BURT: BERT-inspired Universal Representation from Learning Meaningful Segment BURT:从学习有意义的细分中获得BERT启发的通用表示形式
author
Yian Li, Hai Zhao
Abstract
Although pre-trained contextualized language models such as BERT achieve significant performance on various downstream tasks, current language representation still only focuses on linguistic objective at a specific granularity, which may not applicable when multiple levels of linguistic units are involved at the same time. Thus this work introduces and explores the universal representation learning, i.e., embeddings of different levels of linguistic unit in a uniform vector space. We present a universal representation model, BURT (BERT-inspired Universal Representation from learning meaningful segmenT), to encode different levels of linguistic unit into the same vector space. Specifically, we extract and mask meaningful segments based on point-wise mutual information (PMI) to incorporate different granular objectives into the pre-training stage. We conduct experiments on datasets for English and Chinese including the GLUE and CLUE benchmarks, where our model surpasses its baselines and alternatives on a wide range of downstream tasks. We present our approach of constructing analogy datasets in terms of words, phrases and sentences and experiment with multiple representation models to examine geometric properties of the learned vector space through a task-independent evaluation. Finally, we verify the effectiveness of our unified pre-training strategy in two real-world text matching scenarios. As a result, our model significantly outperforms existing information retrieval (IR) methods and yields universal representations that can be directly applied to retrieval-based question-answering and natural language generation tasks.
摘要
尽管经过训练的上下文化语言模型(例如BERT)在各种下游任务上都取得了显着的性能,但是当前的语言表示仍然只专注于特定粒度的语言目标,当同时涉及多个语言单元级别时,这可能不适用。因此,这项工作介绍和探索了通用表示学习,即在统一向量空间中嵌入不同级别的语言单元的方法。我们提出了一种通用表示模型BURT(通过学习有意义的段T来启发BERT的通用表示),以将不同级别的语言单元编码到相同的向量空间中。具体来说,我们根据逐点互信息(PMI)提取和掩盖有意义的细分,以将不同的粒度目标纳入预训练阶段。我们对英语和中文数据集(包括GLUE和CLUE基准)进行了实验,我们的模型在许多下游任务上都超过了其基准和替代方法。我们介绍了根据单词,短语和句子构造类比数据集的方法,并尝试了多种表示模型,以通过独立于任务的评估来检查学习的向量空间的几何特性。最后,我们在两个实际的文本匹配场景中验证了我们统一的预培训策略的有效性。
Artificial Intelligence, Natural Language Processing, Transformer, Language Representation.
1INTRODUCTION
Representations learned by deep neural models have attracted a lot of attention in Natural Language Processing (NLP). However, previous language representation learning methods such as word2vec [1], LASER [2] and USE [3] focus on either words or sentences. Later proposed pre-trained contextualized language representations like ELMo [4], GPT[5], BERT [6] and XLNet [7] may seemingly handle different sized input sentences, but all of them focus on sentence-level specific representation still for each word, which leads to unsatisfactory performance in real-world situations. Although the latest BERT-wwm-ext [8], StructBERT [9] and SpanBERT [10] perform MLM on a higher linguistic level, the masked segments (whole words, trigrams, spans) either follow a pre-defined distribution or focus on a specific granularity. Such sampling strategy ignores important semantic and syntactic information of a sequence, resulting in a large number of meaningless segments.
However, universal representation among different levels of linguistic units may offer a great convenience when it is needed to handle free text in language hierarchy in a unified way. As well known that, embedding representation for a certain linguistic unit (i.e., word) enables linguistics-meaningful arithmetic calculation among different vectors, also known as word analogy. For example, vector (“King”) - vector (“Man”) + vector (“Woman”) results in vector (“Queen”). Thus universal representation may generalize such good analogy features or meaningful arithmetic operation onto free text with all language levels involved together. For example, Eat an onion : Vegetable :: Eat a pear : Fruit. In fact, manipulating embeddings in the vector space reveals syntactic and semantic relations between the original sequences and this feature is indeed useful in true applications. For example, “London is the capital of England.” can be formulized as v(capital)+v(England)∼v(London). Given two documents one of which contains “England” and “capital”, the other contains “London”, we consider these two documents relevant. Such features can be generalized onto higher language levels for phrase/sentence embedding.
In this paper, we explore the regularities of representations including words, phrases and sentences in the same vector space. To this end, we introduce a universal analogy task derived from Google’s word analogy dataset. To solve such task, we present BURT, a pre-trained model that aims at learning universal representations for sequences of various lengths. Our model follows the architecture of BERT but differs from its original masking and training scheme. Specifically, we propose to efficiently extract and prune meaningful segments (n-grams) from unlabeled corpus with little human supervision, and then use them to modify the masking and training objective of BERT. The n-gram pruning algorithm is based on point-wise mutual information (PMI) and automatically captures different levels of language information, which is critical to improving the model capability of handling multiple levels of linguistic objects in a unified way, i.e., embedding sequences of different lengths in the same vector space.
Overall, our pre-trained models improves the performance of our baseline in both English and Chinese. In English, BURT-base reaches one percent gain on average over Google BERT-base. In Chinese, BURT-wwm-ext obtains 74.48% on the WSC test set, 3.45% point absolute improvement compared with BERT-wwm-ext and exceeds the baselines by 0.2% ∼ 0.6% point accuracy on five other CLUE tasks including TNEWS, IFLYTEK, CSL, ChID and CMRC 2018. Extensive experimental results on our universal analogy task demonstrate that BERT is able to map sequences of variable lengths into a shared vector space where similar sequences are close to each other. Meanwhile, addition and subtraction of embeddings reflect semantic and syntactic connections between sequences. Moreover, BURT can be easily applied to real-world applications such as Frequently Asked Questions (FAQ) and Natural Language Generation (NLG) tasks, where it encodes words, sentences and paragraphs into the same embedding space and directly retrieves sequences that are semantically similar to the given query based on cosine similarity. All of the above experimental results demonstrate that our well-trained model leads to universal representation that can adapt to various tasks and applications.
在自然语言处理(NLP)中,由深度神经模型学到的表示形式引起了很多关注。但是,以前的语言表示学习方法(如word2vec [ 1 ],LASER [ 2 ]和USE [ 3 ])专注于单词或句子。后来提出了经过预训练的上下文化语言表示形式,例如ELMo [ 4 ],GPT [ 5 ],BERT [ 6 ]和XLNet [ 7 ]看起来似乎可以处理大小不同的输入句子,但是它们全都集中在每个单词仍然针对句子级别的特定表示上,这导致在实际情况下的表现不尽人意。尽管最新的BERT-wwm-ext [ 8 ],StructBERT [ 9 ]和SpanBERT [ 10 ]在较高的语言水平上执行MLM,但是蒙版句段(整个单词,三字母组,跨度)要么遵循预定义的分布,要么着眼于具体的粒度。这种采样策略忽略了序列的重要语义和句法信息,从而导致了大量无意义的句段。
但是,当需要以统一的方式处理语言层次结构中的自由文本时,不同级别的语言单元之间的通用表示可能会提供极大的便利。众所周知,将表示形式嵌入某个语言单元(即单词)可以实现不同向量之间的语言意义的算术计算,也称为单词类比。例如,vector (“King”) - vector (“Man”) + vector (“Woman”) 来表达vector (“Queen”).。因此,通用表示可以将这种良好的类比功能或有意义的算术运算推广到具有所有语言级别一起的自由文本上。例如,吃洋葱:蔬菜::吃梨:水果。实际上,在向量空间中处理嵌入揭示了原始序列之间的句法和语义关系,并且此功能确实在实际应用中很有用。例如,“伦敦是英格兰的首都。” 可以公式作为$ v(capital) + v(England) \approx v(London) $配制。然后给出了两个文件,其中一个包含“英格兰”和“首都”,另一个包含“伦敦”,我们认为这两个文档是相关的。可以将此类功能推广到更高的语言级别以进行词组/句子嵌入。
在本文中,我们探索了在相同向量空间中包括单词,短语和句子在内的表示形式的规律性。为此,我们引入了一个通用的类比任务,该任务源自Google的单词类比数据集。为了解决这一任务,我们提出了BURT,这是一种预训练的模型,旨在学习各种长度序列的通用表示形式。我们的模型遵循BERT的体系结构,但不同于其原始的掩蔽和训练方案。具体来说,我们建议在没有人工监督的情况下,从未标记的语料库中高效提取和修剪有意义的片段(n- gram),然后使用它们来修改BERT的掩蔽和训练目标。该ñ-gram修剪算法基于点向互信息(PMI),并自动捕获不同级别的语言信息,这对于提高以统一方式处理多个级别的语言对象的模型能力(即嵌入不同序列的语言)至关重要同一向量空间中的长度。
总体而言,我们经过预训练的模型可以提高英语和中文基线的性能。英语上,基于BURT的平均收益要比基于Google BERT的平均收益高1%。在中文中,BURT-wwm-ext在WSC测试集中获得了74.48%,与BERT-wwm-ext相比,绝对提高了3.45%,并且比基线高出0.2%〜在其他五个CLUE任务(包括TNEWS,IFLYTEK,CSL,ChID和CMRC 2018)上,其点精度为0.6%。我们通用类比任务的大量实验结果表明,BERT能够将可变长度的序列映射到相似序列接近的共享向量空间中对彼此。同时,嵌入的加法和减法反映了序列之间的语义和句法联系。此外,BURT可以轻松应用于现实世界中的应用程序,例如常见问题解答(FAQ)和自然语言生成(NLG)任务,在其中将单词,句子和段落编码到相同的嵌入空间中,并直接检索语义相似的序列基于余弦相似度的给定查询。
2 BACKGROUND 背景
2.1WORD AND SENTENCE EMBEDDINGS 单词和句子嵌入
Representing words as real-valued dense vectors is a core technique of deep learning in NLP. Word embedding models [1, 11, 12] map words into a vector space where similar words have similar latent representations. ELMo [4] attempts to learn context-dependent word representations through a two-layer bi-directional LSTM network. In recent years, more and more researchers focus on learning sentence representations. The Skip-Thought model [13] is designed to predict the surrounding sentences for an given sentence. [14] improve the model structure by replacing the RNN decoder with a classifier. InferSent [15] is trained on the Stanford Natural Language Inference (SNLI) dataset [16] in a supervised manner. [17, 3] employ multi-task training and report considerable improvements on downstream tasks. LASER [2] is a BiLSTM encoder designed to learn multilingual sentence embeddings. Nevertheless, most of the previous work focused on a specific granularity. In this work we extend the training goal to a unified level and enables the model to leverage different granular information, including, but not limited to, word, phrase or sentence.
