PromptS tyler: Prompt-driven Style Generation for Source-free Domain Generalization
Abstract
摘要
In a joint vision-language space, a text feature (e.g., from “a photo of a dog”) could effectively represent its relevant image features (e.g., from dog photos). Also, a recent study has demonstrated the cross-modal transfer ability phenomenon of this joint space. From these observations, we propose PromptS tyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. The proposed method learns to generate a variety of style features (from “a $\boldsymbol{S}{*}$ style of a”) via learnable style word vectors for pseudo-words $\boldsymbol{S}{*}$ . To ensure that learned styles do not distort content information, we force style-content features (from “a $\boldsymbol{S}_{\ast}$ style of a [class]”) to be located nearby their corresponding content features (from “[class]”) in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptS tyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, even though it does not require any images for training.
在联合视觉-语言空间中,文本特征(例如来自"一张狗的照片")能有效表征其相关图像特征(例如来自狗的照片)。近期研究还揭示了该联合空间具有跨模态迁移能力现象。基于这些发现,我们提出PromptStyler方法,通过提示词合成多样风格来模拟联合空间中的各类分布偏移,无需使用任何图像即可处理无源域泛化问题。该方法通过学习可训练的风格词向量为伪词$\boldsymbol{S}{*}$生成多种风格特征(来自"一种$\boldsymbol{S}{*}$风格的")。为确保学习到的风格不扭曲内容信息,我们强制要求风格-内容特征(来自"一种$\boldsymbol{S}_{\ast}$风格的[类别]")在联合视觉-语言空间中与其对应内容特征(来自"[类别]")保持邻近。完成风格词向量学习后,我们使用合成的风格-内容特征训练线性分类器。PromptStyler在PACS、VLCS、OfficeHome和DomainNet数据集上实现了最先进的性能,且全程无需任何训练图像。
1. Introduction
1. 引言
Deep neural networks are usually trained with the assumption that training and test data are independent and identically distributed, which makes them vulnerable to substantial distribution shifts between training and test data [23, 52]. This susceptibility is considered as one of the major obstacles to their deployment in real-world applications. To enhance their robustness to such distribution shifts, Domain Adaptation (DA) [2, 24, 32, 33, 54, 56, 57, 68] has been studied; it aims at adapting neural networks to a target domain using target domain data available in training. However, such a target domain is often latent in common training scenarios, which considerably limits the application of DA. Recently, a body of research has addressed this limitation by Domain Generalization (DG) [3, 5, 21, 29, 35, 37, 74] that aims to improve model’s generalization capability to any unseen domains. It has been a common practice in DG to utilize multiple source domains for learning domain-invariant features [61, 69], but it is unclear which source domains are ideal for DG, since arbitrary unseen domains should be addressed. Furthermore, it is costly and sometimes even infeasible to collect and annotate large-scale multi-source domain data for training.
深度神经网络通常在训练和测试数据独立同分布的假设下进行训练,这使得它们容易受到训练和测试数据之间显著分布偏移的影响 [23, 52]。这种敏感性被认为是其在实际应用中部署的主要障碍之一。为了增强对这种分布偏移的鲁棒性,领域自适应 (Domain Adaptation, DA) [2, 24, 32, 33, 54, 56, 57, 68] 被广泛研究;其目标是通过训练中可用的目标域数据使神经网络适应目标域。然而,在常见的训练场景中,这种目标域通常是隐式的,这极大地限制了 DA 的应用。最近,一系列研究通过领域泛化 (Domain Generalization, DG) [3, 5, 21, 29, 35, 37, 74] 解决了这一限制,其目标是提高模型对任何未见领域的泛化能力。在 DG 中,利用多个源域学习领域不变特征已成为常见做法 [61, 69],但由于需要处理任意的未见领域,目前尚不清楚哪些源域最适合 DG。此外,收集和标注大规模多源域数据进行训练成本高昂,有时甚至不可行。
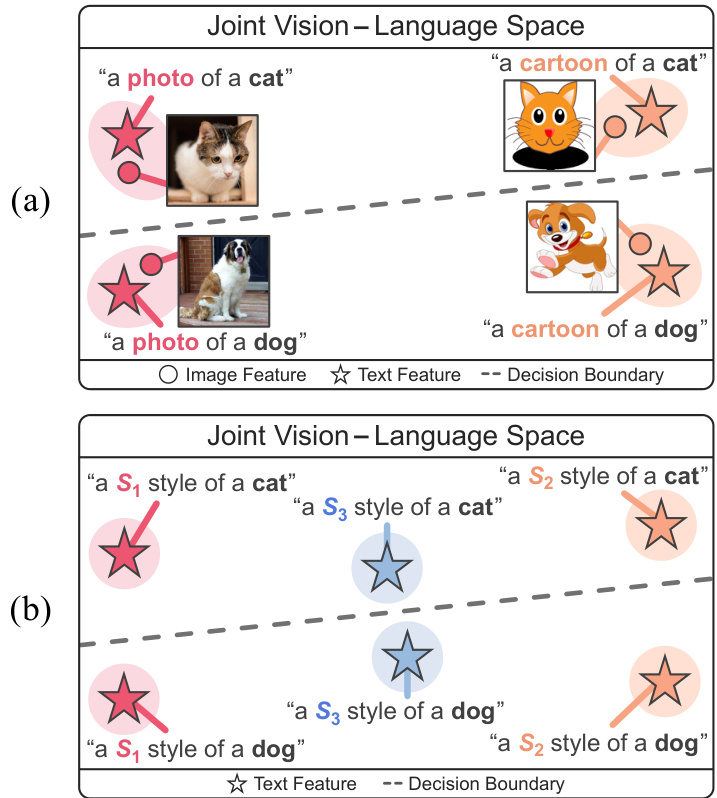
Figure 1: Motivation of our method. (a) Text features could effectively represent various image styles in a joint visionlanguage space. (b) PromptS tyler synthesizes diverse styles in a joint vision-language space via learnable style word vectors for pseudo-words $\boldsymbol{S}_{*}$ without using any images.
图 1: 方法动机。(a) 在联合视觉-语言空间中,文本特征能有效表征多种图像风格。(b) PromptStyler通过可学习的风格词向量 $\boldsymbol{S}_{*}$ 为伪词在联合视觉-语言空间中合成多样风格,无需使用任何图像。
We notice that a large-scale pre-trained model might have already observed a great variety of domains and thus can be used as an efficient proxy of actual multiple source domains. From this perspective, we raised a question “Could we further improve model’s generalization capability by simulating various distribution shifts in the latent space of such a largescale model without using any source domain data?” If this is possible, DG will become immensely practical by effectively and efficiently exploiting such a large-scale model. However, this approach is much more challenging since any actual data of source and target domains are not accessible but only the target task definition (e.g., class names) is given.
我们注意到,大规模预训练模型可能已经观察过多种多样的领域,因此可以作为实际多源域的高效代理。从这个角度出发,我们提出了一个问题:"能否通过在此类大规模模型的潜在空间中模拟各种分布偏移(完全不使用任何源域数据)来进一步提升模型的泛化能力?"若该方法可行,通过高效利用此类大规模模型,领域泛化(DG)将具备极强的实用性。但该方案面临更大挑战——我们无法获取源域和目标域的任何实际数据,仅能获得目标任务定义(例如类别名称)。
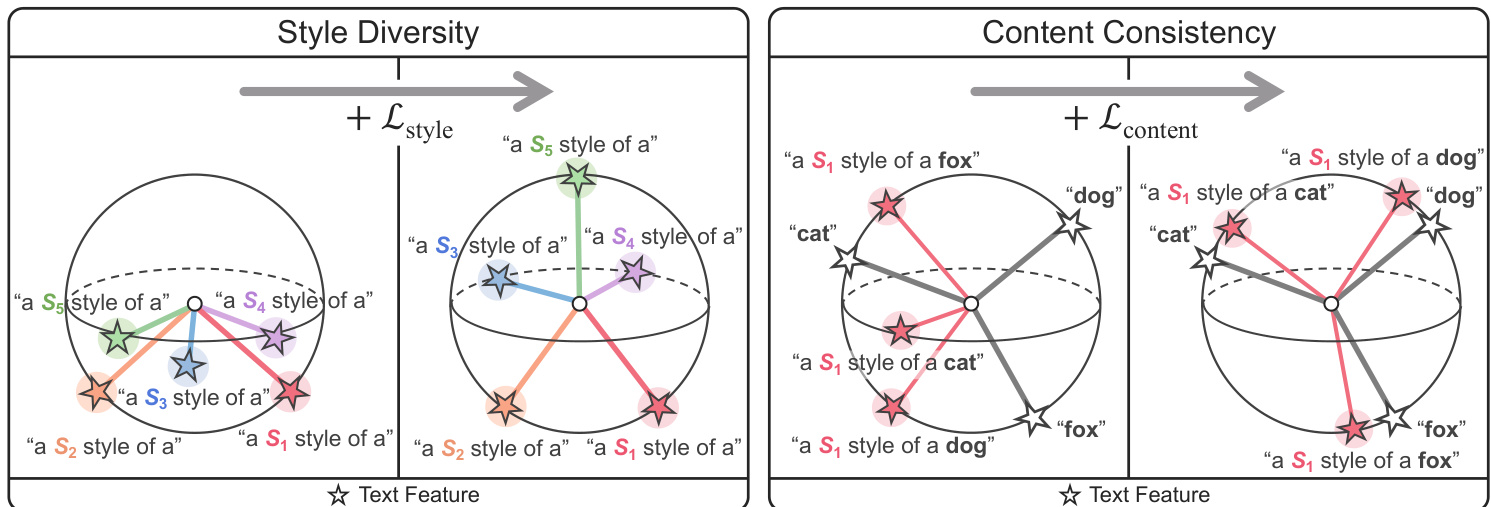
Figure 2: Important factors in the proposed method. PromptS tyler learns style word vectors for pseudo-words $S_{}$ which lead to diverse style features (from “a $\boldsymbol{S}_{}$ style of a”) while preserving content information encoded in style-content features (from “a $\boldsymbol{S}{*}$ style of a [class]”). $\mathcal{L}{\mathrm{style}}$ and $\mathscr{L}_{\mathrm{content}}$ are the loss functions used for maximizing style diversity and content consistency in a hyper spherical joint vision-language space (e.g., CLIP [50] latent space).
图 2: 所提方法中的关键要素。PromptStyler通过为伪词$S_{}$学习风格词向量,在保持风格-内容特征(来自"a $\boldsymbol{S}_{}$ style of a [class]")编码的内容信息同时,实现多样化风格特征(来自"a $\boldsymbol{S}{*}$ style of a")。$\mathcal{L}{\mathrm{style}}$和$\mathscr{L}_{\mathrm{content}}$是用于在超球面联合视觉-语言空间(如CLIP[50]潜在空间)中最大化风格多样性和内容一致性的损失函数。
In this paper, we argue that large-scale vision-language models [26, 50, 64] could shed light on this challenging source-free domain generalization. As conceptually illustrated in Figure 1(a), text features could effectively represent their relevant image features in a joint vision-language space. Despite the modality gap between two modalities in the joint space [39], a recent study has demonstrated the cross-modal transfer ability phenomenon [67]; we could train a classifier using text features while running an inference with the classifier using image features. This training procedure meets the necessary condition for the source-free domain generalization, i.e., source domain images are not required. Using such a joint vision-language space, we could simulate various distribution shifts via prompts without any images.
本文认为,大规模视觉语言模型 [26,50,64] 可为这一极具挑战性的无源域泛化问题提供解决思路。如图 1(a) 所示,在联合视觉语言空间中,文本特征能有效表征其相关图像特征。尽管该联合空间中存在模态间隙 [39],但最新研究揭示了跨模态迁移能力现象 [67]:我们可以使用文本特征训练分类器,再将该分类器应用于图像特征进行推理。这种训练方式符合无源域泛化的核心条件——无需源域图像。通过这种联合视觉语言空间,我们仅需提示词即可模拟多种分布偏移,而无需任何图像。
We propose a prompt-driven style generation method, dubbed PromptS tyler, which synthesizes diverse styles via learnable word vectors to simulate distribution shifts in a hyper spherical joint vision-language space. PromptS tyler is motivated by the observation that a shared style of images could characterize a domain [27, 74] and such a shared style could be captured by a learnable word vector for a pseudoword $S_{}$ using CLIP [50] with a prompt (“a painting in the style of $S_{}^{\mathrm{~}}$ ”) [17]. As shown in Figure 1(b), our method learns a style word vector for $\boldsymbol{S}_{*}$ to represent each style.
