FACT: Federated Adversarial Cross Training
FACT: 联邦对抗交叉训练 (Federated Adversarial Cross Training)
Abstract
摘要
Federated Learning (FL) facilitates distributed model development to aggregate multiple confidential data sources. The information transfer among clients can be compromised by distribution al differences, i.e., by non-i.i.d. data. A particularly challenging scenario is the federated model adaptation to a target client without access to annotated data. We propose Federated Adversarial Cross Training (FACT), which uses the implicit domain differences between source clients to identify domain shifts in the target domain. In each round of FL, FACT cross initializes a pair of source clients to generate domain specialized representations which are then used as a direct adversary to learn a domain invariant data representation. We empirically show that FACT outperforms state-of-the-art federated, non-federated and source-free domain adaptation models on three popular multi-source-singletarget benchmarks, and state-of-the-art Unsupervised Domain Adaptation (UDA) models on single-source-single-target experiments. We further study FACT’s behavior with respect to communication restrictions and the number of participating clients.
联邦学习 (Federated Learning, FL) 支持分布式模型开发以聚合多个机密数据源。客户端间的信息传递可能因分布差异(即非独立同分布数据)而受到影响。一个极具挑战性的场景是联邦模型需适应无法获取标注数据的目标客户端。我们提出联邦对抗交叉训练 (Federated Adversarial Cross Training, FACT),该方法利用源客户端间的隐式领域差异来识别目标领域的域偏移。在每轮联邦学习中,FACT交叉初始化一对源客户端以生成领域专用表征,随后将其作为直接对抗方来学习领域不变的数据表征。实验表明,FACT在三个主流多源单目标基准测试中优于当前最先进的联邦、非联邦和无源域适应模型,并在单源单目标实验中超越了最先进的非监督域适应 (Unsupervised Domain Adaptation, UDA) 模型。我们进一步研究了FACT在通信限制和参与客户端数量方面的表现。
1 Introduction
1 引言
The development of state-of-the-art deep learning models is often limited by the amount of available training data. For instance, applications in precision medicine require a large body of annotated data. Those exist, but are typically distributed across multiple locations and privacy issues prohibit their direct exchange. Federated Learning (FL) [17, 18, 29, 38] overcomes this issue by distributing the training process rather than sharing confidential data. Models are trained locally at multiple clients and subsequently aggregated at a global server to collaborative ly learn. Many FL approaches such as Federated Averaging (FedAvg) [29] assume the data to be generated i.i.d., which usually cannot be guaranteed. For instance, different hospitals might use different experimental equipment, protocols and might treat very different patient populations, which can lead to distribution al differences between the individual data sites. In such a case, covariate shifts have to be addressed, which is particularly challenging in scenarios where the target client does not have access to labeled training data. There, knowledge has to be both extracted from diverse labeled source clients and transferred without direct estimates of the generalization error.
最先进的深度学习模型发展常受限于可用训练数据量。例如,精准医疗应用需要大量标注数据。这些数据虽然存在,但通常分散在多个地点,且隐私问题阻碍了直接交换。联邦学习 (Federated Learning, FL) [17, 18, 29, 38] 通过分布式训练而非共享机密数据来解决这一问题。模型在多个客户端本地训练后,在全局服务器聚合以实现协作学习。许多FL方法(如联邦平均 (Federated Averaging, FedAvg) [29])假设数据是独立同分布生成的,这一假设通常无法保证。例如,不同医院可能使用不同实验设备、治疗方案,且收治患者群体差异显著,这会导致各数据站点间出现分布差异。此类情况下需解决协变量偏移问题,这在目标客户端无法获取标注训练数据的场景中尤为困难——此时必须从多样化的标注源客户端提取知识,并在无法直接估计泛化误差的情况下完成迁移。
Unsupervised Domain Adaptation (UDA) [7, 42, 36] addresses distribution al differences between a label-rich source domain and an unlabeled target domain for improved out-of-distribution performance. Most popular deep learning models utilize an adversarial strategy [7, 42, 36], where an adversary is trained to discriminate whether the samples are generated by the source or target distribution. Simultaneously, the feature generator attempts to fool the adversary by aligning the latent representations of the two data sources, which encourages well supported target predictions if the adversary fails to separate the domains. However, these adversarial strategies generally require concurrent access to both source and target data, prohibiting their use in a federated setting without sharing encrypted data representations [33] or using artificially generated data [46].
无监督域适应 (Unsupervised Domain Adaptation, UDA) [7, 42, 36] 通过解决带标签的源域与无标签目标域之间的分布差异问题,来提升分布外性能。当前主流深度学习模型采用对抗策略 [7, 42, 36],即训练对抗器来判别样本来自源分布还是目标分布,同时特征生成器通过对齐两个数据源的潜在表征来欺骗对抗器。若对抗器无法区分域间差异,该机制能促进目标域预测性能的提升。然而这些对抗策略通常需要同时访问源数据和目标数据,导致其无法在不共享加密数据表征 [33] 或使用人工生成数据 [46] 的联邦学习场景中应用。
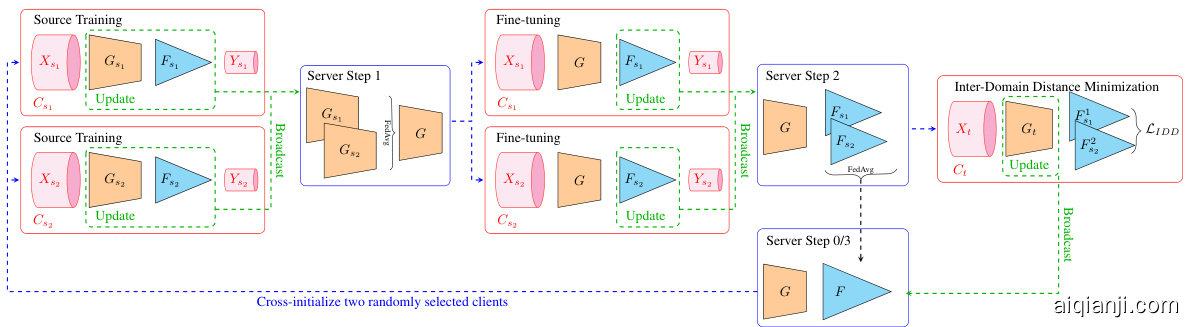
Figure 1: Visualization of the FACT training scheme. The server cross-initializes two source clients for Source Training, which locally optimize the model and broadcast it back to the server. The server then aggregates the generator and shares it with the source clients for an additional FineTuning of the domain dependent classification heads. Afterwards, both classification heads and the global generator are sent to the target client for Inter-Domain Distance Minimization. Finally, the optimized generator is broadcasted back to the server and the classification heads are aggregated for the next round of federated training.
图 1: FACT训练方案的可视化。服务器交叉初始化两个源客户端进行源训练 (Source Training),这些客户端在本地优化模型并将其广播回服务器。随后服务器聚合生成器 (generator) 并与源客户端共享,用于对领域相关分类头 (classification heads) 进行额外微调 (FineTuning)。接着,两个分类头和全局生成器被发送至目标客户端进行跨域距离最小化 (Inter-Domain Distance Minimization)。最终,优化后的生成器被广播回服务器,分类头被聚合以进行下一轮联邦训练。
We propose Federated Adversarial Cross Training (FACT), a federated deep learning approach designed to leverage inter-domain differences between multiple source clients and an unlabeled target domain. Specifically, we address the multi-source-single-target setting with non-i.i.d. data sources distributed across multiple clients. To adapt to the domain of an unlabeled target client, we propose to directly evaluate the inter-domain differences between source domains. This allows us to identify domain specific artifacts without adversarial maximization and thus facilitates distributed training among clients.