将单词表示为实值密集向量是NLP中深度学习的一项核心技术。字嵌入模型[ 1,11,12 ]图字转换为一个向量空间,其中类似的词语具有类似的潜表示。ELMo [ 4 ]尝试通过两层双向LSTM网络学习上下文相关的词表示形式。近年来,越来越多的研究人员致力于学习句子表示。Skip-Thought模型[ 13 ]设计用于预测给定句子的周围句子。[ 14 ]通过用分类器替换RNN解码器来改善模型结构。在Stanford Natural Language Inference(SNLI)数据集[ 16 ]上以有监督的方式训练InferSent [ 15 ]。[ 17,3 ]雇用多任务的训练和报告下游任务相当大的改善。激光[ 2 ]是一种BiLSTM编码器,旨在学习多语言句子嵌入。尽管如此,以前的大多数工作都集中在特定的粒度上。在这项工作中,我们将训练目标扩展到统一的水平,并使模型能够利用不同的详细信息,包括但不限于单词,短语或句子。
2.2PRE-TRAINED LANGUAGE MODELS 预训练语言模型
Most recently, the pre-trained language model BERT [6] has shown its powerful performance on various downstream tasks. BERT is trained on a large amount of unlabeled data including two training targets: Masked Language Model (MLM) for modeling deep bidirectional representations, and Next Sentence Prediction (NSP) for understanding the relationship between two sentences. [18] introduce Sentence-Order Prediction (SOP) as a substitution of NSP. [9] develop a sentence structural objective by combining the random sampling strategy of NSP and continuous sampling as in SOP. However, [19] and [10] use single contiguous sequences of at most 512 tokens for pre-training and show that removing the NSP objective improves the model performance. Besides, BERT-wwm [8], StructBERT [10], SpanBERT [9] perform MLM on higher linguistic levels, augmenting the MLM objective by masking whole words, trigrams or spans, respectively. Nevertheless, we concentrate on enhancing the masking and training procedures from a broader and more general perspective.
最近,经过预训练的语言模型BERT [ 6 ]已显示出其在各种下游任务上的强大性能。BERT对大量未标记的数据进行了训练,包括两个训练目标:用于深层双向表示建模的屏蔽语言模型(MLM)和用于理解两个句子之间关系的下一句预测(NSP)。[ 18 ]引入了句子顺序预测(SOP)作为NSP的替代。[ 9 ]通过结合NSP的随机采样策略和SOP中的连续采样来开发句子结构目标。但是,[ 19 ]和[ 10 ]使用最多512个令牌的单个连续序列进行预训练,并表明删除NSP目标可提高模型性能。此外,BERT-wwm [ 8 ],StructBERT [ 10 ],SpanBERT [ 9 ]以较高的语言水平执行传销,通过分别掩盖整个单词,三字组或跨度来扩大传销目标。尽管如此,我们还是从更广泛,更普遍的角度集中于增强掩蔽和训练程序。
2.3 ANALYSIS ON EMBEDDINGS 嵌入分析
矢量规律的先前勘探主要研究字的嵌入[ 1,20,21 ]。在引入句子编码器和Transformer模型[ 22 ]之后,人们进行了更多工作来研究句子级嵌入。通常在下游任务的执行被认为是用于表示句子的模型能力的测定[ 15,3,23 ]。一些研究提出了探测任务的理解句子的嵌入的某些方面[ 24,25,26 ]。具体来说,[ 27,28,29 ]直视BERT的嵌入和揭示其内部工作机构。此外,[ 30,31 ]探索在句子的嵌入规律性。然而,很少有工作在相同的向量空间中分析单词,短语和句子。在本文中,我们致力于以独立于任务的方式嵌入由不同模型获得的各种长度的序列。
Previous exploration of vector regularities mainly studies word embeddings [1, 20, 21]. After the introduction of sentence encoders and Transformer models [22], more works were done to investigate sentence-level embeddings. Usually the performance in downstream tasks is considered to be the measurement for model ability of representing sentences [15, 3, 23]. Some research proposes probing tasks to understand certain aspects of sentence embeddings [24, 25, 26]. Specifically, [27, 28, 29] look into BERT embeddings and reveal its internal working mechanisms. Besides, [30, 31] explore the regularities in sentence embeddings. Nevertheless, little work analyzes words, phrases and sentences in the same vector space. In this paper, We work on embeddings for sequences of various lengths obtained by different models in a task-independent manner.
2.4 FAQ APPLICATIONS 常见问题解答申请
常见问题解答(FAQ)的目标是从给定查询的预定义数据集中检索最相关的质量检查对。先前的工作集中在基于特征的方法[ 32,33,34 ]。最近,基于Transformer的表示模型在测量查询-问题或查询-答案相似度方面取得了长足的进步。[ 35 ]对Transformer模型进行分析,并提出了一种神经架构来解决FAQ任务。[ 36 ]提出了一个FAQ检索系统,该系统结合了BERT和基于规则的方法的特征。在这项工作中,我们评估FAQ任务上训练有素的通用表示模型的性能。
The goal of a Frequently Asked Question (FAQ) task is to retrieve the most relevant QA pairs from the pre-defined dataset given a query. Previous works focus on feature-based methods [32, 33, 34]. Recently, Transformer-based representation models have made great progress in measuring query-Question or query-Answer similarities. [35] make an analysis on Transformer models and propose a neural architecture to solve the FAQ task. [36] come up with an FAQ retrieval system that combines the characteristics of BERT and rule-based methods. In this work, we evaluate the performance of well-trained universal representation models on the FAQ task.
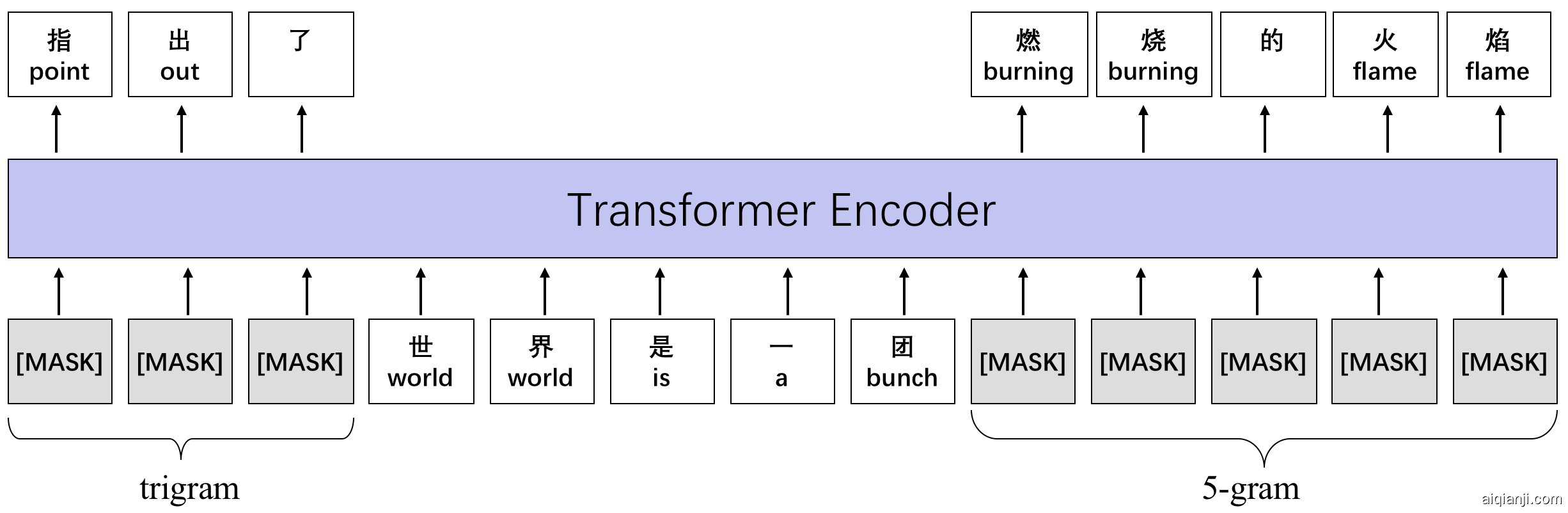
Fig. 1: An illustration of n-gram pre-training.
图1:n -gram预训练的示意图。

Fig. 2: An example from the Chinese Wikipedia corpus. n-grams of different lengths are marked with dashed boxes in different colors in the upper part of the figure. During training, we randomly mask n-grams and only the longest n-gram is masked if there are multiple matches, as shown in the lower part of the figure.
图2:来自中国维基百科语料库的示例。图的上部用不同颜色的虚线框标记了不同长度的n克。在训练过程中,我们随机掩盖n -gram,如果存在多个匹配项,则仅掩盖最长的n -gram,如图下部所示。
3 METHODOLOGY 方法
Our BURT follows the Transformer encoder [22] architecture where the input sequence is first split into subword tokens and a contextualized representation is learned for each token. We only perform MLM training on single sequences as suggested in [10]. The basic idea is to mask some of the tokens from the input and force the model to recover them from the context. Here we propose a unified masking method and training objective considering different grained linguistic units.
Specifically, we apply an pruning mechanism to collect meaningful n-grams from the corpus and then perform n-gram masking and predicting. Our model differs from the original BERT and other BERT-like models in several ways. First, instead of the token-level MLM of BERT, we incorporate different levels of linguistic units into the training objective in a comprehensive manner. Second, unlike SpanBERT and StructBERT which sample random spans or trigrams, our n-gram sampling approach automatically discovers structures within any sequence and is not limited to any granularity.
