大型语言扩散模型
简要说明(TL;DR): 我们推出了 LLaDA,这是一个拥有空前规模的80亿参数的扩散模型,完全从头训练,性能媲美 LLaMA3 8B。


“现在已被证明的,曾经只是想象。” ——威廉·布莱克
动机
我们认为,大型语言模型(LLM)所展现的智能——包括可扩展性、指令遵循能力、上下文学习能力、对话能力和压缩能力——并非源于自回归机制本身,而是源于生成建模的核心原则:通过最大似然估计近似真实的语言分布。
我们引入了LLaDA(Large Language Diffusion with mAsking),一种简单而有原则性的生成范式,用于大型语言模型,并展示了上述卓越的能力。
方法
LLaDA 是一种基于遮蔽的扩散模型[1, 2],其预训练和监督微调(SFT)遵循标准流程,但通过扩散进行采样。在预训练阶段,它以比例 t∼U[0,1] 随机遮蔽所有标记;在 SFT 阶段,仅响应标记可能会被遮蔽。模型模拟从完全遮蔽(t=1)到解除遮蔽(t=0)的过程,每一步同时预测所有遮蔽内容,并灵活地重新遮蔽。

可扩展性
LLaDA 展现了令人印象深刻的可扩展性,整体趋势在相同数据上高度竞争于自回归基线。






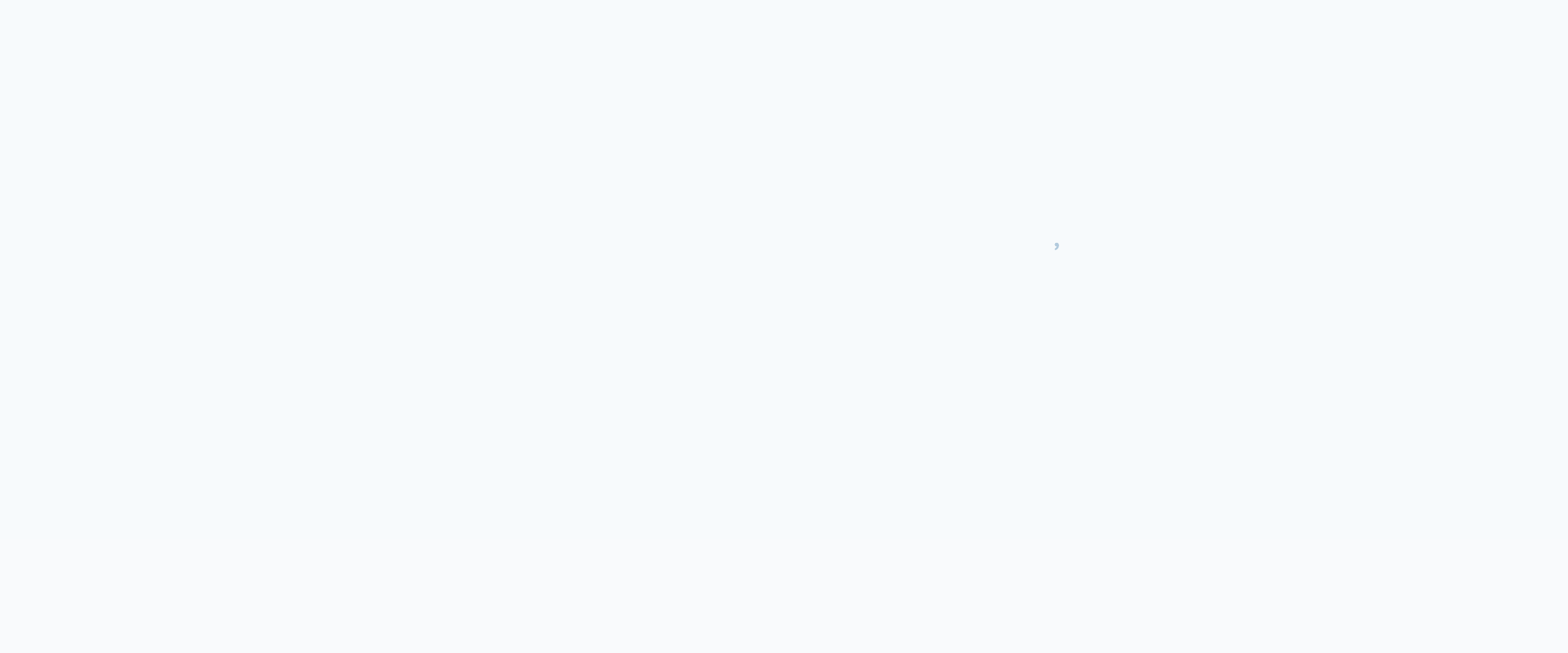