我们提出联邦对抗跨域训练 (FACT),这是一种联邦深度学习方法,旨在利用多个源客户端与未标记目标域之间的跨域差异。具体而言,我们针对数据源非独立同分布且分布在多个客户端的多源单目标场景。为适应未标记目标客户端的域,我们建议直接评估源域之间的跨域差异。这种方法无需对抗最大化即可识别域特定伪影,从而促进客户端间的分布式训练。
In empirical studies we show that FACT substantially improves target predictions on three popular multi-source-single-target benchmarks with respect to state-of-the-art federated, non-federated and source-free domain adaptation models. Moreover, FACT outperforms state-of-the-art UDA models in several standard settings, also comprising standard single-source-single-target UDA, where the basic model assumptions of FACT are violated (i.e., non-i.i.d. source domains). Finally, we investigate the behaviour of FACT in different federated learning scenarios to motivate its application to real world problems. We show that FACT benefits from additional source clients even though they are subject to strong covariate shifts, that FACT is stable in applications with many source clients each carrying only a small number of training samples, and that FACT can be efficiently applied in settings with communication restrictions. Our implementation of FACT, including code to reproduce all results shown in this paper, is publicly available at https://github.com/jonas-lippl/FACT.
在实证研究中,我们证明FACT在三个流行的多源单目标基准测试中显著提升了目标预测性能,优于当前最先进的联邦学习、非联邦学习及无源域适应模型。此外,FACT在多个标准设置(包括违反其基本模型假设的标准单源单目标无监督域适应场景,即非独立同分布源域)中均超越了现有最优的无监督域适应模型。最后,我们探究了FACT在不同联邦学习场景中的表现,以论证其在实际问题中的应用价值。研究表明:FACT能有效利用存在强协变量偏移的额外源客户端数据;在包含大量训练样本稀缺源客户端的应用中保持稳定性;并能在通信受限环境下高效部署。本文所有实验结果的复现代码及FACT实现已开源:https://github.com/jonas-lippl/FACT。
2 Related Work
2 相关工作
Adversarial Unsupervised Domain Adaptation Traditional UDA approaches aim to transfer knowledge from a single labeled source domain to an unlabeled target domain. Proposed methods align the underlying distributions by, e.g., identifying common characteristics of the underlying distributions [3, 41, 39], by utilizing reconstructed data [9, 52] or by using domain adversaries [7, 42, 24, 36]. With a wide variety of possible applications, the standard single-source-single-target setting has been also extended for additional clients, which is non-trivial for unsupervised target clients [10]. The latter also complicates the weighting between the different domains [3]. For a setting with multiple source domains, [49] proposed an improved DANN model [7], Peng et al. [32] proposed moment matching to simultaneously align multiple domains, Ren et al. [34] constructed a pseudo target domain between each source-target pair, and Kim et al. [16] introduce a self-supervised pre-training scheme to alleviate target performance. This is even further extended by Multi-Source Partial Domain Adaptation (MSPDA) models such as Partial Feature Selection and Alignment (PFSA) [6]. All of these approaches assume centralized data and can not be directly applied to the federated setting.
对抗性无监督域适应
传统UDA方法旨在将知识从单个带标签的源域迁移到无标签的目标域。提出的方法通过以下方式对齐底层分布:例如识别底层分布的共同特征[3, 41, 39]、利用重构数据[9, 52]或使用域对抗器[7, 42, 24, 36]。由于应用场景广泛,标准单源单目标设定也被扩展至更多客户端,这对无监督目标客户端具有挑战性[10]。后者还使得不同域之间的权重分配复杂化[3]。针对多源域场景,[49]改进了DANN模型[7],Peng等人[32]提出矩匹配方法实现多域同时对齐,Ren等人[34]在每个源-目标对之间构建伪目标域,Kim等人[16]引入自监督预训练方案以提升目标域性能。多源部分域适应(MSPDA)模型(如部分特征选择与对齐(PFSA)[6])进一步扩展了这些方法。所有这些方法都假设数据集中存储,无法直接应用于联邦学习场景。
Federated Learning FL enables a set of clients to collaborative ly learn a prediction model while maintaining all data locally and thus preserving data confidentiality [29, 4, 17, 18]. This can be achieved by encrypting the data [11, 30] or by sharing locally trained models to aggregate knowledge. Typically, a global model is constructed by averaging the individual clients’ models, e.g., via Federated Averaging (FedAvg) [29]. For non-i.i.d. data, model aggregation can remove client specific characteristics of the data, leading to negative transfer and thus suboptimal performance [51, 1]. Approaches designed for non-i.i.d. data sources adapt distributed multi-task learning [38], use secure transfer learning [26] or inter client domain generalization [48, 25]. Furthermore, improved aggregation strategies for non-i.i.d data were proposed, which consider the client specific momentum [15] or dynamically regularize the clients [1] to align the optimal solutions of global and local models.
联邦学习 (Federated Learning, FL) 使得一组客户端能够协作学习预测模型,同时将所有数据保留在本地,从而保护数据机密性 [29, 4, 17, 18]。这可以通过加密数据 [11, 30] 或共享本地训练的模型以聚合知识来实现。通常,全局模型是通过平均各个客户端的模型构建的,例如通过联邦平均 (Federated Averaging, FedAvg) [29]。对于非独立同分布 (non-i.i.d.) 数据,模型聚合可能会消除数据的客户端特定特征,导致负迁移 (negative transfer) 从而影响性能 [51, 1]。针对非独立同分布数据源的方法采用了分布式多任务学习 [38],使用安全迁移学习 [26] 或客户端间领域泛化 [48, 25]。此外,还提出了改进的非独立同分布数据聚合策略,这些策略考虑了客户端特定的动量 [15] 或动态正则化客户端 [1] 以对齐全局和局部模型的最优解。
Unsupervised Federated Domain Adaptation Unlabeled data naturally occur in many applications of FL. In the special case of completely unlabeled target data, UDA can enhance the out-of-distribution performance provided that the data access restrictions are resolved. Seminal work by Peng et al. [33] introduced Federated Adversarial Domain Adaptation (FADA), which uses local feature extractors to generate privacy preserving representation that can be shared for distribution alignment. Similarly, Federated Knowledge Alignment (FedKA) [40] attempt to align local feature extractors to a global data embedding provided by the cloud using the Multiple Kernel Maximum Mean Discrepancy. Related approaches were recently applied to MRI data [22, 13, 47], demonstrating the benefits of multi-institutional collaborations.
无监督联邦域适应
在许多联邦学习(FL)应用中,未标注数据自然存在。在目标数据完全未标注的特殊情况下,只要解决数据访问限制问题,无监督域适应(UDA)就能提升分布外性能。Peng等人[33]的开创性工作提出了联邦对抗域适应(FADA),该方法利用本地特征提取器生成可共享的隐私保护表征以实现分布对齐。类似地,联邦知识对齐(FedKA)[40]尝试通过多核最大均值差异将本地特征提取器与云端提供的全局数据嵌入对齐。相关方法近期被应用于MRI数据[22,13,47],证明了多机构协作的优势。
A second closely related line of work is source-free domain adaptation [20, 2, 23, 27, 19, 45, 37]. Here, a pre-trained source model is used to transfer knowledge to the target domain and subsequently fine-tuned exclusively on the target data with the objective to make the target predictions both individually certain and diverse [23]. Accordingly, only the pre-trained source model needs to be shared, which guarantees data confidentiality. This approach is basically the one-shot federated setting requiring only a single round of federated communication. In particular, Liang et al. [23] and Ahmed et al. [2] addressed a possible extension to the multi-source-single-target setting by combining the outcome of multiple single-source-single-target models. These models additionally use image augmentation strategies on the source data, which on their own out-perform state-of-the-art domain adaptation settings on multi-source-single target experiments [23, 2]. One should note that this is in contrast to standard UDA and multi-source UDA approaches that attempt to eliminate domain differences algorithmic ally without relying on augmented training samples.
