Class Overwhelms: Mutual Conditional Blended-Target Domain Adaptation
类别压倒性:互条件混合目标域自适应
Pengcheng Xu,1 Boyu Wang, 1, 2 * Charles Ling
彭程旭1,王博宇1, 2*,Charles Ling
1 Western University, London, ON N6A 5B7, Canada 2 Vector Institute, Toronto, ON M5G 1M1, Canada pxu67@uwo.ca, bwang@csd.uwo.ca, charles.ling@uwo.ca
1 加拿大西安大略大学,伦敦市,N6A 5B7 2 加拿大向量研究所,多伦多市,M5G 1M1 pxu67@uwo.ca, bwang@csd.uwo.ca, charles.ling@uwo.ca
Abstract
摘要
Current methods of blended targets domain adaptation (BTDA) usually infer or consider domain label information but under emphasize hybrid categorical feature struc- tures of targets, which yields limited performance, especially under the label distribution shift. We demonstrate that domain labels are not directly necessary for BTDA if categorical distributions of various domains are sufficiently aligned even facing the imbalance of domains and the label distribution shift of classes. However, we observe that the cluster assumption in BTDA does not comprehensively hold. The hybrid categorical feature space hinders the modeling of categorical distributions and the generation of reliable pseudo labels for categorical alignment. To address these, we propose a categorical domain disc rim in at or guided by uncertainty to explicitly model and directly align categorical distributions $P(Z|Y)$ . Simultaneously, we utilize the lowlevel features to augment the single source features with diverse target styles to rectify the biased classifier $P(Y|Z)$ among diverse targets. Such a mutual conditional alignment of $P(Z|Y)$ and $P(Y|Z)$ forms a mutual reinforced mechanism. Our approach outperforms the state-of-the-art in BTDA even compared with methods utilizing domain labels, especially under the label distribution shift, and in single target DA on DomainNet. Source codes are available at https://github.com/Peng cheng pc x/Class-overwhelmsMutual-Conditional-Blended-Target-Domain-Adaptation
当前混合目标域适应(BTDA)方法通常推断或考虑域标签信息,但低估了目标的混合类别特征结构,导致性能受限,尤其在标签分布偏移情况下。我们证明,只要各类别在不同域的分布充分对齐,即使面临域不平衡和类别标签分布偏移,BTDA并不直接需要域标签。然而我们发现BTDA中的聚类假设并不完全成立——混合类别特征空间阻碍了类别分布建模和可靠伪标签生成。为此,我们提出基于不确定性的类别域鉴别器来显式建模并直接对齐类别分布$P(Z|Y)$,同时利用低级特征增强单一源特征以融合多样目标风格,从而校正不同目标间有偏分类器$P(Y|Z)$。这种$P(Z|Y)$与$P(Y|Z)$的互条件对齐形成相互增强机制。我们的方法在BTDA任务上超越了最先进方法(包括使用域标签的方法),尤其在标签分布偏移场景和DomainNet单目标域适应任务中表现突出。源代码见https://github.com/Peng cheng pc x/Class-overwhelmsMutual-Conditional-Blended-Target-Domain-Adaptation
Introduction
引言
Deep learning suffers a serious performance drop under the distribution shift (Ben-David et al. 2006). Unsupervised domain adaptation (UDA) is proposed to adapt a source model to a new unlabeled target domain. Most UDA research considers the adaptation from single or multiple sources to a single target (STDA). However, in reality, the target domain can be diverse and include various styles and textures, and the distribution of each class also varies from each target. These steer us to consider a practical yet challenging setting termed as blended targets domain adaptation (BTDA): 1)Adaptation is conducted from one single source to multiple targets. 2)Neither domain labels nor class labels are available on targets and the model should perform well on each target. 3)Label distributions of different targets can be different (label shift). In the following, we first present the analysis of BTDA, and discuss limitations of current methods due to these essential issues. Finally, we discuss that domain labels are not directly necessary for BTDA and propose the category-oriented mutual conditional domain adaptation (MCDA), which also generalizes to common settings.
深度学习在分布偏移下会出现严重的性能下降 (Ben-David et al. 2006)。无监督域适应 (UDA) 旨在将源模型适配到新的无标注目标域。大多数UDA研究关注从单个或多个源域到单个目标域 (STDA) 的适应。然而现实中,目标域可能具有多样性,包含多种风格和纹理,且每个目标的类别分布也存在差异。这促使我们考虑一个实际但极具挑战性的设定——混合目标域适应 (BTDA):1) 从单一源域适应到多个目标域;2) 目标域既无域标签也无类别标签,且模型需在每个目标域表现良好;3) 不同目标域的标签分布可能存在差异 (标签偏移)。下文首先分析BTDA特性,讨论现有方法因这些核心问题存在的局限性,最后论证域标签对BTDA并非必需,并提出面向类别的互条件域适应 (MCDA),该方法亦可推广至常规设定。
There are two practical issues for distribution al alignment in BTDA: 1)Diverse styles and textures of blended targets. 2)Label shift of various targets. These induced our key observation that categorical feature space in BTDA is hybrid and unstructured as shown in Figure 1. Features of different classes in the blended targets are pervasive and do not form a well-clustered structure. To analyze it, we conduct t-SNE for feature space under BTDA in the left. Besides, we also uniformly sample and calculate K nearest neighbors (KNN) of each class center under STDA and BTDA. The result in the middle shows that the number of samples within the same class in STDA is more than that of BTDA. This indicates that the cluster structure of BTDA is not well formed compared to STDA which corresponds to the hybrid categorical feature space in t-SNE visualization. This weakens the cluster assumption (Chapelle and Zien 2005) that serves as the necessary condition of many adaptation methods (Tachet des Combes et al. 2020; Shu et al. 2018; Tang, Chen, and Jia 2020; Yang et al. 2021). Further, it motivates our analytical perspective from both categorical distribution shift and biased classifier for BTDA.
BTDA中的分布对齐存在两个实际问题:1) 混合目标多样化的风格和纹理。2) 不同目标的标签偏移。这引出了我们的关键观察:如图1所示,BTDA中的类别特征空间是混合且非结构化的。混合目标中不同类别的特征普遍存在,并未形成良好的聚类结构。为分析此现象,我们在左侧对BTDA下的特征空间进行了t-SNE可视化。此外,我们还均匀采样并计算了STDA和BTDA下各类别中心的K近邻(KNN)。中间结果显示,STDA中同类样本数量多于BTDA,这表明相较于STDA,BTDA的聚类结构未充分形成,与t-SNE可视化中混合类别特征空间的现象一致。该现象削弱了作为许多自适应方法必要条件的聚类假设(Chapelle and Zien 2005)(Tachet des Combes et al. 2020; Shu et al. 2018; Tang, Chen, and Jia 2020; Yang et al. 2021),进而促使我们从类别分布偏移和分类器偏差的双重视角对BTDA展开分析。
Current UDA methods yield sub-optimal performance in BTDA due to these. Concretely, methods based on the covariate shift assumption and aligning marginal distributions (Tzeng et al. 2017; Ganin and Lempitsky 2015; Shen et al. 2018) are inevitable to increase the joint error of optimal hypotheses under the label shift (Wu et al. 2019; Tachet des Combes et al. 2020). BTDA worsens the situation with diverse target domains and the more serious imbalance and label shift issues. Some theories further propose conditional alignment formulation to avoid the joint error issue. (Tachet des Combes et al. 2020; Jiang et al. 2020) im- plicitly align conditional distribution by aligning reweighted marginal distributions that still needs cluster assumption. Other methods use the target pseudo labels to model and align conditional distributions through class centroids (Pan et al. 2019; Tanwisuth et al. 2021; Singh 2021), task-oriented class if i ers (Zhang et al. 2019; Saito et al. 2019), and the conditional disc rim in at or (Long et al. 2018). These effective STDA methods produce limited performance under the hybrid feature space in BTDA. Centroid and general adversarial methods may not model distributions well. The biased classifier and clustering labeling algorithm also generate noisy labels in this situation.