我们的BURT遵循Transformer编码器[ 22 ]架构,在该架构中,输入序列首先被拆分为子词标记,并为每个标记学习上下文表示。我们仅按[ 10 ]中的建议对单个序列执行MLM训练。基本思想是屏蔽输入中的某些标记,并强制模型从上下文中恢复它们。在这里,我们提出了一种统一的掩蔽方法和考虑不同粒度语言单元的训练目标。
具体来说,我们应用修剪机制从语料库中收集有意义的n- gram,然后执行n- gram掩蔽和预测。我们的模型在某些方面与原始BERT和其他类似BERT的模型不同。首先,代替BERT的令牌级MLM,我们以综合的方式将不同级别的语言单元合并到训练目标中。其次,与SpanBERT和StructBERT采样随机跨度或三字母组不同,我们的n- gram采样方法可自动发现任何序列内的结构,并且不限于任何粒度。
3.1 N-GRAM PRUNING
In this subsection, we introduce our approach of extracting a large number of meaningful n-grams from the monolingual corpus, which is a critical step of data processing.
First, we scan the corpus and extract all n-grams with lengths up to N using the SRILM toolkithttp://www.speech.sri.com/projects/srilm/download.html [37]. In order to filter out meaningless n-grams and prevent the vocabulary from being too large, we apply pruning by means of point-wise mutual information (PMI) [38]. To be specific, mutual information I(x,y) describes the association between tokens x and y by comparing the probability of observing x and y together with the probabilities of observing x and y independently. Higher mutual information indicates stronger association between the two tokens.
在本小节中,我们介绍了从单语语料库中提取大量有意义的n- gram的方法,这是数据处理的关键步骤。
首先,我们使用SRILM Toolkit http://www.speech.sri.com/projects/srilm/download.html,扫描语料库并提取所有n -dgrops,长度为$ N $。为了滤除毫无意义的n -gram,并防止词汇量过大,我们通过Pock-Wise互信息(PMI)进行修剪。为特定的,通过将$ x $和$ y $和$ x $和$ y D1和$ y $独立于观察$ T1180_0 $和$ y $的概率,互及$ I(x, y) $描述了令牌$ x $和$ y $之间的关联。更高的互信息表示两个令牌之间的更强关联。
$$ I(x, y) = {\rm log}\frac{P(x, y)}{P(x) P(y)} $$
In practice, $ P(x) $ and $ P(y) $ denote the probabilities of $ x $ and $ y $ , respectively, and $ P(x, y) $ represents the joint probability of observing $ x $ followed by $ y $ . This alleviates bias towards high-frequency words and allows tokens that are rarely used individually but often appear together such as " to have higher scores. In our application, an $ \emph{n} $ -gram denoted as $ w = (x_1, \ldots, x_{L_w}) $ , where $ L_w $ is the number of tokens in $ w $ , may contains more than two words. Therefore, we present an extended PMI formula displayed as below:
在实践中,$ P(x) $和$ P(y) $表示概率$ x $和$ y $分别和$ P(x, y) $表示观察$ x $的联合概率,后跟$ y $。这减轻了对高频词的偏见,并且允许单独使用的令牌,但经常出现在一起,如“具有更高的分数。在我们的应用中,n-GRAM表示为$ w = (x_1, \ldots, x_{L_w}) $,其中$ L_w $是$ w $中的令牌数量,可以包含两个以上的单词。因此,我们介绍了如下所示的扩展PMI公式:
$$ PMI(w) = \frac{1}{L_w}\left({\rm log}P(w) - \sum\limits_{k=1}^{L_w}{\rm log}P(x_k) \right) $$
where the probabilities are estimated by counting the number of observations of each token and $ \emph{n} $ -gram in the corpus, and normalizing by the size of the corpus. $ \frac{1}{L_w} $ is an additional normalization factor which avoids extremely low scores for longer -grams. Finally, $ \emph{n} $ -grams with PMI scores below the chosen threshold are filtered out, resulting in a vocabulary of meaningful -grams.
通过计算每个令牌的观察次数来估计概率在语料库中和n-GRAM,并通过语料库的大小进行归一化。$\frac{1}{L_w} $是额外的归一化因子,其避免了更低的分数用于更长的级。最后,n-GRAME具有所选PMI的PMI分数滤网阈值,导致有意义的-gr的词汇ams。
3.2 N-GRAM MASKING
For a given input$ S = {x_1, x_2,\dots, x_L} $, where L is the number of tokens in S, special tokens [CLS] and [SEP] are added at the beginning and end of the sequence, respectively. Before feeding the training data into the Transformer blocks, we identify all the n-grams in the sequence using the aforementioned n-gram vocabulary. An example is shown in Figure 2, where there are overlap between n-grams, which indicates the multi-granular inner structure of the given sequence. In order to make better use of higher-level linguistic information, the longest n-gram is retained if multiple matches exist. Compared with other masking strategies, our method has two advantages. First, n-gram extracting and matching can be efficiently done in an unsupervised manner without introducing random noise. Second, by utilizing n-grams of different lengths, we generalize the masking and training objective of BERT to a unified level where different granular linguistic units are integrated.
Following BERT, we mask 15% of all tokens in each sequence. The data processing algorithm uniformly samples one n-gram at a time until the maximum number of masking tokens is reached. 80% of the time the we replace the entire n-gram with [MASK] tokens. 10% of the time it is replace with random tokens and 10% of the time we keep it unchanged. The original token-level masking is retained and considered as a special case of n-gram masking where n=1. We employ dynamic masking as mentioned in [19], which means masking patterns for the same sequence in different epochs are probably different.
给定输入$ S = {x_1, x_2,\dots, x_L} $,其中$ L $是$ S $中的令牌数量,在特殊的令牌[cls]和[sep]中添加分别的开始和结束。在将训练数据输入到Transformer块中之前,我们使用上述n- gram词汇表识别序列中的所有n - gram。图2中显示了一个示例,其中n- gram之间有重叠,这表示给定序列的多颗粒内部结构。为了更好地利用高级语言信息,如果存在多个匹配项,则保留最长的n- gram。与其他掩蔽策略相比,我们的方法有两个优点。首先,n语法图的提取和匹配可以以无监督的方式高效完成,而不会引入随机噪声。其次,通过利用不同长度的n- gram,我们将BERT的掩蔽和训练目标推广到一个统一的级别,其中集成了不同的粒度语言单元。
在BERT之后,我们在每个序列中屏蔽了15%的令牌。数据处理算法一次均匀地样本,直到达到屏蔽令牌的最大数量。在80%的时间内,我们用[MASK]令牌替换了整个n -gram 。10%的时间将其替换为随机令牌,而10%的时间我们将其保持不变。原始令牌级别的掩码被保留,并被视为n- gram掩码的特殊情况,其中ñ=1个。我们采用了[ 19 ]中提到的动态遮罩,这意味着在不同时期中相同序列的遮罩模式可能会有所不同。
3.3 Traning Objective 训练目标
As depicted in Figure 1, the Transformer encoder generates a fixed-length contextualized representation at each input position and the model only predicts the masked tokens. Ideally, a universal representation model is able to capture features for multiple levels of linguistic units. Therefore, we extend the MLM training objective to a more general situation, where the model is trained to predict n-grams rather than subwords.
如图1所示,Transformer编码器在每个输入位置生成固定长度的上下文表示,并且该模型仅预测被屏蔽的令牌。理想情况下,通用表示模型能够捕获多级语言单元的特征。因此,我们将MLM训练目标扩展到更一般的情况,在该情况下训练模型以预测n元语法词而不是子词。
$$ \max_{\theta}\sum_{w}{\rm log} P(w | \mathbf{\hat x}; \theta) = \max_{\theta}\sum_{(i, j)}{\rm log} P(x_i, \dots, x_j | \mathbf{\hat x}; \theta) $$
where $ w $ is a masked -gram and $ \mathbf{\hat x} $ is a corrupted version of the input sequence. $ (i, j) $ represents the absolute start and end positions of $ w $ .
其中$ w $是masked -gram和$\mathbf{\hat x} $是输入序列的损坏版本。 $(i, j) $表示$ w $的绝对启动和结束位置。
| GLUE | Length | #Train | #Dev | #Test | #L |
|---|---|---|---|---|---|
| CoLA | Short | 8.5k | 1k | 1k | 2 |
| SST-2 | Short | 67k | 872 | 1.8k | 2 |
| MNLI | Short | 393k | 20k | 20k | 3 |
| QNLI | Short | 105k | 5.5k | 5.5k | 2 |
| RTE | Short | 2.5k | 277 | 3k | 2 |
| MRPC | Short | 3.7k | 408 | 1.7k | 2 |
| QQP | Short | 364k | 40k | 391k | 2 |
| STS-B | Short | 5.8k | 1.5k | 1.4k | - |
| CLUE | Length | #Train | #Dev | #Test | #L |
| TNEWS | Short | 53k | 10k | 10k | 15 |
| IFLYTEK | Long | 12k | 2.6k | 2.6k | 119 |
| WSC | Short | 1.2k | 304 | 290 | 2 |
| AFQMC | Short-Short | 34k | 4.3k | 3.9k | 2 |
| CSL | Long-Short | 20k | 3k | 3k | 2 |
| OCNLI | Short-Short | 50k | 3k | 3k | 3 |
| CMRC18 | Long | 10k | 1k | 3.2k | - |
| ChID | Long | 85k | 3.2k | 3.2k | - |
| C3 | Short | 12k | 3.8k | 3.9k | - |
TABLE I: Statistics of datasets from the GLUE and CLUE benchmark. #Train, #Dev, #Test are the size of training, development and test sets, respectively. #L is the number of labels. Sequences are simply divided into two categories according to their length: “Long” and “Short”.
4 Task Setup 任务设定
为了评估处理不同语言单元的模型能力,我们从GLUE和CLUE基准报告了我们模型在下游任务上的性能。此外,我们构造了一个通用类比任务。最后,我们提出了保险FAQ任务和基于检索的语言生成任务,其中的关键是将不同长度的序列嵌入到相同的向量空间中,并检索最接近给定查询的文本。
To evaluate the model ability of handling different linguistic units, we apply our model on downstream tasks from GLUE and CLUE benchmark. Moreover, we construct a universal analogy task based on Google's word analogy dataset to explore the regularity of universal representation. Finally, we present an insurance FAQ task and a retrieval-based language generation task, where the key is to embed sequences of different lengths in the same vector space and retrieve sequences with similar meaning to the given query.