第二个密切相关的工作方向是无源域适应 [20, 2, 23, 27, 19, 45, 37]。该方法利用预训练的源模型将知识迁移到目标域,随后仅针对目标数据进行微调,旨在使目标预测既具备个体确定性又保持多样性 [23]。因此只需共享预训练的源模型,从而确保数据机密性。这种方案本质上是单次联邦学习设置,仅需一轮联邦通信。特别地,Liang等人 [23] 和Ahmed等人 [2] 通过组合多个单源单目标模型的结果,探讨了向多源单目标设置扩展的可能性。这些模型还采用了源数据的图像增强策略,仅凭这些策略就在多源单目标实验中超越了当前最先进的域适应方案 [23, 2]。值得注意的是,这与标准无监督域适应(UDA)和多源UDA方法形成对比——后者试图通过算法消除域差异,而不依赖增强的训练样本。
3 Method
3 方法
In this work, we address the federated multi-source-single-target setting where the data is both non-i.i.d. and distributed across multiple clients. We assume each client to be associated with an individual domain and focus on the out-of-distribution performance on data from a single target client without training labels, corresponding to the Unsupervised Federated Domain Adaptation (UFDA) setting introduced by Peng et al. [33]. Let S be a global server managing the training process for a set of local source clients mathcal{C}_{s} and let Xin{mathcal{X}} be the features associated with K classification labels {1,2,dots,K}=Yinmathcal{Y} . The data are distributed across n source clients C_{s_{1}},dots,C_{s_{n}}in{mathcal{C}}_{s} , associated with annotated training data left({{X}_{{s}_{i}}},{{Y}_{{s}_{i}}}right) and a target client C_{t} that holds solely covariate data left(X_{t}right) not associated with any labels. We assume that the data of all clients share the same input and output mathcal{X}timesmathcal{Y} .
在本工作中,我们研究联邦多源单目标场景下的数据非独立同分布(non-i.i.d.)且分散在多个客户端的情况。假设每个客户端关联独立域,重点关注无训练标签的单一目标客户端数据的分布外性能,对应Peng等人[33]提出的无监督联邦域适应(UFDA)设定。设全局服务器S管理一组本地源客户端mathcal{C}_{s}的训练过程,Xin{mathcal{X}}表示与K个分类标签{1,2,dots,K}=Yinmathcal{Y}关联的特征。数据分布在n个源客户端C_{s_{1}},dots,C_{s_{n}}in{mathcal{C}}_{s}上,对应带标注的训练数据left({{X}_{{s}_{i}}},{{Y}_{{s}_{i}}}right);目标客户端C_{t}仅持有无标签的协变量数据left(X_{t}right)。假设所有客户端数据共享相同的输入输出空间mathcal{X}timesmathcal{Y}。
3.1 Motivation: Exploiting inter-domain differences
3.1 动机:利用跨域差异
Following the general concept of adversarial learning strategies, we attempt to learn a domain invariant data representation to increase the support of target samples. This is usually achieved by evaluating whether a sample is generated by the source or the target distribution and by suppressing
遵循对抗学习策略的通用概念,我们尝试学习一种领域不变的数据表示,以增加目标样本的支持度。这通常通过评估样本是由源分布还是目标分布生成,并通过抑制来实现。
domain specific features. This requires, however, an additional adversarial maximization step to identify such features.
特定领域特征。然而,这需要一个额外的对抗性最大化步骤来识别这些特征。
FL naturally enables the access to multiple source domains exhibiting individual characteristics. FACT assumes the data of each client to be non-i.i.d. and uses these implicit inter-domain differences to evaluate the support of an independent and unlabeled target. Let (X_{1},Y_{1})sim P_{1} and (X_{2},Y_{2})sim P_{2} be generated by two distributions subject to strong domain shifts. Then, two independently trained models F_{1} and F_{2} on X_{1} and X_{2} , respectively, will be biased towards their corresponding source data. This encourages inconsistent classifications for an independent target domain X_{t}sim P_{t} and thus the difference in classifications hat{Y}_{t}^{1} and hat{Y}_{t}^{2} provides a measure of covariate shifts. Thus, using the two source specific models, we define the adversary via the Inter-Domain Distance (IDD):
联邦学习 (FL) 天然支持访问具有个体特征的多源域。FACT 假设每个客户端的数据均为非独立同分布 (non-i.i.d.),并利用这些隐式的域间差异来评估独立未标注目标域的支持度。设 (X_{1},Y_{1})sim P_{1} 和 (X_{2},Y_{2})sim P_{2} 由存在强域偏移的两个分布生成,则在 X_{1} 和 X_{2} 上独立训练的两个模型 F_{1} 和 F_{2} 将分别偏向其对应源数据。这会导致对独立目标域 X_{t}sim P_{t} 的分类结果不一致,因此分类差异 hat{Y}_{t}^{1} 与 hat{Y}_{t}^{2} 可量化协变量偏移。基于这两个源域特定模型,我们通过域间距离 (IDD) 定义对抗度量:
which minimizes the domain specific artifacts with respect to a latent data representation G(X) and as such it enforces agreement between target estimates. The IDD objective is inspired by the discrepancy loss introduced for the Maximum Classifier Discrepancy (MCD) adversary by Saito et al. [36]. There, in contrast to our proposed inter-domain training, the class if i ers are trained on data generated by a single domain. Hence, an adversarial maximization step is essential to bias the two classifications towards contradicting results on the target data. In this step concurrent access to both source and target data is required to account for an uncontrolled loss of target accuracy, restricting the federated application of MCD.
最小化关于潜在数据表示 G(X) 的领域特定伪影,从而强制目标估计之间达成一致。IDD目标受到Saito等人[36]为最大分类器差异(MCD)对抗器引入的差异损失启发。与本文提出的跨域训练不同,该方法的分类器是在单一领域生成的数据上训练的。因此,需要通过对抗性最大化步骤使两个分类器在目标数据上产生矛盾结果。此步骤需要同时访问源数据和目标数据,以防止目标精度不受控下降,这限制了MCD在联邦学习中的应用。
3.2 Federated Adversarial Cross Training
3.2 联邦对抗交叉训练 (Federated Adversarial Cross Training)
We propose Federated Adversarial Cross Training (FACT) as a simple and highly efficient training scheme which leverages the inter-domain differences of distributed data to maximize the information transfer to an independent target domain without access to labeled data. The basic concept of FACT is summarized in Figure 1 and outlined in the following.
我们提出联邦对抗交叉训练(Federated Adversarial Cross Training,简称FACT)作为一种简单高效的训练方案,它利用分布式数据的域间差异,在无需访问标注数据的情况下,将信息最大化地迁移至独立目标域。FACT的基本概念如图1所示,并概述如下。
Model training is managed by a global server S , responsible to distribute, collect and aggregate the individual client models. FACT consists of a global feature generator G which is optimized to yield domain invariant representations for all of the domain specific classification heads F_{s_{i}} , for all source domains s_{i} . At the beginning of the training process the global model generator G and classifier F are initialized at the server. Each round of federated learning r is split into three main steps: source training, source fine-tuning and target inter-domain distance minimization, which are applied iterative ly.