当前的无监督域适应(UDA)方法由于这些原因在BTDA中表现欠佳。具体而言,基于协变量偏移假设和边缘分布对齐的方法(Tzeng et al. 2017; Ganin and Lempitsky 2015; Shen et al. 2018)不可避免地会增加标签偏移下最优假设的联合误差(Wu et al. 2019; Tachet des Combes et al. 2020)。BTDA中多样化的目标域以及更严重的类别不平衡和标签偏移问题进一步恶化了这一状况。部分理论提出条件对齐公式以避免联合误差问题(Tachet des Combes et al. 2020; Jiang et al. 2020),通过对齐重加权边缘分布隐式地对齐条件分布,但仍需依赖聚类假设。其他方法使用目标域伪标签,通过类中心点(Pan et al. 2019; Tanwisuth et al. 2021; Singh 2021)、面向任务的分类器(Zhang et al. 2019; Saito et al. 2019)和条件判别器(Long et al. 2018)来建模和对齐条件分布。这些有效的单目标域适应(STDA)方法在BTDA的混合特征空间中表现有限:中心点方法和通用对抗方法可能无法很好建模分布,有偏分类器和聚类标注算法在此情况下也会产生噪声标签。
Recent multi-target domain adaptation (MTDA) methods produce impressive results by generally inferring or utilizing the domain level information and then conducting STDA methods. Some methods train separated models for each target which is not efficient in practice (Saporta et al. 2021; Isobe et al. 2021; Nguyen-Meidine et al. 2021; Saporta et al. 2021). Other methods utilize graph neural networks with coteaching (Roy et al. 2021a), disentanglement methods (Gholami et al. 2020) and meta-clustering (Chen et al. 2019). These require domain labels and lack consideration for the imbalance and the hybrid target feature space in BTDA.
近期多目标域适应(MTDA)方法通过推断或利用域级信息并执行STDA方法取得了显著成果。部分方法为每个目标训练独立模型(如Saporta等人2021;Isobe等人2021;Nguyen-Meidine等人2021;Saporta等人2021),实际应用效率较低。另一些方法采用图神经网络协同教学(Roy等人2021a)、解耦方法(Gholami等人2020)和元聚类(Chen等人2019),这些方法需要域标签且未考虑BTDA中不平衡的混合目标特征空间。
In this paper, we address two intrinsic issues of BTDA: 1)Domain labels. 2)Hybrid categorical feature space. First, our analysis shows that domain labels are not directly necessary for BTDA only if the categorical distributions of various domains are sufficiently aligned even facing the imbalance and the label shift. However, categorical alignment requires labels. The hybrid categorical feature space in BTDA raises practical issues in modeling categorical distributions and producing reliable pseudo labels. Considering these, we design techniques to explicitly model and align categorical distributions $P(Z|Y)$ of various domains and simultaneously correct the biased classifier $P(Y\vert Z)$ among diverse targets to enhance pseudo labels.
本文解决了BTDA的两个本质问题:(1) 域标签问题;(2) 混合类别特征空间问题。首先,我们的分析表明:只要各类别的分布能充分对齐(即使存在数据不平衡和标签偏移),域标签对BTDA并非必需。但类别对齐本身需要标签支持。BTDA中的混合类别特征空间会引发两个实际问题:类别分布建模困难与伪标签可靠性降低。为此,我们设计了显式建模技术来对齐不同域的类别分布 $P(Z|Y)$,同时校正多目标场景下存在偏差的分类器 $P(Y\vert Z)$ 以提升伪标签质量。
Practically, this motivates two designs on $P(Z|Y)$ and $P(Y\vert Z)$ . Firstly, for modeling and aligning $P(Z|Y)$ , current methods such as prototype (Pan et al. 2019; Tanwisuth et al. 2021) and kernel methods (Wang et al. 2020) inferiorly model conditional distributions of unstructured data features in the hybrid feature space in Figure 1. Leveraging the distribution modeling ability of GAN (Arora et al. 2017; Goodfellow et al. 2014), we propose an uncertainty-guided categorical domain disc rim in at or. We encode categorical distributions within the same semantic space to explicitly model and directly align $P(Z|Y)$ of various domains. Since the disc rim in at or is supervised with source and noisy target labels, we adopt uncertainty to guide it to gradually learn and align categorical distributions. Secondly, to correct the biased classifier for reliable pseudo labels during adaptation, we first adopt balanced sampling on the source data and then utilize the low-level features in convolution neural networks (CNN) to augment the source features with diverse target styles to reduce domain dependent information and balance the classifier training on target classes. Our method shows that one single labeled source can still be augmented with multiple targets to rectify the classifier during adaptation by leveraging the prior of low-level features in CNN.
实践中,这促使我们对 $P(Z|Y)$ 和 $P(Y\vert Z)$ 进行两项设计。首先,在建模和对齐 $P(Z|Y)$ 时,现有方法如原型法 (Pan et al. 2019; Tanwisuth et al. 2021) 和核方法 (Wang et al. 2020) 对图 1 中混合特征空间内非结构化数据特征的条件分布建模效果欠佳。借助生成对抗网络 (GAN, Arora et al. 2017; Goodfellow et al. 2014) 的分布建模能力,我们提出一种不确定性引导的类别域判别器。我们在同一语义空间内编码类别分布,显式建模并直接对齐不同域的 $P(Z|Y)$ 。由于判别器通过带标注的源数据和含噪声的目标标签进行监督,我们采用不确定性引导其逐步学习并对齐类别分布。其次,为在校准过程中修正带有偏差的分类器以获得可靠伪标签,我们首先对源数据采用平衡采样,然后利用卷积神经网络 (CNN) 中的低级特征,通过多样化目标风格增强源特征,从而减少域依赖信息并平衡目标类别的分类器训练。我们的方法表明,通过利用 CNN 中低级特征的先验知识,单个带标注的源数据仍可通过多个目标进行增强,在校准过程中修正分类器。
In summary, our contributions are as follows: 1)We demonstrate that the adaptation can be well-achieved without domain labels in BTDA if categorical distributions are sufficiently aligned even facing the imbalance and label shift. 2)We propose the mutual conditional alignment to directly minimize conditional distributions and simultaneously correct the biased classifier. 3)Practically, to address the hybrid feature space of BTDA, we design an uncertaintyguided categorical domain disc rim in at or to explicitly model and align categorical distributions, and utilize low-level features to mitigates the bias of classifier on blended targets. Our method achieves the state-of-the-art in BTDA even compared with methods using domain labels, especially under the label shift, and in STDA with DomainNet.
综上所述,我们的贡献如下:
- 我们证明在无监督目标域适应(BTDA)中,即使面临数据不平衡和标签偏移,只要类别分布充分对齐,无需域标签也能实现良好适应。
- 我们提出互条件对齐方法,直接最小化条件分布并同步修正偏置分类器。
- 针对BTDA的混合特征空间,设计了不确定性引导的类别域判别器来显式建模对齐类别分布,并利用低级特征缓解分类器在混合目标上的偏置。本方法在BTDA中达到最先进水平(优于使用域标签的方法),在标签偏移场景和DomainNet的STDA任务中表现尤为突出。
Related Works
相关工作
Single target UDA (STDA): STDA is a typical setting that adapts single or multiple sources into one target. Generally, the research includes four categories. One branch minimizes the explicit statistical distance such as Maximum Mean Discrepancy (MMD) to mitigate the domain distribution shift (Long et al. 2015, 2017; Ven kate s war a et al. 2017; Tzeng et al. 2014; Shen et al. 2018; Lee et al. 2019; Xu et al. 2019; Montesuma and Mboula 2021). The second branch leverages the adversarial training to implicitly minimize the domain discrepancy through GAN (Ganin and Lempitsky 2015; Tzeng et al. 2017; Zhang et al. 2019) or entropy minimization (Pan et al. 2020; Vu et al. 2019). The third one utilizes the self-training with the target pseudo labels to train the source model (Liu, Wang, and Long 2021; French, Mackiewicz, and Fisher 2017). The fourth one utilizes image translation techniques to mitigate the semantic irrelevant gap (Sankara narayan an et al. 2018; Roy et al. 2021b; Kim and Byun 2020; Yang et al. 2020a). However, these methods produce limited performance in BTDA. The serious imbalance and label shift issues in blended targets cause a serious incremental error of class if i ers (Wu et al. 2019), and the hybrid target feature space also yields noisy pseudo labels and calibration issues (Mei et al. 2020), which deteriorates the self-training and conditional alignment methods.