我们提出了一种名为PromptStyler的提示驱动风格生成方法,该方法通过可学习词向量合成多样化风格,以模拟超球面联合视觉-语言空间中的分布偏移。PromptStyler的灵感来源于观察发现:图像的共享风格可以表征一个领域[27,74],而这种共享风格可以通过CLIP[50]使用提示语("a painting in the style of $S_{}^{\mathrm{~}}$")[17]来捕获伪词$S_{}$的可学习词向量。如图1(b)所示,我们的方法学习风格词向量$\boldsymbol{S}_{*}$来表示每种风格。
To effectively simulate various distribution shifts, we try to maximize style diversity as illustrated in Figure 2. Specifically, our method encourages learnable style word vectors to result in orthogonal style features in the hyper spherical space, where each style feature is obtained from a style prompt (“a $\boldsymbol{S}{*}$ style of a”) via a pre-trained text encoder. To prevent learned styles from distorting content information, we also consider content consistency as illustrated in Figure 2. Each style-content feature obtained from a style-content prompt (“a $\boldsymbol{S}{*}$ style of a [class]”) is forced to be located closer to its corresponding content feature obtained from a content prompt (“[class]”) than the other content features.
为有效模拟各种分布偏移,我们尝试最大化风格多样性如图 2 所示。具体而言,我们的方法促使可学习风格词向量在超球面空间中生成正交风格特征,其中每个风格特征通过预训练文本编码器从风格提示 ("a $\boldsymbol{S}{*}$ style of a") 获得。为防止学习到的风格扭曲内容信息,我们还考虑了内容一致性如图 2 所示。从风格-内容提示 ("a $\boldsymbol{S}{*}$ style of a [class]") 获得的每个风格-内容特征,被强制要求比其它内容特征更接近其对应的从内容提示 ("[class]") 获得的内容特征。
Learned style word vectors are used to synthesize stylecontent features for training a classifier; these synthesized features could simulate images of known contents with diverse unknown styles in the joint space. These style-content features are fed as input to a linear classifier which is trained by a classification loss using contents (“[class]”) as their class labels. At inference time, an image encoder extracts image features from input images, which are fed as input to the trained classifier. Note that the text and image encoders are derived from the same pre-trained vision-language model (e.g., CLIP [50]); the text encoder is only involved in training and the image encoder is only involved at inference time.
学习到的风格词向量用于合成风格-内容特征以训练分类器;这些合成特征能在联合空间中模拟已知内容但具有多样未知风格的图像。这些风格-内容特征作为输入被送入线性分类器,该分类器通过以内容("[class]")作为类别标签的分类损失进行训练。在推理阶段,图像编码器从输入图像中提取特征,并将其作为输入送入训练好的分类器。需要注意的是,文本编码器和图像编码器均源自同一预训练视觉-语言模型(例如 CLIP [50]);文本编码器仅参与训练过程,而图像编码器仅在推理阶段使用。
The proposed method achieves state-of-the-art results on PACS [34], VLCS [15], OfficeHome [60] and DomainNet [48] without using any actual data of source and target domains. It takes just ${\sim}30$ minutes for the entire training using a single RTX 3090 GPU, and our model is ${\sim}2.6\times$ smaller and ${\sim}243\times$ faster at inference compared with CLIP [50].
所提方法在PACS [34]、VLCS [15]、OfficeHome [60]和DomainNet [48]数据集上取得了最先进的结果,且未使用任何源域和目标域的实际数据。整个训练过程仅需单块RTX 3090 GPU耗时约30分钟,与CLIP [50]相比,我们的模型体积缩小约2.6倍,推理速度提升约243倍。
Our contributions are summarized as follows:
我们的贡献总结如下:
• This work is the first attempt to synthesize a variety of styles in a joint vision-language space via prompts to effectively tackle source-free domain generalization. • This paper proposes a novel method that effectively simulates images of known contents with diverse unknown styles in a joint vision-language space. • PromptS tyler achieves the state of the art on domain generalization benchmarks without using any images.
• 本研究首次尝试通过提示在联合视觉-语言空间中合成多种风格,以有效解决无源域泛化问题。
• 本文提出了一种新方法,能在联合视觉-语言空间中有效模拟已知内容但具有多样未知风格的图像。
• PromptStyler 在不使用任何图像的情况下,在域泛化基准测试中达到了最先进的性能。
Table 1: Different requirements in each setup. Source-free DG only assumes the task definition (i.e., what should be predicted) without requiring source and target domain data.
| 设置 | 源数据 | 目标数据 | 任务定义 |
|---|---|---|---|
| DA | √ | ||
| DG | √ | — | √ |
| 无源DA | — | √ | √ |
| 无源DG | √ |
表 1: 不同设置下的需求差异。无源DG仅假设任务定义(即需要预测的内容)而不需要源域和目标域数据。
2. Related Work
2. 相关工作
Domain Generalization. Model’s generalization capability to arbitrary unseen domains is the key factor to successful deployment of neural networks in real-world applications, since substantial distribution shifts between source and target domains could significantly degrade their performance [23, 52]. To this end, Domain Generalization (DG) [4, 5, 10, 16, 21, 29, 35, 37, 44, 45, 61, 69] has been studied. It assumes target domain data are not accessible while using data from source domains. Generally speaking, existing DG methods could be divided into two categories: multi-source DG [3, 12, 36, 42, 43, 51, 55, 63, 73, 74] and single-source DG [14, 38, 49, 62]. Mostly, multi-source DG methods aim to learn domain-invariant features by exploiting available multiple source domains, and single-source DG methods also aim to learn such features by generating diverse domains based on a single domain and then exploiting the synthesized domains. Source-free Domain Generalization. In this setup, we are not able to access any source and target domains as summarized in Table 1. Thus, source-free DG is much more challenging than multi-source and single-source DG. From the observation that synthesizing new domains from the given source domain could effectively improve model’s generalization capability [27, 38, 62, 72, 73], we also try to generate diverse domains but without using any source domains to deal with source-free DG. By leveraging a large-scale pre-trained model which has already seen a great variety of domains, our method could simulate various distribution shifts in the latent space of the large-scale model. This approach has several advantages compared with existing DG methods; source domain images are not required and there is no concern for catastrophic forgetting which might impede model’s generalization capability. Also, it would be immensely practical to exploit such a large-scale model for downstream visual recognition tasks, since we only need the task definition.
领域泛化。模型对任意未见领域的泛化能力是神经网络在现实应用中成功部署的关键因素,因为源域和目标域之间的显著分布偏移会显著降低其性能 [23, 52]。为此,领域泛化 (Domain Generalization, DG) [4, 5, 10, 16, 21, 29, 35, 37, 44, 45, 61, 69] 被广泛研究。它假设在利用源域数据时无法访问目标域数据。一般而言,现有 DG 方法可分为两类:多源 DG [3, 12, 36, 42, 43, 51, 55, 63, 73, 74] 和单源 DG [14, 38, 49, 62]。多源 DG 方法主要通过利用多个可用源域学习域不变特征,而单源 DG 方法则通过基于单个域生成多样化域,进而利用合成域来学习此类特征。
无源领域泛化。在此设置中,如 表 1 所总结,我们无法访问任何源域和目标域。因此,无源 DG 比多源和单源 DG 更具挑战性。基于从给定源域合成新域可有效提升模型泛化能力的观察 [27, 38, 62, 72, 73],我们同样尝试生成多样化域,但在不依赖任何源域的情况下解决无源 DG 问题。通过利用已见过多种领域的大规模预训练模型,我们的方法能够在该模型的潜在空间中模拟各种分布偏移。与现有 DG 方法相比,此方法具有多重优势:无需源域图像,且无需担忧可能损害模型泛化能力的灾难性遗忘问题。此外,由于仅需任务定义,利用此类大规模模型进行下游视觉识别任务将极具实用性。
Large-scale model in Domain Generalization. Recently, several DG methods [5, 53] exploit a large-scale pre-trained model (e.g., CLIP [50]) to leverage its great generalization capability. While training neural networks on available data, CAD [53] and MIRO [5] try to learn robust features using such a large-scale model. Compared with them, the proposed method could learn domain-invariant features using a largescale pre-trained model without requiring any actual data.
领域泛化中的大规模模型。最近,一些领域泛化方法 [5, 53] 利用大规模预训练模型 (例如 CLIP [50]) 来发挥其强大的泛化能力。在现有数据上训练神经网络时,CAD [53] 和 MIRO [5] 尝试使用这种大规模模型学习鲁棒特征。相比之下,所提出的方法能够在不依赖任何实际数据的情况下,利用大规模预训练模型学习域不变特征。
Joint vision-language space. Large-scale vision-language models [26, 50, 64] are trained with a great amount of imagetext pairs, and achieve state-of-the-art results on downstream visual recognition tasks [20, 41, 66, 70, 71]. By leveraging their joint vision-language spaces, we could also effectively manipulate visual features via prompts [13, 18, 31, 47]. Interestingly, Textual Inversion [17] shows that a learnable style word vector for a pseudo-word $\boldsymbol{S}{*}$ could capture a shared style of images using CLIP [50] with a prompt (“a painting in the style of $\boldsymbol{S}{*}$ ”). From this observation, we argue that learnable style word vectors would be able to seek a variety of styles for simulating various distribution shifts in a joint vision-language space without using any images.
联合视觉-语言空间。大规模视觉-语言模型 [26, 50, 64] 通过海量图文对训练,在下游视觉识别任务中取得了最先进的成果 [20, 41, 66, 70, 71]。借助其联合视觉-语言空间,我们还能通过提示词有效操控视觉特征 [13, 18, 31, 47]。有趣的是,Textual Inversion [17] 研究表明:通过 CLIP [50] 框架配合提示语("a painting in the style of $\boldsymbol{S}{*}$"),可学习样式词向量 $\boldsymbol{S}{*}$ 能捕捉图像的共享风格。基于此发现,我们认为可学习样式词向量能够在无需任何图像的情况下,通过联合视觉-语言空间探索多种风格来模拟各类分布偏移。
3. Method
3. 方法
The overall framework of the proposed method is shown in Figure 3, and pseudo-code of PromptS tyler is described in Algorithm 1. Our method learns style word vectors to represent a variety of styles in a hyper spherical joint visionlanguage space (e.g., CLIP [50] latent space). After learning those style word vectors, we train a linear classifier using synthesized style-content features produced by a pre-trained text encoder $T(\cdot)$ . At inference time, a pre-trained image encoder $I(\cdot)$ extracts image features from input images, which are fed as input to the trained linear classifier. Thanks to the cross-modal transfer ability phenomenon of the joint visionlanguage space [67], this classifier could produce class scores using the image features. Note that we exploit CLIP as our large-scale vision-language model; its image encoder and text encoder are frozen in our entire framework.
所提方法的整体框架如图 3 所示,PromptStyler 的伪代码如算法 1 所述。我们的方法通过学习风格词向量来表示超球面联合视觉-语言空间 (如 CLIP [50] 的潜在空间) 中的多种风格。学习这些风格词向量后,我们使用预训练文本编码器 $T(\cdot)$ 生成的风格-内容合成特征来训练一个线性分类器。在推理阶段,预训练图像编码器 $I(\cdot)$ 从输入图像中提取特征,并将其输入训练好的线性分类器。得益于联合视觉-语言空间的跨模态迁移能力现象 [67],该分类器可以利用图像特征生成类别分数。需要注意的是,我们采用 CLIP 作为大规模视觉-语言模型,其图像编码器和文本编码器在整个框架中保持冻结状态。
3.1. Prompt-driven style generation
3.1. 提示驱动的风格生成
An input text prompt is converted to several tokens via a token iz ation process, and then such tokens are replaced by their corresponding word vectors via a word lookup process. In PromptS tyler, a pseudo-word $S_{i}$ in a prompt is a placeholder which is replaced by a style word vector $\mathbf{s}{i}\in\mathbb{R}^{D}$ during the word lookup process. Note that three kinds of prompts are used in the proposed method: a style prompt $\bar{\mathcal{P}}{i}^{\mathrm{style}}$ (“a $S_{i}$ style of a”), a content prompt $\mathcal{P}{m}^{\mathrm{cc}}$ ontent $(^{6\leftarrow}[\mathrm{class}]{m}^{,\flat})$ , and a style-content prompt $\mathcal{P}{i}^{\mathrm{style}}\circ\mathcal{P}{m}^{\mathrm{cc}}$ ontent (“a $S_{i}$ style of a $[\mathrm{class}]{m}\mathrm{}^{\gamma}$ ). $S{i}$ indicates the placeholder for $i$ -th style word vector and $[\mathrm{class}]_{m}$ denotes $m$ -th class name.