模型训练由全局服务器 S 管理,负责分发、收集和聚合各个客户端模型。FACT包含一个全局特征生成器 G,其优化目标是为所有源域 s_{i} 的域特定分类头 F_{s_{i}} 生成域不变表示。训练开始时,全局模型生成器 G 和分类器 F 在服务器端初始化。每轮联邦学习 r 分为三个主要步骤:源训练、源微调和目标域间距离最小化,这些步骤迭代执行。
Source Training At the beginning of each round r the server S cross-initializes two randomly selected source clients C_{s_{1}}^{r},C_{s_{2}}^{r}inmathcal{C}_{s} with the global model (G^{r},F^{r}) . Each client C_{s_{i}}^{r} updates the full model (G^{r},F^{r}) to fit their respective source data using a standard Cross-Entropy objective
源训练
在每轮 r 开始时,服务器 S 使用全局模型 (G^{r},F^{r}) 交叉初始化两个随机选择的源客户端 C_{s_{1}}^{r},C_{s_{2}}^{r}inmathcal{C}_{s}。每个客户端 C_{s_{i}}^{r} 更新完整模型 (G^{r},F^{r}),以使用标准交叉熵目标拟合各自的源数据。
Table 1: Target client accuracy obtained for four source clients on Digit-Five data. Best performing methods within error bars are highlighted.
表 1: Digit-Five数据集上四个源客户端获得的目标客户端准确率。误差范围内表现最佳的方法已高亮标出。
| 模型 | →MNISTM | →MNIST | →SVHN | →SYN | →USPS | 平均 |
|---|---|---|---|---|---|---|
| MCD | 72.5 ± 0.7 | 96.2 ± 0.8 | 78.9 ± 0.8 | 87.5 ± 0.7 | 95.3 ± 0.7 | 86.1 |
| M3SDA-β | 72.8 ± 1.1 | 98.4 ± 0.7 | 81.3 ± 0.9 | 89.6 ± 0.6 | 96.1 ± 0.8 | 87.7 |
| MDDA | 78.6 ± 0.6 | 98.8 ± 0.4 | 79.3 ± 0.8 | 89.7 ± 0.7 | 93.9 ± 0.5 | 88.1 |
| LtC-MSDA | 85.6 ± 0.8 | 99.0 ± 0.4 | 83.2 ± 0.6 | 93.0 ± 0.5 | 98.3 ± 0.4 | 91.8 |
| PFSA | 89.6 ± 1.2 | 99.4 ± 0.1 | 84.1 ± 1.1 | 95.7 ± 0.3 | 98.6 ± 0.1 | 93.5 |
| FADA | 62.5 ± 0.7 | 91.4 ± 0.7 | 50.5 ± 0.3 | 71.8 ± 0.5 | 91.7 ± 1.0 | 73.6 |
| FedKA | 77.3 ± 1.0 | 96.4 ± 0.2 | 13.8 ± 0.8 | 79.5 ± 0.7 | 96.6 ± 0.4 | 72.7 |
| FACT-NF | 89.6 ± 0.7 | 99.2 ± 0.1 | 88.8 ± 0.3 | 95.0 ± 0.1 | 98.5 ± 0.2 | 94.2 |
| FACT | 92.9 ± 0.7 | 99.2 ± 0.1 | 90.6 ± 0.4 | 95.1 ± 0.1 | 98.4 ± 0.1 | 95.2 |
The updated feature extractor is subsequently broadcasted back to the server to update the global feature extractor G^{prime} :
更新后的特征提取器随后被广播回服务器,以更新全局特征提取器 G^{prime}:
Source Fine-Tuning The aggregation of the global feature extractor changes also the latent represent at ions of the classification heads. This can potentially compromise model performance. To compensate this effect and to further bias the models towards the individual source data, we fine-tune the classification heads F_{s_{1}},F_{s_{2}} to fit the aggregated feature extractor G^{prime r} :
源域微调
全局特征提取器的聚合变化也会影响分类头的潜在表示,这可能会损害模型性能。为补偿这一影响并进一步使模型偏向各源域数据,我们对分类头 F_{s_{1}},F_{s_{2}} 进行微调,使其适配聚合后的特征提取器 G^{prime r}:
Inter-Domain Distance Minimization The two fine-tuned classification heads together with the feature extractor are then transferred to the target client, where the individual model representations are used to quantify domain differences. Those are mitigated by minimizing the IDD loss
跨域距离最小化
随后,将两个微调后的分类头与特征提取器一同迁移至目标客户端,利用各模型表征量化域间差异,并通过最小化IDD损失来缓解这些差异。
with respect to the joint feature generator. Thus, the feature space is updated such that domain differences are mitigated on the target domain. The updated G_{r+1}gets G_{t} is subsequently broadcaster back to the server, where a new global classification head is aggregated and the next round of federated training is initiated.
相对于联合特征生成器。因此,特征空间被更新,以减轻目标域上的域差异。更新后的 G_{r+1}gets G_{t} 随后被广播回服务器,在那里聚合一个新的全局分类头,并启动下一轮联邦训练。
By design, the inter-domain distance provides a direct measure for the support of the target domain. Hence, we select the final model based on minimal IDD in all of the experiments. For practical applications this can speed up the training significantly by reducing the number of trained epochs and client communications. The full training procedure is shown in Algorithm 1. Note that the fine-tuning step can increase communication costs substantially, since it requires an additional transfer of the commonly large generator to the sources clients. Thus, in subsequent experiments, we present results for both FACT and a simplified version of FACT which does not perform the fine-tuning step (FACT-NF).
根据设计,域间距离 (inter-domain distance) 可直接衡量目标域的支持程度。因此,我们在所有实验中均基于最小IDD选择最终模型。实际应用中,该方法能通过减少训练轮次和客户端通信次数显著加速训练。完整训练流程如算法1所示。需注意的是,微调步骤会大幅增加通信成本,因为需要将通常体积较大的生成器额外传输至源客户端。因此在后续实验中,我们同时展示FACT及其简化版本(不执行微调步骤的FACT-NF)的结果。
4 Experiments
4 实验
We evaluate a variety of different federated scenarios with respect to the fraction of correctly predicted classifications for an independent target domain. First, we show the multi-source-single-target setting where each client is associated with an individual domain and a large dataset. Second, we evaluate FACT for the standard single-source-single-target UDA setting by splitting a single domain across two clients, which violates FACT’s assumption of existing domain differences. Finally, we analyze the behavior of FACT in different federated learning scenarios, studying (1) the negative transfer in case of suboptimal source data, (2) the number of participating clients while limiting the data present at each individual location, and (3) the effect of reducing the number of communication rounds.
