474 | 0.009 |
| OpenFlamingofew-shot | 2.08 | 0.669 | 0.288 |
| Med-Flamingo zero-shot | 1.72 | 0.521 | 0.120 |
| Med-Flamingo few-shot | 1.81 | 0.678 | 0.303 |
表 2: PathVQA数据集上的性能指标。最佳分数以粗体显示。在所有评估数据集中,该数据集显示出各模型最低的临床性能。这突显了病理学领域各模型普遍存在的性能缺陷,并证明此前基于分类的指标严重高估了通用医学视觉语言模型(VLM)在该专科的表现。
| Path-VQA | Clinical eval. score | BERT-sim | Exact-match |
|---|---|---|---|
| MedVINT零样本 | 0.13 | 0.608 | 0.272 |
| MedVINT微调( 20K样本) | 1.23 | 0.723 | 0.385 |
| OpenFlamingo零样本 | 2.16 | 0.474 | 0.009 |
| OpenFlamingo少样本 | 2.08 | 0.669 | 0.288 |
| Med-Flamingo零样本 | 1.72 | 0.521 | 0.120 |
| Med-Flamingo少样本 | 1.81 | 0.678 | 0.303 |
Table 3: Performance metrics on the Visual USMLE dataset. Best scores are shown in bold. Due to rather lenghty correct answers, the Exact-match metric was not informative as it was constantly 0 on this dataset.
| VisualUSMLE | Clinical eval. score | BERT-sim |
| MedVINTzero-shot | 0.41 | 0.421 |
| OpenFlamingozero-shot | 4.31 | 0.512 |
| OpenFlamingofew-shot | 3.39 | 0.470 |
| Med-Flamingo zero-shot | 4.18 | 0.473 |
| Med-Flamingo few-shot | 4.33 | 0.431 |
表 3: Visual USMLE 数据集上的性能指标。最佳分数以粗体显示。由于正确答案较长,完全匹配 (Exact-match) 指标在该数据集上始终为 0,因此不具备参考价值。
| VisualUSMLE | Clinical eval. score | BERT-sim |
|---|---|---|
| MedVINT 零样本 | 0.41 | 0.421 |
| OpenFlamingo 零样本 | 4.31 | 0.512 |
| OpenFlamingo 少样本 | 3.39 | 0.470 |
| Med-Flamingo 零样本 | 4.18 | 0.473 |
| Med-Flamingo 少样本 | 4.33 | 0.431 |
Visual USMLE Table 3 shows the results for the Visual USMLE dataset. Med-Flamingo (fewshot) results in the clinically most prefer r able generations, whereas Open Flamingo (zero-shot) is a close runner-up. As the ground truth answers were rather lengthy paragraphs, exact match was not an informative metric (constant 0 for all methods). The few-shot prompted models lead to lower automated scores than their zero-shot counterparts, which we hypothesize has to do with the fact that the USMLE problems are long (long vignettes as well as long answers) which forced us to summarize the questions and answers when designing few-shot prompts (for which we used GPT-4). Hence, it’s possible that those prompts lead to short answers that in terms of BERT-sim score may differ more from the correct answer than a more wordy zero-shot generation.
视觉USMLE
表3展示了视觉USMLE数据集的结果。Med-Flamingo (少样本)在临床最偏好的生成结果中表现最佳,而Open Flamingo (零样本)紧随其后。由于真实答案均为较长的段落,精确匹配并非有效指标(所有方法均为常数0)。少样本提示模型的自动化得分低于零样本模型,我们推测这与USMLE问题较长(冗长的病例描述和答案)有关,这迫使我们在设计少样本提示时(使用GPT-4)对问题和答案进行了总结。因此,这些提示可能导致生成的答案较短,在BERT相似度评分方面与正确答案的差异可能比更冗长的零样本生成更大。
Across datasets Overall, we find that Med-Flamingo’s multimodal in-domain few-shot learning abilities lead to favorable generative VQA performance, leading to the lowest average rank of 1.67 in terms of clinical evaluation score as averaged across all evaluation datasets. As runner-up, Open Flamingo zero-shot achieves a rank of 2.33.