单目标域适应 (STDA): STDA是典型的将单个或多个源域适配至单一目标域的设定。该领域研究主要包含四类方法:第一类通过最小化最大均值差异 (MMD) 等显式统计距离来缓解域分布偏移 [20,21,22,23,24,25,26,27];第二类采用对抗训练,通过生成对抗网络 (GAN) [28,29,30] 或熵最小化 [31,32] 隐式减小域差异;第三类利用目标域伪标签进行自训练来优化源域模型 [33,34];第四类运用图像转换技术消除语义无关差异 [35,36,37,38]。但这些方法在混合目标域适应 (BTDA) 中表现有限——混合目标域严重的类别不平衡与标签偏移会导致分类器误差累积 [39],而混合特征空间还会产生噪声伪标签与校准问题 [40],进而削弱自训练与条件对齐方法的有效性。
Multi-target UDA (MTDA): transfers the knowledge from a single source to multiple targets. MTDA is recently studied in both classification (Gholami et al. 2020; NguyenMeidine et al. 2021; Chen et al. 2019; Roy et al. 2021a; Yang et al. 2020b) and semantic segmentation (Saporta et al. 2021; Isobe et al. 2021). One common approach is to disentangle domain information from multiple targets by adversarial learning and adapt each target with a separated network (Saporta et al. 2021; Gholami et al. 2020). AMEAN (Chen et al. 2019) first clusters blended targets into sub-clusters and adapts the source with each cluster. CGCT (Roy et al. 2021a) use graph convolution network (GCN) for feature aggregation, and use GCN classifier and source classifier for co-teaching. Differently, our method does not require any domain label and conducts BTDA in an united network which is scalable and efficient. Besides, our model considers the hybrid categorical feature space and is robust under the imbalance and label shift in BTDA.
多目标无监督域适应 (MTDA):将知识从单一源域迁移到多个目标域。近年来,MTDA在分类任务 (Gholami et al. 2020; NguyenMeidine et al. 2021; Chen et al. 2019; Roy et al. 2021a; Yang et al. 2020b) 和语义分割任务 (Saporta et al. 2021; Isobe et al. 2021) 中均有研究。常见方法是通过对抗学习从多个目标域中分离域信息,并为每个目标域配备独立网络进行适配 (Saporta et al. 2021; Gholami et al. 2020)。AMEAN (Chen et al. 2019) 先将混合目标域聚类为子簇,再将源域与各子簇分别适配。CGCT (Roy et al. 2021a) 采用图卷积网络 (GCN) 进行特征聚合,并利用GCN分类器与源分类器进行协同教学。不同的是,本方法无需任何域标签,可在统一网络中执行BTDA,具有可扩展性和高效性。此外,本模型考虑了混合类别特征空间,在BTDA中的不平衡和标签偏移情况下表现稳健。
Methodology
方法论
We present our analysis of BTDA and discuss the proposed mutual conditional domain adaptation (MCDA) framework including: explicit categorical adversarial alignment, uncertainty-guided disc rim i native adversarial training, and low-level feature manipulation for the classifier correction.
我们分析了BTDA并讨论了提出的互条件域适应 (MCDA) 框架,包括:显式类别对抗对齐、不确定性引导的判别对抗训练,以及用于分类器校正的低级特征操作。
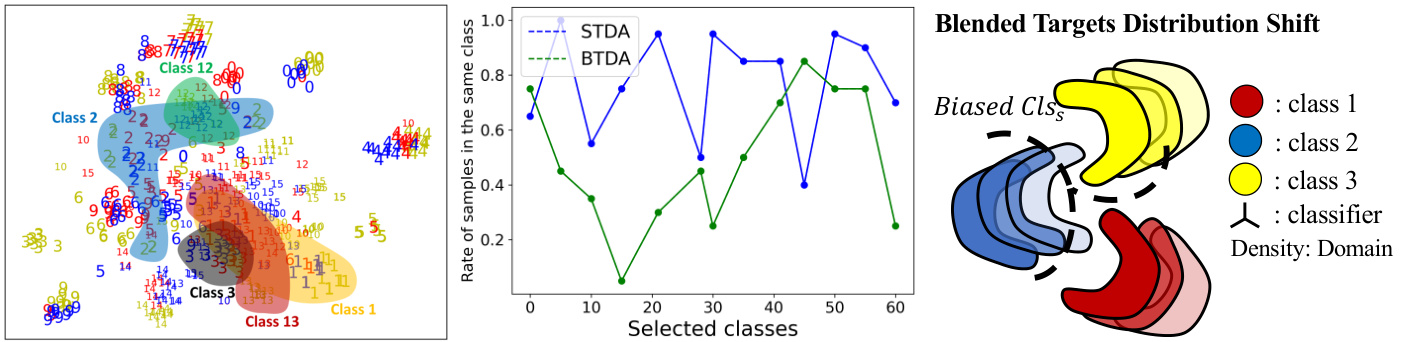
Figure 1: Left: t-SNE for hybrid categorical feature space of BTDA where features of various classes are pervasive and unstructured. The color indicates the domain and the digit indicates the class. Middle: the sample rate of the same class for each class center’s K nearest neighbors. All data are collected from Office-Home (ResNet-50). Right: BTDA distribution shift where features are unstructured and the classifier is biased.
图 1: 左图: BTDA混合类别特征空间的t-SNE可视化,显示各类特征普遍存在且无结构化。颜色表示域,数字表示类别。中图: 每类中心K近邻中同类别样本的采样率。所有数据均来自Office-Home数据集(ResNet-50)。右图: BTDA分布偏移现象,特征呈现无结构化且分类器存在偏差。
Notation. Let us denote the input-output space $\mathcal{X}\times\mathcal{Y}$ where $\mathcal{X}$ represents the image space and $\mathcal{V}$ represents the ${x_{i}^{s},y_{i}^{s}}{i=1}^{|S|}$ and each unlabeled target is denoted as $\begin{array}{l}{\displaystyle{\mathcal{T}}{j}=}\end{array}$ ${\boldsymbol{S}}=$ {xitj }|iT=j1|. Both source and target domains are i.i.d sampled from some distribution $P_{S}(X,Y)$ and $P_{\mathcal{T}_{j}}(X,Y)$ . For the model, we denote the feature extractor $g:\mathcal{X}\rightarrow\mathcal{Z}$ and the classifier $h:\mathcal{Z}\rightarrow\mathcal{Y}$ . The error rate of the model on source $s$ and target $\mathcal{T}_{j}$ are $\epsilon_{S}$ an $\epsilon_{T_{j}}$ , and the blended target error rate is evaluated as ϵT = 1 j ϵTj .
符号表示。我们定义输入-输出空间为 $\mathcal{X}\times\mathcal{Y}$,其中 $\mathcal{X}$ 表示图像空间,$\mathcal{V}$ 表示 ${x_{i}^{s},y_{i}^{s}}{i=1}^{|S|}$。每个未标记的目标表示为 $\begin{array}{l}{\displaystyle{\mathcal{T}}{j}=}\end{array}$ ${\boldsymbol{S}}=$ {xitj }|iT=j1|。源域和目标域均独立同分布于分布 $P_{S}(X,Y)$ 和 $P_{\mathcal{T}_{j}}(X,Y)$。模型方面,特征提取器记为 $g:\mathcal{X}\rightarrow\mathcal{Z}$,分类器记为 $h:\mathcal{Z}\rightarrow\mathcal{Y}$。模型在源域 $s$ 和目标域 $\mathcal{T}_{j}$ 上的错误率分别为 $\epsilon_{S}$ 和 $\epsilon_{T_{j}}$,混合目标错误率计算公式为 ϵT = 1 j ϵTj。
MCDA is a unified framework that adapts a single source to the blended targets such that the model performs well on each single target even facing the label distribution shift across various targets. i.e., ${\bar{P}}{\mathcal{S}}(Y)\neP{\mathcal{T}{j}}(Y)$ and $P{\mathcal{T}{j}}(Y)\ne P{\mathcal{T}{m}}(Y)$ . As proved in (Tachet des Combes et al. 2020), minimizing marginal distribution shift of $P{S}(X)$ and $P_{\mathcal{T}}(X)$ can arbitrarily increase the target error $\epsilon_{T}$ due to the label shift, which fails the adaptation. The situation becomes worse in BTDA since each target can have a different $P_{T_{m}}(Y)$ . In that, we are interested to have a bound such that each term of it can be independently minimized as much as possible, and that is better irrelevant with domain labels.
MCDA是一个统一框架,它通过调整单一源数据以适应混合目标,使得模型即使面对不同目标间的标签分布偏移也能在每个单独目标上表现良好。即 ${\bar{P}}{\mathcal{S}}(Y)\neP{\mathcal{T}{j}}(Y)$ 且 $P{\mathcal{T}{j}}(Y)\ne P{\mathcal{T}{m}}(Y)$。如 (Tachet des Combes et al. 2020) 所证明,由于标签偏移的存在,最小化 $P{S}(X)$ 和 $P_{\mathcal{T}}(X)$ 的边缘分布偏移可能会任意增加目标误差 $\epsilon_{T}$,从而导致适应失败。在BTDA中这种情况更为严重,因为每个目标可能具有不同的 $P_{T_{m}}(Y)$。因此,我们希望获得一个边界,使其各项能够尽可能独立地被最小化,并且最好与域标签无关。
Blended error decomposition theorem. Inspired by the generalized label shift (GLS) theorem in (Tachet des Combes et al. 2020), we intend to align the conditional distributions of each class $P(Z|Y)$ within each target to the same class in the source domain on the feature space $\mathcal{Z}$ .