任务设置
评估处理不同语言单位的模型能力,我们将我们的模型应用于胶水和线索基准的下游任务。此外,我们基于Google的Spalicy DataSet构建一个通用的类比任务,以探索通用表示的规律性。最后,我们介绍了一个保险常见问题任务和基于检索的语言生成任务,其中密钥是在相同的矢量空间中嵌入不同长度的序列,并检索具有与给定查询相似含义的序列。
General Language Understanding 一般语言理解
我们在广泛的自然语言理解任务上评估英语和汉语模型。表I列出了数据集的统计信息。除了任务类型的多样性之外,我们还发现不同的数据集集中在不同长度的序列上,这满足了我们研究代表多个粒度语言单元的模型能力的需求。
Statistics of the GLUE and CLUE benchmarks are listed in Table clue-statistics. Besides the diversity of task types, we also find that different datasets concentrates on sequences of different lengths, which satisfies our need to examine the model ability of representing multiple granular linguistic units.
4.1 GENERAL LANGUAGE UNDERSTANDING
We evaluate both English and Chinese models on a wide range of natural language understanding tasks. Statistics of the datasets are listed in Table I. Besides the diversity of task types, we also find that different datasets concentrates on sequences of different lengths, which satisfies our need to examine the model ability of representing multiple granular linguistic units.
Glue
The General Language Understanding Evaluation (GLUE) benchmark [39] is a collection of tasks that is widely used to evaluate the performance of English language models. We divide eight NLU tasks from the GLUE benchmark into three main categories.
Single-Sentence Classification The Corpus of Linguistic Acceptability (CoLA) [40] is to determine whether a sentence is grammatically acceptability or not. The Stanford Sentiment Treebank (SST-2) [41] is a sentiment classification task that requires the model to predict whether the sentiment of a sentence is positive or negative. In both datasets, each example is a sequence of words annotated with a label.
Natural Language Inference Multi-Genre Natural Language Inference (MNLI) [42], Stanford Question Answering Dataset (QNIL) [43] and Recognizing Textual Entailment (RTE) [rte] are natural language inference tasks, where a pair of sentences are given and the model is trained to identify the relationship between the two sentences from entailment, contradiction, and neutral.
Semantic Similarity Semantic similarity tasks identify whether the two sentences are equivalent or measure the degree of semantic similarity of two sentences according to their representations. Microsoft Paraphrase corpus (MRPC) [44] and Quora Question Pairs (QQP) dataset are paraphrase datasets , where each example consists of two sentences and a label of “1” indicating they are paraphrases or “0” otherwise. The goal of Semantic Textual Similarity benchmark (STS-B) [45] is to predict a continuous scores from 1 to 5 for each pair as the similarity of the two sentences.
通用语言理解评估(GLUE)基准[ 39 ]是一组任务的集合,这些任务被广泛用于评估英语语言模型的性能。我们将GLUE基准测试中的八个NLU任务分为三个主要类别。
单句分类 :语言可接受性语料库(CoLA)[ 40 ]用于确定句子在语法上是否可接受。斯坦福情感树库(SST-2)[ 41 ]是情感分类任务,需要模型预测句子的情感是肯定的还是否定的。在两个数据集中,每个示例都是带有标签的单词序列。
自然语言推理:多类型自然语言推理(MNLI)[ 42 ],斯坦福问答数据集(QNIL)[ 43 ]和认识文字蕴涵(RTE)[ RTE ]是自然语言的推论的任务,其中,一对句子中给出和该模型被训练识别来自两个句子之间的关系蕴涵,矛盾,和中性。
语义相似度:任务语义相似度任务确定两个句子是否相等,或者根据它们的表示来度量两个句子的语义相似度。Microsoft复述语料库(MRPC)[ 44 ]和Quora问题对(QQP)数据集是复述数据集,其中每个示例都包含两个句子,标签“ 1”表示它们是复述,否则为“ 0”。语义文本相似性基准测试(STS-B)[ 45 ]的目标是预测每对从1到5的连续分数作为两个句子的相似性。
Clue
The Chinese General Language Understanding Evaluation (ChineseGLUE or CLUE) benchmark [46] is a Chinese version of the GLUE benchmark for language understanding. We also find nine tasks from the CLUE benchmark can be classified into three groups.
Single Sentence Tasks We utilize three single-sentence classification tasks including TouTiao Text Classification for News Titles (TNEWS), IFLYTEK [47] and the Chinese Winograd Schema Challenge (WSC) dataset. Examples from TNEWS and IFLYTEK are short and long sequences, respectively, and the goal is to predict the category that the given single sequence belongs to. WSC is a coreference resolution task where the model is required to decide whether two spans refer to the same entity in the original sequence.
Sentence Pair Tasks The Ant Financial Question Matching Corpus (AFQMC), Chinese Scientific Literature (CSL) dataset and Original Chinese Natural Language Inference (OCNLI) [48] are three pairwise textual classification tasks. AFQMC contains sentence pairs and binary labels, and the model is asked to examine whether two sentences are semantically similar. Each example in CSL involves a text and several keywords. The model needs to determine whether these keywords are true labels of the text. OCNLI is a natural language inference task following the same collection procedures of MNLI.
Machine Reading Comprehension Tasks CMRC 2018 [49], ChID [50], and C3 [51] are span-extraction based, cloze style and free-form multiple-choice machine reading comprehension datasets, respectively. Answers to the questions in CMRC 2018 are spans extracted from the given passages. ChID is a collection of passages with blanks and corresponding candidates for the model to decide the most suitable option. C3 is similar to RACE and DREAM, where the model has to choose the correct answer from several candidate options based on a text and a question.
中文通用语言理解评估(ChineseGLUE或CLUE)基准[ 46 ]是GLUE用于语言理解的基准的中文版本。我们还发现CLUE基准测试中的九个任务可以分为三类。
单句任务:我们利用三个单句分类任务,包括新闻标题的头条文本分类(TNEWS),IFLYTEK [ 47 ]和中文Winograd Schema Challenge(WSC)数据集。来自TNEWS和IFLYTEK的示例分别是长序列和短序列,目的是预测给定单个序列所属的类别。WSC是共参考解析任务,在该任务中,需要模型来确定两个跨度是否引用原始序列中的同一实体。
句子对任务: 蚁群财务问题匹配语料库(AFQMC),中国科学文献(CSL)数据集和原始中国自然语言推论(OCNLI)[ 48 ]是三个成对的文本分类任务。AFQMC包含句子对和二进制标签,并且要求模型检查两个句子在语义上是否相似。CSL中的每个示例都包含一个文本和几个关键字。模型需要确定这些关键字是否是文本的真实标签。OCNLI是遵循MNLI相同收集过程的自然语言推理任务。
机器阅读理解任务: CMRC 2018 [ 49 ],ChID [ 50 ]和C 3 [ 51 ]分别是基于跨度提取,完形填空和自由形式的多项选择机器阅读理解数据集。CMRC 2018中问题的答案是从给定段落中摘录的跨度。ChID是段落的集合,其中包含空格和模型的相应候选者,以决定最合适的选项。C 3与RACE和DREAM相似,其中模型必须基于文本和问题从多个候选选项中选择正确的答案。
| A : B :: C | Candidates |
|---|---|
| boy👧:brother | daughter, sister, wife, father, son |
| bad:worse::big | bigger, larger, smaller, biggest, better |
| Beijing:China::Paris | France, Europe, Germany, Belgium, London |
| Chile:Chilean::China | Japanese, Chinese, Russian, Korean, Ukrainian |
TABLE II: Examples from our word analogy dataset. The correct answers are in bold.
4.2 Universal Analogy
As a new task, universal representation has to be evaluated in a multiple-granular analogy dataset. The purpose of proposing a task-independent dataset is to avoid determining the quality of the learned vectors and interpret the model based on a specific problem or situation. Since embeddings are essentially dense vectors, it is natural to apply mathematical operations on them. In this subsection, we introduce the procedure of constructing different levels of analogy datasets based on Google's word analogy dataset.
通用类比
作为新任务,必须在多粒类比数据集中进行通用表示。提出独立任务数据集的目的是避免确定学习向量的质量并根据特定问题或情况解释模型。由于嵌入的向量基本上是密集的向量,因此对它们进行数学操作是自然的。在本小节中,我们介绍了基于Google的单词类比数据集构建不同级别的类比数据集的过程。
Word-level analogy 词级类比
Recall that in a word analogy task , two pairs of words that share the same type of relationship, denoted as $ A $ : $ B $ :: $ C $ : $ D $ , are involved. The goal is to solve questions like $ A $ is to $ B $ as $ C $ is to ?", which is to retrieve the last word from the vocabulary given the first three words. The objective can be formulated as maximizing the cosine similarity between the target word embedding and the linear combination of the given vectors: where $ a $ , $ b $ , $ c $ , $ d $ represent embeddings of the corresponding words and are all normalized to unit lengths. To facilitate comparison between models with different vocabularies, we construct a closed-vocabulary analogy task based on Google's word analogy dataset through negative sampling. Concretely, for each question, we use GloVe to rank every word in the vocabulary and the top 5 results are considered to be candidate words. If GloVe fails to retrieve the correct answer, we manually add it to make sure it is included in the candidates. During evaluation, the model is expected to select the correct answer from 5 candidate words. Examples are listed in Table analogy_example.
回想一句话中的一个类比任务,两对单词共享相同类型的关系,表示为$ A $:$ B $ :: $ C $:$ D $。目标是解决像$ A $的问题,如$ B $,因为$ C $是?“,这是从第一个三个单词给出的词汇中的最后一个词。该目标可以制定为最大化余弦相似性在目标字嵌入和给定矢量的线性组合之间:其中$ a $,$ b $,$ c $,$ d $表示相应单词的嵌入,并且全部归一化到单位长度。为了便于模型之间的比较不同的词汇表,通过负面抽样构建基于Google的单词类比数据集的闭合词汇类比任务。具体地说,对于每个问题,我们使用手套在词汇中排列每个词,前5个结果被认为是候选词。如果手套未能检索正确的答案,我们手动添加它以确保它包含在候选者中。在评估期间,预计模型将从5个候选词中选择正确的答案。示例列在表格alpyy_example中。
Phrase/Sentence-level analogy 短语/句子级类比
To investigate the arithmetic properties of vectors for higher levels of linguistic units, we present phrase and sentence analogy tasks based on the proposed word analogy dataset. We only consider a subset of the original analogy task because we find that for some categories, such as Australia" : Australian", the same template phrase/sentence cannot be applied on both words. Statistics are shown in Table statistics.