输入文本提示通过 token 化过程转换为多个 token,随后这些 token 在词查找过程中被对应的词向量替换。在 PromptStyler 中,提示内的伪词 $S_{i}$ 是一个占位符,在词查找过程中会被风格词向量 $\mathbf{s}{i}\in\mathbb{R}^{D}$ 替换。注意,本方法使用了三种提示:风格提示 $\bar{\mathcal{P}}{i}^{\mathrm{style}}$ ("a $S_{i}$ style of a")、内容提示 $\mathcal{P}{m}^{\mathrm{cc}}$ ontent $(^{6\leftarrow}[\mathrm{class}]{m}^{,\flat})$,以及风格-内容提示 $\mathcal{P}{i}^{\mathrm{style}}\circ\mathcal{P}{m}^{\mathrm{cc}}$ ontent ("a $S_{i}$ style of a $[\mathrm{class}]{m}\mathrm{}^{\gamma}$)。$S{i}$ 表示第 $i$ 个风格词向量的占位符,$[\mathrm{class}]_{m}$ 表示第 $m$ 个类别名称。
Suppose we want to generate $K$ different styles in a joint vision-language space. In this case, the proposed method needs to learn $K$ style word vectors ${\mathbf{s}{i}}{i=1}^{K}$ , where each $\mathbf{s}{i}$ is randomly initialized at the beginning. To effectively simulate various distribution shifts in the joint vision-language space, those style word vectors need to be diverse while not distorting content information when they are exploited in style-content prompts. There are two possible design choices for learning such word vectors: (1) learning each style word vector $\mathbf{s}{i}$ in a sequential manner, or (2) learning all style word vectors ${\mathbf{s}{i}}{i=1}^{K}$ in a parallel manner. We choose the former, since it takes much less memory during training. Please refer to the supplementary material (Section A.2) for the empirical justification of our design choice.
假设我们想在联合视觉-语言空间中生成 $K$ 种不同风格。这种情况下,所提出的方法需要学习 $K$ 个风格词向量 ${\mathbf{s}{i}}{i=1}^{K}$ ,其中每个 $\mathbf{s}{i}$ 在开始时随机初始化。为了有效模拟联合视觉-语言空间中的各种分布偏移,这些风格词向量需要保持多样性,同时在用于风格-内容提示时不扭曲内容信息。学习这些词向量有两种可能的设计选择:(1) 以顺序方式学习每个风格词向量 $\mathbf{s}{i}$ ,或 (2) 以并行方式学习所有风格词向量 ${\mathbf{s}{i}}{i=1}^{K}$ 。我们选择前者,因为它在训练期间占用的内存少得多。关于我们设计选择的实证依据,请参阅补充材料 (Section A.2)。
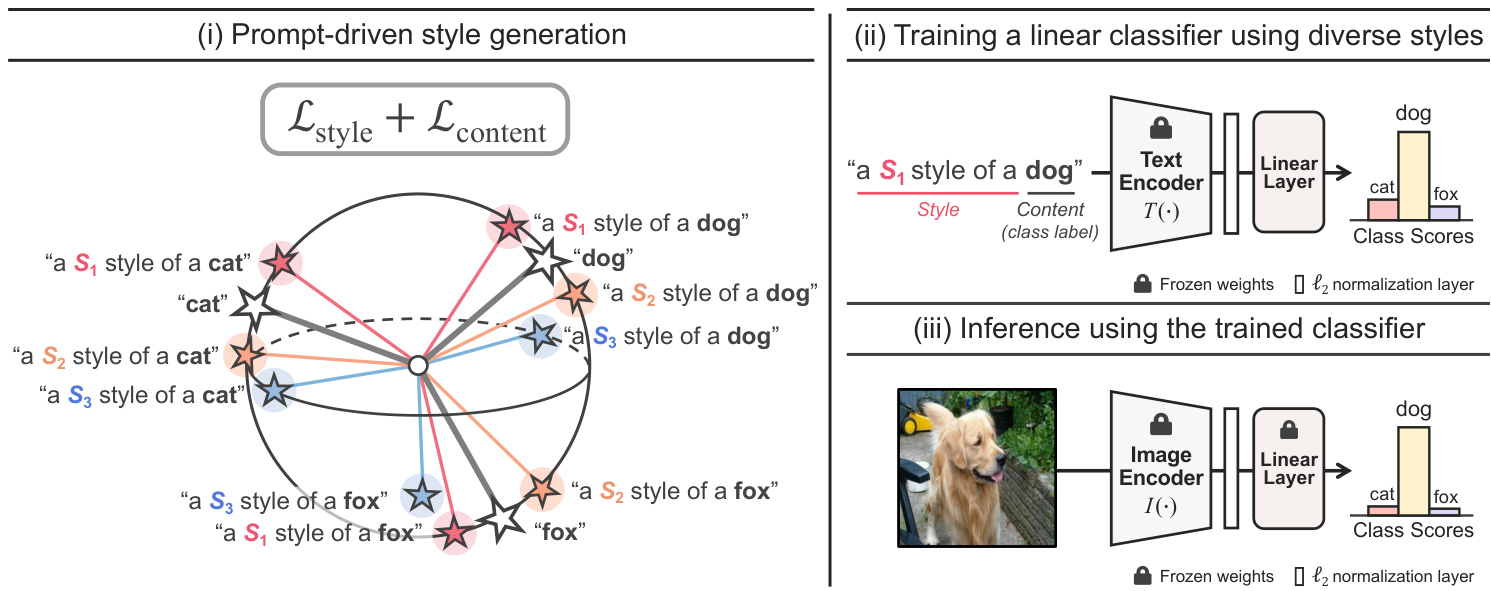
Figure 3: PromptS tyler learns diverse style word vectors which do not distort content information of style-content prompts. After learning style word vectors, we synthesize style-content features (e.g., from “a $S_{1}$ style of a dog”) via a pre-trained text encoder for training a linear classifier. The classifier is trained by a classification loss using those synthesized features and their corresponding class labels (e.g., “dog”). At inference time, a pre-trained image encoder extracts image features, which are fed as input to the trained classifier. Note that the encoders are derived from the same vision-language model (e.g., CLIP [50]).
图 3: PromptStyler 通过学习不扭曲风格-内容提示词内容信息的多样化风格词向量。在习得风格词向量后,我们通过预训练文本编码器合成风格-内容特征(例如从「$S_{1}$ 风格的狗」),用于训练线性分类器。该分类器通过使用这些合成特征及其对应类别标签(如「狗」)的分类损失进行训练。推理阶段,预训练图像编码器提取的图像特征将作为输入馈送至训练好的分类器。注意:这些编码器均源自同一视觉-语言模型(如 CLIP [50])。
Style diversity loss. To maximize the diversity of $K$ styles in a hyper spherical joint vision-language space, we sequentially learn style word vectors ${\mathbf{s}{i}}{i=1}^{K}$ in such a way that $i$ -th style feature $T(\mathcal{P}{i}^{\mathrm{style}})\in\mathbb{R}^{C}$ produced by $i$ -th style word vector $\mathbf{s}{i}$ is orthogonal to ${T(\mathcal{P}{j}^{\mathrm{style}})}{j=1}^{i-1}$ produced by previously learned style word vectors ${\mathbf{s}_{j}}_{j=1}^{i-1}$ . Regarding this, the style diversity loss $\mathcal{L}_{\mathrm{style}}$ for learning $i$ -th style word vector $\mathbf{s}_{i}$ is computed by
风格多样性损失。为了最大化超球面联合视觉-语言空间中 $K$ 种风格的多样性,我们按顺序学习风格词向量 ${\mathbf{s}{i}}{i=1}^{K}$,使得第 $i$ 个风格词向量 $\mathbf{s}{i}$ 生成的第 $i$ 个风格特征 $T(\mathcal{P}{i}^{\mathrm{style}})\in\mathbb{R}^{C}$ 与先前学习的风格词向量 ${\mathbf{s}{j}}{j=1}^{i-1}$ 生成的 ${T(\mathcal{P}_{j}^{\mathrm{style}})}_{j=1}^{i-1}$ 正交。基于此,学习第 $i$ 个风格词向量 $\mathbf{s}_{i}$ 的风格多样性损失 $\mathcal{L}_{\mathrm{style}}$ 通过以下方式计算:
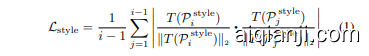
This style loss $\mathcal{L}_{\mathrm{style}}$ aims to minimize the absolute value of the cosine similarity between $i$ -th style feature and each of the existing style features. When the value of this loss becomes zero, it satisfies the orthogonality between $i$ -th style feature and all the existing style features.
该风格损失 $\mathcal{L}_{\mathrm{style}}$ 旨在最小化第 $i$ 个风格特征与每个现有风格特征之间余弦相似度的绝对值。当该损失值变为零时,表明第 $i$ 个风格特征与所有现有风格特征满足正交性。
Content consistency loss. Learning the style word vectors ${\mathbf{s}{i}}{i=1}^{K}$ only using the style diversity loss sometimes leads to undesirable outcome, since a learned style $\mathbf{s}{i}$ could substantially distort content information when used to generate a style-content feature T (P istyle ◦ P mcontent) ∈ RC. To alleviate this problem, we encourage the content information in the style-content feature to be consistent with its corresponding content feature $T(\mathcal{P}{m}^{\mathrm{content}})\in\mathbb{R}^{C}$ while learning each $i$ -th style word vector $\mathbf{s}{i}$ . Specifically, each style-content feature synthesized via $i$ -th style word vector $\mathbf{s}{i}$ should have the highest cosine similarity score with its corresponding content feature. For $i$ -th style word vector $\mathbf{s}{i}$ , a cosine similarity score $z{i m n}$ between a style-content feature with $m$ -th class name and a content feature with $n$ -th class name is computed by
内容一致性损失。仅通过风格多样性损失学习风格词向量 ${\mathbf{s}{i}}{i=1}^{K}$ 有时会导致不理想的结果,因为学习到的风格 $\mathbf{s}{i}$ 在用于生成风格-内容特征 $T(\mathcal{P}{i}^{\mathrm{style}} \circ \mathcal{P}{m}^{\mathrm{content}}) \in \mathbb{R}^{C}$ 时可能严重扭曲内容信息。为缓解此问题,我们在学习每个第 $i$ 个风格词向量 $\mathbf{s}{i}$ 时,鼓励风格-内容特征中的内容信息与其对应的内容特征 $T(\mathcal{P}{m}^{\mathrm{content}}) \in \mathbb{R}^{C}$ 保持一致。具体而言,通过第 $i$ 个风格词向量 $\mathbf{s}{i}$ 合成的每个风格-内容特征,应与其对应的内容特征具有最高的余弦相似度得分。对于第 $i$ 个风格词向量 $\mathbf{s}{i}$,具有第 $m$ 个类名的风格-内容特征与具有第 $n$ 个类名的内容特征之间的余弦相似度得分 $z{i m n}$ 通过下式计算:
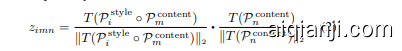
Using cosine similarity scores between style-content features and content features, the content consistency loss $\mathscr{L}{\mathrm{content}}$ for learning $i$ -th style word vector $\mathbf{s}{i}$ is computed by
通过计算风格-内容特征与内容特征之间的余弦相似度得分,学习第$i$个风格词向量$\mathbf{s}{i}$的内容一致性损失$\mathscr{L}{\mathrm{content}}$由下式得出:
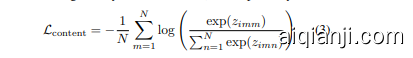
where $N$ denotes the number of classes pre-defined in the target task. This content loss $\mathcal{L}{\mathrm{content}}$ is a contrastive loss which encourages each style-content feature to be located closer to its corresponding content feature so that it forces each $i$ -th style word vector $\mathbf{s}{i}$ to preserve content information when used to synthesize style-content features.
其中 $N$ 表示目标任务中预定义的类别数量。该内容损失 $\mathcal{L}{\mathrm{content}}$ 是一种对比损失,它促使每个风格-内容特征更接近其对应的内容特征,从而强制每个第 $i$ 个风格词向量 $\mathbf{s}{i}$ 在用于合成风格-内容特征时保留内容信息。
Total prompt loss. PromptS tyler learns $K$ style word vec- tors ${\mathbf{s}{i}}{i=1}^{K}$ in a sequential manner, where each $i$ -th style word vector $\mathbf{s}{i}$ is learned using both $\mathcal{L}{\mathrm{style}}$ (Eq. (1)) and $\mathscr{L}{\mathrm{content}}$ (Eq. (3)). In the proposed method, the total loss $\mathcal{L}{\mathrm{prompt}}$ for learning $i$ -th style word vector is computed by
总提示损失。PromptStyler以顺序方式学习$K$个风格词向量${\mathbf{s}{i}}{i=1}^{K}$,其中每个第$i$个风格词向量$\mathbf{s}{i}$通过$\mathcal{L}{\mathrm{style}}$(式(1))和$\mathscr{L}{\mathrm{content}}$(式(3))共同学习。在该方法中,学习第$i$个风格词向量的总损失$\mathcal{L}{\mathrm{prompt}}$通过以下方式计算:
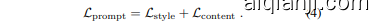
Using this prompt loss $\mathcal{L}{\mathrm{prompt}}$ , we train $i\cdot$ -th style word vector $\mathbf{s}{i}$ for $L$ training iterations.