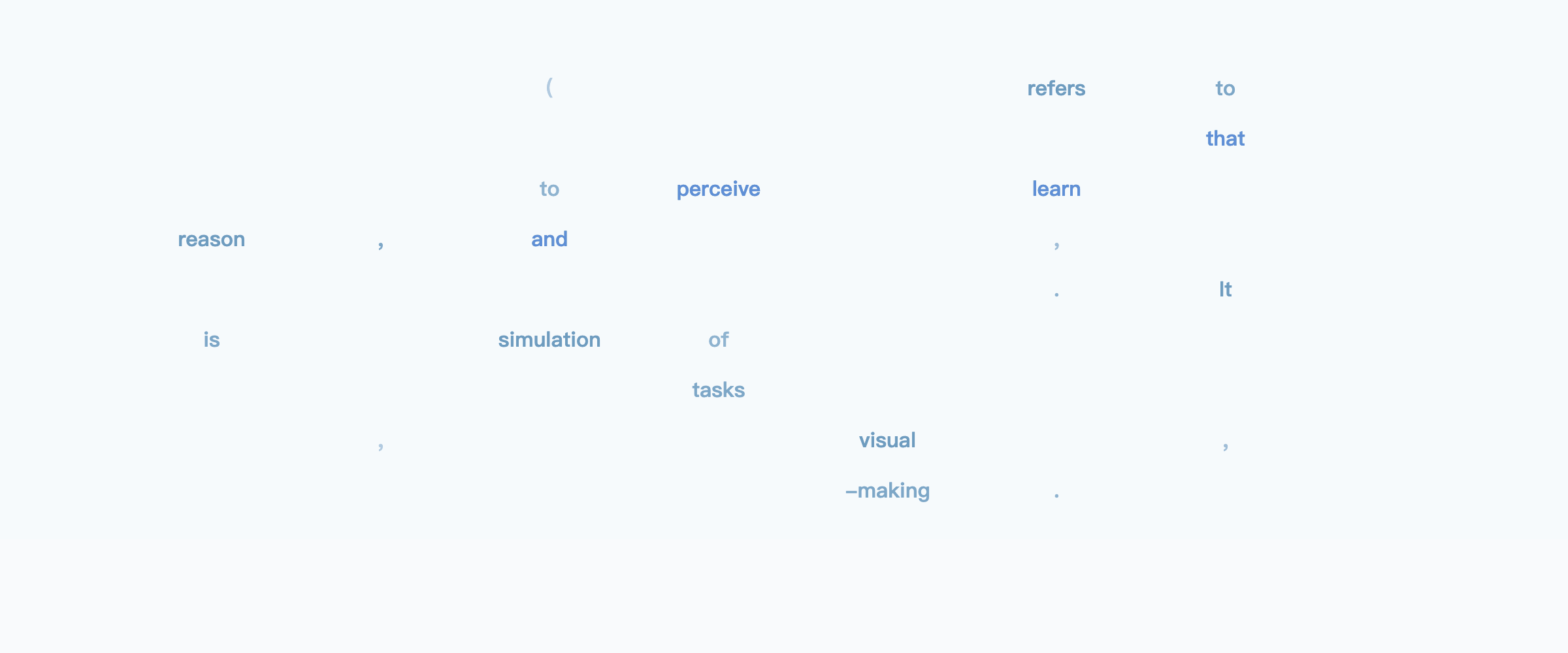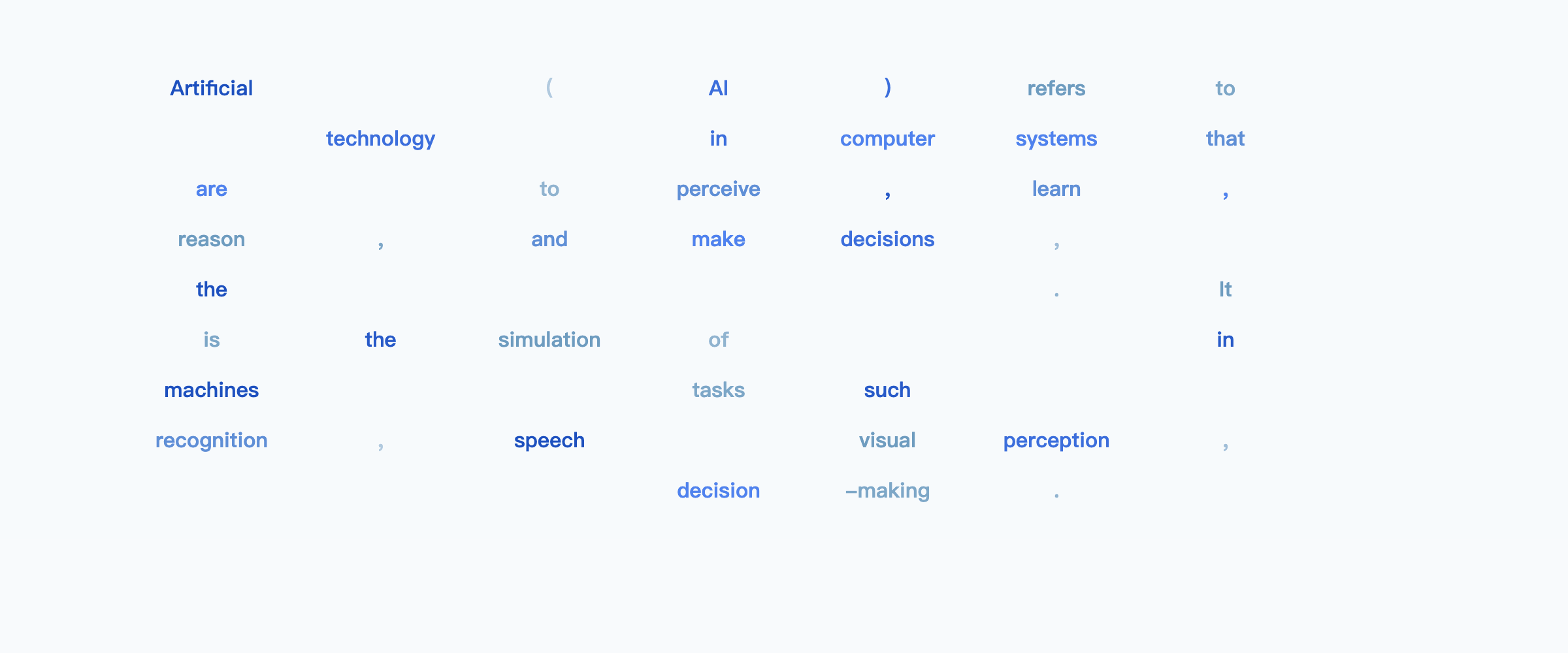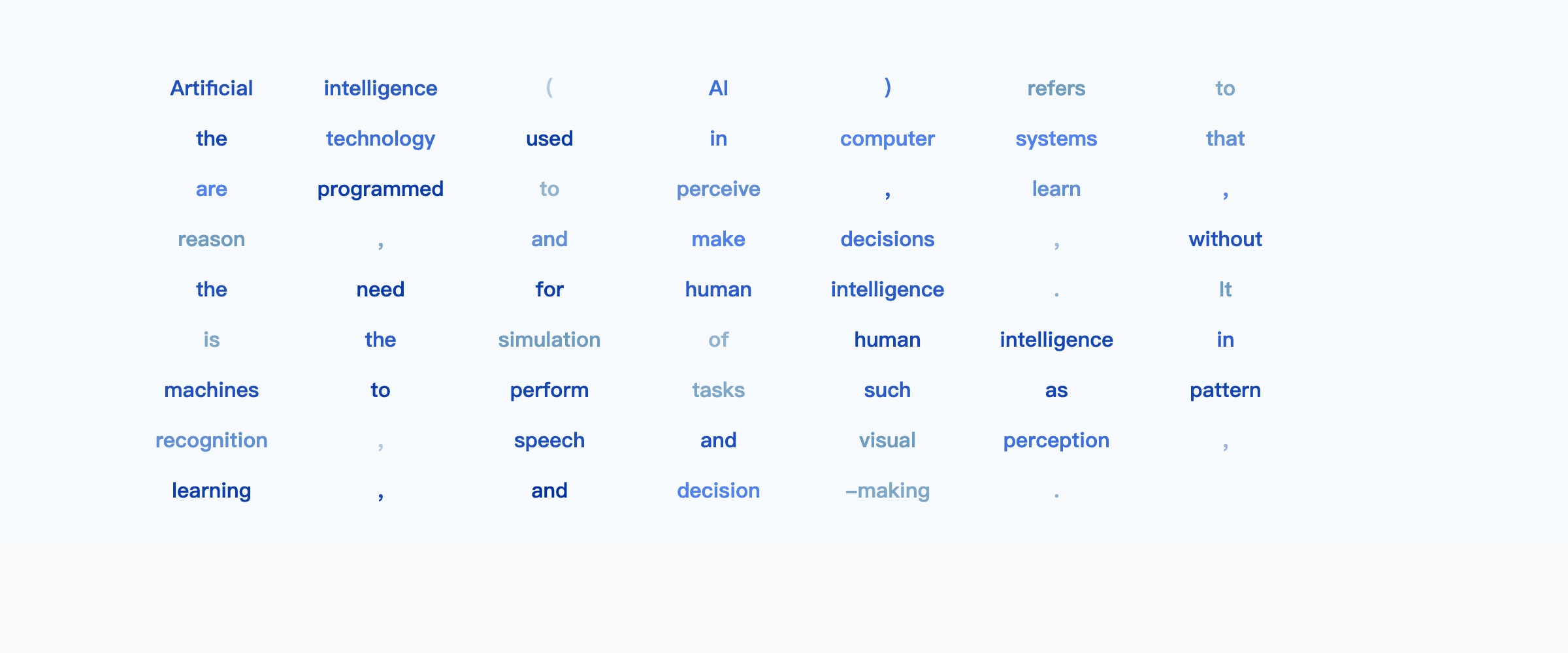
一种不同于传统左到右生成方式的文本生成方法
提示:解释什么是人工智能。
案例研究
数学问题
用户:艾玛决定每周跑4次冲刺,每次5天。她每次冲刺跑75米。她每周总共跑多少米?