为了研究用于更高级别语言单元的向量的算术特性,我们基于提出的词类比数据集提出了短语和句子类比任务。我们仅考虑原始类比任务的一个子集,因为我们发现对于某些类别(例如“ Australia”:“ Australian”),不能在两个单词上应用相同的模板短语/句子。统计信息显示在表LABEL:length和表III中。
| Dataset | #p | #q | #c | #l (p/s) |
|---|---|---|---|---|
| capital-common | 23 | 506 | 5 | 6.0/12.0 |
| capital-world | 116 | 4524 | 5 | 6.0/12.0 |
| city-state | 67 | 2467 | 5 | 6.0/12.0 |
| male-female | 23 | 506 | 5 | 4.1/10.1 |
| present-participle | 33 | 1056 | 2 | 4.8/8.8 |
| positive-comparative | 37 | 1322 | 2 | 3.4/6.1 |
| positive-negative | 29 | 812 | 2 | 4.4/9.2 |
| All | 328 | 11193 | - | 5.4/10.7 |
TABLE III: Statistics of our analogy datasets. #p and #q are the number of pairs and questions for each category. #c is the number of candidates for each dataset. #l (p/s) is the average sequence length in phrase/sentence-level analogy datasets.

Fig. 3: Examples of Question-Answer pairs from our insurance FAQ dataset. The correct match to the query is highlighted.
Semantic Semantic analogies can be divided into four subsets: capital-common", capital-world", city-state" and male-female". The first two sets can be merged into a larger dataset: capital-country", which contains pairs of countries and their capital cities; the third involves states and their cities; the last one contains pairs with gender relations. Considering GloVe's poor performance on word-level country-currency" questions ( $ < $ 32%), we discard this subset in phrase and sentence-level analogies. Then we put words into contexts so that the resulting phrases and sentences also have linear relationships. For example, based on relationship : :: : , we select phrases and sentences that contain the word " from the English Wikipedia Corpus https://dumps.wikimedia.org/enwiki/latest : " and create examples: " : " :: " : ". However, we found that such a question is identical to word-level analogy for BOW methods like averaging GloVe vectors, because they treat embeddings independently despite the content and word order. To avoid lexical overlap between sequences, we replace certain words and phrases with their synonyms and paraphrases, e.g., " : " :: " : ". Usually sentences selected from the corpus have a lot of redundant information. To ensure consistency, we manually modify some words during the construction of templates. However, this procedure will not affect the relationship between sentences.
语义 语义类比可分为四个子集:“资本共通”,“资本世界”,“城市状态”和“男女”。前两个集合可以合并成一个更大的数据集:“ capital-country”,其中包含成对的国家及其首都。第三个涉及州及其城市;最后一个包含成对的性别关系。考虑到GloVe在字级“国家/地区”问题上的表现不佳(<32%),我们会在短语和句子级别的类比中丢弃此子集。然后,我们将单词放入上下文中,以便生成的短语和句子也具有线性关系。例如,基于关系雅典:希腊::巴格达:伊拉克,我们从英语维基百科语料库2中选择包含单词“ Athens ”的短语和句子2个https://dumps.wikimedia.org/enwiki/latest:“他被雅典大学作为物理学教授聘用。”创造的例子:‘由......雅典聘请’:‘由......希腊聘为’::‘由...巴格达聘请’:‘由......伊拉克雇用’。但是,我们发现这样的问题与BOW方法(如平均GloVe向量)的词级类比相同,因为它们不管内容和词序如何都独立地处理嵌入。为了避免序列之间重叠的词汇,我们替换某些单词和短语与他们的同义词和意译,例如“由......雅典聘请”:“由......希腊使用” ::“由...巴格达采用”:“由伊拉克...雇用”。通常,从语料库中选择的句子有很多多余的信息。为了确保一致性,我们在构建模板期间手动修改了一些单词。但是,此过程不会影响句子之间的关系。
| Category | Topics | |
|---|---|---|
| Daily Scenarios | Traveling, Recipe, Skin care, Beauty makeup, Pets | 22 |
| Sport & Health | Outdoor sports, Athletics, Weight loss, Medical treatment | 15 |
| Reviews | Movies, Music, Poetry, Books | 16 |
| Persons | Entrepreneurs, Historical/Public figures, Writers, Directors, Actors | 17 |
| General | Festivals, Hot topics, TV shows | 6 |
| Specialized | Management, Marketing, Commerce, Workplace skills | 17 |
| Others | Relationships, Technology, Education, Literature | 14 |
| All | - | 107 |
TABLE IV: Details of the templates.
表IV:模板的详细信息。
Syntactic We consider three typical syntactic analogies: Tense, Comparative and Negation, corresponding to three subsets: “present-participle”, “positive-comparative”, “positive-negative”, where the model needs to distinguish the correct answer from “past tense”, “superlative” and “positive”, respectively. For example, given phrases “Pigs are bright” : “Pigs are brighter than goats” :: “The train is slow”, the model need to give higher similarity score to the sentence that contains “slower” than the one that contains “slowest”. Similarly, we add synonyms and synonymous phrases for each question to evaluate the model ability of learning context-aware embeddings rather than interpreting each word in the question independently. For instance, “pleasant” ≈ “not unpleasant” and “unpleasant” ≈ “not pleasant”.
句法 我们考虑三个典型的句法类比:时态,比较和否定,分别对应三个子集:“现在分词”,“正比较”,“正否定”,其中模型需要区分正确答案和过去时”,“最高级”和“积极”。例如,给定短语“猪是明亮的”:“猪比山羊明亮” ::“火车慢”,模型需要给包含“较慢”的句子比包含“最慢”的句子更高的相似性评分”。同样,我们为每个问题添加同义词和同义词,以评估学习上下文感知嵌入的模型能力,而不是独立解释问题中的每个单词。例如,“愉快”≈“不是不愉快”和“unpleasant” ≈ “not pleasant”.。
Retrieval-based FAQ 基于检索的常见问题解答
The sentence-level analogy discovers relationships between sentences by directly manipulating sentence vectors. Especially, we observe that sentences with similar meanings are close to each other in the vector space, which we find is consistent with the target of information retrieval task such as Frequently Asked Question (FAQ). Such task is to retrieve relevant documents ( FAQs) given a user query, which can be accurately done by only manipulating vectors representing the sentences, such as calculating and ranking vector distance in terms of cosine similarity. Thus, we present an insurance FAQ task in this subsection to explore the effectiveness of BURT in real-world retrieval applications.
句子级别的类比通过直接操纵句子向量来发现句子之间的关系。尤其是,我们观察到在向量空间中具有相似含义的句子彼此接近,我们发现这与诸如FAQ之类的信息检索任务的目标是一致的。这样的任务是在给定查询(一个问题)的情况下检索相关文档(FAQ),这可以通过仅操纵代表句子的向量来准确地完成,例如根据余弦相似度计算和排列向量距离。因此,我们在本小节中提出了保险常见问题解答任务,以探索BURT在现实世界中的检索应用程序中的有效性。
An FAQ task involves a collection of Question-Answer (QA) pairs denoted as $ {(Q_1, A_1), (Q_2, A_2), ... (Q_N, A_N)} $ , where $ N $ is the number of QA pairs. The goal is to retrieve the most relevant QA pairs for a given query. We collect frequently asked questions and answers between users and customer service from our partners in a Chinese online financial education institution. It contains over 4 types of insurance questions, e.g., concept explanation ("), insurance consultation (", "), judgement (") and recommendation. An example is shown in Figure faq-example. Our dataset is composed of 300 QA pairs that are carefully selected to avoid similar questions so that each query has only one exact match. Because queries are mainly paraphrases of the standard questions, we use query-Question similarity as the ranking score. The test set consists of 875 queries and the average lengths of questions and queries are 14 and 16, respectively. The evaluation metric is Top-1 Accuracy (Acc.) and Mean Reciprocal Rank (MRR) because there is only one correct answer for each query.
常见问题任务涉及包含为${(Q_1, A_1), (Q_2, A_2), ... (Q_N, A_N)} $的问题答案(QA)对的集合,其中$ N $是QA对的数量。目标是检索给定查询的最相关的QA对。我们在中国在线金融教育机构的合作伙伴中收集用户和客户服务之间的常见问题和答案。它包含超过4种保险问题,例如概念解释(“什么”),保险咨询(“为什么”,“如何”),判断(“是否”)和推荐。一个例子如图常见问题解答 - 示例所示。我们的数据集由300 QA对组成,仔细选择以避免类似的问题,以便每个查询只有一个完全匹配。因为查询主要是标准问题的涉及,所以我们使用查询问题相似作为排名分数。测试集由875个查询组成,分别为14和16的平均问题和查询。评估度量是 Top-1 精度(ACC。)和均值倒数排名(MRR),因为每个查询只有一个正确的答案。
4.4 NATURAL LANGUAGE GENERATION 自然语言生成
Moving from word and sentence vectors towards representation for sequences of any lengths, a universal language model may have the ability of capturing semantics of free text and facilitating various applications that are highly dependent on the quality of language representation. In this subsection, we introduce a retrieval-based Natural Language Generation (NLG) task. The task is to generate articles based on manually created templates. Concretely, the goal is to retrieve one paragraph at a time from the corpus which best describes a certain sentence from the template and then combine the retrieved paragraphs into a complete passage. The main difficulty of this task lies in the need to compare semantics of sentence-level queries (usually contain only a few words) and paragraph-level documents (often consist of multiple sentences). We use articles collected by our partners in a media company as our corpus. Each article is split into several paragraphs and each document contains one paragraph. The corpus has a total of 656k documents and cover a wide range of domains, including news, stories and daily scenarios. In addition, we have a collection of manually created templates in terms of 7 main categories, as shown in Table nlg-statistics. Each template $ T = {s_1, s_2, \dots, s_N} $ provides an outline of an article and contains up to $ N=6 $ sentences. Each sentence $ s_i $ describes a particular aspect of the topic. The problem is solved in two steps. First, an index for all the documents is built using BM25. For each query, it will return a set of candidate documents that are related to the topic. Second, we use representation models to re-rank the top 100 candidates: each query-document pair $ (\mathbf q, \mathbf d) $ is mapped to a score $ f(\mathbf q, \mathbf d) $ , where the scoring function $ f $ is based on cosine similarity. Quality of the generated passages was assessed by two native Chinese speakers, who were asked to examine whether the retrieved paragraphs were relevant" to the topic and conveyed the meaning" of the given sentence.