使用这个提示损失 $\mathcal{L}{\mathrm{prompt}}$ ,我们训练第 $i\cdot$ 个风格词向量 $\mathbf{s}{i}$ 进行 $L$ 次训练迭代。
3.2. Training a linear classifier using diverse styles
3.2. 使用多样化风格训练线性分类器
After learning $K$ style word vectors ${\mathbf{s}{i}}{i=1}^{K}$ , we generate $K N$ style-content features for training a linear classifier. To be specific, we synthesize those features using the learned $K$ styles and pre-defined $N$ classes via the text encoder $T(\cdot)$ . The linear classifier is trained by a classification loss using $\ell_{2}$ -normalized style-content features and their class labels; each class label is the class name used to generate each stylecontent feature. To effectively leverage the hyper spherical joint vision-language space, we adopt ArcFace [8] loss as our classification loss $\mathcal{L}_{\mathrm{class}}$ . Note that ArcFace loss is an angular Softmax loss which computes the cosine similarities between classifier input features and classifier weights with an additive angular margin penalty between classes. This angular margin penalty allows for more disc rim i native predictions by pushing features from different classes further apart. Thanks to the property, this angular Softmax loss has been widely used in visual recognition tasks [7, 9, 30, 40, 65].
在学习 $K$ 种风格词向量 ${\mathbf{s}{i}}{i=1}^{K}$ 后,我们生成 $K N$ 个风格-内容特征用于训练线性分类器。具体而言,我们通过文本编码器 $T(\cdot)$ 使用学习到的 $K$ 种风格和预定义的 $N$ 个类别合成这些特征。该线性分类器通过分类损失函数使用 $\ell_{2}$ 归一化的风格-内容特征及其类别标签进行训练;每个类别标签即生成对应风格-内容特征时使用的类别名称。为有效利用超球面联合视觉-语言空间,我们采用 ArcFace [8] 损失作为分类损失 $\mathcal{L}_{\mathrm{class}}$。需注意,ArcFace 损失是一种角度 Softmax 损失,它计算分类器输入特征与分类器权重之间的余弦相似度,并在类别间施加附加角度间隔惩罚。这种角度间隔惩罚通过将不同类别的特征推得更远,从而实现更具判别性的预测。得益于这一特性,该角度 Softmax 损失已广泛应用于视觉识别任务 [7, 9, 30, 40, 65]。
3.3. Inference using the trained classifier
3.3. 使用训练好的分类器进行推理
The trained classifier is used with a pre-trained image encoder $I(\cdot)$ at inference time. Given an input image $\mathbf{x}$ , the image encoder extracts its image feature $I(\mathbf{\bar{x}})\in\mathbb{R}^{\bar{C}}$ , which is mapped to the hyper spherical joint vision-language space by $\ell_{2}$ normalization. Then, the trained classifier produces class scores using the $\ell_{2}$ -normalized image feature. Note that the text encoder $T(\cdot)$ is not used at inference time, while the image encoder $I(\cdot)$ is only exploited at inference time.
训练好的分类器在推理时与预训练的图像编码器 $I(\cdot)$ 配合使用。给定输入图像 $\mathbf{x}$,图像编码器提取其图像特征 $I(\mathbf{\bar{x}})\in\mathbb{R}^{\bar{C}}$,通过 $\ell_{2}$ 归一化将其映射到超球面联合视觉-语言空间。随后,训练好的分类器使用 $\ell_{2}$ 归一化后的图像特征生成类别分数。需要注意的是,文本编码器 $T(\cdot)$ 在推理阶段不会被使用,而图像编码器 $I(\cdot)$ 仅在推理时发挥作用。
4. Experiments
4. 实验
For more comprehensive understanding, please refer to the supplementary material (Section B and D).
如需更全面的了解,请参阅补充材料 (Section B 和 D)。
4.1. Evaluation datasets
4.1. 评估数据集
The proposed method does not require any actual data for training. To analyze its generalization capability, four domain generalization benchmarks are used for evaluation: PACS [34] (4 domains and 7 classes), VLCS [15] (4 domains and 5 classes), OfficeHome [60] (4 domains and 65 classes) and DomainNet [48] (6 domains and 345 classes). On these benchmarks, we repeat each experiment three times using different random seeds and report average top-1 classification accuracies with standard errors. Unlike the leaveone-domain-out cross-validation evaluation protocol [21], we do not exploit any source domain data for training.
所提方法无需任何实际数据进行训练。为分析其泛化能力,我们使用四个领域泛化基准进行评估:PACS [34](4个域7个类别)、VLCS [15](4个域5个类别)、OfficeHome [60](4个域65个类别)和DomainNet [48](6个域345个类别)。在这些基准测试中,我们使用不同随机种子重复每次实验三次,并报告平均top-1分类准确率及标准误差。与留一域交叉验证评估方案 [21] 不同,我们未利用任何源域数据进行训练。
4.2. Implementation details
4.2. 实现细节
PromptS tyler is implemented and trained with the same configuration regardless of the evaluation datasets. Training takes about 30 minutes using a single RTX 3090 GPU.
PromptStyler 的实现和训练配置在所有评估数据集上保持一致,使用单张 RTX 3090 GPU 训练耗时约 30 分钟。
Architecture. We choose CLIP [50] as our large-scale pretrained vision-language model, and use the publicly available pre-trained model.1 The text encoder $T(\cdot)$ used in training is Transformer [59] and the image encoder $I(\cdot)$ used at inference is ResNet-50 [22] as default setting in experiments; our method is also implemented with ViT-B/16 [11] or ViT $\mathrm{L}/14$ [11] for further evaluations as shown in Table 2. Note that text and image encoders are derived from the same CLIP model and frozen in the entire pipeline. The dimension of each text feature or image feature is $C=1024$ when our method is implemented with ResNet-50, while $C=512$ in the case of ViT-B/16 and $C=768$ in the case of ViT-L/14. Learning style word vectors. We follow prompt learning methods [70, 71] when learning the word vectors. Using a tion, we randomly initialize $K$ style w 0o.r0d2 vectors ${\mathbf{s}_{i}}_{i=1}^{K}$ where $K=80$ . The dimension of each style word vector is $D=512$ when the proposed method is implemented with ResNet-50 [22] or ViT-B/16 [11], while $D=768$ in the case of ViT-L/14 [11]. Each $i$ -th style word vector $\mathbf{s}_{i}$ is trained by the prompt loss $\mathcal{L}_{\mathrm{prompt}}$ for $L=100$ training iterations using the SGD optimizer with 0.002 learning rate and 0.9 momentum. The number of classes $N$ is pre-defined by each target task definition, e.g., $N=345$ for DomainNet [48].
架构。我们选择 CLIP [50] 作为大规模预训练的视觉语言模型,并使用公开可用的预训练模型。1 训练中使用的文本编码器 $T(\cdot)$ 为 Transformer [59],实验中默认使用的图像编码器 $I(\cdot)$ 为 ResNet-50 [22];如表 2 所示,我们的方法也采用了 ViT-B/16 [11] 或 ViT $\mathrm{L}/14$ [11] 进行进一步评估。请注意,文本编码器和图像编码器均来自同一 CLIP 模型,且在整个流程中保持冻结状态。当采用 ResNet-50 时,每个文本特征或图像特征的维度为 $C=1024$,而 ViT-B/16 时为 $C=512$,ViT-L/14 时为 $C=768$。学习风格词向量。我们遵循提示学习方法 [70, 71] 来学习词向量。通过随机初始化 $K$ 个风格词向量 ${\mathbf{s}_{i}}_{i=1}^{K}$(其中 $K=80$),在使用 ResNet-50 [22] 或 ViT-B/16 [11] 时,每个风格词向量的维度为 $D=512$,而 ViT-L/14 [11] 时为 $D=768$。每个第 $i$ 个风格词向量 $\mathbf{s}_{i}$ 通过提示损失 $\mathcal{L}_{\mathrm{prompt}}$ 进行训练,使用学习率为 0.002、动量为 0.9 的 SGD 优化器进行 $L=100$ 次训练迭代。类别数量 $N$ 由各目标任务定义预先确定,例如 DomainNet [48] 中 $N=345$。
Training a linear classifier. The classifier is trained for 50 epochs using the SGD optimizer with 0.005 learning rate, 0.9 momentum, and a batch size of 128. In ArcFace [8] loss, its scaling factor is set to 5 with 0.5 angular margin.
训练线性分类器。该分类器使用SGD优化器训练50个周期,学习率为0.005,动量为0.9,批量大小为128。在ArcFace [8]损失函数中,其缩放因子设为5,角度间隔为0.5。
Inference. Input images are pre-processed in the same way with the CLIP model; resized to $224\times224$ and normalized.
推理。输入图像的预处理方式与CLIP模型相同:调整尺寸至$224\times224$并进行归一化。
Table 2: Comparison with the state-of-the-art domain generalization methods. ZS-CLIP (C) denotes zero-shot CLIP using “[class]” as its text prompt, and ZS-CLIP (PC) indicates zero-shot CLIP using “a photo of a [class]” as its text prompt. Note that PromptS tyler does not exploit any source domain data and domain descriptions.
| 方法 | 源域 | 域描述 | PACS | VLCS | OfficeHome | DomainNet | 平均 |
|---|---|---|---|---|---|---|---|
| 基于ImageNet[6]预训练权重的ResNet-50[22] | |||||||
| DANN [19] | - | - | 83.6±0.4 | 78.6±0.4 | 65.9±0.6 | 38.3±0.1 | 66.6 |
| RSC [25] | ← | - | 85.2±0.9 | 77.1±0.5 | 65.5±0.9 | 38.9±0.5 | 66.7 |
| MLDG [35] | - | - | 84.9±1.0 | 77.2±0.4 | 66.8±0.6 | 41.2±0.1 | 67.5 |
| SagNet [46] | - | - | 86.3±0.2 | 77.8±0.5 | 68.1±0.1 | 40.3±0.1 | 68.1 |
| SelfReg [28] | - | - | 85.6±0.4 | 77.8±0.9 | 67.9±0.7 | 42.8±0.0 | 68.5 |
| GVRT [44] | - | - | 85.1±0.3 | 79.0±0.2 | 70.1±0.1 | 44.1±0.1 | 69.6 |
| MIRO [5] | - | - | 85.4±0.4 | 79.0±0.0 | 70.5±0.4 | 44.3±0.2 | 69.8 |
| 基于CLIP[50]预训练权重的ResNet-50[22] | |||||||
| ZS-CLIP (C) [50] | - | - | 90.6±0.0 | 76.0±0.0 | 68.6±0.0 | 45.6±0.0 | 70.2 |
| CAD [53] | - | - | 90.0±0.6 | 81.2±0.6 | 70.5±0.3 | 45.5±2.1 | 71.8 |
| ZS-CLIP (PC) [50] | - | - | 90.7±0.0 | 80.1±0.0 | 72.0±0.0 | 46.2±0.0 | 72.3 |
| PromptStyler | - | - | 93.2±0.0 | 82.3±0.1 | 73.6±0.1 | 49.5±0.0 | 74.7 |
| 基于CLIP[50]预训练权重的ViT-B/16[11] | |||||||
| ZS-CLIP (C) [50] | - | - | 95.7±0.0 | 76.4±0.0 | 79.9±0.0 | 57.8±0.0 | 77.5 |
| MIRO [5] | - | - | 95.6 | 82.2 | 82.5 | 54.0 | 78.6 |
| ZS-CLIP (PC) [50] | - | - | 96.1±0.0 | 82.4±0.0 | 82.3±0.0 | 57.7±0.0 | 79.6 |
| PromptStyler | - | - | 97.2±0.1 | 82.9±0.0 | 83.6±0.0 | 59.4±0.0 | 80.8 |
| 基于CLIP[50]预训练权重的ViT-L/14[11] | |||||||
| ZS-CLIP (C) [50] | - | - | 97.6±0.0 | 77.5±0.0 | 85.9±0.0 | 63.3±0.0 | 81.1 |
| ZS-CLIP (PC) [50] | - | - | 98.5±0.0 | 82.4±0.0 | 86.9±0.0 | 64.0±0.0 | 83.0 |
| PromptStyler | - | - | 98.6±0.0 | 82.4±0.2 | 89.1±0.0 | 65.5±0.0 | 83.9 |
表 2: 与最先进的域泛化方法对比。ZS-CLIP (C) 表示使用"[class]"作为文本提示的零样本 CLIP,ZS-CLIP (PC) 表示使用"a photo of a [class]"作为文本提示的零样本 CLIP。注意 PromptStyler 未使用任何源域数据和域描述。
4.3. Evaluations
4.3. 评估
Main results. PromptS tyler achieves the state of the art in every evaluation on PACS [34], VLCS [15], OfficeHome [60] and DomainNet [48] as shown in Table 2. Note that all existing methods utilize source domain data except for zero-shot CLIP [50] in Table 2. Compared with zero-shot CLIP which generates each text feature using a domain-agnostic prompt (“[class]”), PromptS tyler largely outperforms its records in all evaluations. Our method also shows higher accuracy compared with zero-shot CLIP which produces each text feature using a domain-specific prompt (“a photo of a [class]”), even though we do not exploit any domain descriptions. These results confirm that the proposed method effectively improves the generalization capability of the chosen pre-trained model, i.e., CLIP, without using any images by simulating various distribution shifts via prompts in its latent space.