混合误差分解定理。受 (Tachet des Combes et al. 2020) 中广义标签偏移 (GLS) 定理的启发,我们旨在将每个目标中每个类别的条件分布 $P(Z|Y)$ 对齐到特征空间 $\mathcal{Z}$ 上源域中的同一类别。
Theorem 1 For any classifier ${\hat{Y}}=(h\circ g)(X)$ , the blended target error rate is
定理1 对于任意分类器 ${\hat{Y}}=(h\circ g)(X)$ ,混合目标错误率为

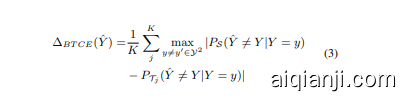
where $|P s(Y)-P_{\mathcal{T}{j}}(Y)|{1}$ represents the $L_{1}$ distance of label distributions between the source and each target and is a constant only depending on the data, $B E R_{P s}(\hat{Y}|Y)$ is the classification performance only related with the source domain. $\Delta_{B T C E}(\hat{Y})$ measures the conditional distribution discrepancy of each class between the source and each target. In this sense, we only need to minimize the $\Delta_{B T C E}(\hat{Y})$ , which is equivalent to minimize the discrepancy between $P s(Z|Y=\stackrel{-}{y})$ and $P_{\mathcal{T}_{j}}(Z|Y=y)$ .
其中 $|P s(Y)-P_{\mathcal{T}{j}}(Y)|{1}$ 表示源域与各目标域标签分布之间的 $L_{1}$ 距离(该值为仅取决于数据的常量),$B E R_{P s}(\hat{Y}|Y)$ 为仅与源域相关的分类性能。$\Delta_{B T C E}(\hat{Y})$ 用于衡量源域与各目标域之间每个类别的条件分布差异。因此,我们只需最小化 $\Delta_{B T C E}(\hat{Y})$ ,这等价于最小化 $P s(Z|Y=\stackrel{-}{y})$ 与 $P_{\mathcal{T}_{j}}(Z|Y=y)$ 之间的差异。
Key differences. First, different from (Tachet des Combes et al. 2020), we argue that the theorem 3.3: clustering structure assumption in (Tachet des Combes et al. 2020) is a strong assumption in BTDA because each target has a different cluster structure $Z_{T_{j}}$ in feature space under the pretrained feature extractor $g_{S}$ , which induces hybrid categorical feature space and different decision boundaries for different target $\mathcal{T}{j}$ as illustrated in Figure 1. When blended together, the cluster of class $a$ in $\tau{m}$ may overlap with the cluster of class $b$ in $\textstyle{\mathcal{T}}{n}$ . Consequently, the sufficient condition for GLS may not hold. Thus, calculating class ratios and aligning reweighted marginal distributions in (Tachet des Combes et al. 2020) do not induce GLS to align the semantic conditional distributions. Second, when the number of classes $\lvert\mathcal{V}\rvert$ is large, solving a quadratic problem to find class ratios require $O(|\mathcal{V}|^{3})$ time which is not efficient and accurate. We do not calculate class ratios. Finally, we do not make any assumption to satisfy GLS. Instead, we adopt the general bound in equation 1 and design model to directly minimize the conditional JS divergence $\mathcal{D}{J S}(P_{S}(Z|Y\overset{\cdot}{=}y)||P_{\mathcal{T}_{j}}(Z|Y\overset{}{=}y))$ to enforce it. However, aligning conditional distribution requires accurate pseudo labels. This motivates us to develop a mutual conditional alignment system to align $P(Z|Y)$ and $P(Y\vert Z)$ simultan e ou sly. Besides, since we only use the class label, the domain label is unnecessary, which suits the BTDA setting.
关键差异。首先,与 (Tachet des Combes et al. 2020) 不同,我们认为定理 3.3: (Tachet des Combes et al. 2020) 中的聚类结构假设在 BTDA 中是一个强假设,因为每个目标在预训练特征提取器 $g_{S}$ 下的特征空间具有不同的聚类结构 $Z_{T_{j}}$ ,这会导致混合的类别特征空间以及不同目标 $\mathcal{T}{j}$ 的不同决策边界,如图 1 所示。当混合在一起时,$\tau{m}$ 中类别 $a$ 的聚类可能与 $\textstyle{\mathcal{T}}{n}$ 中类别 $b$ 的聚类重叠。因此,GLS 的充分条件可能不成立。因此,(Tachet des Combes et al. 2020) 中计算类别比率并对齐重新加权的边缘分布并不能引导 GLS 对齐语义条件分布。其次,当类别数量 $\lvert\mathcal{V}\rvert$ 较大时,通过求解二次问题来寻找类别比率需要 $O(|\mathcal{V}|^{3})$ 时间,效率低且不准确。我们不计算类别比率。最后,我们不做任何满足 GLS 的假设。相反,我们采用方程 1 中的通用边界,并设计模型直接最小化条件 JS 散度 $\mathcal{D}{J S}(P_{S}(Z|Y\overset{\cdot}{=}y)||P_{\mathcal{T}_{j}}(Z|Y\overset{}{=}y))$ 来强制执行。然而,对齐条件分布需要准确的伪标签。这促使我们开发一个相互条件对齐系统,同时对齐 $P(Z|Y)$ 和 $P(Y\vert Z)$ 。此外,由于我们仅使用类别标签,因此不需要域标签,这符合 BTDA 设置。
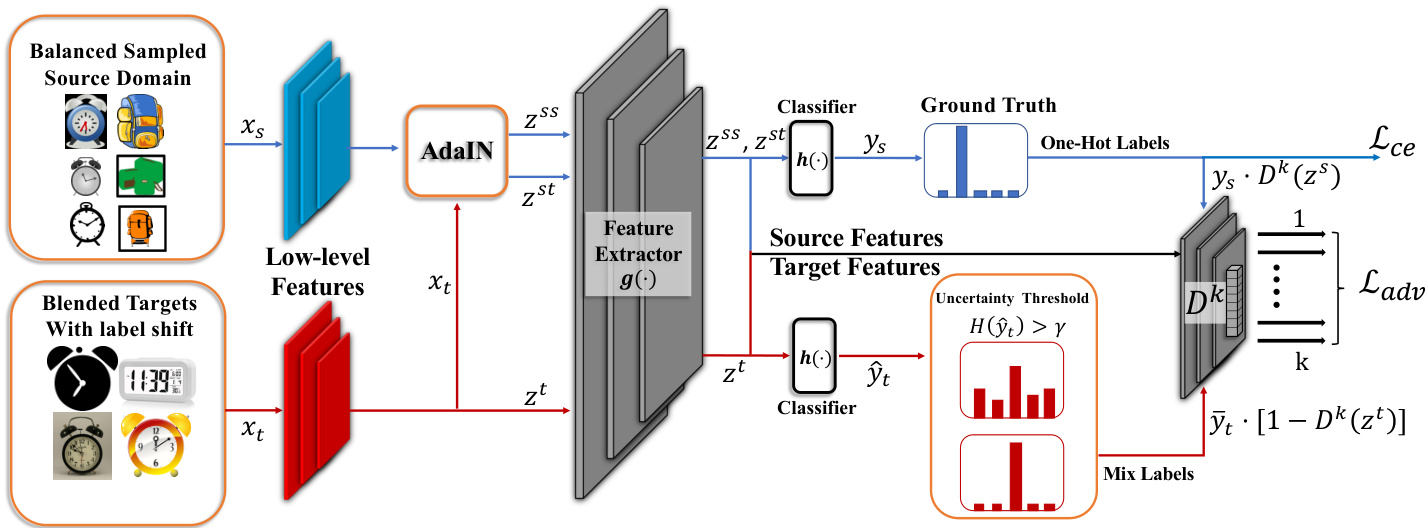
Figure 2: The framework of MCDA. The source data utilizes balanced sampling for training the categorical disc rim in at or and is augmented with blended target styles to train the classifier. The target data is randomly sampled, and the predicted pseudo labels with low uncertainty are converted to one-hot labels to train the categorical domain disc rim in at or.