从单词和句子向量移动到任何长度的序列的表示,通用语言模型可能具有捕获自由文本语义的能力,并促进高度依赖语言表示的质量的各种应用程序。在本小节中,我们介绍了一种基于检索的自然语言生成(NLG)任务。任务是根据手动创建的模板生成文章。具体地,目标是一次从Corpus检索一个段落,该语料库最能从模板中描述某个句子,然后将检索到的段落结合到完整的段落中。此任务的主要难度在于需要比较句子级查询的语义(通常包含几个单词)和段落级别文档(通常由多个句子组成)。
我们使用我们的合作伙伴收集的文章作为我们的语料库。每篇文章都分为几个段落,每份文件都包含一个段落。语料库总共有656K的文件,涵盖了广泛的域,包括新闻,故事和日常情况。此外,我们在7个主要类别中有一系列手动创建的模板,如表NLG统计所示。每个模板$ T = {s_1, s_2, \dots, s_N} $提供了一篇文章的轮廓,最多包含$ N=6 $句子。每个句子$ s_i $介绍了主题的特定方面。问题有两个步骤解决了。首先,使用BM25构建所有文档的索引。对于每个查询,它将返回与主题相关的一组候选文档。其次,我们使用表示模型重新排名前100名候选者:每个查询文件对$(\mathbf q, \mathbf d) $映射到得分$ f(\mathbf d) $,其中评分函数$ f $基于茂密的相似性。由两名母语的发言者评估所生成的段落的质量,被要求检查检索到的段落是否有关“对该主题并传达给定句子的意义”。

TABLE V: CLUE test results scored by the evaluation server44https://www.cluebenchmarks.com/rc.html. “acc” and “EM” denote accuracy and Exact Match, respectively.
表V:评估服务器4对CLUE测试结果的评分4https://www.cluebenchmarks.com/rc.html。“ acc”和“ EM”分别表示准确性和完全匹配。
5 Implementation 实现
Data Processing 数据处理
We download the English and Chinese Wikipedia Corpus https://dumps.wikimedia.org and pre-process with process_wiki.py https://github.com/panyang/Wikipedia_Word2vec/blob/master/v1/process_wiki.py , which extracts text from xml files. Then for the Chinese corpus, we convert the data into simplified characters using OpenCC . In order to extract high-quality -grams, we remove punctuation marks and characters in other languages based on regular expressions, and finally get an English corpus of 2,266M words and a Chinese corpus of 380M characters. We calculate PMI scores of all -grams with a maximum length of $ N=10 $ for each document instead of the entire corpus considering that different documents usually describe different topics. We manually evaluate the extracted -grams and find nearly 50% of the top 2000 -grams contain 3 $ \sim $ 4 words (characters for Chinese), and only less than 0.5%-grams are longer than 7. Although a larger -gram vocabulary can cover longer -grams, it will cause too many meaningless -grams. Therefore, for both English and Chinese corpus, we empirically retain the top 3000 -grams for each document, resulting in vocabularies of -grams with average lengths of 4.6 and 4.5, respectively. Finally, for English, we randomly sample 10M sentences rather than use the entire corpus to reduce training time.
我们下载英文和中文维基百科语料库https://dumps.wikimedia.org和process \ _wiki.py https://github.com/panyang/wikipedia_word2vec/blob/master/ v1 / process \ _wiki.py,其中从XML文件中提取文本。然后,对于中文语料库,我们使用OpenCC将数据转换为简体字符。为了提取高质量的n - gram,我们根据正则表达式删除了其他语言中的标点符号和字符,最后得到了英语单词语料库和3.8亿个字符的中文语料库。
我们计算每个文档的最大长度为$ N=10 $的PMI分数,而不是整个语料库,考虑到不同的文档通常描述不同的主题。我们手动评估了前5000个n- gram,发现前2000个n- gram中有近50%包含3个〜5个单词(中文字符),只有不到0.5%的n- gram比7长。尽管较大的n- gram词汇表可以覆盖更长的n- gram,但它将导致太多无意义的n- gram。因此,我们根据经验将英语和汉语语料库的阈值都设置为3000,从而产生58M个n- gram,平均长度分别为6.4。最后,对于英语,我们随机抽取句子样本,而不是使用整个语料库来减少训练时间。
Pre-training 预训练
As in BERT, sentence pairs are packed into a single sequence and the special [CLS] token is used for sentence-level predicting. While in accordance with Joshi et al. (2020) , we find that single sentence training is better than the original sentence pair scenario. Thus in our experiments, the input is a continuous sequence with a maximum length of 512.
与BERT中一样,句子对被打包为单个序列,特殊的[CLS]令牌用于句子级别的预测。尽管根据[ 10 ],我们发现单句训练比原始句子对方案更好。因此,在我们的实验中,输入是最大长度为512的连续序列。
Instead of training from scratch, we initialize both English and Chinese models with the officially released checkpoints ( bert-base-uncased , bert-large-uncased , bert-base-chinse ) and BERT-wwm-ext, which is trained from the Chinese BERT using whole word masking on extended data . Base models are comprised of 12 Transformer layers, 12 heads, 768 dimensional hidden states and 110M parameters in total. The English BERT-large has 24 Transformer layers, 16 heads, 1024 dimensional hidden states and 340M parameters in total. We use Adam optimizer with initial learning rate of 5e-5 and linear warmup over the first 10% of the training steps. Batch size is set to 16 and dropout rate is 0.1. Each model is trained for one epoch.
模型架构与BERT [ 6 ]相同。无需从头开始训练,我们使用正式发布的检查点(bert-base-uncased,bert-large-uncased,bert-base-chinse,BERT-wwm-ext)初始化英语和中文模型,其中BERT-wwm- ext是使用扩展数据上的全字掩蔽从中文BERT中训练出来的[ 8 ]。基本模型由12个Transformer层,12个heads,768维隐藏状态和110M参数组成。英文BERT-large具有24个Transformer层,16个heads,1024维隐藏状态和总共340M个参数。我们使用Adam 优化器[ 53 ]初始学习率为5e-5,并且在训练步骤的前10%进行线性预热。批次大小设置为16,dropout为0.1。每个模型在两个1080Ti GPU上训练了一个epoch。
Fine-tuning
Following BERT, in the fine-tuning procedure, pairs of sentences are concatenated into a single sequence with a special token [SEP] in between. For both single sentence and sentence pair tasks, the hidden state of the first token [CLS] is used for softmax classification. We use the same sets of hyperparameters for all the evaluated models. All experiments on the GLUE benchmark are ran with a total train batch sizes between 8 and 64 and learning rates of 3e-5 for 3 epochs. For tasks from the CLUE benchmark, we set batch sizes to 8 and 16, learning rates between 1e-5 and 3e-5, and train 50 epochs on WSC and 2 $ \sim $ 5 epochs on the rest tasks.
微调
跟随BERT,在微调过程中,成对的句子被连接成单个序列,中间有一个特殊的标记[SEP]。对于单个句子和句子对任务,第一个标记[CLS]的隐藏状态用于softmax分类。我们对所有评估模型使用相同的超参数集。GLUE基准测试的所有实验均在两个GPU上进行,总火车批量大小在8到64之间,学习时间为3e-5,持续3个时期。对于CLUE基准测试中的任务,我们将批量大小设置为8和16,学习率在1e-5和3e-5之间,并在WSC和2上训练50个时期〜其余任务的5个纪元。
Downstream-task Models
On GLUE and CLUE, we compare our model with three variants: pre-trained models (Chinese BERT/BERT-wwm-ext, English BERT-base/BERT-large), models trained with the same number of additional steps as our model (MLM), and models trained using random span masking with the same number of additional steps as our model (Span). For the Span model, we simply replace our -gram module with the masking strategy as proposed by , where the sampling probability of span length $ l $ is based on a geometric distribution $ l \sim Geo(p) $ . We follow the parameter setting that $ p=0.2 $ and maximum span length $ l_{max}=10 $ . We also evaluate the aforementioned models on our universal analogy task. Baseline models include Bag-of-words (BoW) model from pre-trained word embeddings: GloVe, sentence embedding models: InferSent, GenSen, USE and LASER, pre-trained contextualized language models: BERT, ALBERT, RoBERTa and XLNet. To derive semantically meaningful embeddings, we fine-tune BERT and our model on the Stanford Natural Language Inference (SNLI) and the Multi-Genre NLI Corpus using a Siamese structure following Reimers and Gurevych (2019) .
For FAQ and NLG, we compare our models with statistical methods such as TF-IDF and BM25, a sentence representation model LASER , the pre-trained BERT/BERT-wwm-ext and models trained with additional steps (MLM, Span). We observe that further training on Chinese SNLI and MNLI datasets underperforms BERT on the FAQ dataset. Therefore, we only consider pre-trained models for these two tasks.