主要结果。如表 2 所示,PromptStyler 在 PACS [34]、VLCS [15]、OfficeHome [60] 和 DomainNet [48] 的每项评估中都达到了最先进的水平。请注意,除表 2 中的零样本 CLIP [50] 外,所有现有方法都利用了源域数据。与使用领域无关提示 ("[class]") 生成每个文本特征的零样本 CLIP 相比,PromptStyler 在所有评估中都大幅超越了其记录。即使我们没有利用任何领域描述,与使用领域特定提示 ("a photo of a [class]") 生成每个文本特征的零样本 CLIP 相比,我们的方法也显示出更高的准确率。这些结果证实,所提出的方法通过在其潜在空间中使用提示模拟各种分布偏移,有效提高了所选预训练模型 (即 CLIP) 的泛化能力,而无需使用任何图像。
Computational evaluations. In Table 3, we compare our PromptS tyler and zero-shot CLIP [50] in terms of the number of parameters and inference speed; the inference speed was measured using a single RTX 3090 GPU with a batch size of 1. Note that we do not exploit a text encoder at inference time, which makes our model ${\sim}2.6\times$ smaller and ${\sim}243\times$ faster compared with CLIP. Regarding the inference speed, the proposed model is about $45\times$ faster for the target task OfficeHome [60] (65 classes) and it is about $243\times$ faster for the target task DomainNet [48] (345 classes).
计算评估。在表 3 中,我们从参数量和推理速度方面比较了 PromptStyler 和零样本 CLIP [50];推理速度使用单块 RTX 3090 GPU 在批大小为 1 的条件下测得。需要注意的是,我们的模型在推理时不使用文本编码器,这使得其参数量比 CLIP 少 ${\sim}2.6\times$,推理速度快 ${\sim}243\times$。具体到推理速度,在目标数据集 OfficeHome [60](65 类)上,本模型快约 $45\times$;在目标数据集 DomainNet [48](345 类)上,本模型快约 $243\times$。
Table 3: The number of parameters and inference speed on OfficeHome [60] and DomainNet [48] using ResNet-50 [22] as an image encoder. Note that CLIP [50] text encoder needs to generate text features as many as the number of classes.
| 推理模块 | ||||
|---|---|---|---|---|
| 图像编码器 | 文本编码器 | 参数量 | 帧率(FPS) | |
| ZS-CLIP [50] | √ | 102.0M | 1.6 | |
| PromptStyler | √ | 38.4M | 72.9 | |
| OfficeHome(65类) | ||||
| ZS-CLIP [50] | 102.0M | 0.3 | ||
| PromptStyler | 38.7M | 72.9 | ||
| DomainNet(345类) |
表 3: 使用ResNet-50 [22]作为图像编码器时,在OfficeHome [60]和DomainNet [48]数据集上的参数量及推理速度。注意CLIP [50]文本编码器需要生成与类别数量相同的文本特征。
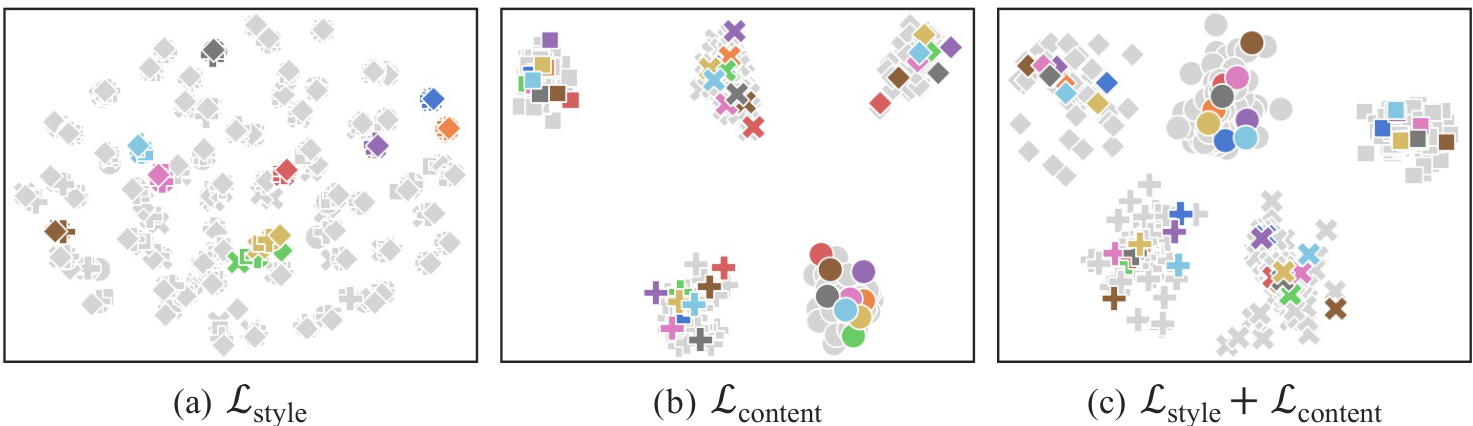
Figure 4: t-SNE [58] visualization results for the target task VLCS [15] (5 classes) using synthesized style-content features. We visualize such features obtained from the learned 80 style word vectors ${{\bf s}{i}}{i=1}^{80}$ and all the 5 classes (bird, car, chair, dog, person). Different colors denote features obtained from different style word vectors, and different shapes indicate features obtained from different class names. We only colorize features from the first 10 styles ${\mathbf{s}{i}}{i=1}^{10}$ . Combining the style diversity loss $\mathcal{L}_{\mathrm{style}}$ and content consistency loss $\mathscr{L}_{\mathrm{content}}$ leads to diverse styles while preserving content information.
图 4: 使用合成风格-内容特征对目标任务 VLCS [15] (5类别) 的 t-SNE [58] 可视化结果。我们展示了从学习的80个风格词向量 ${{\bf s}{i}}{i=1}^{80}$ 和全部5个类别(鸟、汽车、椅子、狗、人)中获取的特征。不同颜色表示来自不同风格词向量的特征,不同形状代表来自不同类别名称的特征。我们仅对前10种风格 ${\mathbf{s}{i}}{i=1}^{10}$ 的特征进行了着色。结合风格多样性损失 $\mathcal{L}_{\mathrm{style}}$ 和内容一致性损失 $\mathscr{L}_{\mathrm{content}}$ 能够在保持内容信息的同时实现多样化的风格。

Figure 5: Text-to-Image synthesis results using style-content features (from “a $\boldsymbol{S}_{*}$ style of a cat”) with 6 different style word vectors. By leveraging the proposed method, we could learn a variety of styles while not distorting content information.
图 5: 使用风格-内容特征(来自"a $\boldsymbol{S}_{*}$ style of a cat")与6种不同风格词向量生成的文生图结果。通过所提方法,我们能够在保持内容信息不变形的同时学习多种风格。
Table 4: Ablation study on the style diversity loss $\mathcal{L}{\mathrm{style}}$ and content consistency loss $\mathcal{L}{\mathrm{content}}$ used in the prompt loss.
| Lstyle | Lcontent | PACS | VLCS | OfficeHome | DomainNet | Avg. |
|---|---|---|---|---|---|---|
| 一 | - | 92.6 | 78.3 | 72.2 | 48.0 | 72.8 |
| √ | 一 | 92.3 | 80.9 | 71.5 | 48.2 | 73.2 |
| 一 | 92.8 | 80.5 | 72.4 | 48.6 | 73.6 | |
| √ | √ | 93.2 | 82.3 | 73.6 | 49.5 | 74.7 |
表 4: 提示损失中使用的风格多样性损失 $\mathcal{L}{\mathrm{style}}$ 和内容一致性损失 $\mathcal{L}{\mathrm{content}}$ 的消融研究。
t-SNE visualization results. In Figure 4, we qualitatively evaluate style-content features synthesized for the target task VLCS [15] (5 classes) using t-SNE [58] visualization. As shown in Figure 4(c), PromptS tyler generates a variety of styles while not distorting content information; style-content features obtained from the same class name share similar semantics with diverse variations. This result confirms that we could effectively simulate various distribution shifts in the latent space of a large-scale vision-language model by synthesizing diverse styles via learnable style word vectors. Text-to-Image synthesis results. In Figure 5, we visualize style-content features (from “a $\boldsymbol{S}_{*}$ style of a cat”) via diffusers library.2 These results are obtained with 6 different style word vectors, where the word vectors are learned for the target task DomainNet [48] using ViT-L/14 [11] model.
t-SNE可视化结果。在图4中,我们通过t-SNE [58]可视化对目标任务VLCS [15](5个类别)合成的风格-内容特征进行定性评估。如图4(c)所示,PromptStyler在保持内容信息不变形的同时生成了多样化的风格;从相同类别名称获得的风格-内容特征具有相似的语义和多样的变化。这一结果证实,通过学习可训练的风格词向量合成多样化风格,我们能够有效模拟大规模视觉-语言模型潜在空间中的各种分布偏移。
文本到图像合成结果。在图5中,我们通过diffusers库可视化风格-内容特征(来自"a $\boldsymbol{S}_{*}$ style of a cat")。这些结果是使用6种不同的风格词向量获得的,其中词向量是为目标任务DomainNet [48]使用ViT-L/14 [11]模型学习的。
Table 5: Ablation study on the classification loss $\mathcal{L}_{\mathrm{class}}$ used for training a linear classifier in the proposed framework.
| Lclass | 准确率 (%) |
|---|---|
| PACS | |
| Softmax | 92.5 |
| ArcFace | 93.2 |
表 5: 在提出的框架中用于训练线性分类器的分类损失 $\mathcal{L}_{\mathrm{class}}$ 的消融研究。
4.4. More analyses
4.4. 更多分析
Ablation study on the prompt loss. In Table 4, we evaluate the effects of $\mathcal{L}{\mathrm{style}}$ and $\mathcal{L}{\mathrm{content}}$ in $\mathcal{L}{\mathrm{prompt}}$ used for learning style words. Interestingly, our method also achieves state-of-the-art results even without using these losses, i.e., the proposed framework (Fig. 3) is substantially effective by itself. Note that randomly initialized style word vectors are already diverse, and CLIP [50] is already good at extracting correct content information from a style-content prompt even without training the word vectors using $\mathscr{L}{\mathrm{content}}$ . When we learn style word vectors using $\mathcal{L}{\mathrm{style}}$ without $\mathscr{L}{\mathrm{content}}$ , style-content features obtained from different class names share more similar features than those from the same class name (Fig. 4(a)). On the other hand, using $\mathcal{L}{\mathrm{content}}$ without $\mathcal{L}{\mathrm{style}}$ leads to less diverse style-content features (Fig. 4(b)). When incorporating both losses, we could generate diverse styles while not distorting content information (Fig. 4(c)).