我们针对独立目标域的正确分类预测比例评估了多种不同的联邦场景。首先展示多源单目标设置,其中每个客户端关联一个独立域和大型数据集。其次通过将单个域拆分到两个客户端来评估FACT在标准单源单目标无监督域适应(UDA)设置中的表现,这违反了FACT关于存在域差异的假设。最后分析FACT在不同联邦学习场景中的行为,研究:(1) 次优源数据情况下的负迁移现象,(2) 限制各节点数据量时的参与客户端数量,(3) 减少通信轮数的影响。
Table 2: Target client accuracy obtained for using two source clients on the Office dataset. (A: Amazon, D:DSLR, W:Webcam)
表 2: 在Office数据集上使用两个源客户端获得的目标客户端准确率。(A: Amazon, D:DSLR, W:Webcam)
| 方法 | →A →D | →W | Avg |
|---|---|---|---|
| MCD M?SDA MDDA LtC-MSDA PFSA | 54.4 99.5 55.4 99.4 56.2 99.2 56.9 99.6 57.0 99.7 | 96.2 96.2 97.1 97.2 97.4 | 83.4 83.7 84.2 84.6 84.7 |
| FACT-NF FACT | 69.1 70.5 | 99.3 99.5 | 95.5 88.0 96.0 88.7 |
Datasets We use three popular benchmark datasets for multi-source-single-target adaptation, namely Digit-Five [32], Office [35] and Office-Caltech10 [12]. Each of them is known to exhibit strong domain shifts: Digit-Five combines five independently generated digit recognition datasets (MNIST, MNIST-M, USPS, Street-View House Numbers (SVHN), synthetic digits (SYN)). Office consists of 31 classes of office appliances collected form three different sources (Amazon.com, Webcam, DSLR pictures). Office-Caltech10 [12] adds Caltech-265 as an additional domain to the Office dataset, resulting in a total of 10 shared classes between all domains. In line with previous work [32, 33, 23, 2], we use an independent target test set for Digit-Five and use the unlabeled data for evaluation for Office and Office-Caltech10. The number of the used train and test samples are listed in the Supplementary Materials.
数据集
我们使用三个流行的多源单目标适应基准数据集:Digit-Five [32]、Office [35] 和 Office-Caltech10 [12]。这些数据集均存在显著的域偏移现象:
- Digit-Five 融合了五个独立生成的数字识别数据集 (MNIST、MNIST-M、USPS、街景门牌号 (SVHN)、合成数字 (SYN))
- Office 包含从三个不同来源 (Amazon.com、网络摄像头、数码单反照片) 采集的31类办公用品
- Office-Caltech10 [12] 在 Office 数据集基础上新增 Caltech-265 作为额外域,最终形成10个所有域共有的类别
遵循先前研究 [32, 33, 23, 2] 的方案:
- 对 Digit-Five 采用独立目标测试集
- 对 Office 和 Office-Caltech10 使用未标注数据进行评估
具体训练和测试样本数量见补充材料。
Baselines We compare FACT to multiple types of state-of-the-art baselines, comprising both federated and non-federated domain adaptation models. The federated baselines are FADA [33], which calculates a DANN based adversary for each domain pair at the server based on an encrypted representation of the private data, and Federated Knowledge Alignment (FedKA) [40], which matches the feature embedding between two domains using a multiple kernel variant of the Maximum Mean Discrepancy in combination with a federated voting strategy for model fine-tuning. Even though data access restrictions prohibit the application of MCD [36] and alike UDA models, we include the less restrictive non-federated benchmarks where all data are available at the same location and can be concurrently accessed. Here, we compare to a multi-source adaptation of MCD [36] and to mathbf{M}^{3}mathbf{S}mathbf{D}mathbf{A}{-}beta as implemented by Peng et al. [32], Multi-source Distilling Domain Adaptation (MDDA) [50], Learning to Combine for Multi-Source Domain Adaptation (LtC-MSDA) [43] and Partial Feature Selection and Alignment (PFSA) [6]. The performances of all competing methods were extracted from the respective original research article, with the exception of the MCD results which were obtained from [33] and [6].
基线模型
我们将FACT与多种类型的先进基线模型进行比较,包括联邦式和非联邦式领域自适应模型。联邦基线包括:FADA [33](基于客户端私有数据的加密表示,在服务器端为每个领域对计算DANN对抗器)和联邦知识对齐 (FedKA) [40](通过多核最大均值差异结合联邦投票策略进行模型微调,实现两领域间特征嵌入匹配)。
尽管数据访问限制排除了MCD [36]等UDA模型的应用,我们仍纳入了限制较少的非联邦基准测试(所有数据位于同一位置且可并行访问)。在此比较了MCD [36]的多源适配版本、Peng等人[32]实现的mathbf{M}^{3}mathbf{S}mathbf{D}mathbf{A}{-}beta、多源蒸馏域适应 (MDDA) [50]、多源域适应的组合学习 (LtC-MSDA) [43]以及部分特征选择与对齐 (PFSA) [6]。除MCD结果引自[33]和[6]外,其余竞争方法的性能指标均取自原始研究论文。
Implementation details Our implementation of FACT is based on PyTorch [31] and is publicly available at https://github.com/jonas-lippl/FACT. The federated setting was simulated on a single machine to speed up computation for all experiments. All calculations were performed on a cluster with 8 NVIDIA A100 gpus and 256 cpu cores. Digit-Five was trained from scratch using randomly initialized layers and for Office and Office-Caltech10, we initialized the feature generator using a pre-trained ResNet101 [14]. Overall, the chosen architecture follows the design choices of Peng et al. [33] to guarantee a fair comparison. The results were averaged over 10 repeated runs for Digit-Five and 5 repeated runs for Office and Office-Caltech10. We used a batch-size of 128 and a learning rate scheduler eta=eta_{0}cdot(1+10cdot p)^{-0.75} as proposed by Ganin et al. [8] with an initial learning rate of eta_{0}=0.005 for the multi-source-multi-target experiments and eta_{0}=0.01 for the single-source-single-target experiments to guarantee convergence. For additional details we refer to the Supplementary Materials.
实现细节
我们的FACT实现基于PyTorch语言[31],代码已开源在https://github.com/jonas-lippl/FACT。为加速实验计算,所有联邦学习场景均在单机模拟完成。全部计算在配备8块NVIDIA A100显卡和256个CPU核心的集群上执行。Digit-Five数据集采用随机初始化层从头训练,而Office和Office-Caltech10数据集则使用预训练的ResNet101[14]初始化特征生成器。整体架构遵循Peng等人[33]的设计方案以确保公平对比。Digit-Five的实验结果取10次运行均值,Office和Office-Caltech10取5次运行均值。我们采用128的批处理量,并按Ganin等人[8]提出的学习率调度器eta=eta_{0}cdot(1+10cdot p)^{-0.75}进行训练:多源多目标实验初始学习率设为eta_{0}=0.005,单源单目标实验设为eta_{0}=0.01以保证收敛。更多细节详见补充材料。
Table 3: Target client accuracy obtained for three source clients on the Office-Caltech10 dataset (C: Caltech, A: Amazon, D:DSLR, W:Webcam).
表 3: Office-Caltech10 数据集上三个源客户端获得的目标客户端准确率 (C: Caltech, A: Amazon, D: DSLR, W: Webcam)。
| 方法 | →C | →A →D | →w | Avg |
|---|---|---|---|---|
| MCD | 91.5 | 92.1 99.1 | 99.5 | 95.6 |
| M3SDA-β FADA | 92.2 | 94.5 99.2 84.2 87.1 | 99.5 88.1 | 96.4 87.1 |
| FedKA | 88.7 39.7 | 59.9 | 30.2 23.4 | 38.3 |
| FACT-NF | 95.0 | 96.1 | 99.1 98.3 | 97.1 |
| FACT | 95.5 | 96.3 | 99.4 99.0 | 97.6 |
4.1 Multi-source-single-target with distinct source domains
4.1 多源单目标跨域迁移
As a baseline, we evaluate the standard federated multi-source-single-target setting [32, 33, 40, 23, 2], where a small number of clients each holds a distinct domain with a large number of available training samples. The results obtained for Digit-Five are shown in Table 1. We observe that FACT outperforms the competing models with an average accuracy of 95.2% , which is followed by PFSA with 94.0% . This performance gain is mainly attributed to the scenario with SVHN and MNISTM as target domain. On the former, FACT achieved an accuracy of 90.6% , which is substantially better than for all competing methods with accuracies ranging from 13.8% (FedKa) to 84.1% (PFSA). Considering the remaining target client scenarios, FACT shows comparable performance to LtC-MSDA and PFSA, and substantially better performance than the other methods, in particular compared to federated baselines FADA and FedKA.