图 2: MCDA框架。源数据采用平衡采样训练分类判别器,并通过混合目标风格增强来训练分类器。目标数据随机采样,将低不确定性的预测伪标签转换为独热(one-hot)标签以训练分类域判别器。
Explicit categorical adversarial alignment
显式类别对抗对齐
Our motivation is to explicitly model and directly align the categorical JS divergence $\mathcal{D}{J S}(P{S}(Z|Y=y)||\dot{P}{\mathcal{T}{j}}(\bar{Z}|Y=$ $y)$ ) between the source and each target under the hybrid feature space. Current categorical alignment methods utilizing task-class if i ers, prototypes, and conditional discriminator (Zhang et al. 2019; Saito et al. 2019; Long et al. 2018) may not represent conditional distributions well in the hybrid categorical feature space in BTDA.
我们的动机是显式建模并直接对齐混合特征空间下源域与各目标域间的分类JS散度 (JS divergence) $\mathcal{D}{J S}(P{S}(Z|Y=y)||\dot{P}{\mathcal{T}{j}}(\bar{Z}|Y=$ $y)$ )。当前基于任务分类器、原型和条件判别器的分类对齐方法 (Zhang et al. 2019; Saito et al. 2019; Long et al. 2018) 可能无法在BTDA的混合分类特征空间中充分表征条件分布。
Leveraging the distribution modeling ability of GAN, we intend to encode categorical distributions of various domains into the same semantic space to explicitly model categorical distributions for optimization. Inspired by DANN (Ganin and Lempitsky 2015), we augment the last layer of a general domain disc rim in at or $D$ into the number of classes $\mathrm{\Delta}k$ , and each logit of such a categorical domain disc rim in at or $D^{k}$ is followed by a sigmoid function to predict the probability of a feature belonging to the source or target domain conditional on the corresponding class. Each logit behaves as a single GAN to minimize the discrepancy of JS divergence of a specific class $P s(Z|Y=y)$ and ${\bf\tilde{\cal P}}{\mathcal{T}{j}}(Z|Y=y)$ . To make each logit corresponds to one class in $D^{k}$ , we feed one feature $g(x_{i})$ into $\bar{D^{k}}$ and get the prediction $d_{i}\in R^{k}$ . Then we use the corresponding one-hot label $y_{i}\in{0,1}^{k}$ to only activate the corresponding logit to compute adversarial loss by $y_{i}\cdot d_{i}$ . To achieve this, we use pseudo target labels and design a strategy to make the categorical adversarial alignment and pseudo label refinement reinforce each other. Then we formulate the optimization as follows
利用GAN的分布建模能力,我们旨在将不同领域的类别分布编码到同一语义空间中,以显式建模类别分布进行优化。受DANN (Ganin and Lempitsky 2015) 启发,我们将通用领域判别器 $D$ 的最后一层扩展为类别数 $\mathrm{\Delta}k$ ,该分类域判别器 $D^{k}$ 的每个logit后接sigmoid函数,用于预测特征在对应类别下属于源域或目标域的概率。每个logit作为独立GAN,用于最小化特定类别 $P s(Z|Y=y)$ 与 ${\bf\tilde{\cal P}}{\mathcal{T}{j}}(Z|Y=y)$ 的JS散度差异。为使 $D^{k}$ 中每个logit对应一个类别,我们将特征 $g(x_{i})$ 输入 $\bar{D^{k}}$ 获得预测结果 $d_{i}\in R^{k}$ ,随后使用对应的one-hot标签 $y_{i}\in{0,1}^{k}$ 仅激活对应logit,通过 $y_{i}\cdot d_{i}$ 计算对抗损失。为此,我们采用伪目标标签并设计策略,使分类对抗对齐与伪标签优化相互促进。最终优化目标表述如下:
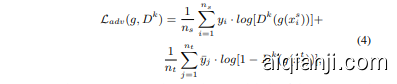
where $y_{i}$ represent the one-hot true labels of the source and ${\bar{y}}_{j}$ represent the mix of soft and one-hot pseudo labels of target. We discuss this in detail in the next section.
其中 $y_{i}$ 表示源数据的独热 (one-hot) 真实标签,${\bar{y}}_{j}$ 表示目标数据的软标签与独热伪标签的混合。我们将在下一节详细讨论这一点。
Uncertainty guided disc rim i native adversarial training
不确定性引导的判别式对抗训练
To train a disc rim i native categorical domain disc rim in at or $D^{k}$ , we require the one-hot true labels of source and blended targets. However, since the initial target labels are noisy, we design the uncertainty-guided training strategy for our categorical domain disc rim in at or. We start with soft target labels and then gradually covert soft target labels with low uncertainty into one-hot encoding as training goes by. We use the entropy as the metric of the uncertainty of each sample, and select the samples based on a threshold $\gamma$ .
为了训练一个判别性分类领域判别器 $D^{k}$,我们需要源域和混合目标域的真实独热(one-hot)标签。然而由于初始目标标签存在噪声,我们为分类领域判别器设计了不确定性引导的训练策略:从软目标标签开始训练,随着训练进程逐步将低不确定性的软目标标签转换为独热编码。我们使用熵作为每个样本不确定性的度量指标,并基于阈值 $\gamma$ 进行样本筛选。
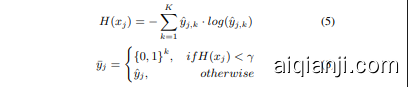
In the early stage, the entropy of soft pseudo labels on the target domain is large so that each digit of $D^{k}$ is assigned with similar probability mass. $D^{k}$ cannot discriminate different classes and behaves as the general disc rim in at or $D$ in DANN since all logits share the same semantics. As the training goes, the entropy of target pseudo labels will decrease, and the labels will become more disc rim i native owing to the distribution alignment. At the same time, the discri mi native target labels will also train $D^{k}$ to distinguish different categories and further align the categorical distributions, which forms a mutually reinforced process.
在早期阶段,目标域上软伪标签的熵较大,因此$D^{k}$的每个数字都被分配了相似的概率质量。此时$D^{k}$无法区分不同类别,其行为类似于DANN中的通用判别器$D$,因为所有logits共享相同的语义。随着训练进行,目标伪标签的熵会降低,由于分布对齐的作用,标签将变得更具有判别性。同时,具有判别性的目标标签也会训练$D^{k}$来区分不同类别,并进一步对齐类别分布,从而形成一个相互强化的过程。
Source-only balanced adversarial training
仅源域平衡对抗训练
We expect our model to be robust under the label shift across various domains such as in a case shown in Figure 3. Equation 1 indicates that the label shift only influences the clas- sification error $B E R_{P_{S}}$ but does not influence the major distribution discrepancy $\Delta_{B T C E}$ . It indicates that only if $\Delta_{B T C E}$ is small enough, the model is robust to label shift even in the blended domains.
我们预期模型能在不同领域的标签偏移(label shift)下保持稳健,如图3所示案例。公式1表明,标签偏移仅影响分类误差 $BER_{P_{S}}$ ,而不会影响主要分布差异 $\Delta_{BTCE}$ 。这意味着只要 $\Delta_{BTCE}$ 足够小,即使在混合领域中,模型对标签偏移也具备鲁棒性。
So, we focus on training $D^{k}$ since the class imbalance will lead to bias to the training of $D^{k}$ . Hence, $D^{k}$ cannot distinguish different classes and align distributions biased towards the majority classes, which will ruin the categorical distribution alignment. To train a balanced $D^{k}$ , we propose to only conduct balanced sampling for the source domain rather than on both domains as in (Jiang et al. 2020) for two reasons: 1)We only have true labels on the source domain, balanced sampling based on the hard target pseudo labels may introduce errors and bias because initially target pseudo labels are inaccurate. Filtering out confident target pseudo labels may rule out some classes, which exacerbates the class imbalance issue. 2)With conventional double-side balanced sampling, target pseudo labels are only updated every epoch. Instead, mixed target pseudo labels can be updated online with the distribution alignment, which is more beneficial for adaptation. We demonstrate the robustness and efficiency in the Experiments section.