关于提示损失(prompt loss)的消融研究。在表4中,我们评估了用于学习风格词的$\mathcal{L}{\mathrm{prompt}}$中$\mathcal{L}{\mathrm{style}}$和$\mathcal{L}{\mathrm{content}}$的效果。有趣的是,即使不使用这些损失函数,我们的方法也能达到最先进的性能,这表明所提出的框架(图3)本身就非常有效。需要注意的是,随机初始化的风格词向量已经具有多样性,且CLIP [50]即使在不使用$\mathscr{L}{\mathrm{content}}$训练词向量的情况下,也能很好地从风格-内容提示中提取正确的内容信息。当我们仅使用$\mathcal{L}{\mathrm{style}}$而不使用$\mathscr{L}{\mathrm{content}}$学习风格词向量时,从不同类名获得的风格-内容特征比来自同类名的特征更相似(图4(a))。另一方面,仅使用$\mathcal{L}{\mathrm{content}}$而不使用$\mathcal{L}{\mathrm{style}}$会导致风格-内容特征的多样性降低(图4(b))。当同时使用这两个损失函数时,我们可以在不扭曲内容信息的情况下生成多样化的风格(图4(c))。
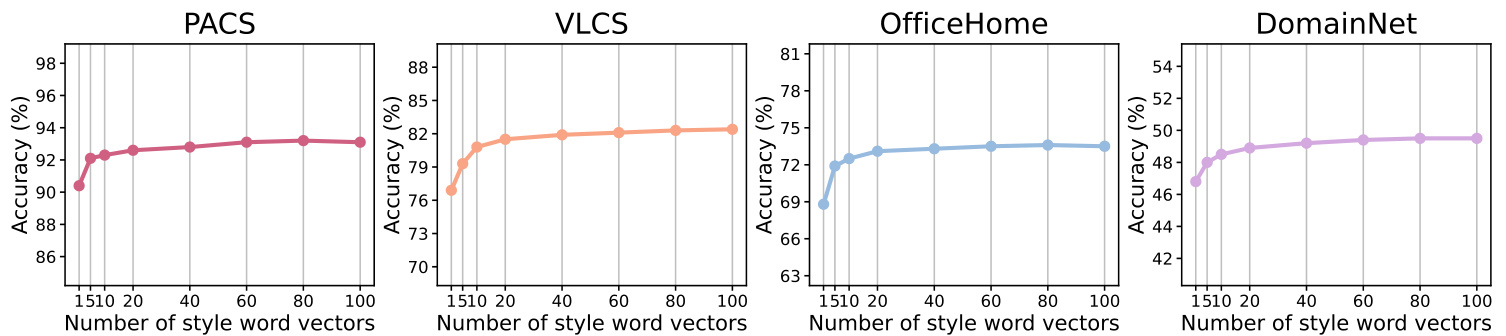
Figure 6: Top-1 classification accuracy on the PACS [34], VLCS [15], OfficeHome [60] and DomainNet [48] datasets with regard to the number of learnable style word vectors $K$ .
图 6: PACS [34]、VLCS [15]、OfficeHome [60] 和 DomainNet [48] 数据集的 Top-1 分类准确率与可学习风格词向量数量 $K$ 的关系。
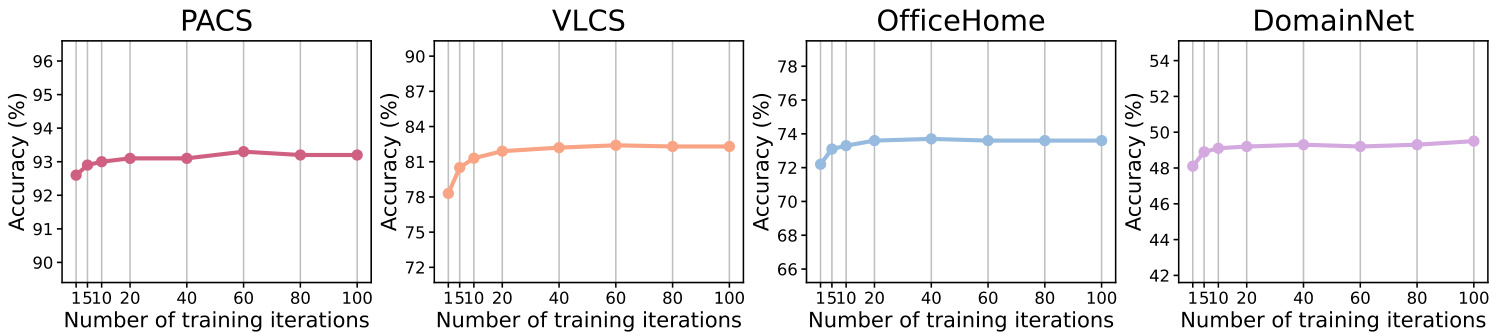
Figure 7: Top-1 classification accuracy on the PACS [34], VLCS [15], OfficeHome [60] and DomainNet [48] datasets with regard to the number of training iterations $L$ for learning each style word vector $\mathbf{s}_{i}$ .
图 7: 在PACS [34]、VLCS [15]、OfficeHome [60]和DomainNet [48]数据集上,关于学习每个风格词向量$\mathbf{s}_{i}$的训练迭代次数$L$的Top-1分类准确率。
Table 6: Unsatisfactory results obtained from CLIP [50] without using source domain data from Terra Incognita [1].
| 配置 | 准确率 (%) | ||
|---|---|---|---|
| 源域 | 域 | ||
| Method ResNet-50[22] with pre-trained weights on ImageNet[6] | Description | TerraIncognita | |
| SelfReg [28] | 47.0±0.3 | ||
| GVRT [44] | 48.0±0.2 | ||
| ResNet-50[22] with pre-trained weights from CLIP[50] | |||
| ZS-CLIP (C) [50] | 19.5±0.0 | ||
| ZS-CLIP (PC) [50] | 23.8±0.0 | ||
| PromptStyler | 30.5±0.8 |
表 6: 未使用 Terra Incognita [1] 源域数据时从 CLIP [50] 获得的不理想结果。
Ablation study on the classification loss. In Table 5, we evaluate the effects of the original Softmax loss and the angular Softmax loss (i.e., ArcFace [8]). PromptS tyler also achieves the state of the art using the original one, which validates that the performance improvement of our method mainly comes from the proposed framework (Fig. 3). Note that the angular Softmax loss further improves its accuracy by leveraging the hyper spherical joint vision-language space. Effect of the number of styles. We evaluate our method with regard to the number of style word vectors $K$ as shown in Figure 6. Interestingly, our PromptS tyler outperforms CLIP [50] using just 5 styles. This evaluation shows that 20 style word vectors are enough to achieve decent results. Effect of the number of iterations. We evaluate our method with regard to the number of training iterations $L$ for learning each style word vector as shown in Figure 7. This evaluation shows that 20 iterations are enough to achieve decent results.
分类损失的消融研究。在表5中,我们评估了原始Softmax损失和角度Softmax损失(即ArcFace [8])的效果。PromptStyler使用原始损失函数也能达到最优性能,这表明我们方法的性能提升主要来自提出的框架(图3)。值得注意的是,角度Softmax损失通过利用超球面联合视觉-语言空间进一步提高了准确性。
风格数量影响。如图6所示,我们评估了风格词向量数量$K$的影响。有趣的是,PromptStyler仅使用5种风格就超越了CLIP [50]。实验表明,20个风格词向量足以取得良好效果。
迭代次数影响。如图7所示,我们评估了学习每个风格词向量的训练迭代次数$L$的影响。实验表明,20次迭代足以取得良好效果。
5. Limitation
5. 局限性
The performance of our method depends on the quality of the joint vision-language space constructed by the chosen vision-language model. For example, although PromptS tyler largely outperforms its base model (i.e., CLIP [50]) in all evaluations, our method shows lower accuracy on the Terra Incognita dataset [1] compared with other methods which utilize several images from the dataset as shown in Table 6. The main reason for this might be due to the low accuracy of CLIP on the dataset. Nevertheless, given that our method consistently outperforms its base model in every evaluation, this limitation could be alleviated with the development of large-scale vision-language models.
我们方法的性能取决于所选视觉语言模型构建的联合视觉语言空间质量。例如,尽管PromptStyler在所有评估中大幅超越其基础模型(即CLIP[50]),但如表6所示,与使用数据集中多张图像的其他方法相比,我们的方法在Terra Incognita数据集[1]上准确率较低。主要原因可能是CLIP在该数据集上的准确率较低。不过,鉴于我们的方法在每次评估中都持续优于其基础模型,这一限制有望随着大规模视觉语言模型的发展得到缓解。
6. Conclusion
6. 结论
We have presented a novel method that synthesizes a variety of styles in a joint vision-language space via learnable style words without exploiting any images to deal with source-free domain generalization. PromptS tyler simulates various distribution shifts in the latent space of a large-scale pre-trained model, which could effectively improve its genera liz ation capability. The proposed method achieves stateof-the-art results without using any source domain data on multiple domain generalization benchmarks. We hope that future work could apply our method to other tasks using different large-scale vision-language models.
我们提出了一种新颖方法,通过在可学习的风格词上联合视觉-语言空间合成多种风格,无需利用任何图像即可处理无源域泛化问题。PromptStyler通过在大规模预训练模型的潜在空间中模拟各种分布偏移,有效提升了其泛化能力。该方法在多个域泛化基准测试中未使用任何源域数据即取得了最先进的结果。我们希望未来工作能将本方法应用于采用不同大规模视觉-语言模型的其他任务。
Acknowledgment. This work was supported by the Agency for Defense Development grant funded by the Korean government.
致谢。本研究由韩国政府资助的国防发展局拨款支持。
PromptS tyler: Prompt-driven Style Generation for Source-free Domain Generalization
PromptStyler: 基于提示驱动的无源域泛化风格生成
— Supplementary Material —
— 补充材料 —
Junhyeong Cho1 Gilhyun Nam1 Sungyeon Kim2 Hunmin Yang1,3 Suha Kwak2 1ADD 2POSTECH 3KAIST https://PromptS tyler.github.io
Junhyeong Cho1 Gilhyun Nam1 Sungyeon Kim2 Hunmin Yang1,3 Suha Kwak2 1ADD 2POSTECH 3KAIST https://PromptStyler.github.io
In this supplementary material, we provide more method details (Section A), analyses on Terra Incognita (Section B), evaluation results (Section C) and discussion (Section D).
在本补充材料中,我们提供了更多方法细节(A部分)、Terra Incognita分析(B部分)、评估结果(C部分)和讨论(D部分)。
A. Method Details
A. 方法详情
This section provides more details of the chosen visionlanguage model (Section A.1) and design choices for learning style word vectors (Section A.2).
本节将详细介绍所选用的视觉语言模型 (附录A.1) 以及学习风格词向量 (附录A.2) 的设计方案。
A.1. Large-scale vision-language model
A.1. 大规模视觉语言模型
We choose CLIP [50] as our pre-trained vision-language model which is a large-scale model trained with 400 million image-text pairs. Note that the proposed method is broadly applicable to the CLIP-like vision-language models [26, 64] which also construct hyper spherical joint vision-language spaces using contrastive learning methods. Given a batch of image-text pairs, such models jointly train an image encoder and a text encoder considering similarity scores obtained from image-text pairings.
我们选择CLIP [50]作为预训练视觉语言模型,这是一个通过4亿个图文对训练的大规模模型。需要注意的是,所提出的方法广泛适用于类似CLIP的视觉语言模型 [26, 64],这些模型同样采用对比学习方法构建超球面联合视觉语言空间。给定一批图文对时,这类模型会联合训练图像编码器和文本编码器,同时考虑从图文配对中获得的相似度分数。
Joint vision-language training. Suppose there is a batch of $M$ image-text pairs. Among all possible $M\times M$ pairings, the matched $M$ pairs are the positive pairs and the other $M^{2}-M$ pairs are the negative pairs. CLIP [50] is trained to maximize cosine similarities of image and text features from the positive $M$ pairs while minimizing the similarities of such features from the negative $M^{2}-M$ pairs.
联合视觉-语言训练。假设有一批 $M$ 个图文对。在所有可能的 $M\times M$ 配对中,匹配的 $M$ 对是正样本对,其余 $M^{2}-M$ 对是负样本对。CLIP [50] 的训练目标是最大化正样本 $M$ 对中图像和文本特征的余弦相似度,同时最小化负样本 $M^{2}-M$ 对中这些特征的相似度。
Image encoder. CLIP [50] utilizes ResNet [22] or ViT [11] as its image encoder. Given an input image, the image encoder extracts its image feature. After that, the image feature is mapped to a hyper spherical joint vision-language space by $\ell_{2}$ normalization.
图像编码器。CLIP [50] 采用 ResNet [22] 或 ViT [11] 作为其图像编码器。给定输入图像后,图像编码器会提取其图像特征,随后通过 $\ell_{2}$ 归一化将图像特征映射到超球面联合视觉-语言空间。
Text encoder. CLIP [50] utilizes Transformer [59] as its text encoder. Given an input text prompt, it is converted to word vectors via a token iz ation process and a word lookup procedure. Using these word vectors, the text encoder generates a text feature which is then mapped to a hyper spherical joint vision-language space by $\ell_{2}$ normalization.