作为基线,我们评估了标准联邦多源单目标设定 [32, 33, 40, 23, 2],其中少量客户端各自持有包含大量可用训练样本的不同领域。Digit-Five的实验结果如 表 1 所示。我们观察到FACT以平均准确率 95.2% 优于其他竞争模型,其次是PFSA的 94.0% 。这一性能提升主要归功于以SVHN和MNISTM作为目标域的场景。在前者中,FACT取得了 90.6% 的准确率,显著优于所有竞争方法(准确率范围从 13.8% (FedKa)到 84.1% (PFSA))。在其他目标客户端场景中,FACT表现出与LtC-MSDA和PFSA相当的性能,并显著优于其他方法,特别是与联邦基线FADA和FedKA相比。
For the Office data (Table 2) no federated baselines were available, hence, we only compare to less restrictive non-federated models. We observe that FACT significantly outperforms the average performance of all non-federated baselines. This is mainly attributed to the increased accuracy on the Amazon target to 70.5% , which might be attributed to the efficient aggregation of the very similar DSLR and Webcam domains. FACT shows slightly compromised performance on the Webcam domain with 96.0% accuracy compared to the best performing model PFSA with 97.4% .
对于Office数据(表2),由于没有可用的联邦基线,因此我们仅与限制较少的非联邦模型进行比较。我们观察到FACT显著优于所有非联邦基线的平均性能。这主要归因于Amazon目标准确率提升至70.5%,可能是由于高度相似的DSLR和Webcam域的高效聚合所致。FACT在Webcam域上表现略逊于最佳模型PFSA(97.4%),准确率为96.0%。
Considering Office-Caltech10 (Table 3), FACT outperforms both the federated and non-federated baselines for three out of four possible targets and at average.
考虑到Office-Caltech10 (表3),FACT在四个可能目标中的三个以及平均表现上均优于联邦和非联邦基线方法。
For all three experiments, we observe that the fine-tuning step improves model performance, as becomes evident from comparing FACT with FACT-NF. This particularly holds true for the more challenging target domains, such as Amazon for the Office dataset or MNISTM and SVHN for the Digit-Five dataset. For the remaining scenarios, FACT-NF closely matches the results of FACT.
在全部三项实验中,我们观察到微调步骤能提升模型性能,通过对比FACT与FACT-NF的结果可以明显看出这一点。这一现象在更具挑战性的目标域(如Office数据集中的Amazon域,或Digit-Five数据集中的MNISTM和SVHN域)中尤为显著。在其他实验场景中,FACT-NF的表现与FACT基本持平。
4.2 FACT improves on baselines even if model assumptions are violated
4.2 即使违反模型假设,FACT 仍优于基线方法
FACT uses inter-domain differences between source domains to identify and mitigate domain shifts in the target domain. Next, we evaluate the performance of FACT in a scenario where the data are approximately i.i.d. and as such violate the assumptions. For this, we consider the standard UDA single-source-single-target scenario. Since FACT requires a minimum of two source clients to apply the proposed training scheme without limitations, we artificially distribute each source domain to two equally sized source clients. Table 4 shows the obtained target accuracies for three popular test settings on Digit-Five compared to state-of-the-art results obtained by Conditional Adversarial Domain Adaptation with Entropy Conditioning mathrm{(CDAN{+}E)} [28], MCD [36], Cluster Alignment with a Teacher (CAT) Deng et al. [5], and robust RevGrad with CAT (rRevGrad+CAT) Deng et al. [5].
FACT利用源域之间的跨域差异来识别并缓解目标域中的域偏移。接下来,我们评估FACT在数据近似独立同分布(i.i.d.)场景下的性能,该场景违反了算法假设。为此,我们考虑标准单源单目标域适应(UDA)场景。由于FACT需要至少两个源客户端才能无限制地应用所提出的训练方案,我们人为地将每个源域划分为两个规模相等的源客户端。表4展示了Digit-Five数据集上三种常用测试设置的目标准确率,并与以下先进方法进行对比:基于熵调节的条件对抗域适应mathrm{(CDAN{+}E)}[28]、MCD[36]、Deng等人提出的教师引导聚类对齐(CAT)[5],以及Deng等人提出的鲁棒逆向梯度结合CAT(rRevGrad+CAT)[5]。
We observe that FACT outperforms the state-of-the-art baselines in two out of three commonly tested scenarios for Digit-Five. For SVHN to MNIST, FACT shows a compromised accuracy of 90.6% compared to 98.8% for the best performing model (rRevGrad+CAT). However, for USPS to MNIST and vice versa, FACT obtained the highest accuracy of all baselines. These finding support FACT’s capability to establish domain robust models even in scenarios where no or little domain differences are present among the source domains.
我们观察到,在Digit-Five的三个常见测试场景中,FACT在其中两个场景下超越了现有最优基线方法。对于SVHN到MNIST的迁移任务,FACT的准确率为90.6%,略低于最佳模型(rRevGrad+CAT)的98.8%。但在USPS与MNIST双向迁移任务中,FACT取得了所有基线方法中的最高准确率。这些发现印证了FACT即使在源域间无明显差异的场景下,仍能建立具有领域鲁棒性的模型。
Table 4: Target accuracies obtained for the standard single-source-single-target UDA setting (S: SVHN, M:MNIST, U: USPS).
表 4: 标准单源单目标无监督域适应(UDA)设置下获得的准确率 (S: SVHN, M: MNIST, U: USPS)
| S→M | U→M M→U | Avg | |
|---|---|---|---|
| CDAN+E | 89.2 | 98.0 95.6 | 94.3 |
| MCD | 96.2 | 94.1 94.2 | 94.8 |
| MCD+CAT | 97.1 | 96.3 95.2 | 96.2 |
| rRevGrad+CAT | 98.8 | 94.0 96.0 | 96.3 |
| FACT | 90.6 | 98.6 98.8 | 96.0 |
4.3 FACT is robust with respect to suboptimal source domains
4.3 FACT 对于次优源域具有鲁棒性
The results from the previous section show that the accuracy obtained for different domain combinations can differ significantly, dependent on the domain shift between the source and the target or the sample sizes. Thus, the combination of heterogeneous source domains might not be beneficial in general but could also introduce negative transfer [44] and could compromise the multi-source predictions. Negative transfer is a common issue for standard model aggregation with FedAvg, since opposing updates for highly homogeneous data sources might cancel each other, leading to slowly or non-converging models [29, 21].