因此,我们专注于训练 $D^{k}$,因为类别不平衡会导致 $D^{k}$ 的训练产生偏差。这样一来,$D^{k}$ 无法区分不同类别,并且分布对齐会偏向多数类,从而破坏类别分布对齐。为了训练一个平衡的 $D^{k}$,我们提出仅对源域进行平衡采样,而不是像 (Jiang et al. 2020) 那样对两个域都进行采样,原因有二:1) 我们仅在源域上有真实标签,基于硬目标伪标签的平衡采样可能会引入错误和偏差,因为初始时目标伪标签并不准确。过滤掉置信度高的目标伪标签可能会排除某些类别,从而加剧类别不平衡问题。2) 传统的双端平衡采样中,目标伪标签仅在每个 epoch 更新一次。相比之下,混合目标伪标签可以随着分布对齐在线更新,这对适应更有利。我们在实验部分展示了其鲁棒性和效率。
Low level feature for classifier correction
用于分类器校正的低层特征
We intend to correct the biased classifier $P(Y\vert Z)$ from a single source to blended targets during the adaptation process. This improves the pseudo label accuracy on blended targets during the adaptation process and further facilitates the training of our categorical domain disc rim in at or. Inspired by the research on low-level features on CNN, we utilize the low-level features of CNN that mainly represent the style and background of images to project blended target styles into the source for correcting the classifier. Denoting the low-level feature maps $\boldsymbol{z}\in\bar{\mathbb{R}^{D\times H\times W}}$ where $D$ represents the channel and $H,\dot{W}$ represents the spatial size, leveraging the AdaIN, we have augmented features $z^{s t}$ with source content and target style as below:
我们旨在适应过程中将偏置分类器 $P(Y\vert Z)$ 从单一源域校正至混合目标域。这提升了适应过程中混合目标域上伪标签的准确性,并进一步促进了分类域判别器的训练。受CNN底层特征研究的启发,我们利用主要表征图像风格和背景的CNN底层特征,将混合目标风格投影至源域以校正分类器。设底层特征图 $\boldsymbol{z}\in\bar{\mathbb{R}^{D\times H\times W}}$ ,其中 $D$ 表示通道数, $H,\dot{W}$ 表示空间尺寸,通过AdaIN方法,我们得到融合源域内容与目标域风格的增强特征 $z^{s t}$ 如下:

Compared with previous image translation methods, our method does not need to generate specific images, which is efficient in practice. Besides, considering the diversity and imbalance of blended targets, our method achieves the correction on two sides: 1)Since the source is evenly resampled on class, the augmented feature $z^{s t}$ with source content is balanced on semantic classes, which forms a balanced classifier for inference. 2)The augmented $z^{s t}$ with diverse target styles mitigate the domain irrelevant information. This regularizes the hybrid categorical feature space in BTDA and make the cluster assumption more practical.
与之前的图像翻译方法相比,我们的方法无需生成特定图像,在实际应用中更为高效。此外,针对混合目标的多样性和不平衡性,我们的方法通过两方面实现校正:1) 由于源数据在类别上进行了均匀重采样,具有源内容特征的增强特征 $z^{s t}$ 在语义类别上达到平衡,从而形成用于推理的平衡分类器;2) 具有多样化目标风格的增强 $z^{s t}$ 减少了与域无关的信息。这规范了BTDA中的混合类别特征空间,使得聚类假设更具实用性。
Overall Objective: Eventually, the final loss function consists of the categorical adversarial loss and the classification loss of various domains. Note that $h^{\prime}$ indicates the networks
总体目标:最终损失函数由分类对抗损失和各领域的分类损失组成。注意 $h^{\prime}$ 表示网络。
excluding the shallow layers.
排除浅层。

Experiments
实验
Datasets. We evaluate our method based on standard BTDA tasks (Chen et al. 2019; Roy et al. 2021a): Office-31 (Saenko et al. 2010), Office-Home (Ven kate s war a et al. 2017), DomainNet (Peng et al. 2019), and a specialized dataset OfficeHome-LMT for label shift in BTDA. Similar to OfficeHome-RS-UT (Jiang et al. 2020), we use Cl, Pr and Rw to resample two reverse long-tailed distributions and one Gaussian distributions for each of them for BTDA with label shift. For evaluation, we use one domain as the source and the rest as blended targets. The performance is evaluated as the mean accuracy of all target domains. We show a concrete example of Ar as the source in the label shift setting in Figure 3.
数据集。我们在标准BTDA任务(Chen et al. 2019; Roy et al. 2021a)上评估我们的方法:Office-31 (Saenko et al. 2010)、Office-Home (Venkateswara et al. 2017)、DomainNet (Peng et al. 2019),以及一个专门用于BTDA标签偏移的数据集OfficeHome-LMT。与OfficeHome-RS-UT (Jiang et al. 2020)类似,我们使用Cl、Pr和Rw为每个数据集重采样两个反向长尾分布和一个高斯分布,用于带标签偏移的BTDA。评估时,我们选择一个域作为源域,其余作为混合目标域。性能评估为所有目标域的平均准确率。图3展示了标签偏移设置中以Ar为源域的具体示例。
Baselines and implementations. We compare our method with previous state-of-the-arts in standard BTDA and that with label shift, i.e., MTDA (Nguyen-Meidine et al. 2021), CGCT (Roy et al. 2021a), MDDIA (Jiang et al. 2020), CST (Liu, Wang, and Long 2021), and SENTRY (Prabhu et al. 2021). For comparison with BTDA under label shift, we also combine the sampling strategies in MDDIA with CGCT. The detailed summary of comparison methods is in the supplementary. We followed the implementations in (Junguang Jiang 2020). For all datasets, we use SGD optimizer with learning rates $\eta_{0}=0.01$ , $\alpha=10$ , and $\beta=0.75$ . We set the uncertainty threshold $\gamma=0.05$ for all datasets. Since CST and SENTRY use Auto Augment for data augmentation, we set the number of transformations $N=1$ and the transform severity $M=2.0$ in Auto Augment (Lim et al. 2019) for a fair comparison.
基准方法与实现。我们将所提方法与标准BTDA及存在标签偏移的先进方法进行比较,包括MTDA (Nguyen-Meidine et al. 2021)、CGCT (Roy et al. 2021a)、MDDIA (Jiang et al. 2020)、CST (Liu, Wang, and Long 2021)以及SENTRY (Prabhu et al. 2021)。为比较标签偏移下的BTDA性能,我们还将MDDIA的采样策略与CGCT结合使用。对比方法的详细总结见补充材料。实验实现遵循(Junguang Jiang 2020)的方案,所有数据集均采用SGD优化器,学习率设为$\eta_{0}=0.01$、$\alpha=10$和$\beta=0.75$,不确定性阈值统一设置为$\gamma=0.05$。由于CST和SENTRY采用Auto Augment进行数据增强,为公平比较,我们设定Auto Augment (Lim et al. 2019)中的变换次数$N=1$和变换强度$M=2.0$。

Figure 3: Label distribution shift of Office-Home-LMT.
图 3: Office-Home-LMT 的标签分布偏移。
Standard BTDA. We summarize the standard BTDA in Table 1. Our method outperforms comparison methods with a clear margin. Concretely, our method outperforms the latest BTDA methods (e.g., AMEAN and CGCT) by $1.4%$ on Office-31, $4.6%$ on Office-Home, and $2.2%$ on DomainNet. Moreover, even compared with methods utilizing ground truth domain labels, our method can still outperform them by $0.8%$ on Office-31 and $1.3%$ on Office-Home. The results validate our argument that categorical distribution alignment overwhelms in BTDA, and echos the theoretical intuition from equation 1 that proper domain alignment is achievable even without domain labels in BTDA.
标准BTDA。我们在表1中总结了标准BTDA。我们的方法以明显优势超越了对比方法。具体而言,在Office-31数据集上我们的方法比最新BTDA方法(如AMEAN和CGCT)高出1.4%,在Office-Home上高出4.6%,在DomainNet上高出2.2%。此外,即使与使用真实域标签的方法相比,我们的方法在Office-31上仍能高出0.8%,在Office-Home上高出1.3%。这些结果验证了我们的观点:在BTDA中,类别分布对齐至关重要,同时也呼应了公式1的理论直觉——即使没有域标签,在BTDA中也能实现适当的域对齐。
Table 1: Accurary $(%)$ of BTDA on Office-31, Office-Home (ResNet-50), and DomainNet (ResNet-101). Best results in Bold. Each domain represents the source and the rest domains are blended as the target. The accuracy is the mean of accuracies of all domains in the blended target. †indicates methods using domain labels.