跨数据集总体而言,我们发现Med-Flamingo的多模态领域内少样本学习能力使其在生成式视觉问答(VQA)任务中表现优异,以1.67的平均临床评估得分在所有评估数据集中排名最低。Open Flamingo的零样本方法以2.33的平均分位列第二。
Qualitative analysis Finally, we showcase few examples of Med-Flamingo generations in more detail in Figures 1,5, and 6. Figure 5 exemplifies that a medical few-shot learner like Med-Flamingo can be prompted to generate rationale for its VQA answer. The shown example is impressive in that the rationale is visually guiding the reader towards the object of interest (calcification of the aortic wall). We note, however, that at this stage, few-shot multimodal prompted rationales may not be robust, especially when a model arrives at a wrong answer.
定性分析
最后,我们在图1、图5和图6中更详细地展示了Med-Flamingo生成的几个示例。图5展示了一个像Med-Flamingo这样的医学少样本学习模型如何被提示生成其视觉问答(VQA)答案的推理过程。该示例令人印象深刻之处在于,其推理过程通过视觉引导读者关注目标对象(主动脉壁钙化)。然而我们注意到,现阶段少样本多模态提示生成的推理可能不够稳健,尤其是当模型得出错误答案时。
Figures 1 and 6 showcase two example problems from the Visual USMLE dataset. The problem descriptions were slightly rephrased and summarized using GPT-4 for display. In Figure 6, MedFlamingo generates the correct answer while not mentioning the underlying diagnosis (urothelial cancer) as it was not asked for. By contrast, we observed baselines to directly diagnose the patient (instead of answering the actual question in a targeted way). The problem in Figure 1 illustrates that Med-Flamingo has the ability to integrate complex medical history information together with visual information to synthesize a comprehensive diagnosis that draws from the information of both modalities.
图1和图6展示了Visual USMLE数据集中的两个示例问题。问题描述经过GPT-4略微改写和总结以便展示。在图6中,MedFlamingo生成了正确答案但未提及潜在诊断(尿路上皮癌),因为问题并未要求。相比之下,我们观察到基线模型会直接诊断患者(而非有针对性地回答实际问题)。图1中的问题表明,Med-Flamingo能够整合复杂的病史信息与视觉信息,从而综合两种模态的信息得出全面诊断。

Figure 6: Example of a Visual USMLE problem.
图 6: 视觉化USMLE试题示例
6 DISCUSSION
6 讨论
In this paper, we presented Med-Flamingo, the first medically adapted multimodal few-shot learner. While this is an early proof-of-concept for a medical multimodal few-shot learner, we expect to see significant improvements with increased model and data scale, more thoroughly cleaned data, as well as with alignment to human preference via instruction tuning or explicit optimization for preferences.
在本文中,我们提出了首个医学领域适配的多模态少样本学习模型Med-Flamingo。尽管这只是医学多模态少样本学习的一个早期概念验证,但我们预期通过扩大模型和数据规模、更彻底的数据清洗,以及基于指令微调或显式偏好优化的人类偏好对齐,将实现显著性能提升。
We expect that the rise of multimodal medical few-shot learners will lead to exciting opportunities with regard to model explain ability (via rationale generation) as well as grounding the model in verified sources (via multimodal retrieval to augment the few-shot prompt). Thereby, our work serves as a first step towards more generalist medical AI models Moor et al. (2023).
我们预计,多模态医疗少样本学习器的兴起将为模型可解释性(通过原理生成)以及将模型基于已验证来源(通过多模态检索增强少样本提示)带来令人振奋的机遇。因此,我们的工作朝着更通用的医疗AI模型迈出了第一步 [20]。
Limitations This work demonstrates a proof-of-concept. As such, Med-Flamingo is not intended nor safe for clinical use. In all VLMs we analyzed, hallucinations were observed. Furthermore, as Med-Flamingo is a pre-trained model without further instruction or preference tuning, it is possible that the model occasionally outputs low-quality generations.