上一节的结果表明,不同领域组合获得的准确率可能存在显著差异,这取决于源领域与目标领域之间的领域偏移 (domain shift) 或样本量大小。因此,异构源领域的组合通常可能并无益处,反而可能引发负迁移 (negative transfer) [44],并影响多源预测的可靠性。负迁移是联邦平均 (FedAvg) 标准模型聚合中的常见问题,因为高度同质化数据源的相反更新可能相互抵消,导致模型收敛缓慢甚至无法收敛 [29, 21]。
Starting from the single-source setting of the previous section we gradually increase the number of participating source domains and evaluate the target accuracy for all possible combinations thereof. The results for Digit-Five are shown in Figure 2a. We observe that each added source domain improves the average accuracy for each target. In particular, SVHN, MNISTM and SYN substantially benefit from additional source clients, which might be due to the large domain shifts these domains exhibit to most of the potential source domains. However, we observe that specific source-target combinations are already able to closely match the performance of FACT using all of the four available sources, i.e., mathrm{SYN}tomathrm{SVHN} with 92.7% , mathrm{SYN}tomathrm{MNISTM} with 88.3% and operatorname{SVHN}rightarrow SYN with 95.7% accuracy, respectively (for the full results of all source-target combinations see the Supplementary Materials). In all three cases, adding additional source clients did not significantly compromise the overall predictions and the small errors of the full model suggest stable model performance. Thus, many source clients might be beneficial in general and minimizing IDD might prevent negative transfer by actively encouraging invariant domains.
从上一节的单源设置出发,我们逐步增加参与源域的数量,并评估所有可能组合的目标准确率。Digit-Five 的结果如图 2a 所示。我们观察到,每个新增的源域都提高了各目标的平均准确率。特别是 SVHN、MNISTM 和 SYN 显著受益于额外的源客户端,这可能是由于这些域与大多数潜在源域之间存在较大的域偏移。然而,我们发现某些特定源-目标组合的性能已能接近使用全部四个可用源的 FACT 模型,例如 mathrm{SYN}tomathrm{SVHN} 达到 92.7%,mathrm{SYN}tomathrm{MNISTM} 达到 88.3%,以及 operatorname{SVHN}rightarrow SYN 达到 95.7%$ 准确率(完整源-目标组合结果见补充材料)。在这三种情况下,添加额外源客户端并未显著影响整体预测,且完整模型的小误差表明模型性能稳定。因此,多源客户端总体上可能有益,而最小化 IDD 可通过主动促进不变域来防止负迁移。
4.4 FACT generalizes to many clients
4.4 FACT 适用于多种客户端
In contrast to the previous experiments, we demonstrate that FACT can efficiently deal with an increased number of source clients. We use all source domains and evenly split each source across 3, 5 and 10 individual clients for a total of 12, 20 and 40 source clients, respectively. Note that the total number of training samples remains constant and only the sample size at each location is reduced and as such it becomes more likely that data from the same domain are used in cross training. We observe (Figure 2b) that the number of clients only marginally impacts the target performance, especially for the USPS and MNIST, suggesting the applicability of FACT also in scenarios with many sources which individually contribute only small-sized data. Noteworthy, the obtained results consistently outcompete the federated and non-federated baselines evaluated without splitting the data into multiple sources.
与之前的实验不同,我们证明FACT能高效处理更多数量的源客户端。我们使用全部源域,并将其均匀分配到3、5和10个独立客户端,分别形成12、20和40个源客户端。请注意,训练样本总数保持不变,仅每个位置的样本量减少,因此跨训练中使用同域数据的概率增加。我们观察到 (图2b) 客户端数量对目标性能影响微弱,尤其是USPS和MNIST数据集,这表明FACT在具有多个小数据量源场景中同样适用。值得注意的是,这些结果始终优于未将数据拆分为多源的联邦与非联邦基线方法。
4.5 FACT’s performance under communication restrictions
4.5 通信限制下的 FACT 性能
Frequent communication with a server can render federated learning approaches impractical. Thus, we systematically study FACT’s performance with respect to the number of communication rounds. For this, we fix the number of totally trained epochs to 1000 but vary the number of communication rounds. On Digit-Five, we observe (Figure 2c) no significant change in accuracy for the three best performing target domains, i.e., MNIST, SYN and USPS, even for as little as 25 rounds of FL. The performance of the more challenging target domains, MNISTM and SVHN, were gradually decreased to 84.4% and 84.7% , respectively. There, however, estimated accuracies showed a high variance, suggesting that frequent communication might be beneficial but is not necessary in general. Moreover, the obtained mean accuracy of all targets is still substantially better than those by the federated and non-federated baselines even for highly restricted communication.
与服务器频繁通信可能导致联邦学习方法难以实际应用。因此,我们系统性地研究了FACT在不同通信轮次下的性能表现。实验设置固定总训练轮次为1000次,仅调整通信轮次。在Digit-Five数据集上观察发现(图2c),性能最佳的三个目标域(MNIST、SYN和USPS)的准确率即使仅进行25轮联邦学习也未出现显著变化。而更具挑战性的目标域MNISTM和SVHN的准确率分别逐步降至84.4%和84.7%。值得注意的是,这些场景下的准确率估计值呈现较高方差,表明频繁通信可能有益但通常并非必需。此外,即使在严格限制通信的情况下,所有目标域的平均准确率仍显著优于联邦与非联邦基线方法。

Figure 2: Target client accuracies obtained on Digit-Five data for (a) a varying number of participating source domains evaluated for all possible domain combinations, (b) additional source clients where the individual source domains are split across multiple clients, and (c) communication restrictions where the number of communication rounds are varied for a fixed number of training epochs.
图 2: 在Digit-Five数据上获得的目标客户端准确率,其中(a)评估所有可能的领域组合时参与源领域数量的变化,(b)将单个源领域拆分到多个客户端的附加源客户端情况,(c)在固定训练轮数下改变通信轮数的通信限制场景。
5 Conclusion
5 结论
We showed that inter-domain distances can be directly leveraged for multi-source-single-target domain adaptation, which also holds true for federated scenarios where privacy issues prohibit direct data exchange between clients. FACT combines only two objectives, namely minimizing a standard classification loss with minimizing inter-domain distances. Although simple, this approach substantially outperforms the state-of-the-art in the majority of the performed experiments.
我们证明了跨域距离可直接用于多源单目标域适应,这一结论同样适用于因隐私问题禁止客户端间直接数据交换的联邦场景。FACT仅结合两个目标:最小化标准分类损失与最小化跨域距离。尽管方法简单,但在大多数实验中该方法显著优于当前最优技术。
This also applies to standard UDA scenarios with a single source domain, violating the main assumption of FACT that data available at different clients are non-i.i.d.. We further showed that a suboptimal selection of source clients has only a minor effect on target accuracy. Further, FACT performs well in scenarios where data are distributed across multiple source clients and where server communication is restricted. In summary, FACT is a simple, highly efficient and highly competitive approach which might be valuable to many federated real world scenarios.
这也适用于单一源域的标准无监督域适应(UDA)场景,违反了FACT的核心假设——不同客户端的数据是非独立同分布的。我们进一步证明,次优的源客户端选择对目标准确率影响甚微。此外,FACT在数据分布于多个源客户端且服务器通信受限的场景中表现优异。总之,FACT是一种简单高效且极具竞争力的方法,对众多现实联邦学习场景具有重要价值。
Limitations We could empirically show that controlling the inter-domain distance among both non-i.i.d. and i.i.d. source clients substantially improves multi-source-single-target domain adaptation. Yet, however, there are no theoretical guarantees to which scenario this concepts applies and to what extend. In particular, for the i.i.d. setting where only sample domain differences might be observed, it may be hard to verify that the identified domain differences are significant enough to guarantee target adaptation. Since the distribution al alignment is based on the joint feature extractor, each client requires sufficient resources to calculate the respective gradients, potentially restricting the applicability of FACT on IoT devices for large models. Similarly, transferring large models between the clients may increase the training time. In this case, reducing the number of communication rounds or neglecting the fine-tuning could be an option.