表 1: BTDA 在 Office-31、Office-Home (ResNet-50) 和 DomainNet (ResNet-101) 上的准确率 $(%)$。最佳结果以粗体显示。每个域代表源域,其余域混合为目标域。准确率为混合目标中所有域准确率的平均值。†表示使用域标签的方法。
| 方法 | A | D | W | Avg. | Ar | C1 | Pr | R1 | Avg. | 方法 | Cli | Inf | Pai | Qui | Rea | Ske | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 68.6 | 70.0 | 66.5 | 68.4 | 47.6 | 42.6 | 44.2 | 51.3 | 46.4 | Source | 25.6 | 16.8 | 25.8 | 9.2 | 20.6 | 22.3 | 20.1 |
| DAN | 79.5 | 80.3 | 81.2 | 80.4 | 55.6 | 56.6 | 48.5 | 56.7 | 54.4 | SE | 21.3 | 8.5 | 14.5 | 13.8 | 16.0 | 19.7 | 15.6 |
| DANN | 80.8 | 82.5 | 83.2 | 82.2 | 58.4 | 58.1 | 52.9 | 62.1 | 57.9 | MCD | 25.1 | 19.1 | 27.0 | 10.4 | 20.2 | 22.5 | 20.7 |
| CDAN | 93.6 | 80.5 | 81.3 | 85.1 | 59.5 | 61.0 | 54.7 | 62.9 | 59.5 | CDAN | 31.6 | 27.1 | 31.8 | 12.5 | 33.2 | 35.8 | 28.7 |
| JAN | 84.2 | 74.4 | 72.0 | 76.9 | 58.3 | 60.5 | 52.2 | 57.5 | 57.1 | DADA | 26.4 | 20.0 | 26.5 | 12.9 | 20.7 | 22.8 | 21.5 |
| AMEAN | 90.1 | 77.0 | 73.4 | 80.2 | 64.3 | 65.5 | 59.5 | 66.7 | 64.0 | MCC | 33.6 | 30.0 | 32.4 | 13.5 | 28.0 | 35.3 | 28.8 |
| CGCT | 93.9 | 85.1 | 85.6 | 88.2 | 67.4 | 68.1 | 61.6 | 68.7 | 66.5 | CGCT | 36.1 | 33.3 | 35.0 | 10.0 | 39.6 | 39.7 | 32.3 |
| Ours | 92.4 | 87.7 | 88.8 | 89.6 | 71.7 | 72.8 | 68.0 | 71.7 | 71.1 | Ours | 37.5 | 37.3 | 36.6 | 17.8 | 36.1 | 41.4 | 34.5 |
| MTDAt | 87.9 | 83.7 | 84.0 | 85.2 | 64.6 | 66.4 | 59.2 | 67.1 | 64.3 | — | — | — | — | ||||
| DCLt | 92.6 | 82.5 | 84.7 | 86.6 | 63.0 | 63.0 | 60.0 | 67.0 | 64.1 | DCLt | 35.1 | 31.4 | 37.0 | 20.5 | 35.4 | 41.0 | 33.4 |
| DCGCTt | 93.4 | 86.0 | 87.1 | 88.8 | 70.5 | 71.6 | 66.0 | 71.2 | 69.8 | DCGCTt | 37.0 | 32.2 | 37.3 | 19.3 | 39.8 | 40.8 | 34.4 |
Table 2: Accurary $(%)$ of Blended-Office-Home-LMT (ResNet-50). aug: using 1 extra augmented data with RandAug (Cubuk et al. 2020). bal: using balanced sampling. oracle: disc rim in at or trained with true source and target labels. $S{+}T$ : supervised learning on source and target.
表 2: Blended-Office-Home-LMT (ResNet-50) 准确率 $(%)$ 。aug: 使用 RandAug (Cubuk et al. 2020) 额外增强 1 份数据。bal: 使用平衡采样。oracle: 使用真实源域和目标域标签训练的判别器。$S{+}T$: 源域和目标域的监督学习。
| Methods | Clipart | Product | Real | Avg. |
|---|---|---|---|---|
| Source | 42.3 | 47.6 | 50.3 | 46.7 |
| BSP | 51.5 | 52.9 | 57.4 | 54.0 |
| CDAN | 50.5 | 53.2 | 56.3 | 53.3 |
| DAN | 51.0 | 49.2 | 56.8 | 52.3 |
| JAN | 51.4 | 50.1 | 57.0 | 53.2 |
| DANN | 46.6 | 50.4 | 53.3 | 50.1 |
| ADDA | 45.0 | 49.7 | 52.8 | 49.2 |
| MCD | 40.2 | 48.6 | 52.3 | 47.0 |
| MDD | 43.7 | 56.0 | 57.8 | 52.5 |
| MDDIA | 61.9 | 58.2 | 63.2 | 61.1 |
| CGCT | 53.7 | 51.5 | 52.0 | 52.4 |
| CGCT+bal | 57.1 | 53.0 | 56.8 | 55.7 |
| Ours | 68.0 | 62.3 | 67.5 | 65.9 |
| CST(aug) | 58.3 | 57.4 | 63.4 | 59.7 |
| SENTRY(aug) | 65.6 | 63.5 | 65.9 | 65.0 |
| Ours(aug) | 69.1 | 66.2 | 68.9 | 68.1 |
| Ours(oracle) | 98.9 | 98.3 | 98.2 | 98.5 |
| S+T | 99.7 | 99.8 | 99.8 | 99.8 |
BTDA with label shift. We analyzed the essential label shift influence on BTDA and summarized results of the specialized Office-Home-LMT in Table 2. The label distribution of each domain is different from each other. Since CST and SENTRY essentially require extra augmented data, we add 1 augmented data for each sample and evaluate CST, SEN
带标签偏移的BTDA。我们分析了标签偏移对BTDA的核心影响,并在表2中汇总了专用Office-Home-LMT的测试结果。各领域的标签分布互不相同。由于CST和SENTRY本质上需要额外增强数据,我们为每个样本添加1个增强数据并评估CST、SEN
TRY, and ours in the same setting (aug). Our method outperforms the label shift UDA method MDDIA by $4.8%$ and SENTRY by $3.1%$ . Compared with latest BTDA method CGCT, we get an improvement of more than $12%$ . We also equip CGCT with balanced sampling strategy in MDDIA (i.e., $\mathrm{CGCT{+}b a l)}$ whose result is still inferior to ours.
TRY,以及我们在相同设置下的方法(增强)。我们的方法在标签偏移无监督域适应(UDA)方法MDDIA上提升了4.8%,在SENTRY上提升了3.1%。与最新的BTDA方法CGCT相比,我们取得了超过12%的改进。我们还在MDDIA中为CGCT配备了平衡采样策略(即CGCT+bal),其结果仍不及我们的方法。
The result first demonstrates the label shift in BTDA seriously impedes the adaptation, especially for the marginal alignment methods. Second, it validates our proposition in theorem 1 that if categorical distribution $\Delta_{B T C E}(Y)$ can be properly minimized, the label shift only reweights the classification error $B E R_{P s}(\hat{Y}|Y)$ , which is relatively small. Besides, our method does not require balanced sampling on target pseudo labels for every epoch, which can be trained and updated online. The extra data augmentation (e.g., RandAug) is not essentially necessary in the algorithm design.
结果首先表明,BTDA中的标签偏移严重阻碍了适应过程,特别是对于边缘对齐方法。其次,它验证了我们在定理1中的命题:如果类别分布$\Delta_{B T C E}(Y)$能够被适当最小化,标签偏移仅会重新加权分类误差$B E R_{P s}(\hat{Y}|Y)$,而该误差相对较小。此外,我们的方法不需要在每一轮对目标伪标签进行平衡采样,可以在线训练和更新。额外的数据增强(如RandAug)在算法设计中并非必需。
STDA. We also validate the generalization ability of our method in STDA (i.e., Office-Home and DomainNet). We compare our method with SRDC (Tang, Chen, and Jia 2020) which considers cluster structures in STDA, and MDDIA (Jiang et al. 2020) which uses balanced sampling on both source and target domains. Our method achieve $72.4%$ on Office-Home, $35.2%$ on DomainNet which outperforms previous state-of-the-art method $\mathrm{MDD+SCDA}$ (Li et al. 2021) by $1.9%$ . Please refer to supplementary for details.
STDA。我们还在STDA(即Office-Home和DomainNet)中验证了方法的泛化能力。与考虑STDA中聚类结构的SRDC (Tang, Chen and Jia 2020)以及同时在源域和目标域使用平衡采样的MDDIA (Jiang et al. 2020)相比,我们的方法在Office-Home上达到72.4%,在DomainNet上达到35.2%,以1.9%的优势超越了之前最先进的MDD+SCDA方法 (Li et al. 2021)。详见补充材料。
Table 3: Ablations on Office-Home and the selected three domains on DomainNet. mix: mix labeling strategy; bal: balanced sampling strategy; flip: low-level features.
表 3: Office-Home和DomainNet上选定三个领域的消融实验。mix: 混合标注策略;bal: 平衡采样策略;flip: 底层特征。
| mix | bal | flip | Office-Home | DomainNet |
|---|---|---|---|---|
| Prod Real Avg. | Real Info Pain Avg. | |||
| 70.9 67.2 32.0 | 31.0 33.4 32.1 |

Figure 4: Samples below uncertainty threshold and pseudo label accuracy during training process on DomainNet.