局限性
这项工作展示了概念验证。因此,Med-Flamingo 既不适合也不安全用于临床。在我们分析的所有视觉语言模型(VLM)中,均观察到幻觉现象。此外,由于 Med-Flamingo 是未经指令微调或偏好调整的预训练模型,该模型可能偶尔会生成低质量内容。
Future work It will be an exciting route for future work to further train Med-Flamingo on clinical data, high-resolution medical image datasets as well as 3D volumes and medical videos. While current general-purpose medical VLMs are pre-trained on the broad medical literature (i.e., they are only “book-smart”), also learning from diverse patient data directly will become crucial for down-stream applications.
未来工作
进一步在临床数据、高分辨率医学影像数据集以及3D体积数据和医学视频上训练Med-Flamingo,将是未来工作中一条令人兴奋的路径。当前通用医学视觉语言模型(VLM)仅基于广泛的医学文献进行预训练(即仅具备"书本智慧"),而从多样化患者数据中直接学习对下游应用至关重要。
ACKNOWLEDGMENTS
致谢
We thank Rok Sosic for his technical support in the data preprocessing.
我们感谢Rok Sosic在数据预处理方面提供的技术支持。
REFERENCES
参考文献
Dani Kiyasseh, Runzhuo Ma, Taseen F Haque, Brian J Miles, Christian Wagner, Daniel A Donoho, Animashree Anandkumar, and Andrew J Hung. A vision transformer for decoding surgeon activity from surgical videos. Nature Biomedical Engineering, pp. 1–17, 2023.
Dani Kiyasseh、Runzhuo Ma、Taseen F Haque、Brian J Miles、Christian Wagner、Daniel A Donoho、Animashree Anandkumar和Andrew J Hung。一种从手术视频解码外科医生活动的视觉Transformer (Vision Transformer)。《自然生物医学工程》,第1-17页,2023年。
A APPENDIX
A 附录
A.1 ADDITIONAL DETAILS FOR MTB DATASET
A.1 MTB数据集的其他细节
Clustering the images In a post-hoc analysis, we clustered the image embeddings of the MTB dataset into a large number of clusters (100) and manually reviewed examples of each cluster to assign an annotation. We discard noisy or unclear clusters and display the remaining clusters and their frequency in Figure 7.
聚类图像
在事后分析(post-hoc analysis)中,我们将MTB数据集的图像嵌入(embeddings)聚类为大量簇(100个),并人工检查每个簇的样本以进行标注。我们剔除了噪声或模糊的簇,剩余簇及其频率展示在图7中。

Figure 7: Distribution of manually annotated image clusters in the MTB dataset.
图 7: MTB数据集中手动标注图像簇的分布。
Classification of book titles Here, we provide further details about the creation of Figure 3. Table 4 lists the categories used to prompt the Claude-1 model to classify each book title. We initially prompted with 3 more very rare categories (Geriatrics, Occupational medicine, Space medicine), but merge them into the ”Other” group for visualization purposes.
书籍标题分类
此处,我们将进一步说明图3的创建细节。表4列出了用于提示Claude-1模型对书籍标题进行分类的类别。我们最初还设置了3个非常罕见的类别(老年医学、职业医学、太空医学),但出于可视化考虑将其合并至"其他"组。
A.2 ADDITIONAL DETAILS FOR VISUAL USMLE DATASET
A.2 视觉USMLE数据集的附加细节

Figure 8: Distribution of specialty topics in the Visual USMLE dataset, as classified by Claude-1 using the categories provided in Table 4.
图 8: Visual USMLE数据集中专科主题的分布情况,由Claude-1根据表4提供的分类标准进行分类。