LLaDA-Instruct:艾玛每次跑4次冲刺,因此她每周总共跑4 x 5 = 20次冲刺。每次冲刺是75米长,所以艾玛每周总共跑20 x 75 = 1500米。最终结果是1500。
日常生活
用户:请给我推荐三部著名的电影。
LLaDA-Instruct:当然!这里有三部广受欢迎并获得广泛好评的著名电影:1. 《肖申克的救赎》(1994年)- 根据短篇小说改编并由弗兰克·德拉邦特执导,这部电影讲述了一个被判谋杀妻子的男子安迪·杜佛瑞,在肖申克监狱中度过严酷生活的经历以及与狱友建立的意想不到的友谊。2. 《教父》(1972年)- 由弗朗西斯·福特·科波拉执导,这部电影基于马里奥·普佐的同名小说。故事围绕着科尔莱昂家族展开,特别是迈克尔·科尔莱昂如何掌权并接管家族犯罪帝国的故事。3. 《帝国反击战》(1980年)- 由乔治·卢卡斯执导,这部电影继续讲述了星战传奇中年轻的天行者的故事。卢克·天行者帮助反抗联盟对抗银河帝国,并摧毁强大的武器——死星。所有这些电影都因其电影艺术成就、有力的叙事和令人难忘的角色而受到赞誉。
代码生成
用户:我正在编写Python代码,我有一个数组,请帮我将其从大到小排序。
LLaDA-Instruct:当然!你可以使用‘sort()’方法或‘sorted()’函数在Python中将数组从大到小排序。以下是一个示例:
### 使用’sort()’方法:
my_array = [3, 1, 4, 1, 5, 2]
my_array.sort(reverse=True)
print(my_array)
翻译(英语 → 中文)
用户:请帮我翻译成中文:“What is now proved was once only imagined”
LLaDA-Instruct:现在被证明的曾经只是想象。
翻译(英语 → 德语)
用户:请帮我翻译成德语:“What is now proved was once only imagined”
LLaDA-Instruct:Wer heute bestätigt ist, war einst nur immaginiert.
多轮对话案例1
用户:请问你能告诉我著名诗歌《未选择的路》的前两行吗?
LLaDA-Instruct:当然!罗伯特·弗罗斯特的著名诗歌《未选择的路》的前两行是:“两条路分岔在黄色的树林中,遗憾我不能同时走。”这两行奠定了诗的基础,介绍了面对两个路径的选择的想法。
用户:请帮我翻译成中文。
LLaDA-Instruct:当然!罗伯特·弗罗斯特的《未选择的路》前两行可以翻译成中文为:“两条路分岔在黄色的树林中,遗憾我不能同时走。”
用户:请翻译成德语。
LLaDA-Instruct:当然!罗伯特·弗罗斯特的《未选择的路》前两行可以翻译成德语为:“Zwei Wege trennten sich im gelben Wald, und leider konnte ich nicht beide tun。”
用户:请也写一首关于人生选择的诗。我需要五句话,每句的第一个词都以C开头。
LLaDA-Instruct:当然!这里有一首关于人生选择的诗,每句都以字母“C”开头:
选择如生命旅程中的洪流,
创造连接每一次决定。
谨慎考虑引领更佳路径,
勇敢选择塑造我们的命运,
明智选择引导我们走过岁月。
多轮对话案例2
用户:娜塔莉在四月向她的48位朋友出售了发夹,然后她在五月卖出了一半的数量。娜塔莉在四月和五月一共卖出了多少发夹?
LLaDA-Instruct:娜塔莉在四月向48位朋友出售了发夹。她在五月卖出了一半的数量,因此她在五月卖出了48/2 = 24个发夹。合计起来,娜塔莉在四月和五月一共卖出了48 + 24 = 72个发夹。最终结果是72。
用户:娜塔莉在六月卖出的商品数量是五月的三倍。娜塔莉这三个月一共卖出了多少发夹?
LLaDA-Instruct:娜塔莉在四月向48位朋友出售了发夹。她在五月卖出了一半的数量,因此她在五月卖出了48/2 = 24个发夹。娜塔莉在六月卖出的商品数量是五月的三倍,因此她在六月卖出了24 * 3 = 72个发夹。合计起来,娜塔莉在这三个月一共卖出了48 + 24 + 72 = 144个发夹。最终结果是144。
BibTeX
@misc{nie2025largelanguagediffusionmodels,
title={Large Language Diffusion Models},
author={Shen Nie and Fengqi Zhu and Zebin You and Xiaolu Zhang and Jingyang Ou and Jun Hu and Jun Zhou and Yankai Lin and Ji-Rong Wen and Chongxuan Li},
year={2025},
eprint={2502.09992},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.09992},
}