文本编码器。CLIP [50] 采用 Transformer [59] 作为其文本编码器。给定输入文本提示时,会通过 token 化过程和单词查找程序将其转换为词向量。利用这些词向量,文本编码器生成文本特征,随后通过 $\ell_{2}$ 归一化将其映射到超球面联合视觉-语言空间。

Figure A1: GPU memory usage when learning $K$ style word vectors for the target task OfficeHome [60] (65 classes) with respect to the design choices, Sequential or Parallel.
图 A1: 在目标任务OfficeHome [60] (65类)中学习$K$个风格词向量时,针对Sequential或Parallel设计选择的GPU内存使用情况。
Zero-shot inference. At inference time, zero-shot CLIP [50] synthesizes classifier weights via the text encoder using $N$ class names pre-defined in the target task. Given an input image, the image encoder extracts its image feature and the text encoder produces $N$ text features using the $N$ class names. Then, it computes cosine similarity scores between the image feature and text features, and selects the class name which results in the highest similarity score as its classification output.
零样本推理。在推理时,零样本CLIP [50]通过文本编码器使用目标任务中预定义的$N$个类别名称合成分类器权重。给定输入图像后,图像编码器提取其图像特征,同时文本编码器利用这$N$个类别名称生成$N$个文本特征。随后,系统计算图像特征与各文本特征间的余弦相似度分数,并选择相似度分数最高的类别名称作为分类输出。
A.2. Empirical justification of our design choice
A.2. 设计选择的实证依据
As described in Section 3.1 of the main paper, there are two possible design choices for learning $K$ style word vectors: (1) learning each style word vector $\mathbf{s}{i}$ in a sequential manner, or (2) learning all style word vectors ${\mathbf{s}{i}}_{i=1}^{K}$ in a parallel manner. We choose the former mainly due to its much less memory overhead. As shown in Figure A1, we could sequentially learn ${\sim}100$ style word vectors with ${\sim}4.2$ GB memory usage. However, it is not possible to learn more than 21 style word vectors in a parallel manner using a single
如主论文第3.1节所述,学习$K$个风格词向量有两种可能的设计选择:(1) 以顺序方式学习每个风格词向量$\mathbf{s}{i}$,或(2) 以并行方式学习所有风格词向量${\mathbf{s}{i}}_{i=1}^{K}$。我们选择前者主要是由于其内存开销小得多。如图A1所示,我们可以用${\sim}4.2$GB的内存使用量顺序学习${\sim}100$个风格词向量。然而,使用单个设备以并行方式学习超过21个风格词向量是不可行的。

Figure B1: Several examples from the Terra Incognita [1] dataset. We visualize class entities using red bounding boxes, since they are not easily recognizable due to their small sizes and complex background scenes.
图 B1: Terra Incognita [1] 数据集中的几个示例。由于目标尺寸较小且背景场景复杂不易识别,我们用红色边界框标出了类别实体。
Table B1: Top-1 classification accuracy on the Terra Incognita [1] dataset. Compared with existing domain generalization methods which utilize source domain data, zero-shot methods using CLIP [50] show unsatisfactory results on this dataset.
| 方法 | 配置 | 准确率 (%) | |||||
|---|---|---|---|---|---|---|---|
| 源域 | 域描述 | Location100 | Location38 | Location43 | Location46 | 平均 | |
| 在ImageNet[6]上预训练的ResNet-50[22] | |||||||
| SelfReg [28] | — | 48.8±0.9 | 41.3±1.8 | 57.3±0.7 | 40.6±0.9 | 47.0 | |
| GVRT [44] | √ | — | 53.9±1.3 | 41.8±1.2 | 58.2±0.9 | 38.0±0.6 | 48.0 |
| 从CLIP[50]预训练的ResNet-50[22] | |||||||
| ZS-CLIP (C) [50] | 8.4±0.0 | 13.7±0.0 | 32.5±0.0 | 23.3±0.0 | 19.5 | ||
| ZS-CLIP (PC)[50] | 9.9±0.0 | 28.3±0.0 | 32.9±0.0 | 24.0±0.0 | 23.8 | ||
| PromptStyler | — | 13.8±1.7 | 39.8±1.3 | 38.0±0.4 | 30.3±0.3 | 30.5 |
表 B1: Terra Incognita [1] 数据集上的 Top-1 分类准确率。与利用源域数据的现有领域泛化方法相比,使用 CLIP [50] 的零样本方法在该数据集上表现不佳。
RTX 3090 GPU (24 GB Memory) due to its large memory overhead. In detail, learning 20 and 21 style word vectors takes $22.4\mathrm{GB}$ and $23.5\mathrm{GB}$ , respectively. The large memory overhead caused by the parallel learning design substantially limits the number of learnable style word vectors.
RTX 3090 GPU (24 GB显存) 因其高内存开销而受限。具体而言,学习20和21个风格词向量分别需要占用 $22.4\mathrm{GB}$ 和 $23.5\mathrm{GB}$ 内存。这种并行学习设计导致的高内存占用极大限制了可学习的风格词向量数量。
To be specific, PromptS tyler with the parallel learning design needs to generate $K$ style features, $K N$ style-content features, and $N$ content features for learning $K$ style word vectors at the same time; these features are used to compute the style diversity loss $\mathcal{L}{\mathrm{style}}$ and the content consistency loss $\mathscr{L}{\mathrm{content}}$ for learning all the style word vectors in a parallel manner. Note that the large memory overhead is mainly caused by the $K N$ style-content features. Suppose we want to learn 80 style word vectors for the target task OfficeHome [60] (65 classes). Then, we need to synthesize $5200(=80\times65)$ style-content features. Even worse, we need to generate $27600(=80\times345)$ style-content features for the target task DomainNet [48] (345 classes). On the other hand, PromptS tyler with the sequential learning design only requires $i$ style features, $N$ style-content features, and $N$ content features for learning $i$ -th style word vector, where $1\leq i\leq K$ . For s cal ability, we chose the sequential learning design since it could handle a lot of learnable style word vectors and numerous classes in the target task.
具体来说,采用并行学习设计的PromptStyler需要同时生成$K$个风格特征、$K N$个风格-内容特征和$N$个内容特征来学习$K$个风格词向量;这些特征用于计算风格多样性损失$\mathcal{L}{\mathrm{style}}$和内容一致性损失$\mathscr{L}{\mathrm{content}}$,以并行方式学习所有风格词向量。需要注意的是,较大的内存开销主要由$K N$个风格-内容特征引起。假设我们要为目标任务OfficeHome [60](65类)学习80个风格词向量,则需要合成$5200(=80\times65)$个风格-内容特征。更糟糕的是,对于目标任务DomainNet [48](345类),我们需要生成$27600(=80\times345)$个风格-内容特征。另一方面,采用顺序学习设计的PromptStyler仅需要$i$个风格特征、$N$个风格-内容特征和$N$个内容特征来学习第$i$个风格词向量,其中$1\leq i\leq K$。出于可扩展性考虑,我们选择了顺序学习设计,因为它可以处理大量可学习的风格词向量以及目标任务中的众多类别。
B. Analyses on Terra Incognita
B. 未知领域分析
As described in Section 5 of the main paper, the quality of the latent space constructed by a large-scale pre-trained model significantly affects the effectiveness of PromptS tyler. To be specific, the proposed method depends on the quality of the joint vision-language space constructed by CLIP [50]. Although our method achieves state-of-the-art results on PACS [34], VLCS [15], OfficeHome [60], and DomainNet [48], its performance on Terra Incognita [1] is not satisfactory. This section provides more analyses on the dataset.
如主论文第5节所述,大规模预训练模型构建的潜在空间质量会显著影响PromptStyler的效果。具体而言,该方法依赖于CLIP [50] 构建的视觉-语言联合空间质量。尽管我们的方法在PACS [34]、VLCS [15]、OfficeHome [60] 和DomainNet [48] 上取得了最先进的结果,但在Terra Incognita [1] 上的表现却不尽如人意。本节将对该数据集进行更多分析。
Table B1 shows that PromptS tyler outperforms zero-shot CLIP [50] for all domains in the Terra Incognita dataset [1]. However, its accuracy on this dataset is lower compared with existing domain generalization methods [28, 44] which utilize several images from the dataset as their source domain data. This unsatisfactory result might be due to the low accuracy of CLIP on the dataset. We suspect that images in the Terra Incognita dataset (Fig. B1) might be significantly different from the domains that CLIP has observed. The distribution shifts between CLIP training dataset and the Terra Incognita dataset might be extreme, and thus such distribution shifts could not be entirely covered by our method which exploits CLIP latent space. We hope this issue could be alleviated with the development of large-scale models.
表 B1 显示,在 Terra Incognita 数据集 [1] 的所有领域中,PromptStyler 的表现均优于零样本 CLIP [50] 。然而,与现有利用该数据集中多张图像作为源域数据的领域泛化方法 [28, 44] 相比,其在该数据集上的准确率较低。这一不理想的结果可能是由于 CLIP 在该数据集上的低准确率所致。我们推测 Terra Incognita 数据集 (图 B1) 中的图像可能与 CLIP 训练时观察到的领域存在显著差异。CLIP 训练数据集与 Terra Incognita 数据集之间的分布偏移可能过于极端,因此这种分布偏移无法完全被我们利用 CLIP 潜在空间的方法所覆盖。我们希望随着大规模模型的发展,这一问题能够得到缓解。
Table C1: Comparison with state-of-the-art domain generalization methods in terms of per-domain top-1 classification accuracy on PACS [34]. We repeat each experiment using three different seeds, and report average accuracies with standard errors. ZS-CLIP (C) denotes zero-shot CLIP using “[class]” as its text prompt, and ZS-CLIP (PC) indicates zero-shot CLIP using “a photo of a [class]” as its text prompt. Note that PromptS tyler does not use any source domain data and domain descriptions.
表 C1: 在PACS [34]数据集上各领域top-1分类准确率的先进领域泛化方法对比。我们使用三种不同随机种子重复实验,并报告平均准确率及标准误差。ZS-CLIP (C)表示使用"[class]"作为文本提示的零样本CLIP,ZS-CLIP (PC)表示使用"a photo of a [class]"作为文本提示的零样本CLIP。请注意PromptStyler不使用任何源领域数据和领域描述。
| 方法 | 配置 | 准确率(%) |
|---|---|---|
| 源领域 | 领域描述 | |
| ResNet-50[22] with ImageNet[6]预训练权重 | ||
| GVRT [44] | - | - |
| SelfReg [28] | - | - |
| ResNet-50[22] with CLIP[50]预训练权重 | ||
| ZS-CLIP (C) [50] | - | - |
| ZS-CLIP (PC) [50] | - | - |
| PromptStyler | - | - |
| ViT-B/16[11] with CLIP[50]预训练权重 | ||
| ZS-CLIP (C) [50] | - | - |
| ZS-CLIP (PC) [50] | - | - |
| PromptStyler | - | - |
| ViT-L/14[11] with CLIP[50]预训练权重 | ||
| ZS-CLIP (C) [50] | - | - |
| ZS-CLIP (PC) [50] | - | - |
| PromptStyler | - | - |
| 方法 | 配置 | 准确率 (%) |
|---|---|---|
| 源域 | 目标域 | |
| ResNet-50[22] (ImageNet[6]预训练权重) | ||
| SelfReg [28] | √ | - |
| GVRT [44] | ||
| ResNet-50[22] (CLIP[50]预训练权重) | ||
| ZS-CLIP (C) [50] | - | |
| ZS-CLIP (PC) [50] | - | ← |
| PromptStyler | - | |
| ViT-B/16 [11] (CLIP[50]预训练权重) | ||
| ZS-CLIP (C) [50] | - | |
| ZS-CLIP (PC) [50] | - | √ |
| PromptStyler | - | - |
| ViT-L/14[11] (CLIP[50]预训练权重) | ||
| ZS-CLIP (C) [50] | - | |
| ZS-CLIP (PC) [50] | ||
| PromptStyler |
Table C2: Comparison with state-of-the-art domain generalization methods in terms of per-domain top-1 classification accuracy on VLCS [15]. We repeat each experiment using three different seeds, and report average accuracies with standard errors. ZS-CLIP (C) denotes zero-shot CLIP using “[class]” as its text prompt, and ZS-CLIP (PC) indicates zero-shot CLIP using “a photo of a [class]” as its text prompt. Note that PromptS tyler does not use any source domain data and domain descriptions.