下游任务模型
在GLUE和CLUE上,我们将模型与三种变体进行了比较:预训练模型(中文BERT / BERT-wwm-ext,英语BERT-base / BERT-large),训练后的模型与BURT具有相同数量的附加步骤(MLM ),以及使用随机跨度遮罩训练的模型,并具有与BURT(Span)相同的附加步骤。对于Span模型,我们只需用[ 10 ]提出的掩蔽策略替换n- gram模块,其中跨度长度的采样概率$ l $基于几何分布$ l \sim Geo(p) $。我们按照$ p=0.2 $和最大跨度长度$ l_{max}=10 $的参数设置。我们还评估了上述模型对我们的普通类比任务。基线模型包括从预训练的Word Embeddings的文字袋(弓)模型:手套,句子嵌入模型:Infersent,Gensen,使用和激光,预先训练的上下文化语言模型:BERT,Albert,Roberta和XLNET。为了获得语义上有意义的嵌入,我们可以使用暹罗和Gurevych(2019)之后的斯坦福自然语言推理(SNLI)和多类型NLI语料库上的微调BERT和我们的模型。
对于常见问题解答和nlg,我们将模型与TF-IDF和BM25等统计方法进行比较,句子表示模型激光,预先训练的BERT / BERT-WWM-EXT和训练的型号额外步骤(MLM,SPAN)。我们观察到常见问题数据集上的中文SNLI和MNLI数据集的进一步训练。因此,我们只考虑这两个任务的预先训练的型号。
Experiments
实验
6.1 GENERAL LANGUAGE UNDERSTANDING 一般语言理解
Table 6 and show the results on the GLUE and CLUE benchmarks, where we find that training BERT with additional MLM steps can hardly bring any improvement except for the WSC task.
表6并显示了GLUE和CLUE基准测试的结果,我们发现,除了WSC任务以外,用其他MLM步骤训练BERT几乎不会带来任何改善。
In Chinese, Span is effective on WSC but is comparable to BERT on other tasks. BERT-wwm-ext is better than our model on classification tasks involving pairs of short sentences such as AFQMC and OCNLI, which may be due to its relative powerful capability of modeling short sequences. Overall, both BURT and BURT-wwm-ext outperform the baseline models on 4 out of 6 tasks with considerable improvement, which sheds light on their effectiveness of modeling sequences of different lengths, and we find that our proposed PMI-based masking method is general and independent with model settings. The most significant improvement is observed on WSC (3.45% over the updated BERT and 2.07% over SpanBERT), where the model is trained to determine whether the given two spans refer to the same entity in the text. We conjecture that the model benefits from learning to predict meaningful spans in the pre-training stage, so it is better at capturing the meanings of spans in the text.
在中文中,Span在WSC上有效,但在其他任务上可与BERT媲美。BERT-wwm-ext在涉及短句子对(例如AFQMC和OCNLI)的分类任务上优于我们的模型,这可能是由于其具有对短序列进行建模的相对强大的能力。总体而言,BURT和BURT-wwm-ext在6个任务中有4个优于基线模型,并且有相当大的改进,这揭示了它们对不同长度的序列建模的有效性,并且我们发现我们提出的基于PMI的掩蔽方法是通用的并且与模型设置无关。在WSC上观察到了最显着的改进(对更新的BERT而言为3.45%,对SpanBERT而言为2.07%),其中训练了模型以确定给定的两个跨度是否指代文本中的同一实体。我们猜想模型的利益从学习预测在训练前预测有意义的跨度,因此更好地捕捉文本中跨度的含义。在英语中,我们的方法还提高了来自Glur基准的各种任务的bert的性能,表明我们所提出的PMI的屏蔽方法是一般的,并且独立于语言设置。

TABLE VI: GLUE test results scored by the evaluation server66https://gluebenchmark.com. We exclude the problematic WNLI set and recalculate the “Avg.” score. Results for BERT-base and BERT-large are obtained from [6]. “mc” and “pc” are Matthews correlation coefficient [52] and Pearson correlation coefficient, respectively.
表VI:评估服务器6对GLUE测试结果的评分6https://gluebenchmark.com。我们排除有问题的WNLI集,然后重新计算“平均”。分数。基于BERT和BERT的结果可从[ 6 ]中获得。“ mc”和“ pc”分别是马修斯相关系数[ 52 ]和皮尔逊相关系数。
Universal Analogy 通用类比
Results on analogy tasks are reported in Table analogy_acc. Generally, semantic analogies are more challenging than the syntactic ones and higher-level relationships between sequences are more difficult to capture, which is observed in almost all the evaluated models. On word analogy tasks, all well pre-trained language models like BERT, ALBERT, RoBERTa and XLNet hardly exhibit arithmetic characteristics and increasing the model size usually leads to a decrease in accuracy. However, our method of pre-training using -grams extracted by the PMI algorithm significantly improves the performance on word analogies compared with BERT, obtaining 72.8%(BURT-base) and 79.4%(BURT-large) accuracy, respectively. Further training BURT-large on SNLI and MNLI results in the highest accuracy (80.5%). Despite the leading performance on word-level analogy datasets of GloVe, InferSent and USE, they do not generalize well on higher level analogy tasks. We conjecture their poor performance is caused by synonyms and paraphrases in sentences which lead the model to produce lower similarity scores to the correct answers. In contrast, Transformer-based models are more advantageous in representing higher-level sequences and are good at identifying paraphrases and capturing relationships between sentences even if they have less lexical overlap. Moreover, fine-tuning pre-trained models achieves considerable improvements on high-level semantic analogies. Overall, SBURT-base achieves the highest average accuracy (60.7%). Examples from the Negation subset are shown in Table pos-neg_example. Notice that the word " does not explicitly appear in the correct answers. Instead, " and " are indicators of negation. As expected, BOW will give a higher similarity score for the sentence that contain both " and " because the word-level information is simply added and subtracted despite the context. By contrast, contextualized models like BURT capture the meanings and relationships of words within the sequence in a comprehensive way, indicating that it has indeed learned universal representations across different linguistic units.
表VIII中列出了类比任务的结果。我们可以得出以下结论。
通常,语义类比比语法类更具挑战性,并且序列之间的高级关系更难以捕获。在几乎所有评估模型中都观察到了这种现象。
在单词类比任务上,GloVe可以达到最高的准确性(80.3%)。所有经过良好训练的语言模型(例如BERT,ALBERT,RoBERTa和XLNet)都几乎没有表现出算术特征,并且增大模型大小通常会导致准确性降低。但是,使用PMI算法提取的n- gram对BERT进行进一步的训练,可以显着提高性能,并且其准确度分别为72.8%(基于BURT)和79.4%(大于BURT)。
尽管在GloVe,InferSent和USE的单词级类比数据集上具有领先的性能,但它们在高级类比任务上的推广效果并不理想。我们推测它们的性能不佳是由句子中的同义词和释义引起的,这些同义词和释义导致模型产生与正确答案相比较低的相似性评分。相反,基于变压器的模型在表示更高级别的序列方面更具优势。特别是,我们的模型擅长识别释义和捕获句子之间的关系,即使它们之间的词法重叠较少。总体而言,基于BURT的语言实现了最高的平均准确度,这表明它确实学会了跨不同语言单位的通用表示形式。
否定子集的示例在表VII中显示。请注意,单词“ not ”没有明确出现在正确的答案中。取而代之的是,“效率低下”和“不知道”是否定的指标。如预期的那样,BOW将为同时包含“ not ”和“ invalid ”的句子提供更高的相似性评分,因为无论上下文如何,单词级信息都被简单地添加和减去。相比之下,诸如BURT之类的语境化模型以一种全面的方式捕获了序列中单词的含义和关系。
| Barton’s inquiry was reasonable : Barton’s inquiry was not reasonable :: Changing the sign of numbers is an efficient algorithm | |||
|---|---|---|---|
| changing the sign of numbers is an inefficient algorithm | GloVe: 0.96 | USE: 0.89 | BURT-base: 0.97 |
| changing the sign of numbers is not an inefficient algorithm | GloVe: 0.97 | USE: 0.90 | BURT-base: 0.96 |
| Members are aware of their political work : Members are not aware of their political work :: This ant is a known species | |||
| This ant is an unknown species | GloVe:0.94 | USE:0.87 | BURT-base: 0.96 |
| This ant is not an unknown species | GloVe: 0.95 | USE:0.82 | BURT-base: 0.95 |

TABLE VII: Questions and candidates from the sentence-level “positive-negative” analogy dataset and similarity scores for each candidate sentence computed by GloVe, USE and BURT-base. The correct sentences are in bold.

TABLE VIII: Performance of different models on universal analogy datasets. Mean-pooling is applied to Transformer-based models to obtain fixed-length embeddings. The last column shows the average accuracy of word, phrase and sentence analogy tasks.

Retrieval-based FAQ
Results are reported in Table faq-results. As we can see, LASER and all pre-trained language models significantly outperform TF-IDF and BM25, indicating the superiority of embedding-based models over statistical methods. Besides, the continued BERT training is often beneficial. Among all the evaluated models, our BURT yields the highest accuracy (82.2%) and MRR (0.872). BURT-wwm-ext achieves a slightly lower accuracy (80.7%) compared with BURT but it still exceeds its baselines by 4.0%(MLM) and 1.4%(Span), respectively.
基于检索的常见问题解答
结果在表常见问题解答中报告。正如我们所看到的,LASER 和所有预先训练的语言模型都显着优于TF-IDF和BM25,表示基于嵌入的模型的优越性通过统计方法。此外,持续的BERT训练通常是有益的。在所有评估模型中,我们的Burt产生最高的精度(82.2%)和MRR(0.872)。 Burt-WWM-EXT与Burt相比略微较低(80.7%),但它仍然超过其基线分别超过4.0%(MLM)和1.4%(跨度)。
Natural Language Generation
Results are summarized in Table nlg-results. Although nearly 62% of the paragraphs retrieved by BM25 are relevant to the topic, only two-thirds of them actually convey the original meaning of the template. Despite LASER's comparable performance to BURT on FAQ, it is less effective when different granular linguistic units are involved at the same time. Re-ranking using BURT substantially improves the quality of the generated paragraphs. We show examples retrieved by BM25 , LASER, the Span model and BURT in Table nlg-example, denoted by $ B $ , $ L $ , $ S $ and $ U $ , respectively. BM25 tends to favor paragraphs that contain the keywords even though the paragraph conveys a different meaning, while BURT selects accurate answers according to semantic meanings of queries and documents.
| Method | Acc. | MRR |
|---|---|---|
| TF-IDF | 73.7 | 0.813 |
| BM25 | 72.1 | 0.802 |
| LASER | 79.9 | 0.856 |
| BERT | 76.8 | 0.831 |
| MLM | 78.3 | 0.843 |
| Span | 78.6 | 0.846 |
| BURT | 82.2 | 0.872 |
| BERT-wwm-ext | 76.7 | 0.834 |
| MLM | 76.7 | 0.834 |
| Span | 79.3 | 0.856 |
| BURT-wwm-ext | 80.7 | 0.863 |
TABLE X: Comparison of statistical methods, the sentence embedding model and pre-trained contextualized language models on the FAQ dataset. “Acc.” represents Top-1 accuracy.