限制
我们通过实验证明,在非独立同分布(non-i.i.d.)和独立同分布(i.i.d.)的源客户端之间控制域间距离,能显著提升多源单目标域适应性能。然而,这一概念适用于何种场景及其适用程度尚缺乏理论保证。特别是在仅能观察到样本域差异的i.i.d.设置中,可能难以验证所识别的域差异是否足以保证目标适应。由于分布对齐基于联合特征提取器,每个客户端需要充足资源来计算相应梯度,这可能限制FACT在物联网设备上运行大型模型的适用性。同样,在客户端间传输大型模型会增加训练时间。此时,减少通信轮次或跳过微调可能是可行方案。
Acknowledgements
致谢
This work was supported by the German Federal Ministry of Education and Research (BMBF) [01KD2209D].
本研究由德国联邦教育与研究部 (BMBF) [01KD2209D] 资助。
References
参考文献
[1] Durmus Alp Emre Acar, Yue Zhao, Ramon Matas Navarro, Matthew Mattina, Paul N Whatmough, and Venkatesh Saligrama. Federated learning based on dynamic regular iz ation. arXiv preprint arXiv:2111.04263, 2021.
[1] Durmus Alp Emre Acar, Yue Zhao, Ramon Matas Navarro, Matthew Mattina, Paul N Whatmough, Venkatesh Saligrama. 基于动态正则化的联邦学习 (Federated Learning Based on Dynamic Regularization). arXiv预印本 arXiv:2111.04263, 2021.
[2] Sk Miraj Ahmed, Dripta S Ray chau dhu ri, Sujoy Paul, Samet Oymak, and Amit K RoyChowdhury. Unsupervised multi-source domain adaptation without access to source data. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10103–10112, 2021.
[2] Sk Miraj Ahmed, Dripta S Ray chau dhu ri, Sujoy Paul, Samet Oymak, Amit K RoyChowdhury. 无监督多源域自适应方法:无需访问源数据. 载于《IEEE/CVF计算机视觉与模式识别会议论文集》, 页码10103–10112, 2021.
Supplementary Materials
补充材料
Implementation Details
实现细节
For Digit-Five [32], we use a feature generator consisting of two convolutional layers and a classifier consisting of three fully connected (FC) layers. The detailed architecture can be found in Table 5. For the Office [35] and Office-Caltech10 [12] data, the generator is provided by a pre-trained ResNet101 [14] and the classifier consists of two FC layers. We additionally use Batch-Normalization (BN) layers and ReLu activation functions as outlined in Table 5. For all experiments, the maximum number of epochs trained at the clients is set to 1000 with a batch-size of B=128 . Further, we use an initial learning rate of eta_{0}=0.005 for all experiments, except for the single-source-single-target setting. In the latter, we use a higher initial learning rate of eta_{0}=0.01 to guarantee convergence within the 1000 training epochs.
对于Digit-Five [32],我们采用由两个卷积层组成的特征生成器和一个由三个全连接(FC)层构成的分类器。具体架构详见表5。在Office [35]和Office-Caltech10 [12]数据集中,生成器采用预训练的ResNet101 [14],分类器则包含两个FC层。如表5所示,我们还使用了批归一化(BN)层和ReLu激活函数。所有实验中,客户端训练的最大周期数设为1000,批处理规模为B=128。此外,除单源单目标设置外,其他实验均采用初始学习率eta_{0}=0.005。在单源单目标场景下,为确保1000个训练周期内收敛,我们使用了更高的初始学习率eta_{0}=0.01。
Table 5: Detailed model architecture used for Digit-Five and the classifier used in combination with the pre-trained ResNet101 for Office and Office-Caltech10.
表 5: Digit-Five使用的详细模型架构以及与预训练ResNet101结合用于Office和Office-Caltech10的分类器。
| 层数 | 配置 |
|---|---|
| 特征生成器 (Digit-Five) | |
| 1 2 | Conv2D (3,64,5,1,2), BN, ReLU, MaxPool Conv2D (64,128,5,1,2), BN, ReLU, MaxPool |
| 分类器 (Digit-Five) | |
| 1 2 3 | DropOut (0.5), FC (8192,3072), BN, ReLU DropOut (0.5), FC (3072,100), BN, ReLU DropOut (0.5), FC (100,10), BN, Softmax |
| ResNet101分类器 | |
| 1 | DropOut (0.5), FC (1000,500), BN, ReLU |
| 2 | FC (500,类别数), BN, ReLU, Softmax |
Single-source-single-target UDA
单源单目标无监督域适应 (UDA)
Table 8 shows the target accuracies obtained by FACT for all possible source-target combinations on the Digit-Five data. The results are averaged over 5 repeated runs. Further note that in order to run FACT without modifications, we equally split the source data between two source clients. As such, the distribution al differences between the two sources are sample dependent, which potentially decreases target convergence. Therefore, we used a higher initial learning rate eta_{0}=0.01 for these experiments.
表 8 展示了 FACT 在 Digit-Five 数据集上所有可能的源-目标组合所获得的目标准确率。结果是 5 次重复运行的平均值。另外需要注意的是,为了在不修改的情况下运行 FACT,我们将源数据均分给两个源客户端。因此,两个源之间的分布差异取决于样本,这可能会降低目标收敛性。为此,我们在这些实验中使用了较高的初始学习率 eta_{0}=0.01。
Table 6: Number of samples for each dataset and domain.
表 6: 各数据集和领域的样本数量。
| Split | MNISTM | MNIST | SVHN | SYN | USPS | Total |
|---|---|---|---|---|---|---|
| Train | 25000 | 25000 | 25000 | 25000 | 7348 | 107348 |
| Test | 9000 | 9000 | 9000 | 9000 | 1860 | 37860 |
| Split | Amazon | DSLR | Webcam | Total | ||
|---|---|---|---|---|---|---|
| Total | 2817 | 498 | 795 | 4110 |
| Split | Amazon | Caltech | DSLR | Webcam | Total | |
|---|---|---|---|---|---|---|
| Total | 958 | 1123 | 157 | 295 | 2533 |
Table 7: Number of classes for each dataset
表 7: 各数据集的类别数量
| Dataset | Number of classes |
|---|---|
| Digit-Five | 10 |
| Office | 31 |
| Office-Caltech10 | 10 |
Table 8: Target accuracies obtained for the standard single-source-single-target UDA setting for all possible source-target combinations of the Digit-Five data.
表 8: Digit-Five数据集在标准单源单目标无监督域适应(UDA)设置下所有可能源-目标组合的准确率结果
| 目标源 | →MNISTM | →MNIST | →SVHN | →SYN | →USPS |
|---|---|---|---|---|---|
| MNISTM | 99.17 ± 0.04 | 29.0±2.52 | 85.86 ± 0.96 | 98.75 ±0.11 | |
| MNIST | 61.27 ± 2.85 | 16.91±3.28 | 64.41 ± 6.05 | 98.75 ±0.11 | |
| SVHN | 54.62±1.31 | 90.58 ±0.61 | 95.74 ± 0.13 | 92.56±4.51 | |
| SYN | 88.28 ± 1.07 | 98.54 ± 0.07 | 92.65 ± 0.25 | 98.2±0.25 | |
| USPS | 67.46 ± 1.02 | 98.58 ±0.04 | 12.19± 1.97 | 60.85± 2.31 |