表 C2: 在VLCS数据集[15]上各领域top-1分类准确率与当前最优领域泛化方法的对比。我们使用三种不同随机种子重复每个实验,并报告平均准确率及标准误差。ZS-CLIP (C)表示使用"[class]"作为文本提示的零样本CLIP,ZS-CLIP (PC)表示使用"a photo of a [class]"作为文本提示的零样本CLIP。请注意PromptStyler未使用任何源域数据和领域描述。
Table C3: Comparison with state-of-the-art domain generalization methods in terms of per-domain top-1 classification accuracy on OfficeHome [60]. We repeat each experiment using three different seeds, and report average accuracies with standard errors. ZS-CLIP (C) denotes zero-shot CLIP using “[class]” as its text prompt, and ZS-CLIP (PC) indicates zero-shot CLIP using “a photo of a [class]” as its text prompt. Note that PromptS tyler does not use any source domain data and domain descriptions.
表 C3: 在OfficeHome [60]数据集上各领域top-1分类准确率的先进领域泛化方法对比。我们使用三种不同随机种子重复每个实验,并报告平均准确率及标准误差。ZS-CLIP (C)表示使用"[class]"作为文本提示的零样本CLIP,ZS-CLIP (PC)表示使用"a photo of a [class]"作为文本提示的零样本CLIP。请注意PromptStyler未使用任何源域数据和领域描述。
| 配置 | 准确率 (%) | ||||||
|---|---|---|---|---|---|---|---|
| 源域描述 | Art | Clipart | Product | Real World | Avg. | ||
| ResNet-50[22] with pre-trained weights on ImageNet[6] | |||||||
| SelfReg [28] | 一 | 63.6±1.4 | 53.1±1.0 | 76.9±0.4 | 78.1±0.4 | 67.9 | |
| GVRT [44] | ← | 66.3±0.1 | 55.8±0.4 | 78.2±0.4 | 80.4±0.2 | 70.1 | |
| ResNet-50 [22] with pre-trained weights from CLIP [50] | |||||||
| ZS-CLIP (C) [50] | 一 | 69.9±0.0 | 46.8±0.0 | 77.7±0.0 | 79.8±0.0 | 68.6 | |
| ZS-CLIP (PC) [50] | 一 | ← | 71.7±0.0 | 52.0±0.0 | 81.6±0.0 | 82.6±0.0 | 72.0 |
| PromptStyler | 一 | 73.4±0.1 | 52.4±0.2 | 84.3±0.1 | 84.1±0.1 | 73.6 | |
| ViT-B/16 [11] with pre-trained weights from CLIP [50] | |||||||
| ZS-CLIP (C) [50] | 一 | 一 | 80.7±0.0 | 64.6±0.0 | 86.3±0.0 | 88.0±0.0 | 79.9 |
| ZS-CLIP (PC) [50] | 一 | 82.7±0.0 | 67.6±0.0 | 89.2±0.0 | 89.7±0.0 | 82.3 | |
| PromptStyler | - | 83.8±0.1 | 68.2±0.0 | 91.6±0.1 | 90.7±0.1 | 83.6 | |
| ViT-L/14[11] with pre-trained weights from CLIP[50] | |||||||
| ZS-CLIP (C) [50] | 一 | 86.2±0.0 | 73.3±0.0 | 92.0±0.0 | 92.2±0.0 | 85.9 | |
| ZS-CLIP (PC) [50] | 一 | √ | 87.2±0.0 | 73.8±0.0 | 93.0±0.0 | 93.4±0.0 | 86.9 |
| PromptStyler | 89.1±0.1 | 77.6±0.1 | 94.8±0.1 | 94.8±0.0 | 89.1 |
| 方法 | 源 | 领域描述 | 剪贴画 | 信息图 | 绘画 | 快速绘图 | 真实 | 素描 | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| ResNet-50[22] (ImageNet[6]预训练权重) | |||||||||
| SelfReg [28] | 60.7±0.1 | 21.6±0.1 | 49.4±0.2 | 12.7±0.1 | 60.7±0.1 | 51.7±0.1 | 42.8 | ||
| GVRT [44] | 一 | 62.4±0.4 | 21.0±0.0 | 50.5±0.4 | 13.8±0.3 | 64.6±0.4 | 52.4±0.2 | 44.1 | |
| ResNet-50[22] (CLIP[50]预训练权重) | |||||||||
| ZS-CLIP (C) [50] | 一 | 53.1±0.0 | 39.2±0.0 | 52.7±0.0 | 6.3±0.0 | 75.2±0.0 | 47.1±0.0 | 45.6 | |
| ZS-CLIP (PC) [50] | 一 | ← | 53.6±0.0 | 39.6±0.0 | 53.4±0.0 | 5.9±0.0 | 76.6±0.0 | 48.0±0.0 | 46.2 |
| PromptStyler | 一 | 57.9±0.0 | 44.3±0.0 | 57.3±0.0 | 6.1±0.1 | 79.5±0.0 | 51.7±0.0 | 49.5 | |
| ViT-B/16[11] (CLIP[50]预训练权重) | |||||||||
| ZS-CLIP (C) [50] | 70.7±0.0 | 49.1±0.0 | 66.4±0.0 | 14.8±0.0 | 82.7±0.0 | 63.1±0.0 | 57.8 | ||
| ZS-CLIP (PC) [50] | 一 一 | 71.0±0.0 | 47.7±0.0 | 66.2±0.0 | 14.0±0.0 | 83.7±0.0 | 63.5±0.0 | 57.7 | |
| PromptStyler | 一 | 一 | 73.1±0.0 | 50.9±0.0 | 68.2±0.1 | 13.3±0.1 | 85.4±0.0 | 65.3±0.0 | 59.4 |
| ViT-L/14[11] (CLIP[50]预训练权重) | |||||||||
| ZS-CLIP (C) [50] | 一 | 78.2±0.0 | 53.0±0.0 | 70.7±0.0 | 21.6±0.0 | 86.0±0.0 | 70.3±0.0 | 63.3 | |
| ZS-CLIP (PC) [50] | ← | 79.2±0.0 | 52.4±0.0 | 71.3±0.0 | 22.5±0.0 | 86.9±0.0 | 71.8±0.0 | 64.0 | |
| PromptStyler | 80.7±0.0 | 55.6±0.1 | 73.8±0.1 | 21.7±0.0 | 88.2±0.0 | 73.2±0.0 | 65.5 |
Table C4: Comparison with state-of-the-art domain generalization methods in terms of per-domain top-1 classification accuracy on DomainNet [48]. We repeat each experiment using three different seeds, and report average accuracies with standard errors. ZS-CLIP (C) denotes zero-shot CLIP using “[class]” as its text prompt, and ZS-CLIP (PC) indicates zero-shot CLIP using “a photo of a [class]” as its text prompt. Note that PromptS tyler does not use any source domain data and domain descriptions.
表 C4: 在DomainNet [48]数据集上按领域划分的top-1分类准确率与当前最优领域泛化方法的对比。我们使用三种不同随机种子重复每个实验,并报告平均准确率及标准误差。ZS-CLIP (C) 表示使用"[class]"作为文本提示的零样本CLIP,ZS-CLIP (PC) 表示使用"a photo of a [class]"作为文本提示的零样本CLIP。请注意PromptStyler未使用任何源域数据和领域描述。
Table C5: Effects of the distributions used for initializing style word vectors. Uniform or Normal distribution is used.
| 分布 | PACS | VLCS | OfficeHome | DomainNet | 平均 |
|---|---|---|---|---|---|
| U(0.00, 0.20) | 93.1 | 82.6 | 73.8 | 49.2 | 74.7 |
| N(0.00, 0.202) | 93.0 | 81.0 | 73.6 | 49.5 | 74.3 |
| N(0.20, 0.022) | 93.1 | 82.5 | 73.5 | 49.3 | 74.6 |
| N(0.00, 0.022) | 93.2 | 82.3 | 73.6 | 49.5 | 74.7 |
表 C5: 风格词向量初始化所用分布的影响。使用均匀分布或正态分布。
C. Evaluation Results
C. 评估结果
Per-domain accuracy. As shown in Table C1–C4, we provide per-domain top-1 classification accuracy on domain generalization benchmarks including PACS [34] (4 domains and 7 classes), VLCS [15] (4 domains and 5 classes), OfficeHome [60] (4 domains and 65 classes) and DomainNet [48] (6 domains and 345 classes); each accuracy is obtained by averaging results from experiments repeated using three different random seeds. Interestingly, compared with zero-shot CLIP [50] which leverages a photo domain description (“a photo of a [class]”), our PromptS tyler achieves similar or better results on photo domains, e.g., on the VLCS dataset which consists of 4 photo domains. Note that the description has more domain-specific information and more detailed contexts compared with the naive prompt ("[class]").
分领域准确率。如表 C1-C4 所示,我们在领域泛化基准测试中提供了各领域的 top-1 分类准确率,包括 PACS [34](4 个领域和 7 个类别)、VLCS [15](4 个领域和 5 个类别)、OfficeHome [60](4 个领域和 65 个类别)和 DomainNet [48](6 个领域和 345 个类别);每个准确率是通过使用三个不同的随机种子重复实验取平均值得到的。有趣的是,与利用照片领域描述("a photo of a [class]")的零样本 CLIP [50] 相比,我们的 PromptStyler 在照片领域上取得了相似或更好的结果,例如在由 4 个照片领域组成的 VLCS 数据集上。需要注意的是,与简单提示("[class]")相比,该描述包含了更多领域特定信息和更详细的上下文。
Different distributions for initializing style word vectors. Following prompt learning methods [70, 71], we initialized learnable style word vectors using zero-mean Gaussian distribution with 0.02 standard deviation. To measure the effect of the used distribution for the initialization, we also quantitatively evaluate PromptS tyler using different distributions for initializing style word vectors. As shown in Table C5, the proposed method also achieves similar results when initializing style word vectors using different distributions.
初始化风格词向量的不同分布。遵循提示学习方法[70, 71],我们使用标准差为0.02的零均值高斯分布来初始化可学习的风格词向量。为了衡量初始化所用分布的影响,我们还定量评估了PromptStyler在使用不同分布初始化风格词向量时的表现。如表C5所示,当使用不同分布初始化风格词向量时,所提出的方法也能取得相似的结果。
D. Discussion
D. 讨论
PromptS tyler aims to improve model’s generalization capability by simulating various distribution shifts in the latent space of a large-scale pre-trained model. To achieve this goal, our method leverages a joint vision-language space where text features could effectively represent their relevant image features. It does not mean that image and text features should be perfectly interchangeable in the joint vision-language space; a recent study has demonstrated the modality gap phenomenon of this joint space [39]. However, thanks to the cross-modal transfer ability in the joint vision-language space [67], the proposed method could still be effective, i.e., we could consider text features as proxies for image features while training a linear classifier (Fig. 3 of the main paper).
PromptStyler旨在通过在大规模预训练模型的潜在空间中模拟各种分布偏移,来提升模型的泛化能力。为实现这一目标,我们的方法利用了联合视觉-语言空间,其中文本特征能有效表征其相关图像特征。这并不意味着图像和文本特征在联合视觉-语言空间中必须完全互换;最近的研究揭示了该联合空间存在模态间隙现象[39]。然而,得益于联合视觉-语言空间的跨模态迁移能力[67],所提方法仍可保持有效性,即在训练线性分类器时(主论文图3),我们可以将文本特征视为图像特征的代理。
When our method is implemented with CLIP [50] and we adopt ArcFace [8] as our classification loss $\mathcal{L}_{\mathrm{class}}$ , there is another interesting interpretation of the proposed method.
当我们的方法采用 CLIP [50] 实现并使用 ArcFace [8] 作为分类损失 $\mathcal{L}_{\mathrm{class}}$ 时,该方法还存在另一种有趣的解释。
As described in Section A.1, CLIP text encoder synthesizes classifier weights using class names for zero-shot inference and then it computes cosine similarity scores between the classifier weights and input image features. Similarly, our method computes cosine similarity scores between classifier weights of the trained classifier (Fig. 3 of the main paper) and input image features. From this perspective, the proposed method improves the decision boundary of the synthesized classifier used in zero-shot CLIP by generating diverse stylecontent features and then training a linear classifier using the style-content features. In other words, the trained classifier could be considered as an improved version of the synthesized classifier used in zero-shot CLIP.
如A.1节所述,CLIP文本编码器通过类别名称合成分类器权重进行零样本推理,随后计算分类器权重与输入图像特征之间的余弦相似度分数。类似地,我们的方法通过计算训练后分类器的权重(主论文图3)与输入图像特征间的余弦相似度分数。从这个角度看,所提方法通过生成多样化的风格-内容特征并利用这些特征训练线性分类器,改进了零样本CLIP中合成分类器的决策边界。换言之,训练后的分类器可视为零样本CLIP所用合成分类器的改进版本。