自然语言生成
结果总结在表NLG-excue中。虽然BM25检索的近62%的段落与主题相关,但其中仅三分之二实际地传达了模板的原始含义。尽管激光对常见问题的博士进行了可比性,但在不同的颗粒语言单位同时涉及不同的情况下,它的效果较小。使用Burt重新排名大大提高了所生成的段落的质量。我们显示BM25,LASS,SPAN模型和BURT检索的示例,如表NLG-示例所示,由$ B $,$ L $,$ S $和$ U $表示。 BM25倾向于有利于包含关键字的段落,即使段落传达了不同的含义,而Burt根据查询和文档的语义含义选择准确的答案。
“B”-BM25, “L”-LASER, “S”-SpanBERT, “U”-BURT
Query: 端午节的由来 (The Origin of the Dragon Boat Festival)
B: 一个中学的高级教师陈老师生动地解读端午节的由来,诵读爱好者进行原创诗歌作品朗诵,深深打动了在场的观众… (Mr. Chen, senior teacher at a middle School, vividly introduced the origin of the Dragon Boat Festival and people are reciting original poems, which deeply moved the audience…)
L: 今天是端午小长假第一天…当天上午,在车厢内满目挂有与端午节相关的民俗故事及有关诗词的文字… (Today is the first day of the Dragon Boat Festival holiday…There are folk stories and poems posted in the carriage…)
S,U: …端午节又称端阳节、龙舟节、浴兰节,是中华民族的传统节日。端午节形成于先秦,发展于汉末魏晋,兴盛于唐… (…Dragon Boat Festival, also known as Duanyang Festival, Longzhou Festival and Yulan Festival is a traditional festival of the Chinese nation. It is formed in the Pre-Qin Dynasty, developed in the late Han and Wei-Jin, and prospered in the Tang…)
Comments: B and L is related to the topic but does not convey the meaning of the query.
Query: 狗的喂养知识 (Dog Feeding Tips)
B: …创建一个“比特狗”账户,并支付99元领养一只“比特狗”。然后购买喂养套餐喂养“比特狗”,“比特狗”就能通过每天挖矿产生BTGS虚拟货币。 (…First create a “Bitdog” account and pay 99 yuan to adopt a “Bitdog”. Then buy a package to feed the “Bitdog”, which can generate virtual currency BTGS through daily mining.)
L: 要养成定时定量喂食的好习惯,帮助狗狗更好的消化和吸收,同时也要选择些低盐健康的狗粮… (It is necessary to feed your dog regularly and quantitatively, which can help them digest and absorb better. Meanwhile, choose some low-salt and healthy dog food…)
S: 泰迪犬容易褪色是受到基因和护理不当的影响,其次是饮食太咸…一定要注意正确护理,定期洗澡,要给泰迪低盐营养的优质狗粮… (Teddy bear dog’s hair is easy to fade because of its genes and improper care. It is also caused by salty diet… So we must take good care of them, such as taking a bath regularly, and preparing dog food with low salt…)
U: 还可以一周自制一次狗粮给狗狗喂食,就是买些肉类,蔬菜,自己动手做。偶尔吃吃自制狗粮也能增加狗狗的营养,和丰富狗狗的口味,这样狗狗就不会那么容易出现挑食,厌食之类的问题。日常的话,建议选择些适口性强的狗粮,有助磨牙,防止口腔疾病。 (You can also make dog food once a week, such as meats and vegetables. Occasionally eating homemade dog food can also supplement nutrition and enrich the taste, so that dogs will not be so picky or anorexic. In daily life, it is recommended to choose some palatable dog food to help their teeth grinding and prevent oral diseases.)
Comments: B is not a relevant paragraph. S is relevant to the topic but is inaccurate.
TABLE IX: Examples of the retrieved paragraphs and corresponding comments from the judges.
| R | Judge1 | Judge2 | Avg. |
|---|---|---|---|
| BM25 | 60.3 | 61.8 | 61.1 |
| LASER | 63.9 | 61.6 | 62.8 |
| BERT | 65.9 | 67.3 | 66.6 |
| MLM | 65.0 | 67.5 | 66.3 |
| Span | 69.3 | 71.5 | 70.4 |
| BURT | 71.8 | 71.0 | 71.4 |
| CM | Judge1 | Judge2 | Avg. |
| BM25 | 43.5 | 41.2 | 42.4 |
| LASER | 42.5 | 38.4 | 40.5 |
| BERT | 48.5 | 47.8 | 48.2 |
| MLM | 46.1 | 45.5 | 45.8 |
| Span | 51.6 | 53.9 | 52.8 |
| BURT | 54.2 | 56.5 | 55.4 |
TABLE XI: Results on NLG according to human judgment. “R” and “CM” represent the percentage of paragraphs that are “relevant” and “convey the meaning”, respectively.
7 Visualization
可视化
Single Pattern
Mikolov et al. (2013) use PCA to project word embeddings into a two-dimensional space to visualize a single pattern captured by the Word2Vec model, while in this work we consider embeddings for different granular linguistic units. All pairs in Figure distance belong to the male-female" category and subtracting the two vectors results in roughly the same direction.
单个图案
mikolov等。 (2013)使用PCA将嵌入式单词嵌入到二维空间中,以可视化Word2VEC模型捕获的单个模式,而在这项工作中我们考虑不同的颗粒语言单位的嵌入。图距离的所有对属于男性 - 女性“类别,并减去两个向量导致大致相同的方向。
| p1 | p2 |
|---|---|
| p_man: employed by the man | p_woman: hired by the woman |
| p_king: employed by the king | p_queen: hired by the queen |
| p_dad: employed by his dad | p_mom: hired by his mom |
| s |
|---|
| s man: He was employed by the man when he was 28. |
| s woman: He was hired by the woman at age 28. |
| s king: He was employed by the king when he was 28. |
| s queen: He was hired by the queen at age 28. |
| s dad: He was employed by his dad when he was 28. |
| s mom: He was hired by his mom at age 28. |
TABLE XII: Annotation of phrases and sentences in Figure 4.

Clustering 聚类
Given that embeddings of sequences with the same kind of relationship will exhibit the same pattern in the vector space, we obtain the difference between pairs of embeddings for words, phrases and sentences from different categories and visualize them by t-SNE. Figure cluster shows that by subtracting two vectors, pairs that belong to the same category automatically fall into the same cluster. Only the pairs from capital-country" and city-state" cannot be totally distinguished, which is reasonable because they all describe the relationship between geographical entities.
给定,具有相同类型关系的序列的嵌入将在矢量空间中表现出相同的模式,我们在不同类别的单词,短语和句子对与不同类别的句子对之间的差异,并通过t-sne可视化它们。如图显示,通过减去两个向量,属于同一类别的对自动落入同一群集。只有首都国家“和城市”的对不能完全区分,这是合理的,因为它们都描述了地理实体之间的关系。

FAQ
We show examples in Figure faq_vector where BURT successfully retrieve the correct answer while TF-IDF and BM25 fail. Both sentences " and " contain the word ", which is a possible reason why TF-IDF tends to believe they highly match with each other, ignoring that the two sentences are actually describing two different issues. In contrast, using vector-based representations, BURT considers " as a paraphrase of ". As depicted in Figure faq_vector, queries are close to the correct responses and away from other sentences.
我们在图形faq_vector中显示示例,其中burt成功检索TF-IDF和BM25失败时的正确答案。两个句子“和”包含这个词“,这是为什么TF-IDF倾向于相信他们彼此高度相匹配的可能原因,忽略了这两个句子实际上描述了两个不同的问题。相比之下,使用基于矢量的表示, Burt认为“作为释义的”。如图Faq_vector所示,查询靠近正确的响应,远离其他句子。

8 Conclusion
This paper formally introduces the task of universal representation learning and then presents a pre-trained language model for such a purpose to map different granular linguistic units into the same vector space where similar sequences have similar representations and enable unified vector operations among different language hierarchies. In detail, we focus on the less concentrated language representation, seeking to learn a uniform vector form across different linguistic unit hierarchies. Far apart from learning either word only or sentence only representation, our method extends BERT's masking and training objective to a more general level, which leverage information from sequences of different lengths in a comprehensive way and effectively learns a universal representation from words, phrases to sentences. Overall, our proposed BURT outperforms its baselines on a wide range of downstream tasks with regard to sequences of different lengths in both English and Chinese languages. We especially provide an universal analogy task, an insurance FAQ dataset and an NLG dataset for extensive evaluation, where our well-trained universal representation model holds the promise for demonstrating accurate vector arithmetic with regard to words, phrases and sentences and in real-world retrieval applications.
结论
本文正式介绍了通用表示学习的任务,然后提出了预先训练的语言模型,以便这样的目的地将不同的粒度语言单元映射到相同的矢量空间,其中相似序列具有相似的表示并实现统一的向量操作不同的语言层次结构。详细介绍,我们专注于较少的语言表示,寻求在不同的语言单位层次结构上学习统一的矢量形式。除了学习仅限单击或句子仅表示时,我们的方法将展开BERT的掩蔽和训练目标延伸到更一般的水平,这通过全面的方式利用不同长度的序列中的信息,并有效地从单词,短语到句子中学习通用表示。总的来说,我们所提出的Burt在英语和中文的不同长度序列方面占据了其基础上的广泛下游任务。我们特别提供一个通用的类比任务,保险常见问题解答数据集和NLG数据集,用于广泛的评估,其中我们训练有素的通用表示模型具有展示关于单词,短语和句子以及现实世界检索的准确向量算术的承诺应用程序。