图 4: DomainNet训练过程中低于不确定性阈值的样本及伪标签准确率

Figure 5: t-SNE feature visualization on Office-Home-LMT with Clipart as the source. 15 classes are sampled for conciseness. Color represents the domain and the digit represents the class. left: sourceonly, right: MCDA.
图 5: Office-Home-LMT数据集上以Clipart为源的t-SNE特征可视化。为简洁起见采样了15个类别。颜色表示域,数字表示类别。左:仅源域 (source-only) ,右:MCDA方法。
Ablation and analysis
消融实验与分析
We present ablations of MCDA in Table 3 on Office-Home and three domains of DomainNet. Each proposed module contributes to the improvement of the final performance.
我们在表3中展示了Office-Home和DomainNet三个域上MCDA的消融实验。每个提出的模块都对最终性能的提升有所贡献。
Effectiveness of uncertainty for guiding adversarial training. To validate the uncertainty and mixed labels to train a categorical disc rim in at or $D^{k}$ that mutually reinforces with target pseudo labels. We show the number of filtered samples below the uncertainty threshold and the corresponding pseudo label accuracy in Figure 4. The results of DomainNet show that during the training, the uncertainty of samples gradually decreases, and more samples pass the threshold. Meanwhile, the accuracy of pseudo labels increases, which justifies our motivation.
不确定性在指导对抗训练中的有效性。为验证不确定性和混合标签用于训练分类判别器 $D^{k}$ 并与目标伪标签相互强化的效果,图4展示了低于不确定性阈值的过滤样本数量及对应伪标签准确率。DomainNet结果表明:训练过程中样本不确定性逐渐降低,更多样本通过阈值,同时伪标签准确率提升,这验证了我们的动机。
Robustness of uncertainty threshold. We validate the robustness of our model under various uncertainty thresholds $\lambda$ in Table 4 for both standard BTDA and BTDA with label shift in Table 4. For main experiments in Table 1 and 2, we set $\lambda$ as 0.05. The performance is stable when $\lambda$ is selected from 0.03 to 0.07. The results of Art on Office-Home have a fluctuation range of $0.4%$ , and results of Clipart on Office-Home-LMT have a fluctuation range of $1.5%$ . These demonstrate the stability and generality of our model for the standard BTDA and label shift setting.
不确定性阈值的鲁棒性。我们在表4中验证了标准BTDA和带标签偏移的BTDA在不同不确定性阈值$\lambda$下的模型鲁棒性。针对表1和表2的主要实验,我们设定$\lambda$为0.05。当$\lambda$取值在0.03至0.07区间时,性能保持稳定。Office-Home数据集上Art类别的结果波动范围为$0.4%$,Office-Home-LMT数据集上Clipart类别的波动范围为$1.5%$。这些数据表明我们的模型在标准BTDA和标签偏移设置下具有稳定性和泛化性。
Verification of error theorem under label shift. We verify our error theorem in equation 1 that if conditional distributions $\Delta_{B T C E}(\hat{Y})$ is sufficiently minimized, the model is robust under label shift in BTDA since the reweighted source error $|P_{S}(Y)\mathrm{-}P_{\mathcal{T}{j}}(Y)|{1}B E R_{P_{S}}(\hat{Y}|Y)$ is relatively small. In Table 2, the oracle are results when the discriminator is trained with true labels of source and target but the classifier is trained only with source labels. In this case, the categorical disc rim in at or is trained to minimize categorical distributions as much as possible under ground truth supervision. The $S{+}T$ are results where the classifier is trained with both source and target labels. These two results approximate to each other which verifies the theorem.
标签偏移下的误差定理验证。我们验证了公式1中的误差定理:如果条件分布$\Delta_{B T C E}(\hat{Y})$被充分最小化,模型在BTDA标签偏移下具有鲁棒性,因为重加权源误差$|P_{S}(Y)\mathrm{-}P_{\mathcal{T}{j}}(Y)|{1}B E R_{P_{S}}(\hat{Y}|Y)$相对较小。表2中,oracle表示判别器使用源域和目标域真实标签训练、而分类器仅使用源域标签训练时的结果。此时,分类判别器在真实标签监督下尽可能最小化类别分布。$S{+}T$表示分类器同时使用源域和目标域标签训练的结果。二者结果相互逼近,验证了该定理。

Figure 6: CAM feature response maps on Office-HomeLMT. The left pervasive one is from sourceonly model while the right class-disc rim i native one is from MCDA.
图 6: Office-HomeLMT上的CAM特征响应图。左侧普遍性响应来自纯源域模型,右侧具有类别区分性的响应来自MCDA。
Table 4: Accuracy $(%)$ of different uncertainty thresholds for $A r t$ in Office-Home and Clipart in Office-Home-LMT for BTDA (ResNet-50).
表 4: 不同不确定性阈值在 Office-Home 的 Art 和 Office-Home-LMT 的 Clipart 上对 BTDA (ResNet-50) 的准确率 $(%)$。
| 阈值 | 0.01 | 0.03 | 0.05 | 0.07 | 0.09 |
|---|---|---|---|---|---|
| Art | 71.9 | 71.9 | 71.7 | 72.3 | 71.8 |
| Clipart | 66.5 | 67.4 | 68.0 | 66.9 | 66.4 |
Essential of domain labels. Our theoretical formulation in equation 1 does not require domain labels to minimize the target error rate in BTDA. The bound is mainly related to the categorical distribution constraint. In comparison with methods (i.e., CGCT (Roy et al. 2021a) and DCL (NguyenMeidine et al. 2021)) using domain labels $\dagger$ in Table 1, our method outperforms previous state-of-the-arts by $0.8%$ on Office-31, $1.3%$ on Office-Home, and $0.1%$ on DomainNet even without domain labels. This validates our proposition that adaptation can be done without domain labels in BTDA if categorical distributions is sufficiently aligned.
领域标签的本质。我们在公式1中的理论推导表明,BTDA中最小化目标错误率并不需要领域标签。该边界主要与类别分布约束相关。与表1中使用领域标签$\dagger$的方法(即CGCT (Roy等人2021a)和DCL (NguyenMeidine等人2021))相比,我们的方法在Office-31上提升了$0.8%$,在Office-Home上提升了$1.3%$,在DomainNet上提升了$0.1%$,且无需领域标签。这验证了我们的观点:只要类别分布充分对齐,BTDA中的适配可以在没有领域标签的情况下完成。
Feature visualization. To show our method learns a regular and meaningful categorical feature space, we visualize features of last convolution layer with t-SNE in Figure 5 and CAM (Selvaraju et al. 2017) in Figure 6. The t-SNE visualization further shows that the sourceonly model generates a hybrid feature space while MCDA produces a more classdisc rim i native feature space, which corroborates our observation on the cluster assumption and categorical alignment on BTDA. The CAM results shows feature response maps of the sourceonly model is pervasive while those of MCDA are more category-disc rim i native. This validates that MCDA make the classifier learns more task-relevant features and achieve better categorical alignment. More visualization results are discussed in the supplementary.
特征可视化。为展示我们的方法学习到一个规律且有意义的类别特征空间,我们在图5中使用t-SNE、在图6中使用CAM (Selvaraju et al. 2017) 对最后卷积层的特征进行可视化。t-SNE可视化进一步表明,仅源域模型生成的是混合特征空间,而MCDA产生了更具类别区分性的特征空间,这印证了我们在BTDA上对聚类假设和类别对齐的观察。CAM结果显示,仅源域模型的特征响应图普遍存在,而MCDA的特征响应图更具类别区分性。这验证了MCDA使分类器学习到更多与任务相关的特征,并实现了更好的类别对齐。更多可视化结果在补充材料中讨论。
Conclusion
结论
In this paper, we demonstrate that adaptation can be well achieved without domain labels for BTDA only if the categorical distributions are sufficiently aligned, even facing the cross-domain label shift. Following this, we present the mutual conditional domain adaptation framework. We explore the uncertainty-guided mechanism and source-only balanced sampling strategy to train a categorical domain discriminator for efficiently modeling categorical distributions in BTDA. And we explore low-level features to correct the biased classifier. Extensive experimental results demonstrate the state-of-the-art performance of the framework in single target DA and BTDA tasks under label shift.
本文证明,只要类别分布充分对齐,即使面临跨域标签偏移,无监督双向域适应(BTDA)也能实现良好适配。基于此,我们提出互条件域适应框架:通过不确定性引导机制和纯源域平衡采样策略训练类别域判别器,有效建模BTDA中的类别分布;同时利用低级特征校正偏置分类器。大量实验表明,该框架在标签偏移下的单目标域适应和BTDA任务中均达到最先进性能。